Weave and Models integration demo
4 minute read
이 노트북은 W&B Weave 와 W&B Models 를 함께 사용하는 방법을 보여줍니다. 특히, 이 예제에서는 두 개의 서로 다른 Teams 를 고려합니다.
- The Model Team: 모델 구축 Team 은 새로운 Chat Model (Llama 3.2)을 파인튜닝하고 W&B Models 를 사용하여 레지스트리에 저장합니다.
- The App Team: 앱 개발 Team 은 Chat Model 을 검색하여 W&B Weave 를 사용하여 새로운 RAG 챗봇을 만들고 평가합니다.
W&B Models 와 W&B Weave 에 대한 공개 워크스페이스는 여기 에서 찾을 수 있습니다.
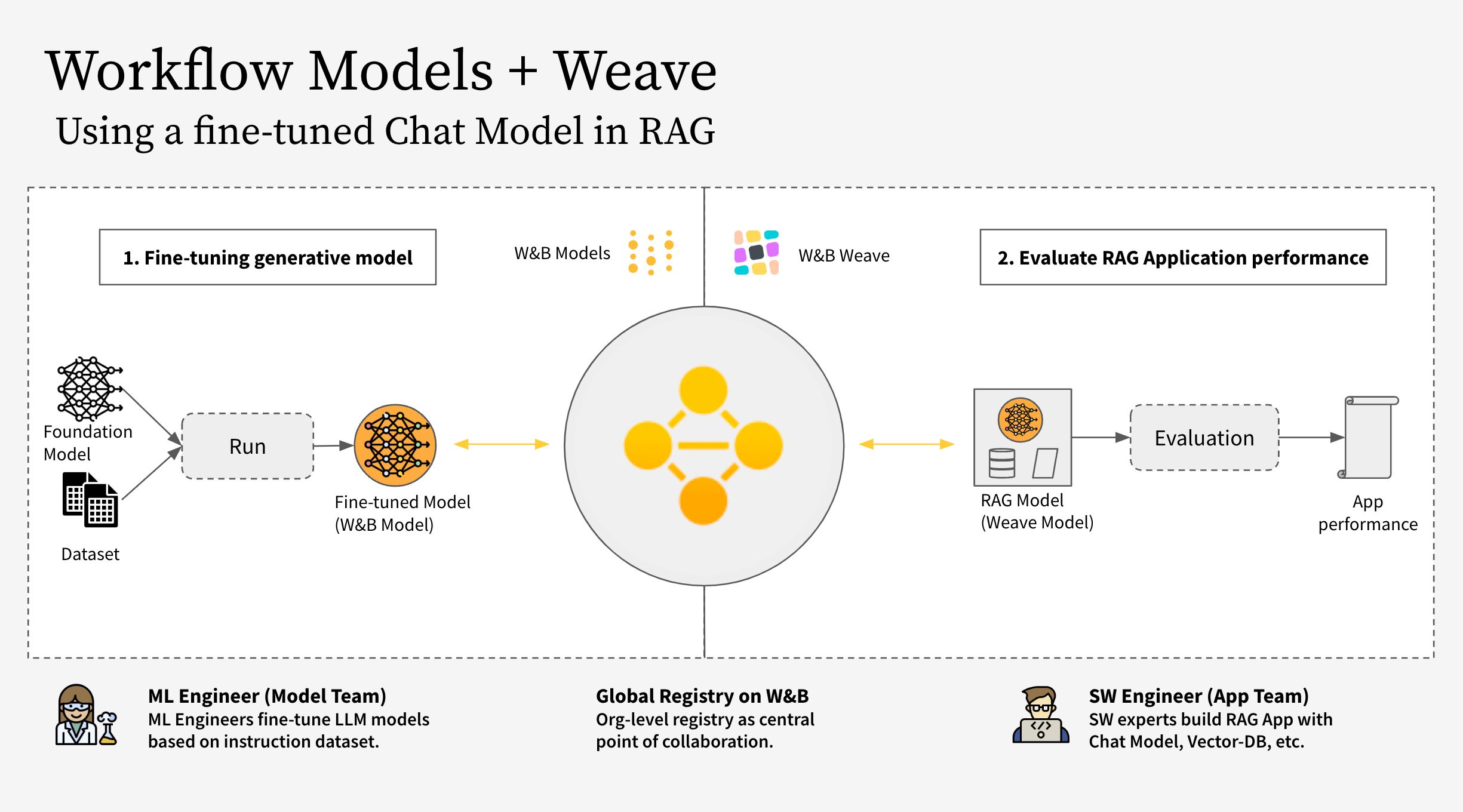
이 워크플로우는 다음 단계를 포함합니다.
