Visualize predictions with tables
5 minute read
이 가이드에서는 MNIST 데이터를 사용하여 PyTorch로 모델 예측을 추적, 시각화 및 비교하는 방법을 설명합니다.
다음 내용을 배우게 됩니다.
- 모델 트레이닝 또는 평가 중에 메트릭, 이미지, 텍스트 등을
wandb.Table()에 로그합니다. - 이러한 테이블을 보고, 정렬하고, 필터링하고, 그룹화하고, 조인하고, 대화식으로 쿼리하고, 탐색합니다.
- 특정 이미지, 하이퍼파라미터/모델 버전 또는 시간 단계에 따라 모델 예측 또는 결과를 동적으로 비교합니다.
Examples
Compare predicted scores for specific images
Live example: compare predictions after 1 vs 5 epochs of training →
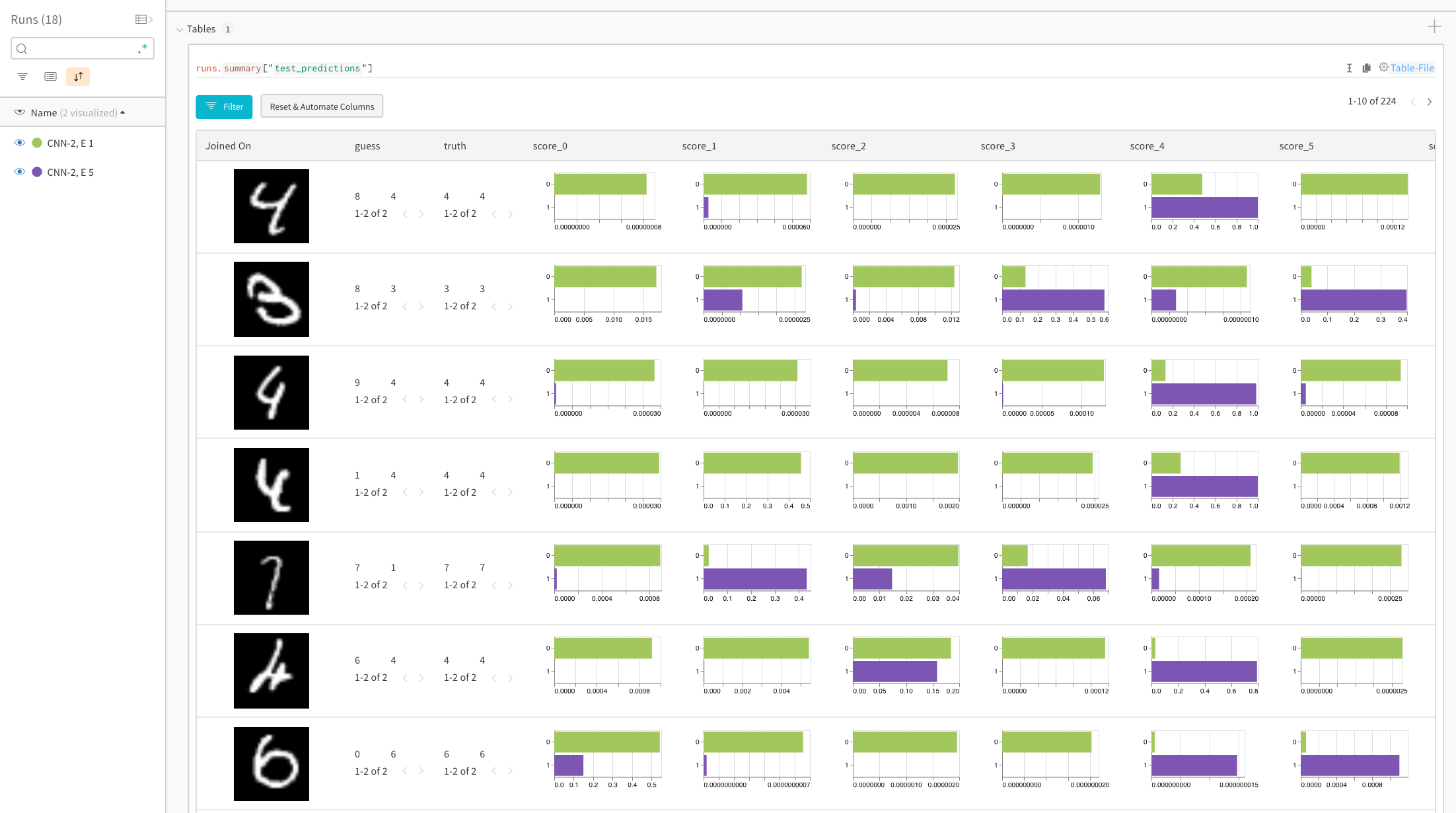
히스토그램은 두 모델 간의 클래스별 점수를 비교합니다. 각 히스토그램의 상단 녹색 막대는 1 에포크 동안만 트레이닝된 모델 “CNN-2, 1 epoch”(id 0)를 나타냅니다. 하단 보라색 막대는 5 에포크 동안 트레이닝된 모델 “CNN-2, 5 epochs”(id 1)를 나타냅니다. 이미지는 모델이 동의하지 않는 경우로 필터링됩니다. 예를 들어 첫 번째 행에서 “4"는 1 에포크 후 가능한 모든 숫자에 대해 높은 점수를 얻지만 5 에포크 후에는 올바른 레이블에서 가장 높은 점수를 얻고 나머지는 매우 낮은 점수를 얻습니다.
