Spin up a single node GPU cluster with Minikube
8 minute read
GPU 워크로드를 예약하고 실행할 수 있는 Minikube 클러스터에 W&B Launch를 설정합니다.
이 튜토리얼은 여러 개의 GPU가 있는 시스템에 직접 엑세스할 수 있는 사용자를 안내하기 위한 것입니다. 클라우드 시스템을 임대하는 사용자에게는 적합하지 않습니다.
클라우드 시스템에 Minikube 클러스터를 설정하려면 클라우드 공급자를 사용하여 GPU를 지원하는 Kubernetes 클러스터를 만드는 것이 좋습니다. 예를 들어 AWS, GCP, Azure, Coreweave 및 기타 클라우드 공급자에는 GPU를 지원하는 Kubernetes 클러스터를 생성하는 툴이 있습니다.
단일 GPU가 있는 시스템에서 GPU 예약을 위해 Minikube 클러스터를 설정하려면 Launch Docker queue를 사용하는 것이 좋습니다. 재미로 튜토리얼을 따라 할 수는 있지만 GPU 예약은 그다지 유용하지 않습니다.
배경
Nvidia container toolkit을 사용하면 Docker에서 GPU 지원 워크플로우를 쉽게 실행할 수 있습니다. 한 가지 제한 사항은 볼륨별 GPU 예약을 기본적으로 지원하지 않는다는 것입니다. docker run 코맨드로 GPU를 사용하려면 ID별로 특정 GPU를 요청하거나 모든 GPU를 요청해야 하므로 많은 분산 GPU 지원 워크로드가 비실용적입니다. Kubernetes는 볼륨 요청별로 예약을 지원하지만 GPU 예약을 통해 로컬 Kubernetes 클러스터를 설정하는 데 상당한 시간과 노력이 필요할 수 있습니다. 가장 인기 있는 단일 노드 Kubernetes 클러스터 실행 툴 중 하나인 Minikube는 최근에 GPU 예약 지원을 출시했습니다. 🎉 이 튜토리얼에서는 다중 GPU 시스템에서 Minikube 클러스터를 생성하고 W&B Launch 🚀를 사용하여 클러스터에 동시 안정 확산 추론 작업을 실행합니다.
전제 조건
시작하기 전에 다음이 필요합니다.
- W&B 계정.
- 다음이 설치 및 실행 중인 Linux 시스템:
- Docker 런타임
- 사용하려는 GPU 드라이버
- Nvidia container toolkit
n1-standard-16 Google Cloud Compute Engine 인스턴스를 사용했습니다.Launch 작업 대기열 생성
먼저 Launch 작업에 대한 Launch 대기열을 만듭니다.
- wandb.ai/launch (또는 개인 W&B 서버를 사용하는 경우
<your-wandb-url>/launch)로 이동합니다. - 화면 오른쪽 상단에서 파란색 대기열 생성 버튼을 클릭합니다. 대기열 생성 서랍이 화면 오른쪽에서 밀려 나옵니다.
- 엔티티를 선택하고 이름을 입력한 다음 대기열 유형으로 Kubernetes를 선택합니다.
- 서랍의 설정 섹션은 Launch 대기열에 대한 Kubernetes 작업 사양을 입력할 위치입니다. 이 대기열에서 실행되는 모든 run은 이 작업 사양을 사용하여 생성되므로 필요에 따라 이 설정을 수정하여 작업을 사용자 정의할 수 있습니다. 이 튜토리얼에서는 아래 샘플 설정을 YAML 또는 JSON으로 대기열 설정에 복사하여 붙여넣을 수 있습니다.
spec:
template:
spec:
containers:
- image: ${image_uri}
resources:
limits:
cpu: 4
memory: 12Gi
nvidia.com/gpu: '{{gpus}}'
restartPolicy: Never
backoffLimit: 0
{
"spec": {
"template": {
"spec": {
"containers": [
{
"image": "${image_uri}",
"resources": {
"limits": {
"cpu": 4,
"memory": "12Gi",
"nvidia.com/gpu": "{{gpus}}"
}
}
}
],
"restartPolicy": "Never"
}
},
"backoffLimit": 0
}
}
대기열 설정에 대한 자세한 내용은 Kubernetes에서 Launch 설정 및 고급 대기열 설정 가이드를 참조하십시오.
