Kubeflow Pipelines (kfp)
3 minute read
Kubeflow Pipelines (kfp) 는 Docker 컨테이너를 기반으로 구축된 휴대 가능하고 확장 가능한 기계 학습(ML) 워크플로우를 구축하고 배포하기 위한 플랫폼입니다.
이 통합을 통해 사용자는 데코레이터를 kfp python functional components에 적용하여 파라미터와 Artifacts를 W&B에 자동으로 기록할 수 있습니다.
이 기능은 wandb==0.12.11에서 활성화되었으며 kfp<2.0.0이 필요합니다.
가입하고 API 키 만들기
API 키는 사용자의 머신을 W&B에 인증합니다. 사용자 프로필에서 API 키를 생성할 수 있습니다.
- 오른쪽 상단 모서리에 있는 사용자 프로필 아이콘을 클릭합니다.
- User Settings를 선택한 다음 API Keys 섹션으로 스크롤합니다.
- Reveal을 클릭합니다. 표시된 API 키를 복사합니다. API 키를 숨기려면 페이지를 새로 고칩니다.
wandb 라이브러리를 설치하고 로그인합니다
로컬에서 wandb 라이브러리를 설치하고 로그인하려면 다음을 수행합니다.
-
WANDB_API_KEY환경 변수를 API 키로 설정합니다.export WANDB_API_KEY=<your_api_key> -
wandb라이브러리를 설치하고 로그인합니다.pip install wandb wandb login
pip install wandb
import wandb
wandb.login()
!pip install wandb
import wandb
wandb.login()
컴포넌트 데코레이팅
@wandb_log 데코레이터를 추가하고 평소처럼 컴포넌트를 생성합니다. 이렇게 하면 파이프라인을 실행할 때마다 입력/출력 파라미터와 Artifacts가 자동으로 W&B에 기록됩니다.
from kfp import components
from wandb.integration.kfp import wandb_log
@wandb_log
def add(a: float, b: float) -> float:
return a + b
add = components.create_component_from_func(add)
컨테이너에 환경 변수 전달
환경 변수를 컨테이너에 명시적으로 전달해야 할 수 있습니다. 양방향 연결을 위해서는 환경 변수 WANDB_KUBEFLOW_URL을 Kubeflow Pipelines 인스턴스의 기본 URL로 설정해야 합니다. 예를 들어, https://kubeflow.mysite.com과 같습니다.
import os
from kubernetes.client.models import V1EnvVar
def add_wandb_env_variables(op):
env = {
"WANDB_API_KEY": os.getenv("WANDB_API_KEY"),
"WANDB_BASE_URL": os.getenv("WANDB_BASE_URL"),
}
for name, value in env.items():
op = op.add_env_variable(V1EnvVar(name, value))
return op
@dsl.pipeline(name="example-pipeline")
def example_pipeline(param1: str, param2: int):
conf = dsl.get_pipeline_conf()
conf.add_op_transformer(add_wandb_env_variables)
프로그래밍 방식으로 데이터에 엑세스
Kubeflow Pipelines UI를 통해
W&B로 로깅된 Kubeflow Pipelines UI에서 Run을 클릭합니다.
Input/Output및ML Metadata탭에서 입력 및 출력에 대한 자세한 내용을 확인합니다.Visualizations탭에서 W&B 웹 앱을 봅니다.