Focus on top errors over time
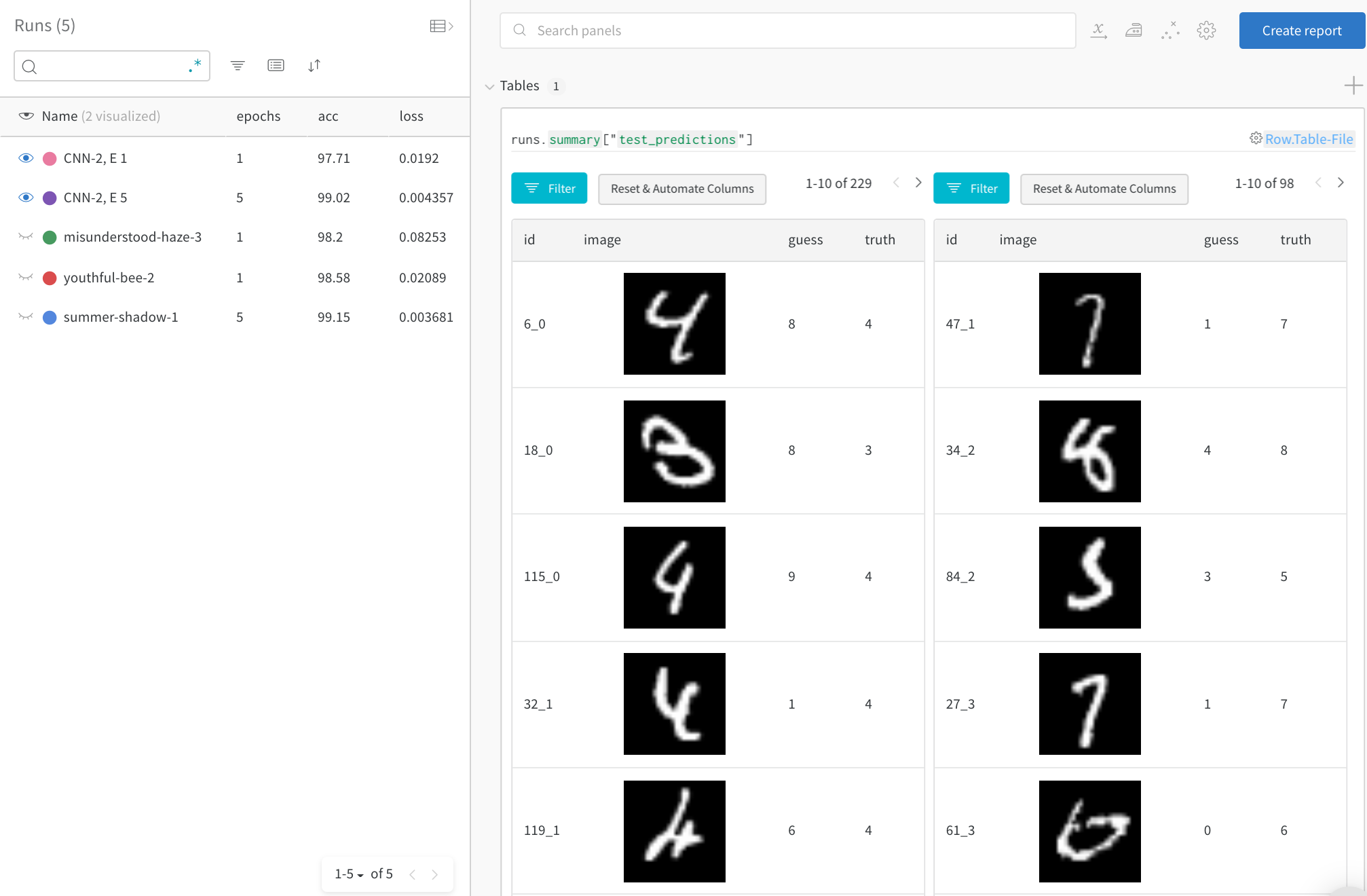
전체 테스트 데이터에서 잘못된 예측(“guess” != “truth"인 행으로 필터링)을 확인합니다. 1 트레이닝 에포크 후에는 229개의 잘못된 추측이 있지만 5 에포크 후에는 98개만 있습니다.
