W&B 인테그레이션을 사용하면 기존 프로젝트 내에서 실험 추적 및 데이터 버전 관리를 빠르고 쉽게 설정할 수 있습니다. PyTorch와 같은 ML 프레임워크, Hugging Face와 같은 ML 라이브러리 또는 Amazon SageMaker와 같은 클라우드 서비스에 대한 인테그레이션을 확인하세요.
관련 자료
Examples: 각 인테그레이션에 대한 노트북 및 스크립트 예제를 사용하여 코드를 사용해 보세요.
A. 사용자가 수동으로 설치하지 않고 wandb 기능을 사용하려고 할 때 오류를 발생시키고 적절한 오류 메시지를 표시합니다.
try:
import wandb
exceptImportError:
raiseImportError(
"You are trying to use wandb which is not currently installed.""Please install it using pip install wandb" )
B. Python 패키지를 빌드하는 경우 pyproject.toml 파일에 wandb를 선택적 종속성으로 추가합니다.
[project]
name = "my_awesome_lib"version = "0.1.0"dependencies = [
"torch",
"sklearn"]
[project.optional-dependencies]
dev = [
"wandb"]
사용자 로그인
API 키 만들기
API 키는 클라이언트 또는 머신을 W&B에 인증합니다. 사용자 프로필에서 API 키를 생성할 수 있습니다.
보다 간소화된 접근 방식을 위해 https://wandb.ai/authorize로 직접 이동하여 API 키를 생성할 수 있습니다. 표시된 API 키를 복사하여 비밀번호 관리자와 같은 안전한 위치에 저장하세요.
오른쪽 상단 모서리에 있는 사용자 프로필 아이콘을 클릭합니다.
사용자 설정을 선택한 다음 API 키 섹션으로 스크롤합니다.
표시를 클릭합니다. 표시된 API 키를 복사합니다. API 키를 숨기려면 페이지를 새로 고침합니다.
for epoch in range(NUM_EPOCHS):
for input, ground_truth in data:
prediction = model(input)
loss = loss_fn(prediction, ground_truth)
metrics = { "loss": loss }
run.log(metrics)
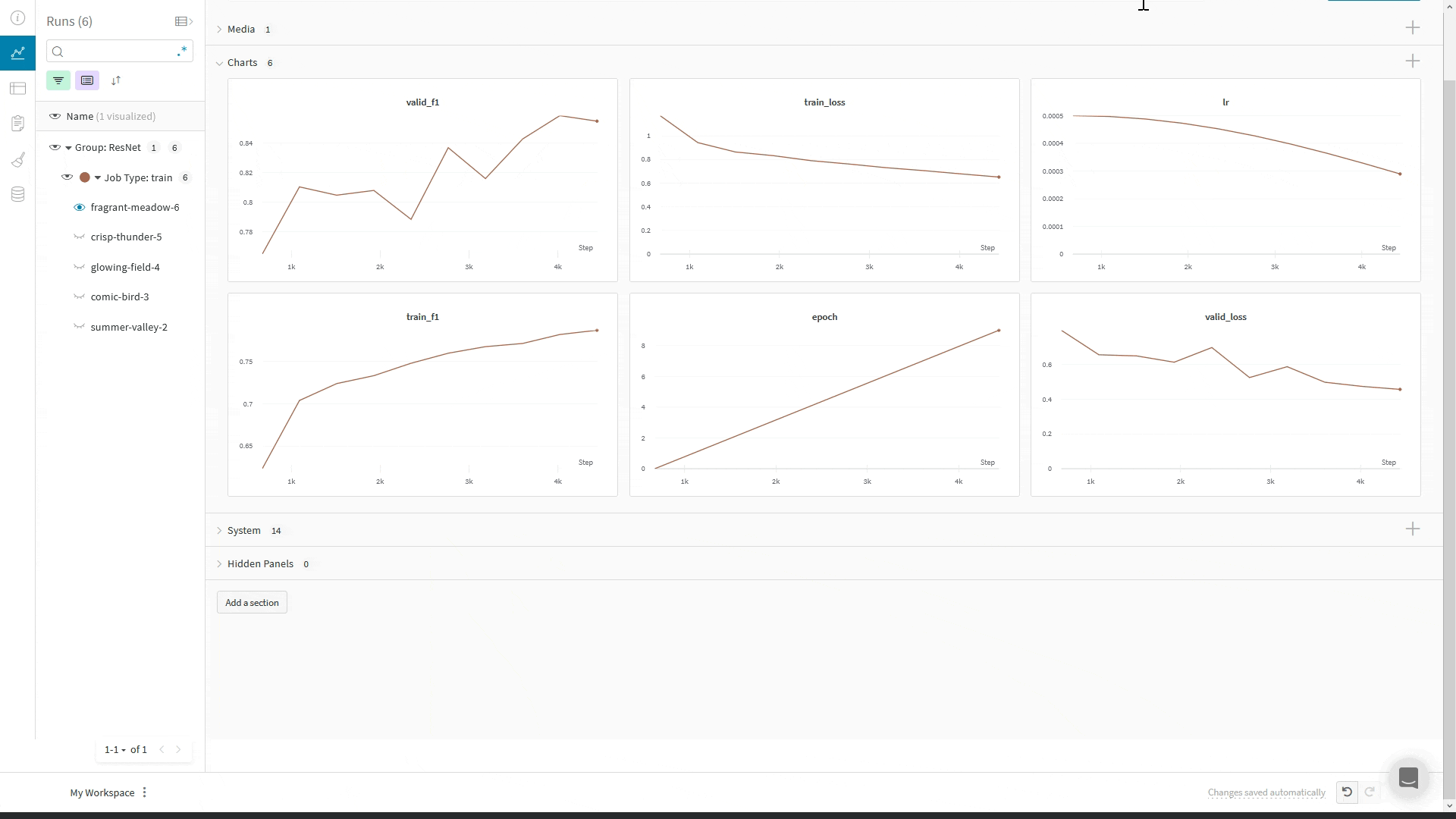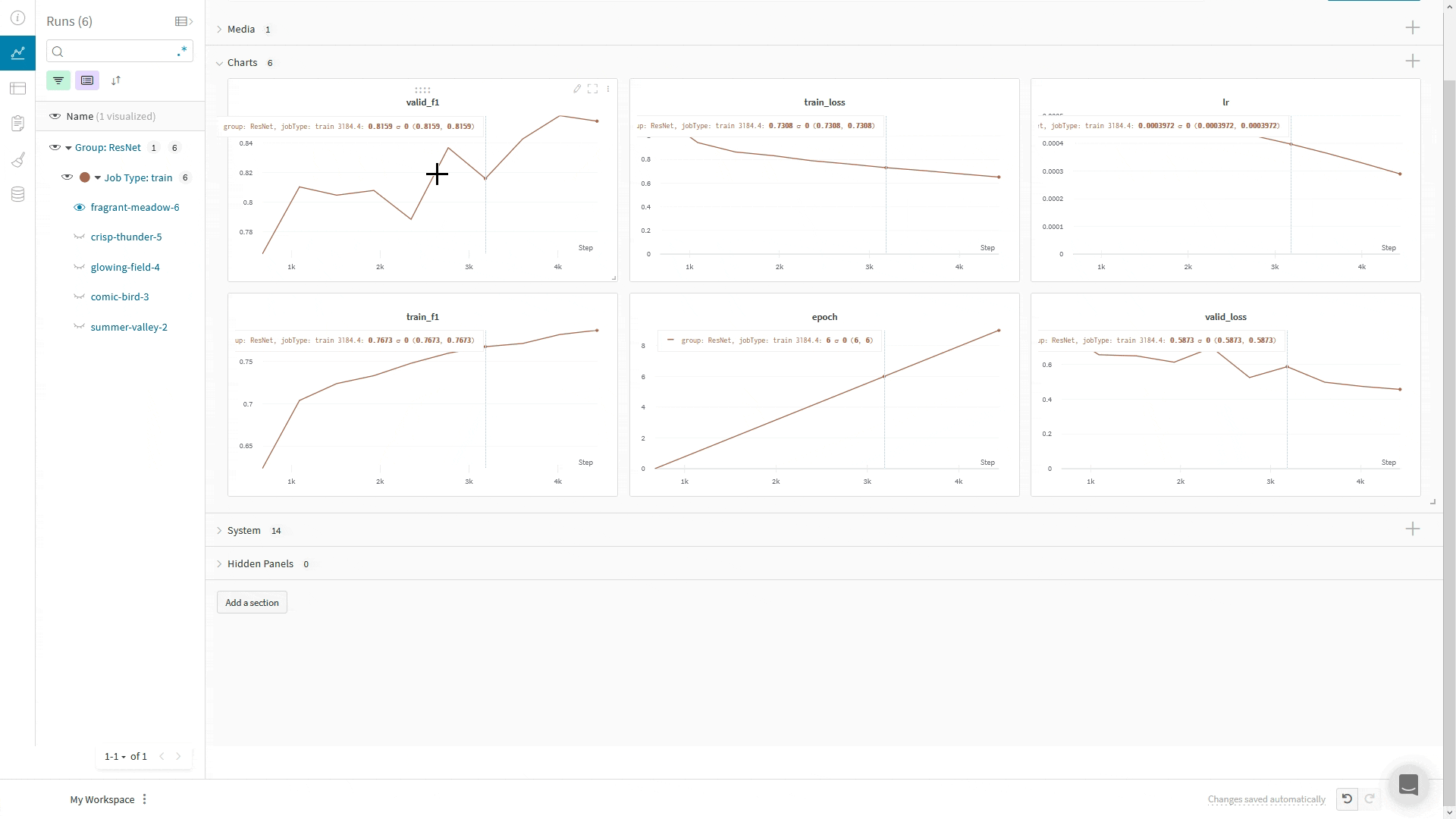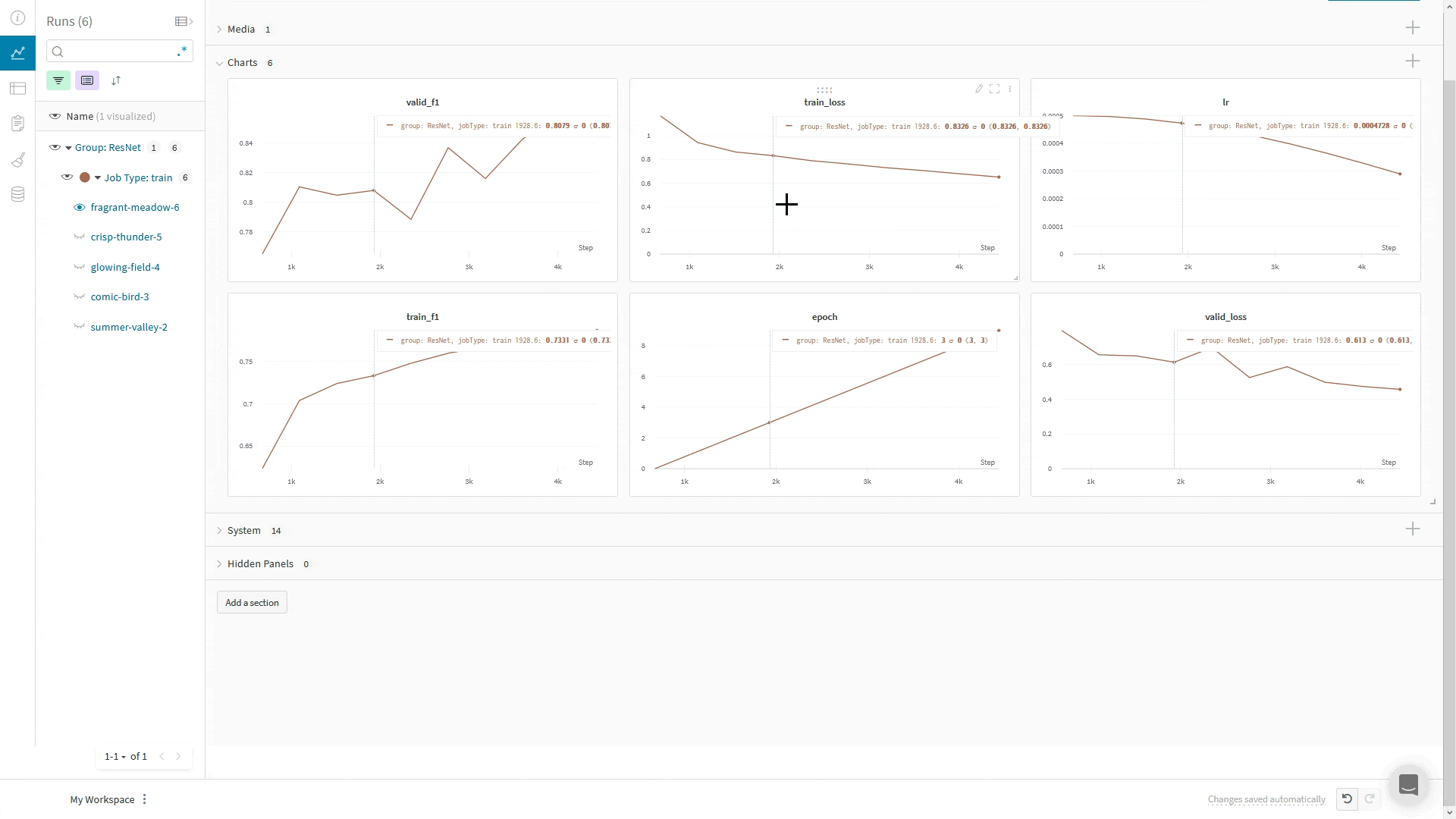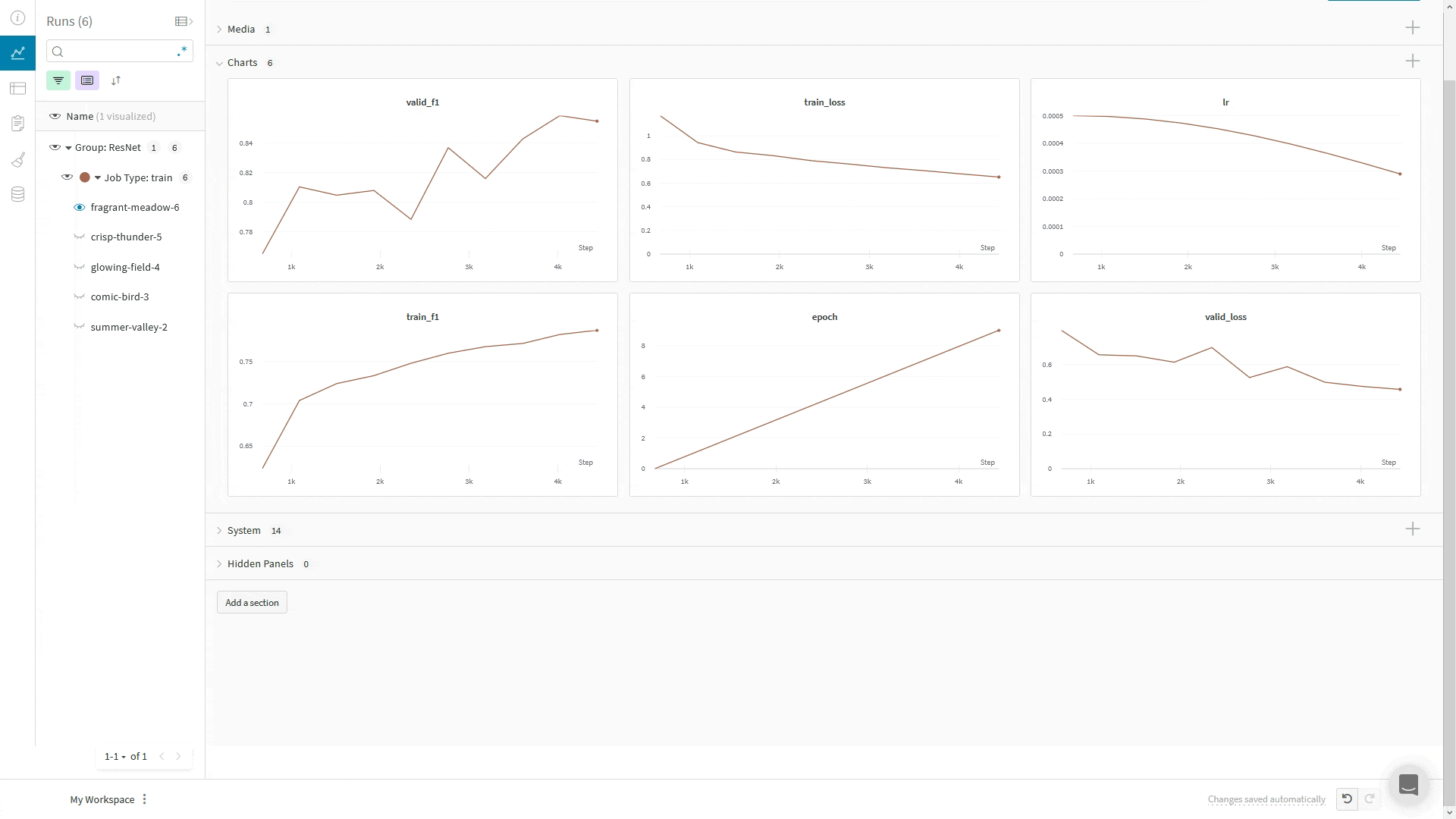
메트릭이 많은 경우 메트릭 이름에 train/... 및 val/...와 같은 접두사를 사용하여 UI에서 자동으로 그룹화할 수 있습니다. 이렇게 하면 트레이닝 및 검증 메트릭 또는 분리하려는 다른 메트릭 유형에 대해 W&B Workspace에 별도의 섹션이 생성됩니다.
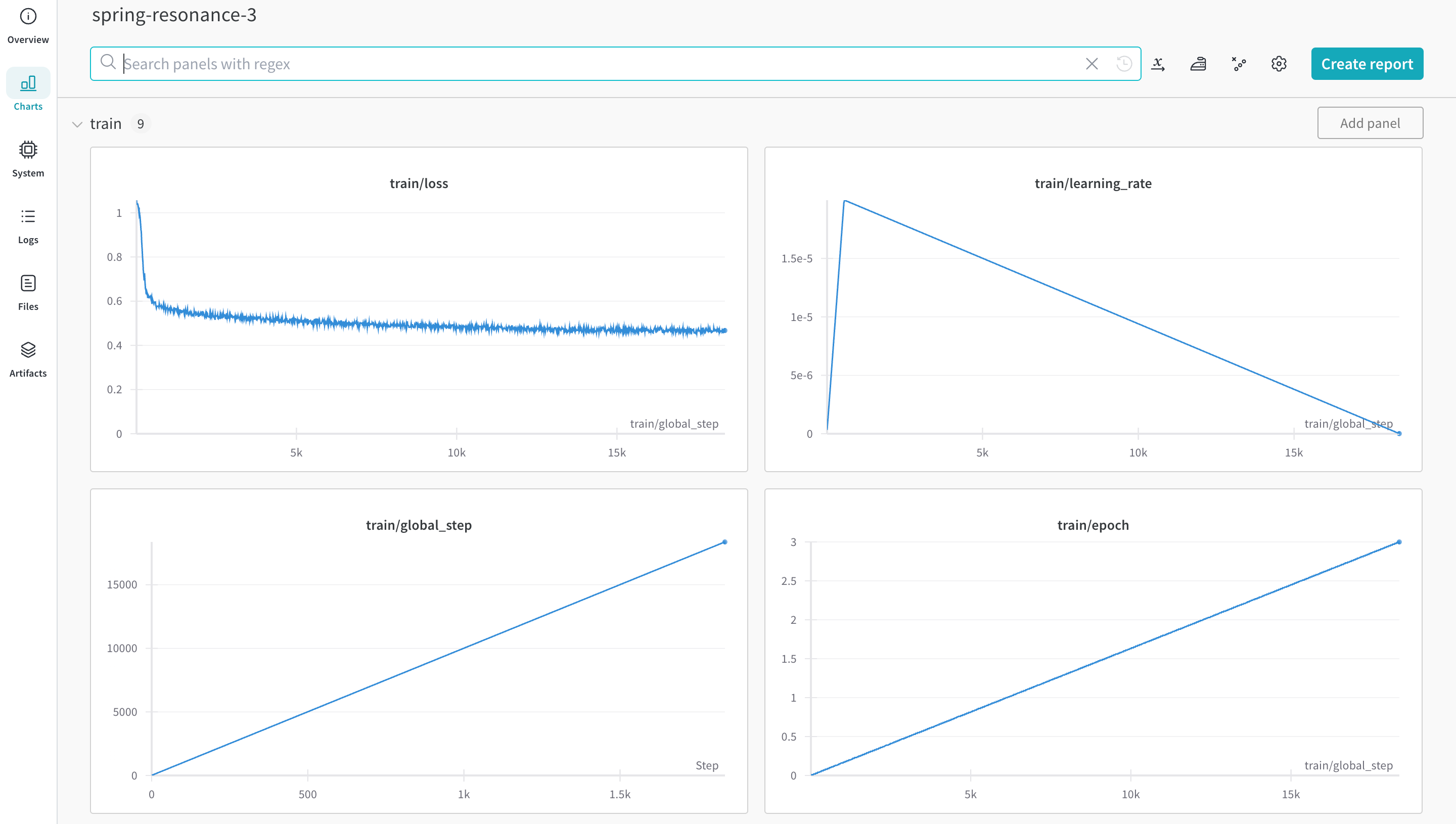
이제 run.log를 호출할 때마다 메트릭, step 메트릭 및 global_step을 로깅합니다.
for step, (input, ground_truth) in enumerate(data):
... run.log({"global_step": step, "train/loss": 0.1})
run.log({"global_step": step, "eval/loss": 0.2})
예를 들어 검증 루프 중에 “global_step"을 사용할 수 없는 경우 독립 단계 변수에 액세스할 수 없는 경우 “global_step"에 대해 이전에 로깅된 값이 wandb에서 자동으로 사용됩니다. 이 경우 메트릭에 필요한 경우 정의되도록 메트릭에 대한 초기 값을 로깅해야 합니다.
이미지, 테이블, 오디오 등 로깅
메트릭 외에도 플롯, 히스토그램, 테이블, 텍스트, 이미지, 비디오, 오디오, 3D 등과 같은 미디어를 로깅할 수 있습니다.
데이터 로깅 시 고려해야 할 사항은 다음과 같습니다.
메트릭을 얼마나 자주 로깅해야 할까요? 선택 사항이어야 할까요?
시각화하는 데 어떤 유형의 데이터가 도움이 될 수 있을까요?
이미지의 경우 시간 경과에 따른 진화를 확인하기 위해 샘플 예측, 분할 마스크 등을 로깅할 수 있습니다.
프레임워크에서 모델 또는 데이터셋을 사용하거나 생성하는 경우 전체 추적성을 위해 로깅하고 wandb가 W&B Artifacts를 통해 전체 파이프라인을 자동으로 모니터링하도록 할 수 있습니다.
Artifacts를 사용할 때 사용자가 다음을 정의하도록 하는 것이 유용하지만 필수는 아닙니다.
모델 체크포인트 또는 데이터셋을 로깅하는 기능(선택 사항으로 만들려는 경우).
입력으로 사용되는 아티팩트의 경로/참조(있는 경우). 예를 들어 user/project/artifact입니다.
Artifacts 로깅 빈도.
모델 체크포인트 로깅
모델 체크포인트를 W&B에 로깅할 수 있습니다. 고유한 wandb Run ID를 활용하여 출력 모델 체크포인트 이름을 지정하여 Runs 간에 차별화하는 것이 유용합니다. 유용한 메타데이터를 추가할 수도 있습니다. 또한 아래와 같이 각 모델에 에일리어스를 추가할 수도 있습니다.
W&B는 Databricks 환경에서 W&B Jupyter 노트북 경험을 사용자 정의하여 Databricks와 통합됩니다.
Databricks 설정
클러스터에 wandb 설치
클러스터 설정으로 이동하여 클러스터를 선택하고 Libraries를 클릭합니다. Install New를 클릭하고 PyPI를 선택한 다음 wandb 패키지를 추가합니다.
인증 설정
W&B 계정을 인증하려면 노트북이 쿼리할 수 있는 Databricks secret을 추가하면 됩니다.
# databricks cli 설치pip install databricks-cli
# databricks UI에서 토큰 생성databricks configure --token
# 다음 두 코맨드 중 하나를 사용하여 스코프를 생성합니다 (databricks에서 보안 기능 활성화 여부에 따라 다름).# 보안 추가 기능 사용databricks secrets create-scope --scope wandb
# 보안 추가 기능 미사용databricks secrets create-scope --scope wandb --initial-manage-principal users
# 다음 위치에서 api_key를 추가합니다: https://app.wandb.ai/authorizedatabricks secrets put --scope wandb --key api_key
DeepChecks를 Weights & Biases 와 함께 사용하려면 먼저 Weights & Biases 계정을 여기에서 가입해야 합니다. DeepChecks의 Weights & Biases 인테그레이션을 사용하면 다음과 같이 빠르게 시작할 수 있습니다.
import wandb
wandb.login()
# deepchecks에서 검사 가져오기from deepchecks.checks import ModelErrorAnalysis
# 검사 실행result = ModelErrorAnalysis()
# 해당 결과를 wandb로 푸시result.to_wandb()
전체 DeepChecks 테스트 스위트를 Weights & Biases 에 로그할 수도 있습니다.
import wandb
wandb.login()
# deepchecks에서 full_suite 테스트 가져오기from deepchecks.suites import full_suite
# DeepChecks 테스트 스위트 생성 및 실행suite_result = full_suite().run(...)
# thes 결과를 wandb로 푸시# 여기에서 필요한 wandb.init 구성 및 인수를 전달할 수 있습니다.suite_result.to_wandb(project="my-suite-project", config={"suite-name": "full-suite"})
예시
``이 Report는 DeepChecks와 Weights & Biases를 사용하는 강력한 기능을 보여줍니다.
