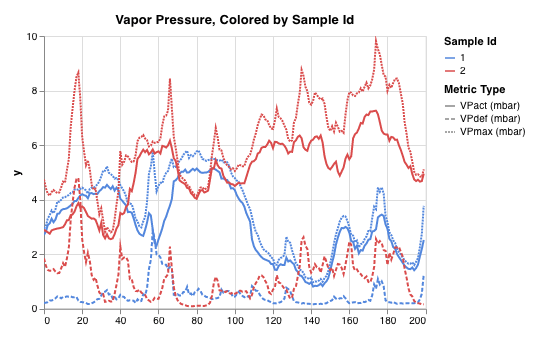
W&B Python SDK를 사용하여 메트릭, 미디어 또는 사용자 정의 오브젝트의 사전을 단계별로 기록합니다. W&B는 각 단계에서 키-값 쌍을 수집하고 wandb.log()로 데이터를 기록할 때마다 하나의 통합된 사전에 저장합니다. 스크립트에서 기록된 데이터는 wandb라는 디렉토리에 로컬로 저장된 다음 W&B 클라우드 또는 개인 서버로 동기화됩니다.
키-값 쌍은 각 단계마다 동일한 값을 전달하는 경우에만 하나의 통합된 사전에 저장됩니다. step에 대해 다른 값을 기록하면 W&B는 수집된 모든 키와 값을 메모리에 씁니다.
wandb.log를 호출할 때마다 기본적으로 새로운 step이 됩니다. W&B는 차트 및 패널을 만들 때 단계를 기본 x축으로 사용합니다. 선택적으로 사용자 정의 x축을 만들고 사용하거나 사용자 정의 요약 메트릭을 캡처할 수 있습니다. 자세한 내용은 로그 축 사용자 정의를 참조하세요.
각 step에 대해 연속적인 값 0, 1, 2 등을 기록하려면 wandb.log()를 사용하세요. 특정 history 단계에 쓸 수는 없습니다. W&B는 “현재” 및 “다음” 단계에만 씁니다.
자동으로 기록되는 데이터
W&B는 W&B Experiments 동안 다음 정보를 자동으로 기록합니다.
시스템 메트릭: CPU 및 GPU 사용률, 네트워크 등. 이러한 메트릭은 run 페이지의 시스템 탭에 표시됩니다. GPU의 경우 이러한 메트릭은 nvidia-smi를 통해 가져옵니다.
커맨드 라인: stdout 및 stderr이 선택되어 run 페이지의 로그 탭에 표시됩니다.
설정 정보: 하이퍼파라미터, 데이터셋 링크 또는 사용 중인 아키텍처 이름을 config 파라미터로 기록합니다. 예: wandb.init(config=your_config_dictionary). 자세한 내용은 PyTorch 인테그레이션 페이지를 참조하세요.
메트릭: 모델의 메트릭을 보려면 wandb.log를 사용합니다. 트레이닝 루프 내에서 정확도 및 손실과 같은 메트릭을 기록하면 UI에서 실시간 업데이트 그래프를 얻을 수 있습니다.
일반적인 워크플로우
최고 정확도 비교: run 간에 메트릭의 최고 값을 비교하려면 해당 메트릭의 요약 값을 설정합니다. 기본적으로 요약은 각 키에 대해 기록한 마지막 값으로 설정됩니다. 이는 UI의 테이블에서 유용합니다. 여기서 요약 메트릭을 기준으로 run을 정렬하고 필터링하여 최종 정확도가 아닌 최고 정확도를 기준으로 테이블 또는 막대 차트에서 run을 비교할 수 있습니다. 예: wandb.run.summary["best_accuracy"] = best_accuracy
하나의 차트에 여러 메트릭 보기: wandb.log({"acc'": 0.9, "loss": 0.1})과 같이 wandb.log에 대한 동일한 호출에서 여러 메트릭을 기록하면 UI에서 플롯하는 데 사용할 수 있습니다.
x축 사용자 정의: 동일한 로그 호출에 사용자 정의 x축을 추가하여 W&B 대시보드에서 다른 축에 대해 메트릭을 시각화합니다. 예: wandb.log({'acc': 0.9, 'epoch': 3, 'batch': 117}). 지정된 메트릭에 대한 기본 x축을 설정하려면 Run.define_metric()을 사용합니다.
wandb.plot의 메소드를 사용하면 트레이닝 중 시간에 따라 변하는 차트를 포함하여 wandb.log로 차트를 추적할 수 있습니다. 사용자 정의 차트 프레임워크에 대해 자세히 알아보려면 이 가이드를 확인하십시오.
기본 차트
이러한 간단한 차트를 사용하면 메트릭 및 결과의 기본 시각화를 쉽게 구성할 수 있습니다.
wandb.plot.line()
임의의 축에서 연결되고 정렬된 점 목록인 사용자 정의 라인 플롯을 기록합니다.
data = [[x, y] for (x, y) in zip(x_values, y_values)]
table = wandb.Table(data=data, columns=["x", "y"])
wandb.log(
{
"my_custom_plot_id": wandb.plot.line(
table, "x", "y", title="Custom Y vs X Line Plot" )
}
)
이를 사용하여 임의의 두 차원에 대한 곡선을 기록할 수 있습니다. 두 값 목록을 서로 플로팅하는 경우 목록의 값 수는 정확히 일치해야 합니다. 예를 들어 각 점에는 x와 y가 있어야 합니다.
몇 줄의 코드로 값 목록을 발생 횟수/빈도별로 bin으로 정렬하는 사용자 정의 히스토그램을 기본적으로 기록합니다. 예측 신뢰도 점수 목록 (scores)이 있고 분포를 시각화하고 싶다고 가정해 보겠습니다.
data = [[s] for s in scores]
table = wandb.Table(data=data, columns=["scores"])
wandb.log({"my_histogram": wandb.plot.histogram(table, "scores", title="Histogram")})
이를 사용하여 임의의 히스토그램을 기록할 수 있습니다. data는 행과 열의 2D 배열을 지원하기 위한 목록의 목록입니다.
전체 사용자 정의를 위해 기본 제공 사용자 정의 차트 사전 설정을 조정하거나 새 사전 설정을 만든 다음 차트를 저장합니다. 차트 ID를 사용하여 스크립트에서 직접 해당 사용자 정의 사전 설정에 데이터를 기록합니다.
# 플로팅할 열이 있는 테이블을 만듭니다.table = wandb.Table(data=data, columns=["step", "height"])
# 테이블의 열에서 차트의 필드로 매핑합니다.fields = {"x": "step", "value": "height"}
# 테이블을 사용하여 새 사용자 정의 차트 사전 설정을 채웁니다.# 자신의 저장된 차트 사전 설정을 사용하려면 vega_spec_name을 변경하십시오.# 제목을 편집하려면 string_fields를 변경하십시오.my_custom_chart = wandb.plot_table(
vega_spec_name="carey/new_chart",
data_table=table,
fields=fields,
string_fields={"title": "Height Histogram"},
)
기본적으로 모든 메트릭은 W&B 내부 step인 동일한 x축에 대해 기록됩니다. 때로는 이전 스텝에 로그하거나 다른 x축을 사용하고 싶을 수 있습니다.
다음은 기본 스텝 대신 사용자 정의 x축 메트릭을 설정하는 예입니다.
import wandb
wandb.init()
# 사용자 정의 x축 메트릭 정의wandb.define_metric("custom_step")
# 어떤 메트릭을 기준으로 플롯할지 정의wandb.define_metric("validation_loss", step_metric="custom_step")
for i in range(10):
log_dict = {
"train_loss": 1/ (i +1),
"custom_step": i**2,
"validation_loss": 1/ (i +1),
}
wandb.log(log_dict)
x축은 glob을 사용하여 설정할 수도 있습니다. 현재 문자열 접두사가 있는 glob만 사용할 수 있습니다. 다음 예제는 접두사 "train/"가 있는 기록된 모든 메트릭을 x축 "train/step"에 플롯합니다.
import wandb
wandb.init()
# 사용자 정의 x축 메트릭 정의wandb.define_metric("train/step")
# 다른 모든 train/ 메트릭이 이 스텝을 사용하도록 설정wandb.define_metric("train/*", step_metric="train/step")
for i in range(10):
log_dict = {
"train/step": 2**i, # 내부 W&B 스텝으로 지수적 증가"train/loss": 1/ (i +1), # x축은 train/step"train/accuracy": 1- (1/ (1+ i)), # x축은 train/step"val/loss": 1/ (1+ i), # x축은 내부 wandb step }
wandb.log(log_dict)
3 - Log distributed training experiments
W&B를 사용하여 여러 개의 GPU로 분산 트레이닝 실험을 로그하세요.
분산 트레이닝에서 모델은 여러 개의 GPU를 병렬로 사용하여 트레이닝됩니다. W&B는 분산 트레이닝 Experiments를 추적하는 두 가지 패턴을 지원합니다.
단일 프로세스: 단일 프로세스에서 W&B (wandb.init)를 초기화하고 Experiments (wandb.log)를 기록합니다. 이는 PyTorch Distributed Data Parallel (DDP) 클래스를 사용하여 분산 트레이닝 Experiments를 로깅하는 일반적인 솔루션입니다. 경우에 따라 사용자는 멀티프로세싱 대기열(또는 다른 통신 기본 요소)을 사용하여 다른 프로세스의 데이터를 기본 로깅 프로세스로 전달합니다.
다중 프로세스: 모든 프로세스에서 W&B (wandb.init)를 초기화하고 Experiments (wandb.log)를 기록합니다. 각 프로세스는 사실상 별도의 experiment입니다. W&B를 초기화할 때 group 파라미터(wandb.init(group='group-name'))를 사용하여 공유 experiment를 정의하고 기록된 값들을 W&B App UI에서 함께 그룹화합니다.
다음 예제는 단일 머신에서 2개의 GPU를 사용하는 PyTorch DDP를 통해 W&B로 메트릭을 추적하는 방법을 보여줍니다. PyTorch DDP(torch.nn의 DistributedDataParallel)는 분산 트레이닝을 위한 널리 사용되는 라이브러리입니다. 기본 원리는 모든 분산 트레이닝 설정에 적용되지만 구현 세부 사항은 다를 수 있습니다.
W&B GitHub 예제 리포지토리 여기에서 이러한 예제의 이면의 코드를 살펴보세요. 특히, 단일 프로세스 및 다중 프로세스 메소드를 구현하는 방법에 대한 정보는 log-dpp.py Python 스크립트를 참조하세요.