Compare model performance and find patterns
See full detail in a live example →
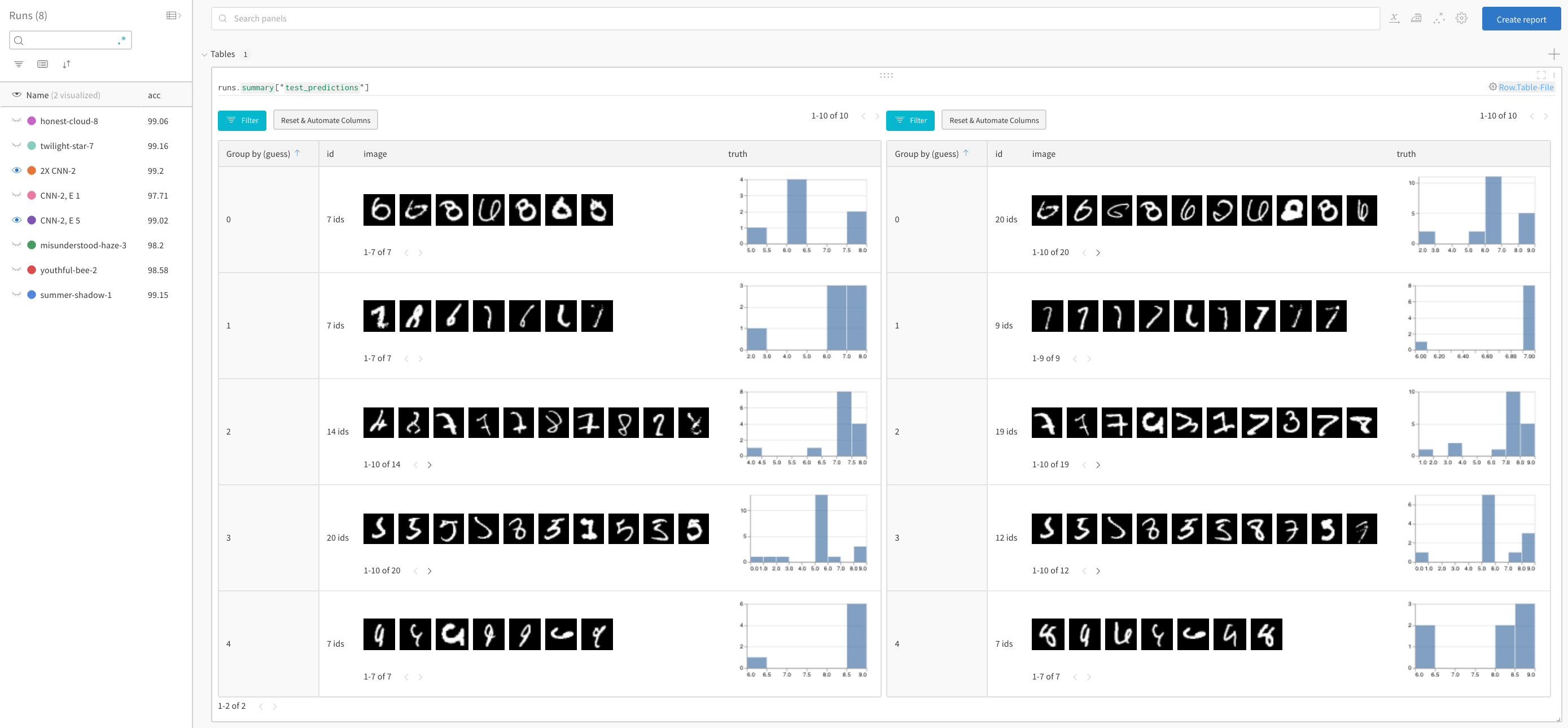
정답을 필터링하고 추측별로 그룹화하여 오분류된 이미지와 기본 실제 레이블 분포의 예를 두 모델에서 나란히 확인합니다. 레이어 크기와 학습률이 2배인 모델 변형이 왼쪽에 있고 베이스라인이 오른쪽에 있습니다. 베이스라인은 추측된 각 클래스에 대해 약간 더 많은 실수를 합니다.
