Tune hyperparameters with sweeps
6 minute read
원하는 메트릭(예: 모델 정확도)을 충족하는 머신 러닝 모델을 찾는 것은 일반적으로 여러 번의 반복이 필요한 중복적인 작업입니다. 설상가상으로, 주어진 트레이닝 run에 어떤 하이퍼파라미터 조합을 사용해야 할지 명확하지 않을 수도 있습니다.
Weights & Biases Sweeps를 사용하여 학습 속도, 배치 크기, 숨겨진 레이어 수, 옵티마이저 유형 등과 같은 하이퍼파라미터 값의 조합을 자동으로 검색하여 원하는 메트릭을 기반으로 모델을 최적화하는 조직적이고 효율적인 방법을 만드십시오.
이 튜토리얼에서는 W&B PyTorch 인테그레이션을 사용하여 하이퍼파라미터 검색을 만듭니다. 비디오 튜토리얼을 따라하십시오.
Sweeps: 개요
Weights & Biases를 사용하여 하이퍼파라미터 스윕을 실행하는 것은 매우 쉽습니다. 간단한 3단계만 거치면 됩니다.
-
스윕 정의: 검색할 파라미터, 검색 전략, 최적화 메트릭 등을 지정하는 사전 또는 YAML 파일을 만들어 이를 수행합니다.
-
스윕 초기화: 한 줄의 코드로 스윕을 초기화하고 스윕 구성 사전을 전달합니다.
sweep_id = wandb.sweep(sweep_config) -
스윕 에이전트 실행: 또한 한 줄의 코드로 수행되며
wandb.agent()를 호출하고 모델 아키텍처를 정의하고 트레이닝하는 함수와 함께 실행할sweep_id를 전달합니다.wandb.agent(sweep_id, function=train)
시작하기 전에
W&B를 설치하고 W&B Python SDK를 노트북으로 가져옵니다.
!pip install로 설치:
!pip install wandb -Uq
- W&B 가져오기:
import wandb
- W&B에 로그인하고 메시지가 표시되면 API 키를 제공합니다.
wandb.login()
1단계: 스윕 정의
W&B Sweep은 수많은 하이퍼파라미터 값을 시도하는 전략과 해당 값을 평가하는 코드를 결합합니다. 스윕을 시작하기 전에 _스윕 구성_으로 스윕 전략을 정의해야 합니다.
Jupyter Notebook에서 스윕을 시작하는 경우 스윕에 대해 생성하는 스윕 구성은 중첩된 사전 형식이어야 합니다.
커맨드라인 내에서 스윕을 실행하는 경우 YAML 파일로 스윕 구성을 지정해야 합니다.
검색 방법 선택
먼저 구성 사전 내에서 하이퍼파라미터 검색 방법을 지정합니다. 선택할 수 있는 세 가지 하이퍼파라미터 검색 전략(Grid, Random, 베이지안 탐색)이 있습니다.
이 튜토리얼에서는 랜덤 검색을 사용합니다. 노트북 내에서 사전을 만들고 method 키에 대해 random을 지정합니다.
sweep_config = {
'method': 'random'
}
최적화할 메트릭을 지정합니다. 랜덤 검색 방법을 사용하는 스윕의 경우 메트릭과 목표를 지정할 필요가 없습니다. 그러나 나중에 참조할 수 있으므로 스윕 목표를 추적하는 것이 좋습니다.
metric = {
'name': 'loss',
'goal': 'minimize'
}
sweep_config['metric'] = metric
검색할 하이퍼파라미터 지정
이제 스윕 구성에 검색 방법이 지정되었으므로 검색할 하이퍼파라미터를 지정합니다.
이를 위해 parameter 키에 하나 이상의 하이퍼파라미터 이름을 지정하고 value 키에 하나 이상의 하이퍼파라미터 값을 지정합니다.
지정된 하이퍼파라미터에 대해 검색하는 값은 조사하는 하이퍼파라미터의 유형에 따라 다릅니다.
