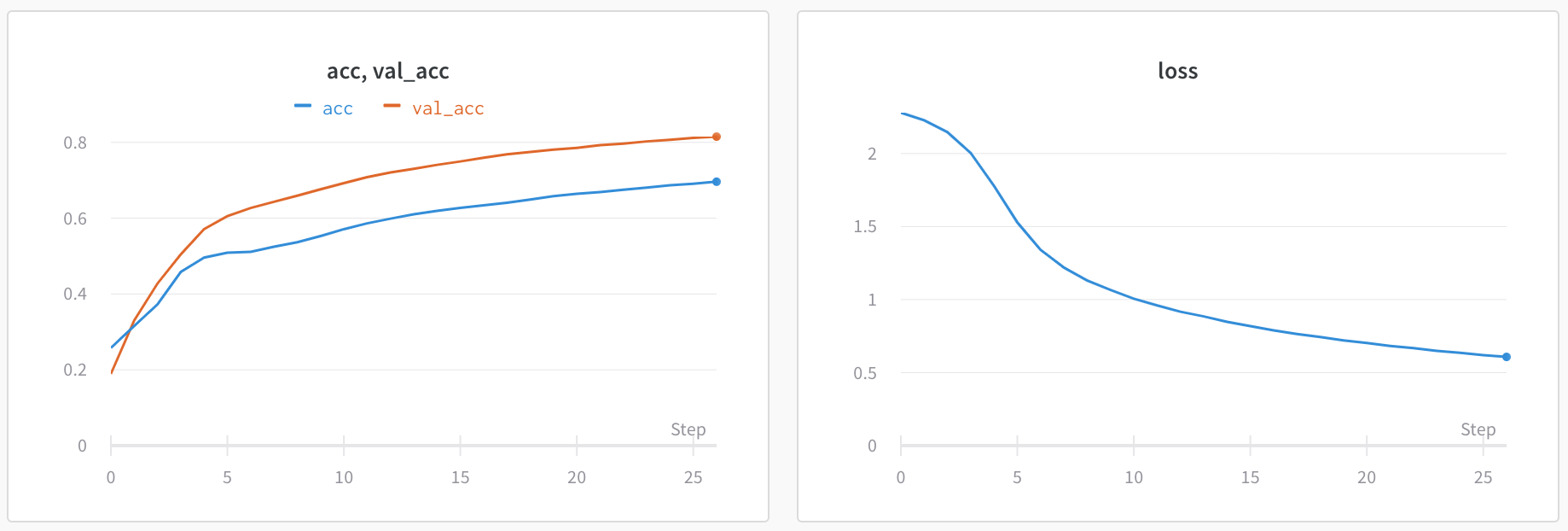
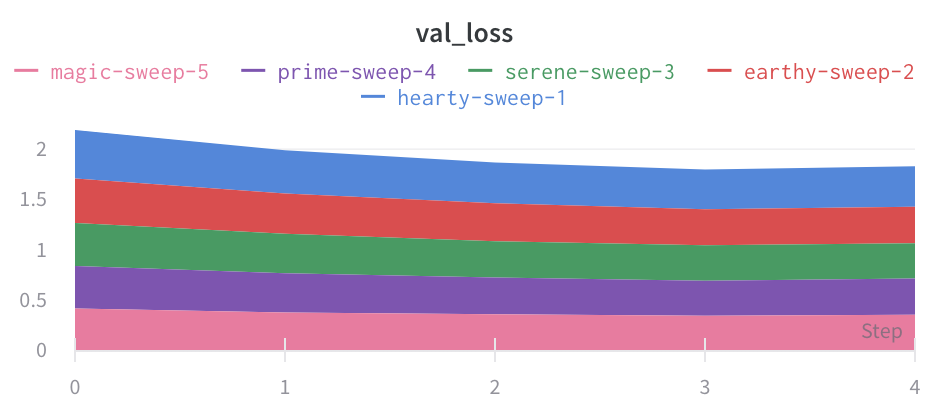
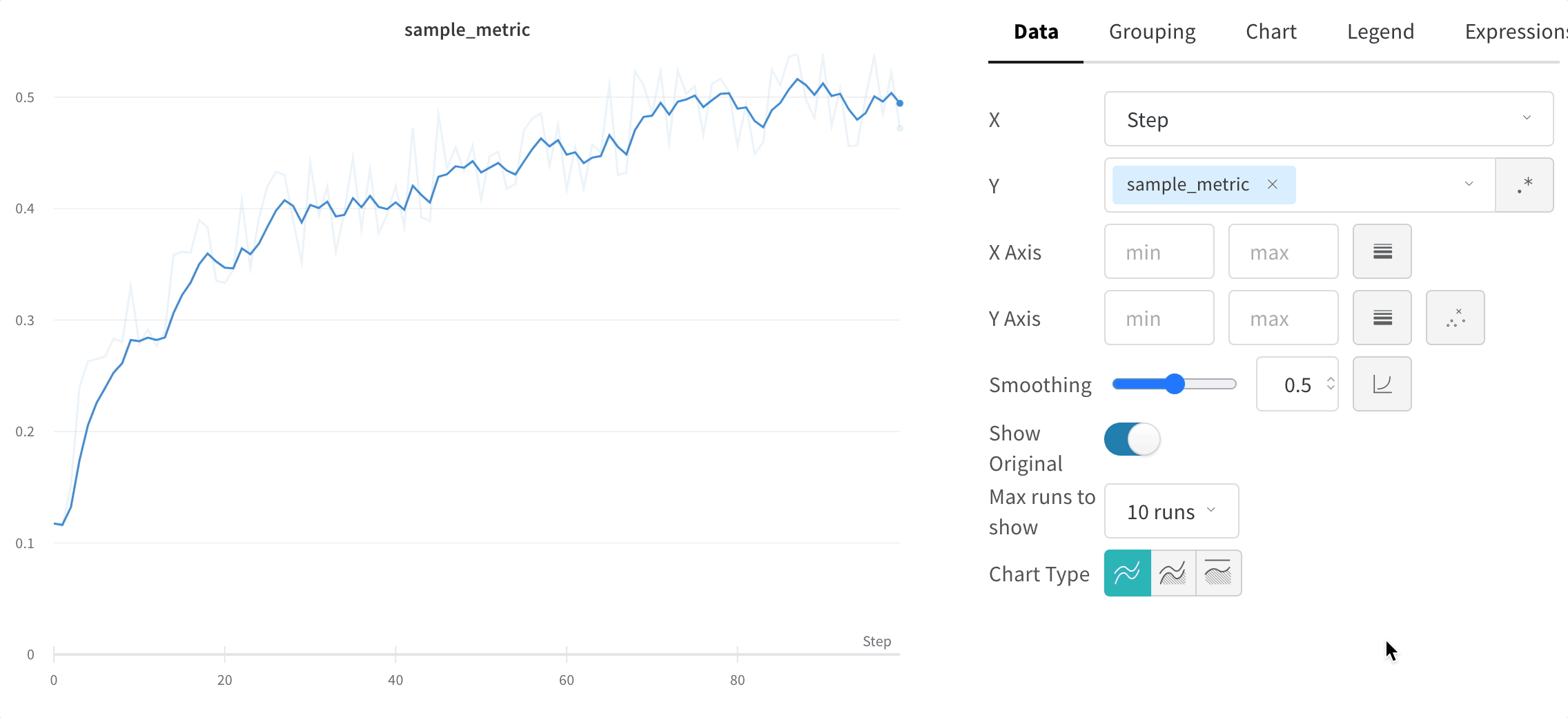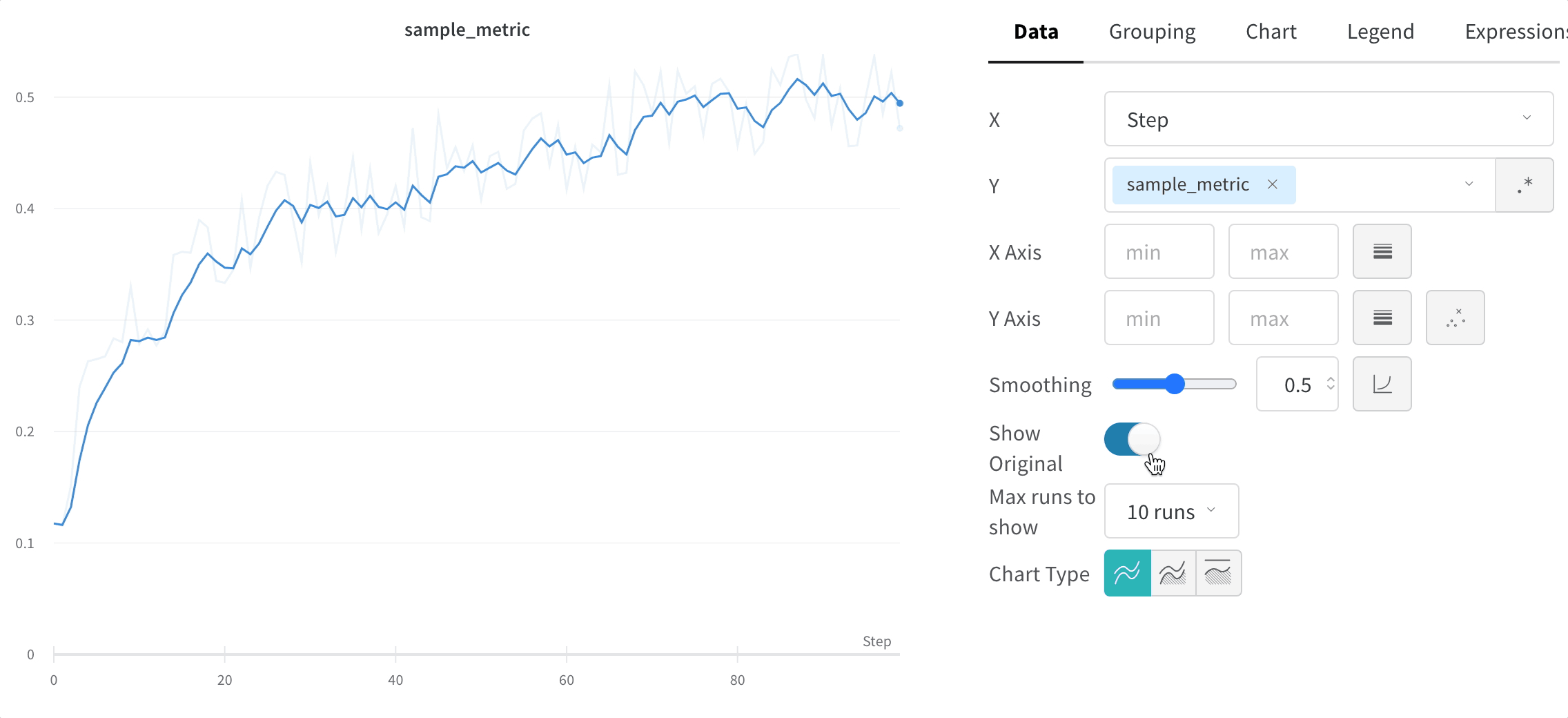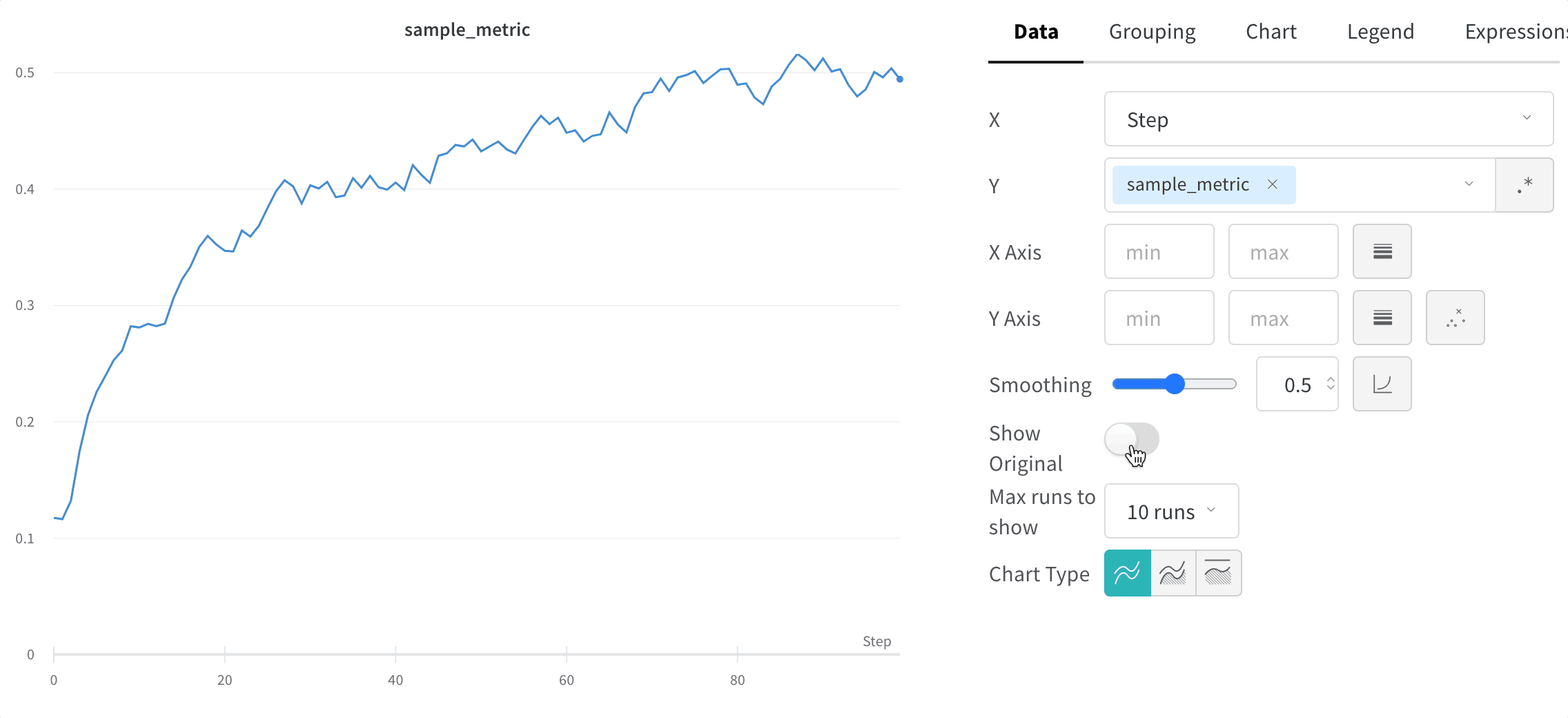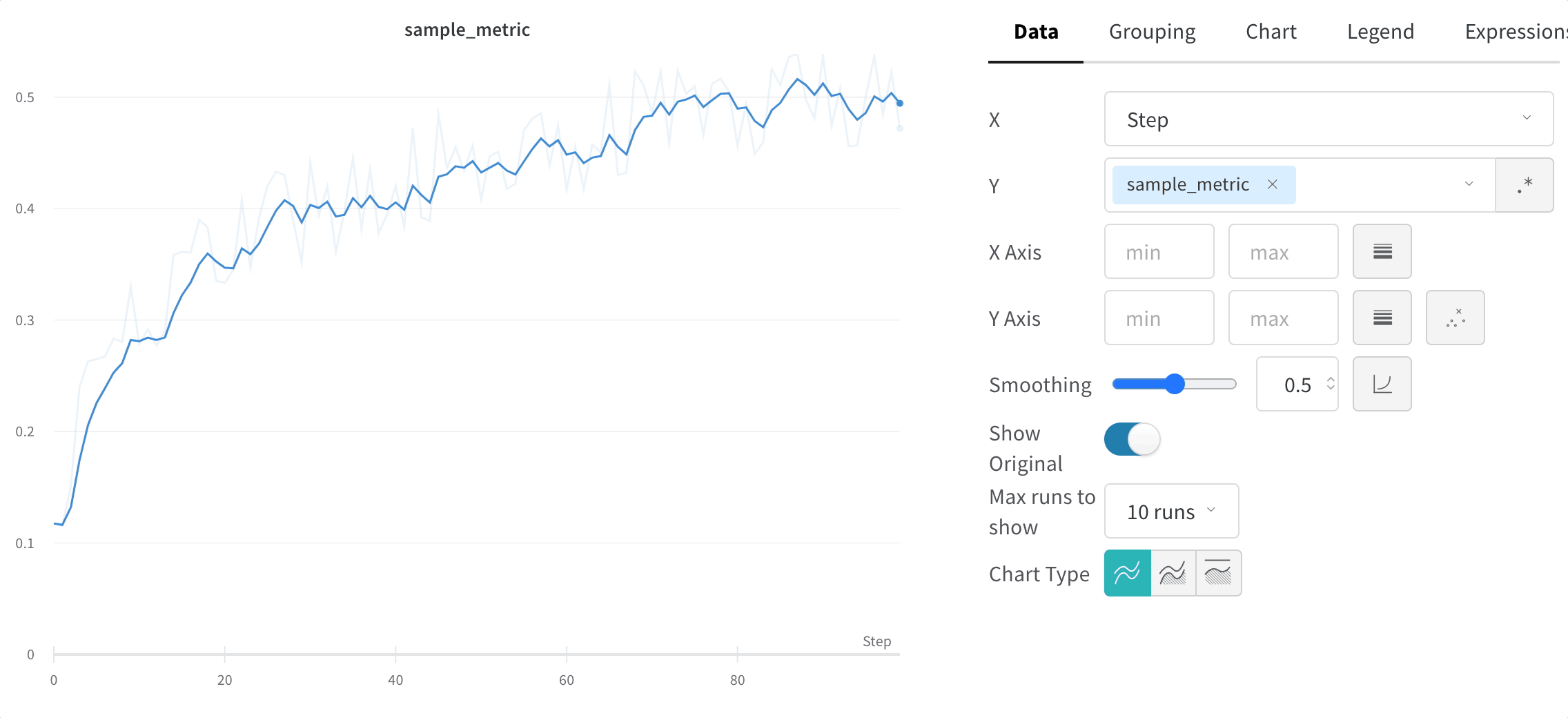
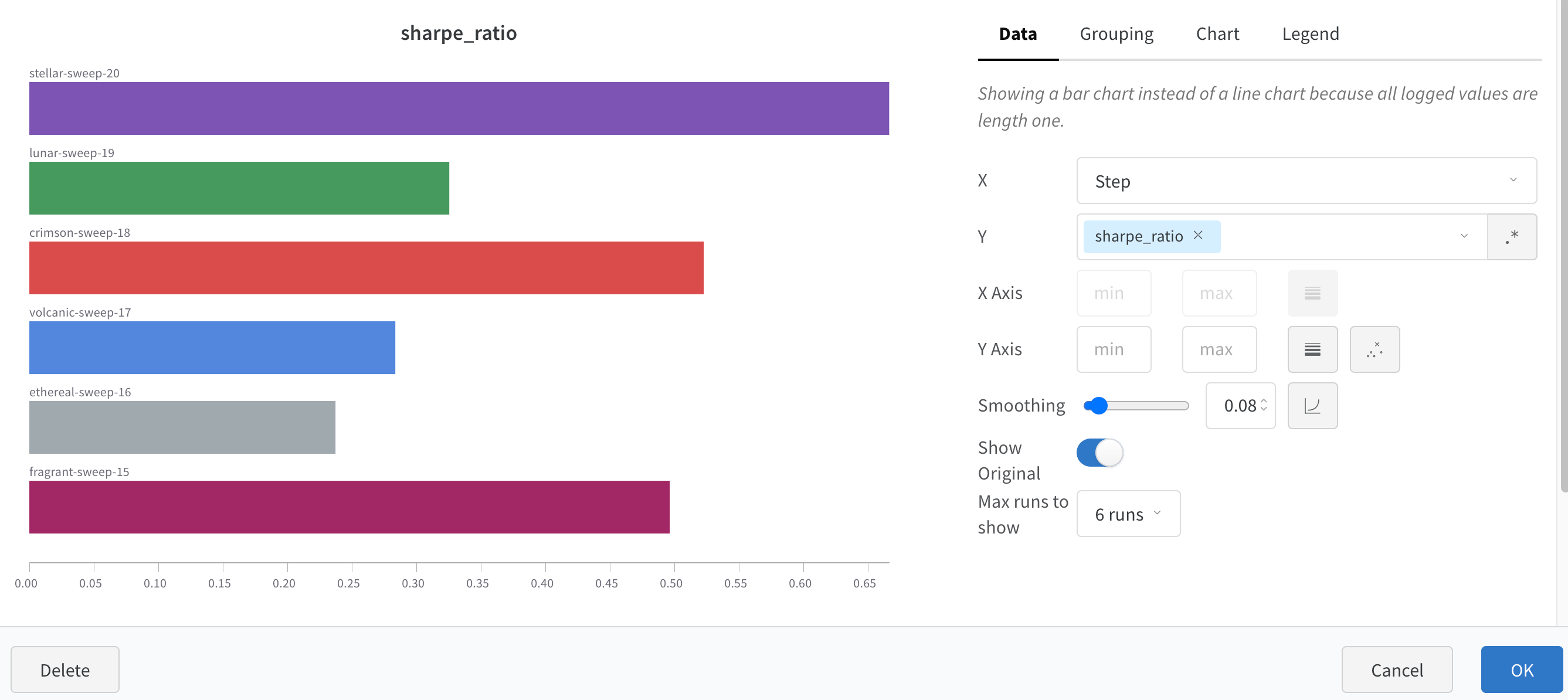
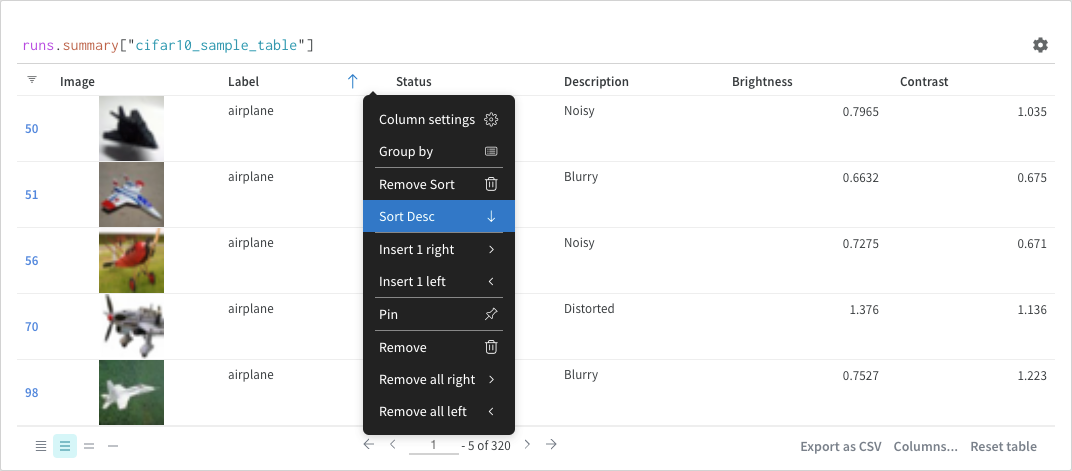
X: X축에 사용할 값을 선택합니다 (기본값은 Step). x축을 Relative Time으로 변경하거나 W&B로 기록하는 값을 기반으로 사용자 정의 축을 선택할 수 있습니다.
Relative Time (Wall) 은 프로세스가 시작된 이후의 시계 시간이므로 run을 시작하고 하루 후에 다시 시작하여 기록한 경우 24시간으로 플롯됩니다.
Relative Time (Process) 는 실행 중인 프로세스 내부의 시간이므로 run을 시작하고 10초 동안 실행한 다음 하루 후에 다시 시작하면 해당 지점이 10초로 플롯됩니다.
Wall Time은 그래프에서 첫 번째 run이 시작된 이후 경과된 시간 (분) 입니다.
Step은 기본적으로 wandb.log()가 호출될 때마다 증가하며 모델에서 기록한 트레이닝 스텝 수를 반영해야 합니다.
Y: 시간에 따라 변하는 메트릭 및 하이퍼파라미터를 포함하여 기록된 값에서 하나 이상의 y축을 선택합니다.
X축 및 Y축 최소 및 최대값 (선택 사항).
포인트 집계 방식. Random sampling (기본값) 또는 Full fidelity. Sampling을 참조하십시오.
Smoothing: 라인 플롯의 Smoothing을 변경합니다. 기본값은 Time weighted EMA입니다. 다른 값으로는 No smoothing, Running average 및 Gaussian이 있습니다.
Outliers: 기본 플롯 최소 및 최대 스케일에서 이상값을 제외하도록 스케일을 재조정합니다.
