XGBoost Sweeps
5 minute read

트리 기반 모델에서 최고의 성능을 짜내려면 적절한 하이퍼파라미터를 선택해야 합니다.
early_stopping_rounds는 몇 번으로 해야 할까요? 트리의 max_depth는 얼마로 설정해야 할까요?
가장 뛰어난 성능의 모델을 찾기 위해 고차원 하이퍼파라미터 공간을 탐색하는 것은 매우 빠르게 복잡해질 수 있습니다. 하이퍼파라미터 Sweeps는 모델 간의 배틀 로얄을 조직적이고 효율적으로 수행하고 승자를 결정하는 방법을 제공합니다. 가장 최적의 값을 찾기 위해 하이퍼파라미터 값의 조합을 자동으로 검색하여 이를 가능하게 합니다.
이 튜토리얼에서는 Weights & Biases를 사용하여 3가지 간단한 단계를 거쳐 XGBoost 모델에서 정교한 하이퍼파라미터 Sweeps를 실행하는 방법을 알아봅니다.
미리 보기를 보려면 아래 그림을 확인하세요.
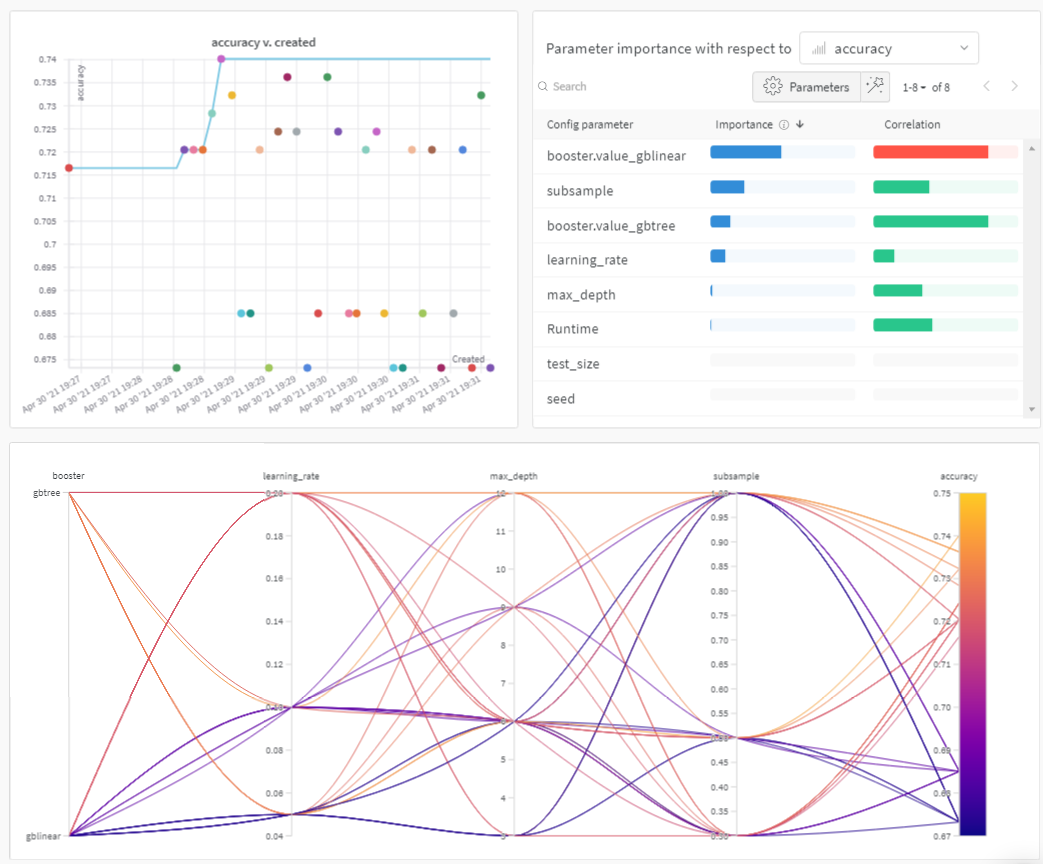
Sweeps: 개요
Weights & Biases로 하이퍼파라미터 스윕을 실행하는 것은 매우 쉽습니다. 3가지 간단한 단계만 거치면 됩니다.
-
스윕 정의: 스윕을 지정하는 사전과 유사한 오브젝트를 생성하여 수행합니다. 검색할 파라미터, 사용할 검색 전략, 최적화할 메트릭을 지정합니다.
