W&B는 결국 W&B Model Registry에 대한 지원을 중단할 예정입니다. 사용자는 대신 모델 아티팩트 버전을 연결하고 공유하기 위해 W&B Registry를 사용하는 것이 좋습니다. W&B Registry는 기존 W&B Model Registry의 기능을 확장합니다. W&B Registry에 대한 자세한 내용은 Registry 문서를 참조하세요.
W&B는 기존 Model Registry에 연결된 기존 모델 아티팩트를 가까운 시일 내에 새로운 W&B Registry로 마이그레이션할 예정입니다. 마이그레이션 프로세스에 대한 자세한 내용은 기존 Model Registry에서 마이그레이션을 참조하세요.
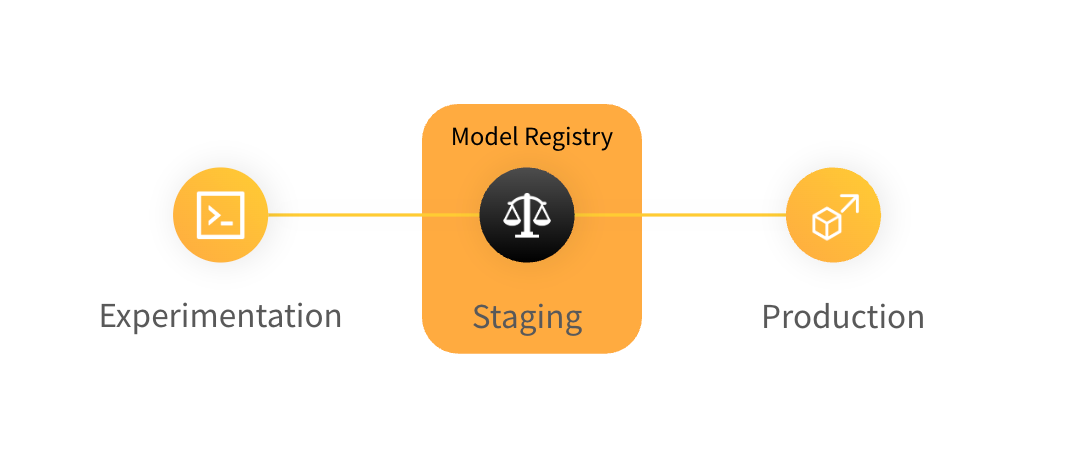
W&B Model Registry는 팀의 트레이닝된 모델을 보관하는 곳으로, ML 전문가가 프로덕션 후보를 게시하여 다운스트림 팀과 이해 관계자가 사용할 수 있습니다. 스테이징된/후보 모델을 보관하고 스테이징과 관련된 워크플로우를 관리하는 데 사용됩니다.
모델 버전 로깅: 트레이닝 스크립트에서 몇 줄의 코드를 추가하여 모델 파일을 아티팩트 로 W&B에 저장합니다.
성능 비교: 라이브 차트를 확인하여 모델 트레이닝 및 유효성 검사에서 메트릭 과 샘플 예측값을 비교합니다. 어떤 모델 버전이 가장 성능이 좋았는지 식별합니다.
레지스트리에 연결: Python에서 프로그래밍 방식으로 또는 W&B UI에서 대화식으로 등록된 모델에 연결하여 최상의 모델 버전을 북마크합니다.
다음 코드 조각은 모델을 Model Registry에 로깅하고 연결하는 방법을 보여줍니다.
import wandb
import random
# Start a new W&B runrun = wandb.init(project="models_quickstart")
# Simulate logging model metricsrun.log({"acc": random.random()})
# Create a simulated model filewith open("my_model.h5", "w") as f:
f.write("Model: "+ str(random.random()))
# Log and link the model to the Model Registryrun.link_model(path="./my_model.h5", registered_model_name="MNIST")
run.finish()
모델 전환을 CI/CD 워크플로우에 연결: 웹훅을 사용하여 워크플로우 단계를 통해 후보 모델을 전환하고 다운스트림 작업 자동화합니다.
W&B Model Registry를 사용하여 모델을 관리 및 버전 관리하고, 계보를 추적하고, 다양한 라이프사이클 단계를 거쳐 모델을 승격합니다.
웹훅을 사용하여 모델 관리 워크플로우를 자동화합니다.
모델 평가, 모니터링 및 배포를 위해 Model Registry가 모델 개발 라이프사이클의 외부 ML 시스템 및 툴 과 어떻게 통합되는지 확인하세요.
1 - Tutorial: Use W&B for model management
W&B를 사용해 모델 관리를 하는 방법을 알아보세요. (Model Management)
다음 가이드에서는 W&B에 모델을 기록하는 방법을 안내합니다. 이 가이드가 끝나면 다음을 수행할 수 있습니다.
MNIST 데이터셋과 Keras 프레임워크를 사용하여 모델을 만들고 트레이닝합니다.
트레이닝한 모델을 W&B project에 기록합니다.
사용된 데이터셋을 생성한 모델의 종속성으로 표시합니다.
해당 모델을 W&B Registry에 연결합니다.
레지스트리에 연결한 모델의 성능을 평가합니다.
모델 버전을 프로덕션 준비 완료로 표시합니다.
이 가이드에 제시된 순서대로 코드 조각을 복사하세요.
Model Registry에 고유하지 않은 코드는 접을 수 있는 셀에 숨겨져 있습니다.
설정
시작하기 전에 이 가이드에 필요한 Python 종속성을 가져옵니다.
import wandb
import numpy as np
