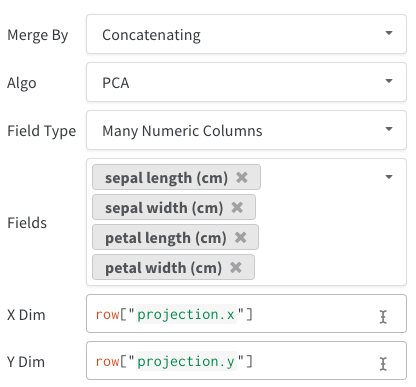
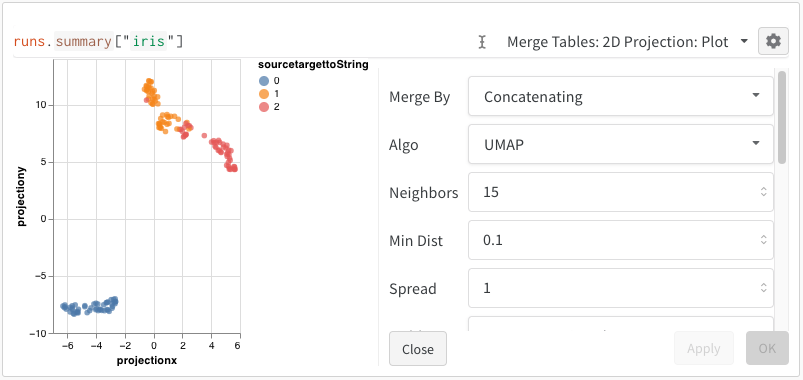
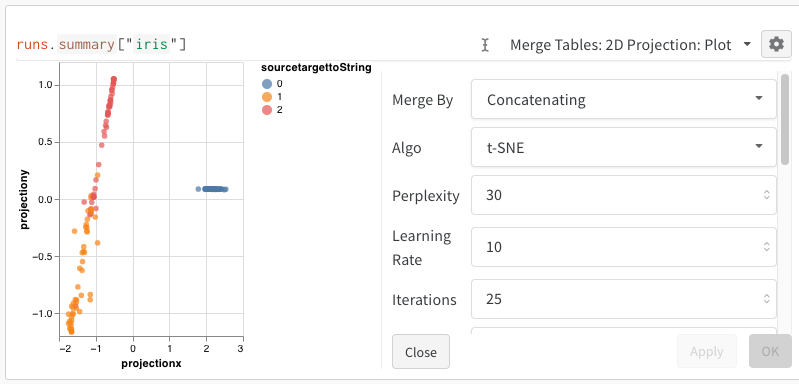
쿼리 패널을 사용하여 데이터를 쿼리하고 대화형으로 시각화하세요.
쿼리 패널 만들기
워크스페이스 또는 리포트 내에 쿼리를 추가하세요.
- 프로젝트 워크스페이스로 이동합니다.
- 오른쪽 상단 모서리에서
패널 추가를 클릭합니다. - 드롭다운에서
쿼리 패널을 선택합니다.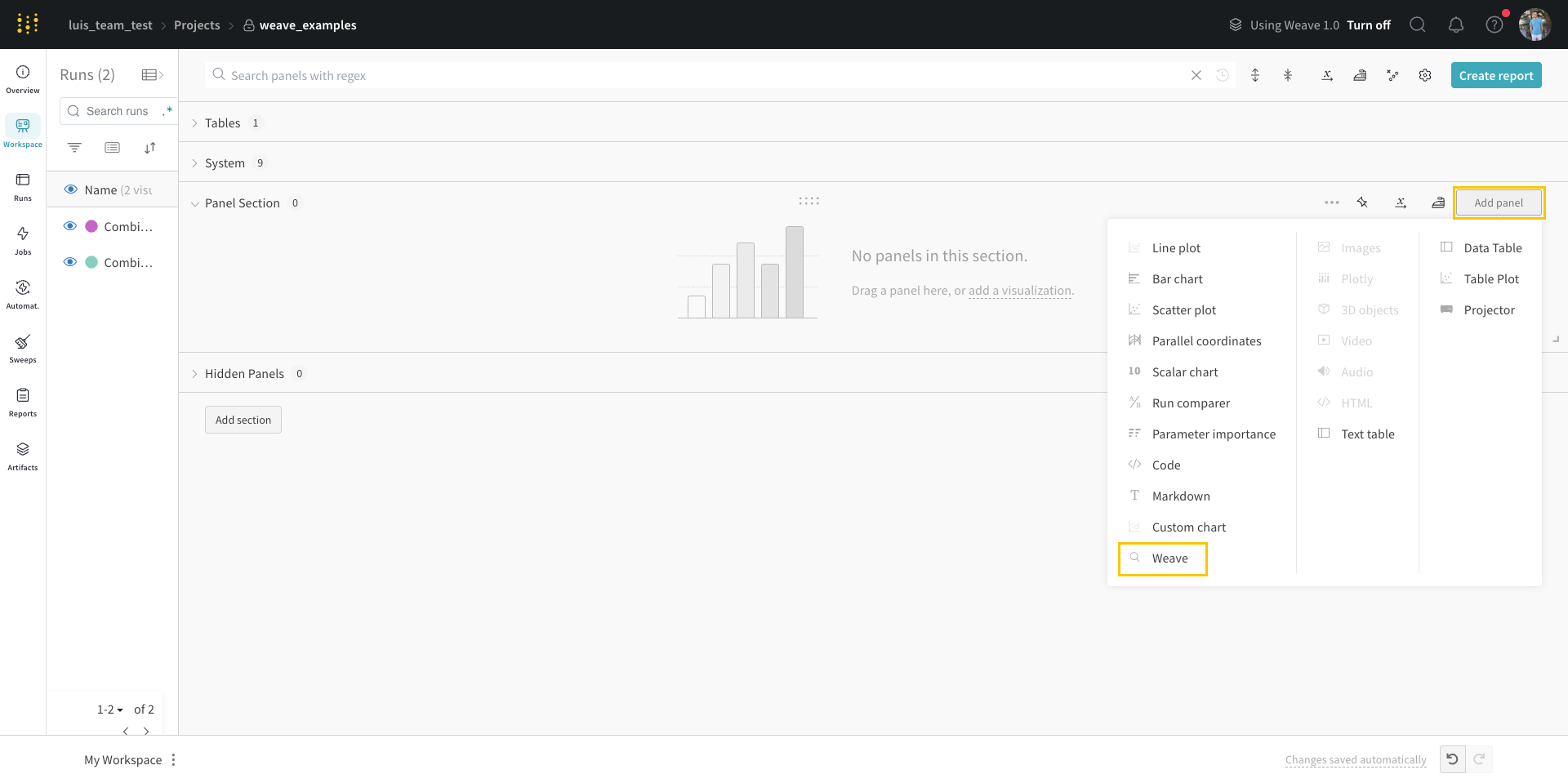
/쿼리 패널을 입력하고 선택합니다.