방법 1: 단일 프로세스
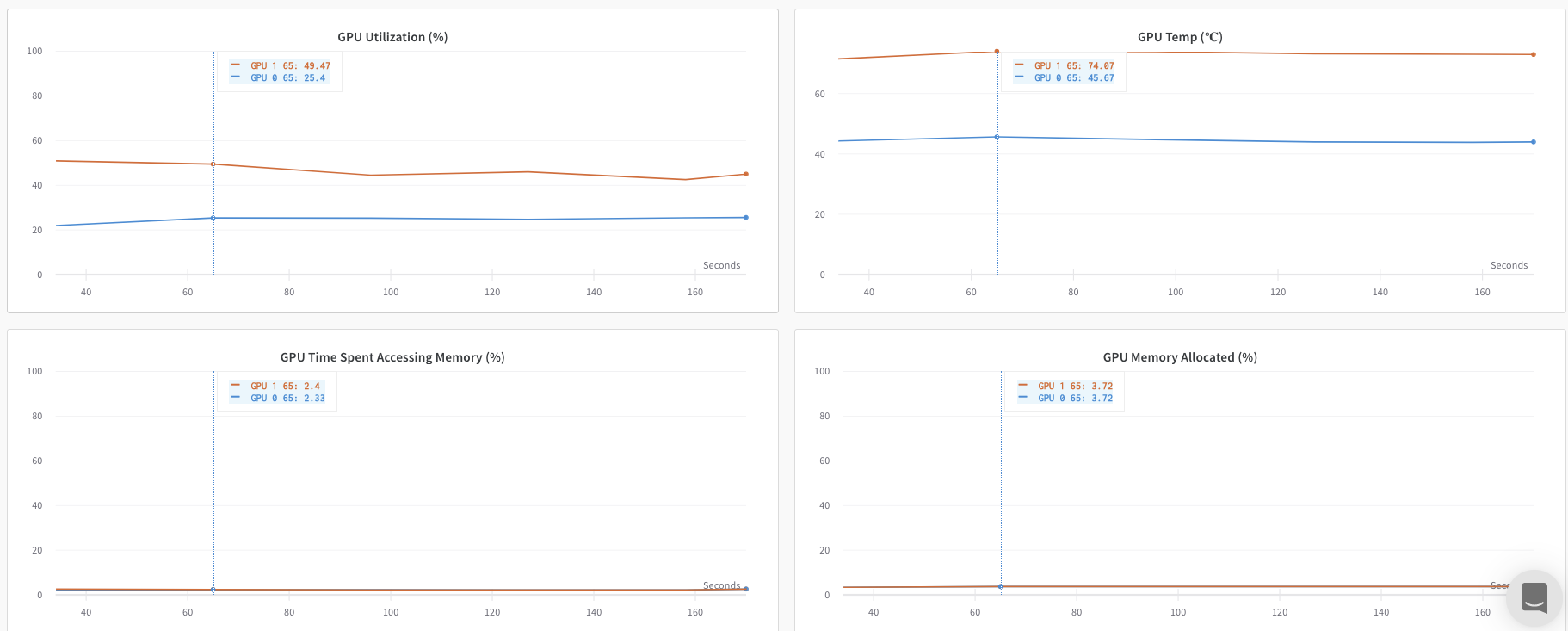
이 방법에서는 순위 0 프로세스만 추적합니다. 이 방법을 구현하려면 W&B(wandb.init)를 초기화하고, W&B Run을 시작하고, 순위 0 프로세스 내에서 메트릭(wandb.log)을 기록합니다. 이 방법은 간단하고 강력하지만 다른 프로세스의 모델 메트릭(예: 배치에서의 손실 값 또는 입력)을 기록하지 않습니다. 사용량 및 메모리와 같은 시스템 메트릭은 해당 정보가 모든 프로세스에서 사용 가능하므로 모든 GPU에 대해 계속 기록됩니다.
이 방법을 사용하여 단일 프로세스에서 사용 가능한 메트릭만 추적하세요. 일반적인 예로는 GPU/CPU 사용률, 공유 검증 세트에서의 행동, 그레이디언트 및 파라미터, 대표적인 데이터 예제에 대한 손실 값이 있습니다.
샘플 Python 스크립트(log-ddp.py) 내에서 순위가 0인지 확인합니다. 이를 구현하기 위해 먼저 torch.distributed.launch를 사용하여 여러 프로세스를 시작합니다. 다음으로 --local_rank 커맨드라인 인수로 순위를 확인합니다. 순위가 0으로 설정된 경우 train() 함수에서 조건부로 wandb 로깅을 설정합니다. Python 스크립트 내에서 다음 검사를 사용합니다.
if __name__ =="__main__":
# Get args args = parse_args()
if args.local_rank ==0: # only on main process# Initialize wandb run run = wandb.init(
entity=args.entity,
project=args.project,
)
# Train model with DDP train(args, run)
else:
train(args)
W&B App UI를 탐색하여 단일 프로세스에서 추적된 메트릭의 예제 대시보드를 확인하세요. 대시보드는 두 GPU에 대해 추적된 온도 및 사용률과 같은 시스템 메트릭을 표시합니다.
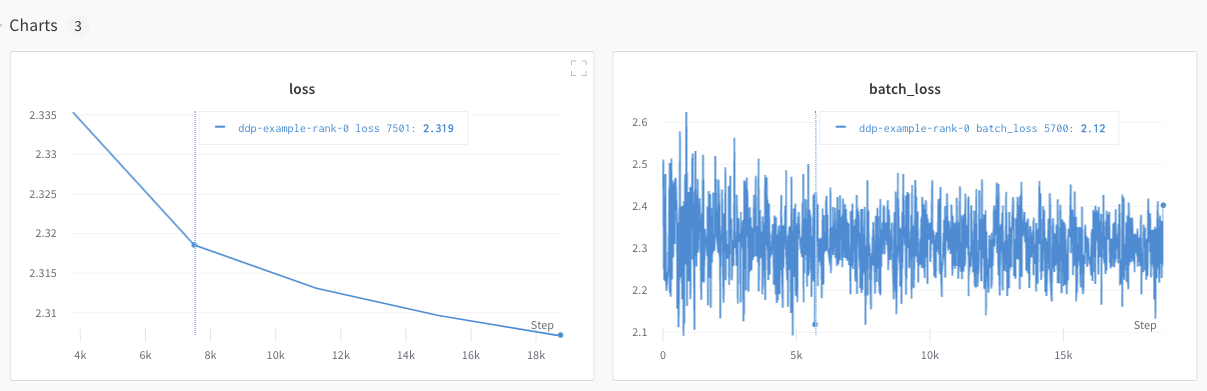
그러나 에포크 및 배치 크기 함수로서의 손실 값은 단일 GPU에서만 기록되었습니다.
방법 2: 다중 프로세스
이 방법에서는 작업의 각 프로세스를 추적하여 각 프로세스에서 wandb.init() 및 wandb.log()를 호출합니다. 트레이닝이 끝나면 wandb.finish()를 호출하여 Run이 완료되었음을 표시하여 모든 프로세스가 올바르게 종료되도록 하는 것이 좋습니다.
이 방법을 사용하면 더 많은 정보를 로깅에 엑세스할 수 있습니다. 그러나 여러 개의 W&B Runs가 W&B App UI에 보고되는 점에 유의하세요. 여러 Experiments에서 W&B Runs를 추적하기 어려울 수 있습니다. 이를 완화하려면 W&B를 초기화할 때 group 파라미터에 값을 제공하여 지정된 experiment에 속하는 W&B Run을 추적하세요. Experiments에서 트레이닝 및 평가 W&B Runs를 추적하는 방법에 대한 자세한 내용은 Run 그룹화를 참조하세요.
개별 프로세스의 메트릭을 추적하려면 이 방법을 사용하세요. 일반적인 예로는 각 노드의 데이터 및 예측(데이터 배포 디버깅용)과 기본 노드 외부의 개별 배치에 대한 메트릭이 있습니다. 이 방법은 모든 노드에서 시스템 메트릭을 가져오거나 기본 노드에서 사용 가능한 요약 통계를 가져오는 데 필요하지 않습니다.
다음 Python 코드 조각은 W&B를 초기화할 때 group 파라미터를 설정하는 방법을 보여줍니다.
if __name__ =="__main__":
# Get args args = parse_args()
# Initialize run run = wandb.init(
entity=args.entity,
project=args.project,
group="DDP", # all runs for the experiment in one group )
# Train model with DDP train(args, run)
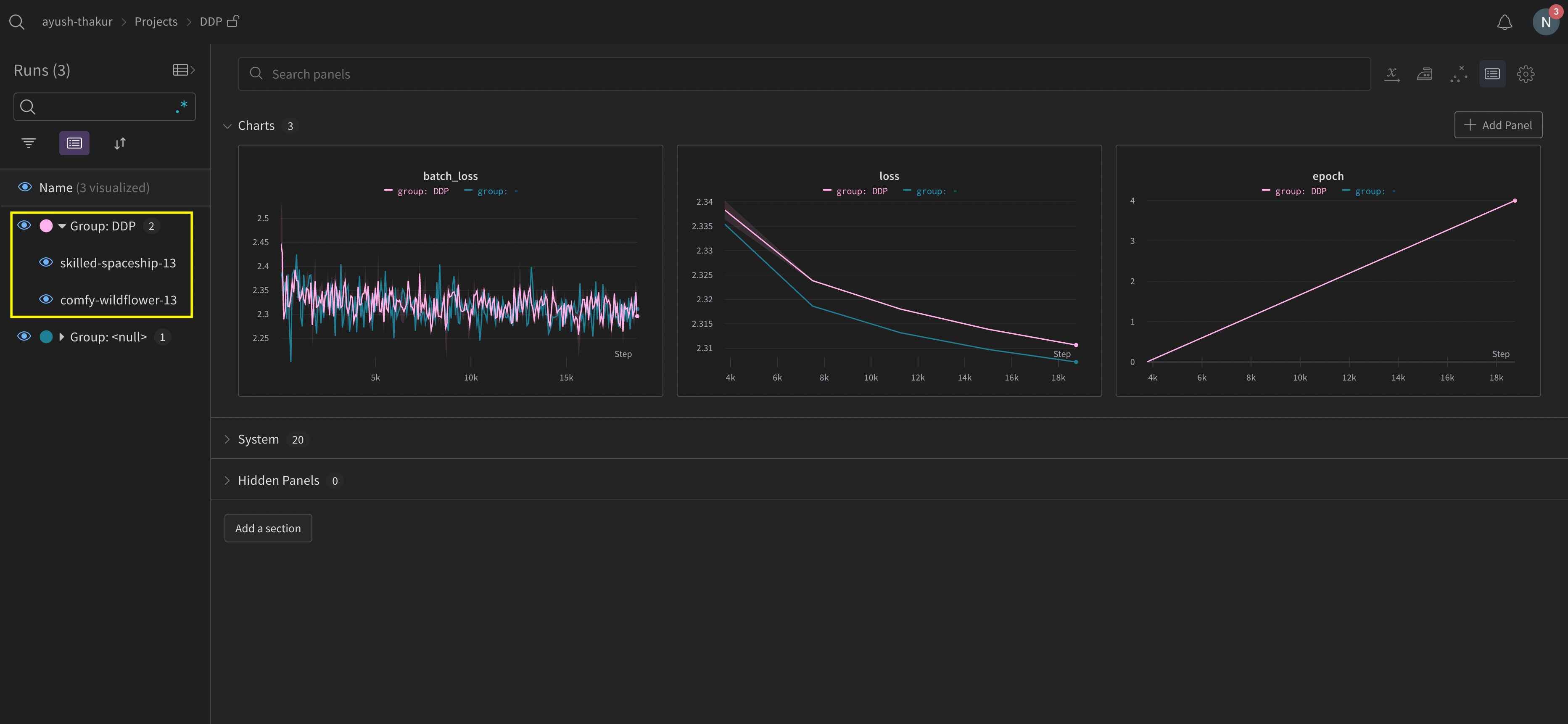
W&B App UI를 탐색하여 여러 프로세스에서 추적된 메트릭의 예제 대시보드를 확인하세요. 왼쪽 사이드바에 함께 그룹화된 두 개의 W&B Runs가 있습니다. 그룹을 클릭하여 experiment에 대한 전용 그룹 페이지를 확인하세요. 전용 그룹 페이지에는 각 프로세스의 메트릭이 개별적으로 표시됩니다.
