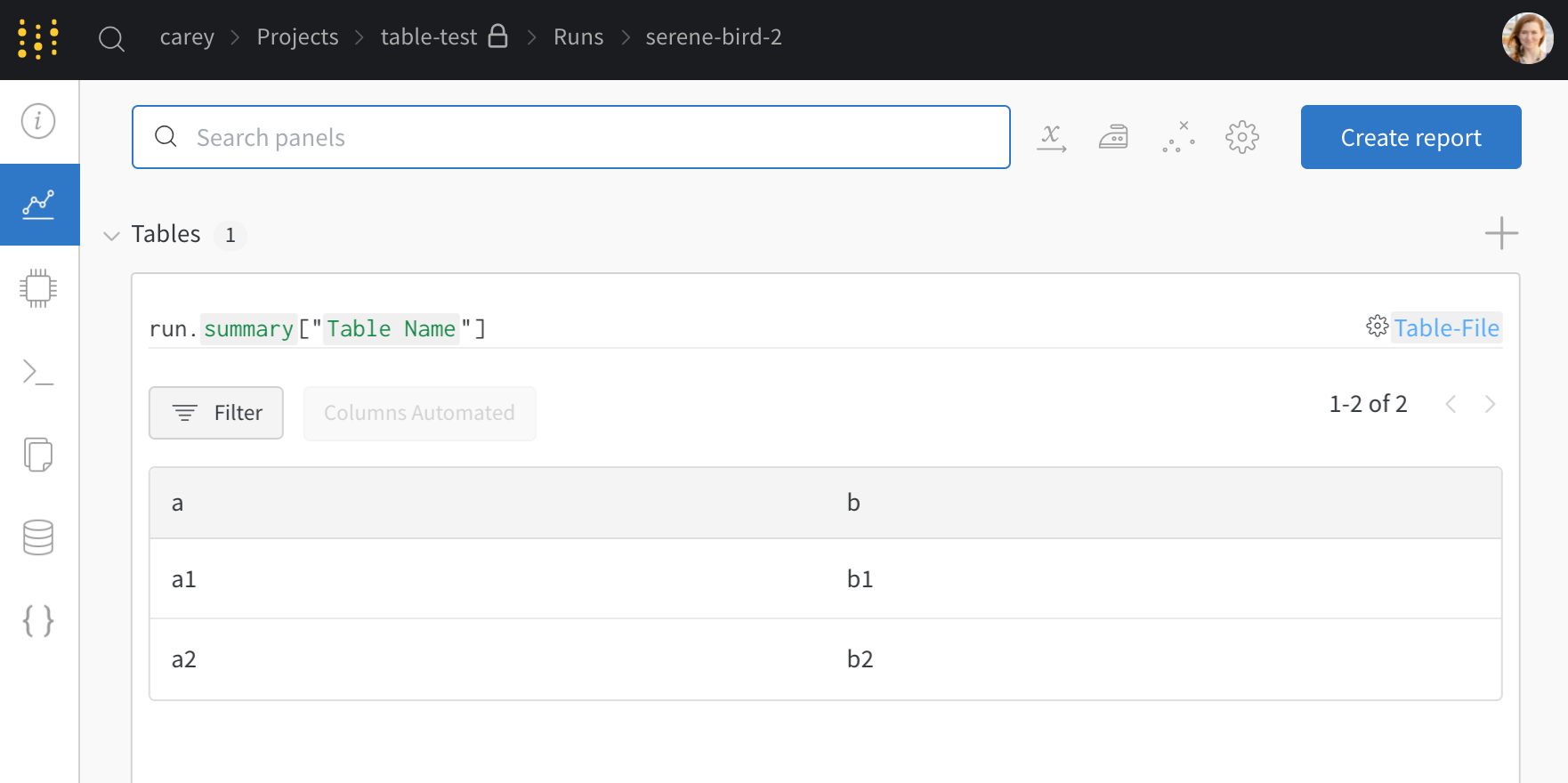
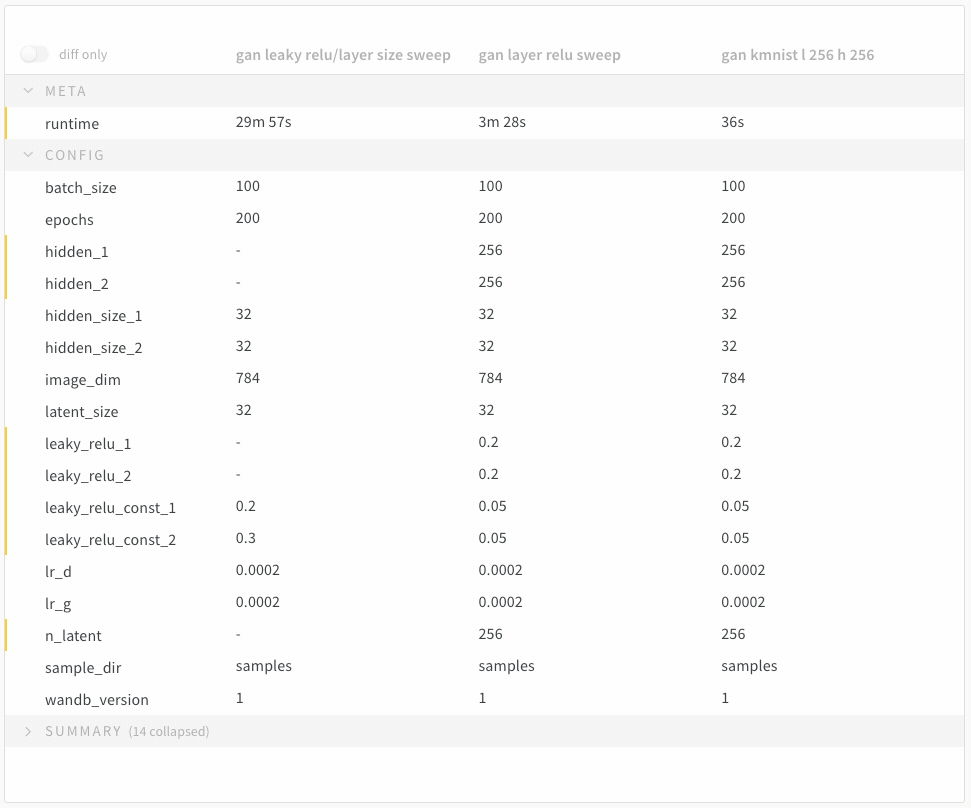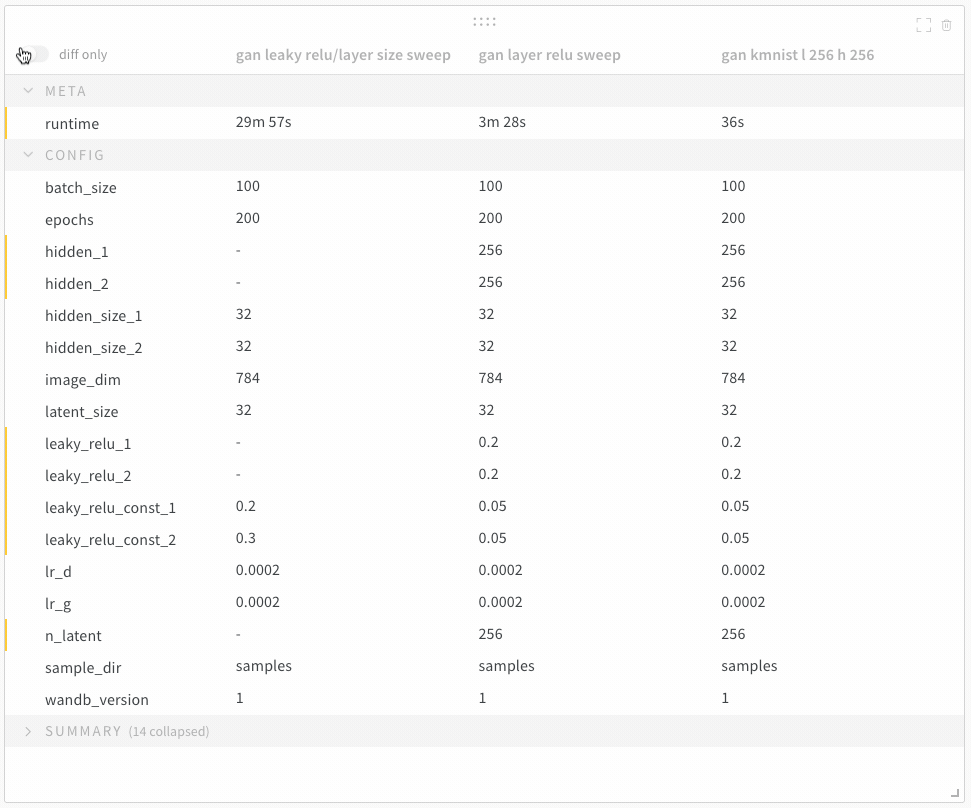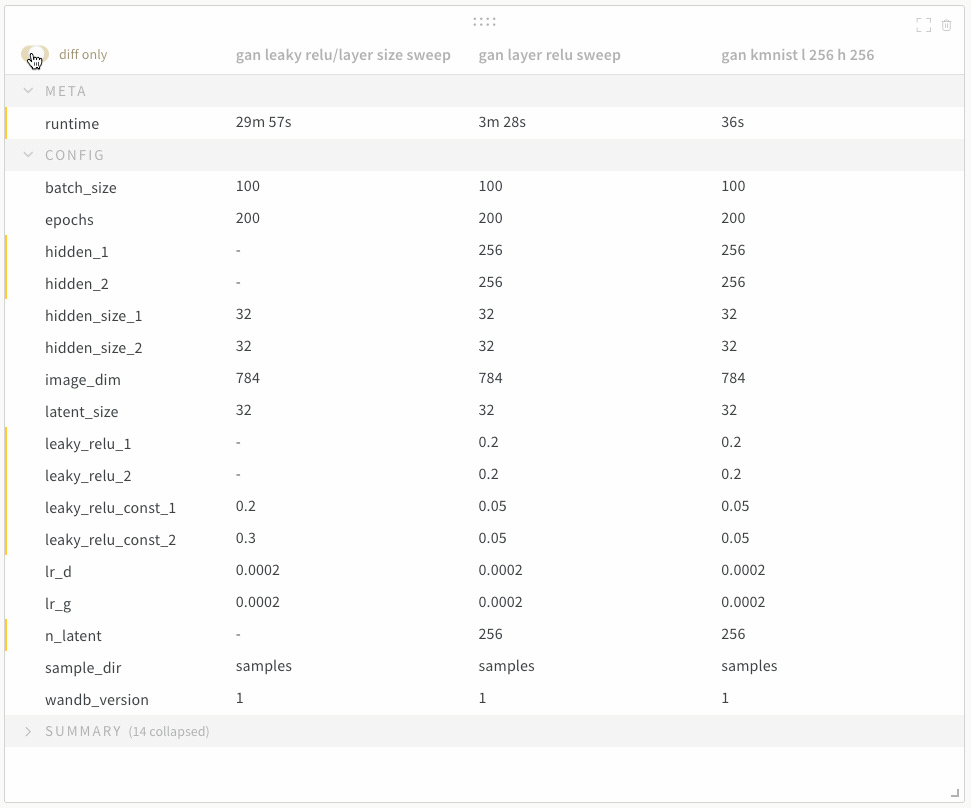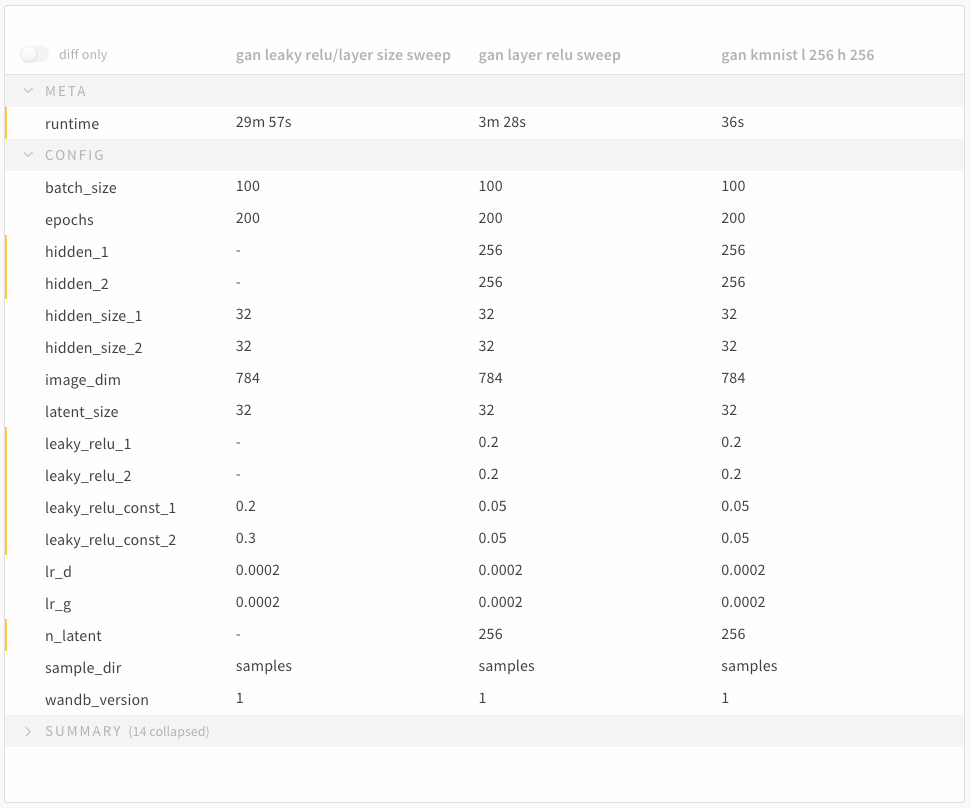
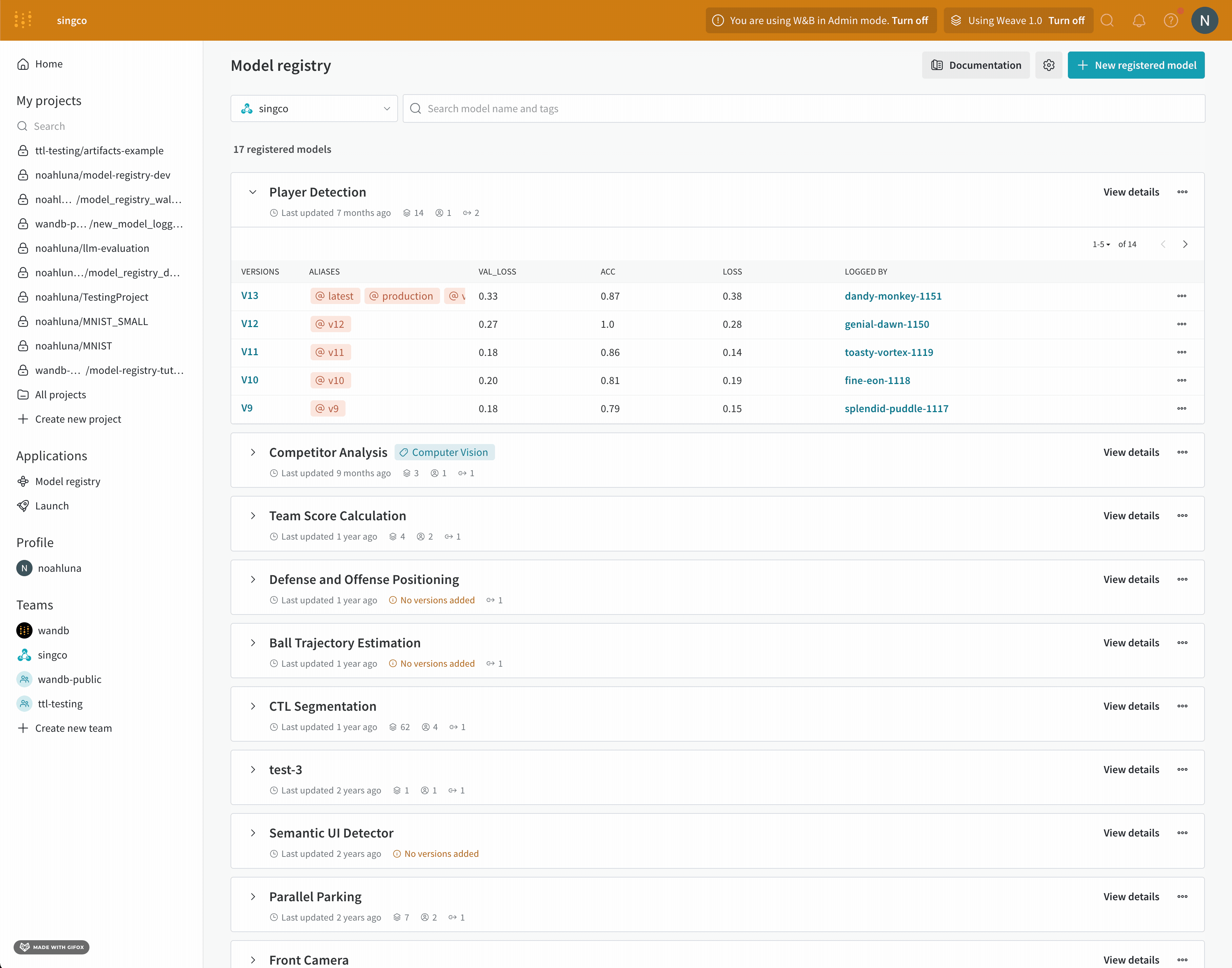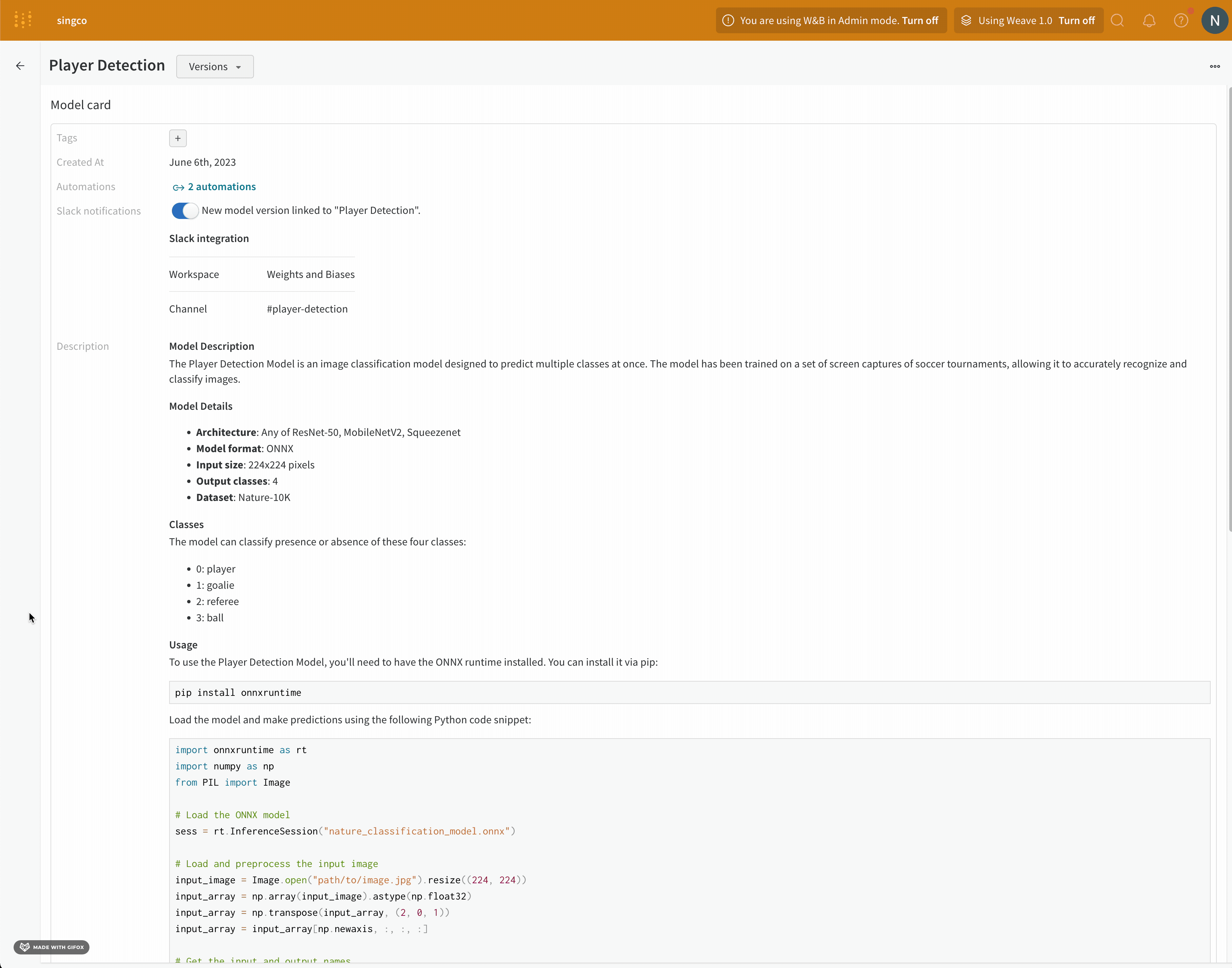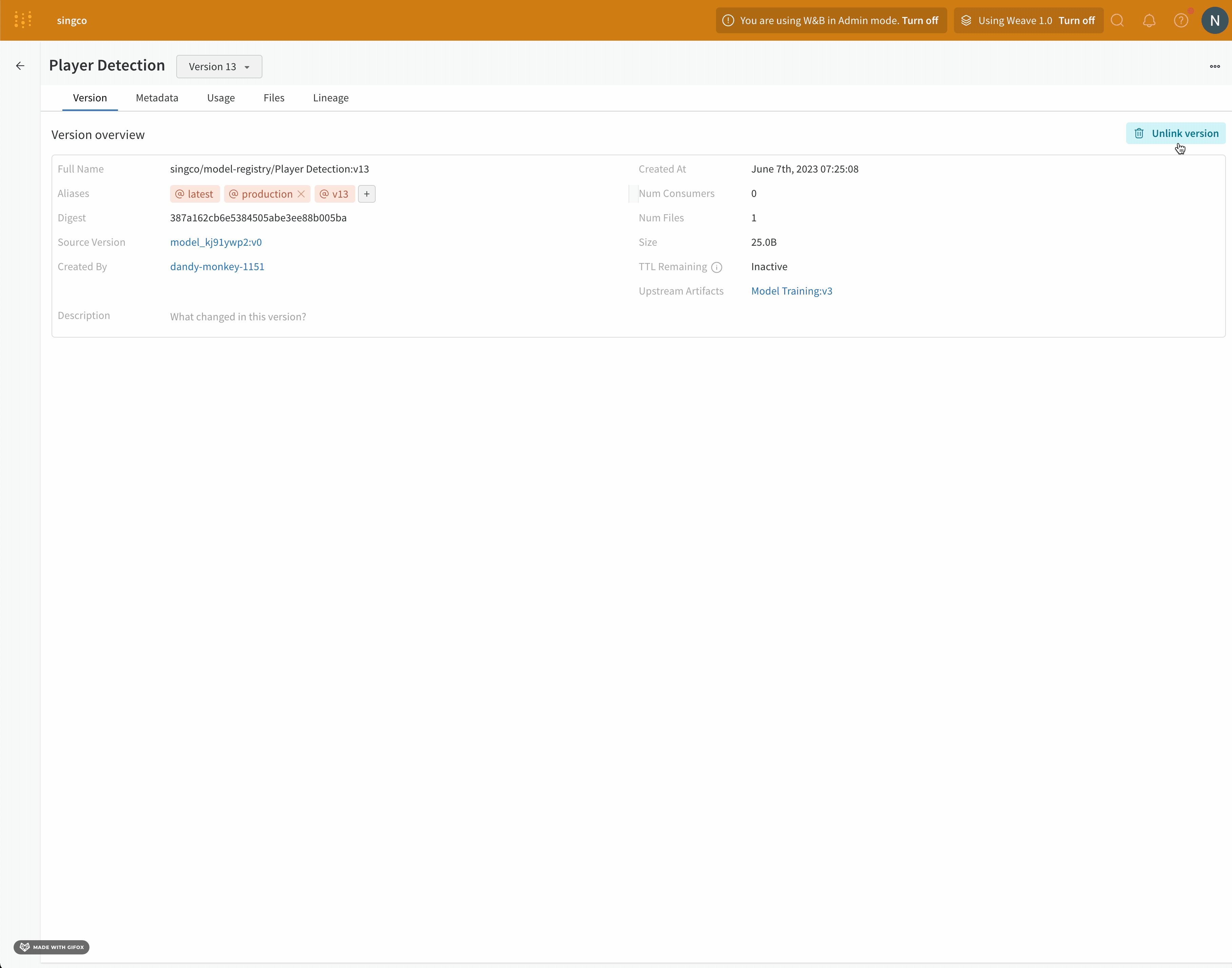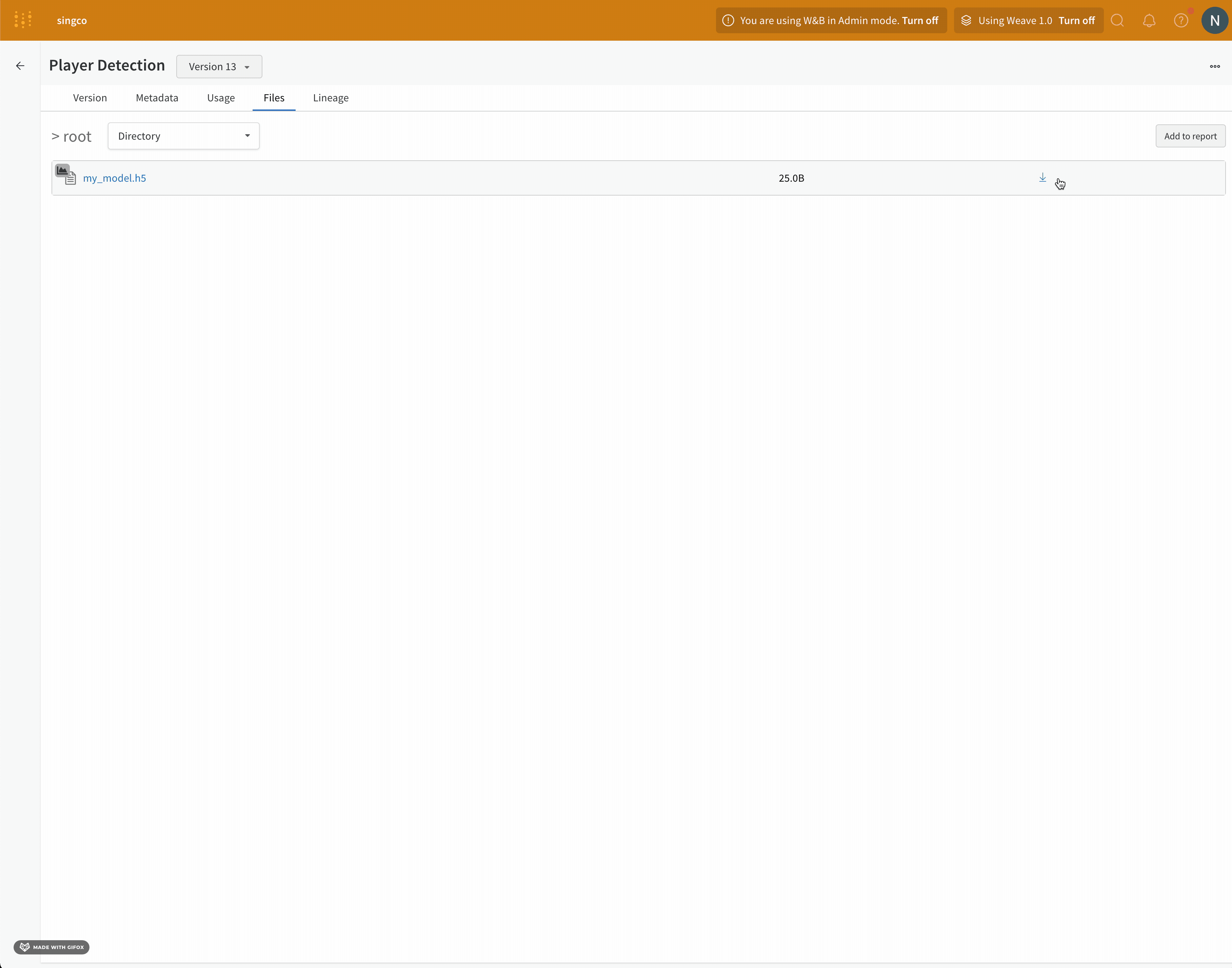
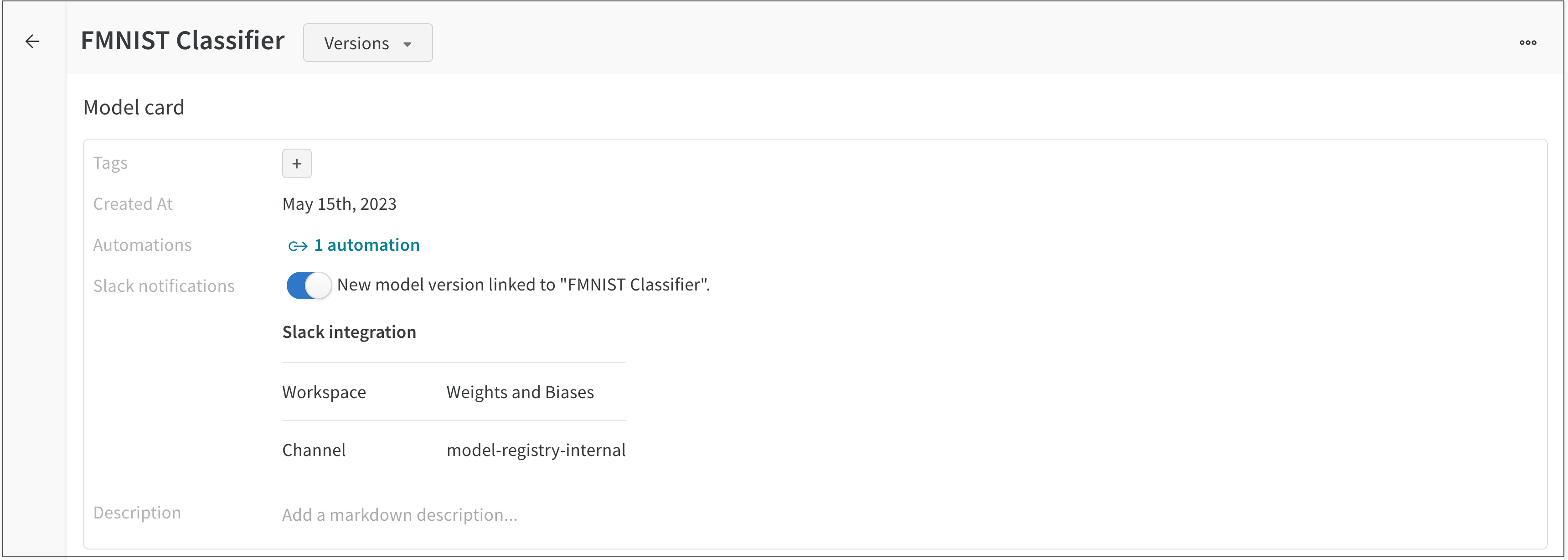
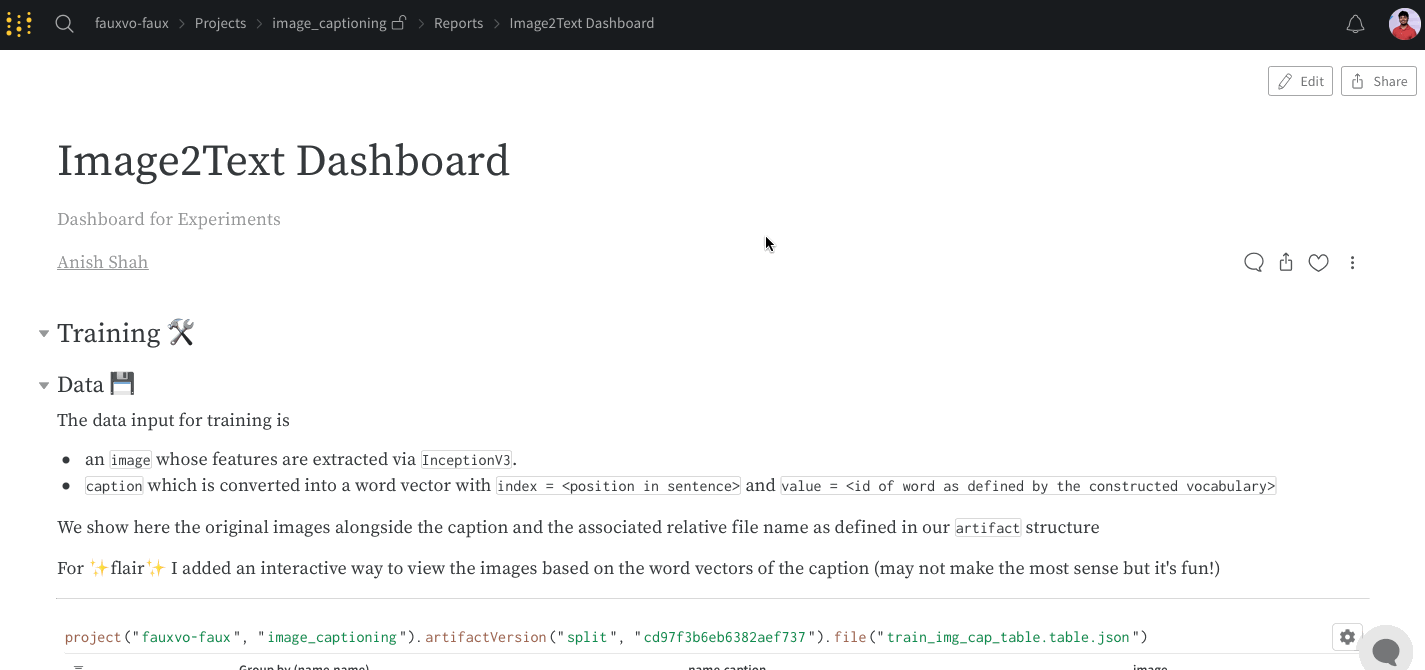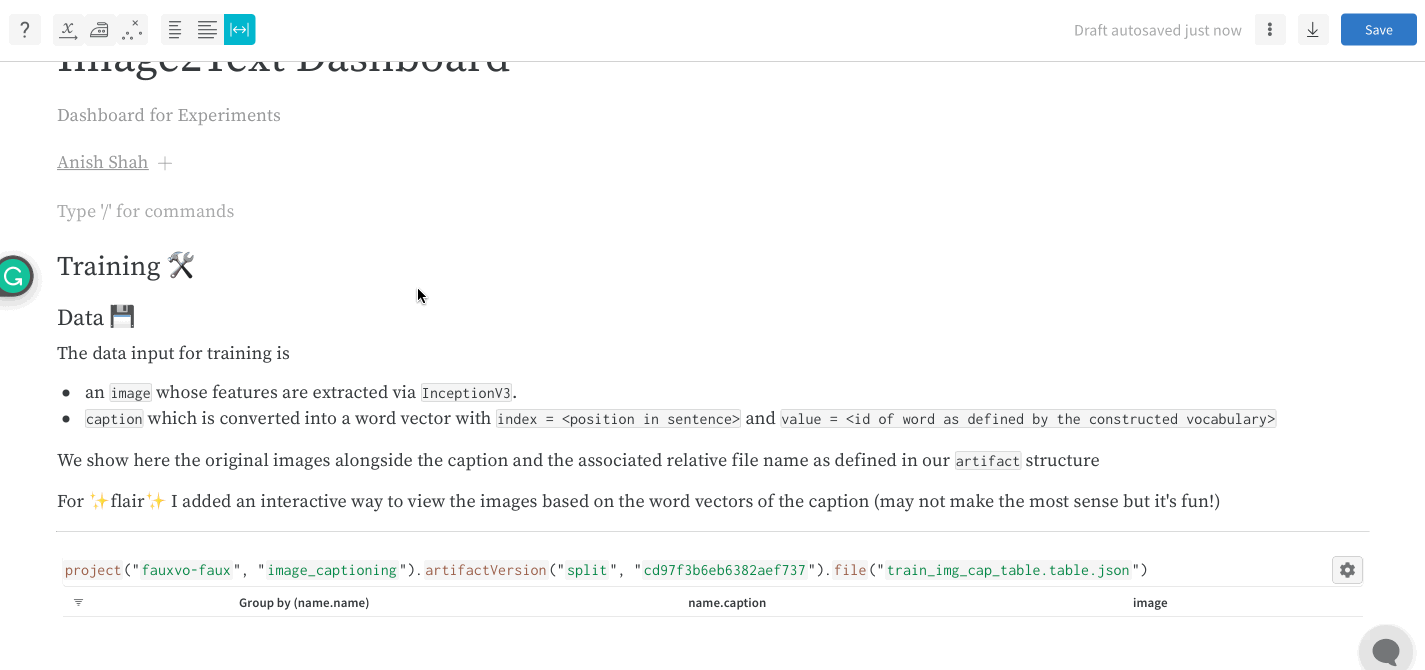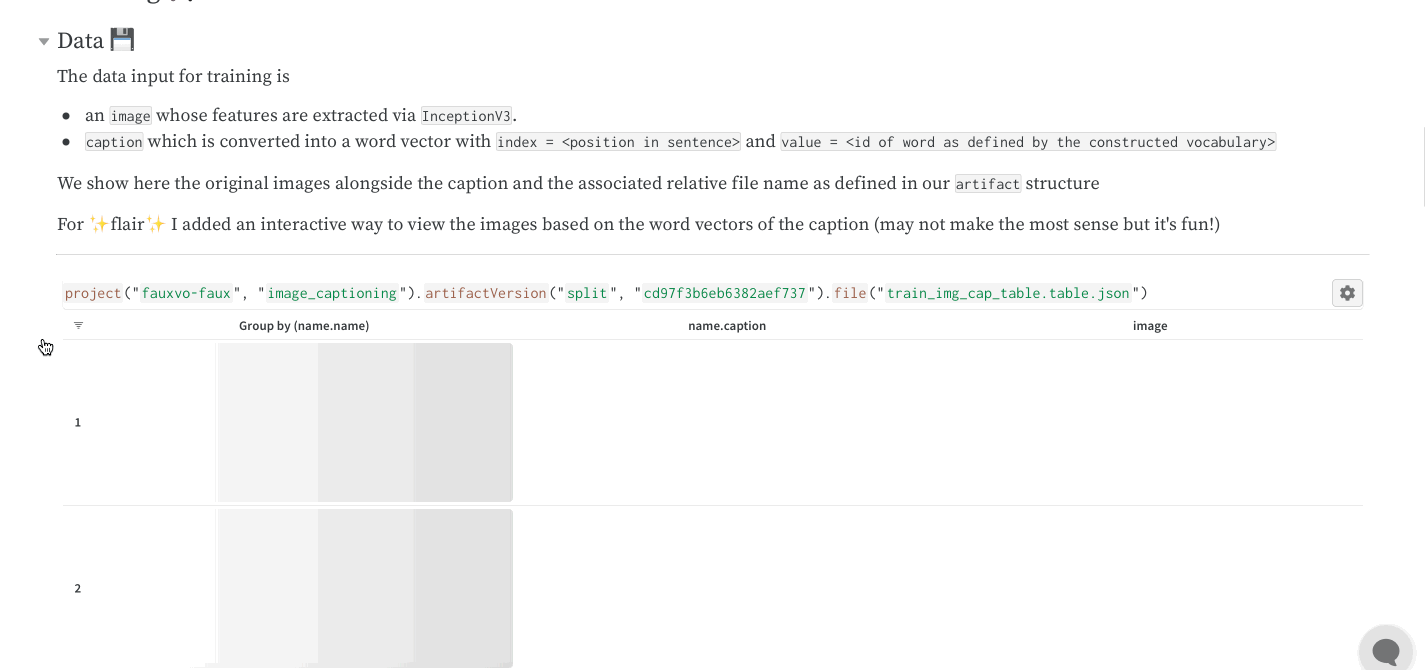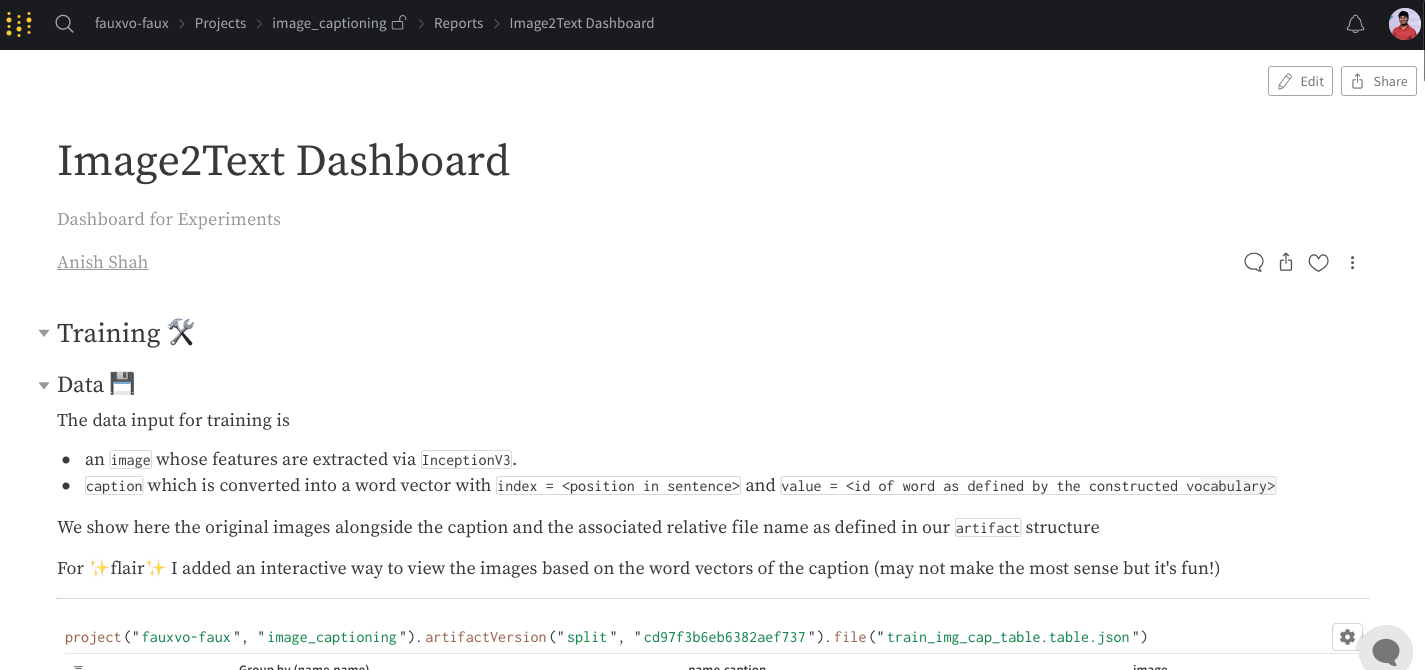
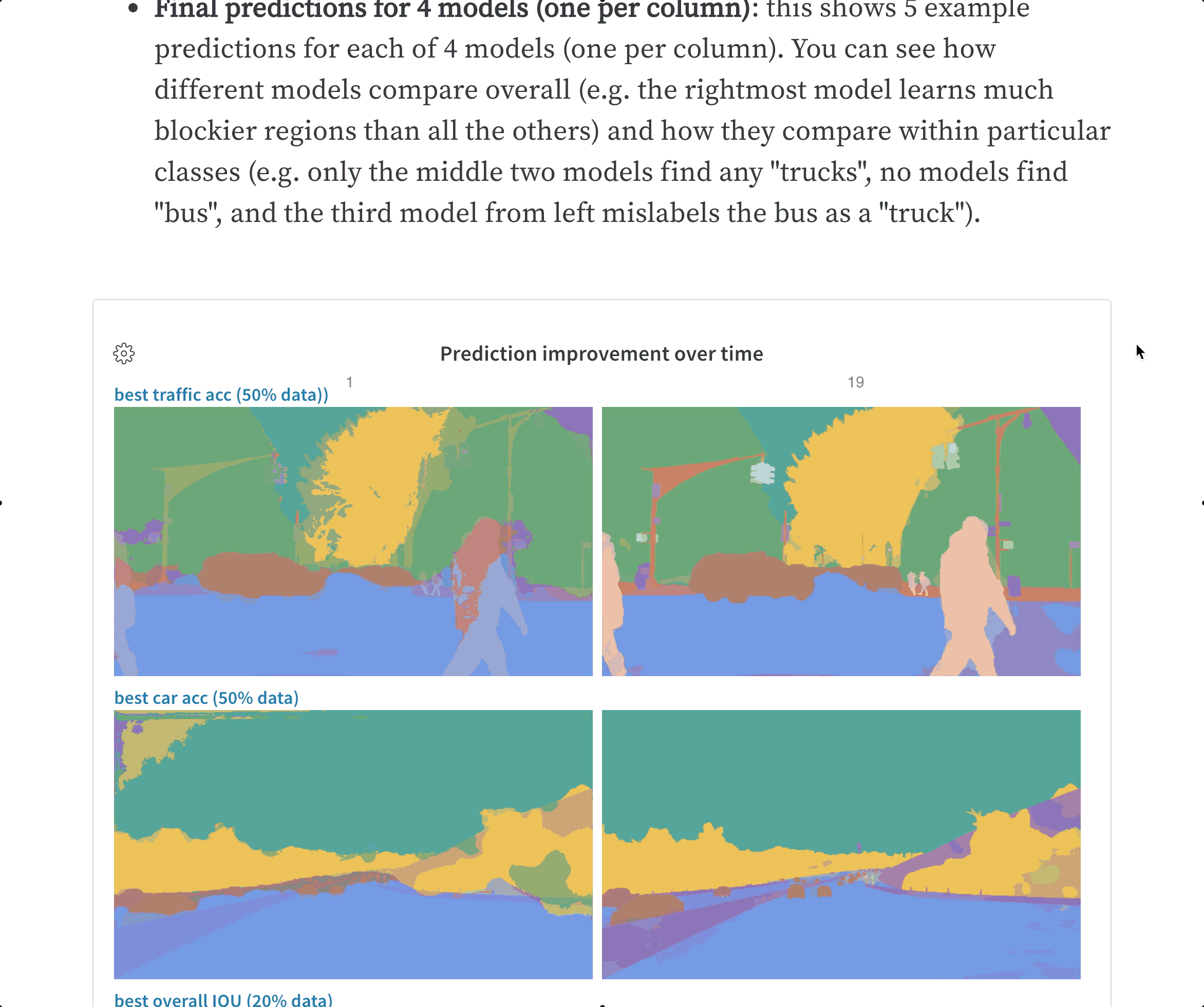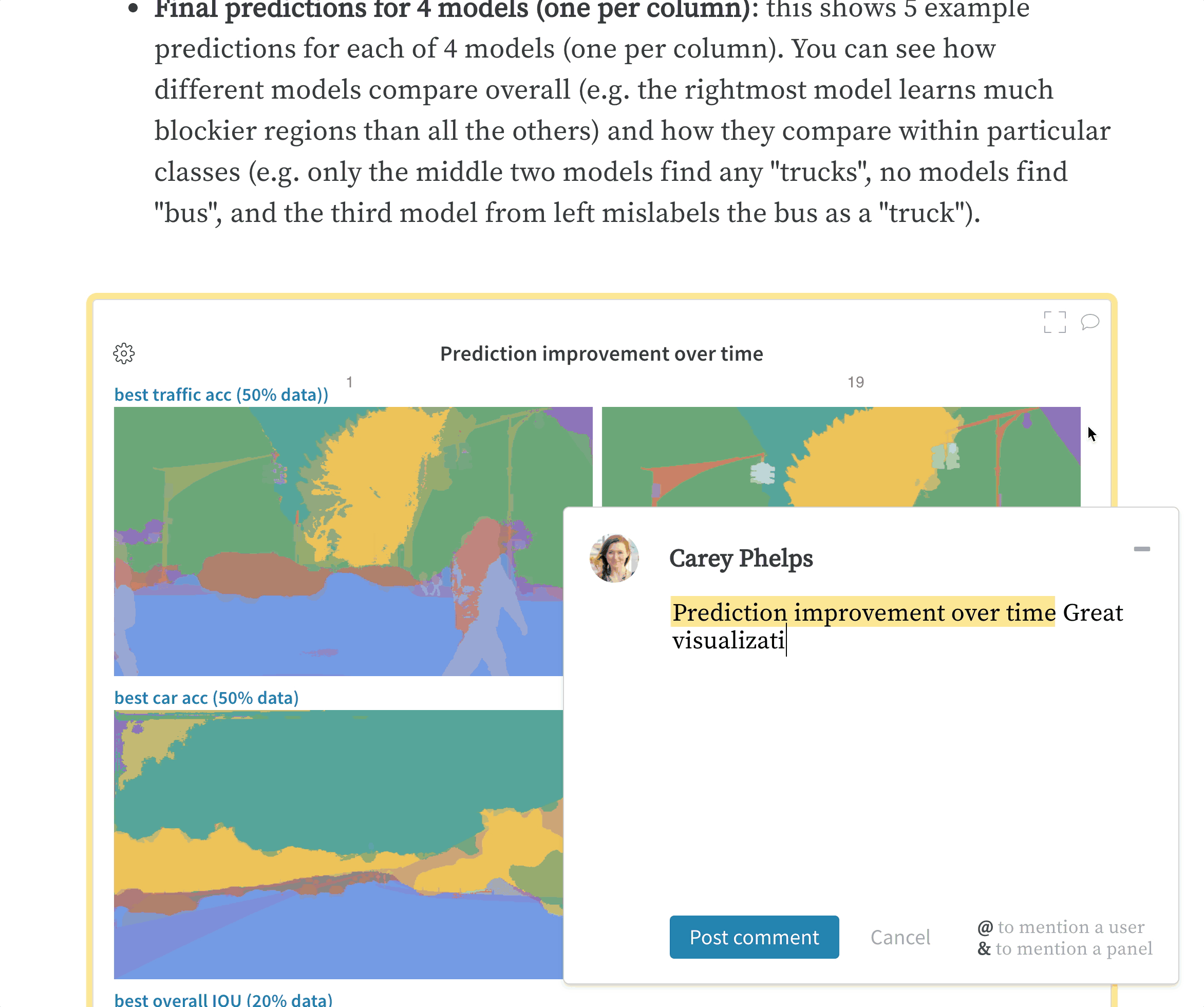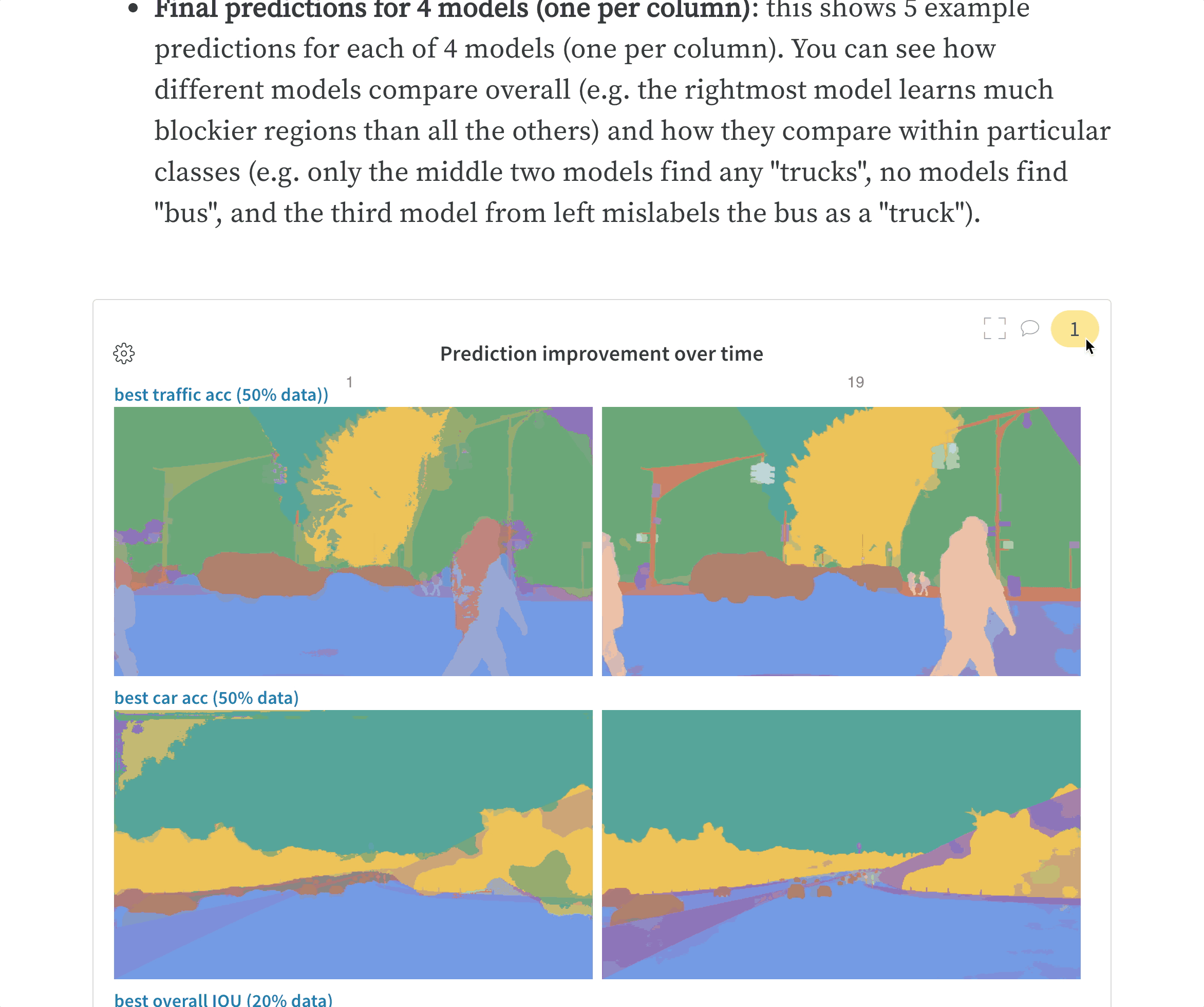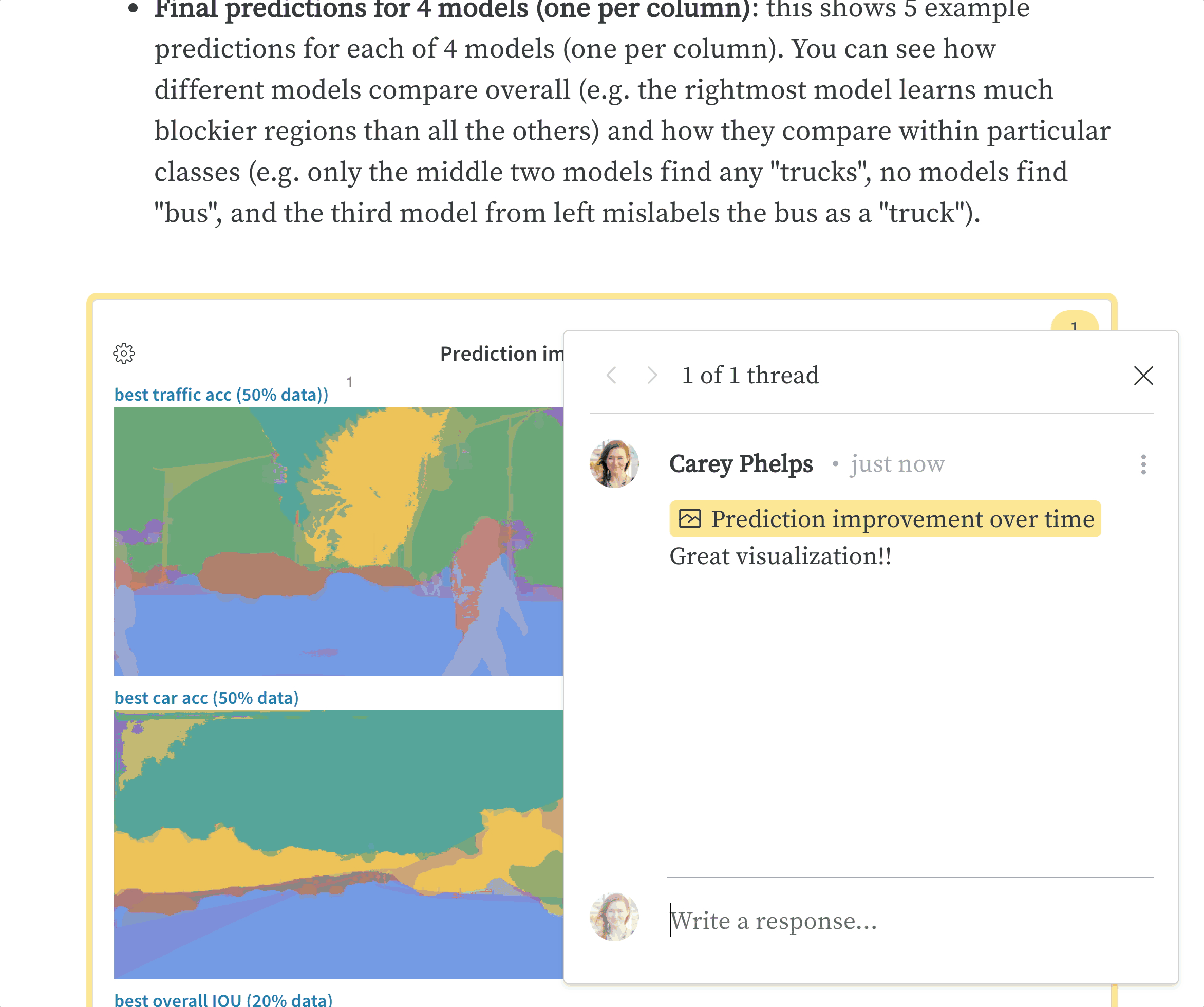
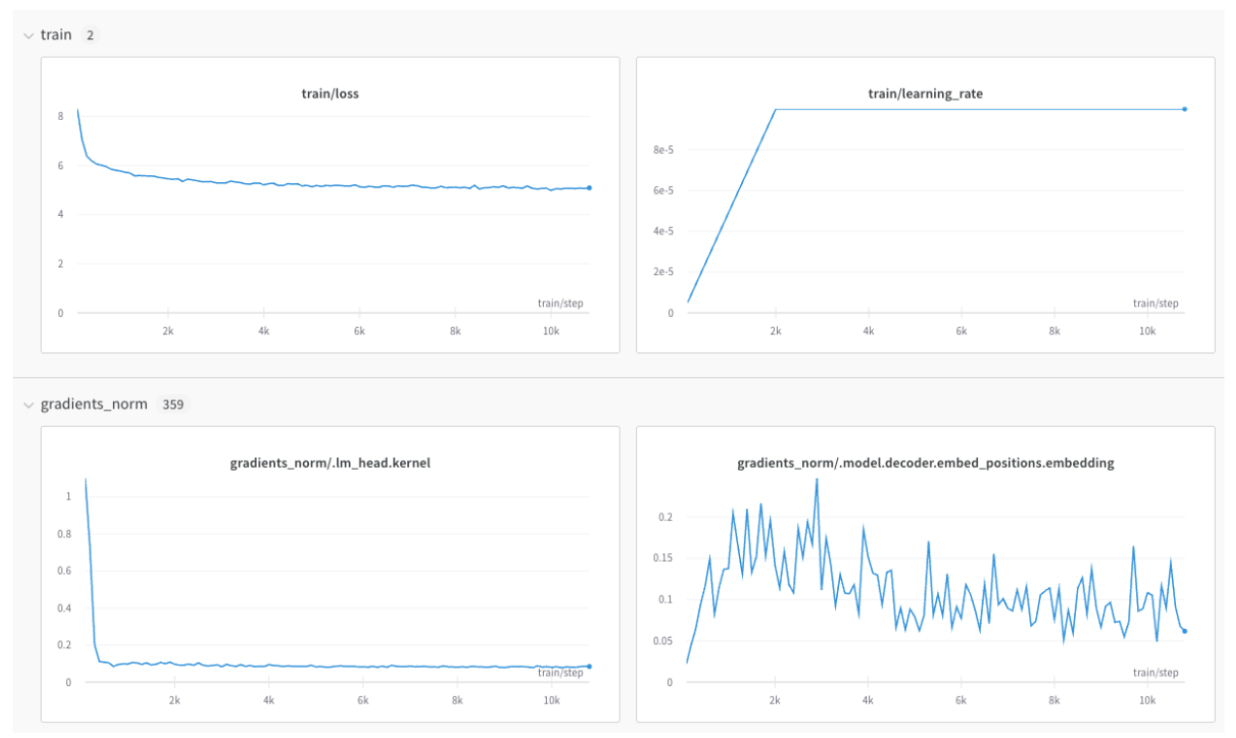
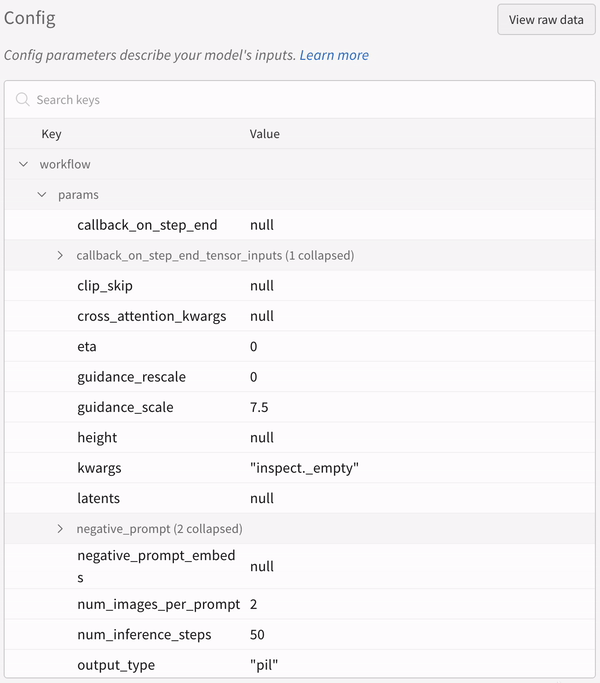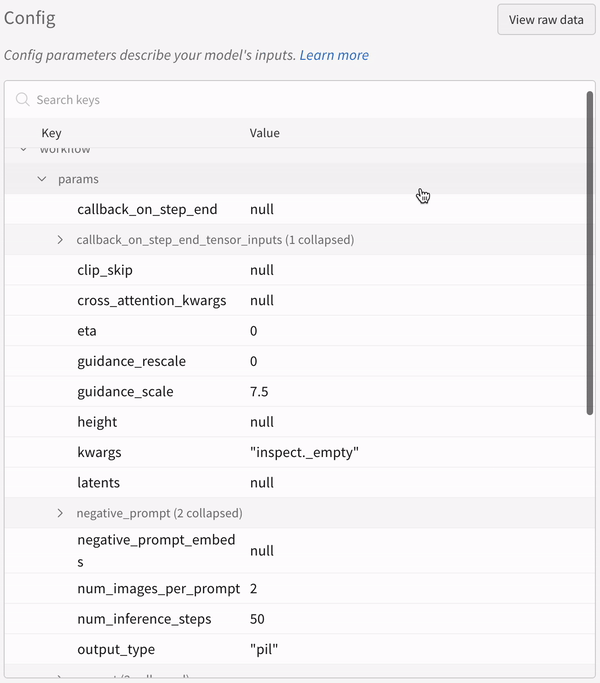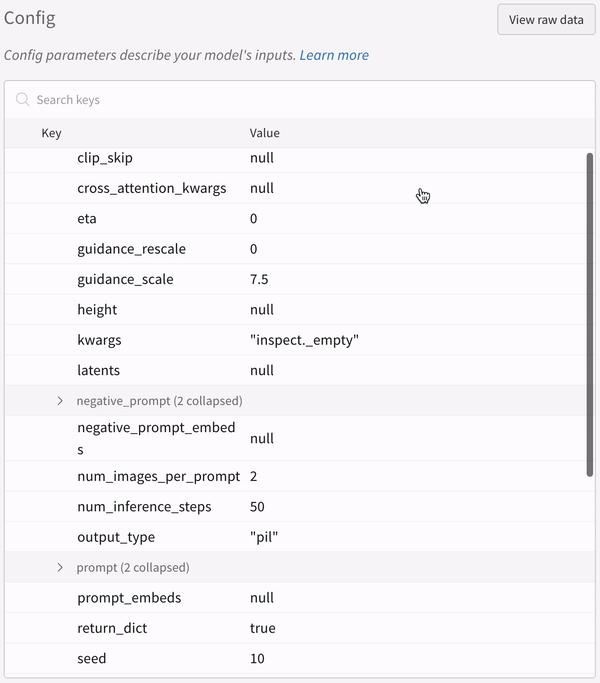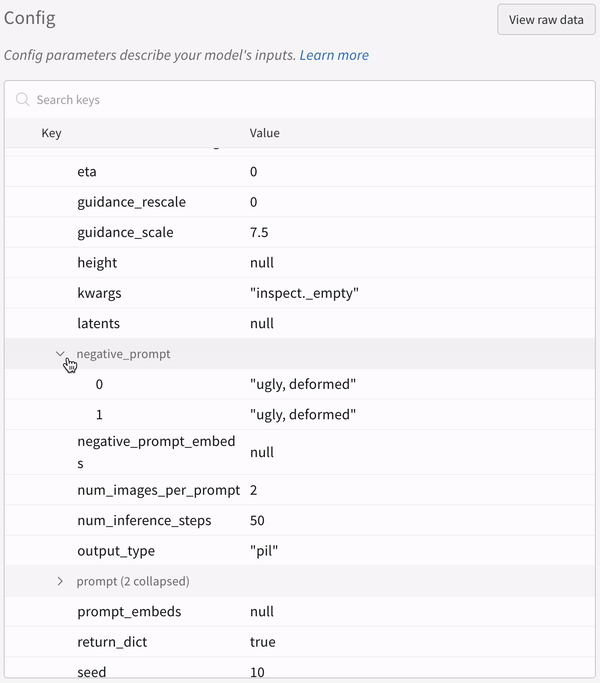
학습률 또는 모델 유형과 같은 하이퍼파라미터 사전을 구성 (run.config)에 저장합니다.
정확도 및 손실과 같은 트레이닝 루프에서 시간 경과에 따른 메트릭 (run.log())을 기록합니다.
모델 weights 또는 예측 테이블과 같은 run 의 출력을 저장합니다.
다음 코드는 일반적인 W&B experiment 추적 워크플로우를 보여줍니다.
# Start a run.## When this block exits, it waits for logged data to finish uploading.# If an exception is raised, the run is marked failed.with wandb.init(entity="", project="my-project-name") as run:
# Save mode inputs and hyperparameters. run.config.learning_rate =0.01# Run your experiment code.for epoch in range(num_epochs):
# Do some training...# Log metrics over time to visualize model performance. run.log({"loss": loss})
# Upload model outputs as artifacts. run.log_artifact(model)
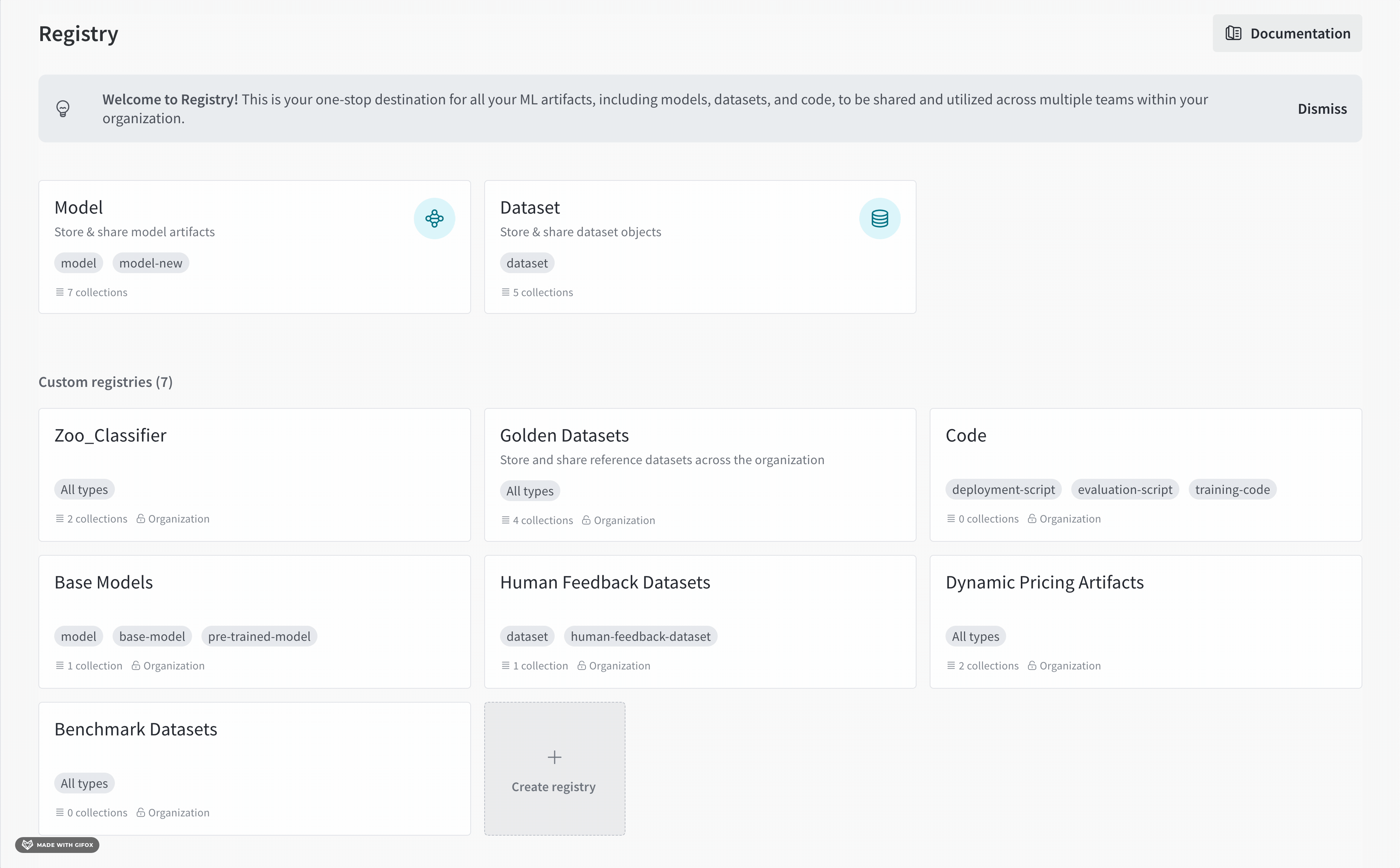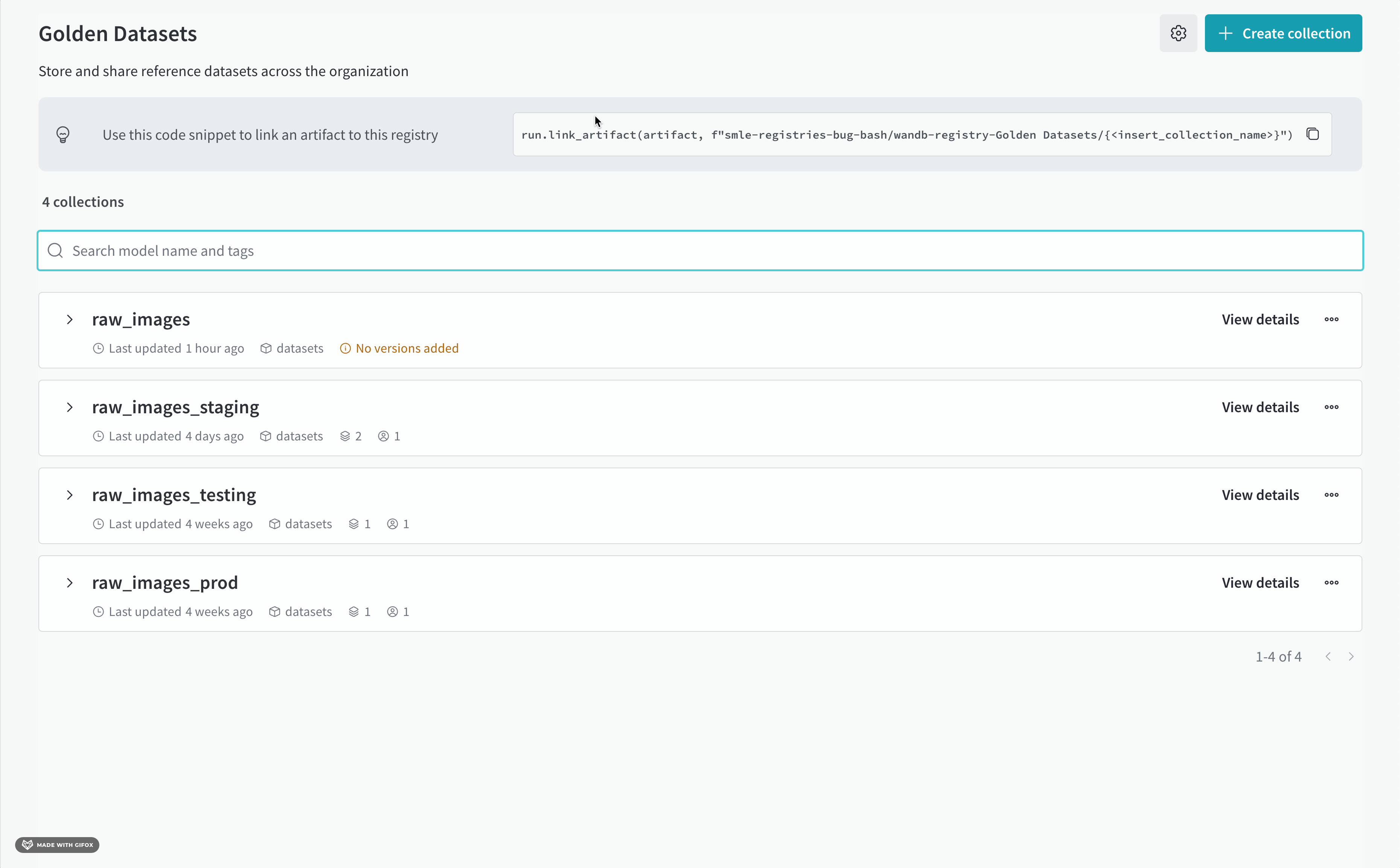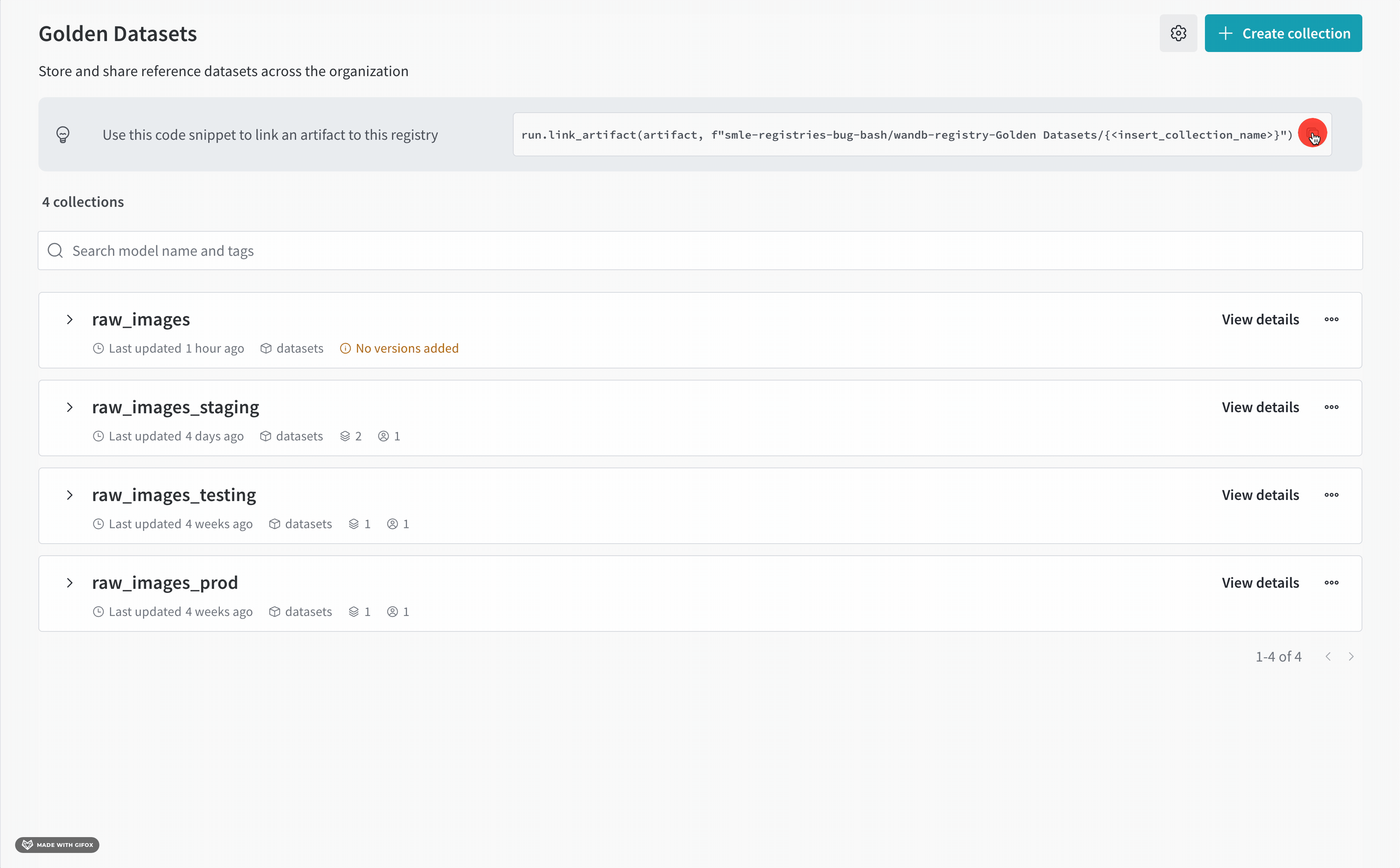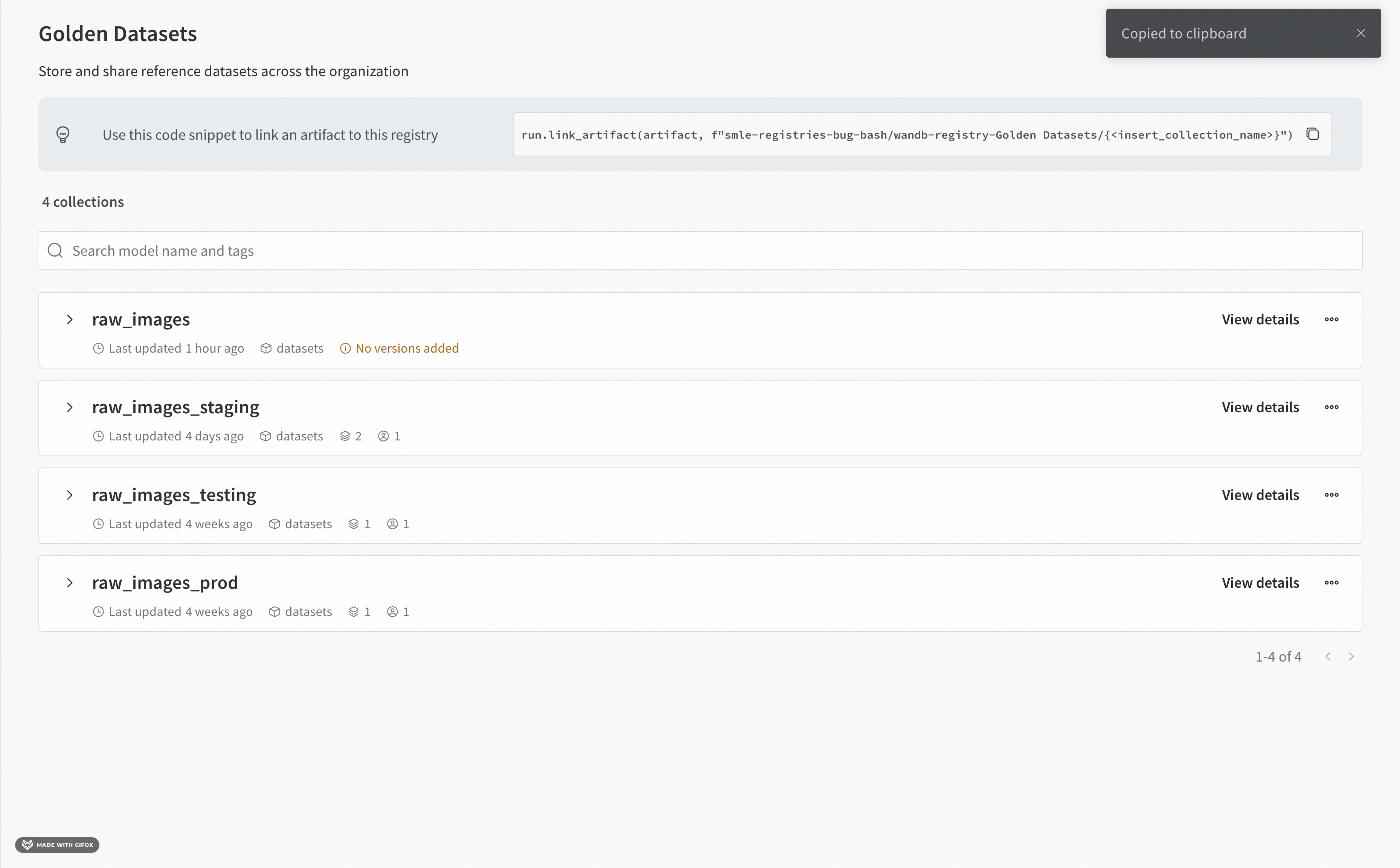
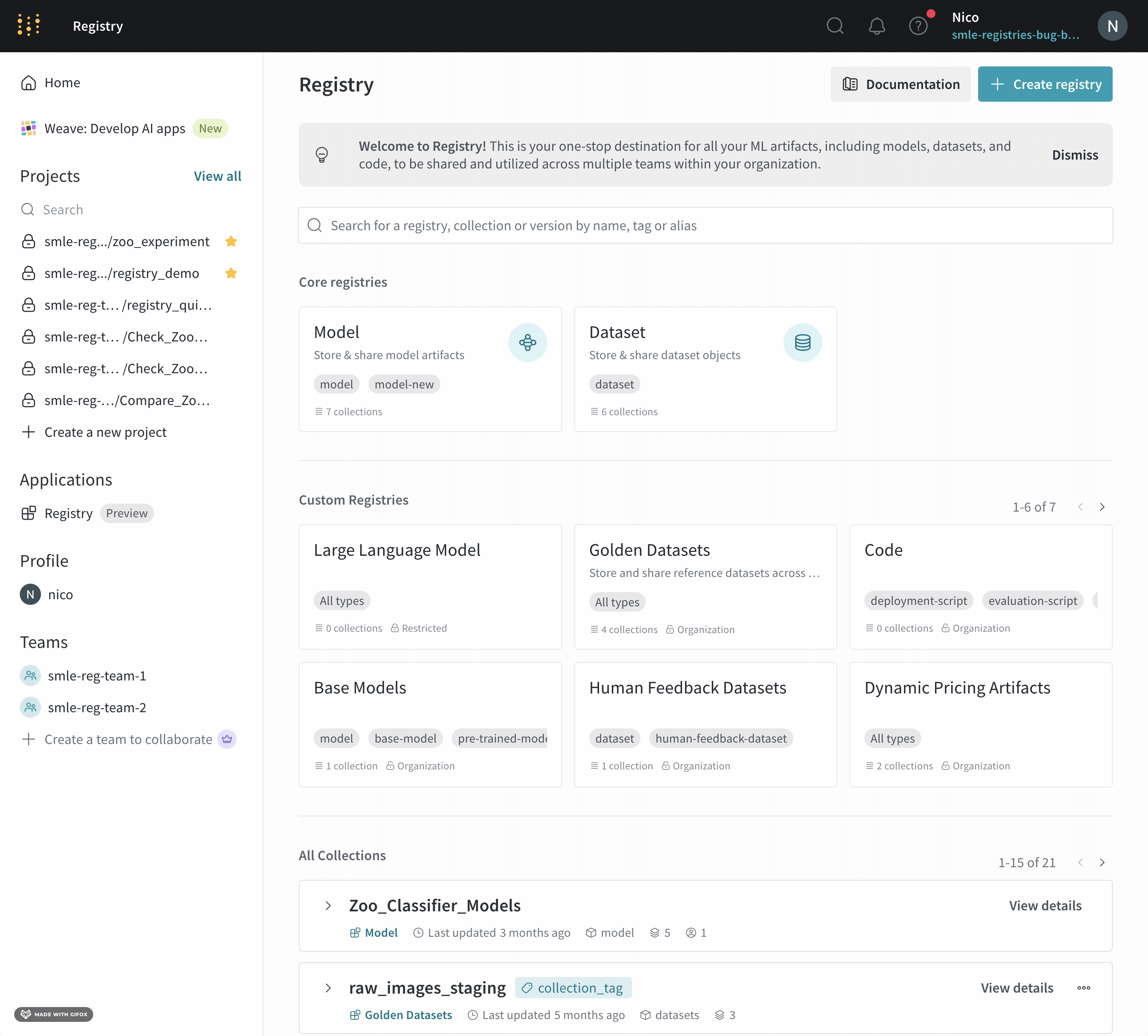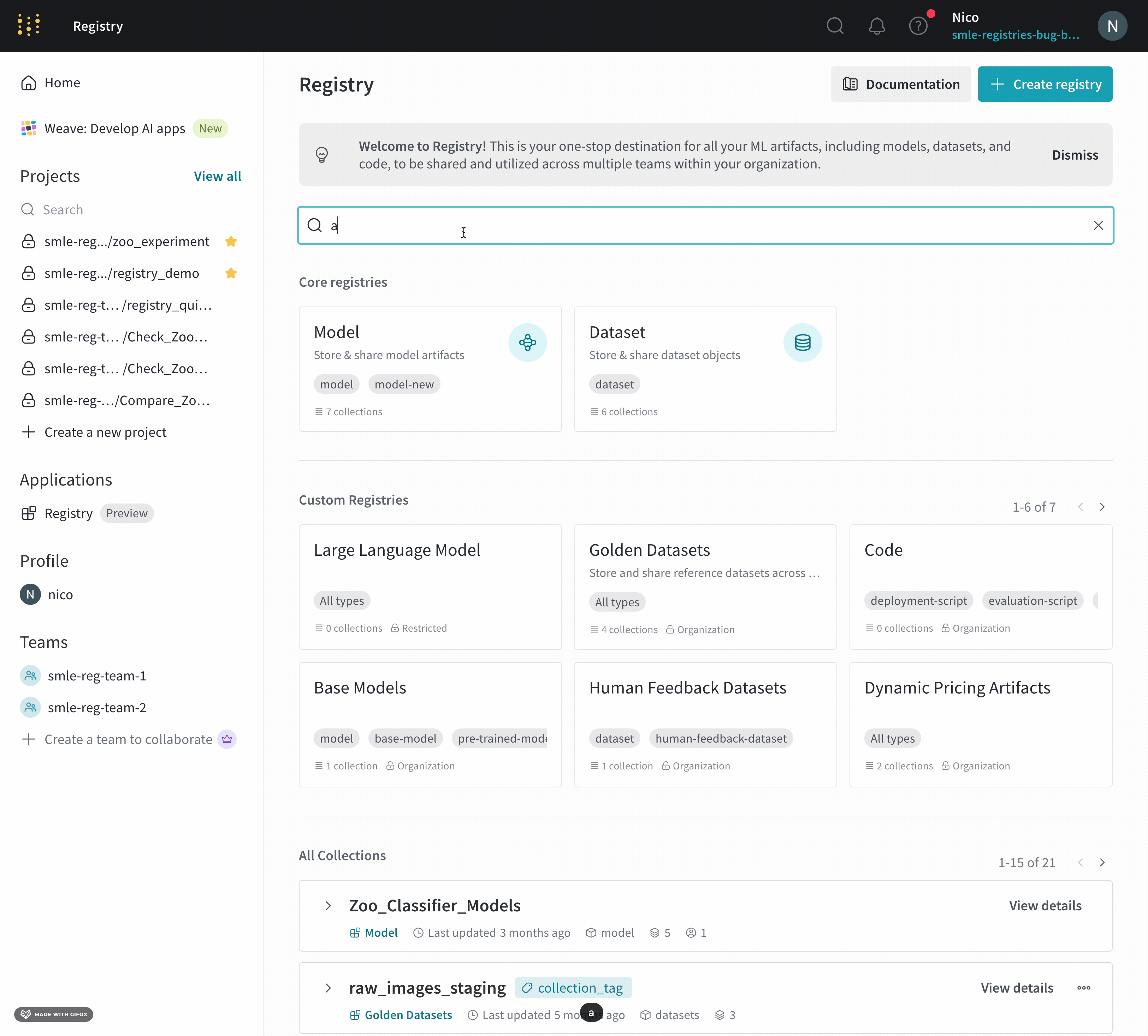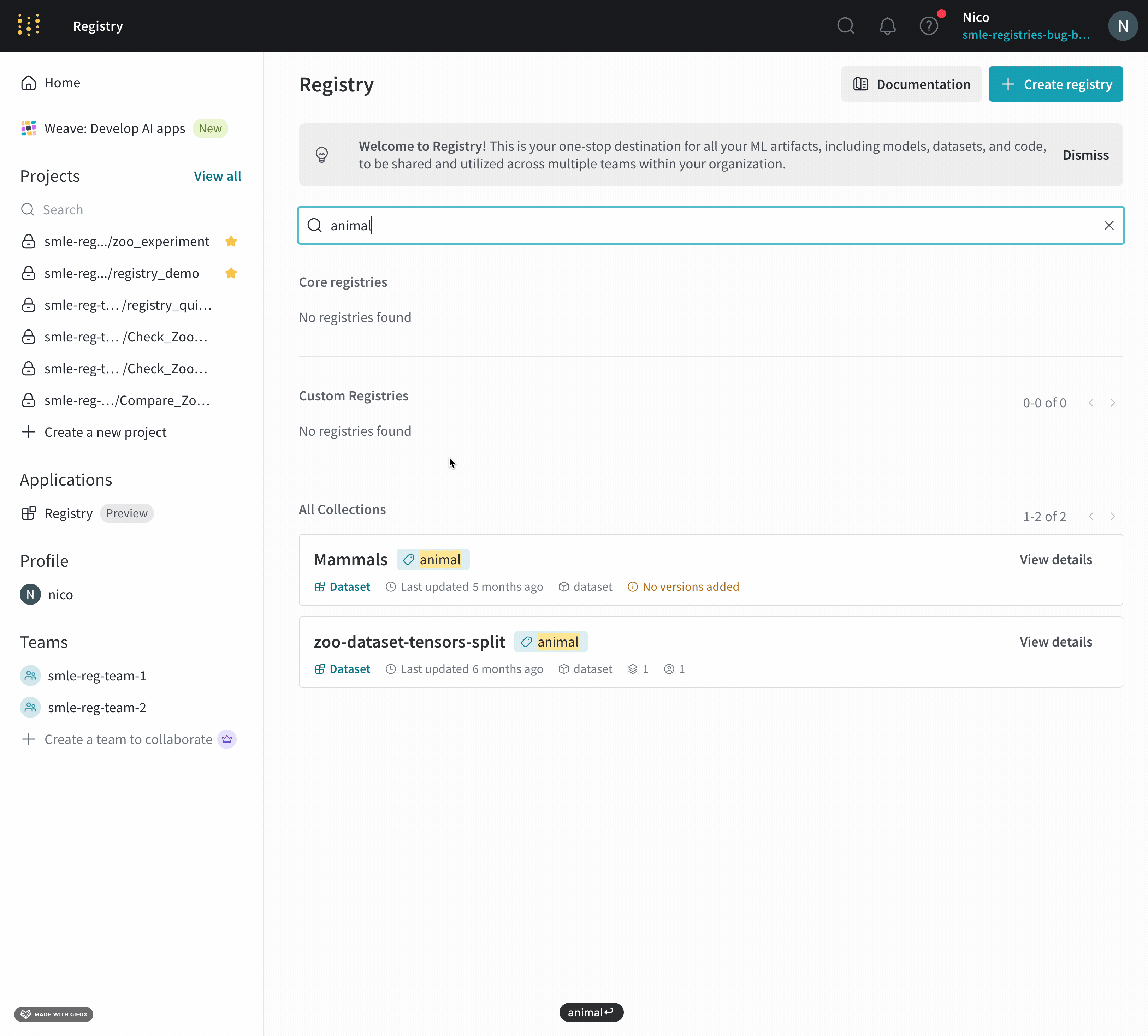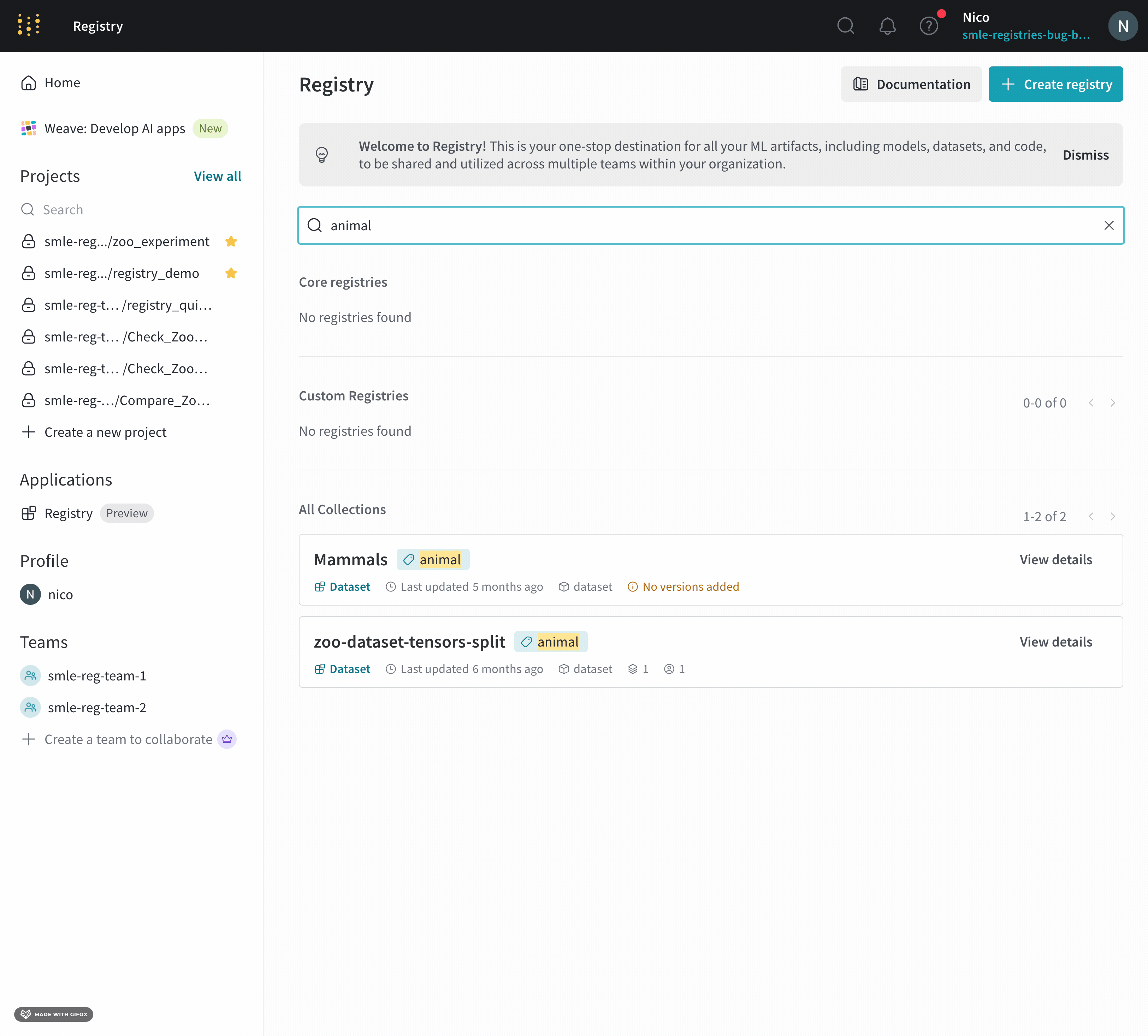
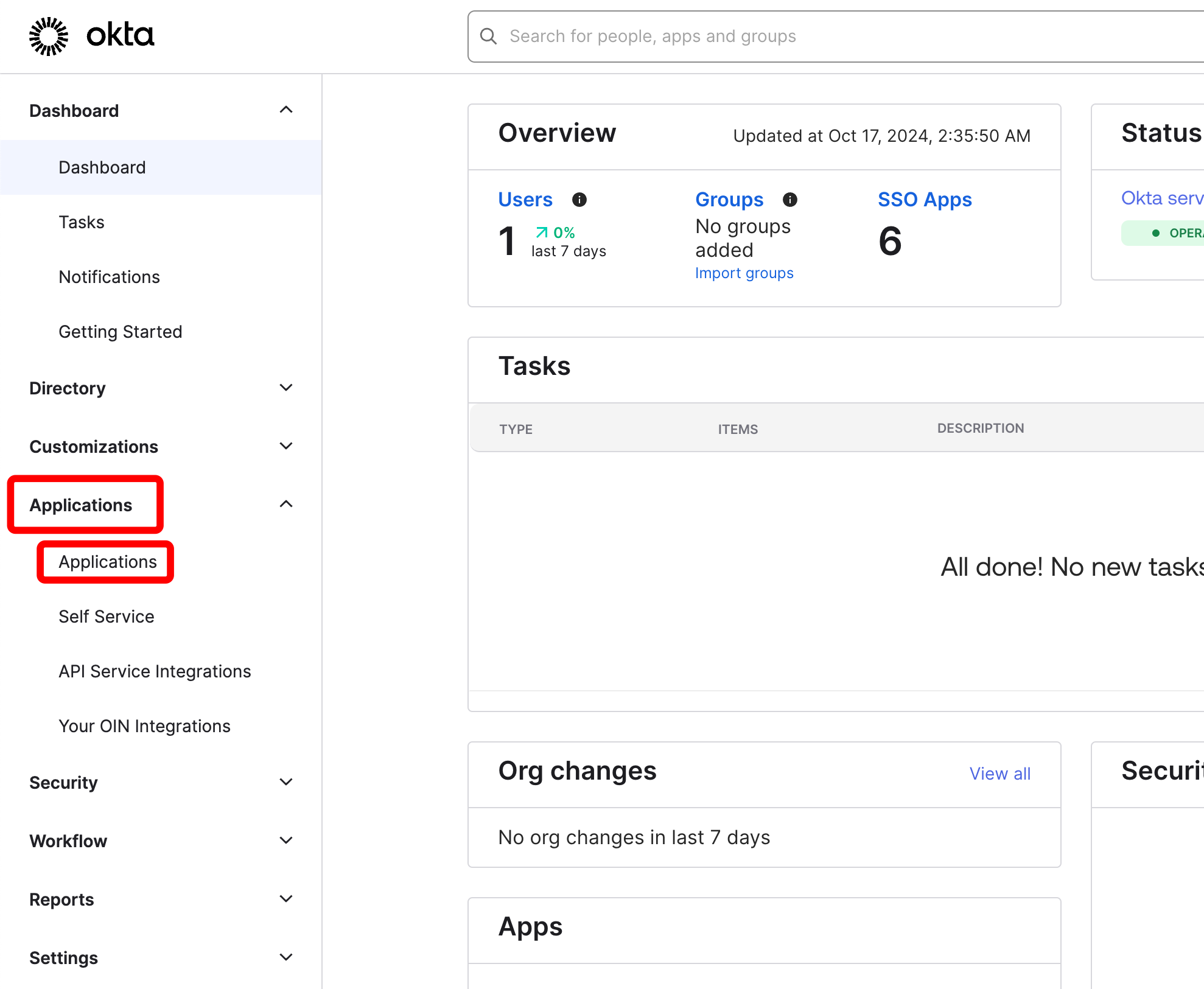
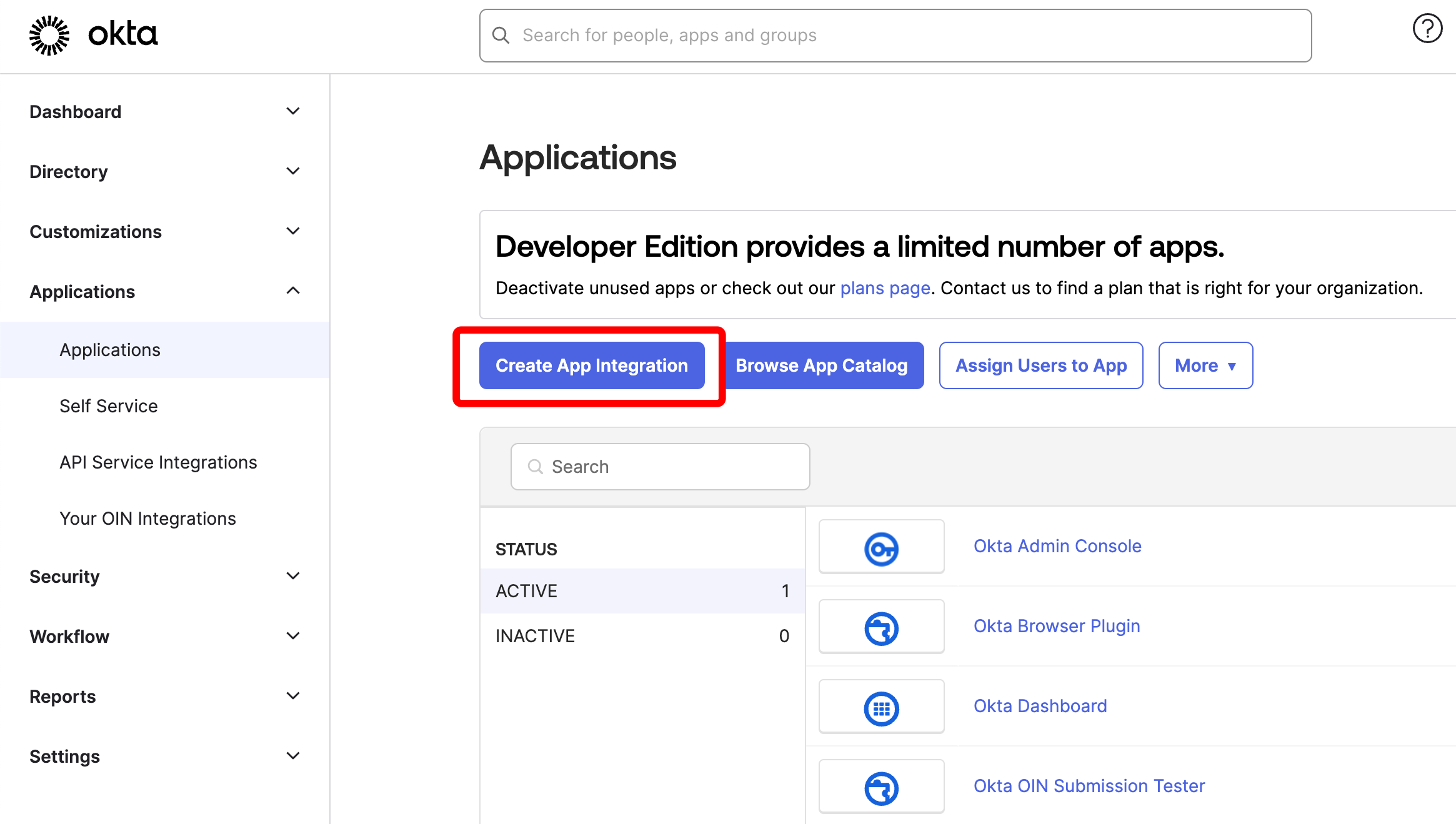
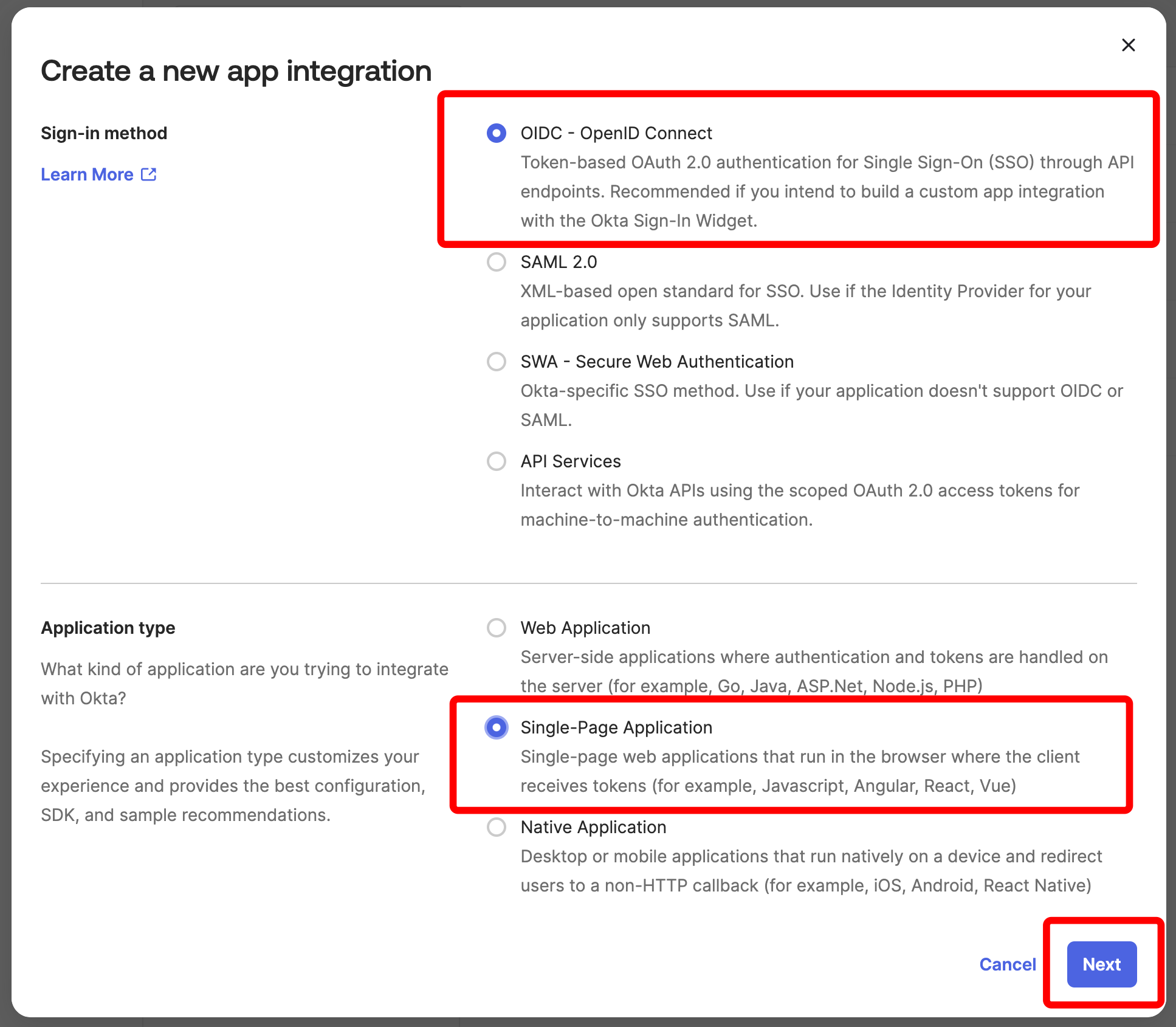
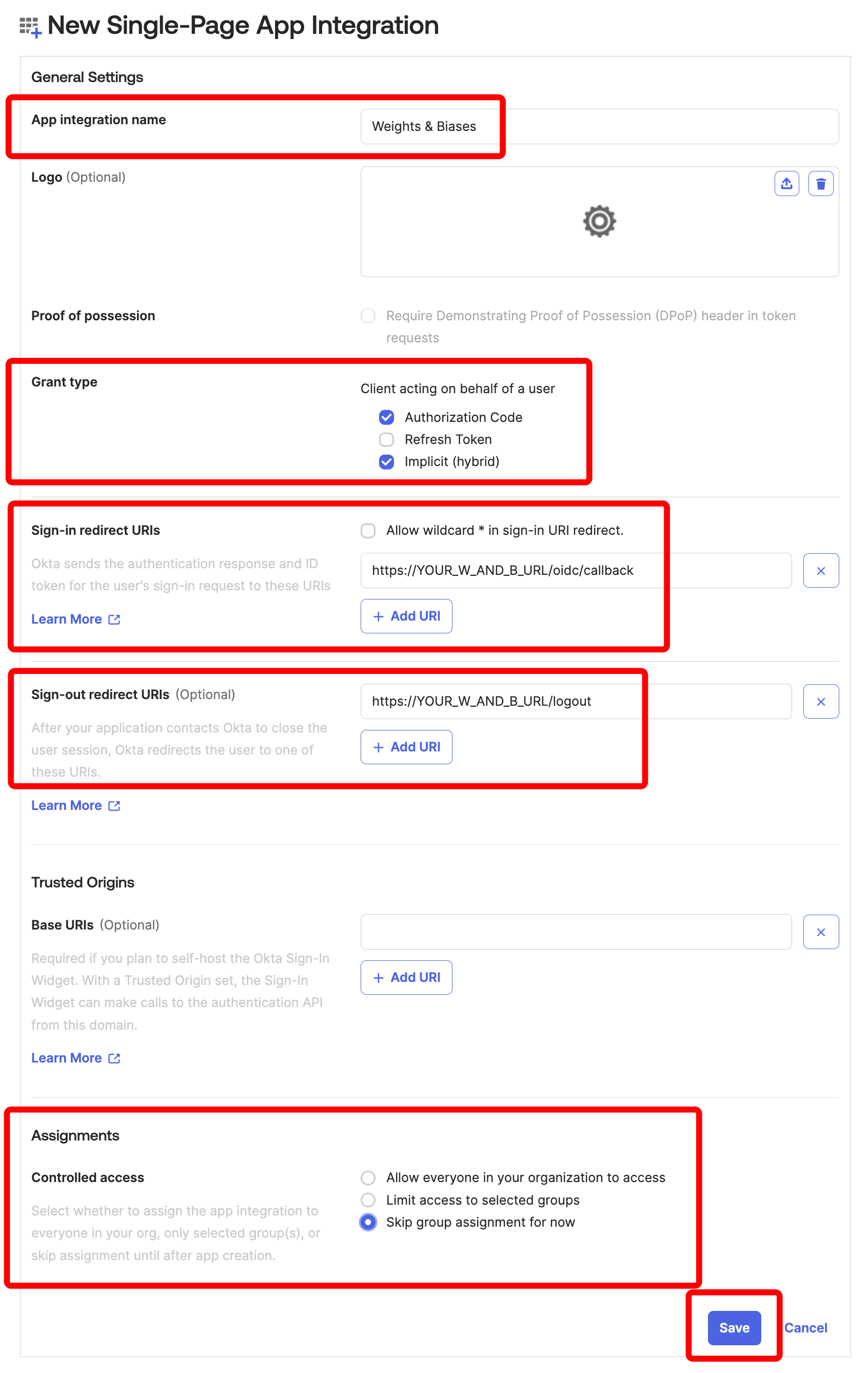
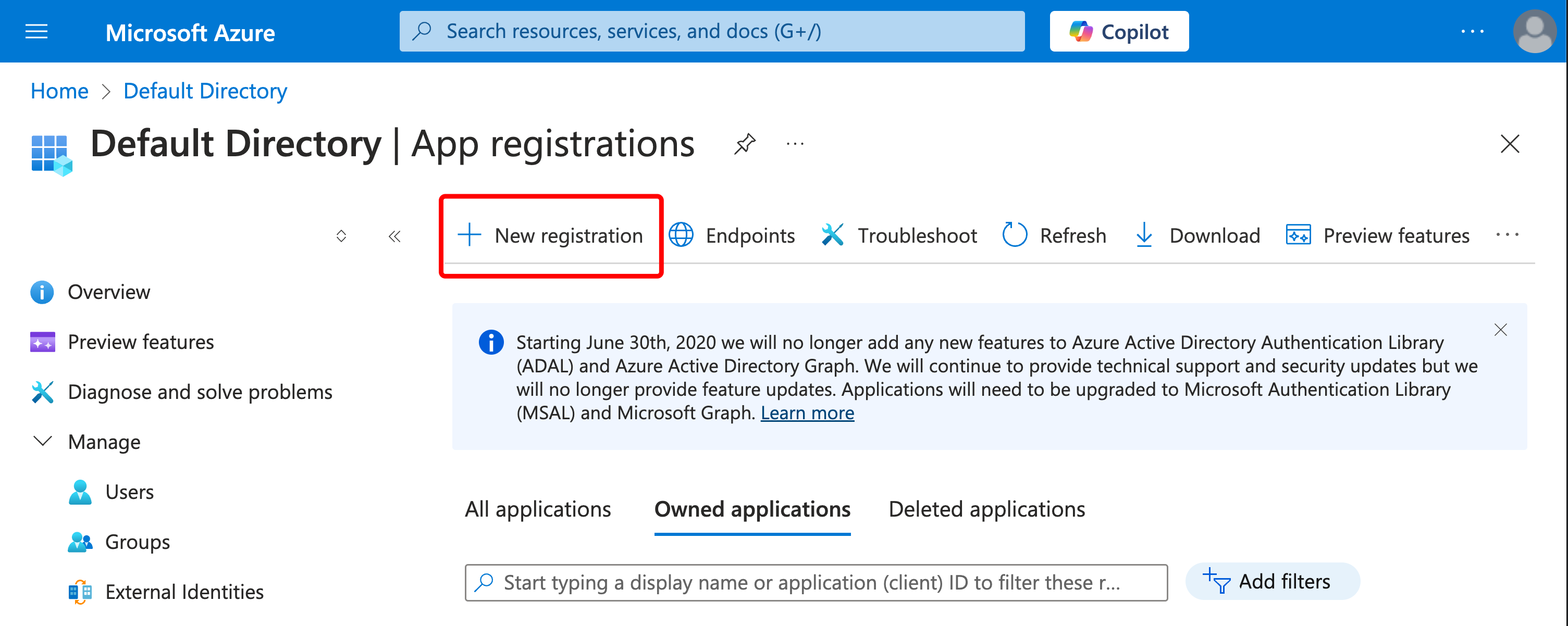
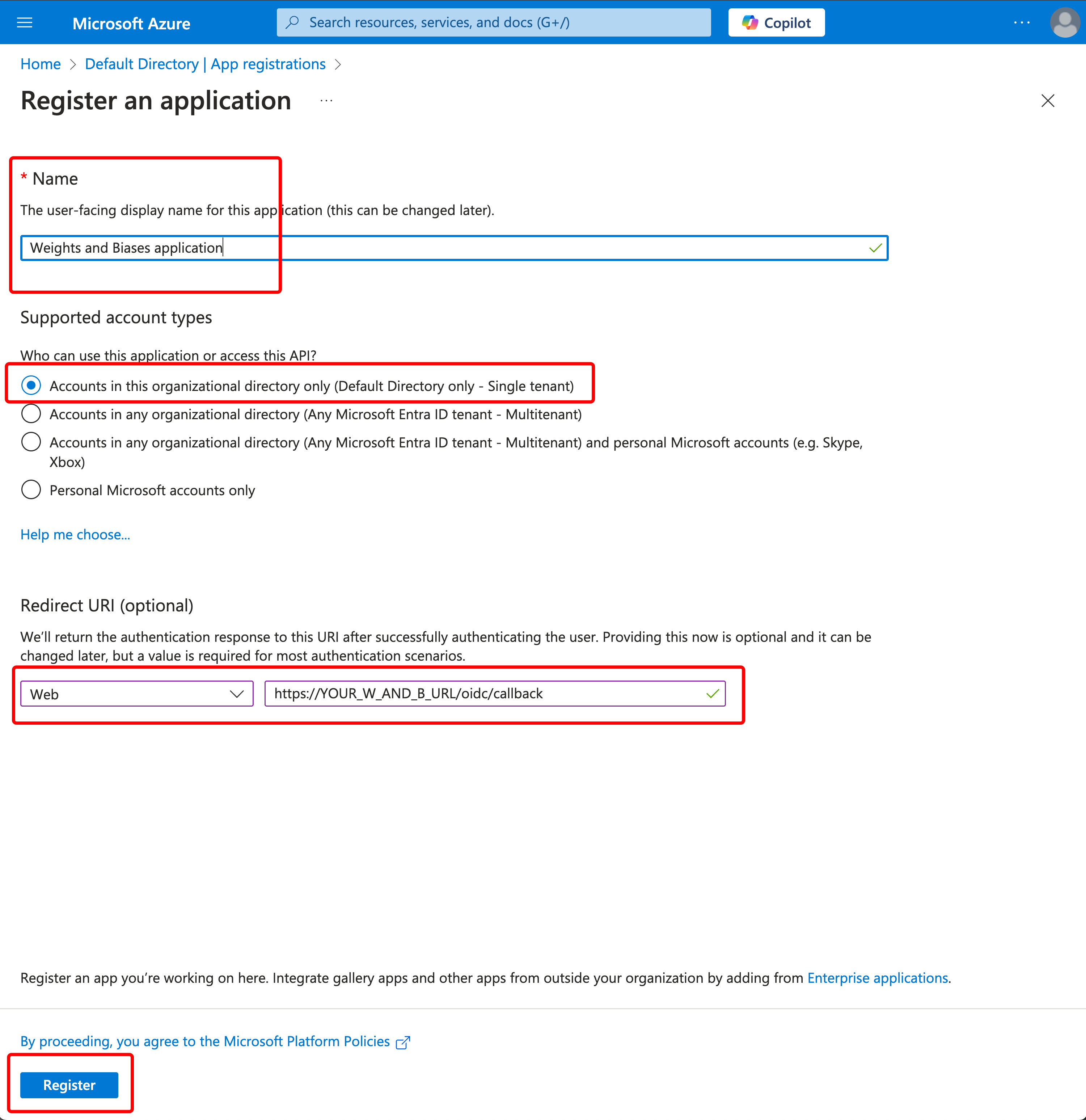
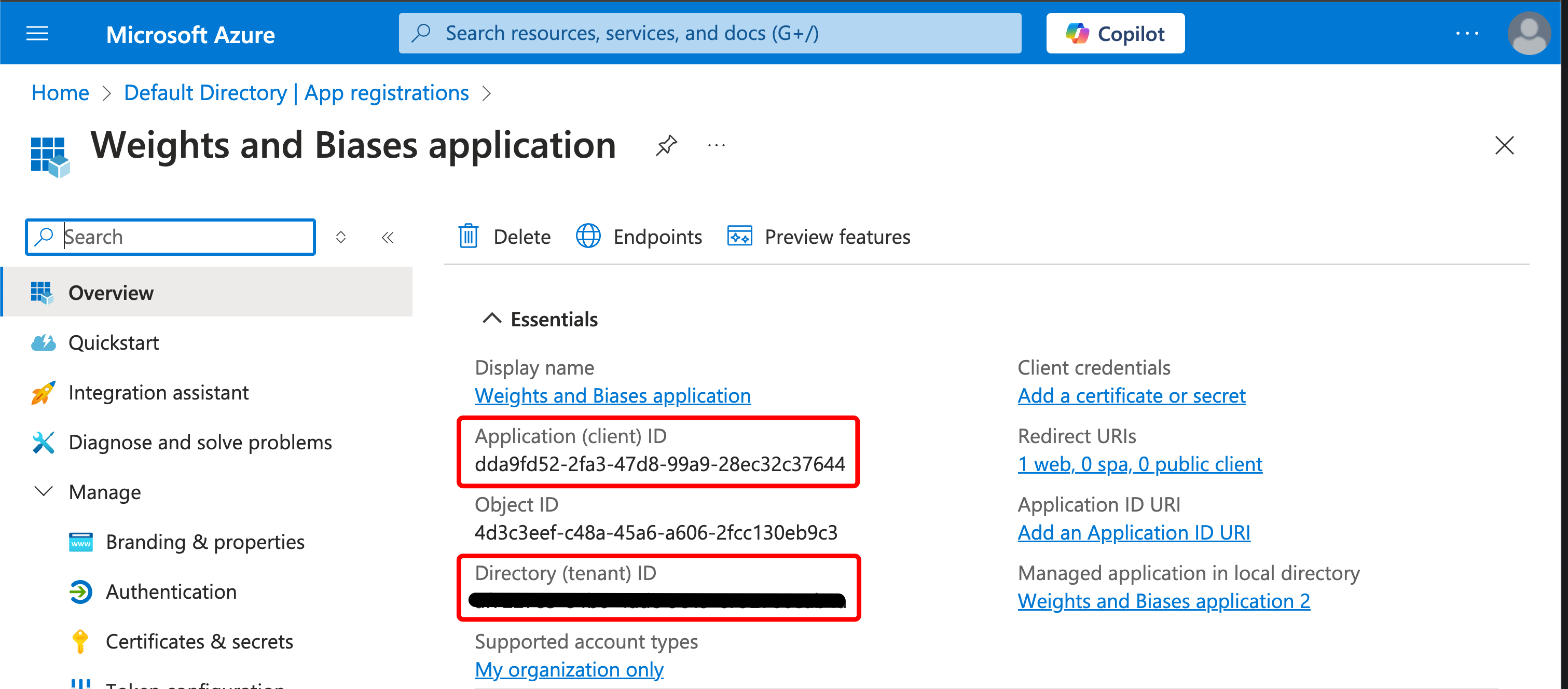
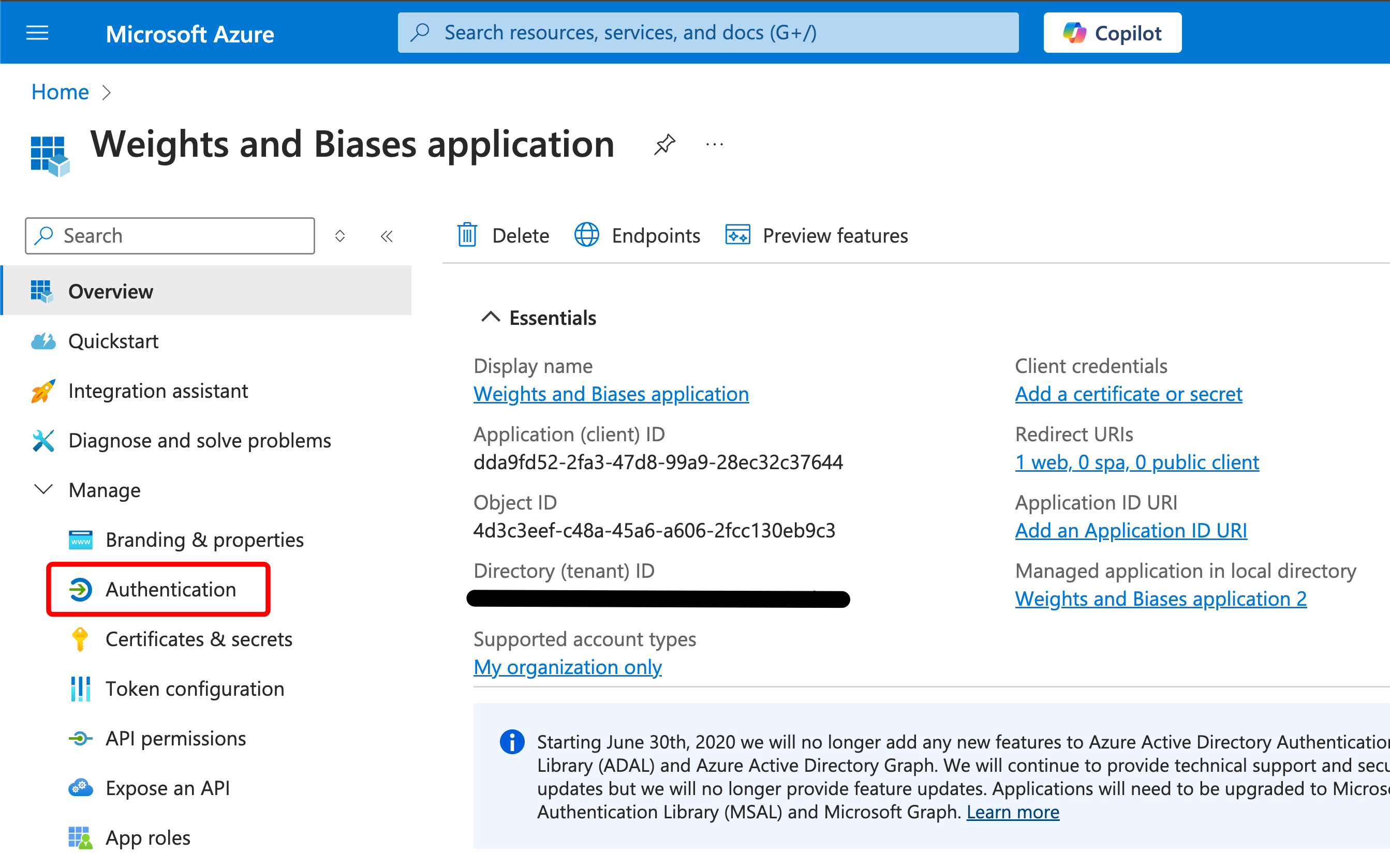
시작하기
유스 케이스에 따라 다음 리소스를 탐색하여 W&B Experiments 를 시작하세요.
데이터셋 artifact 를 생성, 추적 및 사용하는 데 사용할 수 있는 W&B Python SDK 코맨드에 대한 단계별 개요는 W&B 퀵스타트를 참조하세요.
다음 코드 조각은 이 run을 식별하는 데 도움이 되도록 설명이 “My first experiment” 인 “cat-classification”이라는 W&B project에서 run을 만듭니다. 태그 “baseline” 및 “paper1”은 이 run이 향후 논문 출판을 위한 베이스라인 experiment임을 알려줍니다.
import wandb
with wandb.init(
project="cat-classification",
notes="My first experiment",
tags=["baseline", "paper1"],
) as run:
...
참고: wandb.init()를 호출할 때 해당 project가 이미 존재하는 경우 Run은 기존 project에 추가됩니다. 예를 들어 “cat-classification”이라는 project가 이미 있는 경우 해당 project는 계속 존재하며 삭제되지 않습니다. 대신 새 run이 해당 project에 추가됩니다.
하이퍼파라미터 dictionary 캡처
학습률 또는 모델 유형과 같은 하이퍼파라미터 dictionary를 저장합니다. config에서 캡처하는 모델 설정은 나중에 결과를 구성하고 쿼리하는 데 유용합니다.
with wandb.init(
...,
config={"epochs": 100, "learning_rate": 0.001, "batch_size": 128},
) as run:
...
선택적으로 W&B Artifact를 기록합니다. Artifact를 사용하면 데이터셋과 Models를 쉽게 버전 관리할 수 있습니다.
# 모든 파일 또는 디렉토리를 저장할 수 있습니다. 이 예에서는 모델에 ONNX 파일을 출력하는# save() 메소드가 있다고 가정합니다.model.save("path_to_model.onnx")
run.log_artifact("path_to_model.onnx", name="trained-model", type="model")
import wandb
with wandb.init(
project="cat-classification",
notes="",
tags=["baseline", "paper1"],
# run의 하이퍼파라미터를 기록합니다. config={"epochs": 100, "learning_rate": 0.001, "batch_size": 128},
) as run:
# 모델 및 데이터를 설정합니다. model, dataloader = get_model(), get_data()
# 모델 성능을 시각화하기 위해 메트릭을 기록하면서 트레이닝을 실행합니다.for epoch in range(run.config["epochs"]):
for batch in dataloader:
loss, accuracy = model.training_step()
run.log({"accuracy": accuracy, "loss": loss})
# 트레이닝된 모델을 아티팩트로 업로드합니다. model.save("path_to_model.onnx")
run.log_artifact("path_to_model.onnx", name="trained-model", type="model")
다음 단계: experiment 시각화
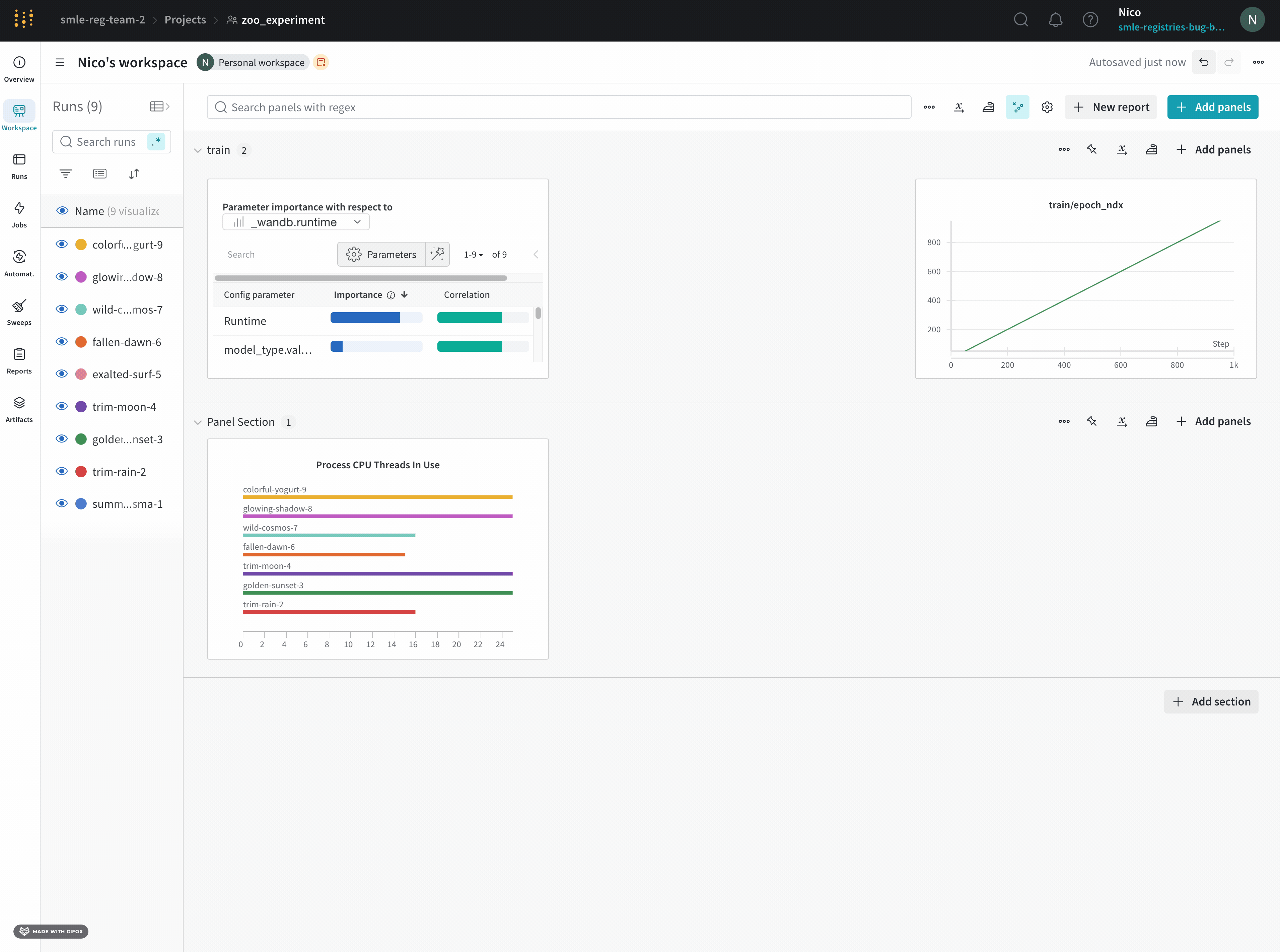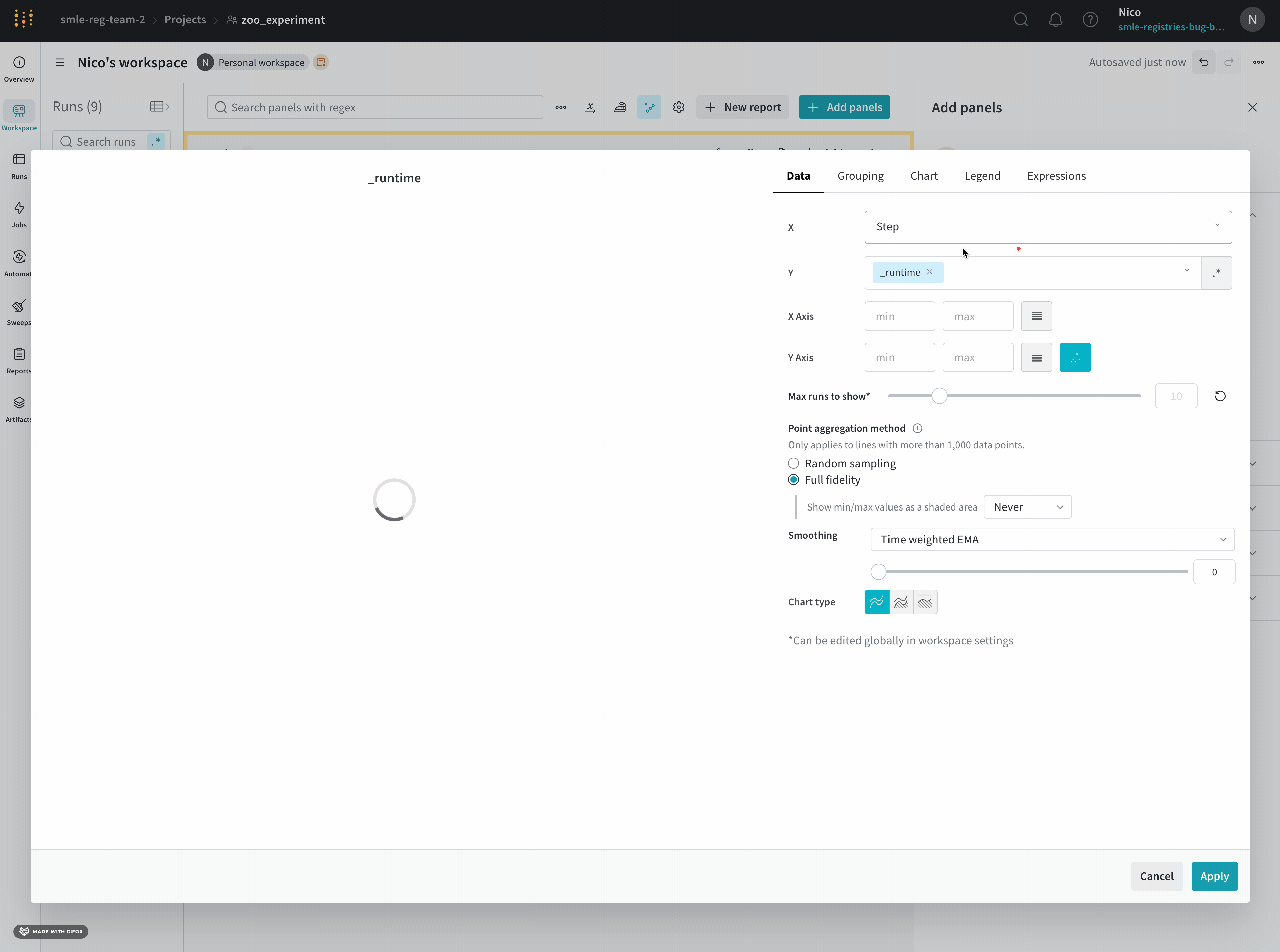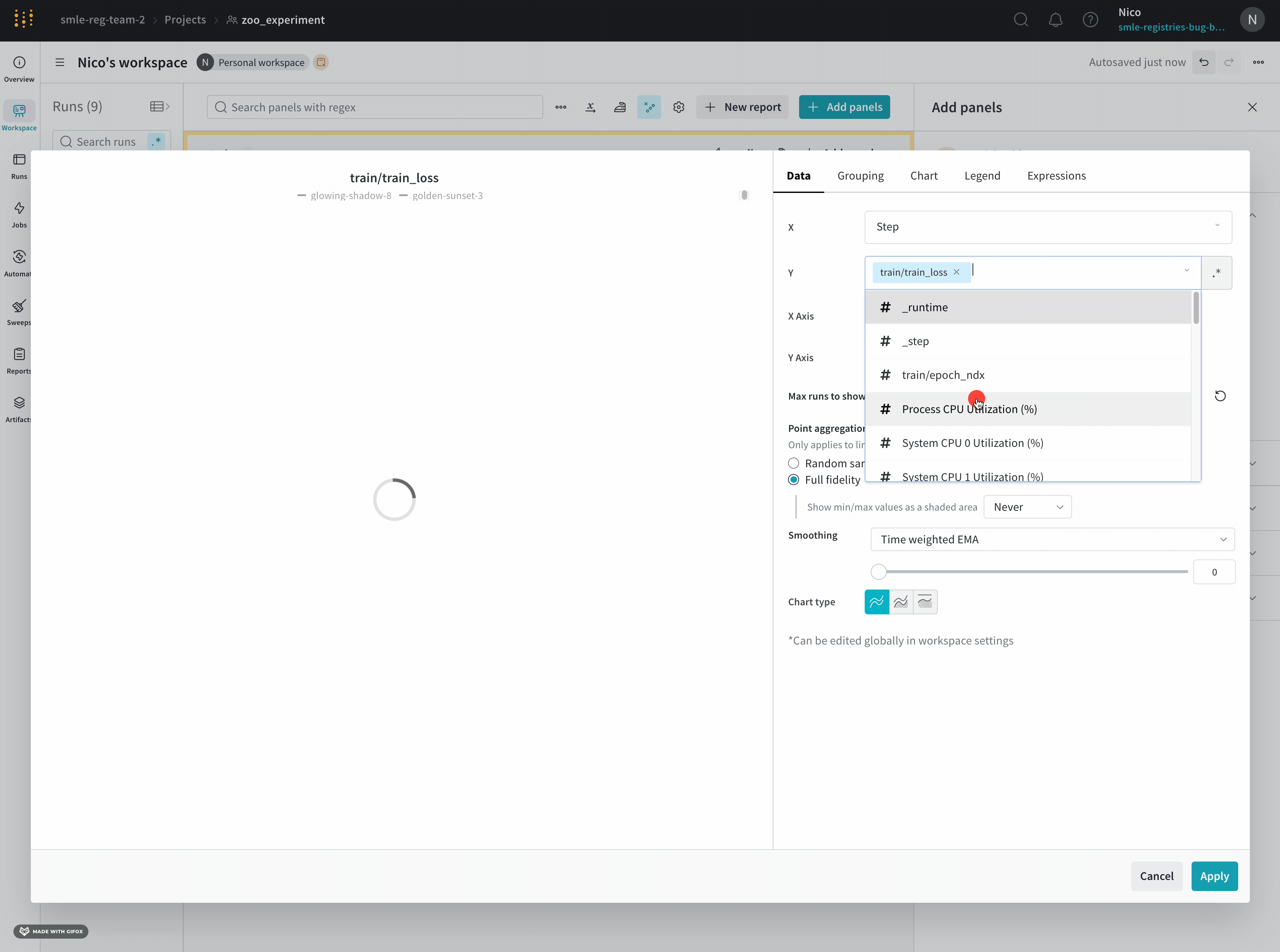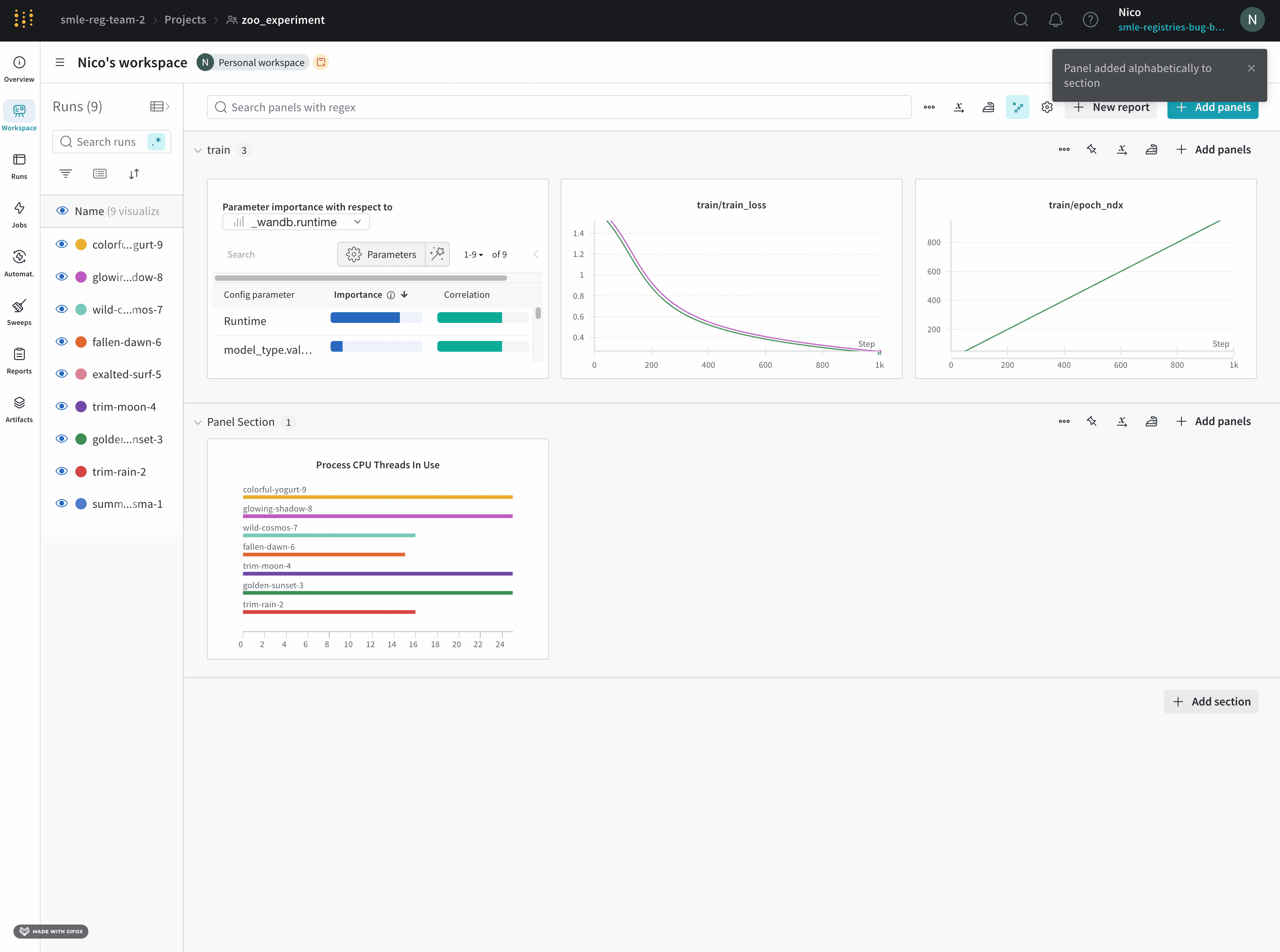
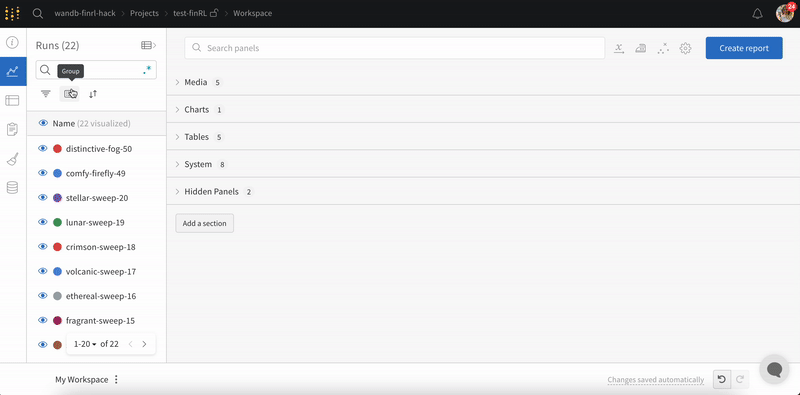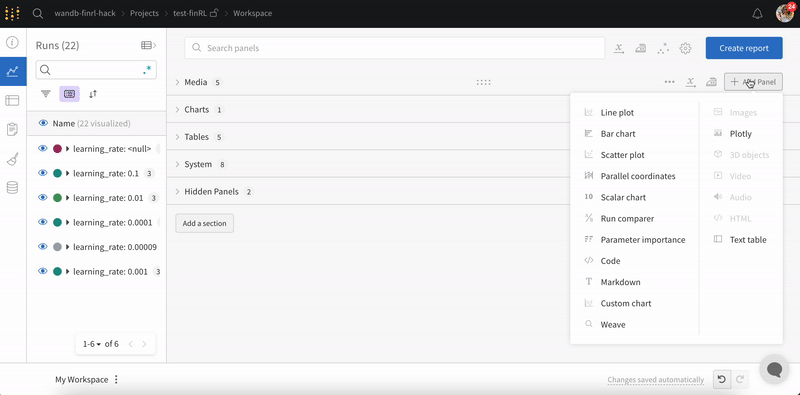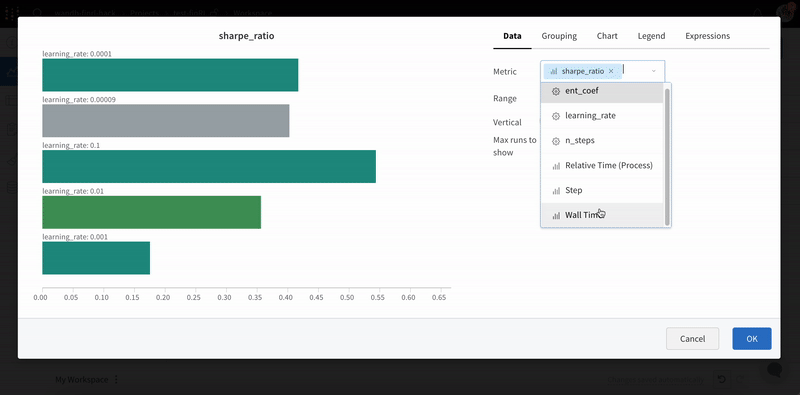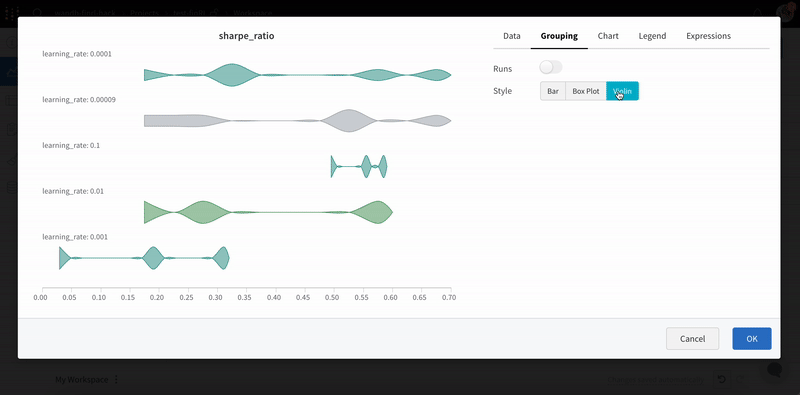
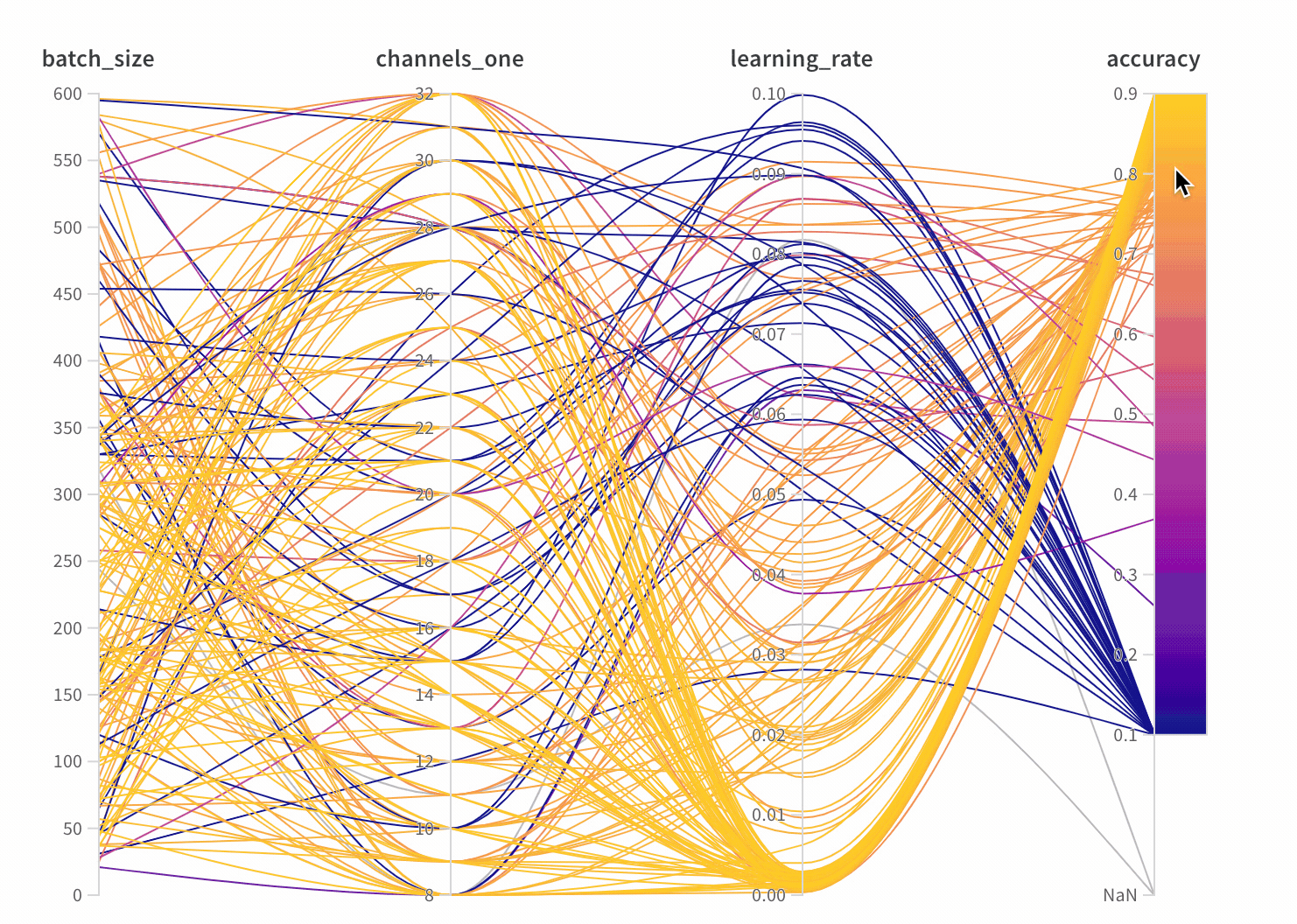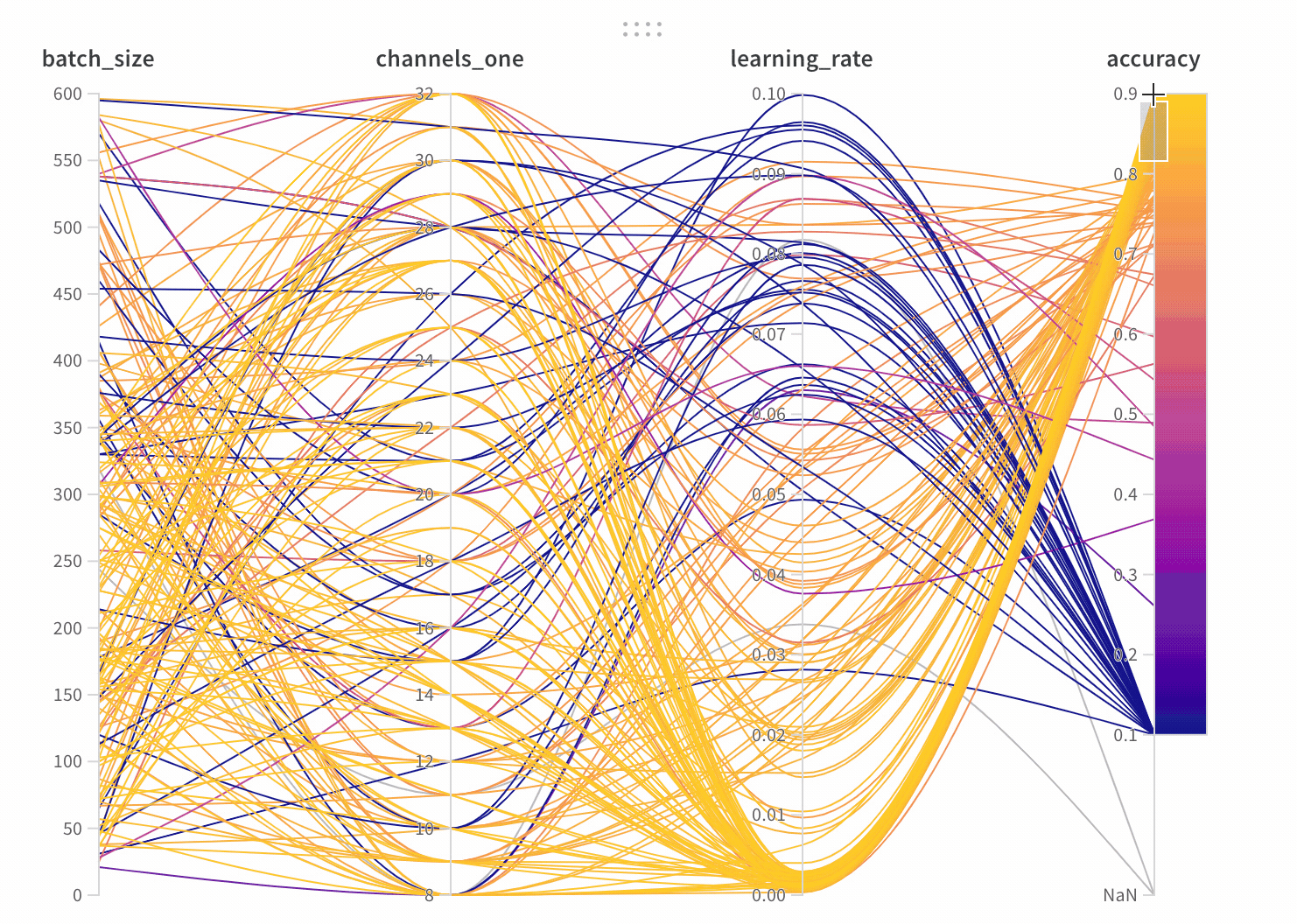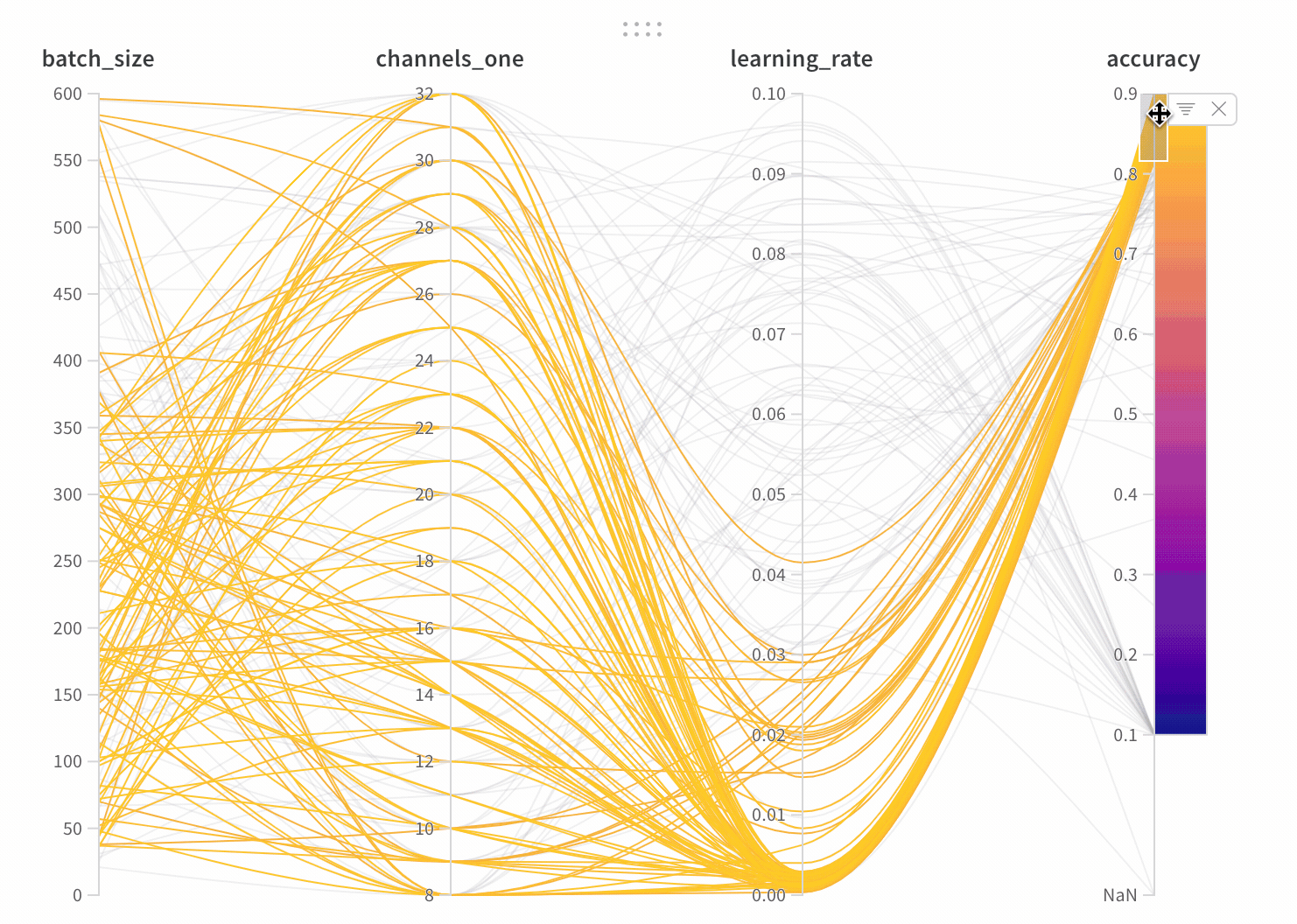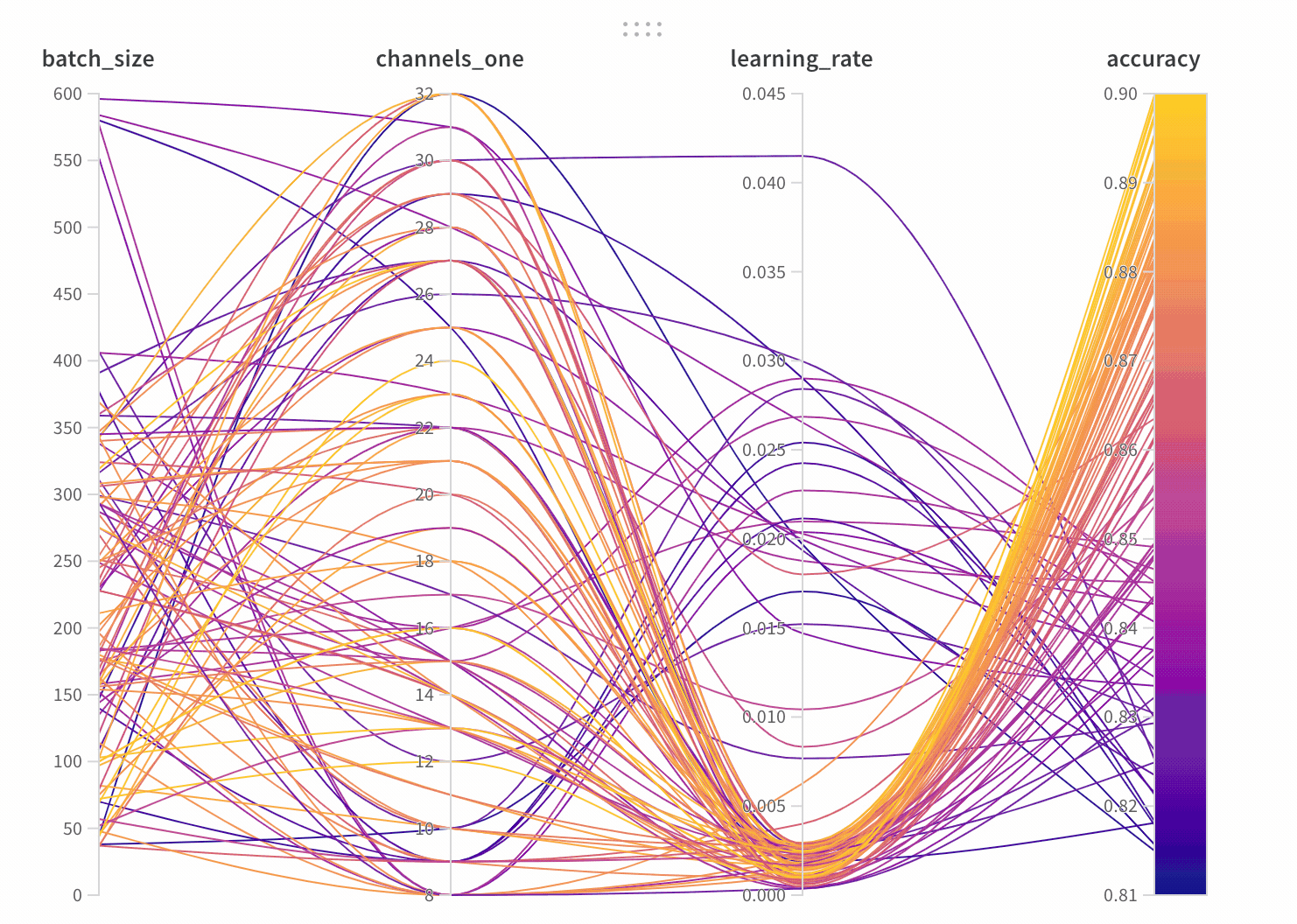
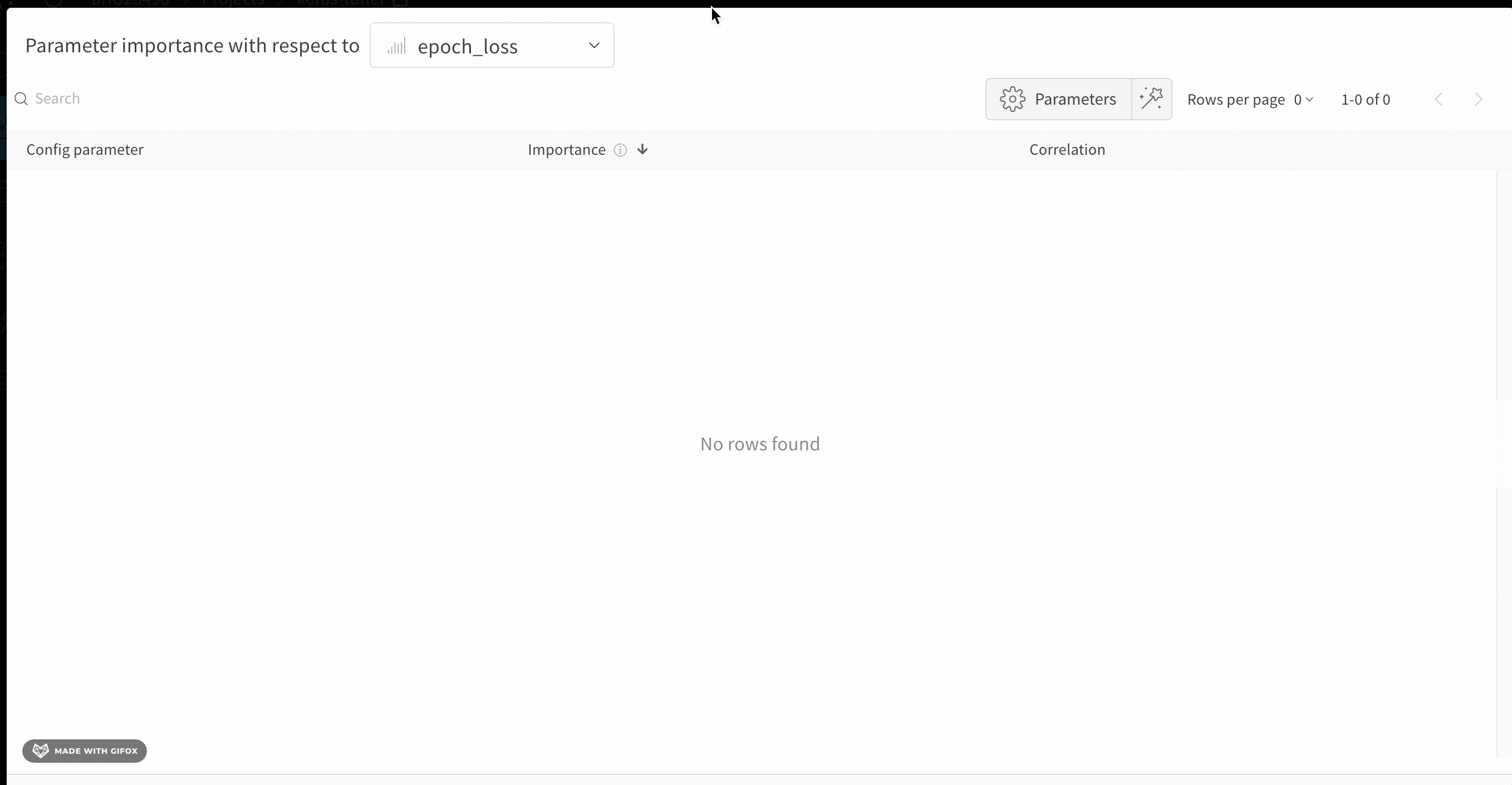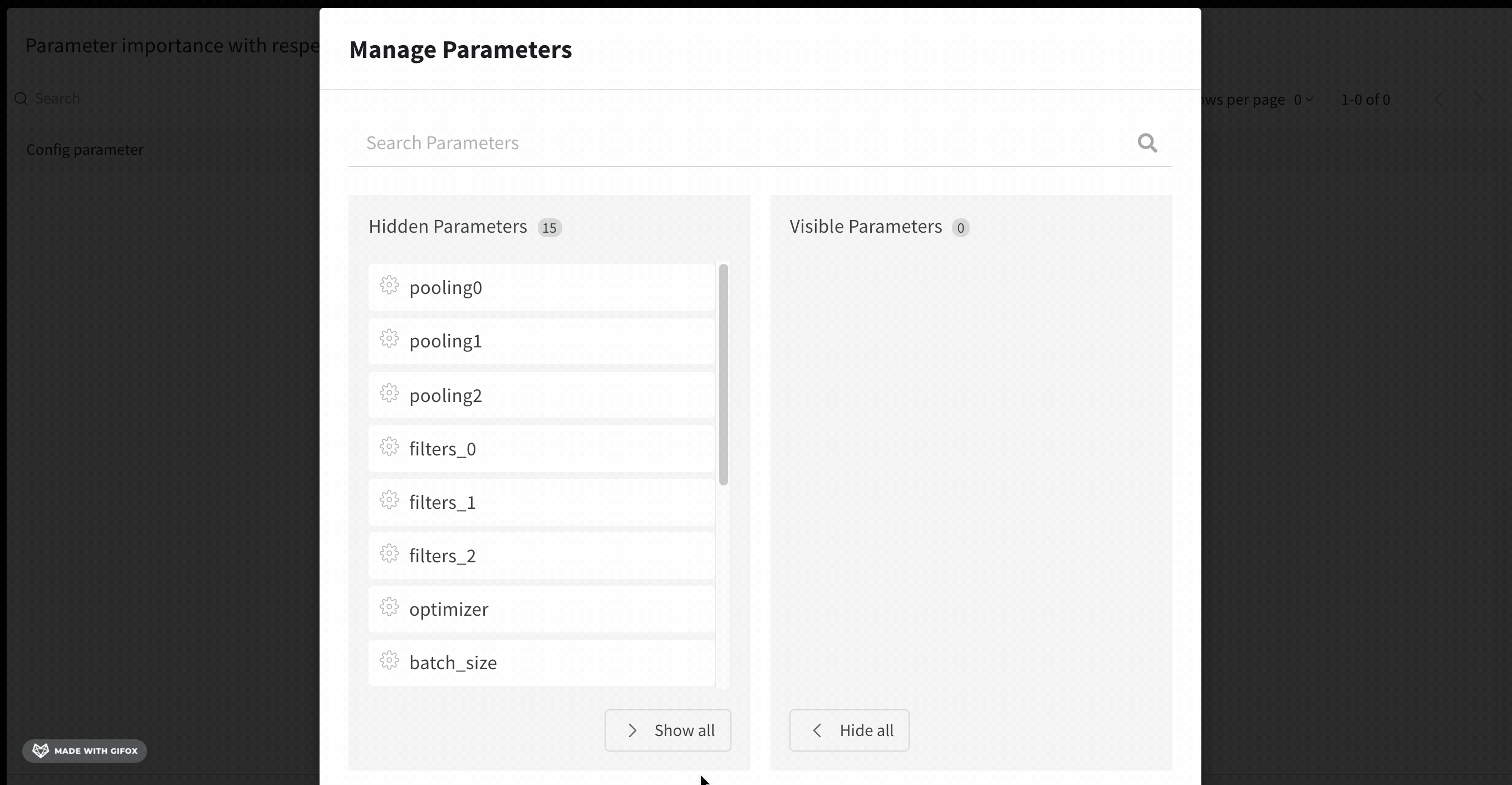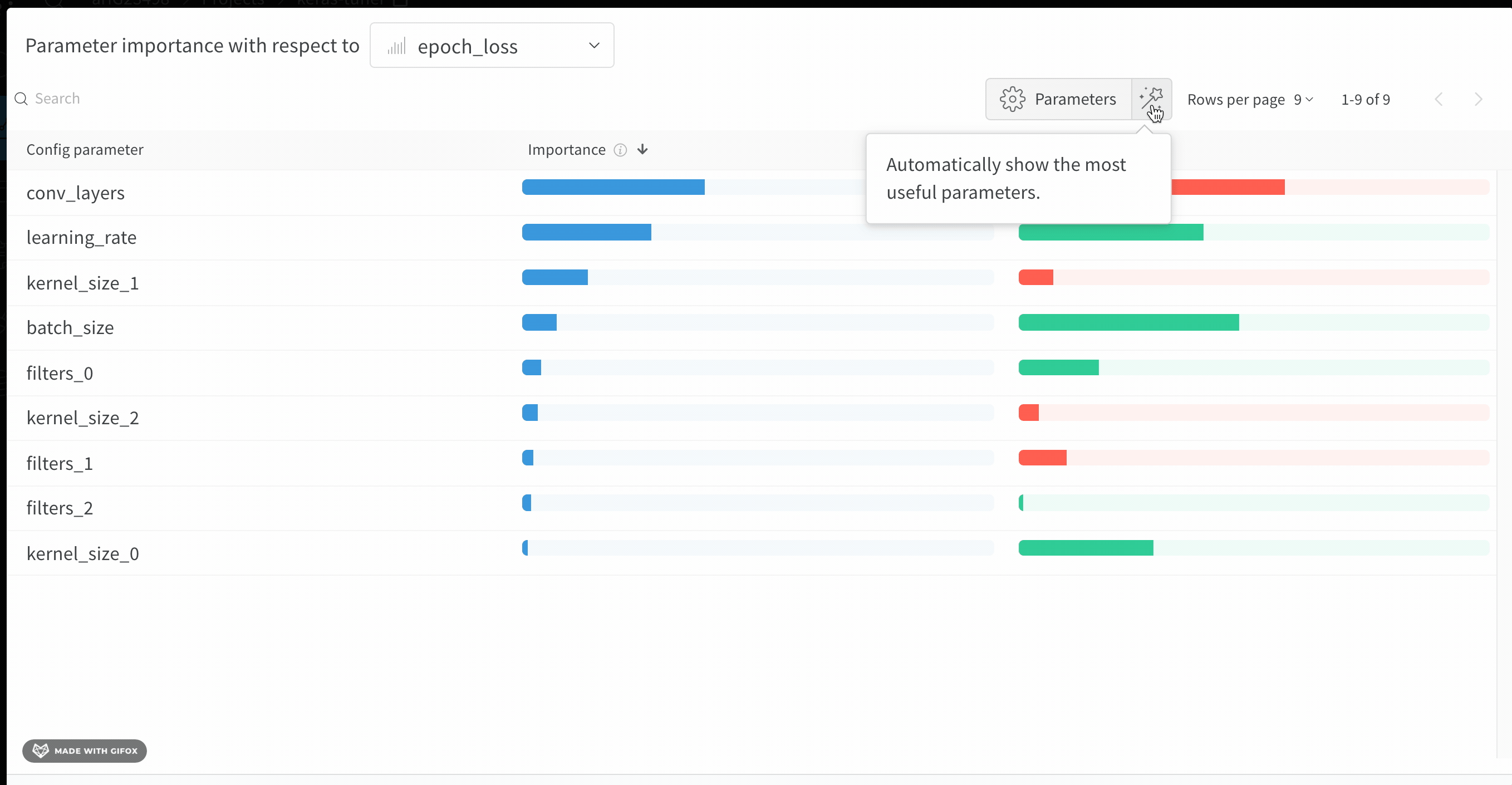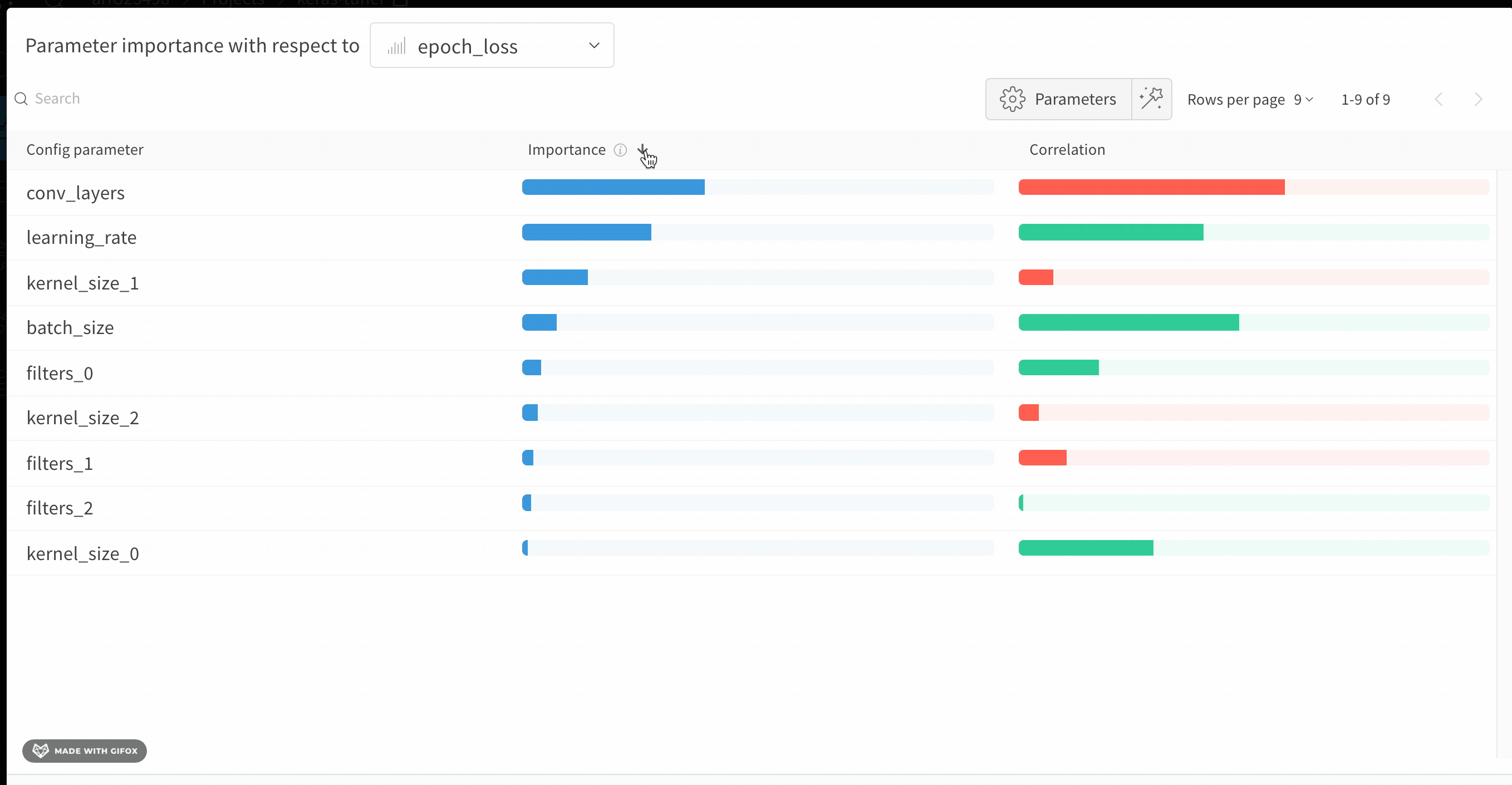
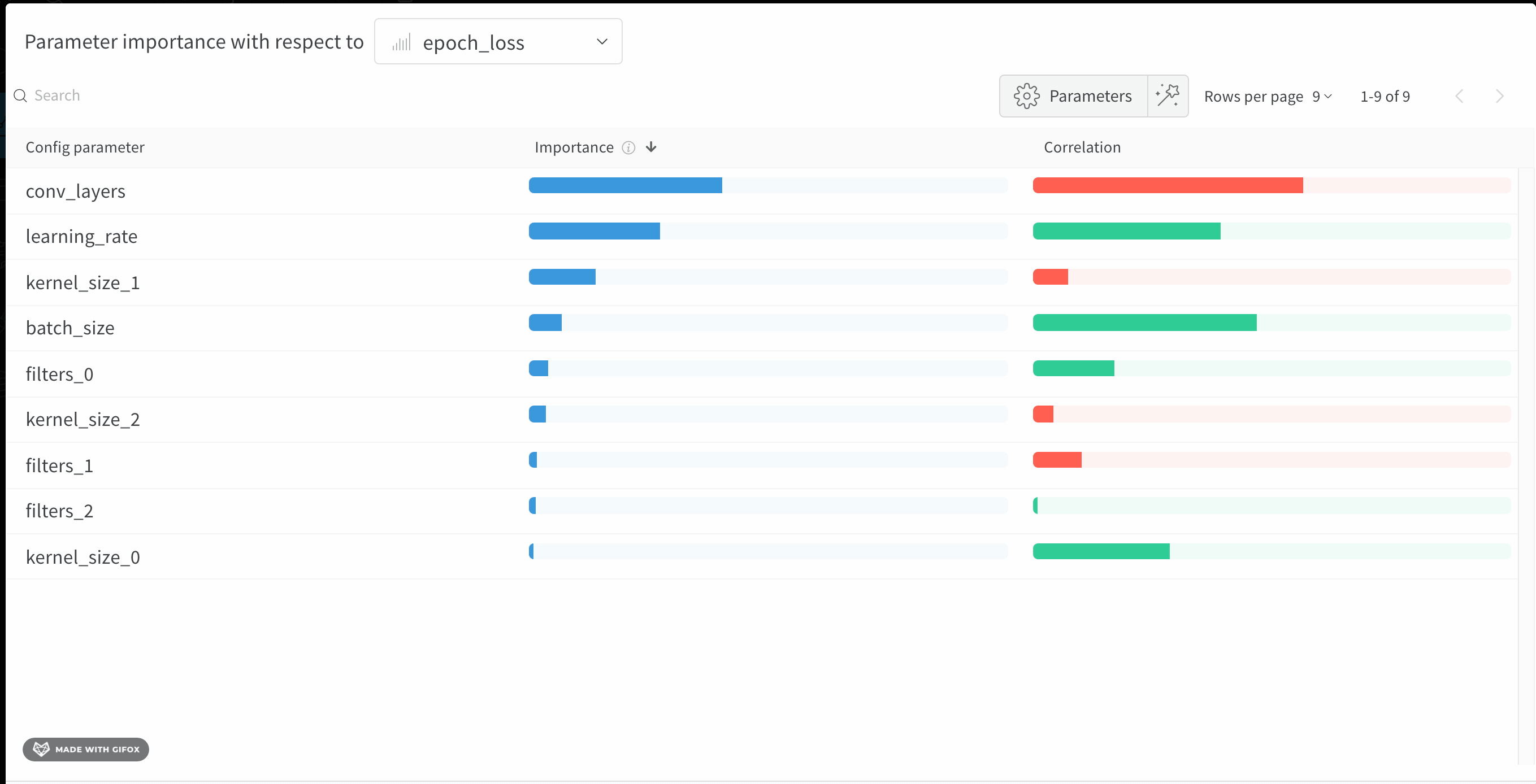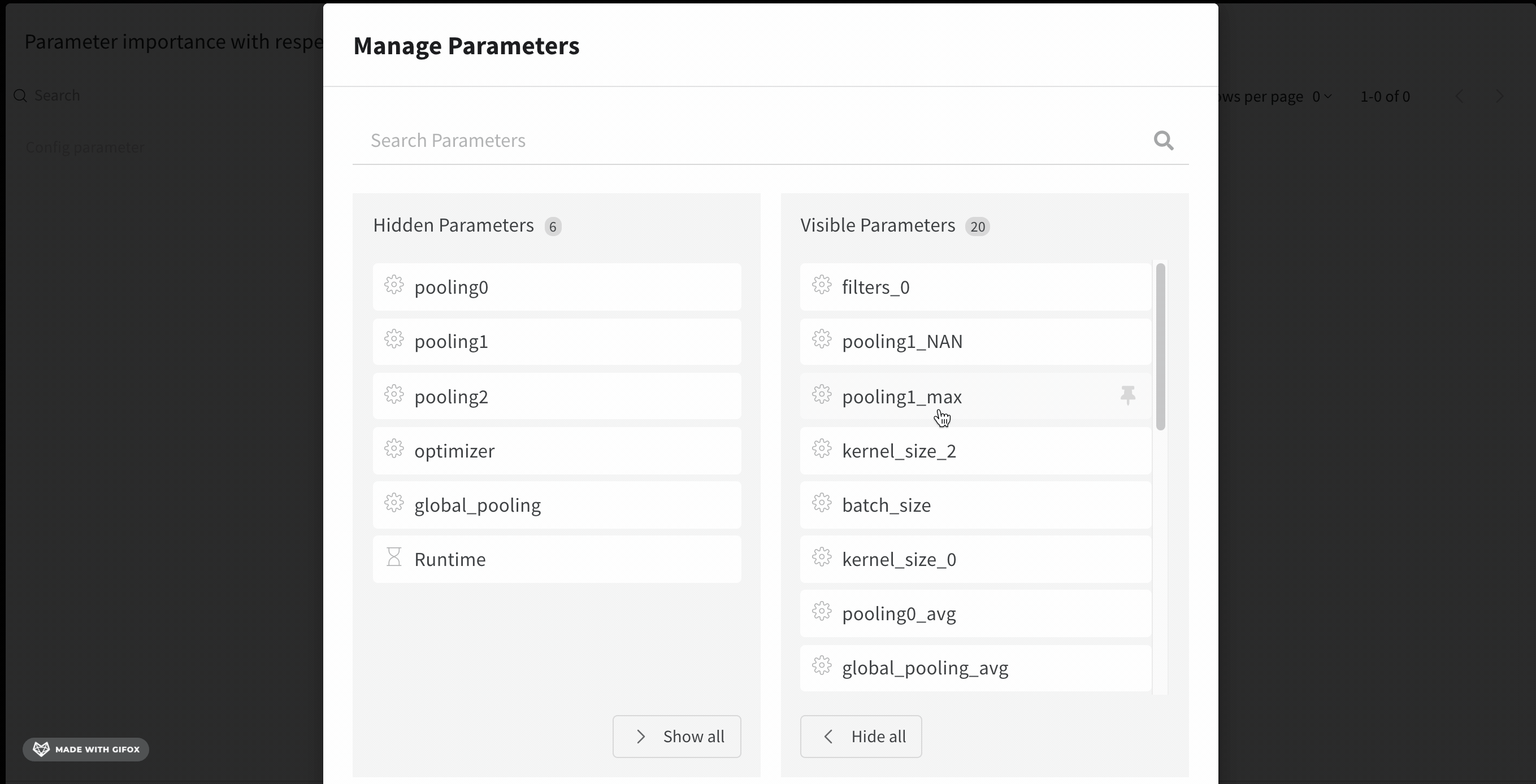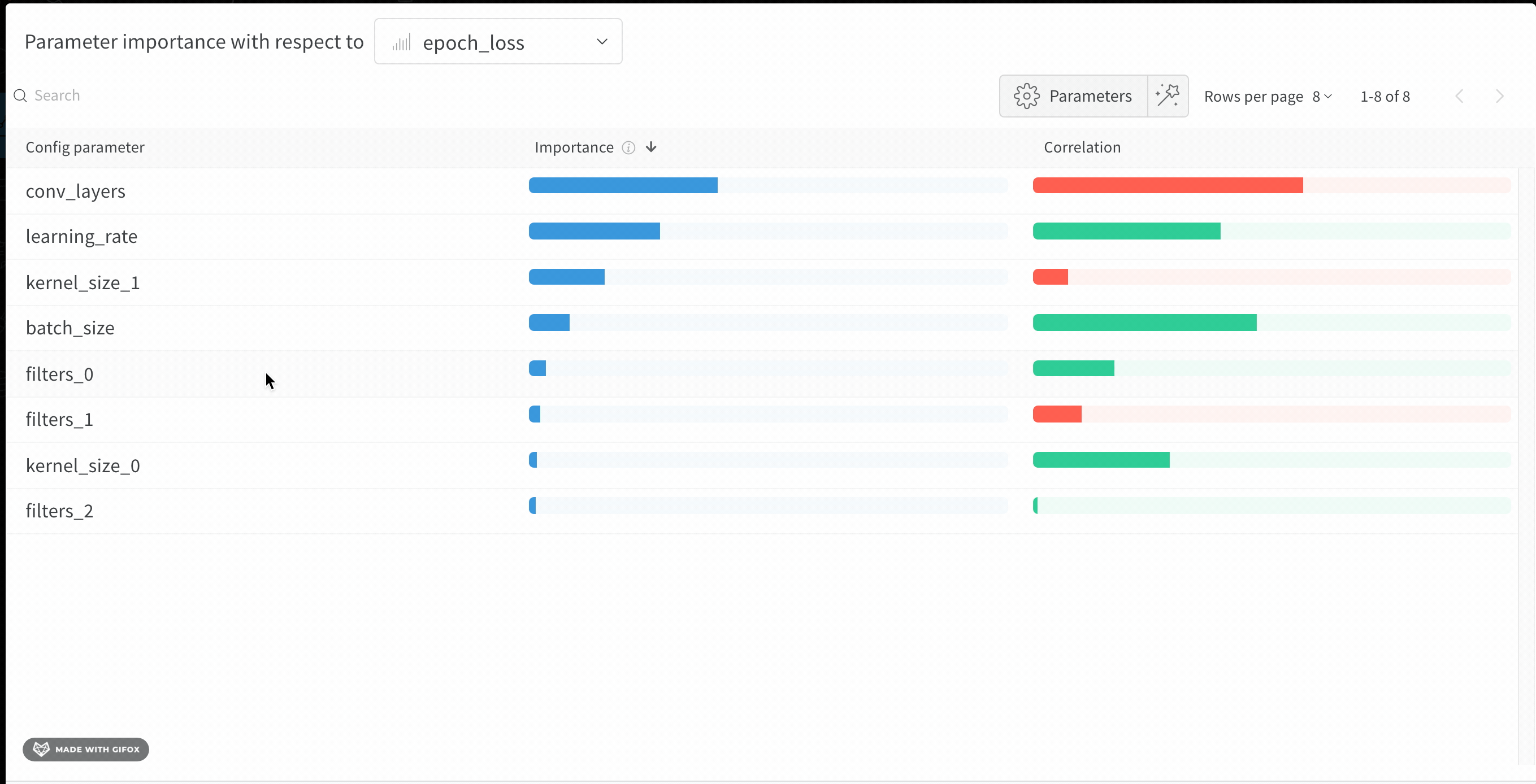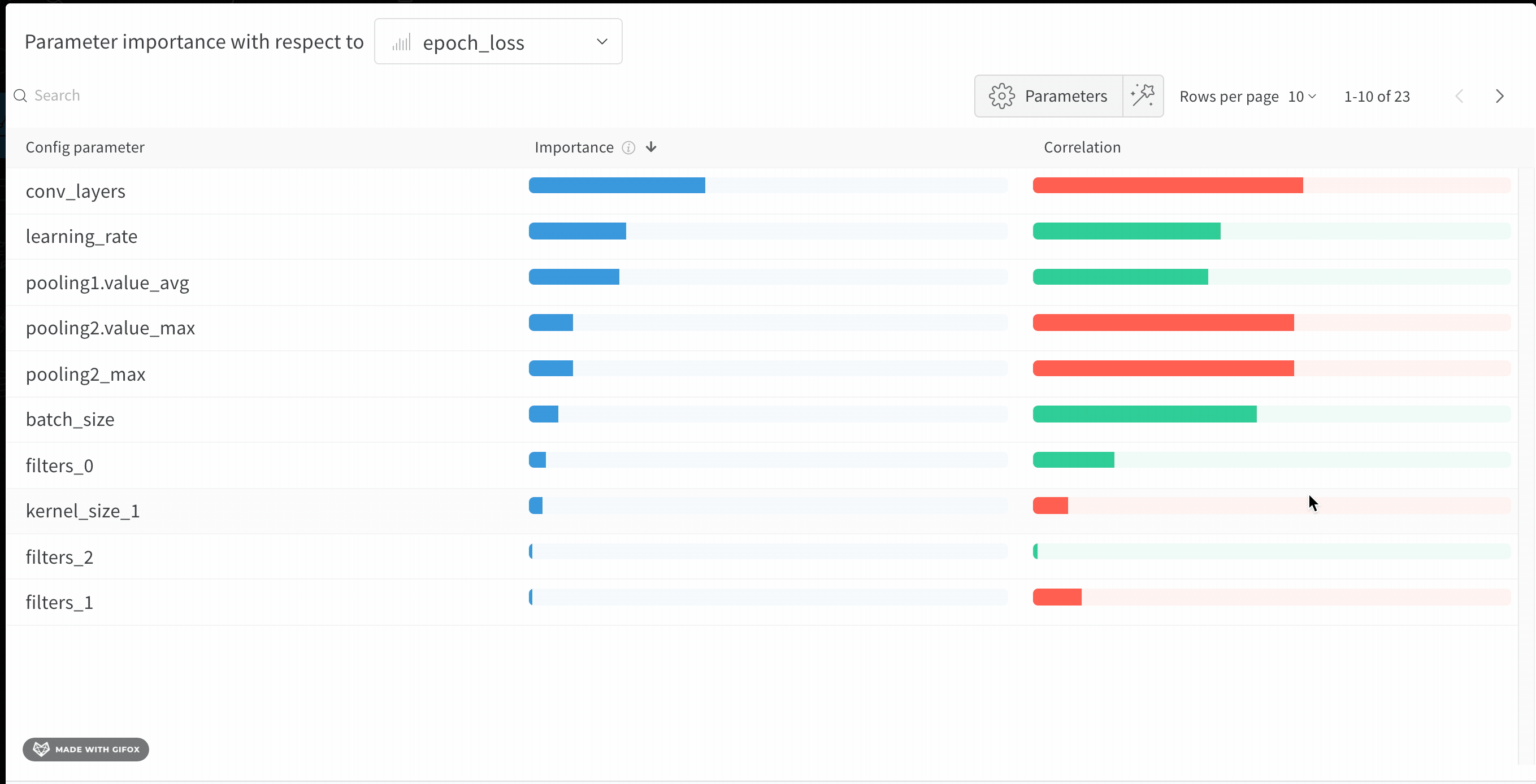
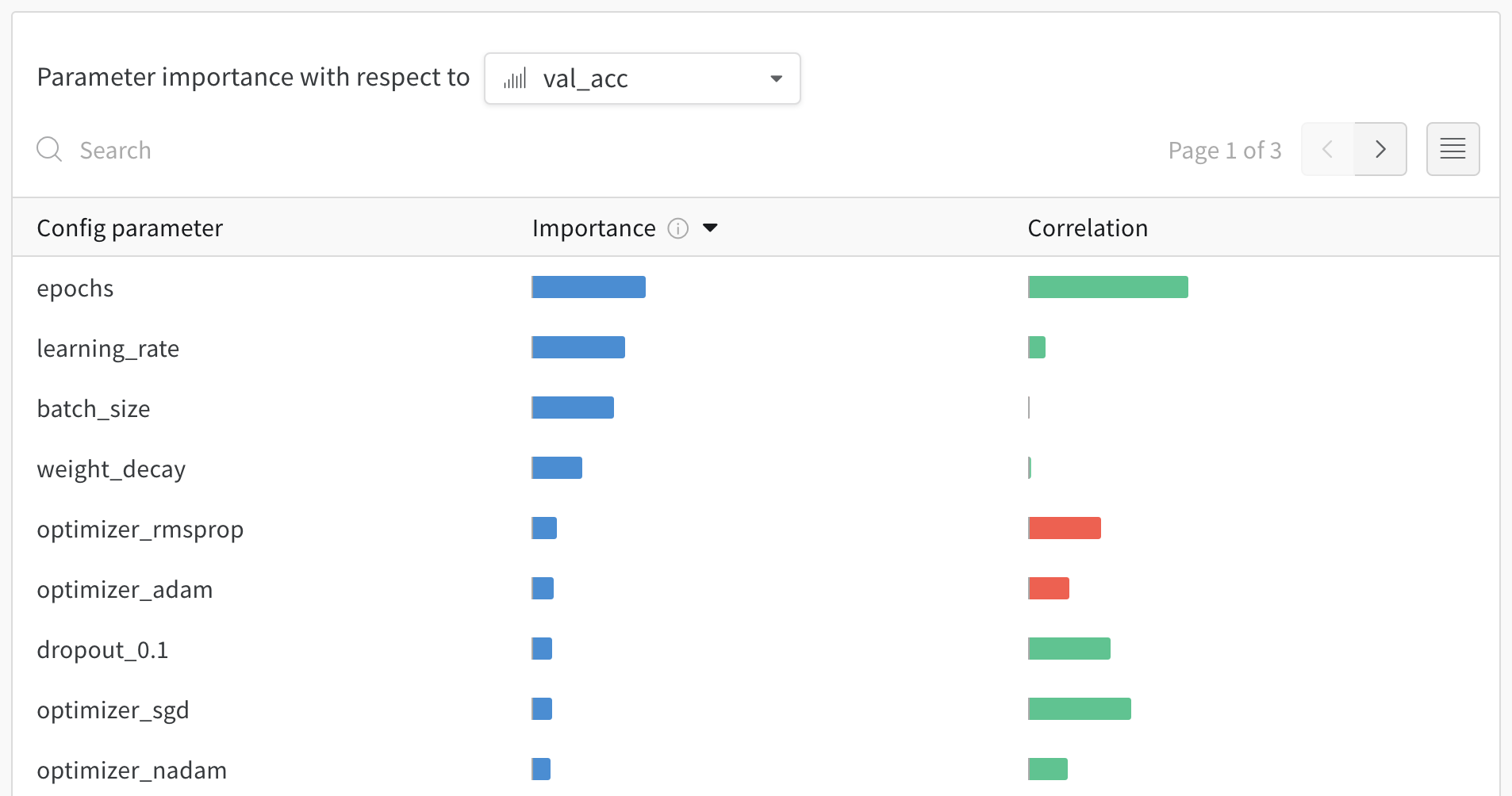
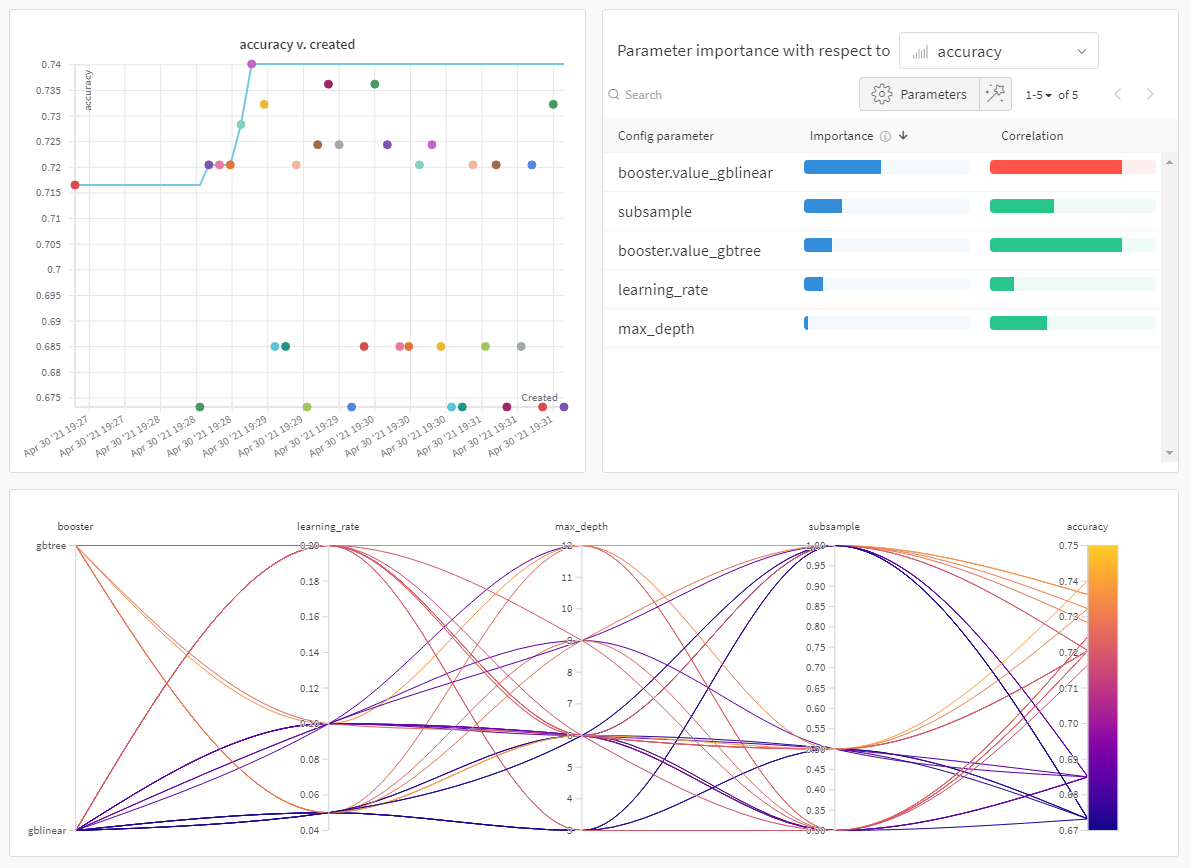
W&B Dashboard를 기계 학습 모델의 결과를 구성하고 시각화하는 중앙 장소로 사용하십시오. 몇 번의 클릭만으로 평행 좌표 플롯, 파라미터 중요도 분석 및 기타와 같은 풍부한 인터랙티브 차트를 구성합니다.
