Dagster
18 minute read
Dagster 와 W&B (Weights & Biases) 를 사용하여 MLOps 파이프라인을 조정하고 ML 자산을 유지 관리합니다. W&B 와의 통합으로 Dagster 내에서 다음을 쉽게 수행할 수 있습니다.
- W&B Artifacts를 사용하고 생성합니다.
- W&B Registry에서 Registered Models를 사용하고 생성합니다.
- W&B Launch를 사용하여 전용 컴퓨팅에서 트레이닝 작업을 실행합니다.
- ops 및 assets에서 wandb 클라이언트를 사용합니다.
W&B Dagster 통합은 W&B 특정 Dagster 리소스 및 IO Manager를 제공합니다.
wandb_resource: W&B API에 인증하고 통신하는 데 사용되는 Dagster 리소스입니다.wandb_artifacts_io_manager: W&B Artifacts를 소비하는 데 사용되는 Dagster IO Manager입니다.
다음 가이드에서는 Dagster에서 W&B 를 사용하기 위한 필수 조건을 충족하는 방법, ops 및 assets에서 W&B Artifacts를 생성하고 사용하는 방법, W&B Launch를 사용하는 방법 및 권장 모범 사례를 보여줍니다.
시작하기 전에
Weights & Biases 내에서 Dagster를 사용하려면 다음 리소스가 필요합니다.
- W&B API 키.
- W&B entity (user 또는 team): entity는 W&B Runs 및 Artifacts를 보내는 사용자 이름 또는 팀 이름입니다. Runs를 기록하기 전에 W&B App UI에서 계정 또는 팀 entity를 생성해야 합니다. entity를 지정하지 않으면 Run은 일반적으로 사용자 이름인 기본 entity로 전송됩니다. Project Defaults에서 설정에서 기본 entity를 변경합니다.
- W&B project: W&B Runs가 저장되는 프로젝트 이름입니다.
W&B App에서 해당 사용자 또는 팀의 프로필 페이지를 확인하여 W&B entity를 찾으십시오. 기존 W&B 프로젝트를 사용하거나 새 프로젝트를 만들 수 있습니다. 새 프로젝트는 W&B App 홈페이지 또는 사용자/팀 프로필 페이지에서 만들 수 있습니다. 프로젝트가 존재하지 않으면 처음 사용할 때 자동으로 생성됩니다. 다음 지침은 API 키를 얻는 방법을 보여줍니다.
API 키를 얻는 방법
- W&B에 로그인합니다. 참고: W&B Server를 사용하는 경우 관리자에게 인스턴스 호스트 이름을 문의하십시오.
- 인증 페이지 또는 사용자/팀 설정에서 API 키를 수집합니다. 프로덕션 환경의 경우 해당 키를 소유할 서비스 계정을 사용하는 것이 좋습니다.
- 해당 API 키에 대한 환경 변수 내보내기
WANDB_API_KEY=YOUR_KEY를 설정합니다.
다음 예제에서는 Dagster 코드에서 API 키를 지정할 위치를 보여줍니다. wandb_config 중첩 사전에 entity 및 프로젝트 이름을 지정해야 합니다. 다른 W&B 프로젝트를 사용하려는 경우 다른 wandb_config 값을 다른 ops/assets에 전달할 수 있습니다. 전달할 수 있는 가능한 키에 대한 자세한 내용은 아래의 Configuration 섹션을 참조하십시오.
@job에 대한 구성 예시
# add this to your config.yaml
# alternatively you can set the config in Dagit's Launchpad or JobDefinition.execute_in_process
# Reference: https://docs.dagster.io/concepts/configuration/config-schema#specifying-runtime-configuration
resources:
wandb_config:
config:
entity: my_entity # replace this with your W&B entity
project: my_project # replace this with your W&B project
@job(
resource_defs={
"wandb_config": make_values_resource(
entity=str,
project=str,
),
"wandb_resource": wandb_resource.configured(
{"api_key": {"env": "WANDB_API_KEY"}}
),
"io_manager": wandb_artifacts_io_manager,
}
)
def simple_job_example():
my_op()
assets를 사용하는 @repository에 대한 구성 예시
from dagster_wandb import wandb_artifacts_io_manager, wandb_resource
from dagster import (
load_assets_from_package_module,
make_values_resource,
repository,
with_resources,
)
from . import assets
@repository
def my_repository():
return [
*with_resources(
load_assets_from_package_module(assets),
resource_defs={
"wandb_config": make_values_resource(
entity=str,
project=str,
),
"wandb_resource": wandb_resource.configured(
{"api_key": {"env": "WANDB_API_KEY"}}
),
"wandb_artifacts_manager": wandb_artifacts_io_manager.configured(
{"cache_duration_in_minutes": 60} # only cache files for one hour
),
},
resource_config_by_key={
"wandb_config": {
"config": {
"entity": "my_entity", # replace this with your W&B entity
"project": "my_project", # replace this with your W&B project
}
}
},
),
]
@job에 대한 예제와는 달리 이 예제에서는 IO Manager 캐시 지속 시간을 구성합니다.
구성
다음 구성 옵션은 통합에서 제공하는 W&B 특정 Dagster 리소스 및 IO Manager의 설정으로 사용됩니다.
wandb_resource: W&B API와 통신하는 데 사용되는 Dagster 리소스입니다. 제공된 API 키를 사용하여 자동으로 인증합니다. 속성:api_key: (str, 필수): W&B API와 통신하는 데 필요한 W&B API 키입니다.host: (str, 선택 사항): 사용하려는 API 호스트 서버입니다. W&B Server를 사용하는 경우에만 필요합니다. 기본적으로 퍼블릭 클라우드 호스트인https://api.wandb.ai입니다.
wandb_artifacts_io_manager: W&B Artifacts를 소비하는 Dagster IO Manager입니다. 속성:base_dir: (int, 선택 사항) 로컬 스토리지 및 캐싱에 사용되는 기본 디렉토리입니다. W&B Artifacts 및 W&B Run 로그는 해당 디렉토리에서 쓰고 읽습니다. 기본적으로DAGSTER_HOME디렉토리를 사용합니다.cache_duration_in_minutes: (int, 선택 사항) W&B Artifacts 및 W&B Run 로그를 로컬 스토리지에 보관해야 하는 시간(분)을 정의합니다. 해당 시간 동안 열리지 않은 파일 및 디렉토리만 캐시에서 제거됩니다. 캐시 제거는 IO Manager 실행이 끝나면 수행됩니다. 캐싱을 완전히 끄려면 0으로 설정할 수 있습니다. 캐싱은 동일한 시스템에서 실행되는 작업 간에 Artifact가 재사용될 때 속도를 향상시킵니다. 기본값은 30일입니다.run_id: (str, 선택 사항): 재개를 위해 사용되는 이 Run에 대한 고유 ID입니다. 프로젝트에서 고유해야 하며 Run을 삭제하면 ID를 재사용할 수 없습니다. Runs 간에 비교하기 위해 하이퍼파라미터를 저장하려면 이름 필드를 짧은 설명 이름으로 사용하거나 config를 사용합니다. ID에는 다음 특수 문자를 포함할 수 없습니다./\#?%:..IO Manager가 Run을 재개할 수 있도록 Dagster 내부에서 실험 추적을 수행할 때 Run ID를 설정해야 합니다. 기본적으로 Dagster Run ID (예:7e4df022-1bf2-44b5-a383-bb852df4077e)로 설정됩니다.run_name: (str, 선택 사항) UI에서 이 Run을 식별하는 데 도움이 되는 이 Run의 짧은 표시 이름입니다. 기본적으로dagster-run-[Dagster Run ID의 처음 8자]형식의 문자열입니다. 예를 들어dagster-run-7e4df022입니다.run_tags: (list[str], 선택 사항): UI에서 이 Run의 태그 목록을 채울 문자열 목록입니다. 태그는 Runs를 함께 구성하거나baseline또는production과 같은 임시 레이블을 적용하는 데 유용합니다. UI에서 태그를 쉽게 추가하고 제거하거나 특정 태그가 있는 Runs만 필터링할 수 있습니다. 통합에서 사용되는 모든 W&B Run에는dagster_wandb태그가 있습니다.