from tensorflow import keras
from tensorflow.keras import layers
from wandb.integration.keras import WandbMetricsLogger
from sklearn.model_selection import train_test_split
W&B entity를 entity 변수에 제공합니다.
entity ="<entity>"
데이터셋 아티팩트 생성
먼저 데이터셋을 만듭니다. 다음 코드 조각은 MNIST 데이터셋을 다운로드하는 함수를 생성합니다.
다음으로 데이터셋을 W&B에 업로드합니다. 이렇게 하려면 artifact 오브젝트를 생성하고 해당 아티팩트에 데이터셋을 추가합니다.
project ="model-registry-dev"model_use_case_id ="mnist"job_type ="build_dataset"# W&B run 초기화run = wandb.init(entity=entity, project=project, job_type=job_type)
# 트레이닝 데이터를 위한 W&B 테이블 생성train_table = wandb.Table(data=[], columns=[])
train_table.add_column("x_train", x_train)
train_table.add_column("y_train", y_train)
train_table.add_computed_columns(lambda ndx, row: {"img": wandb.Image(row["x_train"])})
# 평가 데이터를 위한 W&B 테이블 생성eval_table = wandb.Table(data=[], columns=[])
eval_table.add_column("x_eval", x_eval)
eval_table.add_column("y_eval", y_eval)
eval_table.add_computed_columns(lambda ndx, row: {"img": wandb.Image(row["x_eval"])})
# 아티팩트 오브젝트 생성artifact_name ="{}_dataset".format(model_use_case_id)
artifact = wandb.Artifact(name=artifact_name, type="dataset")
# wandb.WBValue obj를 아티팩트에 추가artifact.add(train_table, "train_table")
artifact.add(eval_table, "eval_table")
# 아티팩트에 대한 변경 사항을 유지합니다.artifact.save()
# W&B에 이 run이 완료되었음을 알립니다.run.finish()
아티팩트에 파일(예: 데이터셋)을 저장하는 것은 모델의 종속성을 추적할 수 있으므로 모델 로깅 컨텍스트에서 유용합니다.
모델 트레이닝
이전 단계에서 생성한 아티팩트 데이터셋으로 모델을 트레이닝합니다.
데이터셋 아티팩트를 run에 대한 입력으로 선언
이전 단계에서 생성한 데이터셋 아티팩트를 W&B run에 대한 입력으로 선언합니다. 아티팩트를 run에 대한 입력으로 선언하면 특정 모델을 트레이닝하는 데 사용된 데이터셋(및 데이터셋 버전)을 추적할 수 있으므로 모델 로깅 컨텍스트에서 특히 유용합니다. W&B는 수집된 정보를 사용하여 lineage map을 만듭니다.
use_artifact API를 사용하여 데이터셋 아티팩트를 run의 입력으로 선언하고 아티팩트 자체를 검색합니다.
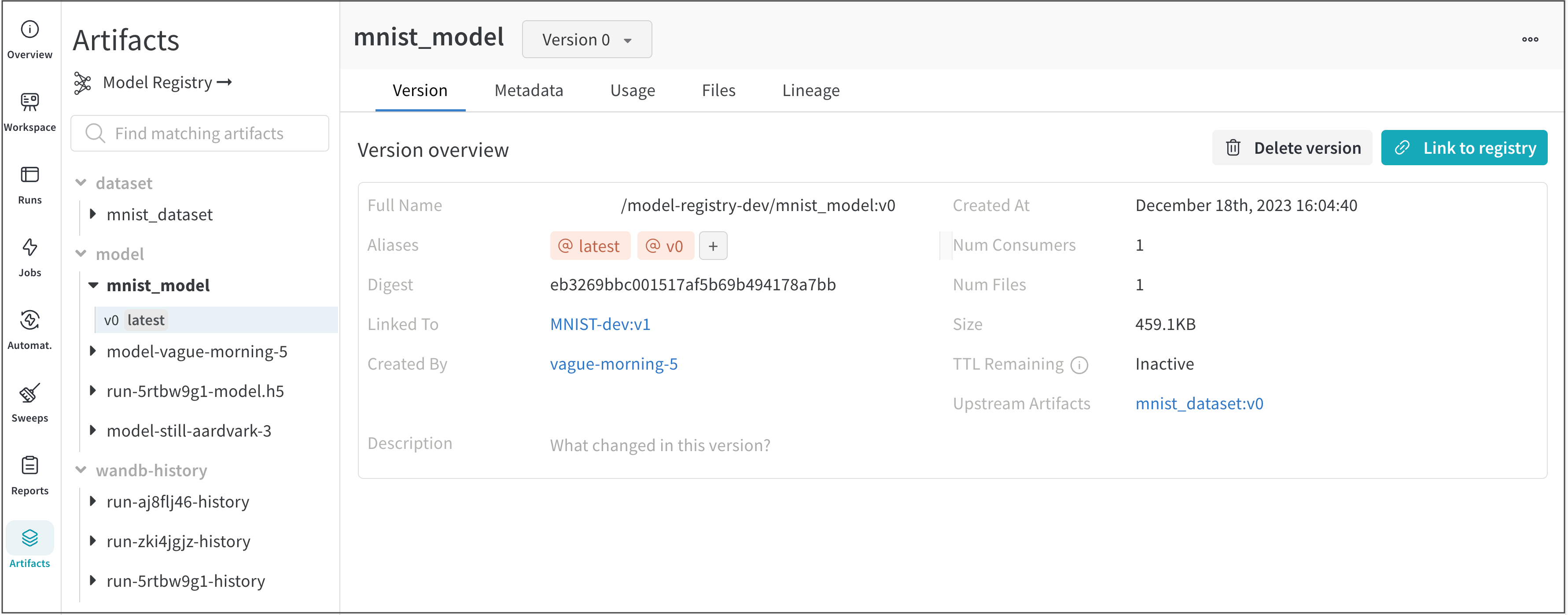
평가할 W&B의 model version을 다운로드합니다. use_model API를 사용하여 모델에 엑세스하고 다운로드합니다.
alias ="latest"# 에일리어스name ="mnist_model"# 모델 아티팩트 이름# 모델에 엑세스하고 다운로드합니다. 다운로드한 아티팩트의 경로를 반환합니다.downloaded_model_path = run.use_model(name=f"{name}:{alias}")