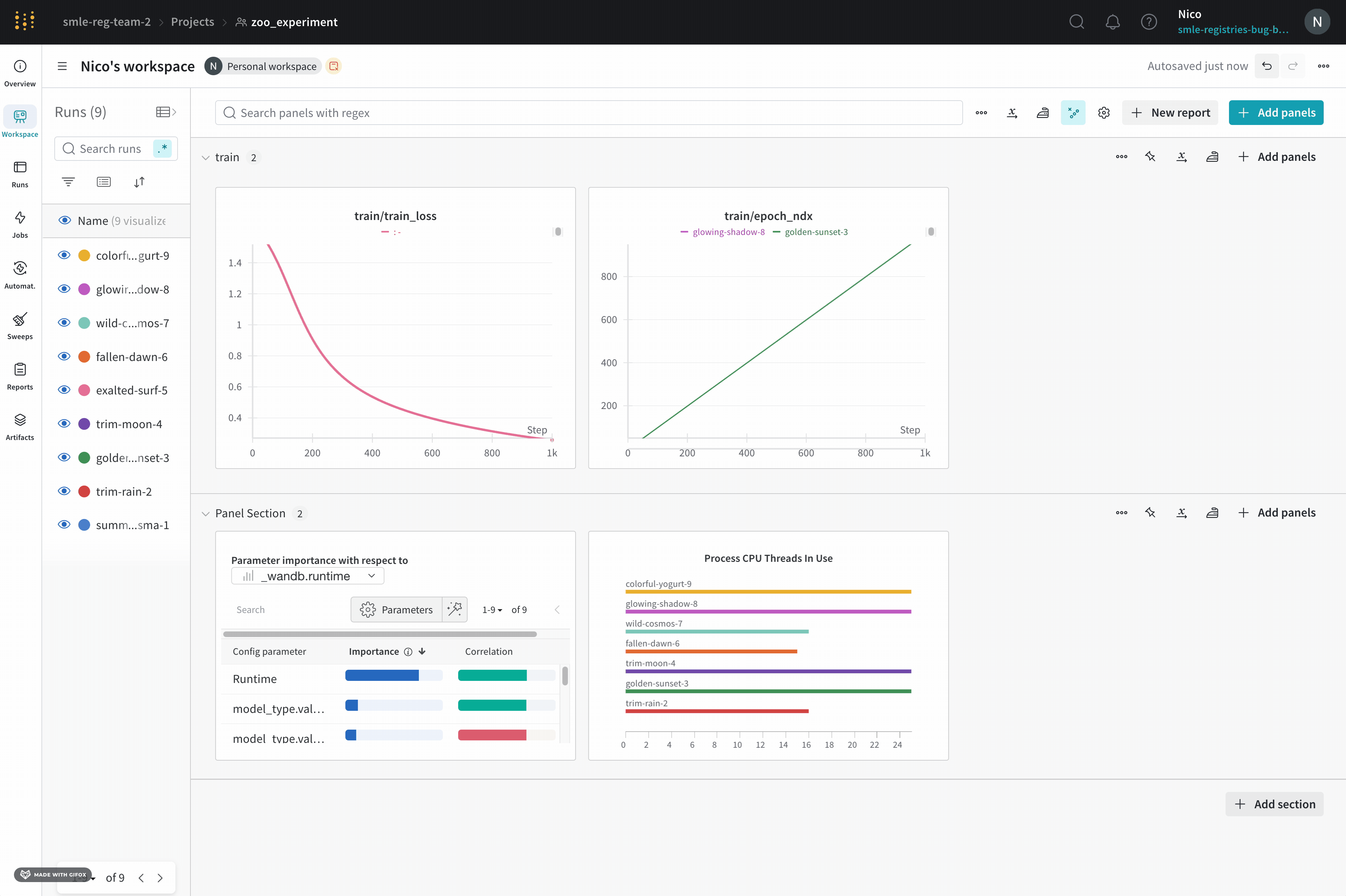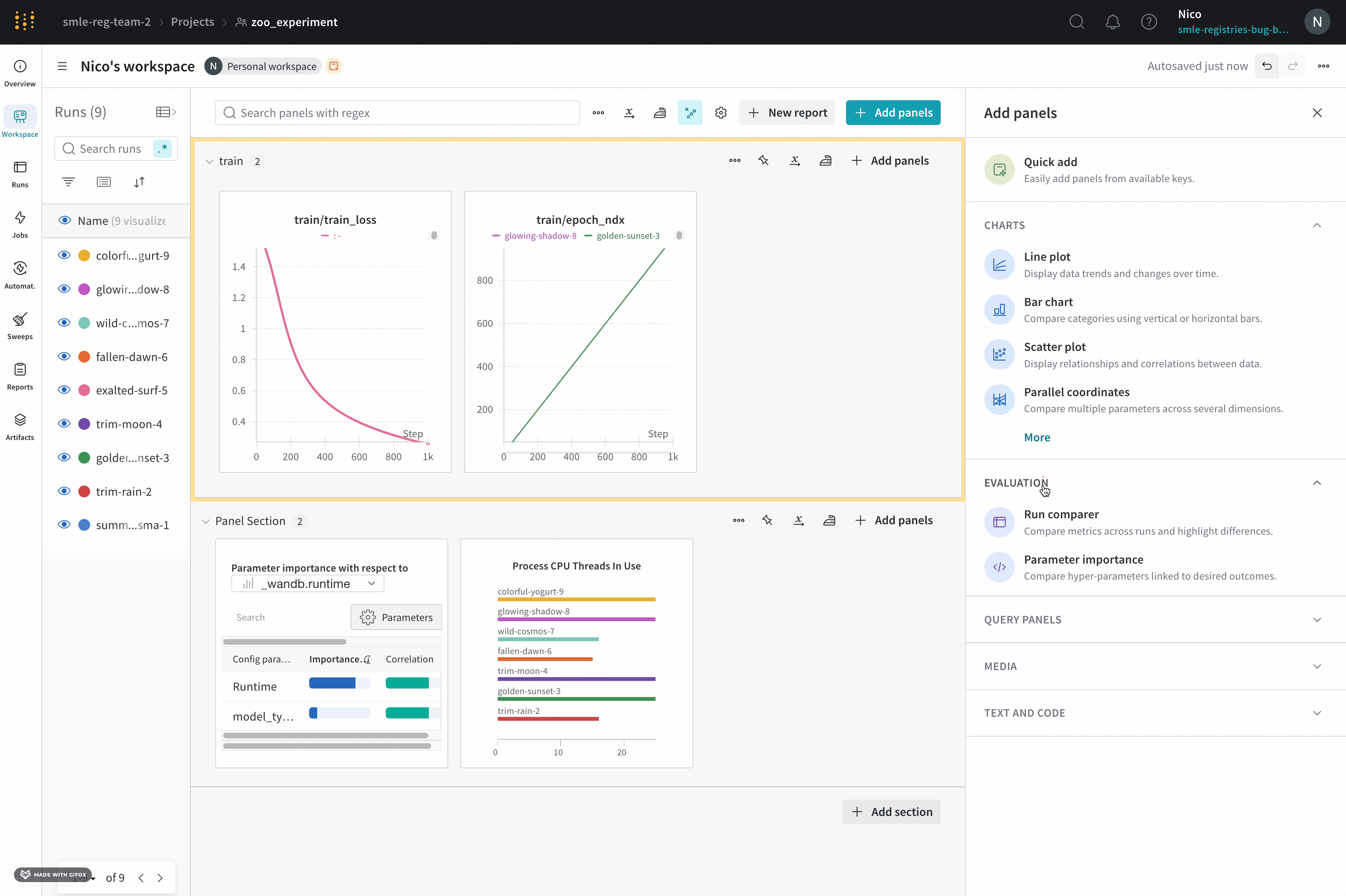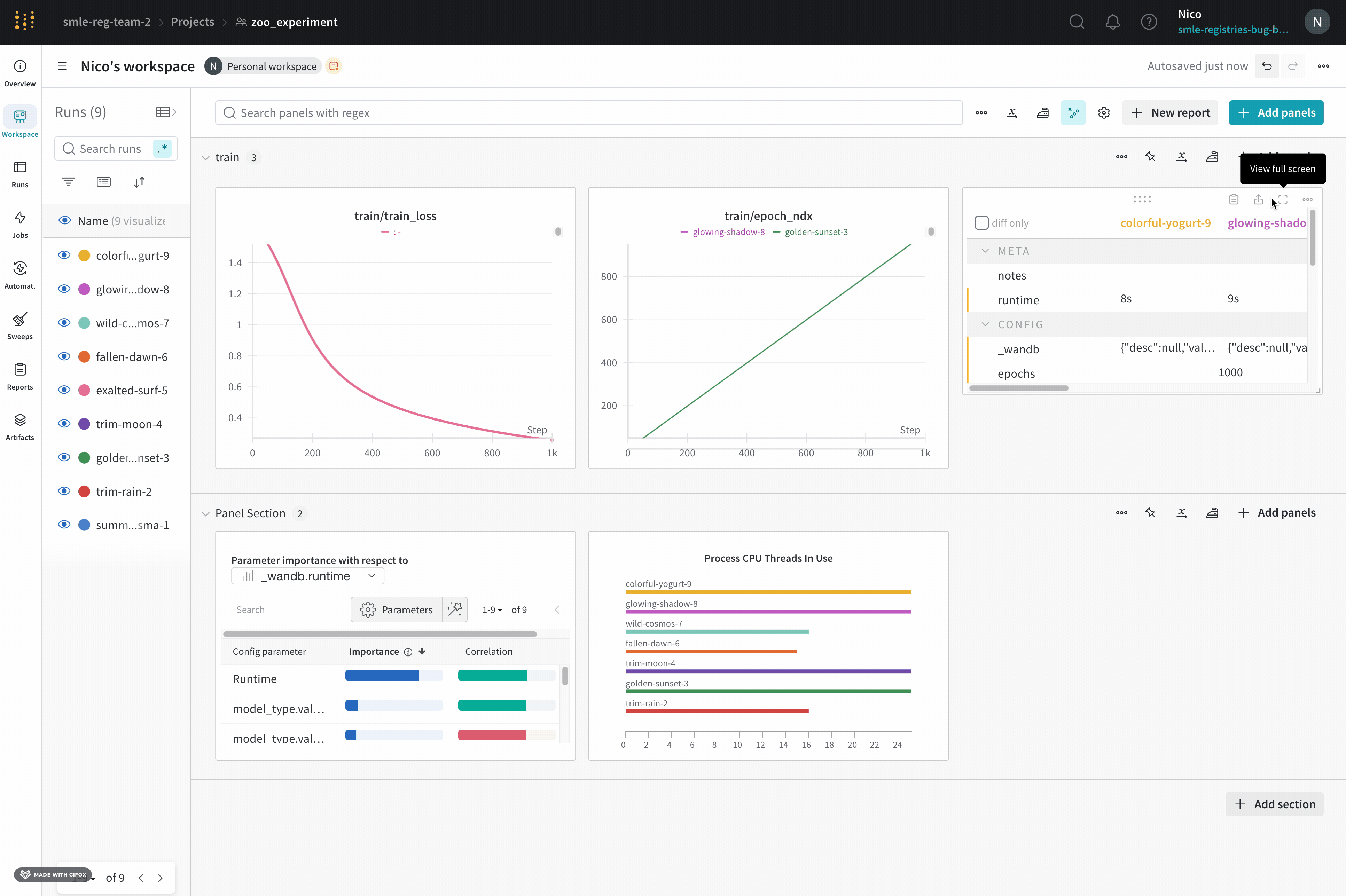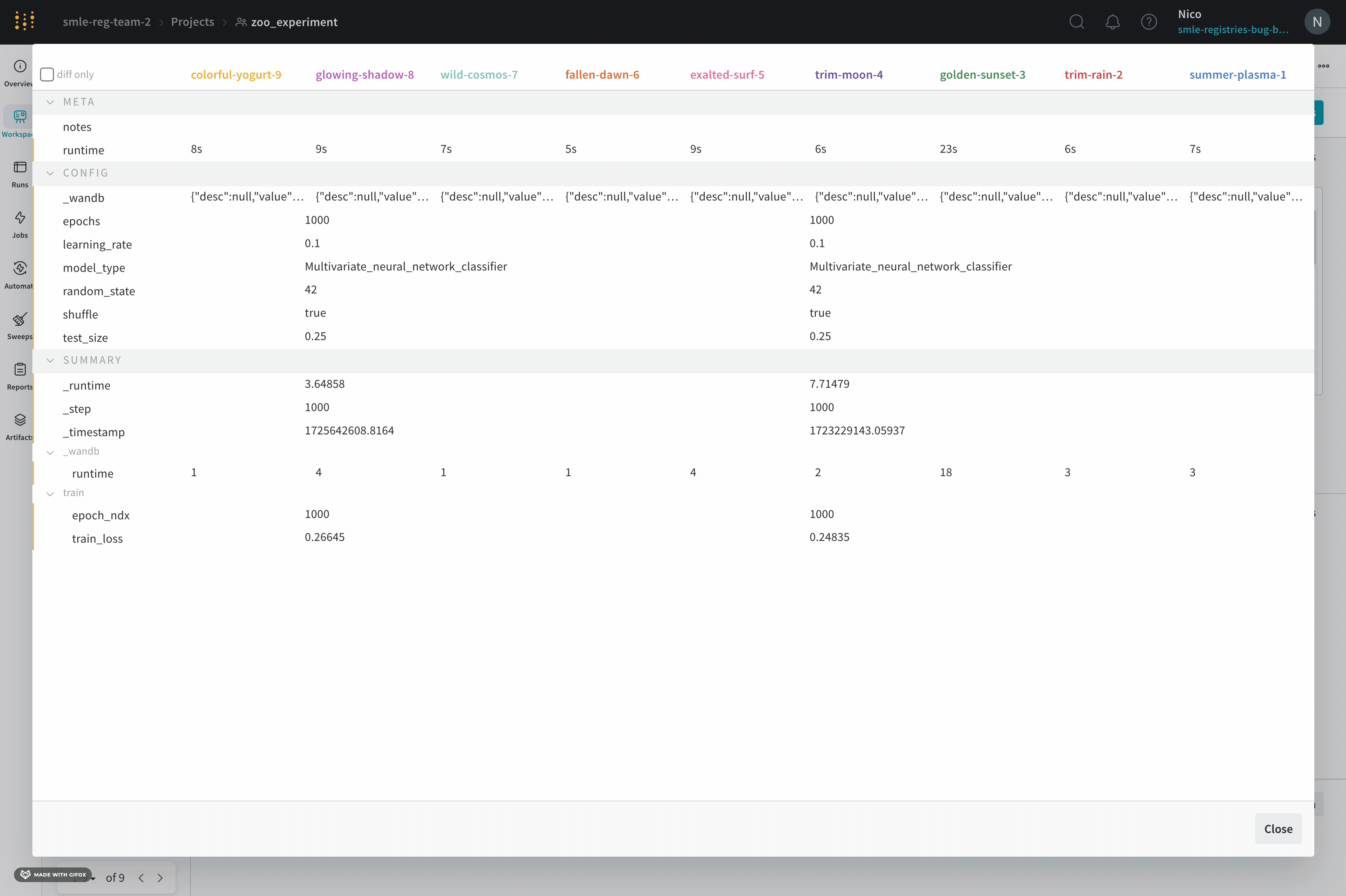
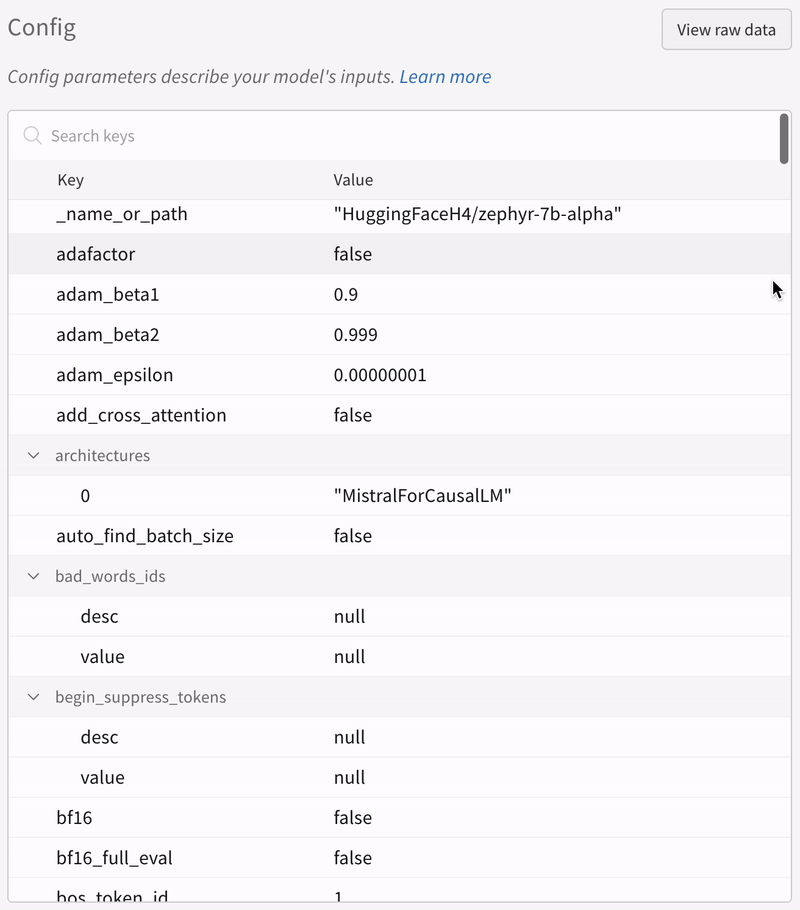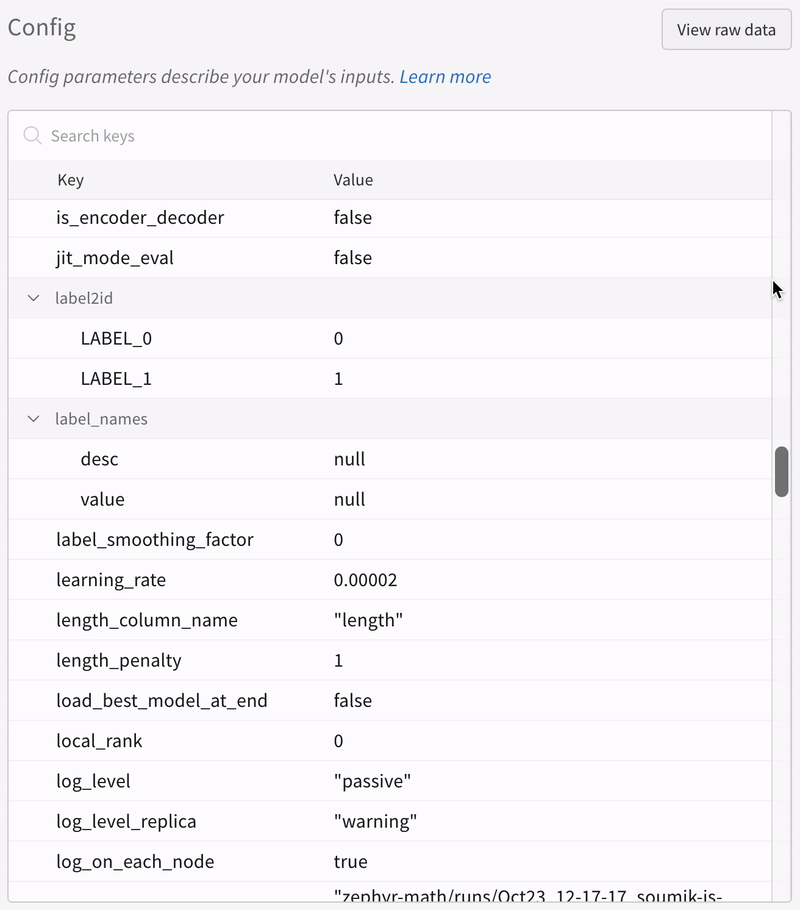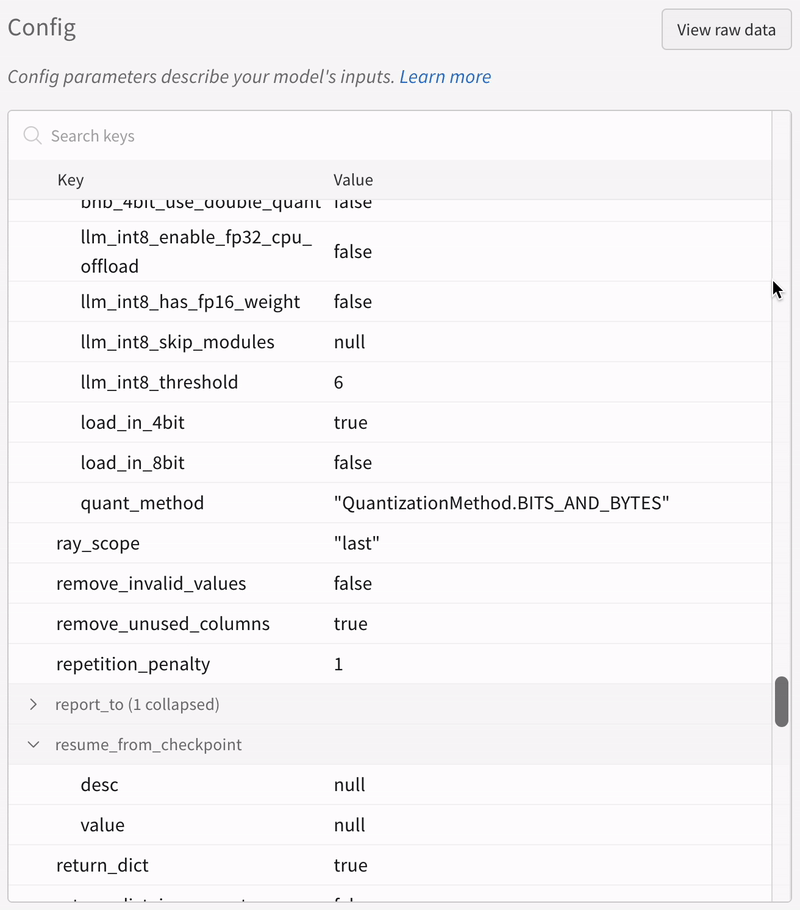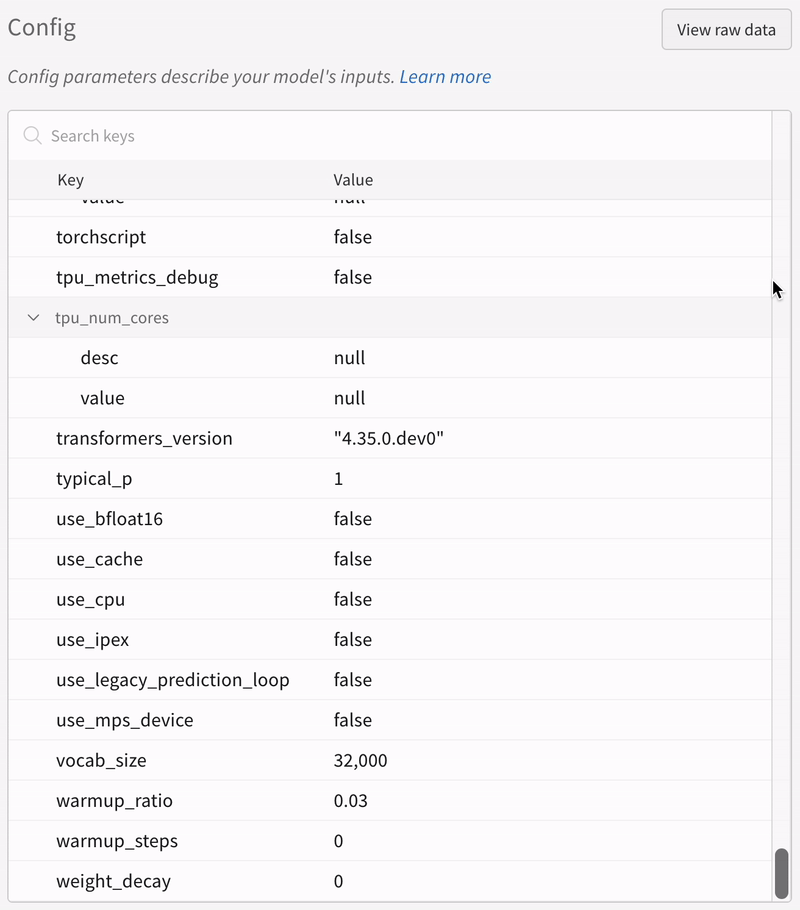
run.config 속성을 사용하면 실험을 쉽게 분석하고 향후 작업을 재현할 수 있습니다. W&B 앱에서 설정 값으로 그룹화하고, 서로 다른 W&B run의 설정을 비교하고, 각 트레이닝 설정이 결과에 미치는 영향을 평가할 수 있습니다. config 속성은 여러 사전과 유사한 오브젝트로 구성될 수 있는 사전과 유사한 오브젝트입니다.
손실 및 정확도와 같은 출력 메트릭 또는 종속 변수를 저장하려면 run.config 대신 run.log를 사용하세요.
실험 설정 구성하기
일반적으로 설정은 트레이닝 스크립트의 시작 부분에 정의됩니다. 그러나 기계 학습 워크플로우는 다를 수 있으므로 트레이닝 스크립트의 시작 부분에 설정을 정의할 필요는 없습니다.
config 변수 이름에는 마침표 (.) 대신 대시 (-) 또는 밑줄 (_)을 사용하세요.
스크립트가 루트 아래의 run.config 키에 엑세스하는 경우 속성 엑세스 구문 config.key.value 대신 사전 엑세스 구문 ["key"]["value"]를 사용하세요.
다음 섹션에서는 실험 설정을 정의하는 다양한 일반적인 시나리오에 대해 설명합니다.
초기화 시 설정 구성하기
W&B Run으로 데이터를 동기화하고 기록하는 백그라운드 프로세스를 생성하기 위해 wandb.init() API를 호출할 때 스크립트 시작 부분에 사전을 전달합니다.
다음 코드 조각은 설정 값으로 Python 사전을 정의하는 방법과 W&B Run을 초기화할 때 해당 사전을 인수로 전달하는 방법을 보여줍니다.
import wandb
# config 사전 오브젝트 정의config = {
"hidden_layer_sizes": [32, 64],
"kernel_sizes": [3],
"activation": "ReLU",
"pool_sizes": [2],
"dropout": 0.5,
"num_classes": 10,
}
# W&B를 초기화할 때 config 사전 전달with wandb.init(project="config_example", config=config) as run:
...
중첩된 사전을 config로 전달하면 W&B는 점을 사용하여 이름을 평면화합니다.
Python에서 다른 사전에 엑세스하는 방법과 유사하게 사전에서 값에 엑세스합니다.
# 키를 인덱스 값으로 사용하여 값에 엑세스hidden_layer_sizes = run.config["hidden_layer_sizes"]
kernel_sizes = run.config["kernel_sizes"]
activation = run.config["activation"]
# Python 사전 get() 메소드hidden_layer_sizes = run.config.get("hidden_layer_sizes")
kernel_sizes = run.config.get("kernel_sizes")
activation = run.config.get("activation")
개발자 가이드 및 예제 전체에서 설정 값을 별도의 변수로 복사합니다. 이 단계는 선택 사항입니다. 가독성을 위해 수행됩니다.
argparse로 설정 구성하기
argparse 오브젝트로 설정을 구성할 수 있습니다. argument parser의 약자인 argparse는 커맨드라인 인수의 모든 유연성과 성능을 활용하는 스크립트를 쉽게 작성할 수 있도록 하는 Python 3.2 이상의 표준 라이브러리 모듈입니다.
이는 커맨드라인에서 실행되는 스크립트의 결과를 추적하는 데 유용합니다.
다음 Python 스크립트는 파서 오브젝트를 정의하여 실험 설정을 정의하고 구성하는 방법을 보여줍니다. 함수 train_one_epoch 및 evaluate_one_epoch는 이 데모의 목적으로 트레이닝 루프를 시뮬레이션하기 위해 제공됩니다.
API에 엔티티, 프로젝트 이름 및 run의 ID를 제공해야 합니다. Run 오브젝트 또는 W&B 앱 UI에서 이러한 세부 정보를 찾을 수 있습니다.
with wandb.init() as run:
...# 현재 스크립트 또는 노트북에서 시작된 경우 Run 오브젝트에서 다음 값을 찾거나 W&B 앱 UI에서 복사할 수 있습니다.username = run.entity
project = run.project
run_id = run.id
# api.run()은 wandb.init()과 다른 유형의 오브젝트를 반환합니다.api = wandb.Api()
api_run = api.run(f"{username}/{project}/{run_id}")
api_run.config["bar"] =32api_run.update()
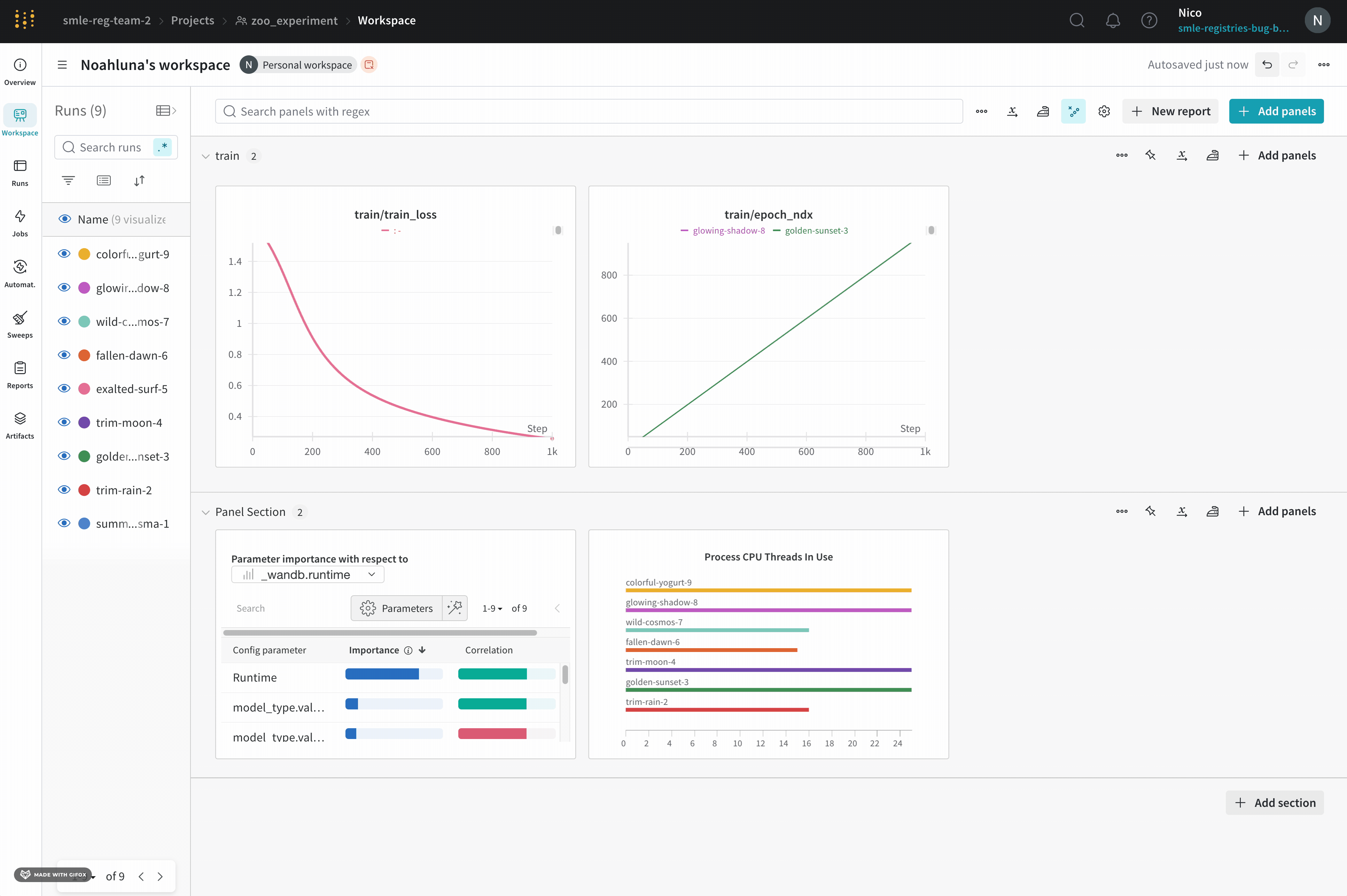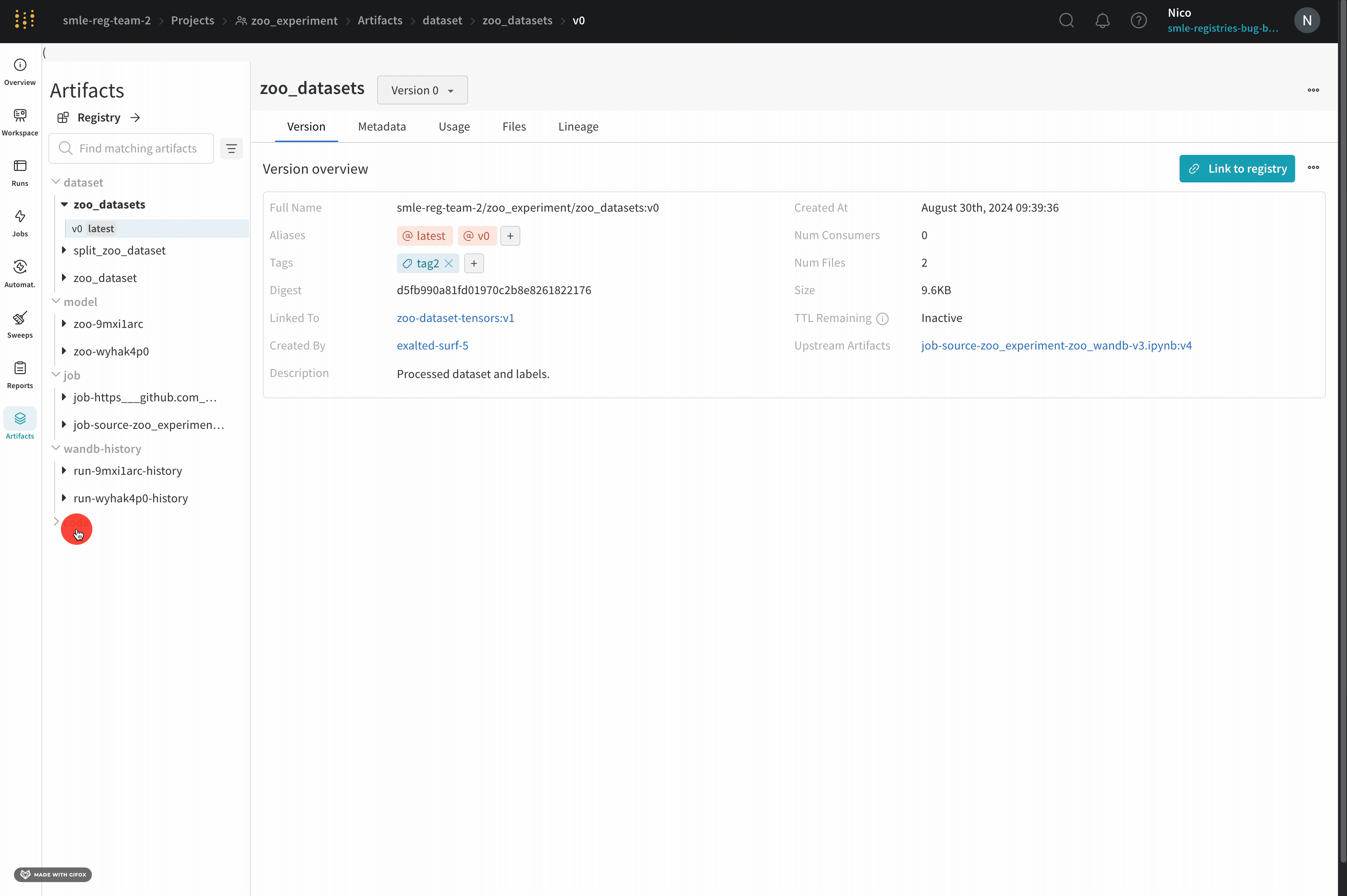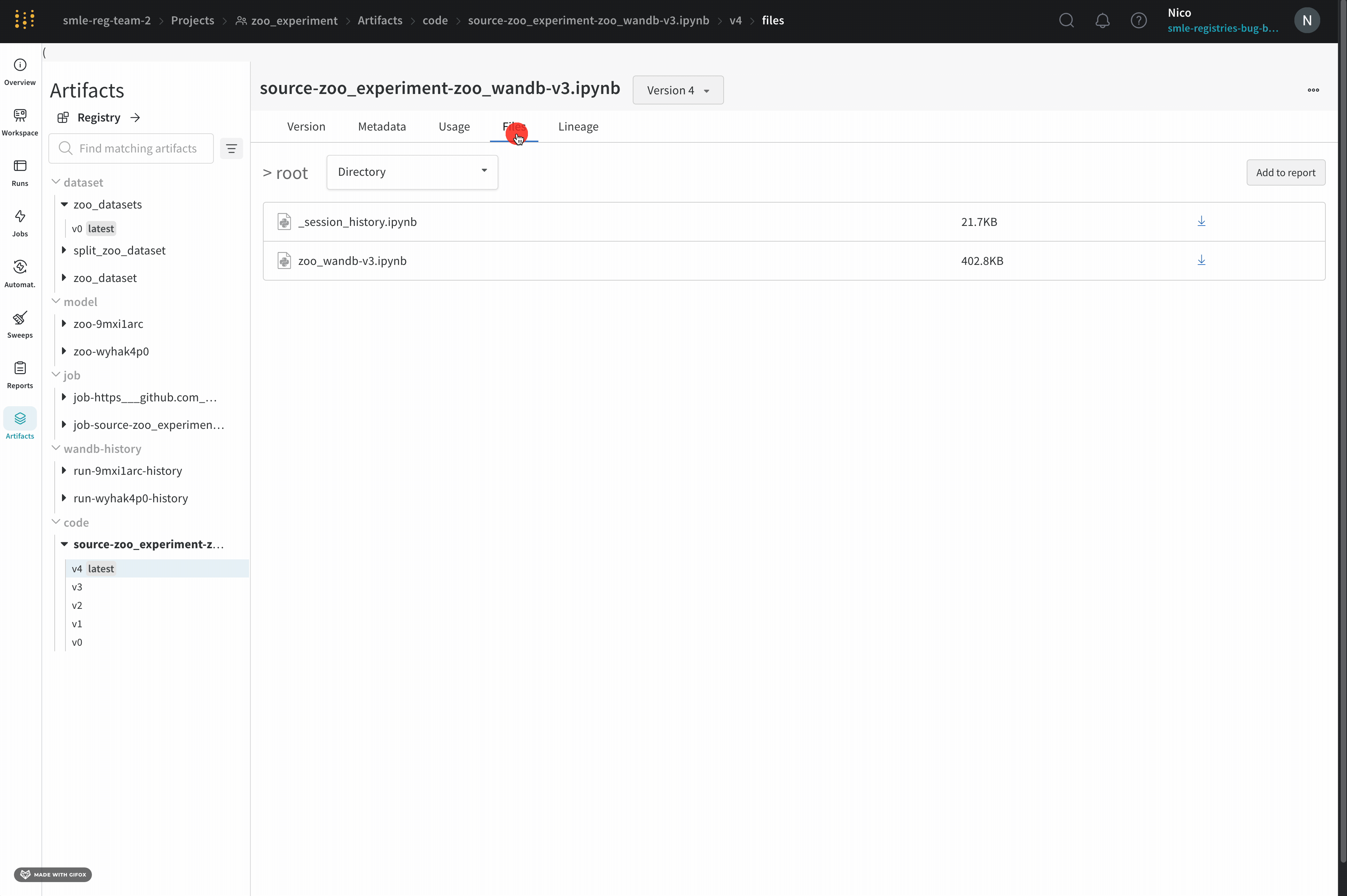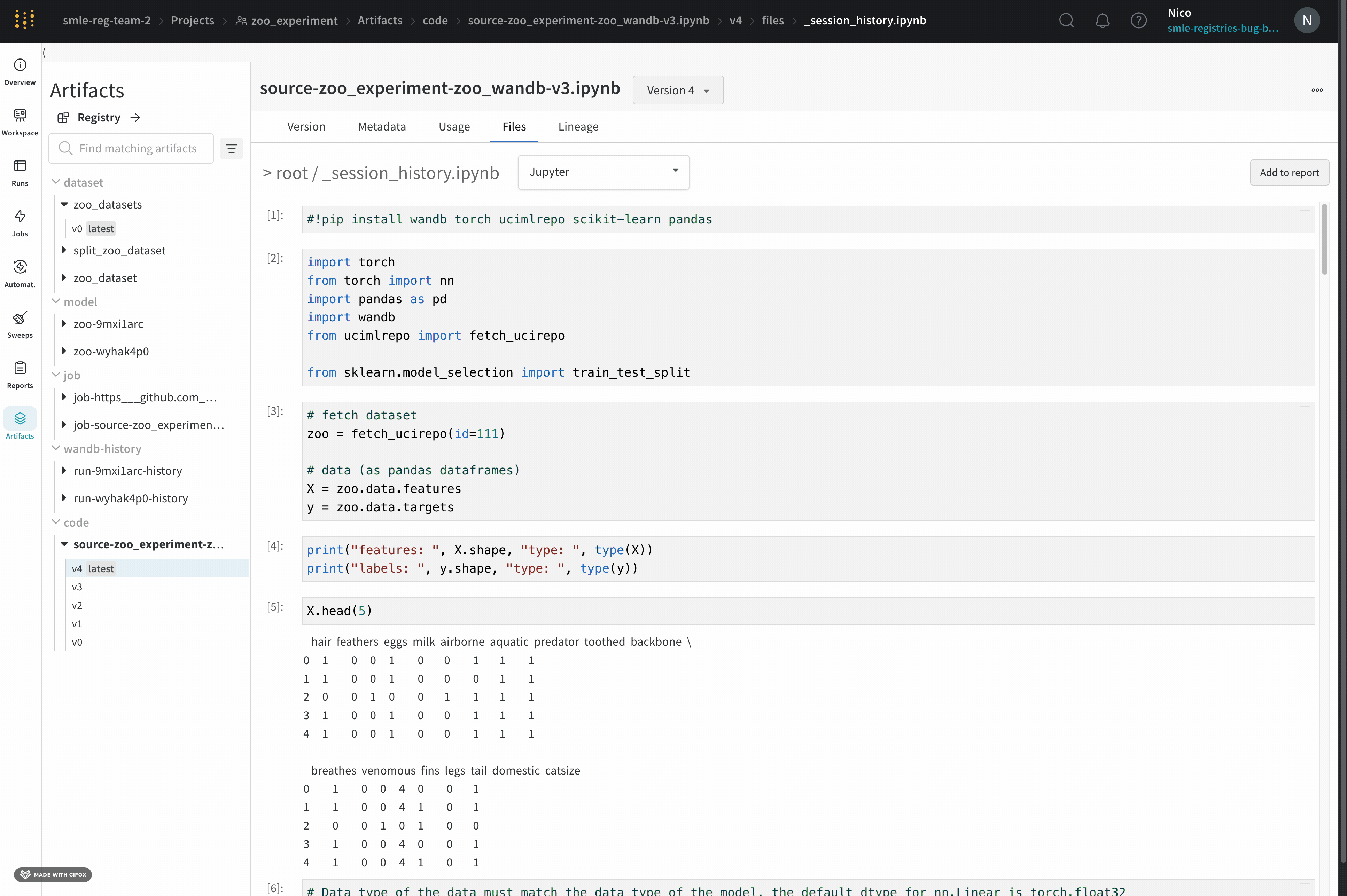
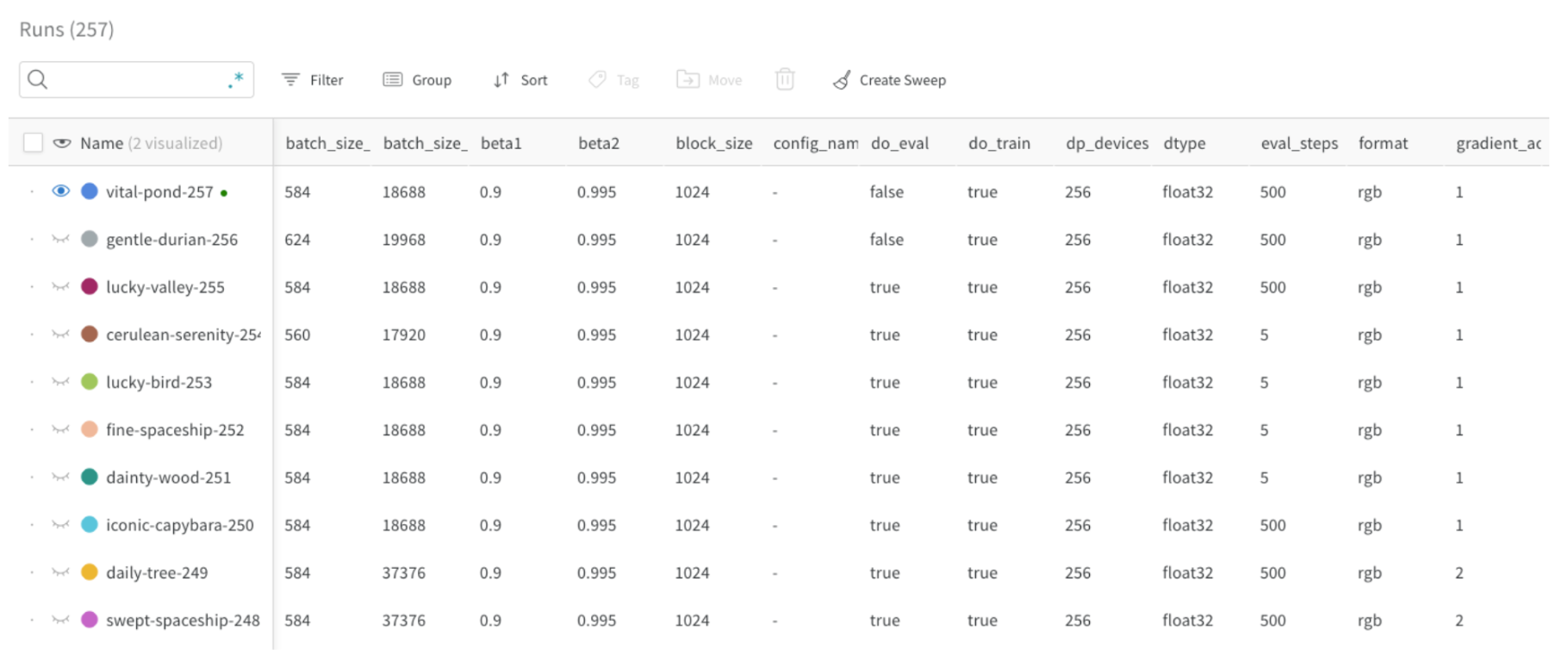
프로젝트의 workspace는 실험을 비교할 수 있는 개인 샌드박스를 제공합니다. 프로젝트를 사용하여 다양한 아키텍처, 하이퍼파라미터, 데이터셋, 전처리 등으로 동일한 문제에 대해 작업하면서 비교할 수 있는 Models를 구성합니다.
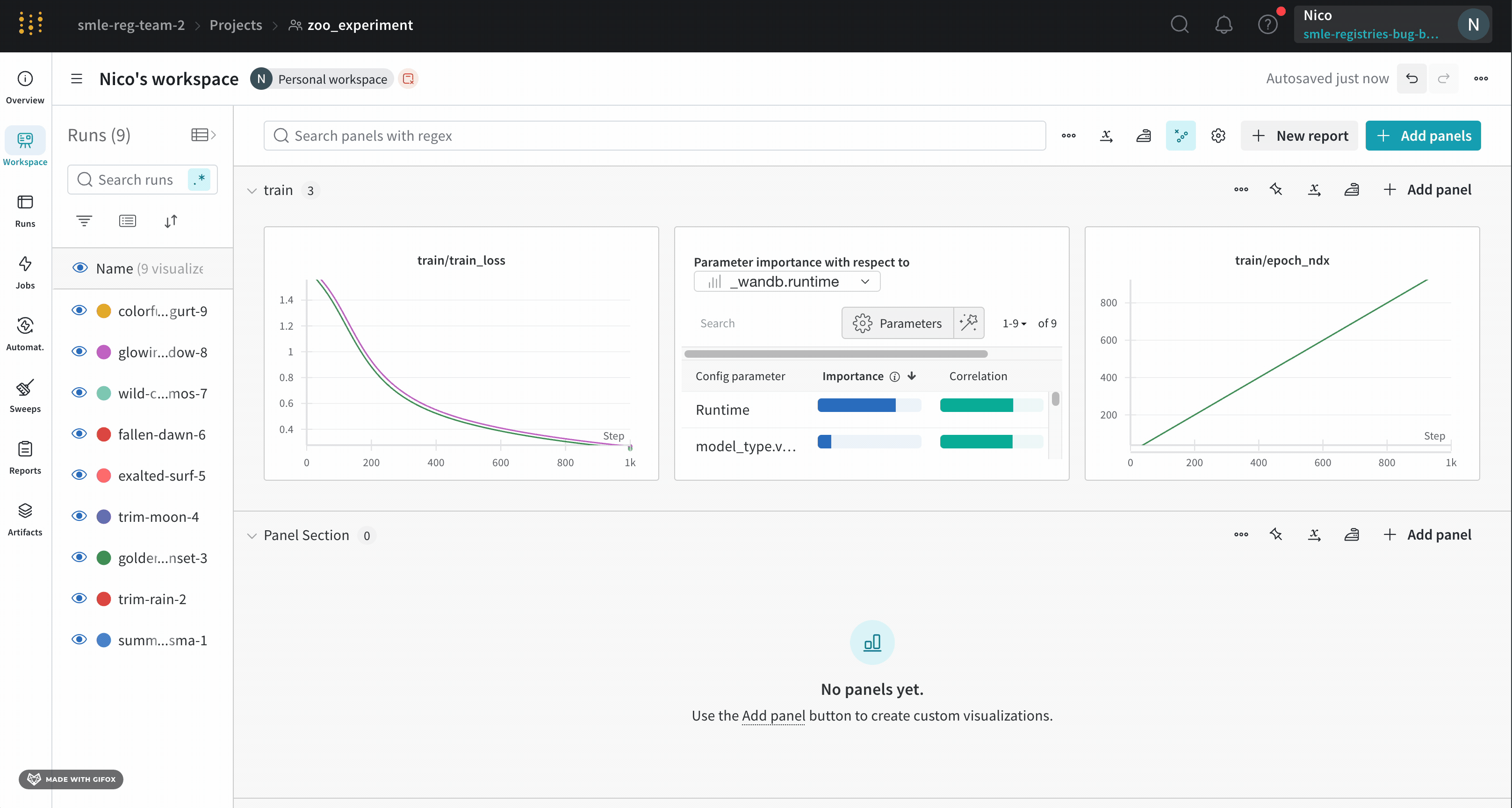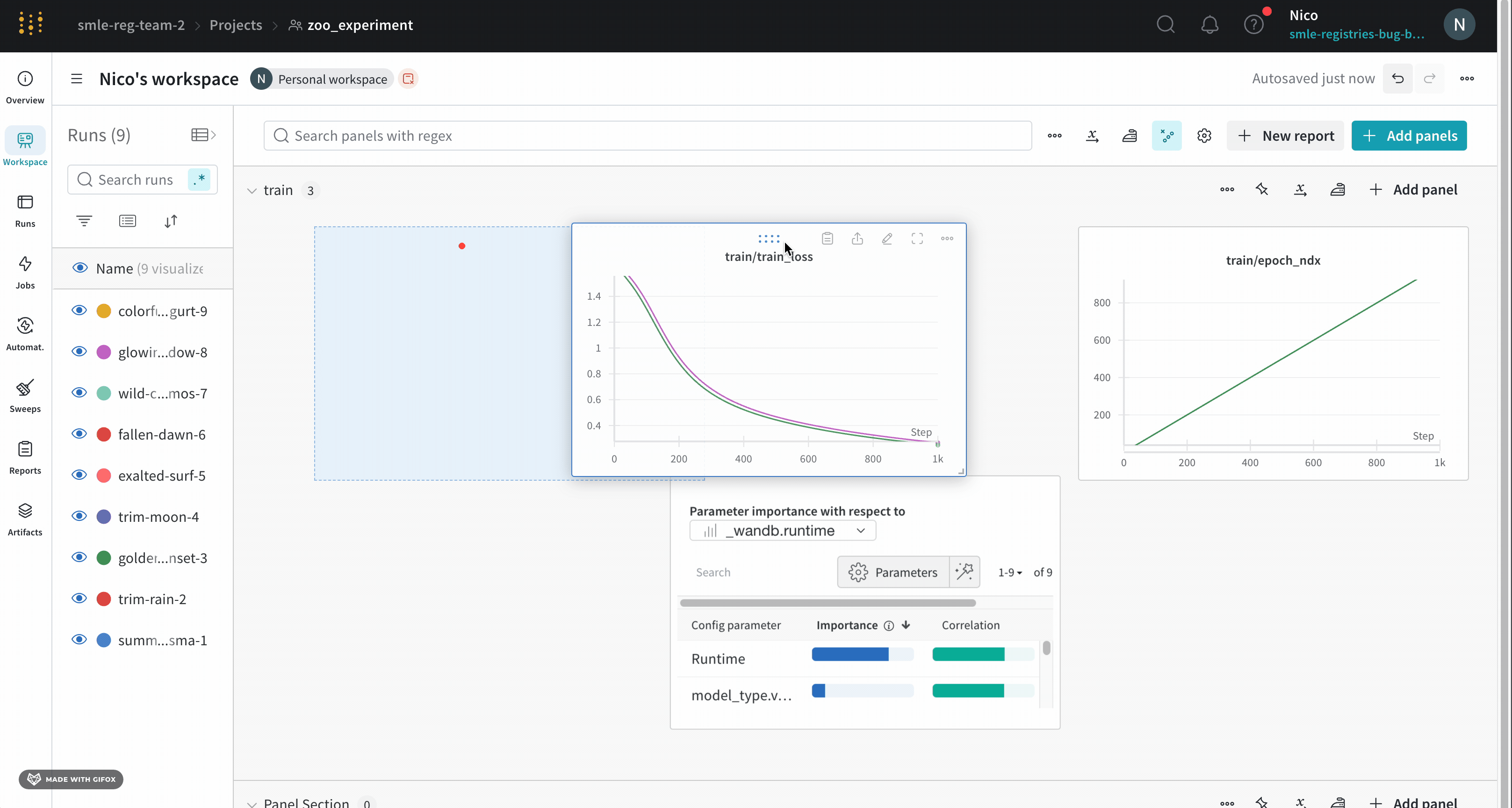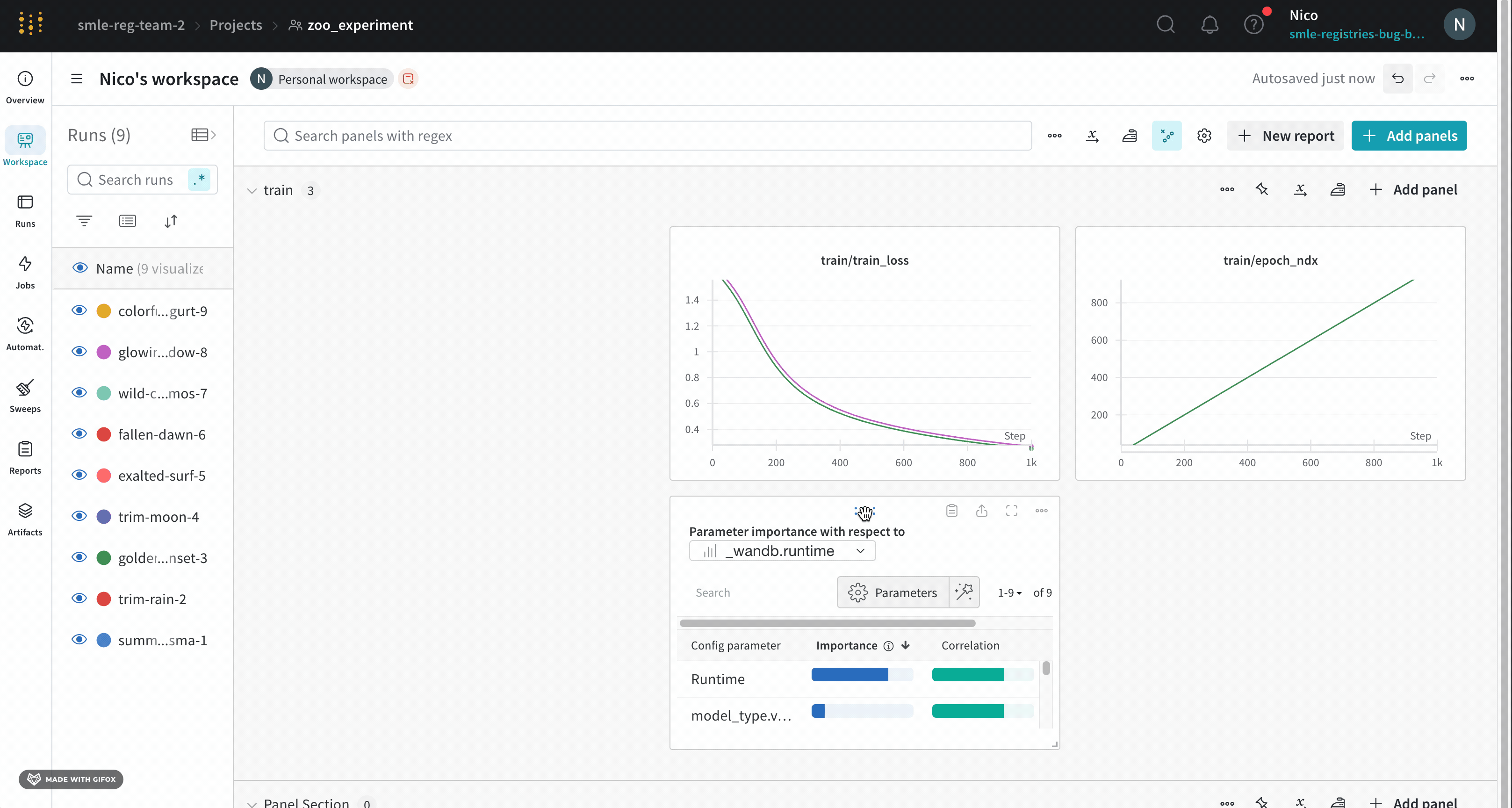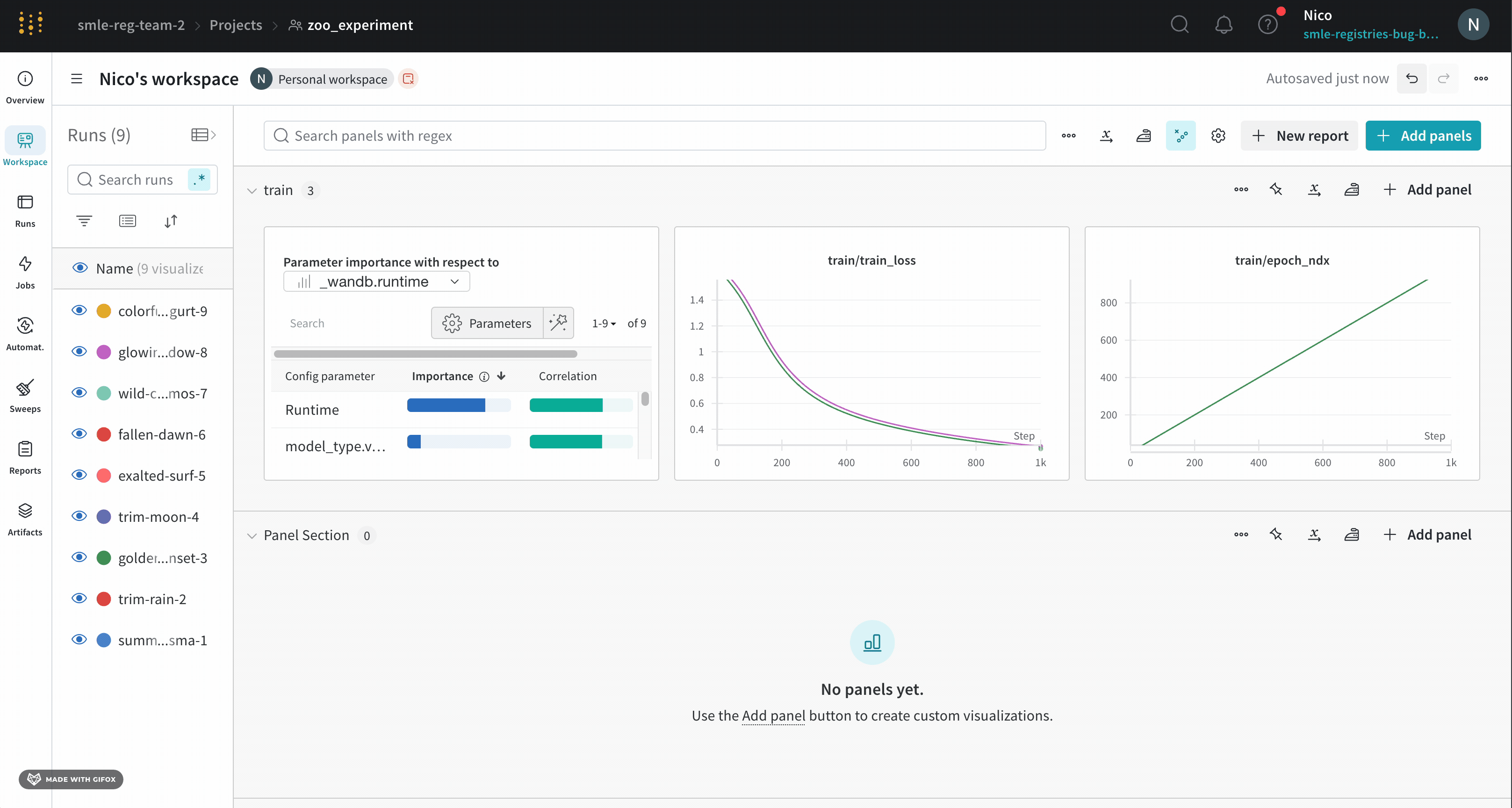
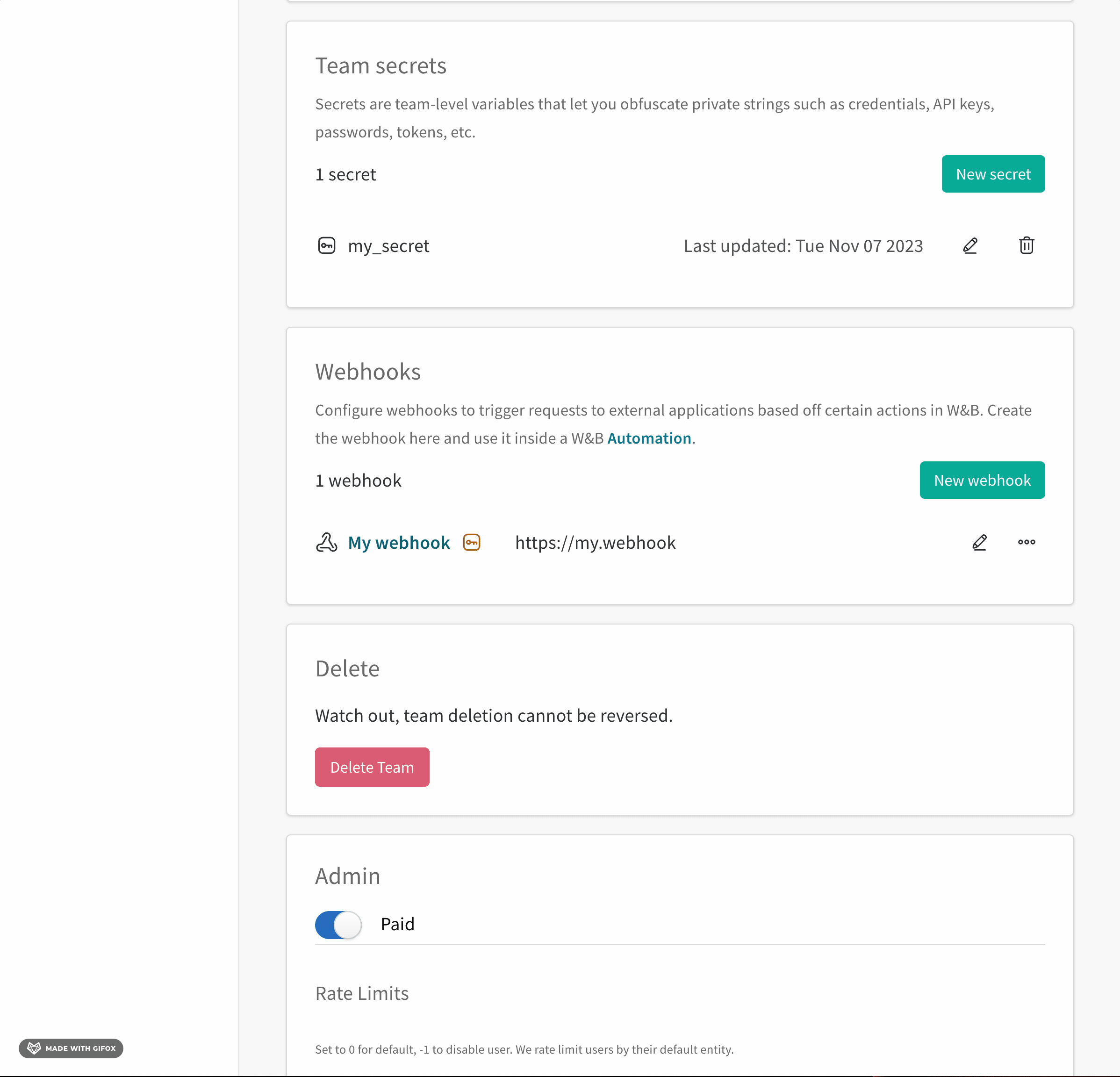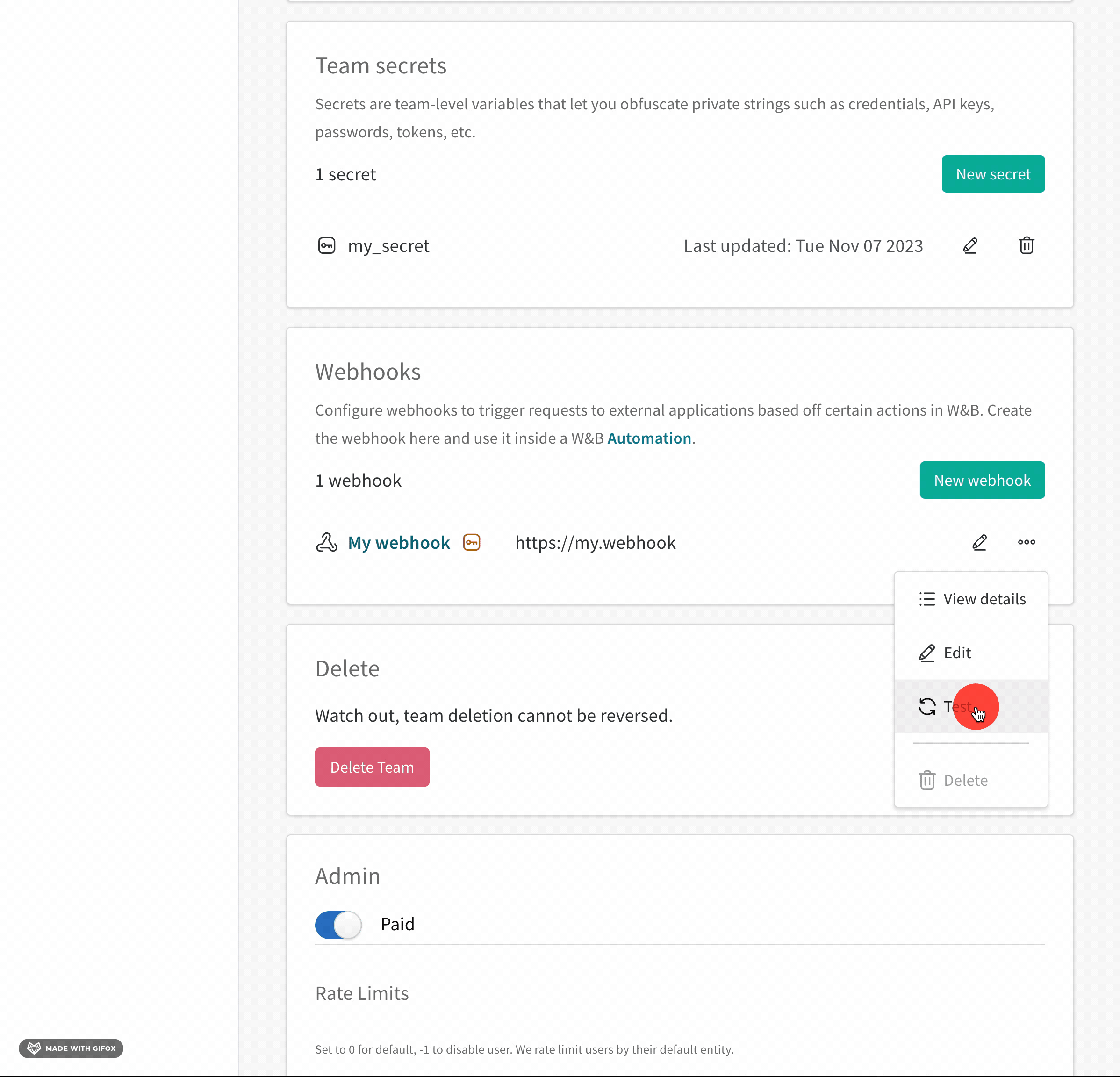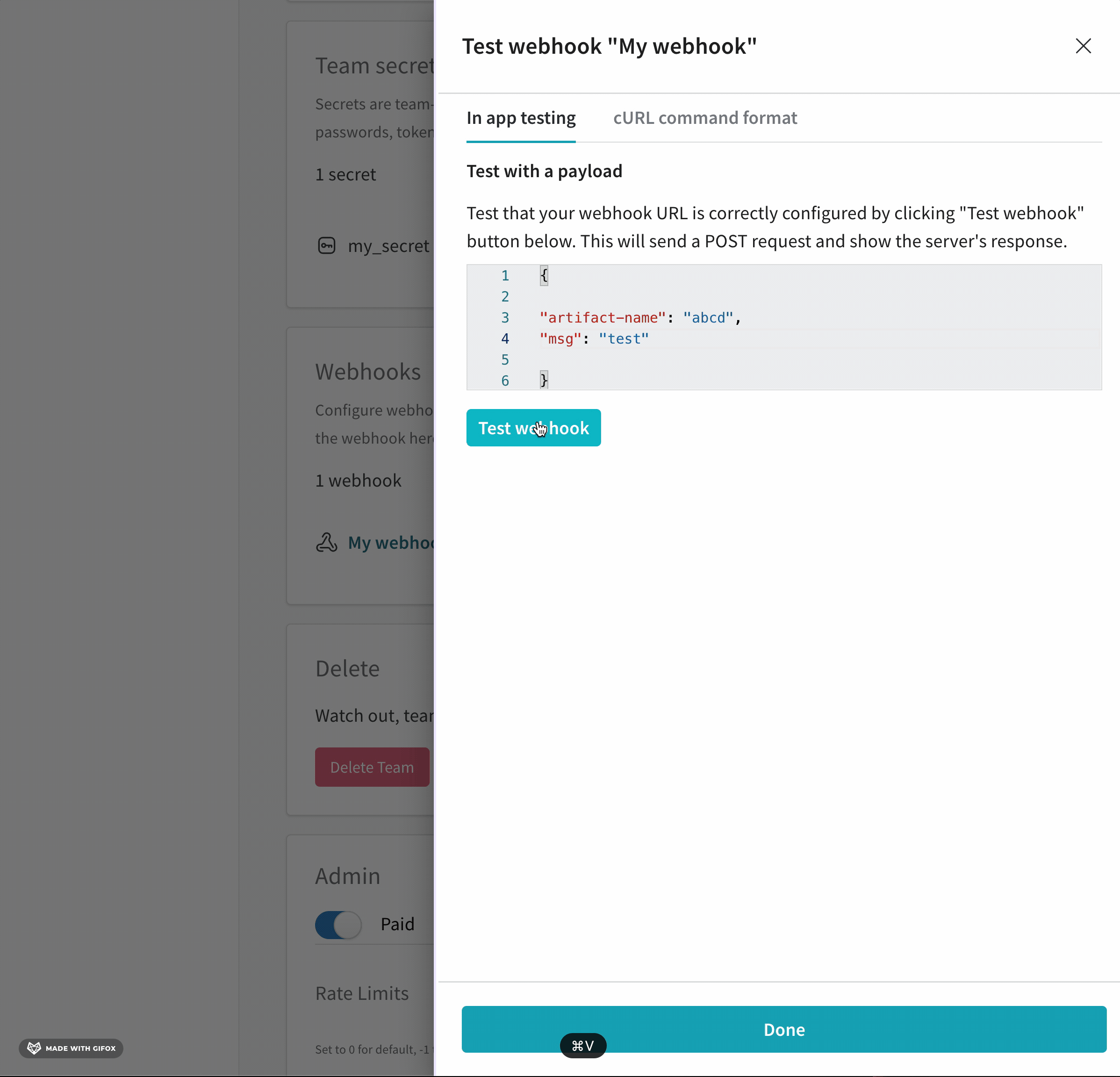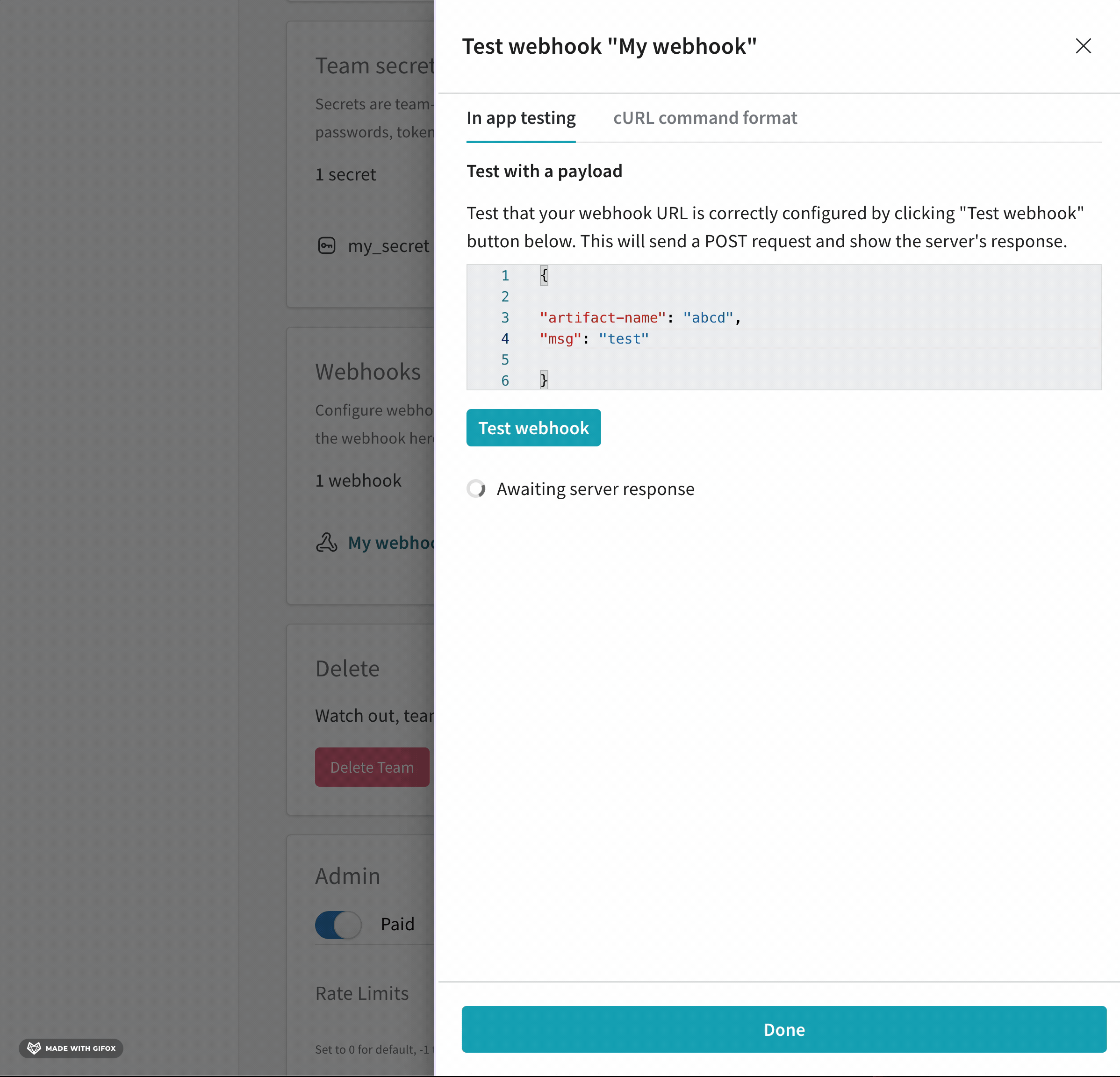
Runs Sidebar: 프로젝트의 모든 Runs 목록입니다.
Dot menu: 사이드바에서 행 위로 마우스를 가져가면 왼쪽에 메뉴가 나타납니다. 이 메뉴를 사용하여 run 이름을 바꾸거나, run을 삭제하거나, 활성 run을 중지합니다.
Visibility icon: 눈을 클릭하여 그래프에서 Runs을 켜고 끕니다.
Color: run 색상을 다른 사전 설정 색상 또는 사용자 지정 색상으로 변경합니다.
Search: 이름으로 Runs을 검색합니다. 이렇게 하면 플롯에서 보이는 Runs도 필터링됩니다.
Filter: 사이드바 필터를 사용하여 보이는 Runs 집합을 좁힙니다.
Group: 아키텍처별로 Runs을 동적으로 그룹화할 구성 열을 선택합니다. 그룹화하면 플롯에 평균 값을 따라 선이 표시되고 그래프에서 점의 분산에 대한 음영 영역이 표시됩니다.
Sort: 가장 낮은 손실 또는 가장 높은 정확도를 가진 Runs과 같이 Runs을 정렬할 값을 선택합니다. 정렬은 그래프에 표시되는 Runs에 영향을 미칩니다.
Expand button: 사이드바를 전체 테이블로 확장합니다.
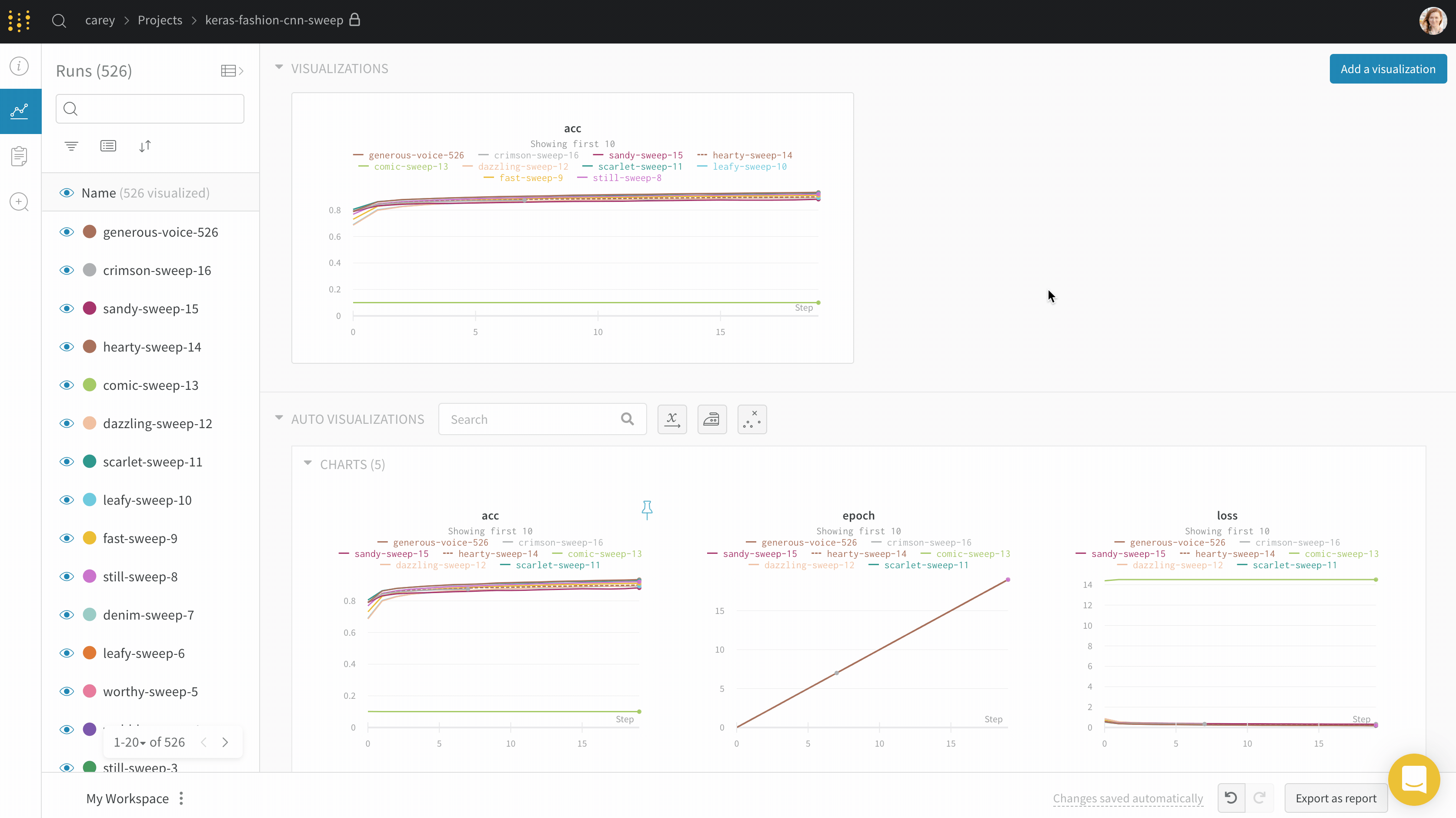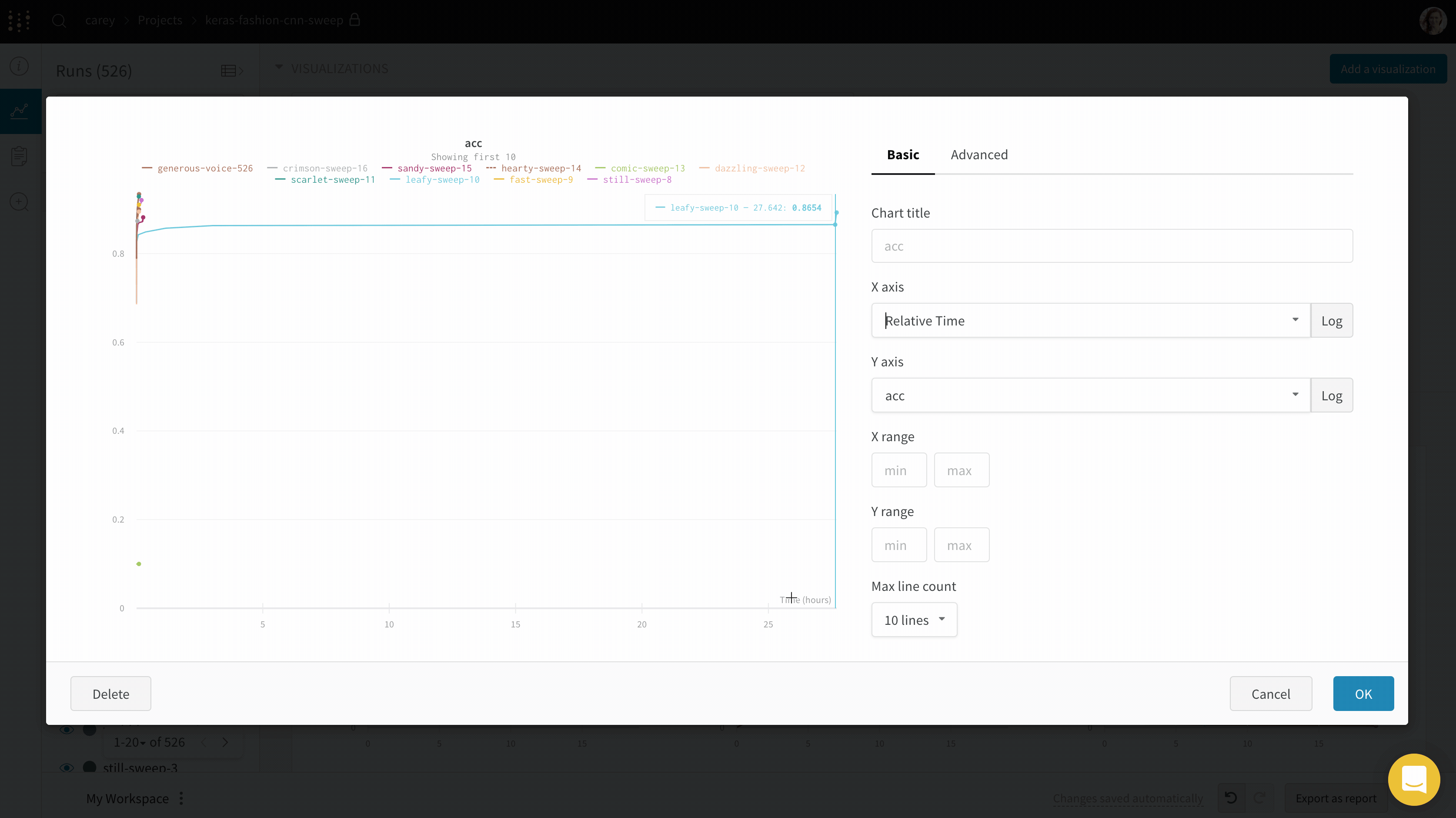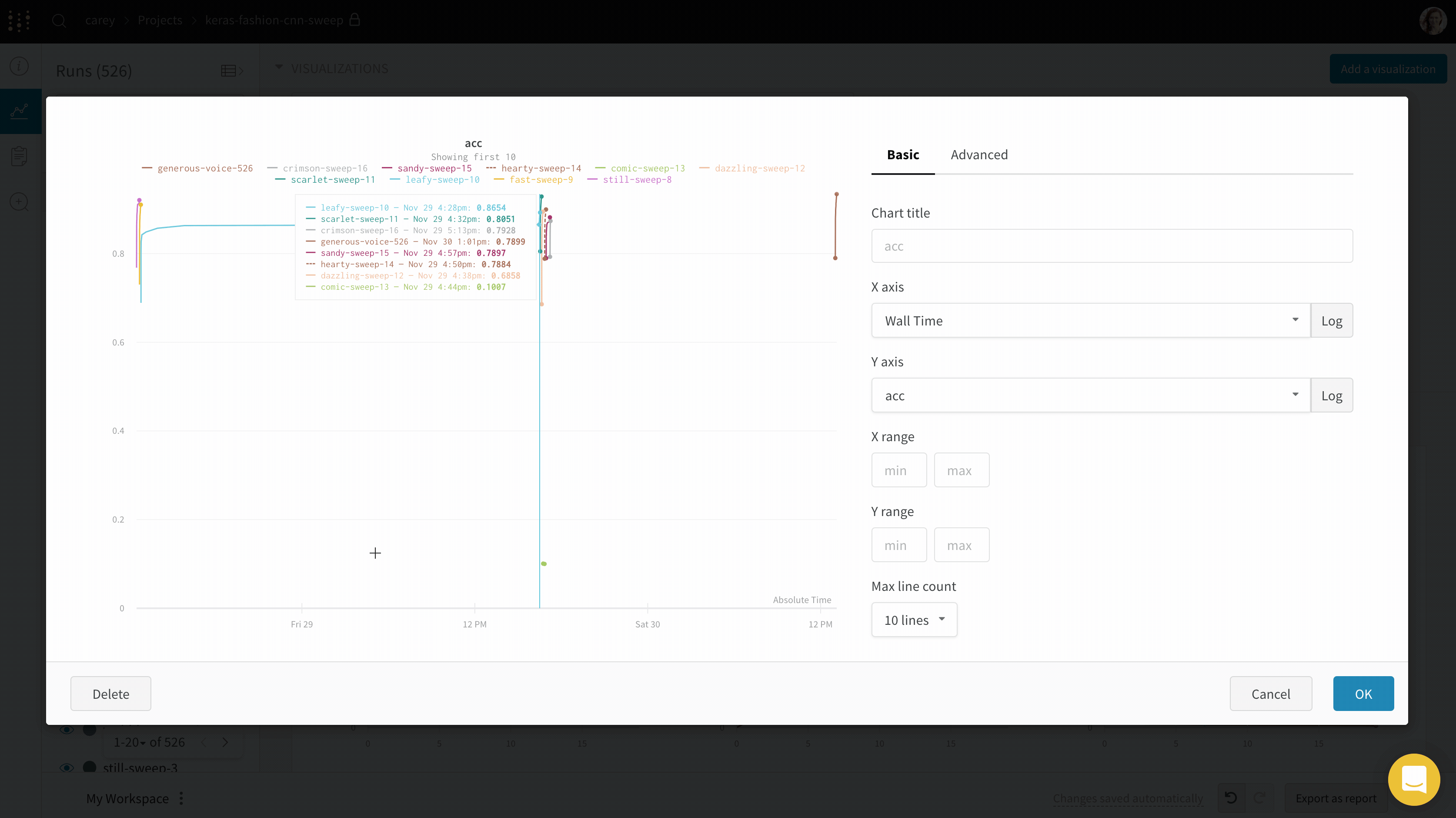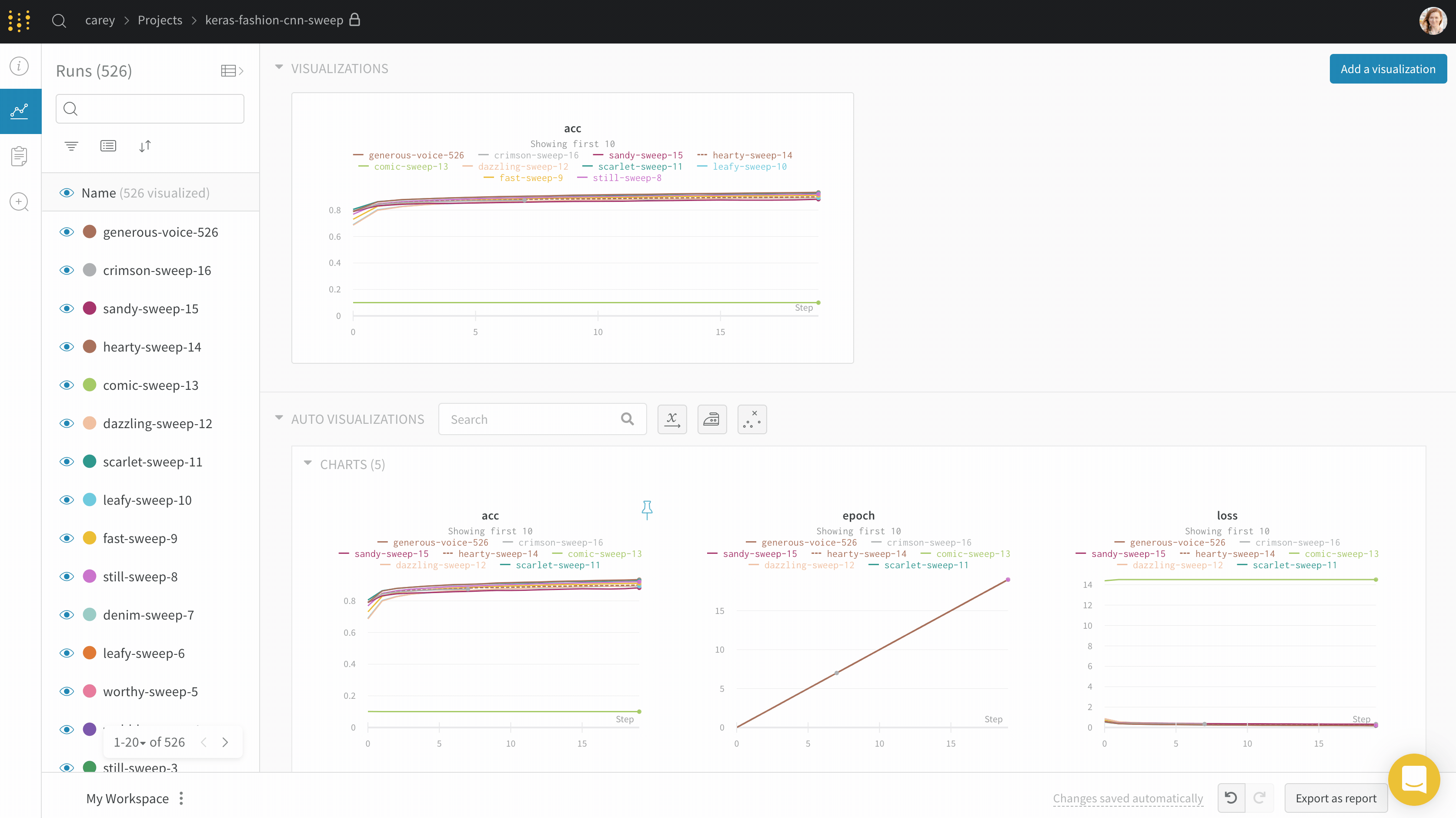
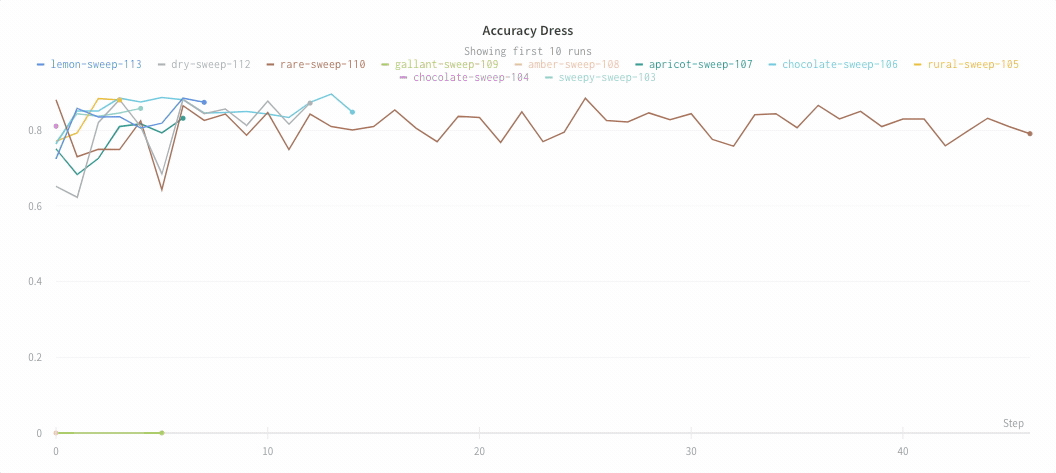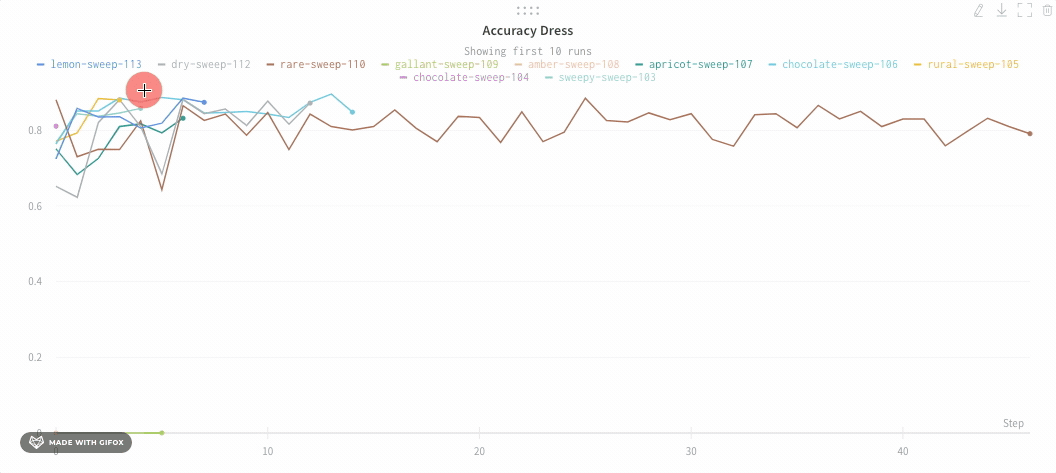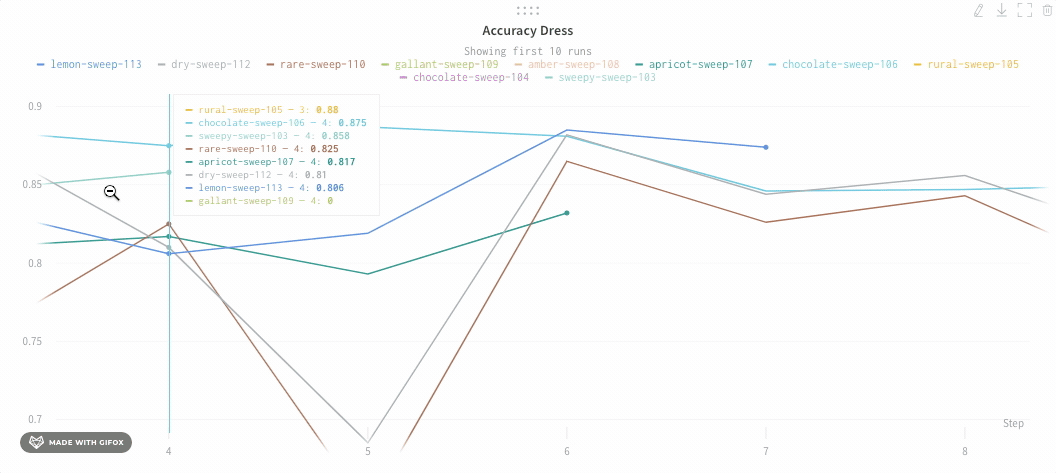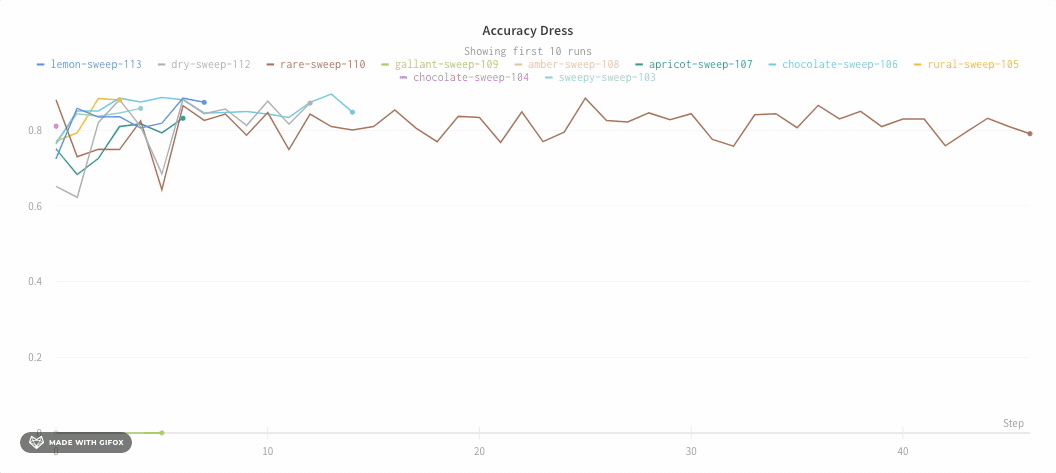
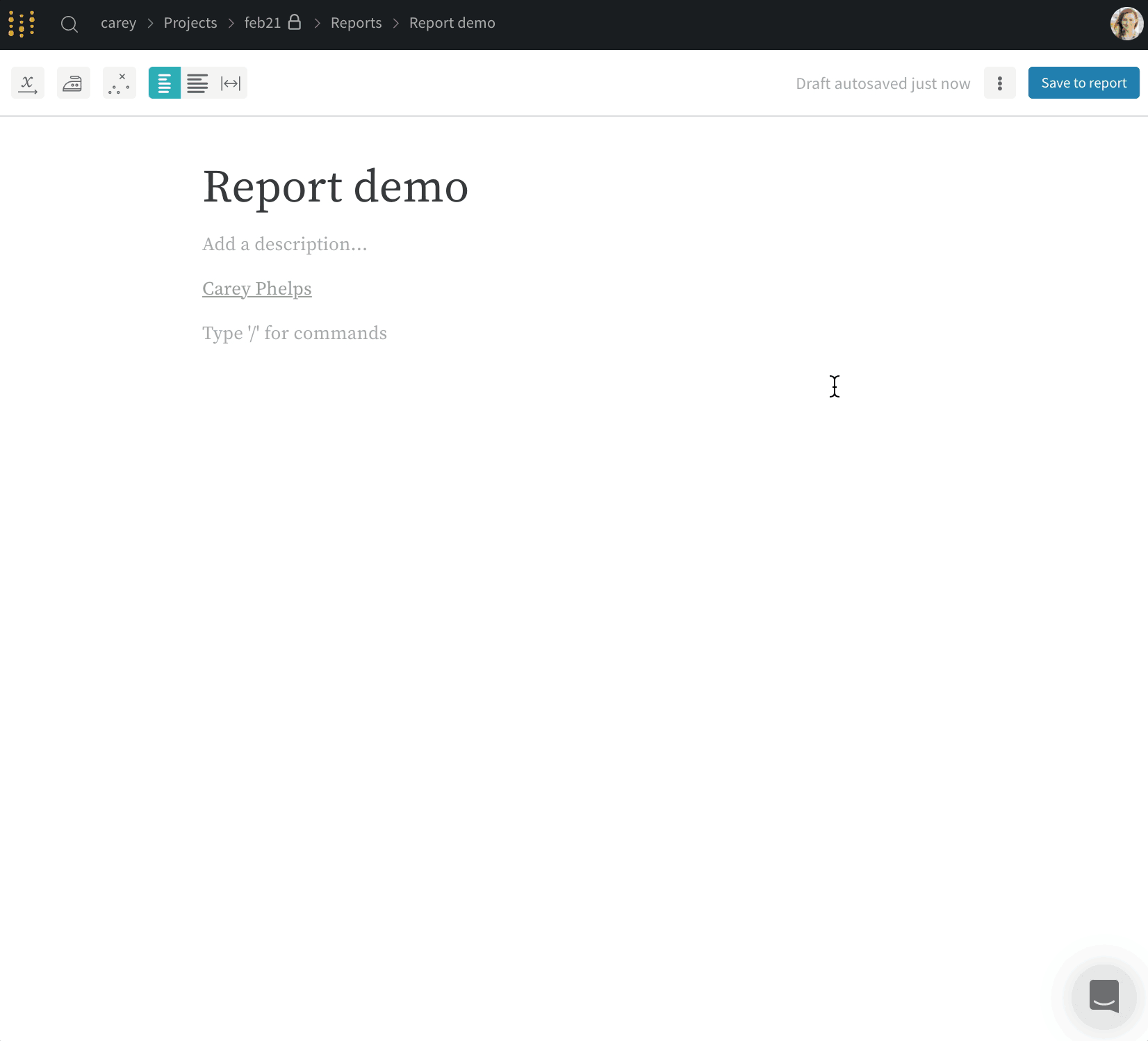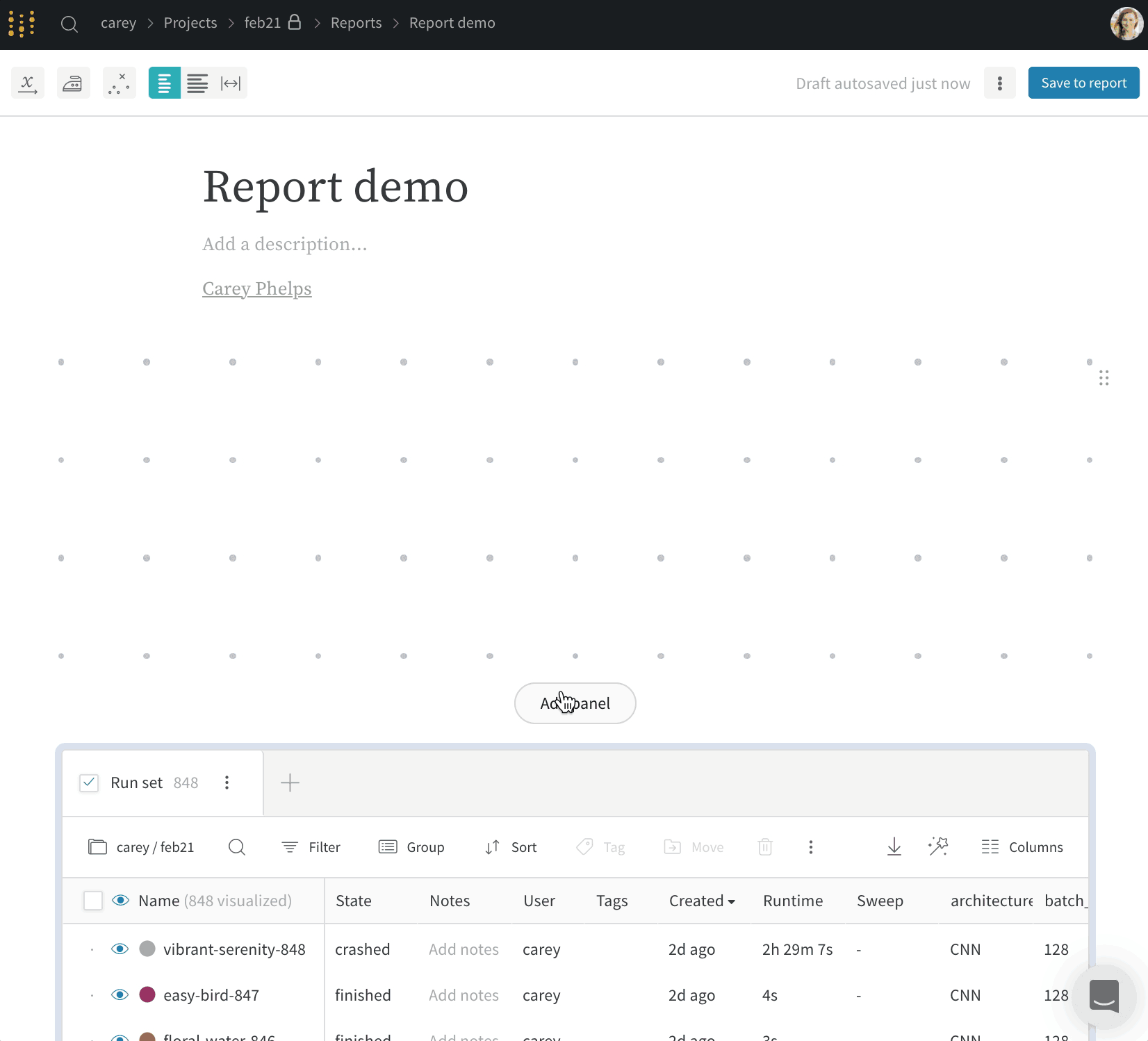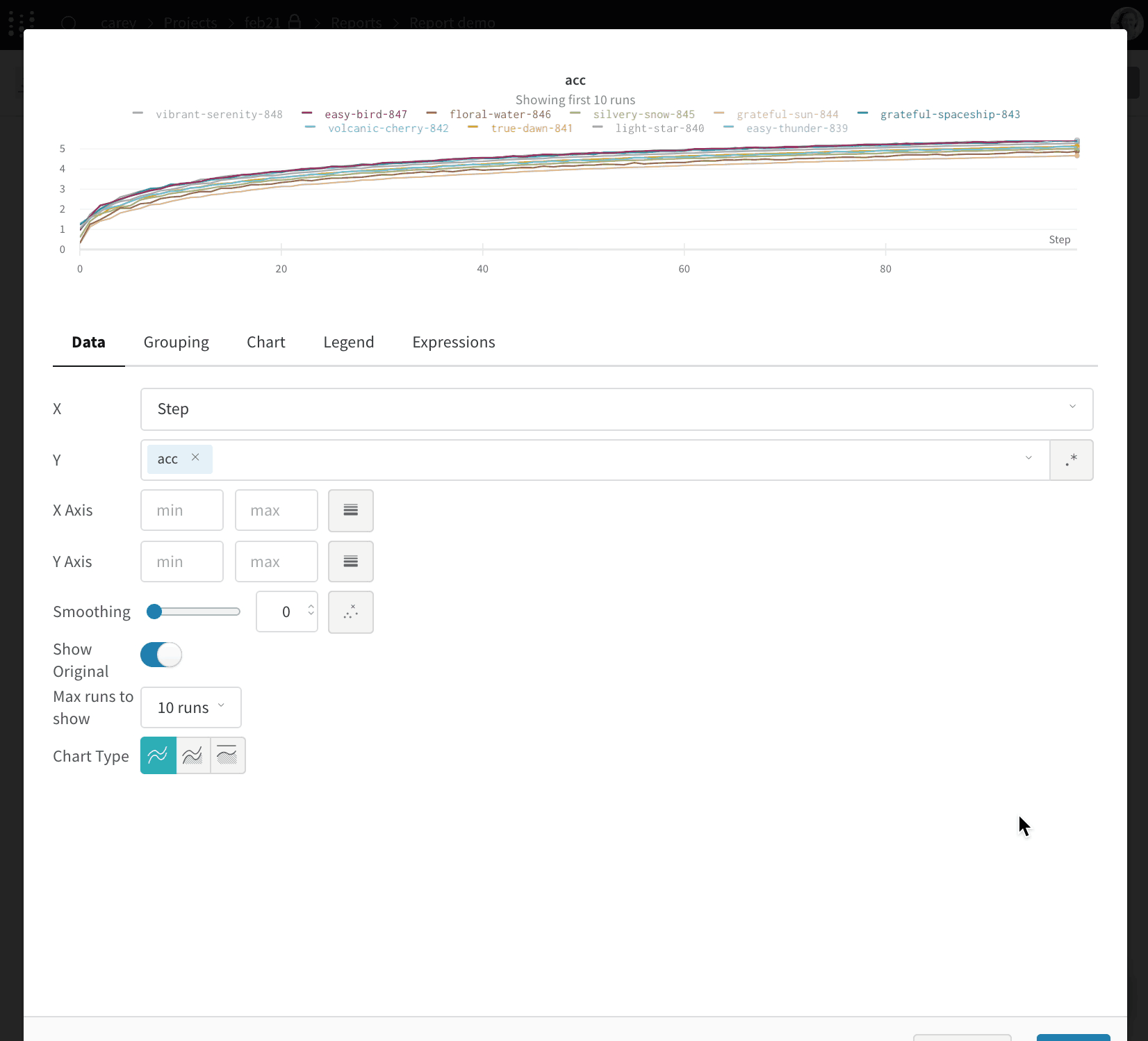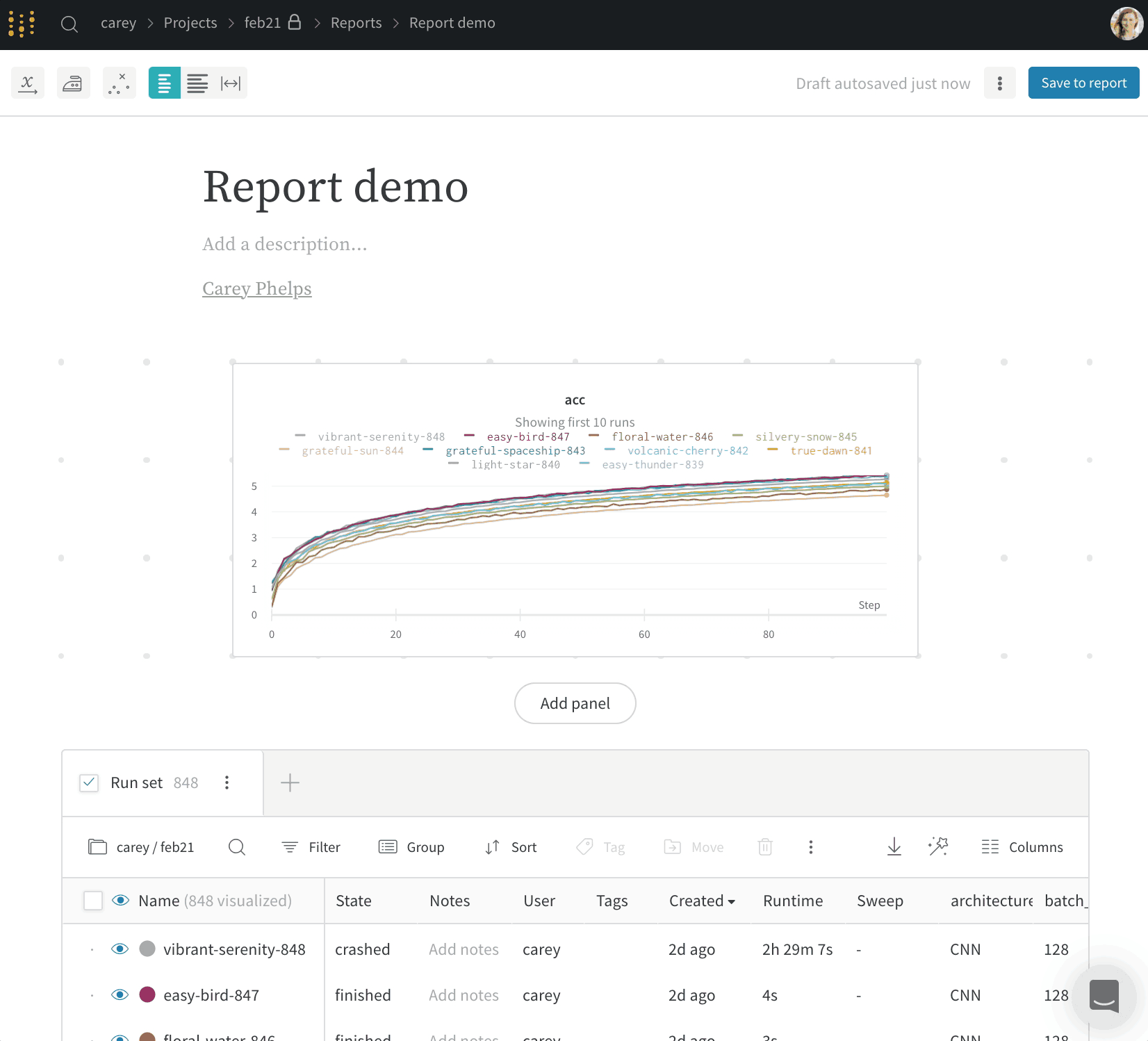
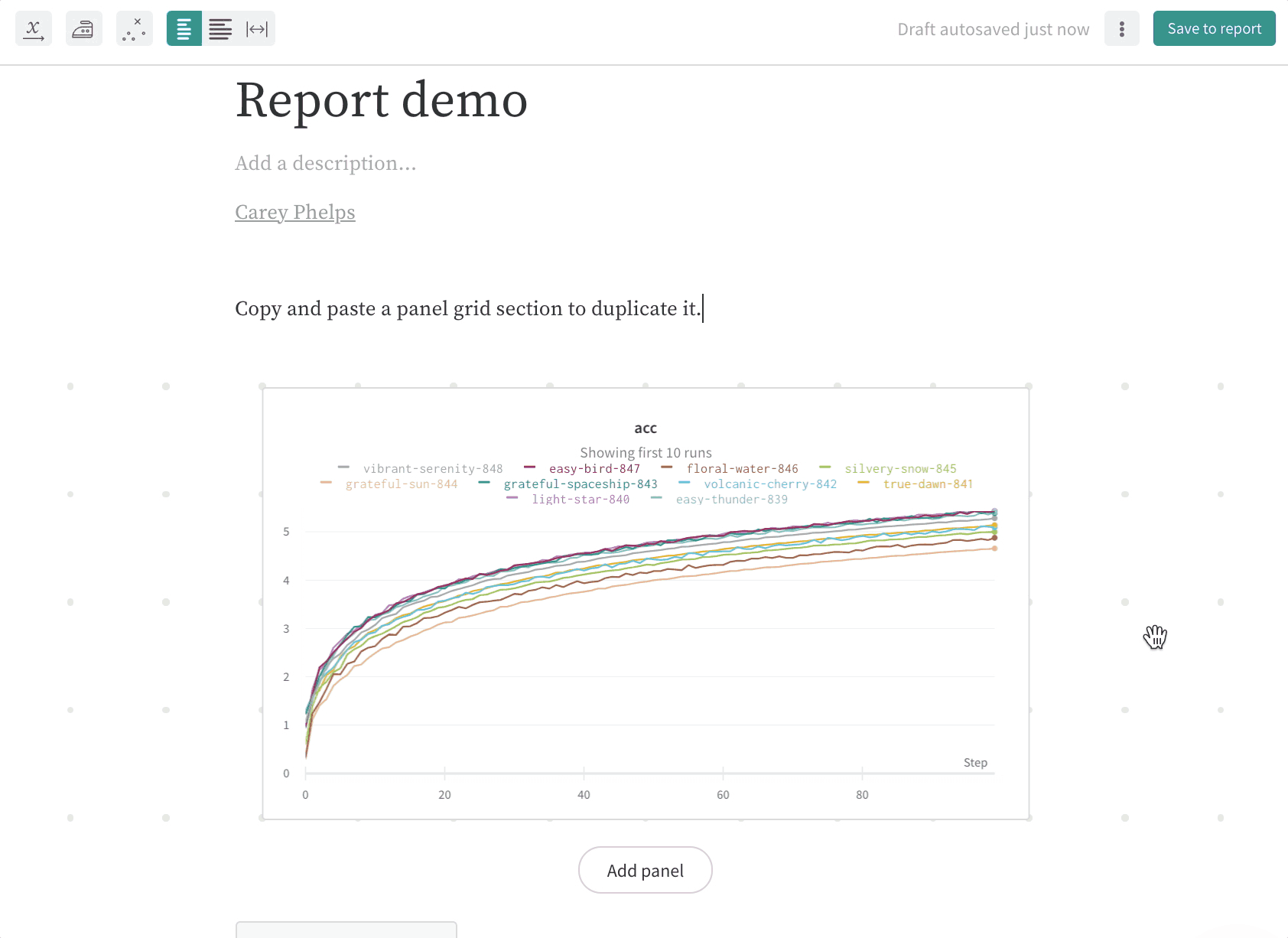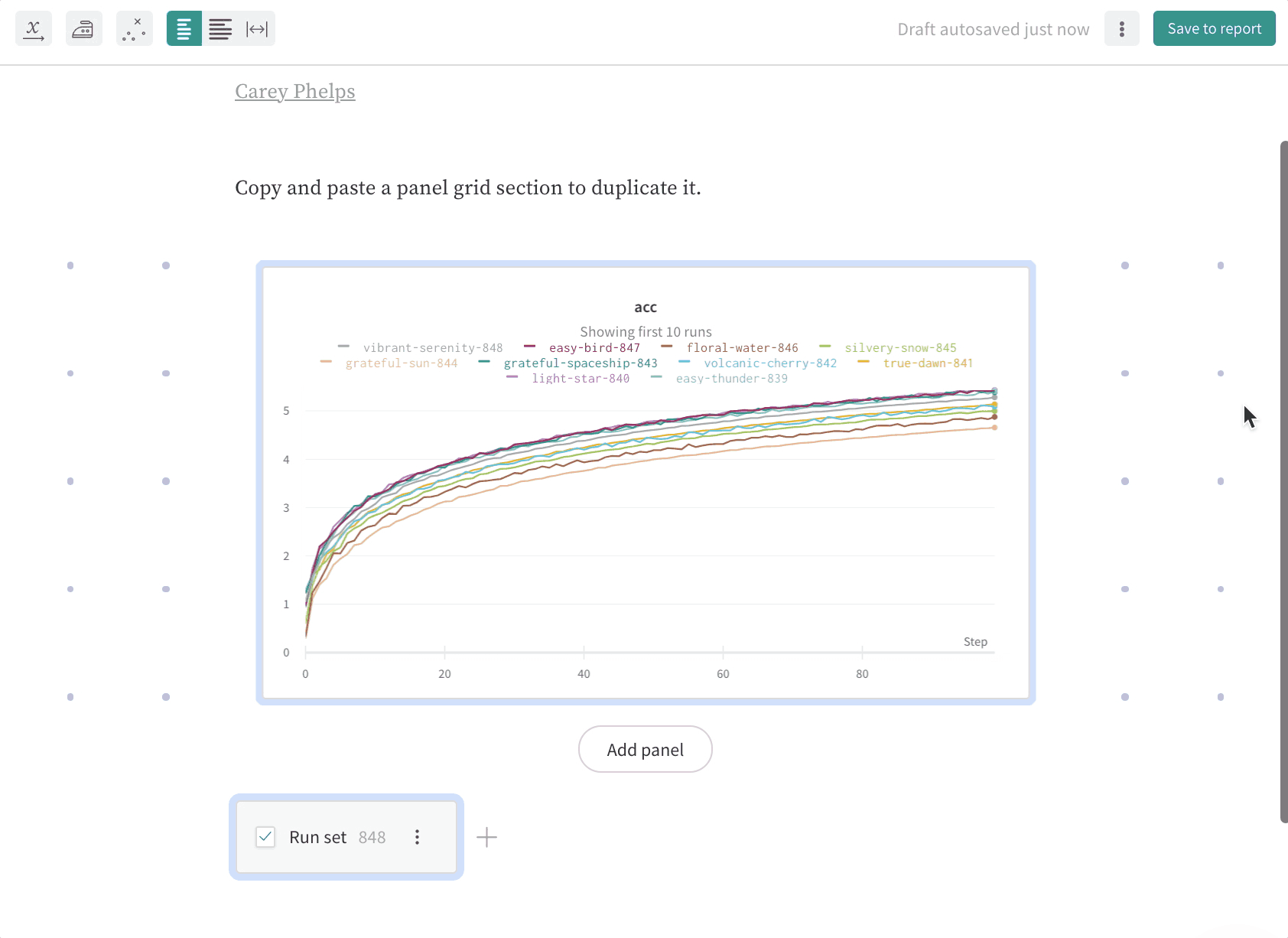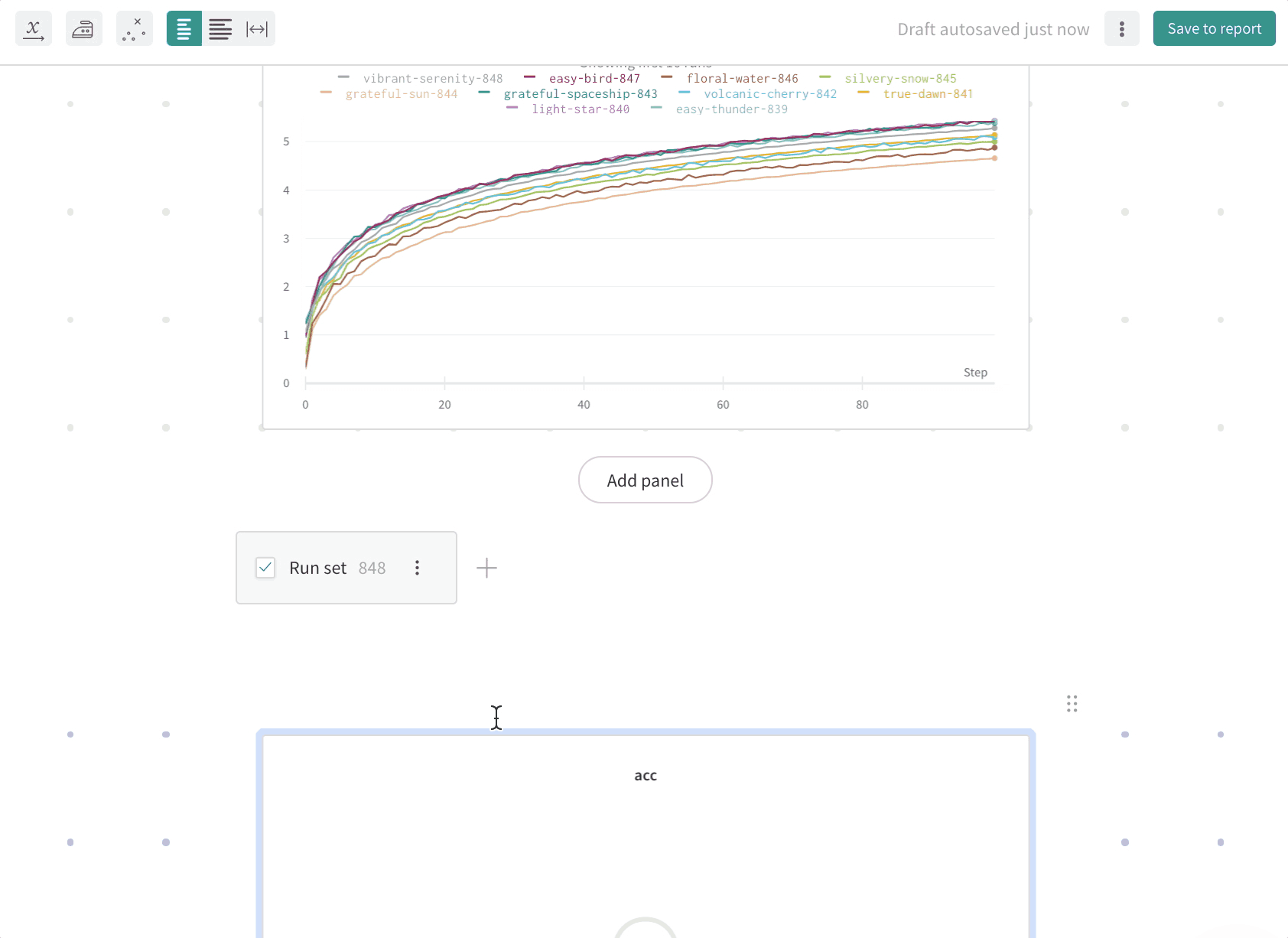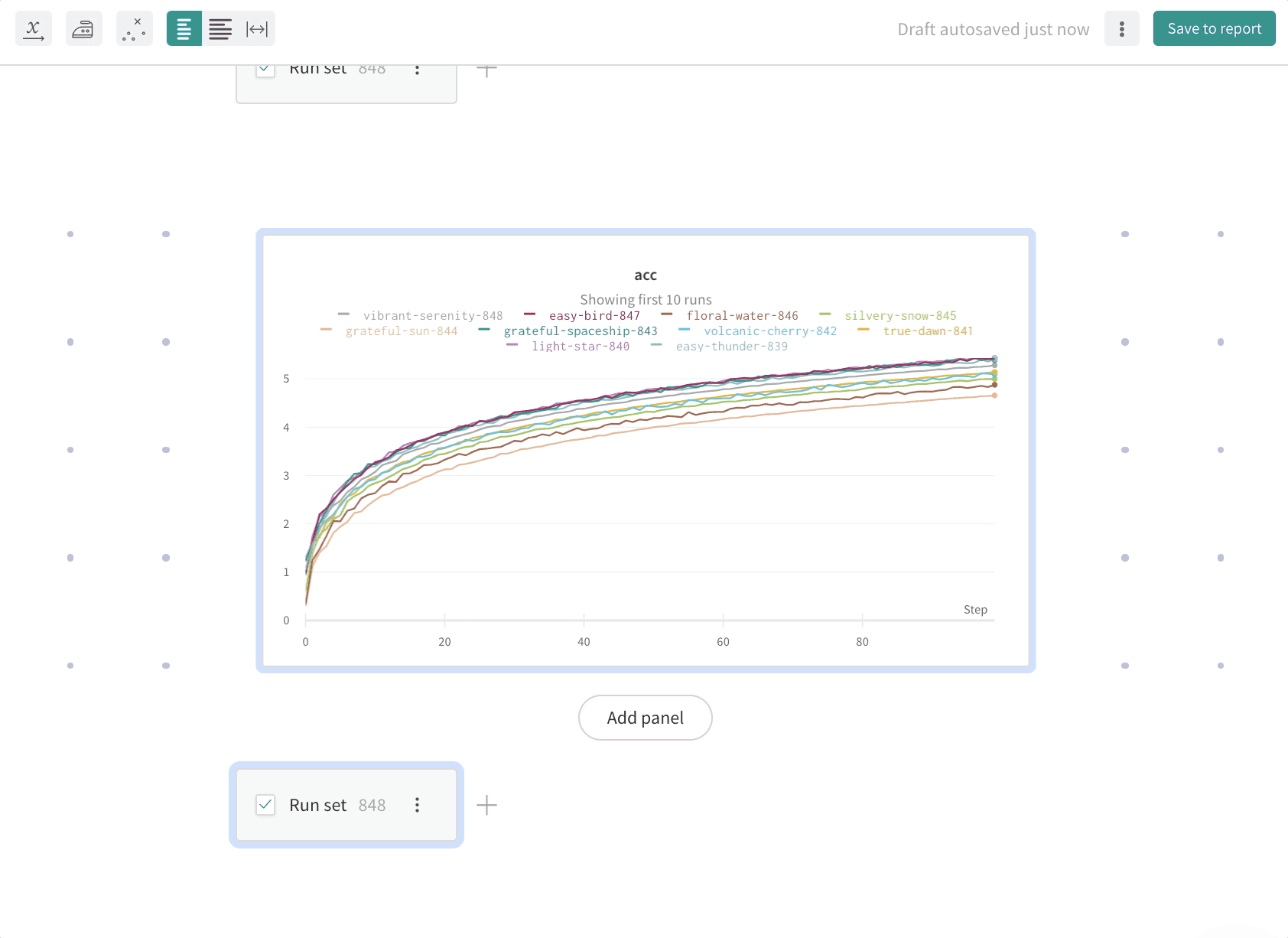
Run count: 상단의 괄호 안의 숫자는 프로젝트의 총 Runs 수입니다. (N visualized) 숫자는 눈이 켜져 있고 각 플롯에서 시각화할 수 있는 Runs 수입니다. 아래 예에서 그래프는 183개의 Runs 중 처음 10개만 보여줍니다. 보이는 Runs의 최대 수를 늘리려면 그래프를 편집합니다.
Runs 탭에서 열을 고정, 숨기거나 순서를 변경하면 Runs 사이드바에 이러한 사용자 지정이 반영됩니다.
Panels layout: 이 스크래치 공간을 사용하여 결과를 탐색하고, 차트를 추가 및 제거하고, 다양한 메트릭을 기반으로 Models 버전을 비교합니다.
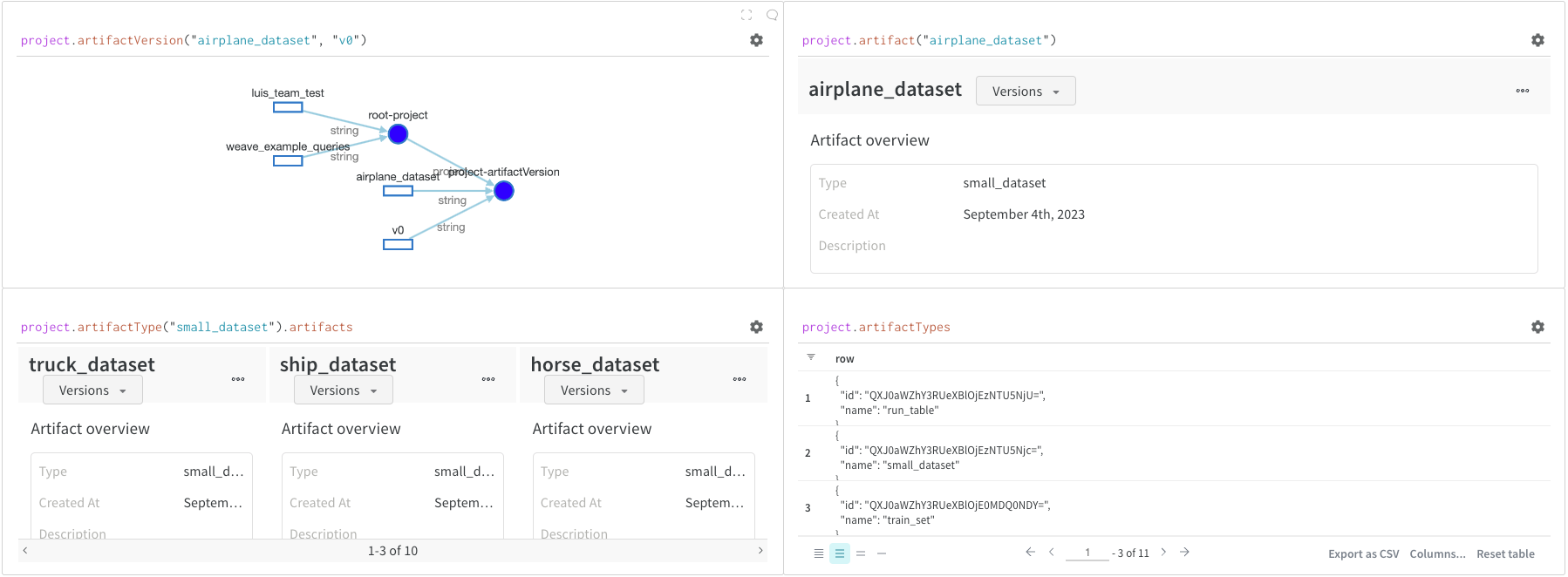
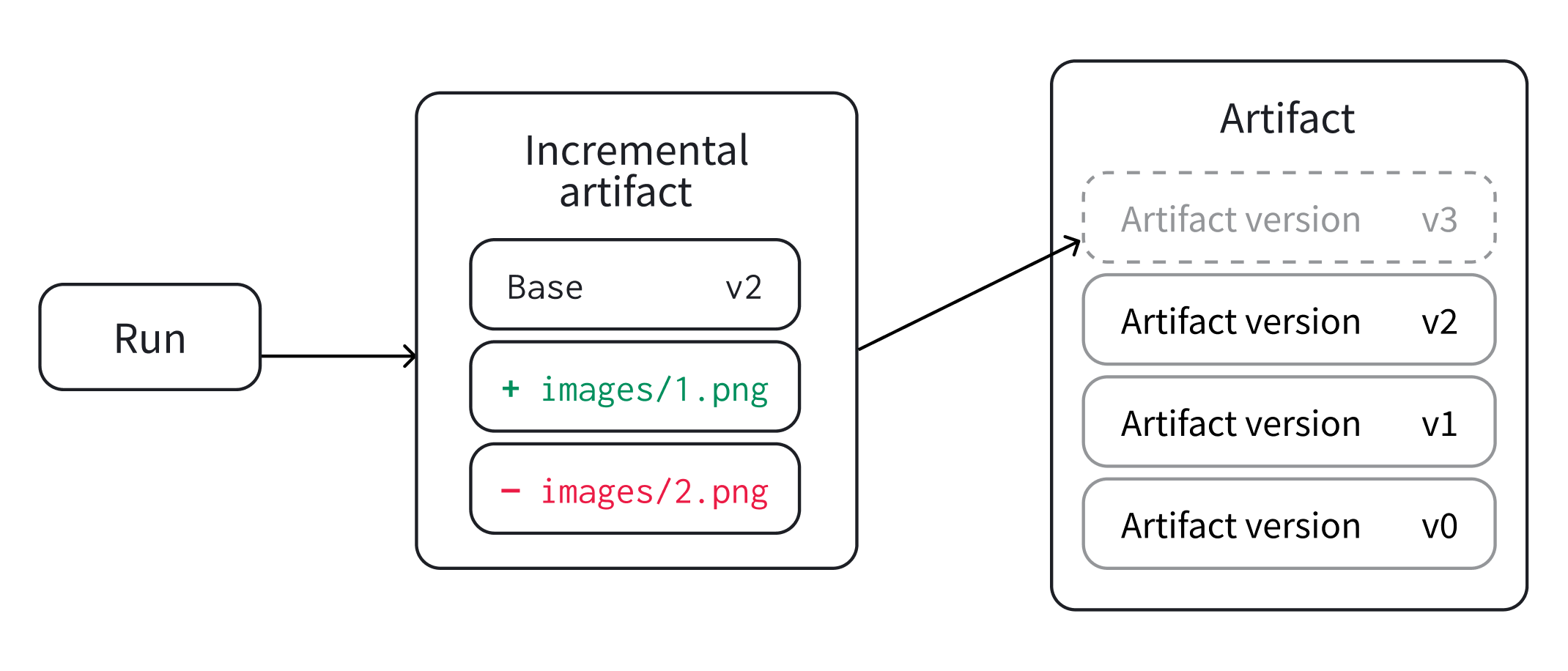
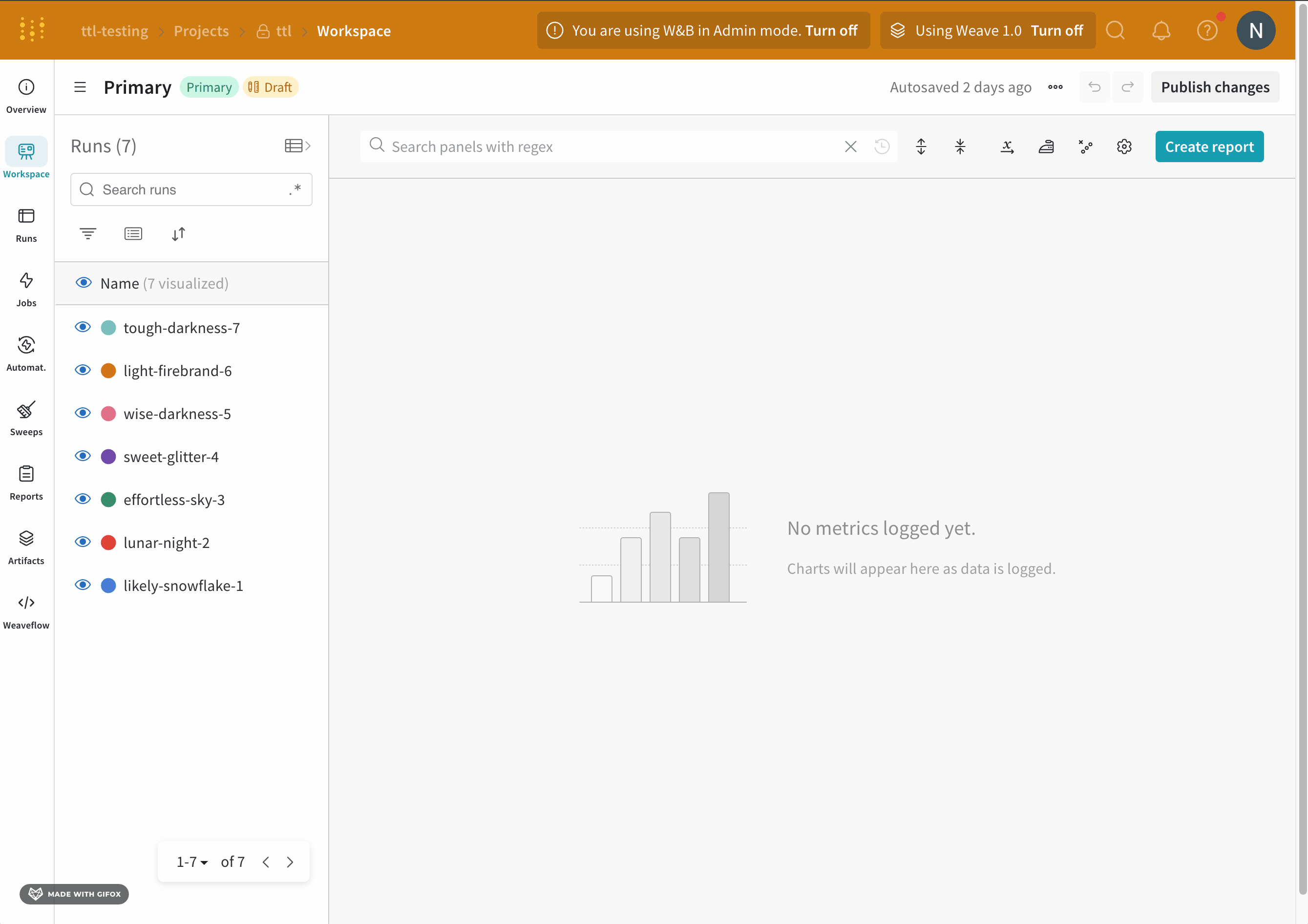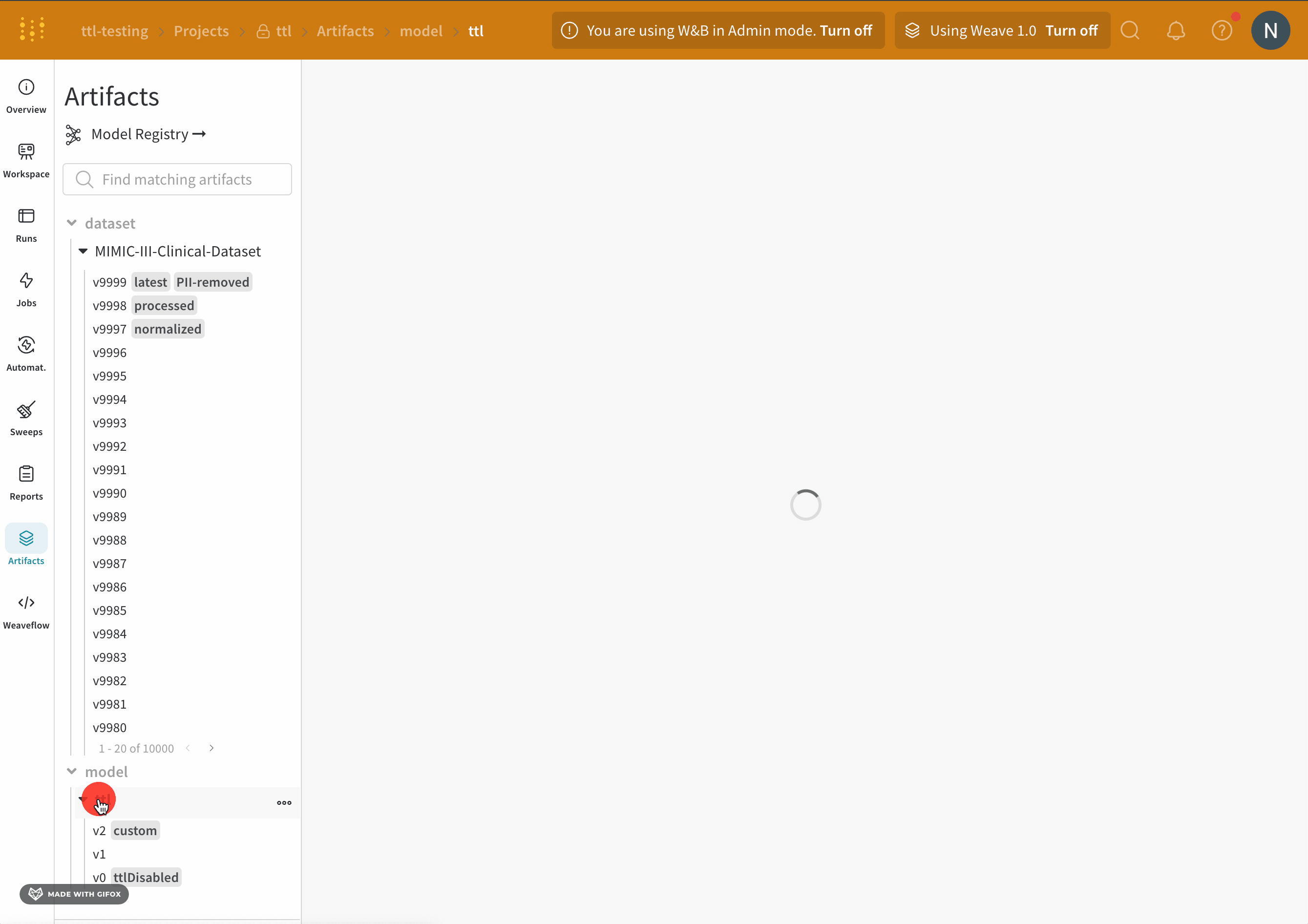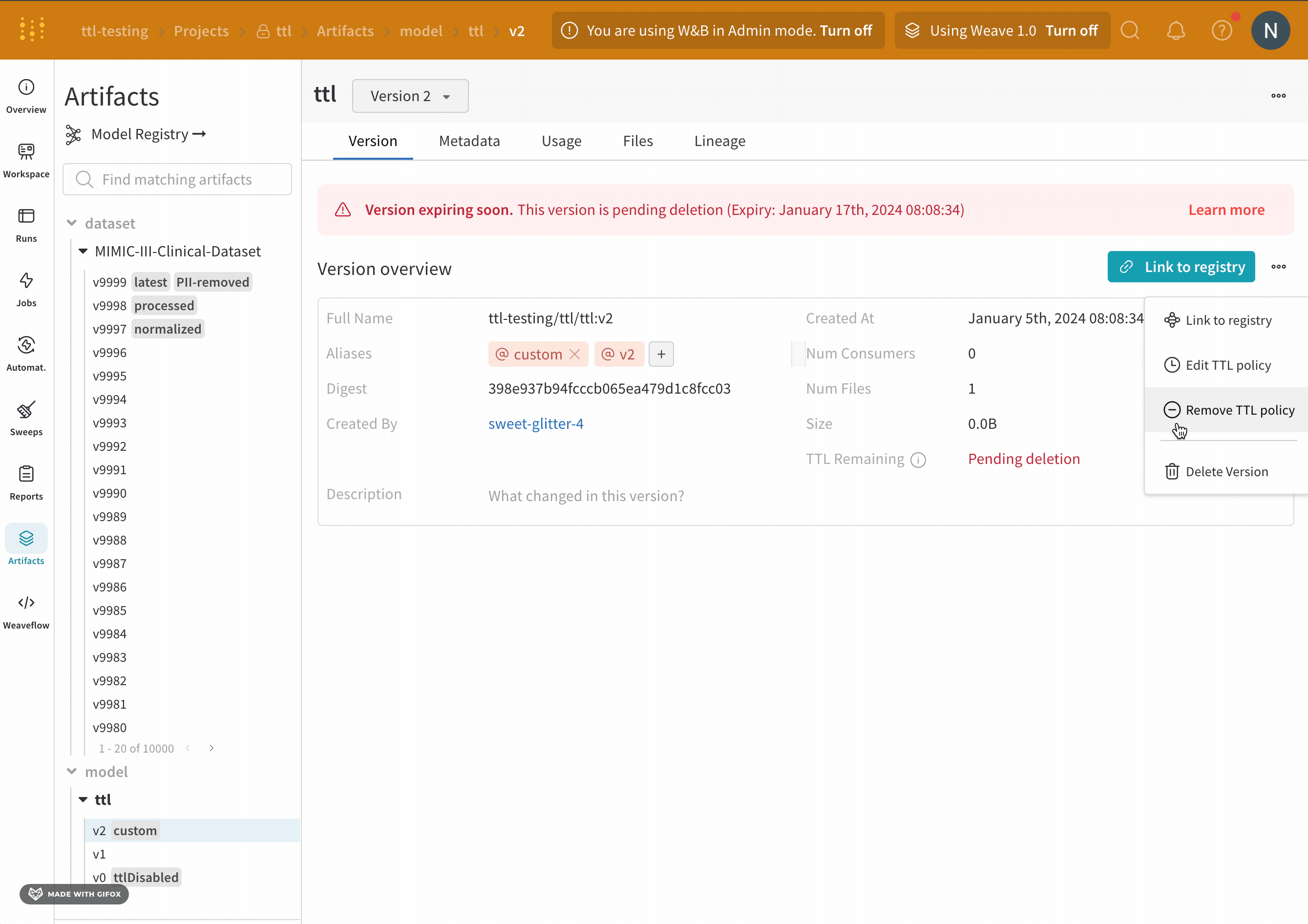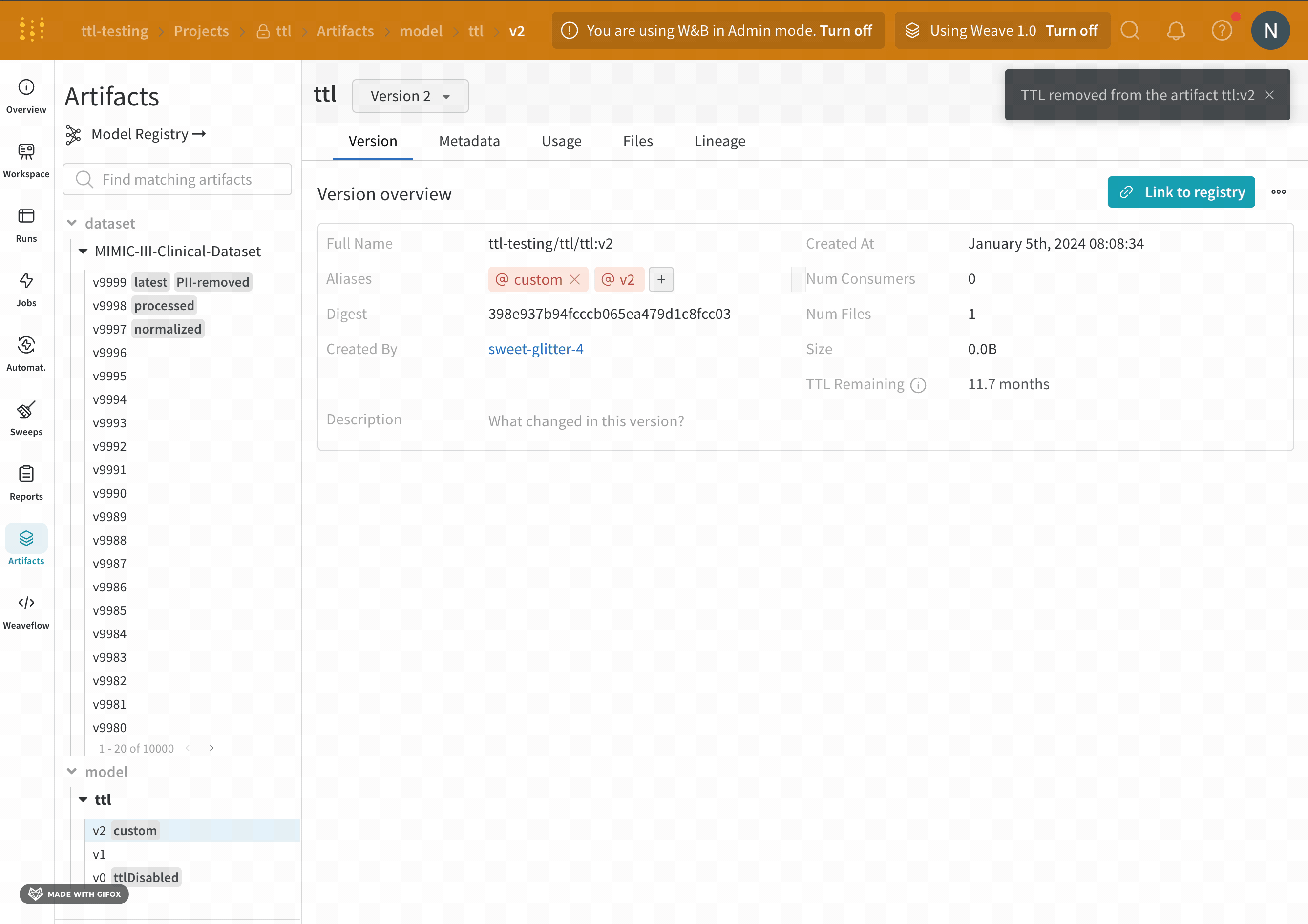
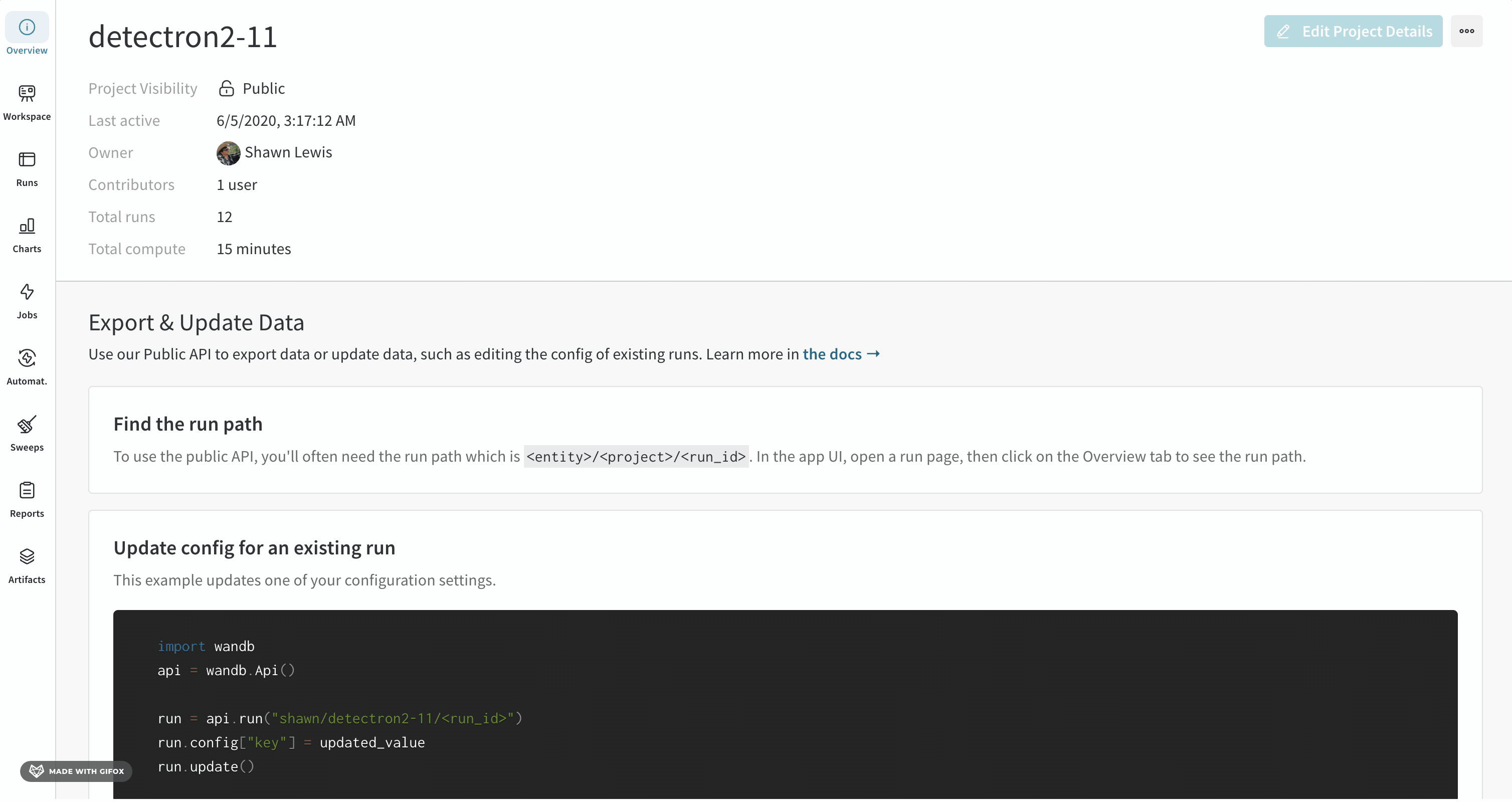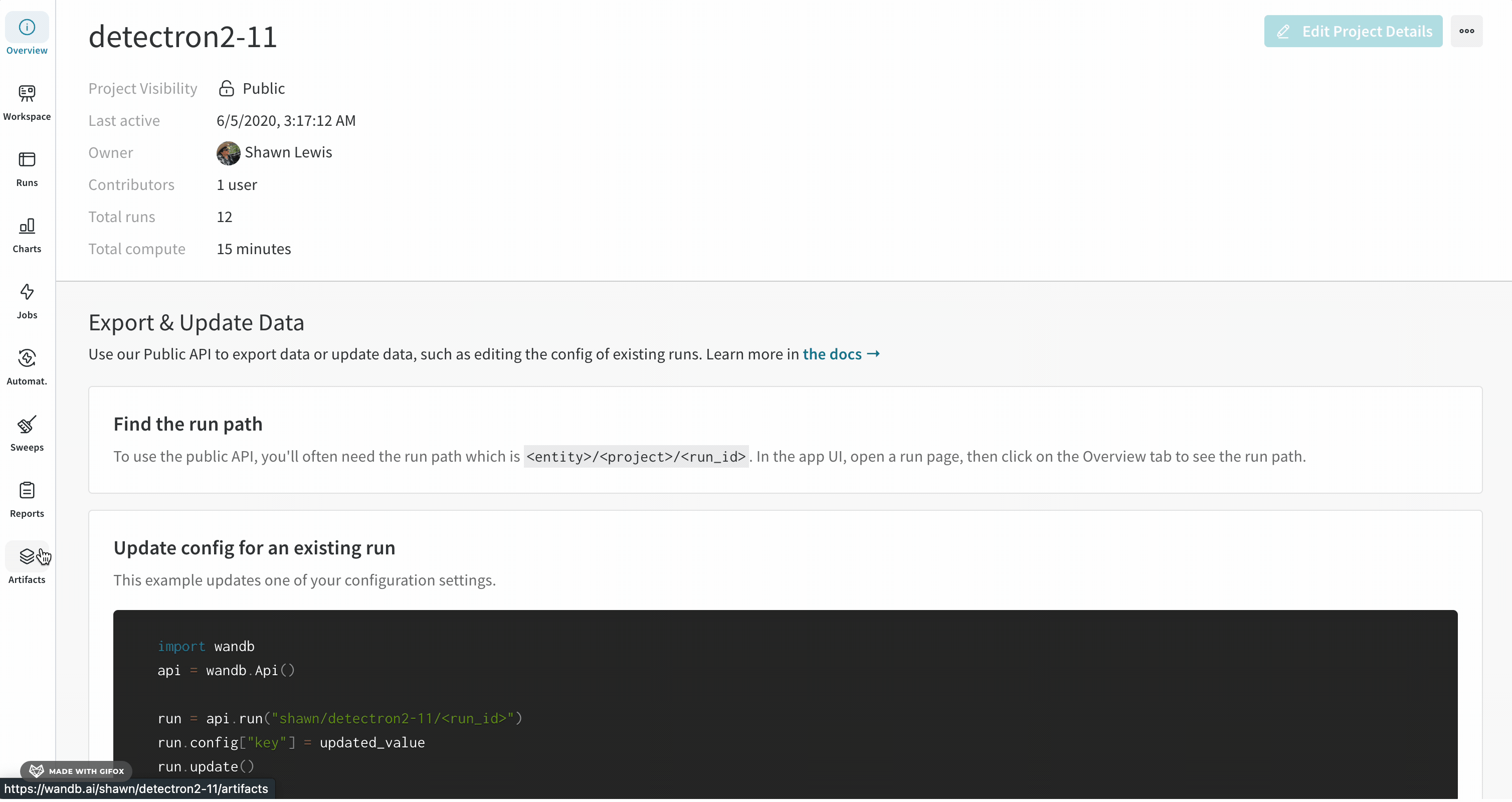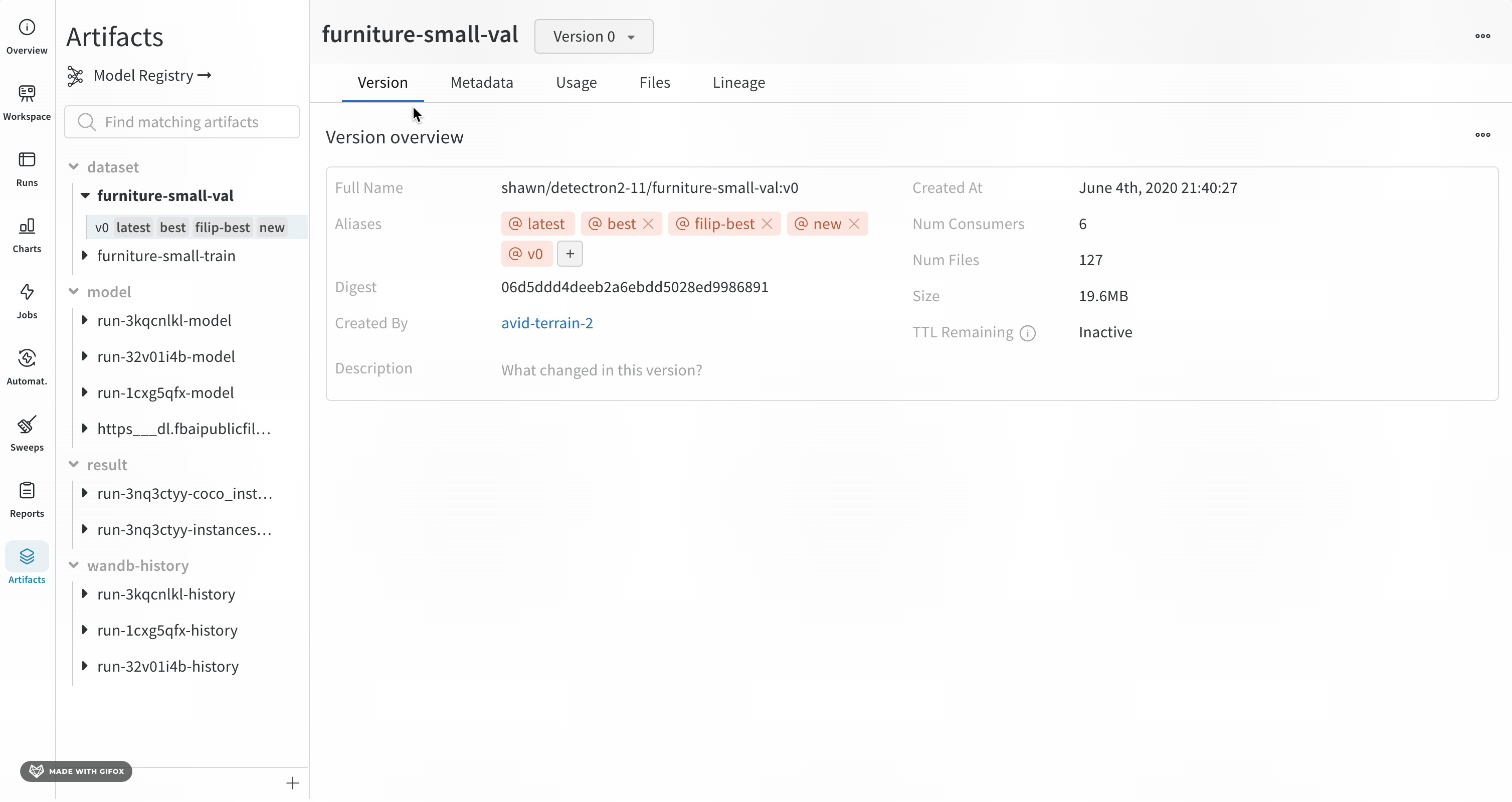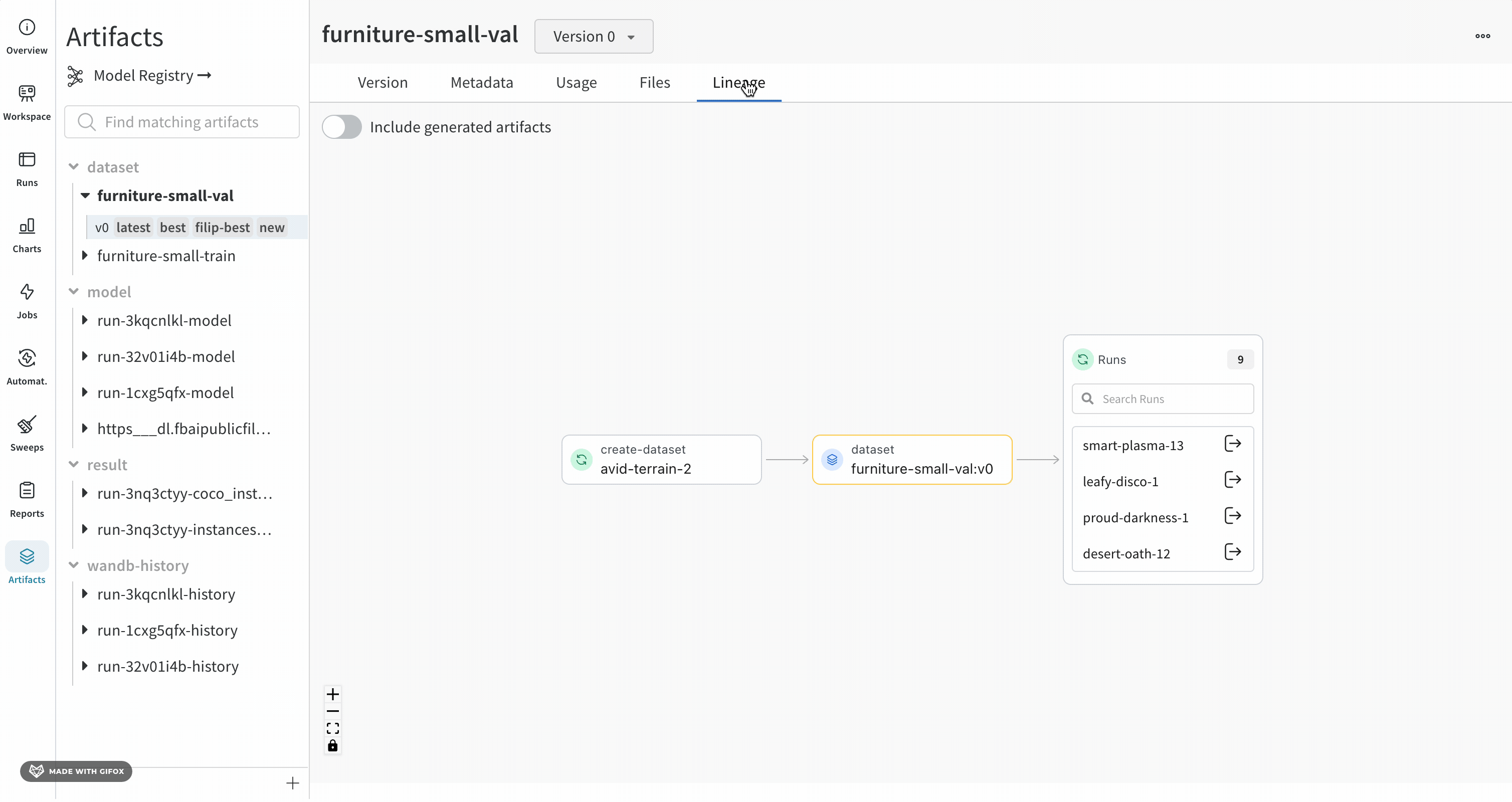
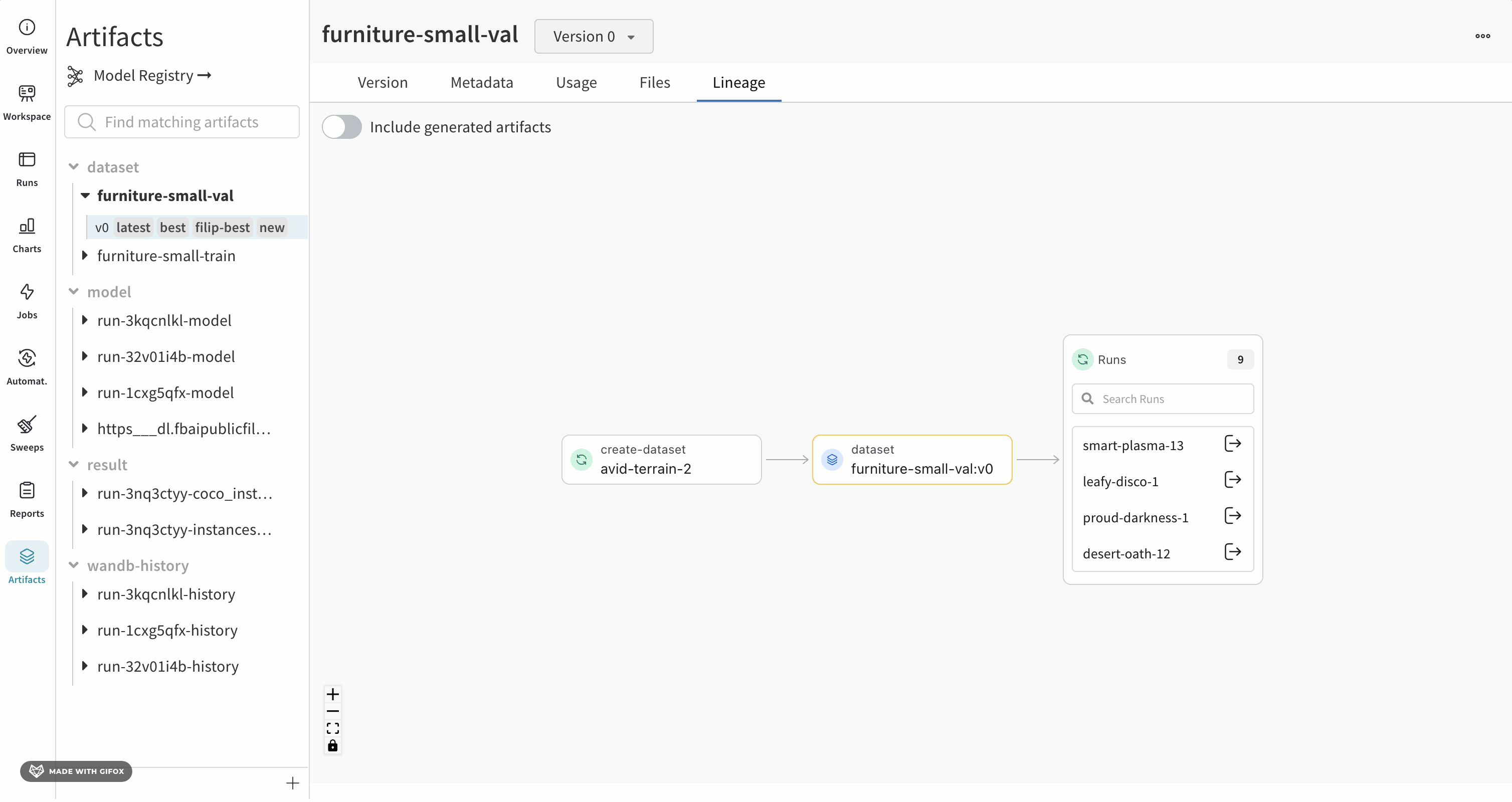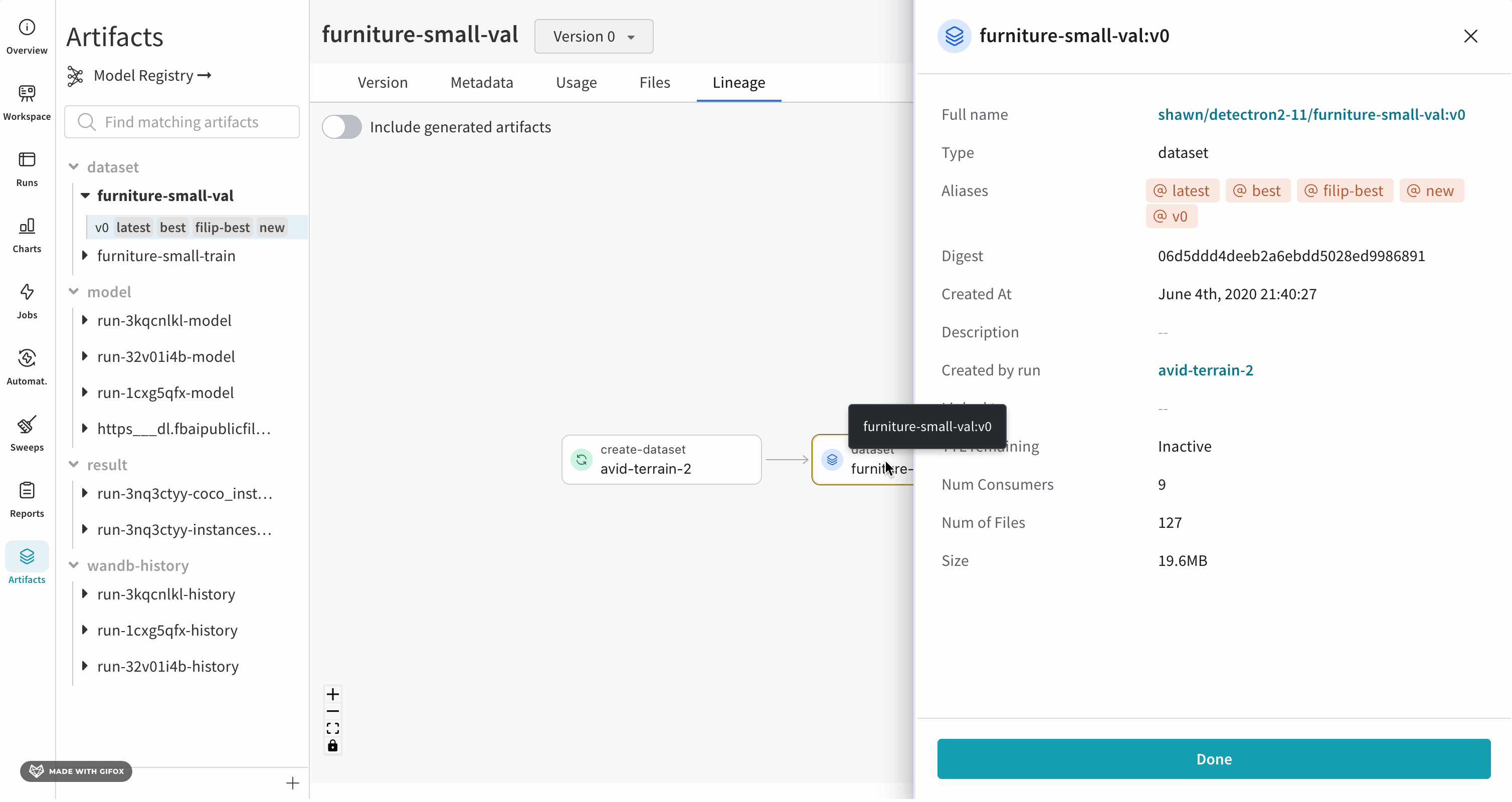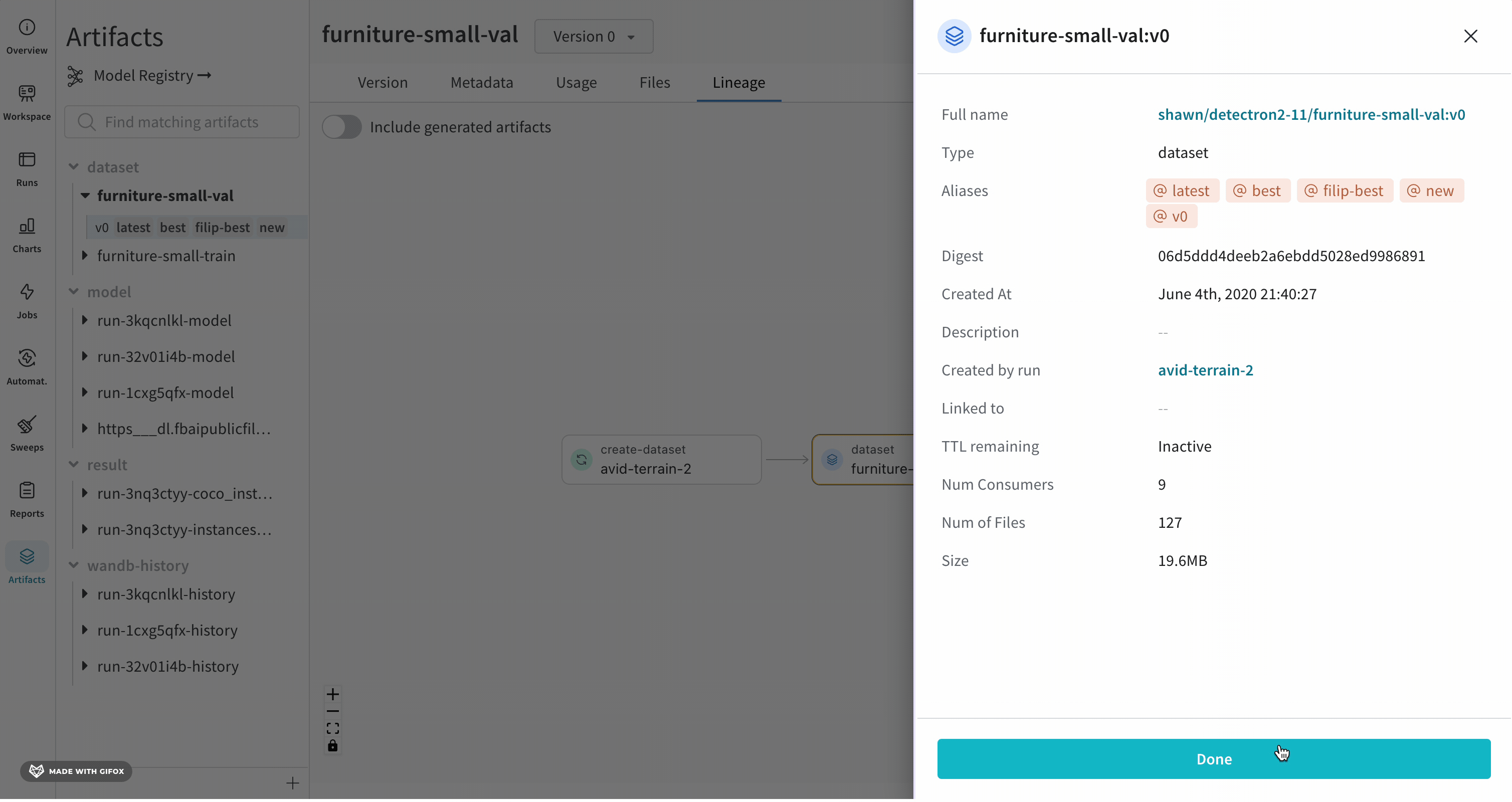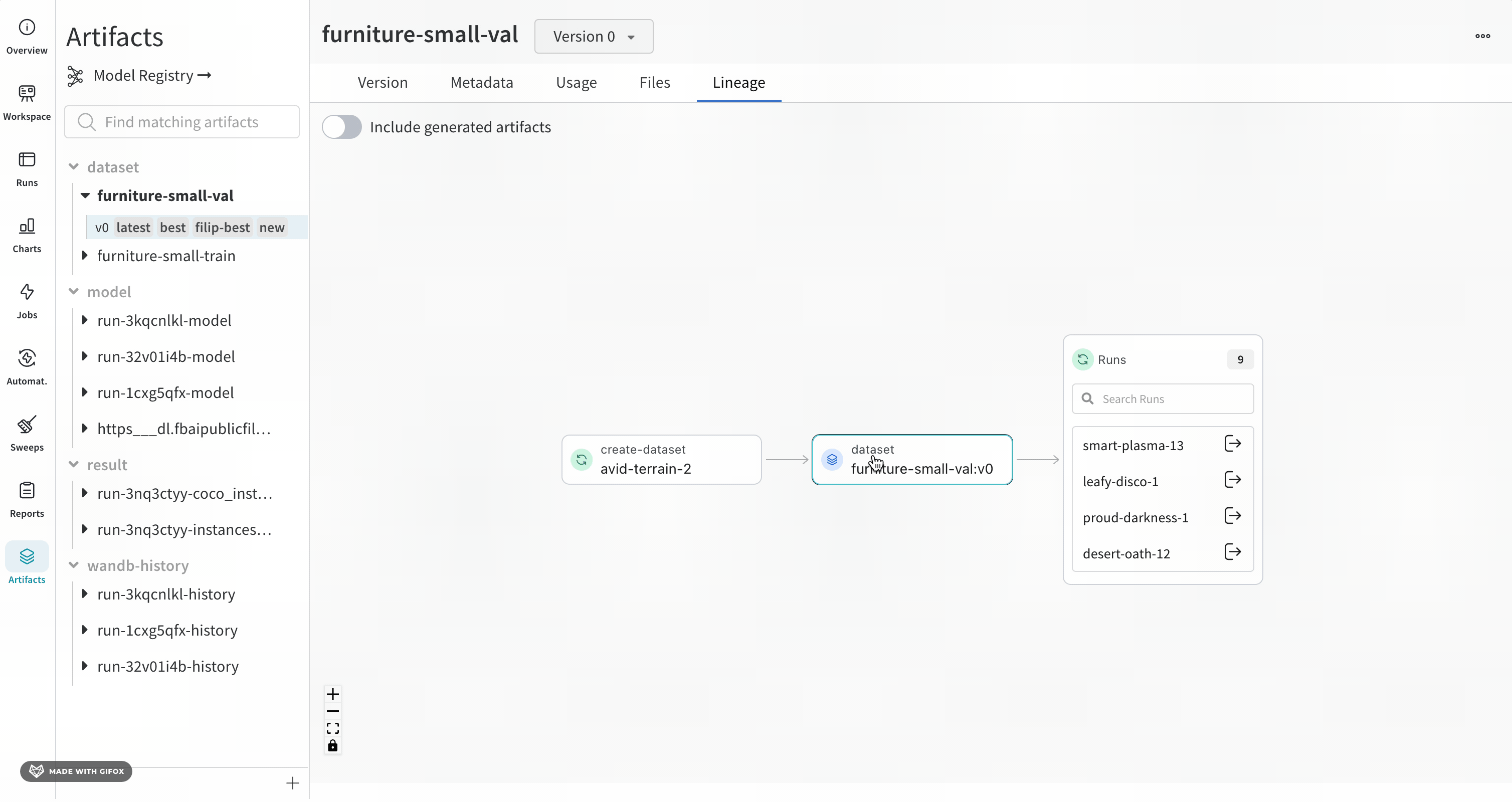
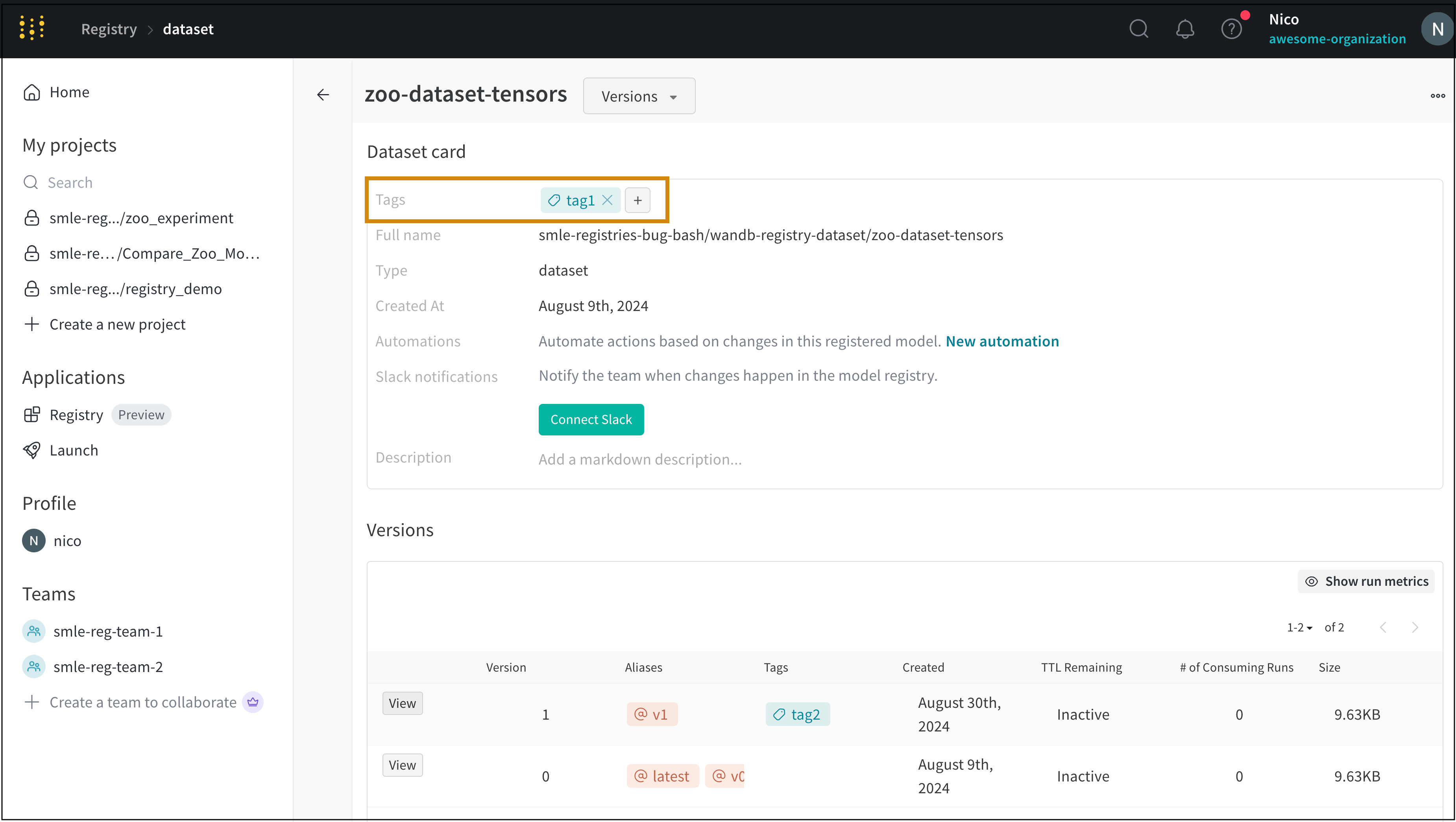
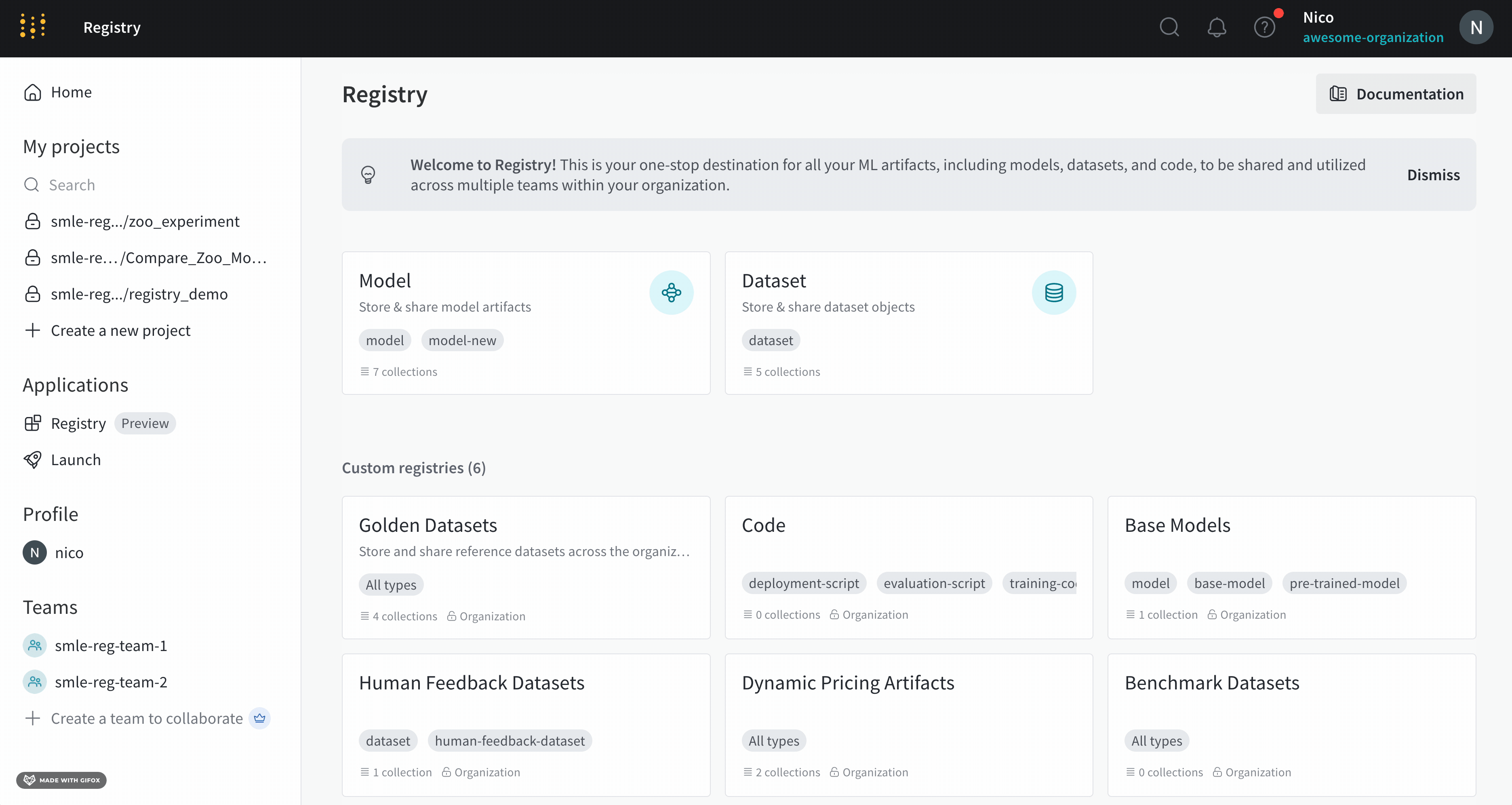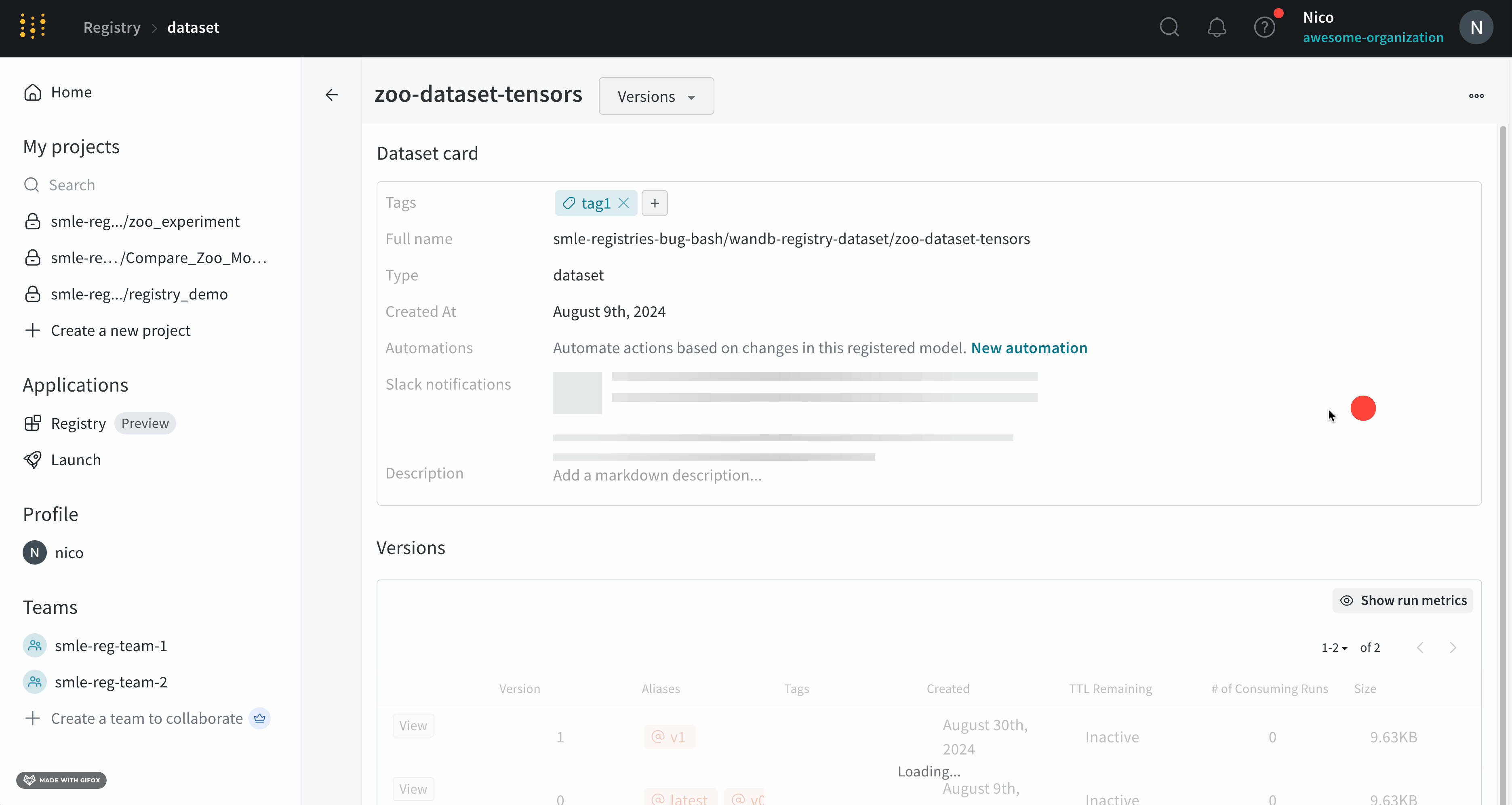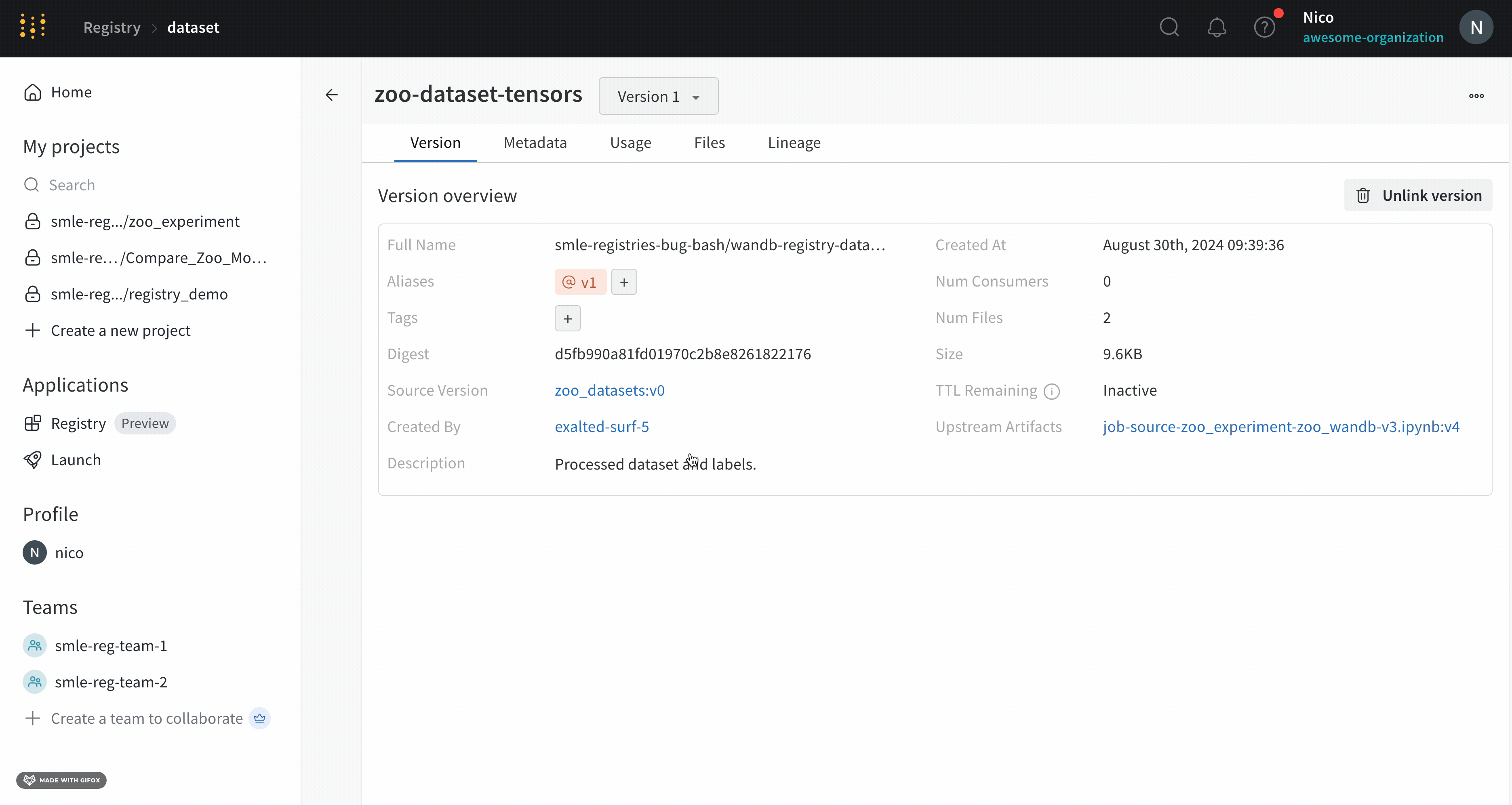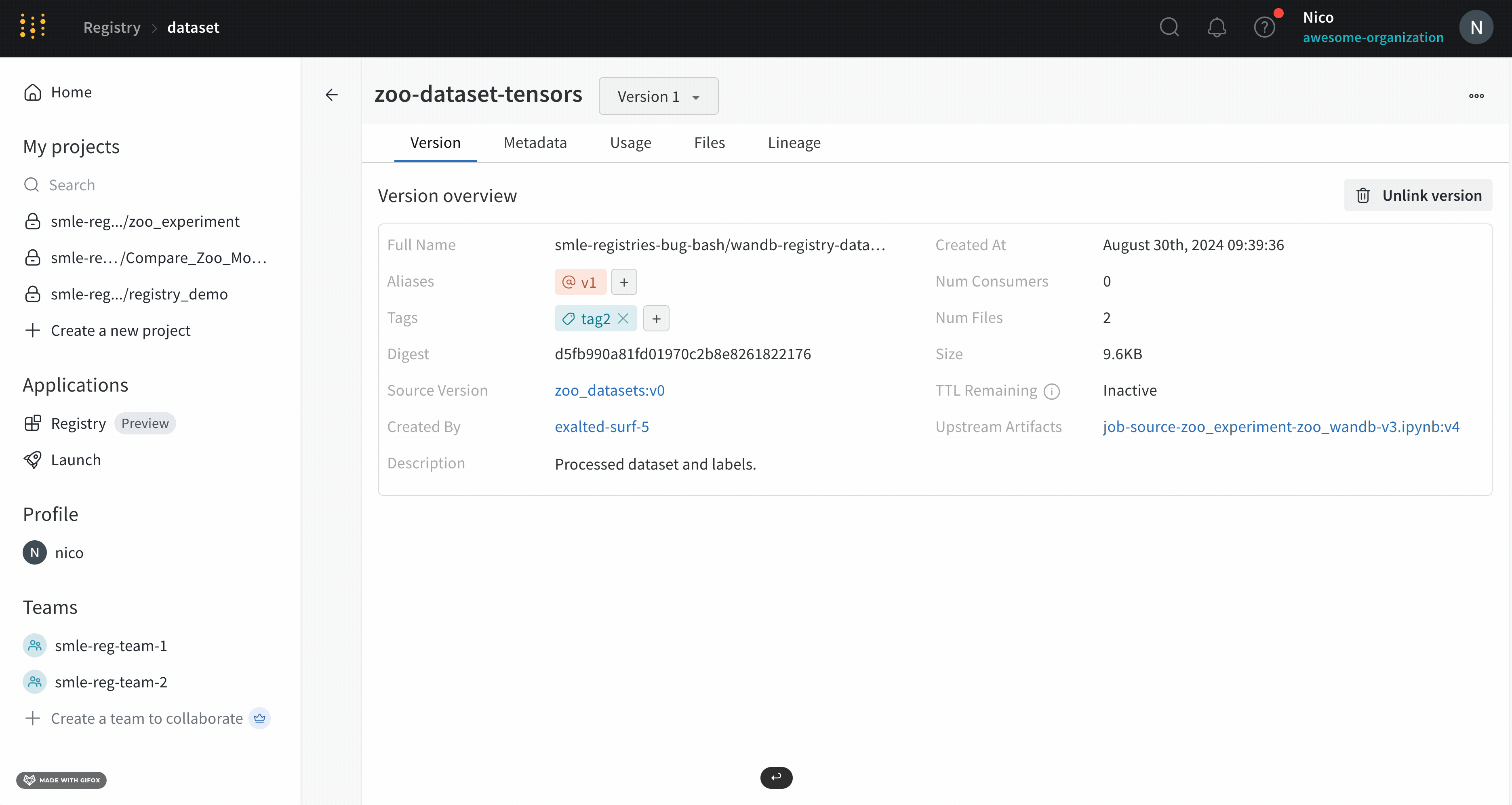
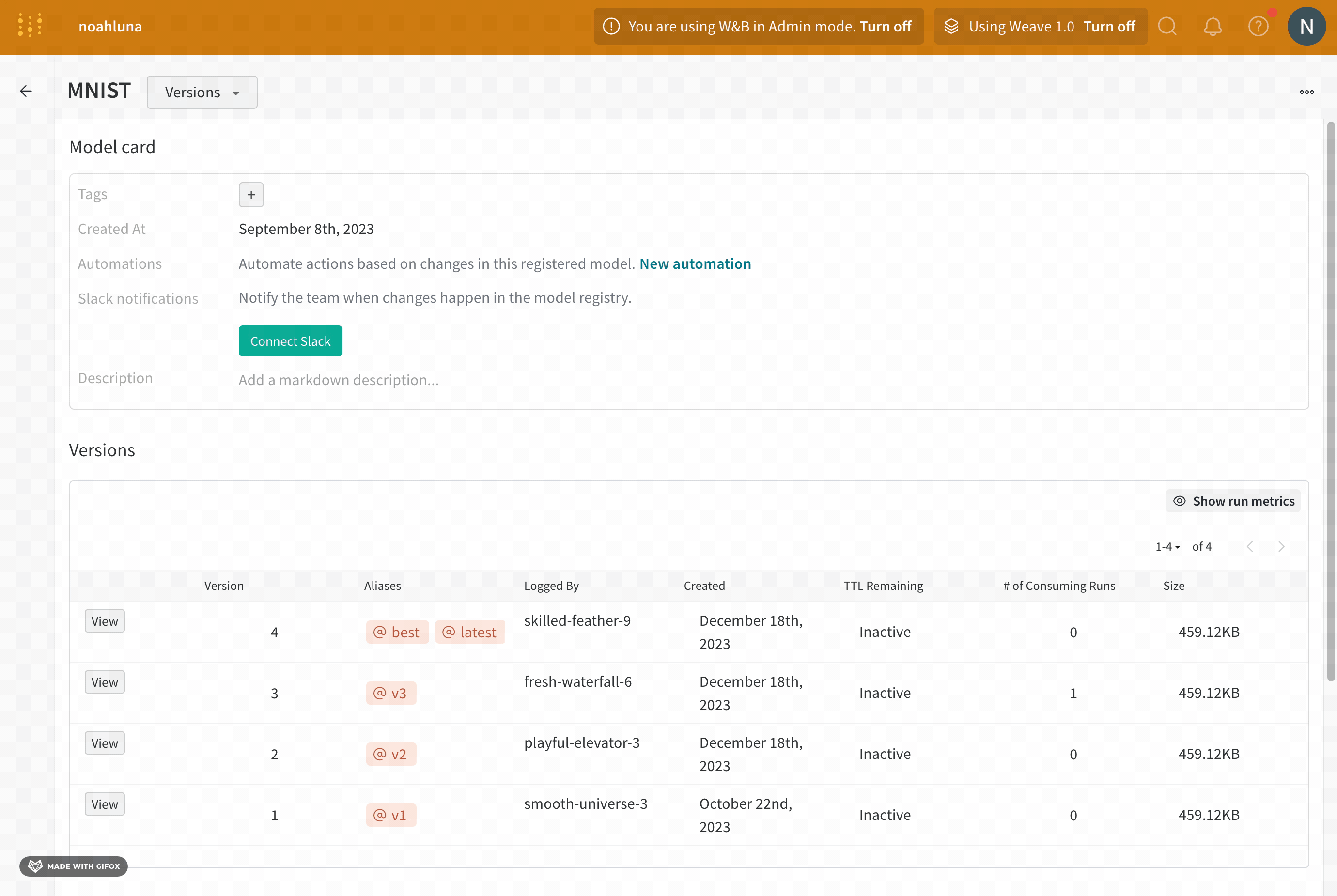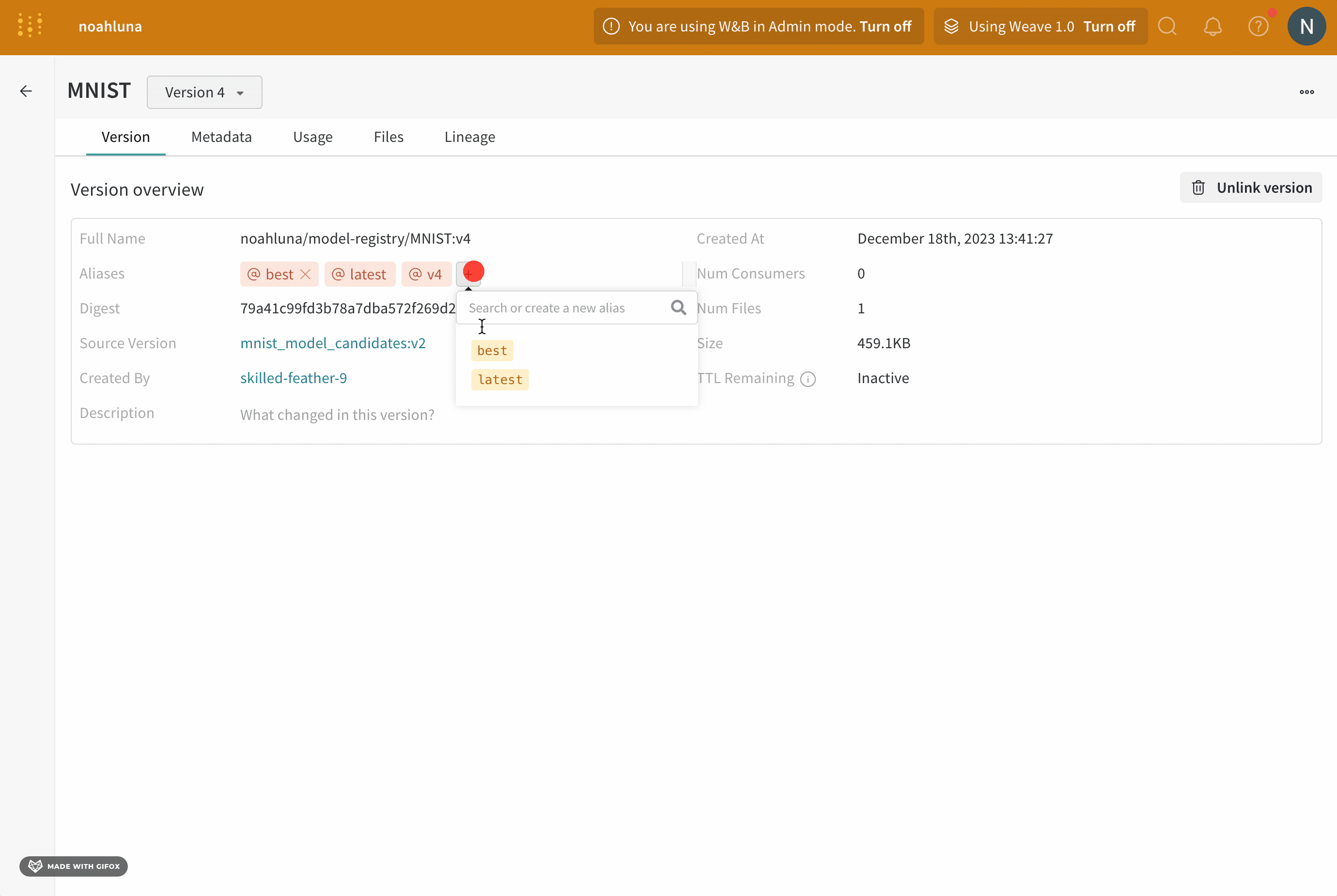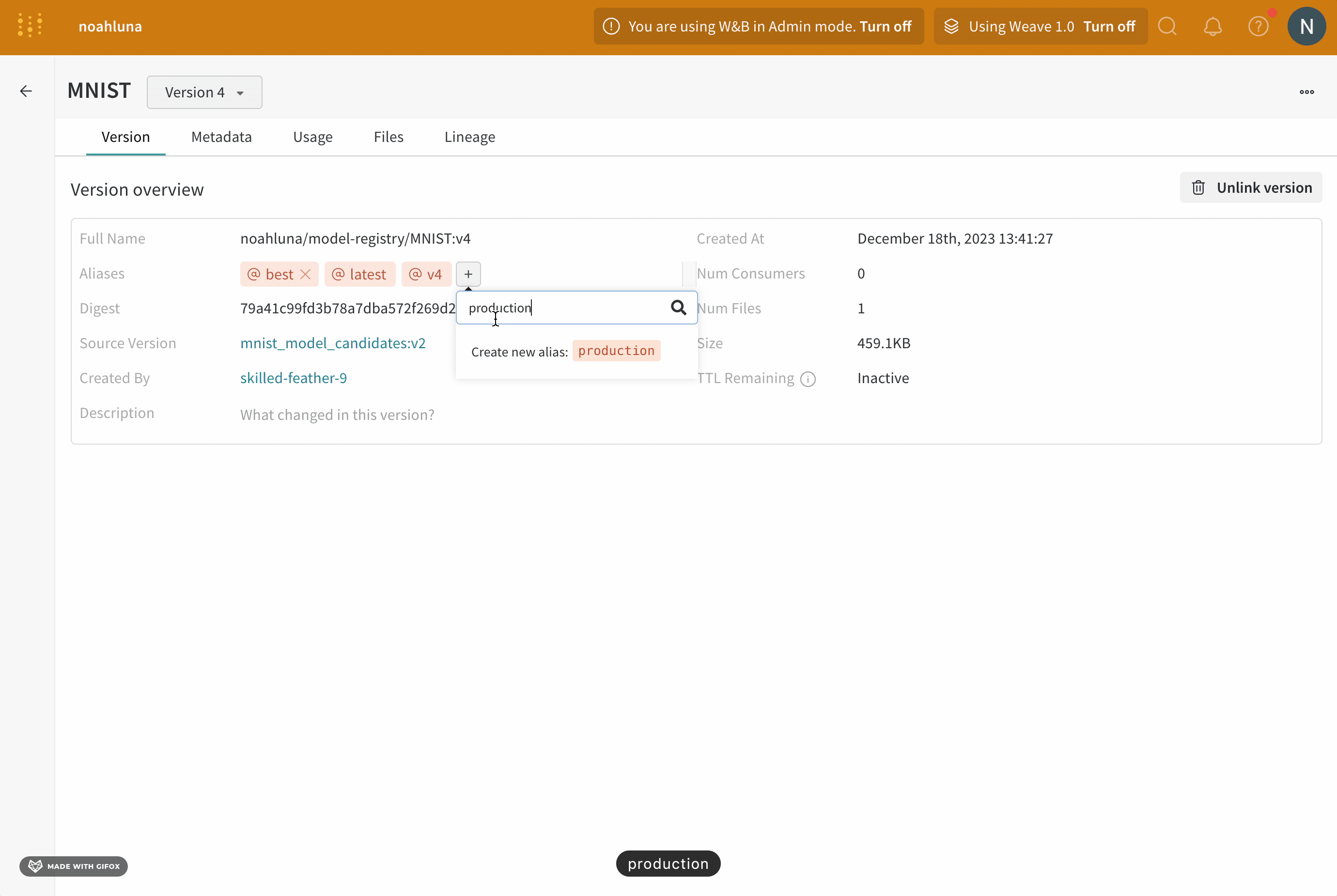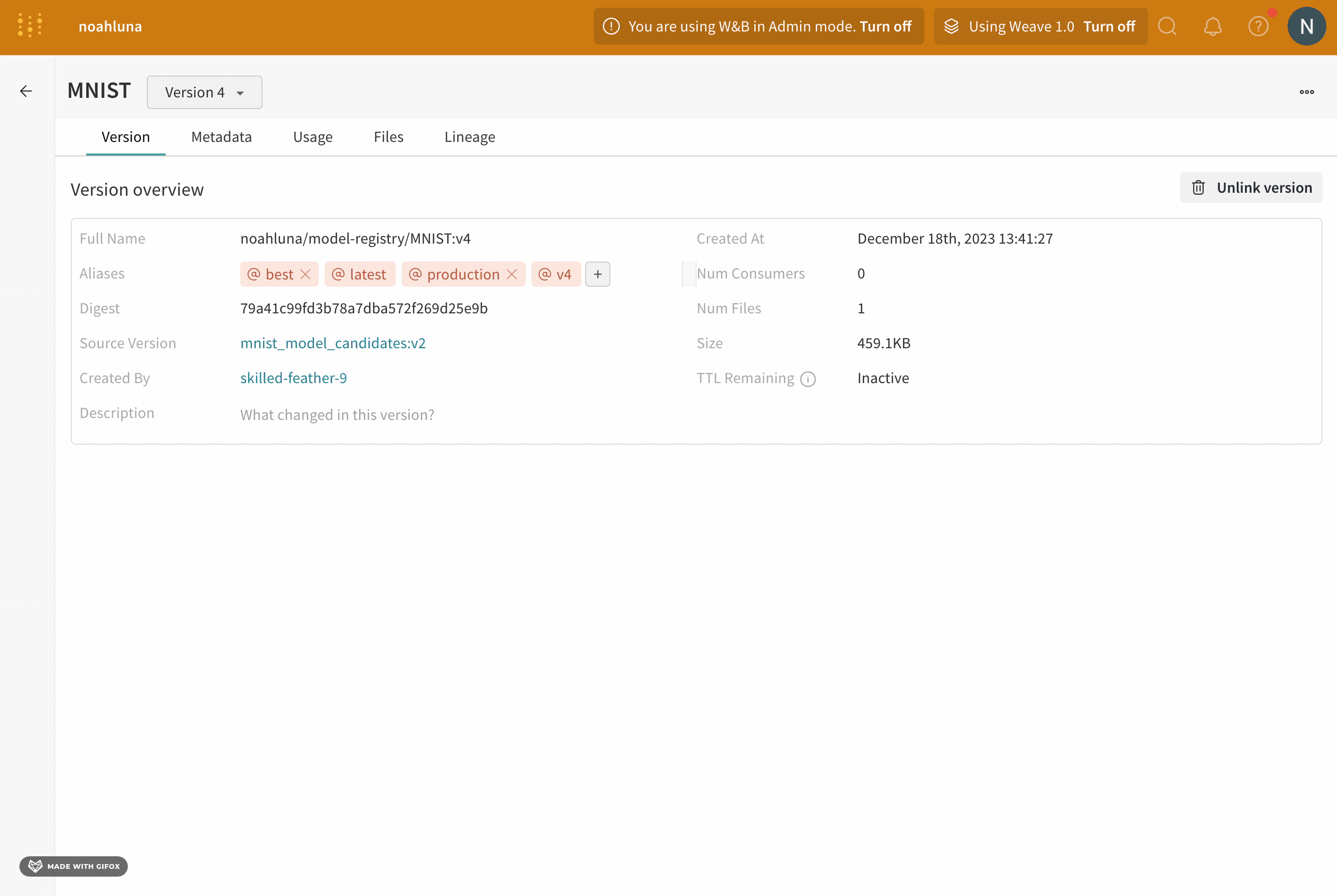
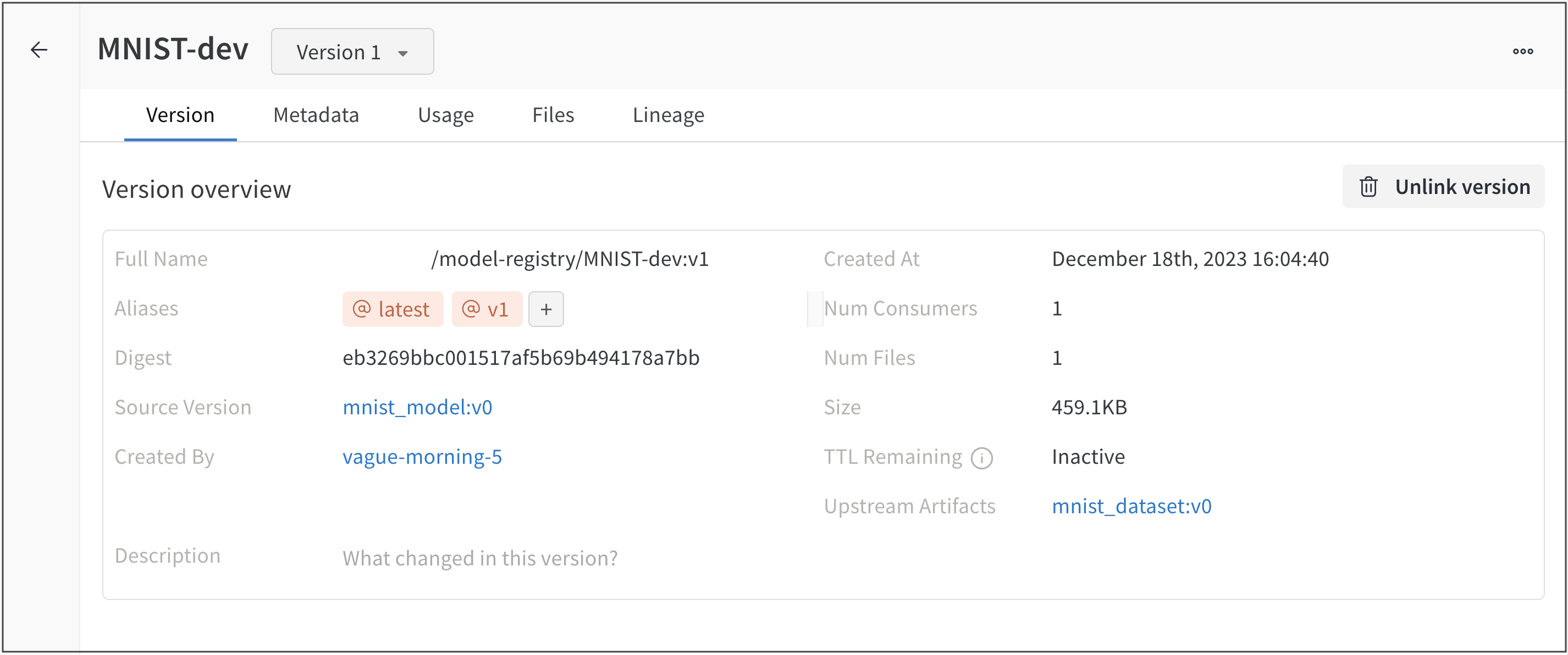
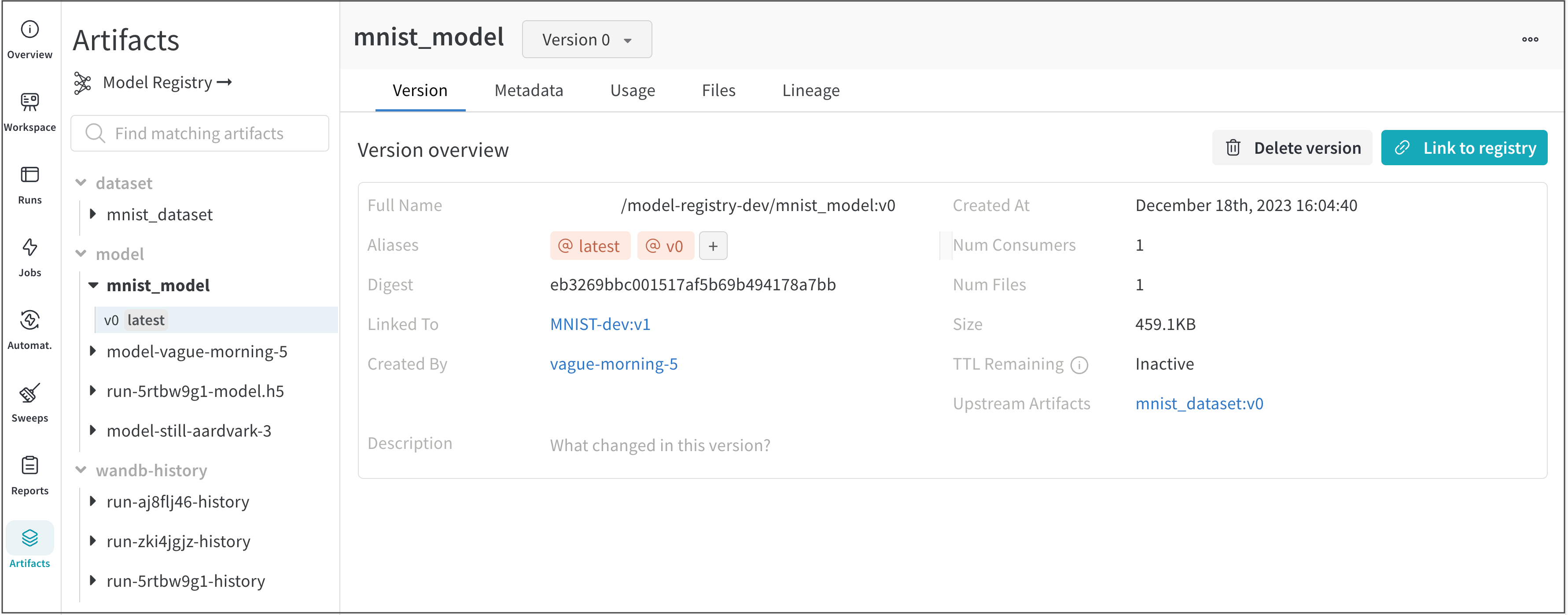
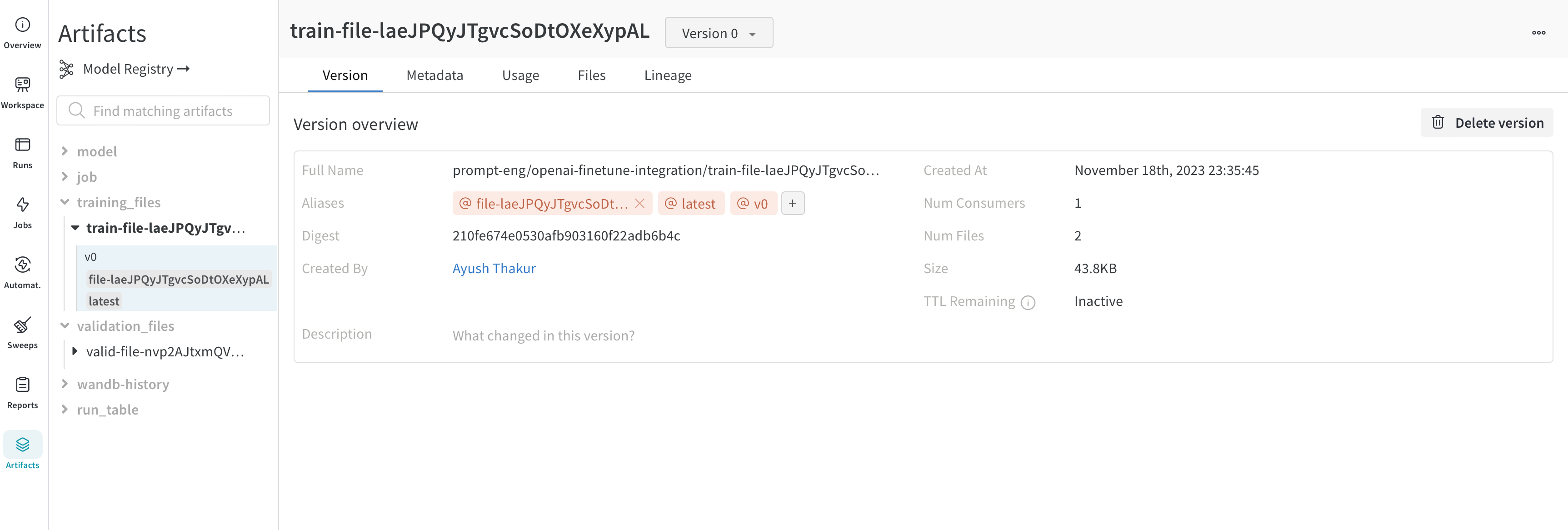
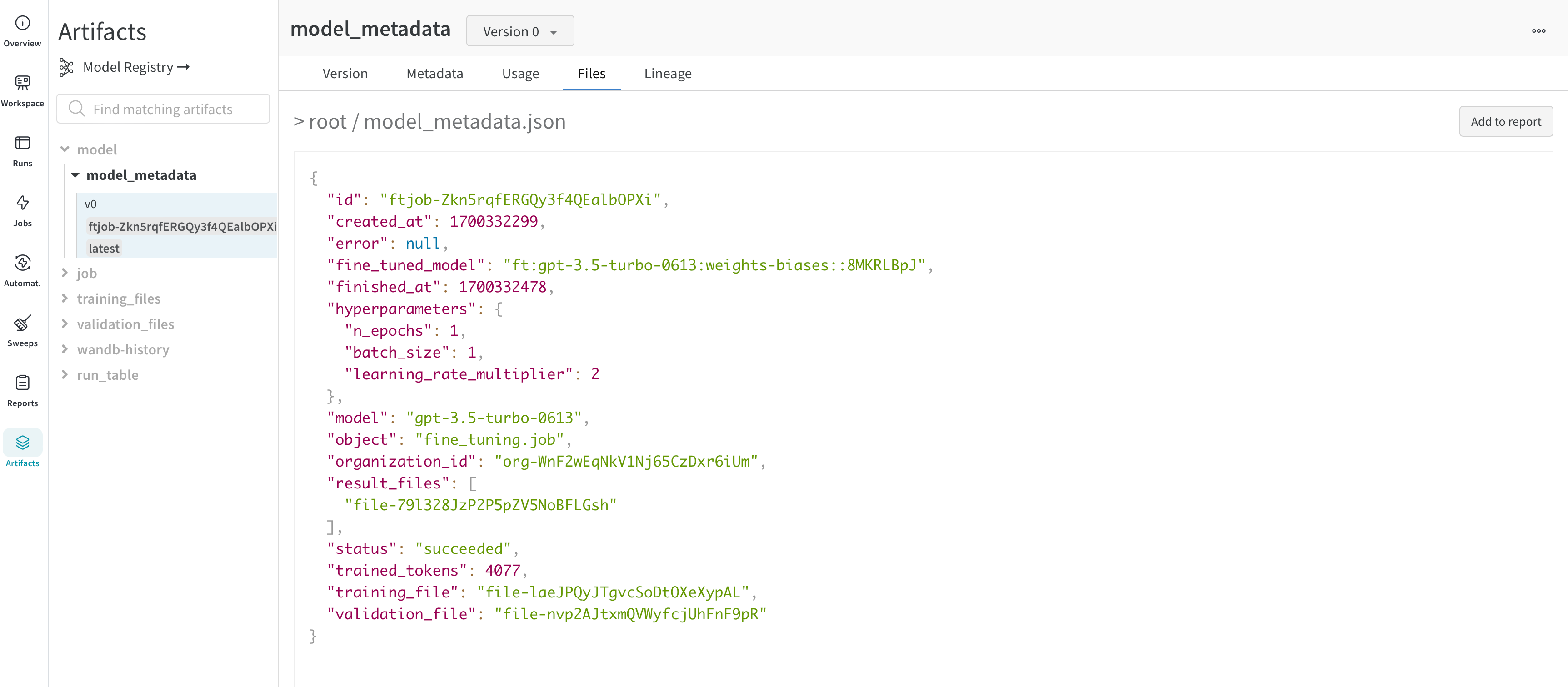
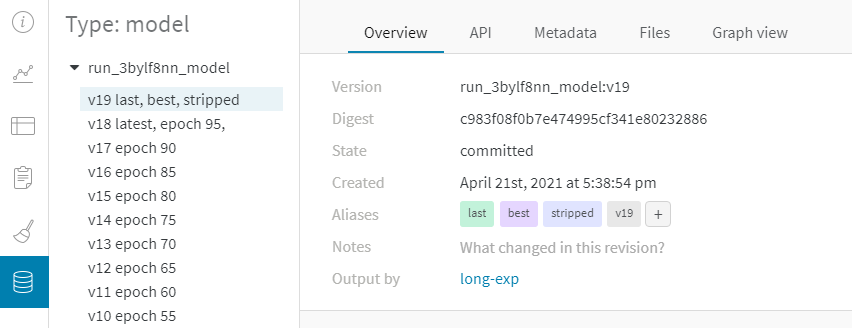
Overview 패널에서는 아티팩트 이름과 버전, 변경 사항을 감지하고 중복을 방지하는 데 사용되는 해시 다이제스트, 생성 날짜, 에일리어스를 포함하여 아티팩트에 대한 다양한 고급 정보를 찾을 수 있습니다. 여기서 에일리어스를 추가하거나 제거하고 버전과 아티팩트 전체에 대한 메모를 작성할 수 있습니다.
