Tables
데이터셋을 반복하고 모델 예측값을 이해합니다
W&B Tables를 사용하여 표 형식 데이터를 시각화하고 쿼리합니다. 예를 들면 다음과 같습니다.
- 동일한 테스트 세트에서 다양한 모델의 성능을 비교합니다.
- 데이터에서 패턴을 식별합니다.
- 샘플 모델 예측값을 시각적으로 살펴봅니다.
- 일반적으로 잘못 분류된 예제를 찾기 위해 쿼리합니다.
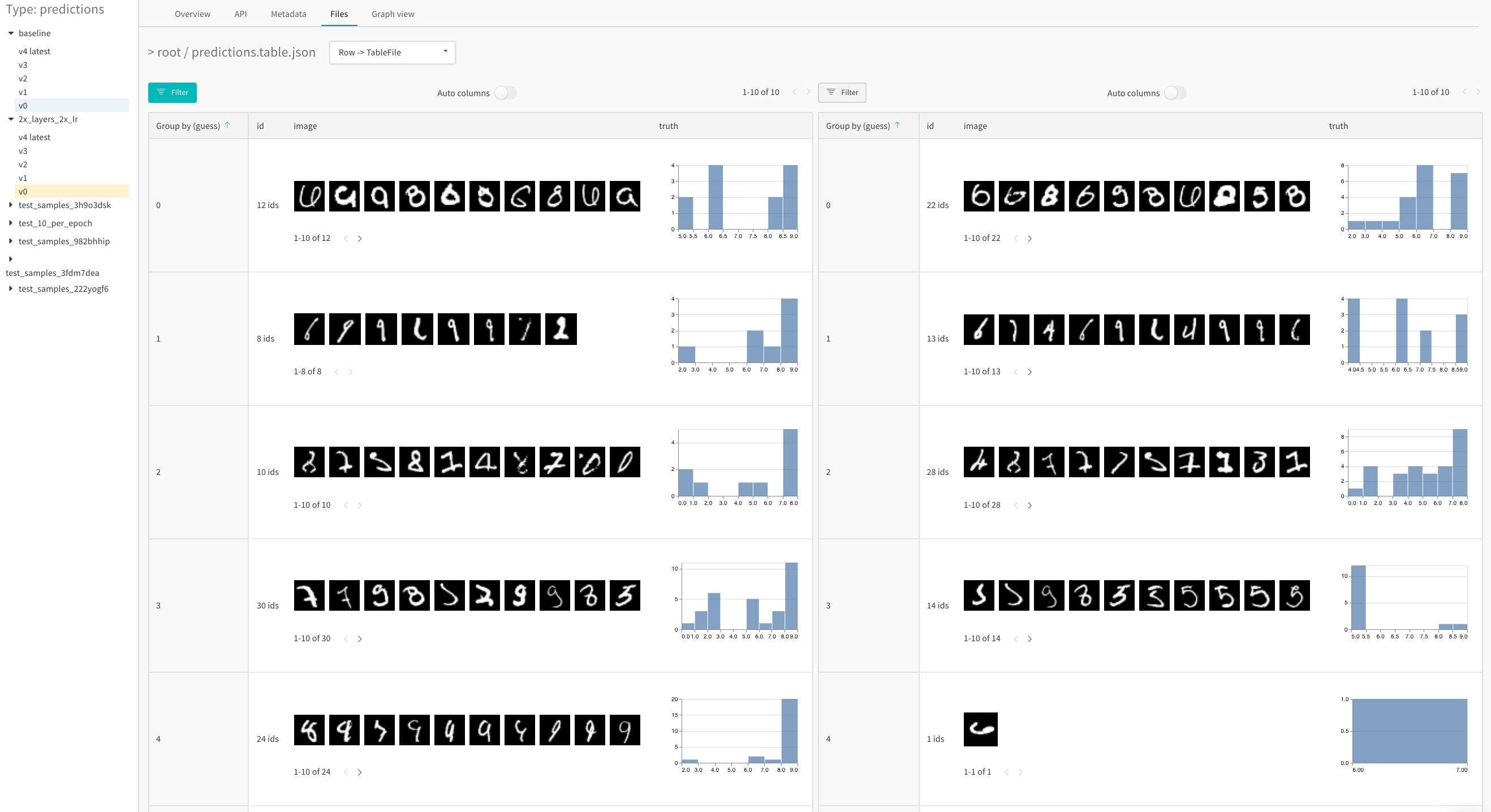
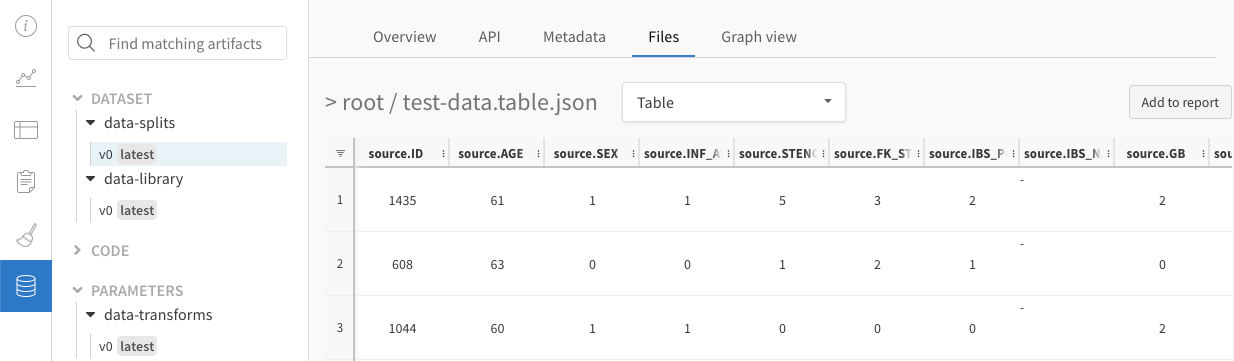
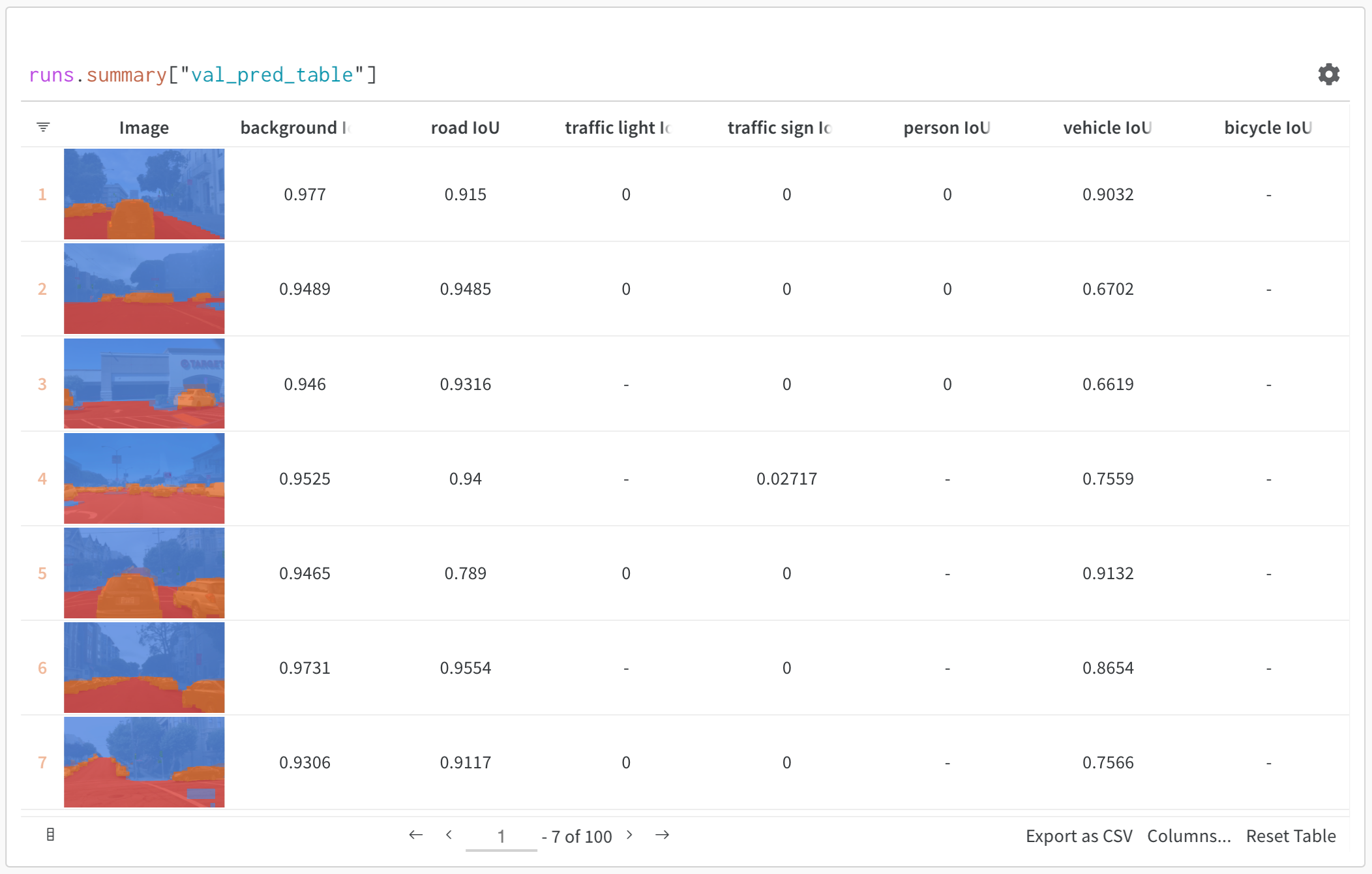 위 이미지는 시멘틱 세분화 및 사용자 정의 메트릭이 있는 테이블을 보여줍니다. W&B ML Course의 샘플 프로젝트에서 이 테이블을 볼 수 있습니다.
위 이미지는 시멘틱 세분화 및 사용자 정의 메트릭이 있는 테이블을 보여줍니다. W&B ML Course의 샘플 프로젝트에서 이 테이블을 볼 수 있습니다.
작동 방식
Table은 각 열에 단일 유형의 데이터가 있는 2차원 데이터 그리드입니다. Tables는 기본 및 숫자 유형은 물론 중첩 목록, 딕셔너리 및 다양한 미디어 유형을 지원합니다.
Table 기록
몇 줄의 코드로 table을 기록합니다.
import wandb
run = wandb.init(project="table-test")
my_table = wandb.Table(columns=["a", "b"], data=[["a1", "b1"], ["a2", "b2"]])
run.log({"Table Name": my_table})
시작 방법
1 - Tutorial: Log tables, visualize and query data
W&B Tables를 사용하는 방법을 이 5분 퀵스타트 에서 알아보세요.
다음 퀵스타트는 데이터 테이블을 기록하고, 데이터를 시각화하고, 데이터를 쿼리하는 방법을 보여줍니다.
아래 버튼을 선택하여 MNIST 데이터에 대한 PyTorch 퀵스타트 예제 프로젝트를 사용해 보세요.
1. 테이블 기록
W&B로 테이블을 기록합니다. 새 테이블을 만들거나 Pandas Dataframe을 전달할 수 있습니다.
새로운 Table을 생성하고 기록하려면 다음을 사용합니다.
예시:
import wandb
run = wandb.init(project="table-test")
# 새로운 테이블을 생성하고 기록합니다.
my_table = wandb.Table(columns=["a", "b"], data=[["a1", "b1"], ["a2", "b2"]])
run.log({"Table Name": my_table})
Pandas Dataframe을 wandb.Table()에 전달하여 새 테이블을 생성합니다.
import wandb
import pandas as pd
df = pd.read_csv("my_data.csv")
run = wandb.init(project="df-table")
my_table = wandb.Table(dataframe=df)
wandb.log({"Table Name": my_table})
지원되는 데이터 유형에 대한 자세한 내용은 W&B API Reference Guide의 wandb.Table을 참조하세요.
2. 프로젝트 워크스페이스에서 테이블 시각화
워크스페이스에서 결과 테이블을 봅니다.
- W&B 앱에서 프로젝트로 이동합니다.
- 프로젝트 워크스페이스에서 run 이름을 선택합니다. 각 고유한 테이블 키에 대해 새로운 패널이 추가됩니다.