W&B Artifacts 사용
W&B Artifact와의 통합은 Dagster IO Manager에 의존합니다.
IO Managers는 asset 또는 op의 출력을 저장하고 다운스트림 assets 또는 ops에 대한 입력으로 로드하는 역할을 하는 사용자 제공 오브젝트입니다. 예를 들어 IO Manager는 파일 시스템의 파일에서 오브젝트를 저장하고 로드할 수 있습니다.
통합은 W&B Artifacts에 대한 IO Manager를 제공합니다. 이를 통해 모든 Dagster @op 또는 @asset이 W&B Artifacts를 기본적으로 생성하고 소비할 수 있습니다. 다음은 Python 목록을 포함하는 dataset 유형의 W&B Artifact를 생성하는 @asset의 간단한 예입니다.
@asset(
name="my_artifact",
metadata={
"wandb_artifact_arguments": {
"type": "dataset",
}
},
io_manager_key="wandb_artifacts_manager",
)
def create_dataset():
return [1, 2, 3] # this will be stored in an Artifact
Artifacts를 쓰기 위해 @op, @asset 및 @multi_asset에 메타데이터 구성을 주석으로 추가할 수 있습니다. 마찬가지로 Dagster 외부에서 생성된 경우에도 W&B Artifacts를 소비할 수 있습니다.
W&B Artifacts 쓰기
계속하기 전에 W&B Artifacts를 사용하는 방법을 잘 이해하는 것이 좋습니다. Artifacts 가이드를 읽어 보십시오.
Python 함수에서 오브젝트를 반환하여 W&B Artifact를 작성합니다. W&B에서 지원하는 오브젝트는 다음과 같습니다.
- Python 오브젝트 (int, dict, list…)
- W&B 오브젝트 (Table, Image, Graph…)
- W&B Artifact 오브젝트
다음 예제에서는 Dagster assets (@asset)로 W&B Artifacts를 쓰는 방법을 보여줍니다.
pickle 모듈로 직렬화할 수 있는 모든 항목이 피클링되고 통합에서 생성된 Artifact에 추가됩니다. 콘텐츠는 Dagster 내부에서 해당 Artifact를 읽을 때 피클링 해제됩니다 (자세한 내용은 Artifacts 읽기 참조).
@asset(
name="my_artifact",
metadata={
"wandb_artifact_arguments": {
"type": "dataset",
}
},
io_manager_key="wandb_artifacts_manager",
)
def create_dataset():
return [1, 2, 3]
W&B는 여러 Pickle 기반 직렬화 모듈을 지원합니다 (pickle, dill, cloudpickle, joblib). ONNX 또는 PMML과 같은 고급 직렬화를 사용할 수도 있습니다. 자세한 내용은 직렬화 섹션을 참조하십시오.
모든 기본 W&B 오브젝트 (예: Table, Image 또는 Graph)가 통합에서 생성된 Artifact에 추가됩니다. 다음은 Table을 사용하는 예입니다.
import wandb
@asset(
name="my_artifact",
metadata={
"wandb_artifact_arguments": {
"type": "dataset",
}
},
io_manager_key="wandb_artifacts_manager",
)
def create_dataset_in_table():
return wandb.Table(columns=["a", "b", "c"], data=[[1, 2, 3]])
복잡한 유스 케이스의 경우 자체 Artifact 오브젝트를 빌드해야 할 수 있습니다. 통합은 여전히 통합 양쪽에서 메타데이터를 보강하는 것과 같은 유용한 추가 기능을 제공합니다.
import wandb
MY_ASSET = "my_asset"
@asset(
name=MY_ASSET,
io_manager_key="wandb_artifacts_manager",
)
def create_artifact():
artifact = wandb.Artifact(MY_ASSET, "dataset")
table = wandb.Table(columns=["a", "b", "c"], data=[[1, 2, 3]])
artifact.add(table, "my_table")
return artifact
구성
wandb_artifact_configuration이라는 구성 사전은 @op, @asset 및 @multi_asset에서 설정할 수 있습니다. 이 사전은 데코레이터 인수로 메타데이터로 전달되어야 합니다. 이 구성은 W&B Artifacts의 IO Manager 읽기 및 쓰기를 제어하는 데 필요합니다.
@op의 경우 Out 메타데이터 인수를 통해 출력 메타데이터에 있습니다.
@asset의 경우 asset의 메타데이터 인수에 있습니다.
@multi_asset의 경우 AssetOut 메타데이터 인수를 통해 각 출력 메타데이터에 있습니다.
다음 코드 예제에서는 @op, @asset 및 @multi_asset 계산에서 사전을 구성하는 방법을 보여줍니다.
@op의 예시:
@op(
out=Out(
metadata={
"wandb_artifact_configuration": {
"name": "my_artifact",
"type": "dataset",
}
}
)
)
def create_dataset():
return [1, 2, 3]
@asset의 예시:
@asset(
name="my_artifact",
metadata={
"wandb_artifact_configuration": {
"type": "dataset",
}
},
io_manager_key="wandb_artifacts_manager",
)
def create_dataset():
return [1, 2, 3]
@asset에는 이미 이름이 있으므로 구성을 통해 이름을 전달할 필요가 없습니다. 통합은 Artifact 이름을 asset 이름으로 설정합니다.
@multi_asset의 예시:
@multi_asset(
name="create_datasets",
outs={
"first_table": AssetOut(
metadata={
"wandb_artifact_configuration": {
"type": "training_dataset",
}
},
io_manager_key="wandb_artifacts_manager",
),
"second_table": AssetOut(
metadata={
"wandb_artifact_configuration": {
"type": "validation_dataset",
}
},
io_manager_key="wandb_artifacts_manager",
),
},
group_name="my_multi_asset_group",
)
def create_datasets():
first_table = wandb.Table(columns=["a", "b", "c"], data=[[1, 2, 3]])
second_table = wandb.Table(columns=["d", "e"], data=[[4, 5]])
return first_table, second_table
지원되는 속성:
name: (str) 이 Artifact에 대한 사람이 읽을 수 있는 이름으로, UI에서 이 Artifact를 식별하거나 use_artifact 호출에서 참조하는 방법입니다. 이름에는 문자, 숫자, 밑줄, 하이픈 및 마침표가 포함될 수 있습니다. 이름은 프로젝트에서 고유해야 합니다.@op에 필요합니다.type: (str) Artifact의 유형으로, Artifact를 구성하고 구별하는 데 사용됩니다. 일반적인 유형에는 dataset 또는 model이 포함되지만 문자, 숫자, 밑줄, 하이픈 및 마침표를 포함하는 모든 문자열을 사용할 수 있습니다. 출력이 Artifact가 아닌 경우에 필요합니다.description: (str) Artifact에 대한 설명을 제공하는 자유 텍스트입니다. 설명은 UI에서 markdown으로 렌더링되므로 테이블, 링크 등을 배치하기에 좋은 위치입니다.aliases: (list[str]) Artifact에 적용하려는 하나 이상의 에일리어스를 포함하는 배열입니다. 통합은 설정 여부에 관계없이 “latest” 태그도 해당 목록에 추가합니다. 이는 모델 및 데이터셋의 버전 관리를 관리하는 효과적인 방법입니다.add_dirs: (list[dict[str, Any]]): Artifact에 포함할 각 로컬 디렉토리에 대한 구성을 포함하는 배열입니다. SDK에서 동종의 메소드와 동일한 인수를 지원합니다.add_files: (list[dict[str, Any]]): Artifact에 포함할 각 로컬 파일에 대한 구성을 포함하는 배열입니다. SDK에서 동종의 메소드와 동일한 인수를 지원합니다.add_references: (list[dict[str, Any]]): Artifact에 포함할 각 외부 참조에 대한 구성을 포함하는 배열입니다. SDK에서 동종의 메소드와 동일한 인수를 지원합니다.serialization_module: (dict) 사용할 직렬화 모듈의 구성입니다. 자세한 내용은 직렬화 섹션을 참조하십시오.name: (str) 직렬화 모듈의 이름입니다. 허용되는 값:pickle,dill,cloudpickle,joblib. 모듈은 로컬에서 사용할 수 있어야 합니다.parameters: (dict[str, Any]) 직렬화 함수에 전달되는 선택적 인수입니다. 해당 모듈의 덤프 메소드와 동일한 파라미터를 허용합니다. 예를 들어{"compress": 3, "protocol": 4}입니다.