또는 쿼리를 run 집합과 연결할 수 있습니다:
- 리포트 내에서
/패널 그리드를 입력하고 선택합니다. 패널 추가버튼을 클릭합니다.- 드롭다운에서
쿼리 패널을 선택합니다.
쿼리 구성 요소
표현식
쿼리 표현식을 사용하여 run, Artifacts, Models, 테이블 등과 같이 W&B에 저장된 데이터를 쿼리합니다.
예시: 테이블 쿼리
W&B Table을 쿼리한다고 가정합니다. 트레이닝 코드에서 "cifar10_sample_table"이라는 테이블을 로깅합니다:
import wandb
wandb.log({"cifar10_sample_table":<MY_TABLE>})
쿼리 패널 내에서 다음을 사용하여 테이블을 쿼리할 수 있습니다:
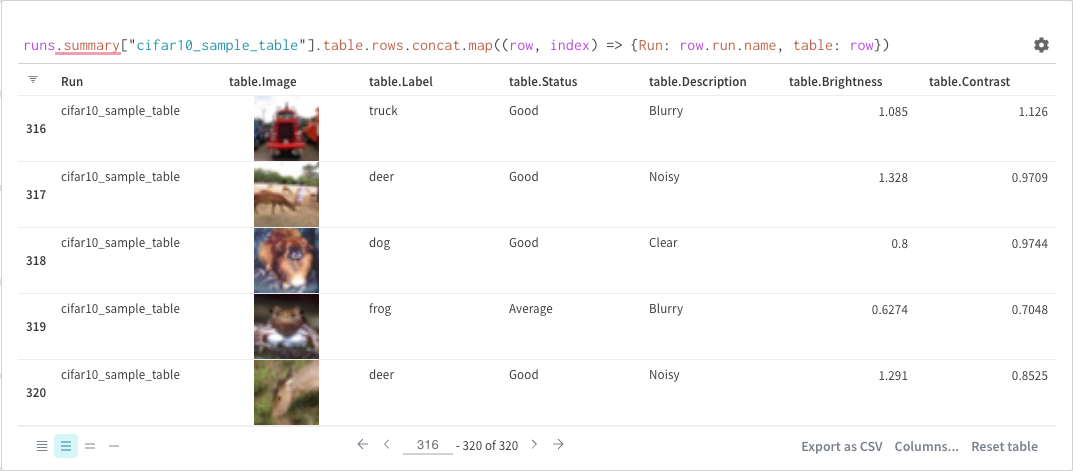
runs.summary["cifar10_sample_table"]

분해하면 다음과 같습니다:
runs는 쿼리 패널이 워크스페이스에 있을 때 쿼리 패널 표현식에 자동으로 삽입되는 변수입니다. “값"은 해당 특정 워크스페이스에 대해 보이는 run 목록입니다. run 내에서 사용할 수 있는 다양한 속성에 대해 자세히 알아보려면 여기를 참조하세요.summary는 Run에 대한 Summary 오브젝트를 반환하는 op입니다. Op는 _매핑_됩니다. 즉, 이 op는 목록의 각 Run에 적용되어 Summary 오브젝트 목록이 생성됩니다.["cifar10_sample_table"]은predictions파라미터가 있는 Pick op(대괄호로 표시)입니다. Summary 오브젝트는 사전 또는 맵과 같이 작동하므로 이 작업은 각 Summary 오브젝트에서predictions필드를 선택합니다.
자신만의 쿼리를 대화형으로 작성하는 방법을 배우려면 이 리포트를 참조하세요.
설정
패널 왼쪽 상단 모서리에 있는 톱니바퀴 아이콘을 선택하여 쿼리 설정을 확장합니다. 이를 통해 사용자는 패널 유형과 결과 패널에 대한 파라미터를 구성할 수 있습니다.