Metadata 패널
Metadata 패널은 아티팩트가 구성될 때 제공되는 아티팩트의 메타데이터에 대한 엑세스를 제공합니다. 이 메타데이터에는 아티팩트를 재구성하는 데 필요한 구성 인수, 더 많은 정보를 찾을 수 있는 URL 또는 아티팩트를 기록한 run 중에 생성된 메트릭이 포함될 수 있습니다. 또한 아티팩트를 생성한 run에 대한 구성과 아티팩트를 로깅할 당시의 기록 메트릭을 볼 수 있습니다.
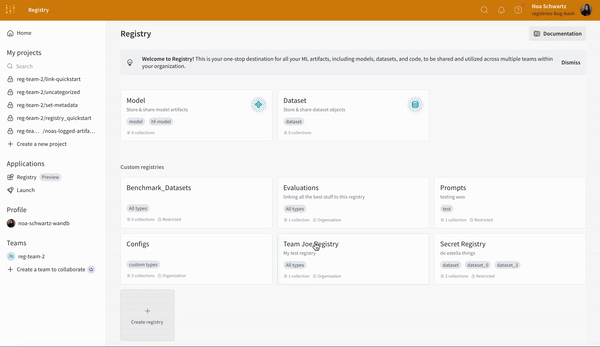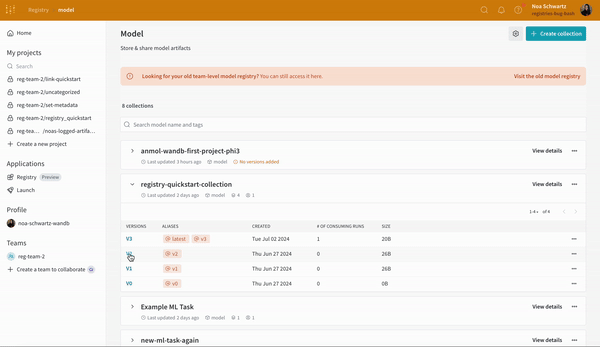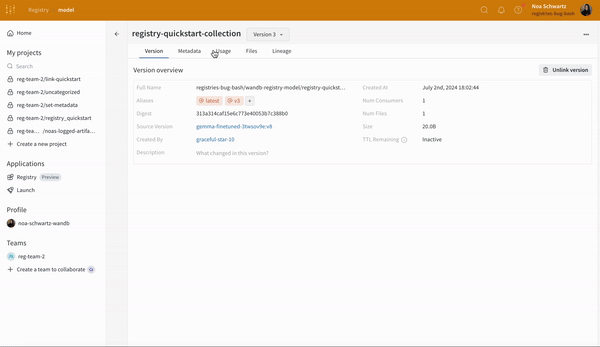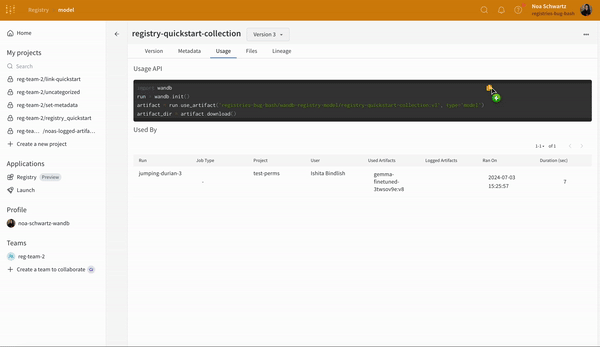
Usage 패널
Usage 패널은 예를 들어 로컬 머신에서 웹 앱 외부에서 사용할 수 있도록 아티팩트를 다운로드하기 위한 코드 조각을 제공합니다. 이 섹션은 또한 아티팩트를 출력하는 run과 아티팩트를 입력으로 사용하는 모든 Runs을 나타내고 링크합니다.
Files 패널
Files 패널은 아티팩트와 연결된 파일 및 폴더를 나열합니다. W&B는 run에 대한 특정 파일을 자동으로 업로드합니다. 예를 들어 requirements.txt는 run에서 사용된 각 라이브러리의 버전을 보여주고 wandb-metadata.json 및 wandb-summary.json에는 run에 대한 정보가 포함되어 있습니다. 다른 파일은 run의 구성에 따라 아티팩트 또는 미디어와 같이 업로드될 수 있습니다. 이 파일 트리를 탐색하고 W&B 웹 앱에서 직접 내용을 볼 수 있습니다.
아티팩트와 연결된 테이블은 특히 풍부하고 대화형입니다. Artifacts와 함께 테이블을 사용하는 방법에 대해 자세히 알아보려면 여기를 참조하세요.
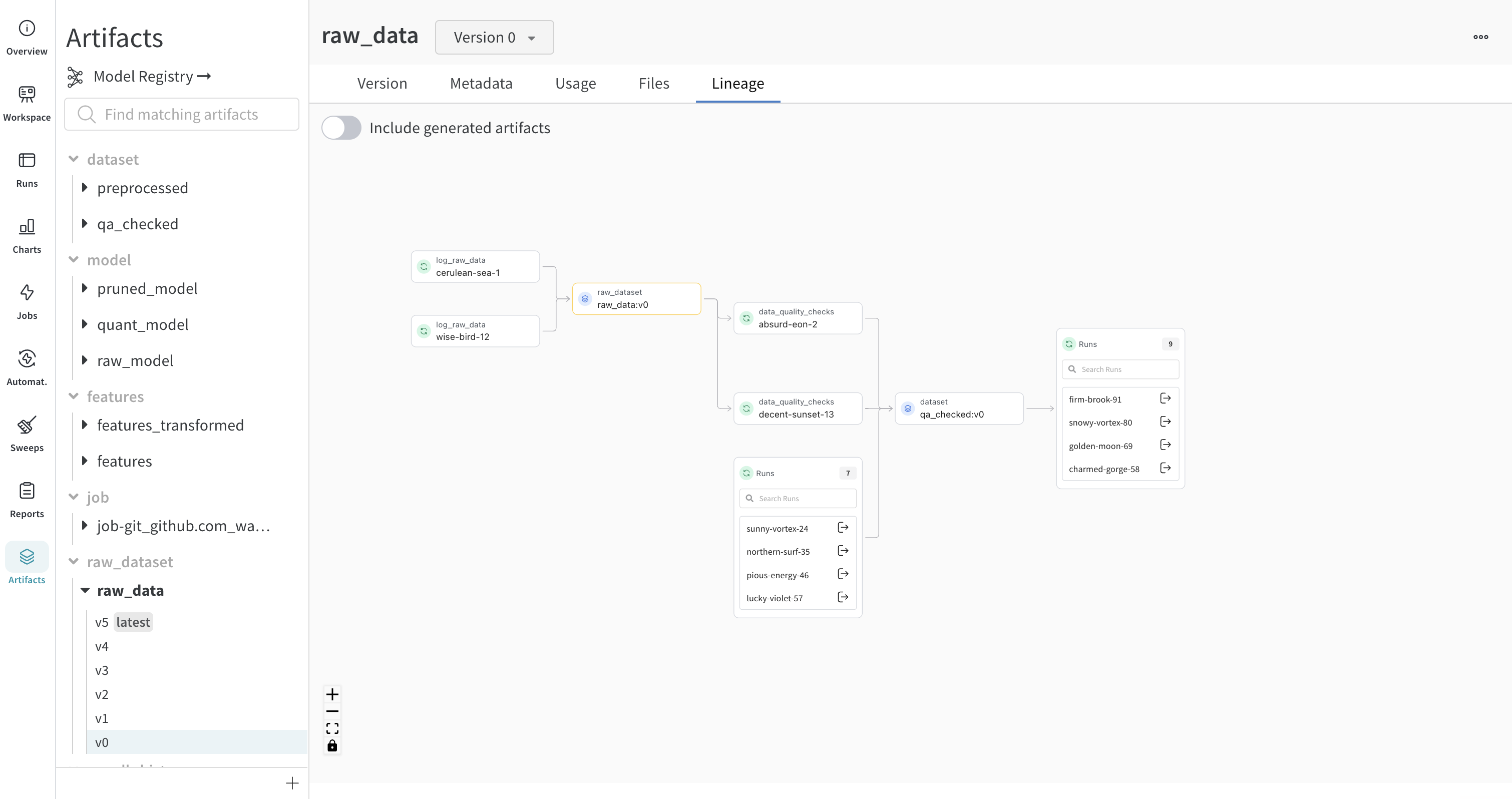
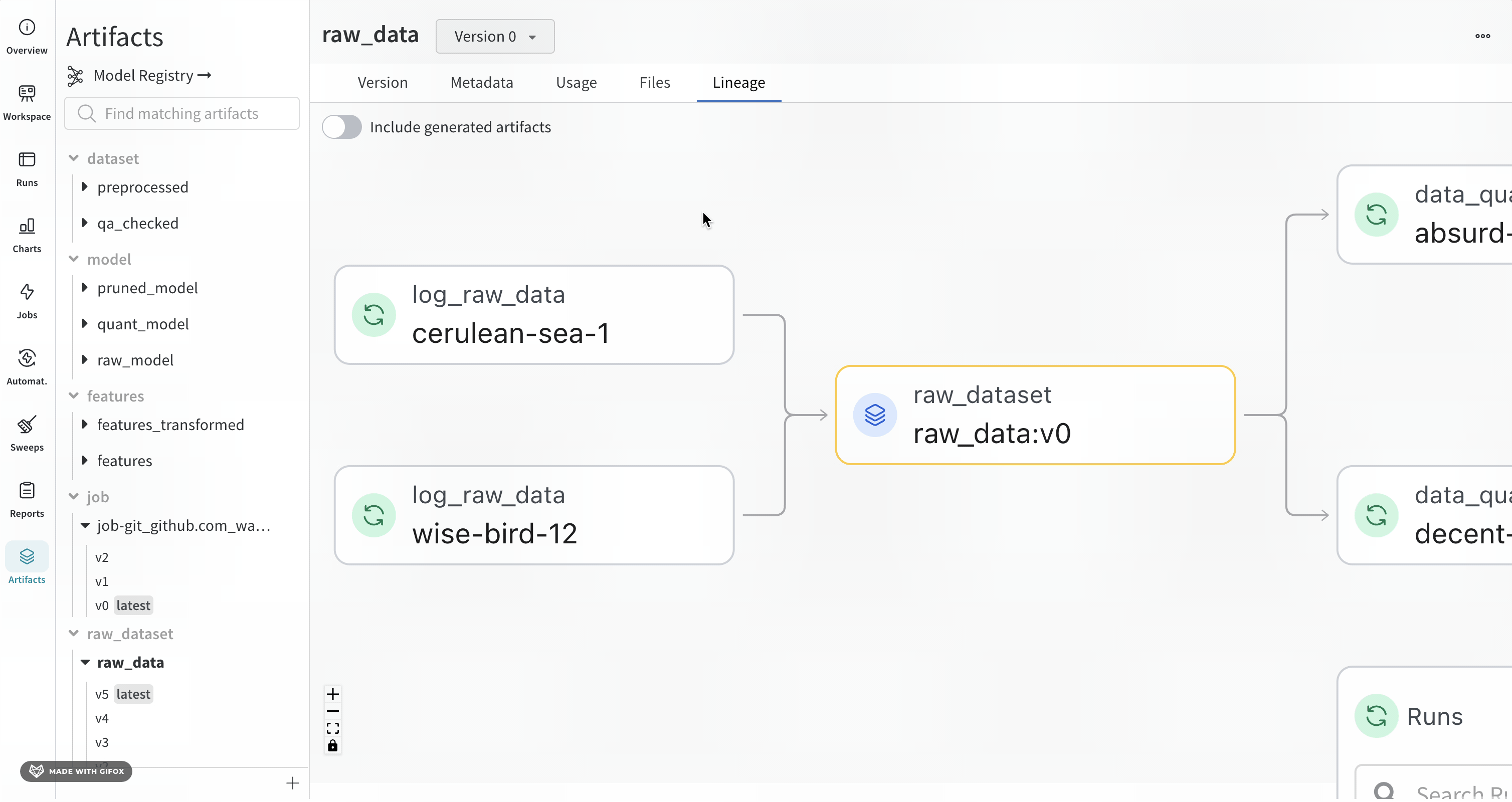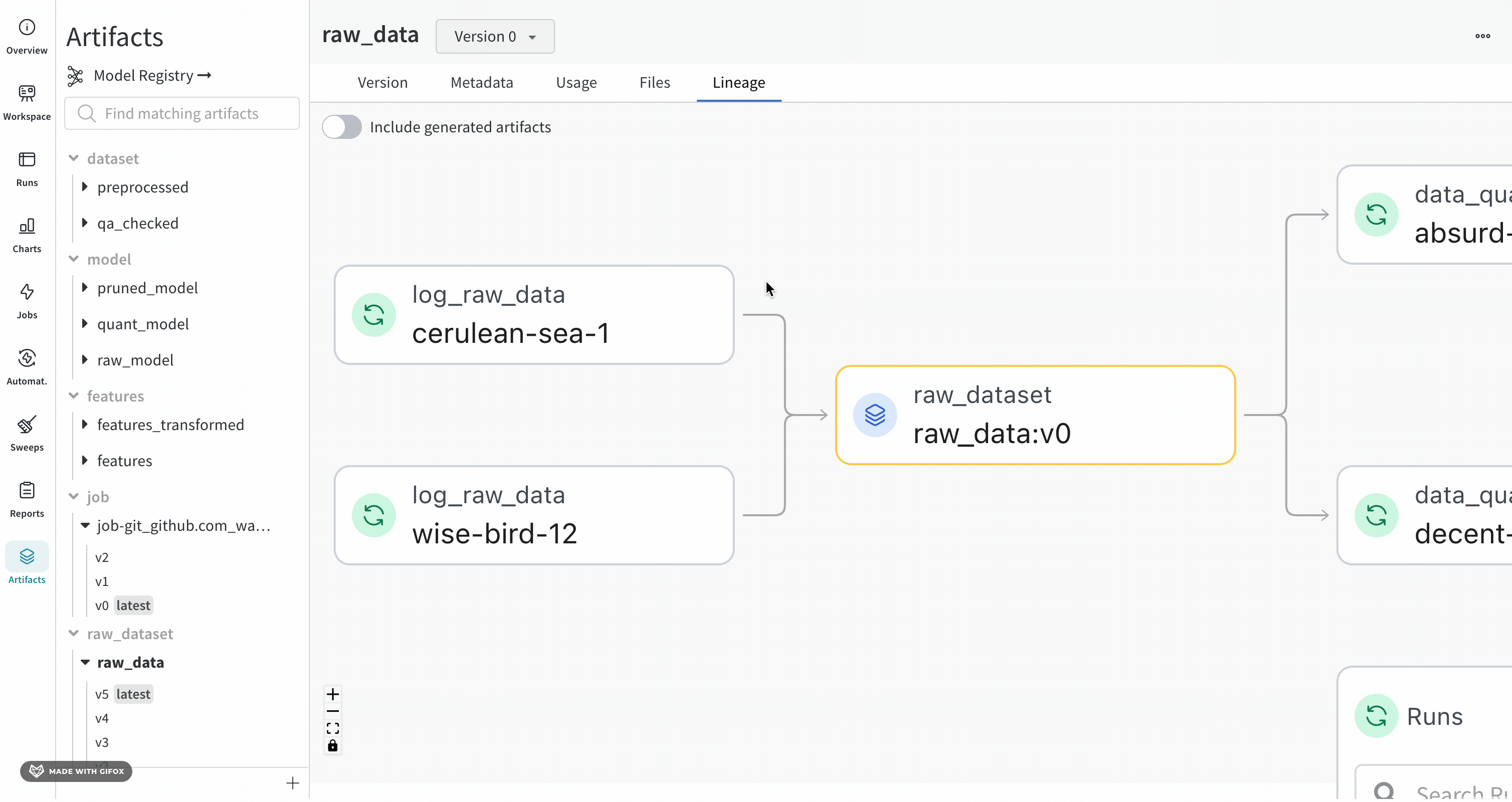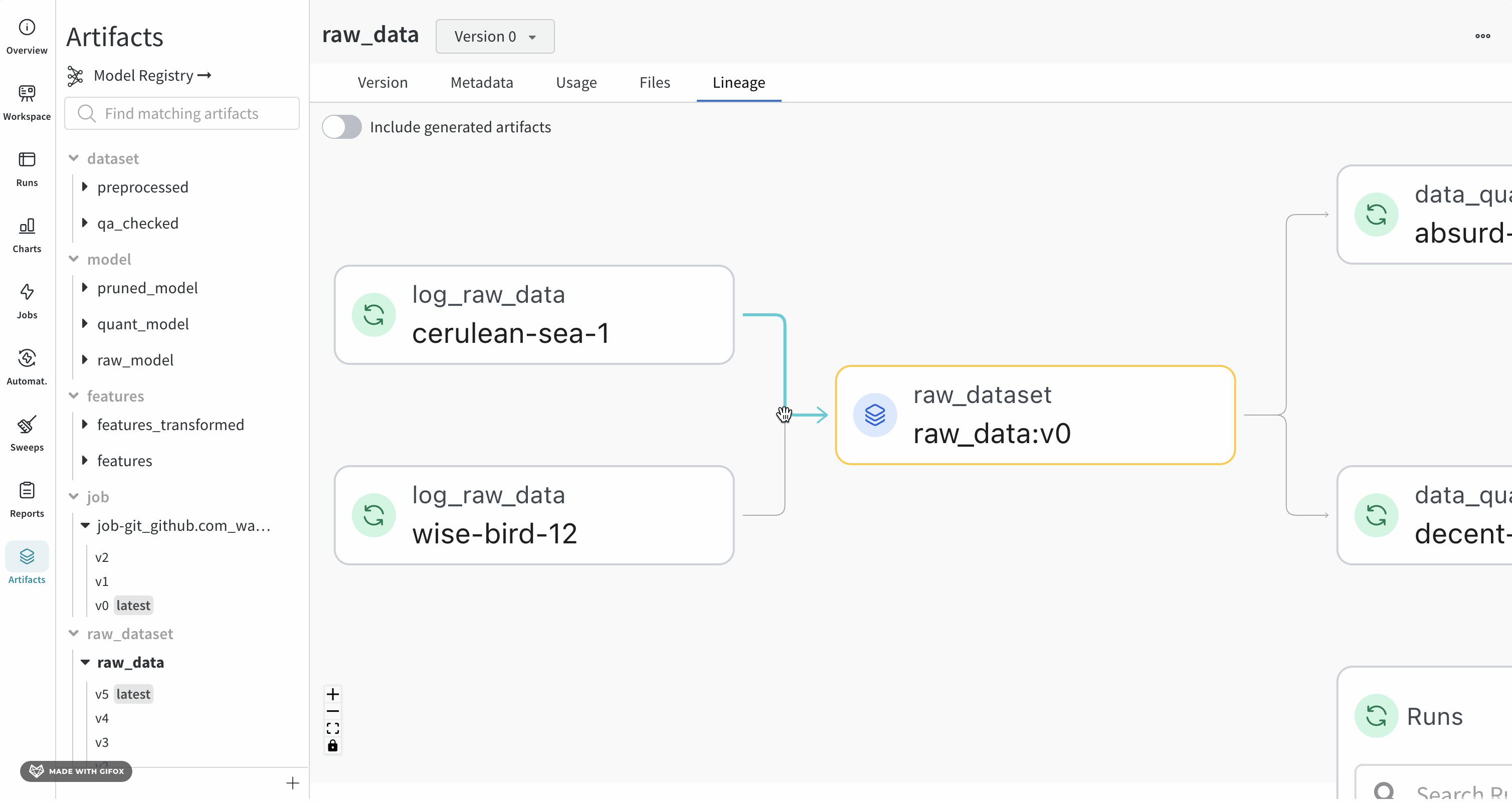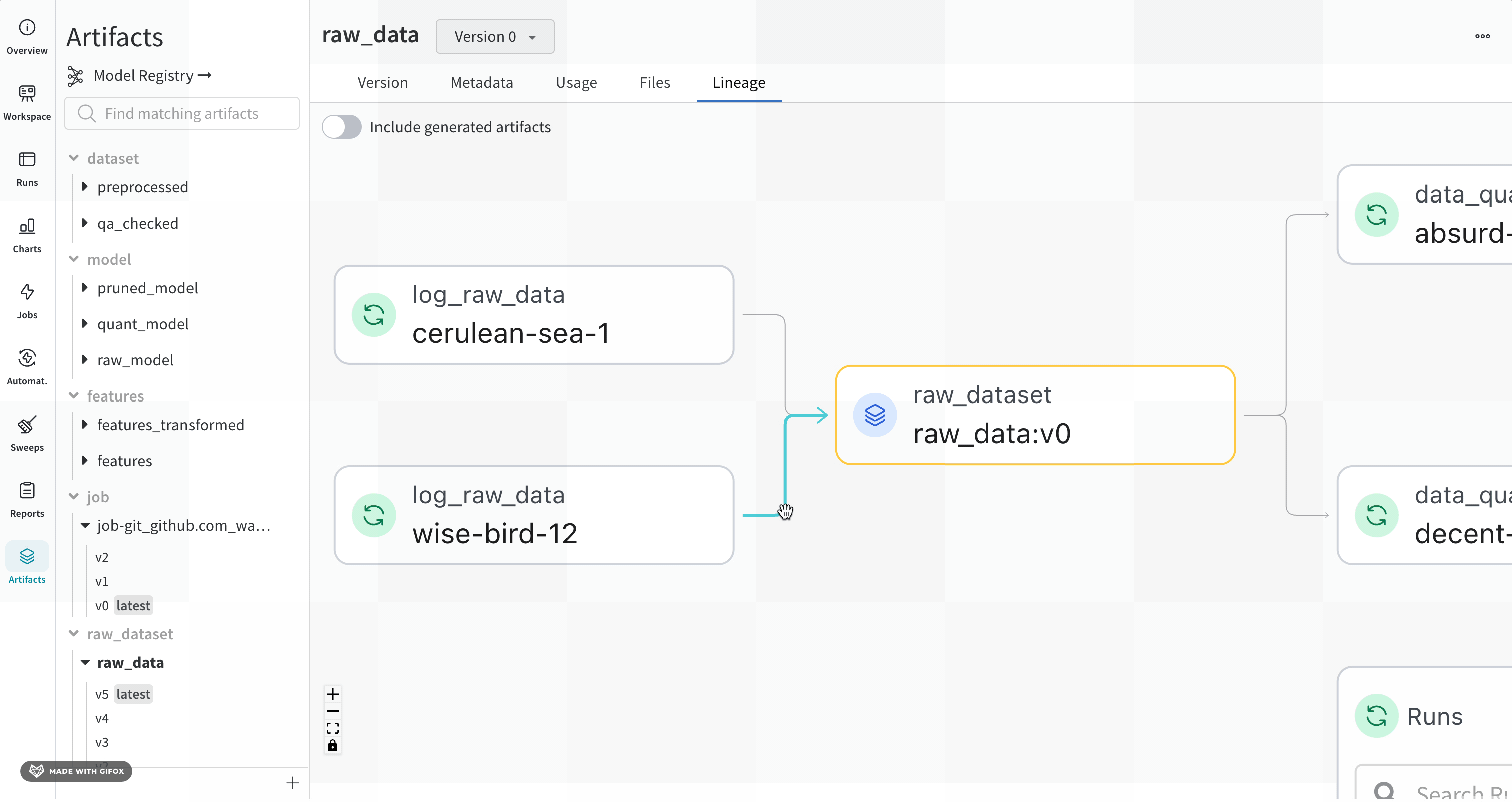
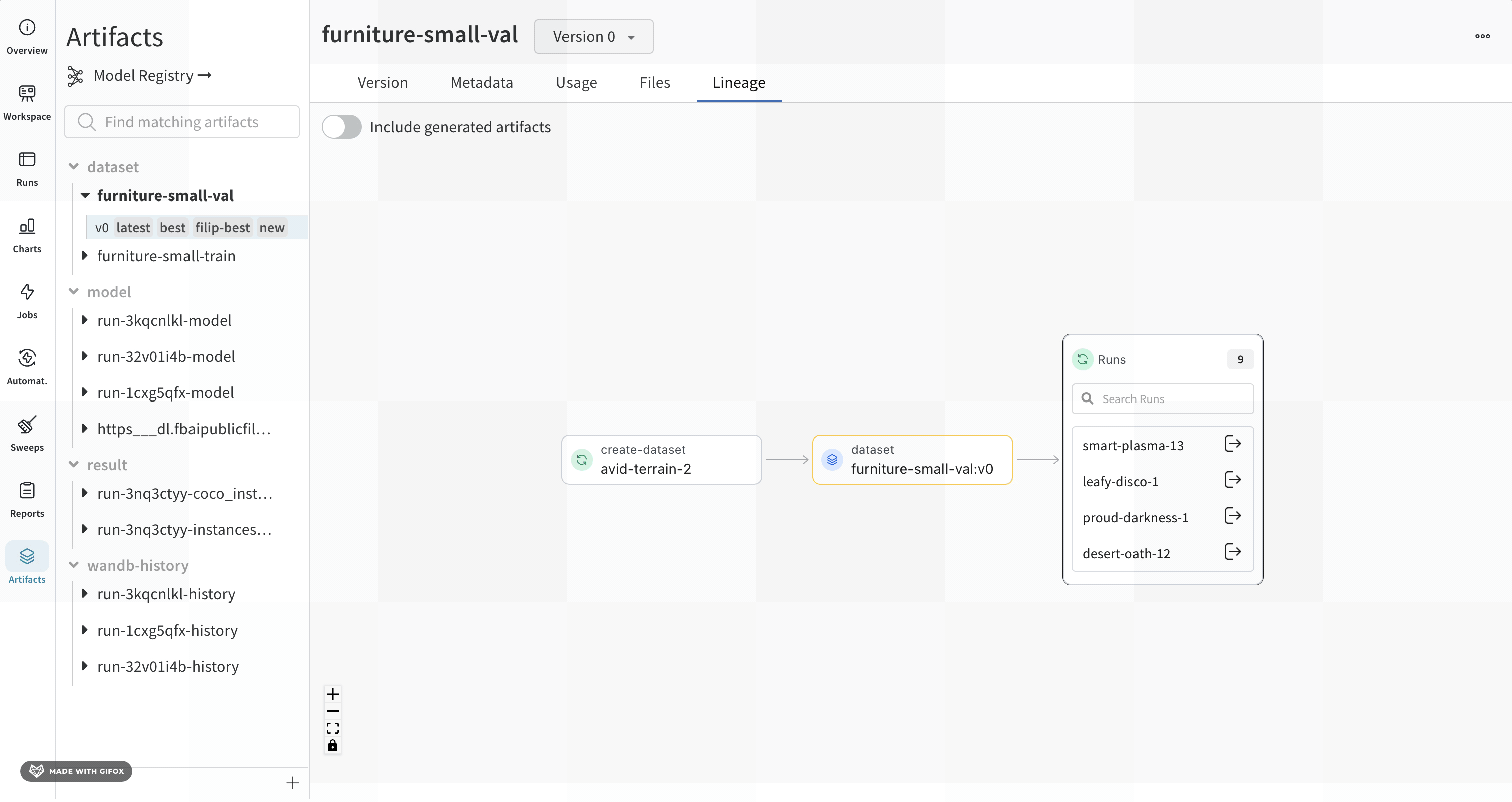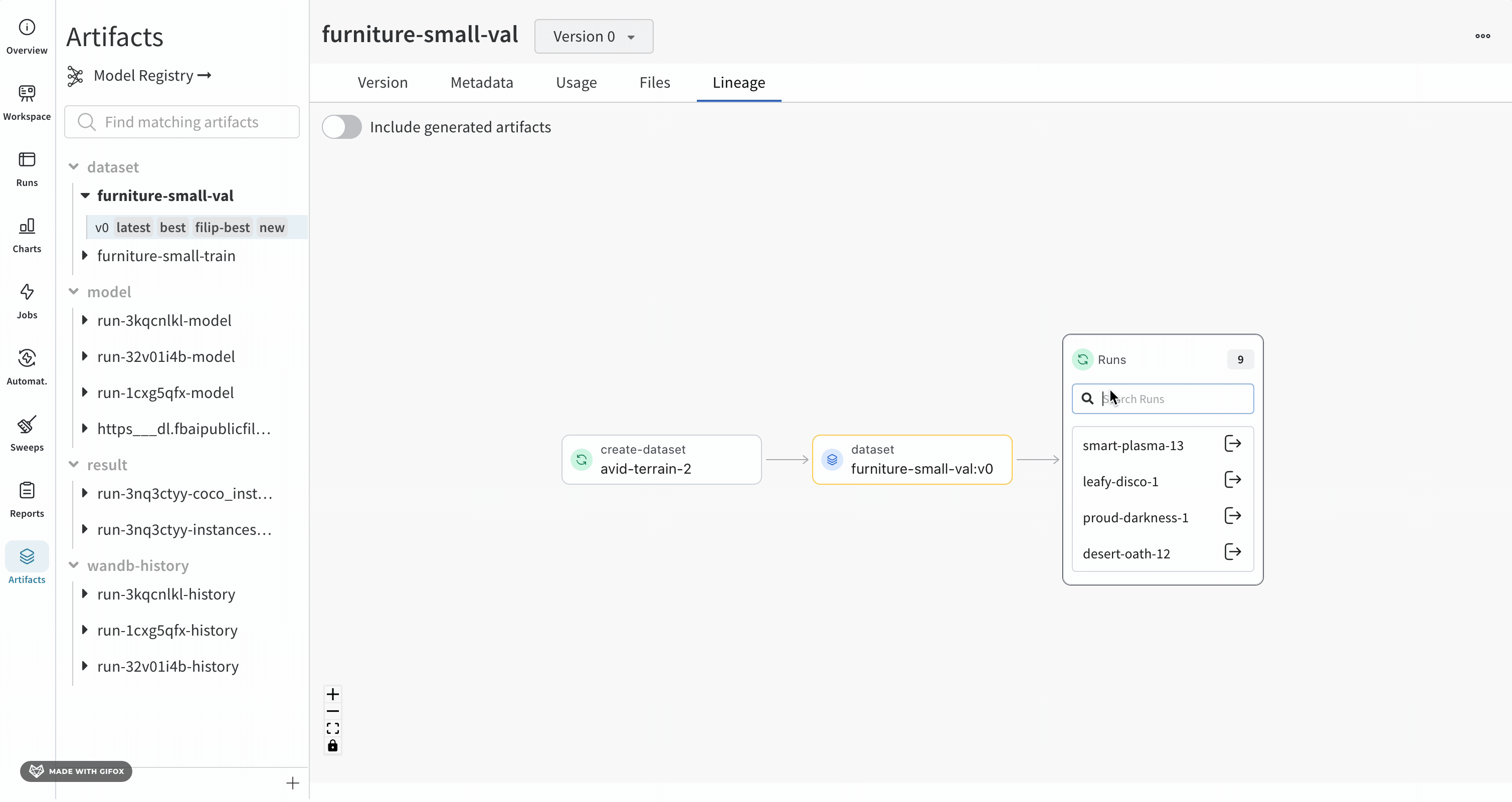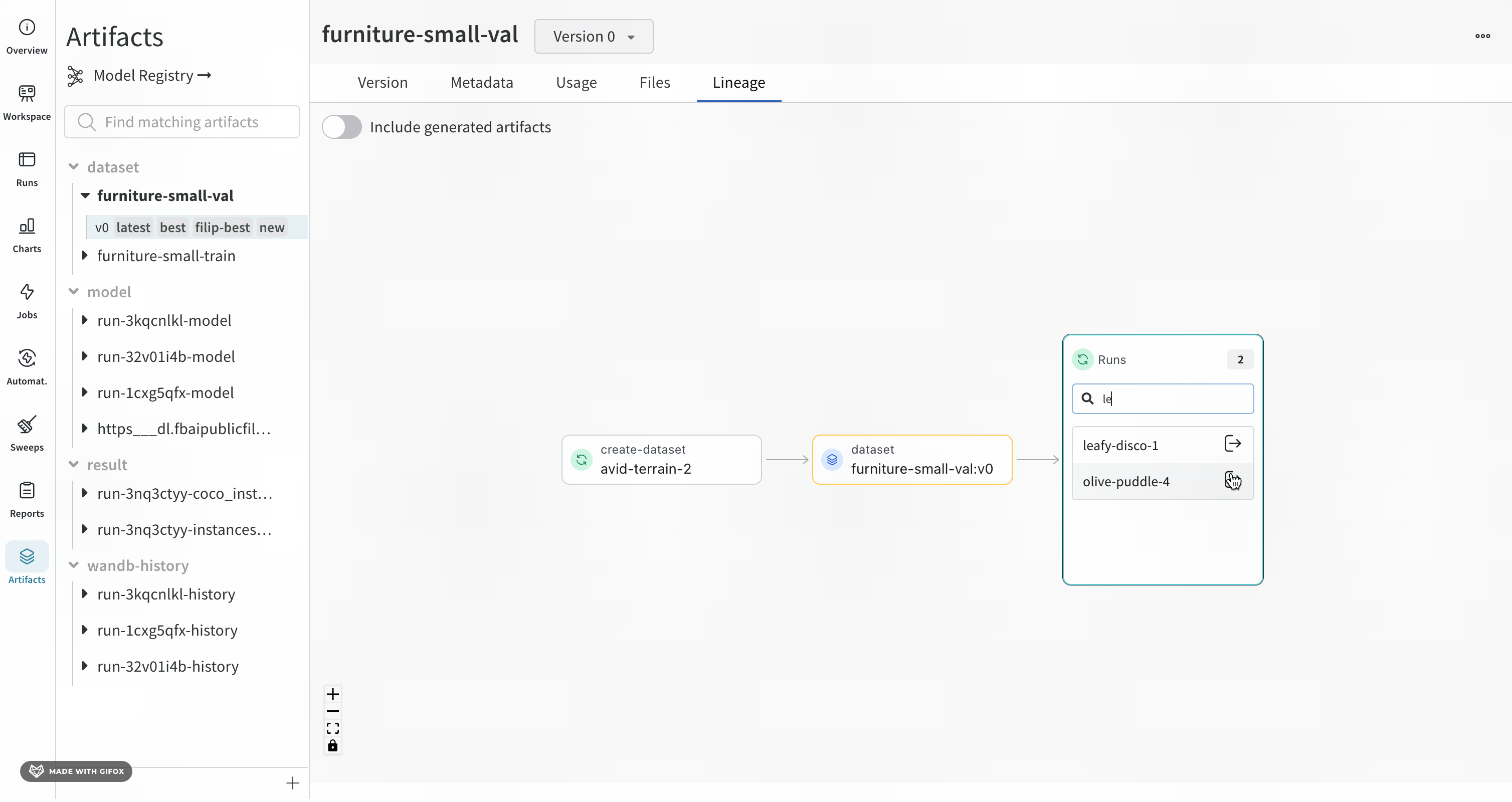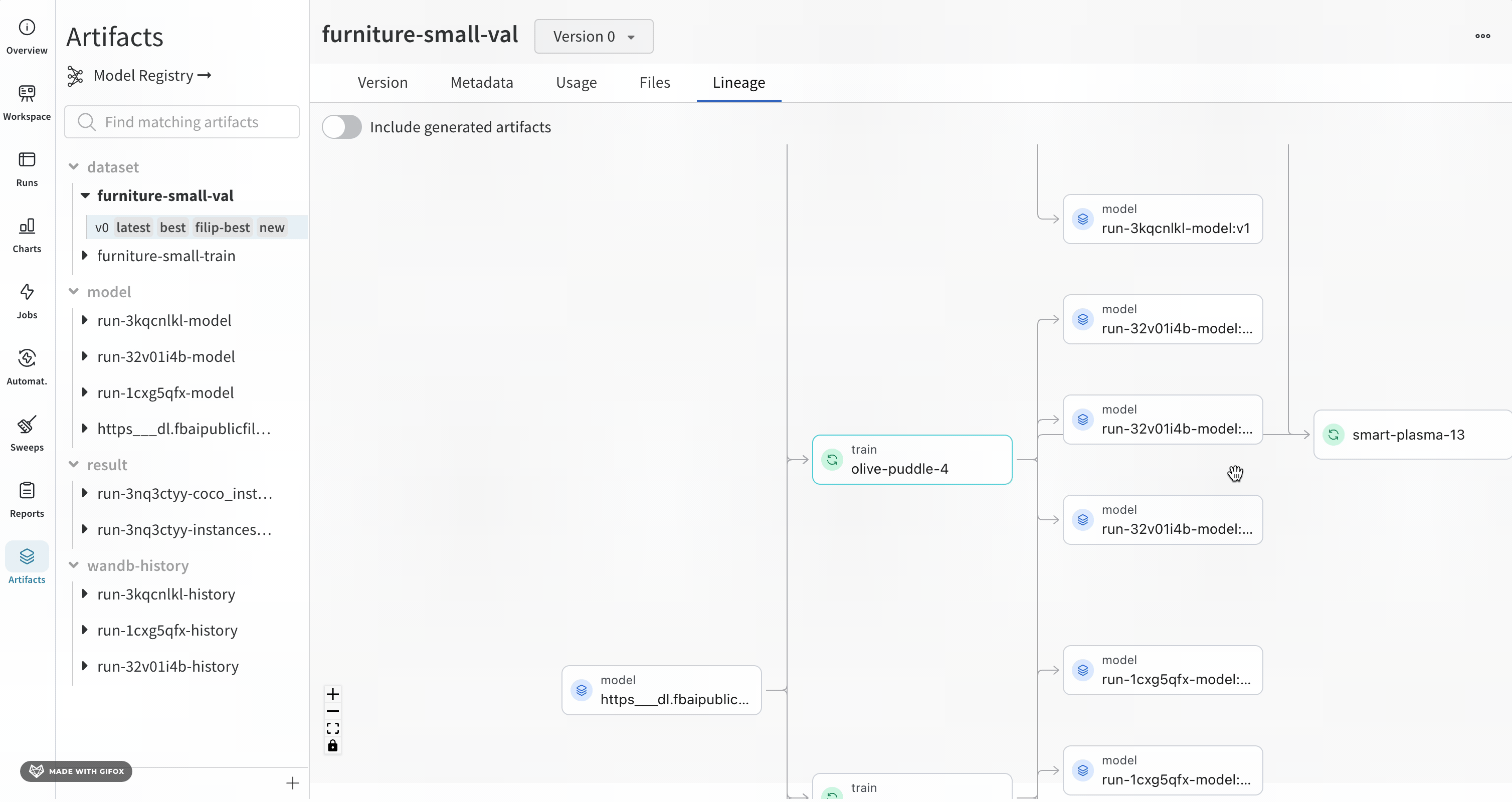
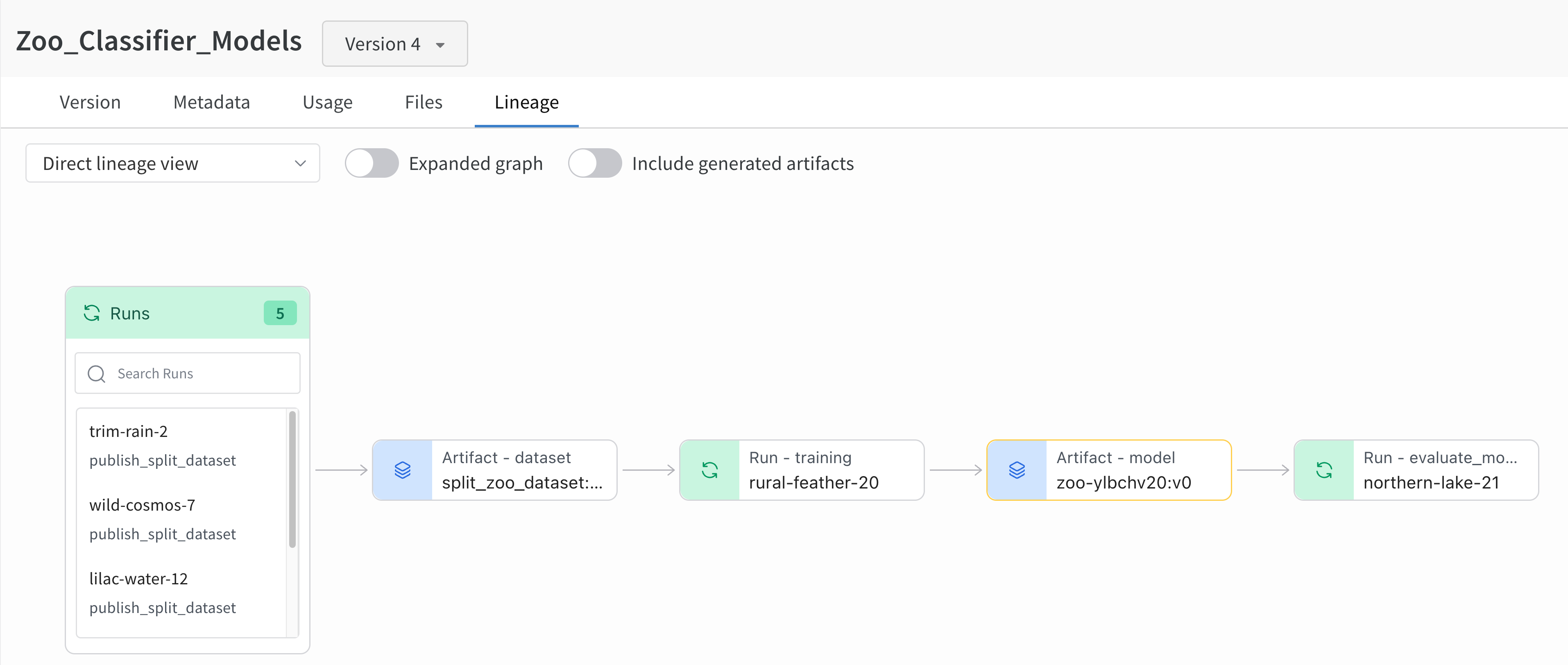
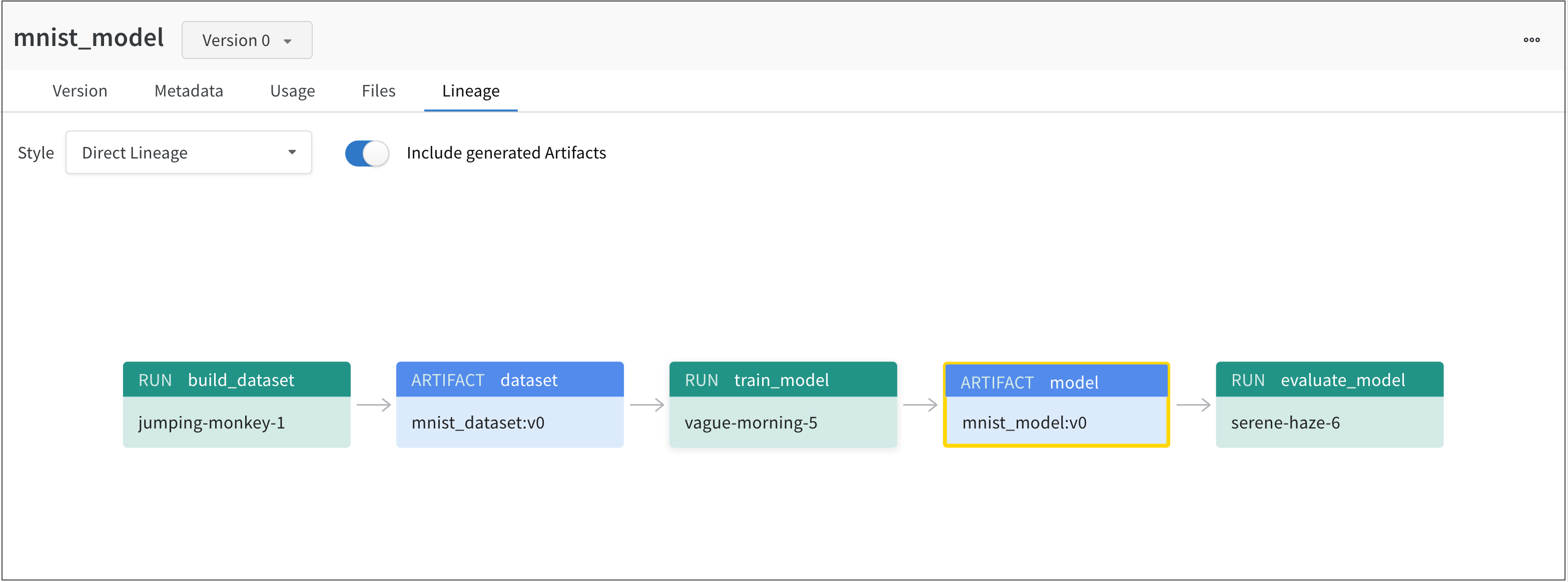
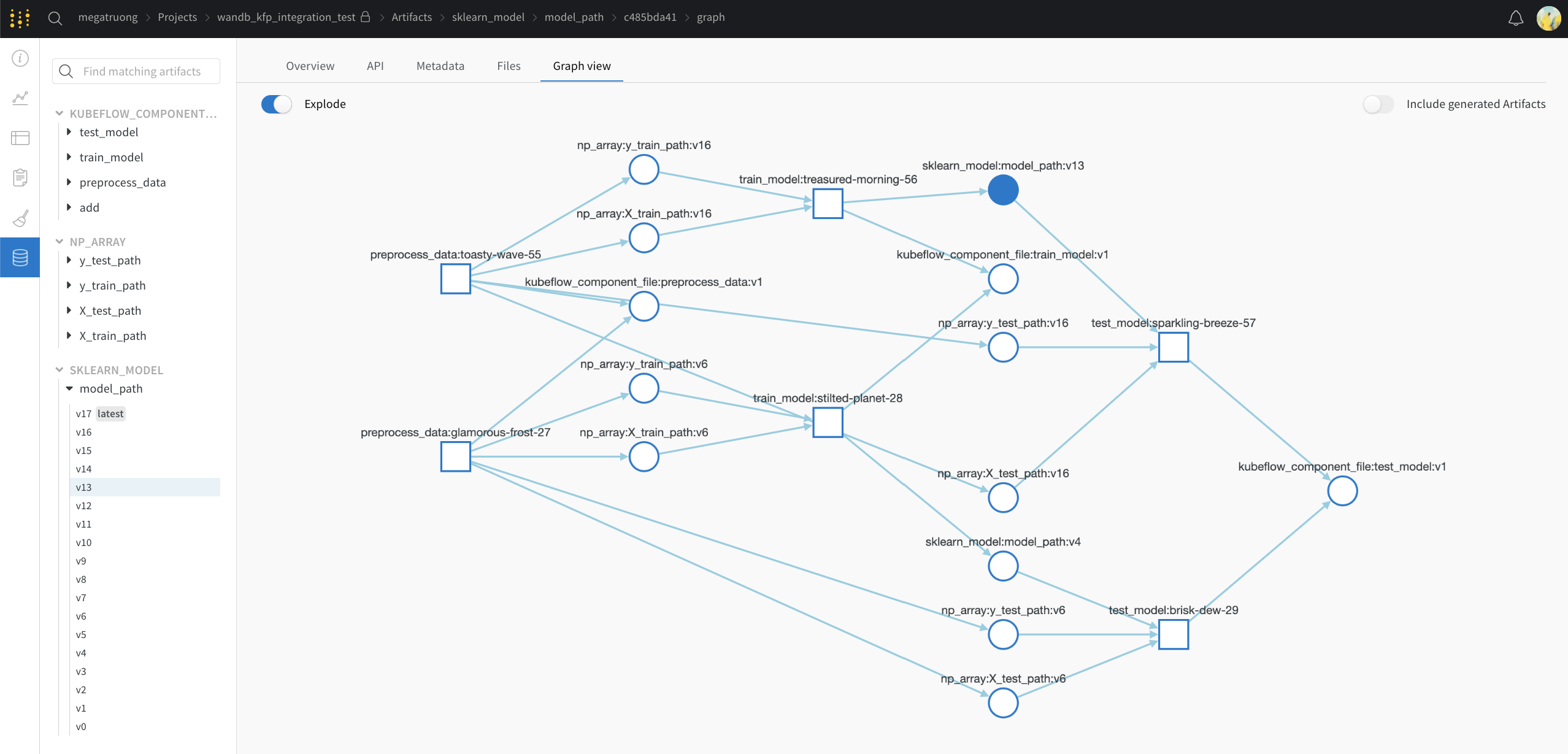
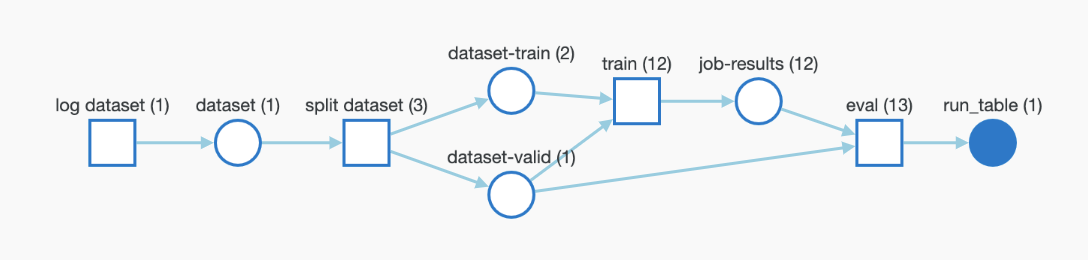
Lineage 패널
Lineage 패널은 프로젝트와 연결된 모든 아티팩트와 서로 연결하는 Runs에 대한 뷰를 제공합니다. run 유형을 블록으로, 아티팩트를 원으로 표시하고 화살표를 사용하여 지정된 유형의 run이 지정된 유형의 아티팩트를 소비하거나 생성하는 시기를 나타냅니다. 왼쪽 열에서 선택한 특정 아티팩트의 유형이 강조 표시됩니다.
개별 아티팩트 버전과 연결하는 특정 Runs을 모두 보려면 Explode 토글을 클릭합니다.
Action History Audit 탭
작업 기록 감사 탭은 리소스의 전체 진화를 감사할 수 있도록 컬렉션에 대한 모든 에일리어스 작업과 멤버십 변경 사항을 보여줍니다.
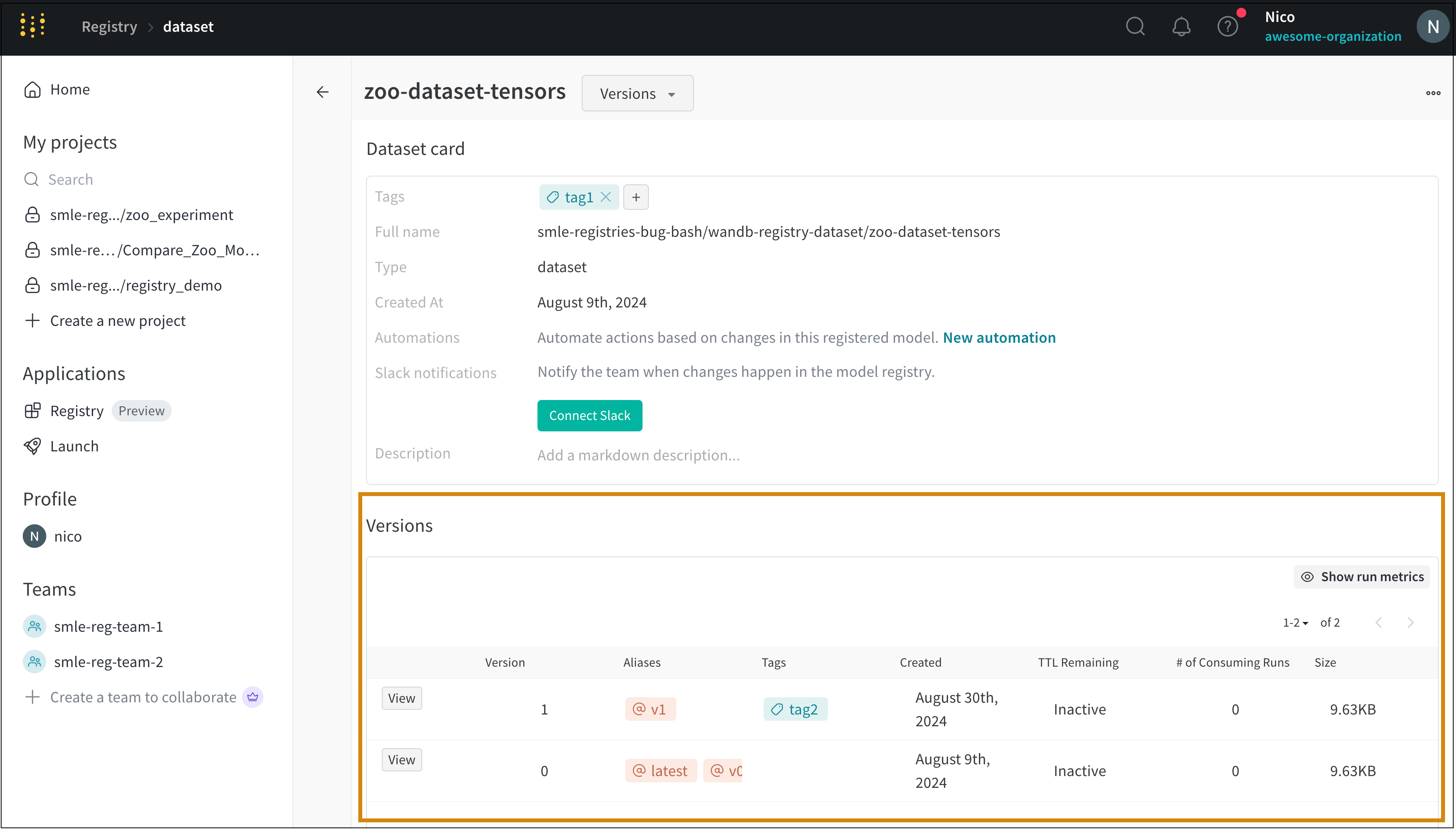
Versions 탭
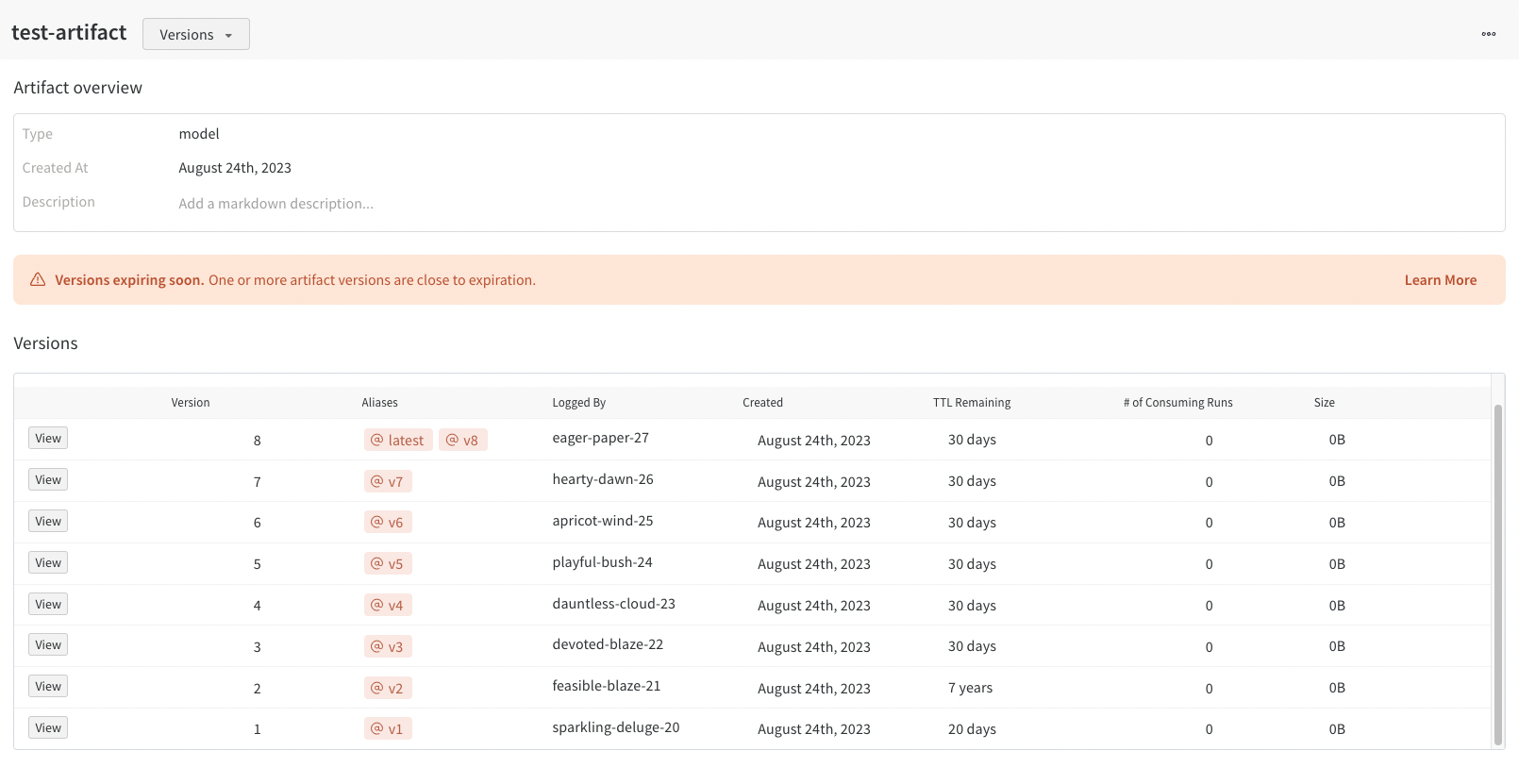
Versions 탭은 아티팩트의 모든 버전과 버전을 로깅할 당시의 Run History의 각 숫자 값에 대한 열을 보여줍니다. 이를 통해 성능을 비교하고 관심 있는 버전을 빠르게 식별할 수 있습니다.
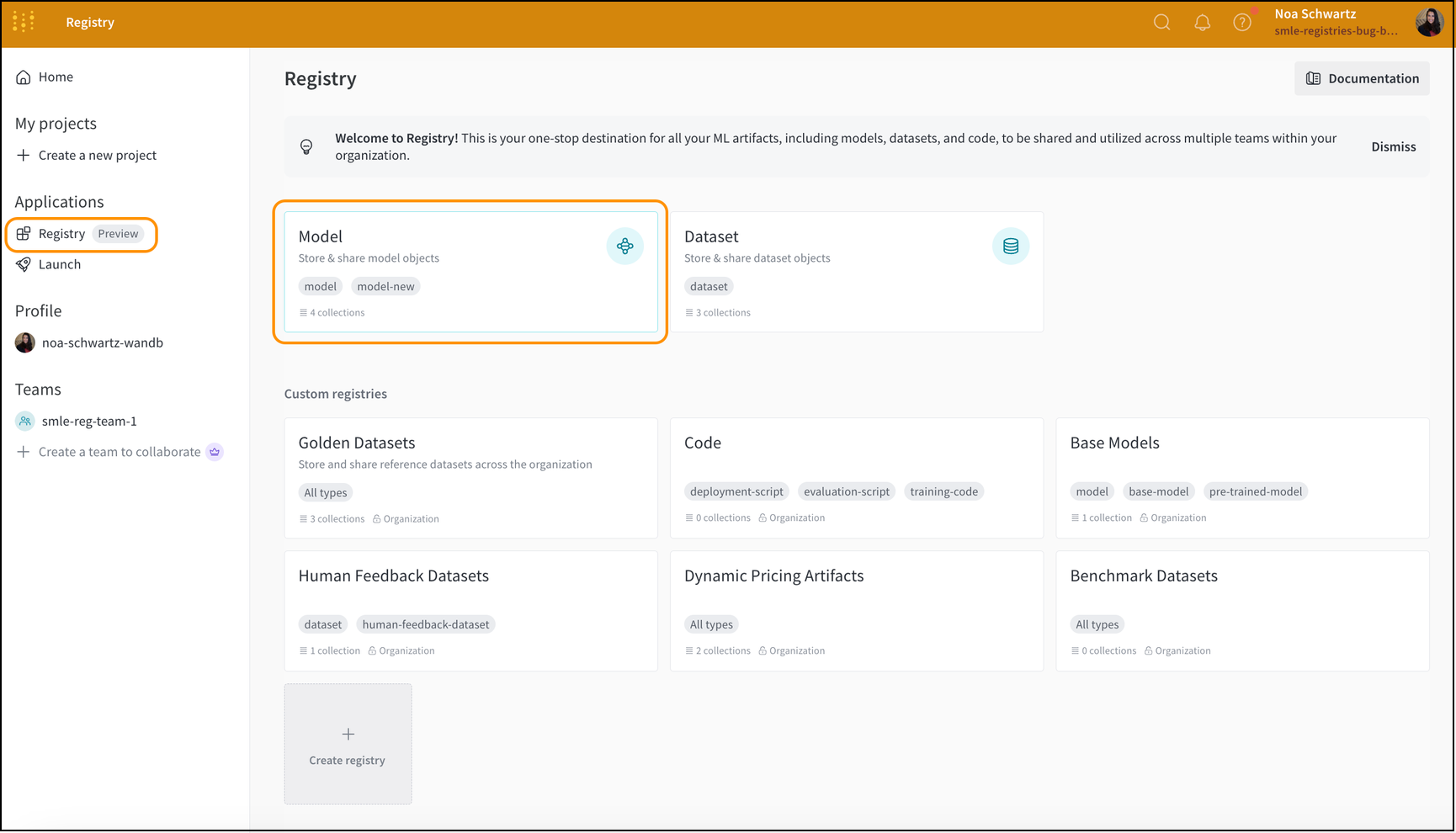
프로젝트에 별표 표시
프로젝트에 별표를 추가하여 해당 프로젝트를 중요하다고 표시합니다. 사용자와 팀이 별표로 중요하다고 표시한 프로젝트는 조직의 홈페이지 상단에 나타납니다.
예를 들어, 다음 이미지는 중요하다고 표시된 두 개의 프로젝트인 zoo_experiment와 registry_demo를 보여줍니다. 두 프로젝트 모두 Starred projects 섹션 내에서 조직의 홈페이지 상단에 나타납니다.
프로젝트를 중요하다고 표시하는 방법에는 프로젝트의 Overview 탭 내에서 또는 팀의 프로필 페이지 내에서 두 가지가 있습니다.
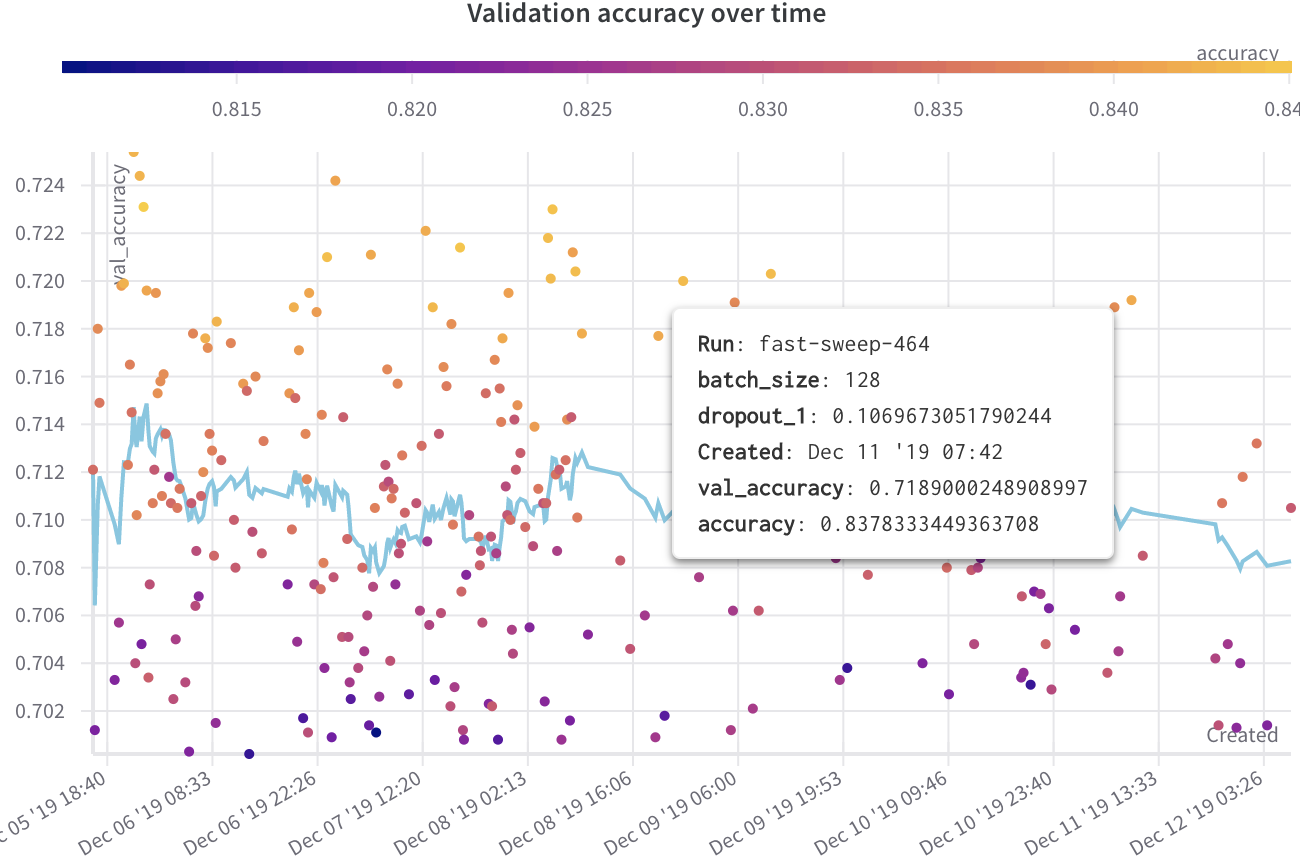
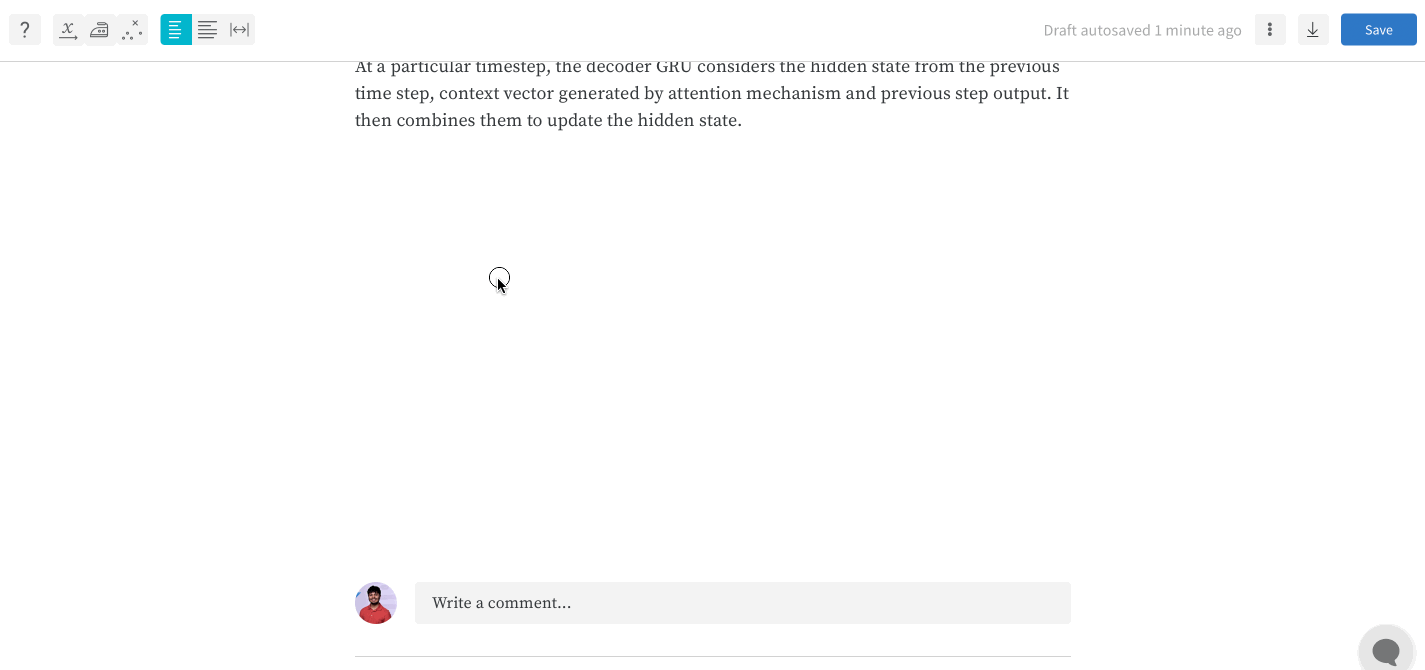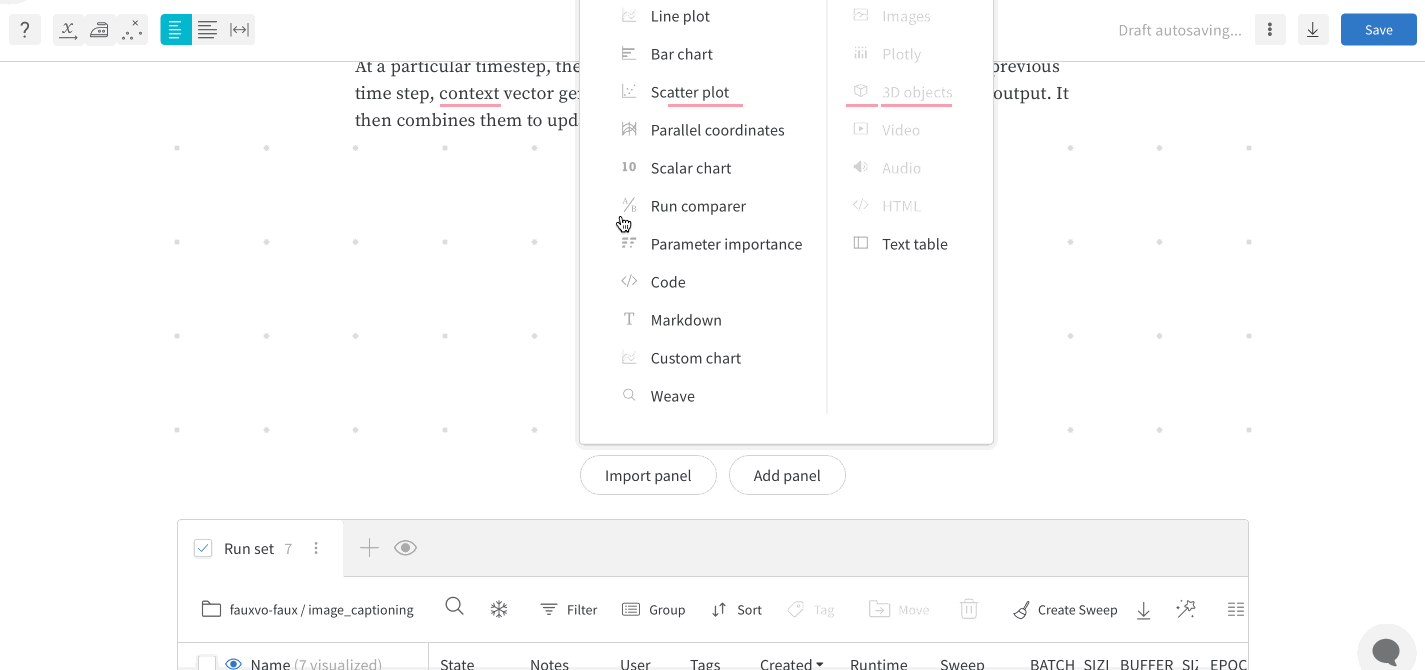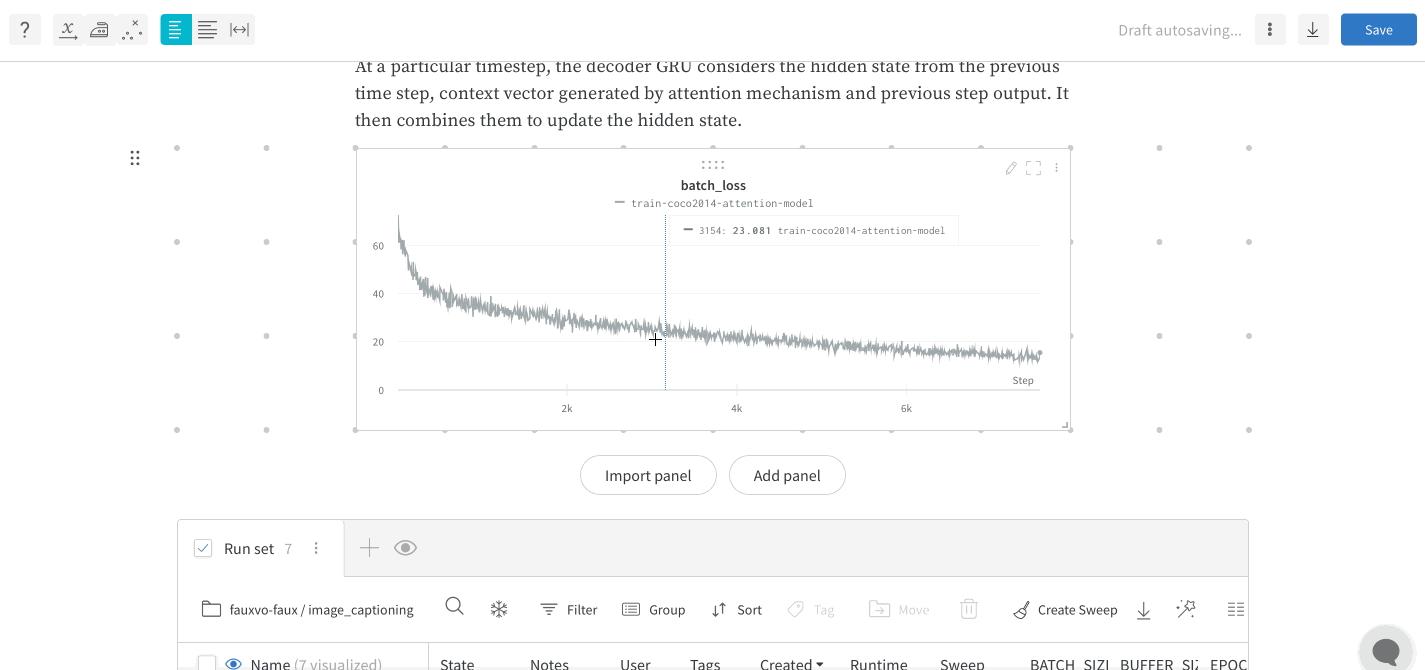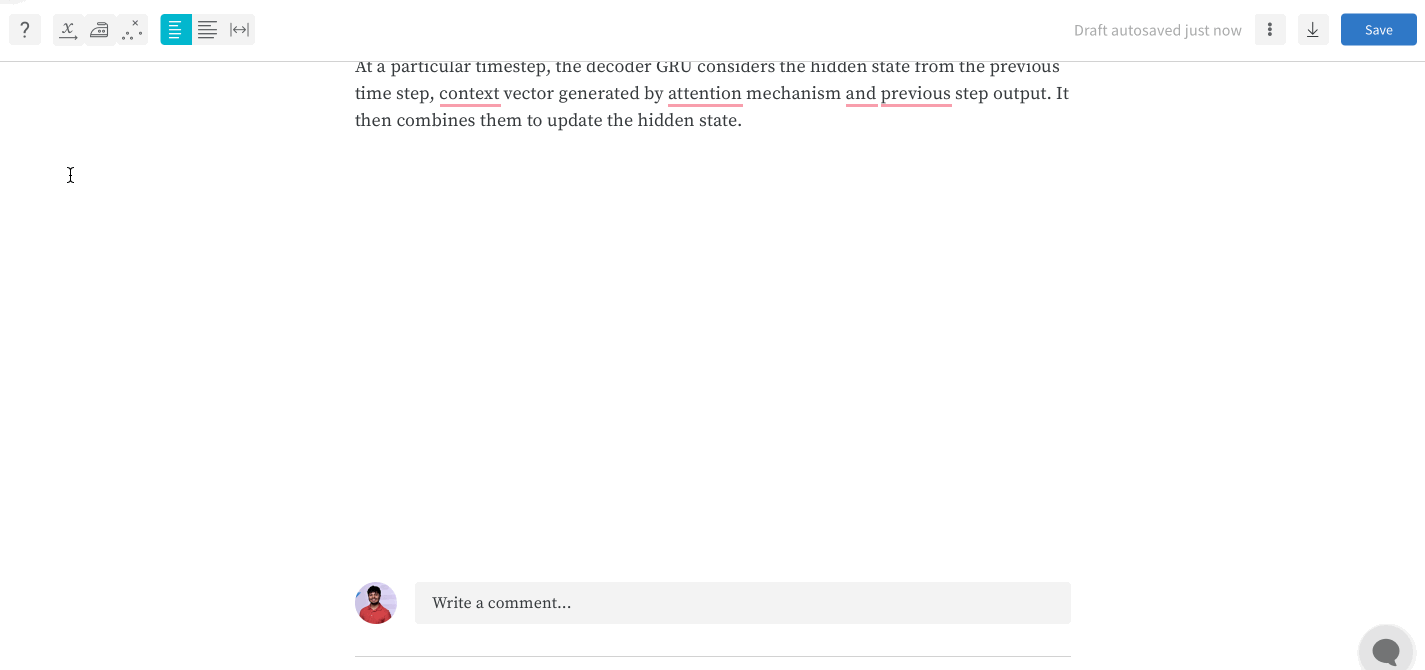
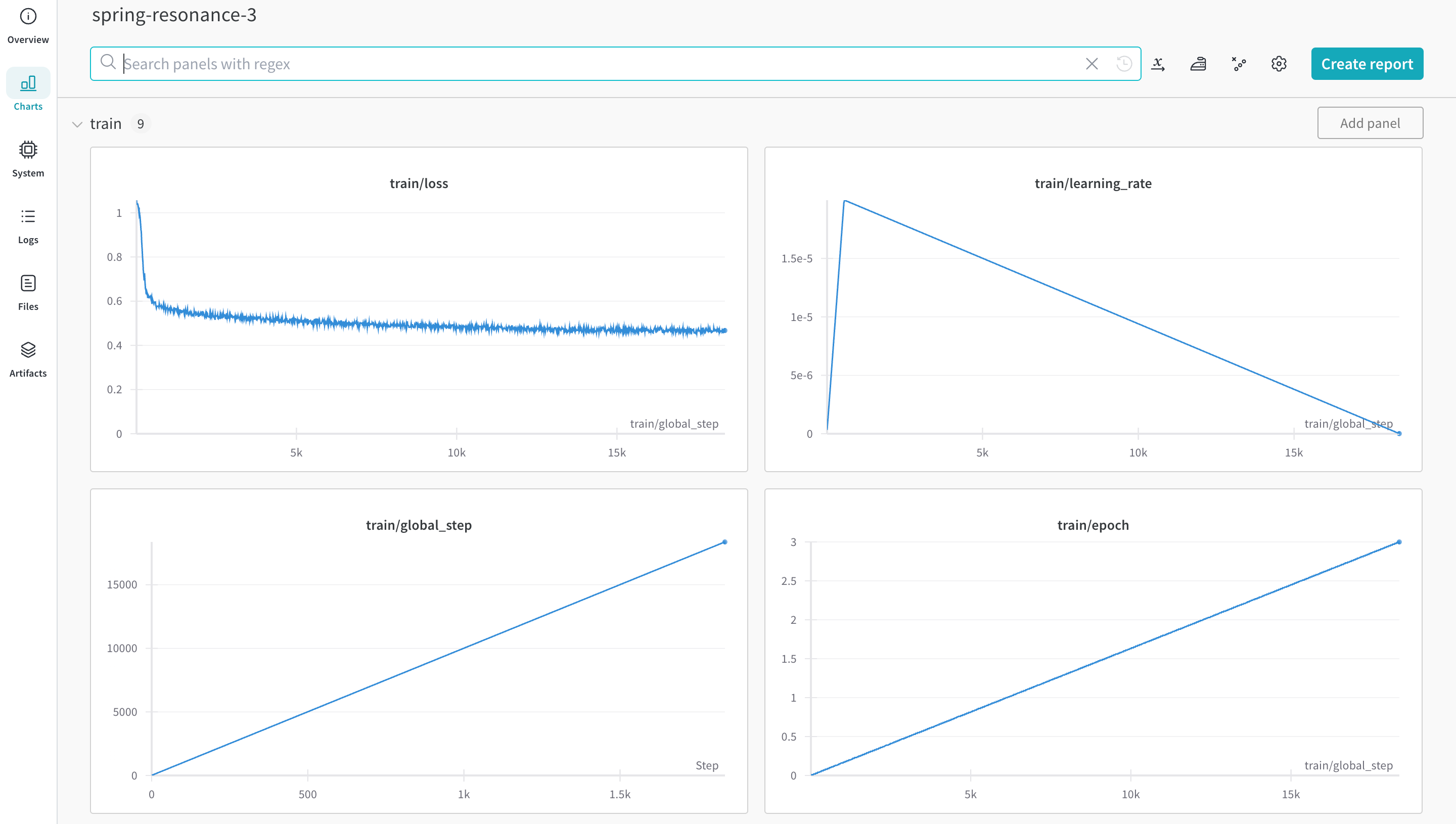
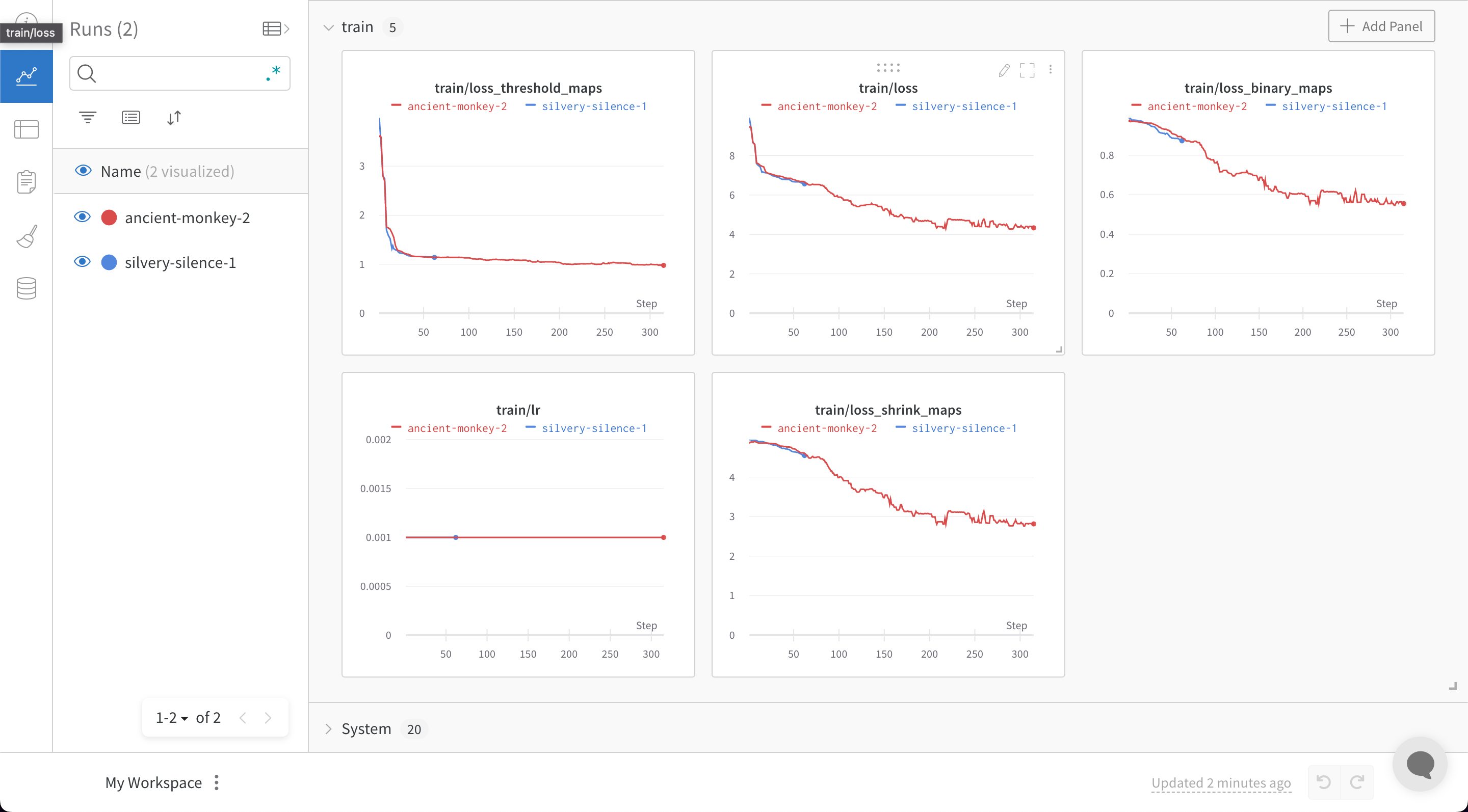
트레이닝 스크립트는 run.log를 10번 호출합니다. 스크립트가 run.log를 호출할 때마다 W&B는 해당 에포크의 정확도와 손실을 기록합니다. W&B가 이전 출력에서 출력하는 URL을 선택하면 W&B 앱 UI에서 run의 워크스페이스로 이동합니다.
스크립트가 wandb.init 메서드를 한 번만 호출하기 때문에 W&B는 시뮬레이션된 트레이닝 루프를 jolly-haze-4라는 단일 run 내에서 캡처합니다.
또 다른 예로, 스윕 중에 W&B는 사용자가 지정한 하이퍼파라미터 검색 공간을 탐색합니다. W&B는 스윕이 생성하는 각 새로운 하이퍼파라미터 조합을 고유한 run으로 구현합니다.
Run 초기화
wandb.init()로 W&B run을 초기화합니다. 다음 코드 조각은 W&B Python SDK를 임포트하고 run을 초기화하는 방법을 보여줍니다.
각도 괄호(<>)로 묶인 값을 사용자 고유의 값으로 바꾸십시오.
import wandb
run = wandb.init(entity="<entity>", project="<project>")
run을 초기화할 때 W&B는 프로젝트 필드에 지정한 프로젝트(wandb.init(project="<project>"))에 run을 기록합니다. W&B는 프로젝트가 아직 존재하지 않으면 새 프로젝트를 만듭니다. 프로젝트가 이미 존재하는 경우 W&B는 해당 프로젝트에 run을 저장합니다.
프로젝트 이름을 지정하지 않으면 W&B는 run을 Uncategorized라는 프로젝트에 저장합니다.
import wandb
run = wandb.init(entity="wandbee", project="awesome-project")
코드 조각은 다음 출력을 생성합니다.
🚀 View run exalted-darkness-6 at:
https://wandb.ai/nico/awesome-project/runs/pgbn9y21
Find logs at: wandb/run-20241106_090747-pgbn9y21/logs
이전 코드는 id 파라미터에 대한 인수를 지정하지 않았으므로 W&B는 고유한 run ID를 만듭니다. 여기서 nico는 run을 기록한 엔터티이고, awesome-project는 run이 기록된 프로젝트의 이름이고, exalted-darkness-6은 run의 이름이고, pgbn9y21은 run ID입니다.
노트북 사용자
run이 끝날 때 run.finish()를 지정하여 run이 완료되었음을 표시합니다. 이렇게 하면 run이 프로젝트에 올바르게 기록되고 백그라운드에서 계속되지 않습니다.
import wandb
run = wandb.init(entity="<entity>", project="<project>")
# Training code, logging, and so forthrun.finish()
각 run에는 run의 현재 상태를 설명하는 상태가 있습니다. 가능한 run 상태의 전체 목록은 Run 상태를 참조하십시오.
Run 상태
다음 표는 run이 가질 수 있는 가능한 상태를 설명합니다.
상태
설명
Finished
run이 종료되고 데이터가 완전히 동기화되었거나 wandb.finish()가 호출되었습니다.
Failed
run이 0이 아닌 종료 상태로 종료되었습니다.
Crashed
run이 내부 프로세스에서 하트비트 전송을 중단했습니다. 이는 머신이 충돌할 경우 발생할 수 있습니다.
변경 불가능한 Run ID 복사:Overview 탭의 오른쪽 상단에 있는 ... 메뉴(세 개의 점)를 클릭합니다. 드롭다운 메뉴에서 Copy Immutable Run ID 옵션을 선택합니다.
이러한 단계를 따르면 run에 대한 안정적이고 변경되지 않는 참조를 갖게 되어 run을 포크하는 데 사용할 수 있습니다.
포크된 run에서 계속하기
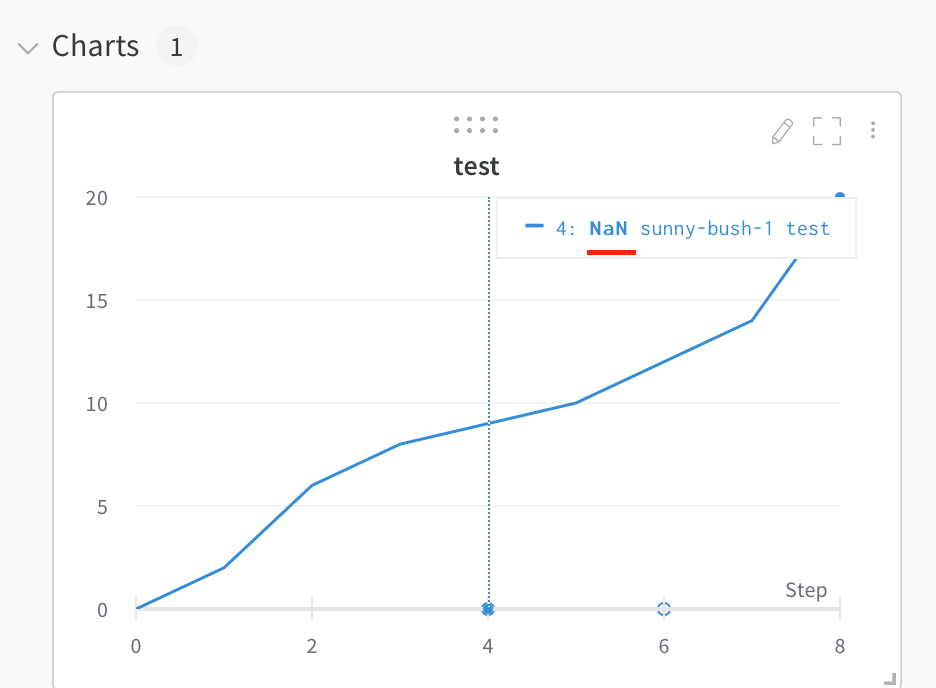
포크된 run을 초기화한 후 새 run에 계속 로그할 수 있습니다. 연속성을 위해 동일한 메트릭을 로그하고 새 메트릭을 도입할 수 있습니다.
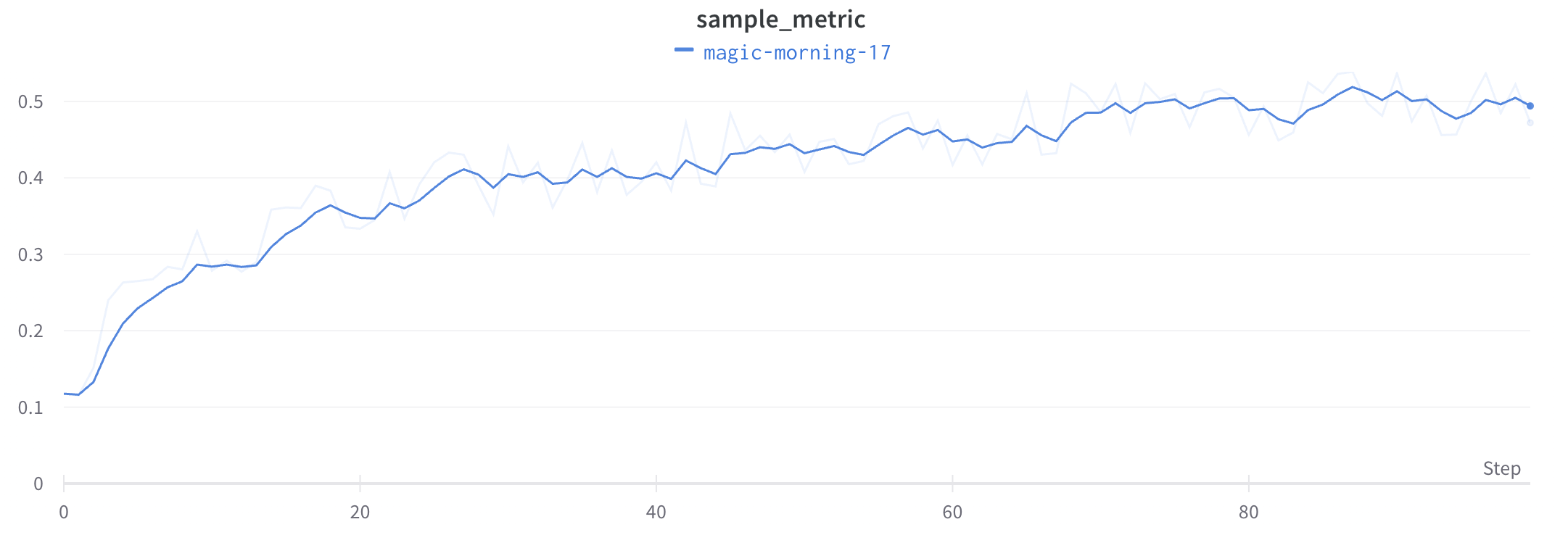
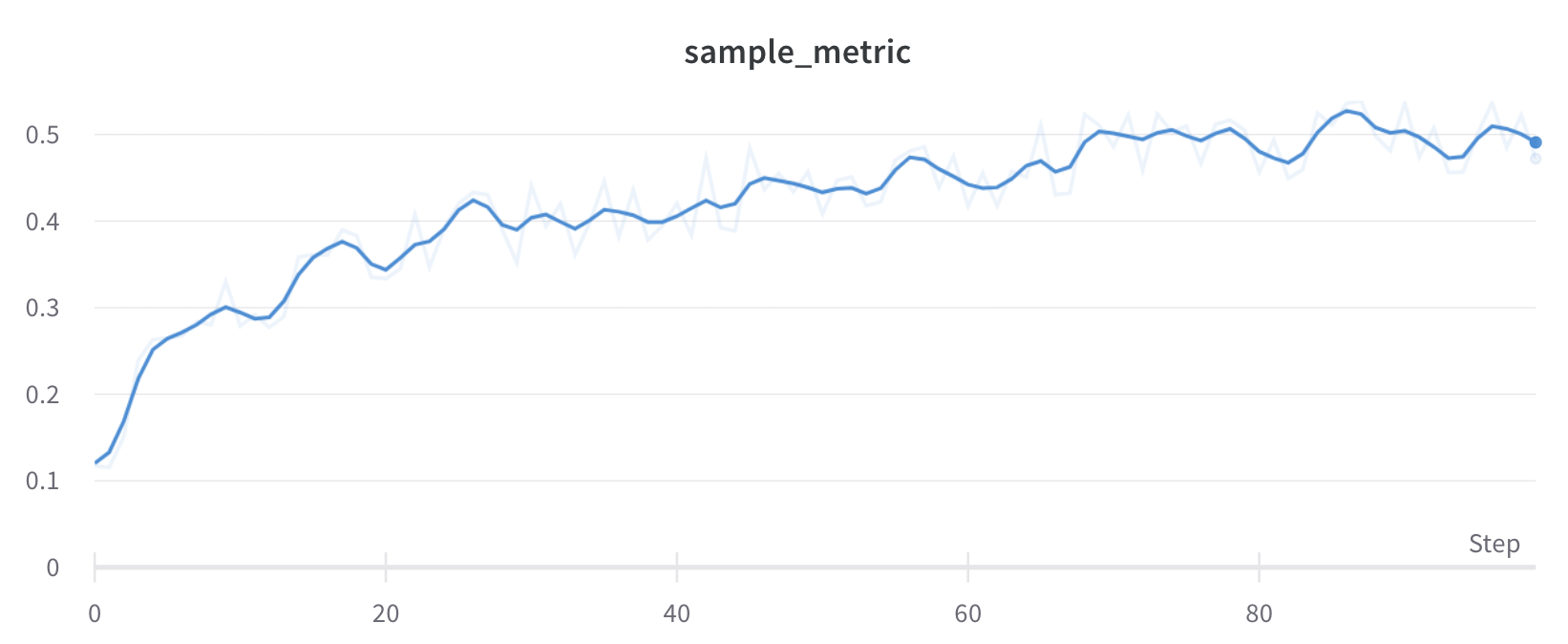
예를 들어 다음 코드 예제에서는 먼저 run을 포크한 다음 트레이닝 step 200부터 포크된 run에 메트릭을 로그하는 방법을 보여줍니다.
import wandb
import math
# 첫 번째 run을 초기화하고 일부 메트릭을 로그합니다run1 = wandb.init("your_project_name", entity="your_entity_name")
for i in range(300):
run1.log({"metric": i})
run1.finish()
# 특정 step에서 첫 번째 run에서 포크하고 step 200부터 메트릭을 로그합니다run2 = wandb.init(
"your_project_name", entity="your_entity_name", fork_from=f"{run1.id}?_step=200")
# 새 run에서 계속 로깅합니다# 처음 몇 steps 동안은 run1에서 메트릭을 그대로 로깅합니다# Step 250 이후에는 스파이크 패턴 로깅을 시작합니다for i in range(200, 300):
if i <250:
run2.log({"metric": i}) # 스파이크 없이 run1에서 계속 로깅합니다else:
# Step 250부터 스파이크 행동을 도입합니다 subtle_spike = i + (2* math.sin(i /3.0)) # 미묘한 스파이크 패턴을 적용합니다 run2.log({"metric": subtle_spike})
# 모든 steps에서 새 메트릭을 추가로 로깅합니다 run2.log({"additional_metric": i *1.1})
run2.finish()
run에서 포크하면 W&B는 특정 시점에서 run에서 새 분기를 생성하여 다른 파라미터 또는 Models를 시도합니다.
run을 되감으면 W&B를 통해 run 기록 자체를 수정하거나 변경할 수 있습니다.
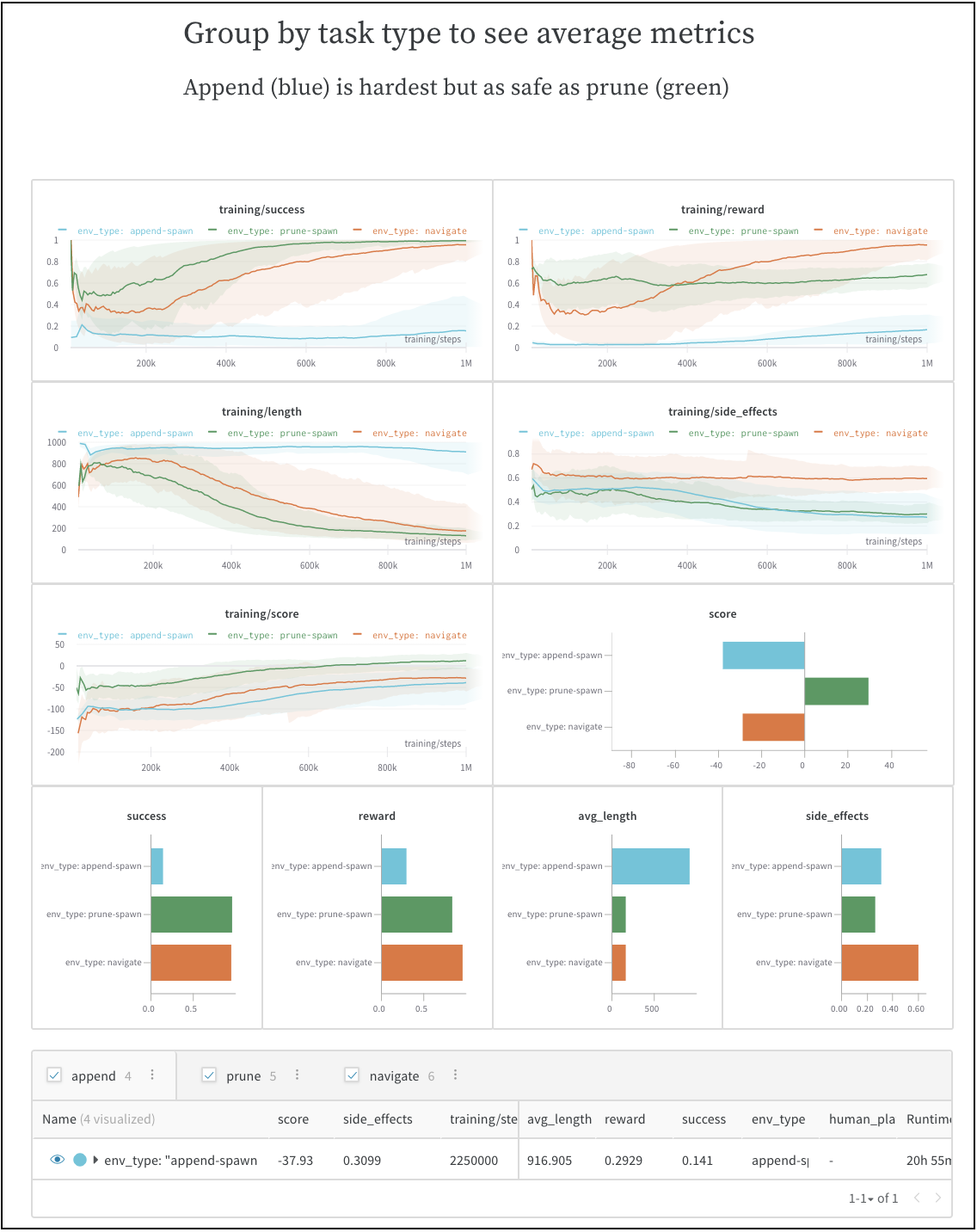
2.1.5.4 - Group runs into experiments
트레이닝 및 평가 run을 그룹화하여 더 큰 Experiments로 구성
개별 작업을 wandb.init() 에 고유한 group 이름을 전달하여 Experiments 로 그룹화합니다.
유스 케이스
분산 트레이닝: Experiments 가 별도의 트레이닝 및 평가 스크립트로 분할되어 더 큰 전체의 일부로 보아야 하는 경우 그룹화를 사용합니다.
다중 프로세스: 여러 개의 작은 프로세스를 하나의 experiment 로 그룹화합니다.
K-겹 교차 검증: 더 큰 experiment 를 보기 위해 다른 임의 시드를 가진 Runs 를 함께 그룹화합니다. 다음은 스윕 및 그룹화를 사용한 k-겹 교차 검증의 예제입니다.
그룹화를 설정하는 세 가지 방법이 있습니다.
1. 스크립트에서 그룹 설정
선택적 group 및 job_type 을 wandb.init() 에 전달합니다. 이렇게 하면 각 experiment 에 대한 전용 그룹 페이지가 제공되며, 여기에는 개별 Runs 가 포함됩니다. 예를 들면 다음과 같습니다. wandb.init(group="experiment_1", job_type="eval")
2. 그룹 환경 변수 설정
WANDB_RUN_GROUP 를 사용하여 Runs 에 대한 그룹을 환경 변수로 지정합니다. 자세한 내용은 환경 변수에 대한 문서를 확인하세요. Group 은 프로젝트 내에서 고유해야 하며 그룹의 모든 Runs 에서 공유해야 합니다. wandb.util.generate_id() 를 사용하여 모든 프로세스에서 사용할 고유한 8자 문자열을 생성할 수 있습니다. 예를 들어 os.environ["WANDB_RUN_GROUP"] = "experiment-" + wandb.util.generate_id() 와 같습니다.
3. UI에서 그룹화 전환
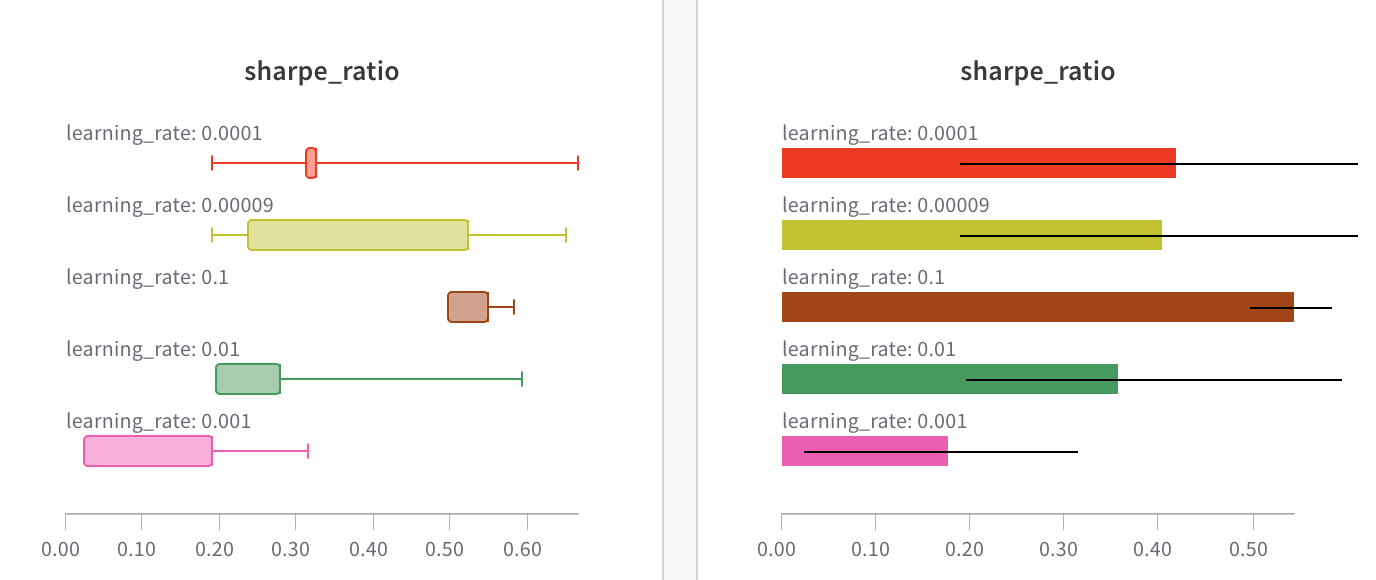
구성 열별로 동적으로 그룹화할 수 있습니다. 예를 들어 wandb.config 를 사용하여 배치 크기 또는 학습률을 로그하면 웹 앱에서 해당 하이퍼파라미터별로 동적으로 그룹화할 수 있습니다.
그룹화를 사용한 분산 트레이닝
wandb.init() 에서 그룹화를 설정하면 UI에서 기본적으로 Runs 가 그룹화됩니다. 테이블 상단의 Group 버튼을 클릭하여 이를 켜거나 끌 수 있습니다. 그룹화를 설정한 샘플 코드에서 생성된 예제 프로젝트가 있습니다. 사이드바에서 각 “Group” 행을 클릭하여 해당 experiment 에 대한 전용 그룹 페이지로 이동할 수 있습니다.
위의 프로젝트 페이지에서 왼쪽 사이드바의 Group 을 클릭하여 이 페이지와 같은 전용 페이지로 이동할 수 있습니다.
UI에서 동적으로 그룹화
예를 들어 하이퍼파라미터별로 열별로 Runs 를 그룹화할 수 있습니다. 다음은 그 모양의 예입니다.
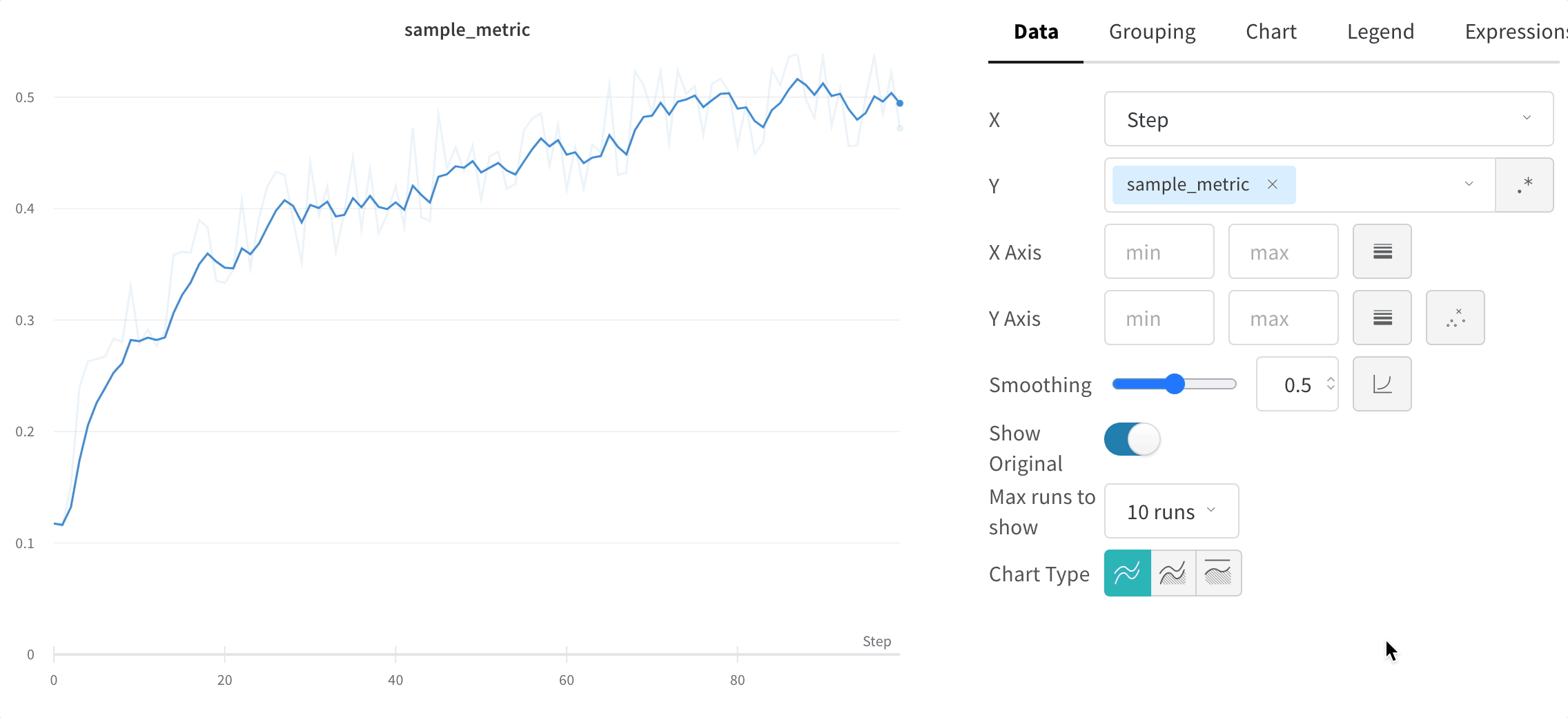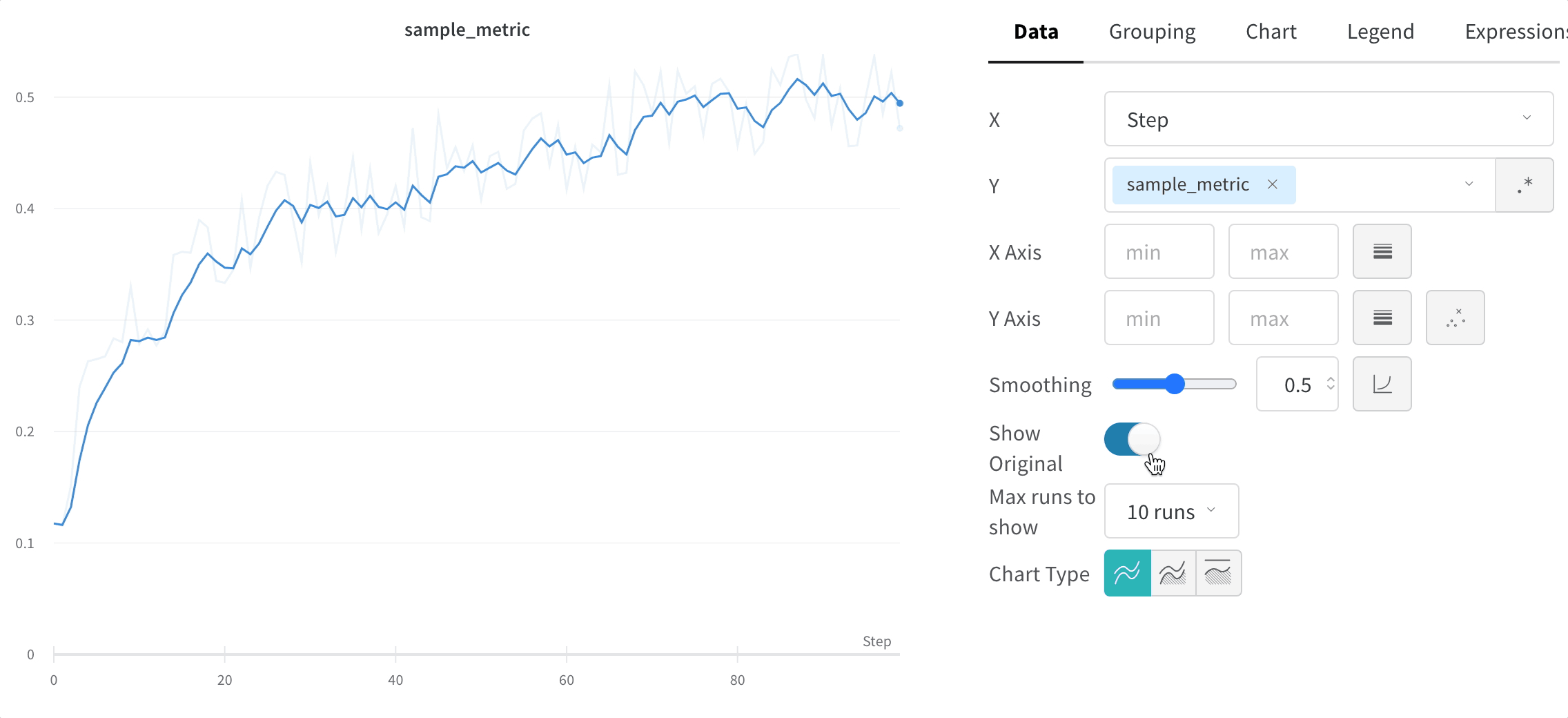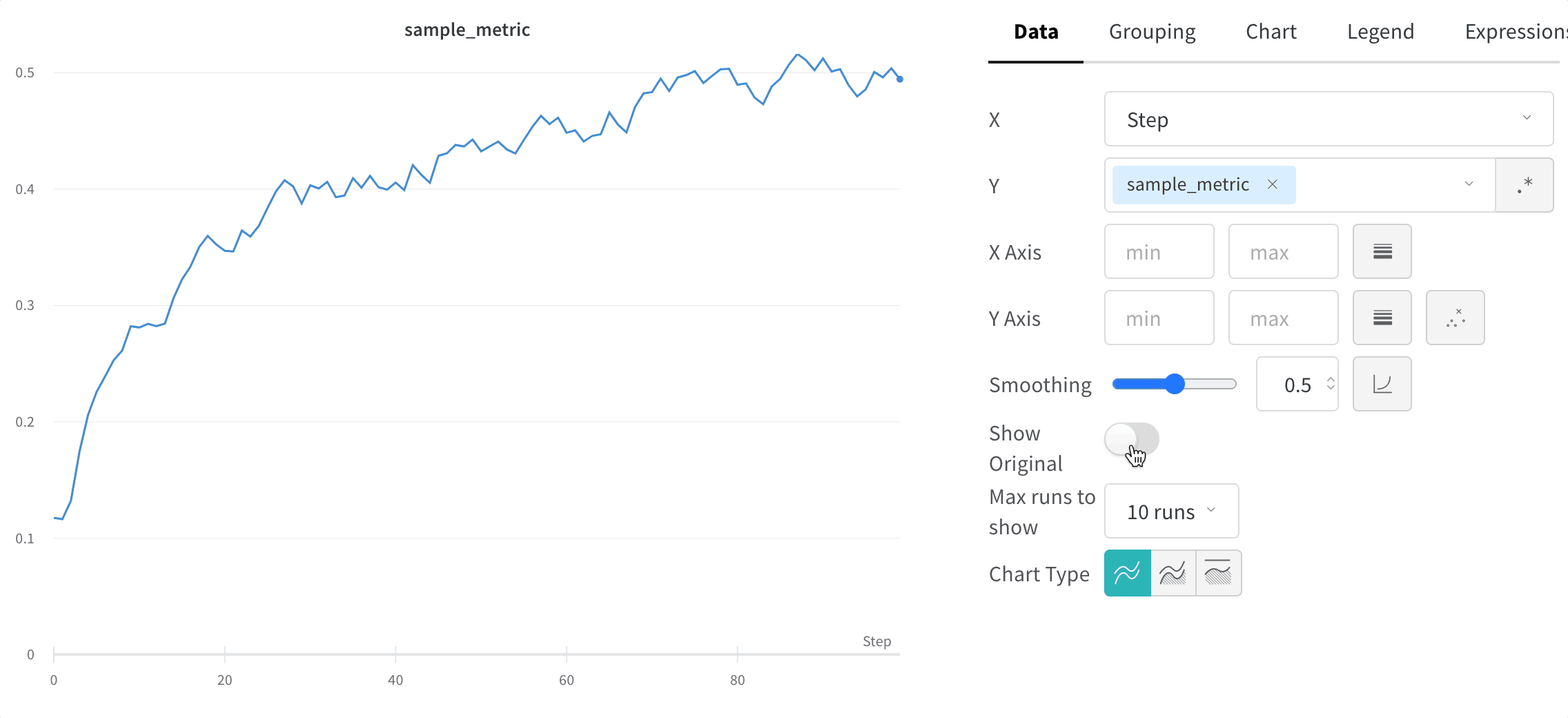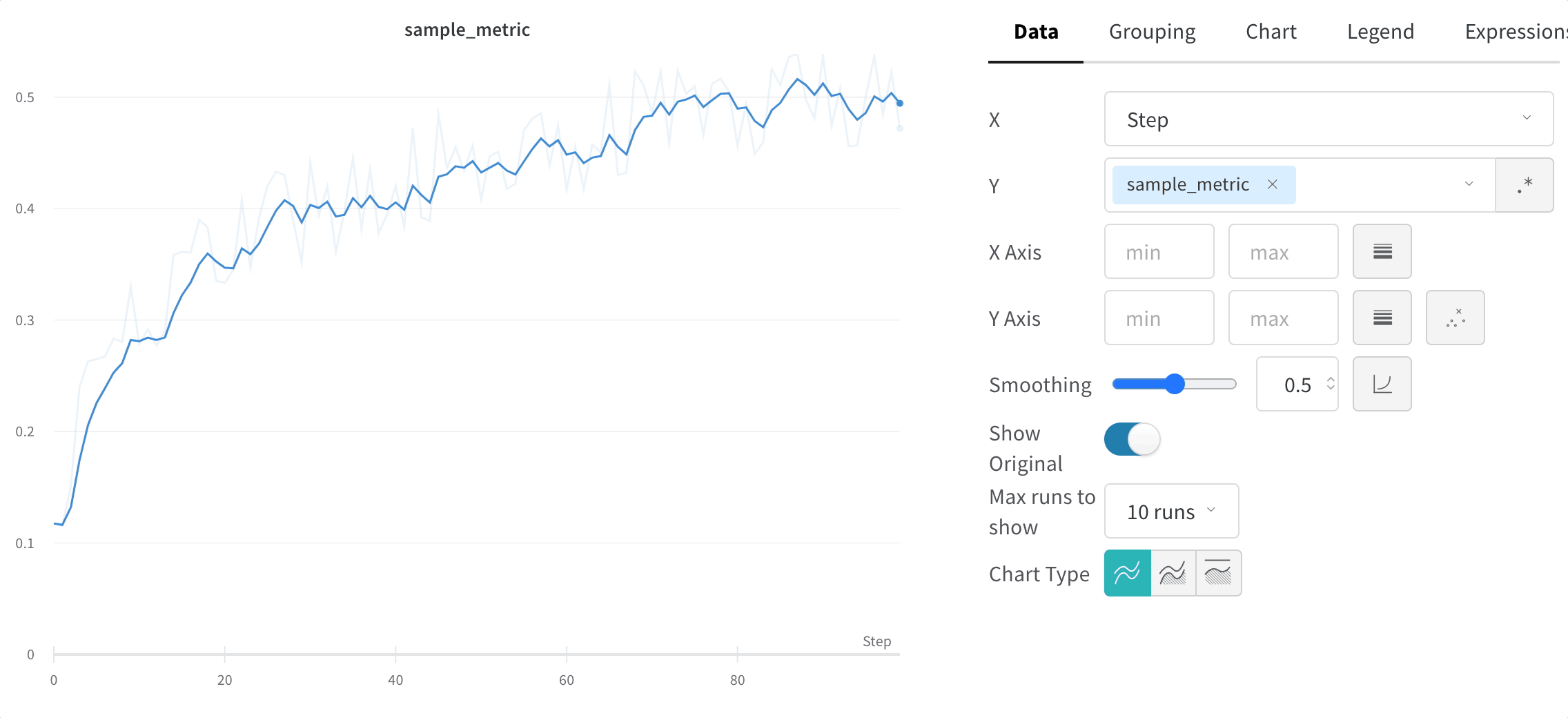
사이드바: Runs 는 에포크 수별로 그룹화됩니다.
그래프: 각 선은 그룹의 평균을 나타내고 음영은 분산을 나타냅니다. 이 동작은 그래프 설정에서 변경할 수 있습니다.
그룹화 끄기
언제든지 그룹화 버튼을 클릭하고 그룹 필드를 지우면 테이블과 그래프가 그룹 해제된 상태로 돌아갑니다.
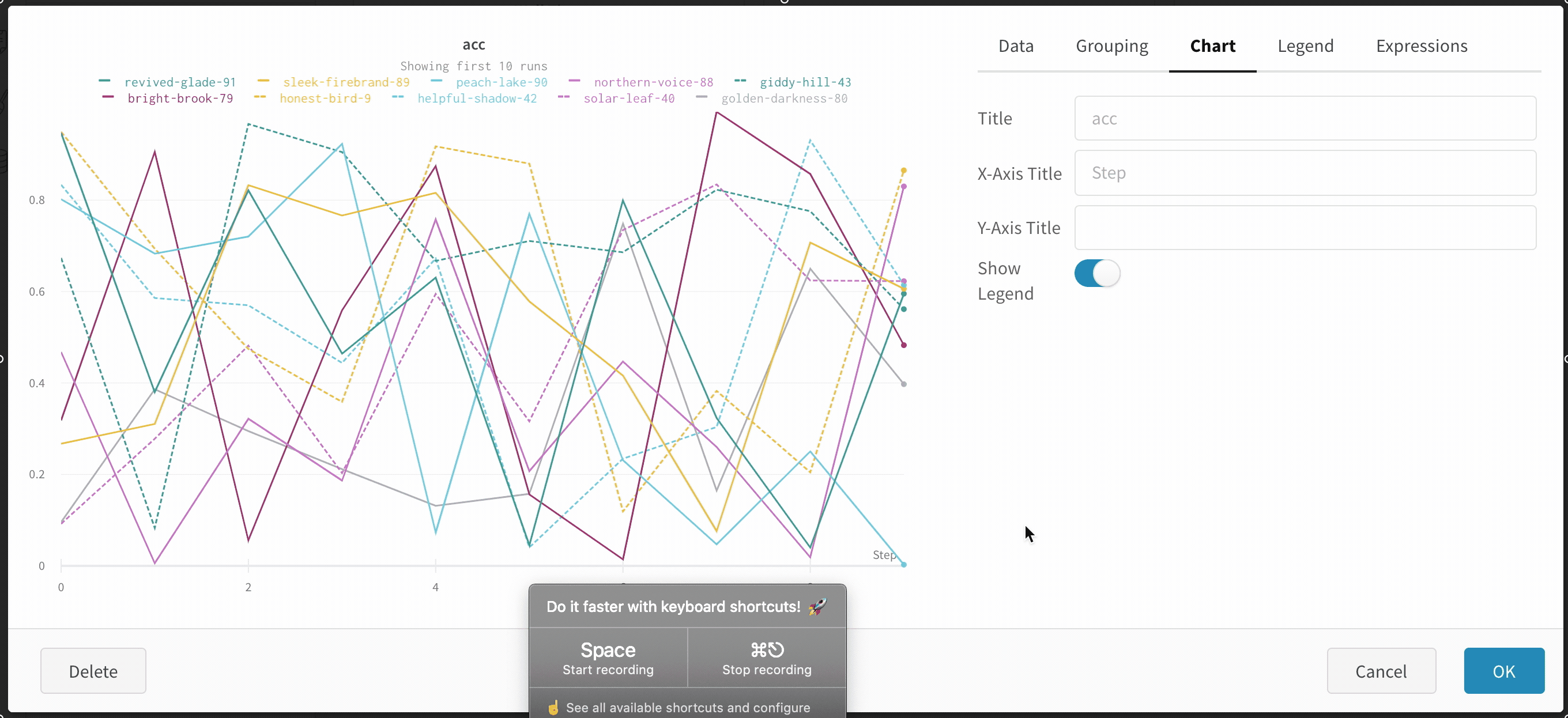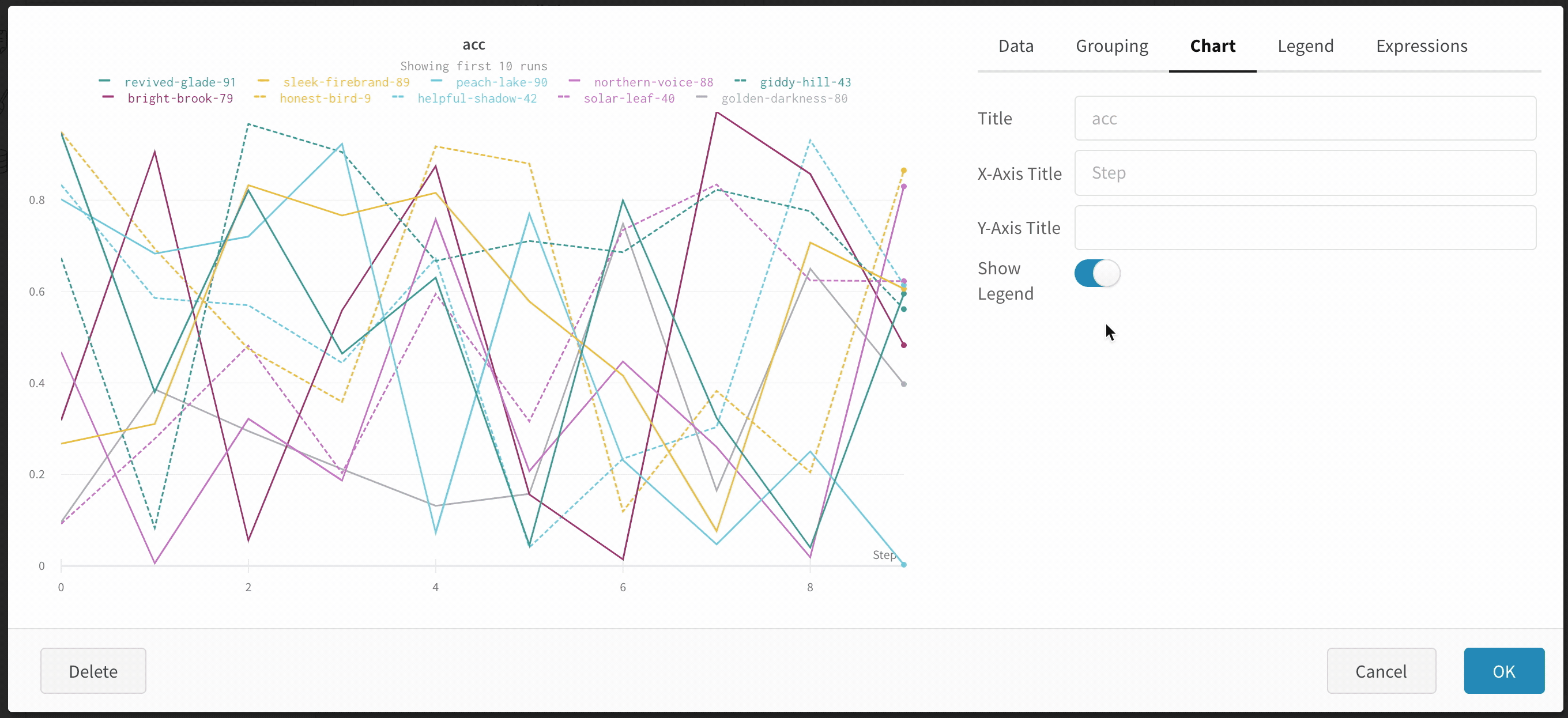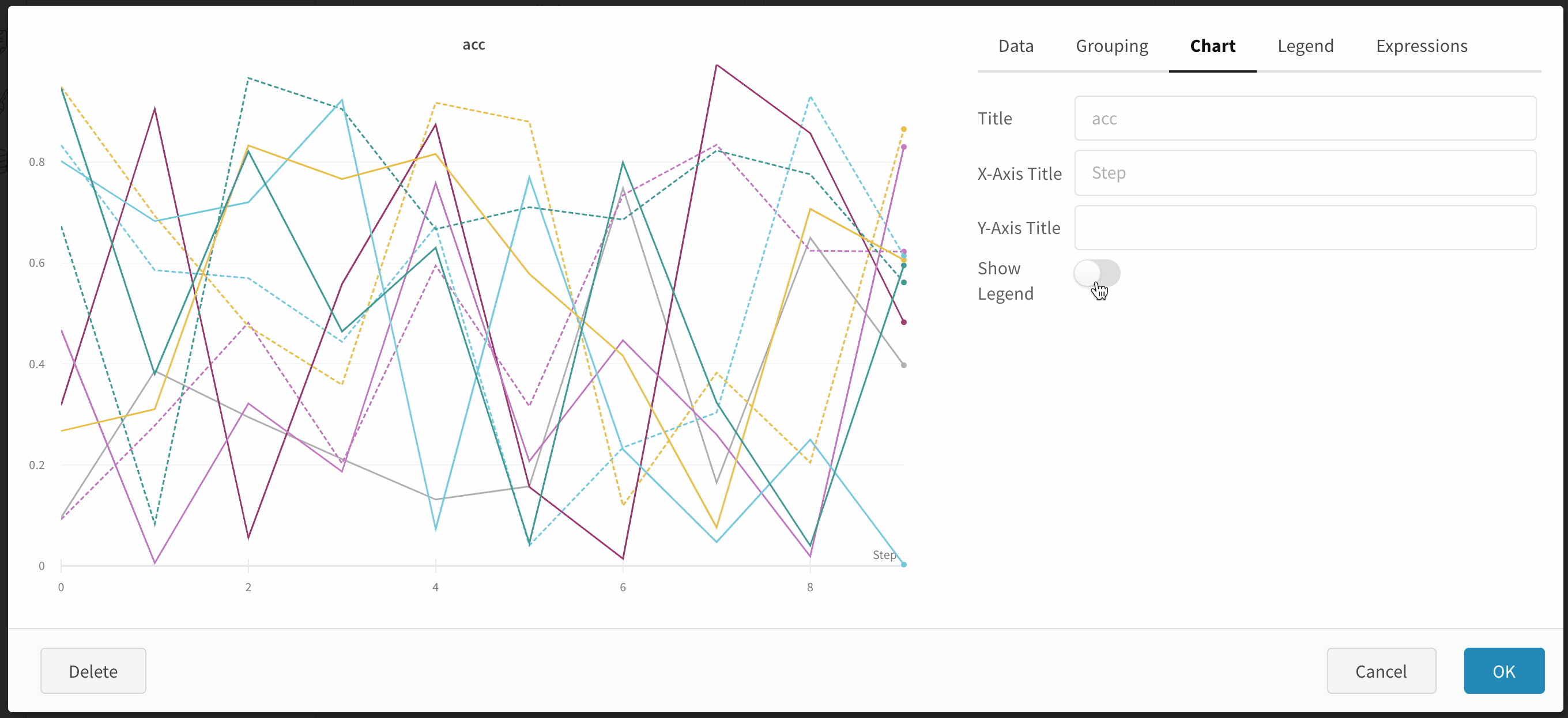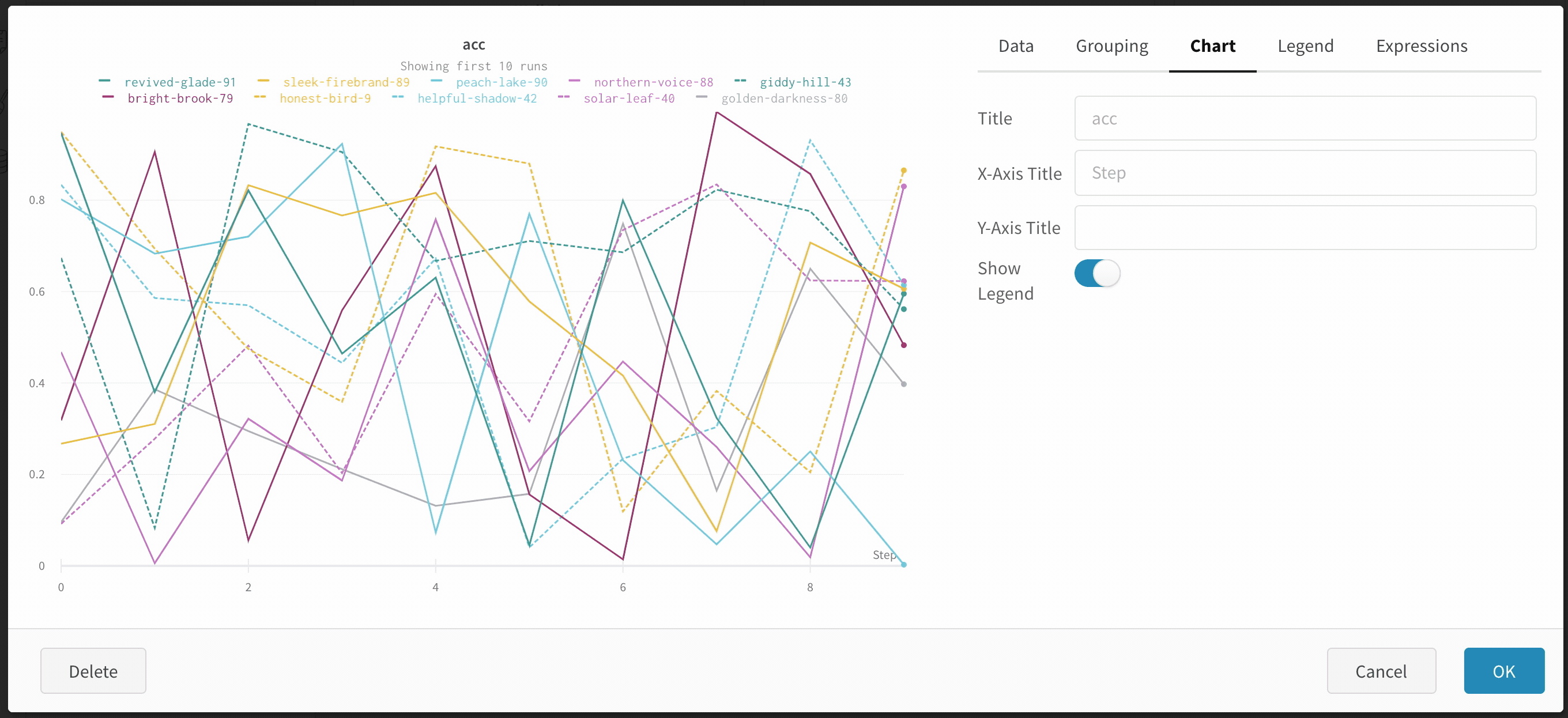
그룹화 그래프 설정
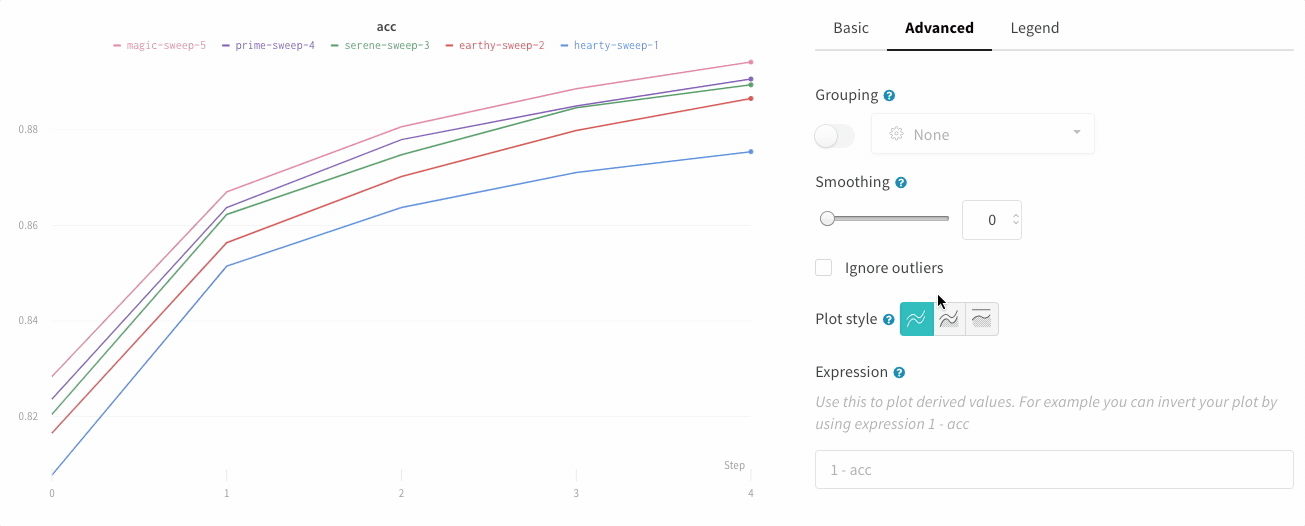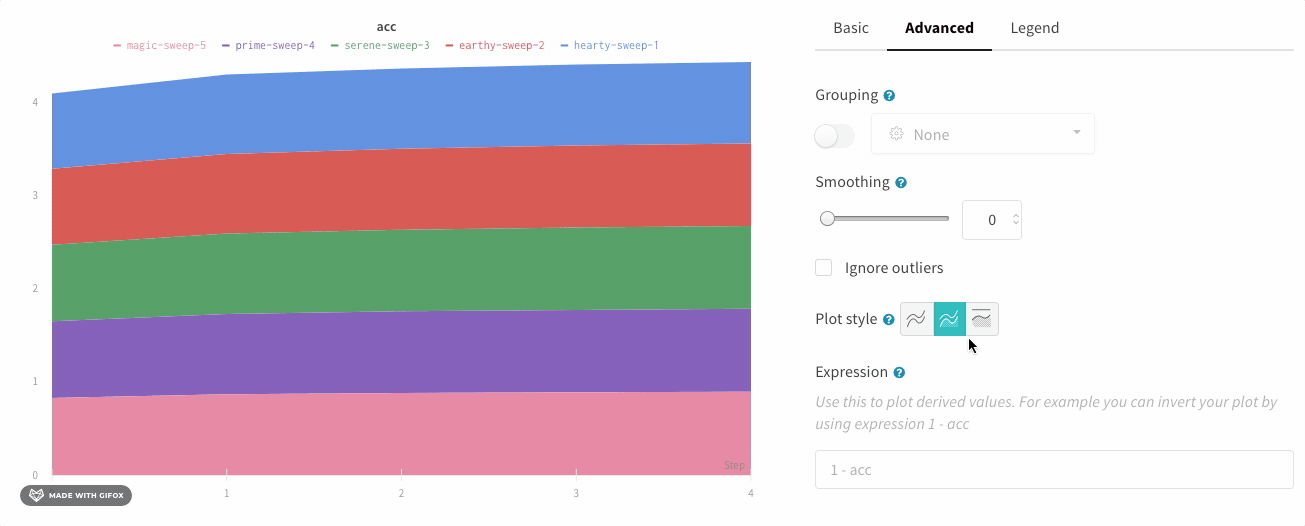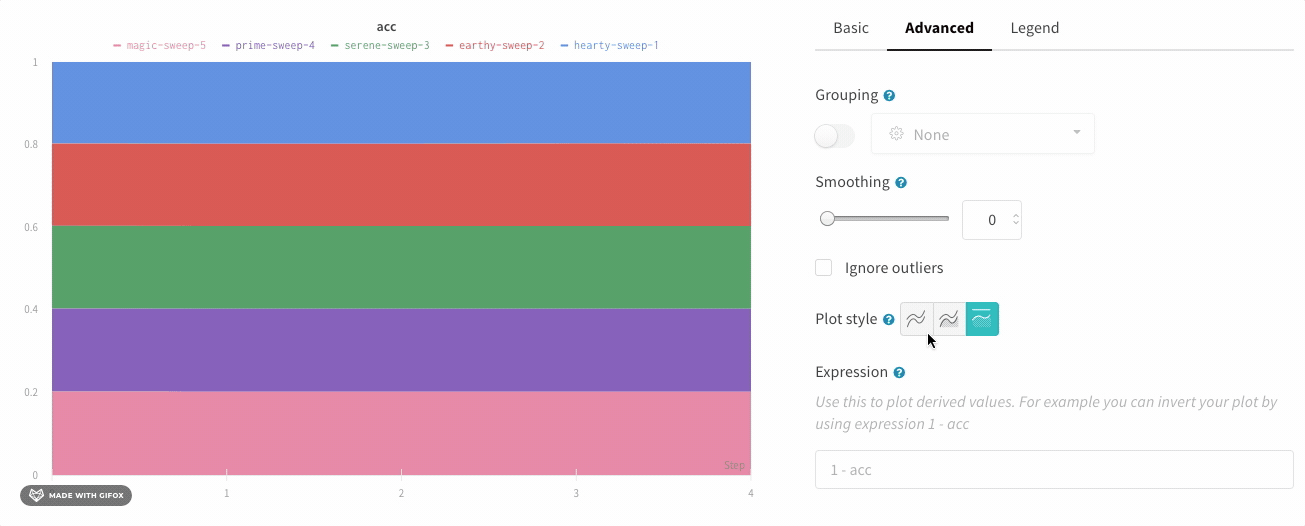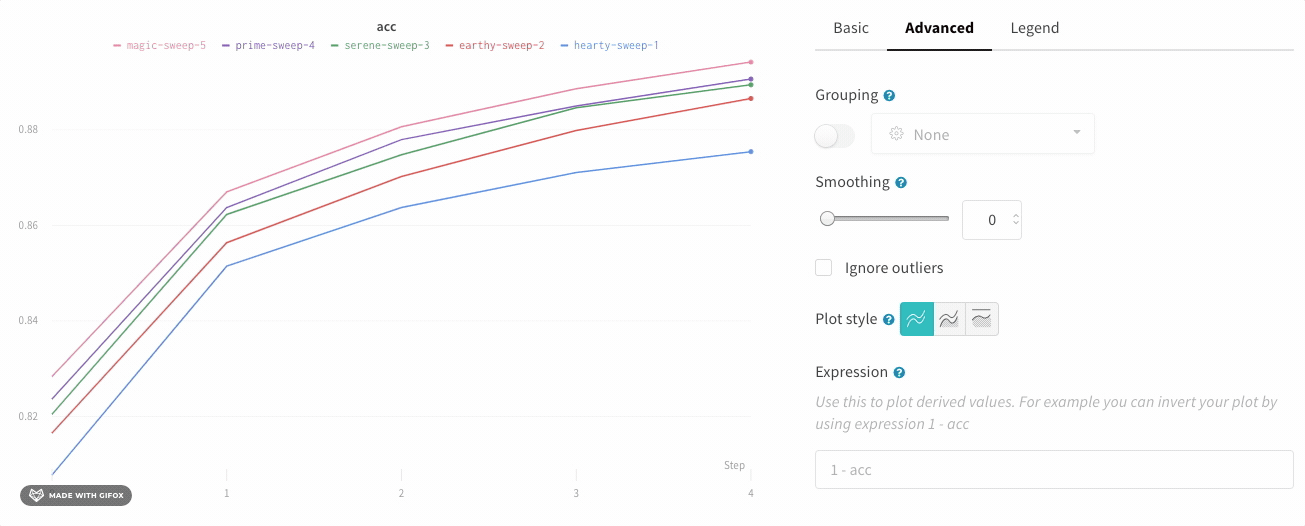
그래프 오른쪽 상단 모서리에 있는 편집 버튼을 클릭하고 Advanced 탭을 선택하여 선과 음영을 변경합니다. 각 그룹에서 선의 평균, 최소값 또는 최대값을 선택할 수 있습니다. 음영의 경우 음영을 끄고 최소값과 최대값, 표준 편차 및 표준 오차를 표시할 수 있습니다.
2.1.5.5 - Move runs
이 페이지에서는 run 을 한 프로젝트에서 다른 프로젝트로, 팀 내부 또는 외부로, 또는 한 팀에서 다른 팀으로 이동하는 방법을 보여줍니다. 현재 위치와 새 위치에서 run 에 대한 엑세스 권한이 있어야 합니다.
터미널 내에서 W&B run ID와 함께 셸 스크립트를 실행할 수 있습니다. 다음 코드조각은 run ID akj172를 전달합니다.
sh run_experiment.sh akj172
자동 재개는 프로세스가 실패한 프로세스와 동일한 파일 시스템에서 다시 시작되는 경우에만 작동합니다.
예를 들어 Users/AwesomeEmployee/Desktop/ImageClassify/training/이라는 디렉토리에서 train.py라는 python 스크립트를 실행한다고 가정합니다. train.py 내에서 스크립트는 자동 재개를 활성화하는 run을 만듭니다. 다음으로 트레이닝 스크립트가 중지되었다고 가정합니다. 이 run을 재개하려면 Users/AwesomeEmployee/Desktop/ImageClassify/training/ 내에서 train.py 스크립트를 다시 시작해야 합니다.
파일 시스템을 공유할 수 없는 경우 WANDB_RUN_ID 환경 변수를 지정하거나 W&B Python SDK로 run ID를 전달합니다. run ID에 대한 자세한 내용은 “Run이란 무엇인가?” 페이지의 Custom run IDs 섹션을 참조하세요.
Preemptible Sweeps Run 재개
중단된 sweep run을 자동으로 다시 큐에 넣습니다. 이는 선점형 큐의 SLURM 작업, EC2 스팟 인스턴스 또는 Google Cloud 선점형 VM과 같이 선점이 적용되는 컴퓨팅 환경에서 sweep agent를 실행하는 경우에 특히 유용합니다.
mark_preempting 함수를 사용하여 W&B가 중단된 sweep run을 자동으로 다시 큐에 넣도록 설정합니다. 예를 들어, 다음 코드조각을 참조하세요.
run = wandb.init() # Run 초기화run.mark_preempting()
다음 표는 sweep run의 종료 상태에 따라 W&B가 run을 처리하는 방법을 간략하게 설명합니다.
상태
행동
상태 코드 0
Run이 성공적으로 종료된 것으로 간주되며 다시 큐에 넣지 않습니다.
0이 아닌 상태
W&B는 run을 sweep과 연결된 run 큐에 자동으로 추가합니다.
상태 없음
Run이 sweep run 큐에 추가됩니다. Sweep agent는 큐가 비워질 때까지 run 큐에서 run을 소비합니다. 큐가 비워지면 sweep 큐는 sweep 검색 알고리즘을 기반으로 새 run 생성을 재개합니다.
2.1.5.7 - Rewind a run
되감기
run 되감기
run을 되감는 옵션은 비공개 미리 보기 상태입니다. 이 기능에 대한 엑세스를 요청하려면 support@wandb.com으로 W&B 지원팀에 문의하십시오.
단조롭게 증가하는 단계를 사용해야 합니다. define_metric()으로 정의된 비단조 단계를 사용하면 run 기록 및 시스템 메트릭의 필수 시간순서가 방해되므로 사용할 수 없습니다.
원본 데이터를 잃지 않고 run 기록을 수정하거나 변경하려면 run을 되감으십시오. 또한 run을 되감을 때 해당 시점부터 새로운 데이터를 로그할 수 있습니다. W&B는 새롭게 기록된 기록을 기반으로 되감은 run에 대한 요약 메트릭을 다시 계산합니다. 이는 다음 동작을 의미합니다.
기록 잘림: W&B는 기록을 되감기 시점까지 자르므로 새로운 데이터 로깅이 가능합니다.
요약 메트릭: 새롭게 기록된 기록을 기반으로 다시 계산됩니다.
설정 보존: W&B는 원래 설정을 보존하고 새로운 설정을 병합할 수 있습니다.
run을 되감을 때 W&B는 원래 데이터를 보존하고 일관된 run ID를 유지하면서 run 상태를 지정된 단계로 재설정합니다. 이는 다음을 의미합니다.
run 보관: W&B는 원래 run을 보관합니다. Run Overview 탭에서 run에 엑세스할 수 있습니다.
아티팩트 연결: 아티팩트를 해당 아티팩트를 생성하는 run과 연결합니다.
변경 불가능한 run ID: 정확한 상태에서 일관된 포크를 위해 도입되었습니다.
변경 불가능한 run ID 복사: 향상된 run 관리를 위해 변경 불가능한 run ID를 복사하는 버튼입니다.
되감기 및 포크 호환성
포크는 되감기를 보완합니다.
run에서 포크할 때 W&B는 다른 파라미터 또는 모델을 시도하기 위해 특정 시점에서 run에서 새로운 분기를 생성합니다.
run을 되감을 때 W&B를 사용하면 run 기록 자체를 수정하거나 변경할 수 있습니다.
run 되감기
resume_from과 함께 wandb.init()을 사용하여 run 기록을 특정 단계로 “되감습니다”. 되감을 run의 이름과 되감을 단계를 지정합니다.
import wandb
import math
# 첫 번째 run을 초기화하고 일부 메트릭을 기록합니다.# your_project_name 및 your_entity_name으로 대체하십시오!run1 = wandb.init(project="your_project_name", entity="your_entity_name")
for i in range(300):
run1.log({"metric": i})
run1.finish()
# 특정 단계에서 첫 번째 run부터 되감고 200단계부터 메트릭을 기록합니다.run2 = wandb.init(project="your_project_name", entity="your_entity_name", resume_from=f"{run1.id}?_step=200")
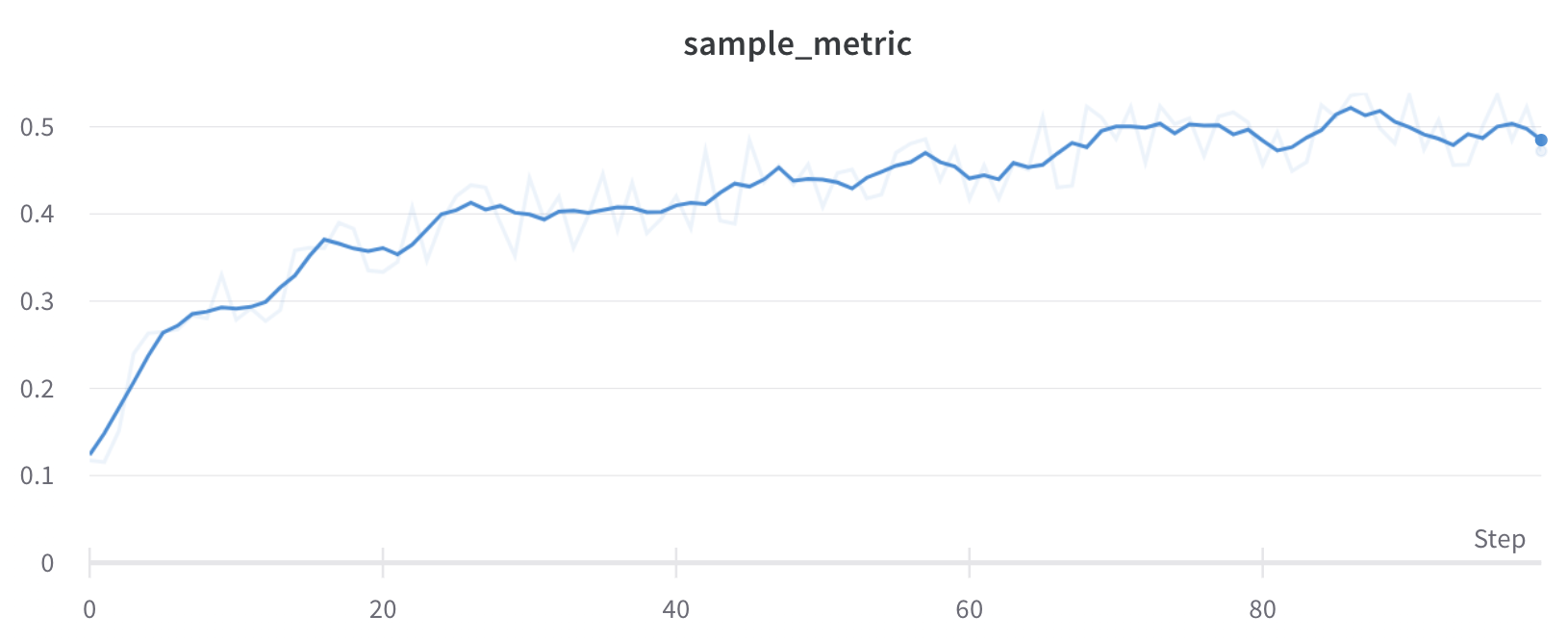
# 새로운 run에서 계속 기록합니다.# 처음 몇 단계에서는 run1에서 메트릭을 그대로 기록합니다.# 250단계 이후에는 스파이크 패턴을 기록하기 시작합니다.for i in range(200, 300):
if i <250:
run2.log({"metric": i, "step": i}) # 스파이크 없이 run1부터 계속 기록합니다.else:
# 250단계부터 스파이크 동작을 도입합니다. subtle_spike = i + (2* math.sin(i /3.0)) # 미묘한 스파이크 패턴을 적용합니다. run2.log({"metric": subtle_spike, "step": i})
# 또한 모든 단계에서 새로운 메트릭을 기록합니다. run2.log({"additional_metric": i *1.1, "step": i})
run2.finish()
보관된 run 보기
run을 되감은 후 W&B App UI를 사용하여 보관된 run을 탐색할 수 있습니다. 보관된 run을 보려면 다음 단계를 따르십시오.
Overview 탭에 엑세스: run 페이지의 Overview 탭으로 이동합니다. 이 탭은 run의 세부 정보 및 기록에 대한 포괄적인 보기를 제공합니다.
Forked From 필드 찾기: Overview 탭 내에서 Forked From 필드를 찾습니다. 이 필드는 재개 기록을 캡처합니다. Forked From 필드에는 소스 run에 대한 링크가 포함되어 있어 원래 run으로 다시 추적하고 전체 되감기 기록을 이해할 수 있습니다.
Forked From 필드를 사용하면 보관된 재개 트리를 쉽게 탐색하고 각 되감기의 순서와 출처에 대한 통찰력을 얻을 수 있습니다.
되감은 run에서 포크
되감은 run에서 포크하려면 wandb.init()에서 fork_from 인수를 사용하고 포크할 소스 run ID와 소스 run의 단계를 지정합니다.
import wandb
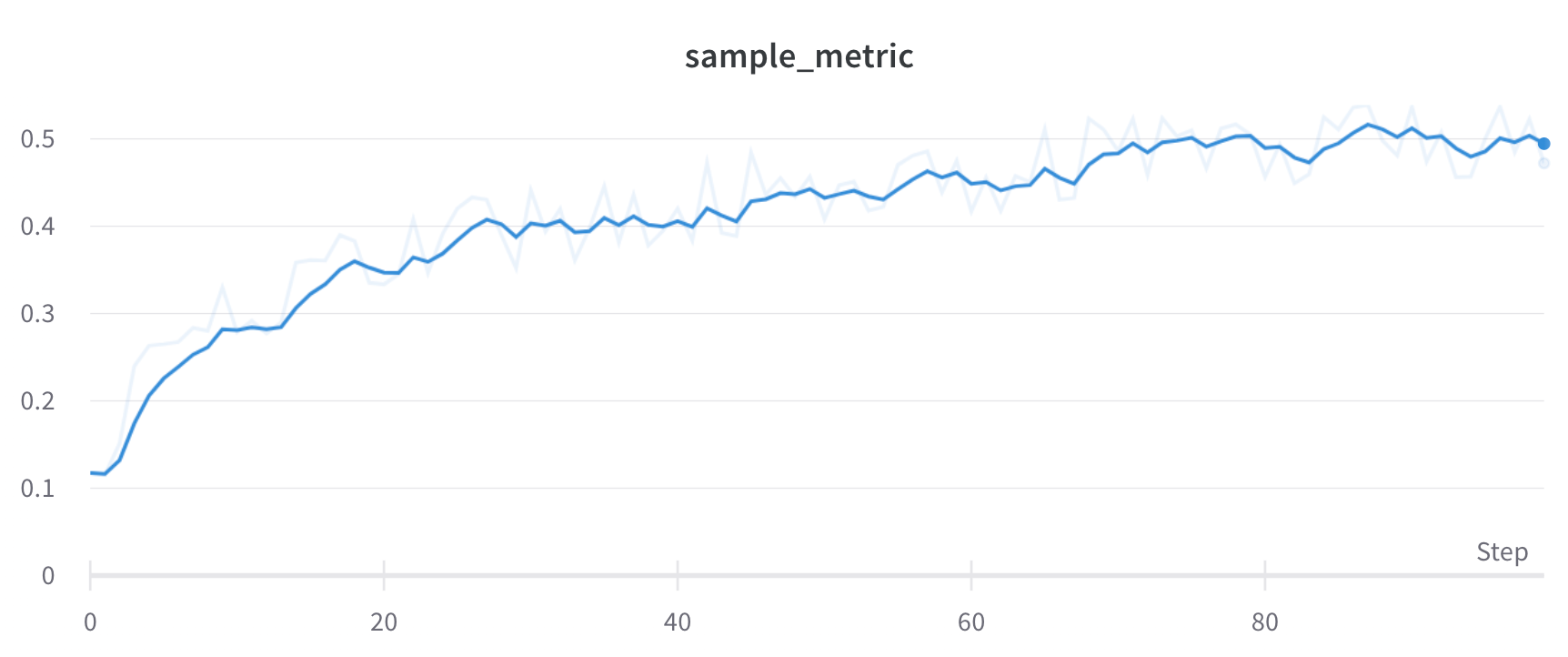
# 특정 단계에서 run을 포크합니다.forked_run = wandb.init(
project="your_project_name",
entity="your_entity_name",
fork_from=f"{rewind_run.id}?_step=500",
)
# 새로운 run에서 계속 기록합니다.for i in range(500, 1000):
forked_run.log({"metric": i*3})
forked_run.finish()
run 이 충돌하거나 사용자 정의 트리거를 사용하는 경우 Slack 또는 이메일로 알림을 생성합니다. 예를 들어, 트레이닝 루프의 그레이디언트가 폭발하기 시작하거나 (NaN을 reports) ML 파이프라인의 단계가 완료되면 알림을 생성할 수 있습니다. 알림은 개인 및 팀 프로젝트를 포함하여 run을 초기화하는 모든 프로젝트에 적용됩니다.
그런 다음 Slack (또는 이메일)에서 W&B Alerts 메시지를 확인합니다:
알림 생성 방법
다음 가이드는 멀티 테넌트 클라우드의 알림에만 적용됩니다.
프라이빗 클라우드 또는 W&B 전용 클라우드에서 W&B Server를 사용하는 경우 이 문서를 참조하여 Slack 알림을 설정하십시오.
Slack 연결을 사용하여 알림을 게시할 Slack 채널을 선택합니다. 알림을 비공개로 유지하므로 Slackbot 채널을 권장합니다.
이메일은 W&B에 가입할 때 사용한 이메일 주소로 전송됩니다. 이러한 모든 알림이 폴더로 이동하여 받은 편지함을 채우지 않도록 이메일에서 필터를 설정하는 것이 좋습니다.
W&B Alerts를 처음 설정하거나 알림 수신 방법을 수정하려는 경우에만 이 작업을 수행하면 됩니다.
2. 코드에 run.alert() 추가
알림을 트리거하려는 위치에서 코드 (노트북 또는 Python 스크립트)에 run.alert()를 추가합니다.
import wandb
run = wandb.init()
run.alert(title="High Loss", text="Loss is increasing rapidly")
3. Slack 또는 이메일 확인
Slack 또는 이메일에서 알림 메시지를 확인합니다. 아무것도 받지 못한 경우 사용자 설정에서 스크립트 가능한 알림에 대해 이메일 또는 Slack이 켜져 있는지 확인하십시오.
예시
이 간단한 알림은 정확도가 임계값 아래로 떨어지면 경고를 보냅니다. 이 예에서는 최소 5분 간격으로 알림을 보냅니다.
import wandb
from wandb import AlertLevel
run = wandb.init()
if acc < threshold:
run.alert(
title="Low accuracy",
text=f"Accuracy {acc} is below the acceptable threshold {threshold}",
level=AlertLevel.WARN,
wait_duration=300,
)
사용자 태그 또는 멘션 방법
알림 제목 또는 텍스트에서 자신 또는 동료를 태그하려면 at 기호 @ 다음에 Slack 사용자 ID를 사용하십시오. Slack 프로필 페이지에서 Slack 사용자 ID를 찾을 수 있습니다.
run.alert(title="Loss is NaN", text=f"Hey <@U1234ABCD> loss has gone to NaN")
팀 알림
팀 관리자는 팀 설정 페이지 wandb.ai/teams/your-team에서 팀에 대한 알림을 설정할 수 있습니다.
팀 알림은 팀의 모든 사용자에게 적용됩니다. W&B는 알림을 비공개로 유지하므로 Slackbot 채널을 사용하는 것이 좋습니다.
알림을 보낼 Slack 채널 변경
알림을 보낼 채널을 변경하려면 Slack 연결 끊기를 클릭한 다음 다시 연결합니다. 다시 연결한 후 다른 Slack 채널을 선택합니다.
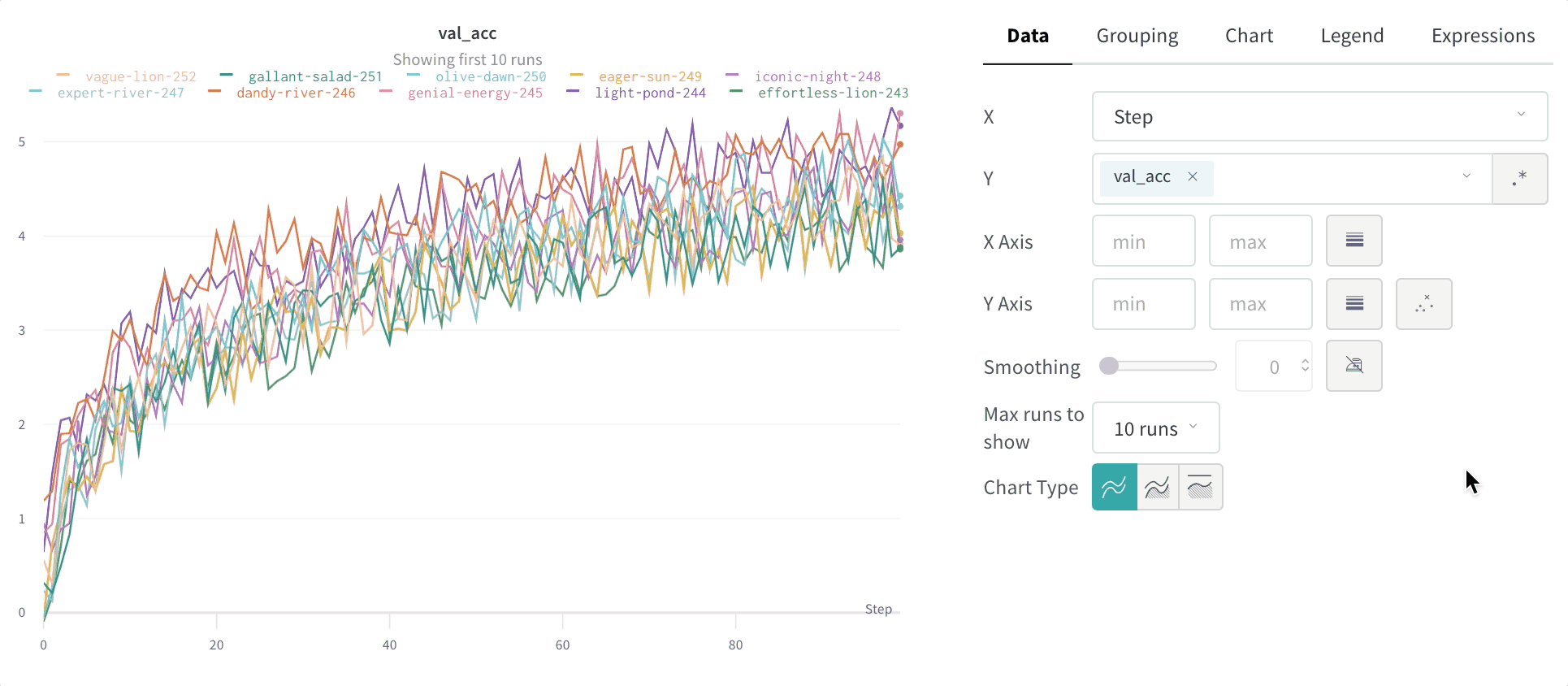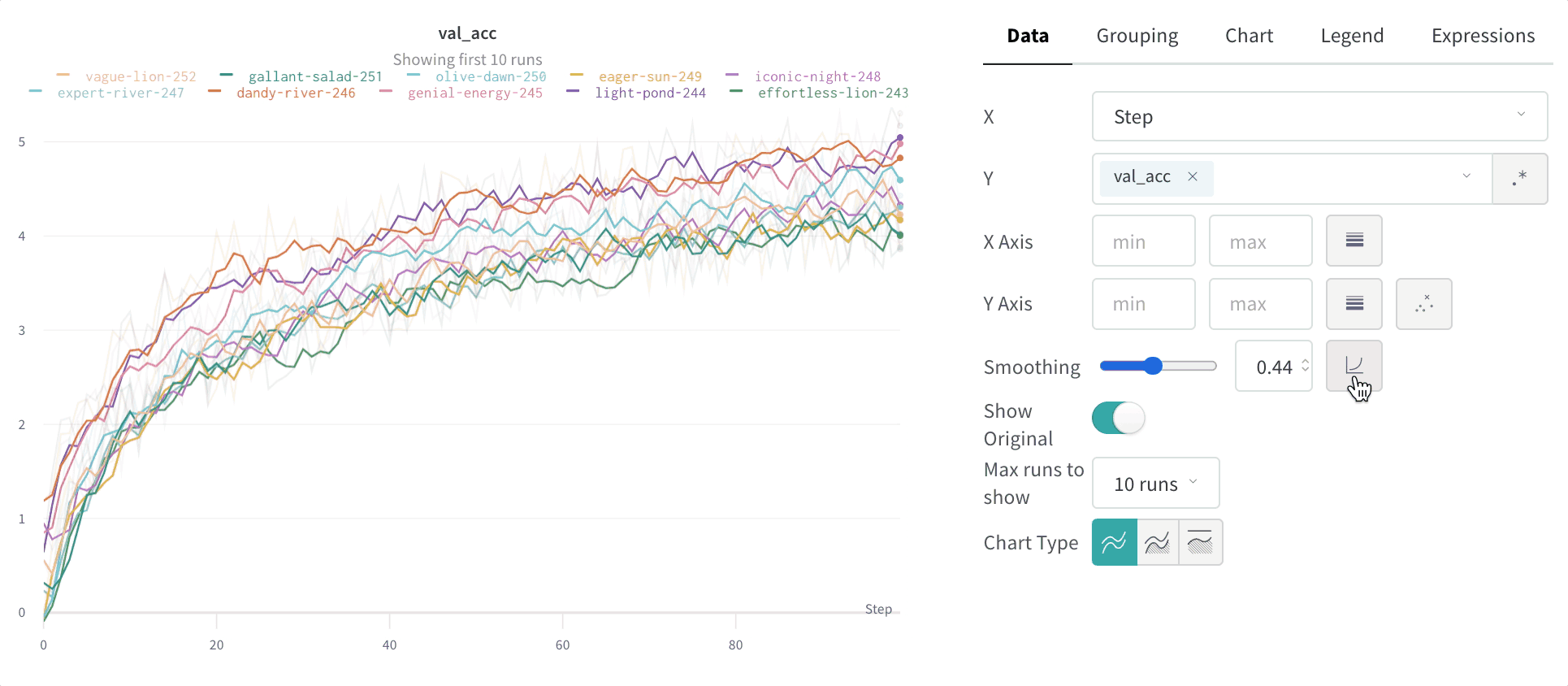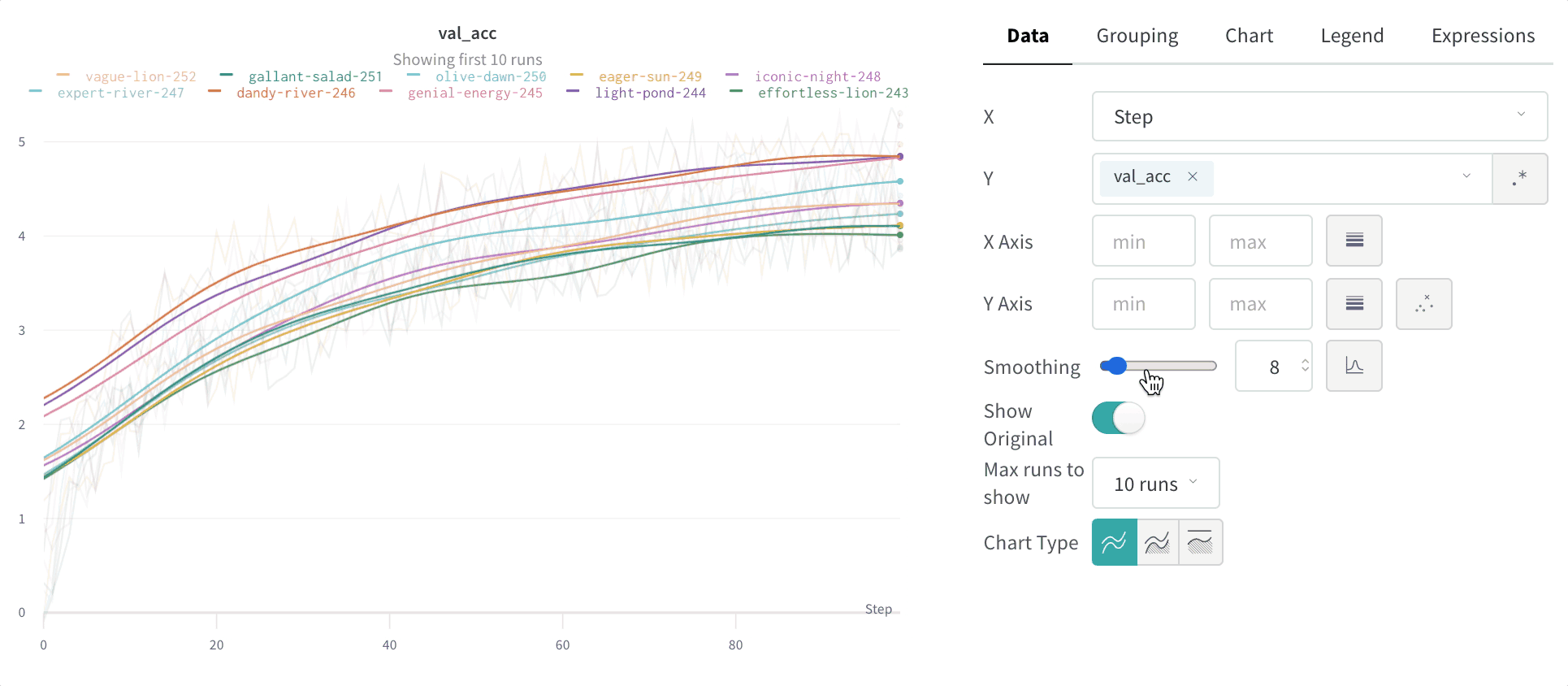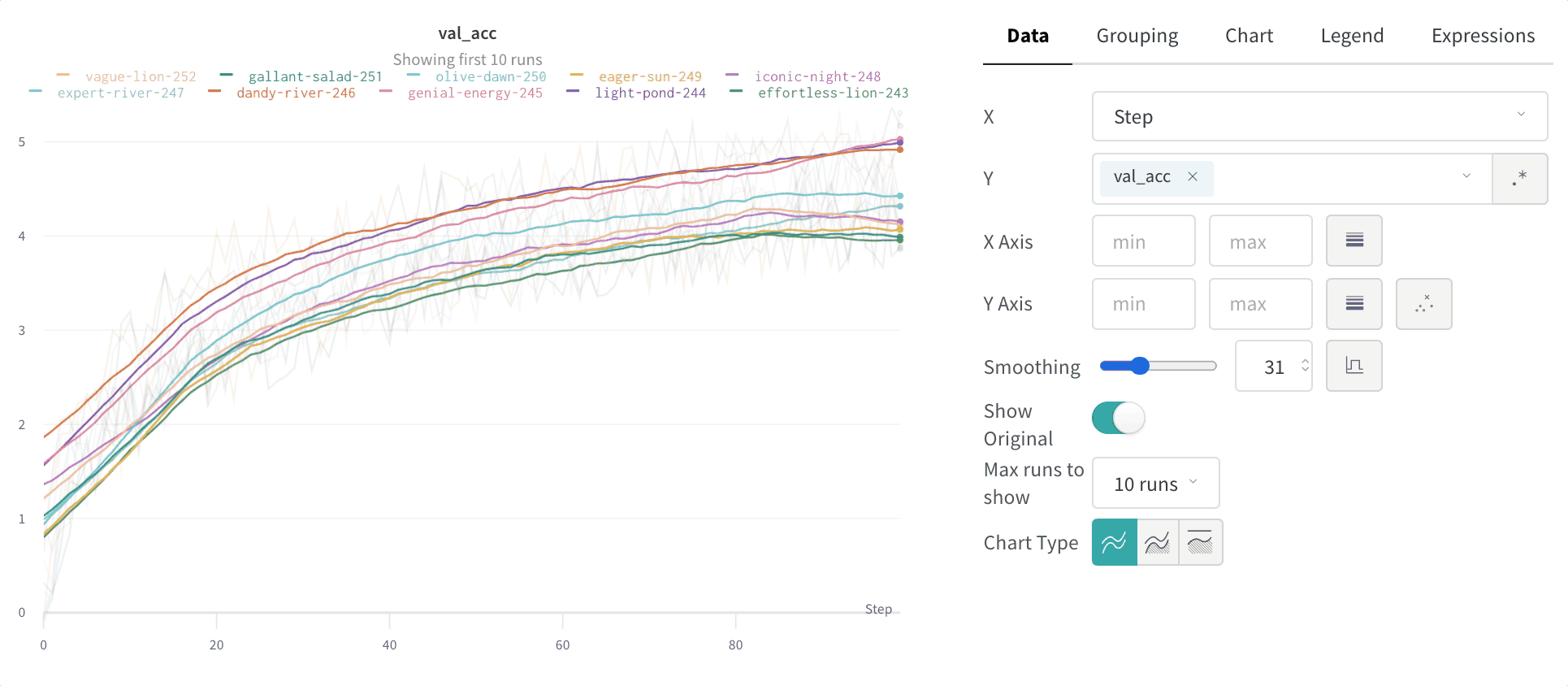
2.1.6 - Log objects and media
메트릭, 비디오, 사용자 정의 플롯 등을 추적하세요.
W&B Python SDK를 사용하여 메트릭, 미디어 또는 사용자 정의 오브젝트의 사전을 단계별로 기록합니다. W&B는 각 단계에서 키-값 쌍을 수집하고 wandb.log()로 데이터를 기록할 때마다 하나의 통합된 사전에 저장합니다. 스크립트에서 기록된 데이터는 wandb라는 디렉토리에 로컬로 저장된 다음 W&B 클라우드 또는 개인 서버로 동기화됩니다.
키-값 쌍은 각 단계마다 동일한 값을 전달하는 경우에만 하나의 통합된 사전에 저장됩니다. step에 대해 다른 값을 기록하면 W&B는 수집된 모든 키와 값을 메모리에 씁니다.
wandb.log를 호출할 때마다 기본적으로 새로운 step이 됩니다. W&B는 차트 및 패널을 만들 때 단계를 기본 x축으로 사용합니다. 선택적으로 사용자 정의 x축을 만들고 사용하거나 사용자 정의 요약 메트릭을 캡처할 수 있습니다. 자세한 내용은 로그 축 사용자 정의를 참조하세요.
각 step에 대해 연속적인 값 0, 1, 2 등을 기록하려면 wandb.log()를 사용하세요. 특정 history 단계에 쓸 수는 없습니다. W&B는 “현재” 및 “다음” 단계에만 씁니다.
자동으로 기록되는 데이터
W&B는 W&B Experiments 동안 다음 정보를 자동으로 기록합니다.
시스템 메트릭: CPU 및 GPU 사용률, 네트워크 등. 이러한 메트릭은 run 페이지의 시스템 탭에 표시됩니다. GPU의 경우 이러한 메트릭은 nvidia-smi를 통해 가져옵니다.
커맨드 라인: stdout 및 stderr이 선택되어 run 페이지의 로그 탭에 표시됩니다.
설정 정보: 하이퍼파라미터, 데이터셋 링크 또는 사용 중인 아키텍처 이름을 config 파라미터로 기록합니다. 예: wandb.init(config=your_config_dictionary). 자세한 내용은 PyTorch 인테그레이션 페이지를 참조하세요.
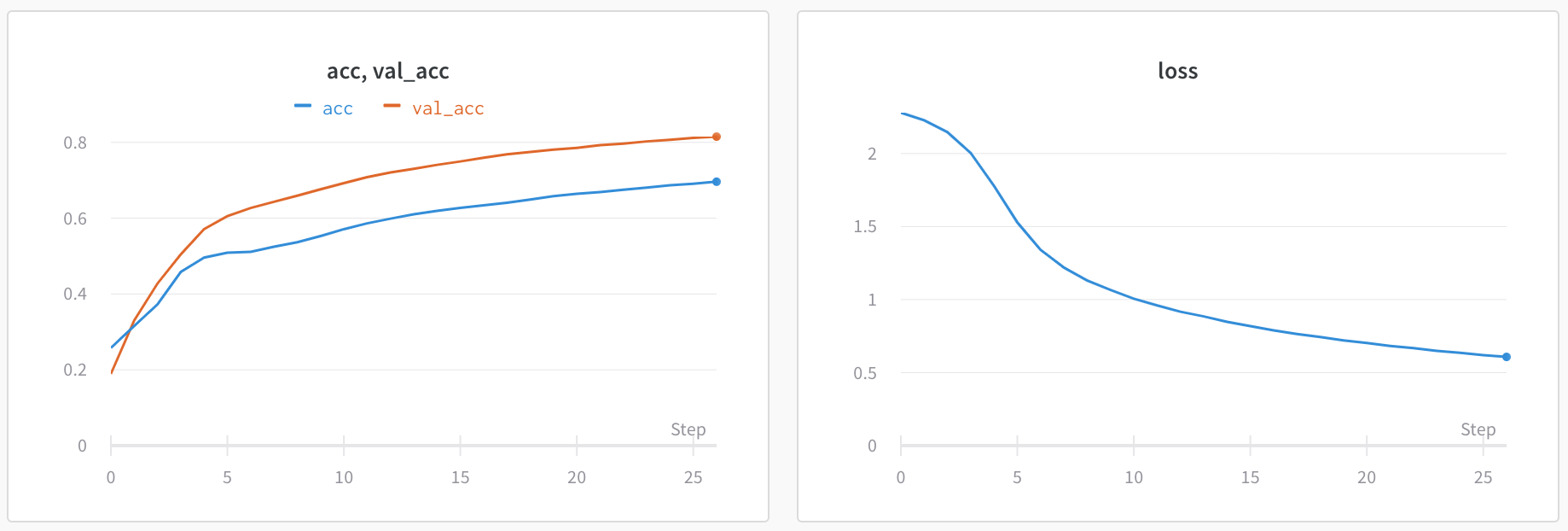
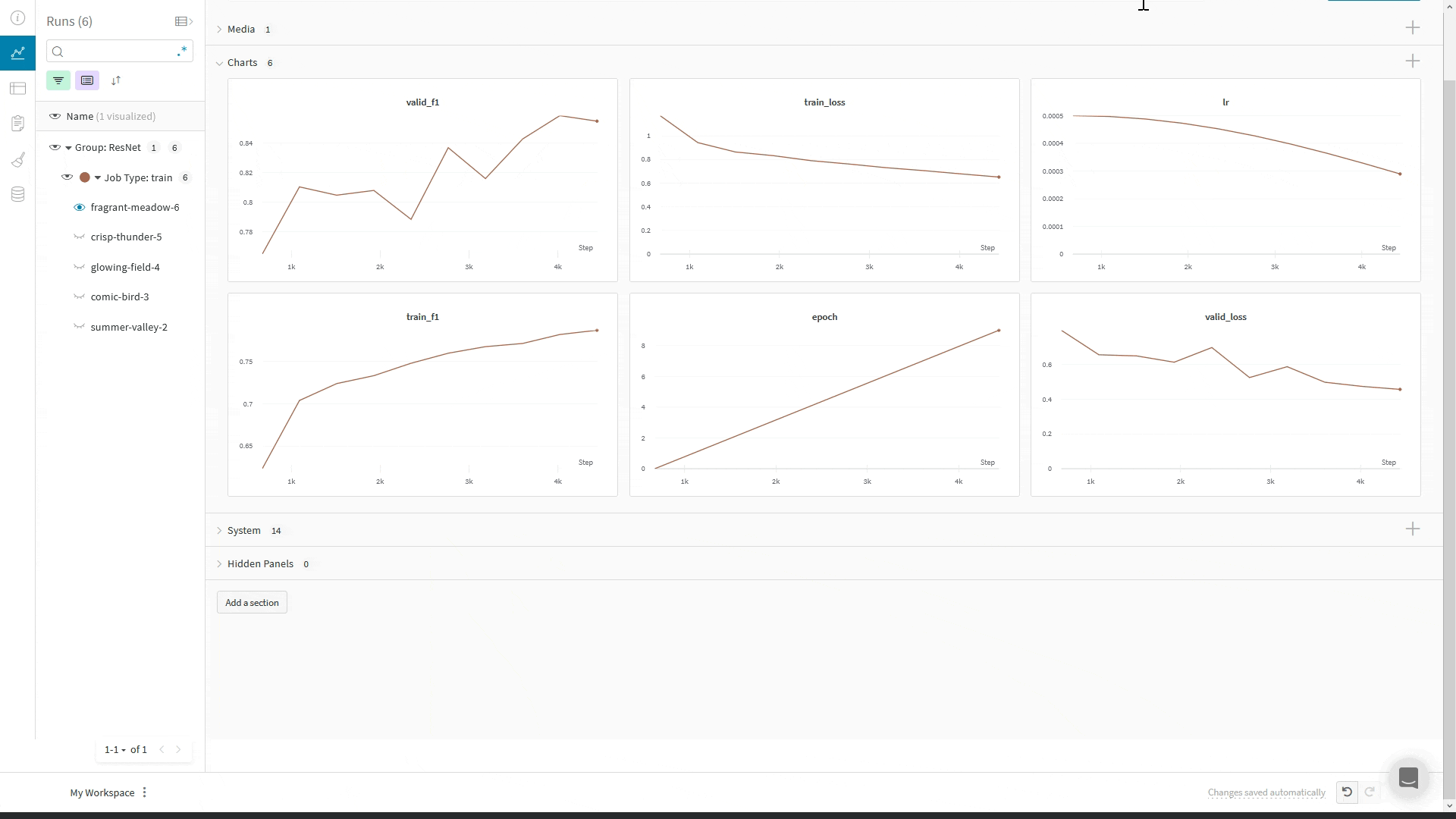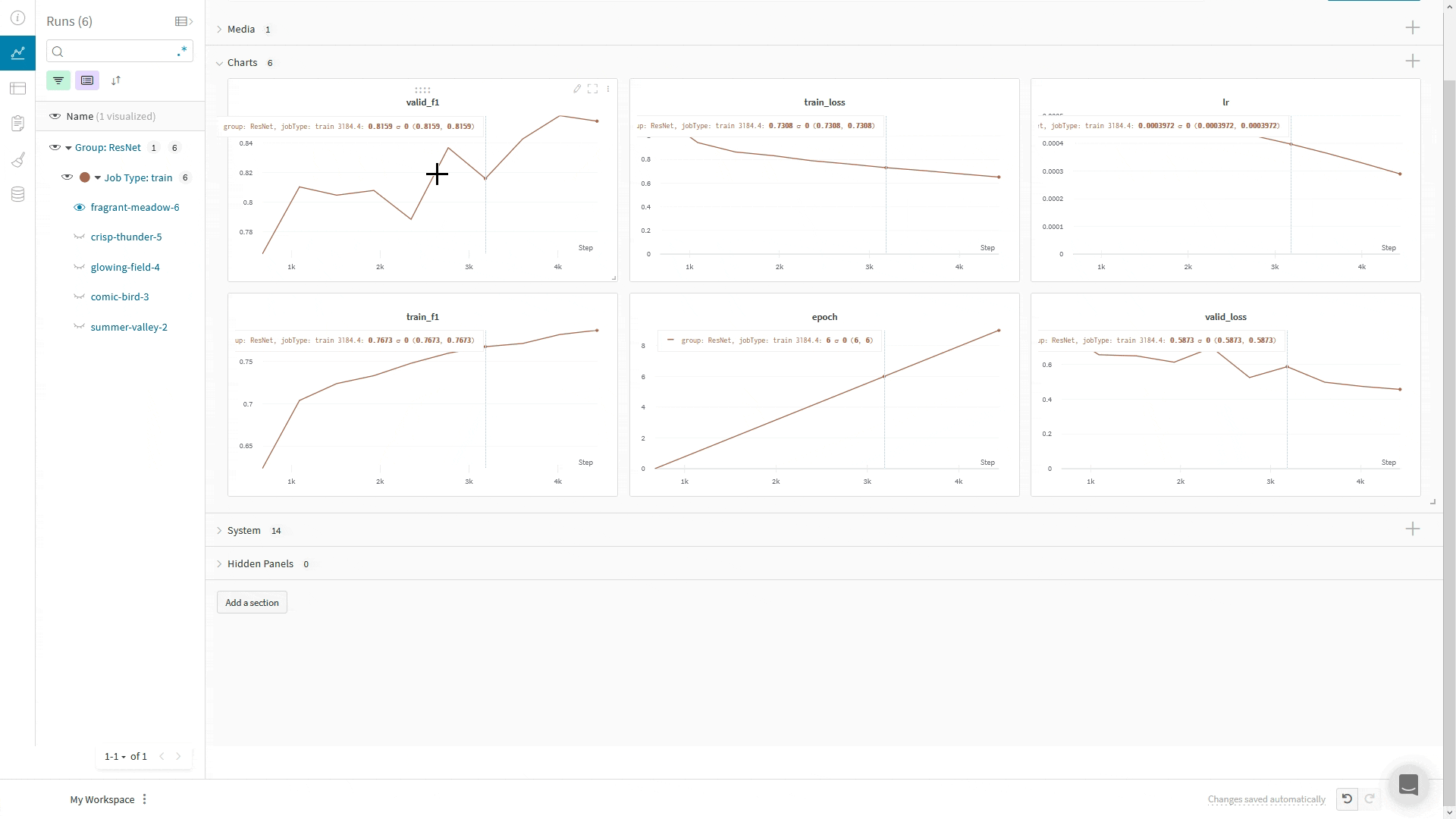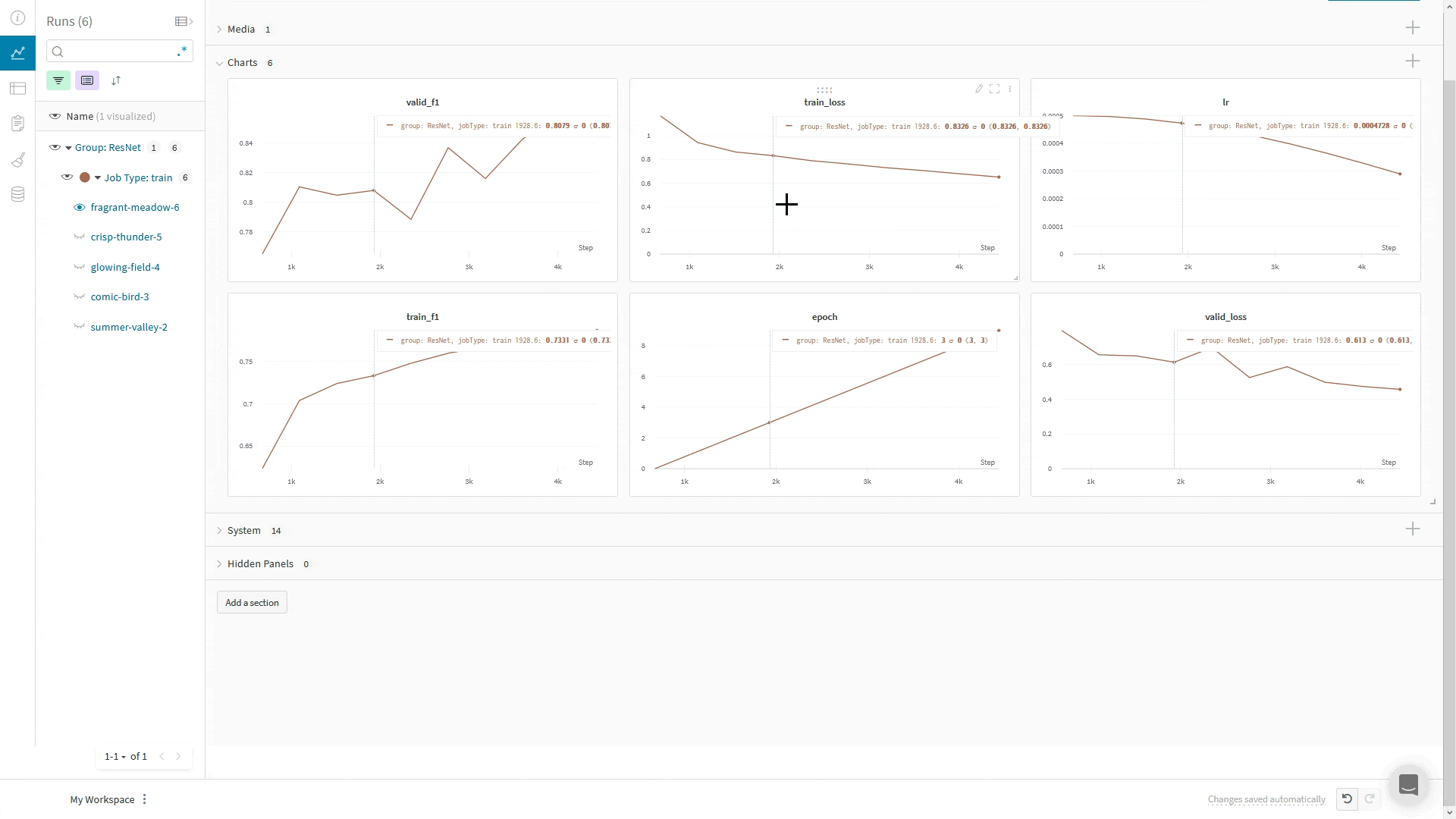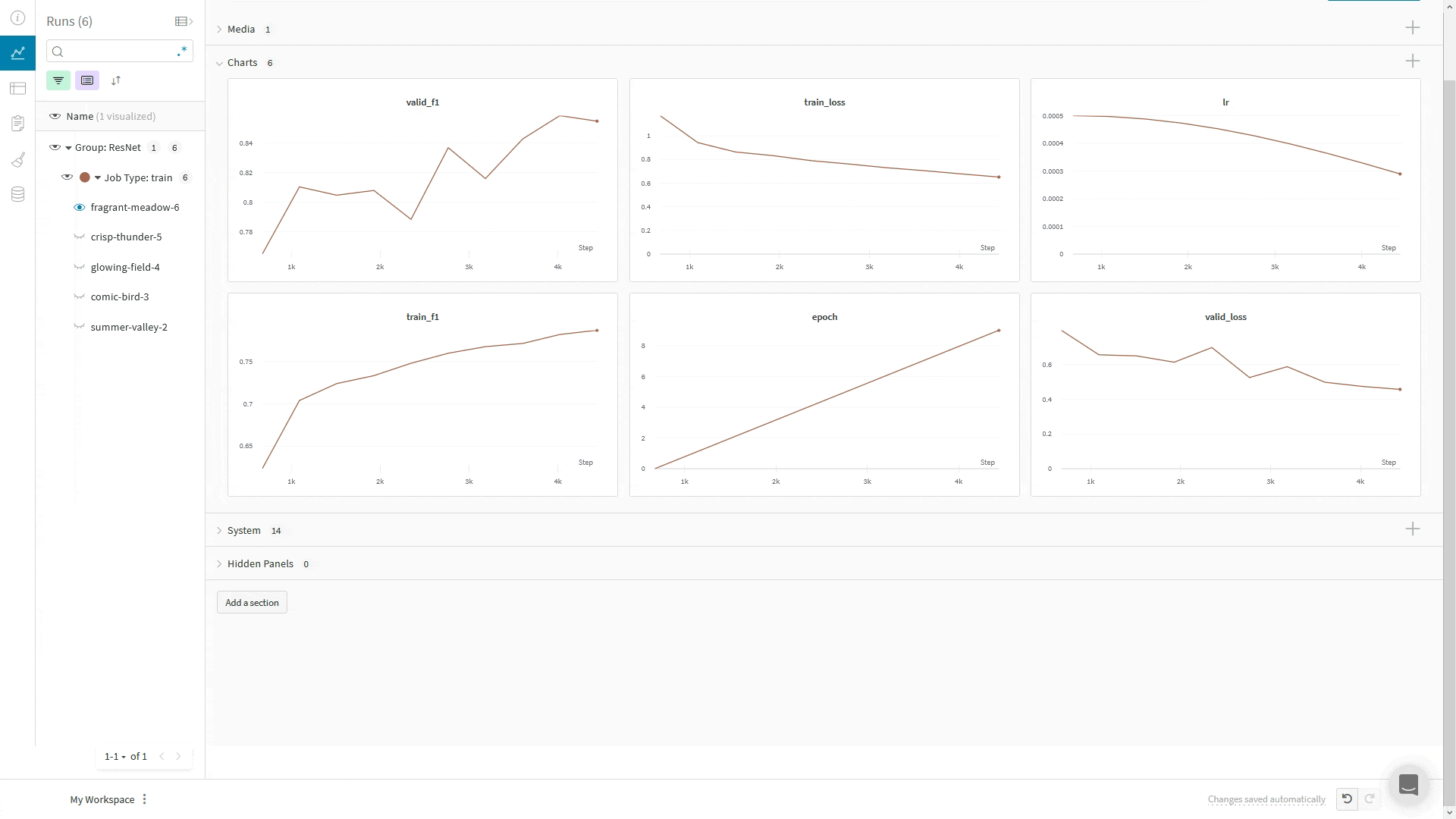
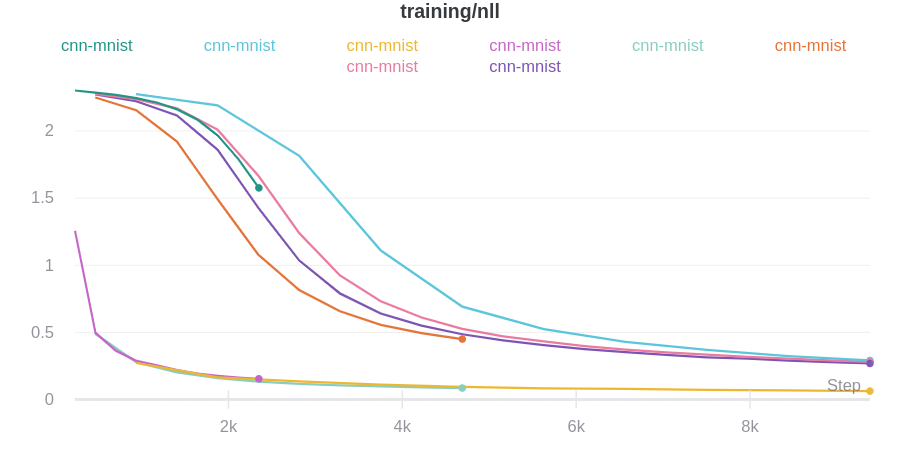
메트릭: 모델의 메트릭을 보려면 wandb.log를 사용합니다. 트레이닝 루프 내에서 정확도 및 손실과 같은 메트릭을 기록하면 UI에서 실시간 업데이트 그래프를 얻을 수 있습니다.