# # 메트릭, 이미지, 테이블 또는 평가에 유용한 모든 데이터를 기록합니다.run.log(data={"loss": (loss, _)})
모델 버전 승격
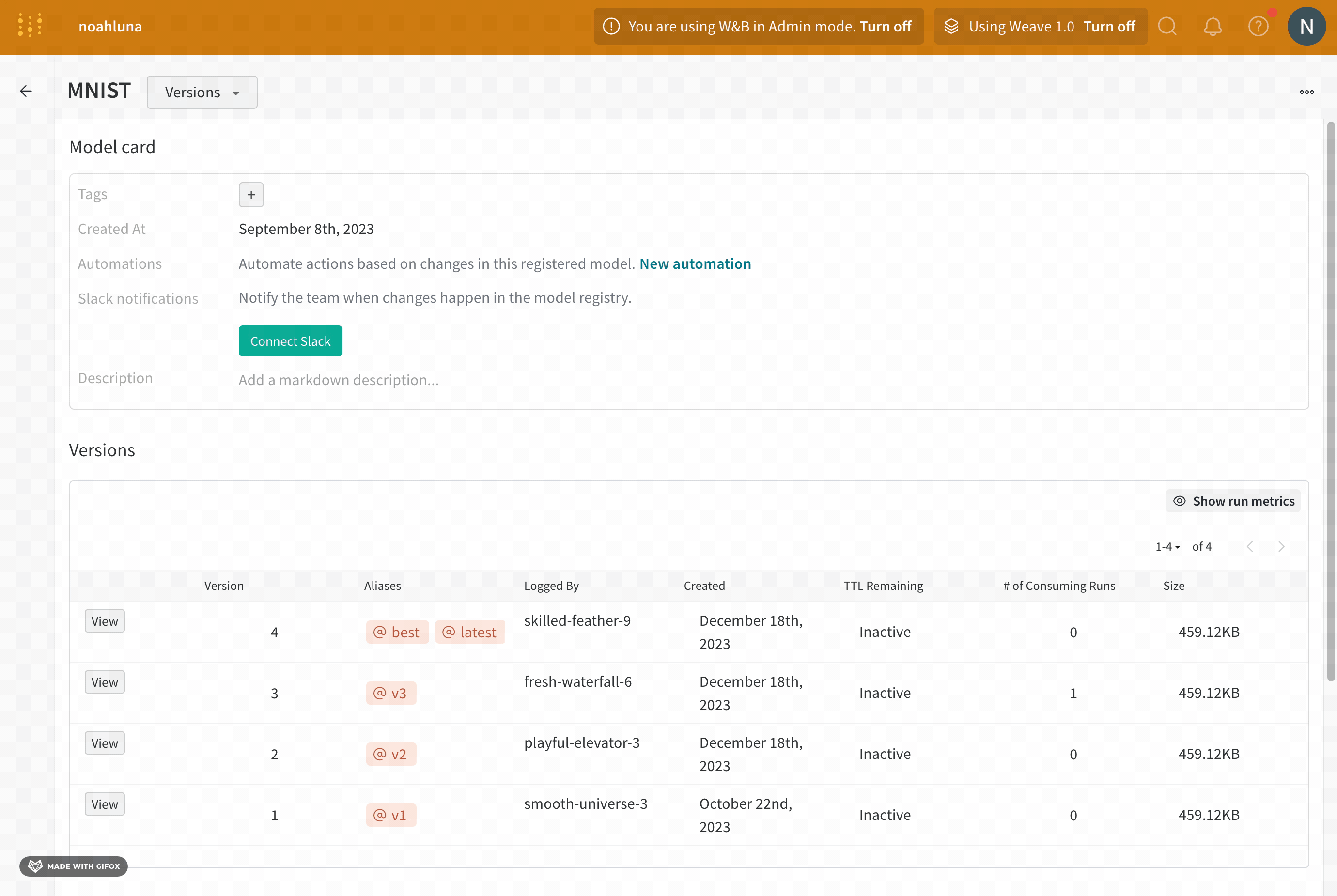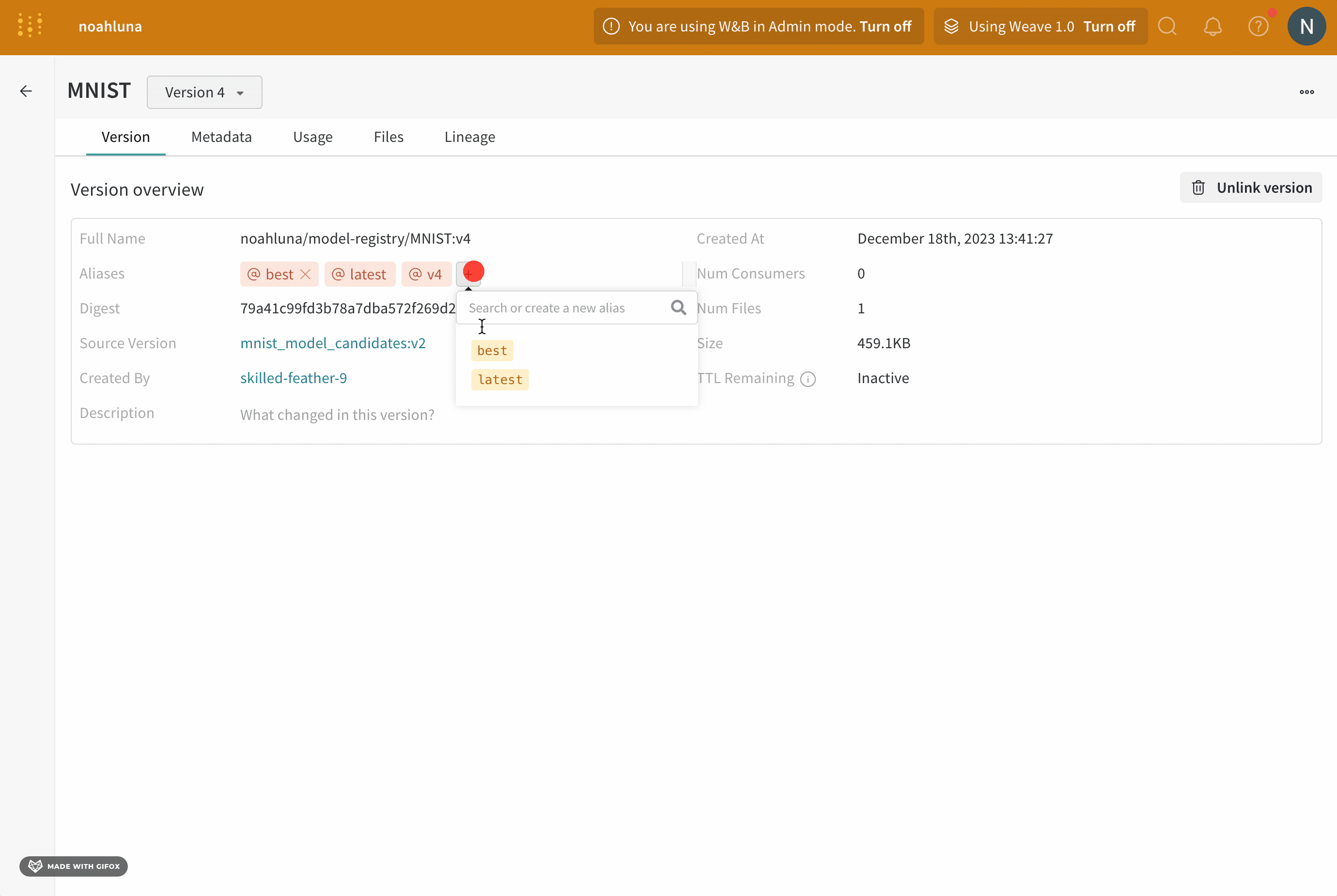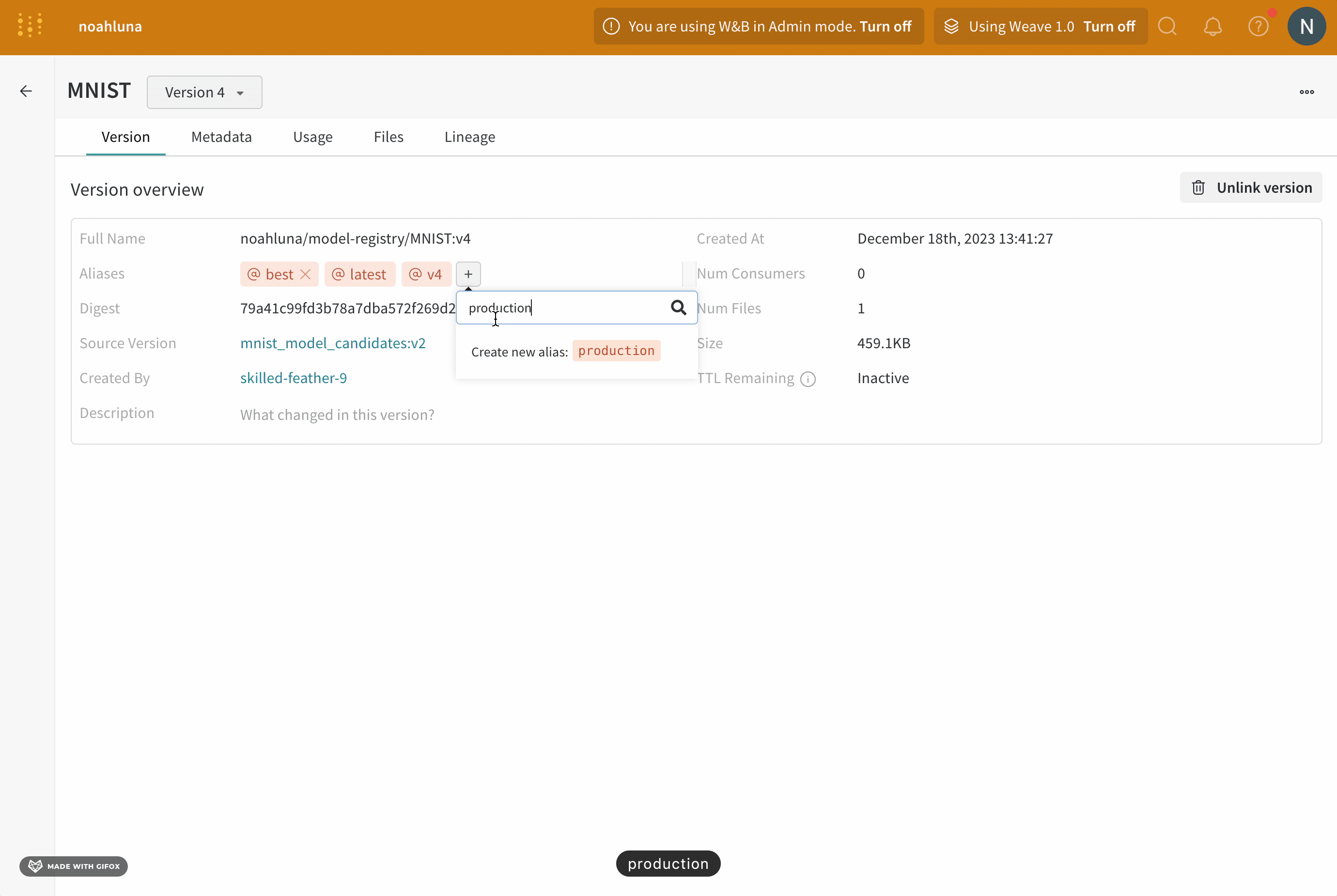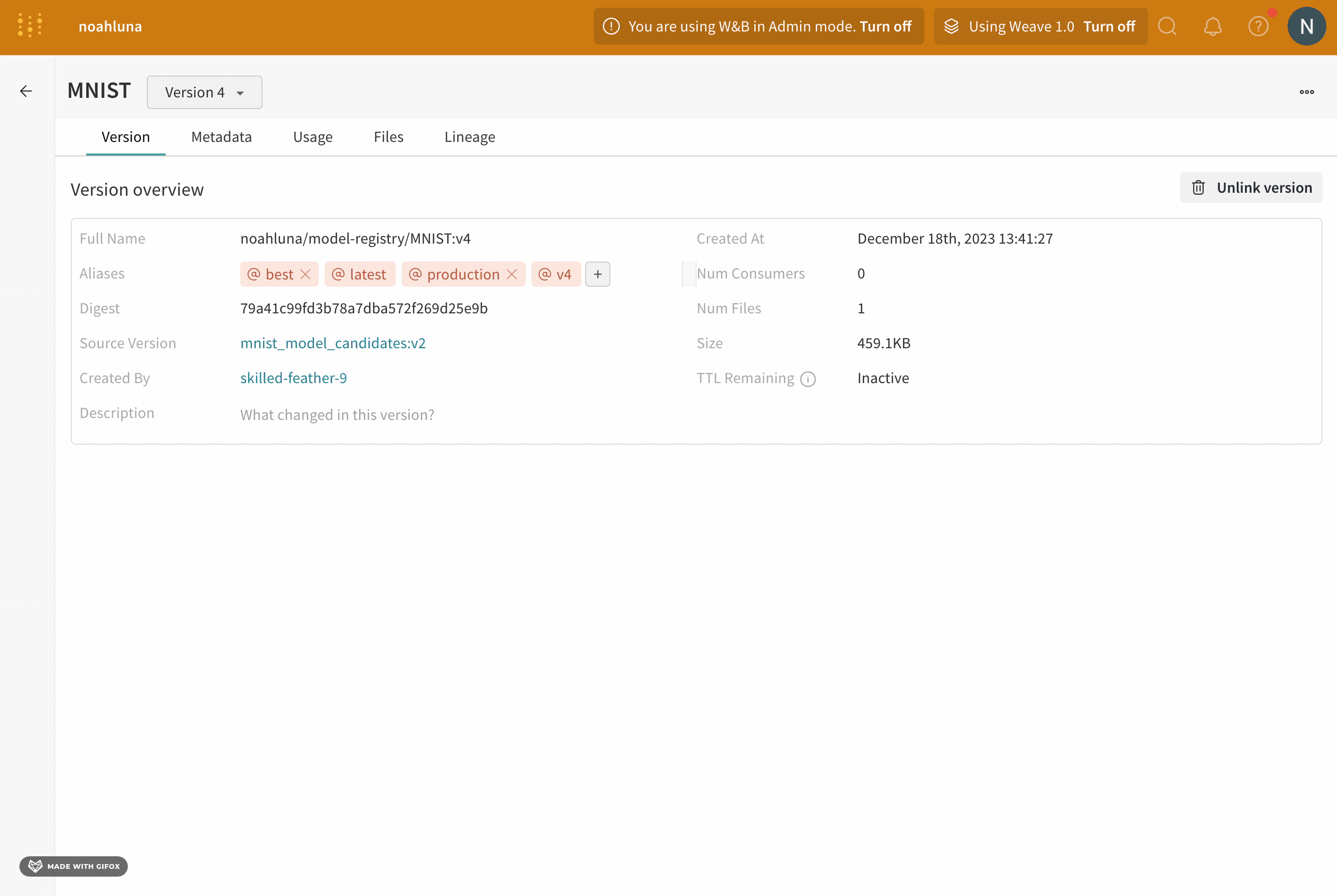
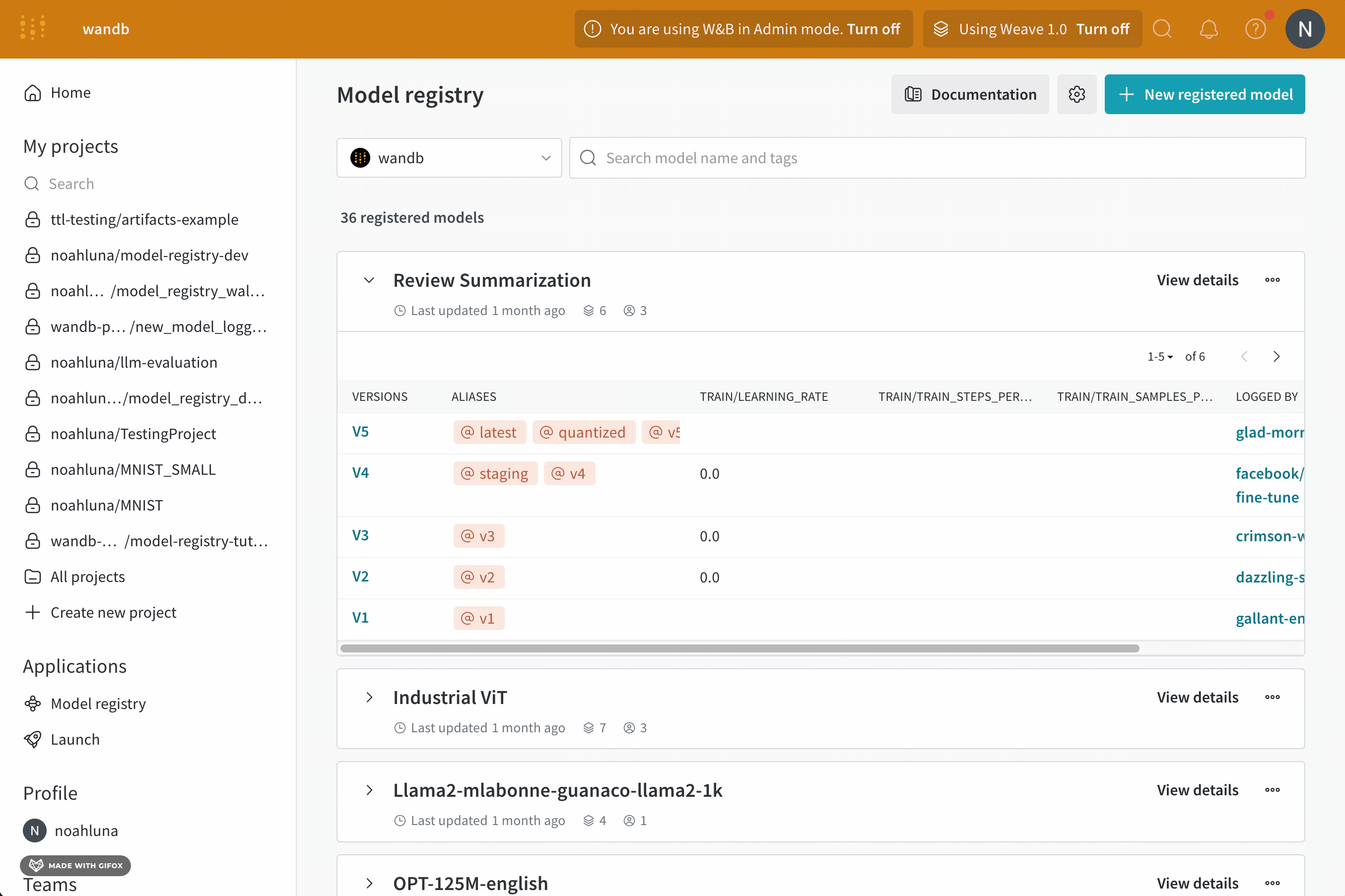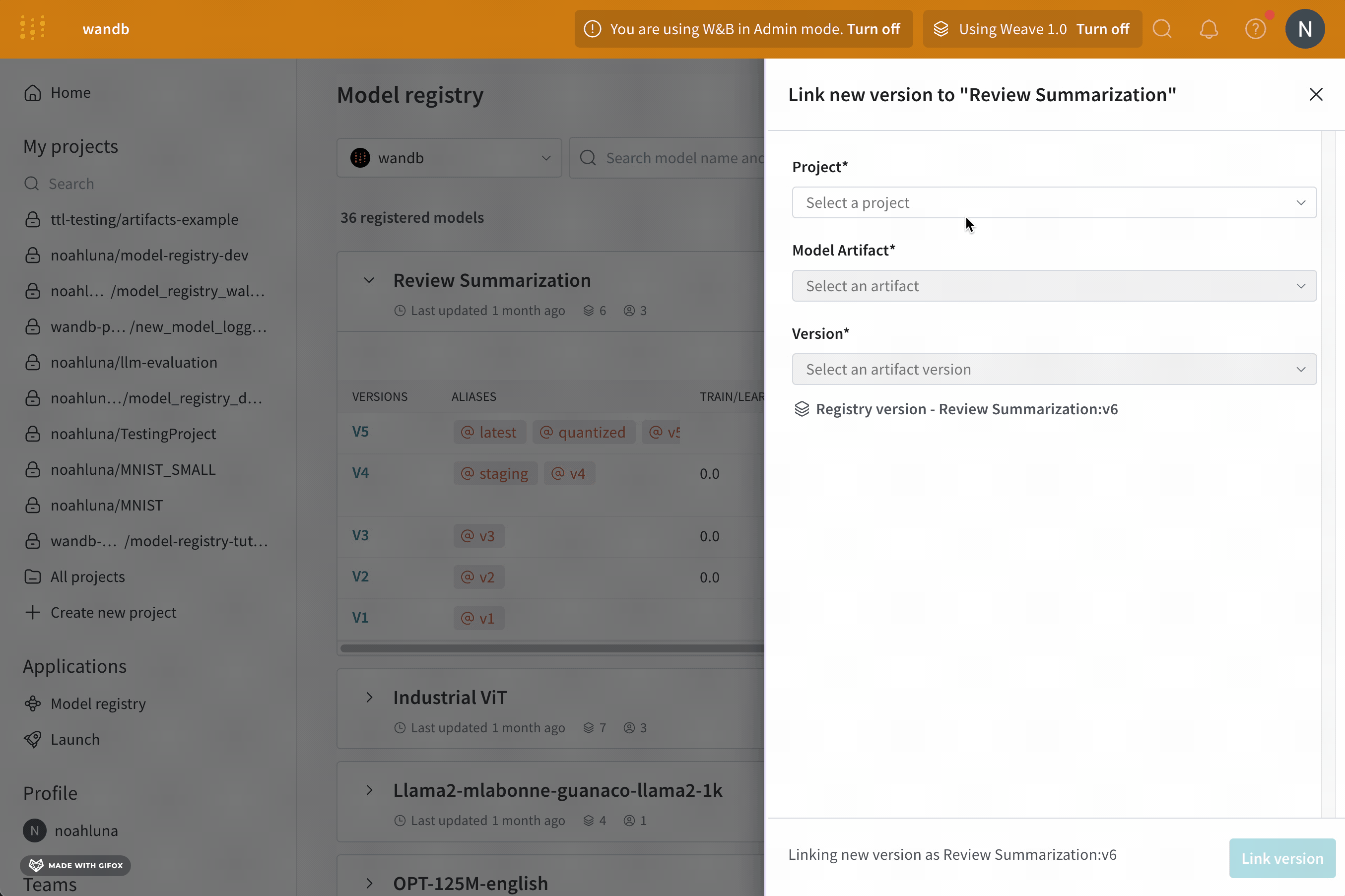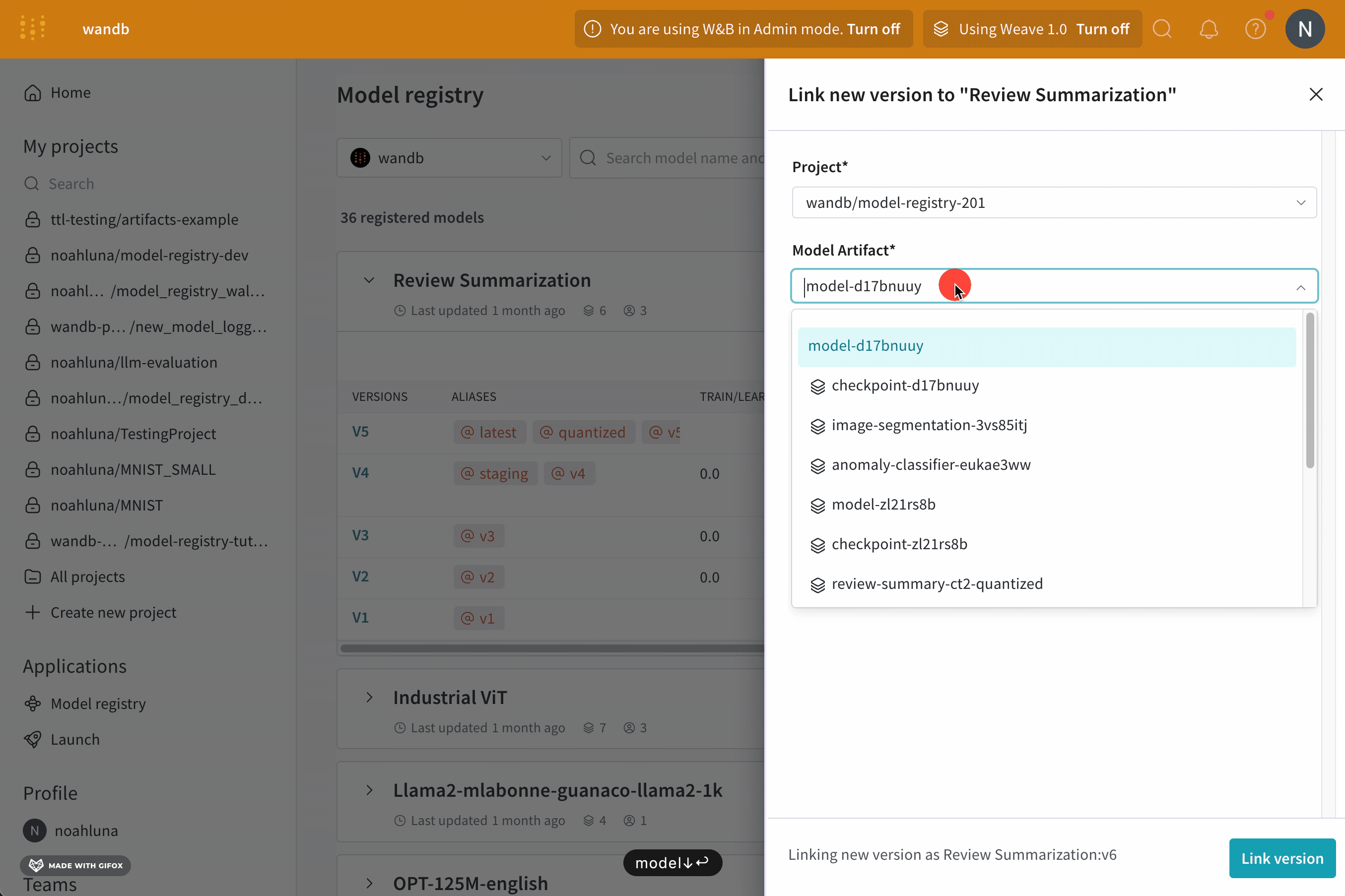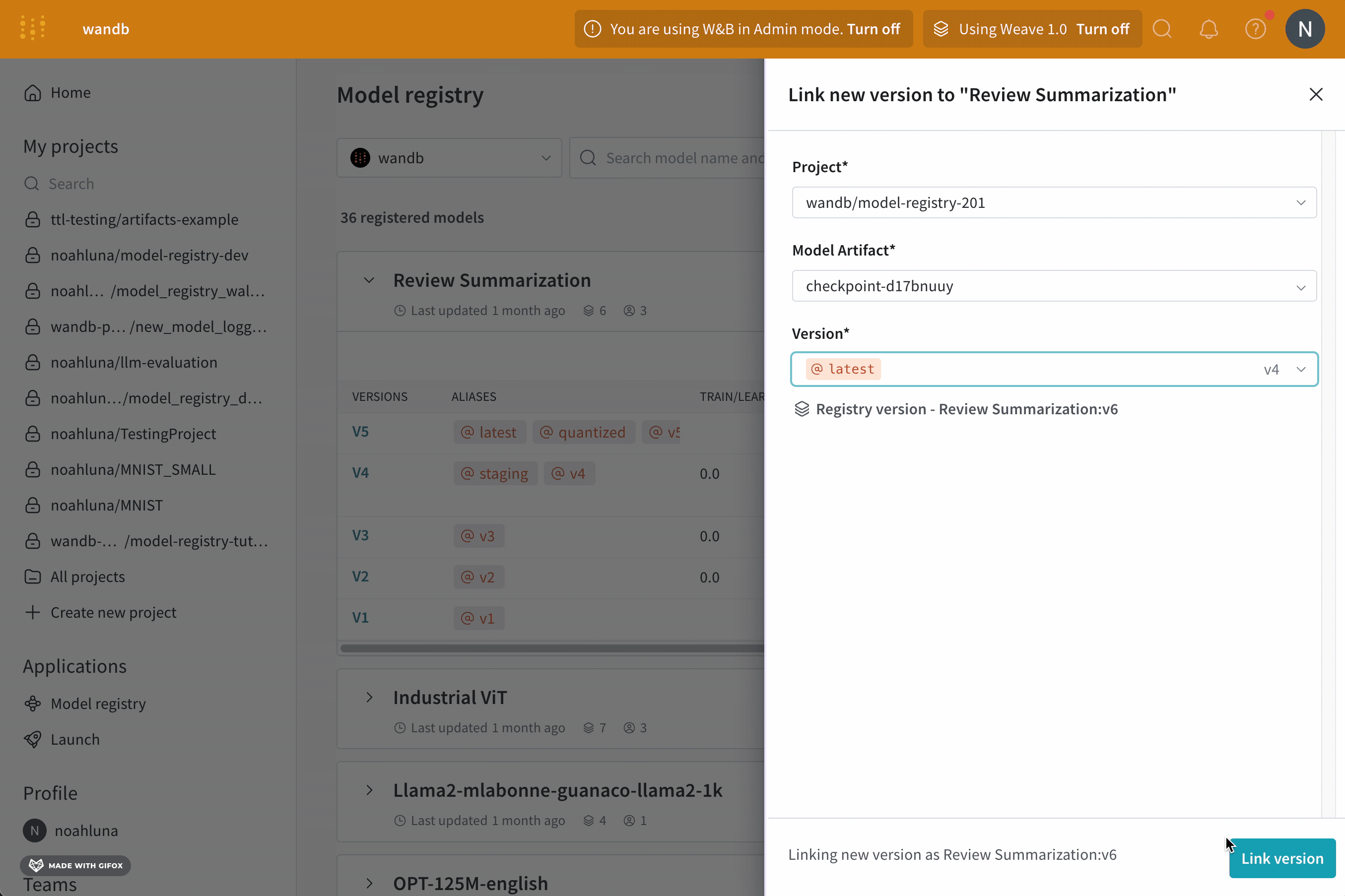
model alias를 사용하여 기계 학습 워크플로우의 다음 단계를 위해 모델 버전을 준비 완료로 표시합니다. 각 registered model에는 하나 이상의 model alias가 있을 수 있습니다. model alias는 한 번에 하나의 model version에만 속할 수 있습니다.
예를 들어, 모델의 성능을 평가한 후 모델이 프로덕션 준비가 되었다고 확신한다고 가정합니다. 해당 모델 버전을 승격하려면 해당 특정 model version에 production 에일리어스를 추가합니다.
production 에일리어스는 모델을 프로덕션 준비로 표시하는 데 사용되는 가장 일반적인 에일리어스 중 하나입니다.
W&B App UI를 사용하여 대화형으로 또는 Python SDK를 사용하여 프로그래밍 방식으로 model version에 에일리어스를 추가할 수 있습니다. 다음 단계에서는 W&B Model Registry App을 사용하여 에일리어스를 추가하는 방법을 보여줍니다.
모델 버전은 단일 모델 체크포인트를 나타냅니다. 모델 버전은 실험 내에서 특정 시점의 모델과 해당 파일의 스냅샷입니다.
모델 버전은 학습된 모델을 설명하는 데이터 및 메타데이터의 변경 불가능한 디렉토리입니다. W&B는 모델 아키텍처와 학습된 파라미터를 나중에 저장하고 복원할 수 있도록 모델 버전에 파일을 추가할 것을 제안합니다.
모델 버전은 하나의 model artifact에만 속합니다. 모델 버전은 0개 이상의 registered models에 속할 수 있습니다. 모델 버전은 모델 아티팩트에 기록된 순서대로 모델 아티팩트에 저장됩니다. W&B는 (동일한 model artifact에) 기록하는 모델이 이전 모델 버전과 다른 콘텐츠를 가지고 있음을 감지하면 자동으로 새 모델 버전을 생성합니다.
모델링 라이브러리에서 제공하는 직렬화 프로세스에서 생성된 파일을 모델 버전 내에 저장합니다(예: PyTorch 및 Keras).
Model alias
모델 에일리어스는 등록된 모델에서 모델 버전을 의미적으로 관련된 식별자로 고유하게 식별하거나 참조할 수 있도록 하는 변경 가능한 문자열입니다. 에일리어스는 등록된 모델의 한 버전에만 할당할 수 있습니다. 이는 에일리어스가 프로그래밍 방식으로 사용될 때 고유한 버전을 참조해야 하기 때문입니다. 또한 에일리어스를 사용하여 모델의 상태(챔피언, 후보, production)를 캡처할 수 있습니다.
"best", "latest", "production" 또는 "staging"과 같은 에일리어스를 사용하여 특수 목적을 가진 모델 버전을 표시하는 것이 일반적입니다.
예를 들어 모델을 만들고 "best" 에일리어스를 할당한다고 가정합니다. run.use_model로 특정 모델을 참조할 수 있습니다.
import wandb
run = wandb.init()
name =f"{entity/project/model_artifact_name}:{alias}"run.use_model(name=name)
Model tags
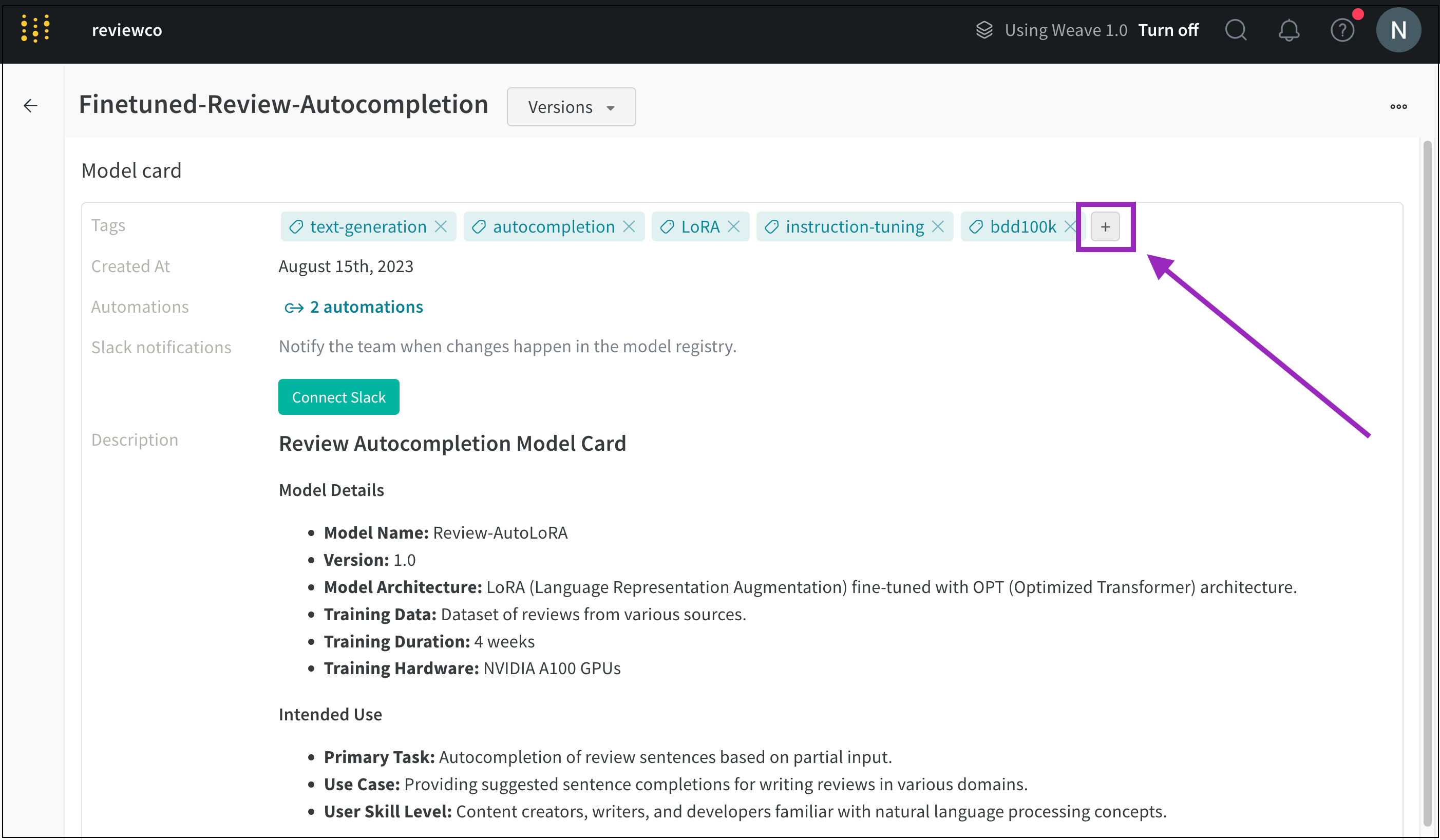
모델 태그는 하나 이상의 registered models에 속하는 키워드 또는 레이블입니다.