예를 들어, 머신 러닝 옵티마이저를 선택하는 경우 Adam 옵티마이저 및 확률적 그레이디언트 하강과 같이 하나 이상의 유한 옵티마이저 이름을 지정해야 합니다.
parameters_dict = {
'optimizer': {
'values': ['adam', 'sgd']
},
'fc_layer_size': {
'values': [128, 256, 512]
},
'dropout': {
'values': [0.3, 0.4, 0.5]
},
}
sweep_config['parameters'] = parameters_dict
때로는 하이퍼파라미터를 추적하되 해당 값을 변경하지 않으려는 경우가 있습니다. 이 경우 하이퍼파라미터를 스윕 구성에 추가하고 사용하려는 정확한 값을 지정합니다. 예를 들어, 다음 코드 셀에서 epochs는 1로 설정됩니다.
parameters_dict.update({
'epochs': {
'value': 1}
})
random 검색의 경우
파라미터의 모든 values는 지정된 run에서 선택될 가능성이 동일합니다.
또는
명명된 distribution과
평균 mu와 normal 분포의 표준 편차 sigma와 같은 파라미터를 지정할 수 있습니다.
parameters_dict.update({
'learning_rate': {
# 0과 0.1 사이의 플랫 분포
'distribution': 'uniform',
'min': 0,
'max': 0.1
},
'batch_size': {
# 32에서 256 사이의 정수
# 균등하게 분포된 로그 사용
'distribution': 'q_log_uniform_values',
'q': 8,
'min': 32,
'max': 256,
}
})
완료되면 sweep_config는
시도하는 데 관심 있는 parameters와
시도하는 데 사용할 method를 정확히 지정하는 중첩된 사전입니다.
스윕 구성이 어떻게 보이는지 살펴봅시다.
import pprint
pprint.pprint(sweep_config)
전체 구성 옵션 목록은 스윕 구성 옵션을 참조하십시오.
values를 시도하는 것이 좋습니다. 예를 들어, 앞의 스윕 구성에는 layer_size 및 dropout 파라미터 키에 대해 지정된 유한 값 목록이 있습니다.2단계: 스윕 초기화
검색 전략을 정의했으면 이제 이를 구현할 항목을 설정할 차례입니다.
W&B는 스윕 컨트롤러를 사용하여 클라우드 또는 로컬에서 하나 이상의 머신에서 스윕을 관리합니다. 이 튜토리얼에서는 W&B에서 관리하는 스윕 컨트롤러를 사용합니다.
스윕 컨트롤러는 스윕을 관리하지만 실제로 스윕을 실행하는 구성 요소를 _스윕 에이전트_라고 합니다.
노트북 내에서 wandb.sweep 메서드를 사용하여 스윕 컨트롤러를 활성화할 수 있습니다. 이전에 정의한 스윕 구성 사전을 sweep_config 필드에 전달합니다.
sweep_id = wandb.sweep(sweep_config, project="pytorch-sweeps-demo")
wandb.sweep 함수는 나중에 스윕을 활성화하는 데 사용할 sweep_id를 반환합니다.
커맨드라인에서 이 함수는 다음으로 대체됩니다.
wandb sweep config.yaml
터미널에서 W&B Sweeps를 만드는 방법에 대한 자세한 내용은 W&B Sweep 연습을 참조하십시오.
3단계: 머신 러닝 코드 정의
스윕을 실행하기 전에 시도하려는 하이퍼파라미터 값을 사용하는 트레이닝 절차를 정의합니다. W&B Sweeps를 트레이닝 코드에 통합하는 핵심은 각 트레이닝 실험에 대해 트레이닝 논리가 스윕 구성에 정의된 하이퍼파라미터 값에 엑세스할 수 있는지 확인하는 것입니다.
진행 중인 코드 예제에서 도우미 함수 build_dataset, build_network, build_optimizer 및 train_epoch는 스윕 하이퍼파라미터 구성 사전에 엑세스합니다.