${image_uri} 및 {{gpus}} 문자열은 대기열 설정에서 사용할 수 있는 두 가지 종류의
변수 템플릿의 예입니다. ${image_uri}
템플릿은 에이전트가 실행하는 작업의 이미지 URI로 대체됩니다. {{gpus}} 템플릿은 작업을 제출할 때 Launch UI, CLI 또는 SDK에서 재정의할 수 있는 템플릿 변수를 만드는 데 사용됩니다. 이러한 값은 작업에서 사용하는 이미지 및 GPU 리소스를 제어하기 위해 올바른 필드를 수정하도록 작업 사양에 배치됩니다.
- 구성 구문 분석 버튼을 클릭하여
gpus템플릿 변수 사용자 정의를 시작합니다. - 유형을
정수로 설정하고 기본값, 최소값 및 최대값을 원하는 값으로 설정합니다. 템플릿 변수의 제약 조건을 위반하는 이 대기열에 run을 제출하려는 시도는 거부됩니다.
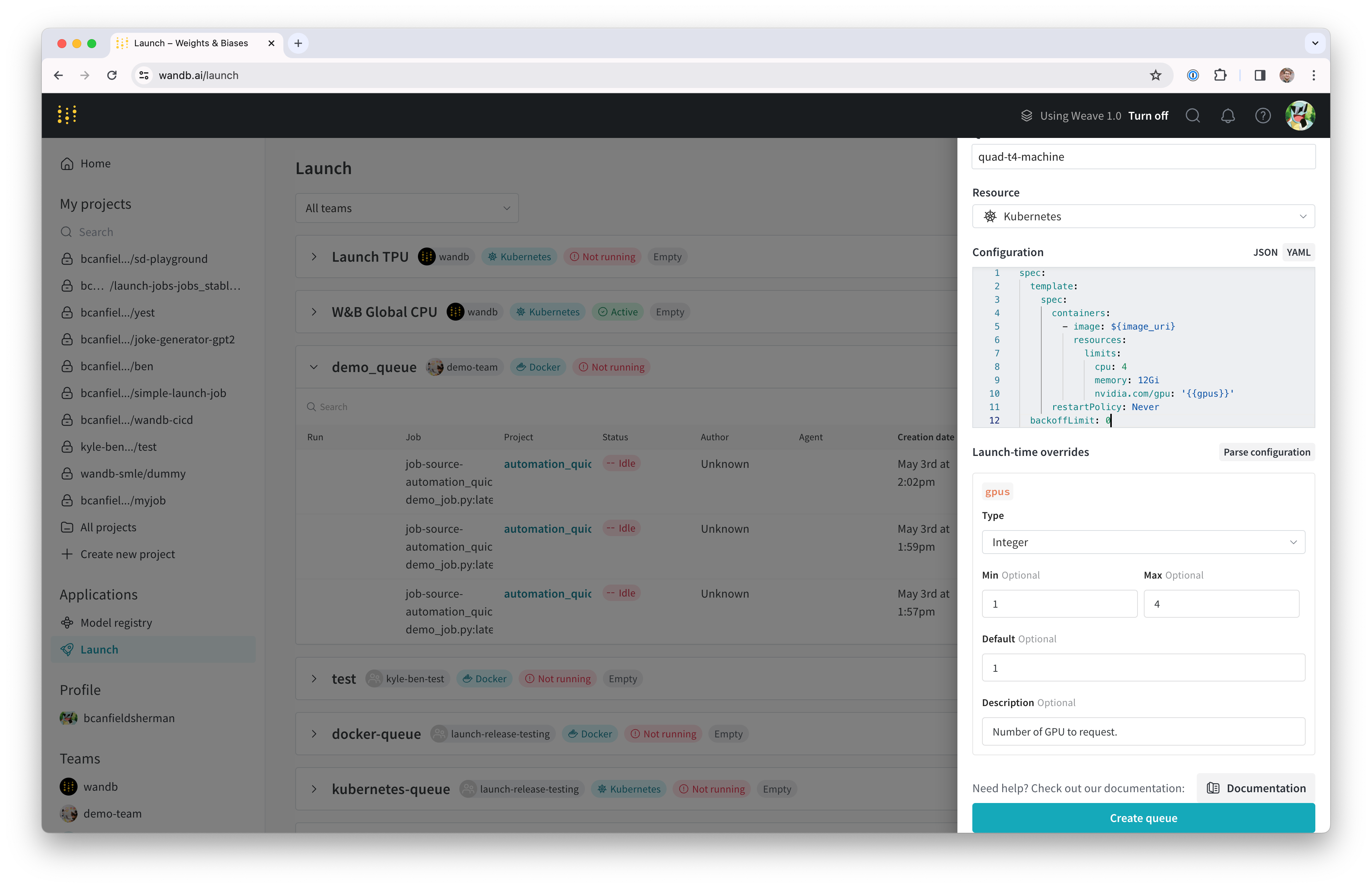
- 대기열 생성을 클릭하여 대기열을 만듭니다. 새 대기열의 대기열 페이지로 리디렉션됩니다.