DeepChem 라이브러리는 약물 발견, 재료 과학, 화학 및 생물학에서 딥러닝 사용을 대중화하는 오픈 소스 툴을 제공합니다. 이 W&B 인테그레이션은 DeepChem을 사용하여 모델을 트레이닝하는 동안 간단하고 사용하기 쉬운 experiment 추적 및 모델 체크포인팅을 추가합니다.
3줄의 코드로 DeepChem 로깅하기
logger = WandbLogger(…)
model = TorchModel(…, wandb_logger=logger)
model.fit(…)
트레이닝 손실 및 평가 메트릭은 W&B에 자동으로 기록될 수 있습니다. DeepChem ValidationCallback을 사용하여 선택적 평가를 활성화할 수 있습니다. WandbLogger는 ValidationCallback 콜백을 감지하고 생성된 메트릭을 기록합니다.
W&B는 코드 가 실행된 Docker 이미지에 대한 포인터를 저장하여 이전의 실험 을 정확한 환경 으로 복원할 수 있도록 합니다. wandb 라이브러리 는 이 상태 를 유지하기 위해 WANDB_DOCKER 환경 변수 를 찾습니다. 이 상태 를 자동으로 설정하는 몇 가지 도우미를 제공합니다.
로컬 개발
wandb docker 는 docker 컨테이너 를 시작하고, wandb 환경 변수 를 전달하고, 코드 를 마운트하고, wandb가 설치되었는지 확인하는 코맨드 입니다. 기본적으로 이 코맨드 는 TensorFlow, PyTorch, Keras 및 Jupyter가 설치된 docker 이미지 를 사용합니다. 동일한 코맨드 를 사용하여 자신의 docker 이미지 를 시작할 수 있습니다: wandb docker my/image:latest. 이 코맨드 는 현재 디렉토리 를 컨테이너 의 “/app” 디렉토리 에 마운트합니다. “–dir” 플래그 를 사용하여 이를 변경할 수 있습니다.
프로덕션
wandb docker-run 코맨드 는 프로덕션 워크로드 를 위해 제공됩니다. nvidia-docker 를 대체할 수 있도록 만들어졌습니다. 이는 docker run 코맨드 에 대한 간단한 래퍼 로, 자격 증명 과 WANDB_DOCKER 환경 변수 를 호출에 추가합니다. “–runtime” 플래그 를 전달하지 않고 시스템에서 nvidia-docker 를 사용할 수 있는 경우 런타임 이 nvidia로 설정됩니다.
Kubernetes
Kubernetes에서 트레이닝 워크로드 를 실행하고 k8s API가 Pod에 노출된 경우 (기본적으로 해당됨) wandb는 docker 이미지 의 다이제스트에 대해 API를 쿼리하고 WANDB_DOCKER 환경 변수 를 자동으로 설정합니다.
복원
WANDB_DOCKER 환경 변수 로 Run이 계측된 경우, wandb restore username/project:run_id 를 호출하면 코드 를 복원하는 새 분기를 체크아웃한 다음, 트레이닝 에 사용된 정확한 docker 이미지 를 원래 코맨드 로 미리 채워 시작합니다.
9 - Farama Gymnasium
Farama Gymnasium과 W&B를 통합하는 방법.
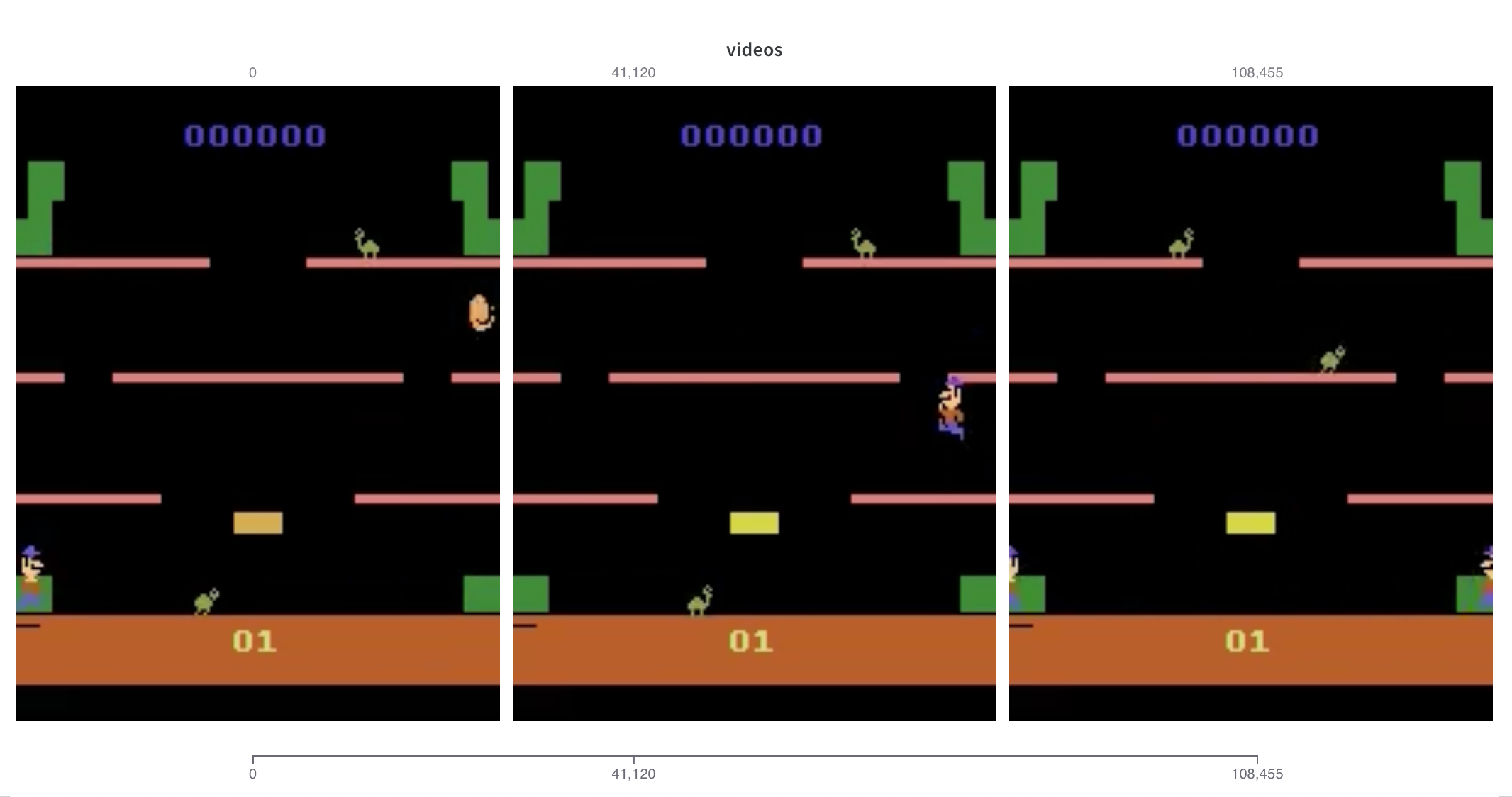
Farama Gymnasium을 사용하는 경우 gymnasium.wrappers.Monitor에서 생성된 환경의 비디오가 자동으로 기록됩니다. wandb.init에 대한 monitor_gym 키워드 인수를 True로 설정하기만 하면 됩니다.
Gymnasium 인테그레이션은 매우 간단합니다. gymnasium에서 기록된 비디오 파일의 이름을 확인하고, 그에 따라 이름을 지정하거나 일치하는 항목을 찾지 못하면 "videos"로 대체합니다. 더 많은 제어를 원한다면 언제든지 수동으로 비디오를 기록할 수 있습니다.
CleanRL 라이브러리와 함께 Gymnasium을 사용하는 방법에 대한 자세한 내용은 이 report를 확인하세요.
import wandb
from fastai.callback.wandb import*# wandb run 로깅 시작wandb.init(project="my_project")
# 하나의 트레이닝 단계에서만 로깅하려면learn.fit(..., cbs=WandbCallback())
# 모든 트레이닝 단계에서 지속적으로 로깅하려면learn = learner(..., cbs=WandbCallback())
위의 예에서 wandb는 프로세스당 하나의 run을 시작합니다. 트레이닝이 끝나면 두 개의 run이 생성됩니다. 이는 혼란스러울 수 있으며 메인 프로세스에서만 로그할 수 있습니다. 이렇게 하려면 어떤 프로세스에 있는지 수동으로 감지하고 다른 모든 프로세스에서 run 생성을 피해야 합니다 (wandb.init 호출).
Hugging Face Transformers 라이브러리를 사용하면 최첨단 NLP 모델(예: BERT)과 혼합 정밀도 및 그레이디언트 체크포인트와 같은 트레이닝 기술을 쉽게 사용할 수 있습니다. W&B 통합은 사용 편의성을 유지하면서도 대화형 중앙 집중식 대시보드에 풍부하고 유연한 실험 추적 및 모델 버전 관리를 추가합니다.
몇 줄의 코드로 차세대 로깅 구현
os.environ["WANDB_PROJECT"] ="<my-amazing-project>"# W&B 프로젝트 이름 지정os.environ["WANDB_LOG_MODEL"] ="checkpoint"# 모든 모델 체크포인트 로깅from transformers import TrainingArguments, Trainer
args = TrainingArguments(..., report_to="wandb") # W&B 로깅 켜기trainer = Trainer(..., args=args)
W&B Project는 관련 Runs에서 기록된 모든 차트, 데이터 및 Models가 저장되는 곳입니다. 프로젝트 이름을 지정하면 작업을 구성하고 단일 프로젝트에 대한 모든 정보를 한 곳에 보관하는 데 도움이 됩니다.
Run을 프로젝트에 추가하려면 WANDB_PROJECT 환경 변수를 프로젝트 이름으로 설정하기만 하면 됩니다. WandbCallback은 이 프로젝트 이름 환경 변수를 가져와 Run을 설정할 때 사용합니다.
WANDB_PROJECT=amazon_sentiment_analysis
import os
os.environ["WANDB_PROJECT"]="amazon_sentiment_analysis"
%env WANDB_PROJECT=amazon_sentiment_analysis
Trainer를 초기화하기 전에 프로젝트 이름을 설정해야 합니다.
프로젝트 이름이 지정되지 않은 경우 프로젝트 이름은 기본적으로 huggingface로 설정됩니다.
트레이닝 Runs를 W&B에 로깅
Trainer 트레이닝 인수를 정의할 때 코드 내부 또는 커맨드라인에서 가장 중요한 단계는 W&B를 사용하여 로깅을 활성화하기 위해 report_to를 "wandb"로 설정하는 것입니다.
TrainingArguments의 logging_steps 인수는 트레이닝 중에 트레이닝 메트릭이 W&B로 푸시되는 빈도를 제어합니다. run_name 인수를 사용하여 W&B에서 트레이닝 Run의 이름을 지정할 수도 있습니다.
이제 모델이 트레이닝하는 동안 손실, 평가 메트릭, 모델 토폴로지 및 그레이디언트를 W&B에 로깅합니다.
python run_glue.py \ # Python 스크립트 실행 --report_to wandb \ # W&B에 로깅 활성화 --run_name bert-base-high-lr \ # W&B Run 이름(선택 사항)# 기타 커맨드라인 인수
from transformers import TrainingArguments, Trainer
args = TrainingArguments(
# 기타 인수 및 kwargs report_to="wandb", # W&B에 로깅 활성화 run_name="bert-base-high-lr", # W&B Run 이름(선택 사항) logging_steps=1, # W&B에 로깅 빈도)
trainer = Trainer(
# 기타 인수 및 kwargs args=args, # 트레이닝 인수)
trainer.train() # 트레이닝을 시작하고 W&B에 로깅
TensorFlow를 사용하고 계신가요? PyTorch Trainer를 TensorFlow TFTrainer로 바꾸기만 하세요.
모델 체크포인트 설정
Artifacts를 사용하면 최대 100GB의 Models 및 Datasets를 무료로 저장한 다음 Weights & Biases Registry를 사용할 수 있습니다. Registry를 사용하면 Models를 등록하여 탐색하고 평가하고, 스테이징을 준비하거나 프로덕션 환경에 배포할 수 있습니다.
Hugging Face 모델 체크포인트를 Artifacts에 로깅하려면 WANDB_LOG_MODEL 환경 변수를 다음 _중 하나_로 설정합니다.
end: load_best_model_at_end도 설정된 경우 트레이닝이 끝나면 모델을 업로드합니다.
false: 모델을 업로드하지 않습니다.
WANDB_LOG_MODEL="checkpoint"
import os
os.environ["WANDB_LOG_MODEL"] ="checkpoint"
%env WANDB_LOG_MODEL="checkpoint"
이제부터 초기화하는 모든 Transformers Trainer는 Models를 W&B Project에 업로드합니다. 로깅하는 모델 체크포인트는 Artifacts UI를 통해 볼 수 있으며 전체 모델 계보가 포함됩니다(UI에서 예제 모델 체크포인트를 보려면 여기 참조).
기본적으로 WANDB_LOG_MODEL이 end로 설정된 경우 모델은 model-{run_id}로 W&B Artifacts에 저장되고, WANDB_LOG_MODEL이 checkpoint로 설정된 경우 checkpoint-{run_id}로 저장됩니다.
그러나 TrainingArguments에서 run_name을 전달하면 모델은 model-{run_name} 또는 checkpoint-{run_name}로 저장됩니다.
W&B Registry
체크포인트를 Artifacts에 로깅한 후에는 **Registry**를 사용하여 최고의 모델 체크포인트를 등록하고 팀 전체에서 중앙 집중화할 수 있습니다. Registry를 사용하면 작업별로 최고의 Models를 구성하고, Models의 라이프사이클을 관리하고, 전체 ML 라이프사이클을 추적 및 감사하고, 다운스트림 작업을 자동화할 수 있습니다.
트레이닝 또는 평가 중 모델 출력을 시각화하는 것은 모델 트레이닝 방식을 실제로 이해하는 데 종종 필수적입니다.
Transformers Trainer의 콜백 시스템을 사용하면 모델의 텍스트 생성 출력 또는 기타 예측과 같은 추가적인 유용한 데이터를 W&B Tables에 로깅할 수 있습니다.
아래의 **사용자 지정 로깅 섹션**에서 트레이닝 중 평가 출력을 로깅하여 다음과 같은 W&B Table에 로깅하는 방법에 대한 전체 가이드를 참조하세요.
W&B Run 종료(노트북 전용)
트레이닝이 Python 스크립트에 캡슐화된 경우 스크립트가 완료되면 W&B Run이 종료됩니다.
Jupyter 또는 Google Colab 노트북을 사용하는 경우 wandb.finish()를 호출하여 트레이닝이 완료되었음을 알려야 합니다.
trainer.train() # 트레이닝을 시작하고 W&B에 로깅# 트레이닝 후 분석, 테스트, 기타 로깅된 코드wandb.finish()
결과 시각화
트레이닝 결과를 로깅했으면 W&B Dashboard에서 결과를 동적으로 탐색할 수 있습니다. 유연하고 대화형 시각화를 통해 한 번에 수십 개의 Runs를 비교하고, 흥미로운 발견을 확대하고, 복잡한 데이터에서 통찰력을 얻는 것이 쉽습니다.
고급 기능 및 FAQ
최고의 모델을 저장하는 방법은 무엇인가요?
TrainingArguments를 load_best_model_at_end=True로 Trainer에 전달하면 W&B는 가장 성능이 좋은 모델 체크포인트를 Artifacts에 저장합니다.
모델 체크포인트를 Artifacts로 저장하는 경우 Registry로 승격할 수 있습니다. Registry에서 다음을 수행할 수 있습니다.
ML 작업별로 최고의 모델 버전을 구성합니다.
Models를 중앙 집중화하고 팀과 공유합니다.
프로덕션을 위해 Models를 스테이징하거나 추가 평가를 위해 북마크합니다.
다운스트림 CI/CD 프로세스를 트리거합니다.
저장된 모델을 로드하는 방법은 무엇인가요?
WANDB_LOG_MODEL을 사용하여 모델을 W&B Artifacts에 저장한 경우 추가 트레이닝을 위해 또는 추론을 실행하기 위해 모델 가중치를 다운로드할 수 있습니다. 이전과 동일한 Hugging Face 아키텍처에 다시 로드하기만 하면 됩니다.
# 새 Run 만들기with wandb.init(project="amazon_sentiment_analysis") as run:
# Artifact 이름 및 버전 전달 my_model_name ="model-bert-base-high-lr:latest" my_model_artifact = run.use_artifact(my_model_name)
# 모델 가중치를 폴더에 다운로드하고 경로 반환 model_dir = my_model_artifact.download()
# 동일한 모델 클래스를 사용하여 해당 폴더에서 Hugging Face 모델 로드 model = AutoModelForSequenceClassification.from_pretrained(
model_dir, num_labels=num_labels
)
# 추가 트레이닝 또는 추론 실행
체크포인트에서 트레이닝을 재개하는 방법은 무엇인가요?
WANDB_LOG_MODEL='checkpoint'를 설정한 경우 model_dir을 TrainingArguments의 model_name_or_path 인수로 사용하고 resume_from_checkpoint=True를 Trainer에 전달하여 트레이닝을 재개할 수도 있습니다.
last_run_id ="xxxxxxxx"# wandb Workspace에서 run_id 가져오기# run_id에서 W&B Run 재개with wandb.init(
project=os.environ["WANDB_PROJECT"],
id=last_run_id,
resume="must",
) as run:
# Artifact를 Run에 연결 my_checkpoint_name =f"checkpoint-{last_run_id}:latest" my_checkpoint_artifact = run.use_artifact(my_model_name)
# 체크포인트를 폴더에 다운로드하고 경로 반환 checkpoint_dir = my_checkpoint_artifact.download()
# 모델 및 Trainer 다시 초기화 model = AutoModelForSequenceClassification.from_pretrained(
"<model_name>", num_labels=num_labels
)
# 멋진 트레이닝 인수 training_args = TrainingArguments()
trainer = Trainer(model=model, args=training_args)
# 체크포인트 디렉터리를 사용하여 체크포인트에서 트레이닝을 재개해야 합니다. trainer.train(resume_from_checkpoint=checkpoint_dir)
트레이닝 중에 평가 샘플을 로깅하고 보는 방법
Transformers Trainer를 통해 W&B에 로깅하는 것은 Transformers 라이브러리의 WandbCallback에서 처리합니다. Hugging Face 로깅을 사용자 지정해야 하는 경우 WandbCallback을 서브클래싱하고 Trainer 클래스의 추가적인 메서드를 활용하는 추가적인 기능을 추가하여 이 콜백을 수정할 수 있습니다.
아래는 이 새로운 콜백을 HF Trainer에 추가하는 일반적인 패턴이며, 아래에는 평가 출력을 W&B Table에 로깅하는 코드 완성 예제가 있습니다.
환경 변수를 설정하여 Trainer로 로깅되는 항목을 추가로 구성할 수 있습니다. W&B 환경 변수의 전체 목록은 여기에서 찾을 수 있습니다.
환경 변수
사용법
WANDB_PROJECT
프로젝트 이름 지정(기본값: huggingface)
WANDB_LOG_MODEL
모델 체크포인트를 W&B Artifact로 로깅(기본값: false)
false(기본값): 모델 체크포인트 없음
checkpoint: 체크포인트는 모든 args.save_steps마다 업로드됩니다(Trainer의 TrainingArguments에서 설정).
end: 최종 모델 체크포인트는 트레이닝이 끝나면 업로드됩니다.
WANDB_WATCH
모델 그레이디언트, 파라미터 또는 둘 다를 로깅할지 여부 설정
false(기본값): 그레이디언트 또는 파라미터 로깅 없음
gradients: 그레이디언트의 히스토그램 로깅
all: 그레이디언트 및 파라미터의 히스토그램 로깅
WANDB_DISABLED
true로 설정하여 로깅을 완전히 끕니다(기본값: false)
WANDB_SILENT
true로 설정하여 wandb에서 인쇄된 출력을 표시하지 않습니다(기본값: false)
WANDB_WATCH=all
WANDB_SILENT=true
%env WANDB_WATCH=all
%env WANDB_SILENT=true
wandb.init를 사용자 지정하는 방법은 무엇인가요?
Trainer가 사용하는 WandbCallback은 Trainer가 초기화될 때 내부적으로 wandb.init를 호출합니다. 또는 Trainer를 초기화하기 전에 wandb.init를 호출하여 Run을 수동으로 설정할 수 있습니다. 이렇게 하면 W&B Run 구성을 완전히 제어할 수 있습니다.
init에 전달할 수 있는 예는 아래와 같습니다. wandb.init를 사용하는 방법에 대한 자세한 내용은 참조 설명서를 확인하세요.
Hugging Face Diffusers는 이미지, 오디오, 심지어 분자의 3D 구조를 생성하기 위한 최첨단 사전학습된 diffusion model을 위한 라이브러리입니다. Weights & Biases 인테그레이션은 사용 편의성을 유지하면서도 대화형 중앙 집중식 대시보드에 풍부하고 유연한 실험 추적, 미디어 시각화, 파이프라인 아키텍처 및 설정 관리를 추가합니다.
단 두 줄로 차원이 다른 로깅을 경험하세요
단 2줄의 코드를 추가하는 것만으로도 실험과 관련된 모든 프롬프트, 부정적 프롬프트, 생성된 미디어 및 설정을 기록할 수 있습니다. 다음은 로깅을 시작하기 위한 2줄의 코드입니다.
