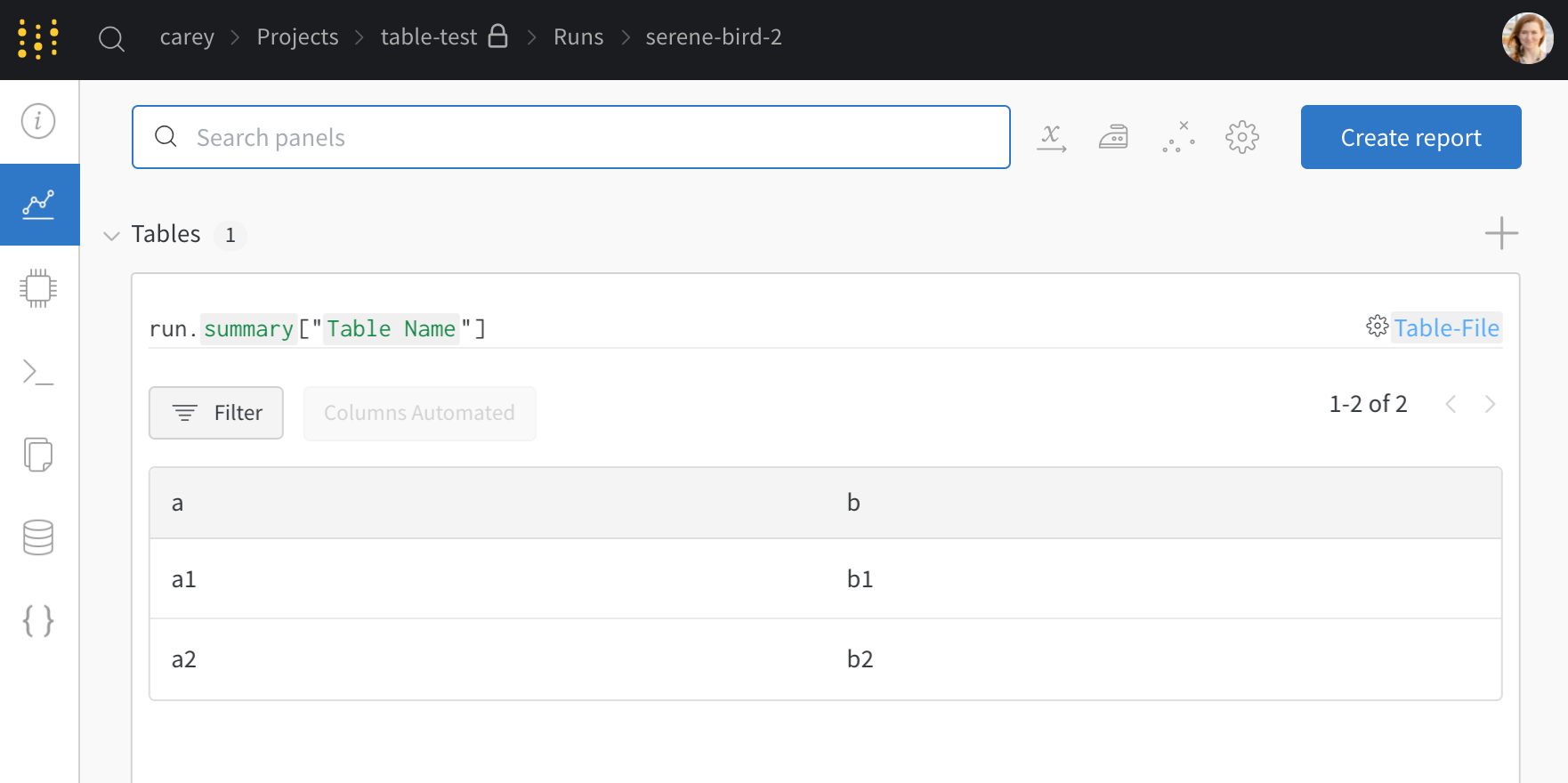
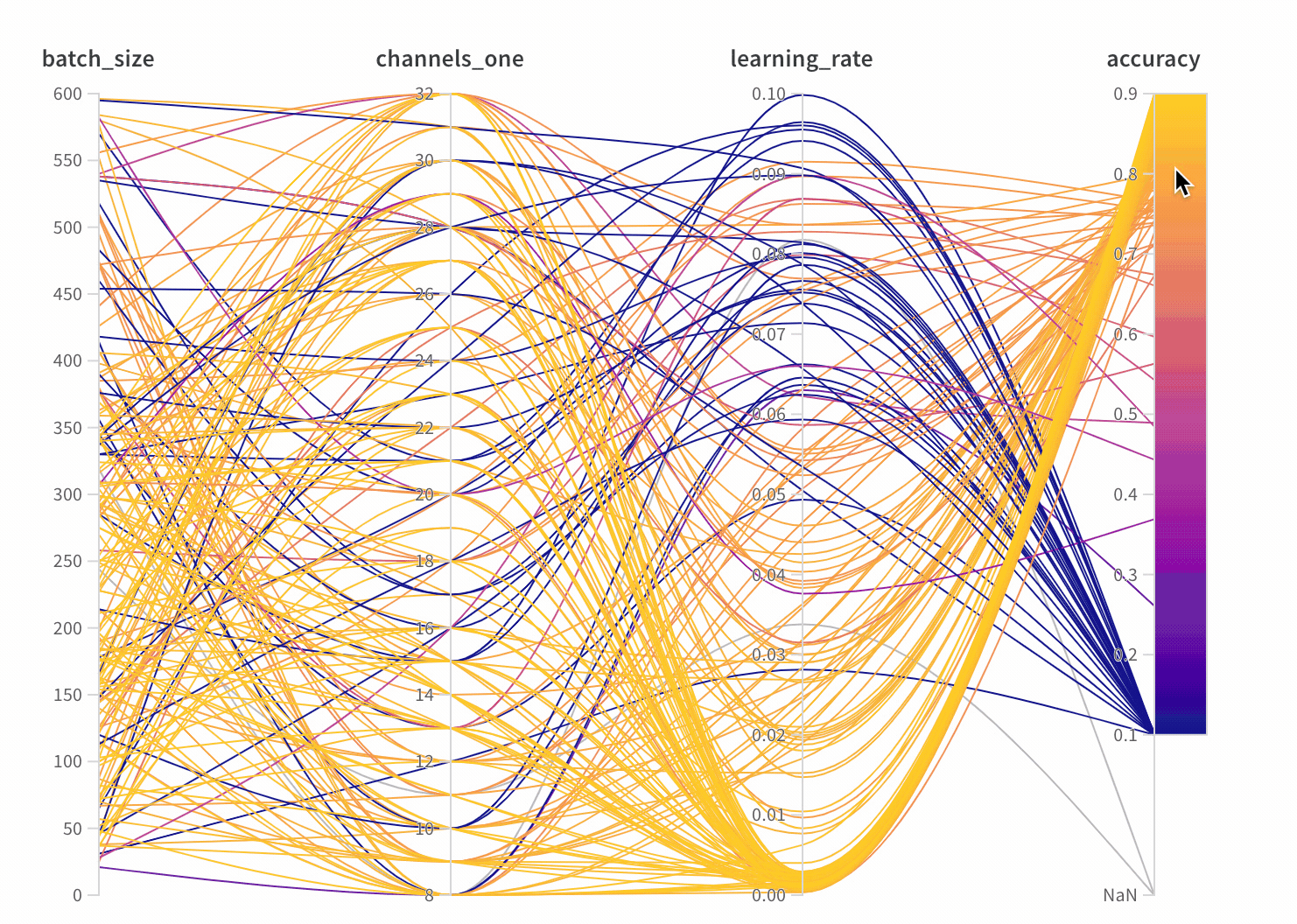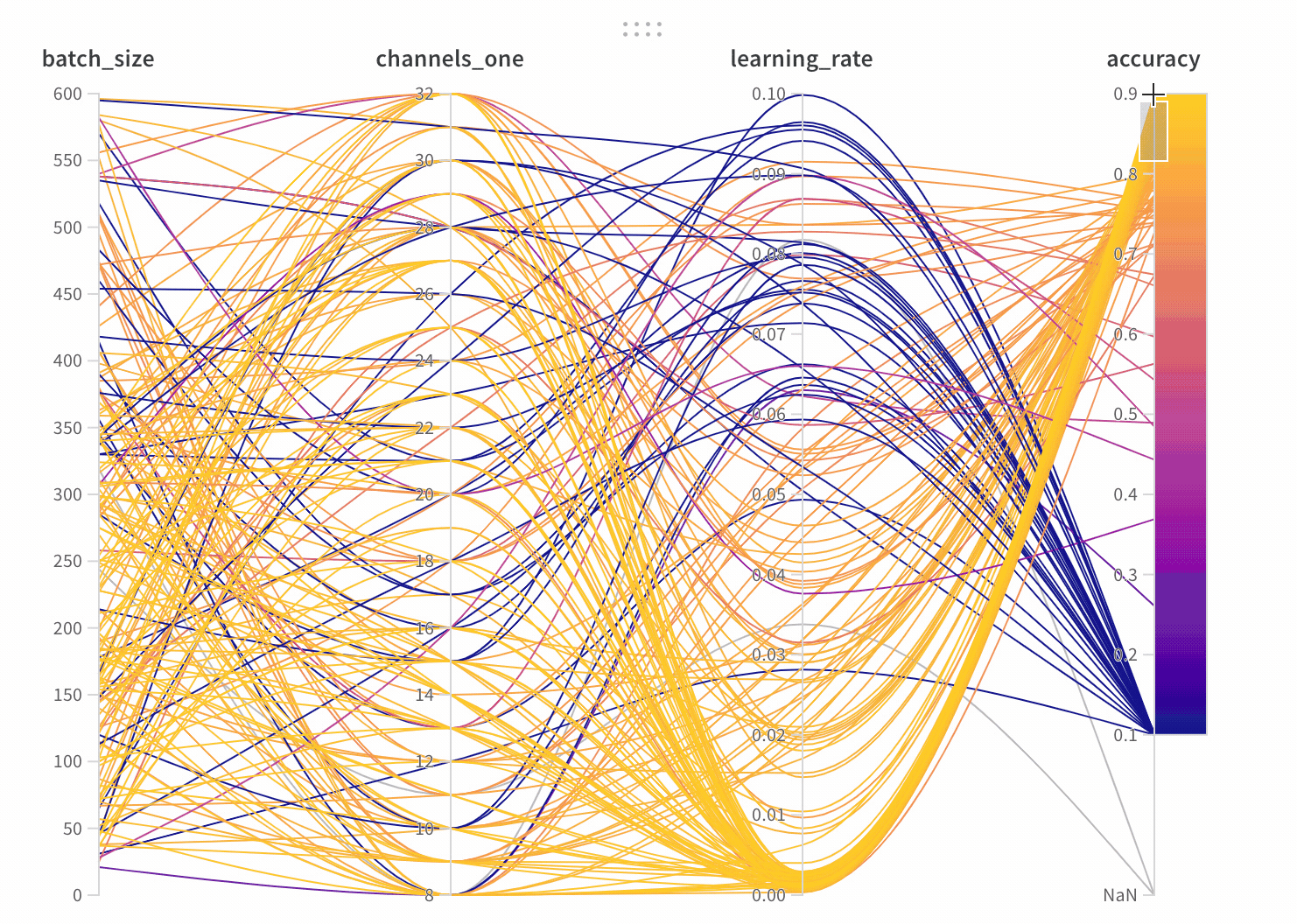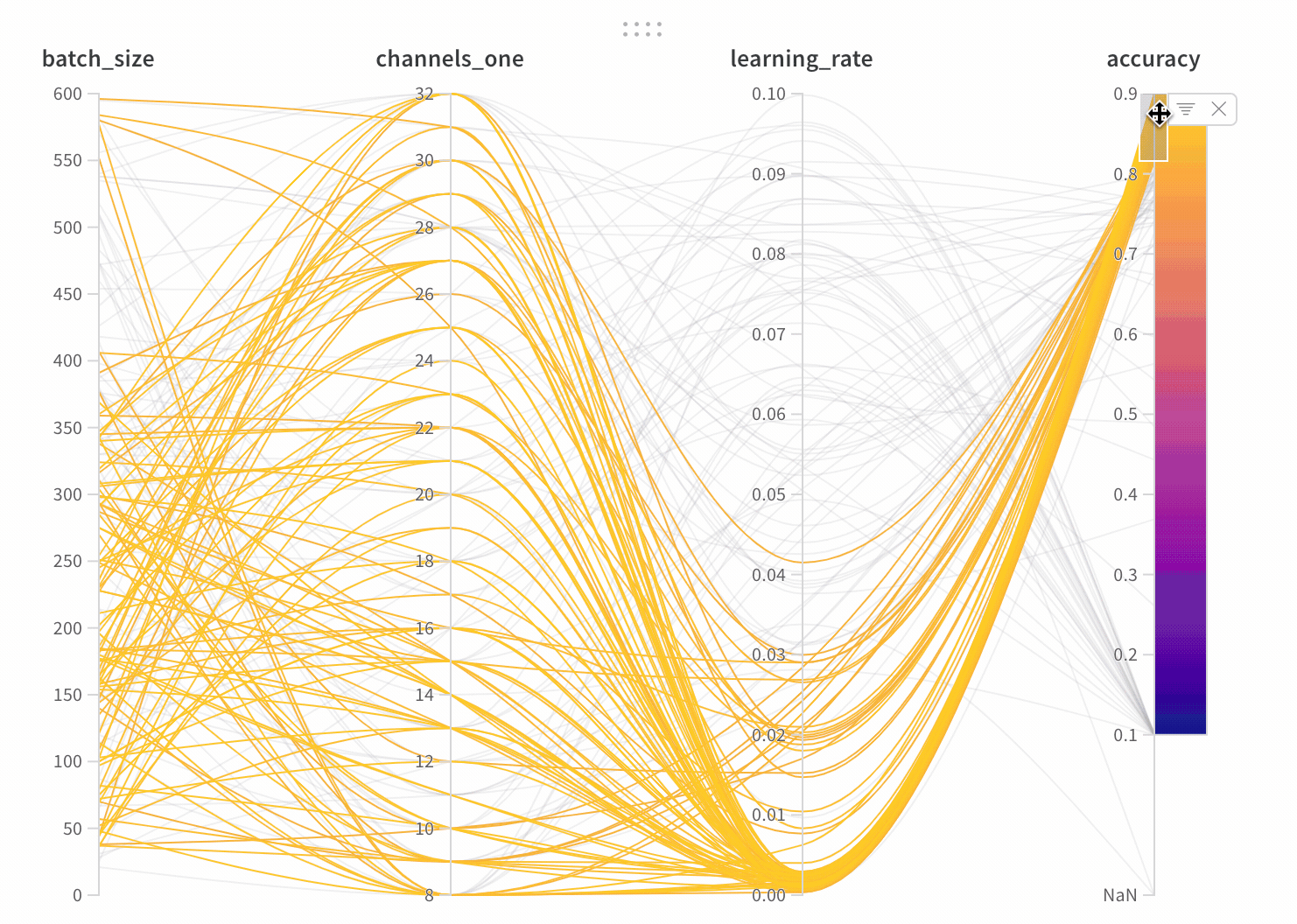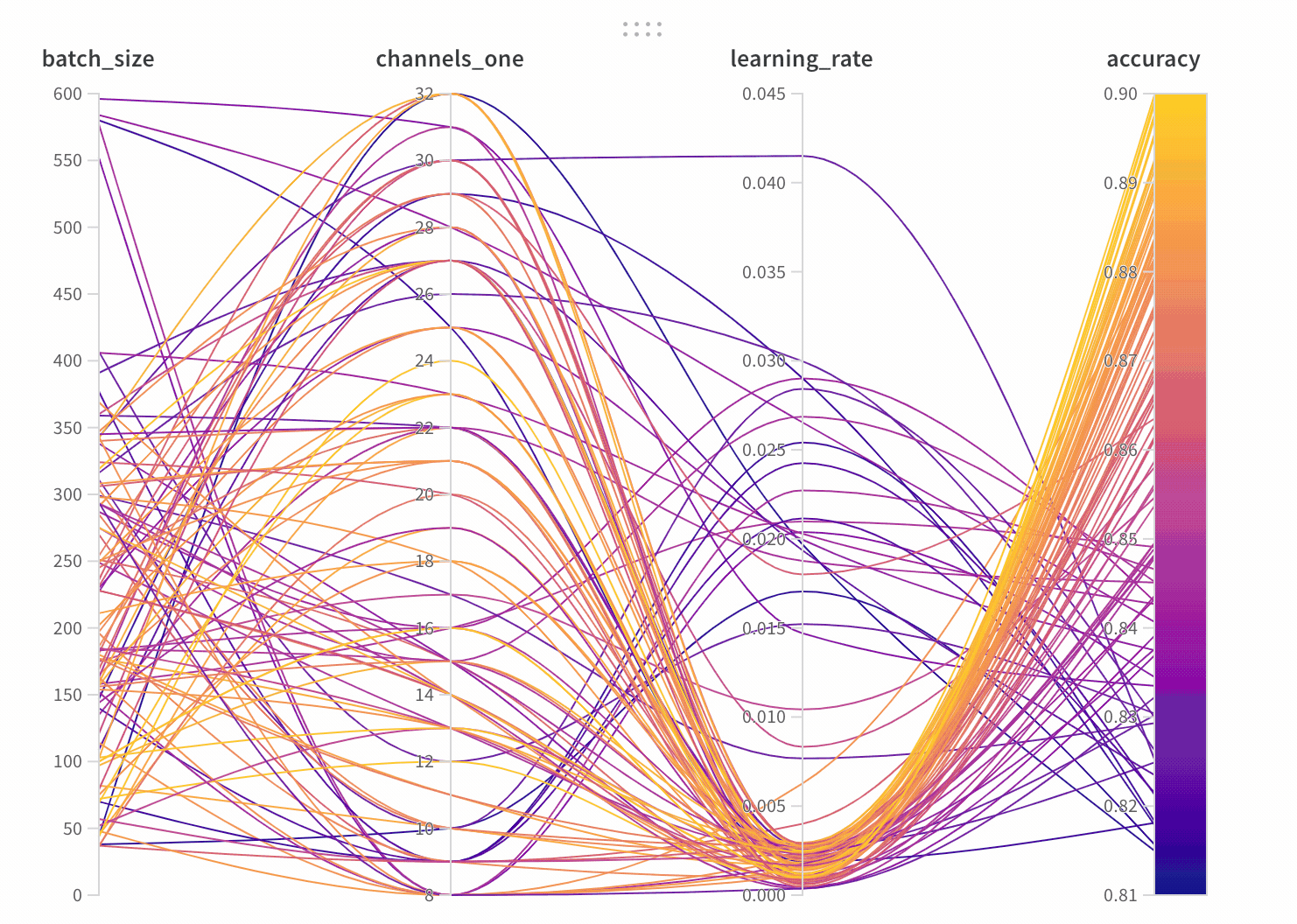
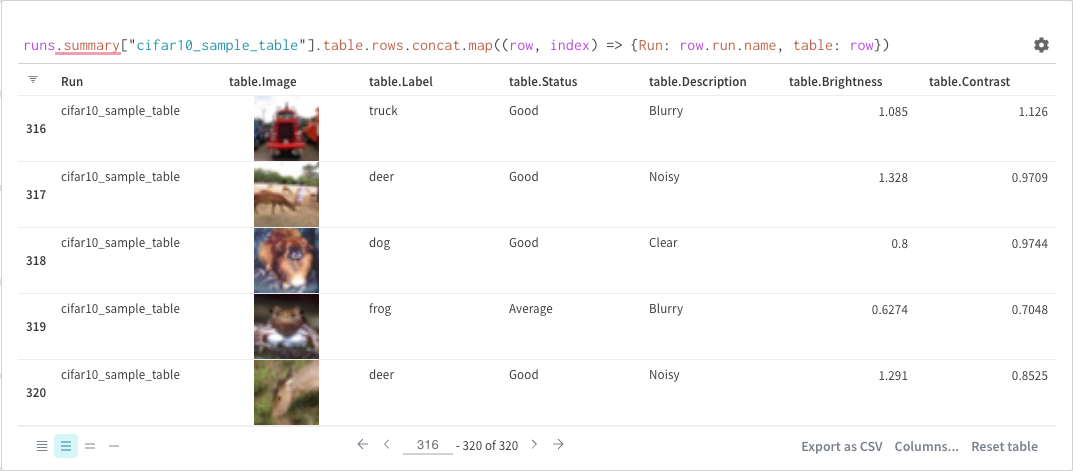
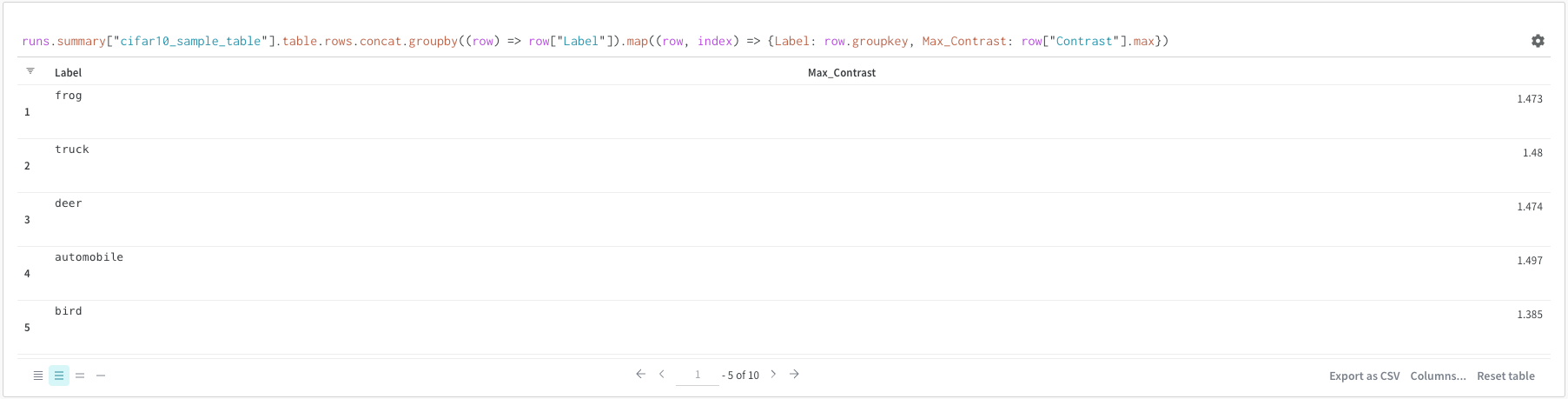
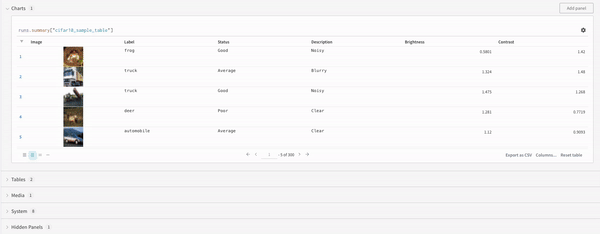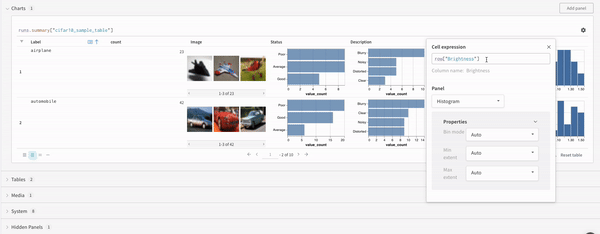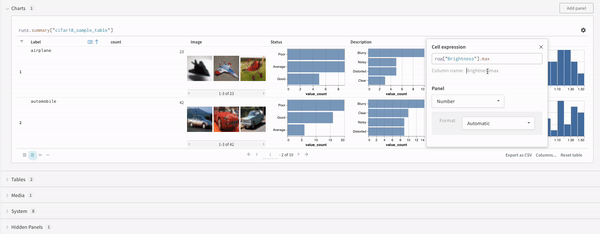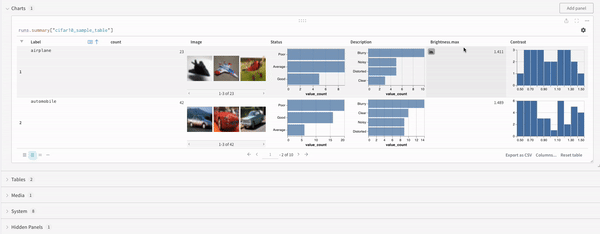
학습률 또는 모델 유형과 같은 하이퍼파라미터 사전을 구성 (run.config)에 저장합니다.
정확도 및 손실과 같은 트레이닝 루프에서 시간 경과에 따른 메트릭 (run.log())을 기록합니다.
모델 weights 또는 예측 테이블과 같은 run 의 출력을 저장합니다.
다음 코드는 일반적인 W&B experiment 추적 워크플로우를 보여줍니다.
# Start a run.## When this block exits, it waits for logged data to finish uploading.# If an exception is raised, the run is marked failed.with wandb.init(entity="", project="my-project-name") as run:
# Save mode inputs and hyperparameters. run.config.learning_rate =0.01# Run your experiment code.for epoch in range(num_epochs):
# Do some training...# Log metrics over time to visualize model performance. run.log({"loss": loss})
# Upload model outputs as artifacts. run.log_artifact(model)
시작하기
유스 케이스에 따라 다음 리소스를 탐색하여 W&B Experiments 를 시작하세요.
데이터셋 artifact 를 생성, 추적 및 사용하는 데 사용할 수 있는 W&B Python SDK 코맨드에 대한 단계별 개요는 W&B 퀵스타트를 참조하세요.
다음 코드 조각은 이 run을 식별하는 데 도움이 되도록 설명이 “My first experiment” 인 “cat-classification”이라는 W&B project에서 run을 만듭니다. 태그 “baseline” 및 “paper1”은 이 run이 향후 논문 출판을 위한 베이스라인 experiment임을 알려줍니다.
import wandb
with wandb.init(
project="cat-classification",
notes="My first experiment",
tags=["baseline", "paper1"],
) as run:
...
참고: wandb.init()를 호출할 때 해당 project가 이미 존재하는 경우 Run은 기존 project에 추가됩니다. 예를 들어 “cat-classification”이라는 project가 이미 있는 경우 해당 project는 계속 존재하며 삭제되지 않습니다. 대신 새 run이 해당 project에 추가됩니다.
하이퍼파라미터 dictionary 캡처
학습률 또는 모델 유형과 같은 하이퍼파라미터 dictionary를 저장합니다. config에서 캡처하는 모델 설정은 나중에 결과를 구성하고 쿼리하는 데 유용합니다.
with wandb.init(
...,
config={"epochs": 100, "learning_rate": 0.001, "batch_size": 128},
) as run:
...
선택적으로 W&B Artifact를 기록합니다. Artifact를 사용하면 데이터셋과 Models를 쉽게 버전 관리할 수 있습니다.
# 모든 파일 또는 디렉토리를 저장할 수 있습니다. 이 예에서는 모델에 ONNX 파일을 출력하는# save() 메소드가 있다고 가정합니다.model.save("path_to_model.onnx")
run.log_artifact("path_to_model.onnx", name="trained-model", type="model")
import wandb
with wandb.init(
project="cat-classification",
notes="",
tags=["baseline", "paper1"],
# run의 하이퍼파라미터를 기록합니다. config={"epochs": 100, "learning_rate": 0.001, "batch_size": 128},
) as run:
# 모델 및 데이터를 설정합니다. model, dataloader = get_model(), get_data()
# 모델 성능을 시각화하기 위해 메트릭을 기록하면서 트레이닝을 실행합니다.for epoch in range(run.config["epochs"]):
for batch in dataloader:
loss, accuracy = model.training_step()
run.log({"accuracy": accuracy, "loss": loss})
# 트레이닝된 모델을 아티팩트로 업로드합니다. model.save("path_to_model.onnx")
run.log_artifact("path_to_model.onnx", name="trained-model", type="model")
다음 단계: experiment 시각화
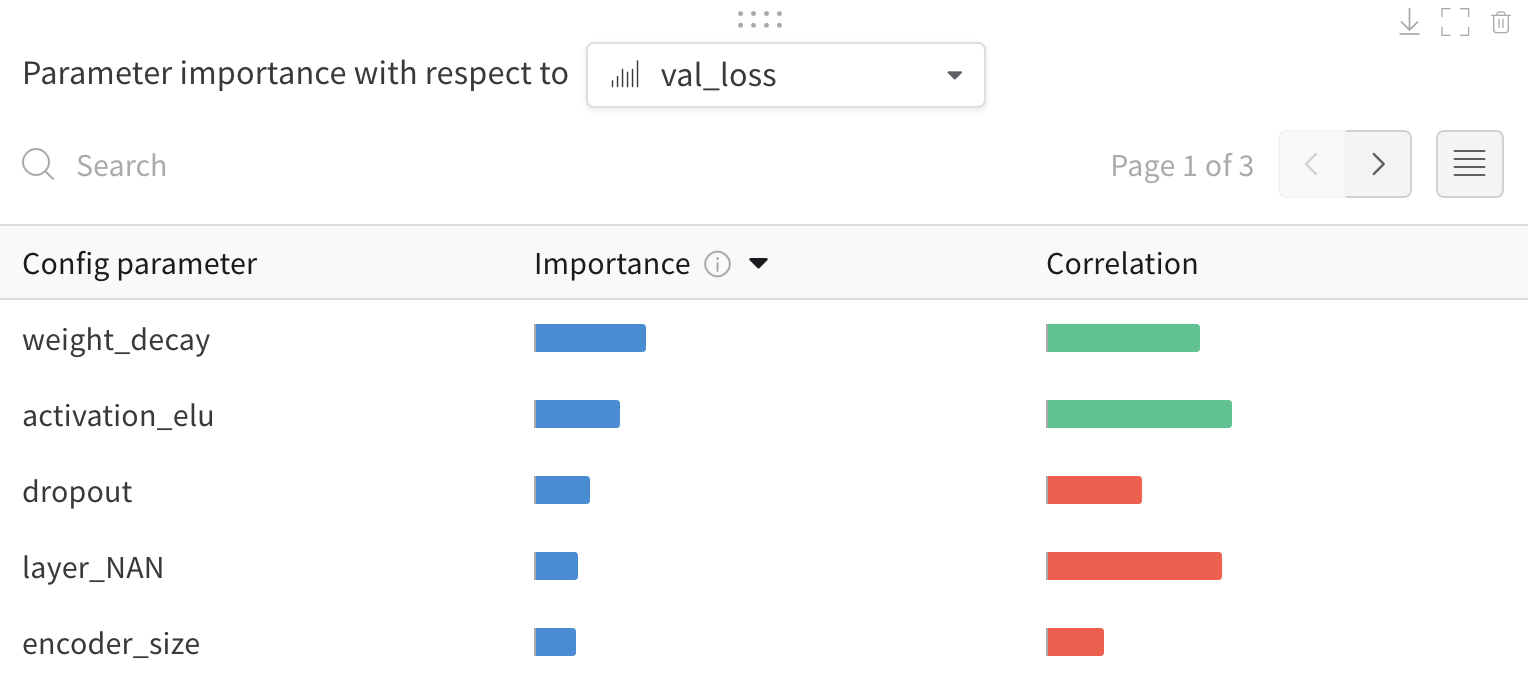
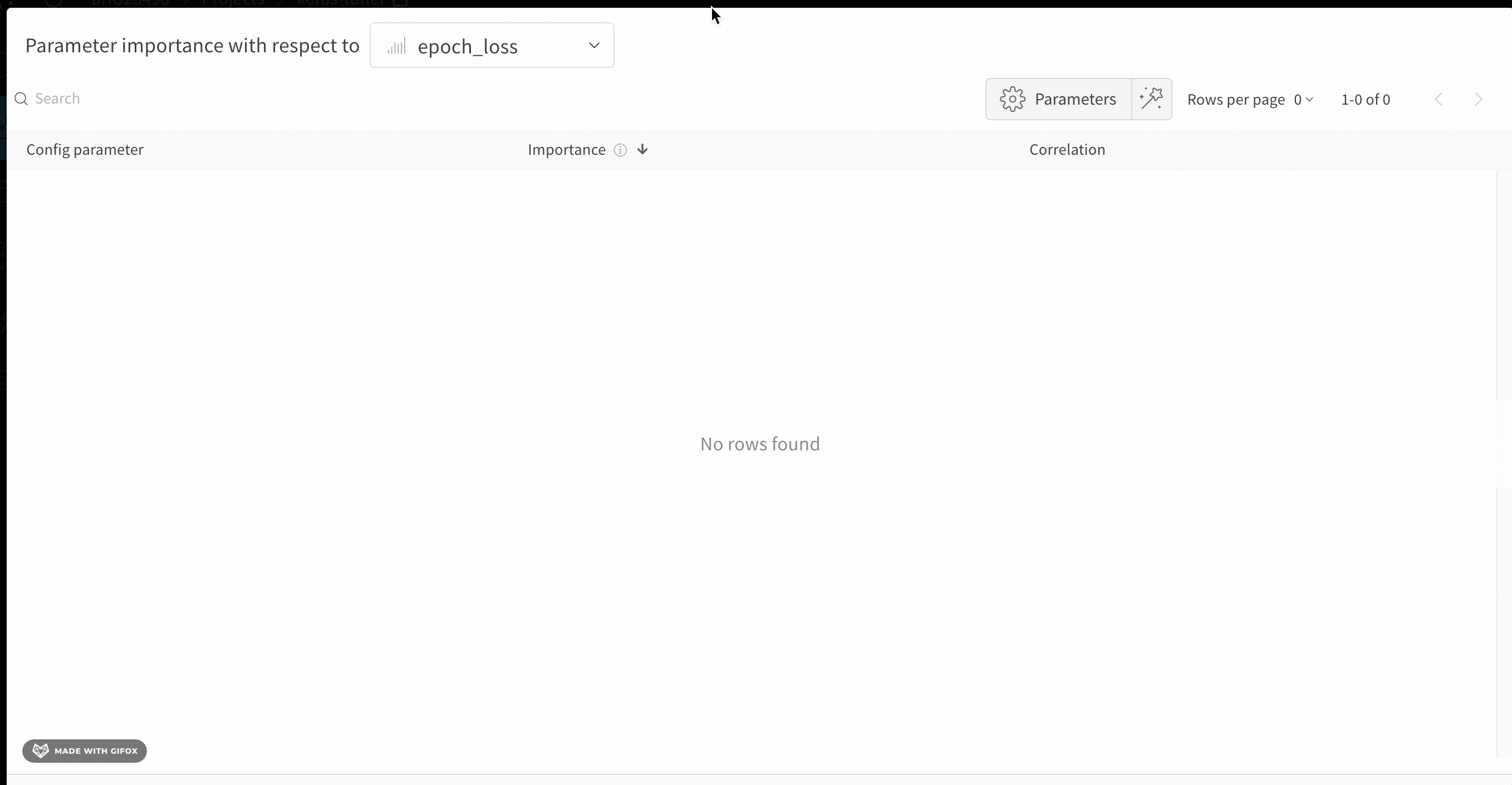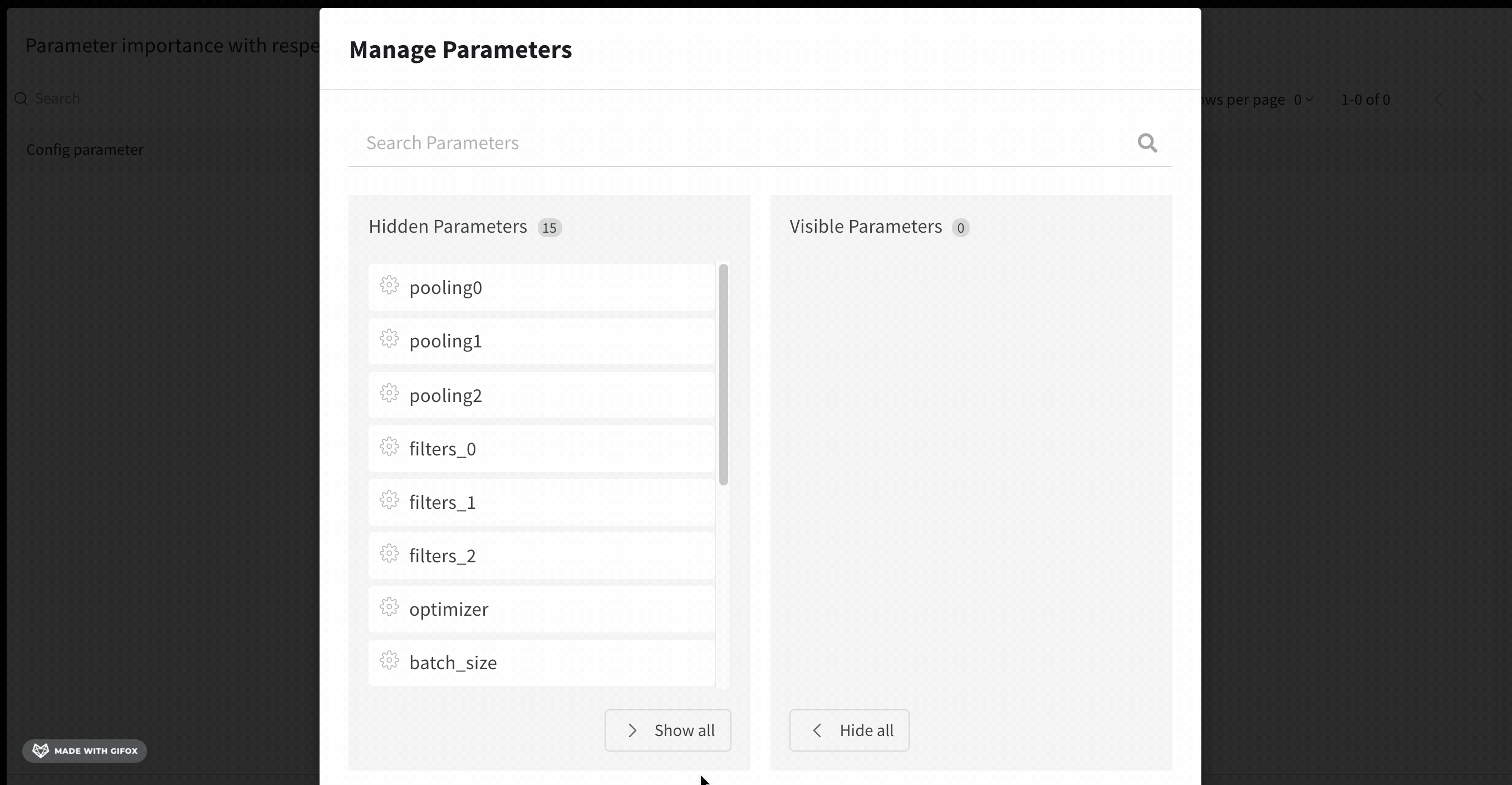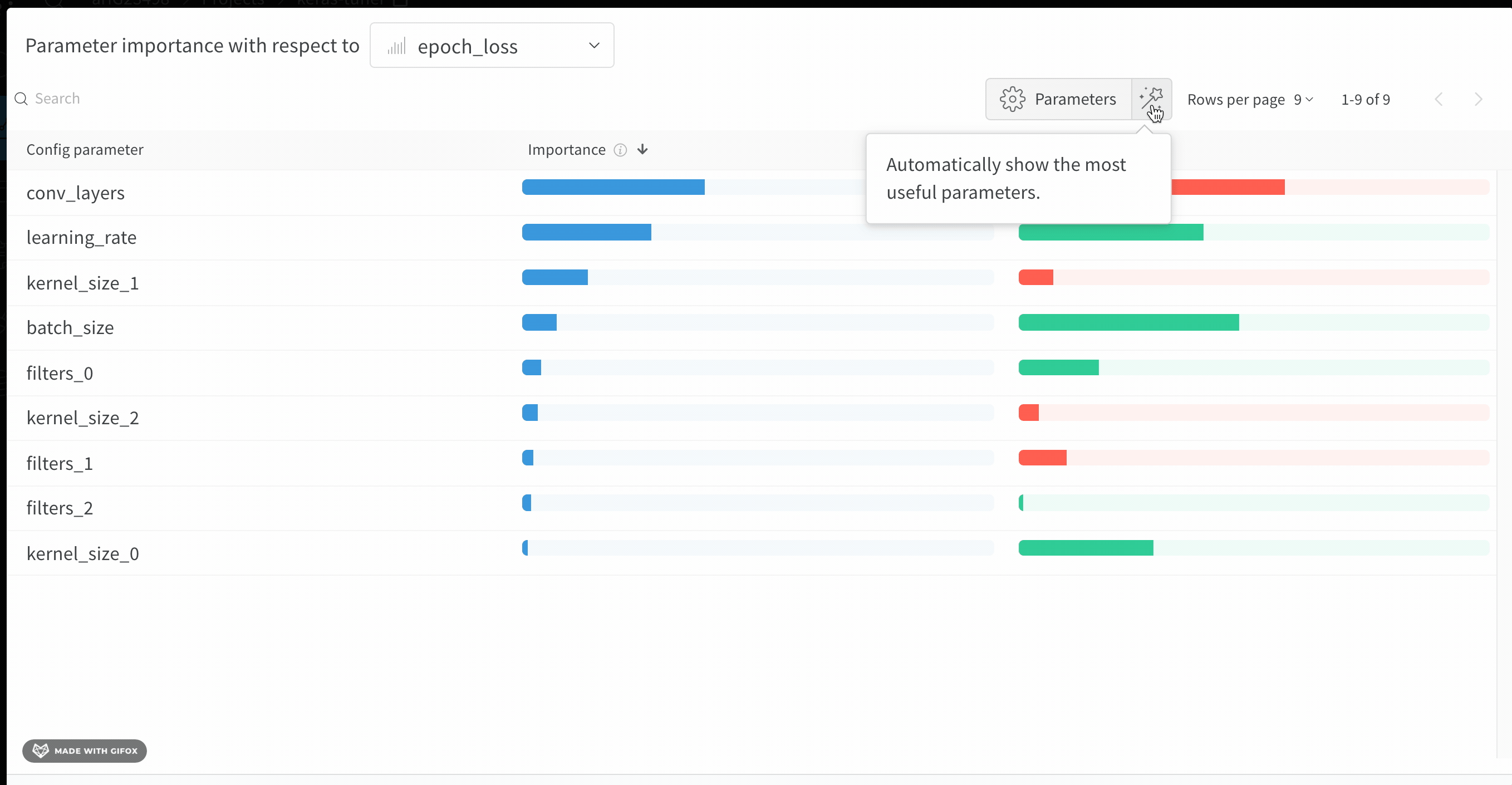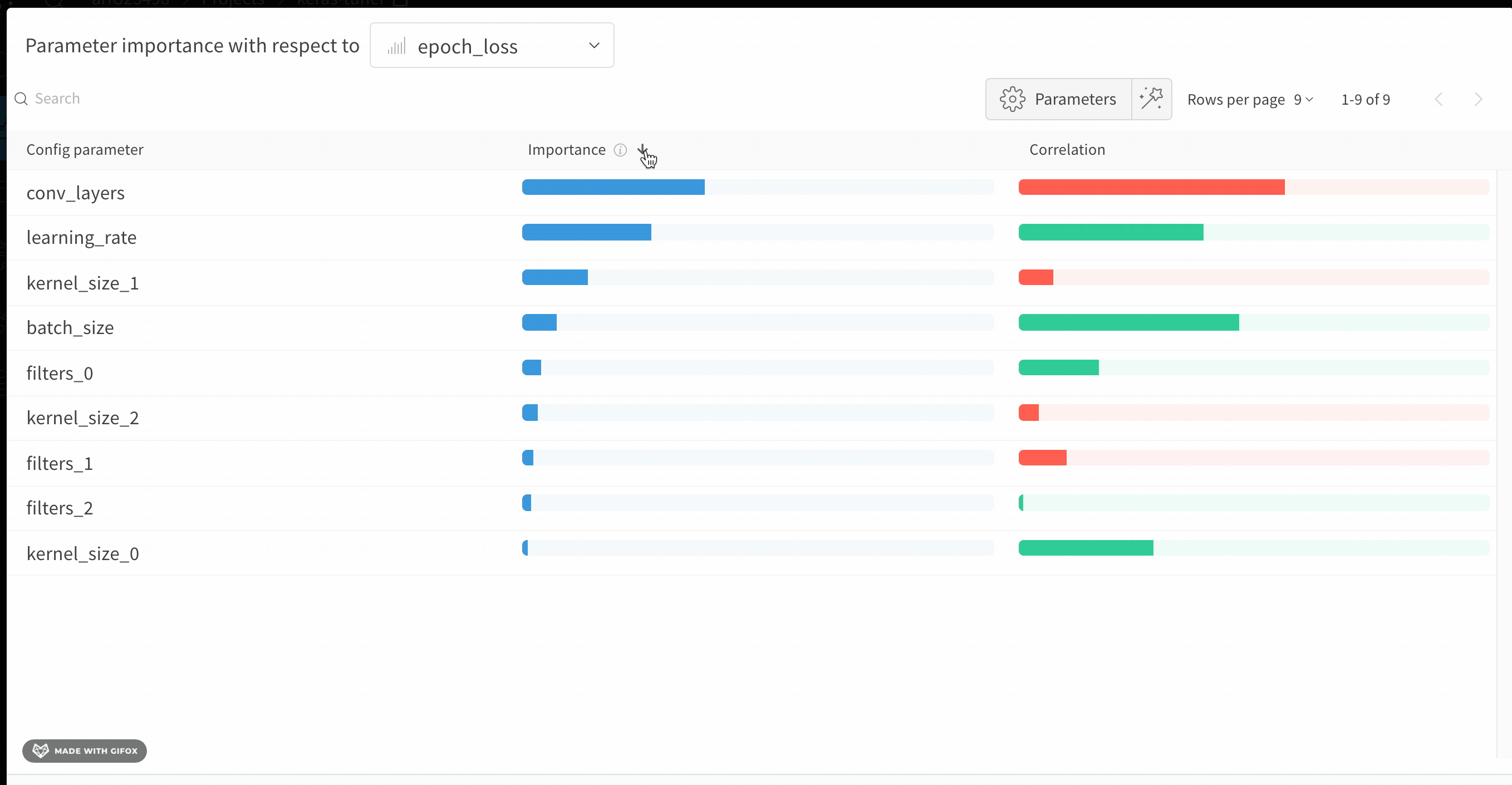
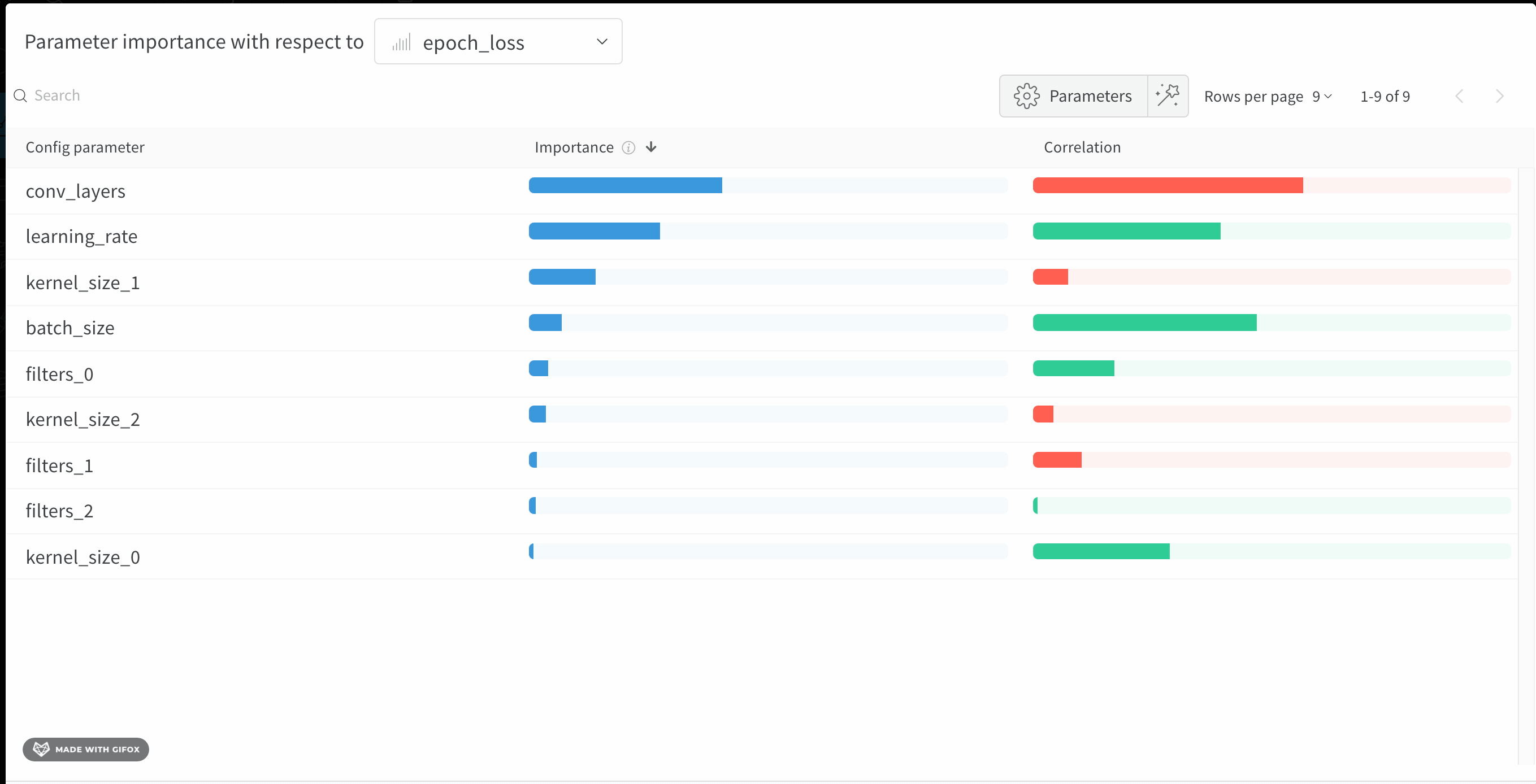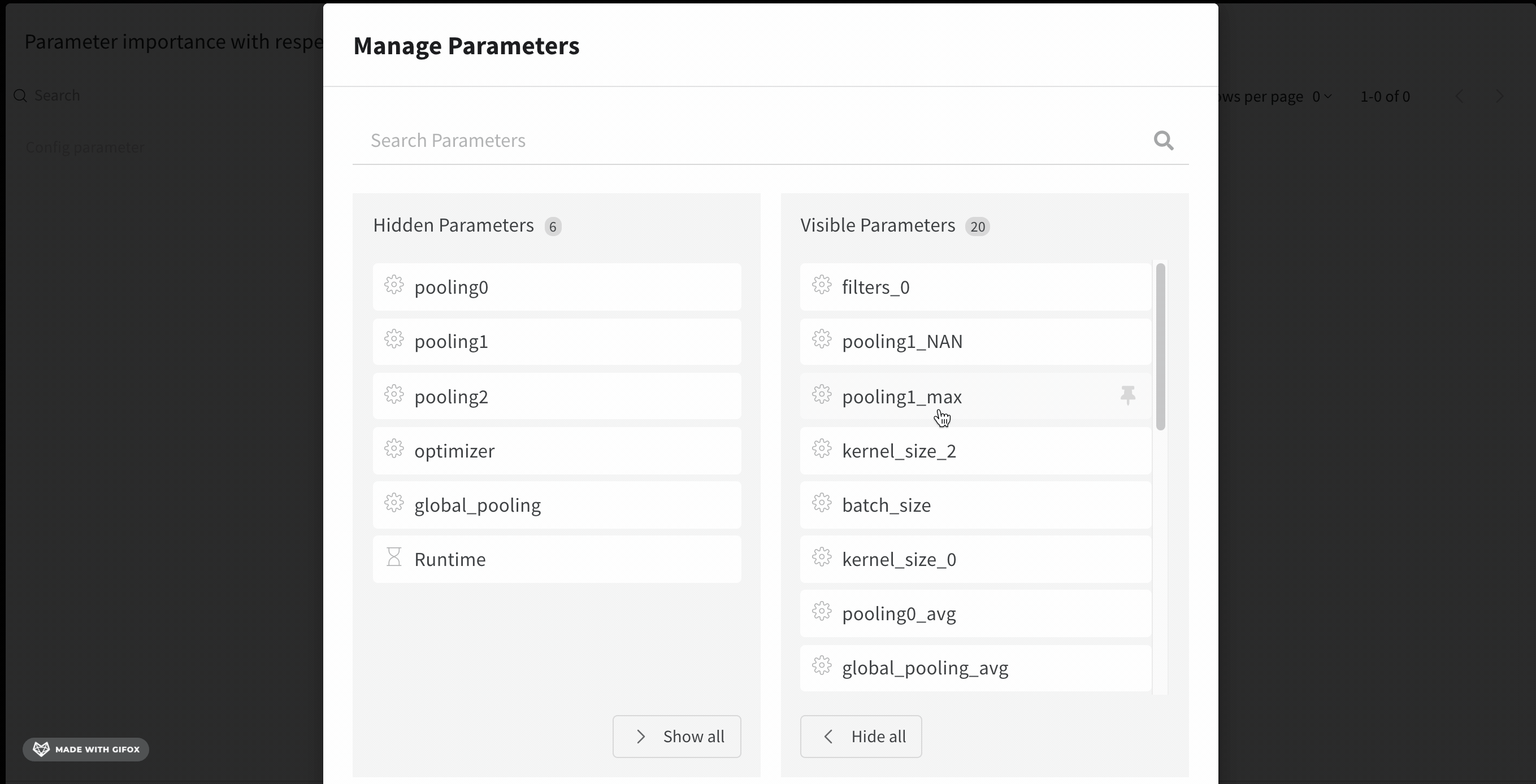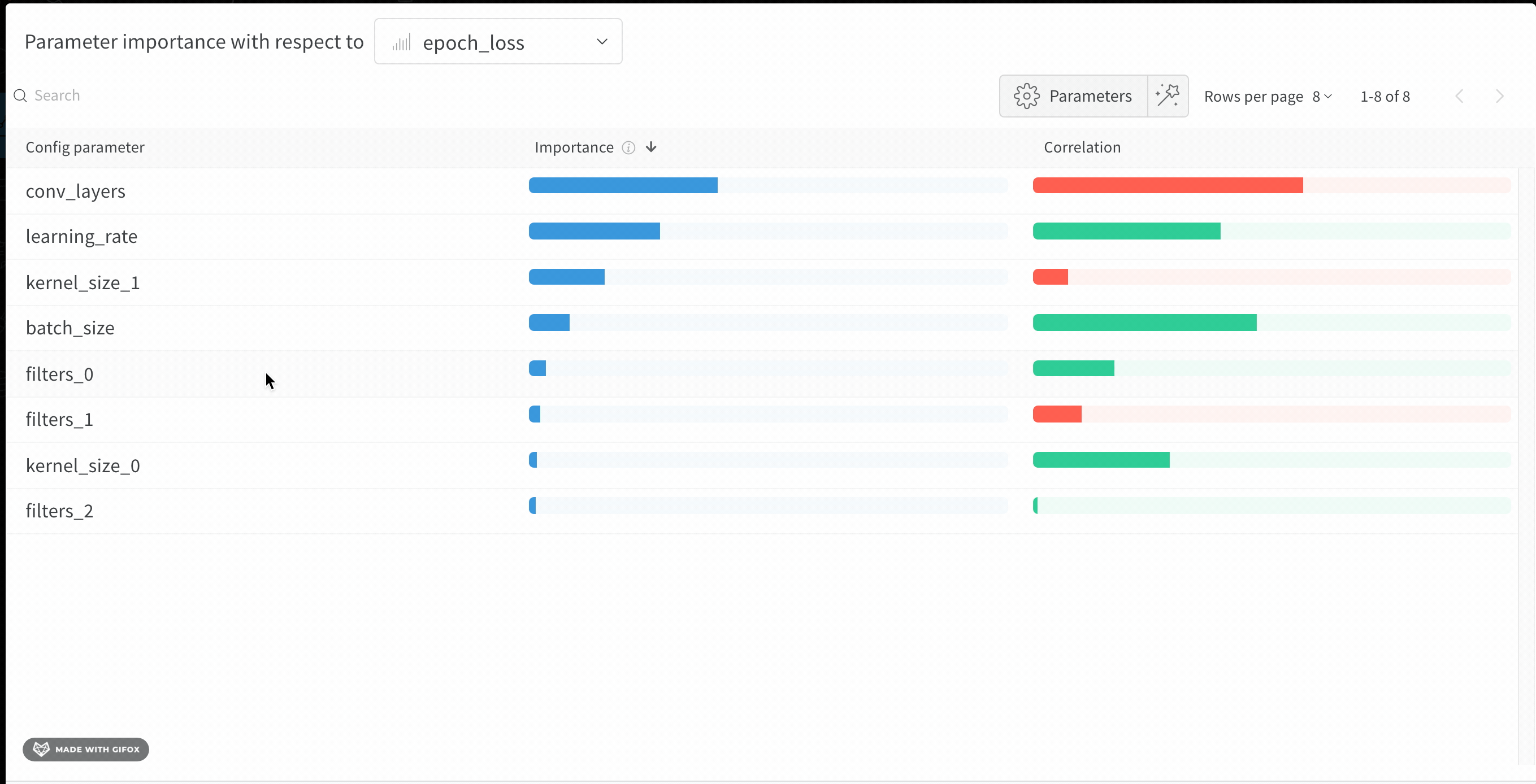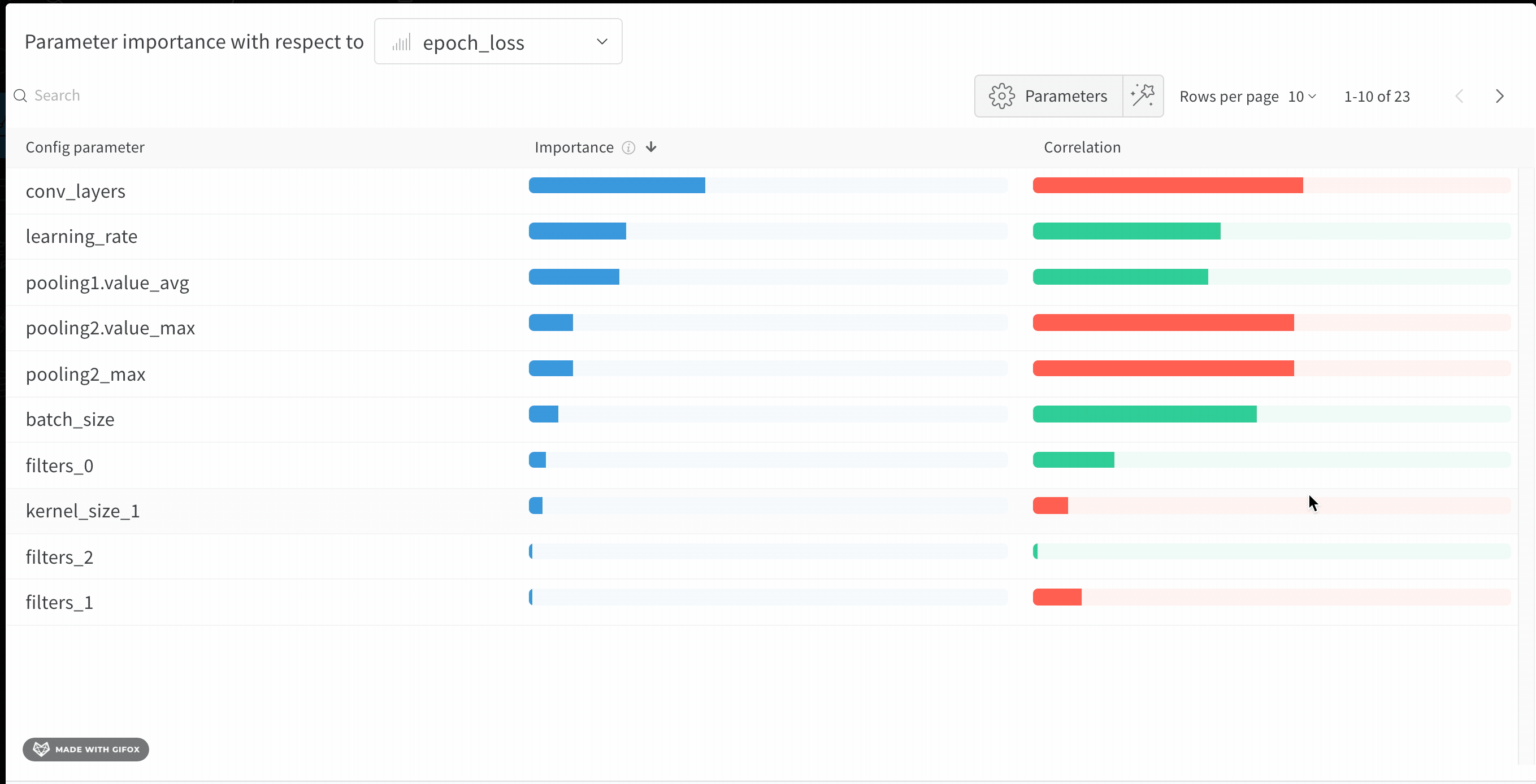
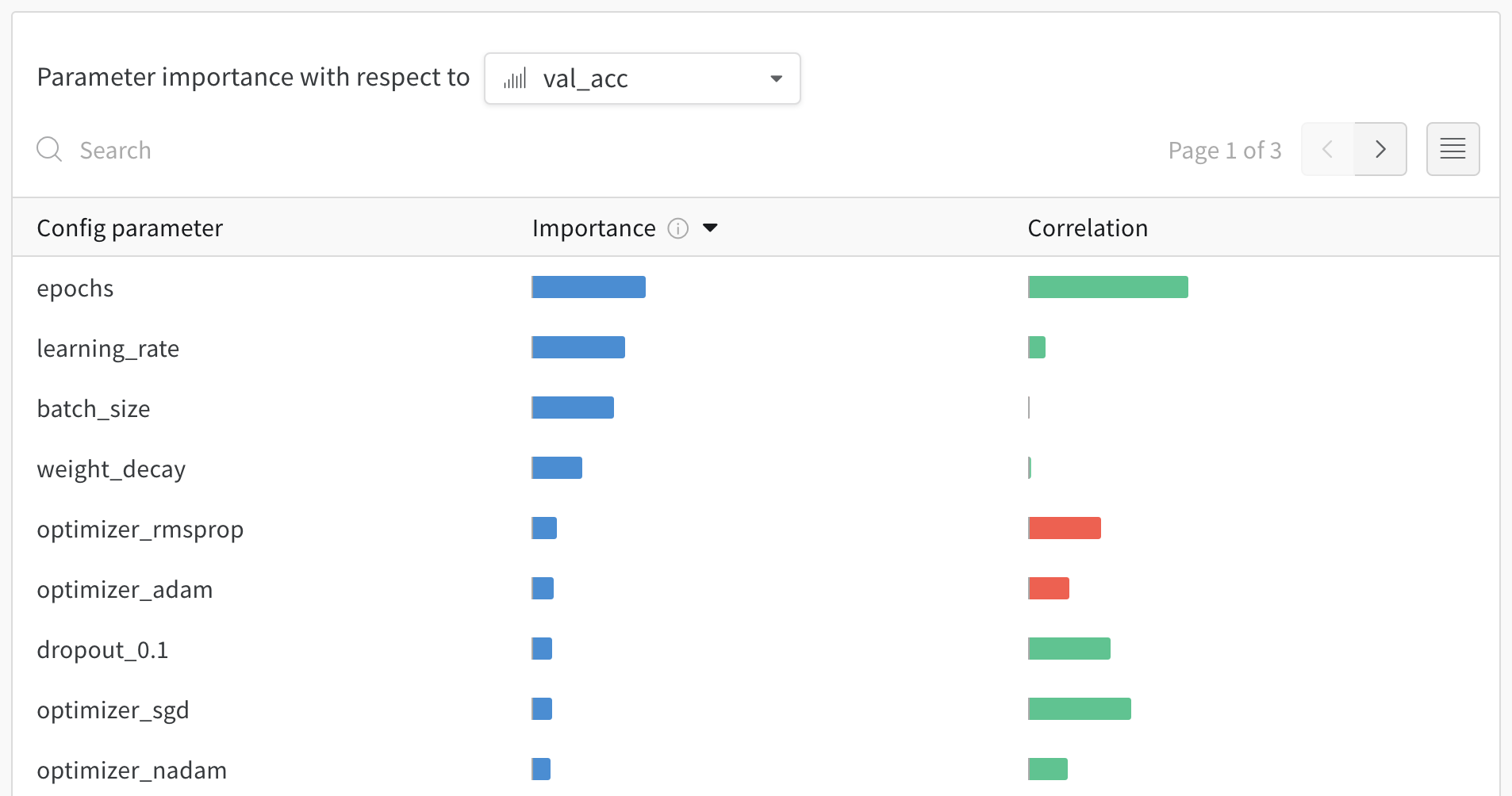
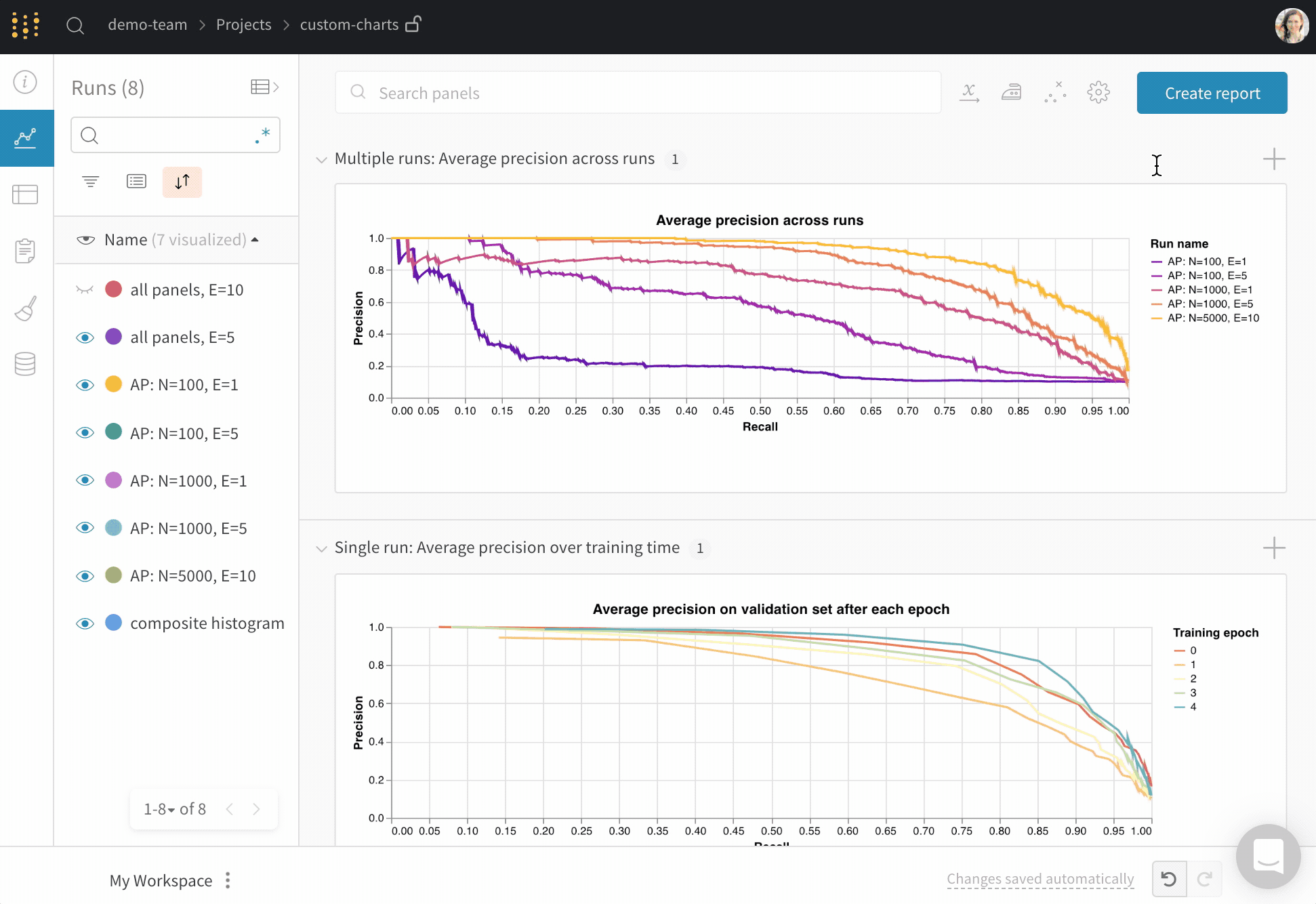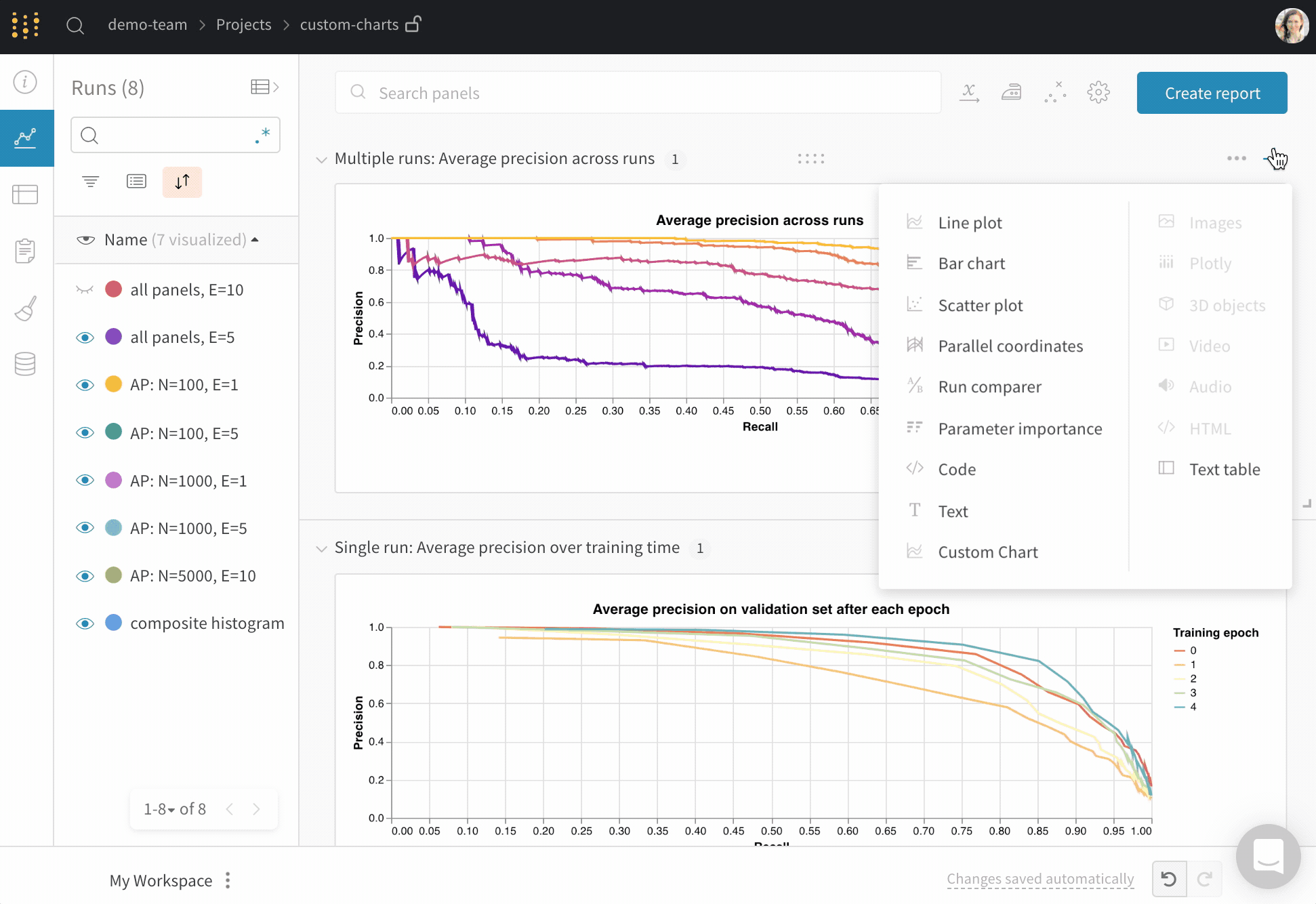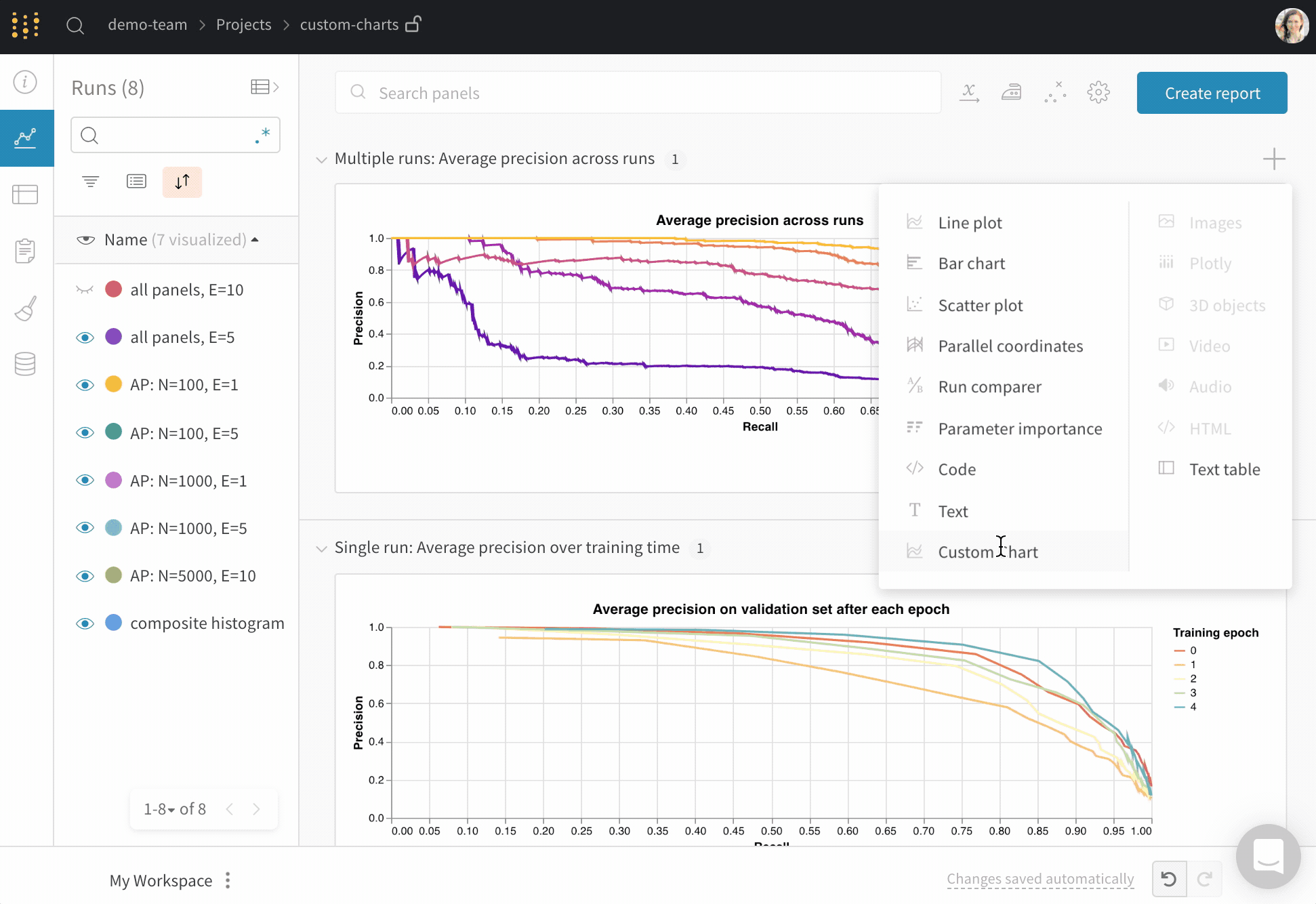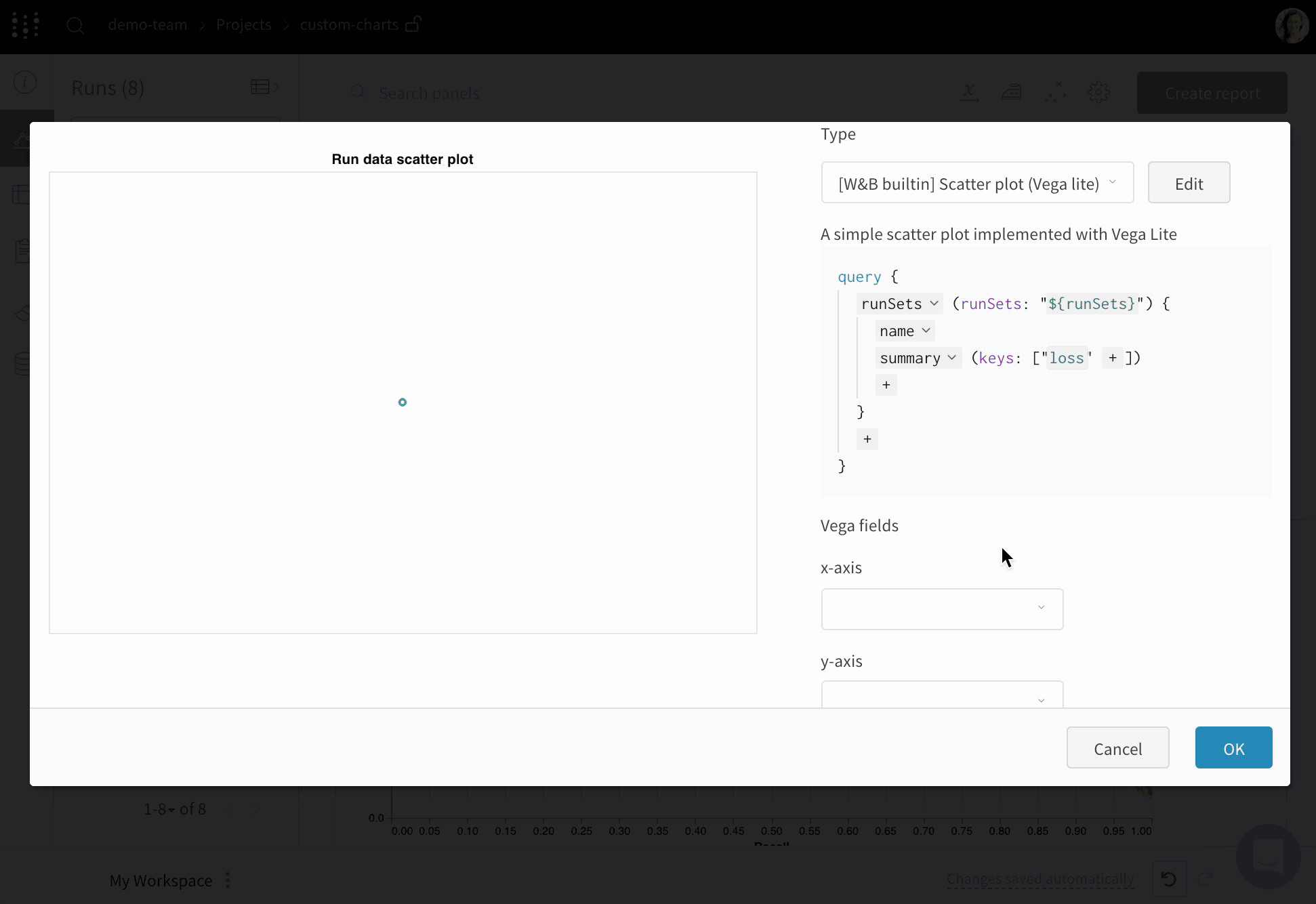
W&B Dashboard를 기계 학습 모델의 결과를 구성하고 시각화하는 중앙 장소로 사용하십시오. 몇 번의 클릭만으로 평행 좌표 플롯, 파라미터 중요도 분석 및 기타와 같은 풍부한 인터랙티브 차트를 구성합니다.
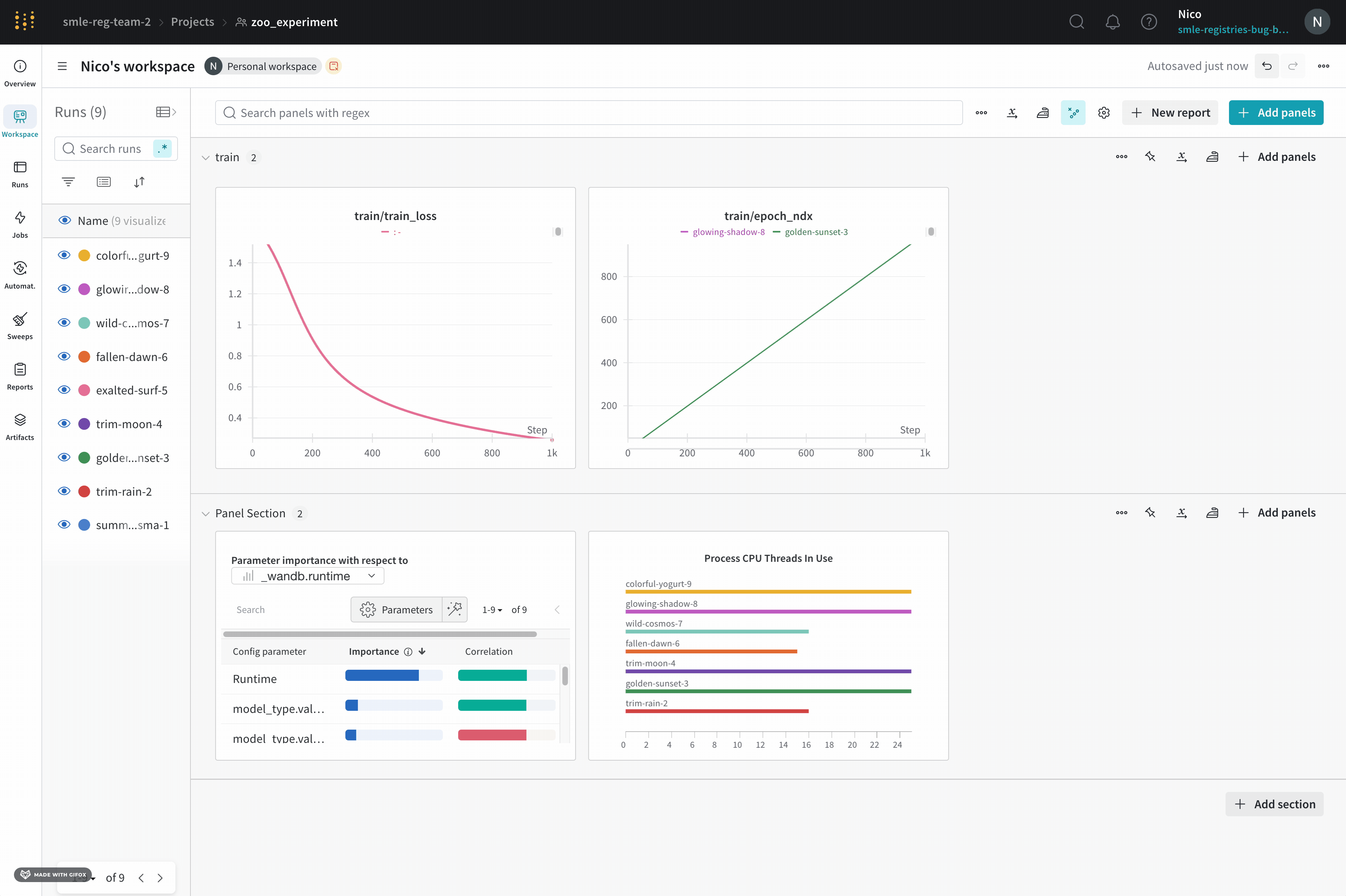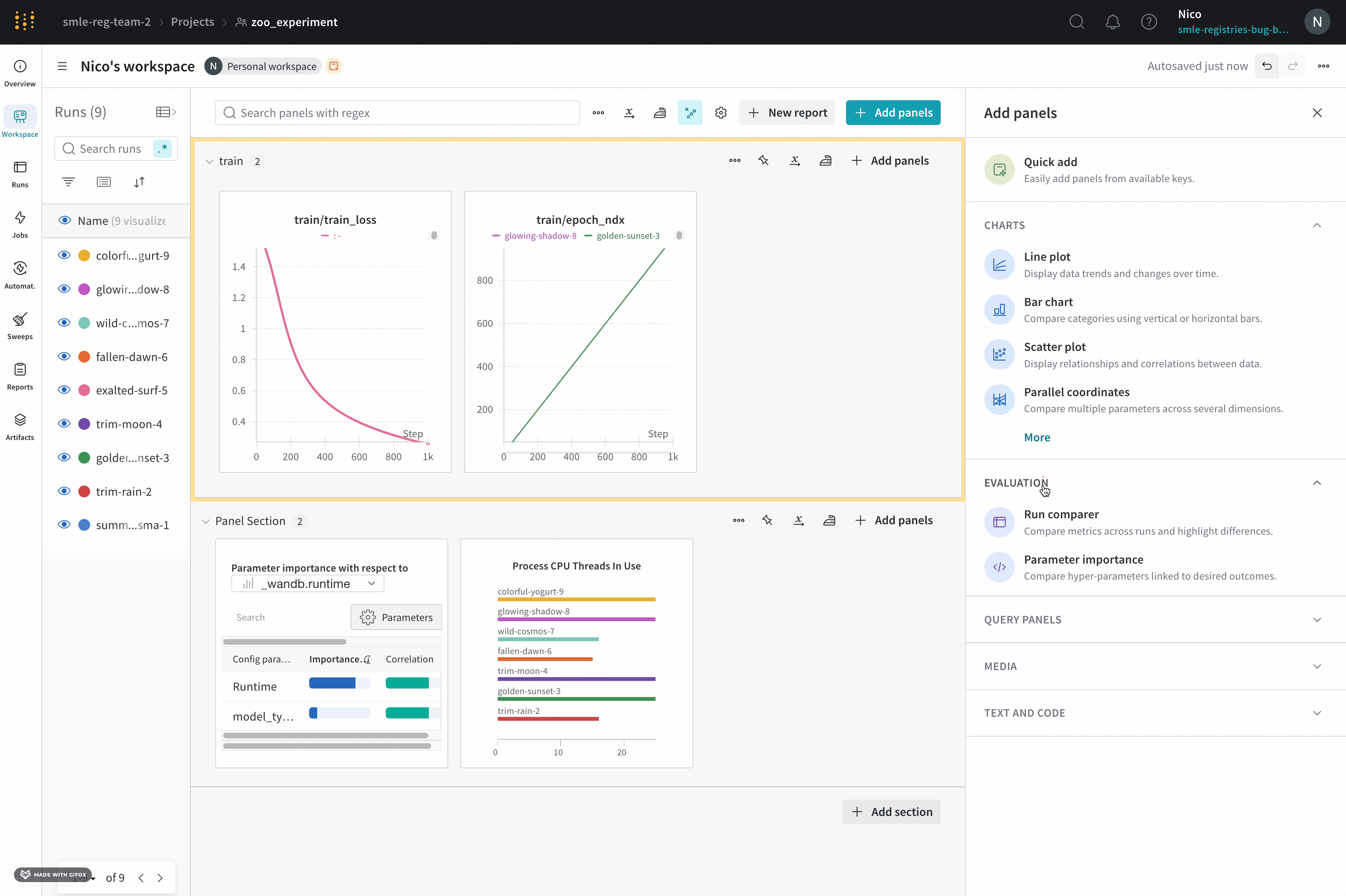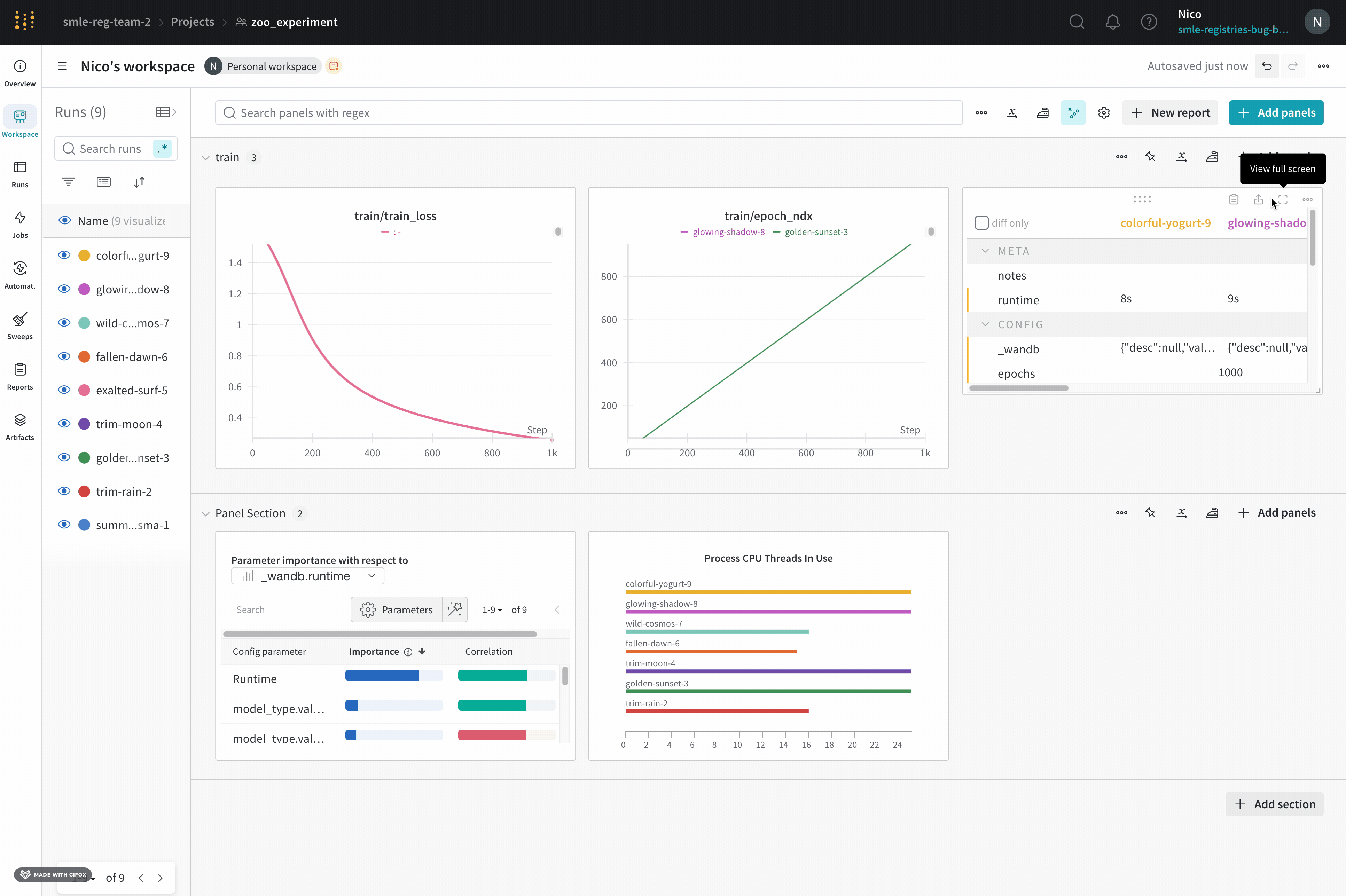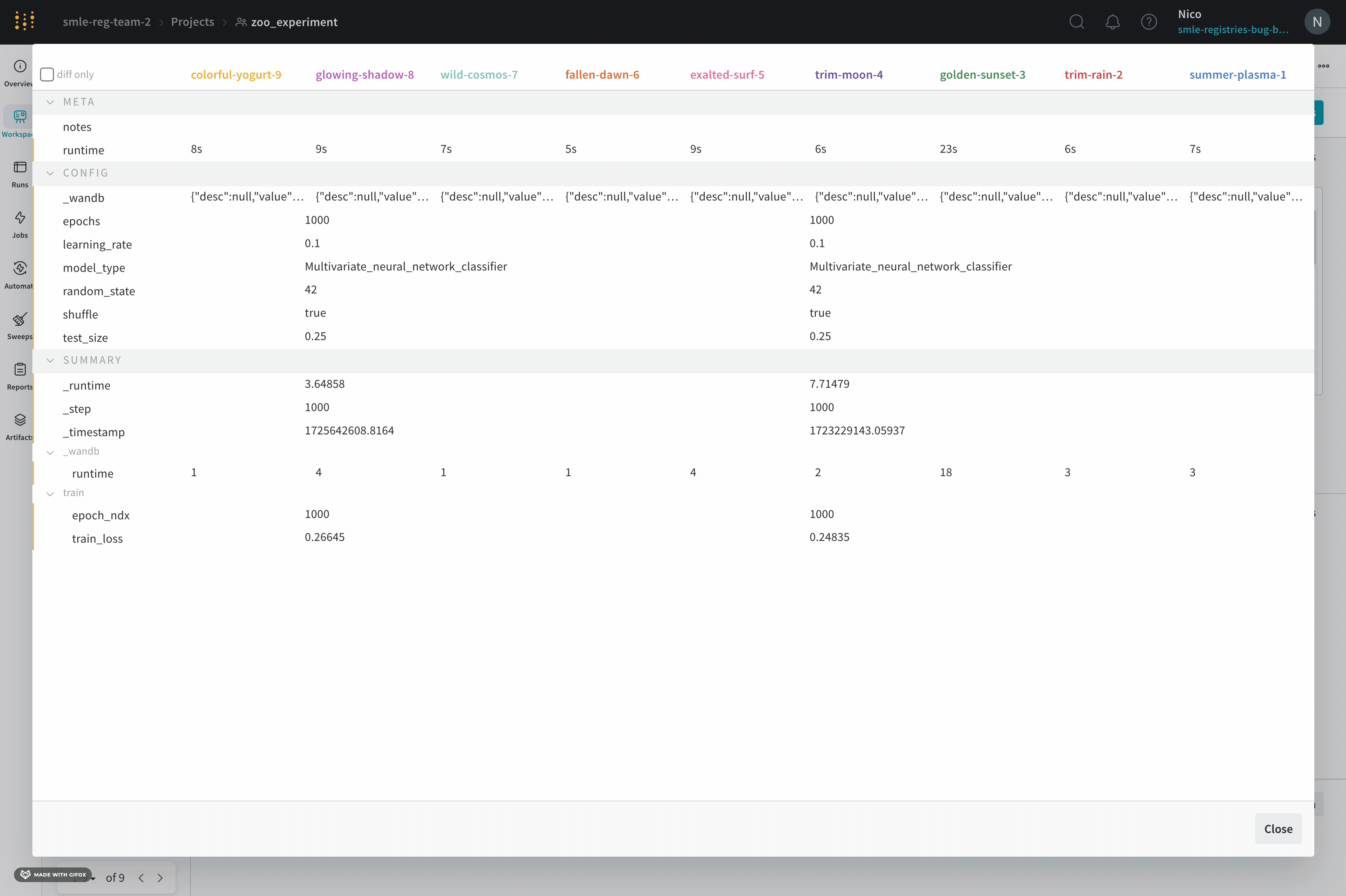
run.config 속성을 사용하면 실험을 쉽게 분석하고 향후 작업을 재현할 수 있습니다. W&B 앱에서 설정 값으로 그룹화하고, 서로 다른 W&B run의 설정을 비교하고, 각 트레이닝 설정이 결과에 미치는 영향을 평가할 수 있습니다. config 속성은 여러 사전과 유사한 오브젝트로 구성될 수 있는 사전과 유사한 오브젝트입니다.
손실 및 정확도와 같은 출력 메트릭 또는 종속 변수를 저장하려면 run.config 대신 run.log를 사용하세요.
실험 설정 구성하기
일반적으로 설정은 트레이닝 스크립트의 시작 부분에 정의됩니다. 그러나 기계 학습 워크플로우는 다를 수 있으므로 트레이닝 스크립트의 시작 부분에 설정을 정의할 필요는 없습니다.
config 변수 이름에는 마침표 (.) 대신 대시 (-) 또는 밑줄 (_)을 사용하세요.
스크립트가 루트 아래의 run.config 키에 엑세스하는 경우 속성 엑세스 구문 config.key.value 대신 사전 엑세스 구문 ["key"]["value"]를 사용하세요.
다음 섹션에서는 실험 설정을 정의하는 다양한 일반적인 시나리오에 대해 설명합니다.
초기화 시 설정 구성하기
W&B Run으로 데이터를 동기화하고 기록하는 백그라운드 프로세스를 생성하기 위해 wandb.init() API를 호출할 때 스크립트 시작 부분에 사전을 전달합니다.
다음 코드 조각은 설정 값으로 Python 사전을 정의하는 방법과 W&B Run을 초기화할 때 해당 사전을 인수로 전달하는 방법을 보여줍니다.
import wandb
# config 사전 오브젝트 정의config = {
"hidden_layer_sizes": [32, 64],
"kernel_sizes": [3],
"activation": "ReLU",
"pool_sizes": [2],
"dropout": 0.5,
"num_classes": 10,
}
# W&B를 초기화할 때 config 사전 전달with wandb.init(project="config_example", config=config) as run:
...
중첩된 사전을 config로 전달하면 W&B는 점을 사용하여 이름을 평면화합니다.
Python에서 다른 사전에 엑세스하는 방법과 유사하게 사전에서 값에 엑세스합니다.
# 키를 인덱스 값으로 사용하여 값에 엑세스hidden_layer_sizes = run.config["hidden_layer_sizes"]
kernel_sizes = run.config["kernel_sizes"]
activation = run.config["activation"]
# Python 사전 get() 메소드hidden_layer_sizes = run.config.get("hidden_layer_sizes")
kernel_sizes = run.config.get("kernel_sizes")
activation = run.config.get("activation")
개발자 가이드 및 예제 전체에서 설정 값을 별도의 변수로 복사합니다. 이 단계는 선택 사항입니다. 가독성을 위해 수행됩니다.
argparse로 설정 구성하기
argparse 오브젝트로 설정을 구성할 수 있습니다. argument parser의 약자인 argparse는 커맨드라인 인수의 모든 유연성과 성능을 활용하는 스크립트를 쉽게 작성할 수 있도록 하는 Python 3.2 이상의 표준 라이브러리 모듈입니다.
이는 커맨드라인에서 실행되는 스크립트의 결과를 추적하는 데 유용합니다.
다음 Python 스크립트는 파서 오브젝트를 정의하여 실험 설정을 정의하고 구성하는 방법을 보여줍니다. 함수 train_one_epoch 및 evaluate_one_epoch는 이 데모의 목적으로 트레이닝 루프를 시뮬레이션하기 위해 제공됩니다.
API에 엔티티, 프로젝트 이름 및 run의 ID를 제공해야 합니다. Run 오브젝트 또는 W&B 앱 UI에서 이러한 세부 정보를 찾을 수 있습니다.
with wandb.init() as run:
...# 현재 스크립트 또는 노트북에서 시작된 경우 Run 오브젝트에서 다음 값을 찾거나 W&B 앱 UI에서 복사할 수 있습니다.username = run.entity
project = run.project
run_id = run.id
# api.run()은 wandb.init()과 다른 유형의 오브젝트를 반환합니다.api = wandb.Api()
api_run = api.run(f"{username}/{project}/{run_id}")
api_run.config["bar"] =32api_run.update()
프로젝트의 workspace는 실험을 비교할 수 있는 개인 샌드박스를 제공합니다. 프로젝트를 사용하여 다양한 아키텍처, 하이퍼파라미터, 데이터셋, 전처리 등으로 동일한 문제에 대해 작업하면서 비교할 수 있는 Models를 구성합니다.