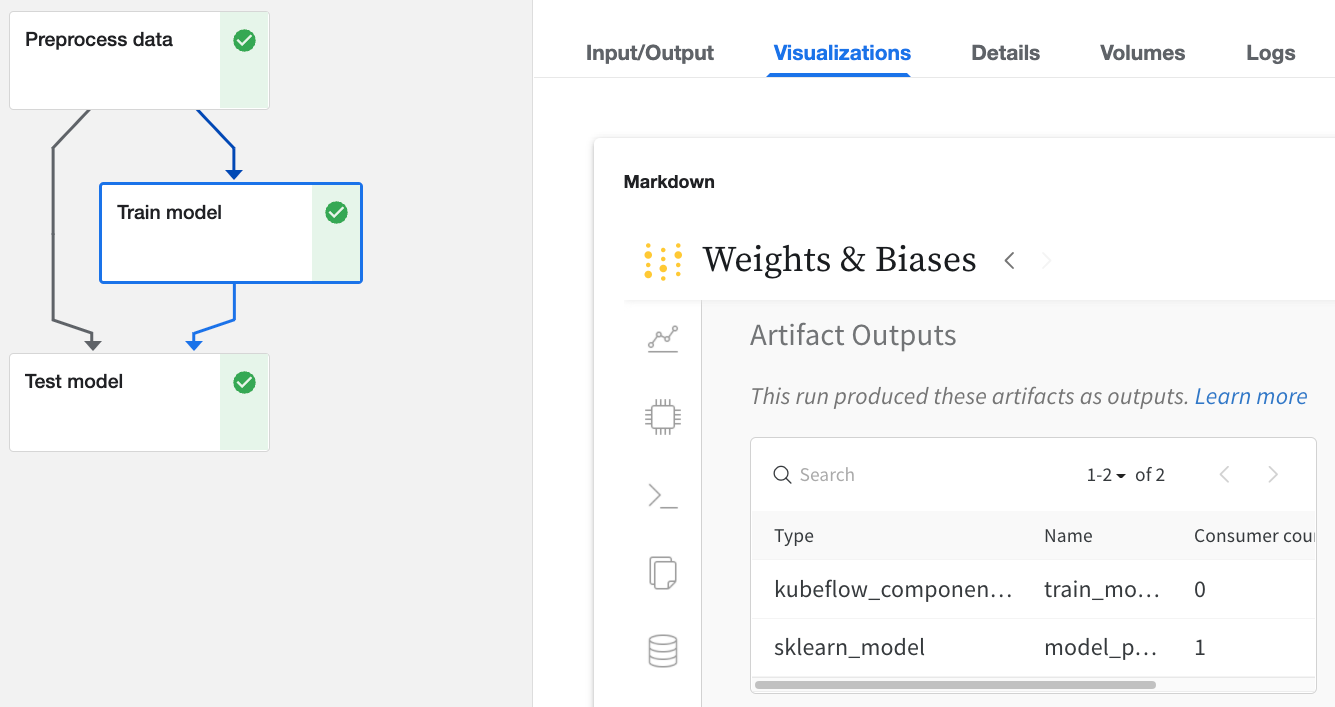
웹 앱 UI를 통해
웹 앱 UI는 Kubeflow Pipelines의 Visualizations 탭과 동일한 콘텐츠를 가지고 있지만 공간이 더 넓습니다. 여기에서 웹 앱 UI에 대해 자세히 알아보세요.
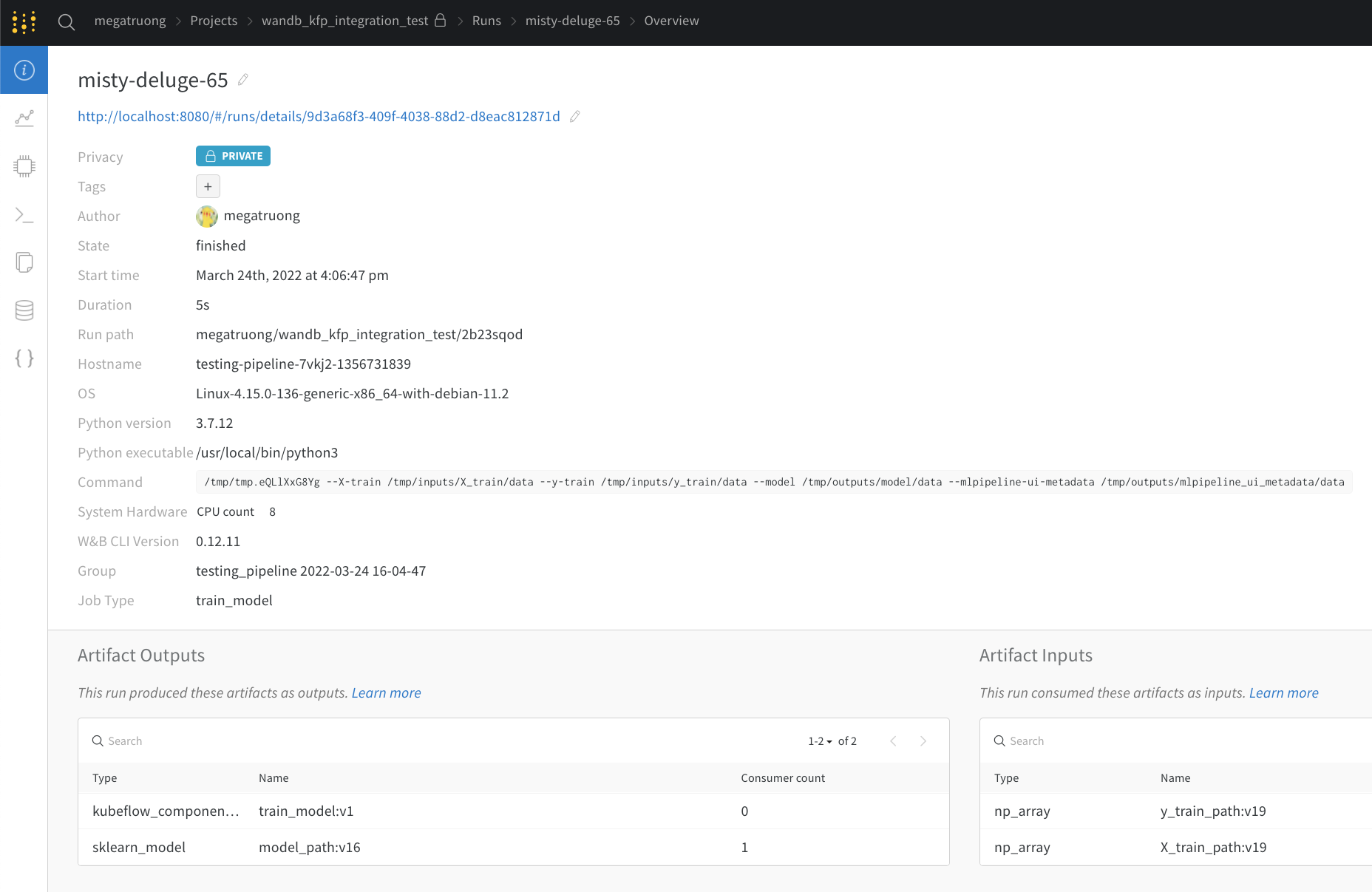
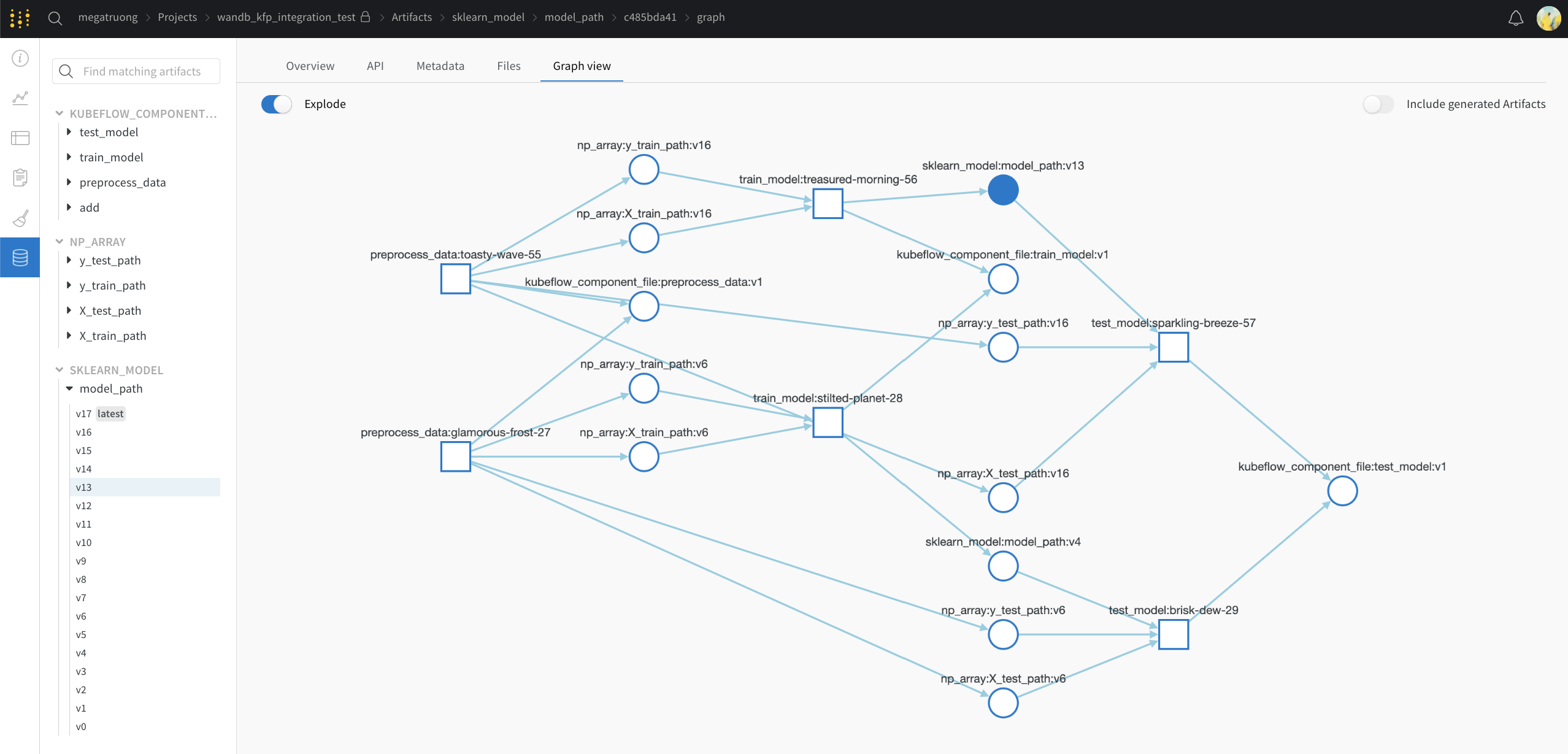
Public API를 통해 (프로그래밍 방식 엑세스용)
- 프로그래밍 방식 엑세스의 경우 Public API를 참조하세요.
Kubeflow Pipelines에서 W&B로의 컨셉 매핑
다음은 Kubeflow Pipelines 컨셉에서 W&B로의 매핑입니다.
| Kubeflow Pipelines | W&B | W&B의 위치 |
|---|---|---|
| Input Scalar | config |
Overview 탭 |
| Output Scalar | summary |
Overview 탭 |
| Input Artifact | Input Artifact | Artifacts 탭 |
| Output Artifact | Output Artifact | Artifacts 탭 |