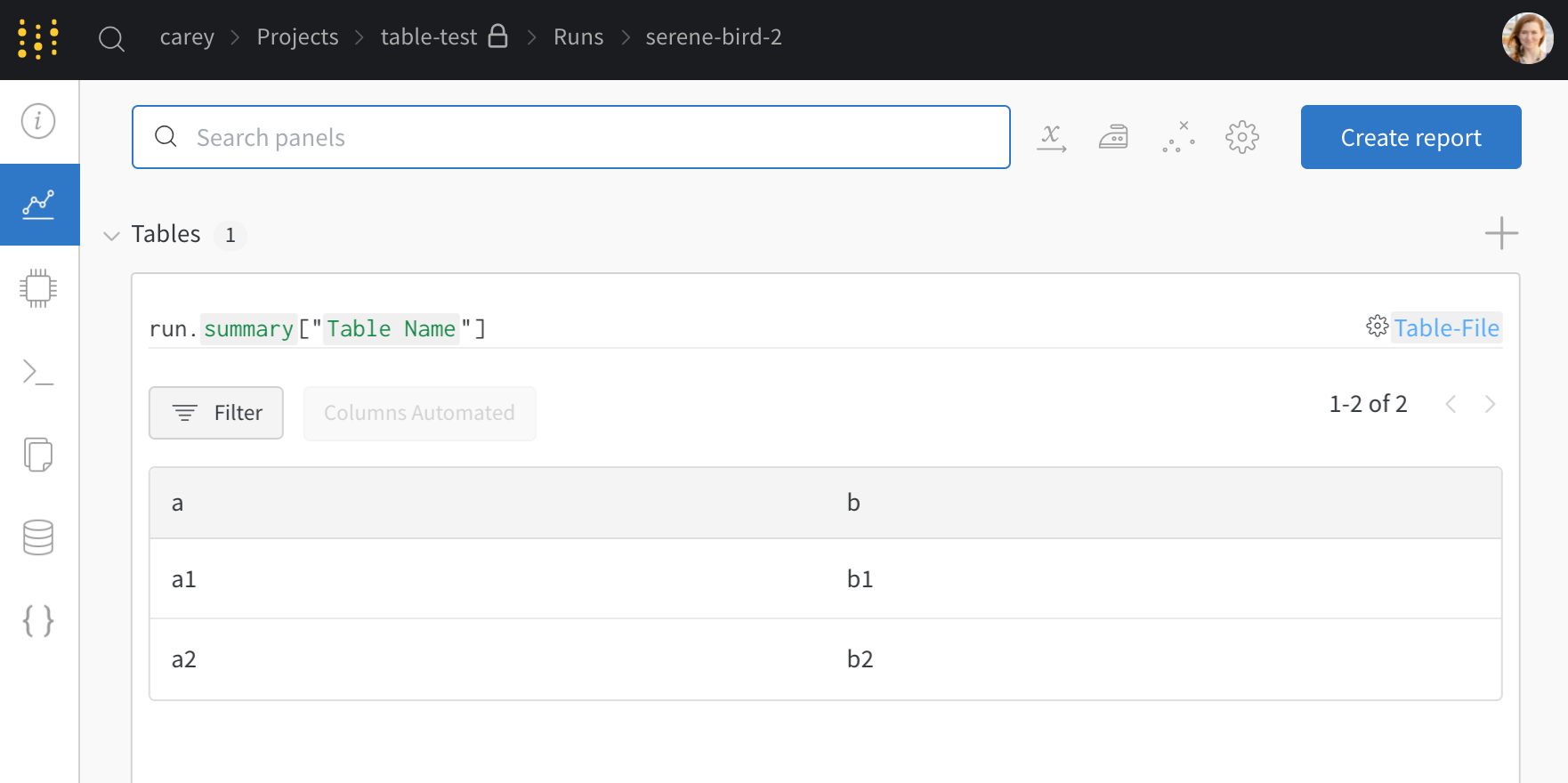
이 예제에서 my_table은 "Table Name" 키 아래에 기록됩니다.
3. 모델 버전 간 비교
여러 W&B Runs에서 샘플 테이블을 기록하고 프로젝트 워크스페이스에서 결과를 비교합니다. 이 example workspace에서는 동일한 테이블에서 여러 다른 버전의 행을 결합하는 방법을 보여줍니다.
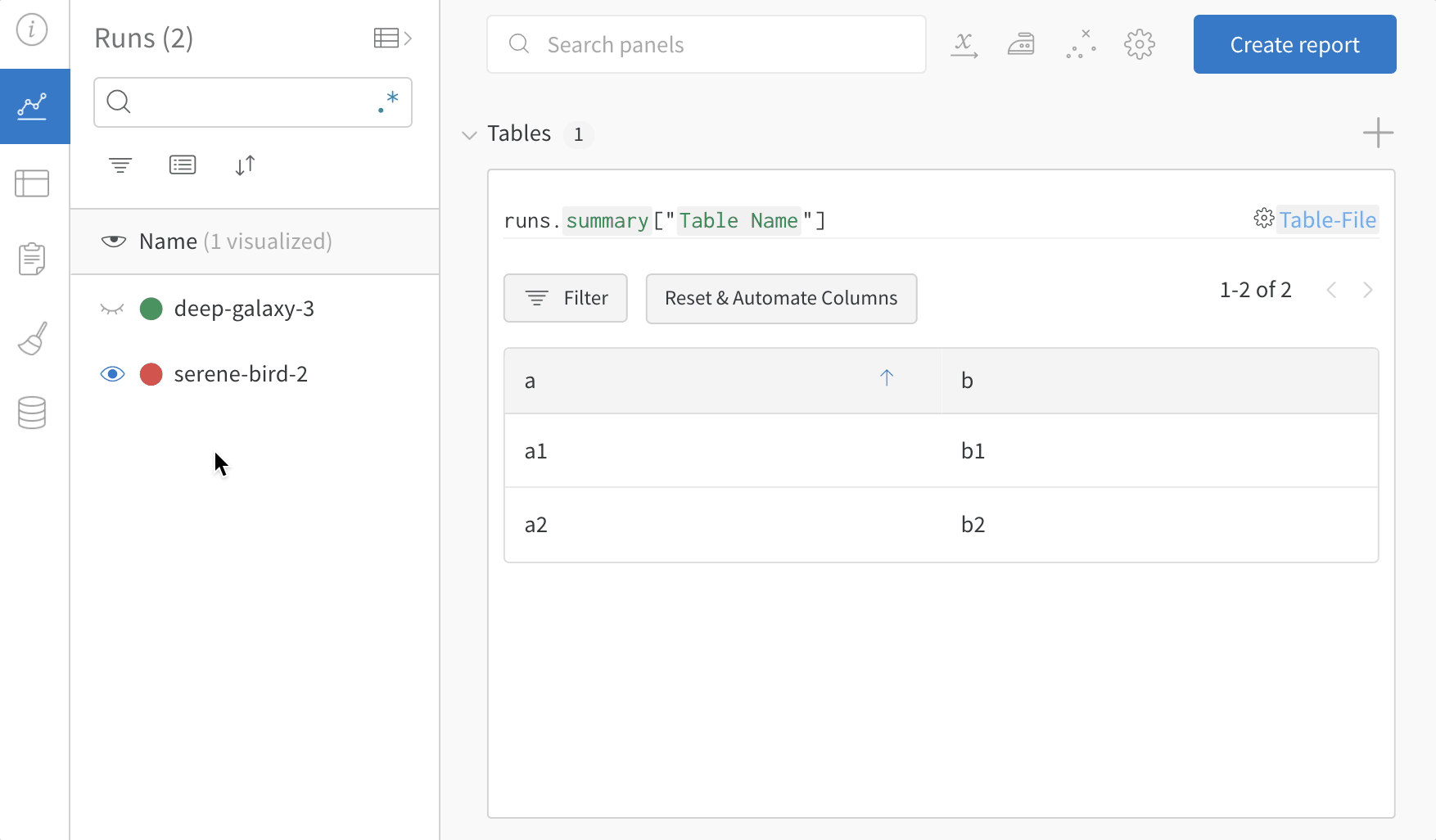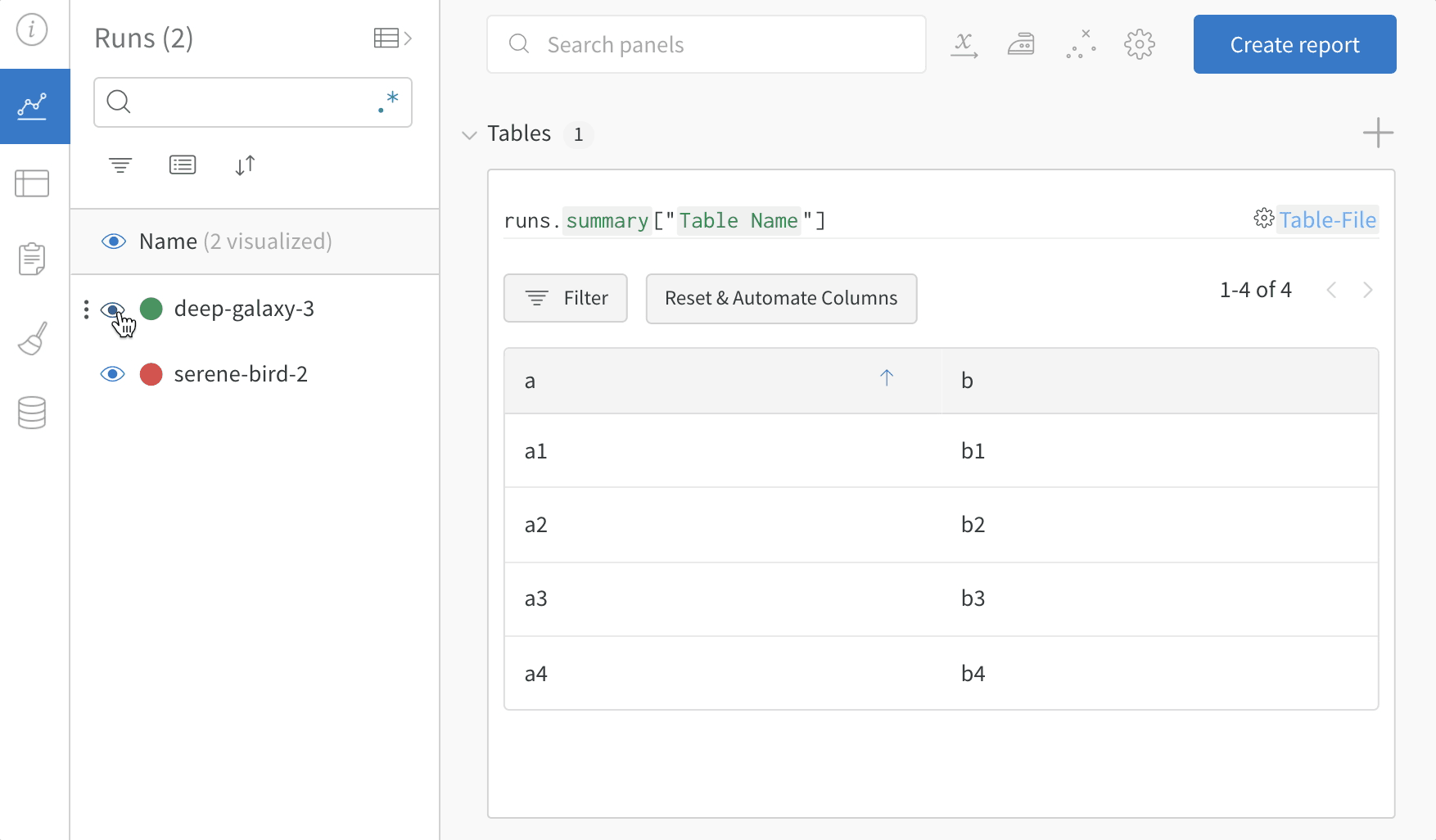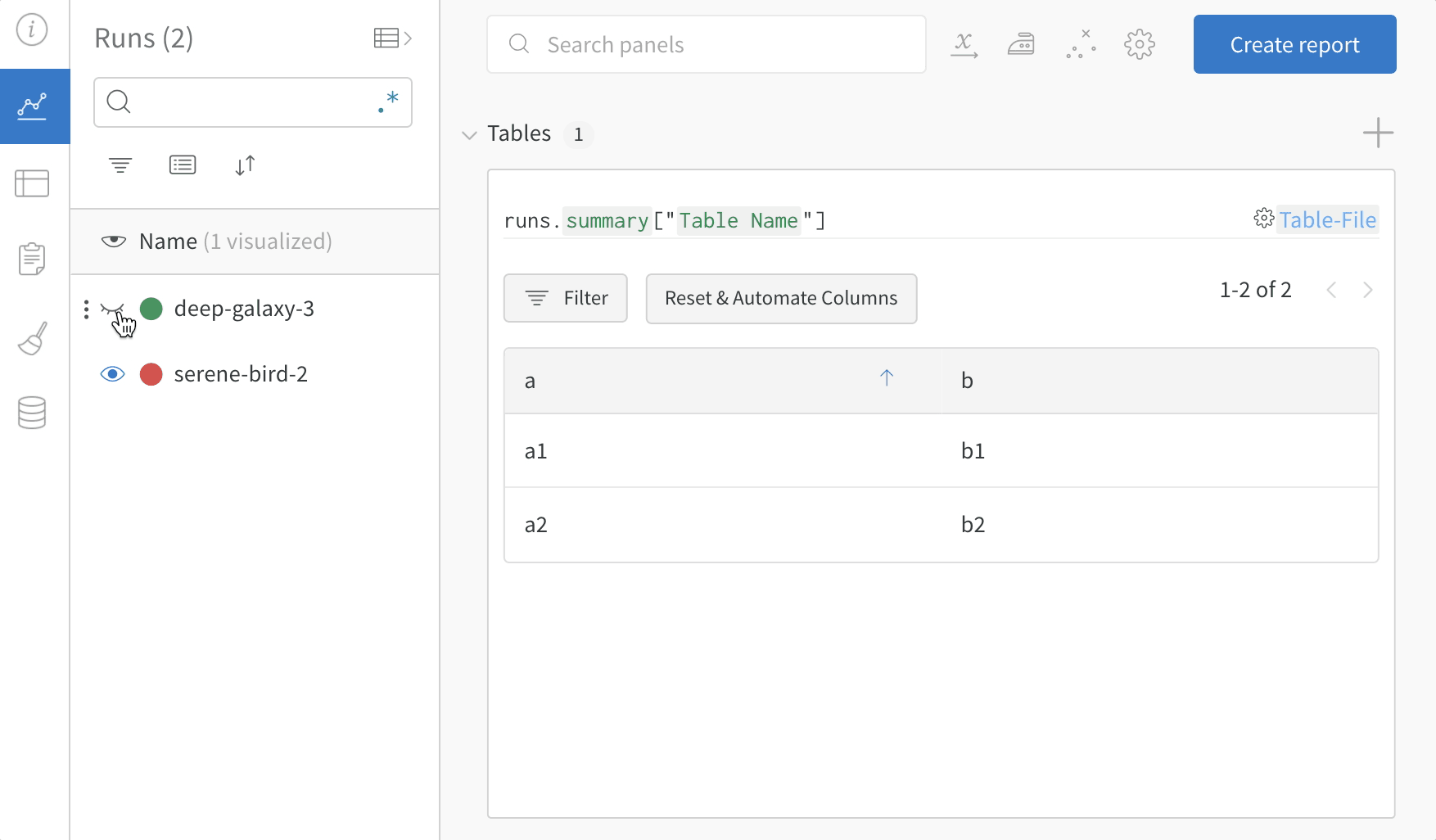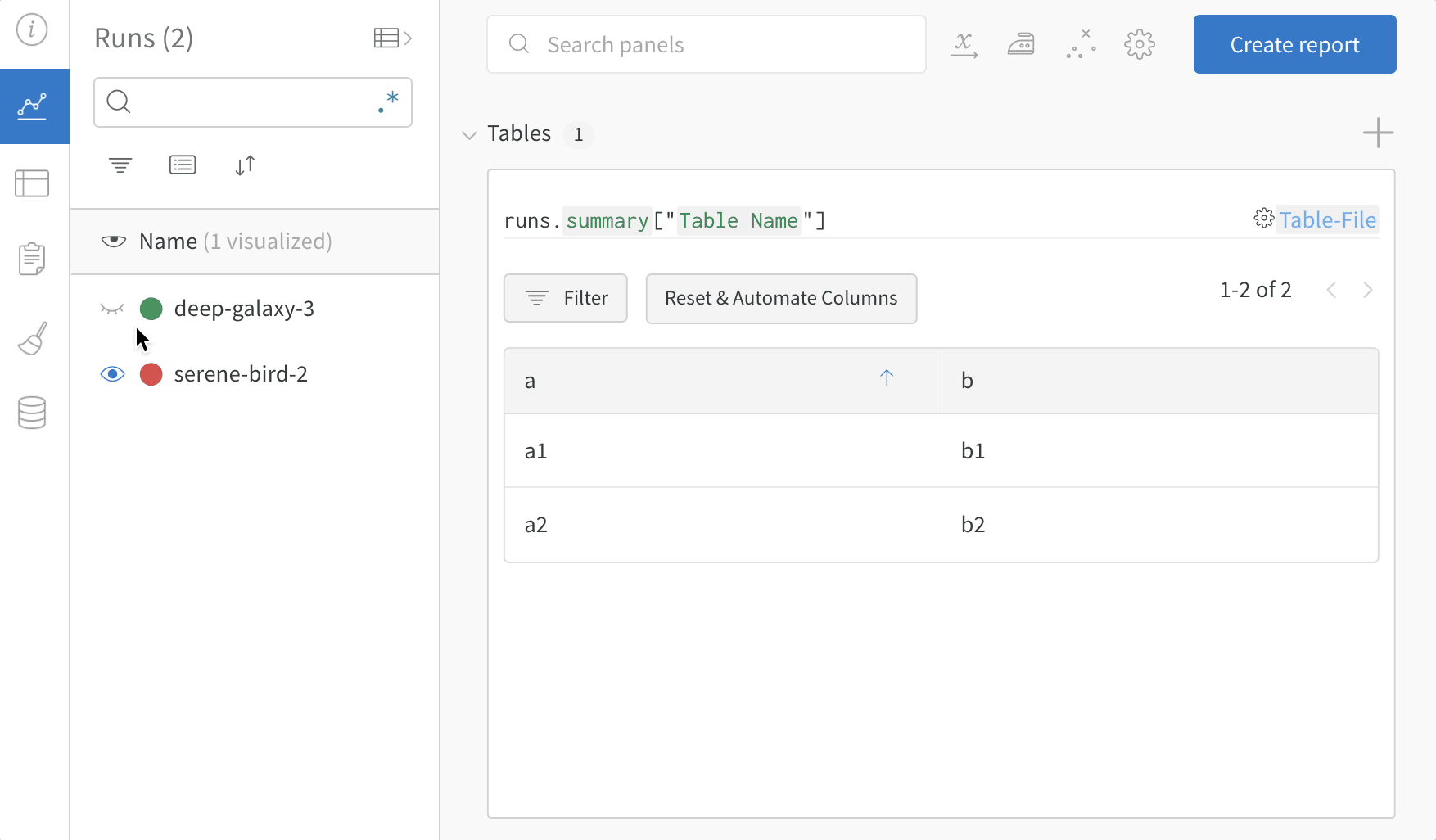
테이블 필터, 정렬 및 그룹화 기능을 사용하여 모델 결과를 탐색하고 평가합니다.
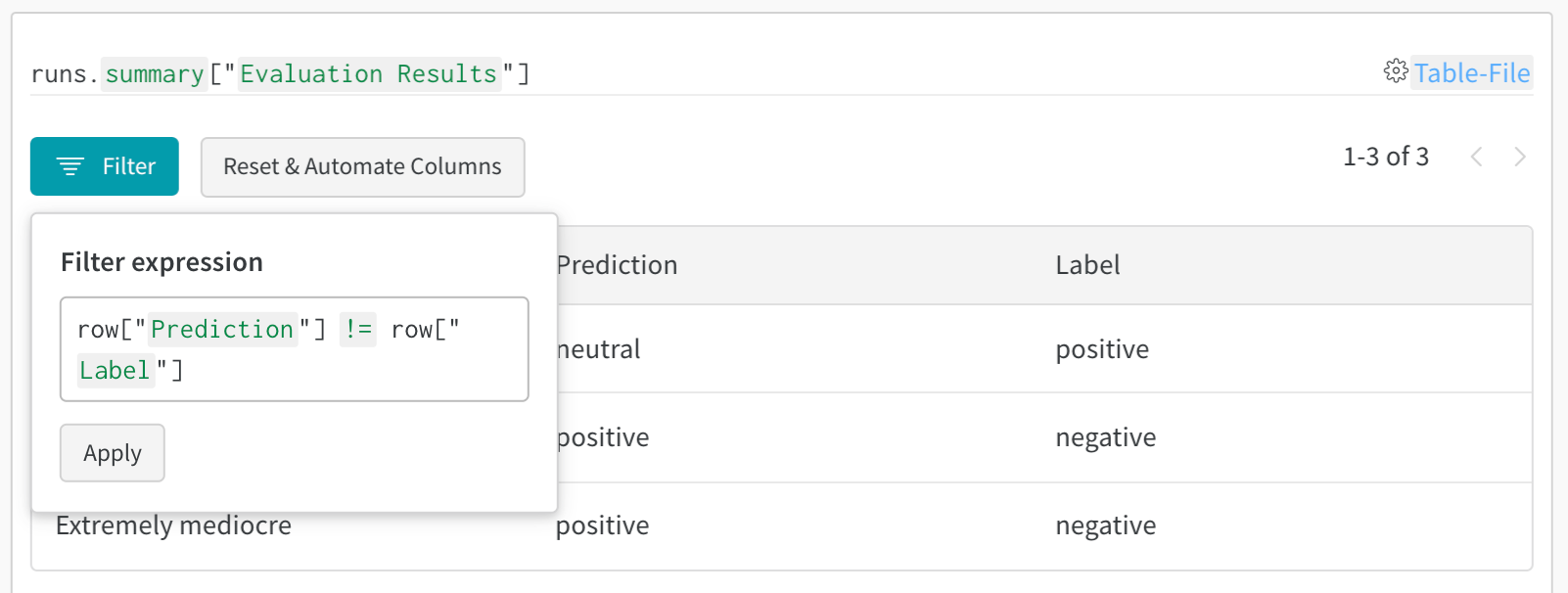
2 - Visualize and analyze tables
W&B Tables를 시각화하고 분석하세요.
W&B Tables를 사용자 정의하여 기계 학습 모델의 성능에 대한 질문에 답변하고, 데이터를 분석하는 등의 작업을 수행할 수 있습니다.