일반적인 워크플로우
최고 정확도 비교: run 간에 메트릭의 최고 값을 비교하려면 해당 메트릭의 요약 값을 설정합니다. 기본적으로 요약은 각 키에 대해 기록한 마지막 값으로 설정됩니다. 이는 UI의 테이블에서 유용합니다. 여기서 요약 메트릭을 기준으로 run을 정렬하고 필터링하여 최종 정확도가 아닌 최고 정확도를 기준으로 테이블 또는 막대 차트에서 run을 비교할 수 있습니다. 예: wandb.run.summary["best_accuracy"] = best_accuracy
하나의 차트에 여러 메트릭 보기: wandb.log({"acc'": 0.9, "loss": 0.1})과 같이 wandb.log에 대한 동일한 호출에서 여러 메트릭을 기록하면 UI에서 플롯하는 데 사용할 수 있습니다.
x축 사용자 정의: 동일한 로그 호출에 사용자 정의 x축을 추가하여 W&B 대시보드에서 다른 축에 대해 메트릭을 시각화합니다. 예: wandb.log({'acc': 0.9, 'epoch': 3, 'batch': 117}). 지정된 메트릭에 대한 기본 x축을 설정하려면 Run.define_metric()을 사용합니다.
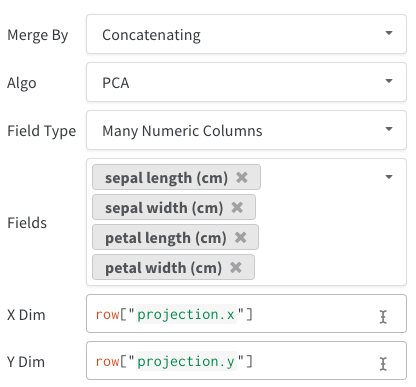
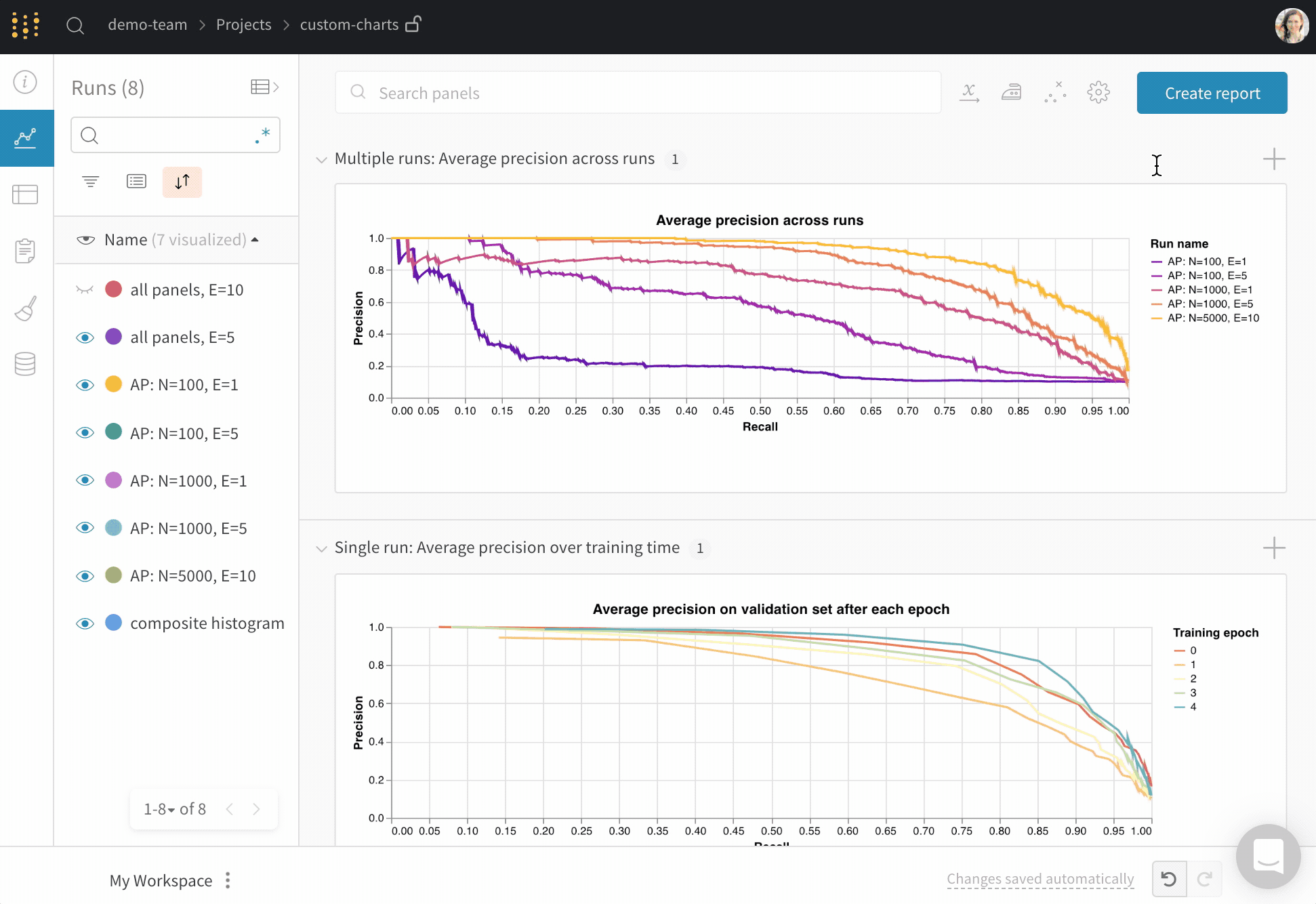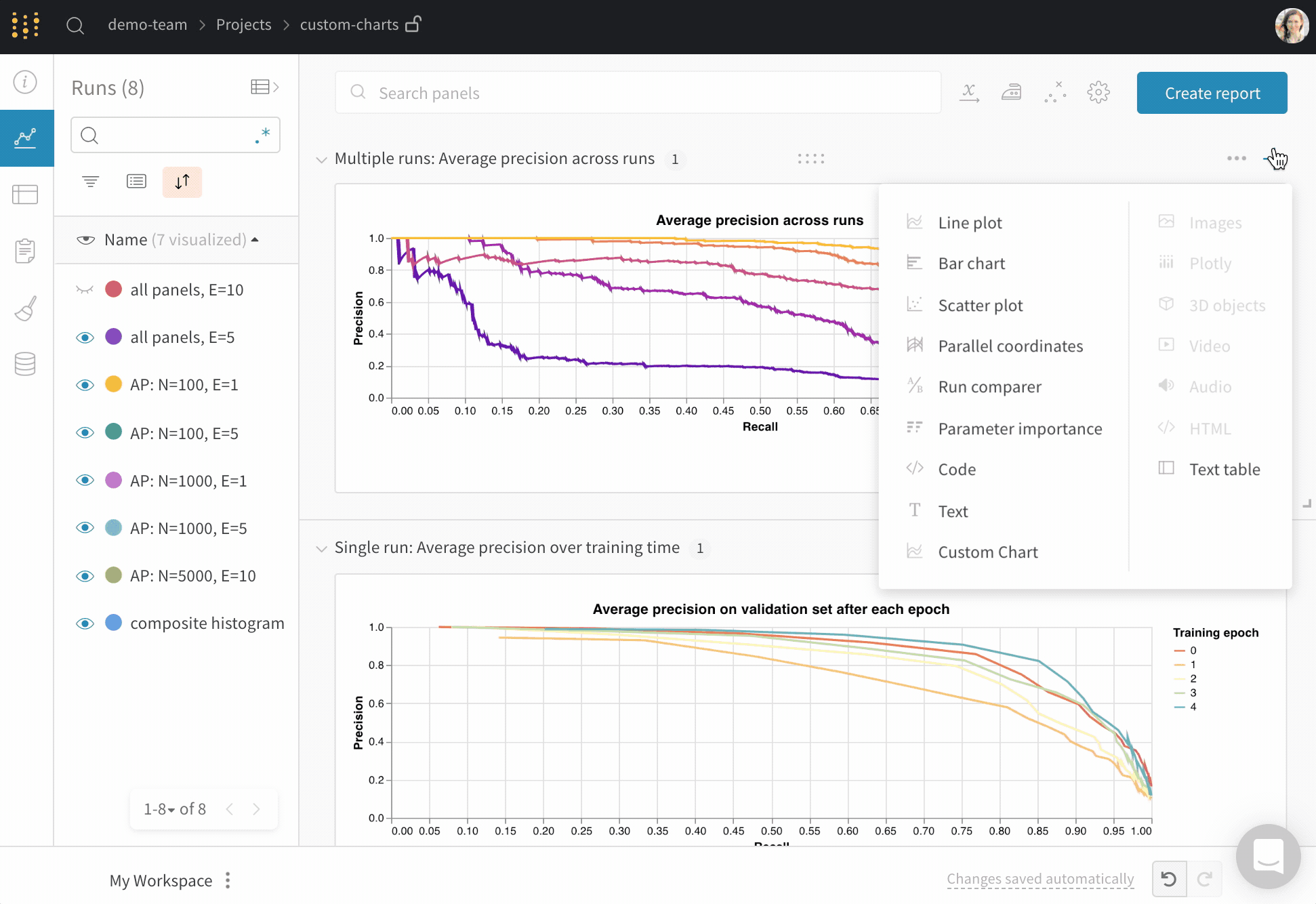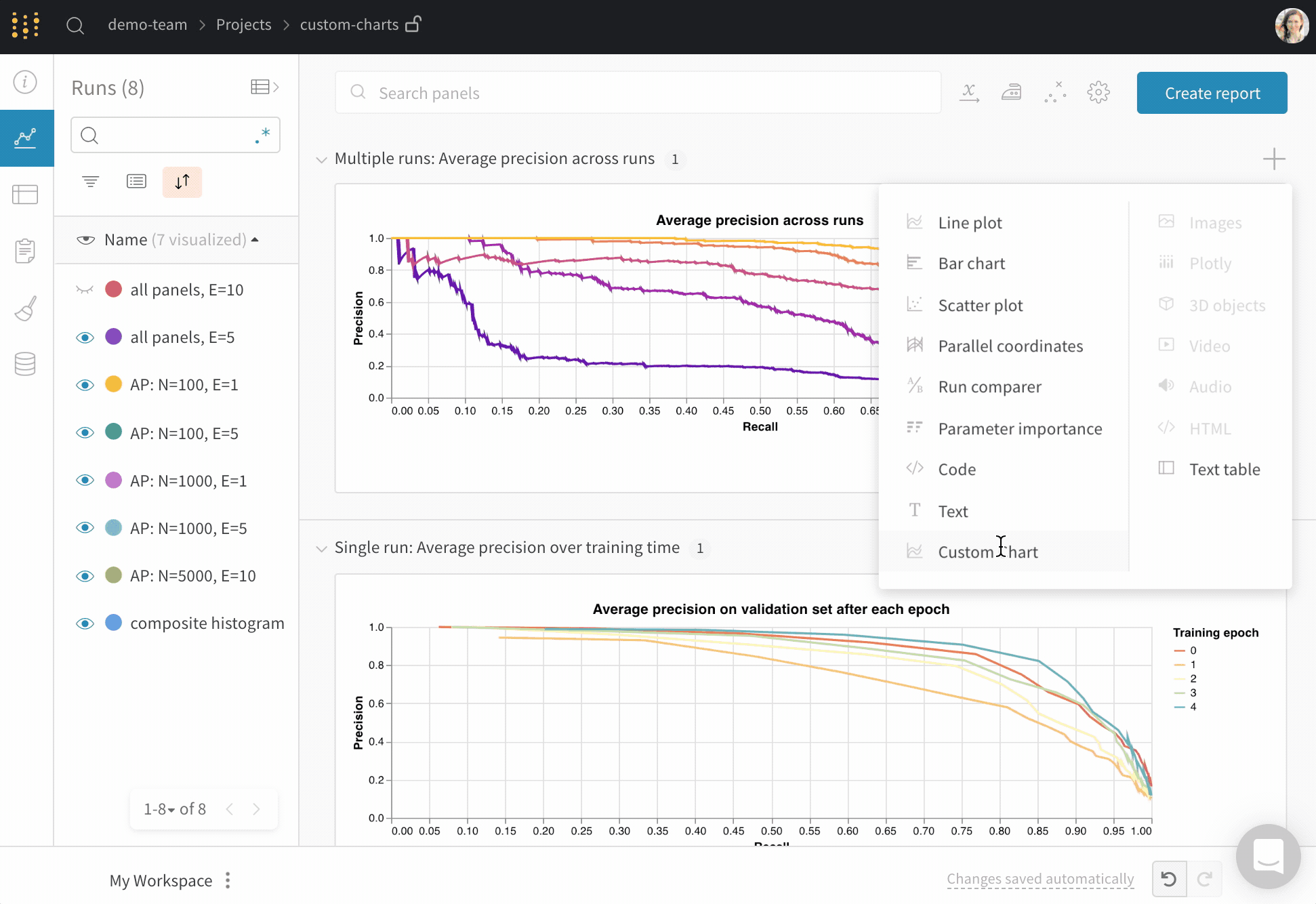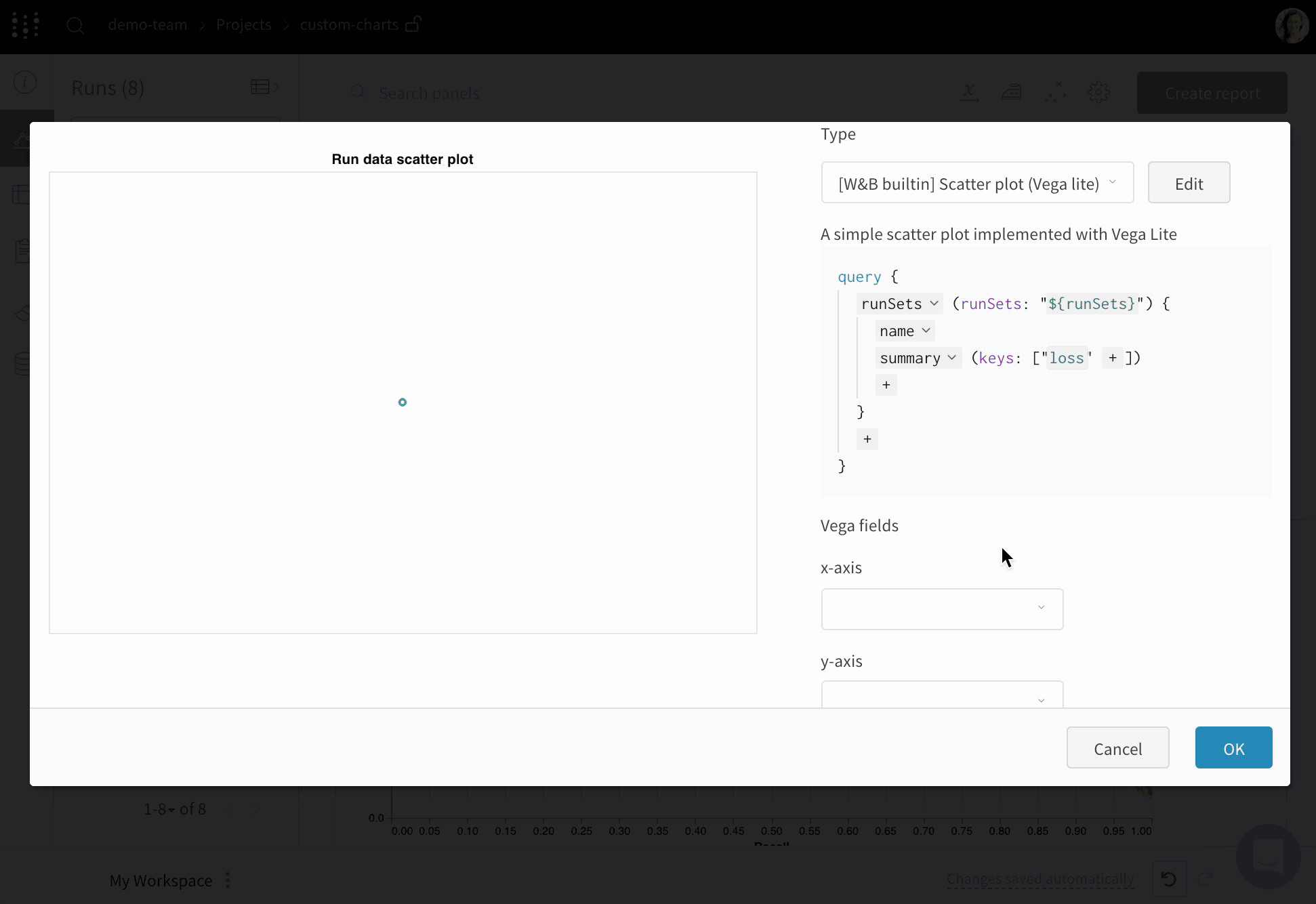
wandb.plot의 메소드를 사용하면 트레이닝 중 시간에 따라 변하는 차트를 포함하여 wandb.log로 차트를 추적할 수 있습니다. 사용자 정의 차트 프레임워크에 대해 자세히 알아보려면 이 가이드를 확인하십시오.
기본 차트
이러한 간단한 차트를 사용하면 메트릭 및 결과의 기본 시각화를 쉽게 구성할 수 있습니다.
wandb.plot.line()
임의의 축에서 연결되고 정렬된 점 목록인 사용자 정의 라인 플롯을 기록합니다.
data = [[x, y] for (x, y) in zip(x_values, y_values)]
table = wandb.Table(data=data, columns=["x", "y"])
wandb.log(
{
"my_custom_plot_id": wandb.plot.line(
table, "x", "y", title="Custom Y vs X Line Plot" )
}
)
이를 사용하여 임의의 두 차원에 대한 곡선을 기록할 수 있습니다. 두 값 목록을 서로 플로팅하는 경우 목록의 값 수는 정확히 일치해야 합니다. 예를 들어 각 점에는 x와 y가 있어야 합니다.
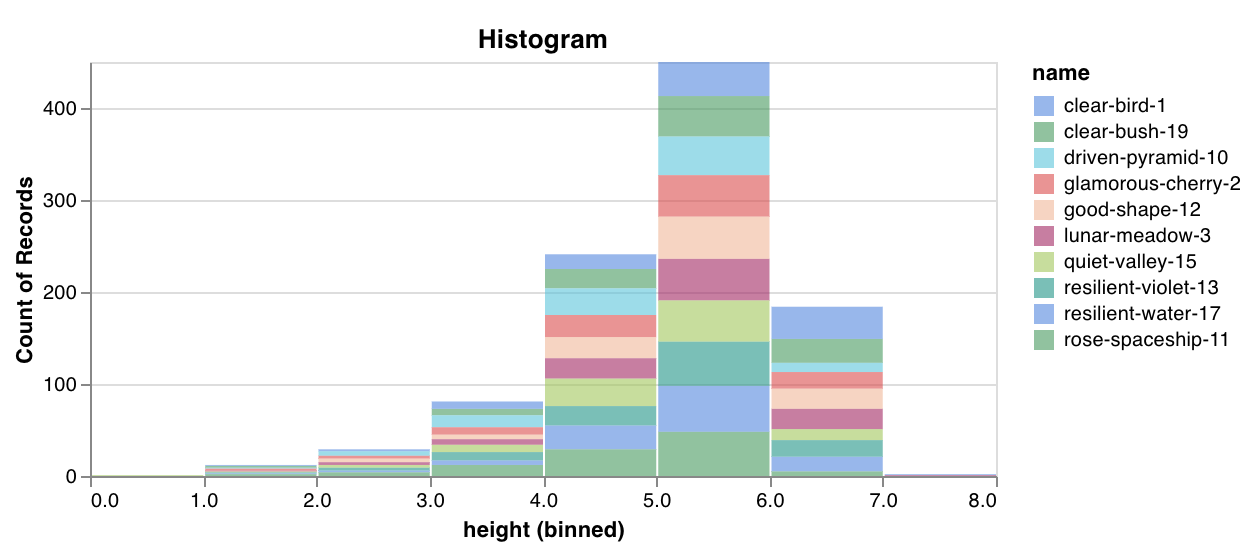
몇 줄의 코드로 값 목록을 발생 횟수/빈도별로 bin으로 정렬하는 사용자 정의 히스토그램을 기본적으로 기록합니다. 예측 신뢰도 점수 목록 (scores)이 있고 분포를 시각화하고 싶다고 가정해 보겠습니다.
data = [[s] for s in scores]
table = wandb.Table(data=data, columns=["scores"])
wandb.log({"my_histogram": wandb.plot.histogram(table, "scores", title="Histogram")})
이를 사용하여 임의의 히스토그램을 기록할 수 있습니다. data는 행과 열의 2D 배열을 지원하기 위한 목록의 목록입니다.
전체 사용자 정의를 위해 기본 제공 사용자 정의 차트 사전 설정을 조정하거나 새 사전 설정을 만든 다음 차트를 저장합니다. 차트 ID를 사용하여 스크립트에서 직접 해당 사용자 정의 사전 설정에 데이터를 기록합니다.
# 플로팅할 열이 있는 테이블을 만듭니다.table = wandb.Table(data=data, columns=["step", "height"])
# 테이블의 열에서 차트의 필드로 매핑합니다.fields = {"x": "step", "value": "height"}
# 테이블을 사용하여 새 사용자 정의 차트 사전 설정을 채웁니다.# 자신의 저장된 차트 사전 설정을 사용하려면 vega_spec_name을 변경하십시오.# 제목을 편집하려면 string_fields를 변경하십시오.my_custom_chart = wandb.plot_table(
vega_spec_name="carey/new_chart",
data_table=table,
fields=fields,
string_fields={"title": "Height Histogram"},
)
기본적으로 모든 메트릭은 W&B 내부 step인 동일한 x축에 대해 기록됩니다. 때로는 이전 스텝에 로그하거나 다른 x축을 사용하고 싶을 수 있습니다.
다음은 기본 스텝 대신 사용자 정의 x축 메트릭을 설정하는 예입니다.
import wandb
wandb.init()
# 사용자 정의 x축 메트릭 정의wandb.define_metric("custom_step")
# 어떤 메트릭을 기준으로 플롯할지 정의wandb.define_metric("validation_loss", step_metric="custom_step")
for i in range(10):
log_dict = {
"train_loss": 1/ (i +1),
"custom_step": i**2,
"validation_loss": 1/ (i +1),
}
wandb.log(log_dict)
x축은 glob을 사용하여 설정할 수도 있습니다. 현재 문자열 접두사가 있는 glob만 사용할 수 있습니다. 다음 예제는 접두사 "train/"가 있는 기록된 모든 메트릭을 x축 "train/step"에 플롯합니다.
import wandb
wandb.init()
# 사용자 정의 x축 메트릭 정의wandb.define_metric("train/step")
# 다른 모든 train/ 메트릭이 이 스텝을 사용하도록 설정wandb.define_metric("train/*", step_metric="train/step")
for i in range(10):
log_dict = {
"train/step": 2**i, # 내부 W&B 스텝으로 지수적 증가"train/loss": 1/ (i +1), # x축은 train/step"train/accuracy": 1- (1/ (1+ i)), # x축은 train/step"val/loss": 1/ (1+ i), # x축은 내부 wandb step }
wandb.log(log_dict)
2.1.6.3 - Log distributed training experiments
W&B를 사용하여 여러 개의 GPU로 분산 트레이닝 실험을 로그하세요.
분산 트레이닝에서 모델은 여러 개의 GPU를 병렬로 사용하여 트레이닝됩니다. W&B는 분산 트레이닝 Experiments를 추적하는 두 가지 패턴을 지원합니다.
단일 프로세스: 단일 프로세스에서 W&B (wandb.init)를 초기화하고 Experiments (wandb.log)를 기록합니다. 이는 PyTorch Distributed Data Parallel (DDP) 클래스를 사용하여 분산 트레이닝 Experiments를 로깅하는 일반적인 솔루션입니다. 경우에 따라 사용자는 멀티프로세싱 대기열(또는 다른 통신 기본 요소)을 사용하여 다른 프로세스의 데이터를 기본 로깅 프로세스로 전달합니다.
다중 프로세스: 모든 프로세스에서 W&B (wandb.init)를 초기화하고 Experiments (wandb.log)를 기록합니다. 각 프로세스는 사실상 별도의 experiment입니다. W&B를 초기화할 때 group 파라미터(wandb.init(group='group-name'))를 사용하여 공유 experiment를 정의하고 기록된 값들을 W&B App UI에서 함께 그룹화합니다.
다음 예제는 단일 머신에서 2개의 GPU를 사용하는 PyTorch DDP를 통해 W&B로 메트릭을 추적하는 방법을 보여줍니다. PyTorch DDP(torch.nn의 DistributedDataParallel)는 분산 트레이닝을 위한 널리 사용되는 라이브러리입니다. 기본 원리는 모든 분산 트레이닝 설정에 적용되지만 구현 세부 사항은 다를 수 있습니다.
W&B GitHub 예제 리포지토리 여기에서 이러한 예제의 이면의 코드를 살펴보세요. 특히, 단일 프로세스 및 다중 프로세스 메소드를 구현하는 방법에 대한 정보는 log-dpp.py Python 스크립트를 참조하세요.
방법 1: 단일 프로세스
이 방법에서는 순위 0 프로세스만 추적합니다. 이 방법을 구현하려면 W&B(wandb.init)를 초기화하고, W&B Run을 시작하고, 순위 0 프로세스 내에서 메트릭(wandb.log)을 기록합니다. 이 방법은 간단하고 강력하지만 다른 프로세스의 모델 메트릭(예: 배치에서의 손실 값 또는 입력)을 기록하지 않습니다. 사용량 및 메모리와 같은 시스템 메트릭은 해당 정보가 모든 프로세스에서 사용 가능하므로 모든 GPU에 대해 계속 기록됩니다.
이 방법을 사용하여 단일 프로세스에서 사용 가능한 메트릭만 추적하세요. 일반적인 예로는 GPU/CPU 사용률, 공유 검증 세트에서의 행동, 그레이디언트 및 파라미터, 대표적인 데이터 예제에 대한 손실 값이 있습니다.
샘플 Python 스크립트(log-ddp.py) 내에서 순위가 0인지 확인합니다. 이를 구현하기 위해 먼저 torch.distributed.launch를 사용하여 여러 프로세스를 시작합니다. 다음으로 --local_rank 커맨드라인 인수로 순위를 확인합니다. 순위가 0으로 설정된 경우 train() 함수에서 조건부로 wandb 로깅을 설정합니다. Python 스크립트 내에서 다음 검사를 사용합니다.
if __name__ =="__main__":
# Get args args = parse_args()
if args.local_rank ==0: # only on main process# Initialize wandb run run = wandb.init(
entity=args.entity,
project=args.project,
)
# Train model with DDP train(args, run)
else:
train(args)
W&B App UI를 탐색하여 단일 프로세스에서 추적된 메트릭의 예제 대시보드를 확인하세요. 대시보드는 두 GPU에 대해 추적된 온도 및 사용률과 같은 시스템 메트릭을 표시합니다.
그러나 에포크 및 배치 크기 함수로서의 손실 값은 단일 GPU에서만 기록되었습니다.
방법 2: 다중 프로세스
이 방법에서는 작업의 각 프로세스를 추적하여 각 프로세스에서 wandb.init() 및 wandb.log()를 호출합니다. 트레이닝이 끝나면 wandb.finish()를 호출하여 Run이 완료되었음을 표시하여 모든 프로세스가 올바르게 종료되도록 하는 것이 좋습니다.
이 방법을 사용하면 더 많은 정보를 로깅에 엑세스할 수 있습니다. 그러나 여러 개의 W&B Runs가 W&B App UI에 보고되는 점에 유의하세요. 여러 Experiments에서 W&B Runs를 추적하기 어려울 수 있습니다. 이를 완화하려면 W&B를 초기화할 때 group 파라미터에 값을 제공하여 지정된 experiment에 속하는 W&B Run을 추적하세요. Experiments에서 트레이닝 및 평가 W&B Runs를 추적하는 방법에 대한 자세한 내용은 Run 그룹화를 참조하세요.
개별 프로세스의 메트릭을 추적하려면 이 방법을 사용하세요. 일반적인 예로는 각 노드의 데이터 및 예측(데이터 배포 디버깅용)과 기본 노드 외부의 개별 배치에 대한 메트릭이 있습니다. 이 방법은 모든 노드에서 시스템 메트릭을 가져오거나 기본 노드에서 사용 가능한 요약 통계를 가져오는 데 필요하지 않습니다.
다음 Python 코드 조각은 W&B를 초기화할 때 group 파라미터를 설정하는 방법을 보여줍니다.
if __name__ =="__main__":
# Get args args = parse_args()
# Initialize run run = wandb.init(
entity=args.entity,
project=args.project,
group="DDP", # all runs for the experiment in one group )
# Train model with DDP train(args, run)
W&B App UI를 탐색하여 여러 프로세스에서 추적된 메트릭의 예제 대시보드를 확인하세요. 왼쪽 사이드바에 함께 그룹화된 두 개의 W&B Runs가 있습니다. 그룹을 클릭하여 experiment에 대한 전용 그룹 페이지를 확인하세요. 전용 그룹 페이지에는 각 프로세스의 메트릭이 개별적으로 표시됩니다.
앞의 이미지는 W&B App UI 대시보드를 보여줍니다. 사이드바에는 두 개의 Experiments가 있습니다. 하나는 ’null’로 레이블이 지정되고 다른 하나는 ‘DPP’(노란색 상자로 묶임)로 표시됩니다. 그룹을 확장하면(그룹 드롭다운 선택) 해당 experiment와 연결된 W&B Runs가 표시됩니다.
W&B Service를 사용하여 일반적인 분산 트레이닝 문제 방지
W&B 및 분산 트레이닝을 사용할 때 발생할 수 있는 두 가지 일반적인 문제가 있습니다.
트레이닝 시작 시 중단 - wandb 멀티프로세싱이 분산 트레이닝의 멀티프로세싱을 방해하는 경우 wandb 프로세스가 중단될 수 있습니다.
트레이닝 종료 시 중단 - wandb 프로세스가 종료해야 할 시점을 알지 못하는 경우 트레이닝 작업이 중단될 수 있습니다. Python 스크립트의 끝에서 wandb.finish() API를 호출하여 W&B에 Run이 완료되었음을 알립니다. wandb.finish() API는 데이터 업로드를 완료하고 W&B가 종료되도록 합니다.
wandb service를 사용하여 분산 작업의 안정성을 개선하는 것이 좋습니다. 앞서 언급한 두 가지 트레이닝 문제는 일반적으로 wandb service를 사용할 수 없는 W&B SDK 버전에서 발견됩니다.
W&B Service 활성화
W&B SDK 버전에 따라 W&B Service가 기본적으로 활성화되어 있을 수 있습니다.
W&B SDK 0.13.0 이상
W&B Service는 W&B SDK 0.13.0 버전 이상에서 기본적으로 활성화되어 있습니다.
W&B SDK 0.12.5 이상
Python 스크립트를 수정하여 W&B SDK 버전 0.12.5 이상에서 W&B Service를 활성화하세요. wandb.require 메소드를 사용하고 기본 함수 내에서 문자열 "service"를 전달하세요.
if __name__ =="__main__":
main()
defmain():
wandb.require("service")
# rest-of-your-script-goes-here
최적의 경험을 위해 최신 버전으로 업그레이드하는 것이 좋습니다.
W&B SDK 0.12.4 이하
W&B SDK 버전 0.12.4 이하를 사용하는 경우 WANDB_START_METHOD 환경 변수를 "thread"로 설정하여 대신 멀티스레딩을 사용하세요.
멀티프로세싱에 대한 예제 유스 케이스
다음 코드 조각은 고급 분산 유스 케이스에 대한 일반적인 방법을 보여줍니다.
프로세스 생성
생성된 프로세스에서 W&B Run을 시작하는 경우 기본 함수에서 wandb.setup() 메소드를 사용하세요.
import multiprocessing as mp
defdo_work(n):
run = wandb.init(config=dict(n=n))
run.log(dict(this=n * n))
defmain():
wandb.setup()
pool = mp.Pool(processes=4)
pool.map(do_work, range(4))
if __name__ =="__main__":
main()
W&B Run 공유
W&B Run 오브젝트를 인수로 전달하여 프로세스 간에 W&B Runs를 공유합니다.
defdo_work(run):
run.log(dict(this=1))
defmain():
run = wandb.init()
p = mp.Process(target=do_work, kwargs=dict(run=run))
p.start()
p.join()
if __name__ =="__main__":
main()
로깅 순서를 보장할 수 없습니다. 동기화는 스크립트 작성자가 수행해야 합니다.
2.1.6.4 - Log media and objects
3D 포인트 클라우드 및 분자에서 HTML 및 히스토그램에 이르기까지 다양한 미디어를 로그
마지막 차원이 1이면 이미지가 회색조, 3이면 RGB, 4이면 RGBA라고 가정합니다. 배열에 float가 포함된 경우 0과 255 사이의 정수로 변환합니다. 이미지를 다르게 정규화하려면 mode를 수동으로 지정하거나 이 패널의 “PIL 이미지 로깅” 탭에 설명된 대로 PIL.Image를 제공하면 됩니다.
배열을 이미지로 변환하는 것을 완벽하게 제어하려면 PIL.Image를 직접 구성하여 제공합니다.
images = [PIL.Image.fromarray(image) for image in image_array]
wandb.log({"examples": [wandb.Image(image) for image in images]})
더욱 완벽하게 제어하려면 원하는 방식으로 이미지를 만들고 디스크에 저장한 다음 파일 경로를 제공합니다.
im = PIL.fromarray(...)
rgb_im = im.convert("RGB")
rgb_im.save("myimage.jpg")
wandb.log({"example": wandb.Image("myimage.jpg")})
이미지 오버레이
W&B UI를 통해 시멘틱 세그멘테이션 마스크를 기록하고 (불투명도 변경, 시간 경과에 따른 변경 사항 보기 등) 상호 작용합니다.
오버레이를 기록하려면 다음 키와 값이 있는 사전을 wandb.Image의 masks 키워드 인수에 제공해야 합니다.
이미지 마스크를 나타내는 두 개의 키 중 하나:
"mask_data": 각 픽셀에 대한 정수 클래스 레이블을 포함하는 2D NumPy 배열
"path": (문자열) 저장된 이미지 마스크 파일의 경로
"class_labels": (선택 사항) 이미지 마스크의 정수 클래스 레이블을 읽을 수 있는 클래스 이름에 매핑하는 사전
리스트, 배열 또는 텐서와 같은 숫자 시퀀스가 첫 번째 인수로 제공되면 np.histogram을 호출하여 히스토그램이 자동으로 구성됩니다. 모든 배열/텐서는 평면화됩니다. 선택적 num_bins 키워드 인수를 사용하여 기본값인 64개 구간을 재정의할 수 있습니다. 지원되는 최대 구간 수는 512개입니다.
UI에서 히스토그램은 x축에 트레이닝 스텝, y축에 메트릭 값, 색상으로 표현되는 개수로 플롯되어 트레이닝 전반에 걸쳐 기록된 히스토그램을 쉽게 비교할 수 있습니다. 일회성 히스토그램 로깅에 대한 자세한 내용은 이 패널의 “요약의 히스토그램” 탭을 참조하세요.
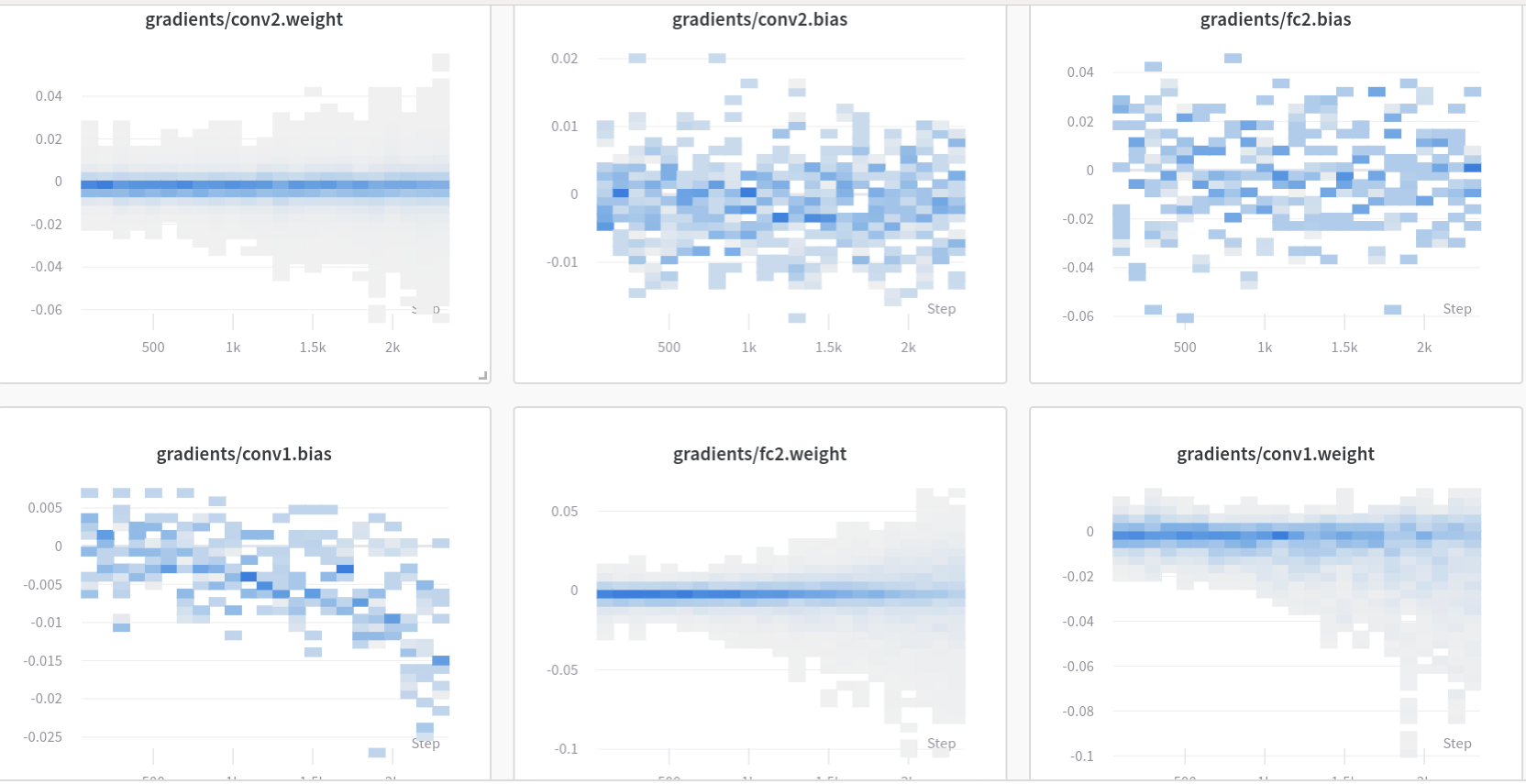
wandb.log({"gradients": wandb.Histogram(grads)})
더 많은 제어를 원하면 np.histogram을 호출하고 반환된 튜플을 np_histogram 키워드 인수에 전달합니다.
numpy 배열이 제공되면 차원은 시간, 채널, 너비, 높이 순서라고 가정합니다. 기본적으로 4fps gif 이미지를 만듭니다 (ffmpeg 및 moviepy python 라이브러리는 numpy 오브젝트를 전달할 때 필요합니다). 지원되는 형식은 "gif", "mp4", "webm" 및 "ogg"입니다. 문자열을 wandb.Video에 전달하면 파일을 업로드하기 전에 파일이 존재하고 지원되는 형식인지 확인합니다. BytesIO 오브젝트를 전달하면 지정된 형식을 확장자로 사용하여 임시 파일이 생성됩니다.
UI에 표시되도록 테이블에 텍스트를 기록하려면 wandb.Table을 사용합니다. 기본적으로 열 헤더는 ["Input", "Output", "Expected"]입니다. 최적의 UI 성능을 보장하기 위해 기본 최대 행 수는 10,000으로 설정됩니다. 그러나 사용자는 wandb.Table.MAX_ROWS = {DESIRED_MAX}를 사용하여 최대값을 명시적으로 재정의할 수 있습니다.
속성 업데이트 (메타데이터, 에일리어스 및 설명)와 같이 이러한 메서드로 생성된 모델 아티팩트와 상호 작용합니다.
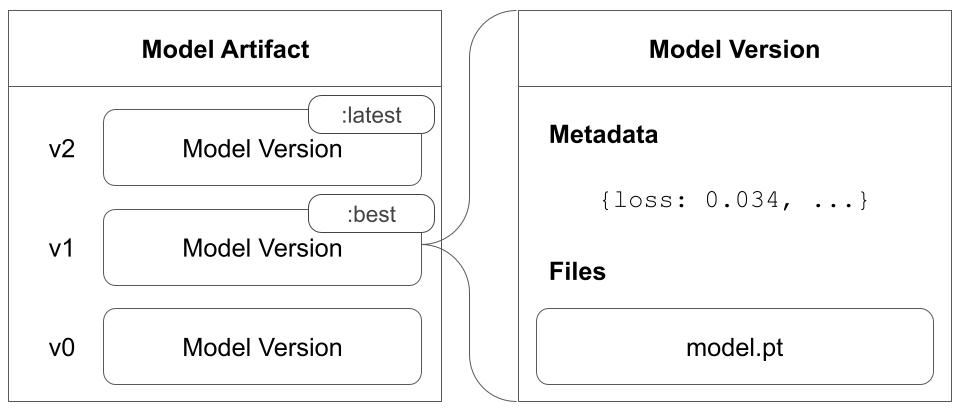
W&B Artifacts 및 고급 버전 관리 유스 케이스에 대한 자세한 내용은 Artifacts 문서를 참조하세요.
모델을 run에 로깅
log_model을 사용하여 지정한 디렉토리 내에 콘텐츠가 포함된 모델 아티팩트를 로깅합니다. log_model 메서드는 결과 모델 아티팩트를 W&B run의 출력으로 표시합니다.
모델을 W&B run의 입력 또는 출력으로 표시하면 모델의 종속성과 모델의 연결을 추적할 수 있습니다. W&B App UI 내에서 모델의 계보를 확인하세요. 자세한 내용은 Artifacts 챕터의 아티팩트 그래프 탐색 및 트래버스 페이지를 참조하세요.
모델 파일이 저장된 경로를 path 파라미터에 제공하세요. 경로는 로컬 파일, 디렉토리 또는 s3://bucket/path와 같은 외부 버킷에 대한 참조 URI일 수 있습니다.
<>로 묶인 값은 사용자 고유의 값으로 바꾸세요.
import wandb
# W&B run 초기화run = wandb.init(project="<your-project>", entity="<your-entity>")
# 모델 로깅run.log_model(path="<path-to-model>", name="<name>")
선택적으로 name 파라미터에 모델 아티팩트 이름을 제공합니다. name이 지정되지 않은 경우 W&B는 run ID가 앞에 붙은 입력 경로의 기본 이름을 이름으로 사용합니다.
사용자 또는 W&B가 모델에 할당한 name을 추적하세요. use_model 메서드로 모델 경로를 검색하려면 모델 이름이 필요합니다.
가능한 파라미터에 대한 자세한 내용은 API 참조 가이드의 log_model을 참조하세요.
예시: 모델을 run에 로깅
import os
import wandb
from tensorflow import keras
from tensorflow.keras import layers
config = {"optimizer": "adam", "loss": "categorical_crossentropy"}
# W&B run 초기화run = wandb.init(entity="charlie", project="mnist-experiments", config=config)
# 하이퍼파라미터loss = run.config["loss"]
optimizer = run.config["optimizer"]
metrics = ["accuracy"]
num_classes =10input_shape = (28, 28, 1)
# 트레이닝 알고리즘model = keras.Sequential(
[
layers.Input(shape=input_shape),
layers.Conv2D(32, kernel_size=(3, 3), activation="relu"),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Conv2D(64, kernel_size=(3, 3), activation="relu"),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Flatten(),
layers.Dropout(0.5),
layers.Dense(num_classes, activation="softmax"),
]
)
# 트레이닝을 위한 모델 구성model.compile(loss=loss, optimizer=optimizer, metrics=metrics)
# 모델 저장model_filename ="model.h5"local_filepath ="./"full_path = os.path.join(local_filepath, model_filename)
model.save(filepath=full_path)
# 모델을 W&B run에 로깅run.log_model(path=full_path, name="MNIST")
run.finish()
사용자가 log_model을 호출하면 MNIST라는 모델 아티팩트가 생성되고 파일 model.h5가 모델 아티팩트에 추가되었습니다. 터미널 또는 노트북에 모델이 로깅된 run에 대한 정보를 찾을 수 있는 위치가 출력됩니다.
View run different-surf-5 at: https://wandb.ai/charlie/mnist-experiments/runs/wlby6fuw
Synced 5 W&B file(s), 0 media file(s), 1 artifact file(s) and0 other file(s)
Find logs at: ./wandb/run-20231206_103511-wlby6fuw/logs
로깅된 모델 다운로드 및 사용
use_model 함수를 사용하여 이전에 W&B run에 로깅된 모델 파일에 엑세스하고 다운로드합니다.
검색하려는 모델 파일이 저장된 모델 아티팩트의 이름을 제공합니다. 제공하는 이름은 기존의 로깅된 모델 아티팩트의 이름과 일치해야 합니다.
log_model로 파일을 원래 로깅할 때 name을 정의하지 않은 경우 할당된 기본 이름은 run ID가 앞에 붙은 입력 경로의 기본 이름입니다.
<>로 묶인 다른 값은 사용자 고유의 값으로 바꾸세요.
import wandb
# run 초기화run = wandb.init(project="<your-project>", entity="<your-entity>")
# 모델에 엑세스 및 다운로드합니다. 다운로드된 아티팩트의 경로를 반환합니다.downloaded_model_path = run.use_model(name="<your-model-name>")
use_model 함수는 다운로드된 모델 파일의 경로를 반환합니다. 나중에 이 모델을 연결하려면 이 경로를 추적하세요. 앞의 코드 조각에서 반환된 경로는 downloaded_model_path라는 변수에 저장됩니다.
예시: 로깅된 모델 다운로드 및 사용
예를 들어, 앞의 코드 조각에서 사용자는 use_model API를 호출했습니다. 그들은 가져오려는 모델 아티팩트의 이름을 지정하고 버전/에일리어스도 제공했습니다. 그런 다음 API에서 반환된 경로를 downloaded_model_path 변수에 저장했습니다.
import wandb
entity ="luka"project ="NLP_Experiments"alias ="latest"# 모델 버전에 대한 시맨틱 닉네임 또는 식별자model_artifact_name ="fine-tuned-model"# run 초기화run = wandb.init(project=project, entity=entity)
# 모델에 엑세스 및 다운로드합니다. 다운로드된 아티팩트의 경로를 반환합니다.downloaded_model_path = run.use_model(name =f"{model_artifact_name}:{alias}")
가능한 파라미터 및 반환 유형에 대한 자세한 내용은 API 참조 가이드의 use_model을 참조하세요.
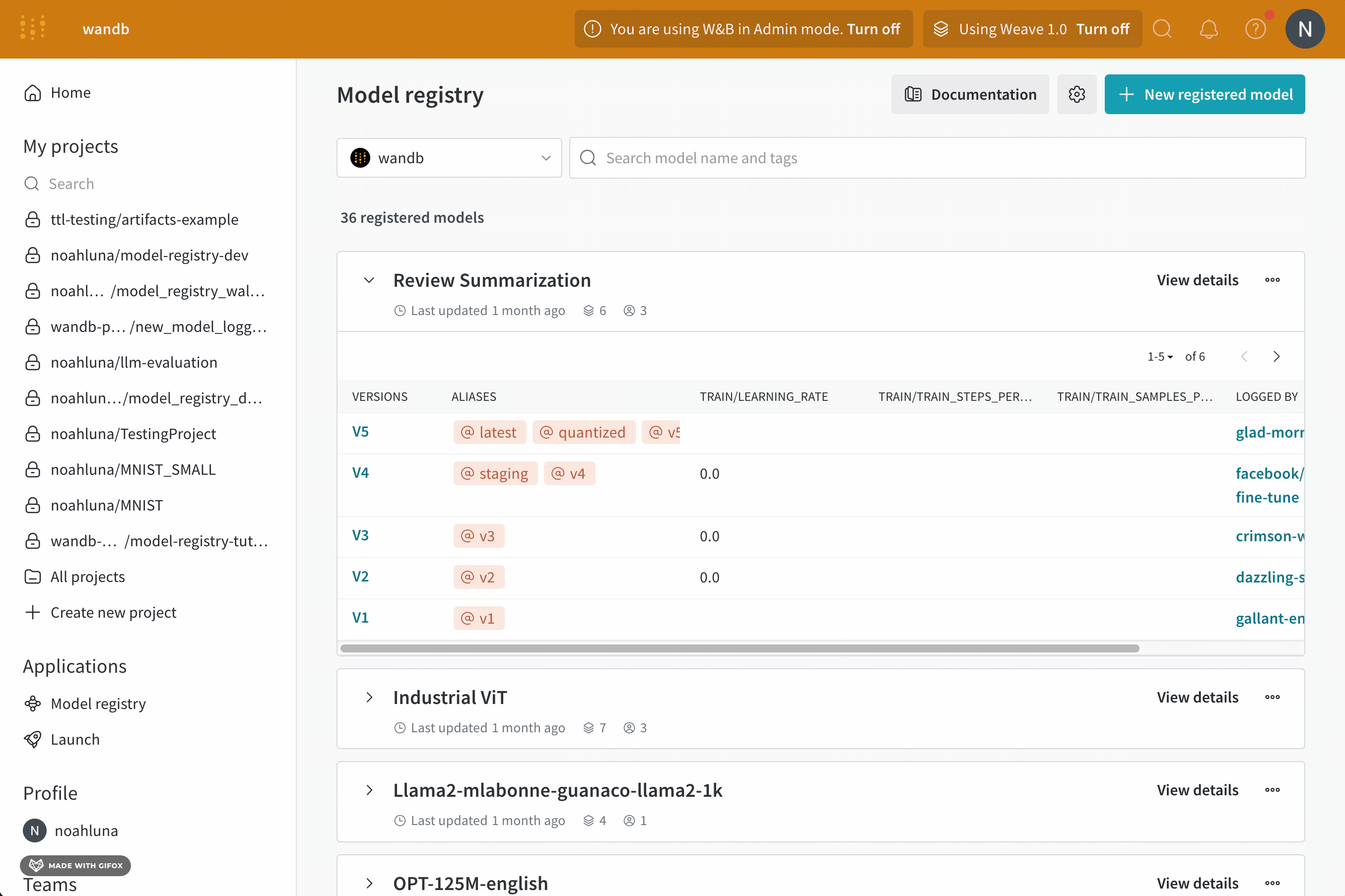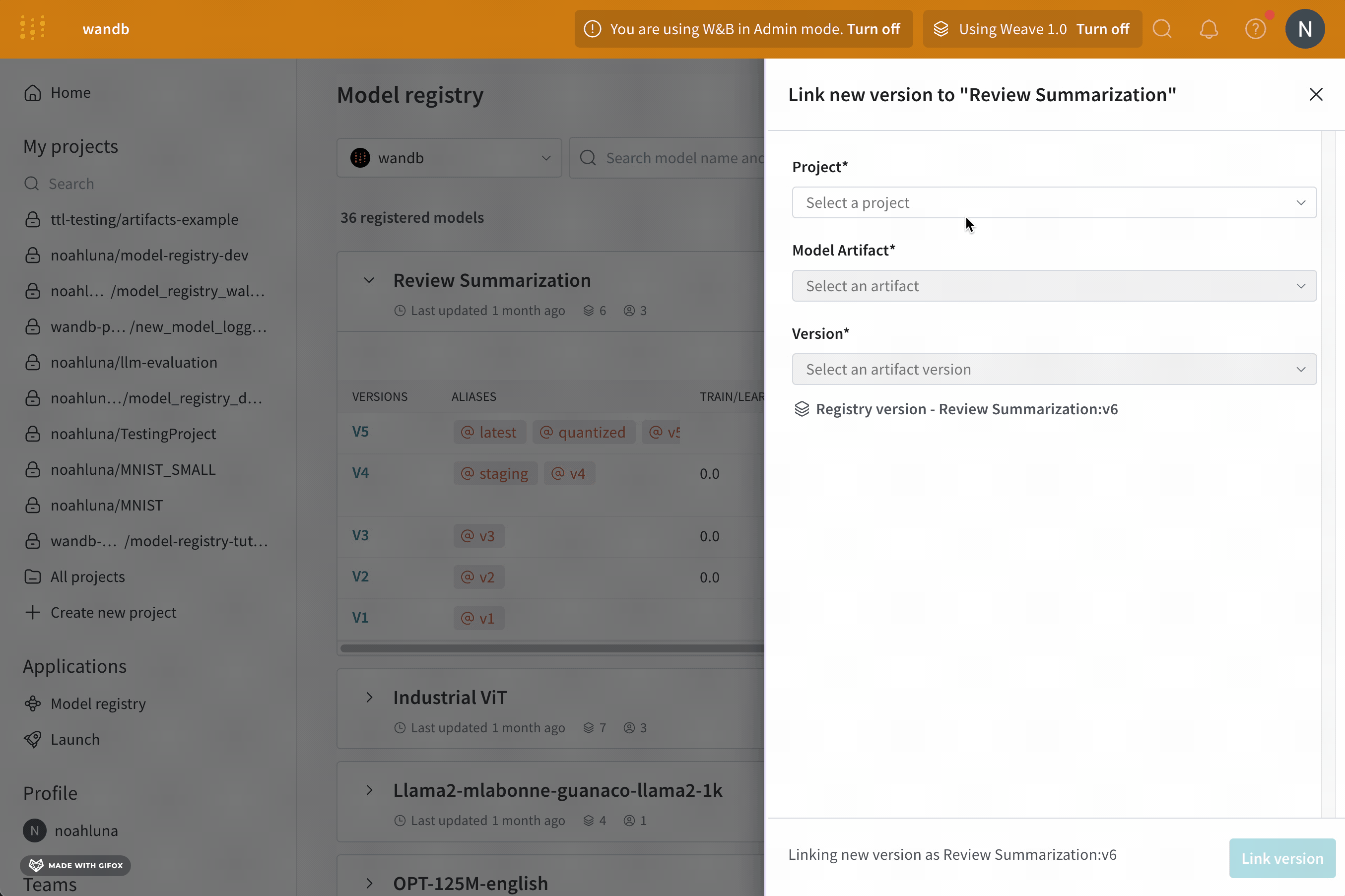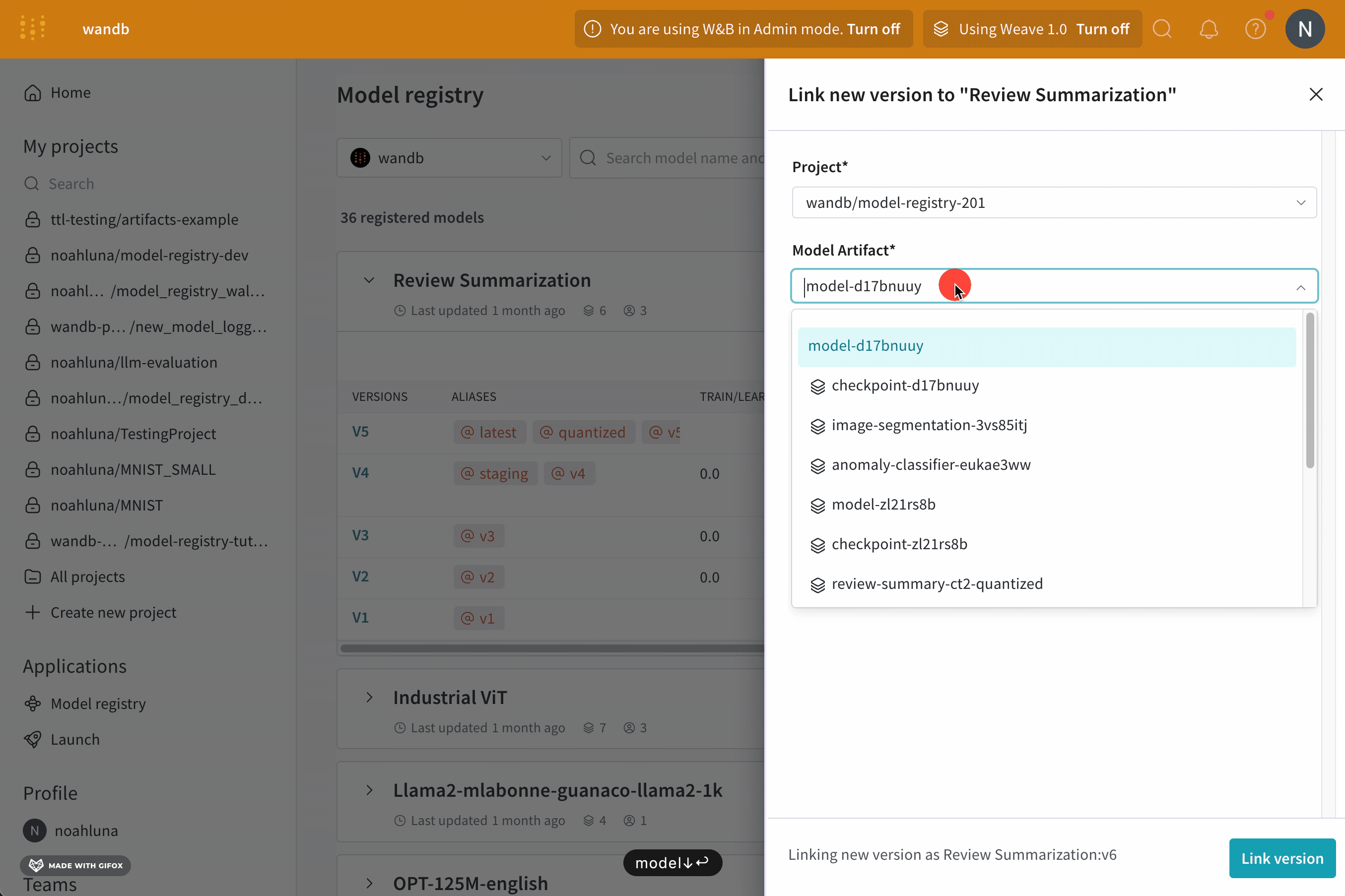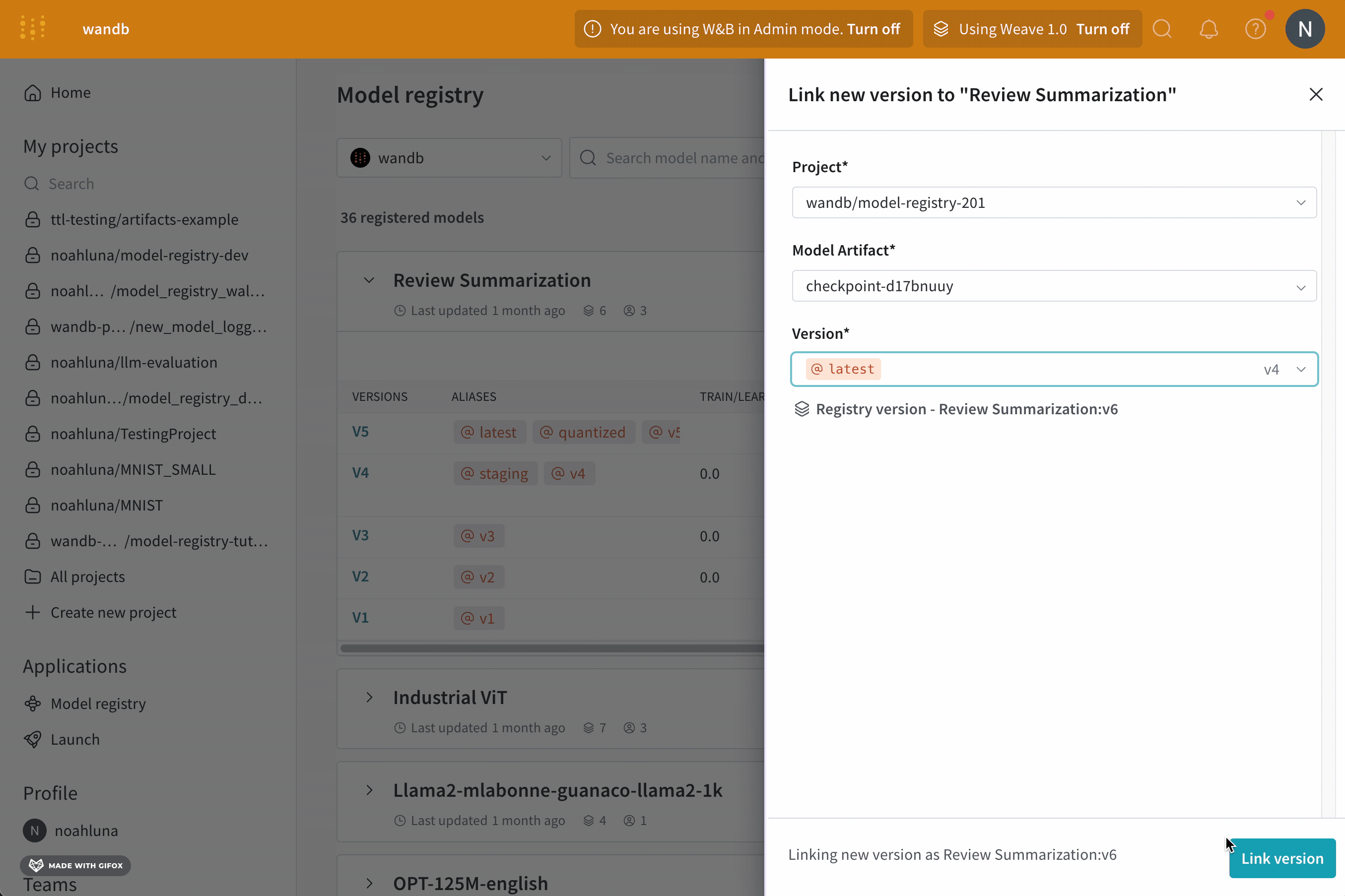
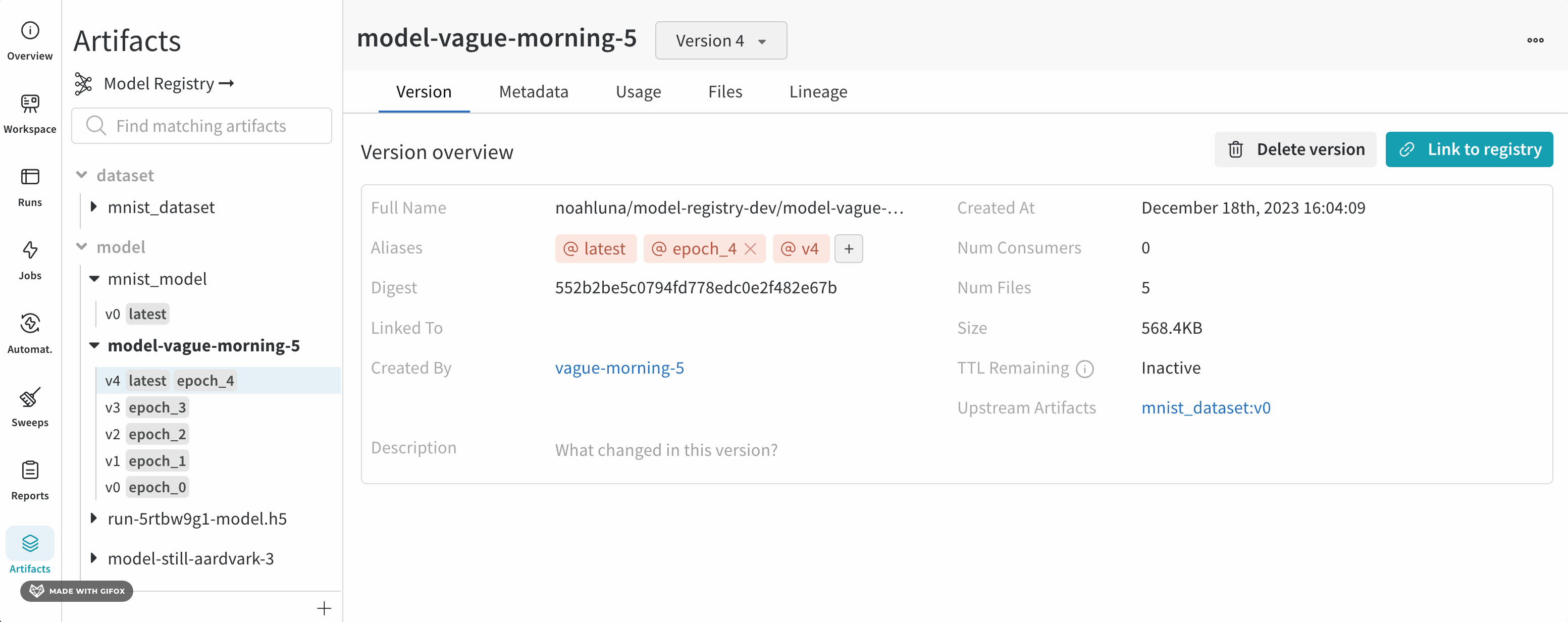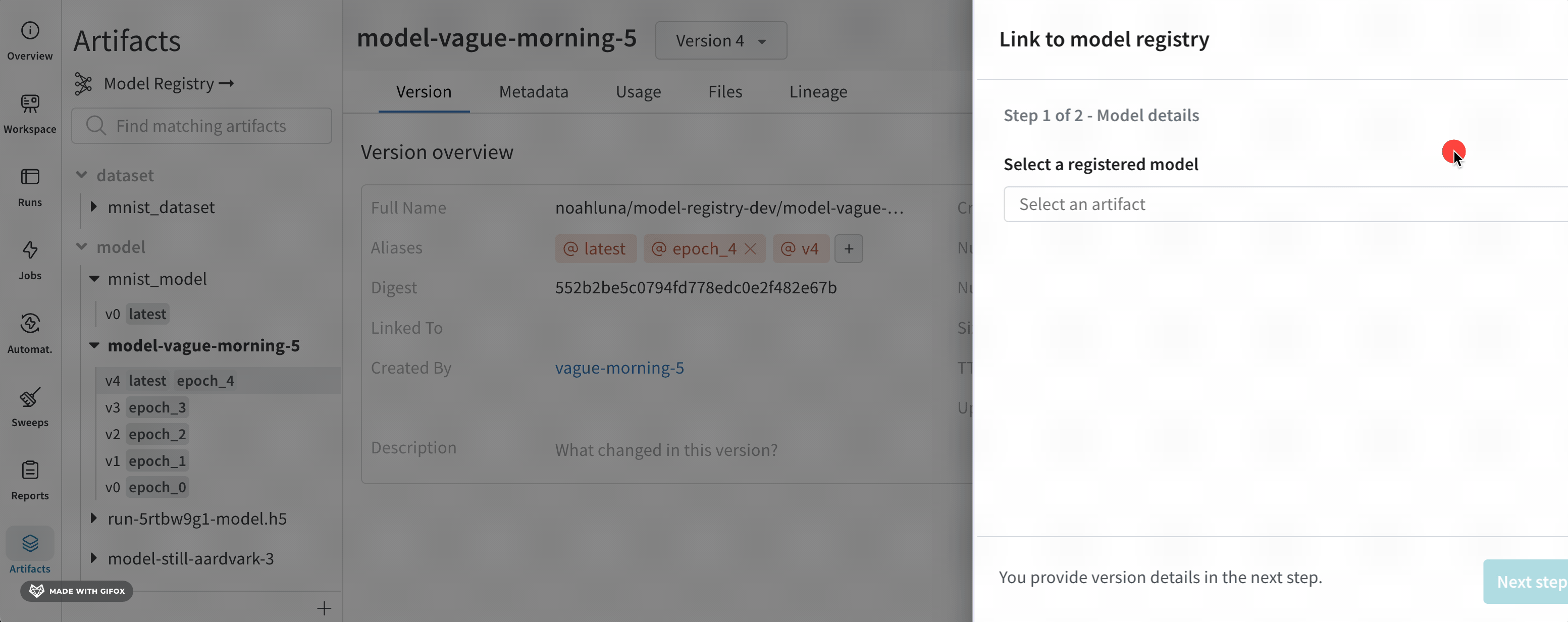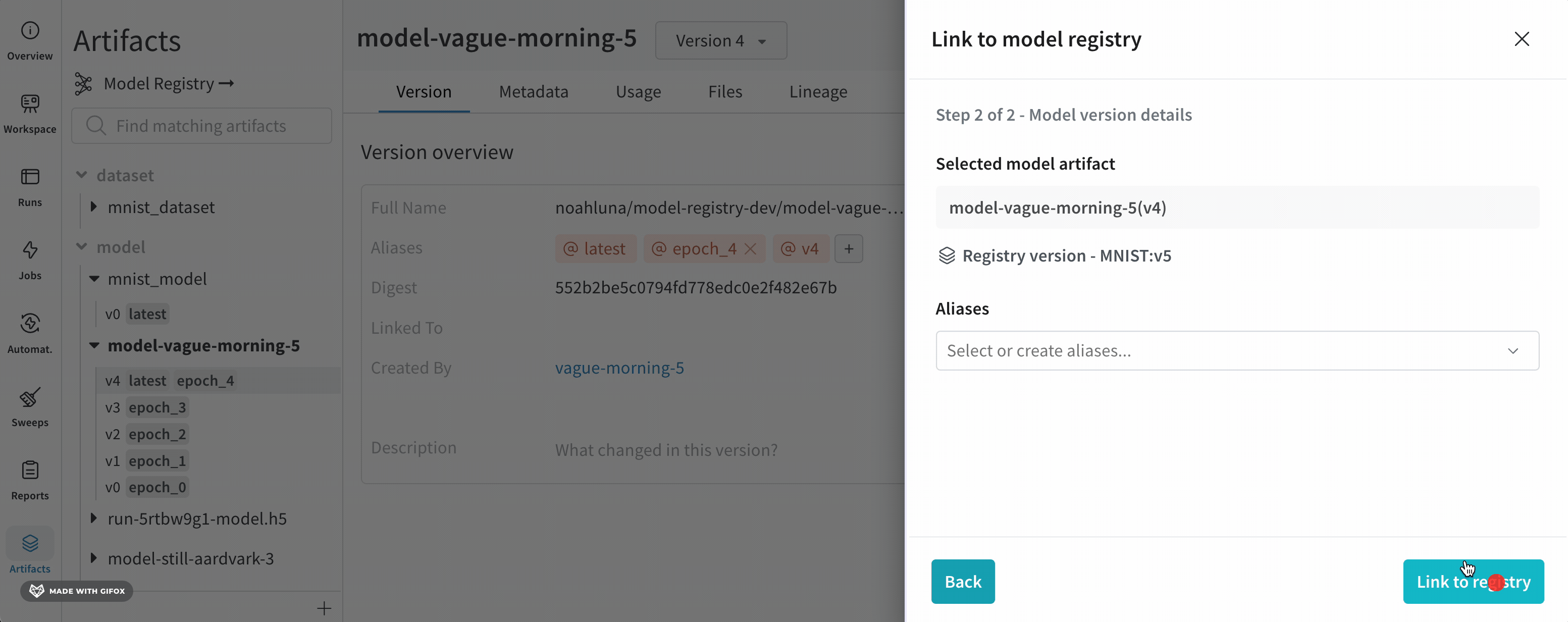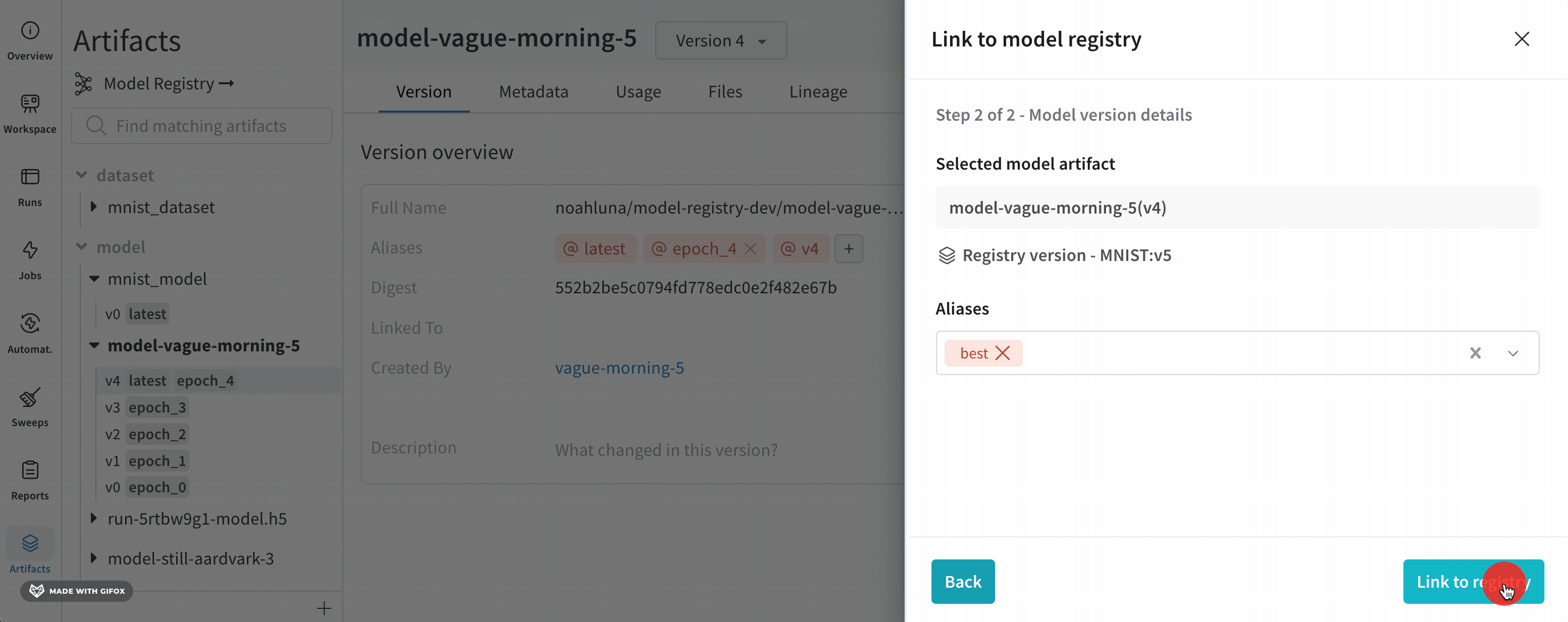
모델을 로깅하고 W&B Model Registry에 연결
link_model 메서드는 곧 사용 중단될 레거시 W&B Model Registry와만 호환됩니다. 새로운 버전의 모델 레지스트리에 모델 아티팩트를 연결하는 방법을 알아보려면 레지스트리 문서를 방문하세요.
link_model 메서드를 사용하여 모델 파일을 W&B run에 로깅하고 W&B Model Registry에 연결합니다. 등록된 모델이 없으면 W&B는 registered_model_name 파라미터에 제공하는 이름으로 새 모델을 만듭니다.
모델을 연결하는 것은 팀의 다른 구성원이 보고 사용할 수 있는 모델의 중앙 집중식 팀 리포지토리에 모델을 ‘북마크’하거나 ‘게시’하는 것과 유사합니다.
모델을 연결하면 해당 모델이 Registry에서 복제되거나 프로젝트에서 레지스트리로 이동되지 않습니다. 연결된 모델은 프로젝트의 원래 모델에 대한 포인터입니다.
Registry를 사용하여 작업별로 최상의 모델을 구성하고, 모델 수명 주기를 관리하고, ML 수명 주기 전반에 걸쳐 간편한 추적 및 감사를 용이하게 하고, 웹 훅 또는 작업을 통해 다운스트림 작업을 자동화합니다.
Registered Model은 Model Registry의 연결된 모델 버전의 컬렉션 또는 폴더입니다. 등록된 모델은 일반적으로 단일 모델링 유스 케이스 또는 작업에 대한 후보 모델을 나타냅니다.
앞의 코드 조각은 link_model API로 모델을 연결하는 방법을 보여줍니다. <>로 묶인 다른 값은 사용자 고유의 값으로 바꾸세요.
import wandb
run = wandb.init(entity="<your-entity>", project="<your-project>")
run.link_model(path="<path-to-model>", registered_model_name="<registered-model-name>")
run.finish()
선택적 파라미터에 대한 자세한 내용은 API 참조 가이드의 link_model을 참조하세요.
registered-model-name이 Model Registry 내에 이미 존재하는 등록된 모델의 이름과 일치하면 모델이 해당 등록된 모델에 연결됩니다. 이러한 등록된 모델이 없으면 새 모델이 생성되고 모델이 첫 번째로 연결됩니다.
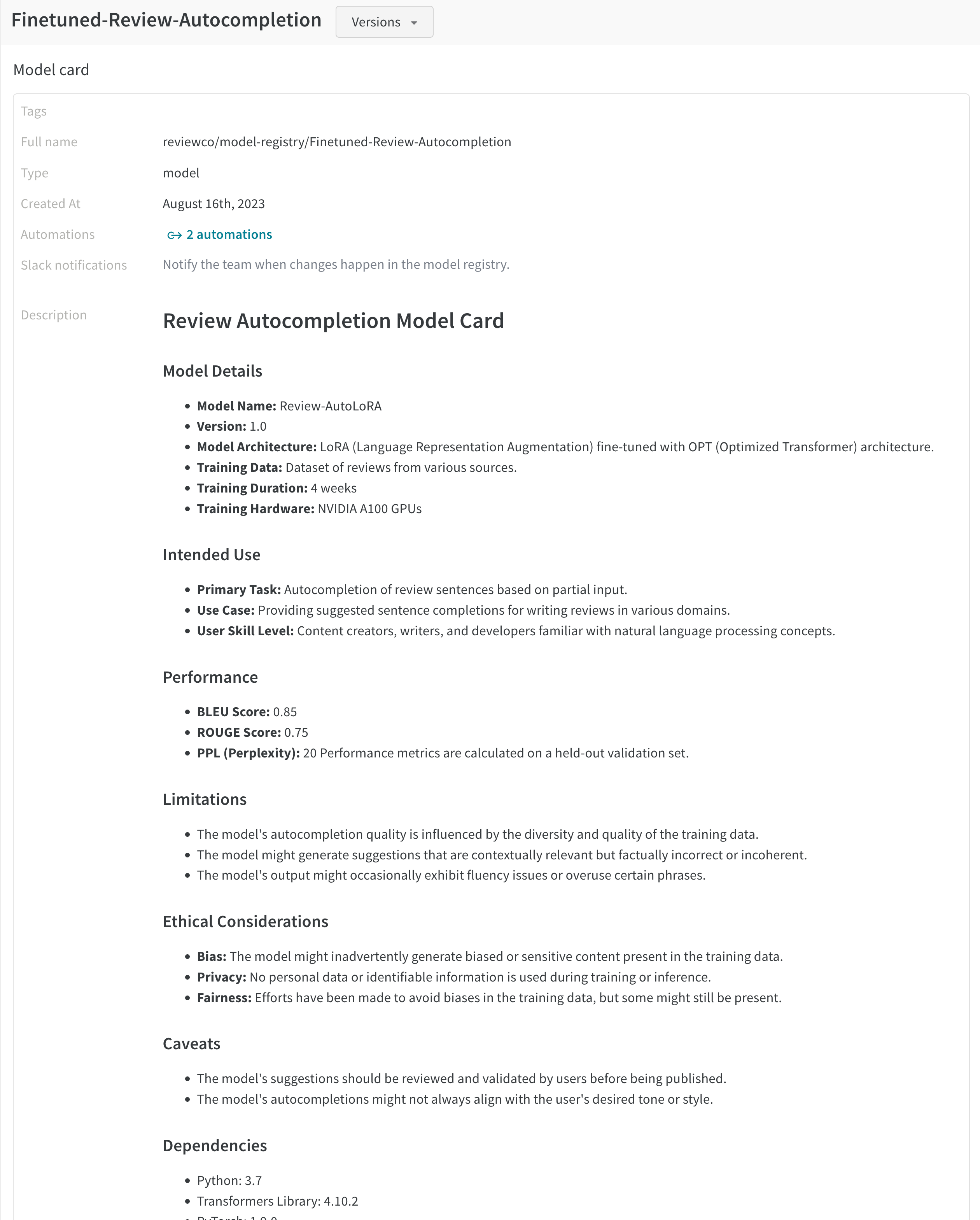
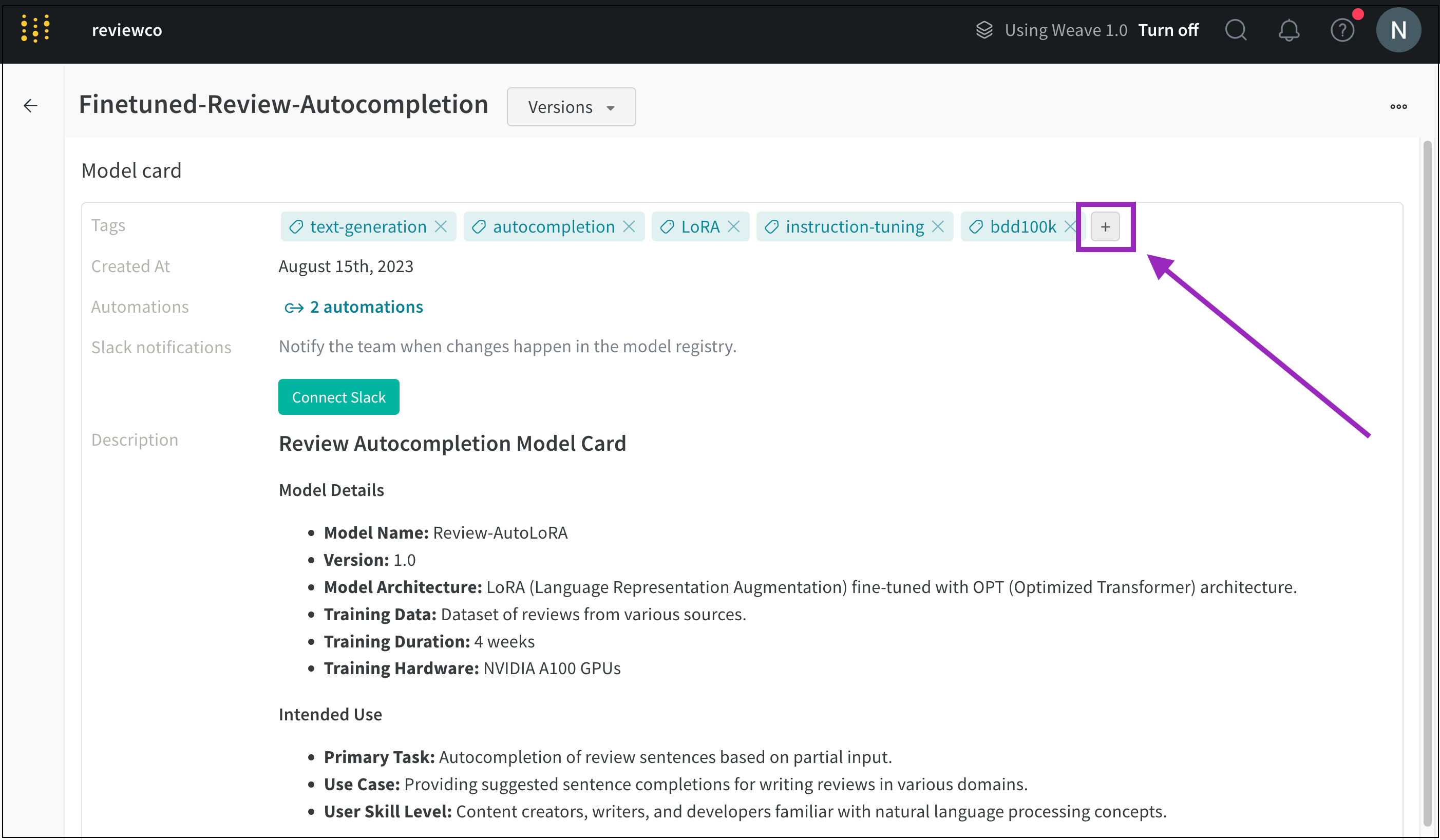
예를 들어, Model Registry에 “Fine-Tuned-Review-Autocompletion"이라는 기존 등록된 모델이 있다고 가정합니다(예제는 여기 참조). 그리고 몇 개의 모델 버전이 이미 v0, v1, v2로 연결되어 있다고 가정합니다. registered-model-name="Fine-Tuned-Review-Autocompletion"으로 link_model을 호출하면 새 모델이 이 기존 등록된 모델에 v3으로 연결됩니다. 이 이름으로 등록된 모델이 없으면 새 모델이 생성되고 새 모델이 v0으로 연결됩니다.
예시: 모델을 로깅하고 W&B Model Registry에 연결
예를 들어, 앞의 코드 조각은 모델 파일을 로깅하고 모델을 등록된 모델 이름 "Fine-Tuned-Review-Autocompletion"에 연결합니다.
이를 위해 사용자는 link_model API를 호출합니다. API를 호출할 때 모델 콘텐츠를 가리키는 로컬 파일 경로(path)를 제공하고 연결할 등록된 모델의 이름(registered_model_name)을 제공합니다.
트레이닝 과정에서 시간이 지남에 따라 변하는 값 외에도, 모델 또는 전처리 단계를 요약하는 단일 값을 추적하는 것이 중요한 경우가 많습니다. W&B Run의 summary 사전에 이 정보를 기록하세요. Run의 summary 사전은 numpy 배열, PyTorch 텐서 또는 TensorFlow 텐서를 처리할 수 있습니다. 값이 이러한 유형 중 하나인 경우 전체 텐서를 바이너리 파일에 유지하고 요약 오브젝트에 최소값, 평균, 분산, 백분위수 등과 같은 높은 수준의 메트릭을 저장합니다.
wandb.log로 기록된 마지막 값은 W&B Run에서 자동으로 summary 사전으로 설정됩니다. summary 메트릭 사전이 수정되면 이전 값은 손실됩니다.
다음 코드 조각은 사용자 정의 summary 메트릭을 W&B에 제공하는 방법을 보여줍니다.
트레이닝이 완료된 후 기존 W&B Run의 summary 속성을 업데이트할 수 있습니다. W&B Public API를 사용하여 summary 속성을 업데이트합니다.
api = wandb.Api()
run = api.run("username/project/run_id")
run.summary["tensor"] = np.random.random(1000)
run.summary.update()
summary 메트릭 사용자 정의
사용자 정의 summary 메트릭은 wandb.summary에서 트레이닝의 최적 단계에서 모델 성능을 캡처하는 데 유용합니다. 예를 들어 최종 값 대신 최대 정확도 또는 최소 손실 값을 캡처할 수 있습니다.
기본적으로 summary는 히스토리의 최종 값을 사용합니다. summary 메트릭을 사용자 정의하려면 define_metric에서 summary 인수를 전달합니다. 다음 값을 사용할 수 있습니다.
"min"
"max"
"mean"
"best"
"last"
"none"
선택적 objective 인수를 "minimize" 또는 "maximize"로 설정한 경우에만 "best"를 사용할 수 있습니다.
다음 예제는 손실 및 정확도의 최소값과 최대값을 summary에 추가합니다.
import wandb
import random
random.seed(1)
wandb.init()
# 손실에 대한 최소값 및 최대값 summarywandb.define_metric("loss", summary="min")
wandb.define_metric("loss", summary="max")
# 정확도에 대한 최소값 및 최대값 summarywandb.define_metric("acc", summary="min")
wandb.define_metric("acc", summary="max")
for i in range(10):
log_dict = {
"loss": random.uniform(0, 1/ (i +1)),
"acc": random.uniform(1/ (i +1), 1),
}
wandb.log(log_dict)
summary 메트릭 보기
run의 Overview 페이지 또는 프로젝트의 runs 테이블에서 summary 값을 봅니다.
W&B 앱으로 이동합니다.
Workspace 탭을 선택합니다.
runs 목록에서 summary 값이 기록된 run의 이름을 클릭합니다.
Overview 탭을 선택합니다.
Summary 섹션에서 summary 값을 봅니다.
W&B 앱으로 이동합니다.
Runs 탭을 선택합니다.
runs 테이블 내에서 summary 값의 이름을 기준으로 열 내에서 summary 값을 볼 수 있습니다.
W&B Public API를 사용하여 run의 summary 값을 가져올 수 있습니다.
다음 코드 예제는 W&B Public API 및 pandas를 사용하여 특정 run에 기록된 summary 값을 검색하는 한 가지 방법을 보여줍니다.
import wandb
import pandas
entity ="<your-entity>"project ="<your-project>"run_name ="<your-run-name>"# summary 값이 있는 run의 이름all_runs = []
for run in api.runs(f"{entity}/{project_name}"):
print("Fetching details for run: ", run.id, run.name)
run_data = {
"id": run.id,
"name": run.name,
"url": run.url,
"state": run.state,
"tags": run.tags,
"config": run.config,
"created_at": run.created_at,
"system_metrics": run.system_metrics,
"summary": run.summary,
"project": run.project,
"entity": run.entity,
"user": run.user,
"path": run.path,
"notes": run.notes,
"read_only": run.read_only,
"history_keys": run.history_keys,
"metadata": run.metadata,
}
all_runs.append(run_data)
# DataFrame으로 변환df = pd.DataFrame(all_runs)
# 열 이름(run)을 기준으로 행을 가져오고 사전으로 변환df[df['name']==run_name].summary.reset_index(drop=True).to_dict()
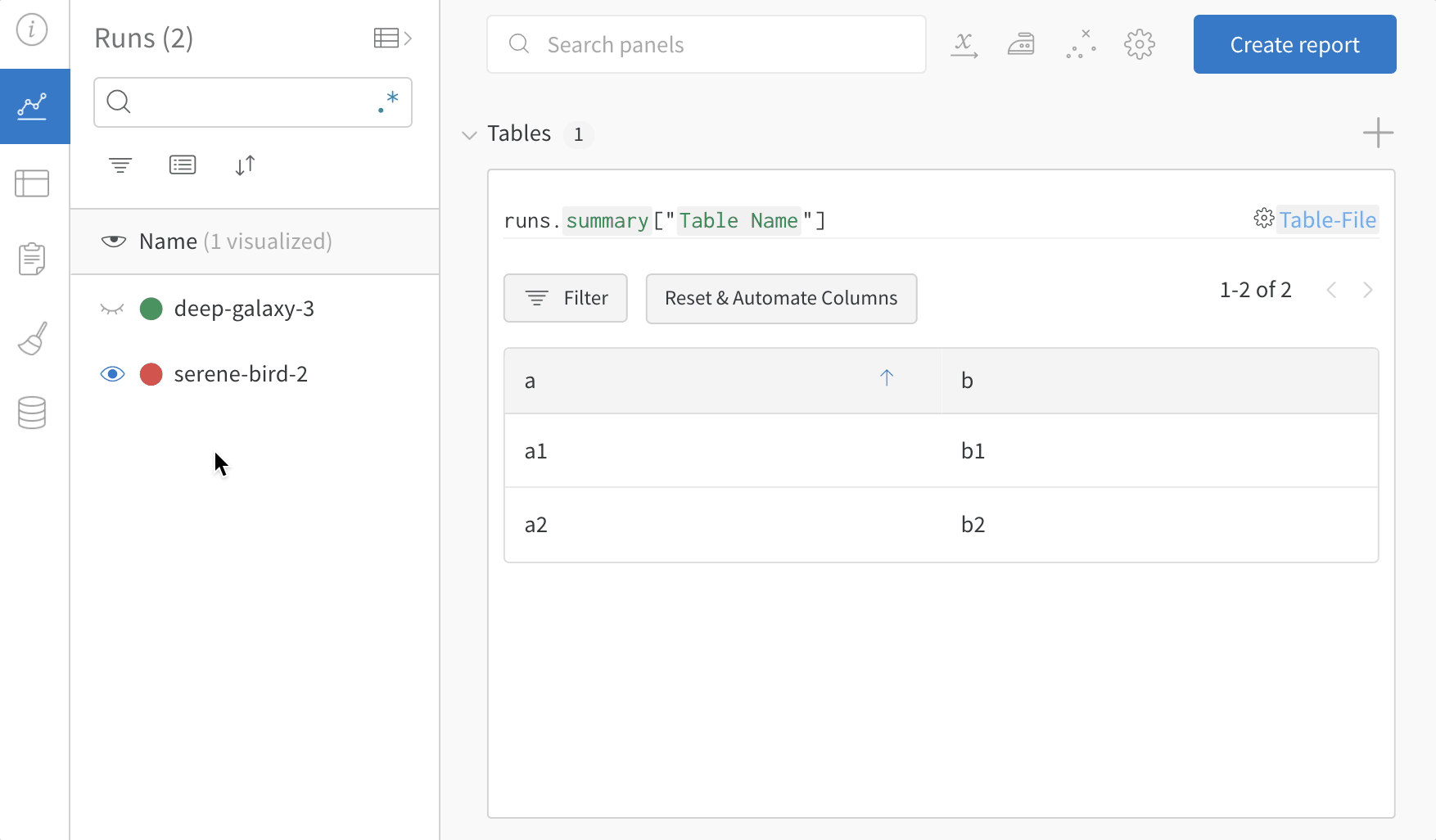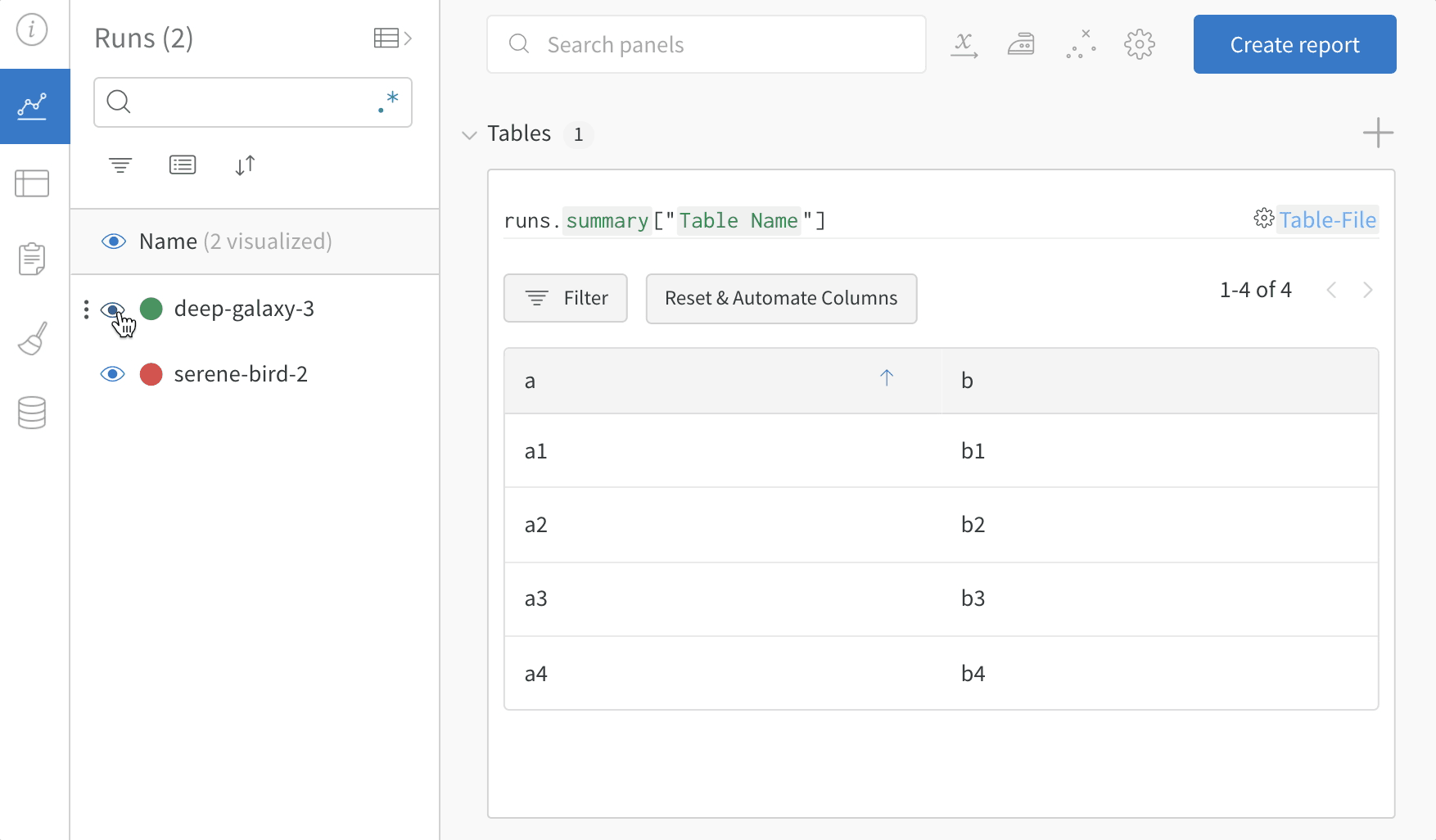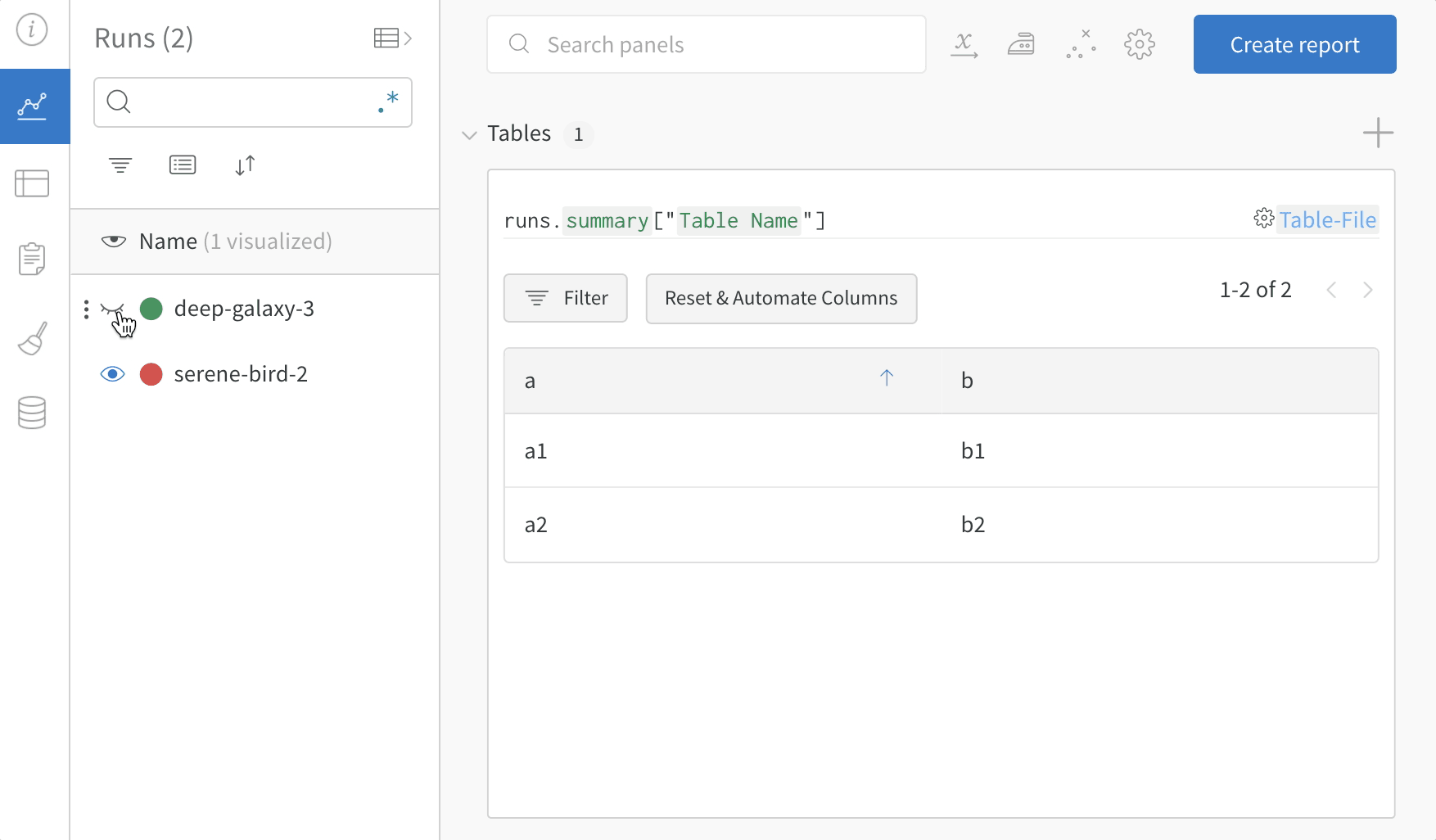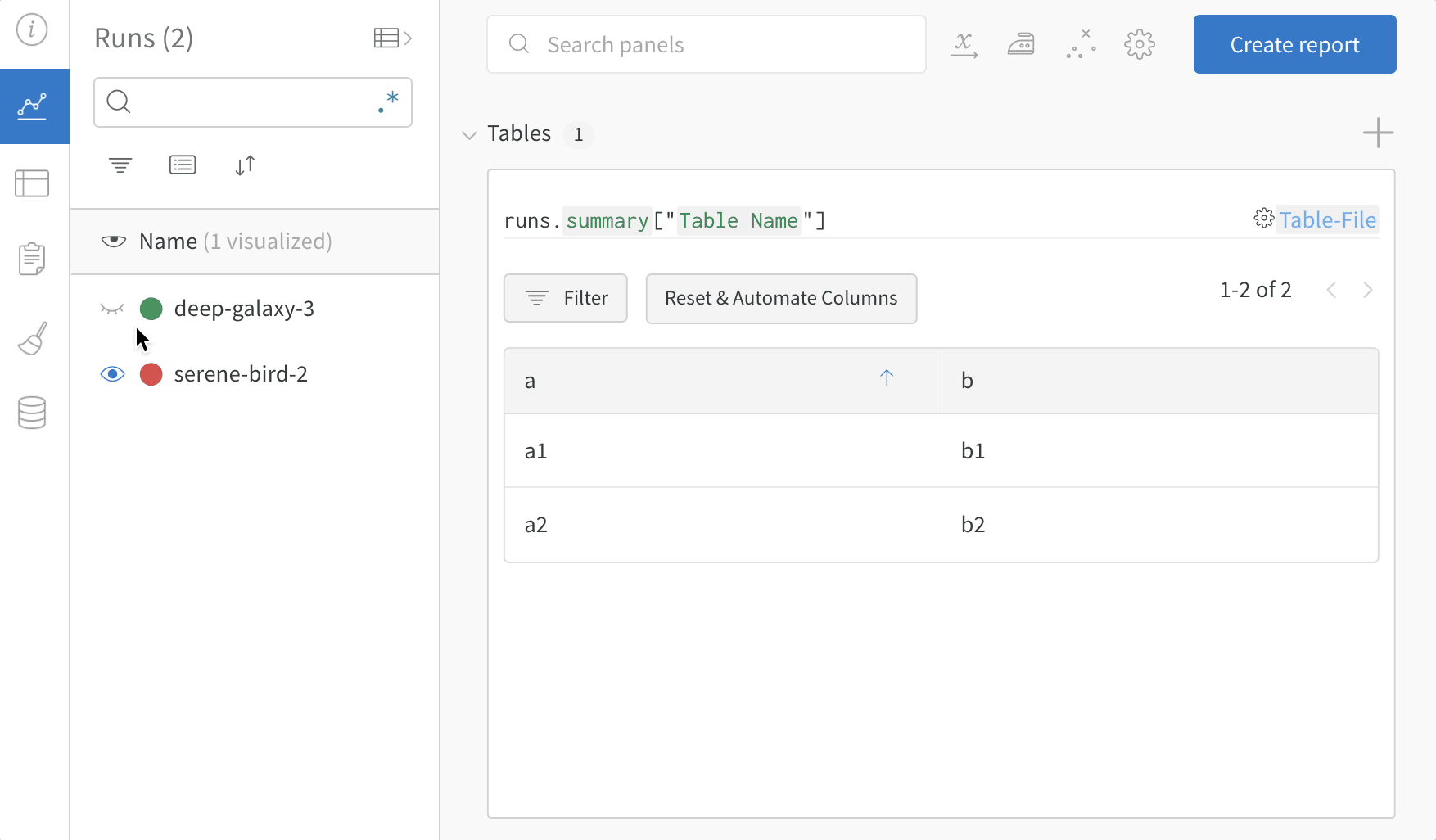
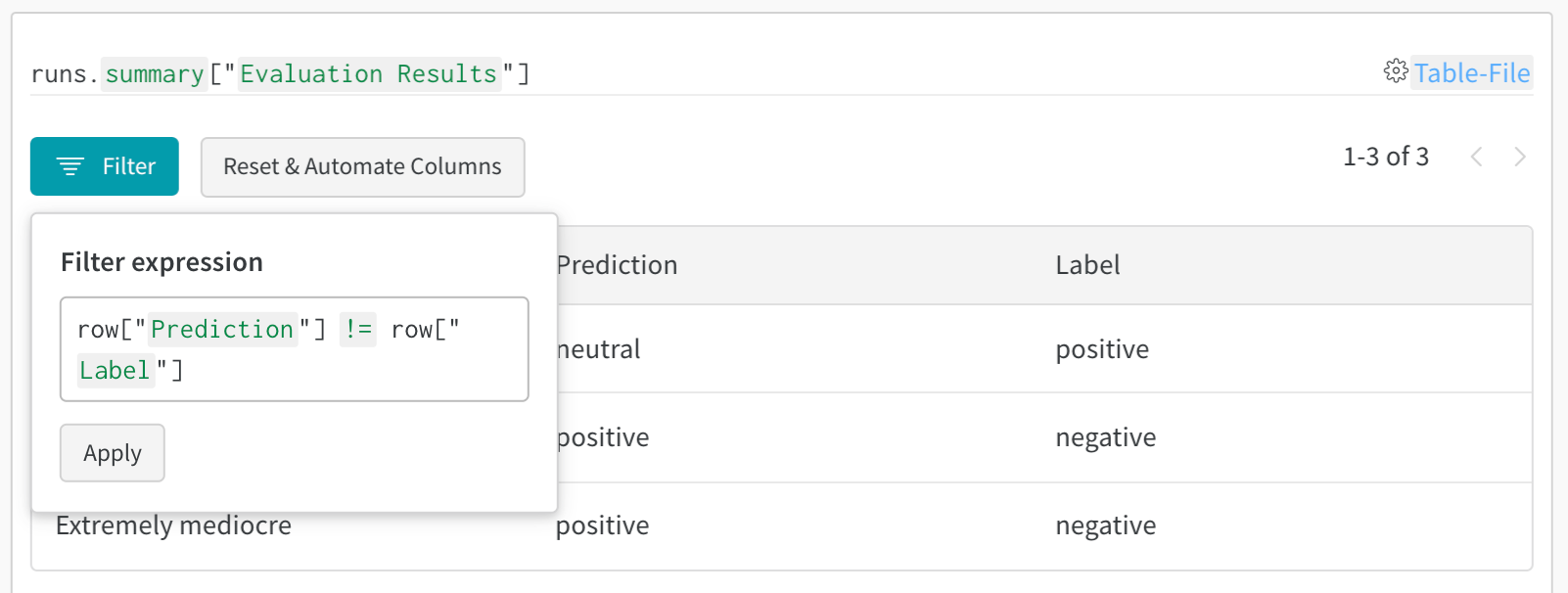
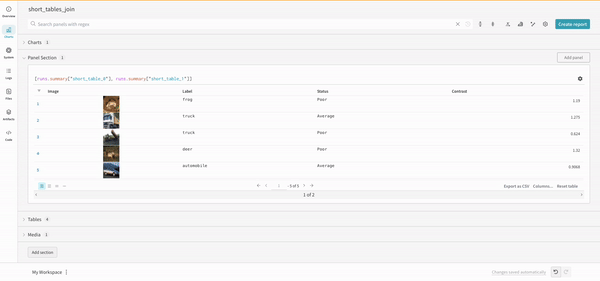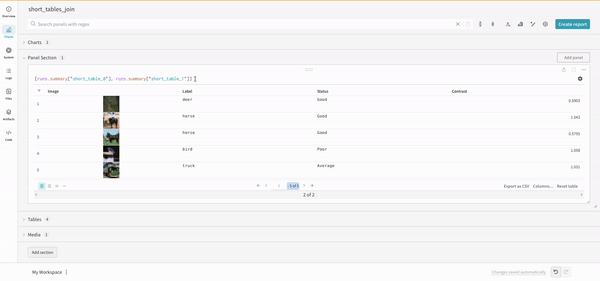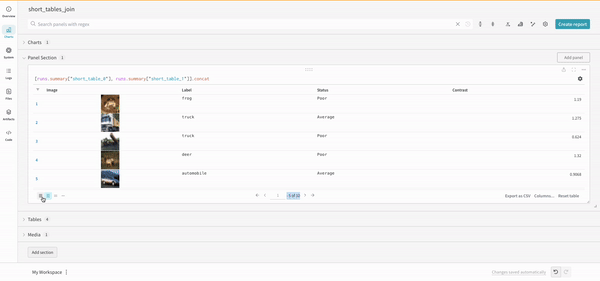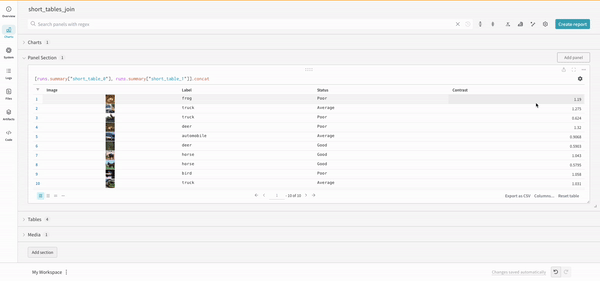
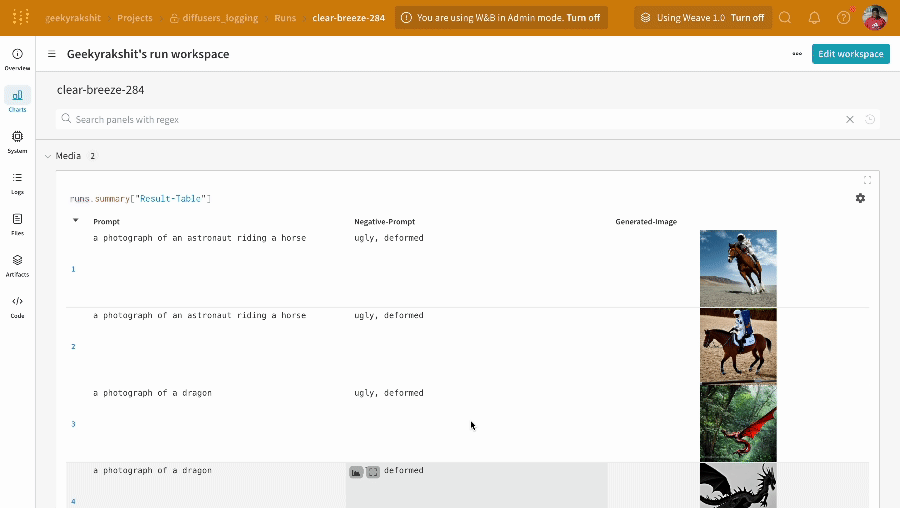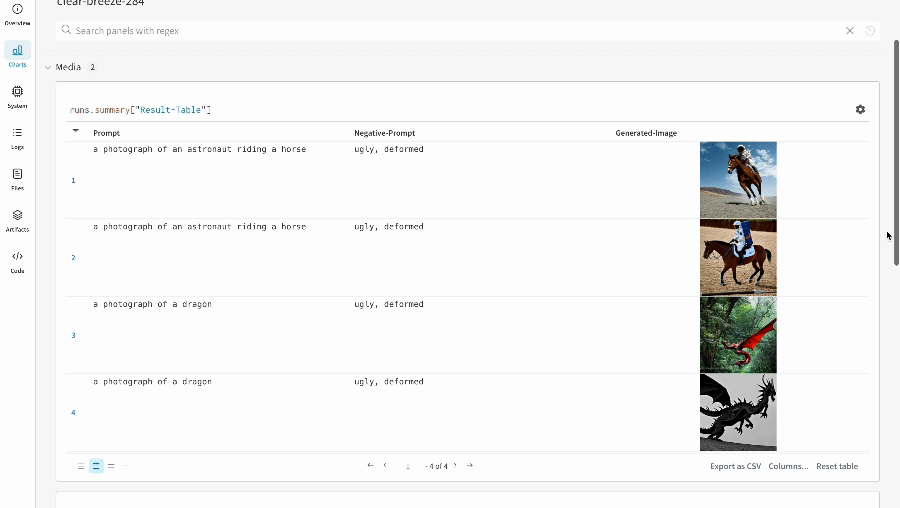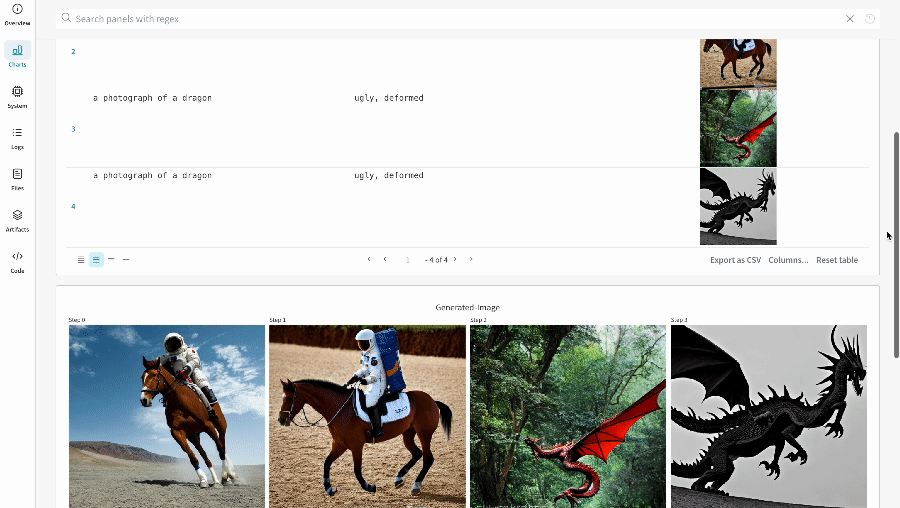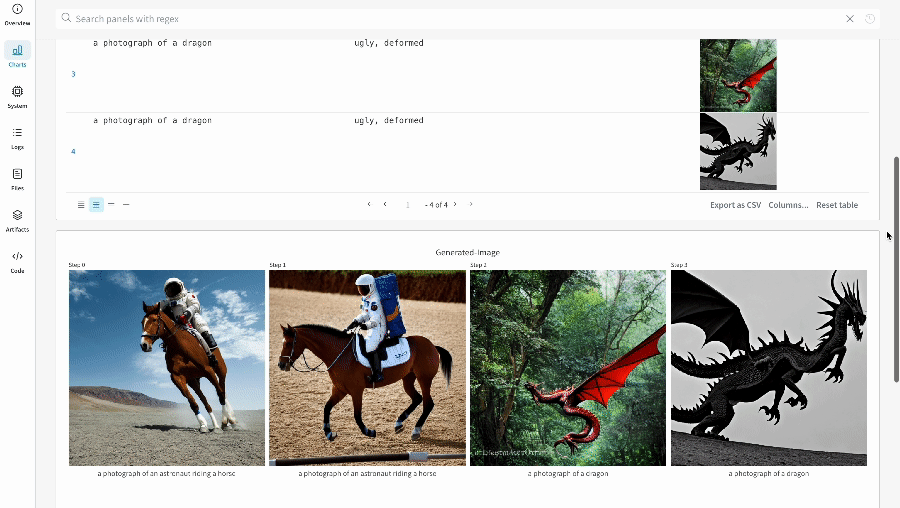
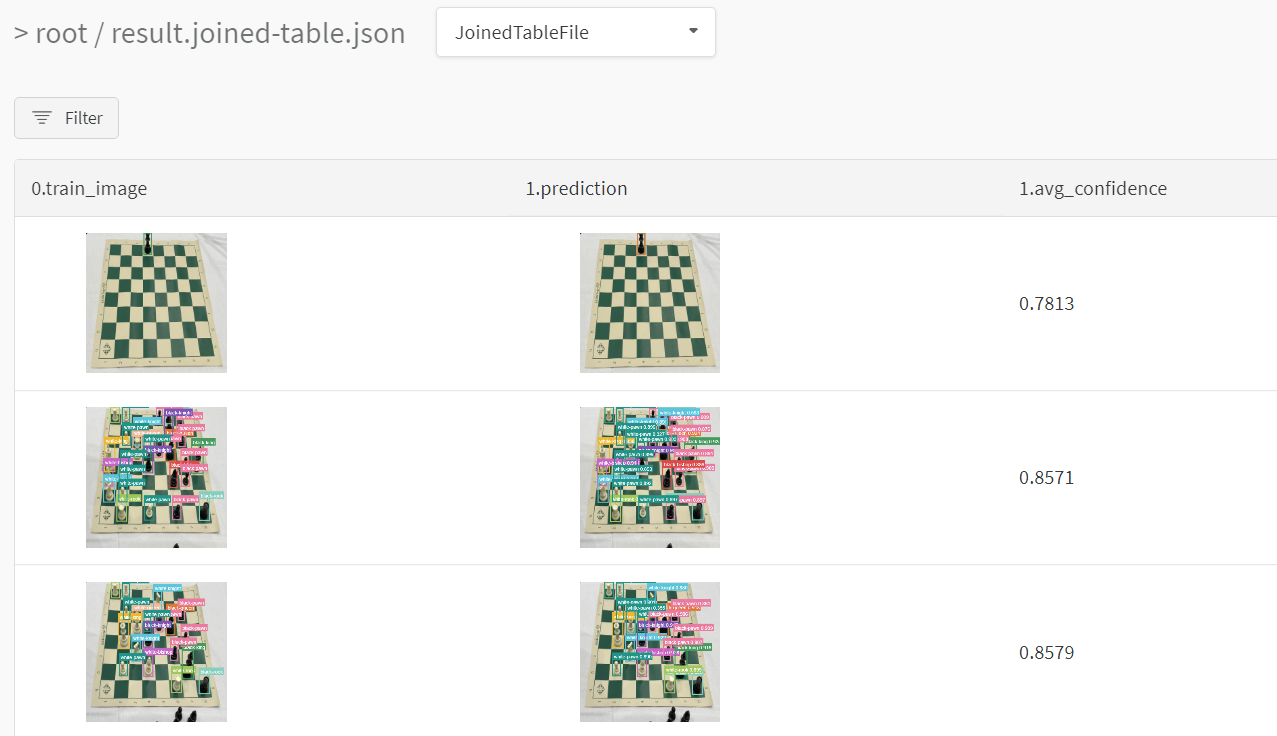
테이블을 정의하려면 데이터의 각 행에 대해 보려는 열을 지정합니다. 각 행은 트레이닝 데이터셋의 단일 항목, 트레이닝 중의 특정 단계 또는 에포크, 테스트 항목에 대한 모델의 예측값, 모델에서 생성된 오브젝트 등이 될 수 있습니다. 각 열에는 숫자, 텍스트, 부울, 이미지, 비디오, 오디오 등 고정된 유형이 있습니다. 유형을 미리 지정할 필요는 없습니다. 각 열에 이름을 지정하고 해당 유형의 데이터만 해당 열 인덱스로 전달해야 합니다. 더 자세한 예는 이 리포트를 참조하십시오.
다음 두 가지 방법 중 하나로 wandb.Table 생성자를 사용합니다.
행 목록: 이름이 지정된 열과 데이터 행을 기록합니다. 예를 들어 다음 코드 조각은 두 개의 행과 세 개의 열이 있는 테이블을 생성합니다.
Pandas DataFrame:wandb.Table(dataframe=my_df)를 사용하여 DataFrame을 기록합니다. 열 이름은 DataFrame에서 추출됩니다.
기존 배열 또는 데이터 프레임에서
# 모델이 다음 필드를 사용할 수 있는 네 개의 이미지에 대한 예측을 반환했다고 가정합니다.# - 이미지 ID# - wandb.Image()로 래핑된 이미지 픽셀# - 모델의 예측 레이블# - 그라운드 트루스 레이블my_data = [
[0, wandb.Image("img_0.jpg"), 0, 0],
[1, wandb.Image("img_1.jpg"), 8, 0],
[2, wandb.Image("img_2.jpg"), 7, 1],
[3, wandb.Image("img_3.jpg"), 1, 1],
]
# 해당 열이 있는 wandb.Table() 생성columns = ["id", "image", "prediction", "truth"]
test_table = wandb.Table(data=my_data, columns=columns)
데이터 추가
테이블은 변경 가능합니다. 스크립트가 실행될 때 테이블에 최대 200,000개의 행까지 더 많은 데이터를 추가할 수 있습니다. 테이블에 데이터를 추가하는 방법에는 두 가지가 있습니다.
행 추가: table.add_data("3a", "3b", "3c"). 새 행은 목록으로 표시되지 않습니다. 행이 목록 형식인 경우 별표 표기법 *을 사용하여 목록을 위치 인수로 확장합니다. table.add_data(*my_row_list). 행에는 테이블의 열 수와 동일한 수의 항목이 포함되어야 합니다.
열 추가: table.add_column(name="col_name", data=col_data). col_data의 길이는 테이블의 현재 행 수와 같아야 합니다. 여기서 col_data는 목록 데이터 또는 NumPy NDArray일 수 있습니다.
점진적으로 데이터 추가
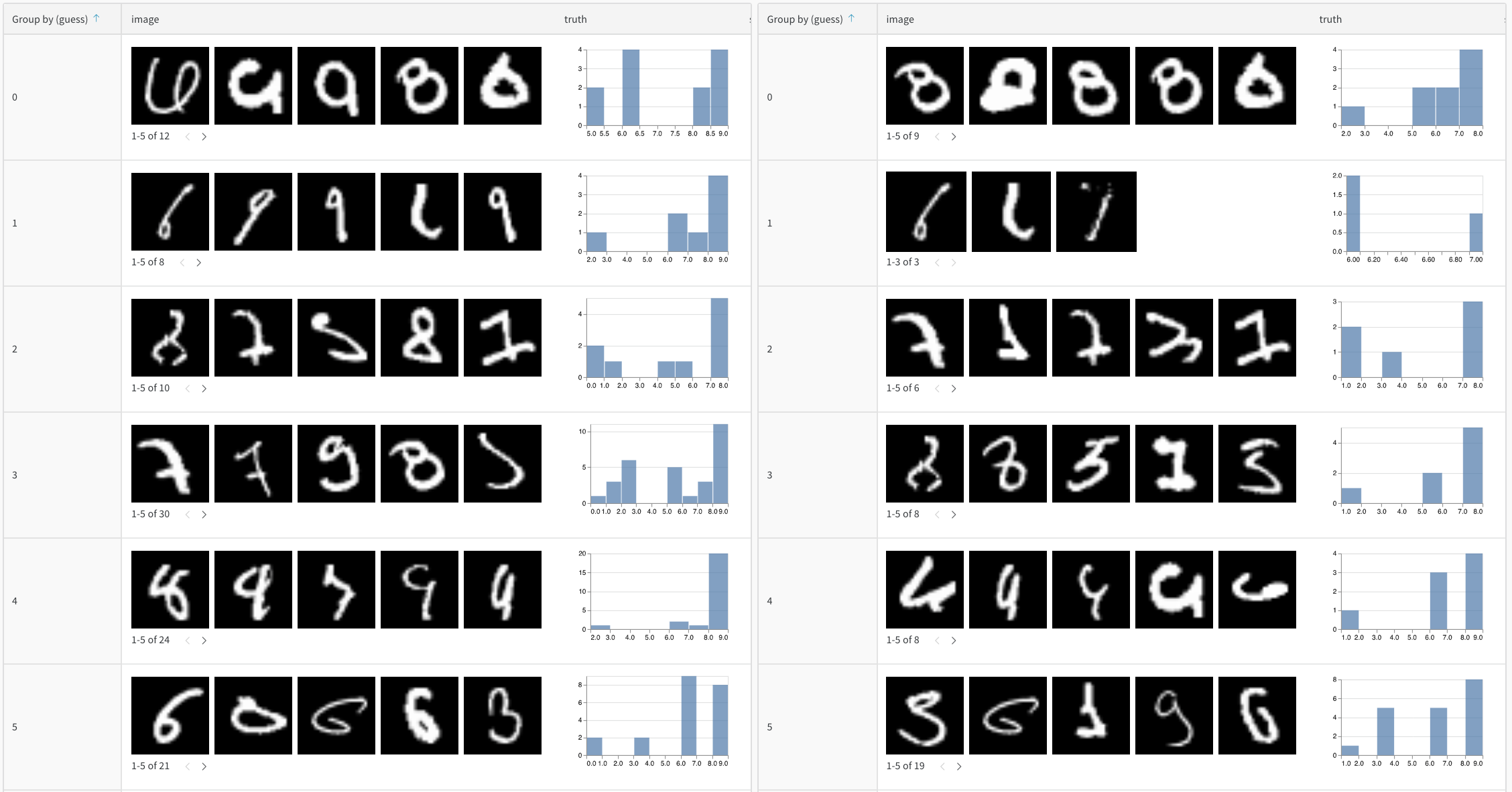
이 코드 샘플은 W&B 테이블을 점진적으로 생성하고 채우는 방법을 보여줍니다. 가능한 모든 레이블에 대한 신뢰도 점수를 포함하여 미리 정의된 열로 테이블을 정의하고 추론 중에 행별로 데이터를 추가합니다. run을 재개할 때 테이블에 점진적으로 데이터를 추가할 수도 있습니다.
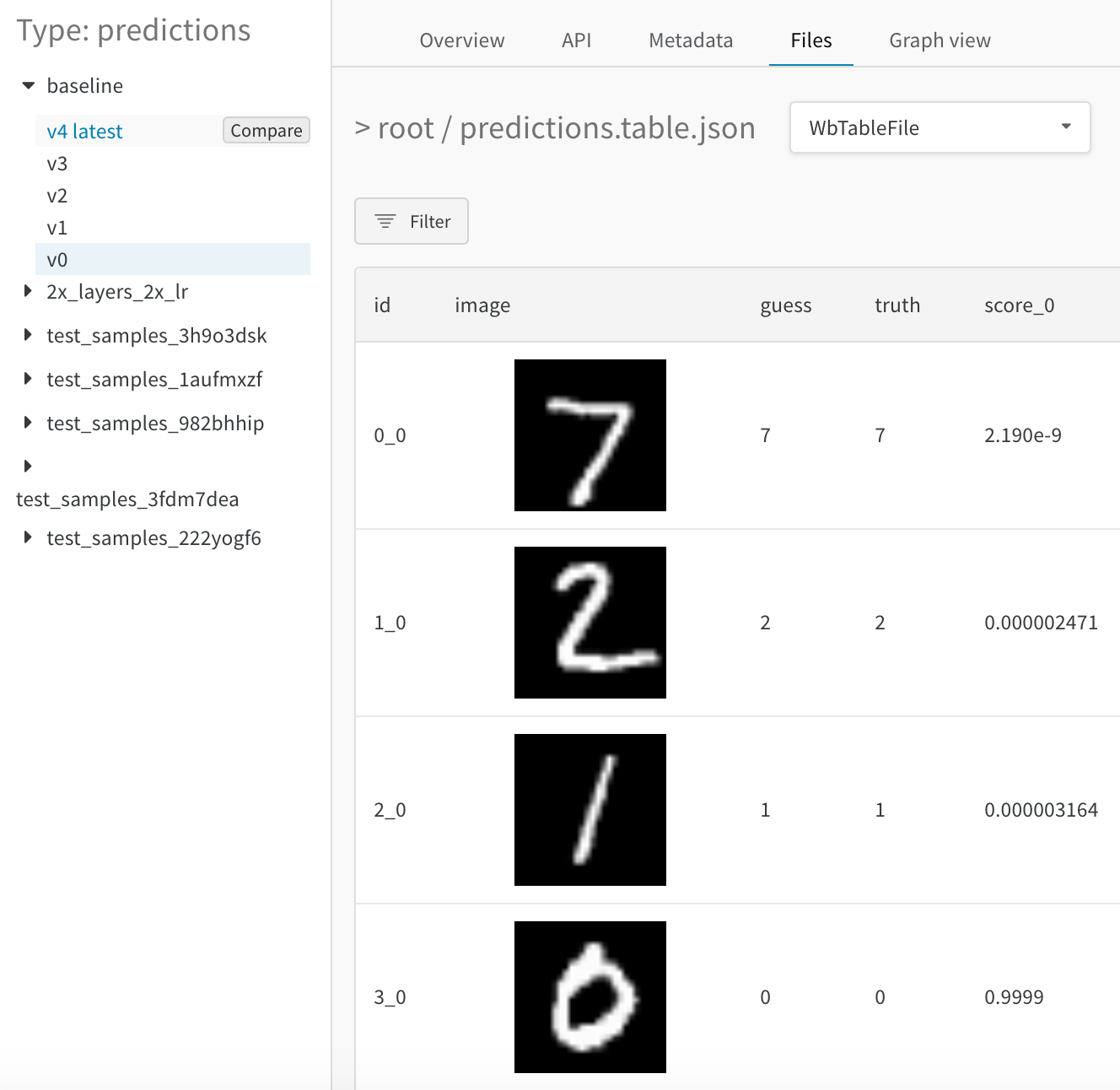
# 각 레이블에 대한 신뢰도 점수를 포함하여 테이블의 열을 정의합니다.columns = ["id", "image", "guess", "truth"]
for digit in range(10): # 각 숫자(0-9)에 대한 신뢰도 점수 열을 추가합니다. columns.append(f"score_{digit}")
# 정의된 열로 테이블을 초기화합니다.test_table = wandb.Table(columns=columns)
# 테스트 데이터셋을 반복하고 데이터를 행별로 테이블에 추가합니다.# 각 행에는 이미지 ID, 이미지, 예측 레이블, 트루 레이블 및 신뢰도 점수가 포함됩니다.for img_id, img in enumerate(mnist_test_data):
true_label = mnist_test_data_labels[img_id] # 그라운드 트루스 레이블 guess_label = my_model.predict(img) # 예측 레이블 test_table.add_data(
img_id, wandb.Image(img), guess_label, true_label
) # 테이블에 행 데이터를 추가합니다.
재개된 run에 데이터 추가
아티팩트에서 기존 테이블을 로드하고, 데이터의 마지막 행을 검색하고, 업데이트된 메트릭을 추가하여 재개된 run에서 W&B 테이블을 점진적으로 업데이트할 수 있습니다. 그런 다음 호환성을 위해 테이블을 다시 초기화하고 업데이트된 버전을 W&B에 다시 기록합니다.
# 아티팩트에서 기존 테이블을 로드합니다.best_checkpt_table = wandb.use_artifact(table_tag).get(table_name)
# 재개를 위해 테이블에서 데이터의 마지막 행을 가져옵니다.best_iter, best_metric_max, best_metric_min = best_checkpt_table.data[-1]
# 필요에 따라 최상의 메트릭을 업데이트합니다.# 업데이트된 데이터를 테이블에 추가합니다.best_checkpt_table.add_data(best_iter, best_metric_max, best_metric_min)
# 호환성을 보장하기 위해 업데이트된 데이터로 테이블을 다시 초기화합니다.best_checkpt_table = wandb.Table(
columns=["col1", "col2", "col3"], data=best_checkpt_table.data
)
# 업데이트된 테이블을 Weights & Biases에 기록합니다.wandb.log({table_name: best_checkpt_table})
데이터 검색
데이터가 테이블에 있으면 열 또는 행별로 엑세스합니다.
행 반복기: 사용자는 for ndx, row in table.iterrows(): ...와 같은 테이블의 행 반복기를 사용하여 데이터의 행을 효율적으로 반복할 수 있습니다.
열 가져오기: 사용자는 table.get_column("col_name")을 사용하여 데이터 열을 검색할 수 있습니다. 편의를 위해 사용자는 convert_to="numpy"를 전달하여 열을 기본 요소의 NumPy NDArray로 변환할 수 있습니다. 이는 열에 기본 데이터에 직접 엑세스할 수 있도록 wandb.Image와 같은 미디어 유형이 포함된 경우에 유용합니다.
테이블 저장
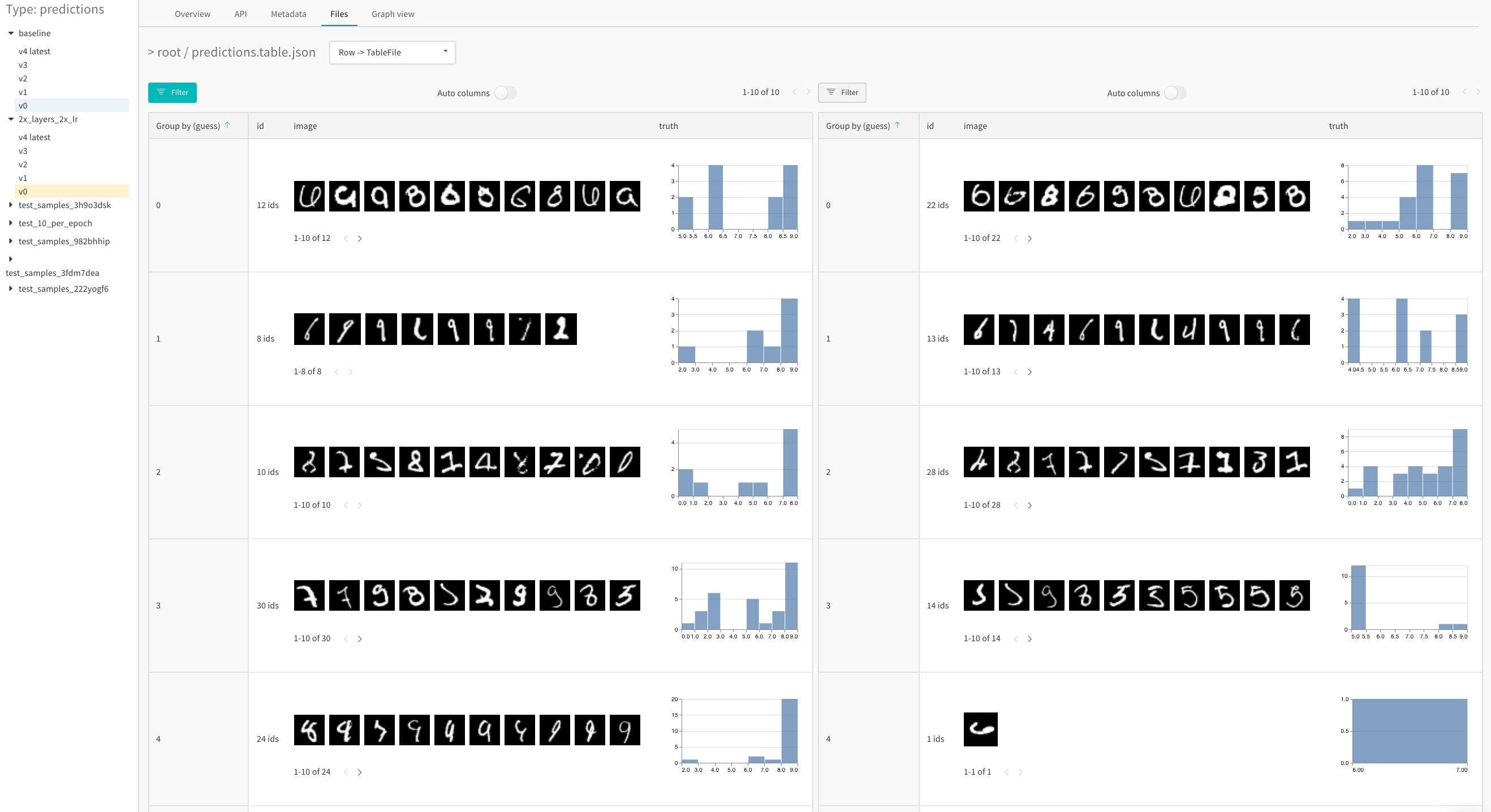
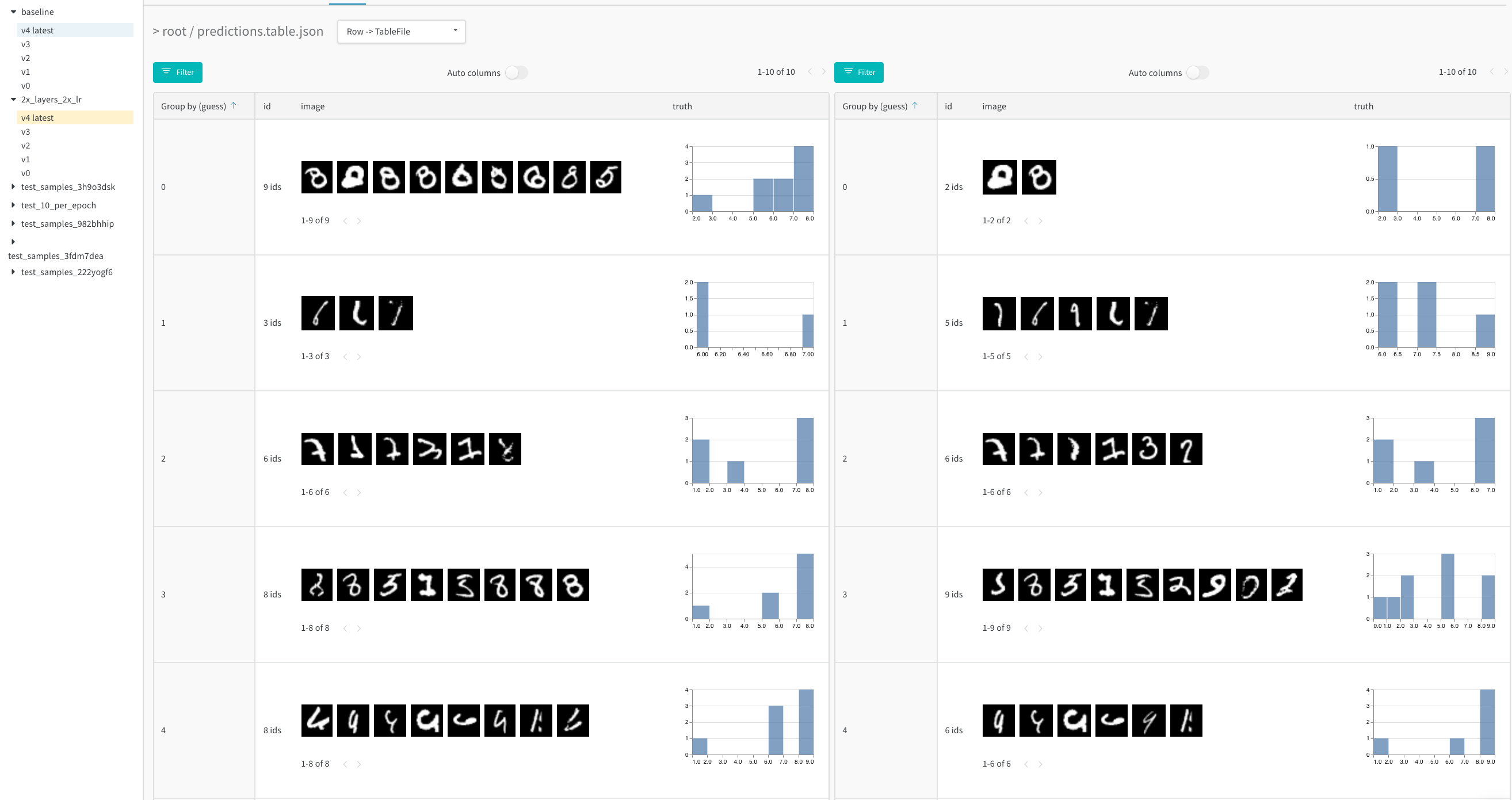
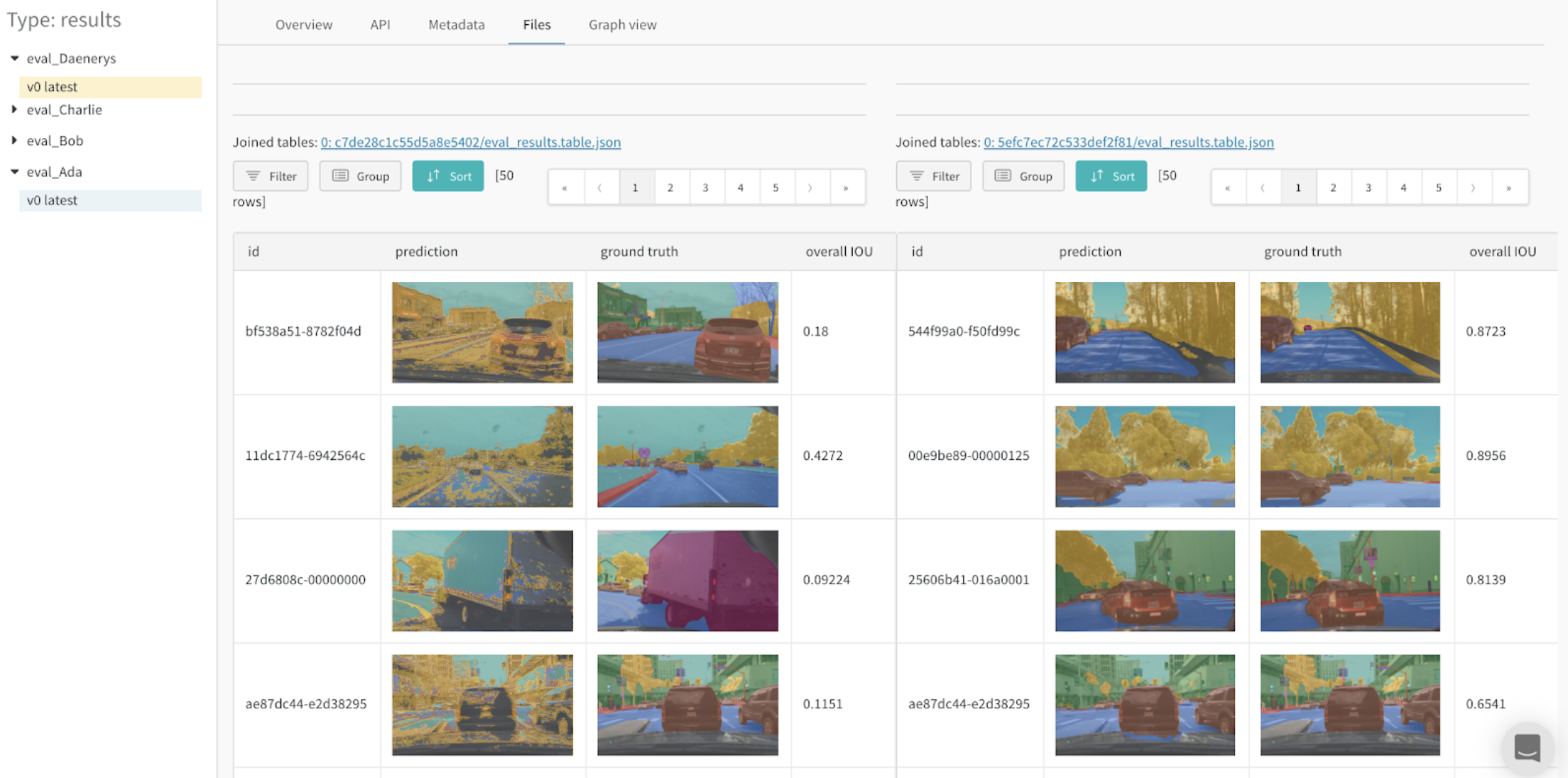
예를 들어 모델 예측 테이블과 같이 스크립트에서 데이터 테이블을 생성한 후 결과를 라이브로 시각화하기 위해 W&B에 저장합니다.
테이블이 동일한 키에 기록될 때마다 테이블의 새 버전이 생성되어 백엔드에 저장됩니다. 즉, 모델 예측이 시간이 지남에 따라 어떻게 향상되는지 확인하기 위해 여러 트레이닝 단계에서 동일한 테이블을 기록하거나 동일한 키에 기록되는 한 다른 run에서 테이블을 비교할 수 있습니다. 최대 200,000개의 행을 기록할 수 있습니다.
200,000개 이상의 행을 기록하려면 다음을 사용하여 제한을 재정의할 수 있습니다.
wandb.Table.MAX_ARTIFACT_ROWS = X
그러나 이렇게 하면 UI에서 쿼리 속도 저하와 같은 성능 문제가 발생할 수 있습니다.
프로그래밍 방식으로 테이블 엑세스
백엔드에서 테이블은 Artifacts로 유지됩니다. 특정 버전에 엑세스하려면 아티팩트 API를 사용하여 엑세스할 수 있습니다.
with wandb.init() as run:
my_table = run.use_artifact("run-<run-id>-<table-name>:<tag>").get("<table-name>")
Artifacts에 대한 자세한 내용은 개발자 가이드의 Artifacts 챕터를 참조하십시오.
테이블 시각화
이러한 방식으로 기록된 테이블은 Run 페이지와 Project 페이지 모두의 Workspace에 표시됩니다. 자세한 내용은 테이블 시각화 및 분석을 참조하십시오.
아티팩트 테이블
artifact.add()를 사용하여 워크스페이스 대신 run의 Artifacts 섹션에 테이블을 기록합니다. 이는 한 번 기록한 다음 향후 run에 참조할 데이터셋이 있는 경우에 유용할 수 있습니다.
run = wandb.init(project="my_project")
# 각 의미 있는 단계에 대한 wandb Artifact 생성test_predictions = wandb.Artifact("mnist_test_preds", type="predictions")
# [위와 같이 예측 데이터 빌드]test_table = wandb.Table(data=data, columns=columns)
test_predictions.add(test_table, "my_test_key")
run.log_artifact(test_predictions)
이미지 데이터와 함께 artifact.add()의 자세한 예는 이 Colab을 참조하고, Artifacts 및 Tables를 사용하여 테이블 형식 데이터의 버전 제어 및 중복 제거하는 방법의 예는 이 리포트를 참조하십시오.
아티팩트 테이블 결합
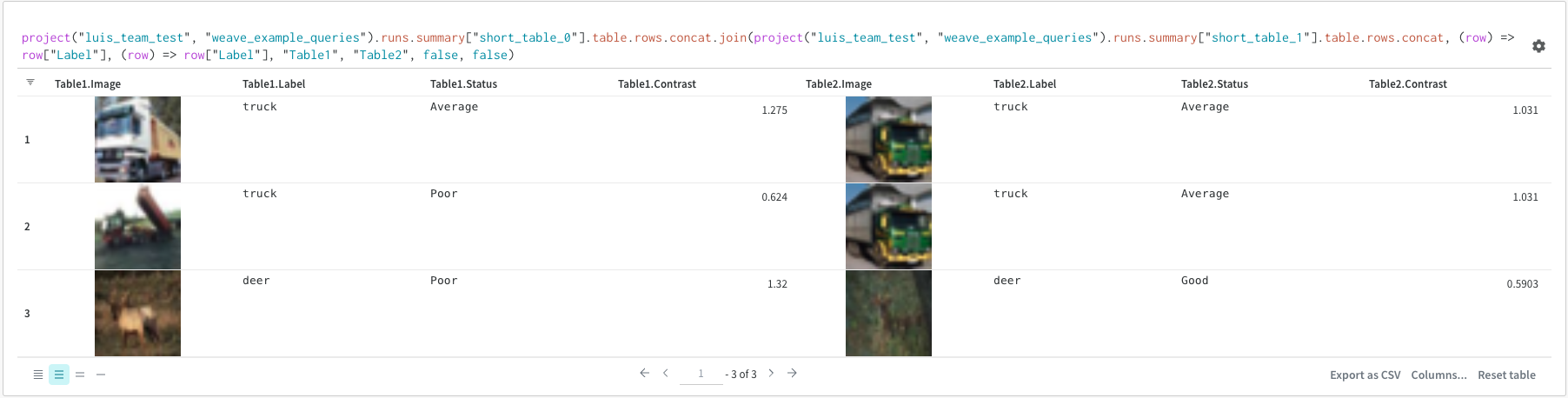
wandb.JoinedTable(table_1, table_2, join_key)를 사용하여 로컬에서 구성한 테이블 또는 다른 아티팩트에서 검색한 테이블을 결합할 수 있습니다.
인수
설명
table_1
(str, wandb.Table, ArtifactEntry) 아티팩트의 wandb.Table 경로, 테이블 오브젝트 또는 ArtifactEntry
table_2
(str, wandb.Table, ArtifactEntry) 아티팩트의 wandb.Table 경로, 테이블 오브젝트 또는 ArtifactEntry
join_key
(str, [str, str]) 결합을 수행할 키
아티팩트 컨텍스트에서 이전에 기록한 두 개의 테이블을 결합하려면 아티팩트에서 가져와 결과를 새 테이블로 결합합니다.
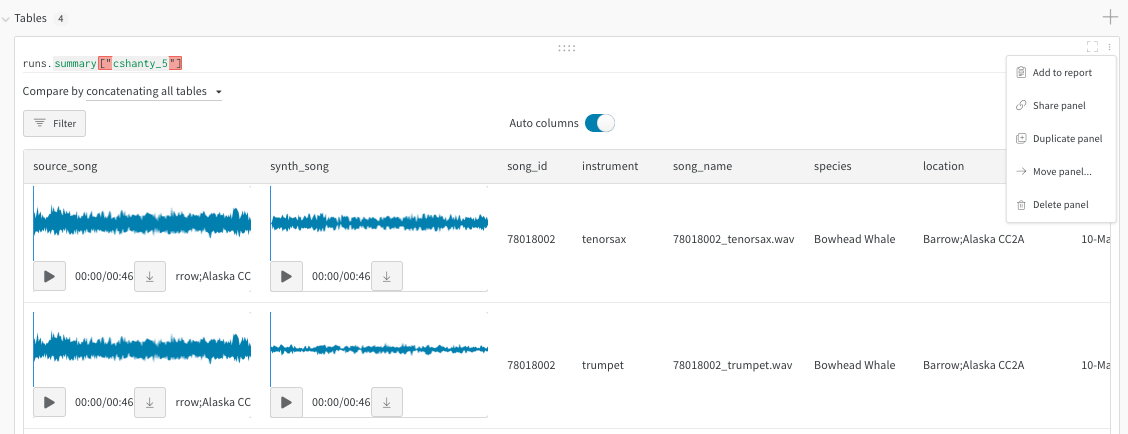
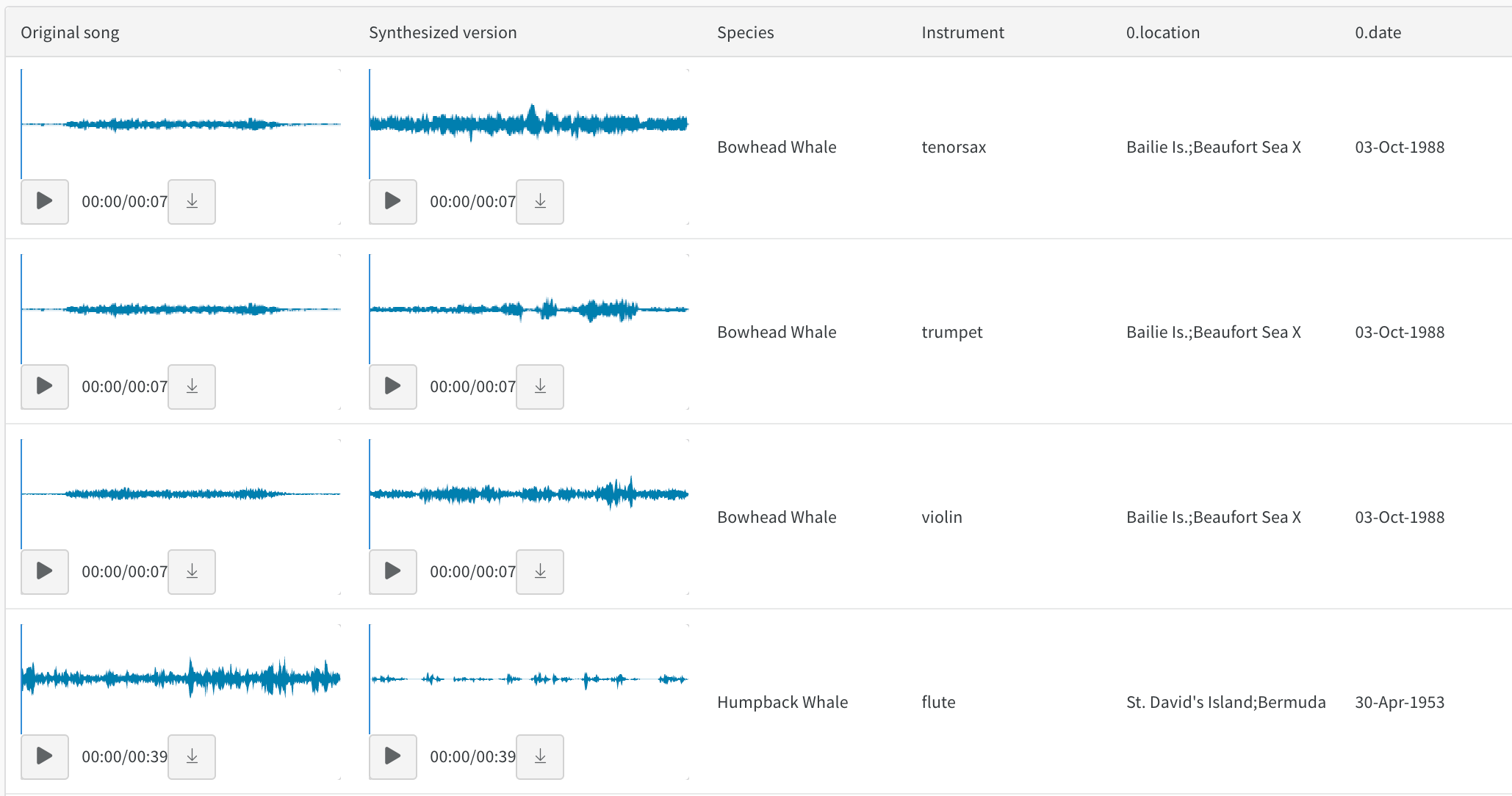
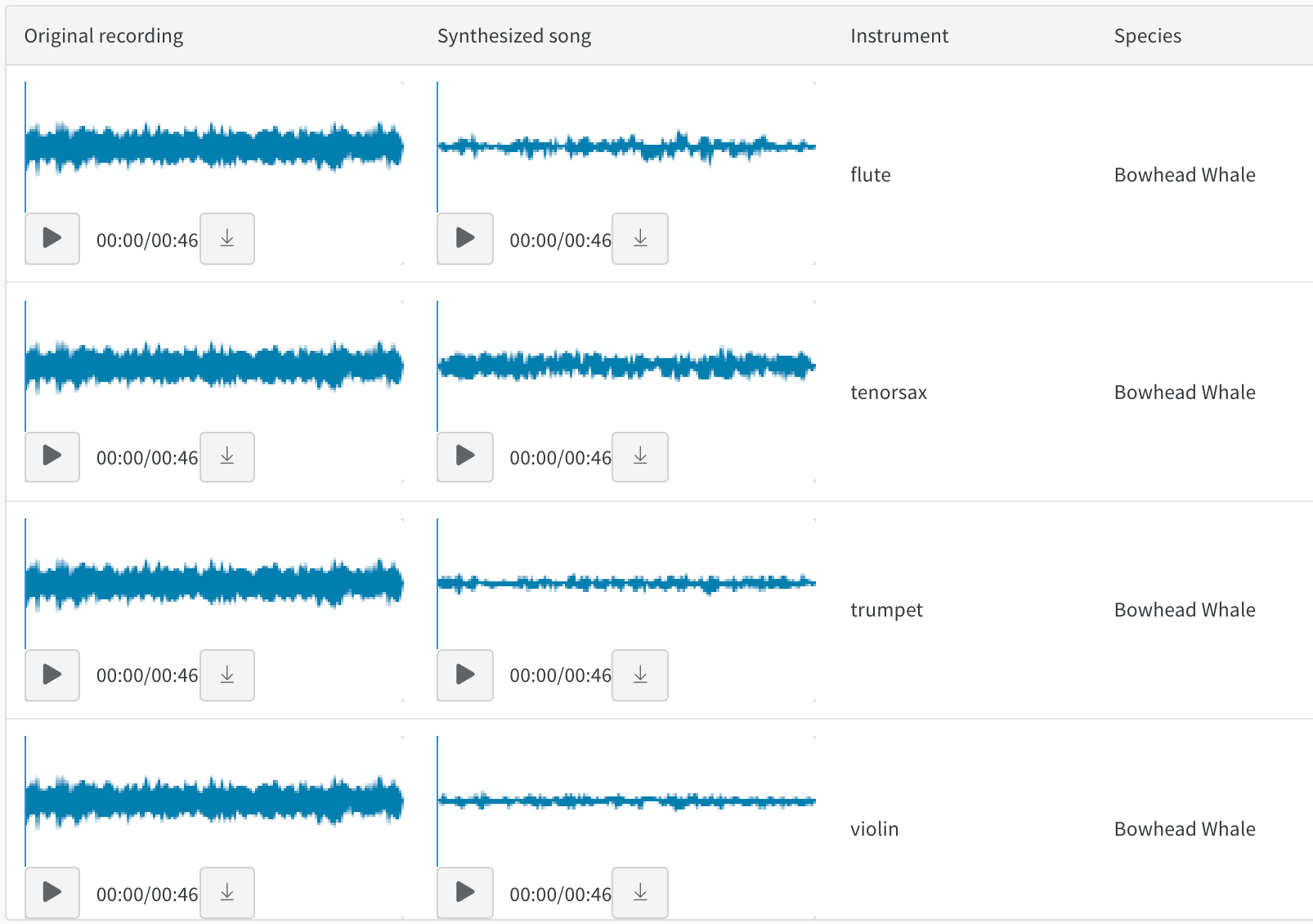
예를 들어 'original_songs'라는 원본 노래의 테이블 하나와 동일한 노래의 합성 버전의 또 다른 테이블인 'synth_songs'를 읽는 방법을 보여줍니다. 다음 코드 예제는 "song_id"에서 두 테이블을 결합하고 결과 테이블을 새 W&B 테이블로 업로드합니다.
# 테이블을 Artifact에 추가하여 행# 제한을 200000으로 늘리고 재사용을 용이하게 합니다.iris_table_artifact = wandb.Artifact("iris_artifact", type="dataset")
iris_table_artifact.add(iris_table, "iris_table")
# 원시 CSV 파일을 Artifact 내에 기록하여 데이터를 보존합니다.iris_table_artifact.add_file("iris.csv")
마지막으로 wandb.init으로 새로운 W&B Run을 시작하여 W&B에 추적하고 기록합니다.
# 데이터를 기록하기 위해 W&B Run 시작run = wandb.init(project="tables-walkthrough")
# Run으로 시각화하기 위해 테이블을 기록합니다...run.log({"iris": iris_table})
# ...사용 가능한 행 제한을 늘리기 위해 Artifact로 기록합니다!run.log_artifact(iris_table_artifact)
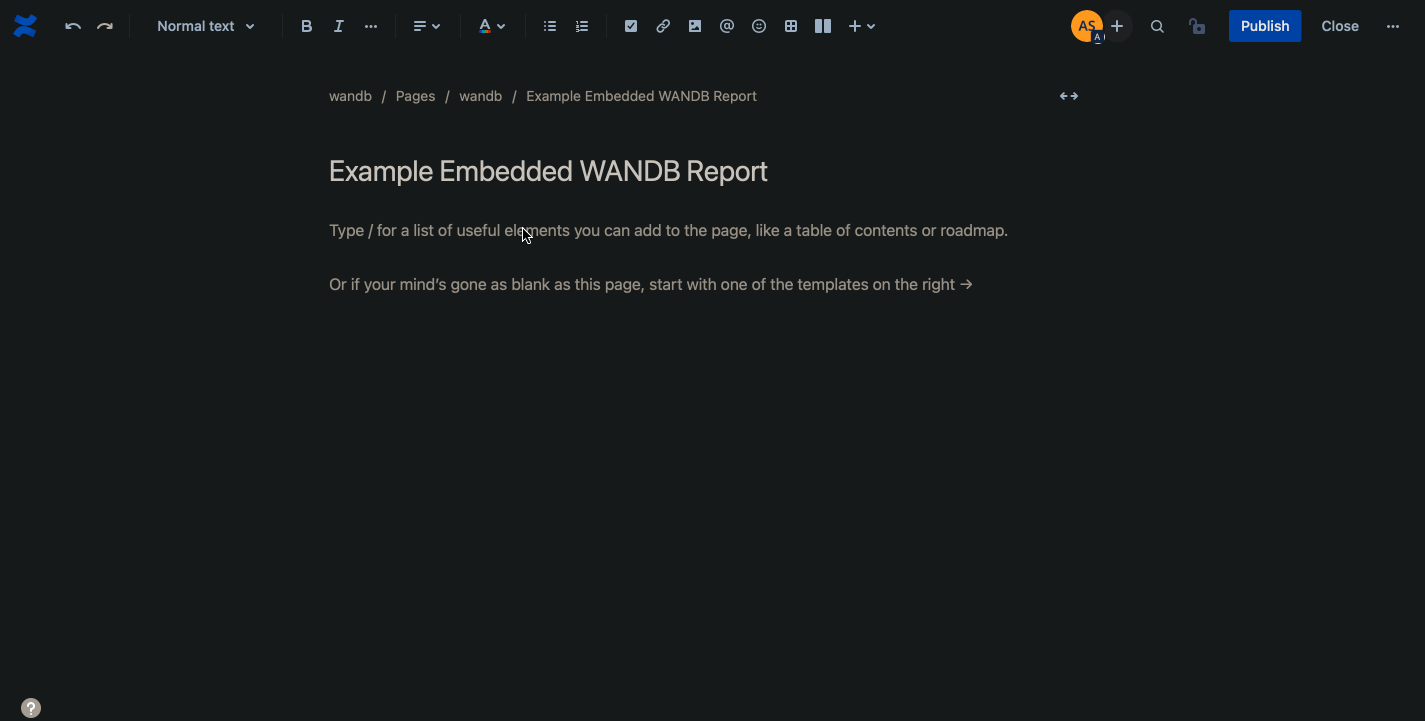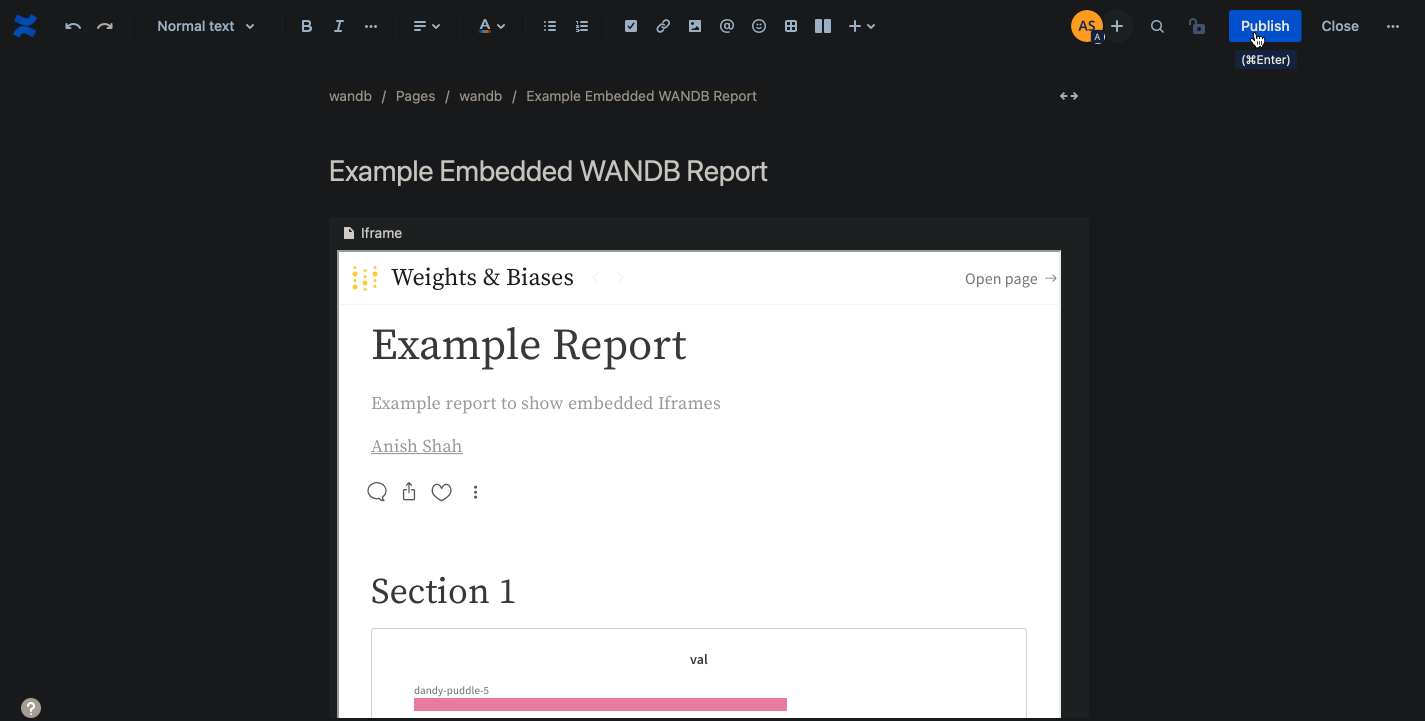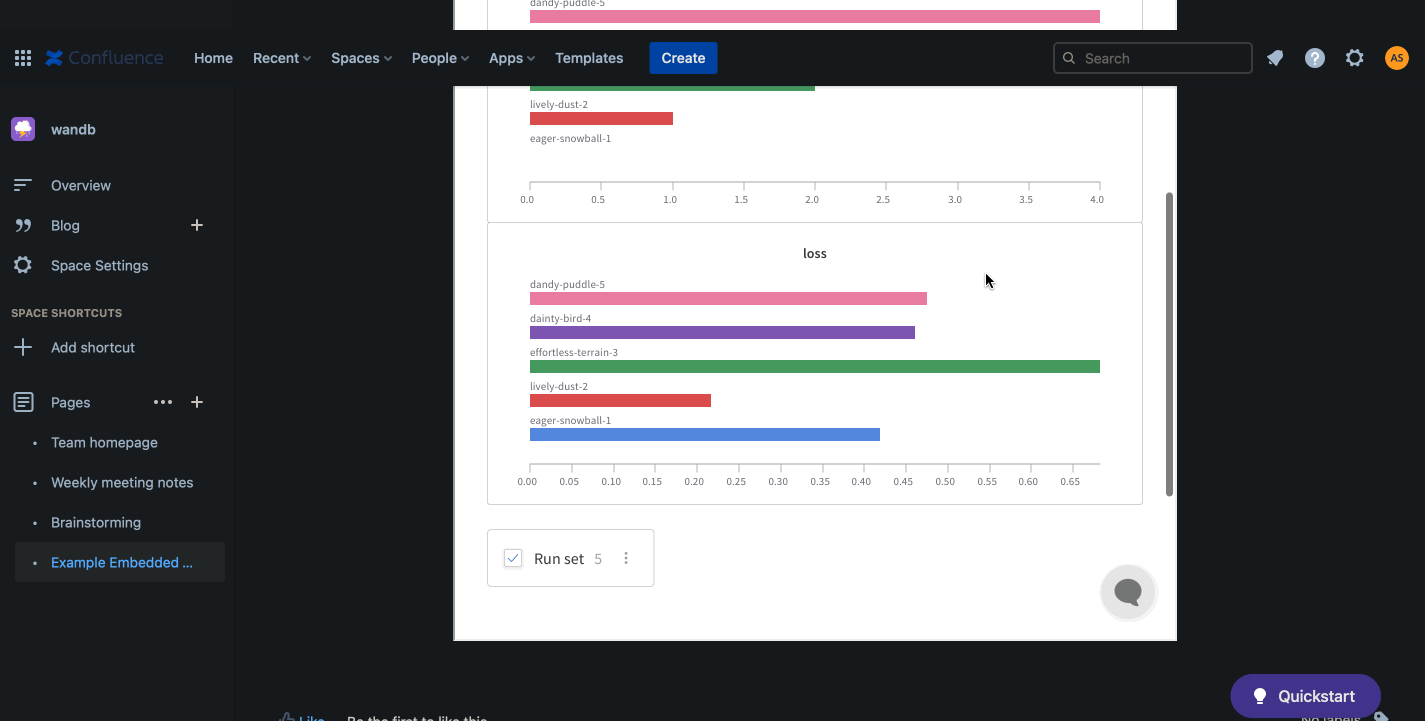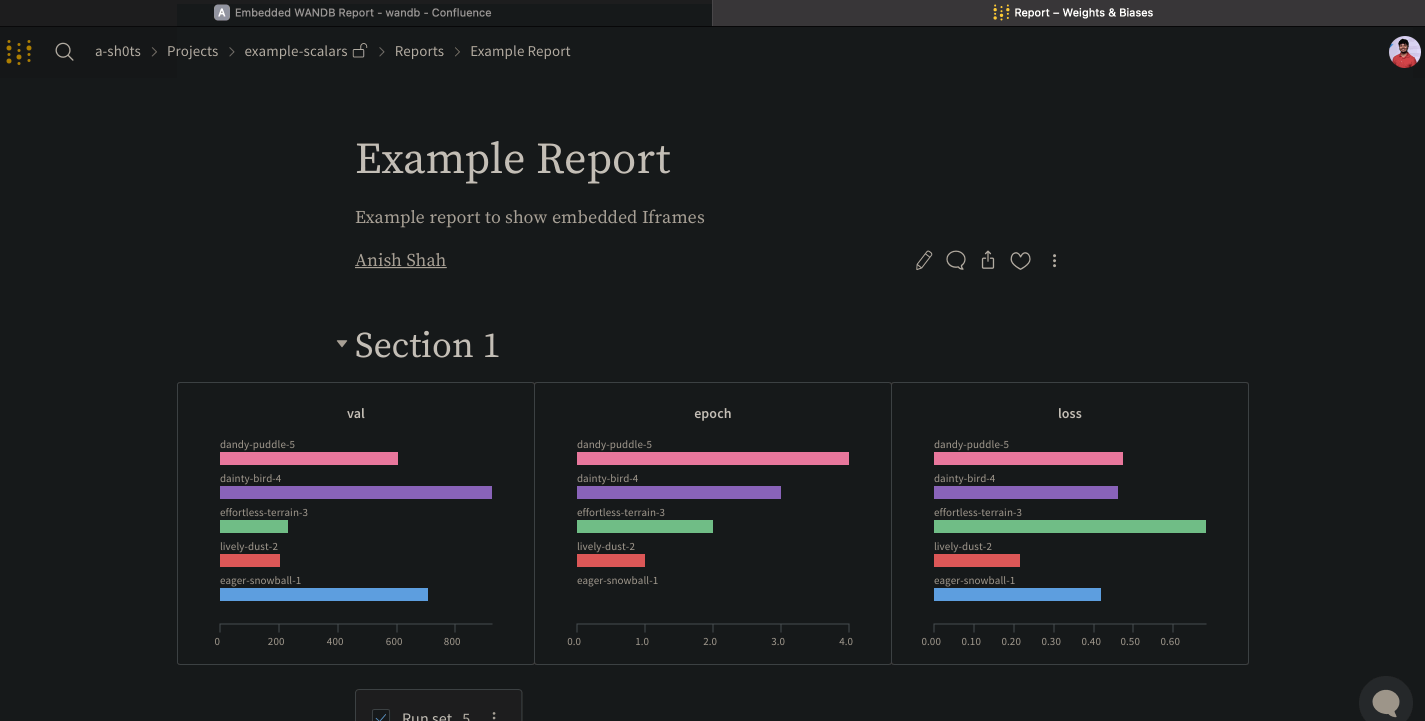
wandb.init() API는 데이터를 Run에 기록하기 위해 새로운 백그라운드 프로세스를 생성하고, wandb.ai에 데이터를 동기화합니다(기본적으로). W&B Workspace 대시보드에서 라이브 시각화를 확인하세요. 다음 이미지는 코드 조각 데모의 출력을 보여줍니다.
앞선 코드 조각이 포함된 전체 스크립트는 아래에서 찾을 수 있습니다.
import wandb
import pandas as pd
# CSV를 새 DataFrame으로 읽기new_iris_dataframe = pd.read_csv("iris.csv")
# DataFrame을 W&B Table로 변환iris_table = wandb.Table(dataframe=new_iris_dataframe)
# 테이블을 Artifact에 추가하여 행# 제한을 200000으로 늘리고 재사용을 용이하게 합니다.iris_table_artifact = wandb.Artifact("iris_artifact", type="dataset")
iris_table_artifact.add(iris_table, "iris_table")
# 원시 CSV 파일을 Artifact 내에 기록하여 데이터를 보존합니다.iris_table_artifact.add_file("iris.csv")
# 데이터를 기록하기 위해 W&B Run 시작run = wandb.init(project="tables-walkthrough")
# Run으로 시각화하기 위해 테이블을 기록합니다...run.log({"iris": iris_table})
# ...사용 가능한 행 제한을 늘리기 위해 Artifact로 기록합니다!run.log_artifact(iris_table_artifact)
# Run 완료 (노트북에서 유용)run.finish()
Experiments의 CSV 가져오기 및 기록
경우에 따라 Experiments 세부 정보가 CSV 파일에 있을 수 있습니다. 이러한 CSV 파일에서 흔히 볼 수 있는 세부 정보는 다음과 같습니다.
%wandb 매직을 사용하여 기존의 대시보드, Sweeps 또는 리포트를 노트북에서 직접 표시할 수도 있습니다.
# Display a project workspace
%wandb USERNAME/PROJECT
# Display a single run
%wandb USERNAME/PROJECT/runs/RUN_ID
# Display a sweep
%wandb USERNAME/PROJECT/sweeps/SWEEP_ID
# Display a report
%wandb USERNAME/PROJECT/reports/REPORT_ID
# Specify the height of embedded iframe
%wandb USERNAME/PROJECT -h 2048
%%wandb 또는 %wandb 매직의 대안으로 wandb.init()를 실행한 후 wandb.run으로 셀을 종료하여 인라인 그래프를 표시하거나 API에서 반환된 리포트, 스윕 또는 Run 오브젝트에서 ipython.display(...)를 호출할 수 있습니다.
# Initialize wandb.run firstwandb.init()
# If cell outputs wandb.run, you'll see live graphswandb.run
Colab에서 간편한 인증: Colab에서 wandb.init를 처음 호출하면 브라우저에서 W&B에 로그인한 경우 런타임이 자동으로 인증됩니다. Run 페이지의 Overview 탭에서 Colab 링크를 볼 수 있습니다.
Jupyter Magic: 대시보드, Sweeps 및 리포트를 노트북에서 직접 표시합니다. %wandb 매직은 프로젝트, Sweeps 또는 리포트의 경로를 허용하고 W&B 인터페이스를 노트북에서 직접 렌더링합니다.
dockerized Jupyter 실행: wandb docker --jupyter를 호출하여 docker 컨테이너를 시작하고, 코드를 마운트하고, Jupyter가 설치되었는지 확인하고, 포트 8888에서 시작합니다.
두려움 없이 임의의 순서로 셀 실행: 기본적으로 Run이 finished로 표시될 때까지 wandb.init가 다음에 호출될 때까지 기다립니다. 이를 통해 여러 셀(예: 데이터 설정, 트레이닝, 테스트)을 원하는 순서로 실행하고 모두 동일한 Run에 기록할 수 있습니다. 설정에서 코드 저장을 켜면 실행된 셀도 순서대로, 그리고 실행된 상태로 기록하여 가장 비선형적인 파이프라인도 재현할 수 있습니다. Jupyter 노트북에서 Run을 수동으로 완료하려면 run.finish를 호출합니다.
import wandb
run = wandb.init()
# training script and logging goes hererun.finish()
2.1.8 - Experiments limits and performance
제안된 범위 내에서 로깅하여 W&B에서 페이지를 더 빠르고 반응적으로 유지하세요.
다음과 같은 권장 범위 내에서 로깅하면 W&B에서 페이지를 더 빠르고 응답성 좋게 유지할 수 있습니다.
로깅 고려 사항
wandb.log를 사용하여 실험 메트릭을 추적합니다. 한 번 로깅되면 이러한 메트릭은 차트를 생성하고 테이블에 표시됩니다. 너무 많은 데이터를 로깅하면 앱이 느려질 수 있습니다.
고유한 메트릭 수
더 빠른 성능을 위해 프로젝트의 총 고유 메트릭 수를 10,000개 미만으로 유지하십시오.
import wandb
wandb.log(
{
"a": 1, # "a"는 고유한 메트릭입니다."b": {
"c": "hello", # "b.c"는 고유한 메트릭입니다."d": [1, 2, 3], # "b.d"는 고유한 메트릭입니다. },
}
)
W&B는 중첩된 값을 자동으로 평면화합니다. 즉, dictionary를 전달하면 W&B는 이를 점으로 구분된 이름으로 바꿉니다. config 값의 경우 W&B는 이름에 점 3개를 지원합니다. summary 값의 경우 W&B는 점 4개를 지원합니다.
워크스페이스가 갑자기 느려지면 최근의 runs이 의도치 않게 수천 개의 새로운 메트릭을 로깅했는지 확인하십시오. (수천 개의 플롯이 있는 섹션에 하나 또는 두 개의 runs만 표시되는지 확인하면 가장 쉽게 알 수 있습니다.) 그렇다면 해당 runs을 삭제하고 원하는 메트릭으로 다시 만드는 것을 고려하십시오.
값 너비
단일 로깅된 값의 크기를 1MB 미만으로 제한하고 단일 wandb.log 호출의 총 크기를 25MB 미만으로 제한합니다. 이 제한은 wandb.Image, wandb.Audio 등과 같은 wandb.Media 유형에는 적용되지 않습니다.
# ❌ 권장하지 않음wandb.log({"wide_key": range(10000000)})
# ❌ 권장하지 않음with f as open("large_file.json", "r"):
large_data = json.load(f)
wandb.log(large_data)
넓은 값은 넓은 값이 있는 메트릭뿐만 아니라 run의 모든 메트릭에 대한 플롯 로드 시간에 영향을 줄 수 있습니다.
권장량보다 넓은 값을 로깅하더라도 데이터는 저장되고 추적됩니다. 그러나 플롯 로드 속도가 느려질 수 있습니다.
메트릭 빈도
로깅하는 메트릭에 적합한 로깅 빈도를 선택하십시오. 일반적으로 메트릭이 넓을수록 로깅 빈도를 줄여야 합니다. W&B는 다음을 권장합니다.
스칼라: 메트릭당 로깅된 포인트 <100,000개
미디어: 메트릭당 로깅된 포인트 <50,000개
히스토그램: 메트릭당 로깅된 포인트 <10,000개
# 총 1백만 단계의 트레이닝 루프for step in range(1000000):
# ❌ 권장하지 않음 wandb.log(
{
"scalar": step, # 스칼라 100,000개"media": wandb.Image(...), # 이미지 100,000개"histogram": wandb.Histogram(...), # 히스토그램 100,000개 }
)
# ✅ 권장if step %1000==0:
wandb.log(
{
"histogram": wandb.Histogram(...), # 히스토그램 10,000개 },
commit=False,
)
if step %200==0:
wandb.log(
{
"media": wandb.Image(...), # 이미지 50,000개 },
commit=False,
)
if step %100==0:
wandb.log(
{
"scalar": step, # 스칼라 100,000개 },
commit=True,
) # 일괄 처리된 단계별 메트릭을 함께 커밋합니다.
지침을 초과하더라도 W&B는 로깅된 데이터를 계속 수락하지만 페이지 로드 속도가 느려질 수 있습니다.
config 크기
run config의 총 크기를 10MB 미만으로 제한하십시오. 큰 값을 로깅하면 프로젝트 워크스페이스 및 runs 테이블 작업 속도가 느려질 수 있습니다.
워크스페이스에 수백 개의 섹션이 있으면 성능이 저하될 수 있습니다. 메트릭의 상위 수준 그룹화를 기반으로 섹션을 만들고 각 메트릭에 대해 하나의 섹션을 만드는 안티 패턴을 피하십시오.
섹션이 너무 많고 성능이 느린 경우 접미사가 아닌 접두사로 섹션을 만드는 워크스페이스 설정을 고려하십시오. 이렇게 하면 섹션 수가 줄어들고 성능이 향상될 수 있습니다.
메트릭 수
Run당 5000~100,000개의 메트릭을 로깅하는 경우 W&B는 수동 워크스페이스를 사용하는 것이 좋습니다. 수동 모드에서는 다양한 메트릭 집합을 탐색하도록 선택할 때 패널을 대량으로 쉽게 추가하고 제거할 수 있습니다. 더 집중적인 플롯 집합을 사용하면 워크스페이스 로드 속도가 빨라집니다. 플롯되지 않은 메트릭은 평소와 같이 계속 수집 및 저장됩니다.
워크스페이스를 수동 모드로 재설정하려면 워크스페이스의 작업 ... 메뉴를 클릭한 다음 워크스페이스 재설정을 클릭합니다. 워크스페이스를 재설정해도 runs에 대한 저장된 메트릭에는 영향을 미치지 않습니다. 워크스페이스 관리에 대해 자세히 알아보십시오.
파일 수
단일 run에 대해 업로드된 총 파일 수를 1,000개 미만으로 유지하십시오. 많은 수의 파일을 로깅해야 하는 경우 W&B Artifacts를 사용할 수 있습니다. 단일 run에서 1,000개가 넘는 파일을 초과하면 run 페이지 속도가 느려질 수 있습니다.
리포트 대 워크스페이스
리포트는 패널, 텍스트 및 미디어를 임의로 배열하여 동료와 통찰력을 쉽게 공유할 수 있는 자유 형식의 컴포지션입니다.
대조적으로 워크스페이스는 수백에서 수십만 개의 runs에 걸쳐 수십에서 수천 개의 메트릭을 고밀도로 효율적으로 분석할 수 있습니다. 워크스페이스는 리포트에 비해 최적화된 캐싱, 쿼리 및 로드 기능을 제공합니다. 워크스페이스는 주로 프레젠테이션보다는 분석에 사용되는 프로젝트에 권장되거나 20개 이상의 플롯을 함께 표시해야 하는 경우에 권장됩니다.
Python 스크립트 성능
Python 스크립트의 성능이 저하되는 몇 가지 방법이 있습니다.
데이터 크기가 너무 큽니다. 데이터 크기가 크면 트레이닝 루프에 >1ms의 오버헤드가 발생할 수 있습니다.
네트워크 속도와 W&B 백엔드 구성 방법
wandb.log를 초당 몇 번 이상 호출합니다. 이는 wandb.log가 호출될 때마다 트레이닝 루프에 작은 대기 시간이 추가되기 때문입니다.
잦은 로깅으로 인해 트레이닝 runs 속도가 느려지나요? 로깅 전략을 변경하여 더 나은 성능을 얻는 방법에 대한 이 Colab을 확인하십시오.
W&B는 속도 제한 외에는 어떠한 제한도 주장하지 않습니다. W&B Python SDK는 제한을 초과하는 요청에 대해 지수 “백오프” 및 “재시도"를 자동으로 완료합니다. W&B Python SDK는 커맨드라인에 “네트워크 실패"로 응답합니다. 유료 계정이 아닌 경우 W&B는 사용량이 합리적인 임계값을 초과하는 극단적인 경우에 연락할 수 있습니다.
속도 제한
W&B SaaS Cloud API는 시스템 무결성을 유지하고 가용성을 보장하기 위해 속도 제한을 구현합니다. 이 측정은 단일 사용자가 공유 인프라에서 사용 가능한 리소스를 독점하는 것을 방지하여 모든 사용자가 서비스에 액세스할 수 있도록 보장합니다. 다양한 이유로 더 낮은 속도 제한이 발생할 수 있습니다.
속도 제한은 변경될 수 있습니다.
속도 제한 HTTP 헤더
이전 표에서는 속도 제한 HTTP 헤더에 대해 설명합니다.
헤더 이름
설명
RateLimit-Limit
시간 창당 사용 가능한 할당량으로, 0~1000 범위로 조정됩니다.
RateLimit-Remaining
현재 속도 제한 창의 할당량으로, 0~1000 범위로 조정됩니다.
RateLimit-Reset
현재 할당량이 재설정될 때까지의 시간(초)
메트릭 로깅 API의 속도 제한
스크립트의 wandb.log 호출은 메트릭 로깅 API를 사용하여 트레이닝 데이터를 W&B에 로깅합니다. 이 API는 온라인 또는 오프라인 동기화를 통해 사용됩니다. 두 경우 모두 롤링 시간 창에서 속도 제한 할당량을 부과합니다. 여기에는 총 요청 크기 및 요청 속도에 대한 제한이 포함되며, 후자는 시간 기간 내의 요청 수를 나타냅니다.
W&B는 W&B 프로젝트당 속도 제한을 적용합니다. 따라서 팀에 3개의 프로젝트가 있는 경우 각 프로젝트에는 자체 속도 제한 할당량이 있습니다. 팀 및 엔터프라이즈 요금제 사용자는 무료 요금제 사용자보다 더 높은 속도 제한을 받습니다.
메트릭 로깅 API를 사용하는 동안 속도 제한에 도달하면 표준 출력에 오류를 나타내는 관련 메시지가 표시됩니다.
메트릭 로깅 API 속도 제한을 초과하지 않기 위한 제안
속도 제한을 초과하면 속도 제한이 재설정될 때까지 run.finish()가 지연될 수 있습니다. 이를 방지하려면 다음 전략을 고려하십시오.
W&B Python SDK 버전 업데이트: 최신 버전의 W&B Python SDK를 사용하고 있는지 확인하십시오. W&B Python SDK는 정기적으로 업데이트되며 요청을 정상적으로 재시도하고 할당량 사용량을 최적화하기 위한 향상된 메커니즘이 포함되어 있습니다.
메트릭 로깅 빈도 줄이기:
할당량을 보존하기 위해 메트릭 로깅 빈도를 최소화합니다. 예를 들어, 모든 에포크 대신 5개의 에포크마다 메트릭을 로깅하도록 코드를 수정할 수 있습니다.
if epoch %5==0: # 5개의 에포크마다 메트릭 로깅 wandb.log({"acc": accuracy, "loss": loss})
수동 데이터 동기화: 속도 제한이 있는 경우 W&B는 run 데이터를 로컬에 저장합니다. 커맨드 wandb sync <run-file-path>를 사용하여 데이터를 수동으로 동기화할 수 있습니다. 자세한 내용은 wandb sync 참조를 참조하십시오.
GraphQL API의 속도 제한
W&B Models UI 및 SDK의 공용 API는 서버에 GraphQL 요청을 보내 데이터를 쿼리하고 수정합니다. SaaS Cloud의 모든 GraphQL 요청에 대해 W&B는 권한이 없는 요청에 대해 IP 어드레스당, 권한이 있는 요청에 대해 사용자당 속도 제한을 적용합니다. 제한은 고정 시간 창 내의 요청 속도(초당 요청)를 기반으로 하며, 요금제에 따라 기본 제한이 결정됩니다. 프로젝트 경로(예: 리포트, runs, 아티팩트)를 지정하는 관련 SDK 요청의 경우 W&B는 데이터베이스 쿼리 시간으로 측정하여 프로젝트당 속도 제한을 적용합니다.
팀 및 엔터프라이즈 요금제 사용자는 무료 요금제 사용자보다 더 높은 속도 제한을 받습니다.
W&B Models SDK의 공용 API를 사용하는 동안 속도 제한에 도달하면 표준 출력에 오류를 나타내는 관련 메시지가 표시됩니다.
GraphQL API 속도 제한을 초과하지 않기 위한 제안
W&B Models SDK의 공용 API를 사용하여 많은 양의 데이터를 가져오는 경우 요청 사이에 최소 1초 이상 기다리는 것을 고려하십시오. 429 상태 코드를 받거나 응답 헤더에 RateLimit-Remaining=0이 표시되면 재시도하기 전에 RateLimit-Reset에 지정된 시간(초) 동안 기다리십시오.
브라우저 고려 사항
W&B 앱은 메모리 사용량이 많을 수 있으며 Chrome에서 가장 잘 작동합니다. 컴퓨터의 메모리에 따라 W&B가 3개 이상의 탭에서 동시에 활성화되어 있으면 성능이 저하될 수 있습니다. 예기치 않게 느린 성능이 발생하는 경우 다른 탭이나 애플리케이션을 닫는 것을 고려하십시오.
W&B에 성능 문제 보고
W&B는 성능을 중요하게 생각하고 지연에 대한 모든 리포트를 조사합니다. 조사를 신속하게 처리하기 위해 로드 시간이 느린 경우 주요 메트릭 및 성능 이벤트를 캡처하는 W&B의 기본 제공 성능 로거를 호출하는 것을 고려하십시오. 로드 속도가 느린 페이지에 URL 파라미터 &PERF_LOGGING을 추가한 다음 콘솔 출력을 계정 팀 또는 지원팀과 공유하십시오.
2.1.9 - Reproduce experiments
팀 멤버가 생성한 실험을 재현하여 결과를 검증하고 유효성을 확인합니다.
실험을 재현하기 전에 다음 사항을 기록해 두어야 합니다.
해당 run이 기록된 프로젝트 이름
재현하려는 run 이름
실험을 재현하는 방법:
해당 run이 기록된 프로젝트로 이동합니다.
왼쪽 사이드바에서 Workspace 탭을 선택합니다.
run 목록에서 재현하려는 run을 선택합니다.
Overview를 클릭합니다.
계속하려면 특정 해시에서 실험 코드를 다운로드하거나 실험의 전체 저장소를 복제합니다.
실험의 Python 스크립트 또는 노트북을 다운로드합니다.
Command 필드에서 실험을 생성한 스크립트 이름을 기록합니다.
왼쪽 네비게이션 바에서 Code 탭을 선택합니다.
스크립트 또는 노트북에 해당하는 파일 옆에 있는 Download를 클릭합니다.
팀 멤버가 실험을 생성할 때 사용한 GitHub 저장소를 복제합니다. 이렇게 하려면 다음을 수행합니다.
필요한 경우 팀 멤버가 실험을 생성하는 데 사용한 GitHub 저장소에 대한 엑세스 권한을 얻습니다.
GitHub 저장소 URL이 포함된 Git repository 필드를 복사합니다.
저장소를 복제합니다.
git clone https://github.com/your-repo.git && cd your-repo
Git state 필드를 복사하여 터미널에 붙여넣습니다. Git 상태는 팀 멤버가 실험을 생성하는 데 사용한 정확한 커밋을 체크아웃하는 Git 코맨드 집합입니다. 다음 코드 조각에 지정된 값을 자신의 값으로 바꿉니다.
기본적으로 importer.collect_runs()는 MLFlow 서버에서 모든 Runs을 수집합니다. 특정 서브셋을 업로드하려면 Runs의 반복 가능한 객체를 직접 구성하여 임포터에 전달할 수 있습니다.
import mlflow
from wandb.apis.importers.mlflow import MlflowRun
client = mlflow.tracking.MlflowClient(mlflow_tracking_uri)
runs: Iterable[MlflowRun] = []
for run in mlflow_client.search_runs(...):
runs.append(MlflowRun(run, client))
importer.import_runs(runs)
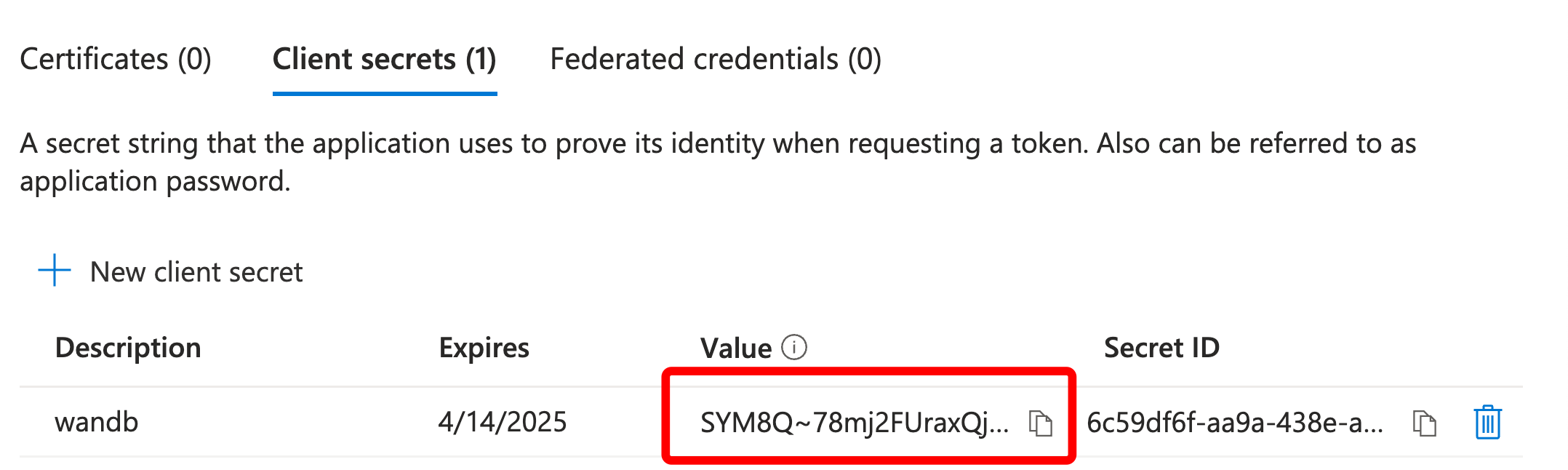
API 키는 W&B에 대한 컴퓨터 인증을 처리합니다. 사용자 프로필에서 API 키를 생성할 수 있습니다.
보다 간소화된 접근 방식을 위해 https://wandb.ai/authorize로 직접 이동하여 API 키를 생성할 수 있습니다. 표시된 API 키를 복사하여 비밀번호 관리자와 같은 안전한 위치에 저장합니다.
오른쪽 상단 모서리에 있는 사용자 프로필 아이콘을 클릭합니다.
사용자 설정을 선택한 다음 API 키 섹션으로 스크롤합니다.
표시를 클릭합니다. 표시된 API 키를 복사합니다. API 키를 숨기려면 페이지를 새로 고칩니다.
Run 경로 찾기
Public API를 사용하려면 <entity>/<project>/<run_id>인 Run 경로가 필요한 경우가 많습니다. 앱 UI에서 Run 페이지를 열고 Overview 탭을 클릭하여 Run 경로를 가져옵니다.