모델 태그를 사용하여 registered models를 카테고리로 구성하고 Model Registry의 검색 창에서 해당 카테고리를 검색합니다. 모델 태그는 Registered Model Card 상단에 나타납니다. ML 작업, 소유 팀 또는 우선 순위별로 registered models를 그룹화하는 데 사용할 수 있습니다. 그룹화를 위해 동일한 모델 태그를 여러 registered models에 추가할 수 있습니다.
그룹화 및 검색 가능성을 위해 registered models에 적용되는 레이블인 모델 태그는 model aliases와 다릅니다. 모델 에일리어스는 모델 버전을 프로그래밍 방식으로 가져오는 데 사용하는 고유 식별자 또는 별칭입니다. 태그를 사용하여 Model Registry에서 작업을 구성하는 방법에 대한 자세한 내용은 모델 구성을 참조하세요.
Model artifact
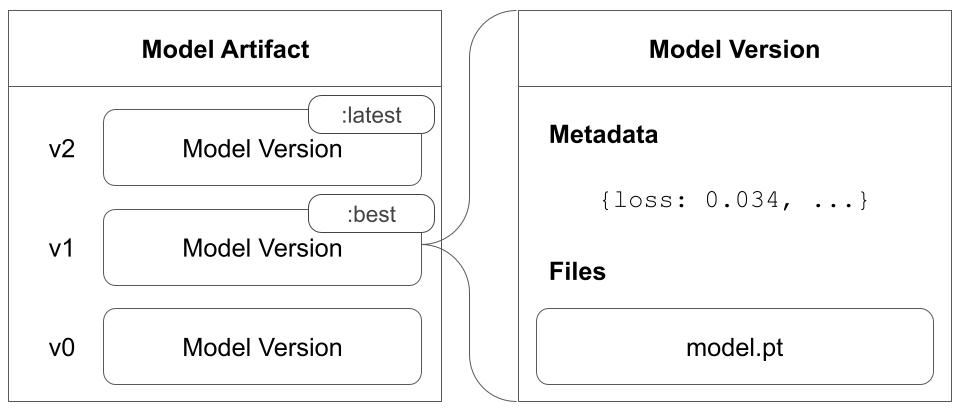
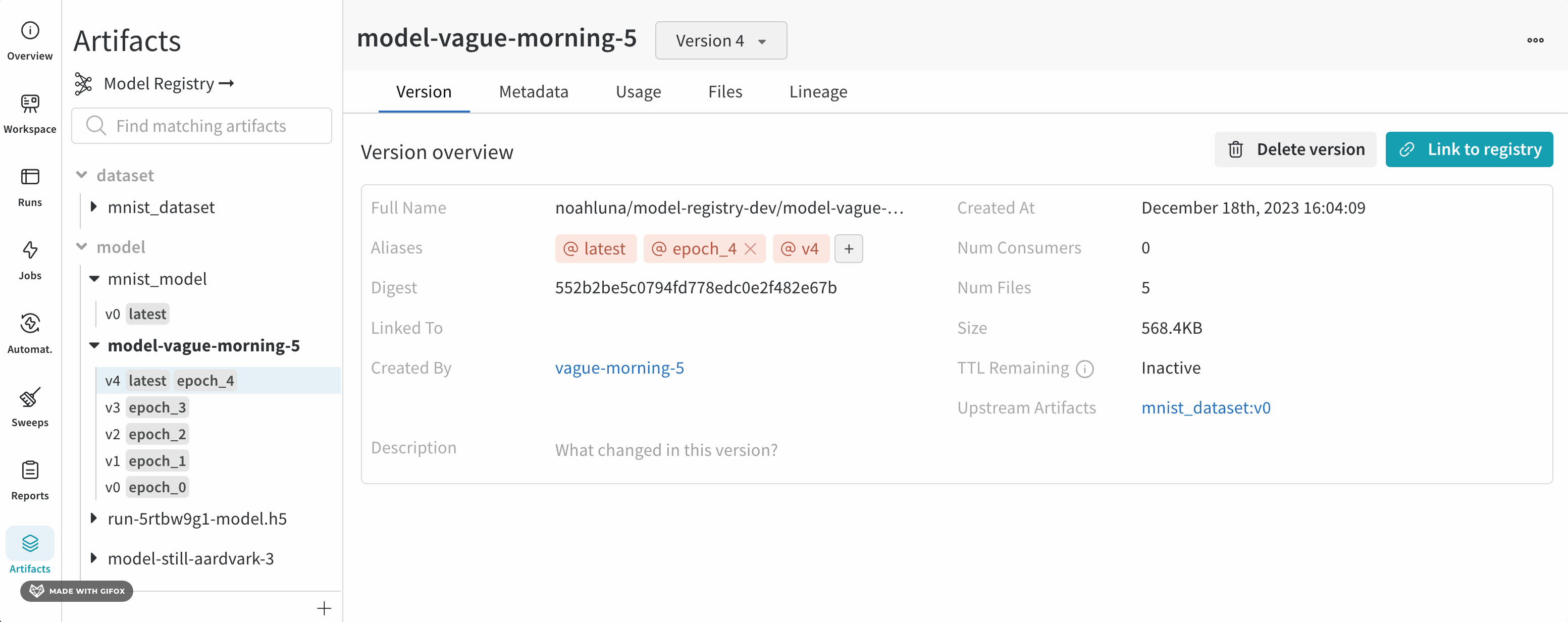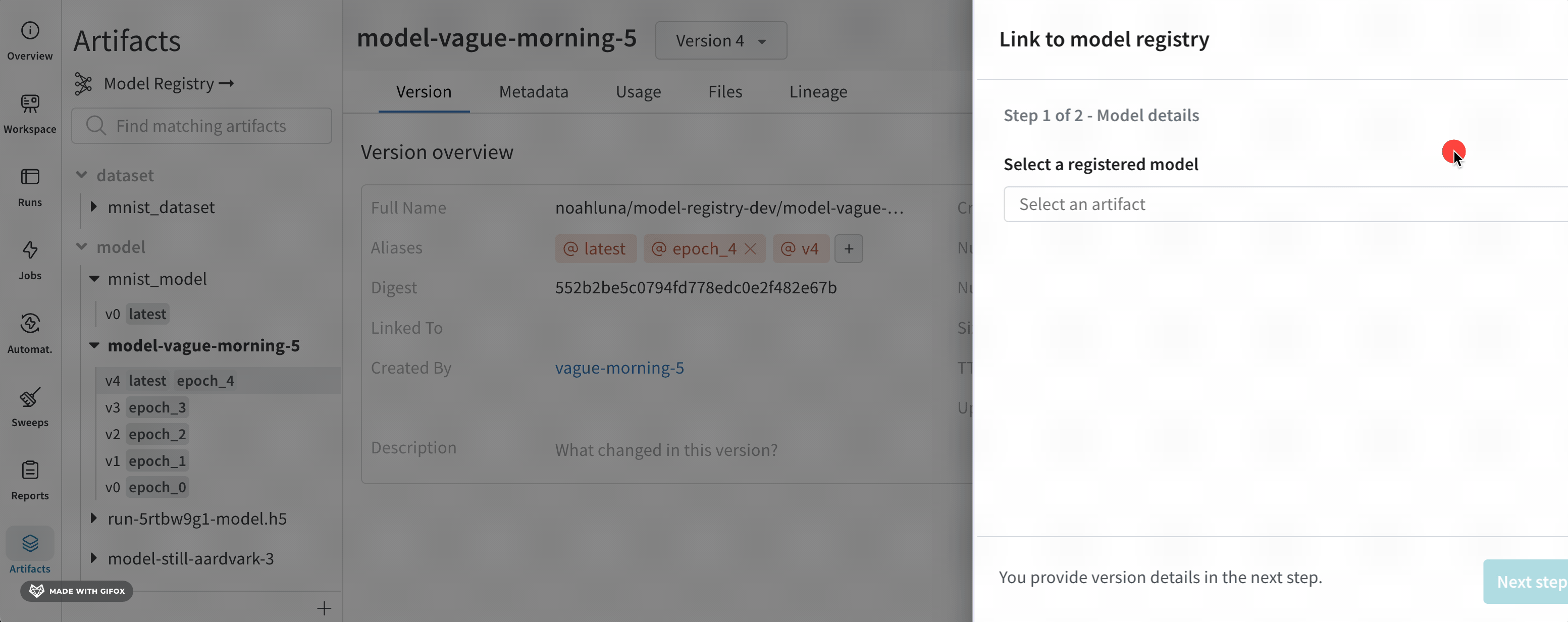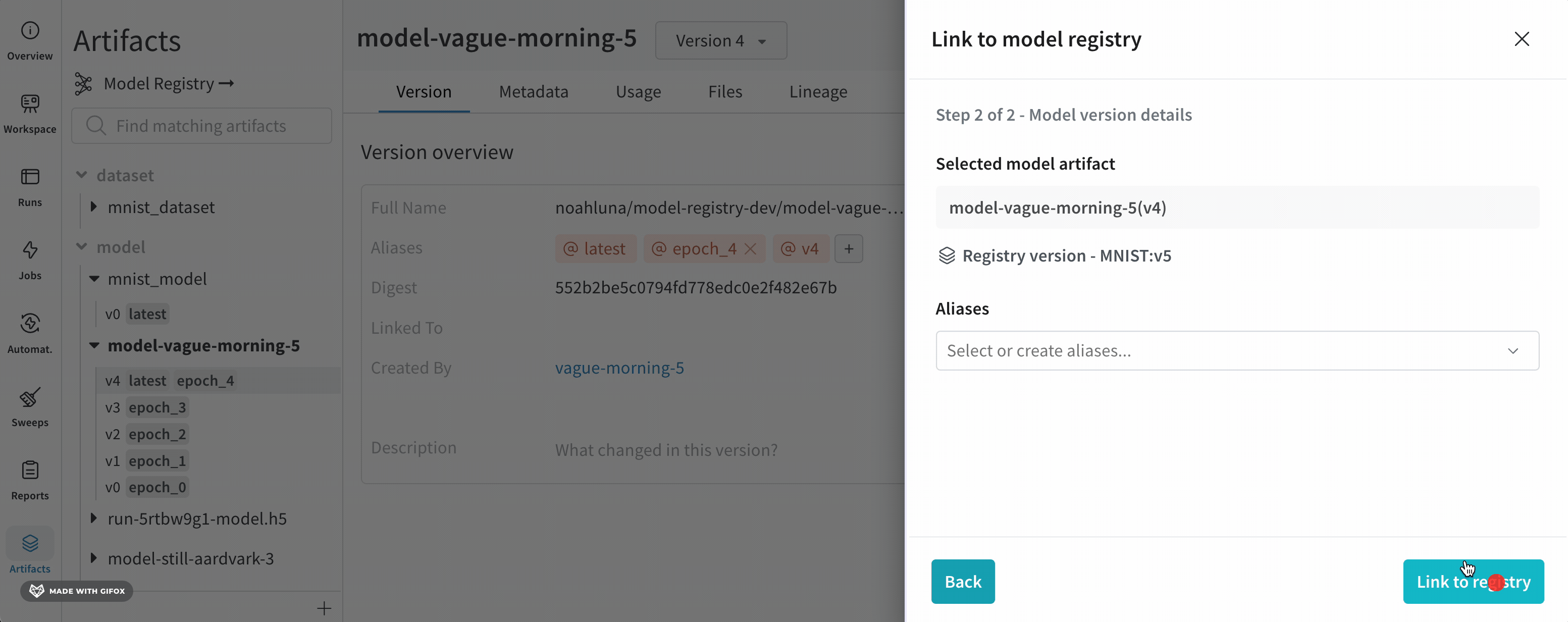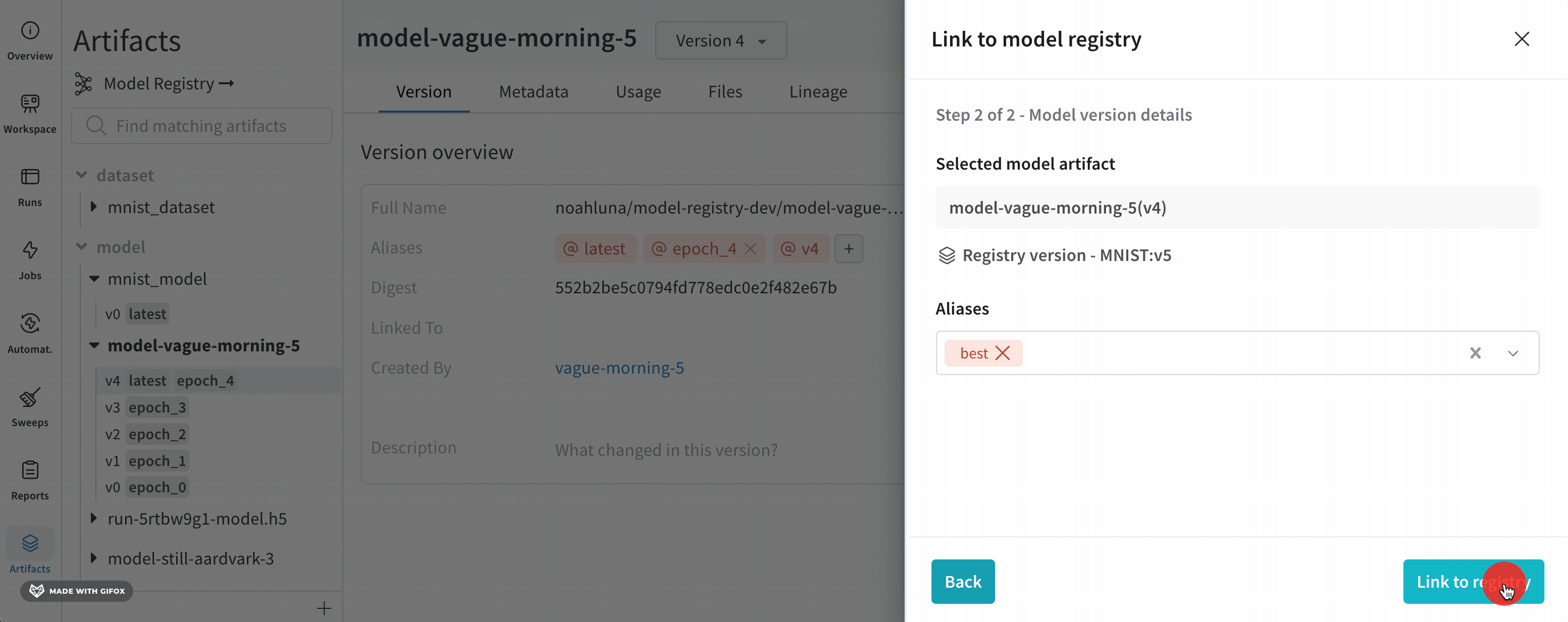
Model artifact는 기록된 model versions의 모음입니다. 모델 버전은 모델 아티팩트에 기록된 순서대로 모델 아티팩트에 저장됩니다.
Model artifact는 하나 이상의 모델 버전을 포함할 수 있습니다. 모델 버전을 기록하지 않으면 Model artifact는 비어 있을 수 있습니다.
예를 들어, Model artifact를 만든다고 가정합니다. 모델 트레이닝 중에 체크포인트 중에 모델을 주기적으로 저장합니다. 각 체크포인트는 자체 model version에 해당합니다. 모델 트레이닝 및 체크포인트 저장 중에 생성된 모든 모델 버전은 트레이닝 스크립트 시작 시 생성한 동일한 Model artifact에 저장됩니다.