세분화된 로깅
로깅을 더 세밀하게 제어하려면 컴포넌트에 wandb.log 및 wandb.log_artifact 호출을 추가할 수 있습니다.
명시적 wandb.log_artifacts 호출 사용
아래 예에서는 모델을 트레이닝하고 있습니다. @wandb_log 데코레이터는 관련 입력 및 출력을 자동으로 추적합니다. 트레이닝 프로세스를 기록하려면 다음과 같이 로깅을 명시적으로 추가할 수 있습니다.
@wandb_log
def train_model(
train_dataloader_path: components.InputPath("dataloader"),
test_dataloader_path: components.InputPath("dataloader"),
model_path: components.OutputPath("pytorch_model"),
):
...
for epoch in epochs:
for batch_idx, (data, target) in enumerate(train_dataloader):
...
if batch_idx % log_interval == 0:
wandb.log(
{"epoch": epoch, "step": batch_idx * len(data), "loss": loss.item()}
)
...
wandb.log_artifact(model_artifact)
암시적 wandb 통합 사용
지원하는 프레임워크 통합을 사용하는 경우 콜백을 직접 전달할 수도 있습니다.
@wandb_log
def train_model(
train_dataloader_path: components.InputPath("dataloader"),
test_dataloader_path: components.InputPath("dataloader"),
model_path: components.OutputPath("pytorch_model"),
):
from pytorch_lightning.loggers import WandbLogger
from pytorch_lightning import Trainer
trainer = Trainer(logger=WandbLogger())
... # do training
[i18n] feedback_title
[i18n] feedback_question
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.