- W&B Weave 로 RAG 앱 코드 계측
- LLM (예: Llama 3.2, 다른 LLM으로 대체 가능)을 파인튜닝하고 W&B Models 로 추적
- 파인튜닝된 모델을 W&B Registry 에 로그
- 새로운 파인튜닝된 모델로 RAG 앱을 구현하고 W&B Weave 로 앱을 평가
- 결과에 만족하면 업데이트된 Rag 앱에 대한 참조를 W&B Registry 에 저장
참고:
아래에서 참조된 RagModel은 완전한 RAG 앱으로 간주할 수 있는 최상위 weave.Model입니다. 여기에는 ChatModel, 벡터 데이터베이스 및 프롬프트가 포함되어 있습니다. ChatModel은 또한 W&B Registry 에서 아티팩트를 다운로드하는 코드를 포함하는 또 다른 weave.Model이며 RagModel의 일부로 다른 챗봇 모델을 지원하도록 변경할 수 있습니다. 자세한 내용은 Weave의 전체 모델 을 참조하십시오.
1. 설정
먼저 weave 와 wandb 를 설치한 다음 API 키로 로그인합니다. API 키는 https://wandb.ai/settings 에서 생성하고 볼 수 있습니다.
pip install weave wandb
import wandb
import weave
import pandas as pd
PROJECT = "weave-cookboook-demo"
ENTITY = "wandb-smle"
wandb.login()
weave.init(ENTITY + "/" + PROJECT)
2. 아티팩트를 기반으로 ChatModel 만들기
Registry 에서 파인튜닝된 챗봇 모델을 검색하고, 다음 단계에서 RagModel 에 직접 연결하기 위해 weave.Model 을 만듭니다. 기존의 ChatModel 과 동일한 파라미터를 사용하며, init 과 predict 만 변경됩니다.
pip install unsloth
pip uninstall unsloth -y && pip install --upgrade --no-cache-dir "unsloth[colab-new] @ git+https://github.com/unslothai/unsloth.git"
모델 Team 은 unsloth 라이브러리를 사용하여 더 빠르게 만들기 위해 다양한 Llama-3.2 모델을 파인튜닝했습니다. 따라서 Registry 에서 다운로드한 모델을 로드하기 위해 어댑터가 있는 특수한 unsloth.FastLanguageModel 또는 peft.AutoPeftModelForCausalLM 모델을 사용합니다. Registry 의 “Use” 탭에서 로딩 코드를 복사하여 model_post_init 에 붙여넣습니다.
import weave
from pydantic import PrivateAttr
from typing import Any, List, Dict, Optional
from unsloth import FastLanguageModel
import torch
class UnslothLoRAChatModel(weave.Model):
"""
모델 이름 외에 더 많은 파라미터를 저장하고 버저닝하기 위해 추가 ChatModel 클래스를 정의합니다.
이를 통해 특정 파라미터에 대한 파인튜닝이 가능합니다.
"""
chat_model: str
cm_temperature: float
cm_max_new_tokens: int
cm_quantize: bool
inference_batch_size: int
dtype: Any
device: str
_model: Any = PrivateAttr()
_tokenizer: Any = PrivateAttr()
def model_post_init(self, __context):
# 레지스트리의 "Use" 탭에서 이것을 붙여넣습니다.
run = wandb.init(project=PROJECT, job_type="model_download")
artifact = run.use_artifact(f"{self.chat_model}")
model_path = artifact.download()
# unsloth 버전(네이티브 2배 빠른 추론 활성화)
self._model, self._tokenizer = FastLanguageModel.from_pretrained(
model_name=model_path,
max_seq_length=self.cm_max_new_tokens,
dtype=self.dtype,
load_in_4bit=self.cm_quantize,
)
FastLanguageModel.for_inference(self._model)
@weave.op()
async def predict(self, query: List[str]) -> dict:
# add_generation_prompt = true - 생성을 위해 추가해야 합니다.
input_ids = self._tokenizer.apply_chat_template(
query,
tokenize=True,
add_generation_prompt=True,
return_tensors="pt",
).to("cuda")
output_ids = self._model.generate(
input_ids=input_ids,
max_new_tokens=64,
use_cache=True,
temperature=1.5,
min_p=0.1,
)
decoded_outputs = self._tokenizer.batch_decode(
output_ids[0][input_ids.shape[1] :], skip_special_tokens=True
)
return "".join(decoded_outputs).strip()
이제 Registry 에서 특정 링크를 사용하여 새 모델을 만듭니다.