# import the autolog functionfrom wandb.integration.diffusers import autolog
# call the autolog before calling the pipelineautolog(init=dict(project="diffusers_logging"))
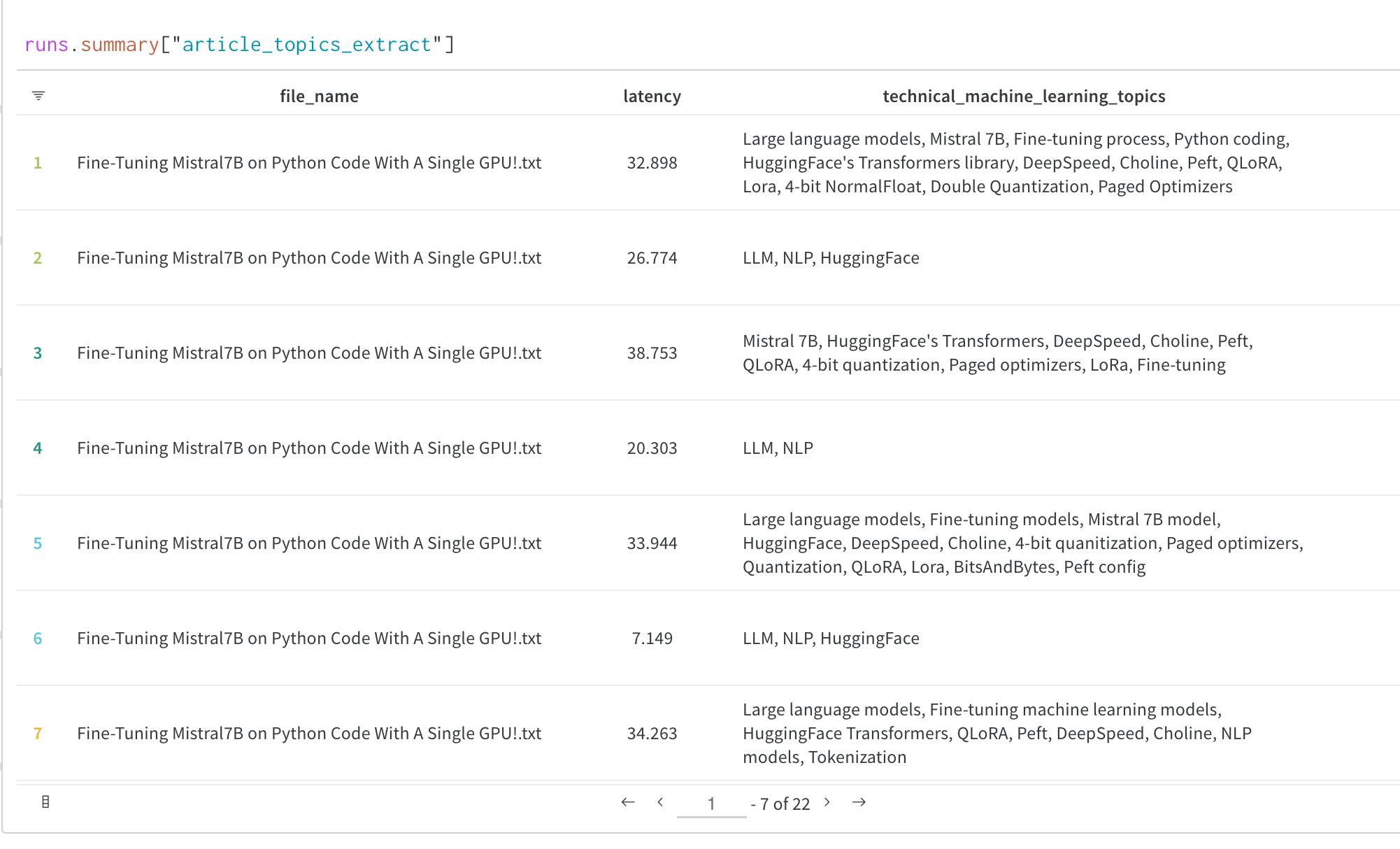
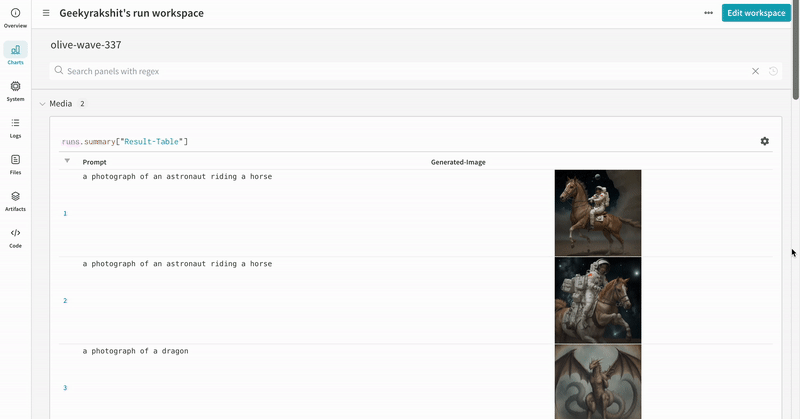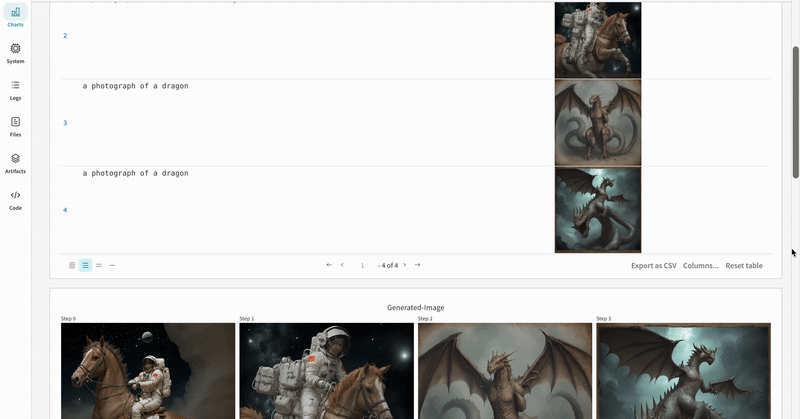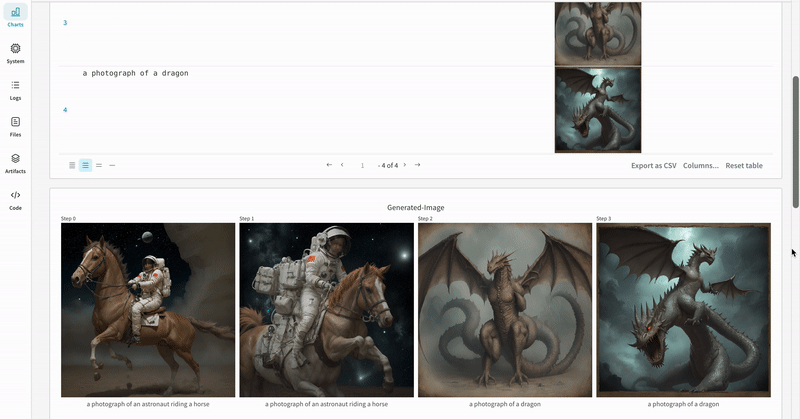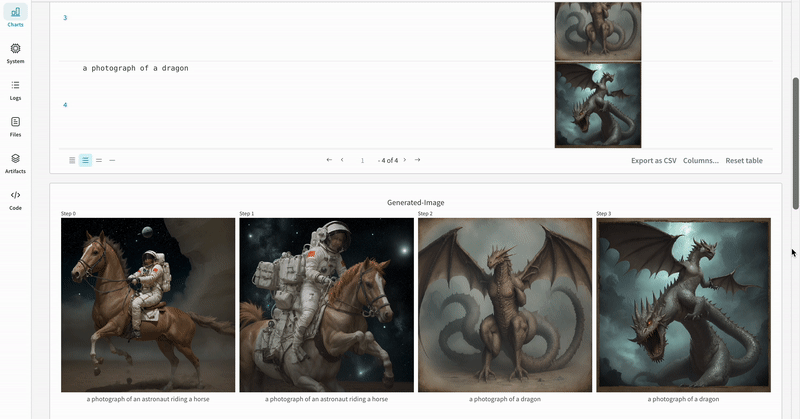
실험 결과가 기록되는 방식의 예시입니다.
시작하기
diffusers, transformers, accelerate 및 wandb를 설치합니다.
지원되는 파이프라인 호출 목록은 [여기](https://github.com/wandb/wandb/blob/main/wandb/integration/diffusers/autologger.py#L12-L72)에서 확인할 수 있습니다. 이 인테그레이션의 새로운 기능을 요청하거나 관련 버그를 보고하려면 [https://github.com/wandb/wandb/issues](https://github.com/wandb/wandb/issues)에 이슈를 여십시오.
예시
Autologging
다음은 autolog의 간단한 엔드투엔드 예시입니다.
import torch
from diffusers import DiffusionPipeline
# import the autolog functionfrom wandb.integration.diffusers import autolog
# call the autolog before calling the pipelineautolog(init=dict(project="diffusers_logging"))
# Initialize the diffusion pipelinepipeline = DiffusionPipeline.from_pretrained(
"stabilityai/stable-diffusion-2-1", torch_dtype=torch.float16
).to("cuda")
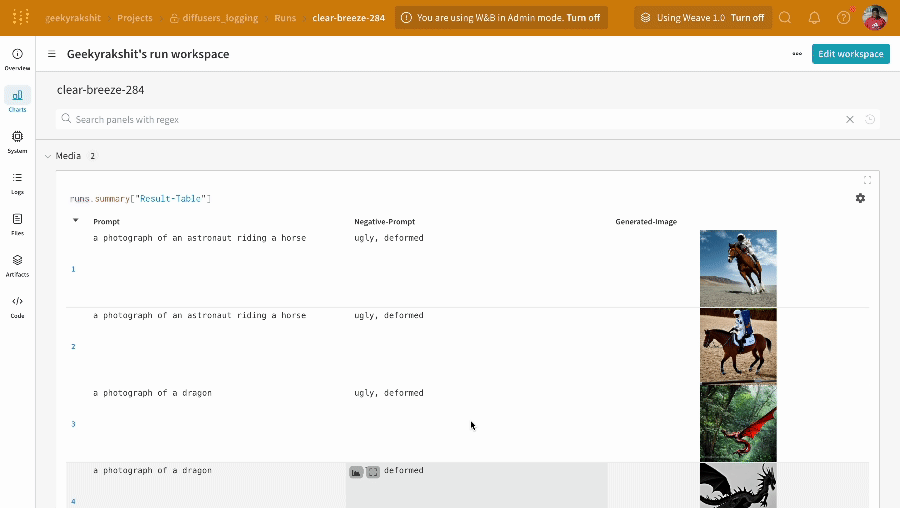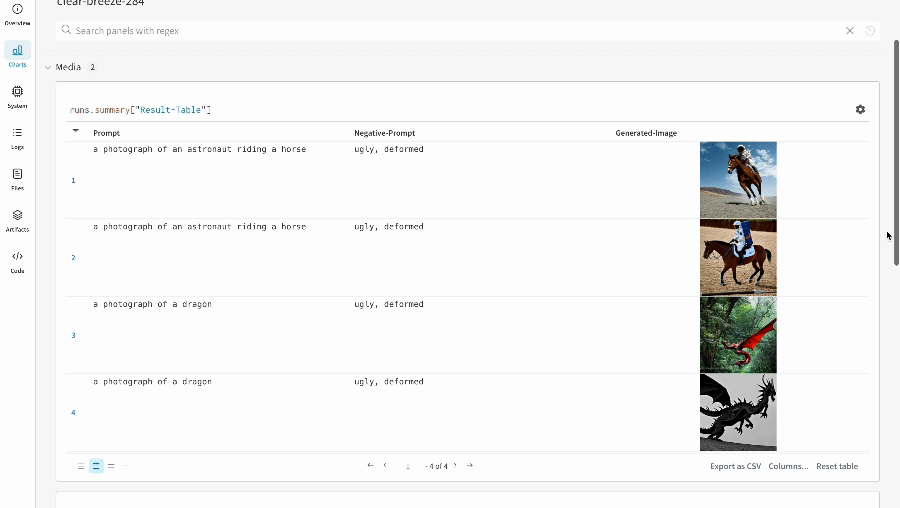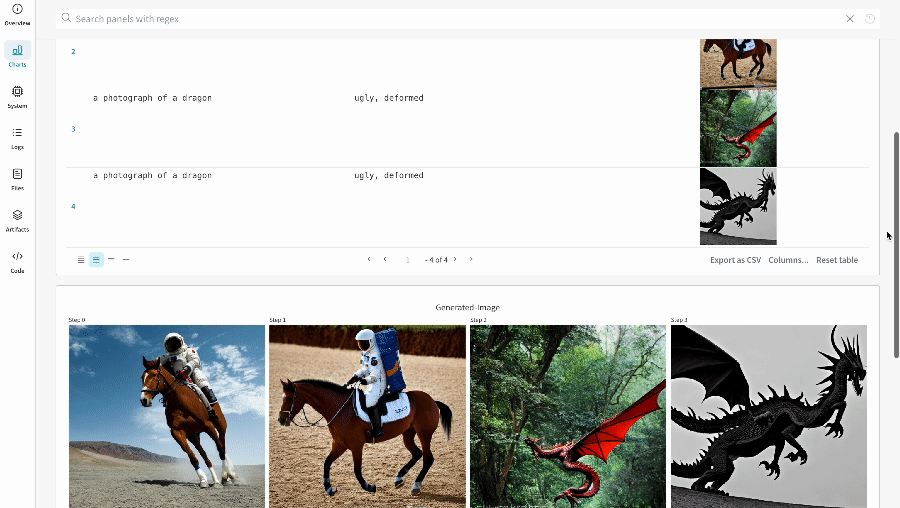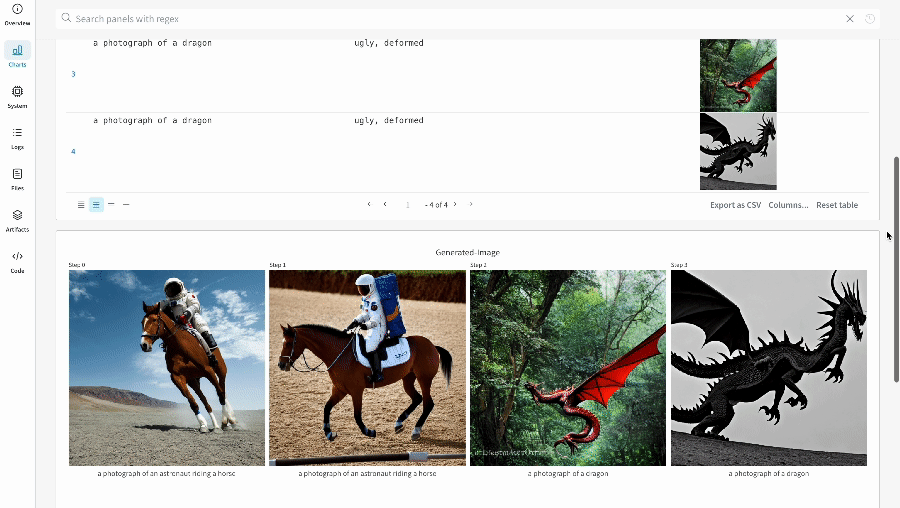
# Define the prompts, negative prompts, and seed.prompt = ["a photograph of an astronaut riding a horse", "a photograph of a dragon"]
negative_prompt = ["ugly, deformed", "ugly, deformed"]
generator = torch.Generator(device="cpu").manual_seed(10)
# call the pipeline to generate the imagesimages = pipeline(
prompt,
negative_prompt=negative_prompt,
num_images_per_prompt=2,
generator=generator,
)
import torch
from diffusers import DiffusionPipeline
import wandb
# import the autolog functionfrom wandb.integration.diffusers import autolog
# call the autolog before calling the pipelineautolog(init=dict(project="diffusers_logging"))
# Initialize the diffusion pipelinepipeline = DiffusionPipeline.from_pretrained(
"stabilityai/stable-diffusion-2-1", torch_dtype=torch.float16
).to("cuda")
# Define the prompts, negative prompts, and seed.prompt = ["a photograph of an astronaut riding a horse", "a photograph of a dragon"]
negative_prompt = ["ugly, deformed", "ugly, deformed"]
generator = torch.Generator(device="cpu").manual_seed(10)
# call the pipeline to generate the imagesimages = pipeline(
prompt,
negative_prompt=negative_prompt,
num_images_per_prompt=2,
generator=generator,
)
# Finish the experimentwandb.finish()
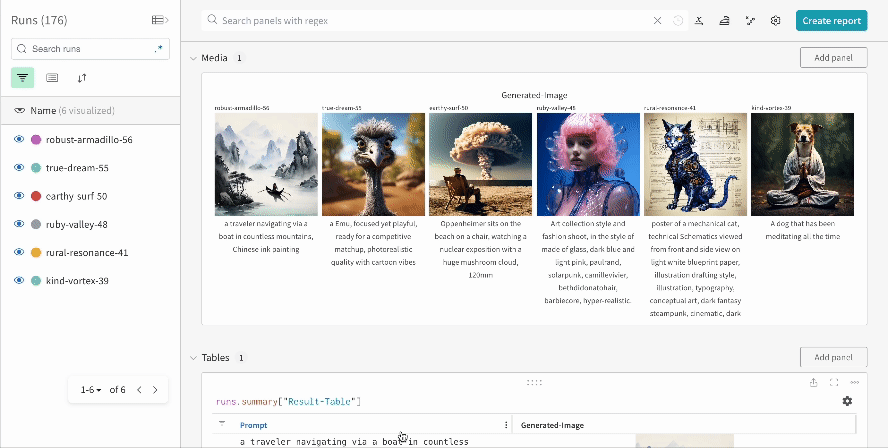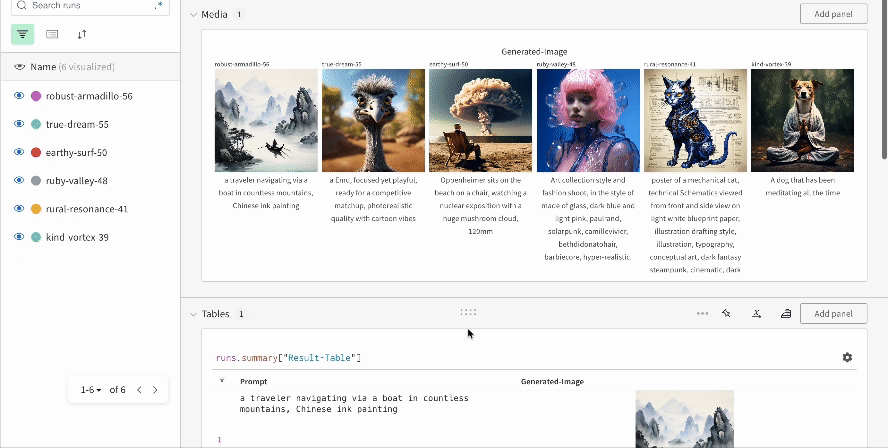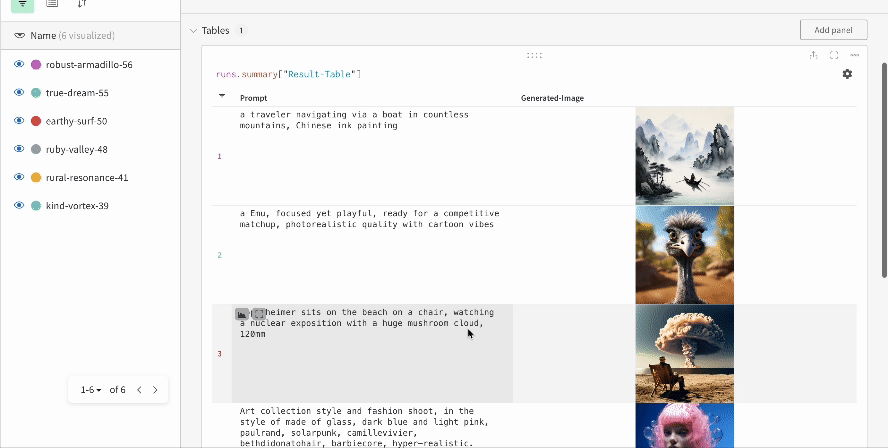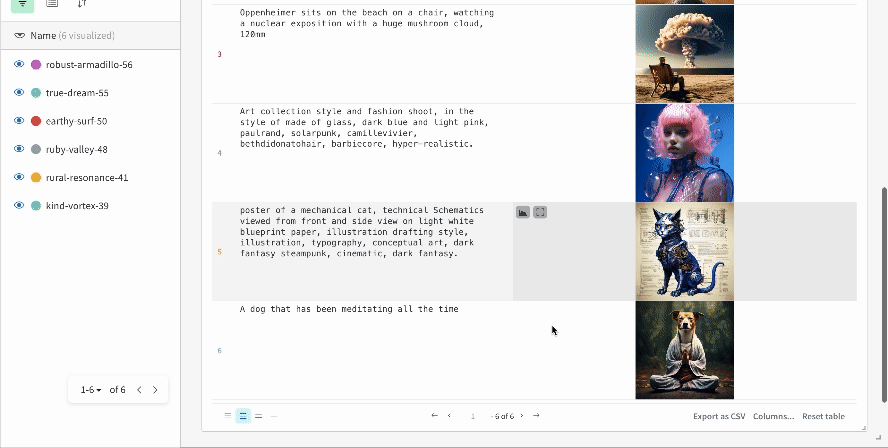
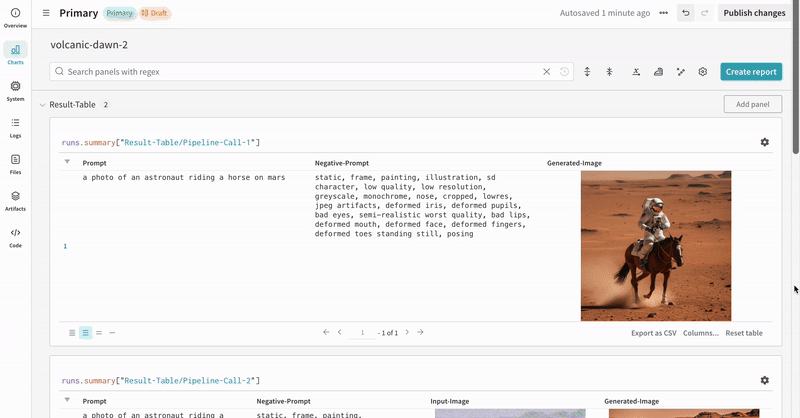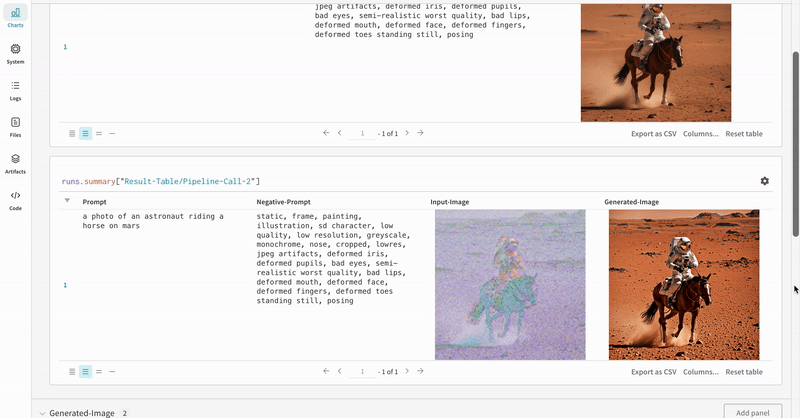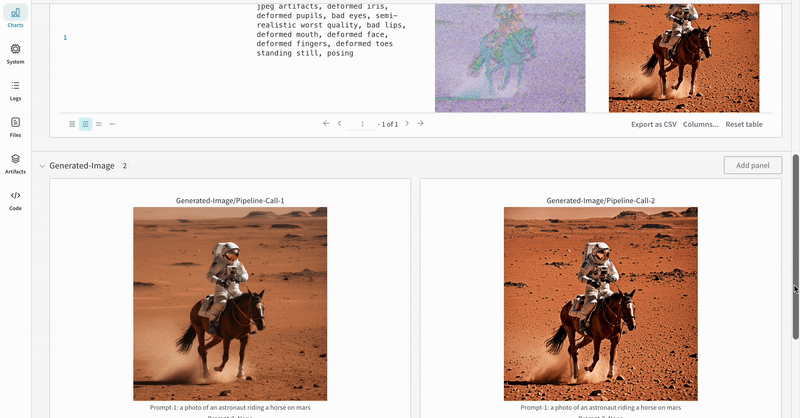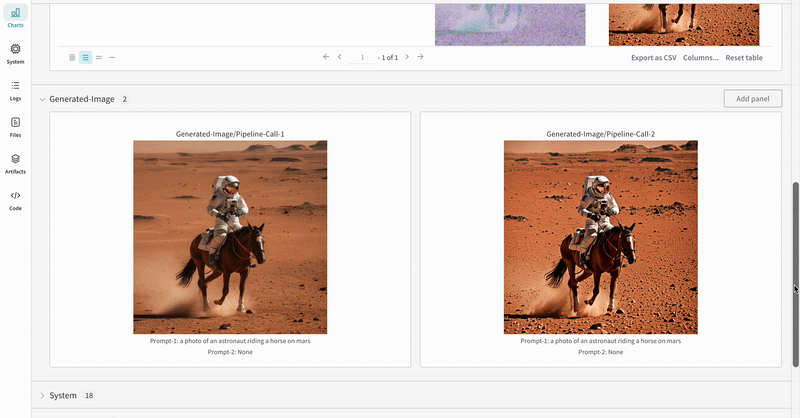
단일 실험의 결과:
여러 실험의 결과:
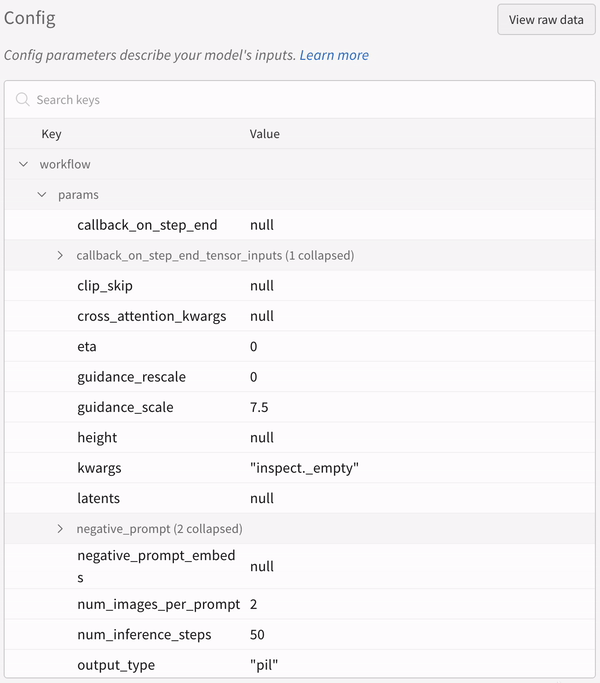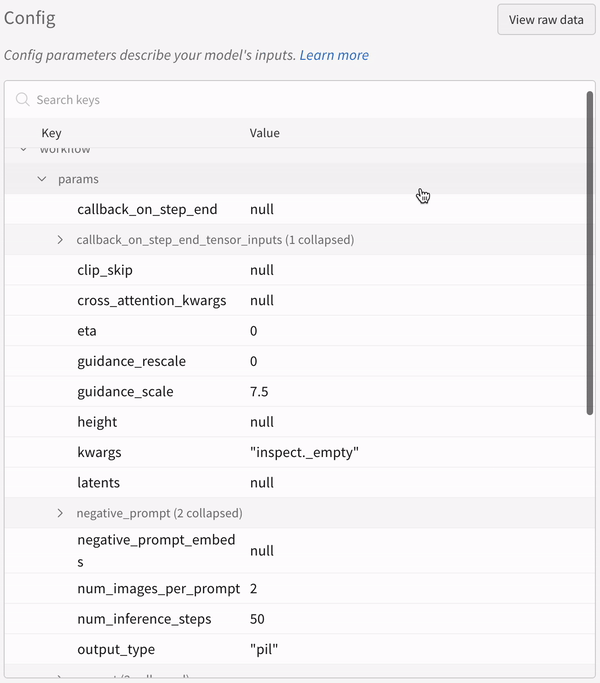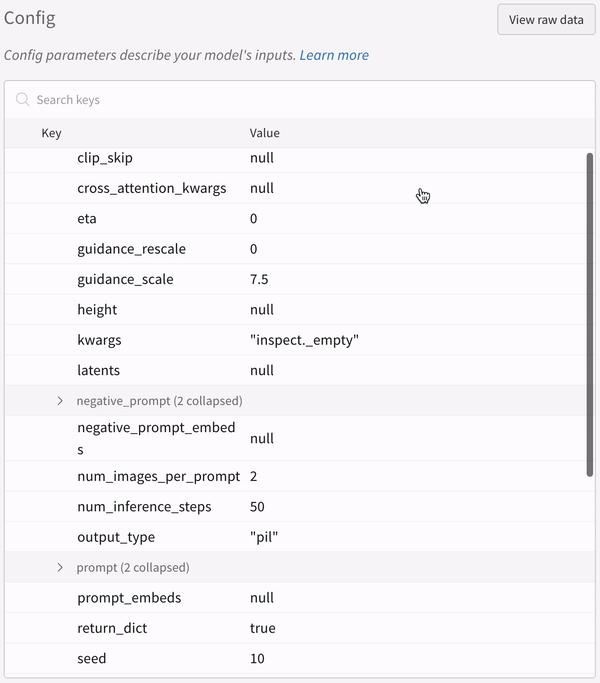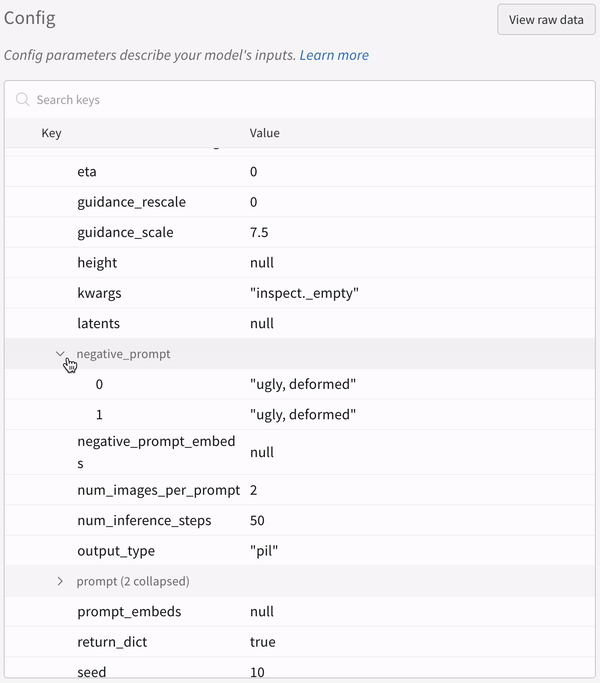
실험의 설정:
파이프라인을 호출한 후 IPython 노트북 환경에서 코드를 실행할 때는 wandb.finish()를 명시적으로 호출해야 합니다. Python 스크립트를 실행할 때는 필요하지 않습니다.
