Tutorial: Use custom charts
W&B UI에서 사용자 정의 차트 기능을 사용하는 방법에 대한 튜토리얼
6 minute read
W&B 프로젝트에서 커스텀 차트를 만드세요. 임의의 데이터 테이블을 기록하고 원하는 방식으로 시각화하세요. Vega의 강력한 기능을 사용하여 글꼴, 색상 및 툴팁의 세부 사항을 제어하세요.
wandb.plot_table()로 스크립트에서 자체 프리셋을 호출합니다.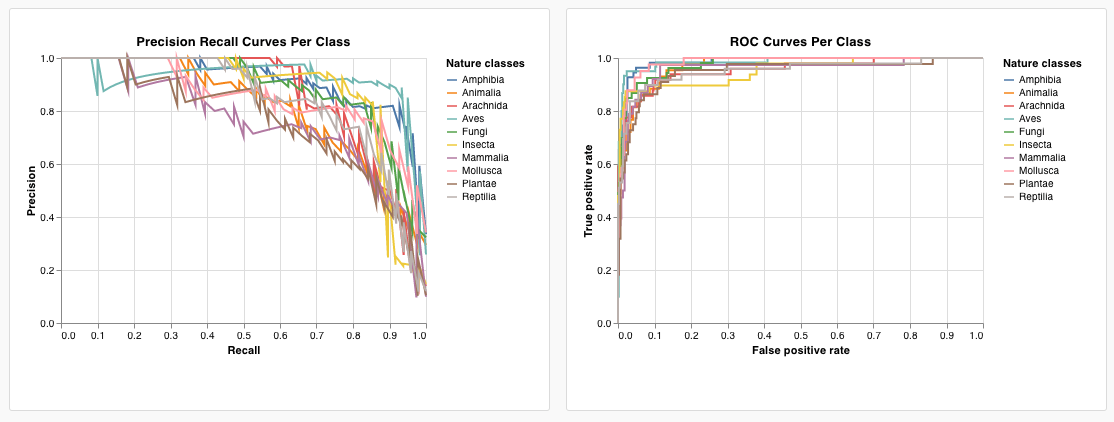
예상되는 데이터가 보이지 않으면 찾고 있는 열이 선택된 runs에 기록되지 않았을 수 있습니다. 차트를 저장하고 runs 테이블로 돌아가서 눈 아이콘을 사용하여 선택한 runs를 확인합니다.
W&B에는 스크립트에서 직접 기록할 수 있는 여러 내장 차트 프리셋이 있습니다. 여기에는 선 플롯, 산점도, 막대 차트, 히스토그램, PR 곡선 및 ROC 곡선이 포함됩니다.
wandb.plot.line()
임의의 축 x와 y에서 연결되고 정렬된 점 목록(x,y)인 사용자 지정 선 플롯을 기록합니다.
data = [[x, y] for (x, y) in zip(x_values, y_values)]
table = wandb.Table(data=data, columns=["x", "y"])
wandb.log(
{
"my_custom_plot_id": wandb.plot.line(
table, "x", "y", title="Custom Y vs X Line Plot"
)
}
)
선 플롯은 두 차원에 대한 곡선을 기록합니다. 두 값 목록을 서로 플롯하는 경우 목록의 값 수는 정확히 일치해야 합니다(예: 각 점에 x와 y가 있어야 함).
예제 리포트를 보거나 예제 Google Colab 노트북을 사용해 보세요.
wandb.plot.scatter()
임의의 축 x와 y 쌍의 점 목록(x, y)인 사용자 지정 산점도를 기록합니다.
data = [[x, y] for (x, y) in zip(class_x_prediction_scores, class_y_prediction_scores)]
table = wandb.Table(data=data, columns=["class_x", "class_y"])
wandb.log({"my_custom_id": wandb.plot.scatter(table, "class_x", "class_y")})
이를 사용하여 두 차원에 대한 산점도를 기록할 수 있습니다. 두 값 목록을 서로 플롯하는 경우 목록의 값 수는 정확히 일치해야 합니다(예: 각 점에 x와 y가 있어야 함).
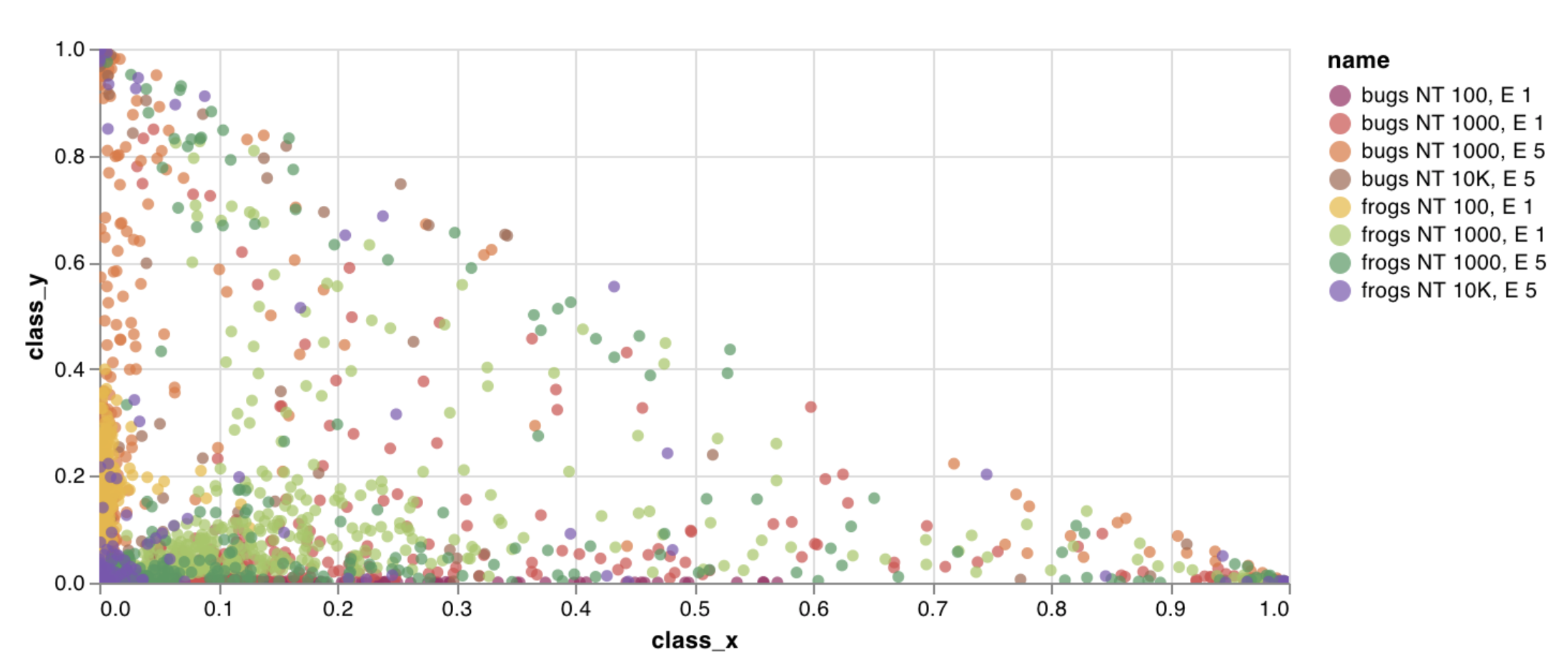
예제 리포트를 보거나 예제 Google Colab 노트북을 사용해 보세요.
wandb.plot.bar()
몇 줄 안에 레이블이 지정된 값 목록을 막대로 사용자 지정 막대 차트로 기본적으로 기록합니다.
data = [[label, val] for (label, val) in zip(labels, values)]
table = wandb.Table(data=data, columns=["label", "value"])
wandb.log(
{
"my_bar_chart_id": wandb.plot.bar(
table, "label", "value", title="Custom Bar Chart"
)
}
)
이를 사용하여 임의의 막대 차트를 기록할 수 있습니다. 목록의 레이블 및 값 수는 정확히 일치해야 합니다(예: 각 데이터 점에 둘 다 있어야 함).
