Scikit-Learn
6 minute read
몇 줄의 코드를 사용하여 scikit-learn 모델의 성능을 시각화하고 비교하기 위해 wandb를 사용할 수 있습니다. 예제 사용해보기 →
시작하기
가입 및 API 키 생성
API 키는 W&B에 대한 장치의 인증을 수행합니다. 사용자 프로필에서 API 키를 생성할 수 있습니다.
- 오른쪽 상단 모서리에 있는 사용자 프로필 아이콘을 클릭합니다.
- User Settings를 선택한 다음 API Keys 섹션으로 스크롤합니다.
- Reveal을 클릭합니다. 표시된 API 키를 복사합니다. API 키를 숨기려면 페이지를 새로 고칩니다.
wandb 라이브러리 설치 및 로그인
로컬에서 wandb 라이브러리를 설치하고 로그인하려면:
-
API 키에 대해
WANDB_API_KEY환경 변수를 설정합니다.export WANDB_API_KEY=<your_api_key> -
wandb라이브러리를 설치하고 로그인합니다.pip install wandb wandb login
pip install wandb
import wandb
wandb.login()
!pip install wandb
import wandb
wandb.login()
메트릭 기록
import wandb
wandb.init(project="visualize-sklearn")
y_pred = clf.predict(X_test)
accuracy = sklearn.metrics.accuracy_score(y_true, y_pred)
# If logging metrics over time, then use wandb.log
wandb.log({"accuracy": accuracy})
# OR to log a final metric at the end of training you can also use wandb.summary
wandb.summary["accuracy"] = accuracy
플롯 생성
1단계: wandb를 가져오고 새 run을 초기화합니다
import wandb
wandb.init(project="visualize-sklearn")
2단계: 플롯 시각화
개별 플롯
모델을 트레이닝하고 예측을 수행한 후 wandb에서 플롯을 생성하여 예측을 분석할 수 있습니다. 지원되는 차트의 전체 목록은 아래의 지원되는 플롯 섹션을 참조하십시오
# Visualize single plot
wandb.sklearn.plot_confusion_matrix(y_true, y_pred, labels)
모든 플롯
W&B에는 여러 관련 플롯을 표시하는 plot_classifier와 같은 기능이 있습니다.
# Visualize all classifier plots
wandb.sklearn.plot_classifier(
clf,
X_train,
X_test,
y_train,
y_test,
y_pred,
y_probas,
labels,
model_name="SVC",
feature_names=None,
)
# All regression plots
wandb.sklearn.plot_regressor(reg, X_train, X_test, y_train, y_test, model_name="Ridge")
# All clustering plots
wandb.sklearn.plot_clusterer(
kmeans, X_train, cluster_labels, labels=None, model_name="KMeans"
)
기존 Matplotlib 플롯
Matplotlib에서 생성된 플롯도 W&B 대시보드에 기록할 수 있습니다. 이를 위해서는 먼저 plotly를 설치해야 합니다.
pip install plotly
마지막으로, 다음과 같이 W&B의 대시보드에 플롯을 기록할 수 있습니다.
import matplotlib.pyplot as plt
import wandb
wandb.init(project="visualize-sklearn")
# do all the plt.plot(), plt.scatter(), etc. here.
# ...
# instead of doing plt.show() do:
wandb.log({"plot": plt})
지원되는 플롯
학습 곡선
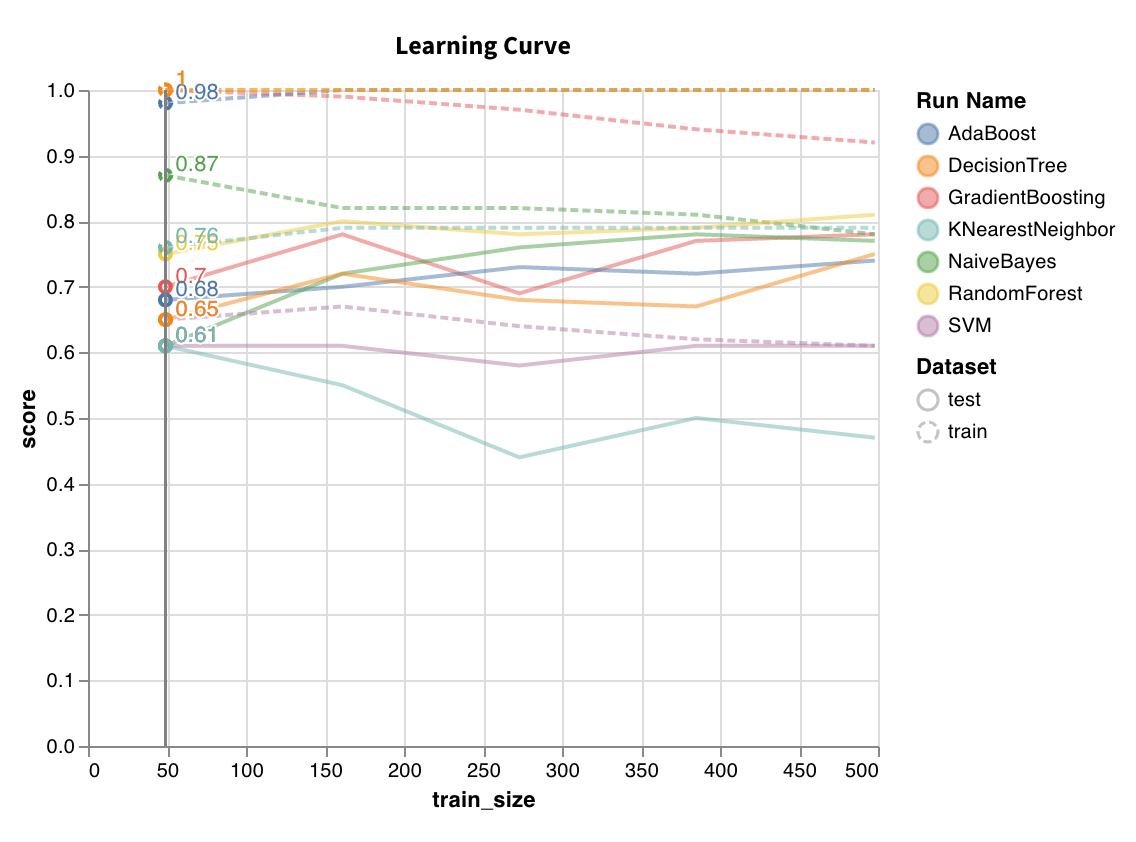
다양한 길이의 데이터셋에서 모델을 트레이닝하고 트레이닝 및 테스트 세트 모두에 대해 교차 검증된 점수 대 데이터셋 크기의 플롯을 생성합니다.