Hugging Face AutoTrain은 자연어 처리 (NLP) 작업, 컴퓨터 비전 (CV) 작업, 음성 작업 및 테이블 형식 작업을 위한 최첨단 모델을 트레이닝하는 노코드 툴입니다.
Weights & Biases는 Hugging Face AutoTrain에 직접 통합되어 experiment 추적 및 config 관리를 제공합니다. 실험을 위해 CLI 코맨드에서 단일 파라미터를 사용하는 것만큼 쉽습니다.
필수 조건 설치
autotrain-advanced 및 wandb를 설치합니다.
pip install --upgrade autotrain-advanced wandb
!pip install --upgrade autotrain-advanced wandb
이러한 변경 사항을 보여주기 위해 이 페이지에서는 수학 데이터셋에서 LLM을 fine-tune하여 GSM8k Benchmarks에서 pass@1로 SoTA 결과를 달성합니다.
데이터셋 준비
Hugging Face AutoTrain은 제대로 작동하기 위해 CSV 커스텀 데이터셋에 특정 형식이 필요합니다.
트레이닝 파일에는 트레이닝에 사용되는 text 열이 있어야 합니다. 최상의 결과를 얻으려면 text 열의 데이터가 ### Human: Question?### Assistant: Answer. 형식을 준수해야 합니다. timdettmers/openassistant-guanaco에서 훌륭한 예를 검토하십시오.
그러나 MetaMathQA 데이터셋에는 query, response 및 type 열이 포함되어 있습니다. 먼저 이 데이터셋을 전처리합니다. type 열을 제거하고 query 및 response 열의 내용을 ### Human: Query?### Assistant: Response. 형식의 새 text 열로 결합합니다. 트레이닝은 결과 데이터셋인 rishiraj/guanaco-style-metamath를 사용합니다.
autotrain을 사용하여 트레이닝
커맨드 라인 또는 노트북에서 autotrain advanced를 사용하여 트레이닝을 시작할 수 있습니다. --log 인수를 사용하거나 --log wandb를 사용하여 결과를 W&B run에 기록합니다.
Hydra는 구성 사전에 연결하는 기본 방법으로 omegaconf를 사용합니다. OmegaConf의 사전은 기본 사전의 서브클래스가 아니므로 Hydra의 Config를 wandb.config에 직접 전달하면 대시보드에서 예기치 않은 결과가 발생합니다. omegaconf.DictConfig를 wandb.config에 전달하기 전에 기본 dict 유형으로 변환해야 합니다.
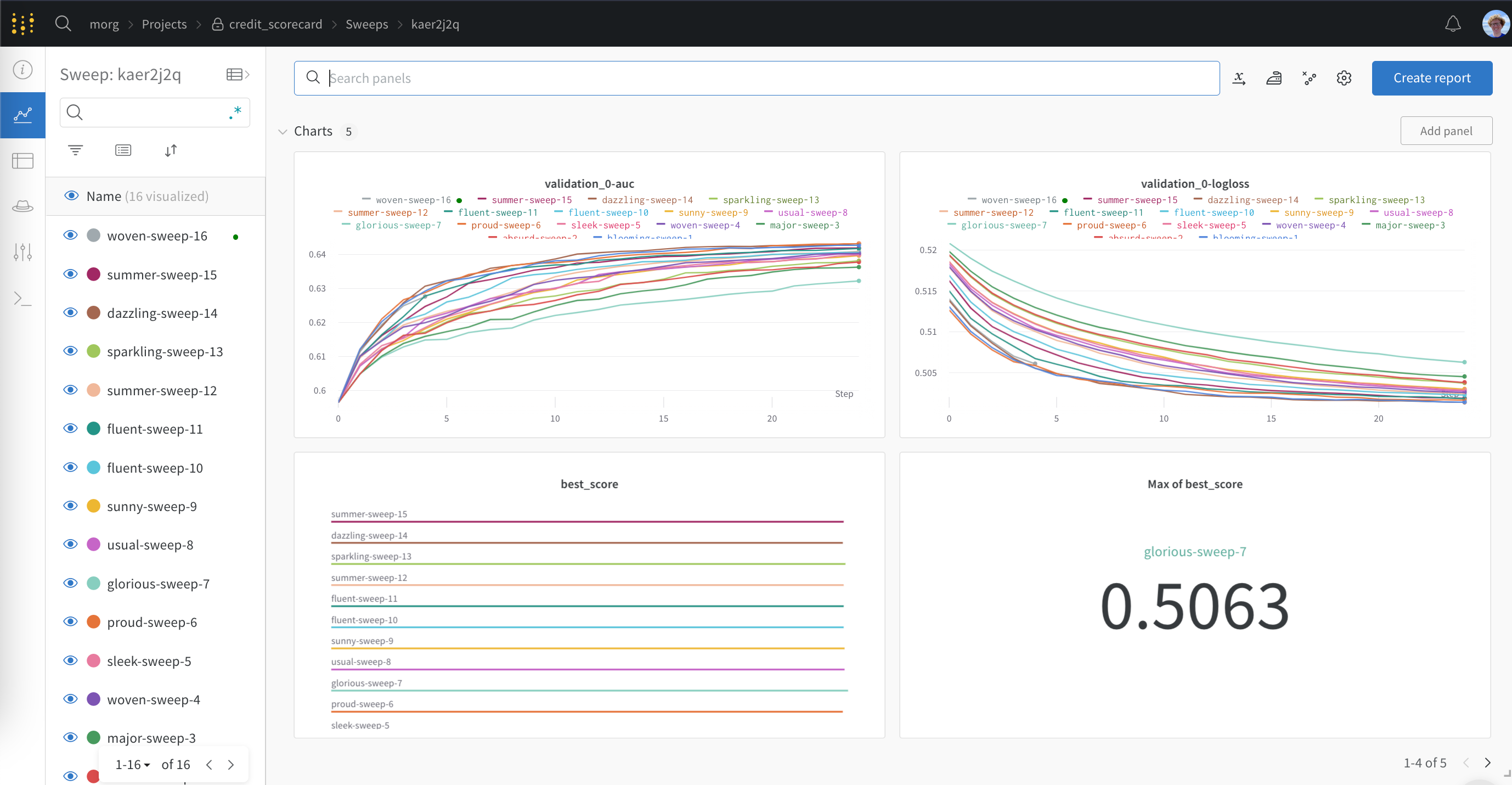
W&B Sweeps는 확장성이 뛰어난 하이퍼파라미터 검색 플랫폼으로, 최소한의 코딩 공간으로 W&B Experiments에 대한 흥미로운 통찰력과 시각화를 제공합니다. Sweeps는 코딩 요구 사항 없이 Hydra Projects와 원활하게 통합됩니다. 필요한 것은 스윕할 다양한 파라미터를 설명하는 구성 파일뿐입니다.
W&B는 자동으로 프로젝트 내부에 스윕을 생성하고 각 머신에서 스윕을 실행할 수 있도록 wandb agent 코맨드를 반환합니다.
Hydra 기본값에 없는 파라미터 전달
Hydra는 커맨드 앞에 +를 사용하여 기본 구성 파일에 없는 추가 파라미터를 커맨드 라인을 통해 전달할 수 있도록 지원합니다. 예를 들어 다음과 같이 호출하여 일부 값이 있는 추가 파라미터를 전달할 수 있습니다.
$ python program.py +experiment=some_experiment
Hydra Experiments를 구성하는 동안 수행하는 작업과 유사하게 이러한 + 구성을 스윕할 수 없습니다. 이를 해결하려면 기본 빈 파일로 experiment 파라미터를 초기화하고 W&B Sweep을 사용하여 각 호출에서 해당 빈 설정을 재정의할 수 있습니다. 자세한 내용은 이 W&B Report를 참조하세요.
import wandb
from wandb.integration.keras import WandbMetricsLogger, WandbModelCheckpoint
# 새로운 W&B run 초기화wandb.init(config={"bs": 12})
# WandbModelCheckpoint를 model.fit에 전달model.fit(
X_train,
y_train,
validation_data=(X_test, y_test),
callbacks=[
WandbMetricsLogger(),
WandbModelCheckpoint("models"),
],
)
WandbModelCheckpoint 참조
파라미터
설명
filepath
(str): 모드 파일을 저장할 경로입니다.
monitor
(str): 모니터링할 메트릭 이름입니다.
verbose
(int): 상세 모드, 0 또는 1. 모드 0은 자동이고 모드 1은 콜백이 작업을 수행할 때 메시지를 표시합니다.
save_best_only
(Boolean): save_best_only=True인 경우 monitor 및 mode 속성으로 정의된 대로 최신 모델 또는 가장 적합하다고 간주되는 모델만 저장합니다.
save_weights_only
(Boolean): True인 경우 모델의 가중치만 저장합니다.
mode
(auto, min 또는 max): val_acc의 경우 max로 설정하고 val_loss의 경우 min으로 설정하는 식입니다.
save_freq
(“epoch” 또는 int): ‘epoch’를 사용하는 경우 콜백은 각 에포크 후에 모델을 저장합니다. 정수를 사용하는 경우 콜백은 이만큼의 배치가 끝날 때 모델을 저장합니다. val_acc 또는 val_loss와 같은 검증 메트릭을 모니터링할 때 이러한 메트릭은 에포크가 끝날 때만 사용할 수 있으므로 save_freq를 “epoch"로 설정해야 합니다.
options
(str): save_weights_only가 true인 경우 선택적 tf.train.CheckpointOptions 오브젝트이거나 save_weights_only가 false인 경우 선택적 tf.saved_model.SaveOptions 오브젝트입니다.
initial_value_threshold
(float): 모니터링할 메트릭의 부동 소수점 초기 “최상” 값입니다.
N 에포크 후에 체크포인트 기록
기본적으로(save_freq="epoch") 콜백은 각 에포크 후에 체크포인트를 만들고 아티팩트로 업로드합니다. 특정 수의 배치 후에 체크포인트를 만들려면 save_freq를 정수로 설정합니다. N 에포크 후에 체크포인트를 만들려면 train 데이터 로더의 카디널리티를 계산하여 save_freq에 전달합니다.
TPU에서 체크포인트를 만드는 동안 UnimplementedError: File system scheme '[local]' not implemented 오류 메시지가 발생할 수 있습니다. 이는 모델 디렉토리(filepath)가 클라우드 스토리지 버킷 경로(gs://bucket-name/...)를 사용해야 하고 이 버킷에 TPU 서버에서 엑세스할 수 있어야 하기 때문에 발생합니다. 그러나 체크포인트를 만드는 데 로컬 경로를 사용할 수 있으며, 이는 Artifacts로 업로드됩니다.
W&B Artifact 페이지에는 Workspace 페이지가 아닌 Table 로그가 기본적으로 포함되어 있습니다.
WandbEvalCallback 참조
파라미터
설명
data_table_columns
(list) data_table의 열 이름 목록입니다.
pred_table_columns
(list) pred_table의 열 이름 목록입니다.
메모리 공간 세부 정보
on_train_begin 메서드가 호출되면 data_table을 W&B에 기록합니다. W&B Artifact로 업로드되면 data_table_ref 클래스 변수를 사용하여 엑세스할 수 있는 이 테이블에 대한 참조가 생성됩니다. data_table_ref는 self.data_table_ref[idx][n]과 같이 인덱싱할 수 있는 2D 목록이며, 여기서 idx는 행 번호이고 n은 열 번호입니다. 아래 예에서 사용법을 살펴보겠습니다.
콜백 사용자 정의
on_train_begin 또는 on_epoch_end 메서드를 재정의하여 더 세분화된 제어를 할 수 있습니다. N 배치 후에 샘플을 기록하려면 on_train_batch_end 메서드를 구현하면 됩니다.
💡 WandbEvalCallback을 상속하여 모델 예측 시각화를 위한 콜백을 구현하고 있으며 설명이 필요하거나 수정해야 할 사항이 있는 경우 문제를 열어 알려주시기 바랍니다.
WandbCallback [기존]
W&B 라이브러리 WandbCallback 클래스를 사용하여 model.fit에서 추적된 모든 메트릭 및 손실 값을 자동으로 저장합니다.
Keras에서 수집한 모든 메트릭(손실 및 keras_model.compile()에 전달된 항목)에서 기록 데이터를 자동으로 기록합니다.
monitor 및 mode 속성으로 정의된 대로 “최상” 트레이닝 단계와 연결된 run에 대한 요약 메트릭을 설정합니다. 기본값은 최소 val_loss가 있는 에포크입니다. WandbCallback은 기본적으로 최상의 epoch와 연결된 모델을 저장합니다.
선택적으로 그레이디언트 및 파라미터 히스토그램을 기록합니다.
선택적으로 시각화를 위해 트레이닝 및 검증 데이터를 wandb에 저장합니다.
WandbCallback 참조
인수
monitor
(str) 모니터링할 메트릭 이름입니다. 기본값은 val_loss입니다.
mode
(str) {auto, min, max} 중 하나입니다. min - 모니터가 최소화될 때 모델 저장 max - 모니터가 최대화될 때 모델 저장 auto - 모델을 저장할 시기를 추측하려고 시도합니다(기본값).
save_model
True - 모니터가 이전의 모든 에포크보다 나을 때 모델 저장 False - 모델을 저장하지 않음
save_graph
(boolean) True인 경우 모델 그래프를 wandb에 저장합니다(기본값은 True).
save_weights_only
(boolean) True인 경우 모델의 가중치(model.save_weights(filepath))만 저장합니다. 그렇지 않으면 전체 모델을 저장합니다.
log_weights
(boolean) True인 경우 모델 레이어의 가중치 히스토그램을 저장합니다.
log_gradients
(boolean) True인 경우 트레이닝 그레이디언트의 히스토그램을 기록합니다.
training_data
(tuple) model.fit에 전달된 것과 동일한 형식 (X,y)입니다. 그레이디언트 계산에 필요합니다. log_gradients가 True인 경우 필수입니다.
validation_data
(tuple) model.fit에 전달된 것과 동일한 형식 (X,y)입니다. wandb가 시각화할 데이터 세트입니다. 이 필드를 설정하면 모든 에포크에서 wandb는 적은 수의 예측을 수행하고 나중에 시각화할 수 있도록 결과를 저장합니다.
generator
(generator) wandb가 시각화할 검증 데이터를 반환하는 생성기입니다. 이 생성기는 튜플 (X,y)를 반환해야 합니다. wandb가 특정 데이터 예제를 시각화하려면 validate_data 또는 생성기를 설정해야 합니다.
validation_steps
(int) validation_data가 생성기인 경우 전체 검증 세트에 대해 생성기를 실행할 단계 수입니다.
labels
(list) wandb로 데이터를 시각화하는 경우 이 레이블 목록은 여러 클래스로 분류기를 빌드하는 경우 숫자 출력을 이해하기 쉬운 문자열로 변환합니다. 이진 분류기의 경우 두 개의 레이블 목록([false 레이블, true 레이블])을 전달할 수 있습니다. validate_data 및 generator가 모두 false인 경우 아무 작업도 수행하지 않습니다.
predictions
(int) 각 에포크에서 시각화를 위해 수행할 예측 수이며, 최대값은 100입니다.
input_type
(string) 시각화를 돕기 위한 모델 입력 유형입니다. (image, images, segmentation_mask) 중 하나일 수 있습니다.
output_type
(string) 시각화를 돕기 위한 모델 출력 유형입니다. (image, images, segmentation_mask) 중 하나일 수 있습니다.
log_evaluation
(boolean) True인 경우 각 에포크에서 검증 데이터와 모델의 예측을 포함하는 Table을 저장합니다. 자세한 내용은 validation_indexes, validation_row_processor 및 output_row_processor를 참조하세요.
class_colors
([float, float, float]) 입력 또는 출력이 분할 마스크인 경우 각 클래스에 대한 rgb 튜플(범위 0-1)을 포함하는 배열입니다.
log_batch_frequency
(integer) None인 경우 콜백은 모든 에포크를 기록합니다. 정수로 설정된 경우 콜백은 log_batch_frequency 배치마다 트레이닝 메트릭을 기록합니다.
log_best_prefix
(string) None인 경우 추가 요약 메트릭을 저장하지 않습니다. 문자열로 설정된 경우 모니터링된 메트릭과 에포크 앞에 접두사를 붙이고 결과를 요약 메트릭으로 저장합니다.
validation_indexes
([wandb.data_types._TableLinkMixin]) 각 검증 예제와 연결할 인덱스 키의 정렬된 목록입니다. log_evaluation이 True이고 validation_indexes를 제공하는 경우 검증 데이터 Table을 만들지 않습니다. 대신 각 예측을 TableLinkMixin으로 표시된 행과 연결합니다. 행 키 목록을 가져오려면 Table.get_index()를 사용하세요.
validation_row_processor
(Callable) 검증 데이터에 적용할 함수로, 일반적으로 데이터를 시각화하는 데 사용됩니다. 이 함수는 ndx(int)와 row(dict)를 받습니다. 모델에 입력이 하나 있는 경우 row["input"]에 행에 대한 입력 데이터가 포함됩니다. 그렇지 않으면 입력 슬롯의 이름이 포함됩니다. 적합 함수가 대상이 하나인 경우 row["target"]에 행에 대한 대상 데이터가 포함됩니다. 그렇지 않으면 출력 슬롯의 이름이 포함됩니다. 예를 들어 입력 데이터가 단일 배열인 경우 데이터를 이미지로 시각화하려면 lambda ndx, row: {"img": wandb.Image(row["input"])}를 프로세서로 제공합니다. log_evaluation이 False이거나 validation_indexes가 있는 경우 무시됩니다.
output_row_processor
(Callable) validation_row_processor와 동일하지만 모델의 출력에 적용됩니다. row["output"]에 모델 출력 결과가 포함됩니다.
infer_missing_processors
(Boolean) 누락된 경우 validation_row_processor 및 output_row_processor를 유추할지 여부를 결정합니다. 기본값은 True입니다. labels를 제공하는 경우 W&B는 적절한 분류 유형 프로세서를 유추하려고 시도합니다.
log_evaluation_frequency
(int) 평가 결과를 기록하는 빈도를 결정합니다. 기본값은 트레이닝이 끝날 때만 기록하는 0입니다. 모든 에포크를 기록하려면 1로 설정하고, 다른 모든 에포크를 기록하려면 2로 설정하는 식입니다. log_evaluation이 False인 경우 아무런 효과가 없습니다.
자주 묻는 질문
wandb로 Keras 멀티프로세싱을 어떻게 사용합니까?
use_multiprocessing=True를 설정하면 다음 오류가 발생할 수 있습니다.
Error("You must call wandb.init() before wandb.config.batch_size")
해결 방법:
Sequence 클래스 구성에서 wandb.init(group='...')를 추가합니다.
main에서 if __name__ == "__main__":를 사용하고 있는지 확인하고 스크립트 로직의 나머지 부분을 그 안에 넣습니다.
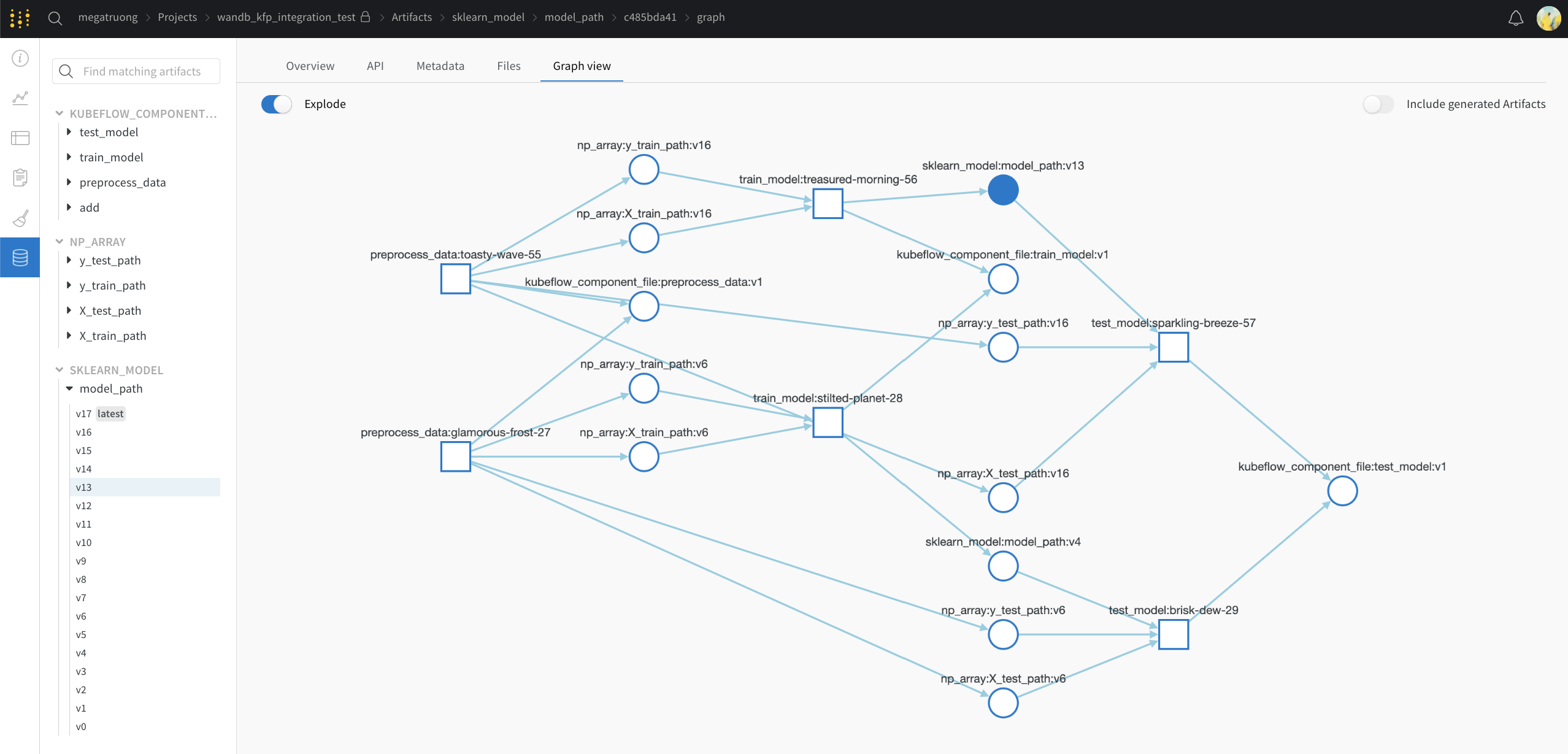
17 - Kubeflow Pipelines (kfp)
W&B를 Kubeflow 파이프라인과 통합하는 방법.
Kubeflow Pipelines (kfp) 는 Docker 컨테이너를 기반으로 구축된 휴대 가능하고 확장 가능한 기계 학습(ML) 워크플로우를 구축하고 배포하기 위한 플랫폼입니다.
이 통합을 통해 사용자는 데코레이터를 kfp python functional components에 적용하여 파라미터와 Artifacts를 W&B에 자동으로 기록할 수 있습니다.
이 기능은 wandb==0.12.11에서 활성화되었으며 kfp<2.0.0이 필요합니다.
가입하고 API 키 만들기
API 키는 사용자의 머신을 W&B에 인증합니다. 사용자 프로필에서 API 키를 생성할 수 있습니다.
보다 간소화된 접근 방식을 위해 https://wandb.ai/authorize로 직접 이동하여 API 키를 생성할 수 있습니다. 표시된 API 키를 복사하여 비밀번호 관리자와 같은 안전한 위치에 저장하십시오.
오른쪽 상단 모서리에 있는 사용자 프로필 아이콘을 클릭합니다.
User Settings를 선택한 다음 API Keys 섹션으로 스크롤합니다.
Reveal을 클릭합니다. 표시된 API 키를 복사합니다. API 키를 숨기려면 페이지를 새로 고칩니다.