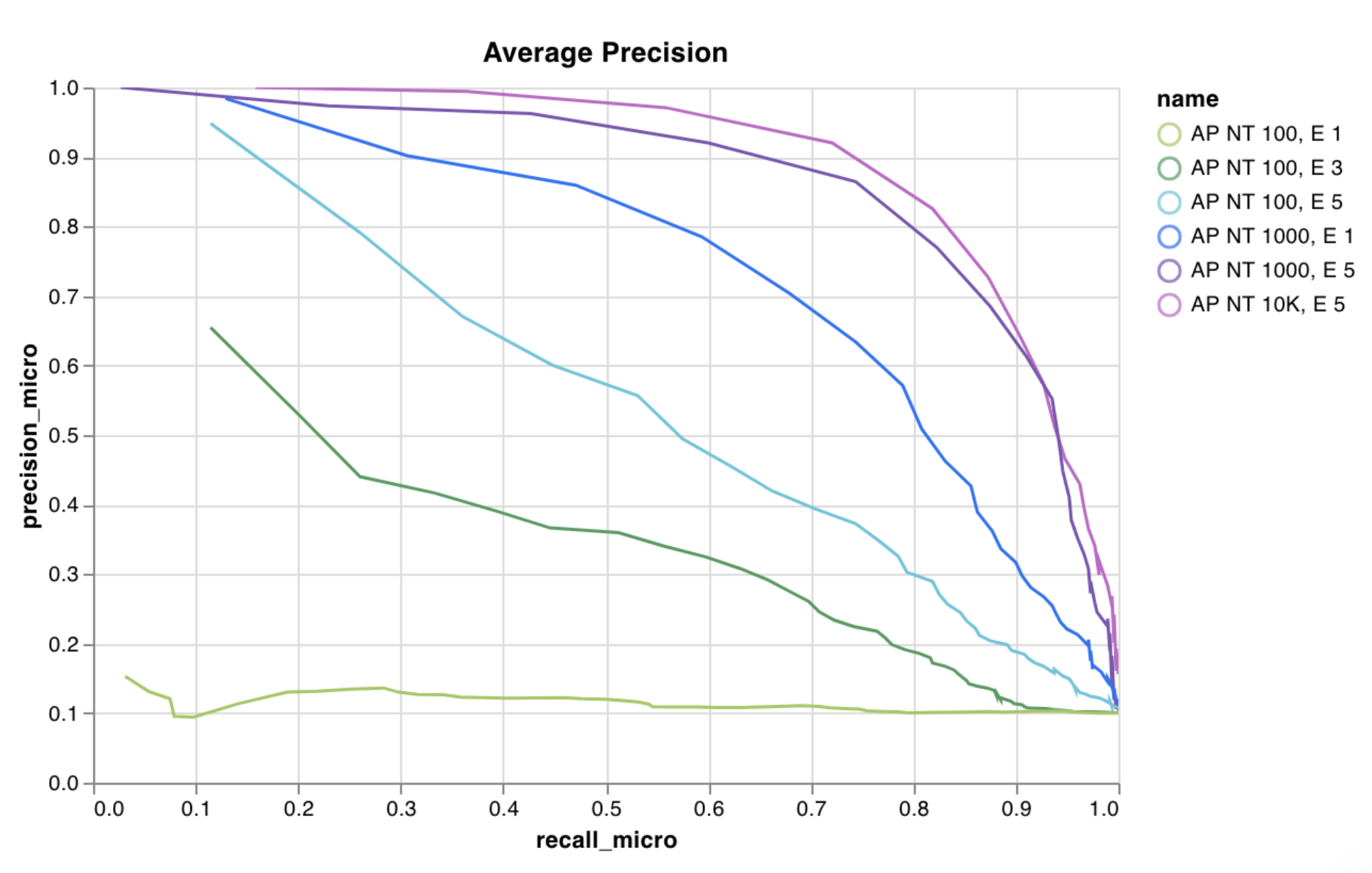
예제 리포트를 보거나 예제 Google Colab 노트북을 사용해 보세요.
wandb.plot.histogram()
값 목록을 발생 횟수/빈도별로 구간으로 정렬하여 사용자 지정 히스토그램으로 기본적으로 몇 줄 안에 기록합니다. 예측 신뢰도 점수 목록(scores)이 있고 해당 분포를 시각화하려는 경우를 예로 들어 보겠습니다.
data = [[s] for s in scores]
table = wandb.Table(data=data, columns=["scores"])
wandb.log({"my_histogram": wandb.plot.histogram(table, "scores", title=None)})
이를 사용하여 임의의 히스토그램을 기록할 수 있습니다. data는 행과 열의 2D 배열을 지원하기 위한 목록의 목록입니다.
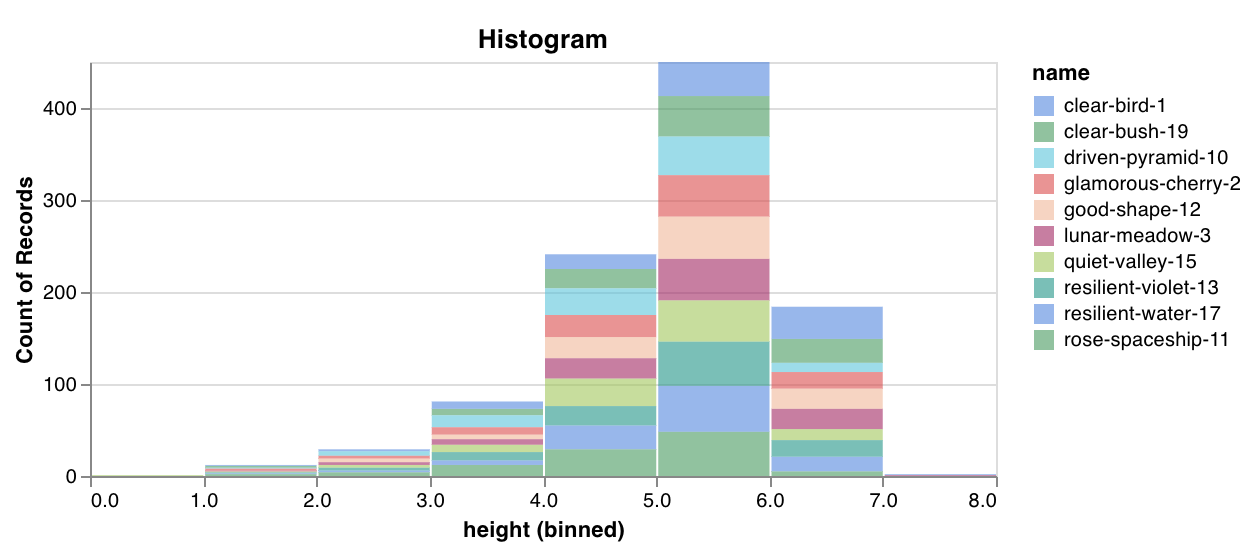
예제 리포트를 보거나 예제 Google Colab 노트북을 사용해 보세요.