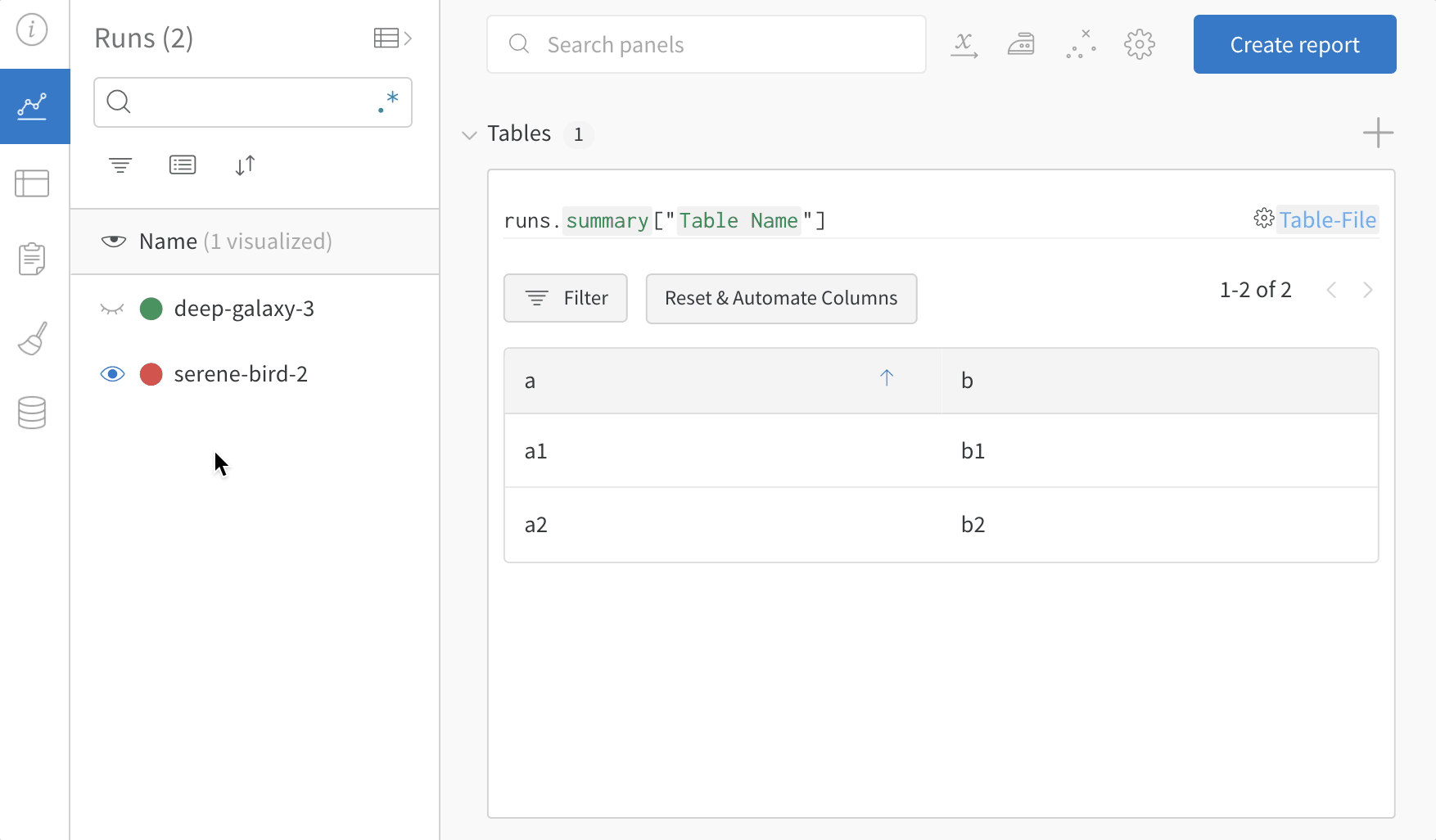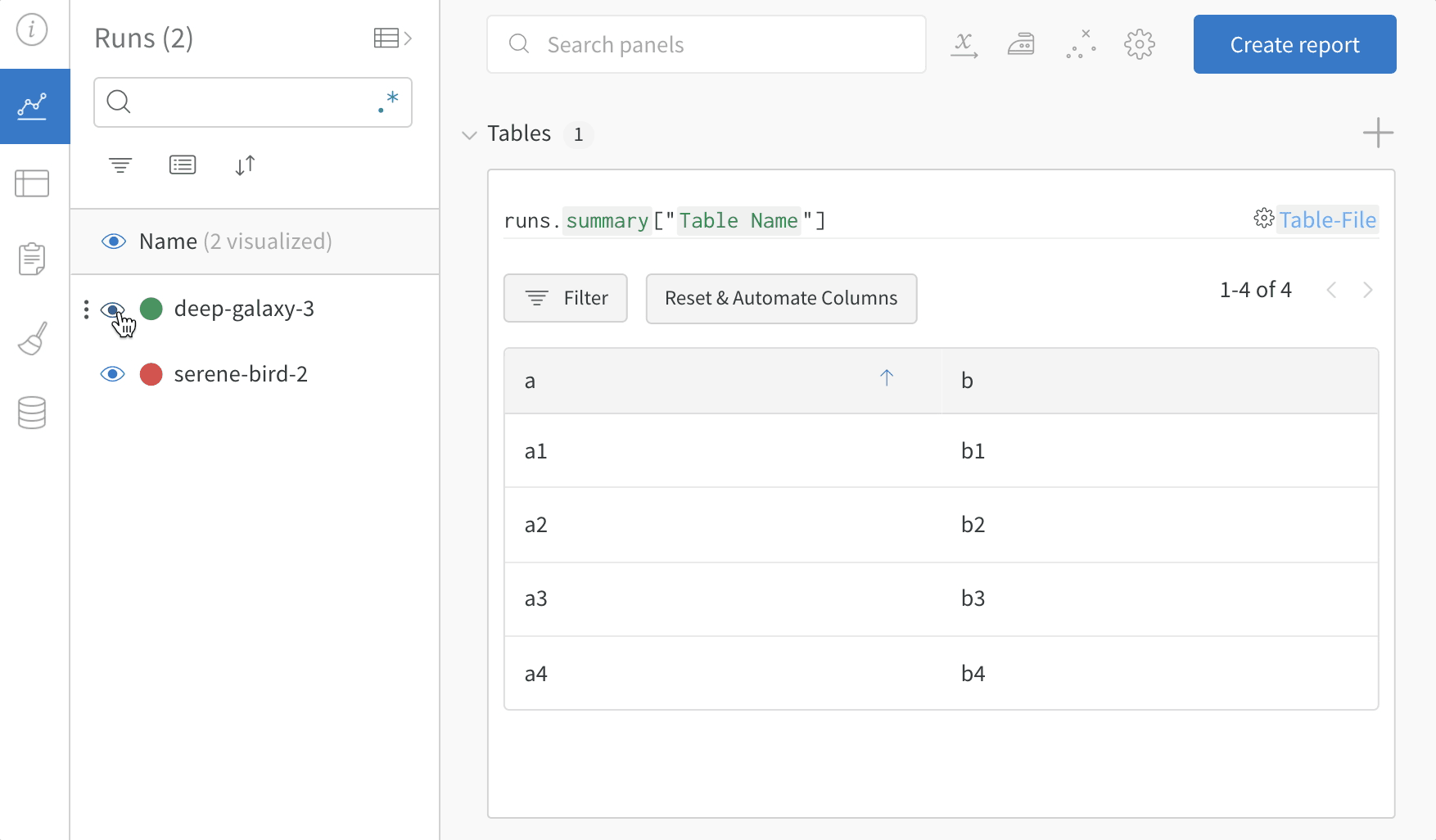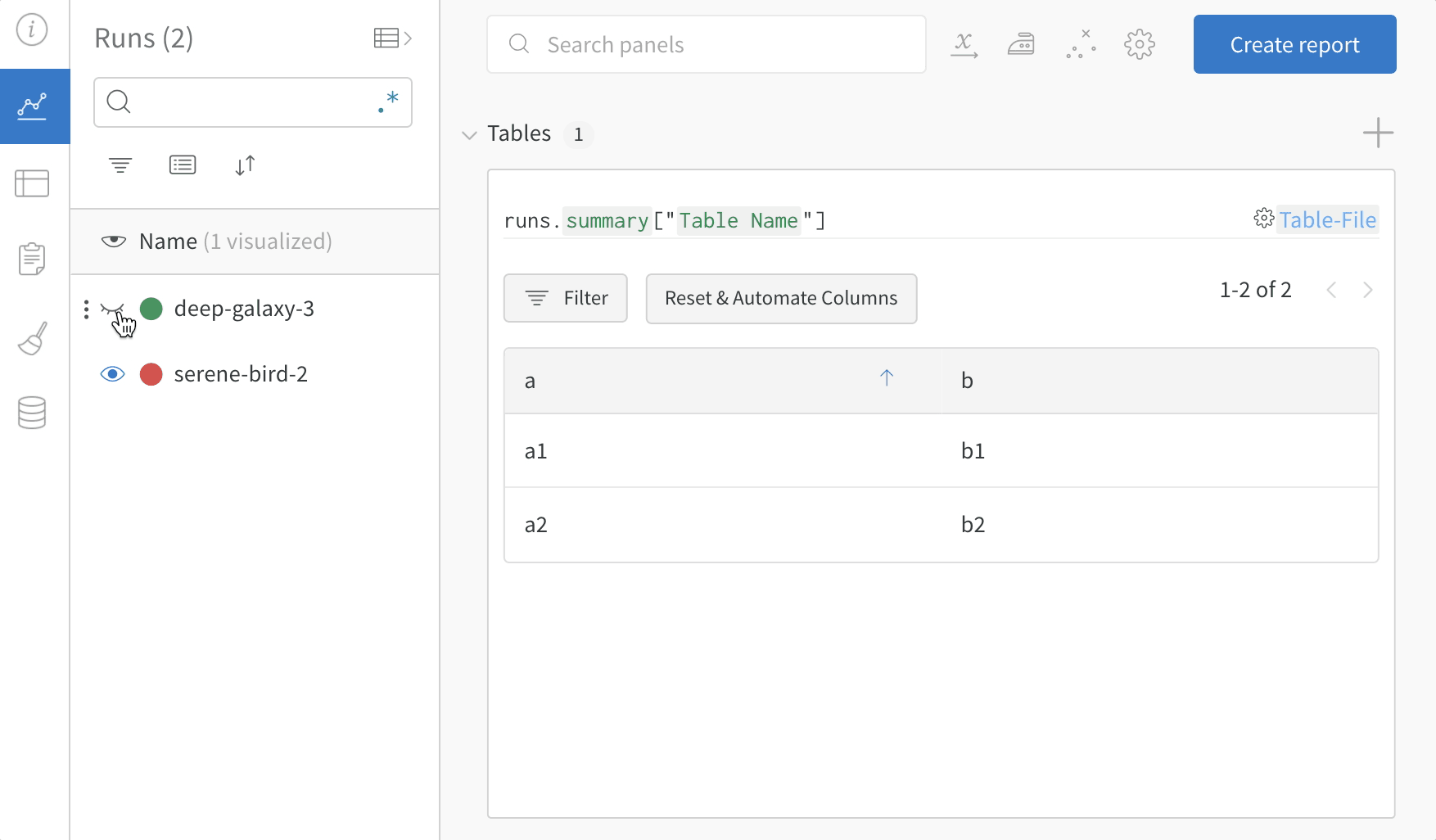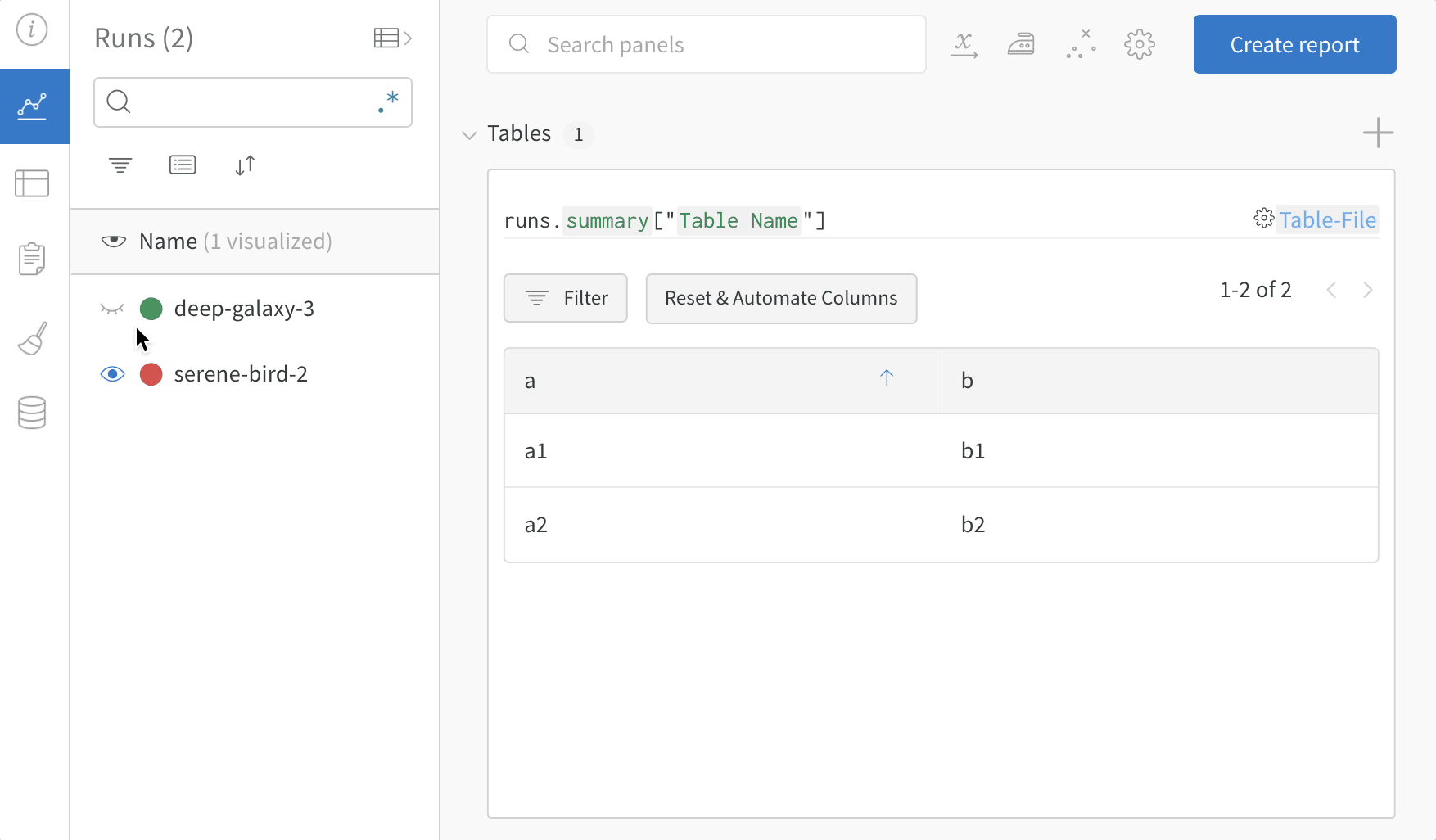
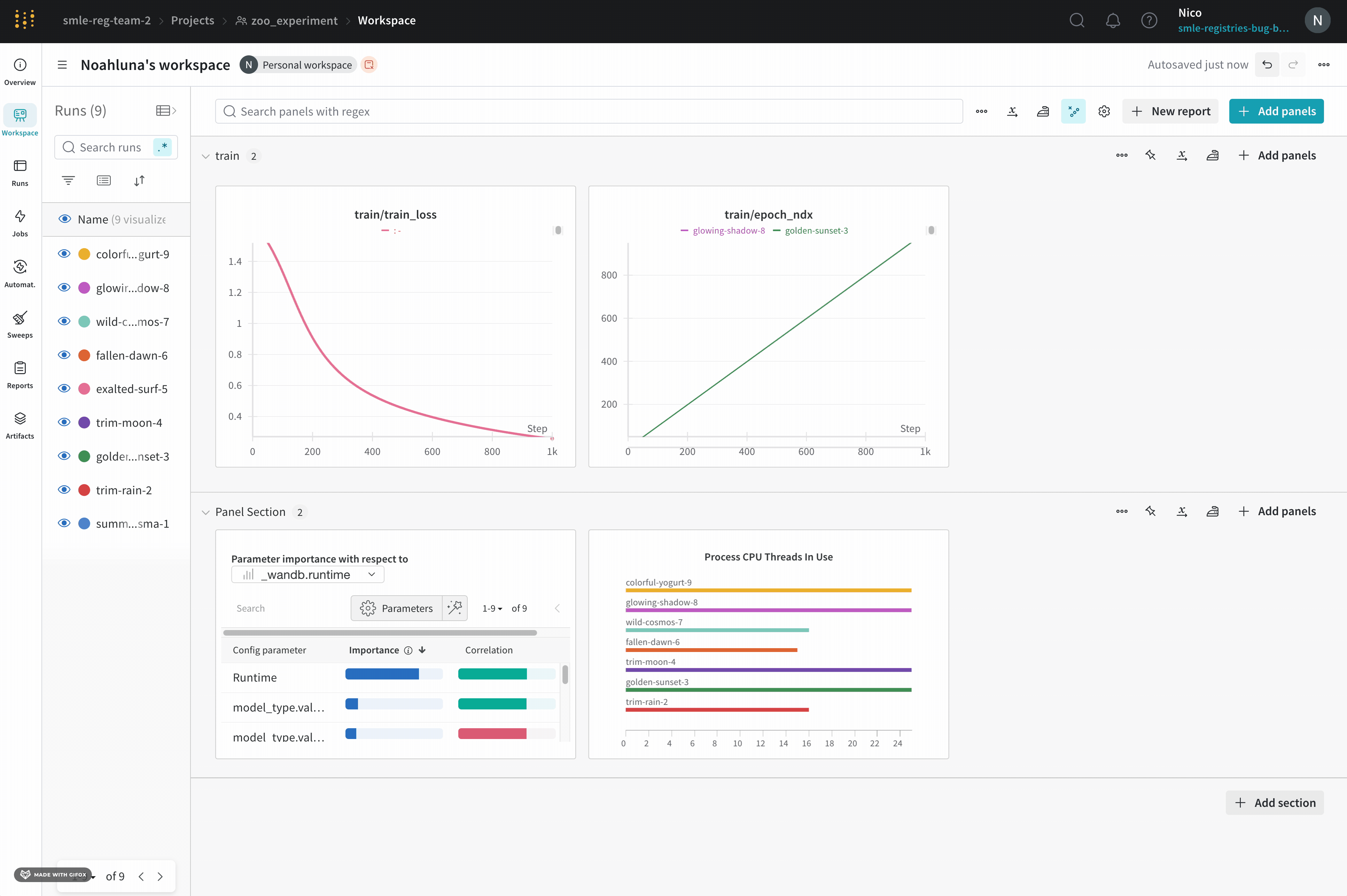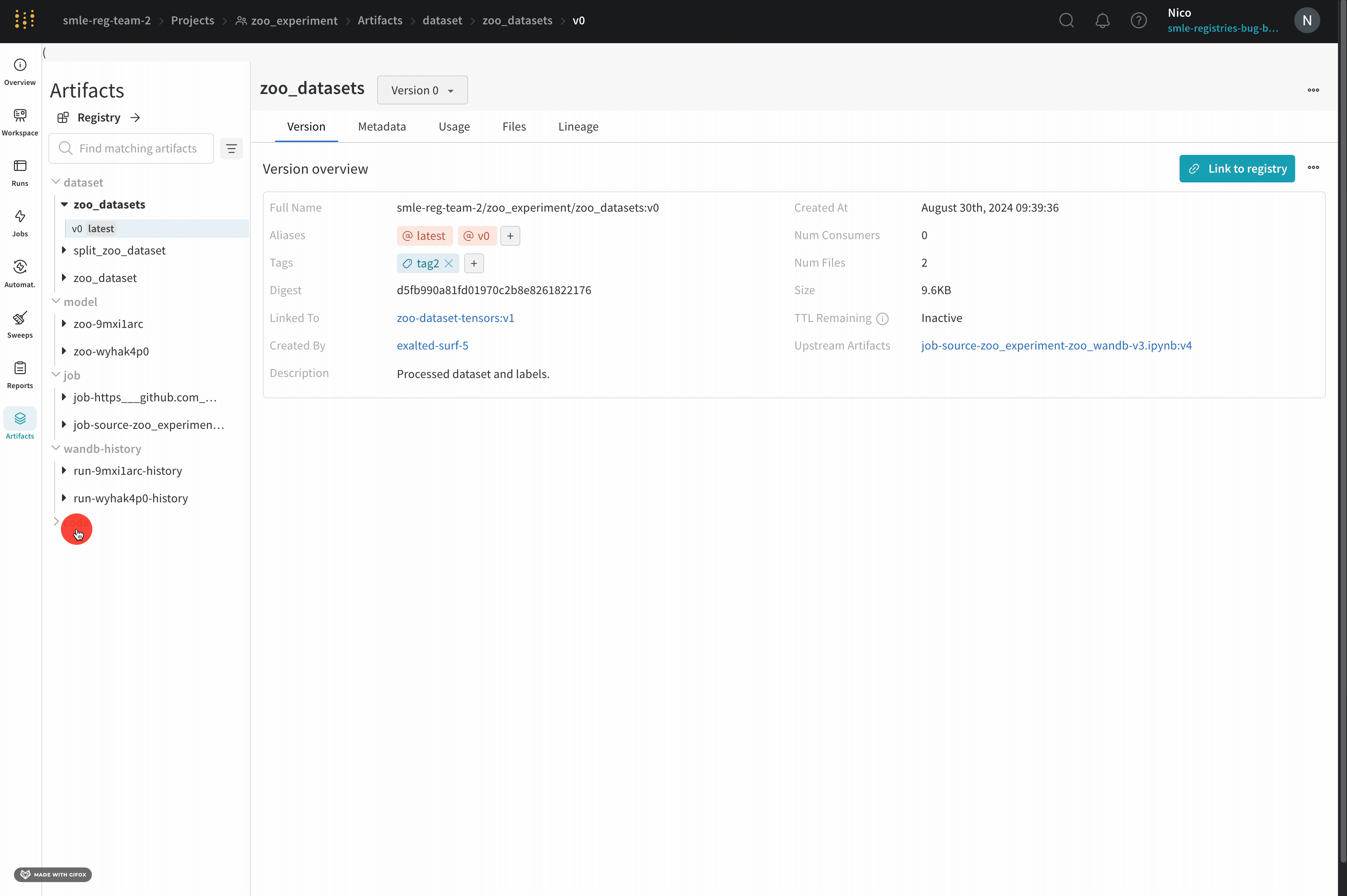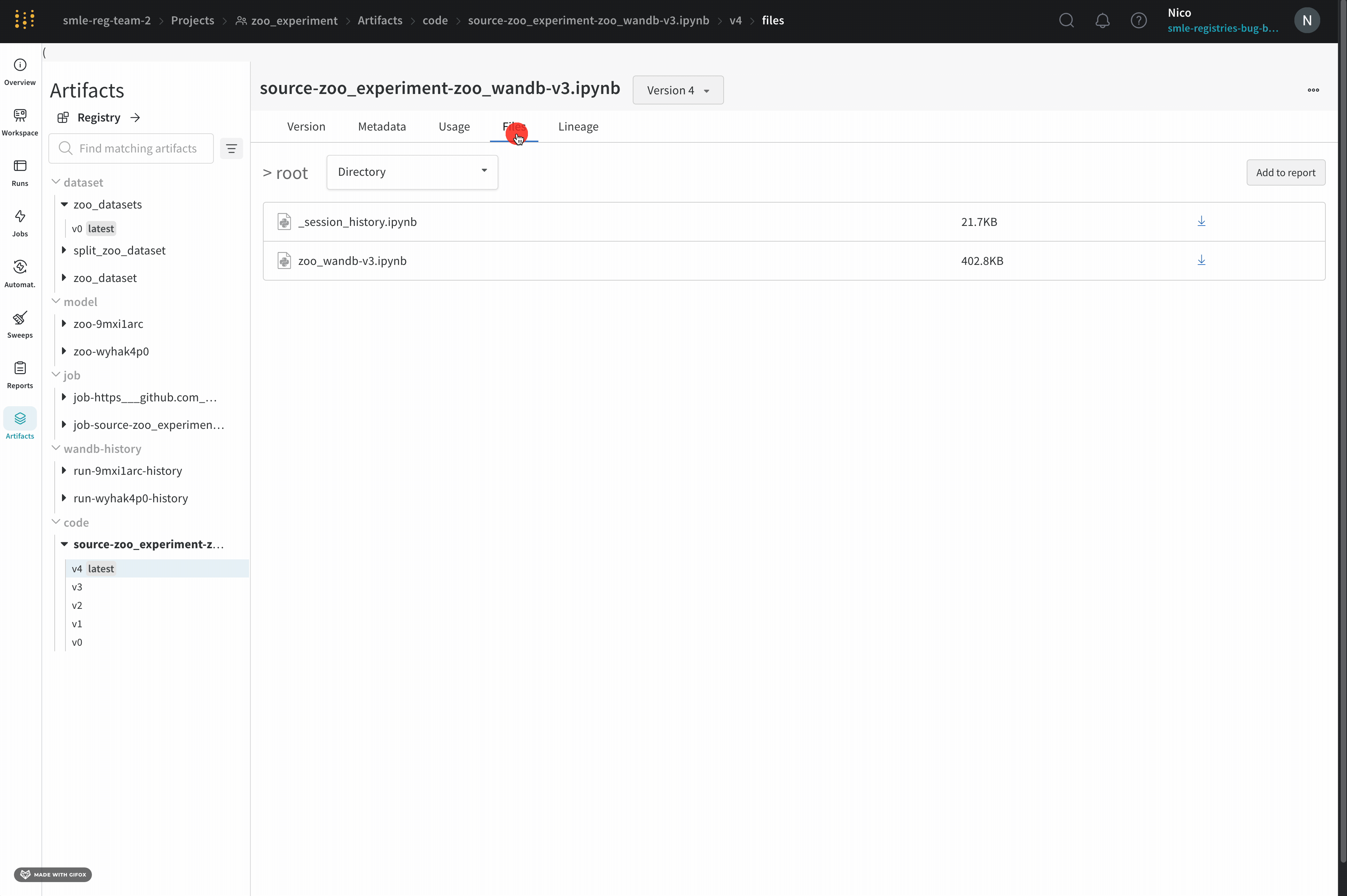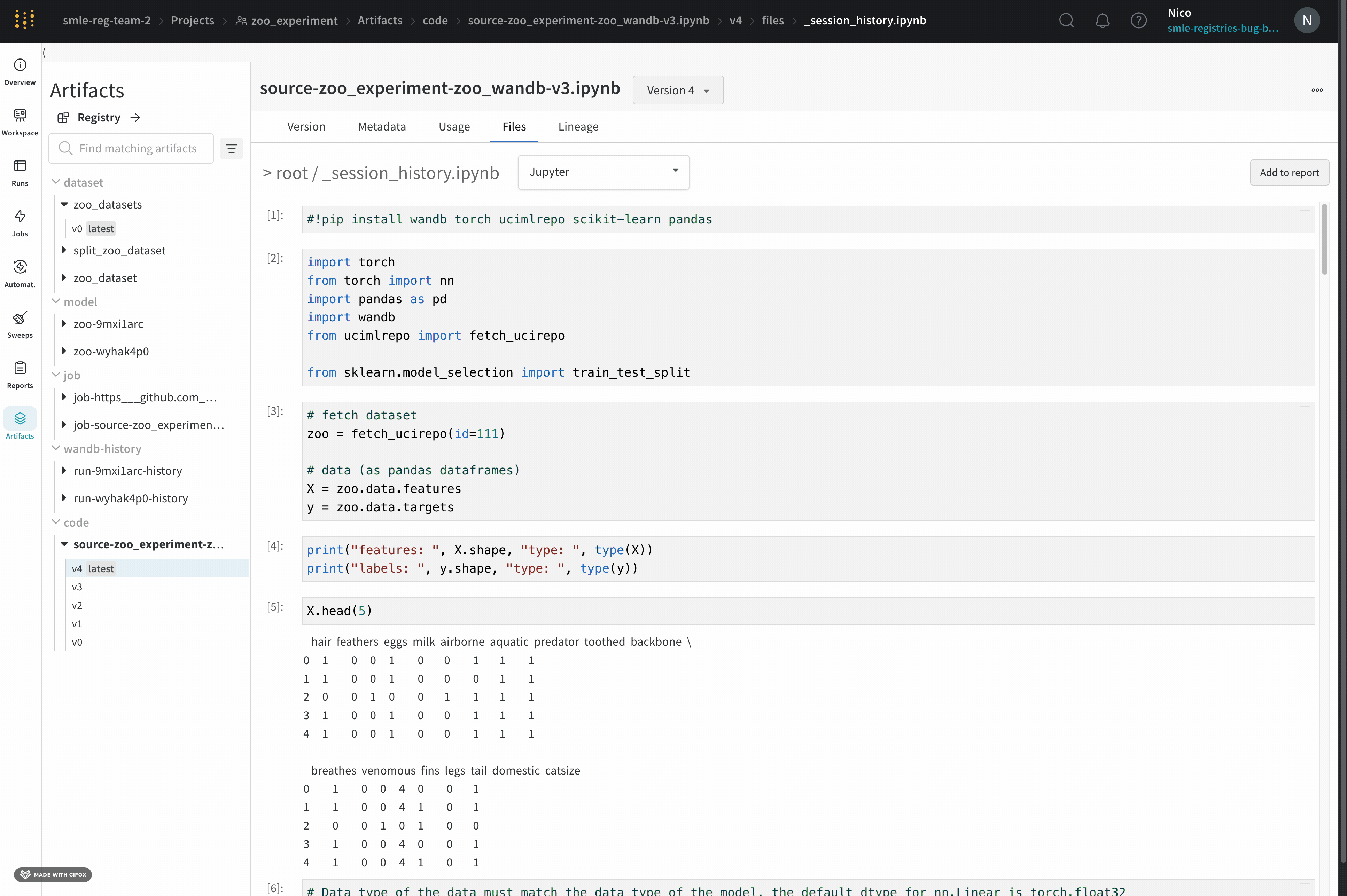
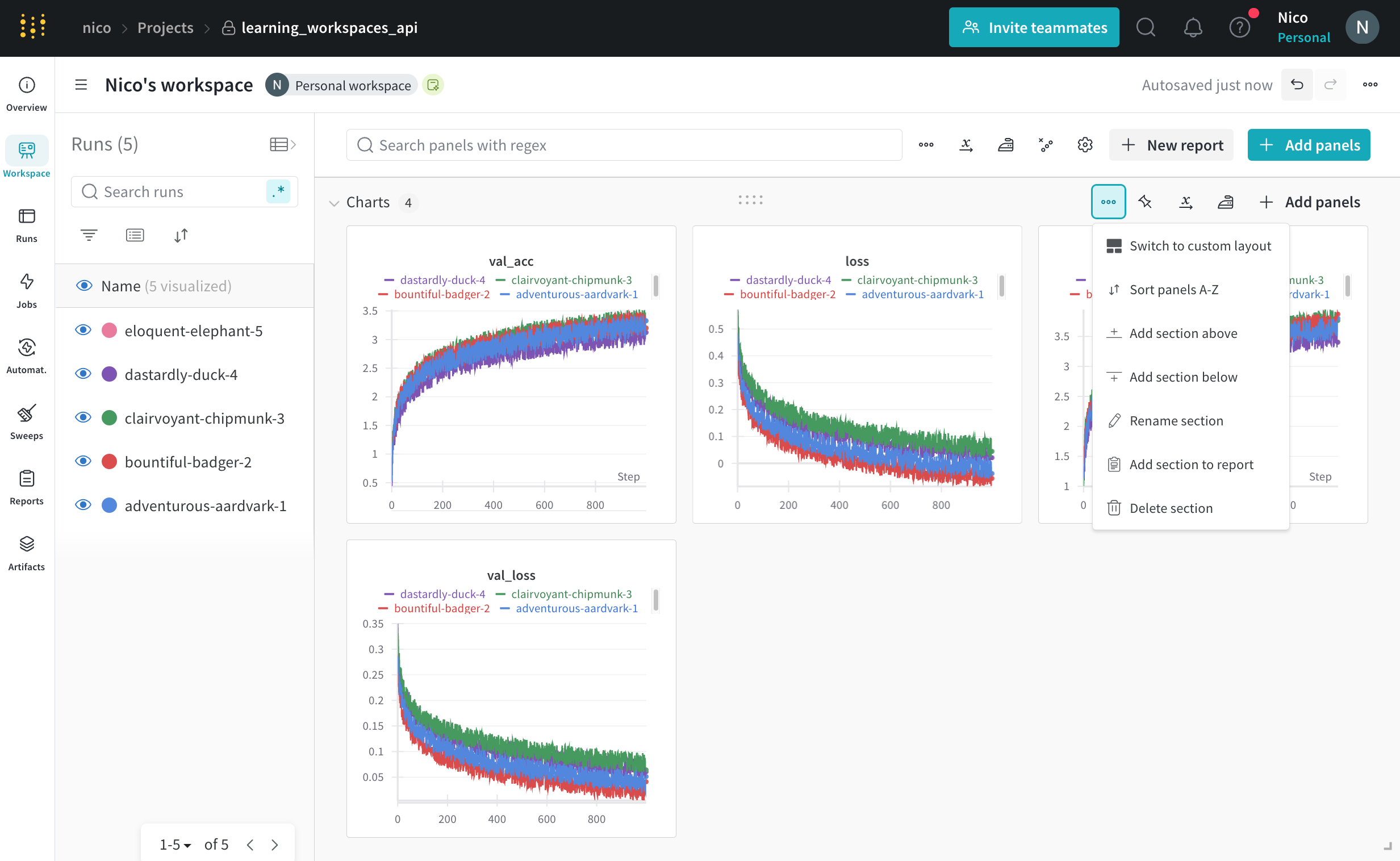
Runs Sidebar: 프로젝트의 모든 Runs 목록입니다.
Dot menu: 사이드바에서 행 위로 마우스를 가져가면 왼쪽에 메뉴가 나타납니다. 이 메뉴를 사용하여 run 이름을 바꾸거나, run을 삭제하거나, 활성 run을 중지합니다.
Visibility icon: 눈을 클릭하여 그래프에서 Runs을 켜고 끕니다.
Color: run 색상을 다른 사전 설정 색상 또는 사용자 지정 색상으로 변경합니다.
Search: 이름으로 Runs을 검색합니다. 이렇게 하면 플롯에서 보이는 Runs도 필터링됩니다.
Filter: 사이드바 필터를 사용하여 보이는 Runs 집합을 좁힙니다.
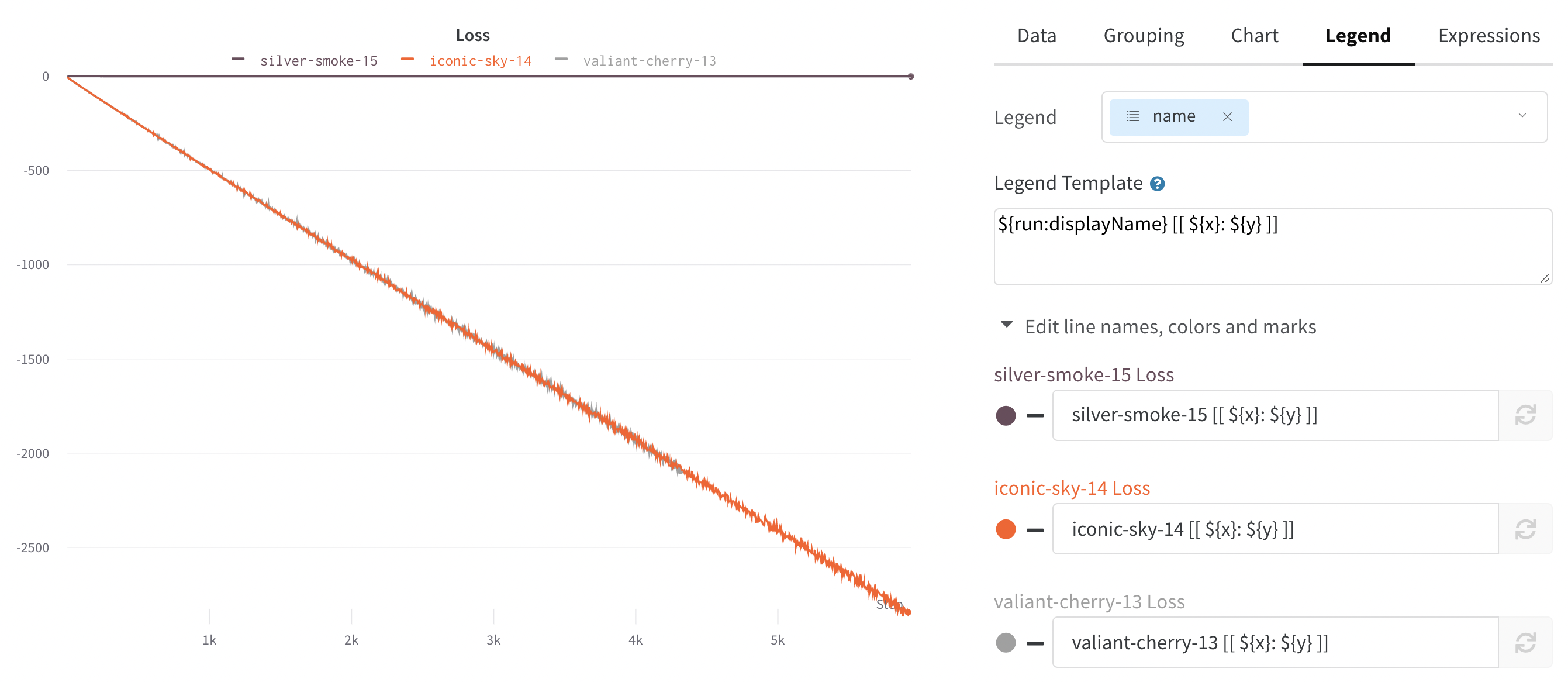
Group: 아키텍처별로 Runs을 동적으로 그룹화할 구성 열을 선택합니다. 그룹화하면 플롯에 평균 값을 따라 선이 표시되고 그래프에서 점의 분산에 대한 음영 영역이 표시됩니다.
Sort: 가장 낮은 손실 또는 가장 높은 정확도를 가진 Runs과 같이 Runs을 정렬할 값을 선택합니다. 정렬은 그래프에 표시되는 Runs에 영향을 미칩니다.
Expand button: 사이드바를 전체 테이블로 확장합니다.
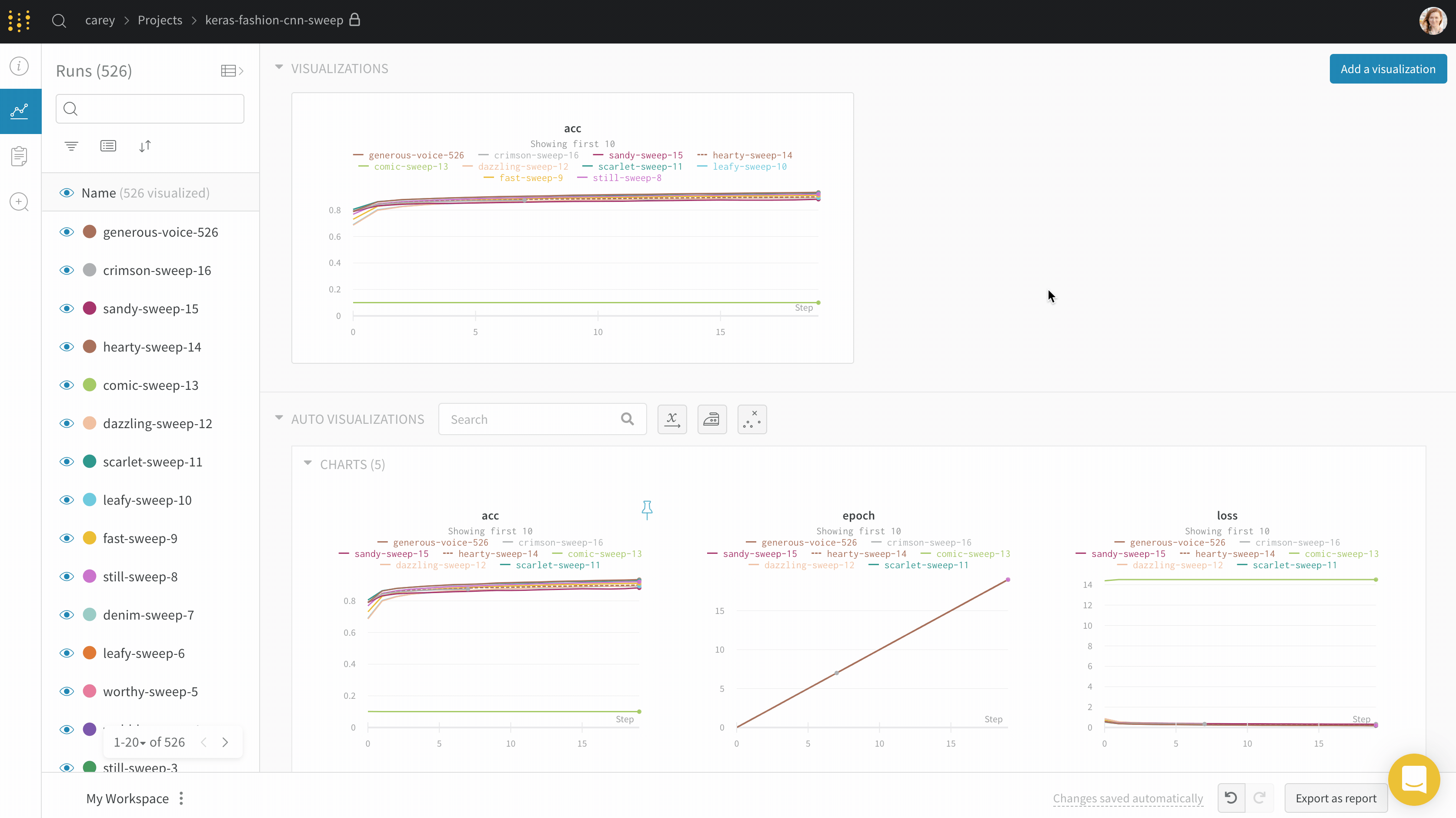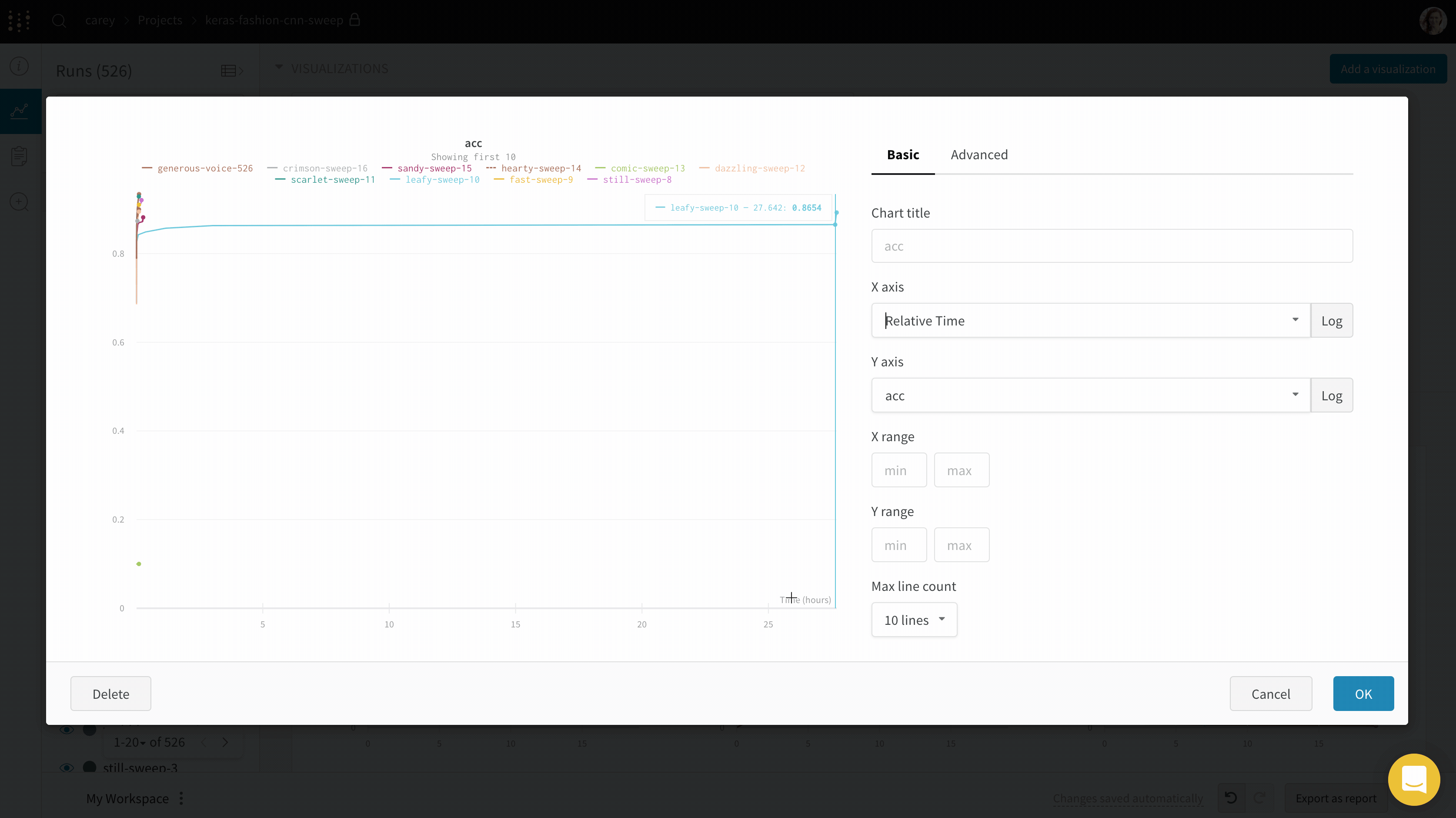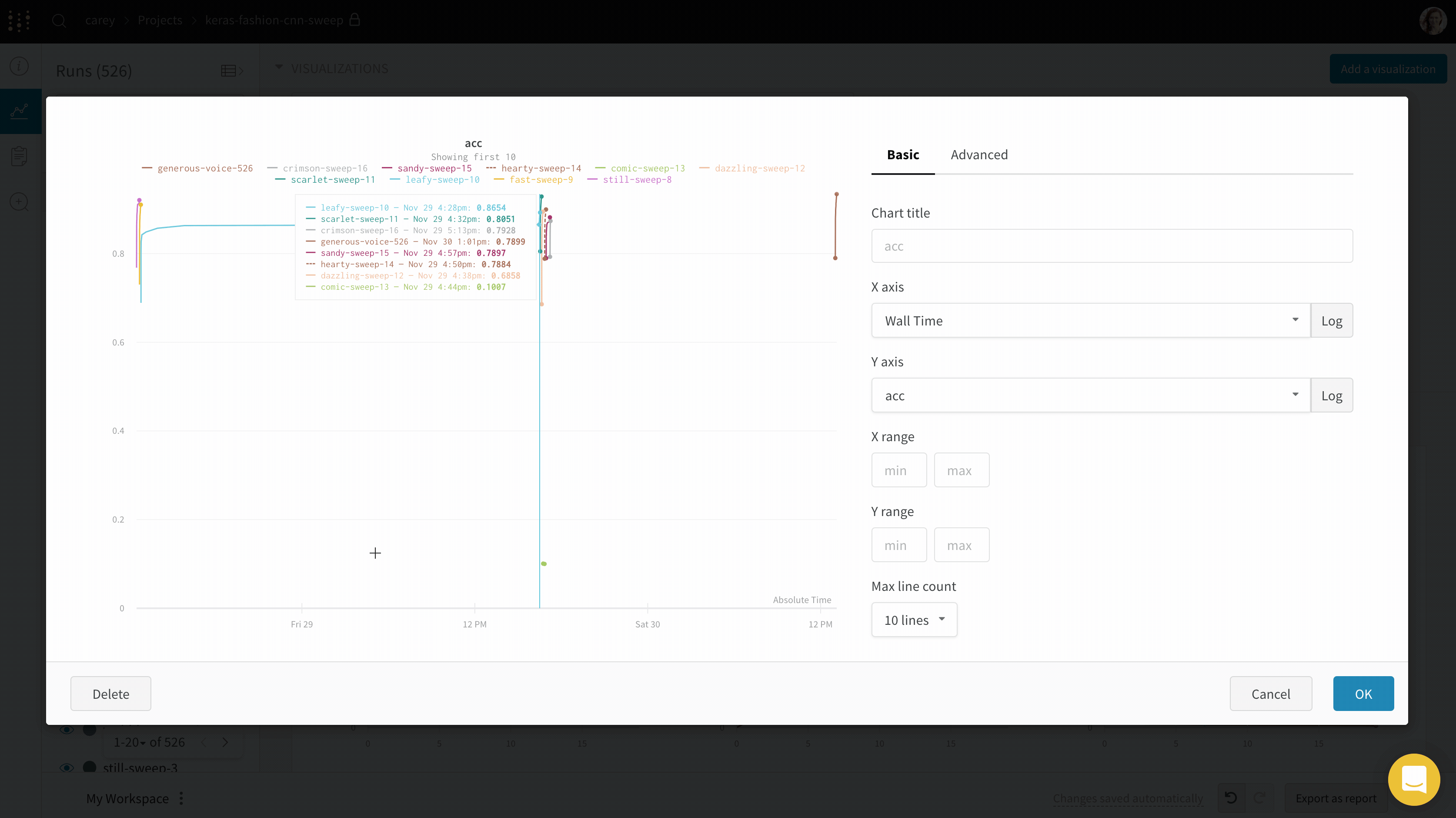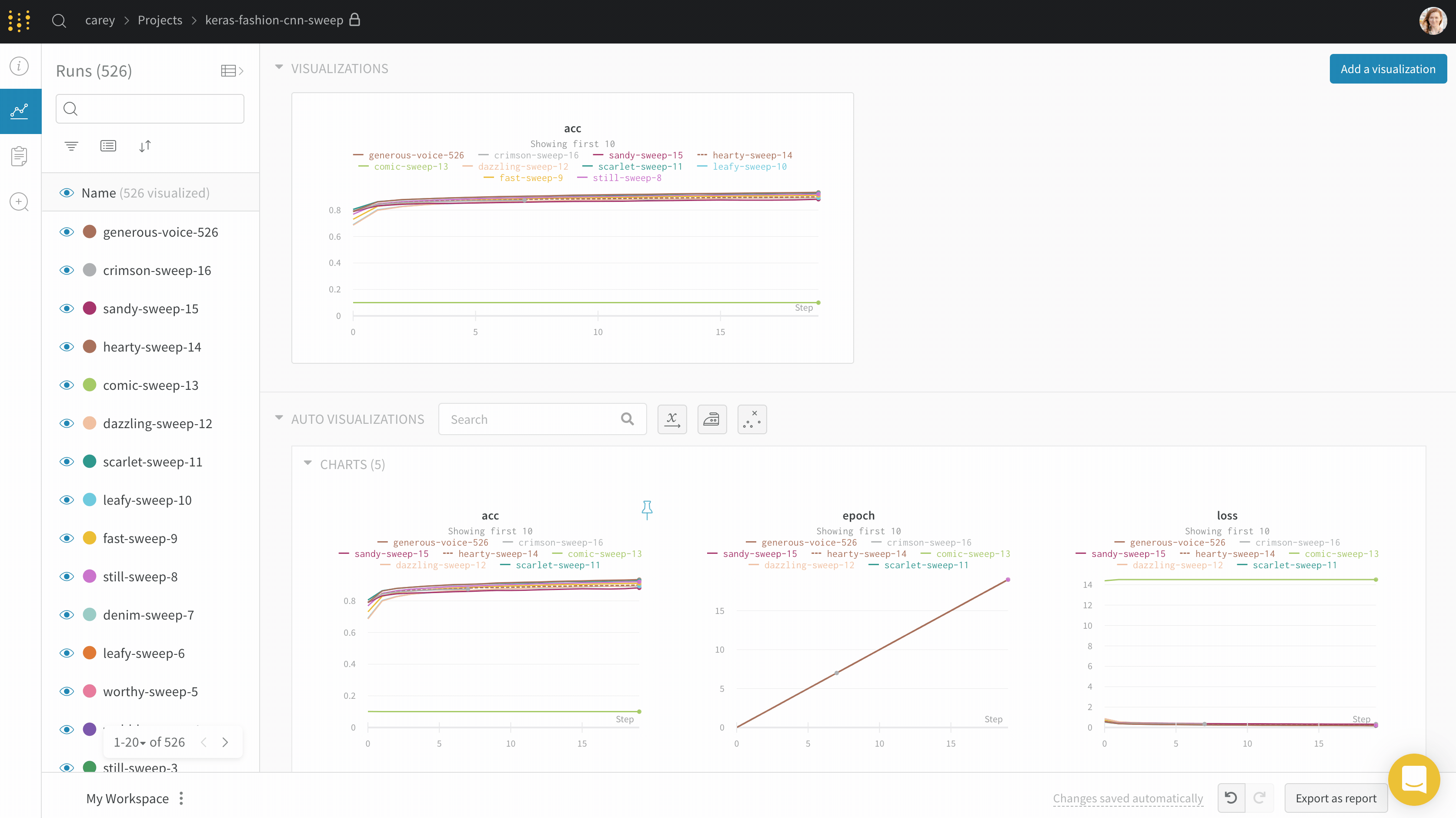
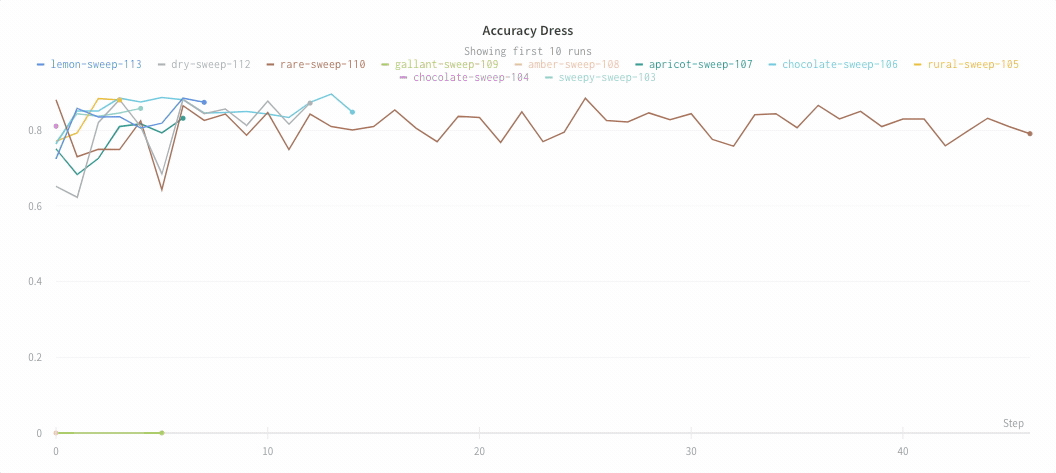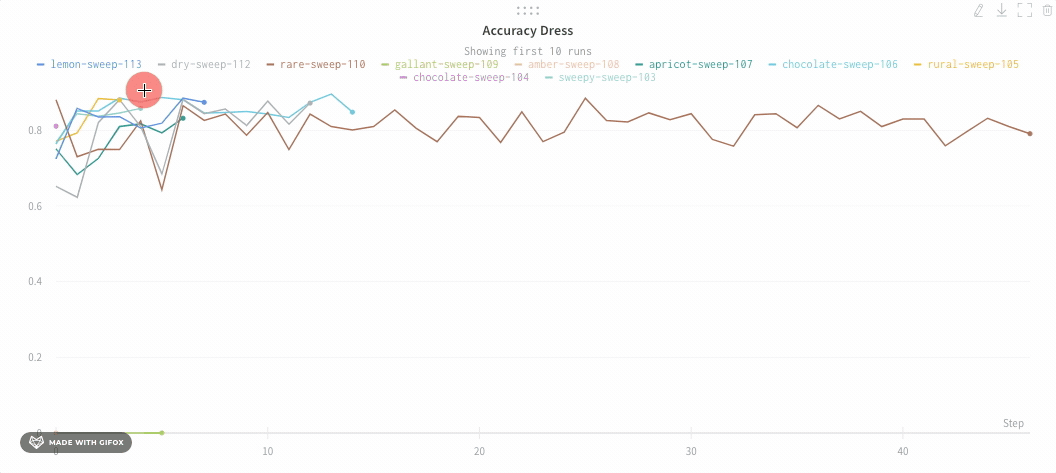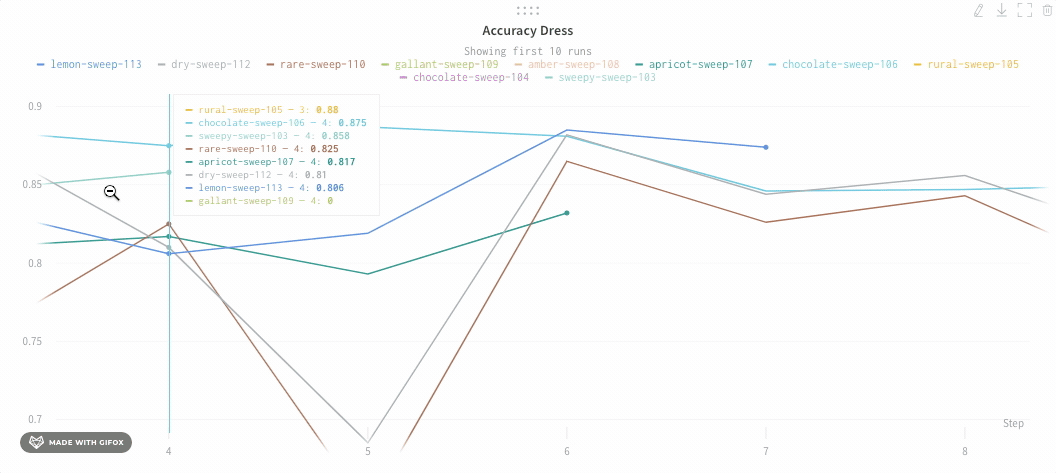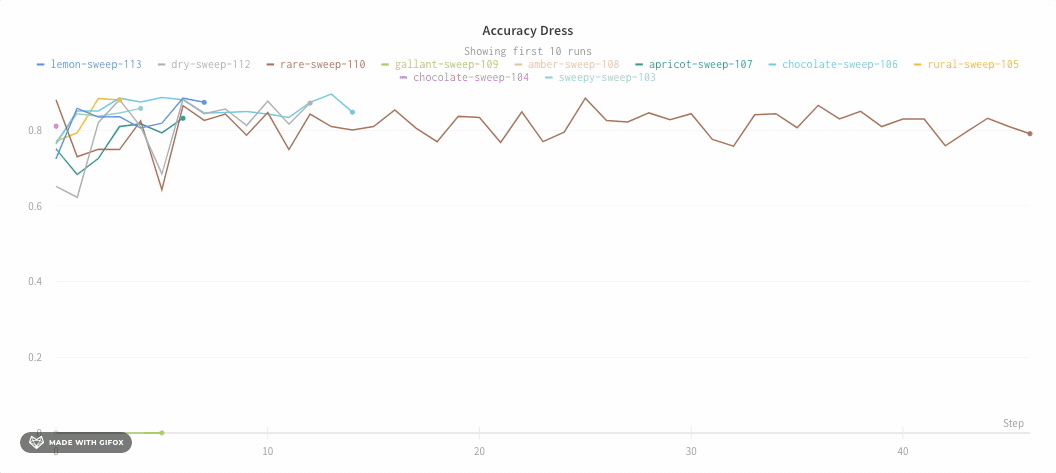
Run count: 상단의 괄호 안의 숫자는 프로젝트의 총 Runs 수입니다. (N visualized) 숫자는 눈이 켜져 있고 각 플롯에서 시각화할 수 있는 Runs 수입니다. 아래 예에서 그래프는 183개의 Runs 중 처음 10개만 보여줍니다. 보이는 Runs의 최대 수를 늘리려면 그래프를 편집합니다.
Runs 탭에서 열을 고정, 숨기거나 순서를 변경하면 Runs 사이드바에 이러한 사용자 지정이 반영됩니다.
Panels layout: 이 스크래치 공간을 사용하여 결과를 탐색하고, 차트를 추가 및 제거하고, 다양한 메트릭을 기반으로 Models 버전을 비교합니다.
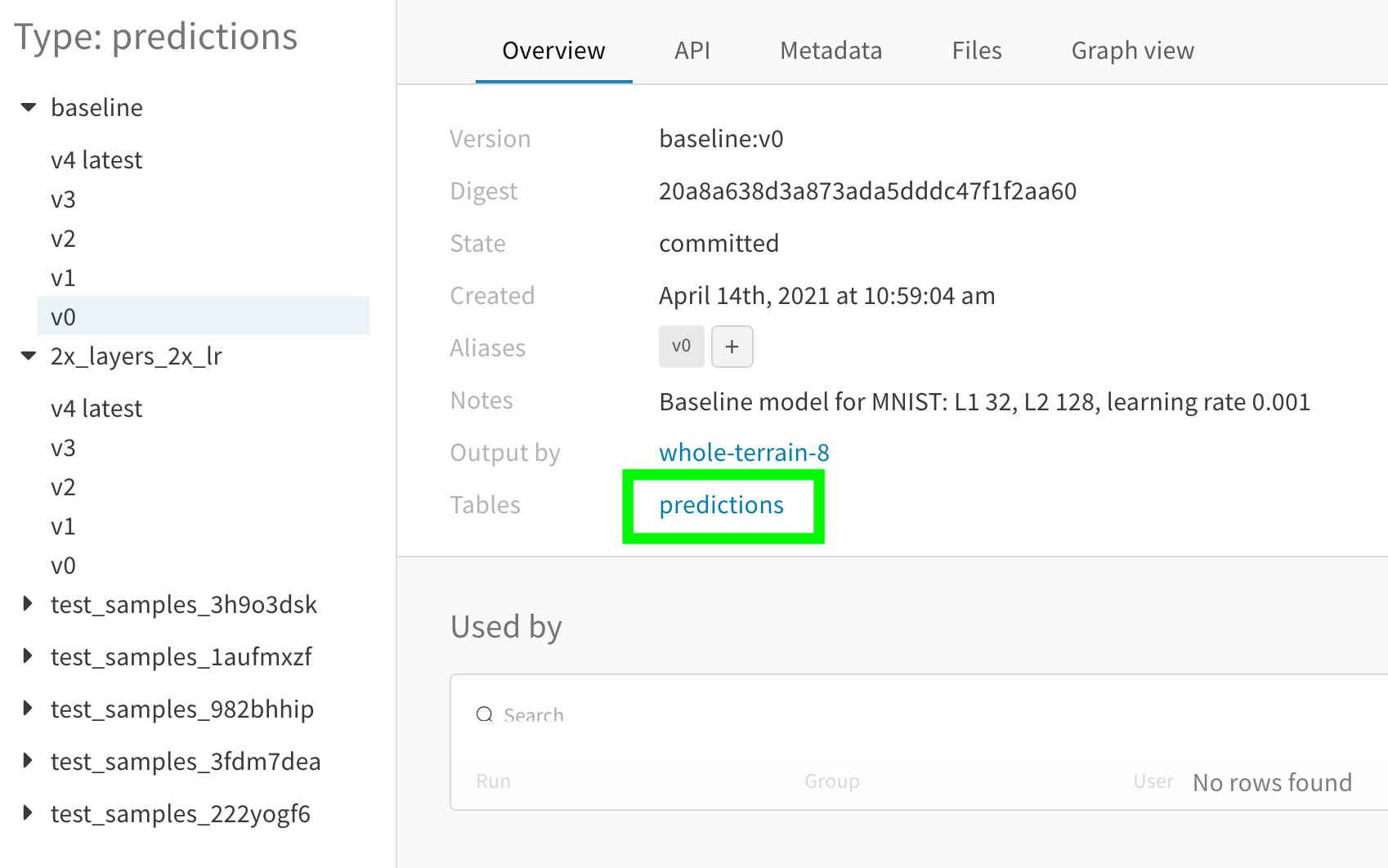
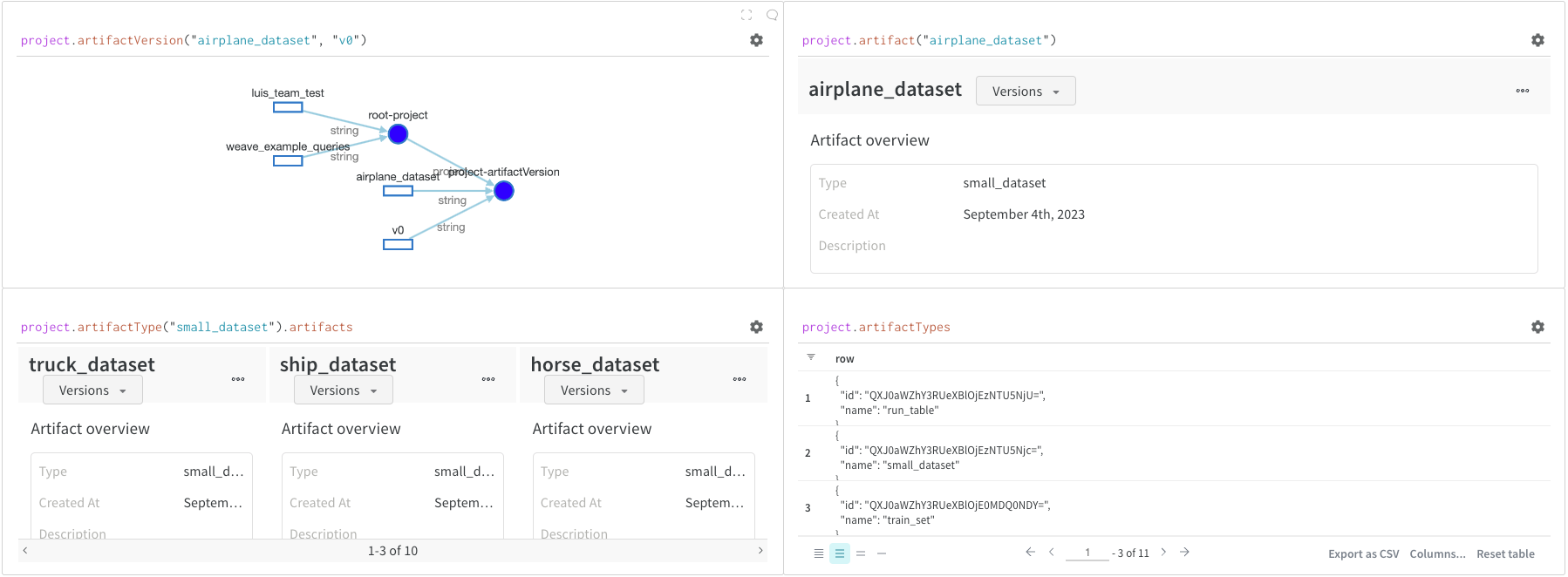
Overview 패널에서는 아티팩트 이름과 버전, 변경 사항을 감지하고 중복을 방지하는 데 사용되는 해시 다이제스트, 생성 날짜, 에일리어스를 포함하여 아티팩트에 대한 다양한 고급 정보를 찾을 수 있습니다. 여기서 에일리어스를 추가하거나 제거하고 버전과 아티팩트 전체에 대한 메모를 작성할 수 있습니다.
Metadata 패널
Metadata 패널은 아티팩트가 구성될 때 제공되는 아티팩트의 메타데이터에 대한 엑세스를 제공합니다. 이 메타데이터에는 아티팩트를 재구성하는 데 필요한 구성 인수, 더 많은 정보를 찾을 수 있는 URL 또는 아티팩트를 기록한 run 중에 생성된 메트릭이 포함될 수 있습니다. 또한 아티팩트를 생성한 run에 대한 구성과 아티팩트를 로깅할 당시의 기록 메트릭을 볼 수 있습니다.
Usage 패널
Usage 패널은 예를 들어 로컬 머신에서 웹 앱 외부에서 사용할 수 있도록 아티팩트를 다운로드하기 위한 코드 조각을 제공합니다. 이 섹션은 또한 아티팩트를 출력하는 run과 아티팩트를 입력으로 사용하는 모든 Runs을 나타내고 링크합니다.
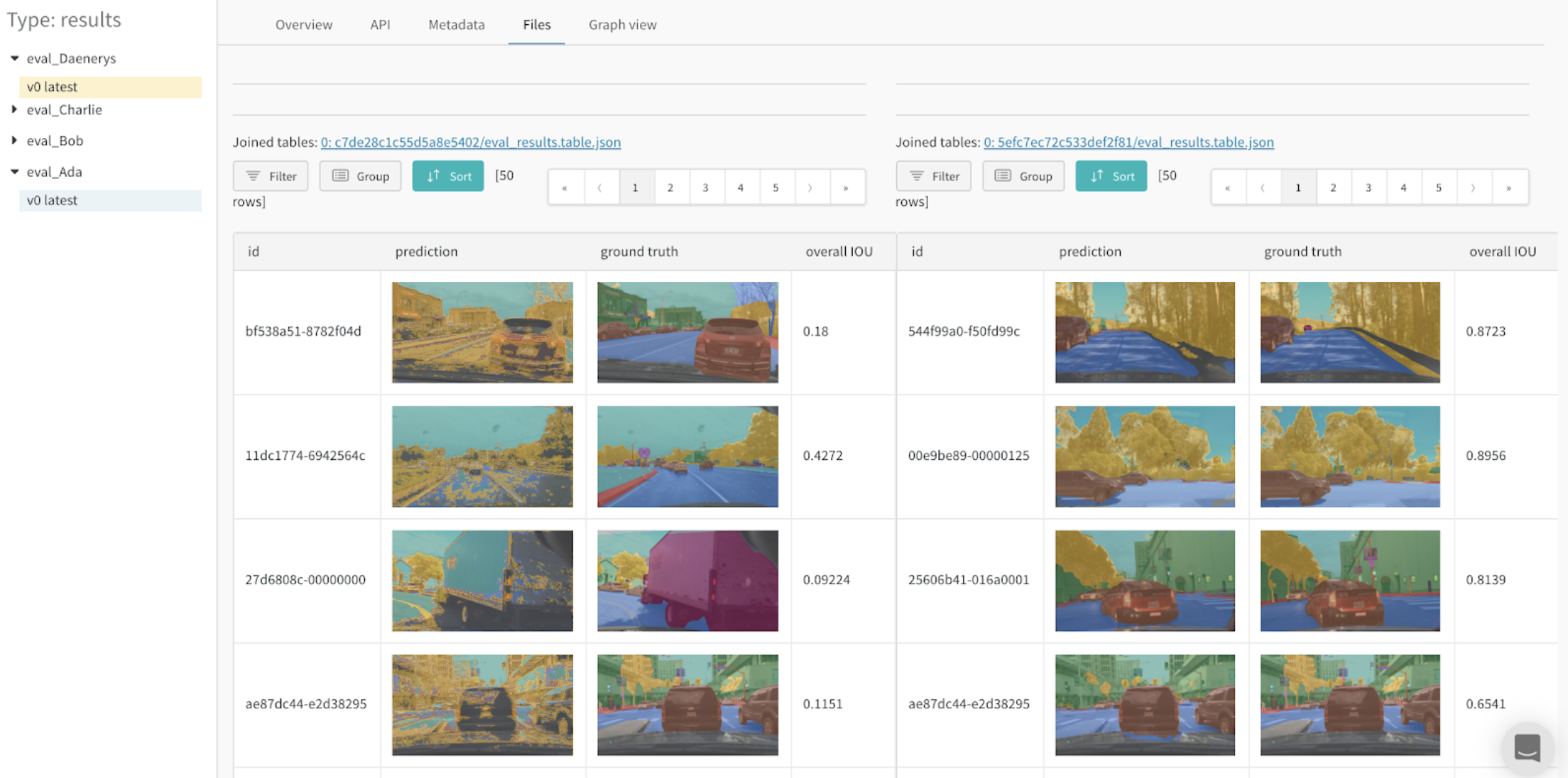
Files 패널
Files 패널은 아티팩트와 연결된 파일 및 폴더를 나열합니다. W&B는 run에 대한 특정 파일을 자동으로 업로드합니다. 예를 들어 requirements.txt는 run에서 사용된 각 라이브러리의 버전을 보여주고 wandb-metadata.json 및 wandb-summary.json에는 run에 대한 정보가 포함되어 있습니다. 다른 파일은 run의 구성에 따라 아티팩트 또는 미디어와 같이 업로드될 수 있습니다. 이 파일 트리를 탐색하고 W&B 웹 앱에서 직접 내용을 볼 수 있습니다.
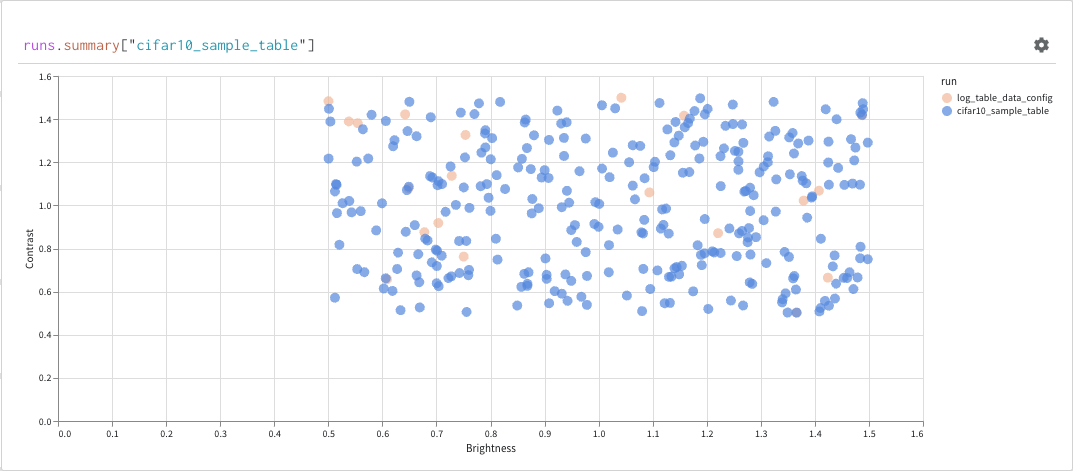
아티팩트와 연결된 테이블은 특히 풍부하고 대화형입니다. Artifacts와 함께 테이블을 사용하는 방법에 대해 자세히 알아보려면 여기를 참조하세요.
Lineage 패널
Lineage 패널은 프로젝트와 연결된 모든 아티팩트와 서로 연결하는 Runs에 대한 뷰를 제공합니다. run 유형을 블록으로, 아티팩트를 원으로 표시하고 화살표를 사용하여 지정된 유형의 run이 지정된 유형의 아티팩트를 소비하거나 생성하는 시기를 나타냅니다. 왼쪽 열에서 선택한 특정 아티팩트의 유형이 강조 표시됩니다.
개별 아티팩트 버전과 연결하는 특정 Runs을 모두 보려면 Explode 토글을 클릭합니다.
Action History Audit 탭
작업 기록 감사 탭은 리소스의 전체 진화를 감사할 수 있도록 컬렉션에 대한 모든 에일리어스 작업과 멤버십 변경 사항을 보여줍니다.
Versions 탭
Versions 탭은 아티팩트의 모든 버전과 버전을 로깅할 당시의 Run History의 각 숫자 값에 대한 열을 보여줍니다. 이를 통해 성능을 비교하고 관심 있는 버전을 빠르게 식별할 수 있습니다.
프로젝트에 별표 표시
프로젝트에 별표를 추가하여 해당 프로젝트를 중요하다고 표시합니다. 사용자와 팀이 별표로 중요하다고 표시한 프로젝트는 조직의 홈페이지 상단에 나타납니다.
예를 들어, 다음 이미지는 중요하다고 표시된 두 개의 프로젝트인 zoo_experiment와 registry_demo를 보여줍니다. 두 프로젝트 모두 Starred projects 섹션 내에서 조직의 홈페이지 상단에 나타납니다.
프로젝트를 중요하다고 표시하는 방법에는 프로젝트의 Overview 탭 내에서 또는 팀의 프로필 페이지 내에서 두 가지가 있습니다.
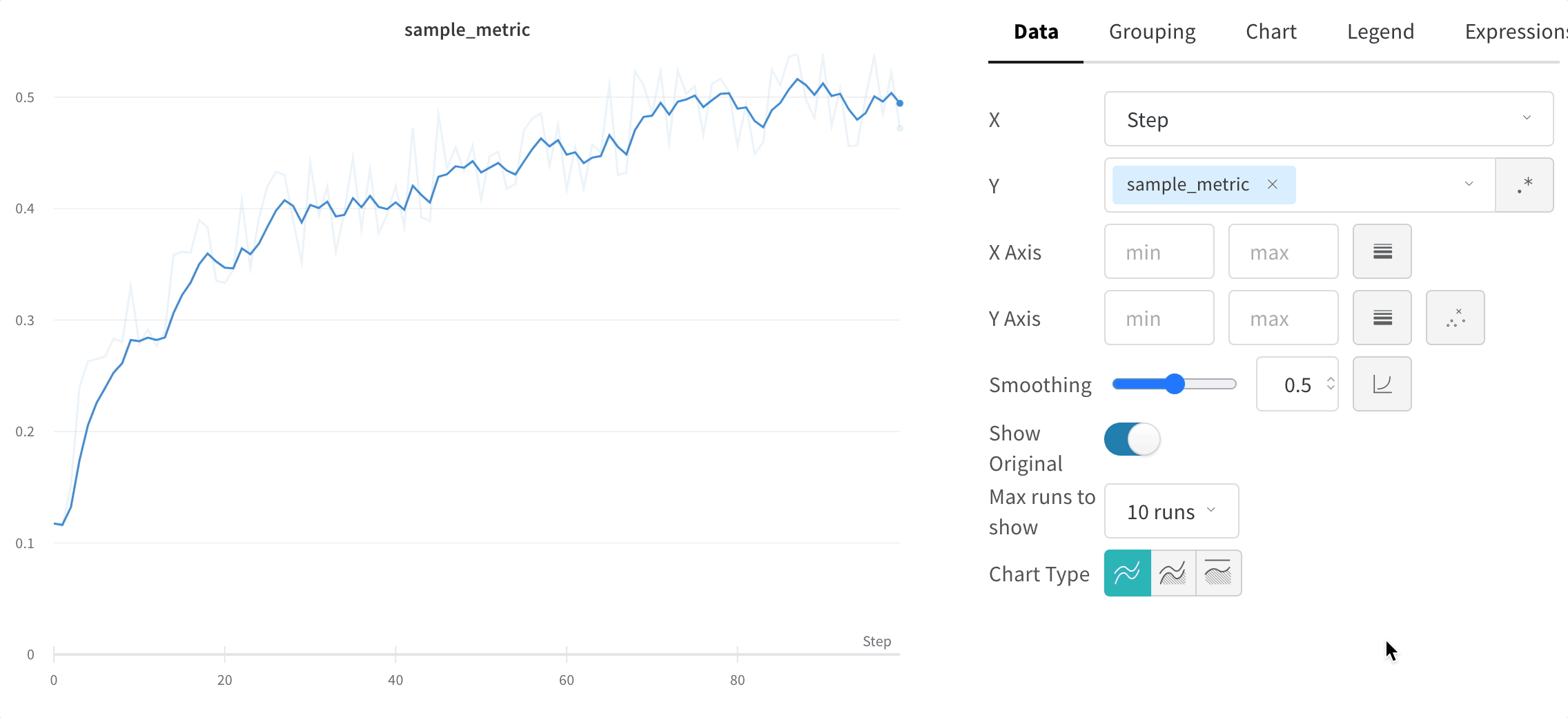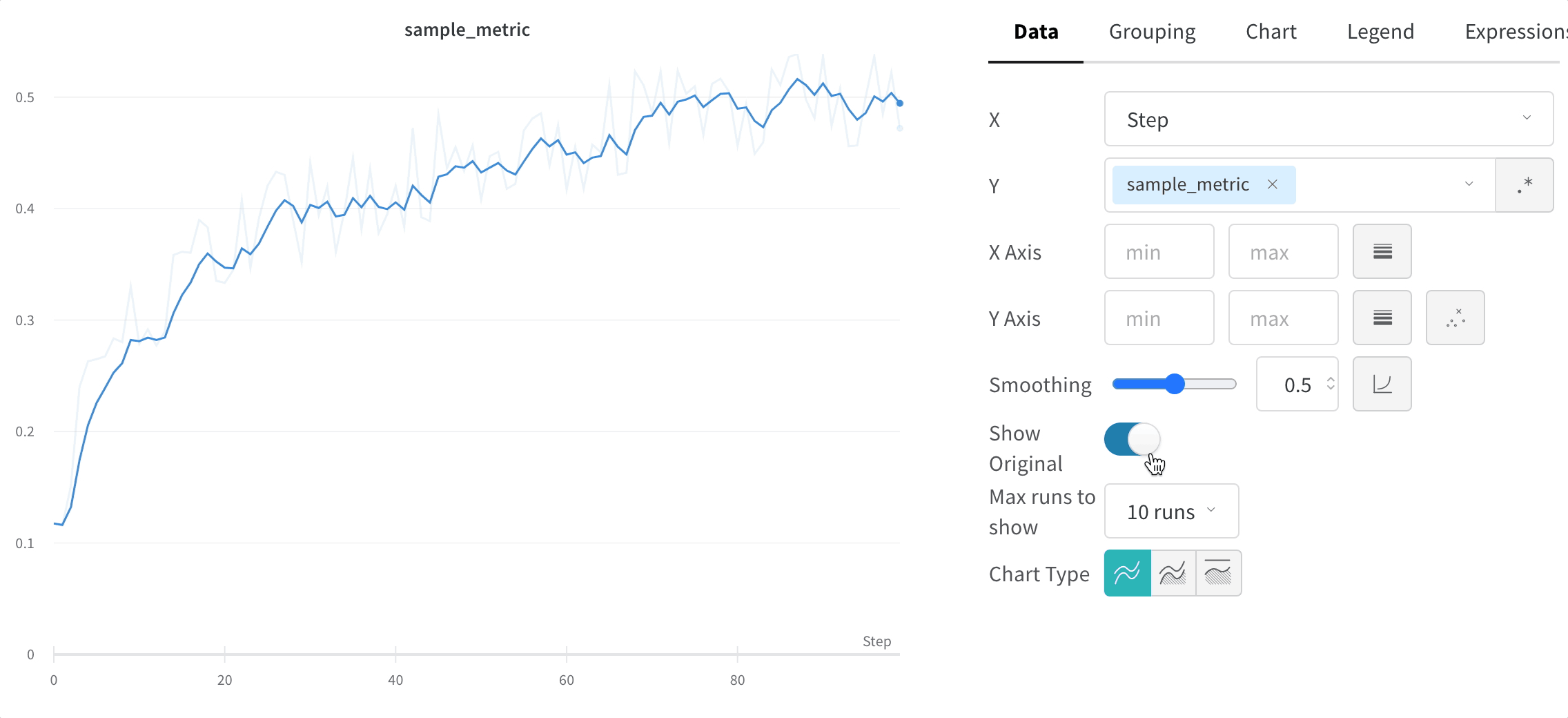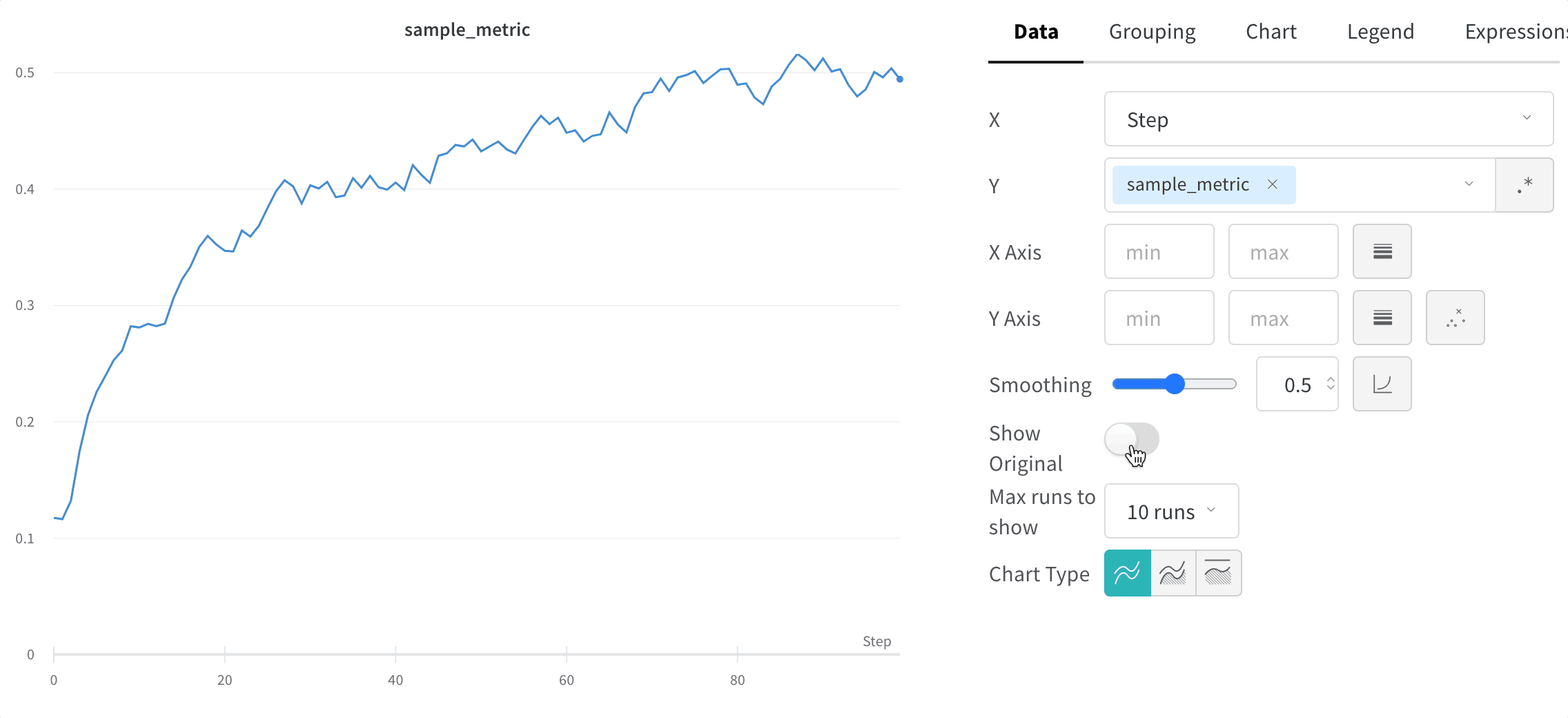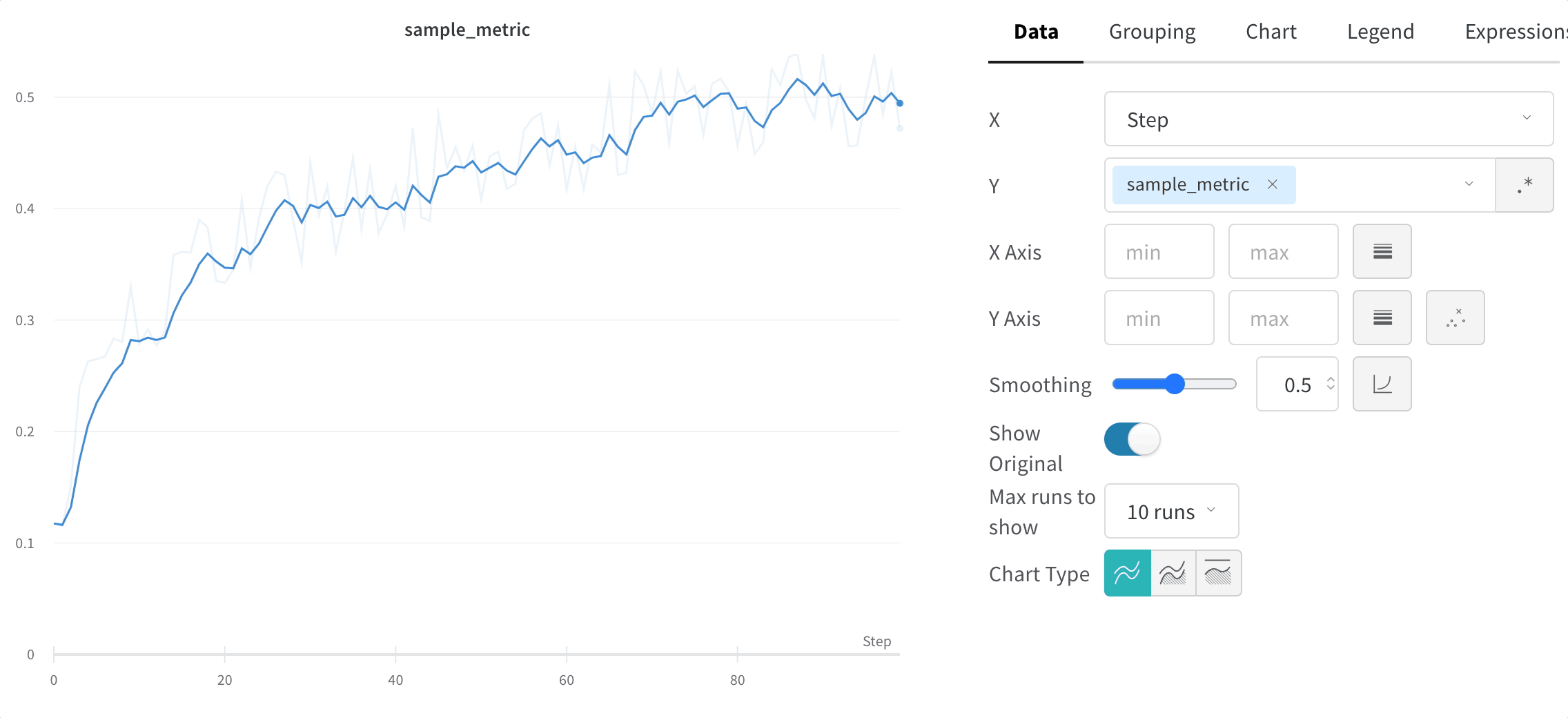
트레이닝 스크립트는 run.log를 10번 호출합니다. 스크립트가 run.log를 호출할 때마다 W&B는 해당 에포크의 정확도와 손실을 기록합니다. W&B가 이전 출력에서 출력하는 URL을 선택하면 W&B 앱 UI에서 run의 워크스페이스로 이동합니다.
스크립트가 wandb.init 메서드를 한 번만 호출하기 때문에 W&B는 시뮬레이션된 트레이닝 루프를 jolly-haze-4라는 단일 run 내에서 캡처합니다.
또 다른 예로, 스윕 중에 W&B는 사용자가 지정한 하이퍼파라미터 검색 공간을 탐색합니다. W&B는 스윕이 생성하는 각 새로운 하이퍼파라미터 조합을 고유한 run으로 구현합니다.
Run 초기화
wandb.init()로 W&B run을 초기화합니다. 다음 코드 조각은 W&B Python SDK를 임포트하고 run을 초기화하는 방법을 보여줍니다.
각도 괄호(<>)로 묶인 값을 사용자 고유의 값으로 바꾸십시오.
import wandb
run = wandb.init(entity="<entity>", project="<project>")
run을 초기화할 때 W&B는 프로젝트 필드에 지정한 프로젝트(wandb.init(project="<project>"))에 run을 기록합니다. W&B는 프로젝트가 아직 존재하지 않으면 새 프로젝트를 만듭니다. 프로젝트가 이미 존재하는 경우 W&B는 해당 프로젝트에 run을 저장합니다.
프로젝트 이름을 지정하지 않으면 W&B는 run을 Uncategorized라는 프로젝트에 저장합니다.
import wandb
run = wandb.init(entity="wandbee", project="awesome-project")
코드 조각은 다음 출력을 생성합니다.
🚀 View run exalted-darkness-6 at:
https://wandb.ai/nico/awesome-project/runs/pgbn9y21
Find logs at: wandb/run-20241106_090747-pgbn9y21/logs
이전 코드는 id 파라미터에 대한 인수를 지정하지 않았으므로 W&B는 고유한 run ID를 만듭니다. 여기서 nico는 run을 기록한 엔터티이고, awesome-project는 run이 기록된 프로젝트의 이름이고, exalted-darkness-6은 run의 이름이고, pgbn9y21은 run ID입니다.
노트북 사용자
run이 끝날 때 run.finish()를 지정하여 run이 완료되었음을 표시합니다. 이렇게 하면 run이 프로젝트에 올바르게 기록되고 백그라운드에서 계속되지 않습니다.
import wandb
run = wandb.init(entity="<entity>", project="<project>")
# Training code, logging, and so forthrun.finish()
각 run에는 run의 현재 상태를 설명하는 상태가 있습니다. 가능한 run 상태의 전체 목록은 Run 상태를 참조하십시오.
Run 상태
다음 표는 run이 가질 수 있는 가능한 상태를 설명합니다.
상태
설명
Finished
run이 종료되고 데이터가 완전히 동기화되었거나 wandb.finish()가 호출되었습니다.
Failed
run이 0이 아닌 종료 상태로 종료되었습니다.
Crashed
run이 내부 프로세스에서 하트비트 전송을 중단했습니다. 이는 머신이 충돌할 경우 발생할 수 있습니다.
변경 불가능한 Run ID 복사:Overview 탭의 오른쪽 상단에 있는 ... 메뉴(세 개의 점)를 클릭합니다. 드롭다운 메뉴에서 Copy Immutable Run ID 옵션을 선택합니다.
이러한 단계를 따르면 run에 대한 안정적이고 변경되지 않는 참조를 갖게 되어 run을 포크하는 데 사용할 수 있습니다.
포크된 run에서 계속하기
포크된 run을 초기화한 후 새 run에 계속 로그할 수 있습니다. 연속성을 위해 동일한 메트릭을 로그하고 새 메트릭을 도입할 수 있습니다.
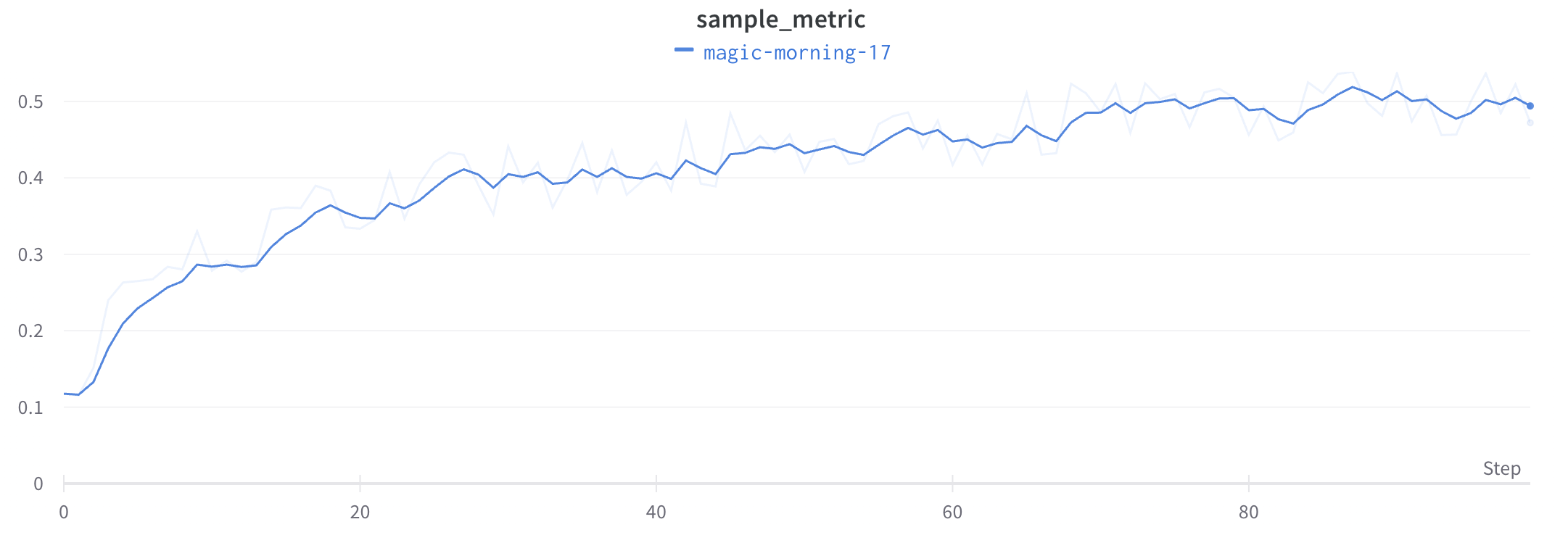
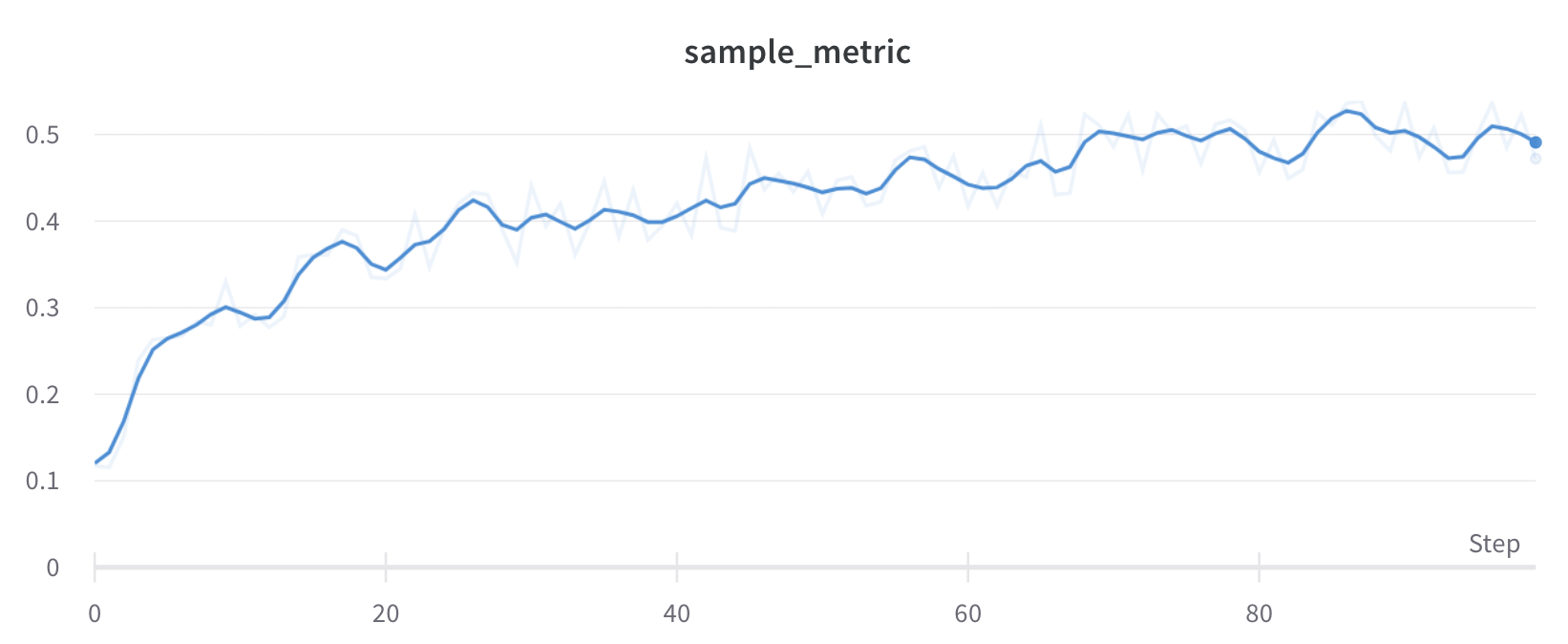
예를 들어 다음 코드 예제에서는 먼저 run을 포크한 다음 트레이닝 step 200부터 포크된 run에 메트릭을 로그하는 방법을 보여줍니다.
import wandb
import math
# 첫 번째 run을 초기화하고 일부 메트릭을 로그합니다run1 = wandb.init("your_project_name", entity="your_entity_name")
for i in range(300):
run1.log({"metric": i})
run1.finish()
# 특정 step에서 첫 번째 run에서 포크하고 step 200부터 메트릭을 로그합니다run2 = wandb.init(
"your_project_name", entity="your_entity_name", fork_from=f"{run1.id}?_step=200")
# 새 run에서 계속 로깅합니다# 처음 몇 steps 동안은 run1에서 메트릭을 그대로 로깅합니다# Step 250 이후에는 스파이크 패턴 로깅을 시작합니다for i in range(200, 300):
if i <250:
run2.log({"metric": i}) # 스파이크 없이 run1에서 계속 로깅합니다else:
# Step 250부터 스파이크 행동을 도입합니다 subtle_spike = i + (2* math.sin(i /3.0)) # 미묘한 스파이크 패턴을 적용합니다 run2.log({"metric": subtle_spike})
# 모든 steps에서 새 메트릭을 추가로 로깅합니다 run2.log({"additional_metric": i *1.1})
run2.finish()
run에서 포크하면 W&B는 특정 시점에서 run에서 새 분기를 생성하여 다른 파라미터 또는 Models를 시도합니다.
run을 되감으면 W&B를 통해 run 기록 자체를 수정하거나 변경할 수 있습니다.
1.5.4 - Group runs into experiments
트레이닝 및 평가 run을 그룹화하여 더 큰 Experiments로 구성
개별 작업을 wandb.init() 에 고유한 group 이름을 전달하여 Experiments 로 그룹화합니다.
유스 케이스
분산 트레이닝: Experiments 가 별도의 트레이닝 및 평가 스크립트로 분할되어 더 큰 전체의 일부로 보아야 하는 경우 그룹화를 사용합니다.
다중 프로세스: 여러 개의 작은 프로세스를 하나의 experiment 로 그룹화합니다.
K-겹 교차 검증: 더 큰 experiment 를 보기 위해 다른 임의 시드를 가진 Runs 를 함께 그룹화합니다. 다음은 스윕 및 그룹화를 사용한 k-겹 교차 검증의 예제입니다.
그룹화를 설정하는 세 가지 방법이 있습니다.
1. 스크립트에서 그룹 설정
선택적 group 및 job_type 을 wandb.init() 에 전달합니다. 이렇게 하면 각 experiment 에 대한 전용 그룹 페이지가 제공되며, 여기에는 개별 Runs 가 포함됩니다. 예를 들면 다음과 같습니다. wandb.init(group="experiment_1", job_type="eval")
2. 그룹 환경 변수 설정
WANDB_RUN_GROUP 를 사용하여 Runs 에 대한 그룹을 환경 변수로 지정합니다. 자세한 내용은 환경 변수에 대한 문서를 확인하세요. Group 은 프로젝트 내에서 고유해야 하며 그룹의 모든 Runs 에서 공유해야 합니다. wandb.util.generate_id() 를 사용하여 모든 프로세스에서 사용할 고유한 8자 문자열을 생성할 수 있습니다. 예를 들어 os.environ["WANDB_RUN_GROUP"] = "experiment-" + wandb.util.generate_id() 와 같습니다.
3. UI에서 그룹화 전환
구성 열별로 동적으로 그룹화할 수 있습니다. 예를 들어 wandb.config 를 사용하여 배치 크기 또는 학습률을 로그하면 웹 앱에서 해당 하이퍼파라미터별로 동적으로 그룹화할 수 있습니다.
그룹화를 사용한 분산 트레이닝
wandb.init() 에서 그룹화를 설정하면 UI에서 기본적으로 Runs 가 그룹화됩니다. 테이블 상단의 Group 버튼을 클릭하여 이를 켜거나 끌 수 있습니다. 그룹화를 설정한 샘플 코드에서 생성된 예제 프로젝트가 있습니다. 사이드바에서 각 “Group” 행을 클릭하여 해당 experiment 에 대한 전용 그룹 페이지로 이동할 수 있습니다.
위의 프로젝트 페이지에서 왼쪽 사이드바의 Group 을 클릭하여 이 페이지와 같은 전용 페이지로 이동할 수 있습니다.
UI에서 동적으로 그룹화
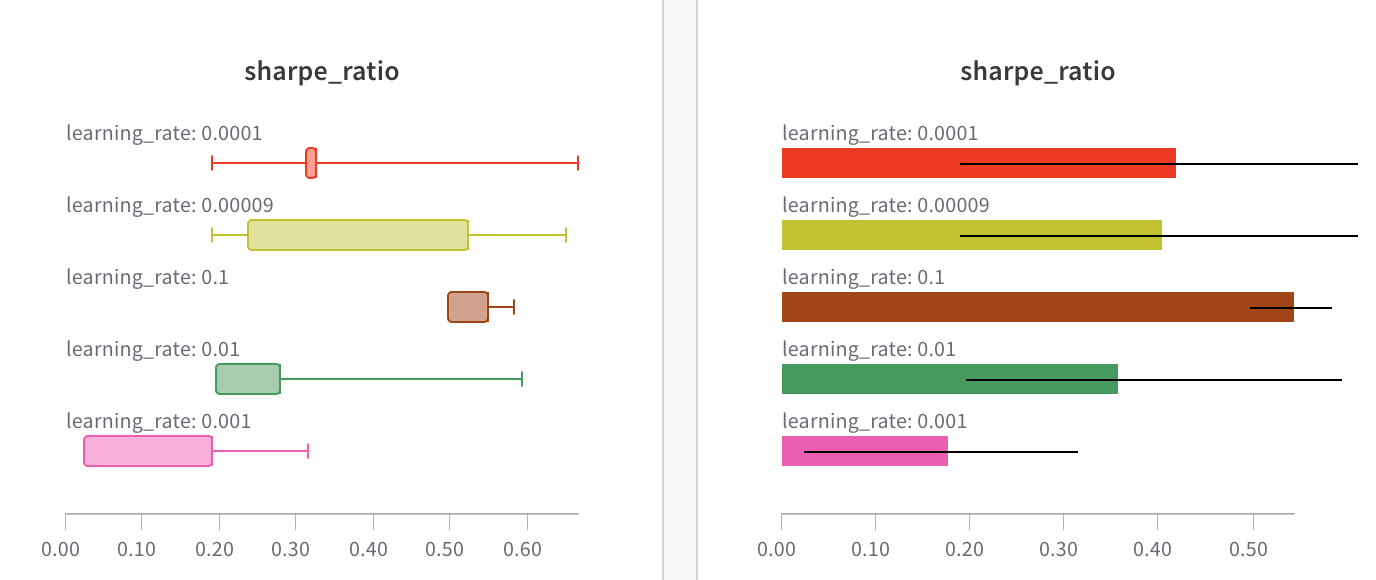
예를 들어 하이퍼파라미터별로 열별로 Runs 를 그룹화할 수 있습니다. 다음은 그 모양의 예입니다.