고급 예시:
@asset(
name="my_advanced_artifact",
metadata={
"wandb_artifact_configuration": {
"type": "dataset",
"description": "My *Markdown* description",
"aliases": ["my_first_alias", "my_second_alias"],
"add_dirs": [
{
"name": "My directory",
"local_path": "path/to/directory",
}
],
"add_files": [
{
"name": "validation_dataset",
"local_path": "path/to/data.json",
},
{
"is_tmp": True,
"local_path": "path/to/temp",
},
],
"add_references": [
{
"uri": "https://picsum.photos/200/300",
"name": "External HTTP reference to an image",
},
{
"uri": "s3://my-bucket/datasets/mnist",
"name": "External S3 reference",
},
],
}
},
io_manager_key="wandb_artifacts_manager",
)
def create_advanced_artifact():
return [1, 2, 3]
asset은 통합 양쪽에서 유용한 메타데이터로 구체화됩니다.
- W&B 측: 소스 통합 이름 및 버전, 사용된 Python 버전, 피클 프로토콜 버전 등입니다.
- Dagster 측:
- Dagster Run ID
- W&B Run: ID, 이름, 경로, URL
- W&B Artifact: ID, 이름, 유형, 버전, 크기, URL
- W&B Entity
- W&B Project
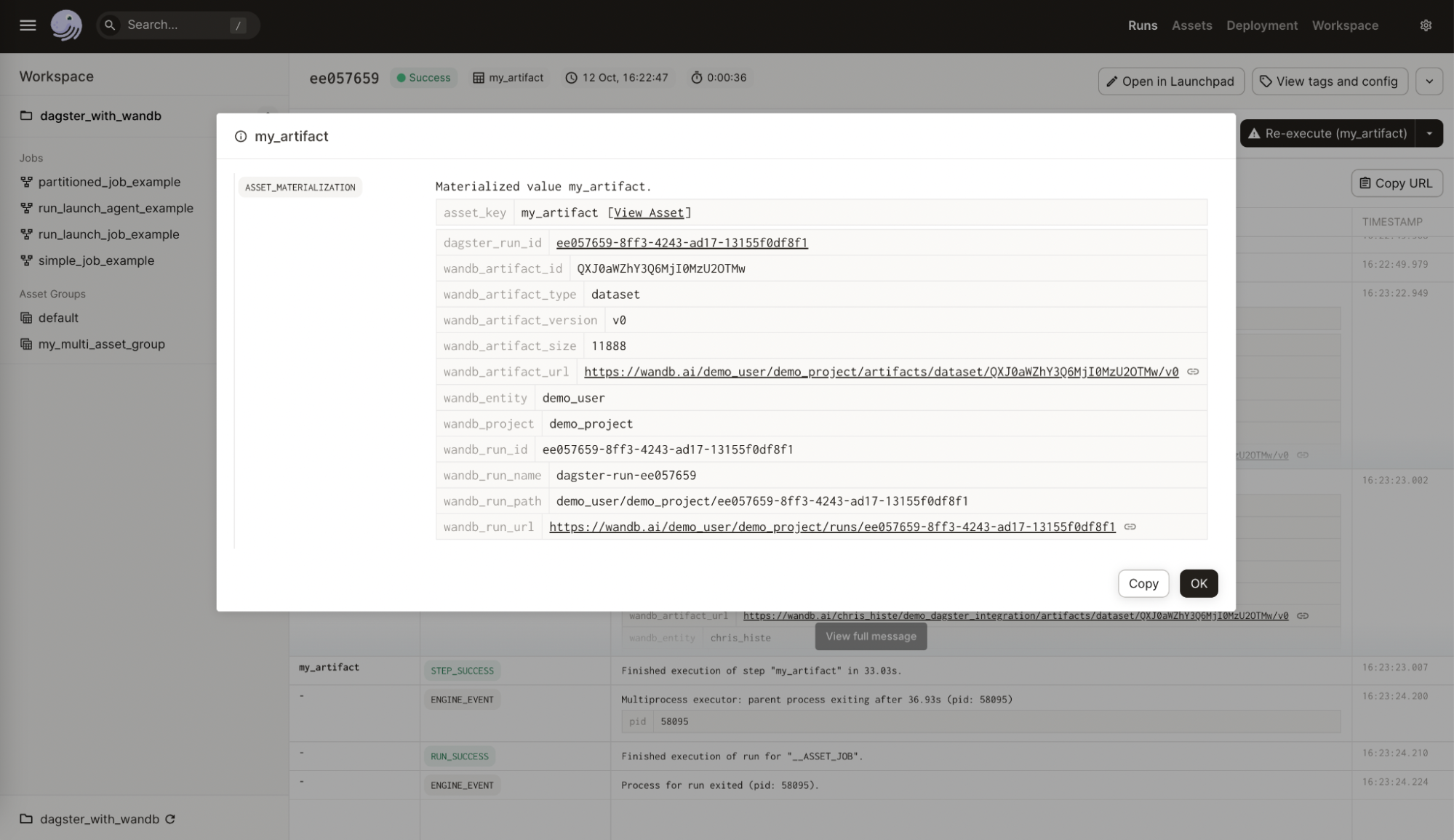
다음 이미지는 Dagster asset에 추가된 W&B의 메타데이터를 보여줍니다. 이 정보는 통합 없이는 사용할 수 없습니다.
다음 이미지는 제공된 구성이 유용한 메타데이터로 W&B Artifact에서 어떻게 보강되었는지 보여줍니다. 이 정보는 재현성 및 유지 관리에 도움이 되어야 합니다. 통합 없이는 사용할 수 없습니다.