-
스윕 초기화: 한 줄의 코드로 스윕을 초기화하고 스윕 구성 사전을 전달합니다.
sweep_id = wandb.sweep(sweep_config) -
스윕 에이전트 실행: 또한 한 줄의 코드로 수행됩니다.
wandb.agent()를 호출하고 모델 아키텍처를 정의하고 트레이닝하는 함수와 함께sweep_id를 전달합니다.wandb.agent(sweep_id, function=train)
하이퍼파라미터 스윕을 실행하는 데 필요한 전부입니다.
아래의 노트북에서는 이러한 3단계를 더 자세히 살펴보겠습니다.
이 노트북을 포크하고, 파라미터를 조정하거나, 자신의 데이터셋으로 모델을 사용해 보는 것이 좋습니다.
참고 자료
!pip install wandb -qU
import wandb
wandb.login()
1. 스윕 정의
Weights & Biases Sweeps는 단 몇 줄의 코드로 원하는 방식으로 스윕을 정확하게 구성할 수 있는 강력한 레버를 제공합니다. 스윕 구성은 사전 또는 YAML 파일로 정의할 수 있습니다.
몇 가지를 함께 살펴보겠습니다.
- 메트릭: 이는 스윕이 최적화하려고 시도하는 메트릭입니다. 메트릭은
name(이 메트릭은 트레이닝 스크립트에 의해 기록되어야 함)과goal(maximize또는minimize)을 사용할 수 있습니다. - 검색 전략:
"method"키를 사용하여 지정합니다. Sweeps를 통해 여러 가지 검색 전략을 지원합니다. - 그리드 검색: 하이퍼파라미터 값의 모든 조합을 반복합니다.
- 랜덤 검색: 하이퍼파라미터 값의 임의로 선택된 조합을 반복합니다.
- 베이지안 탐색: 하이퍼파라미터를 메트릭 점수의 확률에 매핑하는 확률 모델을 생성하고 메트릭을 개선할 가능성이 높은 파라미터를 선택합니다. 베이지안 최적화의 목적은 하이퍼파라미터 값을 선택하는 데 더 많은 시간을 투자하는 것이지만, 그렇게 함으로써 더 적은 수의 하이퍼파라미터 값을 시도하는 것입니다.
- 파라미터: 각 반복에서 값을 가져올 하이퍼파라미터 이름과 불연속 값, 범위 또는 분포를 포함하는 사전입니다.
자세한 내용은 모든 스윕 구성 옵션 목록을 참조하십시오.
sweep_config = {
"method": "random", # try grid or random
"metric": {
"name": "accuracy",
"goal": "maximize"
},
"parameters": {
"booster": {
"values": ["gbtree","gblinear"]
},
"max_depth": {
"values": [3, 6, 9, 12]
},
"learning_rate": {
"values": [0.1, 0.05, 0.2]
},
"subsample": {
"values": [1, 0.5, 0.3]
}
}
}
2. 스윕 초기화
wandb.sweep을 호출하면 스윕 컨트롤러가 시작됩니다. 스윕 컨트롤러는 parameters의 설정을 쿼리하는 모든 사용자에게 제공하고 wandb 로깅을 통해 metrics에 대한 성능을 반환하도록 기대하는 중앙 집중식 프로세스입니다.
sweep_id = wandb.sweep(sweep_config, project="XGBoost-sweeps")
트레이닝 프로세스 정의
스윕을 실행하기 전에 모델을 생성하고 트레이닝하는 함수, 즉 하이퍼파라미터 값을 입력받아 메트릭을 출력하는 함수를 정의해야 합니다.
또한 wandb를 스크립트에 통합해야 합니다.
세 가지 주요 구성 요소가 있습니다.
wandb.init(): 새 W&B run을 초기화합니다. 각 run은 트레이닝 스크립트의 단일 실행입니다.wandb.config: 모든 하이퍼파라미터를 구성 오브젝트에 저장합니다. 이를 통해 저희 앱을 사용하여 하이퍼파라미터 값별로 run을 정렬하고 비교할 수 있습니다.wandb.log(): 이미지, 비디오, 오디오 파일, HTML, 플롯 또는 포인트 클라우드와 같은 메트릭 및 사용자 정의 오브젝트를 기록합니다.
또한 데이터를 다운로드해야 합니다.