앞의 이미지는 W&B App UI 대시보드를 보여줍니다. 사이드바에는 두 개의 Experiments가 있습니다. 하나는 ’null’로 레이블이 지정되고 다른 하나는 ‘DPP’(노란색 상자로 묶임)로 표시됩니다. 그룹을 확장하면(그룹 드롭다운 선택) 해당 experiment와 연결된 W&B Runs가 표시됩니다.
W&B Service를 사용하여 일반적인 분산 트레이닝 문제 방지
W&B 및 분산 트레이닝을 사용할 때 발생할 수 있는 두 가지 일반적인 문제가 있습니다.
트레이닝 시작 시 중단 - wandb 멀티프로세싱이 분산 트레이닝의 멀티프로세싱을 방해하는 경우 wandb 프로세스가 중단될 수 있습니다.
트레이닝 종료 시 중단 - wandb 프로세스가 종료해야 할 시점을 알지 못하는 경우 트레이닝 작업이 중단될 수 있습니다. Python 스크립트의 끝에서 wandb.finish() API를 호출하여 W&B에 Run이 완료되었음을 알립니다. wandb.finish() API는 데이터 업로드를 완료하고 W&B가 종료되도록 합니다.
wandb service를 사용하여 분산 작업의 안정성을 개선하는 것이 좋습니다. 앞서 언급한 두 가지 트레이닝 문제는 일반적으로 wandb service를 사용할 수 없는 W&B SDK 버전에서 발견됩니다.
W&B Service 활성화
W&B SDK 버전에 따라 W&B Service가 기본적으로 활성화되어 있을 수 있습니다.
W&B SDK 0.13.0 이상
W&B Service는 W&B SDK 0.13.0 버전 이상에서 기본적으로 활성화되어 있습니다.
W&B SDK 0.12.5 이상
Python 스크립트를 수정하여 W&B SDK 버전 0.12.5 이상에서 W&B Service를 활성화하세요. wandb.require 메소드를 사용하고 기본 함수 내에서 문자열 "service"를 전달하세요.
if __name__ =="__main__":
main()
defmain():
wandb.require("service")
# rest-of-your-script-goes-here
최적의 경험을 위해 최신 버전으로 업그레이드하는 것이 좋습니다.
W&B SDK 0.12.4 이하
W&B SDK 버전 0.12.4 이하를 사용하는 경우 WANDB_START_METHOD 환경 변수를 "thread"로 설정하여 대신 멀티스레딩을 사용하세요.
멀티프로세싱에 대한 예제 유스 케이스
다음 코드 조각은 고급 분산 유스 케이스에 대한 일반적인 방법을 보여줍니다.
프로세스 생성
생성된 프로세스에서 W&B Run을 시작하는 경우 기본 함수에서 wandb.setup() 메소드를 사용하세요.
import multiprocessing as mp
defdo_work(n):
run = wandb.init(config=dict(n=n))
run.log(dict(this=n * n))
defmain():
wandb.setup()
pool = mp.Pool(processes=4)
pool.map(do_work, range(4))
if __name__ =="__main__":
main()
W&B Run 공유
W&B Run 오브젝트를 인수로 전달하여 프로세스 간에 W&B Runs를 공유합니다.
defdo_work(run):
run.log(dict(this=1))
defmain():
run = wandb.init()
p = mp.Process(target=do_work, kwargs=dict(run=run))
p.start()
p.join()
if __name__ =="__main__":
main()
로깅 순서를 보장할 수 없습니다. 동기화는 스크립트 작성자가 수행해야 합니다.
4 - Log media and objects
3D 포인트 클라우드 및 분자에서 HTML 및 히스토그램에 이르기까지 다양한 미디어를 로그
마지막 차원이 1이면 이미지가 회색조, 3이면 RGB, 4이면 RGBA라고 가정합니다. 배열에 float가 포함된 경우 0과 255 사이의 정수로 변환합니다. 이미지를 다르게 정규화하려면 mode를 수동으로 지정하거나 이 패널의 “PIL 이미지 로깅” 탭에 설명된 대로 PIL.Image를 제공하면 됩니다.
배열을 이미지로 변환하는 것을 완벽하게 제어하려면 PIL.Image를 직접 구성하여 제공합니다.
images = [PIL.Image.fromarray(image) for image in image_array]
wandb.log({"examples": [wandb.Image(image) for image in images]})
더욱 완벽하게 제어하려면 원하는 방식으로 이미지를 만들고 디스크에 저장한 다음 파일 경로를 제공합니다.
im = PIL.fromarray(...)
rgb_im = im.convert("RGB")
rgb_im.save("myimage.jpg")
wandb.log({"example": wandb.Image("myimage.jpg")})
이미지 오버레이
W&B UI를 통해 시멘틱 세그멘테이션 마스크를 기록하고 (불투명도 변경, 시간 경과에 따른 변경 사항 보기 등) 상호 작용합니다.
오버레이를 기록하려면 다음 키와 값이 있는 사전을 wandb.Image의 masks 키워드 인수에 제공해야 합니다.
이미지 마스크를 나타내는 두 개의 키 중 하나:
"mask_data": 각 픽셀에 대한 정수 클래스 레이블을 포함하는 2D NumPy 배열
"path": (문자열) 저장된 이미지 마스크 파일의 경로
"class_labels": (선택 사항) 이미지 마스크의 정수 클래스 레이블을 읽을 수 있는 클래스 이름에 매핑하는 사전
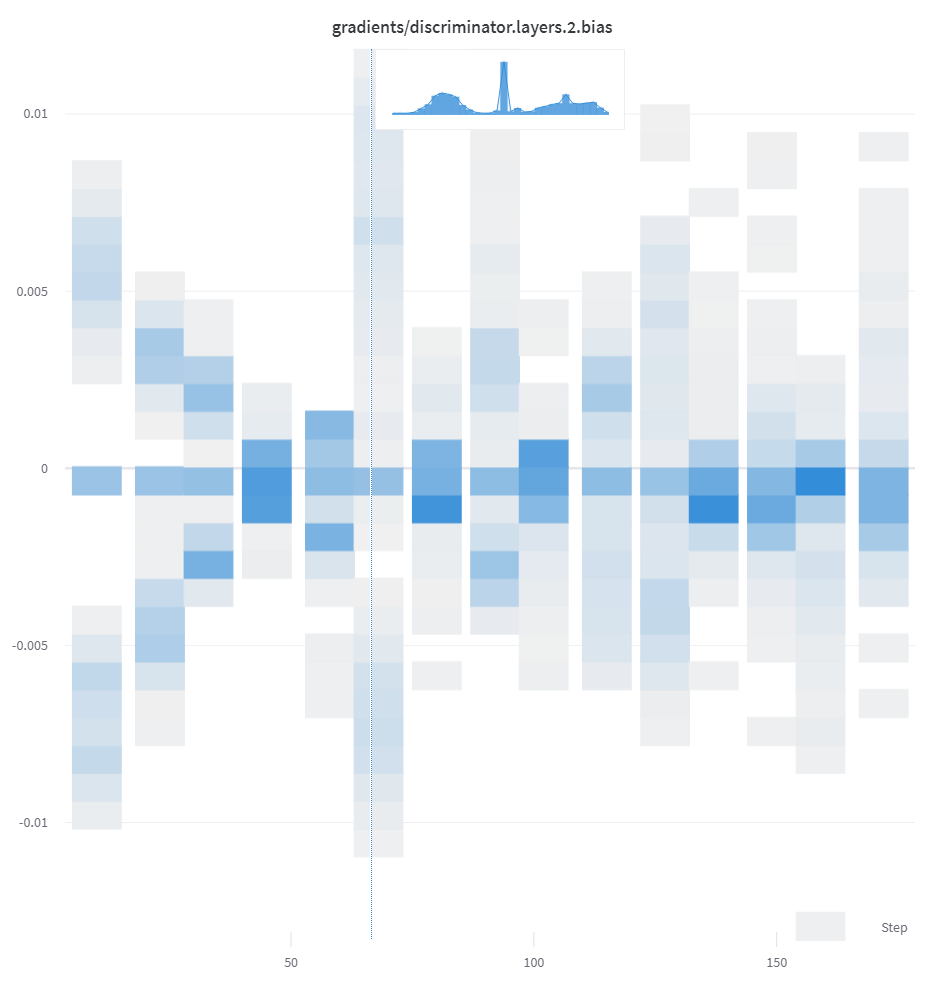
리스트, 배열 또는 텐서와 같은 숫자 시퀀스가 첫 번째 인수로 제공되면 np.histogram을 호출하여 히스토그램이 자동으로 구성됩니다. 모든 배열/텐서는 평면화됩니다. 선택적 num_bins 키워드 인수를 사용하여 기본값인 64개 구간을 재정의할 수 있습니다. 지원되는 최대 구간 수는 512개입니다.
UI에서 히스토그램은 x축에 트레이닝 스텝, y축에 메트릭 값, 색상으로 표현되는 개수로 플롯되어 트레이닝 전반에 걸쳐 기록된 히스토그램을 쉽게 비교할 수 있습니다. 일회성 히스토그램 로깅에 대한 자세한 내용은 이 패널의 “요약의 히스토그램” 탭을 참조하세요.
wandb.log({"gradients": wandb.Histogram(grads)})
더 많은 제어를 원하면 np.histogram을 호출하고 반환된 튜플을 np_histogram 키워드 인수에 전달합니다.
numpy 배열이 제공되면 차원은 시간, 채널, 너비, 높이 순서라고 가정합니다. 기본적으로 4fps gif 이미지를 만듭니다 (ffmpeg 및 moviepy python 라이브러리는 numpy 오브젝트를 전달할 때 필요합니다). 지원되는 형식은 "gif", "mp4", "webm" 및 "ogg"입니다. 문자열을 wandb.Video에 전달하면 파일을 업로드하기 전에 파일이 존재하고 지원되는 형식인지 확인합니다. BytesIO 오브젝트를 전달하면 지정된 형식을 확장자로 사용하여 임시 파일이 생성됩니다.
