Launch multinode jobs with Volcano
3 minute read
이 튜토리얼에서는 Kubernetes에서 W&B와 Volcano를 사용하여 멀티 노드 트레이닝 작업을 시작하는 과정을 안내합니다.
개요
이 튜토리얼에서는 W&B Launch를 사용하여 Kubernetes에서 멀티 노드 작업을 실행하는 방법을 배웁니다. 따라할 단계는 다음과 같습니다.
- Weights & Biases 계정과 Kubernetes 클러스터가 있는지 확인합니다.
- volcano 작업을 위한 Launch 대기열을 만듭니다.
- Launch 에이전트를 Kubernetes 클러스터에 배포합니다.
- 분산 트레이닝 작업을 만듭니다.
- 분산 트레이닝을 시작합니다.
필수 조건
시작하기 전에 다음이 필요합니다.
- Weights & Biases 계정
- Kubernetes 클러스터
Launch 대기열 만들기
첫 번째 단계는 Launch 대기열을 만드는 것입니다. wandb.ai/launch로 이동하여 화면 오른쪽 상단에서 파란색 대기열 만들기 버튼을 누릅니다. 대기열 생성 창이 화면 오른쪽에서 밀려 나옵니다. 엔티티를 선택하고 이름을 입력한 다음 대기열 유형으로 Kubernetes를 선택합니다.
설정 섹션에서 volcano 작업 템플릿을 입력합니다. 이 대기열에서 시작된 모든 run은 이 작업 사양을 사용하여 생성되므로 필요에 따라 이 설정을 수정하여 작업을 사용자 정의할 수 있습니다.
이 설정 블록은 Kubernetes 작업 사양, volcano 작업 사양 또는 시작하려는 다른 사용자 정의 리소스 정의 (CRD)를 허용할 수 있습니다. 설정 블록에서 매크로를 사용할 수 있습니다를 사용하여 이 사양의 내용을 동적으로 설정할 수 있습니다.
이 튜토리얼에서는 volcano의 pytorch 플러그인을 사용하는 멀티 노드 pytorch 트레이닝에 대한 설정을 사용합니다. 다음 구성을 YAML 또는 JSON으로 복사하여 붙여넣을 수 있습니다.
kind: Job
spec:
tasks:
- name: master
policies:
- event: TaskCompleted
action: CompleteJob
replicas: 1
template:
spec:
containers:
- name: master
image: ${image_uri}
imagePullPolicy: IfNotPresent
restartPolicy: OnFailure
- name: worker
replicas: 1
template:
spec:
containers:
- name: worker
image: ${image_uri}
workingDir: /home
imagePullPolicy: IfNotPresent
restartPolicy: OnFailure
plugins:
pytorch:
- --master=master
- --worker=worker
- --port=23456
minAvailable: 1
schedulerName: volcano
metadata:
name: wandb-job-${run_id}
labels:
wandb_entity: ${entity_name}
wandb_project: ${project_name}
namespace: wandb
apiVersion: batch.volcano.sh/v1alpha1
{
"kind": "Job",
"spec": {
"tasks": [
{
"name": "master",
"policies": [
{
"event": "TaskCompleted",
"action": "CompleteJob"
}
],
"replicas": 1,
"template": {
"spec": {
"containers": [
{
"name": "master",
"image": "${image_uri}",
"imagePullPolicy": "IfNotPresent"
}
],
"restartPolicy": "OnFailure"
}
}
},
{
"name": "worker",
"replicas": 1,
"template": {
"spec": {
"containers": [
{
"name": "worker",
"image": "${image_uri}",
"workingDir": "/home",
"imagePullPolicy": "IfNotPresent"
}
],
"restartPolicy": "OnFailure"
}
}
}
],
"plugins": {
"pytorch": [
"--master=master",
"--worker=worker",
"--port=23456"
]
},
"minAvailable": 1,
"schedulerName": "volcano"
},
"metadata": {
"name": "wandb-job-${run_id}",
"labels": {
"wandb_entity": "${entity_name}",
"wandb_project": "${project_name}"
},
"namespace": "wandb"
},
"apiVersion": "batch.volcano.sh/v1alpha1"
}
대기열 생성을 완료하려면 창 하단의 대기열 만들기 버튼을 클릭합니다.
Volcano 설치
Kubernetes 클러스터에 Volcano를 설치하려면 공식 설치 가이드를 따르십시오.
Launch 에이전트 배포
대기열을 만들었으므로 대기열에서 작업을 가져와 실행할 Launch 에이전트를 배포해야 합니다. 가장 쉬운 방법은 W&B의 공식 helm-charts 리포지토리에서 launch-agent 차트를 사용하는 것입니다. README의 지침에 따라 차트를 Kubernetes 클러스터에 설치하고 에이전트가 앞에서 만든 대기열을 폴링하도록 구성해야 합니다.
트레이닝 작업 만들기
Volcano의 pytorch 플러그인은 pytorch 코드가 DDP를 올바르게 사용하는 한 MASTER_ADDR, RANK 및 WORLD_SIZE와 같이 pytorch DPP가 작동하는 데 필요한 환경 변수를 자동으로 구성합니다. 사용자 정의 python 코드에서 DDP를 사용하는 방법에 대한 자세한 내용은 pytorch 설명서를 참조하십시오.