Run 데이터 내보내기
완료되었거나 활성 상태인 Run에서 데이터를 다운로드합니다. 일반적인 사용 사례로는 Jupyter 노트북에서 사용자 정의 분석을 위해 데이터프레임을 다운로드하거나 자동화된 환경에서 사용자 정의 로직을 사용하는 것이 있습니다.
import wandb
api = wandb.Api()
run = api.run("<entity>/<project>/<run_id>")
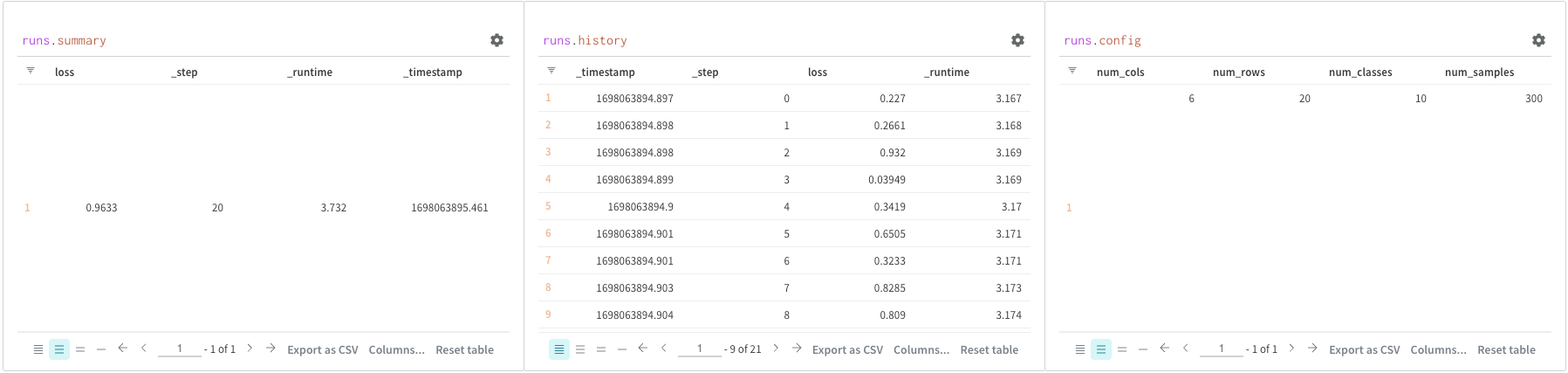
Run 객체의 가장 일반적으로 사용되는 속성은 다음과 같습니다:
속성
의미
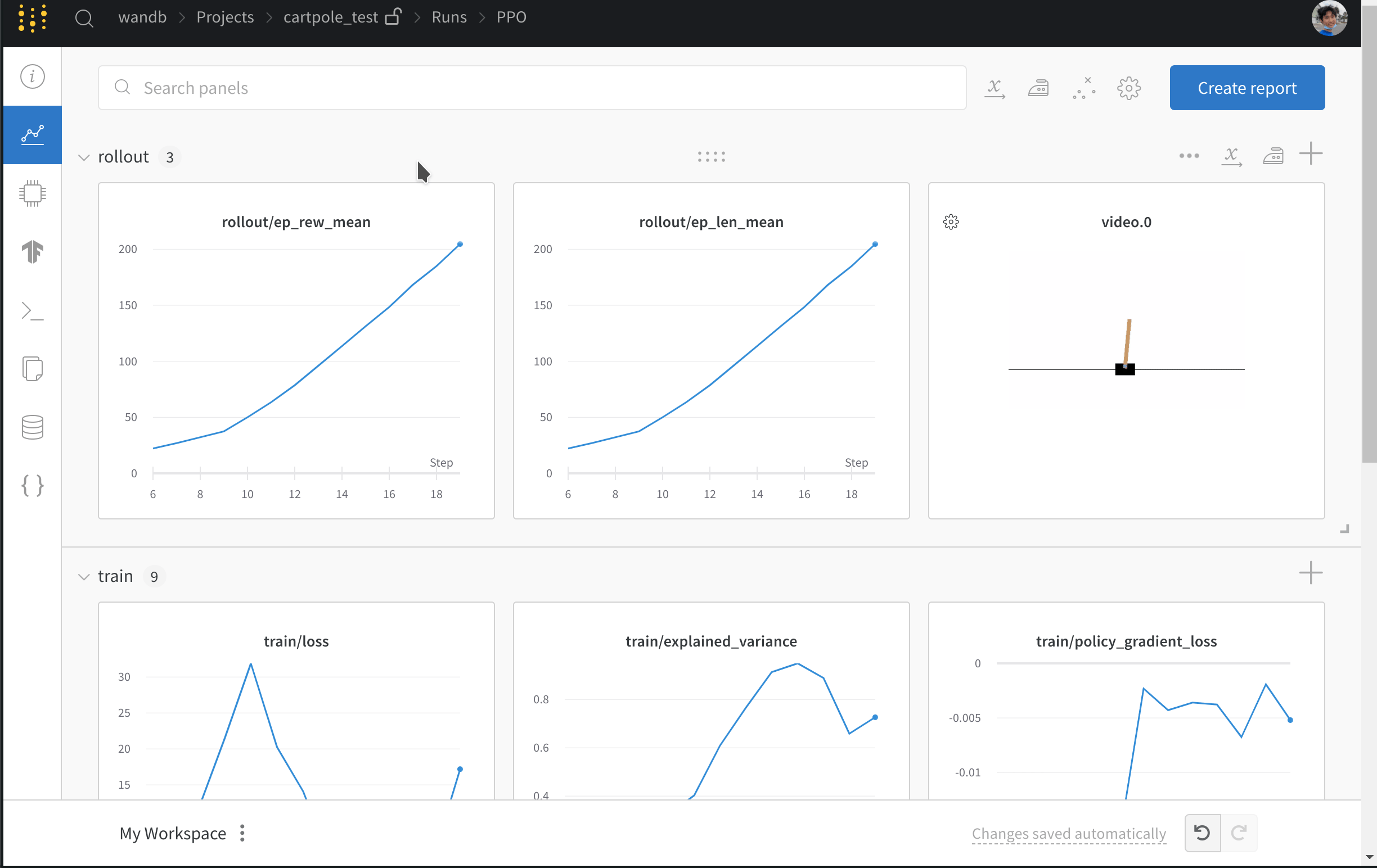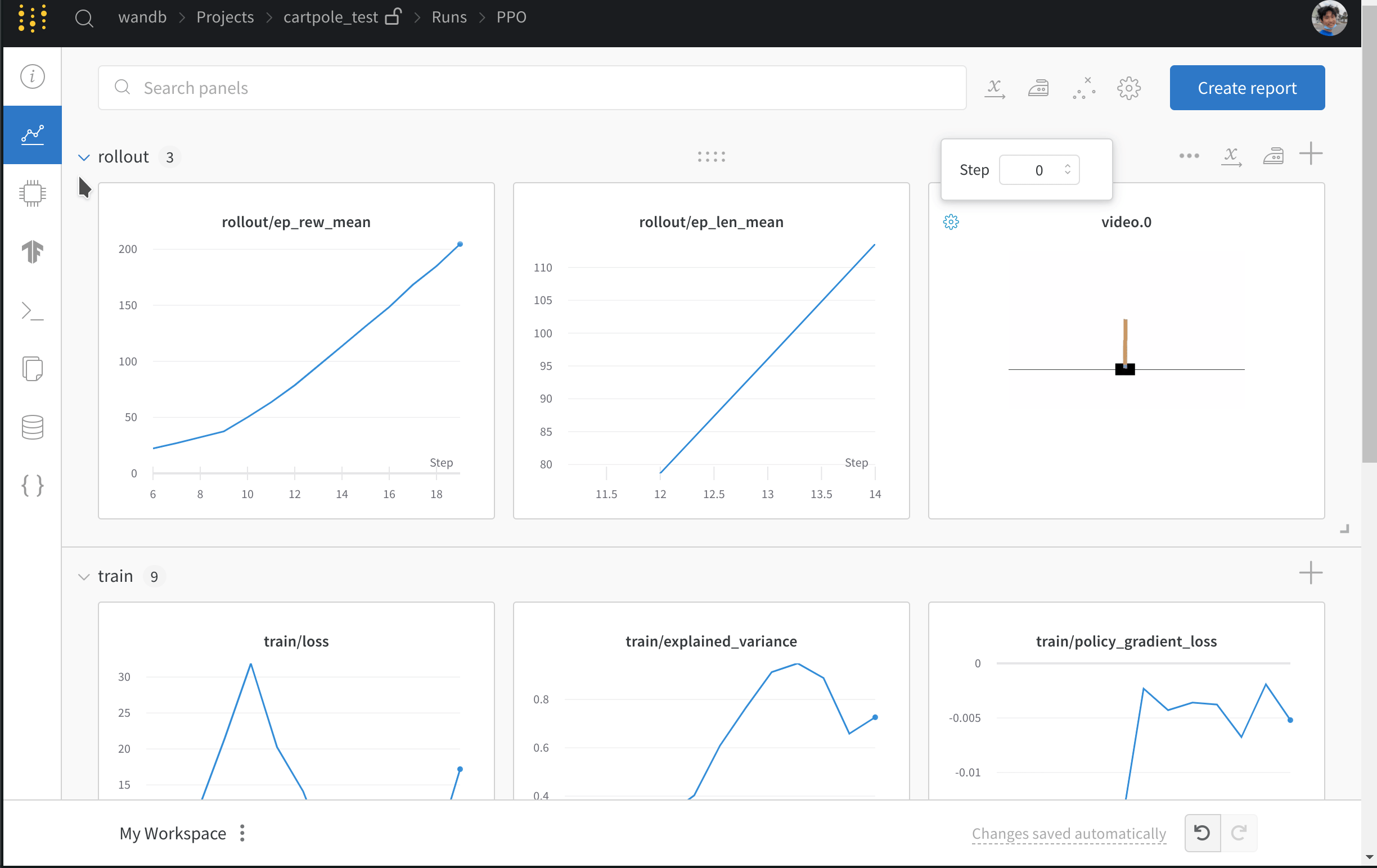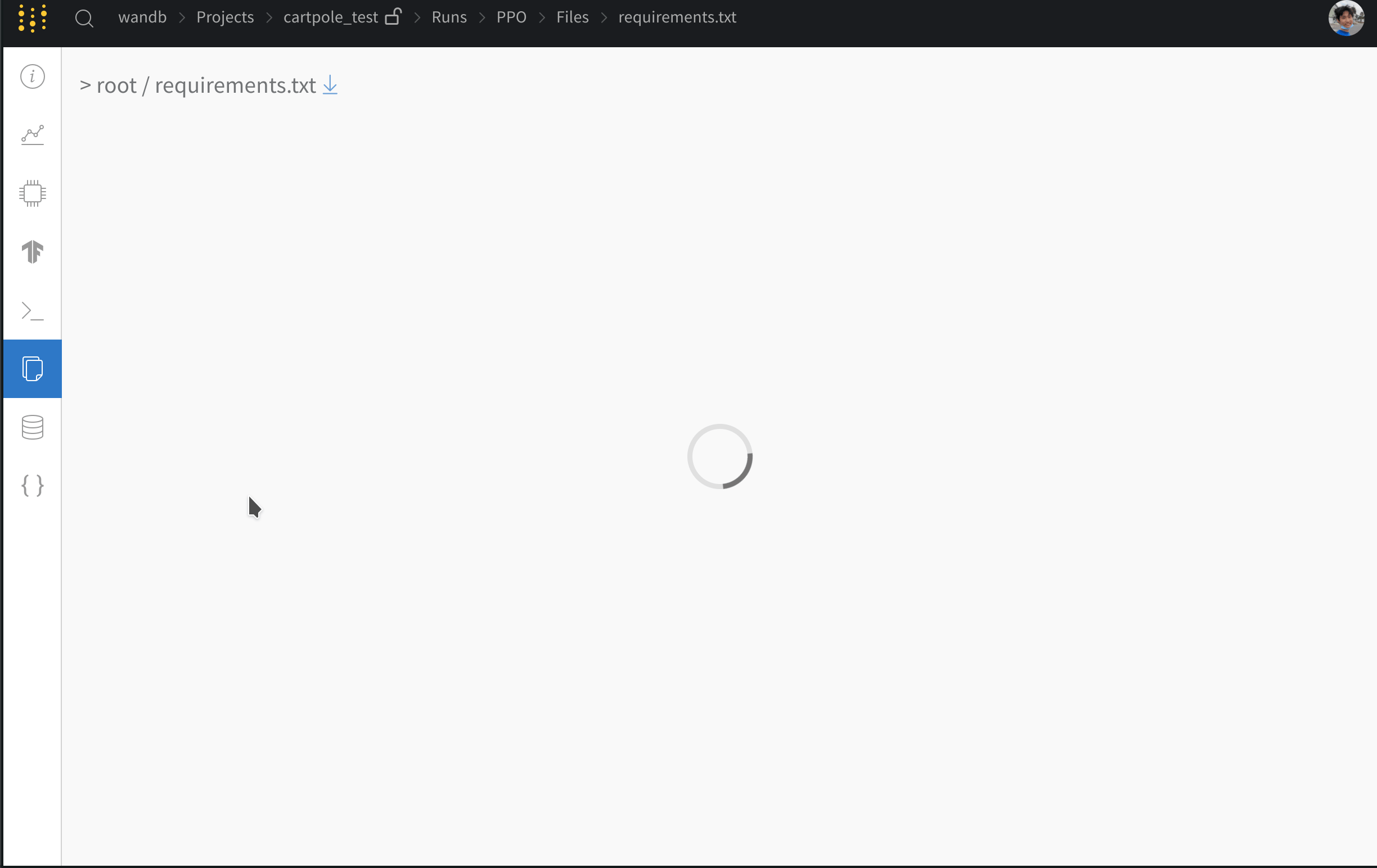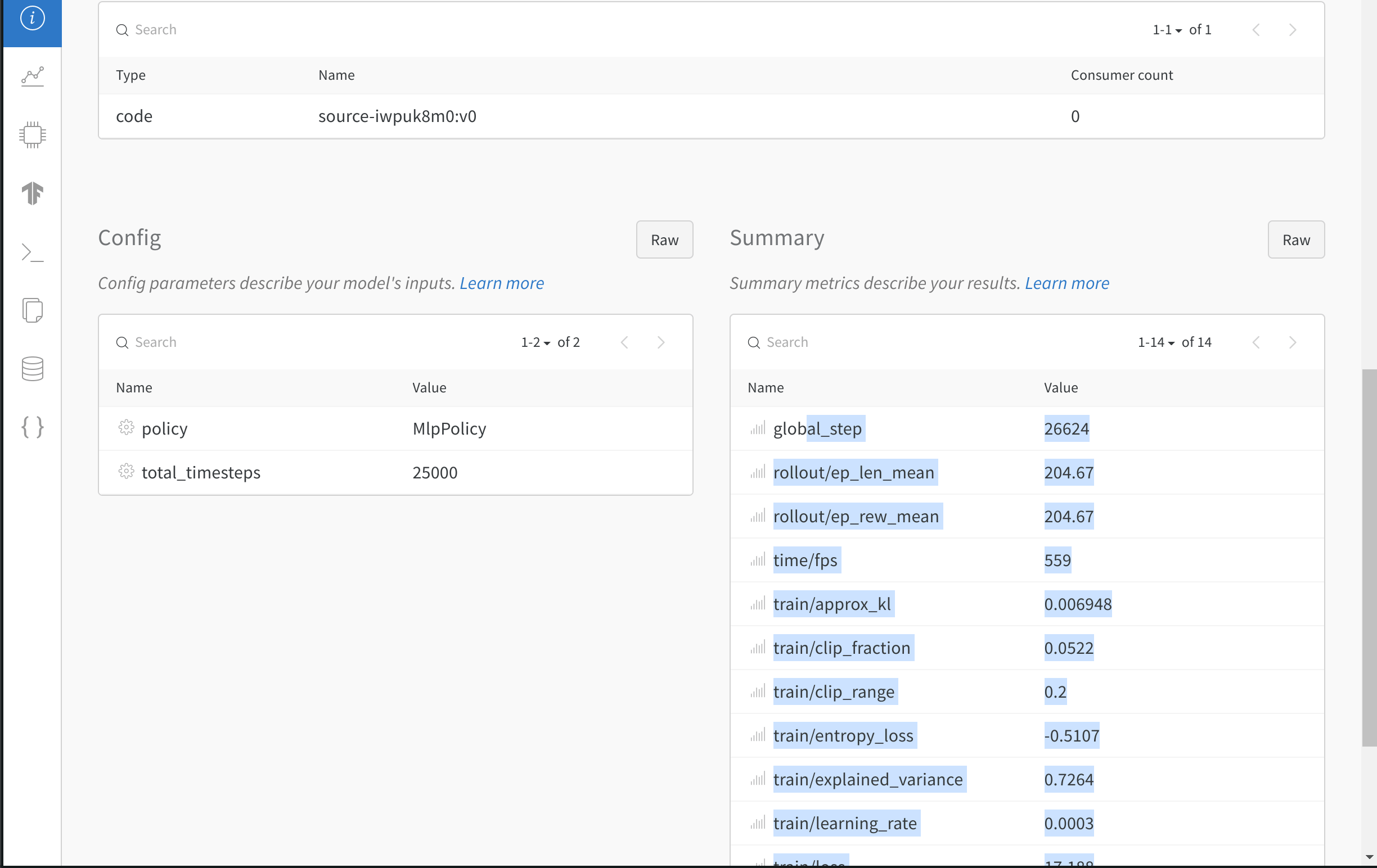
run.config
트레이닝 Run의 하이퍼파라미터 또는 데이터셋 Artifact를 만드는 Run의 전처리 방법과 같은 Run의 구성 정보 사전입니다. 이를 Run의 입력이라고 생각하십시오.
run.history()
손실과 같이 모델이 트레이닝되는 동안 변하는 값을 저장하기 위한 사전 목록입니다. wandb.log() 코맨드는 이 객체에 추가됩니다.
run.summary
Run 결과의 요약 정보 사전입니다. 여기에는 정확도 및 손실과 같은 스칼라 또는 큰 파일이 포함될 수 있습니다. 기본적으로 wandb.log()는 요약을 기록된 시계열의 최종 값으로 설정합니다. 요약 내용은 직접 설정할 수도 있습니다. 요약을 Run의 출력이라고 생각하십시오.
과거 Runs의 데이터를 수정하거나 업데이트할 수도 있습니다. 기본적으로 API 객체의 단일 인스턴스는 모든 네트워크 요청을 캐시합니다. 유스 케이스에서 실행 중인 스크립트의 실시간 정보가 필요한 경우 api.flush()를 호출하여 업데이트된 값을 가져옵니다.
다양한 속성 이해
아래의 Run의 경우
n_epochs =5config = {"n_epochs": n_epochs}
run = wandb.init(project=project, config=config)
for n in range(run.config.get("n_epochs")):
run.log(
{"val": random.randint(0, 1000), "loss": (random.randint(0, 1000) /1000.00)}
)
run.finish()
다음은 위의 Run 객체 속성에 대한 다양한 출력입니다
run.config
{"n_epochs": 5}
run.history()
_step val loss _runtime _timestamp
00500 0.244 416443454121145 0.521 4164434541222240 0.785 416443454123331 0.305 4164434541244525 0.041 41644345412
기본 히스토리 메서드는 메트릭을 고정된 수의 샘플로 샘플링합니다(기본값은 500이며, samples __ 인수로 변경할 수 있음). 대규모 Run에서 모든 데이터를 내보내려면 run.scan_history() 메서드를 사용하면 됩니다. 자세한 내용은 API 참조를 참조하십시오.
여러 Runs 쿼리
이 예제 스크립트는 프로젝트를 찾고 이름, 구성 및 요약 통계가 있는 Runs의 CSV를 출력합니다. <entity> 및 <project>를 W&B 엔티티 및 프로젝트 이름으로 각각 바꿉니다.
import pandas as pd
import wandb
api = wandb.Api()
entity, project ="<entity>", "<project>"runs = api.runs(entity +"/"+ project)
summary_list, config_list, name_list = [], [], []
for run in runs:
# .summary에는 정확도와 같은# 메트릭에 대한 출력 키/값이 포함되어 있습니다.# 큰 파일을 생략하기 위해 ._json_dict를 호출합니다 summary_list.append(run.summary._json_dict)
# .config에는 하이퍼파라미터가 포함되어 있습니다.# _로 시작하는 특수 값을 제거합니다. config_list.append({k: v for k, v in run.config.items() ifnot k.startswith("_")})
# .name은 Run의 사람이 읽을 수 있는 이름입니다. name_list.append(run.name)
runs_df = pd.DataFrame(
{"summary": summary_list, "config": config_list, "name": name_list}
)
runs_df.to_csv("project.csv")
W&B API는 api.runs()를 사용하여 프로젝트의 Runs을 쿼리하는 방법도 제공합니다. 가장 일반적인 유스 케이스는 사용자 정의 분석을 위해 Runs 데이터를 내보내는 것입니다. 쿼리 인터페이스는 MongoDB에서 사용하는 인터페이스와 동일합니다.
api.runs를 호출하면 반복 가능하고 목록처럼 작동하는 Runs 객체가 반환됩니다. 기본적으로 객체는 필요에 따라 한 번에 50개의 Runs을 순서대로 로드하지만 per_page 키워드 인수를 사용하여 페이지당 로드되는 수를 변경할 수 있습니다.
api.runs는 order 키워드 인수도 허용합니다. 기본 순서는 -created_at입니다. 결과를 오름차순으로 정렬하려면 +created_at를 지정합니다. 구성 또는 요약 값으로 정렬할 수도 있습니다. 예를 들어 summary.val_acc 또는 config.experiment_name입니다.
오류 처리
W&B 서버와 통신하는 동안 오류가 발생하면 wandb.CommError가 발생합니다. 원래 예외는 exc 속성을 통해 조사할 수 있습니다.
API를 통해 최신 git 커밋 가져오기
UI에서 Run을 클릭한 다음 Run 페이지에서 Overview 탭을 클릭하여 최신 git 커밋을 확인합니다. 또한 wandb-metadata.json 파일에도 있습니다. Public API를 사용하면 run.commit으로 git 해시를 가져올 수 있습니다.
Run 중 Run의 이름 및 ID 가져오기
wandb.init()를 호출한 후 다음과 같이 스크립트에서 임의 Run ID 또는 사람이 읽을 수 있는 Run 이름을 액세스할 수 있습니다.
고유 Run ID(8자 해시): wandb.run.id
임의 Run 이름(사람이 읽을 수 있음): wandb.run.name
Runs에 유용한 식별자를 설정하는 방법을 고려하고 있다면 다음을 권장합니다.
Run ID: 생성된 해시로 둡니다. 이는 프로젝트의 Runs에서 고유해야 합니다.
Run 이름: 차트에서 여러 줄의 차이점을 알 수 있도록 짧고 읽기 쉽고 가급적이면 고유해야 합니다.
Run 노트: Run에서 수행하는 작업에 대한 간단한 설명을 적어두는 것이 좋습니다. wandb.init(notes="여기에 메모 입력")로 설정할 수 있습니다.
Run 태그: Run 태그에서 동적으로 추적하고 UI에서 필터를 사용하여 테이블을 원하는 Runs로 필터링합니다. 스크립트에서 태그를 설정한 다음 Runs 테이블과 Run 페이지의 Overview 탭 모두에서 UI에서 편집할 수 있습니다. 자세한 내용은 여기의 자세한 지침을 참조하십시오.
Public API 예제
matplotlib 또는 seaborn에서 시각화하기 위해 데이터 내보내기
몇 가지 일반적인 내보내기 패턴은 API 예제를 확인하십시오. 사용자 정의 플롯 또는 확장된 Runs 테이블에서 다운로드 버튼을 클릭하여 브라우저에서 CSV를 다운로드할 수도 있습니다.
Run에서 메트릭 읽기
이 예제는 wandb.log({"accuracy": acc})로 저장된 Run에 대해 "<entity>/<project>/<run_id>"에 저장된 타임스탬프 및 정확도를 출력합니다.
import wandb
api = wandb.Api()
run = api.run("<entity>/<project>/<run_id>")
if run.state =="finished":
for i, row in run.history().iterrows():
print(row["_timestamp"], row["accuracy"])
Run에서 특정 메트릭을 가져오려면 keys 인수를 사용합니다. run.history()를 사용할 때 기본 샘플 수는 500입니다. 특정 메트릭을 포함하지 않는 기록된 단계는 출력 데이터프레임에 NaN으로 표시됩니다. keys 인수를 사용하면 API가 나열된 메트릭 키를 포함하는 단계를 더 자주 샘플링합니다.
import wandb
api = wandb.Api()
run = api.run("<entity>/<project>/<run_id>")
if run.state =="finished":
for i, row in run.history(keys=["accuracy"]).iterrows():
print(row["_timestamp"], row["accuracy"])
이 예제는 이전 Run의 정확도를 0.9로 설정합니다. 또한 이전 Run의 정확도 히스토그램을 numpy_array의 히스토그램으로 수정합니다.
import wandb
api = wandb.Api()
run = api.run("<entity>/<project>/<run_id>")
run.summary["accuracy"] =0.9run.summary["accuracy_histogram"] = wandb.Histogram(numpy_array)
run.summary.update()
완료된 Run에서 메트릭 이름 바꾸기
이 예제는 테이블에서 요약 열의 이름을 바꿉니다.
import wandb
api = wandb.Api()
run = api.run("<entity>/<project>/<run_id>")
run.summary["new_name"] = run.summary["old_name"]
del run.summary["old_name"]
run.summary.update()
열 이름 바꾸기는 테이블에만 적용됩니다. 차트는 여전히 원래 이름으로 메트릭을 참조합니다.
기존 Run에 대한 구성 업데이트
이 예제는 구성 설정 중 하나를 업데이트합니다.
import wandb
api = wandb.Api()
run = api.run("<entity>/<project>/<run_id>")
run.config["key"] = updated_value
run.update()
시스템 리소스 소비를 CSV 파일로 내보내기
아래 코드 조각은 시스템 리소스 소비를 찾은 다음 CSV에 저장합니다.
import wandb
run = wandb.Api().run("<entity>/<project>/<run_id>")
system_metrics = run.history(stream="events")
system_metrics.to_csv("sys_metrics.csv")
샘플링되지 않은 메트릭 데이터 가져오기
히스토리에서 데이터를 가져올 때 기본적으로 500포인트로 샘플링됩니다. run.scan_history()를 사용하여 기록된 모든 데이터 포인트를 가져옵니다. 다음은 히스토리에 기록된 모든 loss 데이터 포인트를 다운로드하는 예입니다.
import wandb
api = wandb.Api()
run = api.run("<entity>/<project>/<run_id>")
history = run.scan_history()
losses = [row["loss"] for row in history]
히스토리에서 페이지가 매겨진 데이터 가져오기
백엔드에서 메트릭을 느리게 가져오거나 API 요청 시간이 초과되는 경우 scan_history에서 페이지 크기를 줄여 개별 요청 시간이 초과되지 않도록 할 수 있습니다. 기본 페이지 크기는 500이므로 다양한 크기를 실험하여 가장 적합한 크기를 확인할 수 있습니다.
import wandb
api = wandb.Api()
run = api.run("<entity>/<project>/<run_id>")
run.scan_history(keys=sorted(cols), page_size=100)
프로젝트의 모든 Runs에서 메트릭을 CSV 파일로 내보내기
이 스크립트는 프로젝트에서 Runs을 가져오고 이름, 구성 및 요약 통계를 포함한 Runs의 데이터프레임과 CSV를 생성합니다. <entity> 및 <project>를 W&B 엔티티 및 프로젝트 이름으로 각각 바꿉니다.
import pandas as pd
import wandb
api = wandb.Api()
entity, project ="<entity>", "<project>"runs = api.runs(entity +"/"+ project)
summary_list, config_list, name_list = [], [], []
for run in runs:
# .summary에는 출력 키/값이 포함되어 있습니다.# 정확도와 같은 메트릭의 경우.# 큰 파일을 생략하기 위해 ._json_dict를 호출합니다 summary_list.append(run.summary._json_dict)
# .config에는 하이퍼파라미터가 포함되어 있습니다.# _로 시작하는 특수 값을 제거합니다. config_list.append({k: v for k, v in run.config.items() ifnot k.startswith("_")})
# .name은 Run의 사람이 읽을 수 있는 이름입니다. name_list.append(run.name)
runs_df = pd.DataFrame(
{"summary": summary_list, "config": config_list, "name": name_list}
)
runs_df.to_csv("project.csv")
Run의 시작 시간 가져오기
이 코드 조각은 Run이 생성된 시간을 검색합니다.
import wandb
api = wandb.Api()
run = api.run("entity/project/run_id")
start_time = run.created_at
완료된 Run에 파일 업로드
아래 코드 조각은 선택한 파일을 완료된 Run에 업로드합니다.
import wandb
api = wandb.Api()
run = api.run("entity/project/run_id")
run.upload_file("file_name.extension")
Run에서 파일 다운로드
이것은 cifar 프로젝트에서 Run ID uxte44z7과 연결된 파일 “model-best.h5"를 찾아 로컬에 저장합니다.
import wandb
api = wandb.Api()
run = api.run("<entity>/<project>/<run_id>")
run.file("model-best.h5").download()
Run에서 모든 파일 다운로드
이것은 Run과 연결된 모든 파일을 찾아 로컬에 저장합니다.
import wandb
api = wandb.Api()
run = api.run("<entity>/<project>/<run_id>")
for file in run.files():
file.download()
best_run은 스위프 구성의 metric 파라미터에 의해 정의된 가장 적합한 메트릭을 가진 Run입니다.
스위프에서 가장 적합한 모델 파일 다운로드
이 코드 조각은 모델 파일을 model.h5에 저장한 Runs이 있는 스위프에서 가장 높은 검증 정확도를 가진 모델 파일을 다운로드합니다.
import wandb
api = wandb.Api()
sweep = api.sweep("<entity>/<project>/<sweep_id>")
runs = sorted(sweep.runs, key=lambda run: run.summary.get("val_acc", 0), reverse=True)
val_acc = runs[0].summary.get("val_acc", 0)
print(f"가장 적합한 Run {runs[0].name} (검증 정확도 {val_acc}%)")
runs[0].file("model.h5").download(replace=True)
print("가장 적합한 모델이 model-best.h5에 저장되었습니다.")
Run에서 지정된 확장명을 가진 모든 파일 삭제
이 코드 조각은 Run에서 지정된 확장명을 가진 파일을 삭제합니다.
import wandb
api = wandb.Api()
run = api.run("<entity>/<project>/<run_id>")
extension =".png"files = run.files()
for file in files:
if file.name.endswith(extension):
file.delete()
시스템 메트릭 데이터 다운로드
이 코드 조각은 Run에 대한 모든 시스템 리소스 소비 메트릭이 포함된 데이터프레임을 생성한 다음 CSV에 저장합니다.
import wandb
api = wandb.Api()
run = api.run("<entity>/<project>/<run_id>")
system_metrics = run.history(stream="events")
system_metrics.to_csv("sys_metrics.csv")
요약 메트릭 업데이트
사전을 전달하여 요약 메트릭을 업데이트할 수 있습니다.
summary.update({"key": val})
Run을 실행한 코맨드 가져오기
각 Run은 Run 개요 페이지에서 실행을 시작한 코맨드를 캡처합니다. API에서 이 코맨드를 가져오려면 다음을 실행할 수 있습니다.
import wandb
api = wandb.Api()
run = api.run("<entity>/<project>/<run_id>")
meta = json.load(run.file("wandb-metadata.json").download())
program = ["python"] + [meta["program"]] + meta["args"]
2.1.11 - Environment variables
W&B 환경 변수를 설정하세요.
자동화된 환경에서 스크립트를 실행할 때 스크립트 실행 전 또는 스크립트 내에서 설정된 환경 변수로 wandb를 제어할 수 있습니다.
# 이것은 비밀이며 버전 관리 시스템에 체크인되어서는 안 됩니다.WANDB_API_KEY=$YOUR_API_KEY
# 이름과 노트는 선택 사항입니다.WANDB_NAME="나의 첫 번째 run"WANDB_NOTES="더 작은 학습률, 더 많은 정규화."
# wandb/settings 파일을 체크인하지 않은 경우에만 필요합니다.WANDB_ENTITY=$username
WANDB_PROJECT=$project
# 스크립트가 클라우드에 동기화되는 것을 원하지 않는 경우os.environ["WANDB_MODE"] ="offline"# 스윕 ID 추적을 Run 오브젝트 및 관련 클래스에 추가os.environ["WANDB_SWEEP_ID"] ="b05fq58z"
선택적 환경 변수
이러한 선택적 환경 변수를 사용하여 원격 머신에서 인증을 설정하는 등의 작업을 수행합니다.
변수 이름
사용법
WANDB_ANONYMOUS
사용자가 비밀 URL로 익명 run을 생성하도록 허용하려면 이 변수를 allow, never 또는 must로 설정합니다.
WANDB_API_KEY
계정과 연결된 인증 키를 설정합니다. 키는 설정 페이지에서 찾을 수 있습니다. 원격 머신에서 wandb login이 실행되지 않은 경우 이 변수를 설정해야 합니다.
WANDB_BASE_URL
wandb/local을 사용하는 경우 이 환경 변수를 http://YOUR_IP:YOUR_PORT로 설정해야 합니다.
WANDB_CACHE_DIR
기본값은 ~/.cache/wandb이며, 이 환경 변수로 이 위치를 재정의할 수 있습니다.
WANDB_CONFIG_DIR
기본값은 ~/.config/wandb이며, 이 환경 변수로 이 위치를 재정의할 수 있습니다.
WANDB_CONFIG_PATHS
wandb.config에 로드할 쉼표로 구분된 yaml 파일 목록입니다. config를 참조하십시오.
WANDB_CONSOLE
stdout / stderr 로깅을 비활성화하려면 이 변수를 “off"로 설정합니다. 기본적으로 이를 지원하는 환경에서는 “on"으로 설정됩니다.
WANDB_DATA_DIR
스테이징 Artifacts가 업로드되는 위치입니다. 기본 위치는 platformdirs Python 패키지의 user_data_dir 값을 사용하기 때문에 플랫폼에 따라 다릅니다.
WANDB_DIR
트레이닝 스크립트를 기준으로 wandb 디렉토리가 아닌 여기에 생성된 모든 파일을 저장하려면 이 변수를 절대 경로로 설정합니다. 이 디렉토리가 존재하고 프로세스가 실행되는 사용자가 쓸 수 있는지 확인하십시오. 이는 다운로드된 Artifacts의 위치에는 영향을 미치지 않으며, 대신 _WANDB_ARTIFACT_DIR_을 사용하여 설정할 수 있습니다.
WANDB_ARTIFACT_DIR
트레이닝 스크립트를 기준으로 artifacts 디렉토리가 아닌 여기에 다운로드된 모든 Artifacts를 저장하려면 이 변수를 절대 경로로 설정합니다. 이 디렉토리가 존재하고 프로세스가 실행되는 사용자가 쓸 수 있는지 확인하십시오. 이는 생성된 메타데이터 파일의 위치에는 영향을 미치지 않으며, 대신 _WANDB_DIR_을 사용하여 설정할 수 있습니다.
WANDB_DISABLE_GIT
wandb가 git 저장소를 검색하고 최신 커밋/diff를 캡처하지 못하도록 합니다.
WANDB_DISABLE_CODE
wandb가 노트북 또는 git diff를 저장하지 못하도록 하려면 이 변수를 true로 설정합니다. git 저장소에 있는 경우 현재 커밋은 계속 저장됩니다.
WANDB_DOCKER
run 복원을 활성화하려면 이 변수를 docker 이미지 다이제스트로 설정합니다. 이는 wandb docker 코맨드로 자동 설정됩니다. wandb docker my/image/name:tag --digest를 실행하여 이미지 다이제스트를 얻을 수 있습니다.
WANDB_ENTITY
run과 연결된 entity입니다. 트레이닝 스크립트의 디렉토리에서 wandb init를 실행한 경우 _wandb_라는 디렉토리가 생성되고 소스 제어에 체크인할 수 있는 기본 entity가 저장됩니다. 해당 파일을 생성하지 않거나 파일을 재정의하려는 경우 환경 변수를 사용할 수 있습니다.
WANDB_ERROR_REPORTING
wandb가 심각한 오류를 오류 추적 시스템에 로깅하지 못하도록 하려면 이 변수를 false로 설정합니다.
WANDB_HOST
시스템에서 제공하는 호스트 이름을 사용하지 않으려는 경우 wandb 인터페이스에 표시할 호스트 이름으로 설정합니다.
WANDB_IGNORE_GLOBS
무시할 파일 glob의 쉼표로 구분된 목록으로 설정합니다. 이러한 파일은 클라우드에 동기화되지 않습니다.
WANDB_JOB_NAME
wandb로 생성된 모든 jobs의 이름을 지정합니다.
WANDB_JOB_TYPE
run의 다양한 유형을 나타내기 위해 “training” 또는 “evaluation"과 같은 job 유형을 지정합니다. 자세한 내용은 grouping을 참조하십시오.
WANDB_MODE
이 변수를 “offline"으로 설정하면 wandb가 run 메타데이터를 로컬에 저장하고 서버에 동기화하지 않습니다. 이 변수를 disabled로 설정하면 wandb가 완전히 꺼집니다.
WANDB_NAME
run의 사람이 읽을 수 있는 이름입니다. 설정하지 않으면 임의로 생성됩니다.
WANDB_NOTEBOOK_NAME
jupyter에서 실행 중인 경우 이 변수로 노트북 이름을 설정할 수 있습니다. 자동으로 감지하려고 시도합니다.
WANDB_NOTES
run에 대한 더 긴 메모입니다. Markdown이 허용되며 나중에 UI에서 편집할 수 있습니다.
WANDB_PROJECT
run과 연결된 project입니다. 이는 wandb init로도 설정할 수 있지만 환경 변수가 값을 재정의합니다.
WANDB_RESUME
기본적으로 이는 _never_로 설정됩니다. _auto_로 설정하면 wandb가 실패한 run을 자동으로 재개합니다. _must_로 설정하면 시작 시 run이 강제로 존재합니다. 항상 고유한 ID를 생성하려면 _allow_로 설정하고 항상 WANDB_RUN_ID를 설정합니다.
WANDB_RUN_GROUP
run을 자동으로 그룹화할 실험 이름을 지정합니다. 자세한 내용은 grouping을 참조하십시오.
WANDB_RUN_ID
스크립트의 단일 run에 해당하는 전역적으로 고유한 문자열(project당)로 설정합니다. 64자 이하여야 합니다. 모든 단어가 아닌 문자는 대시로 변환됩니다. 이는 실패 시 기존 run을 재개하는 데 사용할 수 있습니다.
WANDB_SILENT
wandb 로그 문을 숨기려면 이 변수를 true로 설정합니다. 이 변수를 설정하면 모든 로그가 WANDB_DIR/debug.log에 기록됩니다.
WANDB_SHOW_RUN
운영 체제에서 지원하는 경우 run URL로 브라우저를 자동으로 열려면 이 변수를 true로 설정합니다.
WANDB_SWEEP_ID
스윕 ID 추적을 Run 오브젝트 및 관련 클래스에 추가하고 UI에 표시합니다.
WANDB_TAGS
run에 적용할 쉼표로 구분된 태그 목록입니다.
WANDB_USERNAME
run과 연결된 팀 구성원의 사용자 이름입니다. 이는 서비스 계정 API 키와 함께 사용하여 자동화된 run을 팀 구성원에게 귀속시키는 데 사용할 수 있습니다.
WANDB_USER_EMAIL
run과 연결된 팀 구성원의 이메일입니다. 이는 서비스 계정 API 키와 함께 사용하여 자동화된 run을 팀 구성원에게 귀속시키는 데 사용할 수 있습니다.
Singularity 환경
Singularity에서 컨테이너를 실행하는 경우 위의 변수 앞에 **SINGULARITYENV_**를 붙여 환경 변수를 전달할 수 있습니다. Singularity 환경 변수에 대한 자세한 내용은 여기에서 확인할 수 있습니다.
AWS에서 실행
AWS에서 배치 jobs를 실행하는 경우 W&B 자격 증명으로 머신을 쉽게 인증할 수 있습니다. 설정 페이지에서 API 키를 가져오고 AWS 배치 job 사양에서 WANDB_API_KEY 환경 변수를 설정합니다.
W&B Sweeps 를 사용하여 하이퍼파라미터 검색을 자동화하고 풍부하고 인터랙티브한 experiment 추적을 시각화하세요. Bayesian, 그리드 검색 및 random과 같은 인기 있는 검색 방법 중에서 선택하여 하이퍼파라미터 공간을 검색합니다. 하나 이상의 시스템에서 스윕을 확장하고 병렬화합니다.
터미널에서 Ctrl+C를 눌러 현재 run을 중지합니다. 다시 누르면 에이전트가 종료됩니다.
2.2.2 - Add W&B (wandb) to your code
Python 코드 스크립트 또는 Jupyter 노트북 에 W&B를 추가하세요.
스크립트 또는 Jupyter Notebook에 W&B Python SDK를 추가하는 방법은 다양합니다. 아래에는 W&B Python SDK를 사용자 정의 코드에 통합하는 “모범 사례” 예제가 나와 있습니다.
원본 트레이닝 스크립트
다음 코드가 Python 스크립트에 있다고 가정합니다. 일반적인 트레이닝 루프를 모방하는 main이라는 함수를 정의합니다. 각 에포크마다 트레이닝 및 검증 데이터 세트에서 정확도와 손실이 계산됩니다. 이 예제의 목적을 위해 해당 값은 임의로 생성됩니다.
하이퍼파라미터 값을 저장하는 config라는 사전을 정의했습니다. 셀의 끝에서 main 함수를 호출하여 모의 트레이닝 코드를 실행합니다.
import random
import numpy as np
deftrain_one_epoch(epoch, lr, bs):
acc =0.25+ ((epoch /30) + (random.random() /10))
loss =0.2+ (1- ((epoch -1) /10+ random.random() /5))
return acc, loss
defevaluate_one_epoch(epoch):
acc =0.1+ ((epoch /20) + (random.random() /10))
loss =0.25+ (1- ((epoch -1) /10+ random.random() /6))
return acc, loss
# config 변수, 하이퍼파라미터 값 포함config = {"lr": 0.0001, "bs": 16, "epochs": 5}
defmain():
# 하드 코딩된 값을 정의하는 대신# `wandb.config`에서 값을 정의합니다. lr = config["lr"]
bs = config["bs"]
epochs = config["epochs"]
for epoch in np.arange(1, epochs):
train_acc, train_loss = train_one_epoch(epoch, lr, bs)
val_acc, val_loss = evaluate_one_epoch(epoch)
print("epoch: ", epoch)
print("training accuracy:", train_acc, "training loss:", train_loss)
print("validation accuracy:", val_acc, "training loss:", val_loss)
W&B Python SDK를 사용한 트레이닝 스크립트
다음 코드 예제에서는 W&B Python SDK를 코드에 추가하는 방법을 보여줍니다. CLI에서 W&B Sweep 작업을 시작하는 경우 CLI 탭을 살펴보십시오. Jupyter Notebook 또는 Python 스크립트 내에서 W&B Sweep 작업을 시작하는 경우 Python SDK 탭을 살펴보십시오.
W&B Sweep을 생성하기 위해 코드 예제에 다음을 추가했습니다.
Weights & Biases Python SDK를 가져옵니다.
키-값 쌍이 스윕 구성을 정의하는 사전 오브젝트를 생성합니다. 다음 예제에서는 각 스윕 중에 배치 크기(batch_size), 에포크(epochs) 및 학습률(lr) 하이퍼파라미터가 다양합니다. 스윕 구성을 생성하는 방법에 대한 자세한 내용은 스윕 구성 정의를 참조하십시오.
스윕 구성 사전을 wandb.sweep에 전달합니다. 그러면 스윕이 초기화됩니다. 스윕 ID(sweep_id)가 반환됩니다. 스윕을 초기화하는 방법에 대한 자세한 내용은 스윕 초기화를 참조하십시오.
(선택 사항) 하드 코딩된 값을 정의하는 대신 wandb.config에서 값을 정의합니다.
wandb.log를 사용하여 최적화하려는 메트릭을 기록합니다. 구성에 정의된 메트릭을 기록해야 합니다. 구성 사전(이 예제에서는 sweep_configuration) 내에서 val_acc 값을 최대화하도록 스윕을 정의했습니다.
wandb.agent API 호출로 스윕을 시작합니다. 스윕 ID, 스윕이 실행할 함수의 이름(function=main)을 제공하고 시도할 최대 run 수를 4개(count=4)로 설정합니다. W&B Sweep 시작 방법에 대한 자세한 내용은 스윕 에이전트 시작을 참조하십시오.
import wandb
import numpy as np
import random
# 스윕 구성 정의sweep_configuration = {
"method": "random",
"name": "sweep",
"metric": {"goal": "maximize", "name": "val_acc"},
"parameters": {
"batch_size": {"values": [16, 32, 64]},
"epochs": {"values": [5, 10, 15]},
"lr": {"max": 0.1, "min": 0.0001},
},
}
# 구성을 전달하여 스윕을 초기화합니다.# (선택 사항) 프로젝트 이름을 제공합니다.sweep_id = wandb.sweep(sweep=sweep_configuration, project="my-first-sweep")
# `wandb.config`에서 하이퍼파라미터# 값을 가져와서 모델을 트레이닝하고# 메트릭을 반환하는 트레이닝 함수를 정의합니다.deftrain_one_epoch(epoch, lr, bs):
acc =0.25+ ((epoch /30) + (random.random() /10))
loss =0.2+ (1- ((epoch -1) /10+ random.random() /5))
return acc, loss
defevaluate_one_epoch(epoch):
acc =0.1+ ((epoch /20) + (random.random() /10))
loss =0.25+ (1- ((epoch -1) /10+ random.random() /6))
return acc, loss
defmain():
run = wandb.init()
# 하드 코딩된 값을 정의하는 대신# `wandb.config`에서 값을 정의합니다. lr = wandb.config.lr
bs = wandb.config.batch_size
epochs = wandb.config.epochs
for epoch in np.arange(1, epochs):
train_acc, train_loss = train_one_epoch(epoch, lr, bs)
val_acc, val_loss = evaluate_one_epoch(epoch)
wandb.log(
{
"epoch": epoch,
"train_acc": train_acc,
"train_loss": train_loss,
"val_acc": val_acc,
"val_loss": val_loss,
}
)
# 스윕 작업을 시작합니다.wandb.agent(sweep_id, function=main, count=4)
W&B Sweep을 생성하려면 먼저 YAML 구성 파일을 생성합니다. 구성 파일에는 스윕이 탐색할 하이퍼파라미터가 포함되어 있습니다. 다음 예제에서는 각 스윕 중에 배치 크기(batch_size), 에포크(epochs) 및 학습률(lr) 하이퍼파라미터가 다양합니다.
최상위 parameters 키 내에는 learning_rate, batch_size, epoch 및 optimizer 키가 중첩되어 있습니다. 중첩된 각 키에 대해 하나 이상의 값, 분포, 확률 등을 제공할 수 있습니다. 자세한 내용은 스윕 구성 옵션의 파라미터 섹션을 참조하십시오.
이중 중첩 파라미터
스윕 구성은 중첩된 파라미터를 지원합니다. 중첩된 파라미터를 구분하려면 최상위 파라미터 이름 아래에 추가 parameters 키를 사용하십시오. 스윕 구성은 다단계 중첩을 지원합니다.
베이지안 또는 랜덤 하이퍼파라미터 검색을 사용하는 경우 랜덤 변수에 대한 확률 분포를 지정하십시오. 각 하이퍼파라미터에 대해:
스윕 구성에 최상위 parameters 키를 만듭니다.
parameters 키 내에서 다음을 중첩합니다.
최적화하려는 하이퍼파라미터의 이름을 지정합니다.
distribution 키에 사용할 분포를 지정합니다. 하이퍼파라미터 이름 아래에 distribution 키-값 쌍을 중첩합니다.
탐색할 하나 이상의 값을 지정합니다. 값은 분포 키와 일치해야 합니다.
(선택 사항) 최상위 파라미터 이름 아래에 추가 parameters 키를 사용하여 중첩된 파라미터를 구분합니다.
스윕 구성에 정의된 중첩된 파라미터는 W&B run 구성에 지정된 키를 덮어씁니다.
예를 들어, train.py Python 스크립트에서 다음 구성으로 W&B run을 초기화한다고 가정합니다 (1-2행 참조). 다음으로 sweep_configuration이라는 dictionary에 스윕 구성을 정의합니다 (4-13행 참조). 그런 다음 스윕 구성 dictionary를 wandb.sweep에 전달하여 스윕 구성을 초기화합니다 (16행 참조).
metric 최상위 스윕 구성 키를 사용하여 최적화할 이름, 목표 및 대상 메트릭을 지정합니다.
키
설명
name
최적화할 메트릭의 이름입니다.
goal
minimize 또는 maximize (기본값은 minimize)입니다.
target
최적화하려는 메트릭의 목표 값입니다. 스윕은 run이 지정한 목표 값에 도달하면 새 run을 만들지 않습니다. run을 실행 중인 활성 에이전트는 (run이 목표에 도달하면) 에이전트가 새 run 생성을 중단하기 전에 run이 완료될 때까지 기다립니다.
parameters
YAML 파일 또는 Python 스크립트에서 parameters를 최상위 키로 지정합니다. parameters 키 내에서 최적화하려는 하이퍼파라미터의 이름을 제공합니다. 일반적인 하이퍼파라미터에는 학습률, 배치 크기, 에포크, 옵티마이저 등이 있습니다. 스윕 구성에서 정의하는 각 하이퍼파라미터에 대해 하나 이상의 검색 제약 조건을 지정합니다.
다음 표는 지원되는 하이퍼파라미터 검색 제약 조건을 보여줍니다. 하이퍼파라미터 및 유스 케이스에 따라 아래 검색 제약 조건 중 하나를 사용하여 스윕 에이전트에게 검색하거나 사용할 위치 (분포의 경우) 또는 내용 (value, values 등)을 알려줍니다.
검색 제약 조건
설명
values
이 하이퍼파라미터에 대한 모든 유효한 값을 지정합니다. grid와 호환됩니다.
value
이 하이퍼파라미터에 대한 단일 유효한 값을 지정합니다. grid와 호환됩니다.
distribution
확률 분포를 지정합니다. 기본값에 대한 정보는 이 표 다음에 나오는 참고 사항을 참조하십시오.
probabilities
random을 사용할 때 values의 각 요소를 선택할 확률을 지정합니다.
min, max
(int 또는 float) 최대값 및 최소값입니다. int인 경우 int_uniform 분포된 하이퍼파라미터에 사용됩니다. float인 경우 uniform 분포된 하이퍼파라미터에 사용됩니다.
mu
(float) normal 또는 lognormal 분포된 하이퍼파라미터에 대한 평균 파라미터입니다.
sigma
(float) normal 또는 lognormal 분포된 하이퍼파라미터에 대한 표준 편차 파라미터입니다.
method 키를 사용하여 하이퍼파라미터 검색 전략을 지정합니다. 선택할 수 있는 세 가지 하이퍼파라미터 검색 전략이 있습니다: 그리드, 랜덤, 베이지안 탐색.
그리드 검색
하이퍼파라미터 값의 모든 조합을 반복합니다. 그리드 검색은 각 반복에서 사용할 하이퍼파라미터 값 집합에 대해 정보에 입각하지 않은 결정을 내립니다. 그리드 검색은 계산 비용이 많이 들 수 있습니다.
그리드 검색은 연속 검색 공간 내에서 검색하는 경우 영원히 실행됩니다.
랜덤 검색
각 반복에서 분포에 따라 임의의, 정보에 입각하지 않은 하이퍼파라미터 값 집합을 선택합니다. 랜덤 검색은 커맨드라인, Python 스크립트 또는 W&B 앱 UI 내에서 프로세스를 중지하지 않는 한 영원히 실행됩니다.
랜덤 (method: random) 검색을 선택하는 경우 메트릭 키를 사용하여 분포 공간을 지정합니다.
베이지안 탐색
랜덤 및 그리드 검색과 달리 베이지안 모델은 정보에 입각한 결정을 내립니다. 베이지안 최적화는 확률 모델을 사용하여 목적 함수를 평가하기 전에 대리 함수에서 값을 테스트하는 반복적인 프로세스를 통해 사용할 값을 결정합니다. 베이지안 탐색은 작은 수의 연속 파라미터에 적합하지만 확장성이 떨어집니다. 베이지안 탐색에 대한 자세한 내용은 Bayesian Optimization Primer 논문을 참조하십시오.
베이지안 탐색은 커맨드라인, Python 스크립트 또는 W&B 앱 UI 내에서 프로세스를 중지하지 않는 한 영원히 실행됩니다.
랜덤 및 베이지안 탐색을 위한 분포 옵션
parameter 키 내에서 하이퍼파라미터의 이름을 중첩합니다. 다음으로 distribution 키를 지정하고 값에 대한 분포를 지정합니다.
다음 표는 W&B가 지원하는 분포를 나열합니다.
distribution 키 값
설명
constant
상수 분포. 사용할 상수 값 (value)을 지정해야 합니다.
categorical
범주형 분포. 이 하이퍼파라미터에 대한 모든 유효한 값 (values)을 지정해야 합니다.
int_uniform
정수에 대한 이산 균등 분포. max 및 min을 정수로 지정해야 합니다.
uniform
연속 균등 분포. max 및 min을 부동 소수점으로 지정해야 합니다.
q_uniform
양자화된 균등 분포. round(X / q) * q를 반환합니다. 여기서 X는 균등 분포입니다. q의 기본값은 1입니다.
log_uniform
로그 균등 분포. exp(min)과 exp(max) 사이의 값 X를 반환합니다. 여기서 자연 로그는 min과 max 사이에서 균등하게 분포됩니다.
log_uniform_values
로그 균등 분포. min과 max 사이의 값 X를 반환합니다. 여기서 log(X)는 log(min)과 log(max) 사이에서 균등하게 분포됩니다.
q_log_uniform
양자화된 로그 균등 분포. round(X / q) * q를 반환합니다. 여기서 X는 log_uniform입니다. q의 기본값은 1입니다.
q_log_uniform_values
양자화된 로그 균등 분포. round(X / q) * q를 반환합니다. 여기서 X는 log_uniform_values입니다. q의 기본값은 1입니다.
inv_log_uniform
역 로그 균등 분포. X를 반환합니다. 여기서 log(1/X)는 min과 max 사이에서 균등하게 분포됩니다.
inv_log_uniform_values
역 로그 균등 분포. X를 반환합니다. 여기서 log(1/X)는 log(1/max)와 log(1/min) 사이에서 균등하게 분포됩니다.
normal
정규 분포. 평균 mu (기본값 0) 및 표준 편차 sigma (기본값 1)로 정규 분포된 값을 반환합니다.
q_normal
양자화된 정규 분포. round(X / q) * q를 반환합니다. 여기서 X는 normal입니다. Q의 기본값은 1입니다.
log_normal
로그 정규 분포. 자연 로그 log(X)가 평균 mu (기본값 0) 및 표준 편차 sigma (기본값 1)로 정규 분포된 값 X를 반환합니다.
q_log_normal
양자화된 로그 정규 분포. round(X / q) * q를 반환합니다. 여기서 X는 log_normal입니다. q의 기본값은 1입니다.
early_terminate
조기 종료 (early_terminate)를 사용하여 성능이 낮은 run을 중지합니다. 조기 종료가 발생하면 W&B는 새 하이퍼파라미터 값 집합으로 새 run을 만들기 전에 현재 run을 중지합니다.
early_terminate를 사용하는 경우 중지 알고리즘을 지정해야 합니다. 스윕 구성 내에서 early_terminate 내에 type 키를 중첩합니다.
Hyperband 하이퍼파라미터 최적화는 프로그램을 중지해야 하는지 또는 사전 설정된 하나 이상의 반복 횟수 ( brackets 라고 함)에서 계속해야 하는지 평가합니다.
W&B run이 bracket에 도달하면 스윕은 해당 run의 메트릭을 이전에 보고된 모든 메트릭 값과 비교합니다. 스윕은 run의 메트릭 값이 너무 높으면 (목표가 최소화인 경우) 또는 run의 메트릭 값이 너무 낮으면 (목표가 최대화인 경우) run을 종료합니다.
Brackets는 기록된 반복 횟수를 기반으로 합니다. brackets 수는 최적화하는 메트릭을 기록하는 횟수에 해당합니다. 반복은 단계, 에포크 또는 그 사이의 무언가에 해당할 수 있습니다. 단계 카운터의 숫자 값은 bracket 계산에 사용되지 않습니다.
bracket 일정을 만들려면 min_iter 또는 max_iter를 지정합니다.
키
설명
min_iter
첫 번째 bracket에 대한 반복을 지정합니다.
max_iter
최대 반복 횟수를 지정합니다.
s
총 bracket 수를 지정합니다 (max_iter에 필요).
eta
bracket 승수 일정을 지정합니다 (기본값: 3).
strict
원본 Hyperband 논문을 더 면밀히 따르면서 실행을 적극적으로 정리하는 ‘엄격’ 모드를 활성화합니다. 기본값은 false입니다.
Hyperband는 몇 분마다 종료할 W&B run을 확인합니다. run 또는 반복이 짧으면 종료 run 타임스탬프가 지정된 brackets와 다를 수 있습니다.
command
command 키 내에서 중첩된 값으로 형식과 내용을 수정합니다. 파일 이름과 같은 고정된 구성 요소를 직접 포함할 수 있습니다.
Unix 시스템에서 /usr/bin/env는 OS가 환경에 따라 올바른 Python 인터프리터를 선택하도록 합니다.
W&B는 코맨드의 가변 구성 요소에 대해 다음 매크로를 지원합니다.
코맨드 매크로
설명
${env}
Unix 시스템의 경우 /usr/bin/env, Windows에서는 생략됩니다.
${interpreter}
python으로 확장됩니다.
${program}
스윕 구성 program 키로 지정된 트레이닝 스크립트 파일 이름입니다.
${args}
--param1=value1 --param2=value2 형식의 하이퍼파라미터 및 해당 값입니다.
${args_no_boolean_flags}
--param1=value1 형식의 하이퍼파라미터 및 해당 값입니다. 단, 부울 파라미터는 True이면 --boolean_flag_param 형식이고 False이면 생략됩니다.
${args_no_hyphens}
param1=value1 param2=value2 형식의 하이퍼파라미터 및 해당 값입니다.
${args_json}
JSON으로 인코딩된 하이퍼파라미터 및 해당 값입니다.
${args_json_file}
JSON으로 인코딩된 하이퍼파라미터 및 해당 값이 포함된 파일의 경로입니다.
${envvar}
환경 변수를 전달하는 방법입니다. ${envvar:MYENVVAR}은 MYENVVAR 환경 변수의 값으로 확장됩니다.
2.2.4 - Initialize a sweep
W&B 스윕 초기화
W&B는 클라우드 (표준), 로컬 (local) 환경에서 하나 이상의 머신에서 Sweeps 를 관리하기 위해 Sweep Controller 를 사용합니다. Run이 완료되면, 스윕 컨트롤러는 실행할 새로운 Run을 설명하는 새로운 명령어 세트를 발행합니다. 이 명령어는 실제로 Run을 수행하는 에이전트 에 의해 선택됩니다. 일반적인 W&B 스윕에서 컨트롤러는 W&B 서버에 존재합니다. 에이전트는 사용자 의 머신에 존재합니다.
다음 코드 조각은 CLI 및 Jupyter Notebook 또는 Python 스크립트 내에서 스윕을 초기화하는 방법을 보여줍니다.
스윕을 초기화하기 전에 YAML 파일 또는 스크립트의 중첩된 Python dictionary 오브젝트에 스윕 구성이 정의되어 있는지 확인하세요. 자세한 내용은 스윕 구성 정의를 참조하세요.
W&B Sweep 과 W&B Run 은 동일한 Projects 에 있어야 합니다. 따라서 W&B를 초기화할 때 제공하는 이름(wandb.init)은 W&B Sweep 을 초기화할 때 제공하는 Projects 이름(wandb.sweep)과 일치해야 합니다.
W&B SDK를 사용하여 스윕을 초기화합니다. 스윕 구성 dictionary 를 sweep 파라미터에 전달합니다. 선택적으로 W&B Run 의 출력을 저장할 Projects 파라미터 (project)에 대한 프로젝트 이름을 제공합니다. 프로젝트가 지정되지 않은 경우 Run은 “Uncategorized” 프로젝트에 배치됩니다.
멀티 코어 또는 멀티 GPU 머신에서 W&B 스윕 에이전트를 병렬화하세요. 시작하기 전에 W&B 스윕을 초기화했는지 확인하세요. W&B 스윕을 초기화하는 방법에 대한 자세한 내용은 스윕 초기화를 참조하세요.
멀티 CPU 머신에서 병렬화
유스 케이스에 따라 다음 탭을 살펴보고 CLI 또는 Jupyter Notebook 내에서 W&B 스윕 에이전트를 병렬화하는 방법을 알아보세요.
wandb agent 코맨드를 사용하여 터미널에서 여러 CPU에 걸쳐 W&B 스윕 에이전트를 병렬화하세요. 스윕을 초기화할 때 반환된 스윕 ID를 제공하세요.
로컬 머신에서 둘 이상의 터미널 창을 여세요.
아래 코드 조각을 복사하여 붙여넣고 sweep_id를 스윕 ID로 바꾸세요.
wandb agent sweep_id
W&B Python SDK 라이브러리를 사용하여 Jupyter Notebook 내에서 여러 CPU에 걸쳐 W&B 스윕 에이전트를 병렬화하세요. 스윕을 초기화할 때 반환된 스윕 ID가 있는지 확인하세요. 또한 스윕이 실행할 함수의 이름을 function 파라미터에 제공하세요.
둘 이상의 Jupyter Notebook을 여세요.
여러 Jupyter Notebook에 W&B 스윕 ID를 복사하여 붙여넣어 W&B 스윕을 병렬화하세요. 예를 들어, 스윕 ID가 sweep_id라는 변수에 저장되어 있고 함수의 이름이 function_name인 경우 다음 코드 조각을 여러 Jupyter Notebook에 붙여넣어 스윕을 병렬화할 수 있습니다.
CUDA 툴킷을 사용하여 터미널에서 여러 GPU에 걸쳐 W&B 스윕 에이전트를 병렬화하려면 다음 절차를 따르세요.
로컬 머신에서 둘 이상의 터미널 창을 여세요.
W&B 스윕 작업을 시작할 때 CUDA_VISIBLE_DEVICES를 사용하여 사용할 GPU 인스턴스를 지정하세요(wandb agent). 사용할 GPU 인스턴스에 해당하는 정수 값을 CUDA_VISIBLE_DEVICES에 할당하세요.
예를 들어, 로컬 머신에 두 개의 NVIDIA GPU가 있다고 가정해 보겠습니다. 터미널 창을 열고 CUDA_VISIBLE_DEVICES를 0으로 설정하세요(CUDA_VISIBLE_DEVICES=0). 다음 예제에서 sweep_ID를 W&B 스윕을 초기화할 때 반환되는 W&B 스윕 ID로 바꾸세요.
터미널 1
CUDA_VISIBLE_DEVICES=0 wandb agent sweep_ID
두 번째 터미널 창을 여세요. CUDA_VISIBLE_DEVICES를 1로 설정하세요(CUDA_VISIBLE_DEVICES=1). 이전 코드 조각에 언급된 sweep_ID에 대해 동일한 W&B 스윕 ID를 붙여넣으세요.
터미널 2
CUDA_VISIBLE_DEVICES=1 wandb agent sweep_ID
2.2.7 - Visualize sweep results
W&B App UI를 사용하여 W&B Sweeps의 결과를 시각화하세요.
W&B App UI를 사용하여 W&B Sweeps 의 결과를 시각화합니다. https://wandb.ai/home에서 W&B App UI로 이동합니다. W&B Sweep을 초기화할 때 지정한 project를 선택합니다. project workspace로 리디렉션됩니다. 왼쪽 panel에서 Sweep 아이콘(빗자루 아이콘)을 선택합니다. Sweep UI에서 목록에서 Sweep 이름을 선택합니다.
기본적으로 W&B는 W&B Sweep 작업을 시작할 때 평행 좌표 플롯, 파라미터 중요도 플롯 및 산점도를 자동으로 생성합니다.
평행 좌표 차트는 많은 수의 하이퍼파라미터 와 model metrics 간의 관계를 한눈에 요약합니다. 평행 좌표 플롯에 대한 자세한 내용은 평행 좌표를 참조하십시오.
산점도(왼쪽)는 Sweep 중에 생성된 W&B Runs 을 비교합니다. 산점도에 대한 자세한 내용은 산점도를 참조하십시오.
파라미터 중요도 플롯(오른쪽)은 metrics 의 바람직한 value 와 가장 잘 예측하고 높은 상관 관계가 있는 하이퍼파라미터 를 나열합니다. 자세한 내용은 파라미터 중요도 플롯은 파라미터 중요도를 참조하십시오.
자동으로 사용되는 종속 및 독립 value (x 및 y 축)를 변경할 수 있습니다. 각 panel 에는 Edit panel 이라는 연필 아이콘이 있습니다. Edit panel 을 선택합니다. model 이 나타납니다. 모달 내에서 그래프의 행동을 변경할 수 있습니다.
모든 기본 W&B visualization 옵션에 대한 자세한 내용은 Panels를 참조하십시오. W&B Sweep의 일부가 아닌 W&B Runs 에서 플롯을 만드는 방법에 대한 자세한 내용은 Data Visualization docs를 참조하십시오.
2.2.8 - Manage sweeps with the CLI
CLI를 사용하여 W&B 스윕을 일시 중지, 재개 및 취소합니다.
CLI를 사용하여 W&B 스윕을 일시 중지, 재개 및 취소합니다. W&B 스윕을 일시 중지하면 스윕이 재개될 때까지 새로운 W&B Runs이 실행되지 않도록 W&B 에이전트에 알립니다. 스윕을 재개하면 에이전트가 새로운 W&B Runs을 계속 실행합니다. W&B 스윕을 중지하면 W&B 스윕 에이전트가 새로운 W&B Runs의 생성 또는 실행을 중지합니다. W&B 스윕을 취소하면 스윕 에이전트가 현재 실행 중인 W&B Runs을 중단하고 새로운 Runs 실행을 중지합니다.
각각의 경우, W&B 스윕을 초기화할 때 생성된 W&B 스윕 ID를 제공합니다. 선택적으로 새 터미널 창을 열어 다음 명령을 실행합니다. 새 터미널 창은 W&B 스윕이 현재 터미널 창에 출력문을 인쇄하는 경우 명령을 더 쉽게 실행할 수 있도록 합니다.
다음 지침에 따라 스윕을 일시 중지, 재개 및 취소합니다.
스윕 일시 중지
새로운 W&B Runs 실행을 일시적으로 중단하도록 W&B 스윕을 일시 중지합니다. wandb sweep --pause 코맨드를 사용하여 W&B 스윕을 일시 중지합니다. 일시 중지할 W&B 스윕 ID를 제공합니다.
하이퍼파라미터 컨트롤러는 기본적으로 Weights & Biases에서 클라우드 서비스로 호스팅됩니다. W&B 에이전트는 컨트롤러와 통신하여 트레이닝에 사용할 다음 파라미터 세트를 결정합니다. 또한 컨트롤러는 조기 중단 알고리즘을 실행하여 중단할 수 있는 run을 결정합니다.
로컬 컨트롤러 기능을 사용하면 사용자가 로컬에서 검색 및 중단 알고리즘을 시작할 수 있습니다. 로컬 컨트롤러는 사용자에게 문제를 디버그하고 클라우드 서비스에 통합할 수 있는 새로운 기능을 개발하기 위해 코드를 검사하고 계측할 수 있는 기능을 제공합니다.
이 기능은 Sweeps 툴에 대한 새로운 알고리즘의 더 빠른 개발 및 디버깅을 지원하기 위해 제공됩니다. 실제 하이퍼파라미터 최적화 워크로드에는 적합하지 않습니다.
시작하기 전에 W&B SDK(wandb)를 설치해야 합니다. 커맨드라인에 다음 코드 조각을 입력하세요.
pip install wandb sweeps
다음 예제에서는 이미 구성 파일과 트레이닝 루프가 Python 스크립트 또는 Jupyter Notebook에 정의되어 있다고 가정합니다. 구성 파일을 정의하는 방법에 대한 자세한 내용은 스윕 구성 정의를 참조하세요.
커맨드라인에서 로컬 컨트롤러 실행
W&B에서 클라우드 서비스로 호스팅하는 하이퍼파라미터 컨트롤러를 사용할 때와 유사하게 스윕을 초기화합니다. 컨트롤러 플래그(controller)를 지정하여 W&B 스윕 작업에 로컬 컨트롤러를 사용하려는 의사를 나타냅니다.
반환된 W&B Sweep ID를 기록해 둡니다. 다음으로, Python SDK(wandb.agent) 대신 CLI를 사용하여 wandb agent로 Sweep 작업을 시작합니다. 아래 코드 조각에서 sweep_ID를 이전 단계에서 반환된 Sweep ID로 바꿉니다.
wandb agent sweep_ID
anaconda 400 error
다음 오류는 일반적으로 최적화하려는 메트릭을 로깅하지 않을 때 발생합니다.
wandb: ERROR Error while calling W&B API: anaconda 400 error:
{"code": 400, "message": "TypeError: bad operand type for unary -: 'NoneType'"}
YAML 파일 또는 중첩된 사전 내에서 최적화할 “metric"이라는 키를 지정합니다. 이 메트릭을 반드시 로깅(wandb.log)해야 합니다. 또한 Python 스크립트 또는 Jupyter Notebook 내에서 스윕을 최적화하도록 정의한 정확한 메트릭 이름을 사용해야 합니다. 구성 파일에 대한 자세한 내용은 스윕 구성 정의를 참조하세요.
2.2.12 - Sweeps UI
Sweeps UI의 다양한 구성 요소에 대해 설명합니다.
상태 (State), 생성 시간 (Created), 스윕을 시작한 엔티티 (Creator), 완료된 run 수 (Run count) 및 스윕을 계산하는 데 걸린 시간 (Compute time)이 Sweeps UI에 표시됩니다. 스윕이 생성할 것으로 예상되는 run 수 (Est. Runs)는 이산 검색 공간에서 그리드 검색을 수행할 때 제공됩니다. 인터페이스에서 스윕을 클릭하여 스윕을 일시 중지, 재개, 중지 또는 중단할 수도 있습니다.
프로젝트 페이지에서 사이드바의 Sweep tab을 열고 Create Sweep을 선택합니다.
자동 생성된 설정은 완료한 run을 기반으로 스윕할 값을 추측합니다. 시도할 하이퍼파라미터 범위를 지정하도록 설정을 편집합니다. 스윕을 시작하면 호스팅된 W&B 스윕 서버에서 새 프로세스가 시작됩니다. 이 중앙 집중식 서비스는 트레이닝 작업을 실행하는 머신인 에이전트를 조정합니다.
3. 에이전트 시작
다음으로, 로컬에서 에이전트를 시작합니다. 작업을 분산하고 스윕 작업을 더 빨리 완료하려면 최대 20개의 에이전트를 서로 다른 머신에서 병렬로 시작할 수 있습니다. 에이전트는 다음에 시도할 파라미터 세트를 출력합니다.
이제 스윕을 실행하고 있습니다. 다음 이미지는 예제 스윕 작업이 실행되는 동안 대시보드가 어떻게 보이는지 보여줍니다. 예제 프로젝트 페이지 보기 →
기존 run으로 새 스윕 시드하기
이전에 기록한 기존 run을 사용하여 새 스윕을 시작합니다.
프로젝트 테이블을 엽니다.
테이블 왼쪽에서 확인란을 사용하여 사용할 run을 선택합니다.
드롭다운을 클릭하여 새 스윕을 만듭니다.
이제 스윕이 서버에 설정됩니다. run 실행을 시작하려면 하나 이상의 에이전트를 시작하기만 하면 됩니다.
병합된 뷰 또는 나란히 보기로 두 개의 테이블을 비교합니다. 예를 들어 아래 이미지는 MNIST 데이터의 테이블 비교를 보여줍니다.
다음 단계에 따라 두 개의 테이블을 비교합니다.
W&B App에서 프로젝트로 이동합니다.
왼쪽 패널에서 Artifacts 아이콘을 선택합니다.
아티팩트 버전을 선택합니다.
다음 이미지에서는 5개의 에포크 각각 이후에 MNIST 검증 데이터에 대한 모델의 예측을 보여줍니다(여기에서 대화형 예제 보기).
사이드바에서 비교하려는 두 번째 아티팩트 버전 위로 마우스를 가져간 다음 나타나는 비교를 클릭합니다. 예를 들어 아래 이미지에서는 5 에포크 트레이닝 후 동일한 모델에서 만든 MNIST 예측과 비교하기 위해 “v4"로 레이블이 지정된 버전을 선택합니다.
병합된 뷰
처음에는 두 테이블이 함께 병합되어 표시됩니다. 첫 번째 선택한 테이블은 인덱스 0과 파란색 강조 표시가 있고 두 번째 테이블은 인덱스 1과 노란색 강조 표시가 있습니다. 여기에서 병합된 테이블의 라이브 예제를 봅니다.
병합된 뷰에서 다음을 수행할 수 있습니다.
조인 키 선택: 왼쪽 상단의 드롭다운을 사용하여 두 테이블의 조인 키로 사용할 열을 설정합니다. 일반적으로 이것은 데이터셋의 특정 예제의 파일 이름 또는 생성된 샘플의 증가하는 인덱스와 같은 각 행의 고유 식별자입니다. 현재 모든 열을 선택할 수 있으므로 읽을 수 없는 테이블과 느린 쿼리가 발생할 수 있습니다.
조인 대신 연결: 이 드롭다운에서 “모든 테이블 연결"을 선택하여 열을 조인하는 대신 두 테이블의 _모든 행을 결합_하여 더 큰 Table 하나로 만듭니다.
각 Table을 명시적으로 참조: 필터 표현식에서 0, 1 및 *를 사용하여 하나 또는 두 테이블 인스턴스의 열을 명시적으로 지정합니다.
자세한 숫자 차이를 히스토그램으로 시각화: 모든 셀의 값을 한눈에 비교합니다.
나란히 보기
두 개의 테이블을 나란히 보려면 첫 번째 드롭다운을 “테이블 병합: 테이블"에서 “목록: 테이블"로 변경한 다음 “페이지 크기"를 각각 업데이트합니다. 여기서 첫 번째 선택한 Table은 왼쪽에 있고 두 번째 Table은 오른쪽에 있습니다. 또한 “수직” 확인란을 클릭하여 이러한 테이블을 수직으로 비교할 수도 있습니다.
테이블을 한눈에 비교: 모든 작업 (정렬, 필터, 그룹)을 두 테이블에 동시에 적용하고 변경 사항이나 차이점을 빠르게 찾습니다. 예를 들어 추측별로 그룹화된 잘못된 예측, 가장 어려운 네거티브 전체, 실제 레이블별 신뢰도 점수 분포 등을 봅니다.
트레이닝 시간 동안 모델 성능을 분석하기 위해 트레이닝의 의미 있는 각 단계에 대한 아티팩트에서 테이블을 기록합니다. 예를 들어 모든 검증 단계가 끝날 때, 50 에포크의 트레이닝마다 또는 파이프라인에 적합한 빈도로 테이블을 기록할 수 있습니다. 나란히 보기를 사용하여 모델 예측의 변경 사항을 시각화합니다.
트레이닝 시간 동안 예측을 시각화하는 방법에 대한 자세한 내용은 이 Report와 이 대화형 노트북 예제를 참조하십시오.
모델 변형 간 테이블 비교
서로 다른 구성(하이퍼파라미터, 기본 아키텍처 등)에서 모델 성능을 분석하기 위해 두 개의 다른 모델에 대해 동일한 단계에서 기록된 두 개의 아티팩트 버전을 비교합니다.
예를 들어 baseline과 새 모델 변형 2x_layers_2x_lr 간의 예측을 비교합니다. 여기서 첫 번째 컨볼루션 레이어는 32에서 64로, 두 번째 레이어는 128에서 256으로, 학습률은 0.001에서 0.002로 두 배가 됩니다. 이 라이브 예제에서 나란히 보기를 사용하고 1 (왼쪽 탭) 대 5 트레이닝 에포크 (오른쪽 탭) 후에 잘못된 예측으로 필터링합니다.
뷰 저장
run 워크스페이스, 프로젝트 워크스페이스 또는 Report에서 상호 작용하는 테이블은 뷰 상태를 자동으로 저장합니다. 테이블 작업을 적용한 다음 브라우저를 닫으면 테이블은 다음에 테이블로 이동할 때 마지막으로 본 구성을 유지합니다.
아티팩트 컨텍스트에서 상호 작용하는 테이블은 상태 비저장으로 유지됩니다.
특정 상태의 워크스페이스에서 테이블을 저장하려면 W&B Report로 내보냅니다. 테이블을 Report로 내보내려면:
워크스페이스 시각화 패널의 오른쪽 상단 모서리에 있는 케밥 아이콘 (세 개의 수직 점)을 선택합니다.
음색 전송에 대한 이 report에서 오디오 테이블과 상호 작용합니다. 녹음된 고래 노래와 바이올린이나 트럼펫과 같은 악기로 동일한 멜로디를 합성한 연주를 비교할 수 있습니다. 또한 이 colab을 사용하여 자신의 노래를 녹음하고 W&B에서 합성 버전을 탐색할 수도 있습니다.
텍스트
트레이닝 데이터 또는 생성된 출력에서 텍스트 샘플을 찾아보고, 관련 필드별로 동적으로 그룹화하고, 모델 변형 또는 실험 설정에서 평가를 조정합니다. 텍스트를 Markdown으로 렌더링하거나 시각적 차이 모드를 사용하여 텍스트를 비교합니다. 이 report에서 Shakespeare를 생성하기 위한 간단한 문자 기반 RNN을 탐색합니다.
비디오
트레이닝 중에 기록된 비디오를 찾아보고 집계하여 모델을 이해합니다. 다음은 부작용을 최소화하려는 RL 에이전트에 대한 SafeLife 벤치마크를 사용하는 초기 예제입니다.
W&B Artifacts와 마찬가지로, Tables는 쉬운 데이터 내보내기를 위해 pandas 데이터프레임으로 변환할 수 있습니다.
table을 artifact로 변환하기
먼저, 테이블을 아티팩트로 변환해야 합니다. artifact.get(table, "table_name")을 사용하여 가장 쉽게 수행할 수 있습니다.
# 새로운 테이블을 생성하고 로그합니다.with wandb.init() as r:
artifact = wandb.Artifact("my_dataset", type="dataset")
table = wandb.Table(
columns=["a", "b", "c"], data=[(i, i *2, 2**i) for i in range(10)]
)
artifact.add(table, "my_table")
wandb.log_artifact(artifact)
# 생성된 아티팩트를 사용하여 생성된 테이블을 검색합니다.with wandb.init() as r:
artifact = r.use_artifact("my_dataset:latest")
table = artifact.get("my_table")
artifact를 Dataframe으로 변환하기
다음으로, 테이블을 데이터프레임으로 변환합니다.
# 이전 코드 예제에서 계속됩니다.df = table.get_dataframe()
데이터 내보내기
이제 데이터프레임이 지원하는 모든 방법을 사용하여 내보낼 수 있습니다.
# 테이블 데이터를 .csv로 변환df.to_csv("example.csv", encoding="utf-8")
X: X축에 사용할 값을 선택합니다 (기본값은 Step). x축을 Relative Time으로 변경하거나 W&B로 기록하는 값을 기반으로 사용자 정의 축을 선택할 수 있습니다.
Relative Time (Wall) 은 프로세스가 시작된 이후의 시계 시간이므로 run을 시작하고 하루 후에 다시 시작하여 기록한 경우 24시간으로 플롯됩니다.
Relative Time (Process) 는 실행 중인 프로세스 내부의 시간이므로 run을 시작하고 10초 동안 실행한 다음 하루 후에 다시 시작하면 해당 지점이 10초로 플롯됩니다.
Wall Time은 그래프에서 첫 번째 run이 시작된 이후 경과된 시간 (분) 입니다.
Step은 기본적으로 wandb.log()가 호출될 때마다 증가하며 모델에서 기록한 트레이닝 스텝 수를 반영해야 합니다.
Y: 시간에 따라 변하는 메트릭 및 하이퍼파라미터를 포함하여 기록된 값에서 하나 이상의 y축을 선택합니다.
X축 및 Y축 최소 및 최대값 (선택 사항).
포인트 집계 방식. Random sampling (기본값) 또는 Full fidelity. Sampling을 참조하십시오.
Smoothing: 라인 플롯의 Smoothing을 변경합니다. 기본값은 Time weighted EMA입니다. 다른 값으로는 No smoothing, Running average 및 Gaussian이 있습니다.
Outliers: 기본 플롯 최소 및 최대 스케일에서 이상값을 제외하도록 스케일을 재조정합니다.
최대 run 또는 그룹 수: 이 숫자를 늘려 라인 플롯에 더 많은 라인을 한 번에 표시합니다. 기본값은 10개의 run입니다. 사용 가능한 run이 10개 이상이지만 차트가 보이는 수를 제한하는 경우 차트 상단에 “Showing first 10 runs"라는 메시지가 표시됩니다.
차트 유형: 라인 플롯, 영역 플롯 및 백분율 영역 플롯 간에 변경합니다.
Grouping: 플롯에서 run을 그룹화하고 집계할지 여부와 방법을 구성합니다.
Group by: 열을 선택하면 해당 열에서 동일한 값을 가진 모든 run이 함께 그룹화됩니다.
Agg: 집계— 그래프의 라인 값. 옵션은 그룹의 평균, 중앙값, 최소값 및 최대값입니다.
차트: 패널, X축 및 Y축의 제목과 -축을 지정하고 범례를 숨기거나 표시하고 위치를 구성합니다.
범례: 패널의 범례 모양을 사용자 정의합니다 (활성화된 경우).
범례: 플롯의 각 라인에 대한 범례의 필드입니다.
범례 템플릿: 범례에 대한 완전히 사용자 정의 가능한 템플릿을 정의하여 라인 플롯 상단에 표시할 텍스트와 변수 및 마우스를 플롯 위로 이동할 때 나타나는 범례를 정확하게 지정합니다.
Expressions: 사용자 정의 계산된 표현식을 패널에 추가합니다.
Y축 표현식: 계산된 메트릭을 그래프에 추가합니다. 기록된 메트릭과 하이퍼파라미터와 같은 구성 값을 사용하여 사용자 정의 라인을 계산할 수 있습니다.
X축 표현식: 사용자 정의 표현식을 사용하여 계산된 값을 사용하도록 x축의 스케일을 재조정합니다. 유용한 변수에는 기본 x축에 대한**_step**이 포함되며 요약 값을 참조하는 구문은 ${summary:value}입니다.
섹션의 모든 라인 플롯
섹션의 모든 라인 플롯에 대한 기본 설정을 사용자 정의하려면 라인 플롯에 대한 워크스페이스 설정을 재정의합니다.
섹션의 기어 아이콘을 클릭하여 설정을 엽니다.
나타나는 모달 내에서 데이터 또는 표시 기본 설정 탭을 선택하여 섹션의 기본 설정을 구성합니다. 각 데이터 설정에 대한 자세한 내용은 이전 섹션인 개별 라인 플롯을 참조하십시오. 각 표시 기본 설정에 대한 자세한 내용은 섹션 레이아웃 구성을 참조하십시오.
워크스페이스의 모든 라인 플롯
워크스페이스의 모든 라인 플롯에 대한 기본 설정을 사용자 정의하려면:
워크스페이스의 설정을 클릭합니다. 여기에는 설정 레이블이 있는 기어가 있습니다.
라인 플롯을 클릭합니다.
나타나는 모달 내에서 데이터 또는 표시 기본 설정 탭을 선택하여 워크스페이스의 기본 설정을 구성합니다.
각 표시 기본 설정 섹션에 대한 자세한 내용은 워크스페이스 표시 기본 설정을 참조하십시오. 워크스페이스 수준에서 라인 플롯에 대한 기본 확대/축소 동작을 구성할 수 있습니다. 이 설정은 일치하는 x축 키가 있는 라인 플롯에서 확대/축소를 동기화할지 여부를 제어합니다. 기본적으로 비활성화되어 있습니다.
플롯에서 평균값 시각화
여러 개의 다른 Experiments가 있고 플롯에서 해당 값의 평균을 보려면 테이블에서 그룹화 기능을 사용할 수 있습니다. run 테이블 위에서 “그룹"을 클릭하고 “모두"를 선택하여 그래프에 평균값을 표시합니다.
평균화하기 전의 그래프 모양은 다음과 같습니다.
다음 이미지는 그룹화된 라인을 사용하여 run에서 평균값을 나타내는 그래프를 보여줍니다.
플롯에서 NaN 값 시각화
wandb.log를 사용하여 라인 플롯에 PyTorch 텐서를 포함한 NaN 값을 플롯할 수도 있습니다. 예:
wandb.log({"test": [..., float("nan"), ...]})
하나의 차트에서 두 개의 메트릭 비교
페이지 오른쪽 상단에서 패널 추가 버튼을 선택합니다.
나타나는 왼쪽 패널에서 평가 드롭다운을 확장합니다.
Run comparer를 선택합니다.
라인 플롯의 색상 변경
경우에 따라 run의 기본 색상이 비교에 도움이 되지 않을 수 있습니다. 이를 극복하기 위해 wandb는 색상을 수동으로 변경할 수 있는 두 가지 인스턴스를 제공합니다.
각 run은 초기화 시 기본적으로 임의의 색상이 지정됩니다.
색상 중 하나를 클릭하면 색상 팔레트가 나타나고 여기에서 원하는 색상을 수동으로 선택할 수 있습니다.
설정을 편집할 패널 위로 마우스를 가져갑니다.
나타나는 연필 아이콘을 선택합니다.
범례 탭을 선택합니다.
다른 x축에서 시각화
experiment가 소요된 절대 시간을 보거나 experiment가 실행된 날짜를 보려면 x축을 전환할 수 있습니다. 다음은 단계를 상대 시간으로 전환한 다음 벽 시간으로 전환하는 예입니다.
영역 플롯
라인 플롯 설정의 고급 탭에서 다른 플롯 스타일을 클릭하여 영역 플롯 또는 백분율 영역 플롯을 얻습니다.
확대/축소
사각형을 클릭하고 드래그하여 수직 및 수평으로 동시에 확대/축소합니다. 그러면 x축 및 y축 확대/축소가 변경됩니다.
차트 범례 숨기기
이 간단한 토글로 라인 플롯에서 범례를 끕니다.
2.4.1.1.1 - Line plot reference
X축
W&B.log 로 기록한 값이 항상 숫자로 기록되는 한, 선 그래프의 X축을 원하는 값으로 설정할 수 있습니다.
Y축 변수
wandb.log 로 기록한 값이 숫자, 숫자 배열 또는 숫자 히스토그램인 경우 Y축 변수를 원하는 값으로 설정할 수 있습니다. 변수에 대해 1500개 이상의 포인트를 기록한 경우 W&B 는 1500개 포인트로 샘플링합니다.
Runs 테이블에서 run 의 색상을 변경하여 Y축 선의 색상을 변경할 수 있습니다.
X 범위 및 Y 범위
플롯의 X 및 Y의 최대값과 최소값을 변경할 수 있습니다.
X 범위의 기본값은 X축의 최소값에서 최대값까지입니다.
Y 범위의 기본값은 메트릭의 최소값과 0부터 메트릭의 최대값까지입니다.
최대 Runs/그룹
기본적으로 10개의 run 또는 run 그룹만 플롯됩니다. Runs은 run 테이블 또는 run 세트의 맨 위에서 가져오므로 run 테이블 또는 run 세트를 정렬하면 표시되는 run 을 변경할 수 있습니다.
범례
차트의 범례를 제어하여 생성 시간 또는 run 을 생성한 user 와 같은 run 의 모든 config 값과 메타 데이터를 표시할 수 있습니다.
예시:
${run:displayName} - ${config:dropout} 은 각 run 에 대한 범례 이름을 royal-sweep - 0.5 와 같이 만듭니다. 여기서 royal-sweep 은 run 이름이고 0.5 는 dropout 이라는 config 파라미터입니다.
[[ ]] 안에 값을 설정하여 차트 위로 마우스를 가져갈 때 십자선에 특정 포인트 값을 표시할 수 있습니다. 예를 들어 \[\[ $x: $y ($original) ]] 은 “2: 3 (2.9)” 와 같이 표시됩니다.
[[ ]] 내에서 지원되는 값은 다음과 같습니다.
값
의미
${x}
X 값
${y}
Y 값 (스무딩 조정 포함)
${original}
Y 값 (스무딩 조정 미포함)
${mean}
그룹화된 run 의 평균
${stddev}
그룹화된 run 의 표준 편차
${min}
그룹화된 run 의 최소값
${max}
그룹화된 run 의 최대값
${percent}
합계의 백분율 (누적 영역 차트의 경우)
그룹화
그룹화를 켜서 모든 run 을 집계하거나 개별 변수별로 그룹화할 수 있습니다. 테이블 내에서 그룹화하여 그룹화를 켤 수도 있으며 그룹이 그래프에 자동으로 채워집니다.
스무딩
스무딩 계수를 0과 1 사이로 설정할 수 있습니다. 여기서 0은 스무딩 없음, 1은 최대 스무딩입니다.
이상치 무시
기본 플롯 최소 및 최대 스케일에서 이상치를 제외하도록 플롯의 스케일을 다시 조정합니다. 플롯에 대한 설정의 영향은 플롯의 샘플링 모드에 따라 다릅니다.
임의 샘플링 모드를 사용하는 플롯의 경우 이상치 무시를 활성화하면 5%에서 95%의 포인트만 표시됩니다. 이상치가 표시되더라도 다른 포인트와 다르게 서식이 지정되지는 않습니다.
전체 충실도 모드를 사용하는 플롯의 경우 모든 포인트가 항상 표시되며 각 버킷의 마지막 값으로 압축됩니다. 이상치 무시를 활성화하면 각 버킷의 최소 및 최대 경계가 음영 처리됩니다. 그렇지 않으면 영역이 음영 처리되지 않습니다.
표현식
표현식을 사용하면 1-정확도와 같은 메트릭에서 파생된 값을 플롯할 수 있습니다. 현재 단일 메트릭을 플롯하는 경우에만 작동합니다. 간단한 산술 표현식 +, -, *, / 및 %는 물론 거듭제곱에 대한 **를 수행할 수 있습니다.
플롯 스타일
선 그래프의 스타일을 선택합니다.
선 그래프:
영역 그래프:
백분율 영역 그래프:
2.4.1.1.2 - Point aggregation
Data Visualization 정확도와 성능을 향상시키려면 라인 플롯 내에서 포인트 집계 방법을 사용하세요. 포인트 집계 모드에는 전체 충실도와 임의 샘플링의 두 가지 유형이 있습니다. W&B는 기본적으로 전체 충실도 모드를 사용합니다.
전체 충실도
전체 충실도 모드를 사용하면 W&B는 데이터 포인트 수를 기반으로 x축을 동적 버킷으로 나눕니다. 그런 다음 라인 플롯에 대한 포인트 집계를 렌더링하는 동안 각 버킷 내의 최소값, 최대값 및 평균값을 계산합니다.
포인트 집계에 전체 충실도 모드를 사용하면 다음과 같은 세 가지 주요 이점이 있습니다.
극단값 및 스파이크 보존: 데이터에서 극단값 및 스파이크를 유지합니다.
최소 및 최대 포인트 렌더링 방법 구성: W&B 앱을 사용하여 극단(최소/최대) 값을 음영 영역으로 표시할지 여부를 대화식으로 결정합니다.
데이터 정확도를 잃지 않고 데이터 탐색: 특정 데이터 포인트를 확대하면 W&B가 x축 버킷 크기를 다시 계산합니다. 이는 정확도를 잃지 않고 데이터를 탐색하는 데 도움이 됩니다. 캐싱은 이전에 계산된 집계를 저장하여 로딩 시간을 줄이는 데 사용되며, 이는 대규모 데이터셋을 탐색할 때 특히 유용합니다.
최소 및 최대 포인트 렌더링 방법 구성
라인 플롯 주위에 음영 영역을 사용하여 최소값과 최대값을 표시하거나 숨깁니다.
다음 이미지는 파란색 라인 플롯을 보여줍니다. 밝은 파란색 음영 영역은 각 버킷의 최소값과 최대값을 나타냅니다.
이동 평균은 주어진 x 값 이전과 이후의 창에서 점의 평균으로 점을 대체하는 평활화 알고리즘입니다. https://en.wikipedia.org/wiki/Moving_average의 “Boxcar Filter"를 참조하세요. 이동 평균에 대해 선택된 파라미터는 Weights and Biases에 이동 평균에서 고려할 점의 수를 알려줍니다.
모든 평활화 알고리즘은 샘플링된 데이터에서 실행됩니다. 즉, 1500개 이상의 점을 기록하면 평활화 알고리즘은 서버에서 점을 다운로드한 후에 실행됩니다. 평활화 알고리즘의 의도는 데이터에서 패턴을 빠르게 찾는 데 도움을 주는 것입니다. 많은 수의 기록된 점이 있는 메트릭에 대해 정확한 평활화된 값이 필요한 경우 API를 통해 메트릭을 다운로드하고 자체 평활화 methods를 실행하는 것이 좋습니다.
원본 데이터 숨기기
기본적으로 원본의 평활화되지 않은 데이터가 배경에 희미한 선으로 표시됩니다. 원본 보기 토글을 클릭하여 이 기능을 끄세요.
2.4.1.2 - Bar plots
메트릭을 시각화하고, 축을 사용자 정의하고, 범주형 데이터를 막대로 비교하세요.
막대 그래프는 범주형 데이터를 직사각형 막대로 나타내며, 이 막대는 수직 또는 수평으로 플롯할 수 있습니다. 모든 기록된 값이 길이가 1인 경우 막대 그래프는 기본적으로 wandb.log() 와 함께 표시됩니다.
차트 설정을 사용하여 표시할 최대 Runs 수를 제한하고, 모든 config별로 Runs를 그룹화하고, 레이블 이름을 바꿀 수 있습니다.
막대 그래프 사용자 정의
Box 또는 Violin 플롯을 생성하여 여러 요약 통계를 하나의 차트 유형으로 결합할 수도 있습니다.
Runs 테이블을 통해 Runs를 그룹화합니다.
워크스페이스에서 ‘패널 추가’를 클릭합니다.
표준 ‘막대 차트’를 추가하고 플롯할 메트릭을 선택합니다.
‘그룹화’ 탭에서 ‘box plot’ 또는 ‘Violin’ 등을 선택하여 이러한 스타일 중 하나를 플롯합니다.
이렇게 하면 현재 디렉토리와 모든 하위 디렉토리의 모든 파이썬 소스 코드 파일이 artifact로 캡처됩니다. 저장되는 소스 코드 파일의 유형 및 위치를 보다 세밀하게 제어하려면 참조 문서를 참조하세요.
UI에서 코드 저장 설정
프로그래밍 방식으로 코드 저장을 설정하는 것 외에도 W&B 계정 설정에서 이 기능을 토글할 수도 있습니다. 이는 계정과 연결된 모든 Teams에 대해 코드 저장을 활성화합니다.
기본적으로 W&B는 모든 Teams에 대해 코드 저장을 비활성화합니다.
W&B 계정에 로그인합니다.
Settings > Privacy로 이동합니다.
Project and content security에서 Disable default code saving을 켭니다.
코드 비교기
서로 다른 W&B Runs에서 사용된 코드를 비교합니다.
페이지 오른쪽 상단에서 Add panels 버튼을 선택합니다.
TEXT AND CODE 드롭다운을 확장하고 Code를 선택합니다.
Jupyter 세션 기록
W&B는 Jupyter 노트북 세션에서 실행된 코드의 기록을 저장합니다. Jupyter 내에서 **wandb.init()**을 호출하면 W&B는 현재 세션에서 실행된 코드의 기록이 포함된 Jupyter 노트북을 자동으로 저장하는 훅을 추가합니다.
코드가 포함된 project 워크스페이스로 이동합니다.
왼쪽 네비게이션 바에서 Artifacts 탭을 선택합니다.
code artifact를 확장합니다.
Files 탭을 선택합니다.
이렇게 하면 iPython의 display 메소드를 호출하여 생성된 모든 출력과 함께 세션에서 실행된 셀이 표시됩니다. 이를 통해 지정된 Run 내에서 Jupyter 내에서 실행된 코드를 정확히 볼 수 있습니다. 가능한 경우 W&B는 코드 디렉토리에서도 찾을 수 있는 노트북의 최신 버전도 저장합니다.
2.4.1.6 - Parameter importance
모델의 하이퍼파라미터와 출력 메트릭 간의 관계를 시각화합니다.
어떤 하이퍼파라미터가 가장 예측력이 높고 메트릭의 바람직한 값과 상관관계가 높은지 알아보세요.
**상관 관계(Correlation)**는 하이퍼파라미터와 선택한 메트릭 (이 경우 val_loss) 간의 선형 상관 관계입니다. 따라서 상관 관계가 높다는 것은 하이퍼파라미터의 값이 높을 때 메트릭도 더 높은 값을 갖고 그 반대도 마찬가지임을 의미합니다. 상관 관계는 살펴보기에 좋은 메트릭이지만 입력 간의 2차 상호 작용을 포착할 수 없으며 범위가 매우 다른 입력을 비교하는 것이 복잡해질 수 있습니다.
따라서 W&B는 중요도(importance) 메트릭도 계산합니다. W&B는 하이퍼파라미터를 입력으로, 메트릭을 대상 출력으로 사용하여 랜덤 포레스트를 트레이닝하고 랜덤 포레스트에 대한 특징 중요도 값을 리포트합니다.
이 기술에 대한 아이디어는 Fast.ai에서 하이퍼파라미터 공간을 탐색하기 위해 랜덤 포레스트 특징 중요도를 사용하는 것을 개척한 Jeremy Howard와의 대화에서 영감을 받았습니다. 이 강의 (및 이 노트)를 확인하여 이 분석의 동기에 대해 자세히 알아보는 것이 좋습니다.
하이퍼파라미터 중요도 패널은 상관관계가 높은 하이퍼파라미터 간의 복잡한 상호 작용을 해결합니다. 이를 통해 모델 성능 예측 측면에서 가장 중요한 하이퍼파라미터를 보여줌으로써 하이퍼파라미터 검색을 미세 튜닝하는 데 도움이 됩니다.
하이퍼파라미터 중요도 패널 만들기
W&B 프로젝트로 이동합니다.
패널 추가 버튼을 선택합니다.
차트 드롭다운을 확장하고 드롭다운에서 평행 좌표를 선택합니다.
빈 패널이 나타나면 Runs이 그룹 해제되었는지 확인하십시오.
파라미터 관리자를 사용하면 표시 및 숨겨진 파라미터를 수동으로 설정할 수 있습니다.
하이퍼파라미터 중요도 패널 해석하기
이 패널은 트레이닝 스크립트의 wandb.config오브젝트에 전달된 모든 파라미터를 보여줍니다. 다음으로 이러한 config 파라미터의 특징 중요도와 모델 메트릭과 관련된 상관 관계를 보여줍니다 (이 경우 val_loss).
중요도
중요도 열은 각 하이퍼파라미터가 선택한 메트릭을 예측하는 데 얼마나 유용한지를 보여줍니다. 수많은 하이퍼파라미터를 튜닝하기 시작하고 이 플롯을 사용하여 추가 탐색할 가치가 있는 하이퍼파라미터를 정확히 찾아내는 시나리오를 상상해 보십시오. 후속 스윕은 가장 중요한 하이퍼파라미터로 제한되어 더 좋고 저렴한 모델을 더 빠르게 찾을 수 있습니다.
W&B는 선형 모델보다 트리 기반 모델을 사용하여 중요도를 계산합니다. 전자는 범주형 데이터와 정규화되지 않은 데이터 모두에 더 관대하기 때문입니다.
위의 이미지에서 epochs, learning_rate, batch_size 및 weight_decay가 상당히 중요하다는 것을 알 수 있습니다.
상관 관계
상관 관계는 개별 하이퍼파라미터와 메트릭 값 간의 선형 관계를 캡처합니다. SGD 옵티마이저와 같은 하이퍼파라미터를 사용하는 것과 val_loss 사이에 중요한 관계가 있는지에 대한 질문에 답합니다 (이 경우 답은 ‘예’입니다). 상관 관계 값은 -1에서 1 사이이며, 양수 값은 양의 선형 상관 관계를 나타내고 음수 값은 음의 선형 상관 관계를 나타내고 값 0은 상관 관계가 없음을 나타냅니다. 일반적으로 어느 방향이든 0.7보다 큰 값은 강한 상관 관계를 나타냅니다.
이 그래프를 사용하여 메트릭과 더 높은 상관 관계가 있는 값을 추가로 탐색하거나 (이 경우 rmsprop 또는 nadam보다 stochastic gradient descent 또는 adam을 선택할 수 있음) 더 많은 에포크 동안 트레이닝할 수 있습니다.
상관 관계는 반드시 인과 관계가 아닌 연관성의 증거를 보여줍니다.
상관 관계는 이상치에 민감하며, 특히 시도한 하이퍼파라미터의 샘플 크기가 작은 경우 강한 관계를 보통 관계로 바꿀 수 있습니다.
마지막으로 상관 관계는 하이퍼파라미터와 메트릭 간의 선형 관계만 캡처합니다. 강한 다항 관계가 있는 경우 상관 관계에 의해 캡처되지 않습니다.
중요도와 상관 관계의 차이는 중요도가 하이퍼파라미터 간의 상호 작용을 고려하는 반면 상관 관계는 개별 하이퍼파라미터가 메트릭 값에 미치는 영향만 측정한다는 사실에서 비롯됩니다. 둘째, 상관 관계는 선형 관계만 캡처하는 반면 중요도는 더 복잡한 관계를 캡처할 수 있습니다.
보시다시피 중요도와 상관 관계는 모두 하이퍼파라미터가 모델 성능에 미치는 영향을 이해하는 데 유용한 툴입니다.
2.4.1.7 - Compare run metrics
여러 run에서 메트릭 비교
Run Comparer를 사용하여 여러 run에서 어떤 메트릭이 다른지 확인하세요.
페이지 오른쪽 상단에서 패널 추가 버튼을 선택합니다.
나타나는 왼쪽 패널에서 Evaluation 드롭다운을 확장합니다.
Run Comparer를 선택합니다.
Diff Only 옵션을 켜서 여러 run에서 값이 동일한 행을 숨깁니다.
2.4.1.8 - Query panels
이 페이지의 일부 기능은 베타 버전이며 기능 플래그 뒤에 숨겨져 있습니다. 프로필 페이지의 자기 소개에 weave-plot을 추가하여 관련된 모든 기능을 잠금 해제하세요.
W&B Weave를 찾고 계신가요? W&B의 Generative AI 애플리케이션 구축 툴 모음인가요? weave에 대한 문서는 여기에서 찾으세요: wandb.me/weave.
쿼리 패널을 사용하여 데이터를 쿼리하고 대화형으로 시각화하세요.
쿼리 패널 만들기
워크스페이스 또는 리포트 내에 쿼리를 추가하세요.
프로젝트 워크스페이스로 이동합니다.
오른쪽 상단 모서리에서 패널 추가를 클릭합니다.
드롭다운에서 쿼리 패널을 선택합니다.
/쿼리 패널을 입력하고 선택합니다.
또는 쿼리를 run 집합과 연결할 수 있습니다:
리포트 내에서 /패널 그리드를 입력하고 선택합니다.
패널 추가 버튼을 클릭합니다.
드롭다운에서 쿼리 패널을 선택합니다.
쿼리 구성 요소
표현식
쿼리 표현식을 사용하여 run, Artifacts, Models, 테이블 등과 같이 W&B에 저장된 데이터를 쿼리합니다.
(row) => row["Label"]은 각 테이블에 대한 선택기이며 조인할 열을 결정합니다.
"Table1" 및 "Table2"는 조인될 때 각 테이블의 이름입니다.
true 및 false는 왼쪽 및 오른쪽 내부/외부 조인 설정을 위한 것입니다.
Runs 오브젝트
쿼리 패널을 사용하여 runs 오브젝트에 엑세스합니다. Run 오브젝트는 Experiments 기록을 저장합니다. 이 섹션의 리포트에서 자세한 내용을 확인할 수 있지만, 간략하게 살펴보면 runs 오브젝트는 다음과 같습니다.
summary: run 결과를 요약하는 정보 사전입니다. 여기에는 정확도 및 손실과 같은 스칼라 또는 큰 파일이 포함될 수 있습니다. 기본적으로 wandb.log()는 Summary를 로깅된 시계열의 최종 값으로 설정합니다. Summary 내용을 직접 설정할 수 있습니다. Summary를 run의 출력이라고 생각하세요.
history: 손실과 같이 모델이 트레이닝되는 동안 변경되는 값을 저장하기 위한 사전 목록입니다. wandb.log() 코맨드는 이 오브젝트에 추가됩니다.
config: 트레이닝 Run에 대한 하이퍼파라미터 또는 데이터셋 Artifact를 생성하는 Run에 대한 전처리 메소드와 같은 Run의 설정 정보 사전입니다. 이것을 Run의 “입력"이라고 생각하십시오.
Artifacts 엑세스
Artifacts는 W&B의 핵심 개념입니다. 버전이 지정된 명명된 파일 및 디렉토리 모음입니다. Artifacts를 사용하여 모델 가중치, 데이터셋 및 기타 파일 또는 디렉토리를 추적합니다. Artifacts는 W&B에 저장되며 다운로드하거나 다른 Run에서 사용할 수 있습니다. 이 섹션의 리포트에서 자세한 내용과 예제를 확인할 수 있습니다. Artifacts는 일반적으로 project 오브젝트에서 엑세스됩니다.
project.artifactVersion(): 프로젝트 내에서 주어진 이름과 버전에 대한 특정 아티팩트 버전을 반환합니다.
project.artifact(""): 프로젝트 내에서 주어진 이름에 대한 아티팩트를 반환합니다. 그런 다음 .versions를 사용하여 이 아티팩트의 모든 버전 목록을 가져올 수 있습니다.
project.artifactType(): 프로젝트 내에서 주어진 이름에 대한 artifactType을 반환합니다. 그런 다음 .artifacts를 사용하여 이 유형의 모든 아티팩트 목록을 가져올 수 있습니다.
project.artifactTypes: 프로젝트 아래의 모든 아티팩트 유형 목록을 반환합니다.
2.4.1.8.1 - Embed objects
W&B의 Embedding Projector를 통해 PCA, UMAP, t-SNE와 같은 일반적인 차원 축소 알고리즘을 사용하여 다차원 임베딩을 2D 평면에 플롯할 수 있습니다.
Embeddings는 오브젝트 (사람, 이미지, 게시물, 단어 등)를 숫자 목록 ( vector 라고도 함)으로 나타내는 데 사용됩니다. 기계 학습 및 데이터 과학 유스 케이스에서 Embeddings는 다양한 애플리케이션에서 다양한 접근 방식을 사용하여 생성할 수 있습니다. 이 페이지에서는 독자가 Embeddings에 익숙하고 W&B 내에서 Embeddings를 시각적으로 분석하는 데 관심이 있다고 가정합니다.
위의 코드를 실행하면 W&B 대시보드에 데이터가 포함된 새 Table이 표시됩니다. 오른쪽 상단 패널 선택기에서 2D Projection을 선택하여 Embeddings를 2차원으로 플롯할 수 있습니다. 스마트 기본값이 자동으로 선택되며, 기어 아이콘을 클릭하여 엑세스할 수 있는 설정 메뉴에서 쉽게 재정의할 수 있습니다. 이 예제에서는 사용 가능한 5개의 숫자 차원을 모두 자동으로 사용합니다.
Digits MNIST
위의 예제는 Embeddings 로깅의 기본 메커니즘을 보여 주지만 일반적으로 훨씬 더 많은 차원과 샘플을 사용합니다. MNIST Digits 데이터셋 (UCI ML 손으로 쓴 숫자 데이터셋s)을 고려해 보겠습니다. SciKit-Learn을 통해 사용할 수 있습니다. 이 데이터셋에는 각각 64개의 차원을 가진 1797개의 레코드가 있습니다. 문제는 10개의 클래스 분류 유스 케이스입니다. 시각화를 위해 입력 데이터를 이미지로 변환할 수도 있습니다.
위의 코드를 실행하면 UI에 Table이 다시 표시됩니다. 2D Projection을 선택하면 Embedding 정의, 색상, 알고리즘 (PCA, UMAP, t-SNE), 알고리즘 파라미터를 구성하고 오버레이할 수도 있습니다 (이 경우 점 위로 마우스를 가져갈 때 이미지가 표시됨). 이 특정 경우에서는 이 모든 것이 “스마트 기본값"이며 2D Projection에서 한 번의 클릭으로 매우 유사한 내용을 볼 수 있습니다. (이 예제와 상호 작용하려면 여기를 클릭하십시오.).
로깅 옵션
다양한 형식으로 Embeddings를 로그할 수 있습니다.
단일 Embedding 열: 데이터가 이미 “매트릭스"와 유사한 형식인 경우가 많습니다. 이 경우 셀 값의 데이터 유형이 list[int], list[float] 또는 np.ndarray일 수 있는 단일 Embedding 열을 만들 수 있습니다.
여러 숫자 열: 위의 두 예제에서는 이 접근 방식을 사용하고 각 차원에 대한 열을 만듭니다. 현재 셀에 대해 python int 또는 float를 허용합니다.
또한 모든 테이블과 마찬가지로 테이블 구성 방법에 대한 많은 옵션이 있습니다.
wandb.Table(dataframe=df)를 사용하여 데이터프레임에서 직접
wandb.Table(data=[...], columns=[...])를 사용하여 데이터 목록에서 직접
테이블을 점진적으로 행 단위로 빌드합니다 (코드에 루프가 있는 경우에 적합). table.add_data(...)를 사용하여 테이블에 행을 추가합니다.
테이블에 Embedding 열을 추가합니다 (Embedding 형식의 예측 목록이 있는 경우에 적합): table.add_col("col_name", ...)
계산된 열을 추가합니다 (테이블에서 매핑하려는 함수 또는 model이 있는 경우에 적합): table.add_computed_columns(lambda row, ndx: {"embedding": model.predict(row)})
플로팅 옵션
2D Projection을 선택한 후 기어 아이콘을 클릭하여 렌더링 설정을 편집할 수 있습니다. 원하는 열을 선택하는 것 외에도 (위 참조) 원하는 알고리즘 (원하는 파라미터와 함께)을 선택할 수 있습니다. 아래에서 UMAP 및 t-SNE에 대한 파라미터를 각각 볼 수 있습니다.
참고: 현재 세 가지 알고리즘 모두에 대해 임의의 1000개 행과 50개 차원의 서브셋으로 다운샘플링합니다.
2.4.2 - Custom charts
W&B 프로젝트에서 커스텀 차트를 만드세요. 임의의 데이터 테이블을 기록하고 원하는 방식으로 시각화하세요. Vega의 강력한 기능을 사용하여 글꼴, 색상 및 툴팁의 세부 사항을 제어하세요.
차트 사용자 정의: GraphQL 쿼리로 기록된 데이터를 가져옵니다. 강력한 시각화 문법인 Vega로 쿼리 결과를 시각화합니다.
차트 기록: wandb.plot_table()로 스크립트에서 자체 프리셋을 호출합니다.
예상되는 데이터가 보이지 않으면 찾고 있는 열이 선택된 runs에 기록되지 않았을 수 있습니다. 차트를 저장하고 runs 테이블로 돌아가서 눈 아이콘을 사용하여 선택한 runs를 확인합니다.
스크립트에서 차트 기록
내장 프리셋
W&B에는 스크립트에서 직접 기록할 수 있는 여러 내장 차트 프리셋이 있습니다. 여기에는 선 플롯, 산점도, 막대 차트, 히스토그램, PR 곡선 및 ROC 곡선이 포함됩니다.
wandb.plot.line()
임의의 축 x와 y에서 연결되고 정렬된 점 목록(x,y)인 사용자 지정 선 플롯을 기록합니다.
data = [[x, y] for (x, y) in zip(x_values, y_values)]
table = wandb.Table(data=data, columns=["x", "y"])
wandb.log(
{
"my_custom_plot_id": wandb.plot.line(
table, "x", "y", title="Custom Y vs X Line Plot" )
}
)
선 플롯은 두 차원에 대한 곡선을 기록합니다. 두 값 목록을 서로 플롯하는 경우 목록의 값 수는 정확히 일치해야 합니다(예: 각 점에 x와 y가 있어야 함).
값 목록을 발생 횟수/빈도별로 구간으로 정렬하여 사용자 지정 히스토그램으로 기본적으로 몇 줄 안에 기록합니다. 예측 신뢰도 점수 목록(scores)이 있고 해당 분포를 시각화하려는 경우를 예로 들어 보겠습니다.
data = [[s] for s in scores]
table = wandb.Table(data=data, columns=["scores"])
wandb.log({"my_histogram": wandb.plot.histogram(table, "scores", title=None)})
이를 사용하여 임의의 히스토그램을 기록할 수 있습니다. data는 행과 열의 2D 배열을 지원하기 위한 목록의 목록입니다.
내장 프리셋을 조정하거나 새 프리셋을 만든 다음 차트를 저장합니다. 차트 ID를 사용하여 스크립트에서 해당 커스텀 프리셋에 직접 데이터를 기록합니다. 예제 Google Colab 노트북을 사용해 보세요.
# 플롯할 열이 있는 테이블 만들기table = wandb.Table(data=data, columns=["step", "height"])
# 테이블의 열에서 차트의 필드로 매핑fields = {"x": "step", "value": "height"}
# 테이블을 사용하여 새 커스텀 차트 프리셋 채우기# 자신의 저장된 차트 프리셋을 사용하려면 vega_spec_name을 변경하세요.my_custom_chart = wandb.plot_table(
vega_spec_name="carey/new_chart",
data_table=table,
fields=fields,
)
데이터 기록
스크립트에서 다음 데이터 형식을 기록하고 커스텀 차트에서 사용할 수 있습니다.
Config: 실험의 초기 설정(독립 변수). 여기에는 트레이닝 시작 시 wandb.config에 대한 키로 기록한 명명된 필드가 포함됩니다. 예: wandb.config.learning_rate = 0.0001
요약: 트레이닝 중에 기록된 단일 값(결과 또는 종속 변수). 예: wandb.log({"val_acc" : 0.8}). wandb.log()를 통해 트레이닝 중에 이 키에 여러 번 쓰면 요약이 해당 키의 최종 값으로 설정됩니다.
History: 기록된 스칼라의 전체 시계열은 history 필드를 통해 쿼리에 사용할 수 있습니다.
summaryTable: 여러 값 목록을 기록해야 하는 경우 wandb.Table()을 사용하여 해당 데이터를 저장한 다음 커스텀 패널에서 쿼리합니다.
historyTable: history 데이터를 봐야 하는 경우 커스텀 차트 패널에서 historyTable을 쿼리합니다. wandb.Table()을 호출하거나 커스텀 차트를 기록할 때마다 해당 단계의 history에 새 테이블을 만들고 있습니다.
커스텀 테이블을 기록하는 방법
wandb.Table()을 사용하여 데이터를 2D 배열로 기록합니다. 일반적으로 이 테이블의 각 행은 하나의 데이터 점을 나타내고 각 열은 플롯하려는 각 데이터 점에 대한 관련 필드/차원을 나타냅니다. 커스텀 패널을 구성할 때 전체 테이블은 wandb.log()(custom_data_table 아래)에 전달된 명명된 키를 통해 액세스할 수 있으며 개별 필드는 열 이름(x, y 및 z)을 통해 액세스할 수 있습니다. 실험 전반에 걸쳐 여러 시간 단계에서 테이블을 기록할 수 있습니다. 각 테이블의 최대 크기는 10,000행입니다. 예제 Google Colab을 사용해 보세요.
새 커스텀 차트를 추가하여 시작한 다음 쿼리를 편집하여 표시되는 runs에서 데이터를 선택합니다. 쿼리는 GraphQL을 사용하여 runs의 config, 요약 및 history 필드에서 데이터를 가져옵니다.
커스텀 시각화
오른쪽 상단 모서리에서 차트를 선택하여 기본 프리셋으로 시작합니다. 다음으로 차트 필드를 선택하여 쿼리에서 가져오는 데이터를 차트의 해당 필드에 매핑합니다.
다음 이미지는 메트릭을 선택한 다음 아래의 막대 차트 필드에 매핑하는 방법을 보여주는 예입니다.
Vega를 편집하는 방법
패널 상단의 편집을 클릭하여 Vega 편집 모드로 들어갑니다. 여기에서 UI에서 대화형 차트를 만드는 Vega 사양을 정의할 수 있습니다. 차트의 모든 측면을 변경할 수 있습니다. 예를 들어 제목을 변경하고, 다른 색 구성표를 선택하고, 곡선을 연결된 선 대신 일련의 점으로 표시할 수 있습니다. 또한 Vega 변환을 사용하여 값 배열을 히스토그램으로 비닝하는 등 데이터 자체를 변경할 수도 있습니다. 패널 미리 보기가 대화형으로 업데이트되므로 Vega 사양 또는 쿼리를 편집할 때 변경 사항의 효과를 볼 수 있습니다. Vega 문서 및 튜토리얼을 참조하세요.
필드 참조
W&B에서 차트로 데이터를 가져오려면 Vega 사양의 아무 곳에나 "${field:<field-name>}" 형식의 템플릿 문자열을 추가합니다. 그러면 오른쪽의 차트 필드 영역에 드롭다운이 생성되어 사용자가 쿼리 결과 열을 선택하여 Vega에 매핑할 수 있습니다.
필드의 기본값을 설정하려면 다음 구문을 사용하세요. "${field:<field-name>:<placeholder text>}"
차트 프리셋 저장
모달 하단의 버튼을 사용하여 특정 시각화 패널에 대한 변경 사항을 적용합니다. 또는 Vega 사양을 저장하여 프로젝트의 다른 곳에서 사용할 수 있습니다. 재사용 가능한 차트 정의를 저장하려면 Vega 편집기 상단의 다른 이름으로 저장을 클릭하고 프리셋에 이름을 지정합니다.
사용자 지정 x-y 좌표가 필요한 모델 유효성 검사 메트릭 표시(예: precision-recall 곡선)
두 개의 다른 모델/Experiments의 데이터 분포를 히스토그램으로 오버레이
트레이닝 중 여러 지점에서 스냅샷을 통해 메트릭의 변경 사항 표시
W&B에서 아직 사용할 수 없는 고유한 시각화 만들기(그리고 바라건대 전 세계와 공유)
2.4.2.1 - Tutorial: Use custom charts
W&B UI에서 사용자 정의 차트 기능을 사용하는 방법에 대한 튜토리얼
커스텀 차트를 사용하여 패널에 로드하는 데이터와 시각화를 제어할 수 있습니다.
1. W&B에 데이터 기록
먼저 스크립트에 데이터를 기록합니다. 트레이닝 시작 시 설정된 단일 포인트 (예: 하이퍼파라미터)에는 wandb.config를 사용합니다. 시간에 따른 여러 포인트에는 wandb.log()를 사용하고, wandb.Table()을 사용하여 커스텀 2D 배열을 기록합니다. 기록된 키당 최대 10,000개의 데이터 포인트를 기록하는 것이 좋습니다.
데이터 테이블을 기록하려면 간단한 예제 노트북을 사용해 보고, 다음 단계에서 커스텀 차트를 설정합니다. 라이브 리포트에서 결과 차트가 어떻게 보이는지 확인하세요.
2. 쿼리 만들기
시각화할 데이터를 기록했으면 프로젝트 페이지로 이동하여 + 버튼을 클릭하여 새 패널을 추가한 다음 Custom Chart를 선택합니다. 이 워크스페이스에서 따라 할 수 있습니다.
쿼리 추가
summary를 클릭하고 historyTable을 선택하여 run 기록에서 데이터를 가져오는 새 쿼리를 설정합니다.
wandb.Table()을 기록한 키를 입력합니다. 위의 코드 조각에서는 my_custom_table입니다. 예제 노트북에서 키는 pr_curve 및 roc_curve입니다.
Vega 필드 설정
이제 쿼리가 이러한 열을 로드하므로 Vega 필드 드롭다운 메뉴에서 선택할 수 있는 옵션으로 사용할 수 있습니다.
x-axis: runSets_historyTable_r (recall)
y-axis: runSets_historyTable_p (precision)
color: runSets_historyTable_c (class label)
3. 차트 사용자 정의
이제 보기에 좋지만 산점도에서 선 플롯으로 전환하고 싶습니다. Edit를 클릭하여 이 내장 차트에 대한 Vega 사양을 변경합니다. 이 워크스페이스에서 따라 하세요.
시각화를 사용자 정의하기 위해 Vega 사양을 업데이트했습니다.
플롯, 범례, x축 및 y축에 대한 제목 추가 (각 필드에 대해 “title” 설정)
“mark” 값을 “point"에서 “line"으로 변경
사용되지 않는 “size” 필드 제거
이것을 이 프로젝트의 다른 곳에서 사용할 수 있는 사전 설정으로 저장하려면 페이지 상단의 Save as를 클릭합니다. 결과는 ROC 곡선과 함께 다음과 같습니다.
보너스: 합성 히스토그램
히스토그램은 숫자 분포를 시각화하여 더 큰 데이터셋을 이해하는 데 도움을 줄 수 있습니다. 합성 히스토그램은 동일한 bin에서 여러 분포를 보여주어 서로 다른 모델 간 또는 모델 내의 서로 다른 클래스 간에 두 개 이상의 메트릭을 비교할 수 있습니다. 운전 장면에서 오브젝트를 감지하는 시멘틱 세그멘테이션 모델의 경우 정확도 대 IOU (intersection over union)에 대해 최적화하는 효과를 비교하거나 서로 다른 모델이 자동차 (데이터에서 크고 일반적인 영역) 대 교통 표지판 (훨씬 작고 덜 일반적인 영역)을 얼마나 잘 감지하는지 알고 싶을 수 있습니다. 데모 Colab에서는 10가지 생물 클래스 중 2가지에 대한 신뢰도 점수를 비교할 수 있습니다.
커스텀 합성 히스토그램 패널의 자체 버전을 만들려면:
워크스페이스 또는 리포트에서 새 Custom Chart 패널을 만듭니다 (“Custom Chart” 시각화를 추가하여). 오른쪽 상단의 “Edit” 버튼을 눌러 내장 패널 유형부터 시작하여 Vega 사양을 수정합니다.
해당 내장 Vega 사양을 Vega의 합성 히스토그램에 대한 MVP 코드로 바꿉니다. Vega 구문 Vega syntax를 사용하여 이 Vega 사양에서 메인 제목, 축 제목, 입력 도메인 및 기타 세부 정보를 직접 수정할 수 있습니다 (색상을 변경하거나 세 번째 히스토그램을 추가할 수도 있습니다 :)
오른쪽 쿼리를 수정하여 wandb 로그에서 올바른 데이터를 로드합니다. 필드 summaryTable을 추가하고 해당 tableKey를 class_scores로 설정하여 run에서 기록한 wandb.Table을 가져옵니다. 이렇게 하면 드롭다운 메뉴를 통해 wandb.Table이 class_scores로 기록된 열과 함께 두 개의 히스토그램 bin 세트 (red_bins 및 blue_bins)를 채울 수 있습니다. 내 예제에서는 빨간색 bin에 대한 animal 클래스 예측 점수와 파란색 bin에 대한 plant를 선택했습니다.
미리 보기 렌더링에서 보이는 플롯이 마음에 들 때까지 Vega 사양과 쿼리를 계속 변경할 수 있습니다. 완료되면 상단의 Save as를 클릭하고 나중에 재사용할 수 있도록 커스텀 플롯 이름을 지정합니다. 그런 다음 Apply from panel library를 클릭하여 플롯을 완료합니다.
다음은 매우 간단한 실험에서 얻은 결과입니다. 에포크에 대해 1000개의 예제만으로 트레이닝하면 대부분의 이미지가 식물이 아니고 어떤 이미지가 동물일 수 있는지 매우 불확실한 모델이 생성됩니다.
2.4.3 - Manage workspace, section, and panel settings
특정 워크스페이스 페이지 내에는 워크스페이스, 섹션 및 패널의 세 가지 설정 수준이 있습니다. 워크스페이스 설정은 전체 워크스페이스에 적용됩니다. 섹션 설정은 섹션 내의 모든 패널에 적용됩니다. 패널 설정은 개별 패널에 적용됩니다.
워크스페이스 설정
워크스페이스 설정은 모든 섹션과 해당 섹션 내의 모든 패널에 적용됩니다. 편집할 수 있는 워크스페이스 설정에는 워크스페이스 레이아웃과 라인 플롯의 두 가지 유형이 있습니다. 워크스페이스 레이아웃은 워크스페이스의 구조를 결정하는 반면, 라인 플롯 설정은 워크스페이스에서 라인 플롯의 기본 설정을 제어합니다.
이 워크스페이스의 전체 구조에 적용되는 설정을 편집하려면 다음을 수행하세요.
프로젝트 워크스페이스로 이동합니다.
새 리포트 버튼 옆에 있는 톱니바퀴 아이콘을 클릭하여 워크스페이스 설정을 확인합니다.
워크스페이스 레이아웃을 변경하려면 워크스페이스 레이아웃을 선택하고, 워크스페이스에서 라인 플롯의 기본 설정을 구성하려면 라인 플롯을 선택합니다.
워크스페이스 레이아웃 옵션
워크스페이스의 전체 구조를 정의하도록 워크스페이스 레이아웃을 구성합니다. 여기에는 섹션 나누기 로직과 패널 구성이 포함됩니다.
워크스페이스 레이아웃 옵션 페이지에는 워크스페이스에서 패널을 자동으로 생성하는지 또는 수동으로 생성하는지가 표시됩니다. 워크스페이스의 패널 생성 모드를 조정하려면 패널을 참조하세요.
다음 표는 각 워크스페이스 레이아웃 옵션에 대해 설명합니다.
워크스페이스 설정
설명
검색 중 빈 섹션 숨기기
패널을 검색할 때 패널이 없는 섹션을 숨깁니다.
패널을 알파벳순으로 정렬
워크스페이스의 패널을 알파벳순으로 정렬합니다.
섹션 구성
기존의 모든 섹션과 패널을 제거하고 새 섹션 이름으로 다시 채웁니다. 새로 채워진 섹션을 첫 번째 또는 마지막 접두사로 그룹화합니다.
W&B에서는 마지막 접두사로 그룹화하는 대신 첫 번째 접두사를 그룹화하여 섹션을 구성하는 것이 좋습니다. 첫 번째 접두사로 그룹화하면 섹션 수가 줄어들고 성능이 향상될 수 있습니다.
라인 플롯 옵션
라인 플롯 워크스페이스 설정을 수정하여 워크스페이스에서 라인 플롯의 글로벌 기본값과 사용자 지정 규칙을 설정합니다.
라인 플롯 설정 내에서 데이터와 표시 기본 설정의 두 가지 주요 설정을 편집할 수 있습니다. 데이터 탭에는 다음 설정이 포함되어 있습니다.
라인 플롯 설정
설명
X축
라인 플롯에서 x축의 스케일입니다. x축은 기본적으로 단계로 설정됩니다. x축 옵션 목록은 다음 표를 참조하세요.
범위
x축에 표시할 최소 및 최대 설정입니다.
평활화
라인 플롯에서 평활화를 변경합니다. 평활화에 대한 자세한 내용은 라인 플롯 평활화를 참조하세요.
Weights & Biases 설정 페이지를 사용하여 개별 사용자 프로필 또는 팀 설정을 사용자 정의하세요.
개인 사용자 계정 내에서 프로필 사진, 표시 이름, 지리적 위치, 자기 소개 정보, 계정에 연결된 이메일을 편집하고 Runs 에 대한 알림을 관리할 수 있습니다. 또한 설정 페이지를 사용하여 GitHub 저장소를 연결하고 계정을 삭제할 수도 있습니다. 자세한 내용은 사용자 설정을 참조하세요.
팀 설정 페이지를 사용하여 팀에 새 멤버를 초대하거나 제거하고, 팀 Runs 에 대한 알림을 관리하고, 개인 정보 설정을 변경하고, 저장소 사용량을 보고 관리할 수 있습니다. 팀 설정에 대한 자세한 내용은 팀 설정을 참조하세요.
2.4.4.1 - Manage user settings
사용자 설정 에서 프로필 정보, 계정 기본값, 알림, 베타 제품 참여, GitHub 인테그레이션 , 저장소 사용량, 계정 활성화를 관리하고 팀 을 만드세요.
사용자 프로필 페이지로 이동하여 오른쪽 상단 모서리에 있는 사용자 아이콘을 선택하세요. 드롭다운 메뉴에서 설정을 선택합니다.
프로필
프로필 섹션에서는 계정 이름과 소속 기관을 관리하고 수정할 수 있습니다. 선택적으로 자기소개, 위치, 개인 또는 소속 기관 웹사이트 링크를 추가하고 프로필 이미지를 업로드할 수 있습니다.
자기 소개 편집
자기 소개를 편집하려면 프로필 상단의 편집을 클릭합니다. 열리는 WYSIWYG 편집기는 Markdown을 지원합니다.
줄을 편집하려면 해당 줄을 클릭합니다. 시간을 절약하기 위해 /를 입력하고 목록에서 Markdown을 선택할 수 있습니다.
항목의 드래그 핸들을 사용하여 이동합니다.
블록을 삭제하려면 드래그 핸들을 클릭한 다음 삭제를 클릭합니다.
변경 사항을 저장하려면 저장을 클릭합니다.
소셜 배지 추가
X에서 @weights_biases 계정에 대한 팔로우 배지를 추가하려면 배지 이미지를 가리키는 HTML <img> 태그가 있는 Markdown 스타일 링크를 추가할 수 있습니다.
유료 요금제를 사용하는 조직의 경우, 관리자는 특정 임계값이 충족되면 결제 기간당 한 번 이메일을 통해 알림을 받습니다. 알림에는 결제 관리자인 경우 조직의 제한을 늘리는 방법과 그렇지 않은 경우 결제 관리자에게 문의하는 방법에 대한 세부 정보가 포함됩니다. Pro plan에서는 결제 관리자만 사용량 알림을 받습니다.
이러한 알림은 구성할 수 없으며 다음과 같은 경우에 전송됩니다.
조직이 월간 사용량 범주 제한(사용 시간의 85%)에 가까워지고 요금제에 따라 제한의 100%에 도달했을 때.
조직의 누적 평균 요금이 결제 기간 동안 $200, $450, $700 및 $1000 임계값을 초과했을 때. 이러한 초과 요금은 조직에서 추적 시간, 저장 공간 또는 Weave 데이터 수집에 대해 요금제에 포함된 것보다 더 많은 사용량을 누적할 때 발생합니다.
사용량 또는 결제에 대한 질문은 계정 팀 또는 지원팀에 문의하세요.
결제 방법
이 섹션에서는 조직에 등록된 결제 방법을 보여줍니다. 결제 방법을 추가하지 않은 경우 요금제를 업그레이드하거나 유료 저장 공간을 추가할 때 결제 방법을 추가하라는 메시지가 표시됩니다.
결제 관리자
이 섹션에서는 현재 결제 관리자를 보여줍니다. 결제 관리자는 조직 관리자이며 모든 결제 관련 이메일을 수신하고 결제 방법을 보고 관리할 수 있습니다.
W&B 전용 클라우드에서는 여러 Users가 결제 관리자가 될 수 있습니다. W&B 멀티 테넌트 클라우드에서는 한 번에 한 명의 User만 결제 관리자가 될 수 있습니다.
결제 관리자를 변경하거나 역할을 추가 Users에게 할당하려면:
역할 관리를 클릭하세요.
User를 검색하세요.
해당 User의 행에서 결제 관리자 필드를 클릭하세요.
요약을 읽은 다음 결제 User 변경을 클릭하세요.
송장
신용 카드를 사용하여 결제하는 경우 이 섹션에서 월별 송장을 볼 수 있습니다.
전신 송금을 통해 결제하는 Enterprise 계정의 경우 이 섹션은 비어 있습니다. 질문이 있으면 계정 팀에 문의하세요.
조직에 요금이 발생하지 않으면 송장이 생성되지 않습니다.
2.4.4.3 - Manage team settings
Team 설정 페이지에서 팀의 멤버, 아바타, 알림 및 개인 정보 설정을 관리하세요.
팀 설정
팀 멤버, 아바타, 알림, 개인 정보 보호, 사용량 등 팀 설정을 변경합니다. 조직 관리자와 팀 관리자는 팀 설정을 보고 편집할 수 있습니다.
관리 계정 유형만 팀 설정을 변경하거나 팀에서 멤버를 제거할 수 있습니다.
멤버
멤버 섹션에는 보류 중인 초대 목록과 팀 가입 초대를 수락한 멤버가 모두 표시됩니다. 나열된 각 멤버는 멤버의 이름, 사용자 이름, 이메일, 팀 역할과 조직에서 상속된 Models 및 Weave에 대한 엑세스 권한을 표시합니다. 표준 팀 역할인 Admin, Member 및 View-only 중에서 선택할 수 있습니다. 조직에서 사용자 정의 역할을 생성한 경우 사용자 정의 역할을 대신 할당할 수 있습니다.
팀 생성, 팀 관리, 팀 멤버십 및 역할 관리에 대한 자세한 내용은 팀 추가 및 관리를 참조하세요. 팀에 대한 새로운 멤버 초대 권한을 구성하고 기타 개인 정보 보호 설정을 구성하려면 개인 정보 보호를 참조하세요.
아바타
아바타 섹션으로 이동하여 이미지를 업로드하여 아바타를 설정합니다.
아바타 업데이트를 선택하여 파일 대화 상자를 표시합니다.
파일 대화 상자에서 사용할 이미지를 선택합니다.
알림
Runs이 충돌하거나 완료될 때 또는 사용자 정의 알림을 설정할 때 팀에 알립니다. 팀은 이메일 또는 Slack을 통해 알림을 받을 수 있습니다.
알림을 받을 이벤트 유형 옆에 있는 스위치를 토글합니다. Weights & Biases는 기본적으로 다음과 같은 이벤트 유형 옵션을 제공합니다.
Runs finished: Weights & Biases run이 성공적으로 완료되었는지 여부.
팀 프로필 페이지를 사용자 정의하여 소개를 표시하고 공개 또는 팀 멤버에게 보이는 리포트 및 프로젝트를 소개할 수 있습니다. 리포트, 프로젝트 및 외부 링크를 제시하세요.
최고의 공개 리포트를 소개하여 방문자에게 최고의 연구 결과를 강조하세요.
팀원이 더 쉽게 찾을 수 있도록 가장 활발한 프로젝트를 소개하세요.
회사 또는 연구실 웹사이트 및 게시한 논문에 외부 링크를 추가하여 협력자를 찾으세요.
팀 멤버 제거
팀 관리자는 팀 설정 페이지를 열고 떠나는 멤버의 이름 옆에 있는 삭제 버튼을 클릭할 수 있습니다. 사용자가 떠난 후에도 팀에 기록된 모든 run은 유지됩니다.
팀 역할 및 권한 관리
동료를 팀에 초대할 때 팀 역할을 선택하세요. 다음과 같은 팀 역할 옵션이 있습니다.
관리자: 팀 관리자는 다른 관리자나 팀 멤버를 추가하거나 제거할 수 있습니다. 모든 프로젝트를 수정할 수 있는 권한과 완전한 삭제 권한이 있습니다. 여기에는 run, 프로젝트, 아티팩트 및 스윕 삭제가 포함되지만 이에 국한되지는 않습니다.
멤버: 팀의 일반 멤버입니다. 기본적으로 관리자만 팀 멤버를 초대할 수 있습니다. 이 동작을 변경하려면 팀 설정 관리를 참조하세요.
팀 멤버는 자신이 만든 run만 삭제할 수 있습니다. 멤버 A와 B가 있다고 가정합니다. 멤버 B가 팀 B의 프로젝트에서 멤버 A가 소유한 다른 프로젝트로 run을 이동합니다. 멤버 A는 멤버 B가 멤버 A의 프로젝트로 이동한 run을 삭제할 수 없습니다. 관리자는 모든 팀 멤버가 만든 run과 스윕 run을 관리할 수 있습니다.
보기 전용 (엔터프라이즈 전용 기능): 보기 전용 멤버는 run, 리포트 및 워크스페이스와 같은 팀 내 자산을 볼 수 있습니다. 리포트를 팔로우하고 댓글을 달 수 있지만 프로젝트 개요, 리포트 또는 run을 생성, 편집 또는 삭제할 수는 없습니다.
사용자 정의 역할 (엔터프라이즈 전용 기능): 사용자 정의 역할을 사용하면 조직 관리자가 세분화된 엑세스 제어를 위해 추가 권한과 함께 보기 전용 또는 멤버 역할 중 하나를 기반으로 새 역할을 구성할 수 있습니다. 그런 다음 팀 관리자는 해당 사용자 정의 역할을 각 팀의 사용자에게 할당할 수 있습니다. 자세한 내용은 W&B 팀을 위한 사용자 정의 역할 소개를 참조하세요.
리포트 권한은 리포트를 생성, 보고 편집할 수 있는 엑세스 권한을 부여합니다. 다음 표에는 지정된 팀의 모든 리포트에 적용되는 권한이 나와 있습니다.
권한
보기 전용
팀 멤버
팀 관리자
리포트 보기
X
X
X
리포트 만들기
X
X
리포트 편집
X (팀 멤버는 자신의 리포트만 편집할 수 있음)
X
리포트 삭제
X (팀 멤버는 자신의 리포트만 편집할 수 있음)
X
실험
다음 표에는 지정된 팀의 모든 실험에 적용되는 권한이 나와 있습니다.
권한
보기 전용
팀 멤버
팀 관리자
실험 메타데이터 보기 (기록 메트릭, 시스템 메트릭, 파일 및 로그 포함)
X
X
X
실험 패널 및 워크스페이스 편집
X
X
실험 기록
X
X
실험 삭제
X (팀 멤버는 자신이 만든 실험만 삭제할 수 있음)
X
실험 중지
X (팀 멤버는 자신이 만든 실험만 중지할 수 있음)
X
아티팩트
다음 표에는 지정된 팀의 모든 아티팩트에 적용되는 권한이 나와 있습니다.
권한
보기 전용
팀 멤버
팀 관리자
아티팩트 보기
X
X
X
아티팩트 만들기
X
X
아티팩트 삭제
X
X
메타데이터 편집
X
X
에일리어스 편집
X
X
에일리어스 삭제
X
X
아티팩트 다운로드
X
X
시스템 설정 (W&B 서버만 해당)
시스템 권한을 사용하여 팀 및 팀 멤버를 만들고 관리하고 시스템 설정을 조정합니다. 이러한 권한을 통해 W&B 인스턴스를 효과적으로 관리하고 유지 관리할 수 있습니다.
권한
보기 전용
팀 멤버
팀 관리자
시스템 관리자
시스템 설정 구성
X
팀 생성/삭제
X
팀 서비스 계정 행동
트레이닝 환경에서 팀을 구성할 때 해당 팀의 서비스 계정을 사용하여 해당 팀 내의 비공개 또는 공개 프로젝트에 run을 기록할 수 있습니다. 또한 환경에 WANDB_USERNAME 또는 WANDB_USER_EMAIL 변수가 있고 참조된 사용자가 해당 팀의 구성원인 경우 해당 run을 사용자에게 귀속시킬 수 있습니다.
트레이닝 환경에서 팀을 구성 하지 않고 서비스 계정을 사용하는 경우 run은 해당 서비스 계정의 상위 팀 내에서 명명된 프로젝트에 기록됩니다. 이 경우에도 환경에 WANDB_USERNAME 또는 WANDB_USER_EMAIL 변수가 있고 참조된 사용자가 서비스 계정의 상위 팀의 구성원인 경우 run을 사용자에게 귀속시킬 수 있습니다.
서비스 계정은 상위 팀과 다른 팀의 비공개 프로젝트에 run을 기록할 수 없습니다. 프로젝트가 공개 프로젝트 가시성으로 설정된 경우에만 서비스 계정이 프로젝트에 run을 기록할 수 있습니다.
팀 트라이얼
W&B 요금제에 대한 자세한 내용은 요금 페이지를 참조하세요. 대시보드 UI 또는 내보내기 API를 사용하여 언제든지 모든 데이터를 다운로드할 수 있습니다.
개인 정보 설정
팀 설정 페이지에서 모든 팀 프로젝트의 개인 정보 설정을 확인할 수 있습니다.
app.wandb.ai/teams/your-team-name
고급 구성
보안 스토리지 커넥터
팀 수준 보안 스토리지 커넥터를 사용하면 팀에서 W&B와 함께 자체 클라우드 스토리지 버킷을 사용할 수 있습니다. 이는 매우 민감한 데이터 또는 엄격한 규정 준수 요구 사항이 있는 팀에 대해 더 나은 데이터 엑세스 제어 및 데이터 격리를 제공합니다. 자세한 내용은 보안 스토리지 커넥터를 참조하세요.
2.4.4.6 - Manage storage
W&B 데이터 저장소를 관리하는 방법.
스토리지 한도에 접근하거나 초과하는 경우, 데이터를 관리할 수 있는 여러 가지 방법이 있습니다. 어떤 방법이 가장 적합한지는 계정 유형과 현재 프로젝트 설정에 따라 달라집니다.
스토리지 사용량 관리
W&B는 스토리지 사용량을 최적화할 수 있는 다양한 방법을 제공합니다.
참조 Artifacts를 사용하여 W&B 시스템 외부에서 저장된 파일을 추적하고, W&B 스토리지에 업로드하는 대신 사용할 수 있습니다.
각 AMD GPU 장치에 대해 총 사용 가능한 메모리의 백분율로 GPU 메모리가 할당되었음을 나타냅니다.
W&B는 이 메트릭에 gpu.{gpu_index}.memoryAllocated 태그를 할당합니다.
AMD GPU 온도
각 AMD GPU 장치에 대한 GPU 온도를 섭씨로 나타냅니다.
W&B는 이 메트릭에 gpu.{gpu_index}.temp 태그를 할당합니다.
AMD GPU 전력 사용량 (와트)
각 AMD GPU 장치에 대한 GPU 전력 사용량을 와트 단위로 나타냅니다.
W&B는 이 메트릭에 gpu.{gpu_index}.powerWatts 태그를 할당합니다.
AMD GPU 전력 사용량 백분율
각 AMD GPU 장치에 대한 전력 용량의 백분율로 GPU 전력 사용량을 반영합니다.
W&B는 이 메트릭에 gpu.{gpu_index}.powerPercent 태그를 할당합니다.
Apple ARM Mac GPU
Apple GPU 활용률
Apple GPU 장치, 특히 ARM Mac에서 GPU 활용률을 백분율로 나타냅니다.
W&B는 이 메트릭에 gpu.0.gpu 태그를 할당합니다.
Apple GPU 메모리 할당됨
ARM Mac의 Apple GPU 장치에 대해 총 사용 가능한 메모리의 백분율로 GPU 메모리가 할당되었습니다.
W&B는 이 메트릭에 gpu.0.memoryAllocated 태그를 할당합니다.
Apple GPU 온도
ARM Mac의 Apple GPU 장치에 대한 GPU 온도를 섭씨로 나타냅니다.
W&B는 이 메트릭에 gpu.0.temp 태그를 할당합니다.
Apple GPU 전력 사용량 (와트)
ARM Mac의 Apple GPU 장치에 대한 GPU 전력 사용량을 와트 단위로 나타냅니다.
W&B는 이 메트릭에 gpu.0.powerWatts 태그를 할당합니다.
Apple GPU 전력 사용량 백분율
ARM Mac의 Apple GPU 장치에 대한 전력 용량의 백분율로 GPU 전력 사용량을 나타냅니다.
W&B는 이 메트릭에 gpu.0.powerPercent 태그를 할당합니다.
Graphcore IPU
Graphcore IPU(Intelligence Processing Units)는 기계 학습 작업을 위해 특별히 설계된 고유한 하드웨어 가속기입니다.
IPU 장치 메트릭
이러한 메트릭은 특정 IPU 장치에 대한 다양한 통계를 나타냅니다. 각 메트릭에는 장치를 식별하기 위한 장치 ID(device_id)와 메트릭 키(metric_key)가 있습니다. W&B는 이 메트릭에 ipu.{device_id}.{metric_key} 태그를 할당합니다.
메트릭은 Graphcore의 gcipuinfo 바이너리와 상호 작용하는 독점 gcipuinfo 라이브러리를 사용하여 추출됩니다. sample 메소드는 프로세스 ID(pid)와 연결된 각 IPU 장치에 대해 이러한 메트릭을 가져옵니다. 시간이 지남에 따라 변경되는 메트릭 또는 장치의 메트릭을 처음 가져오는 경우에만 중복된 데이터 로깅을 방지하기 위해 기록됩니다.
각 메트릭에 대해 parse_metric 메소드를 사용하여 원시 문자열 표현에서 메트릭의 값을 추출합니다. 그런 다음 aggregate 메소드를 사용하여 여러 샘플에서 메트릭을 집계합니다.
다음은 사용 가능한 메트릭 및 해당 단위를 나열한 것입니다.
평균 보드 온도 (average board temp (C)): IPU 보드의 온도를 섭씨로 나타냅니다.
평균 다이 온도 (average die temp (C)): IPU 다이의 온도를 섭씨로 나타냅니다.
클럭 속도 (clock (MHz)): IPU의 클럭 속도를 MHz로 나타냅니다.
IPU 전력 (ipu power (W)): IPU의 전력 소비량을 와트 단위로 나타냅니다.
W&B Artifacts를 사용하여 데이터를 W&B Runs의 입력 및 출력으로 추적하고 버전을 관리하세요. 예를 들어, 모델 트레이닝 run은 데이터셋을 입력으로 사용하고 트레이닝된 모델을 출력으로 생성할 수 있습니다. 하이퍼파라미터, 메타데이터, 메트릭을 run에 기록하고, 아티팩트를 사용하여 모델 트레이닝에 사용된 데이터셋을 입력으로, 결과 모델 체크포인트를 출력으로 기록, 추적 및 버전 관리할 수 있습니다.
유스 케이스
runs의 입력 및 출력으로 전체 ML 워크플로우에서 아티팩트를 사용할 수 있습니다. 데이터셋, 모델 또는 기타 아티팩트를 처리 입력으로 사용할 수 있습니다.
Artifacts는 W&B 라이브러리가 처리 방법을 알고 있는 스키마가 URI에 있는 경우 재현성을 위해 체크섬 및 기타 정보를 추적합니다.
add_reference 메소드를 사용하여 외부 URI 참조를 Artifact에 추가합니다. 'uri' 문자열을 자신의 URI로 바꿉니다. 선택적으로 name 파라미터에 대해 Artifact 내에서 원하는 경로를 전달합니다.
# URI 참조 추가artifact.add_reference(uri="uri", name="optional-name")
Artifacts는 현재 다음 URI 스키마를 지원합니다.
http(s)://: HTTP를 통해 액세스할 수 있는 파일의 경로입니다. Artifact는 HTTP 서버가 ETag 및 Content-Length 응답 헤더를 지원하는 경우 etag 형식의 체크섬과 크기 메타데이터를 추적합니다.
s3://: S3의 오브젝트 또는 오브젝트 접두사의 경로입니다. Artifact는 참조된 오브젝트에 대해 체크섬 및 버전 관리 정보(버킷에 오브젝트 버전 관리가 활성화된 경우)를 추적합니다. 오브젝트 접두사는 최대 10,000개의 오브젝트까지 접두사 아래의 오브젝트를 포함하도록 확장됩니다.
gs://: GCS의 오브젝트 또는 오브젝트 접두사의 경로입니다. Artifact는 참조된 오브젝트에 대해 체크섬 및 버전 관리 정보(버킷에 오브젝트 버전 관리가 활성화된 경우)를 추적합니다. 오브젝트 접두사는 최대 10,000개의 오브젝트까지 접두사 아래의 오브젝트를 포함하도록 확장됩니다.
대규모 데이터셋 또는 분산 트레이닝의 경우 여러 병렬 Runs가 단일 Artifact에 기여해야 할 수 있습니다.
import wandb
import time
# 데모 목적으로 ray를 사용하여 Runs를 병렬로 시작합니다.# 원하는 방식으로 병렬 Runs를 오케스트레이션할 수 있습니다.import ray
ray.init()
artifact_type ="dataset"artifact_name ="parallel-artifact"table_name ="distributed_table"parts_path ="parts"num_parallel =5# 병렬 작성기의 각 배치는 자체 고유한 그룹 이름을 가져야 합니다.group_name ="writer-group-{}".format(round(time.time()))
@ray.remotedeftrain(i):
"""
작성기 작업입니다. 각 작성기는 Artifact에 이미지를 하나 추가합니다.
"""with wandb.init(group=group_name) as run:
artifact = wandb.Artifact(name=artifact_name, type=artifact_type)
# 데이터를 wandb 테이블에 추가합니다. 이 경우 예제 데이터를 사용합니다. table = wandb.Table(columns=["a", "b", "c"], data=[[i, i *2, 2**i]])
# Artifact의 폴더에 테이블을 추가합니다. artifact.add(table, "{}/table_{}".format(parts_path, i))
# Artifact를 업서트하면 Artifact에 데이터를 만들거나 추가합니다. run.upsert_artifact(artifact)
# 병렬로 Runs를 시작합니다.result_ids = [train.remote(i) for i in range(num_parallel)]
# 모든 작성기가 완료되었는지 확인하기 위해 모든 작성기에 조인합니다.# Artifact를 완료하기 전에 파일이 추가되었습니다.ray.get(result_ids)
# 모든 작성기가 완료되면 Artifact를 완료합니다.# 준비되었음을 표시합니다.with wandb.init(group=group_name) as run:
artifact = wandb.Artifact(artifact_name, type=artifact_type)
# 테이블 폴더를 가리키는 "PartitionTable"을 만듭니다.# Artifact에 추가합니다. artifact.add(wandb.data_types.PartitionedTable(parts_path), table_name)
# Finish artifact는 Artifact를 완료하고 향후 "upserts"를 허용하지 않습니다.# 이 버전으로. run.finish_artifact(artifact)
4.1.2 - Download and use artifacts
여러 프로젝트에서 아티팩트 를 다운로드하고 사용하세요.
W&B 서버에 이미 저장된 Artifacts를 다운로드하여 사용하거나, 필요에 따라 중복 제거를 위해 Artifact 오브젝트를 생성하여 전달합니다.
보기 전용 권한을 가진 팀 멤버는 Artifacts를 다운로드할 수 없습니다.
W&B에 저장된 Artifacts 다운로드 및 사용
W&B Run 내부 또는 외부에서 W&B에 저장된 Artifacts를 다운로드하여 사용합니다. W&B에 이미 저장된 데이터를 내보내거나 업데이트하려면 퍼블릭 API (wandb.Api)를 사용하세요. 자세한 내용은 W&B 퍼블릭 API 레퍼런스 가이드를 참조하세요.
이것은 name 경로에 있는 파일만 가져옵니다. 다음과 같은 메서드를 가진 Entry 오브젝트를 반환합니다.
Entry.download: name 경로에 있는 Artifact에서 파일을 다운로드합니다.
Entry.ref: add_reference가 항목을 참조로 저장한 경우 URI를 반환합니다.
W&B가 처리하는 방법을 아는 스키마가 있는 참조는 Artifact 파일처럼 다운로드됩니다. 자세한 내용은 외부 파일 추적을 참조하세요.
먼저 W&B SDK를 임포트합니다. 다음으로 퍼블릭 API 클래스에서 Artifact를 생성합니다. 해당 Artifact와 연결된 엔티티, 프로젝트, Artifact 및 에일리어스를 제공합니다.
import wandb
api = wandb.Api()
artifact = api.artifact("entity/project/artifact:alias")
반환된 오브젝트를 사용하여 Artifact의 내용을 다운로드합니다.
artifact.download()
선택적으로 root 파라미터에 경로를 전달하여 Artifact의 내용을 특정 디렉토리로 다운로드할 수 있습니다. 자세한 내용은 API 레퍼런스 가이드를 참조하세요.
wandb artifact get 코맨드를 사용하여 W&B 서버에서 Artifact를 다운로드합니다.
$ wandb artifact get project/artifact:alias --root mnist/
Artifact 부분 다운로드
선택적으로 접두사를 기반으로 Artifact의 일부를 다운로드할 수 있습니다. path_prefix 파라미터를 사용하면 단일 파일 또는 하위 폴더의 콘텐츠를 다운로드할 수 있습니다.
artifact = run.use_artifact("bike-dataset:latest")
artifact.download(path_prefix="bike.png") # bike.png만 다운로드
또는 특정 디렉토리에서 파일을 다운로드할 수 있습니다.
artifact.download(path_prefix="images/bikes/") # images/bikes 디렉토리의 파일 다운로드
다른 프로젝트의 Artifact 사용
Artifact 이름과 함께 프로젝트 이름을 지정하여 Artifact를 참조합니다. Artifact 이름과 함께 엔티티 이름을 지정하여 엔티티 간에 Artifacts를 참조할 수도 있습니다.
다음 코드 예제는 다른 프로젝트의 Artifact를 현재 W&B run에 대한 입력으로 쿼리하는 방법을 보여줍니다.
import wandb
run = wandb.init(project="<example>", job_type="<job-type>")
# 다른 프로젝트의 Artifact에 대해 W&B를 쿼리하고 다음으로 표시합니다.# 이 run에 대한 입력입니다.artifact = run.use_artifact("my-project/artifact:alias")
# 다른 엔티티의 Artifact를 사용하고 이를 입력으로 표시합니다.# 이 run에.artifact = run.use_artifact("my-entity/my-project/artifact:alias")
Artifact를 동시에 구성하고 사용
Artifact를 동시에 구성하고 사용합니다. Artifact 오브젝트를 생성하고 use_artifact에 전달합니다. 이렇게 하면 아직 존재하지 않는 경우 W&B에 Artifact가 생성됩니다. use_artifact API는 idempotent이므로 원하는 만큼 여러 번 호출할 수 있습니다.
import wandb
run = wandb.init(project="<example>")
api = wandb.Api()
artifact = api.artifact_collection(type="<type-name>", collection="<collection-name>")
artifact.name ="<new-collection-name>"artifact.description ="<This is where you'd describe the purpose of your collection.>"artifact.save()
단일 run에서 또는 분산된 run과 협업하여 새로운 아티팩트 버전을 만드세요. 선택적으로 증분 아티팩트라고 알려진 이전 버전에서 새로운 아티팩트 버전을 만들 수 있습니다.
원래 아티팩트의 크기가 상당히 큰 경우 아티팩트에서 파일의 서브셋에 변경 사항을 적용해야 할 때 증분 아티팩트를 만드는 것이 좋습니다.
처음부터 새로운 아티팩트 버전 만들기
새로운 아티팩트 버전을 만드는 방법에는 단일 run에서 만드는 방법과 분산된 run에서 만드는 두 가지 방법이 있습니다. 이들은 다음과 같이 정의됩니다.
단일 run: 단일 run은 새로운 버전에 대한 모든 데이터를 제공합니다. 이것은 가장 일반적인 경우이며, run이 필요한 데이터를 완전히 재 생성할 때 가장 적합합니다. 예를 들어, 분석을 위해 테이블에 저장된 모델 또는 모델 예측값을 출력합니다.
분산된 run: run 집합이 공동으로 새로운 버전에 대한 모든 데이터를 제공합니다. 이것은 여러 run이 데이터를 생성하는 분산 작업에 가장 적합하며, 종종 병렬로 수행됩니다. 예를 들어, 분산 방식으로 모델을 평가하고 예측값을 출력합니다.
W&B는 프로젝트에 존재하지 않는 이름을 wandb.Artifact API에 전달하면 새로운 아티팩트를 생성하고 v0 에일리어스를 할당합니다. 동일한 아티팩트에 다시 로그할 때 W&B는 콘텐츠의 체크섬을 계산합니다. 아티팩트가 변경되면 W&B는 새 버전 v1을 저장합니다.
W&B는 프로젝트에 있는 기존 아티팩트와 일치하는 이름과 아티팩트 유형을 wandb.Artifact API에 전달하면 기존 아티팩트를 검색합니다. 검색된 아티팩트의 버전은 1보다 큽니다.
단일 run
아티팩트의 모든 파일을 생성하는 단일 run으로 Artifact의 새 버전을 기록합니다. 이 경우는 단일 run이 아티팩트의 모든 파일을 생성할 때 발생합니다.
유스 케이스에 따라 아래 탭 중 하나를 선택하여 run 내부 또는 외부에서 새로운 아티팩트 버전을 만드세요.
W&B run 내에서 아티팩트 버전을 만듭니다.
wandb.init으로 run을 만듭니다.
wandb.Artifact로 새로운 아티팩트를 만들거나 기존 아티팩트를 검색합니다.
.add_file로 아티팩트에 파일을 추가합니다.
.log_artifact로 아티팩트를 run에 기록합니다.
with wandb.init() as run:
artifact = wandb.Artifact("artifact_name", "artifact_type")
# `.add`, `.add_file`, `.add_dir`, and `.add_reference`를 사용하여# 아티팩트에 파일 및 에셋을 추가합니다. artifact.add_file("image1.png")
run.log_artifact(artifact)
W&B run 외부에서 아티팩트 버전을 만듭니다.
wanb.Artifact로 새로운 아티팩트를 만들거나 기존 아티팩트를 검색합니다.
.add_file로 아티팩트에 파일을 추가합니다.
.save로 아티팩트를 저장합니다.
artifact = wandb.Artifact("artifact_name", "artifact_type")
# `.add`, `.add_file`, `.add_dir`, and `.add_reference`를 사용하여# 아티팩트에 파일 및 에셋을 추가합니다.artifact.add_file("image1.png")
artifact.save()
분산된 run
커밋하기 전에 run 컬렉션이 버전에서 공동 작업할 수 있도록 합니다. 이는 하나의 run이 새 버전에 대한 모든 데이터를 제공하는 위에서 설명한 단일 run 모드와 대조됩니다.
컬렉션의 각 run은 동일한 버전에 대해 공동 작업하기 위해 동일한 고유 ID ( distributed_id라고 함)를 인식해야 합니다. 기본적으로 W&B는 있는 경우 wandb.init(group=GROUP)에 의해 설정된 run의 group을 distributed_id로 사용합니다.
해당 상태를 영구적으로 잠그는 버전을 “커밋"하는 최종 run이 있어야 합니다.
협업 아티팩트에 추가하려면 upsert_artifact를 사용하고 커밋을 완료하려면 finish_artifact를 사용하세요.
다음 예제를 고려하십시오. 서로 다른 run (아래에 Run 1, Run 2 및 Run 3으로 표시됨)은 upsert_artifact를 사용하여 동일한 아티팩트에 다른 이미지 파일을 추가합니다.
Run 1:
with wandb.init() as run:
artifact = wandb.Artifact("artifact_name", "artifact_type")
# `.add`, `.add_file`, `.add_dir`, and `.add_reference`를 사용하여# 아티팩트에 파일 및 에셋을 추가합니다. artifact.add_file("image1.png")
run.upsert_artifact(artifact, distributed_id="my_dist_artifact")
Run 2:
with wandb.init() as run:
artifact = wandb.Artifact("artifact_name", "artifact_type")
# `.add`, `.add_file`, `.add_dir`, and `.add_reference`를 사용하여# 아티팩트에 파일 및 에셋을 추가합니다. artifact.add_file("image2.png")
run.upsert_artifact(artifact, distributed_id="my_dist_artifact")
Run 3
Run 1과 Run 2가 완료된 후 실행해야 합니다. finish_artifact를 호출하는 Run은 아티팩트에 파일을 포함할 수 있지만 필요하지는 않습니다.
with wandb.init() as run:
artifact = wandb.Artifact("artifact_name", "artifact_type")
# 아티팩트에 파일 및 에셋을 추가합니다.# `.add`, `.add_file`, `.add_dir`, and `.add_reference` artifact.add_file("image3.png")
run.finish_artifact(artifact, distributed_id="my_dist_artifact")
기존 버전에서 새로운 아티팩트 버전 만들기
변경되지 않은 파일을 다시 인덱싱할 필요 없이 이전 아티팩트 버전에서 파일의 서브셋을 추가, 수정 또는 제거합니다. 이전 아티팩트 버전에서 파일의 서브셋을 추가, 수정 또는 제거하면 증분 아티팩트라고 하는 새로운 아티팩트 버전이 생성됩니다.
다음은 발생할 수 있는 각 유형의 증분 변경에 대한 몇 가지 시나리오입니다.
add: 새로운 배치를 수집한 후 데이터셋에 새로운 파일 서브셋을 주기적으로 추가합니다.
remove: 여러 중복 파일을 발견했고 아티팩트에서 제거하고 싶습니다.
update: 파일 서브셋에 대한 주석을 수정했고 이전 파일을 올바른 파일로 바꾸고 싶습니다.
처음부터 아티팩트를 만들어 증분 아티팩트와 동일한 기능을 수행할 수 있습니다. 그러나 처음부터 아티팩트를 만들면 로컬 디스크에 아티팩트의 모든 콘텐츠가 있어야 합니다. 증분 변경을 수행할 때 이전 아티팩트 버전의 파일을 변경하지 않고도 단일 파일을 추가, 제거 또는 수정할 수 있습니다.
마지막으로 변경 사항을 기록하거나 저장합니다. 다음 탭에서는 W&B run 내부 및 외부에서 변경 사항을 저장하는 방법을 보여줍니다. 유스 케이스에 적합한 탭을 선택하세요.
run.log_artifact(draft_artifact)
draft_artifact.save()
모두 합치면 위의 코드 예제는 다음과 같습니다.
with wandb.init(job_type="modify dataset") as run:
saved_artifact = run.use_artifact(
"my_artifact:latest" ) # 아티팩트를 가져와서 run에 입력합니다. draft_artifact = saved_artifact.new_draft() # 초안 버전을 만듭니다.# 초안 버전에서 파일의 서브셋을 수정합니다. draft_artifact.add_file("file_to_add.txt")
draft_artifact.remove("dir_to_remove/")
run.log_artifact(
artifact
) # 변경 사항을 기록하여 새 버전을 만들고 run에 대한 출력으로 표시합니다.
client = wandb.Api()
saved_artifact = client.artifact("my_artifact:latest") # 아티팩트를 로드합니다.draft_artifact = saved_artifact.new_draft() # 초안 버전을 만듭니다.# 초안 버전에서 파일의 서브셋을 수정합니다.draft_artifact.remove("deleted_file.txt")
draft_artifact.add_file("modified_file.txt")
draft_artifact.save() # 초안에 변경 사항을 커밋합니다.
4.1.6 - Track external files
Amazon S3 버킷, GCS 버킷, HTTP 파일 서버 또는 NFS 공유와 같이 W&B 외부에 저장된 파일을 추적합니다.
reference artifacts 를 사용하여 W&B 시스템 외부 (예: Amazon S3 버킷, GCS 버킷, Azure Blob, HTTP 파일 서버 또는 NFS 공유)에 저장된 파일을 추적합니다. W&B CLI를 사용하여 W&B Run 외부에서 아티팩트를 기록합니다.
Run 외부에서 아티팩트 기록
W&B는 run 외부에서 아티팩트를 기록할 때 run을 생성합니다. 각 아티팩트는 run에 속하며, run은 프로젝트에 속합니다. 아티팩트 (버전)는 컬렉션에도 속하며, 유형이 있습니다.
wandb artifact put 코맨드를 사용하여 W&B run 외부의 W&B 서버에 아티팩트를 업로드합니다. 아티팩트가 속할 프로젝트 이름과 아티팩트 이름 (project/artifact_name)을 제공합니다. 선택적으로 유형 (TYPE)을 제공합니다. 아래 코드 조각에서 PATH를 업로드할 아티팩트의 파일 경로로 바꿉니다.
$ wandb artifact put --name project/artifact_name --type TYPE PATH
지정한 프로젝트가 존재하지 않으면 W&B가 새 프로젝트를 생성합니다. 아티팩트 다운로드 방법에 대한 자세한 내용은 아티팩트 다운로드 및 사용을 참조하세요.
W&B 외부에서 아티팩트 추적
데이터셋 버전 관리 및 모델 이력에 W&B Artifacts를 사용하고, reference artifacts 를 사용하여 W&B 서버 외부에서 저장된 파일을 추적합니다. 이 모드에서 아티팩트는 URL, 크기 및 체크섬과 같은 파일에 대한 메타데이터만 저장합니다. 기본 데이터는 시스템을 벗어나지 않습니다. 파일을 W&B 서버에 저장하는 방법에 대한 자세한 내용은 빠른 시작을 참조하세요.
다음은 reference artifacts 를 구성하는 방법과 이를 워크플로우에 통합하는 가장 좋은 방법을 설명합니다.
Amazon S3 / GCS / Azure Blob Storage 참조
클라우드 스토리지 버킷에서 참조를 추적하기 위해 데이터셋 및 모델 버전 관리에 W&B Artifacts를 사용합니다. 아티팩트 참조를 사용하면 기존 스토리지 레이아웃을 수정하지 않고도 버킷 위에 원활하게 추적 기능을 레이어링할 수 있습니다.
Artifacts는 기본 클라우드 스토리지 공급 업체 (예: AWS, GCP 또는 Azure)를 추상화합니다. 다음 섹션에 설명된 정보는 Amazon S3, Google Cloud Storage 및 Azure Blob Storage에 균일하게 적용됩니다.
W&B Artifacts는 MinIO를 포함한 모든 Amazon S3 호환 인터페이스를 지원합니다. AWS_S3_ENDPOINT_URL 환경 변수를 MinIO 서버를 가리키도록 설정하면 아래 스크립트가 그대로 작동합니다.
기본적으로 W&B는 오브젝트 접두사를 추가할 때 10,000개의 오브젝트 제한을 적용합니다. add_reference 호출에서 max_objects=를 지정하여 이 제한을 조정할 수 있습니다.
새 reference artifact 인 mnist:latest는 일반 아티팩트와 유사하게 보이고 작동합니다. 유일한 차이점은 아티팩트가 ETag, 크기 및 버전 ID (오브젝트 버전 관리가 버킷에서 활성화된 경우)와 같은 S3/GCS/Azure 오브젝트에 대한 메타데이터로만 구성된다는 것입니다.
W&B는 기본 메커니즘을 사용하여 사용하는 클라우드 공급자를 기반으로 자격 증명을 찾습니다. 사용된 자격 증명에 대한 자세한 내용은 클라우드 공급자의 문서를 참조하십시오.
AWS의 경우 버킷이 구성된 사용자의 기본 리전에 있지 않으면 AWS_REGION 환경 변수를 버킷 리전과 일치하도록 설정해야 합니다.
일반 아티팩트와 유사하게 이 아티팩트와 상호 작용합니다. App UI에서 파일 브라우저를 사용하여 reference artifact 의 내용을 살펴보고 전체 종속성 그래프를 탐색하고 아티팩트의 버전 관리된 기록을 스캔할 수 있습니다.
이미지, 오디오, 비디오 및 포인트 클라우드와 같은 풍부한 미디어는 버킷의 CORS 구성에 따라 App UI에서 렌더링되지 않을 수 있습니다. 버킷의 CORS 설정에서 app.wandb.ai 목록을 허용하면 App UI가 이러한 풍부한 미디어를 적절하게 렌더링할 수 있습니다.
개인 버킷의 경우 패널이 App UI에서 렌더링되지 않을 수 있습니다. 회사에 VPN이 있는 경우 VPN 내에서 IP를 허용하도록 버킷의 엑세스 정책을 업데이트할 수 있습니다.
W&B는 아티팩트가 기록될 때 기록된 메타데이터를 사용하여 reference artifact 를 다운로드할 때 기본 버킷에서 파일을 검색합니다. 버킷에서 오브젝트 버전 관리를 활성화한 경우 W&B는 아티팩트가 기록될 당시의 파일 상태에 해당하는 오브젝트 버전을 검색합니다. 즉, 버킷 내용을 발전시키더라도 아티팩트가 트레이닝 당시 버킷의 스냅샷 역할을 하므로 지정된 모델이 트레이닝된 데이터의 정확한 반복을 계속 가리킬 수 있습니다.
워크플로우의 일부로 파일을 덮어쓰는 경우 스토리지 버킷에서 ‘오브젝트 버전 관리’를 활성화하는 것이 좋습니다. 버킷에서 버전 관리를 활성화하면 덮어쓴 파일에 대한 참조가 있는 아티팩트가 이전 오브젝트 버전이 유지되므로 여전히 손상되지 않습니다.
유스 케이스에 따라 오브젝트 버전 관리를 활성화하는 방법에 대한 지침을 읽으십시오. AWS, GCP, Azure.
함께 묶기
다음 코드 예제는 Amazon S3, GCS 또는 Azure에서 트레이닝 작업에 제공되는 데이터셋을 추적하는 데 사용할 수 있는 간단한 워크플로우를 보여줍니다.
import wandb
run = wandb.init()
artifact = wandb.Artifact("mnist", type="dataset")
artifact.add_reference("s3://my-bucket/datasets/mnist")
# 아티팩트를 추적하고# 이 run에 대한 입력으로 표시합니다. 새 아티팩트 버전은# 버킷의 파일이 변경된 경우에만 기록됩니다.run.use_artifact(artifact)
artifact_dir = artifact.download()
# 여기서 트레이닝을 수행합니다...
모델을 추적하기 위해 트레이닝 스크립트가 모델 파일을 버킷에 업로드한 후 모델 아티팩트를 기록할 수 있습니다.
데이터셋에 빠르게 엑세스하기 위한 또 다른 일반적인 패턴은 트레이닝 작업을 실행하는 모든 머신에서 원격 파일 시스템에 대한 NFS 마운트 지점을 노출하는 것입니다. 트레이닝 스크립트의 관점에서 파일이 로컬 파일 시스템에 있는 것처럼 보이기 때문에 클라우드 스토리지 버킷보다 훨씬 더 간단한 솔루션이 될 수 있습니다. 다행히 이러한 사용 편의성은 파일 시스템에 대한 참조를 추적하기 위해 Artifacts를 사용하는 데까지 확장됩니다 (마운트 여부와 관계없이).
다음과 같은 구조로 /mount에 파일 시스템이 마운트되어 있다고 가정합니다.
mount
+-- datasets/
| +-- mnist/
+-- models/
+-- cnn/
기본적으로 W&B는 디렉토리에 대한 참조를 추가할 때 10,000개의 파일 제한을 적용합니다. add_reference 호출에서 max_objects=를 지정하여 이 제한을 조정할 수 있습니다.
URL에서 슬래시가 세 개 있다는 점에 유의하십시오. 첫 번째 구성 요소는 파일 시스템 참조 사용을 나타내는 file:// 접두사입니다. 두 번째는 데이터셋 경로인 /mount/datasets/mnist/입니다.
결과 아티팩트인 mnist:latest는 일반 아티팩트와 마찬가지로 보이고 작동합니다. 유일한 차이점은 아티팩트가 크기 및 MD5 체크섬과 같은 파일에 대한 메타데이터로만 구성된다는 것입니다. 파일 자체는 시스템을 벗어나지 않습니다.
일반 아티팩트와 마찬가지로 이 아티팩트와 상호 작용할 수 있습니다. UI에서 파일 브라우저를 사용하여 reference artifact 의 내용을 찾아보고 전체 종속성 그래프를 탐색하고 아티팩트의 버전 관리된 기록을 스캔할 수 있습니다. 그러나 데이터 자체가 아티팩트에 포함되어 있지 않으므로 UI는 이미지, 오디오 등과 같은 풍부한 미디어를 렌더링할 수 없습니다.
파일 시스템 참조의 경우 download() 작업은 참조된 경로에서 파일을 복사하여 아티팩트 디렉토리를 구성합니다. 위의 예에서 /mount/datasets/mnist의 내용은 artifacts/mnist:v0/ 디렉토리에 복사됩니다. 아티팩트에 덮어쓴 파일에 대한 참조가 포함되어 있는 경우 아티팩트를 더 이상 재구성할 수 없으므로 download()에서 오류가 발생합니다.
모든 것을 함께 놓으면 다음은 마운트된 파일 시스템에서 트레이닝 작업에 제공되는 데이터셋을 추적하는 데 사용할 수 있는 간단한 워크플로우입니다.
import wandb
run = wandb.init()
artifact = wandb.Artifact("mnist", type="dataset")
artifact.add_reference("file:///mount/datasets/mnist/")
# 아티팩트를 추적하고# 이 run에 대한 입력으로 표시합니다. 새 아티팩트 버전은# 디렉토리 아래의 파일이# 변경되었습니다.run.use_artifact(artifact)
artifact_dir = artifact.download()
# 여기서 트레이닝을 수행합니다...
모델을 추적하기 위해 트레이닝 스크립트가 모델 파일을 마운트 지점에 쓴 후 모델 아티팩트를 기록할 수 있습니다.
import wandb
run = wandb.init()
# 여기서 트레이닝을 수행합니다...# 디스크에 모델 쓰기model_artifact = wandb.Artifact("cnn", type="model")
model_artifact.add_reference("file:///mount/cnn/my_model.h5")
run.log_artifact(model_artifact)
4.1.7 - Manage data
4.1.7.1 - Delete an artifact
App UI를 통해 대화형으로 또는 W&B SDK를 통해 프로그래밍 방식으로 아티팩트 를 삭제합니다.
App UI 또는 W&B SDK를 사용하여 아티팩트를 대화형으로 삭제할 수 있습니다. 아티팩트를 삭제하면 W&B는 해당 아티팩트를 소프트 삭제로 표시합니다. 즉, 아티팩트는 삭제 대상으로 표시되지만 파일은 즉시 스토리지에서 삭제되지 않습니다.
아티팩트의 내용은 정기적으로 실행되는 가비지 수집 프로세스가 삭제 대상으로 표시된 모든 아티팩트를 검토할 때까지 소프트 삭제 또는 삭제 대기 상태로 유지됩니다. 가비지 수집 프로세스는 아티팩트 및 관련 파일이 이전 또는 이후 아티팩트 버전에서 사용되지 않는 경우 스토리지에서 관련 파일을 삭제합니다.
이 페이지의 섹션에서는 특정 아티팩트 버전을 삭제하는 방법, 아티팩트 컬렉션을 삭제하는 방법, 에일리어스가 있거나 없는 아티팩트를 삭제하는 방법 등을 설명합니다. TTL 정책을 사용하여 W&B에서 아티팩트가 삭제되는 시점을 예약할 수 있습니다. 자세한 내용은 아티팩트 TTL 정책으로 데이터 보존 관리을 참조하세요.
TTL 정책으로 삭제 예약된 Artifacts, W&B SDK로 삭제된 Artifacts 또는 W&B App UI로 삭제된 Artifacts는 먼저 소프트 삭제됩니다. 소프트 삭제된 Artifacts는 하드 삭제되기 전에 가비지 수집을 거칩니다.
아티팩트 버전 삭제
아티팩트 버전을 삭제하려면 다음을 수행하세요.
아티팩트 이름을 선택합니다. 그러면 아티팩트 보기가 확장되고 해당 아티팩트와 연결된 모든 아티팩트 버전이 나열됩니다.
아티팩트 목록에서 삭제할 아티팩트 버전을 선택합니다.
워크스페이스 오른쪽에 있는 케밥 드롭다운을 선택합니다.
삭제를 선택합니다.
아티팩트 버전은 delete() 메소드를 통해 프로그래밍 방식으로 삭제할 수도 있습니다. 아래 예시를 참조하세요.
에일리어스가 있는 여러 아티팩트 버전 삭제
다음 코드 예제는 에일리어스가 연결된 아티팩트를 삭제하는 방법을 보여줍니다. 아티팩트를 만든 엔터티, 프로젝트 이름 및 run ID를 제공합니다.
import wandb
run = api.run("entity/project/run_id")
for artifact in run.logged_artifacts():
artifact.delete()
아티팩트에 에일리어스가 하나 이상 있는 경우 delete_aliases 파라미터를 부울 값 True로 설정하여 에일리어스를 삭제합니다.
import wandb
run = api.run("entity/project/run_id")
for artifact in run.logged_artifacts():
# Set delete_aliases=True in order to delete# artifacts with one more aliases artifact.delete(delete_aliases=True)
특정 에일리어스가 있는 여러 아티팩트 버전 삭제
다음 코드는 특정 에일리어스가 있는 여러 아티팩트 버전을 삭제하는 방법을 보여줍니다. 아티팩트를 만든 엔터티, 프로젝트 이름 및 run ID를 제공합니다. 삭제 로직을 직접 작성하세요.
import wandb
runs = api.run("entity/project_name/run_id")
# Delete artifact ith alias 'v3' and 'v4for artifact_version in runs.logged_artifacts():
# Replace with your own deletion logic.if artifact_version.name[-2:] =="v3"or artifact_version.name[-2:] =="v4":
artifact.delete(delete_aliases=True)
에일리어스가 없는 아티팩트의 모든 버전 삭제
다음 코드 조각은 에일리어스가 없는 아티팩트의 모든 버전을 삭제하는 방법을 보여줍니다. wandb.Api의 project 및 entity 키에 대한 프로젝트 및 엔터티 이름을 각각 제공합니다. <>를 아티팩트 이름으로 바꿉니다.
import wandb
# Provide your entity and a project name when you# use wandb.Api methods.api = wandb.Api(overrides={"project": "project", "entity": "entity"})
artifact_type, artifact_name ="<>"# provide type and namefor v in api.artifact_versions(artifact_type, artifact_name):
# Clean up versions that don't have an alias such as 'latest'.# NOTE: You can put whatever deletion logic you want here.if len(v.aliases) ==0:
v.delete()
아티팩트 컬렉션 삭제
아티팩트 컬렉션을 삭제하려면 다음을 수행하세요.
삭제할 아티팩트 컬렉션으로 이동하여 마우스를 올려 놓습니다.
아티팩트 컬렉션 이름 옆에 있는 케밥 드롭다운을 선택합니다.
삭제를 선택합니다.
delete() 메소드를 사용하여 프로그래밍 방식으로 아티팩트 컬렉션을 삭제할 수도 있습니다. wandb.Api의 project 및 entity 키에 대한 프로젝트 및 엔터티 이름을 각각 제공합니다.
import wandb
# Provide your entity and a project name when you# use wandb.Api methods.api = wandb.Api(overrides={"project": "project", "entity": "entity"})
collection = api.artifact_collection(
"<artifact_type>", "entity/project/artifact_collection_name")
collection.delete()
W&B 호스팅 방식에 따라 가비지 수집을 활성화하는 방법
W&B의 공유 클라우드를 사용하는 경우 가비지 수집은 기본적으로 활성화됩니다. W&B를 호스팅하는 방식에 따라 가비지 수집을 활성화하기 위해 추가 단계를 수행해야 할 수 있습니다.
GORILLA_ARTIFACT_GC_ENABLED 환경 변수를 true로 설정합니다. GORILLA_ARTIFACT_GC_ENABLED=true
AWS, GCP 또는 Minio와 같은 다른 스토리지 공급자를 사용하는 경우 버킷 버전 관리를 활성화합니다. Azure를 사용하는 경우 소프트 삭제를 활성화합니다.
Azure의 소프트 삭제는 다른 스토리지 공급자의 버킷 버전 관리와 동일합니다.
다음 표는 배포 유형에 따라 가비지 수집을 활성화하기 위한 요구 사항을 충족하는 방법을 설명합니다.
W&B Artifact time-to-live (TTL) 정책을 사용하여 Artifacts가 W&B에서 삭제되는 시점을 예약하세요. 아티팩트를 삭제하면 W&B는 해당 아티팩트를 soft-delete 로 표시합니다. 즉, 아티팩트는 삭제 대상으로 표시되지만 파일은 즉시 스토리지에서 삭제되지 않습니다. W&B에서 아티팩트를 삭제하는 방법에 대한 자세한 내용은 아티팩트 삭제 페이지를 참조하세요.
이 비디오 튜토리얼에서 W&B 앱에서 Artifacts TTL로 데이터 보존을 관리하는 방법을 알아보세요.
W&B는 모델 레지스트리에 연결된 모델 아티팩트에 대한 TTL 정책을 설정하는 옵션을 비활성화합니다. 이는 연결된 모델이 프로덕션 워크플로우에서 사용되는 경우 실수로 만료되지 않도록 하기 위함입니다.
팀 관리자만 팀 설정을 보고 (1) 누가 TTL 정책을 설정하거나 편집할 수 있는지 허용하거나 (2) 팀 기본 TTL을 설정하는 것과 같은 팀 수준 TTL 설정에 엑세스할 수 있습니다.
W&B 앱 UI에서 아티팩트 세부 정보에 TTL 정책을 설정하거나 편집하는 옵션이 표시되지 않거나 프로그래밍 방식으로 TTL을 설정해도 아티팩트의 TTL 속성이 성공적으로 변경되지 않으면 팀 관리자가 해당 권한을 부여하지 않은 것입니다.
자동 생성된 Artifacts
사용자가 생성한 아티팩트만 TTL 정책을 사용할 수 있습니다. W&B에서 자동으로 생성된 아티팩트에는 TTL 정책을 설정할 수 없습니다.
트레이닝 중에 W&B는 로그, 아티팩트 및 설정 파일을 다음 로컬 디렉토리에 로컬로 저장합니다.
파일
기본 위치
기본 위치를 변경하려면 다음을 설정하십시오:
logs
./wandb
wandb.init의 dir 또는 WANDB_DIR 환경 변수를 설정하십시오.
artifacts
~/.cache/wandb
WANDB_CACHE_DIR 환경 변수
configs
~/.config/wandb
WANDB_CONFIG_DIR 환경 변수
업로드를 위한 Staging artifacts
~/.cache/wandb-data/
WANDB_DATA_DIR 환경 변수
다운로드된 artifacts
./artifacts
WANDB_ARTIFACT_DIR 환경 변수
환경 변수를 사용하여 W&B를 구성하는 방법에 대한 전체 가이드는 환경 변수 참조를 참조하십시오.
wandb가 초기화된 머신에 따라 이러한 기본 폴더가 파일 시스템의 쓰기 가능한 부분에 위치하지 않을 수 있습니다. 이로 인해 오류가 발생할 수 있습니다.
로컬 아티팩트 캐시 정리
W&B는 공통 파일을 공유하는 버전 간의 다운로드 속도를 높이기 위해 아티팩트 파일을 캐시합니다. 시간이 지남에 따라 이 캐시 디렉토리가 커질 수 있습니다. wandb artifact cache cleanup 명령을 실행하여 캐시를 정리하고 최근에 사용되지 않은 파일을 제거하십시오.
다음 코드 조각은 캐시 크기를 1GB로 제한하는 방법을 보여줍니다. 코드 조각을 복사하여 터미널에 붙여넣으십시오:
$ wandb artifact cache cleanup 1GB
4.1.8 - Explore artifact graphs
자동으로 생성된 직접 비순환 W&B Artifact 그래프를 트래버스합니다.
W&B는 주어진 run이 기록한 Artifacts와 주어진 run이 사용하는 Artifacts를 자동으로 추적합니다. 이러한 Artifacts에는 데이터셋, 모델, 평가 결과 등이 포함될 수 있습니다. Artifact의 계보를 탐색하여 기계 학습 라이프사이클 전반에 걸쳐 생성된 다양한 Artifacts를 추적하고 관리할 수 있습니다.
계보
Artifact의 계보를 추적하면 다음과 같은 주요 이점이 있습니다.
재현성: 모든 Artifacts의 계보를 추적함으로써 팀은 실험, 모델 및 결과를 재현할 수 있습니다. 이는 디버깅, 실험 및 기계 학습 모델 검증에 필수적입니다.
버전 관리: Artifact 계보는 Artifacts의 버전 관리와 시간 경과에 따른 변경 사항 추적을 포함합니다. 이를 통해 팀은 필요한 경우 이전 버전의 데이터 또는 모델로 롤백할 수 있습니다.
감사: Artifacts 및 해당 변환에 대한 자세한 기록을 통해 조직은 규제 및 거버넌스 요구 사항을 준수할 수 있습니다.
협업 및 지식 공유: Artifact 계보는 시도에 대한 명확한 기록과 무엇이 작동했고 무엇이 작동하지 않았는지 제공함으로써 팀 멤버 간의 더 나은 협업을 촉진합니다. 이는 노력의 중복을 피하고 개발 프로세스를 가속화하는 데 도움이 됩니다.
Artifact의 계보 찾기
Artifacts 탭에서 Artifact를 선택하면 해당 Artifact의 계보를 볼 수 있습니다. 이 그래프 보기는 파이프라인의 일반적인 개요를 보여줍니다.
Artifact 그래프를 보려면:
W&B App UI에서 프로젝트로 이동합니다.
왼쪽 패널에서 Artifact 아이콘을 선택합니다.
Lineage를 선택합니다.
계보 그래프 탐색
제공하는 Artifact 또는 job 유형은 이름 앞에 표시되며, Artifacts는 파란색 아이콘으로, runs는 녹색 아이콘으로 표시됩니다. 화살표는 그래프에서 run 또는 Artifact의 입력 및 출력을 자세히 설명합니다.
왼쪽 사이드바와 Lineage 탭에서 Artifact의 유형과 이름을 모두 볼 수 있습니다.
더 자세한 보기를 보려면 개별 Artifact 또는 run을 클릭하여 특정 오브젝트에 대한 자세한 정보를 얻으십시오.
Artifact 클러스터
그래프 수준에 5개 이상의 runs 또는 Artifacts가 있는 경우 클러스터가 생성됩니다. 클러스터에는 특정 버전의 runs 또는 Artifacts를 찾기 위한 검색 창이 있으며 클러스터 내부의 노드 계보를 계속 조사하기 위해 클러스터에서 개별 노드를 가져옵니다.
노드를 클릭하면 노드에 대한 개요가 있는 미리보기가 열립니다. 화살표를 클릭하면 개별 run 또는 Artifact가 추출되어 추출된 노드의 계보를 검사할 수 있습니다.
Artifact를 만듭니다. 먼저 wandb.init으로 run을 만듭니다. 그런 다음 wandb.Artifact로 새 Artifact를 만들거나 기존 Artifact를 검색합니다. 다음으로 .add_file로 Artifact에 파일을 추가합니다. 마지막으로 .log_artifact로 Artifact를 run에 기록합니다. 완성된 코드는 다음과 같습니다.
with wandb.init() as run:
artifact = wandb.Artifact("artifact_name", "artifact_type")
# Add Files and Assets to the artifact using# `.add`, `.add_file`, `.add_dir`, and `.add_reference` artifact.add_file("image1.png")
run.log_artifact(artifact)
Artifact 오브젝트의 logged_by 및 used_by 메서드를 사용하여 Artifact에서 그래프를 탐색합니다.
# Walk up and down the graph from an artifact:producer_run = artifact.logged_by()
consumer_runs = artifact.used_by()
W&B 파일이 기본적으로 어디에 저장되는지 알아보세요. 민감한 정보를 저장하고 보관하는 방법을 살펴보세요.
Artifacts를 로깅할 때 파일은 W&B에서 관리하는 Google Cloud 버킷에 업로드됩니다. 버킷의 내용은 저장 시와 전송 중에 모두 암호화됩니다. 아티팩트 파일은 해당 프로젝트에 엑세스 권한이 있는 사용자에게만 표시됩니다.
아티팩트 버전을 삭제하면 데이터베이스에서 소프트 삭제로 표시되고 스토리지 비용에서 제거됩니다. 전체 아티팩트를 삭제하면 영구 삭제 대기열에 추가되고 모든 콘텐츠가 W&B 버킷에서 제거됩니다. 파일 삭제와 관련된 특정 요구 사항이 있는 경우 고객 지원에 문의하십시오.
멀티 테넌트 환경에 상주할 수 없는 중요한 데이터셋의 경우 클라우드 버킷에 연결된 프라이빗 W&B 서버 또는 _reference artifacts_를 사용할 수 있습니다. 레퍼런스 아티팩트는 파일 내용을 W&B로 보내지 않고 프라이빗 버킷에 대한 레퍼런스를 추적합니다. 레퍼런스 아티팩트는 버킷 또는 서버의 파일에 대한 링크를 유지 관리합니다. 즉, W&B는 파일 자체가 아닌 파일과 연결된 메타데이터만 추적합니다.
레퍼런스가 아닌 아티팩트를 만드는 방법과 유사하게 레퍼런스 아티팩트를 만듭니다.
import wandb
run = wandb.init()
artifact = wandb.Artifact("animals", type="dataset")
artifact.add_reference("s3://my-bucket/animals")
다음 코드 예제는 W&B 서버에 기록하고 저장한 Artifact를 사용하는 단계를 보여줍니다.
먼저 **wandb.init()**으로 새 run 오브젝트를 초기화합니다.
둘째, run 오브젝트 use_artifact() 메소드를 사용하여 사용할 Artifact를 W&B에 알립니다. 그러면 Artifact 오브젝트가 반환됩니다.
셋째, Artifact download() 메소드를 사용하여 Artifact의 내용을 다운로드합니다.
# W&B Run을 만듭니다. 여기서는 'training'을 'type'으로 지정합니다.# 이 run을 사용하여 트레이닝을 추적하기 때문입니다.run = wandb.init(project="artifacts-example", job_type="training")
# Artifact에 대해 W&B를 쿼리하고 이 run에 대한 입력으로 표시합니다.artifact = run.use_artifact("bicycle-dataset:latest")
# Artifact의 내용 다운로드artifact_dir = artifact.download()
또는 Public API (wandb.Api)를 사용하여 Run 외부의 W&B에 이미 저장된 데이터를 내보내거나 (또는 업데이트)할 수 있습니다. 자세한 내용은 외부 파일 추적을 참조하십시오.
4.2 - Secrets
W&B secrets에 대한 개요, 작동 방식, 사용 시작 방법에 대해 설명합니다.
W&B Secret Manager를 사용하면 엑세스 토큰, bearer 토큰, API 키 또는 비밀번호와 같은 중요한 문자열인 _secrets_를 안전하고 중앙 집중식으로 저장, 관리 및 삽입할 수 있습니다. W&B Secret Manager는 중요한 문자열을 코드에 직접 추가하거나 웹 훅의 헤더 또는 페이로드를 구성할 때 불필요하게 만듭니다.
Secrets는 각 팀의 Secret Manager의 팀 설정의 Team secrets 섹션에 저장되고 관리됩니다.
W&B 관리자만 secret을 생성, 편집 또는 삭제할 수 있습니다.
Secrets는 Azure, GCP 또는 AWS에서 호스팅하는 W&B Server 배포를 포함하여 W&B의 핵심 부분으로 포함됩니다. 다른 배포 유형을 사용하는 경우 W&B 계정 팀에 문의하여 W&B에서 secrets를 사용하는 방법에 대해 논의하십시오.
W&B Server에서는 보안 요구 사항을 충족하는 보안 조치를 구성해야 합니다.
W&B는 고급 보안 기능으로 구성된 AWS, GCP 또는 Azure에서 제공하는 클라우드 제공업체의 secrets manager의 W&B 인스턴스에 secrets를 저장하는 것이 좋습니다.
클라우드 secrets manager(AWS, GCP 또는 Azure)의 W&B 인스턴스를 사용할 수 없고 클러스터를 사용하는 경우 발생할 수 있는 보안 취약점을 방지하는 방법을 이해하지 못하는 경우 Kubernetes 클러스터를 secrets 저장소의 백엔드로 사용하지 않는 것이 좋습니다.
secret 추가
secret을 추가하려면:
수신 서비스가 들어오는 웹 훅을 인증하는 데 필요한 경우 필요한 토큰 또는 API 키를 생성합니다. 필요한 경우 비밀번호 관리자와 같이 중요한 문자열을 안전하게 저장합니다.
W&B에 로그인하여 팀의 Settings 페이지로 이동합니다.
Team Secrets 섹션에서 New secret을 클릭합니다.
문자, 숫자 및 밑줄(_)을 사용하여 secret의 이름을 지정합니다.
중요한 문자열을 Secret 필드에 붙여넣습니다.
Add secret을 클릭합니다.
웹 훅을 구성할 때 웹 훅 자동화에 사용할 secrets를 지정합니다. 자세한 내용은 웹 훅 구성 섹션을 참조하십시오.
secret을 생성하면 ${SECRET_NAME} 형식을 사용하여 웹 훅 자동화의 페이로드에서 해당 secret에 엑세스할 수 있습니다.
secret 교체
secret을 교체하고 값을 업데이트하려면:
secret의 행에서 연필 아이콘을 클릭하여 secret의 세부 정보를 엽니다.
Secret을 새 값으로 설정합니다. 선택적으로 Reveal secret을 클릭하여 새 값을 확인합니다.
Add secret을 클릭합니다. secret의 값이 업데이트되고 더 이상 이전 값으로 확인되지 않습니다.
secret을 생성하거나 업데이트한 후에는 더 이상 현재 값을 표시할 수 없습니다. 대신 secret을 새 값으로 교체합니다.
secret 삭제
secret을 삭제하려면:
secret의 행에서 휴지통 아이콘을 클릭합니다.
확인 대화 상자를 읽은 다음 Delete를 클릭합니다. secret이 즉시 영구적으로 삭제됩니다.
secrets에 대한 엑세스 관리
팀의 자동화는 팀의 secrets를 사용할 수 있습니다. secret을 제거하기 전에 secret을 사용하는 자동화가 작동을 멈추지 않도록 업데이트하거나 제거하십시오.
각 registry는 하나 이상의 컬렉션으로 구성됩니다. 각 컬렉션은 고유한 작업 또는 유스 케이스를 나타냅니다.
artifact를 registry에 추가하려면 먼저 특정 artifact 버전을 W&B에 기록합니다. artifact를 기록할 때마다 W&B는 해당 artifact에 버전을 자동으로 할당합니다. artifact 버전은 0부터 인덱싱되므로 첫 번째 버전은 v0, 두 번째 버전은 v1과 같습니다.
artifact를 W&B에 기록한 후에는 해당 특정 artifact 버전을 registry의 컬렉션에 연결할 수 있습니다.
“링크"라는 용어는 W&B가 artifact를 저장하는 위치와 registry에서 artifact에 엑세스할 수 있는 위치를 연결하는 포인터를 나타냅니다. W&B는 artifact를 컬렉션에 연결할 때 artifact를 복제하지 않습니다.
예를 들어, 다음 코드 예제는 “my_model.txt"라는 모델 artifact를 코어 registry의 “first-collection"이라는 컬렉션에 기록하고 연결하는 방법을 보여줍니다.
W&B run을 초기화합니다.
artifact를 W&B에 기록합니다.
artifact 버전을 연결할 컬렉션 및 registry의 이름을 지정합니다.
artifact를 컬렉션에 연결합니다.
이 Python 코드를 스크립트에 저장하고 실행합니다. W&B Python SDK 버전 0.18.6 이상이 필요합니다.
import wandb
import random
# track the artifact를 추적하기 위해 W&B run을 초기화합니다.run = wandb.init(project="registry_quickstart")
# 기록할 수 있도록 시뮬레이션된 모델 파일을 만듭니다.with open("my_model.txt", "w") as f:
f.write("Model: "+ str(random.random()))
# artifact를 W&B에 기록합니다.logged_artifact = run.log_artifact(
artifact_or_path="./my_model.txt",
name="gemma-finetuned",
type="model"# artifact 유형을 지정합니다.)
# artifact를 게시할 컬렉션 및 registry 이름을 지정합니다.COLLECTION_NAME ="first-collection"REGISTRY_NAME ="model"# artifact를 registry에 연결합니다.run.link_artifact(
artifact=logged_artifact,
target_path=f"wandb-registry-{REGISTRY_NAME}/{COLLECTION_NAME}")
반환된 run 오브젝트의 link_artifact(target_path = "") 메소드에서 지정한 컬렉션이 지정한 registry 내에 없는 경우 W&B는 자동으로 컬렉션을 만듭니다.
터미널에 출력되는 URL은 W&B가 artifact를 저장하는 프로젝트로 연결됩니다.
Registry App으로 이동하여 사용자와 조직의 다른 구성원이 게시하는 artifact 버전을 봅니다. 이렇게 하려면 먼저 W&B로 이동합니다. 애플리케이션 아래 왼쪽 사이드바에서 Registry를 선택합니다. “Model” registry를 선택합니다. registry 내에서 연결된 artifact 버전이 있는 “first-collection” 컬렉션을 볼 수 있습니다.
artifact 버전을 registry 내의 컬렉션에 연결하면 조직 구성원은 적절한 권한이 있는 경우 artifact 버전을 보고, 다운로드하고, 관리하고, 다운스트림 자동화를 만들 수 있습니다.
artifact 버전이 (run.log_artifact()를 사용하여) 메트릭을 기록하는 경우 해당 버전의 세부 정보 페이지에서 해당 버전에 대한 메트릭을 볼 수 있으며 컬렉션 페이지에서 artifact 버전 간에 메트릭을 비교할 수 있습니다. registry에서 연결된 artifact 보기를 참조하십시오.
W&B Registry 활성화
배포 유형에 따라 다음 조건을 충족하여 W&B Registry를 활성화합니다.
배포 유형
활성화 방법
Multi-tenant Cloud
별도의 조치가 필요하지 않습니다. W&B Registry는 W&B App에서 사용할 수 있습니다.
Dedicated Cloud
계정 팀에 문의하십시오. SA(Solutions Architect) 팀은 인스턴스의 운영자 콘솔 내에서 W&B Registry를 활성화합니다. 인스턴스가 서버 릴리스 버전 0.59.2 이상인지 확인합니다.
Self-Managed
ENABLE_REGISTRY_UI라는 환경 변수를 활성화합니다. 서버에서 환경 변수를 활성화하는 방법에 대한 자세한 내용은 이 문서를 참조하십시오. 자체 관리형 인스턴스에서는 인프라 관리자가 이 환경 변수를 활성화하고 true로 설정해야 합니다. 인스턴스가 서버 릴리스 버전 0.59.2 이상인지 확인합니다.
초기 데이터 수집부터 최종 모델 배포까지 기계 학습 파이프라인의 각 단계에 대한 custom registry를 만들 수 있습니다.
예를 들어, 트레이닝된 모델의 성능을 평가하기 위해 선별된 데이터셋을 구성하기 위해 “Benchmark_Datasets"라는 레지스트리를 만들 수 있습니다. 이 레지스트리 내에서 모델이 트레이닝 중에 본 적이 없는 사용자 질문과 해당 전문가 검증 답변 세트가 포함된 “User_Query_Insurance_Answer_Test_Data"라는 컬렉션을 가질 수 있습니다.
Custom registry는 organization or restricted visibility를 가질 수 있습니다. registry 관리자는 custom registry의 visibility를 organization에서 restricted로 변경할 수 있습니다. 그러나 registry 관리자는 custom registry의 visibility를 restricted에서 organization visibility로 변경할 수 없습니다.
Registry에서 user의 권한은 개별적으로 또는 Team 멤버십에 의해 해당 user에게 할당된 최고 수준의 권한에 따라 달라집니다.
예를 들어, Registry 관리자가 Nico라는 user를 Registry A에 추가하고 Viewer Registry 역할을 할당한다고 가정합니다. 그런 다음 Registry 관리자가 Foundation Model Team이라는 Team을 Registry A에 추가하고 Foundation Model Team에 Member Registry 역할을 할당합니다.
Nico는 Registry의 Member인 Foundation Model Team의 멤버입니다. Member는 Viewer보다 더 많은 권한을 가지고 있기 때문에 W&B는 Nico에게 Member 역할을 부여합니다.
다음 표는 user의 개별 Registry 역할과 해당 멤버인 Team의 Registry 역할 간의 충돌이 발생할 경우 최고 수준의 권한을 보여줍니다.
Team Registry 역할
개별 Registry 역할
상속된 Registry 역할
Viewer
Viewer
Viewer
Member
Viewer
Member
Admin
Viewer
Admin
충돌이 있는 경우 W&B는 user 이름 옆에 최고 수준의 권한을 표시합니다.
예를 들어, 다음 이미지에서 Alex는 smle-reg-team-1 Team의 멤버이기 때문에 Member 역할 권한을 상속받습니다.
컬렉션 은 레지스트리 내에서 연결된 아티팩트 버전들의 집합입니다. 각 컬렉션은 고유한 작업 또는 유스 케이스를 나타냅니다.
예를 들어, 코어 데이터셋 레지스트리 내에 여러 개의 컬렉션을 가질 수 있습니다. 각 컬렉션은 MNIST, CIFAR-10 또는 ImageNet과 같은 서로 다른 데이터셋을 포함합니다.
또 다른 예로, “chatbot"이라는 레지스트리가 있을 수 있으며, 여기에는 모델 Artifacts에 대한 컬렉션, 데이터셋 Artifacts에 대한 또 다른 컬렉션, 그리고 파인튜닝된 모델 Artifacts에 대한 또 다른 컬렉션이 포함될 수 있습니다.
레지스트리와 컬렉션을 구성하는 방법은 사용자에게 달려 있습니다.
W&B 모델 레지스트리에 익숙하신 분은 등록된 모델에 대해 알고 계실 것입니다. 모델 레지스트리의 등록된 모델은 이제 W&B 레지스트리에서 컬렉션이라고 합니다.
컬렉션 유형
각 컬렉션은 오직 하나의 아티팩트 유형 만을 허용합니다. 지정하는 유형은 사용자와 조직의 다른 구성원이 해당 컬렉션에 연결할 수 있는 Artifacts의 종류를 제한합니다.
아티팩트 유형을 Python과 같은 프로그래밍 언어의 데이터 유형과 유사하게 생각할 수 있습니다. 이 비유에서 컬렉션은 문자열, 정수 또는 부동 소수점을 저장할 수 있지만 이러한 데이터 유형을 혼합하여 저장할 수는 없습니다.
예를 들어, “데이터셋” 아티팩트 유형을 허용하는 컬렉션을 생성한다고 가정합니다. 이는 “데이터셋” 유형을 가진 미래의 Artifacts 버전만 이 컬렉션에 연결할 수 있음을 의미합니다. 마찬가지로, “모델” 아티팩트 유형만 허용하는 컬렉션에는 “모델” 유형의 Artifacts만 연결할 수 있습니다.
아티팩트 오브젝트를 생성할 때 아티팩트의 유형을 지정합니다. wandb.Artifact()의 type 필드를 참고하십시오.
Artifact를 레지스트리에 연결하기 전에 해당 컬렉션에서 허용하는 Artifact 유형을 확인하십시오. 컬렉션 유형에 대한 자세한 내용은 컬렉션 생성 내의 “컬렉션 유형"을 참조하십시오.
유스 케이스에 따라 아래 탭에 설명된 지침을 따르십시오.
Artifact 버전이 메트릭을 기록하는 경우(run.log_artifact() 사용) 해당 버전의 세부 정보 페이지에서 해당 버전에 대한 메트릭을 보고 Artifact 페이지에서 Artifact 버전 간의 메트릭을 비교할 수 있습니다. 레지스트리에서 연결된 Artifact 보기를 참조하십시오.
레지스트리에 연결된 아티팩트를 다운로드하려면 해당 연결된 아티팩트의 경로를 알아야 합니다. 경로는 레지스트리 이름, 컬렉션 이름, 엑세스하려는 아티팩트 버전의 에일리어스 또는 인덱스로 구성됩니다.
레지스트리, 컬렉션, 아티팩트 버전의 에일리어스 또는 인덱스가 있으면 다음 문자열 템플릿을 사용하여 연결된 아티팩트의 경로를 구성할 수 있습니다.
# 버전 인덱스가 지정된 아티팩트 이름f"wandb-registry-{REGISTRY}/{COLLECTION}:v{INDEX}"# 에일리어스가 지정된 아티팩트 이름f"wandb-registry-{REGISTRY}/{COLLECTION}:{ALIAS}"
중괄호 {} 안의 값을 엑세스하려는 레지스트리 이름, 컬렉션 이름, 아티팩트 버전의 에일리어스 또는 인덱스로 바꿉니다.
아티팩트 버전을 핵심 Model registry 또는 핵심 Dataset registry에 연결하려면 model 또는 dataset을 지정하십시오.
연결된 아티팩트의 경로가 있으면 wandb.init.use_artifact 메소드를 사용하여 아티팩트에 엑세스하고 해당 콘텐츠를 다운로드합니다. 다음 코드 조각은 W&B Registry에 연결된 아티팩트를 사용하고 다운로드하는 방법을 보여줍니다. <> 안의 값을 자신의 값으로 바꾸십시오.
다음 코드 예제는 사용자가 Fine-tuned Models 레지스트리의 phi3-finetuned라는 컬렉션에 연결된 아티팩트를 다운로드하는 방법을 보여줍니다. 아티팩트 버전의 에일리어스는 production으로 설정됩니다.
import wandb
TEAM_ENTITY ="product-team-applications"PROJECT_NAME ="user-stories"REGISTRY ="Fine-tuned Models"COLLECTION ="phi3-finetuned"ALIAS ='production'# 지정된 팀 및 프로젝트 내에서 run 초기화run = wandb.init(entity=TEAM_ENTITY, project = PROJECT_NAME)
artifact_name =f"wandb-registry-{REGISTRY}/{COLLECTION}:{ALIAS}"# 아티팩트에 엑세스하고 계보 추적을 위해 run에 대한 입력으로 표시fetched_artifact = run.use_artifact(artifact_or_name = name)
# 아티팩트 다운로드. 다운로드한 콘텐츠의 경로를 반환합니다.downloaded_path = fetched_artifact.download()
여러 조직에 속한 개인 엔터티를 가진 Users는 레지스트리에 연결된 아티팩트에 엑세스할 때 조직 이름을 지정하거나 팀 엔터티를 사용해야 합니다.
import wandb
REGISTRY ="<registry_name>"COLLECTION ="<collection_name>"VERSION ="<version>"# 팀 엔터티를 사용하여 API를 인스턴스화해야 합니다.api = wandb.Api(overrides={"entity": "<team-entity>"})
artifact_name =f"wandb-registry-{REGISTRY}/{COLLECTION}:{VERSION}"artifact = api.artifact(name = artifact_name)
# 경로에 조직 표시 이름 또는 조직 엔터티 사용api = wandb.Api()
artifact_name =f"{ORG_NAME}/wandb-registry-{REGISTRY}/{COLLECTION}:{VERSION}"artifact = api.artifact(name = artifact_name)
여기서 ORG_NAME은 조직의 표시 이름입니다. 멀티 테넌트 SaaS Users는 https://wandb.ai/account-settings/의 조직 설정 페이지에서 조직 이름을 찾을 수 있습니다. Dedicated Cloud 및 Self-Managed Users는 계정 관리자에게 문의하여 조직의 표시 이름을 확인하십시오.
미리 생성된 코드 조각 복사 및 붙여넣기
W&B는 Python 스크립트, 노트북 또는 터미널에 복사하여 붙여넣어 레지스트리에 연결된 아티팩트를 다운로드할 수 있는 코드 조각을 생성합니다.
# 문자열 `model`을 포함하는 모든 registries를 필터링합니다.registry_filters = {
"name": {"$regex": "model"}
}
# 필터와 일치하는 모든 registries의 iterable을 반환합니다.registries = api.registries(filter=registry_filters)
collection 이름에 문자열 yolo를 포함하는 registry에 관계없이 모든 collections을 필터링합니다.
# collection 이름에 문자열 `yolo`를 포함하는 registry에 관계없이# 모든 collections을 필터링합니다.collection_filters = {
"name": {"$regex": "yolo"}
}
# 필터와 일치하는 모든 collections의 iterable을 반환합니다.collections = api.registries().collections(filter=collection_filters)
collection 이름에 문자열 yolo를 포함하고 cnn을 태그로 갖는 registry에 관계없이 모든 collections을 필터링합니다.
# collection 이름에 문자열 `yolo`를 포함하고 `cnn`을 태그로 갖는# registry에 관계없이 모든 collections을 필터링합니다.collection_filters = {
"name": {"$regex": "yolo"},
"tag": "cnn"}
# 필터와 일치하는 모든 collections의 iterable을 반환합니다.collections = api.registries().collections(filter=collection_filters)
문자열 model을 포함하고 태그 image-classification 또는 latest 에일리어스를 갖는 모든 artifact versions을 찾습니다.
# 문자열 `model`을 포함하고# 태그 `image-classification` 또는 `latest` 에일리어스를 갖는 모든 artifact versions을 찾습니다.registry_filters = {
"name": {"$regex": "model"}
}
# 논리적 $or 연산자를 사용하여 artifact versions을 필터링합니다.version_filters = {
"$or": [
{"tag": "image-classification"},
{"alias": "production"}
]
}
# 필터와 일치하는 모든 artifact versions의 iterable을 반환합니다.artifacts = api.registries(filter=registry_filters).collections().versions(filter=version_filters)
이전 코드 조각에서 artifacts iterable의 각 항목은 Artifact 클래스의 인스턴스입니다. 즉, 각 아티팩트의 속성 (예: name, collection, aliases, tags, created_at 등)에 엑세스할 수 있습니다.
for art in artifacts:
print(f"artifact name: {art.name}")
print(f"collection artifact belongs to: { art.collection.name}")
print(f"artifact aliases: {art.aliases}")
print(f"tags attached to artifact: {art.tags}")
print(f"artifact created at: {art.created_at}\n")
아티팩트 오브젝트의 속성 전체 목록은 API Reference 문서의 Artifacts Class를 참조하세요.
2024-01-08과 2025-03-04 13:10 UTC 사이에 생성된 registry 또는 collection에 관계없이 모든 artifact versions을 필터링합니다.
# 2024-01-08과 2025-03-04 13:10 UTC 사이에 생성된 모든 artifact versions을 찾습니다.artifact_filters = {
"alias": "latest",
"created_at" : {"$gte": "2024-01-08", "$lte": "2025-03-04 13:10:00"},
}
# 필터와 일치하는 모든 artifact versions의 iterable을 반환합니다.artifacts = api.registries().collections().versions(filter=artifact_filters)
날짜 및 시간을 YYYY-MM-DD HH:MM:SS 형식으로 지정합니다. 날짜로만 필터링하려면 시간, 분, 초를 생략할 수 있습니다.
