NVIDIA NeMo Inference Microservice Deploy Job
2 minute read
W&B의 모델 아티팩트를 NVIDIA NeMo Inference Microservice에 배포합니다. 이를 위해 W&B Launch를 사용합니다. W&B Launch는 모델 아티팩트를 NVIDIA NeMo Model로 변환하고 실행 중인 NIM/Triton 서버에 배포합니다.
W&B Launch는 현재 다음과 같은 호환 가능한 모델 유형을 지원합니다.
배포 시간은 모델 및 머신 유형에 따라 다릅니다. 기본 Llama2-7b 구성은 GCP의
a2-ultragpu-1g에서 약 1분이 소요됩니다.퀵스타트
-
Launch queue 생성 아직 없는 경우. 아래 예제 queue 구성을 참조하십시오.
net: host gpus: all # can be a specific set of GPUs or `all` to use everything runtime: nvidia # also requires nvidia container runtime volume: - model-store:/model-store/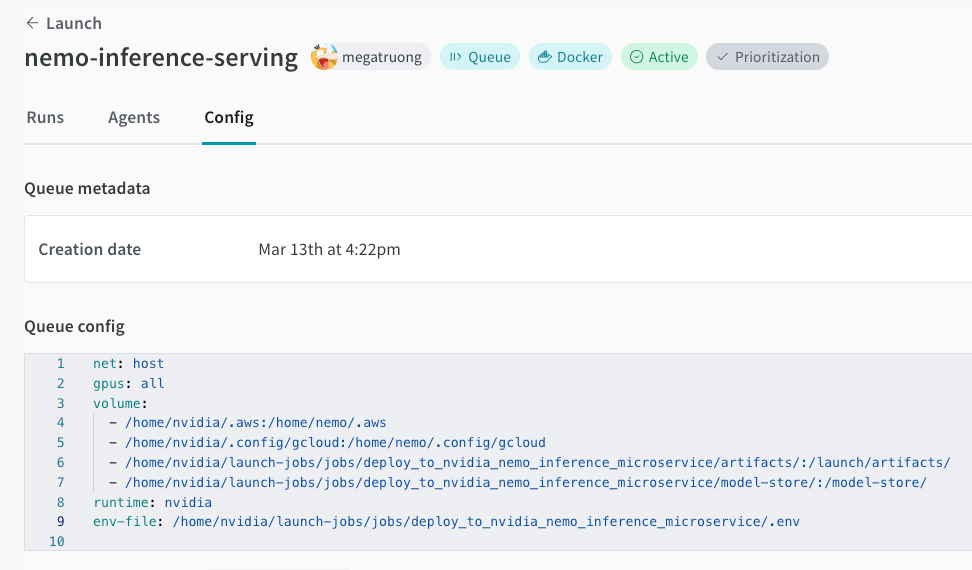
-
다음 작업을 프로젝트에 생성합니다.
wandb job create -n "deploy-to-nvidia-nemo-inference-microservice" \ -e $ENTITY \ -p $PROJECT \ -E jobs/deploy_to_nvidia_nemo_inference_microservice/job.py \ -g andrew/nim-updates \ git https://github.com/wandb/launch-jobs -