데이터를 대화형으로 탐색하여 다음을 수행할 수 있습니다.
- 모델, 에포크 또는 개별 예제 간의 변경 사항을 정확하게 비교합니다.
- 데이터의 상위 수준 패턴을 이해합니다.
- 시각적 샘플을 통해 통찰력을 포착하고 전달합니다.
W&B Tables는 다음과 같은 동작을 보입니다.
- 아티팩트 컨텍스트에서 상태 비저장: 아티팩트 버전과 함께 기록된 모든 테이블은 브라우저 창을 닫은 후 기본 상태로 재설정됩니다.
- 워크스페이스 또는 리포트 컨텍스트에서 상태 저장: 단일 run 워크스페이스, 다중 run 프로젝트 워크스페이스 또는 Report에서 테이블에 적용한 모든 변경 사항은 유지됩니다.
현재 W&B Table 뷰를 저장하는 방법에 대한 자세한 내용은 뷰 저장을 참조하세요.
두 개의 테이블을 보는 방법
병합된 뷰 또는 나란히 보기로 두 개의 테이블을 비교합니다. 예를 들어 아래 이미지는 MNIST 데이터의 테이블 비교를 보여줍니다.
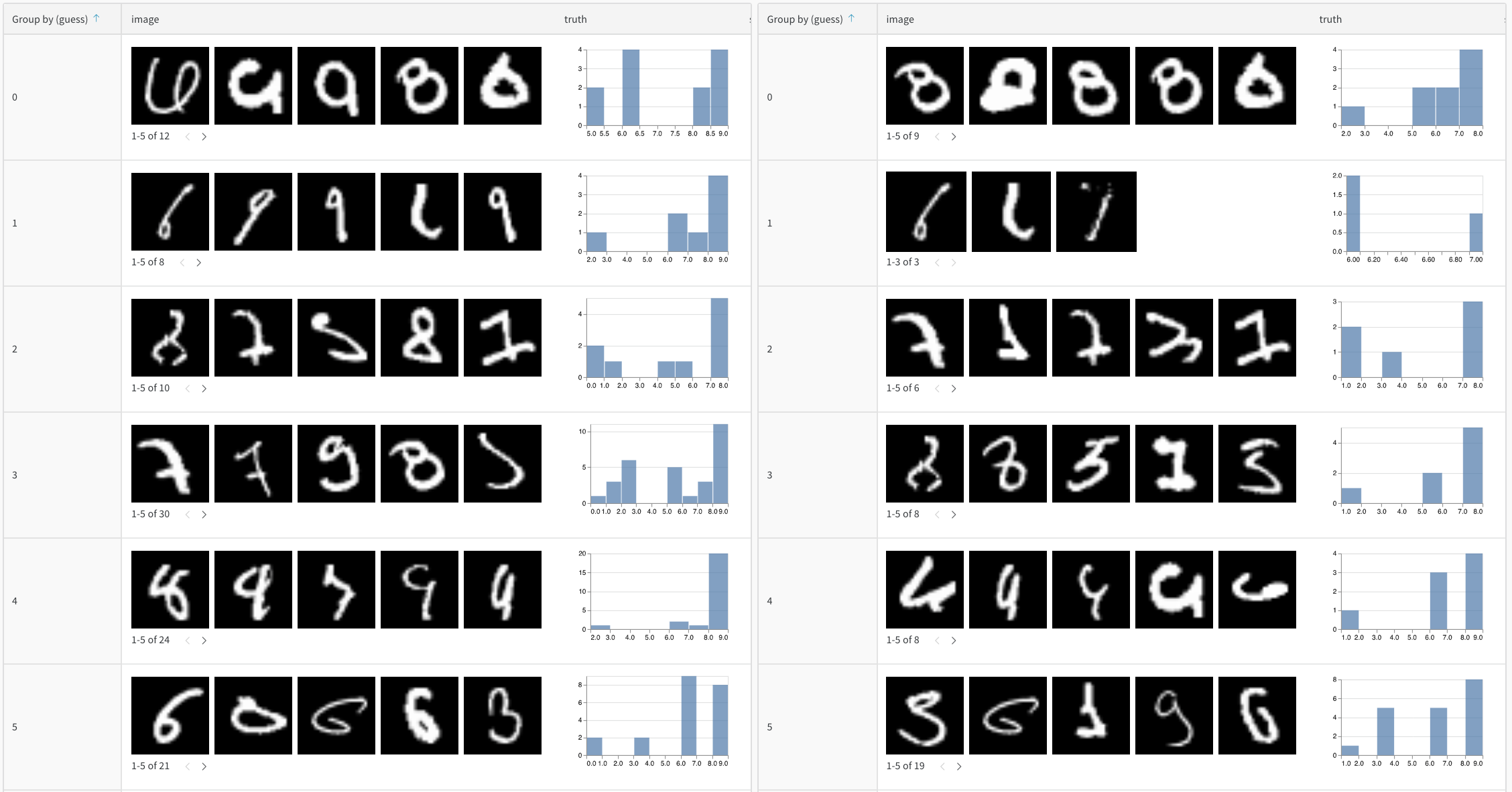
다음 단계에 따라 두 개의 테이블을 비교합니다.