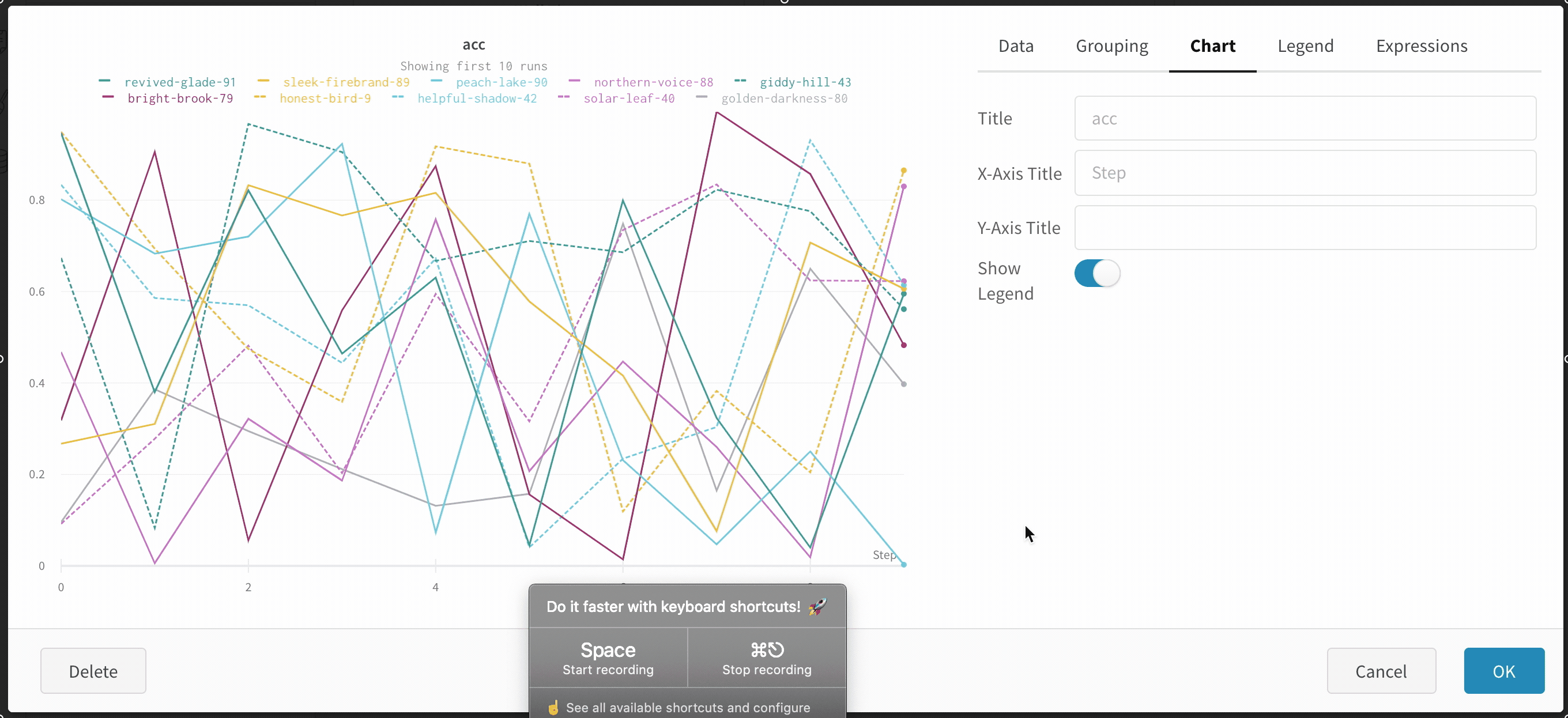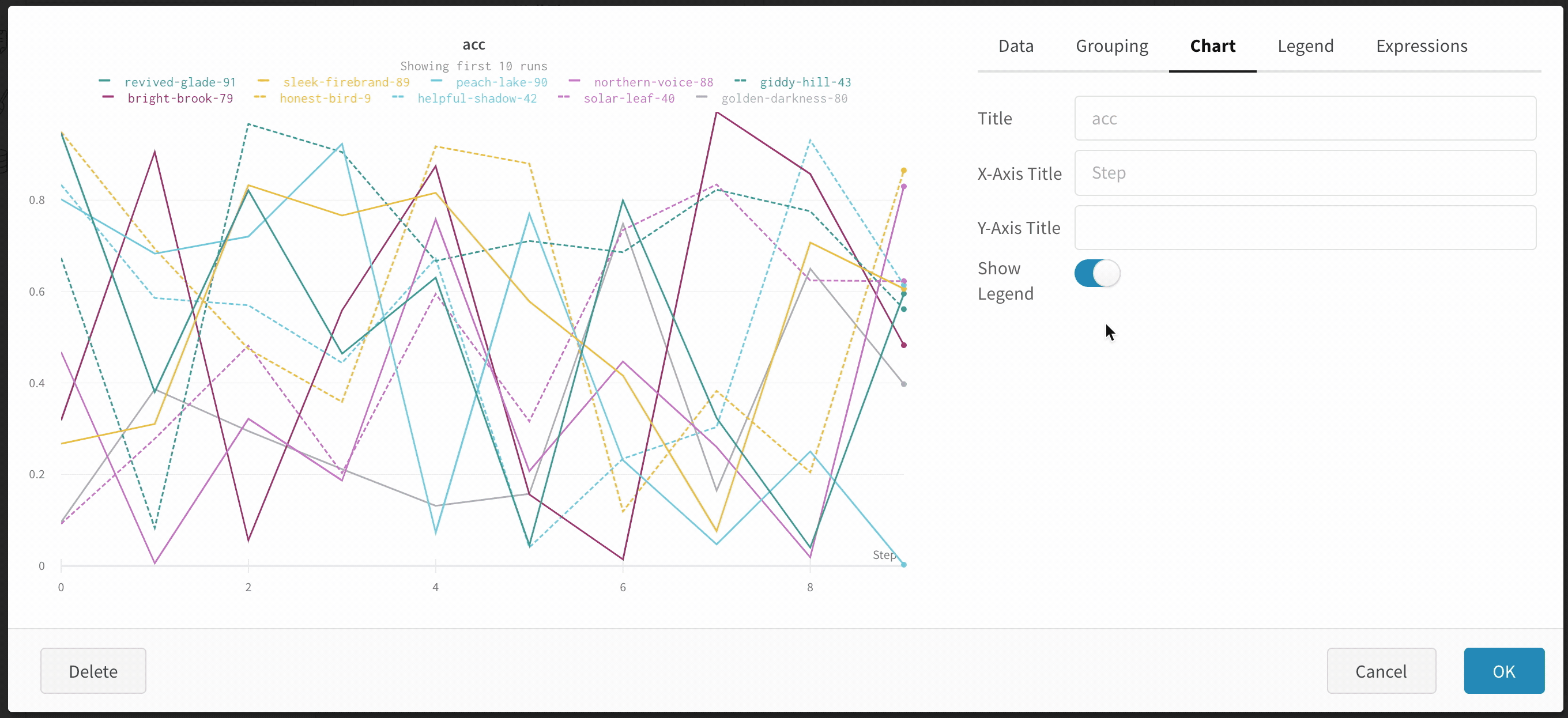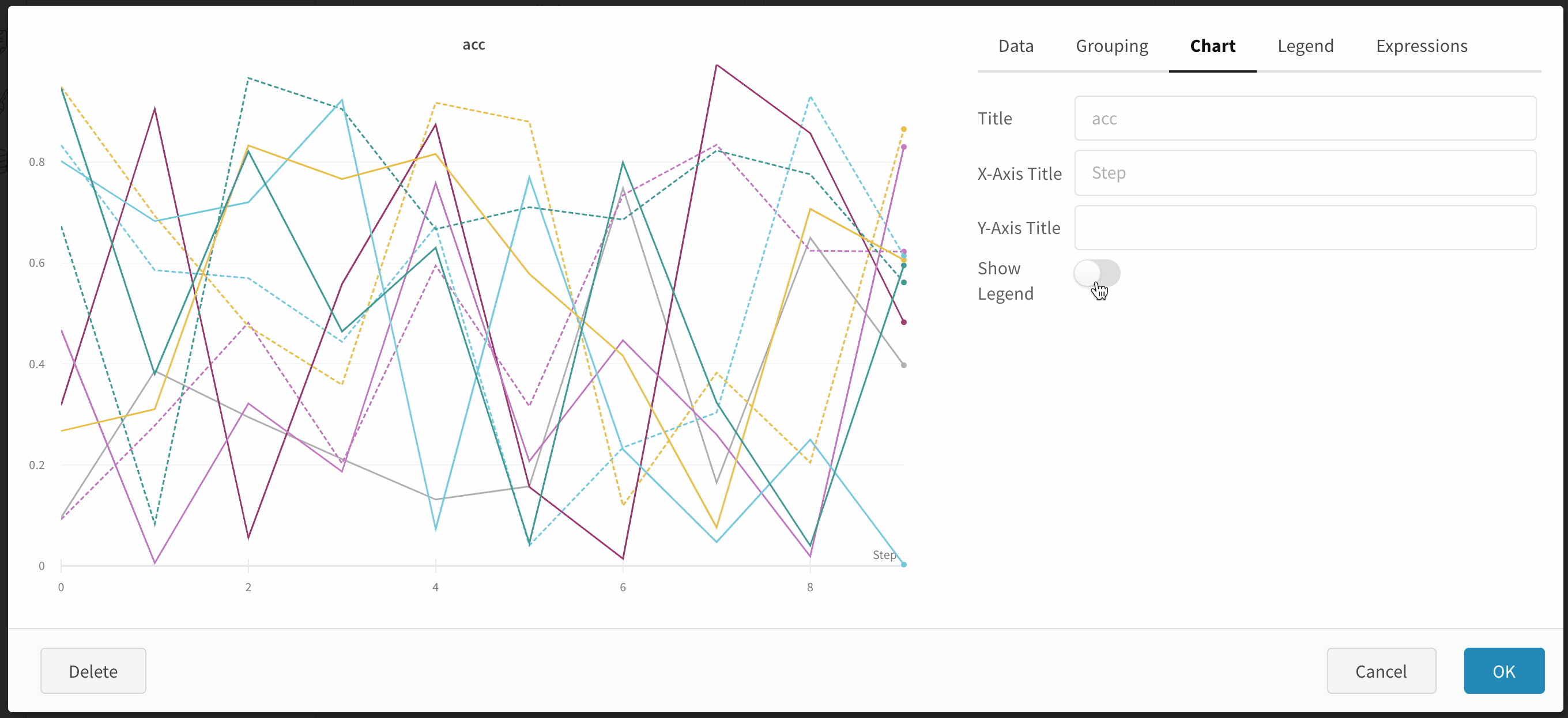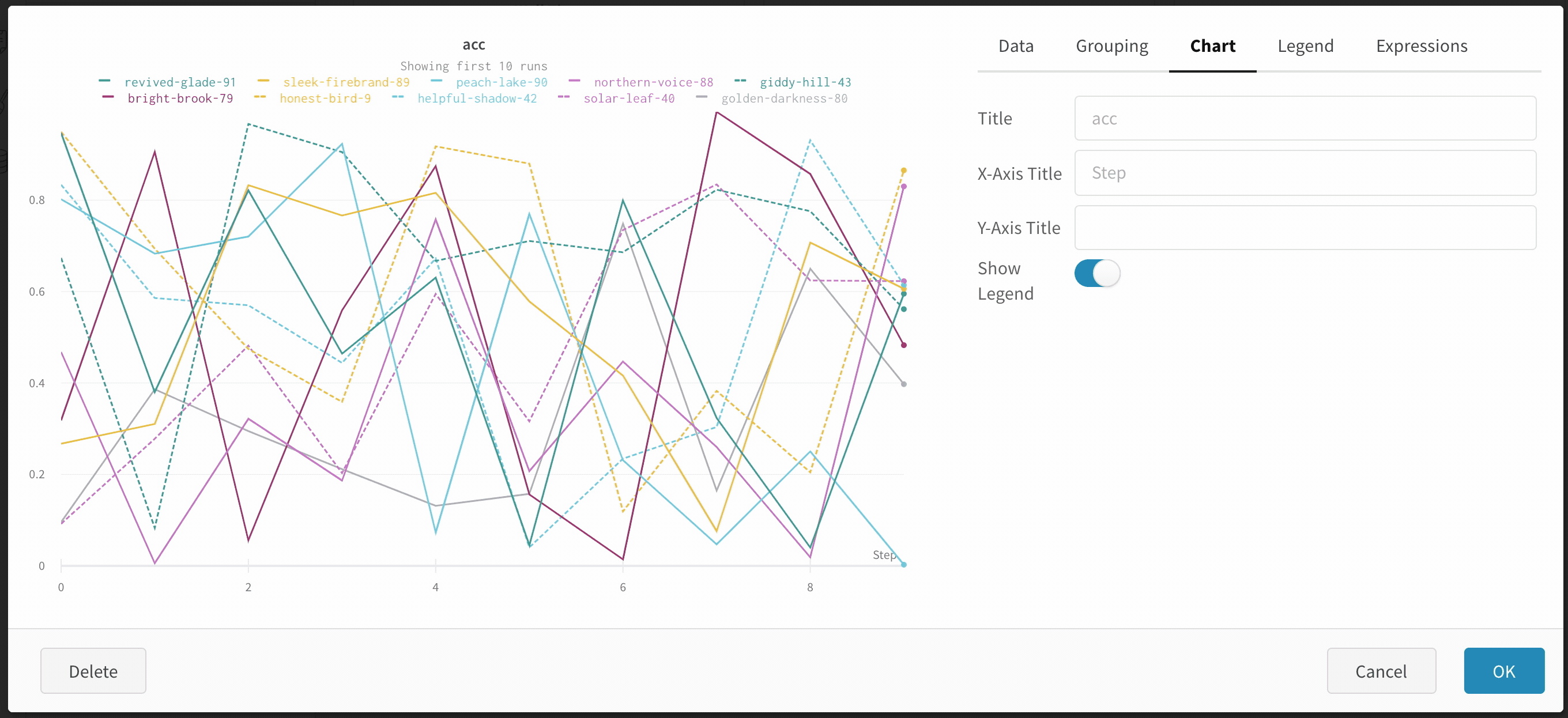
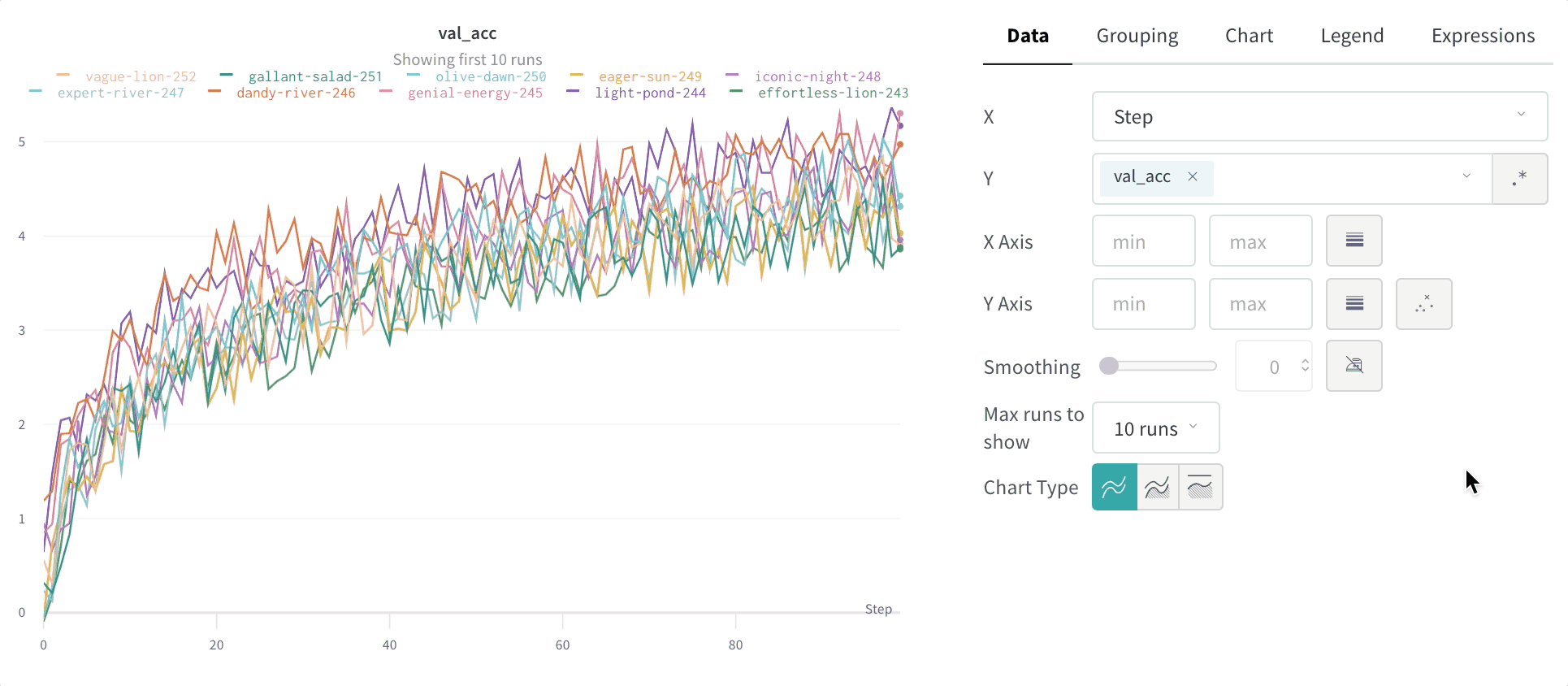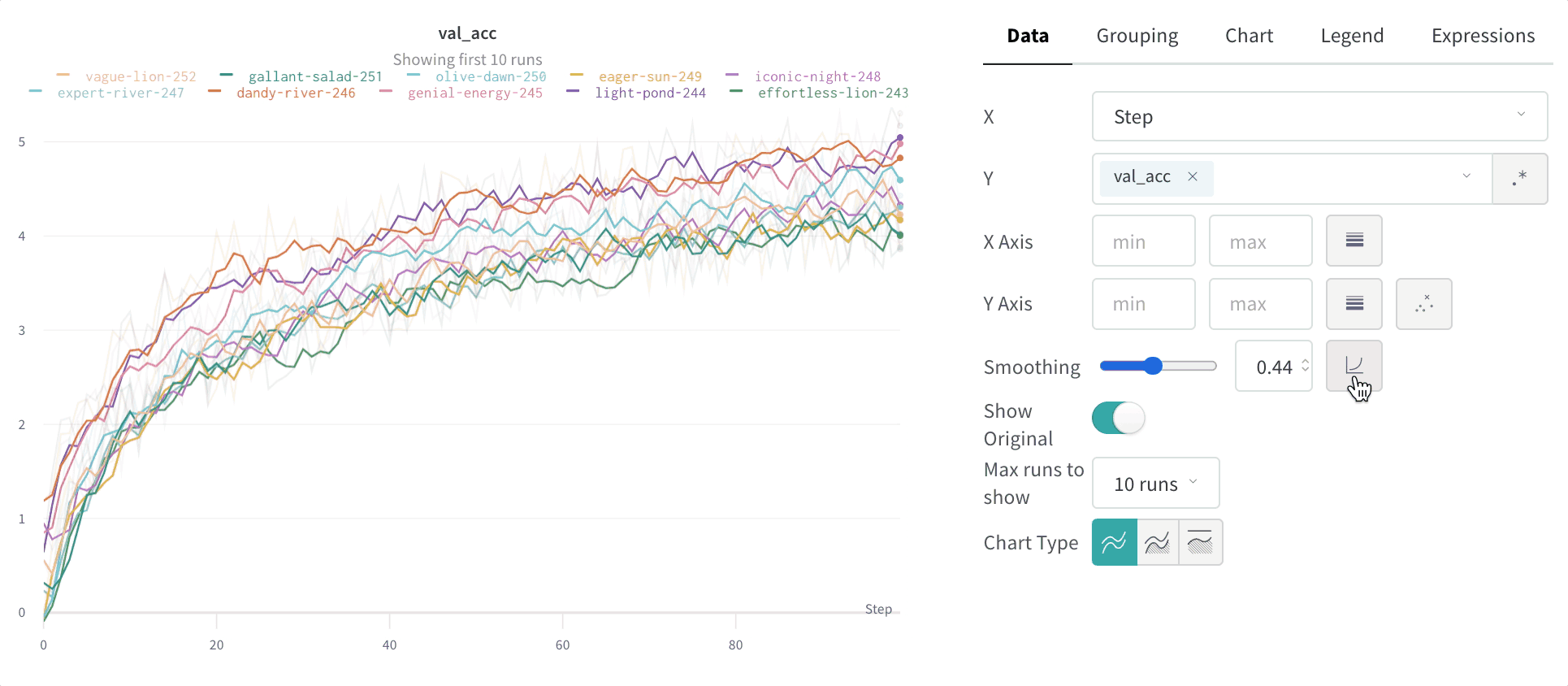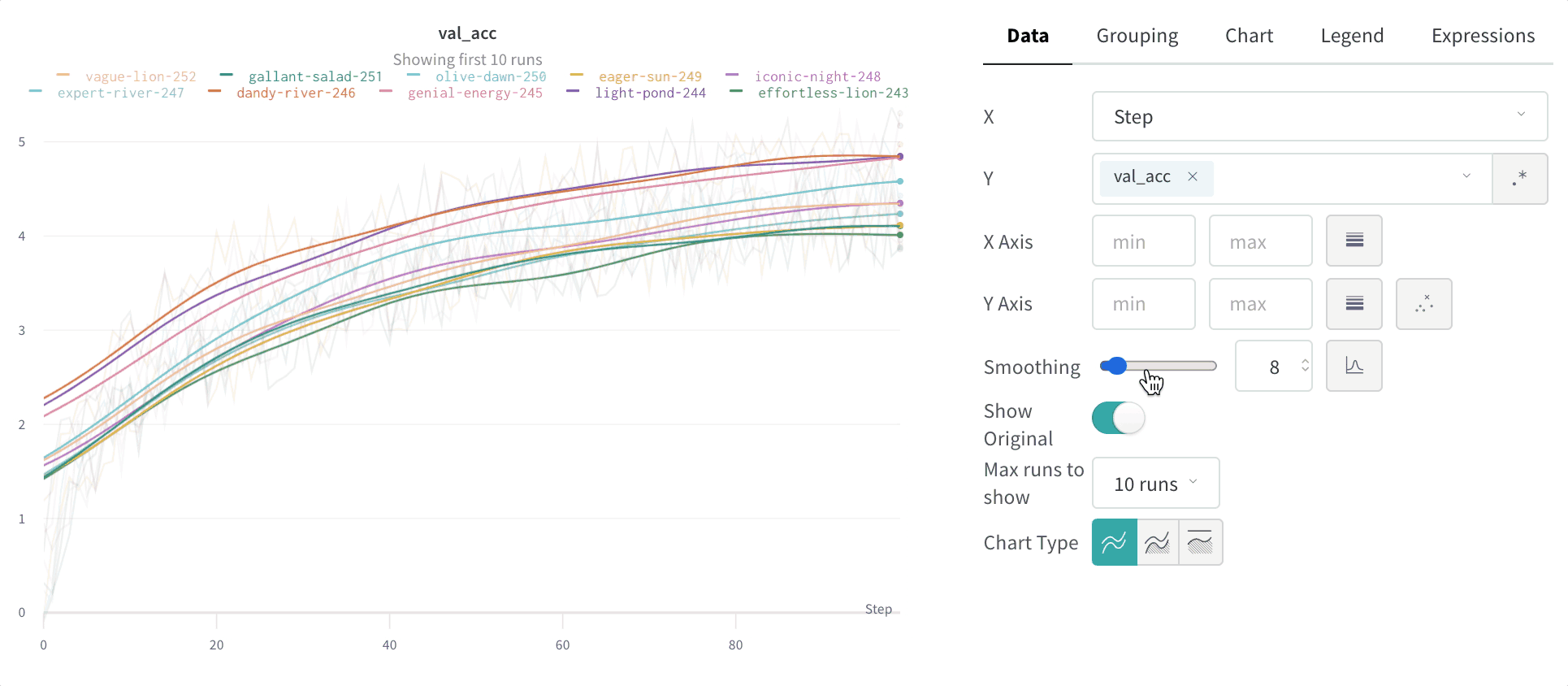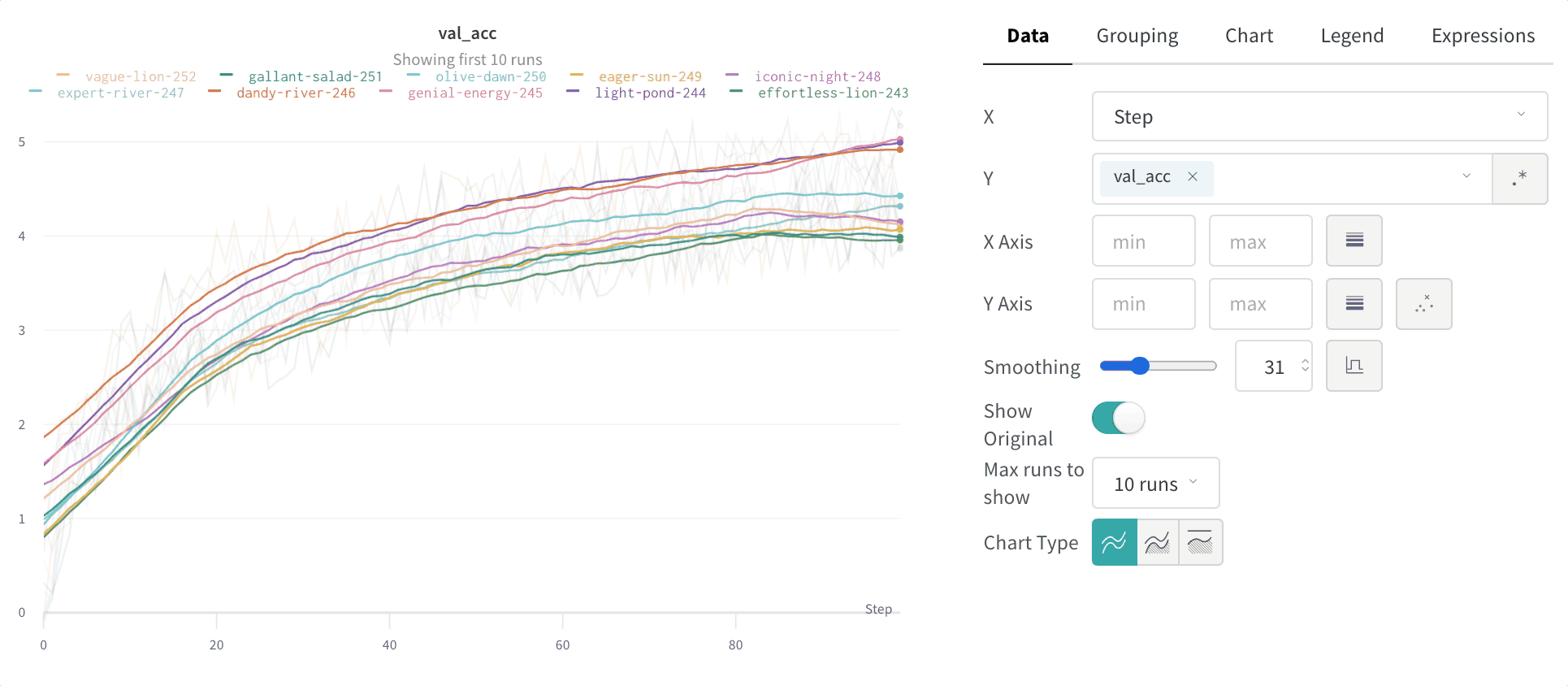
최대 run 또는 그룹 수: 이 숫자를 늘려 라인 플롯에 더 많은 라인을 한 번에 표시합니다. 