GPU 머신에서 에이전트를 실행합니다.
wandb launch-agent -e $ENTITY -p $PROJECT -q $QUEUE -
Launch UI에서 원하는 구성으로 배포 Launch 작업을 제출합니다.
- CLI를 통해 제출할 수도 있습니다.
wandb launch -d gcr.io/playground-111/deploy-to-nemo:latest \ -e $ENTITY \ -p $PROJECT \ -q $QUEUE \ -c $CONFIG_JSON_FNAME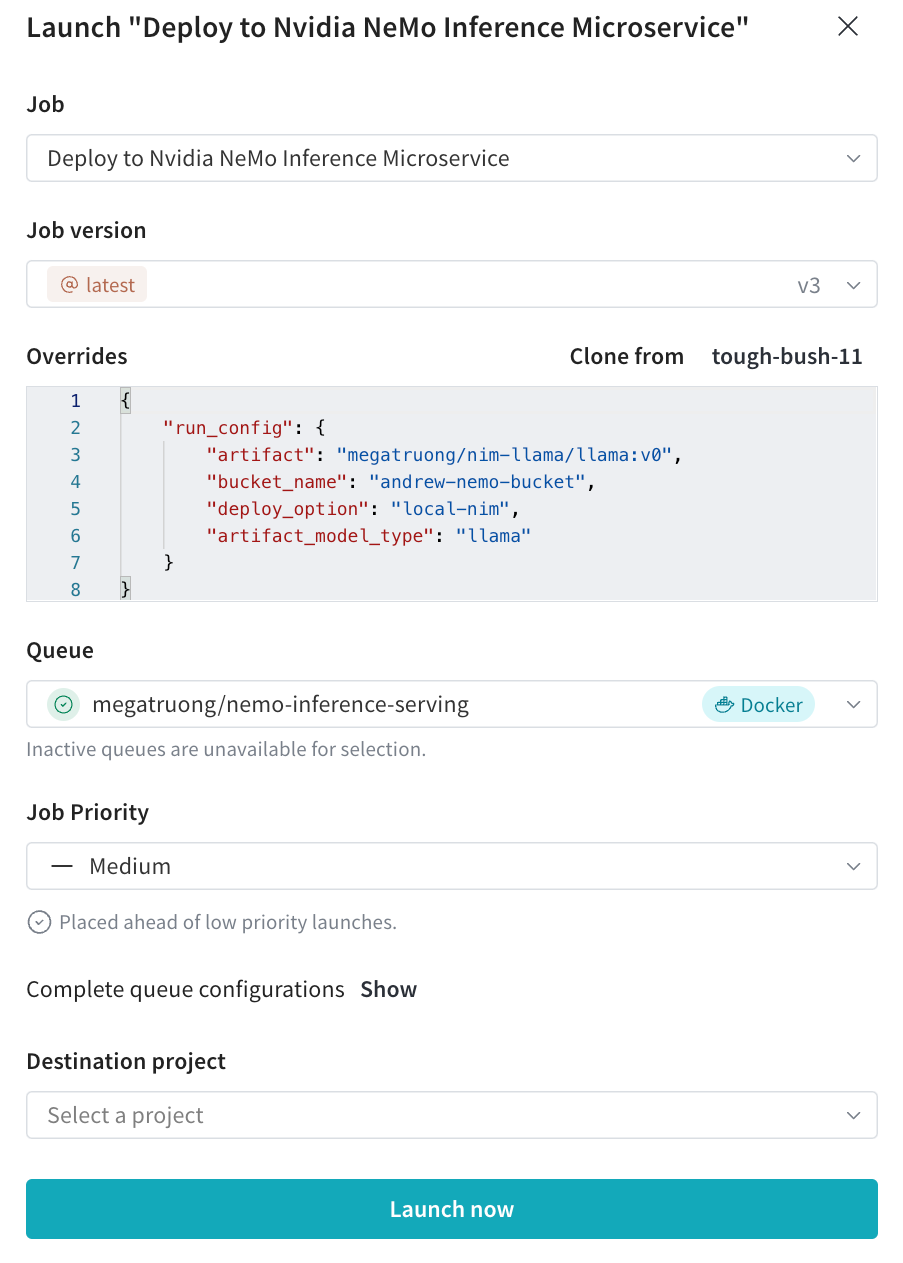
- CLI를 통해 제출할 수도 있습니다.
-
Launch UI에서 배포 프로세스를 추적할 수 있습니다.
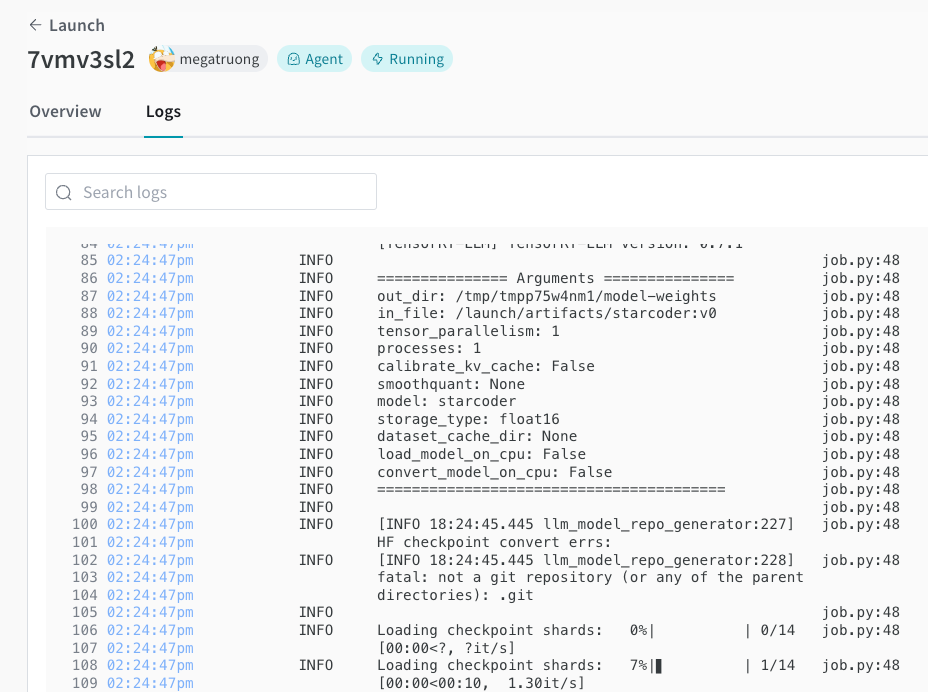
-
완료되면 엔드포인트를 즉시 curl하여 모델을 테스트할 수 있습니다. 모델 이름은 항상
ensemble입니다.#!/bin/bash curl -X POST "http://0.0.0.0:9999/v1/completions" \ -H "accept: application/json" \ -H "Content-Type: application/json" \ -d '{ "model": "ensemble", "prompt": "Tell me a joke", "max_tokens": 256, "temperature": 0.5, "n": 1, "stream": false, "stop": "string", "frequency_penalty": 0.0 }'
[i18n] feedback_title
[i18n] feedback_question
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.