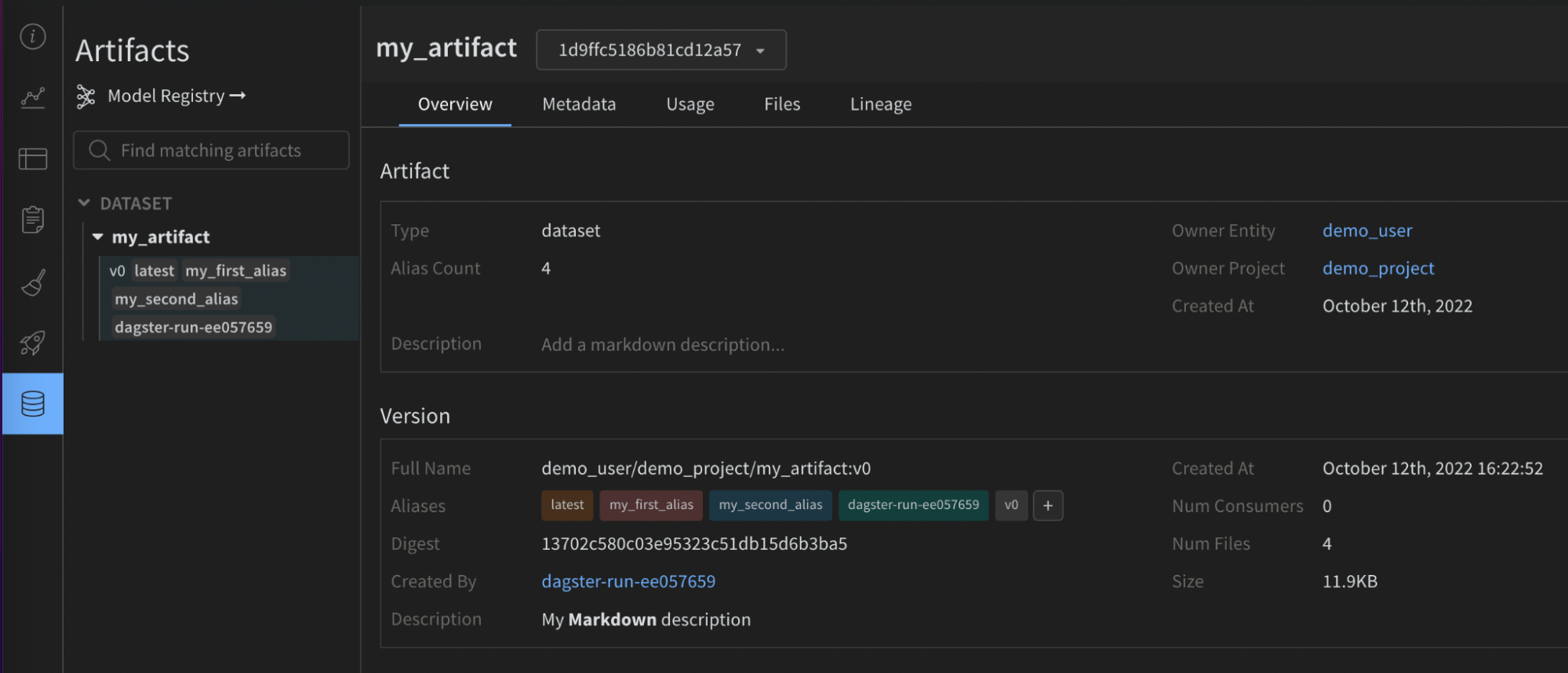
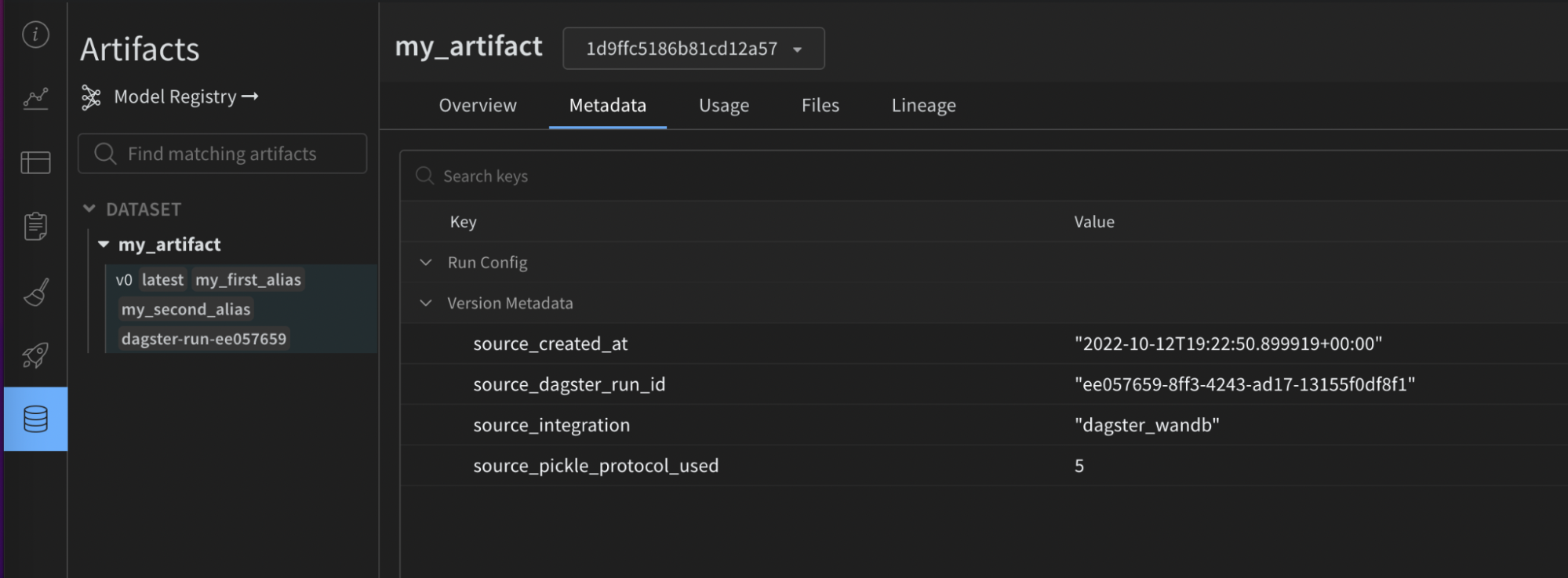
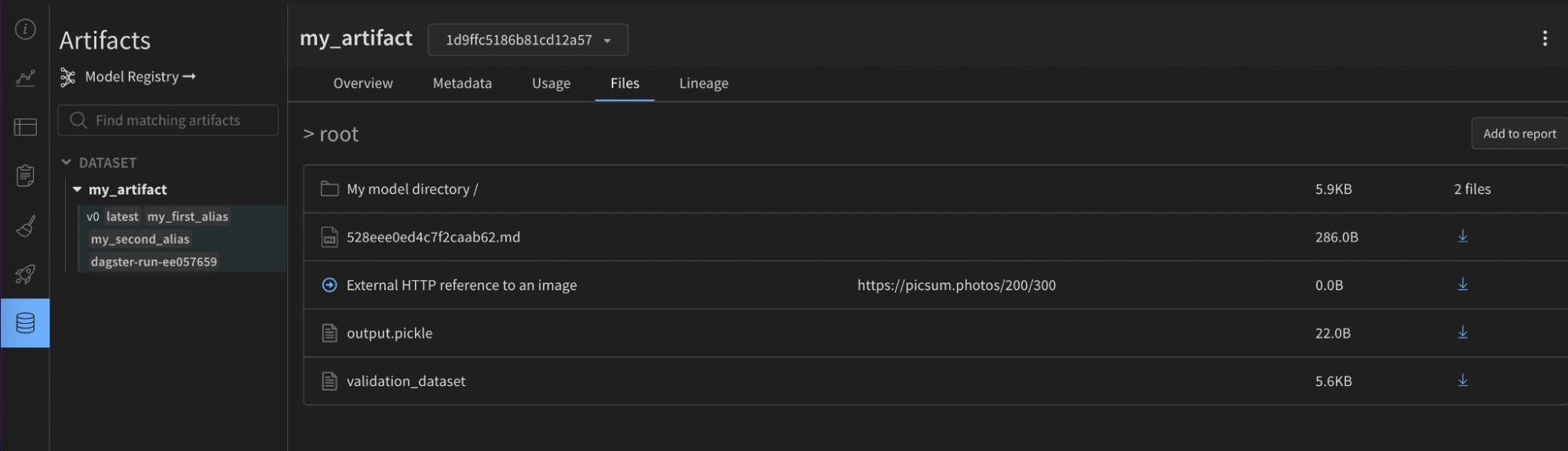
mypy와 같은 정적 유형 검사기를 사용하는 경우 다음을 사용하여 구성 유형 정의 오브젝트를 가져옵니다.
from dagster_wandb import WandbArtifactConfiguration
파티션 사용
통합은 기본적으로 Dagster 파티션을 지원합니다.
다음은 DailyPartitionsDefinition을 사용하여 분할된 예입니다.