기본값은 10개의 run입니다. 사용 가능한 run이 10개 이상이지만 차트가 보이는 수를 제한하는 경우 차트 상단에 “Showing first 10 runs"라는 메시지가 표시됩니다.
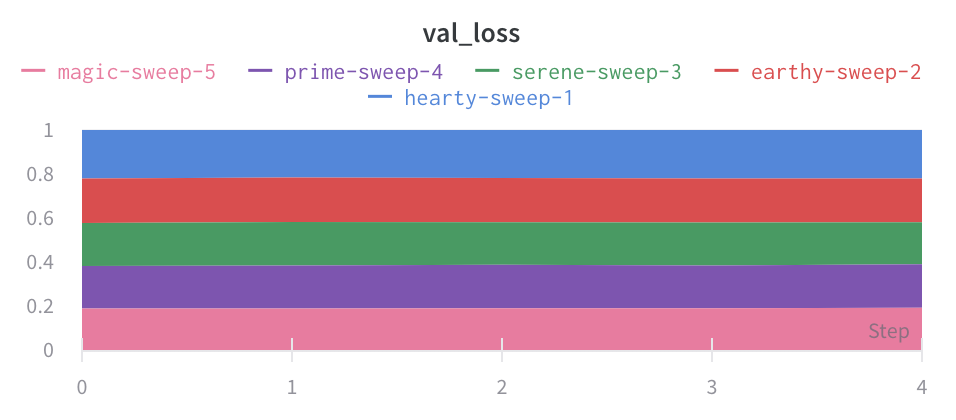
차트 유형: 라인 플롯, 영역 플롯 및 백분율 영역 플롯 간에 변경합니다.
Grouping: 플롯에서 run을 그룹화하고 집계할지 여부와 방법을 구성합니다.
Group by: 열을 선택하면 해당 열에서 동일한 값을 가진 모든 run이 함께 그룹화됩니다.
Agg: 집계— 그래프의 라인 값. 옵션은 그룹의 평균, 중앙값, 최소값 및 최대값입니다.
차트: 패널, X축 및 Y축의 제목과 -축을 지정하고 범례를 숨기거나 표시하고 위치를 구성합니다.