!wget https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.data.csv
# XGBoost model for Pima Indians dataset
from numpy import loadtxt
from xgboost import XGBClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# load data
def train():
config_defaults = {
"booster": "gbtree",
"max_depth": 3,
"learning_rate": 0.1,
"subsample": 1,
"seed": 117,
"test_size": 0.33,
}
wandb.init(config=config_defaults) # defaults are over-ridden during the sweep
config = wandb.config
# load data and split into predictors and targets
dataset = loadtxt("pima-indians-diabetes.data.csv", delimiter=",")
X, Y = dataset[:, :8], dataset[:, 8]
# split data into train and test sets
X_train, X_test, y_train, y_test = train_test_split(X, Y,
test_size=config.test_size,
random_state=config.seed)
# fit model on train
model = XGBClassifier(booster=config.booster, max_depth=config.max_depth,
learning_rate=config.learning_rate, subsample=config.subsample)
model.fit(X_train, y_train)
# make predictions on test
y_pred = model.predict(X_test)
predictions = [round(value) for value in y_pred]
# evaluate predictions
accuracy = accuracy_score(y_test, predictions)
print(f"Accuracy: {accuracy:.0%}")
wandb.log({"accuracy": accuracy})
3. 에이전트로 스윕 실행
이제 wandb.agent를 호출하여 스윕을 시작합니다.
다음을 포함하는 W&B에 로그인한 모든 시스템에서 wandb.agent를 호출할 수 있습니다.
sweep_id,- 데이터셋 및
train함수
그러면 해당 시스템이 스윕에 참여합니다.
참고:
random스윕은 기본적으로 영원히 실행되어 새로운 파라미터 조합을 계속 시도합니다. 소가 집으로 돌아올 때까지 또는 앱 UI에서 스윕을 끌 때까지 계속됩니다.agent가 완료하려는 총 runcount를 제공하여 이를 방지할 수 있습니다.
wandb.agent(sweep_id, train, count=25)
결과 시각화
이제 스윕이 완료되었으므로 결과를 살펴볼 차례입니다.
Weights & Biases는 여러 유용한 플롯을 자동으로 생성합니다.
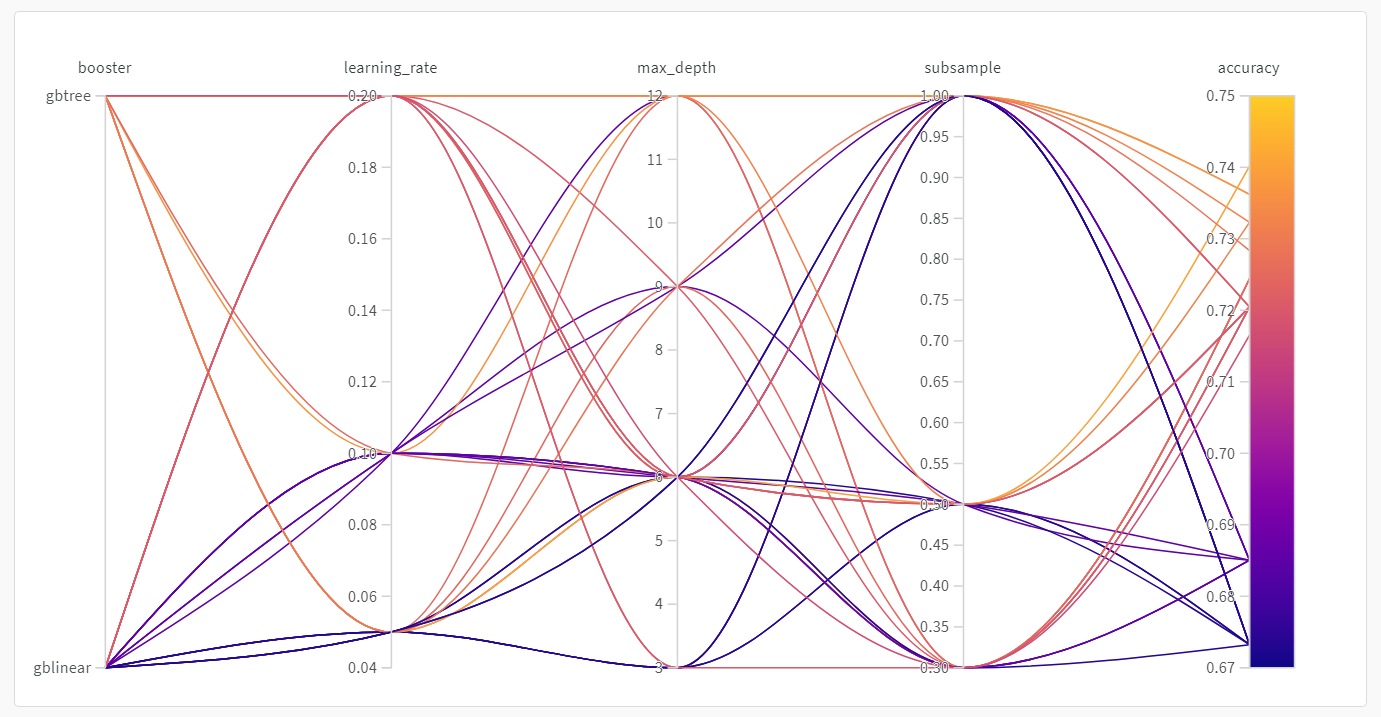
병렬 좌표 플롯
이 플롯은 하이퍼파라미터 값을 모델 메트릭에 매핑합니다. 최고의 모델 성능을 이끌어낸 하이퍼파라미터 조합을 파악하는 데 유용합니다.