wandb.sklearn.plot_learning_curve(model, X, y)
- model (clf 또는 reg): 적합된 회귀 모델 또는 분류 모델을 사용합니다.
- X (arr): 데이터셋 특징.
- y (arr): 데이터셋 레이블.
ROC
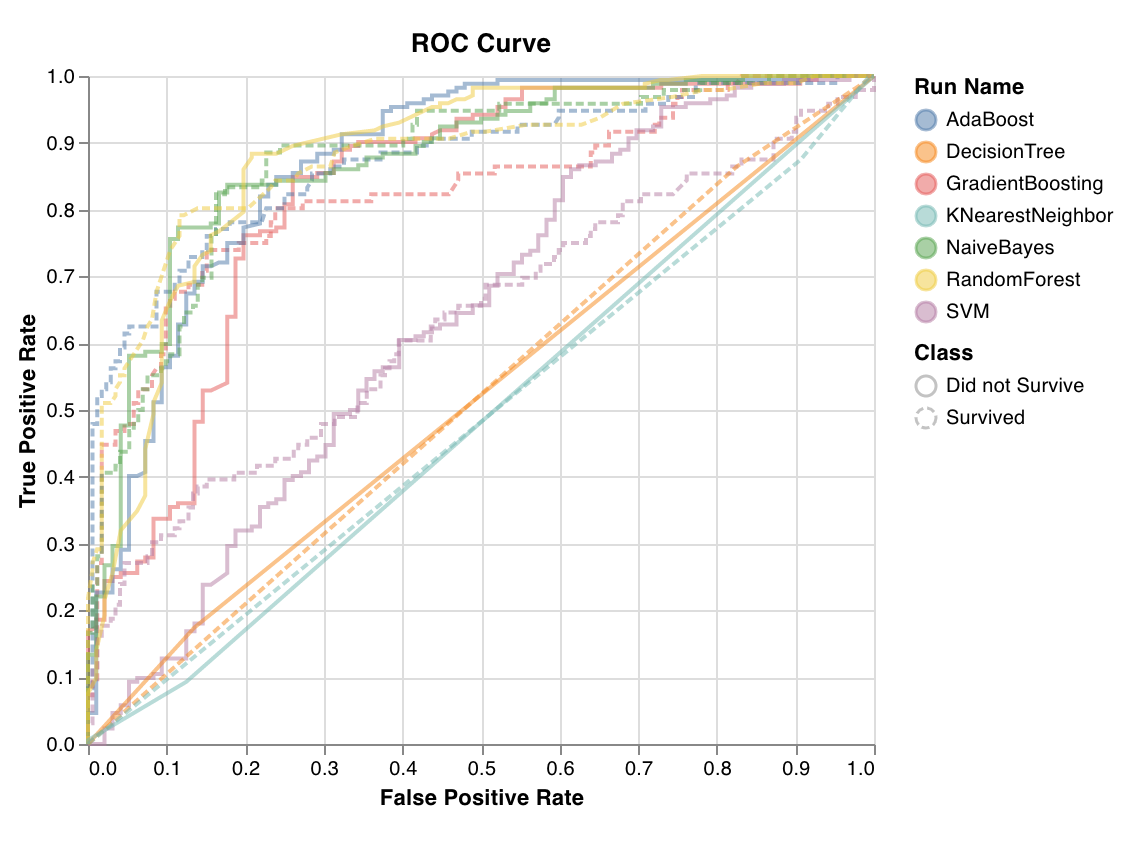
ROC 곡선은 참 긍정 비율(y축) 대 거짓 긍정 비율(x축)을 표시합니다. 이상적인 점수는 TPR = 1 및 FPR = 0이며, 이는 왼쪽 상단의 점입니다. 일반적으로 ROC 곡선 아래 영역(AUC-ROC)을 계산하며 AUC-ROC가 클수록 좋습니다.
wandb.sklearn.plot_roc(y_true, y_probas, labels)
- y_true (arr): 테스트 세트 레이블.
- y_probas (arr): 테스트 세트 예측 확률.
- labels (list): 목표 변수(y)에 대해 명명된 레이블.
클래스 비율

트레이닝 및 테스트 세트에서 목표 클래스의 분포를 표시합니다. 불균형 클래스를 감지하고 한 클래스가 모델에 불균형적인 영향을 미치지 않도록 하는 데 유용합니다.
wandb.sklearn.plot_class_proportions(y_train, y_test, ['dog', 'cat', 'owl'])
- y_train (arr): 트레이닝 세트 레이블.