범례: 패널의 범례 모양을 사용자 정의합니다 (활성화된 경우).
범례: 플롯의 각 라인에 대한 범례의 필드입니다.
범례 템플릿: 범례에 대한 완전히 사용자 정의 가능한 템플릿을 정의하여 라인 플롯 상단에 표시할 텍스트와 변수 및 마우스를 플롯 위로 이동할 때 나타나는 범례를 정확하게 지정합니다.
Expressions: 사용자 정의 계산된 표현식을 패널에 추가합니다.
Y축 표현식: 계산된 메트릭을 그래프에 추가합니다. 기록된 메트릭과 하이퍼파라미터와 같은 구성 값을 사용하여 사용자 정의 라인을 계산할 수 있습니다.
X축 표현식: 사용자 정의 표현식을 사용하여 계산된 값을 사용하도록 x축의 스케일을 재조정합니다. 유용한 변수에는 기본 x축에 대한**_step**이 포함되며 요약 값을 참조하는 구문은 ${summary:value}입니다.
섹션의 모든 라인 플롯
섹션의 모든 라인 플롯에 대한 기본 설정을 사용자 정의하려면 라인 플롯에 대한 워크스페이스 설정을 재정의합니다.
섹션의 기어 아이콘을 클릭하여 설정을 엽니다.
나타나는 모달 내에서 데이터 또는 표시 기본 설정 탭을 선택하여 섹션의 기본 설정을 구성합니다. 각 데이터 설정에 대한 자세한 내용은 이전 섹션인 개별 라인 플롯을 참조하십시오. 각 표시 기본 설정에 대한 자세한 내용은 섹션 레이아웃 구성을 참조하십시오.
워크스페이스의 모든 라인 플롯
워크스페이스의 모든 라인 플롯에 대한 기본 설정을 사용자 정의하려면:
워크스페이스의 설정을 클릭합니다. 여기에는 설정 레이블이 있는 기어가 있습니다.
라인 플롯을 클릭합니다.
나타나는 모달 내에서 데이터 또는 표시 기본 설정 탭을 선택하여 워크스페이스의 기본 설정을 구성합니다.
각 표시 기본 설정 섹션에 대한 자세한 내용은 워크스페이스 표시 기본 설정을 참조하십시오. 워크스페이스 수준에서 라인 플롯에 대한 기본 확대/축소 동작을 구성할 수 있습니다. 이 설정은 일치하는 x축 키가 있는 라인 플롯에서 확대/축소를 동기화할지 여부를 제어합니다. 기본적으로 비활성화되어 있습니다.
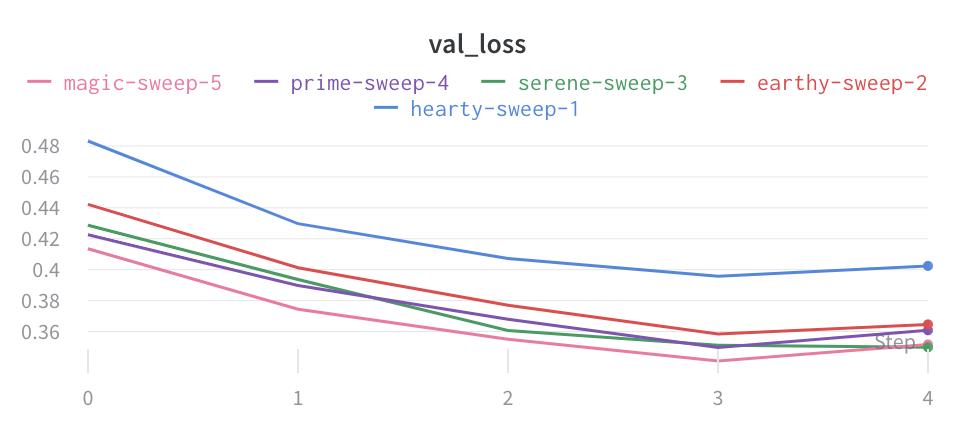
플롯에서 평균값 시각화
여러 개의 다른 Experiments가 있고 플롯에서 해당 값의 평균을 보려면 테이블에서 그룹화 기능을 사용할 수 있습니다. run 테이블 위에서 “그룹"을 클릭하고 “모두"를 선택하여 그래프에 평균값을 표시합니다.
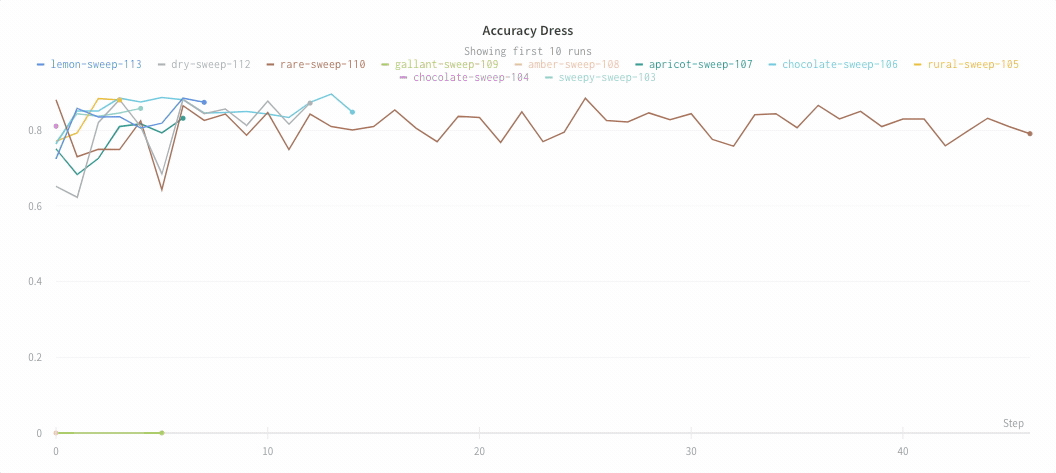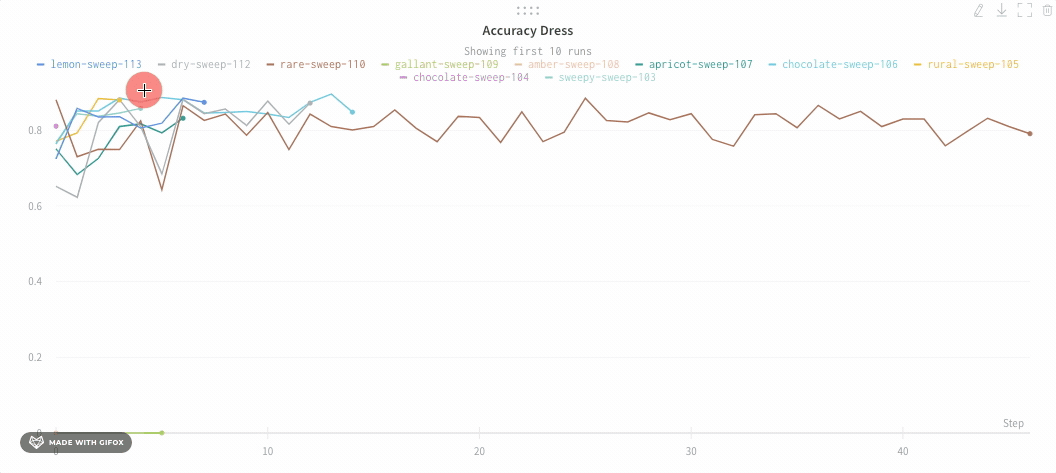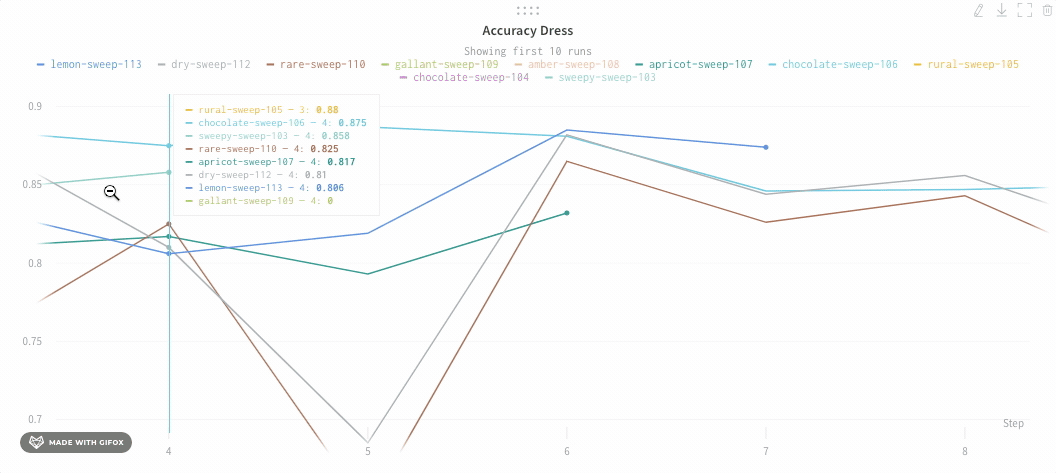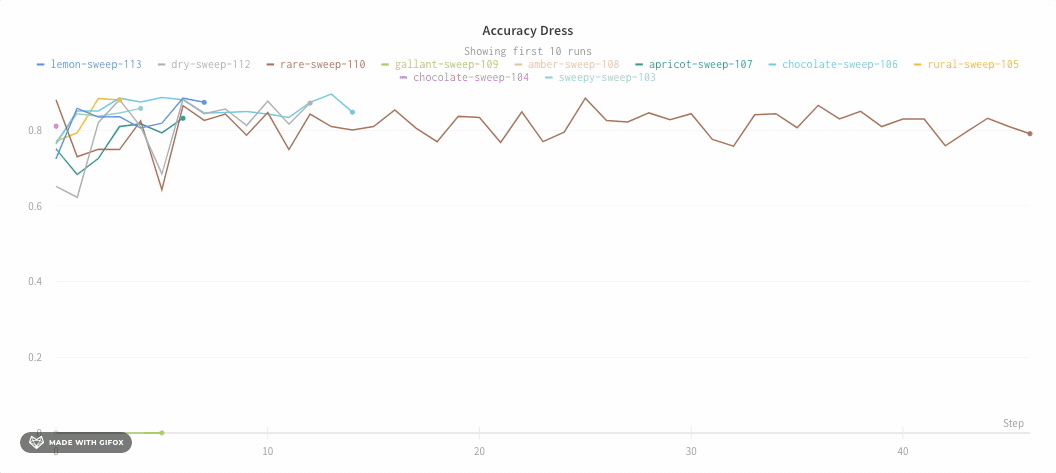
평균화하기 전의 그래프 모양은 다음과 같습니다.
다음 이미지는 그룹화된 라인을 사용하여 run에서 평균값을 나타내는 그래프를 보여줍니다.
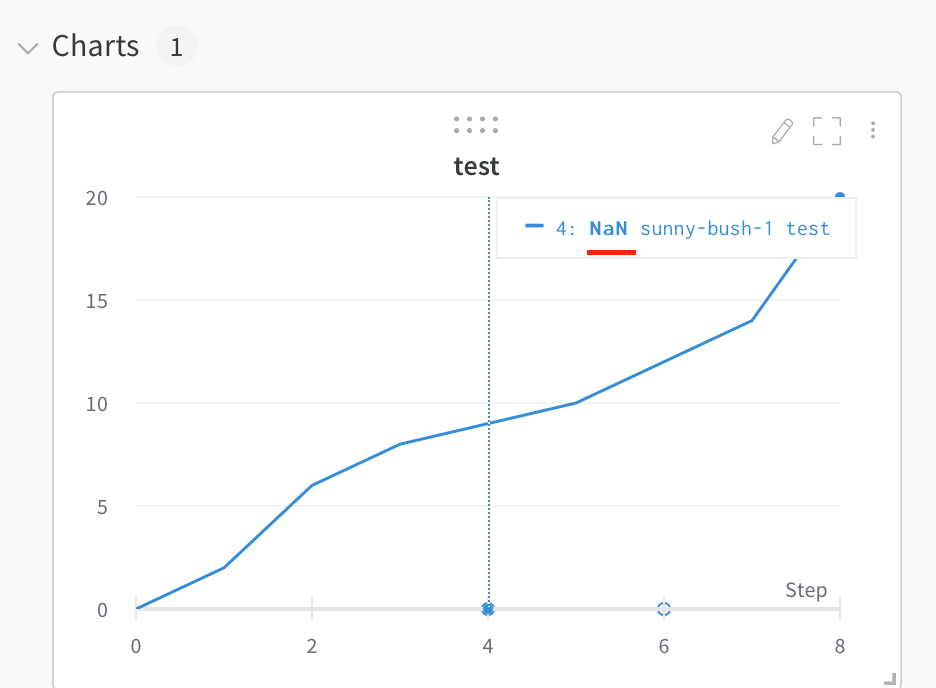
플롯에서 NaN 값 시각화
wandb.log를 사용하여 라인 플롯에 PyTorch 텐서를 포함한 NaN 값을 플롯할 수도 있습니다. 예:
wandb.log({"test": [..., float("nan"), ...]})
하나의 차트에서 두 개의 메트릭 비교
페이지 오른쪽 상단에서 패널 추가 버튼을 선택합니다.
나타나는 왼쪽 패널에서 평가 드롭다운을 확장합니다.
Run comparer를 선택합니다.
라인 플롯의 색상 변경
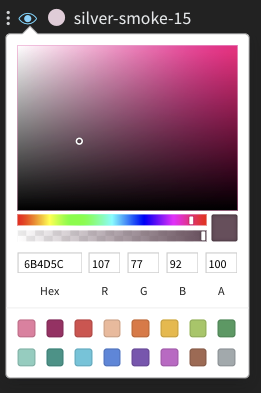
경우에 따라 run의 기본 색상이 비교에 도움이 되지 않을 수 있습니다. 이를 극복하기 위해 wandb는 색상을 수동으로 변경할 수 있는 두 가지 인스턴스를 제공합니다.