이 플롯은 학습기로 트리를 사용하는 것이 학습기로 간단한 선형 모델을 사용하는 것보다 약간 더 나은 성능을 보이지만, 획기적인 수준은 아닌 것으로 보입니다.
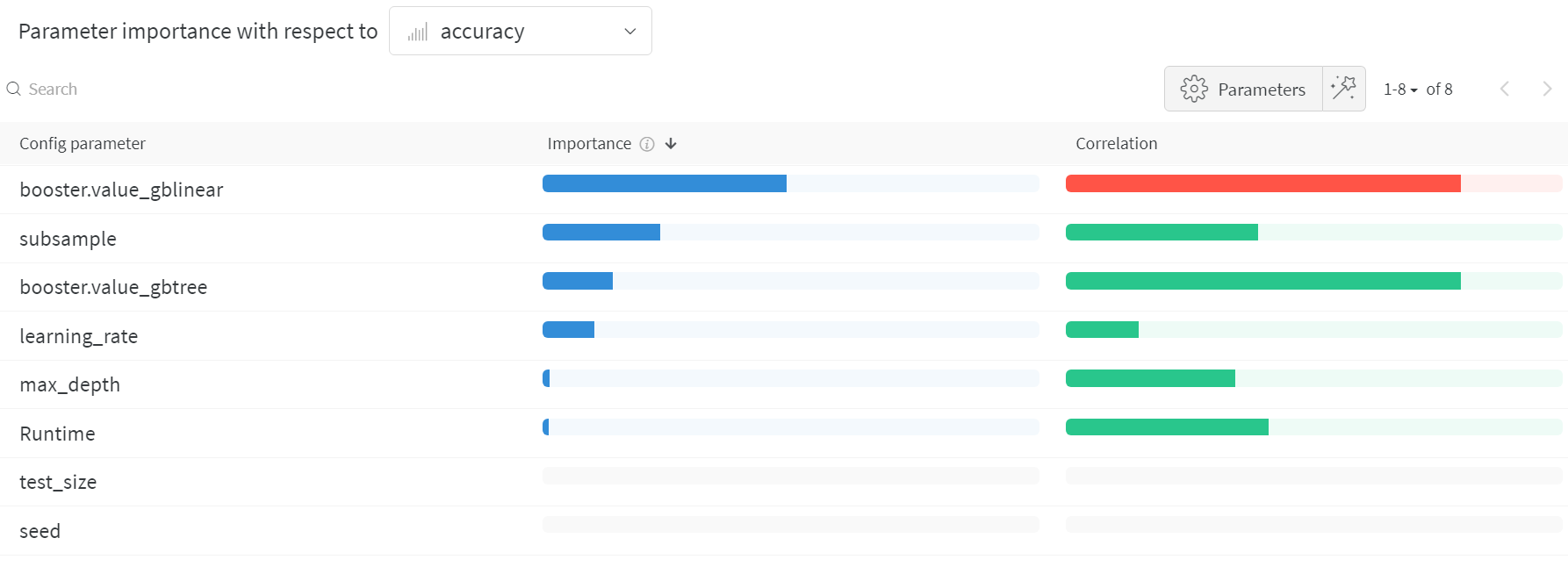
하이퍼파라미터 중요도 플롯
하이퍼파라미터 중요도 플롯은 어떤 하이퍼파라미터 값이 메트릭에 가장 큰 영향을 미쳤는지 보여줍니다.
선형 예측기로 취급하는 상관 관계와 결과에 대한 랜덤 포레스트를 트레이닝한 후의 특징 중요도를 모두 보고하므로 어떤 파라미터가 가장 큰 영향을 미쳤는지, 그리고 그 영향이 긍정적인지 부정적인지 확인할 수 있습니다.
이 차트를 보면 위에서 병렬 좌표 차트에서 발견한 추세를 정량적으로 확인할 수 있습니다. 검증 정확도에 가장 큰 영향을 미친 것은 학습기 선택이었고, gblinear 학습기는 일반적으로 gbtree 학습기보다 성능이 좋지 않았습니다.
이러한 시각화는 가장 중요하고 따라서 더 자세히 탐구할 가치가 있는 파라미터(및 값 범위)에 집중하여 비용이 많이 드는 하이퍼파라미터 최적화를 실행하는 데 드는 시간과 리소스를 절약하는 데 도움이 될 수 있습니다.
[i18n] feedback_title
[i18n] feedback_question
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.