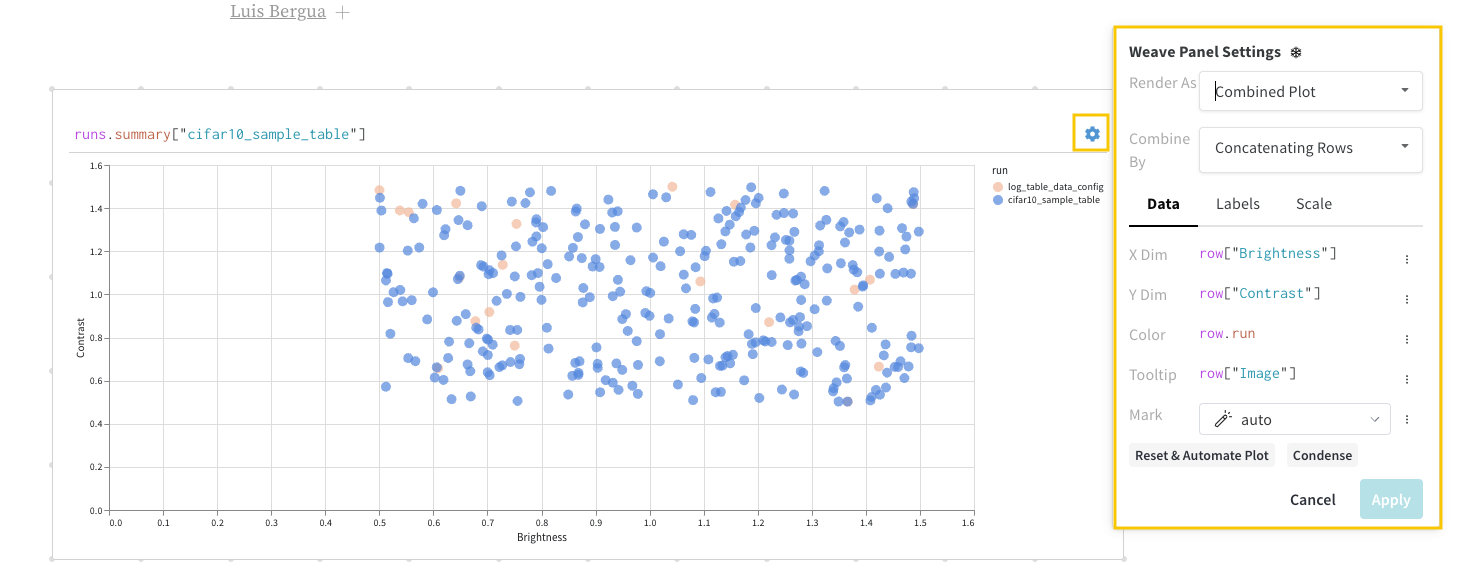
결과 패널
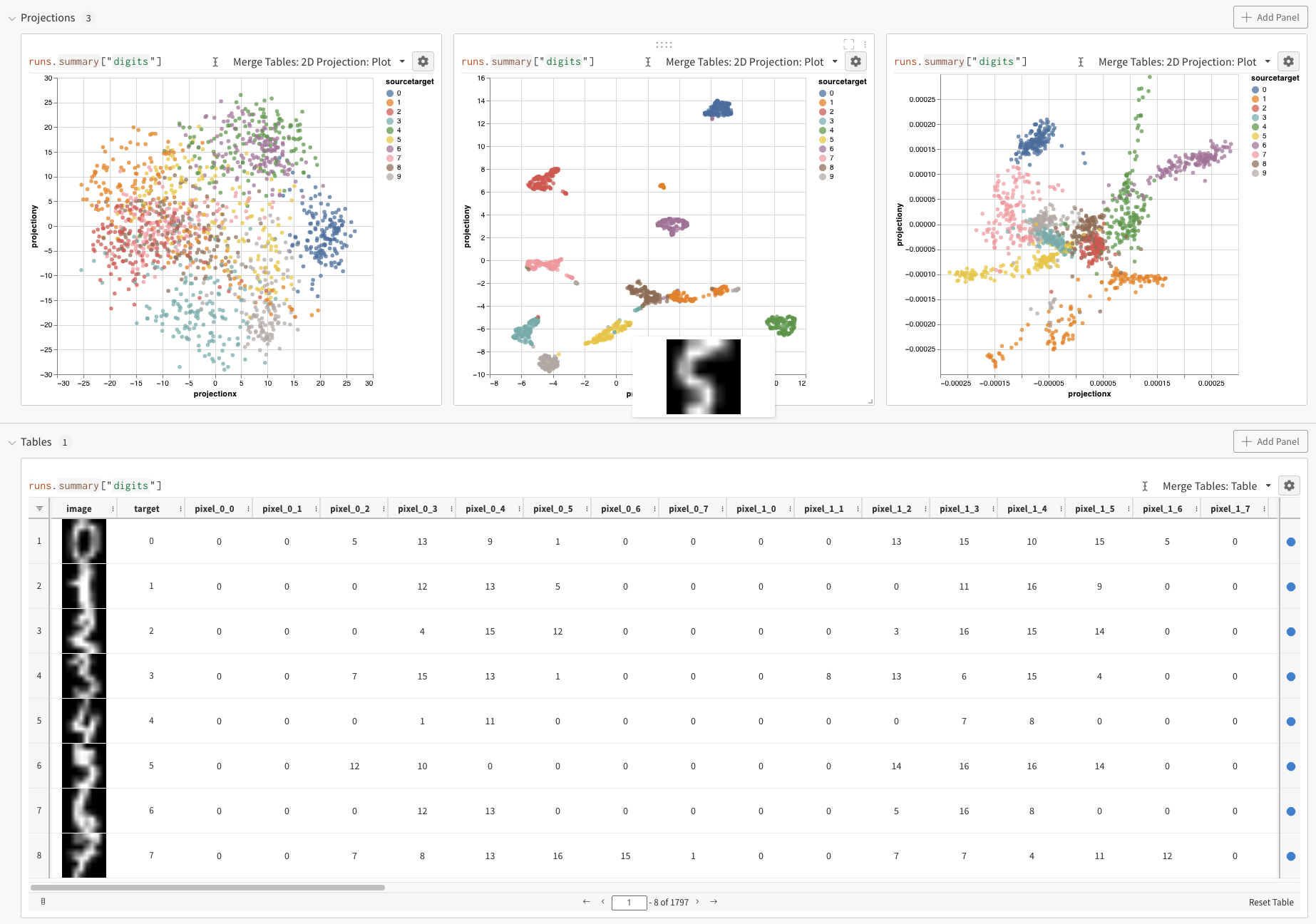
마지막으로 쿼리 결과 패널은 선택한 쿼리 패널을 사용하여 쿼리 표현식의 결과를 렌더링하고, 데이터를 대화형 형식으로 표시하기 위해 설정에 의해 구성됩니다. 다음 이미지는 동일한 데이터의 테이블과 플롯을 보여줍니다.
