Embed objects
3 minute read
Embeddings는 오브젝트 (사람, 이미지, 게시물, 단어 등)를 숫자 목록 ( vector 라고도 함)으로 나타내는 데 사용됩니다. 기계 학습 및 데이터 과학 유스 케이스에서 Embeddings는 다양한 애플리케이션에서 다양한 접근 방식을 사용하여 생성할 수 있습니다. 이 페이지에서는 독자가 Embeddings에 익숙하고 W&B 내에서 Embeddings를 시각적으로 분석하는 데 관심이 있다고 가정합니다.
Embedding 예시
Hello World
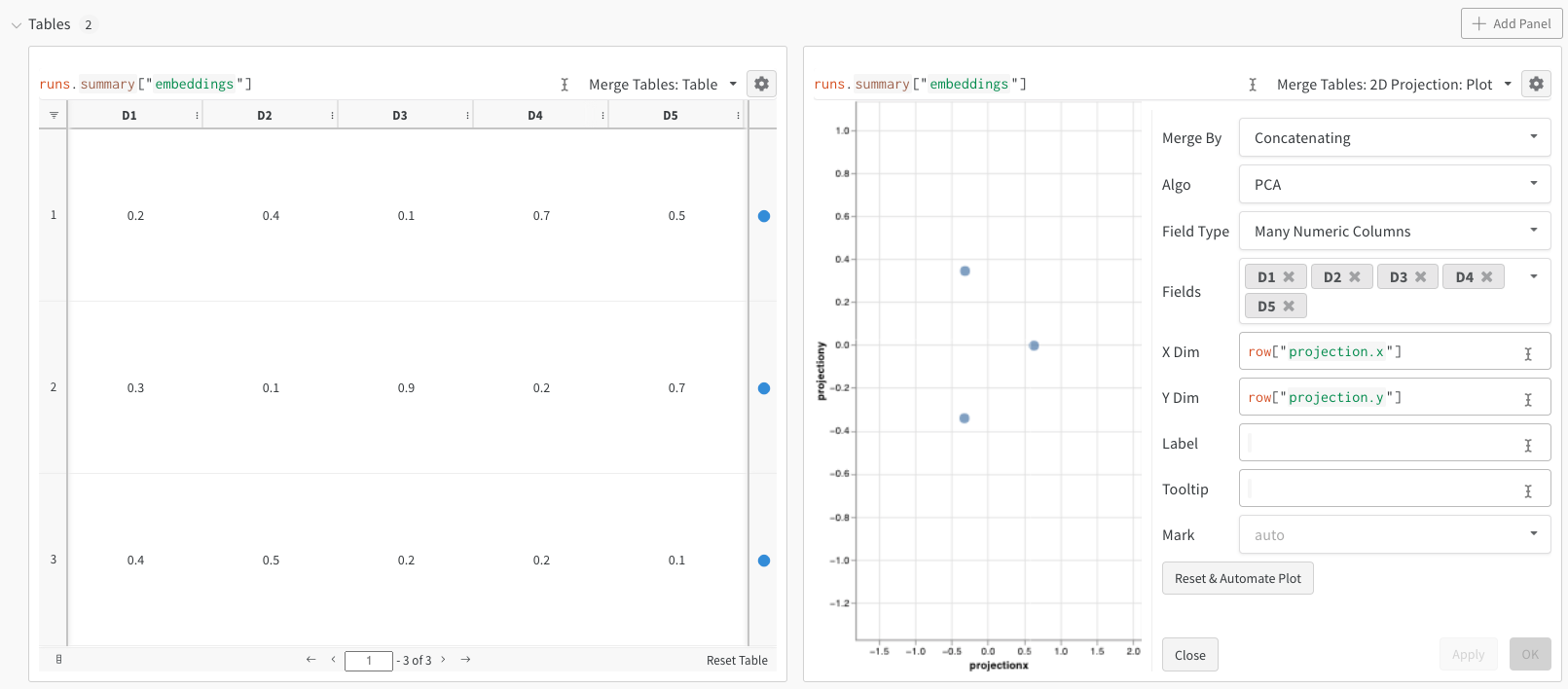
W&B를 사용하면 wandb.Table 클래스를 사용하여 Embeddings를 로그할 수 있습니다. 각각 5개의 차원으로 구성된 3개의 Embeddings의 다음 예제를 고려하십시오.