- W&B App에서 프로젝트로 이동합니다.
- 왼쪽 패널에서 Artifacts 아이콘을 선택합니다.
- 아티팩트 버전을 선택합니다.
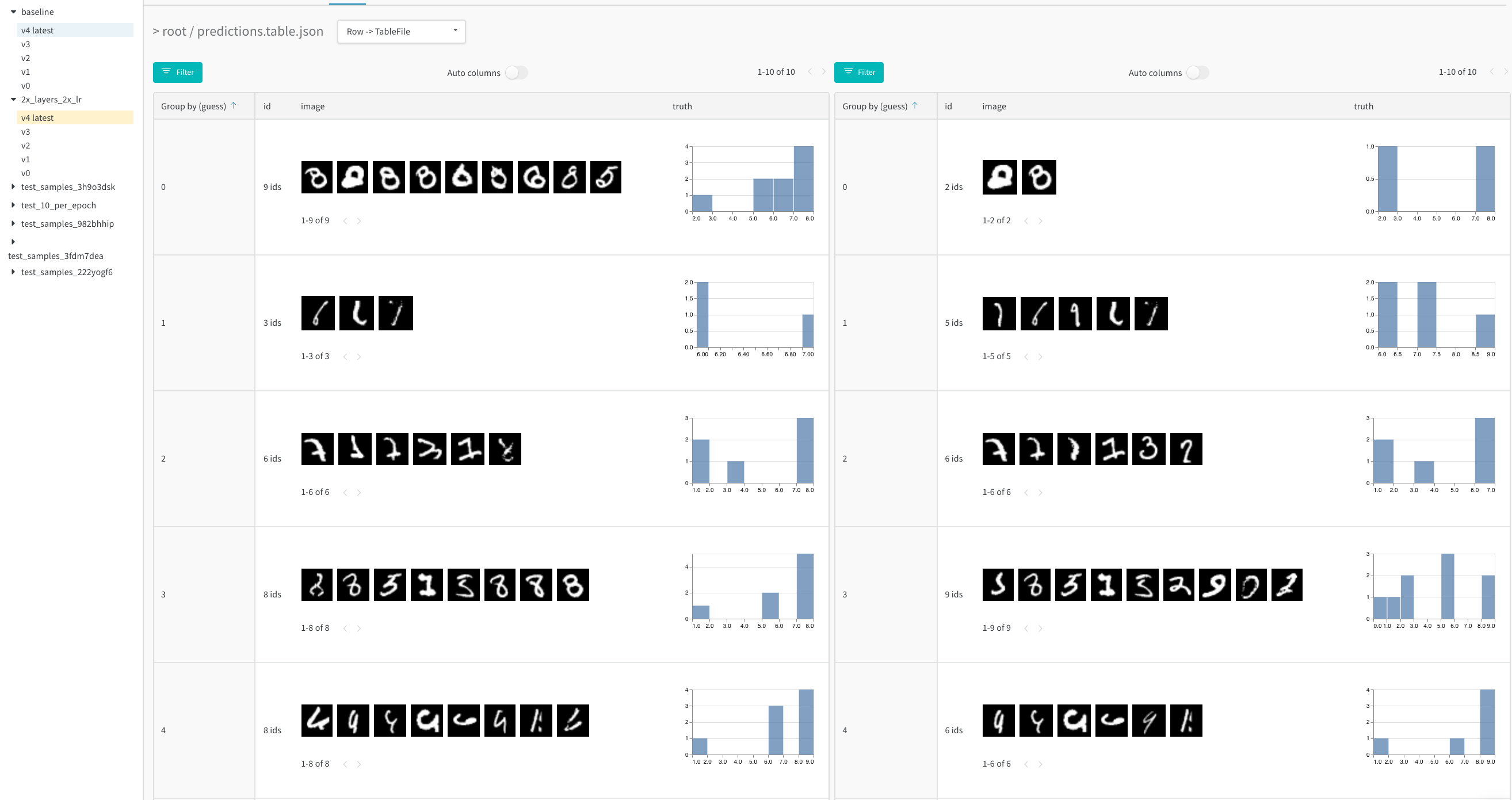
다음 이미지에서는 5개의 에포크 각각 이후에 MNIST 검증 데이터에 대한 모델의 예측을 보여줍니다(여기에서 대화형 예제 보기).
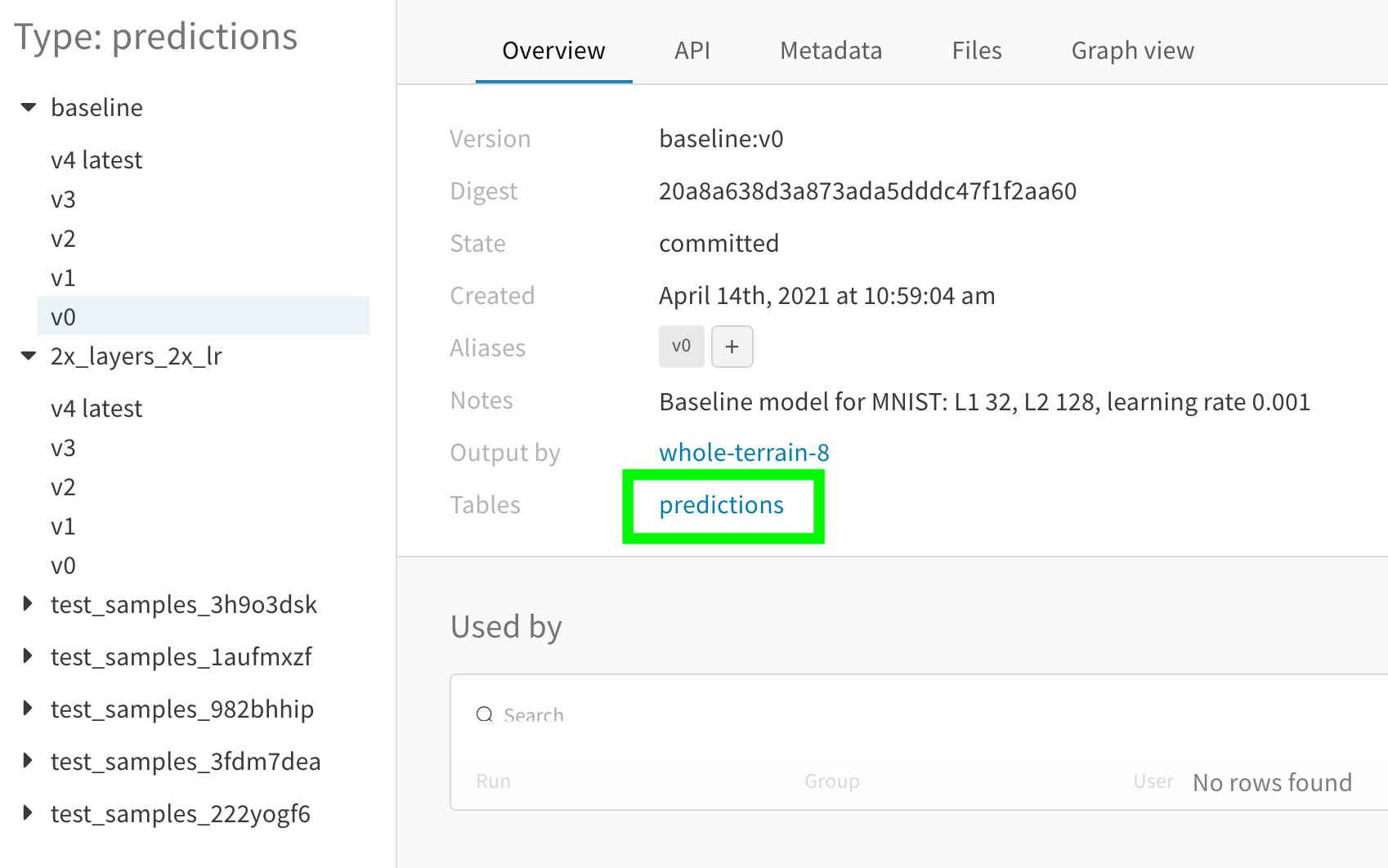
- 사이드바에서 비교하려는 두 번째 아티팩트 버전 위로 마우스를 가져간 다음 나타나는 비교를 클릭합니다. 예를 들어 아래 이미지에서는 5 에포크 트레이닝 후 동일한 모델에서 만든 MNIST 예측과 비교하기 위해 “v4"로 레이블이 지정된 버전을 선택합니다.
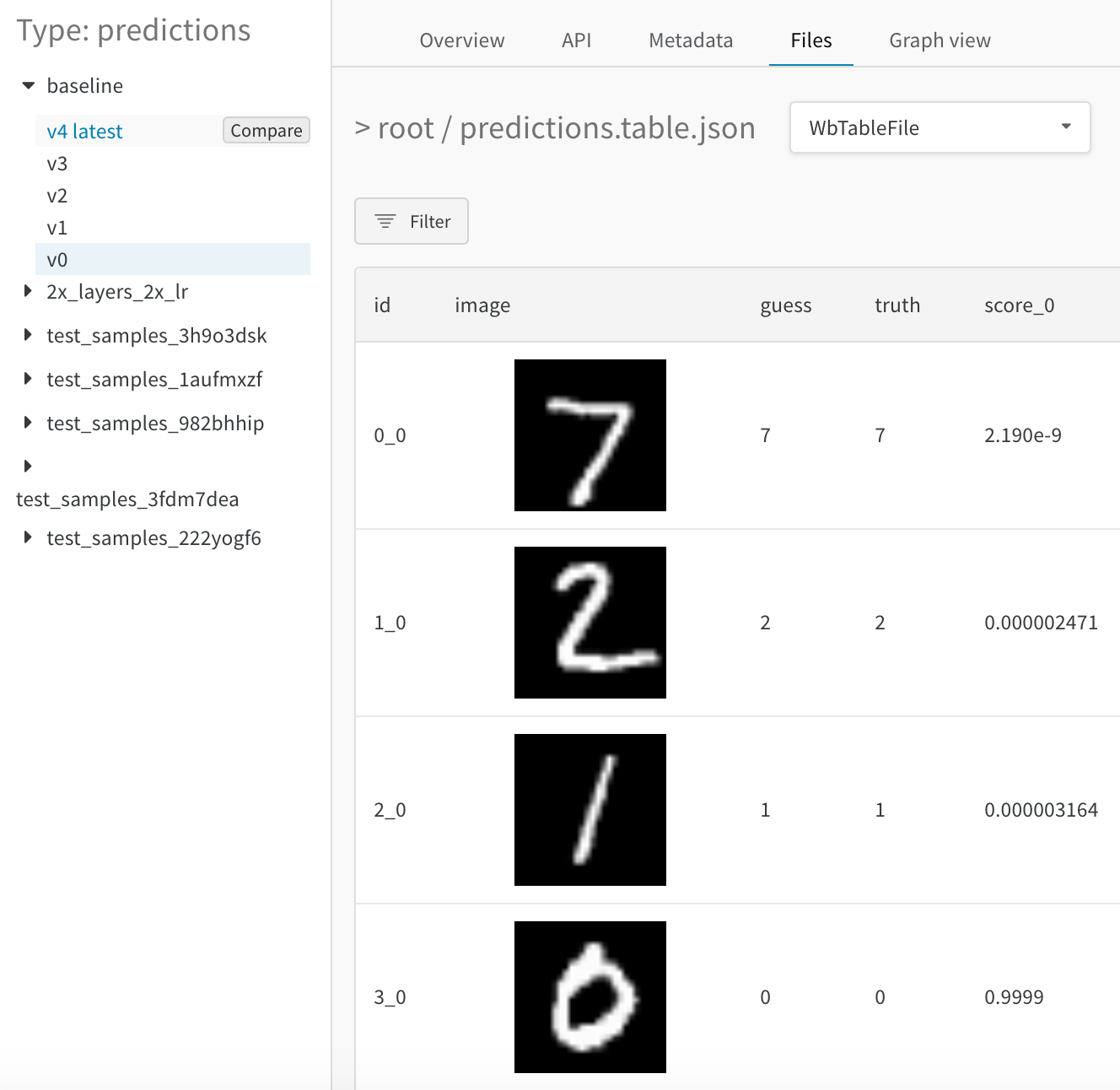
병합된 뷰
처음에는 두 테이블이 함께 병합되어 표시됩니다. 첫 번째 선택한 테이블은 인덱스 0과 파란색 강조 표시가 있고 두 번째 테이블은 인덱스 1과 노란색 강조 표시가 있습니다. 여기에서 병합된 테이블의 라이브 예제를 봅니다.