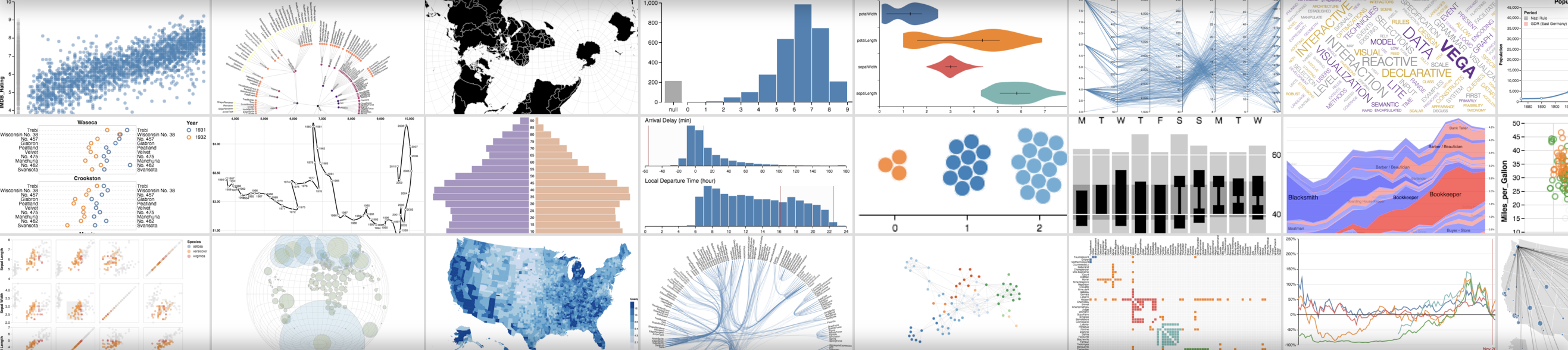
wandb.plot.pr_curve()
한 줄로 Precision-Recall 곡선을 만듭니다.
plot = wandb.plot.pr_curve(ground_truth, predictions, labels=None, classes_to_plot=None)
wandb.log({"pr": plot})
코드가 다음에 엑세스할 수 있을 때마다 이를 기록할 수 있습니다.
predictions)ground_truth)labels=["cat", "dog", "bird"...] 레이블 인덱스 0이 고양이, 1 = 개, 2 = 새 등을 의미하는 경우)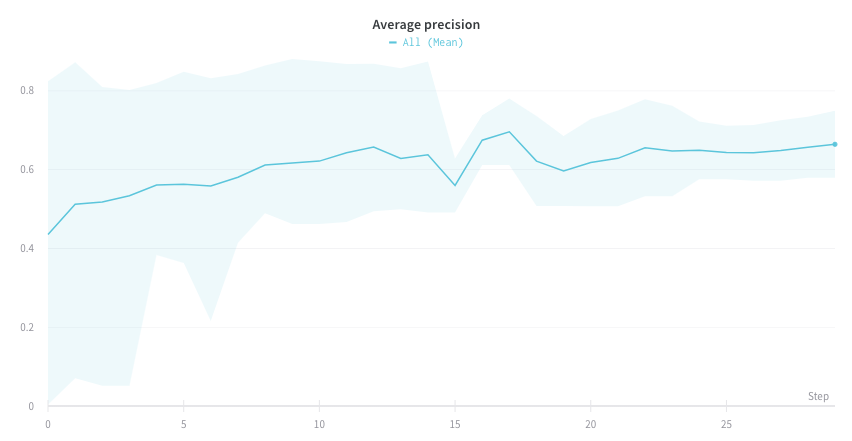
예제 리포트를 보거나 예제 Google Colab 노트북을 사용해 보세요.
wandb.plot.roc_curve()
한 줄로 ROC 곡선을 만듭니다.
plot = wandb.plot.roc_curve(
ground_truth, predictions, labels=None, classes_to_plot=None
)
wandb.log({"roc": plot})
코드가 다음에 엑세스할 수 있을 때마다 이를 기록할 수 있습니다.
predictions)ground_truth)labels=["cat", "dog", "bird"...] 레이블 인덱스 0이 고양이, 1 = 개, 2 = 새 등을 의미하는 경우)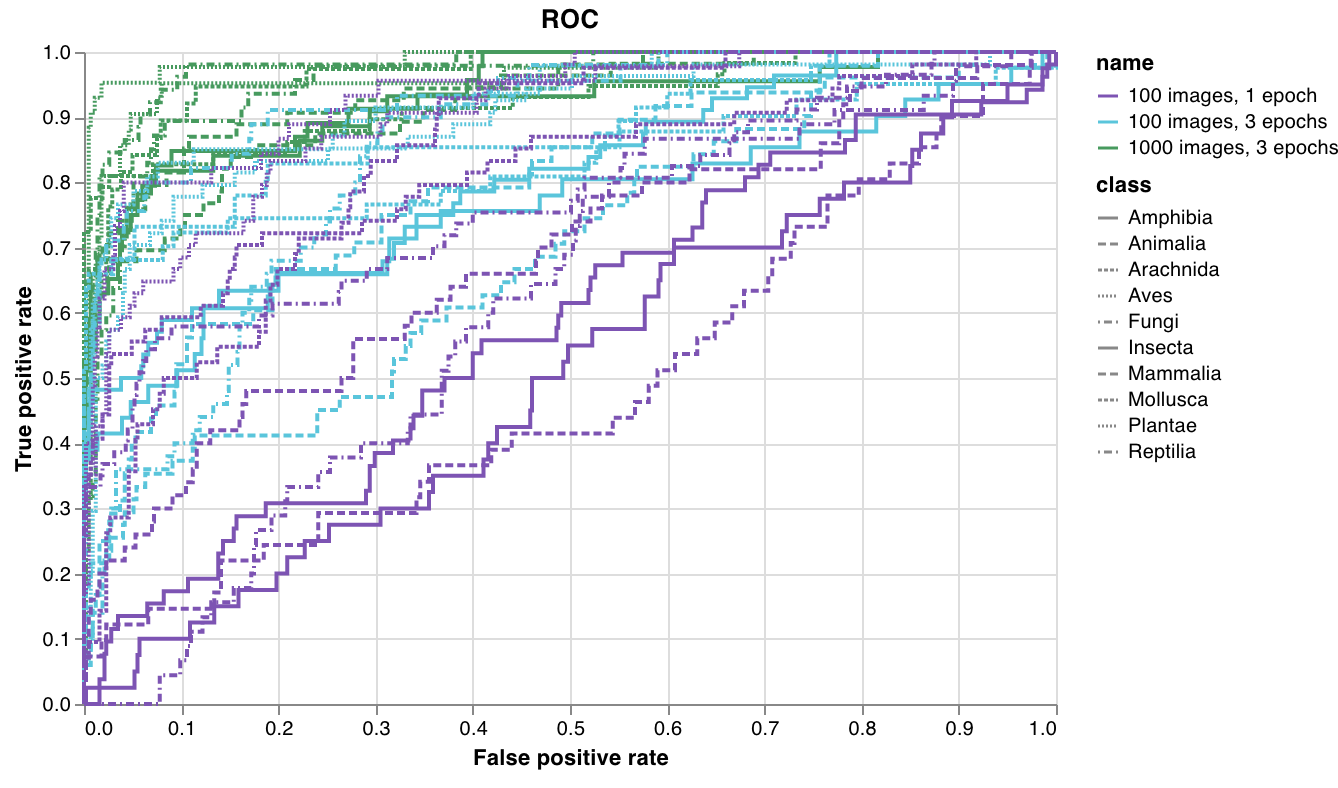
예제 리포트를 보거나 예제 Google Colab 노트북을 사용해 보세요.
