Tutorial: Use W&B for model management
5 minute read
다음 가이드에서는 W&B에 모델을 기록하는 방법을 안내합니다. 이 가이드가 끝나면 다음을 수행할 수 있습니다.
- MNIST 데이터셋과 Keras 프레임워크를 사용하여 모델을 만들고 트레이닝합니다.
- 트레이닝한 모델을 W&B project에 기록합니다.
- 사용된 데이터셋을 생성한 모델의 종속성으로 표시합니다.
- 해당 모델을 W&B Registry에 연결합니다.
- 레지스트리에 연결한 모델의 성능을 평가합니다.
- 모델 버전을 프로덕션 준비 완료로 표시합니다.
- 이 가이드에 제시된 순서대로 코드 조각을 복사하세요.
- Model Registry에 고유하지 않은 코드는 접을 수 있는 셀에 숨겨져 있습니다.
설정
시작하기 전에 이 가이드에 필요한 Python 종속성을 가져옵니다.
import wandb
import numpy as np
from tensorflow import keras
from tensorflow.keras import layers
from wandb.integration.keras import WandbMetricsLogger
from sklearn.model_selection import train_test_split
W&B entity를 entity 변수에 제공합니다.
entity = "<entity>"
데이터셋 아티팩트 생성
먼저 데이터셋을 만듭니다. 다음 코드 조각은 MNIST 데이터셋을 다운로드하는 함수를 생성합니다.
def generate_raw_data(train_size=6000):
eval_size = int(train_size / 6)
(x_train, y_train), (x_eval, y_eval) = keras.datasets.mnist.load_data()
x_train = x_train.astype("float32") / 255
x_eval = x_eval.astype("float32") / 255
x_train = np.expand_dims(x_train, -1)
x_eval = np.expand_dims(x_eval, -1)
print("Generated {} rows of training data.".format(train_size))
# 트레이닝 데이터 {}행 생성됨.
print("Generated {} rows of eval data.".format(eval_size))
# 평가 데이터 {}행 생성됨.
return (x_train[:train_size], y_train[:train_size]), (
x_eval[:eval_size],
y_eval[:eval_size],
)
# 데이터셋 생성
(x_train, y_train), (x_eval, y_eval) = generate_raw_data()
다음으로 데이터셋을 W&B에 업로드합니다. 이렇게 하려면 artifact 오브젝트를 생성하고 해당 아티팩트에 데이터셋을 추가합니다.
project = "model-registry-dev"
model_use_case_id = "mnist"
job_type = "build_dataset"
# W&B run 초기화
run = wandb.init(entity=entity, project=project, job_type=job_type)
# 트레이닝 데이터를 위한 W&B 테이블 생성
train_table = wandb.Table(data=[], columns=[])
train_table.add_column("x_train", x_train)
train_table.add_column("y_train", y_train)
train_table.add_computed_columns(lambda ndx, row: {"img": wandb.Image(row["x_train"])})
# 평가 데이터를 위한 W&B 테이블 생성
eval_table = wandb.Table(data=[], columns=[])
eval_table.add_column("x_eval", x_eval)
eval_table.add_column("y_eval", y_eval)
eval_table.add_computed_columns(lambda ndx, row: {"img": wandb.Image(row["x_eval"])})
# 아티팩트 오브젝트 생성
artifact_name = "{}_dataset".format(model_use_case_id)
artifact = wandb.Artifact(name=artifact_name, type="dataset")
# wandb.WBValue obj를 아티팩트에 추가
artifact.add(train_table, "train_table")
artifact.add(eval_table, "eval_table")
# 아티팩트에 대한 변경 사항을 유지합니다.
artifact.save()
# W&B에 이 run이 완료되었음을 알립니다.
run.finish()
모델 트레이닝
이전 단계에서 생성한 아티팩트 데이터셋으로 모델을 트레이닝합니다.