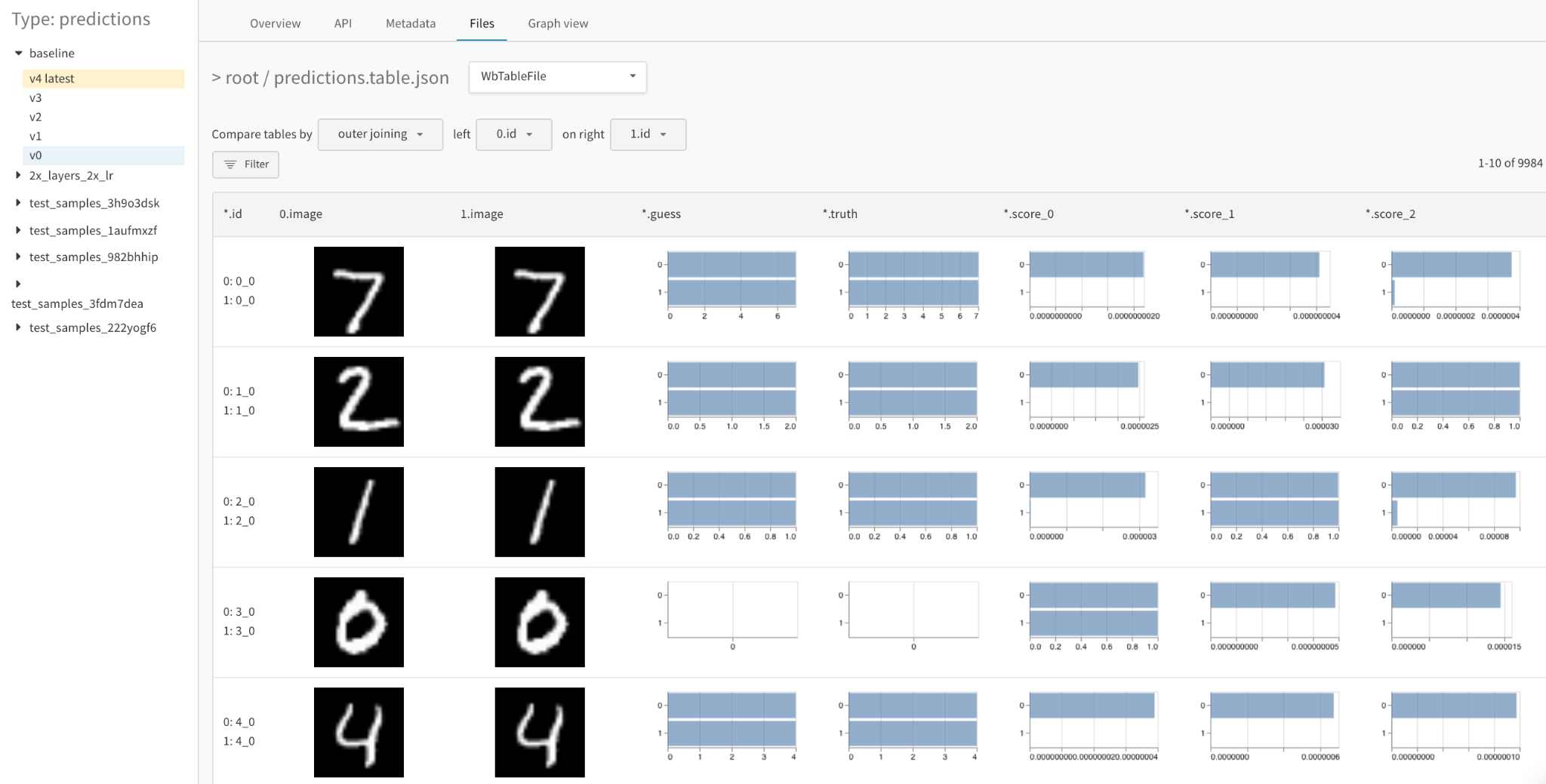
병합된 뷰에서 다음을 수행할 수 있습니다.
- 조인 키 선택: 왼쪽 상단의 드롭다운을 사용하여 두 테이블의 조인 키로 사용할 열을 설정합니다. 일반적으로 이것은 데이터셋의 특정 예제의 파일 이름 또는 생성된 샘플의 증가하는 인덱스와 같은 각 행의 고유 식별자입니다. 현재 모든 열을 선택할 수 있으므로 읽을 수 없는 테이블과 느린 쿼리가 발생할 수 있습니다.
- 조인 대신 연결: 이 드롭다운에서 “모든 테이블 연결"을 선택하여 열을 조인하는 대신 두 테이블의 _모든 행을 결합_하여 더 큰 Table 하나로 만듭니다.
- 각 Table을 명시적으로 참조: 필터 표현식에서 0, 1 및 *를 사용하여 하나 또는 두 테이블 인스턴스의 열을 명시적으로 지정합니다.
- 자세한 숫자 차이를 히스토그램으로 시각화: 모든 셀의 값을 한눈에 비교합니다.
나란히 보기
두 개의 테이블을 나란히 보려면 첫 번째 드롭다운을 “테이블 병합: 테이블"에서 “목록: 테이블"로 변경한 다음 “페이지 크기"를 각각 업데이트합니다. 여기서 첫 번째 선택한 Table은 왼쪽에 있고 두 번째 Table은 오른쪽에 있습니다. 또한 “수직” 확인란을 클릭하여 이러한 테이블을 수직으로 비교할 수도 있습니다.
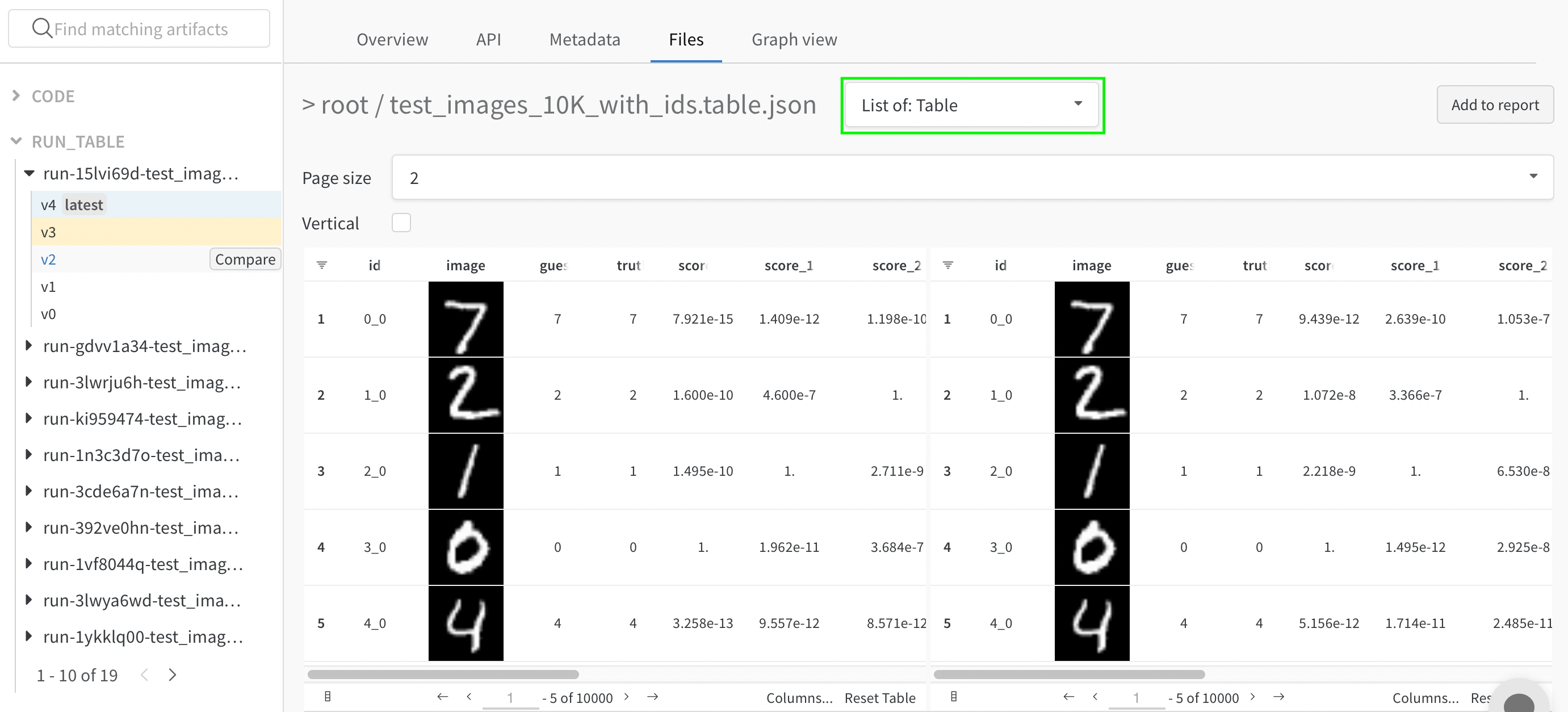
- 테이블을 한눈에 비교: 모든 작업 (정렬, 필터, 그룹)을 두 테이블에 동시에 적용하고 변경 사항이나 차이점을 빠르게 찾습니다. 예를 들어 추측별로 그룹화된 잘못된 예측, 가장 어려운 네거티브 전체, 실제 레이블별 신뢰도 점수 분포 등을 봅니다.
- 두 개의 테이블을 독립적으로 탐색: 관심 있는 측면/행을 스크롤하고 집중합니다.
Artifacts 비교
또한 시간 경과에 따른 테이블 비교 또는 모델 변형 비교를 수행할 수 있습니다.
시간 경과에 따른 테이블 비교
트레이닝 시간 동안 모델 성능을 분석하기 위해 트레이닝의 의미 있는 각 단계에 대한 아티팩트에서 테이블을 기록합니다. 예를 들어 모든 검증 단계가 끝날 때, 50 에포크의 트레이닝마다 또는 파이프라인에 적합한 빈도로 테이블을 기록할 수 있습니다. 나란히 보기를 사용하여 모델 예측의 변경 사항을 시각화합니다.
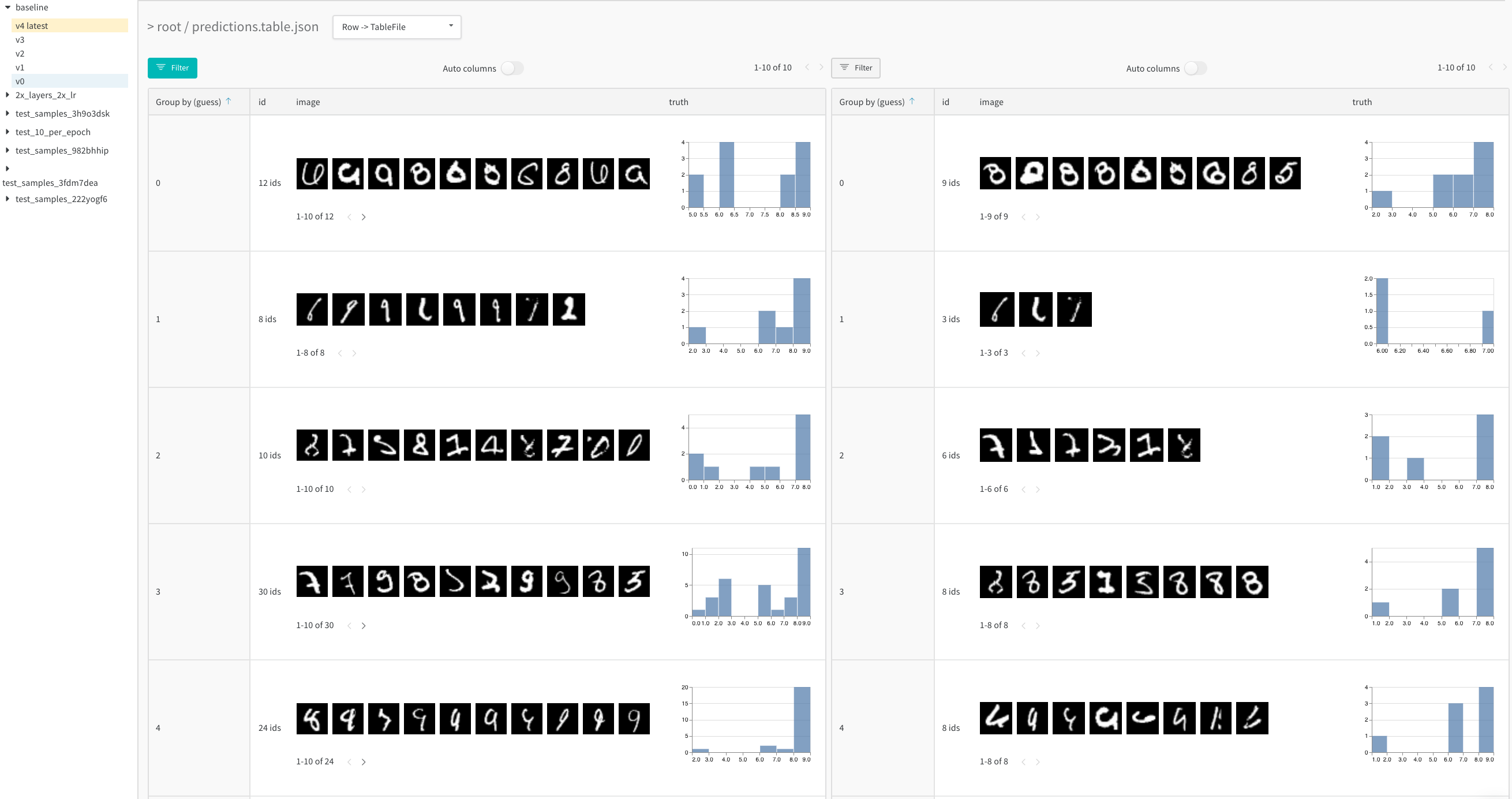
트레이닝 시간 동안 예측을 시각화하는 방법에 대한 자세한 내용은 이 Report와 이 대화형 노트북 예제를 참조하십시오.