사이드바: Runs 는 에포크 수별로 그룹화됩니다.
그래프: 각 선은 그룹의 평균을 나타내고 음영은 분산을 나타냅니다. 이 동작은 그래프 설정에서 변경할 수 있습니다.
그룹화 끄기
언제든지 그룹화 버튼을 클릭하고 그룹 필드를 지우면 테이블과 그래프가 그룹 해제된 상태로 돌아갑니다.
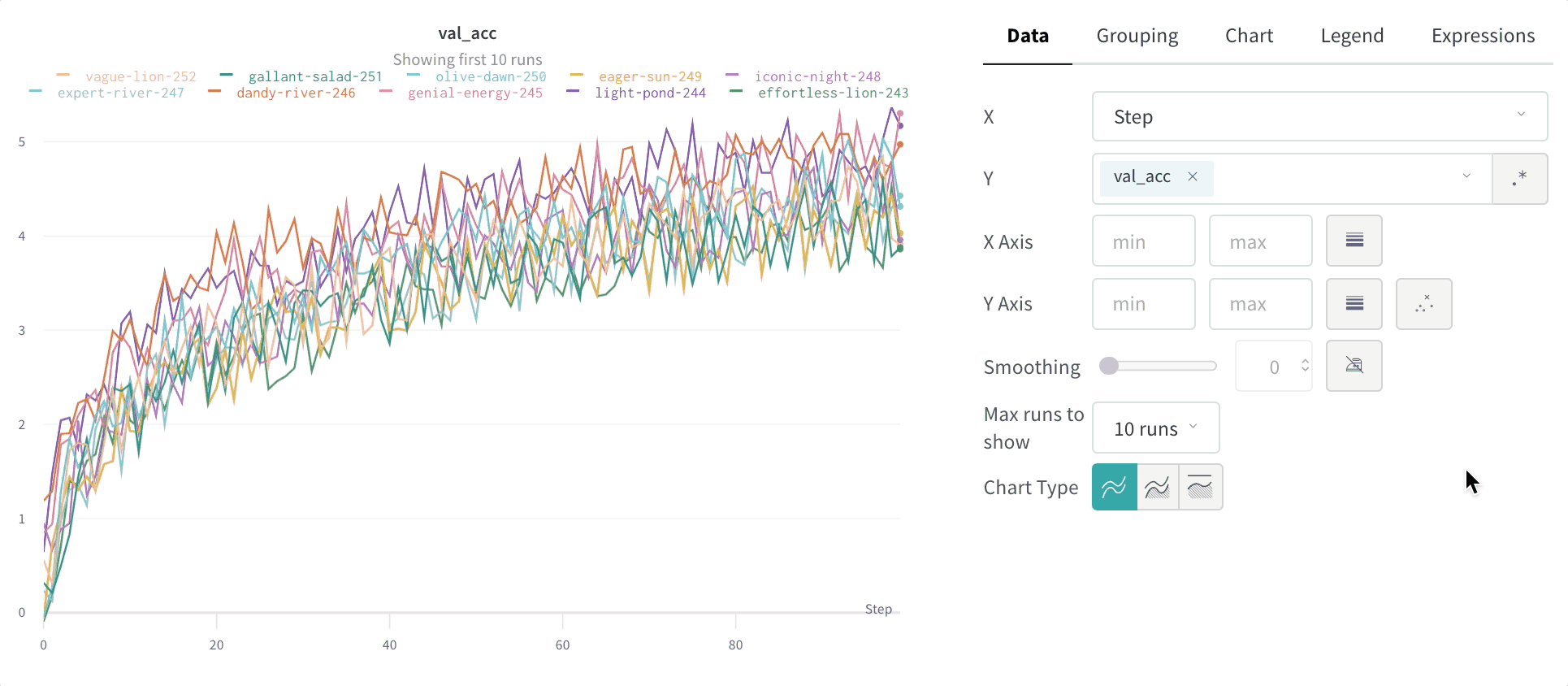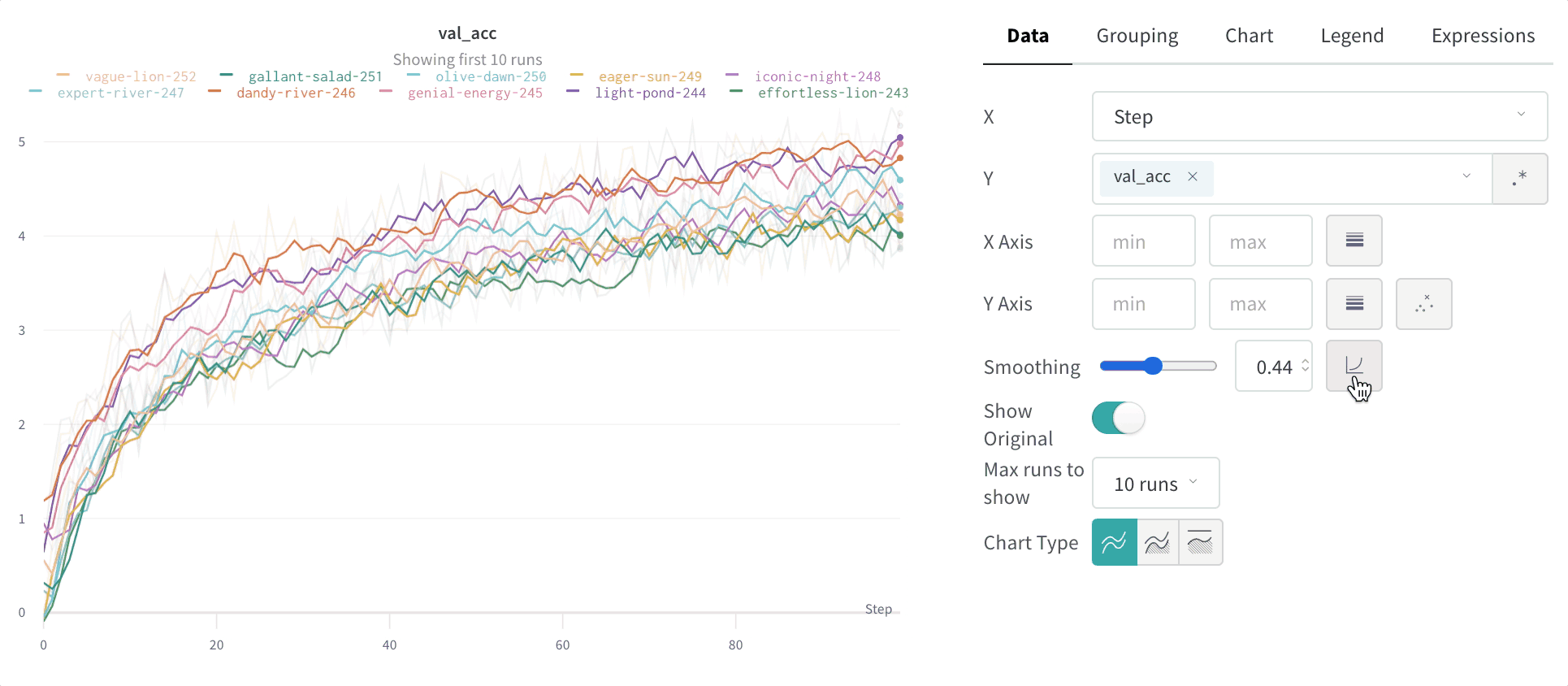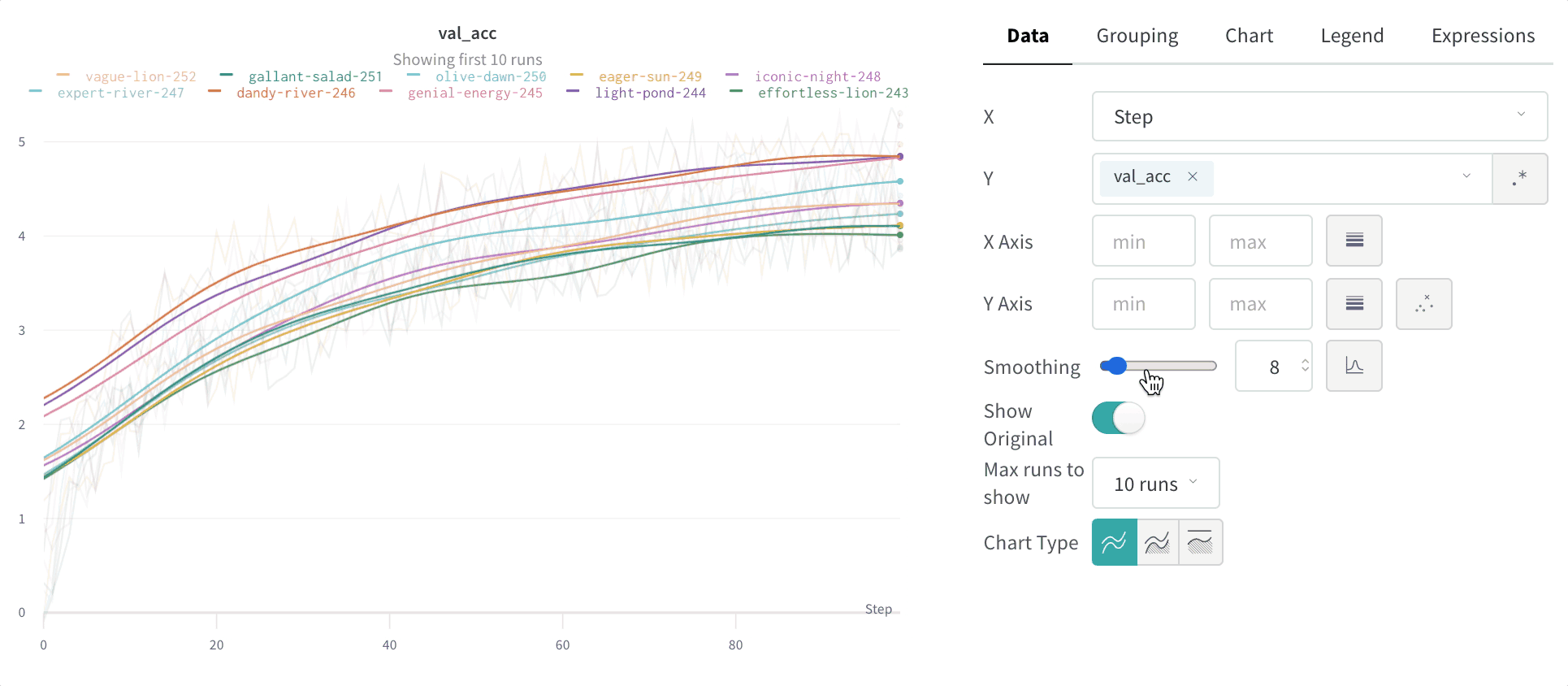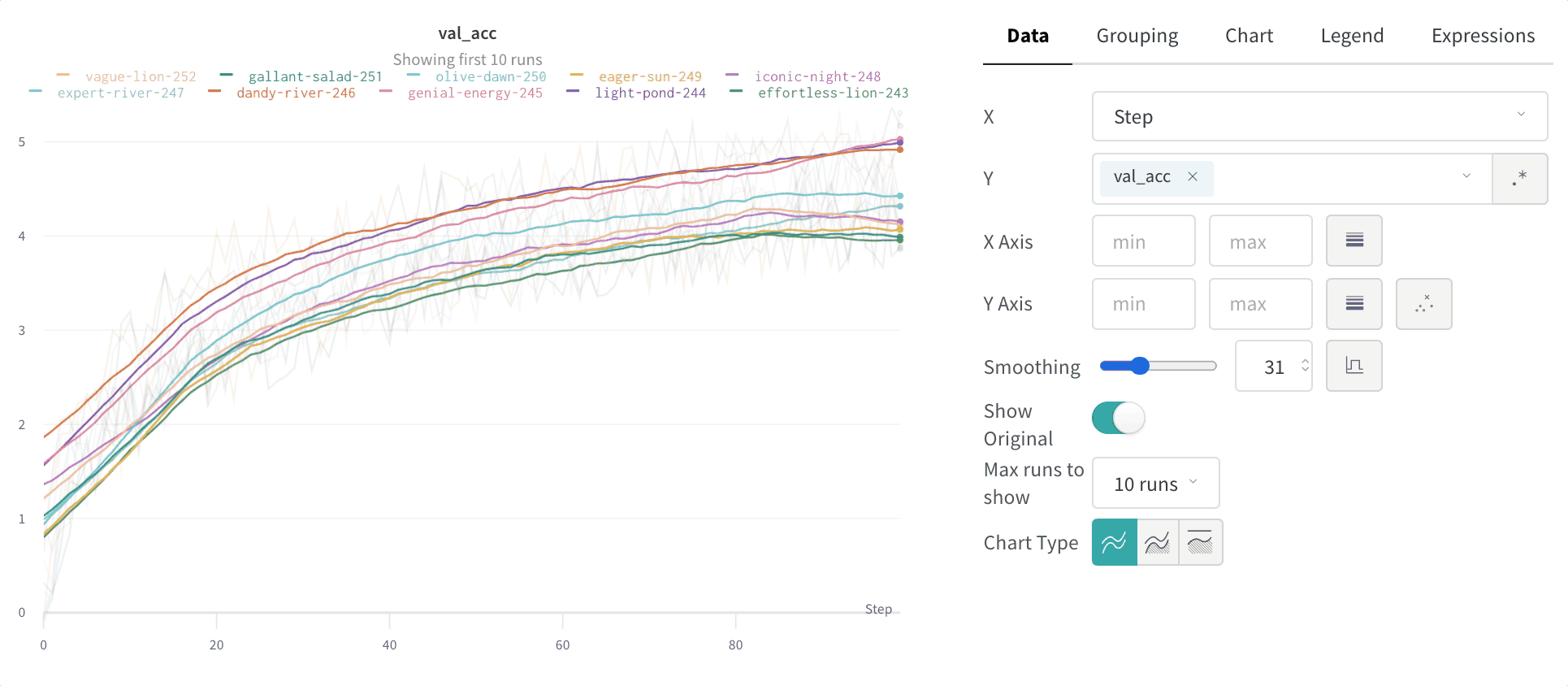
그룹화 그래프 설정
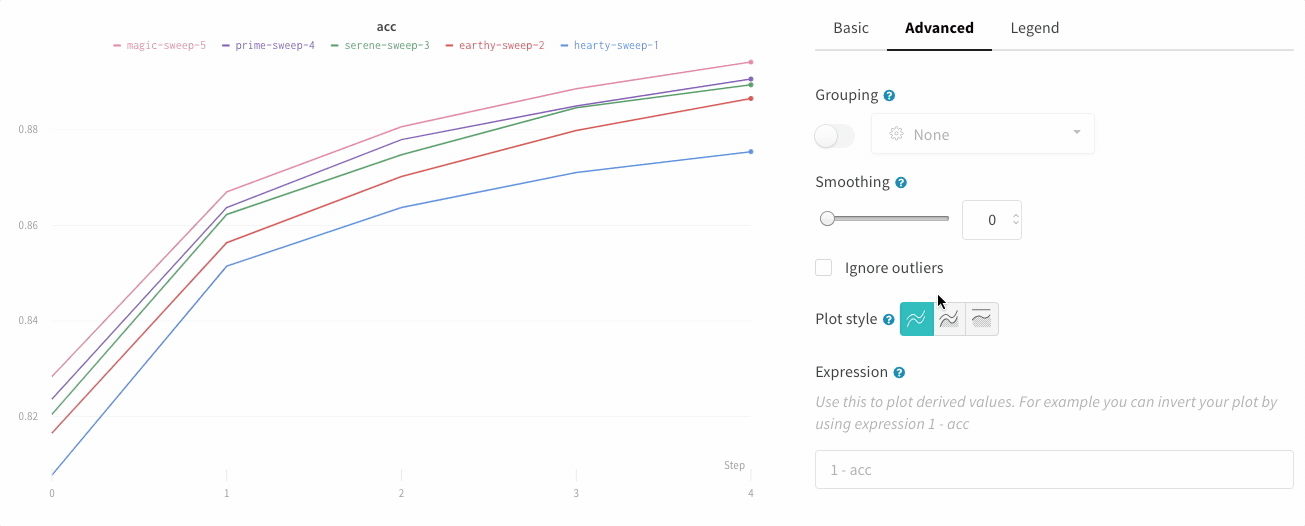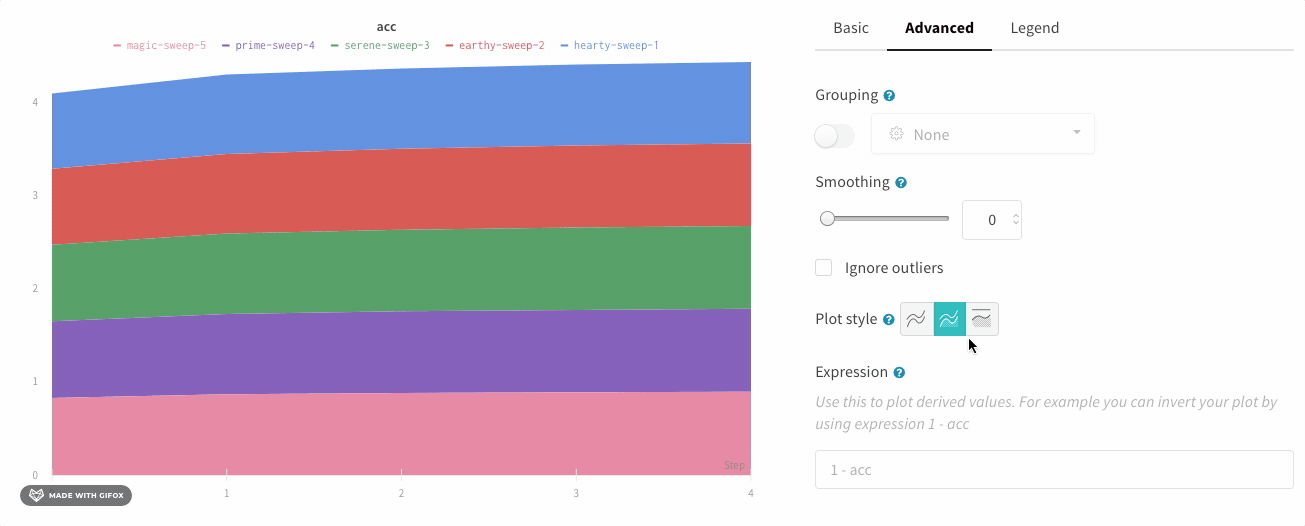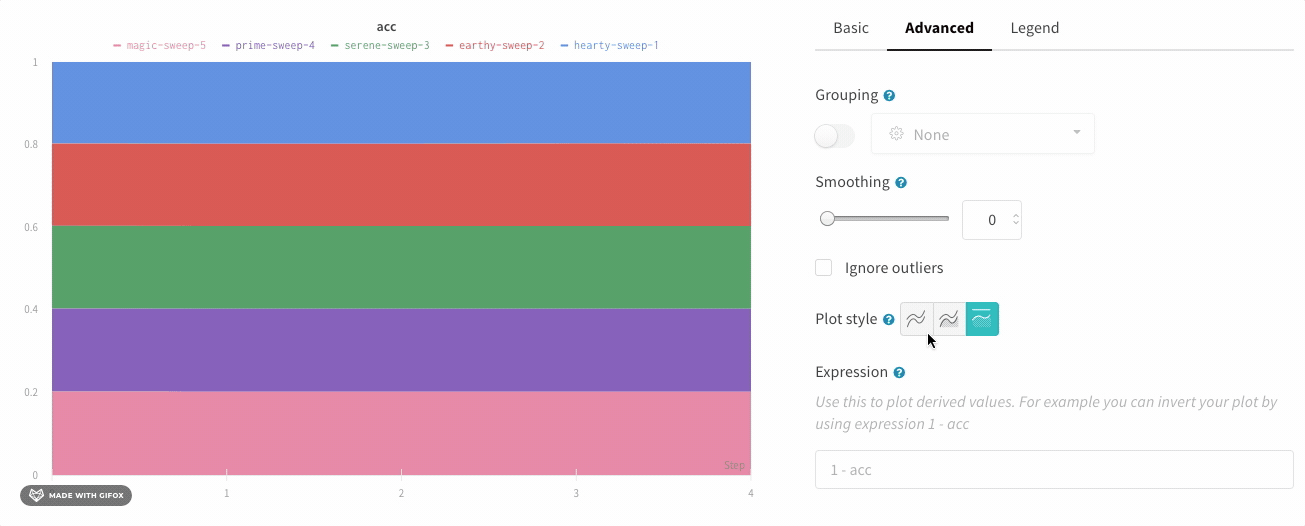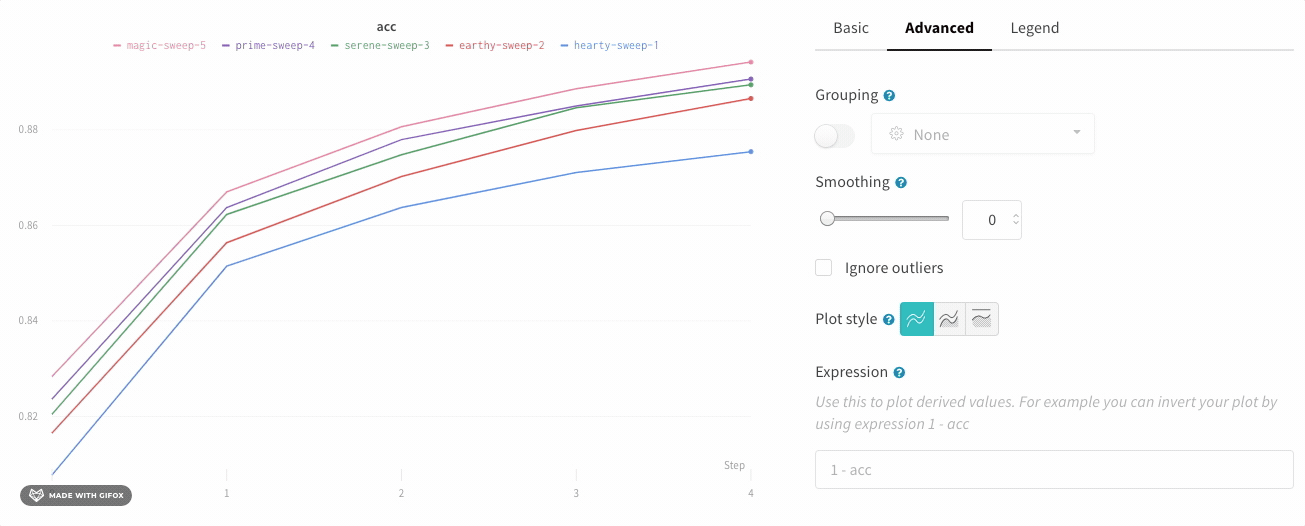
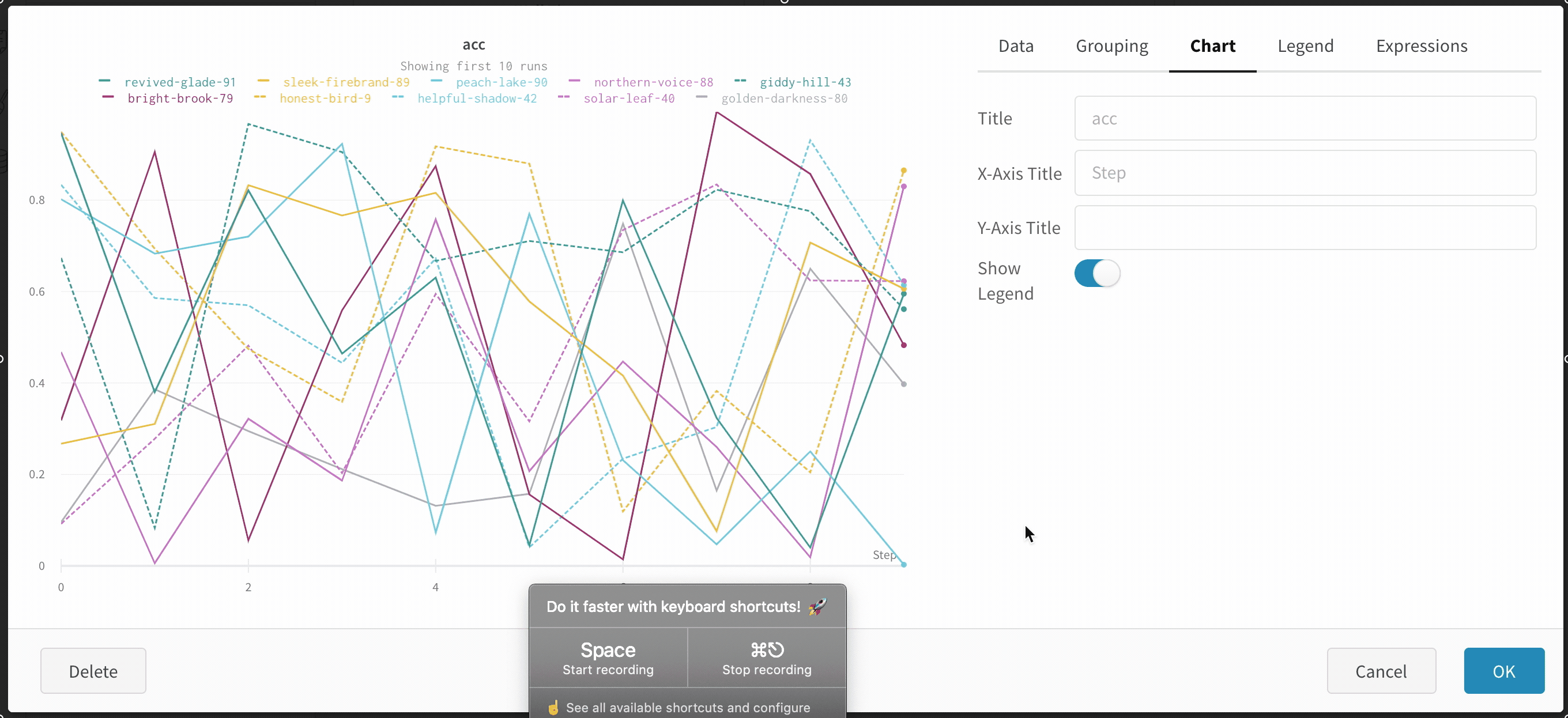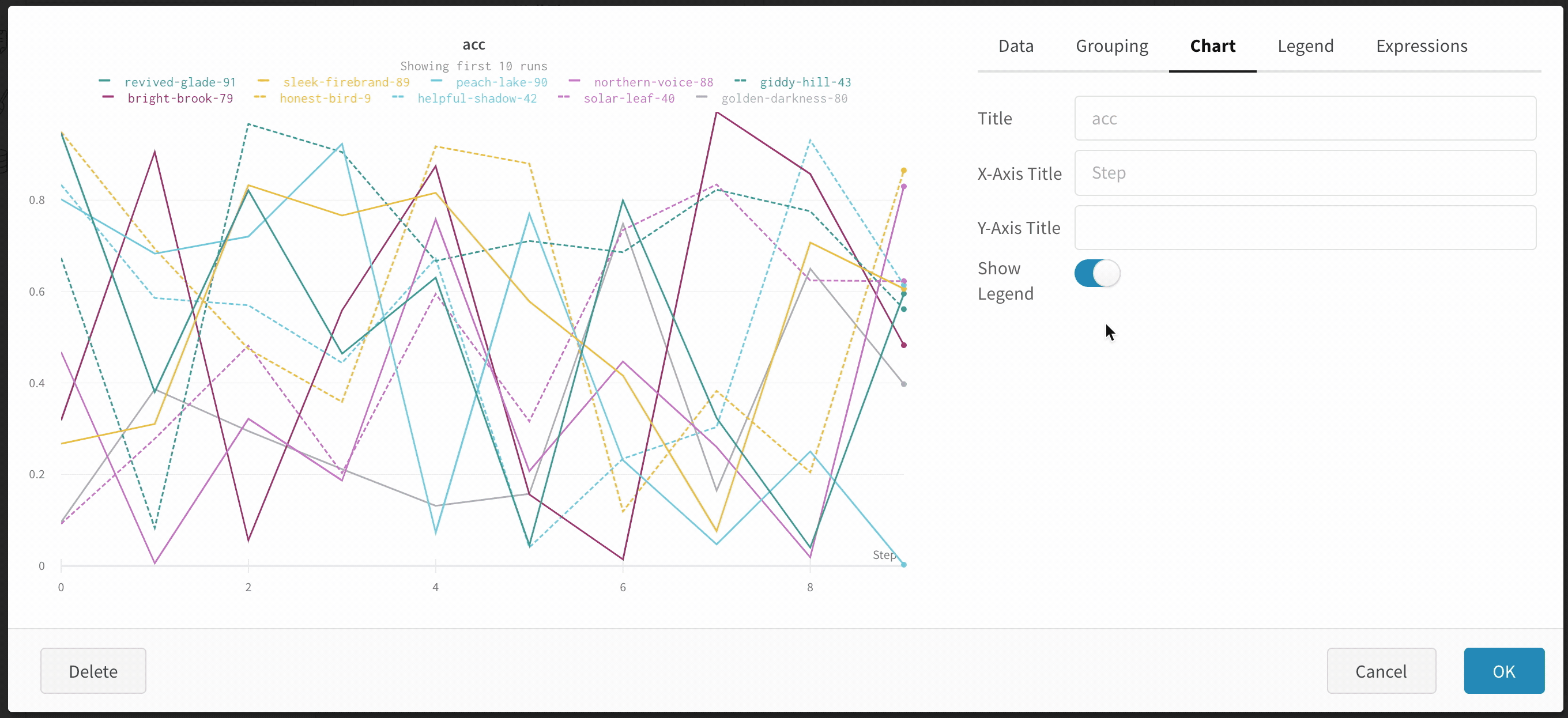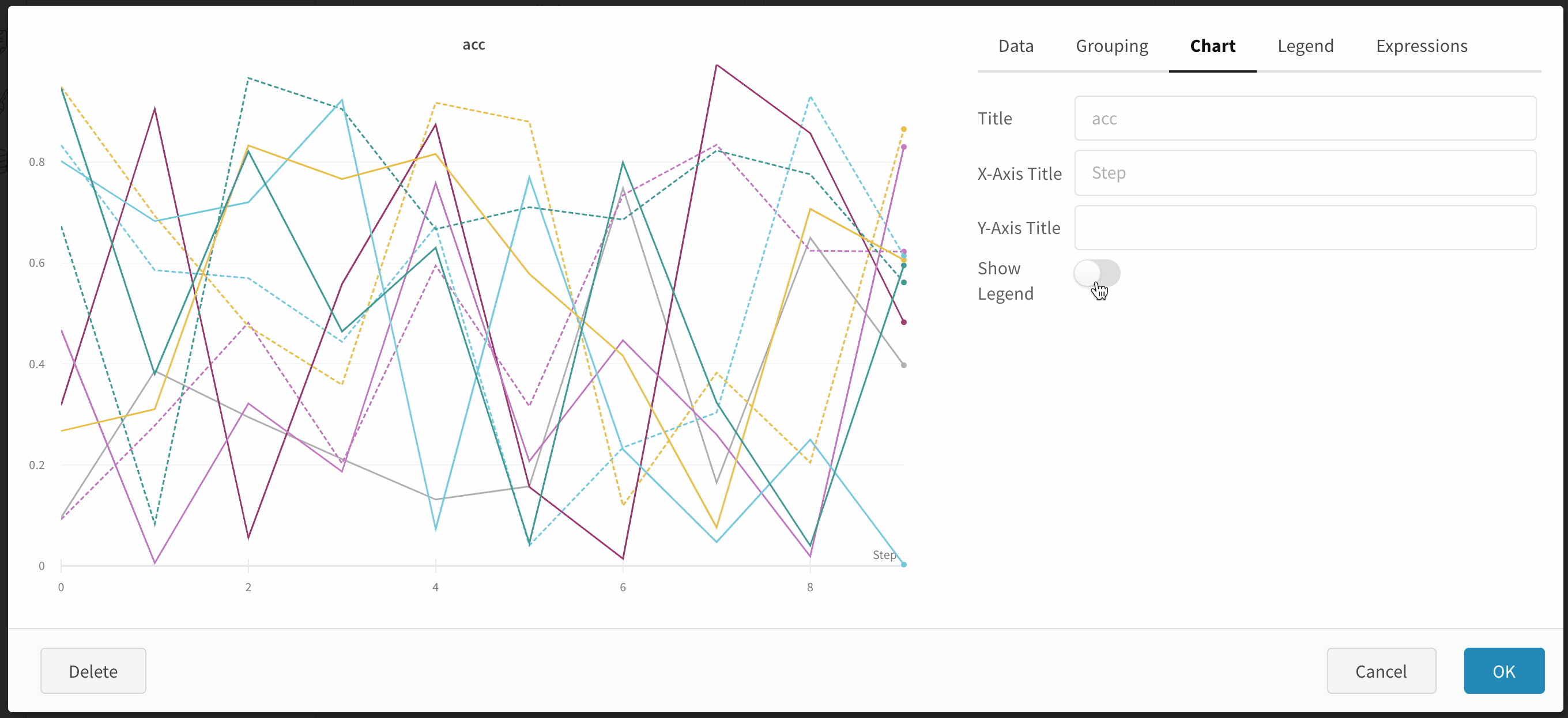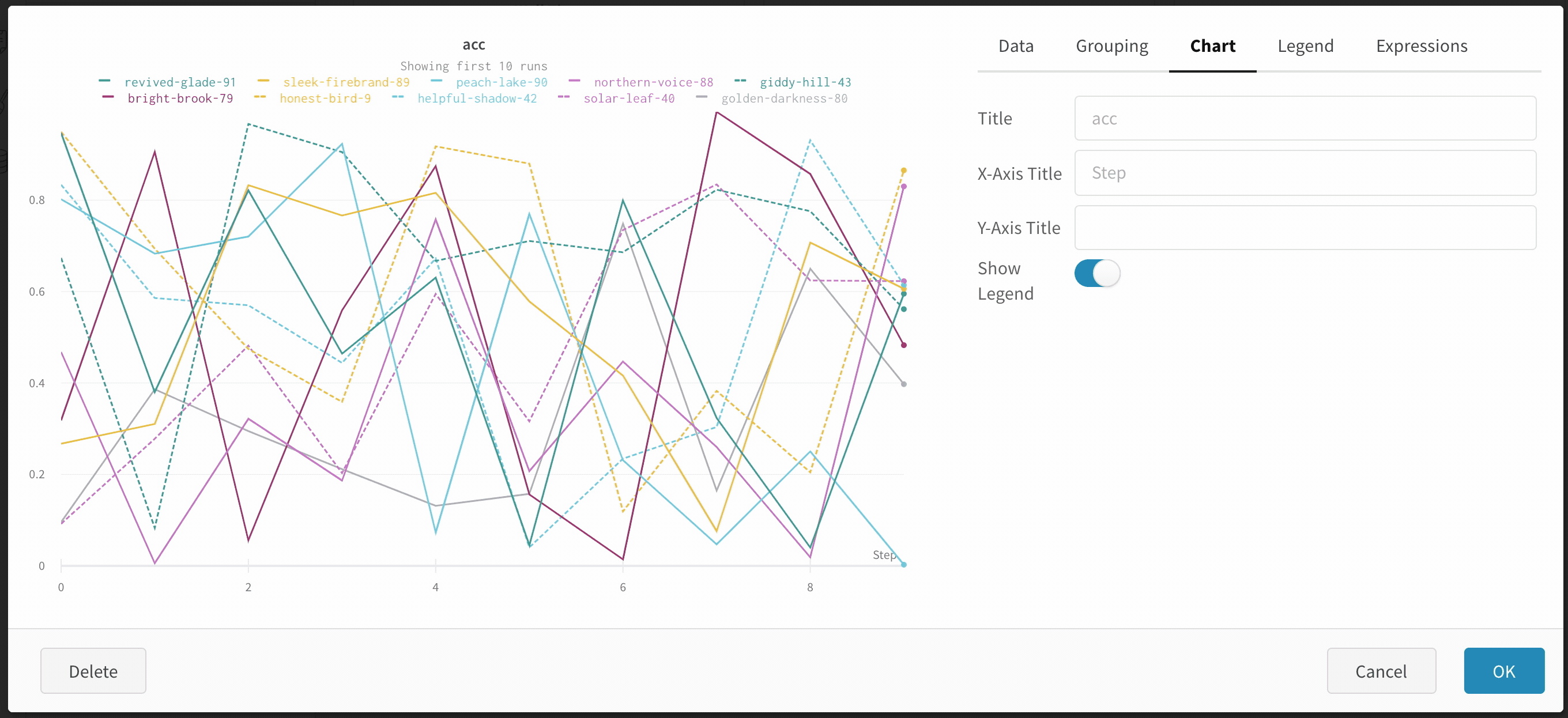
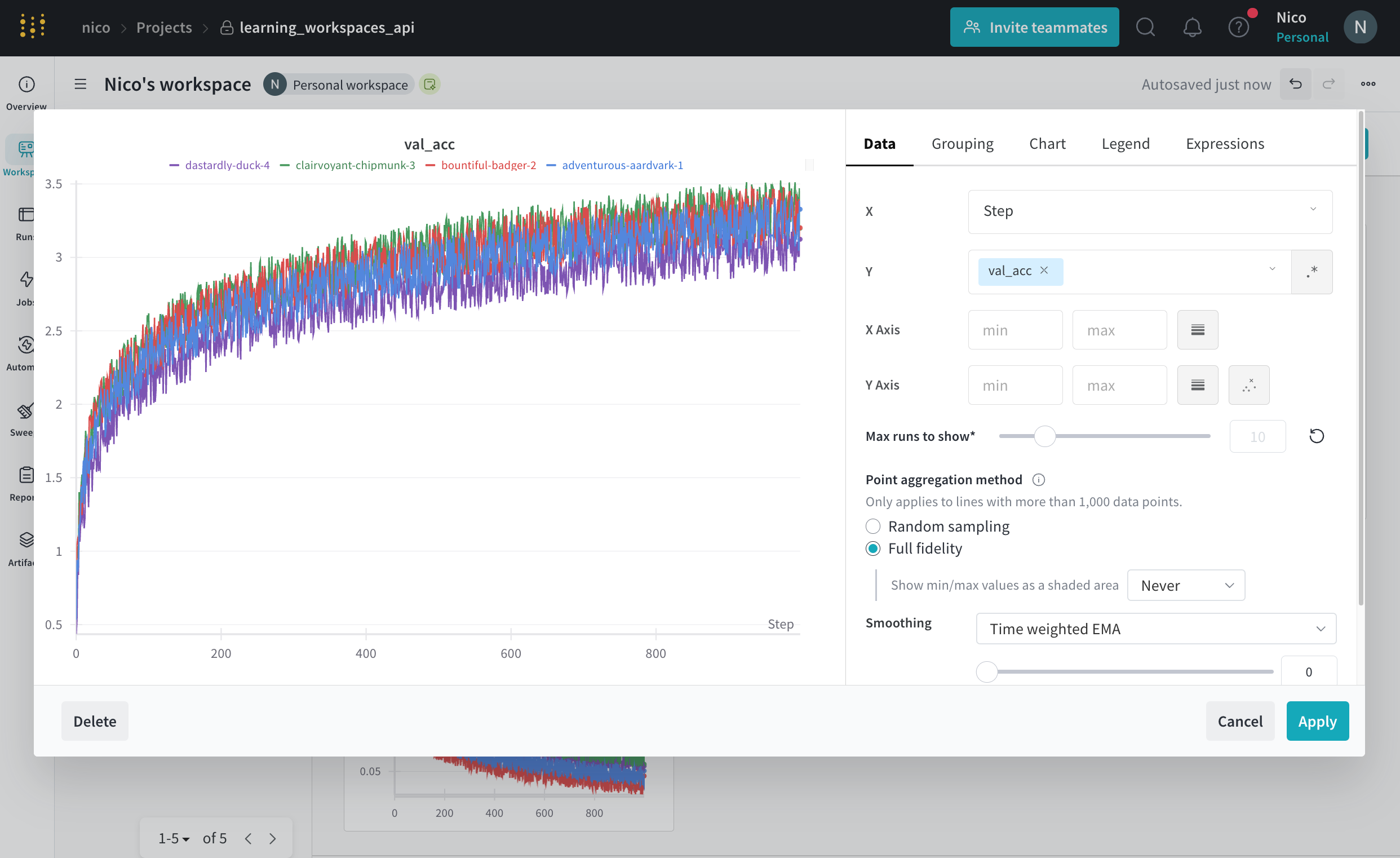
그래프 오른쪽 상단 모서리에 있는 편집 버튼을 클릭하고 Advanced 탭을 선택하여 선과 음영을 변경합니다. 각 그룹에서 선의 평균, 최소값 또는 최대값을 선택할 수 있습니다. 음영의 경우 음영을 끄고 최소값과 최대값, 표준 편차 및 표준 오차를 표시할 수 있습니다.
1.5.5 - Move runs
이 페이지에서는 run 을 한 프로젝트에서 다른 프로젝트로, 팀 내부 또는 외부로, 또는 한 팀에서 다른 팀으로 이동하는 방법을 보여줍니다. 현재 위치와 새 위치에서 run 에 대한 엑세스 권한이 있어야 합니다.
터미널 내에서 W&B run ID와 함께 셸 스크립트를 실행할 수 있습니다. 다음 코드조각은 run ID akj172를 전달합니다.
sh run_experiment.sh akj172
자동 재개는 프로세스가 실패한 프로세스와 동일한 파일 시스템에서 다시 시작되는 경우에만 작동합니다.
예를 들어 Users/AwesomeEmployee/Desktop/ImageClassify/training/이라는 디렉토리에서 train.py라는 python 스크립트를 실행한다고 가정합니다. train.py 내에서 스크립트는 자동 재개를 활성화하는 run을 만듭니다. 다음으로 트레이닝 스크립트가 중지되었다고 가정합니다. 이 run을 재개하려면 Users/AwesomeEmployee/Desktop/ImageClassify/training/ 내에서 train.py 스크립트를 다시 시작해야 합니다.
파일 시스템을 공유할 수 없는 경우 WANDB_RUN_ID 환경 변수를 지정하거나 W&B Python SDK로 run ID를 전달합니다. run ID에 대한 자세한 내용은 “Run이란 무엇인가?” 페이지의 Custom run IDs 섹션을 참조하세요.
Preemptible Sweeps Run 재개
중단된 sweep run을 자동으로 다시 큐에 넣습니다. 이는 선점형 큐의 SLURM 작업, EC2 스팟 인스턴스 또는 Google Cloud 선점형 VM과 같이 선점이 적용되는 컴퓨팅 환경에서 sweep agent를 실행하는 경우에 특히 유용합니다.
mark_preempting 함수를 사용하여 W&B가 중단된 sweep run을 자동으로 다시 큐에 넣도록 설정합니다. 예를 들어, 다음 코드조각을 참조하세요.
run = wandb.init() # Run 초기화run.mark_preempting()
다음 표는 sweep run의 종료 상태에 따라 W&B가 run을 처리하는 방법을 간략하게 설명합니다.
상태
행동
상태 코드 0
Run이 성공적으로 종료된 것으로 간주되며 다시 큐에 넣지 않습니다.
0이 아닌 상태
W&B는 run을 sweep과 연결된 run 큐에 자동으로 추가합니다.
상태 없음
Run이 sweep run 큐에 추가됩니다. Sweep agent는 큐가 비워질 때까지 run 큐에서 run을 소비합니다. 큐가 비워지면 sweep 큐는 sweep 검색 알고리즘을 기반으로 새 run 생성을 재개합니다.
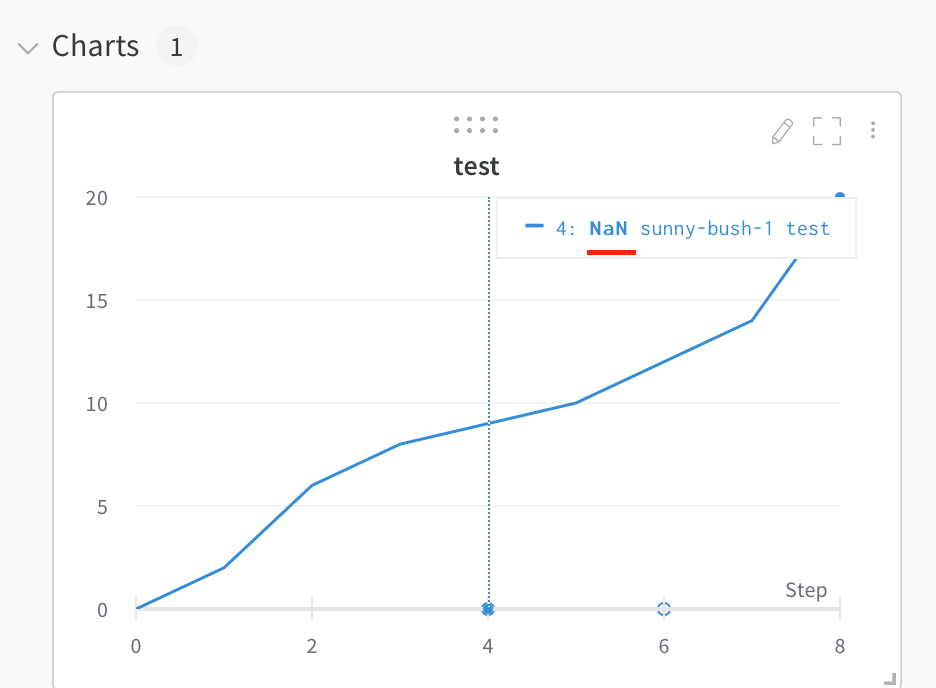
1.5.7 - Rewind a run
되감기
run 되감기
run을 되감는 옵션은 비공개 미리 보기 상태입니다. 이 기능에 대한 엑세스를 요청하려면 support@wandb.com으로 W&B 지원팀에 문의하십시오.
단조롭게 증가하는 단계를 사용해야 합니다. define_metric()으로 정의된 비단조 단계를 사용하면 run 기록 및 시스템 메트릭의 필수 시간순서가 방해되므로 사용할 수 없습니다.
원본 데이터를 잃지 않고 run 기록을 수정하거나 변경하려면 run을 되감으십시오. 또한 run을 되감을 때 해당 시점부터 새로운 데이터를 로그할 수 있습니다. W&B는 새롭게 기록된 기록을 기반으로 되감은 run에 대한 요약 메트릭을 다시 계산합니다. 이는 다음 동작을 의미합니다.
기록 잘림: W&B는 기록을 되감기 시점까지 자르므로 새로운 데이터 로깅이 가능합니다.
요약 메트릭: 새롭게 기록된 기록을 기반으로 다시 계산됩니다.
설정 보존: W&B는 원래 설정을 보존하고 새로운 설정을 병합할 수 있습니다.
run을 되감을 때 W&B는 원래 데이터를 보존하고 일관된 run ID를 유지하면서 run 상태를 지정된 단계로 재설정합니다. 이는 다음을 의미합니다.
run 보관: W&B는 원래 run을 보관합니다. Run Overview 탭에서 run에 엑세스할 수 있습니다.
아티팩트 연결: 아티팩트를 해당 아티팩트를 생성하는 run과 연결합니다.
변경 불가능한 run ID: 정확한 상태에서 일관된 포크를 위해 도입되었습니다.
변경 불가능한 run ID 복사: 향상된 run 관리를 위해 변경 불가능한 run ID를 복사하는 버튼입니다.
되감기 및 포크 호환성
포크는 되감기를 보완합니다.
run에서 포크할 때 W&B는 다른 파라미터 또는 모델을 시도하기 위해 특정 시점에서 run에서 새로운 분기를 생성합니다.
run을 되감을 때 W&B를 사용하면 run 기록 자체를 수정하거나 변경할 수 있습니다.
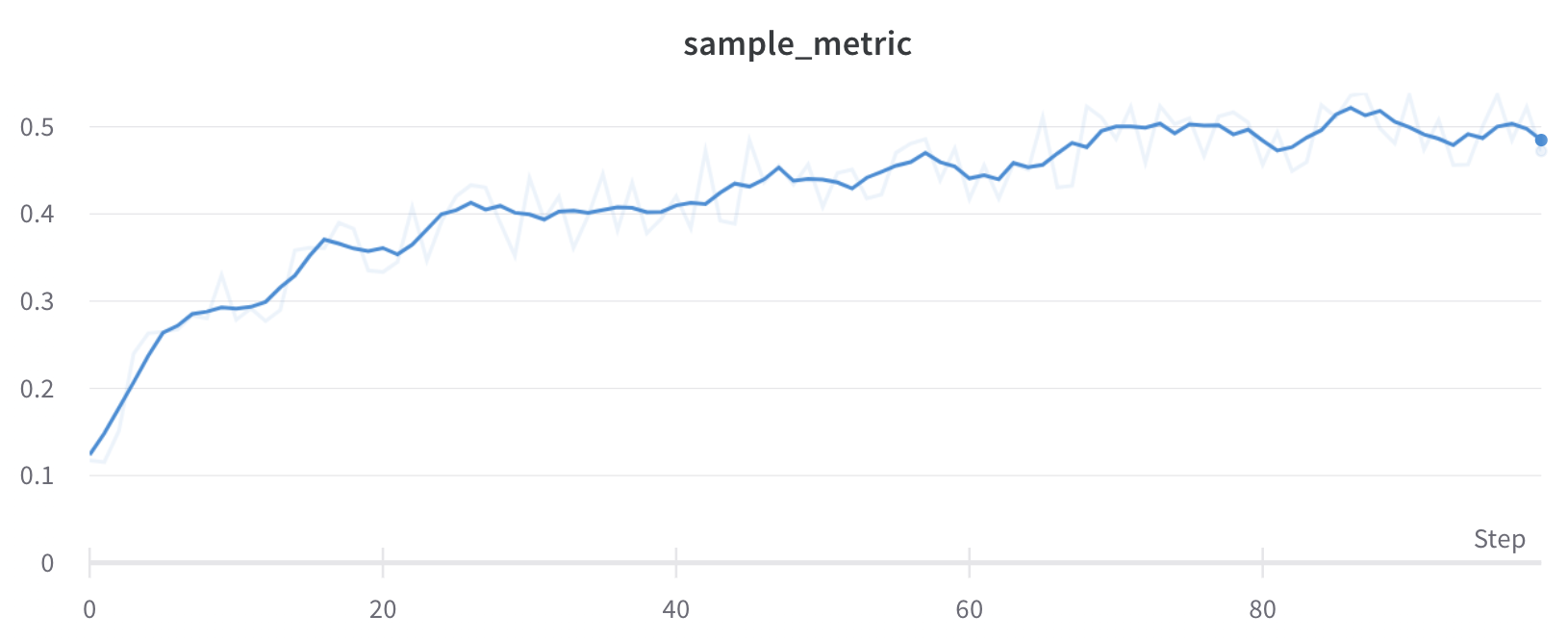
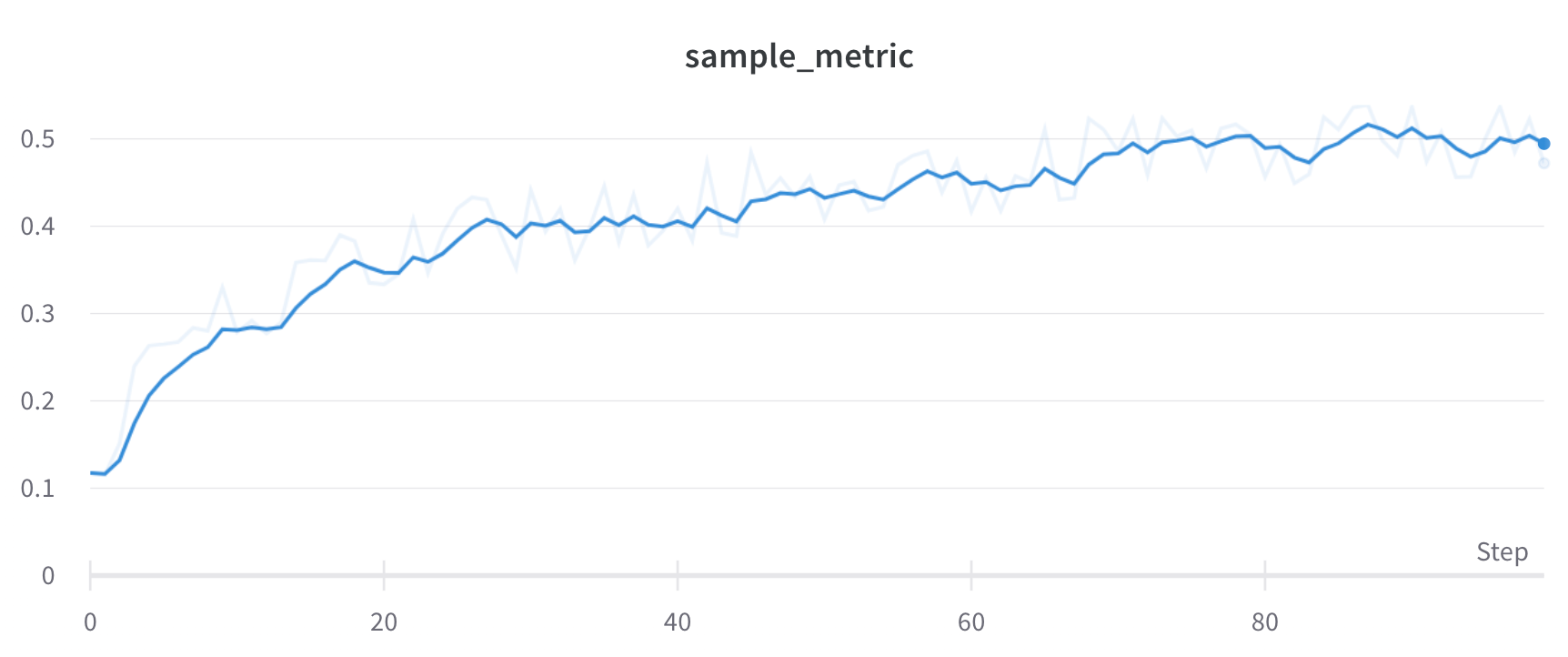
run 되감기
resume_from과 함께 wandb.init()을 사용하여 run 기록을 특정 단계로 “되감습니다”. 되감을 run의 이름과 되감을 단계를 지정합니다.
import wandb
import math
# 첫 번째 run을 초기화하고 일부 메트릭을 기록합니다.# your_project_name 및 your_entity_name으로 대체하십시오!run1 = wandb.init(project="your_project_name", entity="your_entity_name")
for i in range(300):
run1.log({"metric": i})
run1.finish()
# 특정 단계에서 첫 번째 run부터 되감고 200단계부터 메트릭을 기록합니다.run2 = wandb.init(project="your_project_name", entity="your_entity_name", resume_from=f"{run1.id}?_step=200")
# 새로운 run에서 계속 기록합니다.# 처음 몇 단계에서는 run1에서 메트릭을 그대로 기록합니다.# 250단계 이후에는 스파이크 패턴을 기록하기 시작합니다.for i in range(200, 300):
if i <250:
run2.log({"metric": i, "step": i}) # 스파이크 없이 run1부터 계속 기록합니다.else:
# 250단계부터 스파이크 동작을 도입합니다. subtle_spike = i + (2* math.sin(i /3.0)) # 미묘한 스파이크 패턴을 적용합니다. run2.log({"metric": subtle_spike, "step": i})
# 또한 모든 단계에서 새로운 메트릭을 기록합니다. run2.log({"additional_metric": i *1.1, "step": i})
run2.finish()
보관된 run 보기
run을 되감은 후 W&B App UI를 사용하여 보관된 run을 탐색할 수 있습니다. 보관된 run을 보려면 다음 단계를 따르십시오.
Overview 탭에 엑세스: run 페이지의 Overview 탭으로 이동합니다. 이 탭은 run의 세부 정보 및 기록에 대한 포괄적인 보기를 제공합니다.
Forked From 필드 찾기: Overview 탭 내에서 Forked From 필드를 찾습니다. 이 필드는 재개 기록을 캡처합니다. Forked From 필드에는 소스 run에 대한 링크가 포함되어 있어 원래 run으로 다시 추적하고 전체 되감기 기록을 이해할 수 있습니다.
Forked From 필드를 사용하면 보관된 재개 트리를 쉽게 탐색하고 각 되감기의 순서와 출처에 대한 통찰력을 얻을 수 있습니다.
되감은 run에서 포크
되감은 run에서 포크하려면 wandb.init()에서 fork_from 인수를 사용하고 포크할 소스 run ID와 소스 run의 단계를 지정합니다.
import wandb
# 특정 단계에서 run을 포크합니다.forked_run = wandb.init(
project="your_project_name",
entity="your_entity_name",
fork_from=f"{rewind_run.id}?_step=500",
)
# 새로운 run에서 계속 기록합니다.for i in range(500, 1000):
forked_run.log({"metric": i*3})
forked_run.finish()
run 이 충돌하거나 사용자 정의 트리거를 사용하는 경우 Slack 또는 이메일로 알림을 생성합니다. 예를 들어, 트레이닝 루프의 그레이디언트가 폭발하기 시작하거나 (NaN을 reports) ML 파이프라인의 단계가 완료되면 알림을 생성할 수 있습니다. 알림은 개인 및 팀 프로젝트를 포함하여 run을 초기화하는 모든 프로젝트에 적용됩니다.
그런 다음 Slack (또는 이메일)에서 W&B Alerts 메시지를 확인합니다:
알림 생성 방법
다음 가이드는 멀티 테넌트 클라우드의 알림에만 적용됩니다.
프라이빗 클라우드 또는 W&B 전용 클라우드에서 W&B Server를 사용하는 경우 이 문서를 참조하여 Slack 알림을 설정하십시오.
Slack 연결을 사용하여 알림을 게시할 Slack 채널을 선택합니다. 알림을 비공개로 유지하므로 Slackbot 채널을 권장합니다.
이메일은 W&B에 가입할 때 사용한 이메일 주소로 전송됩니다. 이러한 모든 알림이 폴더로 이동하여 받은 편지함을 채우지 않도록 이메일에서 필터를 설정하는 것이 좋습니다.
W&B Alerts를 처음 설정하거나 알림 수신 방법을 수정하려는 경우에만 이 작업을 수행하면 됩니다.
2. 코드에 run.alert() 추가
알림을 트리거하려는 위치에서 코드 (노트북 또는 Python 스크립트)에 run.alert()를 추가합니다.
import wandb
run = wandb.init()
run.alert(title="High Loss", text="Loss is increasing rapidly")
3. Slack 또는 이메일 확인
Slack 또는 이메일에서 알림 메시지를 확인합니다. 아무것도 받지 못한 경우 사용자 설정에서 스크립트 가능한 알림에 대해 이메일 또는 Slack이 켜져 있는지 확인하십시오.
예시
이 간단한 알림은 정확도가 임계값 아래로 떨어지면 경고를 보냅니다. 이 예에서는 최소 5분 간격으로 알림을 보냅니다.
import wandb
from wandb import AlertLevel
run = wandb.init()
if acc < threshold:
run.alert(
title="Low accuracy",
text=f"Accuracy {acc} is below the acceptable threshold {threshold}",
level=AlertLevel.WARN,
wait_duration=300,
)
사용자 태그 또는 멘션 방법
알림 제목 또는 텍스트에서 자신 또는 동료를 태그하려면 at 기호 @ 다음에 Slack 사용자 ID를 사용하십시오. Slack 프로필 페이지에서 Slack 사용자 ID를 찾을 수 있습니다.
run.alert(title="Loss is NaN", text=f"Hey <@U1234ABCD> loss has gone to NaN")
팀 알림
팀 관리자는 팀 설정 페이지 wandb.ai/teams/your-team에서 팀에 대한 알림을 설정할 수 있습니다.
팀 알림은 팀의 모든 사용자에게 적용됩니다. W&B는 알림을 비공개로 유지하므로 Slackbot 채널을 사용하는 것이 좋습니다.
알림을 보낼 Slack 채널 변경
알림을 보낼 채널을 변경하려면 Slack 연결 끊기를 클릭한 다음 다시 연결합니다. 다시 연결한 후 다른 Slack 채널을 선택합니다.
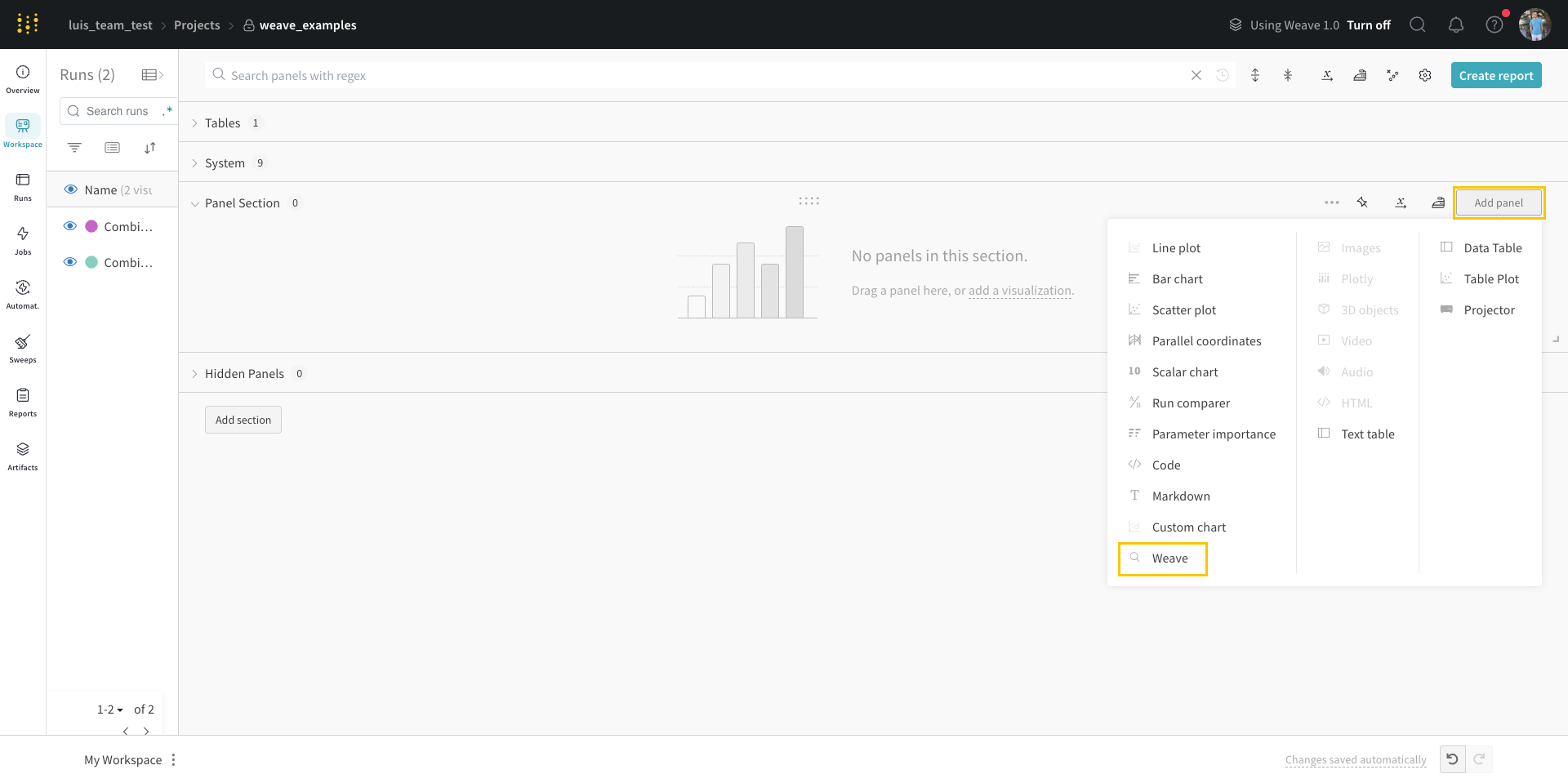
1.6 - Log objects and media
메트릭, 비디오, 사용자 정의 플롯 등을 추적하세요.
W&B Python SDK를 사용하여 메트릭, 미디어 또는 사용자 정의 오브젝트의 사전을 단계별로 기록합니다. W&B는 각 단계에서 키-값 쌍을 수집하고 wandb.log()로 데이터를 기록할 때마다 하나의 통합된 사전에 저장합니다. 스크립트에서 기록된 데이터는 wandb라는 디렉토리에 로컬로 저장된 다음 W&B 클라우드 또는 개인 서버로 동기화됩니다.
키-값 쌍은 각 단계마다 동일한 값을 전달하는 경우에만 하나의 통합된 사전에 저장됩니다. step에 대해 다른 값을 기록하면 W&B는 수집된 모든 키와 값을 메모리에 씁니다.
wandb.log를 호출할 때마다 기본적으로 새로운 step이 됩니다. W&B는 차트 및 패널을 만들 때 단계를 기본 x축으로 사용합니다. 선택적으로 사용자 정의 x축을 만들고 사용하거나 사용자 정의 요약 메트릭을 캡처할 수 있습니다. 자세한 내용은 로그 축 사용자 정의를 참조하세요.
각 step에 대해 연속적인 값 0, 1, 2 등을 기록하려면 wandb.log()를 사용하세요. 특정 history 단계에 쓸 수는 없습니다. W&B는 “현재” 및 “다음” 단계에만 씁니다.
자동으로 기록되는 데이터
W&B는 W&B Experiments 동안 다음 정보를 자동으로 기록합니다.
시스템 메트릭: CPU 및 GPU 사용률, 네트워크 등. 이러한 메트릭은 run 페이지의 시스템 탭에 표시됩니다. GPU의 경우 이러한 메트릭은 nvidia-smi를 통해 가져옵니다.
커맨드 라인: stdout 및 stderr이 선택되어 run 페이지의 로그 탭에 표시됩니다.
설정 정보: 하이퍼파라미터, 데이터셋 링크 또는 사용 중인 아키텍처 이름을 config 파라미터로 기록합니다. 예: wandb.init(config=your_config_dictionary). 자세한 내용은 PyTorch 인테그레이션 페이지를 참조하세요.
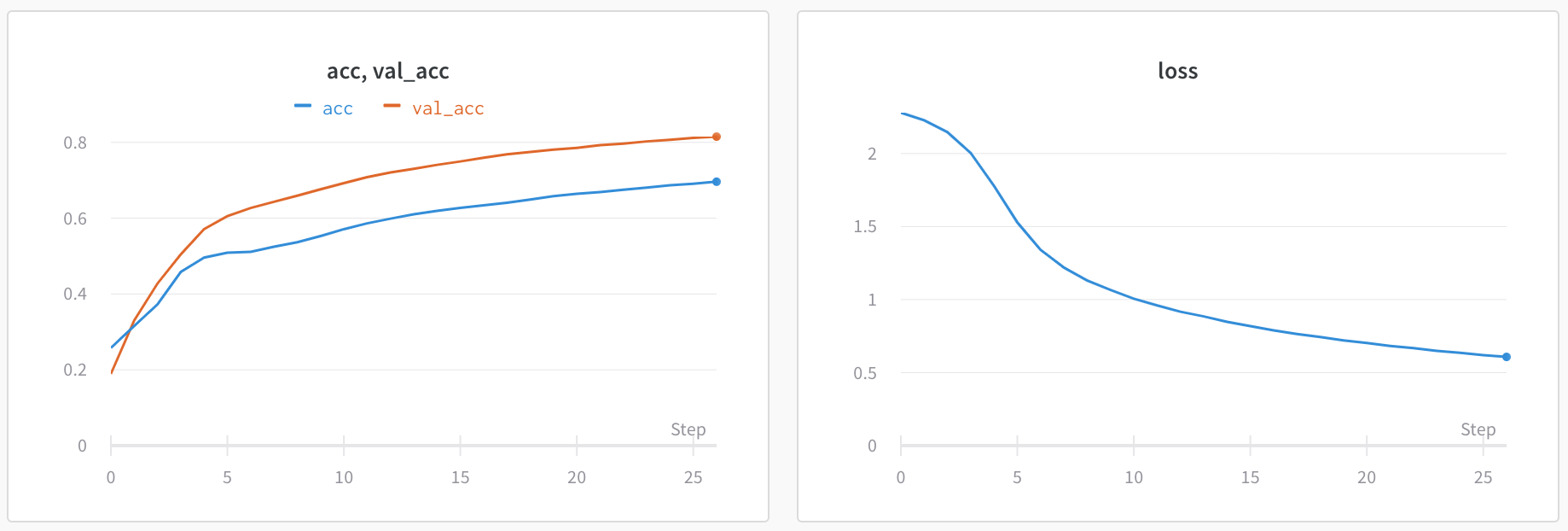
메트릭: 모델의 메트릭을 보려면 wandb.log를 사용합니다. 트레이닝 루프 내에서 정확도 및 손실과 같은 메트릭을 기록하면 UI에서 실시간 업데이트 그래프를 얻을 수 있습니다.
일반적인 워크플로우
최고 정확도 비교: run 간에 메트릭의 최고 값을 비교하려면 해당 메트릭의 요약 값을 설정합니다. 기본적으로 요약은 각 키에 대해 기록한 마지막 값으로 설정됩니다. 이는 UI의 테이블에서 유용합니다. 여기서 요약 메트릭을 기준으로 run을 정렬하고 필터링하여 최종 정확도가 아닌 최고 정확도를 기준으로 테이블 또는 막대 차트에서 run을 비교할 수 있습니다. 예: wandb.run.summary["best_accuracy"] = best_accuracy
하나의 차트에 여러 메트릭 보기: wandb.log({"acc'": 0.9, "loss": 0.1})과 같이 wandb.log에 대한 동일한 호출에서 여러 메트릭을 기록하면 UI에서 플롯하는 데 사용할 수 있습니다.
x축 사용자 정의: 동일한 로그 호출에 사용자 정의 x축을 추가하여 W&B 대시보드에서 다른 축에 대해 메트릭을 시각화합니다. 예: wandb.log({'acc': 0.9, 'epoch': 3, 'batch': 117}). 지정된 메트릭에 대한 기본 x축을 설정하려면 Run.define_metric()을 사용합니다.
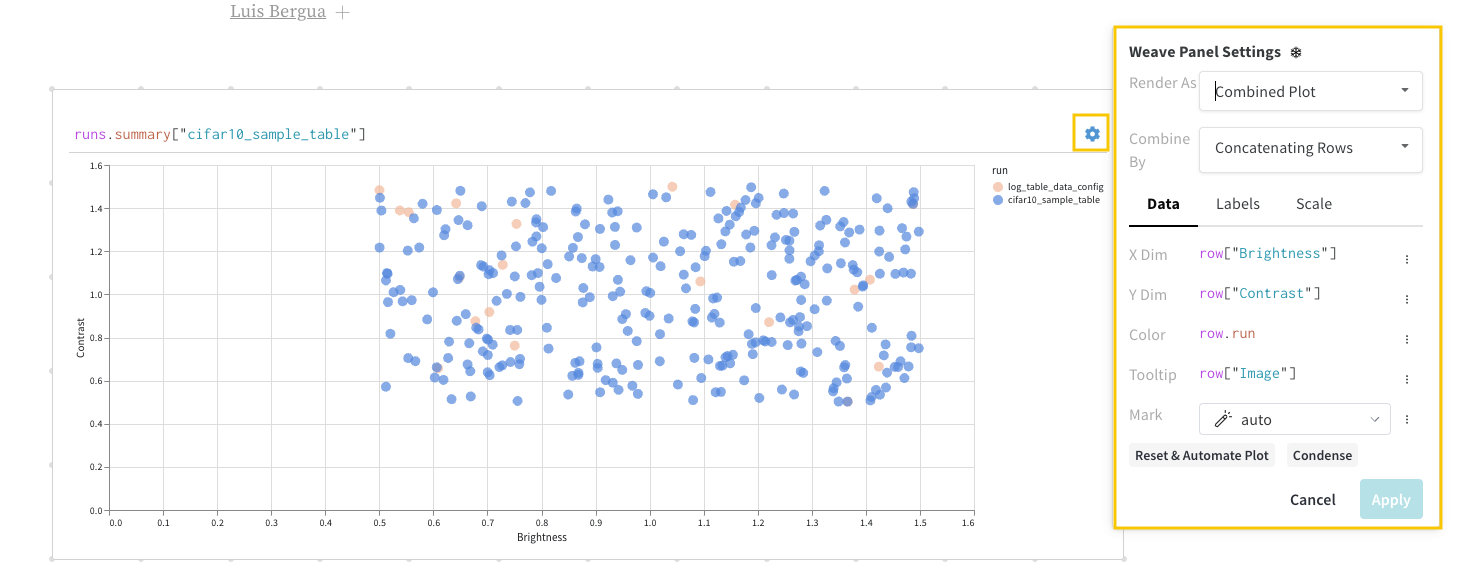
wandb.plot의 메소드를 사용하면 트레이닝 중 시간에 따라 변하는 차트를 포함하여 wandb.log로 차트를 추적할 수 있습니다. 사용자 정의 차트 프레임워크에 대해 자세히 알아보려면 이 가이드를 확인하십시오.
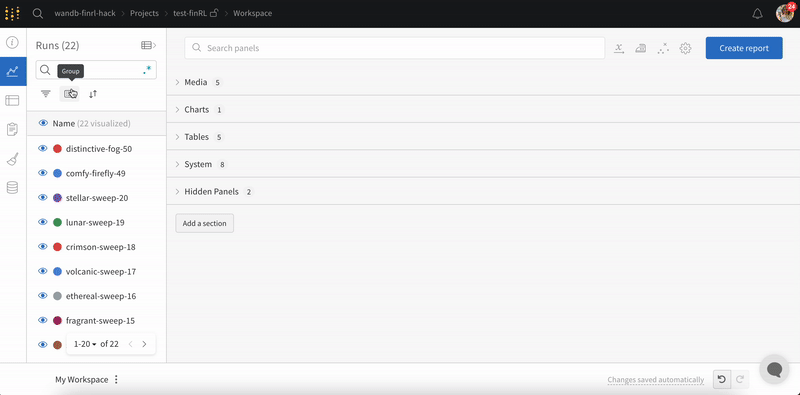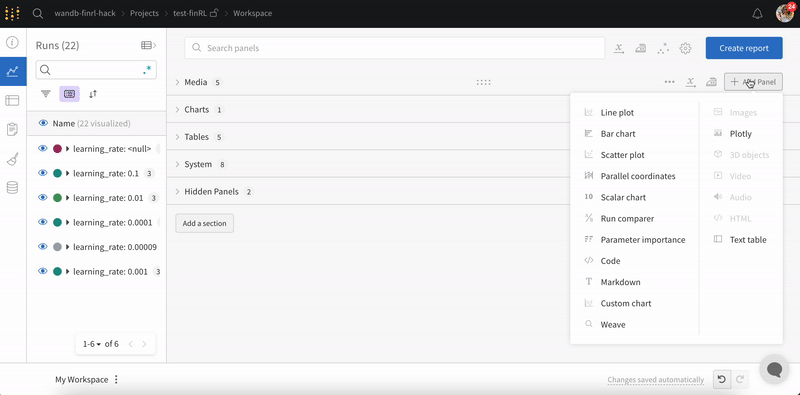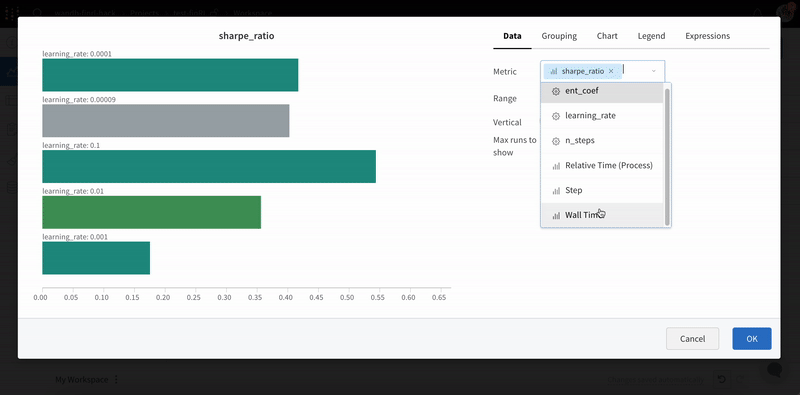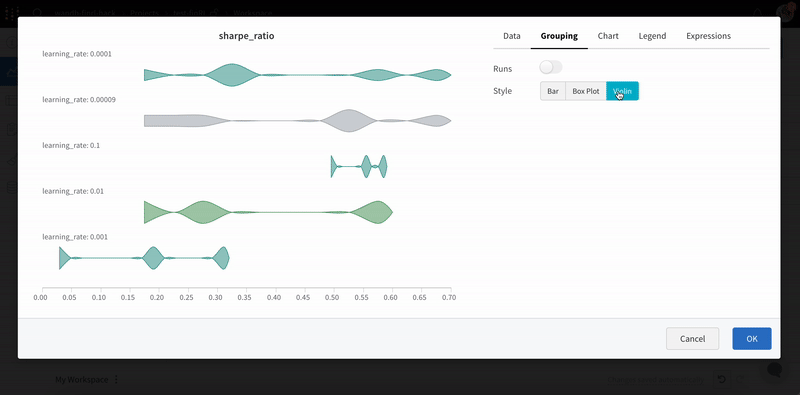
기본 차트
이러한 간단한 차트를 사용하면 메트릭 및 결과의 기본 시각화를 쉽게 구성할 수 있습니다.
wandb.plot.line()
임의의 축에서 연결되고 정렬된 점 목록인 사용자 정의 라인 플롯을 기록합니다.
data = [[x, y] for (x, y) in zip(x_values, y_values)]
table = wandb.Table(data=data, columns=["x", "y"])
wandb.log(
{
"my_custom_plot_id": wandb.plot.line(
table, "x", "y", title="Custom Y vs X Line Plot" )
}
)
이를 사용하여 임의의 두 차원에 대한 곡선을 기록할 수 있습니다. 두 값 목록을 서로 플로팅하는 경우 목록의 값 수는 정확히 일치해야 합니다. 예를 들어 각 점에는 x와 y가 있어야 합니다.
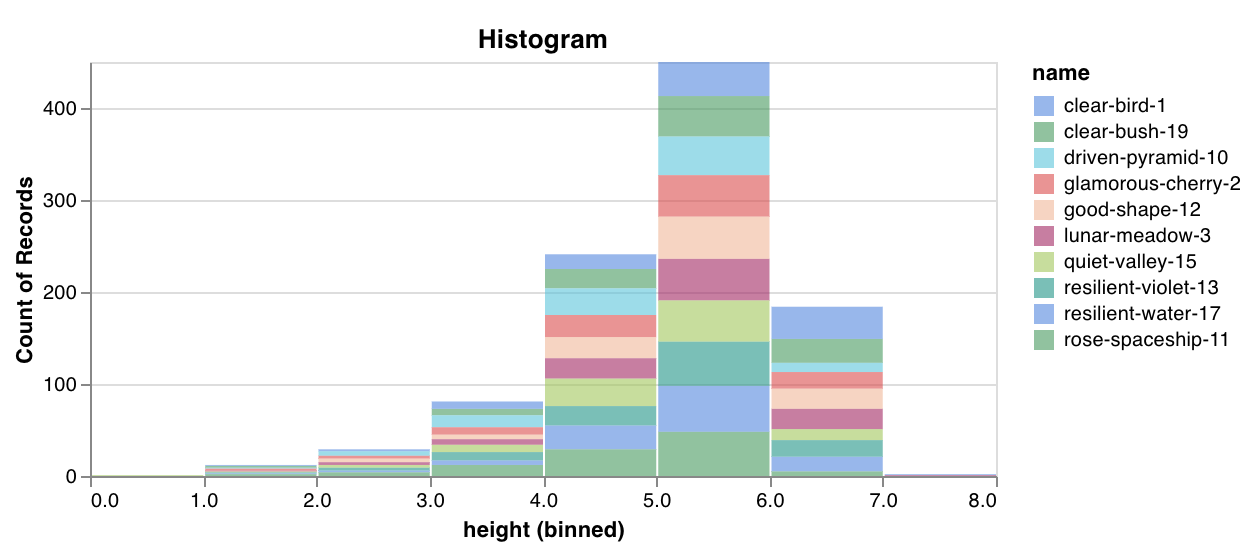
몇 줄의 코드로 값 목록을 발생 횟수/빈도별로 bin으로 정렬하는 사용자 정의 히스토그램을 기본적으로 기록합니다. 예측 신뢰도 점수 목록 (scores)이 있고 분포를 시각화하고 싶다고 가정해 보겠습니다.
data = [[s] for s in scores]
table = wandb.Table(data=data, columns=["scores"])
wandb.log({"my_histogram": wandb.plot.histogram(table, "scores", title="Histogram")})
이를 사용하여 임의의 히스토그램을 기록할 수 있습니다. data는 행과 열의 2D 배열을 지원하기 위한 목록의 목록입니다.
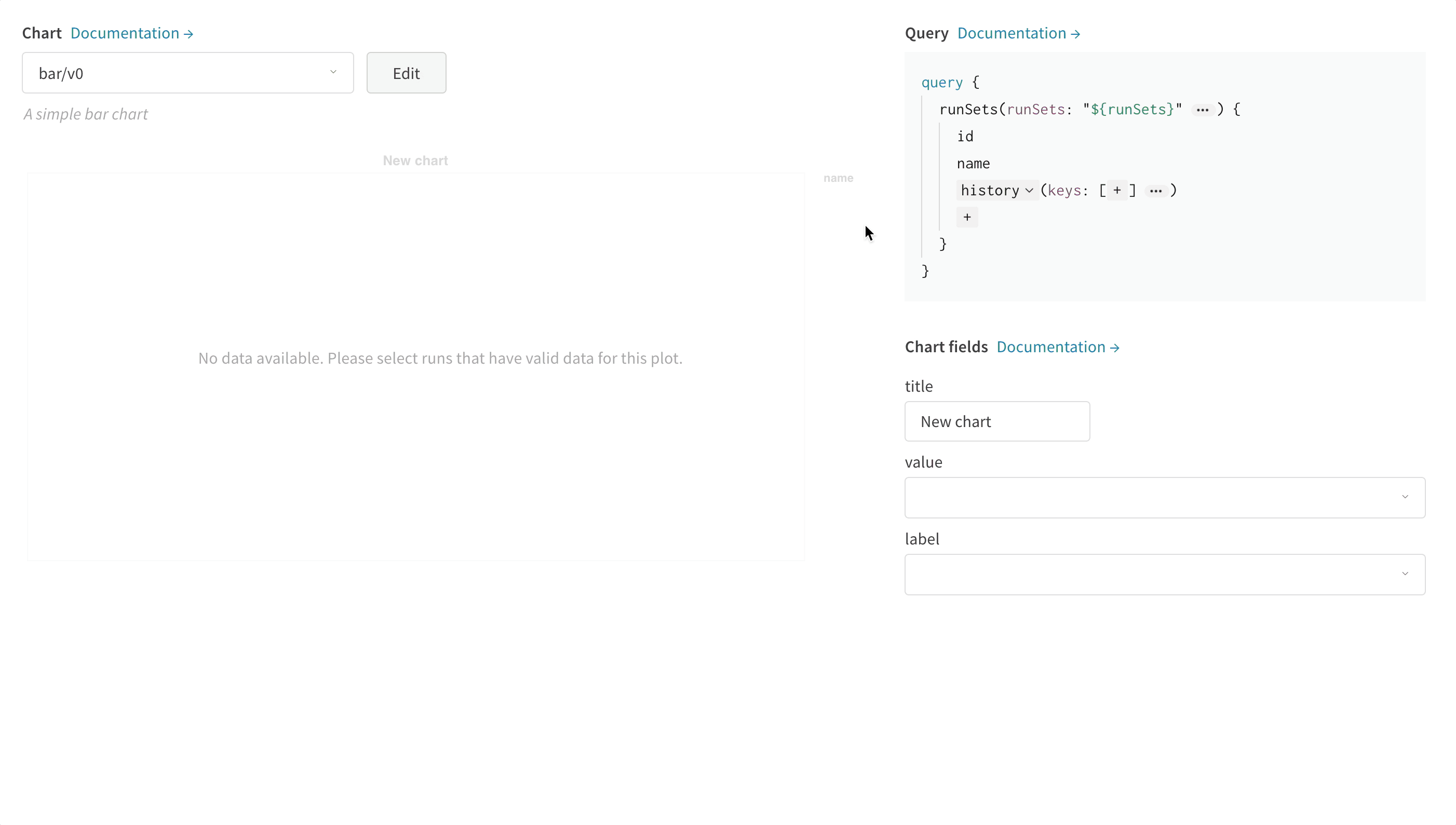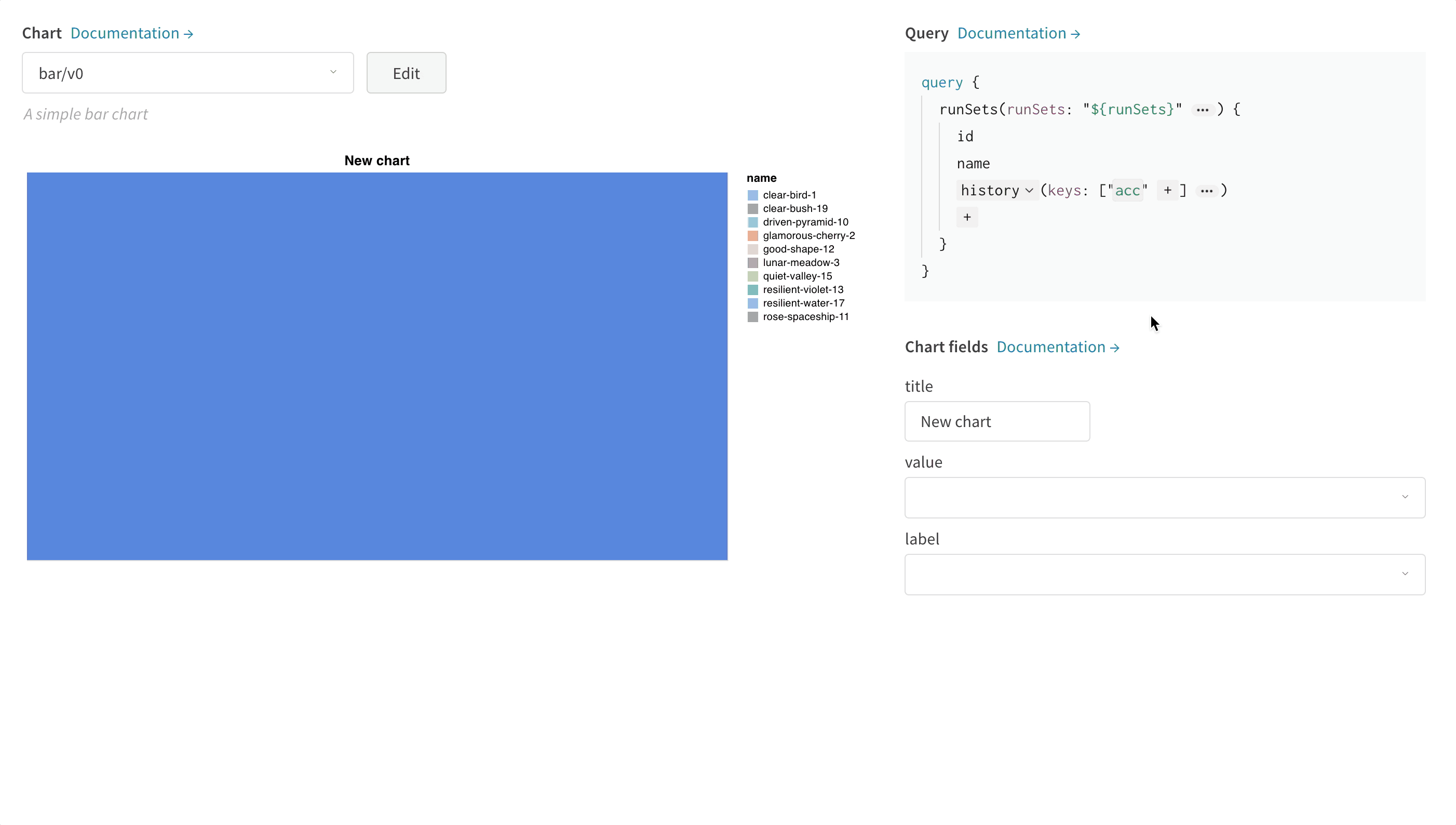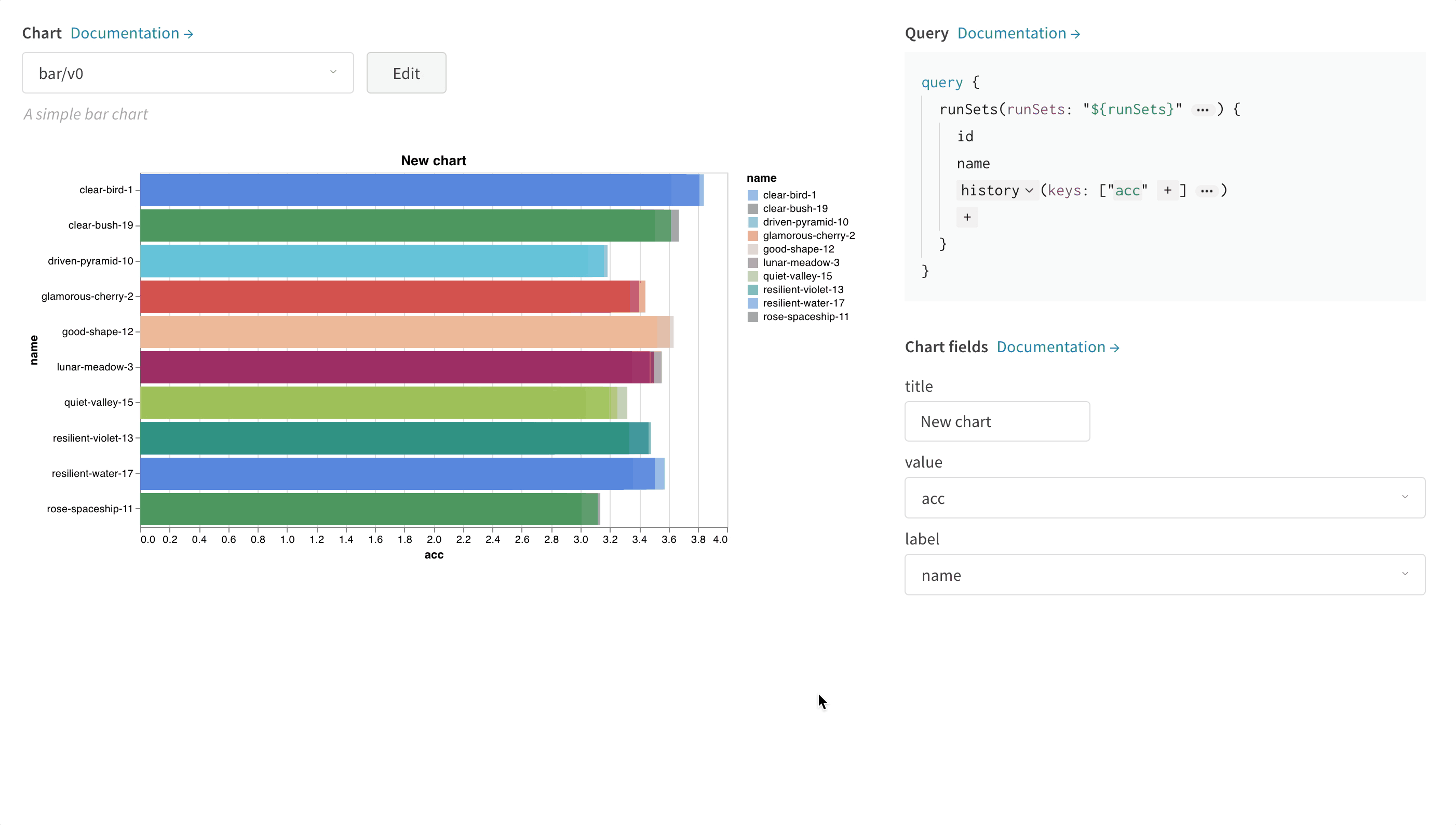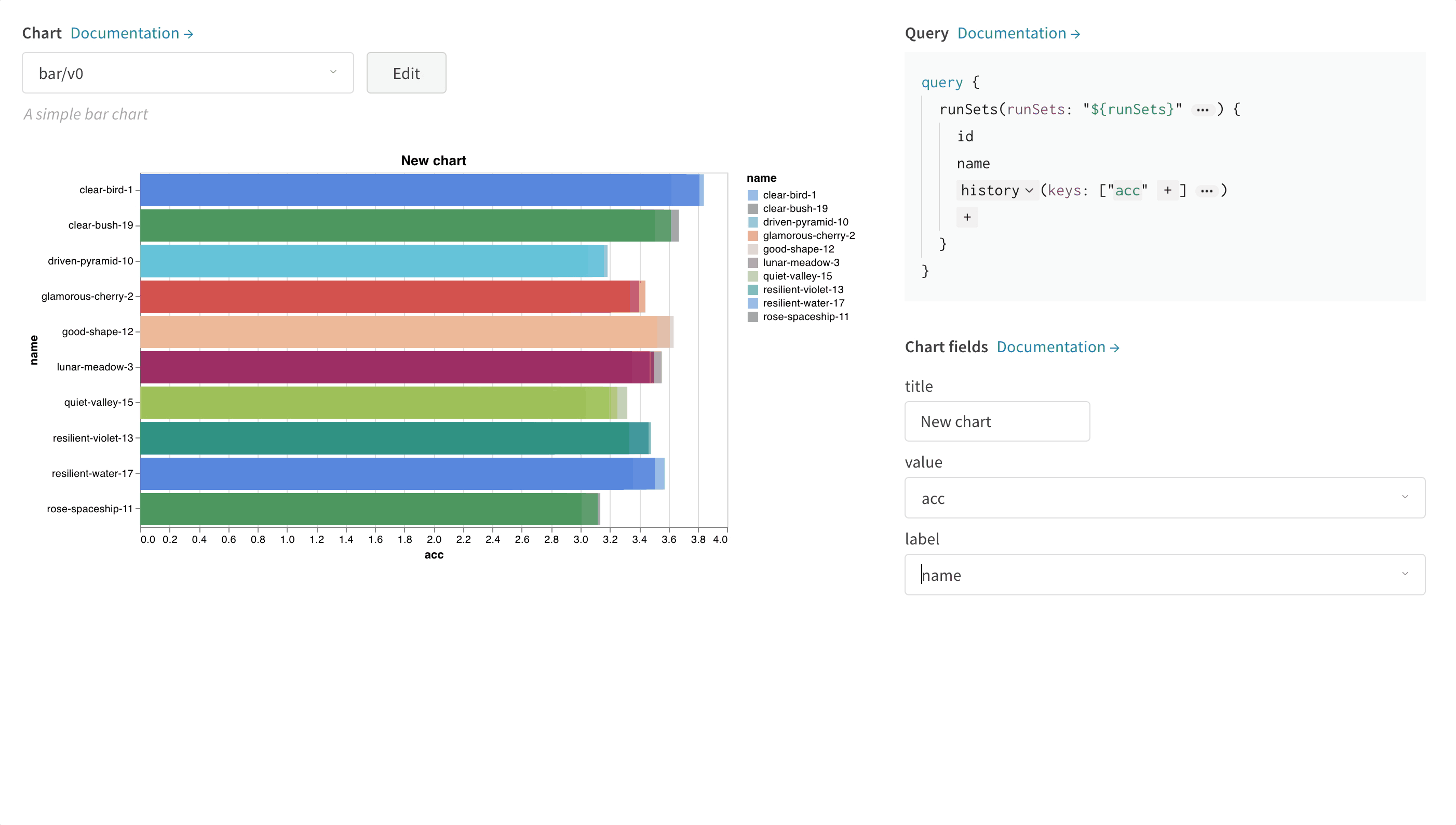
전체 사용자 정의를 위해 기본 제공 사용자 정의 차트 사전 설정을 조정하거나 새 사전 설정을 만든 다음 차트를 저장합니다. 차트 ID를 사용하여 스크립트에서 직접 해당 사용자 정의 사전 설정에 데이터를 기록합니다.
# 플로팅할 열이 있는 테이블을 만듭니다.table = wandb.Table(data=data, columns=["step", "height"])
# 테이블의 열에서 차트의 필드로 매핑합니다.fields = {"x": "step", "value": "height"}
# 테이블을 사용하여 새 사용자 정의 차트 사전 설정을 채웁니다.# 자신의 저장된 차트 사전 설정을 사용하려면 vega_spec_name을 변경하십시오.# 제목을 편집하려면 string_fields를 변경하십시오.my_custom_chart = wandb.plot_table(
vega_spec_name="carey/new_chart",
data_table=table,
fields=fields,
string_fields={"title": "Height Histogram"},
)
기본적으로 모든 메트릭은 W&B 내부 step인 동일한 x축에 대해 기록됩니다. 때로는 이전 스텝에 로그하거나 다른 x축을 사용하고 싶을 수 있습니다.
다음은 기본 스텝 대신 사용자 정의 x축 메트릭을 설정하는 예입니다.
import wandb
wandb.init()
# 사용자 정의 x축 메트릭 정의wandb.define_metric("custom_step")
# 어떤 메트릭을 기준으로 플롯할지 정의wandb.define_metric("validation_loss", step_metric="custom_step")
for i in range(10):
log_dict = {
"train_loss": 1/ (i +1),
"custom_step": i**2,
"validation_loss": 1/ (i +1),
}
wandb.log(log_dict)
x축은 glob을 사용하여 설정할 수도 있습니다. 현재 문자열 접두사가 있는 glob만 사용할 수 있습니다. 다음 예제는 접두사 "train/"가 있는 기록된 모든 메트릭을 x축 "train/step"에 플롯합니다.
import wandb
wandb.init()
# 사용자 정의 x축 메트릭 정의wandb.define_metric("train/step")
# 다른 모든 train/ 메트릭이 이 스텝을 사용하도록 설정wandb.define_metric("train/*", step_metric="train/step")
for i in range(10):
log_dict = {
"train/step": 2**i, # 내부 W&B 스텝으로 지수적 증가"train/loss": 1/ (i +1), # x축은 train/step"train/accuracy": 1- (1/ (1+ i)), # x축은 train/step"val/loss": 1/ (1+ i), # x축은 내부 wandb step }
wandb.log(log_dict)
1.6.3 - Log distributed training experiments
W&B를 사용하여 여러 개의 GPU로 분산 트레이닝 실험을 로그하세요.
분산 트레이닝에서 모델은 여러 개의 GPU를 병렬로 사용하여 트레이닝됩니다. W&B는 분산 트레이닝 Experiments를 추적하는 두 가지 패턴을 지원합니다.
단일 프로세스: 단일 프로세스에서 W&B (wandb.init)를 초기화하고 Experiments (wandb.log)를 기록합니다. 이는 PyTorch Distributed Data Parallel (DDP) 클래스를 사용하여 분산 트레이닝 Experiments를 로깅하는 일반적인 솔루션입니다. 경우에 따라 사용자는 멀티프로세싱 대기열(또는 다른 통신 기본 요소)을 사용하여 다른 프로세스의 데이터를 기본 로깅 프로세스로 전달합니다.
다중 프로세스: 모든 프로세스에서 W&B (wandb.init)를 초기화하고 Experiments (wandb.log)를 기록합니다. 각 프로세스는 사실상 별도의 experiment입니다. W&B를 초기화할 때 group 파라미터(wandb.init(group='group-name'))를 사용하여 공유 experiment를 정의하고 기록된 값들을 W&B App UI에서 함께 그룹화합니다.
다음 예제는 단일 머신에서 2개의 GPU를 사용하는 PyTorch DDP를 통해 W&B로 메트릭을 추적하는 방법을 보여줍니다. PyTorch DDP(torch.nn의 DistributedDataParallel)는 분산 트레이닝을 위한 널리 사용되는 라이브러리입니다. 기본 원리는 모든 분산 트레이닝 설정에 적용되지만 구현 세부 사항은 다를 수 있습니다.
W&B GitHub 예제 리포지토리 여기에서 이러한 예제의 이면의 코드를 살펴보세요. 특히, 단일 프로세스 및 다중 프로세스 메소드를 구현하는 방법에 대한 정보는 log-dpp.py Python 스크립트를 참조하세요.
방법 1: 단일 프로세스
이 방법에서는 순위 0 프로세스만 추적합니다. 이 방법을 구현하려면 W&B(wandb.init)를 초기화하고, W&B Run을 시작하고, 순위 0 프로세스 내에서 메트릭(wandb.log)을 기록합니다. 이 방법은 간단하고 강력하지만 다른 프로세스의 모델 메트릭(예: 배치에서의 손실 값 또는 입력)을 기록하지 않습니다. 사용량 및 메모리와 같은 시스템 메트릭은 해당 정보가 모든 프로세스에서 사용 가능하므로 모든 GPU에 대해 계속 기록됩니다.
이 방법을 사용하여 단일 프로세스에서 사용 가능한 메트릭만 추적하세요. 일반적인 예로는 GPU/CPU 사용률, 공유 검증 세트에서의 행동, 그레이디언트 및 파라미터, 대표적인 데이터 예제에 대한 손실 값이 있습니다.
샘플 Python 스크립트(log-ddp.py) 내에서 순위가 0인지 확인합니다. 이를 구현하기 위해 먼저 torch.distributed.launch를 사용하여 여러 프로세스를 시작합니다. 다음으로 --local_rank 커맨드라인 인수로 순위를 확인합니다. 순위가 0으로 설정된 경우 train() 함수에서 조건부로 wandb 로깅을 설정합니다. Python 스크립트 내에서 다음 검사를 사용합니다.
if __name__ =="__main__":
# Get args args = parse_args()
if args.local_rank ==0: # only on main process# Initialize wandb run run = wandb.init(
entity=args.entity,
project=args.project,
)
# Train model with DDP train(args, run)
else:
train(args)
W&B App UI를 탐색하여 단일 프로세스에서 추적된 메트릭의 예제 대시보드를 확인하세요. 대시보드는 두 GPU에 대해 추적된 온도 및 사용률과 같은 시스템 메트릭을 표시합니다.
그러나 에포크 및 배치 크기 함수로서의 손실 값은 단일 GPU에서만 기록되었습니다.
방법 2: 다중 프로세스
이 방법에서는 작업의 각 프로세스를 추적하여 각 프로세스에서 wandb.init() 및 wandb.log()를 호출합니다. 트레이닝이 끝나면 wandb.finish()를 호출하여 Run이 완료되었음을 표시하여 모든 프로세스가 올바르게 종료되도록 하는 것이 좋습니다.
이 방법을 사용하면 더 많은 정보를 로깅에 엑세스할 수 있습니다. 그러나 여러 개의 W&B Runs가 W&B App UI에 보고되는 점에 유의하세요. 여러 Experiments에서 W&B Runs를 추적하기 어려울 수 있습니다. 이를 완화하려면 W&B를 초기화할 때 group 파라미터에 값을 제공하여 지정된 experiment에 속하는 W&B Run을 추적하세요. Experiments에서 트레이닝 및 평가 W&B Runs를 추적하는 방법에 대한 자세한 내용은 Run 그룹화를 참조하세요.