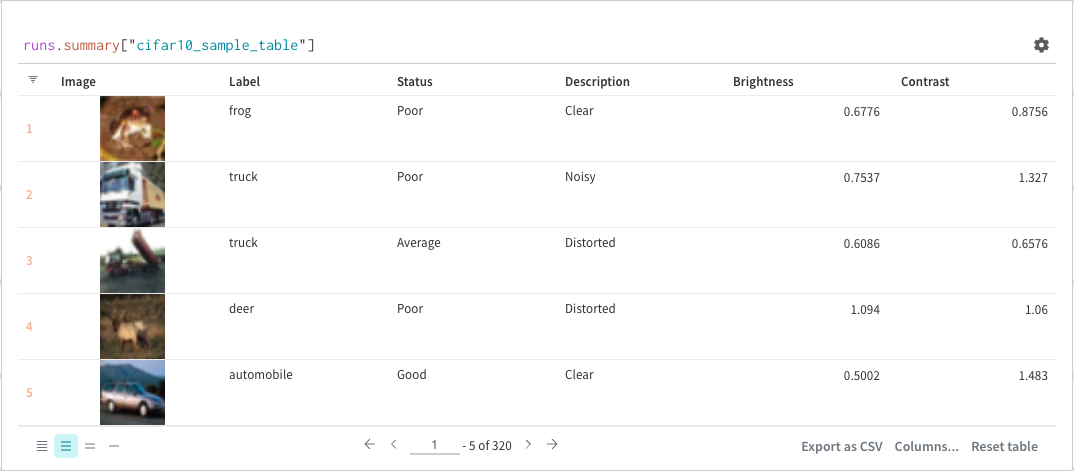
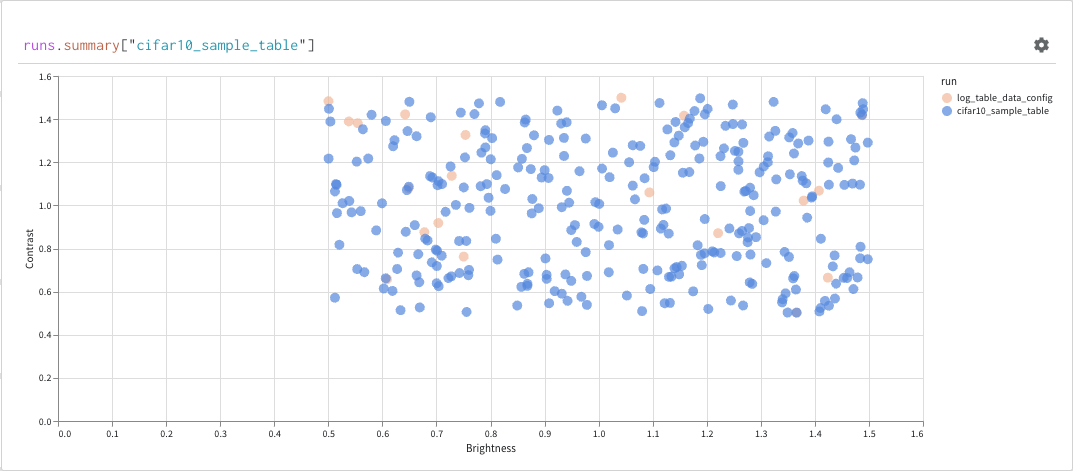
기본 작업
쿼리 패널 내에서 수행할 수 있는 다음의 일반적인 작업입니다.
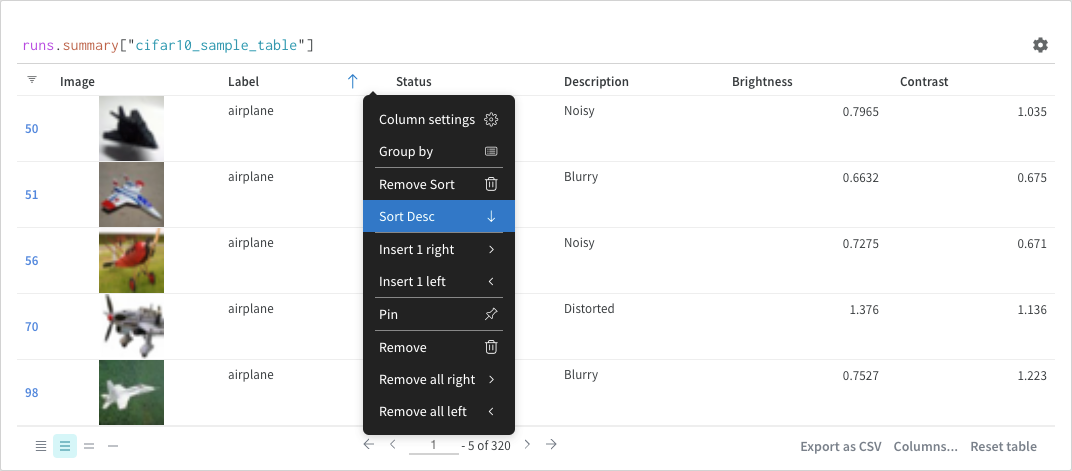
정렬
열 옵션에서 정렬:
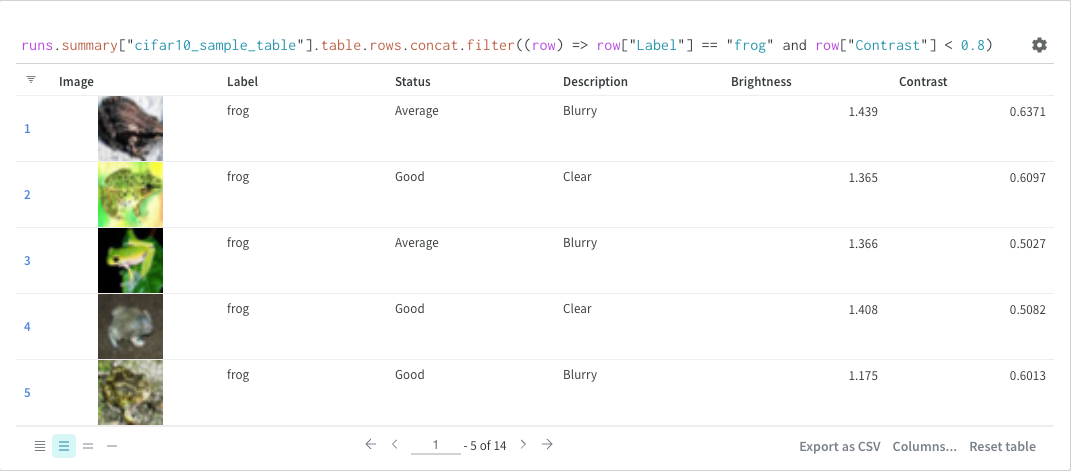
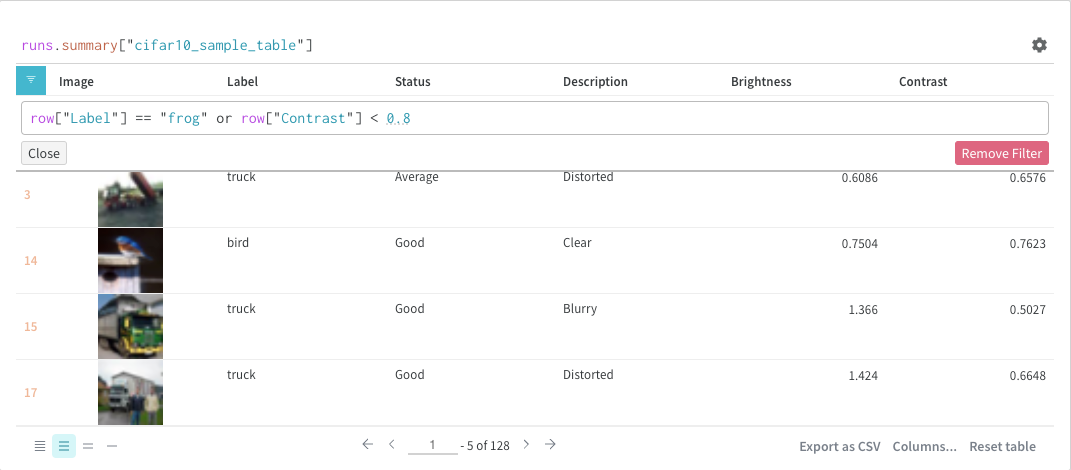
필터