버전 탭 내에서 태그 필드 옆에 있는 더하기 아이콘(+)을 클릭하고 태그 이름을 입력합니다.
키보드에서 Enter 키를 누릅니다.
태그를 추가하거나 업데이트하려는 아티팩트 버전을 가져옵니다. 아티팩트 버전을 가져왔으면 아티팩트 오브젝트의 tag 속성에 액세스하여 해당 아티팩트에 태그를 추가하거나 수정할 수 있습니다. 하나 이상의 태그를 목록으로 아티팩트의 tag 속성에 전달합니다.
다른 Artifacts와 마찬가지로 run을 생성하지 않고도 W&B에서 Artifact를 가져오거나 run을 생성하고 해당 run 내에서 Artifact를 가져올 수 있습니다. 어느 경우든 W&B 서버에서 Artifact를 업데이트하려면 Artifact 오브젝트의 save 메소드를 호출해야 합니다.
아래의 적절한 코드 셀을 복사하여 붙여넣어 아티팩트 버전의 태그를 추가하거나 수정합니다. <> 안의 값을 자신의 값으로 바꿉니다.
다음 코드 조각은 새 run을 생성하지 않고 Artifact를 가져와서 태그를 추가하는 방법을 보여줍니다.
import wandb
ARTIFACT_TYPE ="<TYPE>"ORG_NAME ="<org_name>"REGISTRY_NAME ="<registry_name>"COLLECTION_NAME ="<collection_name>"VERSION ="<artifact_version>"artifact_name =f"{ORG_NAME}/wandb-registry-{REGISTRY_NAME}/{COLLECTION_NAME}:v{VERSION}"artifact = wandb.Api().artifact(name = artifact_name, type = ARTIFACT_TYPE)
artifact.tags = ["tag2"] # 목록에 하나 이상의 태그 제공artifact.save()
다음 코드 조각은 새 run을 생성하여 Artifact를 가져와서 태그를 추가하는 방법을 보여줍니다.
import wandb
ORG_NAME ="<org_name>"REGISTRY_NAME ="<registry_name>"COLLECTION_NAME ="<collection_name>"VERSION ="<artifact_version>"run = wandb.init(entity ="<entity>", project="<project>")
artifact_name =f"{ORG_NAME}/wandb-registry-{REGISTRY_NAME}/{COLLECTION_NAME}:v{VERSION}"artifact = run.use_artifact(artifact_or_name = artifact_name)
artifact.tags = ["tag2"] # 목록에 하나 이상의 태그 제공artifact.save()
아티팩트 버전에 속한 태그 업데이트
tags 속성을 재할당하거나 변경하여 프로그래밍 방식으로 태그를 업데이트합니다. W&B는 제자리 변경 대신 tags 속성을 재할당하는 것을 권장하며, 이는 좋은 Python 방식입니다.
예를 들어, 다음 코드 조각은 재할당을 통해 목록을 업데이트하는 일반적인 방법을 보여줍니다. 간결성을 위해 아티팩트 버전에 태그 추가 섹션의 코드 예제를 계속합니다.
type_name 파라미터에 컬렉션의 유형을 지정하고 name 파라미터에 컬렉션의 전체 이름을 지정합니다. 컬렉션 이름은 접두사 “wandb-registry”, 레지스트리 이름 및 컬렉션 이름으로 구성되며 슬래시로 구분됩니다.
wandb-registry-{REGISTRY_NAME}/{COLLECTION_NAME}
다음 코드 조각을 Python 스크립트 또는 노트북에 복사하여 붙여 넣습니다. 꺾쇠 괄호(<>)로 묶인 값을 자신의 값으로 바꿉니다.
import wandb
api = wandb.Api()
collection = api.artifact_collection(
type_name ="<collection_type>",
name ="<collection_name>" )
collection.description ="This is a description."collection.save()
예를 들어 다음 이미지는 모델 아키텍처, 용도, 성능 정보 등을 문서화하는 컬렉션을 보여줍니다.
4.3.10 - Create and view lineage maps
W&B Registry에서 계보 맵을 만드세요.
W&B 레지스트리의 컬렉션 내에서 ML 실험에서 사용하는 아티팩트의 이력을 볼 수 있습니다. 이 이력을 계보 그래프 라고 합니다.
컬렉션에 속하지 않은 W&B에 기록하는 아티팩트에 대한 계보 그래프를 볼 수도 있습니다.
계보 그래프는 아티팩트를 기록하는 특정 run을 보여줄 수 있습니다. 또한 계보 그래프는 어떤 run이 아티팩트를 입력으로 사용했는지도 보여줄 수 있습니다. 다시 말해, 계보 그래프는 run의 입력과 출력을 보여줄 수 있습니다.
예를 들어, 다음 이미지는 ML 실험 전체에서 생성되고 사용된 아티팩트를 보여줍니다.
왼쪽에서 오른쪽으로 이미지는 다음을 보여줍니다.
여러 개의 run이 split_zoo_dataset:v4 아티팩트를 기록합니다.
“rural-feather-20” run은 트레이닝을 위해 split_zoo_dataset:v4 아티팩트를 사용합니다.
“rural-feather-20” run의 출력은 zoo-ylbchv20:v0이라는 모델 아티팩트입니다.
“northern-lake-21"이라는 run은 모델을 평가하기 위해 모델 아티팩트 zoo-ylbchv20:v0을 사용합니다.
run의 입력 추적
wandb.init.use_artifact API를 사용하여 아티팩트를 run의 입력 또는 종속성으로 표시합니다.
다음 코드 조각은 use_artifact를 사용하는 방법을 보여줍니다. 꺾쇠 괄호(<>)로 묶인 값을 사용자의 값으로 바꿉니다.
아티팩트의 계보 그래프 페이지에 있으면 해당 계보 그래프의 모든 노드에 대한 추가 정보를 볼 수 있습니다.
run 노드를 선택하여 run의 ID, run의 이름, run의 상태 등과 같은 run의 세부 정보를 봅니다. 예를 들어, 다음 이미지는 rural-feather-20 run에 대한 정보를 보여줍니다.
아티팩트 노드를 선택하여 전체 이름, 유형, 생성 시간 및 관련 에일리어스와 같은 해당 아티팩트의 세부 정보를 봅니다.
4.3.11 - Migrate from legacy Model Registry
W&B는 기존 W&B Model Registry의 자산을 새로운 W&B Registry로 이전할 예정입니다. 이 마이그레이션은 W&B에서 완전히 관리하고 트리거하며, 사용자 의 개입은 필요하지 않습니다. 이 프로세스는 기존 워크플로우의 중단을 최소화하면서 최대한 원활하게 진행되도록 설계되었습니다.
이전은 새로운 W&B Registry에 Model Registry에서 현재 사용할 수 있는 모든 기능이 포함되면 진행됩니다. W&B는 현재 워크플로우, 코드 베이스 및 레퍼런스를 보존하려고 노력할 것입니다.
이 가이드 는 살아있는 문서이며 더 많은 정보를 사용할 수 있게 되면 정기적으로 업데이트됩니다. 질문이나 지원이 필요하면 support@wandb.com으로 문의하십시오.
W&B Registry는 기존 Model Registry와 어떻게 다른가요?
W&B Registry는 모델, 데이터 셋 및 기타 Artifacts 관리 를 위한 보다 강력하고 유연한 환경을 제공하도록 설계된 다양한 새로운 기능과 개선 사항을 제공합니다.
기존 Model Registry 를 보려면 W&B App에서 Model Registry로 이동하십시오. 페이지 상단에 기존 Model Registry App UI를 사용할 수 있도록 하는 배너가 나타납니다.
조직 가시성
기존 Model Registry에 연결된 Artifacts는 팀 수준의 가시성을 갖습니다. 즉, 팀 멤버 만이 기존 W&B Model Registry에서 Artifacts를 볼 수 있습니다. W&B Registry는 조직 수준의 가시성을 갖습니다. 즉, 올바른 권한을 가진 조직 전체의 멤버는 레지스트리에 연결된 Artifacts를 볼 수 있습니다.
레지스트리에 대한 가시성 제한
사용자 정의 레지스트리를 보고 액세스할 수 있는 사용자를 제한합니다. 사용자 정의 레지스트리를 만들 때 또는 사용자 정의 레지스트리를 만든 후에 레지스트리에 대한 가시성을 제한할 수 있습니다. 제한된 레지스트리에서는 선택된 멤버만 콘텐츠에 액세스하여 개인 정보 보호 및 제어를 유지할 수 있습니다. 레지스트리 가시성에 대한 자세한 내용은 레지스트리 가시성 유형을 참조하십시오.
사용자 정의 레지스트리 만들기
기존 Model Registry와 달리 W&B Registry는 Models 또는 데이터셋 레지스트리에만 국한되지 않습니다. 특정 워크플로우 또는 프로젝트 요구 사항에 맞게 조정된 사용자 정의 레지스트리를 만들어 임의의 오브젝트 유형을 담을 수 있습니다. 이러한 유연성을 통해 팀은 고유한 요구 사항에 따라 Artifacts를 구성하고 관리할 수 있습니다. 사용자 정의 레지스트리를 만드는 방법에 대한 자세한 내용은 사용자 정의 레지스트리 만들기를 참조하십시오.
사용자 정의 엑세스 제어
각 레지스트리는 멤버에게 관리자, 멤버 또는 뷰어와 같은 특정 역할을 할당할 수 있는 자세한 엑세스 제어를 지원합니다. 관리자는 멤버 추가 또는 제거, 역할 설정 및 가시성 구성 을 포함하여 레지스트리 설정을 관리할 수 있습니다. 이를 통해 팀은 레지스트리에서 Artifacts를 보고, 관리하고, 상호 작용할 수 있는 사용자를 제어할 수 있습니다.
용어 업데이트
Registered Models는 이제 컬렉션이라고 합니다.
변경 사항 요약
기존 W&B Model Registry
W&B Registry
Artifacts 가시성
팀 멤버 만 Artifacts를 보거나 액세스할 수 있습니다.
조직 내 멤버는 올바른 권한으로 레지스트리에 연결된 Artifacts를 보거나 액세스할 수 있습니다.
사용자 정의 엑세스 제어
사용할 수 없음
사용 가능
사용자 정의 레지스트리
사용할 수 없음
사용 가능
용어 업데이트
모델 버전에 대한 포인터(링크) 집합을 registered models라고 합니다.
아티팩트 버전에 대한 포인터(링크) 집합을 컬렉션이라고 합니다.
wandb.init.link_model
Model Registry 특정 API
현재 기존 모델 레지스트리 와만 호환됩니다.
마이그레이션 준비
W&B는 Registered Models(현재 컬렉션이라고 함) 및 관련 아티팩트 버전을 기존 Model Registry에서 W&B Registry로 마이그레이션합니다. 이 프로세스는 자동으로 수행되며 사용자 의 조치가 필요하지 않습니다.
팀 가시성에서 조직 가시성으로
마이그레이션 후 모델 레지스트리는 조직 수준의 가시성을 갖습니다. 역할 할당을 통해 레지스트리에 액세스할 수 있는 사용자를 제한할 수 있습니다. 이를 통해 특정 멤버만 특정 레지스트리에 액세스할 수 있습니다.
마이그레이션은 기존 W&B Model Registry에서 현재 팀 수준으로 등록된 모델(곧 컬렉션이라고 함)의 기존 권한 경계를 유지합니다. 기존 Model Registry에 현재 정의된 권한은 새 레지스트리에서 보존됩니다. 즉, 현재 특정 팀 멤버 로 제한된 컬렉션은 마이그레이션 중과 후에 보호됩니다.
Artifacts 경로 연속성
현재 필요한 조치는 없습니다.
마이그레이션 중
W&B가 마이그레이션 프로세스를 시작합니다. 마이그레이션은 W&B 서비스의 중단을 최소화하는 시간대에 발생합니다. 마이그레이션이 시작되면 기존 Model Registry는 읽기 전용 상태로 전환되고 참조용으로 액세스할 수 있습니다.
마이그레이션 후
마이그레이션 후 컬렉션, Artifacts 버전 및 관련 속성은 새로운 W&B Registry 내에서 완전히 액세스할 수 있습니다. 현재 워크플로우가 그대로 유지되도록 보장하는 데 중점을 두고 있으며, 변경 사항을 탐색하는 데 도움이 되는 지속적인 지원이 제공됩니다.
새로운 레지스트리 사용
사용자는 W&B Registry에서 사용할 수 있는 새로운 기능과 기능을 탐색하는 것이 좋습니다. 레지스트리는 현재 의존하는 기능을 지원할 뿐만 아니라 사용자 정의 레지스트리, 향상된 가시성 및 유연한 엑세스 제어와 같은 향상된 기능도 제공합니다.
W&B Registry를 조기에 사용해 보거나, 기존 W&B Model Registry가 아닌 레지스트리로 시작하는 것을 선호하는 새로운 사용자를 위해 지원이 제공됩니다. 이 기능을 활성화하려면 support@wandb.com 또는 영업 MLE에 문의하십시오. 초기 마이그레이션은 BETA 버전으로 진행됩니다. W&B Registry의 BETA 버전에는 기존 Model Registry의 모든 기능 또는 특징이 없을 수 있습니다.
자세한 내용과 W&B Registry의 전체 기능 범위에 대해 알아보려면 W&B Registry 가이드를 방문하십시오.
FAQ
W&B가 Model Registry에서 W&B Registry로 자산을 마이그레이션하는 이유는 무엇입니까?
W&B는 새로운 레지스트리를 통해 보다 고급 기능과 기능을 제공하기 위해 플랫폼을 발전시키고 있습니다. 이 마이그레이션은 Models, 데이터 셋 및 기타 Artifacts 관리를 위한 보다 통합되고 강력한 툴 세트를 제공하기 위한 단계입니다.
마이그레이션 전에 수행해야 할 작업은 무엇입니까?
마이그레이션 전에 사용자 의 조치가 필요하지 않습니다. W&B는 워크플로우와 레퍼런스가 보존되도록 전환을 처리합니다.
모델 Artifacts에 대한 액세스 권한이 손실됩니까?
아니요, 모델 Artifacts에 대한 액세스 권한은 마이그레이션 후에도 유지됩니다. 기존 Model Registry는 읽기 전용 상태로 유지되고 모든 관련 데이터는 새 레지스트리로 마이그레이션됩니다.
Artifacts와 관련된 메타데이터가 보존됩니까?
예, Artifacts 생성, 계보 및 기타 속성과 관련된 중요한 메타데이터는 마이그레이션 중에 보존됩니다. 사용자는 마이그레이션 후에도 모든 관련 메타데이터에 계속 액세스할 수 있으므로 Artifacts의 무결성과 추적 가능성이 유지됩니다.
도움이 필요하면 누구에게 연락해야 합니까?
질문이나 우려 사항이 있는 경우 지원을 받을 수 있습니다. 지원이 필요하면 support@wandb.com으로 문의하십시오.
4.3.12 - Model registry
트레이닝부터 프로덕션까지 모델 생명주기를 관리하는 모델 레지스트리
W&B는 결국 W&B Model Registry에 대한 지원을 중단할 예정입니다. 사용자는 대신 모델 아티팩트 버전을 연결하고 공유하기 위해 W&B Registry를 사용하는 것이 좋습니다. W&B Registry는 기존 W&B Model Registry의 기능을 확장합니다. W&B Registry에 대한 자세한 내용은 Registry 문서를 참조하세요.
W&B는 기존 Model Registry에 연결된 기존 모델 아티팩트를 가까운 시일 내에 새로운 W&B Registry로 마이그레이션할 예정입니다. 마이그레이션 프로세스에 대한 자세한 내용은 기존 Model Registry에서 마이그레이션을 참조하세요.
W&B Model Registry는 팀의 트레이닝된 모델을 보관하는 곳으로, ML 전문가가 프로덕션 후보를 게시하여 다운스트림 팀과 이해 관계자가 사용할 수 있습니다. 스테이징된/후보 모델을 보관하고 스테이징과 관련된 워크플로우를 관리하는 데 사용됩니다.
모델 버전 로깅: 트레이닝 스크립트에서 몇 줄의 코드를 추가하여 모델 파일을 아티팩트 로 W&B에 저장합니다.
성능 비교: 라이브 차트를 확인하여 모델 트레이닝 및 유효성 검사에서 메트릭 과 샘플 예측값을 비교합니다. 어떤 모델 버전이 가장 성능이 좋았는지 식별합니다.
레지스트리에 연결: Python에서 프로그래밍 방식으로 또는 W&B UI에서 대화식으로 등록된 모델에 연결하여 최상의 모델 버전을 북마크합니다.
다음 코드 조각은 모델을 Model Registry에 로깅하고 연결하는 방법을 보여줍니다.
import wandb
import random
# Start a new W&B runrun = wandb.init(project="models_quickstart")
# Simulate logging model metricsrun.log({"acc": random.random()})
# Create a simulated model filewith open("my_model.h5", "w") as f:
f.write("Model: "+ str(random.random()))
# Log and link the model to the Model Registryrun.link_model(path="./my_model.h5", registered_model_name="MNIST")
run.finish()
모델 전환을 CI/CD 워크플로우에 연결: 웹훅을 사용하여 워크플로우 단계를 통해 후보 모델을 전환하고 다운스트림 작업 자동화합니다.
W&B Model Registry를 사용하여 모델을 관리 및 버전 관리하고, 계보를 추적하고, 다양한 라이프사이클 단계를 거쳐 모델을 승격합니다.
웹훅을 사용하여 모델 관리 워크플로우를 자동화합니다.
모델 평가, 모니터링 및 배포를 위해 Model Registry가 모델 개발 라이프사이클의 외부 ML 시스템 및 툴 과 어떻게 통합되는지 확인하세요.
4.3.12.1 - Tutorial: Use W&B for model management
W&B를 사용해 모델 관리를 하는 방법을 알아보세요. (Model Management)
다음 가이드에서는 W&B에 모델을 기록하는 방법을 안내합니다. 이 가이드가 끝나면 다음을 수행할 수 있습니다.
MNIST 데이터셋과 Keras 프레임워크를 사용하여 모델을 만들고 트레이닝합니다.
트레이닝한 모델을 W&B project에 기록합니다.
사용된 데이터셋을 생성한 모델의 종속성으로 표시합니다.
해당 모델을 W&B Registry에 연결합니다.
레지스트리에 연결한 모델의 성능을 평가합니다.
모델 버전을 프로덕션 준비 완료로 표시합니다.
이 가이드에 제시된 순서대로 코드 조각을 복사하세요.
Model Registry에 고유하지 않은 코드는 접을 수 있는 셀에 숨겨져 있습니다.
설정
시작하기 전에 이 가이드에 필요한 Python 종속성을 가져옵니다.
import wandb
import numpy as np
from tensorflow import keras
from tensorflow.keras import layers
from wandb.integration.keras import WandbMetricsLogger
from sklearn.model_selection import train_test_split
W&B entity를 entity 변수에 제공합니다.
entity ="<entity>"
데이터셋 아티팩트 생성
먼저 데이터셋을 만듭니다. 다음 코드 조각은 MNIST 데이터셋을 다운로드하는 함수를 생성합니다.
다음으로 데이터셋을 W&B에 업로드합니다. 이렇게 하려면 artifact 오브젝트를 생성하고 해당 아티팩트에 데이터셋을 추가합니다.
project ="model-registry-dev"model_use_case_id ="mnist"job_type ="build_dataset"# W&B run 초기화run = wandb.init(entity=entity, project=project, job_type=job_type)
# 트레이닝 데이터를 위한 W&B 테이블 생성train_table = wandb.Table(data=[], columns=[])
train_table.add_column("x_train", x_train)
train_table.add_column("y_train", y_train)
train_table.add_computed_columns(lambda ndx, row: {"img": wandb.Image(row["x_train"])})
# 평가 데이터를 위한 W&B 테이블 생성eval_table = wandb.Table(data=[], columns=[])
eval_table.add_column("x_eval", x_eval)
eval_table.add_column("y_eval", y_eval)
eval_table.add_computed_columns(lambda ndx, row: {"img": wandb.Image(row["x_eval"])})
# 아티팩트 오브젝트 생성artifact_name ="{}_dataset".format(model_use_case_id)
artifact = wandb.Artifact(name=artifact_name, type="dataset")
# wandb.WBValue obj를 아티팩트에 추가artifact.add(train_table, "train_table")
artifact.add(eval_table, "eval_table")
# 아티팩트에 대한 변경 사항을 유지합니다.artifact.save()
# W&B에 이 run이 완료되었음을 알립니다.run.finish()
아티팩트에 파일(예: 데이터셋)을 저장하는 것은 모델의 종속성을 추적할 수 있으므로 모델 로깅 컨텍스트에서 유용합니다.
모델 트레이닝
이전 단계에서 생성한 아티팩트 데이터셋으로 모델을 트레이닝합니다.
데이터셋 아티팩트를 run에 대한 입력으로 선언
이전 단계에서 생성한 데이터셋 아티팩트를 W&B run에 대한 입력으로 선언합니다. 아티팩트를 run에 대한 입력으로 선언하면 특정 모델을 트레이닝하는 데 사용된 데이터셋(및 데이터셋 버전)을 추적할 수 있으므로 모델 로깅 컨텍스트에서 특히 유용합니다. W&B는 수집된 정보를 사용하여 lineage map을 만듭니다.
use_artifact API를 사용하여 데이터셋 아티팩트를 run의 입력으로 선언하고 아티팩트 자체를 검색합니다.
평가할 W&B의 model version을 다운로드합니다. use_model API를 사용하여 모델에 엑세스하고 다운로드합니다.
alias ="latest"# 에일리어스name ="mnist_model"# 모델 아티팩트 이름# 모델에 엑세스하고 다운로드합니다. 다운로드한 아티팩트의 경로를 반환합니다.downloaded_model_path = run.use_model(name=f"{name}:{alias}")
# # 메트릭, 이미지, 테이블 또는 평가에 유용한 모든 데이터를 기록합니다.run.log(data={"loss": (loss, _)})
모델 버전 승격
model alias를 사용하여 기계 학습 워크플로우의 다음 단계를 위해 모델 버전을 준비 완료로 표시합니다. 각 registered model에는 하나 이상의 model alias가 있을 수 있습니다. model alias는 한 번에 하나의 model version에만 속할 수 있습니다.
예를 들어, 모델의 성능을 평가한 후 모델이 프로덕션 준비가 되었다고 확신한다고 가정합니다. 해당 모델 버전을 승격하려면 해당 특정 model version에 production 에일리어스를 추가합니다.
production 에일리어스는 모델을 프로덕션 준비로 표시하는 데 사용되는 가장 일반적인 에일리어스 중 하나입니다.
W&B App UI를 사용하여 대화형으로 또는 Python SDK를 사용하여 프로그래밍 방식으로 model version에 에일리어스를 추가할 수 있습니다. 다음 단계에서는 W&B Model Registry App을 사용하여 에일리어스를 추가하는 방법을 보여줍니다.
모델 버전은 단일 모델 체크포인트를 나타냅니다. 모델 버전은 실험 내에서 특정 시점의 모델과 해당 파일의 스냅샷입니다.
모델 버전은 학습된 모델을 설명하는 데이터 및 메타데이터의 변경 불가능한 디렉토리입니다. W&B는 모델 아키텍처와 학습된 파라미터를 나중에 저장하고 복원할 수 있도록 모델 버전에 파일을 추가할 것을 제안합니다.
모델 버전은 하나의 model artifact에만 속합니다. 모델 버전은 0개 이상의 registered models에 속할 수 있습니다. 모델 버전은 모델 아티팩트에 기록된 순서대로 모델 아티팩트에 저장됩니다. W&B는 (동일한 model artifact에) 기록하는 모델이 이전 모델 버전과 다른 콘텐츠를 가지고 있음을 감지하면 자동으로 새 모델 버전을 생성합니다.
모델링 라이브러리에서 제공하는 직렬화 프로세스에서 생성된 파일을 모델 버전 내에 저장합니다(예: PyTorch 및 Keras).
Model alias
모델 에일리어스는 등록된 모델에서 모델 버전을 의미적으로 관련된 식별자로 고유하게 식별하거나 참조할 수 있도록 하는 변경 가능한 문자열입니다. 에일리어스는 등록된 모델의 한 버전에만 할당할 수 있습니다. 이는 에일리어스가 프로그래밍 방식으로 사용될 때 고유한 버전을 참조해야 하기 때문입니다. 또한 에일리어스를 사용하여 모델의 상태(챔피언, 후보, production)를 캡처할 수 있습니다.
"best", "latest", "production" 또는 "staging"과 같은 에일리어스를 사용하여 특수 목적을 가진 모델 버전을 표시하는 것이 일반적입니다.
예를 들어 모델을 만들고 "best" 에일리어스를 할당한다고 가정합니다. run.use_model로 특정 모델을 참조할 수 있습니다.
import wandb
run = wandb.init()
name =f"{entity/project/model_artifact_name}:{alias}"run.use_model(name=name)
Model tags
모델 태그는 하나 이상의 registered models에 속하는 키워드 또는 레이블입니다.
모델 태그를 사용하여 registered models를 카테고리로 구성하고 Model Registry의 검색 창에서 해당 카테고리를 검색합니다. 모델 태그는 Registered Model Card 상단에 나타납니다. ML 작업, 소유 팀 또는 우선 순위별로 registered models를 그룹화하는 데 사용할 수 있습니다. 그룹화를 위해 동일한 모델 태그를 여러 registered models에 추가할 수 있습니다.
그룹화 및 검색 가능성을 위해 registered models에 적용되는 레이블인 모델 태그는 model aliases와 다릅니다. 모델 에일리어스는 모델 버전을 프로그래밍 방식으로 가져오는 데 사용하는 고유 식별자 또는 별칭입니다. 태그를 사용하여 Model Registry에서 작업을 구성하는 방법에 대한 자세한 내용은 모델 구성을 참조하세요.
Model artifact
Model artifact는 기록된 model versions의 모음입니다. 모델 버전은 모델 아티팩트에 기록된 순서대로 모델 아티팩트에 저장됩니다.
Model artifact는 하나 이상의 모델 버전을 포함할 수 있습니다. 모델 버전을 기록하지 않으면 Model artifact는 비어 있을 수 있습니다.
예를 들어, Model artifact를 만든다고 가정합니다. 모델 트레이닝 중에 체크포인트 중에 모델을 주기적으로 저장합니다. 각 체크포인트는 자체 model version에 해당합니다. 모델 트레이닝 및 체크포인트 저장 중에 생성된 모든 모델 버전은 트레이닝 스크립트 시작 시 생성한 동일한 Model artifact에 저장됩니다.
다음 이미지는 v0, v1 및 v2의 세 가지 모델 버전을 포함하는 Model artifact를 보여줍니다.
Registered model은 모델 버전에 대한 포인터(링크) 모음입니다. Registered model을 동일한 ML 작업에 대한 후보 모델의 “북마크” 폴더라고 생각할 수 있습니다. Registered model의 각 “북마크"는 model artifact에 속한 model version에 대한 포인터입니다. Model tags를 사용하여 Registered models를 그룹화할 수 있습니다.
Registered models는 종종 단일 모델링 유스 케이스 또는 작업에 대한 후보 모델을 나타냅니다. 예를 들어 사용하는 모델을 기반으로 다양한 이미지 분류 작업에 대해 Registered model을 만들 수 있습니다. ImageClassifier-ResNet50, ImageClassifier-VGG16, DogBreedClassifier-MobileNetV2 등. 모델 버전은 Registered model에 연결된 순서대로 버전 번호가 할당됩니다.
import wandb
run = wandb.init(entity="<entity>", project="<project>")
run.link_model(path="<path-to-model>", registered_model_name="<registered-model-name>")
run.finish()
registered-model-name 파라미터에 지정한 이름이 아직 존재하지 않는 경우, W&B가 등록된 모델을 생성합니다.
예를 들어, Model Registry에 “Fine-Tuned-Review-Autocompletion”(registered-model-name="Fine-Tuned-Review-Autocompletion")이라는 등록된 모델이 이미 있다고 가정합니다. 그리고 몇몇 모델 버전이 연결되어 있다고 가정합니다: v0, v1, v2. 새로운 모델을 프로그램 방식으로 연결하고 동일한 등록된 모델 이름(registered-model-name="Fine-Tuned-Review-Autocompletion")을 사용하면, W&B는 이 모델을 기존 등록된 모델에 연결하고 모델 버전 v3을 할당합니다. 이 이름으로 등록된 모델이 없으면 새로운 등록된 모델이 생성되고 모델 버전 v0을 갖게 됩니다.
vague-morning-5 W&B run은 mnist_dataset:v0 데이터셋 아티팩트를 사용하여 모델을 트레이닝했습니다. 이 W&B run의 출력은 mnist_model:v0라는 모델 아티팩트였습니다.
serene-haze-6이라는 run은 모델 아티팩트(mnist_model:v0)를 사용하여 모델을 평가했습니다.
아티팩트 종속성 추적
use_artifact API를 사용하여 데이터셋 아티팩트를 W&B run에 대한 입력으로 선언하여 종속성을 추적합니다.
다음 코드 조각은 use_artifact API를 사용하는 방법을 보여줍니다.
# Initialize a runrun = wandb.init(project=project, entity=entity)
# Get artifact, mark it as a dependencyartifact = run.use_artifact(artifact_or_name="name", aliases="<alias>")
아티팩트를 검색한 후에는 해당 아티팩트를 사용하여 (예를 들어) 모델의 성능을 평가할 수 있습니다.
예시: 모델을 트레이닝하고 데이터셋을 모델의 입력으로 추적
job_type ="train_model"config = {
"optimizer": "adam",
"batch_size": 128,
"epochs": 5,
"validation_split": 0.1,
}
run = wandb.init(project=project, job_type=job_type, config=config)
version ="latest"name ="{}:{}".format("{}_dataset".format(model_use_case_id), version)
artifact = run.use_artifact(name)
train_table = artifact.get("train_table")
x_train = train_table.get_column("x_train", convert_to="numpy")
y_train = train_table.get_column("y_train", convert_to="numpy")
# Store values from our config dictionary into variables for easy accessingnum_classes =10input_shape = (28, 28, 1)
loss ="categorical_crossentropy"optimizer = run.config["optimizer"]
metrics = ["accuracy"]
batch_size = run.config["batch_size"]
epochs = run.config["epochs"]
validation_split = run.config["validation_split"]
# Create model architecturemodel = keras.Sequential(
[
layers.Input(shape=input_shape),
layers.Conv2D(32, kernel_size=(3, 3), activation="relu"),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Conv2D(64, kernel_size=(3, 3), activation="relu"),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Flatten(),
layers.Dropout(0.5),
layers.Dense(num_classes, activation="softmax"),
]
)
model.compile(loss=loss, optimizer=optimizer, metrics=metrics)
# Generate labels for training datay_train = keras.utils.to_categorical(y_train, num_classes)
# Create training and test setx_t, x_v, y_t, y_v = train_test_split(x_train, y_train, test_size=0.33)
# Train the modelmodel.fit(
x=x_t,
y=y_t,
batch_size=batch_size,
epochs=epochs,
validation_data=(x_v, y_v),
callbacks=[WandbCallback(log_weights=True, log_evaluation=True)],
)
# Save model locallypath ="model.h5"model.save(path)
path ="./model.h5"registered_model_name ="MNIST-dev"name ="mnist_model"run.link_model(path=path, registered_model_name=registered_model_name, name=name)
run.finish()
4.3.12.8 - Document machine learning model
모델 카드에 설명을 추가하여 모델을 문서화하세요.
등록된 모델의 모델 카드에 설명을 추가하여 머신러닝 모델의 여러 측면을 문서화하세요. 문서화할 가치가 있는 몇 가지 주제는 다음과 같습니다.
요약: 모델에 대한 요약입니다. 모델의 목적, 모델이 사용하는 머신러닝 프레임워크 등입니다.
트레이닝 데이터: 사용된 트레이닝 데이터, 트레이닝 데이터 세트에 대해 수행된 처리, 해당 데이터가 저장된 위치 등을 설명합니다.
아키텍처: 모델 아키텍처, 레이어 및 특정 설계 선택에 대한 정보입니다.
모델 역직렬화: 팀 구성원이 모델을 메모리에 로드하는 방법에 대한 정보를 제공합니다.
Task: 머신러닝 모델이 수행하도록 설계된 특정 유형의 Task 또는 문제입니다. 모델의 의도된 기능을 분류한 것입니다.
라이선스: 머신러닝 모델 사용과 관련된 법적 조건 및 권한입니다. 이를 통해 모델 사용자는 모델을 활용할 수 있는 법적 프레임워크를 이해할 수 있습니다.
참조: 관련 연구 논문, 데이터셋 또는 외부 리소스에 대한 인용 또는 참조입니다.
배포: 모델이 배포되는 방식 및 위치에 대한 세부 정보와 워크플로우 오케스트레이션 플랫폼과 같은 다른 엔터프라이즈 시스템에 모델을 통합하는 방법에 대한 지침입니다.
Description 필드 내에 머신러닝 모델에 대한 정보를 제공합니다. Markdown 마크업 언어를 사용하여 모델 카드 내에서 텍스트 서식을 지정합니다.
예를 들어 다음 이미지는 신용카드 채무 불이행 예측 등록 모델의 모델 카드를 보여줍니다.
4.3.12.9 - Download a model version
W&B Python SDK로 모델을 다운로드하는 방법
W&B Python SDK를 사용하여 Model Registry에 연결한 모델 아티팩트를 다운로드합니다.
모델을 재구성하고, 역직렬화하여 사용할 수 있는 형태로 만들려면 추가적인 Python 함수와 API 호출을 제공해야 합니다.
W&B에서는 모델을 메모리에 로드하는 방법에 대한 정보를 모델 카드를 통해 문서화할 것을 권장합니다. 자세한 내용은 기계 학습 모델 문서화 페이지를 참조하세요.
<> 안의 값을 직접 변경하세요:
import wandb
# run 초기화run = wandb.init(project="<project>", entity="<entity>")
# 모델에 엑세스하고 다운로드합니다. 다운로드된 아티팩트의 경로를 반환합니다.downloaded_model_path = run.use_model(name="<your-model-name>")
다음 형식 중 하나를 사용하여 모델 버전을 참조하세요:
latest - 가장 최근에 연결된 모델 버전을 지정하려면 latest 에일리어스를 사용합니다.
v# - Registered Model에서 특정 버전을 가져오려면 v0, v1, v2 등을 사용합니다.
alias - 팀에서 모델 버전에 할당한 사용자 지정 에일리어스를 지정합니다.
가능한 파라미터 및 반환 유형에 대한 자세한 내용은 API Reference 가이드의 use_model을 참조하세요.
예시: 기록된 모델 다운로드 및 사용
예를 들어, 다음 코드 조각에서 사용자는 use_model API를 호출했습니다. 가져오려는 모델 아티팩트의 이름을 지정하고 버전/에일리어스도 제공했습니다. 그런 다음 API에서 반환된 경로를 downloaded_model_path 변수에 저장했습니다.
import wandb
entity ="luka"project ="NLP_Experiments"alias ="latest"# 모델 버전에 대한 시맨틱 닉네임 또는 식별자model_artifact_name ="fine-tuned-model"# run 초기화run = wandb.init()
# 모델에 엑세스하고 다운로드합니다. 다운로드된 아티팩트의 경로를 반환합니다.downloaded_model_path = run.use_model(name=f"{entity/project/model_artifact_name}:{alias}")
2024년 W&B Model Registry 지원 중단 예정
다음 탭은 곧 지원이 중단될 Model Registry를 사용하여 모델 아티팩트를 사용하는 방법을 보여줍니다.
W&B Registry를 사용하여 모델 아티팩트를 추적, 구성 및 사용합니다. 자세한 내용은 Registry 문서를 참조하세요.
<> 안의 값을 직접 변경하세요:
import wandb
# run 초기화run = wandb.init(project="<project>", entity="<entity>")
# 모델에 엑세스하고 다운로드합니다. 다운로드된 아티팩트의 경로를 반환합니다.downloaded_model_path = run.use_model(name="<your-model-name>")
다음 형식 중 하나를 사용하여 모델 버전을 참조하세요:
latest - 가장 최근에 연결된 모델 버전을 지정하려면 latest 에일리어스를 사용합니다.
v# - Registered Model에서 특정 버전을 가져오려면 v0, v1, v2 등을 사용합니다.
alias - 팀에서 모델 버전에 할당한 사용자 지정 에일리어스를 지정합니다.
가능한 파라미터 및 반환 유형에 대한 자세한 내용은 API Reference 가이드의 use_model을 참조하세요.
OAuth 페이지에 나타나는 지침에 따라 Slack workspace에서 W&B를 활성화합니다.
팀에 대한 Slack 알림을 구성했으면 알림을 받을 Registered Model을 선택할 수 있습니다.
팀에 대해 Slack 알림을 구성한 경우 Connect Slack 버튼 대신 New model version linked to… 토글이 나타납니다.
아래 스크린샷은 Slack 알림이 있는 FMNIST 분류기 Registered Model을 보여줍니다.
새로운 모델 버전이 FMNIST 분류기 Registered Model에 연결될 때마다 연결된 Slack 채널에 메시지가 자동으로 게시됩니다.
4.3.12.11 - Manage data governance and access control
모델 레지스트리 역할 기반 엑세스 제어(RBAC)를 사용하여 보호된 에일리어스를 업데이트할 수 있는 사람을 제어합니다.
보호된 에일리어스를 사용하여 모델 개발 파이프라인의 주요 단계를 나타냅니다. 모델 레지스트리 관리자 만이 보호된 에일리어스를 추가, 수정 또는 제거할 수 있습니다. 모델 레지스트리 관리자는 보호된 에일리어스를 정의하고 사용할 수 있습니다. W&B는 관리자가 아닌 사용자가 모델 버전에서 보호된 에일리어스를 추가하거나 제거하는 것을 차단합니다.
팀 관리자 또는 현재 레지스트리 관리자만이 레지스트리 관리자 목록을 관리할 수 있습니다.
예를 들어, staging 및 production을 보호된 에일리어스로 설정했다고 가정합니다. 팀의 모든 구성원은 새로운 모델 버전을 추가할 수 있습니다. 그러나 관리자만이 staging 또는 production 에일리어스를 추가할 수 있습니다.
리포트를 프로그래밍 방식으로 편집하려면 W&B Python SDK 외에 wandb-workspaces가 설치되어 있는지 확인하십시오:
pip install wandb wandb-workspaces
플롯 추가
각 패널 그리드에는 run 세트와 패널 세트가 있습니다. 섹션 하단의 run 세트는 그리드의 패널에 표시되는 data를 제어합니다. 서로 다른 run 세트의 data를 가져오는 차트를 추가하려면 새 패널 그리드를 만드십시오.
리포트에 슬래시(/)를 입력하여 드롭다운 메뉴를 표시합니다. 패널 추가 를 선택하여 패널을 추가합니다. 라인 플롯, 산점도 또는 병렬 좌표 차트를 포함하여 W&B에서 지원하는 모든 패널을 추가할 수 있습니다.
SDK를 사용하여 프로그래밍 방식으로 리포트에 플롯을 추가합니다. 하나 이상의 플롯 또는 차트 오브젝트 목록을 PanelGrid Public API Class의 panels 파라미터에 전달합니다. 관련 Python Class를 사용하여 플롯 또는 차트 오브젝트를 생성합니다.
URL을 복사하여 리포트에 붙여넣어 리포트 내에 리치 미디어를 임베드합니다. 다음 애니메이션은 Twitter, YouTube 및 SoundCloud에서 URL을 복사하여 붙여넣는 방법을 보여줍니다.
Twitter
트윗 링크 URL을 복사하여 리포트에 붙여넣어 리포트 내에서 트윗을 봅니다.
Youtube
YouTube 비디오 URL 링크를 복사하여 리포트에 붙여넣어 리포트에 비디오를 임베드합니다.
SoundCloud
SoundCloud 링크를 복사하여 리포트에 붙여넣어 리포트에 오디오 파일을 임베드합니다.
하나 이상의 임베디드 미디어 오브젝트 목록을 wandb.apis.reports.blocks 속성에 전달합니다. 다음 예제는 비디오 및 Twitter 미디어를 리포트에 임베드하는 방법을 보여줍니다.
import wandb
import wandb_workspaces.reports.v2 as wr
report = wr.Report(project="report-editing")
report.blocks = [
wr.Video(url="https://www.youtube.com/embed/6riDJMI-Y8U"),
wr.Twitter(
embed_html='<blockquote class="twitter-tweet"><p lang="en" dir="ltr">The voice of an angel, truly. <a href="https://twitter.com/hashtag/MassEffect?src=hash&ref_src=twsrc%5Etfw">#MassEffect</a> <a href="https://t.co/nMev97Uw7F">pic.twitter.com/nMev97Uw7F</a></p>— Mass Effect (@masseffect) <a href="https://twitter.com/masseffect/status/1428748886655569924?ref_src=twsrc%5Etfw">August 20, 2021</a></blockquote>\n' ),
]
report.save()
패널 그리드 복제 및 삭제
재사용하려는 레이아웃이 있는 경우 패널 그리드를 선택하고 복사하여 붙여넣어 동일한 리포트에서 복제하거나 다른 리포트에 붙여넣을 수도 있습니다.
오른쪽 상단 모서리에 있는 드래그 핸들을 선택하여 전체 패널 그리드 섹션을 강조 표시합니다. 클릭하고 드래그하여 패널 그리드, 텍스트 및 제목과 같은 리포트의 영역을 강조 표시하고 선택합니다.
패널 그리드를 선택하고 키보드에서 delete를 눌러 패널 그리드를 삭제합니다.
헤더를 축소하여 Reports 구성
Report에서 헤더를 축소하여 텍스트 블록 내의 콘텐츠를 숨깁니다. 리포트가 로드되면 확장된 헤더만 콘텐츠를 표시합니다. 리포트에서 헤더를 축소하면 콘텐츠를 구성하고 과도한 data 로드를 방지하는 데 도움이 될 수 있습니다. 다음 gif는 해당 프로세스를 보여줍니다.
여러 차원에 걸쳐 관계 시각화
여러 차원에 걸쳐 관계를 효과적으로 시각화하려면 색상 그레이디언트를 사용하여 변수 중 하나를 나타냅니다. 이렇게 하면 명확성이 향상되고 패턴을 더 쉽게 해석할 수 있습니다.
색상 그레이디언트로 나타낼 변수를 선택합니다(예: 페널티 점수, 학습률 등). 이렇게 하면 트레이닝 시간(x축)에 따라 보상/부작용(y축)과 페널티(색상)가 상호 작용하는 방식을 더 명확하게 이해할 수 있습니다.
주요 추세를 강조 표시합니다. 특정 run 그룹 위에 마우스를 올리면 시각화에서 해당 run이 강조 표시됩니다.
4.4.3 - Collaborate on reports
W&B 리포트 를 동료, 동료 직원 및 팀과 협업하고 공유하세요.
리포트를 저장한 후 공유 버튼을 선택하여 협업할 수 있습니다. 편집 버튼을 선택하면 리포트의 초안 사본이 생성됩니다. 초안 리포트는 자동 저장됩니다. 변경 사항을 공유 리포트에 게시하려면 리포트에 저장을 선택하세요.
편집 충돌이 발생하면 경고 알림이 나타납니다. 이는 사용자와 다른 협업자가 동시에 동일한 리포트를 편집하는 경우에 발생할 수 있습니다. 경고 알림은 잠재적인 편집 충돌을 해결하는 데 도움이 됩니다.
리포트에 댓글 달기
리포트의 패널에 댓글을 직접 추가하려면 해당 패널에서 댓글 버튼을 클릭하세요.
4.4.4 - Clone and export reports
W&B 리포트 를 PDF 또는 LaTeX로 내보내세요.
Reports 내보내기
리포트를 PDF 또는 LaTeX로 내보냅니다. 리포트 내에서 케밥 아이콘을 선택하여 드롭다운 메뉴를 확장합니다. 다운로드를 선택하고 PDF 또는 LaTeX 출력 형식을 선택합니다.
Reports 복제
리포트 내에서 케밥 아이콘을 선택하여 드롭다운 메뉴를 확장합니다. 이 리포트 복제 버튼을 선택합니다. 모달에서 복제된 리포트의 대상을 선택합니다. 리포트 복제를 선택합니다.
프로젝트의 템플릿과 형식을 재사용하기 위해 리포트를 복제합니다. 팀 계정 내에서 프로젝트를 복제하면 복제된 프로젝트가 팀에 표시됩니다. 개인 계정 내에서 복제된 프로젝트는 해당 사용자에게만 표시됩니다.
W&B 리포트 를 Notion에 직접 삽입하거나 HTML IFrame 요소를 사용하여 삽입하세요.
HTML iframe 요소
리포트의 오른쪽 상단 모서리에 있는 Share 버튼을 선택합니다. 모달 창이 나타납니다. 모달 창에서 Copy embed code를 선택합니다. 복사된 코드는 Inline Frame (IFrame) HTML 요소 내에서 렌더링됩니다. 복사된 코드를 원하는 iframe HTML 요소에 붙여넣습니다.
공개 리포트만 임베드되었을 때 볼 수 있습니다.
Confluence
다음 애니메이션은 Confluence의 IFrame 셀 내에 리포트에 대한 직접 링크를 삽입하는 방법을 보여줍니다.
Notion
다음 애니메이션은 Notion의 Embed 블록과 리포트의 임베디드 코드를 사용하여 리포트를 Notion 문서에 삽입하는 방법을 보여줍니다.
Gradio
gr.HTML 요소를 사용하여 Gradio 앱 내에 W&B Reports를 임베드하고 Hugging Face Spaces 내에서 사용할 수 있습니다.
import gradio as gr
defwandb_report(url):
iframe =f'<iframe src={url} style="border:none;height:1024px;width:100%">'return gr.HTML(iframe)
with gr.Blocks() as demo:
report = wandb_report(
"https://wandb.ai/_scott/pytorch-sweeps-demo/reports/loss-22-10-07-16-00-17---VmlldzoyNzU2NzAx" )
demo.launch()
프로젝트 간 리포트를 사용하여 서로 다른 두 프로젝트의 run을 비교하세요. run 세트 테이블에서 프로젝트 선택기를 사용하여 프로젝트를 선택합니다.
섹션의 시각화는 첫 번째 활성 runset에서 열을 가져옵니다. 라인 플롯에서 찾고 있는 메트릭이 보이지 않으면 섹션에서 첫 번째로 선택한 run 세트에 해당 열이 있는지 확인하세요.
이 기능은 시계열 라인의 기록 데이터를 지원하지만, 서로 다른 프로젝트에서 서로 다른 요약 메트릭을 가져오는 것은 지원하지 않습니다. 즉, 다른 프로젝트에만 기록된 열에서 산점도를 만들 수 없습니다.
두 프로젝트의 run을 비교해야 하는데 열이 작동하지 않으면, 한 프로젝트의 run에 태그를 추가한 다음 해당 run을 다른 프로젝트로 이동하세요. 각 프로젝트의 run만 필터링할 수 있지만, 리포트에는 두 세트의 run에 대한 모든 열이 포함됩니다.
보기 전용 리포트 링크
비공개 프로젝트 또는 팀 프로젝트에 있는 리포트에 대한 보기 전용 링크를 공유하세요.
보기 전용 리포트 링크는 URL에 비밀 엑세스 토큰을 추가하므로, 링크를 여는 모든 사람이 페이지를 볼 수 있습니다. 누구나 매직 링크를 사용하여 먼저 로그인하지 않고도 리포트를 볼 수 있습니다. W&B Local 프라이빗 클라우드 설치를 사용하는 고객의 경우, 이러한 링크는 방화벽 내에 유지되므로 팀 구성원 중 프라이빗 인스턴스에 대한 엑세스 권한과 보기 전용 링크에 대한 엑세스 권한이 있는 사람만 리포트를 볼 수 있습니다.
보기 전용 모드에서는 로그인하지 않은 사람도 차트를 보고 마우스를 올려 값의 툴팁을 보고, 차트를 확대/축소하고, 테이블에서 열을 스크롤할 수 있습니다. 보기 모드에서는 데이터를 탐색하기 위해 새 차트 또는 새 테이블 쿼리를 만들 수 없습니다. 리포트 링크의 보기 전용 방문자는 run을 클릭하여 run 페이지로 이동할 수 없습니다. 또한 보기 전용 방문자는 공유 모달을 볼 수 없고 대신 마우스를 올리면 보기 전용 엑세스에는 공유를 사용할 수 없습니다라는 툴팁이 표시됩니다.
매직 링크는 “비공개” 및 “팀” 프로젝트에서만 사용할 수 있습니다. “공개”(누구나 볼 수 있음) 또는 “개방형”(누구나 run을 보고 기여할 수 있음) 프로젝트의 경우, 이 프로젝트는 공개되어 링크가 있는 모든 사람이 이미 사용할 수 있음을 의미하므로 링크를 켜거나 끌 수 없습니다.
그래프를 리포트로 보내기
진행 상황을 추적하기 위해 워크스페이스에서 리포트로 그래프를 보냅니다. 리포트에 복사할 차트 또는 패널의 드롭다운 메뉴를 클릭하고 리포트에 추가를 클릭하여 대상 리포트를 선택합니다.
4.4.7 - Example reports
Reports 갤러리
노트: 빠른 요약과 함께 시각화 추가
프로젝트 개발에서 중요한 관찰 내용, 향후 작업 아이디어 또는 달성한 이정표를 캡처합니다. 리포트의 모든 실험 run은 해당 파라미터, 메트릭, 로그 및 코드로 연결되므로 작업의 전체 컨텍스트를 저장할 수 있습니다.
복잡한 코드베이스에서 가장 좋은 예제를 저장하여 쉽게 참조하고 향후 상호 작용할 수 있습니다. Lyft 데이터 세트의 LIDAR 포인트 클라우드를 시각화하고 3D 경계 상자로 주석을 추가하는 방법에 대한 예는 LIDAR 포인트 클라우드 W&B Report를 참조하십시오.
협업: 동료와 발견한 내용 공유
프로젝트 시작 방법, 지금까지 관찰한 내용 공유, 최신 findings 종합 방법을 설명합니다. 동료는 패널에서 또는 리포트 끝에 있는 댓글을 사용하여 제안하거나 세부 사항을 논의할 수 있습니다.
동료가 직접 탐색하고 추가 통찰력을 얻고 다음 단계를 더 잘 계획할 수 있도록 동적 설정을 포함합니다. 이 예에서는 세 가지 유형의 Experiments를 독립적으로 시각화, 비교 또는 평균화할 수 있습니다.
Experiments에 대한 생각, findings, 주의 사항 및 다음 단계를 프로젝트를 진행하면서 기록하여 모든 것을 한 곳에서 체계적으로 관리합니다. 이를 통해 스크립트 외에 중요한 모든 부분을 “문서화"할 수 있습니다. findings를 보고하는 방법에 대한 예는 누가 그들인가? 변환기를 사용한 텍스트 명확성 W&B Report를 참조하십시오.
프로젝트의 스토리를 전달하면 귀하와 다른 사람들이 나중에 참조하여 model이 개발된 방법과 이유를 이해할 수 있습니다. findings를 보고하는 방법에 대한 내용은 운전석에서 바라본 시각 W&B Report를 참조하십시오.
OpenAI Robotics 팀이 대규모 기계 학습 프로젝트를 실행하기 위해 W&B Reports를 사용한 방법을 탐색하기 위해 W&B Reports가 사용된 방법에 대한 예는 W&B Reports를 사용하여 엔드투엔드 손재주 학습을 참조하십시오.
필요한 경우, 엑세스 토큰, 비밀번호 또는 민감한 구성 세부 정보와 같이 자동화에 필요한 민감한 문자열에 대한 secrets를 구성합니다. Secrets는 Team Settings에서 정의됩니다. Secrets는 일반적으로 훅 자동화에서 자격 증명 또는 토큰을 일반 텍스트로 노출하거나 훅의 페이로드에 하드 코딩하지 않고 훅의 외부 서비스에 안전하게 전달하는 데 사용됩니다.
W&B가 Slack에 게시하거나 사용자를 대신하여 훅을 실행할 수 있도록 훅 또는 Slack 알림을 구성합니다. 단일 자동화 작업(훅 또는 Slack 알림)은 여러 자동화에서 사용할 수 있습니다. 이러한 작업은 Team Settings에서 정의됩니다.
W&B 팀을 Slack에 연결한 후 Registry 또는 Project를 선택한 다음 다음 단계에 따라 Slack 채널에 알림을 보내는 자동화를 만듭니다.
Registry 관리자는 해당 Registry에서 자동화를 생성할 수 있습니다.
W&B에 로그인합니다.
Registry 이름을 클릭하여 세부 정보를 봅니다.
Registry 범위로 자동화를 생성하려면 Automations 탭을 클릭한 다음 자동화 생성을 클릭합니다. Registry 범위로 지정된 자동화는 해당 컬렉션(향후 생성된 컬렉션 포함) 모두에 자동으로 적용됩니다.
Registry에서 특정 컬렉션에만 범위가 지정된 자동화를 생성하려면 컬렉션 작업 ... 메뉴를 클릭한 다음 자동화 생성을 클릭합니다. 또는 컬렉션을 보는 동안 컬렉션 세부 정보 페이지의 Automations 섹션에서 자동화 생성 버튼을 사용하여 컬렉션에 대한 자동화를 만듭니다.
이 페이지에서는 webhook 자동화를 만드는 방법을 보여줍니다. Slack 자동화를 만들려면 Slack 자동화 만들기를 참조하세요.
개략적으로 webhook 자동화를 만들려면 다음 단계를 수행합니다.
필요한 경우 액세스 토큰, 비밀번호 또는 SSH 키와 같이 자동화에 필요한 각 민감한 문자열에 대해 W&B secret 만들기를 수행합니다. secret은 팀 설정에 정의되어 있습니다.
webhook 만들기를 수행하여 엔드포인트 및 인증 세부 정보를 정의하고 통합에 필요한 secret에 대한 엑세스 권한을 부여합니다.
자동화 만들기를 수행하여 감시할 이벤트와 W&B가 보낼 페이로드를 정의합니다. 페이로드에 필요한 secret에 대한 자동화 엑세스 권한을 부여합니다.
webhook 만들기
팀 관리자는 팀에 대한 webhook을 추가할 수 있습니다.
webhook에 Bearer 토큰이 필요하거나 페이로드에 민감한 문자열이 필요한 경우 webhook을 만들기 전에 해당 문자열을 포함하는 secret을 만드세요. webhook에 대해 최대 하나의 엑세스 토큰과 다른 하나의 secret을 구성할 수 있습니다. webhook의 인증 및 권한 부여 요구 사항은 webhook의 서비스에 의해 결정됩니다.
W&B에 로그인하고 팀 설정 페이지로 이동합니다.
Webhooks 섹션에서 New webhook을 클릭합니다.
webhook의 이름을 입력합니다.
webhook의 엔드포인트 URL을 입력합니다.
webhook에 Bearer 토큰이 필요한 경우 Access token을 해당 토큰을 포함하는 secret으로 설정합니다. webhook 자동화를 사용할 때 W&B는 Authorization: Bearer HTTP 헤더를 엑세스 토큰으로 설정하고 ${ACCESS_TOKEN}페이로드 변수에서 토큰에 엑세스할 수 있습니다.
webhook의 페이로드에 비밀번호 또는 기타 민감한 문자열이 필요한 경우 Secret을 해당 문자열을 포함하는 secret으로 설정합니다. webhook을 사용하는 자동화를 구성할 때 이름 앞에 $를 붙여 페이로드 변수로 secret에 엑세스할 수 있습니다.
webhook의 엑세스 토큰이 secret에 저장된 경우 secret을 엑세스 토큰으로 지정하려면 또한 다음 단계를 완료해야 합니다.
W&B가 엔드포인트에 연결하고 인증할 수 있는지 확인하려면:
선택적으로 테스트할 페이로드를 제공합니다. 페이로드에서 webhook이 엑세스할 수 있는 secret을 참조하려면 이름 앞에 $를 붙입니다. 이 페이로드는 테스트에만 사용되며 저장되지 않습니다. 자동화를 만들 때 자동화의 페이로드를 구성합니다. secret과 엑세스 토큰이 POST 요청에 지정된 위치를 보려면 webhook 문제 해결을 참조하세요.
Test를 클릭합니다. W&B는 구성한 자격 증명을 사용하여 webhook의 엔드포인트에 연결을 시도합니다. 페이로드를 제공한 경우 W&B는 해당 페이로드를 보냅니다.
테스트가 성공하지 못하면 webhook의 구성을 확인하고 다시 시도하세요. 필요한 경우 webhook 문제 해결을 참조하세요.
webhook을 구성한 후 Registry 또는 Project를 선택한 다음 다음 단계에 따라 webhook을 트리거하는 자동화를 만듭니다.
Registry 관리자는 해당 Registry에서 자동화를 만들 수 있습니다. Registry 자동화는 향후 추가되는 자동화를 포함하여 Registry의 모든 컬렉션에 적용됩니다.
W&B에 로그인합니다.
Registry 이름을 클릭하여 세부 정보를 확인합니다.
Registry로 범위가 지정된 자동화를 만들려면 Automations 탭을 클릭한 다음 Create automation을 클릭합니다. Registry로 범위가 지정된 자동화는 향후 생성되는 컬렉션을 포함하여 모든 컬렉션에 자동으로 적용됩니다.
Registry의 특정 컬렉션으로만 범위가 지정된 자동화를 만들려면 컬렉션의 액션 ... 메뉴를 클릭한 다음 Create automation을 클릭합니다. 또는 컬렉션을 보는 동안 컬렉션 세부 정보 페이지의 Automations 섹션에 있는 Create automation 버튼을 사용하여 컬렉션에 대한 자동화를 만듭니다.
감시할 Event를 선택합니다. 이벤트에 따라 표시되는 추가 필드를 작성합니다. 예를 들어 An artifact alias is added를 선택한 경우 Alias regex를 지정해야 합니다. Next step을 클릭합니다.
webhook에 대해 엑세스 토큰을 구성한 경우 ${ACCESS_TOKEN}페이로드 변수에서 토큰에 엑세스할 수 있습니다. webhook에 대해 secret을 구성한 경우 이름 앞에 $를 붙여 페이로드에서 해당 secret에 엑세스할 수 있습니다. webhook의 요구 사항은 webhook의 서비스에 의해 결정됩니다.
Next step을 클릭합니다.
자동화 이름을 입력합니다. 선택적으로 설명을 제공합니다. Create automation을 클릭합니다.
webhook에 페이로드가 필요한 경우 페이로드를 구성하여 Payload 필드에 붙여넣습니다. webhook에 대해 엑세스 토큰을 구성한 경우 ${ACCESS_TOKEN}페이로드 변수에서 토큰에 엑세스할 수 있습니다. webhook에 대해 secret을 구성한 경우 이름 앞에 $를 붙여 페이로드에서 해당 secret에 엑세스할 수 있습니다. webhook의 요구 사항은 webhook의 서비스에 의해 결정됩니다.
Next step을 클릭합니다.
자동화 이름을 입력합니다. 선택적으로 설명을 제공합니다. Create automation을 클릭합니다.
자동화 보기 및 관리
Registry의 Automations 탭에서 Registry의 자동화를 관리합니다.
컬렉션 세부 정보 페이지의 Automations 섹션에서 컬렉션의 자동화를 관리합니다.
이러한 페이지에서 Registry 관리자는 기존 자동화를 관리할 수 있습니다.
자동화 세부 정보를 보려면 이름을 클릭합니다.
자동화를 편집하려면 해당 액션 ... 메뉴를 클릭한 다음 Edit automation을 클릭합니다.
자동화를 삭제하려면 해당 액션 ... 메뉴를 클릭한 다음 Delete automation을 클릭합니다. 확인이 필요합니다.
W&B 관리자는 Project의 Automations 탭에서 Project의 자동화를 보고 관리할 수 있습니다.
자동화 세부 정보를 보려면 이름을 클릭합니다.
자동화를 편집하려면 해당 액션 ... 메뉴를 클릭한 다음 Edit automation을 클릭합니다.
자동화를 삭제하려면 해당 액션 ... 메뉴를 클릭한 다음 Delete automation을 클릭합니다. 확인이 필요합니다.
페이로드 참조
이 섹션을 사용하여 webhook의 페이로드를 구성합니다. webhook 및 해당 페이로드 테스트에 대한 자세한 내용은 webhook 문제 해결을 참조하세요.
페이로드 변수
이 섹션에서는 webhook의 페이로드를 구성하는 데 사용할 수 있는 변수에 대해 설명합니다.
변수
세부 정보
${project_name}
액션을 트리거한 변경을 소유한 Project의 이름입니다.
${entity_name}
액션을 트리거한 변경을 소유한 엔터티 또는 팀의 이름입니다.
${event_type}
액션을 트리거한 이벤트 유형입니다.
${event_author}
액션을 트리거한 사용자입니다.
${artifact_collection_name}
아티팩트 버전이 연결된 아티팩트 컬렉션의 이름입니다.
${artifact_metadata.<KEY>}
액션을 트리거한 아티팩트 버전의 임의의 최상위 메타데이터 키의 값입니다. <KEY>를 최상위 메타데이터 키의 이름으로 바꿉니다. 최상위 메타데이터 키만 webhook의 페이로드에서 사용할 수 있습니다.
Project 수준: 자동화는 project 의 모든 컬렉션에서 발생하는 이벤트를 감시합니다.
컬렉션 수준: 지정한 필터와 일치하는 project 의 모든 컬렉션.
Events
Project 자동화는 다음 이벤트를 감시할 수 있습니다.
아티팩트의 새 버전이 컬렉션에 생성됨: 아티팩트의 각 버전에 반복 작업을 적용합니다. 컬렉션 지정은 선택 사항입니다. 예를 들어, 새로운 Dataset 아티팩트 버전이 생성되면 트레이닝 작업을 시작합니다.
아티팩트 에일리어스가 추가됨: project 또는 컬렉션의 새로운 아티팩트 버전에 특정 에일리어스가 적용될 때 워크플로우의 특정 단계를 트리거합니다. 예를 들어, 아티팩트에 test-set-quality-check 에일리어스가 적용되면 일련의 다운스트림 처리 단계를 실행합니다.
W&B Multi-tenant Cloud는 W&B의 클라우드 인프라에 배포된 완전 관리형 서비스로, 원하는 규모로 W&B 제품에 원활하게 엑세스하고, 비용 효율적인 가격 옵션을 활용하며, 최신 기능 및 업데이트를 지속적으로 받을 수 있습니다. 프라이빗 배포의 보안이 필요하지 않고, 셀프 서비스 온보딩이 중요하며, 비용 효율성이 중요한 경우 프로덕션 AI 워크플로우를 관리하기 위해 Multi-tenant Cloud를 사용하는 것이 좋습니다.
W&B Dedicated Cloud는 W&B의 클라우드 인프라에 배포된 싱글 테넌트, 완전 관리형 서비스입니다. 데이터 상주를 포함한 엄격한 거버넌스 제어를 준수해야 하고, 고급 보안 기능이 필요하며, 보안, 확장성 및 성능 특성을 갖춘 필요한 인프라를 구축 및 관리하지 않고도 AI 운영 비용을 최적화하려는 경우 W&B를 온보딩하는 데 가장 적합합니다.
이 옵션을 사용하면 자체 관리형 인프라에 W&B Server를 배포하고 관리할 수 있습니다. W&B Server는 W&B Platform 및 지원되는 W&B 제품을 실행하기 위한 자체 포함 패키지 메커니즘입니다. 기존 인프라가 모두 온프레미스에 있거나, W&B Dedicated Cloud에서 충족되지 않는 엄격한 규제 요구 사항이 있는 경우 이 옵션을 사용하는 것이 좋습니다. 이 옵션을 사용하면 W&B Server를 지원하는 데 필요한 인프라의 프로비저닝, 지속적인 유지 관리 및 업그레이드를 완전히 책임져야 합니다.
W&B 제품을 사용해 보려면 Multi-tenant Cloud를 사용하는 것이 좋습니다. 엔터프라이즈 친화적인 설정을 찾고 있다면 여기에서 트라이얼에 적합한 배포 유형을 선택하십시오.
5.1 - Deployment options
5.1.1 - Use W&B Multi-tenant SaaS
W&B Multi-tenant Cloud는 W&B의 Google Cloud Platform (GCP) 계정의 GPC의 북미 지역에 배포된 완전 관리형 플랫폼입니다. W&B Multi-tenant Cloud는 트래픽 증가 또는 감소에 따라 플랫폼이 적절하게 확장되도록 GCP에서 자동 확장을 활용합니다.
데이터 보안
엔터프라이즈 플랜 사용자가 아닌 경우 모든 데이터는 공유 클라우드 스토리지에만 저장되고 공유 클라우드 컴퓨팅 서비스로 처리됩니다. 요금제에 따라 스토리지 제한이 적용될 수 있습니다.
엔터프라이즈 플랜 사용자는 보안 스토리지 커넥터를 사용하여 자체 버킷(BYOB)을 가져올 수 있습니다팀 레벨에서 모델, 데이터셋 등과 같은 파일을 저장할 수 있습니다. 여러 팀에 대해 단일 버킷을 구성하거나 여러 W&B Teams에 대해 별도의 버킷을 사용할 수 있습니다. 팀에 대해 보안 스토리지 커넥터를 구성하지 않으면 해당 데이터는 공유 클라우드 스토리지에 저장됩니다.
ID 및 엑세스 관리 (IAM)
엔터프라이즈 플랜을 사용하는 경우 W&B 조직에서 안전한 인증 및 효과적인 권한 부여를 위해 ID 및 엑세스 관리 기능을 사용할 수 있습니다. Multi-tenant Cloud의 IAM에 사용할 수 있는 기능은 다음과 같습니다.
OIDC 또는 SAML을 사용한 SSO 인증. 조직에 대해 SSO를 구성하려면 W&B 팀 또는 지원팀에 문의하세요.
W&B 전용 클라우드는 W&B의 AWS, GCP 또는 Azure 클라우드 계정에 배포된 싱글 테넌트, 완전 관리형 플랫폼입니다. 각 전용 클라우드 인스턴스는 다른 W&B 전용 클라우드 인스턴스와 격리된 자체 네트워크, 컴퓨팅 및 스토리지를 가지고 있습니다. W&B 특정 메타데이터 및 데이터는 격리된 클라우드 스토리지에 저장되고 격리된 클라우드 컴퓨팅 서비스를 사용하여 처리됩니다.
AWS, GCP, 및 Azure는 전 세계 여러 위치에서 클라우드 컴퓨팅 서비스를 지원합니다. 글로벌 리전은 데이터 상주 및 규정 준수, 지연 시간, 비용 효율성 등과 관련된 요구 사항을 충족하는 데 도움이 됩니다. W&B는 전용 클라우드에 사용 가능한 여러 글로벌 리전을 지원합니다.
선호하는 AWS, GCP 또는 Azure 리전이 목록에 없으면 W&B 지원팀에 문의하십시오. W&B는 해당 리전에 전용 클라우드에 필요한 모든 서비스가 있는지 확인하고 평가 결과에 따라 지원 우선 순위를 지정할 수 있습니다.
지원되는 AWS 리전
다음 표는 W&B가 현재 전용 클라우드 인스턴스에 대해 지원하는 AWS 리전을 나열합니다.
IT/DevOps/MLOps 팀은 배포 프로비저닝, 업그레이드 관리 및 자체 관리형 W&B Server 인스턴스의 지속적인 유지 관리를 담당합니다.
자체 관리형 클라우드 계정 내에 W&B Server 배포
W&B는 공식 W&B Terraform 스크립트를 사용하여 AWS, GCP 또는 Azure 클라우드 계정에 W&B Server를 배포할 것을 권장합니다.
AWS, GCP 또는 Azure에서 W&B Server를 설정하는 방법에 대한 자세한 내용은 특정 클라우드 공급자 문서를 참조하세요.
온-프레미스 인프라에 W&B Server 배포
온-프레미스 인프라에서 W&B Server를 설정하려면 여러 인프라 구성 요소를 구성해야 합니다. 이러한 구성 요소에는 다음이 포함되지만 이에 국한되지는 않습니다.
(강력 권장) Kubernetes 클러스터
MySQL 8 데이터베이스 클러스터
Amazon S3 호환 오브젝트 스토리지
Redis 캐시 클러스터
온-프레미스 인프라에 W&B Server를 설치하는 방법에 대한 자세한 내용은 온-프레미스 인프라에 설치를 참조하세요. W&B는 다양한 구성 요소에 대한 권장 사항을 제공하고 설치 프로세스에 대한 지침을 제공할 수 있습니다.
사용자 지정 클라우드 플랫폼에 W&B Server 배포
AWS, GCP 또는 Azure가 아닌 클라우드 플랫폼에 W&B Server를 배포할 수 있습니다. 이에 대한 요구 사항은 온-프레미스 인프라에 배포하는 것과 유사합니다.
W&B Server 라이선스 받기
W&B 서버 설정을 완료하려면 W&B 트라이얼 라이선스가 필요합니다. Deploy Manager를 열어 무료 트라이얼 라이선스를 생성하세요.
아직 W&B 계정이 없는 경우 계정을 만들어 무료 라이선스를 생성하세요.
중요한 보안 및 기타 엔터프라이즈 친화적인 기능을 지원하는 W&B Server용 엔터프라이즈 라이선스가 필요한 경우 이 양식을 제출하거나 W&B 팀에 문의하세요.
URL은 W&B Local용 라이선스 받기 양식으로 리디렉션됩니다. 다음 정보를 제공하세요.
플랫폼 선택 단계에서 배포 유형을 선택합니다.
기본 정보 단계에서 라이선스 소유자를 선택하거나 새 조직을 추가합니다.
라이선스 받기 단계의 인스턴스 이름 필드에 인스턴스 이름을 제공하고 필요에 따라 설명 필드에 설명을 제공합니다.
라이선스 키 생성 버튼을 선택합니다.
인스턴스와 연결된 라이선스와 함께 배포 개요가 있는 페이지가 표시됩니다.
5.1.3.1 - Reference Architecture
W&B 참조 아키텍처
이 페이지에서는 Weights & Biases 배포를 위한 참조 아키텍처를 설명하고 플랫폼의 프로덕션 배포를 지원하기 위해 권장되는 인프라 및 리소스를 간략하게 설명합니다.
Weights & Biases(W&B)에 대해 선택한 배포 환경에 따라 다양한 서비스를 통해 배포의 복원력을 향상시킬 수 있습니다.
예를 들어 주요 클라우드 공급자는 데이터베이스 구성, 유지 관리, 고가용성 및 복원력의 복잡성을 줄이는 데 도움이 되는 강력한 관리형 데이터베이스 서비스를 제공합니다.
이 참조 아키텍처는 몇 가지 일반적인 배포 시나리오를 다루고 최적의 성능과 안정성을 위해 W&B 배포를 클라우드 공급업체 서비스와 통합하는 방법을 보여줍니다.
시작하기 전에
모든 애플리케이션을 프로덕션 환경에서 실행하는 데에는 자체적인 어려움이 따르며 W&B도 예외는 아닙니다. Google은 프로세스를 간소화하는 것을 목표로 하지만 고유한 아키텍처 및 설계 결정에 따라 특정 복잡성이 발생할 수 있습니다. 일반적으로 프로덕션 배포를 관리하려면 하드웨어, 운영 체제, 네트워킹, 스토리지, 보안, W&B 플랫폼 자체 및 기타 종속성을 포함한 다양한 구성 요소를 감독해야 합니다. 이 책임은 환경의 초기 설정과 지속적인 유지 관리 모두에 적용됩니다.
W&B를 사용한 자체 관리 방식이 팀 및 특정 요구 사항에 적합한지 신중하게 고려하십시오.
프로덕션 등급 애플리케이션을 실행하고 유지 관리하는 방법에 대한 확실한 이해는 자체 관리 W&B를 배포하기 전에 중요한 전제 조건입니다. 팀에 지원이 필요한 경우 Google의 Professional Services 팀과 파트너가 구현 및 최적화에 대한 지원을 제공합니다.
애플리케이션 레이어는 노드 장애에 대한 복원력을 갖춘 다중 노드 Kubernetes 클러스터로 구성됩니다. Kubernetes 클러스터는 W&B의 포드를 실행하고 유지 관리합니다.
스토리지 레이어
스토리지 레이어는 MySQL 데이터베이스와 오브젝트 스토리지로 구성됩니다. MySQL 데이터베이스는 메타데이터를 저장하고 오브젝트 스토리지는 모델 및 데이터셋과 같은 아티팩트를 저장합니다.
인프라 요구 사항
Kubernetes
W&B Server 애플리케이션은 여러 포드를 배포하는 Kubernetes Operator로 배포됩니다. 이러한 이유로 W&B에는 다음이 포함된 Kubernetes 클러스터가 필요합니다.
완전히 구성되고 작동하는 Ingress 컨트롤러.
Persistent Volumes를 프로비저닝하는 기능.
MySQL
W&B는 메타데이터를 MySQL 데이터베이스에 저장합니다. 데이터베이스의 성능 및 스토리지 요구 사항은 모델 파라미터 및 관련 메타데이터의 형태에 따라 달라집니다. 예를 들어 더 많은 트레이닝 run을 추적할수록 데이터베이스 크기가 커지고 run 테이블, 사용자 워크스페이스 및 리포트의 쿼리를 기반으로 데이터베이스에 대한 부하가 증가합니다.
자체 관리 MySQL 데이터베이스를 배포할 때 다음 사항을 고려하십시오.
백업. 데이터베이스를 별도의 시설에 주기적으로 백업해야 합니다. W&B는 최소 1주일의 보존 기간으로 매일 백업하는 것이 좋습니다.
성능. 서버가 실행되는 디스크는 빨라야 합니다. W&B는 SSD 또는 가속화된 NAS에서 데이터베이스를 실행하는 것이 좋습니다.
모니터링. 데이터베이스의 부하를 모니터링해야 합니다. CPU 사용량이 시스템의 40%를 초과하여 5분 이상 유지되면 서버에 리소스가 부족하다는 좋은 징조일 수 있습니다.
가용성. 가용성 및 내구성 요구 사항에 따라 기본 서버에서 모든 업데이트를 실시간으로 스트리밍하고 기본 서버가 충돌하거나 손상될 경우 장애 조치하는 데 사용할 수 있는 별도의 시스템에서 핫 스탠바이를 구성할 수 있습니다.
오브젝트 스토리지
W&B에는 사전 서명된 URL 및 CORS 지원이 포함된 오브젝트 스토리지가 필요하며 다음 중 하나로 배포됩니다.
Amazon S3
Azure Cloud Storage
Google Cloud Storage
Amazon S3와 호환되는 스토리지 서비스
버전
소프트웨어
최소 버전
Kubernetes
v1.29
MySQL
v8.0.0, “General Availability” 릴리스만 해당
네트워킹
네트워크로 연결된 배포의 경우 설치 및 런타임 모두 중에 이러한 엔드포인트에 대한 송신이 필요합니다.
에어 갭 배포에 대한 자세한 내용은 에어 갭 인스턴스용 Kubernetes operator를 참조하십시오.
W&B와 오브젝트 스토리지에 대한 엑세스는 트레이닝 인프라와 Experiments의 요구 사항을 추적하는 각 시스템에 필요합니다.
DNS
W&B 배포의 정규화된 도메인 이름(FQDN)은 A 레코드를 사용하여 수신/로드 밸런서의 IP 어드레스로 확인되어야 합니다.
SSL/TLS
W&B에는 클라이언트와 서버 간의 보안 통신을 위한 유효한 서명된 SSL/TLS 인증서가 필요합니다. SSL/TLS 종료는 수신/로드 밸런서에서 발생해야 합니다. W&B Server 애플리케이션은 SSL 또는 TLS 연결을 종료하지 않습니다.
참고: W&B는 자체 서명된 인증서 및 사용자 지정 CA의 사용을 권장하지 않습니다.
지원되는 CPU 아키텍처
W&B는 Intel(x86) CPU 아키텍처에서 실행됩니다. ARM은 지원되지 않습니다.
인프라 프로비저닝
Terraform은 프로덕션 환경을 위해 W&B를 배포하는 데 권장되는 방법입니다. Terraform을 사용하면 필요한 리소스, 다른 리소스에 대한 참조 및 종속성을 정의합니다. W&B는 주요 클라우드 공급자를 위한 Terraform 모듈을 제공합니다. 자세한 내용은 자체 관리 클라우드 계정 내에서 W&B Server 배포를 참조하십시오.
크기 조정
배포를 계획할 때 다음 일반 지침을 시작점으로 사용하십시오. W&B는 새로운 배포의 모든 구성 요소를 면밀히 모니터링하고 관찰된 사용 패턴에 따라 조정하는 것이 좋습니다. 시간이 지남에 따라 프로덕션 배포를 계속 모니터링하고 최적의 성능을 유지하기 위해 필요에 따라 조정하십시오.
모델만 해당
Kubernetes
환경
CPU
메모리
디스크
테스트/개발
2 코어
16GB
100GB
프로덕션
8 코어
64GB
100GB
숫자는 Kubernetes 작업자 노드당 개수입니다.
MySQL
환경
CPU
메모리
디스크
테스트/개발
2 코어
16GB
100GB
프로덕션
8 코어
64GB
500GB
숫자는 MySQL 노드당 개수입니다.
Weave만 해당
Kubernetes
환경
CPU
메모리
디스크
테스트/개발
4 코어
32GB
100GB
프로덕션
12 코어
96GB
100GB
숫자는 Kubernetes 작업자 노드당 개수입니다.
MySQL
환경
CPU
메모리
디스크
테스트/개발
2 코어
16GB
100GB
프로덕션
8 코어
64GB
500GB
숫자는 MySQL 노드당 개수입니다.
모델 및 Weave
Kubernetes
환경
CPU
메모리
디스크
테스트/개발
4 코어
32GB
100GB
프로덕션
16 코어
128GB
100GB
숫자는 Kubernetes 작업자 노드당 개수입니다.
MySQL
환경
CPU
메모리
디스크
테스트/개발
2 코어
16GB
100GB
프로덕션
8 코어
64GB
500GB
숫자는 MySQL 노드당 개수입니다.
클라우드 공급자 인스턴스 권장 사항
서비스
클라우드
Kubernetes
MySQL
오브젝트 스토리지
AWS
EKS
RDS Aurora
S3
GCP
GKE
Google Cloud SQL - Mysql
Google Cloud Storage (GCS)
Azure
AKS
Azure Database for Mysql
Azure Blob Storage
머신 유형
이러한 권장 사항은 클라우드 인프라에서 W&B의 자체 관리 배포의 각 노드에 적용됩니다.
AWS
환경
K8s (모델만 해당)
K8s (Weave만 해당)
K8s (모델&Weave)
MySQL
테스트/개발
r6i.large
r6i.xlarge
r6i.xlarge
db.r6g.large
프로덕션
r6i.2xlarge
r6i.4xlarge
r6i.4xlarge
db.r6g.2xlarge
GCP
환경
K8s (모델만 해당)
K8s (Weave만 해당)
K8s (모델&Weave)
MySQL
테스트/개발
n2-highmem-2
n2-highmem-4
n2-highmem-4
db-n1-highmem-2
프로덕션
n2-highmem-8
n2-highmem-16
n2-highmem-16
db-n1-highmem-8
Azure
환경
K8s (모델만 해당)
K8s (Weave만 해당)
K8s (모델&Weave)
MySQL
테스트/개발
Standard_E2_v5
Standard_E4_v5
Standard_E4_v5
MO_Standard_E2ds_v4
프로덕션
Standard_E8_v5
Standard_E16_v5
Standard_E16_v5
MO_Standard_E8ds_v4
5.1.3.2 - Run W&B Server on Kubernetes
Kubernetes Operator로 W&B 플랫폼 배포
W&B Kubernetes Operator
W&B Kubernetes Operator를 사용하면 Kubernetes에서 W&B Server 배포를 간소화하고, 관리하고, 문제를 해결하고, 확장할 수 있습니다. 이 Operator는 W&B 인스턴스를 위한 스마트 도우미라고 생각하면 됩니다.
W&B Server 아키텍처와 디자인은 AI 개발자 툴링 기능을 확장하고, 고성능, 더 나은 확장성, 더 쉬운 관리를 위한 적절한 기본 요소를 제공하기 위해 지속적으로 발전하고 있습니다. 이러한 발전은 컴퓨팅 서비스, 관련 스토리지 및 이들 간의 연결에 적용됩니다. 모든 배포 유형에서 지속적인 업데이트와 개선을 용이하게 하기 위해 W&B는 Kubernetes operator를 사용합니다.
W&B는 이 operator를 사용하여 AWS, GCP 및 Azure 퍼블릭 클라우드에 전용 클라우드 인스턴스를 배포하고 관리합니다.
Kubernetes operator에 대한 자세한 내용은 Kubernetes 설명서의 Operator 패턴을 참조하세요.
아키텍처 전환 이유
과거에는 W&B 애플리케이션이 Kubernetes 클러스터 내의 단일 배포 및 pod 또는 단일 Docker 컨테이너로 배포되었습니다. W&B는 데이터베이스 및 오브젝트 저장소를 외부화할 것을 권장해 왔으며 앞으로도 계속 권장할 것입니다. 데이터베이스 및 오브젝트 저장소를 외부화하면 애플리케이션의 상태가 분리됩니다.
애플리케이션이 성장함에 따라 모놀리식 컨테이너에서 분산 시스템(마이크로서비스)으로 발전해야 할 필요성이 분명해졌습니다. 이러한 변경은 백엔드 로직 처리를 용이하게 하고 내장된 Kubernetes 인프라 기능을 원활하게 도입합니다. 분산 시스템은 또한 W&B가 의존하는 추가 기능에 필수적인 새로운 서비스 배포를 지원합니다.
2024년 이전에는 Kubernetes 관련 변경 사항이 있을 때마다 terraform-kubernetes-wandb Terraform 모듈을 수동으로 업데이트해야 했습니다. Terraform 모듈을 업데이트하면 클라우드 공급자 간의 호환성이 보장되고 필요한 Terraform 변수가 구성되며 각 백엔드 또는 Kubernetes 수준 변경에 대해 Terraform 적용이 실행됩니다.
W&B 지원팀이 각 고객의 Terraform 모듈 업그레이드를 지원해야 했기 때문에 이 프로세스는 확장 가능하지 않았습니다.
해결책은 중앙 deploy.wandb.ai 서버에 연결하여 주어진 릴리스 채널에 대한 최신 사양 변경 사항을 요청하고 적용하는 operator를 구현하는 것이었습니다. 라이선스가 유효한 한 업데이트가 수신됩니다. Helm은 W&B operator의 배포 메커니즘이자 operator가 W&B Kubernetes 스택의 모든 설정 템플릿을 처리하는 수단(Helm-ception)으로 사용됩니다.
작동 방식
helm 또는 소스에서 operator를 설치할 수 있습니다. 자세한 내용은 charts/operator를 참조하세요.
설치 프로세스는 controller-manager라는 배포를 생성하고 weightsandbiases.apps.wandb.com이라는 custom resource 정의(shortName: wandb)를 사용하며, 단일 spec을 가져와 클러스터에 적용합니다.
controller-manager는 커스텀 리소스, 릴리스 채널 및 사용자 정의 설정의 사양을 기반으로 charts/operator-wandb를 설치합니다. 이 설정 사양 계층 구조는 사용자 측에서 최대한의 설정 유연성을 제공하고 W&B가 새로운 이미지, 설정, 기능 및 Helm 업데이트를 자동으로 릴리스할 수 있도록 합니다.
W&B는 W&B Kubernetes operator를 Kubernetes 클러스터에 배포하기 위한 Helm Chart를 제공합니다. 이 접근 방식을 사용하면 Helm CLI 또는 ArgoCD와 같은 지속적인 배포 툴을 사용하여 W&B Server를 배포할 수 있습니다. 위에 언급된 요구 사항이 충족되었는지 확인하세요.
다음 단계에 따라 Helm CLI로 W&B Kubernetes Operator를 설치하세요.
W&B Helm 저장소를 추가합니다. W&B Helm chart는 W&B Helm 저장소에서 사용할 수 있습니다. 다음 코맨드를 사용하여 저장소를 추가합니다.
W&B는 AWS, GCP 및 Azure용 Terraform Modules 세트를 제공합니다. 이러한 모듈은 Kubernetes 클러스터, 로드 밸런서, MySQL 데이터베이스 등을 포함한 전체 인프라와 W&B Server 애플리케이션을 배포합니다. W&B Kubernetes Operator는 다음과 같은 버전의 공식 W&B 클라우드별 Terraform Modules와 함께 미리 준비되어 있습니다.
이 통합은 W&B Kubernetes Operator가 최소한의 설정으로 인스턴스에 사용할 준비가 되어 있는지 확인하여 클라우드 환경에서 W&B Server를 배포하고 관리하는 간소화된 경로를 제공합니다.
이러한 모듈을 사용하는 방법에 대한 자세한 설명은 문서의 자체 관리 설치 섹션의 이 섹션을 참조하세요.
설치 확인
설치를 확인하기 위해 W&B는 W&B CLI를 사용하는 것이 좋습니다. 확인 코맨드는 모든 구성 요소와 구성을 확인하는 여러 테스트를 실행합니다.
이 단계에서는 첫 번째 관리자 사용자 계정이 브라우저로 생성되었다고 가정합니다.
다음 단계에 따라 설치를 확인하세요.
W&B CLI를 설치합니다.
pip install wandb
W&B에 로그인합니다.
wandb login --host=https://YOUR_DNS_DOMAIN
예:
wandb login --host=https://wandb.company-name.com
설치를 확인합니다.
wandb verify
설치가 완료되고 W&B 배포가 완전히 작동하면 다음 출력이 표시됩니다.
Default host selected: https://wandb.company-name.com
Find detailed logs for this test at: /var/folders/pn/b3g3gnc11_sbsykqkm3tx5rh0000gp/T/tmpdtdjbxua/wandb
Checking if logged in...................................................✅
Checking signed URL upload..............................................✅
Checking ability to send large payloads through proxy...................✅
Checking requests to base url...........................................✅
Checking requests made over signed URLs.................................✅
Checking CORs configuration of the bucket...............................✅
Checking wandb package version is up to date............................✅
Checking logged metrics, saving and downloading a file..................✅
Checking artifact save and download workflows...........................✅
W&B Management Console 엑세스
W&B Kubernetes operator에는 관리 콘솔이 함께 제공됩니다. 예를 들어 https://wandb.company-name.com/ 콘솔과 같이 ${HOST_URI}/console에 있습니다.
global:
ldap:
enabled: true# "ldap://" 또는 "ldaps://"를 포함한 LDAP 서버 어드레스host:
# 사용자를 찾는 데 사용할 LDAP 검색 기준baseDN:
# 바인딩할 LDAP 사용자 (익명 바인딩을 사용하지 않는 경우)bindDN:
# 바인딩할 LDAP 비밀번호가 포함된 Secret 이름 및 키 (익명 바인딩을 사용하지 않는 경우)bindPW:
# 쉼표로 구분된 문자열 값으로 된 이메일 및 그룹 ID 어트리뷰트 이름에 대한 LDAP 어트리뷰트입니다.attributes:
# LDAP 그룹 허용 목록groupAllowList:
# LDAP TLS 활성화tls: false
global:
ldap:
enabled: true# "ldap://" 또는 "ldaps://"를 포함한 LDAP 서버 어드레스host:
# 사용자를 찾는 데 사용할 LDAP 검색 기준baseDN:
# 바인딩할 LDAP 사용자 (익명 바인딩을 사용하지 않는 경우)bindDN:
# 바인딩할 LDAP 비밀번호가 포함된 Secret 이름 및 키 (익명 바인딩을 사용하지 않는 경우)bindPW:
# 쉼표로 구분된 문자열 값으로 된 이메일 및 그룹 ID 어트리뷰트 이름에 대한 LDAP 어트리뷰트입니다.attributes:
# LDAP 그룹 허용 목록groupAllowList:
# LDAP TLS 활성화tls: true# LDAP 서버용 CA 인증서가 포함된 ConfigMap 이름 및 키tlsCert:
configMap:
name: "ldap-tls-cert"key: "certificate.crt"
ConfigMap을 사용하는 경우 ConfigMap의 각 키는 .crt로 끝나야 합니다 (예: my-cert.crt 또는 ca-cert1.crt). 이 명명 규칙은 update-ca-certificates가 각 인증서를 구문 분석하고 시스템 CA 저장소에 추가하는 데 필요합니다.
스크립트는 스크립트를 실행한 폴더에 바이너리를 다운로드합니다. 다른 폴더로 이동하려면 다음을 실행합니다.
sudo mv wsm /usr/local/bin
GitHub
W&B 관리 wandb/wsm GitHub 저장소( https://github.com/wandb/wsm )에서 WSM을 다운로드하거나 복제합니다. 최신 릴리스는 wandb/wsm릴리스 노트를 참조하세요.
이미지 및 해당 버전 나열
wsm list를 사용하여 최신 이미지 버전 목록을 가져옵니다.
wsm list
출력은 다음과 같습니다.
:package: 배포에 필요한 모든 이미지를 나열하는 프로세스를 시작합니다...
Operator Images:
wandb/controller:1.16.1
W&B Images:
wandb/local:0.62.2
docker.io/bitnami/redis:7.2.4-debian-12-r9
quay.io/prometheus-operator/prometheus-config-reloader:v0.67.0
quay.io/prometheus/prometheus:v2.47.0
otel/opentelemetry-collector-contrib:0.97.0
wandb/console:2.13.1
다음은 W&B를 배포하는 데 필요한 이미지입니다. 이러한 이미지가 내부 컨테이너 레지스트리에서 사용 가능한지 확인하고 values.yaml을 적절하게 업데이트하십시오.
module"wandb_infra" {
source ="wandb/wandb/aws" version ="1.16.10" ...
}
이 모듈은 인프라를 가동합니다.
module"wandb_app" {
source ="wandb/wandb/kubernetes" version ="1.12.0"}
이 모듈은 애플리케이션을 배포합니다.
Post-Operator 설정
pre-operator.tf에 .disabled 확장명이 있고 post-operator.tf가 활성 상태인지 확인합니다.
post-operator.tfvars에는 추가 변수가 포함되어 있습니다.
...# wandb_version = "0.51.2"는 이제 릴리스 채널을 통해 관리되거나 사용자 사양에 설정됩니다.# 업그레이드에 필요한 운영자 변수:size="small"enable_dummy_dns=trueenable_operator_alb=truecustom_domain_filter="sandbox-aws.wandb.ml"
Weights & Biases에서는 W&B Multi-tenant Cloud 또는 W&B Dedicated Cloud 배포 유형과 같은 완전 관리형 배포 옵션을 권장합니다. Weights & Biases의 완전 관리형 서비스는 사용하기 간편하고 안전하며, 필요한 설정이 최소화되거나 전혀 없습니다.
State File은 모든 구성 요소를 다시 생성하지 않고도 업그레이드를 롤아웃하거나 배포를 변경하는 데 필요한 리소스입니다.
Terraform Module은 다음과 같은 필수 구성 요소를 배포합니다.
Azure Resource Group
Azure Virtual Network (VPC)
Azure MySQL Flexible Server
Azure Storage Account & Blob Storage
Azure Kubernetes Service
Azure Application Gateway
다른 배포 옵션에는 다음과 같은 선택적 구성 요소도 포함될 수 있습니다.
Azure Cache for Redis
Azure Event Grid
전제 조건 권한
AzureRM provider를 구성하는 가장 간단한 방법은 Azure CLI를 이용하는 것이지만, Azure Service Principal을 사용한 자동화도 유용할 수 있습니다.
어떤 인증 방법을 사용하든 Terraform을 실행할 계정은 도입부에 설명된 모든 구성 요소를 생성할 수 있어야 합니다.
MySQL 8.0에서 sort_buffer_size를 처리하는 방식이 변경되었으므로 sort_buffer_size 파라미터를 기본값인 262144에서 업데이트해야 할 수 있습니다. W&B와 함께 MySQL이 효율적으로 작동하도록 값을 67108864 (64MiB)로 설정하는 것이 좋습니다. MySQL은 v8.0.28부터 이 설정을 지원합니다.
데이터베이스 고려 사항
다음 SQL 쿼리를 사용하여 데이터베이스와 사용자를 만듭니다. SOME_PASSWORD를 원하는 비밀번호로 바꿉니다.
CREATEUSER'wandb_local'@'%' IDENTIFIED BY'SOME_PASSWORD';
CREATEDATABASE wandb_local CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;
GRANTALLON wandb_local.*TO'wandb_local'@'%'WITHGRANTOPTION;
이는 SSL 인증서를 신뢰할 수 있는 경우에만 작동합니다. W&B는 자체 서명된 인증서를 지원하지 않습니다.
Amazon S3 호환 오브젝트 스토리지에 연결할 때 연결 문자열에 자격 증명을 지정할 수 있습니다. 예를 들어 다음과 같이 지정할 수 있습니다.
s3://$ACCESS_KEY:$SECRET_KEY@$HOST/$BUCKET_NAME
선택적으로 오브젝트 스토리지에 대해 신뢰할 수 있는 SSL 인증서를 구성한 경우 W&B에 TLS를 통해서만 연결하도록 지시할 수 있습니다. 이렇게 하려면 URL에 tls 쿼리 파라미터를 추가하십시오. 예를 들어 다음 URL 예제는 Amazon S3 URI에 TLS 쿼리 파라미터를 추가하는 방법을 보여줍니다.
기계 학습 페이로드를 실행하는 데 사용되는 모든 장치와 웹 브라우저를 통해 서비스에 액세스하는 데 사용되는 장치가 이 엔드포인트와 통신할 수 있는지 확인하십시오.
SSL / TLS
W&B Server는 SSL을 중지하지 않습니다. 보안 정책에서 신뢰할 수 있는 네트워크 내에서 SSL 통신을 요구하는 경우 Istio와 같은 툴과 side car containers를 사용하는 것이 좋습니다. 로드 밸런서 자체는 유효한 인증서로 SSL을 종료해야 합니다. 자체 서명된 인증서를 사용하는 것은 지원되지 않으며 사용자에게 여러 가지 문제가 발생할 수 있습니다. 가능하다면 Let’s Encrypt와 같은 서비스를 사용하여 로드 밸런서에 신뢰할 수 있는 인증서를 제공하는 것이 좋습니다. Caddy 및 Cloudflare와 같은 서비스는 SSL을 관리합니다.
Nginx 구성 예제
다음은 nginx를 역방향 프록시로 사용하는 구성 예제입니다.
events {}
http {
# If we receive X-Forwarded-Proto, pass it through; otherwise, pass along the
# scheme used to connect to this server
map $http_x_forwarded_proto $proxy_x_forwarded_proto {
default $http_x_forwarded_proto;
'' $scheme;
}
# Also, in the above case, force HTTPS
map $http_x_forwarded_proto $sts {
default'';
"https""max-age=31536000; includeSubDomains";
}
# If we receive X-Forwarded-Host, pass it though; otherwise, pass along $http_host
map $http_x_forwarded_host $proxy_x_forwarded_host {
default $http_x_forwarded_host;
'' $http_host;
}
# If we receive X-Forwarded-Port, pass it through; otherwise, pass along the
# server port the client connected to
map $http_x_forwarded_port $proxy_x_forwarded_port {
default $http_x_forwarded_port;
'' $server_port;
}
# If we receive Upgrade, set Connection to "upgrade"; otherwise, delete any
# Connection header that may have been passed to this server
map $http_upgrade $proxy_connection {
defaultupgrade;
''close;
}
server {
listen443ssl;
server_namewww.example.com;
ssl_certificatewww.example.com.crt;
ssl_certificate_keywww.example.com.key;
proxy_http_version1.1;
proxy_bufferingoff;
proxy_set_headerHost $http_host;
proxy_set_headerUpgrade $http_upgrade;
proxy_set_headerConnection $proxy_connection;
proxy_set_headerX-Real-IP $remote_addr;
proxy_set_headerX-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_headerX-Forwarded-Proto $proxy_x_forwarded_proto;
proxy_set_headerX-Forwarded-Host $proxy_x_forwarded_host;
location/ {
proxy_passhttp://$YOUR_UPSTREAM_SERVER_IP:8080/;
}
keepalive_timeout10;
}
}
설치 확인
W&B Server가 올바르게 구성되었는지 확인하십시오. 터미널에서 다음 코맨드를 실행합니다.
Organization 은 W&B 계정 또는 인스턴스의 루트 범위입니다. 계정 또는 인스턴스의 모든 작업은 사용자 관리, 팀 관리, 팀 내 프로젝트 관리, 사용량 추적 등을 포함하여 해당 루트 범위 내에서 수행됩니다.
Multi-tenant Cloud를 사용하는 경우, 각 Organization은 사업부, 개인 사용자, 다른 기업과의 합작 파트너십 등에 해당할 수 있습니다.
전용 클라우드(Dedicated Cloud) 또는 자체 관리 인스턴스를 사용하는 경우, 하나의 Organization에 해당합니다. 회사는 여러 사업부 또는 부서에 매핑하기 위해 여러 개의 전용 클라우드(Dedicated Cloud) 또는 자체 관리 인스턴스를 가질 수 있지만, 이는 사업 또는 부서 전체에서 AI 실무자를 관리하는 선택적인 방법입니다.
W&B 서버 LDAP 서버로 인증 정보를 인증합니다. 다음 가이드는 W&B 서버의 설정을 구성하는 방법을 설명합니다. 필수 및 선택적 설정과 시스템 설정 UI에서 LDAP 연결을 구성하는 방법에 대한 지침을 다룹니다. 또한 어드레스, 기본 식별 이름, 속성과 같은 LDAP 설정의 다양한 입력에 대한 정보를 제공합니다. 이러한 속성은 W&B 앱 UI 또는 환경 변수를 사용하여 지정할 수 있습니다. 익명 바인딩 또는 관리자 DN 및 비밀번호를 사용하여 바인딩을 설정할 수 있습니다.
W&B 관리자 역할만 LDAP 인증을 활성화하고 구성할 수 있습니다.
LDAP 연결 구성
W&B 앱으로 이동합니다.
오른쪽 상단에서 프로필 아이콘을 선택합니다. 드롭다운에서 시스템 설정을 선택합니다.
LDAP 클라이언트 구성을 토글합니다.
양식에 세부 정보를 추가합니다. 각 입력에 대한 자세한 내용은 설정 파라미터 섹션을 참조하세요.
설정 업데이트를 클릭하여 설정을 테스트합니다. 이렇게 하면 W&B 서버와 테스트 클라이언트/연결이 설정됩니다.
연결이 확인되면 LDAP 인증 활성화를 토글하고 설정 업데이트 버튼을 선택합니다.
다음 환경 변수를 사용하여 LDAP 연결을 설정합니다.
환경 변수
필수
예
LOCAL_LDAP_ADDRESS
예
ldaps://ldap.example.com:636
LOCAL_LDAP_BASE_DN
예
email=mail,group=gidNumber
LOCAL_LDAP_BIND_DN
아니요
cn=admin, dc=example,dc=org
LOCAL_LDAP_BIND_PW
아니요
LOCAL_LDAP_ATTRIBUTES
예
email=mail, group=gidNumber
LOCAL_LDAP_TLS_ENABLE
아니요
LOCAL_LDAP_GROUP_ALLOW_LIST
아니요
LOCAL_LDAP_LOGIN
아니요
각 환경 변수의 정의는 설정 파라미터 섹션을 참조하세요. 명확성을 위해 환경 변수 접두사 LOCAL_LDAP이 정의 이름에서 생략되었습니다.
설정 파라미터
다음 표는 필수 및 선택적 LDAP 설정을 나열하고 설명합니다.
환경 변수
정의
필수
ADDRESS
이는 W&B 서버를 호스팅하는 VPC 내의 LDAP 서버의 어드레스입니다.
예
BASE_DN
루트 경로는 검색이 시작되는 위치이며 이 디렉토리로 쿼리를 수행하는 데 필요합니다.
예
BIND_DN
LDAP 서버에 등록된 관리 사용자의 경로입니다. LDAP 서버가 인증되지 않은 바인딩을 지원하지 않는 경우에 필요합니다. 지정된 경우 W&B 서버는 이 사용자로 LDAP 서버에 연결합니다. 그렇지 않으면 W&B 서버는 익명 바인딩을 사용하여 연결합니다.
아니요
BIND_PW
관리 사용자의 비밀번호이며 바인딩을 인증하는 데 사용됩니다. 비워두면 W&B 서버는 익명 바인딩을 사용하여 연결합니다.
아니요
ATTRIBUTES
이메일 및 그룹 ID 속성 이름을 쉼표로 구분된 문자열 값으로 제공합니다.
예
TLS_ENABLE
TLS를 활성화합니다.
아니요
GROUP_ALLOW_LIST
그룹 허용 목록입니다.
아니요
LOGIN
이는 W&B 서버에 LDAP를 사용하여 인증하도록 지시합니다. True 또는 False로 설정합니다. 선택적으로 LDAP 설정을 테스트하려면 이를 false로 설정합니다. LDAP 인증을 시작하려면 이를 true로 설정합니다.
아니요
5.2.1.2 - Configure SSO with OIDC
Weights & Biases 서버는 OpenID Connect (OIDC) 호환 ID 공급자를 지원하므로 Okta, Keycloak, Auth0, Google, Entra와 같은 외부 ID 공급자를 통해 사용자 ID 및 그룹 멤버십을 관리할 수 있습니다.
OpenID Connect (OIDC)
W&B 서버는 외부 IdP(Identity Provider)와 통합하기 위해 다음과 같은 OIDC 인증 흐름을 지원합니다.
Form Post를 사용하는 암시적 흐름
PKCE(Proof Key for Code Exchange)를 사용하는 Authorization Code 흐름
이러한 흐름은 사용자를 인증하고 엑세스 제어를 관리하는 데 필요한 ID 정보(ID 토큰 형태)를 W&B 서버에 제공합니다.
ID 토큰은 이름, 사용자 이름, 이메일, 그룹 멤버십과 같은 사용자 ID 정보가 포함된 JWT입니다. W&B 서버는 이 토큰을 사용하여 사용자를 인증하고 시스템 내 적절한 역할 또는 그룹에 매핑합니다.
W&B 서버의 맥락에서 엑세스 토큰은 사용자를 대신하여 API에 대한 요청을 승인하지만 W&B 서버의 주요 관심사는 사용자 인증 및 ID이므로 ID 토큰만 필요합니다.
전용 클라우드 또는 자체 관리형 W&B 서버 설치를 위해 ID 공급자를 구성하는 데 도움이 되도록 다양한 IdP에 대한 다음 가이드라인을 따르세요. SaaS 버전의 W&B를 사용하는 경우 조직의 Auth0 테넌트 구성에 대한 지원은 support@wandb.com으로 문의하세요.
기본적으로 선택된 계정 유형은 “이 조직 디렉터리의 계정만 해당(기본 디렉터리만 해당 - 단일 테넌트)“입니다. 필요한 경우 수정합니다.
웹 유형으로 리디렉션 URI를 https://YOUR_W_AND_B_URL/oidc/callback 값으로 구성합니다.
“등록"을 클릭합니다.
“애플리케이션(클라이언트) ID” 및 “디렉터리(테넌트) ID"를 기록해 둡니다.
왼쪽에서 인증을 클릭합니다.
프런트 채널 로그아웃 URL 아래에 https://YOUR_W_AND_B_URL/logout을 지정합니다.
“저장"을 클릭합니다.
왼쪽에서 “인증서 및 암호"를 클릭합니다.
“클라이언트 암호"를 클릭한 다음 “새 클라이언트 암호"를 클릭합니다.
“클라이언트 암호 추가"라는 화면에서 다음과 같이 값을 채웁니다.
설명(예: “wandb”)을 입력합니다.
“만료"는 그대로 두거나 필요한 경우 변경합니다.
“추가"를 클릭합니다.
암호의 “값"을 기록해 둡니다. “암호 ID"는 필요하지 않습니다.
이제 세 가지 값을 기록해 두어야 합니다.
OIDC 클라이언트 ID
OIDC 클라이언트 암호
OIDC 발급자 URL에 테넌트 ID가 필요합니다.
OIDC 발급자 URL의 형식은 https://login.microsoftonline.com/${TenantID}/v2.0입니다.
W&B 서버에서 SSO 설정
SSO를 설정하려면 관리자 권한과 다음 정보가 필요합니다.
OIDC 클라이언트 ID
OIDC 인증 방법(implicit 또는 pkce)
OIDC 발급자 URL
OIDC 클라이언트 암호(선택 사항, IdP 설정 방법에 따라 다름)
IdP에 OIDC 클라이언트 암호가 필요한 경우 OIDC_CLIENT_SECRET 환경 변수를 사용하여 지정합니다.
W&B 서버 UI를 사용하거나 환경 변수를 wandb/local 포드로 전달하여 SSO를 구성할 수 있습니다. 환경 변수가 UI보다 우선합니다.
SSO를 구성한 후 인스턴스에 로그인할 수 없는 경우 LOCAL_RESTORE=true 환경 변수를 설정하여 인스턴스를 다시 시작할 수 있습니다. 그러면 컨테이너 로그에 임시 암호가 출력되고 SSO가 비활성화됩니다. SSO 문제를 해결한 후에는 SSO를 다시 활성화하려면 해당 환경 변수를 제거해야 합니다.
SSO를 구성한 후 인스턴스에 로그인할 수 없는 경우 LOCAL_RESTORE=true 환경 변수를 설정하여 인스턴스를 다시 시작할 수 있습니다. 그러면 컨테이너 로그에 임시 암호가 출력되고 SSO가 꺼집니다. SSO 문제를 해결한 후에는 SSO를 다시 활성화하려면 해당 환경 변수를 제거해야 합니다.
SAML(Security Assertion Markup Language)
W&B 서버는 SAML을 지원하지 않습니다.
5.2.1.3 - Use federated identities with SDK
W&B SDK를 통해 조직의 자격 증명을 사용하여 로그인하려면 아이덴티티 연동을 사용하세요. W&B 조직 관리자가 조직에 대해 SSO를 구성한 경우, 이미 조직의 자격 증명을 사용하여 W&B 앱 UI에 로그인하고 있을 것입니다. 이러한 의미에서 아이덴티티 연동은 W&B SDK에 대한 SSO와 유사하지만 JSON Web Tokens (JWTs)를 직접 사용한다는 차이점이 있습니다. API 키 대신 아이덴티티 연동을 사용할 수 있습니다.
아이덴티티 연동은 모든 플랫폼 유형 (SaaS Cloud, 전용 클라우드, 자체 관리 인스턴스)의 Enterprise 플랜에서 Preview로 사용할 수 있습니다. 질문이 있으시면 W&B 팀에 문의하세요.
이 문서의 목적을 위해 아이덴티티 공급자와 JWT 발급자라는 용어는 상호 교환적으로 사용됩니다. 둘 다 이 기능의 맥락에서 동일한 대상을 지칭합니다.
JWT 발급자 설정
첫 번째 단계로 조직 관리자는 W&B 조직과 공개적으로 엑세스 가능한 JWT 발급자 간의 연동을 설정해야 합니다.
조직 대시보드에서 설정 탭으로 이동합니다.
인증 옵션에서 JWT 발급자 설정을 누릅니다.
텍스트 상자에 JWT 발급자 URL을 추가하고 만들기를 누릅니다.
W&B는 자동으로 ${ISSUER_URL}/.well-known/oidc-configuration 경로에서 OIDC 검색 문서를 찾고 검색 문서의 관련 URL에서 JSON Web Key Set (JWKS)을 찾으려고 시도합니다. JWKS는 JWT가 관련 아이덴티티 공급자에 의해 발급되었는지 확인하기 위해 JWT의 실시간 유효성 검사에 사용됩니다.
JWT를 사용하여 W&B에 엑세스
W&B 조직에 대해 JWT 발급자가 설정되면 사용자는 해당 아이덴티티 공급자가 발급한 JWT를 사용하여 관련 W&B 프로젝트에 엑세스할 수 있습니다. JWT를 사용하는 메커니즘은 다음과 같습니다.
조직에서 사용할 수 있는 메커니즘 중 하나를 사용하여 아이덴티티 공급자에 로그인해야 합니다. 일부 공급자는 API 또는 SDK를 사용하여 자동화된 방식으로 엑세스할 수 있지만 일부는 관련 UI를 사용해야만 엑세스할 수 있습니다. 자세한 내용은 W&B 조직 관리자 또는 JWT 발급자 소유자에게 문의하세요.
아이덴티티 공급자에 로그인한 후 JWT를 검색했으면 안전한 위치의 파일에 저장하고 환경 변수 WANDB_IDENTITY_TOKEN_FILE에 절대 파일 경로를 구성합니다.
W&B SDK 또는 CLI를 사용하여 W&B 프로젝트에 엑세스합니다. SDK 또는 CLI는 JWT를 자동으로 감지하고 JWT가 성공적으로 유효성 검사된 후 W&B 엑세스 토큰으로 교환해야 합니다. W&B 엑세스 토큰은 AI 워크플로우를 활성화하기 위한 관련 API에 엑세스하는 데 사용됩니다. 즉, run, 메트릭, Artifacts 등을 로그합니다. 엑세스 토큰은 기본적으로 ~/.config/wandb/credentials.json 경로에 저장됩니다. 환경 변수 WANDB_CREDENTIALS_FILE을 지정하여 해당 경로를 변경할 수 있습니다.
JWT는 API 키, 비밀번호 등과 같은 오래 지속되는 자격 증명의 단점을 해결하기 위한 짧은 수명의 자격 증명입니다. 아이덴티티 공급자에 구성된 JWT 만료 시간에 따라 JWT를 계속 갱신하고 환경 변수 WANDB_IDENTITY_TOKEN_FILE에서 참조하는 파일에 저장해야 합니다.
W&B 엑세스 토큰에도 기본 만료 기간이 있으며, 그 후 SDK 또는 CLI는 JWT를 사용하여 자동으로 갱신하려고 시도합니다. 해당 시간까지 사용자 JWT도 만료되고 갱신되지 않으면 인증 실패가 발생할 수 있습니다. 가능하다면 JWT 검색 및 만료 후 갱신 메커니즘은 W&B SDK 또는 CLI를 사용하는 AI 워크로드의 일부로 구현해야 합니다.
JWT 유효성 검사
JWT를 W&B 엑세스 토큰으로 교환한 다음 프로젝트에 엑세스하는 워크플로우의 일부로 JWT는 다음 유효성 검사를 거칩니다.
JWT 서명은 W&B 조직 수준에서 JWKS를 사용하여 확인됩니다. 이것이 첫 번째 방어선이며, 실패하면 JWKS 또는 JWT 서명 방식에 문제가 있음을 의미합니다.
JWT의 iss 클레임은 조직 수준에서 구성된 발급자 URL과 같아야 합니다.
JWT의 sub 클레임은 W&B 조직에 구성된 사용자의 이메일 주소와 같아야 합니다.
JWT의 aud 클레임은 AI 워크플로우의 일부로 엑세스하는 프로젝트를 수용하는 W&B 조직의 이름과 같아야 합니다. 전용 클라우드 또는 자체 관리 인스턴스의 경우 인스턴스 수준 환경 변수 SKIP_AUDIENCE_VALIDATION을 true로 구성하여 대상 클레임의 유효성 검사를 건너뛰거나 wandb를 대상으로 사용할 수 있습니다.
JWT의 exp 클레임은 토큰이 유효한지 또는 만료되었는지 확인하기 위해 검사되며 갱신해야 합니다.
외부 서비스 계정
W&B는 오랫동안 오래 지속되는 API 키가 있는 기본 제공 서비스 계정을 지원해 왔습니다. SDK 및 CLI에 대한 아이덴티티 연동 기능을 사용하면 조직 수준에서 구성된 동일한 발급자가 발급한 경우 JWT를 인증에 사용할 수 있는 외부 서비스 계정을 가져올 수도 있습니다. 팀 관리자는 기본 제공 서비스 계정과 마찬가지로 팀 범위 내에서 외부 서비스 계정을 구성할 수 있습니다.
외부 서비스 계정을 구성하려면:
팀의 서비스 계정 탭으로 이동합니다.
새 서비스 계정을 누릅니다.
서비스 계정 이름을 제공하고 인증 방법으로 Federated Identity를 선택하고 Subject를 제공하고 만들기를 누릅니다.
외부 서비스 계정의 sub 클레임은 팀 관리자가 팀 수준 서비스 계정 탭에서 해당 제목으로 구성한 것과 동일해야 합니다. 해당 클레임은 JWT 유효성 검사의 일부로 확인됩니다. aud 클레임 요구 사항은 인간 사용자 JWT의 요구 사항과 유사합니다.
외부 서비스 계정의 JWT를 사용하여 W&B에 엑세스할 때 초기 JWT를 생성하고 지속적으로 갱신하는 워크플로우를 자동화하는 것이 일반적으로 더 쉽습니다. 외부 서비스 계정을 사용하여 기록된 run을 인간 사용자에게 귀속시키려면 기본 제공 서비스 계정에 대해 수행되는 방식과 유사하게 AI 워크플로우에 대해 환경 변수 WANDB_USERNAME 또는 WANDB_USER_EMAIL을 구성할 수 있습니다.
W&B는 유연성과 단순성 사이의 균형을 맞추기 위해 다양한 수준의 데이터 민감도를 가진 AI 워크로드에서 기본 제공 및 외부 서비스 계정의 조합을 사용하는 것이 좋습니다.
5.2.1.4 - Use service accounts to automate workflows
org 및 팀 범위의 서비스 계정을 사용하여 자동화된 워크플로우 또는 비대화형 워크플로우를 관리하세요.
서비스 계정은 팀 내 또는 팀 간의 프로젝트에서 일반적인 작업을 자동으로 수행할 수 있는 비인간 또는 머신 사용자를 나타냅니다.
조직 관리자는 조직 범위에서 서비스 계정을 만들 수 있습니다.
팀 관리자는 해당 팀 범위에서 서비스 계정을 만들 수 있습니다.
서비스 계정의 API 키를 통해 호출자는 서비스 계정 범위 내에서 프로젝트를 읽거나 쓸 수 있습니다.
서비스 계정을 사용하면 여러 사용자 또는 팀에서 워크플로우를 중앙 집중식으로 관리하고, W&B Models에 대한 실험 트래킹을 자동화하거나, W&B Weave에 대한 추적을 기록할 수 있습니다. 환경 변수WANDB_USERNAME 또는 WANDB_USER_EMAIL을 사용하여 서비스 계정에서 관리하는 워크플로우와 인간 사용자의 ID를 연결할 수 있습니다.
조직 범위의 서비스 계정은 제한된 프로젝트를 제외하고 팀에 관계없이 조직의 모든 프로젝트에서 읽고 쓸 수 있는 권한을 갖습니다. 조직 범위의 서비스 계정이 제한된 프로젝트에 엑세스하려면 해당 프로젝트의 관리자가 서비스 계정을 프로젝트에 명시적으로 추가해야 합니다.
조직 관리자는 조직 또는 계정 대시보드의 Service Accounts 탭에서 조직 범위의 서비스 계정에 대한 API 키를 얻을 수 있습니다.
새로운 조직 범위의 서비스 계정을 만들려면:
조직 대시보드의 Service Accounts 탭에서 New service account 버튼을 클릭합니다.
Name을 입력합니다.
서비스 계정의 기본 팀을 선택합니다.
Create를 클릭합니다.
새로 생성된 서비스 계정 옆에 있는 Copy API key를 클릭합니다.
복사한 API 키를 비밀 관리자 또는 안전하지만 엑세스 가능한 다른 위치에 저장합니다.
조직 범위의 서비스 계정은 조직 내의 모든 팀이 소유한 제한되지 않은 프로젝트에 엑세스할 수 있더라도 기본 팀이 필요합니다. 이는 모델 트레이닝 또는 생성적 AI 앱의 환경에서 WANDB_ENTITY 변수가 설정되지 않은 경우 워크로드가 실패하는 것을 방지하는 데 도움이 됩니다. 다른 팀의 프로젝트에 조직 범위의 서비스 계정을 사용하려면 WANDB_ENTITY 환경 변수를 해당 팀으로 설정해야 합니다.
팀 범위 서비스 계정
팀 범위의 서비스 계정은 해당 팀의 제한된 프로젝트를 제외하고 팀 내의 모든 프로젝트에서 읽고 쓸 수 있습니다. 팀 범위의 서비스 계정이 제한된 프로젝트에 엑세스하려면 해당 프로젝트의 관리자가 서비스 계정을 프로젝트에 명시적으로 추가해야 합니다.
팀 관리자는 팀의 <WANDB_HOST_URL>/<your-team-name>/service-accounts에서 팀 범위의 서비스 계정에 대한 API 키를 얻을 수 있습니다. 또는 팀의 Team settings로 이동한 다음 Service Accounts 탭을 참조할 수 있습니다.
팀의 새로운 팀 범위 서비스 계정을 만들려면:
팀의 Service Accounts 탭에서 New service account 버튼을 클릭합니다.
Name을 입력합니다.
인증 방법으로 **Generate API key (Built-in)**을 선택합니다.
Create를 클릭합니다.
새로 생성된 서비스 계정 옆에 있는 Copy API key를 클릭합니다.
복사한 API 키를 비밀 관리자 또는 안전하지만 엑세스 가능한 다른 위치에 저장합니다.
팀 범위의 서비스 계정을 사용하는 모델 트레이닝 또는 생성적 AI 앱 환경에서 팀을 구성하지 않으면 모델 run 또는 weave 추적이 서비스 계정의 상위 팀 내에서 명명된 프로젝트에 기록됩니다. 이러한 시나리오에서 WANDB_USERNAME 또는 WANDB_USER_EMAIL 변수를 사용한 사용자 속성은 참조된 사용자가 서비스 계정의 상위 팀에 속하지 않는 한 작동하지 않습니다.
팀 범위의 서비스 계정은 상위 팀과 다른 팀의 팀 또는 제한 범위 프로젝트에 run을 기록할 수 없지만 다른 팀 내에서 공개 가시성 프로젝트에 run을 기록할 수 있습니다.
외부 서비스 계정
Built-in 서비스 계정 외에도 W&B는 JSON 웹 토큰(JWT)을 발급할 수 있는 ID 공급자(IdP)와 함께 Identity federation를 사용하여 W&B SDK 및 CLI를 통해 팀 범위의 External service accounts를 지원합니다.
5.2.2 - Access management
조직 내에서 사용자 및 팀 관리하기
고유한 조직 도메인으로 W&B에 처음 가입하는 사용자는 해당 조직의 인스턴스 관리자 역할로 지정됩니다. 조직 관리자는 특정 사용자에게 팀 관리자 역할을 할당합니다.
W&B는 조직에 둘 이상의 인스턴스 관리자를 두는 것을 권장합니다. 이는 기본 관리자가 없을 때 관리 작업을 계속할 수 있도록 보장하는 가장 좋은 방법입니다.
팀 관리자는 팀 내에서 관리 권한을 가진 조직의 사용자입니다.
조직 관리자는 https://wandb.ai/account-settings/에서 조직의 계정 설정을 엑세스하고 사용하여 사용자를 초대하고, 사용자의 역할을 할당하거나 업데이트하고, 팀을 만들고, 조직에서 사용자를 제거하고, 청구 관리자를 할당하는 등의 작업을 수행할 수 있습니다. 자세한 내용은 사용자 추가 및 관리를 참조하세요.
조직 관리자가 팀을 생성하면 인스턴스 관리자 또는 팀 관리자는 다음을 수행할 수 있습니다.
기본적으로 관리자만 해당 팀에 사용자를 초대하거나 팀에서 사용자를 제거할 수 있습니다. 이 행동 을 변경하려면 팀 설정을 참조하세요.
팀 멤버의 역할을 할당하거나 업데이트합니다.
새 사용자가 조직에 가입할 때 자동으로 팀에 추가합니다.
조직 관리자와 팀 관리자는 모두 https://wandb.ai/<your-team-name>에서 팀 대시보드 를 사용하여 팀을 관리합니다. 자세한 내용과 팀의 기본 개인 정보 보호 설정을 구성하려면 팀 추가 및 관리를 참조하세요.
특정 Projects 에 대한 가시성 제한
W&B project 의 범위를 정의하여 누가 W&B runs 를 보고, 편집하고, 제출할 수 있는지 제한합니다. 팀이 민감하거나 기밀 데이터를 다루는 경우 project 를 볼 수 있는 사람을 제한하는 것이 특히 유용합니다.
조직 관리자, 팀 관리자 또는 project 소유자는 project 의 가시성을 설정하고 편집할 수 있습니다.
W&B는 자동 프로비저닝 사용자에게 기본적으로 “Member” 역할을 할당합니다. 자동 프로비저닝 사용자의 역할은 언제든지 변경할 수 있습니다.
SSO를 통한 자동 프로비저닝 사용자는 Dedicated Cloud 인스턴스 및 Self-managed 배포에서 기본적으로 켜져 있습니다. 자동 프로비저닝을 끌 수 있습니다. 자동 프로비저닝을 끄면 특정 사용자를 W&B Organization에 선택적으로 추가할 수 있습니다.
다음 탭에서는 배포 유형에 따라 SSO를 끄는 방법을 설명합니다.
Dedicated Cloud 인스턴스를 사용 중이고 SSO를 통한 자동 프로비저닝을 끄려면 W&B Team에 문의하십시오.
W&B Console을 사용하여 SSO를 통한 자동 프로비저닝을 끕니다.
https://<org-name>.io/console/settings/로 이동합니다. <org-name>을 Organization 이름으로 바꿉니다.
Security를 선택합니다.
Disable SSO Provisioning을 선택하여 SSO를 통한 자동 프로비저닝을 끕니다.
SSO를 통한 자동 프로비저닝은 Organization 관리자가 개별 사용자 초대를 생성할 필요가 없기 때문에 대규모로 사용자를 Organization에 추가하는 데 유용합니다.
사용자 지정 역할 만들기
Dedicated Cloud 또는 Self-managed 배포에서 사용자 지정 역할을 만들거나 할당하려면 Enterprise 라이선스가 필요합니다.
Organization 관리자는 View-Only 또는 Member 역할을 기반으로 새 역할을 구성하고 세분화된 엑세스 제어를 위해 추가 권한을 추가할 수 있습니다. Team 관리자는 Team member에게 사용자 지정 역할을 할당할 수 있습니다. 사용자 지정 역할은 Organization 수준에서 생성되지만 Team 수준에서 할당됩니다.
페이지 오른쪽 상단에서 User menu 드롭다운을 선택합니다. 드롭다운의 Account 섹션에서 Settings를 선택합니다.
Roles를 클릭합니다.
Custom roles 섹션에서 Create a role을 클릭합니다.
역할 이름을 입력합니다. 선택적으로 설명을 입력합니다.
사용자 지정 역할의 기반으로 사용할 역할을 선택합니다 (Viewer 또는 Member).
권한을 추가하려면 Search permissions 필드를 클릭한 다음 추가할 권한을 하나 이상 선택합니다.
역할에 있는 권한을 요약하는 Custom role permissions 섹션을 검토합니다.
Create Role을 클릭합니다.
W&B Console을 사용하여 SSO를 통한 자동 프로비저닝을 끕니다.
https://<org-name>.io/console/settings/로 이동합니다. <org-name>을 Organization 이름으로 바꿉니다.
Custom roles 섹션에서 Create a role을 클릭합니다.
역할 이름을 입력합니다. 선택적으로 설명을 입력합니다.
사용자 지정 역할의 기반으로 사용할 역할을 선택합니다 (Viewer 또는 Member).
권한을 추가하려면 Search permissions 필드를 클릭한 다음 추가할 권한을 하나 이상 선택합니다.
역할에 있는 권한을 요약하는 Custom role permissions 섹션을 검토합니다.
Create Role을 클릭합니다.
이제 Team 관리자는 Team 설정에서 Team의 구성원에게 사용자 지정 역할을 할당할 수 있습니다.
도메인 캡처
도메인 캡처는 직원이 회사 Organization에 가입하여 새 사용자가 회사 관할 구역 외부에서 에셋을 생성하지 않도록 하는 데 도움이 됩니다.
도메인은 고유해야 합니다.
도메인은 고유한 식별자입니다. 즉, 다른 Organization에서 이미 사용 중인 도메인은 사용할 수 없습니다.
도메인 캡처를 사용하면 @example.com과 같은 회사 이메일 주소를 가진 사람들을 W&B SaaS Cloud Organization에 자동으로 추가할 수 있습니다. 이는 모든 직원이 올바른 Organization에 가입하고 새 사용자가 회사 관할 구역 외부에서 에셋을 생성하지 않도록 하는 데 도움이 됩니다.
다음 표는 도메인 캡처 활성화 여부에 따른 신규 및 기존 사용자의 행동을 요약한 것입니다.
도메인 캡처 사용
도메인 캡처 사용 안 함
신규 사용자
확인된 도메인에서 W&B에 가입하는 사용자는 Organization의 기본 Team에 자동으로 구성원으로 추가됩니다. Team 가입을 활성화하면 가입 시 추가 Team을 선택할 수 있습니다. 초대장을 통해 다른 Organization 및 Team에 가입할 수도 있습니다.
사용자는 사용 가능한 중앙 집중식 Organization이 있는지 모르고 W&B 계정을 만들 수 있습니다.
초대된 사용자
초대된 사용자는 초대를 수락하면 자동으로 Organization에 가입합니다. 초대된 사용자는 Organization의 기본 Team에 자동으로 구성원으로 추가되지 않습니다. 초대장을 통해 다른 Organization 및 Team에 가입할 수도 있습니다.
초대된 사용자는 초대를 수락하면 자동으로 Organization에 가입합니다. 초대장을 통해 다른 Organization 및 Team에 가입할 수도 있습니다.
기존 사용자
도메인의 확인된 이메일 주소를 가진 기존 사용자는 W&B 앱 내에서 Organization의 Teams에 가입할 수 있습니다. 기존 사용자가 Organization에 가입하기 전에 생성한 모든 데이터는 유지됩니다. W&B는 기존 사용자의 데이터를 마이그레이션하지 않습니다.
기존 W&B 사용자는 여러 Organization 및 Teams에 분산될 수 있습니다.
초대받지 않은 신규 사용자가 Organization에 가입할 때 기본 Team에 자동으로 할당하려면:
페이지 오른쪽 상단에서 User menu 드롭다운을 선택합니다. 드롭다운에서 Settings를 선택합니다.
Settings 탭에서 General을 선택합니다.
Domain capture 내에서 Claim domain 버튼을 선택합니다.
Default team 드롭다운에서 새 사용자를 자동으로 가입시킬 Team을 선택합니다. 사용 가능한 Team이 없으면 Team 설정을 업데이트해야 합니다. Teams 추가 및 관리의 지침을 참조하십시오.
Claim email domain 버튼을 클릭합니다.
초대받지 않은 신규 사용자를 Team에 자동으로 할당하려면 먼저 Team 설정 내에서 도메인 일치를 활성화해야 합니다.
https://wandb.ai/<team-name>에서 Team의 대시보드로 이동합니다. 여기서 <team-name>은 도메인 일치를 활성화할 Team의 이름입니다.
Team 대시보드의 왼쪽 탐색 모음에서 Team settings를 선택합니다.
Privacy 섹션 내에서 “가입 시 일치하는 이메일 도메인을 가진 새 사용자가 이 Team에 가입하도록 추천” 옵션을 토글합니다.
도메인 캡처를 구성하려면 Dedicated 또는 Self-managed 배포 유형을 사용하는 경우 W&B Account Team에 문의하십시오. 구성되면 W&B SaaS 인스턴스는 회사 이메일 주소로 W&B 계정을 만드는 사용자에게 관리자에게 연락하여 Dedicated 또는 Self-managed 인스턴스에 대한 엑세스를 요청하라는 메시지를 자동으로 표시합니다.
도메인 캡처 사용
도메인 캡처 사용 안 함
신규 사용자
확인된 도메인에서 SaaS Cloud에서 W&B에 가입하는 사용자는 사용자 지정하는 이메일 주소로 관리자에게 연락하라는 메시지가 자동으로 표시됩니다. SaaS Cloud에서 Organizations을 만들어 제품을 트라이얼할 수도 있습니다.
사용자는 회사에 중앙 집중식 Dedicated 인스턴스가 있다는 것을 모른 채 W&B SaaS Cloud 계정을 만들 수 있습니다.
기존 사용자
기존 W&B 사용자는 여러 Organization 및 Teams에 분산될 수 있습니다.
기존 W&B 사용자는 여러 Organization 및 Teams에 분산될 수 있습니다.
사용자의 역할 할당 또는 업데이트
Organization의 모든 구성원은 W&B Models 및 Weave 모두에 대한 Organization 역할과 Seat를 갖습니다. 그들이 가지고 있는 Seat 유형은 그들의 결제 상태와 각 제품 라인에서 그들이 할 수 있는 작업을 결정합니다.
사용자를 Organization에 초대할 때 처음으로 Organization 역할을 할당합니다. 나중에 사용자의 역할을 변경할 수 있습니다.
Organization 내의 사용자는 다음 역할 중 하나를 가질 수 있습니다.
역할
설명
admin
다른 사용자를 Organization에 추가하거나 제거하고, 사용자 역할을 변경하고, 사용자 지정 역할을 관리하고, Teams를 추가할 수 있는 인스턴스 관리자입니다. W&B는 관리자가 부재중인 경우를 대비하여 둘 이상의 관리자가 있는지 확인하는 것이 좋습니다.
Member
인스턴스 관리자가 초대한 Organization의 일반 사용자입니다. Organization member는 다른 사용자를 초대하거나 Organization의 기존 사용자를 관리할 수 없습니다.
Viewer (Enterprise 전용 기능)
인스턴스 관리자가 초대한 Organization의 보기 전용 사용자입니다. Viewer는 Organization과 그들이 구성원인 기본 Teams에 대한 읽기 엑세스 권한만 있습니다.
사용자 지정 역할 (Enterprise 전용 기능)
사용자 지정 역할을 통해 Organization 관리자는 이전 View-Only 또는 Member 역할에서 상속하고 세분화된 엑세스 제어를 위해 추가 권한을 추가하여 새 역할을 구성할 수 있습니다. 그런 다음 Team 관리자는 해당 사용자 지정 역할을 각 Teams의 사용자에게 할당할 수 있습니다.
페이지 오른쪽 상단에서 User menu 드롭다운을 선택합니다. 드롭다운에서 Users를 선택합니다.
검색 창에 사용자의 이름 또는 이메일을 입력합니다.
사용자 이름 옆에 있는 TEAM ROLE 드롭다운에서 역할을 선택합니다.
사용자 엑세스 할당 또는 업데이트
Organization 내의 사용자는 다음 Models Seat 또는 Weave 엑세스 유형 중 하나를 갖습니다. full, viewer 또는 no access.
Seat 유형
설명
Full
이 역할 유형을 가진 사용자는 Models 또는 Weave에 대한 데이터를 쓰고, 읽고, 내보낼 수 있는 모든 권한을 갖습니다.
Viewer
Organization의 보기 전용 사용자입니다. Viewer는 Organization과 그들이 속한 기본 Teams에 대한 읽기 엑세스 권한만 있고 Models 또는 Weave에 대한 보기 전용 엑세스 권한만 있습니다.
No access
이 역할을 가진 사용자는 Models 또는 Weave 제품에 대한 엑세스 권한이 없습니다.
Model Seat 유형 및 Weave 엑세스 유형은 Organization 수준에서 정의되며 Team에서 상속됩니다. 사용자의 Seat 유형을 변경하려면 Organization 설정으로 이동하여 다음 단계를 따르십시오.
SaaS 사용자의 경우 https://wandb.ai/account-settings/<organization>/settings에서 Organization 설정으로 이동합니다. 꺾쇠 괄호 (<>)로 묶인 값을 Organization 이름으로 바꿔야 합니다. 다른 Dedicated 및 Self-managed 배포의 경우 https://<your-instance>.wandb.io/org/dashboard로 이동합니다.
Users 탭을 선택합니다.
Role 드롭다운에서 사용자에게 할당할 Seat 유형을 선택합니다.
Organization 역할과 구독 유형에 따라 Organization 내에서 사용할 수 있는 Seat 유형이 결정됩니다.
새 사용자가 가입할 때 Organization 내에서 Teams를 검색할 수 있도록 허용합니다. 새 사용자는 Organization의 확인된 이메일 도메인과 일치하는 확인된 이메일 도메인이 있어야 합니다. 확인된 새 사용자는 W&B 계정에 가입할 때 Organization에 속한 확인된 Teams 목록을 볼 수 있습니다.
Organization 관리자는 도메인 클레임을 활성화해야 합니다. 도메인 캡처를 활성화하려면 도메인 캡처에 설명된 단계를 참조하십시오.
Team member의 역할 할당 또는 업데이트
Team member 이름 옆에 있는 계정 유형 아이콘을 선택합니다.
드롭다운에서 해당 Team member가 가질 계정 유형을 선택합니다.
다음 표는 Team 구성원에게 할당할 수 있는 역할을 나열합니다.
역할
정의
admin
Team에서 다른 사용자를 추가 및 제거하고, 사용자 역할을 변경하고, Team 설정을 구성할 수 있는 사용자입니다.
Member
Team 관리자가 이메일 또는 Organization 수준 사용자 이름으로 초대한 Team의 일반 사용자입니다. member 사용자는 다른 사용자를 Team에 초대할 수 없습니다.
View-Only (Enterprise 전용 기능)
Team 관리자가 이메일 또는 Organization 수준 사용자 이름으로 초대한 Team의 보기 전용 사용자입니다. 보기 전용 사용자는 Team과 그 내용에 대한 읽기 엑세스 권한만 있습니다.
Service (Enterprise 전용 기능)
서비스 작업자 또는 서비스 계정은 run 자동화 툴로 W&B를 활용하는 데 유용한 API 키입니다. Team의 서비스 계정에서 API 키를 사용하는 경우 환경 변수 WANDB_USERNAME을 설정하여 run을 적절한 사용자에게 올바르게 할당해야 합니다.
사용자 지정 역할 (Enterprise 전용 기능)
사용자 지정 역할을 통해 Organization 관리자는 이전 View-Only 또는 Member 역할에서 상속하고 세분화된 엑세스 제어를 위해 추가 권한을 추가하여 새 역할을 구성할 수 있습니다. 그런 다음 Team 관리자는 해당 사용자 지정 역할을 각 Teams의 사용자에게 할당할 수 있습니다. 자세한 내용은 이 문서를 참조하십시오.
Dedicated Cloud 또는 Self-managed 배포의 Enterprise 라이선스만 Team 구성원에게 사용자 지정 역할을 할당할 수 있습니다.
Team에서 사용자 제거
Team의 대시보드를 사용하여 Team에서 사용자를 제거합니다. W&B는 run을 생성한 구성원이 더 이상 해당 Team에 없더라도 Team에서 생성된 run을 보존합니다.
https://wandb.ai/<team-name>로 이동합니다.
왼쪽 네비게이션 바에서 Team settings를 선택합니다.
Users 탭을 선택합니다.
삭제할 사용자 이름 옆에 마우스를 가져갑니다. 나타날 때 줄임표 또는 세 개의 점 아이콘 (…)을 선택합니다.
드롭다운에서 Remove user를 선택합니다.
5.2.2.2 - Manage access control for projects
가시성 범위와 프로젝트 수준 역할을 사용하여 프로젝트 엑세스 를 관리합니다.
W&B 프로젝트의 범위를 정의하여 누가 해당 프로젝트를 보고, 편집하고, W&B run을 제출할 수 있는지 제한합니다.
W&B 팀 내의 모든 프로젝트에 대한 엑세스 수준을 구성하기 위해 몇 가지 제어 기능을 함께 사용할 수 있습니다. 가시성 범위는 더 높은 수준의 메커니즘입니다. 이를 사용하여 어떤 사용자 그룹이 프로젝트에서 run을 보거나 제출할 수 있는지 제어합니다. Team 또는 Restricted 가시성 범위를 가진 프로젝트의 경우 프로젝트 수준 역할을 사용하여 각 사용자가 프로젝트 내에서 갖는 엑세스 수준을 제어할 수 있습니다.
프로젝트 소유자, 팀 관리자 또는 조직 관리자는 프로젝트의 가시성을 설정하거나 편집할 수 있습니다.
가시성 범위
선택할 수 있는 프로젝트 가시성 범위는 네 가지가 있습니다. 가장 공개적인 것부터 가장 사적인 것 순으로 나열하면 다음과 같습니다.
범위
설명
Open
프로젝트에 대해 알고 있는 사람은 누구나 보고 run 또는 리포트를 제출할 수 있습니다.
Public
프로젝트에 대해 알고 있는 사람은 누구나 볼 수 있습니다. 팀만 run 또는 리포트를 제출할 수 있습니다.
Team
상위 팀의 팀 멤버만 프로젝트를 보고 run 또는 리포트를 제출할 수 있습니다. 팀 외부의 사람은 프로젝트에 엑세스할 수 없습니다.
Restricted
상위 팀에서 초대받은 팀 멤버만 프로젝트를 보고 run 또는 리포트를 제출할 수 있습니다.
민감하거나 기밀 데이터와 관련된 워크플로우에서 협업하려면 프로젝트의 범위를 Restricted로 설정하세요. 팀 내에서 제한된 프로젝트를 생성할 때 팀의 특정 팀 멤버를 초대하거나 추가하여 관련 Experiments, Artifacts, 리포트 등에서 협업할 수 있습니다.
다른 프로젝트 범위와 달리 팀의 모든 팀 멤버가 제한된 프로젝트에 대한 암묵적인 엑세스 권한을 얻는 것은 아닙니다. 동시에 팀 관리자는 필요한 경우 제한된 프로젝트에 참여할 수 있습니다.
새 프로젝트 또는 기존 프로젝트에서 가시성 범위 설정
프로젝트를 생성할 때 또는 나중에 편집할 때 프로젝트의 가시성 범위를 설정합니다.
프로젝트 소유자 또는 팀 관리자만 가시성 범위를 설정하거나 편집할 수 있습니다.
팀 관리자가 팀의 개인 정보 설정 내에서 **향후 모든 팀 프로젝트를 비공개로 설정(공개 공유 불가)**를 활성화하면 해당 팀에 대해 Open 및 Public 프로젝트 가시성 범위가 해제됩니다. 이 경우 팀은 Team 및 Restricted 범위만 사용할 수 있습니다.
새 프로젝트를 생성할 때 가시성 범위 설정
SaaS Cloud, 전용 클라우드 또는 자체 관리 인스턴스에서 W&B 조직으로 이동합니다.
왼쪽 사이드바의 내 프로젝트 섹션에서 새 프로젝트 만들기 버튼을 클릭합니다. 또는 팀의 Projects 탭으로 이동하여 오른쪽 상단 모서리에 있는 새 프로젝트 만들기 버튼을 클릭합니다.
상위 팀을 선택하고 프로젝트 이름을 입력한 후 프로젝트 가시성 드롭다운에서 원하는 범위를 선택합니다.
Restricted 가시성을 선택한 경우 다음 단계를 완료하십시오.
팀 멤버 초대 필드에 하나 이상의 W&B 팀 멤버 이름을 입력합니다. 프로젝트에서 협업하는 데 필수적인 팀 멤버만 추가하십시오.
Users 탭에서 나중에 제한된 프로젝트에서 팀 멤버를 추가하거나 제거할 수 있습니다.
기존 프로젝트의 가시성 범위 편집
W&B 프로젝트로 이동합니다.
왼쪽 열에서 Overview 탭을 선택합니다.
오른쪽 상단 모서리에 있는 프로젝트 세부 정보 편집 버튼을 클릭합니다.
프로젝트 가시성 드롭다운에서 원하는 범위를 선택합니다.
Restricted 가시성을 선택한 경우 다음 단계를 완료하십시오.
프로젝트의 Users 탭으로 이동하여 사용자 추가 버튼을 클릭하여 특정 사용자를 제한된 프로젝트에 초대합니다.
필요한 팀 멤버를 프로젝트에 초대하지 않으면 가시성 범위를 Team에서 Restricted로 변경하면 팀의 모든 팀 멤버가 프로젝트에 대한 엑세스 권한을 잃게 됩니다.
가시성 범위를 Restricted에서 Team으로 변경하면 팀의 모든 팀 멤버가 프로젝트에 대한 엑세스 권한을 얻게 됩니다.
제한된 프로젝트의 사용자 목록에서 팀 멤버를 제거하면 해당 프로젝트에 대한 엑세스 권한을 잃게 됩니다.
제한된 범위에 대한 기타 주요 참고 사항
제한된 프로젝트에서 팀 수준 서비스 계정을 사용하려면 해당 계정을 프로젝트에 특별히 초대하거나 추가해야 합니다. 그렇지 않으면 팀 수준 서비스 계정은 기본적으로 제한된 프로젝트에 엑세스할 수 없습니다.
제한된 프로젝트에서 run을 이동할 수는 없지만 제한되지 않은 프로젝트에서 제한된 프로젝트로 run을 이동할 수 있습니다.
팀 개인 정보 설정 **향후 모든 팀 프로젝트를 비공개로 설정(공개 공유 불가)**에 관계없이 제한된 프로젝트의 가시성을 Team 범위로만 변환할 수 있습니다.
제한된 프로젝트의 소유자가 더 이상 상위 팀에 속하지 않으면 팀 관리자는 프로젝트에서 원활한 운영을 보장하기 위해 소유자를 변경해야 합니다.
프로젝트 수준 역할
팀의 Team 또는 Restricted 범위 프로젝트의 경우 사용자에게 특정 역할을 할당할 수 있으며, 이는 해당 사용자의 팀 수준 역할과 다를 수 있습니다. 예를 들어 사용자가 팀 수준에서 Member 역할을 하는 경우 해당 팀의 Team 또는 Restricted 범위 프로젝트 내에서 해당 사용자에게 View-Only 또는 Admin 또는 사용 가능한 사용자 지정 역할을 할당할 수 있습니다.
프로젝트 수준 역할은 SaaS Cloud, 전용 클라우드 및 자체 관리 인스턴스에서 미리 보기로 제공됩니다.
사용자에게 프로젝트 수준 역할 할당
W&B 프로젝트로 이동합니다.
왼쪽 열에서 Overview 탭을 선택합니다.
프로젝트의 Users 탭으로 이동합니다.
프로젝트 역할 필드에서 해당 사용자에 대해 현재 할당된 역할을 클릭하면 다른 사용 가능한 역할 목록이 있는 드롭다운이 열립니다.
드롭다운에서 다른 역할을 선택합니다. 즉시 저장됩니다.
사용자의 프로젝트 수준 역할을 팀 수준 역할과 다르게 변경하면 프로젝트 수준 역할에 차이를 나타내는 *****가 포함됩니다.
프로젝트 수준 역할에 대한 기타 주요 참고 사항
기본적으로 team 또는 restricted 범위 프로젝트의 모든 사용자에 대한 프로젝트 수준 역할은 해당 팀 수준 역할을 상속합니다.
팀 수준에서 View-only 역할을 가진 사용자의 프로젝트 수준 역할은 변경할 수 없습니다.
특정 프로젝트 내에서 사용자의 프로젝트 수준 역할이 팀 수준 역할과 동일하고 팀 관리자가 팀 수준 역할을 변경하면 관련 프로젝트 역할이 자동으로 변경되어 팀 수준 역할을 추적합니다.
특정 프로젝트 내에서 사용자의 프로젝트 수준 역할을 팀 수준 역할과 다르게 변경하고 팀 관리자가 팀 수준 역할을 변경하면 관련 프로젝트 수준 역할은 그대로 유지됩니다.
프로젝트 수준 역할이 팀 수준 역할과 다른 경우 restricted 프로젝트에서 사용자를 제거하고 일정 시간이 지난 후 사용자를 프로젝트에 다시 추가하면 기본 동작으로 인해 팀 수준 역할을 상속합니다. 필요한 경우 프로젝트 수준 역할을 다시 변경하여 팀 수준 역할과 다르게 만들어야 합니다.
5.2.3 - Automate user and team management
SCIM API
SCIM API를 사용하여 사용자 및 사용자가 속한 Teams를 효율적이고 반복 가능한 방식으로 관리합니다. SCIM API를 사용하여 사용자 정의 역할을 관리하거나 W&B organization의 사용자에게 역할을 할당할 수도 있습니다. 역할 엔드포인트는 공식 SCIM 스키마의 일부가 아닙니다. W&B는 사용자 정의 역할의 자동 관리를 지원하기 위해 역할 엔드포인트를 추가합니다.
SCIM API는 다음과 같은 경우에 특히 유용합니다.
사용자 프로비저닝 및 프로비저닝 해제를 대규모로 관리하려는 경우
SCIM을 지원하는 ID 공급자로 사용자를 관리하려는 경우
SCIM API는 크게 User, Group, Roles의 세 가지 범주로 나뉩니다.
User SCIM API
User SCIM API를 사용하면 W&B organization에서 사용자를 생성, 비활성화, 사용자 세부 정보를 가져오거나 모든 사용자 목록을 가져올 수 있습니다. 이 API는 organization의 사용자에게 미리 정의된 역할 또는 사용자 정의 역할을 할당하는 기능도 지원합니다.
DELETE User 엔드포인트를 사용하여 W&B organization 내에서 사용자를 비활성화합니다. 비활성화된 사용자는 더 이상 로그인할 수 없습니다. 그러나 비활성화된 사용자는 organization의 사용자 목록에 계속 표시됩니다.
Group SCIM API를 사용하면 organization에서 Teams를 생성하거나 제거하는 것을 포함하여 W&B Teams를 관리할 수 있습니다. PATCH Group을 사용하여 기존 Team에서 사용자를 추가하거나 제거합니다.
W&B에는 동일한 역할을 가진 사용자 그룹이라는 개념이 없습니다. W&B Team은 그룹과 매우 유사하며, 서로 다른 역할을 가진 다양한 사용자가 관련 Projects 집합에서 공동으로 작업할 수 있도록 합니다. Teams는 서로 다른 사용자 그룹으로 구성될 수 있습니다. Team의 각 사용자에게 Team 관리자, 멤버, 뷰어 또는 사용자 정의 역할과 같은 역할을 할당합니다.
W&B는 그룹과 W&B Teams 간의 유사성 때문에 Group SCIM API 엔드포인트를 W&B Teams에 매핑합니다.
Custom role API
Custom role SCIM API를 사용하면 organization에서 사용자 정의 역할을 생성, 나열 또는 업데이트하는 것을 포함하여 사용자 정의 역할을 관리할 수 있습니다.
사용자 정의 역할을 삭제할 때는 주의하십시오.
DELETE Role 엔드포인트를 사용하여 W&B organization 내에서 사용자 정의 역할을 삭제합니다. 사용자 정의 역할이 상속하는 미리 정의된 역할은 작업 전에 사용자 정의 역할이 할당된 모든 사용자에게 할당됩니다.
PUT Role 엔드포인트를 사용하여 사용자 정의 역할에 대해 상속된 역할을 업데이트합니다. 이 작업은 사용자 정의 역할의 기존 사용자 정의 권한(즉, 상속되지 않은 사용자 정의 권한)에는 영향을 주지 않습니다.
W&B Python SDK API
SCIM API를 통해 사용자 및 Team 관리를 자동화할 수 있는 것처럼 W&B Python SDK API에서 사용할 수 있는 일부 메소드를 사용하여 이 목적을 달성할 수도 있습니다. 다음 메소드를 기록해 두십시오.
SCIM(System for Cross-domain Identity Management) API를 통해 인스턴스 또는 organization 관리자는 W&B organization에서 사용자, 그룹 및 사용자 지정 역할을 관리할 수 있습니다. SCIM 그룹은 W&B Teams에 매핑됩니다.
SCIM API는 <host-url>/scim/에서 액세스할 수 있으며 RC7643 프로토콜에서 찾을 수 있는 필드의 서브셋으로 /Users 및 /Groups 엔드포인트를 지원합니다. 또한 공식 SCIM 스키마의 일부가 아닌 /Roles 엔드포인트도 포함합니다. W&B는 W&B organization에서 사용자 지정 역할의 자동 관리를 지원하기 위해 /Roles 엔드포인트를 추가합니다.
여러 Enterprise SaaS Cloud organization의 관리자인 경우 SCIM API 요청이 전송되는 organization을 구성해야 합니다. 프로필 이미지를 클릭한 다음 User Settings를 클릭합니다. 설정 이름은 Default API organization입니다. 이는 Dedicated Cloud, Self-managed instances 및 SaaS Cloud를 포함한 모든 호스팅 옵션에 필요합니다. SaaS Cloud에서 organization 관리자는 SCIM API 요청이 올바른 organization으로 이동하도록 사용자 설정에서 기본 organization을 구성해야 합니다.
선택한 호스팅 옵션은 이 페이지의 예제에서 사용되는 <host-url> 자리 표시자의 값을 결정합니다.
또한 예제에서는 abc 및 def와 같은 사용자 ID를 사용합니다. 실제 요청 및 응답에는 사용자 ID에 대한 해시된 값이 있습니다.
인증
Organization 또는 인스턴스 관리자는 API 키로 기본 인증을 사용하여 SCIM API에 액세스할 수 있습니다. HTTP 요청의 Authorization 헤더를 Basic 문자열 뒤에 공백, 그런 다음 username:API-KEY 형식으로 base-64로 인코딩된 문자열로 설정합니다. 즉, 사용자 이름과 API 키를 : 문자로 구분된 값으로 바꾸고 결과를 base-64로 인코딩합니다. 예를 들어 demo:p@55w0rd로 인증하려면 헤더는 Authorization: Basic ZGVtbzpwQDU1dzByZA==여야 합니다.
설명: 사용자에게 organization 수준 역할을 할당합니다. 역할은 여기에 설명된 대로 admin, viewer 또는 member 중 하나일 수 있습니다. SaaS Cloud의 경우 사용자 설정에서 SCIM API에 대한 올바른 organization을 구성했는지 확인합니다.
지원되는 필드:
필드
유형
필수
op
문자열
작업 유형. 허용되는 유일한 값은 replace입니다.
path
문자열
역할 할당 작업이 적용되는 범위입니다. 허용되는 유일한 값은 organizationRole입니다.
value
문자열
사용자에게 할당할 미리 정의된 organization 수준 역할입니다. admin, viewer 또는 member 중 하나일 수 있습니다. 이 필드는 미리 정의된 역할에 대해 대소문자를 구분하지 않습니다.
요청 예시:
PATCH /scim/Users/abc
{
"schemas": ["urn:ietf:params:scim:api:messages:2.0:PatchOp"],
"Operations": [
{
"op": "replace",
"path": "organizationRole",
"value": "admin"// 사용자의 organization 범위 역할을 admin으로 설정합니다.
}
]
}
응답 예시:
이것은 User 오브젝트를 반환합니다.
(Status 200)
{
"active": true,
"displayName": "Dev User 1",
"emails": {
"Value": "dev-user1@test.com",
"Display": "",
"Type": "",
"Primary": true },
"id": "abc",
"meta": {
"resourceType": "User",
"created": "2023-10-01T00:00:00Z",
"lastModified": "2023-10-01T00:00:00Z",
"location": "Users/abc" },
"schemas": [
"urn:ietf:params:scim:schemas:core:2.0:User" ],
"userName": "dev-user1",
"teamRoles": [ // 사용자가 속한 모든 Teams에서 사용자의 역할을 반환합니다.
{
"teamName": "team1",
"roleName": "admin" }
],
"organizationRole": "admin"// organization 범위에서 사용자의 역할을 반환합니다.
}
사용자에게 팀 수준 역할 할당
엔드포인트: <host-url>/scim/Users/{id}
메서드: PATCH
설명: 사용자에게 팀 수준 역할을 할당합니다. 역할은 여기에 설명된 대로 admin, viewer, member 또는 사용자 지정 역할 중 하나일 수 있습니다. SaaS Cloud의 경우 사용자 설정에서 SCIM API에 대한 올바른 organization을 구성했는지 확인합니다.
지원되는 필드:
필드
유형
필수
op
문자열
작업 유형. 허용되는 유일한 값은 replace입니다.
path
문자열
역할 할당 작업이 적용되는 범위입니다. 허용되는 유일한 값은 teamRoles입니다.
value
오브젝트 배열
오브젝트가 teamName 및 roleName 속성으로 구성된 단일 오브젝트 배열입니다. teamName은 사용자가 역할을 보유하는 팀의 이름이고, roleName은 admin, viewer, member 또는 사용자 지정 역할 중 하나일 수 있습니다. 이 필드는 미리 정의된 역할에 대해 대소문자를 구분하지 않고 사용자 지정 역할에 대해 대소문자를 구분합니다.
요청 예시:
PATCH /scim/Users/abc
{
"schemas": ["urn:ietf:params:scim:api:messages:2.0:PatchOp"],
"Operations": [
{
"op": "replace",
"path": "teamRoles",
"value": [
{
"roleName": "admin", // 역할 이름은 미리 정의된 역할에 대해 대소문자를 구분하지 않고 사용자 지정 역할에 대해 대소문자를 구분합니다.
"teamName": "team1"// 팀 team1에서 사용자의 역할을 admin으로 설정합니다.
}
]
}
]
}
응답 예시:
이것은 User 오브젝트를 반환합니다.
(Status 200)
{
"active": true,
"displayName": "Dev User 1",
"emails": {
"Value": "dev-user1@test.com",
"Display": "",
"Type": "",
"Primary": true },
"id": "abc",
"meta": {
"resourceType": "User",
"created": "2023-10-01T00:00:00Z",
"lastModified": "2023-10-01T00:00:00Z",
"location": "Users/abc" },
"schemas": [
"urn:ietf:params:scim:schemas:core:2.0:User" ],
"userName": "dev-user1",
"teamRoles": [ // 사용자가 속한 모든 Teams에서 사용자의 역할을 반환합니다.
{
"teamName": "team1",
"roleName": "admin" }
],
"organizationRole": "admin"// organization 범위에서 사용자의 역할을 반환합니다.
}
그룹 리소스
SCIM 그룹 리소스는 W&B Teams에 매핑됩니다. 즉, W&B 배포에서 SCIM 그룹을 만들면 W&B Team이 생성됩니다. 다른 그룹 엔드포인트에도 동일하게 적용됩니다.
팀 삭제는 현재 SCIM API에서 지원되지 않습니다. 팀에 연결된 추가 데이터가 있기 때문입니다. 모든 항목을 삭제할지 확인하려면 앱에서 팀을 삭제하세요.
역할 리소스
SCIM 역할 리소스는 W&B 사용자 지정 역할에 매핑됩니다. 앞에서 언급했듯이 /Roles 엔드포인트는 공식 SCIM 스키마의 일부가 아니며 W&B는 W&B organization에서 사용자 지정 역할의 자동 관리를 지원하기 위해 /Roles 엔드포인트를 추가합니다.
사용자 지정 역할 가져오기
엔드포인트:<host-url>/scim/Roles/{id}
메서드: GET
설명: 역할의 고유 ID를 제공하여 사용자 지정 역할에 대한 정보를 검색합니다.
요청 예시:
GET /scim/Roles/abc
응답 예시:
(Status 200)
{
"description": "A sample custom role for example",
"id": "Um9sZTo3",
"inheritedFrom": "member", // indicates the predefined role
"meta": {
"resourceType": "Role",
"created": "2023-11-20T23:10:14Z",
"lastModified": "2023-11-20T23:31:23Z",
"location": "Roles/Um9sZTo3" },
"name": "Sample custom role",
"organizationID": "T3JnYW5pemF0aW9uOjE0ODQ1OA==",
"permissions": [
{
"name": "artifact:read",
"isInherited": true// inherited from member predefined role
},
...... {
"name": "project:update",
"isInherited": false// custom permission added by admin
}
],
"schemas": [
"" ]
}
사용자 지정 역할 목록
엔드포인트:<host-url>/scim/Roles
메서드: GET
설명: W&B organization의 모든 사용자 지정 역할에 대한 정보를 검색합니다.
요청 예시:
GET /scim/Roles
응답 예시:
(Status 200)
{
"Resources": [
{
"description": "A sample custom role for example",
"id": "Um9sZTo3",
"inheritedFrom": "member", // indicates the predefined role that the custom role inherits from
"meta": {
"resourceType": "Role",
"created": "2023-11-20T23:10:14Z",
"lastModified": "2023-11-20T23:31:23Z",
"location": "Roles/Um9sZTo3" },
"name": "Sample custom role",
"organizationID": "T3JnYW5pemF0aW9uOjE0ODQ1OA==",
"permissions": [
{
"name": "artifact:read",
"isInherited": true// inherited from member predefined role
},
...... {
"name": "project:update",
"isInherited": false// custom permission added by admin
}
],
"schemas": [
"" ]
},
{
"description": "Another sample custom role for example",
"id": "Um9sZToxMg==",
"inheritedFrom": "viewer", // indicates the predefined role that the custom role inherits from
"meta": {
"resourceType": "Role",
"created": "2023-11-21T01:07:50Z",
"location": "Roles/Um9sZToxMg==" },
"name": "Sample custom role 2",
"organizationID": "T3JnYW5pemF0aW9uOjE0ODQ1OA==",
"permissions": [
{
"name": "launchagent:read",
"isInherited": true// inherited from viewer predefined role
},
...... {
"name": "run:stop",
"isInherited": false// custom permission added by admin
}
],
"schemas": [
"" ]
}
],
"itemsPerPage": 9999,
"schemas": [
"urn:ietf:params:scim:api:messages:2.0:ListResponse" ],
"startIndex": 1,
"totalResults": 2}
사용자 지정 역할 생성
엔드포인트: <host-url>/scim/Roles
메서드: POST
설명: W&B organization에서 새 사용자 지정 역할을 만듭니다.
지원되는 필드:
필드
유형
필수
name
문자열
사용자 지정 역할의 이름
description
문자열
사용자 지정 역할에 대한 설명
permissions
오브젝트 배열
각 오브젝트에 w&bobject:operation 형식의 값이 있는 name 문자열 필드가 포함된 권한 오브젝트 배열입니다. 예를 들어 W&B Runs에 대한 삭제 작업에 대한 권한 오브젝트의 name은 run:delete입니다.
inheritedFrom
문자열
사용자 지정 역할이 상속할 미리 정의된 역할입니다. member 또는 viewer일 수 있습니다.
요청 예시:
POST /scim/Roles
{
"schemas": ["urn:ietf:params:scim:schemas:core:2.0:Role"],
"name": "Sample custom role",
"description": "A sample custom role for example",
"permissions": [
{
"name": "project:update" }
],
"inheritedFrom": "member"}
응답 예시:
(Status 201)
{
"description": "A sample custom role for example",
"id": "Um9sZTo3",
"inheritedFrom": "member", // indicates the predefined role
"meta": {
"resourceType": "Role",
"created": "2023-11-20T23:10:14Z",
"lastModified": "2023-11-20T23:31:23Z",
"location": "Roles/Um9sZTo3" },
"name": "Sample custom role",
"organizationID": "T3JnYW5pemF0aW9uOjE0ODQ1OA==",
"permissions": [
{
"name": "artifact:read",
"isInherited": true// inherited from member predefined role
},
...... {
"name": "project:update",
"isInherited": false// custom permission added by admin
}
],
"schemas": [
"" ]
}
사용자 지정 역할 삭제
엔드포인트: <host-url>/scim/Roles/{id}
메서드: DELETE
설명: W&B organization에서 사용자 지정 역할을 삭제합니다. 주의해서 사용하세요. 사용자 지정 역할이 상속된 미리 정의된 역할은 이제 작업 전에 사용자 지정 역할이 할당된 모든 사용자에게 할당됩니다.
요청 예시:
DELETE /scim/Roles/abc
응답 예시:
(Status 204)
사용자 지정 역할 권한 업데이트
엔드포인트: <host-url>/scim/Roles/{id}
메서드: PATCH
설명: W&B organization에서 사용자 지정 역할에 사용자 지정 권한을 추가하거나 제거합니다.
지원되는 필드:
필드
유형
필수
operations
오브젝트 배열
작업 오브젝트 배열
op
문자열
작업 오브젝트 내의 작업 유형입니다. add 또는 remove일 수 있습니다.
path
문자열
작업 오브젝트의 정적 필드입니다. 허용되는 유일한 값은 permissions입니다.
value
오브젝트 배열
각 오브젝트에 w&bobject:operation 형식의 값이 있는 name 문자열 필드가 포함된 권한 오브젝트 배열입니다. 예를 들어 W&B Runs에 대한 삭제 작업에 대한 권한 오브젝트의 name은 run:delete입니다.
요청 예시:
PATCH /scim/Roles/abc
{
"schemas": ["urn:ietf:params:scim:api:messages:2.0:PatchOp"],
"Operations": [
{
"op": "add", // 작업 유형을 나타냅니다. 다른 가능한 값은 `remove`입니다.
"path": "permissions",
"value": [
{
"name": "project:delete" }
]
}
]
}
응답 예시:
(Status 200)
{
"description": "A sample custom role for example",
"id": "Um9sZTo3",
"inheritedFrom": "member", // indicates the predefined role
"meta": {
"resourceType": "Role",
"created": "2023-11-20T23:10:14Z",
"lastModified": "2023-11-20T23:31:23Z",
"location": "Roles/Um9sZTo3" },
"name": "Sample custom role",
"organizationID": "T3JnYW5pemF0aW9uOjE0ODQ1OA==",
"permissions": [
{
"name": "artifact:read",
"isInherited": true// inherited from member predefined role
},
...... {
"name": "project:update",
"isInherited": false// existing custom permission added by admin before the update
},
{
"name": "project:delete",
"isInherited": false// new custom permission added by admin as part of the update
}
],
"schemas": [
"" ]
}
사용자 지정 역할 메타데이터 업데이트
엔드포인트: <host-url>/scim/Roles/{id}
메서드: PUT
설명: W&B organization에서 사용자 지정 역할의 이름, 설명 또는 상속된 역할을 업데이트합니다. 이 작업은 사용자 지정 역할의 기존 비상속 사용자 지정 권한에 영향을 미치지 않습니다.
지원되는 필드:
필드
유형
필수
name
문자열
사용자 지정 역할의 이름
description
문자열
사용자 지정 역할에 대한 설명
inheritedFrom
문자열
사용자 지정 역할이 상속할 미리 정의된 역할입니다. member 또는 viewer일 수 있습니다.
요청 예시:
PUT /scim/Roles/abc
{
"schemas": ["urn:ietf:params:scim:schemas:core:2.0:Role"],
"name": "Sample custom role",
"description": "A sample custom role for example but now based on viewer",
"inheritedFrom": "viewer"}
응답 예시:
(Status 200)
{
"description": "A sample custom role for example but now based on viewer", // changed the descripton per the request
"id": "Um9sZTo3",
"inheritedFrom": "viewer", // indicates the predefined role which is changed per the request
"meta": {
"resourceType": "Role",
"created": "2023-11-20T23:10:14Z",
"lastModified": "2023-11-20T23:31:23Z",
"location": "Roles/Um9sZTo3" },
"name": "Sample custom role",
"organizationID": "T3JnYW5pemF0aW9uOjE0ODQ1OA==",
"permissions": [
{
"name": "artifact:read",
"isInherited": true// inherited from viewer predefined role
},
...// Any permissions that are in member predefined role but not in viewer will not be inherited post the update
{
"name": "project:update",
"isInherited": false// custom permission added by admin
},
{
"name": "project:delete",
"isInherited": false// custom permission added by admin
}
],
"schemas": [
"" ]
}
5.2.5 - Advanced IAM configuration
기본적인 환경 변수 외에도, 환경 변수를 사용하여 전용 클라우드 또는 자체 관리 인스턴스에 대한 IAM 옵션을 구성할 수 있습니다.
IAM 요구 사항에 따라 인스턴스에 대해 다음 환경 변수 중 하나를 선택하십시오.
환경 변수
설명
DISABLE_SSO_PROVISIONING
W&B 인스턴스에서 사용자 자동 프로비저닝을 끄려면 이 값을 true로 설정하십시오.
SESSION_LENGTH
기본 사용자 세션 만료 시간을 변경하려면 이 변수를 원하는 시간 수로 설정하십시오. 예를 들어 세션 만료 시간을 24시간으로 구성하려면 SESSION_LENGTH를 24로 설정하십시오. 기본값은 720시간입니다.
GORILLA_ENABLE_SSO_GROUP_CLAIMS
OIDC 기반 SSO를 사용하는 경우 이 변수를 true로 설정하여 OIDC 그룹을 기반으로 인스턴스에서 W&B team 멤버십을 자동화하십시오. 사용자 OIDC 토큰에 groups 클레임을 추가하십시오. 각 항목이 사용자가 속해야 하는 W&B team의 이름인 문자열 배열이어야 합니다. 배열에는 사용자가 속한 모든 team이 포함되어야 합니다.
GORILLA_LDAP_GROUP_SYNC
LDAP 기반 SSO를 사용하는 경우 이 값을 true로 설정하여 LDAP 그룹을 기반으로 인스턴스에서 W&B team 멤버십을 자동화하십시오.
GORILLA_OIDC_CUSTOM_SCOPES
OIDC 기반 SSO를 사용하는 경우 W&B 인스턴스가 ID 공급자에게 요청해야 하는 추가 scopes를 지정할 수 있습니다. W&B는 이러한 사용자 정의 scopes로 인해 SSO 기능을 변경하지 않습니다.
GORILLA_USE_IDENTIFIER_CLAIMS
OIDC 기반 SSO를 사용하는 경우 이 변수를 true로 설정하여 ID 공급자의 특정 OIDC 클레임을 사용하여 사용자의 사용자 이름과 전체 이름을 적용하십시오. 설정된 경우 preferred_username 및 name OIDC 클레임에서 적용된 사용자 이름과 전체 이름을 구성해야 합니다. 사용자 이름은 영숫자 문자와 특수 문자(밑줄 및 하이픈)만 포함할 수 있습니다.
GORILLA_DISABLE_PERSONAL_ENTITY
W&B 인스턴스에서 개인 user projects를 끄려면 이 값을 true로 설정하십시오. 설정된 경우 users는 개인 Entities에서 새 개인 projects를 만들 수 없으며 기존 개인 projects에 대한 쓰기가 꺼집니다.
GORILLA_DISABLE_ADMIN_TEAM_ACCESS
Organization 또는 Instance Admins가 W&B team에 자체 가입하거나 추가하는 것을 제한하려면 이 값을 true로 설정하여 Data & AI 담당자만 team 내의 projects에 액세스할 수 있도록 합니다.
W&B는 GORILLA_DISABLE_ADMIN_TEAM_ACCESS와 같은 일부 설정을 활성화하기 전에 주의를 기울이고 모든 의미를 이해할 것을 권장합니다. 질문이 있는 경우 W&B team에 문의하십시오.
5.3 - Data security
5.3.1 - Bring your own bucket (BYOB)
Bring your own bucket(BYOB)을 사용하면 W&B 아티팩트 및 기타 관련 민감한 데이터를 자체 클라우드 또는 온프레미스 인프라에 저장할 수 있습니다. 전용 클라우드 또는 SaaS Cloud의 경우 버킷에 저장하는 데이터는 W&B 관리 인프라에 복사되지 않습니다.
W&B SDK / CLI / UI와 버킷 간의 통신은 사전 서명된 URL을 사용하여 이루어집니다.
W&B는 가비지 컬렉션 프로세스를 사용하여 W&B Artifacts를 삭제합니다. 자세한 내용은 Artifacts 삭제를 참조하세요.
버킷을 구성할 때 하위 경로를 지정하여 W&B가 버킷 루트의 폴더에 파일을 저장하지 않도록 할 수 있습니다. 이는 조직의 버킷 관리 정책을 준수하는 데 도움이 될 수 있습니다.
중앙 데이터베이스와 버킷에 저장되는 데이터
BYOB 기능을 사용할 때 특정 유형의 데이터는 W&B 중앙 데이터베이스에 저장되고 다른 유형은 버킷에 저장됩니다.
데이터베이스
사용자, 팀, 아티팩트, Experiments 및 프로젝트에 대한 메타데이터
Reports
Experiment 로그
시스템 메트릭
버킷
Experiment 파일 및 메트릭
Artifact 파일
미디어 파일
Run 파일
설정 옵션
스토리지 버킷을 구성할 수 있는 범위는 인스턴스 수준 또는 팀 수준의 두 가지입니다.
인스턴스 수준: 조직 내에서 관련 권한을 가진 모든 사용자가 인스턴스 수준 스토리지 버킷에 저장된 파일에 엑세스할 수 있습니다.
팀 수준: W&B Teams의 팀 멤버는 팀 수준에서 구성된 버킷에 저장된 파일에 엑세스할 수 있습니다. 팀 수준 스토리지 버킷은 매우 민감한 데이터 또는 엄격한 규정 준수 요구 사항이 있는 팀을 위해 더 강력한 데이터 엑세스 제어 및 데이터 격리를 제공합니다.
인스턴스 수준에서 버킷을 구성하고 조직 내의 하나 이상의 팀에 대해 별도로 구성할 수 있습니다.
예를 들어 조직에 Kappa라는 팀이 있다고 가정합니다. 조직(및 Team Kappa)은 기본적으로 인스턴스 수준 스토리지 버킷을 사용합니다. 다음으로 Omega라는 팀을 만듭니다. Team Omega를 만들 때 해당 팀에 대한 팀 수준 스토리지 버킷을 구성합니다. Team Omega에서 생성된 파일은 Team Kappa에서 엑세스할 수 없습니다. 그러나 Team Kappa에서 만든 파일은 Team Omega에서 엑세스할 수 있습니다. Team Kappa에 대한 데이터를 격리하려면 해당 팀에 대한 팀 수준 스토리지 버킷도 구성해야 합니다.
팀 수준 스토리지 버킷은 특히 다양한 사업부 및 부서가 인프라 및 관리 리소스를 효율적으로 활용하기 위해 인스턴스를 공유할 때 자체 관리 인스턴스에 대해 동일한 이점을 제공합니다. 이는 별도의 고객 참여에 대한 AI 워크플로우를 관리하는 별도의 프로젝트 팀이 있는 회사에도 적용됩니다.
가용성 매트릭스
다음 표는 다양한 W&B 서버 배포 유형에서 BYOB의 가용성을 보여줍니다. X는 특정 배포 유형에서 기능을 사용할 수 있음을 의미합니다.
W&B 서버 배포 유형
인스턴스 수준
팀 수준
추가 정보
전용 클라우드
X
X
인스턴스 및 팀 수준 BYOB는 Amazon Web Services, Google Cloud Platform 및 Microsoft Azure에서 사용할 수 있습니다. 팀 수준 BYOB의 경우 동일하거나 다른 클라우드의 클라우드 네이티브 스토리지 버킷 또는 클라우드 또는 온프레미스 인프라에서 호스팅되는 MinIO와 같은 S3 호환 보안 스토리지에 연결할 수 있습니다.
SaaS Cloud
해당 사항 없음
X
팀 수준 BYOB는 Amazon Web Services 및 Google Cloud Platform에서만 사용할 수 있습니다. W&B는 Microsoft Azure에 대한 기본 및 유일한 스토리지 버킷을 완전히 관리합니다.
자체 관리
X
X
인스턴스가 사용자에 의해 완전히 관리되므로 인스턴스 수준 BYOB가 기본값입니다. 자체 관리 인스턴스가 클라우드에 있는 경우 팀 수준 BYOB에 대해 동일하거나 다른 클라우드의 클라우드 네이티브 스토리지 버킷에 연결할 수 있습니다. 인스턴스 또는 팀 수준 BYOB에 MinIO와 같은 S3 호환 보안 스토리지를 사용할 수도 있습니다.
전용 클라우드 또는 자체 관리 인스턴스에 대해 인스턴스 또는 팀 수준 스토리지 버킷을 구성하거나 SaaS Cloud 계정에 대해 팀 수준 스토리지 버킷을 구성하면 해당 범위에 대한 스토리지 버킷을 변경하거나 재구성할 수 없습니다. 여기에는 데이터를 다른 버킷으로 마이그레이션하고 주요 제품 스토리지에서 관련 참조를 다시 매핑할 수 없는 것도 포함됩니다. W&B는 인스턴스 또는 팀 수준 범위에 대해 구성하기 전에 스토리지 버킷 레이아웃을 신중하게 계획할 것을 권장합니다. 질문이 있으면 W&B 팀에 문의하십시오.
팀 수준 BYOB를 위한 크로스 클라우드 또는 S3 호환 스토리지
전용 클라우드 또는 자체 관리 인스턴스에서 팀 수준 BYOB에 대해 다른 클라우드의 클라우드 네이티브 스토리지 버킷 또는 MinIO와 같은 S3 호환 스토리지 버킷에 연결할 수 있습니다.
크로스 클라우드 또는 S3 호환 스토리지 사용을 활성화하려면 W&B 인스턴스에 대한 GORILLA_SUPPORTED_FILE_STORES 환경 변수를 사용하여 다음 형식 중 하나로 관련 엑세스 키를 포함하는 스토리지 버킷을 지정합니다.
전용 클라우드 또는 자체 관리 인스턴스에서 팀 수준 BYOB에 대한 S3 호환 스토리지 구성
팀 수준 BYOB에 대한 S3 호환 스토리지 연결은 SaaS Cloud에서 사용할 수 없습니다. 또한 팀 수준 BYOB에 대한 AWS 버킷 연결은 해당 인스턴스가 GCP에 있으므로 SaaS Cloud에서 크로스 클라우드입니다. 해당 크로스 클라우드 연결은 이전에 전용 클라우드 및 자체 관리 인스턴스에 대해 설명한 대로 엑세스 키 및 환경 변수 기반 메커니즘을 사용하지 않습니다.
gsutil cors set cors-policy.json gs://<bucket_name>
버킷의 정책을 확인합니다. <bucket_name>을 올바른 버킷 이름으로 바꿉니다.
gsutil cors get gs://<bucket_name>
SaaS Cloud 또는 전용 클라우드를 사용하는 경우 W&B 플랫폼에 연결된 GCP 서비스 계정에 Storage Admin 역할을 부여합니다.
SaaS Cloud의 경우 계정은 wandb-integration@wandb-production.iam.gserviceaccount.com입니다.
전용 클라우드의 경우 계정은 deploy@wandb-production.iam.gserviceaccount.com입니다.
버킷 이름을 기록해 둡니다. 전용 클라우드를 사용하는 경우 인스턴스 수준 BYOB의 경우 버킷 이름을 W&B 팀과 공유합니다. 모든 배포 유형에서 팀 수준 BYOB의 경우 팀을 만드는 동안 버킷을 구성합니다.
Azure Blob Storage 프로비저닝
인스턴스 수준 BYOB의 경우 이 Terraform 모듈을 사용하지 않는 경우 아래 단계에 따라 Azure 구독에서 Azure Blob Storage 버킷을 프로비저닝합니다.
원하는 이름으로 버킷을 만듭니다. 선택적으로 모든 W&B 파일을 저장하기 위해 하위 경로로 구성할 수 있는 폴더를 만듭니다.
Blob 및 컨테이너 소프트 삭제를 활성화합니다.
버전 관리를 활성화합니다.
버킷에서 CORS 정책을 구성합니다.
UI를 통해 CORS 정책을 설정하려면 Blob Storage로 이동하여 설정/리소스 공유(CORS)로 스크롤한 다음 다음을 설정합니다.
파라미터
값
허용된 원본
*
허용된 메소드
GET, HEAD, PUT
허용된 헤더
*
노출된 헤더
*
최대 사용 기간
3600
스토리지 계정 엑세스 키를 생성하고 스토리지 계정 이름과 함께 기록해 둡니다. 전용 클라우드를 사용하는 경우 보안 공유 메커니즘을 사용하여 스토리지 계정 이름과 엑세스 키를 W&B 팀과 공유합니다.
팀 수준 BYOB의 경우 W&B는 필요한 엑세스 메커니즘 및 권한과 함께 Azure Blob Storage 버킷을 프로비저닝하기 위해 Terraform을 사용하는 것이 좋습니다. 전용 클라우드를 사용하는 경우 인스턴스에 대한 OIDC 발급자 URL을 제공합니다. 팀을 만드는 동안 버킷을 구성하는 데 필요한 세부 정보를 기록해 둡니다.
스토리지 계정 이름
스토리지 컨테이너 이름
관리 ID 클라이언트 ID
Azure 테넌트 ID
W&B에서 BYOB 구성
전용 클라우드 또는 자체 관리 인스턴스에서 팀 수준 BYOB에 대해 다른 클라우드의 클라우드 네이티브 스토리지 버킷 또는 MinIO와 같은 S3 호환 스토리지 버킷에 연결하는 경우 팀 수준 BYOB에 대한 크로스 클라우드 또는 S3 호환 스토리지를 참조하십시오. 이러한 경우 아래 지침을 사용하여 팀에 대해 구성하기 전에 W&B 인스턴스에 대한 GORILLA_SUPPORTED_FILE_STORES 환경 변수를 사용하여 스토리지 버킷을 지정해야 합니다.
필요한 경우 네트워크 내의 AI 워크로드 또는 사용자 브라우저 클라이언트가 W&B Platform에서 사전 서명된 URL을 요청합니다. 그러면 W&B Platform은 관련 blob storage에 엑세스하여 필요한 권한으로 사전 서명된 URL을 생성하고 클라이언트에 다시 반환합니다. 그런 다음 클라이언트는 사전 서명된 URL을 사용하여 오브젝트 업로드 또는 검색 작업을 위해 blob storage에 엑세스합니다. 오브젝트 다운로드를 위한 URL 만료 시간은 1시간이고, 일부 대형 오브젝트는 청크 단위로 업로드하는 데 더 많은 시간이 필요할 수 있으므로 오브젝트 업로드는 24시간입니다.
팀 레벨 엑세스 제어
각 사전 서명된 URL은 W&B platform의 팀 레벨 엑세스 제어를 기반으로 특정 버킷으로 제한됩니다. 사용자가 보안 스토리지 커넥터를 사용하여 blob storage 버킷에 매핑된 팀에 속하고 해당 사용자만 해당 팀에 속한 경우, 해당 요청에 대해 생성된 사전 서명된 URL은 다른 팀에 매핑된 blob storage 버킷에 엑세스할 수 있는 권한이 없습니다.
W&B는 사용자를 자신이 속해야 하는 팀에만 추가할 것을 권장합니다.
네트워크 제한
W&B는 버킷에 대한 IAM 정책 기반 제한을 사용하여 사전 서명된 URL을 사용하여 blob storage에 엑세스할 수 있는 네트워크를 제한하는 것이 좋습니다.
AWS의 경우 VPC 또는 IP 어드레스 기반 네트워크 제한을 사용할 수 있습니다. 이렇게 하면 W&B 특정 버킷이 AI 워크로드가 실행 중인 네트워크 또는 사용자가 W&B UI를 사용하여 Artifacts에 엑세스하는 경우 사용자 머신에 매핑되는 게이트웨이 IP 어드레스에서만 엑세스할 수 있습니다.
사전 서명된 URL은 W&B에서 지원되는 유일한 blob storage 엑세스 메커니즘입니다. W&B는 위험 감수 성향에 따라 위에 나열된 보안 제어 중 일부 또는 전부를 구성할 것을 권장합니다.
5.3.3 - Configure IP allowlisting for Dedicated Cloud
승인된 IP 어드레스 목록에서만 전용 클라우드 인스턴스에 대한 엑세스를 제한할 수 있습니다. 이는 AI 워크로드에서 W&B API로의 엑세스와 사용자 브라우저에서 W&B 앱 UI로의 엑세스에도 적용됩니다. 전용 클라우드 인스턴스에 대해 IP 허용 목록이 설정되면 W&B는 승인되지 않은 다른 위치에서 오는 모든 요청을 거부합니다. 전용 클라우드 인스턴스에 대한 IP 허용 목록을 구성하려면 W&B 팀에 문의하십시오.
IP 허용 목록은 AWS, GCP 및 Azure의 전용 클라우드 인스턴스에서 사용할 수 있습니다.
보안 사설 연결과 함께 IP 허용 목록을 사용할 수 있습니다. 보안 사설 연결과 함께 IP 허용 목록을 사용하는 경우 W&B는 AI 워크로드의 모든 트래픽과 가능한 경우 사용자 브라우저의 대부분의 트래픽에 대해 보안 사설 연결을 사용하는 동시에 권한 있는 위치에서 인스턴스 관리를 위해 IP 허용 목록을 사용하는 것이 좋습니다.
W&B는 개별 /32 IP 어드레스가 아닌 회사 또는 비즈니스 이그레스 게이트웨이에 할당된 CIDR 블록을 사용하는 것이 좋습니다. 개별 IP 어드레스를 사용하는 것은 확장성이 떨어지고 클라우드당 엄격한 제한이 있습니다.
5.3.4 - Configure private connectivity to Dedicated Cloud
클라우드 공급자의 보안 사설 네트워크를 통해 전용 클라우드 인스턴스에 연결할 수 있습니다. 이는 AI 워크로드에서 W&B API로의 엑세스와 선택적으로 사용자 브라우저에서 W&B 앱 UI로의 엑세스에도 적용됩니다. 사설 연결을 사용하는 경우 관련 요청 및 응답은 공용 네트워크 또는 인터넷을 통해 전송되지 않습니다.
보안 사설 연결은 곧 전용 클라우드의 고급 보안 옵션으로 제공될 예정입니다.
보안 사설 연결은 AWS, GCP 및 Azure의 전용 클라우드 인스턴스에서 사용할 수 있습니다.
활성화되면 W&B는 인스턴스에 대한 사설 엔드포인트 서비스를 생성하고 연결할 관련 DNS URI를 제공합니다. 이를 통해 클라우드 계정에서 사설 엔드포인트를 생성하여 관련 트래픽을 사설 엔드포인트 서비스로 라우팅할 수 있습니다. 사설 엔드포인트는 클라우드 VPC 또는 VNet 내에서 실행되는 AI 트레이닝 워크로드에 대해 더 쉽게 설정할 수 있습니다. 사용자 브라우저에서 W&B 앱 UI로의 트래픽에 대해 동일한 메커니즘을 사용하려면 회사 네트워크에서 클라우드 계정의 사설 엔드포인트로 적절한 DNS 기반 라우팅을 구성해야 합니다.
이 기능을 사용하려면 W&B 팀에 문의하십시오.
IP 허용 목록과 함께 보안 사설 연결을 사용할 수 있습니다. IP 허용 목록에 보안 사설 연결을 사용하는 경우 W&B는 AI 워크로드의 모든 트래픽과 가능한 경우 사용자 브라우저의 대부분 트래픽에 대해 보안 사설 연결을 사용하고 권한 있는 위치에서 인스턴스 관리에 IP 허용 목록을 사용하는 것이 좋습니다.
5.3.5 - Data encryption in Dedicated cloud
W&B는 각 전용 클라우드에서 클라우드 공급자의 고객 관리 암호화 키 (CMEK) 기능을 사용하여 W&B 관리 데이터베이스 및 오브젝트 스토리지를 암호화하기 위해 W&B 관리 클라우드 네이티브 키를 사용합니다. 이 경우 W&B는 클라우드 공급자의 customer 역할을 하며, W&B 플랫폼을 서비스로 제공합니다. W&B 관리 키를 사용한다는 것은 W&B가 각 클라우드에서 데이터를 암호화하는 데 사용하는 키를 제어하여 모든 고객에게 매우 안전하고 보안이 뛰어난 플랫폼을 제공하겠다는 약속을 강화한다는 의미입니다.
W&B는 각 고객 인스턴스의 데이터를 암호화하기 위해 unique key를 사용하여 전용 클라우드 테넌트 간에 또 다른 격리 계층을 제공합니다. 이 기능은 AWS, Azure 및 GCP에서 사용할 수 있습니다.
2024년 8월 이전에 W&B가 프로비저닝한 GCP 및 Azure의 전용 클라우드 인스턴스는 W&B 관리 데이터베이스 및 오브젝트 스토리지 암호화에 대해 기본 클라우드 공급자 관리 키를 사용합니다. 2024년 8월부터 W&B가 생성한 새로운 인스턴스만 관련 암호화에 대해 W&B 관리 클라우드 네이티브 키를 사용합니다.
AWS의 전용 클라우드 인스턴스는 2024년 8월 이전부터 암호화에 대해 W&B 관리 클라우드 네이티브 키를 사용하고 있습니다.
W&B는 일반적으로 고객이 전용 클라우드 인스턴스에서 W&B 관리 데이터베이스 및 오브젝트 스토리지를 암호화하기 위해 자체 클라우드 네이티브 키를 가져오는 것을 허용하지 않습니다. 조직의 여러 Teams 및 사용자가 다양한 이유로 클라우드 인프라에 엑세스할 수 있기 때문입니다. 이러한 Teams 또는 사용자는 조직의 기술 스택에서 중요한 구성 요소인 W&B에 대한 컨텍스트가 없을 수 있으므로 클라우드 네이티브 키를 완전히 제거하거나 W&B의 엑세스를 취소할 수 있습니다. 이러한 조치는 조직의 W&B 인스턴스에 있는 모든 데이터를 손상시켜 복구 불가능한 상태로 만들 수 있습니다.
AI 워크플로우에 전용 클라우드 사용을 승인하기 위해 조직에서 자체 클라우드 네이티브 키를 사용하여 W&B 관리 데이터베이스 및 오브젝트 스토리지를 암호화해야 하는 경우 W&B는 예외적으로 이를 검토할 수 있습니다. 승인되면 암호화에 대한 클라우드 네이티브 키 사용은 W&B 전용 클라우드의 shared responsibility model을 준수합니다. 전용 클라우드 인스턴스가 활성 상태일 때 조직의 사용자가 키를 제거하거나 W&B의 엑세스를 취소하는 경우 W&B는 그로 인한 데이터 손실 또는 손상에 대해 책임을 지지 않으며 해당 데이터 복구에 대한 책임도 지지 않습니다.
5.4 - Configure privacy settings
조직 및 팀 관리자는 조직 및 팀 범위에서 각각 개인 정보 보호 설정을 구성할 수 있습니다. 조직 범위에서 구성된 경우 조직 관리자는 해당 조직의 모든 팀에 대해 해당 설정을 적용합니다.
W&B는 조직 관리자가 조직 내 모든 팀 관리자와 사용자에게 미리 알린 후에만 개인 정보 보호 설정을 적용할 것을 권장합니다. 이는 워크플로우에서 예기치 않은 변경을 방지하기 위함입니다.
팀 개인 정보 보호 설정 구성
팀 관리자는 팀 Settings 탭의 Privacy 섹션에서 각 팀에 대한 개인 정보 보호 설정을 구성할 수 있습니다. 각 설정은 조직 범위에서 적용되지 않는 한 구성할 수 있습니다.
이 팀을 모든 비 멤버에게 숨기기
향후 모든 팀 Projects를 비공개로 설정 (공개 공유 불허)
모든 팀 멤버가 다른 멤버를 초대하도록 허용 (관리자만 가능하지 않음)
비공개 Projects의 Reports에 대한 팀 외부 공개 공유를 해제합니다. 이렇게 하면 기존의 매직 링크가 해제됩니다.
특정 기간 동안 감사 로그를 보존해야 하는 경우 W&B는 스토리지 버킷 또는 감사 로깅 API를 사용하여 장기 스토리지로 로그를 주기적으로 전송하는 것이 좋습니다.
1996년 건강 보험 양도 및 책임에 관한 법률 (HIPAA)의 적용을 받는 경우 감사 로그는 의무 보존 기간이 끝나기 전에 내부 또는 외부 행위자가 삭제하거나 수정할 수 없는 환경에서 최소 6년 동안 보존해야 합니다. BYOB가 있는 HIPAA 규정 준수 전용 클라우드 인스턴스의 경우 장기 보존 스토리지를 포함하여 관리형 스토리지에 대한 가드레일을 구성해야 합니다.
감사 로그 스키마
이 표는 감사 로그 항목에 나타날 수 있는 모든 키를 알파벳순으로 보여줍니다. 작업 및 상황에 따라 특정 로그 항목에는 가능한 필드의 서브셋만 포함될 수 있습니다.
startDate와 numDays를 모두 설정하지 않으면 today에 대한 로그만 반환됩니다.
웹 브라우저 또는 Postman, HTTPie 또는 cURL과 같은 툴을 사용하여 구성된 정규화된 전체 API 엔드포인트에서 HTTP GET 요청을 실행합니다.
API 응답에는 줄 바꿈으로 구분된 JSON 오브젝트가 포함됩니다. 오브젝트에는 감사 로그가 인스턴스 수준 버킷에 동기화될 때와 마찬가지로 스키마에 설명된 필드가 포함됩니다. 이러한 경우 감사 로그는 버킷의 /wandb-audit-logs 디렉토리에 있습니다.
기본 인증 사용
API 키로 기본 인증을 사용하여 감사 로그 API에 액세스하려면 HTTP 요청의 Authorization 헤더를 Basic 문자열로 설정하고 공백을 추가한 다음 username:API-KEY 형식으로 base-64로 인코딩된 문자열을 설정합니다. 즉, 사용자 이름과 API 키를 : 문자로 구분된 값으로 바꾸고 결과를 base-64로 인코딩합니다. 예를 들어 demo:p@55w0rd로 인증하려면 헤더는 Authorization: Basic ZGVtbzpwQDU1dzByZA==여야 합니다.
감사 로그를 가져올 때 PII 제외
자체 관리 및 전용 클라우드의 경우 W&B 조직 또는 인스턴스 관리자는 감사 로그를 가져올 때 PII를 제외할 수 있습니다. SaaS Cloud의 경우 API 엔드포인트는 항상 PII를 포함하여 감사 로그에 대한 관련 필드를 반환합니다. 이는 구성할 수 없습니다.
PII를 제외하려면 anonymize=true URL 파라미터를 전달합니다. 예를 들어 W&B 인스턴스 URL이 https://mycompany.wandb.io이고 지난 주 동안의 사용자 활동에 대한 감사 로그를 가져오고 PII를 제외하려면 다음과 같은 API 엔드포인트를 사용합니다.
Users 탭에서 조직에서 W&B를 사용하는 방법에 대한 세부 정보를 CSV 형식으로 볼 수 있습니다.
Invite new user 버튼 옆에 있는 작업 ... 메뉴를 클릭합니다.
Export as CSV를 클릭합니다. 다운로드되는 CSV 파일에는 user 이름 및 이메일 어드레스, 마지막 활동 시간, 역할 등과 같은 조직의 각 user에 대한 세부 정보가 나열됩니다.
user 활동 보기
Users 탭의 Last Active 열을 사용하여 개별 user의 Activity summary를 가져옵니다.
Last Active별로 user 목록을 정렬하려면 열 이름을 클릭합니다.
user의 마지막 활동에 대한 세부 정보를 보려면 user의 Last Active 필드 위에 마우스를 가져갑니다. user가 추가된 시기와 user가 총 며칠 동안 활성 상태였는지 보여주는 툴팁이 나타납니다.
다음과 같은 경우 user는 active 상태입니다.
W&B에 로그인합니다.
W&B App에서 페이지를 봅니다.
Runs를 로그합니다.
SDK를 사용하여 experiment를 추적합니다.
어떤 방식으로든 W&B Server와 상호 작용합니다.
시간 경과에 따른 활성 user 보기
Activity 탭의 플롯을 사용하여 시간 경과에 따라 얼마나 많은 user가 활성 상태였는지에 대한 집계 보기를 얻을 수 있습니다.
Activity 탭을 클릭합니다.
Total active users 플롯은 특정 기간 동안 얼마나 많은 user가 활성 상태였는지 보여줍니다 (기본값은 3개월).
Users active over time 플롯은 특정 기간 동안 활성 user의 변동을 보여줍니다 (기본값은 6개월). 해당 날짜의 user 수를 보려면 포인트 위에 마우스를 가져갑니다.
플롯의 기간을 변경하려면 드롭다운을 사용합니다. 다음을 선택할 수 있습니다.
Last 30 days
Last 3 months
Last 6 months
Last 12 months
All time
5.6 - Configure SMTP
W&B server에서 인스턴스 또는 팀에 사용자를 추가하면 이메일 초대가 트리거됩니다. 이러한 이메일 초대를 보내기 위해 W&B는 타사 메일 서버를 사용합니다. 경우에 따라 조직은 회사 네트워크를 떠나는 트래픽에 대해 엄격한 정책을 적용하여 이러한 이메일 초대가 최종 사용자에게 전송되지 않을 수 있습니다. W&B server는 내부 SMTP 서버를 통해 이러한 초대 이메일을 보내도록 구성하는 옵션을 제공합니다.
구성하려면 다음 단계를 따르세요.
docker 컨테이너 또는 Kubernetes 배포에서 GORILLA_EMAIL_SINK 환경 변수를 smtp://<user:password>@smtp.host.com:<port>로 설정합니다.
username 및 password는 선택 사항입니다.
인증되지 않도록 설계된 SMTP 서버를 사용하는 경우 GORILLA_EMAIL_SINK=smtp://smtp.host.com:<port>와 같이 환경 변수의 값을 설정하기만 하면 됩니다.
SMTP에 일반적으로 사용되는 포트 번호는 587, 465 및 25 포트입니다. 이는 사용 중인 메일 서버의 유형에 따라 다를 수 있습니다.
SMTP의 기본 발신자 이메일 어드레스를 구성하려면(초기에는 noreply@wandb.com으로 설정됨) 서버에서 GORILLA_EMAIL_FROM_ADDRESS 환경 변수를 원하는 발신자 이메일 어드레스로 업데이트하면 됩니다.
5.7 - Configure environment variables
W&B 서버 설치를 구성하는 방법
System Settings 관리자 UI를 통해 인스턴스 수준 설정을 구성하는 것 외에도, W&B는 환경 변수를 사용하여 코드를 통해 이러한 값들을 구성하는 방법을 제공합니다. 또한, IAM 고급 설정을 참조하세요.
환경 변수 참조
환경 변수
설명
LICENSE
wandb/local 라이선스
MYSQL
MySQL 연결 문자열
BUCKET
데이터 저장용 S3 / GCS 버킷
BUCKET_QUEUE
오브젝트 생성 이벤트를 위한 SQS / Google PubSub 대기열
NOTIFICATIONS_QUEUE
run 이벤트를 게시할 SQS 대기열
AWS_REGION
버킷이 있는 AWS 리전
HOST
인스턴스의 FQD, 즉 https://my.domain.net
OIDC_ISSUER
Open ID Connect ID 공급자의 URL, 즉 https://cognito-idp.us-east-1.amazonaws.com/us-east-1_uiIFNdacd
OIDC_CLIENT_ID
ID 공급자 애플리케이션의 Client ID
OIDC_AUTH_METHOD
Implicit (기본값) 또는 pkce, 자세한 내용은 아래 참조
SLACK_CLIENT_ID
알림에 사용할 Slack 애플리케이션의 client ID
SLACK_SECRET
알림에 사용할 Slack 애플리케이션의 secret
LOCAL_RESTORE
인스턴스에 엑세스할 수 없는 경우 임시로 true로 설정할 수 있습니다. 임시 자격 증명에 대한 컨테이너의 로그를 확인하십시오.
REDIS
W&B와 함께 외부 REDIS 인스턴스를 설정하는 데 사용할 수 있습니다.
LOGGING_ENABLED
true로 설정하면 엑세스 로그가 stdout으로 스트리밍됩니다. 이 변수를 설정하지 않고도 사이드카 컨테이너를 마운트하고 /var/log/gorilla.log를 tail할 수도 있습니다.
GORILLA_ALLOW_USER_TEAM_CREATION
true로 설정하면 관리자가 아닌 사용자가 새 팀을 만들 수 있습니다. 기본값은 False입니다.
GORILLA_DATA_RETENTION_PERIOD
삭제된 run의 데이터를 보관하는 기간(시간)입니다. 삭제된 run 데이터는 복구할 수 없습니다. 입력 값에 h를 추가하십시오. 예를 들어, "24h"입니다.
ENABLE_REGISTRY_UI
true로 설정하면 새로운 W&B Registry UI가 활성화됩니다.
GORILLA_DATA_RETENTION_PERIOD 환경 변수를 사용할 때는 주의하십시오. 환경 변수가 설정되면 데이터가 즉시 제거됩니다. 이 플래그를 활성화하기 전에 데이터베이스와 스토리지 버킷을 모두 백업하는 것이 좋습니다.
고급 안정성 설정
Redis
외부 Redis 서버 구성은 선택 사항이지만 프로덕션 시스템에는 권장됩니다. Redis는 서비스 안정성을 향상시키고 특히 대규모 Projects에서 로드 시간을 줄이기 위해 캐싱을 활성화하는 데 도움이 됩니다. 고가용성(HA) 및 다음 사양을 갖춘 ElastiCache와 같은 관리형 Redis 서비스를 사용하십시오.
최소 4GB 메모리, 8GB 권장
Redis 버전 6.x
전송 중 암호화
인증 활성화
W&B로 Redis 인스턴스를 구성하려면 http(s)://YOUR-W&B-SERVER-HOST/system-admin의 W&B 설정 페이지로 이동하십시오. “외부 Redis 인스턴스 사용” 옵션을 활성화하고 다음 형식으로 Redis 연결 문자열을 입력하십시오.
컨테이너 또는 Kubernetes 배포에서 환경 변수 REDIS를 사용하여 Redis를 구성할 수도 있습니다. 또는 REDIS를 Kubernetes secret으로 설정할 수도 있습니다.
이 페이지에서는 Redis 인스턴스가 기본 포트 6379에서 실행 중이라고 가정합니다. 다른 포트를 구성하고 인증을 설정하고 redis 인스턴스에서 TLS를 활성화하려면 연결 문자열 형식이 redis://$USER:$PASSWORD@$HOST:$PORT?tls=true와 같이 표시됩니다.
5.8 - Release process for W&B Server
W&B 서버 릴리스 프로세스
빈도 및 배포 유형
W&B Server 릴리스는 전용 클라우드 및 자체 관리 배포에 적용됩니다. 서버 릴리스에는 세 가지 종류가 있습니다.
릴리스 유형
설명
월별
월별 릴리스에는 새로운 기능, 개선 사항, 중간 및 낮은 심각도의 버그 수정이 포함됩니다.
패치
패치 릴리스에는 중요 및 높은 심각도의 버그 수정이 포함됩니다. 패치는 필요에 따라 드물게 릴리스됩니다.
기능
기능 릴리스는 새로운 제품 기능에 대한 특정 릴리스 날짜를 대상으로 하며, 이는 표준 월별 릴리스보다 간혹 먼저 발생합니다.
모든 릴리스는 인수 테스트 단계가 완료되는 즉시 모든 전용 클라우드 인스턴스에 즉시 배포됩니다. 이렇게 하면 관리되는 인스턴스가 완전히 업데이트되어 최신 기능 및 수정 사항을 관련 고객에게 제공할 수 있습니다. 자체 관리 인스턴스를 사용하는 고객은 자체 일정에 따라 업데이트 프로세스를 수행해야 하며, 여기서 최신 Docker 이미지를 사용할 수 있습니다. 릴리스 지원 및 수명 종료를 참조하십시오.
일부 고급 기능은 엔터프라이즈 라이선스에서만 사용할 수 있습니다. 따라서 최신 Docker 이미지를 얻더라도 엔터프라이즈 라이선스가 없으면 관련 고급 기능을 활용할 수 없습니다.
일부 새로운 기능은 비공개 미리보기로 시작됩니다. 즉, 디자인 파트너 또는 얼리 어답터만 사용할 수 있습니다. 인스턴스에서 비공개 미리보기 기능을 사용하려면 W&B 팀에서 활성화해야 합니다.
릴리스 정보
모든 릴리스에 대한 릴리스 정보는 GitHub의 W&B Server Releases에서 확인할 수 있습니다. Slack을 사용하는 고객은 W&B Slack 채널에서 자동 릴리스 알림을 받을 수 있습니다. W&B 팀에 문의하여 이러한 업데이트를 활성화하십시오.
릴리스 업데이트 및 가동 중지 시간
일반적으로 서버 릴리스는 전용 클라우드 인스턴스 및 적절한 롤링 업데이트 프로세스를 구현한 자체 관리 배포 고객에게 인스턴스 가동 중지 시간을 요구하지 않습니다.
다음 시나리오에서는 가동 중지 시간이 발생할 수 있습니다.
새로운 기능 또는 개선 사항으로 인해 컴퓨팅, 스토리지 또는 네트워크와 같은 기본 인프라를 변경해야 합니다. W&B는 관련 사전 알림을 전용 클라우드 고객에게 보내려고 노력합니다.
보안 패치 또는 특정 버전에 대한 ‘수명 종료 지원’을 피하기 위한 인프라 변경. 긴급한 변경의 경우 전용 클라우드 고객은 사전 알림을 받지 못할 수 있습니다. 여기서 우선 순위는 fleet을 안전하게 유지하고 완전히 지원하는 것입니다.
두 경우 모두 업데이트는 예외 없이 모든 전용 클라우드 인스턴스에 롤아웃됩니다. 자체 관리 인스턴스를 사용하는 고객은 자체 일정에 따라 이러한 업데이트를 관리해야 합니다. 릴리스 지원 및 수명 종료를 참조하십시오.
릴리스 지원 및 수명 종료 정책
W&B는 릴리스 날짜로부터 6개월 동안 모든 서버 릴리스를 지원합니다. 전용 클라우드 인스턴스는 자동으로 업데이트됩니다. 자체 관리 인스턴스를 사용하는 고객은 지원 정책을 준수하기 위해 제때 배포를 업데이트해야 합니다. W&B의 지원을 크게 제한할 수 있으므로 6개월 이상 된 버전을 사용하지 마십시오.
W&B는 자체 관리 인스턴스를 사용하는 고객에게 최소한 분기마다 최신 릴리스로 배포를 업데이트할 것을 강력히 권장합니다. 이렇게 하면 최신의 가장 훌륭한 기능을 사용하는 동시에 릴리스 수명 종료를 훨씬 앞서 유지할 수 있습니다.
6 - Integrations
W&B 인테그레이션을 사용하면 기존 프로젝트 내에서 실험 추적 및 데이터 버전 관리를 빠르고 쉽게 설정할 수 있습니다. PyTorch와 같은 ML 프레임워크, Hugging Face와 같은 ML 라이브러리 또는 Amazon SageMaker와 같은 클라우드 서비스에 대한 인테그레이션을 확인하세요.
관련 자료
Examples: 각 인테그레이션에 대한 노트북 및 스크립트 예제를 사용하여 코드를 사용해 보세요.
A. 사용자가 수동으로 설치하지 않고 wandb 기능을 사용하려고 할 때 오류를 발생시키고 적절한 오류 메시지를 표시합니다.
try:
import wandb
exceptImportError:
raiseImportError(
"You are trying to use wandb which is not currently installed.""Please install it using pip install wandb" )
B. Python 패키지를 빌드하는 경우 pyproject.toml 파일에 wandb를 선택적 종속성으로 추가합니다.
[project]
name = "my_awesome_lib"version = "0.1.0"dependencies = [
"torch",
"sklearn"]
[project.optional-dependencies]
dev = [
"wandb"]
사용자 로그인
API 키 만들기
API 키는 클라이언트 또는 머신을 W&B에 인증합니다. 사용자 프로필에서 API 키를 생성할 수 있습니다.
보다 간소화된 접근 방식을 위해 https://wandb.ai/authorize로 직접 이동하여 API 키를 생성할 수 있습니다. 표시된 API 키를 복사하여 비밀번호 관리자와 같은 안전한 위치에 저장하세요.
오른쪽 상단 모서리에 있는 사용자 프로필 아이콘을 클릭합니다.
사용자 설정을 선택한 다음 API 키 섹션으로 스크롤합니다.
표시를 클릭합니다. 표시된 API 키를 복사합니다. API 키를 숨기려면 페이지를 새로 고침합니다.
for epoch in range(NUM_EPOCHS):
for input, ground_truth in data:
prediction = model(input)
loss = loss_fn(prediction, ground_truth)
metrics = { "loss": loss }
run.log(metrics)
메트릭이 많은 경우 메트릭 이름에 train/... 및 val/...와 같은 접두사를 사용하여 UI에서 자동으로 그룹화할 수 있습니다. 이렇게 하면 트레이닝 및 검증 메트릭 또는 분리하려는 다른 메트릭 유형에 대해 W&B Workspace에 별도의 섹션이 생성됩니다.
이제 run.log를 호출할 때마다 메트릭, step 메트릭 및 global_step을 로깅합니다.
for step, (input, ground_truth) in enumerate(data):
... run.log({"global_step": step, "train/loss": 0.1})
run.log({"global_step": step, "eval/loss": 0.2})
예를 들어 검증 루프 중에 “global_step"을 사용할 수 없는 경우 독립 단계 변수에 액세스할 수 없는 경우 “global_step"에 대해 이전에 로깅된 값이 wandb에서 자동으로 사용됩니다. 이 경우 메트릭에 필요한 경우 정의되도록 메트릭에 대한 초기 값을 로깅해야 합니다.
이미지, 테이블, 오디오 등 로깅
메트릭 외에도 플롯, 히스토그램, 테이블, 텍스트, 이미지, 비디오, 오디오, 3D 등과 같은 미디어를 로깅할 수 있습니다.
데이터 로깅 시 고려해야 할 사항은 다음과 같습니다.
메트릭을 얼마나 자주 로깅해야 할까요? 선택 사항이어야 할까요?
시각화하는 데 어떤 유형의 데이터가 도움이 될 수 있을까요?
이미지의 경우 시간 경과에 따른 진화를 확인하기 위해 샘플 예측, 분할 마스크 등을 로깅할 수 있습니다.
프레임워크에서 모델 또는 데이터셋을 사용하거나 생성하는 경우 전체 추적성을 위해 로깅하고 wandb가 W&B Artifacts를 통해 전체 파이프라인을 자동으로 모니터링하도록 할 수 있습니다.
Artifacts를 사용할 때 사용자가 다음을 정의하도록 하는 것이 유용하지만 필수는 아닙니다.
모델 체크포인트 또는 데이터셋을 로깅하는 기능(선택 사항으로 만들려는 경우).
입력으로 사용되는 아티팩트의 경로/참조(있는 경우). 예를 들어 user/project/artifact입니다.
Artifacts 로깅 빈도.
모델 체크포인트 로깅
모델 체크포인트를 W&B에 로깅할 수 있습니다. 고유한 wandb Run ID를 활용하여 출력 모델 체크포인트 이름을 지정하여 Runs 간에 차별화하는 것이 유용합니다. 유용한 메타데이터를 추가할 수도 있습니다. 또한 아래와 같이 각 모델에 에일리어스를 추가할 수도 있습니다.