Sign up or login
Sign up or login to W&B to see and interact with your experiments in the browser.
이 예에서는 Google Colab을 편리한 호스팅 환경으로 사용하지만 어디에서든 자체 트레이닝 스크립트를 실행하고 W&B의 experiment tracking tool을 사용하여 메트릭을 시각화할 수 있습니다.
!pip install wandb -qqq
계정에 로그인합니다.
import wandb
wandb.login()
WANDB_PROJECT = "mnist-viz"
0. 설정
종속성을 설치하고 MNIST를 다운로드하고 PyTorch를 사용하여 트레인 및 테스트 데이터셋을 만듭니다.
import torch
import torch.nn as nn
import torchvision
import torchvision.transforms as T
import torch.nn.functional as F
device = "cuda:0" if torch.cuda.is_available() else "cpu"
# 트레인 및 테스트 데이터로더를 만듭니다.
def get_dataloader(is_train, batch_size, slice=5):
"트레이닝 데이터로더를 가져옵니다."
ds = torchvision.datasets.MNIST(root=".", train=is_train, transform=T.ToTensor(), download=True)
loader = torch.utils.data.DataLoader(dataset=ds,
batch_size=batch_size,
shuffle=True if is_train else False,
pin_memory=True, num_workers=2)
return loader
1. 모델 및 트레이닝 스케줄 정의
- 실행할 에포크 수를 설정합니다. 각 에포크는 트레이닝 단계와 유효성 검사(테스트) 단계로 구성됩니다. 선택적으로 테스트 단계당 기록할 데이터 양을 구성합니다. 여기서는 데모를 단순화하기 위해 시각화할 배치 수와 배치당 이미지 수가 낮게 설정됩니다.
- 간단한 convolutional neural net을 정의합니다(pytorch-tutorial 코드 참조).
- PyTorch를 사용하여 트레인 및 테스트 세트를 로드합니다.
# 실행할 에포크 수
# 각 에포크에는 트레이닝 단계와 테스트 단계가 포함되므로
# 테스트 예측의 테이블 수를 설정하여 기록합니다.
EPOCHS = 1
# 각 테스트 단계에 대해 테스트 데이터에서 기록할 배치 수
# (데모를 단순화하기 위해 기본적으로 낮게 설정됨)
NUM_BATCHES_TO_LOG = 10 #79
# 테스트 배치당 기록할 이미지 수
# (데모를 단순화하기 위해 기본적으로 낮게 설정됨)
NUM_IMAGES_PER_BATCH = 32 #128
# 트레이닝 설정 및 하이퍼파라미터
NUM_CLASSES = 10
BATCH_SIZE = 32
LEARNING_RATE = 0.001
L1_SIZE = 32
L2_SIZE = 64
# 이를 변경하려면 인접 레이어의 모양을 변경해야 할 수 있습니다.
CONV_KERNEL_SIZE = 5
# 2 레이어 convolutional neural network를 정의합니다.
class ConvNet(nn.Module):
def __init__(self, num_classes=10):
super(ConvNet, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(1, L1_SIZE, CONV_KERNEL_SIZE, stride=1, padding=2),
nn.BatchNorm2d(L1_SIZE),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2))
self.layer2 = nn.Sequential(
nn.Conv2d(L1_SIZE, L2_SIZE, CONV_KERNEL_SIZE, stride=1, padding=2),
nn.BatchNorm2d(L2_SIZE),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2))
self.fc = nn.Linear(7*7*L2_SIZE, NUM_CLASSES)
self.softmax = nn.Softmax(NUM_CLASSES)
def forward(self, x):
# 주어진 레이어의 모양을 보려면 주석 처리를 해제하십시오.
#print("x: ", x.size())
out = self.layer1(x)
out = self.layer2(out)
out = out.reshape(out.size(0), -1)
out = self.fc(out)
return out
train_loader = get_dataloader(is_train=True, batch_size=BATCH_SIZE)
test_loader = get_dataloader(is_train=False, batch_size=2*BATCH_SIZE)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
2. 트레이닝을 실행하고 테스트 예측을 기록합니다.