import wandb
wandb.init(project="embedding_tutorial")
embeddings = [
# D1 D2 D3 D4 D5
[0.2, 0.4, 0.1, 0.7, 0.5], # embedding 1
[0.3, 0.1, 0.9, 0.2, 0.7], # embedding 2
[0.4, 0.5, 0.2, 0.2, 0.1], # embedding 3
]
wandb.log(
{"embeddings": wandb.Table(columns=["D1", "D2", "D3", "D4", "D5"], data=embeddings)}
)
wandb.finish()
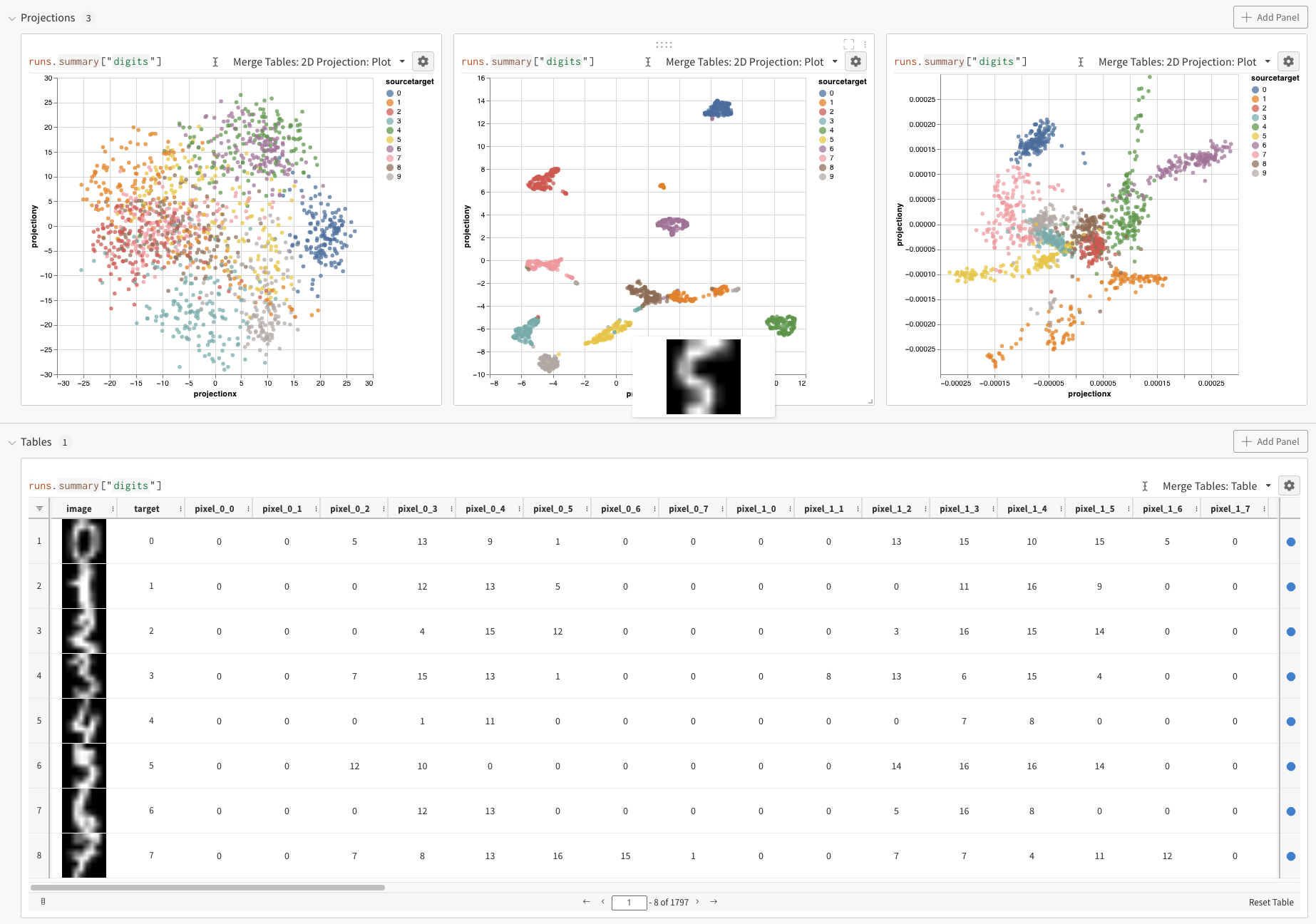
위의 코드를 실행하면 W&B 대시보드에 데이터가 포함된 새 Table이 표시됩니다. 오른쪽 상단 패널 선택기에서 2D Projection을 선택하여 Embeddings를 2차원으로 플롯할 수 있습니다. 스마트 기본값이 자동으로 선택되며, 기어 아이콘을 클릭하여 엑세스할 수 있는 설정 메뉴에서 쉽게 재정의할 수 있습니다. 이 예제에서는 사용 가능한 5개의 숫자 차원을 모두 자동으로 사용합니다.
Digits MNIST
위의 예제는 Embeddings 로깅의 기본 메커니즘을 보여 주지만 일반적으로 훨씬 더 많은 차원과 샘플을 사용합니다. MNIST Digits 데이터셋 (UCI ML 손으로 쓴 숫자 데이터셋s)을 고려해 보겠습니다. SciKit-Learn을 통해 사용할 수 있습니다. 이 데이터셋에는 각각 64개의 차원을 가진 1797개의 레코드가 있습니다. 문제는 10개의 클래스 분류 유스 케이스입니다. 시각화를 위해 입력 데이터를 이미지로 변환할 수도 있습니다.
import wandb
from sklearn.datasets import load_digits
wandb.init(project="embedding_tutorial")