@asset(
partitions_def=DailyPartitionsDefinition(start_date="2023-01-01", end_date="2023-02-01"),
name="my_daily_partitioned_asset",
compute_kind="wandb",
metadata={
"wandb_artifact_configuration": {
"type": "dataset",
}
},
)
def create_my_daily_partitioned_asset(context):
partition_key = context.asset_partition_key_for_output()
context.log.info(f"Creating partitioned asset for {partition_key}")
return random.randint(0, 100)
이 코드는 각 파티션에 대해 하나의 W&B Artifact를 생성합니다. asset 이름 아래의 Artifact 패널 (UI)에서 파티션 키가 추가된 Artifact를 봅니다. 예를 들어 my_daily_partitioned_asset.2023-01-01, my_daily_partitioned_asset.2023-01-02 또는 my_daily_partitioned_asset.2023-01-03입니다. 여러 차원으로 분할된 assets는 각 차원을 점으로 구분된 형식으로 표시합니다. 예를 들어 my_asset.car.blue입니다.
통합은 하나의 Run 내에서 여러 파티션의 구체화를 허용하지 않습니다. assets를 구체화하려면 여러 Runs를 수행해야 합니다. assets를 구체화할 때 Dagit에서 실행할 수 있습니다.
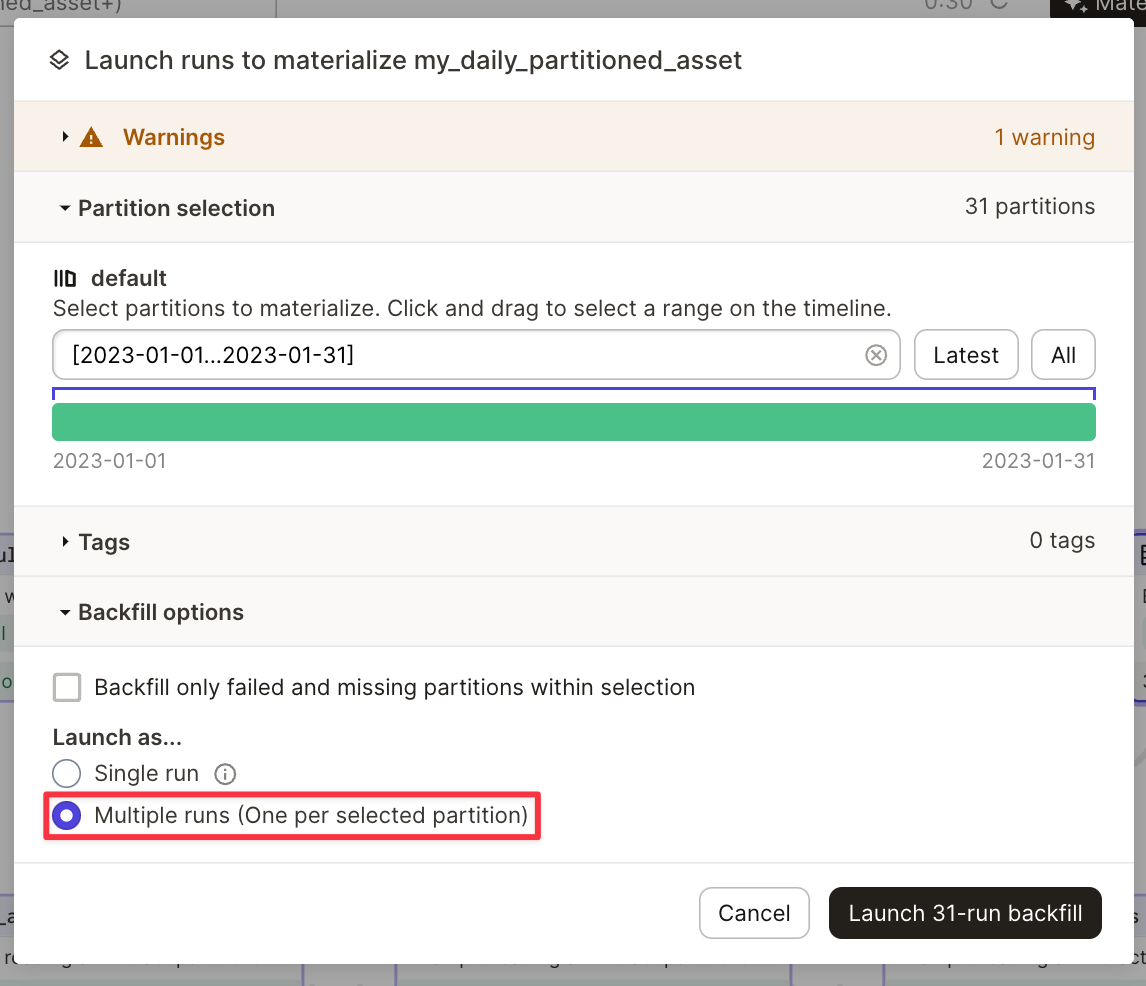
고급 사용법
W&B Artifacts 읽기
W&B Artifacts를 읽는 것은 쓰는 것과 유사합니다. wandb_artifact_configuration이라는 구성 사전은 @op 또는 @asset에서 설정할 수 있습니다. 유일한 차이점은 출력이 아닌 입력에 구성을 설정해야 한다는 것입니다.
@op의 경우 In 메타데이터 인수를 통해 입력 메타데이터에 있습니다. Artifact 이름을 명시적으로 전달해야 합니다.
@asset의 경우 Asset In 메타데이터 인수를 통해 입력 메타데이터에 있습니다. 상위 asset의 이름과 일치해야 하므로 Artifact 이름을 전달해서는 안 됩니다.
통합 외부에서 생성된 Artifact에 대한 종속성이 필요한 경우 SourceAsset을 사용해야 합니다. 항상 해당 asset의 최신 버전을 읽습니다.
다음 예제에서는 다양한 ops에서 Artifact를 읽는 방법을 보여줍니다.
@op에서 Artifact 읽기
@op(
ins={
"artifact": In(
metadata={
"wandb_artifact_configuration": {
"name": "my_artifact",
}
}
)
},
io_manager_key="wandb_artifacts_manager"
)
def read_artifact(context, artifact):
context.log.info(artifact)
다른 @asset에서 생성한 Artifact 읽기
@asset(
name="my_asset",
ins={
"artifact": AssetIn(
# if you don't want to rename the input argument you can remove 'key'
key="parent_dagster_asset_name",
input_manager_key="wandb_artifacts_manager",
)
},
)
def read_artifact(context, artifact):
context.log.info(artifact)
Dagster 외부에서 생성한 Artifact 읽기:
my_artifact = SourceAsset(
key=AssetKey("my_artifact"), # the name of the W&B Artifact
description="Artifact created outside Dagster",
io_manager_key="wandb_artifacts_manager",
)
@asset
def read_artifact(context, my_artifact):
context.log.info(my_artifact)
구성
다음 구성은 IO Manager가 데코레이팅된 함수에 대한 입력으로 수집하고 제공해야 하는 항목을 나타내는 데 사용됩니다. 다음과 같은 읽기 패턴이 지원됩니다.
- Artifact 내에 포함된 명명된 오브젝트를 가져오려면 get을 사용합니다.
@asset(
ins={
"table": AssetIn(
key="my_artifact_with_table",
metadata={
"wandb_artifact_configuration": {
"get": "my_table",
}
},
input_manager_key="wandb_artifacts_manager",
)
}
)
def get_table(context, table):
context.log.info(table.get_column("a"))
- Artifact 내에 포함된 다운로드한 파일의 로컬 경로를 가져오려면 get_path를 사용합니다.
@asset(
ins={
"path": AssetIn(
key="my_artifact_with_file",
metadata={
"wandb_artifact_configuration": {
"get_path": "name_of_file",
}
},
input_manager_key="wandb_artifacts_manager",
)
}
)
def get_path(context, path):
context.log.info(path)
- 전체 Artifact 오브젝트를 가져오려면 (콘텐츠가 로컬에 다운로드됨):
@asset(
ins={
"artifact": AssetIn(
key="my_artifact",
input_manager_key="wandb_artifacts_manager",
)
},
)
def get_artifact(context, artifact):
context.log.info(artifact.name)
지원되는 속성
get: (str) Artifact 상대 이름에 있는 W&B 오브젝트를 가져옵니다.get_path: (str) Artifact 상대 이름에 있는 파일의 경로를 가져옵니다.