다음 섹션에서는 생성한 대기열에서 작업을 가져와 실행할 수 있는 에이전트를 설정합니다.
Docker + NVIDIA CTK 설정
이미 시스템에 Docker 및 Nvidia container toolkit이 설정되어 있는 경우 이 섹션을 건너뛸 수 있습니다.
시스템에 Docker 컨테이너 엔진을 설정하는 방법에 대한 지침은 Docker 설명서를 참조하십시오.
Docker를 설치한 후 Nvidia 설명서의 지침에 따라 Nvidia container toolkit을 설치합니다.
컨테이너 런타임이 GPU에 엑세스할 수 있는지 확인하려면 다음을 실행할 수 있습니다.
docker run --gpus all ubuntu nvidia-smi
시스템에 연결된 GPU를 설명하는 nvidia-smi 출력이 표시됩니다. 예를 들어 설정에서 출력은 다음과 같습니다.
Wed Nov 8 23:25:53 2023
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 525.105.17 Driver Version: 525.105.17 CUDA Version: 12.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla T4 Off | 00000000:00:04.0 Off | 0 |
| N/A 38C P8 9W / 70W | 2MiB / 15360MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
| 1 Tesla T4 Off | 00000000:00:05.0 Off | 0 |
| N/A 38C P8 9W / 70W | 2MiB / 15360MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
| 2 Tesla T4 Off | 00000000:00:06.0 Off | 0 |
| N/A 40C P8 9W / 70W | 2MiB / 15360MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
| 3 Tesla T4 Off | 00000000:00:07.0 Off | 0 |
| N/A 39C P8 9W / 70W | 2MiB / 15360MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
Minikube 설정
Minikube의 GPU 지원에는 v1.32.0 이상의 버전이 필요합니다. 최신 설치 도움말은 Minikube 설치 설명서를 참조하십시오. 이 튜토리얼에서는 다음 코맨드를 사용하여 최신 Minikube 릴리스를 설치했습니다.
curl -LO https://storage.googleapis.com/minikube/releases/latest/minikube-linux-amd64
sudo install minikube-linux-amd64 /usr/local/bin/minikube
다음 단계는 GPU를 사용하여 Minikube 클러스터를 시작하는 것입니다. 시스템에서 다음을 실행합니다.
minikube start --gpus all
위의 코맨드 출력은 클러스터가 성공적으로 생성되었는지 여부를 나타냅니다.
Launch 에이전트 시작
새 클러스터에 대한 Launch 에이전트는 wandb launch-agent를 직접 호출하거나 W&B에서 관리하는 헬름 차트를 사용하여 Launch 에이전트를 배포하여 시작할 수 있습니다.
이 튜토리얼에서는 호스트 시스템에서 직접 에이전트를 실행합니다.