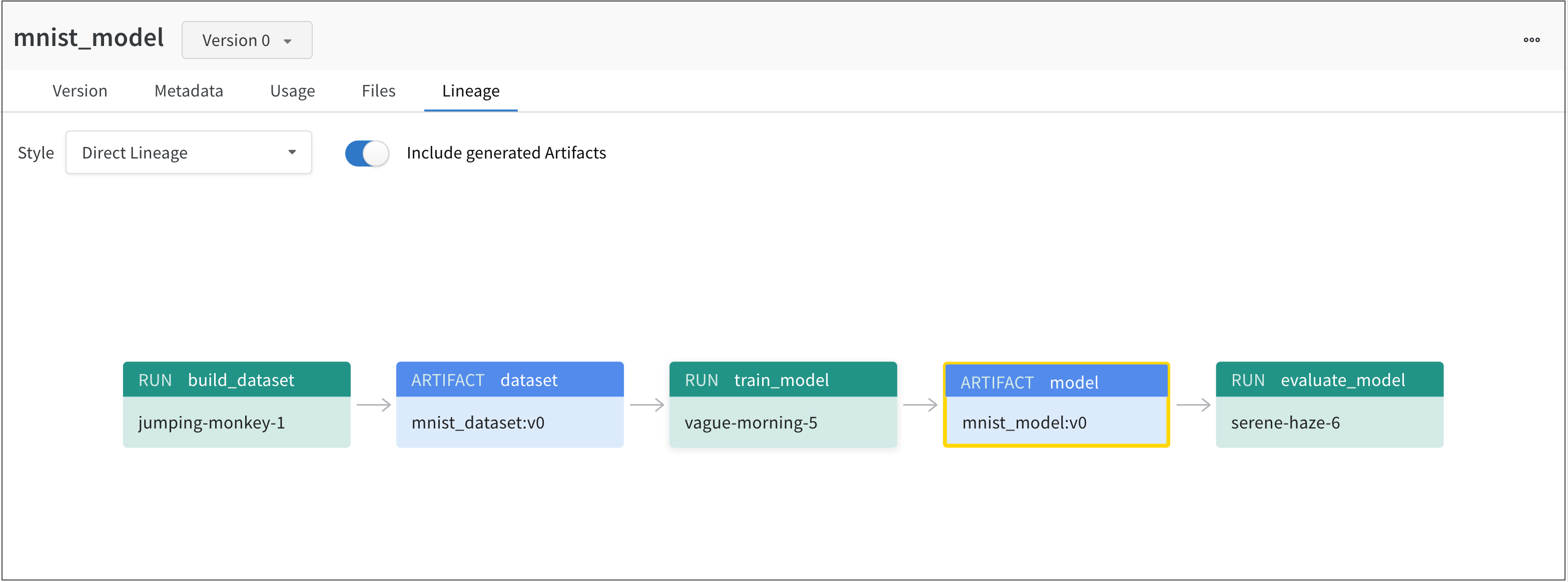
다음 이미지는 v0, v1 및 v2의 세 가지 모델 버전을 포함하는 Model artifact를 보여줍니다.
Registered model은 모델 버전에 대한 포인터(링크) 모음입니다. Registered model을 동일한 ML 작업에 대한 후보 모델의 “북마크” 폴더라고 생각할 수 있습니다. Registered model의 각 “북마크"는 model artifact에 속한 model version에 대한 포인터입니다. Model tags를 사용하여 Registered models를 그룹화할 수 있습니다.
Registered models는 종종 단일 모델링 유스 케이스 또는 작업에 대한 후보 모델을 나타냅니다. 예를 들어 사용하는 모델을 기반으로 다양한 이미지 분류 작업에 대해 Registered model을 만들 수 있습니다. ImageClassifier-ResNet50, ImageClassifier-VGG16, DogBreedClassifier-MobileNetV2 등. 모델 버전은 Registered model에 연결된 순서대로 버전 번호가 할당됩니다.
import wandb
run = wandb.init(entity="<entity>", project="<project>")
run.link_model(path="<path-to-model>", registered_model_name="<registered-model-name>")
run.finish()
registered-model-name 파라미터에 지정한 이름이 아직 존재하지 않는 경우, W&B가 등록된 모델을 생성합니다.
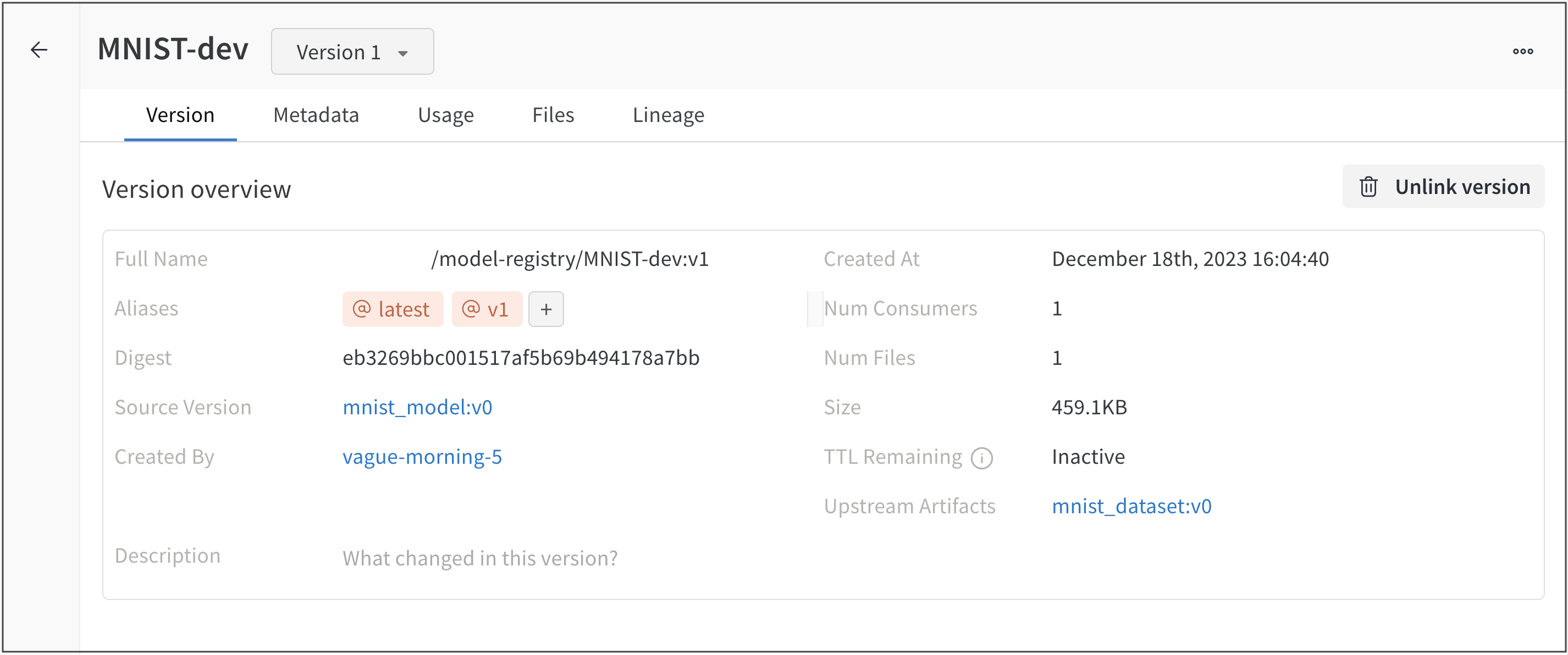
예를 들어, Model Registry에 “Fine-Tuned-Review-Autocompletion”(registered-model-name="Fine-Tuned-Review-Autocompletion")이라는 등록된 모델이 이미 있다고 가정합니다. 그리고 몇몇 모델 버전이 연결되어 있다고 가정합니다: v0, v1, v2. 새로운 모델을 프로그램 방식으로 연결하고 동일한 등록된 모델 이름(registered-model-name="Fine-Tuned-Review-Autocompletion")을 사용하면, W&B는 이 모델을 기존 등록된 모델에 연결하고 모델 버전 v3을 할당합니다. 이 이름으로 등록된 모델이 없으면 새로운 등록된 모델이 생성되고 모델 버전 v0을 갖게 됩니다.
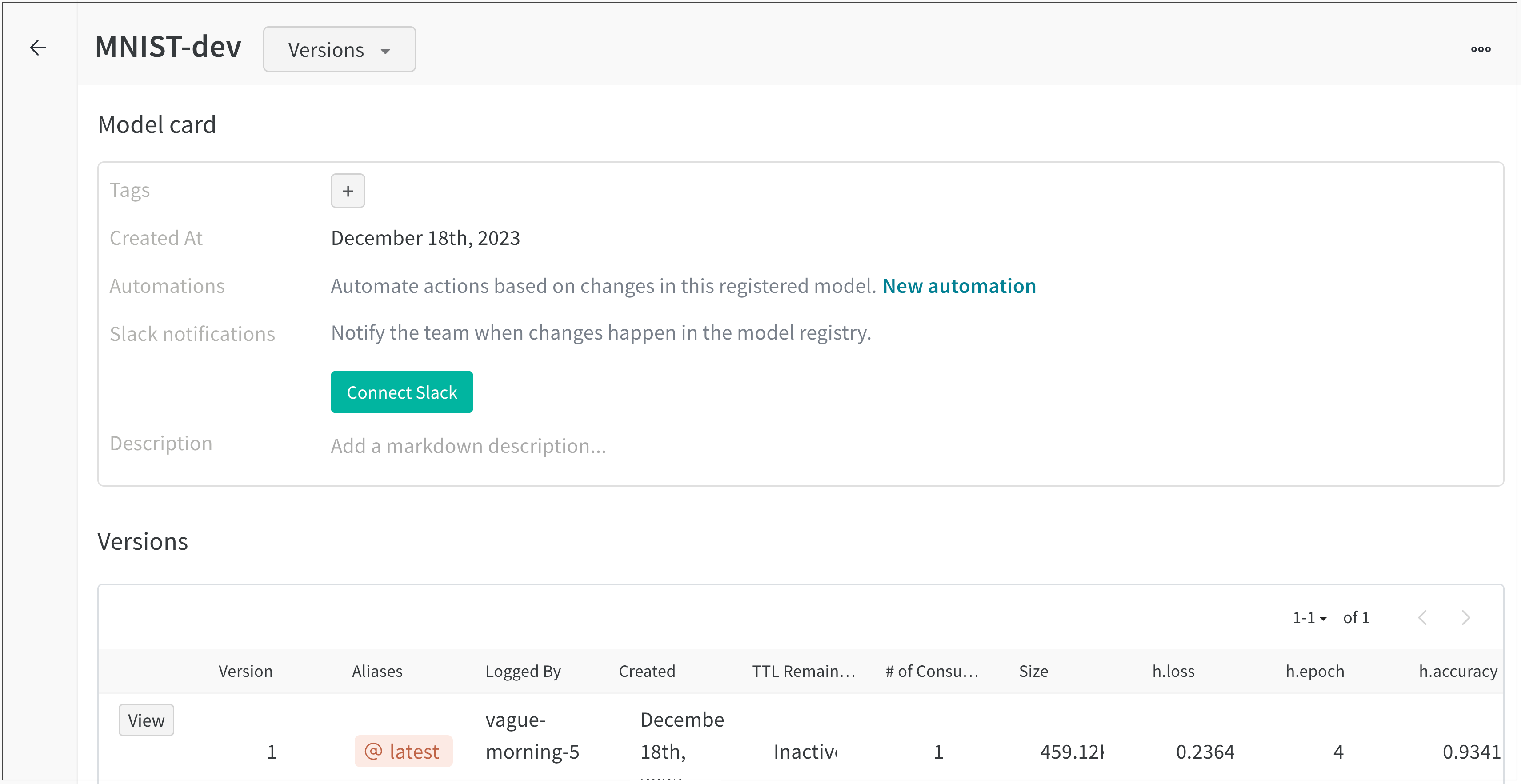
vague-morning-5 W&B run은 mnist_dataset:v0 데이터셋 아티팩트를 사용하여 모델을 트레이닝했습니다. 이 W&B run의 출력은 mnist_model:v0라는 모델 아티팩트였습니다.
serene-haze-6이라는 run은 모델 아티팩트(mnist_model:v0)를 사용하여 모델을 평가했습니다.
아티팩트 종속성 추적
use_artifact API를 사용하여 데이터셋 아티팩트를 W&B run에 대한 입력으로 선언하여 종속성을 추적합니다.
다음 코드 조각은 use_artifact API를 사용하는 방법을 보여줍니다.
# Initialize a runrun = wandb.init(project=project, entity=entity)
# Get artifact, mark it as a dependencyartifact = run.use_artifact(artifact_or_name="name", aliases="<alias>")
아티팩트를 검색한 후에는 해당 아티팩트를 사용하여 (예를 들어) 모델의 성능을 평가할 수 있습니다.
예시: 모델을 트레이닝하고 데이터셋을 모델의 입력으로 추적
job_type ="train_model"config = {
"optimizer": "adam",
"batch_size": 128,
"epochs": 5,
"validation_split": 0.1,
}
run = wandb.init(project=project, job_type=job_type, config=config)
version ="latest"name ="{}:{}".format("{}_dataset".format(model_use_case_id), version)
artifact = run.use_artifact(name)
train_table = artifact.get("train_table")
x_train = train_table.get_column("x_train", convert_to="numpy")
y_train = train_table.get_column("y_train", convert_to="numpy")
# Store values from our config dictionary into variables for easy accessingnum_classes =10input_shape = (28, 28, 1)
loss ="categorical_crossentropy"optimizer = run.config["optimizer"]
metrics = ["accuracy"]
batch_size = run.config["batch_size"]
epochs = run.config["epochs"]
validation_split = run.config["validation_split"]
# Create model architecturemodel = keras.Sequential(
[
layers.Input(shape=input_shape),
layers.Conv2D(32, kernel_size=(3, 3), activation="relu"),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Conv2D(64, kernel_size=(3, 3), activation="relu"),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Flatten(),
layers.Dropout(0.5),
layers.Dense(num_classes, activation="softmax"),
]
)
model.compile(loss=loss, optimizer=optimizer, metrics=metrics)
# Generate labels for training datay_train = keras.utils.to_categorical(y_train, num_classes)
# Create training and test setx_t, x_v, y_t, y_v = train_test_split(x_train, y_train, test_size=0.33)
# Train the modelmodel.fit(
x=x_t,
y=y_t,
batch_size=batch_size,
epochs=epochs,
validation_data=(x_v, y_v),
callbacks=[WandbCallback(log_weights=True, log_evaluation=True)],
)
# Save model locallypath ="model.h5"model.save(path)
path ="./model.h5"registered_model_name ="MNIST-dev"name ="mnist_model"run.link_model(path=path, registered_model_name=registered_model_name, name=name)
run.finish()
8 - Document machine learning model
모델 카드에 설명을 추가하여 모델을 문서화하세요.
등록된 모델의 모델 카드에 설명을 추가하여 머신러닝 모델의 여러 측면을 문서화하세요. 문서화할 가치가 있는 몇 가지 주제는 다음과 같습니다.
요약: 모델에 대한 요약입니다. 모델의 목적, 모델이 사용하는 머신러닝 프레임워크 등입니다.
트레이닝 데이터: 사용된 트레이닝 데이터, 트레이닝 데이터 세트에 대해 수행된 처리, 해당 데이터가 저장된 위치 등을 설명합니다.
아키텍처: 모델 아키텍처, 레이어 및 특정 설계 선택에 대한 정보입니다.
모델 역직렬화: 팀 구성원이 모델을 메모리에 로드하는 방법에 대한 정보를 제공합니다.
Task: 머신러닝 모델이 수행하도록 설계된 특정 유형의 Task 또는 문제입니다. 모델의 의도된 기능을 분류한 것입니다.
라이선스: 머신러닝 모델 사용과 관련된 법적 조건 및 권한입니다. 이를 통해 모델 사용자는 모델을 활용할 수 있는 법적 프레임워크를 이해할 수 있습니다.
참조: 관련 연구 논문, 데이터셋 또는 외부 리소스에 대한 인용 또는 참조입니다.