직렬화 구성
기본적으로 통합은 표준 pickle 모듈을 사용하지만 일부 오브젝트는 호환되지 않습니다. 예를 들어 yield가 있는 함수는 피클링하려고 하면 오류가 발생합니다.
더 많은 Pickle 기반 직렬화 모듈을 지원합니다 (dill, cloudpickle, joblib). 직렬화된 문자열을 반환하거나 Artifact를 직접 만들어 ONNX 또는 PMML과 같은 고급 직렬화를 사용할 수도 있습니다. 올바른 선택은 유스 케이스에 따라 달라집니다. 이 주제에 대한 사용 가능한 문헌을 참조하십시오.
Pickle 기반 직렬화 모듈
wandb_artifact_configuration에서 serialization_module 사전을 통해 사용된 직렬화를 구성할 수 있습니다. Dagster를 실행하는 시스템에서 모듈을 사용할 수 있는지 확인하십시오.
통합은 해당 Artifact를 읽을 때 사용할 직렬화 모듈을 자동으로 인식합니다.
현재 지원되는 모듈은 pickle, dill, cloudpickle 및 joblib입니다.
다음은 joblib로 직렬화된 “model"을 만들고 추론에 사용하는 단순화된 예입니다.
@asset(
name="my_joblib_serialized_model",
compute_kind="Python",
metadata={
"wandb_artifact_configuration": {
"type": "model",
"serialization_module": {
"name": "joblib"
},
}
},
io_manager_key="wandb_artifacts_manager",
)
def create_model_serialized_with_joblib():
# This is not a real ML model but this would not be possible with the pickle module
return lambda x, y: x + y
@asset(
name="inference_result_from_joblib_serialized_model",
compute_kind="Python",
ins={
"my_joblib_serialized_model": AssetIn(
input_manager_key="wandb_artifacts_manager",
)
},
metadata={
"wandb_artifact_configuration": {
"type": "results",
}
},
io_manager_key="wandb_artifacts_manager",
)
def use_model_serialized_with_joblib(
context: OpExecutionContext, my_joblib_serialized_model
):
inference_result = my_joblib_serialized_model(1, 2)
context.log.info(inference_result) # Prints: 3
return inference_result
고급 직렬화 형식 (ONNX, PMML)
ONNX 및 PMML과 같은 교환 파일 형식을 사용하는 것이 일반적입니다. 통합은 이러한 형식을 지원하지만 Pickle 기반 직렬화보다 더 많은 작업이 필요합니다.
이러한 형식을 사용하는 두 가지 다른 방법이 있습니다.
- 모델을 선택한 형식으로 변환한 다음 해당 형식의 문자열 표현을 일반 Python 오브젝트인 것처럼 반환합니다. 통합은 해당 문자열을 피클링합니다. 그런 다음 해당 문자열을 사용하여 모델을 다시 빌드할 수 있습니다.
- 직렬화된 모델로 새 로컬 파일을 만든 다음 add_file 구성을 사용하여 해당 파일로 사용자 지정 Artifact를 빌드합니다.
다음은 ONNX를 사용하여 직렬화되는 Scikit-learn 모델의 예입니다.
import numpy
import onnxruntime as rt
from skl2onnx import convert_sklearn
from skl2onnx.common.data_types import FloatTensorType
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from dagster import AssetIn, AssetOut, asset, multi_asset
@multi_asset(
compute_kind="Python",
outs={
"my_onnx_model": AssetOut(
metadata={
"wandb_artifact_configuration": {
"type": "model",
}
},
io_manager_key="wandb_artifacts_manager",
),
"my_test_set": AssetOut(
metadata={
"wandb_artifact_configuration": {
"type": "test_set",
}
},
io_manager_key="wandb_artifacts_manager",
),
},
group_name="onnx_example",
)
def create_onnx_model():
# Inspired from https://onnx.ai/sklearn-onnx/
# Train a model.
iris = load_iris()
X, y = iris.data, iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y)
clr = RandomForestClassifier()
clr.fit(X_train, y_train)
# Convert into ONNX format
initial_type = [("float_input", FloatTensorType([None, 4]))]
onx = convert_sklearn(clr, initial_types=initial_type)
# Write artifacts (model + test_set)
return onx.SerializeToString(), {"X_test": X_test, "y_test": y_test}
@asset(
name="experiment_results",
compute_kind="Python",
ins={
"my_onnx_model": AssetIn(
input_manager_key="wandb_artifacts_manager",
),
"my_test_set": AssetIn(
input_manager_key="wandb_artifacts_manager",
),
},
group_name="onnx_example",
)
def use_onnx_model(context, my_onnx_model, my_test_set):
# Inspired from https://onnx.ai/sklearn-onnx/
# Compute the prediction with ONNX Runtime
sess = rt.InferenceSession(my_onnx_model)
input_name = sess.get_inputs()[0].name
label_name = sess.get_outputs()[0].name
pred_onx = sess.run(
[label_name], {input_name: my_test_set["X_test"].astype(numpy.float32)}
)[0]
context.log.info(pred_onx)
return pred_onx
파티션 사용
통합은 기본적으로 Dagster 파티션을 지원합니다.
asset의 하나, 여러 또는 모든 파티션을 선택적으로 읽을 수 있습니다.
모든 파티션은 파티션 키와 Artifact 콘텐츠를 각각 나타내는 키와 값으로 사전에서 제공됩니다.
업스트림 @asset의 모든 파티션을 읽습니다. 이는 사전으로 제공됩니다. 이 사전에서 키와 값은 각각 파티션 키와 Artifact 콘텐츠와 관련됩니다.
@asset(
compute_kind="wandb",
ins={"my_daily_partitioned_asset": AssetIn()},
output_required=False,
)
def read_all_partitions(context, my_daily_partitioned_asset):
for partition, content in my_daily_partitioned_asset.items():
context.log.info(f"partition={partition}, content={content}")
AssetIn의 partition_mapping 구성을 통해 특정 파티션을 선택할 수 있습니다. 이 경우 TimeWindowPartitionMapping을 사용합니다.
@asset(
partitions_def=DailyPartitionsDefinition(start_date="2023-01-01", end_date="2023-02-01"),
compute_kind="wandb",
ins={
"my_daily_partitioned_asset": AssetIn(
partition_mapping=TimeWindowPartitionMapping(start_offset=-1)
)
},
output_required=False,
)
def read_specific_partitions(context, my_daily_partitioned_asset):
for partition, content in my_daily_partitioned_asset.items():
context.log.info(f"partition={partition}, content={content}")
구성 오브젝트인 metadata는 Weights & Biases (wandb)가 프로젝트의 다른 Artifact 파티션과 상호 작용하는 방식을 구성하는 데 사용됩니다.
오브젝트 metadata에는 중첩된 오브젝트 partitions를 추가로 포함하는 wandb_artifact_configuration이라는 키가 포함되어 있습니다.
partitions 오브젝트는 각 파티션의 이름을 해당 구성에 매핑합니다. 각 파티션의 구성은 해당 파티션에서 데이터를 검색하는 방법을 지정할 수 있습니다. 이러한 구성에는 각 파티션의 요구 사항에 따라 get, version 및 alias라는 여러 키가 포함될 수 있습니다.
구성 키
get:get키는 데이터를 가져올 W&B 오브젝트 (Table, Image…)의 이름을 지정합니다.version: Artifact에 대한 특정 버전을 가져오려는 경우version키가 사용됩니다.alias:alias키를 사용하면 에일리어스로 Artifact를 가져올 수 있습니다.
와일드카드 구성
와일드카드 "*"는 구성되지 않은 모든 파티션을 나타냅니다. 이는 partitions` 오브젝트에 명시적으로 언급되지 않은 파티션에 대한 기본 구성을 제공합니다.
예를 들어,
"*": {
"get": "default_table_name",
},
이 구성은 명시적으로 구성되지 않은 모든 파티션에 대해 default_table_name이라는 테이블에서 데이터를 가져온다는 것을 의미합니다.