모델 변형 간 테이블 비교
서로 다른 구성(하이퍼파라미터, 기본 아키텍처 등)에서 모델 성능을 분석하기 위해 두 개의 다른 모델에 대해 동일한 단계에서 기록된 두 개의 아티팩트 버전을 비교합니다.
예를 들어 baseline과 새 모델 변형 2x_layers_2x_lr 간의 예측을 비교합니다. 여기서 첫 번째 컨볼루션 레이어는 32에서 64로, 두 번째 레이어는 128에서 256으로, 학습률은 0.001에서 0.002로 두 배가 됩니다. 이 라이브 예제에서 나란히 보기를 사용하고 1 (왼쪽 탭) 대 5 트레이닝 에포크 (오른쪽 탭) 후에 잘못된 예측으로 필터링합니다.
뷰 저장
run 워크스페이스, 프로젝트 워크스페이스 또는 Report에서 상호 작용하는 테이블은 뷰 상태를 자동으로 저장합니다. 테이블 작업을 적용한 다음 브라우저를 닫으면 테이블은 다음에 테이블로 이동할 때 마지막으로 본 구성을 유지합니다.
아티팩트 컨텍스트에서 상호 작용하는 테이블은 상태 비저장으로 유지됩니다.
특정 상태의 워크스페이스에서 테이블을 저장하려면 W&B Report로 내보냅니다. 테이블을 Report로 내보내려면:
- 워크스페이스 시각화 패널의 오른쪽 상단 모서리에 있는 케밥 아이콘 (세 개의 수직 점)을 선택합니다.
- 패널 공유 또는 Report에 추가를 선택합니다.
예제
다음 Reports는 W&B Tables의 다양한 유스 케이스를 강조합니다.
3 - Example tables
W&B Tables 예시
다음 섹션에서는 테이블을 사용할 수 있는 몇 가지 방법을 중점적으로 설명합니다.
데이터 보기
모델 트레이닝 또는 평가 중에 메트릭과 풍부한 미디어를 기록한 다음, 클라우드 또는 호스팅 인스턴스에 동기화된 영구 데이터베이스에서 결과를 시각화합니다.
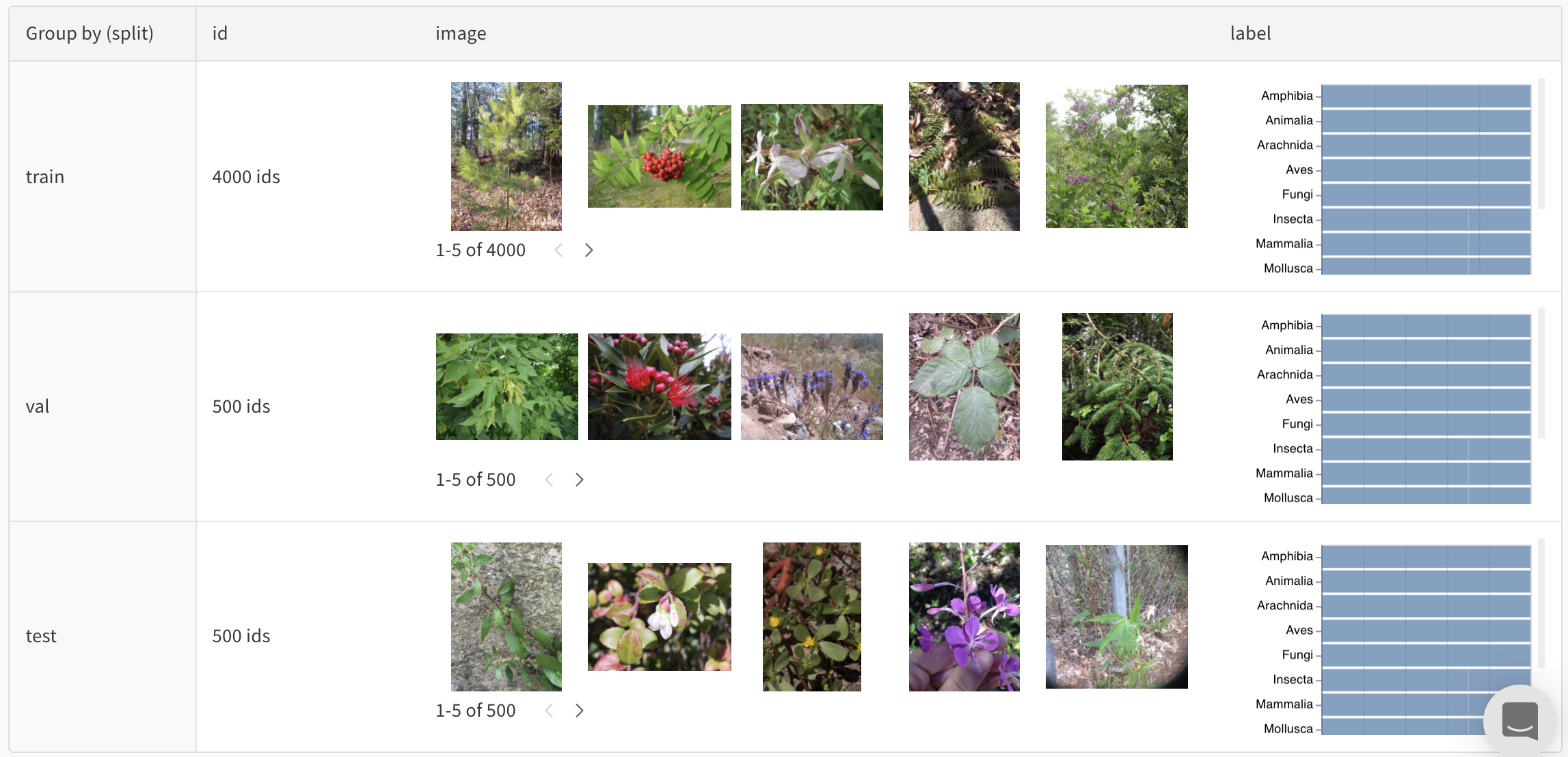
예를 들어, 사진 데이터셋의 균형 잡힌 분할을 보여주는 테이블을 확인해 보세요.
데이터 대화형으로 탐색하기
테이블을 보고, 정렬하고, 필터링하고, 그룹화하고, 조인하고, 쿼리하여 데이터와 모델 성능을 이해합니다. 정적 파일을 찾아보거나 분석 스크립트를 다시 실행할 필요가 없습니다.
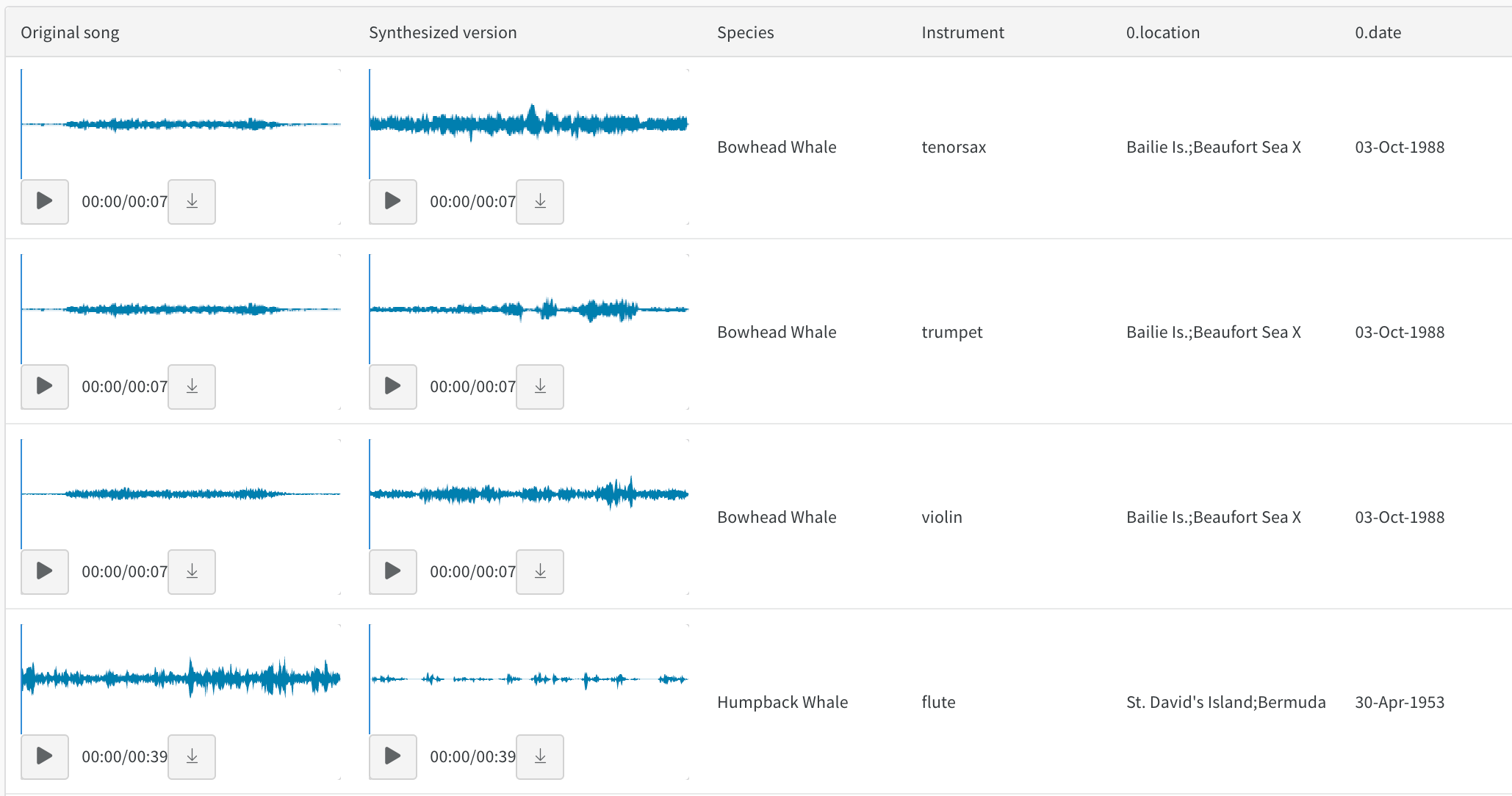
예를 들어, 스타일이 전송된 오디오에 대한 이 report를 참조하세요.
모델 버전 비교
다양한 트레이닝 에포크, 데이터셋, 하이퍼파라미터 선택, 모델 아키텍처 등에서 결과를 빠르게 비교합니다.
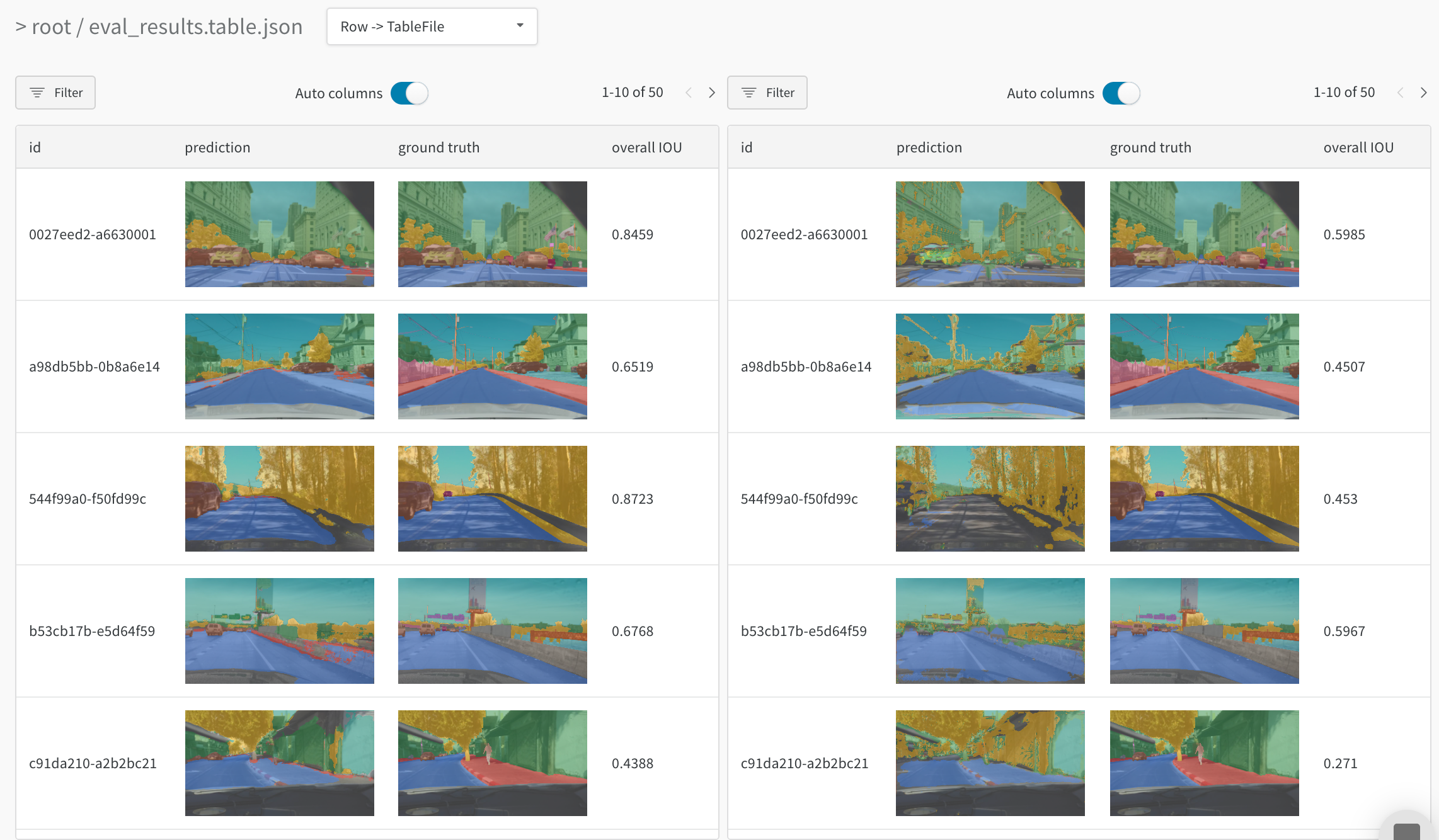
예를 들어, 동일한 테스트 이미지에서 두 모델을 비교하는 테이블을 참조하세요.