UI에 표시되도록 테이블에 텍스트를 기록하려면 wandb.Table을 사용합니다. 기본적으로 열 헤더는 ["Input", "Output", "Expected"]입니다. 최적의 UI 성능을 보장하기 위해 기본 최대 행 수는 10,000으로 설정됩니다. 그러나 사용자는 wandb.Table.MAX_ROWS = {DESIRED_MAX}를 사용하여 최대값을 명시적으로 재정의할 수 있습니다.
속성 업데이트 (메타데이터, 에일리어스 및 설명)와 같이 이러한 메서드로 생성된 모델 아티팩트와 상호 작용합니다.
W&B Artifacts 및 고급 버전 관리 유스 케이스에 대한 자세한 내용은 Artifacts 문서를 참조하세요.
모델을 run에 로깅
log_model을 사용하여 지정한 디렉토리 내에 콘텐츠가 포함된 모델 아티팩트를 로깅합니다. log_model 메서드는 결과 모델 아티팩트를 W&B run의 출력으로 표시합니다.
모델을 W&B run의 입력 또는 출력으로 표시하면 모델의 종속성과 모델의 연결을 추적할 수 있습니다. W&B App UI 내에서 모델의 계보를 확인하세요. 자세한 내용은 Artifacts 챕터의 아티팩트 그래프 탐색 및 트래버스 페이지를 참조하세요.
모델 파일이 저장된 경로를 path 파라미터에 제공하세요. 경로는 로컬 파일, 디렉토리 또는 s3://bucket/path와 같은 외부 버킷에 대한 참조 URI일 수 있습니다.
<>로 묶인 값은 사용자 고유의 값으로 바꾸세요.
import wandb
# W&B run 초기화run = wandb.init(project="<your-project>", entity="<your-entity>")
# 모델 로깅run.log_model(path="<path-to-model>", name="<name>")
선택적으로 name 파라미터에 모델 아티팩트 이름을 제공합니다. name이 지정되지 않은 경우 W&B는 run ID가 앞에 붙은 입력 경로의 기본 이름을 이름으로 사용합니다.
사용자 또는 W&B가 모델에 할당한 name을 추적하세요. use_model 메서드로 모델 경로를 검색하려면 모델 이름이 필요합니다.
가능한 파라미터에 대한 자세한 내용은 API 참조 가이드의 log_model을 참조하세요.
예시: 모델을 run에 로깅
import os
import wandb
from tensorflow import keras
from tensorflow.keras import layers
config = {"optimizer": "adam", "loss": "categorical_crossentropy"}
# W&B run 초기화run = wandb.init(entity="charlie", project="mnist-experiments", config=config)
# 하이퍼파라미터loss = run.config["loss"]
optimizer = run.config["optimizer"]
metrics = ["accuracy"]
num_classes =10input_shape = (28, 28, 1)
# 트레이닝 알고리즘model = keras.Sequential(
[
layers.Input(shape=input_shape),
layers.Conv2D(32, kernel_size=(3, 3), activation="relu"),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Conv2D(64, kernel_size=(3, 3), activation="relu"),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Flatten(),
layers.Dropout(0.5),
layers.Dense(num_classes, activation="softmax"),
]
)
# 트레이닝을 위한 모델 구성model.compile(loss=loss, optimizer=optimizer, metrics=metrics)
# 모델 저장model_filename ="model.h5"local_filepath ="./"full_path = os.path.join(local_filepath, model_filename)
model.save(filepath=full_path)
# 모델을 W&B run에 로깅run.log_model(path=full_path, name="MNIST")
run.finish()
사용자가 log_model을 호출하면 MNIST라는 모델 아티팩트가 생성되고 파일 model.h5가 모델 아티팩트에 추가되었습니다. 터미널 또는 노트북에 모델이 로깅된 run에 대한 정보를 찾을 수 있는 위치가 출력됩니다.
View run different-surf-5 at: https://wandb.ai/charlie/mnist-experiments/runs/wlby6fuw
Synced 5 W&B file(s), 0 media file(s), 1 artifact file(s) and0 other file(s)
Find logs at: ./wandb/run-20231206_103511-wlby6fuw/logs
로깅된 모델 다운로드 및 사용
use_model 함수를 사용하여 이전에 W&B run에 로깅된 모델 파일에 엑세스하고 다운로드합니다.
검색하려는 모델 파일이 저장된 모델 아티팩트의 이름을 제공합니다. 제공하는 이름은 기존의 로깅된 모델 아티팩트의 이름과 일치해야 합니다.
log_model로 파일을 원래 로깅할 때 name을 정의하지 않은 경우 할당된 기본 이름은 run ID가 앞에 붙은 입력 경로의 기본 이름입니다.
<>로 묶인 다른 값은 사용자 고유의 값으로 바꾸세요.
import wandb
# run 초기화run = wandb.init(project="<your-project>", entity="<your-entity>")
# 모델에 엑세스 및 다운로드합니다. 다운로드된 아티팩트의 경로를 반환합니다.downloaded_model_path = run.use_model(name="<your-model-name>")
use_model 함수는 다운로드된 모델 파일의 경로를 반환합니다. 나중에 이 모델을 연결하려면 이 경로를 추적하세요. 앞의 코드 조각에서 반환된 경로는 downloaded_model_path라는 변수에 저장됩니다.
예시: 로깅된 모델 다운로드 및 사용
예를 들어, 앞의 코드 조각에서 사용자는 use_model API를 호출했습니다. 그들은 가져오려는 모델 아티팩트의 이름을 지정하고 버전/에일리어스도 제공했습니다. 그런 다음 API에서 반환된 경로를 downloaded_model_path 변수에 저장했습니다.
import wandb
entity ="luka"project ="NLP_Experiments"alias ="latest"# 모델 버전에 대한 시맨틱 닉네임 또는 식별자model_artifact_name ="fine-tuned-model"# run 초기화run = wandb.init(project=project, entity=entity)
# 모델에 엑세스 및 다운로드합니다. 다운로드된 아티팩트의 경로를 반환합니다.downloaded_model_path = run.use_model(name =f"{model_artifact_name}:{alias}")
가능한 파라미터 및 반환 유형에 대한 자세한 내용은 API 참조 가이드의 use_model을 참조하세요.
모델을 로깅하고 W&B Model Registry에 연결
link_model 메서드는 곧 사용 중단될 레거시 W&B Model Registry와만 호환됩니다. 새로운 버전의 모델 레지스트리에 모델 아티팩트를 연결하는 방법을 알아보려면 레지스트리 문서를 방문하세요.
link_model 메서드를 사용하여 모델 파일을 W&B run에 로깅하고 W&B Model Registry에 연결합니다. 등록된 모델이 없으면 W&B는 registered_model_name 파라미터에 제공하는 이름으로 새 모델을 만듭니다.
모델을 연결하는 것은 팀의 다른 구성원이 보고 사용할 수 있는 모델의 중앙 집중식 팀 리포지토리에 모델을 ‘북마크’하거나 ‘게시’하는 것과 유사합니다.
모델을 연결하면 해당 모델이 Registry에서 복제되거나 프로젝트에서 레지스트리로 이동되지 않습니다. 연결된 모델은 프로젝트의 원래 모델에 대한 포인터입니다.
Registry를 사용하여 작업별로 최상의 모델을 구성하고, 모델 수명 주기를 관리하고, ML 수명 주기 전반에 걸쳐 간편한 추적 및 감사를 용이하게 하고, 웹 훅 또는 작업을 통해 다운스트림 작업을 자동화합니다.
Registered Model은 Model Registry의 연결된 모델 버전의 컬렉션 또는 폴더입니다. 등록된 모델은 일반적으로 단일 모델링 유스 케이스 또는 작업에 대한 후보 모델을 나타냅니다.
앞의 코드 조각은 link_model API로 모델을 연결하는 방법을 보여줍니다. <>로 묶인 다른 값은 사용자 고유의 값으로 바꾸세요.
import wandb
run = wandb.init(entity="<your-entity>", project="<your-project>")
run.link_model(path="<path-to-model>", registered_model_name="<registered-model-name>")
run.finish()
선택적 파라미터에 대한 자세한 내용은 API 참조 가이드의 link_model을 참조하세요.
registered-model-name이 Model Registry 내에 이미 존재하는 등록된 모델의 이름과 일치하면 모델이 해당 등록된 모델에 연결됩니다. 이러한 등록된 모델이 없으면 새 모델이 생성되고 모델이 첫 번째로 연결됩니다.
예를 들어, Model Registry에 “Fine-Tuned-Review-Autocompletion"이라는 기존 등록된 모델이 있다고 가정합니다(예제는 여기 참조). 그리고 몇 개의 모델 버전이 이미 v0, v1, v2로 연결되어 있다고 가정합니다. registered-model-name="Fine-Tuned-Review-Autocompletion"으로 link_model을 호출하면 새 모델이 이 기존 등록된 모델에 v3으로 연결됩니다. 이 이름으로 등록된 모델이 없으면 새 모델이 생성되고 새 모델이 v0으로 연결됩니다.
예시: 모델을 로깅하고 W&B Model Registry에 연결
예를 들어, 앞의 코드 조각은 모델 파일을 로깅하고 모델을 등록된 모델 이름 "Fine-Tuned-Review-Autocompletion"에 연결합니다.
이를 위해 사용자는 link_model API를 호출합니다. API를 호출할 때 모델 콘텐츠를 가리키는 로컬 파일 경로(path)를 제공하고 연결할 등록된 모델의 이름(registered_model_name)을 제공합니다.