데이터셋 아티팩트를 run에 대한 입력으로 선언
이전 단계에서 생성한 데이터셋 아티팩트를 W&B run에 대한 입력으로 선언합니다. 아티팩트를 run에 대한 입력으로 선언하면 특정 모델을 트레이닝하는 데 사용된 데이터셋(및 데이터셋 버전)을 추적할 수 있으므로 모델 로깅 컨텍스트에서 특히 유용합니다. W&B는 수집된 정보를 사용하여 lineage map을 만듭니다.
use_artifact API를 사용하여 데이터셋 아티팩트를 run의 입력으로 선언하고 아티팩트 자체를 검색합니다.
job_type = "train_model"
config = {
"optimizer": "adam",
"batch_size": 128,
"epochs": 5,
"validation_split": 0.1,
}
# W&B run 초기화
run = wandb.init(project=project, job_type=job_type, config=config)
# 데이터셋 아티팩트 검색
version = "latest"
name = "{}:{}".format("{}_dataset".format(model_use_case_id), version)
artifact = run.use_artifact(artifact_or_name=name)
# 데이터프레임에서 특정 콘텐츠 가져오기
train_table = artifact.get("train_table")
x_train = train_table.get_column("x_train", convert_to="numpy")
y_train = train_table.get_column("y_train", convert_to="numpy")
모델의 입력 및 출력 추적에 대한 자세한 내용은 모델 계보 맵 만들기를 참조하세요.
모델 정의 및 트레이닝
이 가이드에서는 Keras를 사용하여 MNIST 데이터셋의 이미지를 분류하기 위해 2D Convolutional Neural Network (CNN)를 정의합니다.
MNIST 데이터에서 CNN 트레이닝
# 구성 사전의 값을 변수에 저장하여 쉽게 엑세스
num_classes = 10
input_shape = (28, 28, 1)
loss = "categorical_crossentropy"
optimizer = run.config["optimizer"]
metrics = ["accuracy"]
batch_size = run.config["batch_size"]
epochs = run.config["epochs"]
validation_split = run.config["validation_split"]
# 모델 아키텍처 생성
model = keras.Sequential(
[
layers.Input(shape=input_shape),
layers.Conv2D(32, kernel_size=(3, 3), activation="relu"),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Conv2D(64, kernel_size=(3, 3), activation="relu"),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Flatten(),
layers.Dropout(0.5),
layers.Dense(num_classes, activation="softmax"),
]
)
model.compile(loss=loss, optimizer=optimizer, metrics=metrics)
# 트레이닝 데이터에 대한 레이블 생성
y_train = keras.utils.to_categorical(y_train, num_classes)
# 트레이닝 및 테스트 세트 생성
x_t, x_v, y_t, y_v = train_test_split(x_train, y_train, test_size=0.33)
다음으로 모델을 트레이닝합니다.
# 모델 트레이닝
model.fit(
x=x_t,
y=y_t,
batch_size=batch_size,
epochs=epochs,
validation_data=(x_v, y_v),
callbacks=[WandbCallback(log_weights=True, log_evaluation=True)],
)
마지막으로 모델을 로컬 머신에 저장합니다.
# 모델을 로컬에 저장
path = "model.h5"
model.save(path)
모델을 Model Registry에 로깅하고 연결
link_model API를 사용하여 하나 이상의 모델 파일을 W&B run에 로깅하고 W&B Model Registry에 연결합니다.
path = "./model.h5"
registered_model_name = "MNIST-dev"
run.link_model(path=path, registered_model_name=registered_model_name)
run.finish()
registered-model-name에 대해 지정한 이름이 아직 존재하지 않으면 W&B가 registered model을 생성합니다.
선택적 파라미터에 대한 자세한 내용은 API Reference 가이드의 link_model을 참조하세요.
모델 성능 평가
하나 이상의 모델의 성능을 평가하는 것이 일반적인 방법입니다.
먼저 이전 단계에서 W&B에 저장된 평가 데이터셋 아티팩트를 가져옵니다.
job_type = "evaluate_model"
# run 초기화
run = wandb.init(project=project, entity=entity, job_type=job_type)
model_use_case_id = "mnist"
version = "latest"
# 데이터셋 아티팩트를 가져오고 종속성으로 표시합니다.
artifact = run.use_artifact(
"{}:{}".format("{}_dataset".format(model_use_case_id), version)
)
# 원하는 데이터프레임 가져오기
eval_table = artifact.get("eval_table")
x_eval = eval_table.get_column("x_eval", convert_to="numpy")
y_eval = eval_table.get_column("y_eval", convert_to="numpy")
평가할 W&B의 model version을 다운로드합니다. use_model API를 사용하여 모델에 엑세스하고 다운로드합니다.
alias = "latest" # 에일리어스
name = "mnist_model" # 모델 아티팩트 이름
# 모델에 엑세스하고 다운로드합니다. 다운로드한 아티팩트의 경로를 반환합니다.
downloaded_model_path = run.use_model(name=f"{name}:{alias}")
Keras 모델을 로드하고 손실을 계산합니다.
model = keras.models.load_model(downloaded_model_path)
y_eval = keras.utils.to_categorical(y_eval, 10)
(loss, _) = model.evaluate(x_eval, y_eval)
score = (loss, _)
마지막으로 손실 메트릭을 W&B run에 기록합니다.