배포: 모델이 배포되는 방식 및 위치에 대한 세부 정보와 워크플로우 오케스트레이션 플랫폼과 같은 다른 엔터프라이즈 시스템에 모델을 통합하는 방법에 대한 지침입니다.
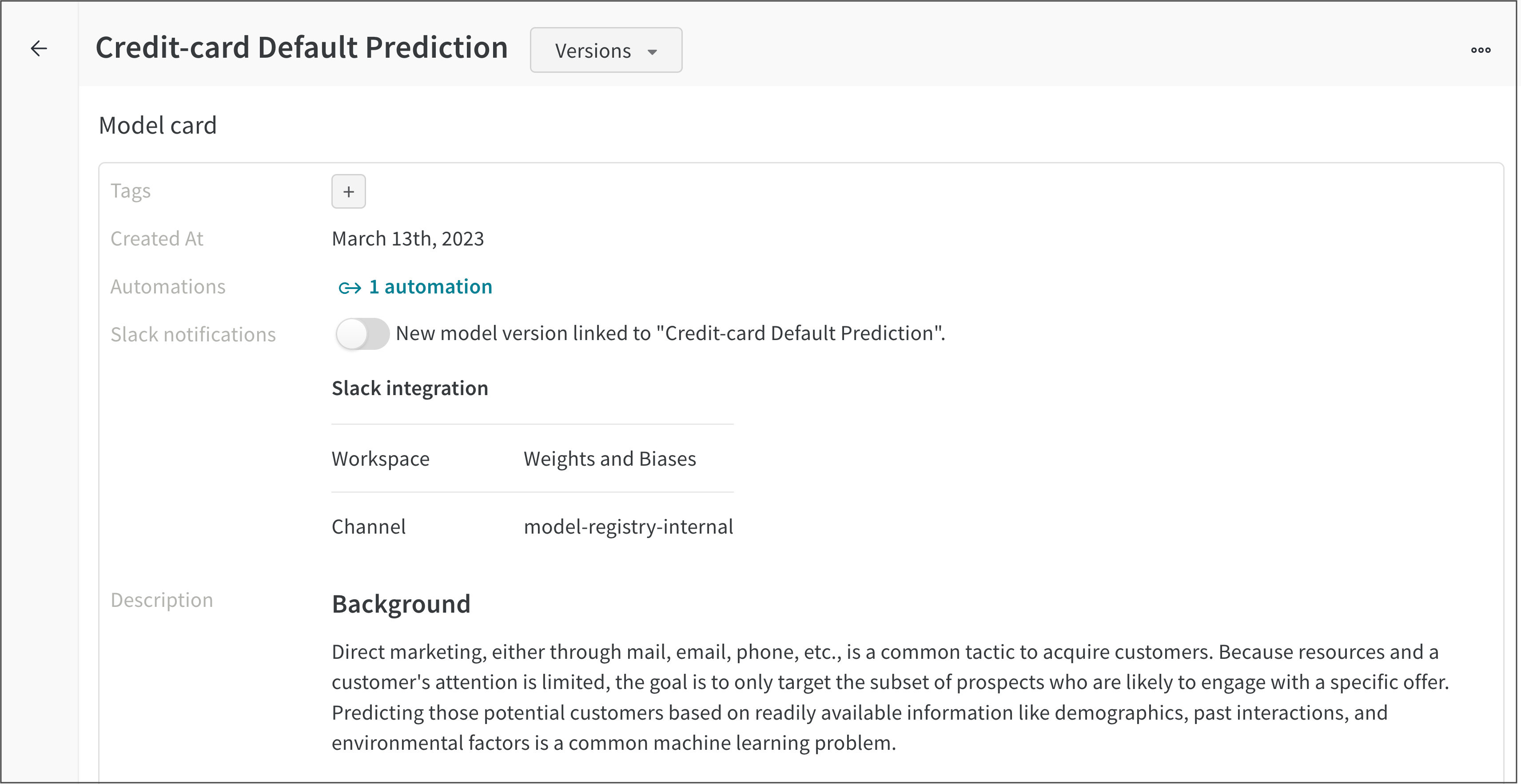
Description 필드 내에 머신러닝 모델에 대한 정보를 제공합니다. Markdown 마크업 언어를 사용하여 모델 카드 내에서 텍스트 서식을 지정합니다.
예를 들어 다음 이미지는 신용카드 채무 불이행 예측 등록 모델의 모델 카드를 보여줍니다.
9 - Download a model version
W&B Python SDK로 모델을 다운로드하는 방법
W&B Python SDK를 사용하여 Model Registry에 연결한 모델 아티팩트를 다운로드합니다.
모델을 재구성하고, 역직렬화하여 사용할 수 있는 형태로 만들려면 추가적인 Python 함수와 API 호출을 제공해야 합니다.
W&B에서는 모델을 메모리에 로드하는 방법에 대한 정보를 모델 카드를 통해 문서화할 것을 권장합니다. 자세한 내용은 기계 학습 모델 문서화 페이지를 참조하세요.
<> 안의 값을 직접 변경하세요:
import wandb
# run 초기화run = wandb.init(project="<project>", entity="<entity>")
# 모델에 엑세스하고 다운로드합니다. 다운로드된 아티팩트의 경로를 반환합니다.downloaded_model_path = run.use_model(name="<your-model-name>")
다음 형식 중 하나를 사용하여 모델 버전을 참조하세요:
latest - 가장 최근에 연결된 모델 버전을 지정하려면 latest 에일리어스를 사용합니다.
v# - Registered Model에서 특정 버전을 가져오려면 v0, v1, v2 등을 사용합니다.
alias - 팀에서 모델 버전에 할당한 사용자 지정 에일리어스를 지정합니다.
가능한 파라미터 및 반환 유형에 대한 자세한 내용은 API Reference 가이드의 use_model을 참조하세요.
예시: 기록된 모델 다운로드 및 사용
예를 들어, 다음 코드 조각에서 사용자는 use_model API를 호출했습니다. 가져오려는 모델 아티팩트의 이름을 지정하고 버전/에일리어스도 제공했습니다. 그런 다음 API에서 반환된 경로를 downloaded_model_path 변수에 저장했습니다.
import wandb
entity ="luka"project ="NLP_Experiments"alias ="latest"# 모델 버전에 대한 시맨틱 닉네임 또는 식별자model_artifact_name ="fine-tuned-model"# run 초기화run = wandb.init()
# 모델에 엑세스하고 다운로드합니다. 다운로드된 아티팩트의 경로를 반환합니다.downloaded_model_path = run.use_model(name=f"{entity/project/model_artifact_name}:{alias}")
2024년 W&B Model Registry 지원 중단 예정
다음 탭은 곧 지원이 중단될 Model Registry를 사용하여 모델 아티팩트를 사용하는 방법을 보여줍니다.
W&B Registry를 사용하여 모델 아티팩트를 추적, 구성 및 사용합니다. 자세한 내용은 Registry 문서를 참조하세요.
<> 안의 값을 직접 변경하세요:
import wandb
# run 초기화run = wandb.init(project="<project>", entity="<entity>")
# 모델에 엑세스하고 다운로드합니다. 다운로드된 아티팩트의 경로를 반환합니다.downloaded_model_path = run.use_model(name="<your-model-name>")
다음 형식 중 하나를 사용하여 모델 버전을 참조하세요:
latest - 가장 최근에 연결된 모델 버전을 지정하려면 latest 에일리어스를 사용합니다.
v# - Registered Model에서 특정 버전을 가져오려면 v0, v1, v2 등을 사용합니다.
alias - 팀에서 모델 버전에 할당한 사용자 지정 에일리어스를 지정합니다.
가능한 파라미터 및 반환 유형에 대한 자세한 내용은 API Reference 가이드의 use_model을 참조하세요.
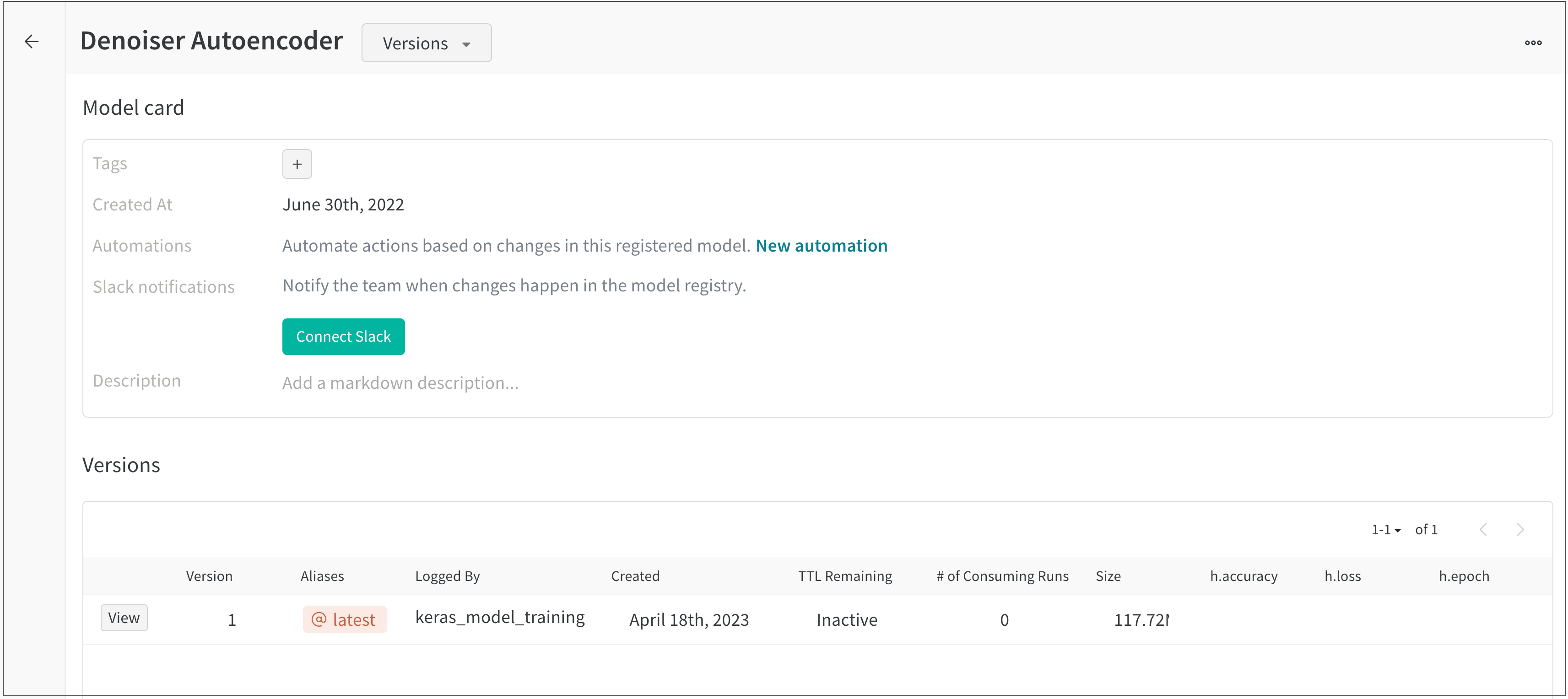
OAuth 페이지에 나타나는 지침에 따라 Slack workspace에서 W&B를 활성화합니다.
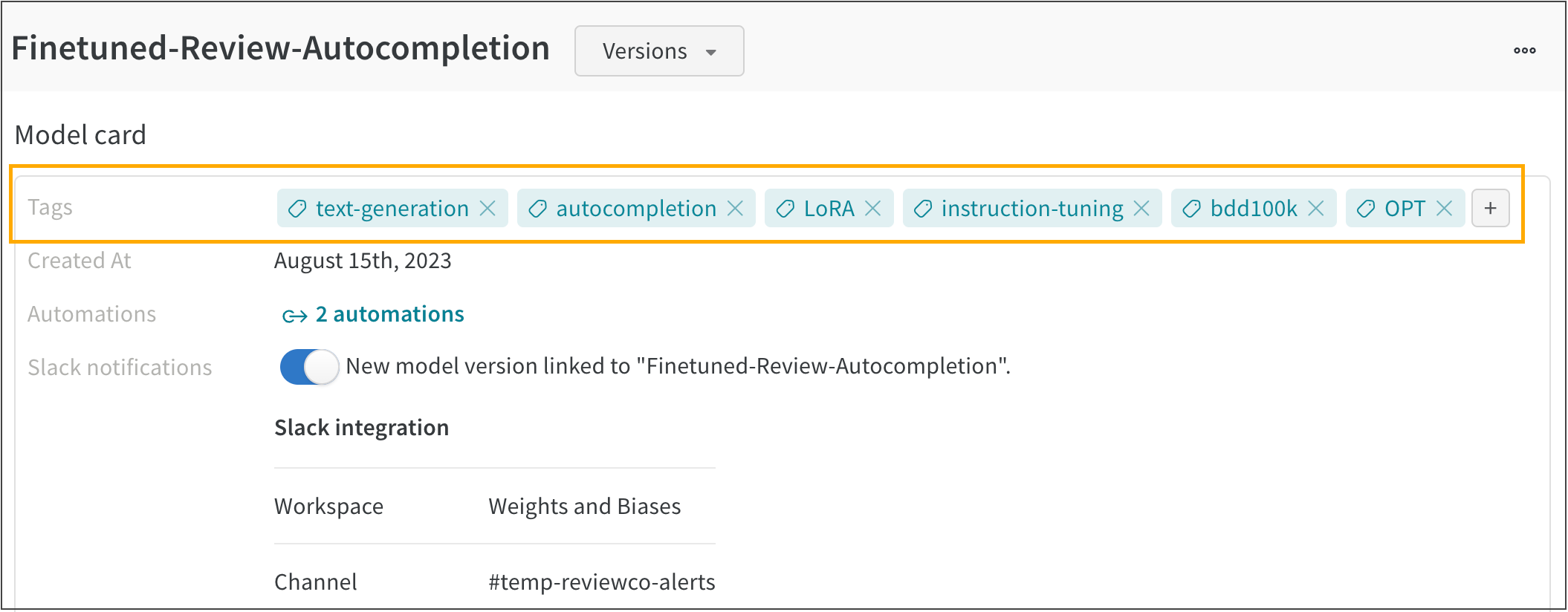
팀에 대한 Slack 알림을 구성했으면 알림을 받을 Registered Model을 선택할 수 있습니다.
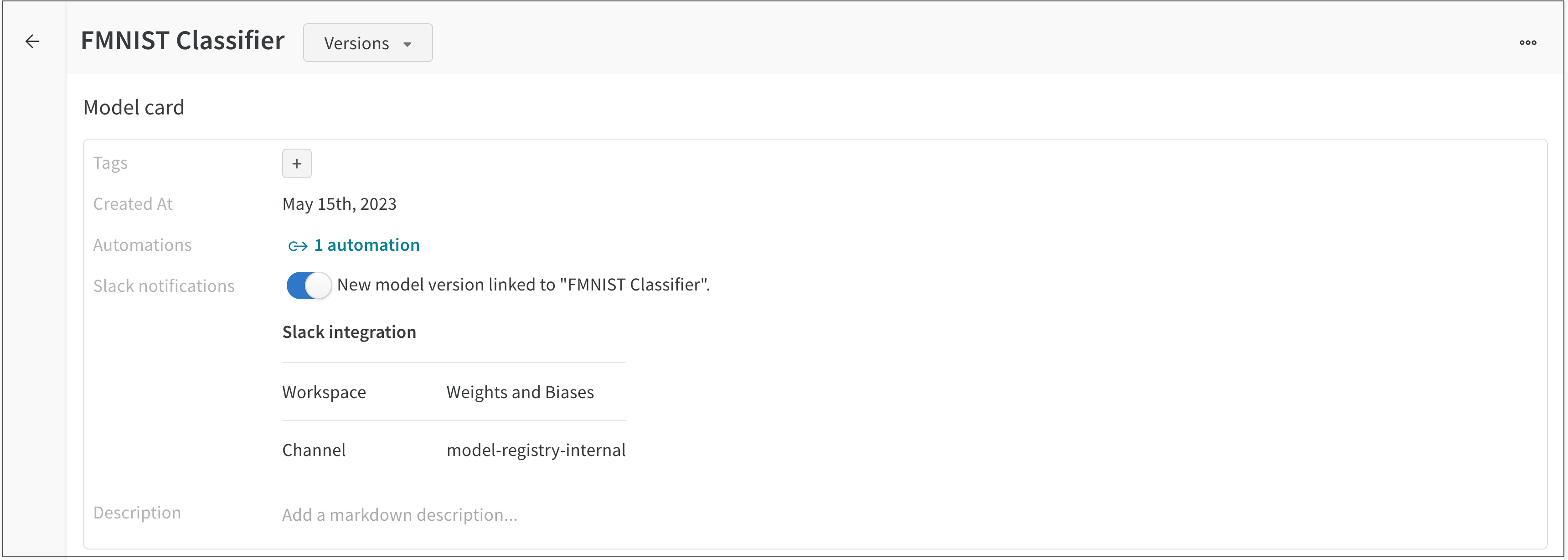
팀에 대해 Slack 알림을 구성한 경우 Connect Slack 버튼 대신 New model version linked to… 토글이 나타납니다.