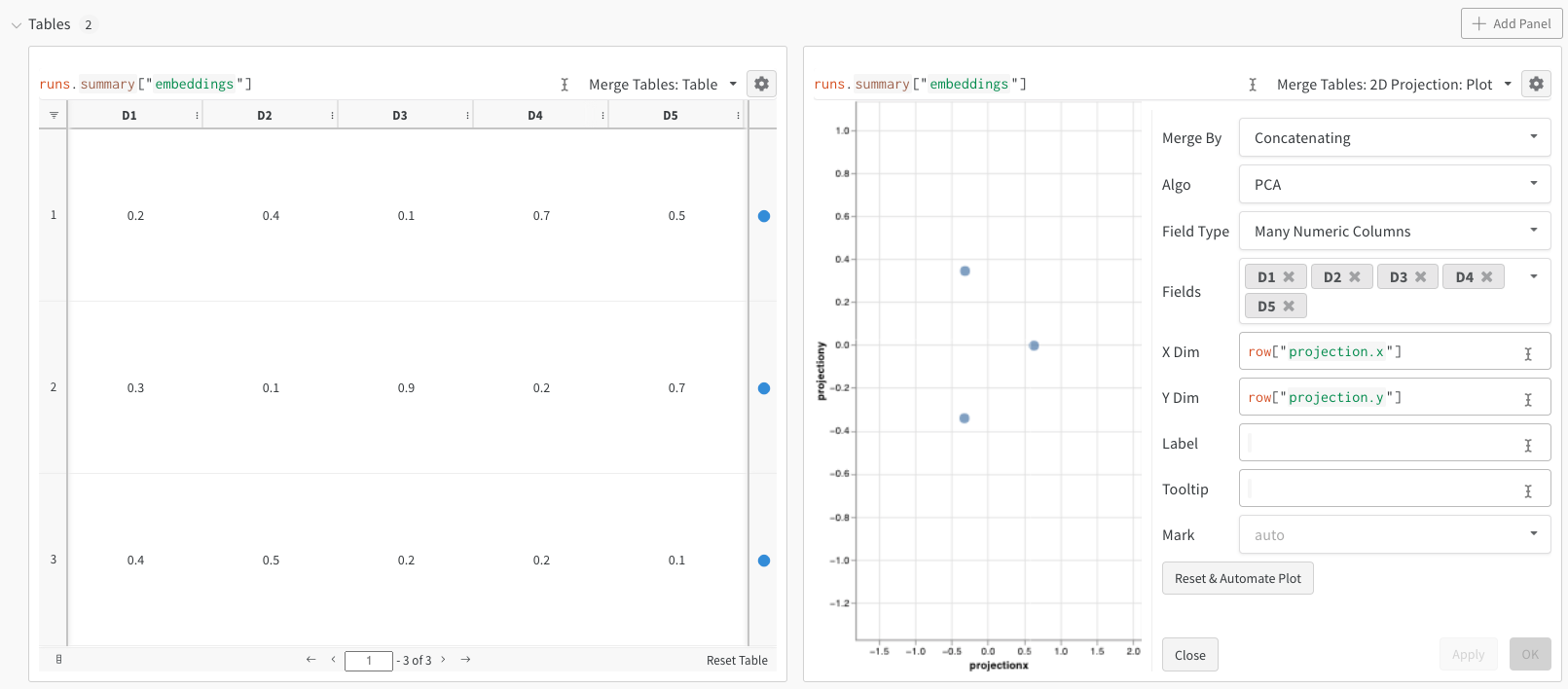
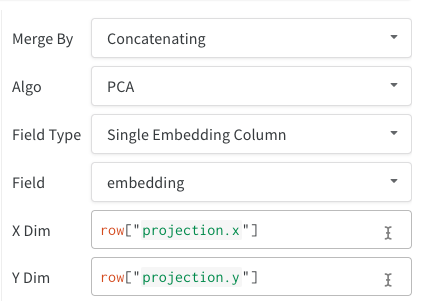
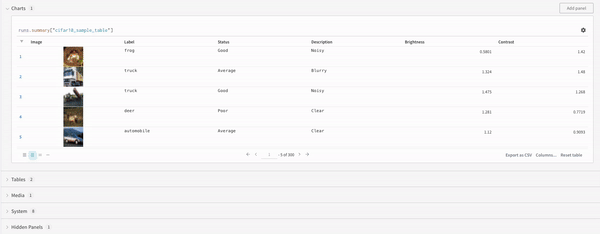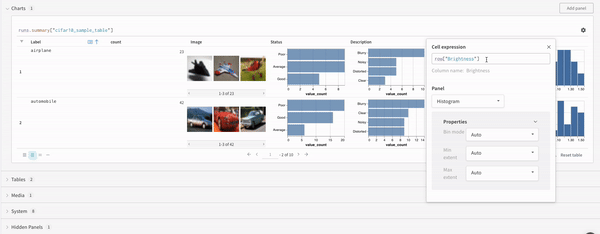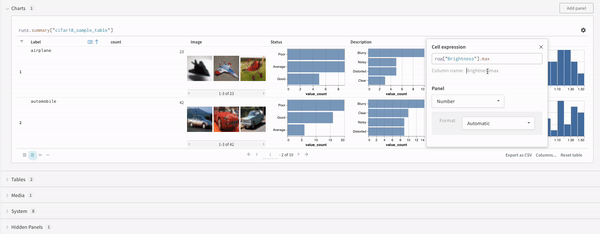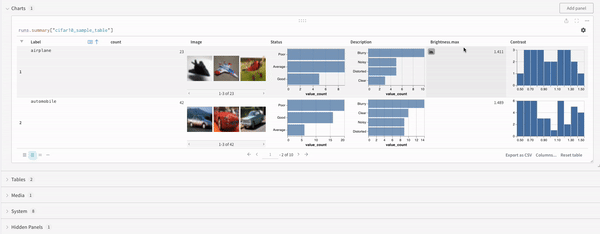