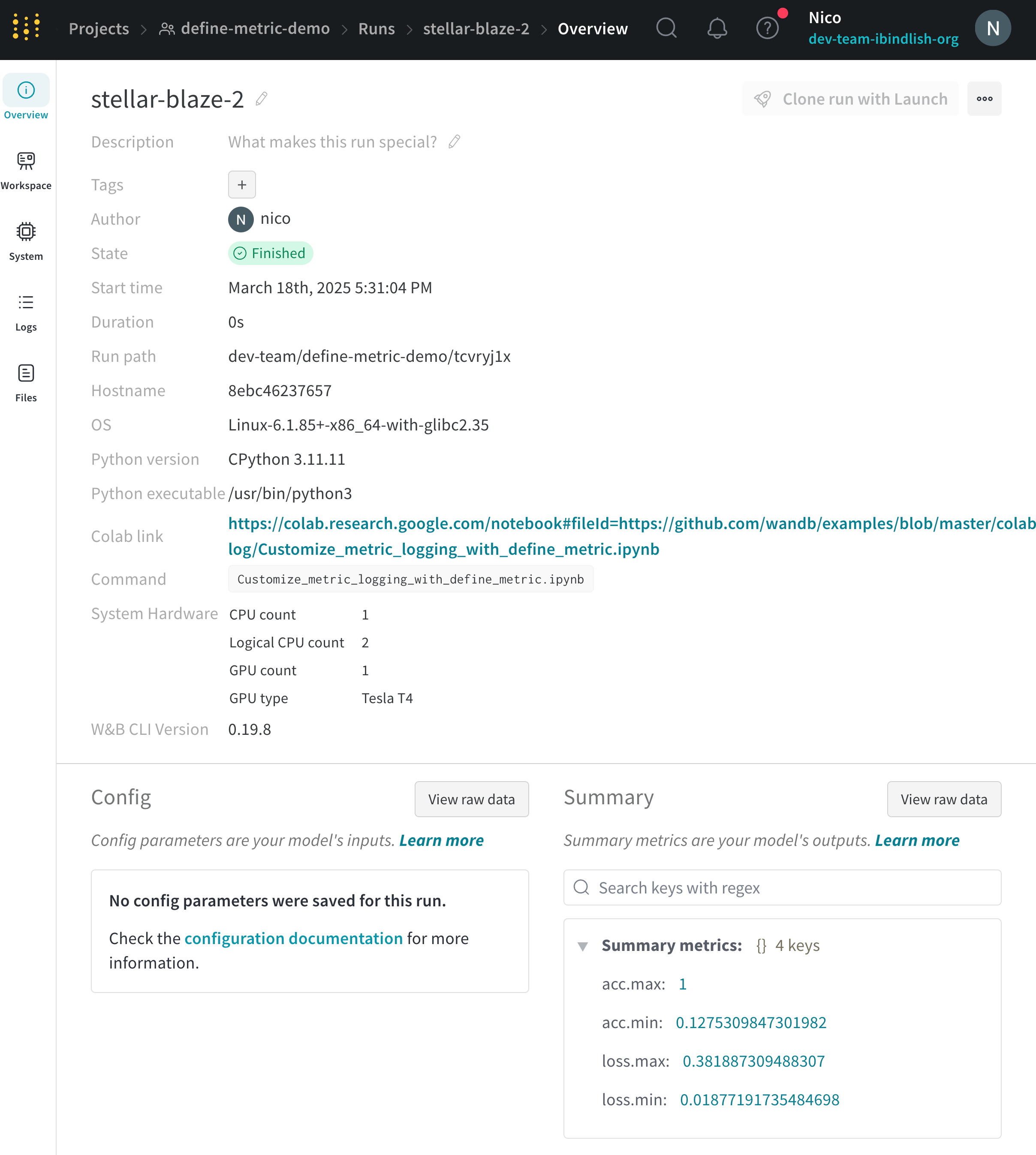
트레이닝 과정에서 시간이 지남에 따라 변하는 값 외에도, 모델 또는 전처리 단계를 요약하는 단일 값을 추적하는 것이 중요한 경우가 많습니다. W&B Run의 summary 사전에 이 정보를 기록하세요. Run의 summary 사전은 numpy 배열, PyTorch 텐서 또는 TensorFlow 텐서를 처리할 수 있습니다. 값이 이러한 유형 중 하나인 경우 전체 텐서를 바이너리 파일에 유지하고 요약 오브젝트에 최소값, 평균, 분산, 백분위수 등과 같은 높은 수준의 메트릭을 저장합니다.
wandb.log로 기록된 마지막 값은 W&B Run에서 자동으로 summary 사전으로 설정됩니다. summary 메트릭 사전이 수정되면 이전 값은 손실됩니다.
다음 코드 조각은 사용자 정의 summary 메트릭을 W&B에 제공하는 방법을 보여줍니다.
트레이닝이 완료된 후 기존 W&B Run의 summary 속성을 업데이트할 수 있습니다. W&B Public API를 사용하여 summary 속성을 업데이트합니다.
api = wandb.Api()
run = api.run("username/project/run_id")
run.summary["tensor"] = np.random.random(1000)
run.summary.update()
summary 메트릭 사용자 정의
사용자 정의 summary 메트릭은 wandb.summary에서 트레이닝의 최적 단계에서 모델 성능을 캡처하는 데 유용합니다. 예를 들어 최종 값 대신 최대 정확도 또는 최소 손실 값을 캡처할 수 있습니다.
기본적으로 summary는 히스토리의 최종 값을 사용합니다. summary 메트릭을 사용자 정의하려면 define_metric에서 summary 인수를 전달합니다. 다음 값을 사용할 수 있습니다.
"min"
"max"
"mean"
"best"
"last"
"none"
선택적 objective 인수를 "minimize" 또는 "maximize"로 설정한 경우에만 "best"를 사용할 수 있습니다.
다음 예제는 손실 및 정확도의 최소값과 최대값을 summary에 추가합니다.
import wandb
import random
random.seed(1)
wandb.init()
# 손실에 대한 최소값 및 최대값 summarywandb.define_metric("loss", summary="min")
wandb.define_metric("loss", summary="max")
# 정확도에 대한 최소값 및 최대값 summarywandb.define_metric("acc", summary="min")
wandb.define_metric("acc", summary="max")
for i in range(10):
log_dict = {
"loss": random.uniform(0, 1/ (i +1)),
"acc": random.uniform(1/ (i +1), 1),
}
wandb.log(log_dict)
summary 메트릭 보기
run의 Overview 페이지 또는 프로젝트의 runs 테이블에서 summary 값을 봅니다.
W&B 앱으로 이동합니다.
Workspace 탭을 선택합니다.
runs 목록에서 summary 값이 기록된 run의 이름을 클릭합니다.
Overview 탭을 선택합니다.
Summary 섹션에서 summary 값을 봅니다.
W&B 앱으로 이동합니다.
Runs 탭을 선택합니다.
runs 테이블 내에서 summary 값의 이름을 기준으로 열 내에서 summary 값을 볼 수 있습니다.
W&B Public API를 사용하여 run의 summary 값을 가져올 수 있습니다.
다음 코드 예제는 W&B Public API 및 pandas를 사용하여 특정 run에 기록된 summary 값을 검색하는 한 가지 방법을 보여줍니다.
import wandb
import pandas
entity ="<your-entity>"project ="<your-project>"run_name ="<your-run-name>"# summary 값이 있는 run의 이름all_runs = []
for run in api.runs(f"{entity}/{project_name}"):
print("Fetching details for run: ", run.id, run.name)
run_data = {
"id": run.id,
"name": run.name,
"url": run.url,
"state": run.state,
"tags": run.tags,
"config": run.config,
"created_at": run.created_at,
"system_metrics": run.system_metrics,
"summary": run.summary,
"project": run.project,
"entity": run.entity,
"user": run.user,
"path": run.path,
"notes": run.notes,
"read_only": run.read_only,
"history_keys": run.history_keys,
"metadata": run.metadata,
}
all_runs.append(run_data)
# DataFrame으로 변환df = pd.DataFrame(all_runs)
# 열 이름(run)을 기준으로 행을 가져오고 사전으로 변환df[df['name']==run_name].summary.reset_index(drop=True).to_dict()
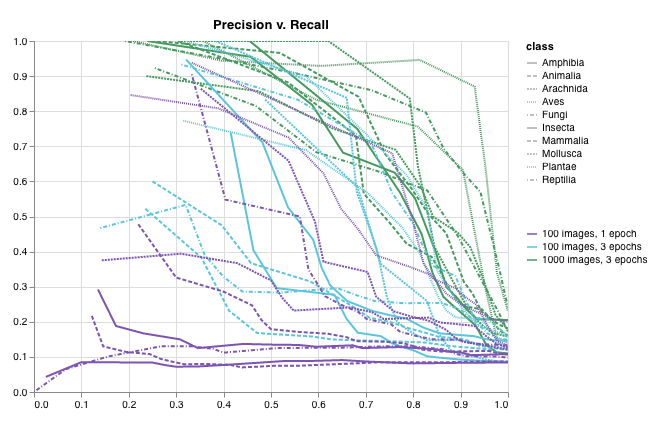
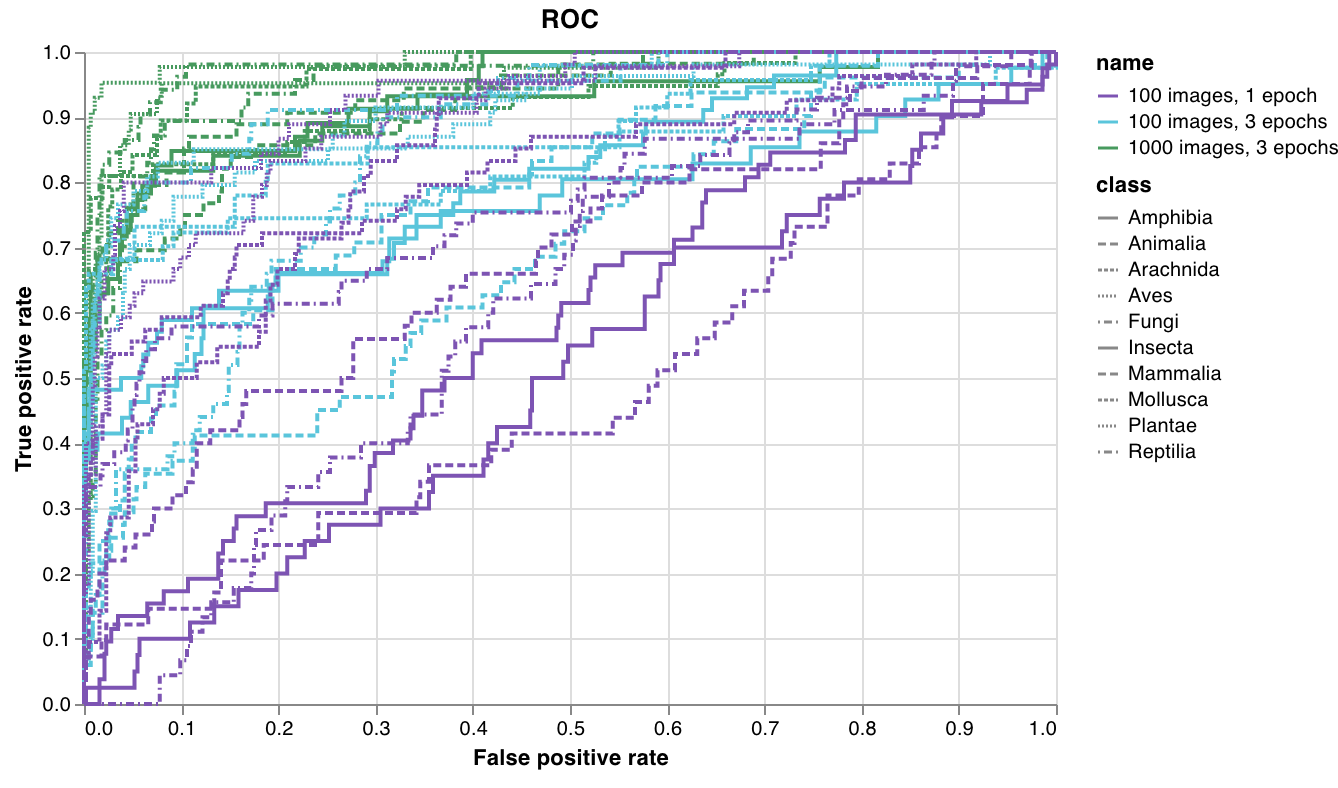
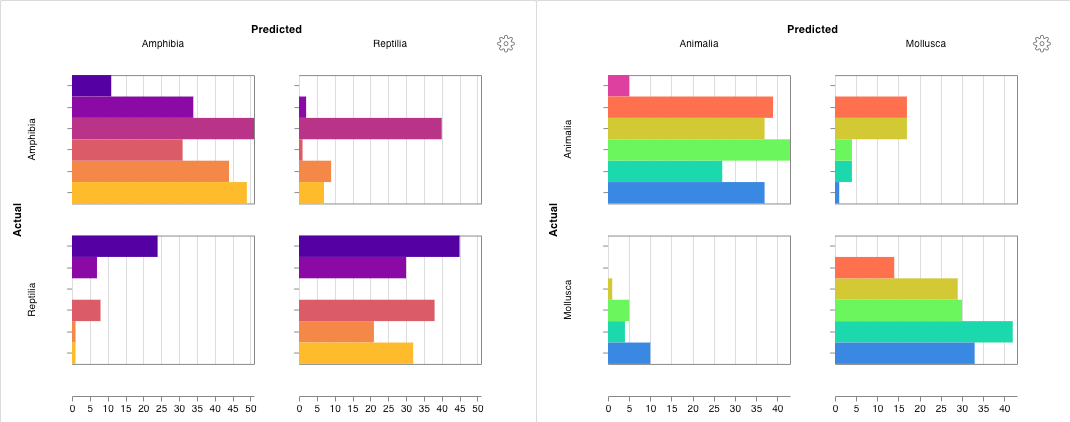
테이블을 정의하려면 데이터의 각 행에 대해 보려는 열을 지정합니다. 각 행은 트레이닝 데이터셋의 단일 항목, 트레이닝 중의 특정 단계 또는 에포크, 테스트 항목에 대한 모델의 예측값, 모델에서 생성된 오브젝트 등이 될 수 있습니다. 각 열에는 숫자, 텍스트, 부울, 이미지, 비디오, 오디오 등 고정된 유형이 있습니다. 유형을 미리 지정할 필요는 없습니다. 각 열에 이름을 지정하고 해당 유형의 데이터만 해당 열 인덱스로 전달해야 합니다. 더 자세한 예는 이 리포트를 참조하십시오.