# Load the dataset
ds = load_digits(as_frame=True)
df = ds.data
# Create a "target" column
df["target"] = ds.target.astype(str)
cols = df.columns.tolist()
df = df[cols[-1:] + cols[:-1]]
# Create an "image" column
df["image"] = df.apply(
lambda row: wandb.Image(row[1:].values.reshape(8, 8) / 16.0), axis=1
)
cols = df.columns.tolist()
df = df[cols[-1:] + cols[:-1]]
wandb.log({"digits": df})
wandb.finish()
위의 코드를 실행하면 UI에 Table이 다시 표시됩니다. 2D Projection을 선택하면 Embedding 정의, 색상, 알고리즘 (PCA, UMAP, t-SNE), 알고리즘 파라미터를 구성하고 오버레이할 수도 있습니다 (이 경우 점 위로 마우스를 가져갈 때 이미지가 표시됨). 이 특정 경우에서는 이 모든 것이 “스마트 기본값"이며 2D Projection에서 한 번의 클릭으로 매우 유사한 내용을 볼 수 있습니다. (이 예제와 상호 작용하려면 여기를 클릭하십시오.).
로깅 옵션
다양한 형식으로 Embeddings를 로그할 수 있습니다.
- 단일 Embedding 열: 데이터가 이미 “매트릭스"와 유사한 형식인 경우가 많습니다. 이 경우 셀 값의 데이터 유형이
list[int],list[float]또는np.ndarray일 수 있는 단일 Embedding 열을 만들 수 있습니다. - 여러 숫자 열: 위의 두 예제에서는 이 접근 방식을 사용하고 각 차원에 대한 열을 만듭니다. 현재 셀에 대해 python
int또는float를 허용합니다.