@wandb_log 데코레이터를 추가하고 평소처럼 컴포넌트를 생성합니다. 이렇게 하면 파이프라인을 실행할 때마다 입력/출력 파라미터와 Artifacts가 자동으로 W&B에 기록됩니다.
from kfp import components
from wandb.integration.kfp import wandb_log
@wandb_logdefadd(a: float, b: float) -> float:
return a + b
add = components.create_component_from_func(add)
컨테이너에 환경 변수 전달
환경 변수를 컨테이너에 명시적으로 전달해야 할 수 있습니다. 양방향 연결을 위해서는 환경 변수 WANDB_KUBEFLOW_URL을 Kubeflow Pipelines 인스턴스의 기본 URL로 설정해야 합니다. 예를 들어, https://kubeflow.mysite.com과 같습니다.
import os
from kubernetes.client.models import V1EnvVar
defadd_wandb_env_variables(op):
env = {
"WANDB_API_KEY": os.getenv("WANDB_API_KEY"),
"WANDB_BASE_URL": os.getenv("WANDB_BASE_URL"),
}
for name, value in env.items():
op = op.add_env_variable(V1EnvVar(name, value))
return op
@dsl.pipeline(name="example-pipeline")
defexample_pipeline(param1: str, param2: int):
conf = dsl.get_pipeline_conf()
conf.add_op_transformer(add_wandb_env_variables)
프로그래밍 방식으로 데이터에 엑세스
Kubeflow Pipelines UI를 통해
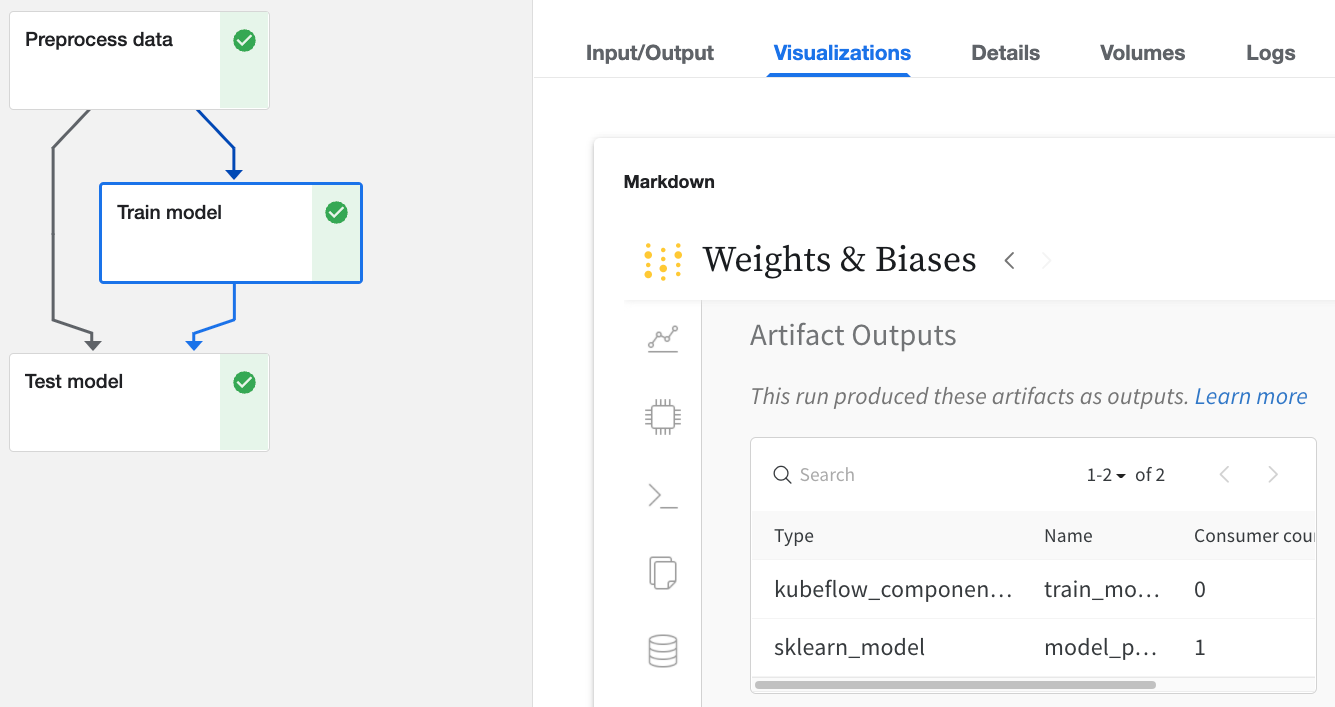
W&B로 로깅된 Kubeflow Pipelines UI에서 Run을 클릭합니다.
Input/Output 및 ML Metadata 탭에서 입력 및 출력에 대한 자세한 내용을 확인합니다.
Visualizations 탭에서 W&B 웹 앱을 봅니다.
웹 앱 UI를 통해
웹 앱 UI는 Kubeflow Pipelines의 Visualizations 탭과 동일한 콘텐츠를 가지고 있지만 공간이 더 넓습니다. 여기에서 웹 앱 UI에 대해 자세히 알아보세요.
wandb 라이브러리에는 LightGBM을 위한 특별한 콜백이 포함되어 있습니다. 또한 Weights & Biases의 일반적인 로깅 기능을 사용하여 하이퍼파라미터 스윕과 같은 대규모 Experiments를 쉽게 추적할 수 있습니다.
from wandb.integration.lightgbm import wandb_callback, log_summary
import lightgbm as lgb
# Log metrics to W&Bgbm = lgb.train(..., callbacks=[wandb_callback()])
# Log feature importance plot and upload model checkpoint to W&Blog_summary(gbm, save_model_checkpoint=True)
from wandb.integration.metaflow import wandb_log
classWandbExampleFlow(FlowSpec):
@wandb_log(datasets=True, models=True, settings=wandb.Settings(...))
@stepdefstart(self):
self.raw_df = pd.read_csv(...).# pd.DataFrame -> upload as dataset self.model_file = torch.load(...) # nn.Module -> upload as model self.next(self.transform)
흐름을 데코레이팅하는 것은 구성 단계를 모두 기본값으로 데코레이팅하는 것과 같습니다.
이 경우 WandbExampleFlow의 모든 단계는 기본적으로 데이터셋과 Models를 기록하도록 기본 설정되어 있습니다. 이는 각 단계를 @wandb_log(datasets=True, models=True)로 데코레이팅하는 것과 같습니다.
from wandb.integration.metaflow import wandb_log
@wandb_log(datasets=True, models=True) # decorate all @step classWandbExampleFlow(FlowSpec):
@stepdefstart(self):
self.raw_df = pd.read_csv(...).# pd.DataFrame -> upload as dataset self.model_file = torch.load(...) # nn.Module -> upload as model self.next(self.transform)
흐름을 데코레이팅하는 것은 모든 단계를 기본값으로 데코레이팅하는 것과 같습니다. 즉, 나중에 다른 @wandb_log로 단계를 데코레이팅하면 흐름 수준 데코레이션이 재정의됩니다.
이 예에서:
start 및 mid는 데이터셋과 Models를 모두 기록합니다.
end는 데이터셋과 Models를 모두 기록하지 않습니다.
from wandb.integration.metaflow import wandb_log
@wandb_log(datasets=True, models=True) # same as decorating start and midclassWandbExampleFlow(FlowSpec):
# this step will log datasets and models@stepdefstart(self):
self.raw_df = pd.read_csv(...).# pd.DataFrame -> upload as dataset self.model_file = torch.load(...) # nn.Module -> upload as model self.next(self.mid)
# this step will also log datasets and models@stepdefmid(self):
self.raw_df = pd.read_csv(...).# pd.DataFrame -> upload as dataset self.model_file = torch.load(...) # nn.Module -> upload as model self.next(self.end)
# this step is overwritten and will NOT log datasets OR models@wandb_log(datasets=False, models=False)
@stepdefend(self):
self.raw_df = pd.read_csv(...). self.model_file = torch.load(...)
MMEngine은 OpenMMLab에서 만든 PyTorch 기반 딥러닝 모델 트레이닝을 위한 기본 라이브러리입니다. MMEngine은 OpenMMLab 알고리즘 라이브러리를 위한 차세대 트레이닝 아키텍처를 구현하여 OpenMMLab 내의 30개 이상의 알고리즘 라이브러리에 통합된 실행 기반을 제공합니다. 핵심 구성 요소로는 트레이닝 엔진, 평가 엔진 및 모듈 관리가 있습니다.
from mmengine.visualization import Visualizer
# define the visualization configsvisualization_cfg = dict(
name="wandb_visualizer",
vis_backends=[
dict(
type='WandbVisBackend',
init_kwargs=dict(project="mmengine"),
)
],
save_dir="runs/wandb")
# get the visualizer from the visualization configsvisualizer = Visualizer.get_instance(**visualization_cfg)
[W&B run 초기화](/ko/ref/python/init/) 입력 파라미터에 대한 인수의 사전을 `init_kwargs`에 전달합니다.
visualizer로 runner를 초기화하고 runner.train()을 호출합니다.
from mmengine.runner import Runner
# build the mmengine Runner which is a training helper for PyTorchrunner = Runner(
model,
work_dir='runs/gan/',
train_dataloader=train_dataloader,
train_cfg=train_cfg,
optim_wrapper=opt_wrapper_dict,
visualizer=visualizer, # pass the visualizer)
# start trainingrunner.train()
OpenMMLab 컴퓨터 비전 라이브러리와 함께 WandbVisBackend 사용
WandbVisBackend를 사용하여 MMDetection과 같은 OpenMMLab 컴퓨터 비전 라이브러리로 Experiments를 쉽게 추적할 수도 있습니다.
# inherit base configs from the default runtime configs_base_ = ["../_base_/default_runtime.py"]
# Assign the `WandbVisBackend` config dictionary to the# `vis_backends` of the `visualizer` from the base configs_base_.visualizer.vis_backends = [
dict(
type='WandbVisBackend',
init_kwargs={
'project': 'mmdet',
'entity': 'geekyrakshit' },
),
]
21 - MMF
Meta AI의 MMF와 W&B를 통합하는 방법.
Meta AI의 MMF 라이브러리의 WandbLogger 클래스를 사용하면 Weights & Biases가 트레이닝/유효성 검사 메트릭, 시스템 (GPU 및 CPU) 메트릭, 모델 체크포인트 및 구성 파라미터를 기록할 수 있습니다.
현재 기능
MMF의 WandbLogger에서 현재 지원하는 기능은 다음과 같습니다.
트레이닝 및 유효성 검사 메트릭
시간에 따른 학습률
W&B Artifacts에 모델 체크포인트 저장
GPU 및 CPU 시스템 메트릭
트레이닝 구성 파라미터
구성 파라미터
wandb 로깅을 활성화하고 사용자 정의하기 위해 MMF 구성에서 다음 옵션을 사용할 수 있습니다.
training:
wandb:
enabled: true
# 엔터티는 Runs을 보내는 사용자 이름 또는 팀 이름입니다.
# 기본적으로 사용자 계정에 Run을 기록합니다.
entity: null
# wandb로 실험을 기록하는 동안 사용할 프로젝트 이름
project: mmf
# wandb로 프로젝트에서 실험을 기록하는 데 사용할 실험/run 이름
# 기본 실험 이름은 다음과 같습니다: ${training.experiment_name}
name: ${training.experiment_name}
# 모델 체크포인트 설정을 켜고 체크포인트를 W&B Artifacts에 저장합니다
log_model_checkpoint: true
# wandb.init()에 전달할 추가 인수 값입니다.
# 사용 가능한 인수를 보려면 /ref/python/init에서 설명서를 확인하세요(예:
# job_type: 'train'
# tags: ['tag1', 'tag2']
env:
# wandb 메타데이터가 저장될 디렉토리의 경로를 변경하려면(기본값: env.log_dir):
wandb_logdir: ${env:MMF_WANDB_LOGDIR,}
Composer는 신경망을 더 좋고, 더 빠르고, 더 저렴하게 트레이닝하기 위한 라이브러리입니다. 여기에는 신경망 트레이닝을 가속화하고 일반화를 개선하기 위한 최첨단 메소드가 많이 포함되어 있으며, 다양한 개선 사항을 쉽게 구성 할 수 있는 선택적 Trainer API가 함께 제공됩니다.
Weights & Biases는 ML Experiments 로깅을 위한 간단한 래퍼를 제공합니다. 하지만 직접 결합할 필요가 없습니다. W&B는 WandBLogger를 통해 Composer 라이브러리에 직접 통합됩니다.
W&B에 로깅 시작하기
from composer import Trainer
from composer.loggers import WandBLogger
trainer = Trainer(..., logger=WandBLogger())
Composer의 WandBLogger 사용
Composer 라이브러리는 Trainer에서 WandBLogger 클래스를 사용하여 메트릭을 Weights and Biases에 기록합니다. 로거를 인스턴스화하고 Trainer에 전달하는 것만큼 간단합니다.
rank-zero 프로세스에서만 기록할지 여부. Artifacts를 기록할 때는 모든 순위에서 기록하는 것이 좋습니다. 순위 ≥1의 Artifacts는 저장되지 않으므로 관련 정보가 삭제될 수 있습니다. 예를 들어 Deepspeed ZeRO를 사용하는 경우 모든 순위의 Artifacts 없이는 체크포인트에서 복원할 수 없습니다. 기본값: True (bool, optional)
init_kwargs
wandb config 등과 같은 wandb.init에 전달할 파라미터 전체 목록은 여기에서 wandb.init이 허용하는 파라미터를 참조하세요.
일반적인 사용법은 다음과 같습니다.
init_kwargs = {"notes":"이 실험에서 더 높은 학습률 테스트",
"config":{"arch":"Llama",
"use_mixed_precision":True
}
}
wandb_logger = WandBLogger(log_artifacts=True, init_kwargs=init_kwargs)
예측 샘플 기록
Composer의 콜백 시스템을 사용하여 WandBLogger를 통해 Weights & Biases에 로깅할 시기를 제어할 수 있습니다. 이 예에서는 유효성 검사 이미지 및 예측 샘플이 기록됩니다.
W&B OpenAI API 인테그레이션을 사용하여 모든 OpenAI 모델 (파인튜닝된 모델 포함)에 대한 요청, 응답, 토큰 수 및 모델 메타데이터를 기록합니다.
W&B를 사용하여 파인튜닝 Experiments, Models, Datasets을 추적하고 결과를 동료와 공유하는 방법에 대한 자세한 내용은 OpenAI 파인튜닝 인테그레이션을 참조하세요.
API 입력 및 출력을 기록하면 다양한 프롬프트의 성능을 빠르게 평가하고, 다양한 모델 설정 (예: temperature)을 비교하고, 토큰 사용량과 같은 기타 사용량 메트릭을 추적할 수 있습니다.
OpenAI Python API 라이브러리 설치
W&B autolog 인테그레이션은 OpenAI 버전 0.28.1 이하에서 작동합니다.
OpenAI Python API 버전 0.28.1을 설치하려면 다음을 실행합니다.
pip install openai==0.28.1
OpenAI Python API 사용
1. autolog 임포트 및 초기화
먼저 wandb.integration.openai에서 autolog를 임포트하고 초기화합니다.
import os
import openai
from wandb.integration.openai import autolog
autolog({"project": "gpt5"})
선택적으로 wandb.init()이 허용하는 인수가 있는 사전을 autolog에 전달할 수 있습니다. 여기에는 프로젝트 이름, 팀 이름, Entity 등이 포함됩니다. wandb.init에 대한 자세한 내용은 API Reference Guide를 참조하세요.
2. OpenAI API 호출
OpenAI API를 호출할 때마다 W&B에 자동으로 기록됩니다.
os.environ["OPENAI_API_KEY"] ="XXX"chat_request_kwargs = dict(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Who won the world series in 2020?"},
{"role": "assistant", "content": "The Los Angeles Dodgers"},
{"role": "user", "content": "Where was it played?"},
],
)
response = openai.ChatCompletion.create(**chat_request_kwargs)
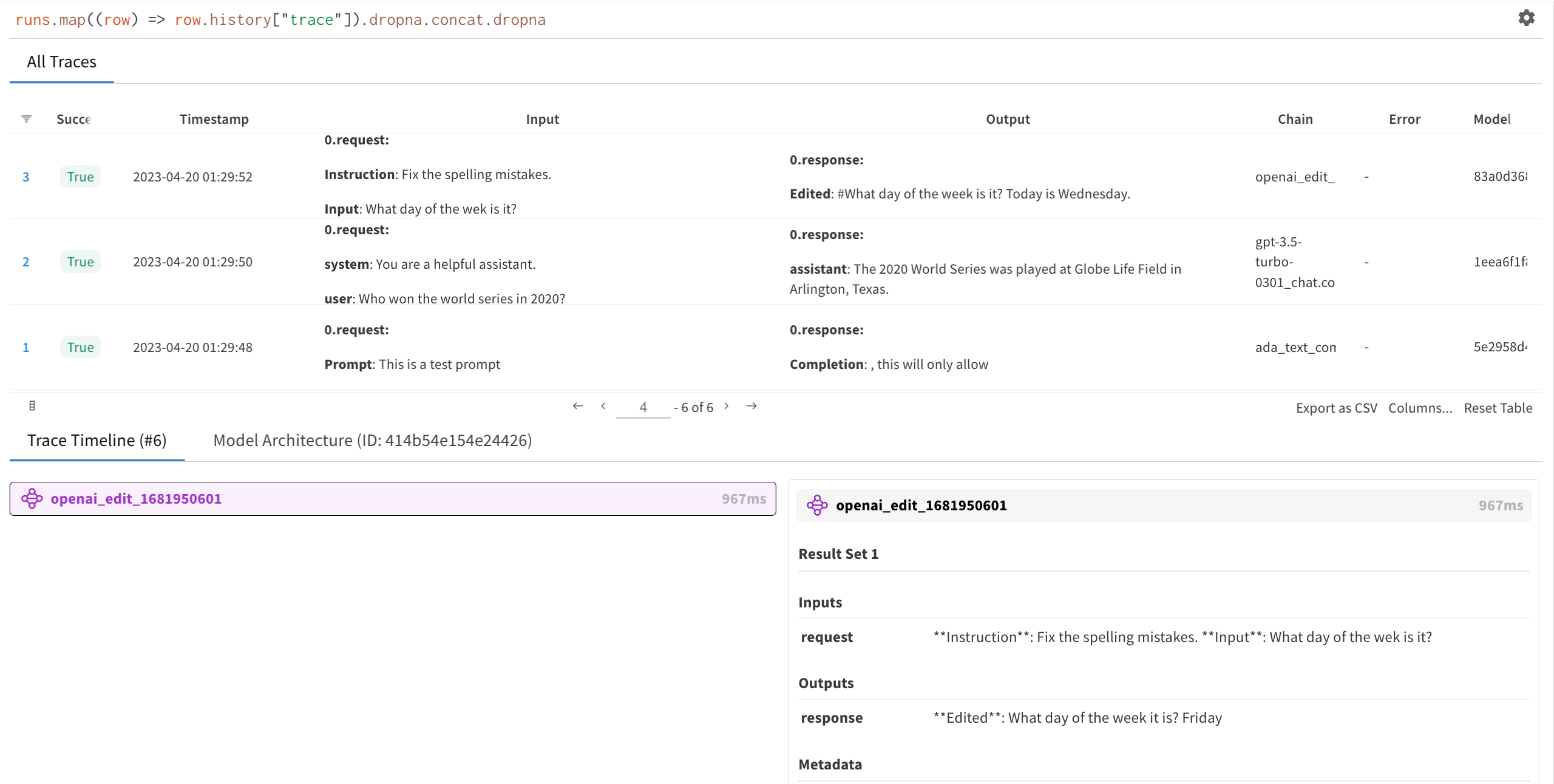
3. OpenAI API 입력 및 응답 보기
1단계에서 autolog에 의해 생성된 W&B run 링크를 클릭합니다. 그러면 W&B 앱의 프로젝트 Workspace로 리디렉션됩니다.
생성한 Run을 선택하여 추적 테이블, 추적 타임라인 및 사용된 OpenAI LLM의 모델 아키텍처를 봅니다.
autolog 끄기
OpenAI API 사용을 마친 후에는 모든 W&B 프로세스를 닫기 위해 disable()을 호출하는 것이 좋습니다.
W&B OpenAI 파인튜닝 통합은 OpenAI 버전 1.0 이상에서 작동합니다. OpenAI Python API 라이브러리의 최신 버전은 PyPI 문서를 참조하세요.
OpenAI Python API를 설치하려면 다음을 실행하세요:
pip install openai
OpenAI Python API가 이미 설치되어 있는 경우 다음을 사용하여 업데이트할 수 있습니다:
pip install -U openai
OpenAI 파인튜닝 결과 동기화
W&B를 OpenAI의 파인튜닝 API와 통합하여 파인튜닝 메트릭과 설정을 W&B에 기록합니다. 이를 위해 wandb.integration.openai.fine_tuning 모듈의 WandbLogger 클래스를 사용합니다.
from wandb.integration.openai.fine_tuning import WandbLogger
# Finetuning logicWandbLogger.sync(fine_tune_job_id=FINETUNE_JOB_ID)
파인튜닝 동기화
스크립트에서 결과를 동기화합니다.
from wandb.integration.openai.fine_tuning import WandbLogger
# 한 줄 코맨드WandbLogger.sync()
# 옵션 파라미터 전달WandbLogger.sync(
fine_tune_job_id=None,
num_fine_tunes=None,
project="OpenAI-Fine-Tune",
entity=None,
overwrite=False,
model_artifact_name="model-metadata",
model_artifact_type="model",
**kwargs_wandb_init
)
참조
인수
설명
fine_tune_job_id
이는 client.fine_tuning.jobs.create를 사용하여 파인튜닝 job을 생성할 때 얻는 OpenAI Fine-Tune ID입니다. 이 인수가 None(기본값)인 경우, 아직 동기화되지 않은 모든 OpenAI 파인튜닝 job이 W&B에 동기화됩니다.
openai_client
초기화된 OpenAI 클라이언트를 sync에 전달합니다. 클라이언트가 제공되지 않으면 로거 자체에서 초기화됩니다. 기본적으로 None입니다.
num_fine_tunes
ID가 제공되지 않으면 동기화되지 않은 모든 파인튜닝이 W&B에 기록됩니다. 이 인수를 사용하면 동기화할 최근 파인튜닝 수를 선택할 수 있습니다. num_fine_tunes가 5이면 가장 최근의 파인튜닝 5개를 선택합니다.
project
파인튜닝 메트릭, Models, Data 등이 기록될 Weights & Biases 프로젝트 이름입니다. 기본적으로 프로젝트 이름은 “OpenAI-Fine-Tune"입니다.
entity
Runs을 보낼 W&B 사용자 이름 또는 팀 이름입니다. 기본적으로 기본 엔터티가 사용되며, 이는 일반적으로 사용자 이름입니다.
overwrite
동일한 파인튜닝 job의 기존 wandb run을 강제로 로깅하고 덮어씁니다. 기본적으로 False입니다.
wait_for_job_success
OpenAI 파인튜닝 job이 시작되면 일반적으로 시간이 좀 걸립니다. 파인튜닝 job이 완료되는 즉시 메트릭이 W&B에 기록되도록 하려면 이 설정을 통해 파인튜닝 job 상태가 succeeded로 변경되는지 60초마다 확인합니다. 파인튜닝 job이 성공한 것으로 감지되면 메트릭이 자동으로 W&B에 동기화됩니다. 기본적으로 True로 설정됩니다.
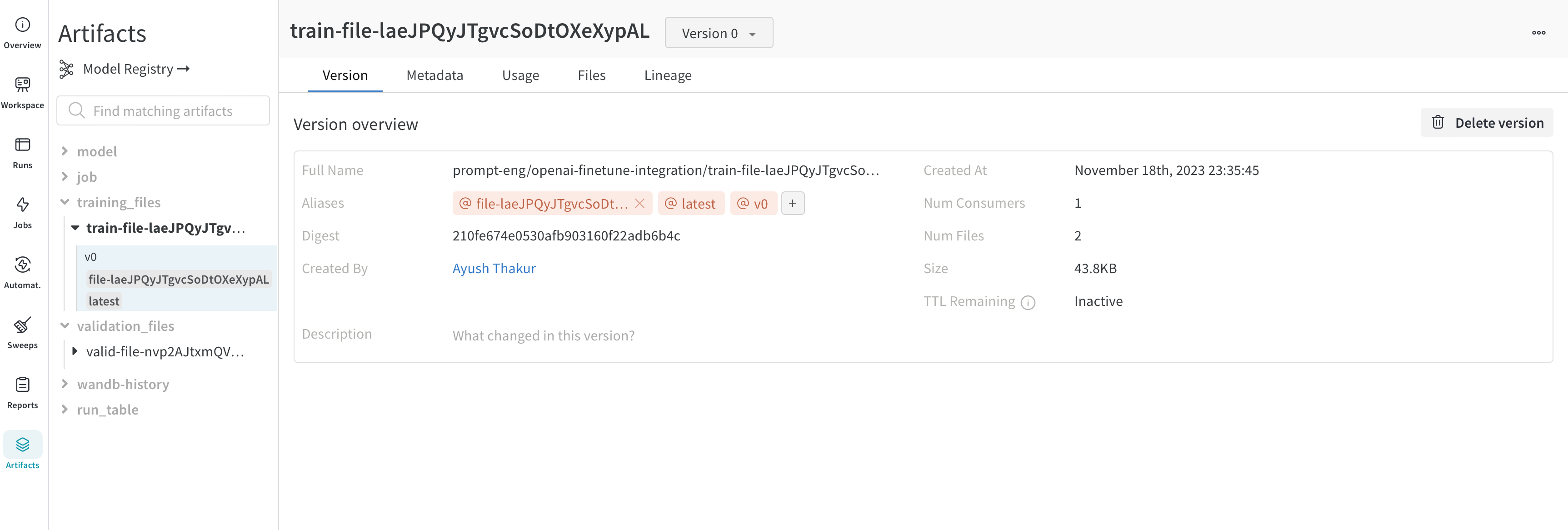
파인튜닝을 위해 OpenAI에 업로드하는 트레이닝 및 검증 데이터는 더 쉬운 버전 관리를 위해 자동으로 W&B Artifacts로 기록됩니다. 아래는 Artifacts의 트레이닝 파일 보기입니다. 여기서 이 파일을 기록한 W&B run, 기록된 시기, 이 데이터셋의 버전, 메타데이터 및 트레이닝 Data에서 트레이닝된 Model까지의 DAG 계보를 확인할 수 있습니다.