다음 두 가지 방법 중 하나로 wandb.Table 생성자를 사용합니다.
행 목록: 이름이 지정된 열과 데이터 행을 기록합니다. 예를 들어 다음 코드 조각은 두 개의 행과 세 개의 열이 있는 테이블을 생성합니다.
Pandas DataFrame:wandb.Table(dataframe=my_df)를 사용하여 DataFrame을 기록합니다. 열 이름은 DataFrame에서 추출됩니다.
기존 배열 또는 데이터 프레임에서
# 모델이 다음 필드를 사용할 수 있는 네 개의 이미지에 대한 예측을 반환했다고 가정합니다.# - 이미지 ID# - wandb.Image()로 래핑된 이미지 픽셀# - 모델의 예측 레이블# - 그라운드 트루스 레이블my_data = [
[0, wandb.Image("img_0.jpg"), 0, 0],
[1, wandb.Image("img_1.jpg"), 8, 0],
[2, wandb.Image("img_2.jpg"), 7, 1],
[3, wandb.Image("img_3.jpg"), 1, 1],
]
# 해당 열이 있는 wandb.Table() 생성columns = ["id", "image", "prediction", "truth"]
test_table = wandb.Table(data=my_data, columns=columns)
데이터 추가
테이블은 변경 가능합니다. 스크립트가 실행될 때 테이블에 최대 200,000개의 행까지 더 많은 데이터를 추가할 수 있습니다. 테이블에 데이터를 추가하는 방법에는 두 가지가 있습니다.
행 추가: table.add_data("3a", "3b", "3c"). 새 행은 목록으로 표시되지 않습니다. 행이 목록 형식인 경우 별표 표기법 *을 사용하여 목록을 위치 인수로 확장합니다. table.add_data(*my_row_list). 행에는 테이블의 열 수와 동일한 수의 항목이 포함되어야 합니다.
열 추가: table.add_column(name="col_name", data=col_data). col_data의 길이는 테이블의 현재 행 수와 같아야 합니다. 여기서 col_data는 목록 데이터 또는 NumPy NDArray일 수 있습니다.
점진적으로 데이터 추가
이 코드 샘플은 W&B 테이블을 점진적으로 생성하고 채우는 방법을 보여줍니다. 가능한 모든 레이블에 대한 신뢰도 점수를 포함하여 미리 정의된 열로 테이블을 정의하고 추론 중에 행별로 데이터를 추가합니다. run을 재개할 때 테이블에 점진적으로 데이터를 추가할 수도 있습니다.
# 각 레이블에 대한 신뢰도 점수를 포함하여 테이블의 열을 정의합니다.columns = ["id", "image", "guess", "truth"]
for digit in range(10): # 각 숫자(0-9)에 대한 신뢰도 점수 열을 추가합니다. columns.append(f"score_{digit}")
# 정의된 열로 테이블을 초기화합니다.test_table = wandb.Table(columns=columns)
# 테스트 데이터셋을 반복하고 데이터를 행별로 테이블에 추가합니다.# 각 행에는 이미지 ID, 이미지, 예측 레이블, 트루 레이블 및 신뢰도 점수가 포함됩니다.for img_id, img in enumerate(mnist_test_data):
true_label = mnist_test_data_labels[img_id] # 그라운드 트루스 레이블 guess_label = my_model.predict(img) # 예측 레이블 test_table.add_data(
img_id, wandb.Image(img), guess_label, true_label
) # 테이블에 행 데이터를 추가합니다.
재개된 run에 데이터 추가
아티팩트에서 기존 테이블을 로드하고, 데이터의 마지막 행을 검색하고, 업데이트된 메트릭을 추가하여 재개된 run에서 W&B 테이블을 점진적으로 업데이트할 수 있습니다. 그런 다음 호환성을 위해 테이블을 다시 초기화하고 업데이트된 버전을 W&B에 다시 기록합니다.
# 아티팩트에서 기존 테이블을 로드합니다.best_checkpt_table = wandb.use_artifact(table_tag).get(table_name)
# 재개를 위해 테이블에서 데이터의 마지막 행을 가져옵니다.best_iter, best_metric_max, best_metric_min = best_checkpt_table.data[-1]
# 필요에 따라 최상의 메트릭을 업데이트합니다.# 업데이트된 데이터를 테이블에 추가합니다.best_checkpt_table.add_data(best_iter, best_metric_max, best_metric_min)
# 호환성을 보장하기 위해 업데이트된 데이터로 테이블을 다시 초기화합니다.best_checkpt_table = wandb.Table(
columns=["col1", "col2", "col3"], data=best_checkpt_table.data
)
# 업데이트된 테이블을 Weights & Biases에 기록합니다.wandb.log({table_name: best_checkpt_table})
데이터 검색
데이터가 테이블에 있으면 열 또는 행별로 엑세스합니다.
행 반복기: 사용자는 for ndx, row in table.iterrows(): ...와 같은 테이블의 행 반복기를 사용하여 데이터의 행을 효율적으로 반복할 수 있습니다.
열 가져오기: 사용자는 table.get_column("col_name")을 사용하여 데이터 열을 검색할 수 있습니다. 편의를 위해 사용자는 convert_to="numpy"를 전달하여 열을 기본 요소의 NumPy NDArray로 변환할 수 있습니다. 이는 열에 기본 데이터에 직접 엑세스할 수 있도록 wandb.Image와 같은 미디어 유형이 포함된 경우에 유용합니다.
테이블 저장
예를 들어 모델 예측 테이블과 같이 스크립트에서 데이터 테이블을 생성한 후 결과를 라이브로 시각화하기 위해 W&B에 저장합니다.
테이블이 동일한 키에 기록될 때마다 테이블의 새 버전이 생성되어 백엔드에 저장됩니다. 즉, 모델 예측이 시간이 지남에 따라 어떻게 향상되는지 확인하기 위해 여러 트레이닝 단계에서 동일한 테이블을 기록하거나 동일한 키에 기록되는 한 다른 run에서 테이블을 비교할 수 있습니다. 최대 200,000개의 행을 기록할 수 있습니다.
200,000개 이상의 행을 기록하려면 다음을 사용하여 제한을 재정의할 수 있습니다.
wandb.Table.MAX_ARTIFACT_ROWS = X
그러나 이렇게 하면 UI에서 쿼리 속도 저하와 같은 성능 문제가 발생할 수 있습니다.
프로그래밍 방식으로 테이블 엑세스
백엔드에서 테이블은 Artifacts로 유지됩니다. 특정 버전에 엑세스하려면 아티팩트 API를 사용하여 엑세스할 수 있습니다.
with wandb.init() as run:
my_table = run.use_artifact("run-<run-id>-<table-name>:<tag>").get("<table-name>")
Artifacts에 대한 자세한 내용은 개발자 가이드의 Artifacts 챕터를 참조하십시오.
테이블 시각화
이러한 방식으로 기록된 테이블은 Run 페이지와 Project 페이지 모두의 Workspace에 표시됩니다. 자세한 내용은 테이블 시각화 및 분석을 참조하십시오.
아티팩트 테이블
artifact.add()를 사용하여 워크스페이스 대신 run의 Artifacts 섹션에 테이블을 기록합니다. 이는 한 번 기록한 다음 향후 run에 참조할 데이터셋이 있는 경우에 유용할 수 있습니다.
run = wandb.init(project="my_project")
# 각 의미 있는 단계에 대한 wandb Artifact 생성test_predictions = wandb.Artifact("mnist_test_preds", type="predictions")
# [위와 같이 예측 데이터 빌드]test_table = wandb.Table(data=data, columns=columns)
test_predictions.add(test_table, "my_test_key")
run.log_artifact(test_predictions)
이미지 데이터와 함께 artifact.add()의 자세한 예는 이 Colab을 참조하고, Artifacts 및 Tables를 사용하여 테이블 형식 데이터의 버전 제어 및 중복 제거하는 방법의 예는 이 리포트를 참조하십시오.
아티팩트 테이블 결합
wandb.JoinedTable(table_1, table_2, join_key)를 사용하여 로컬에서 구성한 테이블 또는 다른 아티팩트에서 검색한 테이블을 결합할 수 있습니다.
인수
설명
table_1
(str, wandb.Table, ArtifactEntry) 아티팩트의 wandb.Table 경로, 테이블 오브젝트 또는 ArtifactEntry
table_2
(str, wandb.Table, ArtifactEntry) 아티팩트의 wandb.Table 경로, 테이블 오브젝트 또는 ArtifactEntry
join_key
(str, [str, str]) 결합을 수행할 키
아티팩트 컨텍스트에서 이전에 기록한 두 개의 테이블을 결합하려면 아티팩트에서 가져와 결과를 새 테이블로 결합합니다.