특정 파티션 구성
키를 사용하여 특정 구성을 제공하여 특정 파티션에 대한 와일드카드 구성을 재정의할 수 있습니다.
예를 들어,
"yellow": {
"get": "custom_table_name",
},
이 구성은 yellow라는 파티션의 경우 custom_table_name이라는 테이블에서 데이터를 가져와 와일드카드 구성을 재정의한다는 것을 의미합니다.
버전 관리 및 에일리어싱
버전 관리 및 에일리어싱을 위해 구성에서 특정 version 및 alias 키를 제공할 수 있습니다.
버전의 경우,
"orange": {
"version": "v0",
},
이 구성은 orange Artifact 파티션의 v0 버전에서 데이터를 가져옵니다.
에일리어스의 경우,
"blue": {
"alias": "special_alias",
},
이 구성은 에일리어스 special_alias가 있는 Artifact 파티션의 테이블 default_table_name에서 데이터를 가져옵니다 (구성에서 blue라고 함).
고급 사용법
통합의 고급 사용법을 보려면 다음 전체 코드 예제를 참조하십시오.
W&B Launch 사용
계속하기 전에 W&B Launch를 사용하는 방법을 잘 이해하는 것이 좋습니다. Launch 가이드: /guides/launch를 읽어보십시오.
Dagster 통합은 다음을 지원합니다.
- Dagster 인스턴스에서 하나 이상의 Launch 에이전트를 실행합니다.
- Dagster 인스턴스 내에서 로컬 Launch 작업을 실행합니다.
- 온프레미스 또는 클라우드에서 원격 Launch 작업을 실행합니다.
Launch 에이전트
통합은 run_launch_agent라는 가져올 수 있는 @op를 제공합니다. Launch Agent를 시작하고 수동으로 중지할 때까지 장기 실행 프로세스로 실행합니다.
에이전트는 Launch 대기열을 폴링하고 작업을 실행하거나 실행할 외부 서비스에 디스패치하는 프로세스입니다.
구성에 대한 참조 문서를 참조하십시오.
Launchpad에서 모든 속성에 대한 유용한 설명을 볼 수도 있습니다.
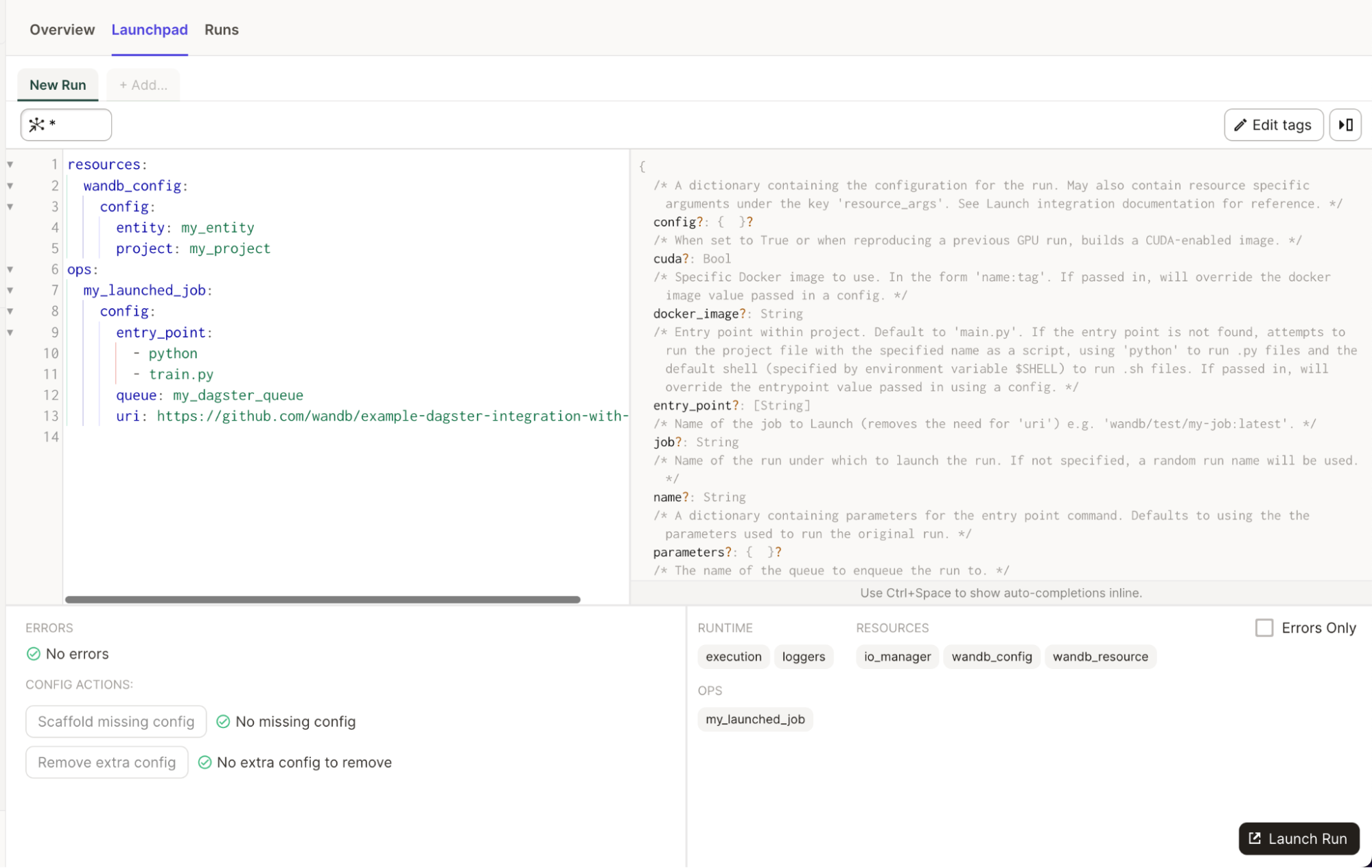
간단한 예:
# add this to your config.yaml
# alternatively you can set the config in Dagit's Launchpad or JobDefinition.execute_in_process
# Reference: https://docs.dagster.io/concepts/configuration/config-schema#specifying-runtime-configuration
resources:
wandb_config:
config:
entity: my_entity # replace this with your W&B entity
project: my_project # replace this with your W&B project
ops:
run_launch_agent:
config:
max_jobs: -1
queues:
- my_dagster_queue
from dagster_wandb.launch.ops import run_launch_agent
from dagster_wandb.resources import wandb_resource
from dagster import job, make_values_resource
@job(
resource_defs={
"wandb_config": make_values_resource(
entity=str,
project=str,
),
"wandb_resource": wandb_resource.configured(
{"api_key": {"env": "WANDB_API_KEY"}}
),
},
)
def run_launch_agent_example():
run_launch_agent()
Launch 작업
통합은 run_launch_job이라는 가져올 수 있는 @op를 제공합니다. Launch 작업을 실행합니다.
Launch 작업은 실행을 위해 대기열에 할당됩니다. 대기열을 만들거나 기본 대기열을 사용할 수 있습니다. 해당 대기열을 수신하는 활성 에이전트가 있는지 확인하십시오. Dagster 인스턴스 내에서 에이전트를 실행할 수 있지만 Kubernetes에서 배포 가능한 에이전트를 사용하는 것도 고려할 수 있습니다.
구성에 대한 참조 문서를 참조하십시오.
Launchpad에서 모든 속성에 대한 유용한 설명을 볼 수도 있습니다.