각 run은 초기화 시 기본적으로 임의의 색상이 지정됩니다.
색상 중 하나를 클릭하면 색상 팔레트가 나타나고 여기에서 원하는 색상을 수동으로 선택할 수 있습니다.
설정을 편집할 패널 위로 마우스를 가져갑니다.
나타나는 연필 아이콘을 선택합니다.
범례 탭을 선택합니다.
다른 x축에서 시각화
experiment가 소요된 절대 시간을 보거나 experiment가 실행된 날짜를 보려면 x축을 전환할 수 있습니다. 다음은 단계를 상대 시간으로 전환한 다음 벽 시간으로 전환하는 예입니다.
영역 플롯
라인 플롯 설정의 고급 탭에서 다른 플롯 스타일을 클릭하여 영역 플롯 또는 백분율 영역 플롯을 얻습니다.
확대/축소
사각형을 클릭하고 드래그하여 수직 및 수평으로 동시에 확대/축소합니다. 그러면 x축 및 y축 확대/축소가 변경됩니다.
차트 범례 숨기기
이 간단한 토글로 라인 플롯에서 범례를 끕니다.
1.1 - Line plot reference
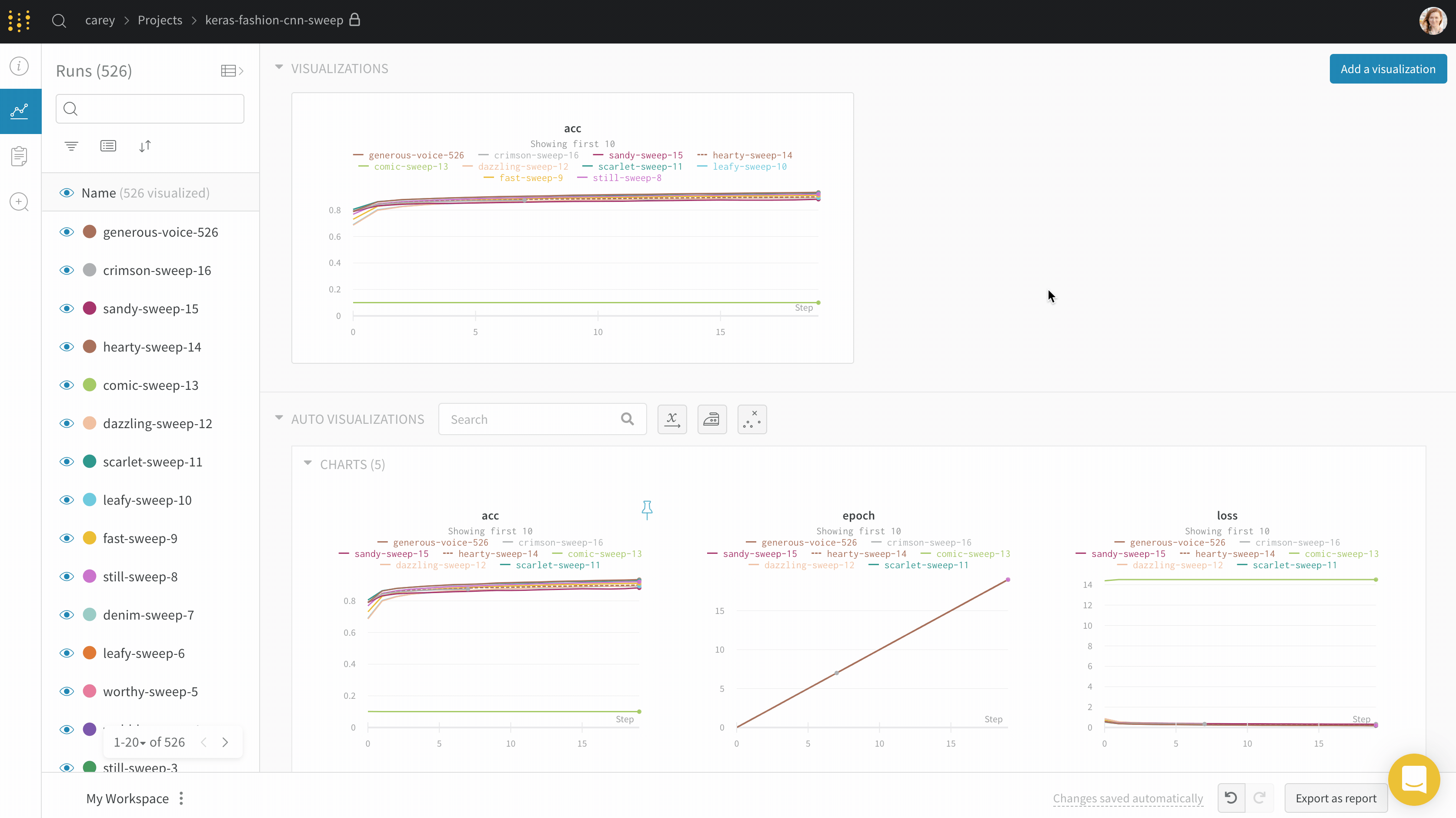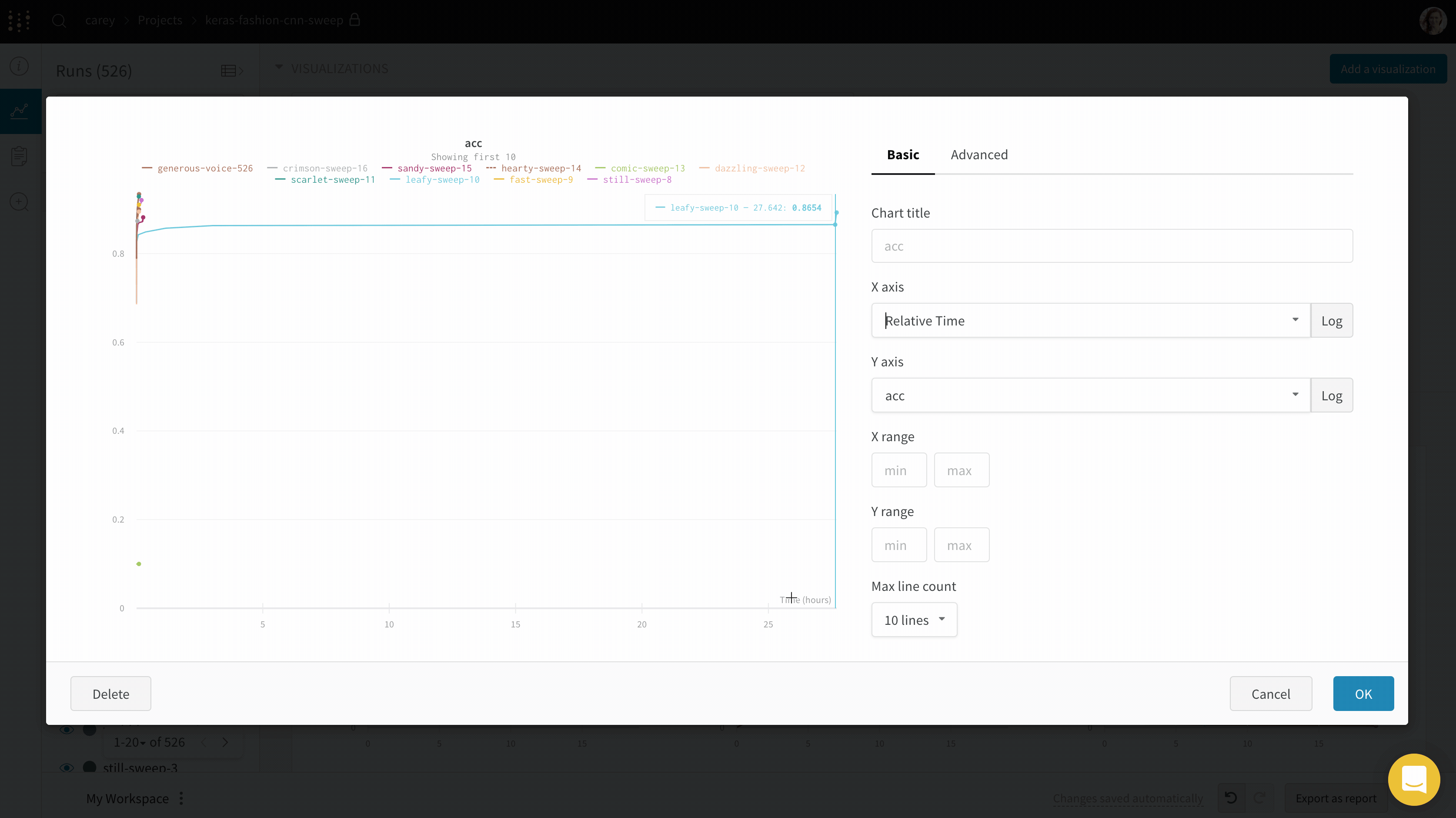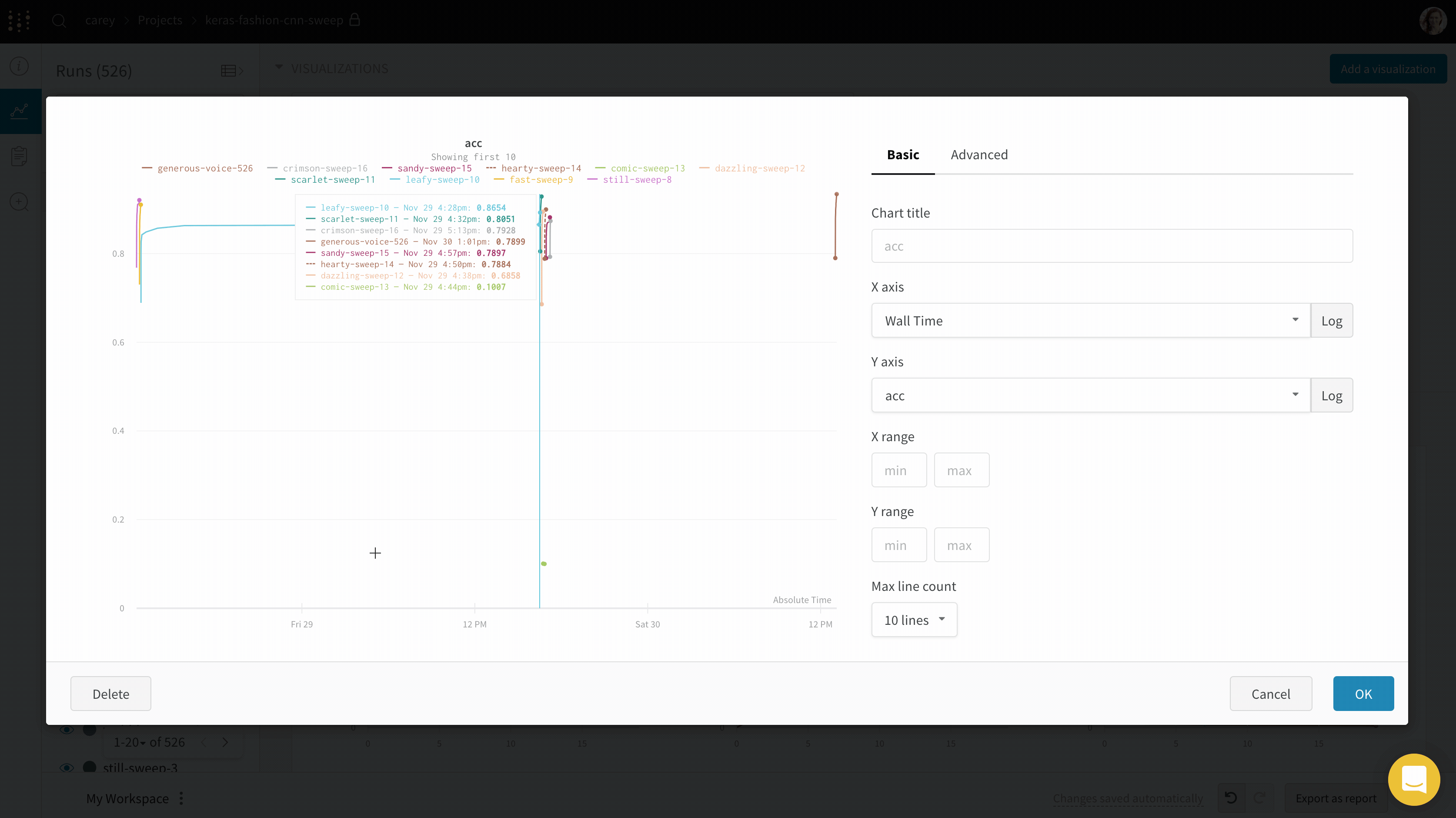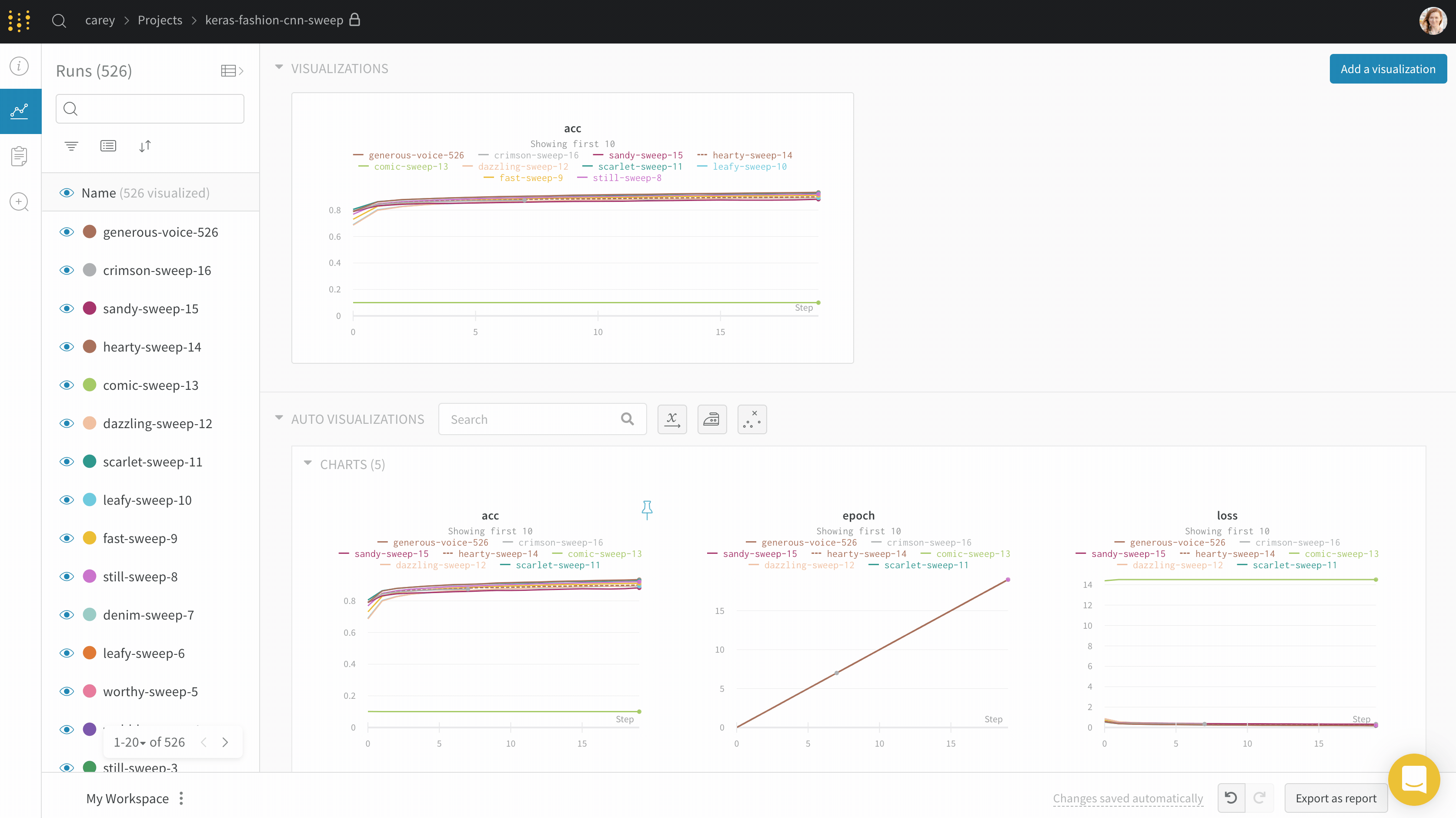
X축
W&B.log 로 기록한 값이 항상 숫자로 기록되는 한, 선 그래프의 X축을 원하는 값으로 설정할 수 있습니다.