예를 들어 'original_songs'라는 원본 노래의 테이블 하나와 동일한 노래의 합성 버전의 또 다른 테이블인 'synth_songs'를 읽는 방법을 보여줍니다. 다음 코드 예제는 "song_id"에서 두 테이블을 결합하고 결과 테이블을 새 W&B 테이블로 업로드합니다.
# 테이블을 Artifact에 추가하여 행# 제한을 200000으로 늘리고 재사용을 용이하게 합니다.iris_table_artifact = wandb.Artifact("iris_artifact", type="dataset")
iris_table_artifact.add(iris_table, "iris_table")
# 원시 CSV 파일을 Artifact 내에 기록하여 데이터를 보존합니다.iris_table_artifact.add_file("iris.csv")
마지막으로 wandb.init으로 새로운 W&B Run을 시작하여 W&B에 추적하고 기록합니다.
# 데이터를 기록하기 위해 W&B Run 시작run = wandb.init(project="tables-walkthrough")
# Run으로 시각화하기 위해 테이블을 기록합니다...run.log({"iris": iris_table})
# ...사용 가능한 행 제한을 늘리기 위해 Artifact로 기록합니다!run.log_artifact(iris_table_artifact)
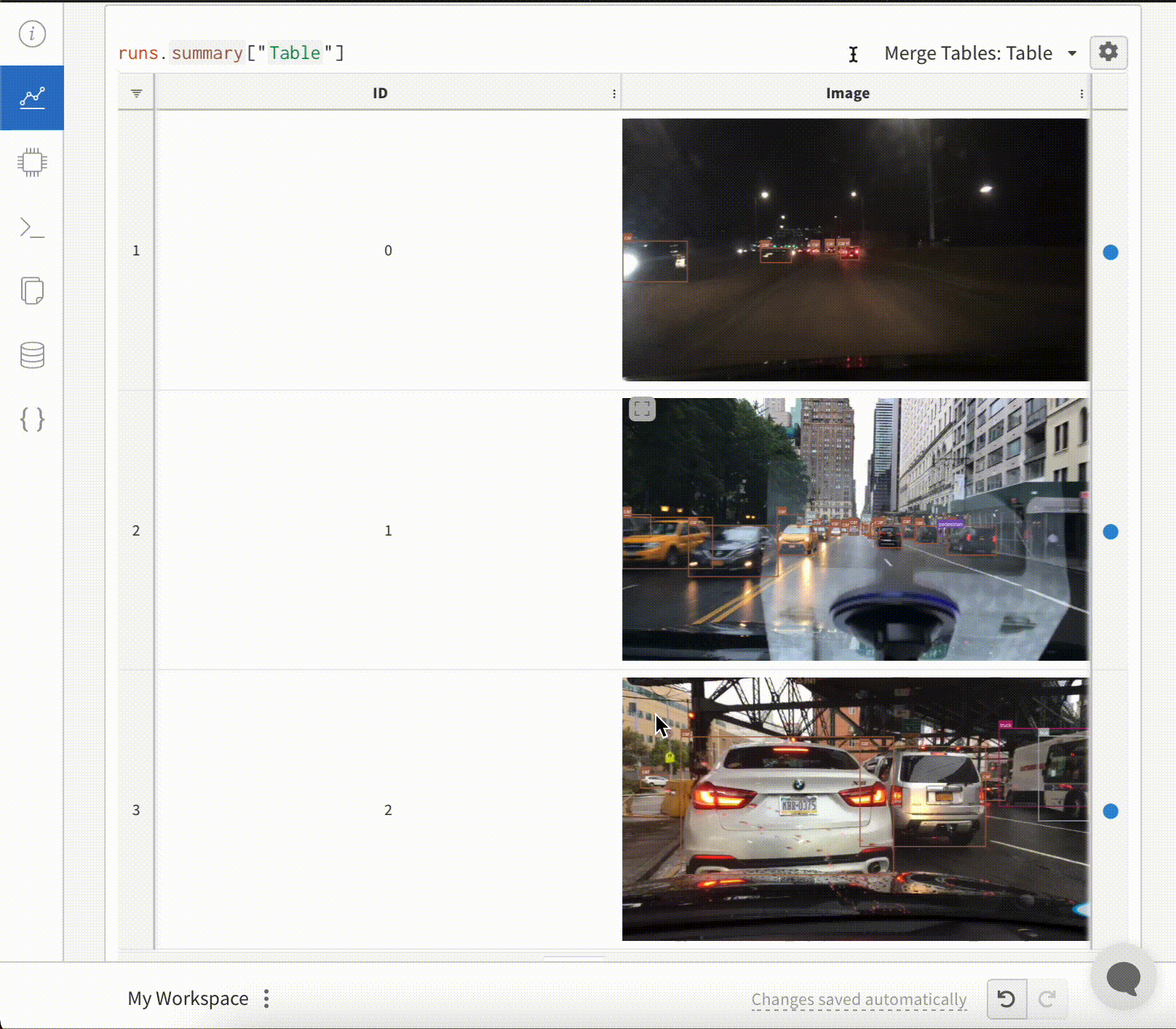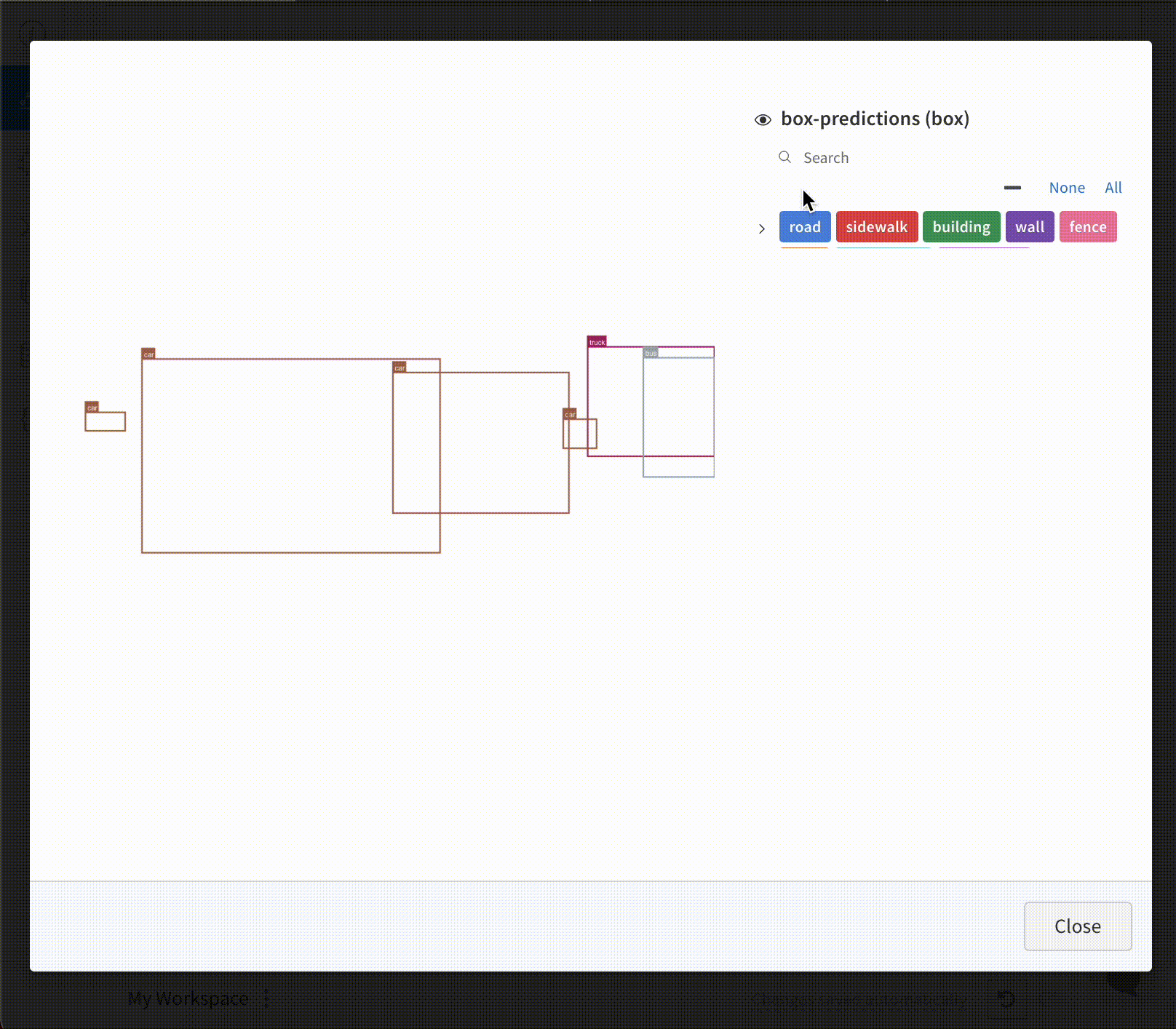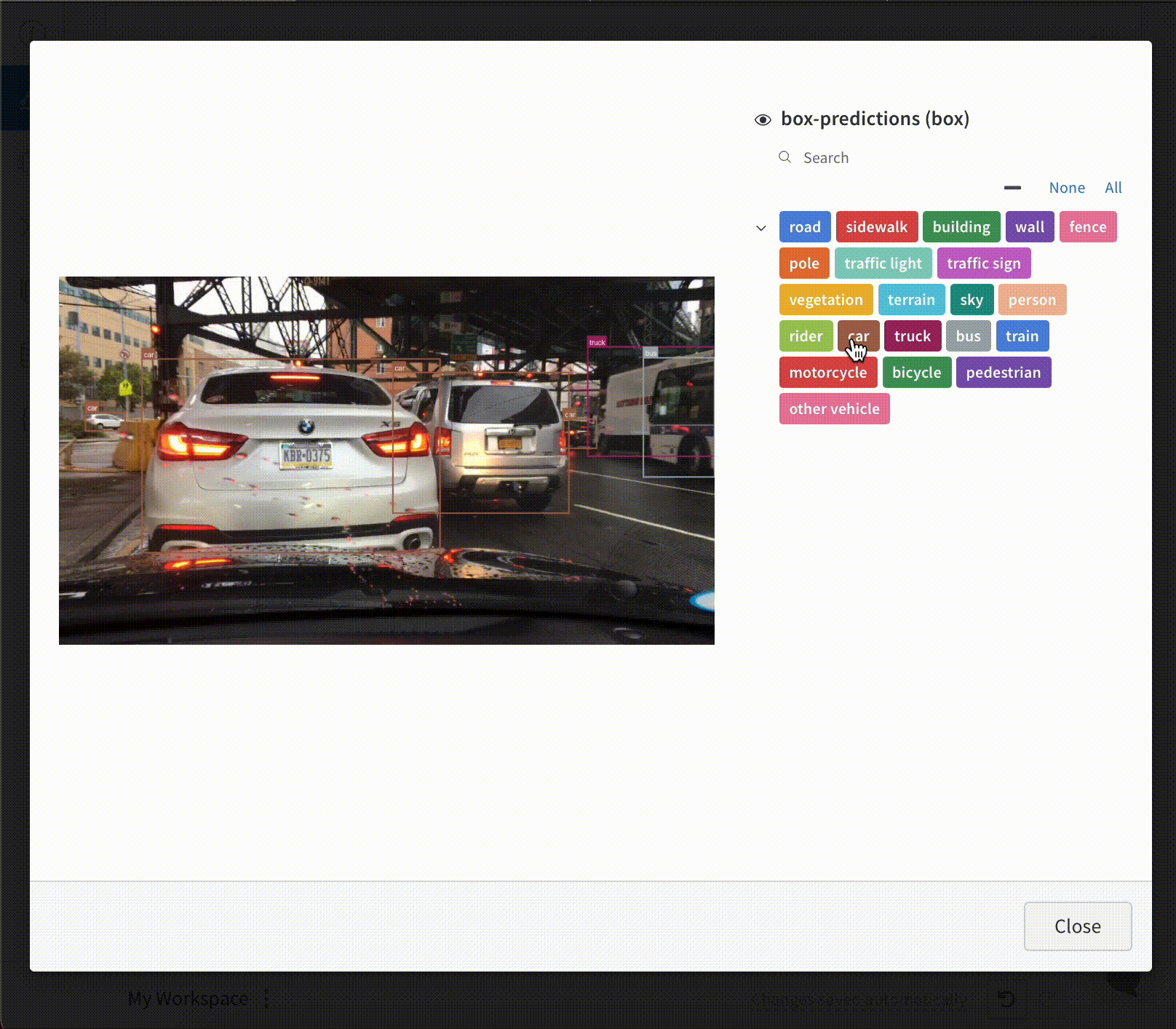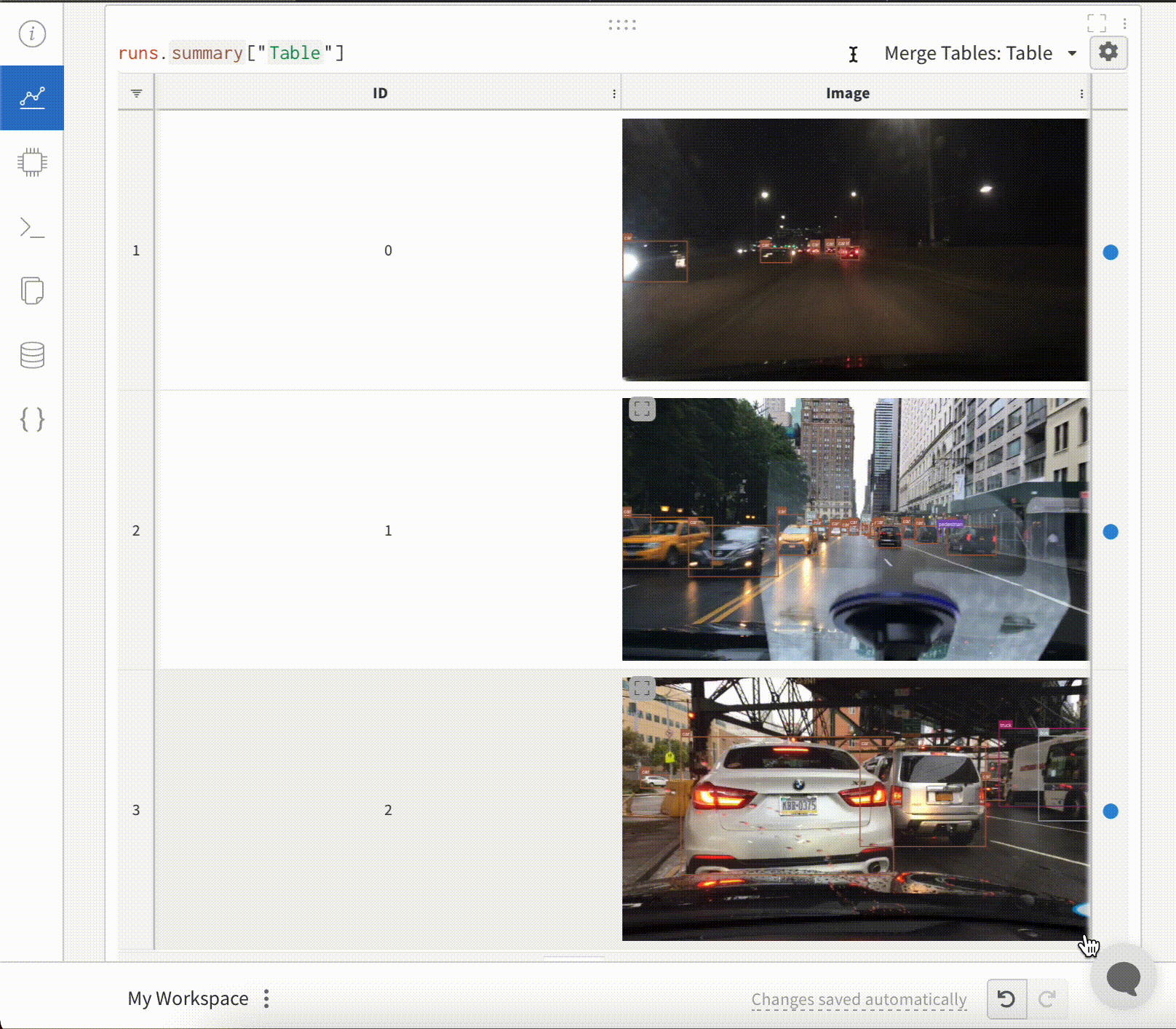
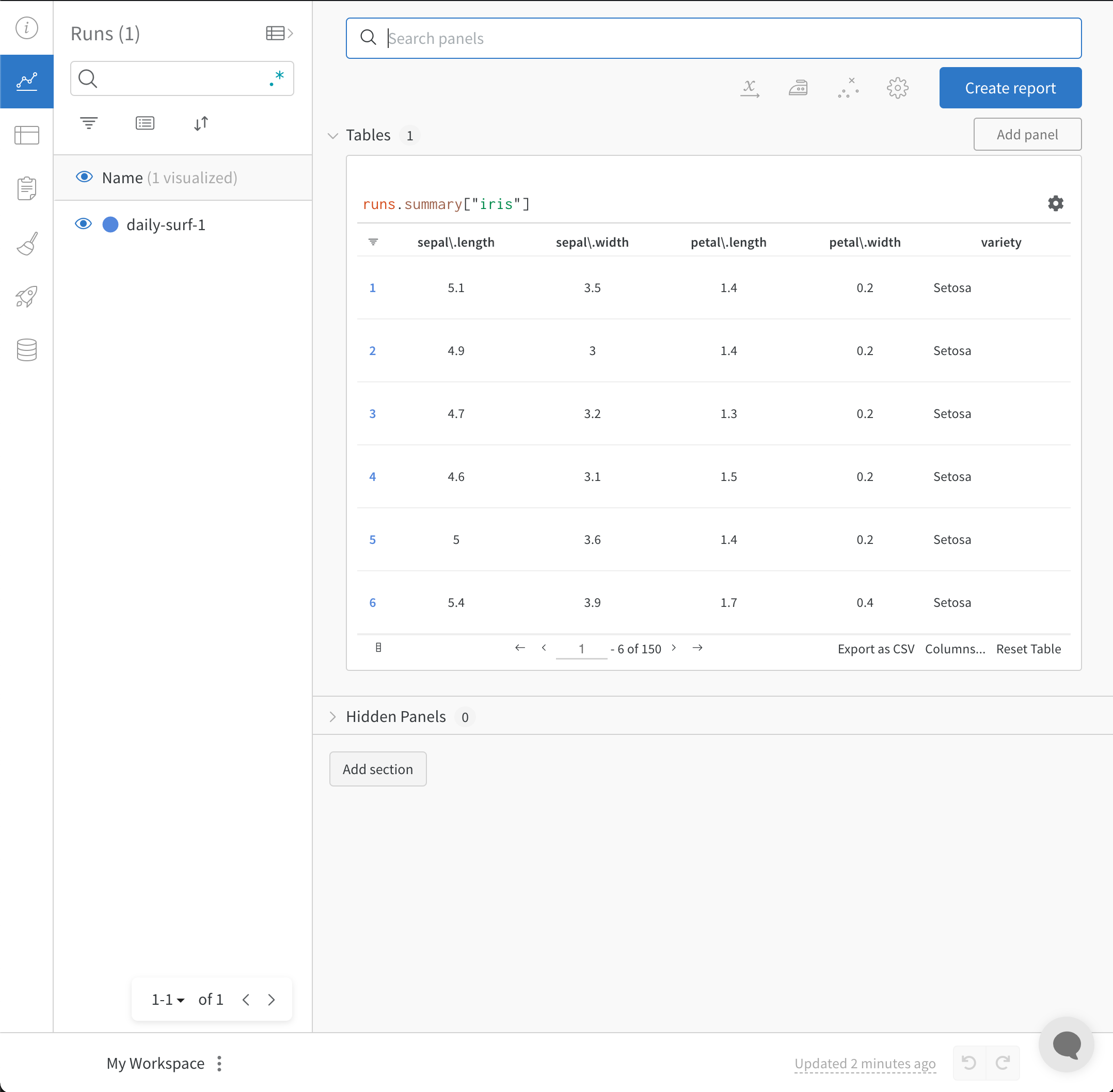