에이전트를 로컬로 실행하려면 기본 Kubernetes API 컨텍스트가 Minikube 클러스터를 참조하는지 확인하십시오. 그런 다음 다음을 실행합니다.
pip install "wandb[launch]"
에이전트의 종속성을 설치합니다. 에이전트 인증을 설정하려면 wandb login을 실행하거나 WANDB_API_KEY 환경 변수를 설정합니다.
에이전트를 시작하려면 다음 코맨드를 실행합니다.
wandb launch-agent -j <max-number-concurrent-jobs> -q <queue-name> -e <queue-entity>
터미널 내에서 Launch 에이전트가 폴링 메시지를 인쇄하기 시작하는 것을 볼 수 있습니다.
축하합니다. Launch 대기열을 폴링하는 Launch 에이전트가 있습니다. 작업이 대기열에 추가되면 에이전트가 작업을 선택하고 Minikube 클러스터에서 실행되도록 예약합니다.
작업 실행
에이전트에 작업을 보내 보겠습니다. W&B 계정에 로그인한 터미널에서 다음을 사용하여 간단한 “hello world"를 실행할 수 있습니다.
wandb launch -d wandb/job_hello_world:main -p <target-wandb-project> -q <your-queue-name> -e <your-queue-entity>
원하는 작업 또는 이미지로 테스트할 수 있지만 클러스터에서 이미지를 가져올 수 있는지 확인하십시오. 자세한 내용은 Minikube 설명서를 참조하십시오. 공개 작업 중 하나를 사용하여 테스트할 수도 있습니다.
(선택 사항) NFS를 사용한 모델 및 데이터 캐싱
ML 워크로드의 경우 여러 작업에서 동일한 데이터에 엑세스해야 하는 경우가 많습니다. 예를 들어 데이터셋 또는 모델 가중치와 같은 대규모 아티팩트를 반복적으로 다운로드하지 않도록 공유 캐시를 사용하고 싶을 수 있습니다. Kubernetes는 영구 볼륨 및 영구 볼륨 클레임을 통해 이를 지원합니다. 영구 볼륨은 Kubernetes 워크로드에서 volumeMounts를 생성하는 데 사용할 수 있으며 공유 캐시에 대한 직접 파일 시스템 엑세스를 제공합니다.
이 단계에서는 모델 가중치에 대한 공유 캐시로 사용할 수 있는 네트워크 파일 시스템 (NFS) 서버를 설정합니다. 첫 번째 단계는 NFS를 설치하고 구성하는 것입니다. 이 프로세스는 운영 체제에 따라 다릅니다. VM이 Ubuntu를 실행 중이므로 nfs-kernel-server를 설치하고 /srv/nfs/kubedata에 내보내기를 구성했습니다.
sudo apt-get install nfs-kernel-server
sudo mkdir -p /srv/nfs/kubedata
sudo chown nobody:nogroup /srv/nfs/kubedata
sudo sh -c 'echo "/srv/nfs/kubedata *(rw,sync,no_subtree_check,no_root_squash,no_all_squash,insecure)" >> /etc/exports'
sudo exportfs -ra
sudo systemctl restart nfs-kernel-server
호스트 파일 시스템에서 서버의 내보내기 위치와 NFS 서버의 로컬 IP 어드레스를 기록해 두십시오. 다음 단계에서 이 정보가 필요합니다.
다음으로 이 NFS에 대한 영구 볼륨 및 영구 볼륨 클레임을 만들어야 합니다. 영구 볼륨은 고도로 사용자 정의할 수 있지만 단순성을 위해 여기서는 간단한 구성을 사용합니다.
아래 yaml을 nfs-persistent-volume.yaml이라는 파일에 복사하고 원하는 볼륨 용량과 클레임 요청을 채우십시오. PersistentVolume.spec.capcity.storage 필드는 기본 볼륨의 최대 크기를 제어합니다. PersistentVolumeClaim.spec.resources.requests.stroage는 특정 클레임에 할당된 볼륨 용량을 제한하는 데 사용할 수 있습니다. 유스 케이스의 경우 각각에 대해 동일한 값을 사용하는 것이 좋습니다.
apiVersion: v1
kind: PersistentVolume
metadata:
name: nfs-pv
spec:
capacity:
storage: 100Gi # 원하는 용량으로 설정하십시오.