- y_test (arr): 테스트 세트 레이블.
- labels (list): 목표 변수(y)에 대해 명명된 레이블.
정밀도 재현율 곡선
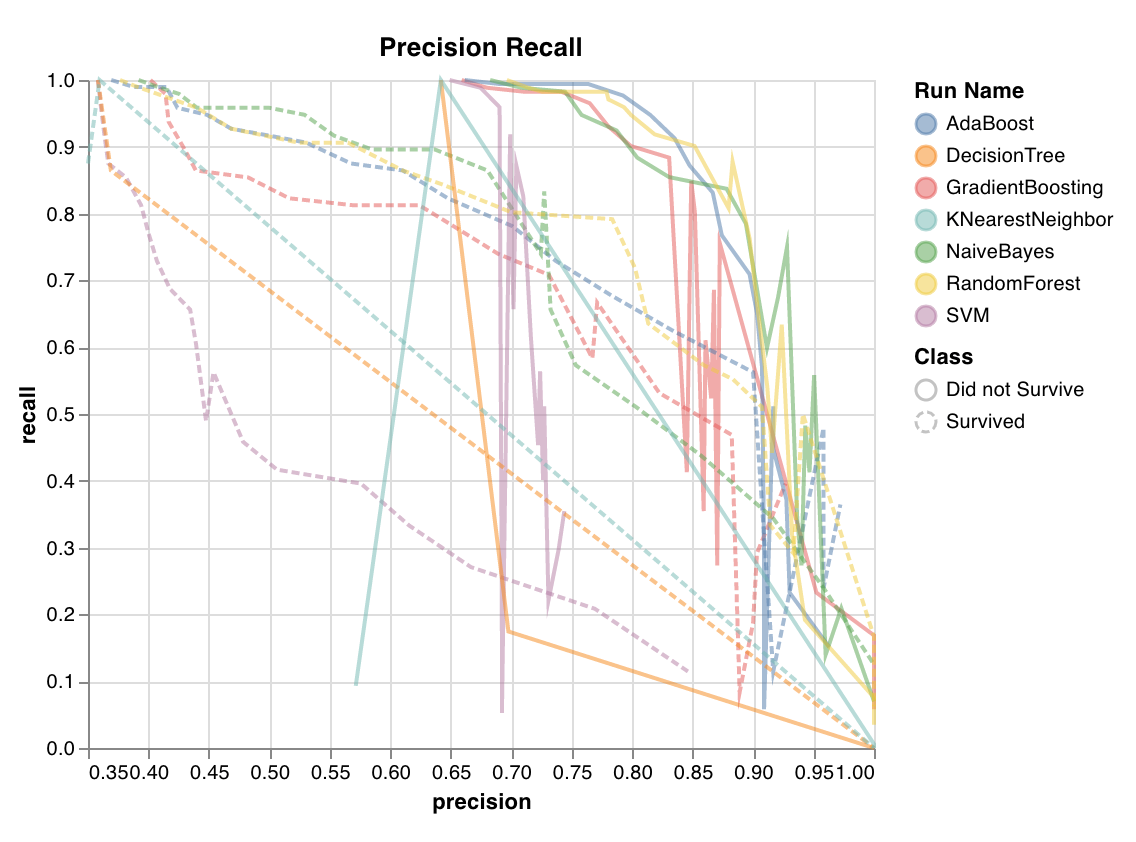
서로 다른 임계값에 대한 정밀도와 재현율 간의 균형을 계산합니다. 곡선 아래의 높은 영역은 높은 재현율과 높은 정밀도를 모두 나타냅니다. 여기서 높은 정밀도는 낮은 거짓 긍정 비율과 관련이 있고 높은 재현율은 낮은 거짓 부정 비율과 관련이 있습니다.
두 점수 모두 높으면 분류 모델이 정확한 결과(높은 정밀도)를 반환할 뿐만 아니라 모든 긍정적인 결과의 대부분(높은 재현율)을 반환한다는 것을 나타냅니다. PR 곡선은 클래스가 매우 불균형할 때 유용합니다.
wandb.sklearn.plot_precision_recall(y_true, y_probas, labels)
- y_true (arr): 테스트 세트 레이블.
- y_probas (arr): 테스트 세트 예측 확률.
- labels (list): 목표 변수(y)에 대해 명명된 레이블.
특징 중요도
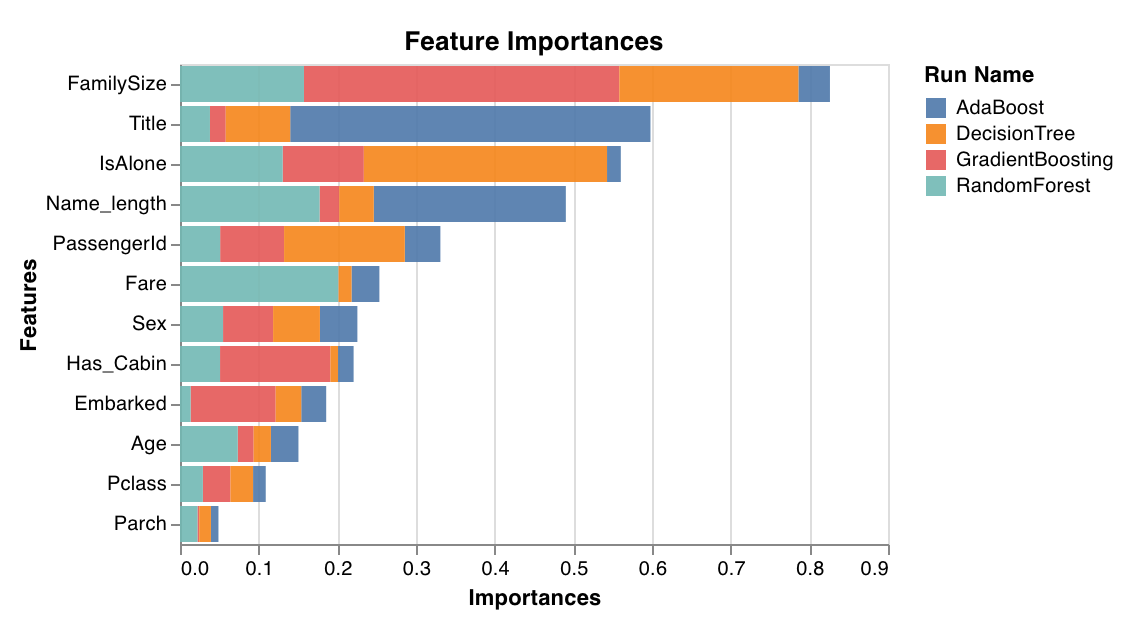
분류 작업에 대한 각 특징의 중요도를 평가하고 표시합니다. 트리와 같이 feature_importances_ 속성이 있는 분류 모델에서만 작동합니다.