노트북에서 진행 중인 머신 러닝 트레이닝 코드를 실행합니다. 이 함수는 PyTorch에서 기본 완전 연결 신경망을 정의합니다.
import torch
import torch.optim as optim
import torch.nn.functional as F
import torch.nn as nn
from torchvision import datasets, transforms
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
def train(config=None):
# Initialize a new wandb run
with wandb.init(config=config):
# If called by wandb.agent, as below,
# this config will be set by Sweep Controller
config = wandb.config
loader = build_dataset(config.batch_size)
network = build_network(config.fc_layer_size, config.dropout)
optimizer = build_optimizer(network, config.optimizer, config.learning_rate)
for epoch in range(config.epochs):
avg_loss = train_epoch(network, loader, optimizer)
wandb.log({"loss": avg_loss, "epoch": epoch})
train 함수 내에서 다음 W&B Python SDK 메서드를 확인할 수 있습니다.
wandb.init(): 새 W&B run을 초기화합니다. 각 run은 트레이닝 함수를 한 번 실행하는 것입니다.wandb.config: 실험하려는 하이퍼파라미터로 스윕 구성을 전달합니다.wandb.log(): 각 에포크에 대한 트레이닝 손실을 기록합니다.
진행 중인 셀은 네 가지 함수 build_dataset, build_network, build_optimizer 및 train_epoch를 정의합니다.
이러한 함수는 기본 PyTorch 파이프라인의 표준 부분이며
해당 구현은 W&B의 사용에 영향을 받지 않습니다.
def build_dataset(batch_size):
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))])
# download MNIST training dataset
dataset = datasets.MNIST(".", train=True, download=True,
transform=transform)
sub_dataset = torch.utils.data.Subset(
dataset, indices=range(0, len(dataset), 5))
loader = torch.utils.data.DataLoader(sub_dataset, batch_size=batch_size)
return loader
def build_network(fc_layer_size, dropout):
network = nn.Sequential( # fully connected, single hidden layer
nn.Flatten(),
nn.Linear(784, fc_layer_size), nn.ReLU(),
nn.Dropout(dropout),
nn.Linear(fc_layer_size, 10),
nn.LogSoftmax(dim=1))
return network.to(device)
def build_optimizer(network, optimizer, learning_rate):
if optimizer == "sgd":
optimizer = optim.SGD(network.parameters(),
lr=learning_rate, momentum=0.9)
elif optimizer == "adam":
optimizer = optim.Adam(network.parameters(),
lr=learning_rate)
return optimizer
def train_epoch(network, loader, optimizer):
cumu_loss = 0
for _, (data, target) in enumerate(loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
# ➡ Forward pass
loss = F.nll_loss(network(data), target)
cumu_loss += loss.item()
# ⬅ Backward pass + weight update
loss.backward()
optimizer.step()
wandb.log({"batch loss": loss.item()})
return cumu_loss / len(loader)
PyTorch로 W&B를 계측하는 방법에 대한 자세한 내용은 이 Colab을 참조하십시오.
4단계: 스윕 에이전트 활성화
이제 스윕 구성이 정의되었고 해당 하이퍼파라미터를 대화형으로 활용할 수 있는 트레이닝 스크립트가 있으므로 스윕 에이전트를 활성화할 준비가 되었습니다. 스윕 에이전트는 스윕 구성에 정의된 하이퍼파라미터 값 집합으로 실험을 실행하는 역할을 합니다.
wandb.agent 메서드로 스윕 에이전트를 만듭니다. 다음을 제공합니다.
- 에이전트가 속한 스윕(
sweep_id) - 스윕이 실행해야 하는 함수. 이 예제에서는 스윕이
train함수를 사용합니다. - (선택 사항) 스윕 컨트롤러에 요청할 구성 수(
count)
sweep_id로 여러 스윕 에이전트를 시작할 수 있습니다
다른 컴퓨팅 리소스에서. 스윕 컨트롤러는 정의한 스윕 구성에 따라 함께 작동하는지 확인합니다.진행 중인 셀은 트레이닝 함수(train)를 5번 실행하는 스윕 에이전트를 활성화합니다.
wandb.agent(sweep_id, train, count=5)
random 검색 방법이 지정되었으므로 스윕 컨트롤러는 무작위로 생성된 하이퍼파라미터 값을 제공합니다.터미널에서 W&B Sweeps를 만드는 방법에 대한 자세한 내용은 W&B Sweep 연습을 참조하십시오.