쿼리에서 직접 또는 왼쪽 상단 모서리에 있는 필터 버튼을 사용하여 필터링할 수 있습니다(두 번째 이미지).
맵
맵 작업은 목록을 반복하고 데이터의 각 요소에 함수를 적용합니다. 패널 쿼리를 통해 직접 또는 열 옵션에서 새 열을 삽입하여 이를 수행할 수 있습니다.

Groupby
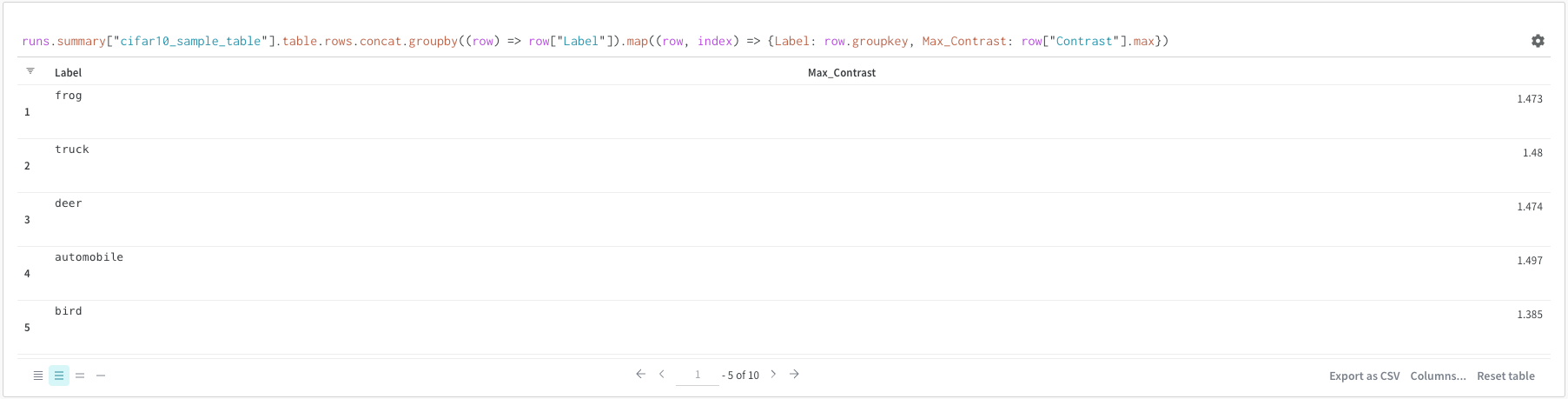
쿼리 또는 열 옵션에서 groupby를 사용할 수 있습니다.
Concat
concat 작업을 통해 2개의 테이블을 연결하고 패널 설정에서 연결하거나 조인할 수 있습니다.