accessModes:
- ReadWriteMany
nfs:
server: <your-nfs-server-ip> # TODO: 이 부분을 채우십시오.
path: '/srv/nfs/kubedata' # 또는 사용자 정의 경로
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: nfs-pvc
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 100Gi # 원하는 용량으로 설정하십시오.
storageClassName: ''
volumeName: nfs-pv
다음을 사용하여 클러스터에서 리소스를 만듭니다.
kubectl apply -f nfs-persistent-volume.yaml
run이 이 캐시를 사용하려면 Launch 대기열 설정에 volumes 및 volumeMounts를 추가해야 합니다. Launch 설정을 편집하려면 wandb.ai/launch (또는 wandb 서버의 사용자의 경우 <your-wandb-url>/launch)로 돌아가서 대기열을 찾고 대기열 페이지를 클릭한 다음 설정 편집 탭을 클릭합니다. 원래 설정을 다음과 같이 수정할 수 있습니다.
spec:
template:
spec:
containers:
- image: ${image_uri}
resources:
limits:
cpu: 4
memory: 12Gi
nvidia.com/gpu: "{{gpus}}"
volumeMounts:
- name: nfs-storage
mountPath: /root/.cache
restartPolicy: Never
volumes:
- name: nfs-storage
persistentVolumeClaim:
claimName: nfs-pvc
backoffLimit: 0
{
"spec": {
"template": {
"spec": {
"containers": [
{
"image": "${image_uri}",
"resources": {
"limits": {
"cpu": 4,
"memory": "12Gi",
"nvidia.com/gpu": "{{gpus}}"
},
"volumeMounts": [
{
"name": "nfs-storage",
"mountPath": "/root/.cache"
}
]
}
}
],
"restartPolicy": "Never",
"volumes": [
{
"name": "nfs-storage",
"persistentVolumeClaim": {
"claimName": "nfs-pvc"
}
}
]
}
},
"backoffLimit": 0
}
}
이제 NFS가 작업 실행 컨테이너의 /root/.cache에 마운트됩니다. 컨테이너가 root가 아닌 다른 사용자로 실행되는 경우 마운트 경로를 조정해야 합니다. Huggingface의 라이브러리와 W&B Artifacts는 모두 기본적으로 $HOME/.cache/를 사용하므로 다운로드는 한 번만 발생해야 합니다.
안정 확산으로 플레이하기
새 시스템을 테스트하기 위해 안정 확산의 추론 파라미터를 실험해 보겠습니다. 기본 프롬프트와 정상적인 파라미터를 사용하여 간단한 안정 확산 추론 작업을 실행하려면 다음을 실행합니다.
wandb launch -d wandb/job_stable_diffusion_inference:main -p <target-wandb-project> -q <your-queue-name> -e <your-queue-entity>
위의 코맨드는 컨테이너 이미지 wandb/job_stable_diffusion_inference:main을 대기열에 제출합니다.
에이전트가 작업을 선택하고 클러스터에서 실행되도록 예약하면
연결에 따라 이미지를 가져오는 데 시간이 걸릴 수 있습니다.
wandb.ai/launch (또는 wandb 서버의 사용자의 경우 <your-wandb-url>/launch)의 대기열 페이지에서 작업 상태를 확인할 수 있습니다.
run이 완료되면 지정한 프로젝트에 작업 아티팩트가 있어야 합니다.
프로젝트의 작업 페이지 (<project-url>/jobs)에서 작업 아티팩트를 찾을 수 있습니다. 기본 이름은
job-wandb_job_stable_diffusion_inference여야 하지만 작업 페이지에서 이름을 원하는 대로 변경할 수 있습니다.
작업 이름 옆에 있는 연필 아이콘을 클릭합니다.