시각화
Datasets은 W&B Tables로 시각화되어 데이터셋을 탐색, 검색 및 상호 작용할 수 있습니다. 아래에서 W&B Tables를 사용하여 시각화된 트레이닝 샘플을 확인하세요.
파인튜닝된 Model 및 Model 버전 관리
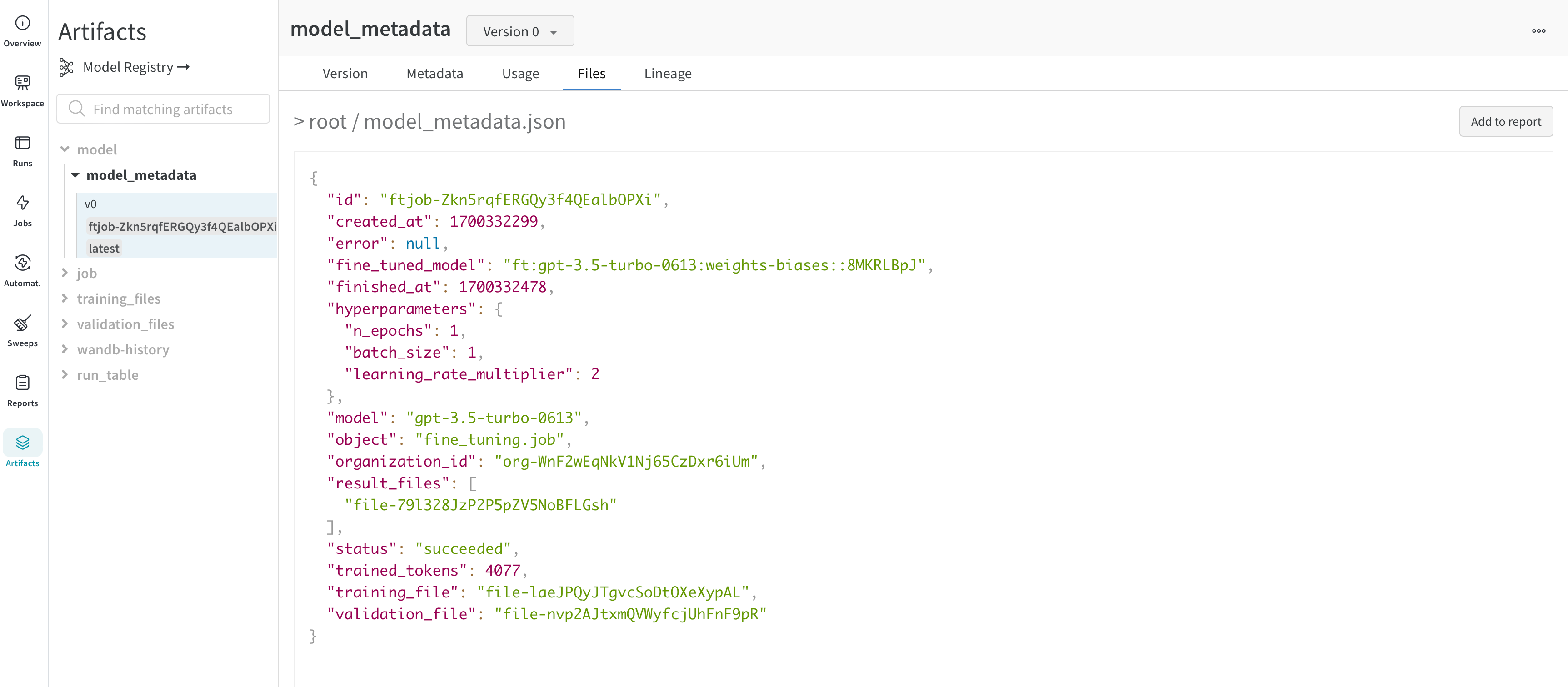
OpenAI는 파인튜닝된 Model의 ID를 제공합니다. Model 가중치에 엑세스할 수 없으므로 WandbLogger는 Model의 모든 세부 정보 (하이퍼파라미터, Data 파일 ID 등)와 fine_tuned_model ID가 포함된 model_metadata.json 파일을 생성하고 W&B Artifacts로 기록합니다.
이 Model (메타데이터) 아티팩트는 W&B Registry의 Model에 추가로 연결될 수 있습니다.
자주 묻는 질문
W&B에서 팀과 파인튜닝 결과를 공유하려면 어떻게 해야 하나요?
다음을 사용하여 팀 계정에 파인튜닝 job을 기록합니다:
WandbLogger.sync(entity="YOUR_TEAM_NAME")
Runs을 어떻게 구성할 수 있나요?
W&B Runs은 자동으로 구성되며 job 유형, 기본 Model, 학습률, 트레이닝 파일 이름 및 기타 하이퍼파라미터와 같은 모든 구성 파라미터를 기반으로 필터링/정렬할 수 있습니다.
또한 Runs 이름을 바꾸거나 메모를 추가하거나 태그를 만들어 그룹화할 수 있습니다.
만족스러우면 워크스페이스를 저장하고 이를 사용하여 리포트를 생성하고 Runs 및 저장된 Artifacts (트레이닝/검증 파일)에서 Data를 가져올 수 있습니다.
파인튜닝된 Model에 어떻게 엑세스할 수 있나요?
파인튜닝된 Model ID는 Artifacts(model_metadata.json) 및 구성으로 W&B에 기록됩니다.
“2021년부터 Gym을 유지 관리해 온 팀은 향후 모든 개발을 Gym의 대체품인 Gymnasium으로 이전했으며(gymnasium을 gym으로 가져오기), Gym은 더 이상 업데이트를 받지 않습니다.” (출처)
Gym은 더 이상 활발하게 유지 관리되는 프로젝트가 아니므로 Gymnasium과의 통합을 사용해 보십시오.
OpenAI Gym을 사용하는 경우, Weights & Biases는 gym.wrappers.Monitor에 의해 생성된 환경 비디오를 자동으로 기록합니다. monitor_gym 키워드 인수를 wandb.init에 True로 설정하거나 wandb.gym.monitor()를 호출하기만 하면 됩니다.
저희 gym integration은 매우 가볍습니다. gym에서 기록된 비디오 파일의 이름을 확인하여 그에 따라 이름을 지정하거나 일치하는 항목을 찾지 못하면 "videos"로 대체합니다. 더 많은 제어를 원하시면 언제든지 수동으로 비디오를 기록할 수 있습니다.
PaddleOCR 은 PaddlePaddle에 구현되어 사용자가 더 나은 모델을 트레이닝하고 실제에 적용할 수 있도록 다국어, 멋진, 선도적이고 실용적인 OCR 툴을 만드는 것을 목표로 합니다. PaddleOCR은 OCR과 관련된 다양한 최첨단 알고리즘을 지원하고 산업 솔루션을 개발했습니다. PaddleOCR은 이제 해당 메타데이터와 함께 모델 체크포인트와 함께 트레이닝 및 평가 메트릭을 로깅하기 위한 Weights & Biases 통합 기능을 제공합니다.
예제 블로그 & Colab
ICDAR2015 데이터셋에서 PaddleOCR로 모델을 트레이닝하는 방법은 여기 에서 확인하세요. Google Colab 도 함께 제공되며, 해당 라이브 W&B 대시보드는 여기 에서 확인할 수 있습니다. 이 블로그의 중국어 버전은 W&B对您的OCR模型进行训练和调试 에서 확인할 수 있습니다.
가입하고 API 키 만들기
API 키는 사용자의 머신을 W&B에 인증합니다. 사용자 프로필에서 API 키를 생성할 수 있습니다.
보다 간소화된 접근 방식을 위해 https://wandb.ai/authorize 로 직접 이동하여 API 키를 생성할 수 있습니다. 표시된 API 키를 복사하여 비밀번호 관리자와 같은 안전한 위치에 저장하세요.
오른쪽 상단에서 사용자 프로필 아이콘을 클릭합니다.
User Settings를 선택한 다음 API Keys 섹션으로 스크롤합니다.
Reveal을 클릭합니다. 표시된 API 키를 복사합니다. API 키를 숨기려면 페이지를 새로 고칩니다.
PaddleOCR은 yaml 파일을 사용하여 구성 변수를 제공해야 합니다. 구성 yaml 파일의 끝에 다음 스니펫을 추가하면 모든 트레이닝 및 유효성 검사 메트릭이 모델 체크포인트와 함께 W&B 대시보드에 자동으로 기록됩니다.
Global:
use_wandb: True
wandb.init 에 전달하려는 추가적인 선택적 인수는 yaml 파일의 wandb 헤더 아래에 추가할 수도 있습니다.
wandb:
project: CoolOCR # (선택 사항) wandb 프로젝트 이름입니다.
entity: my_team # (선택 사항) wandb Team을 사용하는 경우 Team 이름을 여기에 전달할 수 있습니다.
name: MyOCRModel # (선택 사항) wandb run의 이름입니다.
config.yml 파일을 train.py 에 전달
그런 다음 yaml 파일은 PaddleOCR 저장소에서 사용할 수 있는 트레이닝 스크립트 에 인수로 제공됩니다.
python tools/train.py -c config.yml
Weights & Biases가 켜진 상태에서 train.py 파일을 실행하면 W&B 대시보드로 이동하는 링크가 생성됩니다.
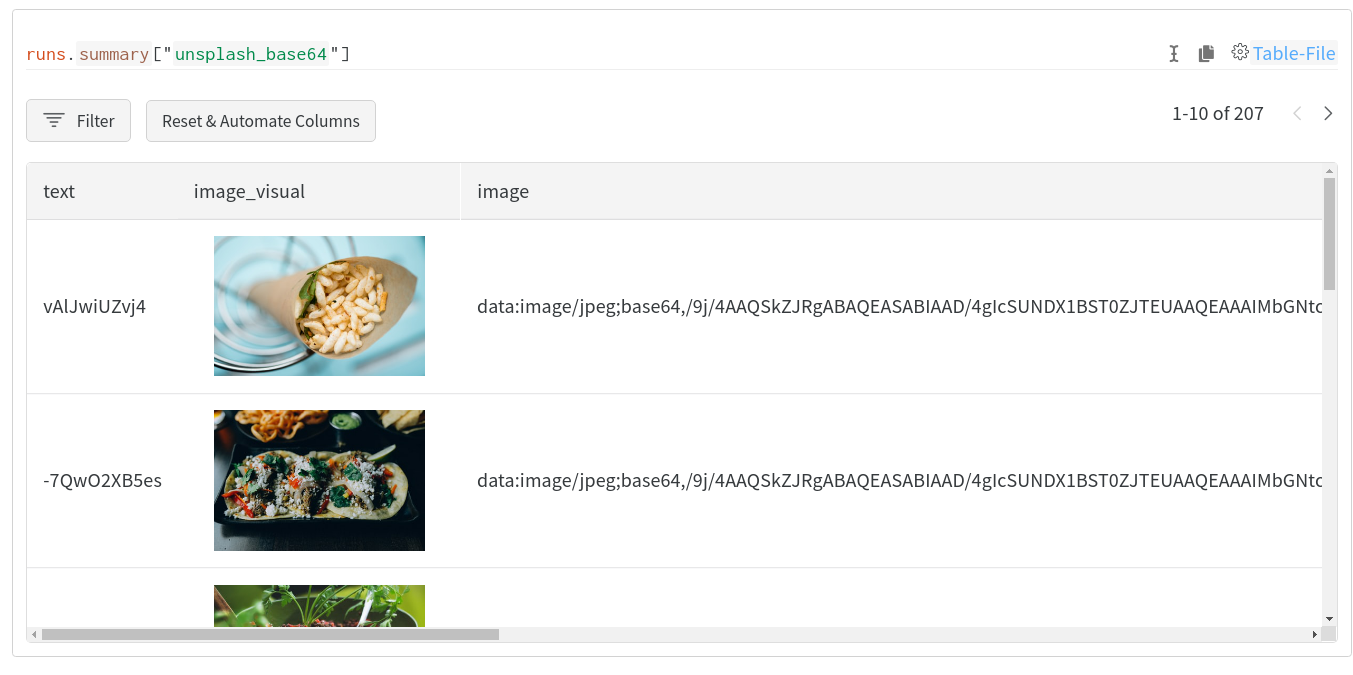
Prodigy 는 기계 학습 모델, 오류 분석, 데이터 검사 및 정리을 위한 트레이닝 및 평가 데이터를 생성하기 위한 주석 툴입니다. W&B Tables 를 사용하면 W&B 내에서 데이터셋 (및 더 많은 것!) 을 기록, 시각화, 분석 및 공유할 수 있습니다.
Prodigy 와의 W&B 통합 은 Prodigy 로 주석이 달린 데이터셋을 Tables 에서 사용할 수 있도록 W&B 에 직접 업로드하는 간단하고 사용하기 쉬운 기능을 추가합니다.
다음과 같은 몇 줄의 코드를 실행합니다.
import wandb
from wandb.integration.prodigy import upload_dataset
with wandb.init(project="prodigy"):
upload_dataset("news_headlines_ner")
다음과 같은 시각적이고, 상호 작용적이며, 공유 가능한 테이블을 얻으세요.
퀵스타트
wandb.integration.prodigy.upload_dataset 을 사용하여 주석이 달린 Prodigy 데이터셋을 로컬 Prodigy 데이터베이스에서 W&B 의 Table 형식으로 직접 업로드합니다. 설치 및 설정을 포함한 Prodigy 에 대한 자세한 내용은 Prodigy documentation 을 참조하십시오.
W&B 는 이미지 및 명명된 엔티티 필드를 wandb.Image 및 wandb.Html 로 자동 변환하려고 시도합니다. 이러한 시각화를 포함하기 위해 결과 테이블에 추가 열이 추가될 수 있습니다.
gradient를 자동으로 기록하려면 wandb.watch를 호출하고 PyTorch model을 전달하면 됩니다.
import wandb
wandb.init(config=args)
model =...# set up your model# Magicwandb.watch(model, log_freq=100)
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
if batch_idx % args.log_interval ==0:
wandb.log({"loss": loss})
동일한 스크립트에서 여러 model을 추적해야 하는 경우 각 model에서 wandb.watch를 개별적으로 호출할 수 있습니다. 이 함수에 대한 참조 문서는 여기에 있습니다.
gradient, metrics 및 그래프는 순방향 및 역방향 패스 후에 wandb.log가 호출될 때까지 기록되지 않습니다.
이미지 및 미디어 로그
이미지 데이터가 포함된 PyTorch Tensors를 wandb.Image로 전달할 수 있으며, torchvision의 유틸리티가 자동으로 이미지를 변환하는 데 사용됩니다.
images_t =...# generate or load images as PyTorch Tensorswandb.log({"examples": [wandb.Image(im) for im in images_t]})
PyTorch 및 기타 프레임워크에서 W&B에 rich media를 로깅하는 방법에 대한 자세한 내용은 미디어 로깅 가이드를 확인하세요.
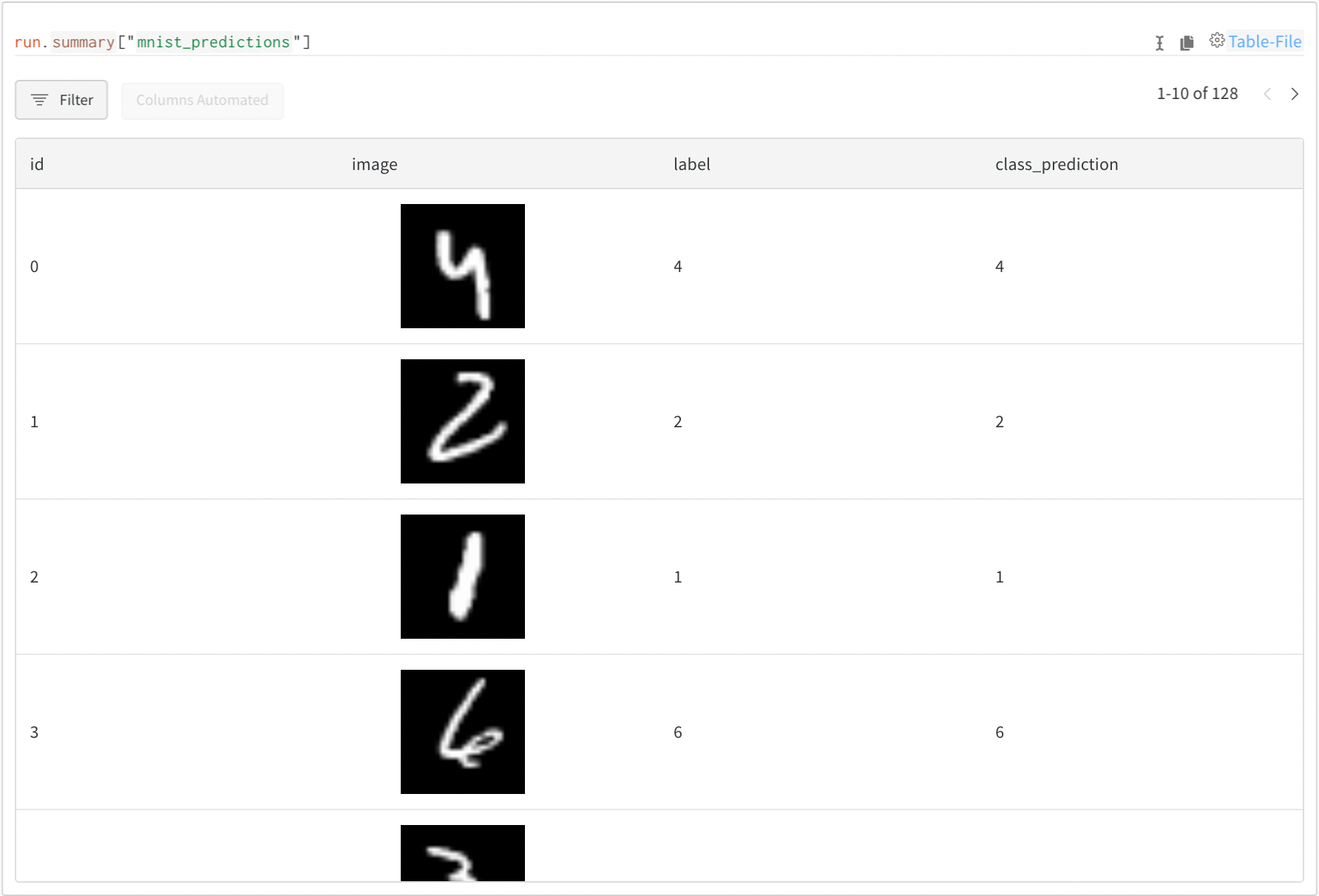
model의 예측 또는 파생 메트릭과 같은 정보를 미디어와 함께 포함하려면 wandb.Table을 사용하세요.
my_table = wandb.Table()
my_table.add_column("image", images_t)
my_table.add_column("label", labels)
my_table.add_column("class_prediction", predictions_t)
# Log your Table to W&Bwandb.log({"mnist_predictions": my_table})
데이터셋 및 model 로깅 및 시각화에 대한 자세한 내용은 W&B Tables 가이드를 확인하세요.
profile_dir ="path/to/run/tbprofile/"profiler = torch.profiler.profile(
schedule=schedule, # see the profiler docs for details on scheduling on_trace_ready=torch.profiler.tensorboard_trace_handler(profile_dir),
with_stack=True,
)
with profiler:
...# run the code you want to profile here# see the profiler docs for detailed usage information# create a wandb Artifactprofile_art = wandb.Artifact("trace", type="profile")
# add the pt.trace.json files to the Artifactprofile_art.add_file(glob.glob(profile_dir +".pt.trace.json"))
# log the artifactprofile_art.save()
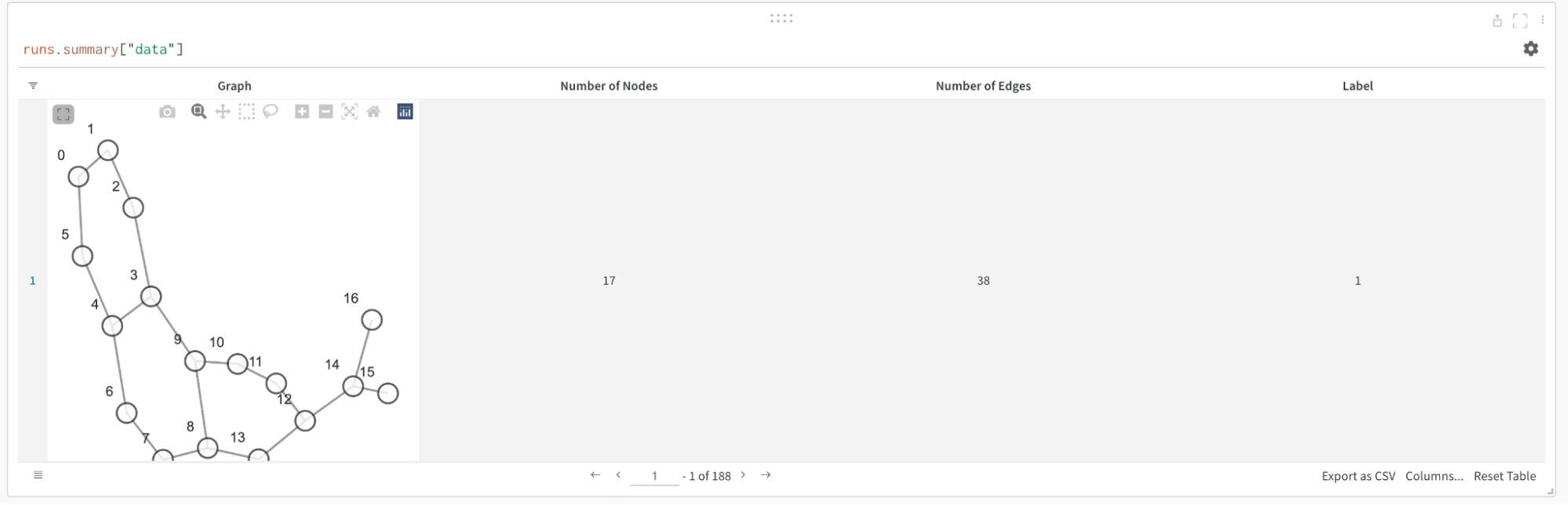
엣지 수, 노드 수 등 입력 그래프에 대한 세부 정보를 저장할 수 있습니다. W&B는 Plotly 차트 및 HTML 패널 로깅을 지원하므로 그래프에 대해 생성하는 모든 시각화를 W&B에 로깅할 수도 있습니다.
PyVis 사용
다음 스니펫은 PyVis 및 HTML을 사용하여 이를 수행하는 방법을 보여줍니다.
from pyvis.network import Network
Import wandb
wandb.init(project=’graph_vis’)
net = Network(height="750px", width="100%", bgcolor="#222222", font_color="white")
# Add the edges from the PyG graph to the PyVis networkfor e in tqdm(g.edge_index.T):
src = e[0].item()
dst = e[1].item()
net.add_node(dst)
net.add_node(src)
net.add_edge(src, dst, value=0.1)
# Save the PyVis visualisation to a HTML filenet.show("graph.html")
wandb.log({"eda/graph": wandb.Html("graph.html")})
wandb.finish()
Plotly 사용
Plotly를 사용하여 그래프 시각화를 만들려면 먼저 PyG 그래프를 networkx 오브젝트로 변환해야 합니다. 다음으로 노드와 엣지 모두에 대해 Plotly 산점도를 만들어야 합니다. 아래 스니펫을 이 작업에 사용할 수 있습니다.
metric_logger 섹션을 수정하여 레시피 구성 파일에서 W&B 로깅을 활성화합니다. _component_ 를 torchtune.utils.metric_logging.WandBLogger 클래스로 변경합니다. project 이름과 log_every_n_steps 를 전달하여 로깅 행동을 사용자 정의할 수도 있습니다.
wandb.init 메소드에 전달하는 것처럼 다른 kwargs 를 전달할 수도 있습니다. 예를 들어 팀에서 작업하는 경우 entity 인수를 WandBLogger 클래스에 전달하여 팀 이름을 지정할 수 있습니다.