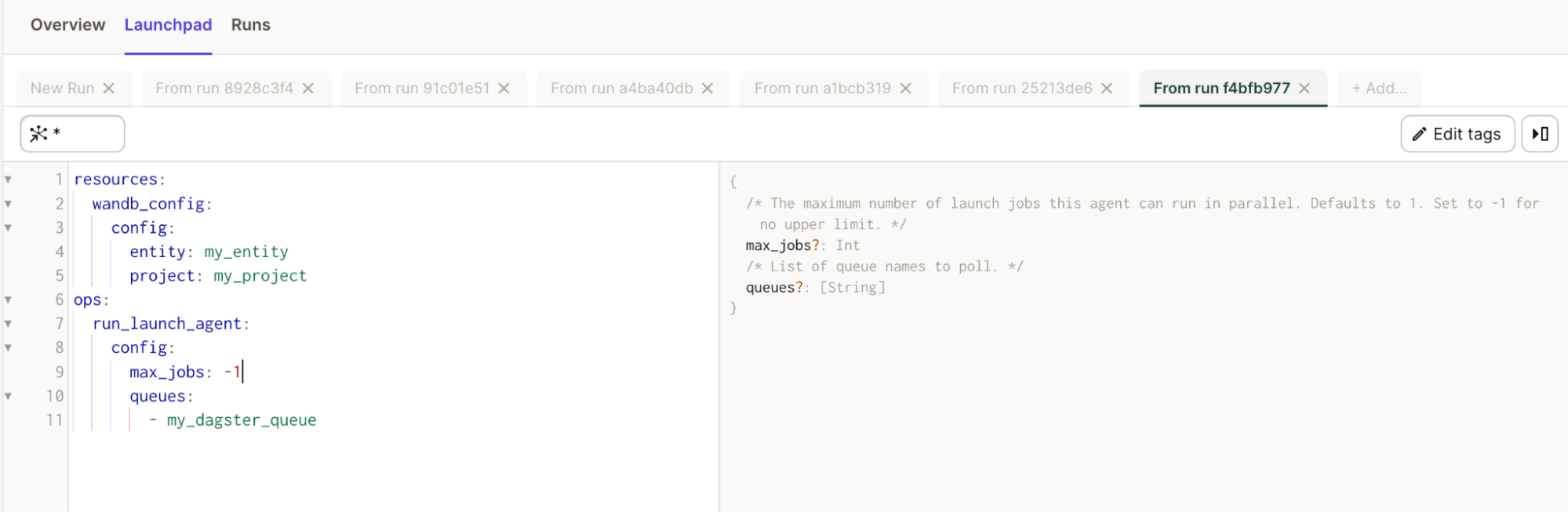
간단한 예:
# add this to your config.yaml
# alternatively you can set the config in Dagit's Launchpad or JobDefinition.execute_in_process
# Reference: https://docs.dagster.io/concepts/configuration/config-schema#specifying-runtime-configuration
resources:
wandb_config:
config:
entity: my_entity # replace this with your W&B entity
project: my_project # replace this with your W&B project
ops:
my_launched_job:
config:
entry_point:
- python
- train.py
queue: my_dagster_queue
uri: https://github.com/wandb/example-dagster-integration-with-launch
from dagster_wandb.launch.ops import run_launch_job
from dagster_wandb.resources import wandb_resource
from dagster import job, make_values_resource
@job(resource_defs={
"wandb_config": make_values_resource(
entity=str,
project=str,
),
"wandb_resource": wandb_resource.configured(
{"api_key": {"env": "WANDB_API_KEY"}}
),
},
)
def run_launch_job_example():
run_launch_job.alias("my_launched_job")() # we rename the job with an alias
모범 사례
-
IO Manager를 사용하여 Artifacts를 읽고 씁니다.
Artifact.download()또는Run.log_artifact()를 직접 사용할 필요가 없습니다. 이러한 메소드는 통합에서 처리합니다. Artifact에 저장하려는 데이터를 반환하고 통합에서 나머지를 처리하도록 합니다. 이렇게 하면 W&B에서 Artifact에 대한 더 나은 계보가 제공됩니다. -
복잡한 유스 케이스에 대해서만 Artifact 오브젝트를 직접 빌드합니다. Python 오브젝트 및 W&B 오브젝트는 ops/assets에서 반환되어야 합니다. 통합은 Artifact 번들링을 처리합니다. 복잡한 유스 케이스의 경우 Dagster 작업에서 Artifact를 직접 빌드할 수 있습니다. 소스 통합 이름 및 버전, 사용된 Python 버전, 피클 프로토콜 버전 등과 같은 메타데이터 보강을 위해 Artifact 오브젝트를 통합에 전달하는 것이 좋습니다.
-
메타데이터를 통해 파일, 디렉토리 및 외부 참조를 Artifacts에 추가합니다. 통합
wandb_artifact_configuration오브젝트를 사용하여 파일, 디렉토리 또는 외부 참조 (Amazon S3, GCS, HTTP…)를 추가합니다. 자세한 내용은 Artifact 구성 섹션의 고급 예제를 참조하십시오. -
Artifact가 생성되면 @op 대신 @asset을 사용합니다. Artifacts는 assets입니다. Dagster가 해당 asset을 유지 관리하는 경우 asset을 사용하는 것이 좋습니다. 이렇게 하면 Dagit Asset Catalog에서 더 나은 가시성을 제공합니다.
-
SourceAsset을 사용하여 Dagster 외부에서 생성된 Artifact를 소비합니다. 이를 통해 통합을 활용하여 외부에서 생성된 Artifacts를 읽을 수 있습니다. 그렇지 않으면 통합에서 생성된 Artifacts만 사용할 수 있습니다.
-
W&B Launch를 사용하여 대규모 모델에 대한 전용 컴퓨팅에서 트레이닝을 오케스트레이션합니다. Dagster 클러스터 내부에서 작은 모델을 트레이닝할 수 있으며 GPU 노드가 있는 Kubernetes 클러스터에서 Dagster를 실행할 수 있습니다. 대규모 모델 트레이닝에는 W&B Launch를 사용하는 것이 좋습니다. 이렇게 하면 인스턴스 과부하를 방지하고 더 적절한 컴퓨팅에 액세스할 수 있습니다.
-
Dagster 내에서 실험 추적을 수행할 때 W&B Run ID를 Dagster Run ID 값으로 설정합니다. Run을 재개 가능하게 만들고 W&B Run ID를 Dagster Run ID 또는 원하는 문자열로 설정하는 것이 좋습니다. 이 권장 사항을 따르면 Dagster 내부에서 모델을 트레이닝할 때 W&B 메트릭 및 W&B Artifacts가 동일한 W&B Run에 저장됩니다.
W&B Run ID를 Dagster Run ID로 설정합니다.
wandb.init(
id=context.run_id,
resume="allow",
...
)
또는 자체 W&B Run ID를 선택하고 IO Manager 구성에 전달합니다.
wandb.init(
id="my_resumable_run_id",
resume="allow",
...
)
@job(
resource_defs={
"io_manager": wandb_artifacts_io_manager.configured(
{"wandb_run_id": "my_resumable_run_id"}
),
}
)
-
대규모 W&B Artifacts의 경우 get 또는 get_path로 필요한 데이터만 수집합니다. 기본적으로 통합은 전체 Artifact를 다운로드합니다. 매우 큰 Artifacts를 사용하는 경우 필요한 특정 파일 또는 오브젝트만 수집할 수 있습니다. 이렇게 하면 속도와 리소스 활용도가 향상됩니다.
-
Python 오브젝트의 경우 유스 케이스에 맞게 피클링 모듈을 조정합니다. 기본적으로 W&B 통합은 표준 pickle 모듈을 사용합니다. 그러나 일부 오브젝트는 호환되지 않습니다. 예를 들어 yield가 있는 함수는 피클링하려고 하면 오류가 발생합니다. W&B는 다른 Pickle 기반 직렬화 모듈을 지원합니다 (dill, cloudpickle, joblib).
직렬화된 문자열을 반환하거나 Artifact를 직접 만들어 ONNX 또는 PMML과 같은 고급 직렬화를 사용할 수도 있습니다. 올바른 선택은 유스 케이스에 따라 달라집니다. 이 주제에 대한 사용 가능한 문헌을 참조하십시오.
[i18n] feedback_title
[i18n] feedback_question
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.