W&B는 Databricks 환경에서 W&B Jupyter 노트북 경험을 사용자 정의하여 Databricks와 통합됩니다.
Databricks 설정
클러스터에 wandb 설치
클러스터 설정으로 이동하여 클러스터를 선택하고 Libraries를 클릭합니다. Install New를 클릭하고 PyPI를 선택한 다음 wandb 패키지를 추가합니다.
인증 설정
W&B 계정을 인증하려면 노트북이 쿼리할 수 있는 Databricks secret을 추가하면 됩니다.
# databricks cli 설치pip install databricks-cli
# databricks UI에서 토큰 생성databricks configure --token
# 다음 두 코맨드 중 하나를 사용하여 스코프를 생성합니다 (databricks에서 보안 기능 활성화 여부에 따라 다름).# 보안 추가 기능 사용databricks secrets create-scope --scope wandb
# 보안 추가 기능 미사용databricks secrets create-scope --scope wandb --initial-manage-principal users
# 다음 위치에서 api_key를 추가합니다: https://app.wandb.ai/authorizedatabricks secrets put --scope wandb --key api_key
DeepChecks를 Weights & Biases 와 함께 사용하려면 먼저 Weights & Biases 계정을 여기에서 가입해야 합니다. DeepChecks의 Weights & Biases 인테그레이션을 사용하면 다음과 같이 빠르게 시작할 수 있습니다.
import wandb
wandb.login()
# deepchecks에서 검사 가져오기from deepchecks.checks import ModelErrorAnalysis
# 검사 실행result = ModelErrorAnalysis()
# 해당 결과를 wandb로 푸시result.to_wandb()
전체 DeepChecks 테스트 스위트를 Weights & Biases 에 로그할 수도 있습니다.
import wandb
wandb.login()
# deepchecks에서 full_suite 테스트 가져오기from deepchecks.suites import full_suite
# DeepChecks 테스트 스위트 생성 및 실행suite_result = full_suite().run(...)
# thes 결과를 wandb로 푸시# 여기에서 필요한 wandb.init 구성 및 인수를 전달할 수 있습니다.suite_result.to_wandb(project="my-suite-project", config={"suite-name": "full-suite"})
예시
``이 Report는 DeepChecks와 Weights & Biases를 사용하는 강력한 기능을 보여줍니다.
DeepChem 라이브러리는 약물 발견, 재료 과학, 화학 및 생물학에서 딥러닝 사용을 대중화하는 오픈 소스 툴을 제공합니다. 이 W&B 인테그레이션은 DeepChem을 사용하여 모델을 트레이닝하는 동안 간단하고 사용하기 쉬운 experiment 추적 및 모델 체크포인팅을 추가합니다.
3줄의 코드로 DeepChem 로깅하기
logger = WandbLogger(…)
model = TorchModel(…, wandb_logger=logger)
model.fit(…)
트레이닝 손실 및 평가 메트릭은 W&B에 자동으로 기록될 수 있습니다. DeepChem ValidationCallback을 사용하여 선택적 평가를 활성화할 수 있습니다. WandbLogger는 ValidationCallback 콜백을 감지하고 생성된 메트릭을 기록합니다.
W&B는 코드 가 실행된 Docker 이미지에 대한 포인터를 저장하여 이전의 실험 을 정확한 환경 으로 복원할 수 있도록 합니다. wandb 라이브러리 는 이 상태 를 유지하기 위해 WANDB_DOCKER 환경 변수 를 찾습니다. 이 상태 를 자동으로 설정하는 몇 가지 도우미를 제공합니다.
로컬 개발
wandb docker 는 docker 컨테이너 를 시작하고, wandb 환경 변수 를 전달하고, 코드 를 마운트하고, wandb가 설치되었는지 확인하는 코맨드 입니다. 기본적으로 이 코맨드 는 TensorFlow, PyTorch, Keras 및 Jupyter가 설치된 docker 이미지 를 사용합니다. 동일한 코맨드 를 사용하여 자신의 docker 이미지 를 시작할 수 있습니다: wandb docker my/image:latest. 이 코맨드 는 현재 디렉토리 를 컨테이너 의 “/app” 디렉토리 에 마운트합니다. “–dir” 플래그 를 사용하여 이를 변경할 수 있습니다.
프로덕션
wandb docker-run 코맨드 는 프로덕션 워크로드 를 위해 제공됩니다. nvidia-docker 를 대체할 수 있도록 만들어졌습니다. 이는 docker run 코맨드 에 대한 간단한 래퍼 로, 자격 증명 과 WANDB_DOCKER 환경 변수 를 호출에 추가합니다. “–runtime” 플래그 를 전달하지 않고 시스템에서 nvidia-docker 를 사용할 수 있는 경우 런타임 이 nvidia로 설정됩니다.
Kubernetes
Kubernetes에서 트레이닝 워크로드 를 실행하고 k8s API가 Pod에 노출된 경우 (기본적으로 해당됨) wandb는 docker 이미지 의 다이제스트에 대해 API를 쿼리하고 WANDB_DOCKER 환경 변수 를 자동으로 설정합니다.
복원
WANDB_DOCKER 환경 변수 로 Run이 계측된 경우, wandb restore username/project:run_id 를 호출하면 코드 를 복원하는 새 분기를 체크아웃한 다음, 트레이닝 에 사용된 정확한 docker 이미지 를 원래 코맨드 로 미리 채워 시작합니다.
6.9 - Farama Gymnasium
Farama Gymnasium과 W&B를 통합하는 방법.
Farama Gymnasium을 사용하는 경우 gymnasium.wrappers.Monitor에서 생성된 환경의 비디오가 자동으로 기록됩니다. wandb.init에 대한 monitor_gym 키워드 인수를 True로 설정하기만 하면 됩니다.
Gymnasium 인테그레이션은 매우 간단합니다. gymnasium에서 기록된 비디오 파일의 이름을 확인하고, 그에 따라 이름을 지정하거나 일치하는 항목을 찾지 못하면 "videos"로 대체합니다. 더 많은 제어를 원한다면 언제든지 수동으로 비디오를 기록할 수 있습니다.
CleanRL 라이브러리와 함께 Gymnasium을 사용하는 방법에 대한 자세한 내용은 이 report를 확인하세요.
import wandb
from fastai.callback.wandb import*# wandb run 로깅 시작wandb.init(project="my_project")
# 하나의 트레이닝 단계에서만 로깅하려면learn.fit(..., cbs=WandbCallback())
# 모든 트레이닝 단계에서 지속적으로 로깅하려면learn = learner(..., cbs=WandbCallback())
위의 예에서 wandb는 프로세스당 하나의 run을 시작합니다. 트레이닝이 끝나면 두 개의 run이 생성됩니다. 이는 혼란스러울 수 있으며 메인 프로세스에서만 로그할 수 있습니다. 이렇게 하려면 어떤 프로세스에 있는지 수동으로 감지하고 다른 모든 프로세스에서 run 생성을 피해야 합니다 (wandb.init 호출).
Hugging Face Transformers 라이브러리를 사용하면 최첨단 NLP 모델(예: BERT)과 혼합 정밀도 및 그레이디언트 체크포인트와 같은 트레이닝 기술을 쉽게 사용할 수 있습니다. W&B 통합은 사용 편의성을 유지하면서도 대화형 중앙 집중식 대시보드에 풍부하고 유연한 실험 추적 및 모델 버전 관리를 추가합니다.
몇 줄의 코드로 차세대 로깅 구현
os.environ["WANDB_PROJECT"] ="<my-amazing-project>"# W&B 프로젝트 이름 지정os.environ["WANDB_LOG_MODEL"] ="checkpoint"# 모든 모델 체크포인트 로깅from transformers import TrainingArguments, Trainer
args = TrainingArguments(..., report_to="wandb") # W&B 로깅 켜기trainer = Trainer(..., args=args)
W&B Project는 관련 Runs에서 기록된 모든 차트, 데이터 및 Models가 저장되는 곳입니다. 프로젝트 이름을 지정하면 작업을 구성하고 단일 프로젝트에 대한 모든 정보를 한 곳에 보관하는 데 도움이 됩니다.
Run을 프로젝트에 추가하려면 WANDB_PROJECT 환경 변수를 프로젝트 이름으로 설정하기만 하면 됩니다. WandbCallback은 이 프로젝트 이름 환경 변수를 가져와 Run을 설정할 때 사용합니다.
WANDB_PROJECT=amazon_sentiment_analysis
import os
os.environ["WANDB_PROJECT"]="amazon_sentiment_analysis"
%env WANDB_PROJECT=amazon_sentiment_analysis
Trainer를 초기화하기 전에 프로젝트 이름을 설정해야 합니다.
프로젝트 이름이 지정되지 않은 경우 프로젝트 이름은 기본적으로 huggingface로 설정됩니다.
트레이닝 Runs를 W&B에 로깅
Trainer 트레이닝 인수를 정의할 때 코드 내부 또는 커맨드라인에서 가장 중요한 단계는 W&B를 사용하여 로깅을 활성화하기 위해 report_to를 "wandb"로 설정하는 것입니다.
TrainingArguments의 logging_steps 인수는 트레이닝 중에 트레이닝 메트릭이 W&B로 푸시되는 빈도를 제어합니다. run_name 인수를 사용하여 W&B에서 트레이닝 Run의 이름을 지정할 수도 있습니다.
이제 모델이 트레이닝하는 동안 손실, 평가 메트릭, 모델 토폴로지 및 그레이디언트를 W&B에 로깅합니다.
python run_glue.py \ # Python 스크립트 실행 --report_to wandb \ # W&B에 로깅 활성화 --run_name bert-base-high-lr \ # W&B Run 이름(선택 사항)# 기타 커맨드라인 인수
from transformers import TrainingArguments, Trainer
args = TrainingArguments(
# 기타 인수 및 kwargs report_to="wandb", # W&B에 로깅 활성화 run_name="bert-base-high-lr", # W&B Run 이름(선택 사항) logging_steps=1, # W&B에 로깅 빈도)
trainer = Trainer(
# 기타 인수 및 kwargs args=args, # 트레이닝 인수)
trainer.train() # 트레이닝을 시작하고 W&B에 로깅
TensorFlow를 사용하고 계신가요? PyTorch Trainer를 TensorFlow TFTrainer로 바꾸기만 하세요.
모델 체크포인트 설정
Artifacts를 사용하면 최대 100GB의 Models 및 Datasets를 무료로 저장한 다음 Weights & Biases Registry를 사용할 수 있습니다. Registry를 사용하면 Models를 등록하여 탐색하고 평가하고, 스테이징을 준비하거나 프로덕션 환경에 배포할 수 있습니다.
Hugging Face 모델 체크포인트를 Artifacts에 로깅하려면 WANDB_LOG_MODEL 환경 변수를 다음 _중 하나_로 설정합니다.
end: load_best_model_at_end도 설정된 경우 트레이닝이 끝나면 모델을 업로드합니다.
false: 모델을 업로드하지 않습니다.
WANDB_LOG_MODEL="checkpoint"
import os
os.environ["WANDB_LOG_MODEL"] ="checkpoint"
%env WANDB_LOG_MODEL="checkpoint"
이제부터 초기화하는 모든 Transformers Trainer는 Models를 W&B Project에 업로드합니다. 로깅하는 모델 체크포인트는 Artifacts UI를 통해 볼 수 있으며 전체 모델 계보가 포함됩니다(UI에서 예제 모델 체크포인트를 보려면 여기 참조).
기본적으로 WANDB_LOG_MODEL이 end로 설정된 경우 모델은 model-{run_id}로 W&B Artifacts에 저장되고, WANDB_LOG_MODEL이 checkpoint로 설정된 경우 checkpoint-{run_id}로 저장됩니다.
그러나 TrainingArguments에서 run_name을 전달하면 모델은 model-{run_name} 또는 checkpoint-{run_name}로 저장됩니다.
W&B Registry
체크포인트를 Artifacts에 로깅한 후에는 **Registry**를 사용하여 최고의 모델 체크포인트를 등록하고 팀 전체에서 중앙 집중화할 수 있습니다. Registry를 사용하면 작업별로 최고의 Models를 구성하고, Models의 라이프사이클을 관리하고, 전체 ML 라이프사이클을 추적 및 감사하고, 다운스트림 작업을 자동화할 수 있습니다.
트레이닝 또는 평가 중 모델 출력을 시각화하는 것은 모델 트레이닝 방식을 실제로 이해하는 데 종종 필수적입니다.
Transformers Trainer의 콜백 시스템을 사용하면 모델의 텍스트 생성 출력 또는 기타 예측과 같은 추가적인 유용한 데이터를 W&B Tables에 로깅할 수 있습니다.
아래의 **사용자 지정 로깅 섹션**에서 트레이닝 중 평가 출력을 로깅하여 다음과 같은 W&B Table에 로깅하는 방법에 대한 전체 가이드를 참조하세요.
W&B Run 종료(노트북 전용)
트레이닝이 Python 스크립트에 캡슐화된 경우 스크립트가 완료되면 W&B Run이 종료됩니다.
Jupyter 또는 Google Colab 노트북을 사용하는 경우 wandb.finish()를 호출하여 트레이닝이 완료되었음을 알려야 합니다.
trainer.train() # 트레이닝을 시작하고 W&B에 로깅# 트레이닝 후 분석, 테스트, 기타 로깅된 코드wandb.finish()
결과 시각화
트레이닝 결과를 로깅했으면 W&B Dashboard에서 결과를 동적으로 탐색할 수 있습니다. 유연하고 대화형 시각화를 통해 한 번에 수십 개의 Runs를 비교하고, 흥미로운 발견을 확대하고, 복잡한 데이터에서 통찰력을 얻는 것이 쉽습니다.
고급 기능 및 FAQ
최고의 모델을 저장하는 방법은 무엇인가요?
TrainingArguments를 load_best_model_at_end=True로 Trainer에 전달하면 W&B는 가장 성능이 좋은 모델 체크포인트를 Artifacts에 저장합니다.
모델 체크포인트를 Artifacts로 저장하는 경우 Registry로 승격할 수 있습니다. Registry에서 다음을 수행할 수 있습니다.
ML 작업별로 최고의 모델 버전을 구성합니다.
Models를 중앙 집중화하고 팀과 공유합니다.
프로덕션을 위해 Models를 스테이징하거나 추가 평가를 위해 북마크합니다.
다운스트림 CI/CD 프로세스를 트리거합니다.
저장된 모델을 로드하는 방법은 무엇인가요?
WANDB_LOG_MODEL을 사용하여 모델을 W&B Artifacts에 저장한 경우 추가 트레이닝을 위해 또는 추론을 실행하기 위해 모델 가중치를 다운로드할 수 있습니다. 이전과 동일한 Hugging Face 아키텍처에 다시 로드하기만 하면 됩니다.
# 새 Run 만들기with wandb.init(project="amazon_sentiment_analysis") as run:
# Artifact 이름 및 버전 전달 my_model_name ="model-bert-base-high-lr:latest" my_model_artifact = run.use_artifact(my_model_name)
# 모델 가중치를 폴더에 다운로드하고 경로 반환 model_dir = my_model_artifact.download()
# 동일한 모델 클래스를 사용하여 해당 폴더에서 Hugging Face 모델 로드 model = AutoModelForSequenceClassification.from_pretrained(
model_dir, num_labels=num_labels
)
# 추가 트레이닝 또는 추론 실행
체크포인트에서 트레이닝을 재개하는 방법은 무엇인가요?
WANDB_LOG_MODEL='checkpoint'를 설정한 경우 model_dir을 TrainingArguments의 model_name_or_path 인수로 사용하고 resume_from_checkpoint=True를 Trainer에 전달하여 트레이닝을 재개할 수도 있습니다.
last_run_id ="xxxxxxxx"# wandb Workspace에서 run_id 가져오기# run_id에서 W&B Run 재개with wandb.init(
project=os.environ["WANDB_PROJECT"],
id=last_run_id,
resume="must",
) as run:
# Artifact를 Run에 연결 my_checkpoint_name =f"checkpoint-{last_run_id}:latest" my_checkpoint_artifact = run.use_artifact(my_model_name)
# 체크포인트를 폴더에 다운로드하고 경로 반환 checkpoint_dir = my_checkpoint_artifact.download()
# 모델 및 Trainer 다시 초기화 model = AutoModelForSequenceClassification.from_pretrained(
"<model_name>", num_labels=num_labels
)
# 멋진 트레이닝 인수 training_args = TrainingArguments()
trainer = Trainer(model=model, args=training_args)
# 체크포인트 디렉터리를 사용하여 체크포인트에서 트레이닝을 재개해야 합니다. trainer.train(resume_from_checkpoint=checkpoint_dir)
트레이닝 중에 평가 샘플을 로깅하고 보는 방법
Transformers Trainer를 통해 W&B에 로깅하는 것은 Transformers 라이브러리의 WandbCallback에서 처리합니다. Hugging Face 로깅을 사용자 지정해야 하는 경우 WandbCallback을 서브클래싱하고 Trainer 클래스의 추가적인 메서드를 활용하는 추가적인 기능을 추가하여 이 콜백을 수정할 수 있습니다.
아래는 이 새로운 콜백을 HF Trainer에 추가하는 일반적인 패턴이며, 아래에는 평가 출력을 W&B Table에 로깅하는 코드 완성 예제가 있습니다.
환경 변수를 설정하여 Trainer로 로깅되는 항목을 추가로 구성할 수 있습니다. W&B 환경 변수의 전체 목록은 여기에서 찾을 수 있습니다.
환경 변수
사용법
WANDB_PROJECT
프로젝트 이름 지정(기본값: huggingface)
WANDB_LOG_MODEL
모델 체크포인트를 W&B Artifact로 로깅(기본값: false)
false(기본값): 모델 체크포인트 없음
checkpoint: 체크포인트는 모든 args.save_steps마다 업로드됩니다(Trainer의 TrainingArguments에서 설정).
end: 최종 모델 체크포인트는 트레이닝이 끝나면 업로드됩니다.
WANDB_WATCH
모델 그레이디언트, 파라미터 또는 둘 다를 로깅할지 여부 설정
false(기본값): 그레이디언트 또는 파라미터 로깅 없음
gradients: 그레이디언트의 히스토그램 로깅
all: 그레이디언트 및 파라미터의 히스토그램 로깅
WANDB_DISABLED
true로 설정하여 로깅을 완전히 끕니다(기본값: false)
WANDB_SILENT
true로 설정하여 wandb에서 인쇄된 출력을 표시하지 않습니다(기본값: false)
WANDB_WATCH=all
WANDB_SILENT=true
%env WANDB_WATCH=all
%env WANDB_SILENT=true
wandb.init를 사용자 지정하는 방법은 무엇인가요?
Trainer가 사용하는 WandbCallback은 Trainer가 초기화될 때 내부적으로 wandb.init를 호출합니다. 또는 Trainer를 초기화하기 전에 wandb.init를 호출하여 Run을 수동으로 설정할 수 있습니다. 이렇게 하면 W&B Run 구성을 완전히 제어할 수 있습니다.
init에 전달할 수 있는 예는 아래와 같습니다. wandb.init를 사용하는 방법에 대한 자세한 내용은 참조 설명서를 확인하세요.
Hugging Face Diffusers는 이미지, 오디오, 심지어 분자의 3D 구조를 생성하기 위한 최첨단 사전학습된 diffusion model을 위한 라이브러리입니다. Weights & Biases 인테그레이션은 사용 편의성을 유지하면서도 대화형 중앙 집중식 대시보드에 풍부하고 유연한 실험 추적, 미디어 시각화, 파이프라인 아키텍처 및 설정 관리를 추가합니다.
단 두 줄로 차원이 다른 로깅을 경험하세요
단 2줄의 코드를 추가하는 것만으로도 실험과 관련된 모든 프롬프트, 부정적 프롬프트, 생성된 미디어 및 설정을 기록할 수 있습니다. 다음은 로깅을 시작하기 위한 2줄의 코드입니다.
# import the autolog functionfrom wandb.integration.diffusers import autolog
# call the autolog before calling the pipelineautolog(init=dict(project="diffusers_logging"))
실험 결과가 기록되는 방식의 예시입니다.
시작하기
diffusers, transformers, accelerate 및 wandb를 설치합니다.
지원되는 파이프라인 호출 목록은 [여기](https://github.com/wandb/wandb/blob/main/wandb/integration/diffusers/autologger.py#L12-L72)에서 확인할 수 있습니다. 이 인테그레이션의 새로운 기능을 요청하거나 관련 버그를 보고하려면 [https://github.com/wandb/wandb/issues](https://github.com/wandb/wandb/issues)에 이슈를 여십시오.
예시
Autologging
다음은 autolog의 간단한 엔드투엔드 예시입니다.
import torch
from diffusers import DiffusionPipeline
# import the autolog functionfrom wandb.integration.diffusers import autolog
# call the autolog before calling the pipelineautolog(init=dict(project="diffusers_logging"))
# Initialize the diffusion pipelinepipeline = DiffusionPipeline.from_pretrained(
"stabilityai/stable-diffusion-2-1", torch_dtype=torch.float16
).to("cuda")
# Define the prompts, negative prompts, and seed.prompt = ["a photograph of an astronaut riding a horse", "a photograph of a dragon"]
negative_prompt = ["ugly, deformed", "ugly, deformed"]
generator = torch.Generator(device="cpu").manual_seed(10)
# call the pipeline to generate the imagesimages = pipeline(
prompt,
negative_prompt=negative_prompt,
num_images_per_prompt=2,
generator=generator,
)
import torch
from diffusers import DiffusionPipeline
import wandb
# import the autolog functionfrom wandb.integration.diffusers import autolog
# call the autolog before calling the pipelineautolog(init=dict(project="diffusers_logging"))
# Initialize the diffusion pipelinepipeline = DiffusionPipeline.from_pretrained(
"stabilityai/stable-diffusion-2-1", torch_dtype=torch.float16
).to("cuda")
# Define the prompts, negative prompts, and seed.prompt = ["a photograph of an astronaut riding a horse", "a photograph of a dragon"]
negative_prompt = ["ugly, deformed", "ugly, deformed"]
generator = torch.Generator(device="cpu").manual_seed(10)
# call the pipeline to generate the imagesimages = pipeline(
prompt,
negative_prompt=negative_prompt,
num_images_per_prompt=2,
generator=generator,
)
# Finish the experimentwandb.finish()
단일 실험의 결과:
여러 실험의 결과:
실험의 설정:
파이프라인을 호출한 후 IPython 노트북 환경에서 코드를 실행할 때는 wandb.finish()를 명시적으로 호출해야 합니다. Python 스크립트를 실행할 때는 필요하지 않습니다.
Hugging Face AutoTrain은 자연어 처리 (NLP) 작업, 컴퓨터 비전 (CV) 작업, 음성 작업 및 테이블 형식 작업을 위한 최첨단 모델을 트레이닝하는 노코드 툴입니다.
Weights & Biases는 Hugging Face AutoTrain에 직접 통합되어 experiment 추적 및 config 관리를 제공합니다. 실험을 위해 CLI 코맨드에서 단일 파라미터를 사용하는 것만큼 쉽습니다.
필수 조건 설치
autotrain-advanced 및 wandb를 설치합니다.
pip install --upgrade autotrain-advanced wandb
!pip install --upgrade autotrain-advanced wandb
이러한 변경 사항을 보여주기 위해 이 페이지에서는 수학 데이터셋에서 LLM을 fine-tune하여 GSM8k Benchmarks에서 pass@1로 SoTA 결과를 달성합니다.
데이터셋 준비
Hugging Face AutoTrain은 제대로 작동하기 위해 CSV 커스텀 데이터셋에 특정 형식이 필요합니다.
트레이닝 파일에는 트레이닝에 사용되는 text 열이 있어야 합니다. 최상의 결과를 얻으려면 text 열의 데이터가 ### Human: Question?### Assistant: Answer. 형식을 준수해야 합니다. timdettmers/openassistant-guanaco에서 훌륭한 예를 검토하십시오.
그러나 MetaMathQA 데이터셋에는 query, response 및 type 열이 포함되어 있습니다. 먼저 이 데이터셋을 전처리합니다. type 열을 제거하고 query 및 response 열의 내용을 ### Human: Query?### Assistant: Response. 형식의 새 text 열로 결합합니다. 트레이닝은 결과 데이터셋인 rishiraj/guanaco-style-metamath를 사용합니다.
autotrain을 사용하여 트레이닝
커맨드 라인 또는 노트북에서 autotrain advanced를 사용하여 트레이닝을 시작할 수 있습니다. --log 인수를 사용하거나 --log wandb를 사용하여 결과를 W&B run에 기록합니다.
Hydra는 구성 사전에 연결하는 기본 방법으로 omegaconf를 사용합니다. OmegaConf의 사전은 기본 사전의 서브클래스가 아니므로 Hydra의 Config를 wandb.config에 직접 전달하면 대시보드에서 예기치 않은 결과가 발생합니다. omegaconf.DictConfig를 wandb.config에 전달하기 전에 기본 dict 유형으로 변환해야 합니다.
W&B Sweeps는 확장성이 뛰어난 하이퍼파라미터 검색 플랫폼으로, 최소한의 코딩 공간으로 W&B Experiments에 대한 흥미로운 통찰력과 시각화를 제공합니다. Sweeps는 코딩 요구 사항 없이 Hydra Projects와 원활하게 통합됩니다. 필요한 것은 스윕할 다양한 파라미터를 설명하는 구성 파일뿐입니다.
W&B는 자동으로 프로젝트 내부에 스윕을 생성하고 각 머신에서 스윕을 실행할 수 있도록 wandb agent 코맨드를 반환합니다.
Hydra 기본값에 없는 파라미터 전달
Hydra는 커맨드 앞에 +를 사용하여 기본 구성 파일에 없는 추가 파라미터를 커맨드 라인을 통해 전달할 수 있도록 지원합니다. 예를 들어 다음과 같이 호출하여 일부 값이 있는 추가 파라미터를 전달할 수 있습니다.
$ python program.py +experiment=some_experiment
Hydra Experiments를 구성하는 동안 수행하는 작업과 유사하게 이러한 + 구성을 스윕할 수 없습니다. 이를 해결하려면 기본 빈 파일로 experiment 파라미터를 초기화하고 W&B Sweep을 사용하여 각 호출에서 해당 빈 설정을 재정의할 수 있습니다. 자세한 내용은 이 W&B Report를 참조하세요.
import wandb
from wandb.integration.keras import WandbMetricsLogger, WandbModelCheckpoint
# 새로운 W&B run 초기화wandb.init(config={"bs": 12})
# WandbModelCheckpoint를 model.fit에 전달model.fit(
X_train,
y_train,
validation_data=(X_test, y_test),
callbacks=[
WandbMetricsLogger(),
WandbModelCheckpoint("models"),
],
)
WandbModelCheckpoint 참조
파라미터
설명
filepath
(str): 모드 파일을 저장할 경로입니다.
monitor
(str): 모니터링할 메트릭 이름입니다.
verbose
(int): 상세 모드, 0 또는 1. 모드 0은 자동이고 모드 1은 콜백이 작업을 수행할 때 메시지를 표시합니다.
save_best_only
(Boolean): save_best_only=True인 경우 monitor 및 mode 속성으로 정의된 대로 최신 모델 또는 가장 적합하다고 간주되는 모델만 저장합니다.
save_weights_only
(Boolean): True인 경우 모델의 가중치만 저장합니다.
mode
(auto, min 또는 max): val_acc의 경우 max로 설정하고 val_loss의 경우 min으로 설정하는 식입니다.
save_freq
(“epoch” 또는 int): ‘epoch’를 사용하는 경우 콜백은 각 에포크 후에 모델을 저장합니다. 정수를 사용하는 경우 콜백은 이만큼의 배치가 끝날 때 모델을 저장합니다. val_acc 또는 val_loss와 같은 검증 메트릭을 모니터링할 때 이러한 메트릭은 에포크가 끝날 때만 사용할 수 있으므로 save_freq를 “epoch"로 설정해야 합니다.
options
(str): save_weights_only가 true인 경우 선택적 tf.train.CheckpointOptions 오브젝트이거나 save_weights_only가 false인 경우 선택적 tf.saved_model.SaveOptions 오브젝트입니다.
initial_value_threshold
(float): 모니터링할 메트릭의 부동 소수점 초기 “최상” 값입니다.
N 에포크 후에 체크포인트 기록
기본적으로(save_freq="epoch") 콜백은 각 에포크 후에 체크포인트를 만들고 아티팩트로 업로드합니다. 특정 수의 배치 후에 체크포인트를 만들려면 save_freq를 정수로 설정합니다. N 에포크 후에 체크포인트를 만들려면 train 데이터 로더의 카디널리티를 계산하여 save_freq에 전달합니다.
TPU에서 체크포인트를 만드는 동안 UnimplementedError: File system scheme '[local]' not implemented 오류 메시지가 발생할 수 있습니다. 이는 모델 디렉토리(filepath)가 클라우드 스토리지 버킷 경로(gs://bucket-name/...)를 사용해야 하고 이 버킷에 TPU 서버에서 엑세스할 수 있어야 하기 때문에 발생합니다. 그러나 체크포인트를 만드는 데 로컬 경로를 사용할 수 있으며, 이는 Artifacts로 업로드됩니다.
W&B Artifact 페이지에는 Workspace 페이지가 아닌 Table 로그가 기본적으로 포함되어 있습니다.
WandbEvalCallback 참조
파라미터
설명
data_table_columns
(list) data_table의 열 이름 목록입니다.
pred_table_columns
(list) pred_table의 열 이름 목록입니다.
메모리 공간 세부 정보
on_train_begin 메서드가 호출되면 data_table을 W&B에 기록합니다. W&B Artifact로 업로드되면 data_table_ref 클래스 변수를 사용하여 엑세스할 수 있는 이 테이블에 대한 참조가 생성됩니다. data_table_ref는 self.data_table_ref[idx][n]과 같이 인덱싱할 수 있는 2D 목록이며, 여기서 idx는 행 번호이고 n은 열 번호입니다. 아래 예에서 사용법을 살펴보겠습니다.
콜백 사용자 정의
on_train_begin 또는 on_epoch_end 메서드를 재정의하여 더 세분화된 제어를 할 수 있습니다. N 배치 후에 샘플을 기록하려면 on_train_batch_end 메서드를 구현하면 됩니다.
💡 WandbEvalCallback을 상속하여 모델 예측 시각화를 위한 콜백을 구현하고 있으며 설명이 필요하거나 수정해야 할 사항이 있는 경우 문제를 열어 알려주시기 바랍니다.
WandbCallback [기존]
W&B 라이브러리 WandbCallback 클래스를 사용하여 model.fit에서 추적된 모든 메트릭 및 손실 값을 자동으로 저장합니다.
Keras에서 수집한 모든 메트릭(손실 및 keras_model.compile()에 전달된 항목)에서 기록 데이터를 자동으로 기록합니다.
monitor 및 mode 속성으로 정의된 대로 “최상” 트레이닝 단계와 연결된 run에 대한 요약 메트릭을 설정합니다. 기본값은 최소 val_loss가 있는 에포크입니다. WandbCallback은 기본적으로 최상의 epoch와 연결된 모델을 저장합니다.
선택적으로 그레이디언트 및 파라미터 히스토그램을 기록합니다.
선택적으로 시각화를 위해 트레이닝 및 검증 데이터를 wandb에 저장합니다.
WandbCallback 참조
인수
monitor
(str) 모니터링할 메트릭 이름입니다. 기본값은 val_loss입니다.
mode
(str) {auto, min, max} 중 하나입니다. min - 모니터가 최소화될 때 모델 저장 max - 모니터가 최대화될 때 모델 저장 auto - 모델을 저장할 시기를 추측하려고 시도합니다(기본값).
save_model
True - 모니터가 이전의 모든 에포크보다 나을 때 모델 저장 False - 모델을 저장하지 않음
save_graph
(boolean) True인 경우 모델 그래프를 wandb에 저장합니다(기본값은 True).
save_weights_only
(boolean) True인 경우 모델의 가중치(model.save_weights(filepath))만 저장합니다. 그렇지 않으면 전체 모델을 저장합니다.
log_weights
(boolean) True인 경우 모델 레이어의 가중치 히스토그램을 저장합니다.
log_gradients
(boolean) True인 경우 트레이닝 그레이디언트의 히스토그램을 기록합니다.
training_data
(tuple) model.fit에 전달된 것과 동일한 형식 (X,y)입니다. 그레이디언트 계산에 필요합니다. log_gradients가 True인 경우 필수입니다.
validation_data
(tuple) model.fit에 전달된 것과 동일한 형식 (X,y)입니다. wandb가 시각화할 데이터 세트입니다. 이 필드를 설정하면 모든 에포크에서 wandb는 적은 수의 예측을 수행하고 나중에 시각화할 수 있도록 결과를 저장합니다.
generator
(generator) wandb가 시각화할 검증 데이터를 반환하는 생성기입니다. 이 생성기는 튜플 (X,y)를 반환해야 합니다. wandb가 특정 데이터 예제를 시각화하려면 validate_data 또는 생성기를 설정해야 합니다.
validation_steps
(int) validation_data가 생성기인 경우 전체 검증 세트에 대해 생성기를 실행할 단계 수입니다.
labels
(list) wandb로 데이터를 시각화하는 경우 이 레이블 목록은 여러 클래스로 분류기를 빌드하는 경우 숫자 출력을 이해하기 쉬운 문자열로 변환합니다. 이진 분류기의 경우 두 개의 레이블 목록([false 레이블, true 레이블])을 전달할 수 있습니다. validate_data 및 generator가 모두 false인 경우 아무 작업도 수행하지 않습니다.
predictions
(int) 각 에포크에서 시각화를 위해 수행할 예측 수이며, 최대값은 100입니다.
input_type
(string) 시각화를 돕기 위한 모델 입력 유형입니다. (image, images, segmentation_mask) 중 하나일 수 있습니다.
output_type
(string) 시각화를 돕기 위한 모델 출력 유형입니다. (image, images, segmentation_mask) 중 하나일 수 있습니다.
log_evaluation
(boolean) True인 경우 각 에포크에서 검증 데이터와 모델의 예측을 포함하는 Table을 저장합니다. 자세한 내용은 validation_indexes, validation_row_processor 및 output_row_processor를 참조하세요.
class_colors
([float, float, float]) 입력 또는 출력이 분할 마스크인 경우 각 클래스에 대한 rgb 튜플(범위 0-1)을 포함하는 배열입니다.
log_batch_frequency
(integer) None인 경우 콜백은 모든 에포크를 기록합니다. 정수로 설정된 경우 콜백은 log_batch_frequency 배치마다 트레이닝 메트릭을 기록합니다.
log_best_prefix
(string) None인 경우 추가 요약 메트릭을 저장하지 않습니다. 문자열로 설정된 경우 모니터링된 메트릭과 에포크 앞에 접두사를 붙이고 결과를 요약 메트릭으로 저장합니다.
validation_indexes
([wandb.data_types._TableLinkMixin]) 각 검증 예제와 연결할 인덱스 키의 정렬된 목록입니다. log_evaluation이 True이고 validation_indexes를 제공하는 경우 검증 데이터 Table을 만들지 않습니다. 대신 각 예측을 TableLinkMixin으로 표시된 행과 연결합니다. 행 키 목록을 가져오려면 Table.get_index()를 사용하세요.
validation_row_processor
(Callable) 검증 데이터에 적용할 함수로, 일반적으로 데이터를 시각화하는 데 사용됩니다. 이 함수는 ndx(int)와 row(dict)를 받습니다. 모델에 입력이 하나 있는 경우 row["input"]에 행에 대한 입력 데이터가 포함됩니다. 그렇지 않으면 입력 슬롯의 이름이 포함됩니다. 적합 함수가 대상이 하나인 경우 row["target"]에 행에 대한 대상 데이터가 포함됩니다. 그렇지 않으면 출력 슬롯의 이름이 포함됩니다. 예를 들어 입력 데이터가 단일 배열인 경우 데이터를 이미지로 시각화하려면 lambda ndx, row: {"img": wandb.Image(row["input"])}를 프로세서로 제공합니다. log_evaluation이 False이거나 validation_indexes가 있는 경우 무시됩니다.
output_row_processor
(Callable) validation_row_processor와 동일하지만 모델의 출력에 적용됩니다. row["output"]에 모델 출력 결과가 포함됩니다.
infer_missing_processors
(Boolean) 누락된 경우 validation_row_processor 및 output_row_processor를 유추할지 여부를 결정합니다. 기본값은 True입니다. labels를 제공하는 경우 W&B는 적절한 분류 유형 프로세서를 유추하려고 시도합니다.
log_evaluation_frequency
(int) 평가 결과를 기록하는 빈도를 결정합니다. 기본값은 트레이닝이 끝날 때만 기록하는 0입니다. 모든 에포크를 기록하려면 1로 설정하고, 다른 모든 에포크를 기록하려면 2로 설정하는 식입니다. log_evaluation이 False인 경우 아무런 효과가 없습니다.
자주 묻는 질문
wandb로 Keras 멀티프로세싱을 어떻게 사용합니까?
use_multiprocessing=True를 설정하면 다음 오류가 발생할 수 있습니다.
Error("You must call wandb.init() before wandb.config.batch_size")
해결 방법:
Sequence 클래스 구성에서 wandb.init(group='...')를 추가합니다.
main에서 if __name__ == "__main__":를 사용하고 있는지 확인하고 스크립트 로직의 나머지 부분을 그 안에 넣습니다.
6.17 - Kubeflow Pipelines (kfp)
W&B를 Kubeflow 파이프라인과 통합하는 방법.
Kubeflow Pipelines (kfp) 는 Docker 컨테이너를 기반으로 구축된 휴대 가능하고 확장 가능한 기계 학습(ML) 워크플로우를 구축하고 배포하기 위한 플랫폼입니다.
이 통합을 통해 사용자는 데코레이터를 kfp python functional components에 적용하여 파라미터와 Artifacts를 W&B에 자동으로 기록할 수 있습니다.
이 기능은 wandb==0.12.11에서 활성화되었으며 kfp<2.0.0이 필요합니다.
가입하고 API 키 만들기
API 키는 사용자의 머신을 W&B에 인증합니다. 사용자 프로필에서 API 키를 생성할 수 있습니다.
보다 간소화된 접근 방식을 위해 https://wandb.ai/authorize로 직접 이동하여 API 키를 생성할 수 있습니다. 표시된 API 키를 복사하여 비밀번호 관리자와 같은 안전한 위치에 저장하십시오.
오른쪽 상단 모서리에 있는 사용자 프로필 아이콘을 클릭합니다.
User Settings를 선택한 다음 API Keys 섹션으로 스크롤합니다.
Reveal을 클릭합니다. 표시된 API 키를 복사합니다. API 키를 숨기려면 페이지를 새로 고칩니다.
@wandb_log 데코레이터를 추가하고 평소처럼 컴포넌트를 생성합니다. 이렇게 하면 파이프라인을 실행할 때마다 입력/출력 파라미터와 Artifacts가 자동으로 W&B에 기록됩니다.
from kfp import components
from wandb.integration.kfp import wandb_log
@wandb_logdefadd(a: float, b: float) -> float:
return a + b
add = components.create_component_from_func(add)
컨테이너에 환경 변수 전달
환경 변수를 컨테이너에 명시적으로 전달해야 할 수 있습니다. 양방향 연결을 위해서는 환경 변수 WANDB_KUBEFLOW_URL을 Kubeflow Pipelines 인스턴스의 기본 URL로 설정해야 합니다. 예를 들어, https://kubeflow.mysite.com과 같습니다.
import os
from kubernetes.client.models import V1EnvVar
defadd_wandb_env_variables(op):
env = {
"WANDB_API_KEY": os.getenv("WANDB_API_KEY"),
"WANDB_BASE_URL": os.getenv("WANDB_BASE_URL"),
}
for name, value in env.items():
op = op.add_env_variable(V1EnvVar(name, value))
return op
@dsl.pipeline(name="example-pipeline")
defexample_pipeline(param1: str, param2: int):
conf = dsl.get_pipeline_conf()
conf.add_op_transformer(add_wandb_env_variables)
프로그래밍 방식으로 데이터에 엑세스
Kubeflow Pipelines UI를 통해
W&B로 로깅된 Kubeflow Pipelines UI에서 Run을 클릭합니다.
Input/Output 및 ML Metadata 탭에서 입력 및 출력에 대한 자세한 내용을 확인합니다.
Visualizations 탭에서 W&B 웹 앱을 봅니다.
웹 앱 UI를 통해
웹 앱 UI는 Kubeflow Pipelines의 Visualizations 탭과 동일한 콘텐츠를 가지고 있지만 공간이 더 넓습니다. 여기에서 웹 앱 UI에 대해 자세히 알아보세요.
wandb 라이브러리에는 LightGBM을 위한 특별한 콜백이 포함되어 있습니다. 또한 Weights & Biases의 일반적인 로깅 기능을 사용하여 하이퍼파라미터 스윕과 같은 대규모 Experiments를 쉽게 추적할 수 있습니다.
from wandb.integration.lightgbm import wandb_callback, log_summary
import lightgbm as lgb
# Log metrics to W&Bgbm = lgb.train(..., callbacks=[wandb_callback()])
# Log feature importance plot and upload model checkpoint to W&Blog_summary(gbm, save_model_checkpoint=True)
from wandb.integration.metaflow import wandb_log
classWandbExampleFlow(FlowSpec):
@wandb_log(datasets=True, models=True, settings=wandb.Settings(...))
@stepdefstart(self):
self.raw_df = pd.read_csv(...).# pd.DataFrame -> upload as dataset self.model_file = torch.load(...) # nn.Module -> upload as model self.next(self.transform)
흐름을 데코레이팅하는 것은 구성 단계를 모두 기본값으로 데코레이팅하는 것과 같습니다.
이 경우 WandbExampleFlow의 모든 단계는 기본적으로 데이터셋과 Models를 기록하도록 기본 설정되어 있습니다. 이는 각 단계를 @wandb_log(datasets=True, models=True)로 데코레이팅하는 것과 같습니다.
from wandb.integration.metaflow import wandb_log
@wandb_log(datasets=True, models=True) # decorate all @step classWandbExampleFlow(FlowSpec):
@stepdefstart(self):
self.raw_df = pd.read_csv(...).# pd.DataFrame -> upload as dataset self.model_file = torch.load(...) # nn.Module -> upload as model self.next(self.transform)
흐름을 데코레이팅하는 것은 모든 단계를 기본값으로 데코레이팅하는 것과 같습니다. 즉, 나중에 다른 @wandb_log로 단계를 데코레이팅하면 흐름 수준 데코레이션이 재정의됩니다.
이 예에서:
start 및 mid는 데이터셋과 Models를 모두 기록합니다.
end는 데이터셋과 Models를 모두 기록하지 않습니다.
from wandb.integration.metaflow import wandb_log
@wandb_log(datasets=True, models=True) # same as decorating start and midclassWandbExampleFlow(FlowSpec):
# this step will log datasets and models@stepdefstart(self):
self.raw_df = pd.read_csv(...).# pd.DataFrame -> upload as dataset self.model_file = torch.load(...) # nn.Module -> upload as model self.next(self.mid)
# this step will also log datasets and models@stepdefmid(self):
self.raw_df = pd.read_csv(...).# pd.DataFrame -> upload as dataset self.model_file = torch.load(...) # nn.Module -> upload as model self.next(self.end)
# this step is overwritten and will NOT log datasets OR models@wandb_log(datasets=False, models=False)
@stepdefend(self):
self.raw_df = pd.read_csv(...). self.model_file = torch.load(...)
MMEngine은 OpenMMLab에서 만든 PyTorch 기반 딥러닝 모델 트레이닝을 위한 기본 라이브러리입니다. MMEngine은 OpenMMLab 알고리즘 라이브러리를 위한 차세대 트레이닝 아키텍처를 구현하여 OpenMMLab 내의 30개 이상의 알고리즘 라이브러리에 통합된 실행 기반을 제공합니다. 핵심 구성 요소로는 트레이닝 엔진, 평가 엔진 및 모듈 관리가 있습니다.
from mmengine.visualization import Visualizer
# define the visualization configsvisualization_cfg = dict(
name="wandb_visualizer",
vis_backends=[
dict(
type='WandbVisBackend',
init_kwargs=dict(project="mmengine"),
)
],
save_dir="runs/wandb")
# get the visualizer from the visualization configsvisualizer = Visualizer.get_instance(**visualization_cfg)
[W&B run 초기화](/ko/ref/python/init/) 입력 파라미터에 대한 인수의 사전을 `init_kwargs`에 전달합니다.
visualizer로 runner를 초기화하고 runner.train()을 호출합니다.
from mmengine.runner import Runner
# build the mmengine Runner which is a training helper for PyTorchrunner = Runner(
model,
work_dir='runs/gan/',
train_dataloader=train_dataloader,
train_cfg=train_cfg,
optim_wrapper=opt_wrapper_dict,
visualizer=visualizer, # pass the visualizer)
# start trainingrunner.train()
OpenMMLab 컴퓨터 비전 라이브러리와 함께 WandbVisBackend 사용
WandbVisBackend를 사용하여 MMDetection과 같은 OpenMMLab 컴퓨터 비전 라이브러리로 Experiments를 쉽게 추적할 수도 있습니다.
# inherit base configs from the default runtime configs_base_ = ["../_base_/default_runtime.py"]
# Assign the `WandbVisBackend` config dictionary to the# `vis_backends` of the `visualizer` from the base configs_base_.visualizer.vis_backends = [
dict(
type='WandbVisBackend',
init_kwargs={
'project': 'mmdet',
'entity': 'geekyrakshit' },
),
]
6.21 - MMF
Meta AI의 MMF와 W&B를 통합하는 방법.
Meta AI의 MMF 라이브러리의 WandbLogger 클래스를 사용하면 Weights & Biases가 트레이닝/유효성 검사 메트릭, 시스템 (GPU 및 CPU) 메트릭, 모델 체크포인트 및 구성 파라미터를 기록할 수 있습니다.
현재 기능
MMF의 WandbLogger에서 현재 지원하는 기능은 다음과 같습니다.
트레이닝 및 유효성 검사 메트릭
시간에 따른 학습률
W&B Artifacts에 모델 체크포인트 저장
GPU 및 CPU 시스템 메트릭
트레이닝 구성 파라미터
구성 파라미터
wandb 로깅을 활성화하고 사용자 정의하기 위해 MMF 구성에서 다음 옵션을 사용할 수 있습니다.
training:
wandb:
enabled: true
# 엔터티는 Runs을 보내는 사용자 이름 또는 팀 이름입니다.
# 기본적으로 사용자 계정에 Run을 기록합니다.
entity: null
# wandb로 실험을 기록하는 동안 사용할 프로젝트 이름
project: mmf
# wandb로 프로젝트에서 실험을 기록하는 데 사용할 실험/run 이름
# 기본 실험 이름은 다음과 같습니다: ${training.experiment_name}
name: ${training.experiment_name}
# 모델 체크포인트 설정을 켜고 체크포인트를 W&B Artifacts에 저장합니다
log_model_checkpoint: true
# wandb.init()에 전달할 추가 인수 값입니다.
# 사용 가능한 인수를 보려면 /ref/python/init에서 설명서를 확인하세요(예:
# job_type: 'train'
# tags: ['tag1', 'tag2']
env:
# wandb 메타데이터가 저장될 디렉토리의 경로를 변경하려면(기본값: env.log_dir):
wandb_logdir: ${env:MMF_WANDB_LOGDIR,}
Composer는 신경망을 더 좋고, 더 빠르고, 더 저렴하게 트레이닝하기 위한 라이브러리입니다. 여기에는 신경망 트레이닝을 가속화하고 일반화를 개선하기 위한 최첨단 메소드가 많이 포함되어 있으며, 다양한 개선 사항을 쉽게 구성 할 수 있는 선택적 Trainer API가 함께 제공됩니다.
Weights & Biases는 ML Experiments 로깅을 위한 간단한 래퍼를 제공합니다. 하지만 직접 결합할 필요가 없습니다. W&B는 WandBLogger를 통해 Composer 라이브러리에 직접 통합됩니다.
W&B에 로깅 시작하기
from composer import Trainer
from composer.loggers import WandBLogger
trainer = Trainer(..., logger=WandBLogger())
Composer의 WandBLogger 사용
Composer 라이브러리는 Trainer에서 WandBLogger 클래스를 사용하여 메트릭을 Weights and Biases에 기록합니다. 로거를 인스턴스화하고 Trainer에 전달하는 것만큼 간단합니다.
rank-zero 프로세스에서만 기록할지 여부. Artifacts를 기록할 때는 모든 순위에서 기록하는 것이 좋습니다. 순위 ≥1의 Artifacts는 저장되지 않으므로 관련 정보가 삭제될 수 있습니다. 예를 들어 Deepspeed ZeRO를 사용하는 경우 모든 순위의 Artifacts 없이는 체크포인트에서 복원할 수 없습니다. 기본값: True (bool, optional)
init_kwargs
wandb config 등과 같은 wandb.init에 전달할 파라미터 전체 목록은 여기에서 wandb.init이 허용하는 파라미터를 참조하세요.
일반적인 사용법은 다음과 같습니다.
init_kwargs = {"notes":"이 실험에서 더 높은 학습률 테스트",
"config":{"arch":"Llama",
"use_mixed_precision":True
}
}
wandb_logger = WandBLogger(log_artifacts=True, init_kwargs=init_kwargs)
예측 샘플 기록
Composer의 콜백 시스템을 사용하여 WandBLogger를 통해 Weights & Biases에 로깅할 시기를 제어할 수 있습니다. 이 예에서는 유효성 검사 이미지 및 예측 샘플이 기록됩니다.
W&B OpenAI API 인테그레이션을 사용하여 모든 OpenAI 모델 (파인튜닝된 모델 포함)에 대한 요청, 응답, 토큰 수 및 모델 메타데이터를 기록합니다.
W&B를 사용하여 파인튜닝 Experiments, Models, Datasets을 추적하고 결과를 동료와 공유하는 방법에 대한 자세한 내용은 OpenAI 파인튜닝 인테그레이션을 참조하세요.
API 입력 및 출력을 기록하면 다양한 프롬프트의 성능을 빠르게 평가하고, 다양한 모델 설정 (예: temperature)을 비교하고, 토큰 사용량과 같은 기타 사용량 메트릭을 추적할 수 있습니다.
OpenAI Python API 라이브러리 설치
W&B autolog 인테그레이션은 OpenAI 버전 0.28.1 이하에서 작동합니다.
OpenAI Python API 버전 0.28.1을 설치하려면 다음을 실행합니다.
pip install openai==0.28.1
OpenAI Python API 사용
1. autolog 임포트 및 초기화
먼저 wandb.integration.openai에서 autolog를 임포트하고 초기화합니다.
import os
import openai
from wandb.integration.openai import autolog
autolog({"project": "gpt5"})
선택적으로 wandb.init()이 허용하는 인수가 있는 사전을 autolog에 전달할 수 있습니다. 여기에는 프로젝트 이름, 팀 이름, Entity 등이 포함됩니다. wandb.init에 대한 자세한 내용은 API Reference Guide를 참조하세요.
2. OpenAI API 호출
OpenAI API를 호출할 때마다 W&B에 자동으로 기록됩니다.
os.environ["OPENAI_API_KEY"] ="XXX"chat_request_kwargs = dict(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Who won the world series in 2020?"},
{"role": "assistant", "content": "The Los Angeles Dodgers"},
{"role": "user", "content": "Where was it played?"},
],
)
response = openai.ChatCompletion.create(**chat_request_kwargs)
3. OpenAI API 입력 및 응답 보기
1단계에서 autolog에 의해 생성된 W&B run 링크를 클릭합니다. 그러면 W&B 앱의 프로젝트 Workspace로 리디렉션됩니다.
생성한 Run을 선택하여 추적 테이블, 추적 타임라인 및 사용된 OpenAI LLM의 모델 아키텍처를 봅니다.
autolog 끄기
OpenAI API 사용을 마친 후에는 모든 W&B 프로세스를 닫기 위해 disable()을 호출하는 것이 좋습니다.
W&B OpenAI 파인튜닝 통합은 OpenAI 버전 1.0 이상에서 작동합니다. OpenAI Python API 라이브러리의 최신 버전은 PyPI 문서를 참조하세요.
OpenAI Python API를 설치하려면 다음을 실행하세요:
pip install openai
OpenAI Python API가 이미 설치되어 있는 경우 다음을 사용하여 업데이트할 수 있습니다:
pip install -U openai
OpenAI 파인튜닝 결과 동기화
W&B를 OpenAI의 파인튜닝 API와 통합하여 파인튜닝 메트릭과 설정을 W&B에 기록합니다. 이를 위해 wandb.integration.openai.fine_tuning 모듈의 WandbLogger 클래스를 사용합니다.
from wandb.integration.openai.fine_tuning import WandbLogger
# Finetuning logicWandbLogger.sync(fine_tune_job_id=FINETUNE_JOB_ID)
파인튜닝 동기화
스크립트에서 결과를 동기화합니다.
from wandb.integration.openai.fine_tuning import WandbLogger
# 한 줄 코맨드WandbLogger.sync()
# 옵션 파라미터 전달WandbLogger.sync(
fine_tune_job_id=None,
num_fine_tunes=None,
project="OpenAI-Fine-Tune",
entity=None,
overwrite=False,
model_artifact_name="model-metadata",
model_artifact_type="model",
**kwargs_wandb_init
)
참조
인수
설명
fine_tune_job_id
이는 client.fine_tuning.jobs.create를 사용하여 파인튜닝 job을 생성할 때 얻는 OpenAI Fine-Tune ID입니다. 이 인수가 None(기본값)인 경우, 아직 동기화되지 않은 모든 OpenAI 파인튜닝 job이 W&B에 동기화됩니다.
openai_client
초기화된 OpenAI 클라이언트를 sync에 전달합니다. 클라이언트가 제공되지 않으면 로거 자체에서 초기화됩니다. 기본적으로 None입니다.
num_fine_tunes
ID가 제공되지 않으면 동기화되지 않은 모든 파인튜닝이 W&B에 기록됩니다. 이 인수를 사용하면 동기화할 최근 파인튜닝 수를 선택할 수 있습니다. num_fine_tunes가 5이면 가장 최근의 파인튜닝 5개를 선택합니다.
project
파인튜닝 메트릭, Models, Data 등이 기록될 Weights & Biases 프로젝트 이름입니다. 기본적으로 프로젝트 이름은 “OpenAI-Fine-Tune"입니다.
entity
Runs을 보낼 W&B 사용자 이름 또는 팀 이름입니다. 기본적으로 기본 엔터티가 사용되며, 이는 일반적으로 사용자 이름입니다.
overwrite
동일한 파인튜닝 job의 기존 wandb run을 강제로 로깅하고 덮어씁니다. 기본적으로 False입니다.
wait_for_job_success
OpenAI 파인튜닝 job이 시작되면 일반적으로 시간이 좀 걸립니다. 파인튜닝 job이 완료되는 즉시 메트릭이 W&B에 기록되도록 하려면 이 설정을 통해 파인튜닝 job 상태가 succeeded로 변경되는지 60초마다 확인합니다. 파인튜닝 job이 성공한 것으로 감지되면 메트릭이 자동으로 W&B에 동기화됩니다. 기본적으로 True로 설정됩니다.
파인튜닝을 위해 OpenAI에 업로드하는 트레이닝 및 검증 데이터는 더 쉬운 버전 관리를 위해 자동으로 W&B Artifacts로 기록됩니다. 아래는 Artifacts의 트레이닝 파일 보기입니다. 여기서 이 파일을 기록한 W&B run, 기록된 시기, 이 데이터셋의 버전, 메타데이터 및 트레이닝 Data에서 트레이닝된 Model까지의 DAG 계보를 확인할 수 있습니다.
시각화
Datasets은 W&B Tables로 시각화되어 데이터셋을 탐색, 검색 및 상호 작용할 수 있습니다. 아래에서 W&B Tables를 사용하여 시각화된 트레이닝 샘플을 확인하세요.
파인튜닝된 Model 및 Model 버전 관리
OpenAI는 파인튜닝된 Model의 ID를 제공합니다. Model 가중치에 엑세스할 수 없으므로 WandbLogger는 Model의 모든 세부 정보 (하이퍼파라미터, Data 파일 ID 등)와 fine_tuned_model ID가 포함된 model_metadata.json 파일을 생성하고 W&B Artifacts로 기록합니다.
이 Model (메타데이터) 아티팩트는 W&B Registry의 Model에 추가로 연결될 수 있습니다.
자주 묻는 질문
W&B에서 팀과 파인튜닝 결과를 공유하려면 어떻게 해야 하나요?
다음을 사용하여 팀 계정에 파인튜닝 job을 기록합니다:
WandbLogger.sync(entity="YOUR_TEAM_NAME")
Runs을 어떻게 구성할 수 있나요?
W&B Runs은 자동으로 구성되며 job 유형, 기본 Model, 학습률, 트레이닝 파일 이름 및 기타 하이퍼파라미터와 같은 모든 구성 파라미터를 기반으로 필터링/정렬할 수 있습니다.
또한 Runs 이름을 바꾸거나 메모를 추가하거나 태그를 만들어 그룹화할 수 있습니다.
만족스러우면 워크스페이스를 저장하고 이를 사용하여 리포트를 생성하고 Runs 및 저장된 Artifacts (트레이닝/검증 파일)에서 Data를 가져올 수 있습니다.
파인튜닝된 Model에 어떻게 엑세스할 수 있나요?
파인튜닝된 Model ID는 Artifacts(model_metadata.json) 및 구성으로 W&B에 기록됩니다.
“2021년부터 Gym을 유지 관리해 온 팀은 향후 모든 개발을 Gym의 대체품인 Gymnasium으로 이전했으며(gymnasium을 gym으로 가져오기), Gym은 더 이상 업데이트를 받지 않습니다.” (출처)
Gym은 더 이상 활발하게 유지 관리되는 프로젝트가 아니므로 Gymnasium과의 통합을 사용해 보십시오.
OpenAI Gym을 사용하는 경우, Weights & Biases는 gym.wrappers.Monitor에 의해 생성된 환경 비디오를 자동으로 기록합니다. monitor_gym 키워드 인수를 wandb.init에 True로 설정하거나 wandb.gym.monitor()를 호출하기만 하면 됩니다.
저희 gym integration은 매우 가볍습니다. gym에서 기록된 비디오 파일의 이름을 확인하여 그에 따라 이름을 지정하거나 일치하는 항목을 찾지 못하면 "videos"로 대체합니다. 더 많은 제어를 원하시면 언제든지 수동으로 비디오를 기록할 수 있습니다.
PaddleOCR 은 PaddlePaddle에 구현되어 사용자가 더 나은 모델을 트레이닝하고 실제에 적용할 수 있도록 다국어, 멋진, 선도적이고 실용적인 OCR 툴을 만드는 것을 목표로 합니다. PaddleOCR은 OCR과 관련된 다양한 최첨단 알고리즘을 지원하고 산업 솔루션을 개발했습니다. PaddleOCR은 이제 해당 메타데이터와 함께 모델 체크포인트와 함께 트레이닝 및 평가 메트릭을 로깅하기 위한 Weights & Biases 통합 기능을 제공합니다.
예제 블로그 & Colab
ICDAR2015 데이터셋에서 PaddleOCR로 모델을 트레이닝하는 방법은 여기 에서 확인하세요. Google Colab 도 함께 제공되며, 해당 라이브 W&B 대시보드는 여기 에서 확인할 수 있습니다. 이 블로그의 중국어 버전은 W&B对您的OCR模型进行训练和调试 에서 확인할 수 있습니다.
가입하고 API 키 만들기
API 키는 사용자의 머신을 W&B에 인증합니다. 사용자 프로필에서 API 키를 생성할 수 있습니다.
보다 간소화된 접근 방식을 위해 https://wandb.ai/authorize 로 직접 이동하여 API 키를 생성할 수 있습니다. 표시된 API 키를 복사하여 비밀번호 관리자와 같은 안전한 위치에 저장하세요.
오른쪽 상단에서 사용자 프로필 아이콘을 클릭합니다.
User Settings를 선택한 다음 API Keys 섹션으로 스크롤합니다.
Reveal을 클릭합니다. 표시된 API 키를 복사합니다. API 키를 숨기려면 페이지를 새로 고칩니다.
PaddleOCR은 yaml 파일을 사용하여 구성 변수를 제공해야 합니다. 구성 yaml 파일의 끝에 다음 스니펫을 추가하면 모든 트레이닝 및 유효성 검사 메트릭이 모델 체크포인트와 함께 W&B 대시보드에 자동으로 기록됩니다.
Global:
use_wandb: True
wandb.init 에 전달하려는 추가적인 선택적 인수는 yaml 파일의 wandb 헤더 아래에 추가할 수도 있습니다.
wandb:
project: CoolOCR # (선택 사항) wandb 프로젝트 이름입니다.
entity: my_team # (선택 사항) wandb Team을 사용하는 경우 Team 이름을 여기에 전달할 수 있습니다.
name: MyOCRModel # (선택 사항) wandb run의 이름입니다.
config.yml 파일을 train.py 에 전달
그런 다음 yaml 파일은 PaddleOCR 저장소에서 사용할 수 있는 트레이닝 스크립트 에 인수로 제공됩니다.
python tools/train.py -c config.yml
Weights & Biases가 켜진 상태에서 train.py 파일을 실행하면 W&B 대시보드로 이동하는 링크가 생성됩니다.
Prodigy 는 기계 학습 모델, 오류 분석, 데이터 검사 및 정리을 위한 트레이닝 및 평가 데이터를 생성하기 위한 주석 툴입니다. W&B Tables 를 사용하면 W&B 내에서 데이터셋 (및 더 많은 것!) 을 기록, 시각화, 분석 및 공유할 수 있습니다.
Prodigy 와의 W&B 통합 은 Prodigy 로 주석이 달린 데이터셋을 Tables 에서 사용할 수 있도록 W&B 에 직접 업로드하는 간단하고 사용하기 쉬운 기능을 추가합니다.
다음과 같은 몇 줄의 코드를 실행합니다.
import wandb
from wandb.integration.prodigy import upload_dataset
with wandb.init(project="prodigy"):
upload_dataset("news_headlines_ner")
다음과 같은 시각적이고, 상호 작용적이며, 공유 가능한 테이블을 얻으세요.
퀵스타트
wandb.integration.prodigy.upload_dataset 을 사용하여 주석이 달린 Prodigy 데이터셋을 로컬 Prodigy 데이터베이스에서 W&B 의 Table 형식으로 직접 업로드합니다. 설치 및 설정을 포함한 Prodigy 에 대한 자세한 내용은 Prodigy documentation 을 참조하십시오.
W&B 는 이미지 및 명명된 엔티티 필드를 wandb.Image 및 wandb.Html 로 자동 변환하려고 시도합니다. 이러한 시각화를 포함하기 위해 결과 테이블에 추가 열이 추가될 수 있습니다.
gradient를 자동으로 기록하려면 wandb.watch를 호출하고 PyTorch model을 전달하면 됩니다.
import wandb
wandb.init(config=args)
model =...# set up your model# Magicwandb.watch(model, log_freq=100)
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
if batch_idx % args.log_interval ==0:
wandb.log({"loss": loss})
동일한 스크립트에서 여러 model을 추적해야 하는 경우 각 model에서 wandb.watch를 개별적으로 호출할 수 있습니다. 이 함수에 대한 참조 문서는 여기에 있습니다.
gradient, metrics 및 그래프는 순방향 및 역방향 패스 후에 wandb.log가 호출될 때까지 기록되지 않습니다.
이미지 및 미디어 로그
이미지 데이터가 포함된 PyTorch Tensors를 wandb.Image로 전달할 수 있으며, torchvision의 유틸리티가 자동으로 이미지를 변환하는 데 사용됩니다.
images_t =...# generate or load images as PyTorch Tensorswandb.log({"examples": [wandb.Image(im) for im in images_t]})
PyTorch 및 기타 프레임워크에서 W&B에 rich media를 로깅하는 방법에 대한 자세한 내용은 미디어 로깅 가이드를 확인하세요.
model의 예측 또는 파생 메트릭과 같은 정보를 미디어와 함께 포함하려면 wandb.Table을 사용하세요.
my_table = wandb.Table()
my_table.add_column("image", images_t)
my_table.add_column("label", labels)
my_table.add_column("class_prediction", predictions_t)
# Log your Table to W&Bwandb.log({"mnist_predictions": my_table})
데이터셋 및 model 로깅 및 시각화에 대한 자세한 내용은 W&B Tables 가이드를 확인하세요.
profile_dir ="path/to/run/tbprofile/"profiler = torch.profiler.profile(
schedule=schedule, # see the profiler docs for details on scheduling on_trace_ready=torch.profiler.tensorboard_trace_handler(profile_dir),
with_stack=True,
)
with profiler:
...# run the code you want to profile here# see the profiler docs for detailed usage information# create a wandb Artifactprofile_art = wandb.Artifact("trace", type="profile")
# add the pt.trace.json files to the Artifactprofile_art.add_file(glob.glob(profile_dir +".pt.trace.json"))
# log the artifactprofile_art.save()
엣지 수, 노드 수 등 입력 그래프에 대한 세부 정보를 저장할 수 있습니다. W&B는 Plotly 차트 및 HTML 패널 로깅을 지원하므로 그래프에 대해 생성하는 모든 시각화를 W&B에 로깅할 수도 있습니다.
PyVis 사용
다음 스니펫은 PyVis 및 HTML을 사용하여 이를 수행하는 방법을 보여줍니다.
from pyvis.network import Network
Import wandb
wandb.init(project=’graph_vis’)
net = Network(height="750px", width="100%", bgcolor="#222222", font_color="white")
# Add the edges from the PyG graph to the PyVis networkfor e in tqdm(g.edge_index.T):
src = e[0].item()
dst = e[1].item()
net.add_node(dst)
net.add_node(src)
net.add_edge(src, dst, value=0.1)
# Save the PyVis visualisation to a HTML filenet.show("graph.html")
wandb.log({"eda/graph": wandb.Html("graph.html")})
wandb.finish()
Plotly 사용
Plotly를 사용하여 그래프 시각화를 만들려면 먼저 PyG 그래프를 networkx 오브젝트로 변환해야 합니다. 다음으로 노드와 엣지 모두에 대해 Plotly 산점도를 만들어야 합니다. 아래 스니펫을 이 작업에 사용할 수 있습니다.
metric_logger 섹션을 수정하여 레시피 구성 파일에서 W&B 로깅을 활성화합니다. _component_ 를 torchtune.utils.metric_logging.WandBLogger 클래스로 변경합니다. project 이름과 log_every_n_steps 를 전달하여 로깅 행동을 사용자 정의할 수도 있습니다.
wandb.init 메소드에 전달하는 것처럼 다른 kwargs 를 전달할 수도 있습니다. 예를 들어 팀에서 작업하는 경우 entity 인수를 WandBLogger 클래스에 전달하여 팀 이름을 지정할 수 있습니다.
W&B 대시보드를 탐색하여 기록된 메트릭을 확인할 수 있습니다. 기본적으로 W&B 는 구성 파일 및 실행 재정의의 모든 하이퍼파라미터를 기록합니다.
W&B 는 Overview 탭에서 확인된 구성을 캡처합니다. W&B 는 또한 YAML 형식으로 파일 탭에 구성을 저장합니다.
로깅된 메트릭
각 레시피에는 자체 트레이닝 루프가 있습니다. 각 개별 레시피를 확인하여 기본적으로 포함되는 로깅된 메트릭을 확인하십시오.
Metric
Description
loss
모델의 손실
lr
학습률
tokens_per_second
모델의 초당 토큰 수
grad_norm
모델의 그레이디언트 norm
global_step
트레이닝 루프의 현재 단계를 나타냅니다. 그레이디언트 누적을 고려하며, 기본적으로 옵티마이저 단계가 수행될 때마다 모델이 업데이트되고, 그레이디언트가 누적되며, 모델은 gradient_accumulation_steps 마다 한 번 업데이트됩니다.
global_step 은 트레이닝 단계 수와 동일하지 않습니다. 트레이닝 루프의 현재 단계를 나타냅니다. 그레이디언트 누적을 고려하며, 기본적으로 옵티마이저 단계가 수행될 때마다 global_step 은 1 씩 증가합니다. 예를 들어 데이터 로더에 10 개의 배치, 그레이디언트 누적 단계가 2 이고 3 에포크 동안 실행되는 경우 옵티마이저는 15 번 단계별로 진행되며, 이 경우 global_step 은 1 에서 15 까지입니다.
torchtune 의 간소화된 설계를 통해 사용자 정의 메트릭을 쉽게 추가하거나 기존 메트릭을 수정할 수 있습니다. 예를 들어, 레시피 파일을 수정하여 총 에포크 수의 백분율로 current_epoch 을 계산하여 로깅할 수 있습니다.
# inside `train.py` function in the recipe fileself._metric_logger.log_dict(
{"current_epoch": self.epochs * self.global_step / self._steps_per_epoch},
step=self.global_step,
)
이것은 빠르게 진화하는 라이브러리이며 현재 메트릭은 변경될 수 있습니다. 사용자 정의 메트릭을 추가하려면 레시피를 수정하고 해당 self._metric_logger.* 함수를 호출해야 합니다.
체크포인트 저장 및 로드
torchtune 라이브러리는 다양한 체크포인트 형식을 지원합니다. 사용 중인 모델의 출처에 따라 적절한 체크포인터 클래스로 전환해야 합니다.
모델 체크포인트를 W&B Artifacts에 저장하려면 해당 레시피 내에서 save_checkpoint 함수를 재정의하는 것이 가장 간단한 해결책입니다.
다음은 모델 체크포인트를 W&B Artifacts 에 저장하기 위해 save_checkpoint 함수를 재정의하는 방법의 예입니다.
defsave_checkpoint(self, epoch: int) ->None:
...## Let's save the checkpoint to W&B## depending on the Checkpointer Class the file will be named differently## Here is an example for the full_finetune case checkpoint_file = Path.joinpath(
self._checkpointer._output_dir, f"torchtune_model_{epoch}" ).with_suffix(".pt")
wandb_artifact = wandb.Artifact(
name=f"torchtune_model_{epoch}",
type="model",
# description of the model checkpoint description="Model checkpoint",
# you can add whatever metadata you want as a dict metadata={
utils.SEED_KEY: self.seed,
utils.EPOCHS_KEY: self.epochs_run,
utils.TOTAL_EPOCHS_KEY: self.total_epochs,
utils.MAX_STEPS_KEY: self.max_steps_per_epoch,
},
)
wandb_artifact.add_file(checkpoint_file)
wandb.log_artifact(wandb_artifact)
Ignite는 트레이닝 및 검증 중에 메트릭, 모델/옵티마이저 파라미터, 그레이디언트를 기록하기 위해 Weights & Biases 핸들러를 지원합니다. 또한 모델 체크포인트를 Weights & Biases cloud에 기록하는 데 사용할 수도 있습니다. 이 클래스는 wandb 모듈의 래퍼이기도 합니다. 즉, 이 래퍼를 사용하여 모든 wandb 함수를 호출할 수 있습니다. 모델 파라미터와 그레이디언트를 저장하는 방법에 대한 예시를 참조하세요.
기본 설정
from argparse import ArgumentParser
import wandb
import torch
from torch import nn
from torch.optim import SGD
from torch.utils.data import DataLoader
import torch.nn.functional as F
from torchvision.transforms import Compose, ToTensor, Normalize
from torchvision.datasets import MNIST
from ignite.engine import Events, create_supervised_trainer, create_supervised_evaluator
from ignite.metrics import Accuracy, Loss
from tqdm import tqdm
classNet(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
self.conv2_drop = nn.Dropout2d()
self.fc1 = nn.Linear(320, 50)
self.fc2 = nn.Linear(50, 10)
defforward(self, x):
x = F.relu(F.max_pool2d(self.conv1(x), 2))
x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2))
x = x.view(-1, 320)
x = F.relu(self.fc1(x))
x = F.dropout(x, training=self.training)
x = self.fc2(x)
return F.log_softmax(x, dim=-1)
defget_data_loaders(train_batch_size, val_batch_size):
data_transform = Compose([ToTensor(), Normalize((0.1307,), (0.3081,))])
train_loader = DataLoader(MNIST(download=True, root=".", transform=data_transform, train=True),
batch_size=train_batch_size, shuffle=True)
val_loader = DataLoader(MNIST(download=False, root=".", transform=data_transform, train=False),
batch_size=val_batch_size, shuffle=False)
return train_loader, val_loader
ignite에서 WandBLogger를 사용하는 것은 모듈식 프로세스입니다. 먼저, WandBLogger 오브젝트를 만듭니다. 다음으로, 메트릭을 자동으로 기록하기 위해 트레이너 또는 평가기에 연결합니다. 다음은 이 예시입니다.
PyTorch Lightning 은 PyTorch 코드를 구성하고 분산 트레이닝 및 16비트 정밀도와 같은 고급 기능을 쉽게 추가할 수 있는 가벼운 래퍼를 제공합니다. W&B는 ML Experiments을 로깅하기 위한 가벼운 래퍼를 제공합니다. 하지만 이 둘을 직접 결합할 필요는 없습니다. Weights & Biases는 WandbLogger를 통해 PyTorch Lightning 라이브러리에 직접 통합됩니다.
Lightning 과 통합
from lightning.pytorch.loggers import WandbLogger
from lightning.pytorch import Trainer
wandb_logger = WandbLogger(log_model="all")
trainer = Trainer(logger=wandb_logger)
wandb.log() 사용:WandbLogger는 Trainer의 global_step을 사용하여 W&B에 로깅합니다. 코드에서 wandb.log를 직접 추가로 호출하는 경우 wandb.log()에서 step 인수를 사용하지 마십시오.
# 파라미터 하나 추가wandb_logger.experiment.config["key"] = value
# 여러 파라미터 추가wandb_logger.experiment.config.update({key1: val1, key2: val2})
# wandb 모듈을 직접 사용wandb.config["key"] = value
wandb.config.update()
그레이디언트, 파라미터 히스토그램 및 모델 토폴로지 로깅
모델 오브젝트를 wandblogger.watch()에 전달하여 트레이닝하는 동안 모델의 그레이디언트와 파라미터를 모니터링할 수 있습니다. PyTorch Lightning WandbLogger 설명서를 참조하십시오.
메트릭 로깅
training_step 또는 validation_step methods와 같이 LightningModule 내에서 self.log('my_metric_name', metric_vale)을 호출하여 WandbLogger를 사용할 때 메트릭을 W&B에 로깅할 수 있습니다.
아래 코드 조각은 메트릭과 LightningModule 하이퍼파라미터를 로깅하도록 LightningModule을 정의하는 방법을 보여줍니다. 이 예제에서는 torchmetrics 라이브러리를 사용하여 메트릭을 계산합니다.
import torch
from torch.nn import Linear, CrossEntropyLoss, functional as F
from torch.optim import Adam
from torchmetrics.functional import accuracy
from lightning.pytorch import LightningModule
classMy_LitModule(LightningModule):
def __init__(self, n_classes=10, n_layer_1=128, n_layer_2=256, lr=1e-3):
"""모델 파라미터를 정의하는 데 사용되는 메소드""" super().__init__()
# mnist 이미지는 (1, 28, 28) (채널, 너비, 높이)입니다. self.layer_1 = Linear(28*28, n_layer_1)
self.layer_2 = Linear(n_layer_1, n_layer_2)
self.layer_3 = Linear(n_layer_2, n_classes)
self.loss = CrossEntropyLoss()
self.lr = lr
# 하이퍼파라미터를 self.hparams에 저장합니다(W&B에서 자동 로깅). self.save_hyperparameters()
defforward(self, x):
"""추론 입력 -> 출력에 사용되는 메소드"""# (b, 1, 28, 28) -> (b, 1*28*28) batch_size, channels, width, height = x.size()
x = x.view(batch_size, -1)
# 3 x (linear + relu)를 수행해 보겠습니다. x = F.relu(self.layer_1(x))
x = F.relu(self.layer_2(x))
x = self.layer_3(x)
return x
deftraining_step(self, batch, batch_idx):
"""단일 배치에서 손실을 반환해야 합니다.""" _, loss, acc = self._get_preds_loss_accuracy(batch)
# 손실 및 메트릭 로깅 self.log("train_loss", loss)
self.log("train_accuracy", acc)
return loss
defvalidation_step(self, batch, batch_idx):
"""메트릭 로깅에 사용""" preds, loss, acc = self._get_preds_loss_accuracy(batch)
# 손실 및 메트릭 로깅 self.log("val_loss", loss)
self.log("val_accuracy", acc)
return preds
defconfigure_optimizers(self):
"""모델 옵티마이저를 정의합니다."""return Adam(self.parameters(), lr=self.lr)
def_get_preds_loss_accuracy(self, batch):
"""train/valid/test 단계가 유사하므로 편의 함수""" x, y = batch
logits = self(x)
preds = torch.argmax(logits, dim=1)
loss = self.loss(logits, y)
acc = accuracy(preds, y)
return preds, loss, acc
import lightning as L
import torch
import torchvision as tv
from wandb.integration.lightning.fabric import WandbLogger
import wandb
fabric = L.Fabric(loggers=[wandb_logger])
fabric.launch()
model = tv.models.resnet18()
optimizer = torch.optim.SGD(model.parameters(), lr=lr)
model, optimizer = fabric.setup(model, optimizer)
train_dataloader = fabric.setup_dataloaders(
torch.utils.data.DataLoader(train_dataset, batch_size=batch_size)
)
model.train()
for epoch in range(num_epochs):
for batch in train_dataloader:
optimizer.zero_grad()
loss = model(batch)
loss.backward()
optimizer.step()
fabric.log_dict({"loss": loss})
메트릭의 최소/최대값 로깅
wandb의 define_metric 함수를 사용하여 W&B 요약 메트릭에 해당 메트릭의 최소, 최대, 평균 또는 최적값을 표시할지 여부를 정의할 수 있습니다. define_metric _이(가) 사용되지 않으면 로깅된 마지막 값이 요약 메트릭에 나타납니다. define_metric참조 문서(여기)와 가이드(여기)를 참조하십시오.
W&B가 W&B 요약 메트릭에서 최대 검증 정확도를 추적하도록 지시하려면 트레이닝 시작 시 wandb.define_metric을 한 번만 호출하십시오.
여기에서 작업별로 최고의 모델을 구성하고, 모델 수명 주기를 관리하고, ML 수명 주기 전반에 걸쳐 쉬운 추적 및 감사를 용이하게 하고, 웹후크 또는 작업을 통해 다운스트림 작업을 자동화할 수 있습니다.
이미지, 텍스트 등 로깅
WandbLogger에는 미디어를 로깅하기 위한 log_image, log_text 및 log_table 메소드가 있습니다.
wandb.log 또는 trainer.logger.experiment.log를 직접 호출하여 오디오, 분자, 포인트 클라우드, 3D 오브젝트 등과 같은 다른 미디어 유형을 로깅할 수도 있습니다.
# 텐서, numpy 어레이 또는 PIL 이미지 사용wandb_logger.log_image(key="samples", images=[img1, img2])
# 캡션 추가wandb_logger.log_image(key="samples", images=[img1, img2], caption=["tree", "person"])
# 파일 경로 사용wandb_logger.log_image(key="samples", images=["img_1.jpg", "img_2.jpg"])
# 트레이너에서 .log 사용trainer.logger.experiment.log(
{"samples": [wandb.Image(img, caption=caption) for (img, caption) in my_images]},
step=current_trainer_global_step,
)
# 데이터는 목록 목록이어야 합니다.columns = ["input", "label", "prediction"]
my_data = [["cheese", "english", "english"], ["fromage", "french", "spanish"]]
# 열 및 데이터 사용wandb_logger.log_text(key="my_samples", columns=columns, data=my_data)
# pandas DataFrame 사용wandb_logger.log_text(key="my_samples", dataframe=my_dataframe)
# 텍스트 캡션, 이미지 및 오디오가 있는 W&B Table 로깅columns = ["caption", "image", "sound"]
# 데이터는 목록 목록이어야 합니다.my_data = [
["cheese", wandb.Image(img_1), wandb.Audio(snd_1)],
["wine", wandb.Image(img_2), wandb.Audio(snd_2)],
]
# Table 로깅wandb_logger.log_table(key="my_samples", columns=columns, data=data)
Lightning의 콜백 시스템을 사용하여 WandbLogger를 통해 Weights & Biases에 로깅하는 시점을 제어할 수 있습니다. 이 예에서는 검증 이미지 및 예측 샘플을 로깅합니다.
import torch
import wandb
import lightning.pytorch as pl
from lightning.pytorch.loggers import WandbLogger
# 또는# from wandb.integration.lightning.fabric import WandbLoggerclassLogPredictionSamplesCallback(Callback):
defon_validation_batch_end(
self, trainer, pl_module, outputs, batch, batch_idx, dataloader_idx
):
"""검증 배치가 종료되면 호출됩니다."""# `outputs`는 `LightningModule.validation_step`에서 가져옵니다.# 이 경우 모델 예측에 해당합니다.# 첫 번째 배치에서 20개의 샘플 이미지 예측을 로깅해 보겠습니다.if batch_idx ==0:
n =20 x, y = batch
images = [img for img in x[:n]]
captions = [
f"Ground Truth: {y_i} - Prediction: {y_pred}"for y_i, y_pred in zip(y[:n], outputs[:n])
]
# 옵션 1: `WandbLogger.log_image`로 이미지 로깅 wandb_logger.log_image(key="sample_images", images=images, caption=captions)
# 옵션 2: 이미지 및 예측을 W&B Table로 로깅 columns = ["image", "ground truth", "prediction"]
data = [
[wandb.Image(x_i), y_i, y_pred] or x_i,
y_i,
y_pred in list(zip(x[:n], y[:n], outputs[:n])),
]
wandb_logger.log_table(key="sample_table", columns=columns, data=data)
trainer = pl.Trainer(callbacks=[LogPredictionSamplesCallback()])
Lightning 및 W&B로 여러 GPU 사용
PyTorch Lightning은 DDP 인터페이스를 통해 Multi-GPU를 지원합니다. 그러나 PyTorch Lightning의 디자인에서는 GPU를 인스턴스화하는 방법에 주의해야 합니다.
Lightning은 트레이닝 루프의 각 GPU(또는 순위)가 동일한 초기 조건으로 정확히 동일한 방식으로 인스턴스화되어야 한다고 가정합니다. 그러나 순위 0 프로세스만 wandb.run 오브젝트에 엑세스할 수 있으며 0이 아닌 순위 프로세스의 경우 wandb.run = None입니다. 이로 인해 0이 아닌 프로세스가 실패할 수 있습니다. 이러한 상황은 순위 0 프로세스가 이미 충돌한 0이 아닌 순위 프로세스가 조인될 때까지 대기하기 때문에 교착 상태에 놓일 수 있습니다.
이러한 이유로 트레이닝 코드를 설정하는 방법에 주의하십시오. 설정하는 데 권장되는 방법은 코드가 wandb.run 오브젝트와 독립적이도록 하는 것입니다.
classMNISTClassifier(pl.LightningModule):
def __init__(self):
super(MNISTClassifier, self).__init__()
self.model = nn.Sequential(
nn.Flatten(),
nn.Linear(28*28, 128),
nn.ReLU(),
nn.Linear(128, 10),
)
self.loss = nn.CrossEntropyLoss()
defforward(self, x):
return self.model(x)
deftraining_step(self, batch, batch_idx):
x, y = batch
y_hat = self.forward(x)
loss = self.loss(y_hat, y)
self.log("train/loss", loss)
return {"train_loss": loss}
defvalidation_step(self, batch, batch_idx):
x, y = batch
y_hat = self.forward(x)
loss = self.loss(y_hat, y)
self.log("val/loss", loss)
return {"val_loss": loss}
defconfigure_optimizers(self):
return torch.optim.Adam(self.parameters(), lr=0.001)
defmain():
# 모든 랜덤 시드를 동일한 값으로 설정합니다.# 이는 분산 트레이닝 설정에서 중요합니다.# 각 순위는 자체 초기 weights 집합을 가져옵니다.# 일치하지 않으면 그레이디언트도 일치하지 않습니다.# 수렴하지 않을 수 있는 트레이닝으로 이어집니다. pl.seed_everything(1)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True, num_workers=4)
val_loader = DataLoader(val_dataset, batch_size=64, shuffle=False, num_workers=4)
model = MNISTClassifier()
wandb_logger = WandbLogger(project="<project_name>")
callbacks = [
ModelCheckpoint(
dirpath="checkpoints",
every_n_train_steps=100,
),
]
trainer = pl.Trainer(
max_epochs=3, gpus=2, logger=wandb_logger, strategy="ddp", callbacks=callbacks
)
trainer.fit(model, train_loader, val_loader)
모델 체크포인트를 W&B에 저장하여 볼 수 있거나 향후 run에서 사용하기 위해 다운로드할 수 있습니다. 또한 GPU 사용량 및 네트워크 I/O와 같은 시스템 메트릭, 하드웨어 및 OS 정보와 같은 환경 정보, 코드 상태 (git 커밋 및 차이 패치, 노트북 콘텐츠 및 세션 기록 포함) 및 표준 출력에 인쇄된 모든 항목을 캡처합니다.
트레이닝 설정에서 wandb.run을 사용해야 하는 경우는 어떻게 해야 합니까?
엑세스해야 하는 변수의 범위를 직접 확장해야 합니다. 즉, 모든 프로세스에서 초기 조건이 동일한지 확인하십시오.
if os.environ.get("LOCAL_RANK", None) isNone:
os.environ["WANDB_DIR"] = wandb.run.dir
그렇다면 os.environ["WANDB_DIR"]을 사용하여 모델 체크포인트 디렉토리를 설정할 수 있습니다. 이렇게 하면 0이 아닌 모든 순위 프로세스가 wandb.run.dir에 엑세스할 수 있습니다.
W&B 는 Amazon SageMaker 와 통합되어 하이퍼파라미터를 자동으로 읽고, 분산된 Runs 를 그룹화하며, 체크포인트에서 Runs 를 재개합니다.
인증
W&B 는 트레이닝 스크립트와 관련된 secrets.env 라는 파일을 찾고 wandb.init() 가 호출될 때 해당 파일을 환경에 로드합니다. secrets.env 파일은 실험을 시작하는 데 사용하는 스크립트에서 wandb.sagemaker_auth(path="source_dir") 를 호출하여 생성할 수 있습니다. 이 파일을 .gitignore 에 추가해야 합니다!
기존 estimator
SageMaker 의 사전 구성된 estimator 중 하나를 사용하는 경우, wandb 를 포함하는 requirements.txt 를 소스 디렉터리에 추가해야 합니다.
wandb
Python 2 를 실행하는 estimator 를 사용하는 경우, wandb 를 설치하기 전에 이 wheel 에서 psutil 을 직접 설치해야 합니다.
import wandb
wandb.init(project="visualize-sklearn")
y_pred = clf.predict(X_test)
accuracy = sklearn.metrics.accuracy_score(y_true, y_pred)
# If logging metrics over time, then use wandb.logwandb.log({"accuracy": accuracy})
# OR to log a final metric at the end of training you can also use wandb.summarywandb.summary["accuracy"] = accuracy
Matplotlib에서 생성된 플롯도 W&B 대시보드에 기록할 수 있습니다. 이를 위해서는 먼저 plotly를 설치해야 합니다.
pip install plotly
마지막으로, 다음과 같이 W&B의 대시보드에 플롯을 기록할 수 있습니다.
import matplotlib.pyplot as plt
import wandb
wandb.init(project="visualize-sklearn")
# do all the plt.plot(), plt.scatter(), etc. here.# ...# instead of doing plt.show() do:wandb.log({"plot": plt})
지원되는 플롯
학습 곡선
다양한 길이의 데이터셋에서 모델을 트레이닝하고 트레이닝 및 테스트 세트 모두에 대해 교차 검증된 점수 대 데이터셋 크기의 플롯을 생성합니다.
wandb.sklearn.plot_learning_curve(model, X, y)
model (clf 또는 reg): 적합된 회귀 모델 또는 분류 모델을 사용합니다.
X (arr): 데이터셋 특징.
y (arr): 데이터셋 레이블.
ROC
ROC 곡선은 참 긍정 비율(y축) 대 거짓 긍정 비율(x축)을 표시합니다. 이상적인 점수는 TPR = 1 및 FPR = 0이며, 이는 왼쪽 상단의 점입니다. 일반적으로 ROC 곡선 아래 영역(AUC-ROC)을 계산하며 AUC-ROC가 클수록 좋습니다.
wandb.sklearn.plot_roc(y_true, y_probas, labels)
y_true (arr): 테스트 세트 레이블.
y_probas (arr): 테스트 세트 예측 확률.
labels (list): 목표 변수(y)에 대해 명명된 레이블.
클래스 비율
트레이닝 및 테스트 세트에서 목표 클래스의 분포를 표시합니다. 불균형 클래스를 감지하고 한 클래스가 모델에 불균형적인 영향을 미치지 않도록 하는 데 유용합니다.
feature_names (list): 특징 이름. 특징 인덱스를 해당 이름으로 대체하여 플롯을 더 쉽게 읽을 수 있습니다.
보정 곡선
분류 모델의 예측 확률이 얼마나 잘 보정되었는지, 보정되지 않은 분류 모델을 보정하는 방법을 표시합니다. 베이스라인 로지스틱 회귀 모델, 인수로 전달된 모델, 등방성 보정 및 시그모이드 보정 모두에 의해 추정된 예측 확률을 비교합니다.
보정 곡선이 대각선에 가까울수록 좋습니다. 전치된 시그모이드와 같은 곡선은 과적합된 분류 모델을 나타내고 시그모이드와 같은 곡선은 과소적합된 분류 모델을 나타냅니다. 모델의 등방성 및 시그모이드 보정을 트레이닝하고 해당 곡선을 비교하여 모델이 과적합 또는 과소적합되었는지, 그렇다면 어떤 보정(시그모이드 또는 등방성)이 이를 수정하는 데 도움이 될 수 있는지 파악할 수 있습니다.
이 라이브러리는 Hugging Face의 Transformers 라이브러리를 기반으로 합니다. Simple Transformers를 사용하면 Transformer 모델을 빠르게 트레이닝하고 평가할 수 있습니다. 모델을 초기화하고, 모델을 트레이닝하고, 모델을 평가하는 데 단 3줄의 코드만 필요합니다. Sequence Classification, Token Classification (NER), Question Answering, Language Model Fine-Tuning, Language Model Training, Language Generation, T5 Model, Seq2Seq Tasks, Multi-Modal Classification 및 Conversational AI를 지원합니다.
모델 트레이닝을 시각화하기 위해 Weights and Biases를 사용하려면 args dictionary의 wandb_project 속성에서 W&B에 대한 프로젝트 이름을 설정하세요. 이렇게 하면 모든 하이퍼파라미터 값, 트레이닝 손실 및 평가 메트릭이 지정된 프로젝트에 기록됩니다.
model = ClassificationModel('roberta', 'roberta-base', args={'wandb_project': 'project-name'})
wandb.init에 들어가는 추가 인수는 wandb_kwargs로 전달할 수 있습니다.
구조
이 라이브러리는 모든 NLP 작업을 위한 별도의 클래스를 갖도록 설계되었습니다. 유사한 기능을 제공하는 클래스는 함께 그룹화됩니다.
simpletransformers.classification - 모든 Classification 모델을 포함합니다.
ClassificationModel
MultiLabelClassificationModel
simpletransformers.ner - 모든 Named Entity Recognition 모델을 포함합니다.
NERModel
simpletransformers.question_answering - 모든 Question Answering 모델을 포함합니다.
QuestionAnsweringModel
다음은 몇 가지 최소한의 예입니다.
MultiLabel Classification
model = MultiLabelClassificationModel("distilbert","distilbert-base-uncased",num_labels=6,
args={"reprocess_input_data": True, "overwrite_output_dir": True, "num_train_epochs":epochs,'learning_rate':learning_rate,
'wandb_project': "simpletransformers"},
)
# 모델 트레이닝
model.train_model(train_df)
# 모델 평가
result, model_outputs, wrong_predictions = model.eval_model(eval_df)
Skorch와 함께 Weights & Biases를 사용하여 모든 모델 성능 메트릭, 모델 토폴로지 및 컴퓨팅 리소스와 함께 최고의 성능을 보이는 모델을 각 에포크 후에 자동으로 기록할 수 있습니다. wandb_run.dir에 저장된 모든 파일은 자동으로 W&B 서버에 기록됩니다.
# wandb 설치... pip install wandb
import wandb
from skorch.callbacks import WandbLogger
# wandb Run 생성wandb_run = wandb.init()
# 대안: W&B 계정 없이 wandb Run 생성wandb_run = wandb.init(anonymous="allow")
# 하이퍼 파라미터 기록 (선택 사항)wandb_run.config.update({"learning rate": 1e-3, "batch size": 32})
net = NeuralNet(..., callbacks=[WandbLogger(wandb_run)])
net.fit(X, y)
메소드 레퍼런스
메소드
설명
initialize()
콜백의 초기 상태를 (다시) 설정합니다.
on_batch_begin(net[, X, y, training])
각 배치 시작 시 호출됩니다.
on_batch_end(net[, X, y, training])
각 배치 종료 시 호출됩니다.
on_epoch_begin(net[, dataset_train, …])
각 에포크 시작 시 호출됩니다.
on_epoch_end(net, **kwargs)
마지막 기록 단계의 값을 기록하고 최고의 모델을 저장합니다.
on_grad_computed(net, named_parameters[, X, …])
그레이디언트가 계산되었지만 업데이트 단계가 수행되기 전에 배치당 한 번 호출됩니다.
on_train_begin(net, **kwargs)
모델 토폴로지를 기록하고 그레이디언트에 대한 훅을 추가합니다.
on_train_end(net[, X, y])
트레이닝 종료 시 호출됩니다.
6.39 - spaCy
spaCy는 빠르고 정확한 모델을 간편하게 사용할 수 있도록 하는 유명한 “산업용” NLP 라이브러리입니다. spaCy v3부터는 Weights & Biases를 spacy train과 함께 사용하여 spaCy 모델의 트레이닝 메트릭을 추적하고 모델과 데이터셋을 저장 및 버저닝할 수 있습니다. 설정에 몇 줄만 추가하면 됩니다.
가입하고 API 키 만들기
API 키는 사용자의 머신이 W&B에 인증되도록 합니다. 사용자 프로필에서 API 키를 생성할 수 있습니다.
보다 간소화된 접근 방식을 위해 https://wandb.ai/authorize로 직접 이동하여 API 키를 생성할 수 있습니다. 표시된 API 키를 복사하여 비밀번호 관리자와 같은 안전한 위치에 저장합니다.
오른쪽 상단 모서리에 있는 사용자 프로필 아이콘을 클릭합니다.
User Settings를 선택한 다음 API Keys 섹션으로 스크롤합니다.
Reveal을 클릭합니다. 표시된 API 키를 복사합니다. API 키를 숨기려면 페이지를 새로 고칩니다.
spaCy 설정 파일은 로깅뿐만 아니라 트레이닝의 모든 측면(GPU 할당, 옵티마이저 선택, 데이터셋 경로 등)을 지정하는 데 사용됩니다. 최소한 [training.logger] 아래에 @loggers 키를 값 "spacy.WandbLogger.v3"와 함께 제공하고 project_name을 제공해야 합니다.
spaCy 트레이닝 설정 파일의 작동 방식과 트레이닝을 사용자 정의하기 위해 전달할 수 있는 기타 옵션에 대한 자세한 내용은 spaCy 설명서를 참조하십시오.
wandb와 함께 Tensorboard를 사용할 때 Tensorboard를 어떻게 구성합니까?
TensorBoard 패치 방법을 보다 세밀하게 제어하려면 wandb.init에 sync_tensorboard=True를 전달하는 대신 wandb.tensorboard.patch를 호출할 수 있습니다.
import wandb
wandb.tensorboard.patch(root_logdir="<logging_directory>")
wandb.init()
# W&B에 tensorboard 로그를 업로드하기 위해 wandb run을 완료합니다(노트북에서 실행하는 경우).wandb.finish()
TensorBoard > 1.14를 PyTorch와 함께 사용하는 경우 vanilla TensorBoard가 패치되었는지 확인하려면 tensorboard_x=False를 이 메소드에 전달하고, 패치되었는지 확인하려면 pytorch=True를 전달할 수 있습니다. 이러한 옵션은 모두 이러한 라이브러리의 버전에 따라 스마트 기본값을 갖습니다.
기본적으로 tfevents 파일과 모든 .pbtxt 파일도 동기화합니다. 이를 통해 사용자를 대신하여 TensorBoard 인스턴스를 시작할 수 있습니다. run 페이지에 TensorBoard 탭이 표시됩니다. 이 동작은 wandb.tensorboard.patch에 save=False를 전달하여 끌 수 있습니다.
import wandb
wandb.init()
wandb.tensorboard.patch(save=False, tensorboard_x=True)
# 노트북에서 실행하는 경우 W&B에 tensorboard 로그를 업로드하기 위해 wandb run을 완료합니다.wandb.finish()
tf.summary.create_file_writer를 호출하거나 torch.utils.tensorboard를 통해 SummaryWriter를 구성하기 전에wandb.init 또는 wandb.tensorboard.patch를 호출해야 합니다.
이전 TensorBoard run을 어떻게 동기화합니까?
로컬에 저장된 기존 tfevents 파일이 있고 이를 W&B로 가져오려면 wandb sync log_dir을 실행합니다. 여기서 log_dir은 tfevents 파일이 포함된 로컬 디렉토리입니다.
Google Colab 또는 Jupyter를 TensorBoard와 함께 어떻게 사용합니까?
Jupyter 또는 Colab 노트북에서 코드를 실행하는 경우 트레이닝이 끝나면 wandb.finish()를 호출해야 합니다. 이렇게 하면 wandb run이 완료되고 tensorboard 로그가 W&B에 업로드되어 시각화할 수 있습니다. .py 스크립트가 완료되면 wandb가 자동으로 완료되므로 이는 필요하지 않습니다.
노트북 환경에서 셸 코맨드를 실행하려면 !wandb sync directoryname과 같이 !를 앞에 붙여야 합니다.
PyTorch를 TensorBoard와 함께 어떻게 사용합니까?
PyTorch의 TensorBoard 인테그레이션을 사용하는 경우 PyTorch Profiler JSON 파일을 수동으로 업로드해야 할 수 있습니다.
무엇이 기록되는지 더 세부적으로 제어하려면 wandb는 TensorFlow estimator에 대한 훅도 제공합니다. 그래프의 모든 tf.summary 값을 기록합니다.
import tensorflow as tf
import wandb
wandb.init(config=tf.FLAGS)
estimator.train(hooks=[wandb.tensorflow.WandbHook(steps_per_log=1000)])
수동으로 기록
TensorFlow에서 메트릭을 기록하는 가장 간단한 방법은 TensorFlow 로거를 사용하여 tf.summary를 기록하는 것입니다.
import wandb
with tf.Session() as sess:
# ... wandb.tensorflow.log(tf.summary.merge_all())
TensorFlow 2에서는 사용자 정의 루프를 사용하여 모델을 트레이닝하는 권장 방법은 tf.GradientTape를 사용하는 것입니다. 자세한 내용은 여기에서 확인할 수 있습니다. 사용자 정의 TensorFlow 트레이닝 루프에서 메트릭을 기록하기 위해 wandb를 통합하려면 다음 스니펫을 따르세요.
with tf.GradientTape() as tape:
# 예측값 가져오기 predictions = model(features)
# 손실 계산 loss = loss_func(labels, predictions)
# 메트릭 기록 wandb.log("loss": loss.numpy())
# 그레이디언트 가져오기 gradients = tape.gradient(loss, model.trainable_variables)
# 가중치 업데이트 optimizer.apply_gradients(zip(gradients, model.trainable_variables))
공동 창립자들이 W&B 작업을 시작했을 때 OpenAI의 불만을 가진 TensorBoard 사용자들을 위한 툴을 구축하라는 영감을 받았습니다. 개선에 집중한 몇 가지 사항은 다음과 같습니다.
모델 재현: Weights & Biases는 실험, 탐색 및 나중에 모델을 재현하는 데 유용합니다. 메트릭뿐만 아니라 하이퍼파라미터와 코드 버전을 캡처하고, 프로젝트를 재현할 수 있도록 버전 제어 상태와 모델 체크포인트를 저장할 수 있습니다.
자동 구성: 협업자로부터 프로젝트를 넘겨받거나, 휴가에서 돌아오거나, 오래된 프로젝트를 다시 시작하는 경우에도 W&B를 사용하면 시도된 모든 모델을 쉽게 볼 수 있으므로 GPU 주기 또는 탄소 재실행 Experiments에 시간을 낭비하는 사람이 없습니다.
빠르고 유연한 통합: 5분 안에 프로젝트에 W&B를 추가하세요. 무료 오픈 소스 Python 패키지를 설치하고 코드에 두 줄을 추가하면 모델을 실행할 때마다 멋지게 기록된 메트릭과 레코드를 얻을 수 있습니다.
영구적인 중앙 집중식 대시보드: 로컬 머신, 공유 랩 클러스터 또는 클라우드의 스팟 인스턴스 등 모델을 트레이닝하는 위치에 관계없이 결과는 동일한 중앙 집중식 대시보드에 공유됩니다. 서로 다른 머신에서 TensorBoard 파일을 복사하고 구성하는 데 시간을 할애할 필요가 없습니다.
강력한 테이블: 다양한 모델의 결과를 검색, 필터링, 정렬 및 그룹화합니다. 수천 개의 모델 버전을 살펴보고 다양한 작업에 가장 적합한 모델을 쉽게 찾을 수 있습니다. TensorBoard는 대규모 프로젝트에서 잘 작동하도록 구축되지 않았습니다.
협업 툴: W&B를 사용하여 복잡한 기계학습 프로젝트를 구성합니다. W&B에 대한 링크를 쉽게 공유할 수 있으며, 비공개 Teams를 사용하여 모든 사람이 결과를 공유 프로젝트로 보낼 수 있습니다. 또한 Reports를 통한 협업도 지원합니다. 대화형 시각화 자료를 추가하고 작업을 markdown으로 설명합니다. 이것은 작업 로그를 유지하고, 지도교수와 발견한 내용을 공유하거나, 랩 또는 팀에 발견한 내용을 발표하는 좋은 방법입니다.
Julia 프로그래밍 언어로 기계 학습 Experiments 를 실행하는 사용자를 위해 커뮤니티 기여자가 wandb.jl 이라는 비공식 Julia 바인딩 세트를 만들었습니다.
wandb.jl 저장소의 documentation 에서 예제를 찾을 수 있습니다. “Getting Started” 예제는 다음과 같습니다.
using Wandb, Dates, Logging
# Start a new run, tracking hyperparameters in configlg = WandbLogger(project ="Wandb.jl",
name ="wandbjl-demo-$(now())",
config =Dict("learning_rate"=>0.01,
"dropout"=>0.2,
"architecture"=>"CNN",
"dataset"=>"CIFAR-100"))
# Use LoggingExtras.jl to log to multiple loggers togetherglobal_logger(lg)
# Simulating the training or evaluation loopfor x ∈1:50 acc = log(1+ x + rand() * get_config(lg, "learning_rate") + rand() + get_config(lg, "dropout"))
loss =10- log(1+ x + rand() + x * get_config(lg, "learning_rate") + rand() + get_config(lg, "dropout"))
# Log metrics from your script to W&B@info"metrics" accuracy=acc loss=loss
end# Finish the runclose(lg)
wandb 라이브러리에는 XGBoost를 사용한 트레이닝에서 메트릭, 설정 및 저장된 부스터를 로깅하기 위한 WandbCallback 콜백이 있습니다. 여기에서 XGBoost WandbCallback의 출력이 포함된 **라이브 Weights & Biases 대시보드**를 볼 수 있습니다.
시작하기
Weights & Biases에 XGBoost 메트릭, 설정 및 부스터 모델을 로깅하는 것은 WandbCallback을 XGBoost에 전달하는 것만큼 쉽습니다.
from wandb.integration.xgboost import WandbCallback
import xgboost as XGBClassifier
...# wandb run 시작run = wandb.init()
# WandbCallback을 모델에 전달bst = XGBClassifier()
bst.fit(X_train, y_train, callbacks=[WandbCallback(log_model=True)])
# wandb run 종료run.finish()
XGBoost 및 Weights & Biases를 사용한 로깅에 대한 포괄적인 내용은 **이 노트북**을 열어 확인하십시오.
WandbCallback 참조
기능
WandbCallback을 XGBoost 모델에 전달하면 다음과 같은 작업이 수행됩니다.
부스터 모델 설정을 Weights & Biases에 로깅합니다.
XGBoost에서 수집한 평가 메트릭(예: rmse, 정확도 등)을 Weights & Biases에 로깅합니다.
XGBoost에서 수집한 트레이닝 메트릭을 로깅합니다(eval_set에 데이터를 제공하는 경우).
Ultralytics는 이미지 분류, 오브젝트 검출, 이미지 세분화 및 포즈 추정과 같은 작업을 위한 최첨단 컴퓨터 비전 모델의 본거지입니다. 실시간 오브젝트 검출 모델인 YOLO 시리즈의 최신 반복인 YOLOv8뿐만 아니라 SAM (Segment Anything Model), RT-DETR, YOLO-NAS 등과 같은 다른 강력한 컴퓨터 비전 모델도 호스팅합니다. Ultralytics는 이러한 모델의 구현을 제공하는 것 외에도 사용하기 쉬운 API를 사용하여 이러한 모델을 트레이닝, 파인튜닝 및 적용할 수 있는 즉시 사용 가능한 워크플로우를 제공합니다.
Ultralytics와 W&B 통합을 사용하려면 wandb.integration.ultralytics.add_wandb_callback 함수를 가져옵니다.
import wandb
from wandb.integration.ultralytics import add_wandb_callback
from ultralytics import YOLO
선택한 YOLO 모델을 초기화하고 모델로 추론을 수행하기 전에 add_wandb_callback 함수를 호출합니다. 이렇게 하면 트레이닝, 파인튜닝, 검증 또는 추론을 수행할 때 experiment 로그와 이미지가 자동으로 저장되고, 컴퓨터 비전 작업을 위한 대화형 오버레이를 사용하여 각각의 예측 결과와 함께 W&B의 wandb.Table에 추가 인사이트와 함께 오버레이됩니다.
# YOLO 모델 초기화model = YOLO("yolov8n.pt")
# Ultralytics에 W&B 콜백 추가add_wandb_callback(model, enable_model_checkpointing=True)
# 모델 트레이닝/파인튜닝# 각 에포크가 끝나면 검증 배치에 대한 예측이 기록됩니다.# 컴퓨터 비전 작업을 위한 통찰력 있고 상호 작용적인 오버레이가 있는 W&B 테이블에model.train(project="ultralytics", data="coco128.yaml", epochs=5, imgsz=640)
# W&B run 종료wandb.finish()
다음은 Ultralytics 트레이닝 또는 파인튜닝 워크플로우에 대해 W&B를 사용하여 추적된 Experiments의 모습입니다.
# W&B run 초기화wandb.init(project="ultralytics", job_type="inference")
다음으로 원하는 YOLO 모델을 초기화하고 모델로 추론을 수행하기 전에 add_wandb_callback 함수를 호출합니다. 이렇게 하면 추론을 수행할 때 컴퓨터 비전 작업을 위한 대화형 오버레이와 함께 wandb.Table에 추가 인사이트와 함께 이미지가 자동으로 기록됩니다.
# YOLO 모델 초기화model = YOLO("yolov8n.pt")
# Ultralytics에 W&B 콜백 추가add_wandb_callback(model, enable_model_checkpointing=True)
# W&B 테이블에 자동으로 기록되는 예측 수행# 경계 상자, 세분화 마스크에 대한 대화형 오버레이 포함model(
[
"./assets/img1.jpeg",
"./assets/img3.png",
"./assets/img4.jpeg",
"./assets/img5.jpeg",
]
)
# W&B run 종료wandb.finish()
트레이닝 또는 파인튜닝 워크플로우의 경우 wandb.init()을 사용하여 명시적으로 run을 초기화할 필요가 없습니다. 그러나 코드에 예측만 포함된 경우 run을 명시적으로 생성해야 합니다.
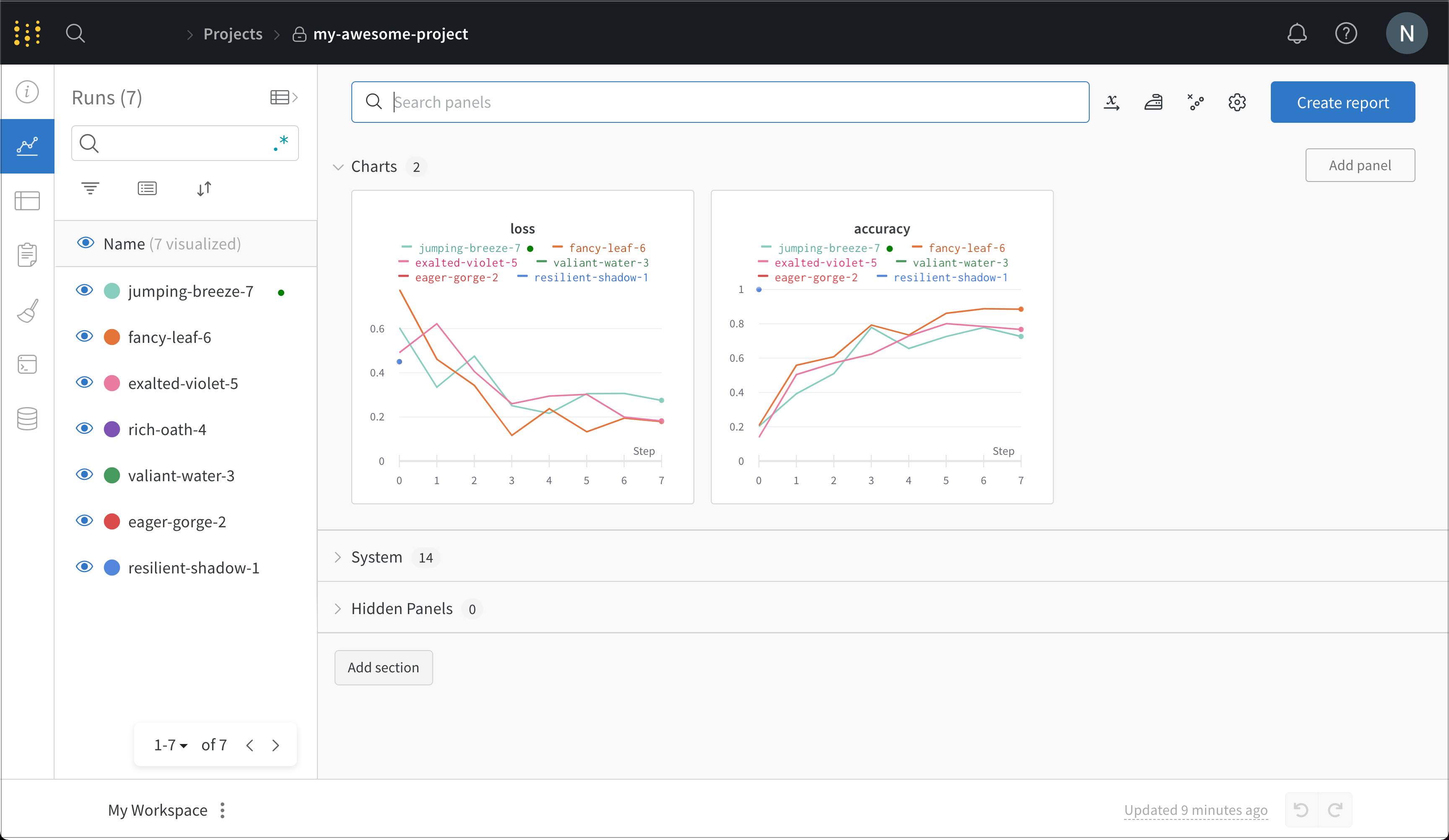
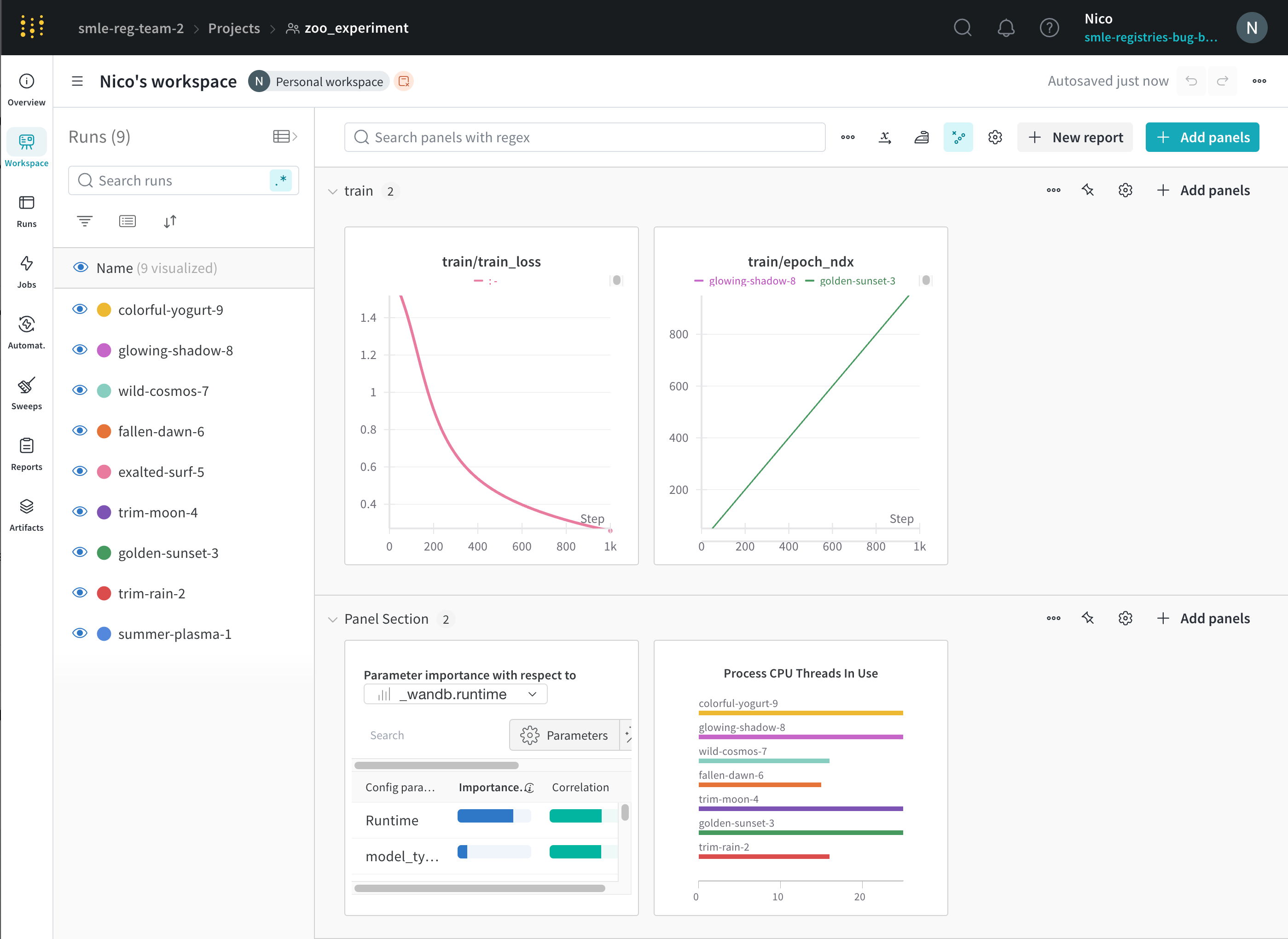
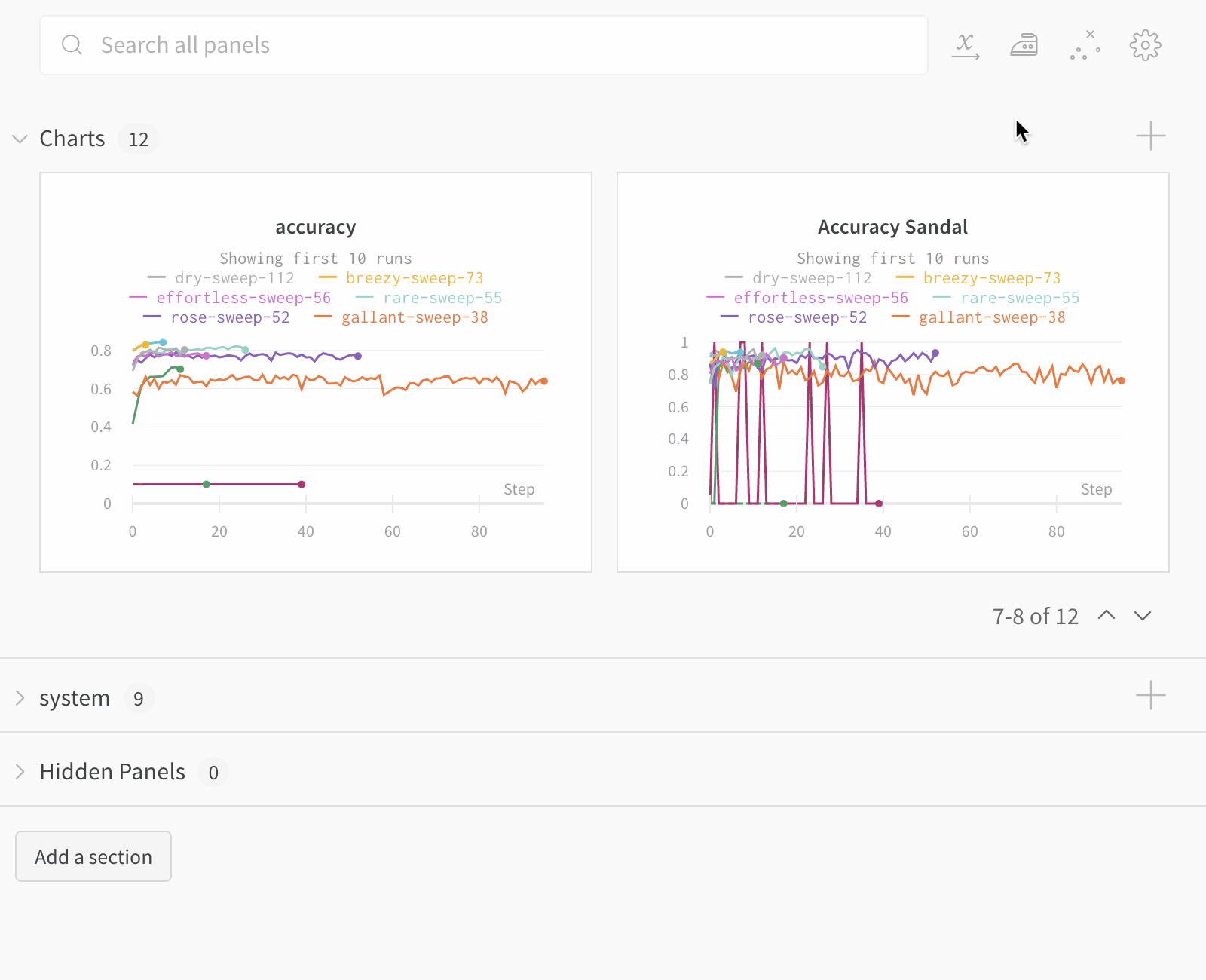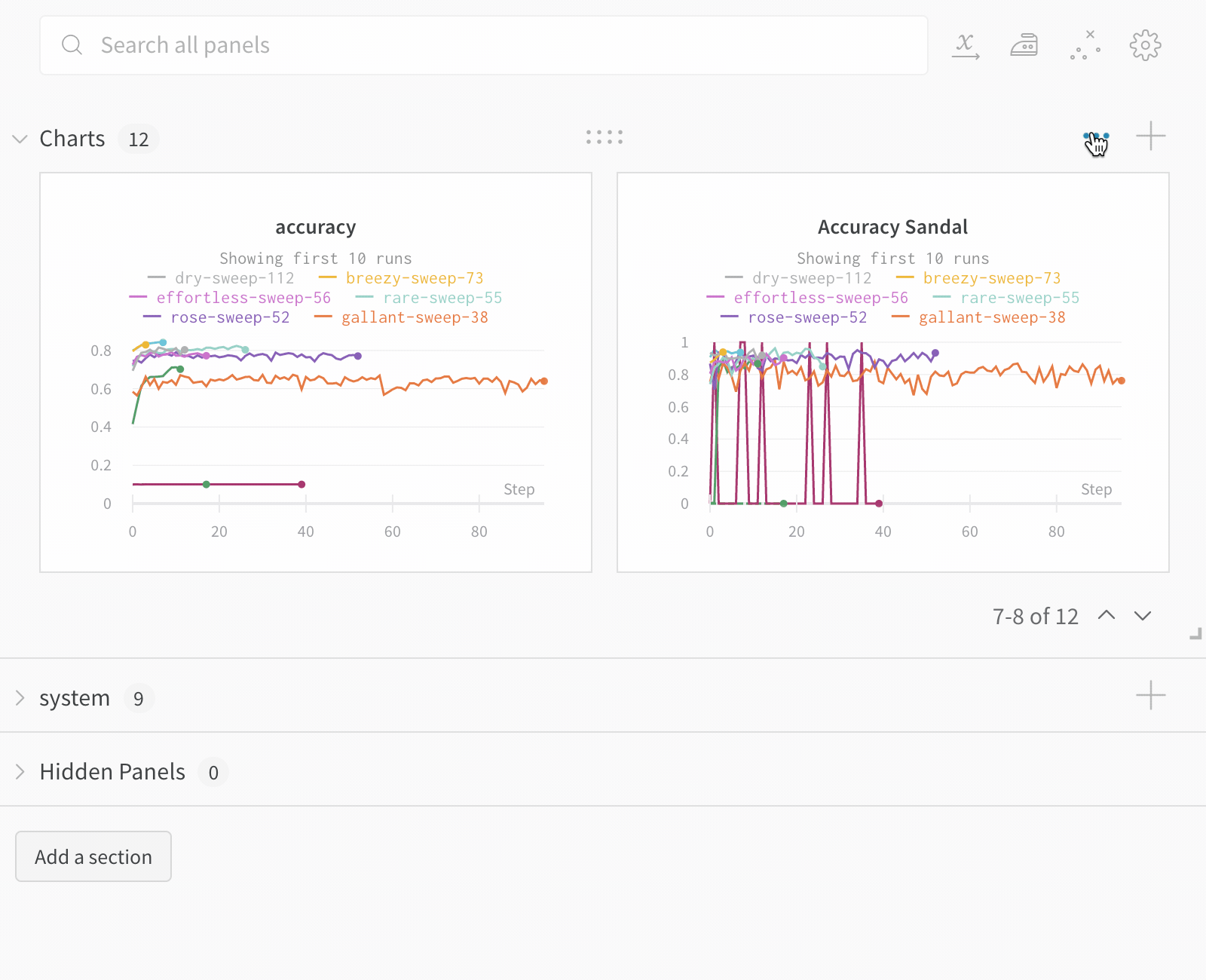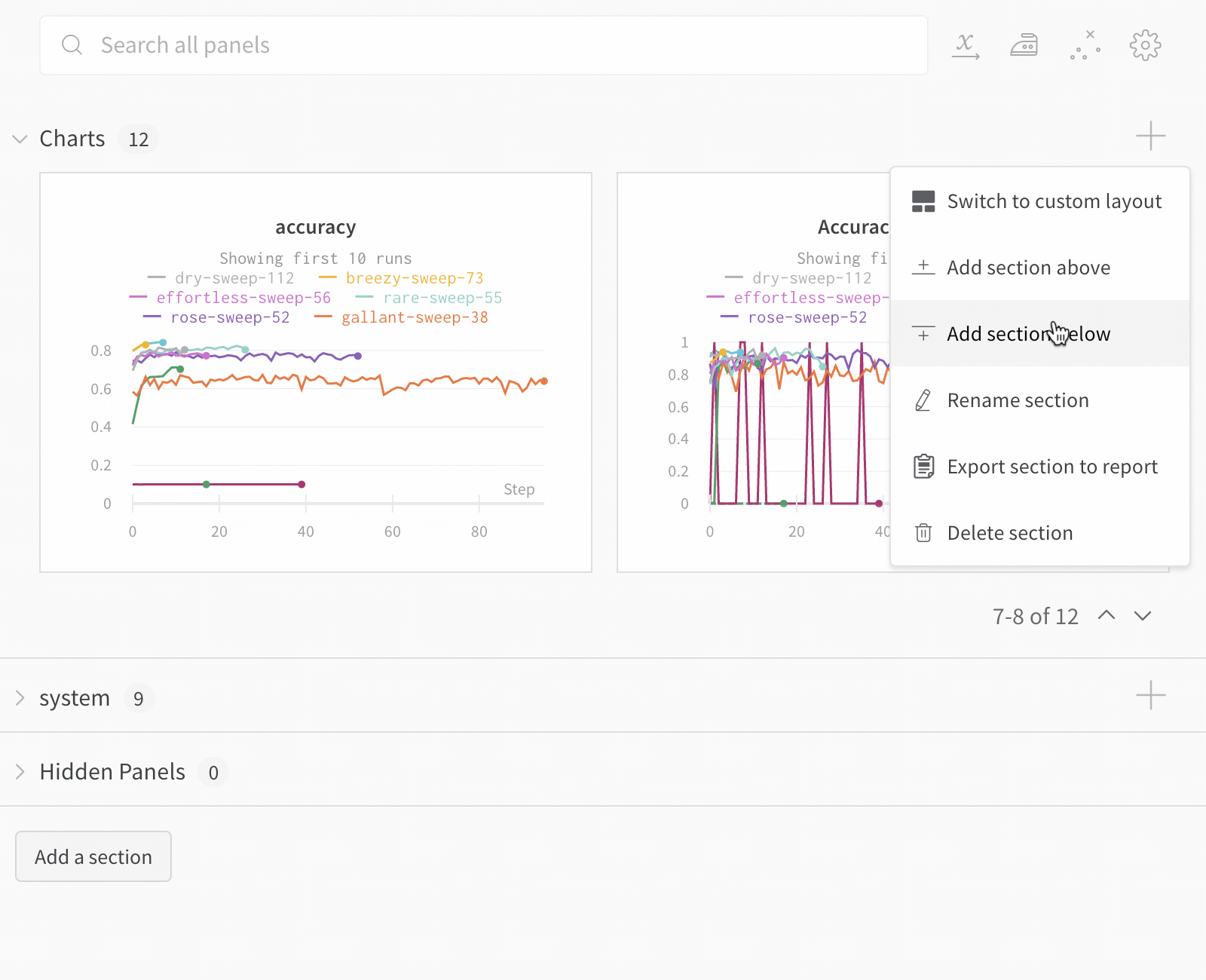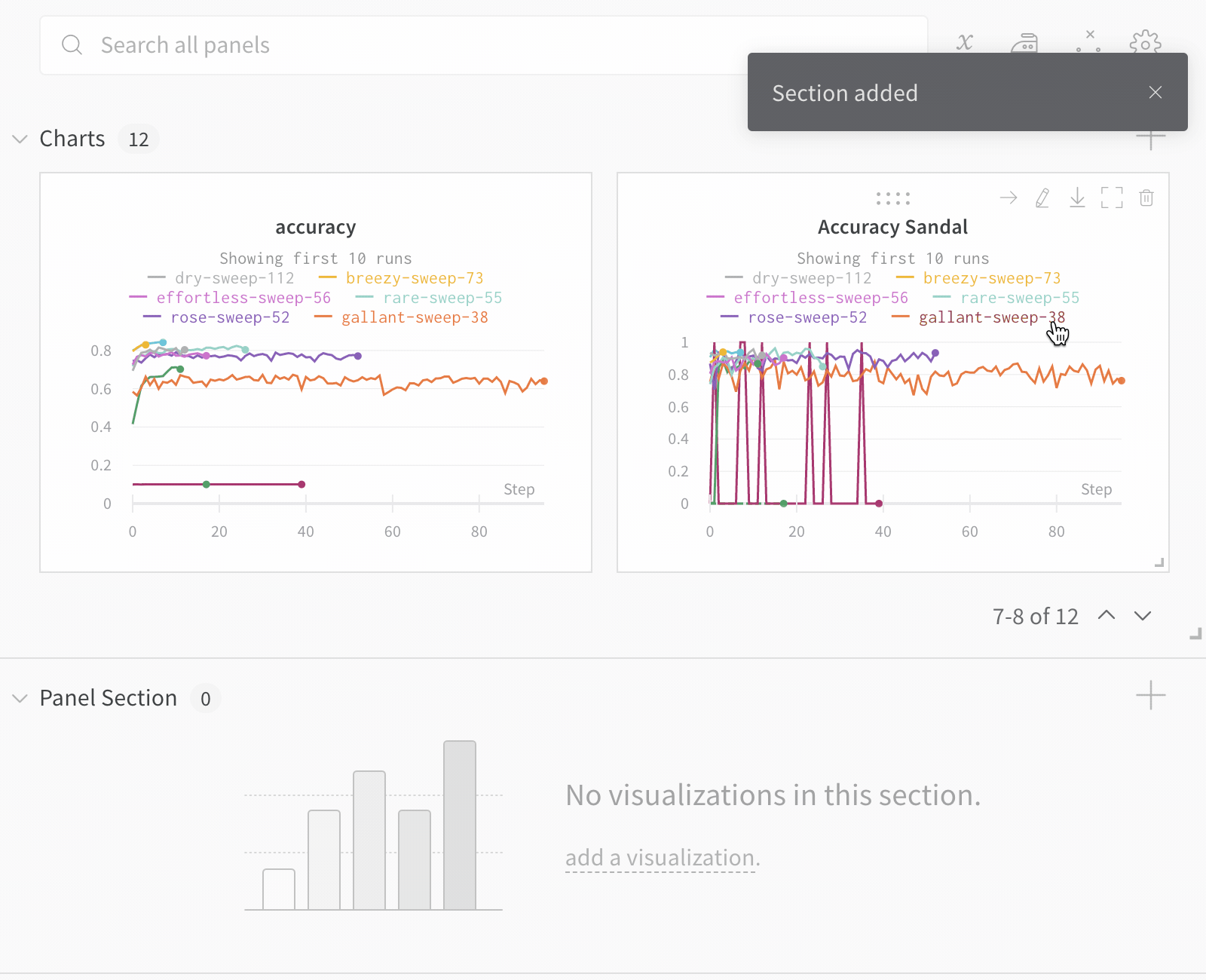
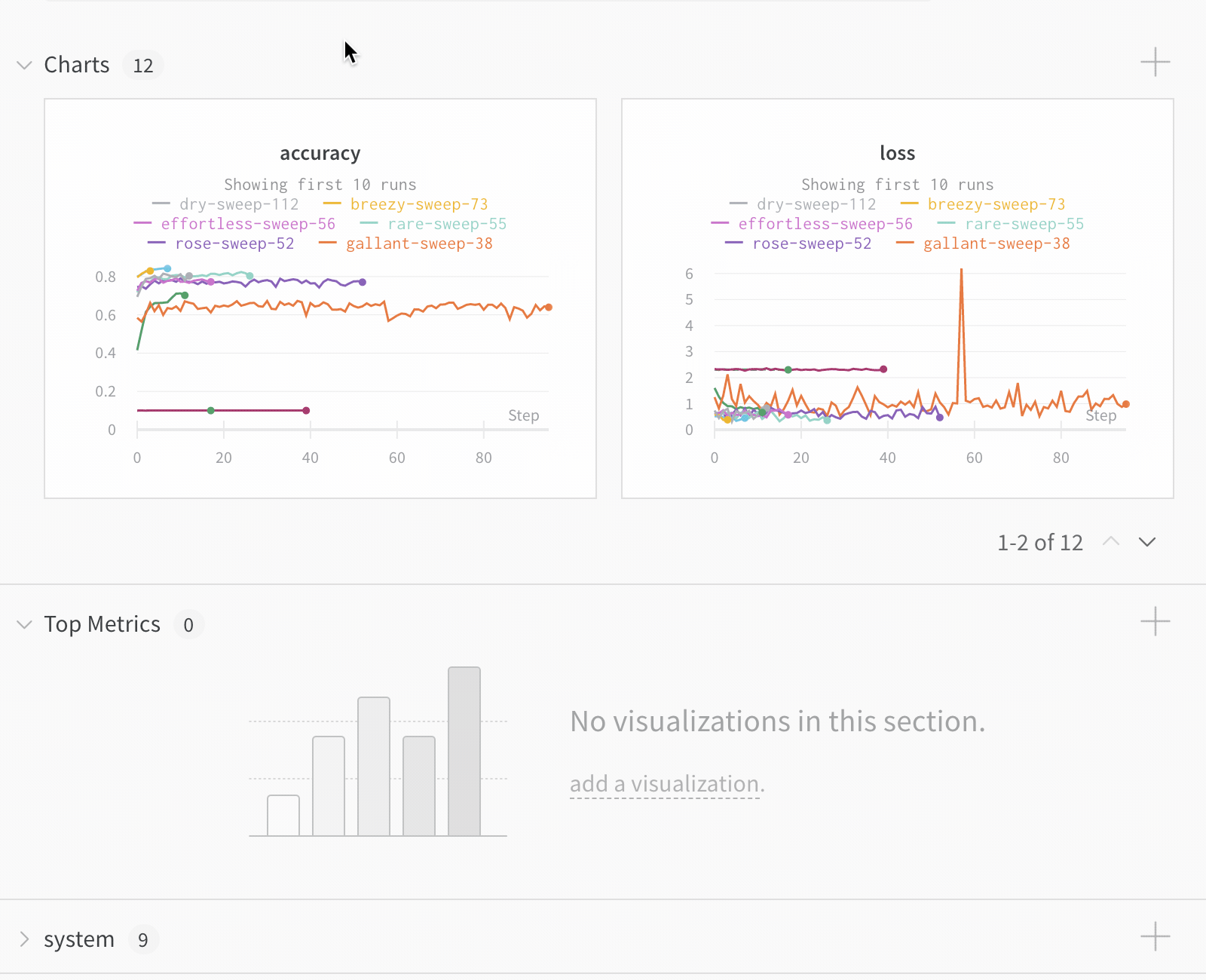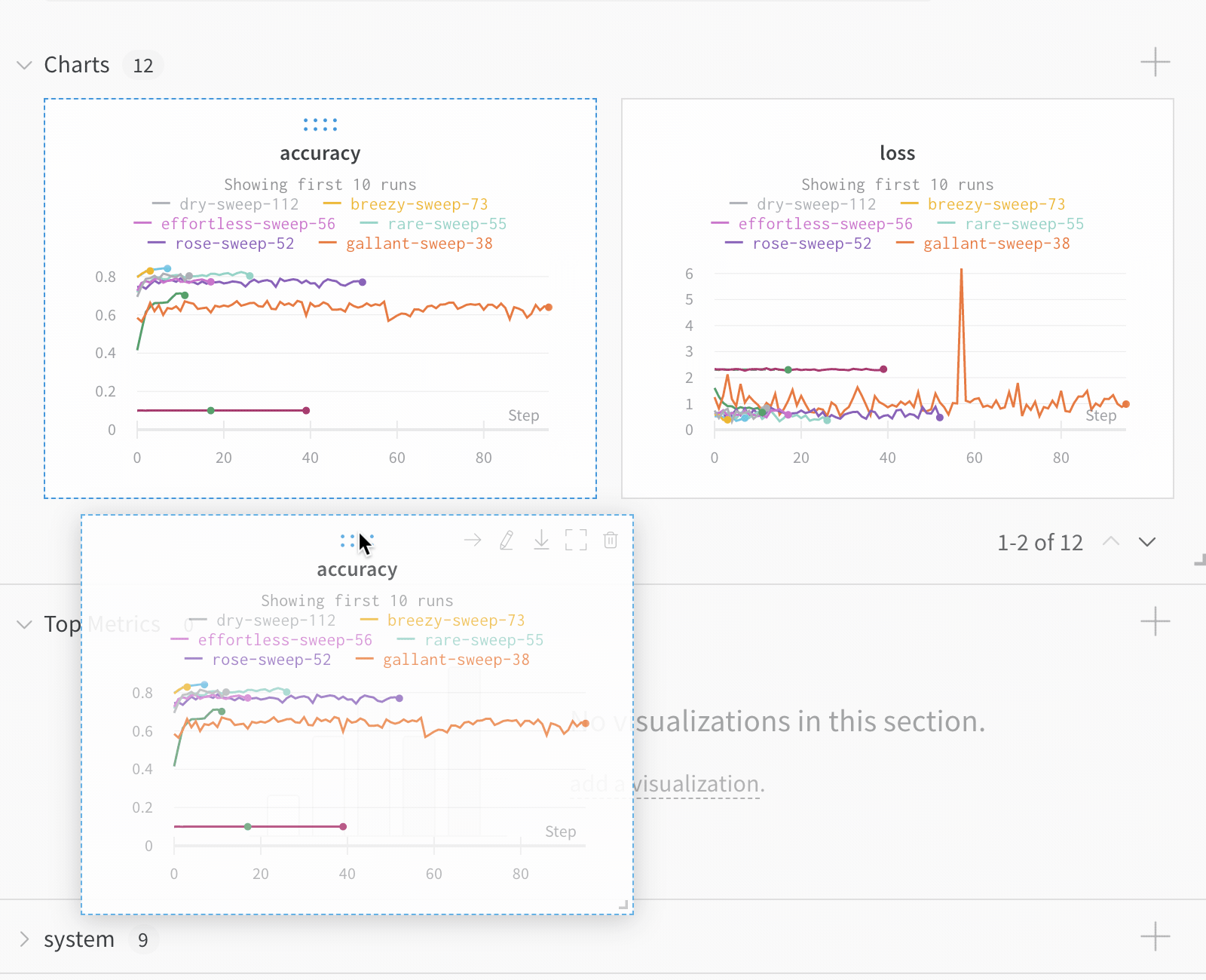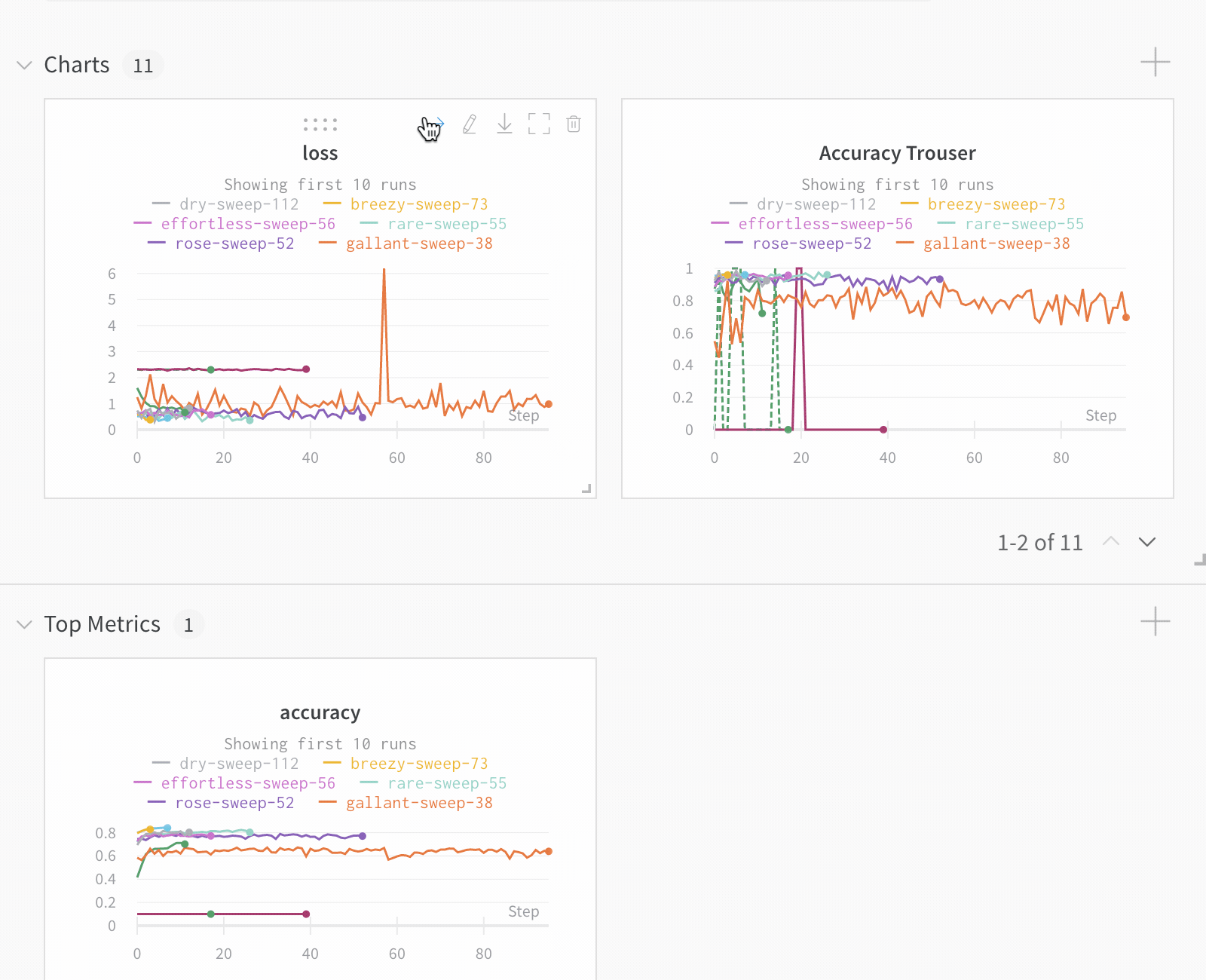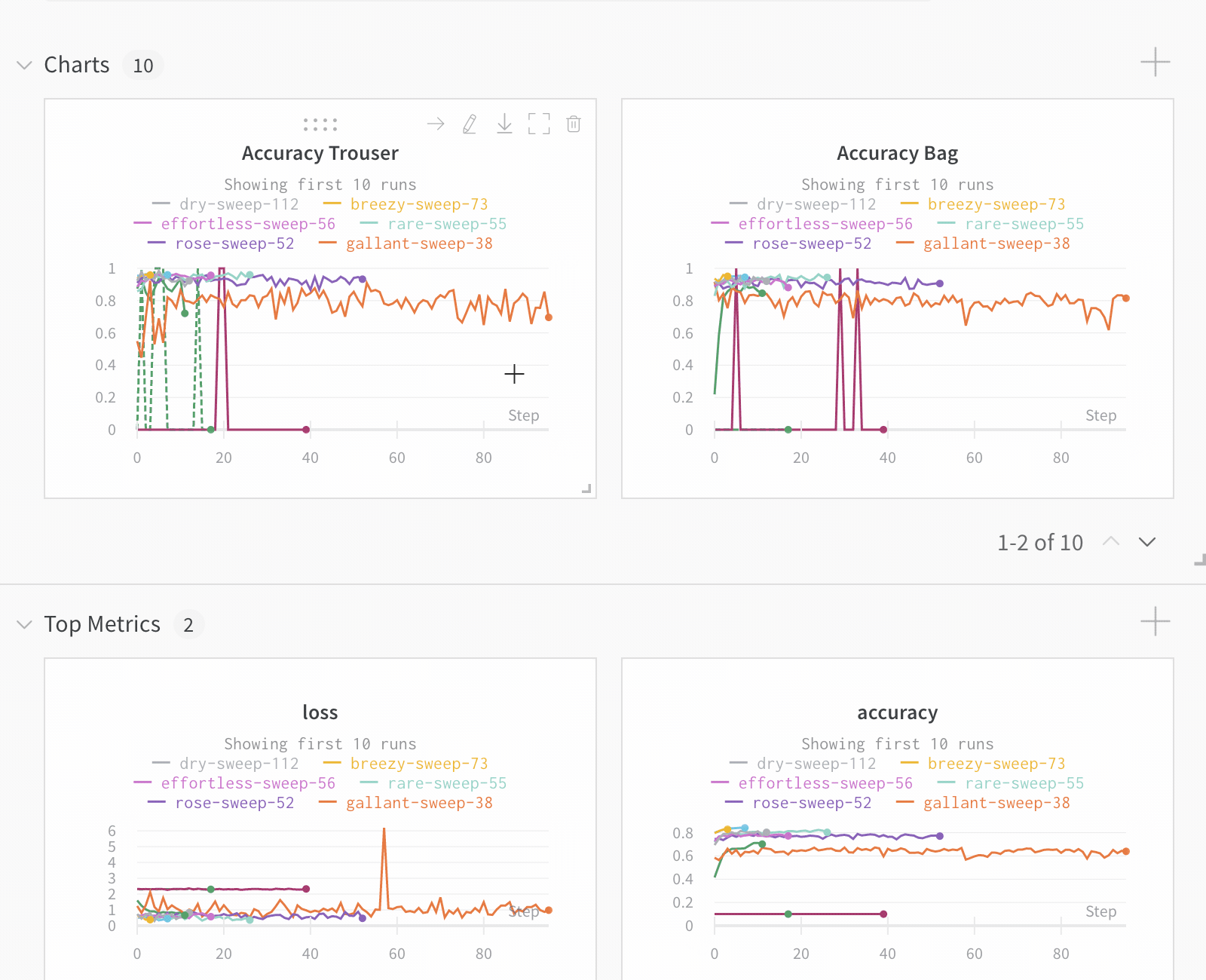
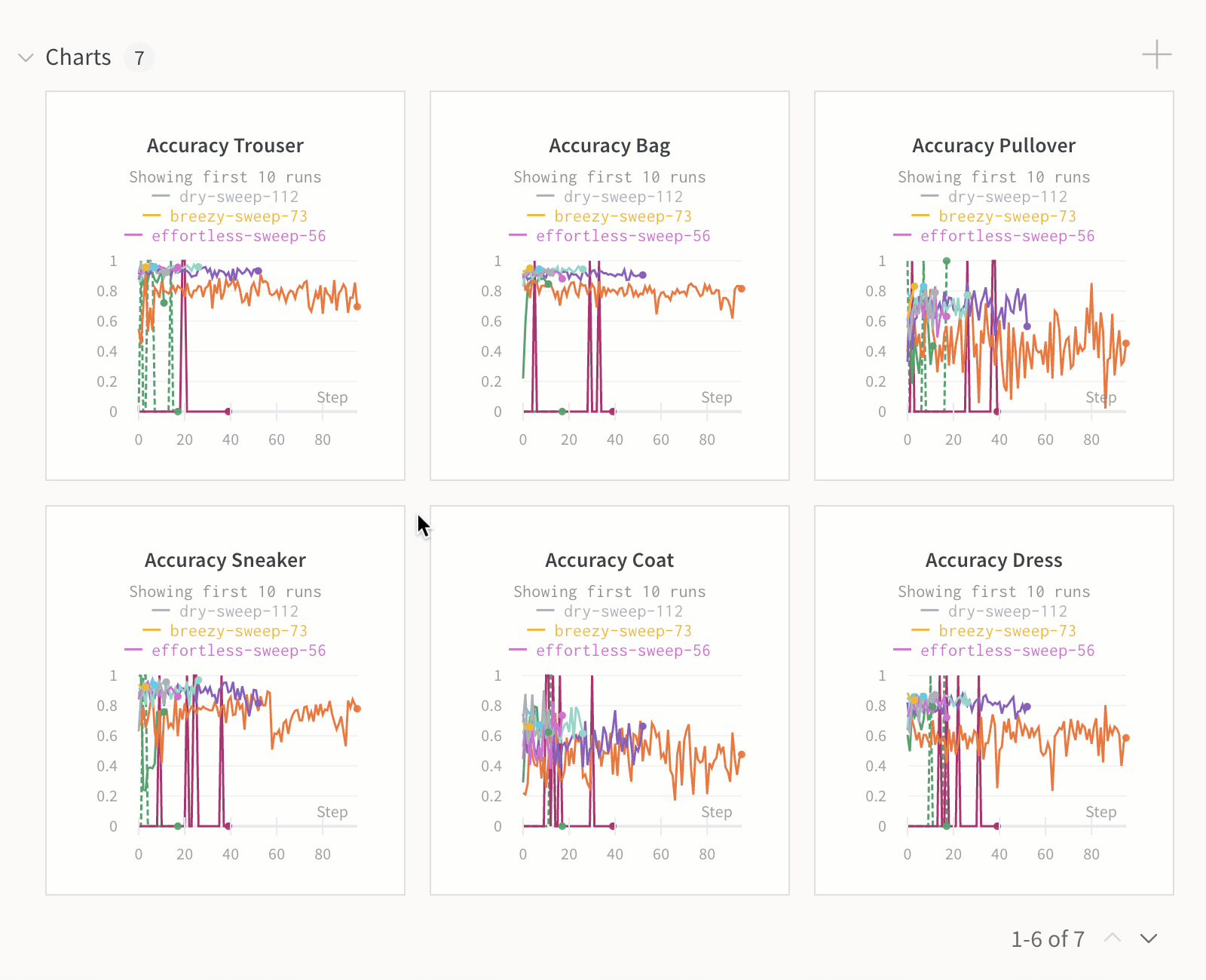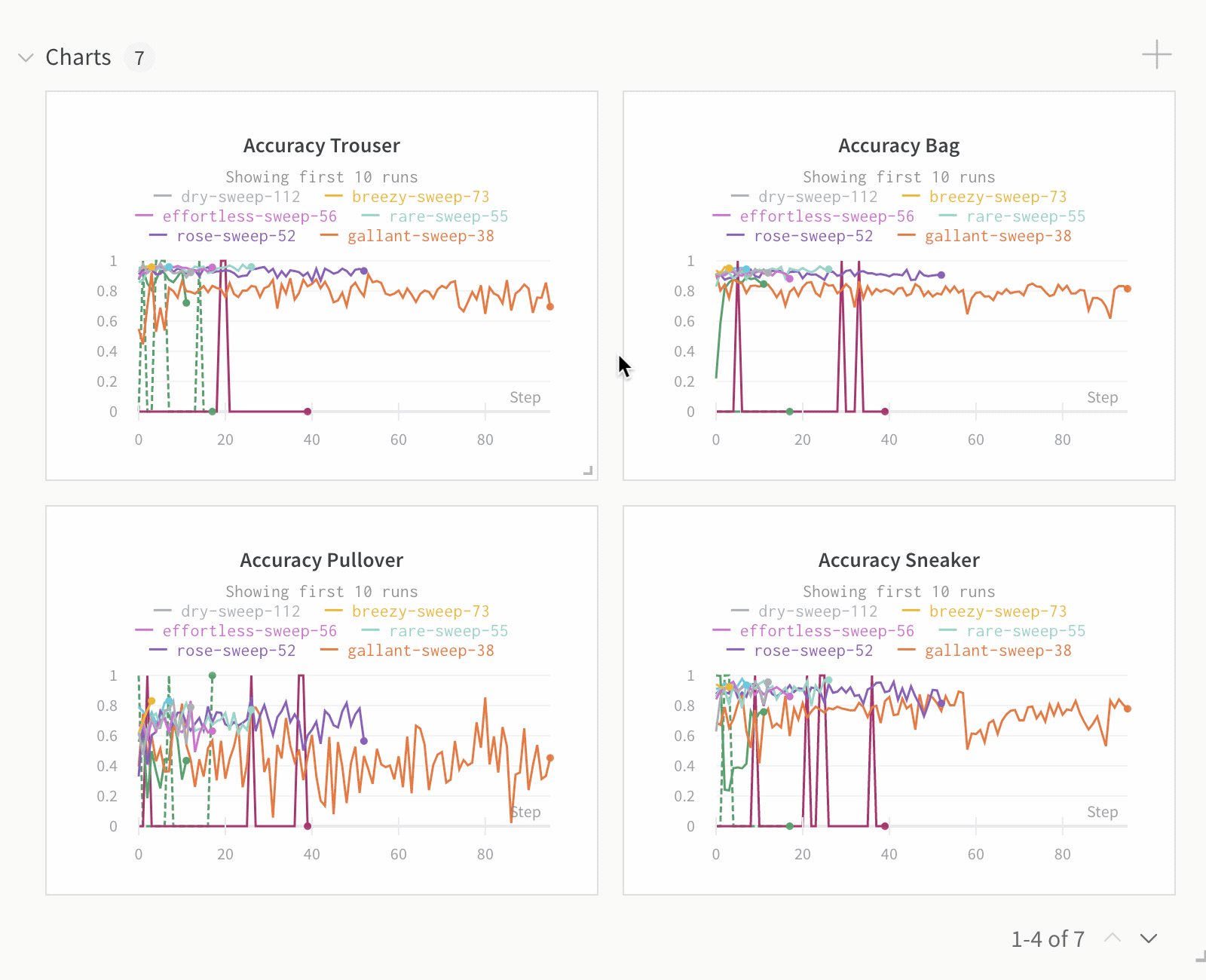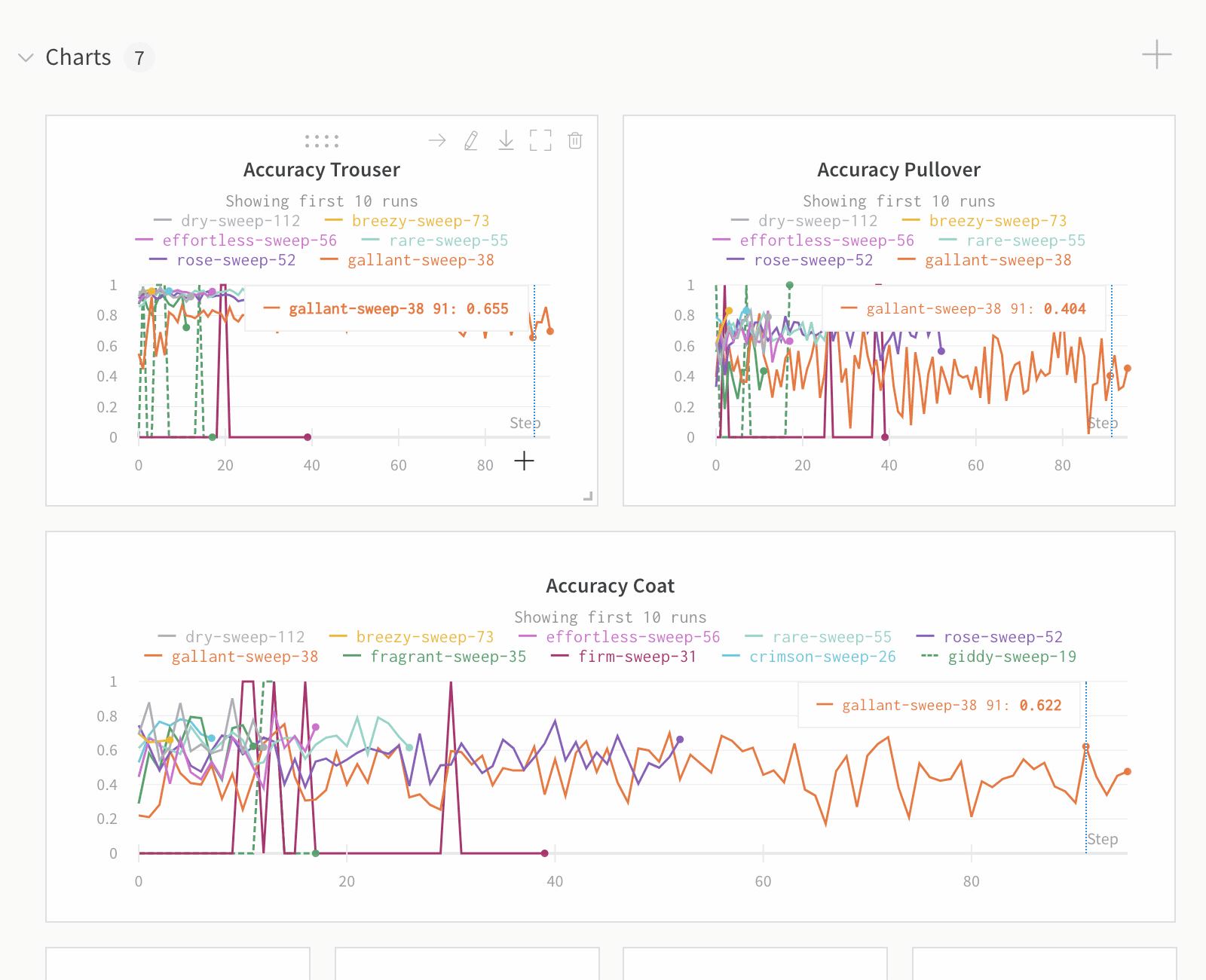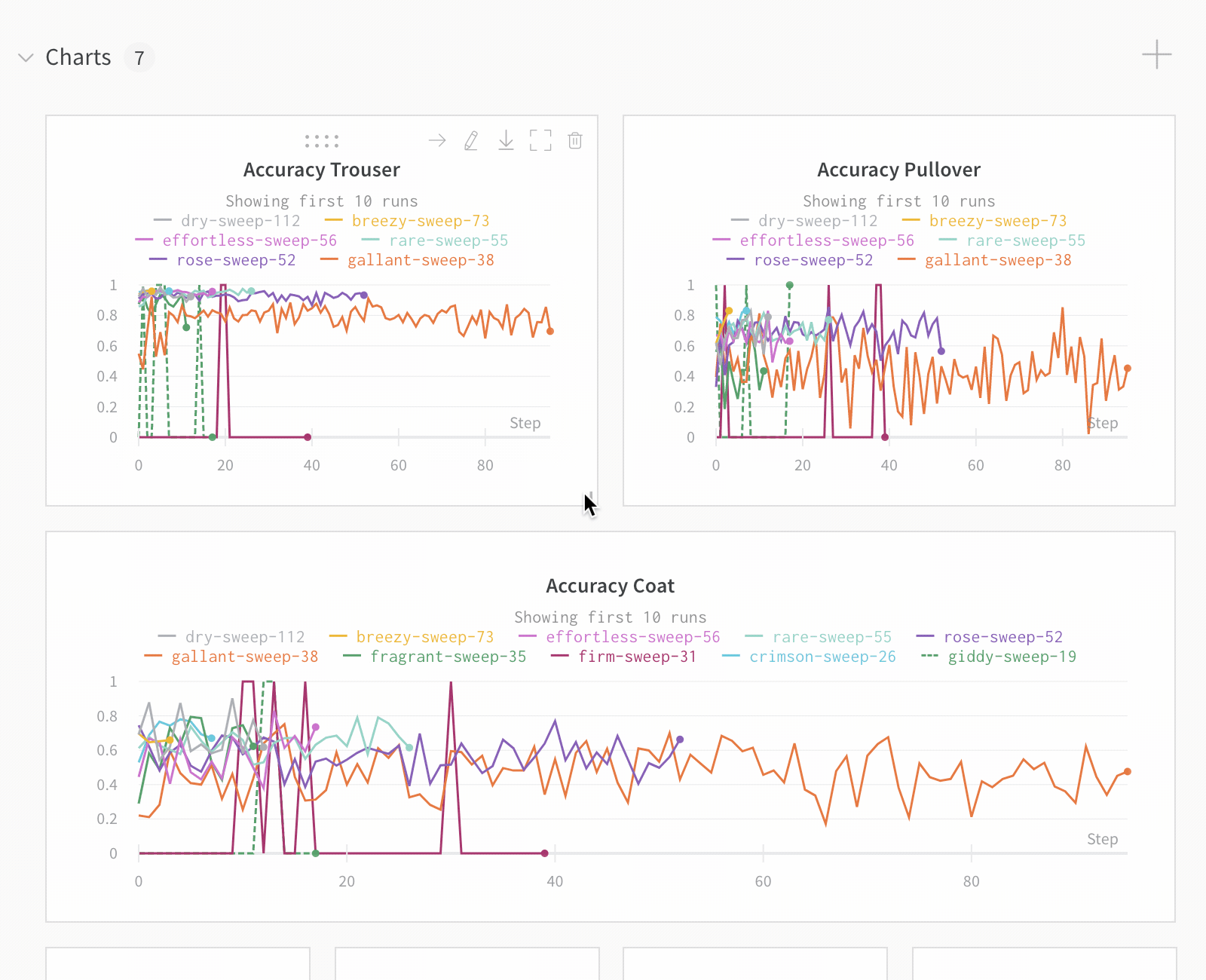
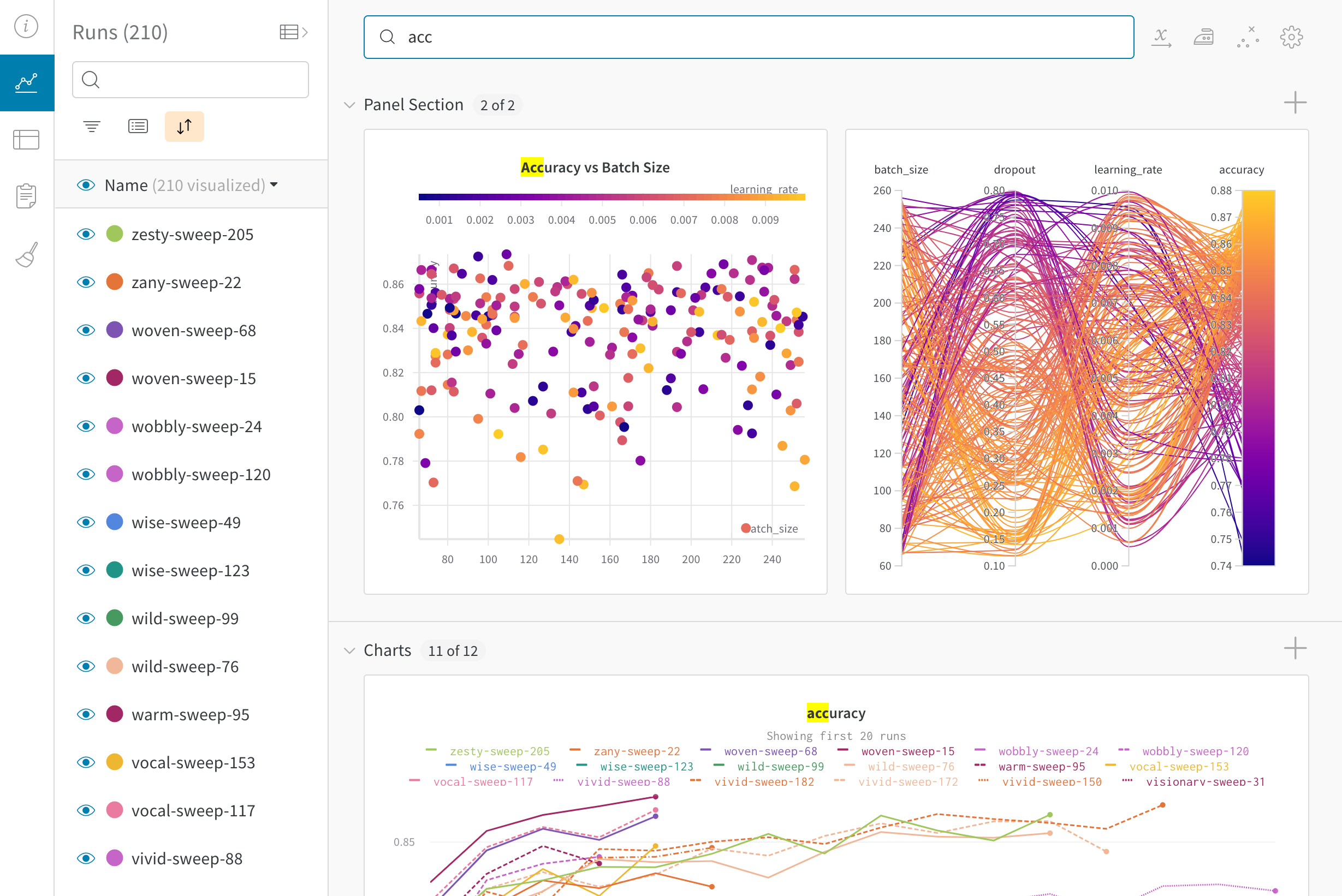
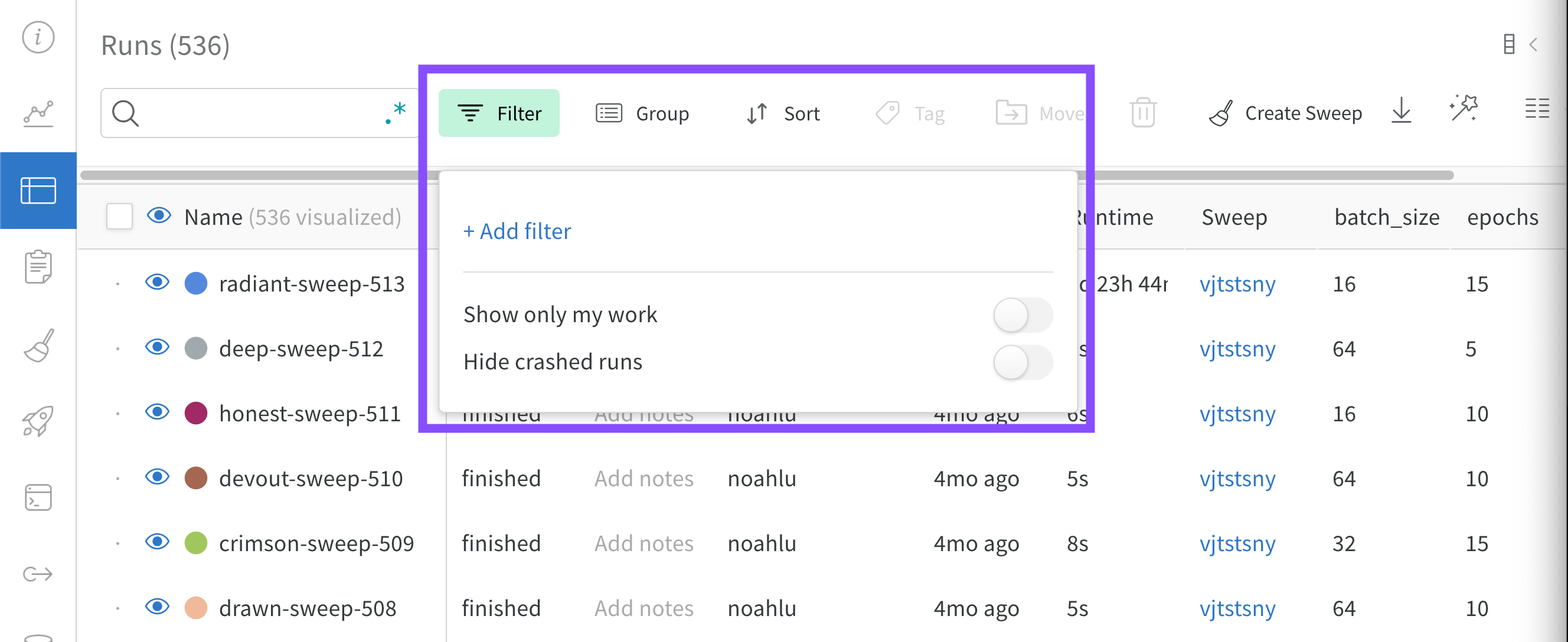
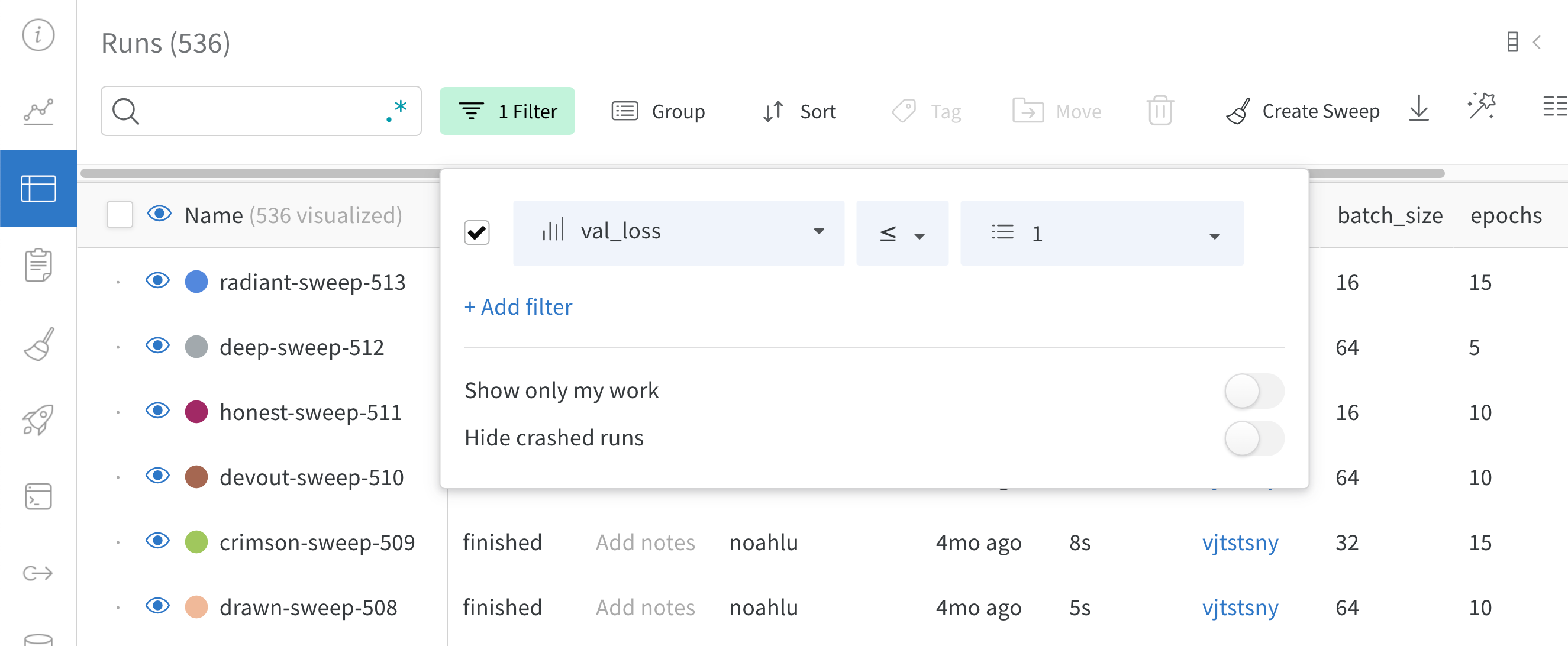 위의 이미지는 `val_loss` 열을 기반으로 하는 필터를 보여줍니다. 필터는 유효성 검사 손실이 1 이하인 Runs을 보여줍니다.
위의 이미지는 `val_loss` 열을 기반으로 하는 필터를 보여줍니다. 필터는 유효성 검사 손실이 1 이하인 Runs을 보여줍니다.