wandb.sklearn.plot_feature_importances(model, ['width', 'height, 'length'])
- model (clf): 적합된 분류 모델을 사용합니다.
- feature_names (list): 특징 이름. 특징 인덱스를 해당 이름으로 대체하여 플롯을 더 쉽게 읽을 수 있습니다.
보정 곡선
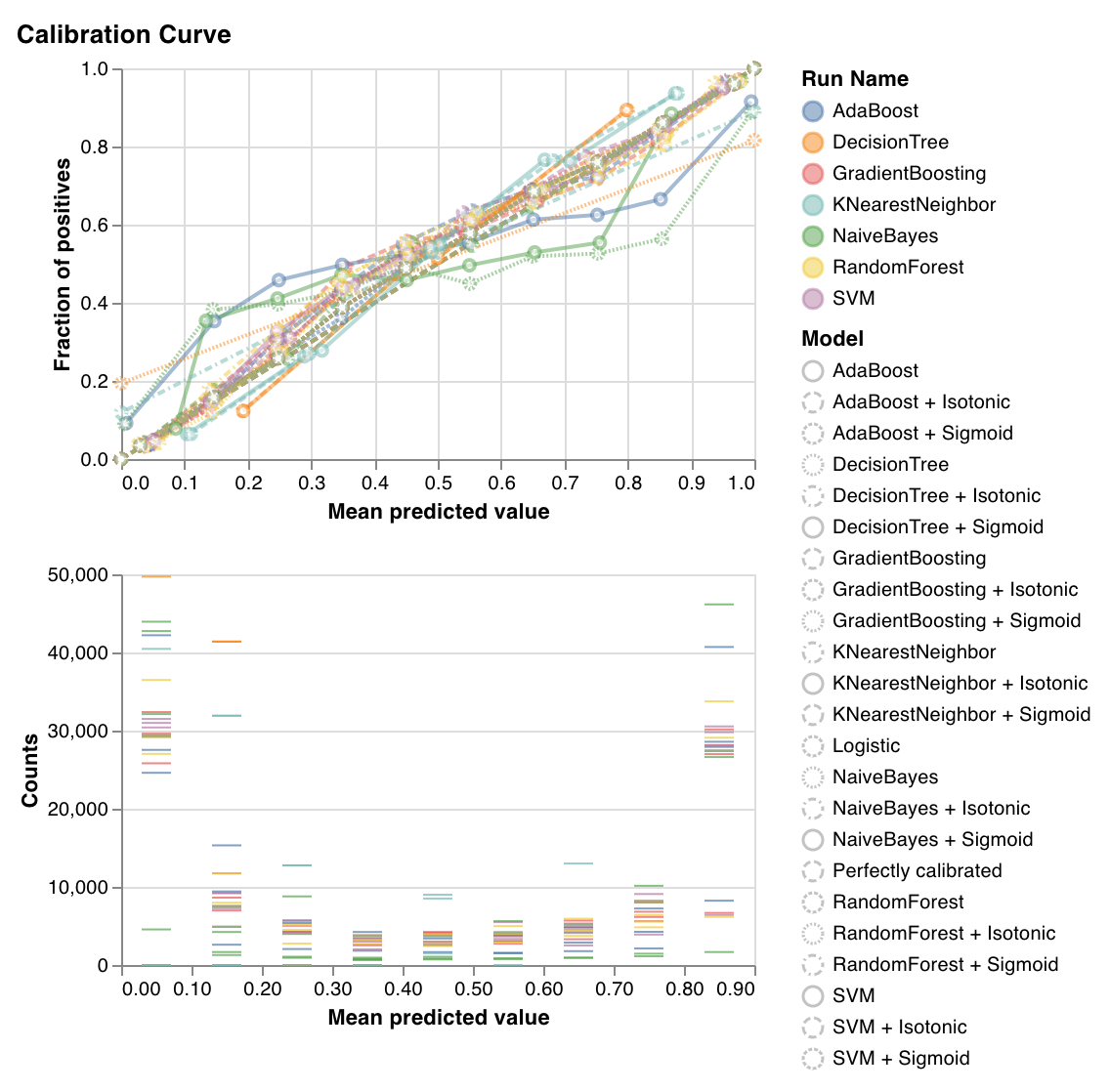
분류 모델의 예측 확률이 얼마나 잘 보정되었는지, 보정되지 않은 분류 모델을 보정하는 방법을 표시합니다. 베이스라인 로지스틱 회귀 모델, 인수로 전달된 모델, 등방성 보정 및 시그모이드 보정 모두에 의해 추정된 예측 확률을 비교합니다.