아래 스크린샷은 Slack 알림이 있는 FMNIST 분류기 Registered Model을 보여줍니다.
새로운 모델 버전이 FMNIST 분류기 Registered Model에 연결될 때마다 연결된 Slack 채널에 메시지가 자동으로 게시됩니다.
11 - Manage data governance and access control
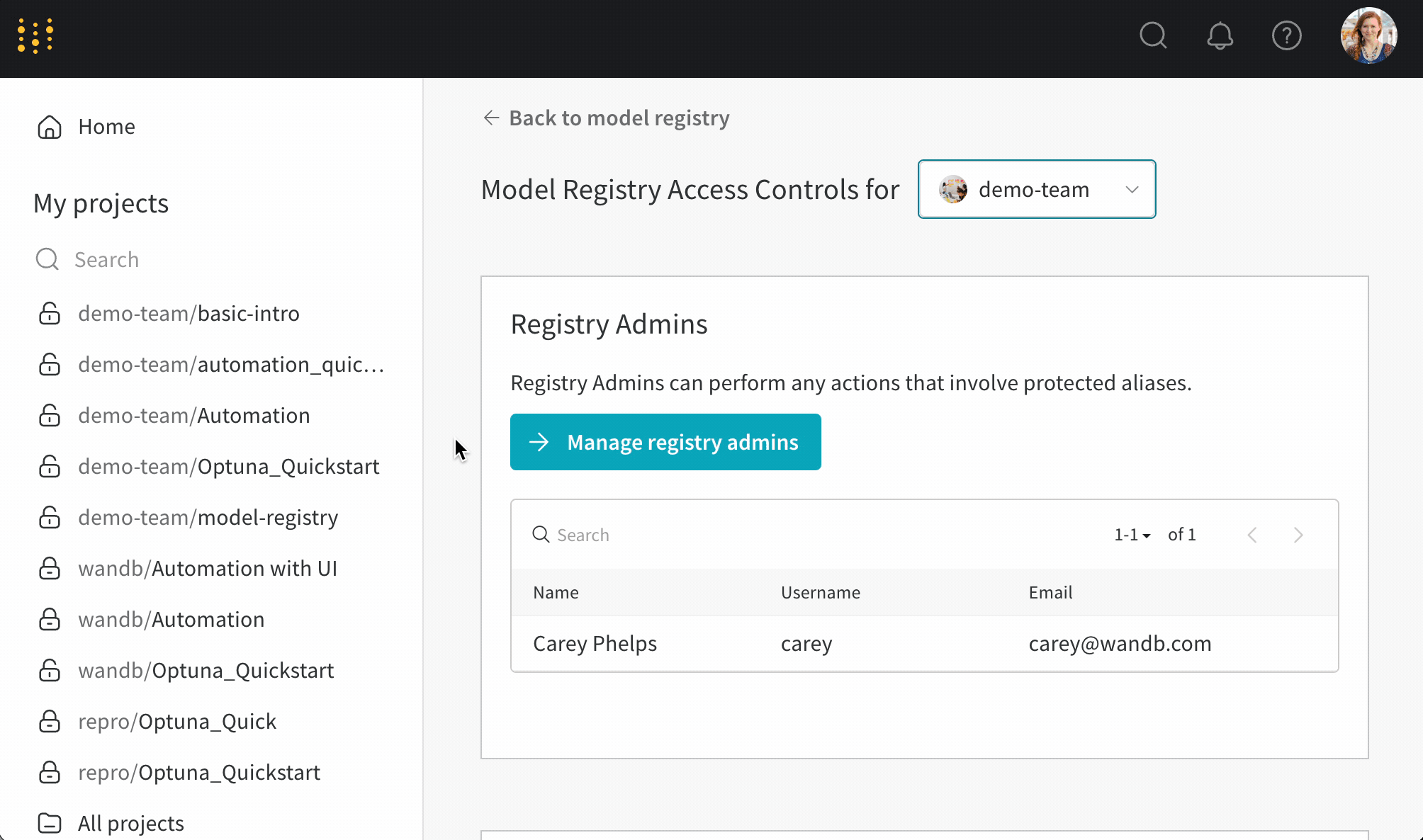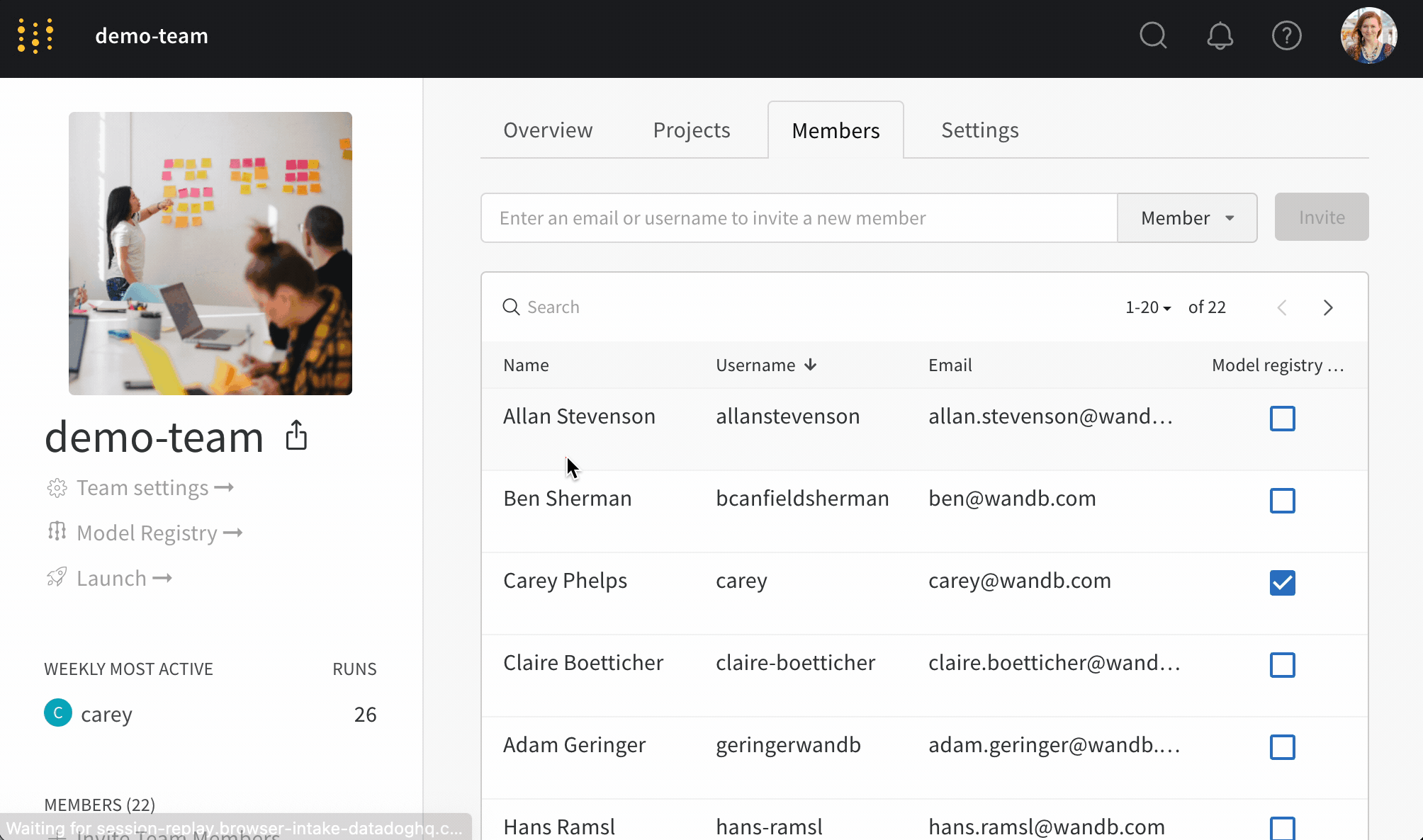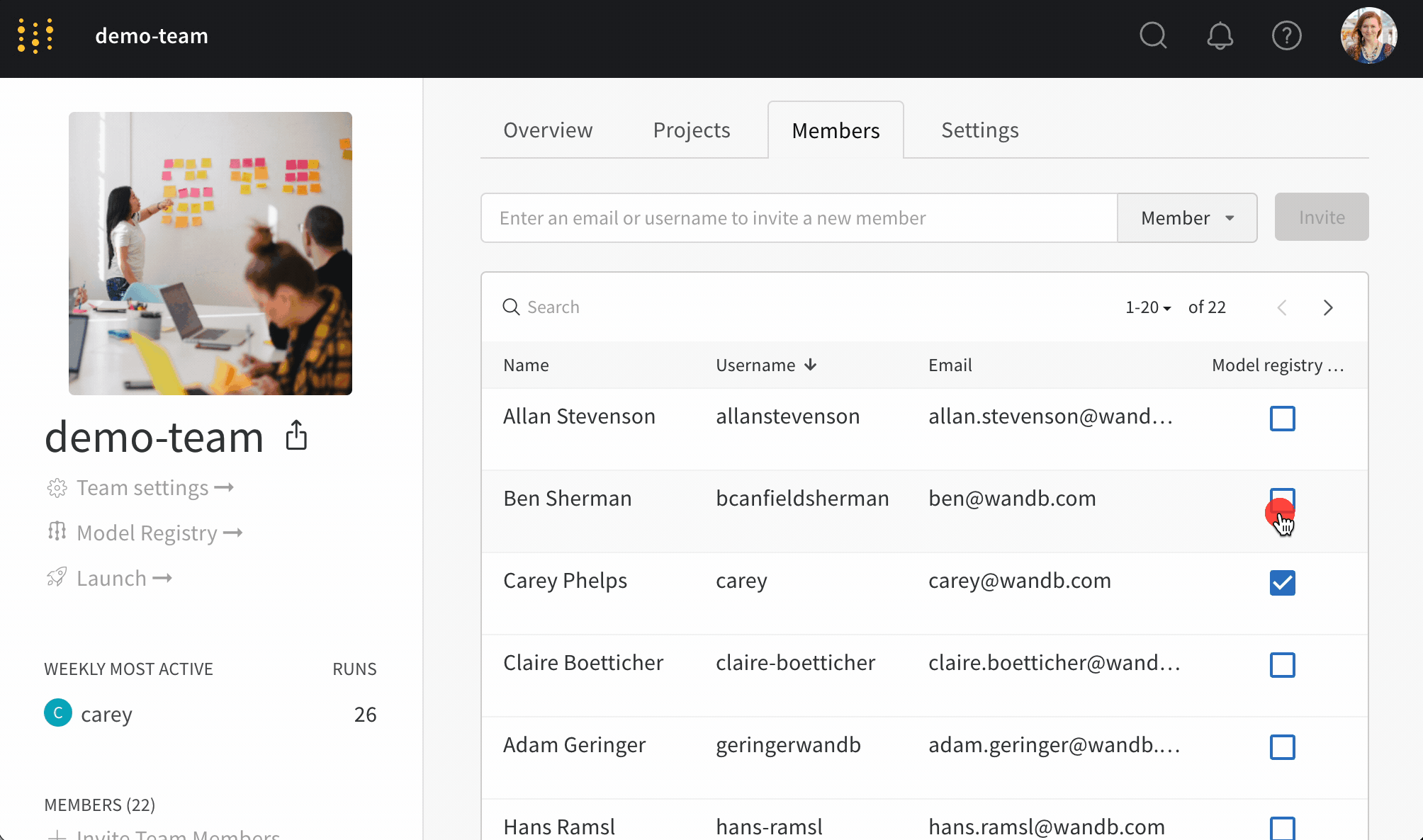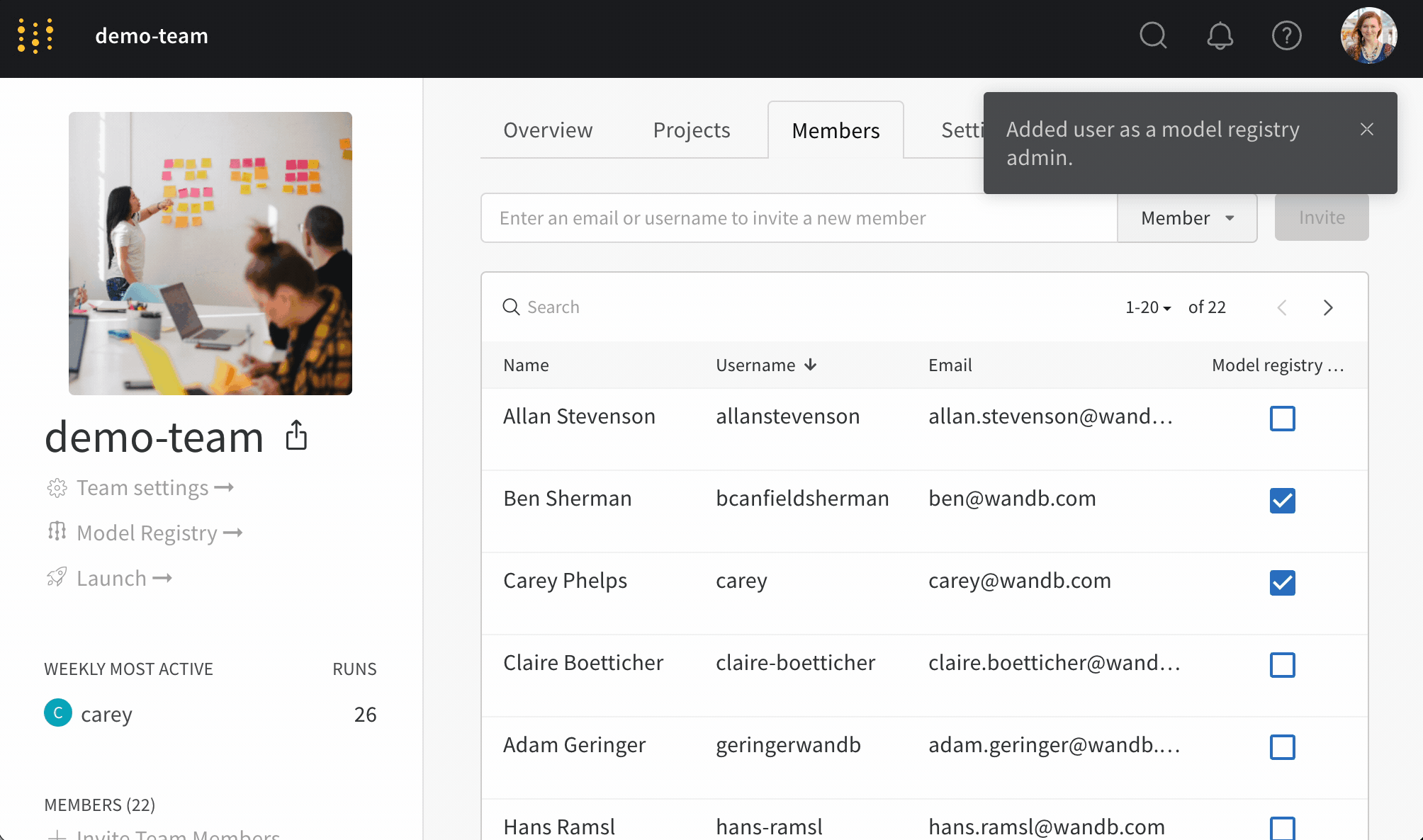
모델 레지스트리 역할 기반 엑세스 제어(RBAC)를 사용하여 보호된 에일리어스를 업데이트할 수 있는 사람을 제어합니다.