내장 프리셋을 조정하거나 새 프리셋을 만든 다음 차트를 저장합니다. 차트 ID를 사용하여 스크립트에서 해당 커스텀 프리셋에 직접 데이터를 기록합니다. 예제 Google Colab 노트북을 사용해 보세요.
# 플롯할 열이 있는 테이블 만들기
table = wandb.Table(data=data, columns=["step", "height"])
# 테이블의 열에서 차트의 필드로 매핑
fields = {"x": "step", "value": "height"}
# 테이블을 사용하여 새 커스텀 차트 프리셋 채우기
# 자신의 저장된 차트 프리셋을 사용하려면 vega_spec_name을 변경하세요.
my_custom_chart = wandb.plot_table(
vega_spec_name="carey/new_chart",
data_table=table,
fields=fields,
)
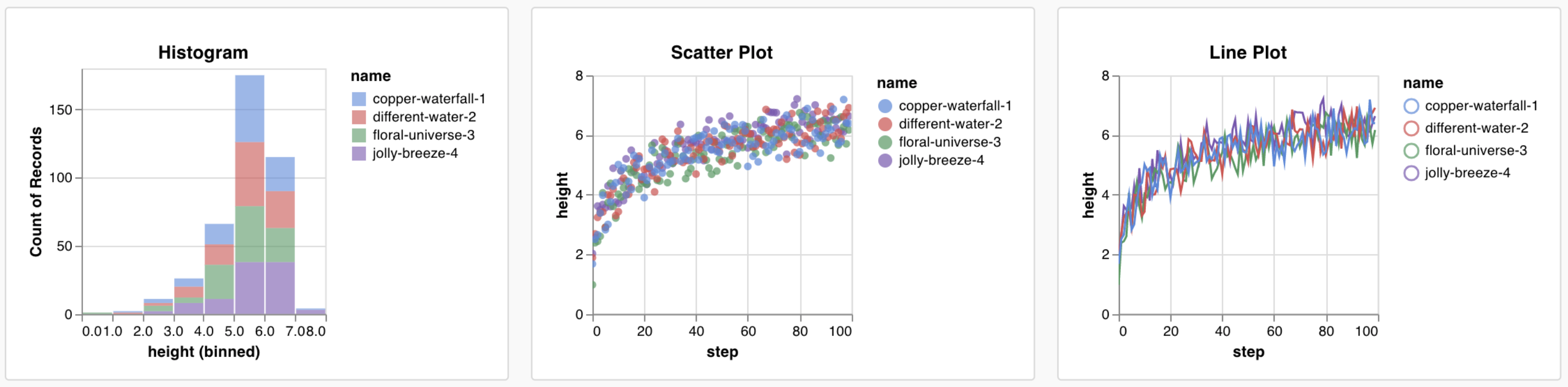
스크립트에서 다음 데이터 형식을 기록하고 커스텀 차트에서 사용할 수 있습니다.