개별 프로세스의 메트릭을 추적하려면 이 방법을 사용하세요. 일반적인 예로는 각 노드의 데이터 및 예측(데이터 배포 디버깅용)과 기본 노드 외부의 개별 배치에 대한 메트릭이 있습니다. 이 방법은 모든 노드에서 시스템 메트릭을 가져오거나 기본 노드에서 사용 가능한 요약 통계를 가져오는 데 필요하지 않습니다.
다음 Python 코드 조각은 W&B를 초기화할 때 group 파라미터를 설정하는 방법을 보여줍니다.
if __name__ =="__main__":
# Get args args = parse_args()
# Initialize run run = wandb.init(
entity=args.entity,
project=args.project,
group="DDP", # all runs for the experiment in one group )
# Train model with DDP train(args, run)
W&B App UI를 탐색하여 여러 프로세스에서 추적된 메트릭의 예제 대시보드를 확인하세요. 왼쪽 사이드바에 함께 그룹화된 두 개의 W&B Runs가 있습니다. 그룹을 클릭하여 experiment에 대한 전용 그룹 페이지를 확인하세요. 전용 그룹 페이지에는 각 프로세스의 메트릭이 개별적으로 표시됩니다.
앞의 이미지는 W&B App UI 대시보드를 보여줍니다. 사이드바에는 두 개의 Experiments가 있습니다. 하나는 ’null’로 레이블이 지정되고 다른 하나는 ‘DPP’(노란색 상자로 묶임)로 표시됩니다. 그룹을 확장하면(그룹 드롭다운 선택) 해당 experiment와 연결된 W&B Runs가 표시됩니다.
W&B Service를 사용하여 일반적인 분산 트레이닝 문제 방지
W&B 및 분산 트레이닝을 사용할 때 발생할 수 있는 두 가지 일반적인 문제가 있습니다.
트레이닝 시작 시 중단 - wandb 멀티프로세싱이 분산 트레이닝의 멀티프로세싱을 방해하는 경우 wandb 프로세스가 중단될 수 있습니다.
트레이닝 종료 시 중단 - wandb 프로세스가 종료해야 할 시점을 알지 못하는 경우 트레이닝 작업이 중단될 수 있습니다. Python 스크립트의 끝에서 wandb.finish() API를 호출하여 W&B에 Run이 완료되었음을 알립니다. wandb.finish() API는 데이터 업로드를 완료하고 W&B가 종료되도록 합니다.
wandb service를 사용하여 분산 작업의 안정성을 개선하는 것이 좋습니다. 앞서 언급한 두 가지 트레이닝 문제는 일반적으로 wandb service를 사용할 수 없는 W&B SDK 버전에서 발견됩니다.
W&B Service 활성화
W&B SDK 버전에 따라 W&B Service가 기본적으로 활성화되어 있을 수 있습니다.
W&B SDK 0.13.0 이상
W&B Service는 W&B SDK 0.13.0 버전 이상에서 기본적으로 활성화되어 있습니다.
W&B SDK 0.12.5 이상
Python 스크립트를 수정하여 W&B SDK 버전 0.12.5 이상에서 W&B Service를 활성화하세요. wandb.require 메소드를 사용하고 기본 함수 내에서 문자열 "service"를 전달하세요.
if __name__ =="__main__":
main()
defmain():
wandb.require("service")
# rest-of-your-script-goes-here
최적의 경험을 위해 최신 버전으로 업그레이드하는 것이 좋습니다.
W&B SDK 0.12.4 이하
W&B SDK 버전 0.12.4 이하를 사용하는 경우 WANDB_START_METHOD 환경 변수를 "thread"로 설정하여 대신 멀티스레딩을 사용하세요.
멀티프로세싱에 대한 예제 유스 케이스
다음 코드 조각은 고급 분산 유스 케이스에 대한 일반적인 방법을 보여줍니다.
프로세스 생성
생성된 프로세스에서 W&B Run을 시작하는 경우 기본 함수에서 wandb.setup() 메소드를 사용하세요.
import multiprocessing as mp
defdo_work(n):
run = wandb.init(config=dict(n=n))
run.log(dict(this=n * n))
defmain():
wandb.setup()
pool = mp.Pool(processes=4)
pool.map(do_work, range(4))
if __name__ =="__main__":
main()
W&B Run 공유
W&B Run 오브젝트를 인수로 전달하여 프로세스 간에 W&B Runs를 공유합니다.
defdo_work(run):
run.log(dict(this=1))
defmain():
run = wandb.init()
p = mp.Process(target=do_work, kwargs=dict(run=run))
p.start()
p.join()
if __name__ =="__main__":
main()
로깅 순서를 보장할 수 없습니다. 동기화는 스크립트 작성자가 수행해야 합니다.
1.6.4 - Log media and objects
3D 포인트 클라우드 및 분자에서 HTML 및 히스토그램에 이르기까지 다양한 미디어를 로그
마지막 차원이 1이면 이미지가 회색조, 3이면 RGB, 4이면 RGBA라고 가정합니다. 배열에 float가 포함된 경우 0과 255 사이의 정수로 변환합니다. 이미지를 다르게 정규화하려면 mode를 수동으로 지정하거나 이 패널의 “PIL 이미지 로깅” 탭에 설명된 대로 PIL.Image를 제공하면 됩니다.
배열을 이미지로 변환하는 것을 완벽하게 제어하려면 PIL.Image를 직접 구성하여 제공합니다.
images = [PIL.Image.fromarray(image) for image in image_array]
wandb.log({"examples": [wandb.Image(image) for image in images]})
더욱 완벽하게 제어하려면 원하는 방식으로 이미지를 만들고 디스크에 저장한 다음 파일 경로를 제공합니다.
im = PIL.fromarray(...)
rgb_im = im.convert("RGB")
rgb_im.save("myimage.jpg")
wandb.log({"example": wandb.Image("myimage.jpg")})
이미지 오버레이
W&B UI를 통해 시멘틱 세그멘테이션 마스크를 기록하고 (불투명도 변경, 시간 경과에 따른 변경 사항 보기 등) 상호 작용합니다.
오버레이를 기록하려면 다음 키와 값이 있는 사전을 wandb.Image의 masks 키워드 인수에 제공해야 합니다.
이미지 마스크를 나타내는 두 개의 키 중 하나:
"mask_data": 각 픽셀에 대한 정수 클래스 레이블을 포함하는 2D NumPy 배열
"path": (문자열) 저장된 이미지 마스크 파일의 경로
"class_labels": (선택 사항) 이미지 마스크의 정수 클래스 레이블을 읽을 수 있는 클래스 이름에 매핑하는 사전
리스트, 배열 또는 텐서와 같은 숫자 시퀀스가 첫 번째 인수로 제공되면 np.histogram을 호출하여 히스토그램이 자동으로 구성됩니다. 모든 배열/텐서는 평면화됩니다. 선택적 num_bins 키워드 인수를 사용하여 기본값인 64개 구간을 재정의할 수 있습니다. 지원되는 최대 구간 수는 512개입니다.
UI에서 히스토그램은 x축에 트레이닝 스텝, y축에 메트릭 값, 색상으로 표현되는 개수로 플롯되어 트레이닝 전반에 걸쳐 기록된 히스토그램을 쉽게 비교할 수 있습니다. 일회성 히스토그램 로깅에 대한 자세한 내용은 이 패널의 “요약의 히스토그램” 탭을 참조하세요.
wandb.log({"gradients": wandb.Histogram(grads)})
더 많은 제어를 원하면 np.histogram을 호출하고 반환된 튜플을 np_histogram 키워드 인수에 전달합니다.
numpy 배열이 제공되면 차원은 시간, 채널, 너비, 높이 순서라고 가정합니다. 기본적으로 4fps gif 이미지를 만듭니다 (ffmpeg 및 moviepy python 라이브러리는 numpy 오브젝트를 전달할 때 필요합니다). 지원되는 형식은 "gif", "mp4", "webm" 및 "ogg"입니다. 문자열을 wandb.Video에 전달하면 파일을 업로드하기 전에 파일이 존재하고 지원되는 형식인지 확인합니다. BytesIO 오브젝트를 전달하면 지정된 형식을 확장자로 사용하여 임시 파일이 생성됩니다.
UI에 표시되도록 테이블에 텍스트를 기록하려면 wandb.Table을 사용합니다. 기본적으로 열 헤더는 ["Input", "Output", "Expected"]입니다. 최적의 UI 성능을 보장하기 위해 기본 최대 행 수는 10,000으로 설정됩니다. 그러나 사용자는 wandb.Table.MAX_ROWS = {DESIRED_MAX}를 사용하여 최대값을 명시적으로 재정의할 수 있습니다.
속성 업데이트 (메타데이터, 에일리어스 및 설명)와 같이 이러한 메서드로 생성된 모델 아티팩트와 상호 작용합니다.
W&B Artifacts 및 고급 버전 관리 유스 케이스에 대한 자세한 내용은 Artifacts 문서를 참조하세요.
모델을 run에 로깅
log_model을 사용하여 지정한 디렉토리 내에 콘텐츠가 포함된 모델 아티팩트를 로깅합니다. log_model 메서드는 결과 모델 아티팩트를 W&B run의 출력으로 표시합니다.
모델을 W&B run의 입력 또는 출력으로 표시하면 모델의 종속성과 모델의 연결을 추적할 수 있습니다. W&B App UI 내에서 모델의 계보를 확인하세요. 자세한 내용은 Artifacts 챕터의 아티팩트 그래프 탐색 및 트래버스 페이지를 참조하세요.
모델 파일이 저장된 경로를 path 파라미터에 제공하세요. 경로는 로컬 파일, 디렉토리 또는 s3://bucket/path와 같은 외부 버킷에 대한 참조 URI일 수 있습니다.
<>로 묶인 값은 사용자 고유의 값으로 바꾸세요.
import wandb
# W&B run 초기화run = wandb.init(project="<your-project>", entity="<your-entity>")
# 모델 로깅run.log_model(path="<path-to-model>", name="<name>")
선택적으로 name 파라미터에 모델 아티팩트 이름을 제공합니다. name이 지정되지 않은 경우 W&B는 run ID가 앞에 붙은 입력 경로의 기본 이름을 이름으로 사용합니다.
사용자 또는 W&B가 모델에 할당한 name을 추적하세요. use_model 메서드로 모델 경로를 검색하려면 모델 이름이 필요합니다.
가능한 파라미터에 대한 자세한 내용은 API 참조 가이드의 log_model을 참조하세요.
예시: 모델을 run에 로깅
import os
import wandb
from tensorflow import keras
from tensorflow.keras import layers
config = {"optimizer": "adam", "loss": "categorical_crossentropy"}
# W&B run 초기화run = wandb.init(entity="charlie", project="mnist-experiments", config=config)
# 하이퍼파라미터loss = run.config["loss"]
optimizer = run.config["optimizer"]
metrics = ["accuracy"]
num_classes =10input_shape = (28, 28, 1)
# 트레이닝 알고리즘model = keras.Sequential(
[
layers.Input(shape=input_shape),
layers.Conv2D(32, kernel_size=(3, 3), activation="relu"),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Conv2D(64, kernel_size=(3, 3), activation="relu"),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Flatten(),
layers.Dropout(0.5),
layers.Dense(num_classes, activation="softmax"),
]
)
# 트레이닝을 위한 모델 구성model.compile(loss=loss, optimizer=optimizer, metrics=metrics)
# 모델 저장model_filename ="model.h5"local_filepath ="./"full_path = os.path.join(local_filepath, model_filename)
model.save(filepath=full_path)
# 모델을 W&B run에 로깅run.log_model(path=full_path, name="MNIST")
run.finish()
사용자가 log_model을 호출하면 MNIST라는 모델 아티팩트가 생성되고 파일 model.h5가 모델 아티팩트에 추가되었습니다. 터미널 또는 노트북에 모델이 로깅된 run에 대한 정보를 찾을 수 있는 위치가 출력됩니다.
View run different-surf-5 at: https://wandb.ai/charlie/mnist-experiments/runs/wlby6fuw
Synced 5 W&B file(s), 0 media file(s), 1 artifact file(s) and0 other file(s)
Find logs at: ./wandb/run-20231206_103511-wlby6fuw/logs
로깅된 모델 다운로드 및 사용
use_model 함수를 사용하여 이전에 W&B run에 로깅된 모델 파일에 엑세스하고 다운로드합니다.
검색하려는 모델 파일이 저장된 모델 아티팩트의 이름을 제공합니다. 제공하는 이름은 기존의 로깅된 모델 아티팩트의 이름과 일치해야 합니다.
log_model로 파일을 원래 로깅할 때 name을 정의하지 않은 경우 할당된 기본 이름은 run ID가 앞에 붙은 입력 경로의 기본 이름입니다.
<>로 묶인 다른 값은 사용자 고유의 값으로 바꾸세요.
import wandb
# run 초기화run = wandb.init(project="<your-project>", entity="<your-entity>")
# 모델에 엑세스 및 다운로드합니다. 다운로드된 아티팩트의 경로를 반환합니다.downloaded_model_path = run.use_model(name="<your-model-name>")
use_model 함수는 다운로드된 모델 파일의 경로를 반환합니다. 나중에 이 모델을 연결하려면 이 경로를 추적하세요. 앞의 코드 조각에서 반환된 경로는 downloaded_model_path라는 변수에 저장됩니다.
예시: 로깅된 모델 다운로드 및 사용
예를 들어, 앞의 코드 조각에서 사용자는 use_model API를 호출했습니다. 그들은 가져오려는 모델 아티팩트의 이름을 지정하고 버전/에일리어스도 제공했습니다. 그런 다음 API에서 반환된 경로를 downloaded_model_path 변수에 저장했습니다.
import wandb
entity ="luka"project ="NLP_Experiments"alias ="latest"# 모델 버전에 대한 시맨틱 닉네임 또는 식별자model_artifact_name ="fine-tuned-model"# run 초기화run = wandb.init(project=project, entity=entity)
# 모델에 엑세스 및 다운로드합니다. 다운로드된 아티팩트의 경로를 반환합니다.downloaded_model_path = run.use_model(name =f"{model_artifact_name}:{alias}")
가능한 파라미터 및 반환 유형에 대한 자세한 내용은 API 참조 가이드의 use_model을 참조하세요.
모델을 로깅하고 W&B Model Registry에 연결
link_model 메서드는 곧 사용 중단될 레거시 W&B Model Registry와만 호환됩니다. 새로운 버전의 모델 레지스트리에 모델 아티팩트를 연결하는 방법을 알아보려면 레지스트리 문서를 방문하세요.
link_model 메서드를 사용하여 모델 파일을 W&B run에 로깅하고 W&B Model Registry에 연결합니다. 등록된 모델이 없으면 W&B는 registered_model_name 파라미터에 제공하는 이름으로 새 모델을 만듭니다.
모델을 연결하는 것은 팀의 다른 구성원이 보고 사용할 수 있는 모델의 중앙 집중식 팀 리포지토리에 모델을 ‘북마크’하거나 ‘게시’하는 것과 유사합니다.
모델을 연결하면 해당 모델이 Registry에서 복제되거나 프로젝트에서 레지스트리로 이동되지 않습니다. 연결된 모델은 프로젝트의 원래 모델에 대한 포인터입니다.
Registry를 사용하여 작업별로 최상의 모델을 구성하고, 모델 수명 주기를 관리하고, ML 수명 주기 전반에 걸쳐 간편한 추적 및 감사를 용이하게 하고, 웹 훅 또는 작업을 통해 다운스트림 작업을 자동화합니다.
Registered Model은 Model Registry의 연결된 모델 버전의 컬렉션 또는 폴더입니다. 등록된 모델은 일반적으로 단일 모델링 유스 케이스 또는 작업에 대한 후보 모델을 나타냅니다.
앞의 코드 조각은 link_model API로 모델을 연결하는 방법을 보여줍니다. <>로 묶인 다른 값은 사용자 고유의 값으로 바꾸세요.
import wandb
run = wandb.init(entity="<your-entity>", project="<your-project>")
run.link_model(path="<path-to-model>", registered_model_name="<registered-model-name>")
run.finish()
선택적 파라미터에 대한 자세한 내용은 API 참조 가이드의 link_model을 참조하세요.
registered-model-name이 Model Registry 내에 이미 존재하는 등록된 모델의 이름과 일치하면 모델이 해당 등록된 모델에 연결됩니다. 이러한 등록된 모델이 없으면 새 모델이 생성되고 모델이 첫 번째로 연결됩니다.
예를 들어, Model Registry에 “Fine-Tuned-Review-Autocompletion"이라는 기존 등록된 모델이 있다고 가정합니다(예제는 여기 참조). 그리고 몇 개의 모델 버전이 이미 v0, v1, v2로 연결되어 있다고 가정합니다. registered-model-name="Fine-Tuned-Review-Autocompletion"으로 link_model을 호출하면 새 모델이 이 기존 등록된 모델에 v3으로 연결됩니다. 이 이름으로 등록된 모델이 없으면 새 모델이 생성되고 새 모델이 v0으로 연결됩니다.
예시: 모델을 로깅하고 W&B Model Registry에 연결
예를 들어, 앞의 코드 조각은 모델 파일을 로깅하고 모델을 등록된 모델 이름 "Fine-Tuned-Review-Autocompletion"에 연결합니다.
이를 위해 사용자는 link_model API를 호출합니다. API를 호출할 때 모델 콘텐츠를 가리키는 로컬 파일 경로(path)를 제공하고 연결할 등록된 모델의 이름(registered_model_name)을 제공합니다.
트레이닝 과정에서 시간이 지남에 따라 변하는 값 외에도, 모델 또는 전처리 단계를 요약하는 단일 값을 추적하는 것이 중요한 경우가 많습니다. W&B Run의 summary 사전에 이 정보를 기록하세요. Run의 summary 사전은 numpy 배열, PyTorch 텐서 또는 TensorFlow 텐서를 처리할 수 있습니다. 값이 이러한 유형 중 하나인 경우 전체 텐서를 바이너리 파일에 유지하고 요약 오브젝트에 최소값, 평균, 분산, 백분위수 등과 같은 높은 수준의 메트릭을 저장합니다.
wandb.log로 기록된 마지막 값은 W&B Run에서 자동으로 summary 사전으로 설정됩니다. summary 메트릭 사전이 수정되면 이전 값은 손실됩니다.
다음 코드 조각은 사용자 정의 summary 메트릭을 W&B에 제공하는 방법을 보여줍니다.
트레이닝이 완료된 후 기존 W&B Run의 summary 속성을 업데이트할 수 있습니다. W&B Public API를 사용하여 summary 속성을 업데이트합니다.
api = wandb.Api()
run = api.run("username/project/run_id")
run.summary["tensor"] = np.random.random(1000)
run.summary.update()
summary 메트릭 사용자 정의
사용자 정의 summary 메트릭은 wandb.summary에서 트레이닝의 최적 단계에서 모델 성능을 캡처하는 데 유용합니다. 예를 들어 최종 값 대신 최대 정확도 또는 최소 손실 값을 캡처할 수 있습니다.
기본적으로 summary는 히스토리의 최종 값을 사용합니다. summary 메트릭을 사용자 정의하려면 define_metric에서 summary 인수를 전달합니다. 다음 값을 사용할 수 있습니다.
"min"
"max"
"mean"
"best"
"last"
"none"
선택적 objective 인수를 "minimize" 또는 "maximize"로 설정한 경우에만 "best"를 사용할 수 있습니다.
다음 예제는 손실 및 정확도의 최소값과 최대값을 summary에 추가합니다.
import wandb
import random
random.seed(1)
wandb.init()
# 손실에 대한 최소값 및 최대값 summarywandb.define_metric("loss", summary="min")
wandb.define_metric("loss", summary="max")
# 정확도에 대한 최소값 및 최대값 summarywandb.define_metric("acc", summary="min")
wandb.define_metric("acc", summary="max")
for i in range(10):
log_dict = {
"loss": random.uniform(0, 1/ (i +1)),
"acc": random.uniform(1/ (i +1), 1),
}
wandb.log(log_dict)
summary 메트릭 보기
run의 Overview 페이지 또는 프로젝트의 runs 테이블에서 summary 값을 봅니다.
W&B 앱으로 이동합니다.
Workspace 탭을 선택합니다.
runs 목록에서 summary 값이 기록된 run의 이름을 클릭합니다.
Overview 탭을 선택합니다.
Summary 섹션에서 summary 값을 봅니다.
W&B 앱으로 이동합니다.
Runs 탭을 선택합니다.
runs 테이블 내에서 summary 값의 이름을 기준으로 열 내에서 summary 값을 볼 수 있습니다.
W&B Public API를 사용하여 run의 summary 값을 가져올 수 있습니다.
다음 코드 예제는 W&B Public API 및 pandas를 사용하여 특정 run에 기록된 summary 값을 검색하는 한 가지 방법을 보여줍니다.
import wandb
import pandas
entity ="<your-entity>"project ="<your-project>"run_name ="<your-run-name>"# summary 값이 있는 run의 이름all_runs = []
for run in api.runs(f"{entity}/{project_name}"):
print("Fetching details for run: ", run.id, run.name)
run_data = {
"id": run.id,
"name": run.name,
"url": run.url,
"state": run.state,
"tags": run.tags,
"config": run.config,
"created_at": run.created_at,
"system_metrics": run.system_metrics,
"summary": run.summary,
"project": run.project,
"entity": run.entity,
"user": run.user,
"path": run.path,
"notes": run.notes,
"read_only": run.read_only,
"history_keys": run.history_keys,
"metadata": run.metadata,
}
all_runs.append(run_data)
# DataFrame으로 변환df = pd.DataFrame(all_runs)
# 열 이름(run)을 기준으로 행을 가져오고 사전으로 변환df[df['name']==run_name].summary.reset_index(drop=True).to_dict()
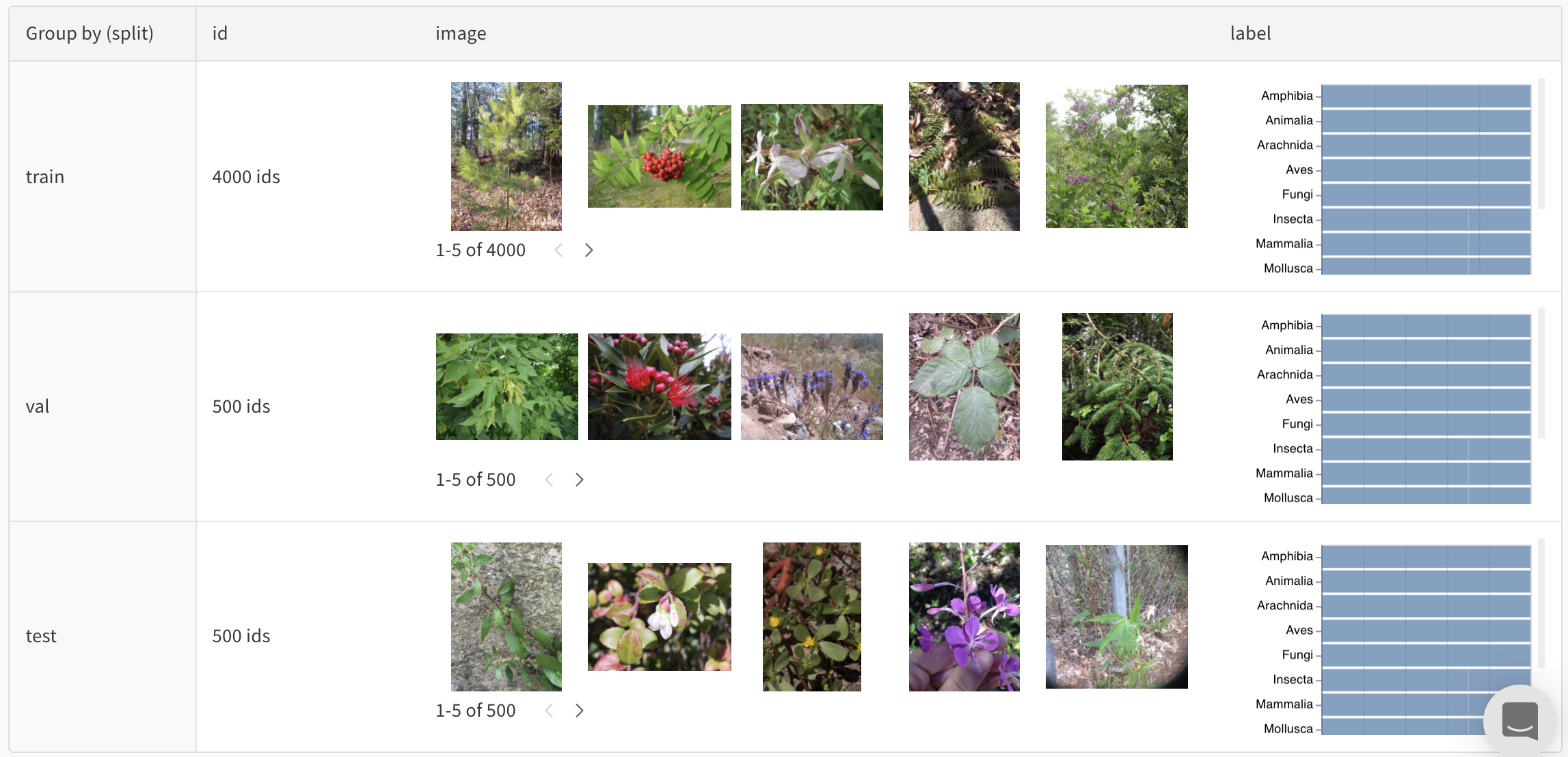
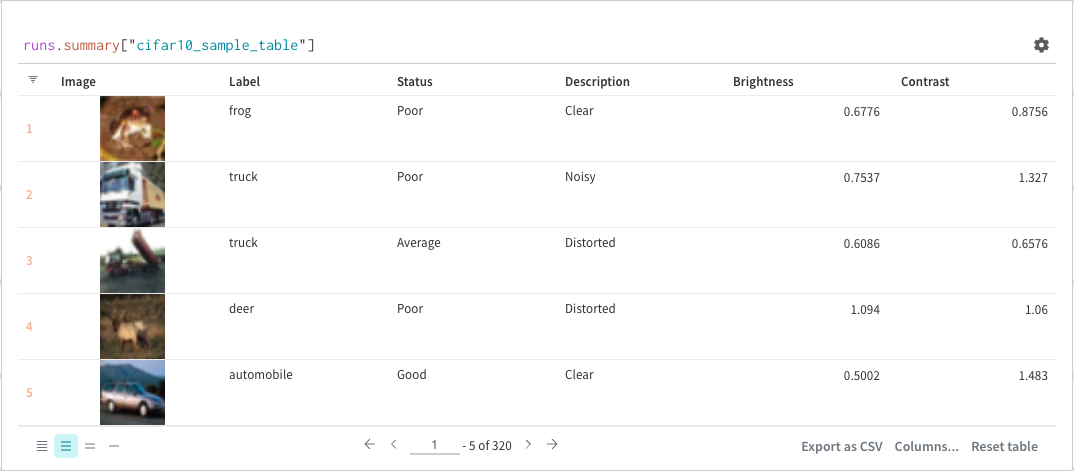
테이블을 정의하려면 데이터의 각 행에 대해 보려는 열을 지정합니다. 각 행은 트레이닝 데이터셋의 단일 항목, 트레이닝 중의 특정 단계 또는 에포크, 테스트 항목에 대한 모델의 예측값, 모델에서 생성된 오브젝트 등이 될 수 있습니다. 각 열에는 숫자, 텍스트, 부울, 이미지, 비디오, 오디오 등 고정된 유형이 있습니다. 유형을 미리 지정할 필요는 없습니다. 각 열에 이름을 지정하고 해당 유형의 데이터만 해당 열 인덱스로 전달해야 합니다. 더 자세한 예는 이 리포트를 참조하십시오.
다음 두 가지 방법 중 하나로 wandb.Table 생성자를 사용합니다.
행 목록: 이름이 지정된 열과 데이터 행을 기록합니다. 예를 들어 다음 코드 조각은 두 개의 행과 세 개의 열이 있는 테이블을 생성합니다.
Pandas DataFrame:wandb.Table(dataframe=my_df)를 사용하여 DataFrame을 기록합니다. 열 이름은 DataFrame에서 추출됩니다.
기존 배열 또는 데이터 프레임에서
# 모델이 다음 필드를 사용할 수 있는 네 개의 이미지에 대한 예측을 반환했다고 가정합니다.# - 이미지 ID# - wandb.Image()로 래핑된 이미지 픽셀# - 모델의 예측 레이블# - 그라운드 트루스 레이블my_data = [
[0, wandb.Image("img_0.jpg"), 0, 0],
[1, wandb.Image("img_1.jpg"), 8, 0],
[2, wandb.Image("img_2.jpg"), 7, 1],
[3, wandb.Image("img_3.jpg"), 1, 1],
]
# 해당 열이 있는 wandb.Table() 생성columns = ["id", "image", "prediction", "truth"]
test_table = wandb.Table(data=my_data, columns=columns)
데이터 추가
테이블은 변경 가능합니다. 스크립트가 실행될 때 테이블에 최대 200,000개의 행까지 더 많은 데이터를 추가할 수 있습니다. 테이블에 데이터를 추가하는 방법에는 두 가지가 있습니다.
행 추가: table.add_data("3a", "3b", "3c"). 새 행은 목록으로 표시되지 않습니다. 행이 목록 형식인 경우 별표 표기법 *을 사용하여 목록을 위치 인수로 확장합니다. table.add_data(*my_row_list). 행에는 테이블의 열 수와 동일한 수의 항목이 포함되어야 합니다.
열 추가: table.add_column(name="col_name", data=col_data). col_data의 길이는 테이블의 현재 행 수와 같아야 합니다. 여기서 col_data는 목록 데이터 또는 NumPy NDArray일 수 있습니다.
점진적으로 데이터 추가
이 코드 샘플은 W&B 테이블을 점진적으로 생성하고 채우는 방법을 보여줍니다. 가능한 모든 레이블에 대한 신뢰도 점수를 포함하여 미리 정의된 열로 테이블을 정의하고 추론 중에 행별로 데이터를 추가합니다. run을 재개할 때 테이블에 점진적으로 데이터를 추가할 수도 있습니다.
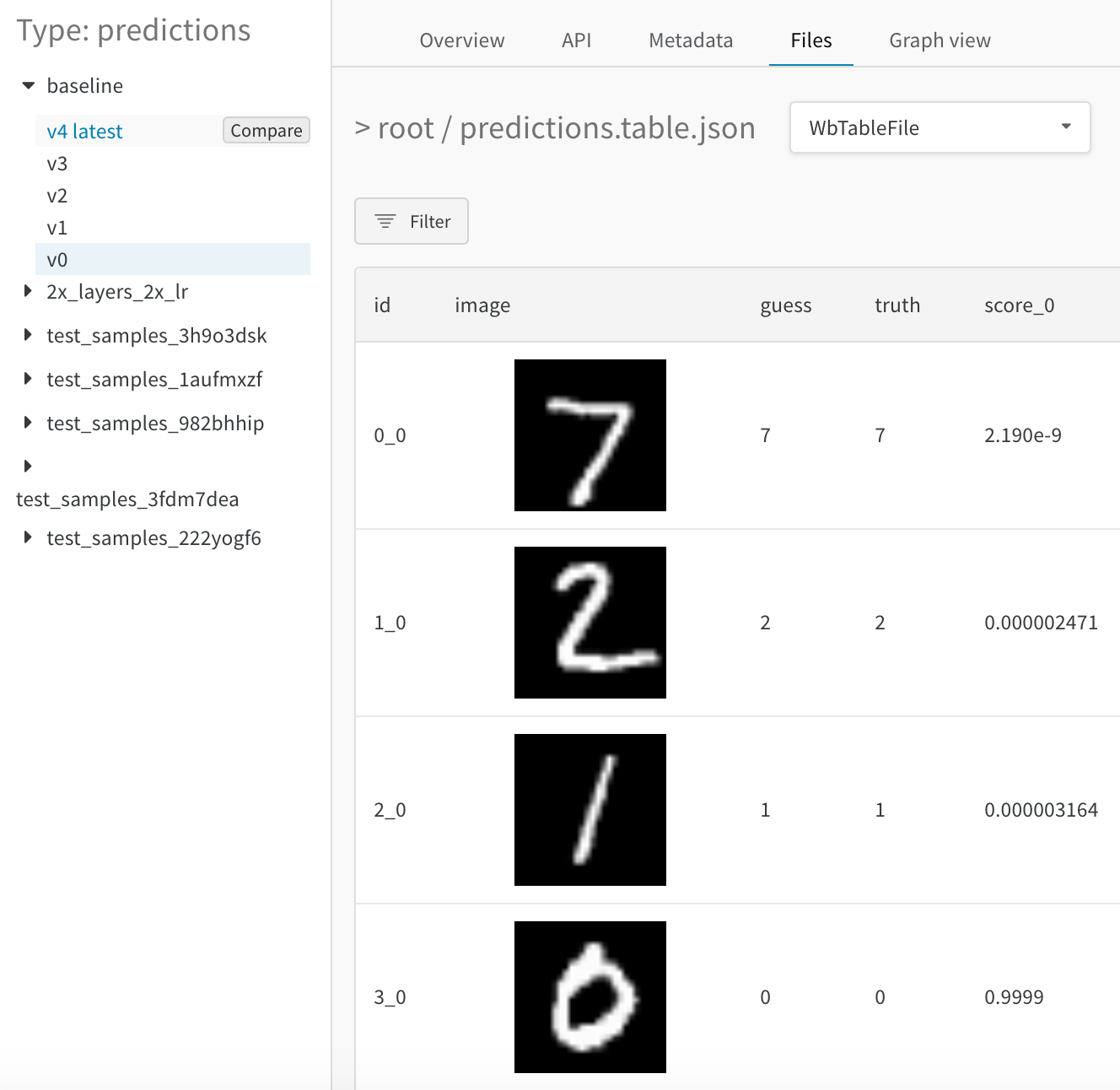
# 각 레이블에 대한 신뢰도 점수를 포함하여 테이블의 열을 정의합니다.columns = ["id", "image", "guess", "truth"]
for digit in range(10): # 각 숫자(0-9)에 대한 신뢰도 점수 열을 추가합니다. columns.append(f"score_{digit}")
# 정의된 열로 테이블을 초기화합니다.test_table = wandb.Table(columns=columns)
# 테스트 데이터셋을 반복하고 데이터를 행별로 테이블에 추가합니다.# 각 행에는 이미지 ID, 이미지, 예측 레이블, 트루 레이블 및 신뢰도 점수가 포함됩니다.for img_id, img in enumerate(mnist_test_data):
true_label = mnist_test_data_labels[img_id] # 그라운드 트루스 레이블 guess_label = my_model.predict(img) # 예측 레이블 test_table.add_data(
img_id, wandb.Image(img), guess_label, true_label
) # 테이블에 행 데이터를 추가합니다.
재개된 run에 데이터 추가
아티팩트에서 기존 테이블을 로드하고, 데이터의 마지막 행을 검색하고, 업데이트된 메트릭을 추가하여 재개된 run에서 W&B 테이블을 점진적으로 업데이트할 수 있습니다. 그런 다음 호환성을 위해 테이블을 다시 초기화하고 업데이트된 버전을 W&B에 다시 기록합니다.
# 아티팩트에서 기존 테이블을 로드합니다.best_checkpt_table = wandb.use_artifact(table_tag).get(table_name)
# 재개를 위해 테이블에서 데이터의 마지막 행을 가져옵니다.best_iter, best_metric_max, best_metric_min = best_checkpt_table.data[-1]
# 필요에 따라 최상의 메트릭을 업데이트합니다.# 업데이트된 데이터를 테이블에 추가합니다.best_checkpt_table.add_data(best_iter, best_metric_max, best_metric_min)
# 호환성을 보장하기 위해 업데이트된 데이터로 테이블을 다시 초기화합니다.best_checkpt_table = wandb.Table(
columns=["col1", "col2", "col3"], data=best_checkpt_table.data
)
# 업데이트된 테이블을 Weights & Biases에 기록합니다.wandb.log({table_name: best_checkpt_table})
데이터 검색
데이터가 테이블에 있으면 열 또는 행별로 엑세스합니다.
행 반복기: 사용자는 for ndx, row in table.iterrows(): ...와 같은 테이블의 행 반복기를 사용하여 데이터의 행을 효율적으로 반복할 수 있습니다.
열 가져오기: 사용자는 table.get_column("col_name")을 사용하여 데이터 열을 검색할 수 있습니다. 편의를 위해 사용자는 convert_to="numpy"를 전달하여 열을 기본 요소의 NumPy NDArray로 변환할 수 있습니다. 이는 열에 기본 데이터에 직접 엑세스할 수 있도록 wandb.Image와 같은 미디어 유형이 포함된 경우에 유용합니다.
테이블 저장
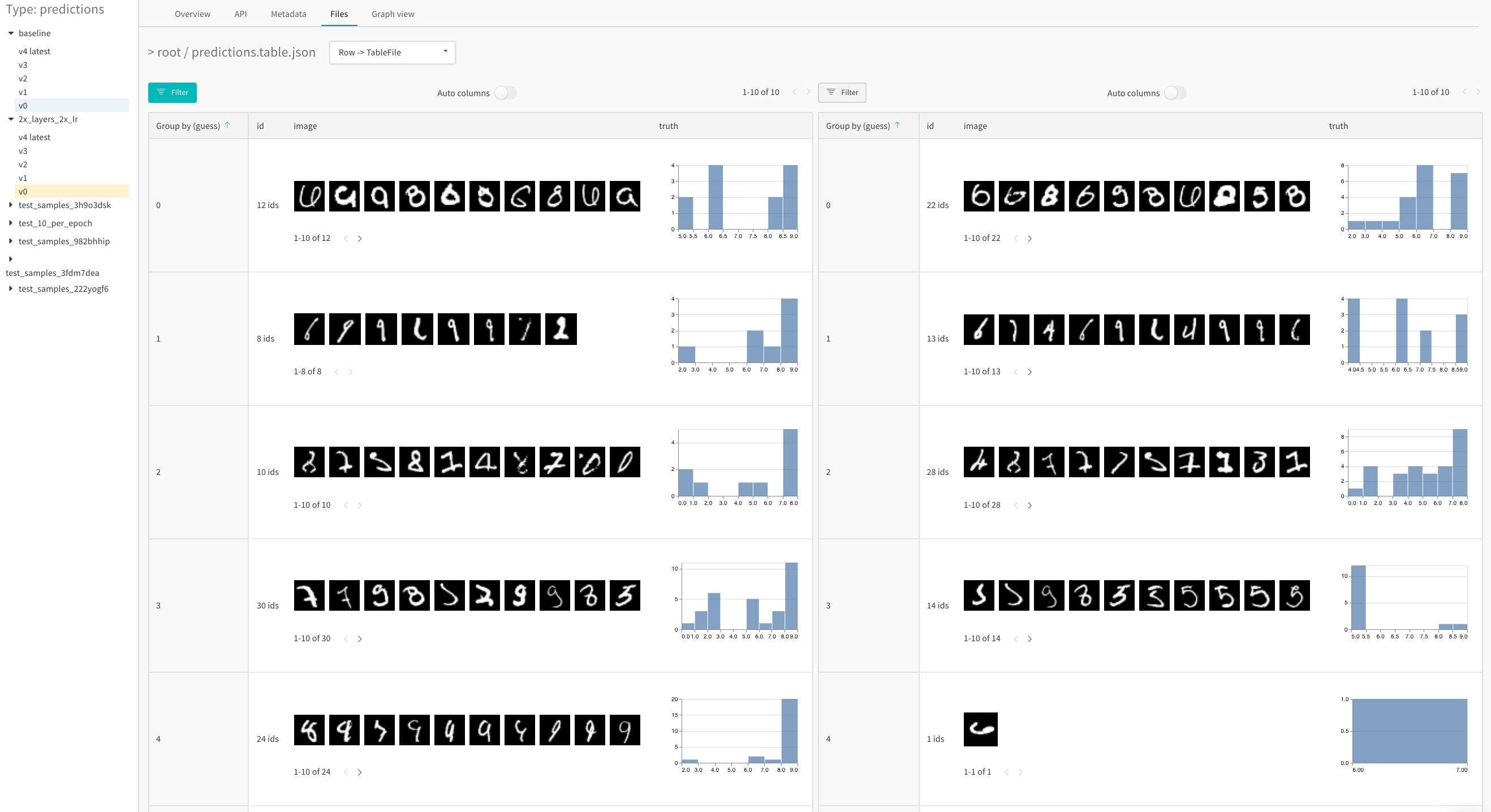
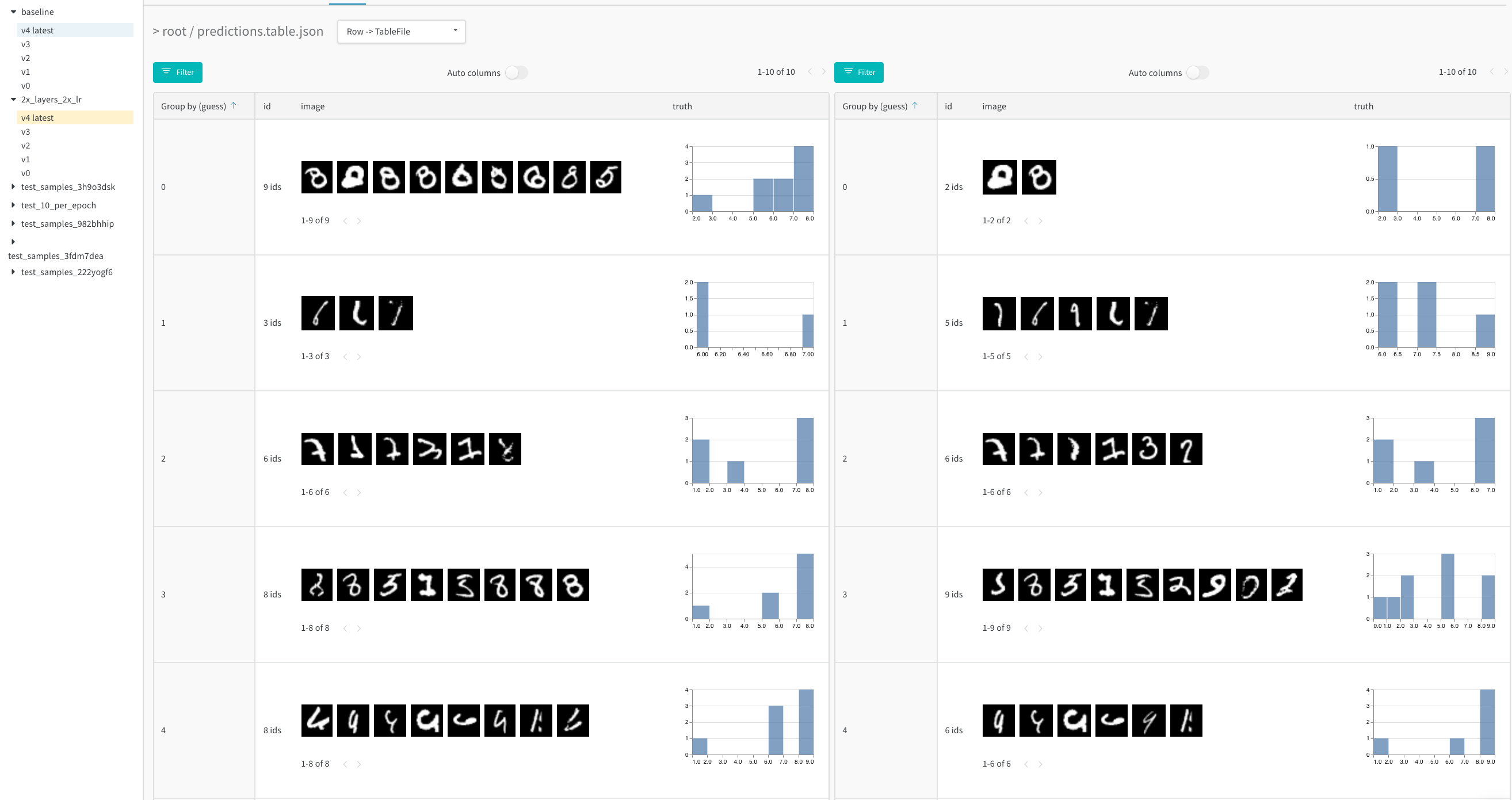
예를 들어 모델 예측 테이블과 같이 스크립트에서 데이터 테이블을 생성한 후 결과를 라이브로 시각화하기 위해 W&B에 저장합니다.
테이블이 동일한 키에 기록될 때마다 테이블의 새 버전이 생성되어 백엔드에 저장됩니다. 즉, 모델 예측이 시간이 지남에 따라 어떻게 향상되는지 확인하기 위해 여러 트레이닝 단계에서 동일한 테이블을 기록하거나 동일한 키에 기록되는 한 다른 run에서 테이블을 비교할 수 있습니다. 최대 200,000개의 행을 기록할 수 있습니다.
200,000개 이상의 행을 기록하려면 다음을 사용하여 제한을 재정의할 수 있습니다.
wandb.Table.MAX_ARTIFACT_ROWS = X
그러나 이렇게 하면 UI에서 쿼리 속도 저하와 같은 성능 문제가 발생할 수 있습니다.
프로그래밍 방식으로 테이블 엑세스
백엔드에서 테이블은 Artifacts로 유지됩니다. 특정 버전에 엑세스하려면 아티팩트 API를 사용하여 엑세스할 수 있습니다.
with wandb.init() as run:
my_table = run.use_artifact("run-<run-id>-<table-name>:<tag>").get("<table-name>")
Artifacts에 대한 자세한 내용은 개발자 가이드의 Artifacts 챕터를 참조하십시오.
테이블 시각화
이러한 방식으로 기록된 테이블은 Run 페이지와 Project 페이지 모두의 Workspace에 표시됩니다. 자세한 내용은 테이블 시각화 및 분석을 참조하십시오.
아티팩트 테이블
artifact.add()를 사용하여 워크스페이스 대신 run의 Artifacts 섹션에 테이블을 기록합니다. 이는 한 번 기록한 다음 향후 run에 참조할 데이터셋이 있는 경우에 유용할 수 있습니다.
run = wandb.init(project="my_project")
# 각 의미 있는 단계에 대한 wandb Artifact 생성test_predictions = wandb.Artifact("mnist_test_preds", type="predictions")
# [위와 같이 예측 데이터 빌드]test_table = wandb.Table(data=data, columns=columns)
test_predictions.add(test_table, "my_test_key")
run.log_artifact(test_predictions)
이미지 데이터와 함께 artifact.add()의 자세한 예는 이 Colab을 참조하고, Artifacts 및 Tables를 사용하여 테이블 형식 데이터의 버전 제어 및 중복 제거하는 방법의 예는 이 리포트를 참조하십시오.
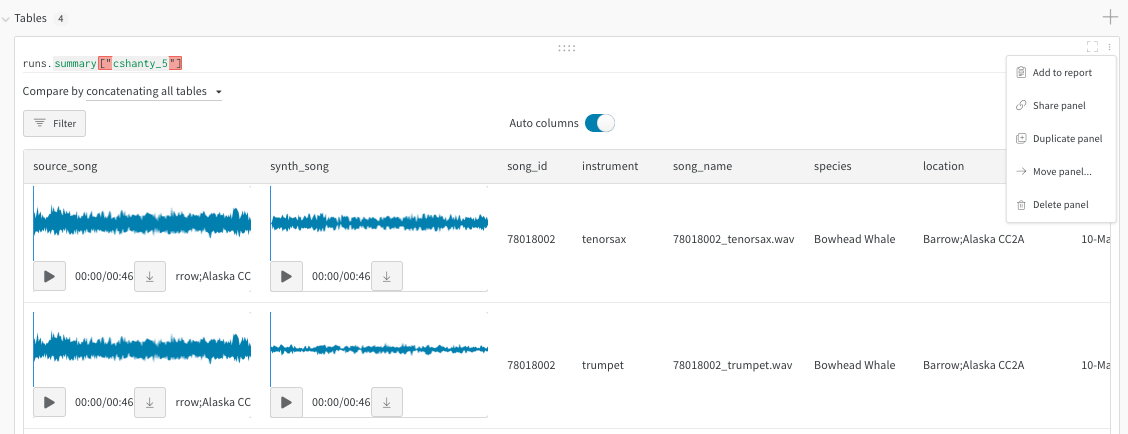
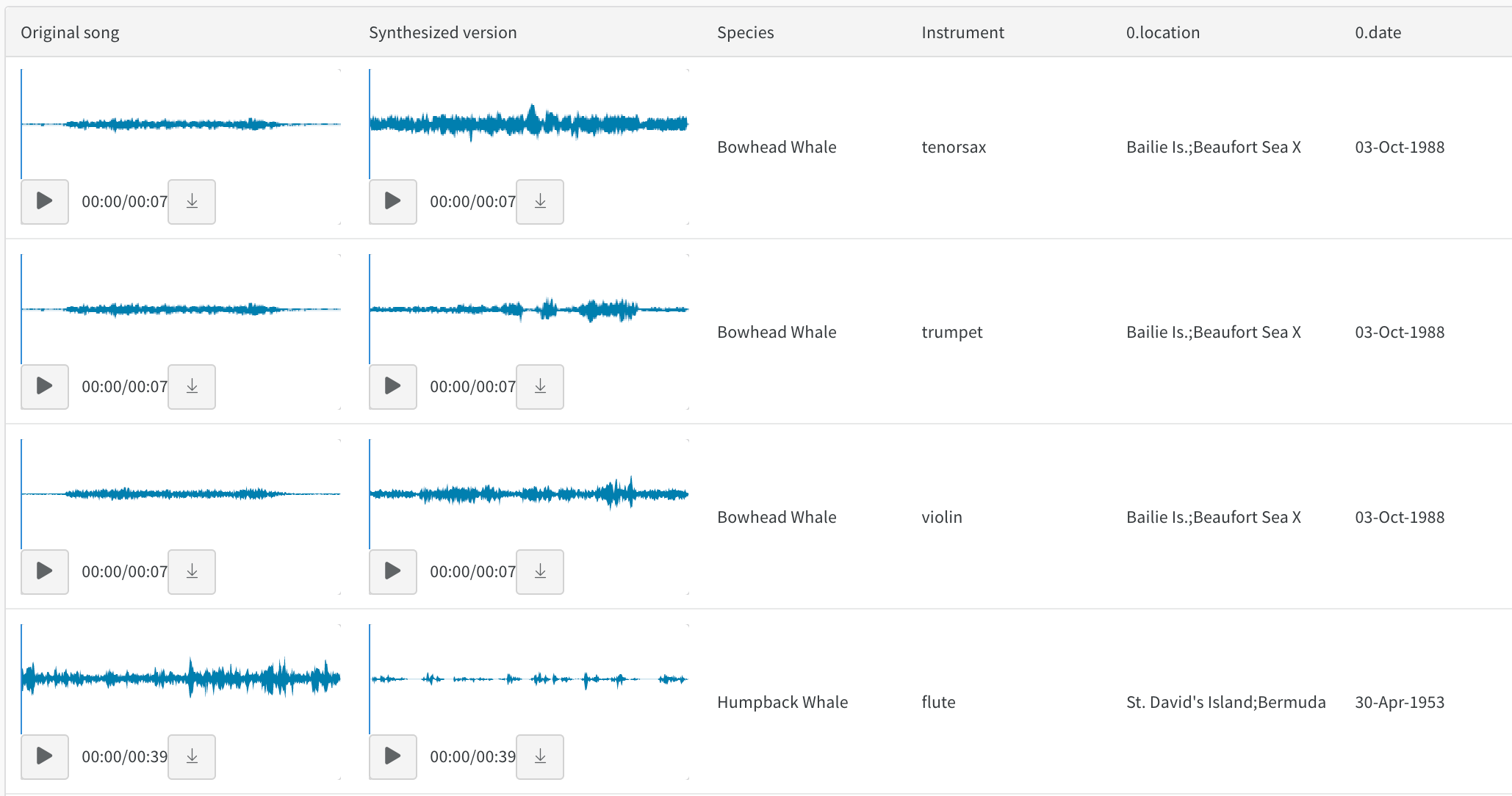
아티팩트 테이블 결합
wandb.JoinedTable(table_1, table_2, join_key)를 사용하여 로컬에서 구성한 테이블 또는 다른 아티팩트에서 검색한 테이블을 결합할 수 있습니다.
인수
설명
table_1
(str, wandb.Table, ArtifactEntry) 아티팩트의 wandb.Table 경로, 테이블 오브젝트 또는 ArtifactEntry
table_2
(str, wandb.Table, ArtifactEntry) 아티팩트의 wandb.Table 경로, 테이블 오브젝트 또는 ArtifactEntry
join_key
(str, [str, str]) 결합을 수행할 키
아티팩트 컨텍스트에서 이전에 기록한 두 개의 테이블을 결합하려면 아티팩트에서 가져와 결과를 새 테이블로 결합합니다.
예를 들어 'original_songs'라는 원본 노래의 테이블 하나와 동일한 노래의 합성 버전의 또 다른 테이블인 'synth_songs'를 읽는 방법을 보여줍니다. 다음 코드 예제는 "song_id"에서 두 테이블을 결합하고 결과 테이블을 새 W&B 테이블로 업로드합니다.
# 테이블을 Artifact에 추가하여 행# 제한을 200000으로 늘리고 재사용을 용이하게 합니다.iris_table_artifact = wandb.Artifact("iris_artifact", type="dataset")
iris_table_artifact.add(iris_table, "iris_table")
# 원시 CSV 파일을 Artifact 내에 기록하여 데이터를 보존합니다.iris_table_artifact.add_file("iris.csv")
마지막으로 wandb.init으로 새로운 W&B Run을 시작하여 W&B에 추적하고 기록합니다.
# 데이터를 기록하기 위해 W&B Run 시작run = wandb.init(project="tables-walkthrough")
# Run으로 시각화하기 위해 테이블을 기록합니다...run.log({"iris": iris_table})
# ...사용 가능한 행 제한을 늘리기 위해 Artifact로 기록합니다!run.log_artifact(iris_table_artifact)
wandb.init() API는 데이터를 Run에 기록하기 위해 새로운 백그라운드 프로세스를 생성하고, wandb.ai에 데이터를 동기화합니다(기본적으로). W&B Workspace 대시보드에서 라이브 시각화를 확인하세요. 다음 이미지는 코드 조각 데모의 출력을 보여줍니다.
앞선 코드 조각이 포함된 전체 스크립트는 아래에서 찾을 수 있습니다.
import wandb
import pandas as pd
# CSV를 새 DataFrame으로 읽기new_iris_dataframe = pd.read_csv("iris.csv")
# DataFrame을 W&B Table로 변환iris_table = wandb.Table(dataframe=new_iris_dataframe)
# 테이블을 Artifact에 추가하여 행# 제한을 200000으로 늘리고 재사용을 용이하게 합니다.iris_table_artifact = wandb.Artifact("iris_artifact", type="dataset")
iris_table_artifact.add(iris_table, "iris_table")
# 원시 CSV 파일을 Artifact 내에 기록하여 데이터를 보존합니다.iris_table_artifact.add_file("iris.csv")
# 데이터를 기록하기 위해 W&B Run 시작run = wandb.init(project="tables-walkthrough")
# Run으로 시각화하기 위해 테이블을 기록합니다...run.log({"iris": iris_table})
# ...사용 가능한 행 제한을 늘리기 위해 Artifact로 기록합니다!run.log_artifact(iris_table_artifact)
# Run 완료 (노트북에서 유용)run.finish()
Experiments의 CSV 가져오기 및 기록
경우에 따라 Experiments 세부 정보가 CSV 파일에 있을 수 있습니다. 이러한 CSV 파일에서 흔히 볼 수 있는 세부 정보는 다음과 같습니다.
%wandb 매직을 사용하여 기존의 대시보드, Sweeps 또는 리포트를 노트북에서 직접 표시할 수도 있습니다.
# Display a project workspace
%wandb USERNAME/PROJECT
# Display a single run
%wandb USERNAME/PROJECT/runs/RUN_ID
# Display a sweep
%wandb USERNAME/PROJECT/sweeps/SWEEP_ID
# Display a report
%wandb USERNAME/PROJECT/reports/REPORT_ID
# Specify the height of embedded iframe
%wandb USERNAME/PROJECT -h 2048
%%wandb 또는 %wandb 매직의 대안으로 wandb.init()를 실행한 후 wandb.run으로 셀을 종료하여 인라인 그래프를 표시하거나 API에서 반환된 리포트, 스윕 또는 Run 오브젝트에서 ipython.display(...)를 호출할 수 있습니다.
# Initialize wandb.run firstwandb.init()
# If cell outputs wandb.run, you'll see live graphswandb.run
Colab에서 간편한 인증: Colab에서 wandb.init를 처음 호출하면 브라우저에서 W&B에 로그인한 경우 런타임이 자동으로 인증됩니다. Run 페이지의 Overview 탭에서 Colab 링크를 볼 수 있습니다.
Jupyter Magic: 대시보드, Sweeps 및 리포트를 노트북에서 직접 표시합니다. %wandb 매직은 프로젝트, Sweeps 또는 리포트의 경로를 허용하고 W&B 인터페이스를 노트북에서 직접 렌더링합니다.
dockerized Jupyter 실행: wandb docker --jupyter를 호출하여 docker 컨테이너를 시작하고, 코드를 마운트하고, Jupyter가 설치되었는지 확인하고, 포트 8888에서 시작합니다.
두려움 없이 임의의 순서로 셀 실행: 기본적으로 Run이 finished로 표시될 때까지 wandb.init가 다음에 호출될 때까지 기다립니다. 이를 통해 여러 셀(예: 데이터 설정, 트레이닝, 테스트)을 원하는 순서로 실행하고 모두 동일한 Run에 기록할 수 있습니다. 설정에서 코드 저장을 켜면 실행된 셀도 순서대로, 그리고 실행된 상태로 기록하여 가장 비선형적인 파이프라인도 재현할 수 있습니다. Jupyter 노트북에서 Run을 수동으로 완료하려면 run.finish를 호출합니다.
import wandb
run = wandb.init()
# training script and logging goes hererun.finish()
1.8 - Experiments limits and performance
제안된 범위 내에서 로깅하여 W&B에서 페이지를 더 빠르고 반응적으로 유지하세요.
다음과 같은 권장 범위 내에서 로깅하면 W&B에서 페이지를 더 빠르고 응답성 좋게 유지할 수 있습니다.
로깅 고려 사항
wandb.log를 사용하여 실험 메트릭을 추적합니다. 한 번 로깅되면 이러한 메트릭은 차트를 생성하고 테이블에 표시됩니다. 너무 많은 데이터를 로깅하면 앱이 느려질 수 있습니다.
고유한 메트릭 수
더 빠른 성능을 위해 프로젝트의 총 고유 메트릭 수를 10,000개 미만으로 유지하십시오.
import wandb
wandb.log(
{
"a": 1, # "a"는 고유한 메트릭입니다."b": {
"c": "hello", # "b.c"는 고유한 메트릭입니다."d": [1, 2, 3], # "b.d"는 고유한 메트릭입니다. },
}
)
W&B는 중첩된 값을 자동으로 평면화합니다. 즉, dictionary를 전달하면 W&B는 이를 점으로 구분된 이름으로 바꿉니다. config 값의 경우 W&B는 이름에 점 3개를 지원합니다. summary 값의 경우 W&B는 점 4개를 지원합니다.
워크스페이스가 갑자기 느려지면 최근의 runs이 의도치 않게 수천 개의 새로운 메트릭을 로깅했는지 확인하십시오. (수천 개의 플롯이 있는 섹션에 하나 또는 두 개의 runs만 표시되는지 확인하면 가장 쉽게 알 수 있습니다.) 그렇다면 해당 runs을 삭제하고 원하는 메트릭으로 다시 만드는 것을 고려하십시오.
값 너비
단일 로깅된 값의 크기를 1MB 미만으로 제한하고 단일 wandb.log 호출의 총 크기를 25MB 미만으로 제한합니다. 이 제한은 wandb.Image, wandb.Audio 등과 같은 wandb.Media 유형에는 적용되지 않습니다.
# ❌ 권장하지 않음wandb.log({"wide_key": range(10000000)})
# ❌ 권장하지 않음with f as open("large_file.json", "r"):
large_data = json.load(f)
wandb.log(large_data)
넓은 값은 넓은 값이 있는 메트릭뿐만 아니라 run의 모든 메트릭에 대한 플롯 로드 시간에 영향을 줄 수 있습니다.
권장량보다 넓은 값을 로깅하더라도 데이터는 저장되고 추적됩니다. 그러나 플롯 로드 속도가 느려질 수 있습니다.
메트릭 빈도
로깅하는 메트릭에 적합한 로깅 빈도를 선택하십시오. 일반적으로 메트릭이 넓을수록 로깅 빈도를 줄여야 합니다. W&B는 다음을 권장합니다.
스칼라: 메트릭당 로깅된 포인트 <100,000개
미디어: 메트릭당 로깅된 포인트 <50,000개
히스토그램: 메트릭당 로깅된 포인트 <10,000개
# 총 1백만 단계의 트레이닝 루프for step in range(1000000):
# ❌ 권장하지 않음 wandb.log(
{
"scalar": step, # 스칼라 100,000개"media": wandb.Image(...), # 이미지 100,000개"histogram": wandb.Histogram(...), # 히스토그램 100,000개 }
)
# ✅ 권장if step %1000==0:
wandb.log(
{
"histogram": wandb.Histogram(...), # 히스토그램 10,000개 },
commit=False,
)
if step %200==0:
wandb.log(
{
"media": wandb.Image(...), # 이미지 50,000개 },
commit=False,
)
if step %100==0:
wandb.log(
{
"scalar": step, # 스칼라 100,000개 },
commit=True,
) # 일괄 처리된 단계별 메트릭을 함께 커밋합니다.
지침을 초과하더라도 W&B는 로깅된 데이터를 계속 수락하지만 페이지 로드 속도가 느려질 수 있습니다.
config 크기
run config의 총 크기를 10MB 미만으로 제한하십시오. 큰 값을 로깅하면 프로젝트 워크스페이스 및 runs 테이블 작업 속도가 느려질 수 있습니다.
워크스페이스에 수백 개의 섹션이 있으면 성능이 저하될 수 있습니다. 메트릭의 상위 수준 그룹화를 기반으로 섹션을 만들고 각 메트릭에 대해 하나의 섹션을 만드는 안티 패턴을 피하십시오.
섹션이 너무 많고 성능이 느린 경우 접미사가 아닌 접두사로 섹션을 만드는 워크스페이스 설정을 고려하십시오. 이렇게 하면 섹션 수가 줄어들고 성능이 향상될 수 있습니다.
메트릭 수
Run당 5000~100,000개의 메트릭을 로깅하는 경우 W&B는 수동 워크스페이스를 사용하는 것이 좋습니다. 수동 모드에서는 다양한 메트릭 집합을 탐색하도록 선택할 때 패널을 대량으로 쉽게 추가하고 제거할 수 있습니다. 더 집중적인 플롯 집합을 사용하면 워크스페이스 로드 속도가 빨라집니다. 플롯되지 않은 메트릭은 평소와 같이 계속 수집 및 저장됩니다.
워크스페이스를 수동 모드로 재설정하려면 워크스페이스의 작업 ... 메뉴를 클릭한 다음 워크스페이스 재설정을 클릭합니다. 워크스페이스를 재설정해도 runs에 대한 저장된 메트릭에는 영향을 미치지 않습니다. 워크스페이스 관리에 대해 자세히 알아보십시오.
파일 수
단일 run에 대해 업로드된 총 파일 수를 1,000개 미만으로 유지하십시오. 많은 수의 파일을 로깅해야 하는 경우 W&B Artifacts를 사용할 수 있습니다. 단일 run에서 1,000개가 넘는 파일을 초과하면 run 페이지 속도가 느려질 수 있습니다.
리포트 대 워크스페이스
리포트는 패널, 텍스트 및 미디어를 임의로 배열하여 동료와 통찰력을 쉽게 공유할 수 있는 자유 형식의 컴포지션입니다.
대조적으로 워크스페이스는 수백에서 수십만 개의 runs에 걸쳐 수십에서 수천 개의 메트릭을 고밀도로 효율적으로 분석할 수 있습니다. 워크스페이스는 리포트에 비해 최적화된 캐싱, 쿼리 및 로드 기능을 제공합니다. 워크스페이스는 주로 프레젠테이션보다는 분석에 사용되는 프로젝트에 권장되거나 20개 이상의 플롯을 함께 표시해야 하는 경우에 권장됩니다.
Python 스크립트 성능
Python 스크립트의 성능이 저하되는 몇 가지 방법이 있습니다.
데이터 크기가 너무 큽니다. 데이터 크기가 크면 트레이닝 루프에 >1ms의 오버헤드가 발생할 수 있습니다.
네트워크 속도와 W&B 백엔드 구성 방법
wandb.log를 초당 몇 번 이상 호출합니다. 이는 wandb.log가 호출될 때마다 트레이닝 루프에 작은 대기 시간이 추가되기 때문입니다.
잦은 로깅으로 인해 트레이닝 runs 속도가 느려지나요? 로깅 전략을 변경하여 더 나은 성능을 얻는 방법에 대한 이 Colab을 확인하십시오.
W&B는 속도 제한 외에는 어떠한 제한도 주장하지 않습니다. W&B Python SDK는 제한을 초과하는 요청에 대해 지수 “백오프” 및 “재시도"를 자동으로 완료합니다. W&B Python SDK는 커맨드라인에 “네트워크 실패"로 응답합니다. 유료 계정이 아닌 경우 W&B는 사용량이 합리적인 임계값을 초과하는 극단적인 경우에 연락할 수 있습니다.
속도 제한
W&B SaaS Cloud API는 시스템 무결성을 유지하고 가용성을 보장하기 위해 속도 제한을 구현합니다. 이 측정은 단일 사용자가 공유 인프라에서 사용 가능한 리소스를 독점하는 것을 방지하여 모든 사용자가 서비스에 액세스할 수 있도록 보장합니다. 다양한 이유로 더 낮은 속도 제한이 발생할 수 있습니다.
속도 제한은 변경될 수 있습니다.
속도 제한 HTTP 헤더
이전 표에서는 속도 제한 HTTP 헤더에 대해 설명합니다.
헤더 이름
설명
RateLimit-Limit
시간 창당 사용 가능한 할당량으로, 0~1000 범위로 조정됩니다.
RateLimit-Remaining
현재 속도 제한 창의 할당량으로, 0~1000 범위로 조정됩니다.
RateLimit-Reset
현재 할당량이 재설정될 때까지의 시간(초)
메트릭 로깅 API의 속도 제한
스크립트의 wandb.log 호출은 메트릭 로깅 API를 사용하여 트레이닝 데이터를 W&B에 로깅합니다. 이 API는 온라인 또는 오프라인 동기화를 통해 사용됩니다. 두 경우 모두 롤링 시간 창에서 속도 제한 할당량을 부과합니다. 여기에는 총 요청 크기 및 요청 속도에 대한 제한이 포함되며, 후자는 시간 기간 내의 요청 수를 나타냅니다.
W&B는 W&B 프로젝트당 속도 제한을 적용합니다. 따라서 팀에 3개의 프로젝트가 있는 경우 각 프로젝트에는 자체 속도 제한 할당량이 있습니다. 팀 및 엔터프라이즈 요금제 사용자는 무료 요금제 사용자보다 더 높은 속도 제한을 받습니다.
메트릭 로깅 API를 사용하는 동안 속도 제한에 도달하면 표준 출력에 오류를 나타내는 관련 메시지가 표시됩니다.
메트릭 로깅 API 속도 제한을 초과하지 않기 위한 제안
속도 제한을 초과하면 속도 제한이 재설정될 때까지 run.finish()가 지연될 수 있습니다. 이를 방지하려면 다음 전략을 고려하십시오.
W&B Python SDK 버전 업데이트: 최신 버전의 W&B Python SDK를 사용하고 있는지 확인하십시오. W&B Python SDK는 정기적으로 업데이트되며 요청을 정상적으로 재시도하고 할당량 사용량을 최적화하기 위한 향상된 메커니즘이 포함되어 있습니다.
메트릭 로깅 빈도 줄이기:
할당량을 보존하기 위해 메트릭 로깅 빈도를 최소화합니다. 예를 들어, 모든 에포크 대신 5개의 에포크마다 메트릭을 로깅하도록 코드를 수정할 수 있습니다.
if epoch %5==0: # 5개의 에포크마다 메트릭 로깅 wandb.log({"acc": accuracy, "loss": loss})
수동 데이터 동기화: 속도 제한이 있는 경우 W&B는 run 데이터를 로컬에 저장합니다. 커맨드 wandb sync <run-file-path>를 사용하여 데이터를 수동으로 동기화할 수 있습니다. 자세한 내용은 wandb sync 참조를 참조하십시오.
GraphQL API의 속도 제한
W&B Models UI 및 SDK의 공용 API는 서버에 GraphQL 요청을 보내 데이터를 쿼리하고 수정합니다. SaaS Cloud의 모든 GraphQL 요청에 대해 W&B는 권한이 없는 요청에 대해 IP 어드레스당, 권한이 있는 요청에 대해 사용자당 속도 제한을 적용합니다. 제한은 고정 시간 창 내의 요청 속도(초당 요청)를 기반으로 하며, 요금제에 따라 기본 제한이 결정됩니다. 프로젝트 경로(예: 리포트, runs, 아티팩트)를 지정하는 관련 SDK 요청의 경우 W&B는 데이터베이스 쿼리 시간으로 측정하여 프로젝트당 속도 제한을 적용합니다.
팀 및 엔터프라이즈 요금제 사용자는 무료 요금제 사용자보다 더 높은 속도 제한을 받습니다.
W&B Models SDK의 공용 API를 사용하는 동안 속도 제한에 도달하면 표준 출력에 오류를 나타내는 관련 메시지가 표시됩니다.
GraphQL API 속도 제한을 초과하지 않기 위한 제안
W&B Models SDK의 공용 API를 사용하여 많은 양의 데이터를 가져오는 경우 요청 사이에 최소 1초 이상 기다리는 것을 고려하십시오. 429 상태 코드를 받거나 응답 헤더에 RateLimit-Remaining=0이 표시되면 재시도하기 전에 RateLimit-Reset에 지정된 시간(초) 동안 기다리십시오.
브라우저 고려 사항
W&B 앱은 메모리 사용량이 많을 수 있으며 Chrome에서 가장 잘 작동합니다. 컴퓨터의 메모리에 따라 W&B가 3개 이상의 탭에서 동시에 활성화되어 있으면 성능이 저하될 수 있습니다. 예기치 않게 느린 성능이 발생하는 경우 다른 탭이나 애플리케이션을 닫는 것을 고려하십시오.
W&B에 성능 문제 보고
W&B는 성능을 중요하게 생각하고 지연에 대한 모든 리포트를 조사합니다. 조사를 신속하게 처리하기 위해 로드 시간이 느린 경우 주요 메트릭 및 성능 이벤트를 캡처하는 W&B의 기본 제공 성능 로거를 호출하는 것을 고려하십시오. 로드 속도가 느린 페이지에 URL 파라미터 &PERF_LOGGING을 추가한 다음 콘솔 출력을 계정 팀 또는 지원팀과 공유하십시오.
1.9 - Reproduce experiments
팀 멤버가 생성한 실험을 재현하여 결과를 검증하고 유효성을 확인합니다.
실험을 재현하기 전에 다음 사항을 기록해 두어야 합니다.
해당 run이 기록된 프로젝트 이름
재현하려는 run 이름
실험을 재현하는 방법:
해당 run이 기록된 프로젝트로 이동합니다.
왼쪽 사이드바에서 Workspace 탭을 선택합니다.
run 목록에서 재현하려는 run을 선택합니다.
Overview를 클릭합니다.
계속하려면 특정 해시에서 실험 코드를 다운로드하거나 실험의 전체 저장소를 복제합니다.
실험의 Python 스크립트 또는 노트북을 다운로드합니다.
Command 필드에서 실험을 생성한 스크립트 이름을 기록합니다.
왼쪽 네비게이션 바에서 Code 탭을 선택합니다.
스크립트 또는 노트북에 해당하는 파일 옆에 있는 Download를 클릭합니다.
팀 멤버가 실험을 생성할 때 사용한 GitHub 저장소를 복제합니다. 이렇게 하려면 다음을 수행합니다.
필요한 경우 팀 멤버가 실험을 생성하는 데 사용한 GitHub 저장소에 대한 엑세스 권한을 얻습니다.
GitHub 저장소 URL이 포함된 Git repository 필드를 복사합니다.
저장소를 복제합니다.
git clone https://github.com/your-repo.git && cd your-repo
Git state 필드를 복사하여 터미널에 붙여넣습니다. Git 상태는 팀 멤버가 실험을 생성하는 데 사용한 정확한 커밋을 체크아웃하는 Git 코맨드 집합입니다. 다음 코드 조각에 지정된 값을 자신의 값으로 바꿉니다.
기본적으로 importer.collect_runs()는 MLFlow 서버에서 모든 Runs을 수집합니다. 특정 서브셋을 업로드하려면 Runs의 반복 가능한 객체를 직접 구성하여 임포터에 전달할 수 있습니다.
import mlflow
from wandb.apis.importers.mlflow import MlflowRun
client = mlflow.tracking.MlflowClient(mlflow_tracking_uri)
runs: Iterable[MlflowRun] = []
for run in mlflow_client.search_runs(...):
runs.append(MlflowRun(run, client))
importer.import_runs(runs)
API 키는 W&B에 대한 컴퓨터 인증을 처리합니다. 사용자 프로필에서 API 키를 생성할 수 있습니다.
보다 간소화된 접근 방식을 위해 https://wandb.ai/authorize로 직접 이동하여 API 키를 생성할 수 있습니다. 표시된 API 키를 복사하여 비밀번호 관리자와 같은 안전한 위치에 저장합니다.
오른쪽 상단 모서리에 있는 사용자 프로필 아이콘을 클릭합니다.
사용자 설정을 선택한 다음 API 키 섹션으로 스크롤합니다.
표시를 클릭합니다. 표시된 API 키를 복사합니다. API 키를 숨기려면 페이지를 새로 고칩니다.
Run 경로 찾기
Public API를 사용하려면 <entity>/<project>/<run_id>인 Run 경로가 필요한 경우가 많습니다. 앱 UI에서 Run 페이지를 열고 Overview 탭을 클릭하여 Run 경로를 가져옵니다.
Run 데이터 내보내기
완료되었거나 활성 상태인 Run에서 데이터를 다운로드합니다. 일반적인 사용 사례로는 Jupyter 노트북에서 사용자 정의 분석을 위해 데이터프레임을 다운로드하거나 자동화된 환경에서 사용자 정의 로직을 사용하는 것이 있습니다.
import wandb
api = wandb.Api()
run = api.run("<entity>/<project>/<run_id>")
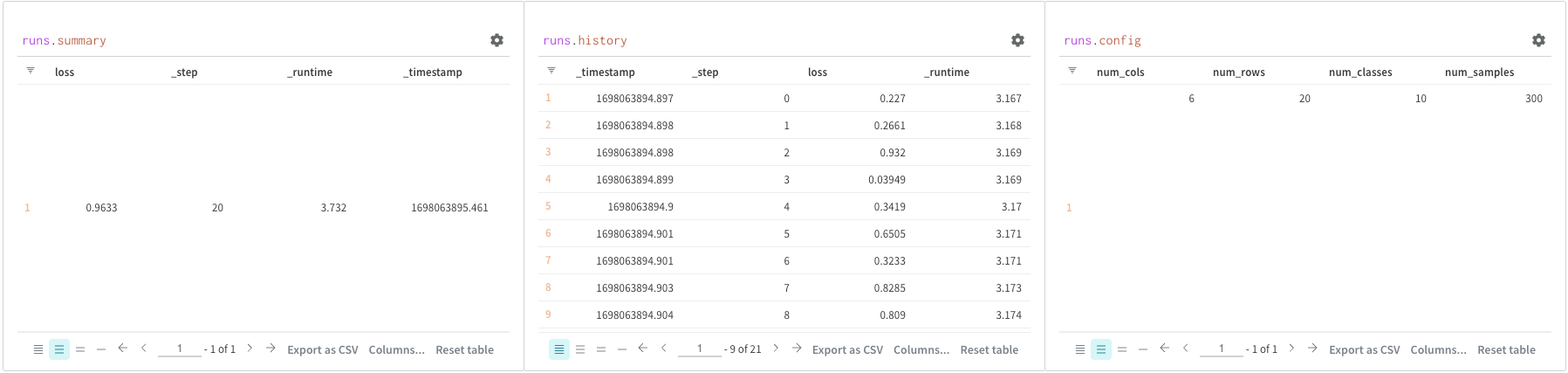
Run 객체의 가장 일반적으로 사용되는 속성은 다음과 같습니다:
속성
의미
run.config
트레이닝 Run의 하이퍼파라미터 또는 데이터셋 Artifact를 만드는 Run의 전처리 방법과 같은 Run의 구성 정보 사전입니다. 이를 Run의 입력이라고 생각하십시오.
run.history()
손실과 같이 모델이 트레이닝되는 동안 변하는 값을 저장하기 위한 사전 목록입니다. wandb.log() 코맨드는 이 객체에 추가됩니다.
run.summary
Run 결과의 요약 정보 사전입니다. 여기에는 정확도 및 손실과 같은 스칼라 또는 큰 파일이 포함될 수 있습니다. 기본적으로 wandb.log()는 요약을 기록된 시계열의 최종 값으로 설정합니다. 요약 내용은 직접 설정할 수도 있습니다. 요약을 Run의 출력이라고 생각하십시오.
과거 Runs의 데이터를 수정하거나 업데이트할 수도 있습니다. 기본적으로 API 객체의 단일 인스턴스는 모든 네트워크 요청을 캐시합니다. 유스 케이스에서 실행 중인 스크립트의 실시간 정보가 필요한 경우 api.flush()를 호출하여 업데이트된 값을 가져옵니다.
다양한 속성 이해
아래의 Run의 경우
n_epochs =5config = {"n_epochs": n_epochs}
run = wandb.init(project=project, config=config)
for n in range(run.config.get("n_epochs")):
run.log(
{"val": random.randint(0, 1000), "loss": (random.randint(0, 1000) /1000.00)}
)
run.finish()
다음은 위의 Run 객체 속성에 대한 다양한 출력입니다
run.config
{"n_epochs": 5}
run.history()
_step val loss _runtime _timestamp
00500 0.244 416443454121145 0.521 4164434541222240 0.785 416443454123331 0.305 4164434541244525 0.041 41644345412
기본 히스토리 메서드는 메트릭을 고정된 수의 샘플로 샘플링합니다(기본값은 500이며, samples __ 인수로 변경할 수 있음). 대규모 Run에서 모든 데이터를 내보내려면 run.scan_history() 메서드를 사용하면 됩니다. 자세한 내용은 API 참조를 참조하십시오.
여러 Runs 쿼리
이 예제 스크립트는 프로젝트를 찾고 이름, 구성 및 요약 통계가 있는 Runs의 CSV를 출력합니다. <entity> 및 <project>를 W&B 엔티티 및 프로젝트 이름으로 각각 바꿉니다.
import pandas as pd
import wandb
api = wandb.Api()
entity, project ="<entity>", "<project>"runs = api.runs(entity +"/"+ project)
summary_list, config_list, name_list = [], [], []
for run in runs:
# .summary에는 정확도와 같은# 메트릭에 대한 출력 키/값이 포함되어 있습니다.# 큰 파일을 생략하기 위해 ._json_dict를 호출합니다 summary_list.append(run.summary._json_dict)
# .config에는 하이퍼파라미터가 포함되어 있습니다.# _로 시작하는 특수 값을 제거합니다. config_list.append({k: v for k, v in run.config.items() ifnot k.startswith("_")})
# .name은 Run의 사람이 읽을 수 있는 이름입니다. name_list.append(run.name)
runs_df = pd.DataFrame(
{"summary": summary_list, "config": config_list, "name": name_list}
)
runs_df.to_csv("project.csv")
W&B API는 api.runs()를 사용하여 프로젝트의 Runs을 쿼리하는 방법도 제공합니다. 가장 일반적인 유스 케이스는 사용자 정의 분석을 위해 Runs 데이터를 내보내는 것입니다. 쿼리 인터페이스는 MongoDB에서 사용하는 인터페이스와 동일합니다.
api.runs를 호출하면 반복 가능하고 목록처럼 작동하는 Runs 객체가 반환됩니다. 기본적으로 객체는 필요에 따라 한 번에 50개의 Runs을 순서대로 로드하지만 per_page 키워드 인수를 사용하여 페이지당 로드되는 수를 변경할 수 있습니다.
api.runs는 order 키워드 인수도 허용합니다. 기본 순서는 -created_at입니다. 결과를 오름차순으로 정렬하려면 +created_at를 지정합니다. 구성 또는 요약 값으로 정렬할 수도 있습니다. 예를 들어 summary.val_acc 또는 config.experiment_name입니다.
오류 처리
W&B 서버와 통신하는 동안 오류가 발생하면 wandb.CommError가 발생합니다. 원래 예외는 exc 속성을 통해 조사할 수 있습니다.
API를 통해 최신 git 커밋 가져오기
UI에서 Run을 클릭한 다음 Run 페이지에서 Overview 탭을 클릭하여 최신 git 커밋을 확인합니다. 또한 wandb-metadata.json 파일에도 있습니다. Public API를 사용하면 run.commit으로 git 해시를 가져올 수 있습니다.
Run 중 Run의 이름 및 ID 가져오기
wandb.init()를 호출한 후 다음과 같이 스크립트에서 임의 Run ID 또는 사람이 읽을 수 있는 Run 이름을 액세스할 수 있습니다.
고유 Run ID(8자 해시): wandb.run.id
임의 Run 이름(사람이 읽을 수 있음): wandb.run.name
Runs에 유용한 식별자를 설정하는 방법을 고려하고 있다면 다음을 권장합니다.
Run ID: 생성된 해시로 둡니다. 이는 프로젝트의 Runs에서 고유해야 합니다.
Run 이름: 차트에서 여러 줄의 차이점을 알 수 있도록 짧고 읽기 쉽고 가급적이면 고유해야 합니다.
Run 노트: Run에서 수행하는 작업에 대한 간단한 설명을 적어두는 것이 좋습니다. wandb.init(notes="여기에 메모 입력")로 설정할 수 있습니다.
Run 태그: Run 태그에서 동적으로 추적하고 UI에서 필터를 사용하여 테이블을 원하는 Runs로 필터링합니다. 스크립트에서 태그를 설정한 다음 Runs 테이블과 Run 페이지의 Overview 탭 모두에서 UI에서 편집할 수 있습니다. 자세한 내용은 여기의 자세한 지침을 참조하십시오.
Public API 예제
matplotlib 또는 seaborn에서 시각화하기 위해 데이터 내보내기
몇 가지 일반적인 내보내기 패턴은 API 예제를 확인하십시오. 사용자 정의 플롯 또는 확장된 Runs 테이블에서 다운로드 버튼을 클릭하여 브라우저에서 CSV를 다운로드할 수도 있습니다.
Run에서 메트릭 읽기
이 예제는 wandb.log({"accuracy": acc})로 저장된 Run에 대해 "<entity>/<project>/<run_id>"에 저장된 타임스탬프 및 정확도를 출력합니다.
import wandb
api = wandb.Api()
run = api.run("<entity>/<project>/<run_id>")
if run.state =="finished":
for i, row in run.history().iterrows():
print(row["_timestamp"], row["accuracy"])
Run에서 특정 메트릭을 가져오려면 keys 인수를 사용합니다. run.history()를 사용할 때 기본 샘플 수는 500입니다. 특정 메트릭을 포함하지 않는 기록된 단계는 출력 데이터프레임에 NaN으로 표시됩니다. keys 인수를 사용하면 API가 나열된 메트릭 키를 포함하는 단계를 더 자주 샘플링합니다.
import wandb
api = wandb.Api()
run = api.run("<entity>/<project>/<run_id>")
if run.state =="finished":
for i, row in run.history(keys=["accuracy"]).iterrows():
print(row["_timestamp"], row["accuracy"])
이 예제는 이전 Run의 정확도를 0.9로 설정합니다. 또한 이전 Run의 정확도 히스토그램을 numpy_array의 히스토그램으로 수정합니다.
import wandb
api = wandb.Api()
run = api.run("<entity>/<project>/<run_id>")
run.summary["accuracy"] =0.9run.summary["accuracy_histogram"] = wandb.Histogram(numpy_array)
run.summary.update()
완료된 Run에서 메트릭 이름 바꾸기
이 예제는 테이블에서 요약 열의 이름을 바꿉니다.
import wandb
api = wandb.Api()
run = api.run("<entity>/<project>/<run_id>")
run.summary["new_name"] = run.summary["old_name"]
del run.summary["old_name"]
run.summary.update()
열 이름 바꾸기는 테이블에만 적용됩니다. 차트는 여전히 원래 이름으로 메트릭을 참조합니다.
기존 Run에 대한 구성 업데이트
이 예제는 구성 설정 중 하나를 업데이트합니다.
import wandb
api = wandb.Api()
run = api.run("<entity>/<project>/<run_id>")
run.config["key"] = updated_value
run.update()
시스템 리소스 소비를 CSV 파일로 내보내기
아래 코드 조각은 시스템 리소스 소비를 찾은 다음 CSV에 저장합니다.
import wandb
run = wandb.Api().run("<entity>/<project>/<run_id>")
system_metrics = run.history(stream="events")
system_metrics.to_csv("sys_metrics.csv")
샘플링되지 않은 메트릭 데이터 가져오기
히스토리에서 데이터를 가져올 때 기본적으로 500포인트로 샘플링됩니다. run.scan_history()를 사용하여 기록된 모든 데이터 포인트를 가져옵니다. 다음은 히스토리에 기록된 모든 loss 데이터 포인트를 다운로드하는 예입니다.
import wandb
api = wandb.Api()
run = api.run("<entity>/<project>/<run_id>")
history = run.scan_history()
losses = [row["loss"] for row in history]
히스토리에서 페이지가 매겨진 데이터 가져오기
백엔드에서 메트릭을 느리게 가져오거나 API 요청 시간이 초과되는 경우 scan_history에서 페이지 크기를 줄여 개별 요청 시간이 초과되지 않도록 할 수 있습니다. 기본 페이지 크기는 500이므로 다양한 크기를 실험하여 가장 적합한 크기를 확인할 수 있습니다.
import wandb
api = wandb.Api()
run = api.run("<entity>/<project>/<run_id>")
run.scan_history(keys=sorted(cols), page_size=100)
프로젝트의 모든 Runs에서 메트릭을 CSV 파일로 내보내기
이 스크립트는 프로젝트에서 Runs을 가져오고 이름, 구성 및 요약 통계를 포함한 Runs의 데이터프레임과 CSV를 생성합니다. <entity> 및 <project>를 W&B 엔티티 및 프로젝트 이름으로 각각 바꿉니다.
import pandas as pd
import wandb
api = wandb.Api()
entity, project ="<entity>", "<project>"runs = api.runs(entity +"/"+ project)
summary_list, config_list, name_list = [], [], []
for run in runs:
# .summary에는 출력 키/값이 포함되어 있습니다.# 정확도와 같은 메트릭의 경우.# 큰 파일을 생략하기 위해 ._json_dict를 호출합니다 summary_list.append(run.summary._json_dict)
# .config에는 하이퍼파라미터가 포함되어 있습니다.# _로 시작하는 특수 값을 제거합니다. config_list.append({k: v for k, v in run.config.items() ifnot k.startswith("_")})
# .name은 Run의 사람이 읽을 수 있는 이름입니다. name_list.append(run.name)
runs_df = pd.DataFrame(
{"summary": summary_list, "config": config_list, "name": name_list}
)
runs_df.to_csv("project.csv")
Run의 시작 시간 가져오기
이 코드 조각은 Run이 생성된 시간을 검색합니다.
import wandb
api = wandb.Api()
run = api.run("entity/project/run_id")
start_time = run.created_at
완료된 Run에 파일 업로드
아래 코드 조각은 선택한 파일을 완료된 Run에 업로드합니다.
import wandb
api = wandb.Api()
run = api.run("entity/project/run_id")
run.upload_file("file_name.extension")
Run에서 파일 다운로드
이것은 cifar 프로젝트에서 Run ID uxte44z7과 연결된 파일 “model-best.h5"를 찾아 로컬에 저장합니다.
import wandb
api = wandb.Api()
run = api.run("<entity>/<project>/<run_id>")
run.file("model-best.h5").download()
Run에서 모든 파일 다운로드
이것은 Run과 연결된 모든 파일을 찾아 로컬에 저장합니다.
import wandb
api = wandb.Api()
run = api.run("<entity>/<project>/<run_id>")
for file in run.files():
file.download()
best_run은 스위프 구성의 metric 파라미터에 의해 정의된 가장 적합한 메트릭을 가진 Run입니다.
스위프에서 가장 적합한 모델 파일 다운로드
이 코드 조각은 모델 파일을 model.h5에 저장한 Runs이 있는 스위프에서 가장 높은 검증 정확도를 가진 모델 파일을 다운로드합니다.
import wandb
api = wandb.Api()
sweep = api.sweep("<entity>/<project>/<sweep_id>")
runs = sorted(sweep.runs, key=lambda run: run.summary.get("val_acc", 0), reverse=True)
val_acc = runs[0].summary.get("val_acc", 0)
print(f"가장 적합한 Run {runs[0].name} (검증 정확도 {val_acc}%)")
runs[0].file("model.h5").download(replace=True)
print("가장 적합한 모델이 model-best.h5에 저장되었습니다.")
Run에서 지정된 확장명을 가진 모든 파일 삭제
이 코드 조각은 Run에서 지정된 확장명을 가진 파일을 삭제합니다.
import wandb
api = wandb.Api()
run = api.run("<entity>/<project>/<run_id>")
extension =".png"files = run.files()
for file in files:
if file.name.endswith(extension):
file.delete()
시스템 메트릭 데이터 다운로드
이 코드 조각은 Run에 대한 모든 시스템 리소스 소비 메트릭이 포함된 데이터프레임을 생성한 다음 CSV에 저장합니다.
import wandb
api = wandb.Api()
run = api.run("<entity>/<project>/<run_id>")
system_metrics = run.history(stream="events")
system_metrics.to_csv("sys_metrics.csv")
요약 메트릭 업데이트
사전을 전달하여 요약 메트릭을 업데이트할 수 있습니다.
summary.update({"key": val})
Run을 실행한 코맨드 가져오기
각 Run은 Run 개요 페이지에서 실행을 시작한 코맨드를 캡처합니다. API에서 이 코맨드를 가져오려면 다음을 실행할 수 있습니다.
import wandb
api = wandb.Api()
run = api.run("<entity>/<project>/<run_id>")
meta = json.load(run.file("wandb-metadata.json").download())
program = ["python"] + [meta["program"]] + meta["args"]
1.11 - Environment variables
W&B 환경 변수를 설정하세요.
자동화된 환경에서 스크립트를 실행할 때 스크립트 실행 전 또는 스크립트 내에서 설정된 환경 변수로 wandb를 제어할 수 있습니다.
# 이것은 비밀이며 버전 관리 시스템에 체크인되어서는 안 됩니다.WANDB_API_KEY=$YOUR_API_KEY
# 이름과 노트는 선택 사항입니다.WANDB_NAME="나의 첫 번째 run"WANDB_NOTES="더 작은 학습률, 더 많은 정규화."
# wandb/settings 파일을 체크인하지 않은 경우에만 필요합니다.WANDB_ENTITY=$username
WANDB_PROJECT=$project
# 스크립트가 클라우드에 동기화되는 것을 원하지 않는 경우os.environ["WANDB_MODE"] ="offline"# 스윕 ID 추적을 Run 오브젝트 및 관련 클래스에 추가os.environ["WANDB_SWEEP_ID"] ="b05fq58z"
선택적 환경 변수
이러한 선택적 환경 변수를 사용하여 원격 머신에서 인증을 설정하는 등의 작업을 수행합니다.
변수 이름
사용법
WANDB_ANONYMOUS
사용자가 비밀 URL로 익명 run을 생성하도록 허용하려면 이 변수를 allow, never 또는 must로 설정합니다.
WANDB_API_KEY
계정과 연결된 인증 키를 설정합니다. 키는 설정 페이지에서 찾을 수 있습니다. 원격 머신에서 wandb login이 실행되지 않은 경우 이 변수를 설정해야 합니다.
WANDB_BASE_URL
wandb/local을 사용하는 경우 이 환경 변수를 http://YOUR_IP:YOUR_PORT로 설정해야 합니다.
WANDB_CACHE_DIR
기본값은 ~/.cache/wandb이며, 이 환경 변수로 이 위치를 재정의할 수 있습니다.
WANDB_CONFIG_DIR
기본값은 ~/.config/wandb이며, 이 환경 변수로 이 위치를 재정의할 수 있습니다.
WANDB_CONFIG_PATHS
wandb.config에 로드할 쉼표로 구분된 yaml 파일 목록입니다. config를 참조하십시오.
WANDB_CONSOLE
stdout / stderr 로깅을 비활성화하려면 이 변수를 “off"로 설정합니다. 기본적으로 이를 지원하는 환경에서는 “on"으로 설정됩니다.
WANDB_DATA_DIR
스테이징 Artifacts가 업로드되는 위치입니다. 기본 위치는 platformdirs Python 패키지의 user_data_dir 값을 사용하기 때문에 플랫폼에 따라 다릅니다.
WANDB_DIR
트레이닝 스크립트를 기준으로 wandb 디렉토리가 아닌 여기에 생성된 모든 파일을 저장하려면 이 변수를 절대 경로로 설정합니다. 이 디렉토리가 존재하고 프로세스가 실행되는 사용자가 쓸 수 있는지 확인하십시오. 이는 다운로드된 Artifacts의 위치에는 영향을 미치지 않으며, 대신 _WANDB_ARTIFACT_DIR_을 사용하여 설정할 수 있습니다.
WANDB_ARTIFACT_DIR
트레이닝 스크립트를 기준으로 artifacts 디렉토리가 아닌 여기에 다운로드된 모든 Artifacts를 저장하려면 이 변수를 절대 경로로 설정합니다. 이 디렉토리가 존재하고 프로세스가 실행되는 사용자가 쓸 수 있는지 확인하십시오. 이는 생성된 메타데이터 파일의 위치에는 영향을 미치지 않으며, 대신 _WANDB_DIR_을 사용하여 설정할 수 있습니다.
WANDB_DISABLE_GIT
wandb가 git 저장소를 검색하고 최신 커밋/diff를 캡처하지 못하도록 합니다.
WANDB_DISABLE_CODE
wandb가 노트북 또는 git diff를 저장하지 못하도록 하려면 이 변수를 true로 설정합니다. git 저장소에 있는 경우 현재 커밋은 계속 저장됩니다.
WANDB_DOCKER
run 복원을 활성화하려면 이 변수를 docker 이미지 다이제스트로 설정합니다. 이는 wandb docker 코맨드로 자동 설정됩니다. wandb docker my/image/name:tag --digest를 실행하여 이미지 다이제스트를 얻을 수 있습니다.
WANDB_ENTITY
run과 연결된 entity입니다. 트레이닝 스크립트의 디렉토리에서 wandb init를 실행한 경우 _wandb_라는 디렉토리가 생성되고 소스 제어에 체크인할 수 있는 기본 entity가 저장됩니다. 해당 파일을 생성하지 않거나 파일을 재정의하려는 경우 환경 변수를 사용할 수 있습니다.
WANDB_ERROR_REPORTING
wandb가 심각한 오류를 오류 추적 시스템에 로깅하지 못하도록 하려면 이 변수를 false로 설정합니다.
WANDB_HOST
시스템에서 제공하는 호스트 이름을 사용하지 않으려는 경우 wandb 인터페이스에 표시할 호스트 이름으로 설정합니다.
WANDB_IGNORE_GLOBS
무시할 파일 glob의 쉼표로 구분된 목록으로 설정합니다. 이러한 파일은 클라우드에 동기화되지 않습니다.
WANDB_JOB_NAME
wandb로 생성된 모든 jobs의 이름을 지정합니다.
WANDB_JOB_TYPE
run의 다양한 유형을 나타내기 위해 “training” 또는 “evaluation"과 같은 job 유형을 지정합니다. 자세한 내용은 grouping을 참조하십시오.
WANDB_MODE
이 변수를 “offline"으로 설정하면 wandb가 run 메타데이터를 로컬에 저장하고 서버에 동기화하지 않습니다. 이 변수를 disabled로 설정하면 wandb가 완전히 꺼집니다.
WANDB_NAME
run의 사람이 읽을 수 있는 이름입니다. 설정하지 않으면 임의로 생성됩니다.
WANDB_NOTEBOOK_NAME
jupyter에서 실행 중인 경우 이 변수로 노트북 이름을 설정할 수 있습니다. 자동으로 감지하려고 시도합니다.
WANDB_NOTES
run에 대한 더 긴 메모입니다. Markdown이 허용되며 나중에 UI에서 편집할 수 있습니다.
WANDB_PROJECT
run과 연결된 project입니다. 이는 wandb init로도 설정할 수 있지만 환경 변수가 값을 재정의합니다.
WANDB_RESUME
기본적으로 이는 _never_로 설정됩니다. _auto_로 설정하면 wandb가 실패한 run을 자동으로 재개합니다. _must_로 설정하면 시작 시 run이 강제로 존재합니다. 항상 고유한 ID를 생성하려면 _allow_로 설정하고 항상 WANDB_RUN_ID를 설정합니다.
WANDB_RUN_GROUP
run을 자동으로 그룹화할 실험 이름을 지정합니다. 자세한 내용은 grouping을 참조하십시오.
WANDB_RUN_ID
스크립트의 단일 run에 해당하는 전역적으로 고유한 문자열(project당)로 설정합니다. 64자 이하여야 합니다. 모든 단어가 아닌 문자는 대시로 변환됩니다. 이는 실패 시 기존 run을 재개하는 데 사용할 수 있습니다.
WANDB_SILENT
wandb 로그 문을 숨기려면 이 변수를 true로 설정합니다. 이 변수를 설정하면 모든 로그가 WANDB_DIR/debug.log에 기록됩니다.
WANDB_SHOW_RUN
운영 체제에서 지원하는 경우 run URL로 브라우저를 자동으로 열려면 이 변수를 true로 설정합니다.
WANDB_SWEEP_ID
스윕 ID 추적을 Run 오브젝트 및 관련 클래스에 추가하고 UI에 표시합니다.
WANDB_TAGS
run에 적용할 쉼표로 구분된 태그 목록입니다.
WANDB_USERNAME
run과 연결된 팀 구성원의 사용자 이름입니다. 이는 서비스 계정 API 키와 함께 사용하여 자동화된 run을 팀 구성원에게 귀속시키는 데 사용할 수 있습니다.
WANDB_USER_EMAIL
run과 연결된 팀 구성원의 이메일입니다. 이는 서비스 계정 API 키와 함께 사용하여 자동화된 run을 팀 구성원에게 귀속시키는 데 사용할 수 있습니다.
Singularity 환경
Singularity에서 컨테이너를 실행하는 경우 위의 변수 앞에 **SINGULARITYENV_**를 붙여 환경 변수를 전달할 수 있습니다. Singularity 환경 변수에 대한 자세한 내용은 여기에서 확인할 수 있습니다.
AWS에서 실행
AWS에서 배치 jobs를 실행하는 경우 W&B 자격 증명으로 머신을 쉽게 인증할 수 있습니다. 설정 페이지에서 API 키를 가져오고 AWS 배치 job 사양에서 WANDB_API_KEY 환경 변수를 설정합니다.
W&B Sweeps 를 사용하여 하이퍼파라미터 검색을 자동화하고 풍부하고 인터랙티브한 experiment 추적을 시각화하세요. Bayesian, 그리드 검색 및 random과 같은 인기 있는 검색 방법 중에서 선택하여 하이퍼파라미터 공간을 검색합니다. 하나 이상의 시스템에서 스윕을 확장하고 병렬화합니다.
터미널에서 Ctrl+C를 눌러 현재 run을 중지합니다. 다시 누르면 에이전트가 종료됩니다.
2.2 - Add W&B (wandb) to your code
Python 코드 스크립트 또는 Jupyter 노트북 에 W&B를 추가하세요.
스크립트 또는 Jupyter Notebook에 W&B Python SDK를 추가하는 방법은 다양합니다. 아래에는 W&B Python SDK를 사용자 정의 코드에 통합하는 “모범 사례” 예제가 나와 있습니다.
원본 트레이닝 스크립트
다음 코드가 Python 스크립트에 있다고 가정합니다. 일반적인 트레이닝 루프를 모방하는 main이라는 함수를 정의합니다. 각 에포크마다 트레이닝 및 검증 데이터 세트에서 정확도와 손실이 계산됩니다. 이 예제의 목적을 위해 해당 값은 임의로 생성됩니다.
하이퍼파라미터 값을 저장하는 config라는 사전을 정의했습니다. 셀의 끝에서 main 함수를 호출하여 모의 트레이닝 코드를 실행합니다.
import random
import numpy as np
deftrain_one_epoch(epoch, lr, bs):
acc =0.25+ ((epoch /30) + (random.random() /10))
loss =0.2+ (1- ((epoch -1) /10+ random.random() /5))
return acc, loss
defevaluate_one_epoch(epoch):
acc =0.1+ ((epoch /20) + (random.random() /10))
loss =0.25+ (1- ((epoch -1) /10+ random.random() /6))
return acc, loss
# config 변수, 하이퍼파라미터 값 포함config = {"lr": 0.0001, "bs": 16, "epochs": 5}
defmain():
# 하드 코딩된 값을 정의하는 대신# `wandb.config`에서 값을 정의합니다. lr = config["lr"]
bs = config["bs"]
epochs = config["epochs"]
for epoch in np.arange(1, epochs):
train_acc, train_loss = train_one_epoch(epoch, lr, bs)
val_acc, val_loss = evaluate_one_epoch(epoch)
print("epoch: ", epoch)
print("training accuracy:", train_acc, "training loss:", train_loss)
print("validation accuracy:", val_acc, "training loss:", val_loss)
W&B Python SDK를 사용한 트레이닝 스크립트
다음 코드 예제에서는 W&B Python SDK를 코드에 추가하는 방법을 보여줍니다. CLI에서 W&B Sweep 작업을 시작하는 경우 CLI 탭을 살펴보십시오. Jupyter Notebook 또는 Python 스크립트 내에서 W&B Sweep 작업을 시작하는 경우 Python SDK 탭을 살펴보십시오.
W&B Sweep을 생성하기 위해 코드 예제에 다음을 추가했습니다.
Weights & Biases Python SDK를 가져옵니다.
키-값 쌍이 스윕 구성을 정의하는 사전 오브젝트를 생성합니다. 다음 예제에서는 각 스윕 중에 배치 크기(batch_size), 에포크(epochs) 및 학습률(lr) 하이퍼파라미터가 다양합니다. 스윕 구성을 생성하는 방법에 대한 자세한 내용은 스윕 구성 정의를 참조하십시오.