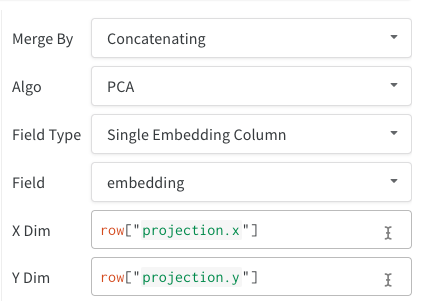
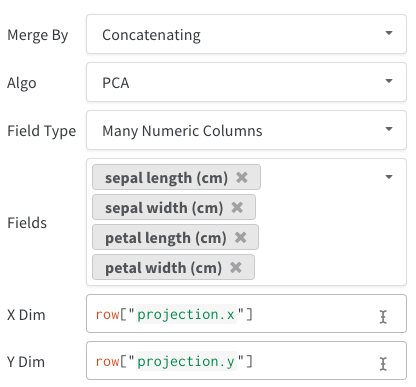
또한 모든 테이블과 마찬가지로 테이블 구성 방법에 대한 많은 옵션이 있습니다.
wandb.Table(dataframe=df)를 사용하여 데이터프레임에서 직접wandb.Table(data=[...], columns=[...])를 사용하여 데이터 목록에서 직접- 테이블을 점진적으로 행 단위로 빌드합니다 (코드에 루프가 있는 경우에 적합).
table.add_data(...)를 사용하여 테이블에 행을 추가합니다. - 테이블에 Embedding 열을 추가합니다 (Embedding 형식의 예측 목록이 있는 경우에 적합):
table.add_col("col_name", ...) - 계산된 열을 추가합니다 (테이블에서 매핑하려는 함수 또는 model이 있는 경우에 적합):
table.add_computed_columns(lambda row, ndx: {"embedding": model.predict(row)})
플로팅 옵션
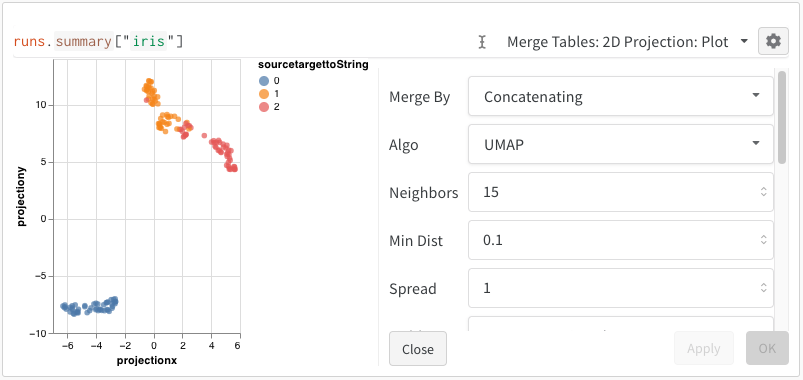
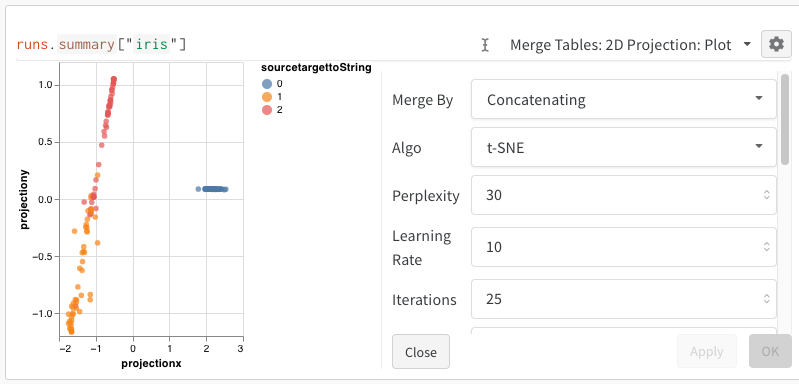
2D Projection을 선택한 후 기어 아이콘을 클릭하여 렌더링 설정을 편집할 수 있습니다. 원하는 열을 선택하는 것 외에도 (위 참조) 원하는 알고리즘 (원하는 파라미터와 함께)을 선택할 수 있습니다. 아래에서 UMAP 및 t-SNE에 대한 파라미터를 각각 볼 수 있습니다.
[i18n] feedback_title
[i18n] feedback_question
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.