보정 곡선이 대각선에 가까울수록 좋습니다. 전치된 시그모이드와 같은 곡선은 과적합된 분류 모델을 나타내고 시그모이드와 같은 곡선은 과소적합된 분류 모델을 나타냅니다. 모델의 등방성 및 시그모이드 보정을 트레이닝하고 해당 곡선을 비교하여 모델이 과적합 또는 과소적합되었는지, 그렇다면 어떤 보정(시그모이드 또는 등방성)이 이를 수정하는 데 도움이 될 수 있는지 파악할 수 있습니다.
자세한 내용은 sklearn 문서를 참조하십시오.
wandb.sklearn.plot_calibration_curve(clf, X, y, 'RandomForestClassifier')
- model (clf): 적합된 분류 모델을 사용합니다.
- X (arr): 트레이닝 세트 특징.
- y (arr): 트레이닝 세트 레이블.
- model_name (str): 모델 이름. 기본값은 ‘Classifier’입니다.
혼동 행렬
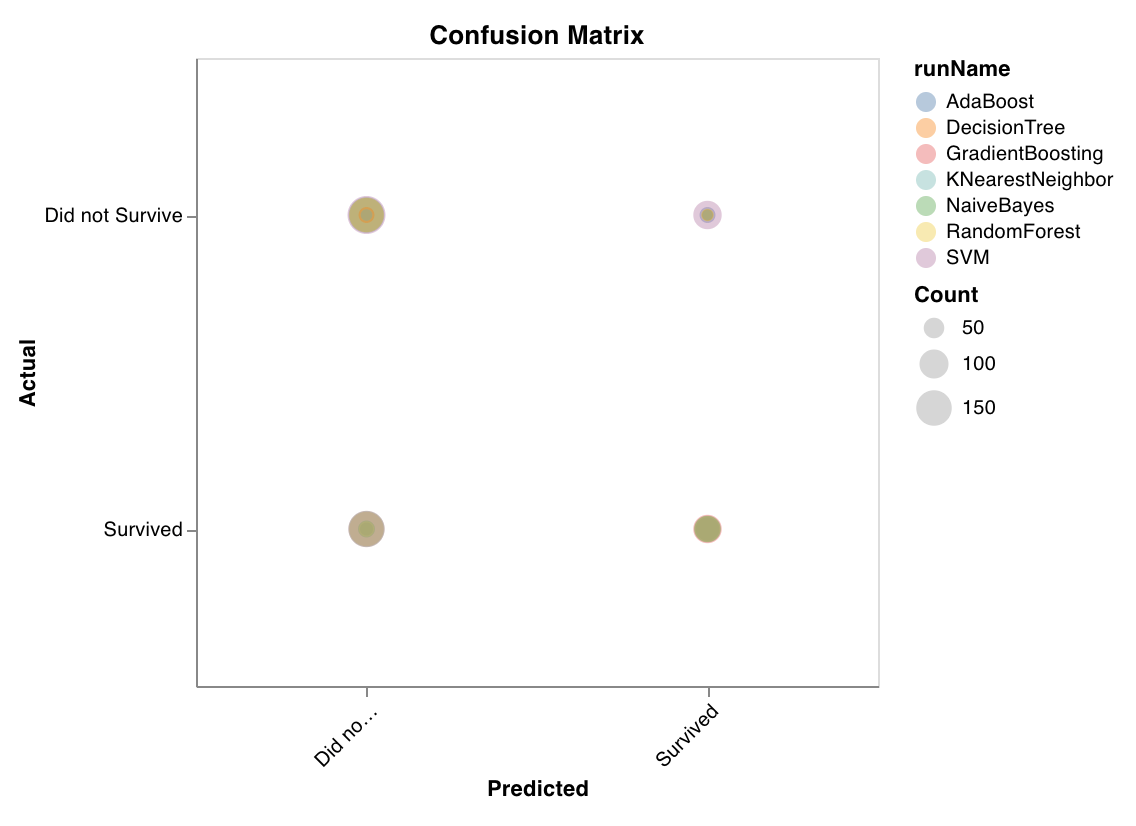
혼동 행렬을 계산하여 분류의 정확도를 평가합니다. 모델 예측의 품질을 평가하고 모델이 잘못된 예측에서 패턴을 찾는 데 유용합니다. 대각선은 실제 레이블이 예측 레이블과 같은 경우와 같이 모델이 올바르게 가져온 예측을 나타냅니다.
wandb.sklearn.plot_confusion_matrix(y_true, y_pred, labels)
- y_true (arr): 테스트 세트 레이블.
- y_pred (arr): 테스트 세트 예측 레이블.
- labels (list): 목표 변수(y)에 대해 명명된 레이블.