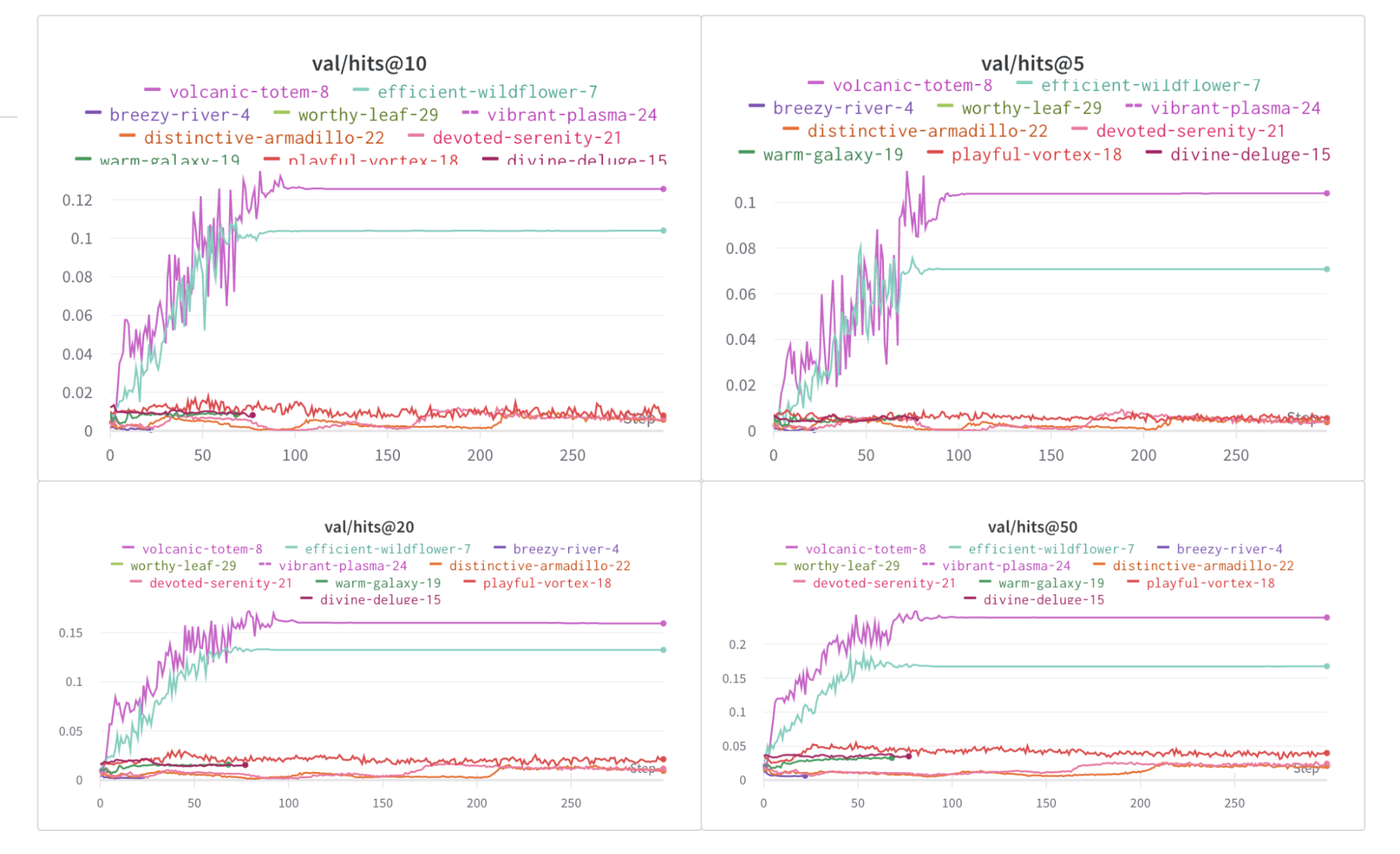
W&B 대시보드를 탐색하여 기록된 메트릭을 확인할 수 있습니다. 기본적으로 W&B 는 구성 파일 및 실행 재정의의 모든 하이퍼파라미터를 기록합니다.
W&B 는 Overview 탭에서 확인된 구성을 캡처합니다. W&B 는 또한 YAML 형식으로 파일 탭에 구성을 저장합니다.
로깅된 메트릭
각 레시피에는 자체 트레이닝 루프가 있습니다. 각 개별 레시피를 확인하여 기본적으로 포함되는 로깅된 메트릭을 확인하십시오.
Metric
Description
loss
모델의 손실
lr
학습률
tokens_per_second
모델의 초당 토큰 수
grad_norm
모델의 그레이디언트 norm
global_step
트레이닝 루프의 현재 단계를 나타냅니다. 그레이디언트 누적을 고려하며, 기본적으로 옵티마이저 단계가 수행될 때마다 모델이 업데이트되고, 그레이디언트가 누적되며, 모델은 gradient_accumulation_steps 마다 한 번 업데이트됩니다.
global_step 은 트레이닝 단계 수와 동일하지 않습니다. 트레이닝 루프의 현재 단계를 나타냅니다. 그레이디언트 누적을 고려하며, 기본적으로 옵티마이저 단계가 수행될 때마다 global_step 은 1 씩 증가합니다. 예를 들어 데이터 로더에 10 개의 배치, 그레이디언트 누적 단계가 2 이고 3 에포크 동안 실행되는 경우 옵티마이저는 15 번 단계별로 진행되며, 이 경우 global_step 은 1 에서 15 까지입니다.
torchtune 의 간소화된 설계를 통해 사용자 정의 메트릭을 쉽게 추가하거나 기존 메트릭을 수정할 수 있습니다. 예를 들어, 레시피 파일을 수정하여 총 에포크 수의 백분율로 current_epoch 을 계산하여 로깅할 수 있습니다.
# inside `train.py` function in the recipe fileself._metric_logger.log_dict(
{"current_epoch": self.epochs * self.global_step / self._steps_per_epoch},
step=self.global_step,
)
이것은 빠르게 진화하는 라이브러리이며 현재 메트릭은 변경될 수 있습니다. 사용자 정의 메트릭을 추가하려면 레시피를 수정하고 해당 self._metric_logger.* 함수를 호출해야 합니다.
체크포인트 저장 및 로드
torchtune 라이브러리는 다양한 체크포인트 형식을 지원합니다. 사용 중인 모델의 출처에 따라 적절한 체크포인터 클래스로 전환해야 합니다.
모델 체크포인트를 W&B Artifacts에 저장하려면 해당 레시피 내에서 save_checkpoint 함수를 재정의하는 것이 가장 간단한 해결책입니다.
다음은 모델 체크포인트를 W&B Artifacts 에 저장하기 위해 save_checkpoint 함수를 재정의하는 방법의 예입니다.
defsave_checkpoint(self, epoch: int) ->None:
...## Let's save the checkpoint to W&B## depending on the Checkpointer Class the file will be named differently## Here is an example for the full_finetune case checkpoint_file = Path.joinpath(
self._checkpointer._output_dir, f"torchtune_model_{epoch}" ).with_suffix(".pt")
wandb_artifact = wandb.Artifact(
name=f"torchtune_model_{epoch}",
type="model",
# description of the model checkpoint description="Model checkpoint",
# you can add whatever metadata you want as a dict metadata={
utils.SEED_KEY: self.seed,
utils.EPOCHS_KEY: self.epochs_run,
utils.TOTAL_EPOCHS_KEY: self.total_epochs,
utils.MAX_STEPS_KEY: self.max_steps_per_epoch,
},
)
wandb_artifact.add_file(checkpoint_file)
wandb.log_artifact(wandb_artifact)
Ignite는 트레이닝 및 검증 중에 메트릭, 모델/옵티마이저 파라미터, 그레이디언트를 기록하기 위해 Weights & Biases 핸들러를 지원합니다. 또한 모델 체크포인트를 Weights & Biases cloud에 기록하는 데 사용할 수도 있습니다. 이 클래스는 wandb 모듈의 래퍼이기도 합니다. 즉, 이 래퍼를 사용하여 모든 wandb 함수를 호출할 수 있습니다. 모델 파라미터와 그레이디언트를 저장하는 방법에 대한 예시를 참조하세요.
기본 설정
from argparse import ArgumentParser
import wandb
import torch
from torch import nn
from torch.optim import SGD
from torch.utils.data import DataLoader
import torch.nn.functional as F
from torchvision.transforms import Compose, ToTensor, Normalize
from torchvision.datasets import MNIST
from ignite.engine import Events, create_supervised_trainer, create_supervised_evaluator
from ignite.metrics import Accuracy, Loss
from tqdm import tqdm
classNet(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
self.conv2_drop = nn.Dropout2d()
self.fc1 = nn.Linear(320, 50)
self.fc2 = nn.Linear(50, 10)
defforward(self, x):
x = F.relu(F.max_pool2d(self.conv1(x), 2))
x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2))
x = x.view(-1, 320)
x = F.relu(self.fc1(x))
x = F.dropout(x, training=self.training)
x = self.fc2(x)
return F.log_softmax(x, dim=-1)
defget_data_loaders(train_batch_size, val_batch_size):
data_transform = Compose([ToTensor(), Normalize((0.1307,), (0.3081,))])
train_loader = DataLoader(MNIST(download=True, root=".", transform=data_transform, train=True),
batch_size=train_batch_size, shuffle=True)
val_loader = DataLoader(MNIST(download=False, root=".", transform=data_transform, train=False),
batch_size=val_batch_size, shuffle=False)
return train_loader, val_loader
ignite에서 WandBLogger를 사용하는 것은 모듈식 프로세스입니다. 먼저, WandBLogger 오브젝트를 만듭니다. 다음으로, 메트릭을 자동으로 기록하기 위해 트레이너 또는 평가기에 연결합니다. 다음은 이 예시입니다.
PyTorch Lightning 은 PyTorch 코드를 구성하고 분산 트레이닝 및 16비트 정밀도와 같은 고급 기능을 쉽게 추가할 수 있는 가벼운 래퍼를 제공합니다. W&B는 ML Experiments을 로깅하기 위한 가벼운 래퍼를 제공합니다. 하지만 이 둘을 직접 결합할 필요는 없습니다. Weights & Biases는 WandbLogger를 통해 PyTorch Lightning 라이브러리에 직접 통합됩니다.
Lightning 과 통합
from lightning.pytorch.loggers import WandbLogger
from lightning.pytorch import Trainer
wandb_logger = WandbLogger(log_model="all")
trainer = Trainer(logger=wandb_logger)
wandb.log() 사용:WandbLogger는 Trainer의 global_step을 사용하여 W&B에 로깅합니다. 코드에서 wandb.log를 직접 추가로 호출하는 경우 wandb.log()에서 step 인수를 사용하지 마십시오.
# 파라미터 하나 추가wandb_logger.experiment.config["key"] = value
# 여러 파라미터 추가wandb_logger.experiment.config.update({key1: val1, key2: val2})
# wandb 모듈을 직접 사용wandb.config["key"] = value
wandb.config.update()
그레이디언트, 파라미터 히스토그램 및 모델 토폴로지 로깅
모델 오브젝트를 wandblogger.watch()에 전달하여 트레이닝하는 동안 모델의 그레이디언트와 파라미터를 모니터링할 수 있습니다. PyTorch Lightning WandbLogger 설명서를 참조하십시오.
메트릭 로깅
training_step 또는 validation_step methods와 같이 LightningModule 내에서 self.log('my_metric_name', metric_vale)을 호출하여 WandbLogger를 사용할 때 메트릭을 W&B에 로깅할 수 있습니다.
아래 코드 조각은 메트릭과 LightningModule 하이퍼파라미터를 로깅하도록 LightningModule을 정의하는 방법을 보여줍니다. 이 예제에서는 torchmetrics 라이브러리를 사용하여 메트릭을 계산합니다.
import torch
from torch.nn import Linear, CrossEntropyLoss, functional as F
from torch.optim import Adam
from torchmetrics.functional import accuracy
from lightning.pytorch import LightningModule
classMy_LitModule(LightningModule):
def __init__(self, n_classes=10, n_layer_1=128, n_layer_2=256, lr=1e-3):
"""모델 파라미터를 정의하는 데 사용되는 메소드""" super().__init__()
# mnist 이미지는 (1, 28, 28) (채널, 너비, 높이)입니다. self.layer_1 = Linear(28*28, n_layer_1)
self.layer_2 = Linear(n_layer_1, n_layer_2)
self.layer_3 = Linear(n_layer_2, n_classes)
self.loss = CrossEntropyLoss()
self.lr = lr
# 하이퍼파라미터를 self.hparams에 저장합니다(W&B에서 자동 로깅). self.save_hyperparameters()
defforward(self, x):
"""추론 입력 -> 출력에 사용되는 메소드"""# (b, 1, 28, 28) -> (b, 1*28*28) batch_size, channels, width, height = x.size()
x = x.view(batch_size, -1)
# 3 x (linear + relu)를 수행해 보겠습니다. x = F.relu(self.layer_1(x))
x = F.relu(self.layer_2(x))
x = self.layer_3(x)
return x
deftraining_step(self, batch, batch_idx):
"""단일 배치에서 손실을 반환해야 합니다.""" _, loss, acc = self._get_preds_loss_accuracy(batch)
# 손실 및 메트릭 로깅 self.log("train_loss", loss)
self.log("train_accuracy", acc)
return loss
defvalidation_step(self, batch, batch_idx):
"""메트릭 로깅에 사용""" preds, loss, acc = self._get_preds_loss_accuracy(batch)
# 손실 및 메트릭 로깅 self.log("val_loss", loss)
self.log("val_accuracy", acc)
return preds
defconfigure_optimizers(self):
"""모델 옵티마이저를 정의합니다."""return Adam(self.parameters(), lr=self.lr)
def_get_preds_loss_accuracy(self, batch):
"""train/valid/test 단계가 유사하므로 편의 함수""" x, y = batch
logits = self(x)
preds = torch.argmax(logits, dim=1)
loss = self.loss(logits, y)
acc = accuracy(preds, y)
return preds, loss, acc
import lightning as L
import torch
import torchvision as tv
from wandb.integration.lightning.fabric import WandbLogger
import wandb
fabric = L.Fabric(loggers=[wandb_logger])
fabric.launch()
model = tv.models.resnet18()
optimizer = torch.optim.SGD(model.parameters(), lr=lr)
model, optimizer = fabric.setup(model, optimizer)
train_dataloader = fabric.setup_dataloaders(
torch.utils.data.DataLoader(train_dataset, batch_size=batch_size)
)
model.train()
for epoch in range(num_epochs):
for batch in train_dataloader:
optimizer.zero_grad()
loss = model(batch)
loss.backward()
optimizer.step()
fabric.log_dict({"loss": loss})
메트릭의 최소/최대값 로깅
wandb의 define_metric 함수를 사용하여 W&B 요약 메트릭에 해당 메트릭의 최소, 최대, 평균 또는 최적값을 표시할지 여부를 정의할 수 있습니다. define_metric _이(가) 사용되지 않으면 로깅된 마지막 값이 요약 메트릭에 나타납니다. define_metric참조 문서(여기)와 가이드(여기)를 참조하십시오.
W&B가 W&B 요약 메트릭에서 최대 검증 정확도를 추적하도록 지시하려면 트레이닝 시작 시 wandb.define_metric을 한 번만 호출하십시오.
여기에서 작업별로 최고의 모델을 구성하고, 모델 수명 주기를 관리하고, ML 수명 주기 전반에 걸쳐 쉬운 추적 및 감사를 용이하게 하고, 웹후크 또는 작업을 통해 다운스트림 작업을 자동화할 수 있습니다.
이미지, 텍스트 등 로깅
WandbLogger에는 미디어를 로깅하기 위한 log_image, log_text 및 log_table 메소드가 있습니다.
wandb.log 또는 trainer.logger.experiment.log를 직접 호출하여 오디오, 분자, 포인트 클라우드, 3D 오브젝트 등과 같은 다른 미디어 유형을 로깅할 수도 있습니다.
# 텐서, numpy 어레이 또는 PIL 이미지 사용wandb_logger.log_image(key="samples", images=[img1, img2])
# 캡션 추가wandb_logger.log_image(key="samples", images=[img1, img2], caption=["tree", "person"])
# 파일 경로 사용wandb_logger.log_image(key="samples", images=["img_1.jpg", "img_2.jpg"])
# 트레이너에서 .log 사용trainer.logger.experiment.log(
{"samples": [wandb.Image(img, caption=caption) for (img, caption) in my_images]},
step=current_trainer_global_step,
)
# 데이터는 목록 목록이어야 합니다.columns = ["input", "label", "prediction"]
my_data = [["cheese", "english", "english"], ["fromage", "french", "spanish"]]
# 열 및 데이터 사용wandb_logger.log_text(key="my_samples", columns=columns, data=my_data)
# pandas DataFrame 사용wandb_logger.log_text(key="my_samples", dataframe=my_dataframe)
# 텍스트 캡션, 이미지 및 오디오가 있는 W&B Table 로깅columns = ["caption", "image", "sound"]
# 데이터는 목록 목록이어야 합니다.my_data = [
["cheese", wandb.Image(img_1), wandb.Audio(snd_1)],
["wine", wandb.Image(img_2), wandb.Audio(snd_2)],
]
# Table 로깅wandb_logger.log_table(key="my_samples", columns=columns, data=data)
Lightning의 콜백 시스템을 사용하여 WandbLogger를 통해 Weights & Biases에 로깅하는 시점을 제어할 수 있습니다. 이 예에서는 검증 이미지 및 예측 샘플을 로깅합니다.
import torch
import wandb
import lightning.pytorch as pl
from lightning.pytorch.loggers import WandbLogger
# 또는# from wandb.integration.lightning.fabric import WandbLoggerclassLogPredictionSamplesCallback(Callback):
defon_validation_batch_end(
self, trainer, pl_module, outputs, batch, batch_idx, dataloader_idx
):
"""검증 배치가 종료되면 호출됩니다."""# `outputs`는 `LightningModule.validation_step`에서 가져옵니다.# 이 경우 모델 예측에 해당합니다.# 첫 번째 배치에서 20개의 샘플 이미지 예측을 로깅해 보겠습니다.if batch_idx ==0:
n =20 x, y = batch
images = [img for img in x[:n]]
captions = [
f"Ground Truth: {y_i} - Prediction: {y_pred}"for y_i, y_pred in zip(y[:n], outputs[:n])
]
# 옵션 1: `WandbLogger.log_image`로 이미지 로깅 wandb_logger.log_image(key="sample_images", images=images, caption=captions)
# 옵션 2: 이미지 및 예측을 W&B Table로 로깅 columns = ["image", "ground truth", "prediction"]
data = [
[wandb.Image(x_i), y_i, y_pred] or x_i,
y_i,
y_pred in list(zip(x[:n], y[:n], outputs[:n])),
]
wandb_logger.log_table(key="sample_table", columns=columns, data=data)
trainer = pl.Trainer(callbacks=[LogPredictionSamplesCallback()])
Lightning 및 W&B로 여러 GPU 사용
PyTorch Lightning은 DDP 인터페이스를 통해 Multi-GPU를 지원합니다. 그러나 PyTorch Lightning의 디자인에서는 GPU를 인스턴스화하는 방법에 주의해야 합니다.
Lightning은 트레이닝 루프의 각 GPU(또는 순위)가 동일한 초기 조건으로 정확히 동일한 방식으로 인스턴스화되어야 한다고 가정합니다. 그러나 순위 0 프로세스만 wandb.run 오브젝트에 엑세스할 수 있으며 0이 아닌 순위 프로세스의 경우 wandb.run = None입니다. 이로 인해 0이 아닌 프로세스가 실패할 수 있습니다. 이러한 상황은 순위 0 프로세스가 이미 충돌한 0이 아닌 순위 프로세스가 조인될 때까지 대기하기 때문에 교착 상태에 놓일 수 있습니다.
이러한 이유로 트레이닝 코드를 설정하는 방법에 주의하십시오. 설정하는 데 권장되는 방법은 코드가 wandb.run 오브젝트와 독립적이도록 하는 것입니다.
classMNISTClassifier(pl.LightningModule):
def __init__(self):
super(MNISTClassifier, self).__init__()
self.model = nn.Sequential(
nn.Flatten(),
nn.Linear(28*28, 128),
nn.ReLU(),
nn.Linear(128, 10),
)
self.loss = nn.CrossEntropyLoss()
defforward(self, x):
return self.model(x)
deftraining_step(self, batch, batch_idx):
x, y = batch
y_hat = self.forward(x)
loss = self.loss(y_hat, y)
self.log("train/loss", loss)
return {"train_loss": loss}
defvalidation_step(self, batch, batch_idx):
x, y = batch
y_hat = self.forward(x)
loss = self.loss(y_hat, y)
self.log("val/loss", loss)
return {"val_loss": loss}
defconfigure_optimizers(self):
return torch.optim.Adam(self.parameters(), lr=0.001)
defmain():
# 모든 랜덤 시드를 동일한 값으로 설정합니다.# 이는 분산 트레이닝 설정에서 중요합니다.# 각 순위는 자체 초기 weights 집합을 가져옵니다.# 일치하지 않으면 그레이디언트도 일치하지 않습니다.# 수렴하지 않을 수 있는 트레이닝으로 이어집니다. pl.seed_everything(1)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True, num_workers=4)
val_loader = DataLoader(val_dataset, batch_size=64, shuffle=False, num_workers=4)
model = MNISTClassifier()
wandb_logger = WandbLogger(project="<project_name>")
callbacks = [
ModelCheckpoint(
dirpath="checkpoints",
every_n_train_steps=100,
),
]
trainer = pl.Trainer(
max_epochs=3, gpus=2, logger=wandb_logger, strategy="ddp", callbacks=callbacks
)
trainer.fit(model, train_loader, val_loader)
모델 체크포인트를 W&B에 저장하여 볼 수 있거나 향후 run에서 사용하기 위해 다운로드할 수 있습니다. 또한 GPU 사용량 및 네트워크 I/O와 같은 시스템 메트릭, 하드웨어 및 OS 정보와 같은 환경 정보, 코드 상태 (git 커밋 및 차이 패치, 노트북 콘텐츠 및 세션 기록 포함) 및 표준 출력에 인쇄된 모든 항목을 캡처합니다.
트레이닝 설정에서 wandb.run을 사용해야 하는 경우는 어떻게 해야 합니까?
엑세스해야 하는 변수의 범위를 직접 확장해야 합니다. 즉, 모든 프로세스에서 초기 조건이 동일한지 확인하십시오.
if os.environ.get("LOCAL_RANK", None) isNone:
os.environ["WANDB_DIR"] = wandb.run.dir
그렇다면 os.environ["WANDB_DIR"]을 사용하여 모델 체크포인트 디렉토리를 설정할 수 있습니다. 이렇게 하면 0이 아닌 모든 순위 프로세스가 wandb.run.dir에 엑세스할 수 있습니다.
W&B 는 Amazon SageMaker 와 통합되어 하이퍼파라미터를 자동으로 읽고, 분산된 Runs 를 그룹화하며, 체크포인트에서 Runs 를 재개합니다.
인증
W&B 는 트레이닝 스크립트와 관련된 secrets.env 라는 파일을 찾고 wandb.init() 가 호출될 때 해당 파일을 환경에 로드합니다. secrets.env 파일은 실험을 시작하는 데 사용하는 스크립트에서 wandb.sagemaker_auth(path="source_dir") 를 호출하여 생성할 수 있습니다. 이 파일을 .gitignore 에 추가해야 합니다!
기존 estimator
SageMaker 의 사전 구성된 estimator 중 하나를 사용하는 경우, wandb 를 포함하는 requirements.txt 를 소스 디렉터리에 추가해야 합니다.
wandb
Python 2 를 실행하는 estimator 를 사용하는 경우, wandb 를 설치하기 전에 이 wheel 에서 psutil 을 직접 설치해야 합니다.
import wandb
wandb.init(project="visualize-sklearn")
y_pred = clf.predict(X_test)
accuracy = sklearn.metrics.accuracy_score(y_true, y_pred)
# If logging metrics over time, then use wandb.logwandb.log({"accuracy": accuracy})
# OR to log a final metric at the end of training you can also use wandb.summarywandb.summary["accuracy"] = accuracy
Matplotlib에서 생성된 플롯도 W&B 대시보드에 기록할 수 있습니다. 이를 위해서는 먼저 plotly를 설치해야 합니다.
pip install plotly
마지막으로, 다음과 같이 W&B의 대시보드에 플롯을 기록할 수 있습니다.
import matplotlib.pyplot as plt
import wandb
wandb.init(project="visualize-sklearn")
# do all the plt.plot(), plt.scatter(), etc. here.# ...# instead of doing plt.show() do:wandb.log({"plot": plt})
지원되는 플롯
학습 곡선
다양한 길이의 데이터셋에서 모델을 트레이닝하고 트레이닝 및 테스트 세트 모두에 대해 교차 검증된 점수 대 데이터셋 크기의 플롯을 생성합니다.
wandb.sklearn.plot_learning_curve(model, X, y)
model (clf 또는 reg): 적합된 회귀 모델 또는 분류 모델을 사용합니다.
X (arr): 데이터셋 특징.
y (arr): 데이터셋 레이블.