스윕 구성 사전을 wandb.sweep에 전달합니다. 그러면 스윕이 초기화됩니다. 스윕 ID(sweep_id)가 반환됩니다. 스윕을 초기화하는 방법에 대한 자세한 내용은 스윕 초기화를 참조하십시오.
(선택 사항) 하드 코딩된 값을 정의하는 대신 wandb.config에서 값을 정의합니다.
wandb.log를 사용하여 최적화하려는 메트릭을 기록합니다. 구성에 정의된 메트릭을 기록해야 합니다. 구성 사전(이 예제에서는 sweep_configuration) 내에서 val_acc 값을 최대화하도록 스윕을 정의했습니다.
wandb.agent API 호출로 스윕을 시작합니다. 스윕 ID, 스윕이 실행할 함수의 이름(function=main)을 제공하고 시도할 최대 run 수를 4개(count=4)로 설정합니다. W&B Sweep 시작 방법에 대한 자세한 내용은 스윕 에이전트 시작을 참조하십시오.
import wandb
import numpy as np
import random
# 스윕 구성 정의sweep_configuration = {
"method": "random",
"name": "sweep",
"metric": {"goal": "maximize", "name": "val_acc"},
"parameters": {
"batch_size": {"values": [16, 32, 64]},
"epochs": {"values": [5, 10, 15]},
"lr": {"max": 0.1, "min": 0.0001},
},
}
# 구성을 전달하여 스윕을 초기화합니다.# (선택 사항) 프로젝트 이름을 제공합니다.sweep_id = wandb.sweep(sweep=sweep_configuration, project="my-first-sweep")
# `wandb.config`에서 하이퍼파라미터# 값을 가져와서 모델을 트레이닝하고# 메트릭을 반환하는 트레이닝 함수를 정의합니다.deftrain_one_epoch(epoch, lr, bs):
acc =0.25+ ((epoch /30) + (random.random() /10))
loss =0.2+ (1- ((epoch -1) /10+ random.random() /5))
return acc, loss
defevaluate_one_epoch(epoch):
acc =0.1+ ((epoch /20) + (random.random() /10))
loss =0.25+ (1- ((epoch -1) /10+ random.random() /6))
return acc, loss
defmain():
run = wandb.init()
# 하드 코딩된 값을 정의하는 대신# `wandb.config`에서 값을 정의합니다. lr = wandb.config.lr
bs = wandb.config.batch_size
epochs = wandb.config.epochs
for epoch in np.arange(1, epochs):
train_acc, train_loss = train_one_epoch(epoch, lr, bs)
val_acc, val_loss = evaluate_one_epoch(epoch)
wandb.log(
{
"epoch": epoch,
"train_acc": train_acc,
"train_loss": train_loss,
"val_acc": val_acc,
"val_loss": val_loss,
}
)
# 스윕 작업을 시작합니다.wandb.agent(sweep_id, function=main, count=4)
W&B Sweep을 생성하려면 먼저 YAML 구성 파일을 생성합니다. 구성 파일에는 스윕이 탐색할 하이퍼파라미터가 포함되어 있습니다. 다음 예제에서는 각 스윕 중에 배치 크기(batch_size), 에포크(epochs) 및 학습률(lr) 하이퍼파라미터가 다양합니다.
최상위 parameters 키 내에는 learning_rate, batch_size, epoch 및 optimizer 키가 중첩되어 있습니다. 중첩된 각 키에 대해 하나 이상의 값, 분포, 확률 등을 제공할 수 있습니다. 자세한 내용은 스윕 구성 옵션의 파라미터 섹션을 참조하십시오.
이중 중첩 파라미터
스윕 구성은 중첩된 파라미터를 지원합니다. 중첩된 파라미터를 구분하려면 최상위 파라미터 이름 아래에 추가 parameters 키를 사용하십시오. 스윕 구성은 다단계 중첩을 지원합니다.
베이지안 또는 랜덤 하이퍼파라미터 검색을 사용하는 경우 랜덤 변수에 대한 확률 분포를 지정하십시오. 각 하이퍼파라미터에 대해:
스윕 구성에 최상위 parameters 키를 만듭니다.
parameters 키 내에서 다음을 중첩합니다.
최적화하려는 하이퍼파라미터의 이름을 지정합니다.
distribution 키에 사용할 분포를 지정합니다. 하이퍼파라미터 이름 아래에 distribution 키-값 쌍을 중첩합니다.
탐색할 하나 이상의 값을 지정합니다. 값은 분포 키와 일치해야 합니다.
(선택 사항) 최상위 파라미터 이름 아래에 추가 parameters 키를 사용하여 중첩된 파라미터를 구분합니다.
스윕 구성에 정의된 중첩된 파라미터는 W&B run 구성에 지정된 키를 덮어씁니다.
예를 들어, train.py Python 스크립트에서 다음 구성으로 W&B run을 초기화한다고 가정합니다 (1-2행 참조). 다음으로 sweep_configuration이라는 dictionary에 스윕 구성을 정의합니다 (4-13행 참조). 그런 다음 스윕 구성 dictionary를 wandb.sweep에 전달하여 스윕 구성을 초기화합니다 (16행 참조).
metric 최상위 스윕 구성 키를 사용하여 최적화할 이름, 목표 및 대상 메트릭을 지정합니다.
키
설명
name
최적화할 메트릭의 이름입니다.
goal
minimize 또는 maximize (기본값은 minimize)입니다.
target
최적화하려는 메트릭의 목표 값입니다. 스윕은 run이 지정한 목표 값에 도달하면 새 run을 만들지 않습니다. run을 실행 중인 활성 에이전트는 (run이 목표에 도달하면) 에이전트가 새 run 생성을 중단하기 전에 run이 완료될 때까지 기다립니다.
parameters
YAML 파일 또는 Python 스크립트에서 parameters를 최상위 키로 지정합니다. parameters 키 내에서 최적화하려는 하이퍼파라미터의 이름을 제공합니다. 일반적인 하이퍼파라미터에는 학습률, 배치 크기, 에포크, 옵티마이저 등이 있습니다. 스윕 구성에서 정의하는 각 하이퍼파라미터에 대해 하나 이상의 검색 제약 조건을 지정합니다.
다음 표는 지원되는 하이퍼파라미터 검색 제약 조건을 보여줍니다. 하이퍼파라미터 및 유스 케이스에 따라 아래 검색 제약 조건 중 하나를 사용하여 스윕 에이전트에게 검색하거나 사용할 위치 (분포의 경우) 또는 내용 (value, values 등)을 알려줍니다.
검색 제약 조건
설명
values
이 하이퍼파라미터에 대한 모든 유효한 값을 지정합니다. grid와 호환됩니다.
value
이 하이퍼파라미터에 대한 단일 유효한 값을 지정합니다. grid와 호환됩니다.
distribution
확률 분포를 지정합니다. 기본값에 대한 정보는 이 표 다음에 나오는 참고 사항을 참조하십시오.
probabilities
random을 사용할 때 values의 각 요소를 선택할 확률을 지정합니다.
min, max
(int 또는 float) 최대값 및 최소값입니다. int인 경우 int_uniform 분포된 하이퍼파라미터에 사용됩니다. float인 경우 uniform 분포된 하이퍼파라미터에 사용됩니다.
mu
(float) normal 또는 lognormal 분포된 하이퍼파라미터에 대한 평균 파라미터입니다.
sigma
(float) normal 또는 lognormal 분포된 하이퍼파라미터에 대한 표준 편차 파라미터입니다.
method 키를 사용하여 하이퍼파라미터 검색 전략을 지정합니다. 선택할 수 있는 세 가지 하이퍼파라미터 검색 전략이 있습니다: 그리드, 랜덤, 베이지안 탐색.
그리드 검색
하이퍼파라미터 값의 모든 조합을 반복합니다. 그리드 검색은 각 반복에서 사용할 하이퍼파라미터 값 집합에 대해 정보에 입각하지 않은 결정을 내립니다. 그리드 검색은 계산 비용이 많이 들 수 있습니다.
그리드 검색은 연속 검색 공간 내에서 검색하는 경우 영원히 실행됩니다.
랜덤 검색
각 반복에서 분포에 따라 임의의, 정보에 입각하지 않은 하이퍼파라미터 값 집합을 선택합니다. 랜덤 검색은 커맨드라인, Python 스크립트 또는 W&B 앱 UI 내에서 프로세스를 중지하지 않는 한 영원히 실행됩니다.
랜덤 (method: random) 검색을 선택하는 경우 메트릭 키를 사용하여 분포 공간을 지정합니다.
베이지안 탐색
랜덤 및 그리드 검색과 달리 베이지안 모델은 정보에 입각한 결정을 내립니다. 베이지안 최적화는 확률 모델을 사용하여 목적 함수를 평가하기 전에 대리 함수에서 값을 테스트하는 반복적인 프로세스를 통해 사용할 값을 결정합니다. 베이지안 탐색은 작은 수의 연속 파라미터에 적합하지만 확장성이 떨어집니다. 베이지안 탐색에 대한 자세한 내용은 Bayesian Optimization Primer 논문을 참조하십시오.
베이지안 탐색은 커맨드라인, Python 스크립트 또는 W&B 앱 UI 내에서 프로세스를 중지하지 않는 한 영원히 실행됩니다.
랜덤 및 베이지안 탐색을 위한 분포 옵션
parameter 키 내에서 하이퍼파라미터의 이름을 중첩합니다. 다음으로 distribution 키를 지정하고 값에 대한 분포를 지정합니다.
다음 표는 W&B가 지원하는 분포를 나열합니다.
distribution 키 값
설명
constant
상수 분포. 사용할 상수 값 (value)을 지정해야 합니다.
categorical
범주형 분포. 이 하이퍼파라미터에 대한 모든 유효한 값 (values)을 지정해야 합니다.
int_uniform
정수에 대한 이산 균등 분포. max 및 min을 정수로 지정해야 합니다.
uniform
연속 균등 분포. max 및 min을 부동 소수점으로 지정해야 합니다.
q_uniform
양자화된 균등 분포. round(X / q) * q를 반환합니다. 여기서 X는 균등 분포입니다. q의 기본값은 1입니다.
log_uniform
로그 균등 분포. exp(min)과 exp(max) 사이의 값 X를 반환합니다. 여기서 자연 로그는 min과 max 사이에서 균등하게 분포됩니다.
log_uniform_values
로그 균등 분포. min과 max 사이의 값 X를 반환합니다. 여기서 log(X)는 log(min)과 log(max) 사이에서 균등하게 분포됩니다.
q_log_uniform
양자화된 로그 균등 분포. round(X / q) * q를 반환합니다. 여기서 X는 log_uniform입니다. q의 기본값은 1입니다.
q_log_uniform_values
양자화된 로그 균등 분포. round(X / q) * q를 반환합니다. 여기서 X는 log_uniform_values입니다. q의 기본값은 1입니다.
inv_log_uniform
역 로그 균등 분포. X를 반환합니다. 여기서 log(1/X)는 min과 max 사이에서 균등하게 분포됩니다.
inv_log_uniform_values
역 로그 균등 분포. X를 반환합니다. 여기서 log(1/X)는 log(1/max)와 log(1/min) 사이에서 균등하게 분포됩니다.
normal
정규 분포. 평균 mu (기본값 0) 및 표준 편차 sigma (기본값 1)로 정규 분포된 값을 반환합니다.
q_normal
양자화된 정규 분포. round(X / q) * q를 반환합니다. 여기서 X는 normal입니다. Q의 기본값은 1입니다.
log_normal
로그 정규 분포. 자연 로그 log(X)가 평균 mu (기본값 0) 및 표준 편차 sigma (기본값 1)로 정규 분포된 값 X를 반환합니다.
q_log_normal
양자화된 로그 정규 분포. round(X / q) * q를 반환합니다. 여기서 X는 log_normal입니다. q의 기본값은 1입니다.
early_terminate
조기 종료 (early_terminate)를 사용하여 성능이 낮은 run을 중지합니다. 조기 종료가 발생하면 W&B는 새 하이퍼파라미터 값 집합으로 새 run을 만들기 전에 현재 run을 중지합니다.
early_terminate를 사용하는 경우 중지 알고리즘을 지정해야 합니다. 스윕 구성 내에서 early_terminate 내에 type 키를 중첩합니다.
Hyperband 하이퍼파라미터 최적화는 프로그램을 중지해야 하는지 또는 사전 설정된 하나 이상의 반복 횟수 ( brackets 라고 함)에서 계속해야 하는지 평가합니다.
W&B run이 bracket에 도달하면 스윕은 해당 run의 메트릭을 이전에 보고된 모든 메트릭 값과 비교합니다. 스윕은 run의 메트릭 값이 너무 높으면 (목표가 최소화인 경우) 또는 run의 메트릭 값이 너무 낮으면 (목표가 최대화인 경우) run을 종료합니다.
Brackets는 기록된 반복 횟수를 기반으로 합니다. brackets 수는 최적화하는 메트릭을 기록하는 횟수에 해당합니다. 반복은 단계, 에포크 또는 그 사이의 무언가에 해당할 수 있습니다. 단계 카운터의 숫자 값은 bracket 계산에 사용되지 않습니다.
bracket 일정을 만들려면 min_iter 또는 max_iter를 지정합니다.
키
설명
min_iter
첫 번째 bracket에 대한 반복을 지정합니다.
max_iter
최대 반복 횟수를 지정합니다.
s
총 bracket 수를 지정합니다 (max_iter에 필요).
eta
bracket 승수 일정을 지정합니다 (기본값: 3).
strict
원본 Hyperband 논문을 더 면밀히 따르면서 실행을 적극적으로 정리하는 ‘엄격’ 모드를 활성화합니다. 기본값은 false입니다.
Hyperband는 몇 분마다 종료할 W&B run을 확인합니다. run 또는 반복이 짧으면 종료 run 타임스탬프가 지정된 brackets와 다를 수 있습니다.
command
command 키 내에서 중첩된 값으로 형식과 내용을 수정합니다. 파일 이름과 같은 고정된 구성 요소를 직접 포함할 수 있습니다.
Unix 시스템에서 /usr/bin/env는 OS가 환경에 따라 올바른 Python 인터프리터를 선택하도록 합니다.
W&B는 코맨드의 가변 구성 요소에 대해 다음 매크로를 지원합니다.
코맨드 매크로
설명
${env}
Unix 시스템의 경우 /usr/bin/env, Windows에서는 생략됩니다.
${interpreter}
python으로 확장됩니다.
${program}
스윕 구성 program 키로 지정된 트레이닝 스크립트 파일 이름입니다.
${args}
--param1=value1 --param2=value2 형식의 하이퍼파라미터 및 해당 값입니다.
${args_no_boolean_flags}
--param1=value1 형식의 하이퍼파라미터 및 해당 값입니다. 단, 부울 파라미터는 True이면 --boolean_flag_param 형식이고 False이면 생략됩니다.
${args_no_hyphens}
param1=value1 param2=value2 형식의 하이퍼파라미터 및 해당 값입니다.
${args_json}
JSON으로 인코딩된 하이퍼파라미터 및 해당 값입니다.
${args_json_file}
JSON으로 인코딩된 하이퍼파라미터 및 해당 값이 포함된 파일의 경로입니다.
${envvar}
환경 변수를 전달하는 방법입니다. ${envvar:MYENVVAR}은 MYENVVAR 환경 변수의 값으로 확장됩니다.
2.4 - Initialize a sweep
W&B 스윕 초기화
W&B는 클라우드 (표준), 로컬 (local) 환경에서 하나 이상의 머신에서 Sweeps 를 관리하기 위해 Sweep Controller 를 사용합니다. Run이 완료되면, 스윕 컨트롤러는 실행할 새로운 Run을 설명하는 새로운 명령어 세트를 발행합니다. 이 명령어는 실제로 Run을 수행하는 에이전트 에 의해 선택됩니다. 일반적인 W&B 스윕에서 컨트롤러는 W&B 서버에 존재합니다. 에이전트는 사용자 의 머신에 존재합니다.
다음 코드 조각은 CLI 및 Jupyter Notebook 또는 Python 스크립트 내에서 스윕을 초기화하는 방법을 보여줍니다.
스윕을 초기화하기 전에 YAML 파일 또는 스크립트의 중첩된 Python dictionary 오브젝트에 스윕 구성이 정의되어 있는지 확인하세요. 자세한 내용은 스윕 구성 정의를 참조하세요.
W&B Sweep 과 W&B Run 은 동일한 Projects 에 있어야 합니다. 따라서 W&B를 초기화할 때 제공하는 이름(wandb.init)은 W&B Sweep 을 초기화할 때 제공하는 Projects 이름(wandb.sweep)과 일치해야 합니다.
W&B SDK를 사용하여 스윕을 초기화합니다. 스윕 구성 dictionary 를 sweep 파라미터에 전달합니다. 선택적으로 W&B Run 의 출력을 저장할 Projects 파라미터 (project)에 대한 프로젝트 이름을 제공합니다. 프로젝트가 지정되지 않은 경우 Run은 “Uncategorized” 프로젝트에 배치됩니다.
멀티 코어 또는 멀티 GPU 머신에서 W&B 스윕 에이전트를 병렬화하세요. 시작하기 전에 W&B 스윕을 초기화했는지 확인하세요. W&B 스윕을 초기화하는 방법에 대한 자세한 내용은 스윕 초기화를 참조하세요.
멀티 CPU 머신에서 병렬화
유스 케이스에 따라 다음 탭을 살펴보고 CLI 또는 Jupyter Notebook 내에서 W&B 스윕 에이전트를 병렬화하는 방법을 알아보세요.
wandb agent 코맨드를 사용하여 터미널에서 여러 CPU에 걸쳐 W&B 스윕 에이전트를 병렬화하세요. 스윕을 초기화할 때 반환된 스윕 ID를 제공하세요.
로컬 머신에서 둘 이상의 터미널 창을 여세요.
아래 코드 조각을 복사하여 붙여넣고 sweep_id를 스윕 ID로 바꾸세요.
wandb agent sweep_id
W&B Python SDK 라이브러리를 사용하여 Jupyter Notebook 내에서 여러 CPU에 걸쳐 W&B 스윕 에이전트를 병렬화하세요. 스윕을 초기화할 때 반환된 스윕 ID가 있는지 확인하세요. 또한 스윕이 실행할 함수의 이름을 function 파라미터에 제공하세요.
둘 이상의 Jupyter Notebook을 여세요.
여러 Jupyter Notebook에 W&B 스윕 ID를 복사하여 붙여넣어 W&B 스윕을 병렬화하세요. 예를 들어, 스윕 ID가 sweep_id라는 변수에 저장되어 있고 함수의 이름이 function_name인 경우 다음 코드 조각을 여러 Jupyter Notebook에 붙여넣어 스윕을 병렬화할 수 있습니다.
CUDA 툴킷을 사용하여 터미널에서 여러 GPU에 걸쳐 W&B 스윕 에이전트를 병렬화하려면 다음 절차를 따르세요.
로컬 머신에서 둘 이상의 터미널 창을 여세요.
W&B 스윕 작업을 시작할 때 CUDA_VISIBLE_DEVICES를 사용하여 사용할 GPU 인스턴스를 지정하세요(wandb agent). 사용할 GPU 인스턴스에 해당하는 정수 값을 CUDA_VISIBLE_DEVICES에 할당하세요.
예를 들어, 로컬 머신에 두 개의 NVIDIA GPU가 있다고 가정해 보겠습니다. 터미널 창을 열고 CUDA_VISIBLE_DEVICES를 0으로 설정하세요(CUDA_VISIBLE_DEVICES=0). 다음 예제에서 sweep_ID를 W&B 스윕을 초기화할 때 반환되는 W&B 스윕 ID로 바꾸세요.
터미널 1
CUDA_VISIBLE_DEVICES=0 wandb agent sweep_ID
두 번째 터미널 창을 여세요. CUDA_VISIBLE_DEVICES를 1로 설정하세요(CUDA_VISIBLE_DEVICES=1). 이전 코드 조각에 언급된 sweep_ID에 대해 동일한 W&B 스윕 ID를 붙여넣으세요.
터미널 2
CUDA_VISIBLE_DEVICES=1 wandb agent sweep_ID
2.7 - Visualize sweep results
W&B App UI를 사용하여 W&B Sweeps의 결과를 시각화하세요.
W&B App UI를 사용하여 W&B Sweeps 의 결과를 시각화합니다. https://wandb.ai/home에서 W&B App UI로 이동합니다. W&B Sweep을 초기화할 때 지정한 project를 선택합니다. project workspace로 리디렉션됩니다. 왼쪽 panel에서 Sweep 아이콘(빗자루 아이콘)을 선택합니다. Sweep UI에서 목록에서 Sweep 이름을 선택합니다.
기본적으로 W&B는 W&B Sweep 작업을 시작할 때 평행 좌표 플롯, 파라미터 중요도 플롯 및 산점도를 자동으로 생성합니다.
평행 좌표 차트는 많은 수의 하이퍼파라미터 와 model metrics 간의 관계를 한눈에 요약합니다. 평행 좌표 플롯에 대한 자세한 내용은 평행 좌표를 참조하십시오.
산점도(왼쪽)는 Sweep 중에 생성된 W&B Runs 을 비교합니다. 산점도에 대한 자세한 내용은 산점도를 참조하십시오.
파라미터 중요도 플롯(오른쪽)은 metrics 의 바람직한 value 와 가장 잘 예측하고 높은 상관 관계가 있는 하이퍼파라미터 를 나열합니다. 자세한 내용은 파라미터 중요도 플롯은 파라미터 중요도를 참조하십시오.
자동으로 사용되는 종속 및 독립 value (x 및 y 축)를 변경할 수 있습니다. 각 panel 에는 Edit panel 이라는 연필 아이콘이 있습니다. Edit panel 을 선택합니다. model 이 나타납니다. 모달 내에서 그래프의 행동을 변경할 수 있습니다.
모든 기본 W&B visualization 옵션에 대한 자세한 내용은 Panels를 참조하십시오. W&B Sweep의 일부가 아닌 W&B Runs 에서 플롯을 만드는 방법에 대한 자세한 내용은 Data Visualization docs를 참조하십시오.
2.8 - Manage sweeps with the CLI
CLI를 사용하여 W&B 스윕을 일시 중지, 재개 및 취소합니다.
CLI를 사용하여 W&B 스윕을 일시 중지, 재개 및 취소합니다. W&B 스윕을 일시 중지하면 스윕이 재개될 때까지 새로운 W&B Runs이 실행되지 않도록 W&B 에이전트에 알립니다. 스윕을 재개하면 에이전트가 새로운 W&B Runs을 계속 실행합니다. W&B 스윕을 중지하면 W&B 스윕 에이전트가 새로운 W&B Runs의 생성 또는 실행을 중지합니다. W&B 스윕을 취소하면 스윕 에이전트가 현재 실행 중인 W&B Runs을 중단하고 새로운 Runs 실행을 중지합니다.
각각의 경우, W&B 스윕을 초기화할 때 생성된 W&B 스윕 ID를 제공합니다. 선택적으로 새 터미널 창을 열어 다음 명령을 실행합니다. 새 터미널 창은 W&B 스윕이 현재 터미널 창에 출력문을 인쇄하는 경우 명령을 더 쉽게 실행할 수 있도록 합니다.
다음 지침에 따라 스윕을 일시 중지, 재개 및 취소합니다.
스윕 일시 중지
새로운 W&B Runs 실행을 일시적으로 중단하도록 W&B 스윕을 일시 중지합니다. wandb sweep --pause 코맨드를 사용하여 W&B 스윕을 일시 중지합니다. 일시 중지할 W&B 스윕 ID를 제공합니다.
하이퍼파라미터 컨트롤러는 기본적으로 Weights & Biases에서 클라우드 서비스로 호스팅됩니다. W&B 에이전트는 컨트롤러와 통신하여 트레이닝에 사용할 다음 파라미터 세트를 결정합니다. 또한 컨트롤러는 조기 중단 알고리즘을 실행하여 중단할 수 있는 run을 결정합니다.
로컬 컨트롤러 기능을 사용하면 사용자가 로컬에서 검색 및 중단 알고리즘을 시작할 수 있습니다. 로컬 컨트롤러는 사용자에게 문제를 디버그하고 클라우드 서비스에 통합할 수 있는 새로운 기능을 개발하기 위해 코드를 검사하고 계측할 수 있는 기능을 제공합니다.
이 기능은 Sweeps 툴에 대한 새로운 알고리즘의 더 빠른 개발 및 디버깅을 지원하기 위해 제공됩니다. 실제 하이퍼파라미터 최적화 워크로드에는 적합하지 않습니다.
시작하기 전에 W&B SDK(wandb)를 설치해야 합니다. 커맨드라인에 다음 코드 조각을 입력하세요.
pip install wandb sweeps
다음 예제에서는 이미 구성 파일과 트레이닝 루프가 Python 스크립트 또는 Jupyter Notebook에 정의되어 있다고 가정합니다. 구성 파일을 정의하는 방법에 대한 자세한 내용은 스윕 구성 정의를 참조하세요.
커맨드라인에서 로컬 컨트롤러 실행
W&B에서 클라우드 서비스로 호스팅하는 하이퍼파라미터 컨트롤러를 사용할 때와 유사하게 스윕을 초기화합니다. 컨트롤러 플래그(controller)를 지정하여 W&B 스윕 작업에 로컬 컨트롤러를 사용하려는 의사를 나타냅니다.
반환된 W&B Sweep ID를 기록해 둡니다. 다음으로, Python SDK(wandb.agent) 대신 CLI를 사용하여 wandb agent로 Sweep 작업을 시작합니다. 아래 코드 조각에서 sweep_ID를 이전 단계에서 반환된 Sweep ID로 바꿉니다.
wandb agent sweep_ID
anaconda 400 error
다음 오류는 일반적으로 최적화하려는 메트릭을 로깅하지 않을 때 발생합니다.
wandb: ERROR Error while calling W&B API: anaconda 400 error:
{"code": 400, "message": "TypeError: bad operand type for unary -: 'NoneType'"}
YAML 파일 또는 중첩된 사전 내에서 최적화할 “metric"이라는 키를 지정합니다. 이 메트릭을 반드시 로깅(wandb.log)해야 합니다. 또한 Python 스크립트 또는 Jupyter Notebook 내에서 스윕을 최적화하도록 정의한 정확한 메트릭 이름을 사용해야 합니다. 구성 파일에 대한 자세한 내용은 스윕 구성 정의를 참조하세요.
2.12 - Sweeps UI
Sweeps UI의 다양한 구성 요소에 대해 설명합니다.
상태 (State), 생성 시간 (Created), 스윕을 시작한 엔티티 (Creator), 완료된 run 수 (Run count) 및 스윕을 계산하는 데 걸린 시간 (Compute time)이 Sweeps UI에 표시됩니다. 스윕이 생성할 것으로 예상되는 run 수 (Est. Runs)는 이산 검색 공간에서 그리드 검색을 수행할 때 제공됩니다. 인터페이스에서 스윕을 클릭하여 스윕을 일시 중지, 재개, 중지 또는 중단할 수도 있습니다.
프로젝트 페이지에서 사이드바의 Sweep tab을 열고 Create Sweep을 선택합니다.
자동 생성된 설정은 완료한 run을 기반으로 스윕할 값을 추측합니다. 시도할 하이퍼파라미터 범위를 지정하도록 설정을 편집합니다. 스윕을 시작하면 호스팅된 W&B 스윕 서버에서 새 프로세스가 시작됩니다. 이 중앙 집중식 서비스는 트레이닝 작업을 실행하는 머신인 에이전트를 조정합니다.
3. 에이전트 시작
다음으로, 로컬에서 에이전트를 시작합니다. 작업을 분산하고 스윕 작업을 더 빨리 완료하려면 최대 20개의 에이전트를 서로 다른 머신에서 병렬로 시작할 수 있습니다. 에이전트는 다음에 시도할 파라미터 세트를 출력합니다.
이제 스윕을 실행하고 있습니다. 다음 이미지는 예제 스윕 작업이 실행되는 동안 대시보드가 어떻게 보이는지 보여줍니다. 예제 프로젝트 페이지 보기 →
기존 run으로 새 스윕 시드하기
이전에 기록한 기존 run을 사용하여 새 스윕을 시작합니다.
프로젝트 테이블을 엽니다.
테이블 왼쪽에서 확인란을 사용하여 사용할 run을 선택합니다.
드롭다운을 클릭하여 새 스윕을 만듭니다.
이제 스윕이 서버에 설정됩니다. run 실행을 시작하려면 하나 이상의 에이전트를 시작하기만 하면 됩니다.
병합된 뷰 또는 나란히 보기로 두 개의 테이블을 비교합니다. 예를 들어 아래 이미지는 MNIST 데이터의 테이블 비교를 보여줍니다.
다음 단계에 따라 두 개의 테이블을 비교합니다.
W&B App에서 프로젝트로 이동합니다.
왼쪽 패널에서 Artifacts 아이콘을 선택합니다.
아티팩트 버전을 선택합니다.
다음 이미지에서는 5개의 에포크 각각 이후에 MNIST 검증 데이터에 대한 모델의 예측을 보여줍니다(여기에서 대화형 예제 보기).
사이드바에서 비교하려는 두 번째 아티팩트 버전 위로 마우스를 가져간 다음 나타나는 비교를 클릭합니다. 예를 들어 아래 이미지에서는 5 에포크 트레이닝 후 동일한 모델에서 만든 MNIST 예측과 비교하기 위해 “v4"로 레이블이 지정된 버전을 선택합니다.
병합된 뷰
처음에는 두 테이블이 함께 병합되어 표시됩니다. 첫 번째 선택한 테이블은 인덱스 0과 파란색 강조 표시가 있고 두 번째 테이블은 인덱스 1과 노란색 강조 표시가 있습니다. 여기에서 병합된 테이블의 라이브 예제를 봅니다.
병합된 뷰에서 다음을 수행할 수 있습니다.
조인 키 선택: 왼쪽 상단의 드롭다운을 사용하여 두 테이블의 조인 키로 사용할 열을 설정합니다. 일반적으로 이것은 데이터셋의 특정 예제의 파일 이름 또는 생성된 샘플의 증가하는 인덱스와 같은 각 행의 고유 식별자입니다. 현재 모든 열을 선택할 수 있으므로 읽을 수 없는 테이블과 느린 쿼리가 발생할 수 있습니다.
조인 대신 연결: 이 드롭다운에서 “모든 테이블 연결"을 선택하여 열을 조인하는 대신 두 테이블의 _모든 행을 결합_하여 더 큰 Table 하나로 만듭니다.
각 Table을 명시적으로 참조: 필터 표현식에서 0, 1 및 *를 사용하여 하나 또는 두 테이블 인스턴스의 열을 명시적으로 지정합니다.
자세한 숫자 차이를 히스토그램으로 시각화: 모든 셀의 값을 한눈에 비교합니다.
나란히 보기
두 개의 테이블을 나란히 보려면 첫 번째 드롭다운을 “테이블 병합: 테이블"에서 “목록: 테이블"로 변경한 다음 “페이지 크기"를 각각 업데이트합니다. 여기서 첫 번째 선택한 Table은 왼쪽에 있고 두 번째 Table은 오른쪽에 있습니다. 또한 “수직” 확인란을 클릭하여 이러한 테이블을 수직으로 비교할 수도 있습니다.
테이블을 한눈에 비교: 모든 작업 (정렬, 필터, 그룹)을 두 테이블에 동시에 적용하고 변경 사항이나 차이점을 빠르게 찾습니다. 예를 들어 추측별로 그룹화된 잘못된 예측, 가장 어려운 네거티브 전체, 실제 레이블별 신뢰도 점수 분포 등을 봅니다.
트레이닝 시간 동안 모델 성능을 분석하기 위해 트레이닝의 의미 있는 각 단계에 대한 아티팩트에서 테이블을 기록합니다. 예를 들어 모든 검증 단계가 끝날 때, 50 에포크의 트레이닝마다 또는 파이프라인에 적합한 빈도로 테이블을 기록할 수 있습니다. 나란히 보기를 사용하여 모델 예측의 변경 사항을 시각화합니다.
트레이닝 시간 동안 예측을 시각화하는 방법에 대한 자세한 내용은 이 Report와 이 대화형 노트북 예제를 참조하십시오.
모델 변형 간 테이블 비교
서로 다른 구성(하이퍼파라미터, 기본 아키텍처 등)에서 모델 성능을 분석하기 위해 두 개의 다른 모델에 대해 동일한 단계에서 기록된 두 개의 아티팩트 버전을 비교합니다.
예를 들어 baseline과 새 모델 변형 2x_layers_2x_lr 간의 예측을 비교합니다. 여기서 첫 번째 컨볼루션 레이어는 32에서 64로, 두 번째 레이어는 128에서 256으로, 학습률은 0.001에서 0.002로 두 배가 됩니다. 이 라이브 예제에서 나란히 보기를 사용하고 1 (왼쪽 탭) 대 5 트레이닝 에포크 (오른쪽 탭) 후에 잘못된 예측으로 필터링합니다.
뷰 저장
run 워크스페이스, 프로젝트 워크스페이스 또는 Report에서 상호 작용하는 테이블은 뷰 상태를 자동으로 저장합니다. 테이블 작업을 적용한 다음 브라우저를 닫으면 테이블은 다음에 테이블로 이동할 때 마지막으로 본 구성을 유지합니다.
아티팩트 컨텍스트에서 상호 작용하는 테이블은 상태 비저장으로 유지됩니다.
특정 상태의 워크스페이스에서 테이블을 저장하려면 W&B Report로 내보냅니다. 테이블을 Report로 내보내려면:
워크스페이스 시각화 패널의 오른쪽 상단 모서리에 있는 케밥 아이콘 (세 개의 수직 점)을 선택합니다.
음색 전송에 대한 이 report에서 오디오 테이블과 상호 작용합니다. 녹음된 고래 노래와 바이올린이나 트럼펫과 같은 악기로 동일한 멜로디를 합성한 연주를 비교할 수 있습니다. 또한 이 colab을 사용하여 자신의 노래를 녹음하고 W&B에서 합성 버전을 탐색할 수도 있습니다.
텍스트
트레이닝 데이터 또는 생성된 출력에서 텍스트 샘플을 찾아보고, 관련 필드별로 동적으로 그룹화하고, 모델 변형 또는 실험 설정에서 평가를 조정합니다. 텍스트를 Markdown으로 렌더링하거나 시각적 차이 모드를 사용하여 텍스트를 비교합니다. 이 report에서 Shakespeare를 생성하기 위한 간단한 문자 기반 RNN을 탐색합니다.
비디오
트레이닝 중에 기록된 비디오를 찾아보고 집계하여 모델을 이해합니다. 다음은 부작용을 최소화하려는 RL 에이전트에 대한 SafeLife 벤치마크를 사용하는 초기 예제입니다.
W&B Artifacts와 마찬가지로, Tables는 쉬운 데이터 내보내기를 위해 pandas 데이터프레임으로 변환할 수 있습니다.
table을 artifact로 변환하기
먼저, 테이블을 아티팩트로 변환해야 합니다. artifact.get(table, "table_name")을 사용하여 가장 쉽게 수행할 수 있습니다.
# 새로운 테이블을 생성하고 로그합니다.with wandb.init() as r:
artifact = wandb.Artifact("my_dataset", type="dataset")
table = wandb.Table(
columns=["a", "b", "c"], data=[(i, i *2, 2**i) for i in range(10)]
)
artifact.add(table, "my_table")
wandb.log_artifact(artifact)
# 생성된 아티팩트를 사용하여 생성된 테이블을 검색합니다.with wandb.init() as r:
artifact = r.use_artifact("my_dataset:latest")
table = artifact.get("my_table")
artifact를 Dataframe으로 변환하기
다음으로, 테이블을 데이터프레임으로 변환합니다.
# 이전 코드 예제에서 계속됩니다.df = table.get_dataframe()
데이터 내보내기
이제 데이터프레임이 지원하는 모든 방법을 사용하여 내보낼 수 있습니다.
# 테이블 데이터를 .csv로 변환df.to_csv("example.csv", encoding="utf-8")
X: X축에 사용할 값을 선택합니다 (기본값은 Step). x축을 Relative Time으로 변경하거나 W&B로 기록하는 값을 기반으로 사용자 정의 축을 선택할 수 있습니다.
Relative Time (Wall) 은 프로세스가 시작된 이후의 시계 시간이므로 run을 시작하고 하루 후에 다시 시작하여 기록한 경우 24시간으로 플롯됩니다.
Relative Time (Process) 는 실행 중인 프로세스 내부의 시간이므로 run을 시작하고 10초 동안 실행한 다음 하루 후에 다시 시작하면 해당 지점이 10초로 플롯됩니다.
Wall Time은 그래프에서 첫 번째 run이 시작된 이후 경과된 시간 (분) 입니다.
Step은 기본적으로 wandb.log()가 호출될 때마다 증가하며 모델에서 기록한 트레이닝 스텝 수를 반영해야 합니다.
Y: 시간에 따라 변하는 메트릭 및 하이퍼파라미터를 포함하여 기록된 값에서 하나 이상의 y축을 선택합니다.
X축 및 Y축 최소 및 최대값 (선택 사항).
포인트 집계 방식. Random sampling (기본값) 또는 Full fidelity. Sampling을 참조하십시오.
Smoothing: 라인 플롯의 Smoothing을 변경합니다. 기본값은 Time weighted EMA입니다. 다른 값으로는 No smoothing, Running average 및 Gaussian이 있습니다.
Outliers: 기본 플롯 최소 및 최대 스케일에서 이상값을 제외하도록 스케일을 재조정합니다.
최대 run 또는 그룹 수: 이 숫자를 늘려 라인 플롯에 더 많은 라인을 한 번에 표시합니다. 기본값은 10개의 run입니다. 사용 가능한 run이 10개 이상이지만 차트가 보이는 수를 제한하는 경우 차트 상단에 “Showing first 10 runs"라는 메시지가 표시됩니다.
차트 유형: 라인 플롯, 영역 플롯 및 백분율 영역 플롯 간에 변경합니다.
Grouping: 플롯에서 run을 그룹화하고 집계할지 여부와 방법을 구성합니다.
Group by: 열을 선택하면 해당 열에서 동일한 값을 가진 모든 run이 함께 그룹화됩니다.
Agg: 집계— 그래프의 라인 값. 옵션은 그룹의 평균, 중앙값, 최소값 및 최대값입니다.
차트: 패널, X축 및 Y축의 제목과 -축을 지정하고 범례를 숨기거나 표시하고 위치를 구성합니다.
범례: 패널의 범례 모양을 사용자 정의합니다 (활성화된 경우).
범례: 플롯의 각 라인에 대한 범례의 필드입니다.
범례 템플릿: 범례에 대한 완전히 사용자 정의 가능한 템플릿을 정의하여 라인 플롯 상단에 표시할 텍스트와 변수 및 마우스를 플롯 위로 이동할 때 나타나는 범례를 정확하게 지정합니다.
Expressions: 사용자 정의 계산된 표현식을 패널에 추가합니다.
Y축 표현식: 계산된 메트릭을 그래프에 추가합니다. 기록된 메트릭과 하이퍼파라미터와 같은 구성 값을 사용하여 사용자 정의 라인을 계산할 수 있습니다.
X축 표현식: 사용자 정의 표현식을 사용하여 계산된 값을 사용하도록 x축의 스케일을 재조정합니다. 유용한 변수에는 기본 x축에 대한**_step**이 포함되며 요약 값을 참조하는 구문은 ${summary:value}입니다.
섹션의 모든 라인 플롯
섹션의 모든 라인 플롯에 대한 기본 설정을 사용자 정의하려면 라인 플롯에 대한 워크스페이스 설정을 재정의합니다.
섹션의 기어 아이콘을 클릭하여 설정을 엽니다.
나타나는 모달 내에서 데이터 또는 표시 기본 설정 탭을 선택하여 섹션의 기본 설정을 구성합니다. 각 데이터 설정에 대한 자세한 내용은 이전 섹션인 개별 라인 플롯을 참조하십시오. 각 표시 기본 설정에 대한 자세한 내용은 섹션 레이아웃 구성을 참조하십시오.
워크스페이스의 모든 라인 플롯
워크스페이스의 모든 라인 플롯에 대한 기본 설정을 사용자 정의하려면:
워크스페이스의 설정을 클릭합니다. 여기에는 설정 레이블이 있는 기어가 있습니다.
라인 플롯을 클릭합니다.
나타나는 모달 내에서 데이터 또는 표시 기본 설정 탭을 선택하여 워크스페이스의 기본 설정을 구성합니다.
각 표시 기본 설정 섹션에 대한 자세한 내용은 워크스페이스 표시 기본 설정을 참조하십시오. 워크스페이스 수준에서 라인 플롯에 대한 기본 확대/축소 동작을 구성할 수 있습니다. 이 설정은 일치하는 x축 키가 있는 라인 플롯에서 확대/축소를 동기화할지 여부를 제어합니다. 기본적으로 비활성화되어 있습니다.
플롯에서 평균값 시각화
여러 개의 다른 Experiments가 있고 플롯에서 해당 값의 평균을 보려면 테이블에서 그룹화 기능을 사용할 수 있습니다. run 테이블 위에서 “그룹"을 클릭하고 “모두"를 선택하여 그래프에 평균값을 표시합니다.
평균화하기 전의 그래프 모양은 다음과 같습니다.
다음 이미지는 그룹화된 라인을 사용하여 run에서 평균값을 나타내는 그래프를 보여줍니다.
플롯에서 NaN 값 시각화
wandb.log를 사용하여 라인 플롯에 PyTorch 텐서를 포함한 NaN 값을 플롯할 수도 있습니다. 예:
wandb.log({"test": [..., float("nan"), ...]})
하나의 차트에서 두 개의 메트릭 비교
페이지 오른쪽 상단에서 패널 추가 버튼을 선택합니다.
나타나는 왼쪽 패널에서 평가 드롭다운을 확장합니다.
Run comparer를 선택합니다.
라인 플롯의 색상 변경
경우에 따라 run의 기본 색상이 비교에 도움이 되지 않을 수 있습니다. 이를 극복하기 위해 wandb는 색상을 수동으로 변경할 수 있는 두 가지 인스턴스를 제공합니다.
각 run은 초기화 시 기본적으로 임의의 색상이 지정됩니다.
색상 중 하나를 클릭하면 색상 팔레트가 나타나고 여기에서 원하는 색상을 수동으로 선택할 수 있습니다.
설정을 편집할 패널 위로 마우스를 가져갑니다.
나타나는 연필 아이콘을 선택합니다.
범례 탭을 선택합니다.
다른 x축에서 시각화
experiment가 소요된 절대 시간을 보거나 experiment가 실행된 날짜를 보려면 x축을 전환할 수 있습니다. 다음은 단계를 상대 시간으로 전환한 다음 벽 시간으로 전환하는 예입니다.
영역 플롯
라인 플롯 설정의 고급 탭에서 다른 플롯 스타일을 클릭하여 영역 플롯 또는 백분율 영역 플롯을 얻습니다.
확대/축소
사각형을 클릭하고 드래그하여 수직 및 수평으로 동시에 확대/축소합니다. 그러면 x축 및 y축 확대/축소가 변경됩니다.
차트 범례 숨기기
이 간단한 토글로 라인 플롯에서 범례를 끕니다.
4.1.1.1 - Line plot reference
X축
W&B.log 로 기록한 값이 항상 숫자로 기록되는 한, 선 그래프의 X축을 원하는 값으로 설정할 수 있습니다.
Y축 변수
wandb.log 로 기록한 값이 숫자, 숫자 배열 또는 숫자 히스토그램인 경우 Y축 변수를 원하는 값으로 설정할 수 있습니다. 변수에 대해 1500개 이상의 포인트를 기록한 경우 W&B 는 1500개 포인트로 샘플링합니다.
Runs 테이블에서 run 의 색상을 변경하여 Y축 선의 색상을 변경할 수 있습니다.
X 범위 및 Y 범위
플롯의 X 및 Y의 최대값과 최소값을 변경할 수 있습니다.
X 범위의 기본값은 X축의 최소값에서 최대값까지입니다.
Y 범위의 기본값은 메트릭의 최소값과 0부터 메트릭의 최대값까지입니다.
최대 Runs/그룹
기본적으로 10개의 run 또는 run 그룹만 플롯됩니다. Runs은 run 테이블 또는 run 세트의 맨 위에서 가져오므로 run 테이블 또는 run 세트를 정렬하면 표시되는 run 을 변경할 수 있습니다.
범례
차트의 범례를 제어하여 생성 시간 또는 run 을 생성한 user 와 같은 run 의 모든 config 값과 메타 데이터를 표시할 수 있습니다.
예시:
${run:displayName} - ${config:dropout} 은 각 run 에 대한 범례 이름을 royal-sweep - 0.5 와 같이 만듭니다. 여기서 royal-sweep 은 run 이름이고 0.5 는 dropout 이라는 config 파라미터입니다.
[[ ]] 안에 값을 설정하여 차트 위로 마우스를 가져갈 때 십자선에 특정 포인트 값을 표시할 수 있습니다. 예를 들어 \[\[ $x: $y ($original) ]] 은 “2: 3 (2.9)” 와 같이 표시됩니다.
[[ ]] 내에서 지원되는 값은 다음과 같습니다.
값
의미
${x}
X 값
${y}
Y 값 (스무딩 조정 포함)
${original}
Y 값 (스무딩 조정 미포함)
${mean}
그룹화된 run 의 평균
${stddev}
그룹화된 run 의 표준 편차
${min}
그룹화된 run 의 최소값
${max}
그룹화된 run 의 최대값
${percent}
합계의 백분율 (누적 영역 차트의 경우)
그룹화
그룹화를 켜서 모든 run 을 집계하거나 개별 변수별로 그룹화할 수 있습니다. 테이블 내에서 그룹화하여 그룹화를 켤 수도 있으며 그룹이 그래프에 자동으로 채워집니다.
스무딩
스무딩 계수를 0과 1 사이로 설정할 수 있습니다. 여기서 0은 스무딩 없음, 1은 최대 스무딩입니다.
이상치 무시
기본 플롯 최소 및 최대 스케일에서 이상치를 제외하도록 플롯의 스케일을 다시 조정합니다. 플롯에 대한 설정의 영향은 플롯의 샘플링 모드에 따라 다릅니다.
임의 샘플링 모드를 사용하는 플롯의 경우 이상치 무시를 활성화하면 5%에서 95%의 포인트만 표시됩니다. 이상치가 표시되더라도 다른 포인트와 다르게 서식이 지정되지는 않습니다.
전체 충실도 모드를 사용하는 플롯의 경우 모든 포인트가 항상 표시되며 각 버킷의 마지막 값으로 압축됩니다. 이상치 무시를 활성화하면 각 버킷의 최소 및 최대 경계가 음영 처리됩니다. 그렇지 않으면 영역이 음영 처리되지 않습니다.
표현식
표현식을 사용하면 1-정확도와 같은 메트릭에서 파생된 값을 플롯할 수 있습니다. 현재 단일 메트릭을 플롯하는 경우에만 작동합니다. 간단한 산술 표현식 +, -, *, / 및 %는 물론 거듭제곱에 대한 **를 수행할 수 있습니다.
플롯 스타일
선 그래프의 스타일을 선택합니다.
선 그래프:
영역 그래프:
백분율 영역 그래프:
4.1.1.2 - Point aggregation
Data Visualization 정확도와 성능을 향상시키려면 라인 플롯 내에서 포인트 집계 방법을 사용하세요. 포인트 집계 모드에는 전체 충실도와 임의 샘플링의 두 가지 유형이 있습니다. W&B는 기본적으로 전체 충실도 모드를 사용합니다.
전체 충실도
전체 충실도 모드를 사용하면 W&B는 데이터 포인트 수를 기반으로 x축을 동적 버킷으로 나눕니다. 그런 다음 라인 플롯에 대한 포인트 집계를 렌더링하는 동안 각 버킷 내의 최소값, 최대값 및 평균값을 계산합니다.
포인트 집계에 전체 충실도 모드를 사용하면 다음과 같은 세 가지 주요 이점이 있습니다.
극단값 및 스파이크 보존: 데이터에서 극단값 및 스파이크를 유지합니다.
최소 및 최대 포인트 렌더링 방법 구성: W&B 앱을 사용하여 극단(최소/최대) 값을 음영 영역으로 표시할지 여부를 대화식으로 결정합니다.
데이터 정확도를 잃지 않고 데이터 탐색: 특정 데이터 포인트를 확대하면 W&B가 x축 버킷 크기를 다시 계산합니다. 이는 정확도를 잃지 않고 데이터를 탐색하는 데 도움이 됩니다. 캐싱은 이전에 계산된 집계를 저장하여 로딩 시간을 줄이는 데 사용되며, 이는 대규모 데이터셋을 탐색할 때 특히 유용합니다.
최소 및 최대 포인트 렌더링 방법 구성
라인 플롯 주위에 음영 영역을 사용하여 최소값과 최대값을 표시하거나 숨깁니다.
다음 이미지는 파란색 라인 플롯을 보여줍니다. 밝은 파란색 음영 영역은 각 버킷의 최소값과 최대값을 나타냅니다.
이동 평균은 주어진 x 값 이전과 이후의 창에서 점의 평균으로 점을 대체하는 평활화 알고리즘입니다. https://en.wikipedia.org/wiki/Moving_average의 “Boxcar Filter"를 참조하세요. 이동 평균에 대해 선택된 파라미터는 Weights and Biases에 이동 평균에서 고려할 점의 수를 알려줍니다.
모든 평활화 알고리즘은 샘플링된 데이터에서 실행됩니다. 즉, 1500개 이상의 점을 기록하면 평활화 알고리즘은 서버에서 점을 다운로드한 후에 실행됩니다. 평활화 알고리즘의 의도는 데이터에서 패턴을 빠르게 찾는 데 도움을 주는 것입니다. 많은 수의 기록된 점이 있는 메트릭에 대해 정확한 평활화된 값이 필요한 경우 API를 통해 메트릭을 다운로드하고 자체 평활화 methods를 실행하는 것이 좋습니다.
원본 데이터 숨기기
기본적으로 원본의 평활화되지 않은 데이터가 배경에 희미한 선으로 표시됩니다. 원본 보기 토글을 클릭하여 이 기능을 끄세요.
4.1.2 - Bar plots
메트릭을 시각화하고, 축을 사용자 정의하고, 범주형 데이터를 막대로 비교하세요.
막대 그래프는 범주형 데이터를 직사각형 막대로 나타내며, 이 막대는 수직 또는 수평으로 플롯할 수 있습니다. 모든 기록된 값이 길이가 1인 경우 막대 그래프는 기본적으로 wandb.log() 와 함께 표시됩니다.
차트 설정을 사용하여 표시할 최대 Runs 수를 제한하고, 모든 config별로 Runs를 그룹화하고, 레이블 이름을 바꿀 수 있습니다.
막대 그래프 사용자 정의
Box 또는 Violin 플롯을 생성하여 여러 요약 통계를 하나의 차트 유형으로 결합할 수도 있습니다.
Runs 테이블을 통해 Runs를 그룹화합니다.
워크스페이스에서 ‘패널 추가’를 클릭합니다.
표준 ‘막대 차트’를 추가하고 플롯할 메트릭을 선택합니다.
‘그룹화’ 탭에서 ‘box plot’ 또는 ‘Violin’ 등을 선택하여 이러한 스타일 중 하나를 플롯합니다.
이렇게 하면 현재 디렉토리와 모든 하위 디렉토리의 모든 파이썬 소스 코드 파일이 artifact로 캡처됩니다. 저장되는 소스 코드 파일의 유형 및 위치를 보다 세밀하게 제어하려면 참조 문서를 참조하세요.
UI에서 코드 저장 설정
프로그래밍 방식으로 코드 저장을 설정하는 것 외에도 W&B 계정 설정에서 이 기능을 토글할 수도 있습니다. 이는 계정과 연결된 모든 Teams에 대해 코드 저장을 활성화합니다.
기본적으로 W&B는 모든 Teams에 대해 코드 저장을 비활성화합니다.
W&B 계정에 로그인합니다.
Settings > Privacy로 이동합니다.
Project and content security에서 Disable default code saving을 켭니다.
코드 비교기
서로 다른 W&B Runs에서 사용된 코드를 비교합니다.
페이지 오른쪽 상단에서 Add panels 버튼을 선택합니다.
TEXT AND CODE 드롭다운을 확장하고 Code를 선택합니다.
Jupyter 세션 기록
W&B는 Jupyter 노트북 세션에서 실행된 코드의 기록을 저장합니다. Jupyter 내에서 **wandb.init()**을 호출하면 W&B는 현재 세션에서 실행된 코드의 기록이 포함된 Jupyter 노트북을 자동으로 저장하는 훅을 추가합니다.
코드가 포함된 project 워크스페이스로 이동합니다.
왼쪽 네비게이션 바에서 Artifacts 탭을 선택합니다.
code artifact를 확장합니다.
Files 탭을 선택합니다.
이렇게 하면 iPython의 display 메소드를 호출하여 생성된 모든 출력과 함께 세션에서 실행된 셀이 표시됩니다. 이를 통해 지정된 Run 내에서 Jupyter 내에서 실행된 코드를 정확히 볼 수 있습니다. 가능한 경우 W&B는 코드 디렉토리에서도 찾을 수 있는 노트북의 최신 버전도 저장합니다.
4.1.6 - Parameter importance
모델의 하이퍼파라미터와 출력 메트릭 간의 관계를 시각화합니다.
어떤 하이퍼파라미터가 가장 예측력이 높고 메트릭의 바람직한 값과 상관관계가 높은지 알아보세요.
**상관 관계(Correlation)**는 하이퍼파라미터와 선택한 메트릭 (이 경우 val_loss) 간의 선형 상관 관계입니다. 따라서 상관 관계가 높다는 것은 하이퍼파라미터의 값이 높을 때 메트릭도 더 높은 값을 갖고 그 반대도 마찬가지임을 의미합니다. 상관 관계는 살펴보기에 좋은 메트릭이지만 입력 간의 2차 상호 작용을 포착할 수 없으며 범위가 매우 다른 입력을 비교하는 것이 복잡해질 수 있습니다.
따라서 W&B는 중요도(importance) 메트릭도 계산합니다. W&B는 하이퍼파라미터를 입력으로, 메트릭을 대상 출력으로 사용하여 랜덤 포레스트를 트레이닝하고 랜덤 포레스트에 대한 특징 중요도 값을 리포트합니다.
이 기술에 대한 아이디어는 Fast.ai에서 하이퍼파라미터 공간을 탐색하기 위해 랜덤 포레스트 특징 중요도를 사용하는 것을 개척한 Jeremy Howard와의 대화에서 영감을 받았습니다. 이 강의 (및 이 노트)를 확인하여 이 분석의 동기에 대해 자세히 알아보는 것이 좋습니다.
하이퍼파라미터 중요도 패널은 상관관계가 높은 하이퍼파라미터 간의 복잡한 상호 작용을 해결합니다. 이를 통해 모델 성능 예측 측면에서 가장 중요한 하이퍼파라미터를 보여줌으로써 하이퍼파라미터 검색을 미세 튜닝하는 데 도움이 됩니다.
하이퍼파라미터 중요도 패널 만들기
W&B 프로젝트로 이동합니다.
패널 추가 버튼을 선택합니다.
차트 드롭다운을 확장하고 드롭다운에서 평행 좌표를 선택합니다.
빈 패널이 나타나면 Runs이 그룹 해제되었는지 확인하십시오.
파라미터 관리자를 사용하면 표시 및 숨겨진 파라미터를 수동으로 설정할 수 있습니다.
하이퍼파라미터 중요도 패널 해석하기
이 패널은 트레이닝 스크립트의 wandb.config오브젝트에 전달된 모든 파라미터를 보여줍니다. 다음으로 이러한 config 파라미터의 특징 중요도와 모델 메트릭과 관련된 상관 관계를 보여줍니다 (이 경우 val_loss).
중요도
중요도 열은 각 하이퍼파라미터가 선택한 메트릭을 예측하는 데 얼마나 유용한지를 보여줍니다. 수많은 하이퍼파라미터를 튜닝하기 시작하고 이 플롯을 사용하여 추가 탐색할 가치가 있는 하이퍼파라미터를 정확히 찾아내는 시나리오를 상상해 보십시오. 후속 스윕은 가장 중요한 하이퍼파라미터로 제한되어 더 좋고 저렴한 모델을 더 빠르게 찾을 수 있습니다.
W&B는 선형 모델보다 트리 기반 모델을 사용하여 중요도를 계산합니다. 전자는 범주형 데이터와 정규화되지 않은 데이터 모두에 더 관대하기 때문입니다.
위의 이미지에서 epochs, learning_rate, batch_size 및 weight_decay가 상당히 중요하다는 것을 알 수 있습니다.
상관 관계
상관 관계는 개별 하이퍼파라미터와 메트릭 값 간의 선형 관계를 캡처합니다. SGD 옵티마이저와 같은 하이퍼파라미터를 사용하는 것과 val_loss 사이에 중요한 관계가 있는지에 대한 질문에 답합니다 (이 경우 답은 ‘예’입니다). 상관 관계 값은 -1에서 1 사이이며, 양수 값은 양의 선형 상관 관계를 나타내고 음수 값은 음의 선형 상관 관계를 나타내고 값 0은 상관 관계가 없음을 나타냅니다. 일반적으로 어느 방향이든 0.7보다 큰 값은 강한 상관 관계를 나타냅니다.
이 그래프를 사용하여 메트릭과 더 높은 상관 관계가 있는 값을 추가로 탐색하거나 (이 경우 rmsprop 또는 nadam보다 stochastic gradient descent 또는 adam을 선택할 수 있음) 더 많은 에포크 동안 트레이닝할 수 있습니다.
상관 관계는 반드시 인과 관계가 아닌 연관성의 증거를 보여줍니다.
상관 관계는 이상치에 민감하며, 특히 시도한 하이퍼파라미터의 샘플 크기가 작은 경우 강한 관계를 보통 관계로 바꿀 수 있습니다.
마지막으로 상관 관계는 하이퍼파라미터와 메트릭 간의 선형 관계만 캡처합니다. 강한 다항 관계가 있는 경우 상관 관계에 의해 캡처되지 않습니다.
중요도와 상관 관계의 차이는 중요도가 하이퍼파라미터 간의 상호 작용을 고려하는 반면 상관 관계는 개별 하이퍼파라미터가 메트릭 값에 미치는 영향만 측정한다는 사실에서 비롯됩니다. 둘째, 상관 관계는 선형 관계만 캡처하는 반면 중요도는 더 복잡한 관계를 캡처할 수 있습니다.
보시다시피 중요도와 상관 관계는 모두 하이퍼파라미터가 모델 성능에 미치는 영향을 이해하는 데 유용한 툴입니다.
4.1.7 - Compare run metrics
여러 run에서 메트릭 비교
Run Comparer를 사용하여 여러 run에서 어떤 메트릭이 다른지 확인하세요.
페이지 오른쪽 상단에서 패널 추가 버튼을 선택합니다.
나타나는 왼쪽 패널에서 Evaluation 드롭다운을 확장합니다.
Run Comparer를 선택합니다.
Diff Only 옵션을 켜서 여러 run에서 값이 동일한 행을 숨깁니다.
4.1.8 - Query panels
이 페이지의 일부 기능은 베타 버전이며 기능 플래그 뒤에 숨겨져 있습니다. 프로필 페이지의 자기 소개에 weave-plot을 추가하여 관련된 모든 기능을 잠금 해제하세요.
W&B Weave를 찾고 계신가요? W&B의 Generative AI 애플리케이션 구축 툴 모음인가요? weave에 대한 문서는 여기에서 찾으세요: wandb.me/weave.
쿼리 패널을 사용하여 데이터를 쿼리하고 대화형으로 시각화하세요.
쿼리 패널 만들기
워크스페이스 또는 리포트 내에 쿼리를 추가하세요.
프로젝트 워크스페이스로 이동합니다.
오른쪽 상단 모서리에서 패널 추가를 클릭합니다.
드롭다운에서 쿼리 패널을 선택합니다.
/쿼리 패널을 입력하고 선택합니다.
또는 쿼리를 run 집합과 연결할 수 있습니다:
리포트 내에서 /패널 그리드를 입력하고 선택합니다.
패널 추가 버튼을 클릭합니다.
드롭다운에서 쿼리 패널을 선택합니다.
쿼리 구성 요소
표현식
쿼리 표현식을 사용하여 run, Artifacts, Models, 테이블 등과 같이 W&B에 저장된 데이터를 쿼리합니다.
(row) => row["Label"]은 각 테이블에 대한 선택기이며 조인할 열을 결정합니다.
"Table1" 및 "Table2"는 조인될 때 각 테이블의 이름입니다.
true 및 false는 왼쪽 및 오른쪽 내부/외부 조인 설정을 위한 것입니다.
Runs 오브젝트
쿼리 패널을 사용하여 runs 오브젝트에 엑세스합니다. Run 오브젝트는 Experiments 기록을 저장합니다. 이 섹션의 리포트에서 자세한 내용을 확인할 수 있지만, 간략하게 살펴보면 runs 오브젝트는 다음과 같습니다.
summary: run 결과를 요약하는 정보 사전입니다. 여기에는 정확도 및 손실과 같은 스칼라 또는 큰 파일이 포함될 수 있습니다. 기본적으로 wandb.log()는 Summary를 로깅된 시계열의 최종 값으로 설정합니다. Summary 내용을 직접 설정할 수 있습니다. Summary를 run의 출력이라고 생각하세요.
history: 손실과 같이 모델이 트레이닝되는 동안 변경되는 값을 저장하기 위한 사전 목록입니다. wandb.log() 코맨드는 이 오브젝트에 추가됩니다.
config: 트레이닝 Run에 대한 하이퍼파라미터 또는 데이터셋 Artifact를 생성하는 Run에 대한 전처리 메소드와 같은 Run의 설정 정보 사전입니다. 이것을 Run의 “입력"이라고 생각하십시오.
Artifacts 엑세스
Artifacts는 W&B의 핵심 개념입니다. 버전이 지정된 명명된 파일 및 디렉토리 모음입니다. Artifacts를 사용하여 모델 가중치, 데이터셋 및 기타 파일 또는 디렉토리를 추적합니다. Artifacts는 W&B에 저장되며 다운로드하거나 다른 Run에서 사용할 수 있습니다. 이 섹션의 리포트에서 자세한 내용과 예제를 확인할 수 있습니다. Artifacts는 일반적으로 project 오브젝트에서 엑세스됩니다.
project.artifactVersion(): 프로젝트 내에서 주어진 이름과 버전에 대한 특정 아티팩트 버전을 반환합니다.
project.artifact(""): 프로젝트 내에서 주어진 이름에 대한 아티팩트를 반환합니다. 그런 다음 .versions를 사용하여 이 아티팩트의 모든 버전 목록을 가져올 수 있습니다.
project.artifactType(): 프로젝트 내에서 주어진 이름에 대한 artifactType을 반환합니다. 그런 다음 .artifacts를 사용하여 이 유형의 모든 아티팩트 목록을 가져올 수 있습니다.
project.artifactTypes: 프로젝트 아래의 모든 아티팩트 유형 목록을 반환합니다.
4.1.8.1 - Embed objects
W&B의 Embedding Projector를 통해 PCA, UMAP, t-SNE와 같은 일반적인 차원 축소 알고리즘을 사용하여 다차원 임베딩을 2D 평면에 플롯할 수 있습니다.
Embeddings는 오브젝트 (사람, 이미지, 게시물, 단어 등)를 숫자 목록 ( vector 라고도 함)으로 나타내는 데 사용됩니다. 기계 학습 및 데이터 과학 유스 케이스에서 Embeddings는 다양한 애플리케이션에서 다양한 접근 방식을 사용하여 생성할 수 있습니다. 이 페이지에서는 독자가 Embeddings에 익숙하고 W&B 내에서 Embeddings를 시각적으로 분석하는 데 관심이 있다고 가정합니다.
위의 코드를 실행하면 W&B 대시보드에 데이터가 포함된 새 Table이 표시됩니다. 오른쪽 상단 패널 선택기에서 2D Projection을 선택하여 Embeddings를 2차원으로 플롯할 수 있습니다. 스마트 기본값이 자동으로 선택되며, 기어 아이콘을 클릭하여 엑세스할 수 있는 설정 메뉴에서 쉽게 재정의할 수 있습니다. 이 예제에서는 사용 가능한 5개의 숫자 차원을 모두 자동으로 사용합니다.
Digits MNIST
위의 예제는 Embeddings 로깅의 기본 메커니즘을 보여 주지만 일반적으로 훨씬 더 많은 차원과 샘플을 사용합니다. MNIST Digits 데이터셋 (UCI ML 손으로 쓴 숫자 데이터셋s)을 고려해 보겠습니다. SciKit-Learn을 통해 사용할 수 있습니다. 이 데이터셋에는 각각 64개의 차원을 가진 1797개의 레코드가 있습니다. 문제는 10개의 클래스 분류 유스 케이스입니다. 시각화를 위해 입력 데이터를 이미지로 변환할 수도 있습니다.
위의 코드를 실행하면 UI에 Table이 다시 표시됩니다. 2D Projection을 선택하면 Embedding 정의, 색상, 알고리즘 (PCA, UMAP, t-SNE), 알고리즘 파라미터를 구성하고 오버레이할 수도 있습니다 (이 경우 점 위로 마우스를 가져갈 때 이미지가 표시됨). 이 특정 경우에서는 이 모든 것이 “스마트 기본값"이며 2D Projection에서 한 번의 클릭으로 매우 유사한 내용을 볼 수 있습니다. (이 예제와 상호 작용하려면 여기를 클릭하십시오.).
로깅 옵션
다양한 형식으로 Embeddings를 로그할 수 있습니다.
단일 Embedding 열: 데이터가 이미 “매트릭스"와 유사한 형식인 경우가 많습니다. 이 경우 셀 값의 데이터 유형이 list[int], list[float] 또는 np.ndarray일 수 있는 단일 Embedding 열을 만들 수 있습니다.
여러 숫자 열: 위의 두 예제에서는 이 접근 방식을 사용하고 각 차원에 대한 열을 만듭니다. 현재 셀에 대해 python int 또는 float를 허용합니다.
또한 모든 테이블과 마찬가지로 테이블 구성 방법에 대한 많은 옵션이 있습니다.
wandb.Table(dataframe=df)를 사용하여 데이터프레임에서 직접
wandb.Table(data=[...], columns=[...])를 사용하여 데이터 목록에서 직접
테이블을 점진적으로 행 단위로 빌드합니다 (코드에 루프가 있는 경우에 적합). table.add_data(...)를 사용하여 테이블에 행을 추가합니다.
테이블에 Embedding 열을 추가합니다 (Embedding 형식의 예측 목록이 있는 경우에 적합): table.add_col("col_name", ...)
계산된 열을 추가합니다 (테이블에서 매핑하려는 함수 또는 model이 있는 경우에 적합): table.add_computed_columns(lambda row, ndx: {"embedding": model.predict(row)})
플로팅 옵션
2D Projection을 선택한 후 기어 아이콘을 클릭하여 렌더링 설정을 편집할 수 있습니다. 원하는 열을 선택하는 것 외에도 (위 참조) 원하는 알고리즘 (원하는 파라미터와 함께)을 선택할 수 있습니다. 아래에서 UMAP 및 t-SNE에 대한 파라미터를 각각 볼 수 있습니다.
참고: 현재 세 가지 알고리즘 모두에 대해 임의의 1000개 행과 50개 차원의 서브셋으로 다운샘플링합니다.
4.2 - Custom charts
W&B 프로젝트에서 커스텀 차트를 만드세요. 임의의 데이터 테이블을 기록하고 원하는 방식으로 시각화하세요. Vega의 강력한 기능을 사용하여 글꼴, 색상 및 툴팁의 세부 사항을 제어하세요.
차트 사용자 정의: GraphQL 쿼리로 기록된 데이터를 가져옵니다. 강력한 시각화 문법인 Vega로 쿼리 결과를 시각화합니다.
차트 기록: wandb.plot_table()로 스크립트에서 자체 프리셋을 호출합니다.
예상되는 데이터가 보이지 않으면 찾고 있는 열이 선택된 runs에 기록되지 않았을 수 있습니다. 차트를 저장하고 runs 테이블로 돌아가서 눈 아이콘을 사용하여 선택한 runs를 확인합니다.
스크립트에서 차트 기록
내장 프리셋
W&B에는 스크립트에서 직접 기록할 수 있는 여러 내장 차트 프리셋이 있습니다. 여기에는 선 플롯, 산점도, 막대 차트, 히스토그램, PR 곡선 및 ROC 곡선이 포함됩니다.
wandb.plot.line()
임의의 축 x와 y에서 연결되고 정렬된 점 목록(x,y)인 사용자 지정 선 플롯을 기록합니다.
data = [[x, y] for (x, y) in zip(x_values, y_values)]
table = wandb.Table(data=data, columns=["x", "y"])
wandb.log(
{
"my_custom_plot_id": wandb.plot.line(
table, "x", "y", title="Custom Y vs X Line Plot" )
}
)
선 플롯은 두 차원에 대한 곡선을 기록합니다. 두 값 목록을 서로 플롯하는 경우 목록의 값 수는 정확히 일치해야 합니다(예: 각 점에 x와 y가 있어야 함).
값 목록을 발생 횟수/빈도별로 구간으로 정렬하여 사용자 지정 히스토그램으로 기본적으로 몇 줄 안에 기록합니다. 예측 신뢰도 점수 목록(scores)이 있고 해당 분포를 시각화하려는 경우를 예로 들어 보겠습니다.
data = [[s] for s in scores]
table = wandb.Table(data=data, columns=["scores"])
wandb.log({"my_histogram": wandb.plot.histogram(table, "scores", title=None)})
이를 사용하여 임의의 히스토그램을 기록할 수 있습니다. data는 행과 열의 2D 배열을 지원하기 위한 목록의 목록입니다.
내장 프리셋을 조정하거나 새 프리셋을 만든 다음 차트를 저장합니다. 차트 ID를 사용하여 스크립트에서 해당 커스텀 프리셋에 직접 데이터를 기록합니다. 예제 Google Colab 노트북을 사용해 보세요.
# 플롯할 열이 있는 테이블 만들기table = wandb.Table(data=data, columns=["step", "height"])
# 테이블의 열에서 차트의 필드로 매핑fields = {"x": "step", "value": "height"}
# 테이블을 사용하여 새 커스텀 차트 프리셋 채우기# 자신의 저장된 차트 프리셋을 사용하려면 vega_spec_name을 변경하세요.my_custom_chart = wandb.plot_table(
vega_spec_name="carey/new_chart",
data_table=table,
fields=fields,
)
데이터 기록
스크립트에서 다음 데이터 형식을 기록하고 커스텀 차트에서 사용할 수 있습니다.
Config: 실험의 초기 설정(독립 변수). 여기에는 트레이닝 시작 시 wandb.config에 대한 키로 기록한 명명된 필드가 포함됩니다. 예: wandb.config.learning_rate = 0.0001
요약: 트레이닝 중에 기록된 단일 값(결과 또는 종속 변수). 예: wandb.log({"val_acc" : 0.8}). wandb.log()를 통해 트레이닝 중에 이 키에 여러 번 쓰면 요약이 해당 키의 최종 값으로 설정됩니다.
History: 기록된 스칼라의 전체 시계열은 history 필드를 통해 쿼리에 사용할 수 있습니다.
summaryTable: 여러 값 목록을 기록해야 하는 경우 wandb.Table()을 사용하여 해당 데이터를 저장한 다음 커스텀 패널에서 쿼리합니다.
historyTable: history 데이터를 봐야 하는 경우 커스텀 차트 패널에서 historyTable을 쿼리합니다. wandb.Table()을 호출하거나 커스텀 차트를 기록할 때마다 해당 단계의 history에 새 테이블을 만들고 있습니다.
커스텀 테이블을 기록하는 방법
wandb.Table()을 사용하여 데이터를 2D 배열로 기록합니다. 일반적으로 이 테이블의 각 행은 하나의 데이터 점을 나타내고 각 열은 플롯하려는 각 데이터 점에 대한 관련 필드/차원을 나타냅니다. 커스텀 패널을 구성할 때 전체 테이블은 wandb.log()(custom_data_table 아래)에 전달된 명명된 키를 통해 액세스할 수 있으며 개별 필드는 열 이름(x, y 및 z)을 통해 액세스할 수 있습니다. 실험 전반에 걸쳐 여러 시간 단계에서 테이블을 기록할 수 있습니다. 각 테이블의 최대 크기는 10,000행입니다. 예제 Google Colab을 사용해 보세요.
새 커스텀 차트를 추가하여 시작한 다음 쿼리를 편집하여 표시되는 runs에서 데이터를 선택합니다. 쿼리는 GraphQL을 사용하여 runs의 config, 요약 및 history 필드에서 데이터를 가져옵니다.
커스텀 시각화
오른쪽 상단 모서리에서 차트를 선택하여 기본 프리셋으로 시작합니다. 다음으로 차트 필드를 선택하여 쿼리에서 가져오는 데이터를 차트의 해당 필드에 매핑합니다.
다음 이미지는 메트릭을 선택한 다음 아래의 막대 차트 필드에 매핑하는 방법을 보여주는 예입니다.
Vega를 편집하는 방법
패널 상단의 편집을 클릭하여 Vega 편집 모드로 들어갑니다. 여기에서 UI에서 대화형 차트를 만드는 Vega 사양을 정의할 수 있습니다. 차트의 모든 측면을 변경할 수 있습니다. 예를 들어 제목을 변경하고, 다른 색 구성표를 선택하고, 곡선을 연결된 선 대신 일련의 점으로 표시할 수 있습니다. 또한 Vega 변환을 사용하여 값 배열을 히스토그램으로 비닝하는 등 데이터 자체를 변경할 수도 있습니다. 패널 미리 보기가 대화형으로 업데이트되므로 Vega 사양 또는 쿼리를 편집할 때 변경 사항의 효과를 볼 수 있습니다. Vega 문서 및 튜토리얼을 참조하세요.
필드 참조
W&B에서 차트로 데이터를 가져오려면 Vega 사양의 아무 곳에나 "${field:<field-name>}" 형식의 템플릿 문자열을 추가합니다. 그러면 오른쪽의 차트 필드 영역에 드롭다운이 생성되어 사용자가 쿼리 결과 열을 선택하여 Vega에 매핑할 수 있습니다.
필드의 기본값을 설정하려면 다음 구문을 사용하세요. "${field:<field-name>:<placeholder text>}"
차트 프리셋 저장
모달 하단의 버튼을 사용하여 특정 시각화 패널에 대한 변경 사항을 적용합니다. 또는 Vega 사양을 저장하여 프로젝트의 다른 곳에서 사용할 수 있습니다. 재사용 가능한 차트 정의를 저장하려면 Vega 편집기 상단의 다른 이름으로 저장을 클릭하고 프리셋에 이름을 지정합니다.
사용자 지정 x-y 좌표가 필요한 모델 유효성 검사 메트릭 표시(예: precision-recall 곡선)
두 개의 다른 모델/Experiments의 데이터 분포를 히스토그램으로 오버레이
트레이닝 중 여러 지점에서 스냅샷을 통해 메트릭의 변경 사항 표시
W&B에서 아직 사용할 수 없는 고유한 시각화 만들기(그리고 바라건대 전 세계와 공유)
4.2.1 - Tutorial: Use custom charts
W&B UI에서 사용자 정의 차트 기능을 사용하는 방법에 대한 튜토리얼
커스텀 차트를 사용하여 패널에 로드하는 데이터와 시각화를 제어할 수 있습니다.
1. W&B에 데이터 기록
먼저 스크립트에 데이터를 기록합니다. 트레이닝 시작 시 설정된 단일 포인트 (예: 하이퍼파라미터)에는 wandb.config를 사용합니다. 시간에 따른 여러 포인트에는 wandb.log()를 사용하고, wandb.Table()을 사용하여 커스텀 2D 배열을 기록합니다. 기록된 키당 최대 10,000개의 데이터 포인트를 기록하는 것이 좋습니다.
데이터 테이블을 기록하려면 간단한 예제 노트북을 사용해 보고, 다음 단계에서 커스텀 차트를 설정합니다. 라이브 리포트에서 결과 차트가 어떻게 보이는지 확인하세요.
2. 쿼리 만들기
시각화할 데이터를 기록했으면 프로젝트 페이지로 이동하여 + 버튼을 클릭하여 새 패널을 추가한 다음 Custom Chart를 선택합니다. 이 워크스페이스에서 따라 할 수 있습니다.
쿼리 추가
summary를 클릭하고 historyTable을 선택하여 run 기록에서 데이터를 가져오는 새 쿼리를 설정합니다.
wandb.Table()을 기록한 키를 입력합니다. 위의 코드 조각에서는 my_custom_table입니다. 예제 노트북에서 키는 pr_curve 및 roc_curve입니다.
Vega 필드 설정
이제 쿼리가 이러한 열을 로드하므로 Vega 필드 드롭다운 메뉴에서 선택할 수 있는 옵션으로 사용할 수 있습니다.
x-axis: runSets_historyTable_r (recall)
y-axis: runSets_historyTable_p (precision)
color: runSets_historyTable_c (class label)
3. 차트 사용자 정의
이제 보기에 좋지만 산점도에서 선 플롯으로 전환하고 싶습니다. Edit를 클릭하여 이 내장 차트에 대한 Vega 사양을 변경합니다. 이 워크스페이스에서 따라 하세요.
시각화를 사용자 정의하기 위해 Vega 사양을 업데이트했습니다.
플롯, 범례, x축 및 y축에 대한 제목 추가 (각 필드에 대해 “title” 설정)
“mark” 값을 “point"에서 “line"으로 변경
사용되지 않는 “size” 필드 제거
이것을 이 프로젝트의 다른 곳에서 사용할 수 있는 사전 설정으로 저장하려면 페이지 상단의 Save as를 클릭합니다. 결과는 ROC 곡선과 함께 다음과 같습니다.
보너스: 합성 히스토그램
히스토그램은 숫자 분포를 시각화하여 더 큰 데이터셋을 이해하는 데 도움을 줄 수 있습니다. 합성 히스토그램은 동일한 bin에서 여러 분포를 보여주어 서로 다른 모델 간 또는 모델 내의 서로 다른 클래스 간에 두 개 이상의 메트릭을 비교할 수 있습니다. 운전 장면에서 오브젝트를 감지하는 시멘틱 세그멘테이션 모델의 경우 정확도 대 IOU (intersection over union)에 대해 최적화하는 효과를 비교하거나 서로 다른 모델이 자동차 (데이터에서 크고 일반적인 영역) 대 교통 표지판 (훨씬 작고 덜 일반적인 영역)을 얼마나 잘 감지하는지 알고 싶을 수 있습니다. 데모 Colab에서는 10가지 생물 클래스 중 2가지에 대한 신뢰도 점수를 비교할 수 있습니다.
커스텀 합성 히스토그램 패널의 자체 버전을 만들려면:
워크스페이스 또는 리포트에서 새 Custom Chart 패널을 만듭니다 (“Custom Chart” 시각화를 추가하여). 오른쪽 상단의 “Edit” 버튼을 눌러 내장 패널 유형부터 시작하여 Vega 사양을 수정합니다.
해당 내장 Vega 사양을 Vega의 합성 히스토그램에 대한 MVP 코드로 바꿉니다. Vega 구문 Vega syntax를 사용하여 이 Vega 사양에서 메인 제목, 축 제목, 입력 도메인 및 기타 세부 정보를 직접 수정할 수 있습니다 (색상을 변경하거나 세 번째 히스토그램을 추가할 수도 있습니다 :)
오른쪽 쿼리를 수정하여 wandb 로그에서 올바른 데이터를 로드합니다. 필드 summaryTable을 추가하고 해당 tableKey를 class_scores로 설정하여 run에서 기록한 wandb.Table을 가져옵니다. 이렇게 하면 드롭다운 메뉴를 통해 wandb.Table이 class_scores로 기록된 열과 함께 두 개의 히스토그램 bin 세트 (red_bins 및 blue_bins)를 채울 수 있습니다. 내 예제에서는 빨간색 bin에 대한 animal 클래스 예측 점수와 파란색 bin에 대한 plant를 선택했습니다.
미리 보기 렌더링에서 보이는 플롯이 마음에 들 때까지 Vega 사양과 쿼리를 계속 변경할 수 있습니다. 완료되면 상단의 Save as를 클릭하고 나중에 재사용할 수 있도록 커스텀 플롯 이름을 지정합니다. 그런 다음 Apply from panel library를 클릭하여 플롯을 완료합니다.
다음은 매우 간단한 실험에서 얻은 결과입니다. 에포크에 대해 1000개의 예제만으로 트레이닝하면 대부분의 이미지가 식물이 아니고 어떤 이미지가 동물일 수 있는지 매우 불확실한 모델이 생성됩니다.
4.3 - Manage workspace, section, and panel settings
특정 워크스페이스 페이지 내에는 워크스페이스, 섹션 및 패널의 세 가지 설정 수준이 있습니다. 워크스페이스 설정은 전체 워크스페이스에 적용됩니다. 섹션 설정은 섹션 내의 모든 패널에 적용됩니다. 패널 설정은 개별 패널에 적용됩니다.
워크스페이스 설정
워크스페이스 설정은 모든 섹션과 해당 섹션 내의 모든 패널에 적용됩니다. 편집할 수 있는 워크스페이스 설정에는 워크스페이스 레이아웃과 라인 플롯의 두 가지 유형이 있습니다. 워크스페이스 레이아웃은 워크스페이스의 구조를 결정하는 반면, 라인 플롯 설정은 워크스페이스에서 라인 플롯의 기본 설정을 제어합니다.
이 워크스페이스의 전체 구조에 적용되는 설정을 편집하려면 다음을 수행하세요.
프로젝트 워크스페이스로 이동합니다.
새 리포트 버튼 옆에 있는 톱니바퀴 아이콘을 클릭하여 워크스페이스 설정을 확인합니다.
워크스페이스 레이아웃을 변경하려면 워크스페이스 레이아웃을 선택하고, 워크스페이스에서 라인 플롯의 기본 설정을 구성하려면 라인 플롯을 선택합니다.
워크스페이스 레이아웃 옵션
워크스페이스의 전체 구조를 정의하도록 워크스페이스 레이아웃을 구성합니다. 여기에는 섹션 나누기 로직과 패널 구성이 포함됩니다.
워크스페이스 레이아웃 옵션 페이지에는 워크스페이스에서 패널을 자동으로 생성하는지 또는 수동으로 생성하는지가 표시됩니다. 워크스페이스의 패널 생성 모드를 조정하려면 패널을 참조하세요.
다음 표는 각 워크스페이스 레이아웃 옵션에 대해 설명합니다.
워크스페이스 설정
설명
검색 중 빈 섹션 숨기기
패널을 검색할 때 패널이 없는 섹션을 숨깁니다.
패널을 알파벳순으로 정렬
워크스페이스의 패널을 알파벳순으로 정렬합니다.
섹션 구성
기존의 모든 섹션과 패널을 제거하고 새 섹션 이름으로 다시 채웁니다. 새로 채워진 섹션을 첫 번째 또는 마지막 접두사로 그룹화합니다.
W&B에서는 마지막 접두사로 그룹화하는 대신 첫 번째 접두사를 그룹화하여 섹션을 구성하는 것이 좋습니다. 첫 번째 접두사로 그룹화하면 섹션 수가 줄어들고 성능이 향상될 수 있습니다.
라인 플롯 옵션
라인 플롯 워크스페이스 설정을 수정하여 워크스페이스에서 라인 플롯의 글로벌 기본값과 사용자 지정 규칙을 설정합니다.
라인 플롯 설정 내에서 데이터와 표시 기본 설정의 두 가지 주요 설정을 편집할 수 있습니다. 데이터 탭에는 다음 설정이 포함되어 있습니다.
라인 플롯 설정
설명
X축
라인 플롯에서 x축의 스케일입니다. x축은 기본적으로 단계로 설정됩니다. x축 옵션 목록은 다음 표를 참조하세요.
범위
x축에 표시할 최소 및 최대 설정입니다.
평활화
라인 플롯에서 평활화를 변경합니다. 평활화에 대한 자세한 내용은 라인 플롯 평활화를 참조하세요.
Weights & Biases 설정 페이지를 사용하여 개별 사용자 프로필 또는 팀 설정을 사용자 정의하세요.
개인 사용자 계정 내에서 프로필 사진, 표시 이름, 지리적 위치, 자기 소개 정보, 계정에 연결된 이메일을 편집하고 Runs 에 대한 알림을 관리할 수 있습니다. 또한 설정 페이지를 사용하여 GitHub 저장소를 연결하고 계정을 삭제할 수도 있습니다. 자세한 내용은 사용자 설정을 참조하세요.
팀 설정 페이지를 사용하여 팀에 새 멤버를 초대하거나 제거하고, 팀 Runs 에 대한 알림을 관리하고, 개인 정보 설정을 변경하고, 저장소 사용량을 보고 관리할 수 있습니다. 팀 설정에 대한 자세한 내용은 팀 설정을 참조하세요.
4.4.1 - Manage user settings
사용자 설정 에서 프로필 정보, 계정 기본값, 알림, 베타 제품 참여, GitHub 인테그레이션 , 저장소 사용량, 계정 활성화를 관리하고 팀 을 만드세요.
사용자 프로필 페이지로 이동하여 오른쪽 상단 모서리에 있는 사용자 아이콘을 선택하세요. 드롭다운 메뉴에서 설정을 선택합니다.
프로필
프로필 섹션에서는 계정 이름과 소속 기관을 관리하고 수정할 수 있습니다. 선택적으로 자기소개, 위치, 개인 또는 소속 기관 웹사이트 링크를 추가하고 프로필 이미지를 업로드할 수 있습니다.
자기 소개 편집
자기 소개를 편집하려면 프로필 상단의 편집을 클릭합니다. 열리는 WYSIWYG 편집기는 Markdown을 지원합니다.
줄을 편집하려면 해당 줄을 클릭합니다. 시간을 절약하기 위해 /를 입력하고 목록에서 Markdown을 선택할 수 있습니다.
항목의 드래그 핸들을 사용하여 이동합니다.
블록을 삭제하려면 드래그 핸들을 클릭한 다음 삭제를 클릭합니다.
변경 사항을 저장하려면 저장을 클릭합니다.
소셜 배지 추가
X에서 @weights_biases 계정에 대한 팔로우 배지를 추가하려면 배지 이미지를 가리키는 HTML <img> 태그가 있는 Markdown 스타일 링크를 추가할 수 있습니다.
유료 요금제를 사용하는 조직의 경우, 관리자는 특정 임계값이 충족되면 결제 기간당 한 번 이메일을 통해 알림을 받습니다. 알림에는 결제 관리자인 경우 조직의 제한을 늘리는 방법과 그렇지 않은 경우 결제 관리자에게 문의하는 방법에 대한 세부 정보가 포함됩니다. Pro plan에서는 결제 관리자만 사용량 알림을 받습니다.
이러한 알림은 구성할 수 없으며 다음과 같은 경우에 전송됩니다.
조직이 월간 사용량 범주 제한(사용 시간의 85%)에 가까워지고 요금제에 따라 제한의 100%에 도달했을 때.
조직의 누적 평균 요금이 결제 기간 동안 $200, $450, $700 및 $1000 임계값을 초과했을 때. 이러한 초과 요금은 조직에서 추적 시간, 저장 공간 또는 Weave 데이터 수집에 대해 요금제에 포함된 것보다 더 많은 사용량을 누적할 때 발생합니다.
사용량 또는 결제에 대한 질문은 계정 팀 또는 지원팀에 문의하세요.
결제 방법
이 섹션에서는 조직에 등록된 결제 방법을 보여줍니다. 결제 방법을 추가하지 않은 경우 요금제를 업그레이드하거나 유료 저장 공간을 추가할 때 결제 방법을 추가하라는 메시지가 표시됩니다.
결제 관리자
이 섹션에서는 현재 결제 관리자를 보여줍니다. 결제 관리자는 조직 관리자이며 모든 결제 관련 이메일을 수신하고 결제 방법을 보고 관리할 수 있습니다.
W&B 전용 클라우드에서는 여러 Users가 결제 관리자가 될 수 있습니다. W&B 멀티 테넌트 클라우드에서는 한 번에 한 명의 User만 결제 관리자가 될 수 있습니다.
결제 관리자를 변경하거나 역할을 추가 Users에게 할당하려면:
역할 관리를 클릭하세요.
User를 검색하세요.
해당 User의 행에서 결제 관리자 필드를 클릭하세요.
요약을 읽은 다음 결제 User 변경을 클릭하세요.
송장
신용 카드를 사용하여 결제하는 경우 이 섹션에서 월별 송장을 볼 수 있습니다.
전신 송금을 통해 결제하는 Enterprise 계정의 경우 이 섹션은 비어 있습니다. 질문이 있으면 계정 팀에 문의하세요.
조직에 요금이 발생하지 않으면 송장이 생성되지 않습니다.
4.4.3 - Manage team settings
Team 설정 페이지에서 팀의 멤버, 아바타, 알림 및 개인 정보 설정을 관리하세요.
팀 설정
팀 멤버, 아바타, 알림, 개인 정보 보호, 사용량 등 팀 설정을 변경합니다. 조직 관리자와 팀 관리자는 팀 설정을 보고 편집할 수 있습니다.
관리 계정 유형만 팀 설정을 변경하거나 팀에서 멤버를 제거할 수 있습니다.
멤버
멤버 섹션에는 보류 중인 초대 목록과 팀 가입 초대를 수락한 멤버가 모두 표시됩니다. 나열된 각 멤버는 멤버의 이름, 사용자 이름, 이메일, 팀 역할과 조직에서 상속된 Models 및 Weave에 대한 엑세스 권한을 표시합니다. 표준 팀 역할인 Admin, Member 및 View-only 중에서 선택할 수 있습니다. 조직에서 사용자 정의 역할을 생성한 경우 사용자 정의 역할을 대신 할당할 수 있습니다.
팀 생성, 팀 관리, 팀 멤버십 및 역할 관리에 대한 자세한 내용은 팀 추가 및 관리를 참조하세요. 팀에 대한 새로운 멤버 초대 권한을 구성하고 기타 개인 정보 보호 설정을 구성하려면 개인 정보 보호를 참조하세요.
아바타
아바타 섹션으로 이동하여 이미지를 업로드하여 아바타를 설정합니다.
아바타 업데이트를 선택하여 파일 대화 상자를 표시합니다.
파일 대화 상자에서 사용할 이미지를 선택합니다.
알림
Runs이 충돌하거나 완료될 때 또는 사용자 정의 알림을 설정할 때 팀에 알립니다. 팀은 이메일 또는 Slack을 통해 알림을 받을 수 있습니다.
알림을 받을 이벤트 유형 옆에 있는 스위치를 토글합니다. Weights & Biases는 기본적으로 다음과 같은 이벤트 유형 옵션을 제공합니다.
Runs finished: Weights & Biases run이 성공적으로 완료되었는지 여부.
팀 프로필 페이지를 사용자 정의하여 소개를 표시하고 공개 또는 팀 멤버에게 보이는 리포트 및 프로젝트를 소개할 수 있습니다. 리포트, 프로젝트 및 외부 링크를 제시하세요.
최고의 공개 리포트를 소개하여 방문자에게 최고의 연구 결과를 강조하세요.
팀원이 더 쉽게 찾을 수 있도록 가장 활발한 프로젝트를 소개하세요.
회사 또는 연구실 웹사이트 및 게시한 논문에 외부 링크를 추가하여 협력자를 찾으세요.
팀 멤버 제거
팀 관리자는 팀 설정 페이지를 열고 떠나는 멤버의 이름 옆에 있는 삭제 버튼을 클릭할 수 있습니다. 사용자가 떠난 후에도 팀에 기록된 모든 run은 유지됩니다.
팀 역할 및 권한 관리
동료를 팀에 초대할 때 팀 역할을 선택하세요. 다음과 같은 팀 역할 옵션이 있습니다.
관리자: 팀 관리자는 다른 관리자나 팀 멤버를 추가하거나 제거할 수 있습니다. 모든 프로젝트를 수정할 수 있는 권한과 완전한 삭제 권한이 있습니다. 여기에는 run, 프로젝트, 아티팩트 및 스윕 삭제가 포함되지만 이에 국한되지는 않습니다.
멤버: 팀의 일반 멤버입니다. 기본적으로 관리자만 팀 멤버를 초대할 수 있습니다. 이 동작을 변경하려면 팀 설정 관리를 참조하세요.
팀 멤버는 자신이 만든 run만 삭제할 수 있습니다. 멤버 A와 B가 있다고 가정합니다. 멤버 B가 팀 B의 프로젝트에서 멤버 A가 소유한 다른 프로젝트로 run을 이동합니다. 멤버 A는 멤버 B가 멤버 A의 프로젝트로 이동한 run을 삭제할 수 없습니다. 관리자는 모든 팀 멤버가 만든 run과 스윕 run을 관리할 수 있습니다.
보기 전용 (엔터프라이즈 전용 기능): 보기 전용 멤버는 run, 리포트 및 워크스페이스와 같은 팀 내 자산을 볼 수 있습니다. 리포트를 팔로우하고 댓글을 달 수 있지만 프로젝트 개요, 리포트 또는 run을 생성, 편집 또는 삭제할 수는 없습니다.
사용자 정의 역할 (엔터프라이즈 전용 기능): 사용자 정의 역할을 사용하면 조직 관리자가 세분화된 엑세스 제어를 위해 추가 권한과 함께 보기 전용 또는 멤버 역할 중 하나를 기반으로 새 역할을 구성할 수 있습니다. 그런 다음 팀 관리자는 해당 사용자 정의 역할을 각 팀의 사용자에게 할당할 수 있습니다. 자세한 내용은 W&B 팀을 위한 사용자 정의 역할 소개를 참조하세요.
리포트 권한은 리포트를 생성, 보고 편집할 수 있는 엑세스 권한을 부여합니다. 다음 표에는 지정된 팀의 모든 리포트에 적용되는 권한이 나와 있습니다.
권한
보기 전용
팀 멤버
팀 관리자
리포트 보기
X
X
X
리포트 만들기
X
X
리포트 편집
X (팀 멤버는 자신의 리포트만 편집할 수 있음)
X
리포트 삭제
X (팀 멤버는 자신의 리포트만 편집할 수 있음)
X
실험
다음 표에는 지정된 팀의 모든 실험에 적용되는 권한이 나와 있습니다.
권한
보기 전용
팀 멤버
팀 관리자
실험 메타데이터 보기 (기록 메트릭, 시스템 메트릭, 파일 및 로그 포함)
X
X
X
실험 패널 및 워크스페이스 편집
X
X
실험 기록
X
X
실험 삭제
X (팀 멤버는 자신이 만든 실험만 삭제할 수 있음)
X
실험 중지
X (팀 멤버는 자신이 만든 실험만 중지할 수 있음)
X
아티팩트
다음 표에는 지정된 팀의 모든 아티팩트에 적용되는 권한이 나와 있습니다.
권한
보기 전용
팀 멤버
팀 관리자
아티팩트 보기
X
X
X
아티팩트 만들기
X
X
아티팩트 삭제
X
X
메타데이터 편집
X
X
에일리어스 편집
X
X
에일리어스 삭제
X
X
아티팩트 다운로드
X
X
시스템 설정 (W&B 서버만 해당)
시스템 권한을 사용하여 팀 및 팀 멤버를 만들고 관리하고 시스템 설정을 조정합니다. 이러한 권한을 통해 W&B 인스턴스를 효과적으로 관리하고 유지 관리할 수 있습니다.
권한
보기 전용
팀 멤버
팀 관리자
시스템 관리자
시스템 설정 구성
X
팀 생성/삭제
X
팀 서비스 계정 행동
트레이닝 환경에서 팀을 구성할 때 해당 팀의 서비스 계정을 사용하여 해당 팀 내의 비공개 또는 공개 프로젝트에 run을 기록할 수 있습니다. 또한 환경에 WANDB_USERNAME 또는 WANDB_USER_EMAIL 변수가 있고 참조된 사용자가 해당 팀의 구성원인 경우 해당 run을 사용자에게 귀속시킬 수 있습니다.
트레이닝 환경에서 팀을 구성 하지 않고 서비스 계정을 사용하는 경우 run은 해당 서비스 계정의 상위 팀 내에서 명명된 프로젝트에 기록됩니다. 이 경우에도 환경에 WANDB_USERNAME 또는 WANDB_USER_EMAIL 변수가 있고 참조된 사용자가 서비스 계정의 상위 팀의 구성원인 경우 run을 사용자에게 귀속시킬 수 있습니다.
서비스 계정은 상위 팀과 다른 팀의 비공개 프로젝트에 run을 기록할 수 없습니다. 프로젝트가 공개 프로젝트 가시성으로 설정된 경우에만 서비스 계정이 프로젝트에 run을 기록할 수 있습니다.
팀 트라이얼
W&B 요금제에 대한 자세한 내용은 요금 페이지를 참조하세요. 대시보드 UI 또는 내보내기 API를 사용하여 언제든지 모든 데이터를 다운로드할 수 있습니다.
개인 정보 설정
팀 설정 페이지에서 모든 팀 프로젝트의 개인 정보 설정을 확인할 수 있습니다.
app.wandb.ai/teams/your-team-name
고급 구성
보안 스토리지 커넥터
팀 수준 보안 스토리지 커넥터를 사용하면 팀에서 W&B와 함께 자체 클라우드 스토리지 버킷을 사용할 수 있습니다. 이는 매우 민감한 데이터 또는 엄격한 규정 준수 요구 사항이 있는 팀에 대해 더 나은 데이터 엑세스 제어 및 데이터 격리를 제공합니다. 자세한 내용은 보안 스토리지 커넥터를 참조하세요.
4.4.6 - Manage storage
W&B 데이터 저장소를 관리하는 방법.
스토리지 한도에 접근하거나 초과하는 경우, 데이터를 관리할 수 있는 여러 가지 방법이 있습니다. 어떤 방법이 가장 적합한지는 계정 유형과 현재 프로젝트 설정에 따라 달라집니다.
스토리지 사용량 관리
W&B는 스토리지 사용량을 최적화할 수 있는 다양한 방법을 제공합니다.
참조 Artifacts를 사용하여 W&B 시스템 외부에서 저장된 파일을 추적하고, W&B 스토리지에 업로드하는 대신 사용할 수 있습니다.
각 AMD GPU 장치에 대해 총 사용 가능한 메모리의 백분율로 GPU 메모리가 할당되었음을 나타냅니다.
W&B는 이 메트릭에 gpu.{gpu_index}.memoryAllocated 태그를 할당합니다.
AMD GPU 온도
각 AMD GPU 장치에 대한 GPU 온도를 섭씨로 나타냅니다.
W&B는 이 메트릭에 gpu.{gpu_index}.temp 태그를 할당합니다.
AMD GPU 전력 사용량 (와트)
각 AMD GPU 장치에 대한 GPU 전력 사용량을 와트 단위로 나타냅니다.
W&B는 이 메트릭에 gpu.{gpu_index}.powerWatts 태그를 할당합니다.
AMD GPU 전력 사용량 백분율
각 AMD GPU 장치에 대한 전력 용량의 백분율로 GPU 전력 사용량을 반영합니다.
W&B는 이 메트릭에 gpu.{gpu_index}.powerPercent 태그를 할당합니다.
Apple ARM Mac GPU
Apple GPU 활용률
Apple GPU 장치, 특히 ARM Mac에서 GPU 활용률을 백분율로 나타냅니다.
W&B는 이 메트릭에 gpu.0.gpu 태그를 할당합니다.
Apple GPU 메모리 할당됨
ARM Mac의 Apple GPU 장치에 대해 총 사용 가능한 메모리의 백분율로 GPU 메모리가 할당되었습니다.
W&B는 이 메트릭에 gpu.0.memoryAllocated 태그를 할당합니다.
Apple GPU 온도
ARM Mac의 Apple GPU 장치에 대한 GPU 온도를 섭씨로 나타냅니다.
W&B는 이 메트릭에 gpu.0.temp 태그를 할당합니다.
Apple GPU 전력 사용량 (와트)
ARM Mac의 Apple GPU 장치에 대한 GPU 전력 사용량을 와트 단위로 나타냅니다.
W&B는 이 메트릭에 gpu.0.powerWatts 태그를 할당합니다.
Apple GPU 전력 사용량 백분율
ARM Mac의 Apple GPU 장치에 대한 전력 용량의 백분율로 GPU 전력 사용량을 나타냅니다.
W&B는 이 메트릭에 gpu.0.powerPercent 태그를 할당합니다.
Graphcore IPU
Graphcore IPU(Intelligence Processing Units)는 기계 학습 작업을 위해 특별히 설계된 고유한 하드웨어 가속기입니다.
IPU 장치 메트릭
이러한 메트릭은 특정 IPU 장치에 대한 다양한 통계를 나타냅니다. 각 메트릭에는 장치를 식별하기 위한 장치 ID(device_id)와 메트릭 키(metric_key)가 있습니다. W&B는 이 메트릭에 ipu.{device_id}.{metric_key} 태그를 할당합니다.
메트릭은 Graphcore의 gcipuinfo 바이너리와 상호 작용하는 독점 gcipuinfo 라이브러리를 사용하여 추출됩니다. sample 메소드는 프로세스 ID(pid)와 연결된 각 IPU 장치에 대해 이러한 메트릭을 가져옵니다. 시간이 지남에 따라 변경되는 메트릭 또는 장치의 메트릭을 처음 가져오는 경우에만 중복된 데이터 로깅을 방지하기 위해 기록됩니다.
각 메트릭에 대해 parse_metric 메소드를 사용하여 원시 문자열 표현에서 메트릭의 값을 추출합니다. 그런 다음 aggregate 메소드를 사용하여 여러 샘플에서 메트릭을 집계합니다.
다음은 사용 가능한 메트릭 및 해당 단위를 나열한 것입니다.
평균 보드 온도 (average board temp (C)): IPU 보드의 온도를 섭씨로 나타냅니다.
평균 다이 온도 (average die temp (C)): IPU 다이의 온도를 섭씨로 나타냅니다.
클럭 속도 (clock (MHz)): IPU의 클럭 속도를 MHz로 나타냅니다.
IPU 전력 (ipu power (W)): IPU의 전력 소비량을 와트 단위로 나타냅니다.