스윕 결과 시각화
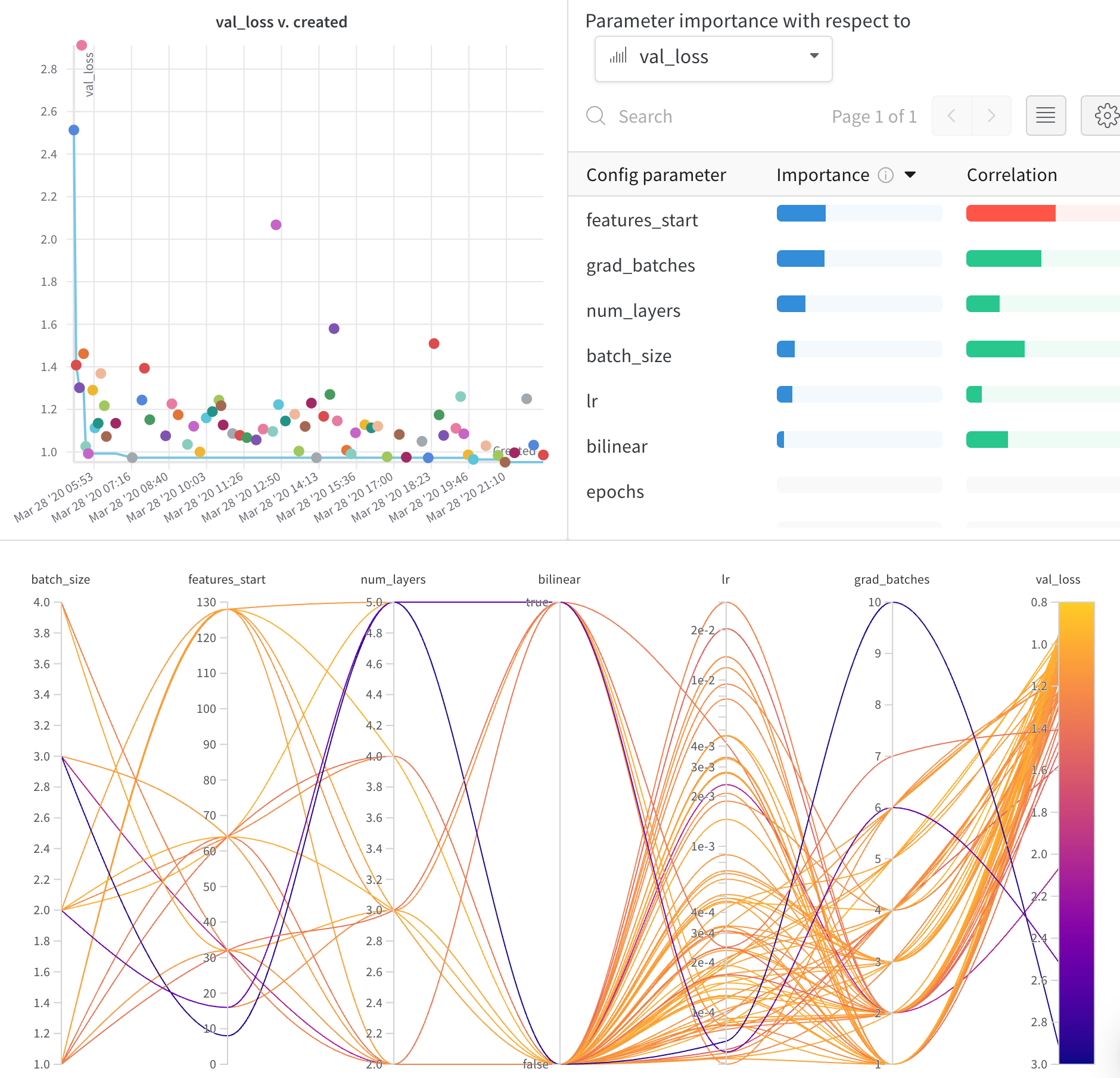
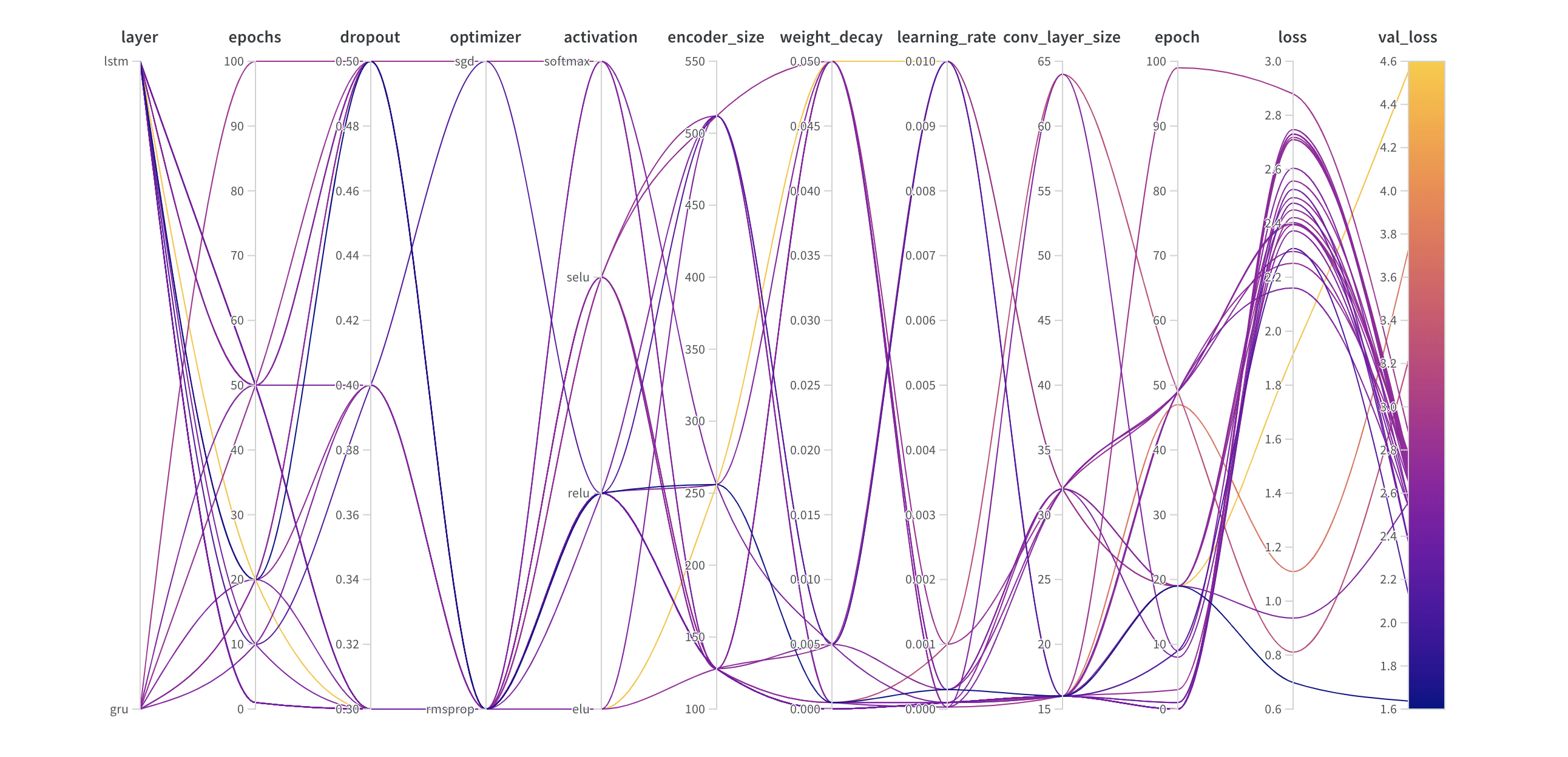
병렬 좌표 플롯
이 플롯은 하이퍼파라미터 값을 모델 메트릭에 매핑합니다. 최고의 모델 성능으로 이어진 하이퍼파라미터 조합을 파악하는 데 유용합니다.
하이퍼파라미터 중요도 플롯
하이퍼파라미터 중요도 플롯은 메트릭의 가장 적합한 예측 변수인 하이퍼파라미터를 나타냅니다. 기능 중요도(랜덤 포레스트 모델에서)와 상관 관계(암시적으로 선형 모델)를 보고합니다.