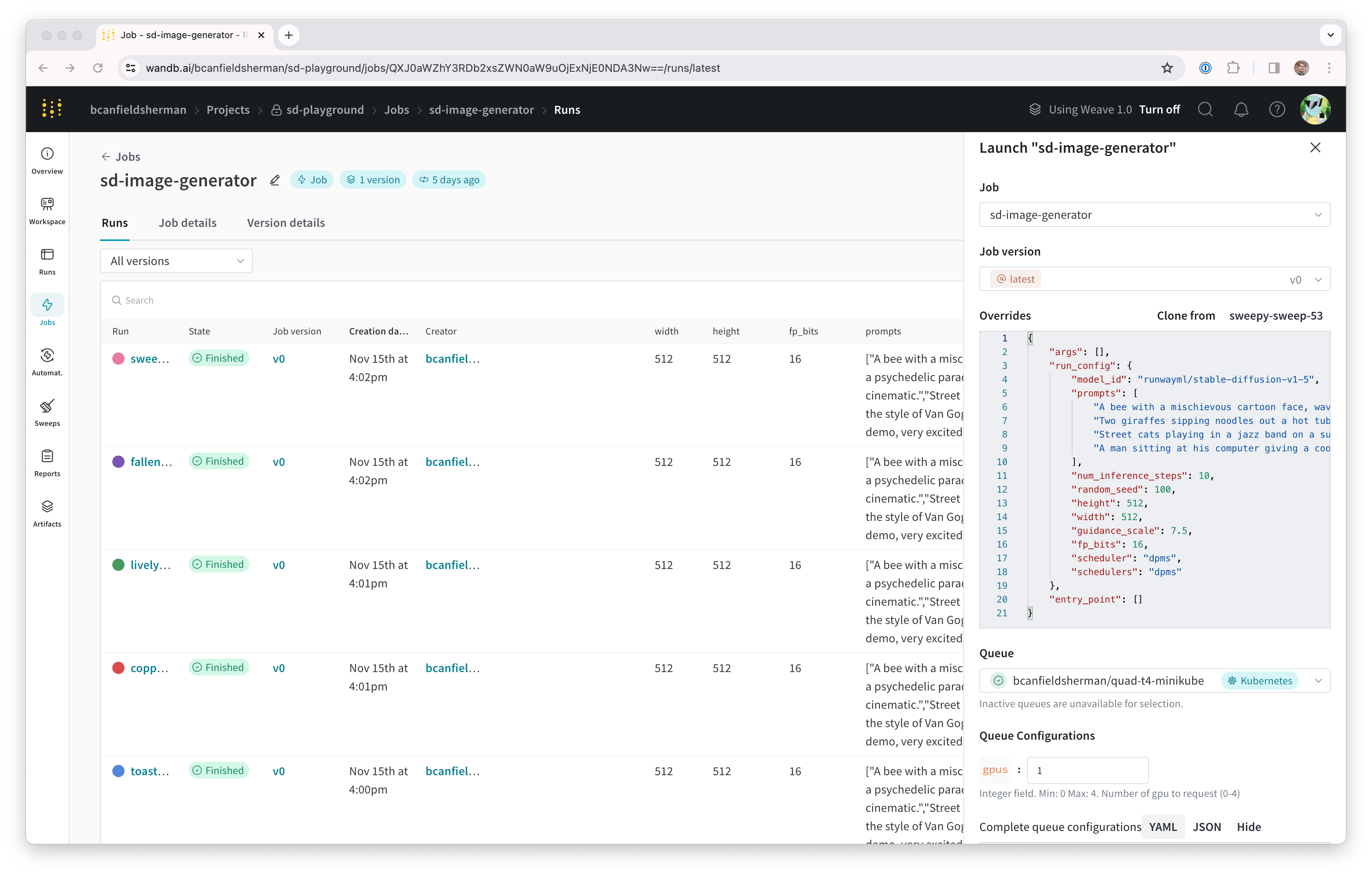
이제 이 작업을 사용하여 클러스터에서 더 많은 안정 확산 추론을 실행할 수 있습니다. 작업 페이지에서 오른쪽 상단 모서리에 있는 실행 버튼을 클릭하여 새 추론 작업을 구성하고 대기열에 제출할 수 있습니다. 작업 구성 페이지는 원래 run의 파라미터로 미리 채워지지만 재정의 섹션에서 값을 수정하여 원하는 대로 변경할 수 있습니다. Launch 서랍.
[i18n] feedback_title
[i18n] feedback_question
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.