# # 메트릭, 이미지, 테이블 또는 평가에 유용한 모든 데이터를 기록합니다.
run.log(data={"loss": (loss, _)})
모델 버전 승격
model alias를 사용하여 기계 학습 워크플로우의 다음 단계를 위해 모델 버전을 준비 완료로 표시합니다. 각 registered model에는 하나 이상의 model alias가 있을 수 있습니다. model alias는 한 번에 하나의 model version에만 속할 수 있습니다.
예를 들어, 모델의 성능을 평가한 후 모델이 프로덕션 준비가 되었다고 확신한다고 가정합니다. 해당 모델 버전을 승격하려면 해당 특정 model version에 production 에일리어스를 추가합니다.
production 에일리어스는 모델을 프로덕션 준비로 표시하는 데 사용되는 가장 일반적인 에일리어스 중 하나입니다.W&B App UI를 사용하여 대화형으로 또는 Python SDK를 사용하여 프로그래밍 방식으로 model version에 에일리어스를 추가할 수 있습니다. 다음 단계에서는 W&B Model Registry App을 사용하여 에일리어스를 추가하는 방법을 보여줍니다.
- https://wandb.ai/registry/model에서 Model Registry App으로 이동합니다.
- registered model 이름 옆에 있는 View details를 클릭합니다.
- Versions 섹션 내에서 승격하려는 model version 이름 옆에 있는 View 버튼을 클릭합니다.
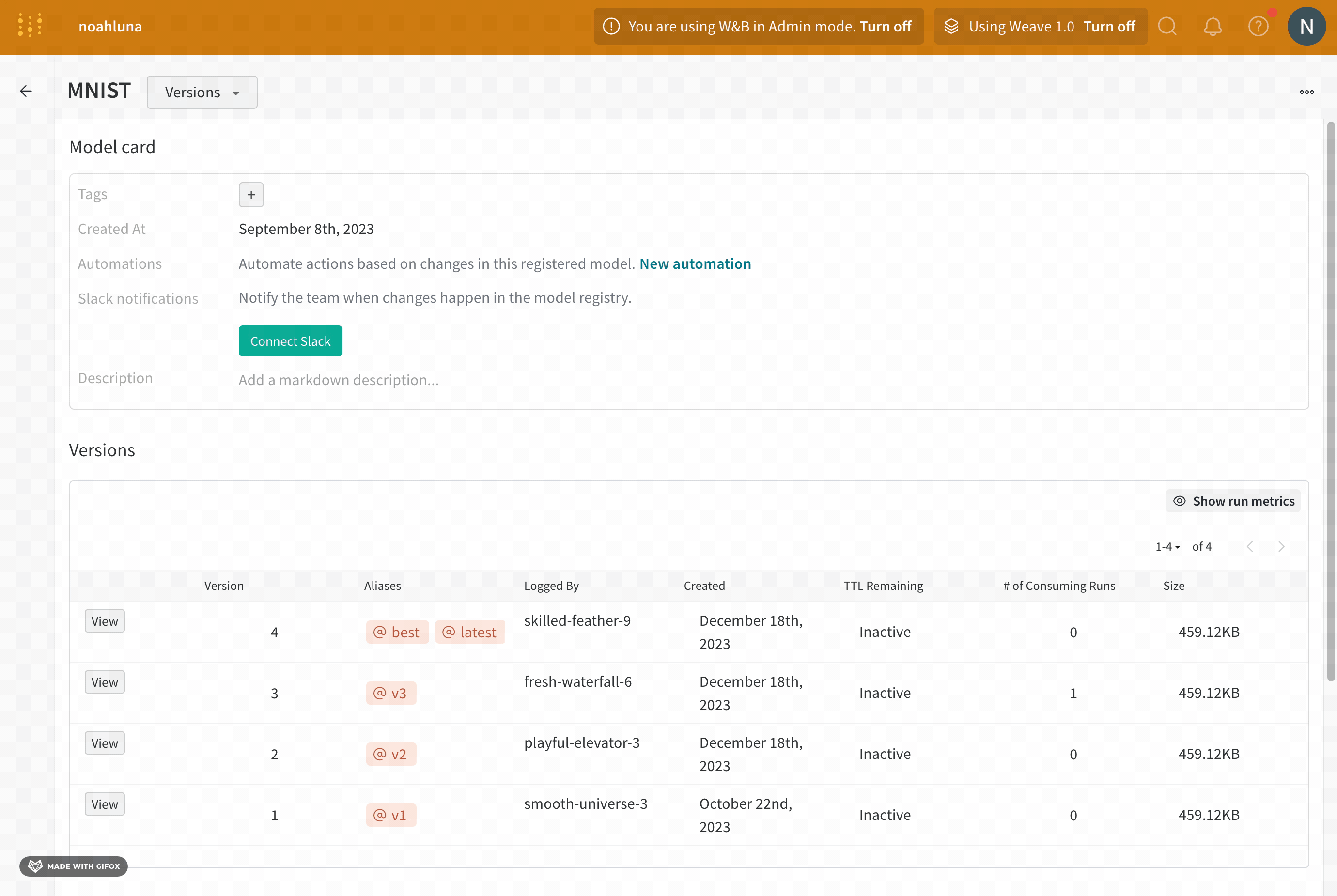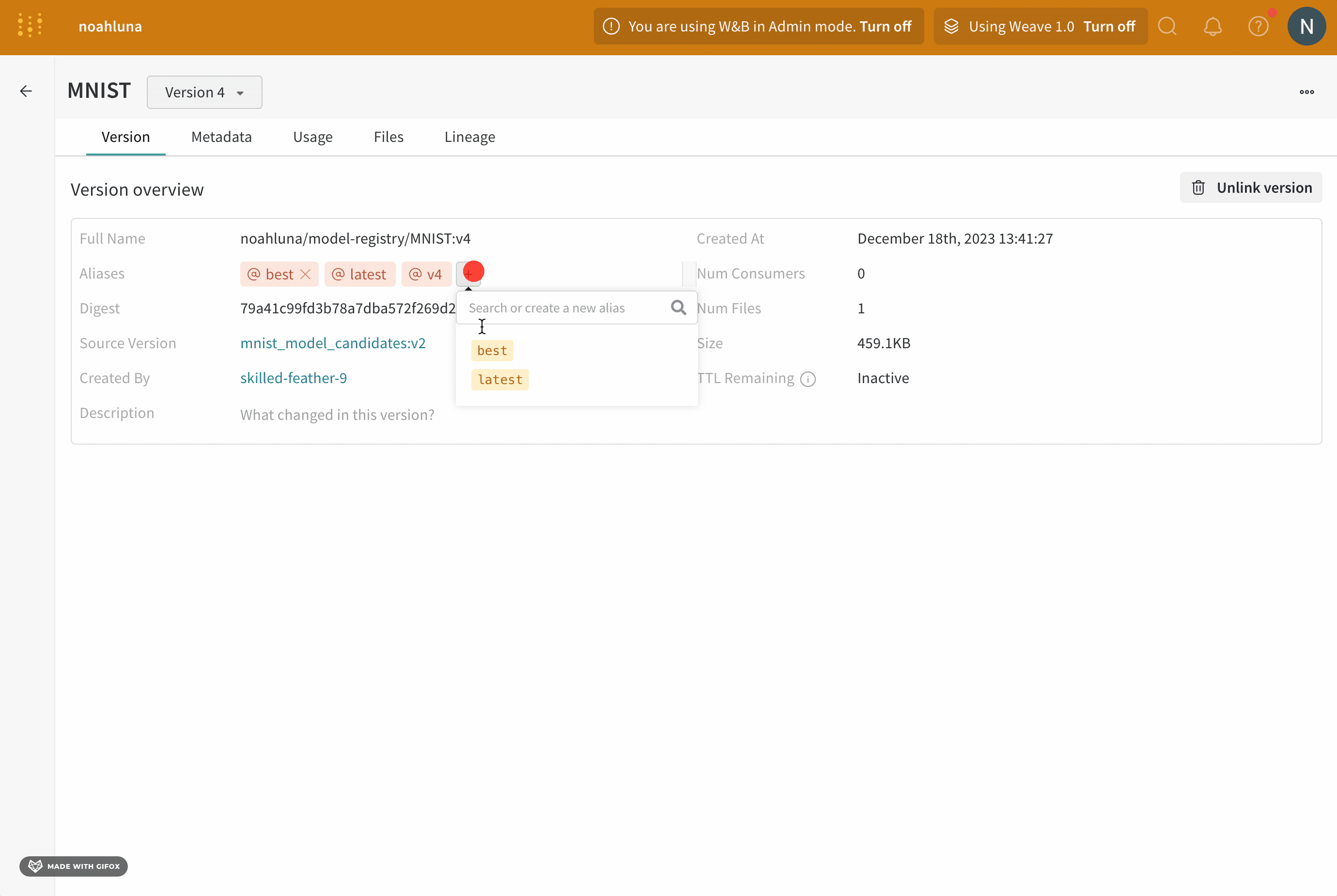