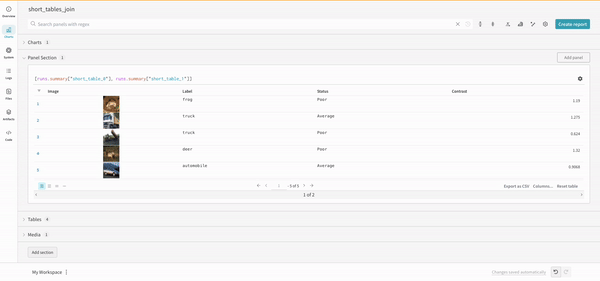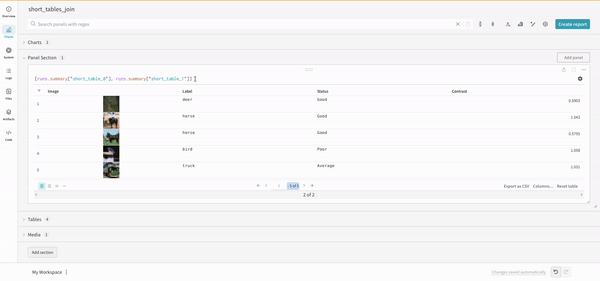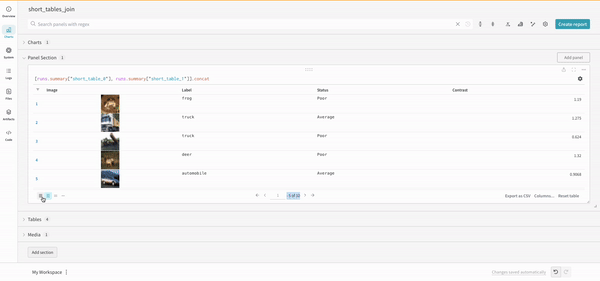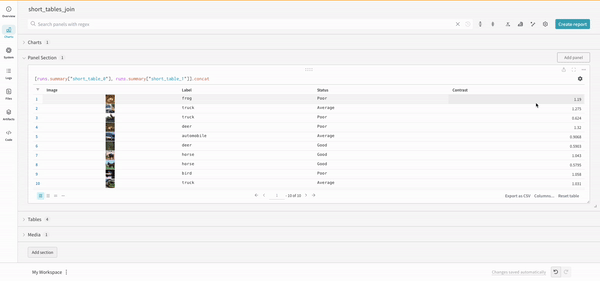
Join
쿼리에서 직접 테이블을 조인할 수도 있습니다. 다음 쿼리 표현식을 고려하십시오:
project("luis_team_test", "weave_example_queries").runs.summary["short_table_0"].table.rows.concat.join(\
project("luis_team_test", "weave_example_queries").runs.summary["short_table_1"].table.rows.concat,\
(row) => row["Label"],(row) => row["Label"], "Table1", "Table2",\
"false", "false")
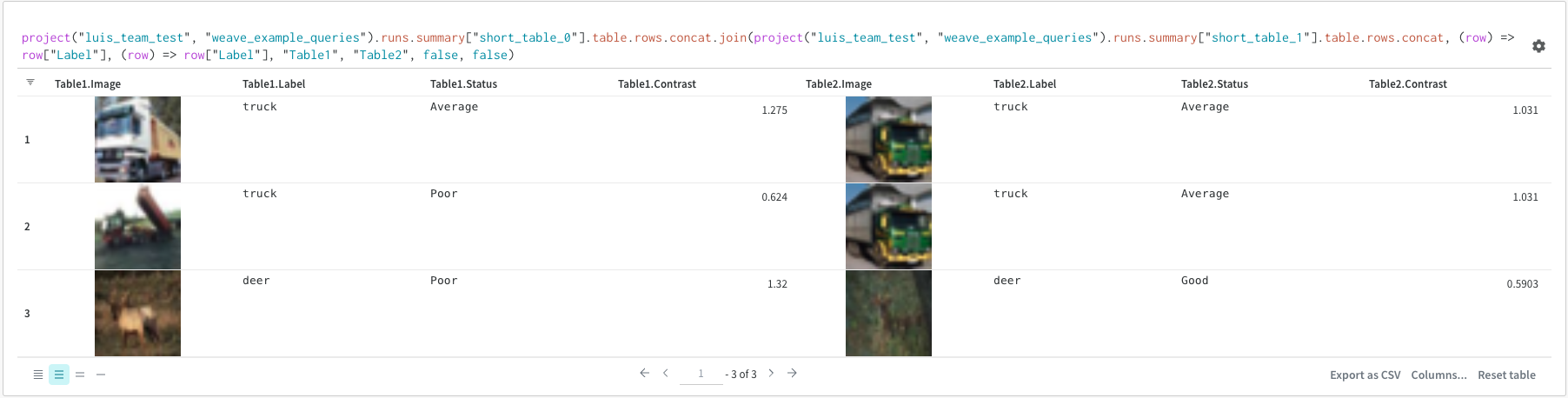
왼쪽 테이블은 다음에서 생성됩니다:
project("luis_team_test", "weave_example_queries").\
runs.summary["short_table_0"].table.rows.concat.join
오른쪽 테이블은 다음에서 생성됩니다:
project("luis_team_test", "weave_example_queries").\
runs.summary["short_table_1"].table.rows.concat
여기서:
(row) => row["Label"]은 각 테이블에 대한 선택기이며 조인할 열을 결정합니다."Table1"및"Table2"는 조인될 때 각 테이블의 이름입니다.true및false는 왼쪽 및 오른쪽 내부/외부 조인 설정을 위한 것입니다.
Runs 오브젝트
쿼리 패널을 사용하여 runs 오브젝트에 엑세스합니다. Run 오브젝트는 Experiments 기록을 저장합니다. 이 섹션의 리포트에서 자세한 내용을 확인할 수 있지만, 간략하게 살펴보면 runs 오브젝트는 다음과 같습니다.