wandb.config에 대한 키로 기록한 명명된 필드가 포함됩니다. 예: wandb.config.learning_rate = 0.0001wandb.log({"val_acc" : 0.8}). wandb.log()를 통해 트레이닝 중에 이 키에 여러 번 쓰면 요약이 해당 키의 최종 값으로 설정됩니다.history 필드를 통해 쿼리에 사용할 수 있습니다.wandb.Table()을 사용하여 해당 데이터를 저장한 다음 커스텀 패널에서 쿼리합니다.historyTable을 쿼리합니다. wandb.Table()을 호출하거나 커스텀 차트를 기록할 때마다 해당 단계의 history에 새 테이블을 만들고 있습니다.wandb.Table()을 사용하여 데이터를 2D 배열로 기록합니다. 일반적으로 이 테이블의 각 행은 하나의 데이터 점을 나타내고 각 열은 플롯하려는 각 데이터 점에 대한 관련 필드/차원을 나타냅니다. 커스텀 패널을 구성할 때 전체 테이블은 wandb.log()(custom_data_table 아래)에 전달된 명명된 키를 통해 액세스할 수 있으며 개별 필드는 열 이름(x, y 및 z)을 통해 액세스할 수 있습니다. 실험 전반에 걸쳐 여러 시간 단계에서 테이블을 기록할 수 있습니다. 각 테이블의 최대 크기는 10,000행입니다. 예제 Google Colab을 사용해 보세요.
# 데이터의 커스텀 테이블 기록
my_custom_data = [[x1, y1, z1], [x2, y2, z2]]
wandb.log(
{"custom_data_table": wandb.Table(data=my_custom_data, columns=["x", "y", "z"])}
)
새 커스텀 차트를 추가하여 시작한 다음 쿼리를 편집하여 표시되는 runs에서 데이터를 선택합니다. 쿼리는 GraphQL을 사용하여 runs의 config, 요약 및 history 필드에서 데이터를 가져옵니다.
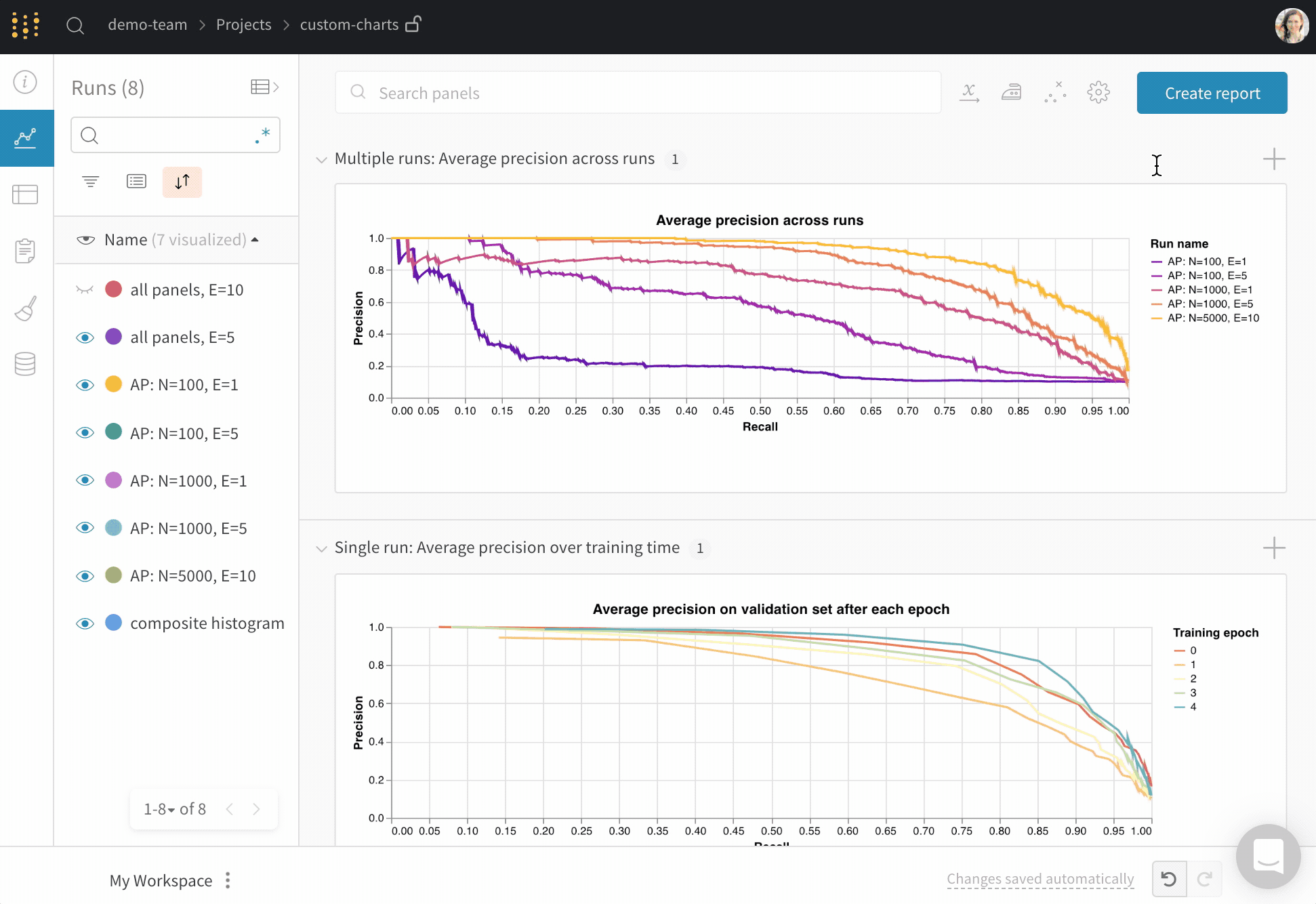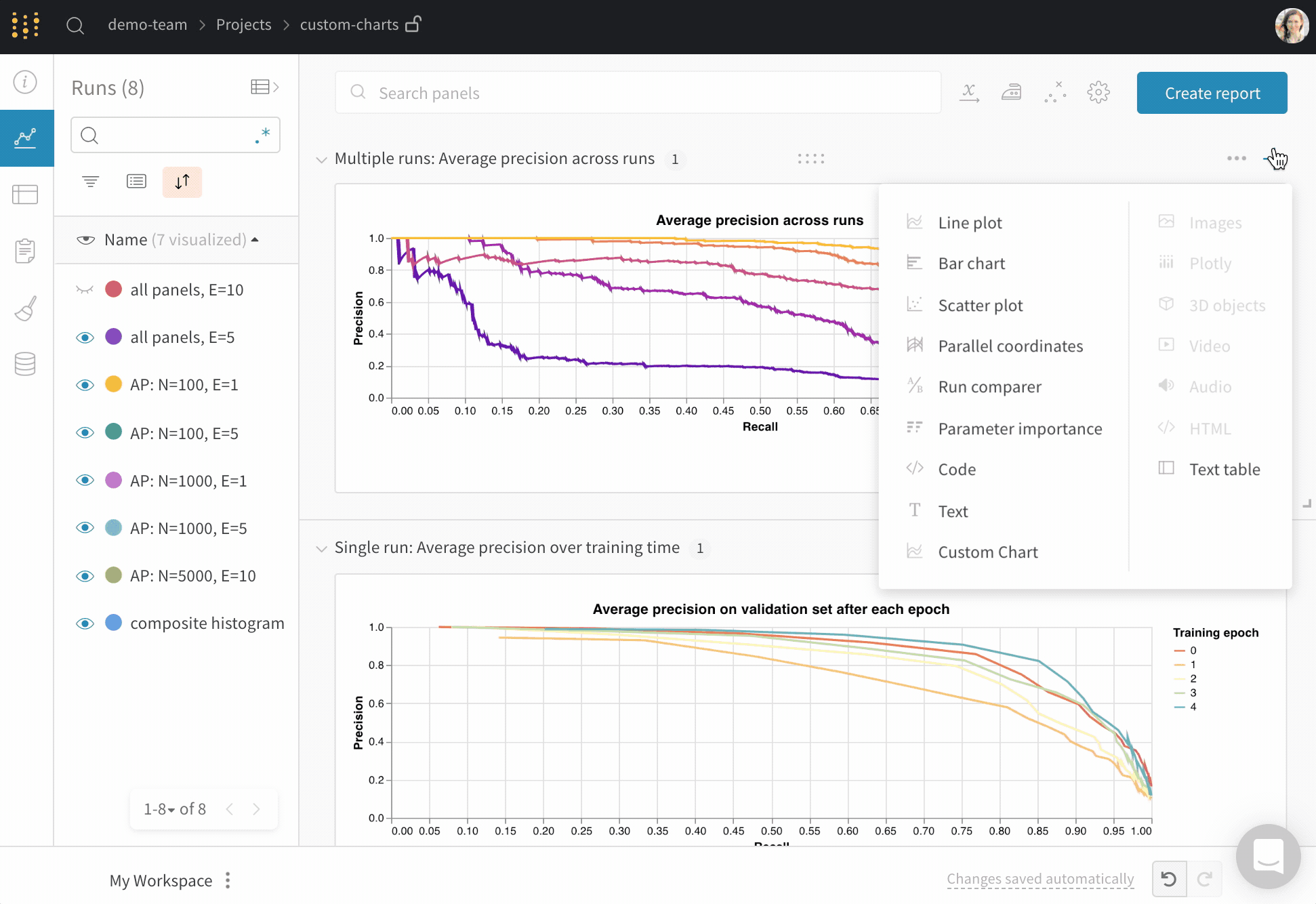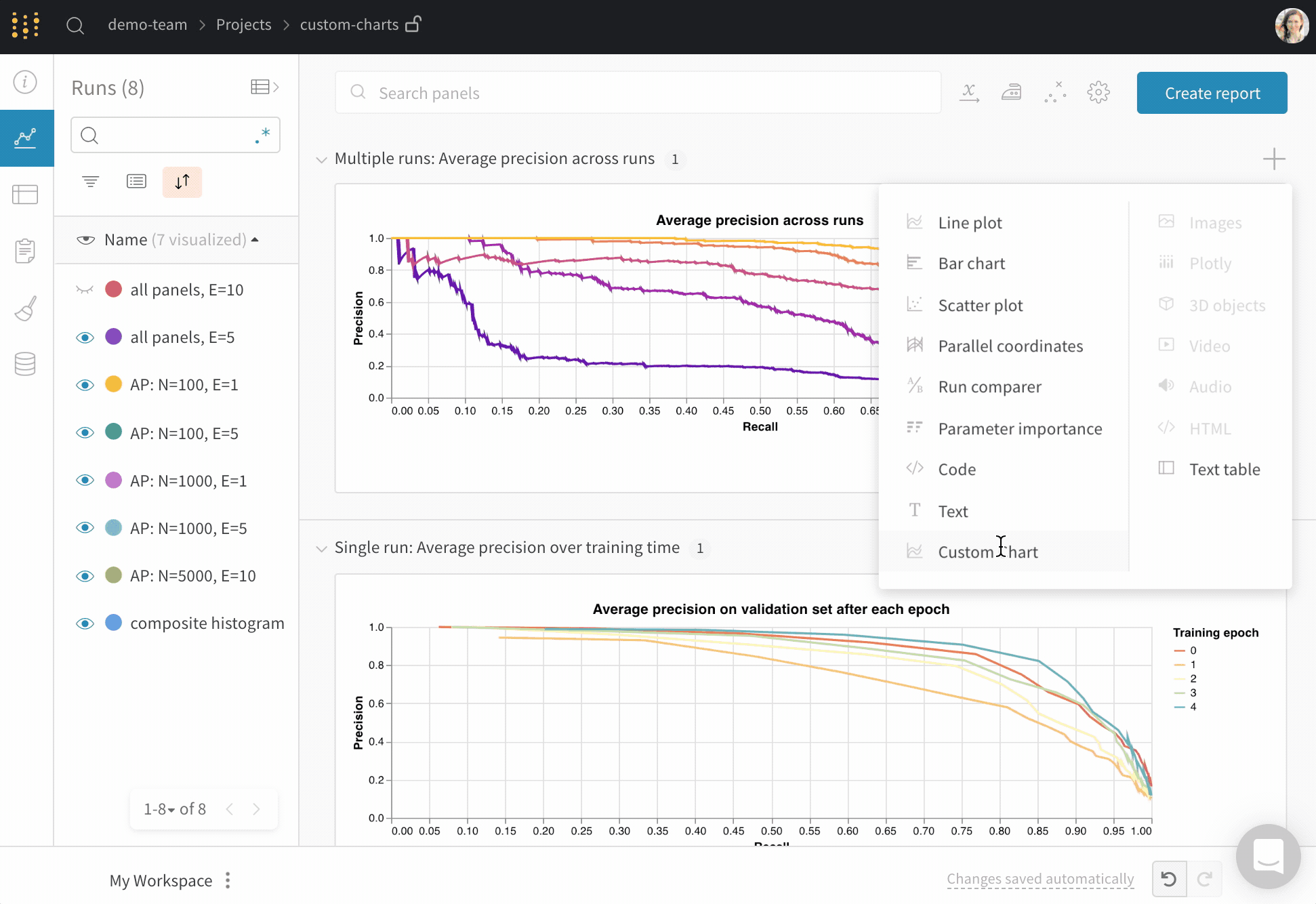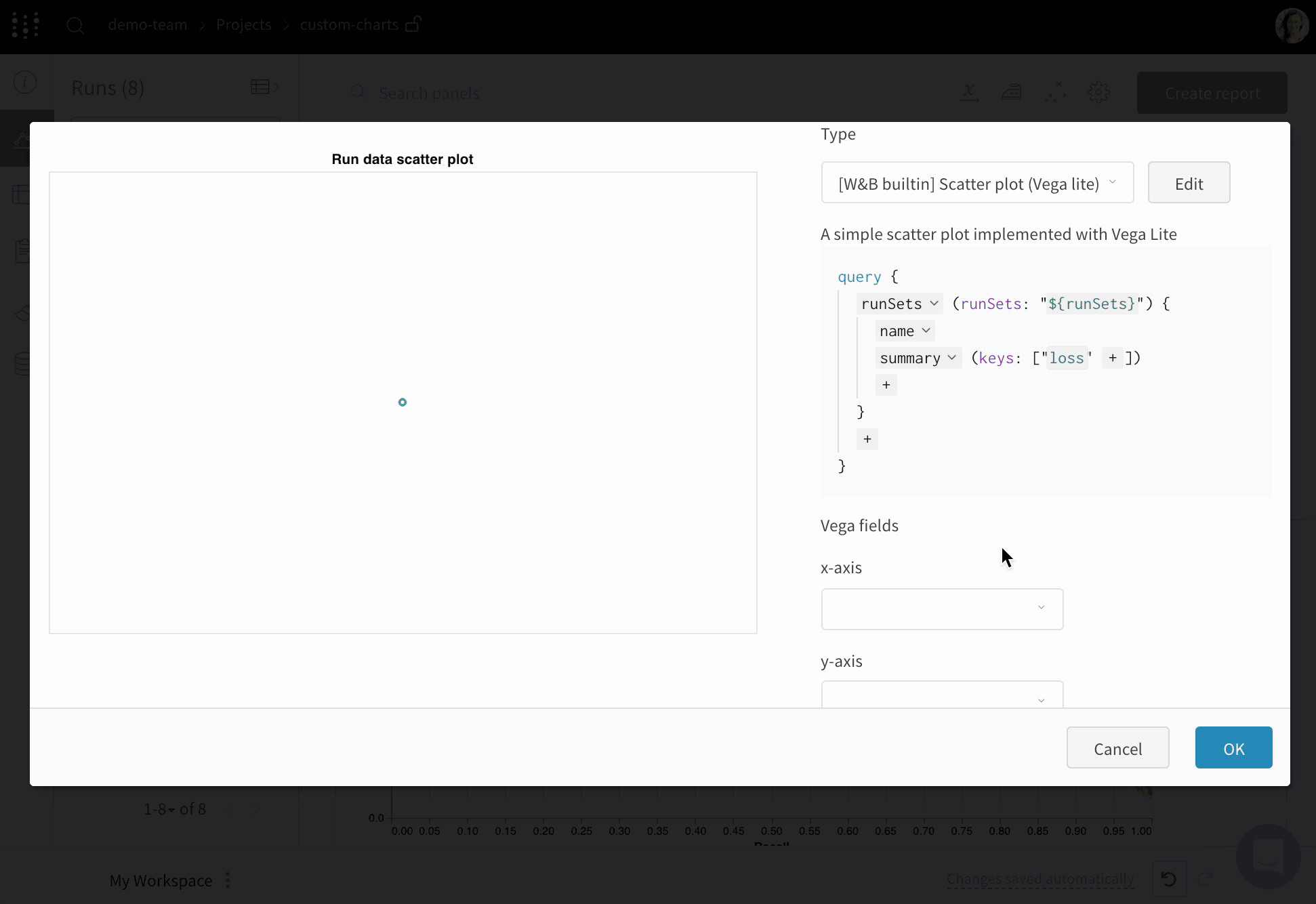