Trainer를 통한 멀티 노드 트레이닝과도 호환됩니다.Launch 🚀
이제 대기열과 클러스터가 설정되었으므로 분산 트레이닝을 시작할 때입니다. 먼저 volcano의 pytorch 플러그인을 사용하여 임의의 데이터에 대해 간단한 다층 퍼셉트론을 트레이닝하는 작업을 사용합니다. 작업에 대한 소스 코드는 여기에서 찾을 수 있습니다.
이 작업을 시작하려면 작업 페이지로 이동하여 화면 오른쪽 상단에서 Launch 버튼을 클릭합니다. 작업을 시작할 대기열을 선택하라는 메시지가 표시됩니다.
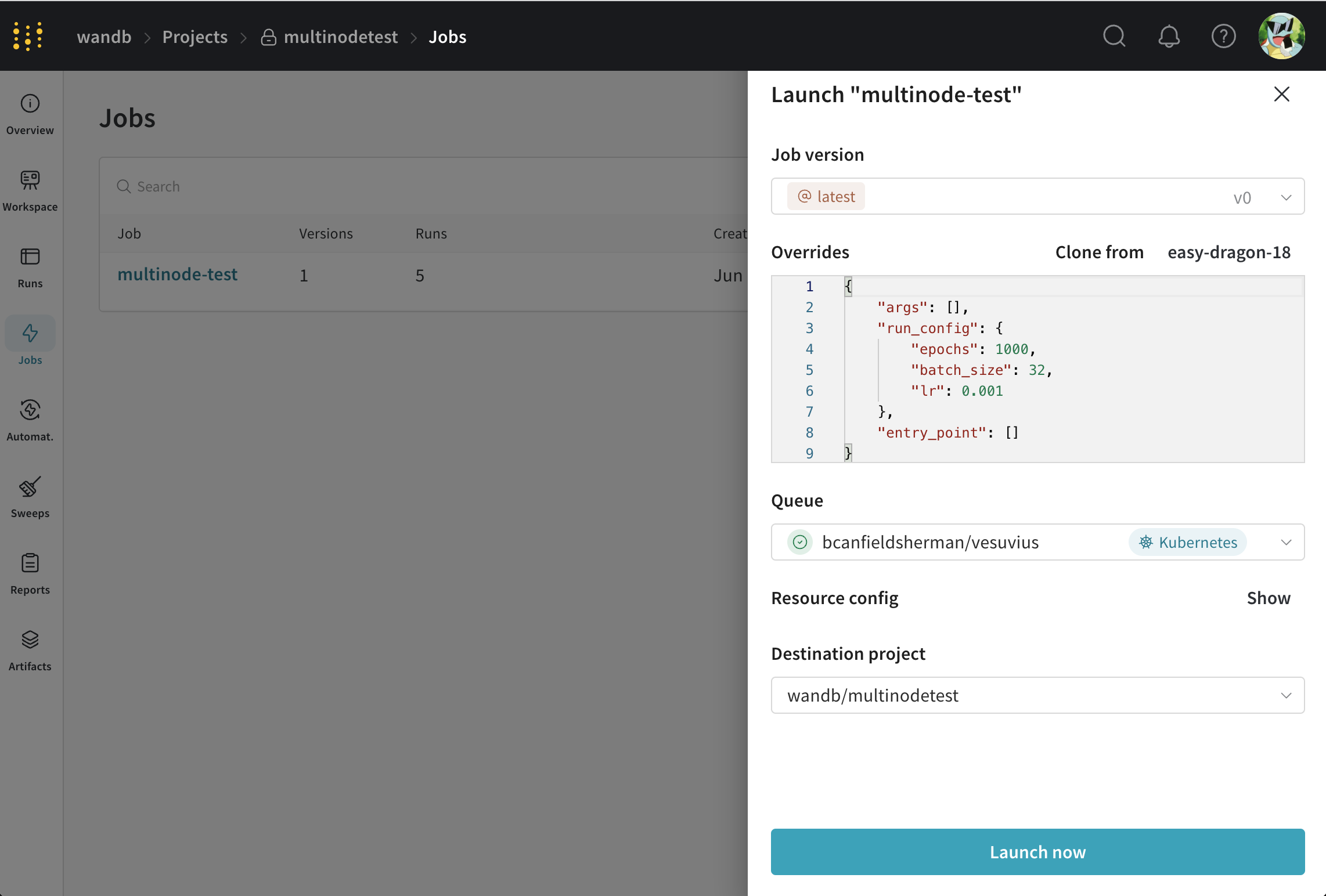
- 원하는 대로 작업 파라미터를 설정합니다.
- 앞에서 만든 대기열을 선택합니다.
- 리소스 구성 섹션에서 volcano 작업을 수정하여 작업의 파라미터를 수정합니다. 예를 들어
worker작업에서replicas필드를 변경하여 작업자 수를 변경할 수 있습니다. - Launch 🚀를 클릭합니다.
W&B UI에서 진행 상황을 모니터링하고 필요한 경우 작업을 중지할 수 있습니다.
[i18n] feedback_title
[i18n] feedback_question
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.