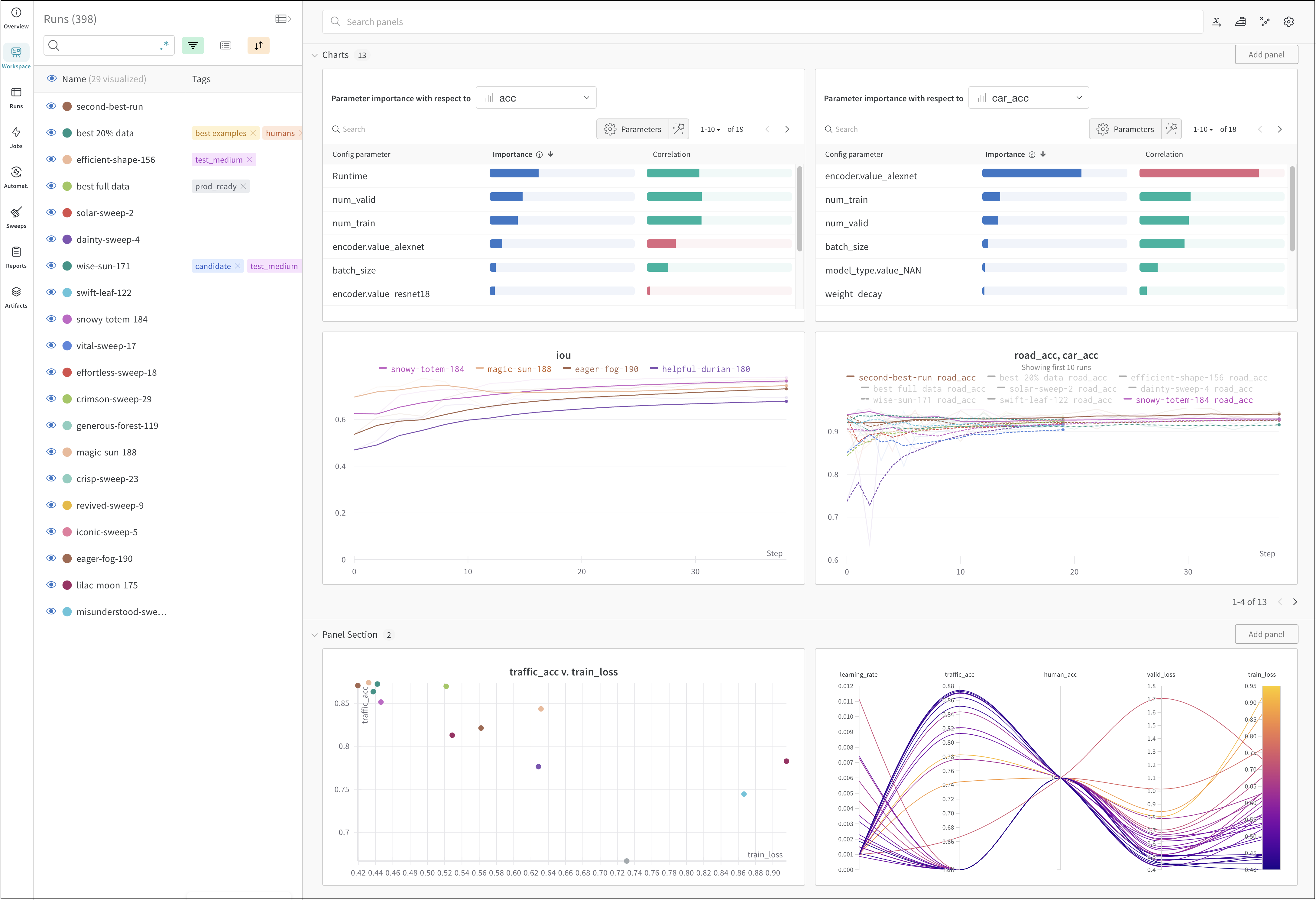
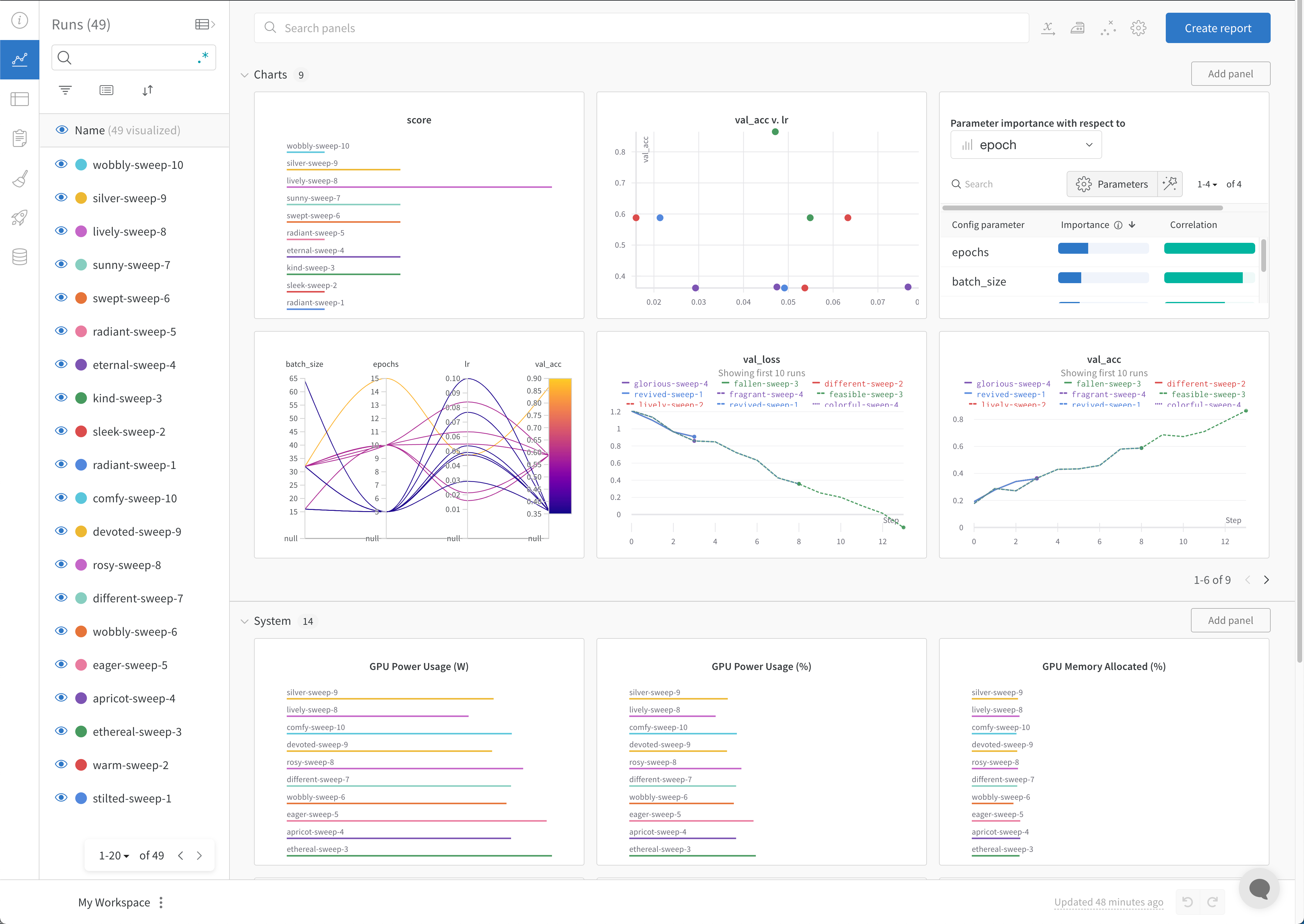
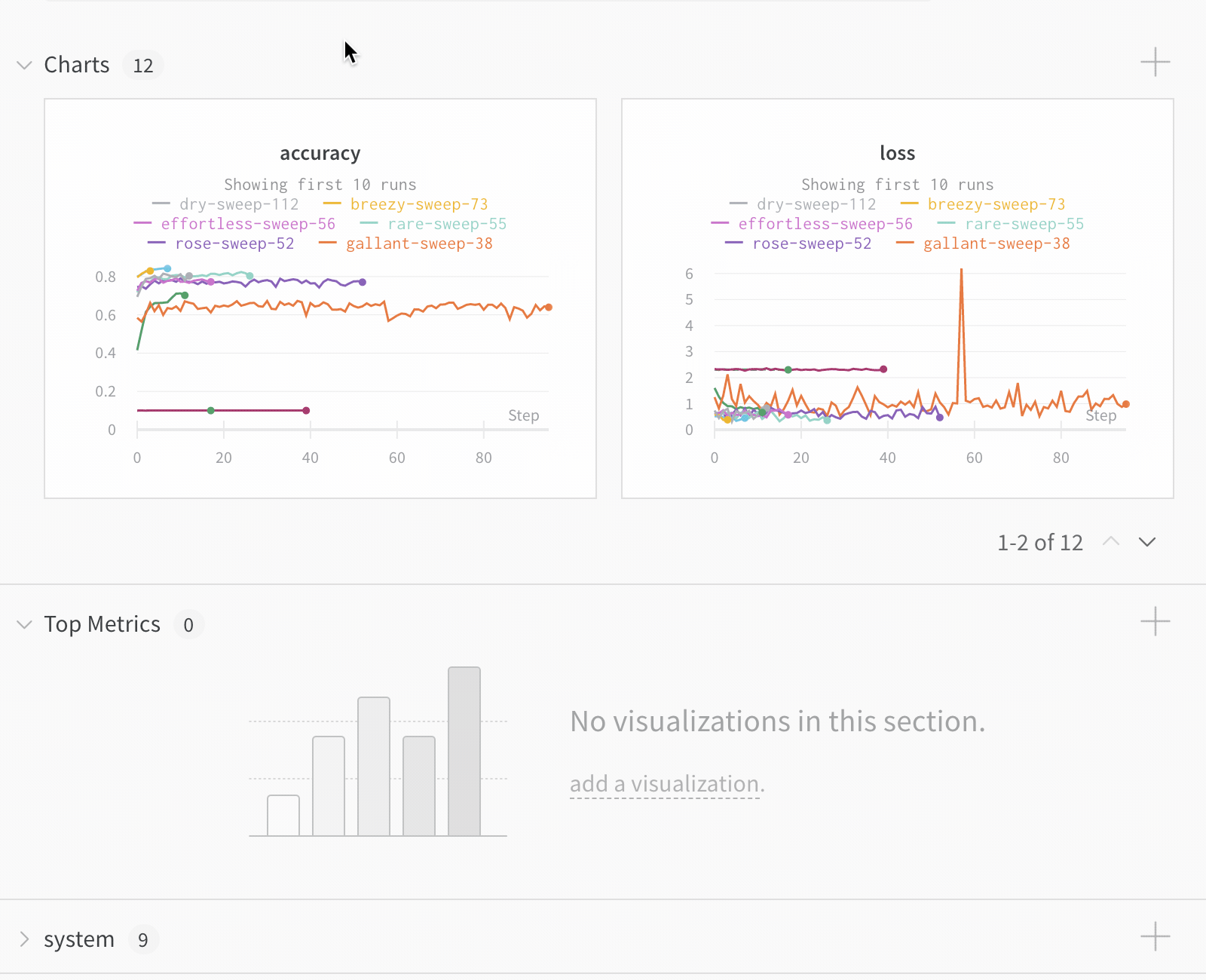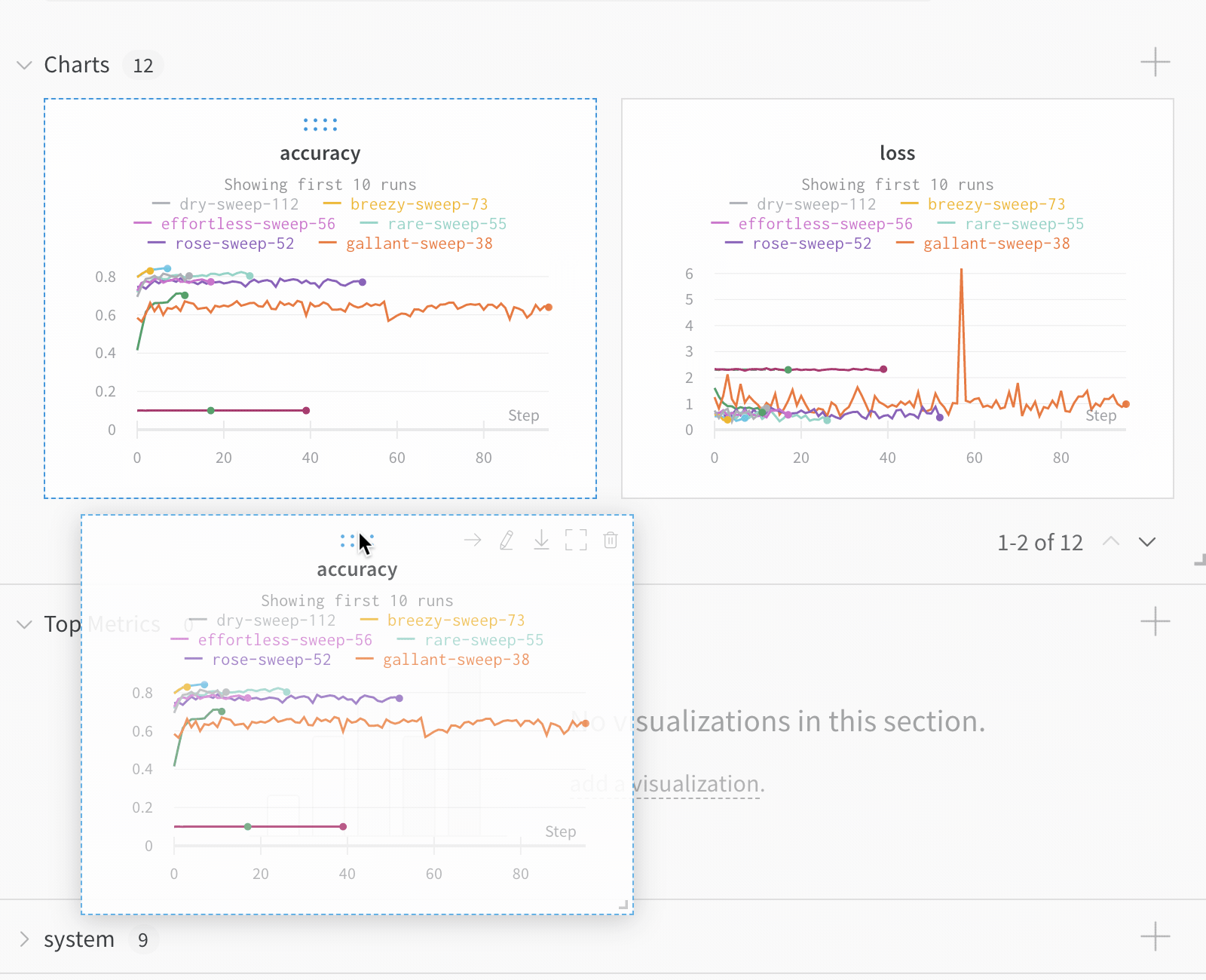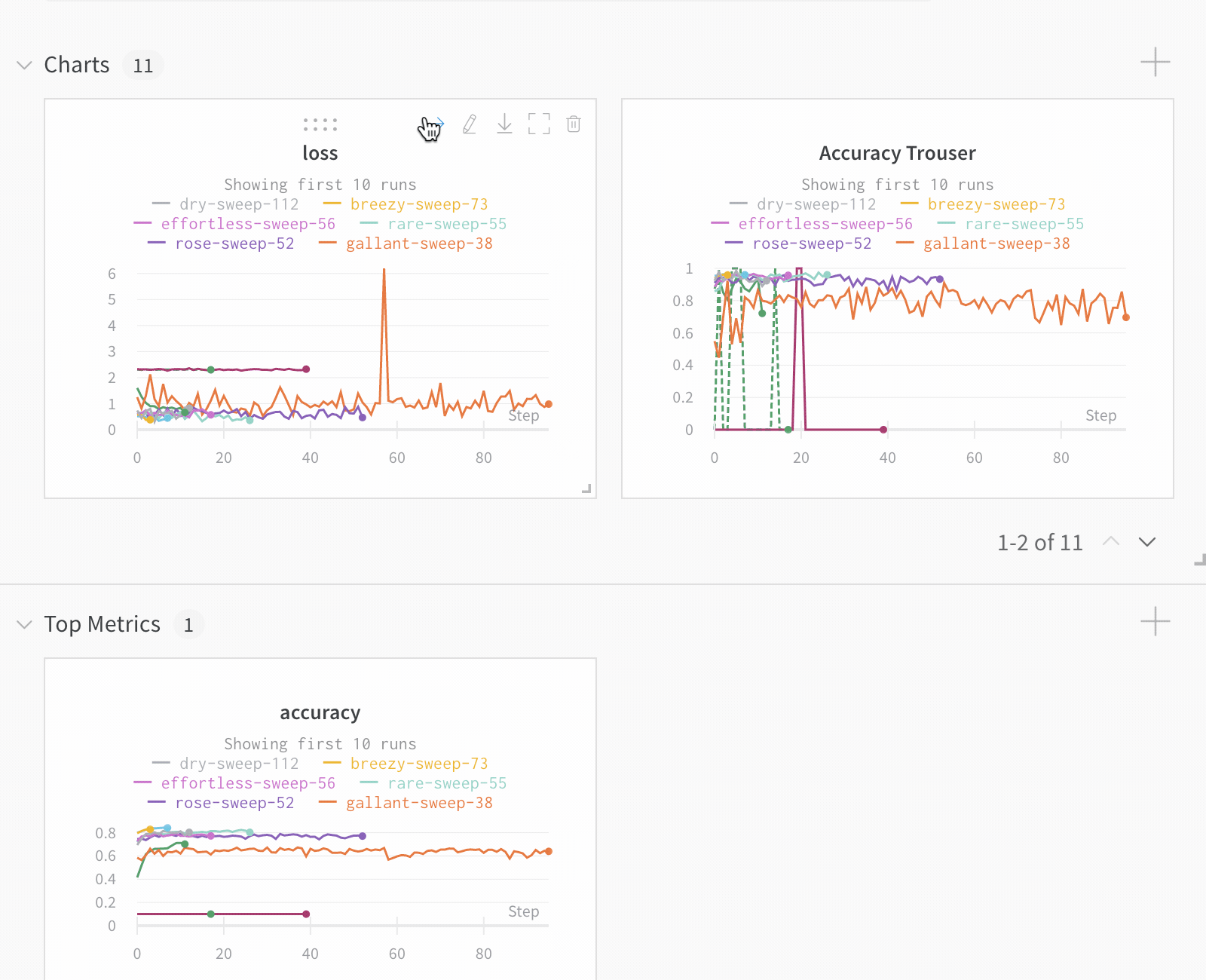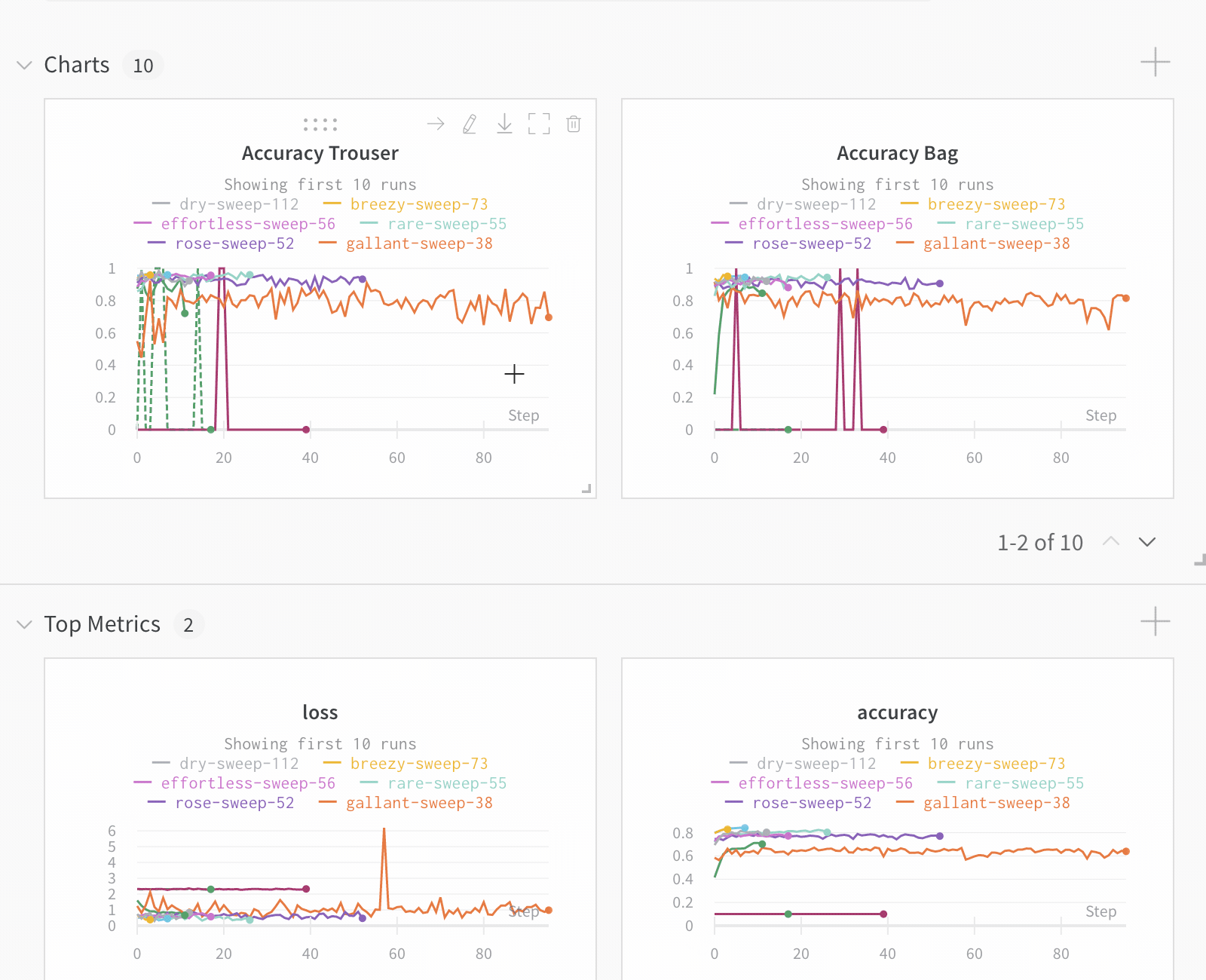
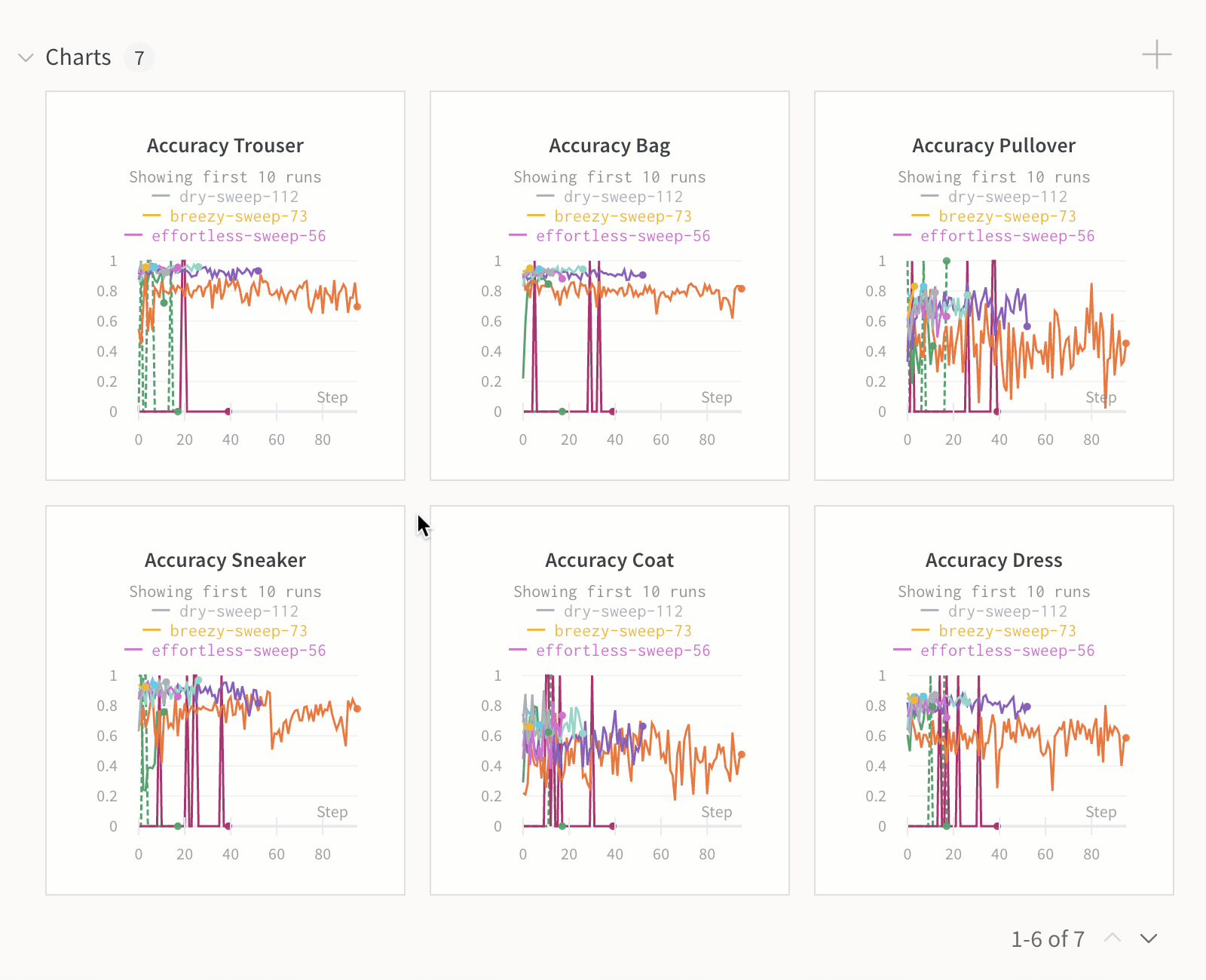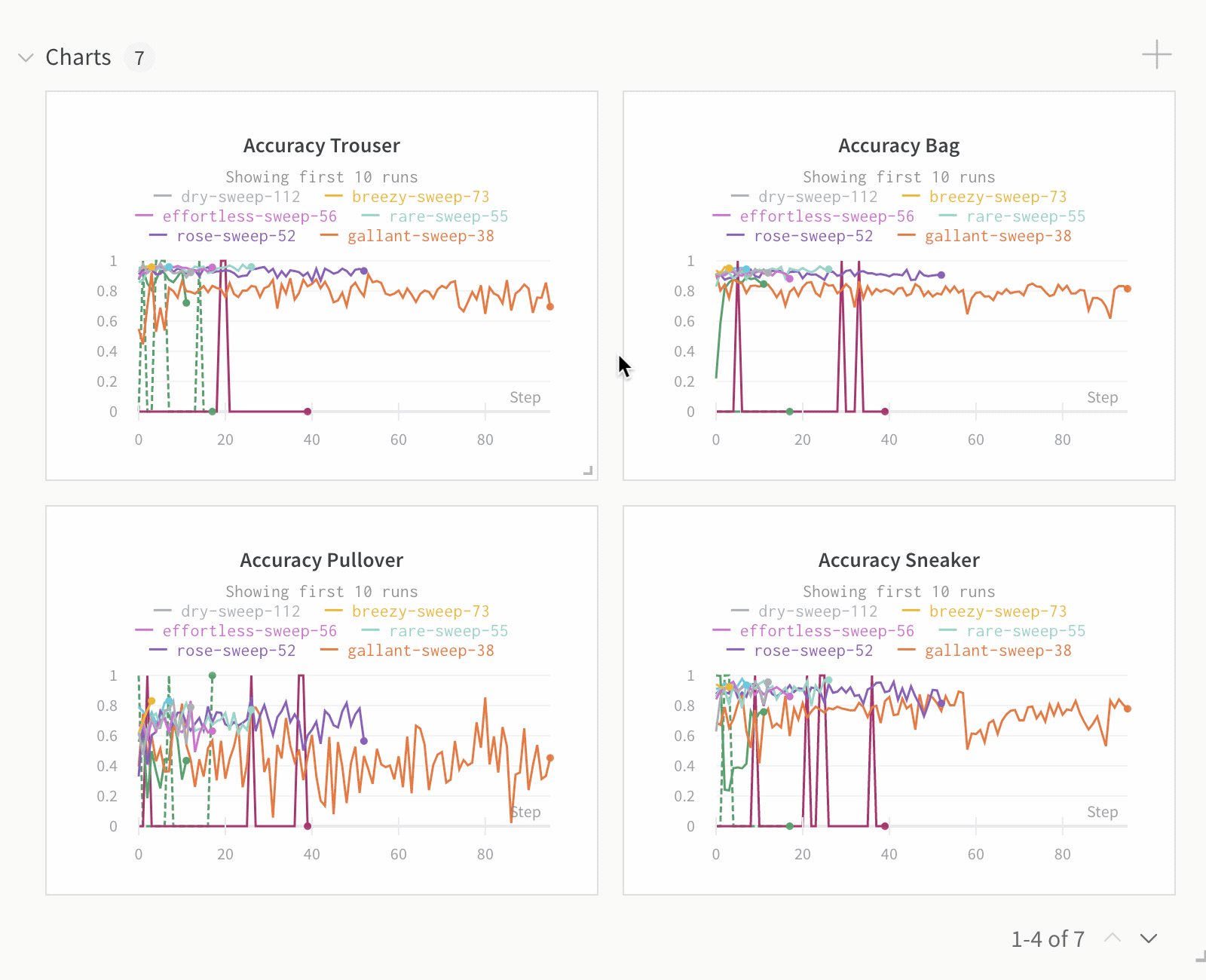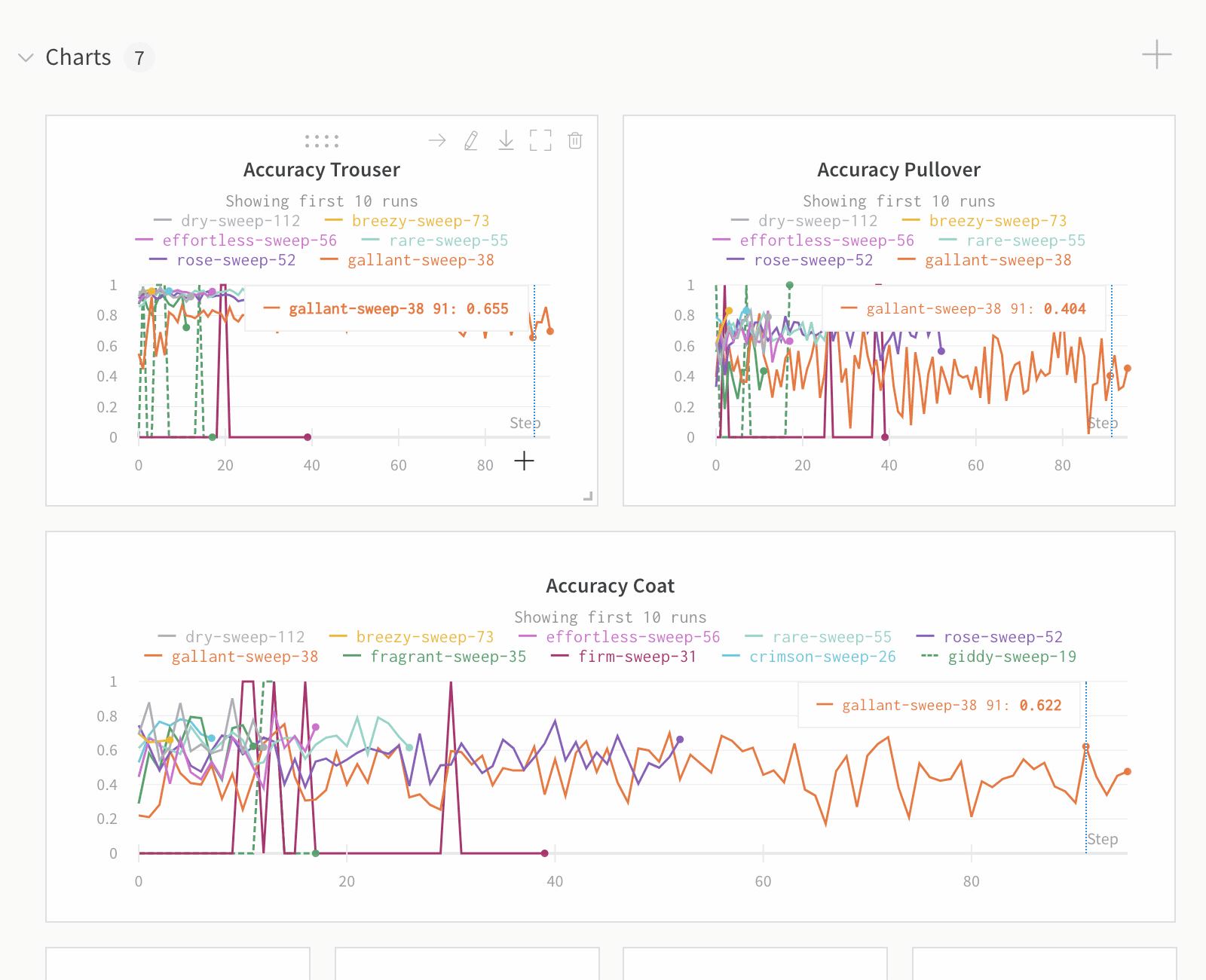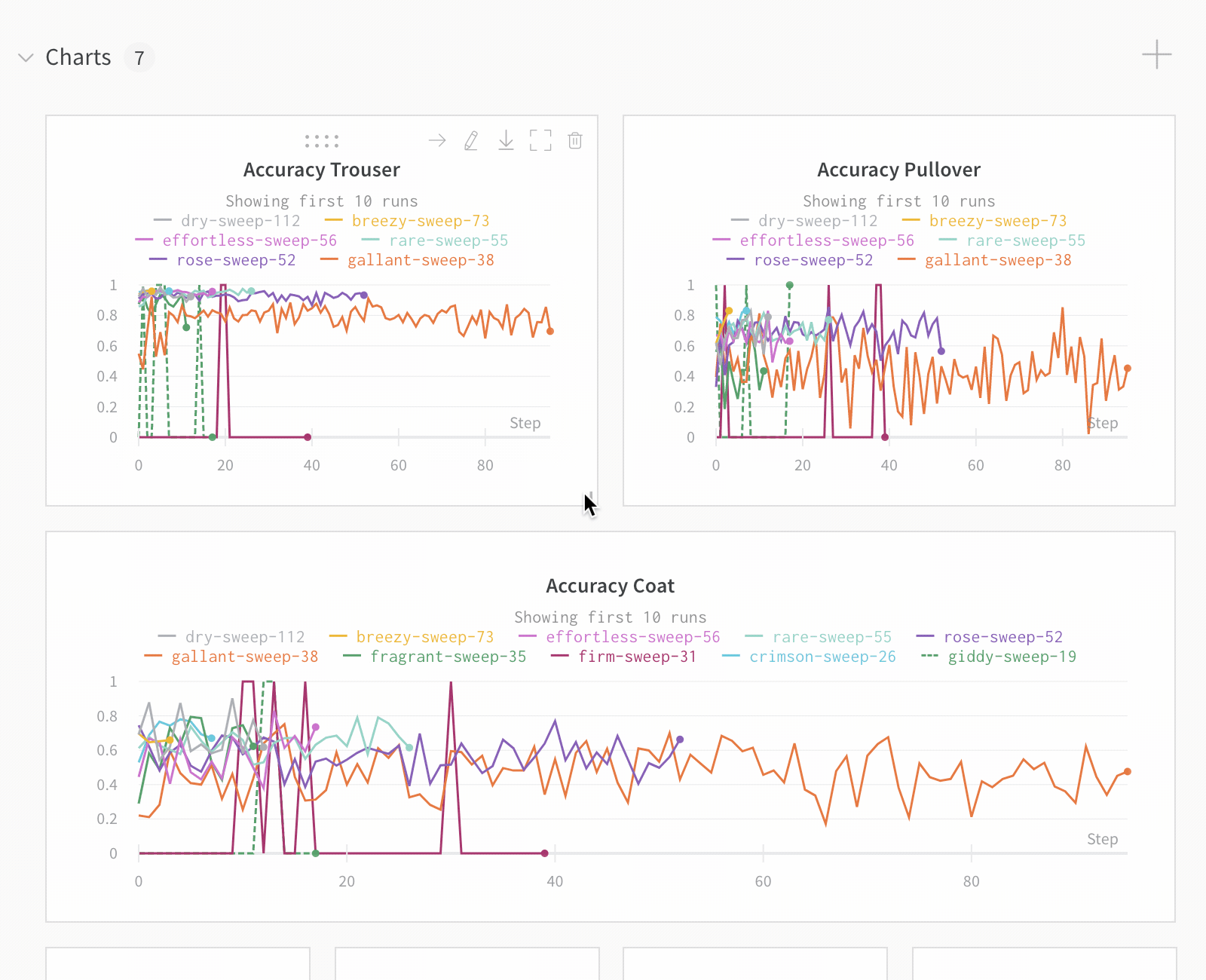
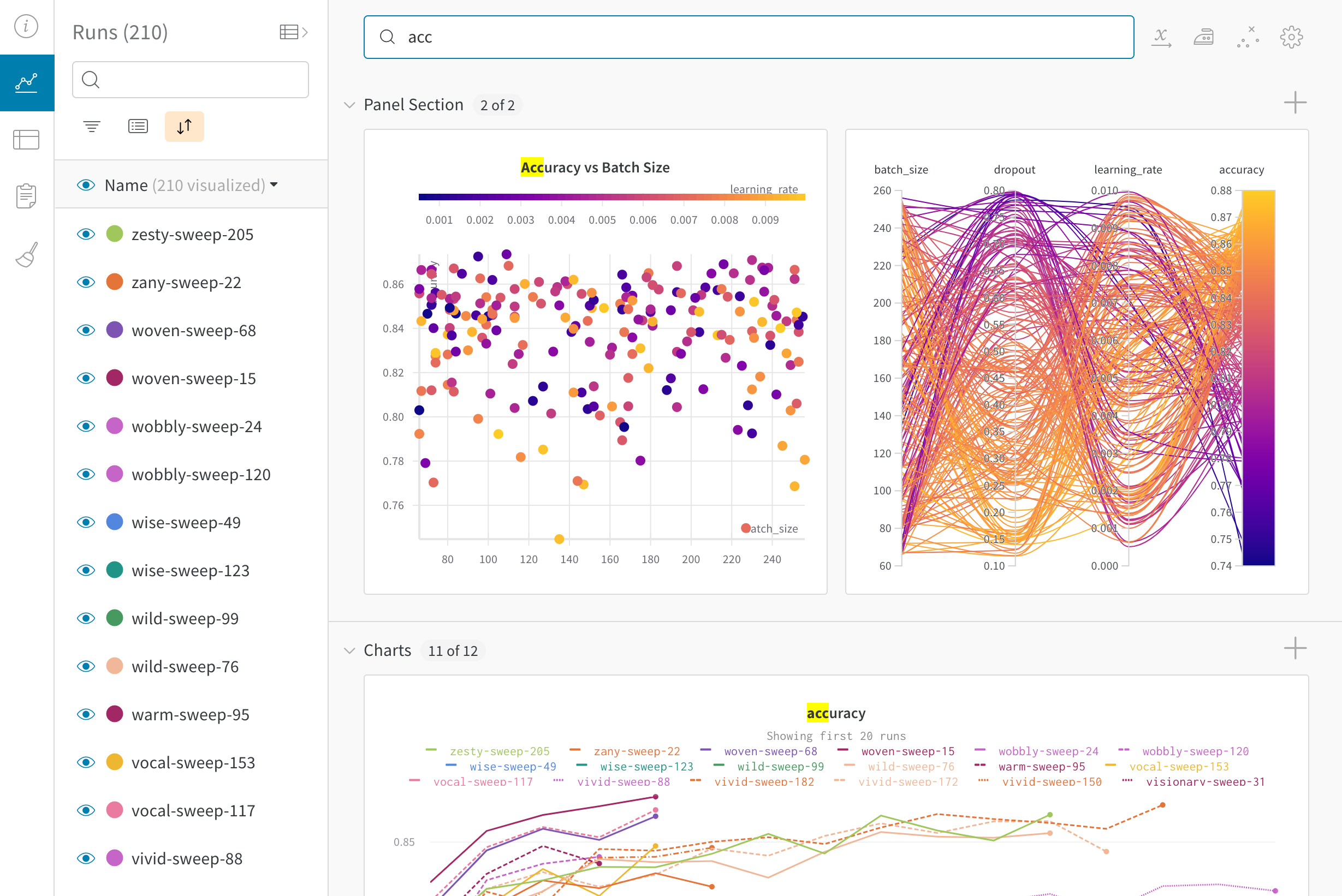
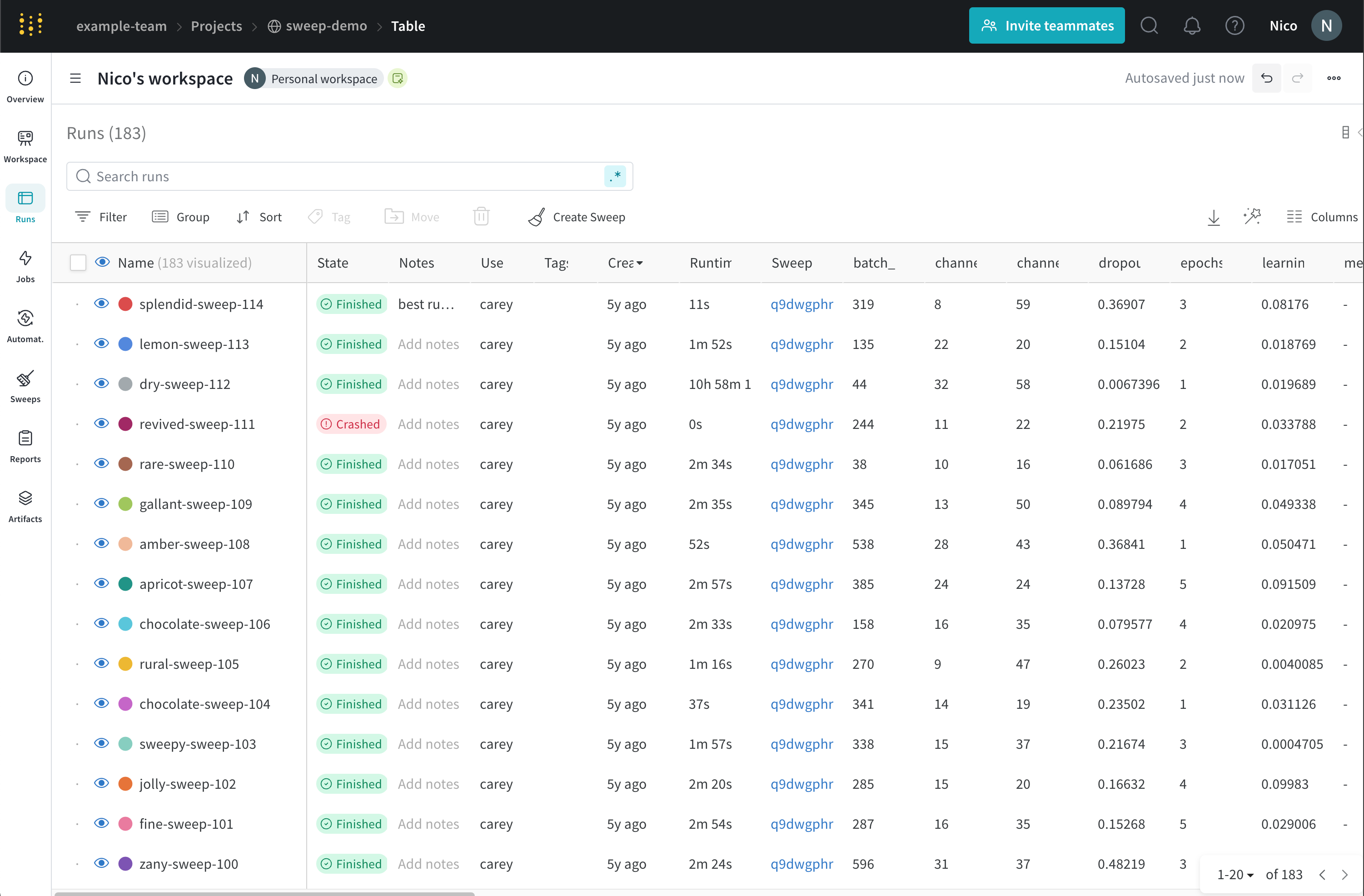
 위의 이미지는 `val_loss` 열을 기반으로 하는 필터를 보여줍니다. 필터는 유효성 검사 손실이 1 이하인 Runs을 보여줍니다.
위의 이미지는 `val_loss` 열을 기반으로 하는 필터를 보여줍니다. 필터는 유효성 검사 손실이 1 이하인 Runs을 보여줍니다.
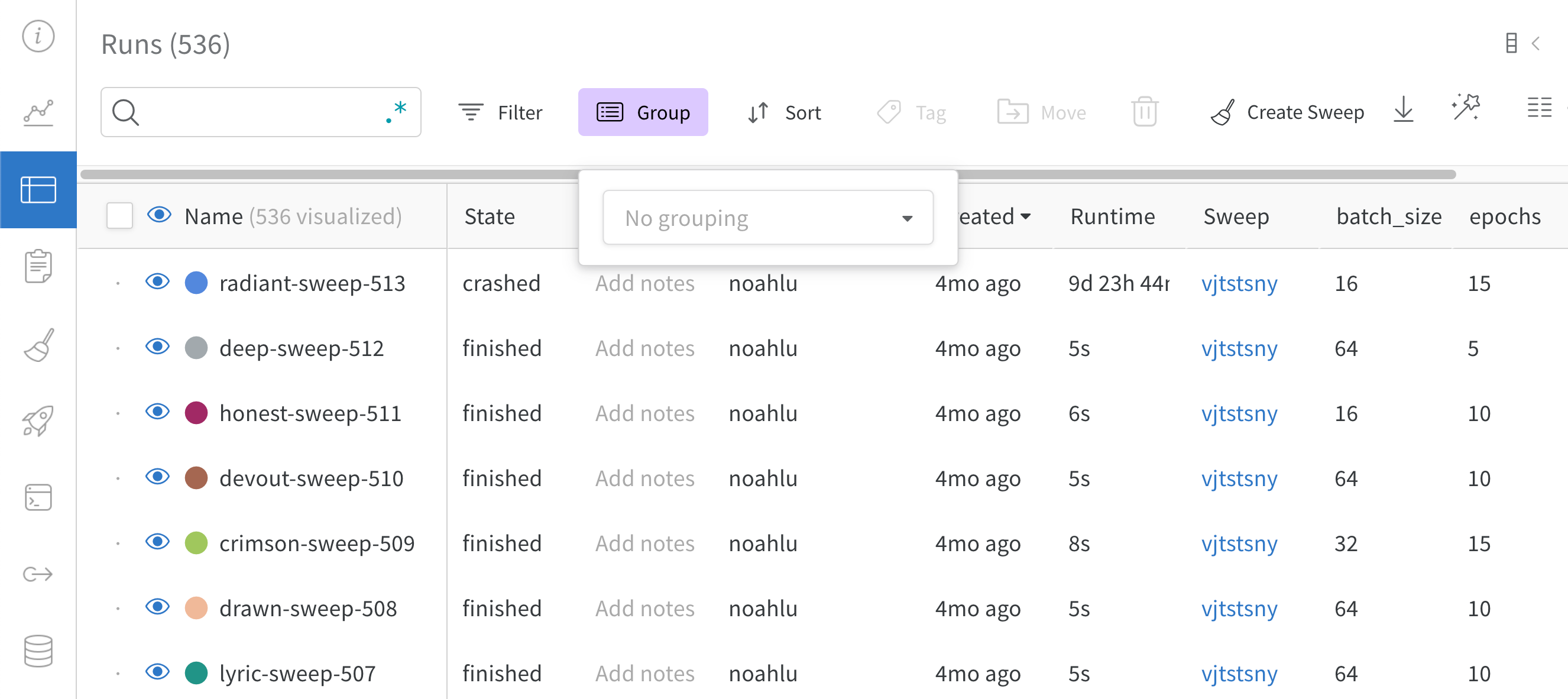
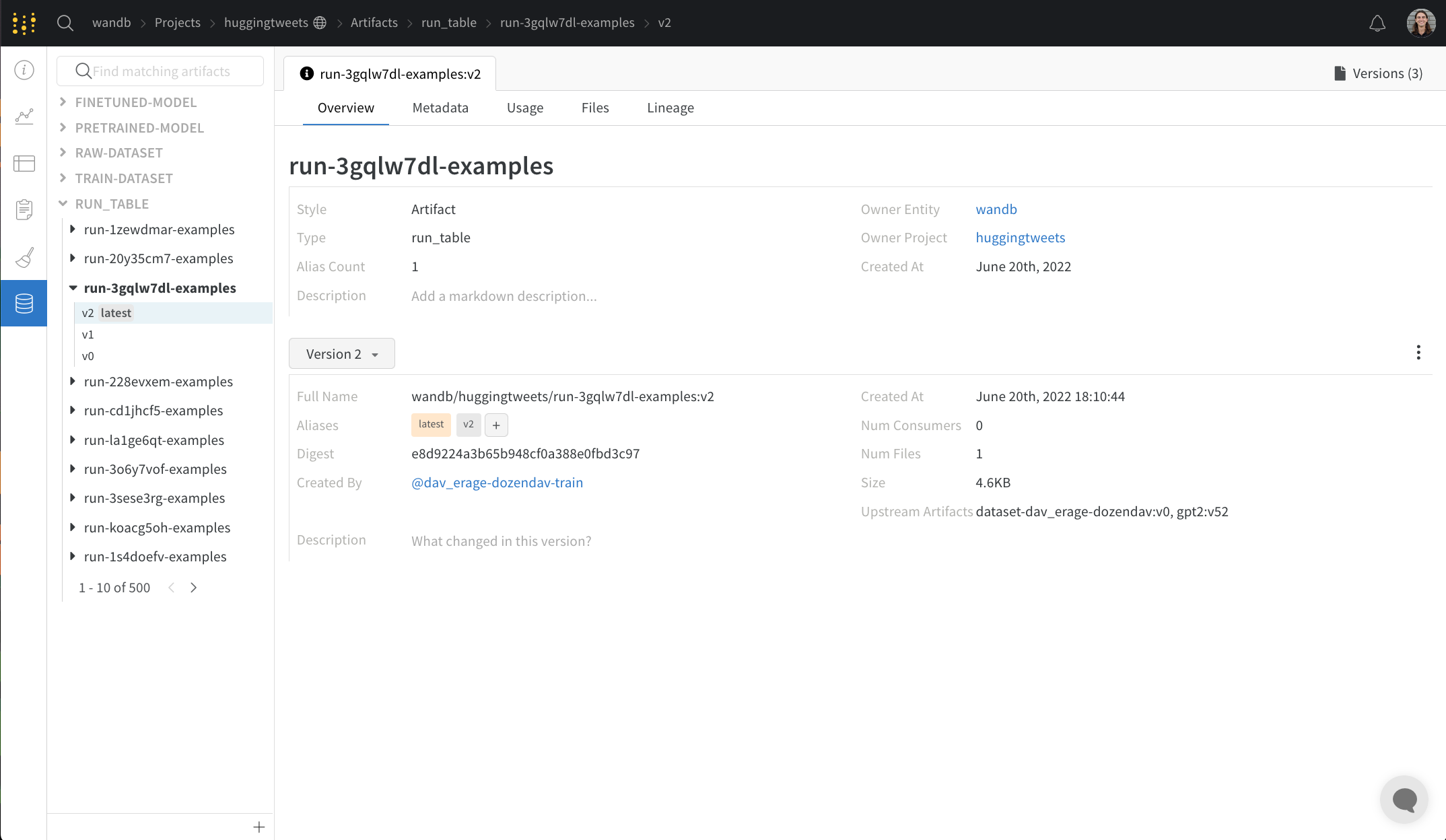
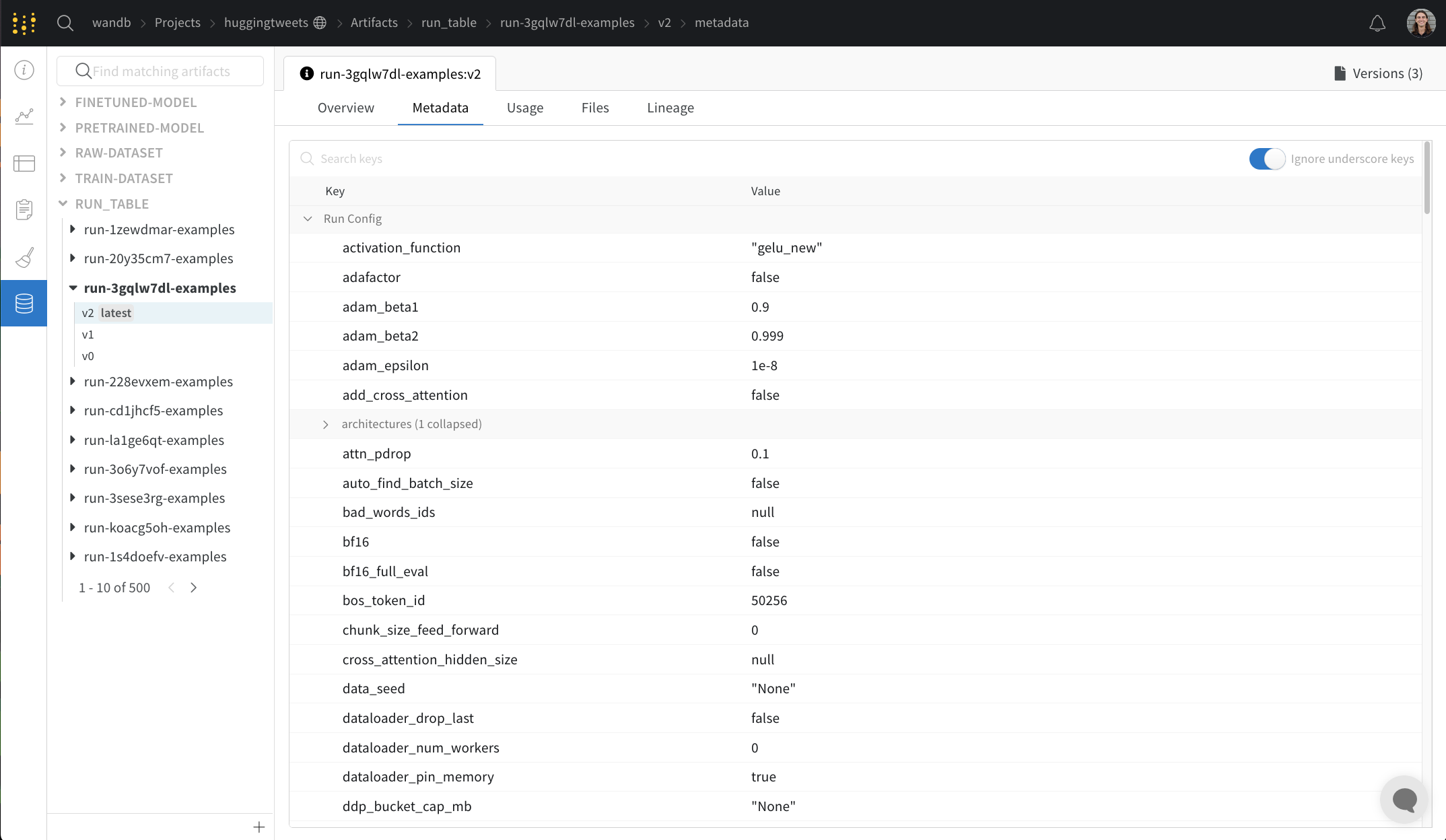
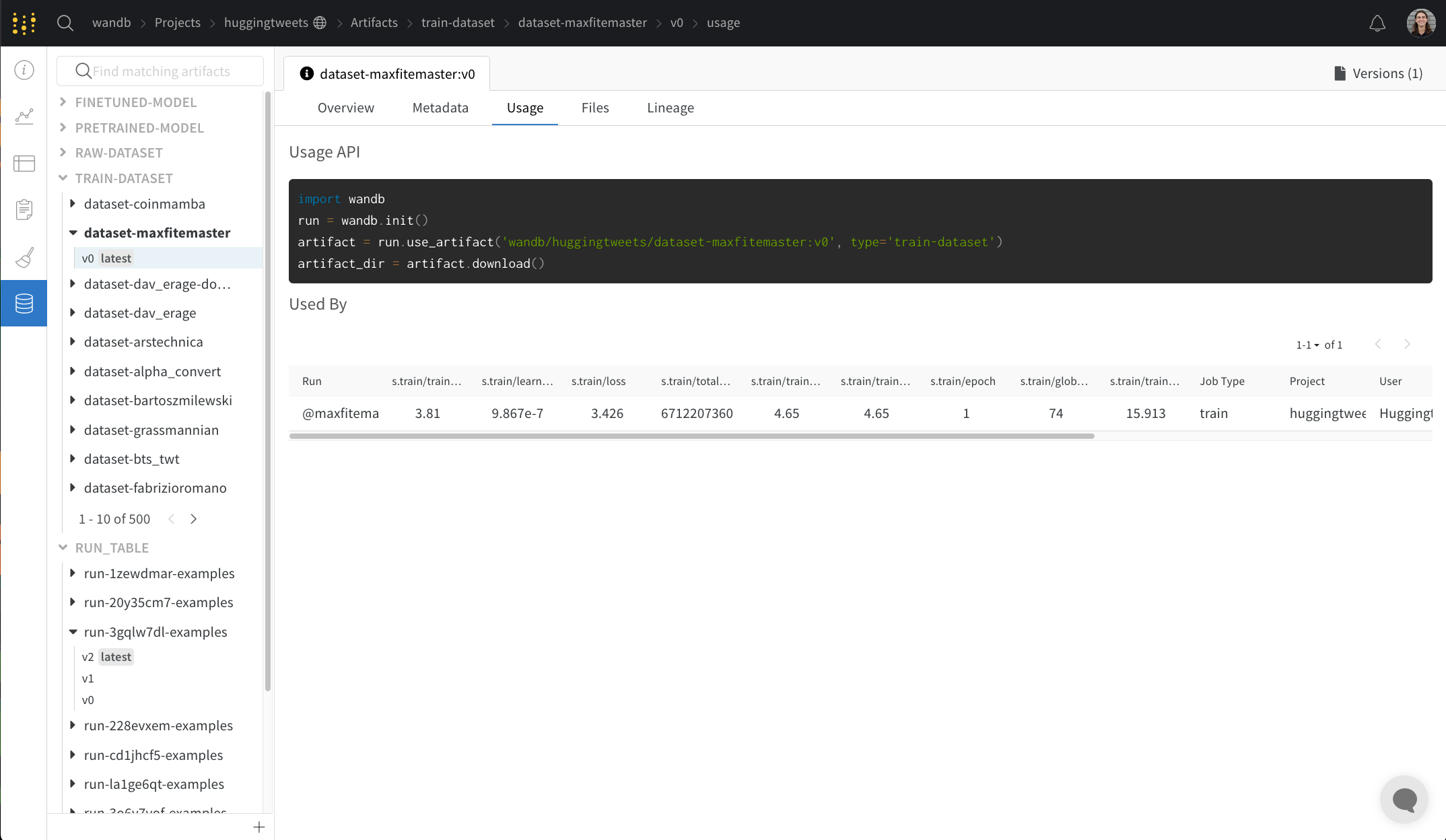
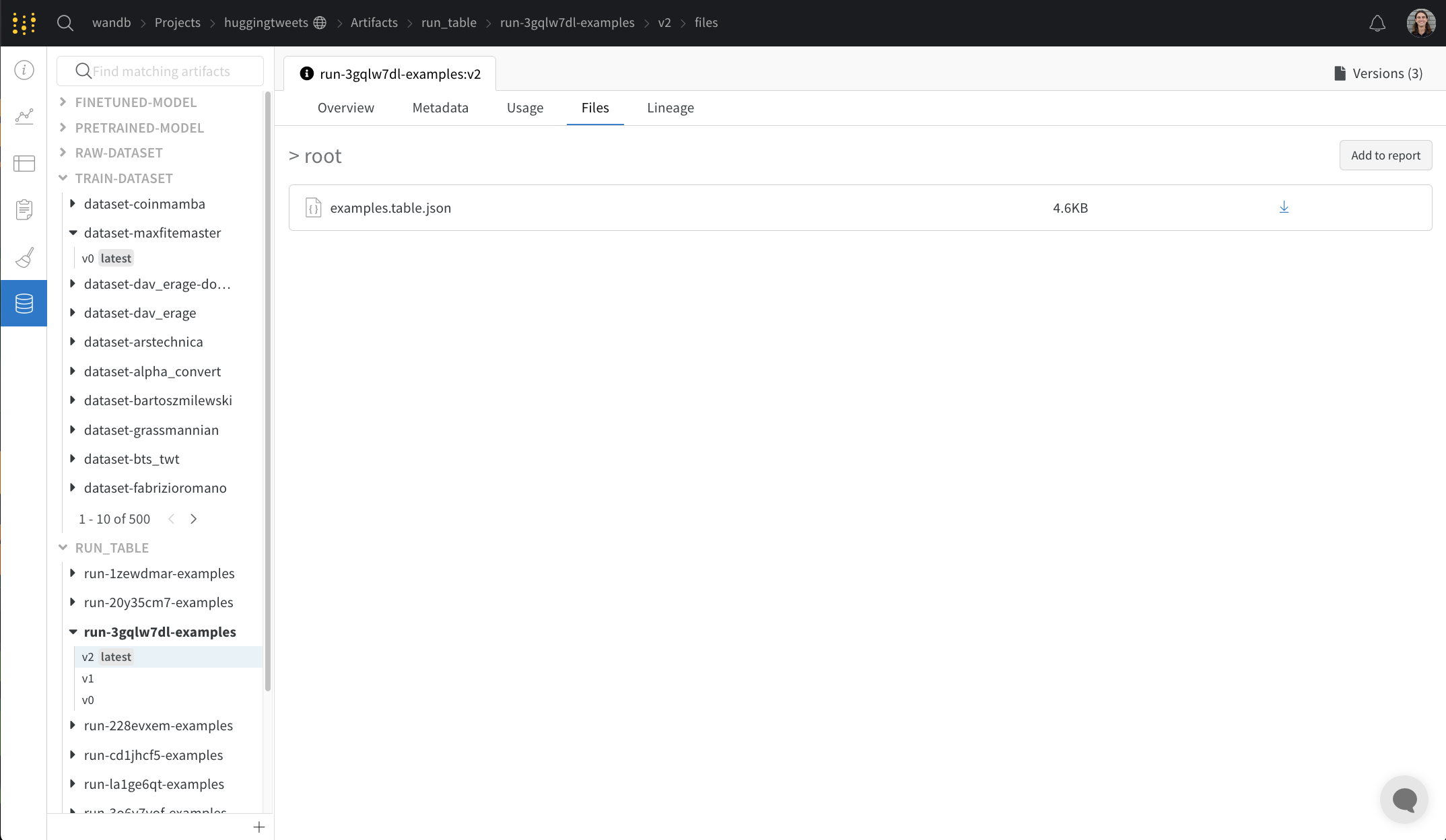
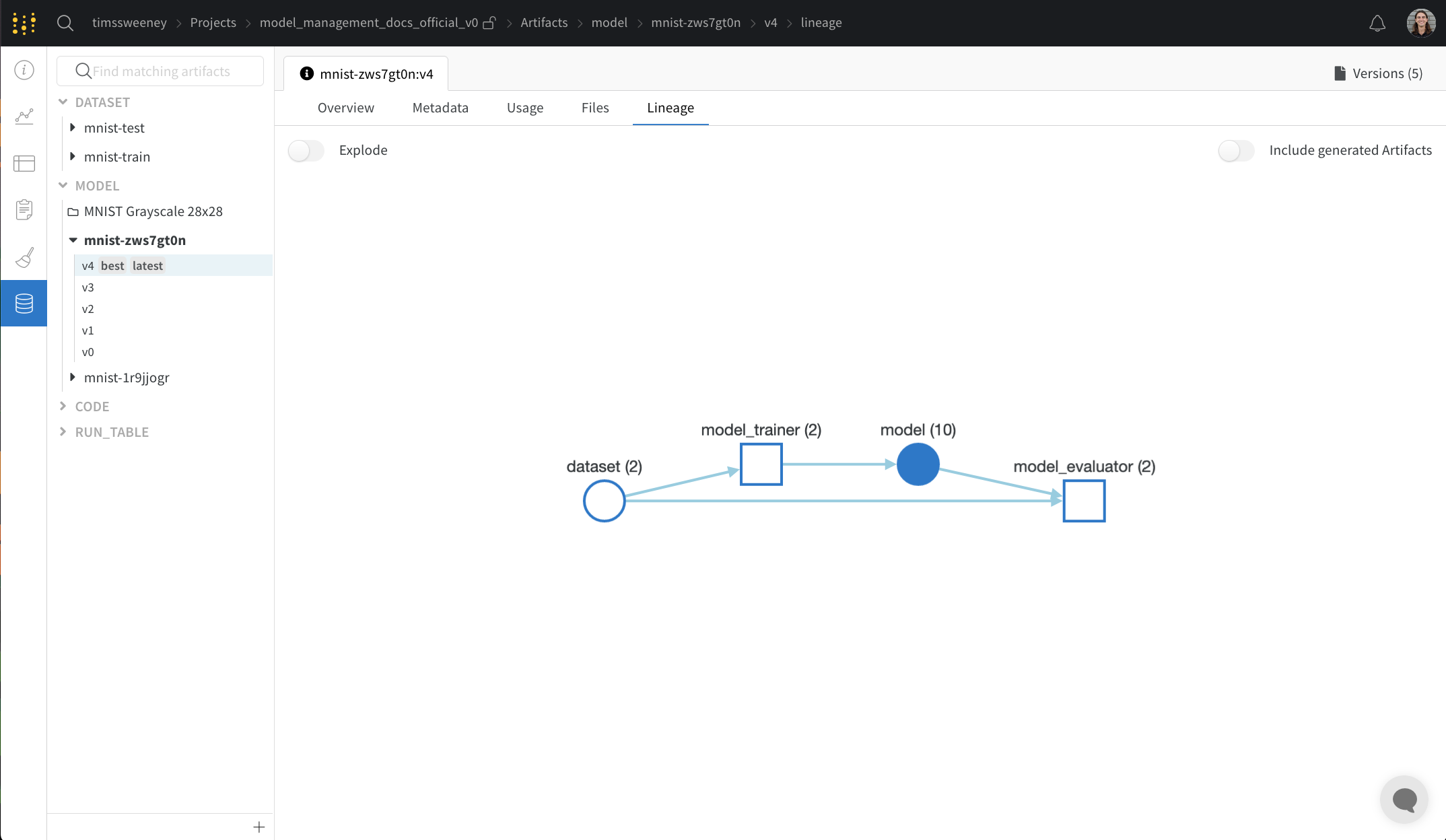
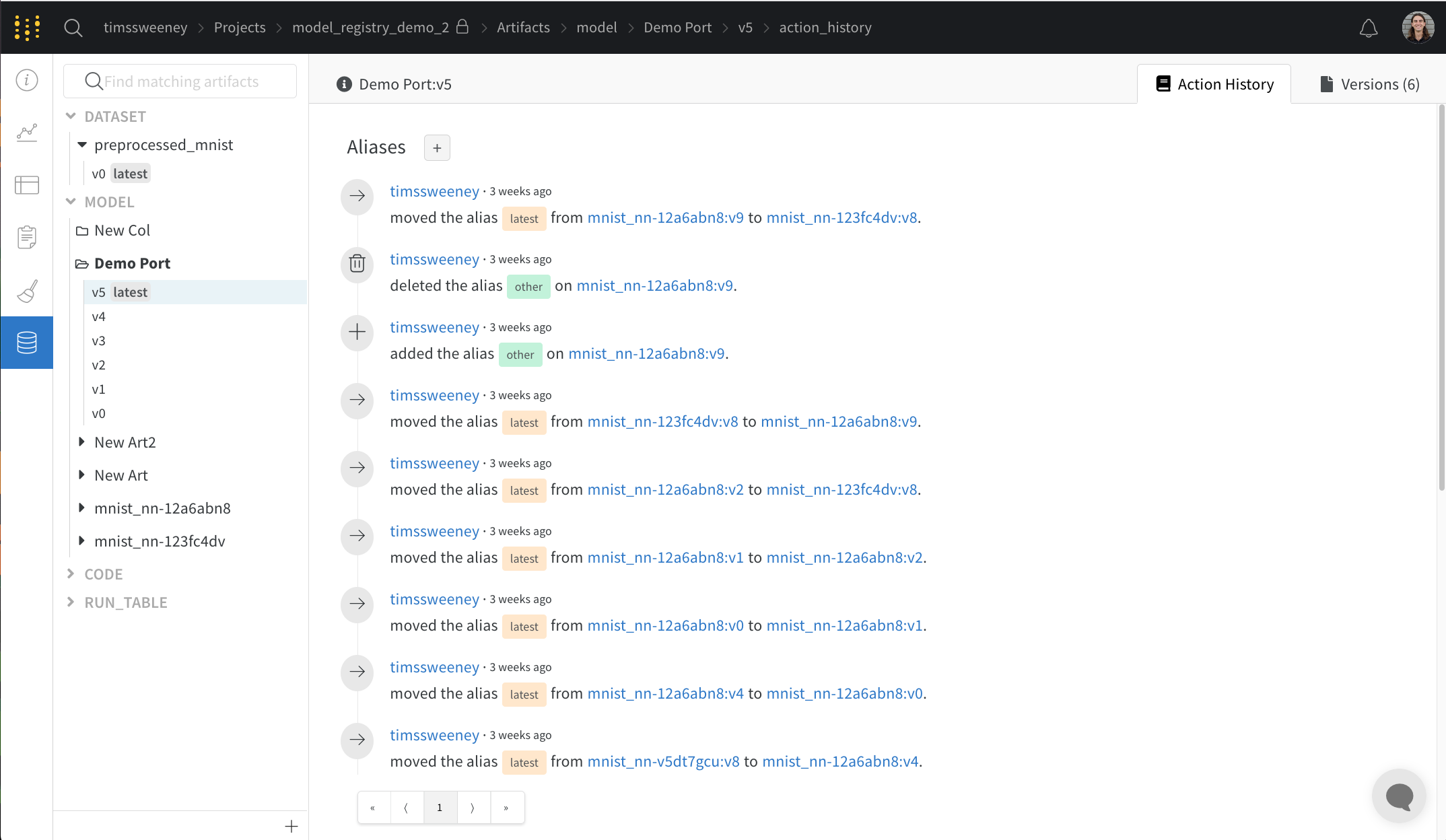

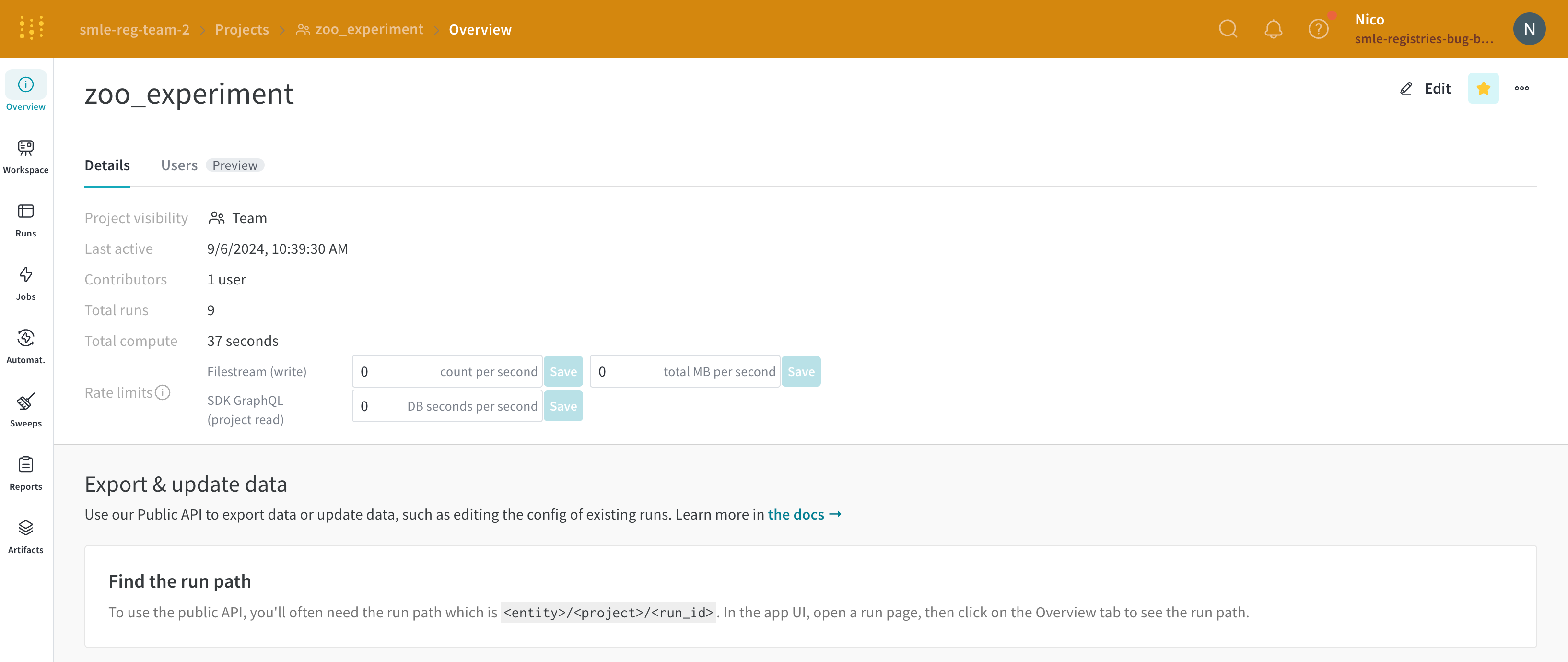
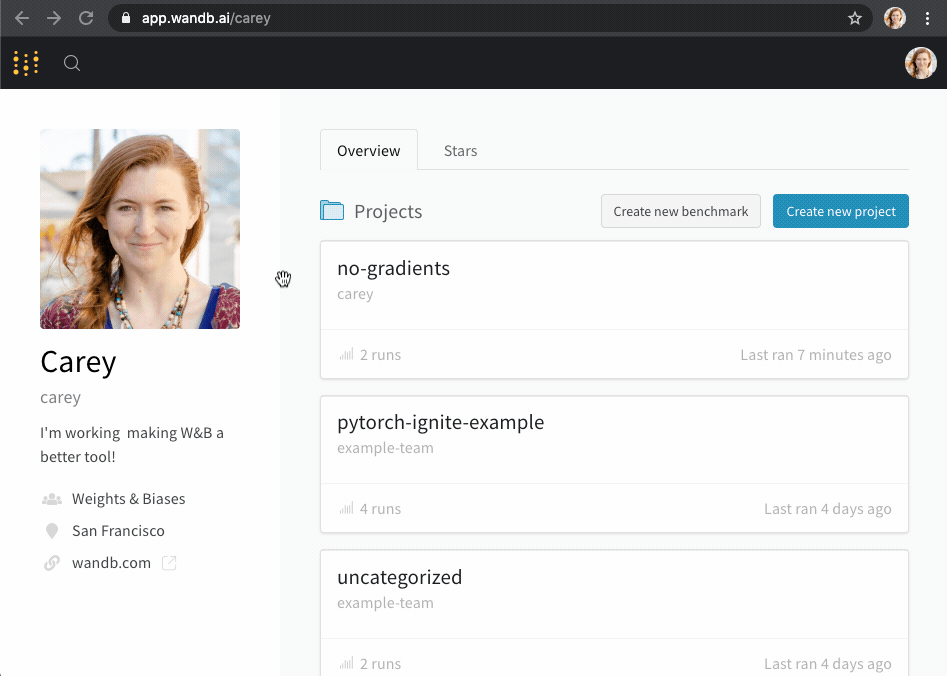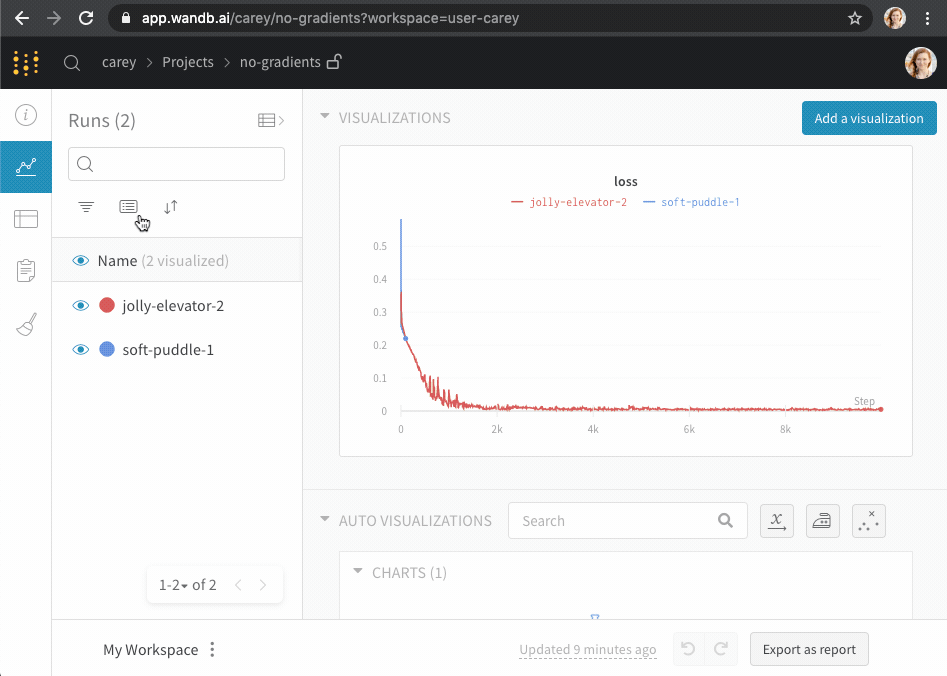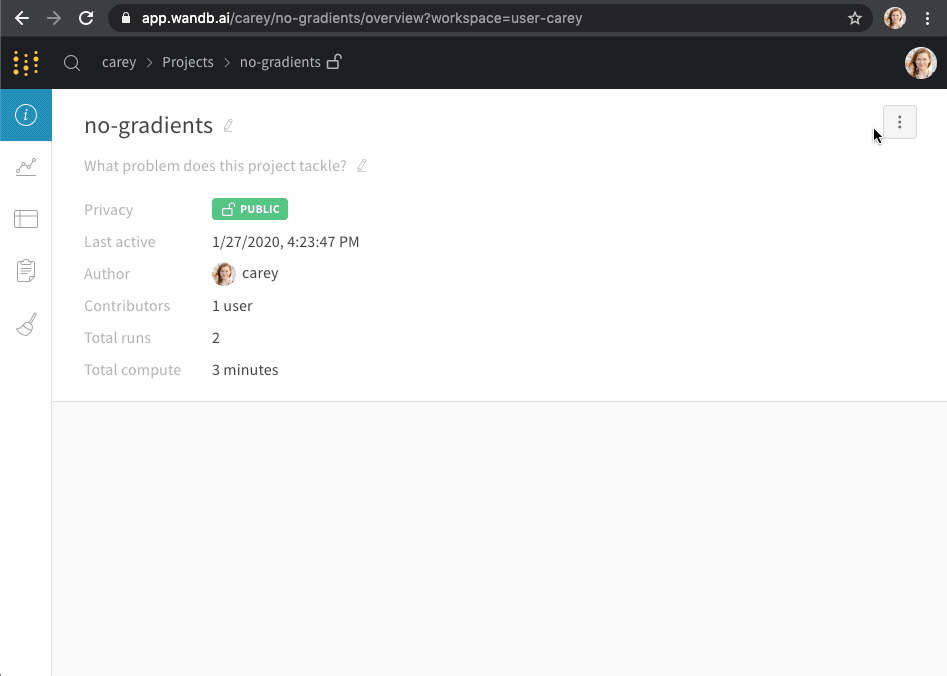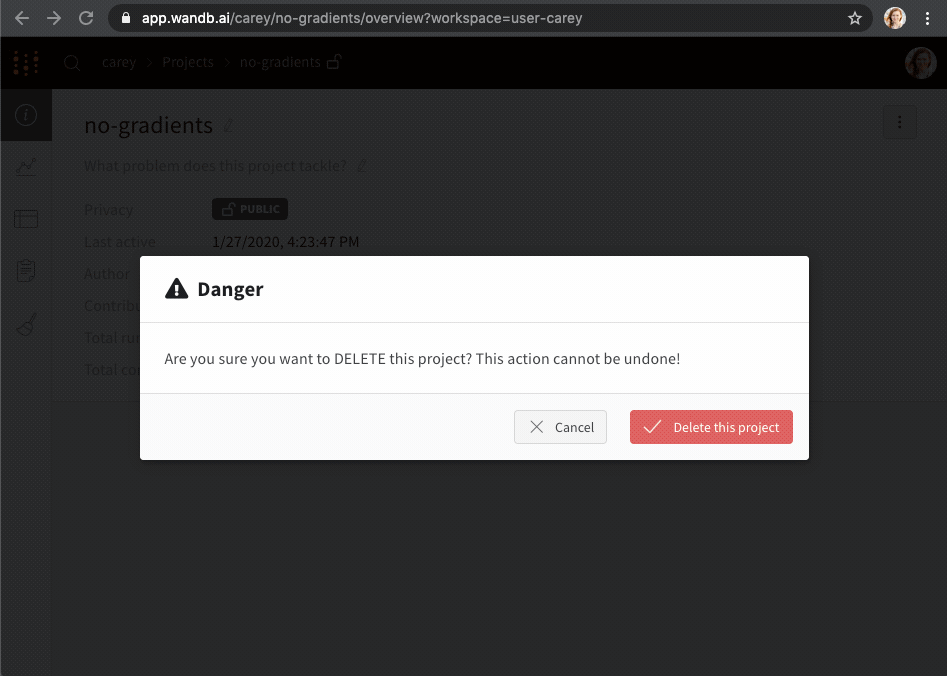
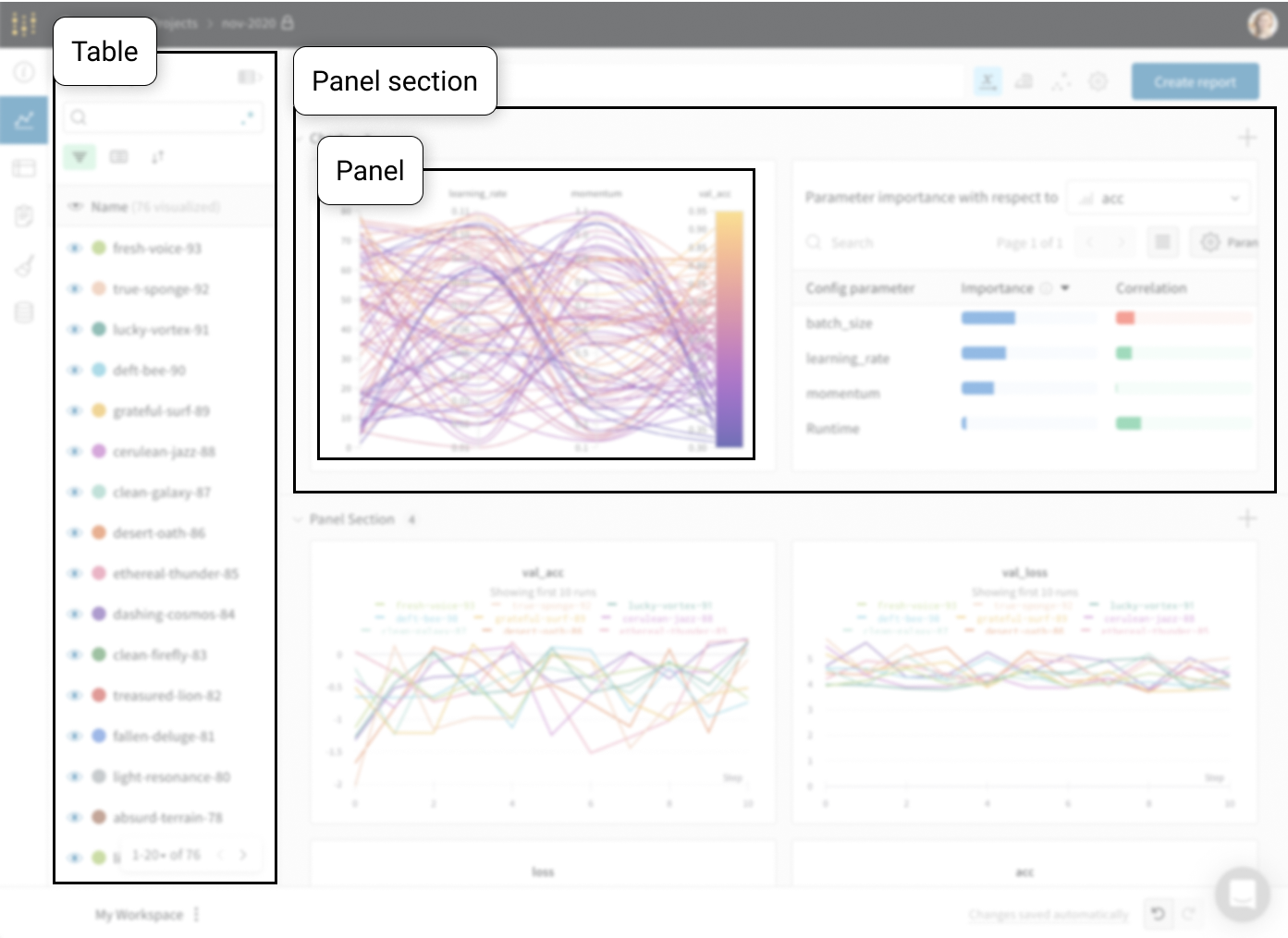
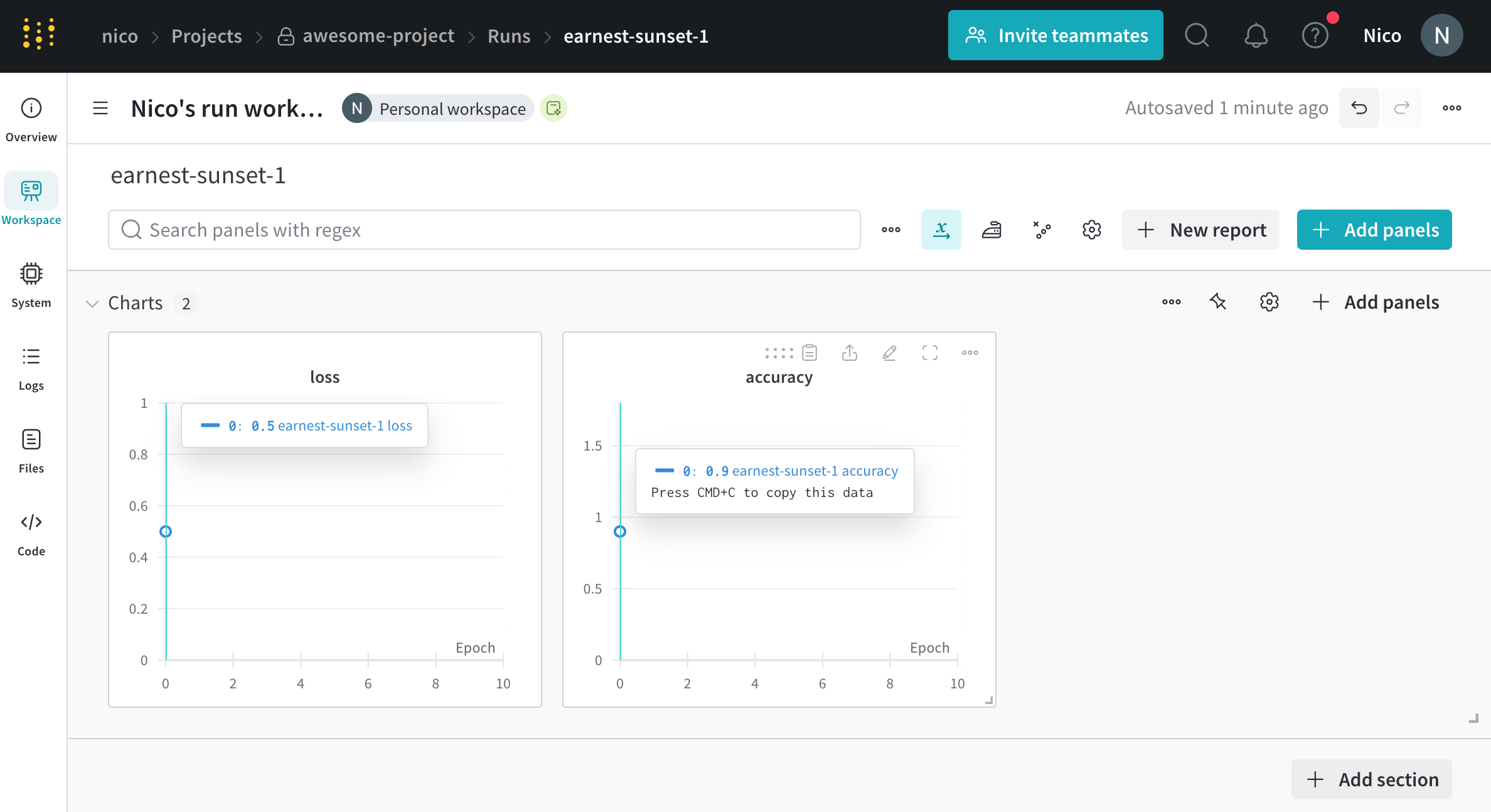
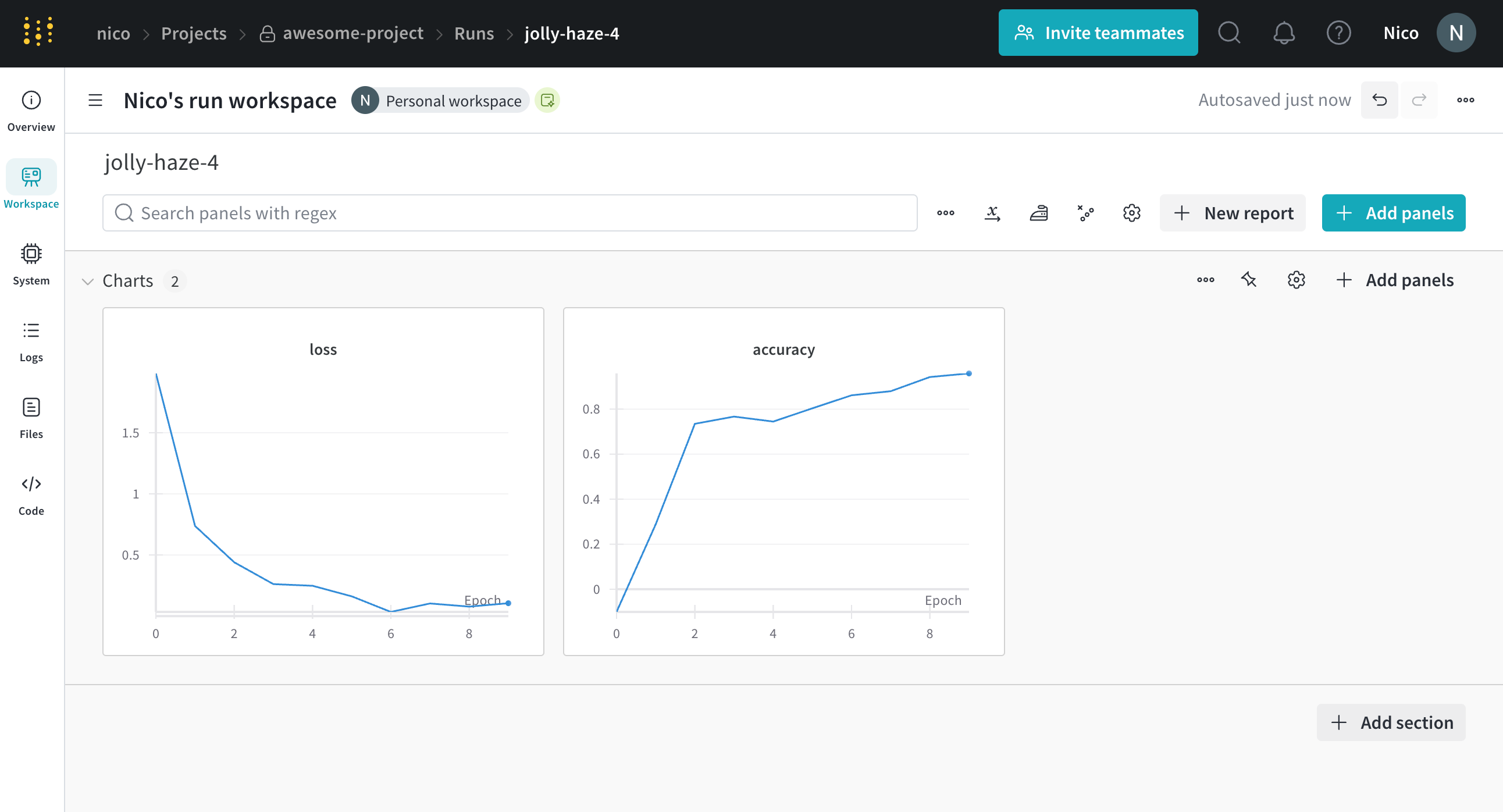
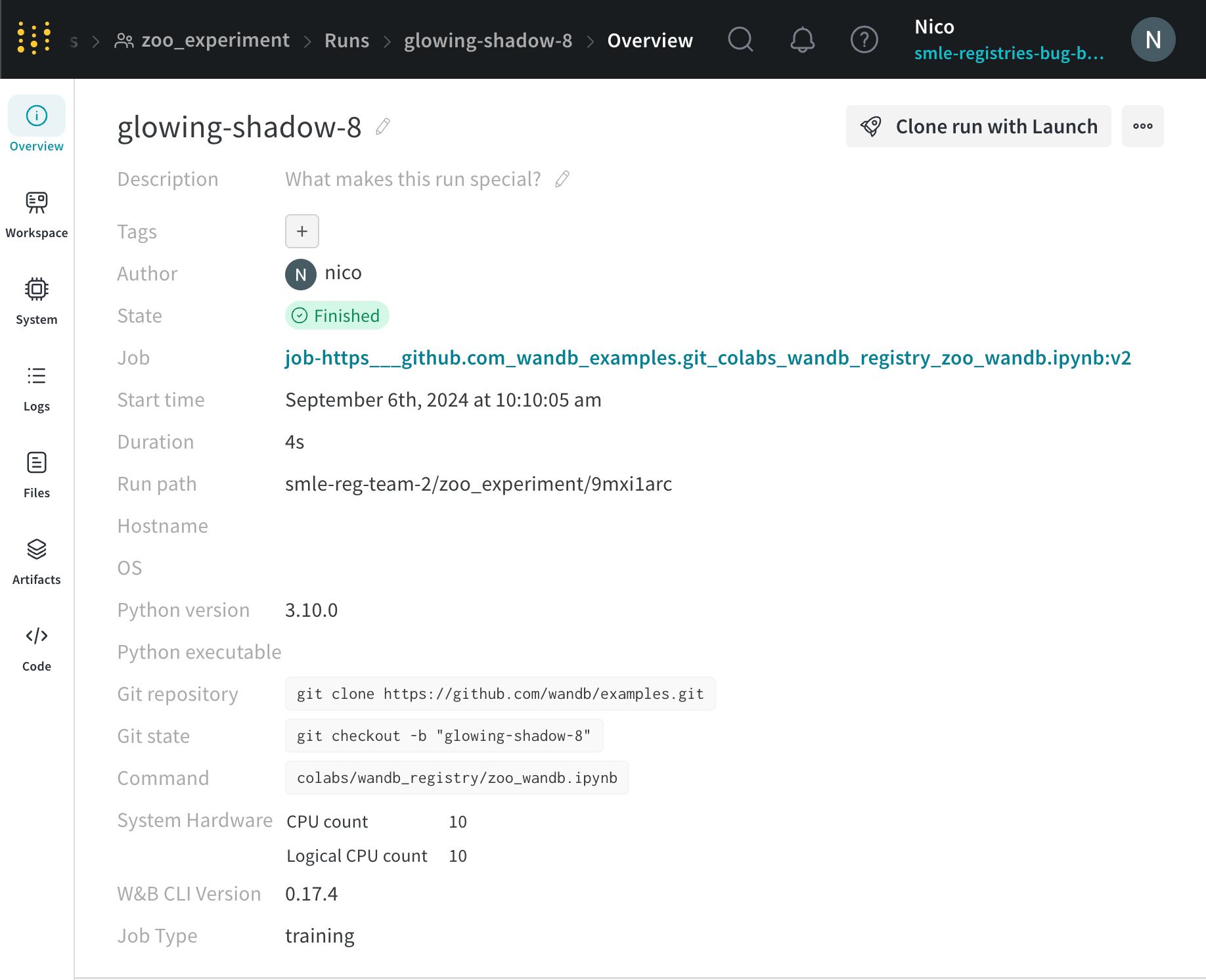