모든 에포크에 대해 트레이닝 단계와 테스트 단계를 실행합니다. 각 테스트 단계마다 테스트 예측을 저장할 wandb.Table()을 만듭니다. 이러한 예측은 브라우저에서 시각화하고, 동적으로 쿼리하고, 나란히 비교할 수 있습니다.
# W&B: 이 모델의 트레이닝을 추적하기 위해 새 run을 초기화합니다.
wandb.init(project="table-quickstart")
# W&B: 구성을 사용하여 하이퍼파라미터를 기록합니다.
cfg = wandb.config
cfg.update({"epochs" : EPOCHS, "batch_size": BATCH_SIZE, "lr" : LEARNING_RATE,
"l1_size" : L1_SIZE, "l2_size": L2_SIZE,
"conv_kernel" : CONV_KERNEL_SIZE,
"img_count" : min(10000, NUM_IMAGES_PER_BATCH*NUM_BATCHES_TO_LOG)})
# 모델, 손실 및 옵티마이저를 정의합니다.
model = ConvNet(NUM_CLASSES).to(device)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=LEARNING_RATE)
# 테스트 이미지 배치의 예측을 기록하는 편의 함수
def log_test_predictions(images, labels, outputs, predicted, test_table, log_counter):
# 모든 클래스에 대한 신뢰도 점수를 얻습니다.
scores = F.softmax(outputs.data, dim=1)
log_scores = scores.cpu().numpy()
log_images = images.cpu().numpy()
log_labels = labels.cpu().numpy()
log_preds = predicted.cpu().numpy()
# 이미지 순서에 따라 ID를 추가합니다.
_id = 0
for i, l, p, s in zip(log_images, log_labels, log_preds, log_scores):
# 데이터 테이블에 필요한 정보를 추가합니다.
# ID, 이미지 픽셀, 모델의 추측, 실제 레이블, 모든 클래스에 대한 점수
img_id = str(_id) + "_" + str(log_counter)
test_table.add_data(img_id, wandb.Image(i), p, l, *s)
_id += 1
if _id == NUM_IMAGES_PER_BATCH:
break
# 모델을 트레이닝합니다.
total_step = len(train_loader)
for epoch in range(EPOCHS):
# 트레이닝 단계
for i, (images, labels) in enumerate(train_loader):
images = images.to(device)
labels = labels.to(device)
# forward 패스
outputs = model(images)
loss = criterion(outputs, labels)
# backward 및 최적화
optimizer.zero_grad()
loss.backward()
optimizer.step()
# W&B: UI에서 실시간으로 시각화된 트레이닝 단계에 대한 손실을 기록합니다.
wandb.log({"loss" : loss})
if (i+1) % 100 == 0:
print ('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}'
.format(epoch+1, EPOCHS, i+1, total_step, loss.item()))
# W&B: 각 테스트 단계에 대한 예측을 저장할 테이블을 만듭니다.
columns=["id", "image", "guess", "truth"]
for digit in range(10):
columns.append("score_" + str(digit))
test_table = wandb.Table(columns=columns)
# 모델을 테스트합니다.
model.eval()
log_counter = 0
with torch.no_grad():
correct = 0
total = 0
for images, labels in test_loader:
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
if log_counter < NUM_BATCHES_TO_LOG:
log_test_predictions(images, labels, outputs, predicted, test_table, log_counter)
log_counter += 1
total += labels.size(0)
correct += (predicted == labels).sum().item()
acc = 100 * correct / total
# W&B: UI에서 시각화하기 위해 트레이닝 에포크에서 정확도를 기록합니다.
wandb.log({"epoch" : epoch, "acc" : acc})
print('Test Accuracy of the model on the 10000 test images: {} %'.format(acc))
# W&B: 예측 테이블을 wandb에 기록합니다.
wandb.log({"test_predictions" : test_table})
# W&B: run을 완료된 것으로 표시합니다(다중 셀 노트북에 유용).
wandb.finish()
What’s next?
The next tutorial, you will learn how to optimize hyperparameters using W&B Sweeps. 다음 튜토리얼에서는 W&B Sweeps를 사용하여 하이퍼파라미터를 최적화하는 방법을 배웁니다.
[i18n] feedback_title
[i18n] feedback_question
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.