summary: run 결과를 요약하는 정보 사전입니다. 여기에는 정확도 및 손실과 같은 스칼라 또는 큰 파일이 포함될 수 있습니다. 기본적으로wandb.log()는 Summary를 로깅된 시계열의 최종 값으로 설정합니다. Summary 내용을 직접 설정할 수 있습니다. Summary를 run의 출력이라고 생각하세요.history: 손실과 같이 모델이 트레이닝되는 동안 변경되는 값을 저장하기 위한 사전 목록입니다.wandb.log()코맨드는 이 오브젝트에 추가됩니다.config: 트레이닝 Run에 대한 하이퍼파라미터 또는 데이터셋 Artifact를 생성하는 Run에 대한 전처리 메소드와 같은 Run의 설정 정보 사전입니다. 이것을 Run의 “입력"이라고 생각하십시오.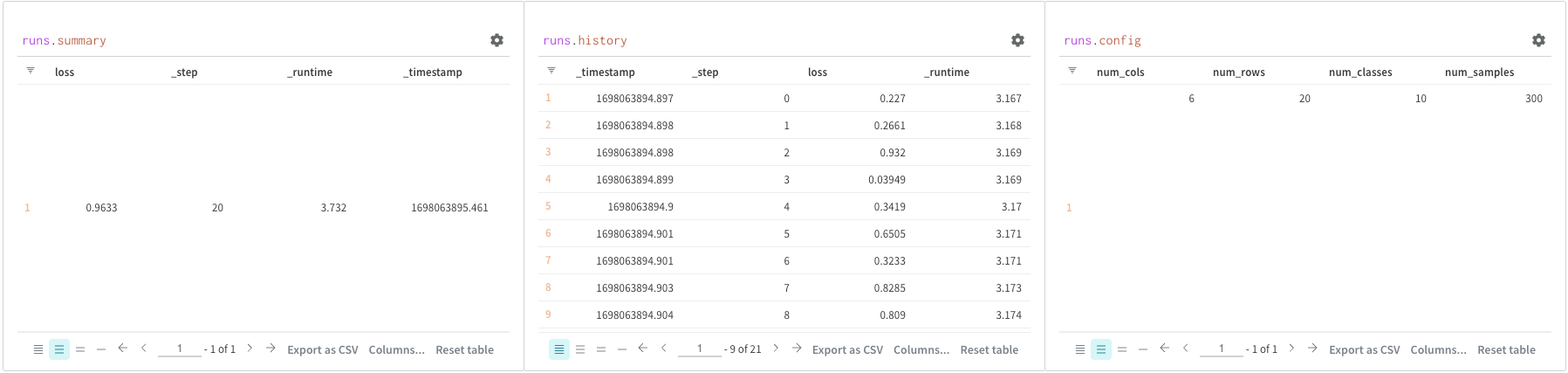
Artifacts 엑세스
Artifacts는 W&B의 핵심 개념입니다. 버전이 지정된 명명된 파일 및 디렉토리 모음입니다. Artifacts를 사용하여 모델 가중치, 데이터셋 및 기타 파일 또는 디렉토리를 추적합니다. Artifacts는 W&B에 저장되며 다운로드하거나 다른 Run에서 사용할 수 있습니다. 이 섹션의 리포트에서 자세한 내용과 예제를 확인할 수 있습니다. Artifacts는 일반적으로 project 오브젝트에서 엑세스됩니다.
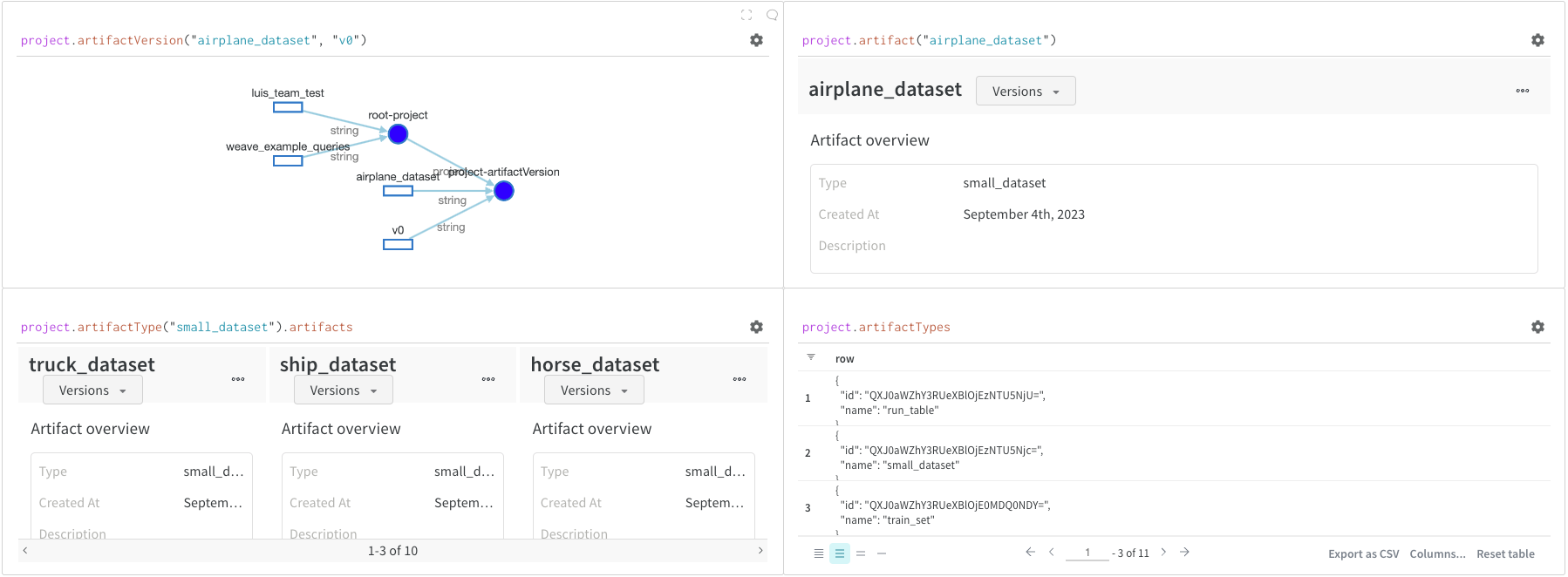
project.artifactVersion(): 프로젝트 내에서 주어진 이름과 버전에 대한 특정 아티팩트 버전을 반환합니다.project.artifact(""): 프로젝트 내에서 주어진 이름에 대한 아티팩트를 반환합니다. 그런 다음.versions를 사용하여 이 아티팩트의 모든 버전 목록을 가져올 수 있습니다.project.artifactType(): 프로젝트 내에서 주어진 이름에 대한artifactType을 반환합니다. 그런 다음.artifacts를 사용하여 이 유형의 모든 아티팩트 목록을 가져올 수 있습니다.project.artifactTypes: 프로젝트 아래의 모든 아티팩트 유형 목록을 반환합니다.