요약 메트릭
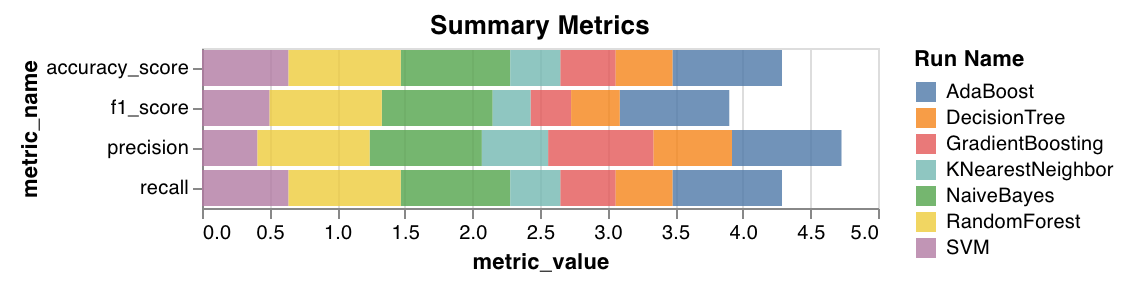
mse,mae및r2점수와 같은 분류에 대한 요약 메트릭을 계산합니다.f1, 정확도, 정밀도 및 재현율과 같은 회귀에 대한 요약 메트릭을 계산합니다.
wandb.sklearn.plot_summary_metrics(model, X_train, y_train, X_test, y_test)
- model (clf 또는 reg): 적합된 회귀 모델 또는 분류 모델을 사용합니다.
- X (arr): 트레이닝 세트 특징.
- y (arr): 트레이닝 세트 레이블.
- X_test (arr): 테스트 세트 특징.
- y_test (arr): 테스트 세트 레이블.
엘보우 플롯
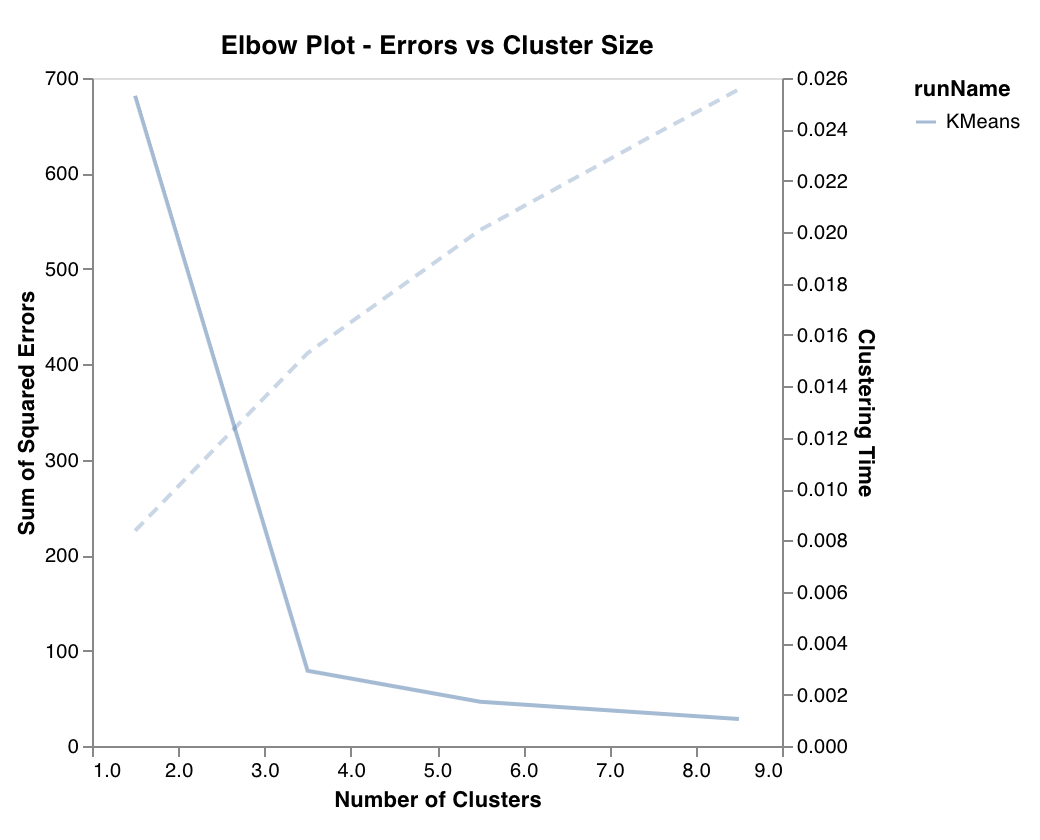
클러스터 수의 함수로 설명된 분산의 백분율과 트레이닝 시간을 측정하고 표시합니다. 최적의 클러스터 수를 선택하는 데 유용합니다.
wandb.sklearn.plot_elbow_curve(model, X_train)
- model (clusterer): 적합된 클러스터링 모델을 사용합니다.
- X (arr): 트레이닝 세트 특징.