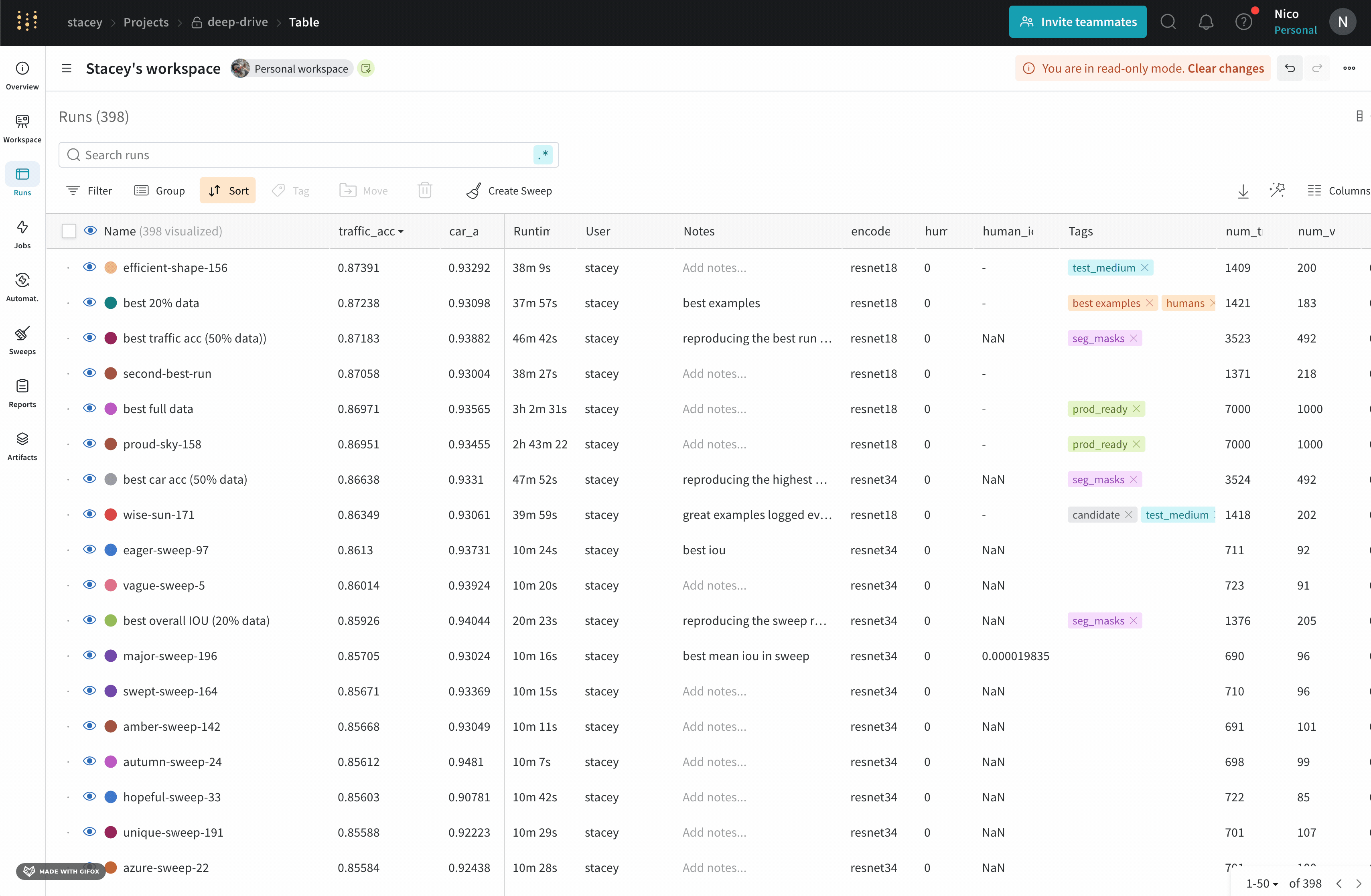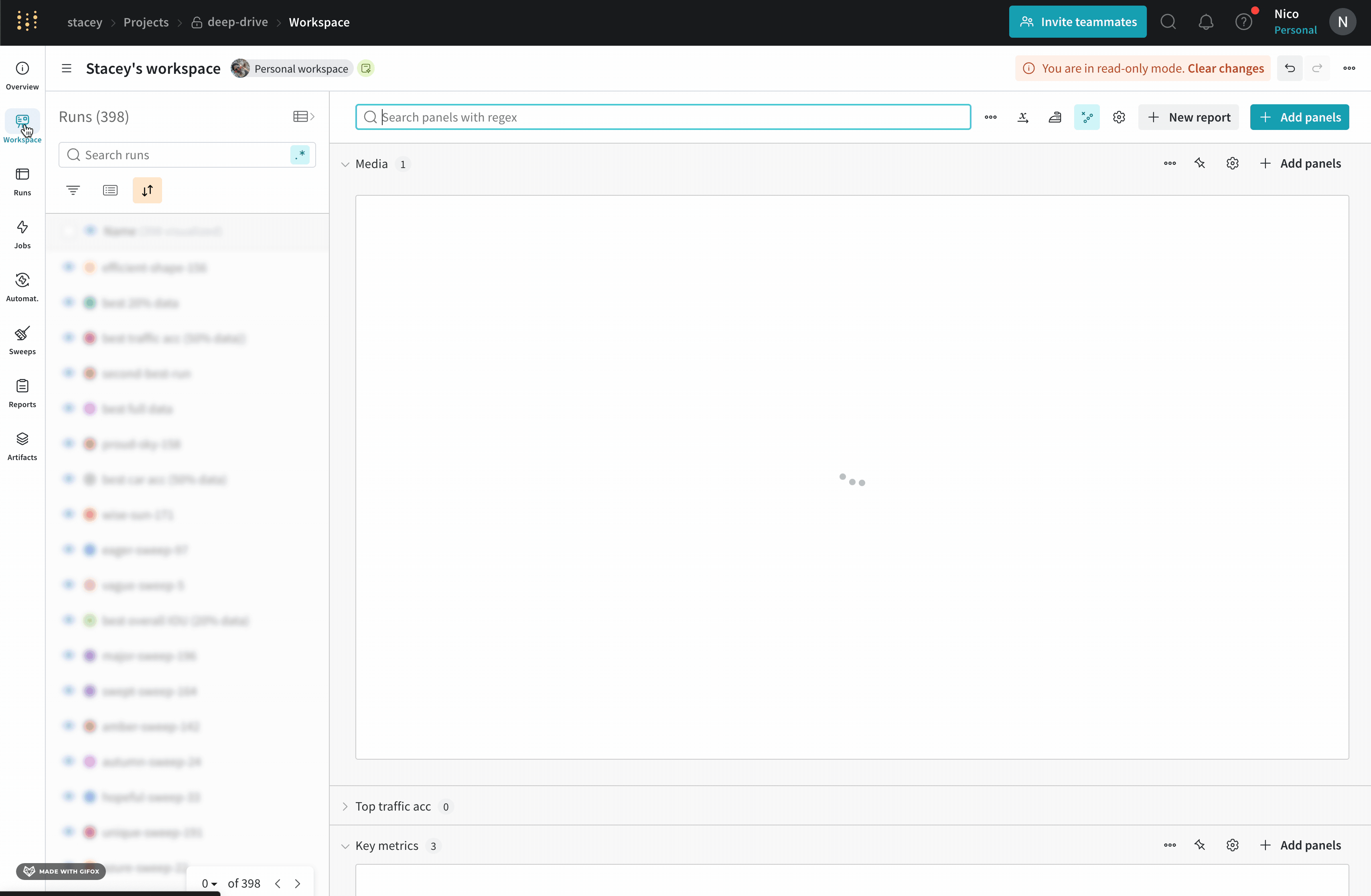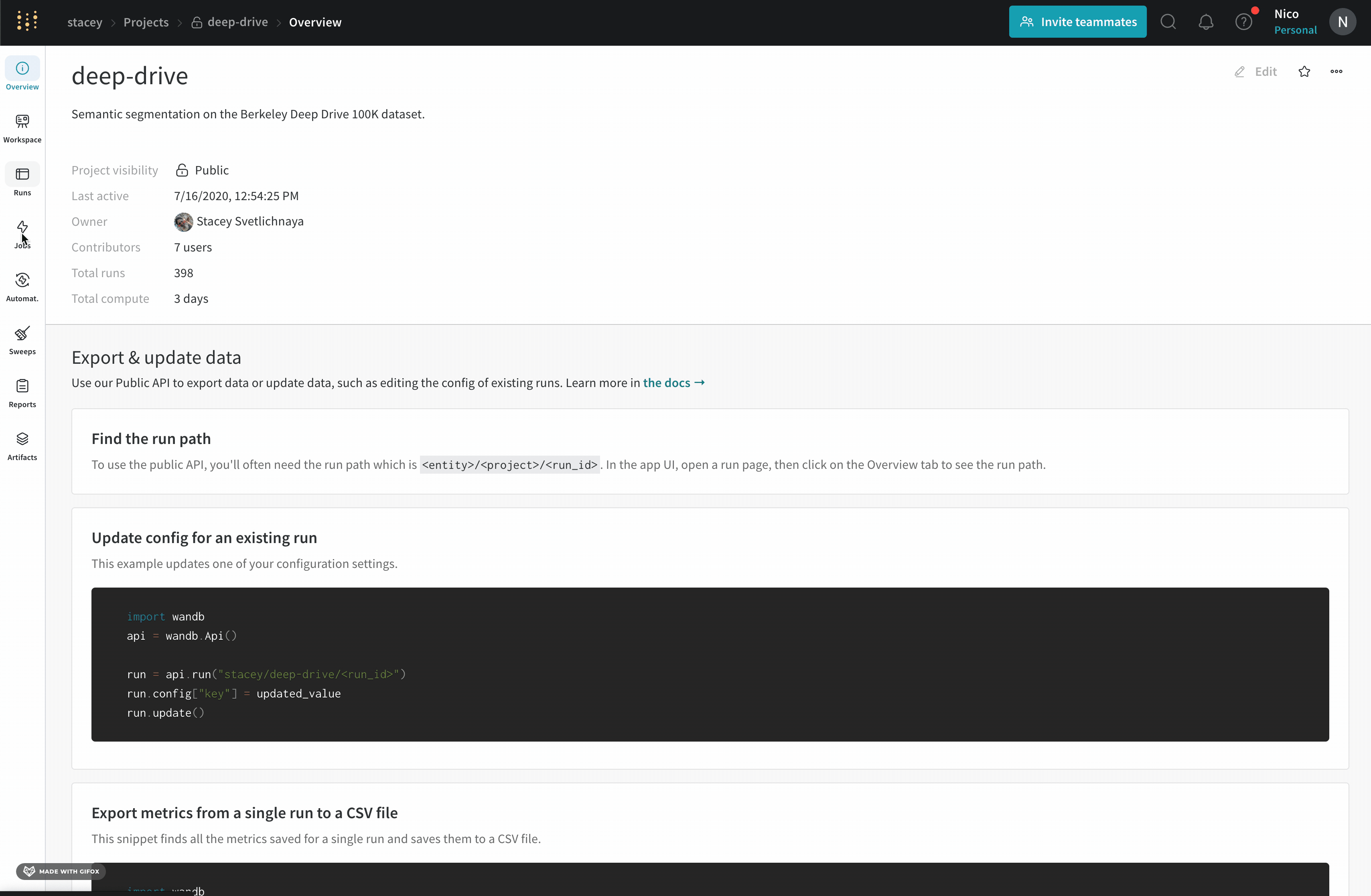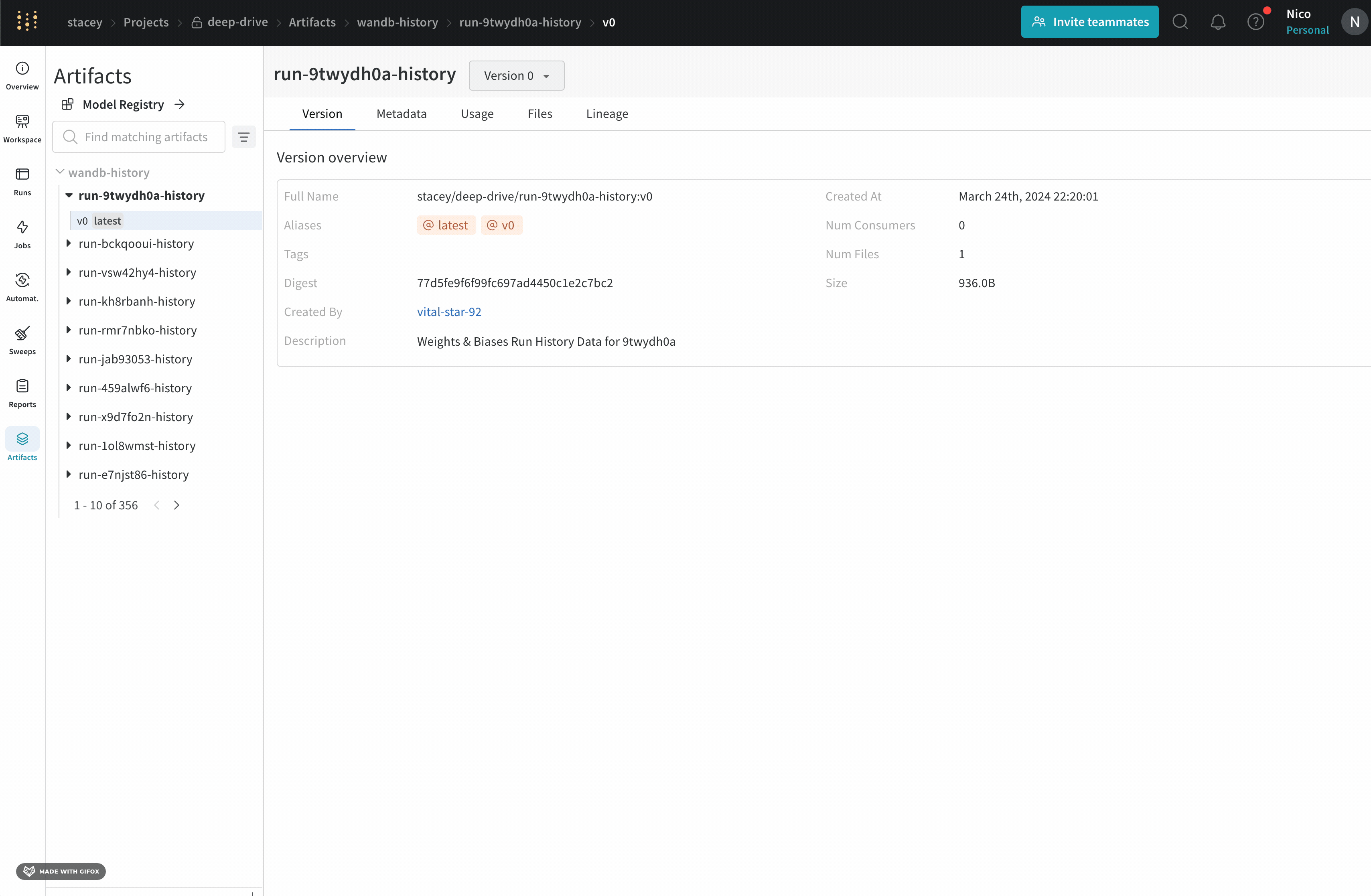
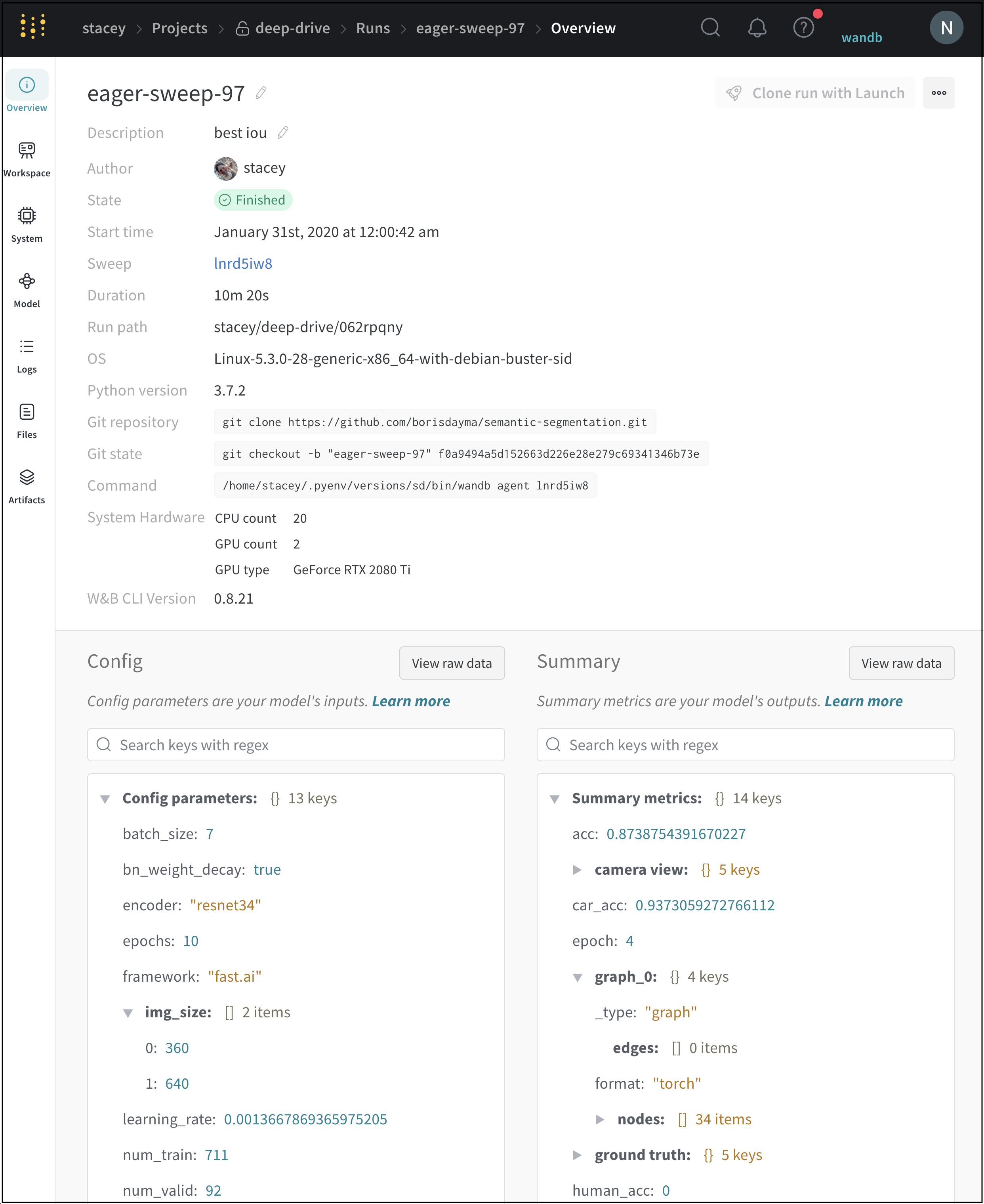
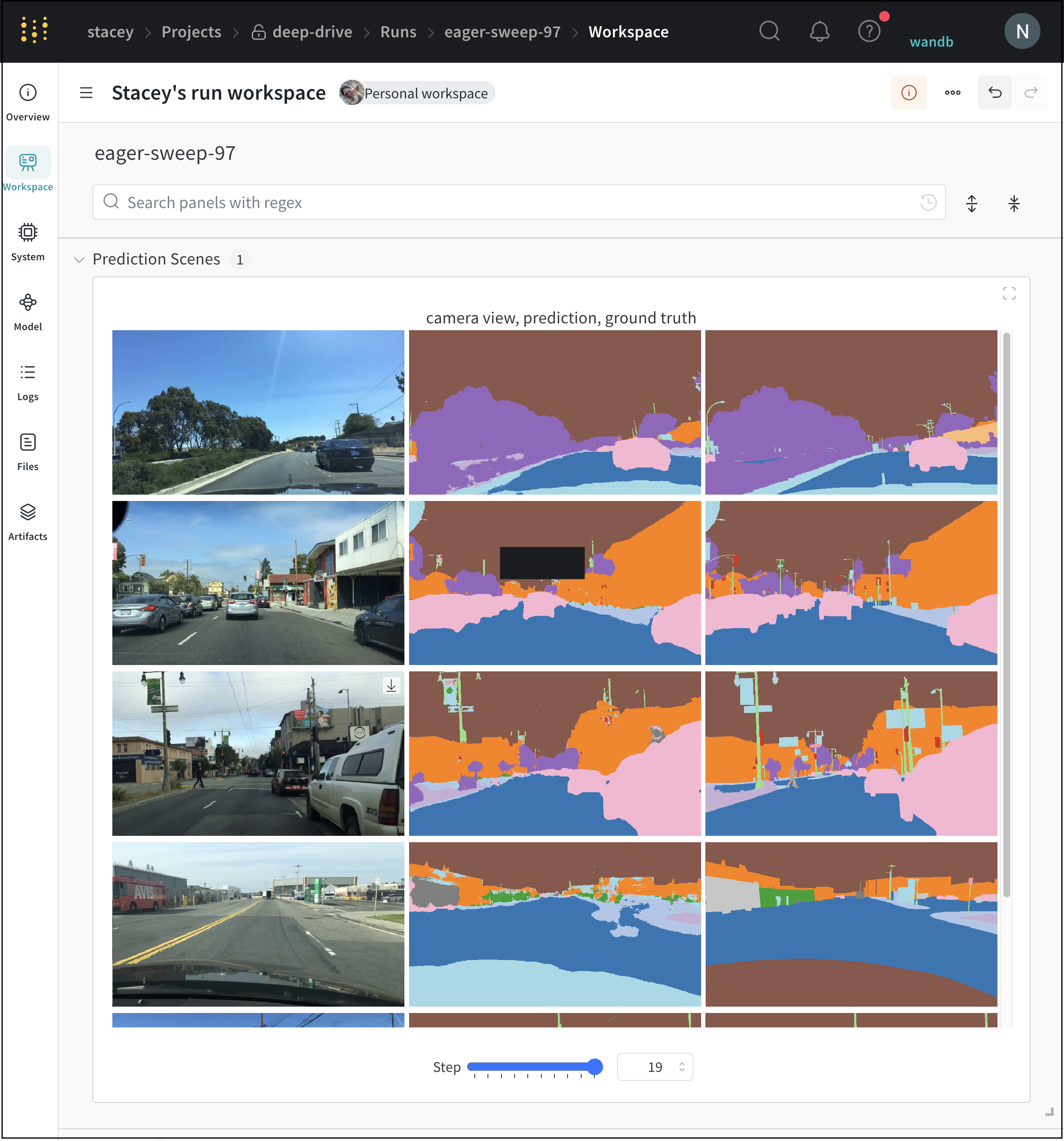
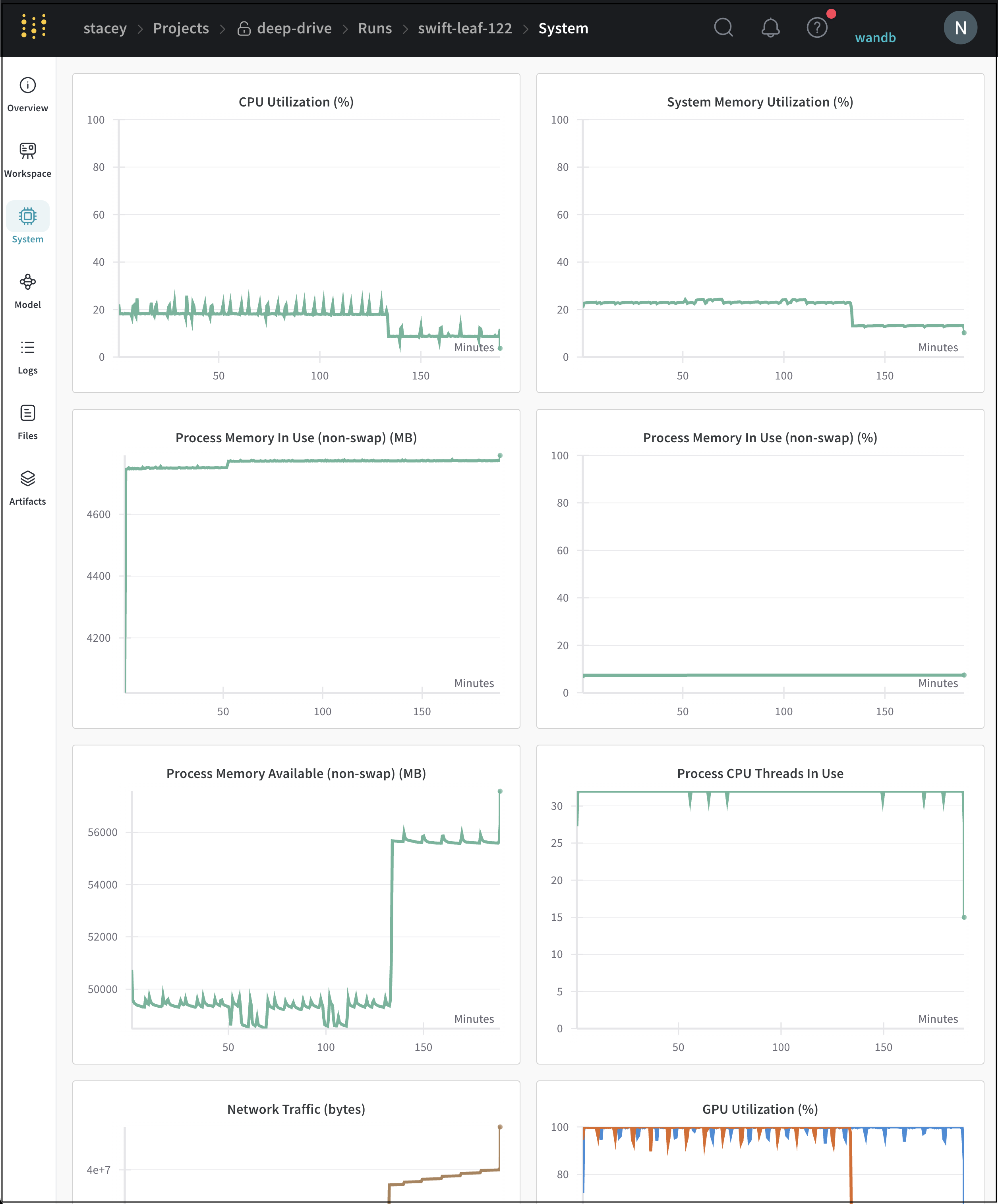
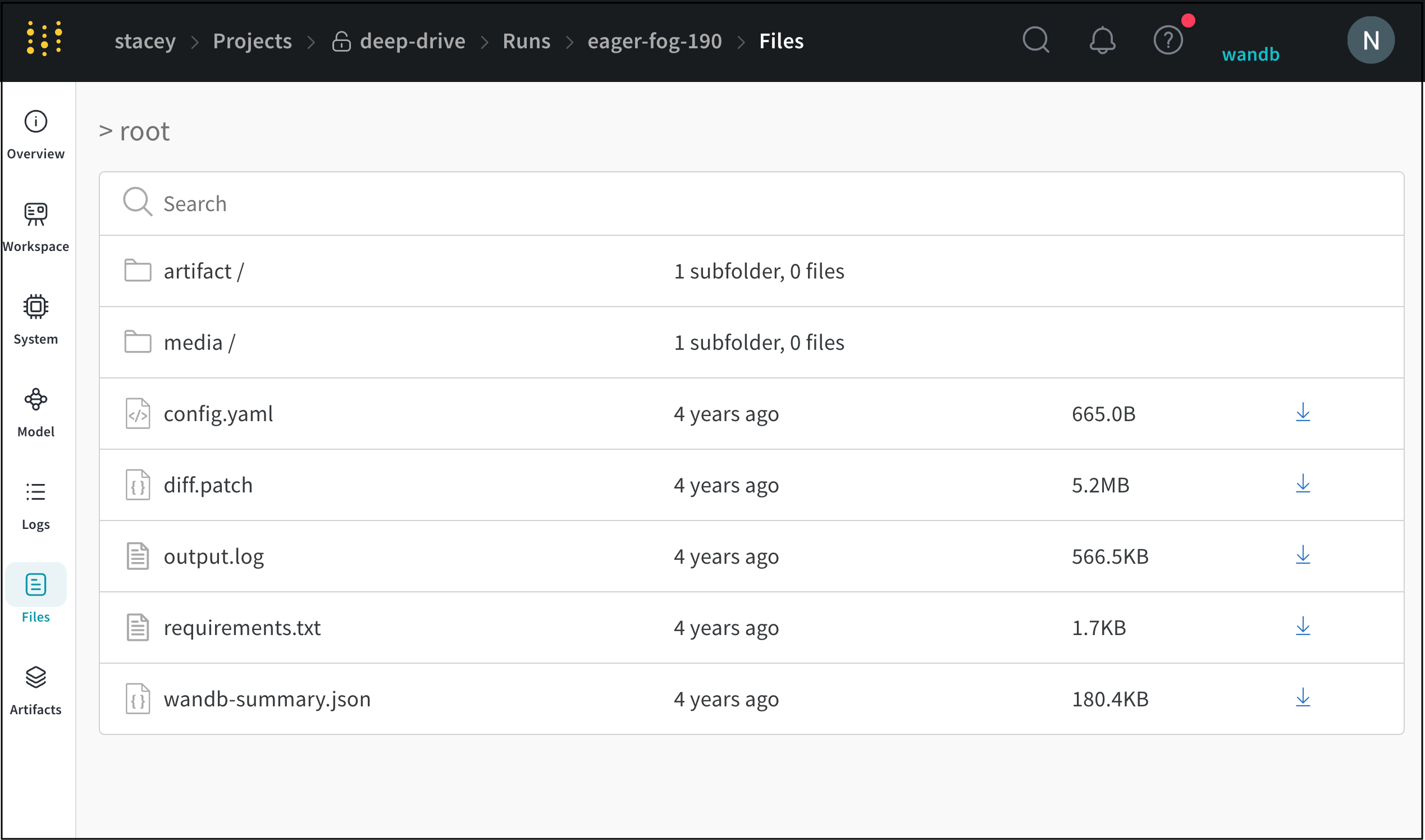
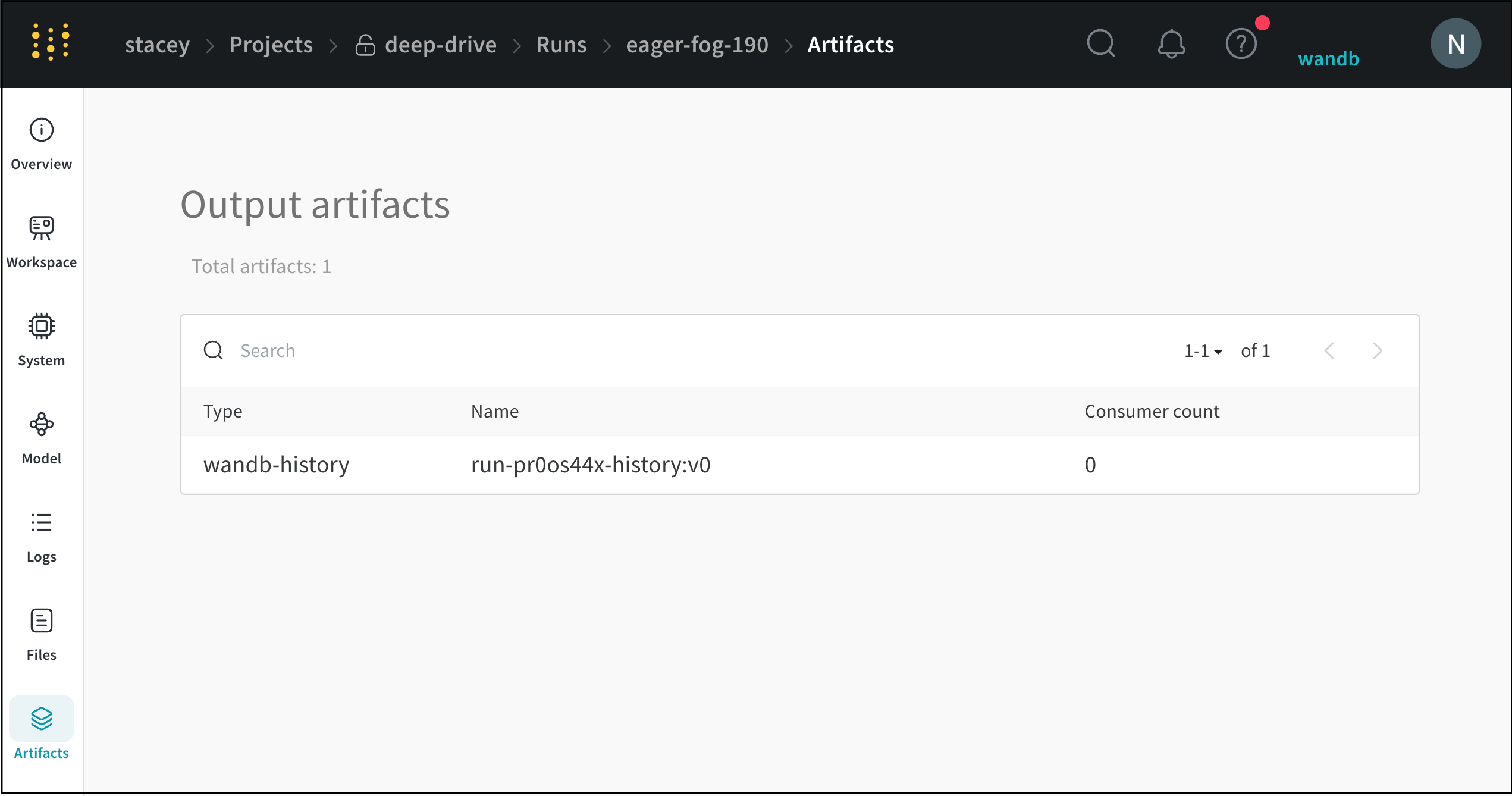
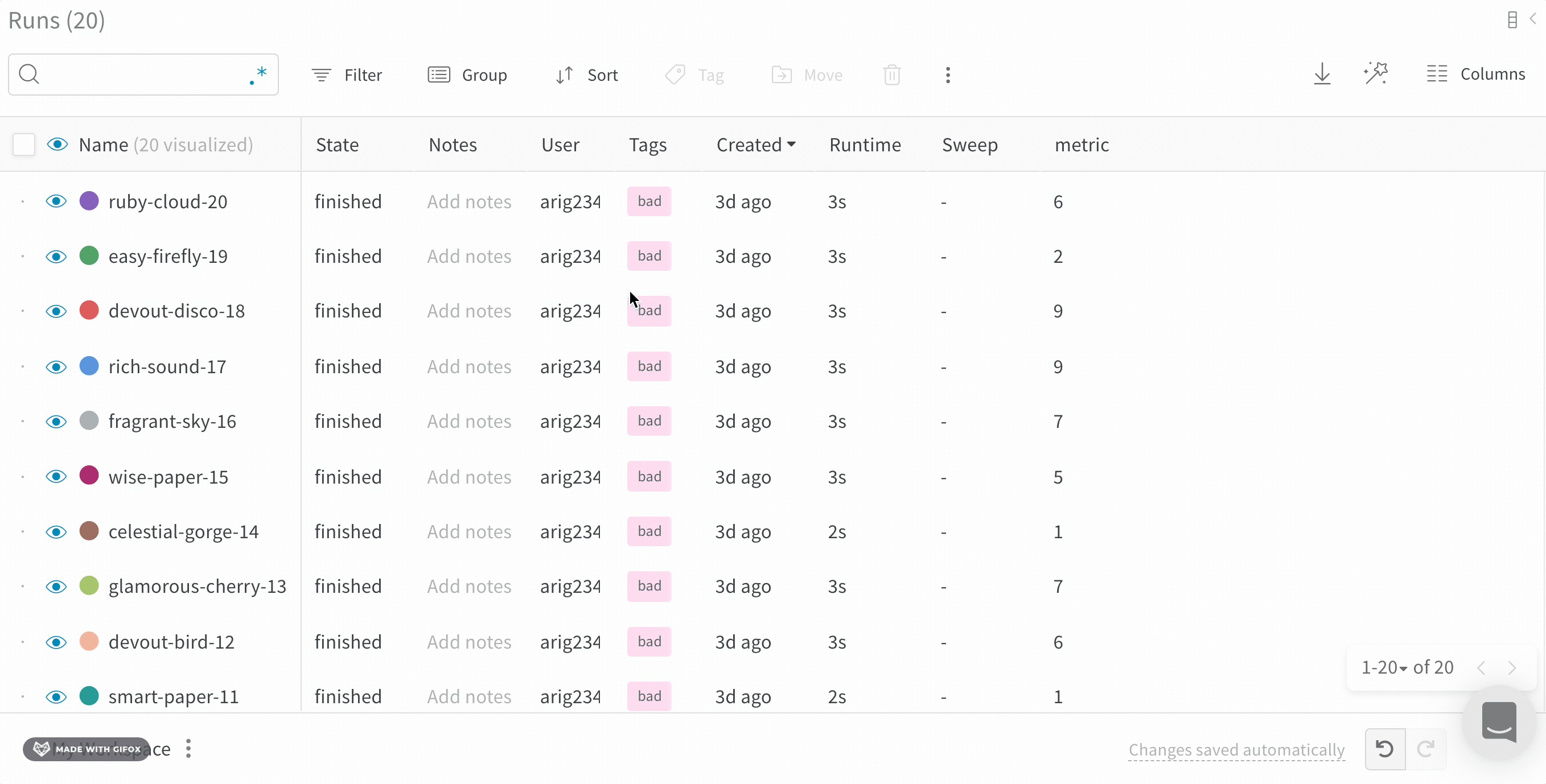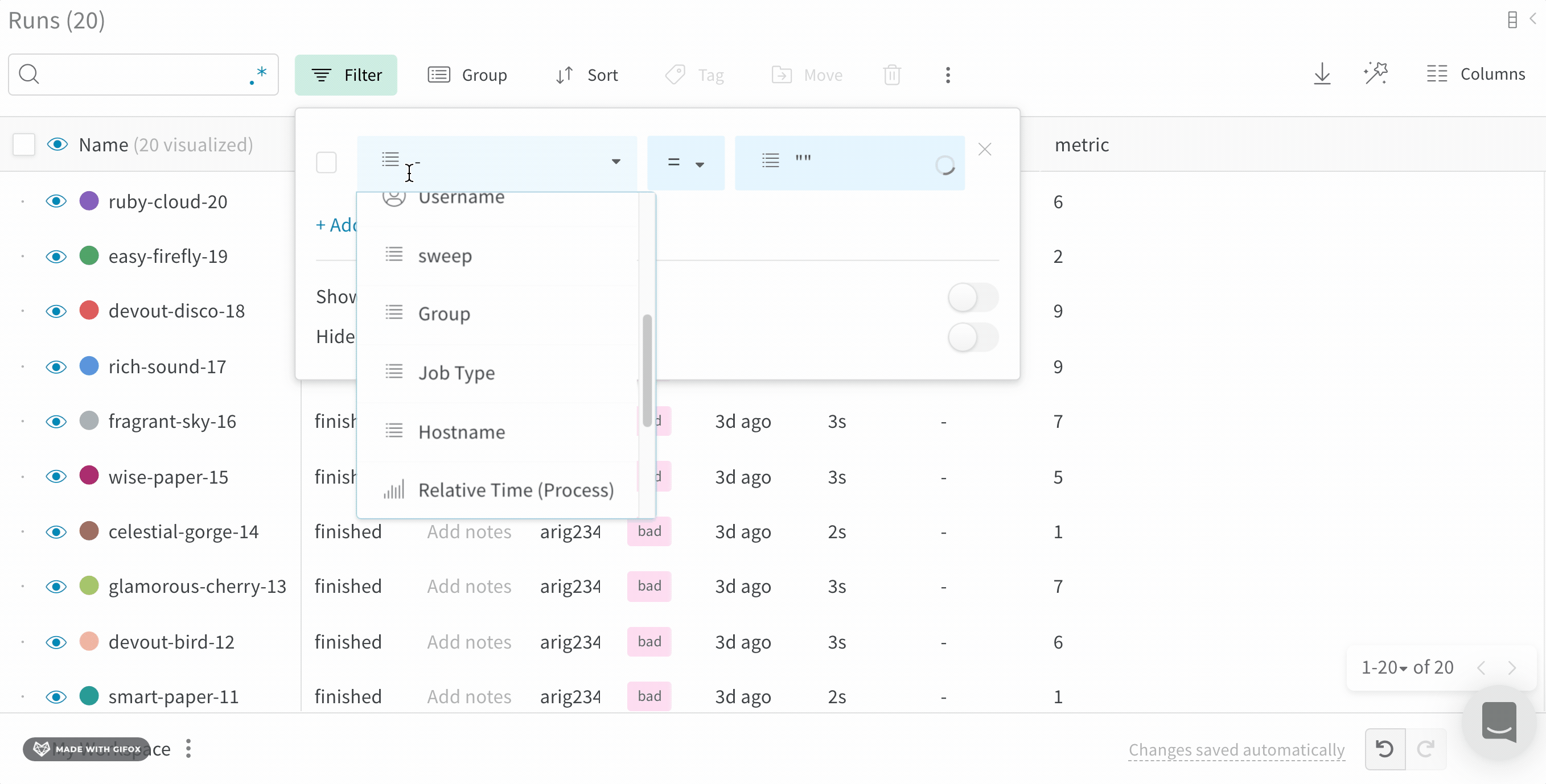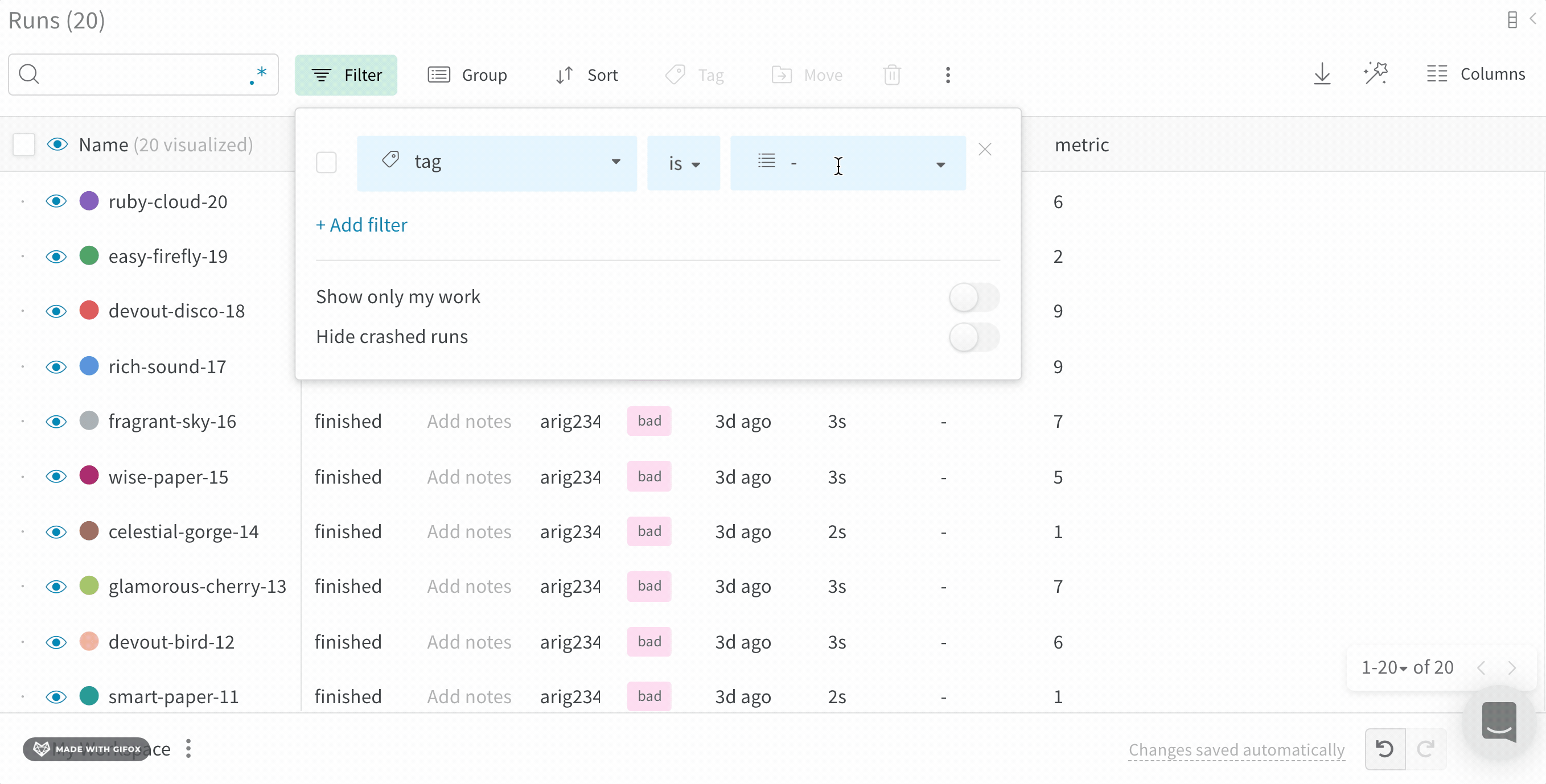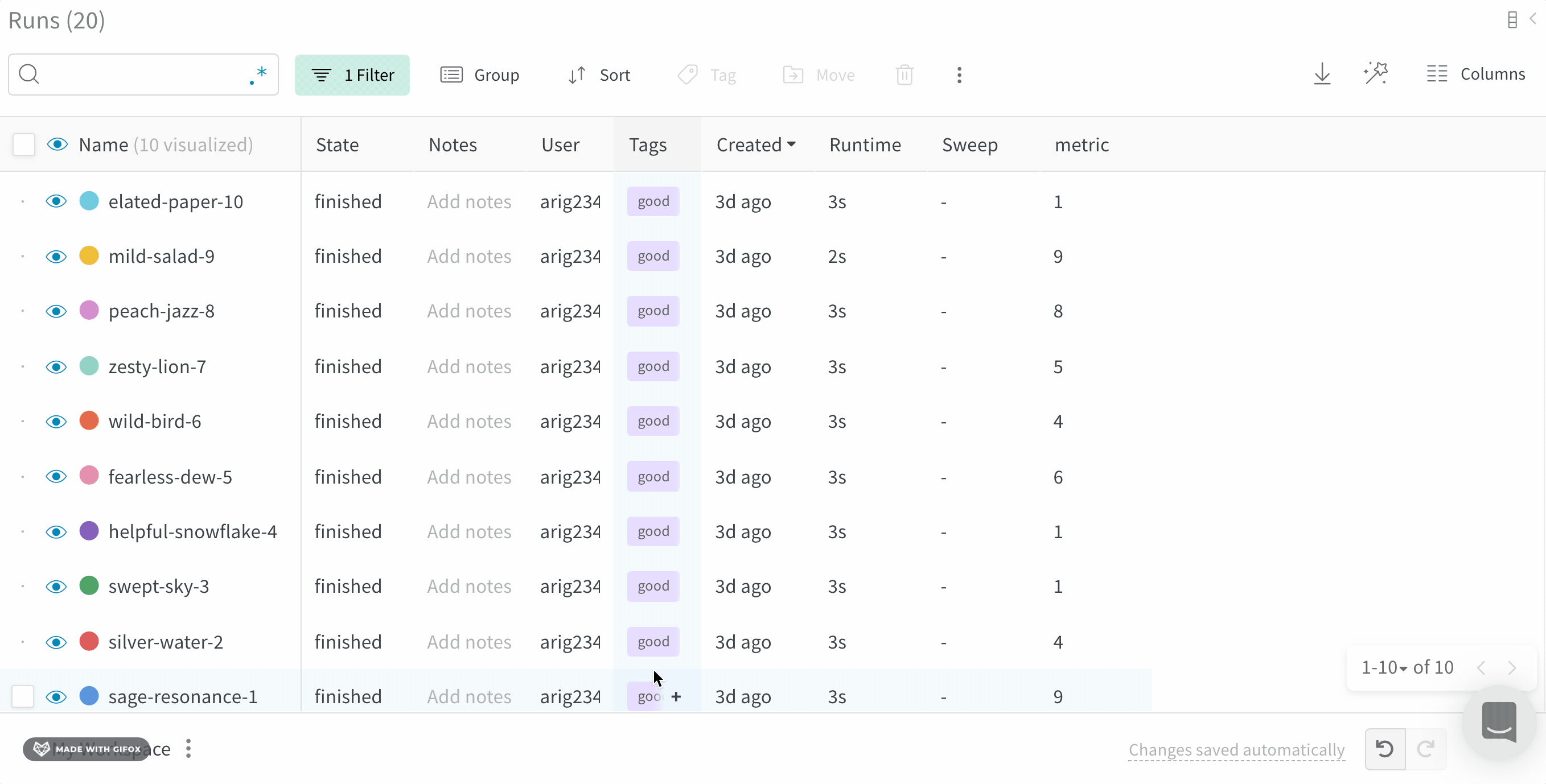
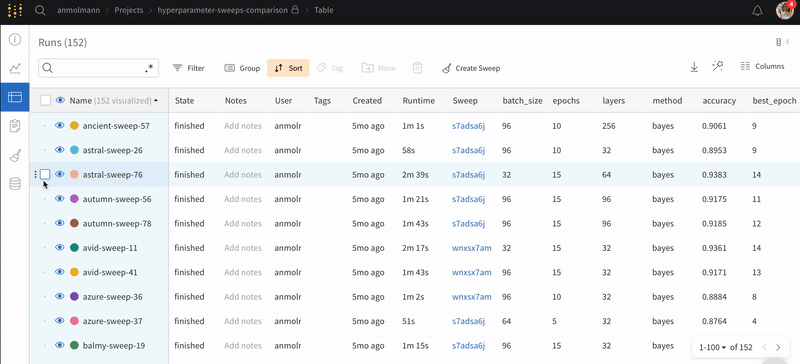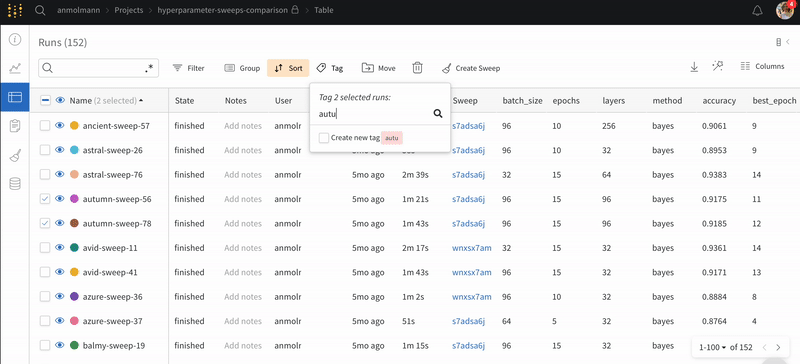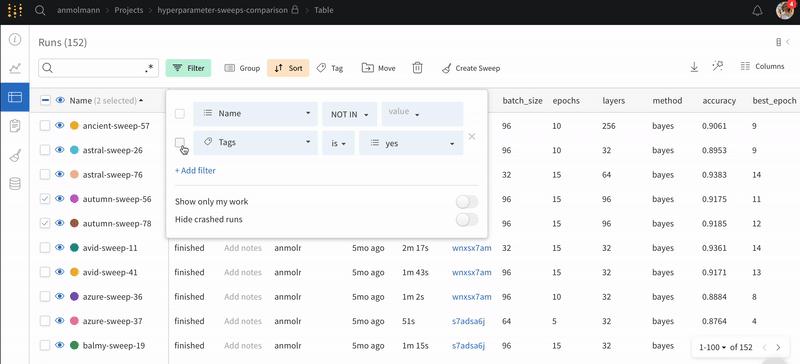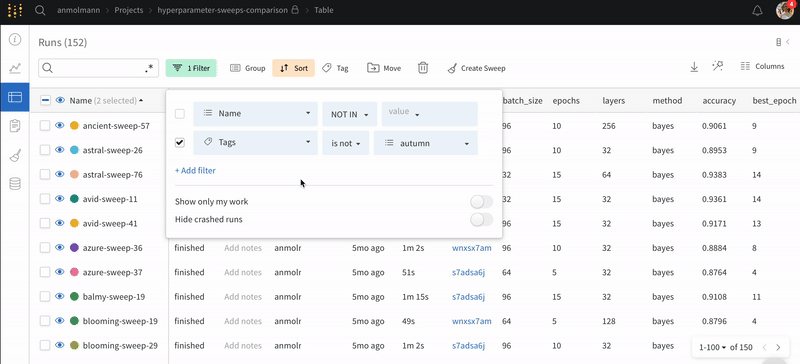
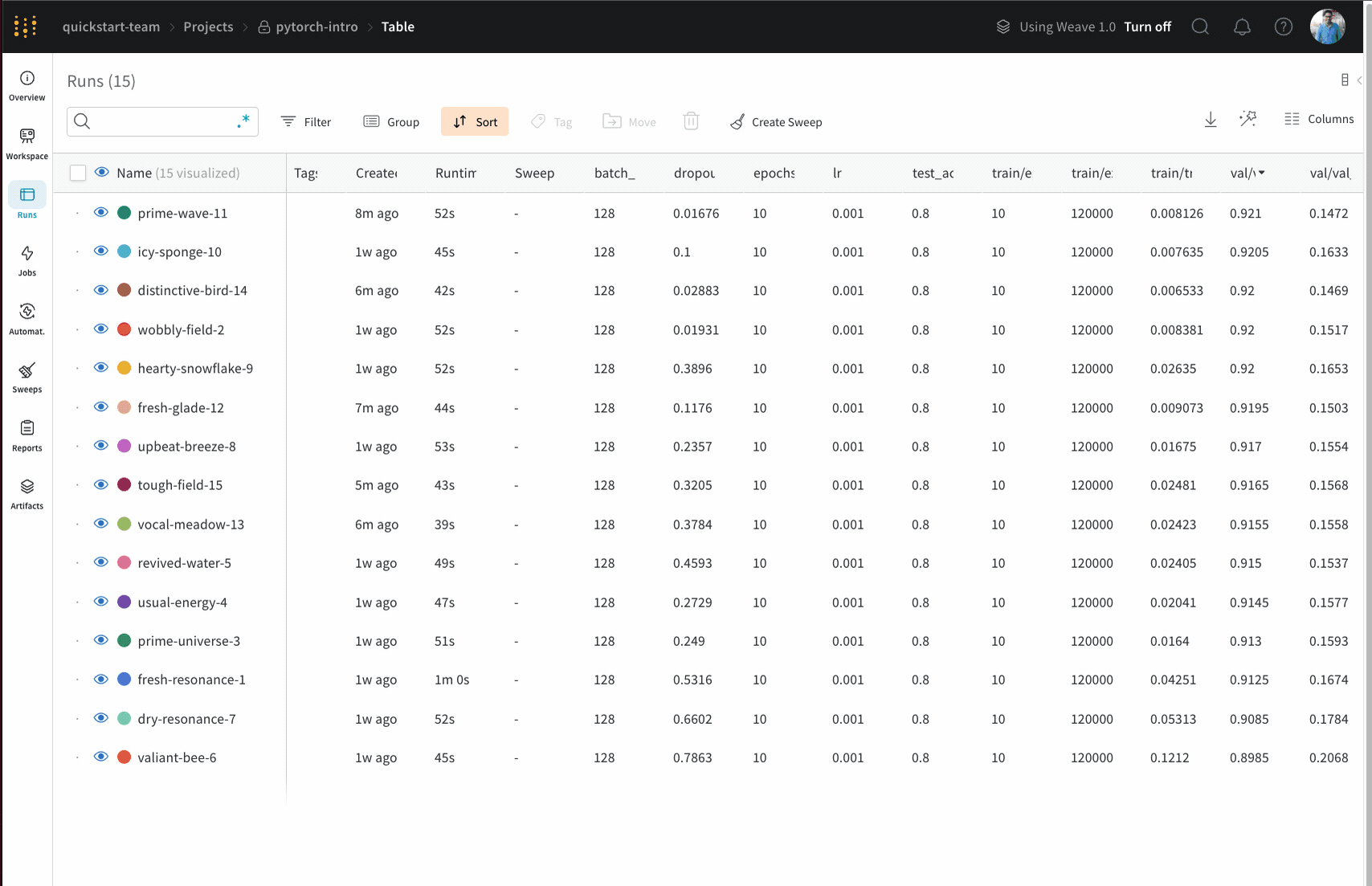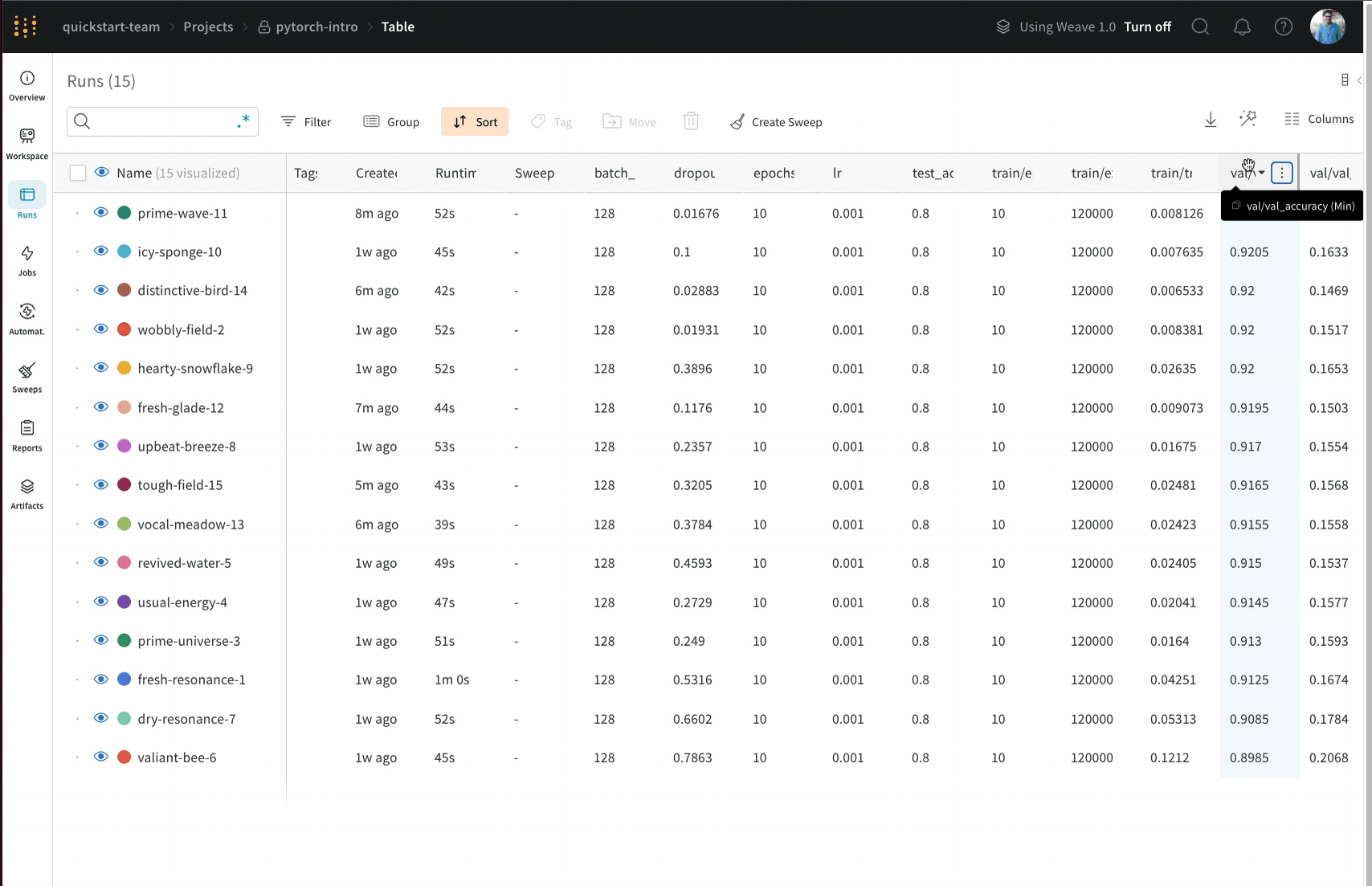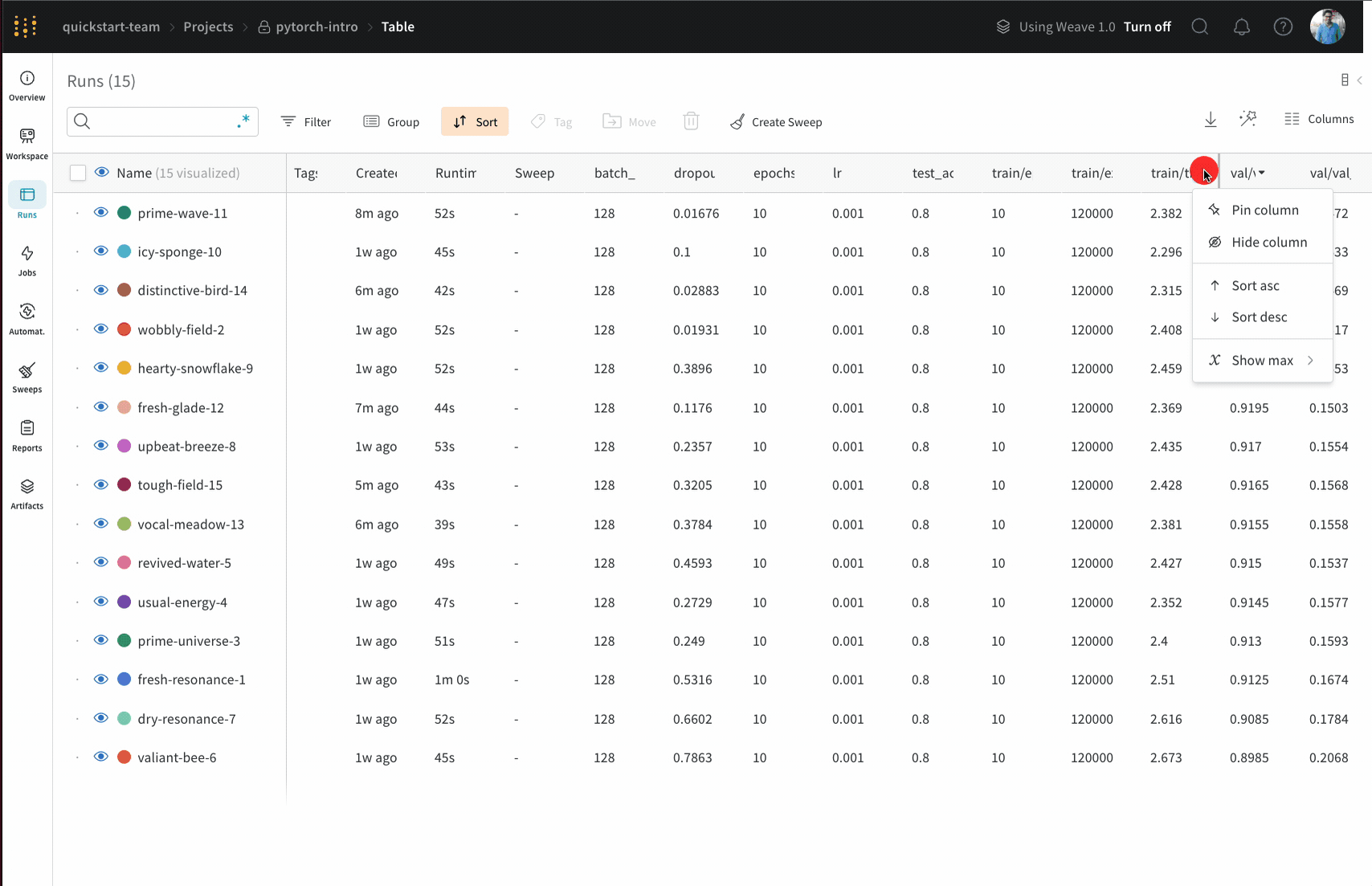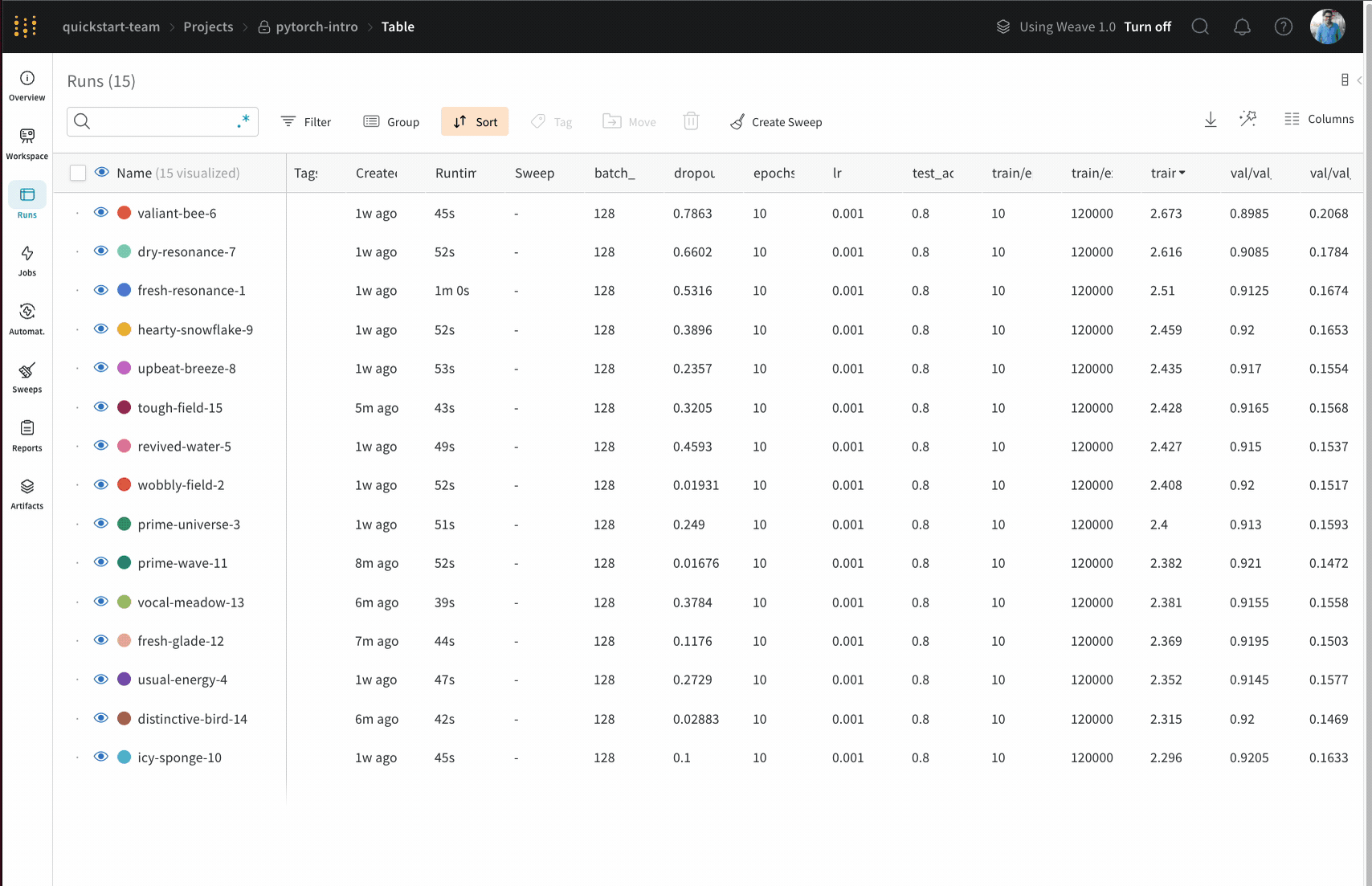
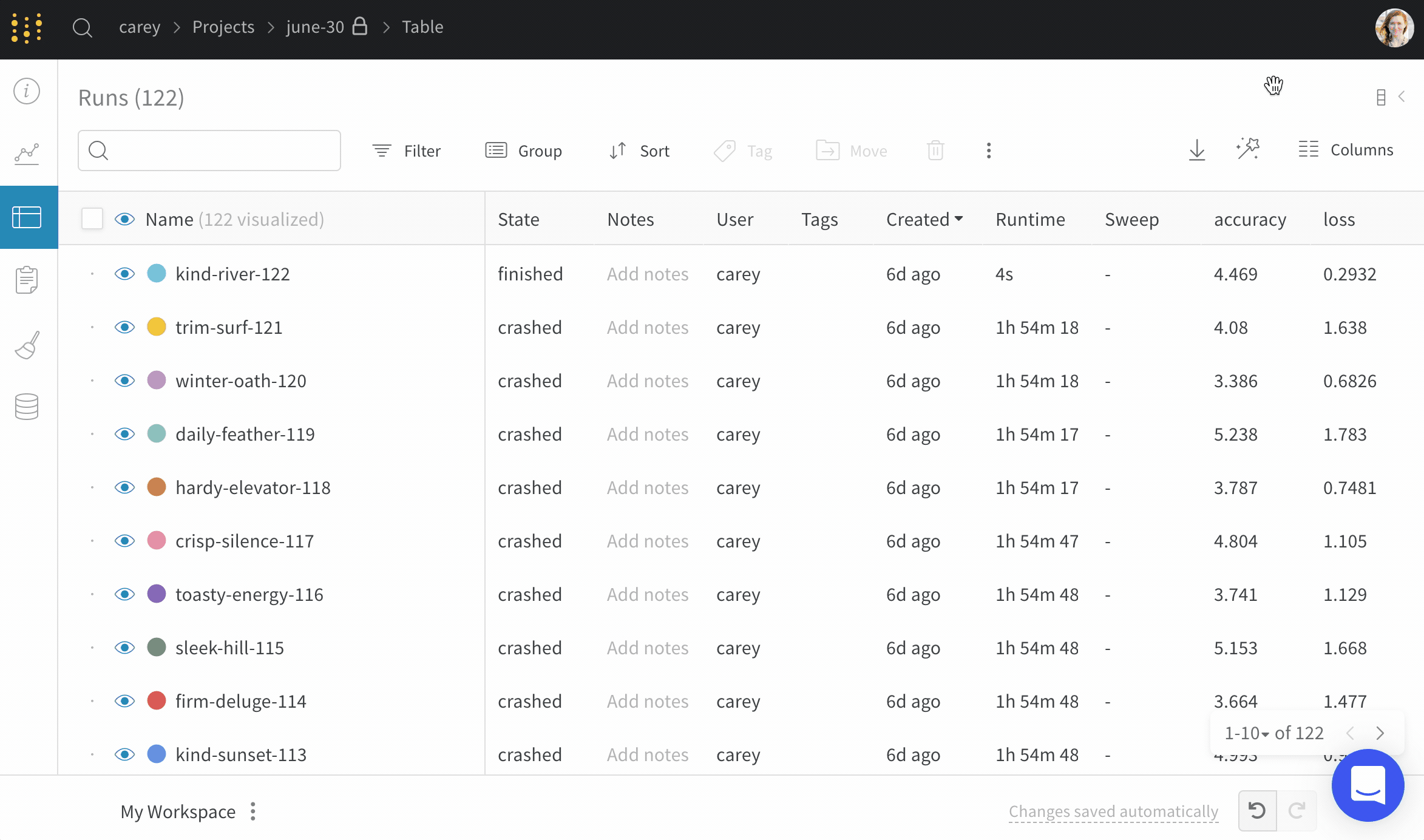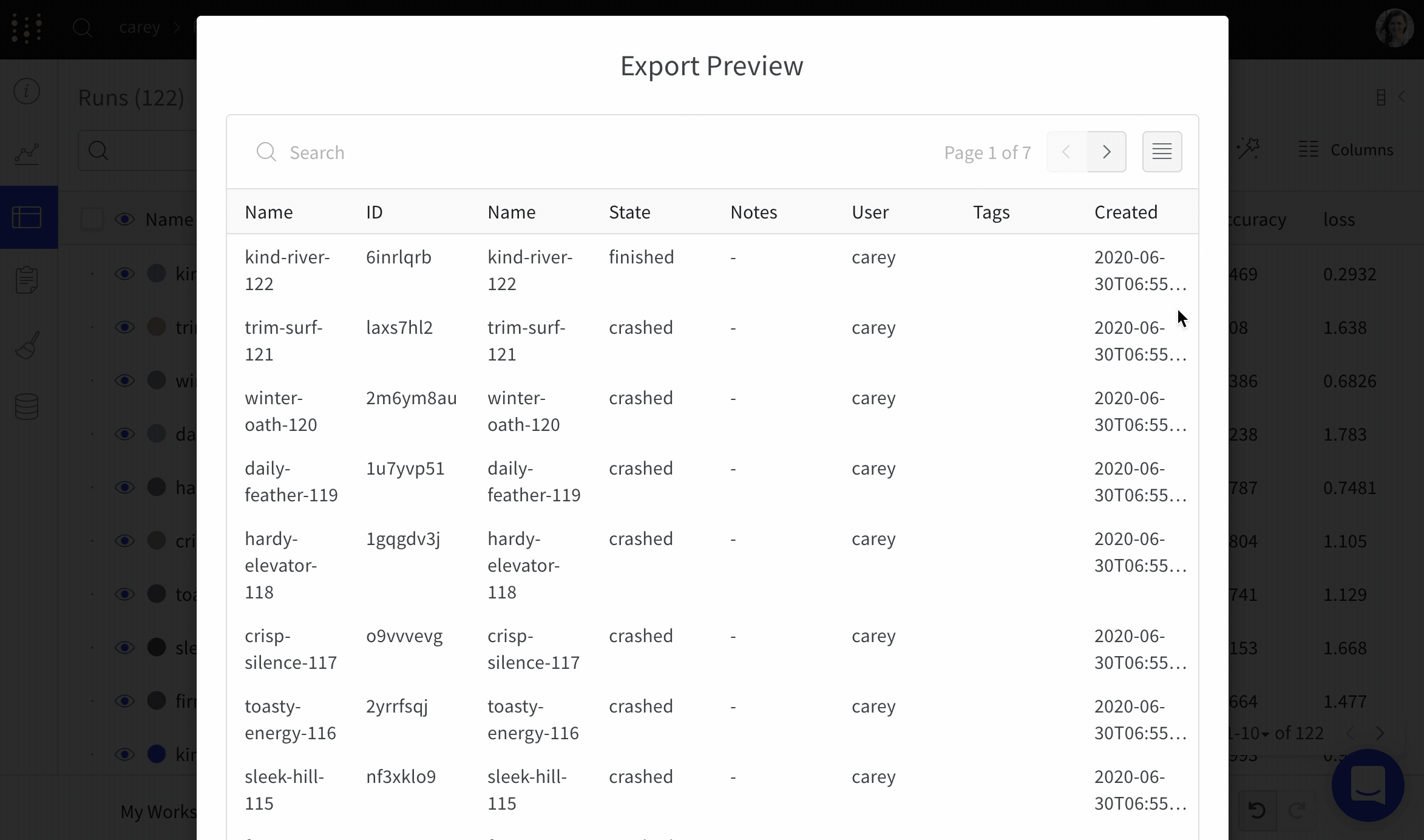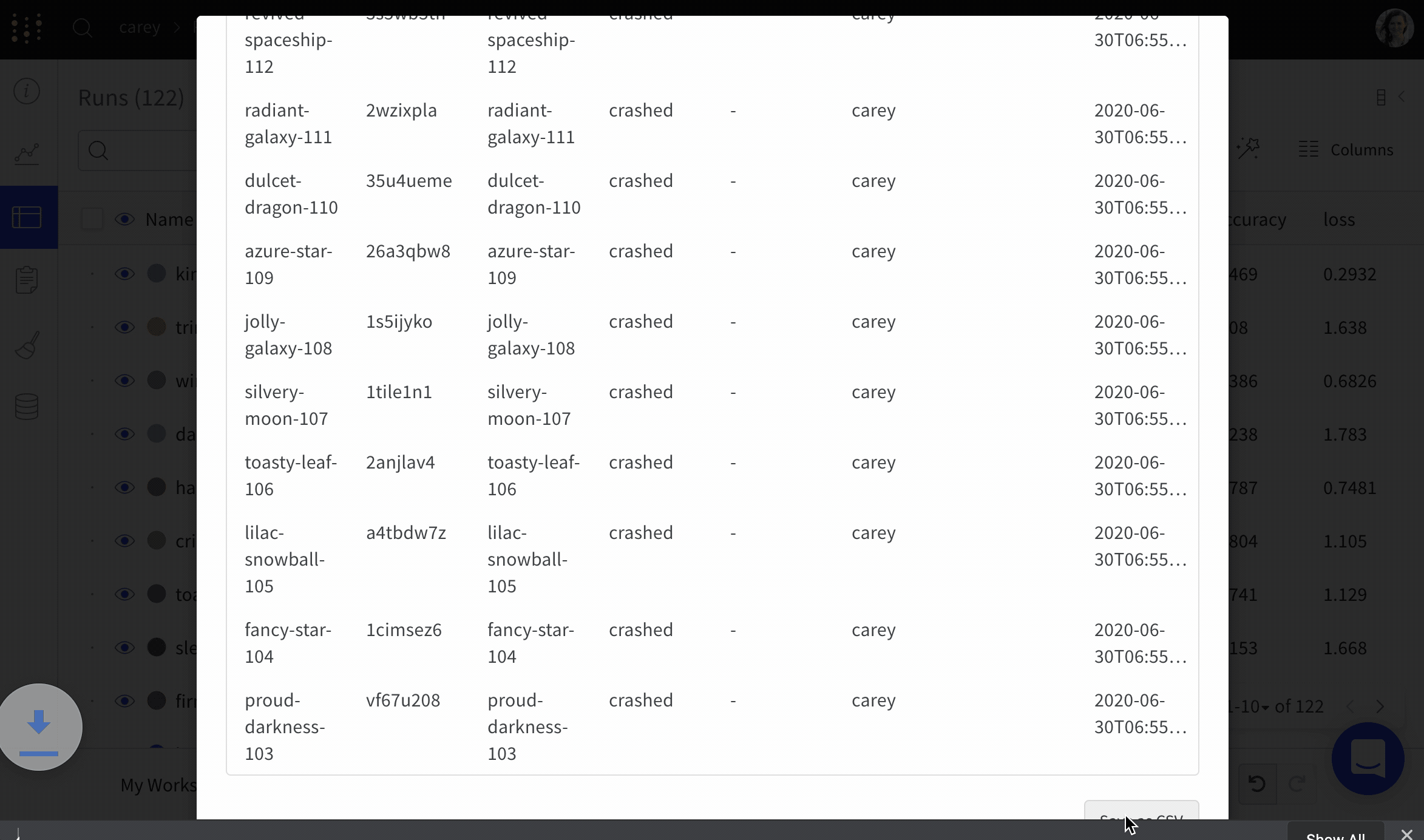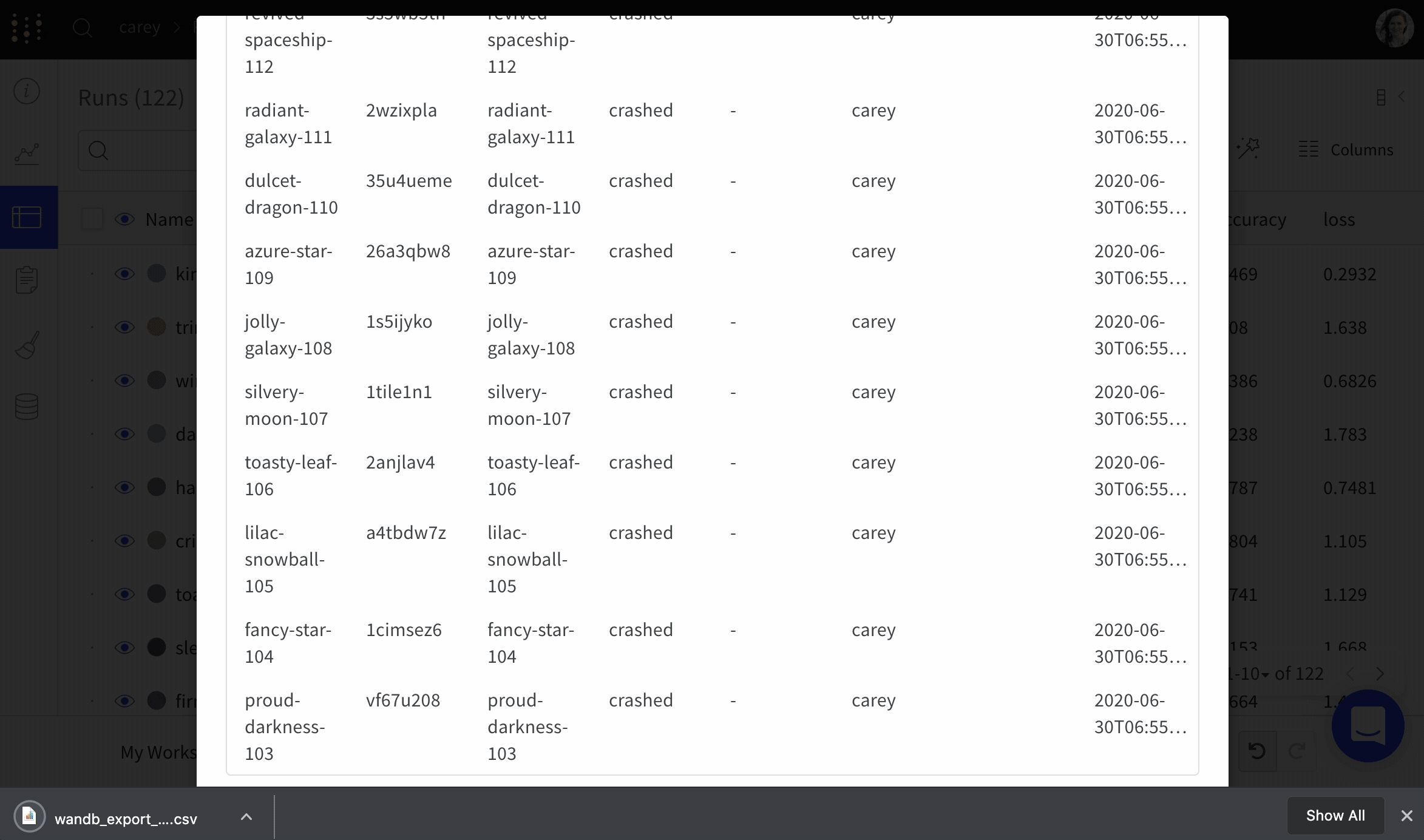
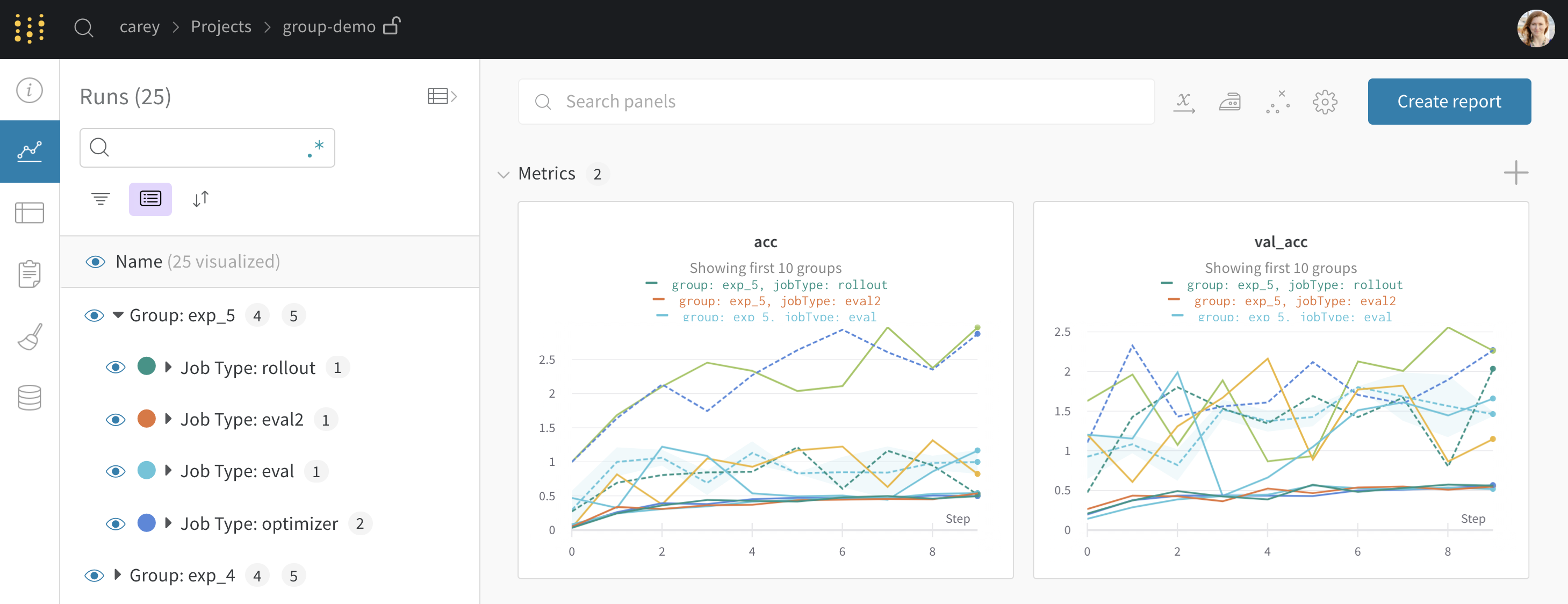
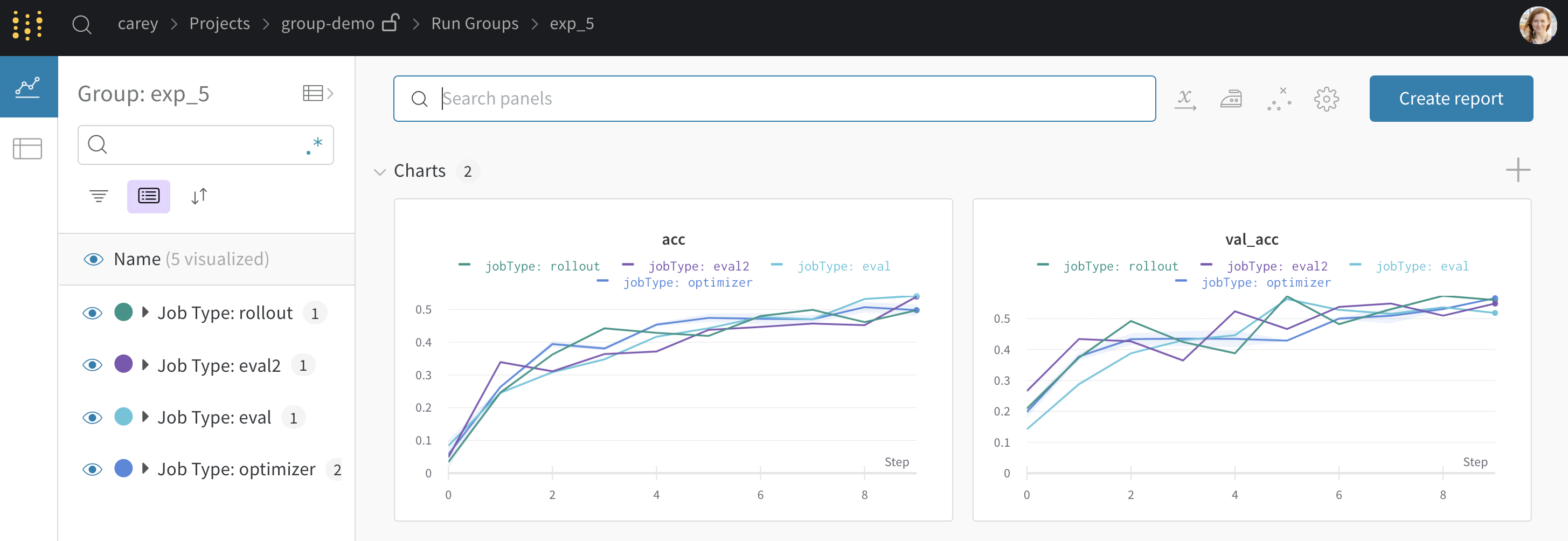
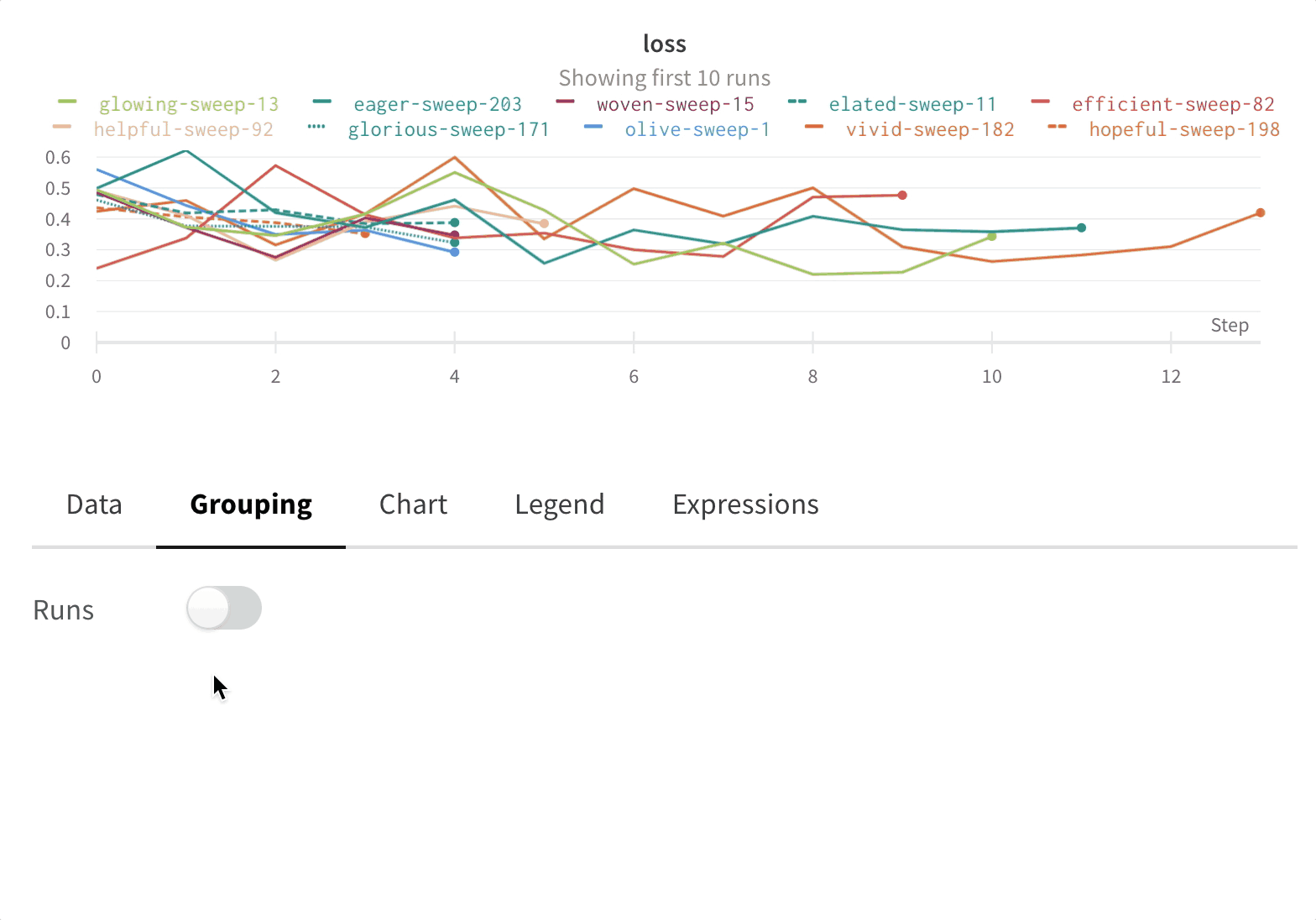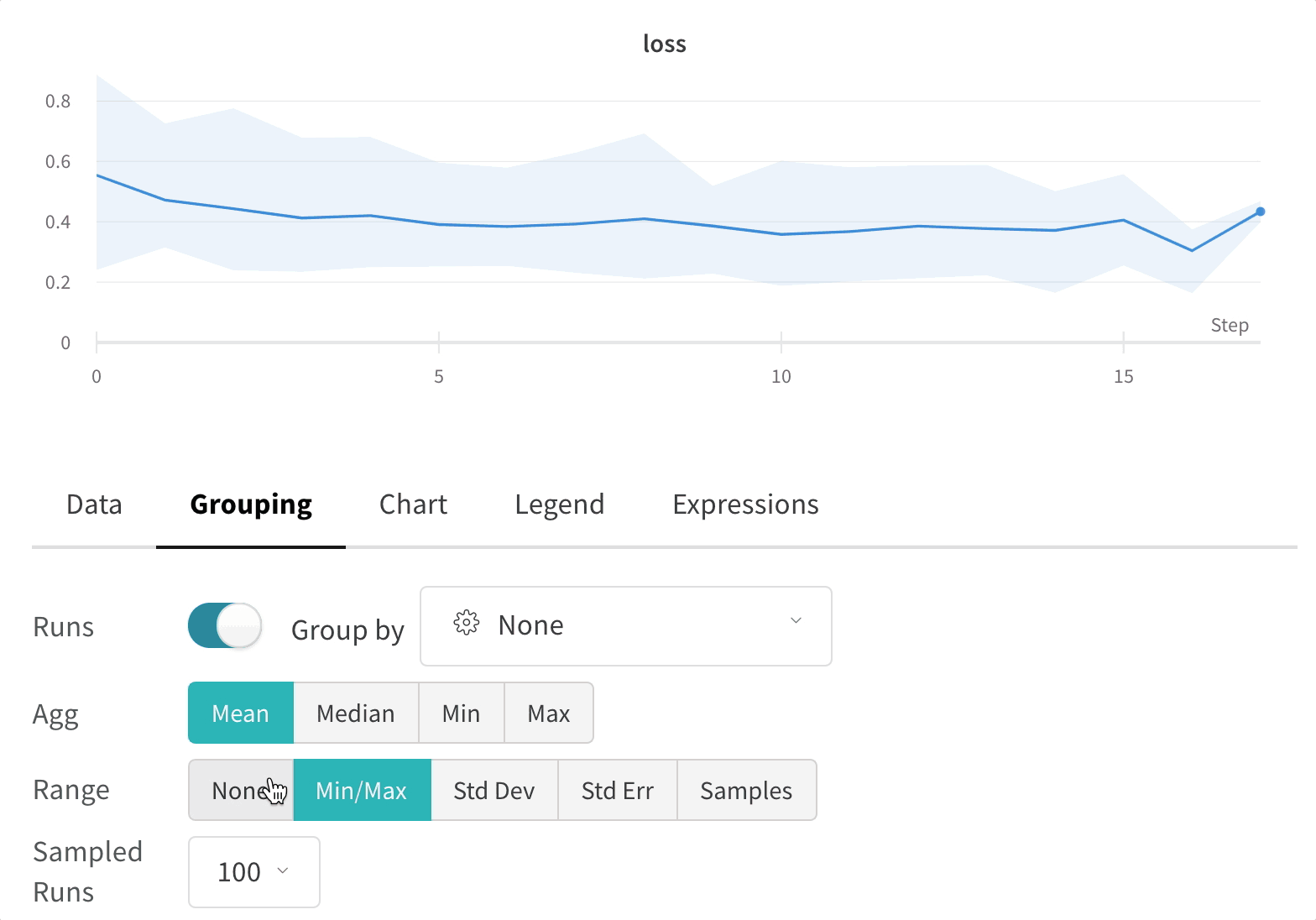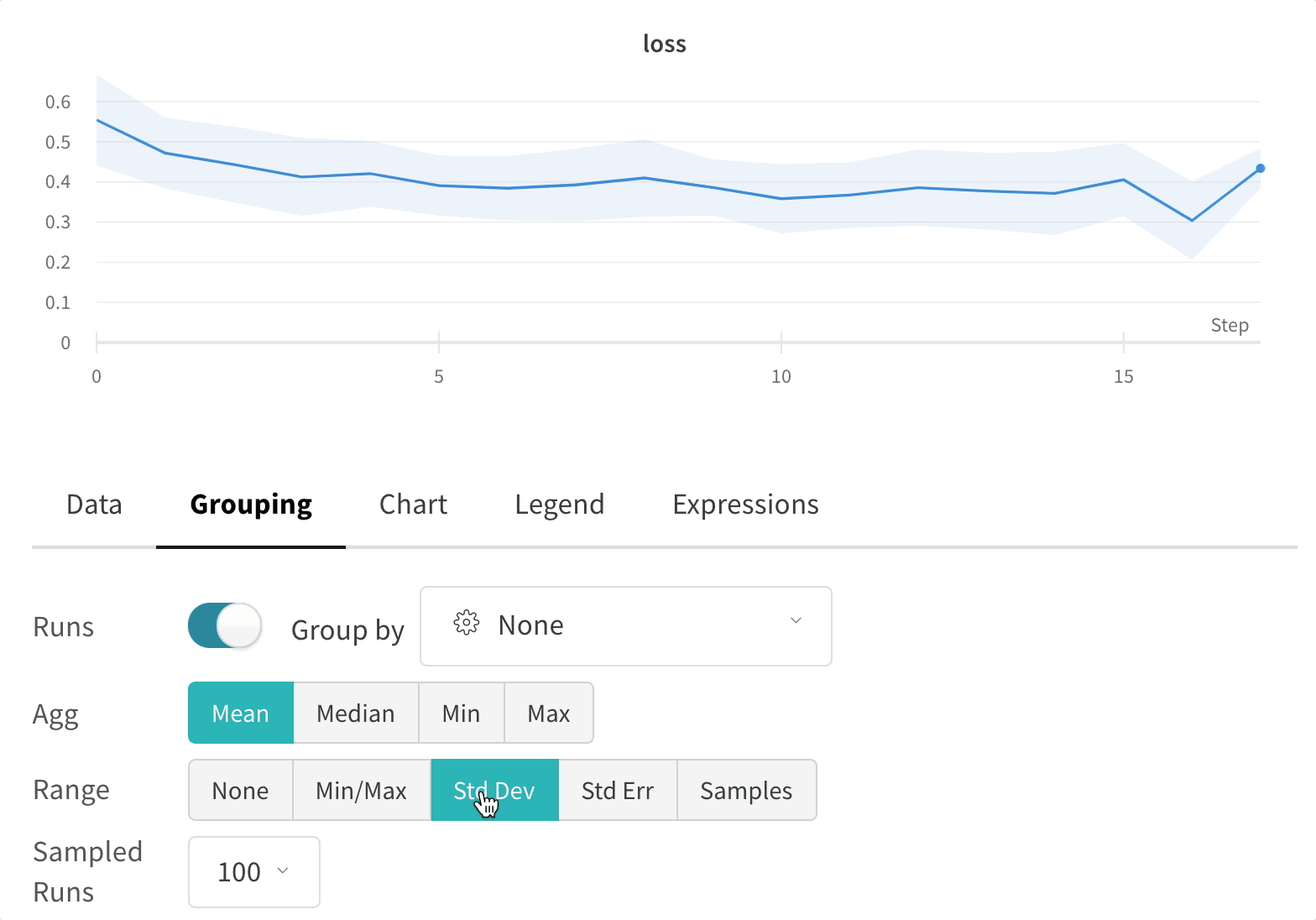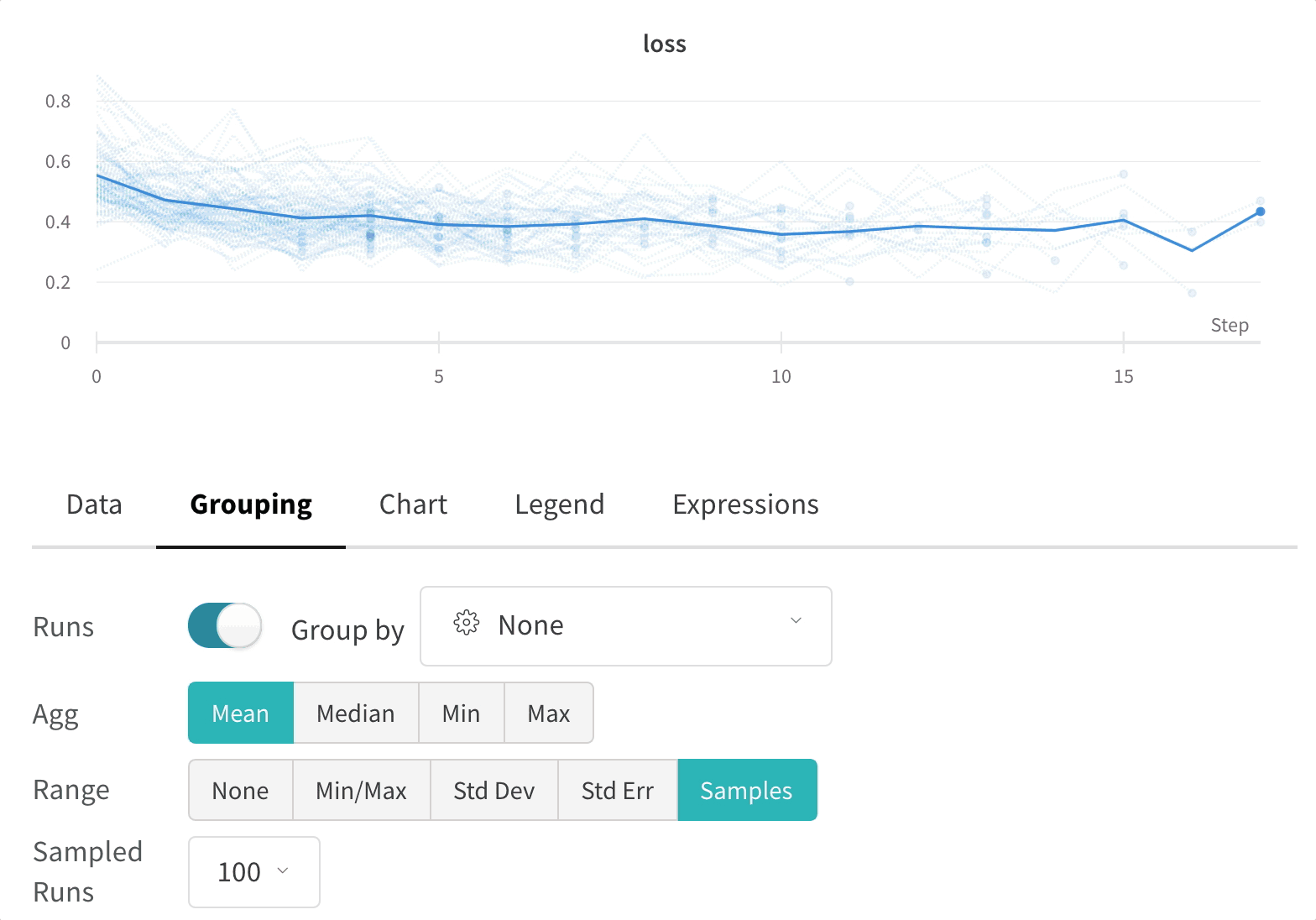
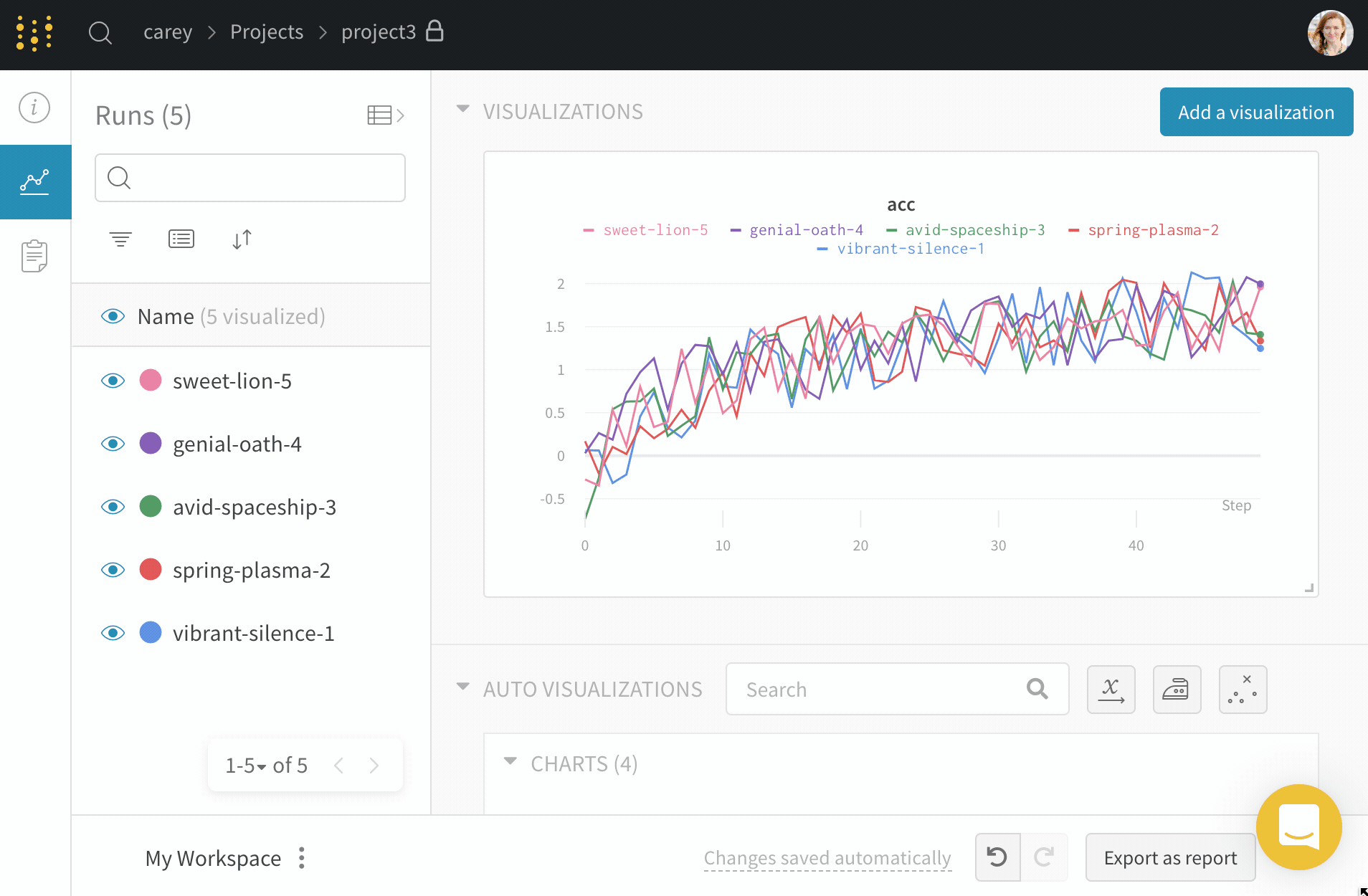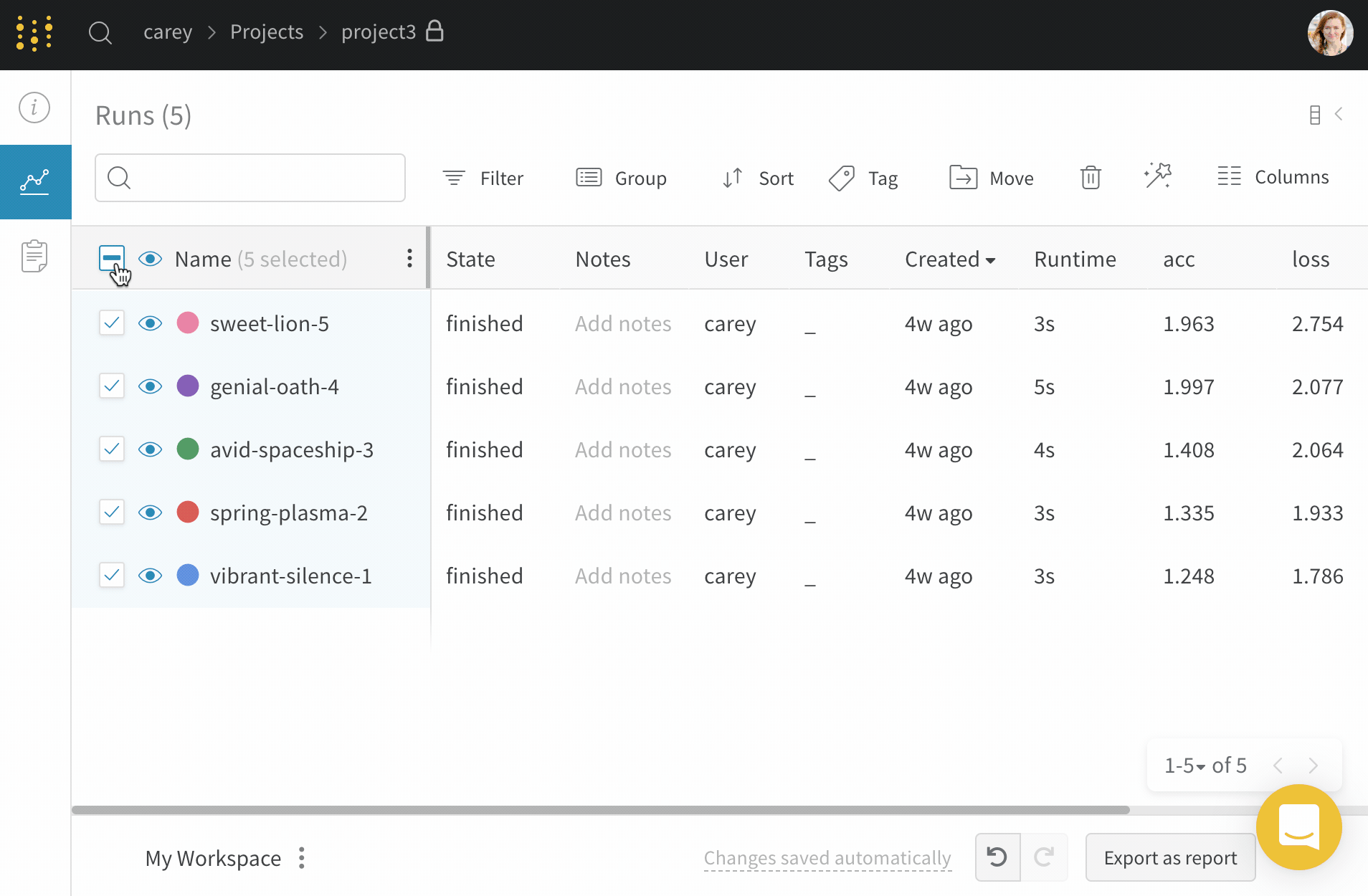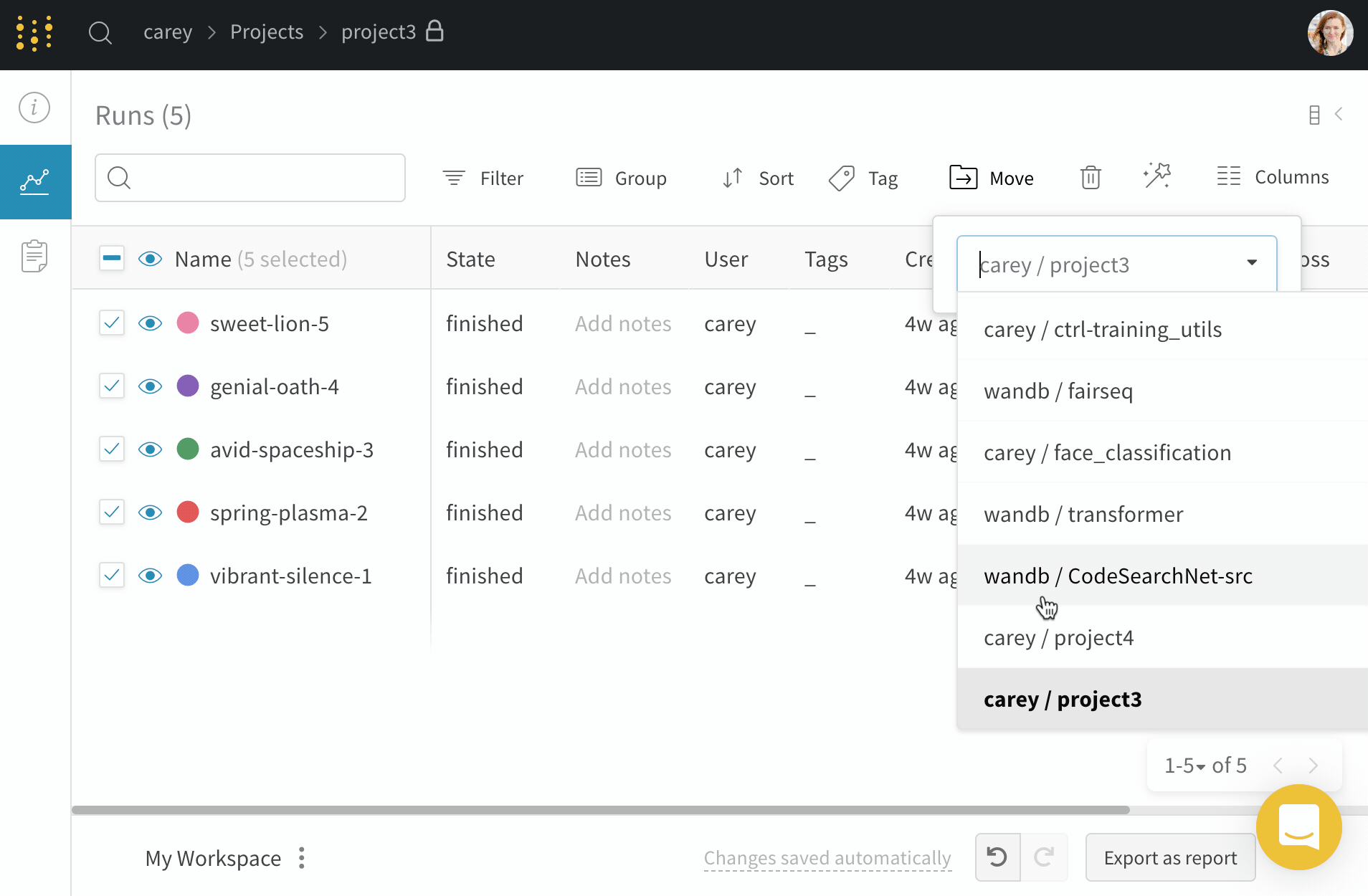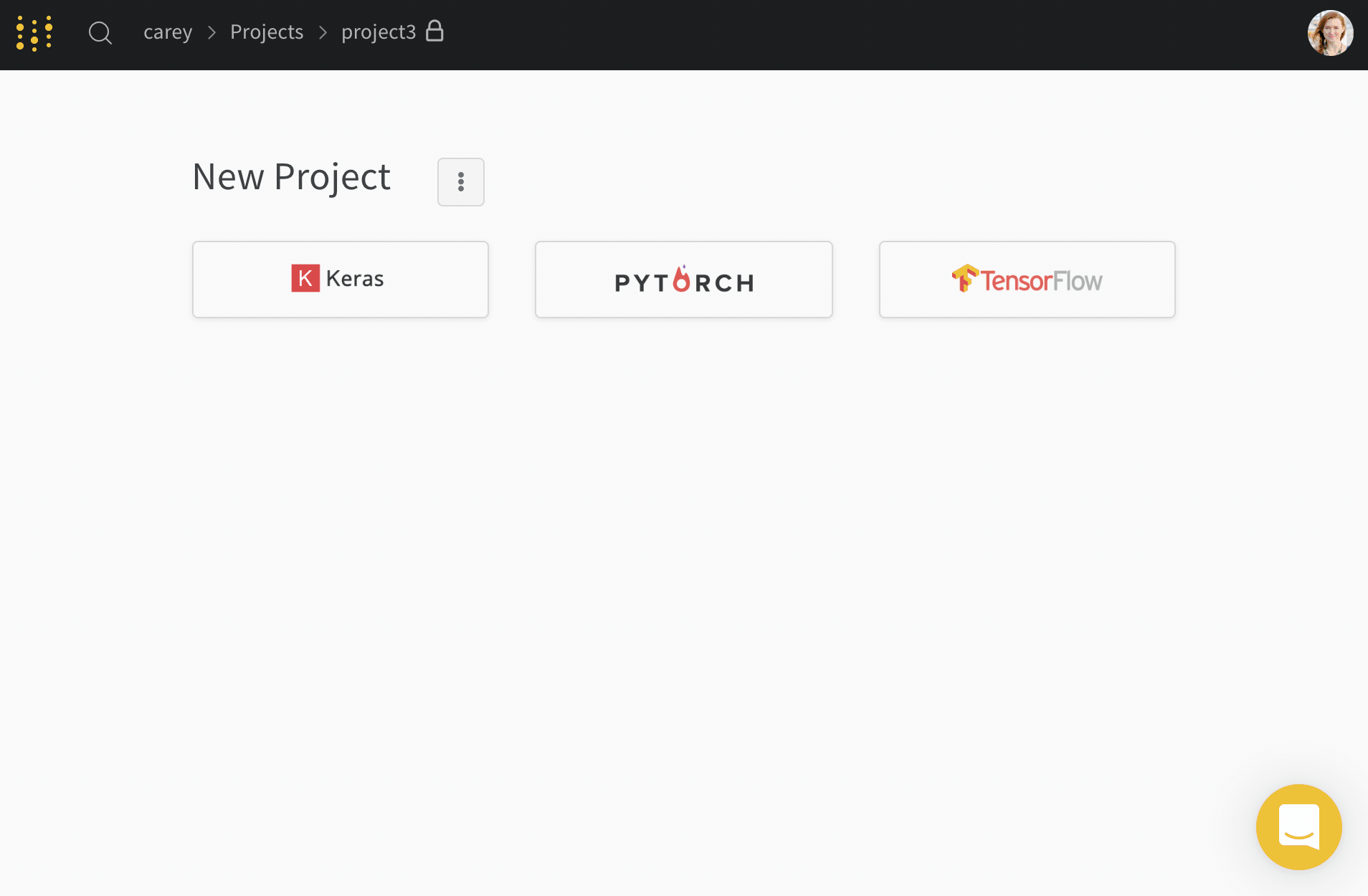