모든 세부 사항을 추적하고 더 큰 그림 보기
특정 단계에서 특정 예측을 시각화하기 위해 확대합니다. 집계 통계를 보고, 오류 패턴을 식별하고, 개선 기회를 파악하기 위해 축소합니다. 이 tool은 단일 모델 트레이닝의 단계를 비교하거나 서로 다른 모델 버전의 결과를 비교하는 데 사용할 수 있습니다.
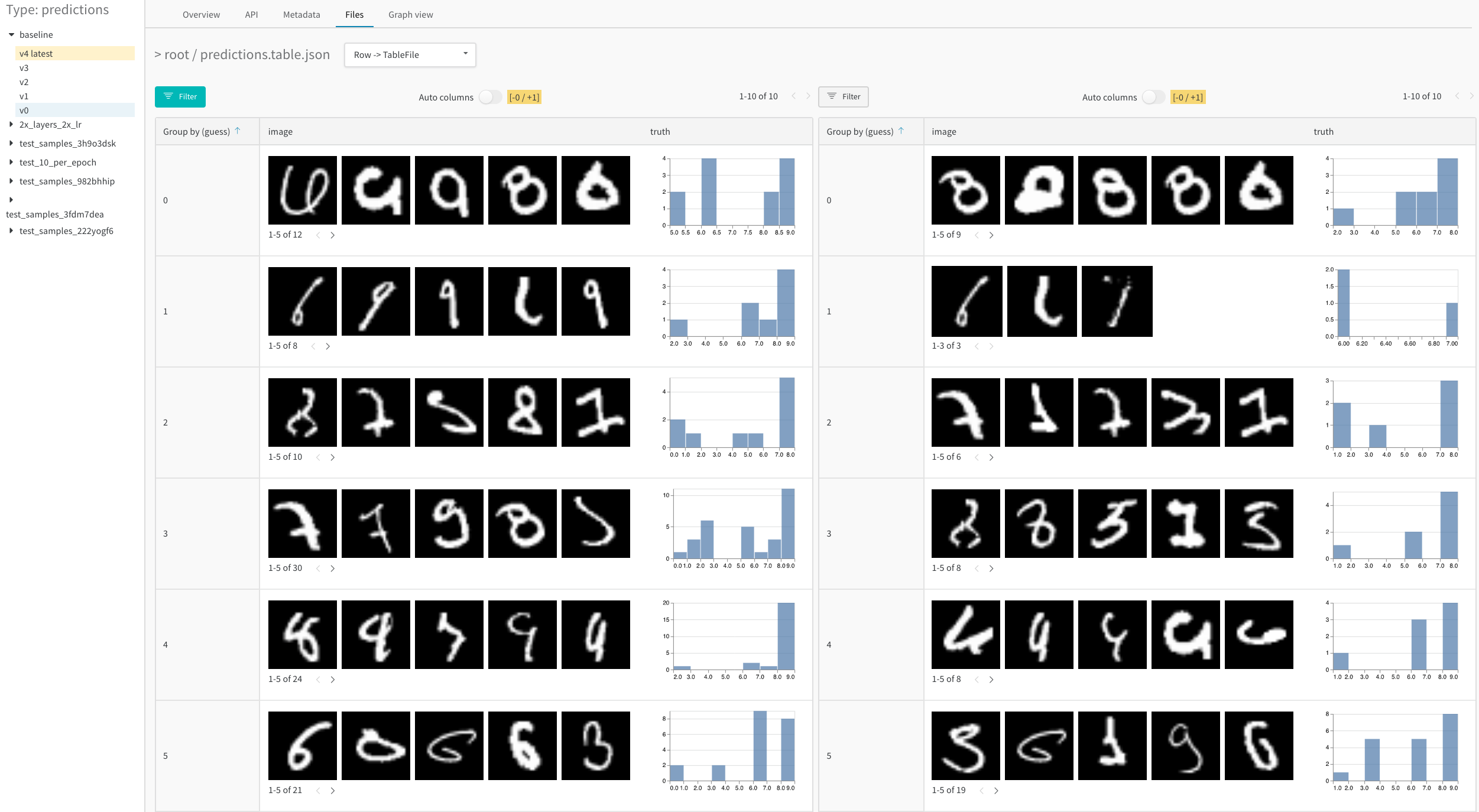
예를 들어, MNIST 데이터셋에서 1에포크 후, 5에포크 후의 결과를 분석하는 예제 테이블을 참조하세요.
W&B Tables를 사용한 예제 Projects
다음은 W&B Tables를 사용하는 실제 W&B Projects를 강조합니다.
이미지 분류
이 report를 읽고, 이 colab을 따르거나, artifacts 컨텍스트를 탐색하여 CNN이 iNaturalist 사진에서 10가지 유형의 생물(식물, 새, 곤충 등)을 식별하는 방법을 확인하세요.
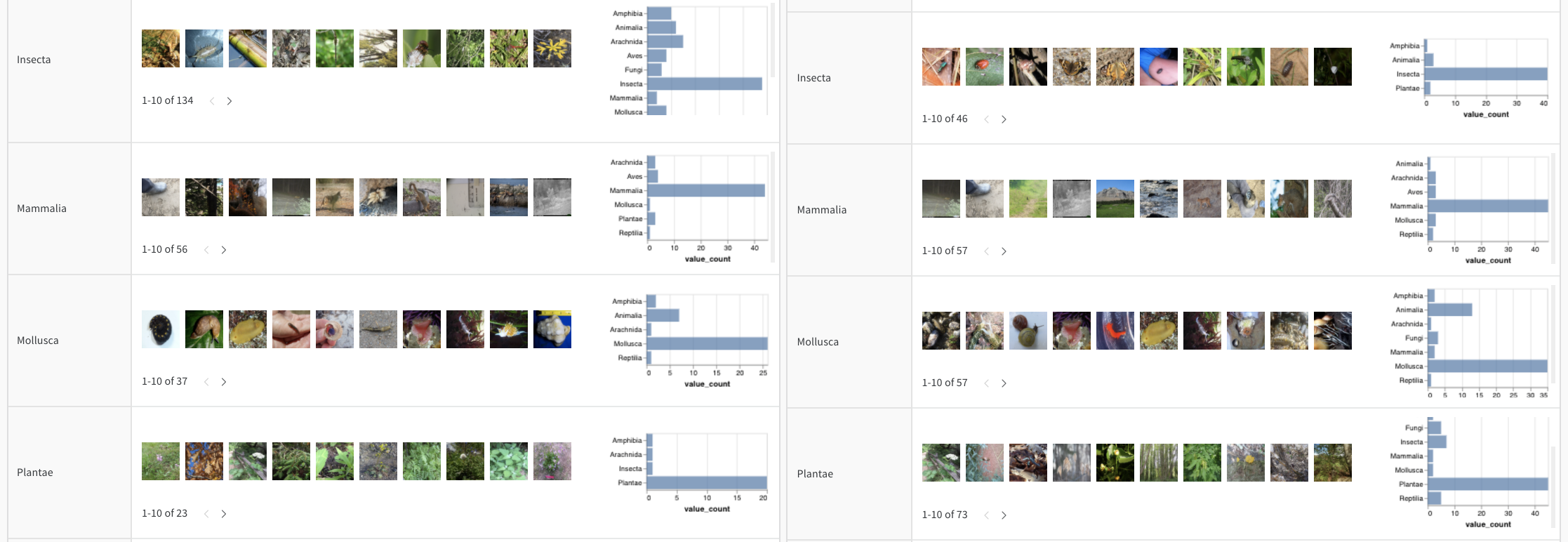
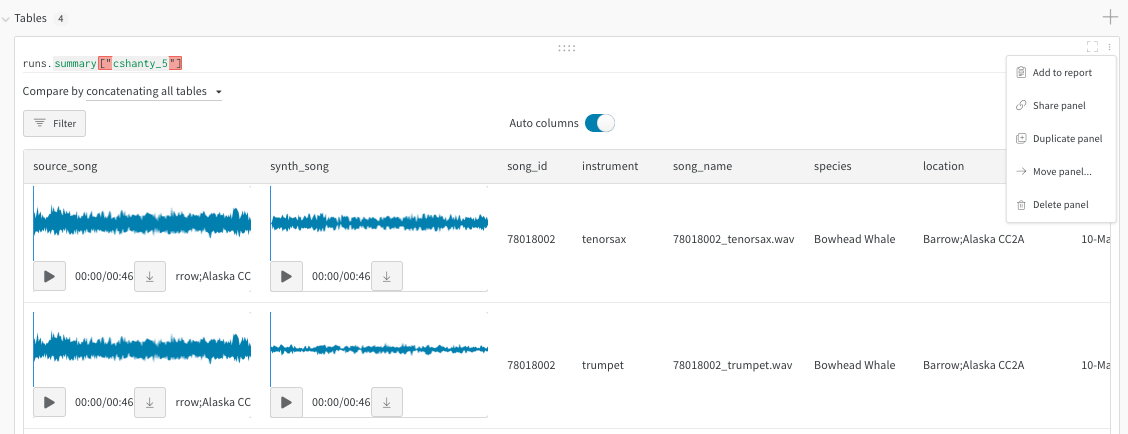
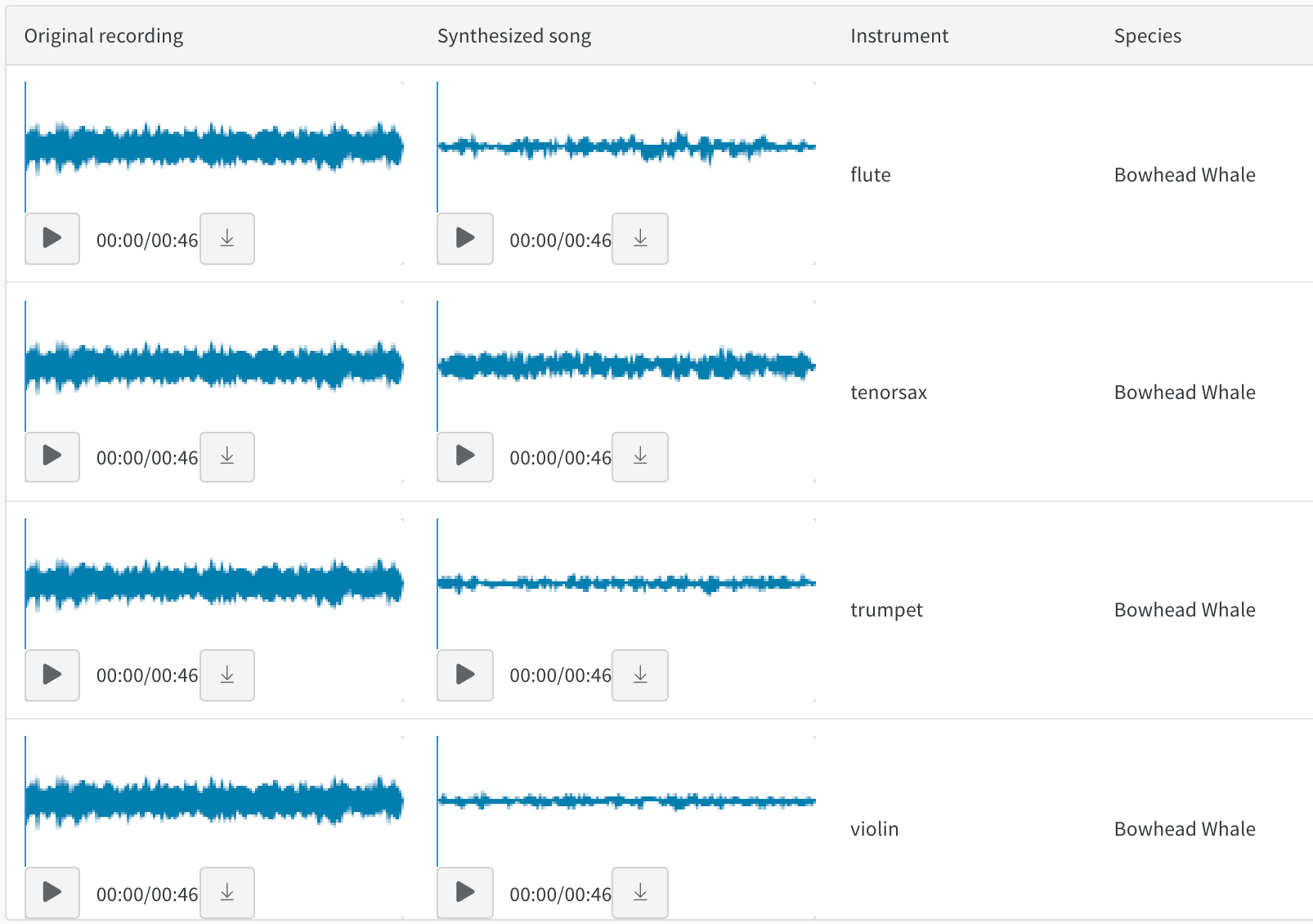
오디오
음색 전송에 대한 이 report에서 오디오 테이블과 상호 작용합니다. 녹음된 고래 노래와 바이올린이나 트럼펫과 같은 악기로 동일한 멜로디를 합성한 연주를 비교할 수 있습니다. 또한 이 colab을 사용하여 자신의 노래를 녹음하고 W&B에서 합성 버전을 탐색할 수도 있습니다.