실루엣 플롯
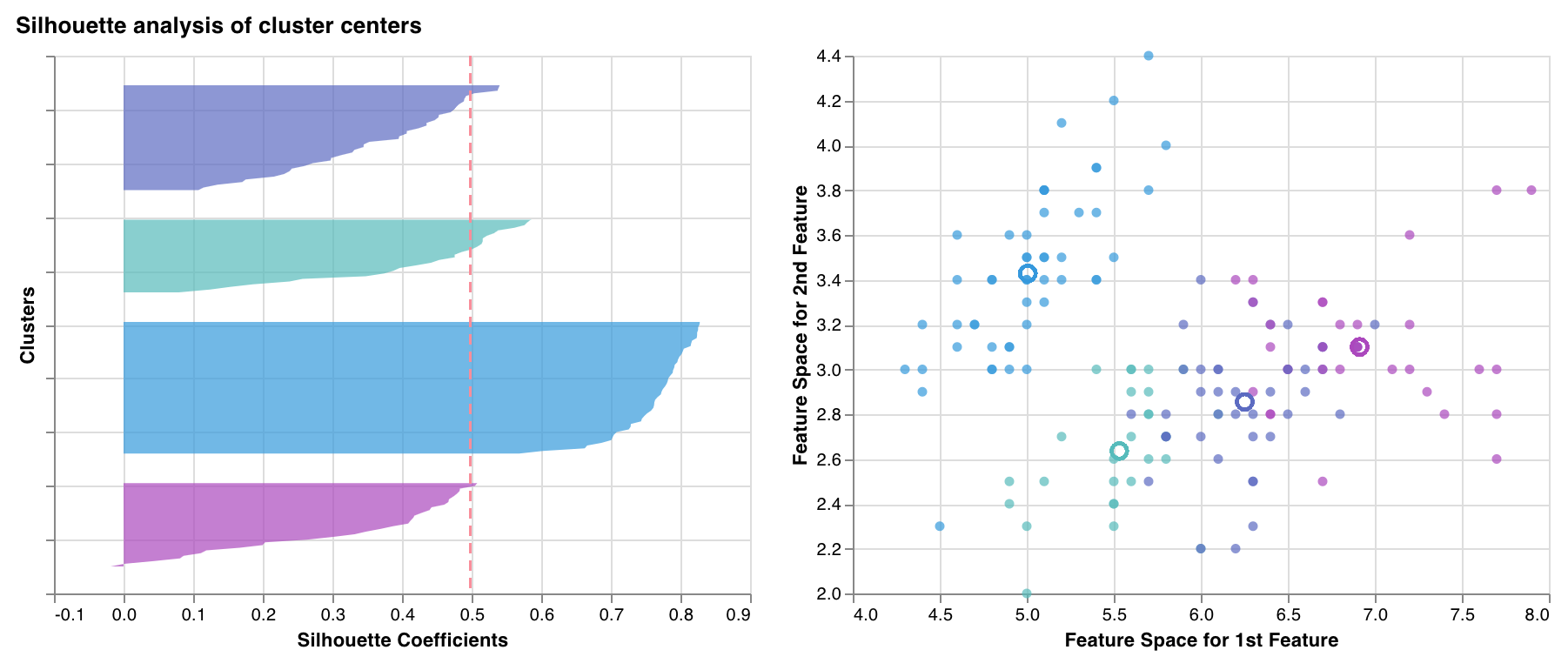
한 클러스터의 각 점이 인접한 클러스터의 점에 얼마나 가까운지 측정하고 표시합니다. 클러스터의 두께는 클러스터 크기에 해당합니다. 수직선은 모든 점의 평균 실루엣 점수를 나타냅니다.
+1에 가까운 실루엣 계수는 샘플이 인접한 클러스터에서 멀리 떨어져 있음을 나타냅니다. 0 값은 샘플이 두 개의 인접한 클러스터 사이의 결정 경계에 있거나 매우 가까이에 있음을 나타내고 음수 값은 해당 샘플이 잘못된 클러스터에 할당되었을 수 있음을 나타냅니다.
일반적으로 모든 실루엣 클러스터 점수가 평균 이상(빨간색 선을 지나)이고 가능한 한 1에 가깝기를 바랍니다. 또한 데이터의 기본 패턴을 반영하는 클러스터 크기를 선호합니다.
wandb.sklearn.plot_silhouette(model, X_train, ['spam', 'not spam'])
- model (clusterer): 적합된 클러스터링 모델을 사용합니다.
- X (arr): 트레이닝 세트 특징.
- cluster_labels (list): 클러스터 레이블 이름. 클러스터 인덱스를 해당 이름으로 대체하여 플롯을 더 쉽게 읽을 수 있습니다.
이상치 후보 플롯
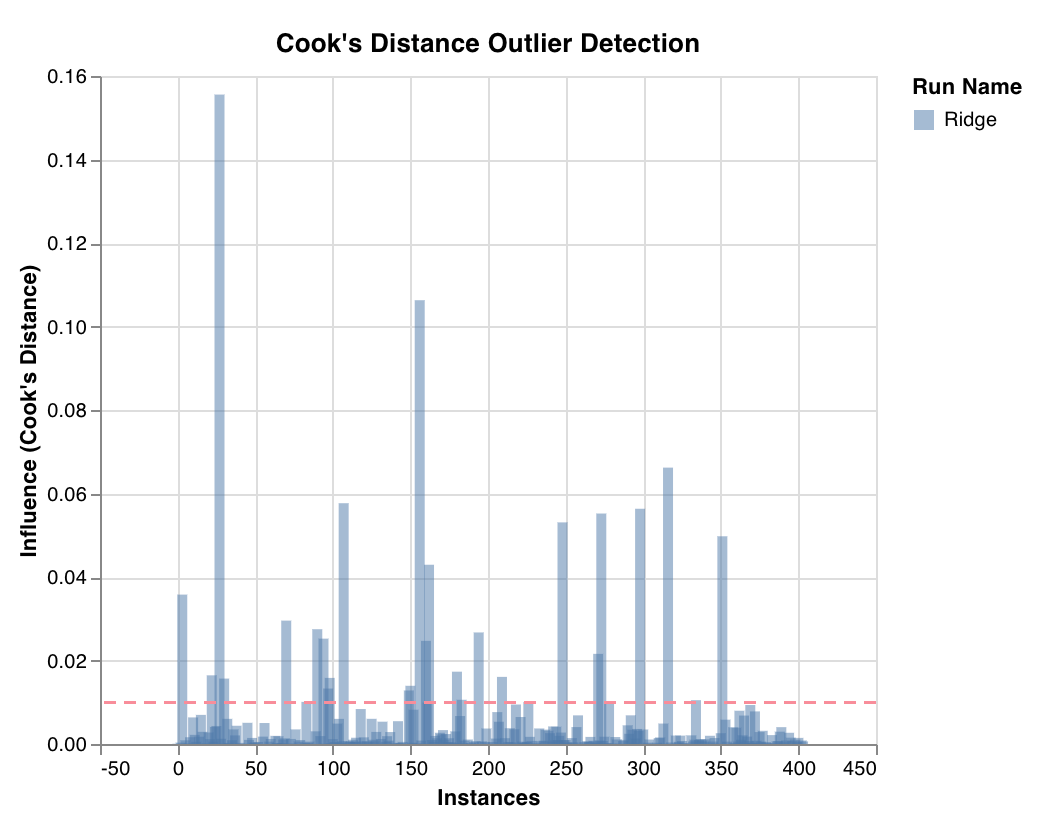
쿡 거리를 통해 회귀 모델에 대한 데이터 포인트의 영향을 측정합니다. 심하게 치우친 영향을 미치는 인스턴스는 잠재적으로 이상치일 수 있습니다. 이상치 탐지에 유용합니다.