MODEL_REG_URL = "wandb32/wandb-registry-RAG Chat Models/Finetuned Llama-3.2:v3"
max_seq_length = 2048
dtype = None
load_in_4bit = True
new_chat_model = UnslothLoRAChatModel(
name="UnslothLoRAChatModelRag",
chat_model=MODEL_REG_URL,
cm_temperature=1.0,
cm_max_new_tokens=max_seq_length,
cm_quantize=load_in_4bit,
inference_batch_size=max_seq_length,
dtype=dtype,
device="auto",
)
마지막으로 평가를 비동기적으로 실행합니다.
await new_chat_model.predict(
[{"role": "user", "content": "What is the capital of Germany?"}]
)
3. 새로운 ChatModel 버전을 RagModel 에 통합
파인튜닝된 챗봇 모델에서 RAG 앱을 구축하면 특히 대화형 AI 시스템의 성능과 다양성을 향상시키는 데 여러 가지 이점을 제공할 수 있습니다.
이제 기존 Weave 프로젝트에서 RagModel 을 검색하고 (아래 이미지에 표시된 대로 사용 탭에서 현재 RagModel 에 대한 Weave 참조를 가져올 수 있음) ChatModel 을 새 모델로 교체합니다. 다른 구성 요소(VDB, 프롬프트 등)를 변경하거나 다시 만들 필요가 없습니다!

pip install litellm faiss-gpu
RagModel = weave.ref(
"weave:///wandb-smle/weave-cookboook-demo/object/RagModel:cqRaGKcxutBWXyM0fCGTR1Yk2mISLsNari4wlGTwERo"
).get()
# MAGIC: chat_model 교환 및 새 버전 게시 (다른 RAG 구성 요소에 대해 걱정할 필요가 없음)
RagModel.chat_model = new_chat_model
# 먼저 예측 중에 참조되도록 새 버전을 게시합니다.
PUB_REFERENCE = weave.publish(RagModel, "RagModel")
await RagModel.predict("When was the first conference on climate change?")
4. 기존 Models Run 에 연결하여 새로운 weave.Evaluation 실행
마지막으로 기존 weave.Evaluation 에서 새 RagModel 을 평가합니다. 통합을 최대한 쉽게 만들기 위해 다음 변경 사항을 포함합니다.
Models 관점에서:
- Registry 에서 모델을 가져오면 챗봇 모델의 E2E 계보의 일부인 새로운
wandb.run이 생성됩니다. - 해당 Weave 페이지로 이동할 수 있도록 모델 Team 이 링크를 클릭할 수 있도록 실행 구성에 Trace ID (현재 eval ID 포함)를 추가합니다.
Weave 관점에서:
- 아티팩트 / Registry 링크를
ChatModel의 입력으로 저장 (즉,RagModel) weave.attributes로 traces 에 run.id 를 추가 열로 저장
# MAGIC: 평가 데이터셋과 스코어를 사용하여 평가를 가져와서 사용합니다.
WEAVE_EVAL = "weave:///wandb-smle/weave-cookboook-demo/object/climate_rag_eval:ntRX6qn3Tx6w3UEVZXdhIh1BWGh7uXcQpOQnIuvnSgo"
climate_rag_eval = weave.ref(WEAVE_EVAL).get()
with weave.attributes({"wandb-run-id": wandb.run.id}):
# Models 에 eval trace 를 저장하기 위해 결과와 호출을 모두 검색하려면 .call 속성을 사용합니다.
summary, call = await climate_rag_eval.evaluate.call(climate_rag_eval, ` RagModel `)
5. Registry 에 새로운 RAG 모델 저장
새로운 RAG Model 을 효과적으로 공유하기 위해 Weave 버전을 에일리어스로 추가하여 참조 아티팩트로 Registry 에 푸시합니다.
MODELS_OBJECT_VERSION = PUB_REFERENCE.digest # Weave 오브젝트 버전
MODELS_OBJECT_NAME = PUB_REFERENCE.name # Weave 오브젝트 이름
models_url = f"https://wandb.ai/{ENTITY}/{PROJECT}/weave/objects/{MODELS_OBJECT_NAME}/versions/{MODELS_OBJECT_VERSION}"
models_link = (
f"weave:///{ENTITY}/{PROJECT}/object/{MODELS_OBJECT_NAME}:{MODELS_OBJECT_VERSION}"
)
with wandb.init(project=PROJECT, entity=ENTITY) as run:
# 새 Artifact 생성
artifact_model = wandb.Artifact(
name="RagModel",
type="model",
description="Weave의 RagModel 모델 링크",
metadata={"url": models_url},
)
artifact_model.add_reference(models_link, name="model", checksum=False)
# 새 아티팩트 로그
run.log_artifact(artifact_model, aliases=[MODELS_OBJECT_VERSION])
# Registry 에 링크
run.link_artifact(
artifact_model, target_path="wandb32/wandb-registry-RAG Models/RAG Model"
)
[i18n] feedback_title
[i18n] feedback_question
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.