ROC
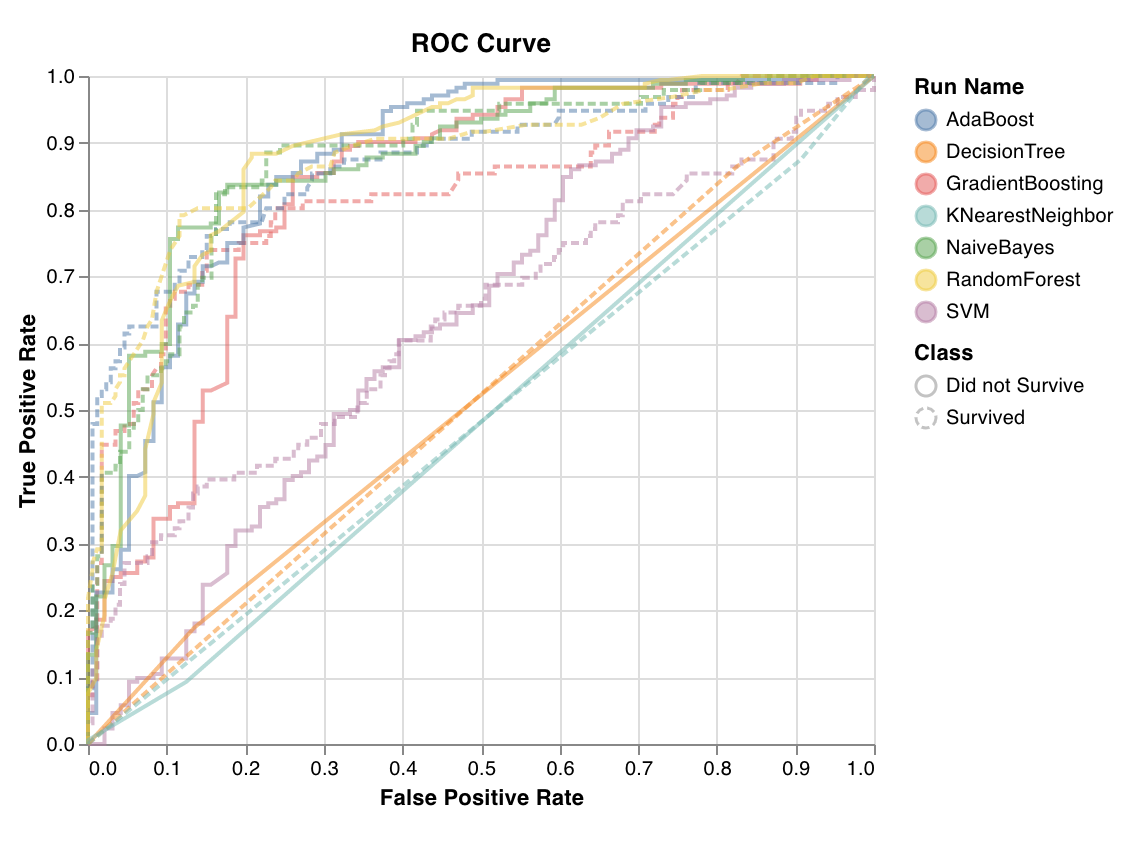
ROC 곡선은 참 긍정 비율(y축) 대 거짓 긍정 비율(x축)을 표시합니다. 이상적인 점수는 TPR = 1 및 FPR = 0이며, 이는 왼쪽 상단의 점입니다. 일반적으로 ROC 곡선 아래 영역(AUC-ROC)을 계산하며 AUC-ROC가 클수록 좋습니다.
wandb.sklearn.plot_roc(y_true, y_probas, labels)
y_true (arr): 테스트 세트 레이블.
y_probas (arr): 테스트 세트 예측 확률.
labels (list): 목표 변수(y)에 대해 명명된 레이블.
클래스 비율
트레이닝 및 테스트 세트에서 목표 클래스의 분포를 표시합니다. 불균형 클래스를 감지하고 한 클래스가 모델에 불균형적인 영향을 미치지 않도록 하는 데 유용합니다.
feature_names (list): 특징 이름. 특징 인덱스를 해당 이름으로 대체하여 플롯을 더 쉽게 읽을 수 있습니다.
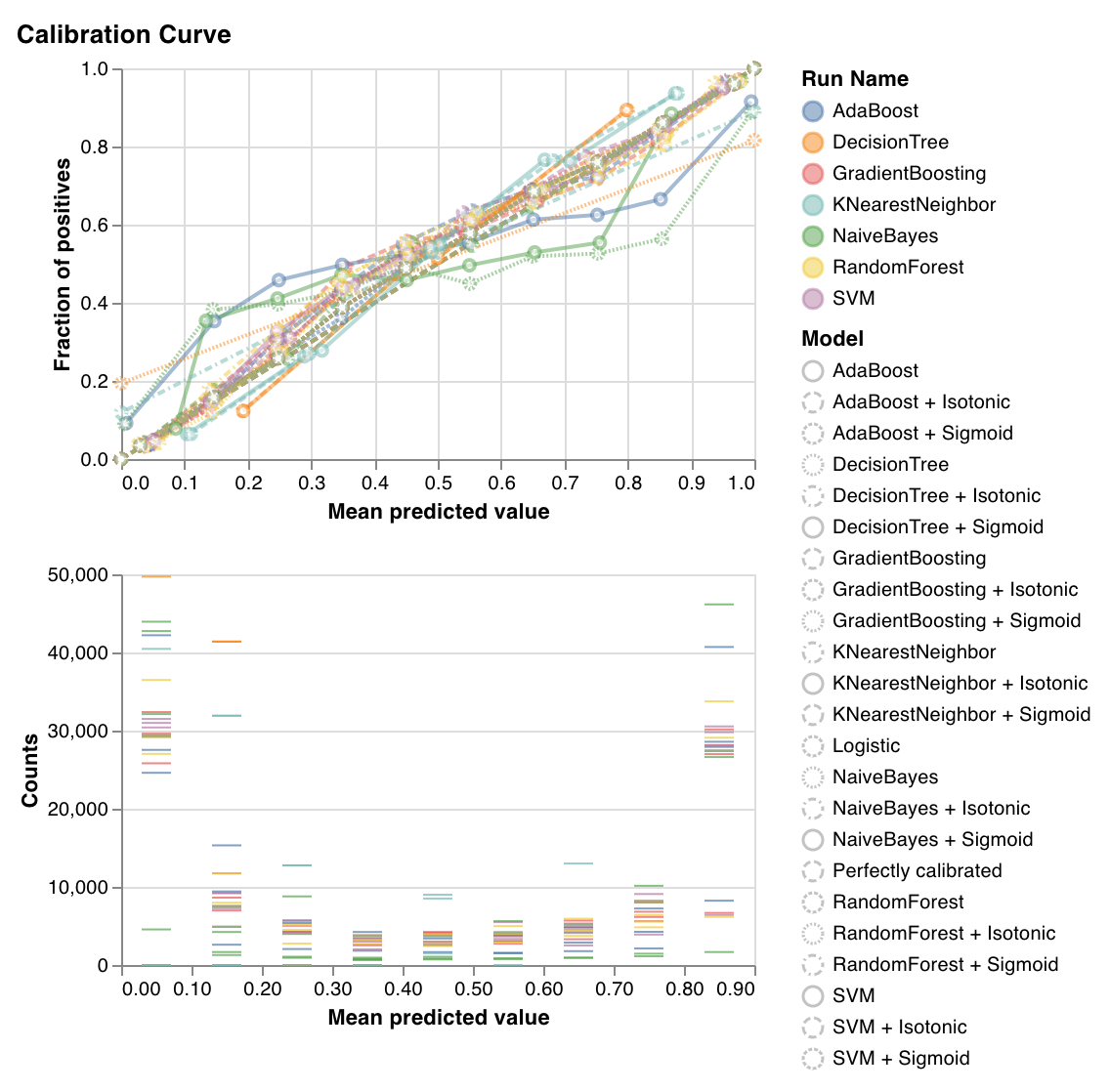
보정 곡선
분류 모델의 예측 확률이 얼마나 잘 보정되었는지, 보정되지 않은 분류 모델을 보정하는 방법을 표시합니다. 베이스라인 로지스틱 회귀 모델, 인수로 전달된 모델, 등방성 보정 및 시그모이드 보정 모두에 의해 추정된 예측 확률을 비교합니다.
보정 곡선이 대각선에 가까울수록 좋습니다. 전치된 시그모이드와 같은 곡선은 과적합된 분류 모델을 나타내고 시그모이드와 같은 곡선은 과소적합된 분류 모델을 나타냅니다. 모델의 등방성 및 시그모이드 보정을 트레이닝하고 해당 곡선을 비교하여 모델이 과적합 또는 과소적합되었는지, 그렇다면 어떤 보정(시그모이드 또는 등방성)이 이를 수정하는 데 도움이 될 수 있는지 파악할 수 있습니다.
이 라이브러리는 Hugging Face의 Transformers 라이브러리를 기반으로 합니다. Simple Transformers를 사용하면 Transformer 모델을 빠르게 트레이닝하고 평가할 수 있습니다. 모델을 초기화하고, 모델을 트레이닝하고, 모델을 평가하는 데 단 3줄의 코드만 필요합니다. Sequence Classification, Token Classification (NER), Question Answering, Language Model Fine-Tuning, Language Model Training, Language Generation, T5 Model, Seq2Seq Tasks, Multi-Modal Classification 및 Conversational AI를 지원합니다.
모델 트레이닝을 시각화하기 위해 Weights and Biases를 사용하려면 args dictionary의 wandb_project 속성에서 W&B에 대한 프로젝트 이름을 설정하세요. 이렇게 하면 모든 하이퍼파라미터 값, 트레이닝 손실 및 평가 메트릭이 지정된 프로젝트에 기록됩니다.
model = ClassificationModel('roberta', 'roberta-base', args={'wandb_project': 'project-name'})
wandb.init에 들어가는 추가 인수는 wandb_kwargs로 전달할 수 있습니다.
구조
이 라이브러리는 모든 NLP 작업을 위한 별도의 클래스를 갖도록 설계되었습니다. 유사한 기능을 제공하는 클래스는 함께 그룹화됩니다.
simpletransformers.classification - 모든 Classification 모델을 포함합니다.
ClassificationModel
MultiLabelClassificationModel
simpletransformers.ner - 모든 Named Entity Recognition 모델을 포함합니다.
NERModel
simpletransformers.question_answering - 모든 Question Answering 모델을 포함합니다.
QuestionAnsweringModel
다음은 몇 가지 최소한의 예입니다.
MultiLabel Classification
model = MultiLabelClassificationModel("distilbert","distilbert-base-uncased",num_labels=6,
args={"reprocess_input_data": True, "overwrite_output_dir": True, "num_train_epochs":epochs,'learning_rate':learning_rate,
'wandb_project': "simpletransformers"},
)
# 모델 트레이닝
model.train_model(train_df)
# 모델 평가
result, model_outputs, wrong_predictions = model.eval_model(eval_df)
Skorch와 함께 Weights & Biases를 사용하여 모든 모델 성능 메트릭, 모델 토폴로지 및 컴퓨팅 리소스와 함께 최고의 성능을 보이는 모델을 각 에포크 후에 자동으로 기록할 수 있습니다. wandb_run.dir에 저장된 모든 파일은 자동으로 W&B 서버에 기록됩니다.
# wandb 설치... pip install wandb
import wandb
from skorch.callbacks import WandbLogger
# wandb Run 생성wandb_run = wandb.init()
# 대안: W&B 계정 없이 wandb Run 생성wandb_run = wandb.init(anonymous="allow")
# 하이퍼 파라미터 기록 (선택 사항)wandb_run.config.update({"learning rate": 1e-3, "batch size": 32})
net = NeuralNet(..., callbacks=[WandbLogger(wandb_run)])
net.fit(X, y)
메소드 레퍼런스
메소드
설명
initialize()
콜백의 초기 상태를 (다시) 설정합니다.
on_batch_begin(net[, X, y, training])
각 배치 시작 시 호출됩니다.
on_batch_end(net[, X, y, training])
각 배치 종료 시 호출됩니다.
on_epoch_begin(net[, dataset_train, …])
각 에포크 시작 시 호출됩니다.
on_epoch_end(net, **kwargs)
마지막 기록 단계의 값을 기록하고 최고의 모델을 저장합니다.
on_grad_computed(net, named_parameters[, X, …])
그레이디언트가 계산되었지만 업데이트 단계가 수행되기 전에 배치당 한 번 호출됩니다.
on_train_begin(net, **kwargs)
모델 토폴로지를 기록하고 그레이디언트에 대한 훅을 추가합니다.
on_train_end(net[, X, y])
트레이닝 종료 시 호출됩니다.
39 - spaCy
spaCy는 빠르고 정확한 모델을 간편하게 사용할 수 있도록 하는 유명한 “산업용” NLP 라이브러리입니다. spaCy v3부터는 Weights & Biases를 spacy train과 함께 사용하여 spaCy 모델의 트레이닝 메트릭을 추적하고 모델과 데이터셋을 저장 및 버저닝할 수 있습니다. 설정에 몇 줄만 추가하면 됩니다.
가입하고 API 키 만들기
API 키는 사용자의 머신이 W&B에 인증되도록 합니다. 사용자 프로필에서 API 키를 생성할 수 있습니다.
보다 간소화된 접근 방식을 위해 https://wandb.ai/authorize로 직접 이동하여 API 키를 생성할 수 있습니다. 표시된 API 키를 복사하여 비밀번호 관리자와 같은 안전한 위치에 저장합니다.
오른쪽 상단 모서리에 있는 사용자 프로필 아이콘을 클릭합니다.
User Settings를 선택한 다음 API Keys 섹션으로 스크롤합니다.
Reveal을 클릭합니다. 표시된 API 키를 복사합니다. API 키를 숨기려면 페이지를 새로 고칩니다.
spaCy 설정 파일은 로깅뿐만 아니라 트레이닝의 모든 측면(GPU 할당, 옵티마이저 선택, 데이터셋 경로 등)을 지정하는 데 사용됩니다. 최소한 [training.logger] 아래에 @loggers 키를 값 "spacy.WandbLogger.v3"와 함께 제공하고 project_name을 제공해야 합니다.
spaCy 트레이닝 설정 파일의 작동 방식과 트레이닝을 사용자 정의하기 위해 전달할 수 있는 기타 옵션에 대한 자세한 내용은 spaCy 설명서를 참조하십시오.
wandb와 함께 Tensorboard를 사용할 때 Tensorboard를 어떻게 구성합니까?
TensorBoard 패치 방법을 보다 세밀하게 제어하려면 wandb.init에 sync_tensorboard=True를 전달하는 대신 wandb.tensorboard.patch를 호출할 수 있습니다.
import wandb
wandb.tensorboard.patch(root_logdir="<logging_directory>")
wandb.init()
# W&B에 tensorboard 로그를 업로드하기 위해 wandb run을 완료합니다(노트북에서 실행하는 경우).wandb.finish()
TensorBoard > 1.14를 PyTorch와 함께 사용하는 경우 vanilla TensorBoard가 패치되었는지 확인하려면 tensorboard_x=False를 이 메소드에 전달하고, 패치되었는지 확인하려면 pytorch=True를 전달할 수 있습니다. 이러한 옵션은 모두 이러한 라이브러리의 버전에 따라 스마트 기본값을 갖습니다.
기본적으로 tfevents 파일과 모든 .pbtxt 파일도 동기화합니다. 이를 통해 사용자를 대신하여 TensorBoard 인스턴스를 시작할 수 있습니다. run 페이지에 TensorBoard 탭이 표시됩니다. 이 동작은 wandb.tensorboard.patch에 save=False를 전달하여 끌 수 있습니다.
import wandb
wandb.init()
wandb.tensorboard.patch(save=False, tensorboard_x=True)
# 노트북에서 실행하는 경우 W&B에 tensorboard 로그를 업로드하기 위해 wandb run을 완료합니다.wandb.finish()
tf.summary.create_file_writer를 호출하거나 torch.utils.tensorboard를 통해 SummaryWriter를 구성하기 전에wandb.init 또는 wandb.tensorboard.patch를 호출해야 합니다.
이전 TensorBoard run을 어떻게 동기화합니까?
로컬에 저장된 기존 tfevents 파일이 있고 이를 W&B로 가져오려면 wandb sync log_dir을 실행합니다. 여기서 log_dir은 tfevents 파일이 포함된 로컬 디렉토리입니다.
Google Colab 또는 Jupyter를 TensorBoard와 함께 어떻게 사용합니까?
Jupyter 또는 Colab 노트북에서 코드를 실행하는 경우 트레이닝이 끝나면 wandb.finish()를 호출해야 합니다. 이렇게 하면 wandb run이 완료되고 tensorboard 로그가 W&B에 업로드되어 시각화할 수 있습니다. .py 스크립트가 완료되면 wandb가 자동으로 완료되므로 이는 필요하지 않습니다.
노트북 환경에서 셸 코맨드를 실행하려면 !wandb sync directoryname과 같이 !를 앞에 붙여야 합니다.
PyTorch를 TensorBoard와 함께 어떻게 사용합니까?
PyTorch의 TensorBoard 인테그레이션을 사용하는 경우 PyTorch Profiler JSON 파일을 수동으로 업로드해야 할 수 있습니다.
무엇이 기록되는지 더 세부적으로 제어하려면 wandb는 TensorFlow estimator에 대한 훅도 제공합니다. 그래프의 모든 tf.summary 값을 기록합니다.
import tensorflow as tf
import wandb
wandb.init(config=tf.FLAGS)
estimator.train(hooks=[wandb.tensorflow.WandbHook(steps_per_log=1000)])
수동으로 기록
TensorFlow에서 메트릭을 기록하는 가장 간단한 방법은 TensorFlow 로거를 사용하여 tf.summary를 기록하는 것입니다.
import wandb
with tf.Session() as sess:
# ... wandb.tensorflow.log(tf.summary.merge_all())
TensorFlow 2에서는 사용자 정의 루프를 사용하여 모델을 트레이닝하는 권장 방법은 tf.GradientTape를 사용하는 것입니다. 자세한 내용은 여기에서 확인할 수 있습니다. 사용자 정의 TensorFlow 트레이닝 루프에서 메트릭을 기록하기 위해 wandb를 통합하려면 다음 스니펫을 따르세요.
with tf.GradientTape() as tape:
# 예측값 가져오기 predictions = model(features)
# 손실 계산 loss = loss_func(labels, predictions)
# 메트릭 기록 wandb.log("loss": loss.numpy())
# 그레이디언트 가져오기 gradients = tape.gradient(loss, model.trainable_variables)
# 가중치 업데이트 optimizer.apply_gradients(zip(gradients, model.trainable_variables))
공동 창립자들이 W&B 작업을 시작했을 때 OpenAI의 불만을 가진 TensorBoard 사용자들을 위한 툴을 구축하라는 영감을 받았습니다. 개선에 집중한 몇 가지 사항은 다음과 같습니다.
모델 재현: Weights & Biases는 실험, 탐색 및 나중에 모델을 재현하는 데 유용합니다. 메트릭뿐만 아니라 하이퍼파라미터와 코드 버전을 캡처하고, 프로젝트를 재현할 수 있도록 버전 제어 상태와 모델 체크포인트를 저장할 수 있습니다.
자동 구성: 협업자로부터 프로젝트를 넘겨받거나, 휴가에서 돌아오거나, 오래된 프로젝트를 다시 시작하는 경우에도 W&B를 사용하면 시도된 모든 모델을 쉽게 볼 수 있으므로 GPU 주기 또는 탄소 재실행 Experiments에 시간을 낭비하는 사람이 없습니다.
빠르고 유연한 통합: 5분 안에 프로젝트에 W&B를 추가하세요. 무료 오픈 소스 Python 패키지를 설치하고 코드에 두 줄을 추가하면 모델을 실행할 때마다 멋지게 기록된 메트릭과 레코드를 얻을 수 있습니다.
영구적인 중앙 집중식 대시보드: 로컬 머신, 공유 랩 클러스터 또는 클라우드의 스팟 인스턴스 등 모델을 트레이닝하는 위치에 관계없이 결과는 동일한 중앙 집중식 대시보드에 공유됩니다. 서로 다른 머신에서 TensorBoard 파일을 복사하고 구성하는 데 시간을 할애할 필요가 없습니다.
강력한 테이블: 다양한 모델의 결과를 검색, 필터링, 정렬 및 그룹화합니다. 수천 개의 모델 버전을 살펴보고 다양한 작업에 가장 적합한 모델을 쉽게 찾을 수 있습니다. TensorBoard는 대규모 프로젝트에서 잘 작동하도록 구축되지 않았습니다.
협업 툴: W&B를 사용하여 복잡한 기계학습 프로젝트를 구성합니다. W&B에 대한 링크를 쉽게 공유할 수 있으며, 비공개 Teams를 사용하여 모든 사람이 결과를 공유 프로젝트로 보낼 수 있습니다. 또한 Reports를 통한 협업도 지원합니다. 대화형 시각화 자료를 추가하고 작업을 markdown으로 설명합니다. 이것은 작업 로그를 유지하고, 지도교수와 발견한 내용을 공유하거나, 랩 또는 팀에 발견한 내용을 발표하는 좋은 방법입니다.
Julia 프로그래밍 언어로 기계 학습 Experiments 를 실행하는 사용자를 위해 커뮤니티 기여자가 wandb.jl 이라는 비공식 Julia 바인딩 세트를 만들었습니다.
wandb.jl 저장소의 documentation 에서 예제를 찾을 수 있습니다. “Getting Started” 예제는 다음과 같습니다.
using Wandb, Dates, Logging
# Start a new run, tracking hyperparameters in configlg = WandbLogger(project ="Wandb.jl",
name ="wandbjl-demo-$(now())",
config =Dict("learning_rate"=>0.01,
"dropout"=>0.2,
"architecture"=>"CNN",
"dataset"=>"CIFAR-100"))
# Use LoggingExtras.jl to log to multiple loggers togetherglobal_logger(lg)
# Simulating the training or evaluation loopfor x ∈1:50 acc = log(1+ x + rand() * get_config(lg, "learning_rate") + rand() + get_config(lg, "dropout"))
loss =10- log(1+ x + rand() + x * get_config(lg, "learning_rate") + rand() + get_config(lg, "dropout"))
# Log metrics from your script to W&B@info"metrics" accuracy=acc loss=loss
end# Finish the runclose(lg)
wandb 라이브러리에는 XGBoost를 사용한 트레이닝에서 메트릭, 설정 및 저장된 부스터를 로깅하기 위한 WandbCallback 콜백이 있습니다. 여기에서 XGBoost WandbCallback의 출력이 포함된 **라이브 Weights & Biases 대시보드**를 볼 수 있습니다.
시작하기
Weights & Biases에 XGBoost 메트릭, 설정 및 부스터 모델을 로깅하는 것은 WandbCallback을 XGBoost에 전달하는 것만큼 쉽습니다.
from wandb.integration.xgboost import WandbCallback
import xgboost as XGBClassifier
...# wandb run 시작run = wandb.init()
# WandbCallback을 모델에 전달bst = XGBClassifier()
bst.fit(X_train, y_train, callbacks=[WandbCallback(log_model=True)])
# wandb run 종료run.finish()
XGBoost 및 Weights & Biases를 사용한 로깅에 대한 포괄적인 내용은 **이 노트북**을 열어 확인하십시오.
WandbCallback 참조
기능
WandbCallback을 XGBoost 모델에 전달하면 다음과 같은 작업이 수행됩니다.
부스터 모델 설정을 Weights & Biases에 로깅합니다.
XGBoost에서 수집한 평가 메트릭(예: rmse, 정확도 등)을 Weights & Biases에 로깅합니다.
XGBoost에서 수집한 트레이닝 메트릭을 로깅합니다(eval_set에 데이터를 제공하는 경우).
Ultralytics는 이미지 분류, 오브젝트 검출, 이미지 세분화 및 포즈 추정과 같은 작업을 위한 최첨단 컴퓨터 비전 모델의 본거지입니다. 실시간 오브젝트 검출 모델인 YOLO 시리즈의 최신 반복인 YOLOv8뿐만 아니라 SAM (Segment Anything Model), RT-DETR, YOLO-NAS 등과 같은 다른 강력한 컴퓨터 비전 모델도 호스팅합니다. Ultralytics는 이러한 모델의 구현을 제공하는 것 외에도 사용하기 쉬운 API를 사용하여 이러한 모델을 트레이닝, 파인튜닝 및 적용할 수 있는 즉시 사용 가능한 워크플로우를 제공합니다.
Ultralytics와 W&B 통합을 사용하려면 wandb.integration.ultralytics.add_wandb_callback 함수를 가져옵니다.
import wandb
from wandb.integration.ultralytics import add_wandb_callback
from ultralytics import YOLO
선택한 YOLO 모델을 초기화하고 모델로 추론을 수행하기 전에 add_wandb_callback 함수를 호출합니다. 이렇게 하면 트레이닝, 파인튜닝, 검증 또는 추론을 수행할 때 experiment 로그와 이미지가 자동으로 저장되고, 컴퓨터 비전 작업을 위한 대화형 오버레이를 사용하여 각각의 예측 결과와 함께 W&B의 wandb.Table에 추가 인사이트와 함께 오버레이됩니다.
# YOLO 모델 초기화model = YOLO("yolov8n.pt")
# Ultralytics에 W&B 콜백 추가add_wandb_callback(model, enable_model_checkpointing=True)
# 모델 트레이닝/파인튜닝# 각 에포크가 끝나면 검증 배치에 대한 예측이 기록됩니다.# 컴퓨터 비전 작업을 위한 통찰력 있고 상호 작용적인 오버레이가 있는 W&B 테이블에model.train(project="ultralytics", data="coco128.yaml", epochs=5, imgsz=640)
# W&B run 종료wandb.finish()
다음은 Ultralytics 트레이닝 또는 파인튜닝 워크플로우에 대해 W&B를 사용하여 추적된 Experiments의 모습입니다.
# W&B run 초기화wandb.init(project="ultralytics", job_type="inference")
다음으로 원하는 YOLO 모델을 초기화하고 모델로 추론을 수행하기 전에 add_wandb_callback 함수를 호출합니다. 이렇게 하면 추론을 수행할 때 컴퓨터 비전 작업을 위한 대화형 오버레이와 함께 wandb.Table에 추가 인사이트와 함께 이미지가 자동으로 기록됩니다.
# YOLO 모델 초기화model = YOLO("yolov8n.pt")
# Ultralytics에 W&B 콜백 추가add_wandb_callback(model, enable_model_checkpointing=True)
# W&B 테이블에 자동으로 기록되는 예측 수행# 경계 상자, 세분화 마스크에 대한 대화형 오버레이 포함model(
[
"./assets/img1.jpeg",
"./assets/img3.png",
"./assets/img4.jpeg",
"./assets/img5.jpeg",
]
)
# W&B run 종료wandb.finish()
트레이닝 또는 파인튜닝 워크플로우의 경우 wandb.init()을 사용하여 명시적으로 run을 초기화할 필요가 없습니다. 그러나 코드에 예측만 포함된 경우 run을 명시적으로 생성해야 합니다.