Y축 변수
wandb.log 로 기록한 값이 숫자, 숫자 배열 또는 숫자 히스토그램인 경우 Y축 변수를 원하는 값으로 설정할 수 있습니다. 변수에 대해 1500개 이상의 포인트를 기록한 경우 W&B 는 1500개 포인트로 샘플링합니다.
Runs 테이블에서 run 의 색상을 변경하여 Y축 선의 색상을 변경할 수 있습니다.
X 범위 및 Y 범위
플롯의 X 및 Y의 최대값과 최소값을 변경할 수 있습니다.
X 범위의 기본값은 X축의 최소값에서 최대값까지입니다.
Y 범위의 기본값은 메트릭의 최소값과 0부터 메트릭의 최대값까지입니다.
최대 Runs/그룹
기본적으로 10개의 run 또는 run 그룹만 플롯됩니다. Runs은 run 테이블 또는 run 세트의 맨 위에서 가져오므로 run 테이블 또는 run 세트를 정렬하면 표시되는 run 을 변경할 수 있습니다.
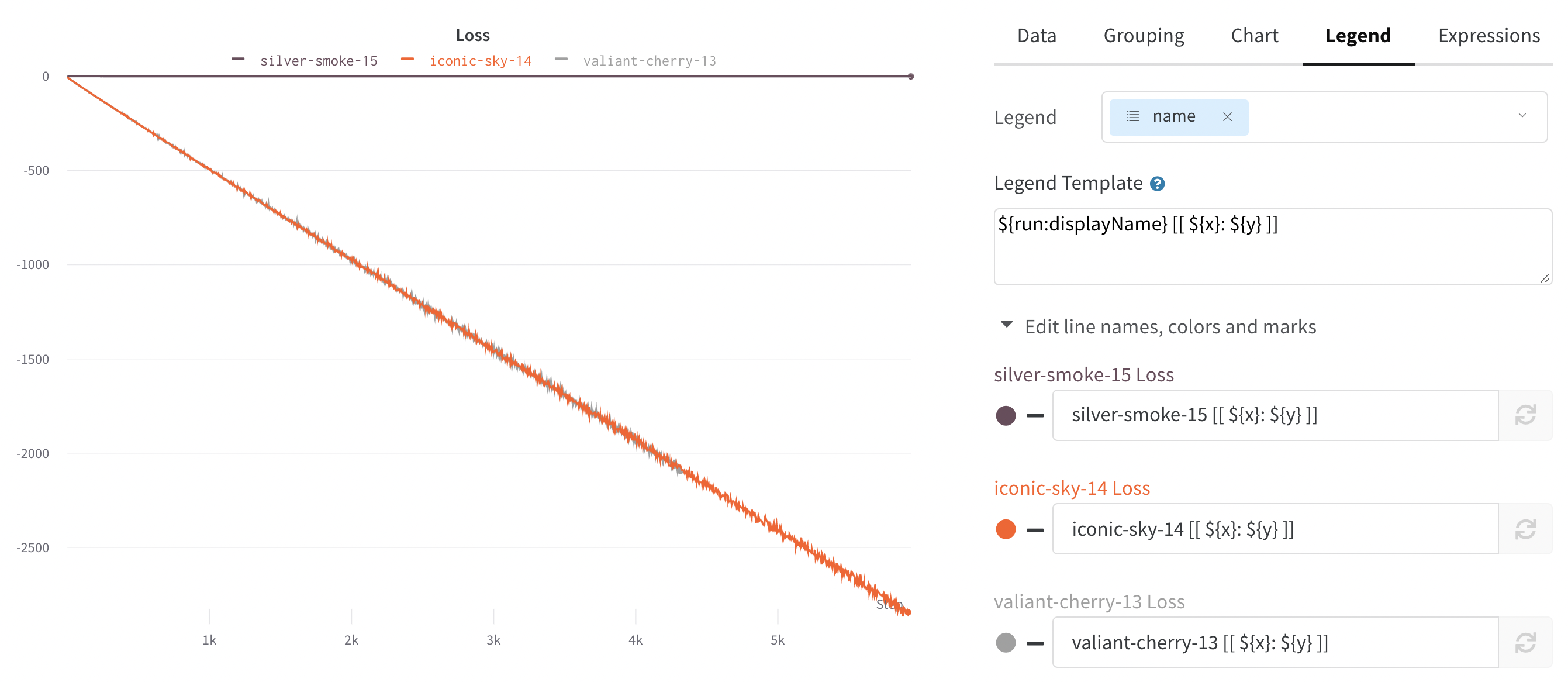
범례
차트의 범례를 제어하여 생성 시간 또는 run 을 생성한 user 와 같은 run 의 모든 config 값과 메타 데이터를 표시할 수 있습니다.
예시:
${run:displayName} - ${config:dropout} 은 각 run 에 대한 범례 이름을 royal-sweep - 0.5 와 같이 만듭니다. 여기서 royal-sweep 은 run 이름이고 0.5 는 dropout 이라는 config 파라미터입니다.
[[ ]] 안에 값을 설정하여 차트 위로 마우스를 가져갈 때 십자선에 특정 포인트 값을 표시할 수 있습니다. 예를 들어 \[\[ $x: $y ($original) ]] 은 “2: 3 (2.9)” 와 같이 표시됩니다.
[[ ]] 내에서 지원되는 값은 다음과 같습니다.
값
의미
${x}
X 값
${y}
Y 값 (스무딩 조정 포함)
${original}
Y 값 (스무딩 조정 미포함)
${mean}
그룹화된 run 의 평균
${stddev}
그룹화된 run 의 표준 편차
${min}
그룹화된 run 의 최소값
${max}
그룹화된 run 의 최대값
${percent}
합계의 백분율 (누적 영역 차트의 경우)
그룹화
그룹화를 켜서 모든 run 을 집계하거나 개별 변수별로 그룹화할 수 있습니다. 테이블 내에서 그룹화하여 그룹화를 켤 수도 있으며 그룹이 그래프에 자동으로 채워집니다.
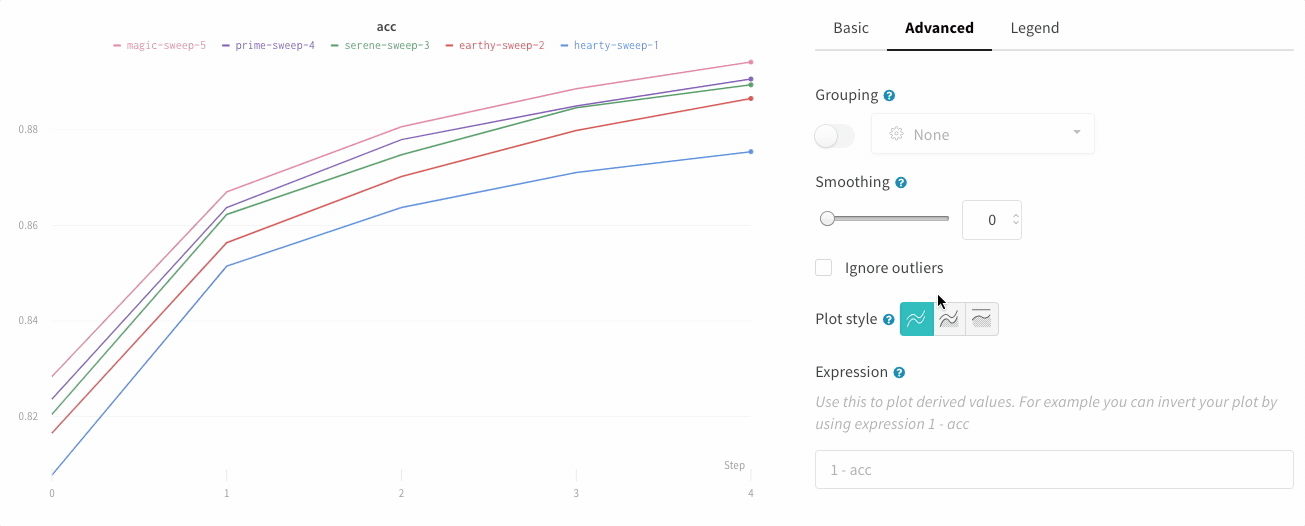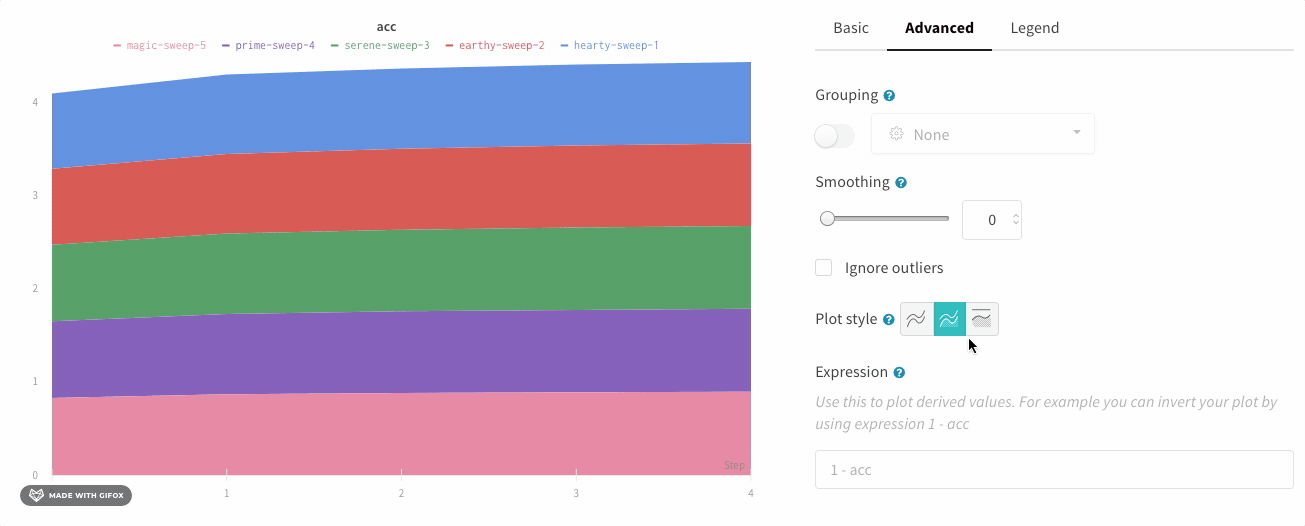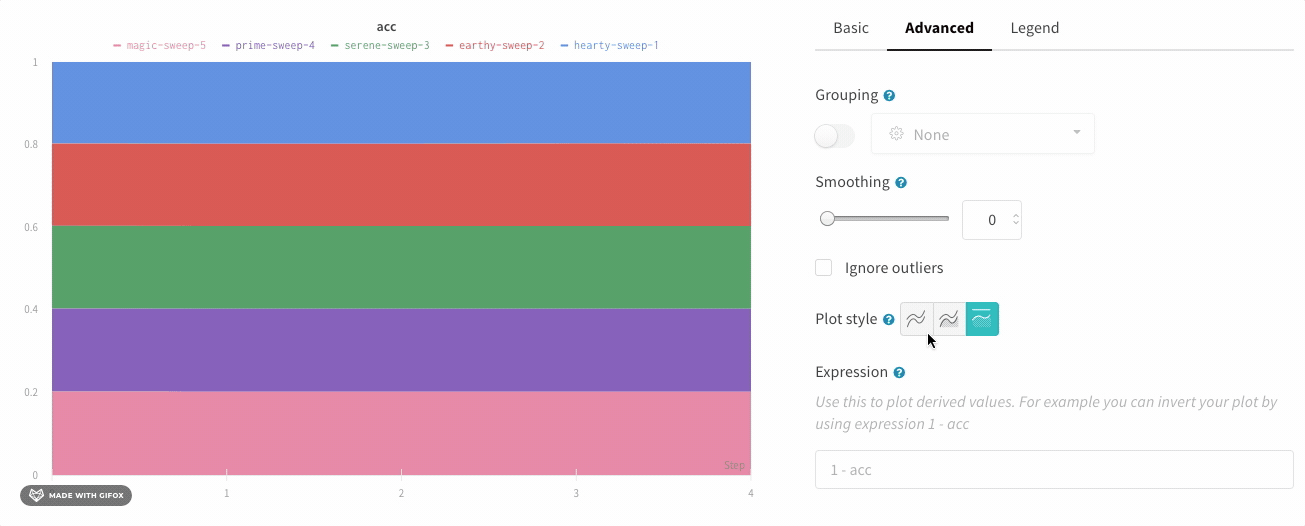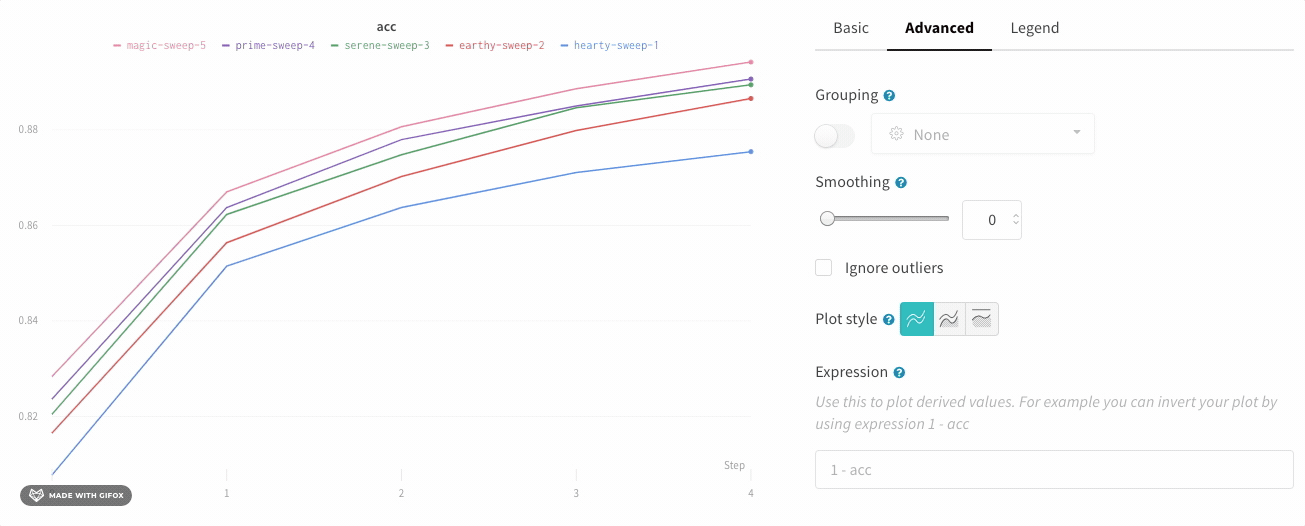
스무딩
스무딩 계수를 0과 1 사이로 설정할 수 있습니다. 여기서 0은 스무딩 없음, 1은 최대 스무딩입니다.