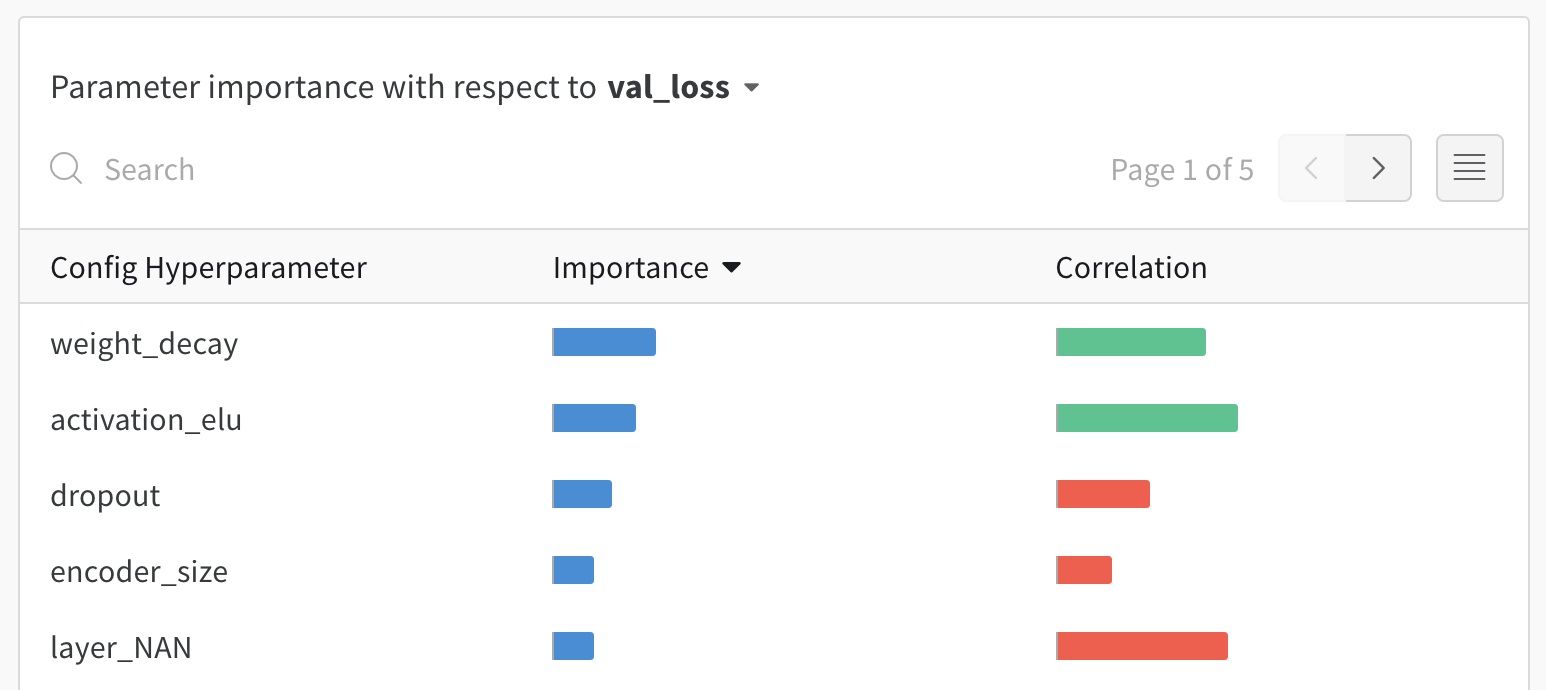
이러한 시각화는 가장 중요한 파라미터(및 값 범위)에 집중하여 추가 탐색할 가치가 있으므로 비싼 하이퍼파라미터 최적화를 실행하는 데 시간과 리소스를 절약하는 데 도움이 될 수 있습니다.
W&B Sweeps에 대해 자세히 알아보기
간단한 트레이닝 스크립트와 몇 가지 스윕 구성 방식을 만들어 사용해 볼 수 있습니다. 이러한 방식을 사용해 보시기 바랍니다.
해당 리포지토리에는 베이지안 Hyperband 및 Hyperopt와 같은 고급 스윕 기능을 사용해 보는 데 도움이 되는 예제도 있습니다.
[i18n] feedback_title
[i18n] feedback_question
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.