wandb.init() API는 데이터를 Run에 기록하기 위해 새로운 백그라운드 프로세스를 생성하고, wandb.ai에 데이터를 동기화합니다(기본적으로). W&B Workspace 대시보드에서 라이브 시각화를 확인하세요. 다음 이미지는 코드 조각 데모의 출력을 보여줍니다.
앞선 코드 조각이 포함된 전체 스크립트는 아래에서 찾을 수 있습니다.
import wandb
import pandas as pd
# CSV를 새 DataFrame으로 읽기new_iris_dataframe = pd.read_csv("iris.csv")
# DataFrame을 W&B Table로 변환iris_table = wandb.Table(dataframe=new_iris_dataframe)
# 테이블을 Artifact에 추가하여 행# 제한을 200000으로 늘리고 재사용을 용이하게 합니다.iris_table_artifact = wandb.Artifact("iris_artifact", type="dataset")
iris_table_artifact.add(iris_table, "iris_table")
# 원시 CSV 파일을 Artifact 내에 기록하여 데이터를 보존합니다.iris_table_artifact.add_file("iris.csv")
# 데이터를 기록하기 위해 W&B Run 시작run = wandb.init(project="tables-walkthrough")
# Run으로 시각화하기 위해 테이블을 기록합니다...run.log({"iris": iris_table})
# ...사용 가능한 행 제한을 늘리기 위해 Artifact로 기록합니다!run.log_artifact(iris_table_artifact)
# Run 완료 (노트북에서 유용)run.finish()
Experiments의 CSV 가져오기 및 기록
경우에 따라 Experiments 세부 정보가 CSV 파일에 있을 수 있습니다. 이러한 CSV 파일에서 흔히 볼 수 있는 세부 정보는 다음과 같습니다.