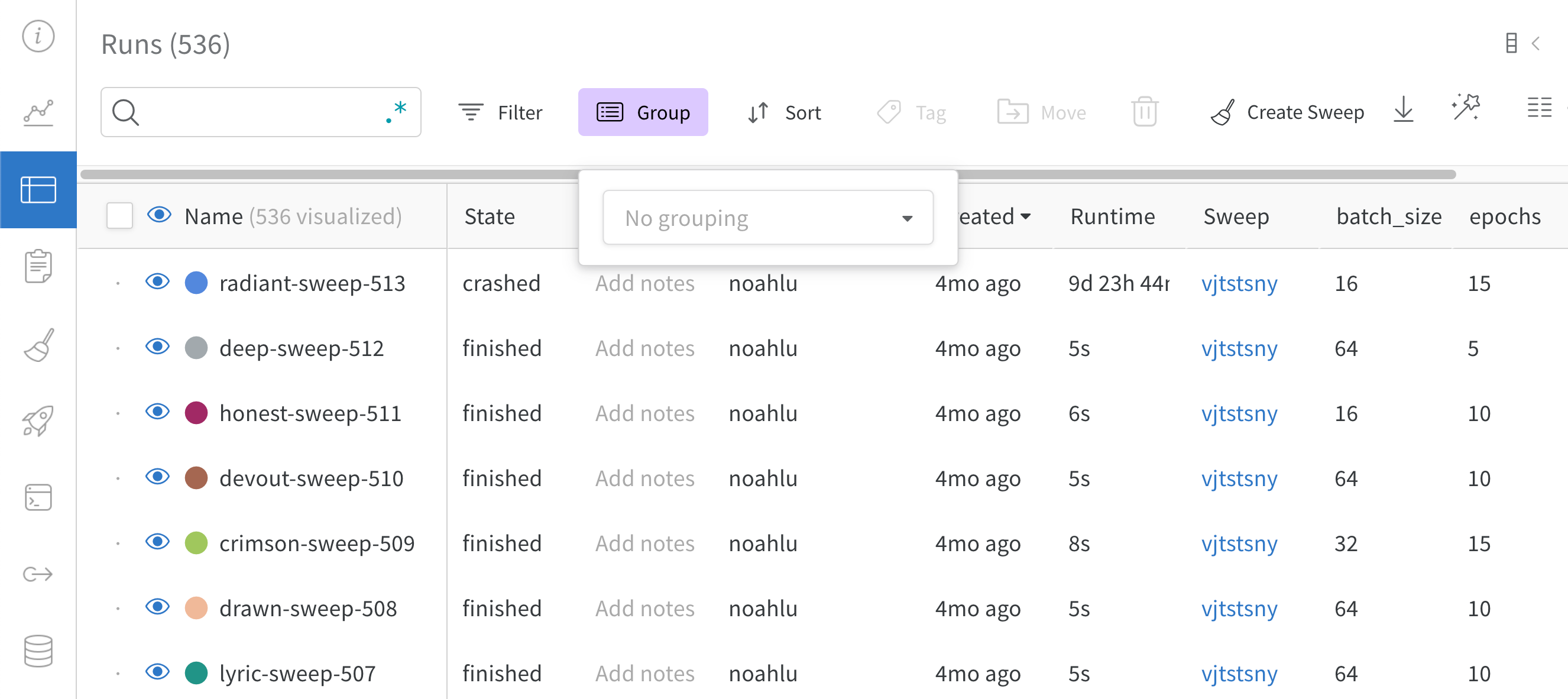
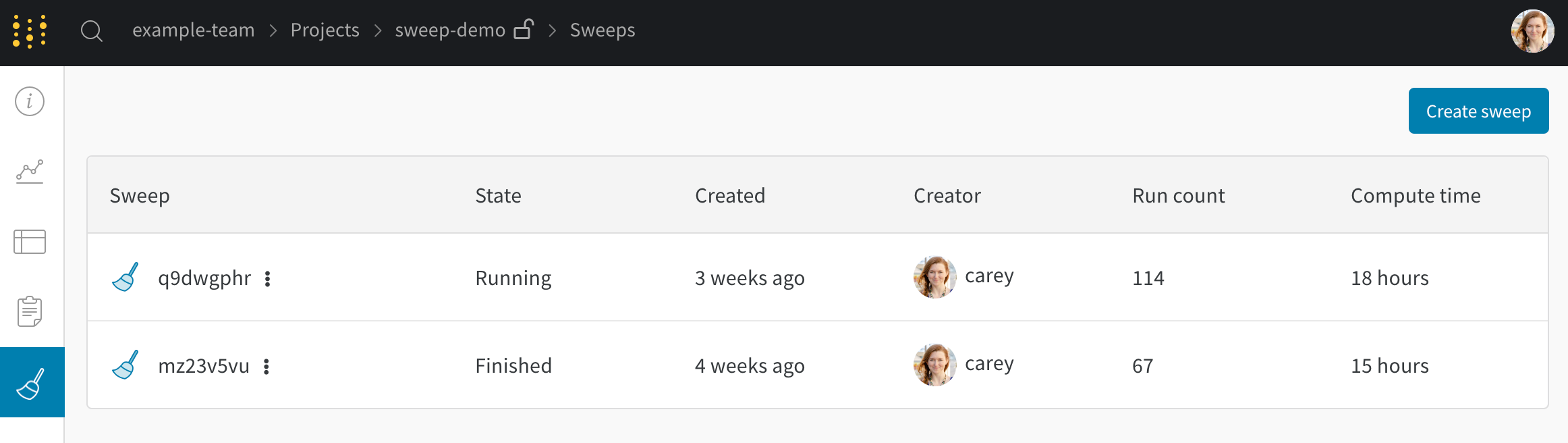
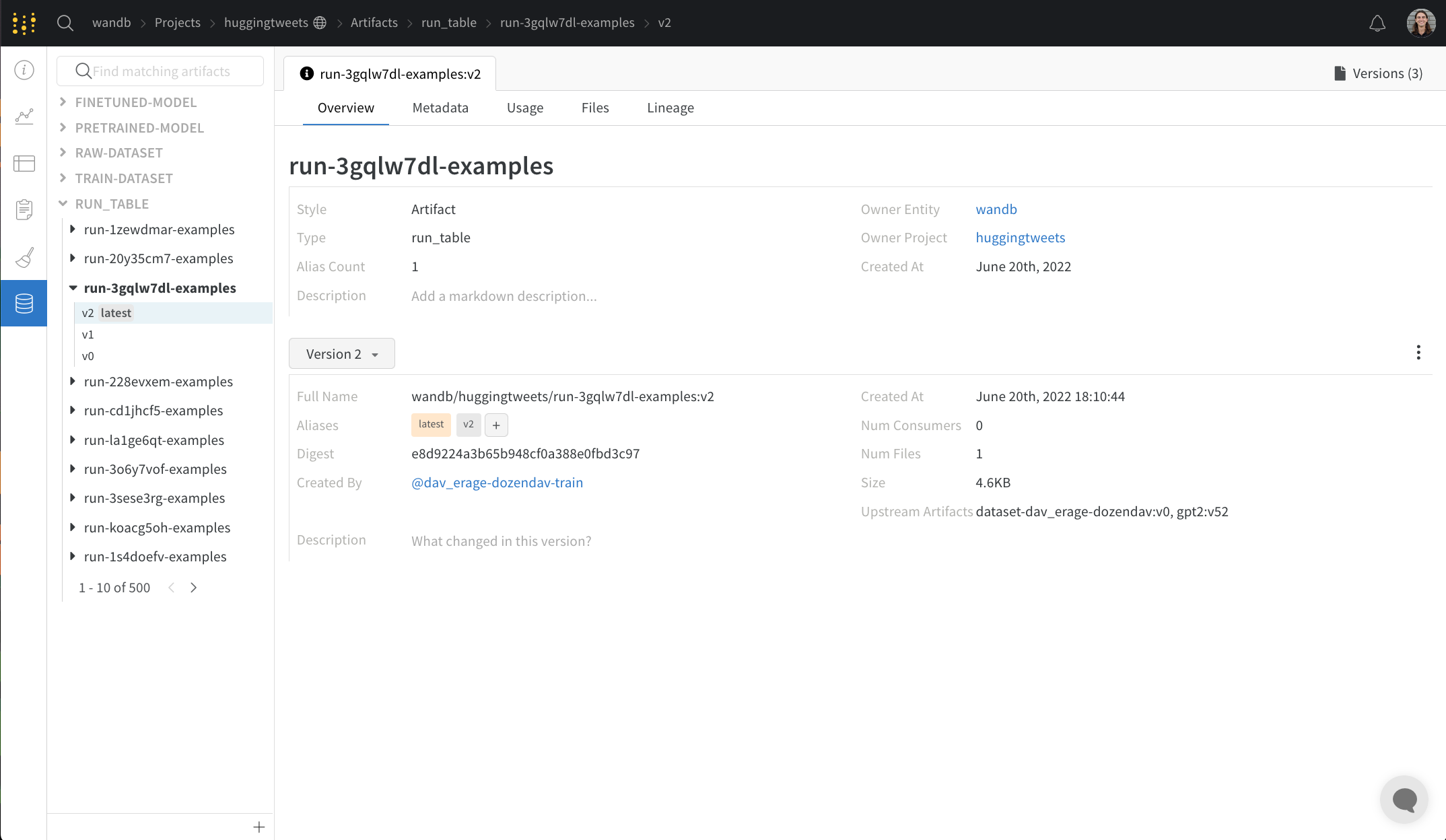
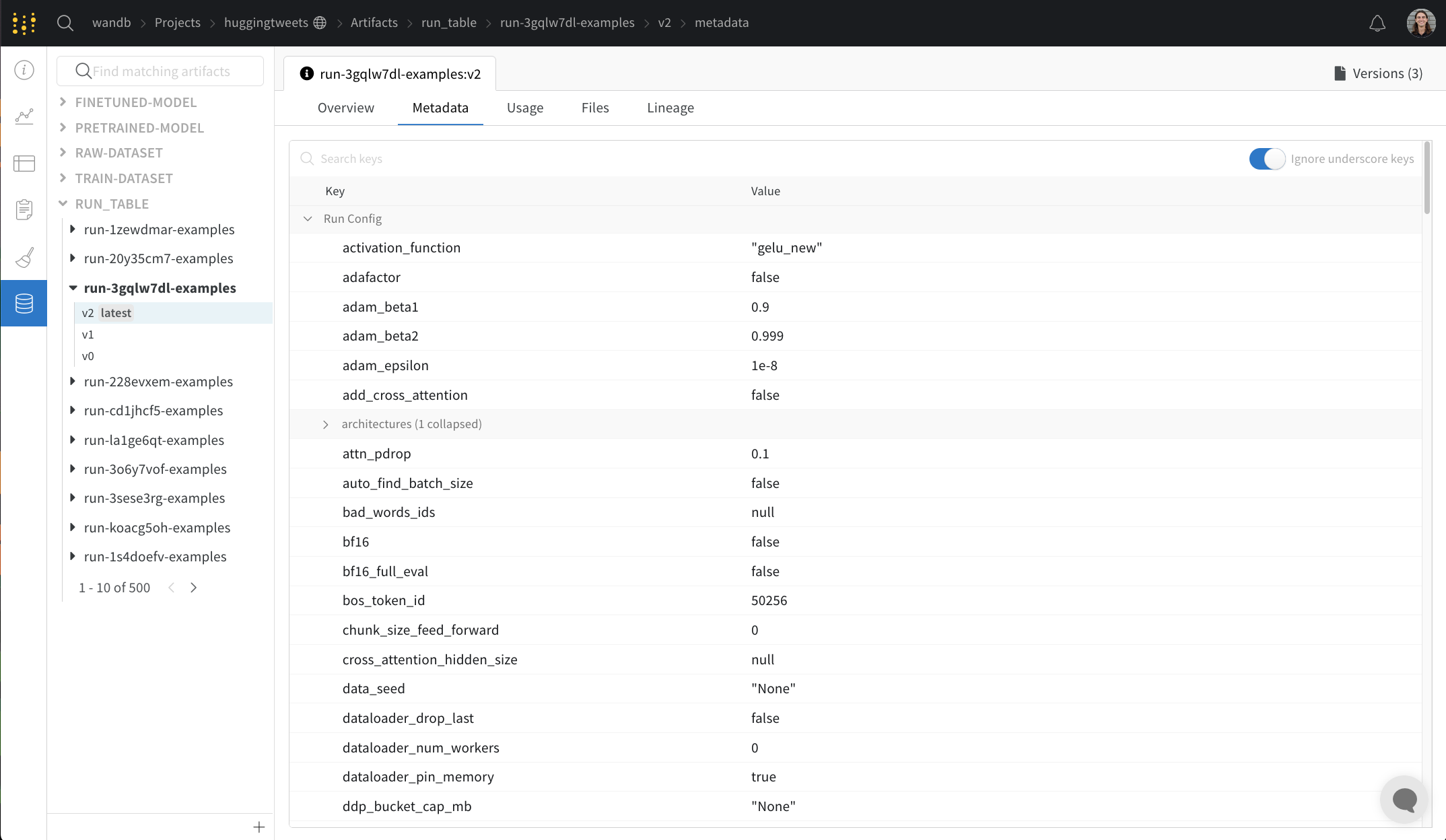
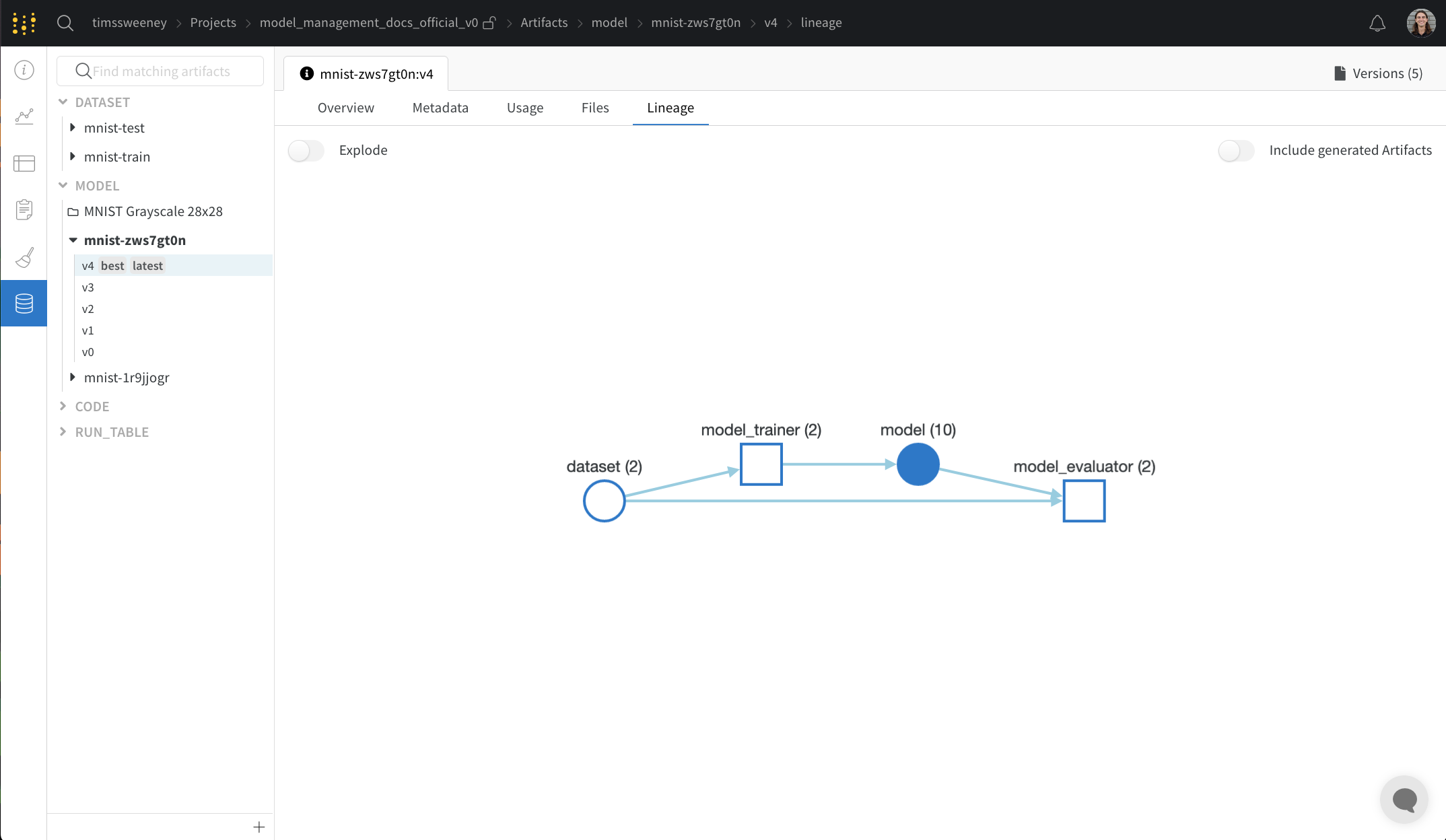
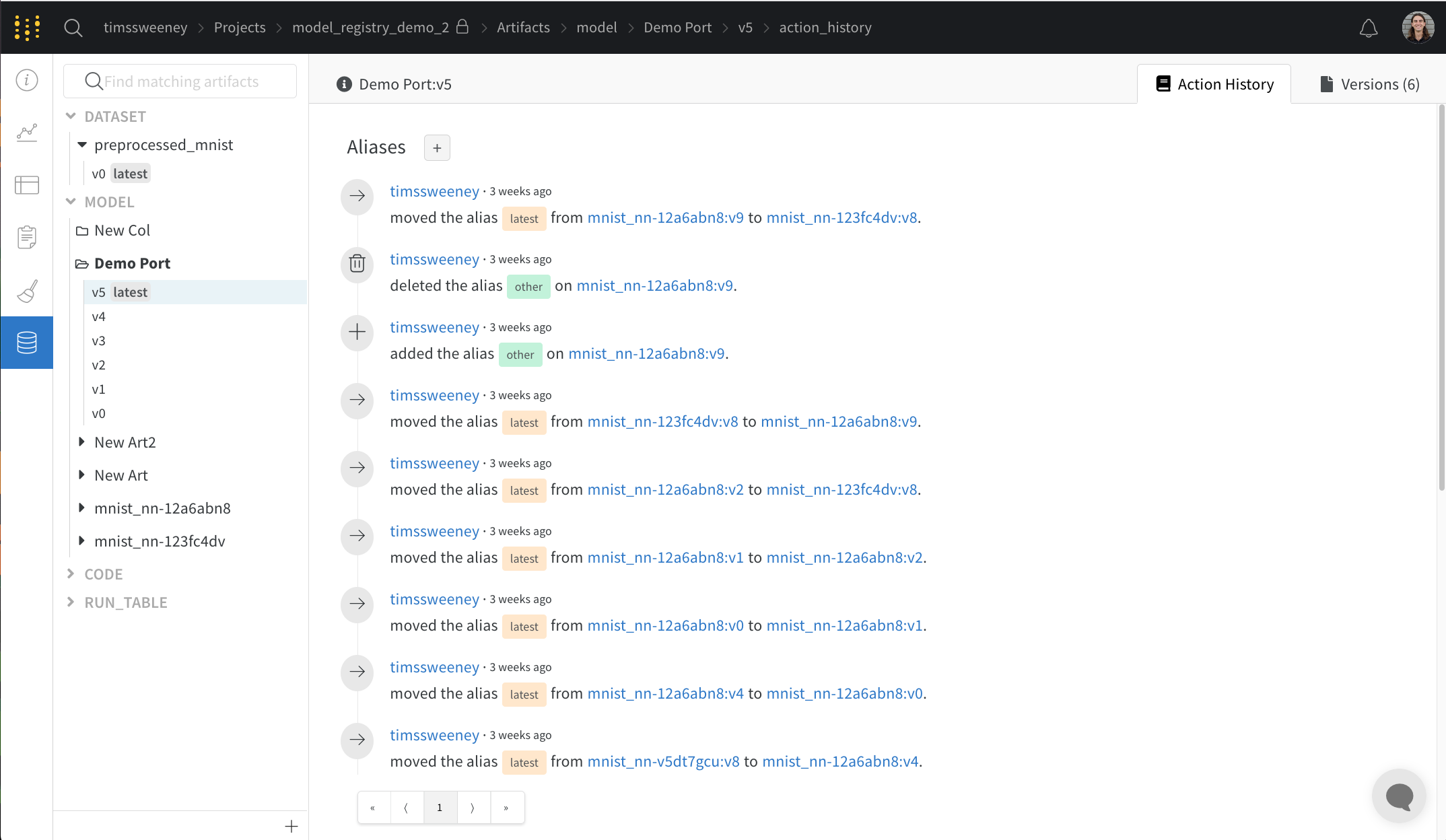
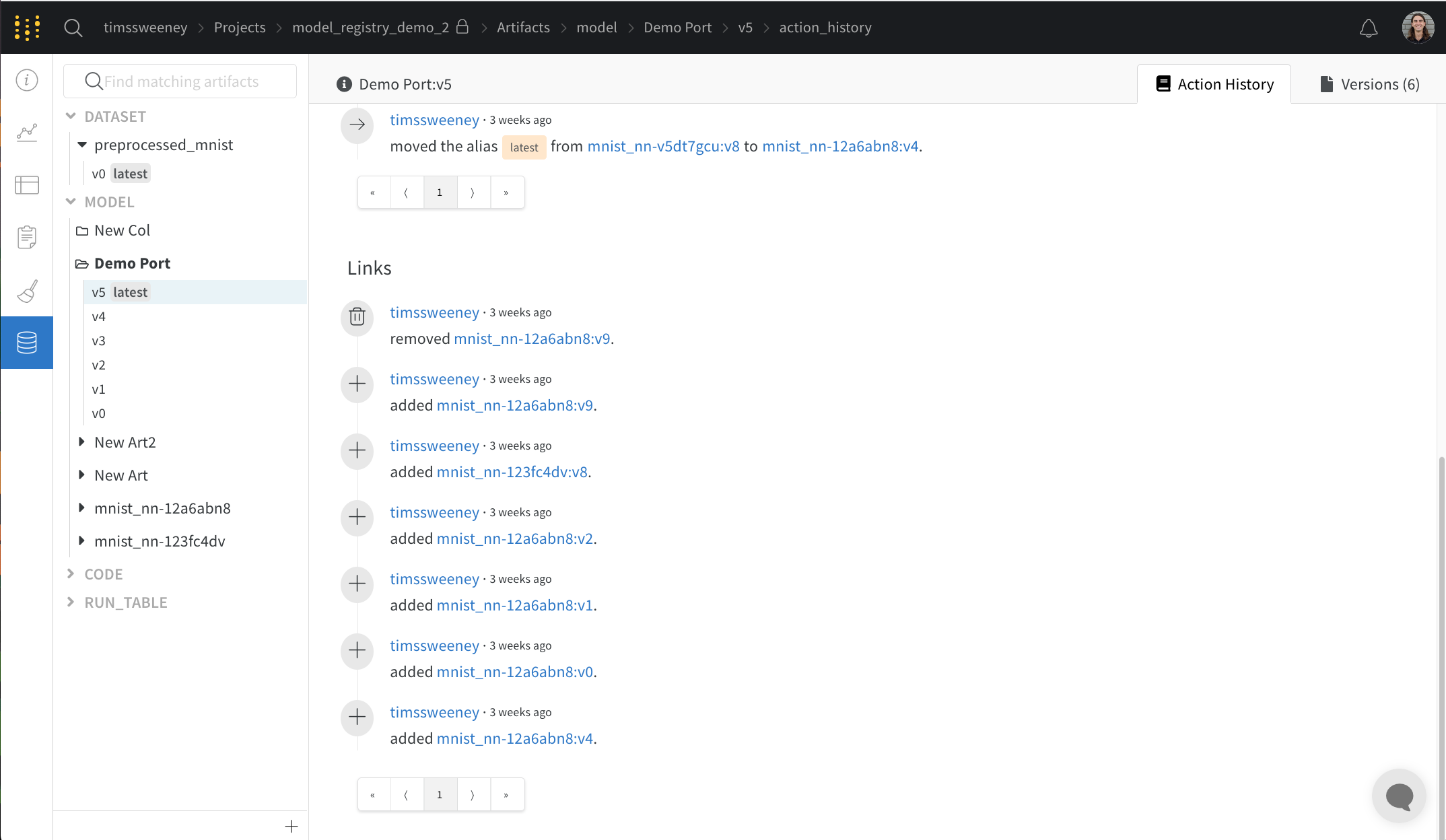

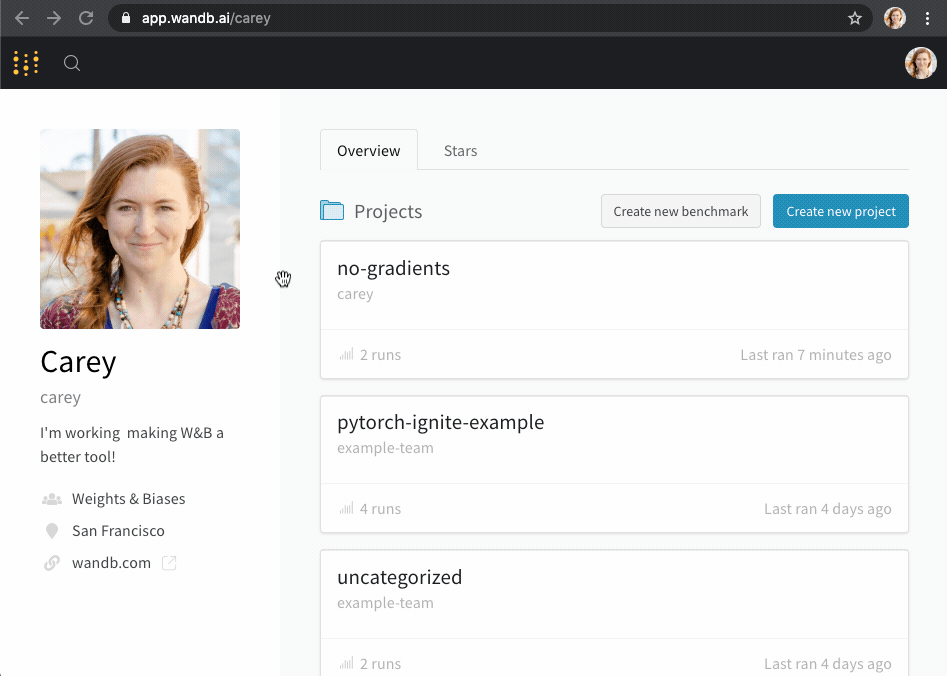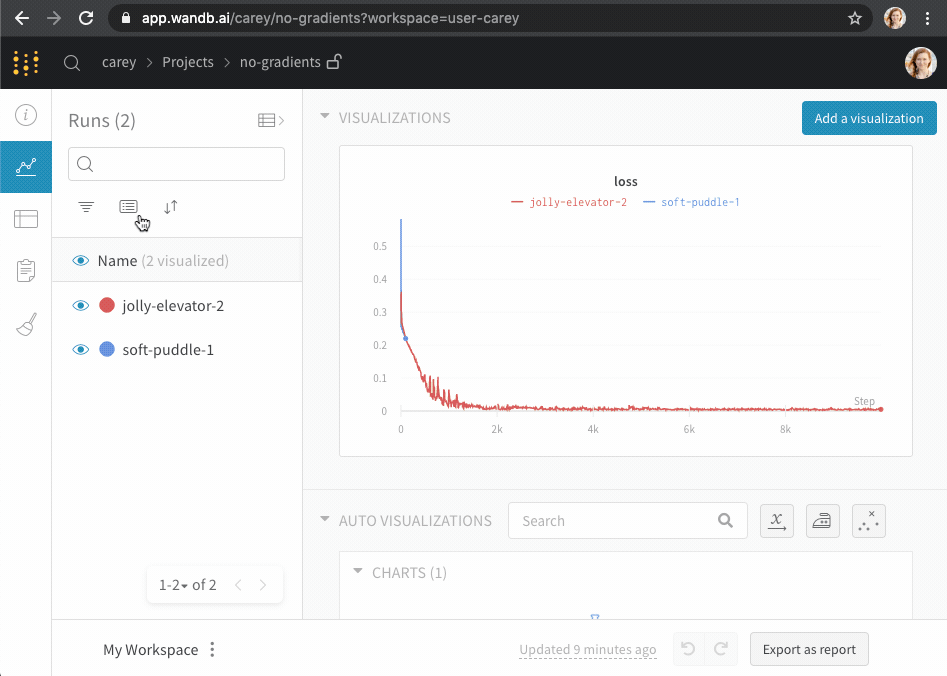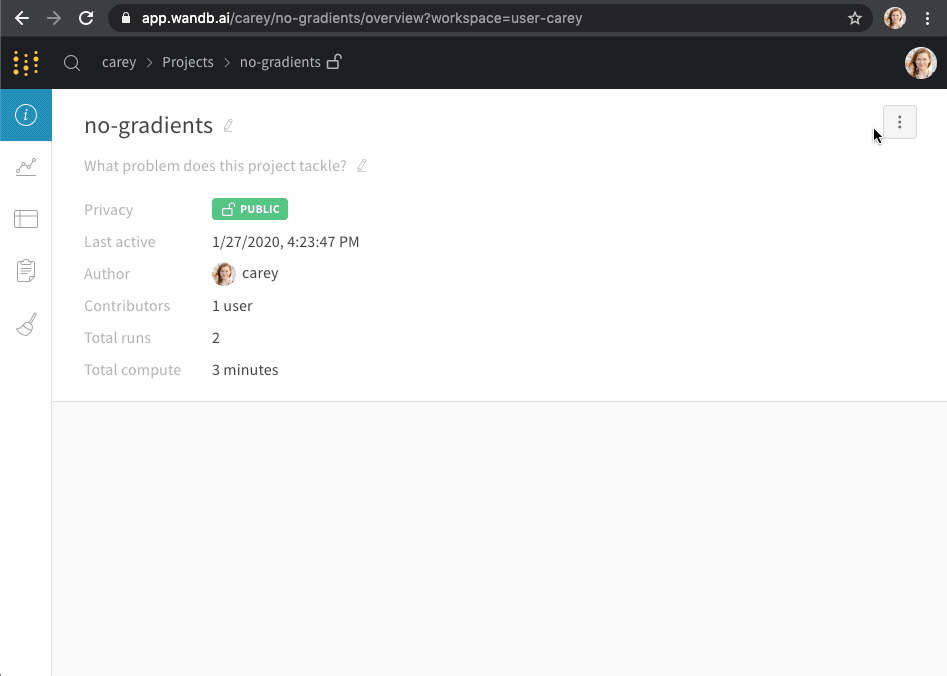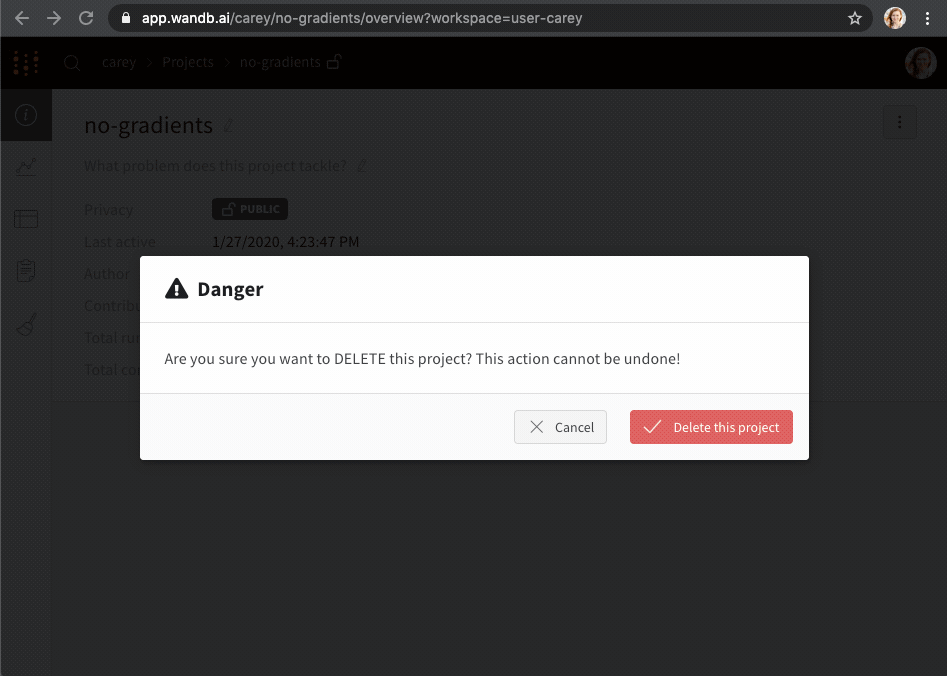
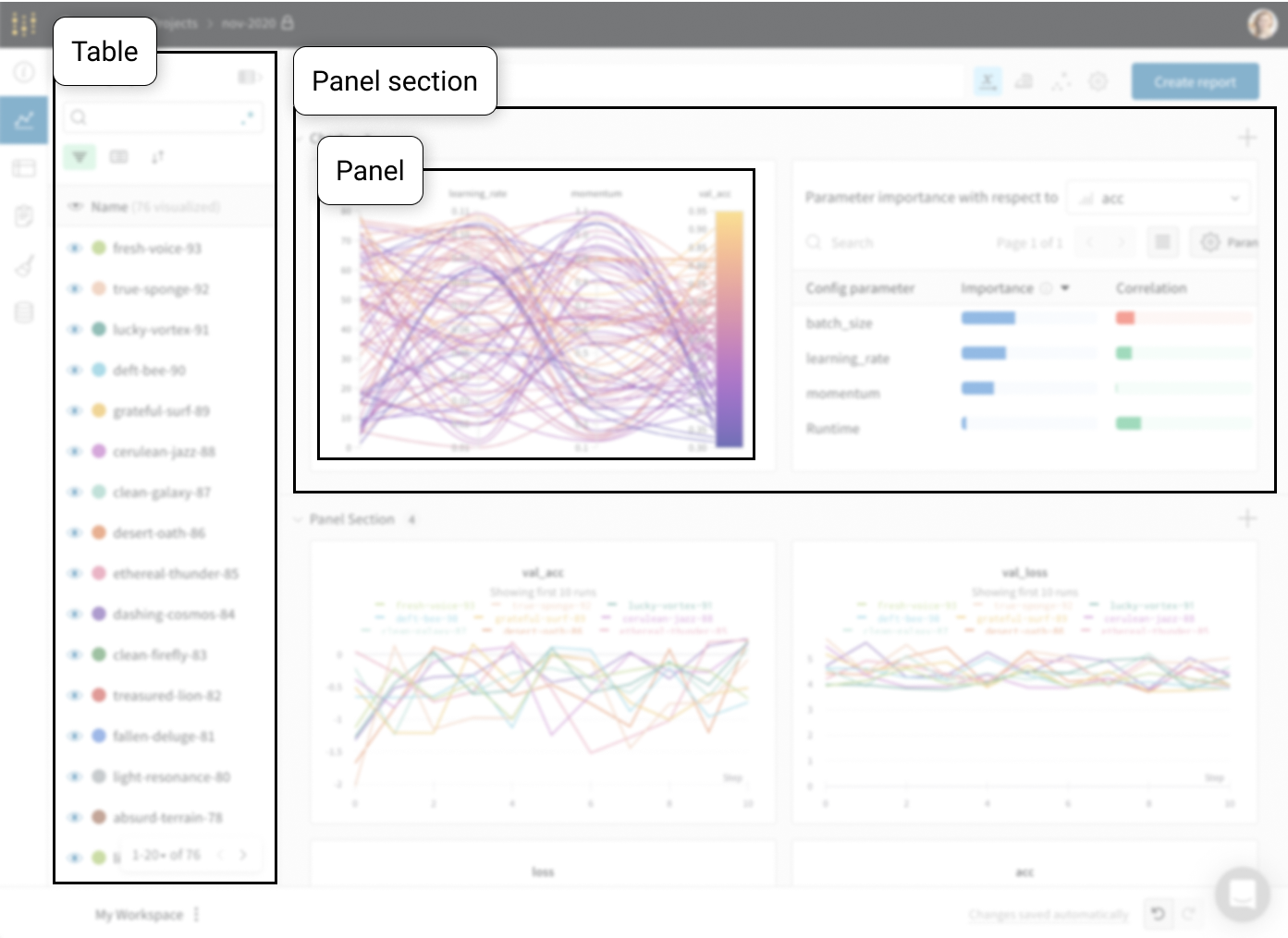
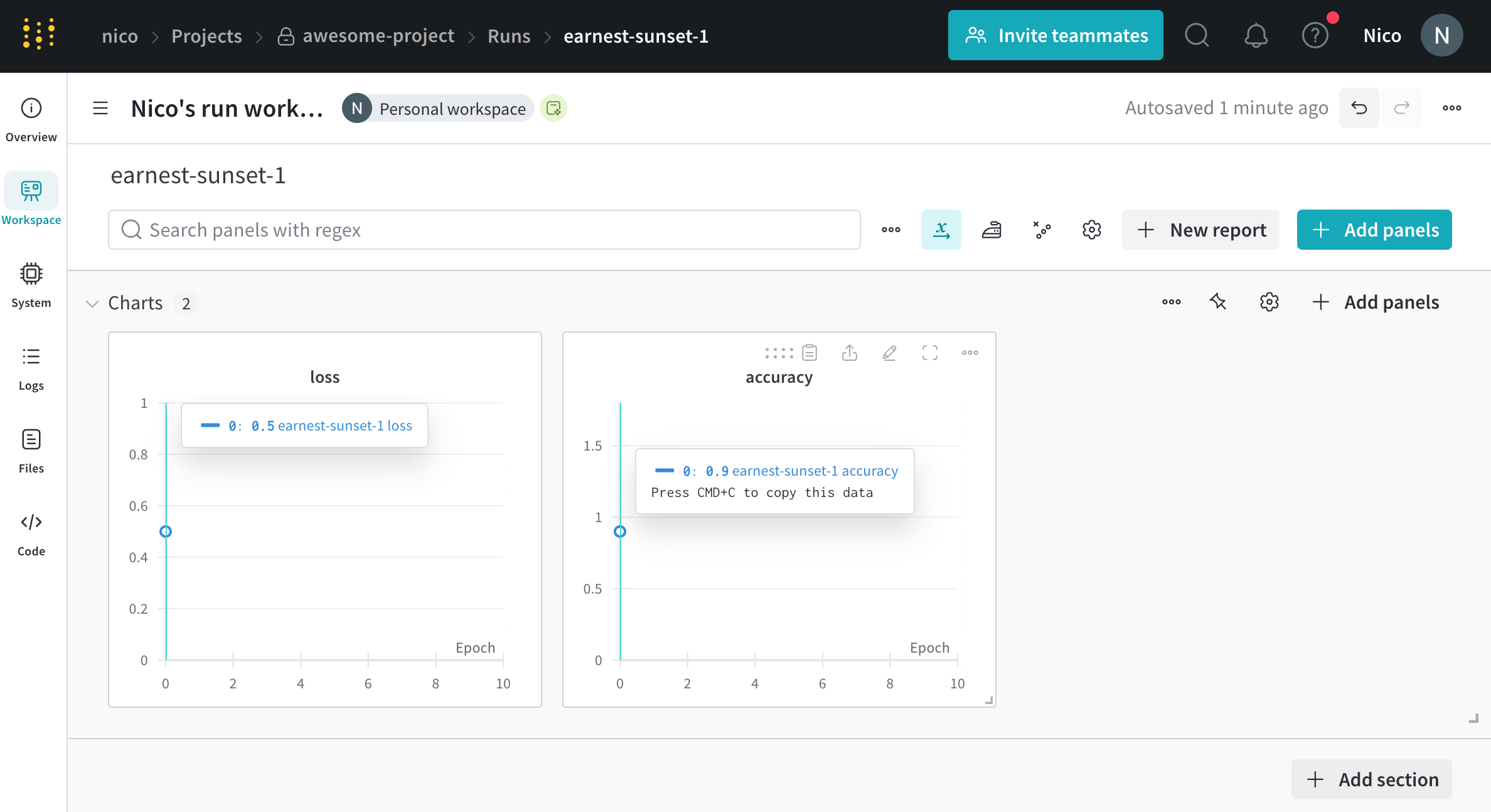
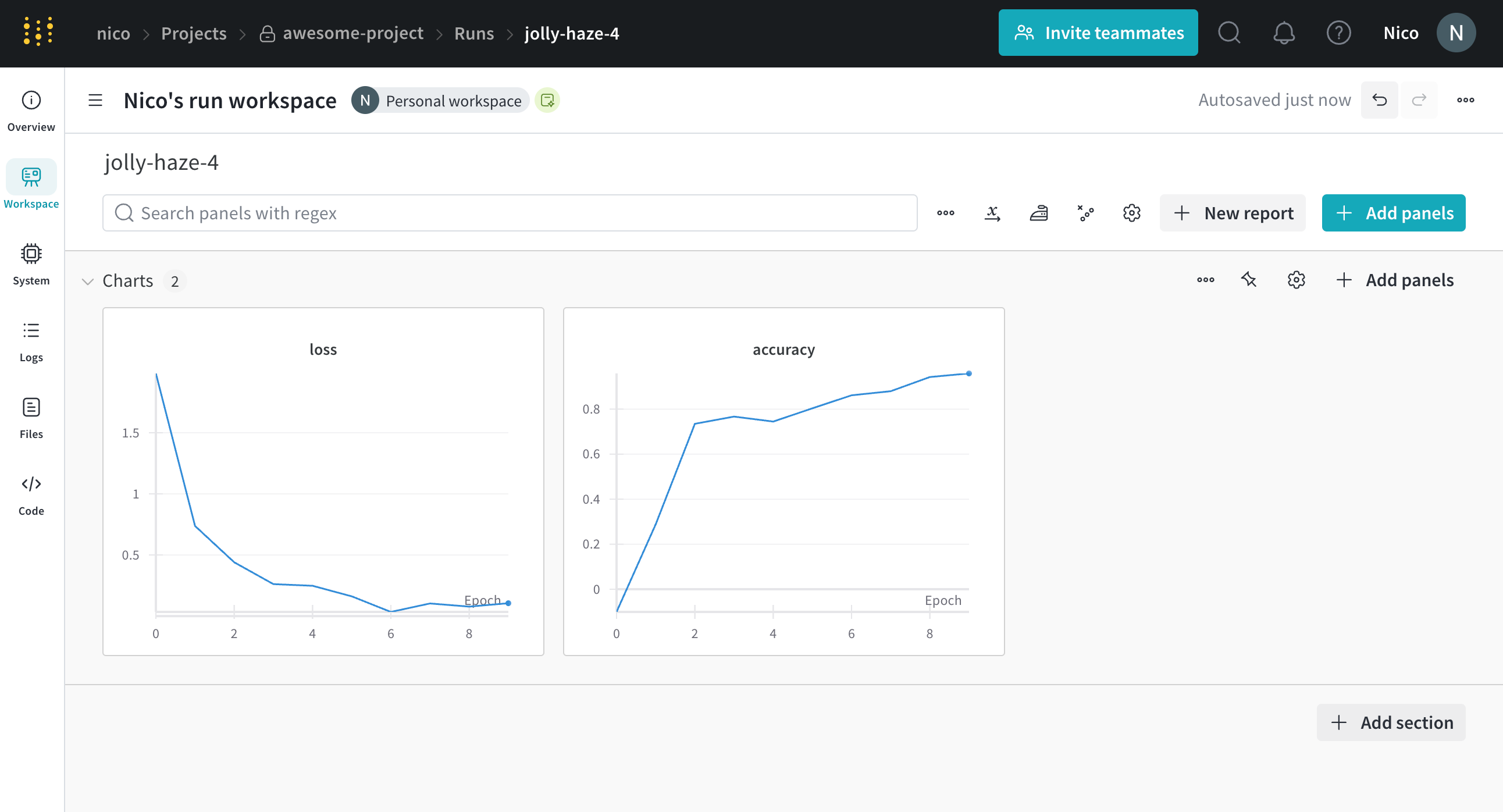
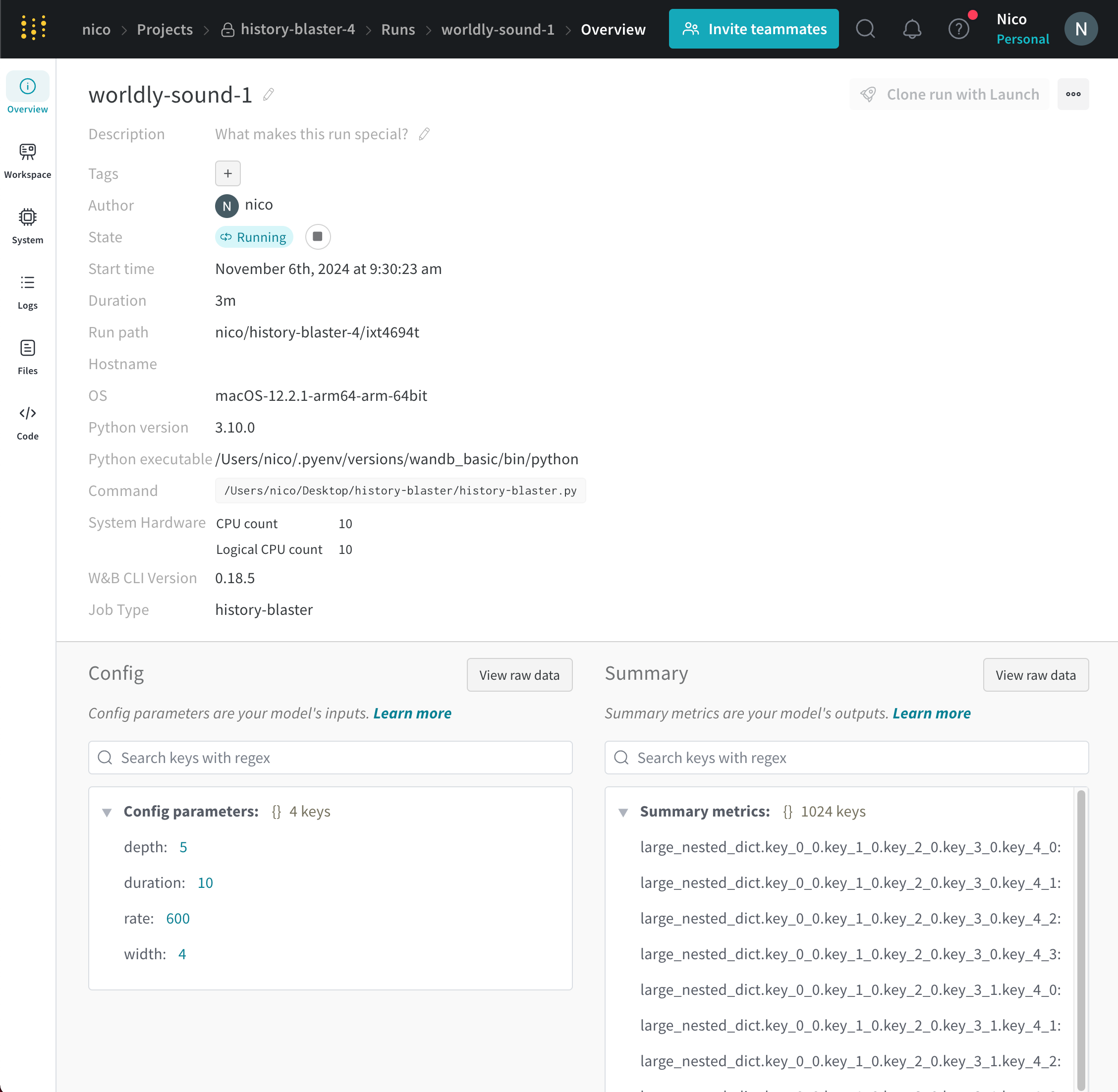
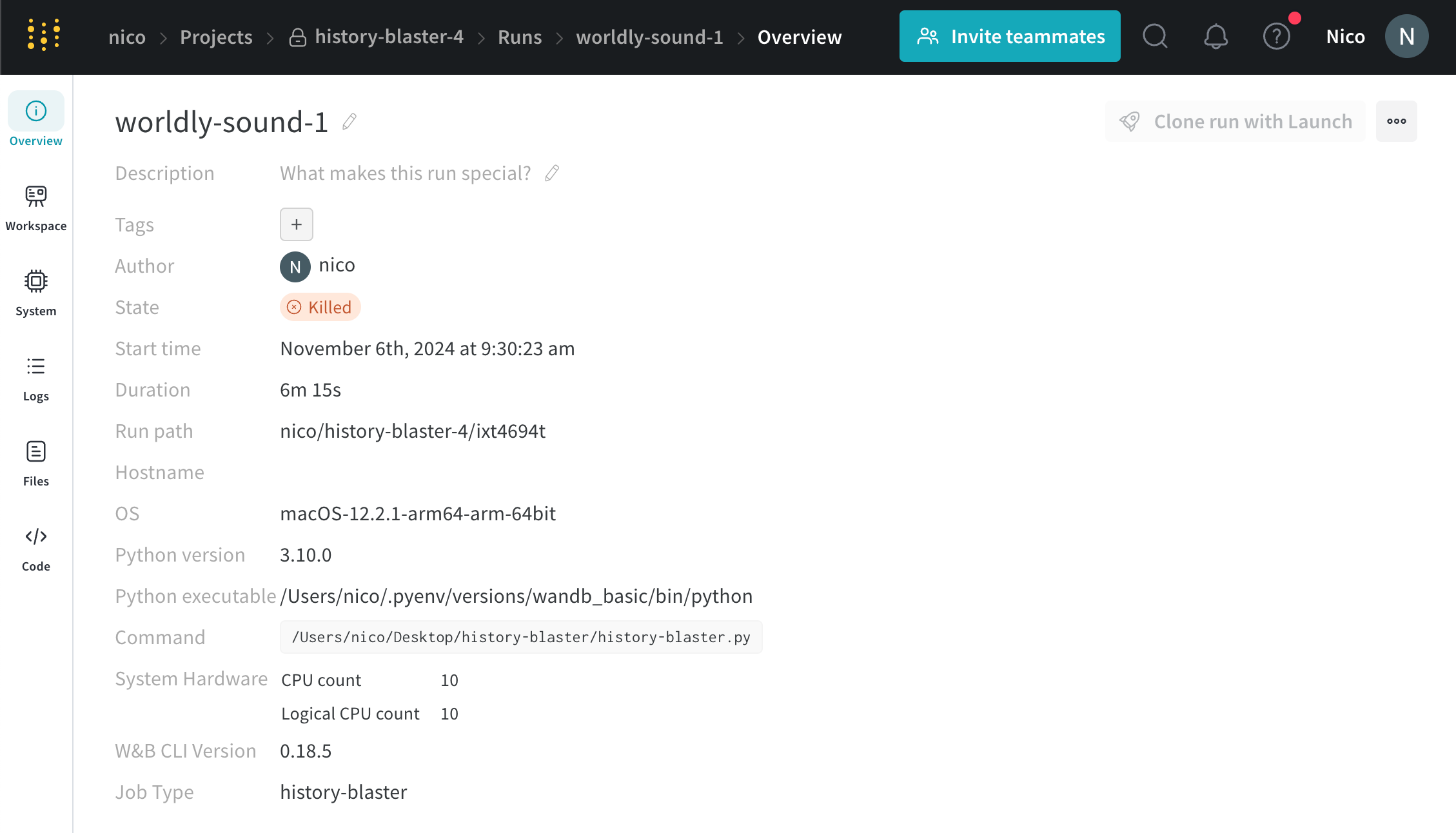
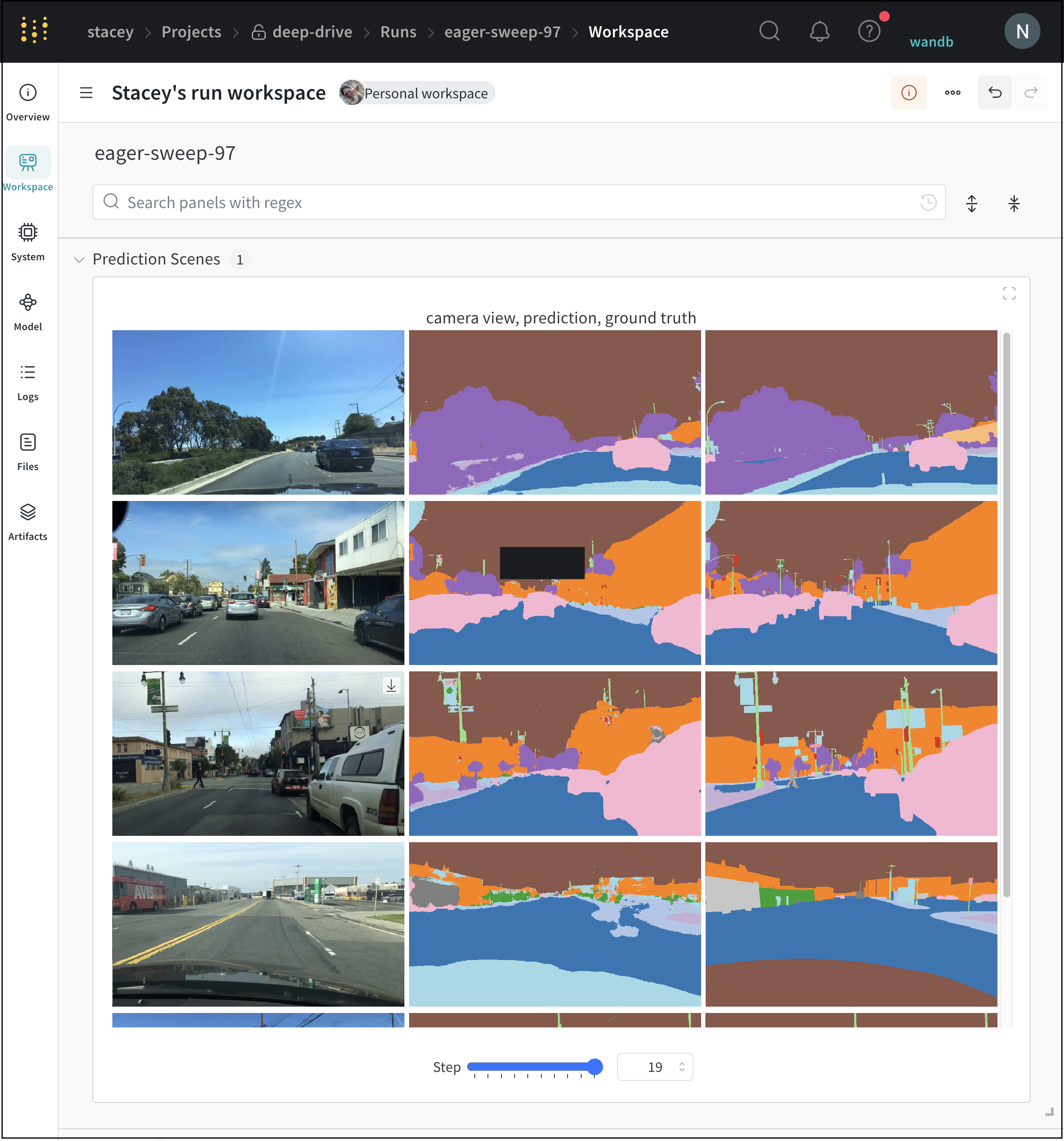
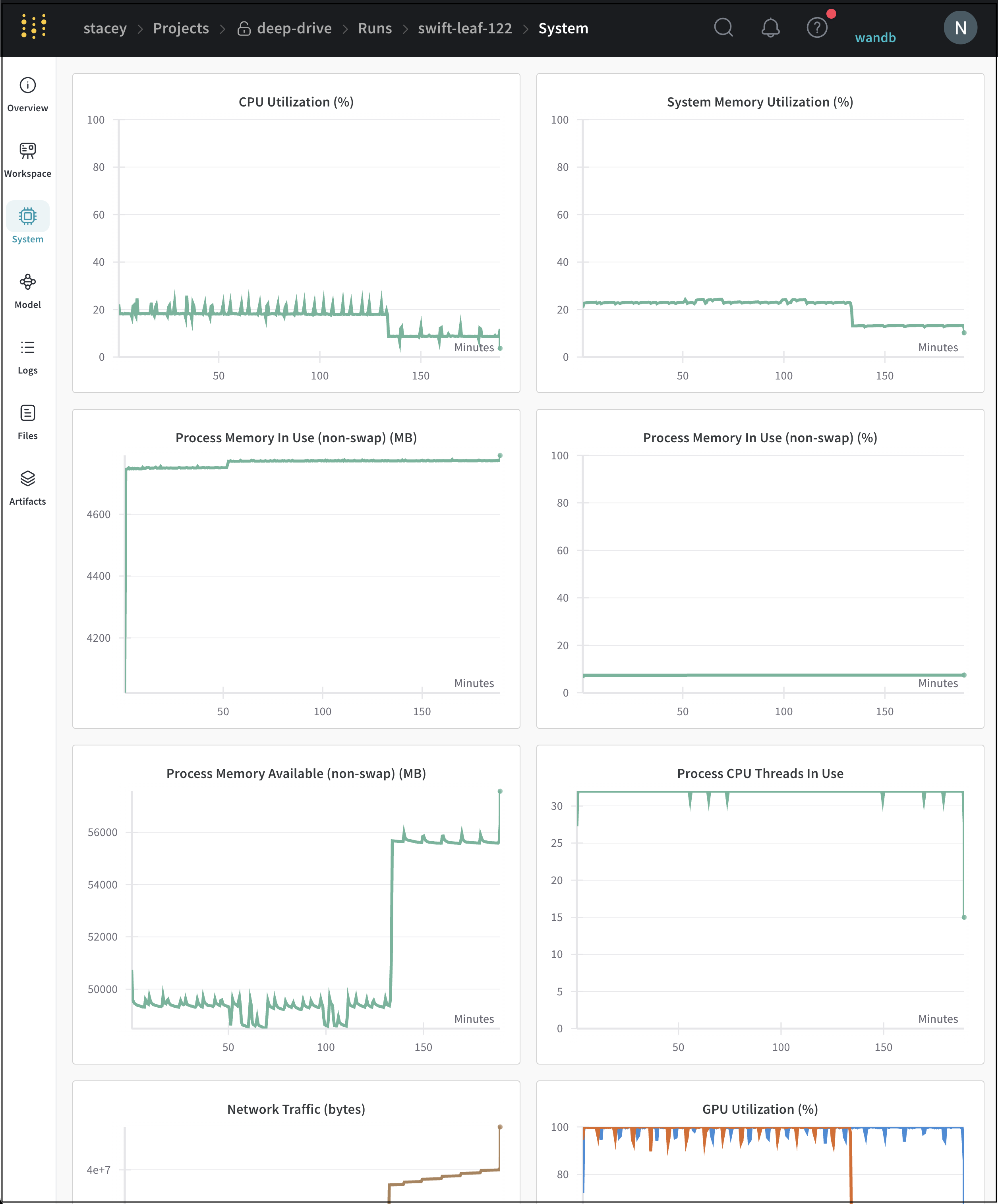
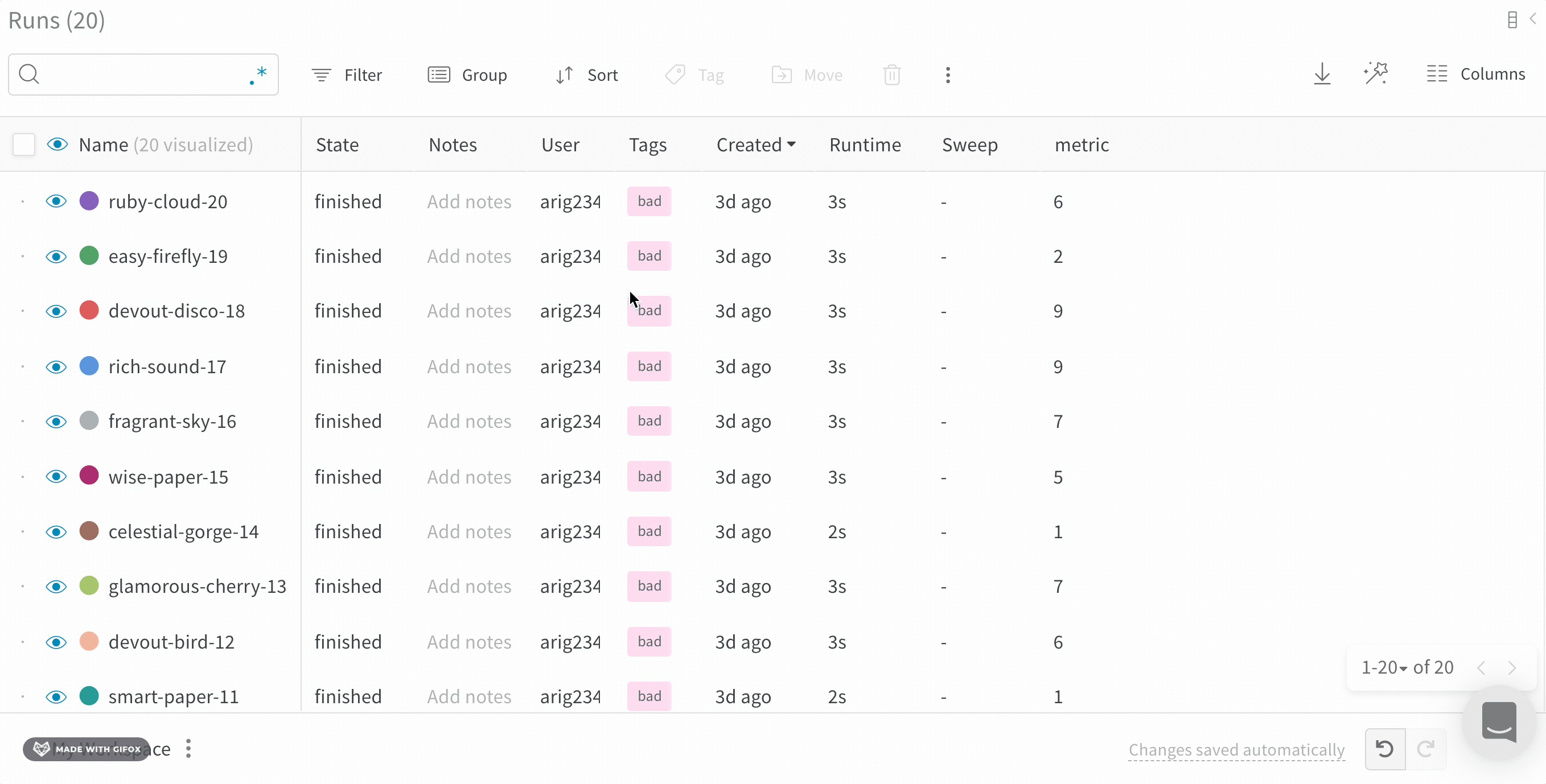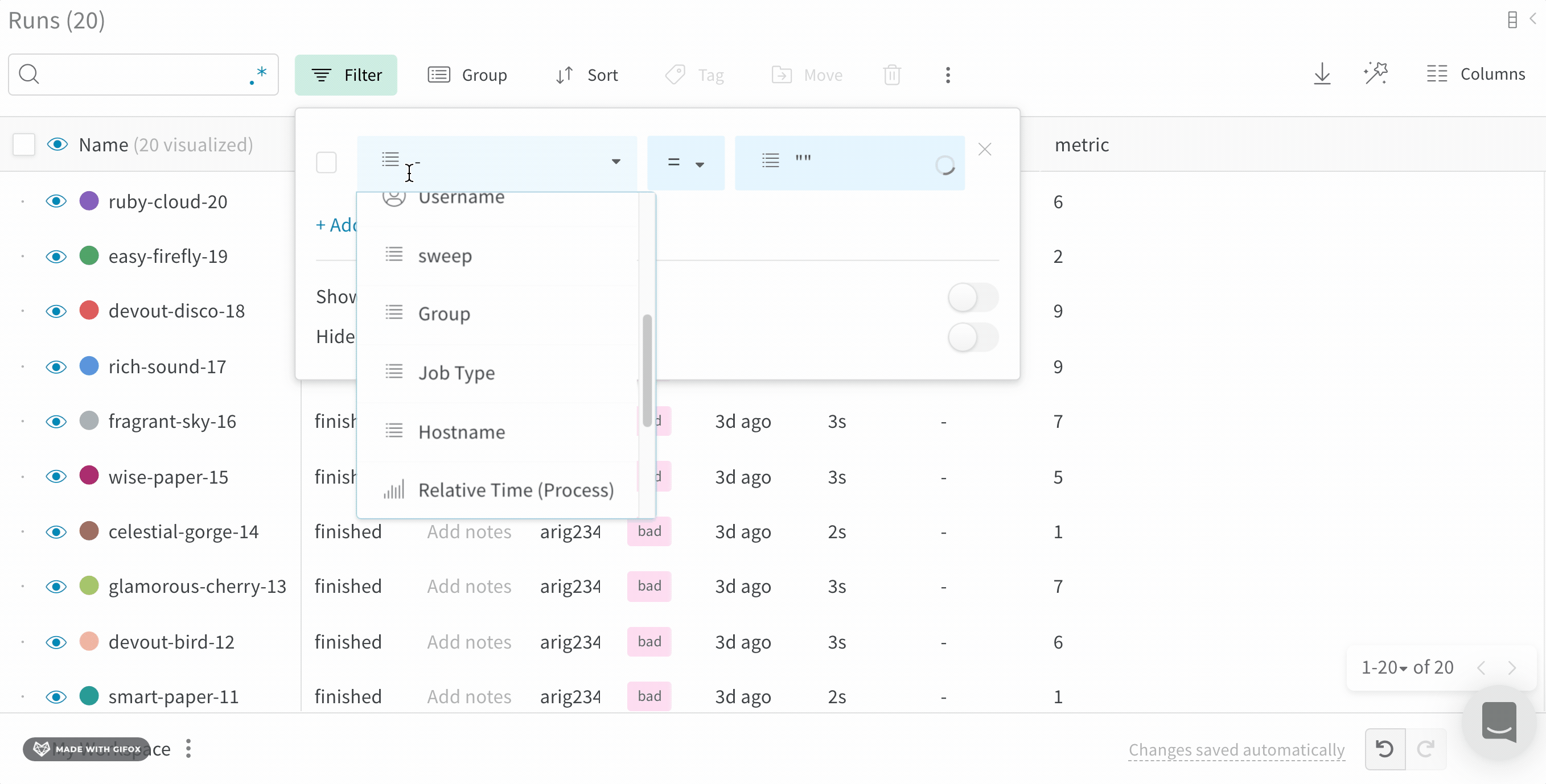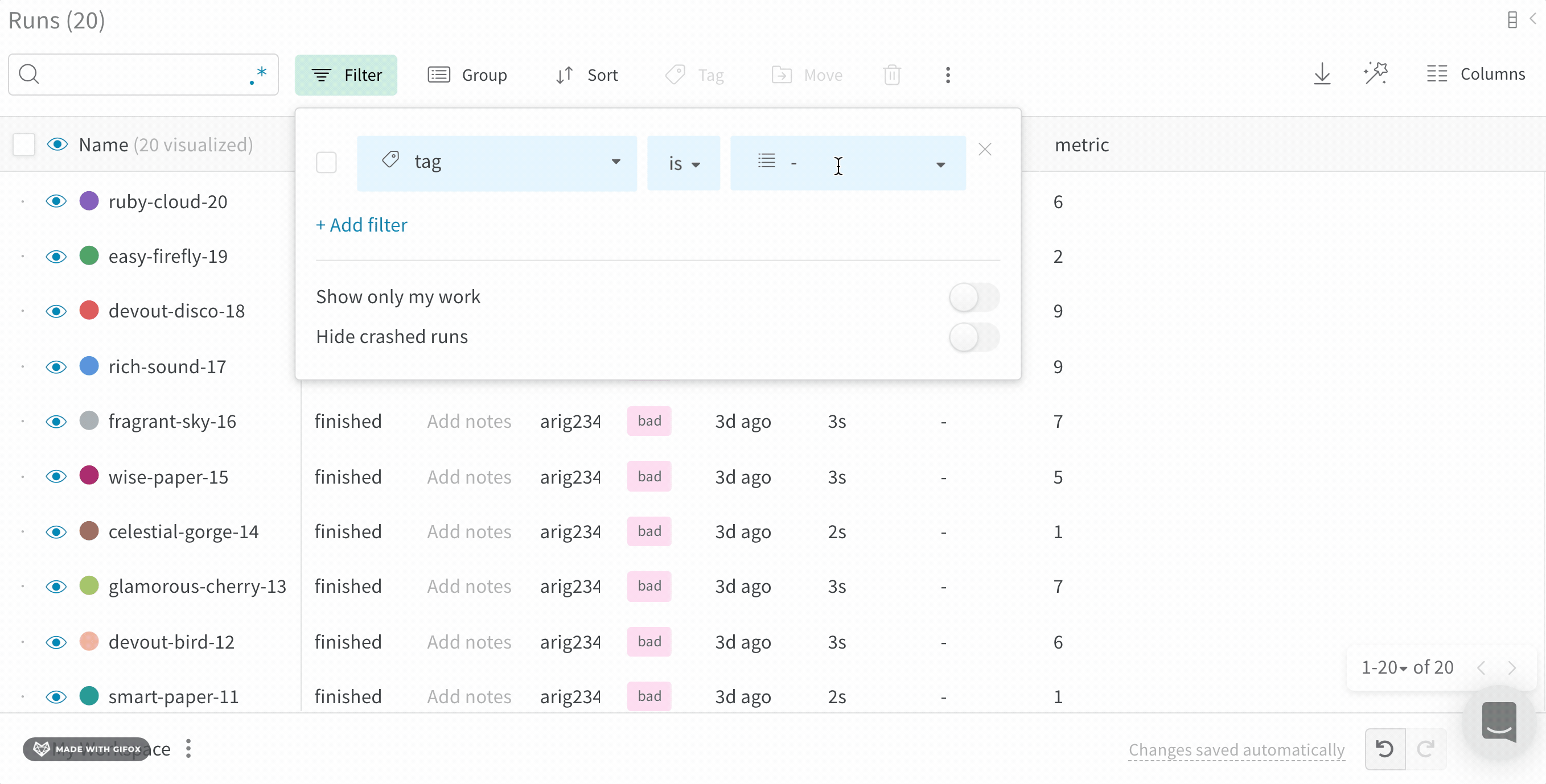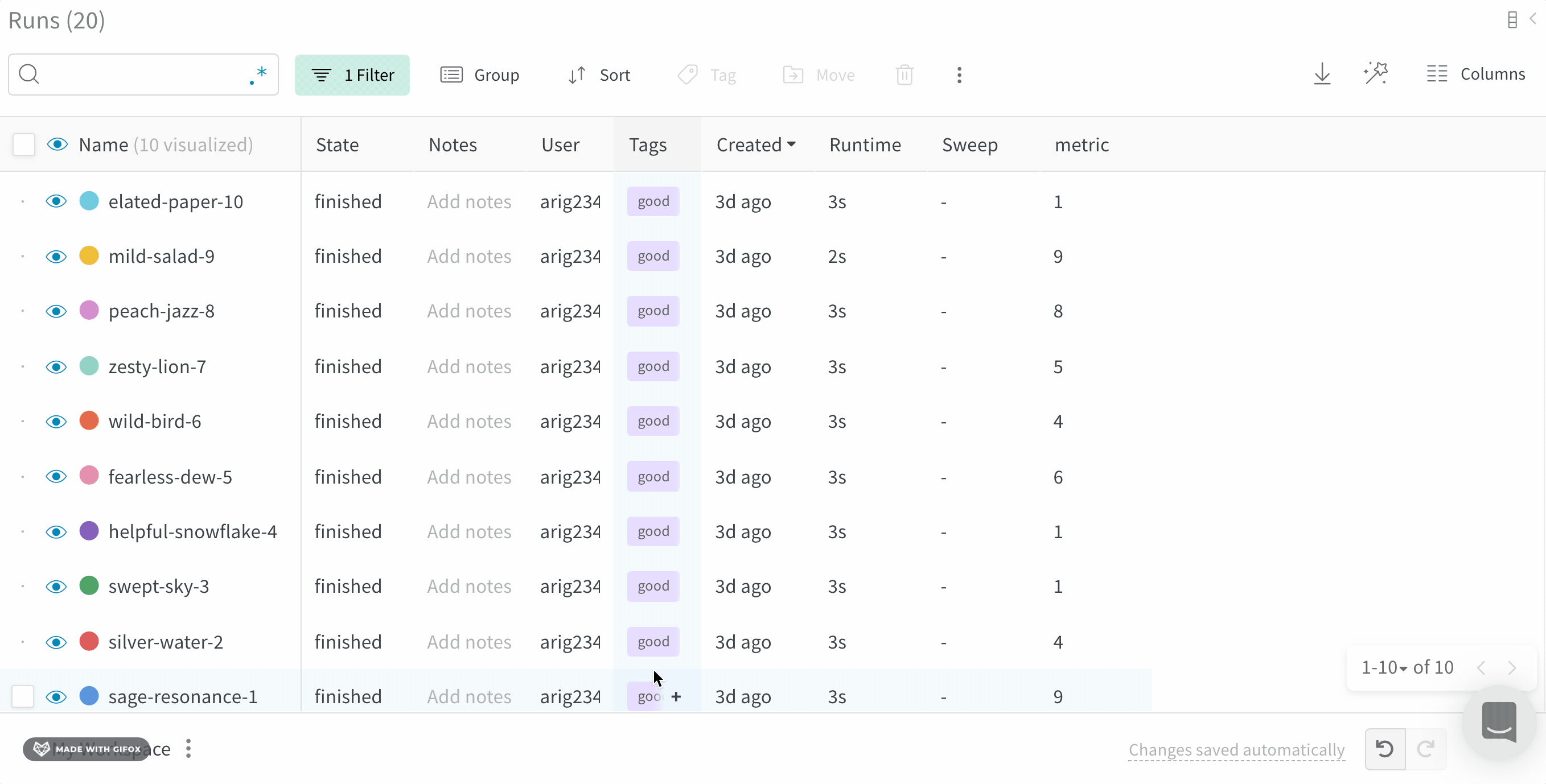
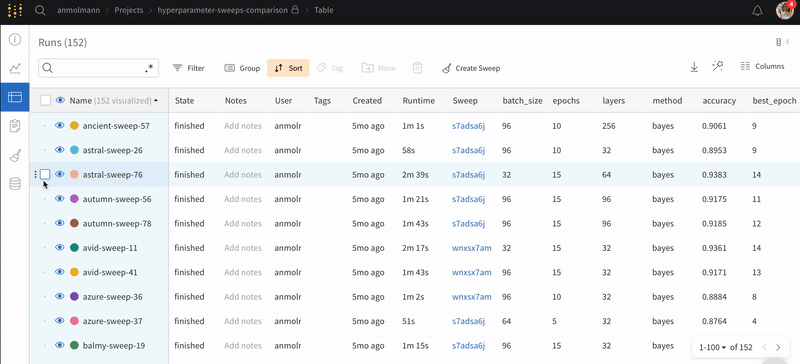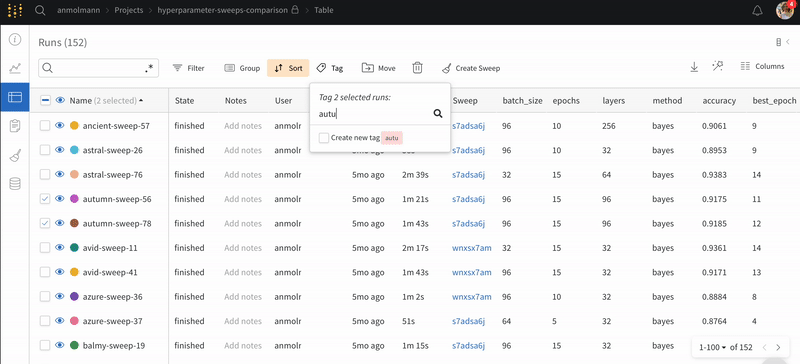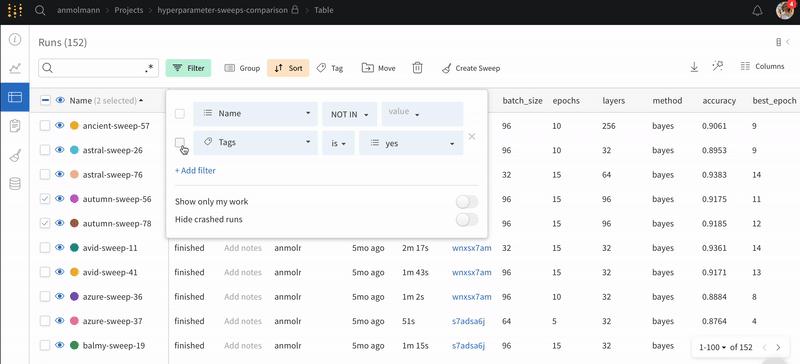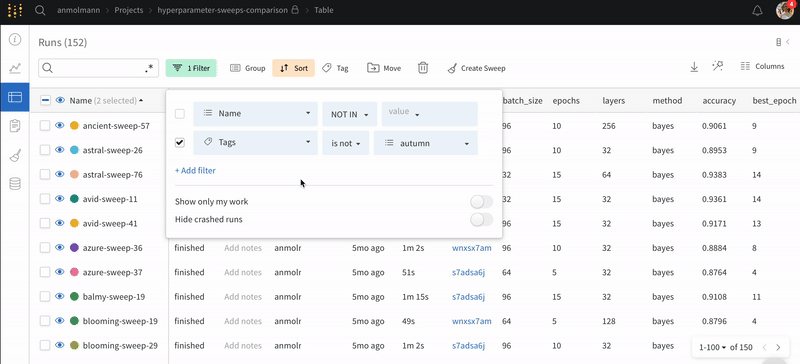
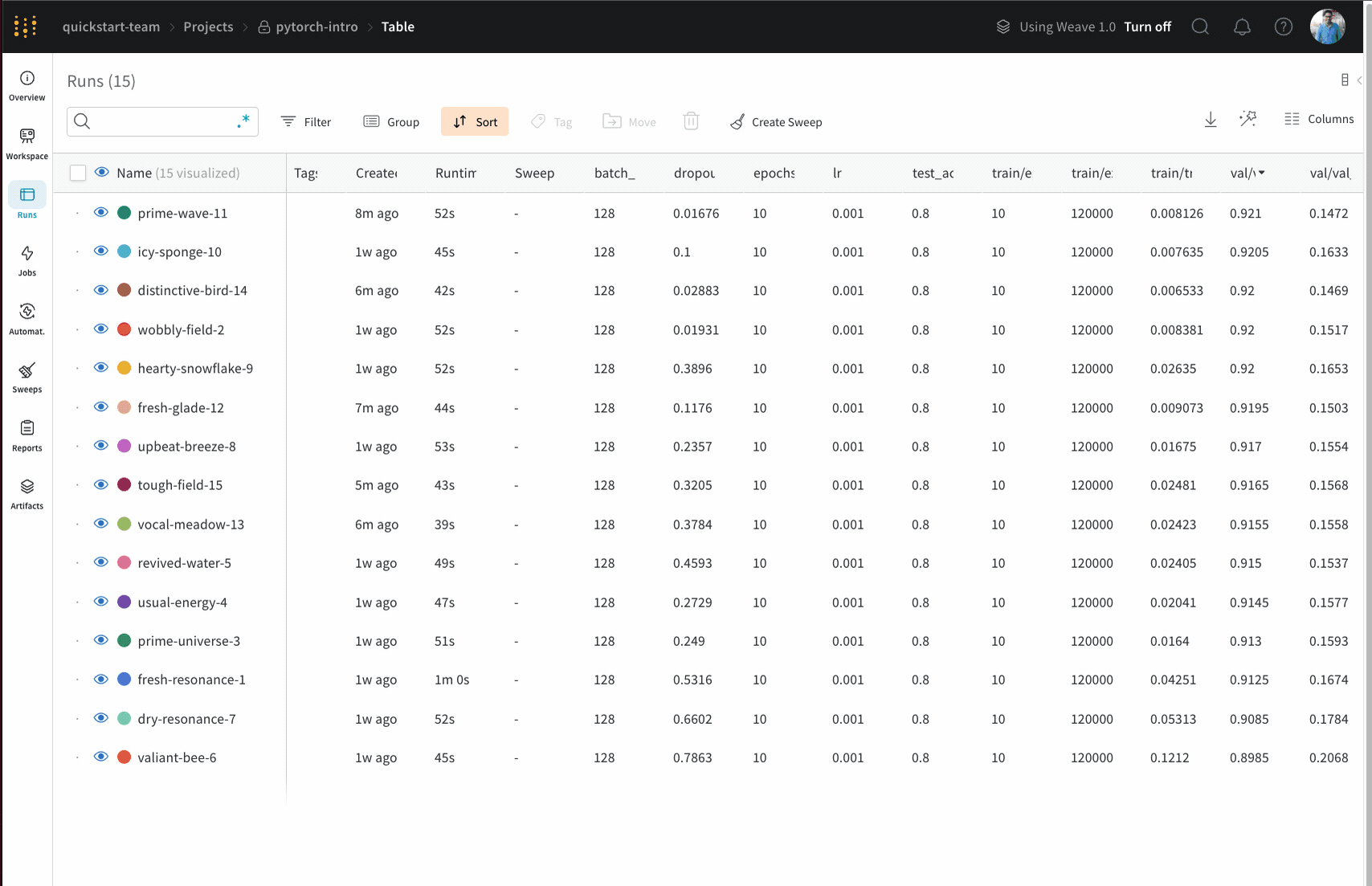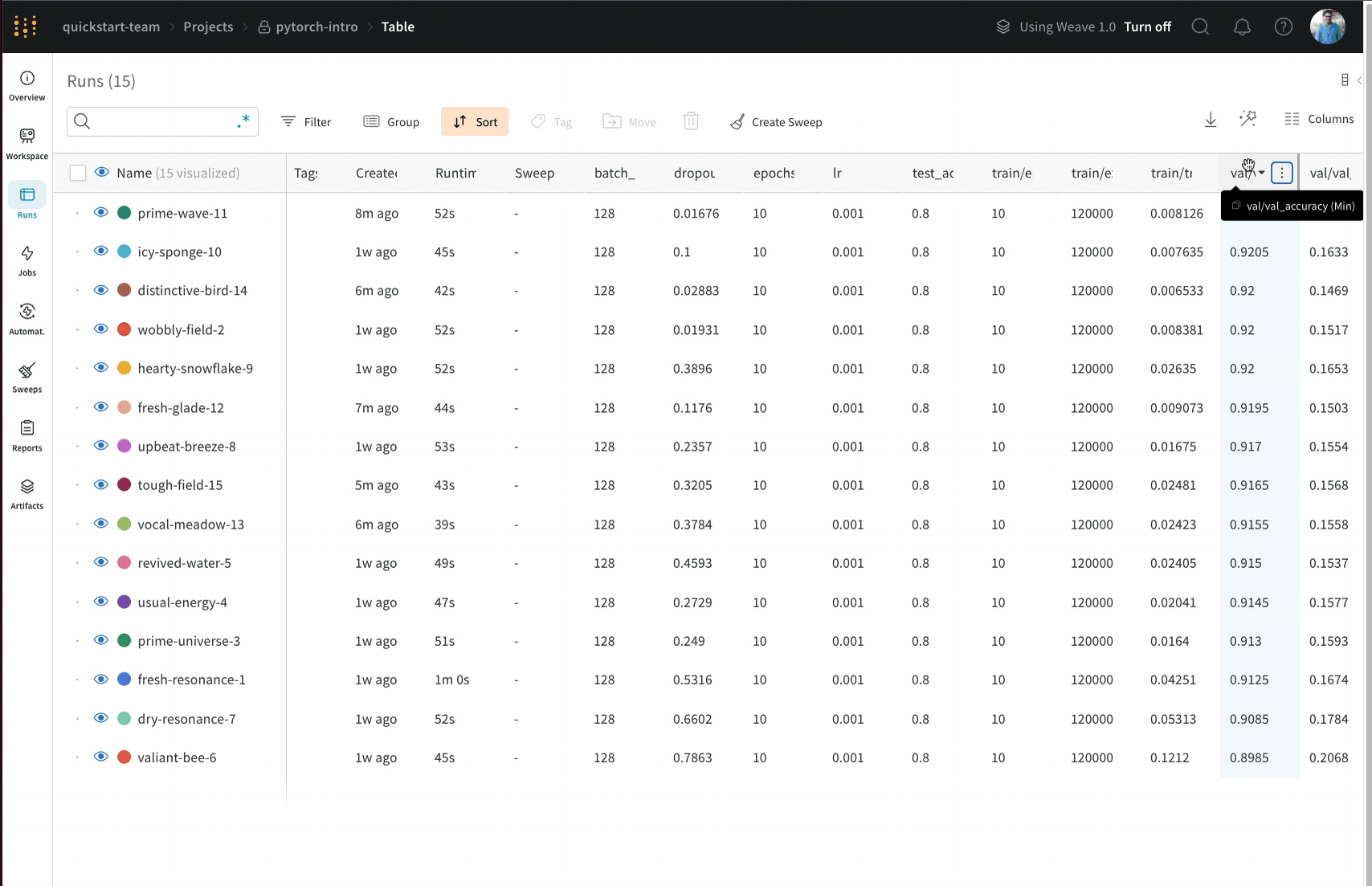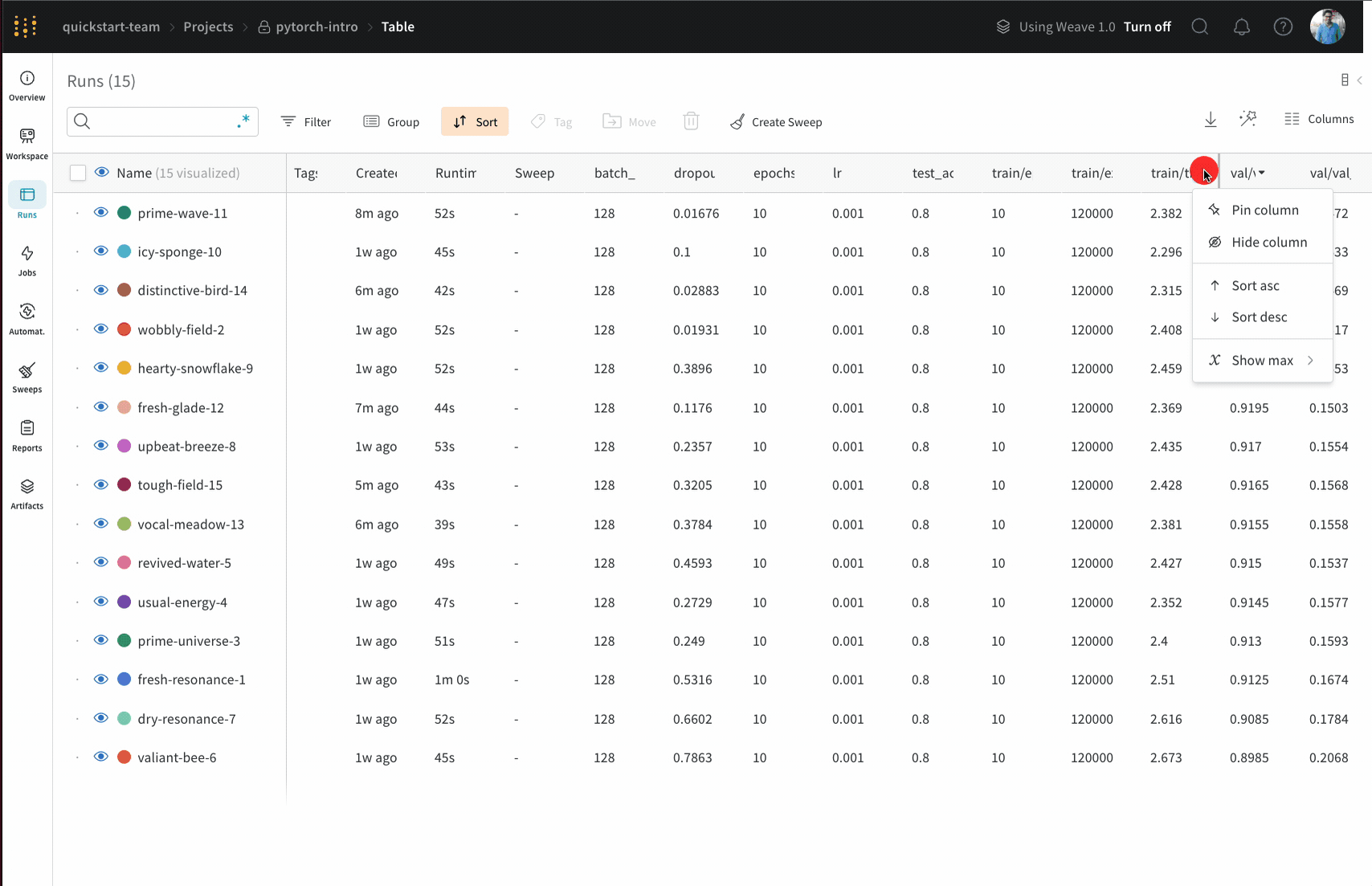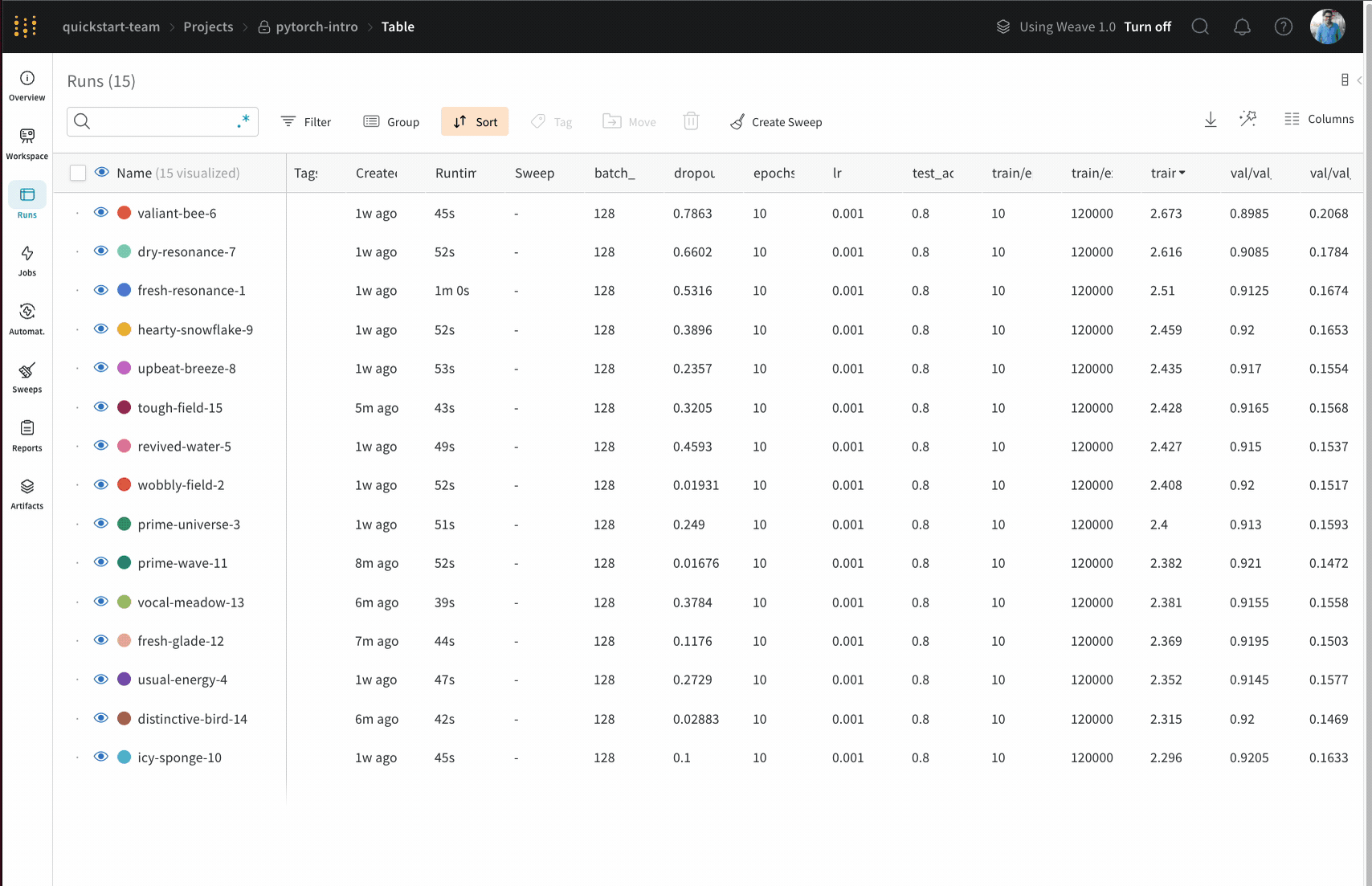
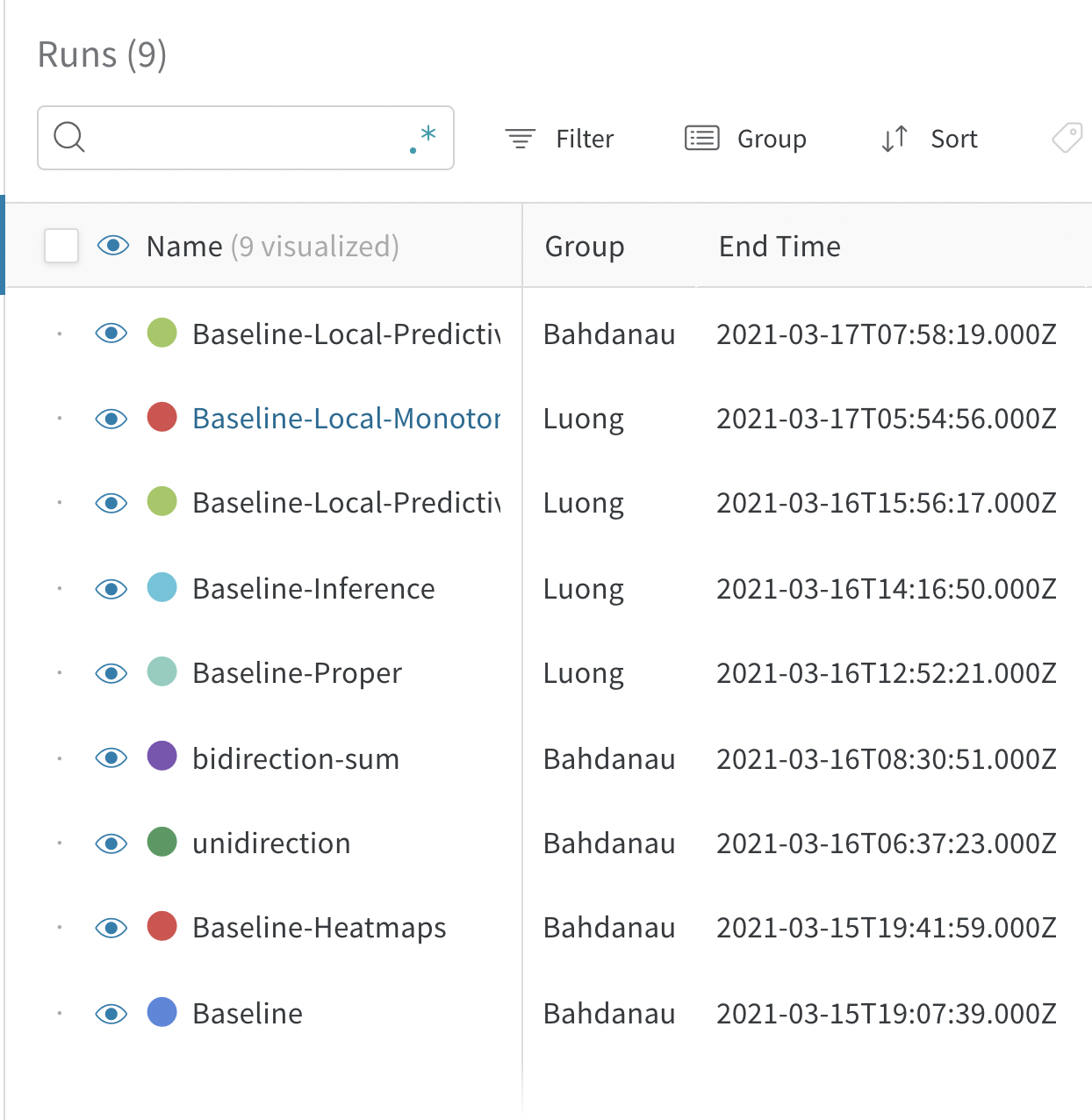
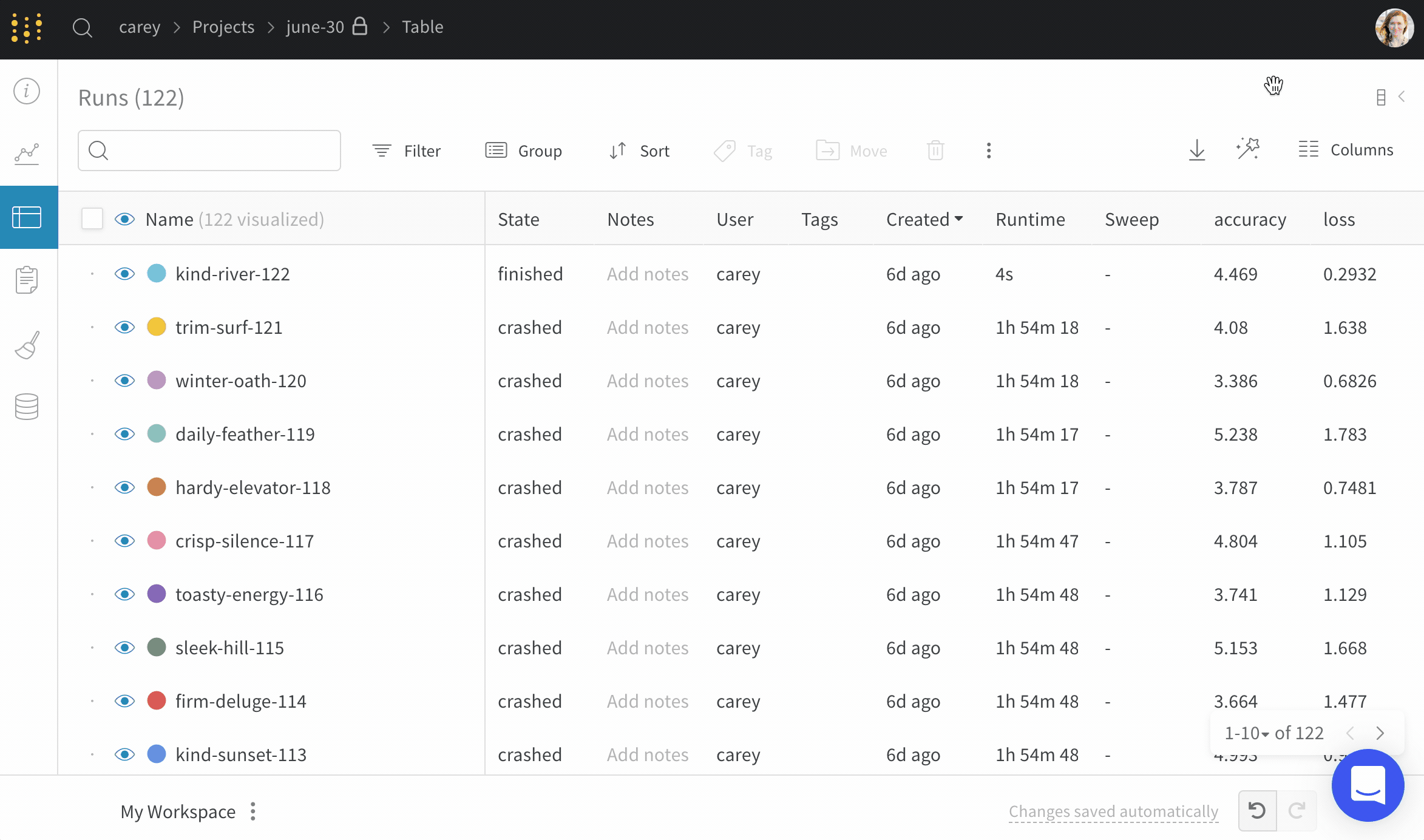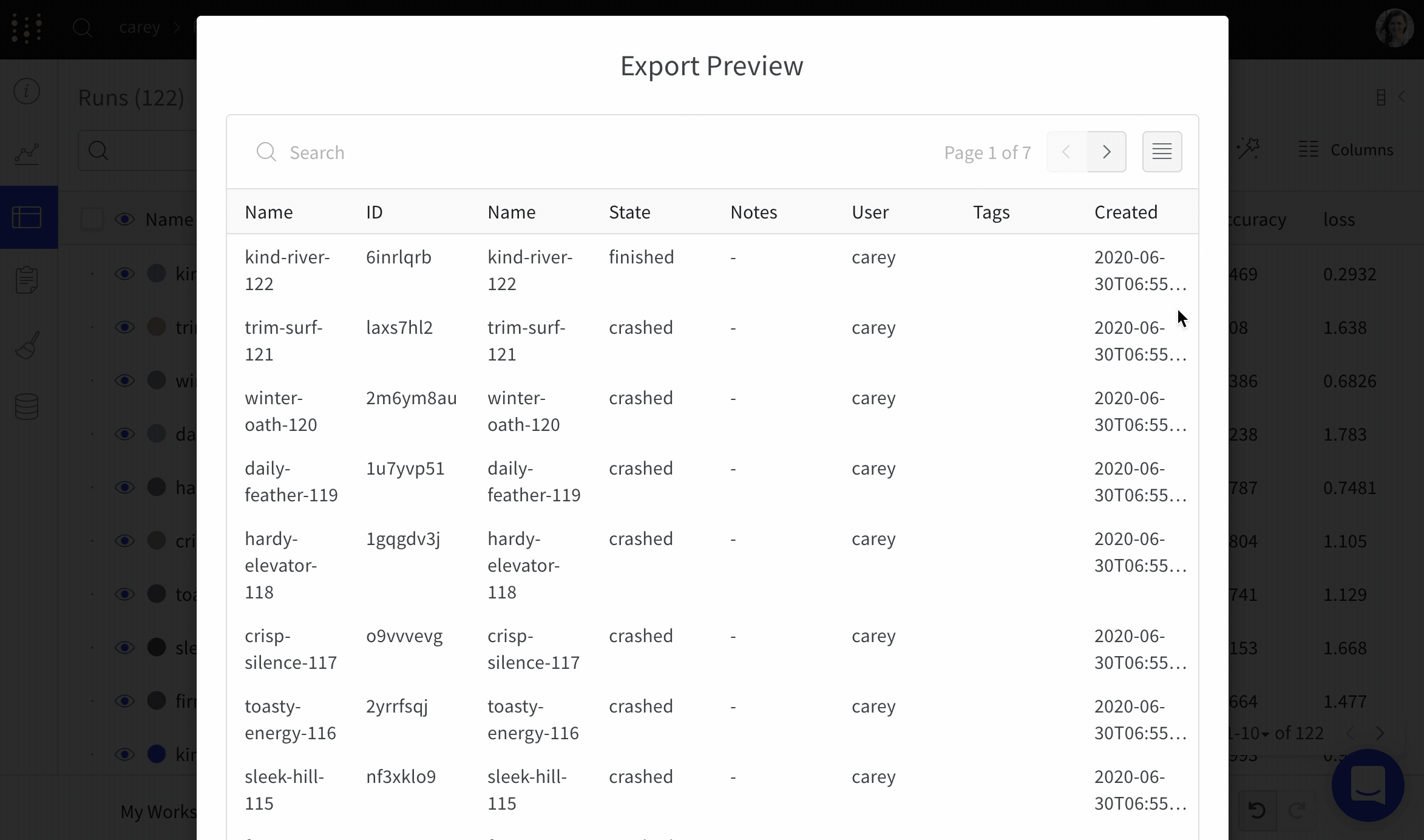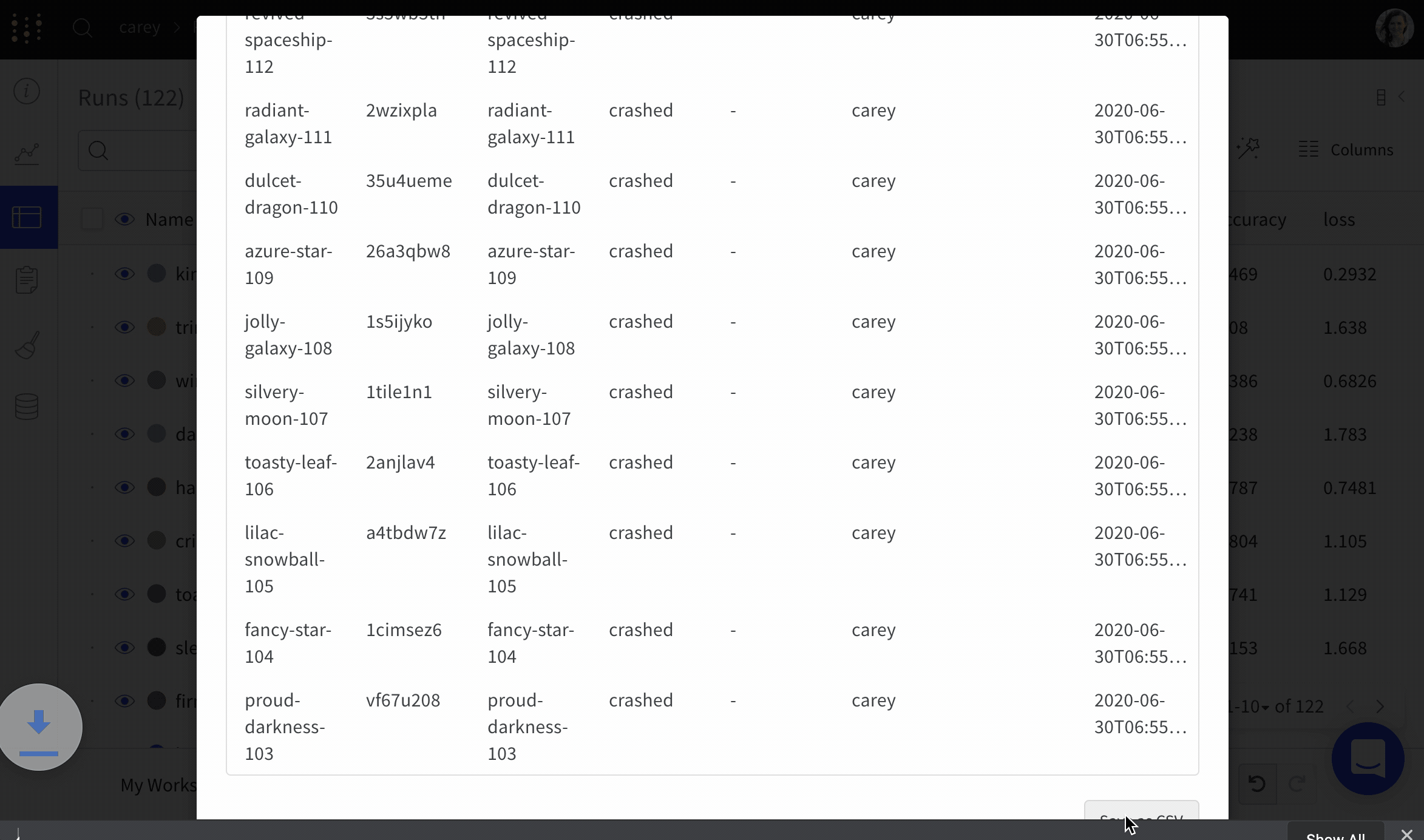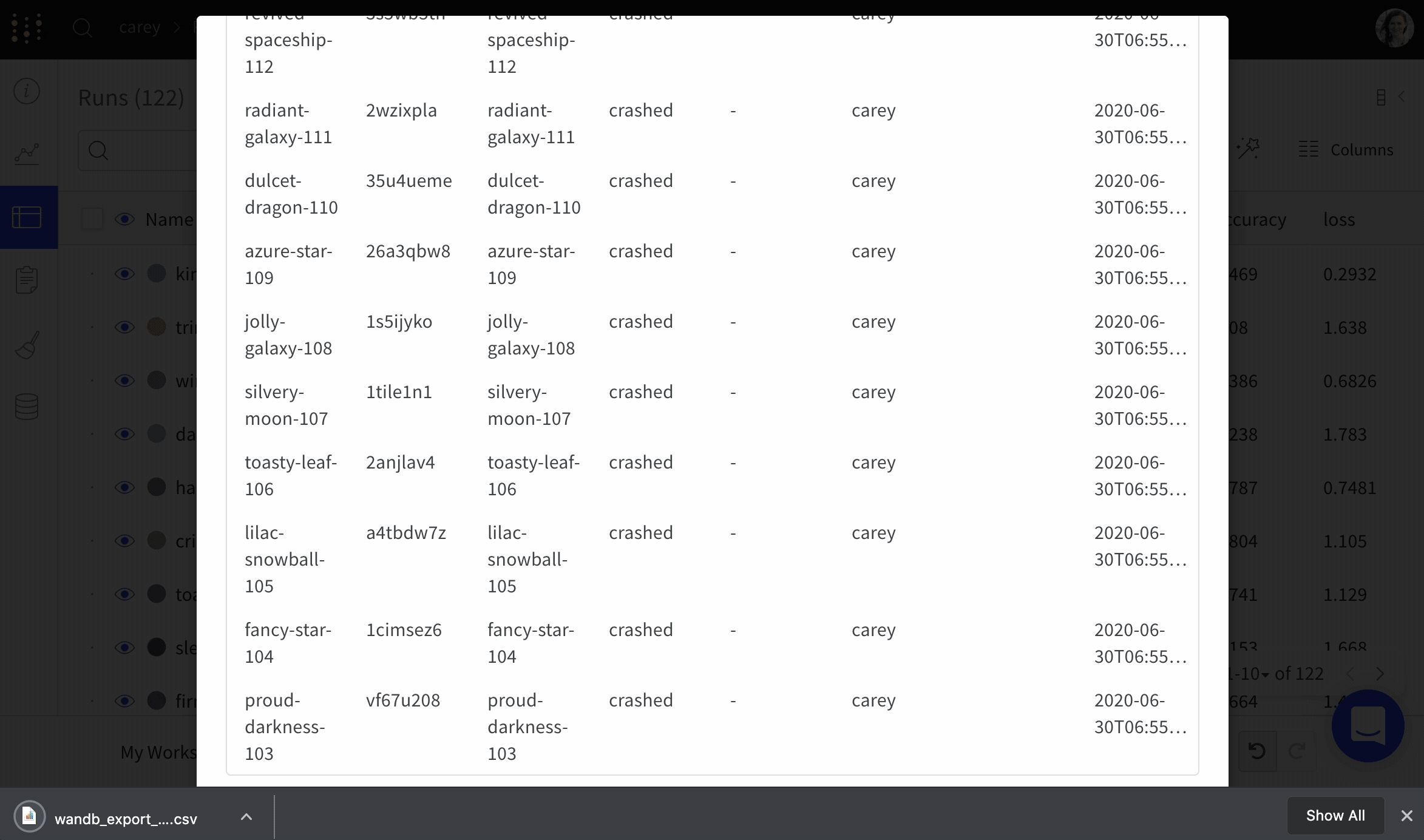
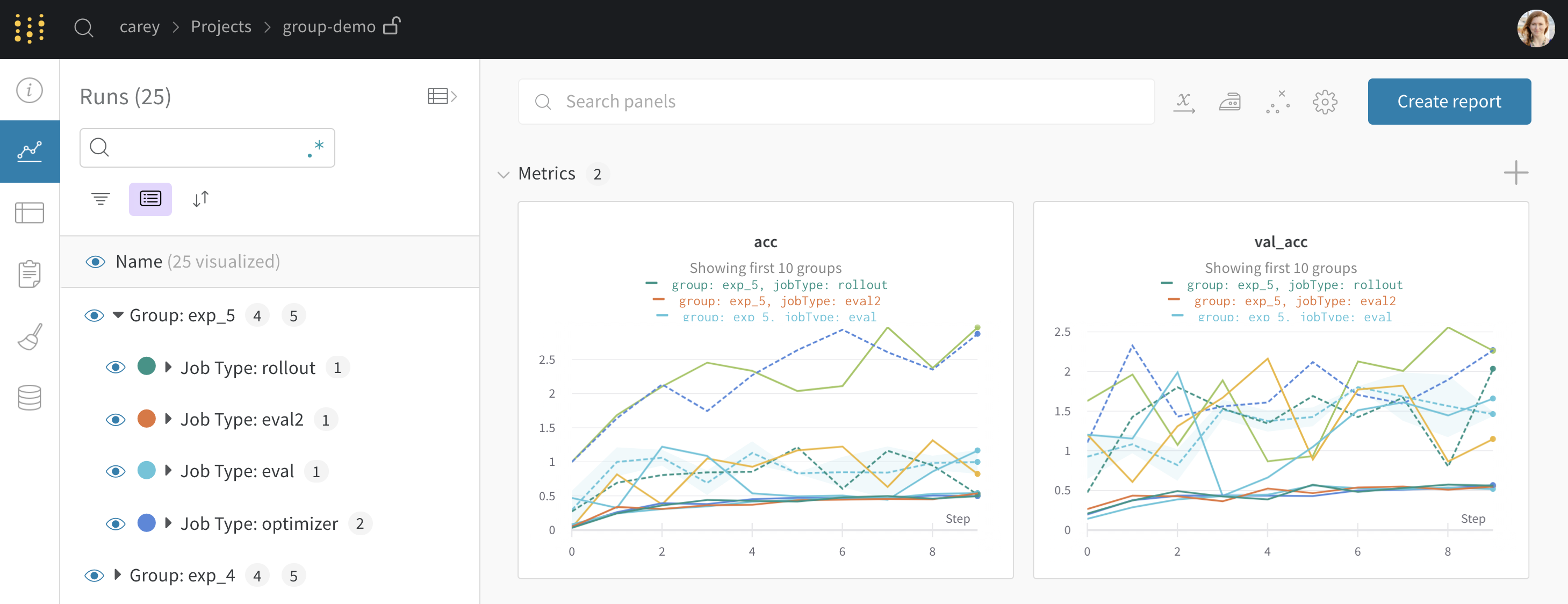
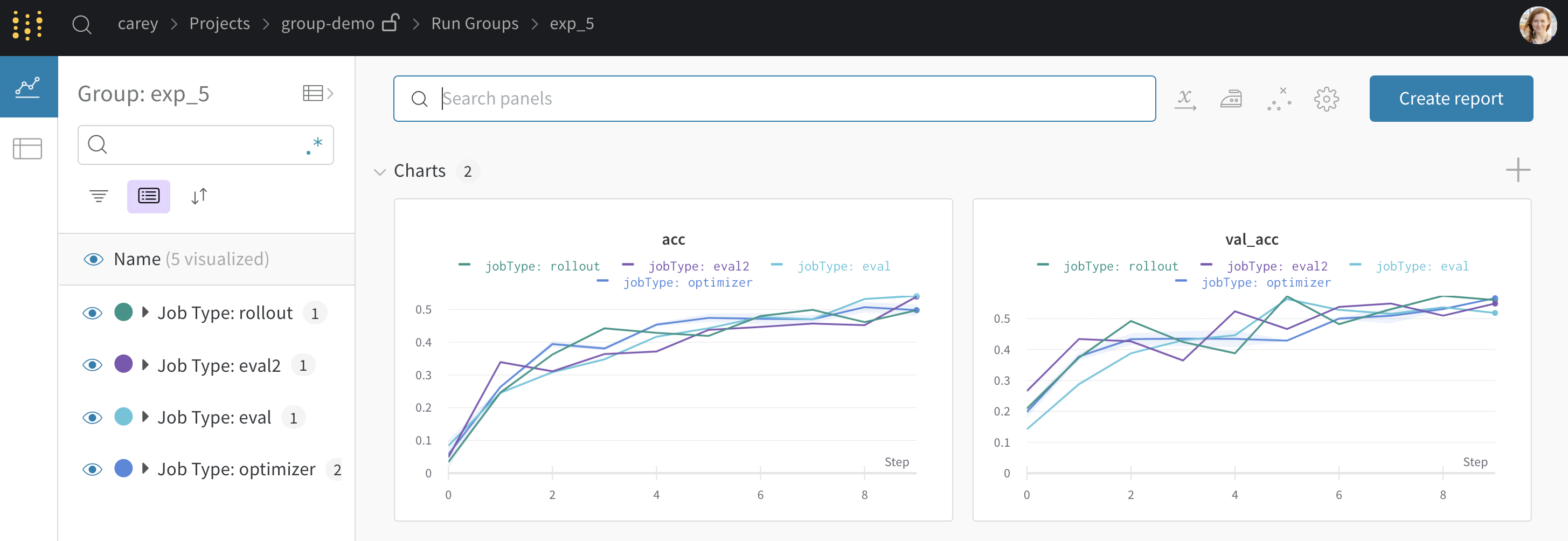
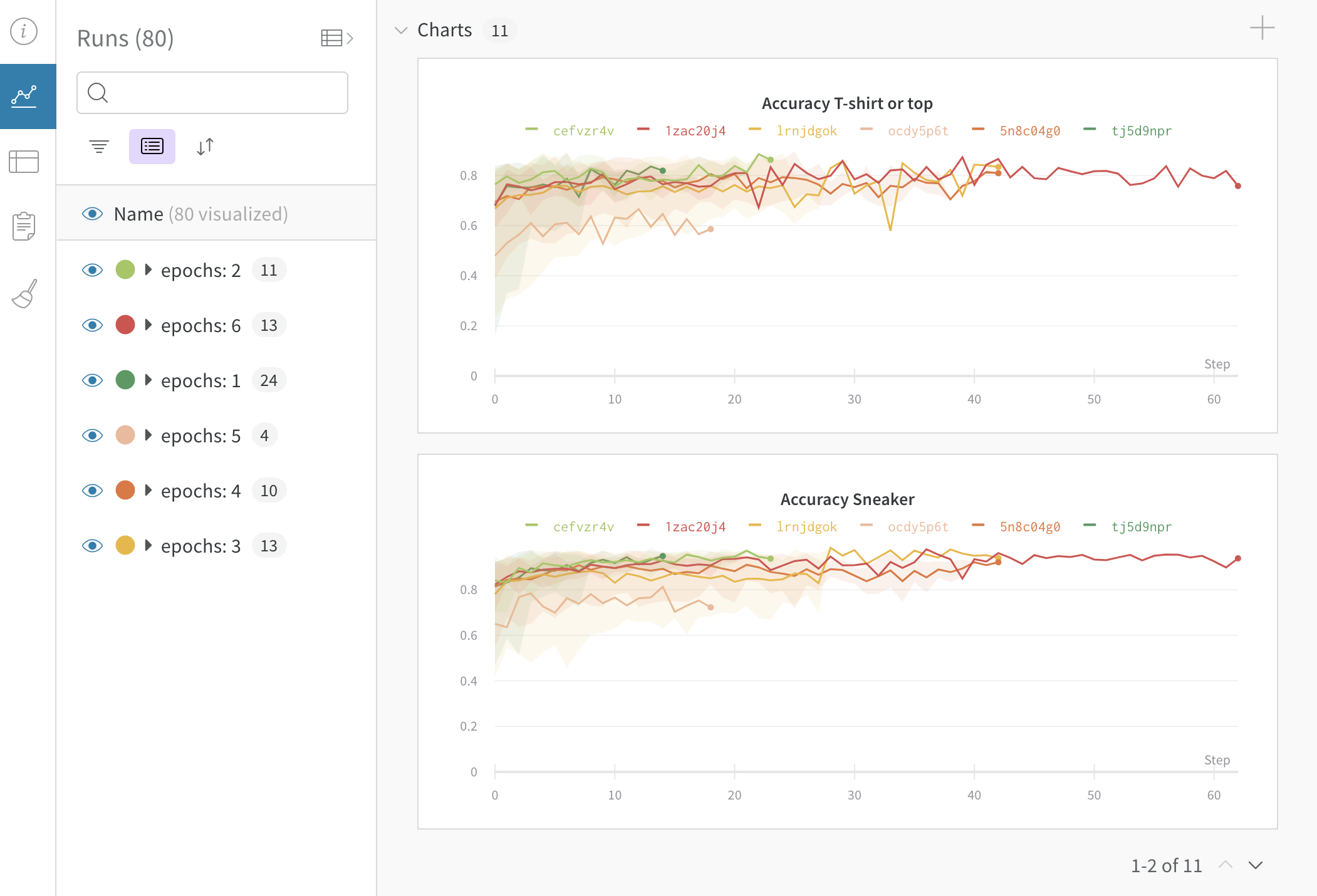
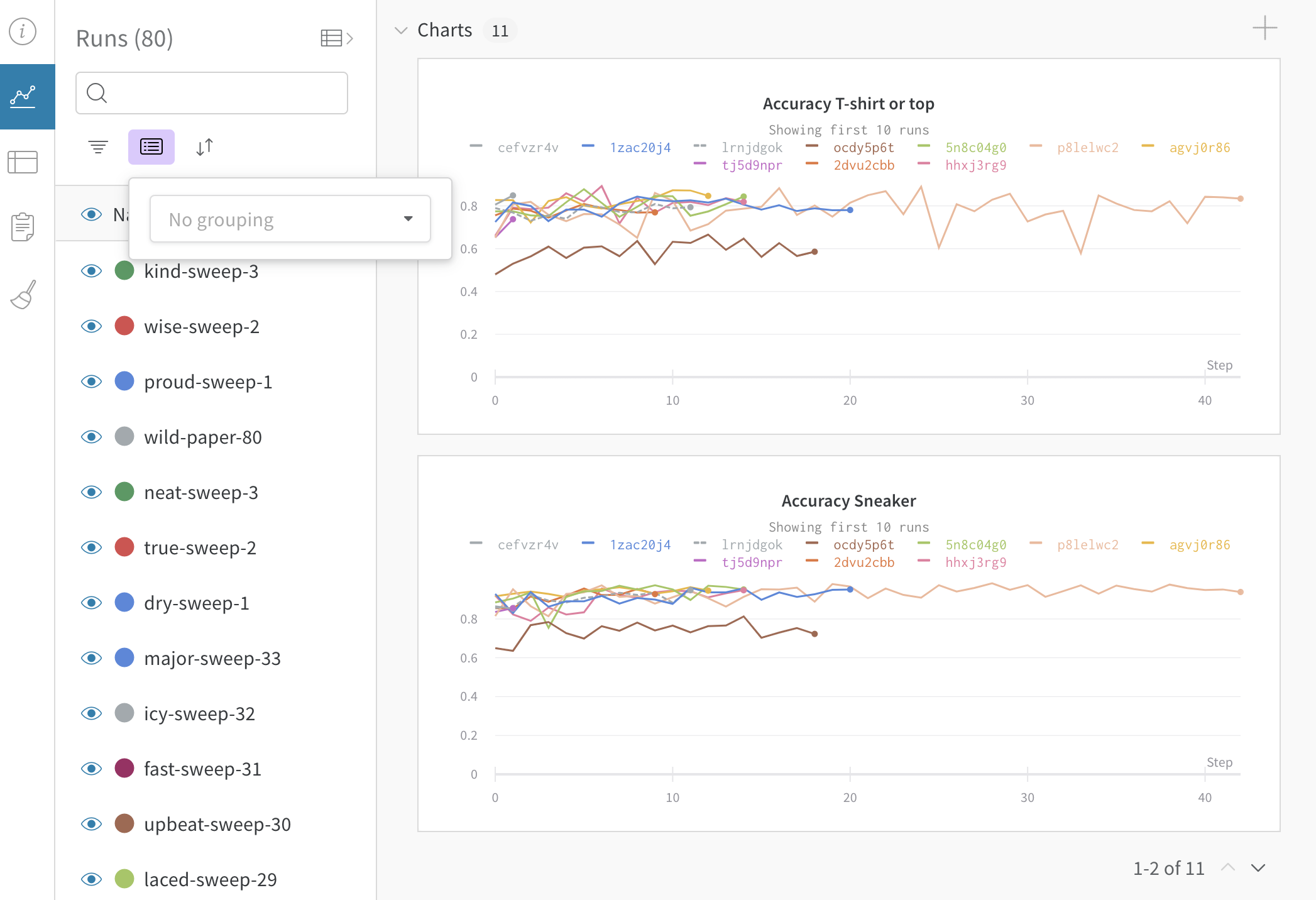
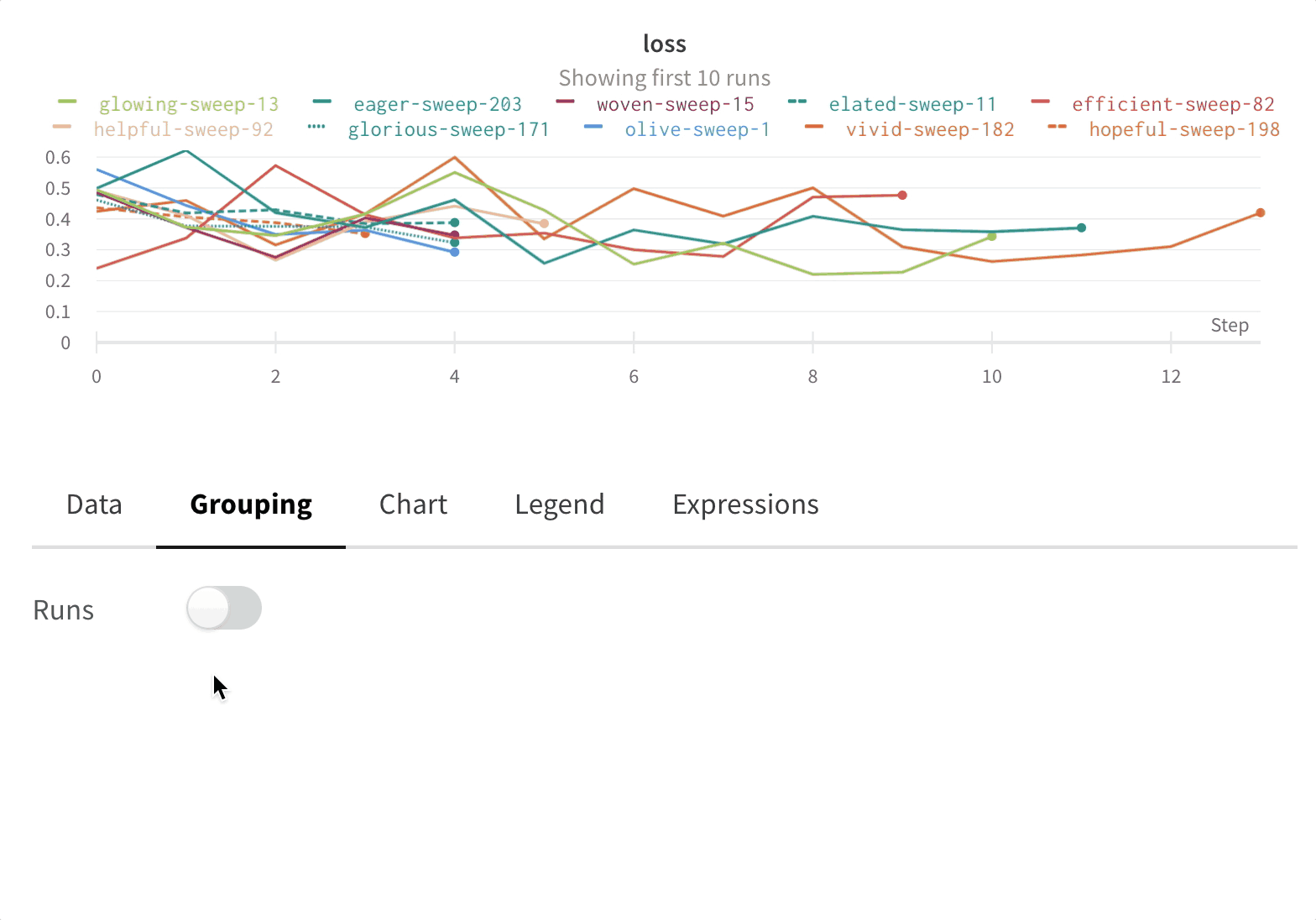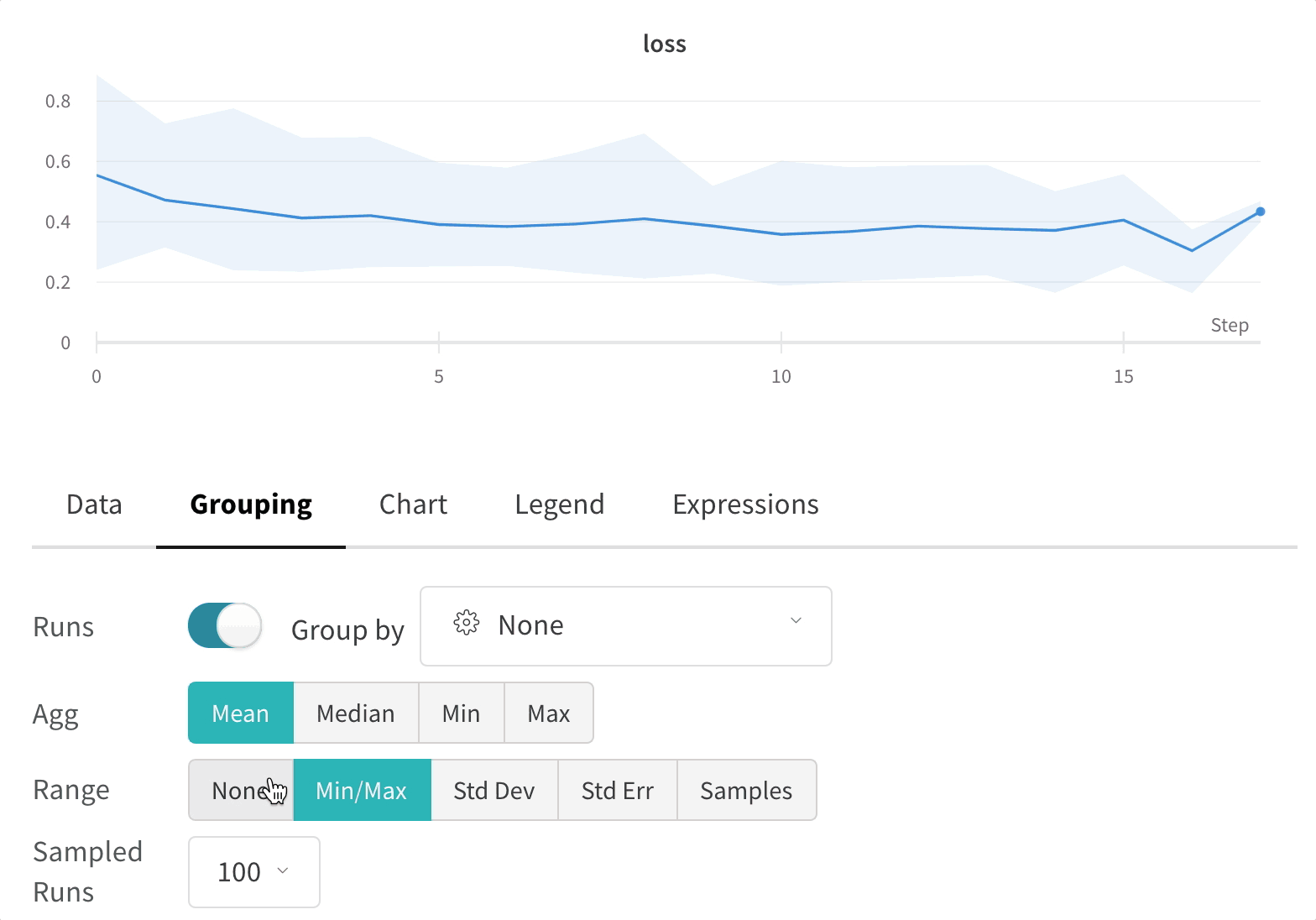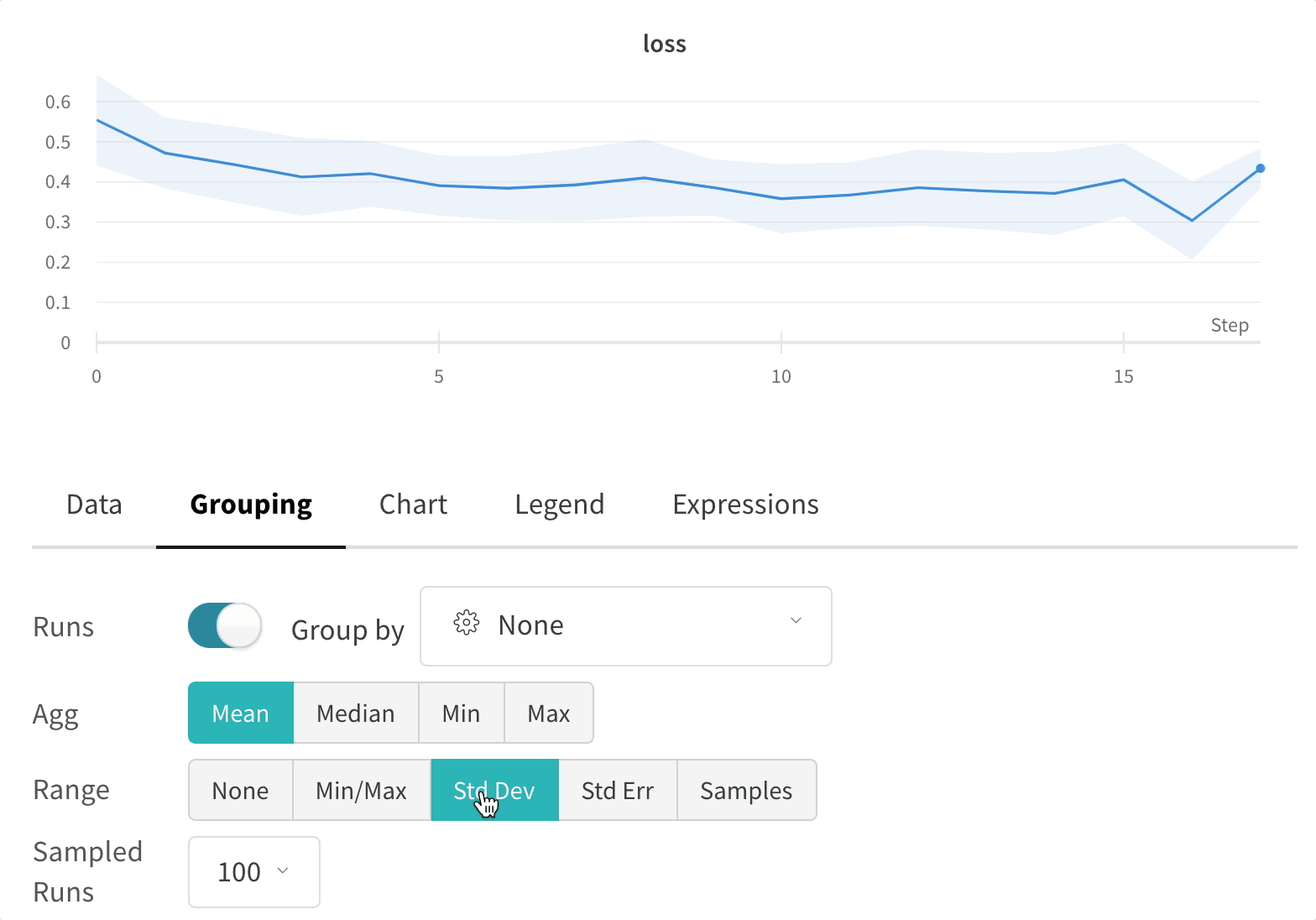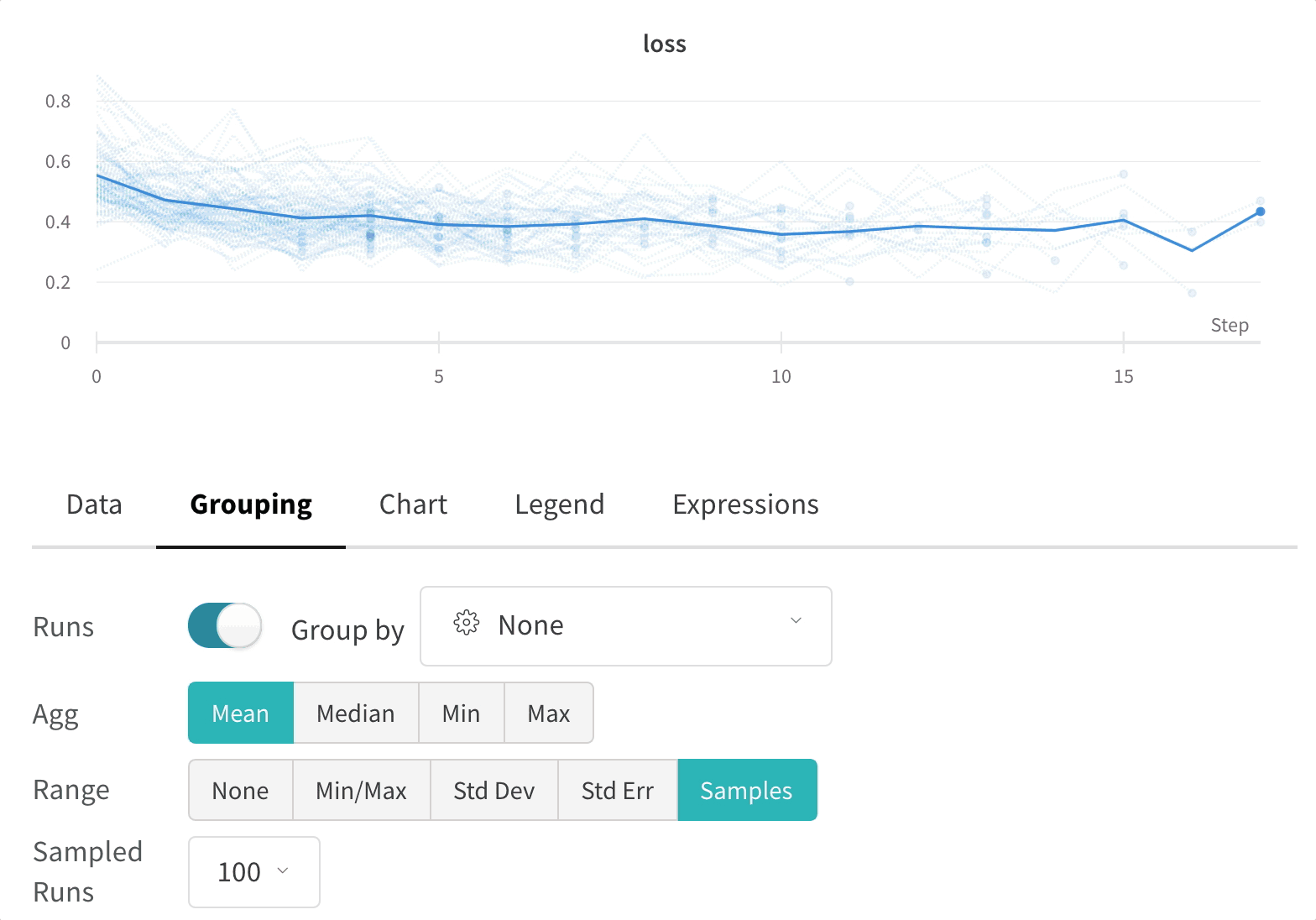
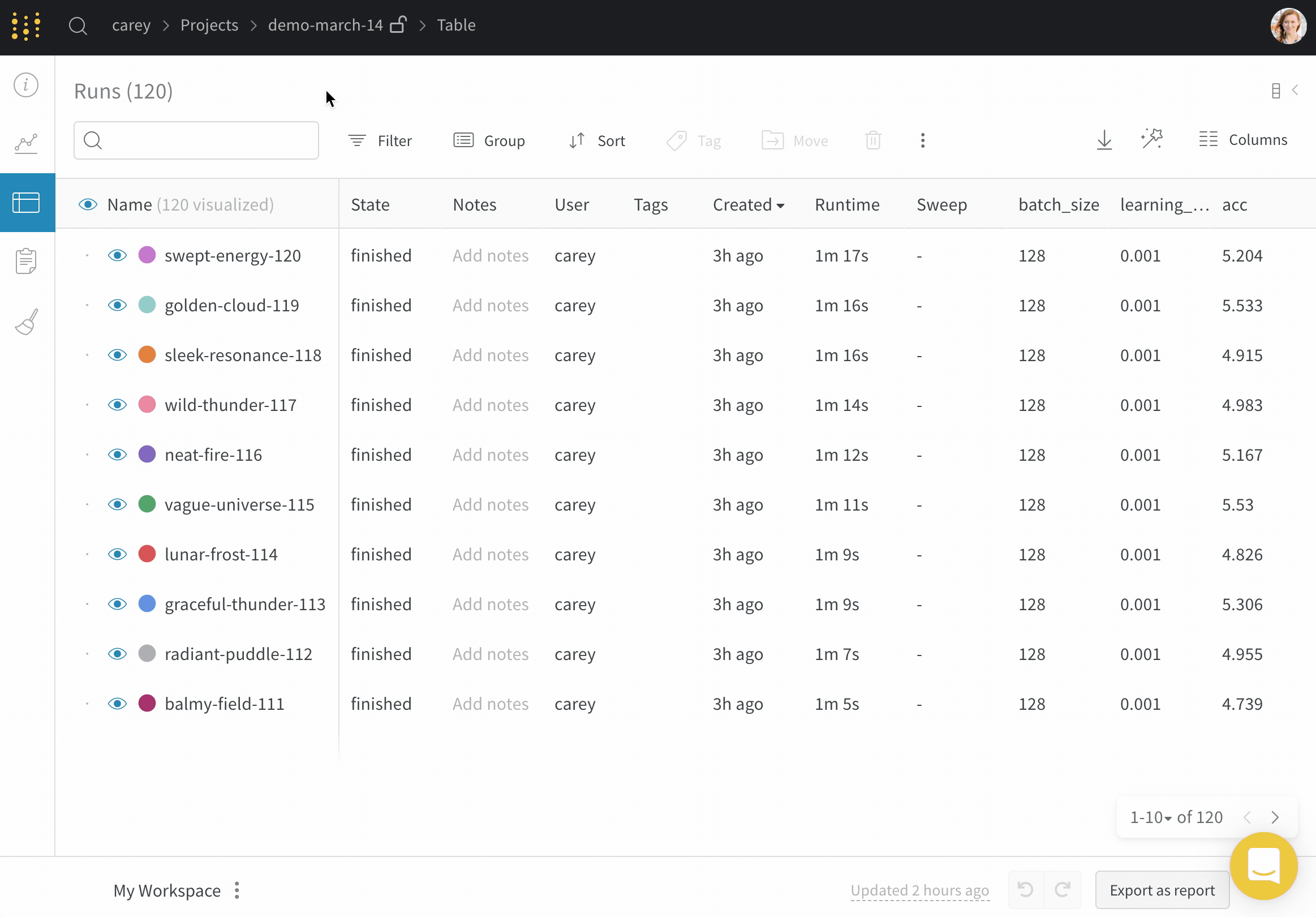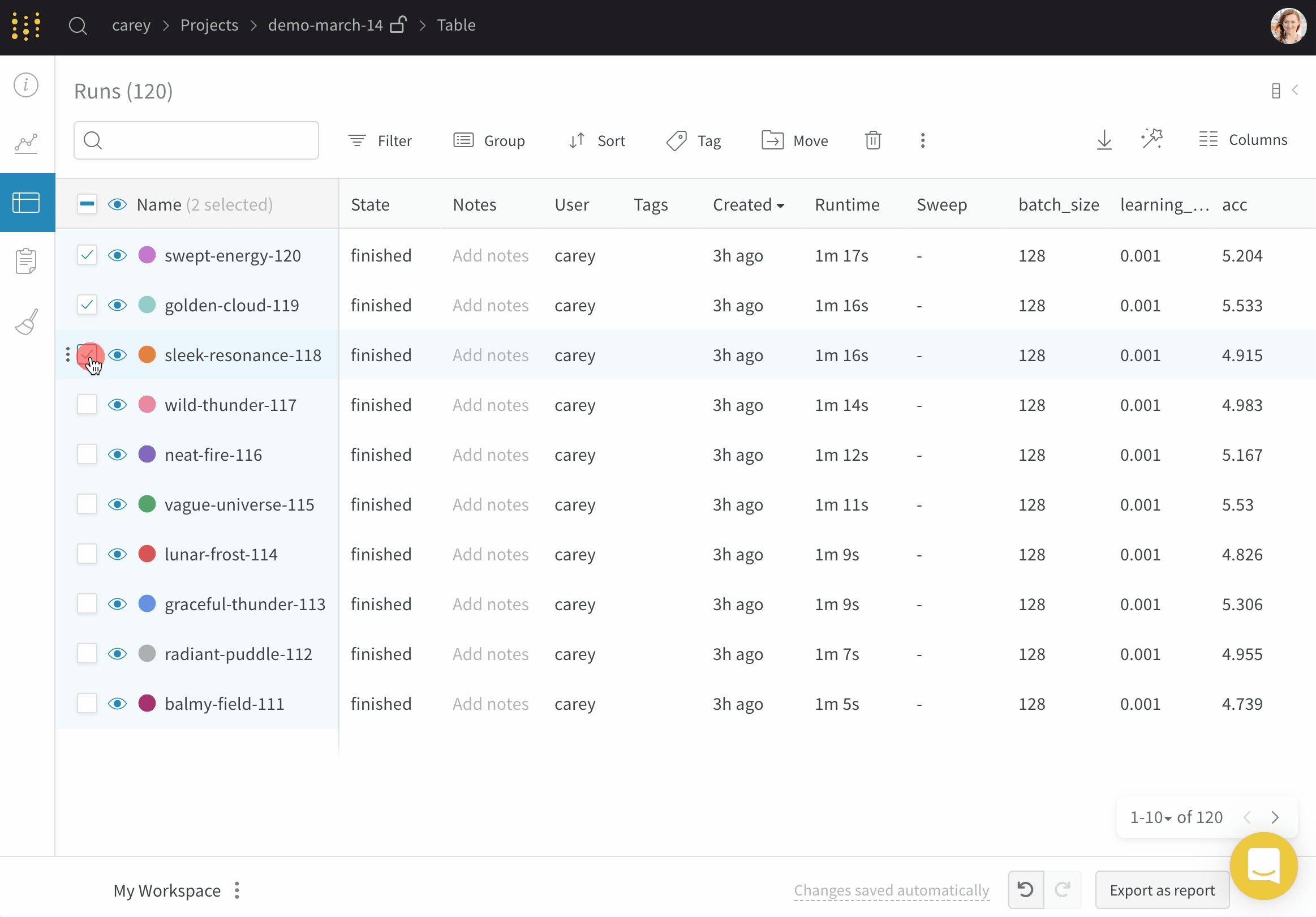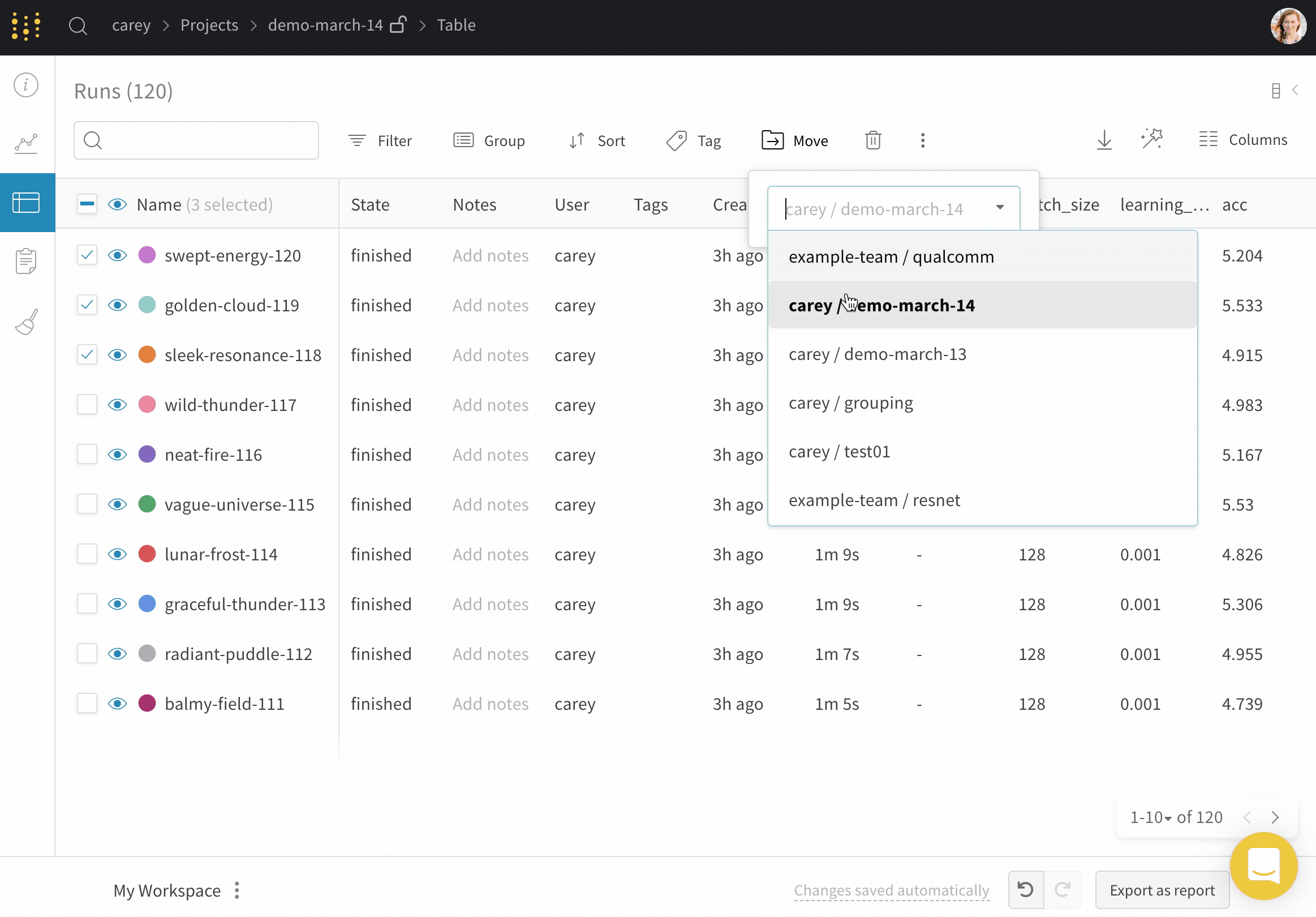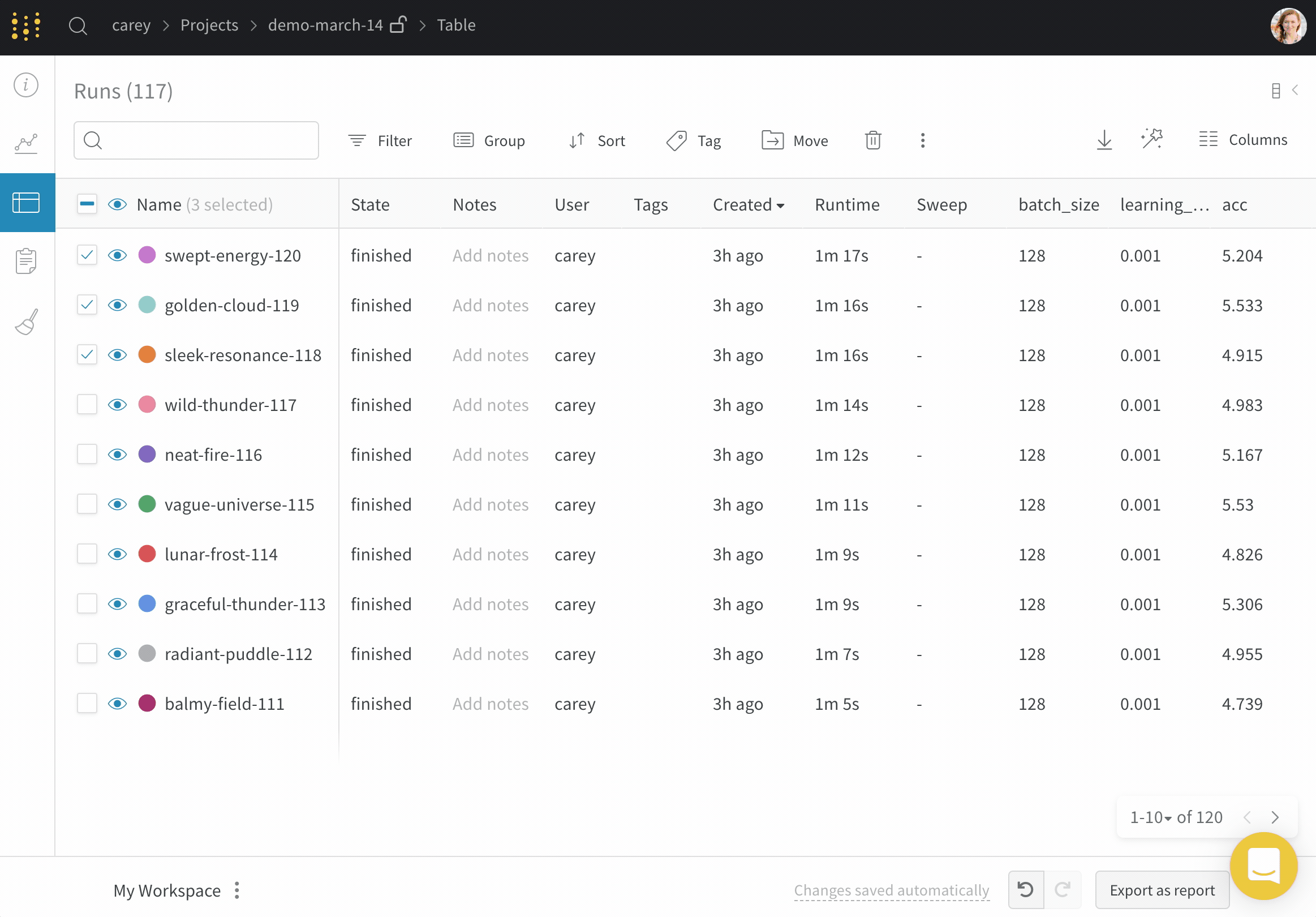
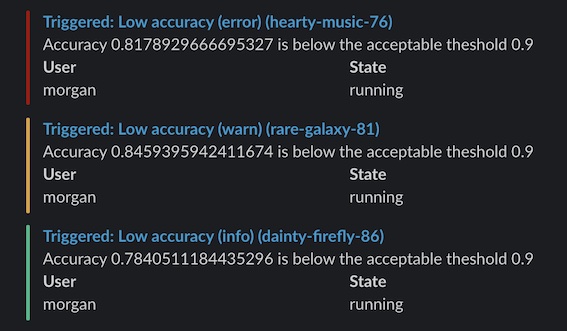
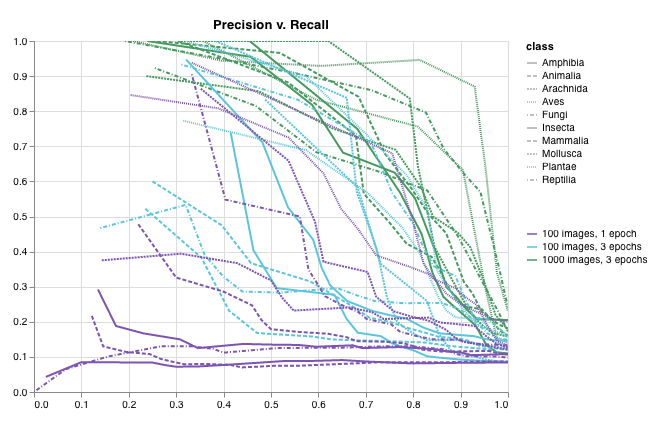
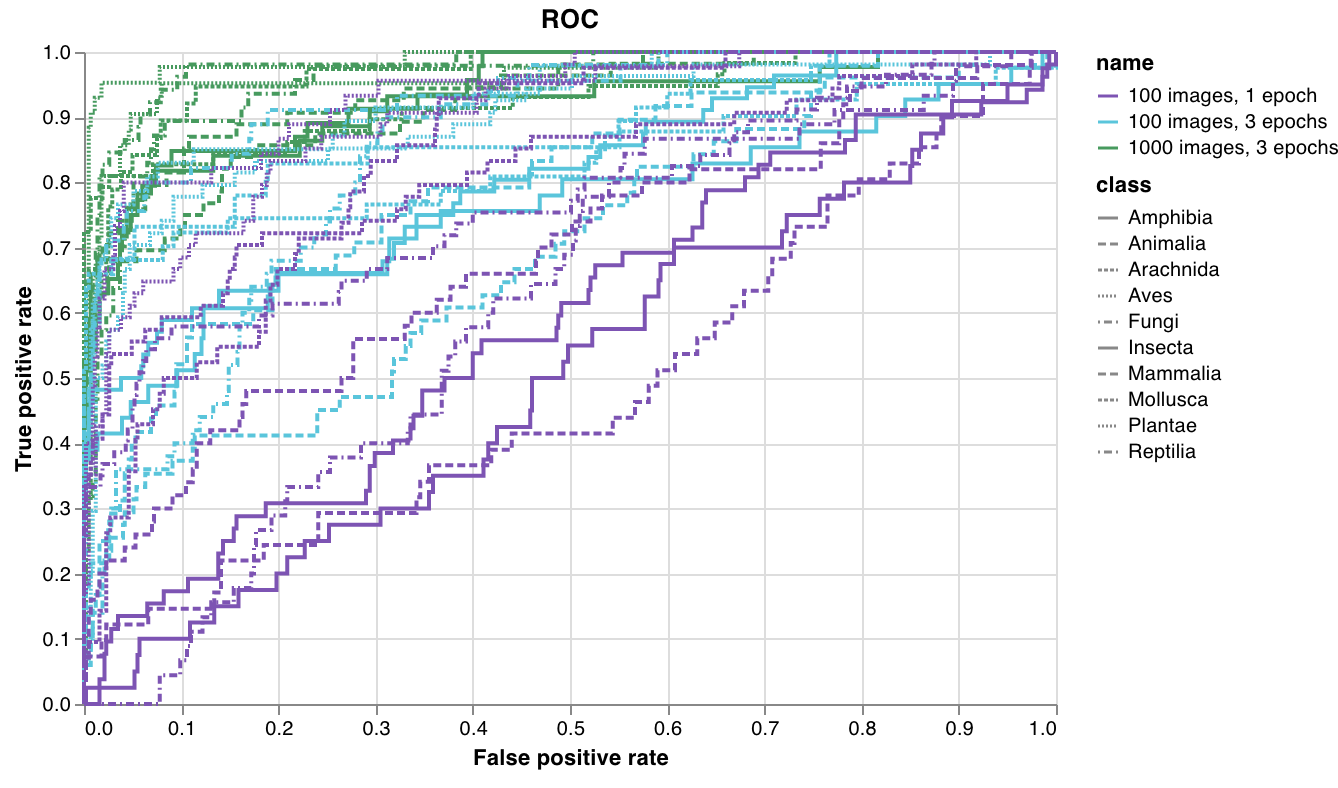
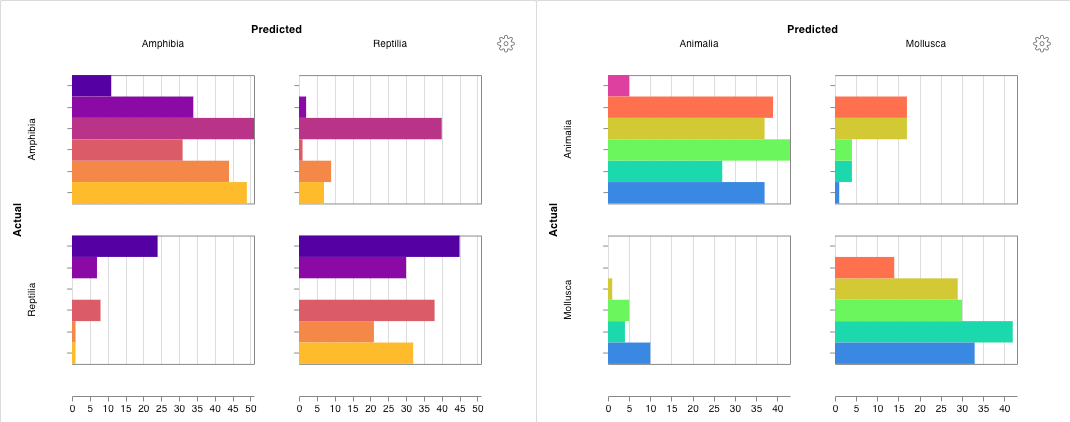
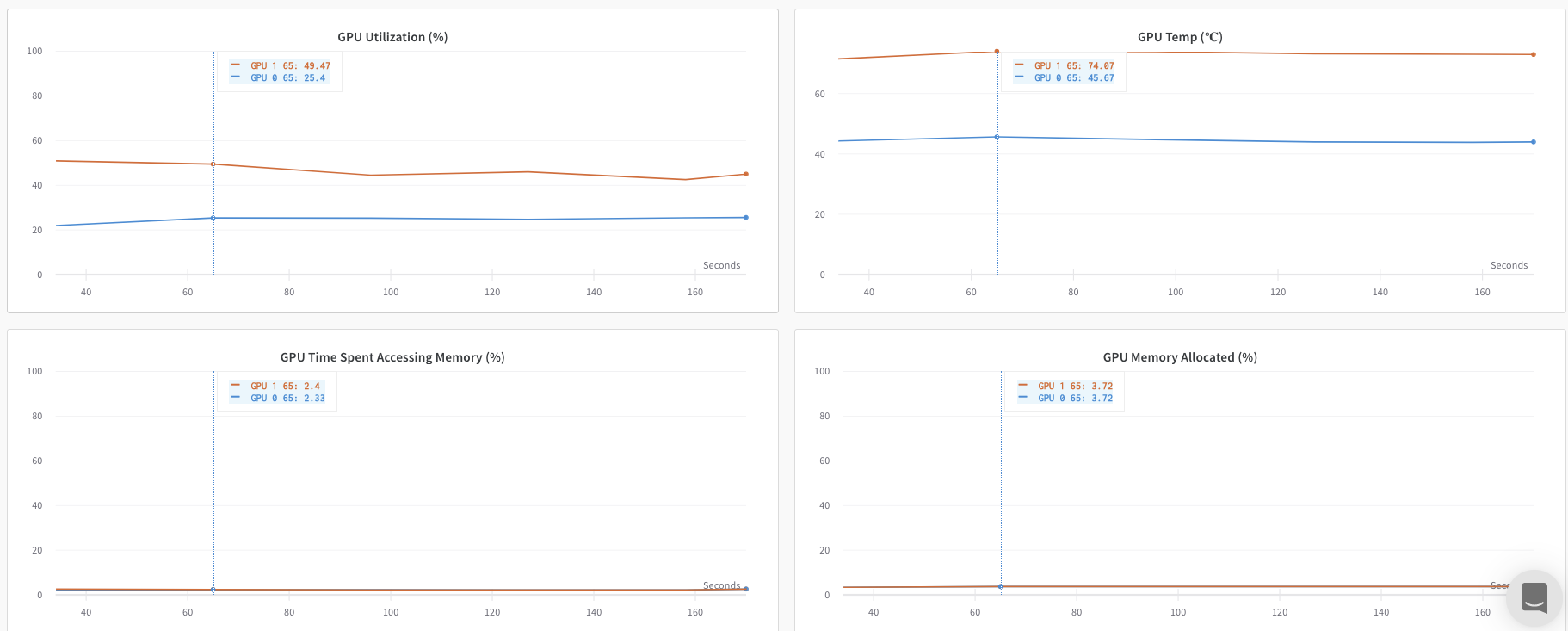
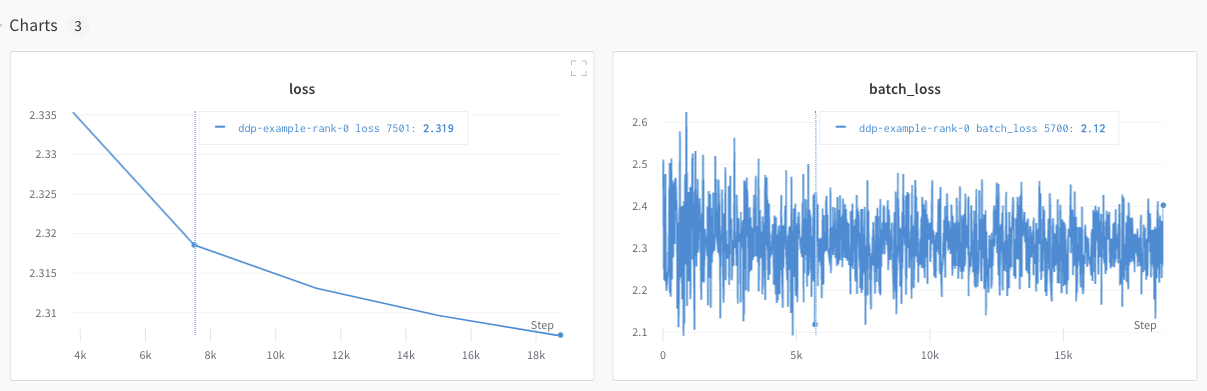
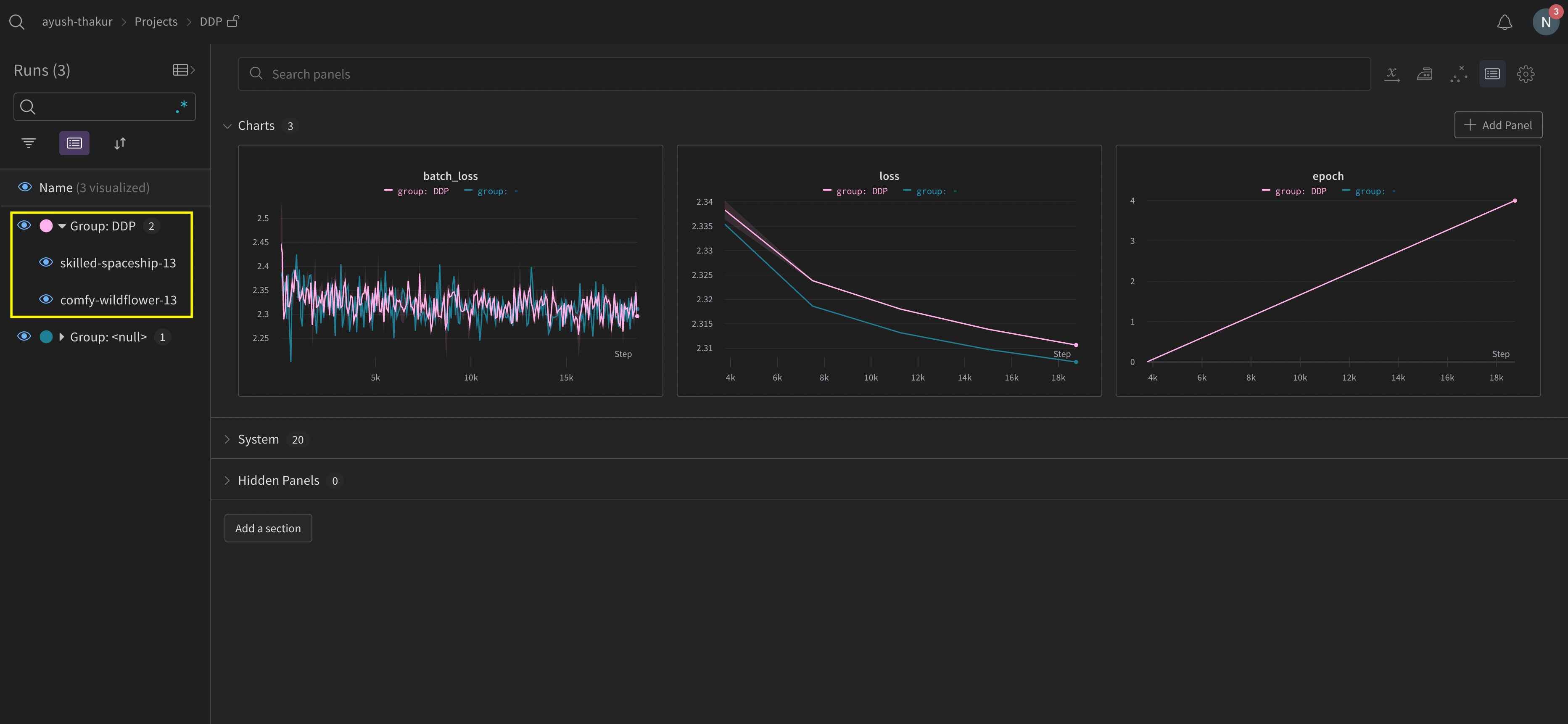


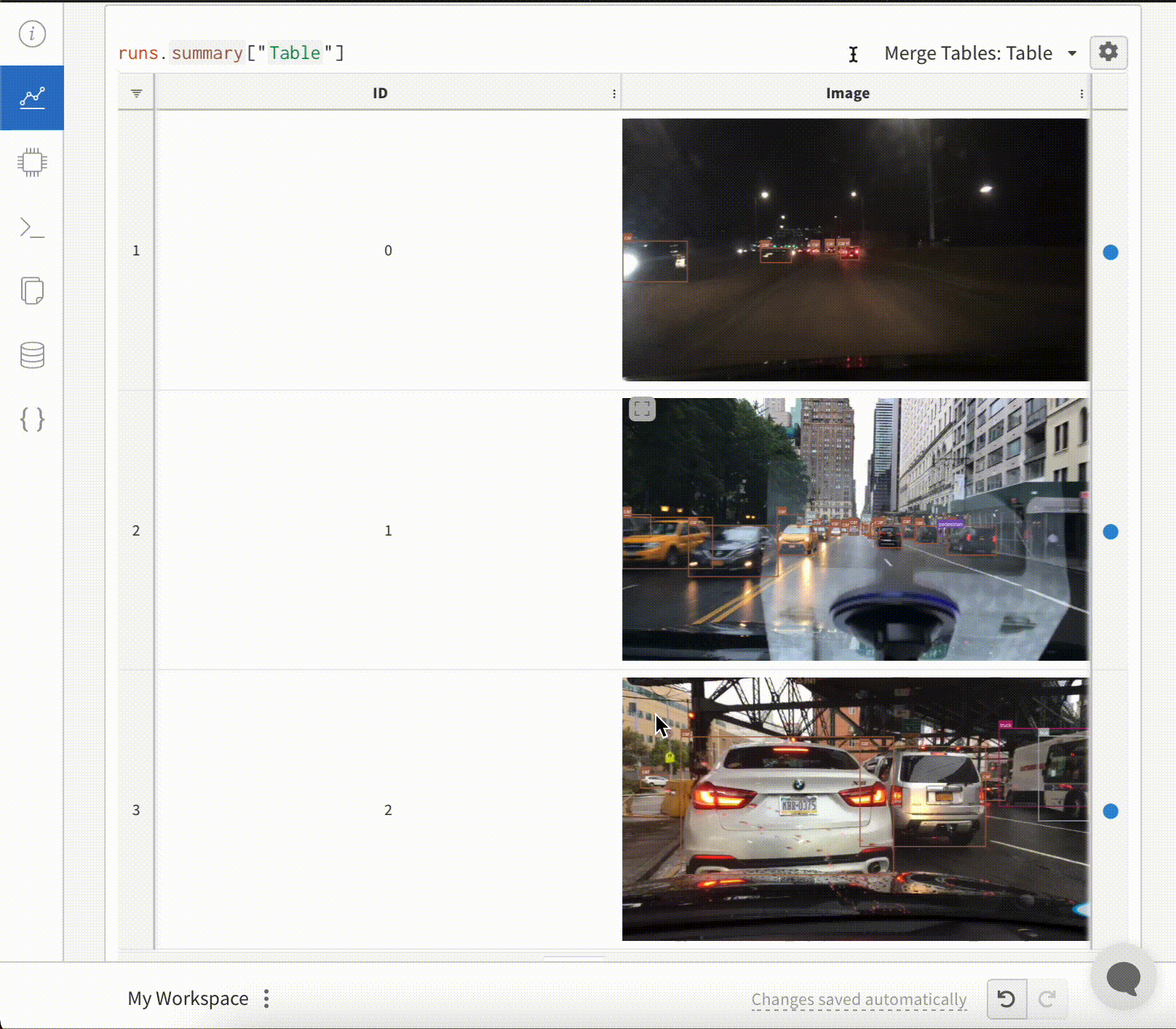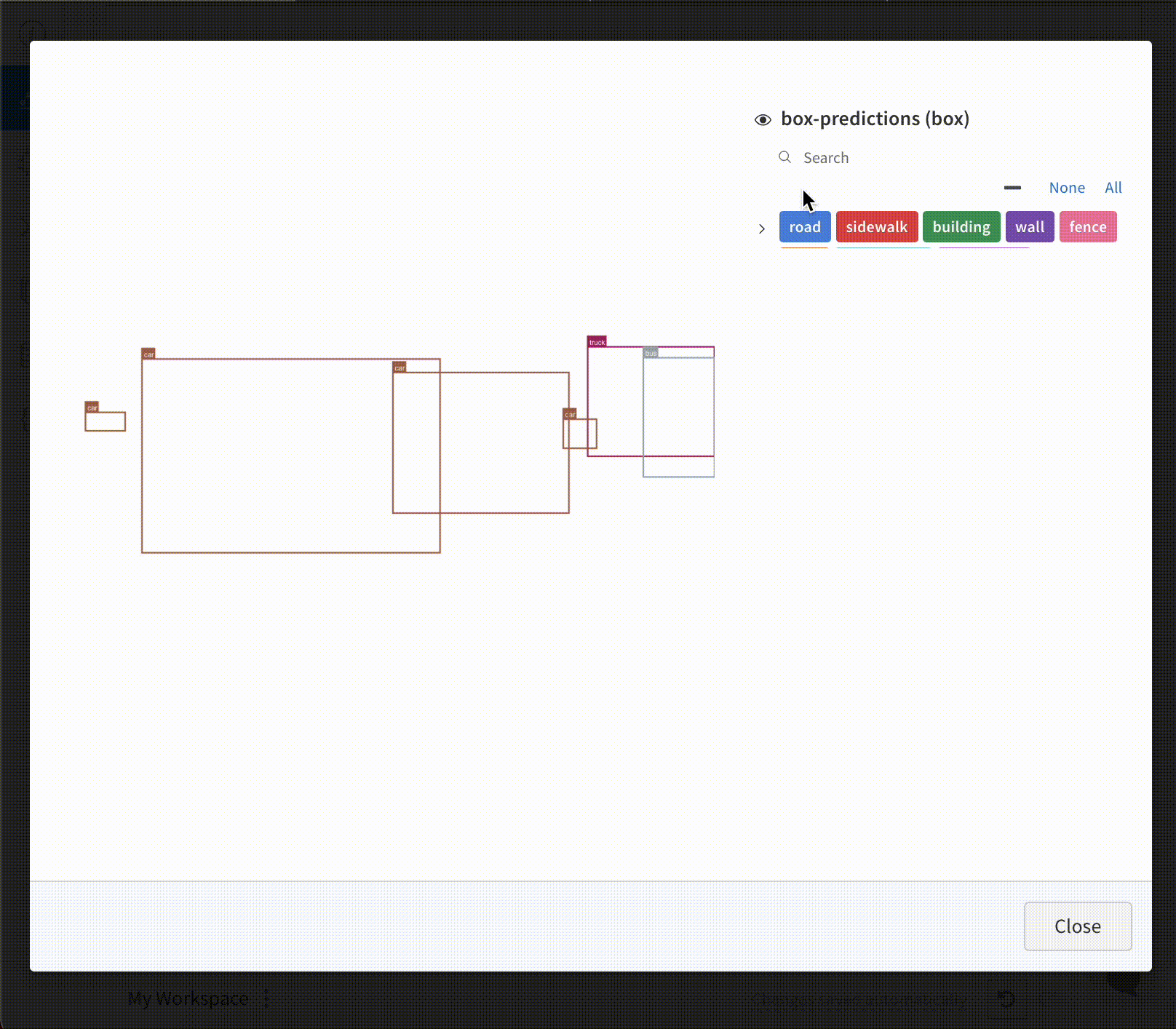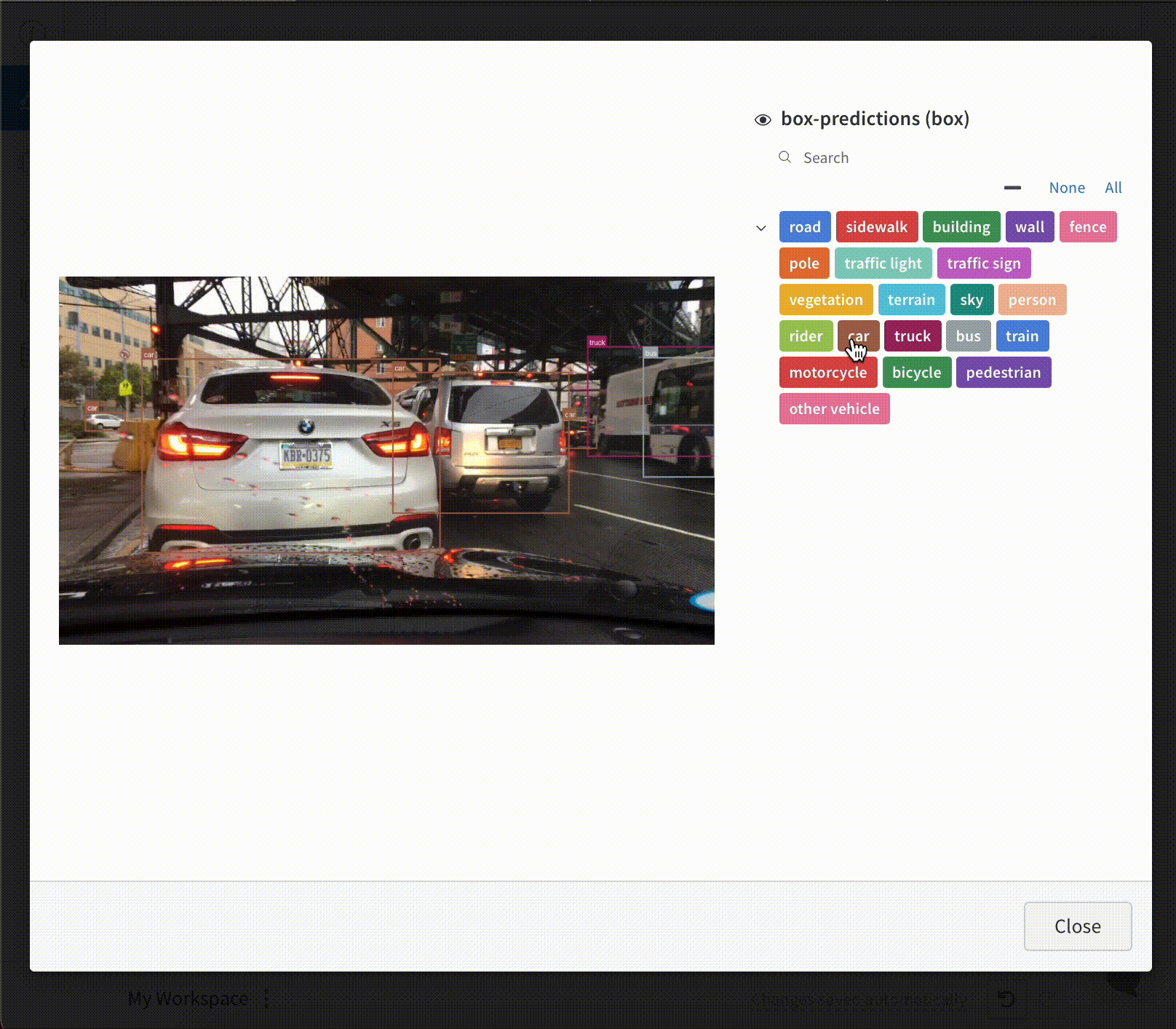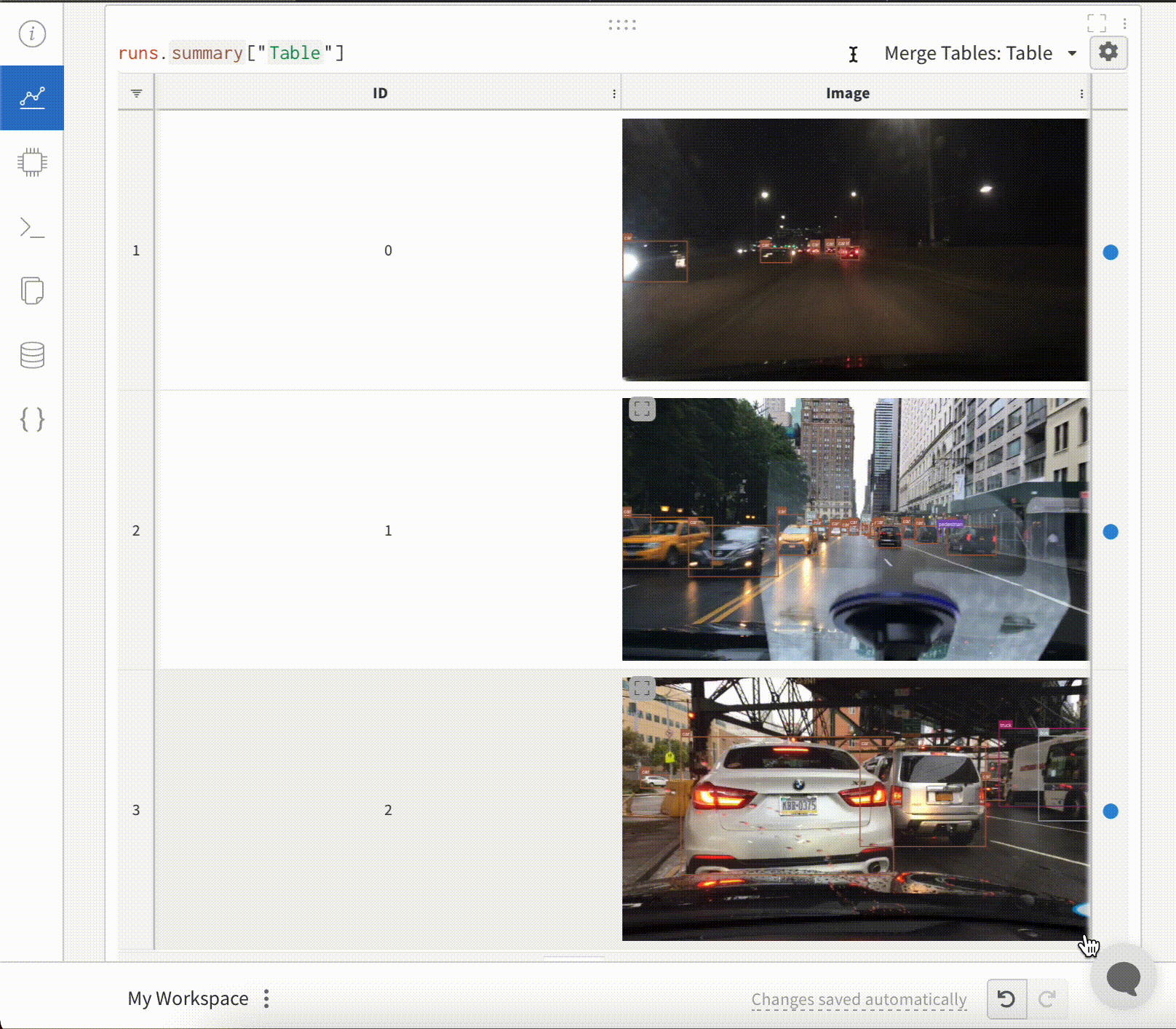
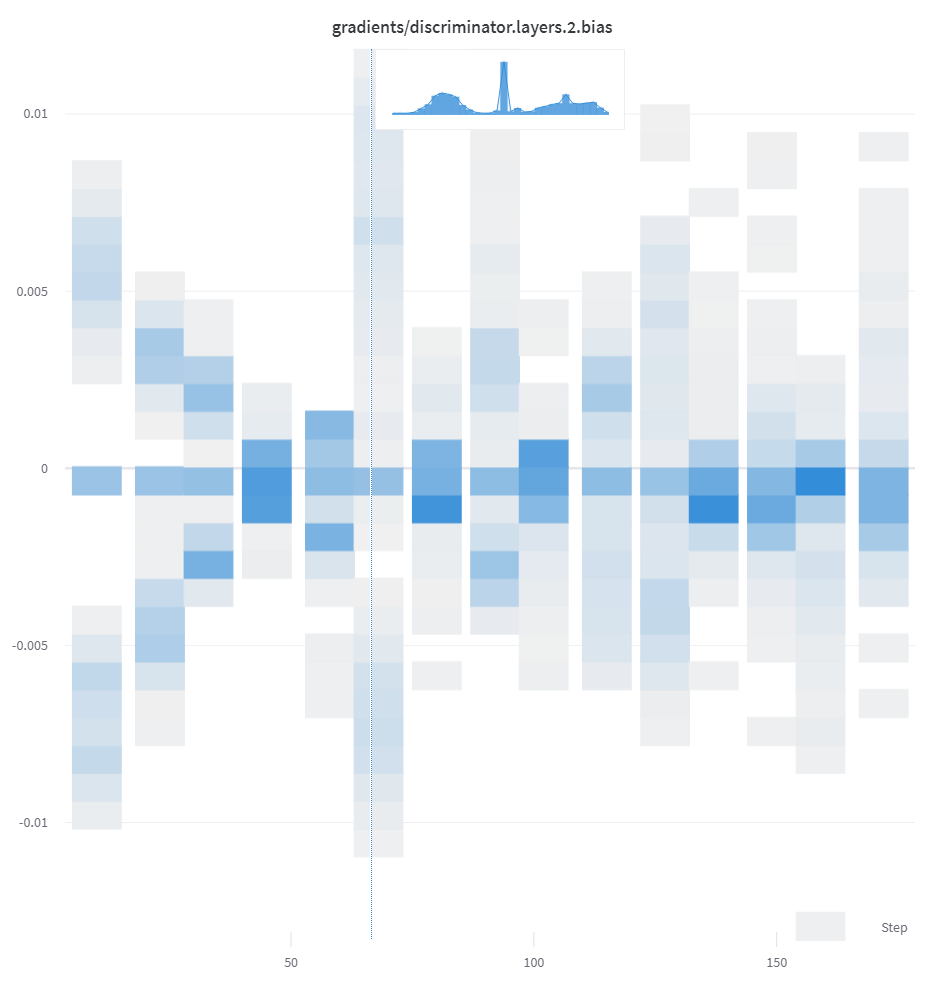
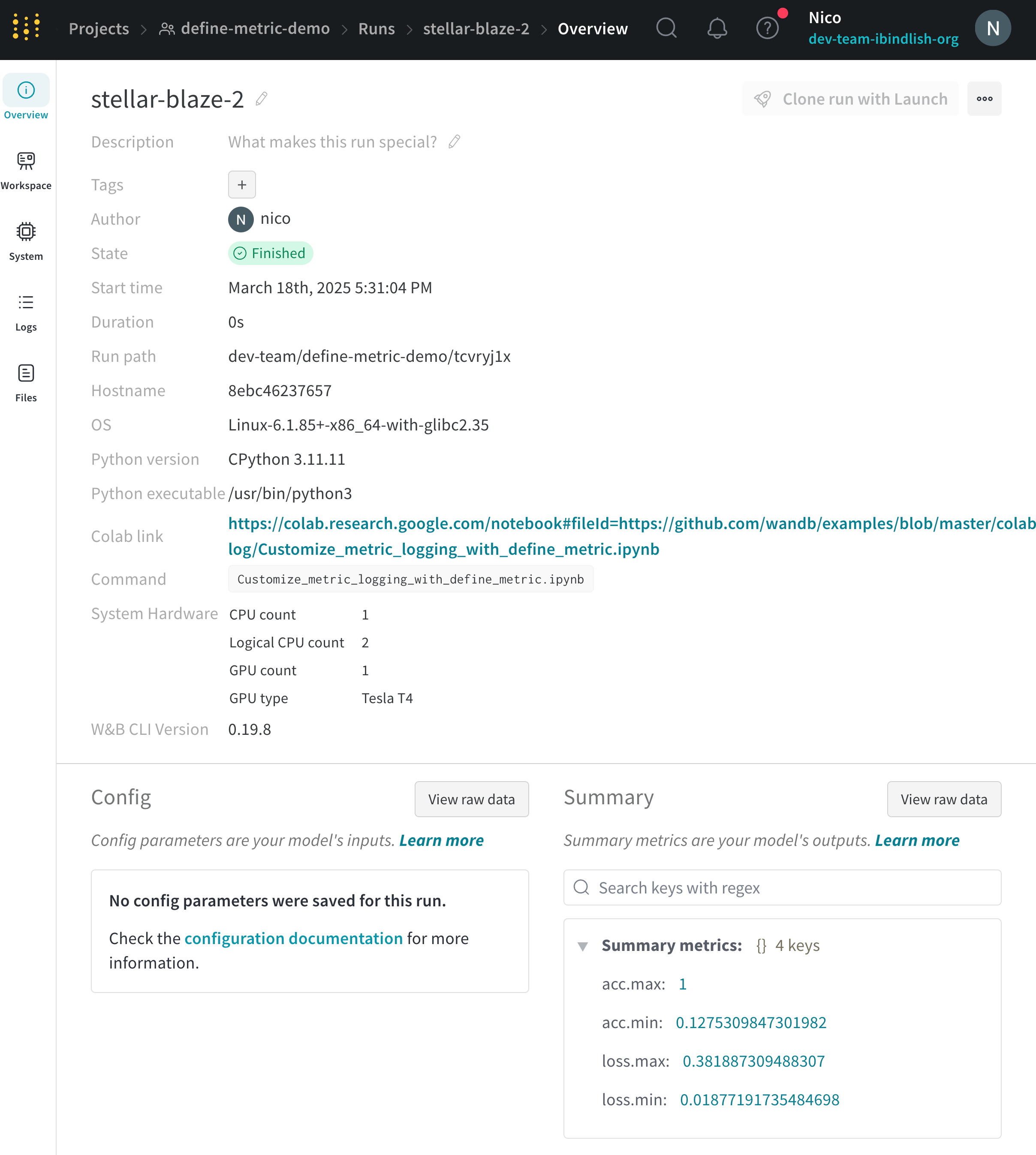
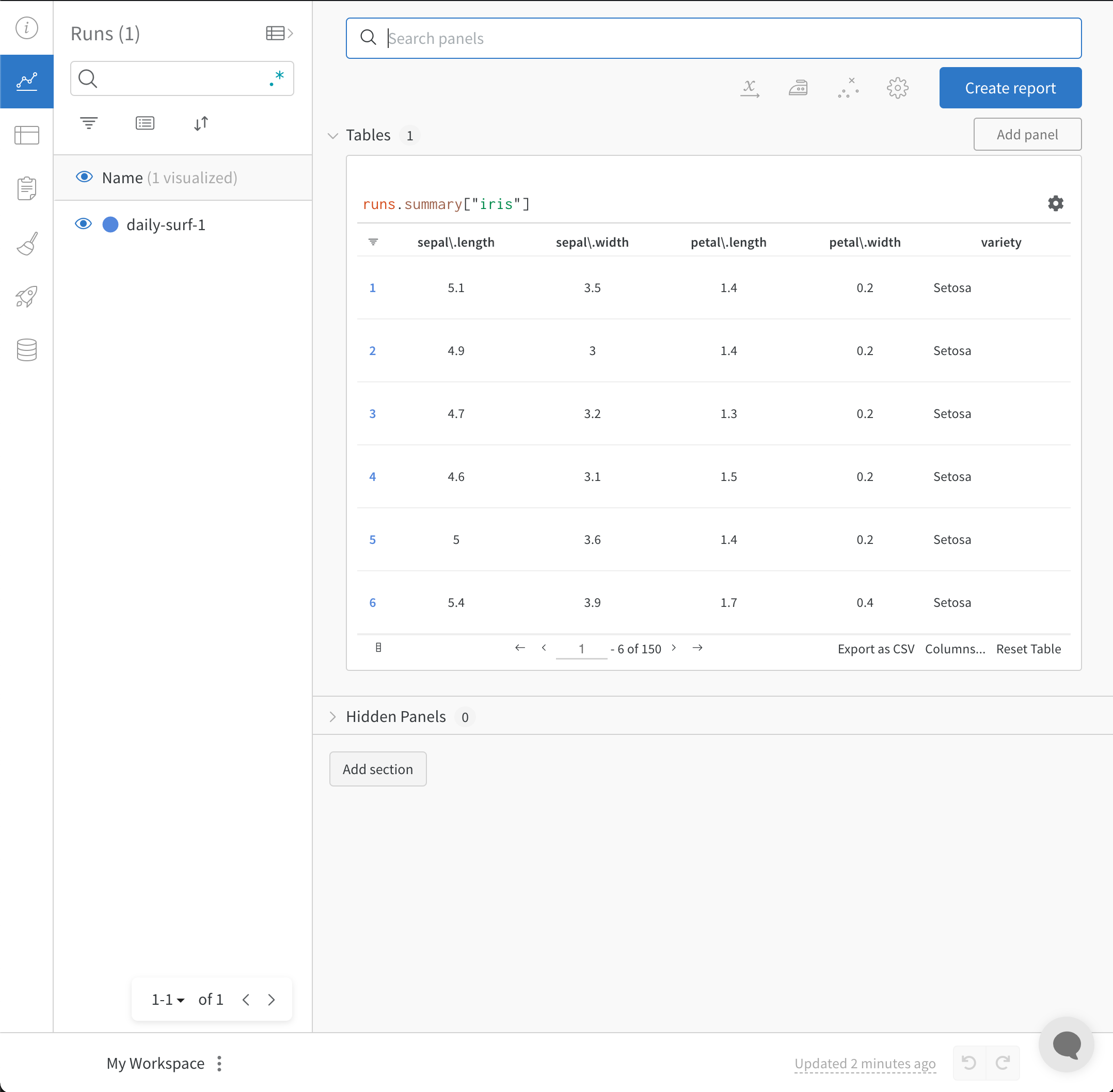
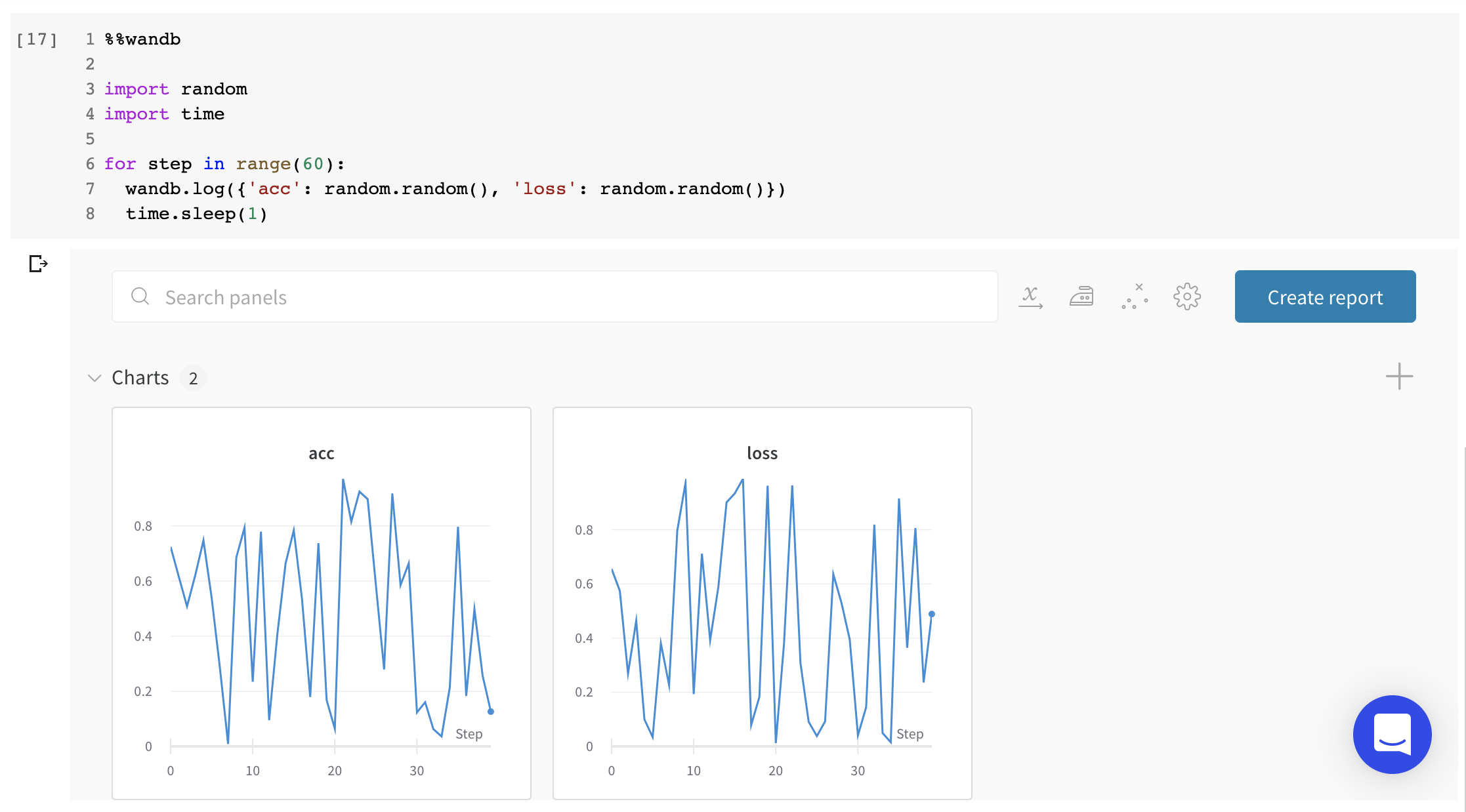
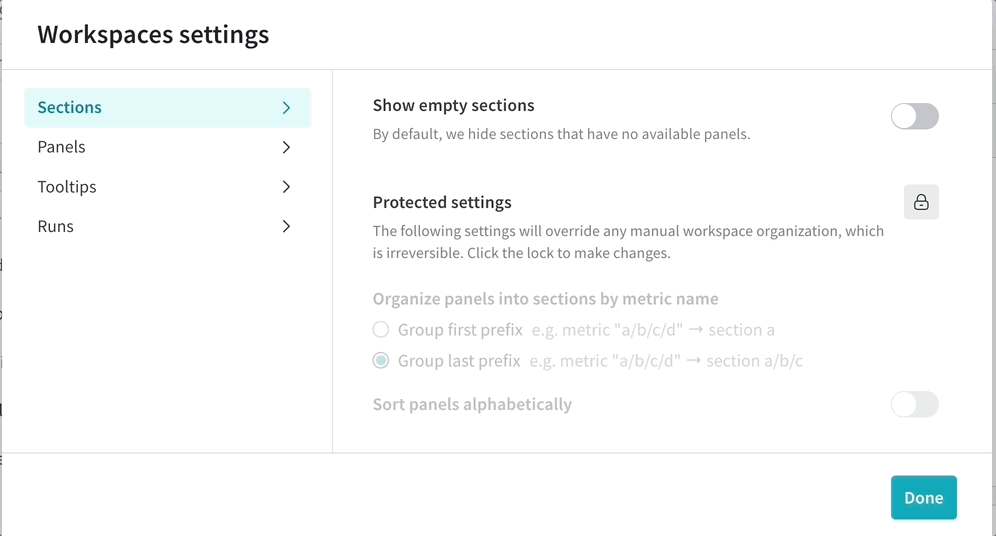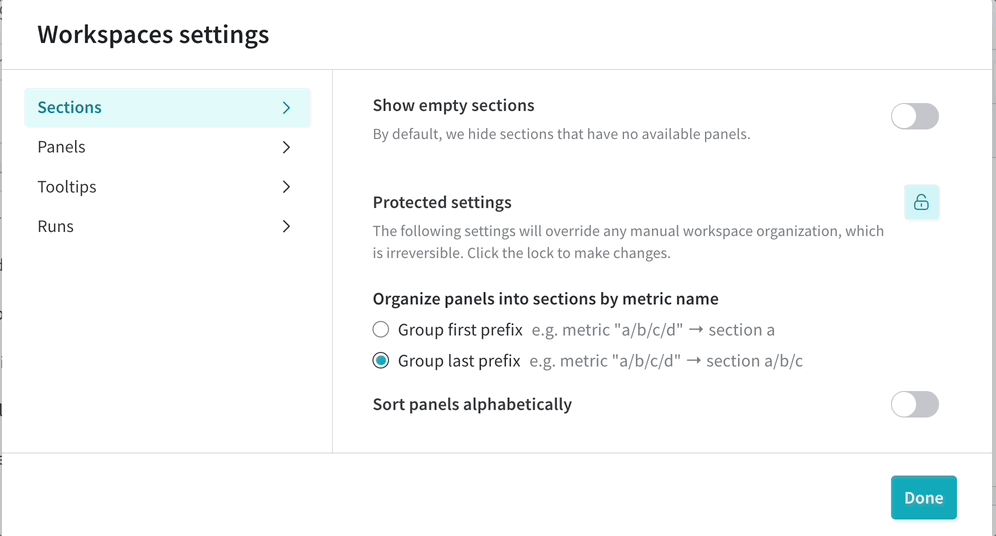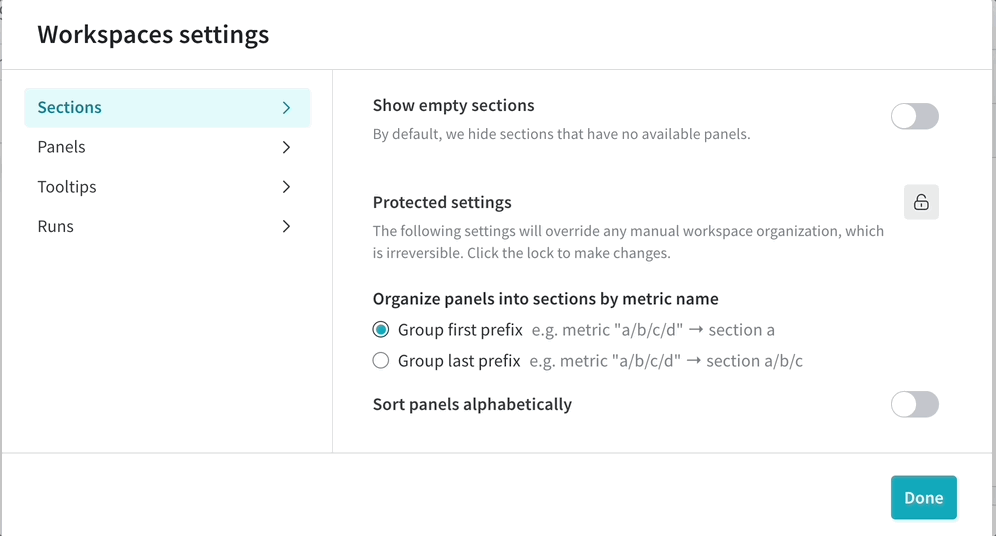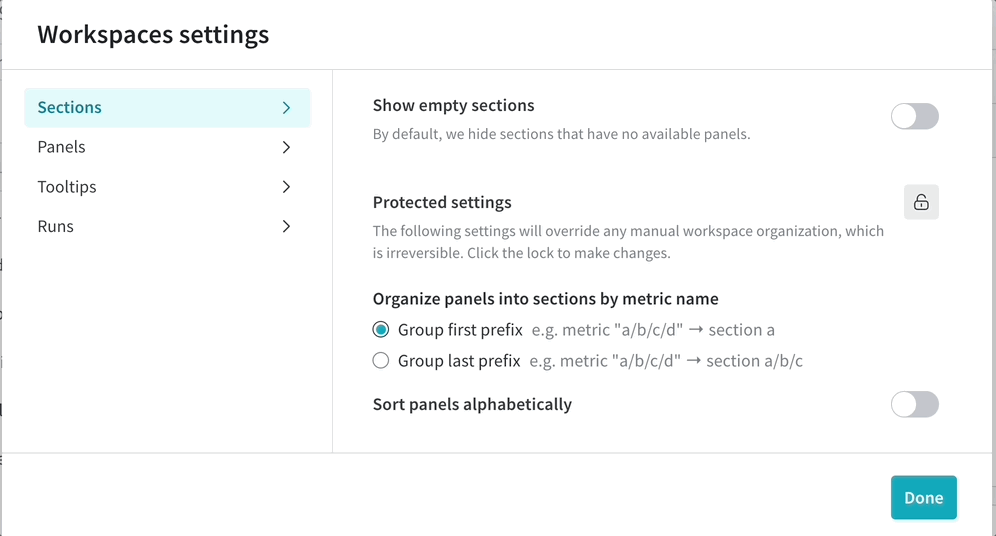
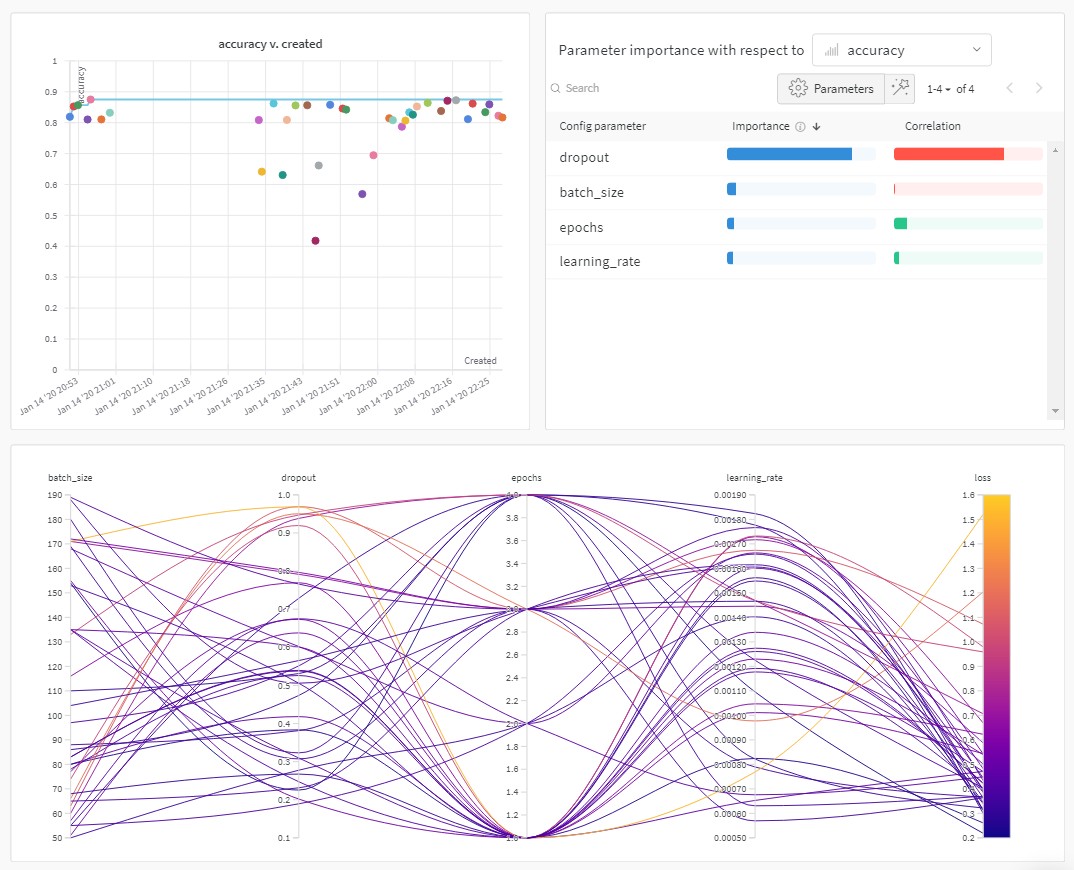
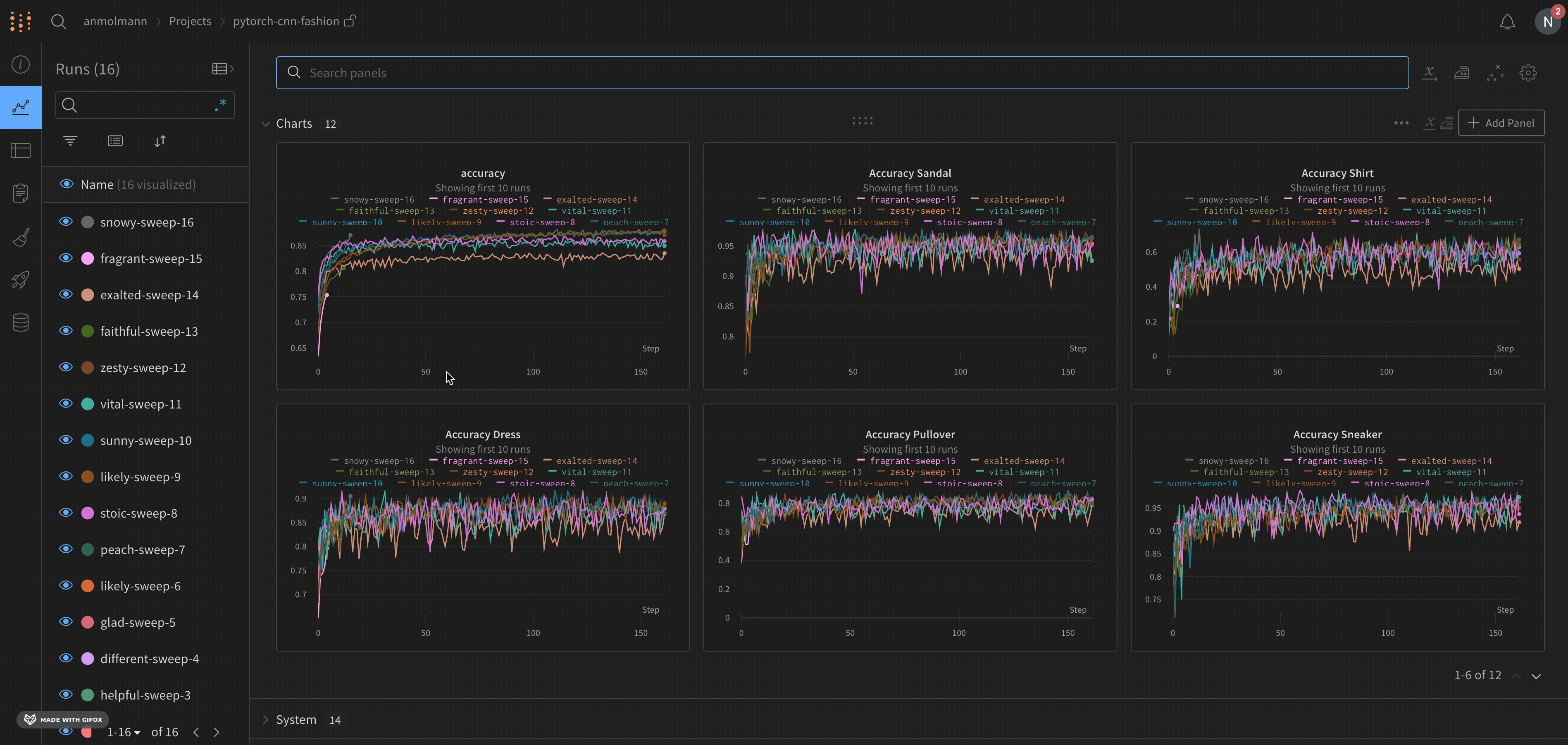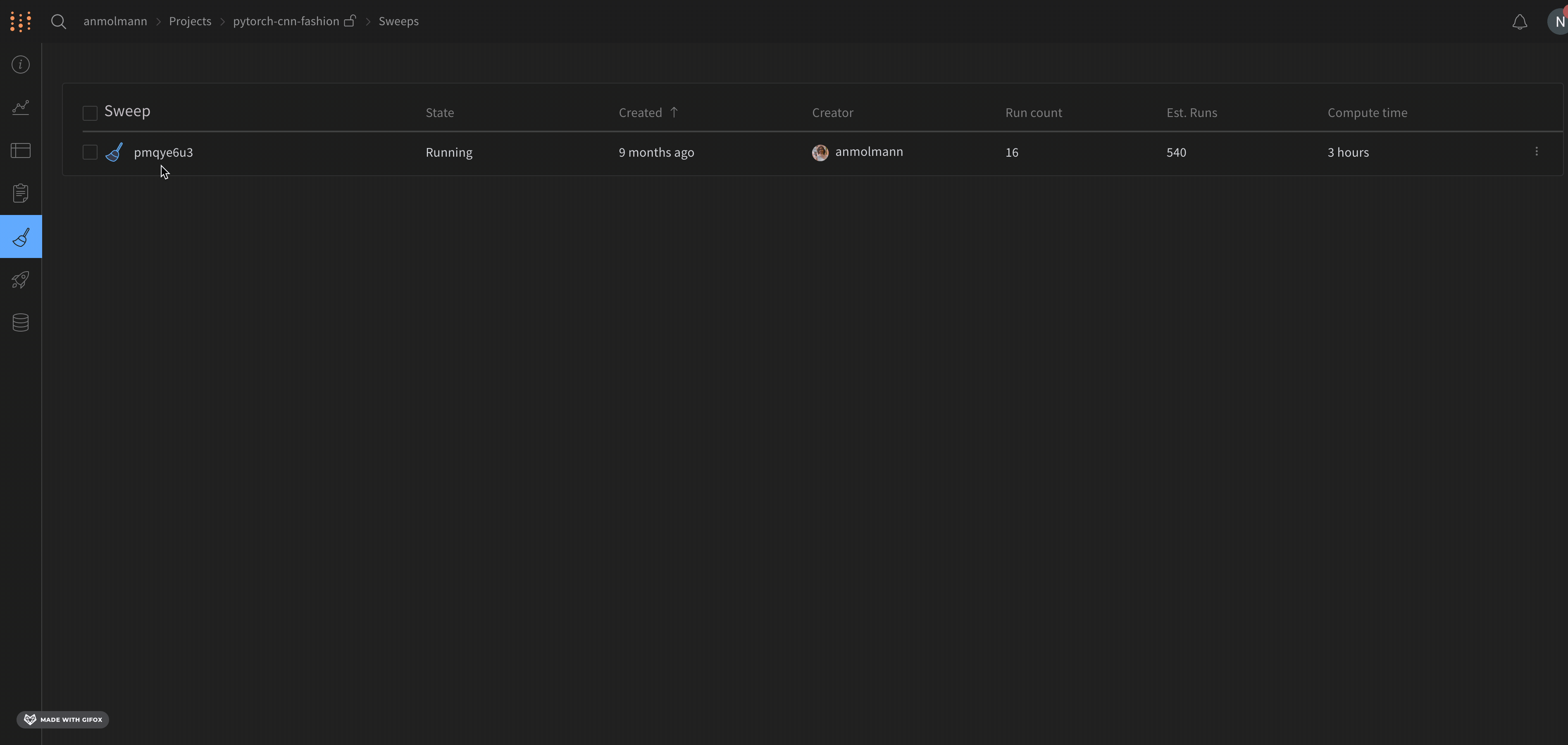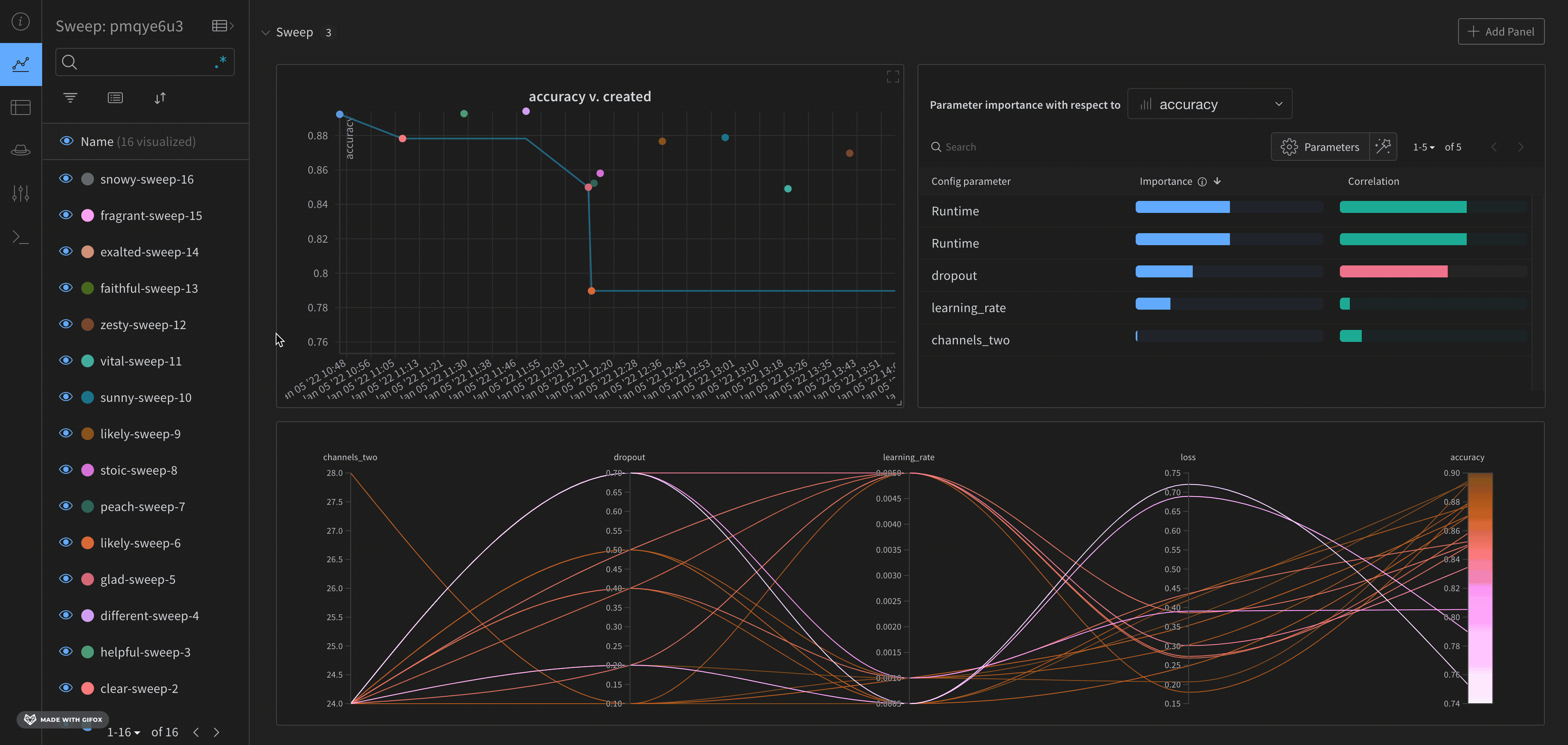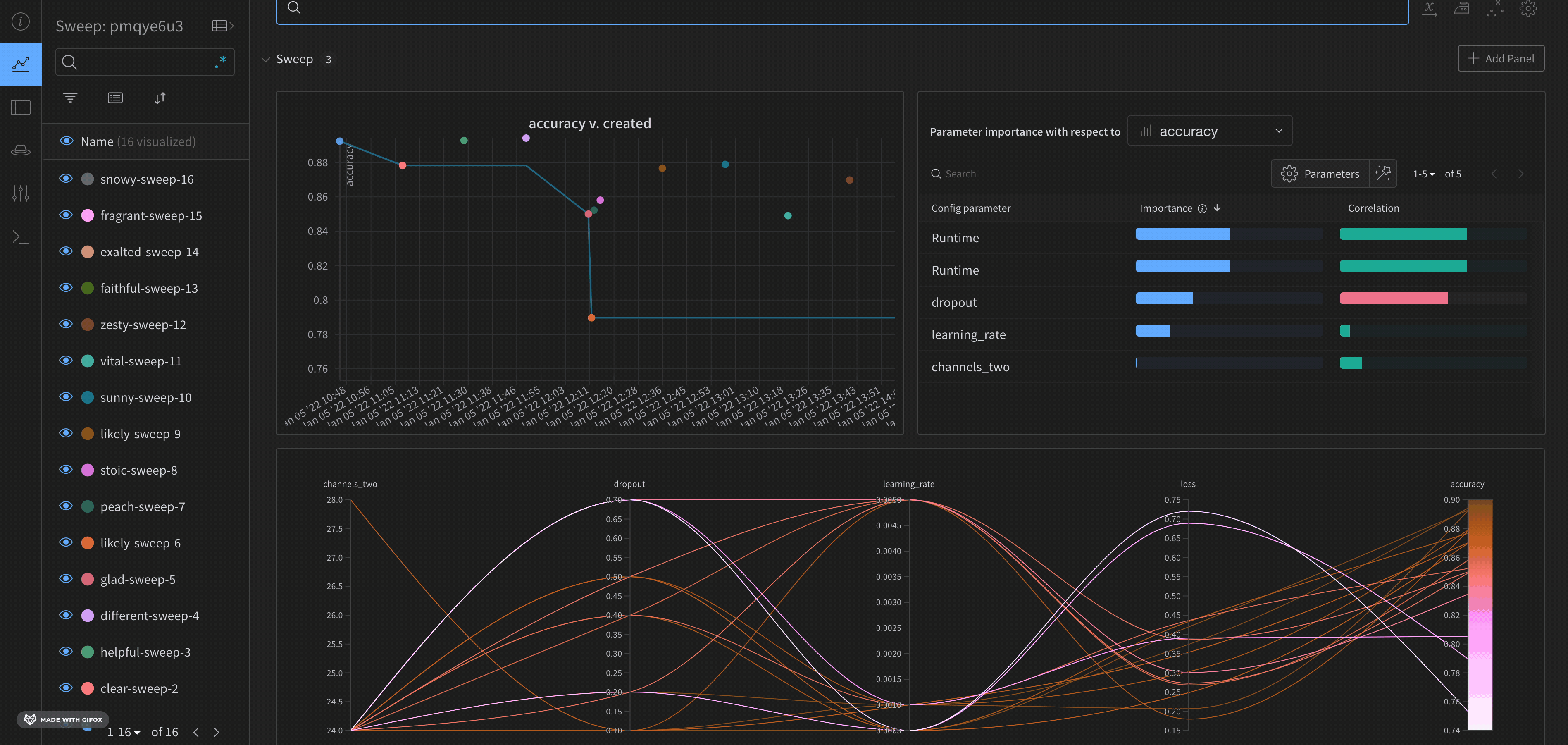
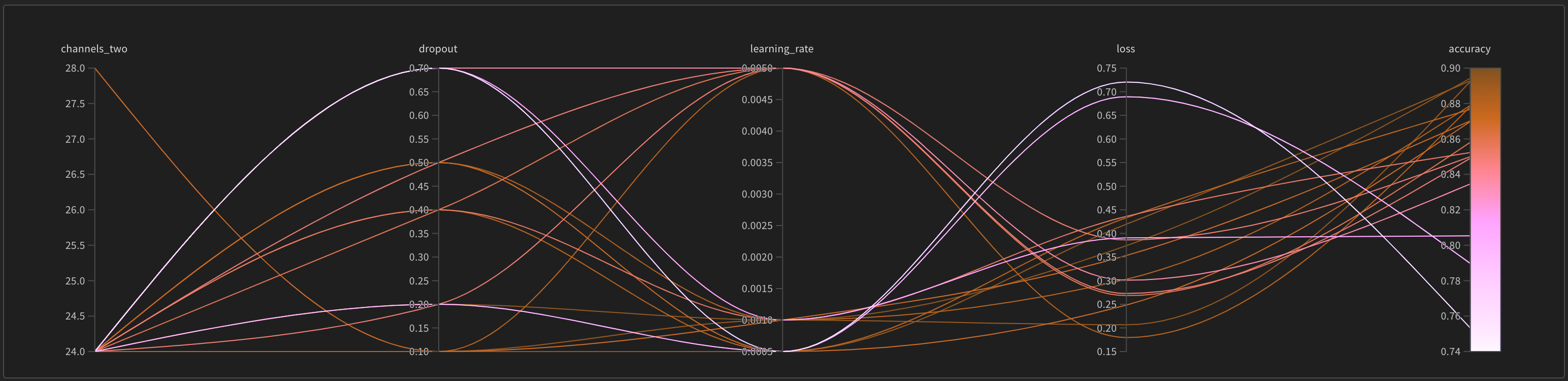
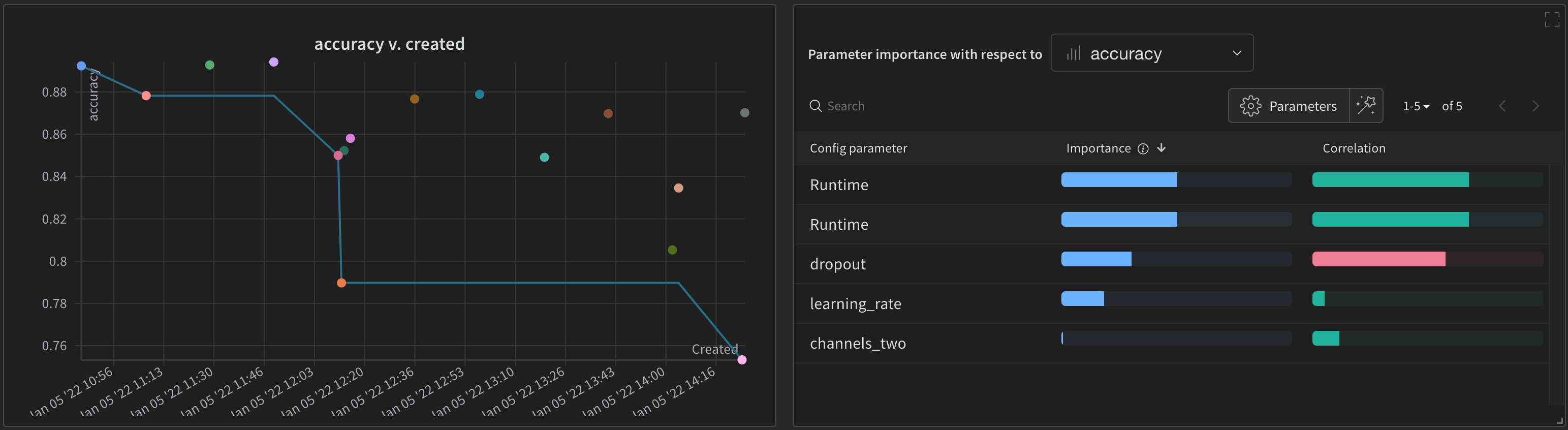
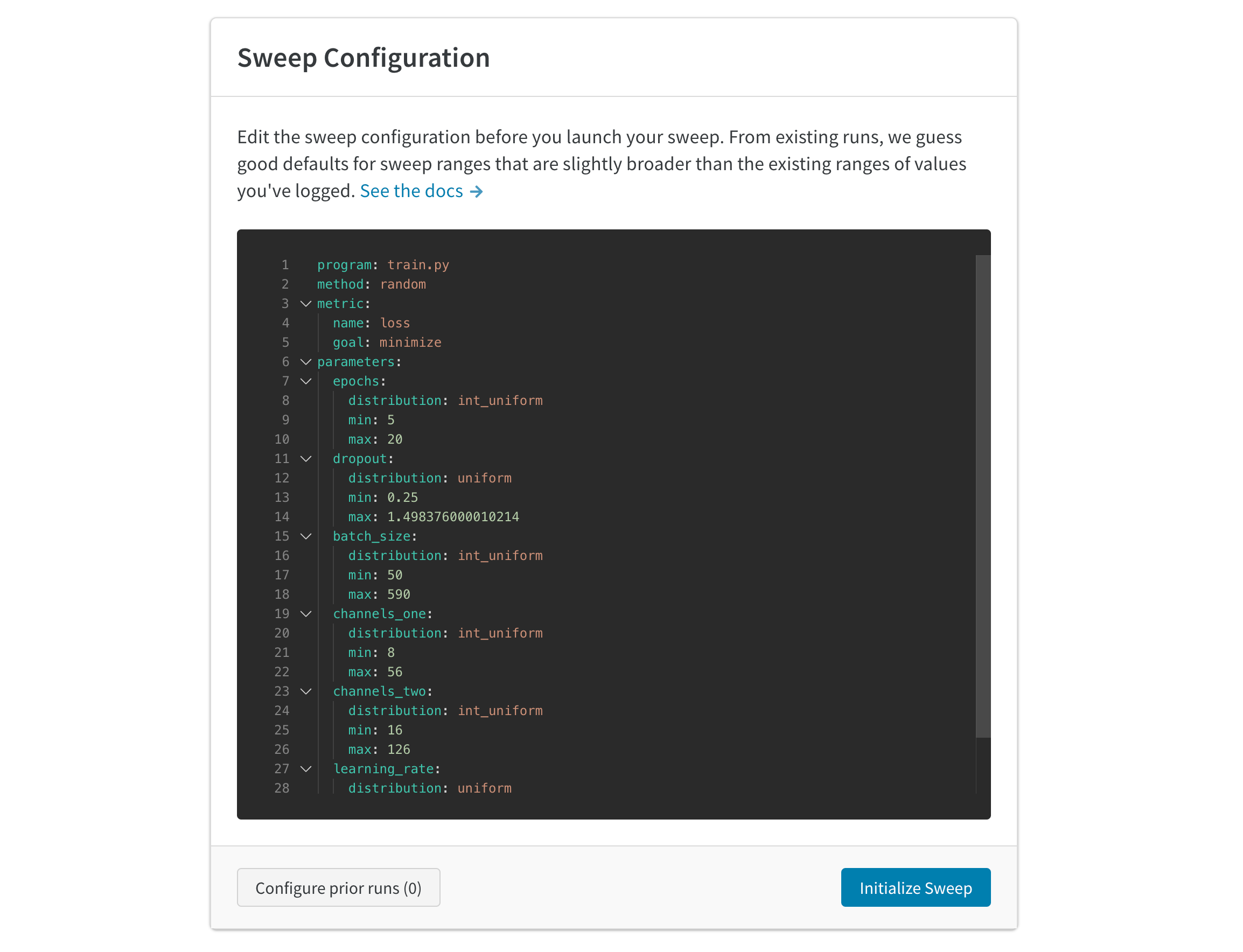
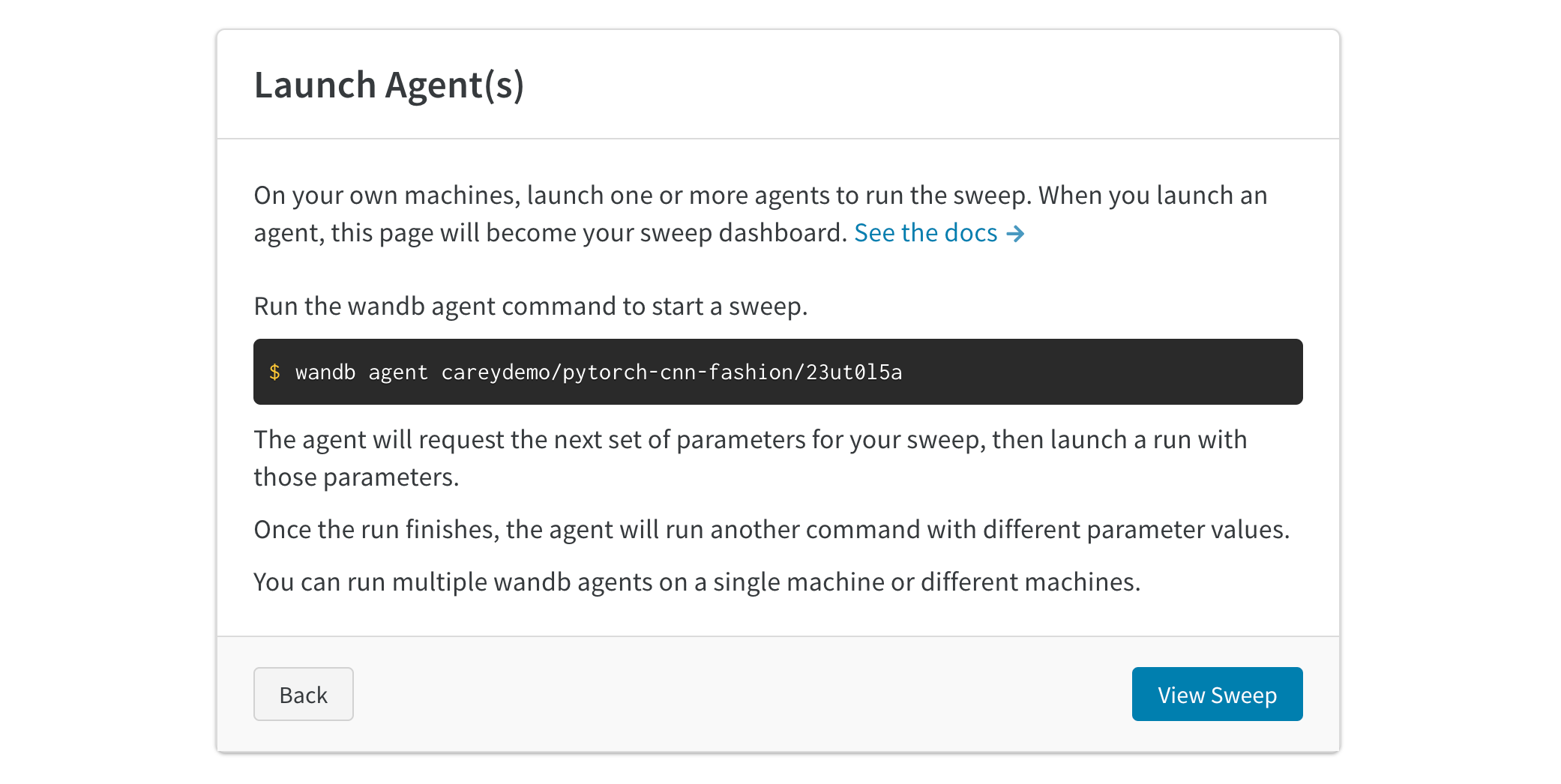
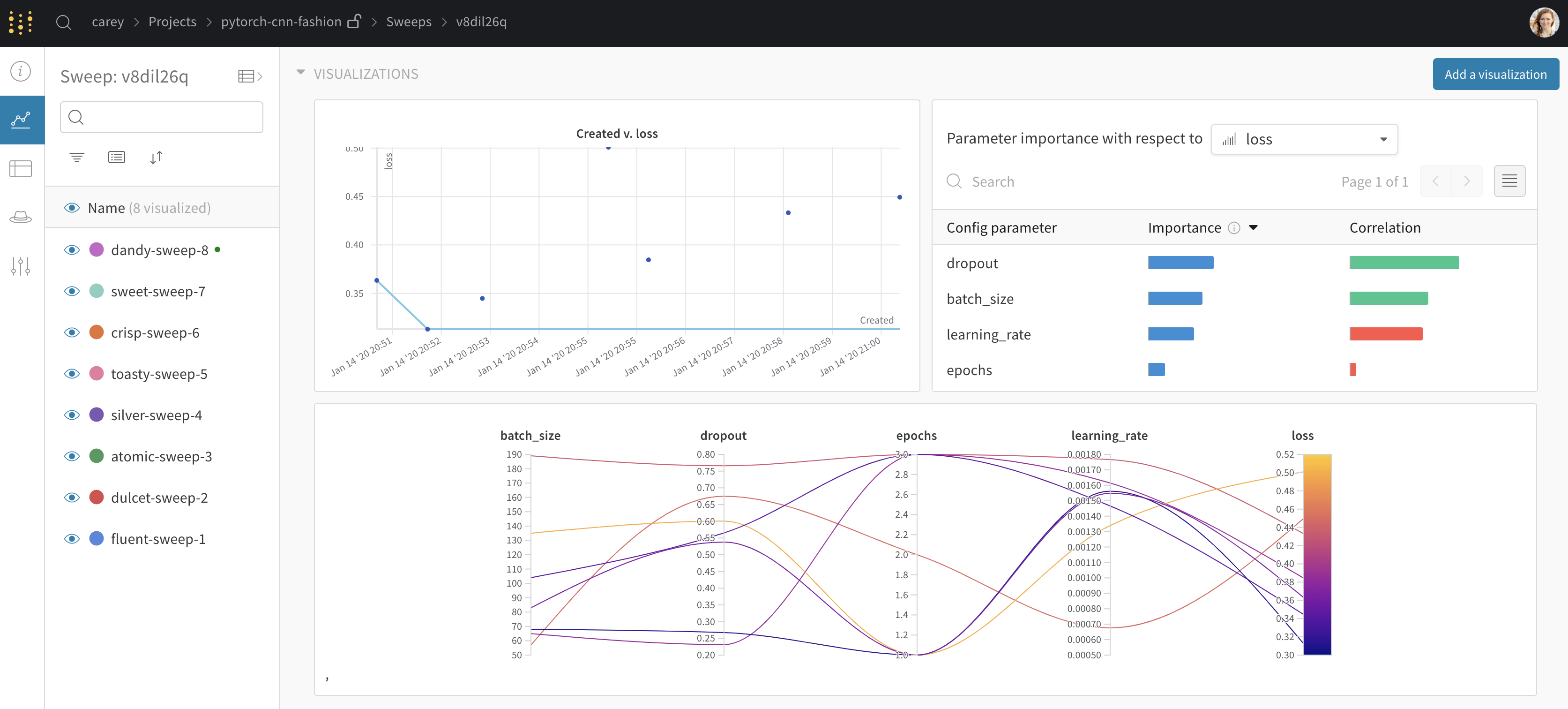
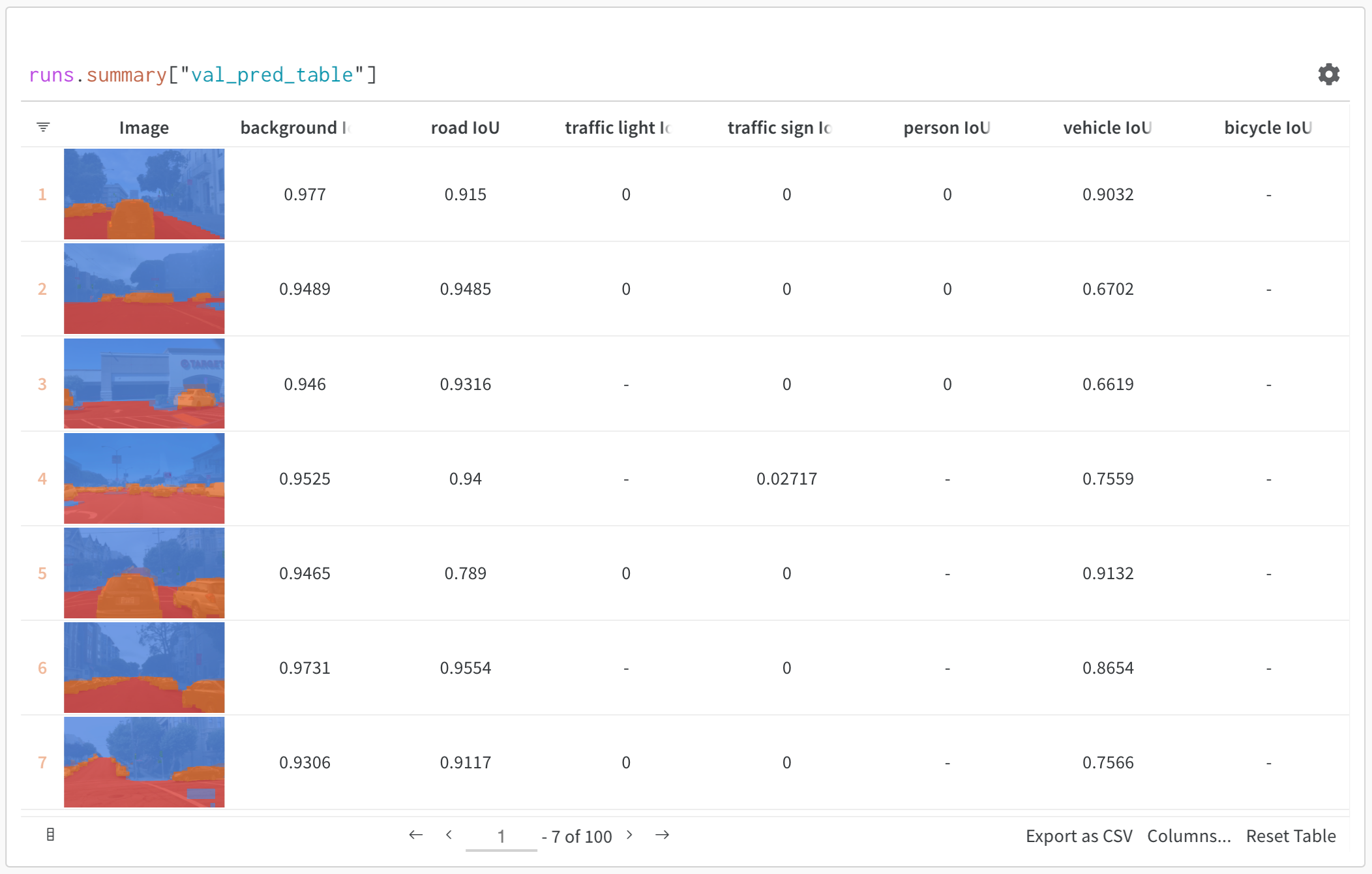 위 이미지는 시멘틱 세분화 및 사용자 정의 메트릭이 있는 테이블을 보여줍니다.
위 이미지는 시멘틱 세분화 및 사용자 정의 메트릭이 있는 테이블을 보여줍니다.