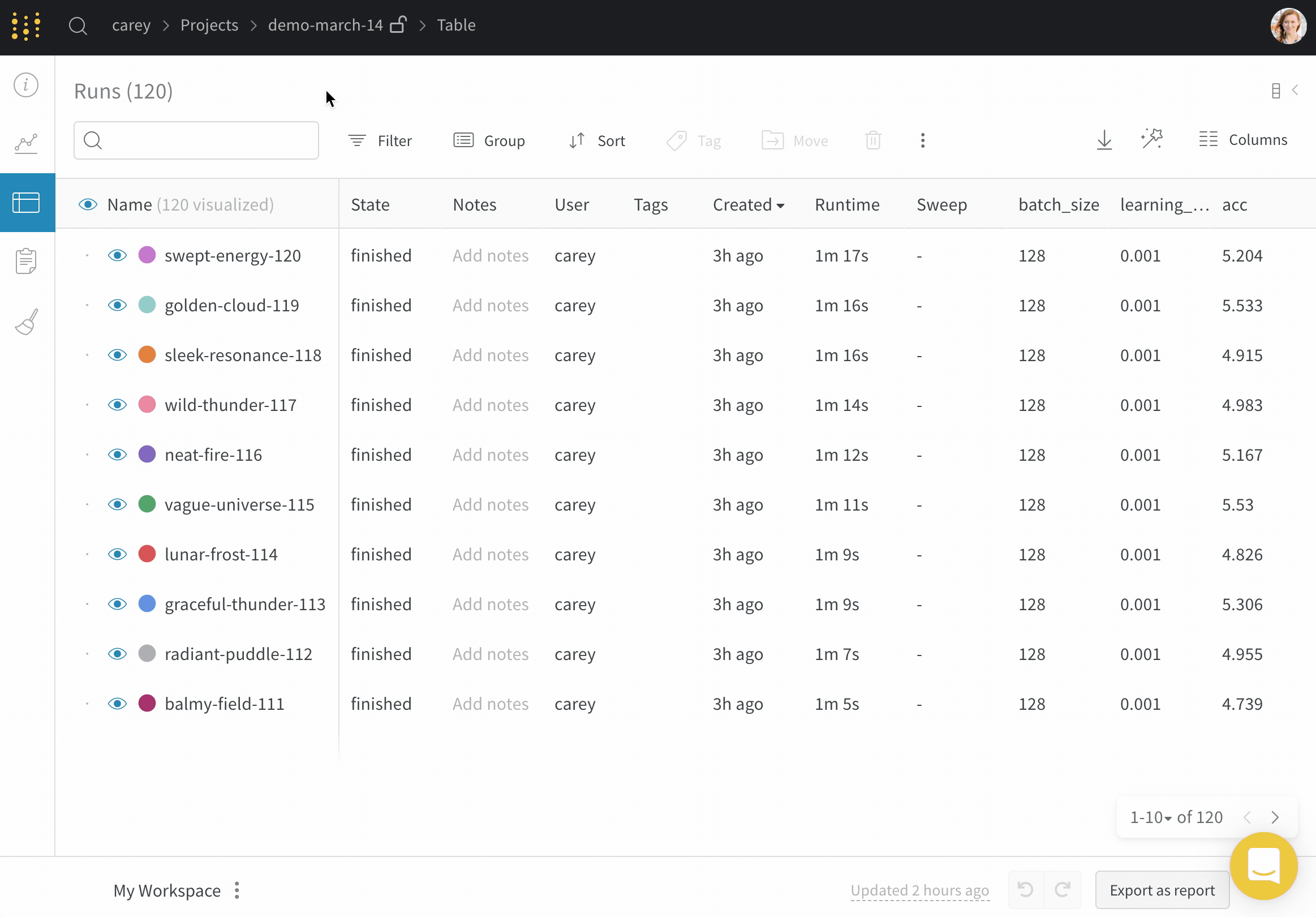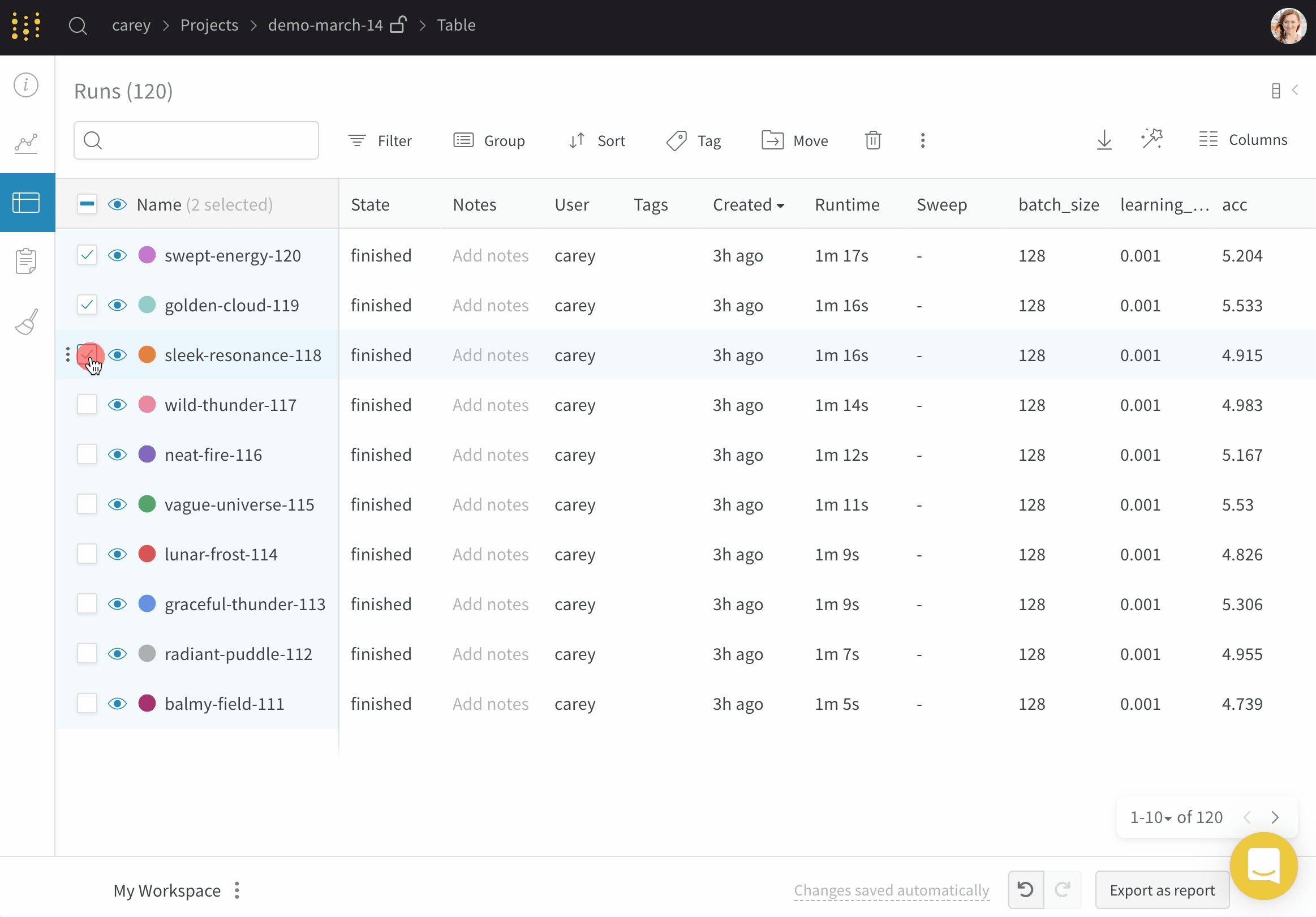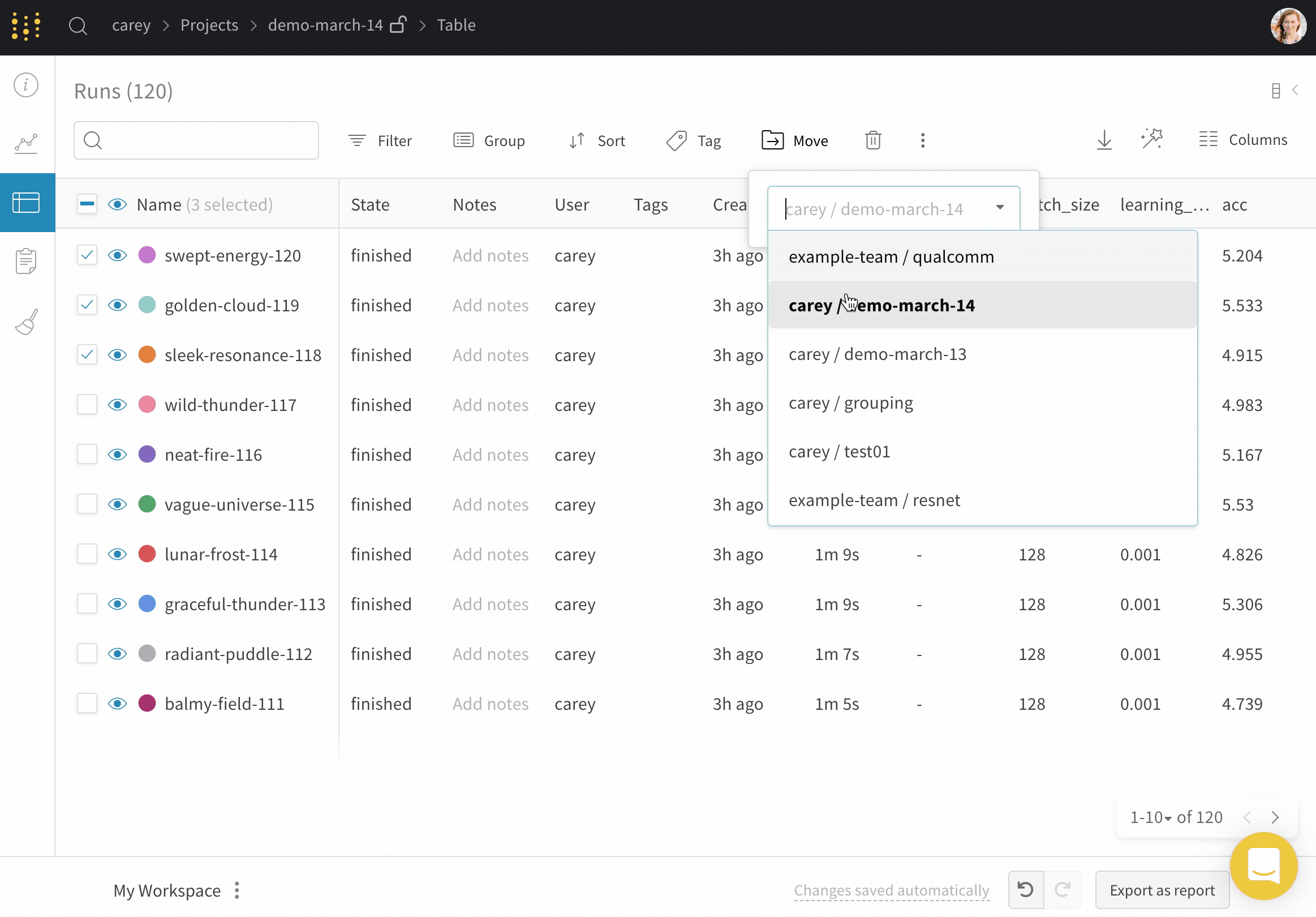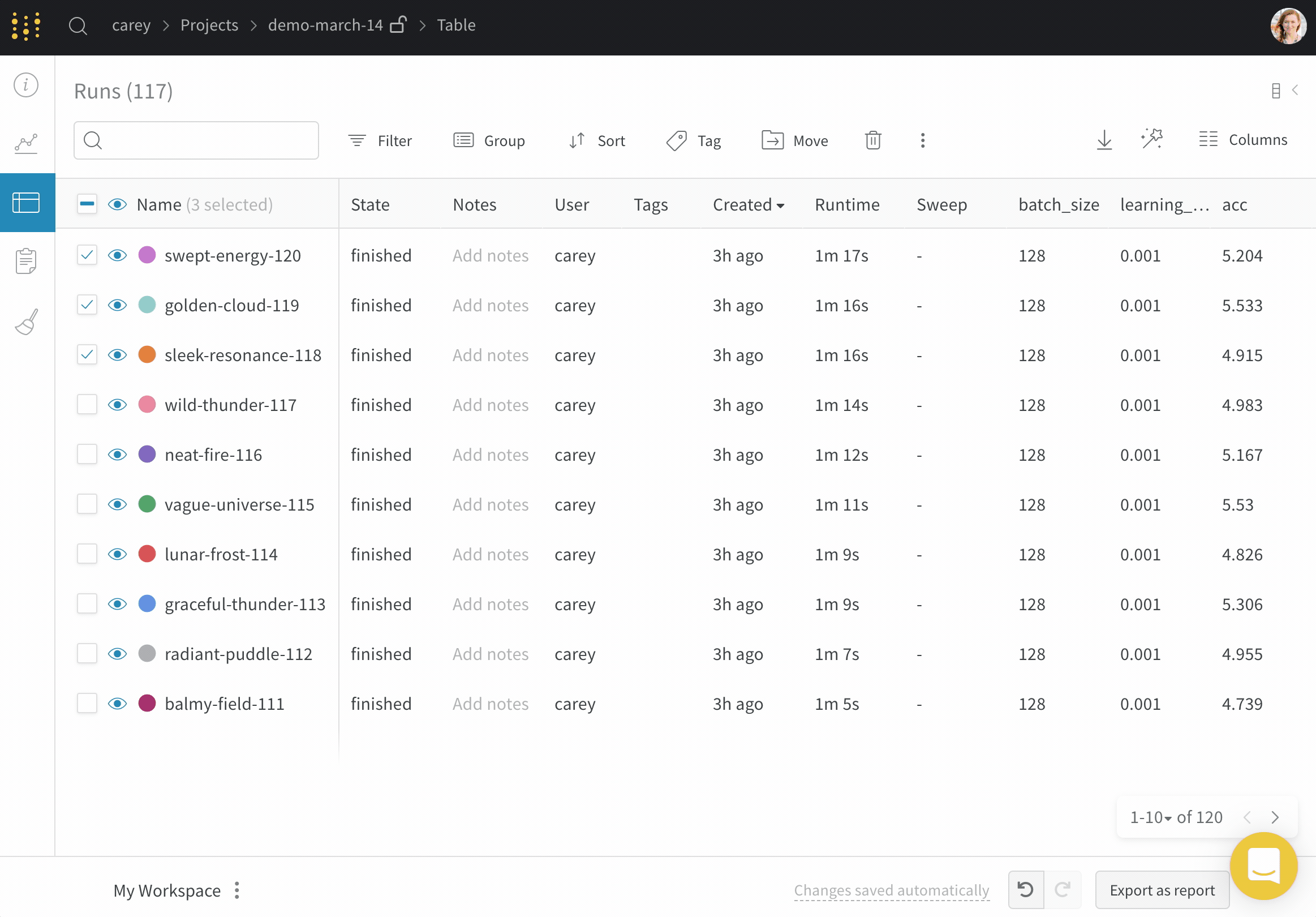
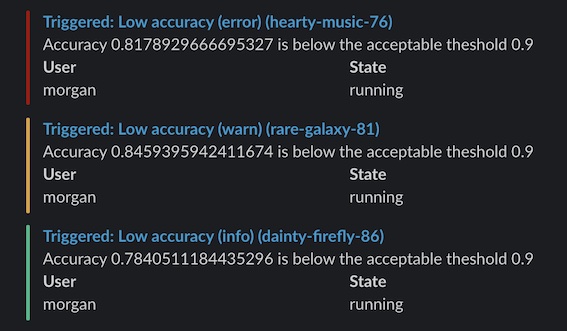
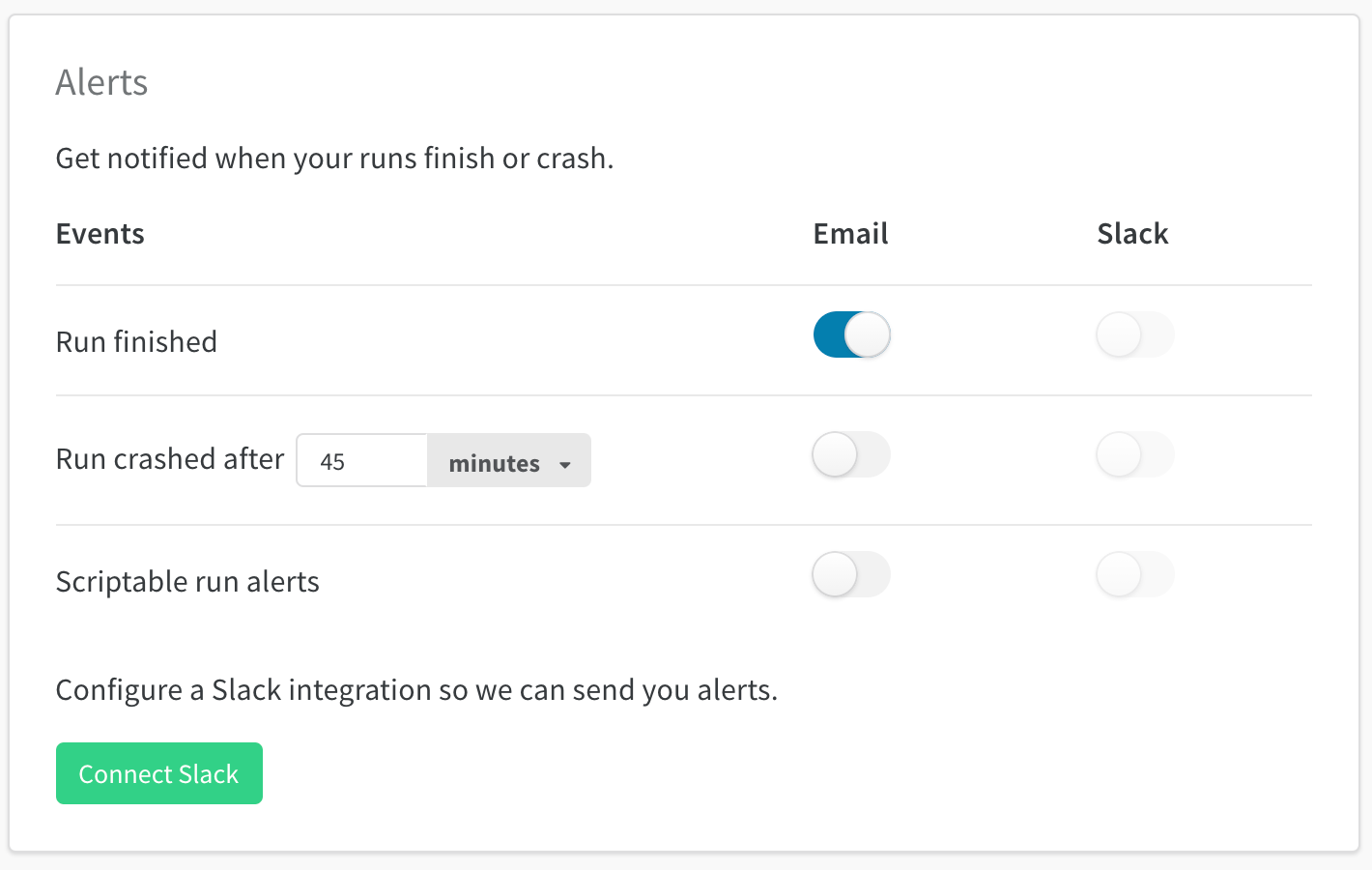
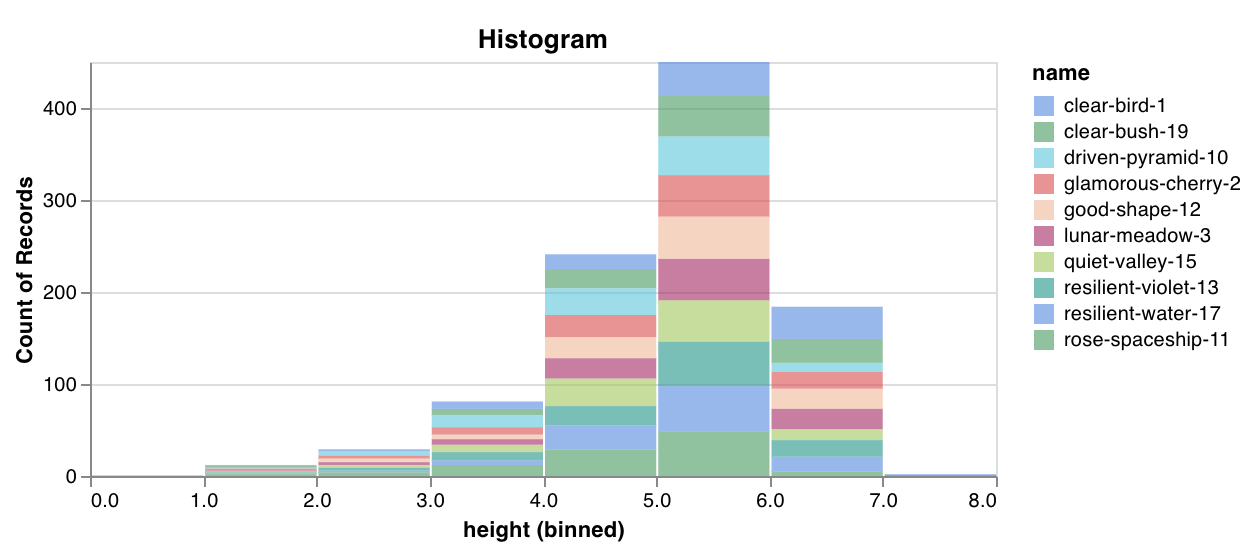
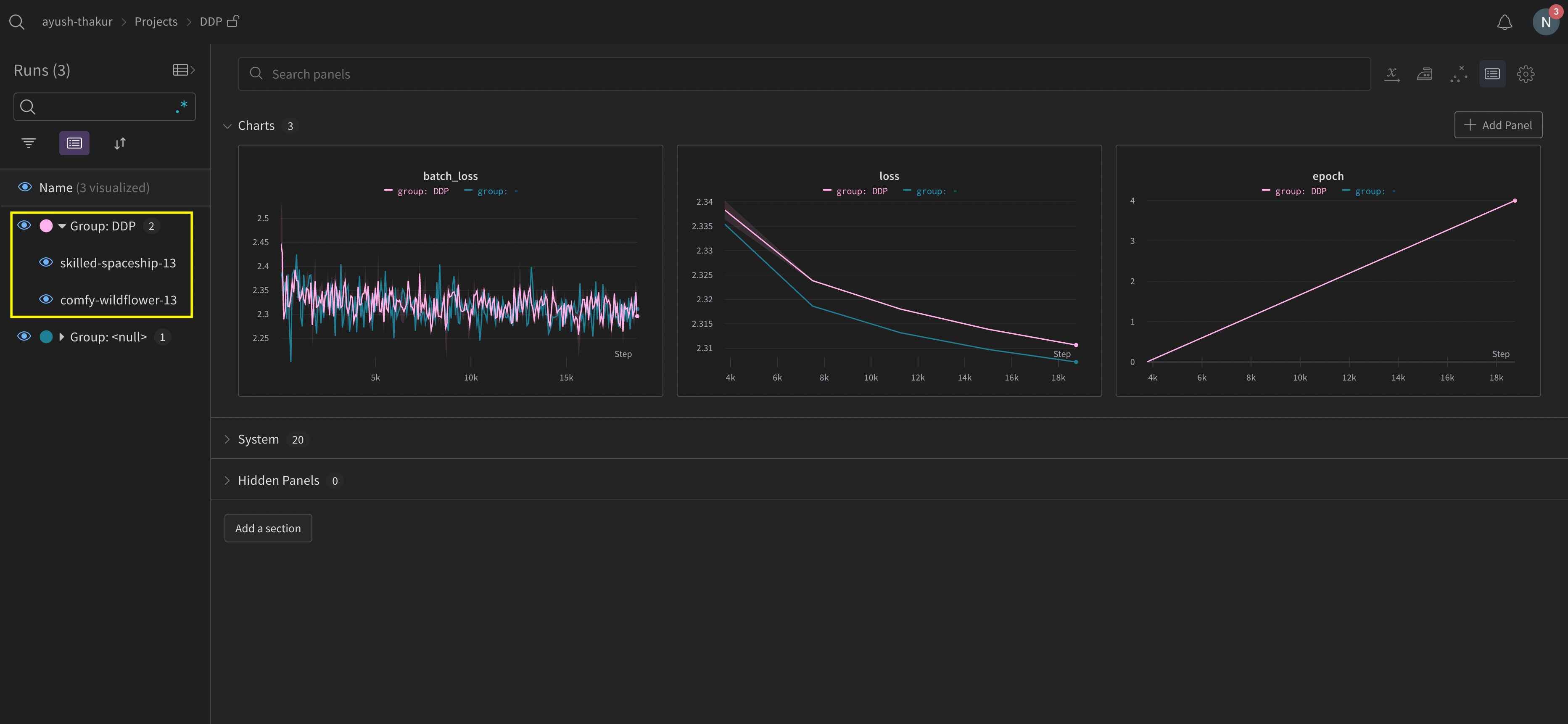


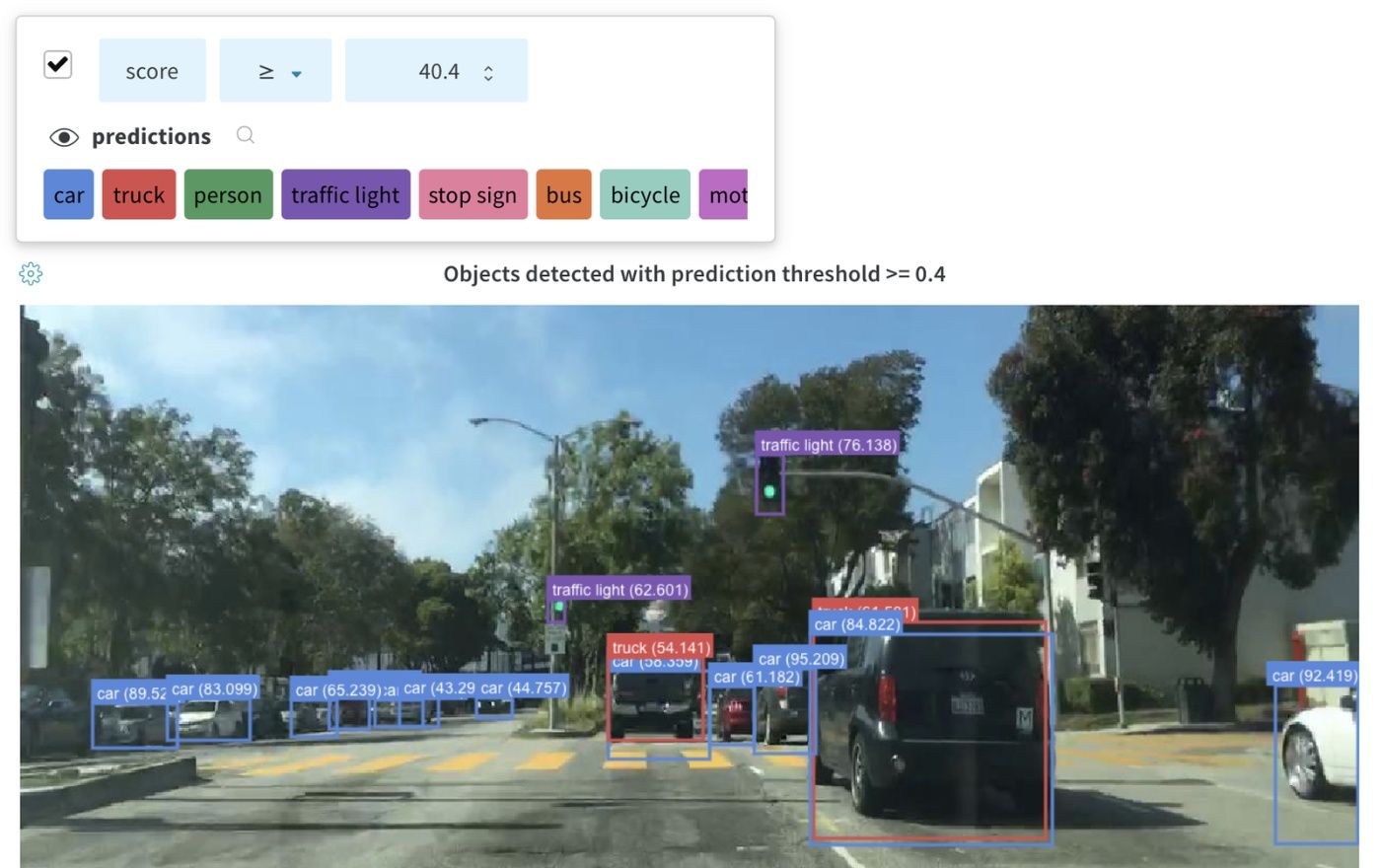
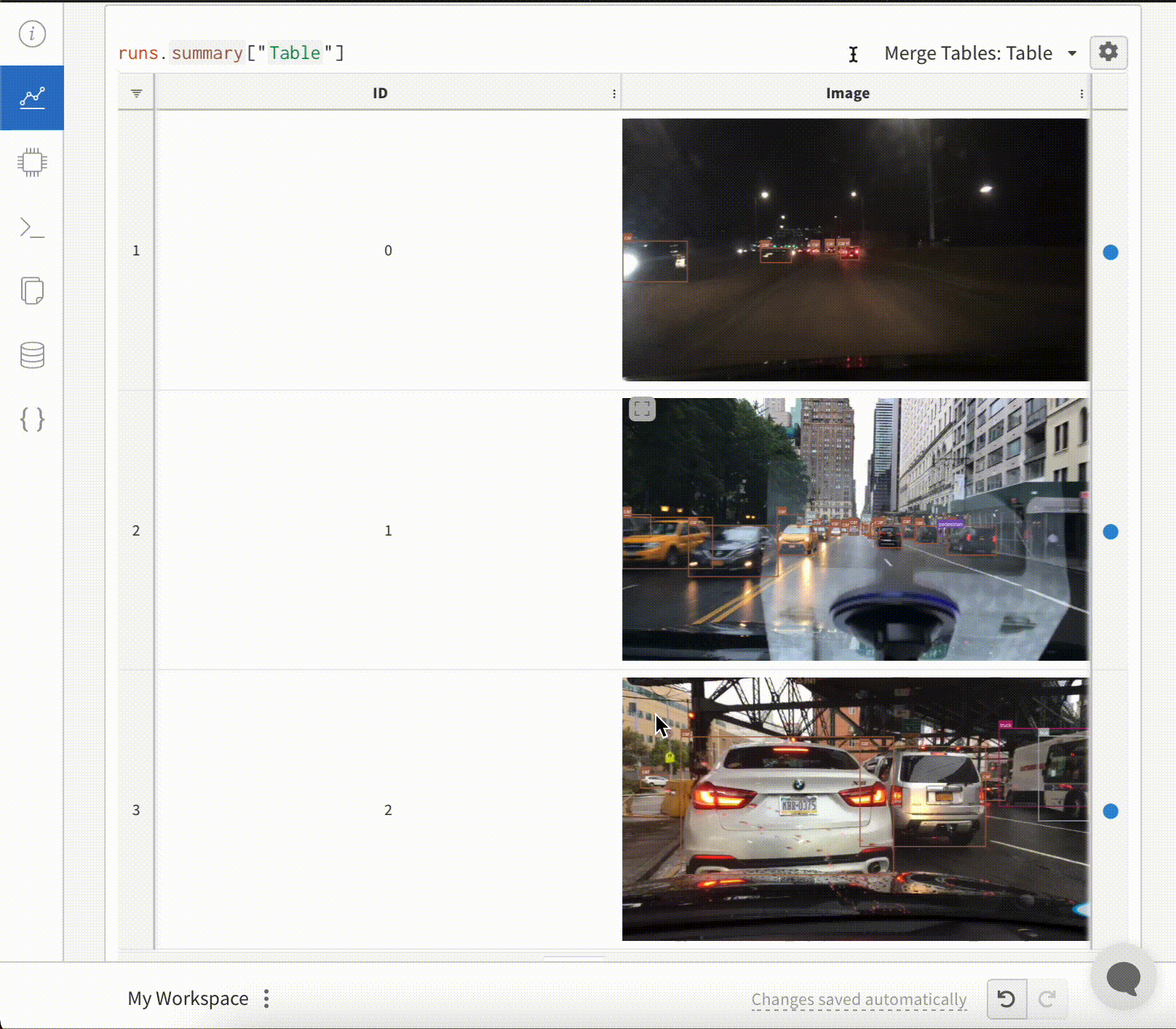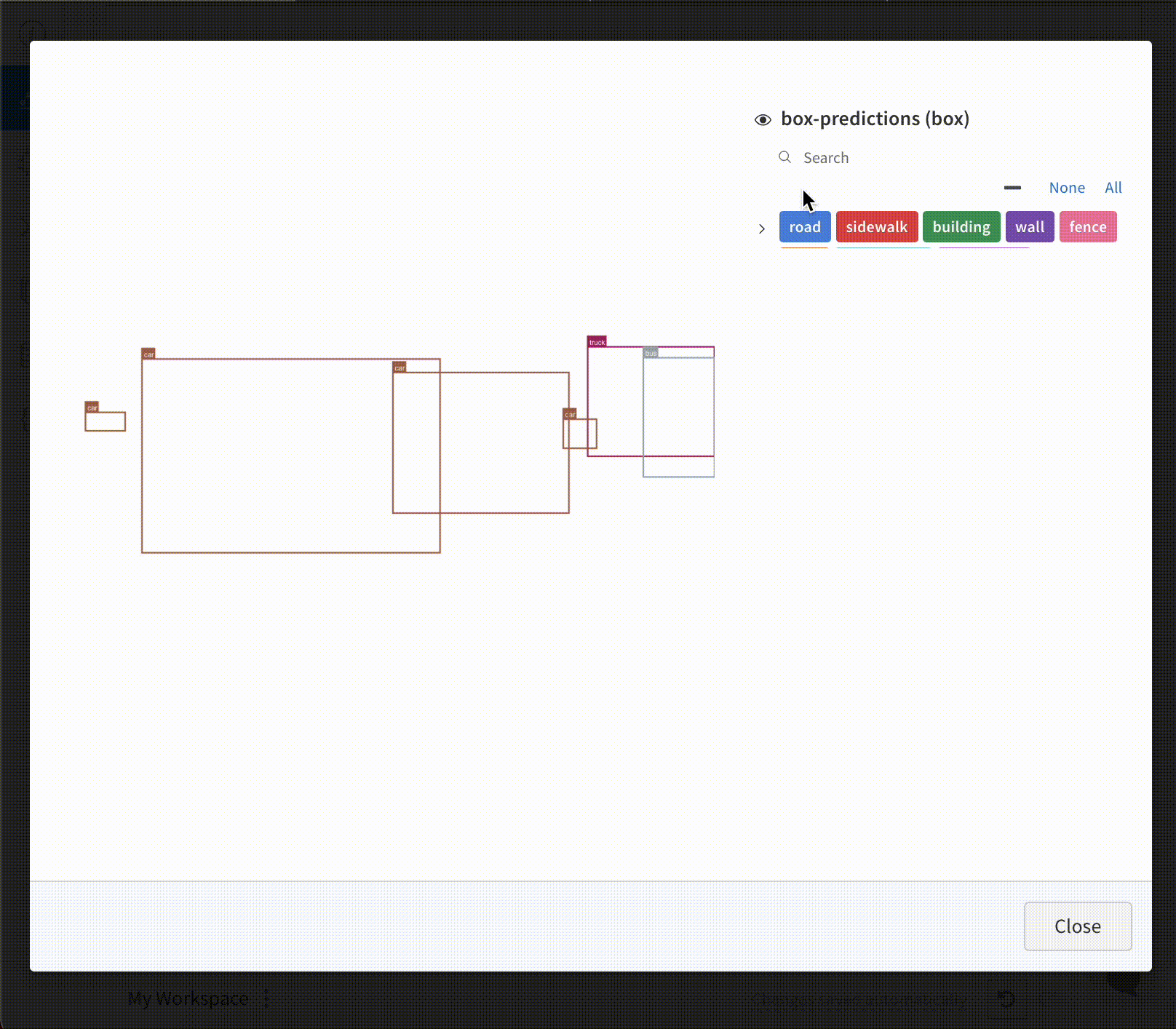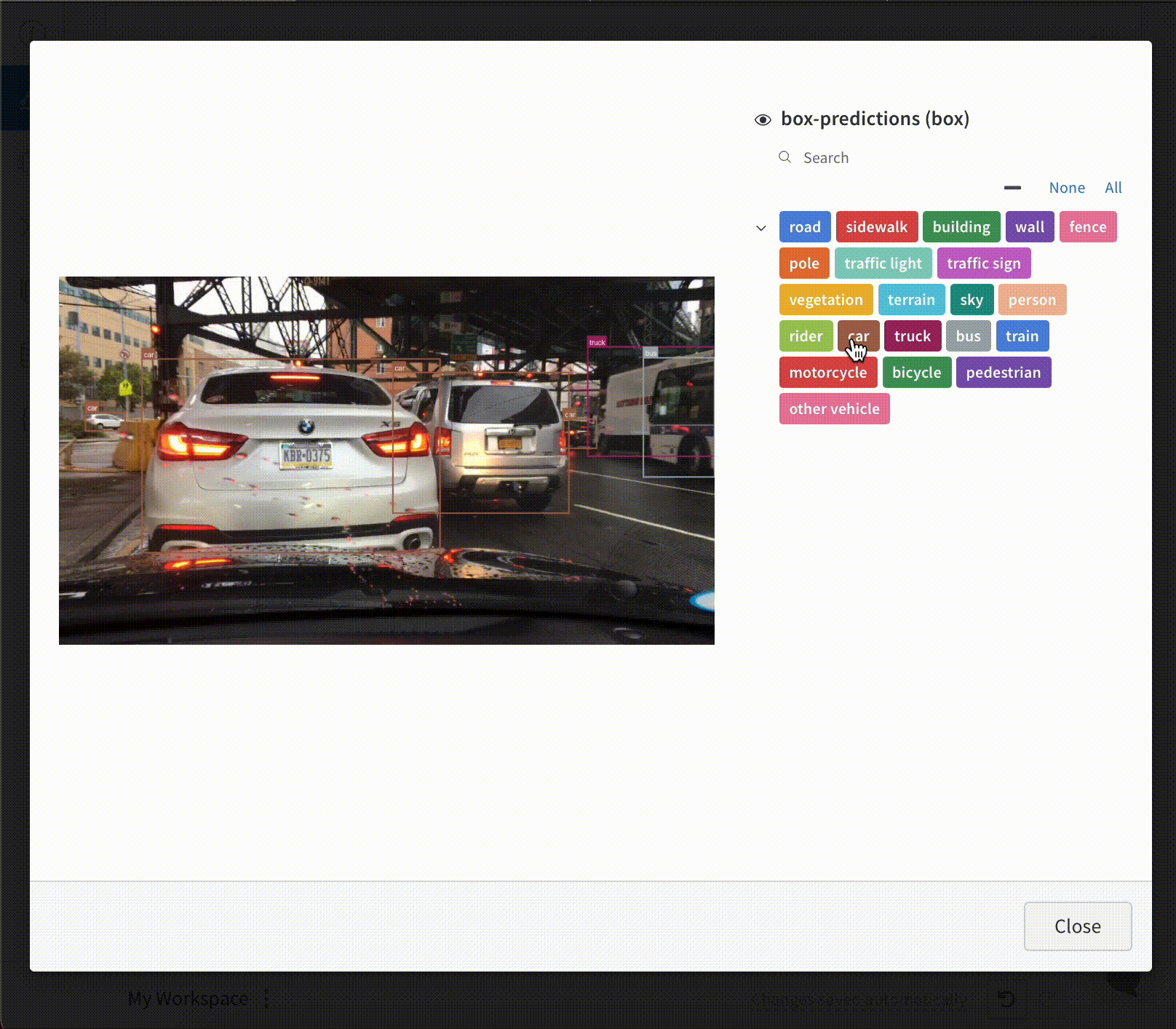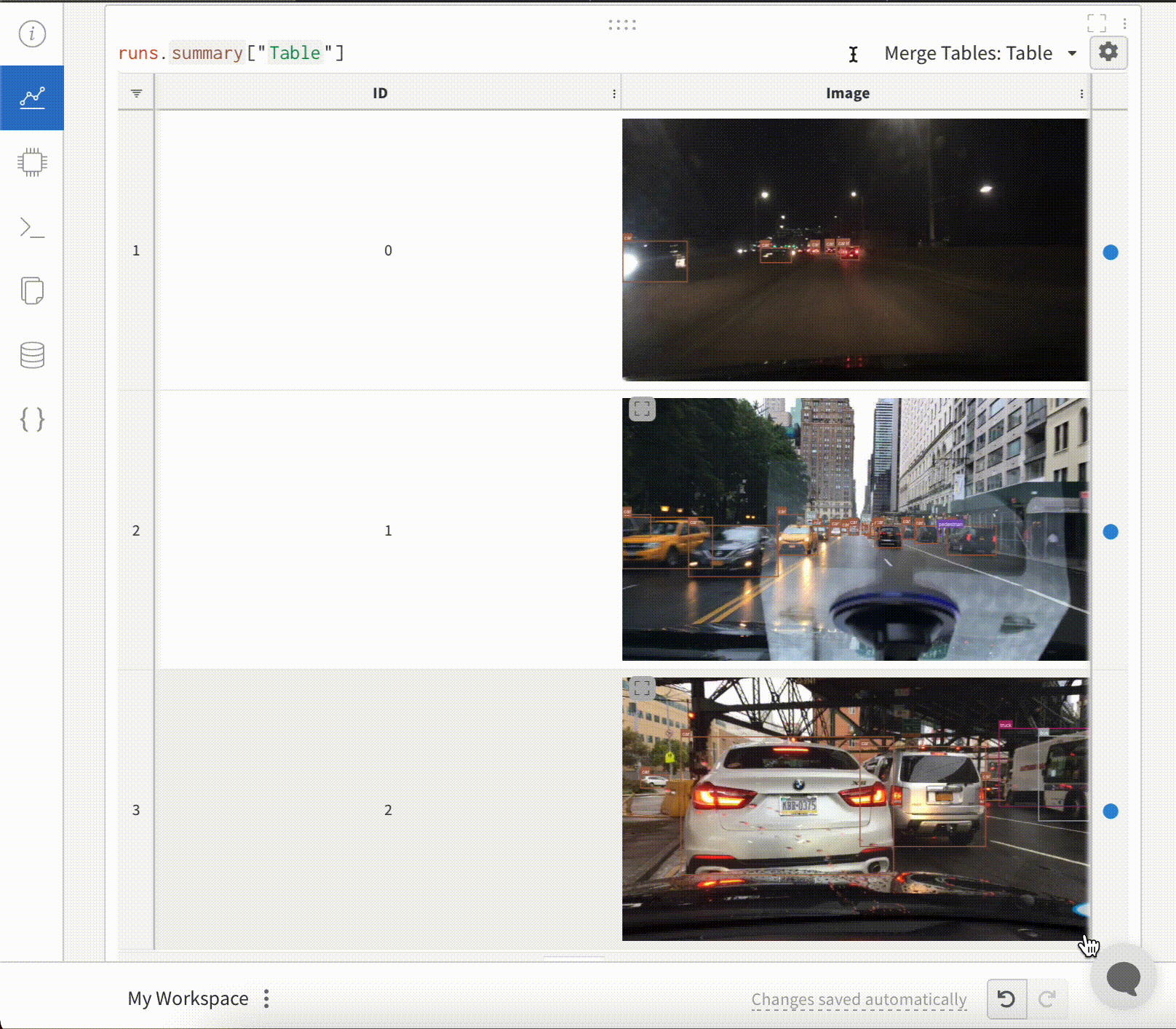
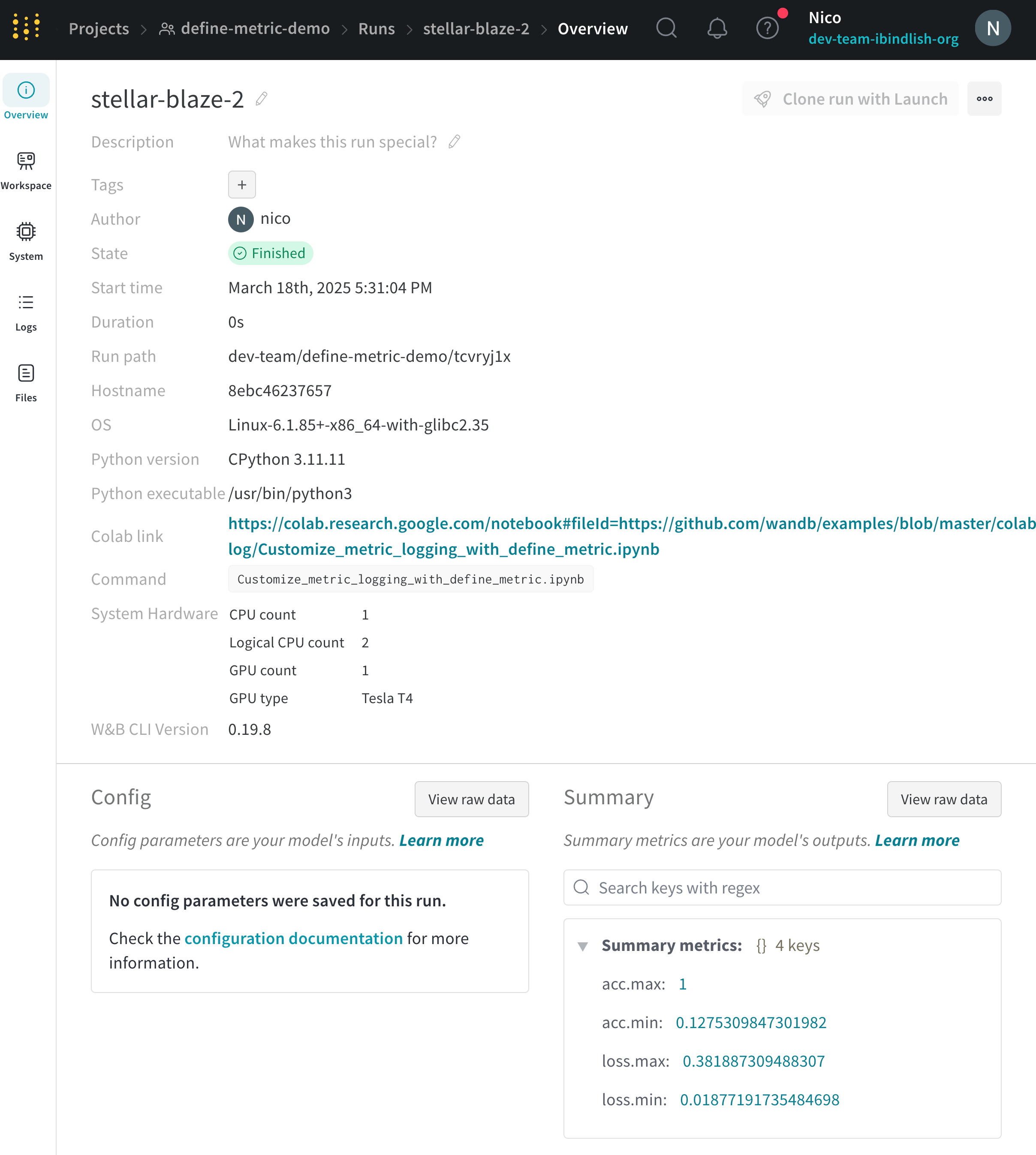
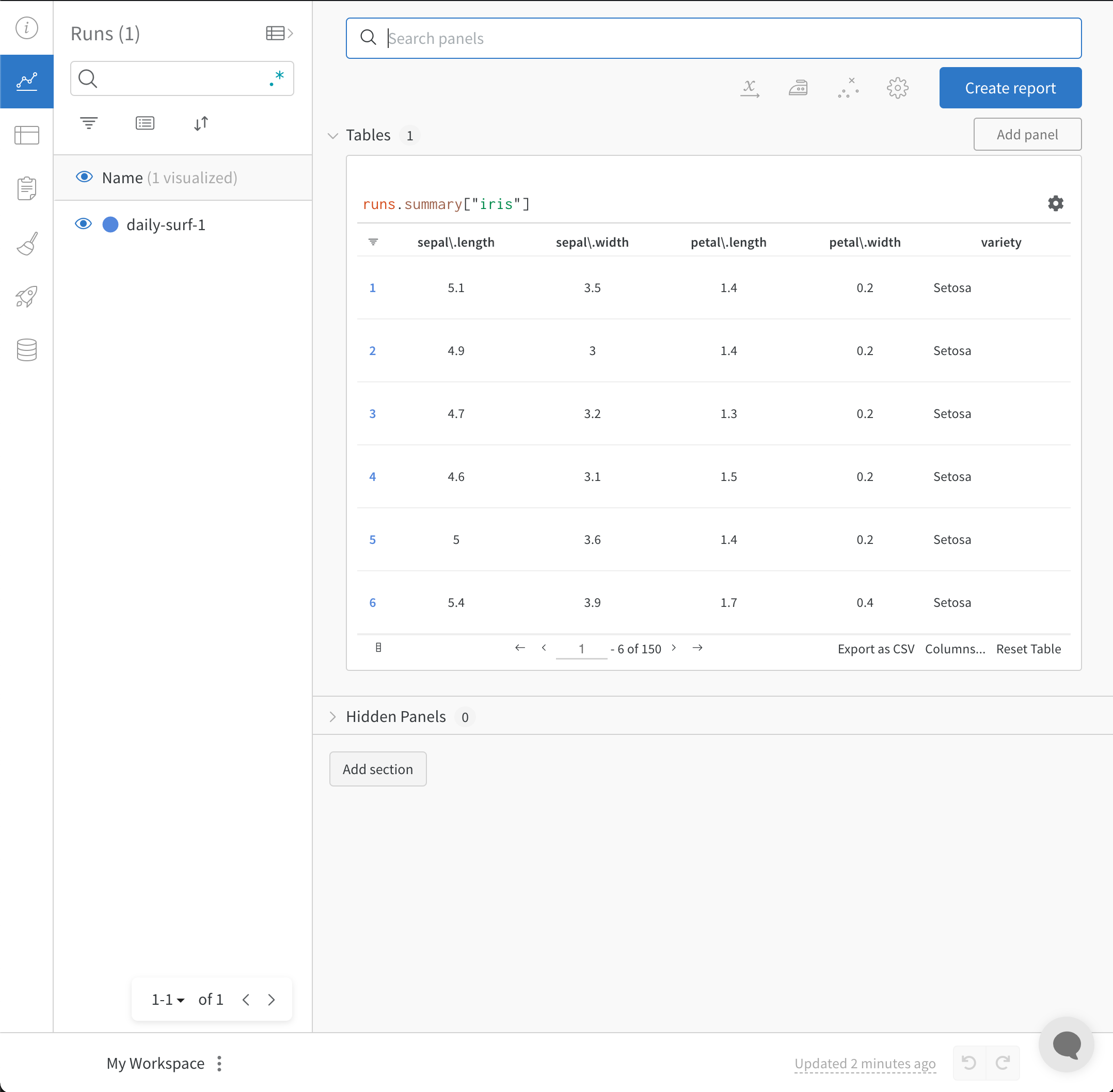
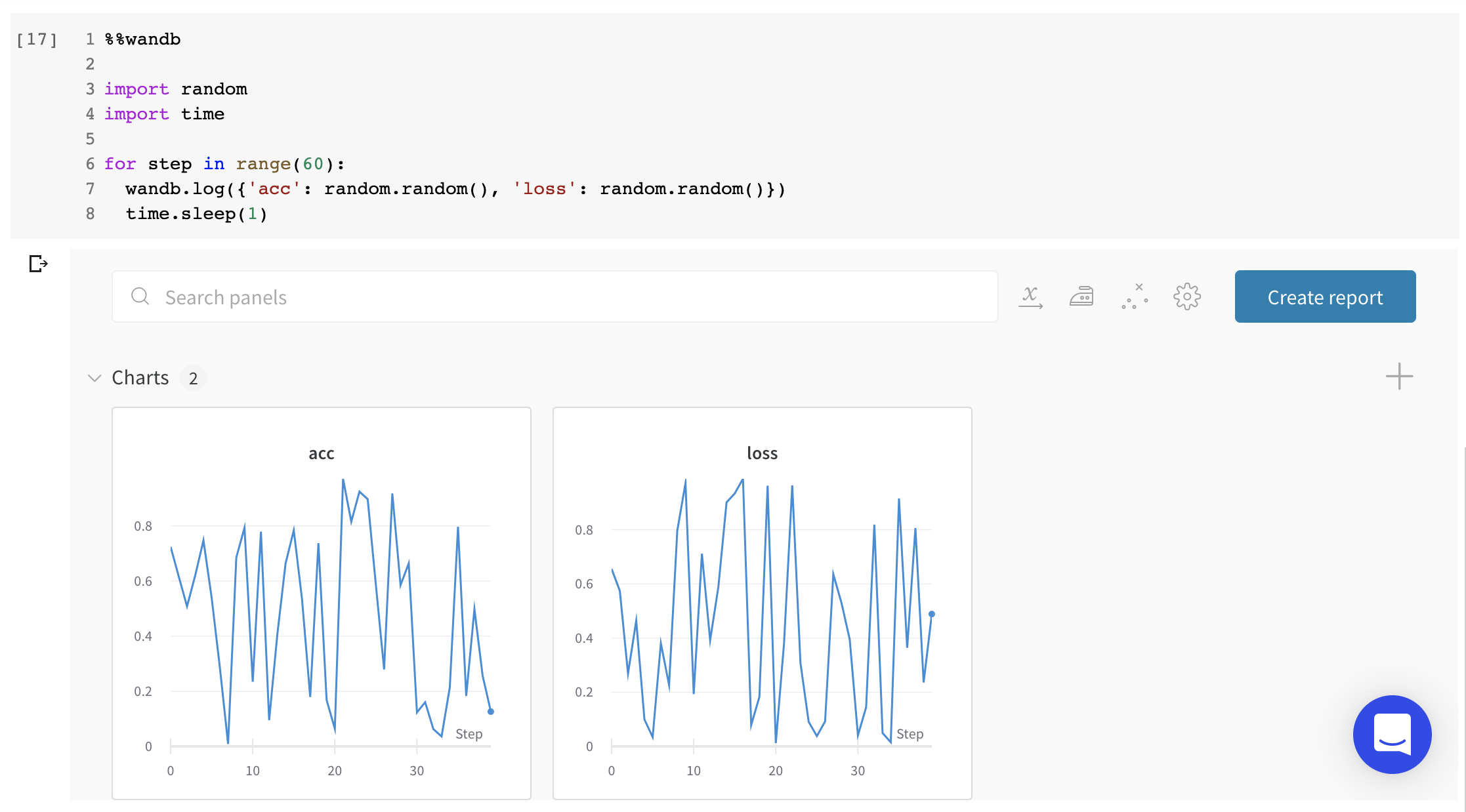
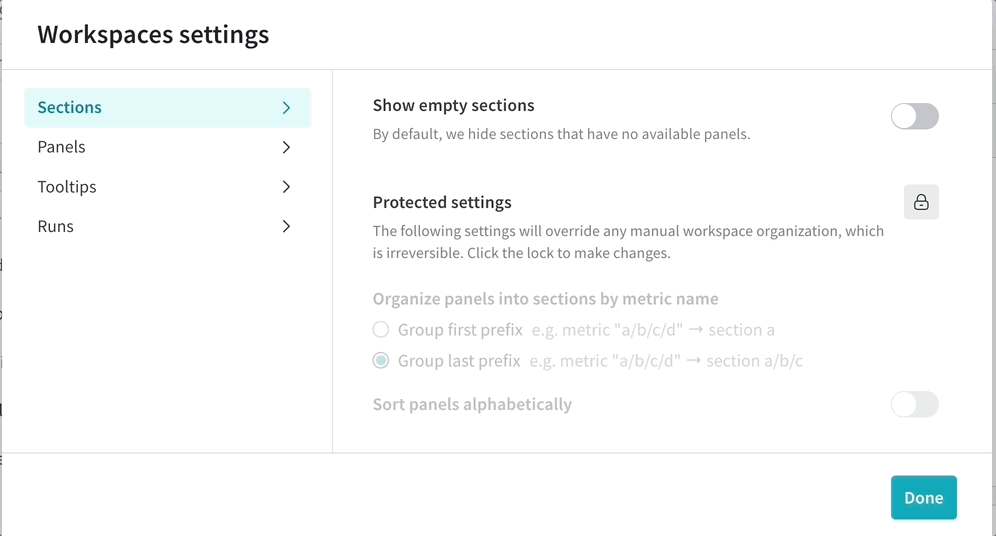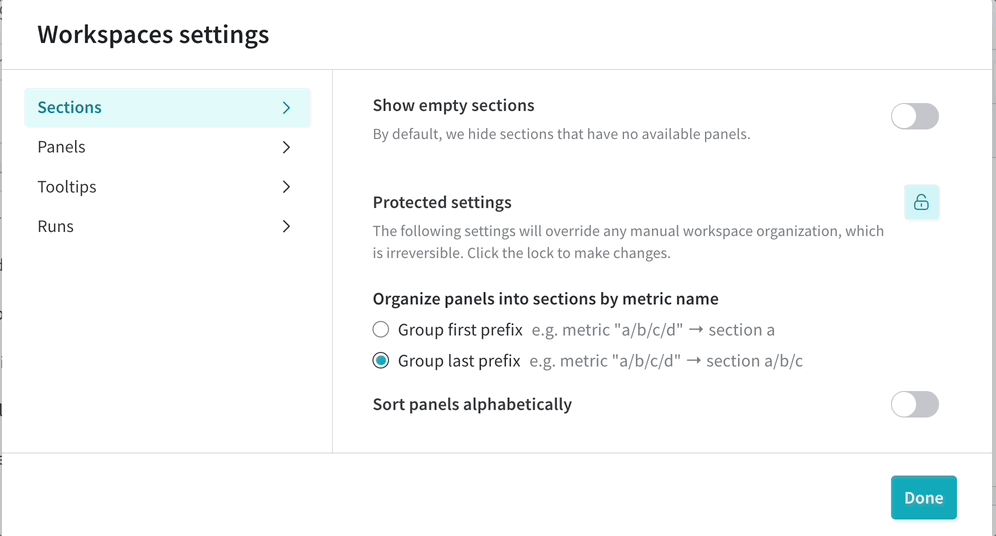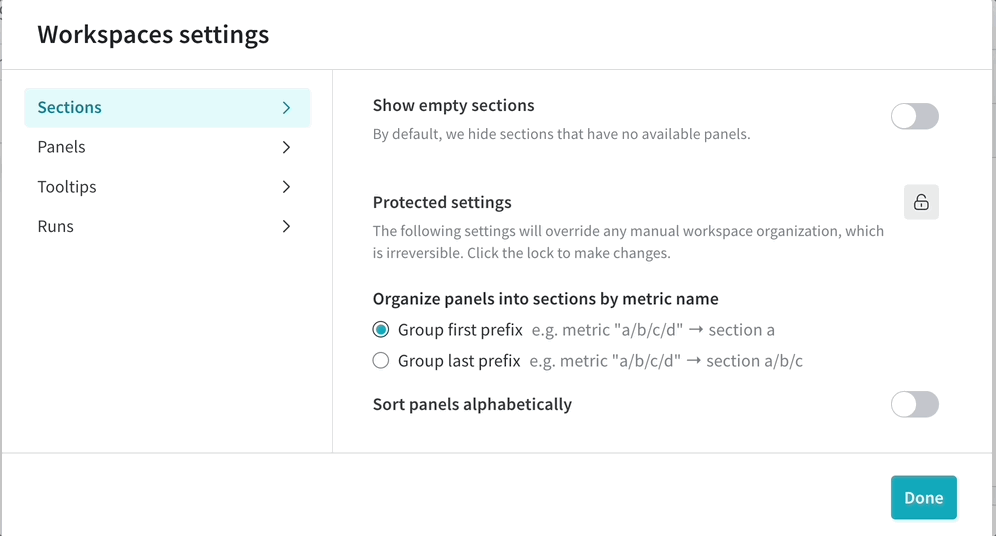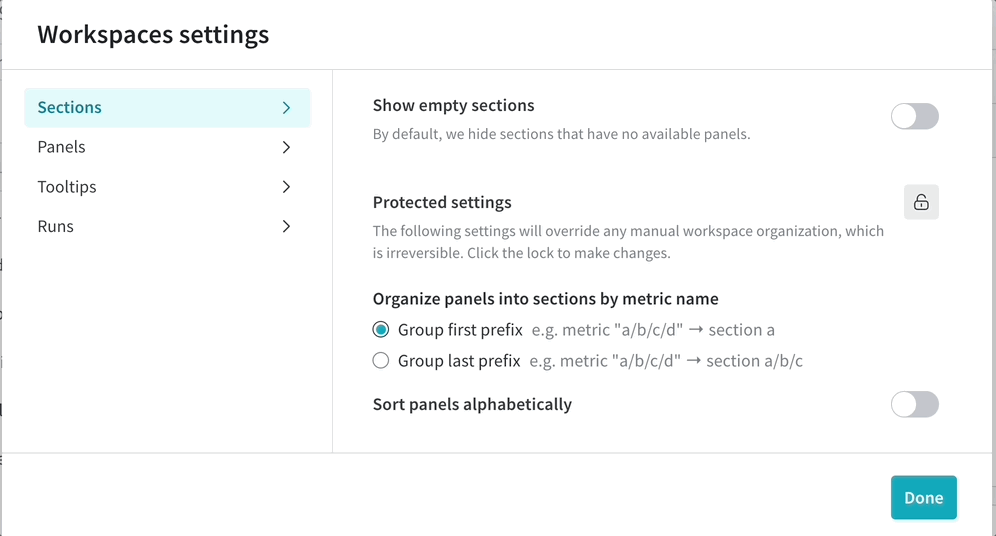
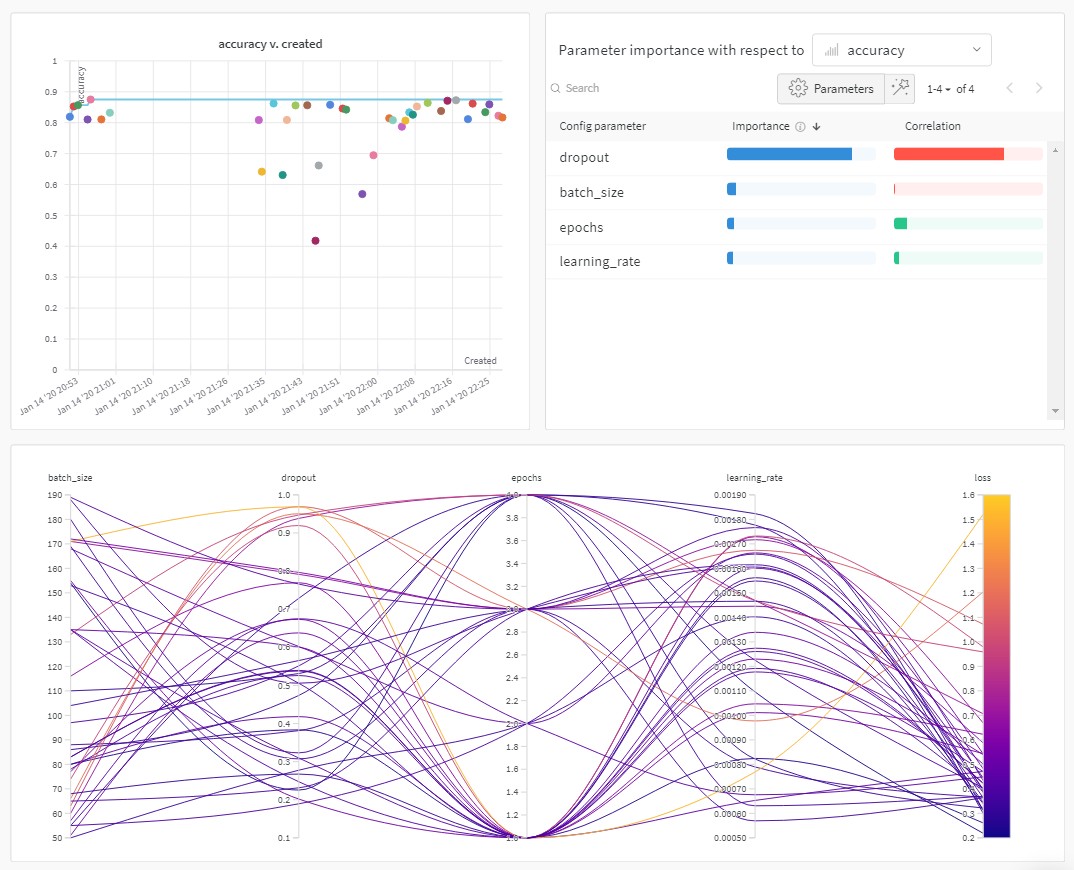
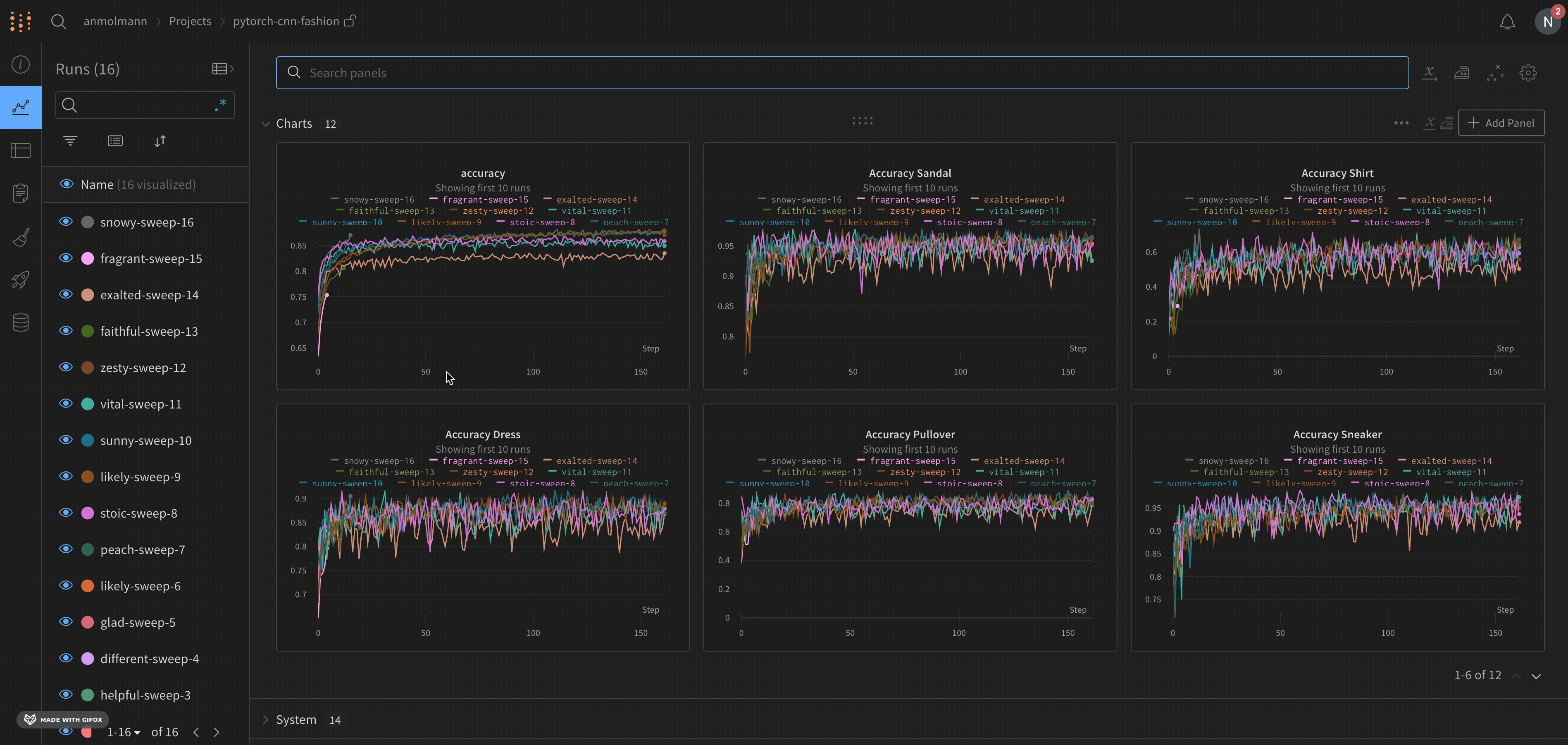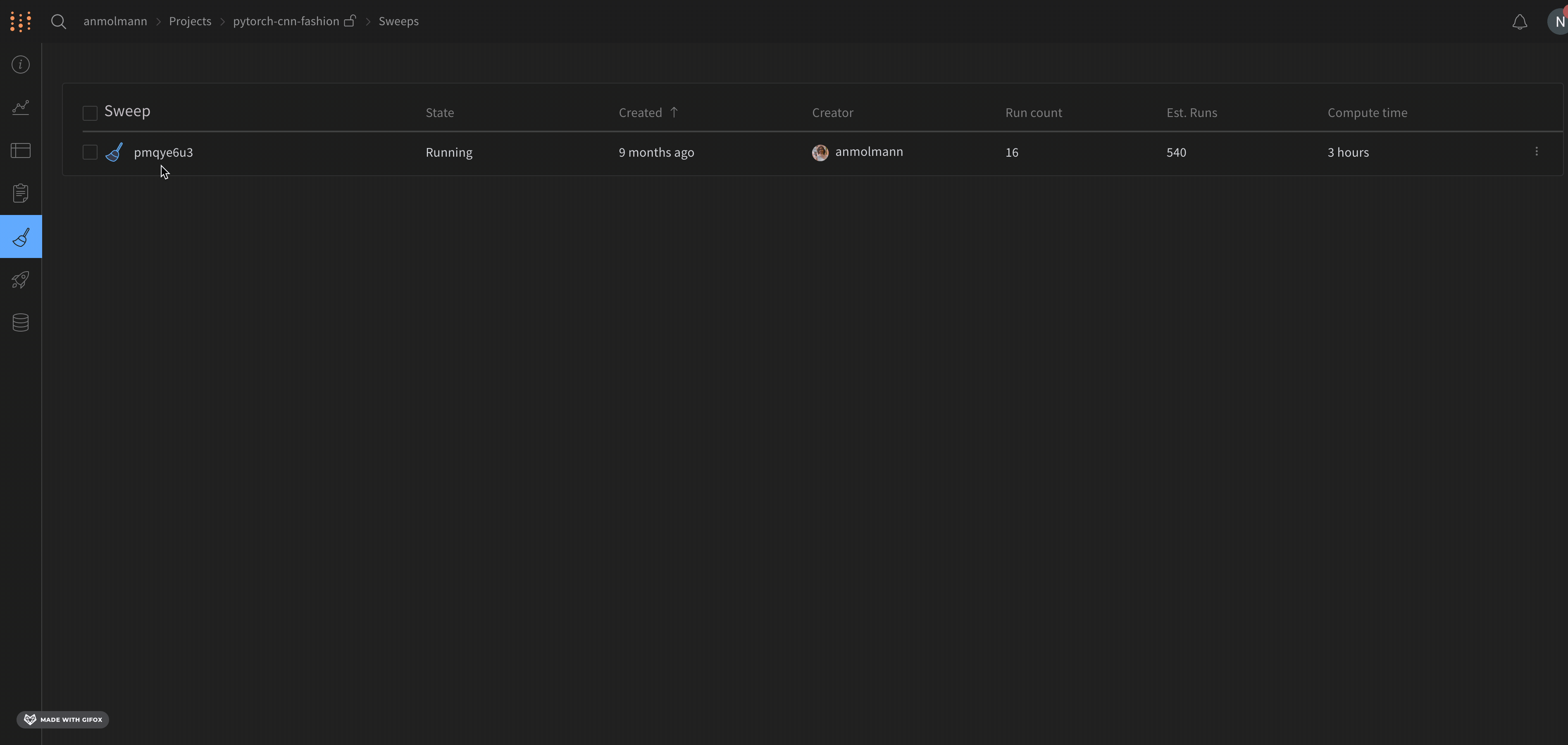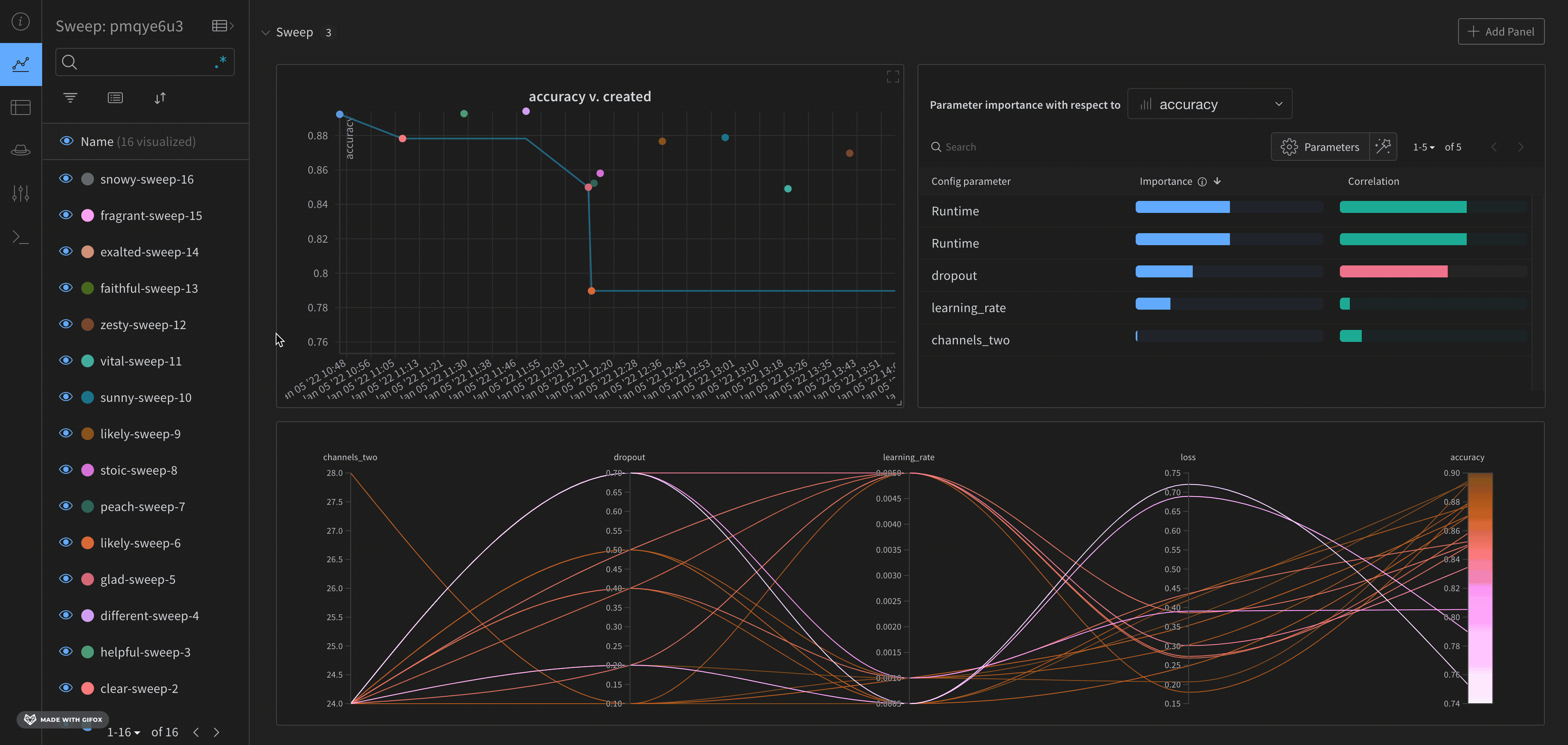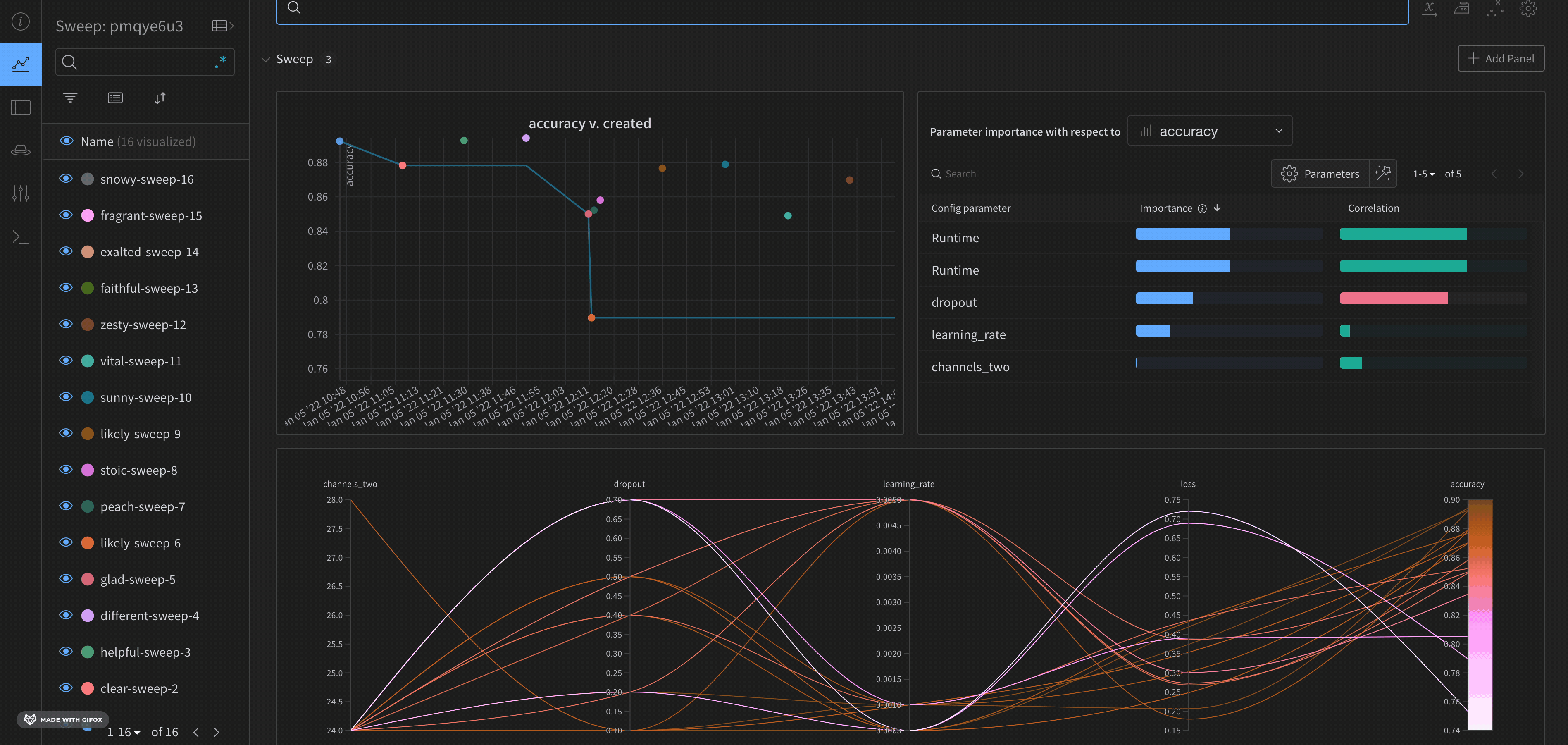
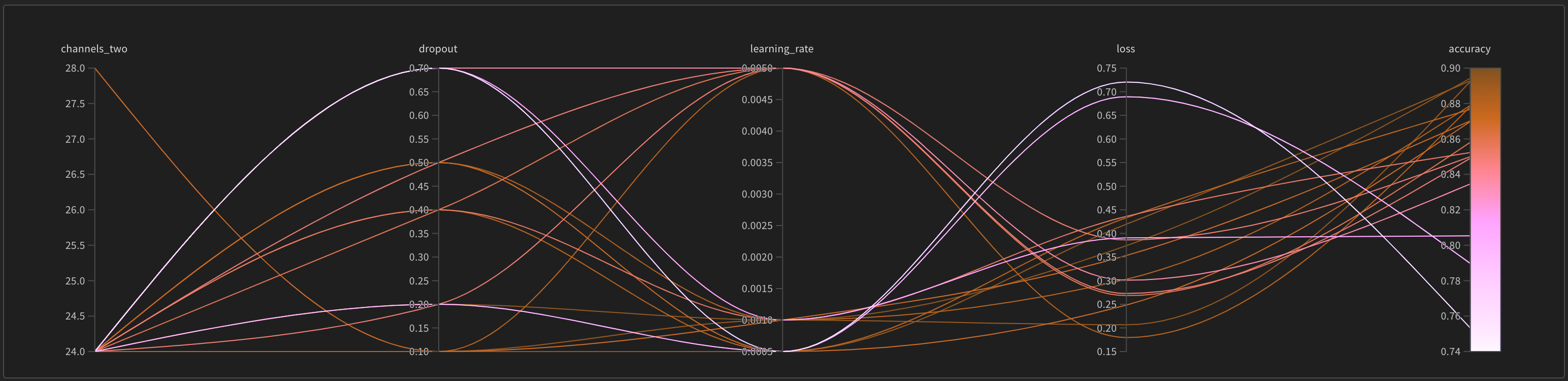
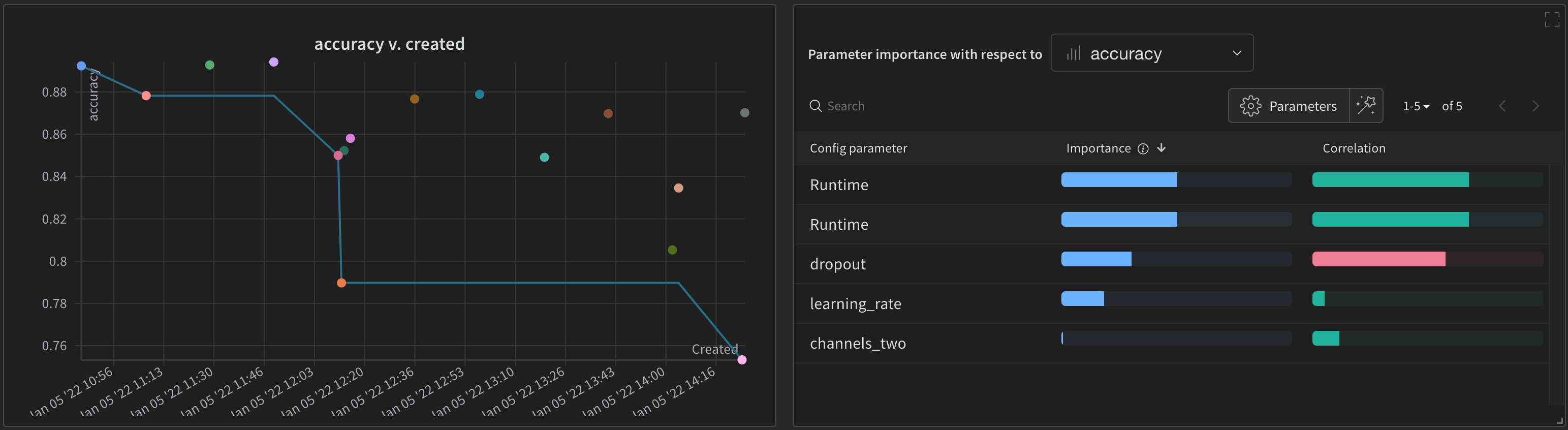
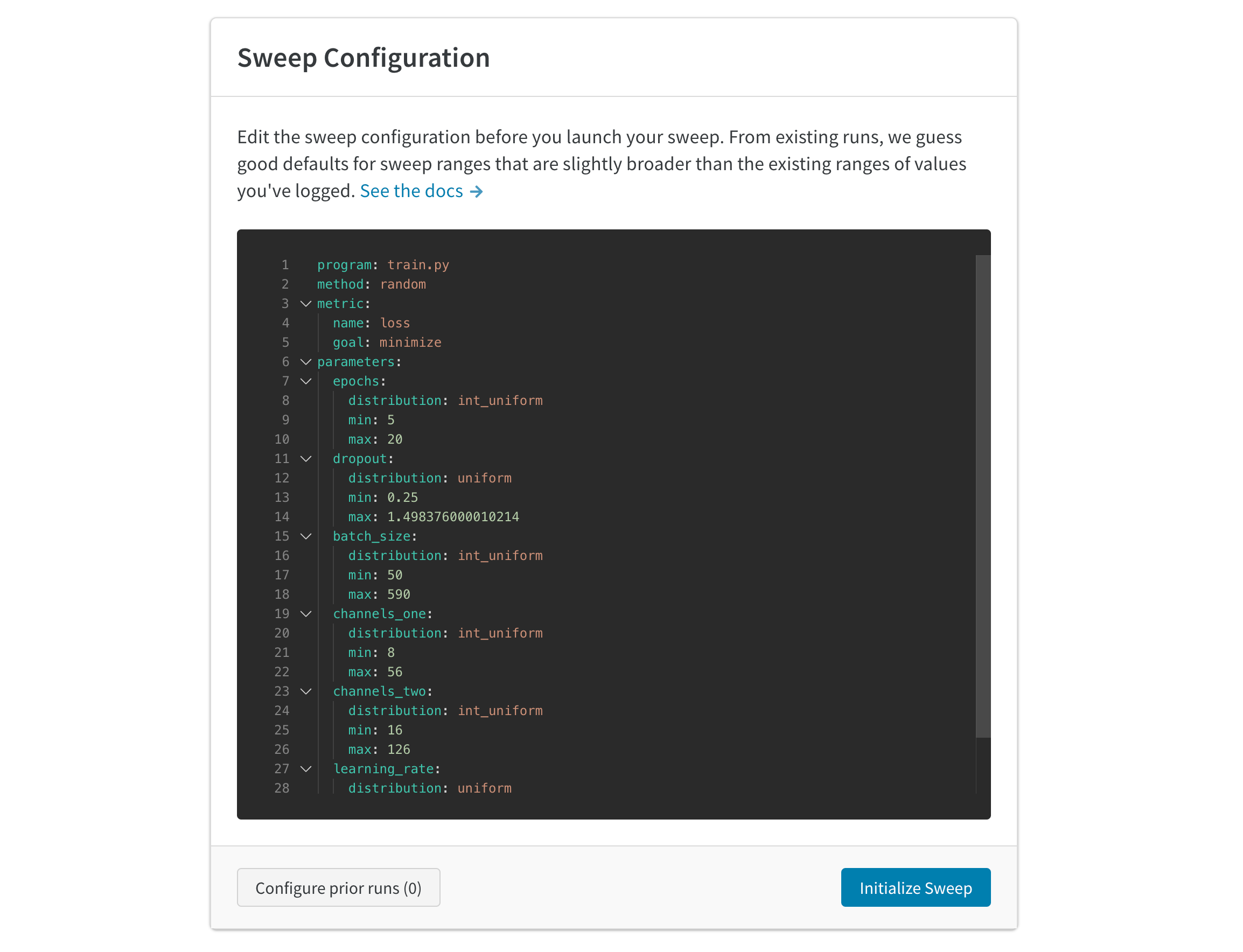
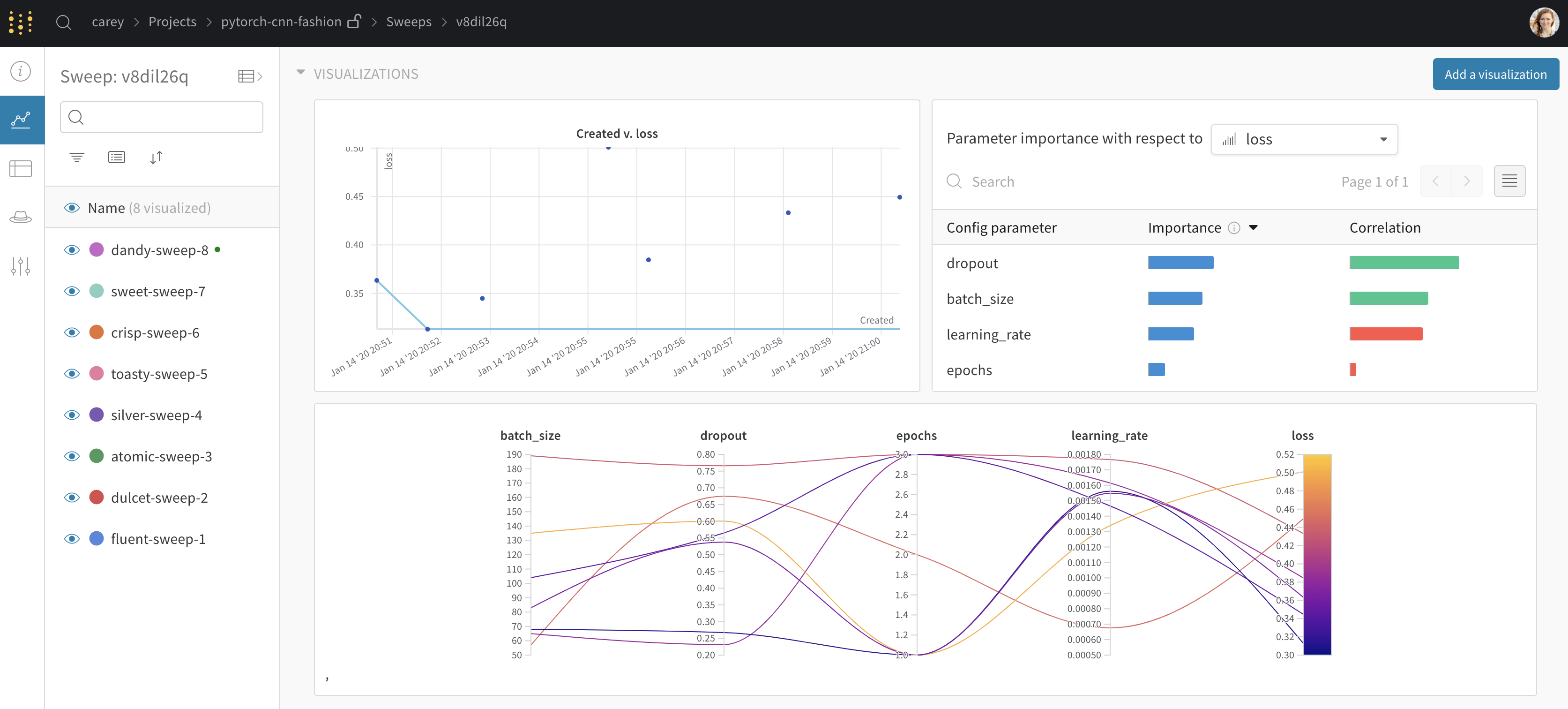
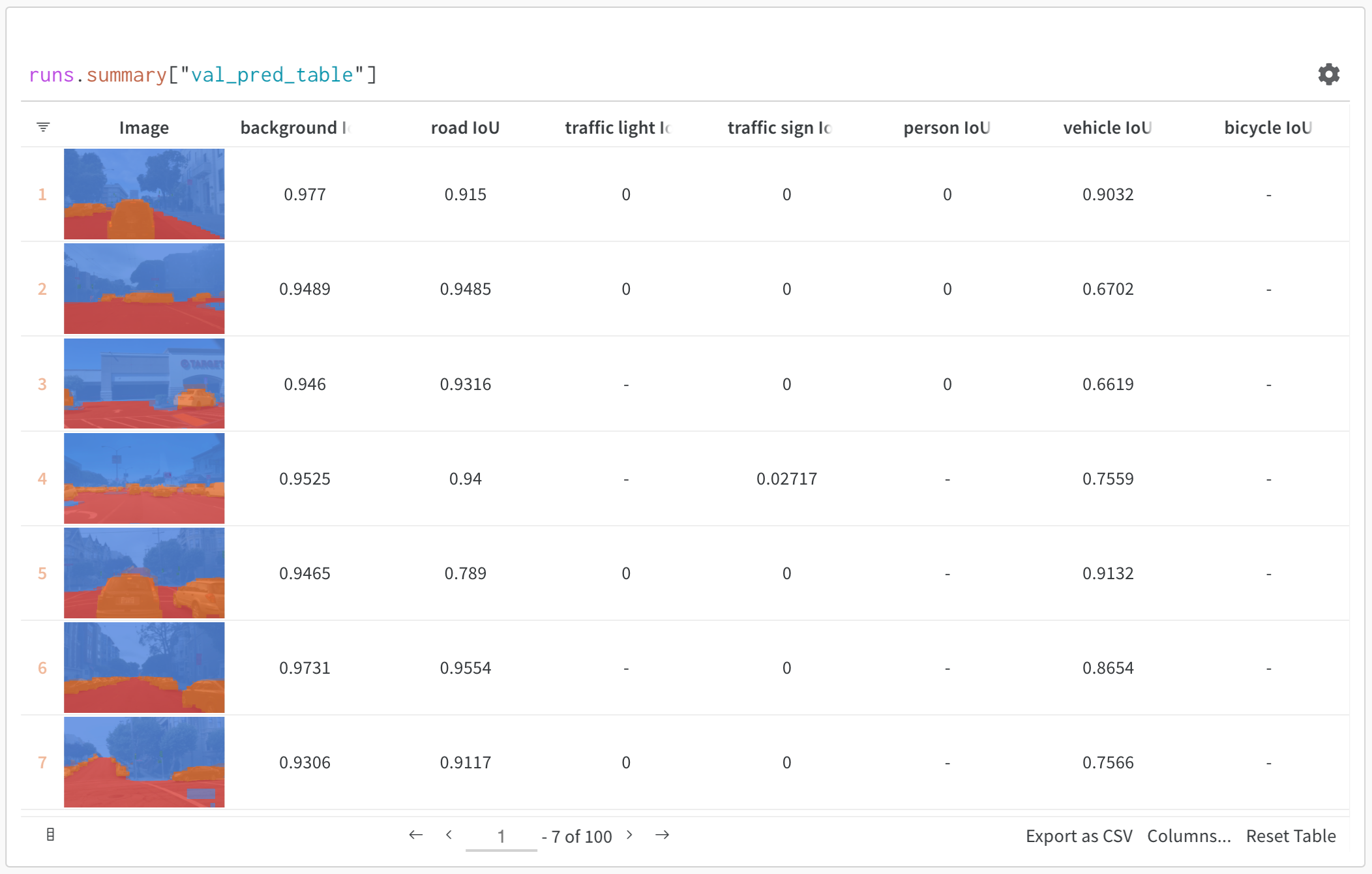 위 이미지는 시멘틱 세분화 및 사용자 정의 메트릭이 있는 테이블을 보여줍니다.
위 이미지는 시멘틱 세분화 및 사용자 정의 메트릭이 있는 테이블을 보여줍니다.