오른쪽 상단 모서리에서 차트를 선택하여 기본 프리셋으로 시작합니다. 다음으로 차트 필드를 선택하여 쿼리에서 가져오는 데이터를 차트의 해당 필드에 매핑합니다.
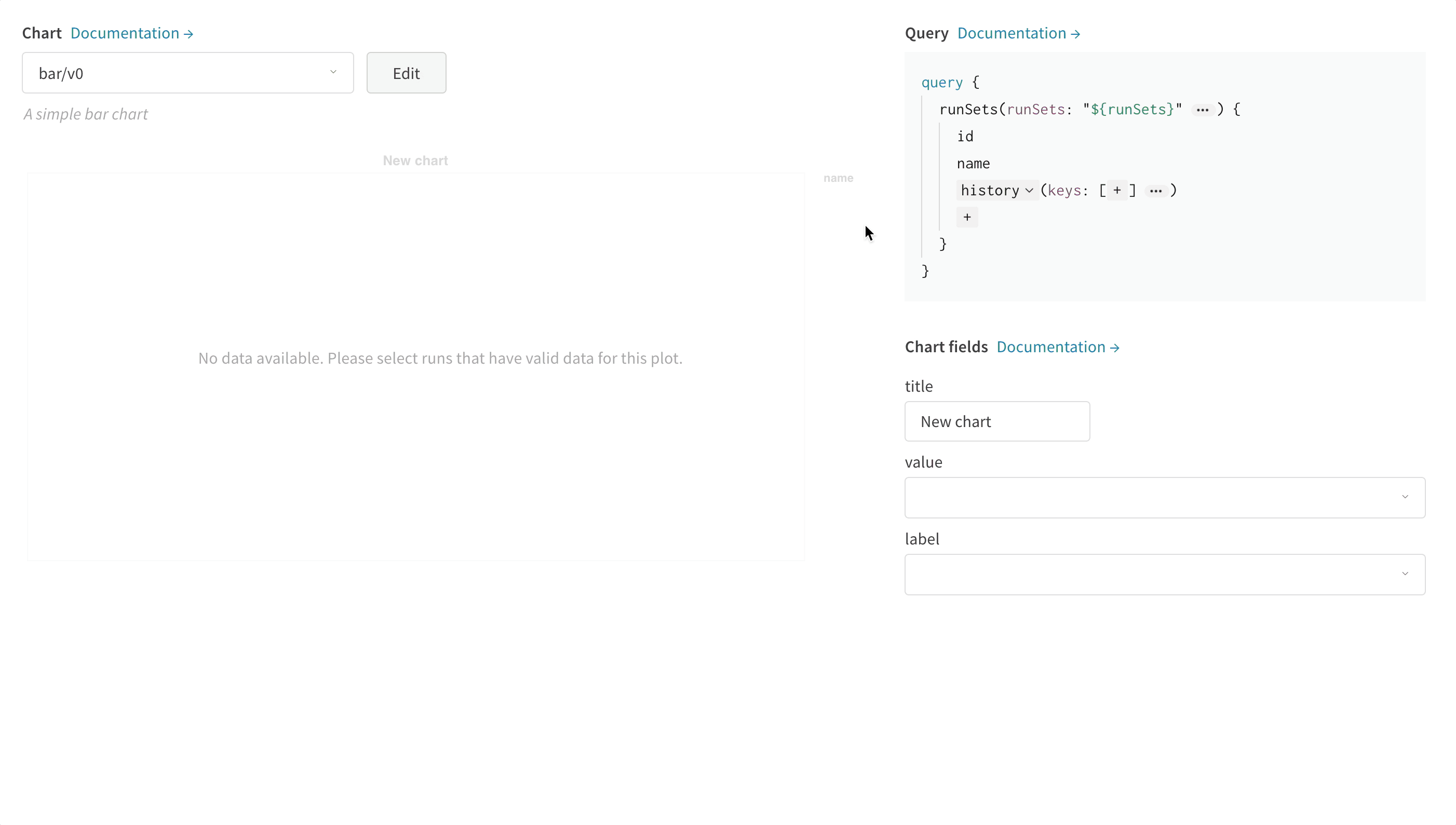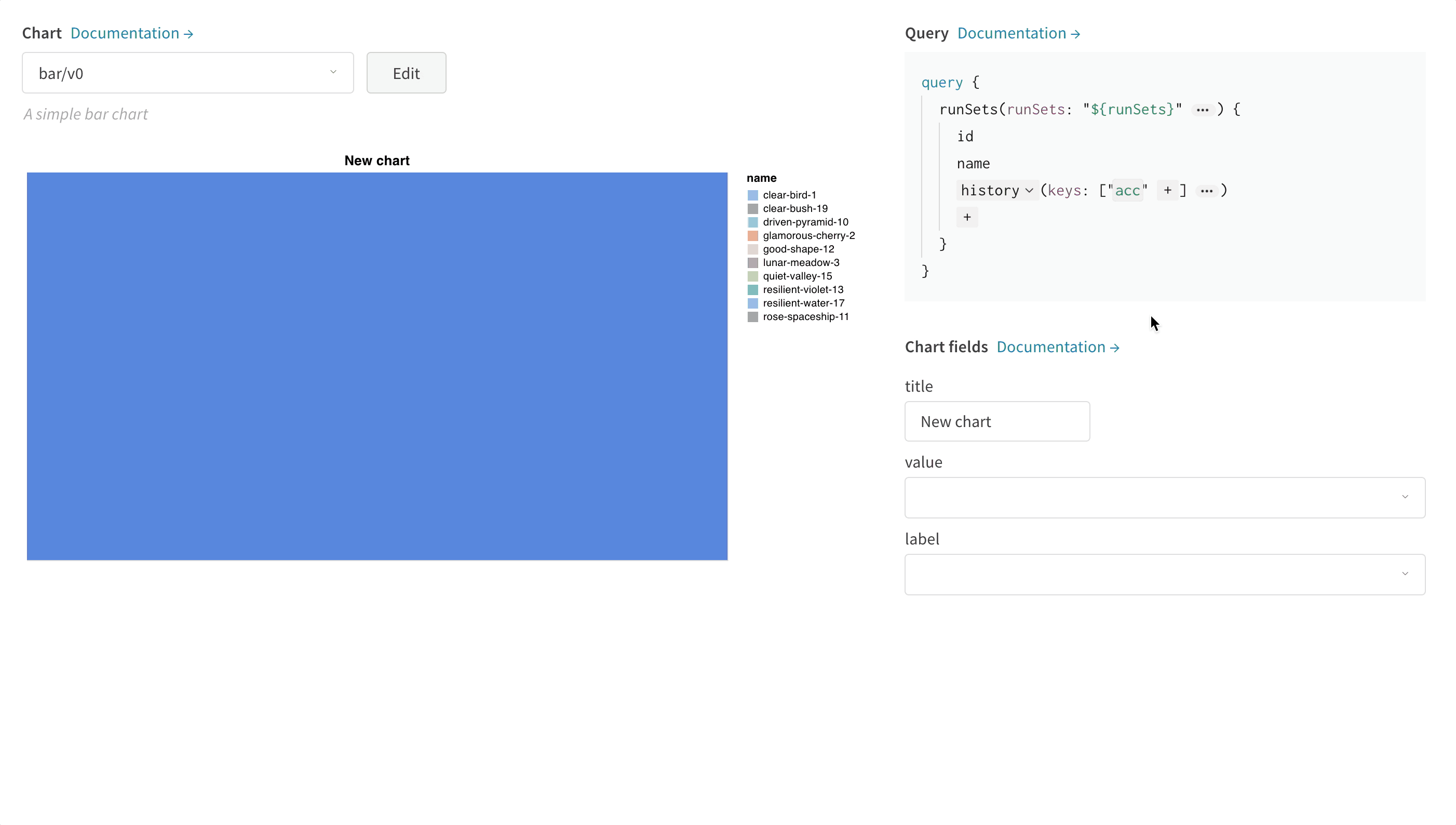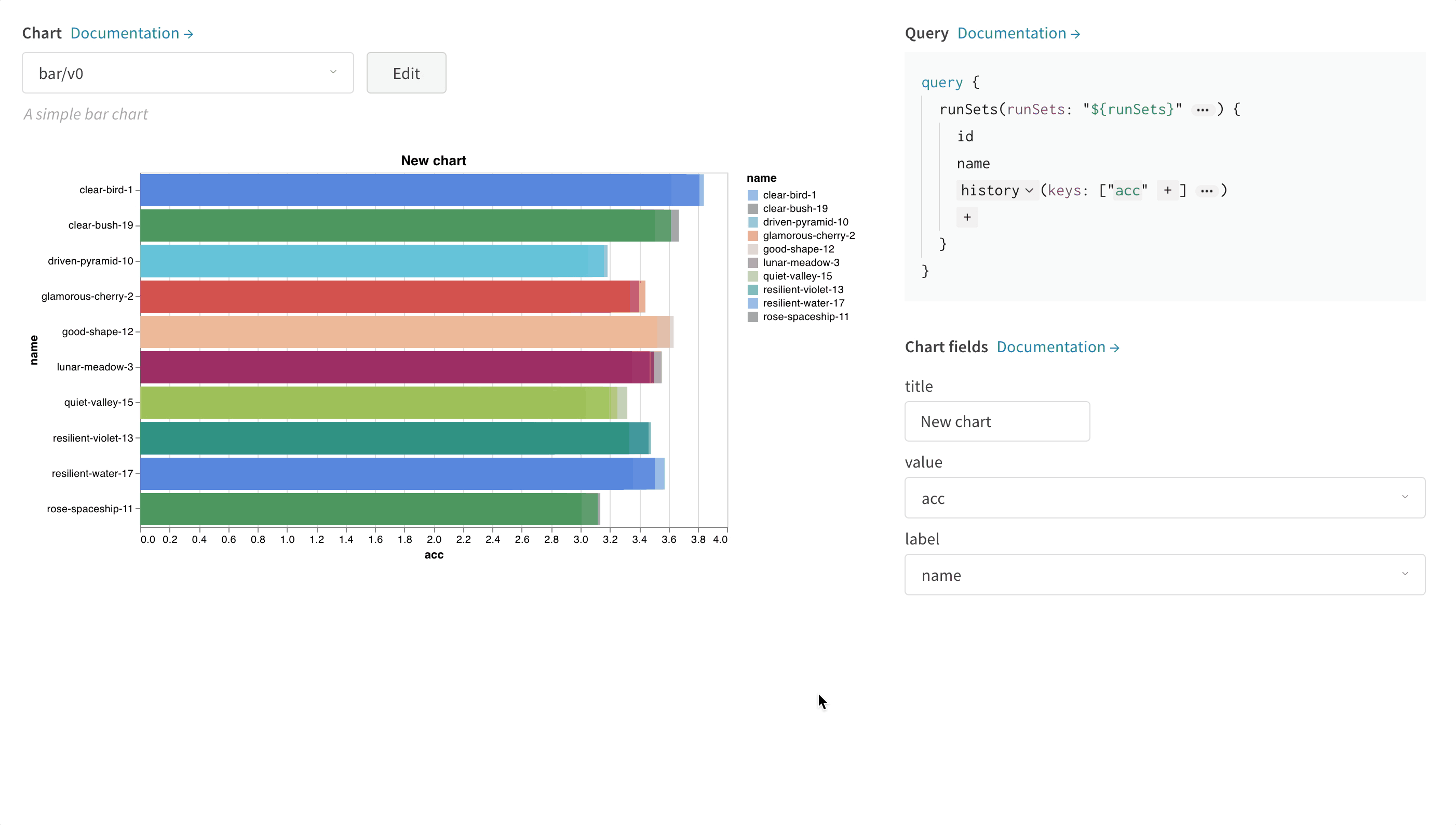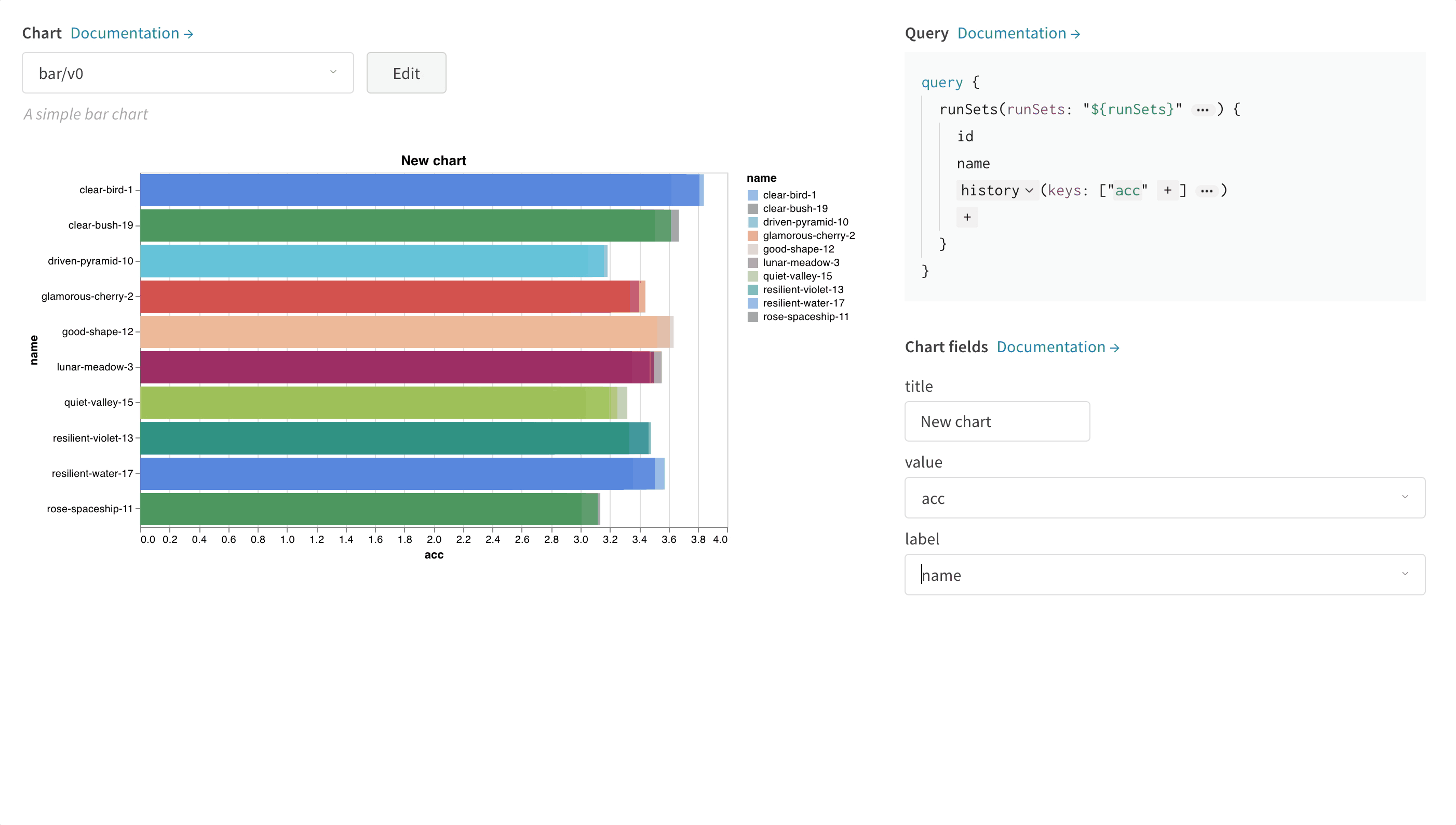
다음 이미지는 메트릭을 선택한 다음 아래의 막대 차트 필드에 매핑하는 방법을 보여주는 예입니다.
패널 상단의 편집을 클릭하여 Vega 편집 모드로 들어갑니다. 여기에서 UI에서 대화형 차트를 만드는 Vega 사양을 정의할 수 있습니다. 차트의 모든 측면을 변경할 수 있습니다. 예를 들어 제목을 변경하고, 다른 색 구성표를 선택하고, 곡선을 연결된 선 대신 일련의 점으로 표시할 수 있습니다. 또한 Vega 변환을 사용하여 값 배열을 히스토그램으로 비닝하는 등 데이터 자체를 변경할 수도 있습니다. 패널 미리 보기가 대화형으로 업데이트되므로 Vega 사양 또는 쿼리를 편집할 때 변경 사항의 효과를 볼 수 있습니다. Vega 문서 및 튜토리얼을 참조하세요.
필드 참조
W&B에서 차트로 데이터를 가져오려면 Vega 사양의 아무 곳에나 "${field:<field-name>}" 형식의 템플릿 문자열을 추가합니다. 그러면 오른쪽의 차트 필드 영역에 드롭다운이 생성되어 사용자가 쿼리 결과 열을 선택하여 Vega에 매핑할 수 있습니다.
필드의 기본값을 설정하려면 다음 구문을 사용하세요. "${field:<field-name>:<placeholder text>}"
모달 하단의 버튼을 사용하여 특정 시각화 패널에 대한 변경 사항을 적용합니다. 또는 Vega 사양을 저장하여 프로젝트의 다른 곳에서 사용할 수 있습니다. 재사용 가능한 차트 정의를 저장하려면 Vega 편집기 상단의 다른 이름으로 저장을 클릭하고 프리셋에 이름을 지정합니다.
W&B UI에서 사용자 정의 차트 기능을 사용하는 방법에 대한 튜토리얼
[i18n] feedback_question
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.