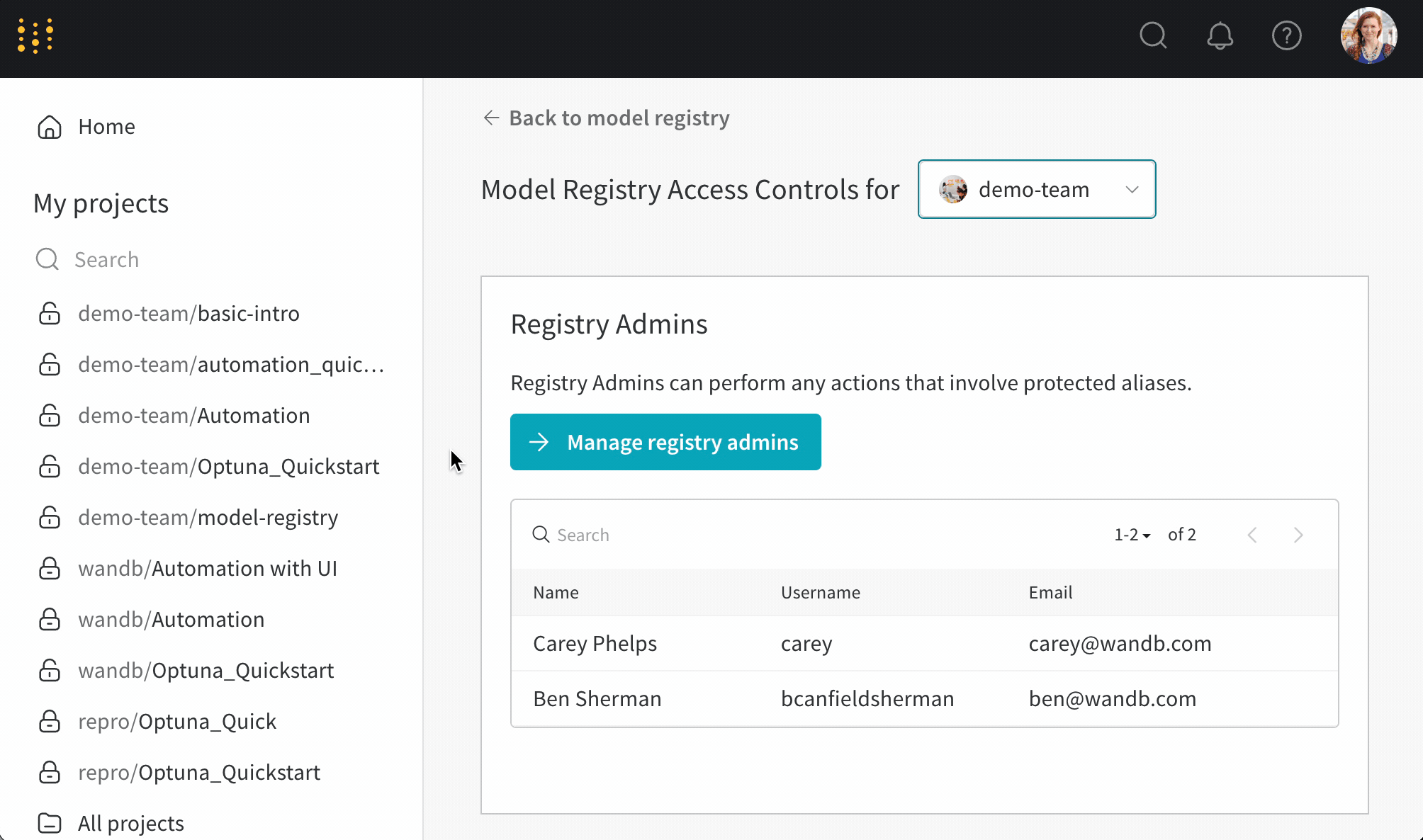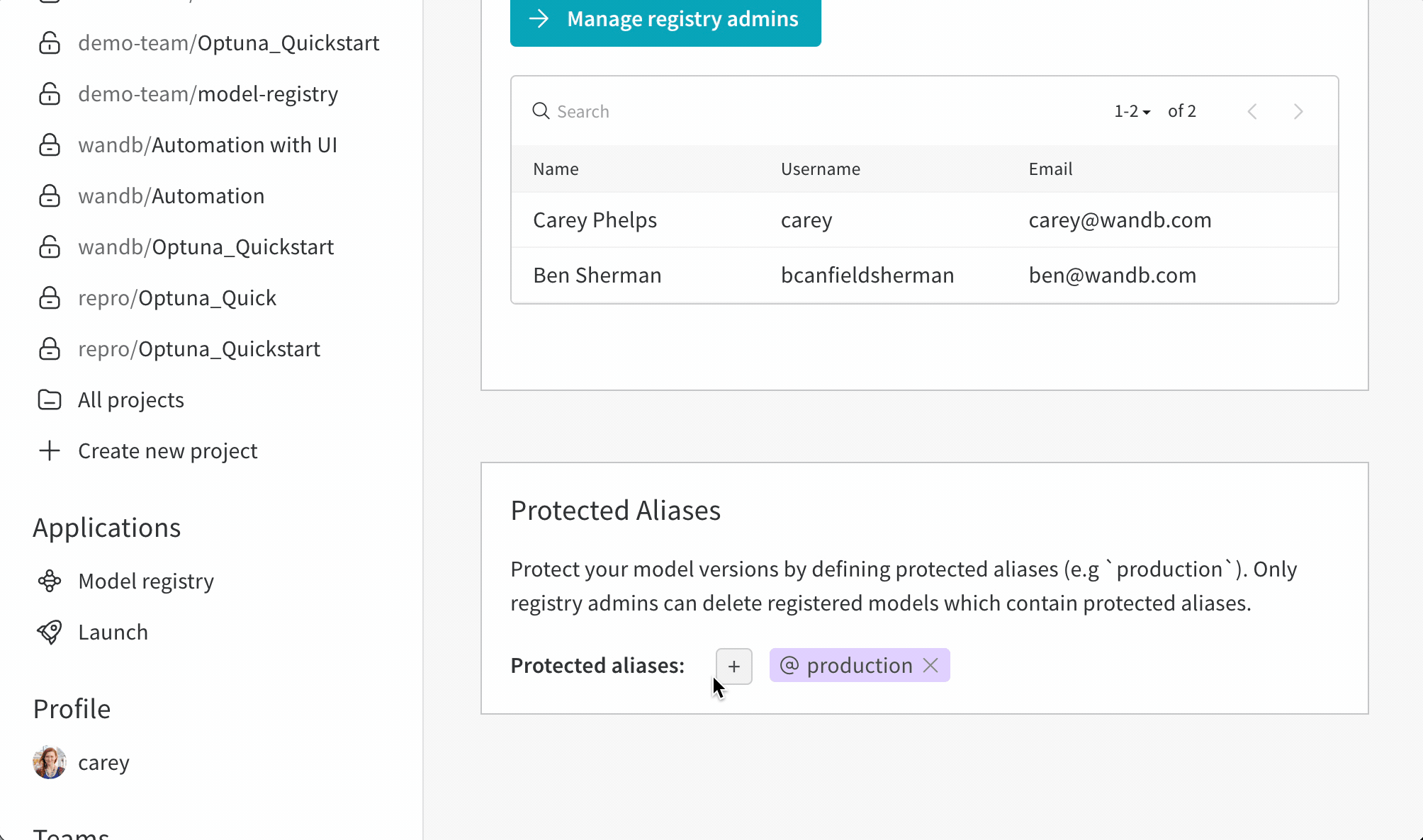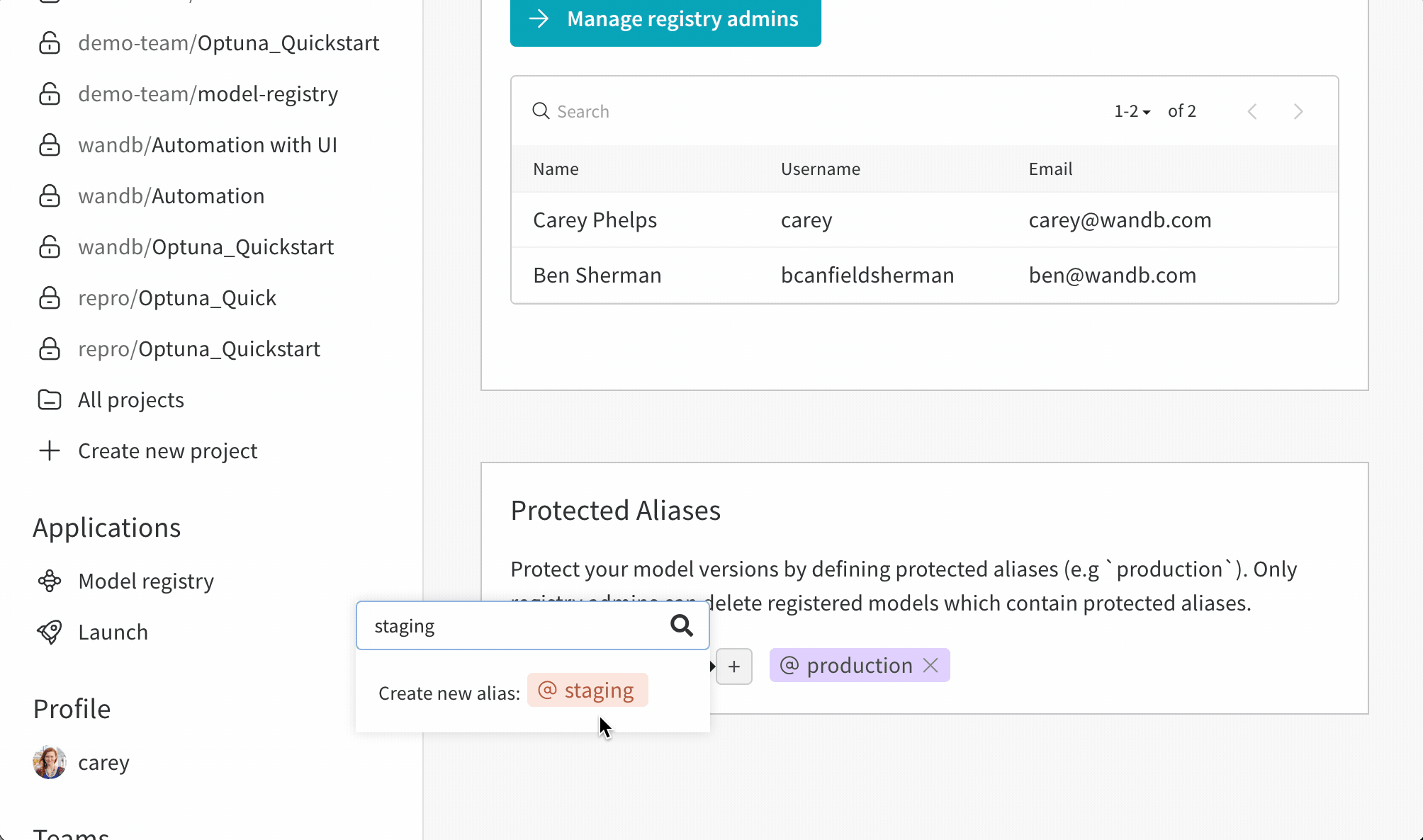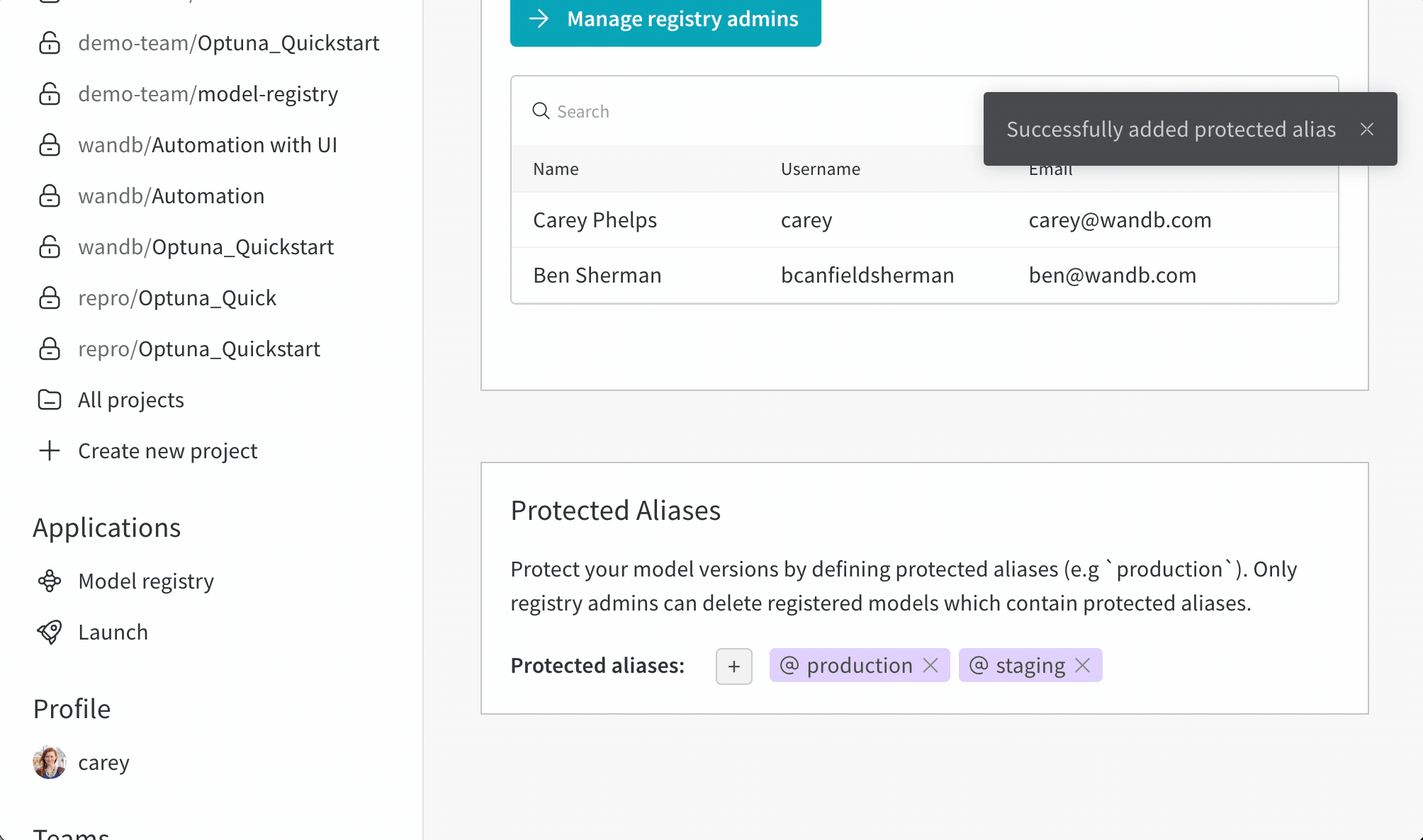
보호된 에일리어스를 사용하여 모델 개발 파이프라인의 주요 단계를 나타냅니다. 모델 레지스트리 관리자 만이 보호된 에일리어스를 추가, 수정 또는 제거할 수 있습니다. 모델 레지스트리 관리자는 보호된 에일리어스를 정의하고 사용할 수 있습니다. W&B는 관리자가 아닌 사용자가 모델 버전에서 보호된 에일리어스를 추가하거나 제거하는 것을 차단합니다.
팀 관리자 또는 현재 레지스트리 관리자만이 레지스트리 관리자 목록을 관리할 수 있습니다.
예를 들어, staging 및 production을 보호된 에일리어스로 설정했다고 가정합니다. 팀의 모든 구성원은 새로운 모델 버전을 추가할 수 있습니다. 그러나 관리자만이 staging 또는 production 에일리어스를 추가할 수 있습니다.