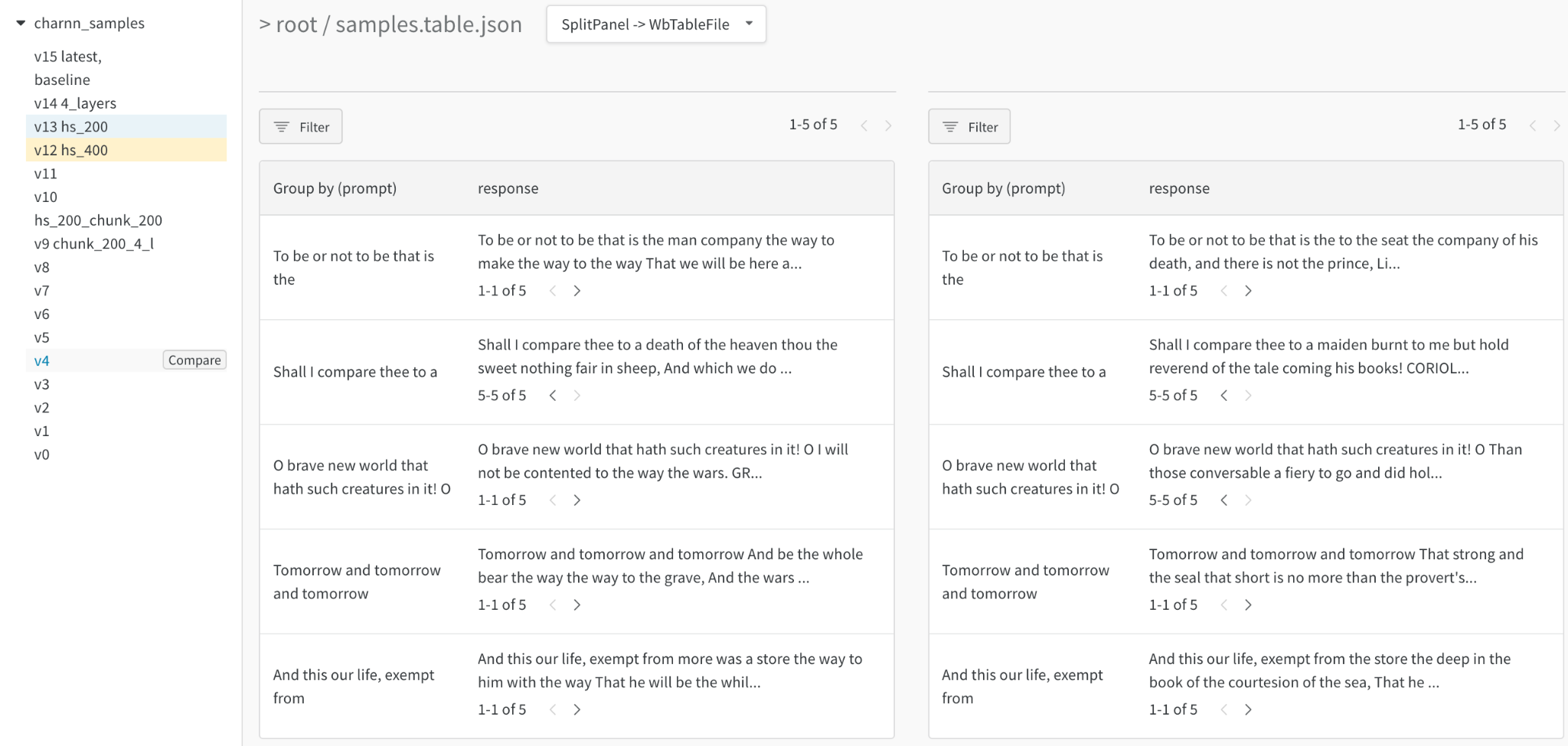
텍스트
트레이닝 데이터 또는 생성된 출력에서 텍스트 샘플을 찾아보고, 관련 필드별로 동적으로 그룹화하고, 모델 변형 또는 실험 설정에서 평가를 조정합니다. 텍스트를 Markdown으로 렌더링하거나 시각적 차이 모드를 사용하여 텍스트를 비교합니다. 이 report에서 Shakespeare를 생성하기 위한 간단한 문자 기반 RNN을 탐색합니다.
비디오
트레이닝 중에 기록된 비디오를 찾아보고 집계하여 모델을 이해합니다. 다음은 부작용을 최소화하려는 RL 에이전트에 대한 SafeLife 벤치마크를 사용하는 초기 예제입니다.
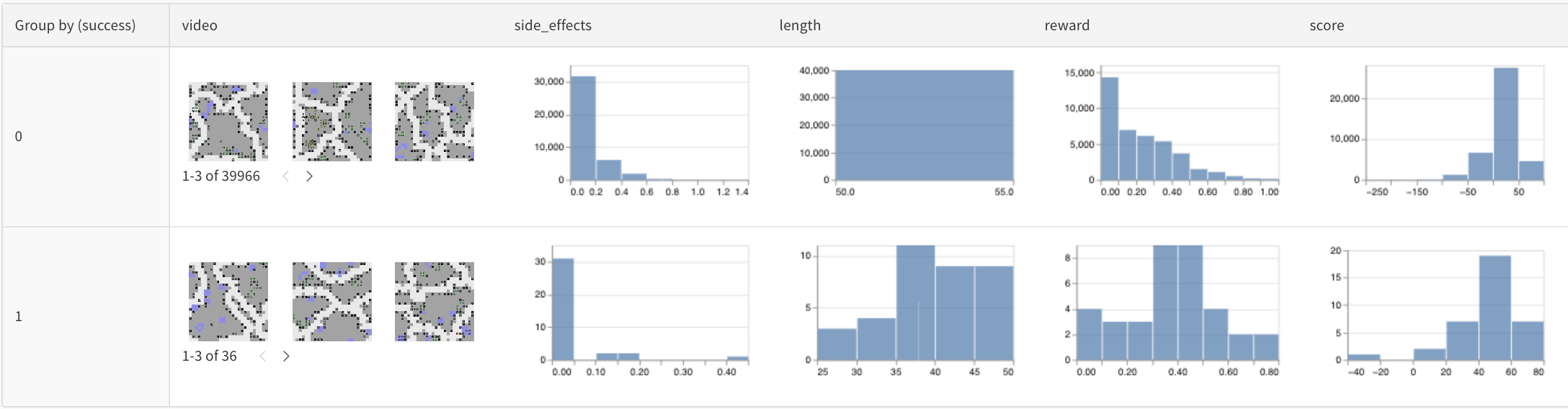
표 형식 데이터
버전 관리 및 중복 제거를 통해 표 형식 데이터를 분할하고 사전 처리하는 방법에 대한 report를 봅니다.
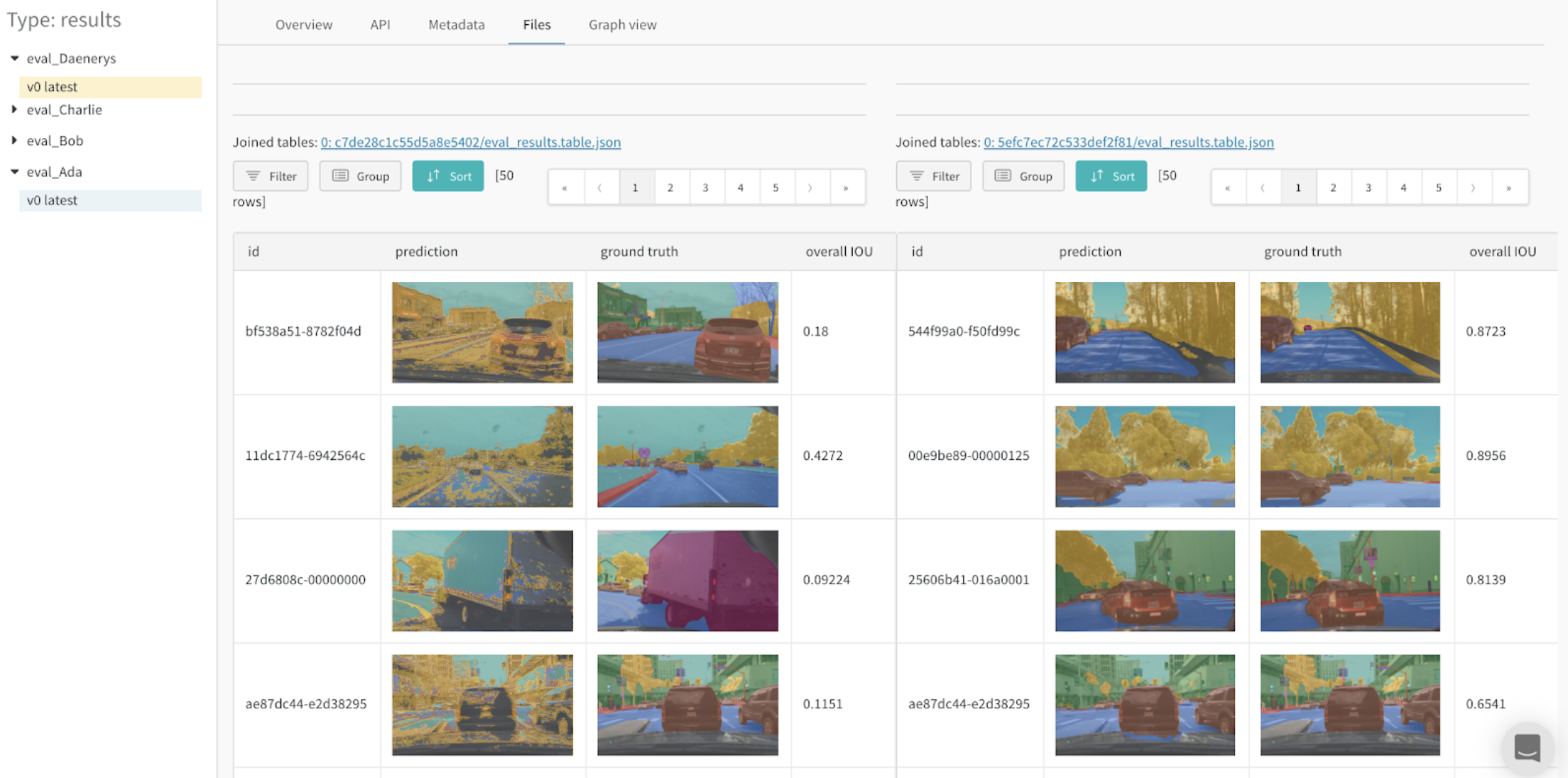
모델 변형 비교 (시멘틱 세분화)
시멘틱 세분화에 대한 테이블을 기록하고 서로 다른 모델을 비교하는 대화형 노트북 및 라이브 예제입니다. 이 테이블에서 자신의 쿼리를 시도해 보세요.
트레이닝 시간 경과에 따른 개선 분석
시간 경과에 따른 예측 시각화 방법에 대한 자세한 report와 함께 제공되는 대화형 노트북입니다.
4 - Export table data
테이블에서 데이터를 내보내는 방법.
W&B Artifacts와 마찬가지로, Tables는 쉬운 데이터 내보내기를 위해 pandas 데이터프레임으로 변환할 수 있습니다.
table을 artifact로 변환하기
먼저, 테이블을 아티팩트로 변환해야 합니다. artifact.get(table, "table_name")을 사용하여 가장 쉽게 수행할 수 있습니다.
# 새로운 테이블을 생성하고 로그합니다.
with wandb.init() as r:
artifact = wandb.Artifact("my_dataset", type="dataset")
table = wandb.Table(
columns=["a", "b", "c"], data=[(i, i * 2, 2**i) for i in range(10)]
)
artifact.add(table, "my_table")
wandb.log_artifact(artifact)
# 생성된 아티팩트를 사용하여 생성된 테이블을 검색합니다.
with wandb.init() as r:
artifact = r.use_artifact("my_dataset:latest")
table = artifact.get("my_table")
artifact를 Dataframe으로 변환하기
다음으로, 테이블을 데이터프레임으로 변환합니다.
# 이전 코드 예제에서 계속됩니다.
df = table.get_dataframe()
데이터 내보내기
이제 데이터프레임이 지원하는 모든 방법을 사용하여 내보낼 수 있습니다.
# 테이블 데이터를 .csv로 변환
df.to_csv("example.csv", encoding="utf-8")
다음 단계