wandb.sklearn.plot_outlier_candidates(model, X, y)
- model (regressor): 적합된 분류 모델을 사용합니다.
- X (arr): 트레이닝 세트 특징.
- y (arr): 트레이닝 세트 레이블.
잔차 플롯
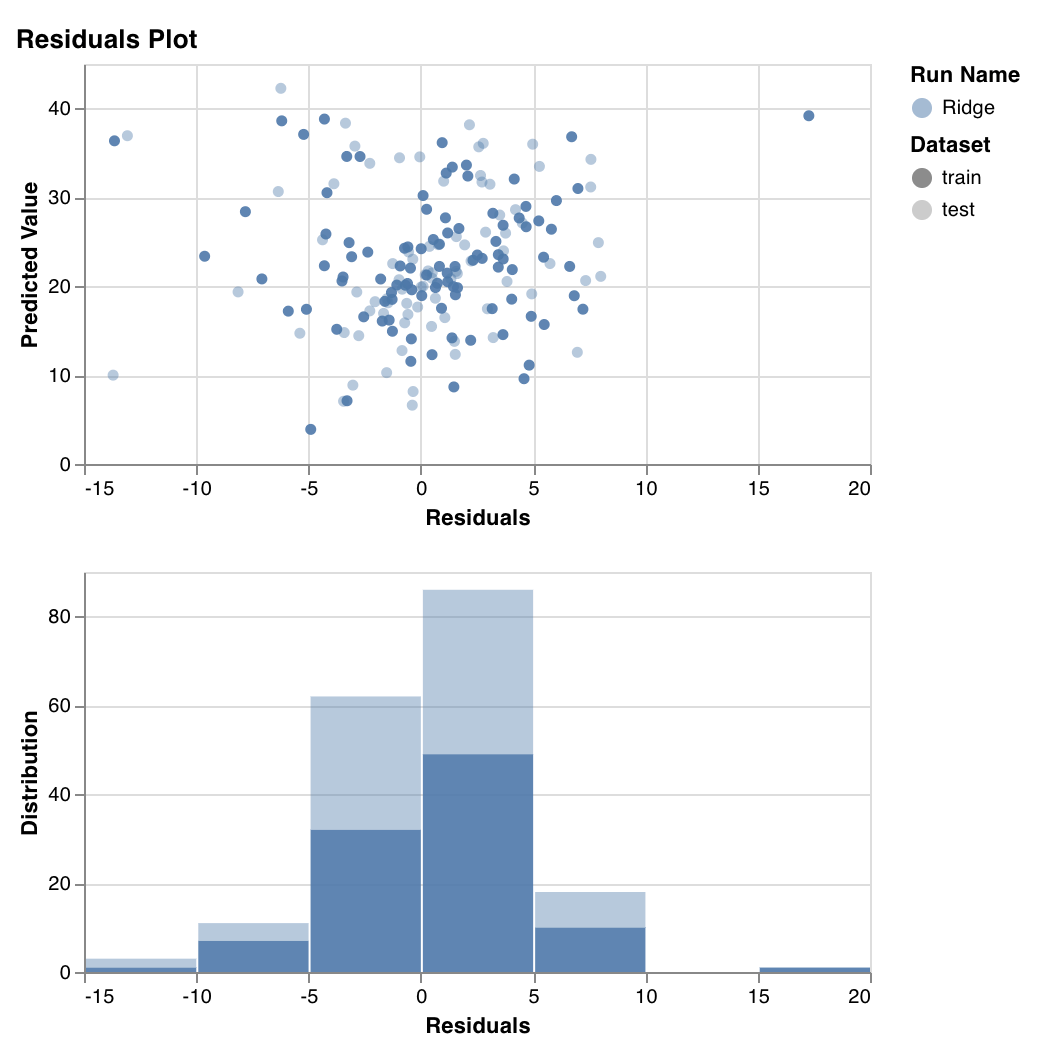
예측된 목표 값(y축)과 실제 목표 값과 예측된 목표 값의 차이(x축), 잔차 오류의 분포를 측정하고 표시합니다.
일반적으로 적합한 모델의 잔차는 임의로 분포되어야 합니다. 왜냐하면 좋은 모델은 임의 오류를 제외하고 데이터셋의 대부분의 현상을 설명하기 때문입니다.
wandb.sklearn.plot_residuals(model, X, y)
-
model (regressor): 적합된 분류 모델을 사용합니다.
-
X (arr): 트레이닝 세트 특징.
-
y (arr): 트레이닝 세트 레이블.
질문이 있으시면 slack 커뮤니티에서 답변해 드리겠습니다.
예제
- Colab에서 실행: 시작하는 데 도움이 되는 간단한 노트북
[i18n] feedback_title
[i18n] feedback_question
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.