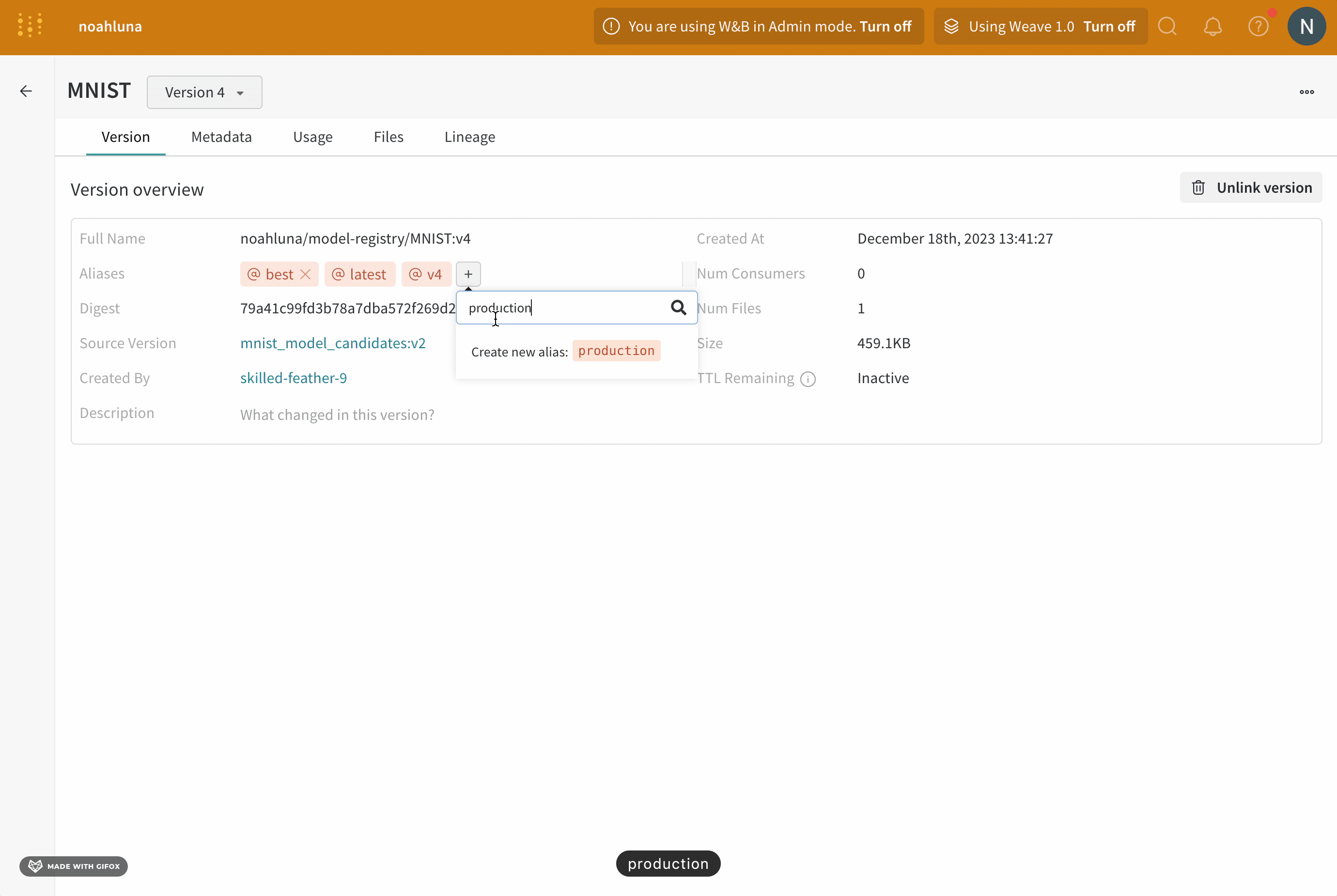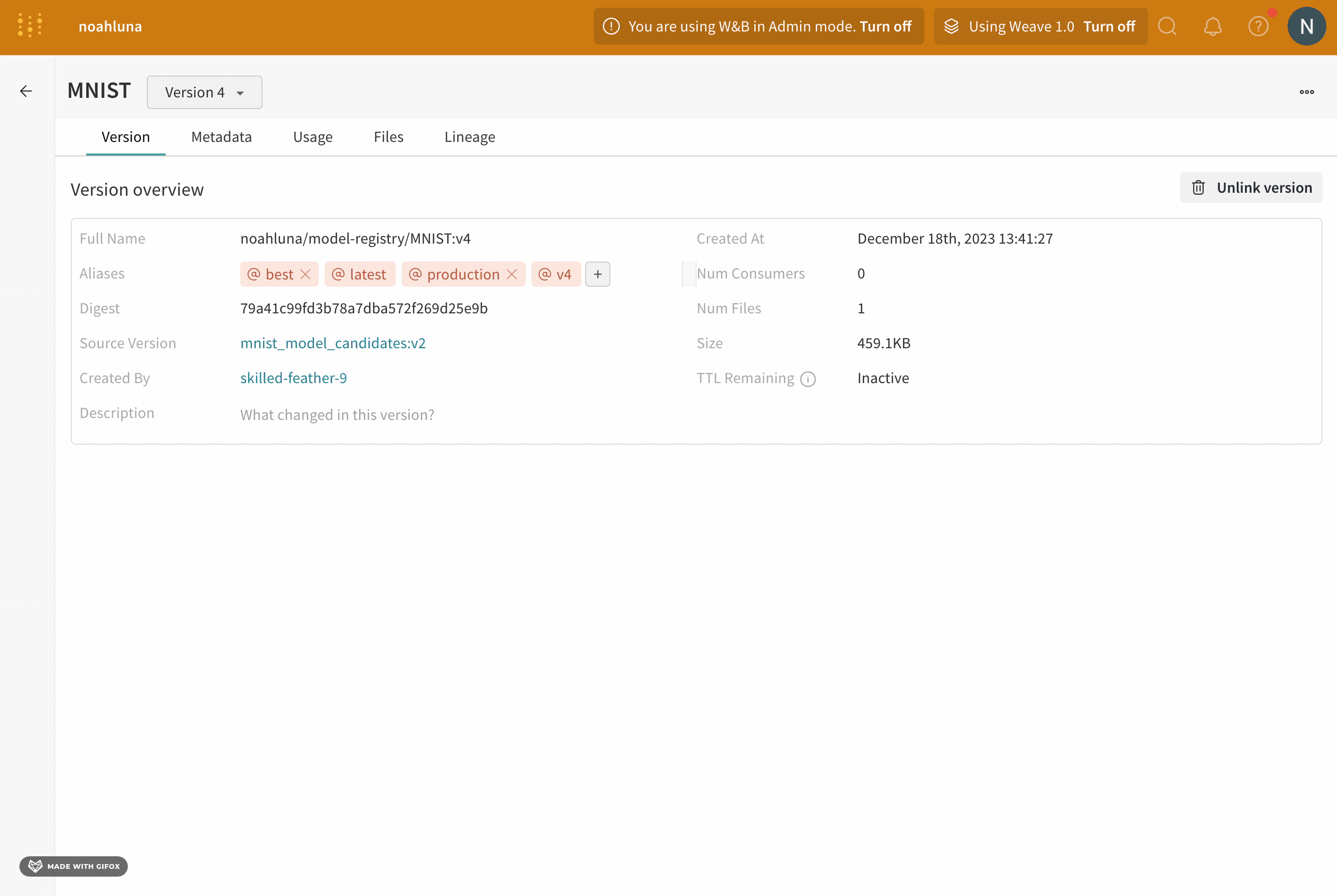
- Aliases 필드 옆에 있는 더하기 아이콘(+)을 클릭합니다.
- 나타나는 필드에
production을 입력합니다. - 키보드에서 Enter 키를 누릅니다.
[i18n] feedback_title
[i18n] feedback_question
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.