이상치 무시
기본 플롯 최소 및 최대 스케일에서 이상치를 제외하도록 플롯의 스케일을 다시 조정합니다. 플롯에 대한 설정의 영향은 플롯의 샘플링 모드에 따라 다릅니다.
임의 샘플링 모드를 사용하는 플롯의 경우 이상치 무시를 활성화하면 5%에서 95%의 포인트만 표시됩니다. 이상치가 표시되더라도 다른 포인트와 다르게 서식이 지정되지는 않습니다.
전체 충실도 모드를 사용하는 플롯의 경우 모든 포인트가 항상 표시되며 각 버킷의 마지막 값으로 압축됩니다. 이상치 무시를 활성화하면 각 버킷의 최소 및 최대 경계가 음영 처리됩니다. 그렇지 않으면 영역이 음영 처리되지 않습니다.
표현식
표현식을 사용하면 1-정확도와 같은 메트릭에서 파생된 값을 플롯할 수 있습니다. 현재 단일 메트릭을 플롯하는 경우에만 작동합니다. 간단한 산술 표현식 +, -, *, / 및 %는 물론 거듭제곱에 대한 **를 수행할 수 있습니다.
플롯 스타일
선 그래프의 스타일을 선택합니다.
선 그래프:
영역 그래프:
백분율 영역 그래프:
1.2 - Point aggregation
Data Visualization 정확도와 성능을 향상시키려면 라인 플롯 내에서 포인트 집계 방법을 사용하세요. 포인트 집계 모드에는 전체 충실도와 임의 샘플링의 두 가지 유형이 있습니다. W&B는 기본적으로 전체 충실도 모드를 사용합니다.
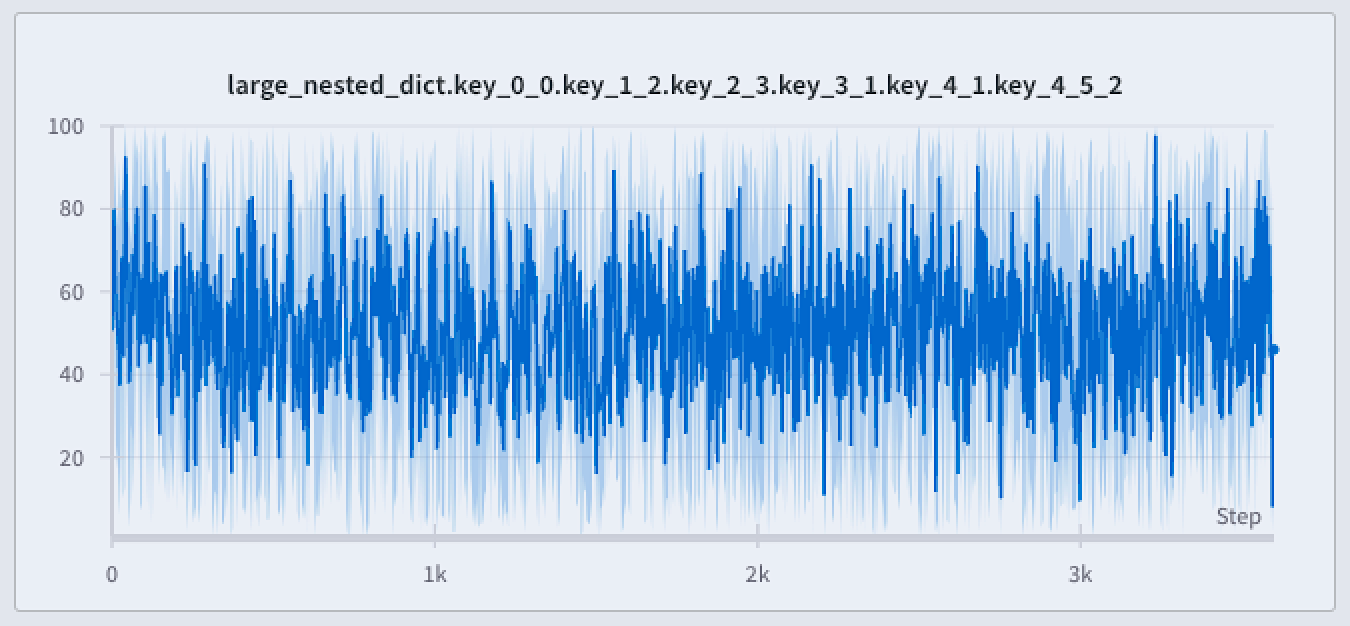
전체 충실도
전체 충실도 모드를 사용하면 W&B는 데이터 포인트 수를 기반으로 x축을 동적 버킷으로 나눕니다. 그런 다음 라인 플롯에 대한 포인트 집계를 렌더링하는 동안 각 버킷 내의 최소값, 최대값 및 평균값을 계산합니다.
포인트 집계에 전체 충실도 모드를 사용하면 다음과 같은 세 가지 주요 이점이 있습니다.
극단값 및 스파이크 보존: 데이터에서 극단값 및 스파이크를 유지합니다.
최소 및 최대 포인트 렌더링 방법 구성: W&B 앱을 사용하여 극단(최소/최대) 값을 음영 영역으로 표시할지 여부를 대화식으로 결정합니다.
데이터 정확도를 잃지 않고 데이터 탐색: 특정 데이터 포인트를 확대하면 W&B가 x축 버킷 크기를 다시 계산합니다. 이는 정확도를 잃지 않고 데이터를 탐색하는 데 도움이 됩니다. 캐싱은 이전에 계산된 집계를 저장하여 로딩 시간을 줄이는 데 사용되며, 이는 대규모 데이터셋을 탐색할 때 특히 유용합니다.
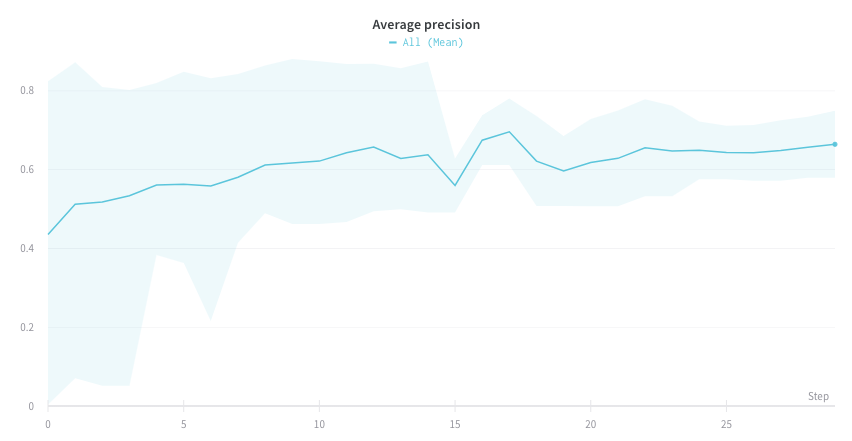
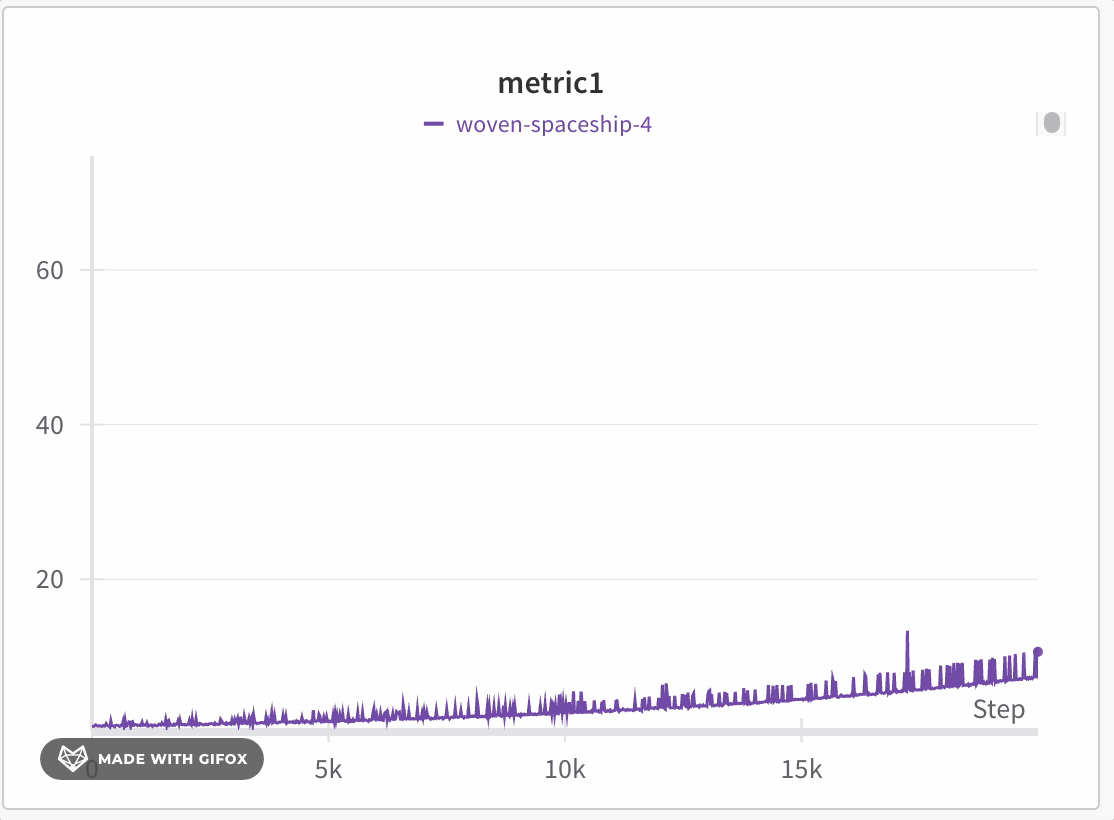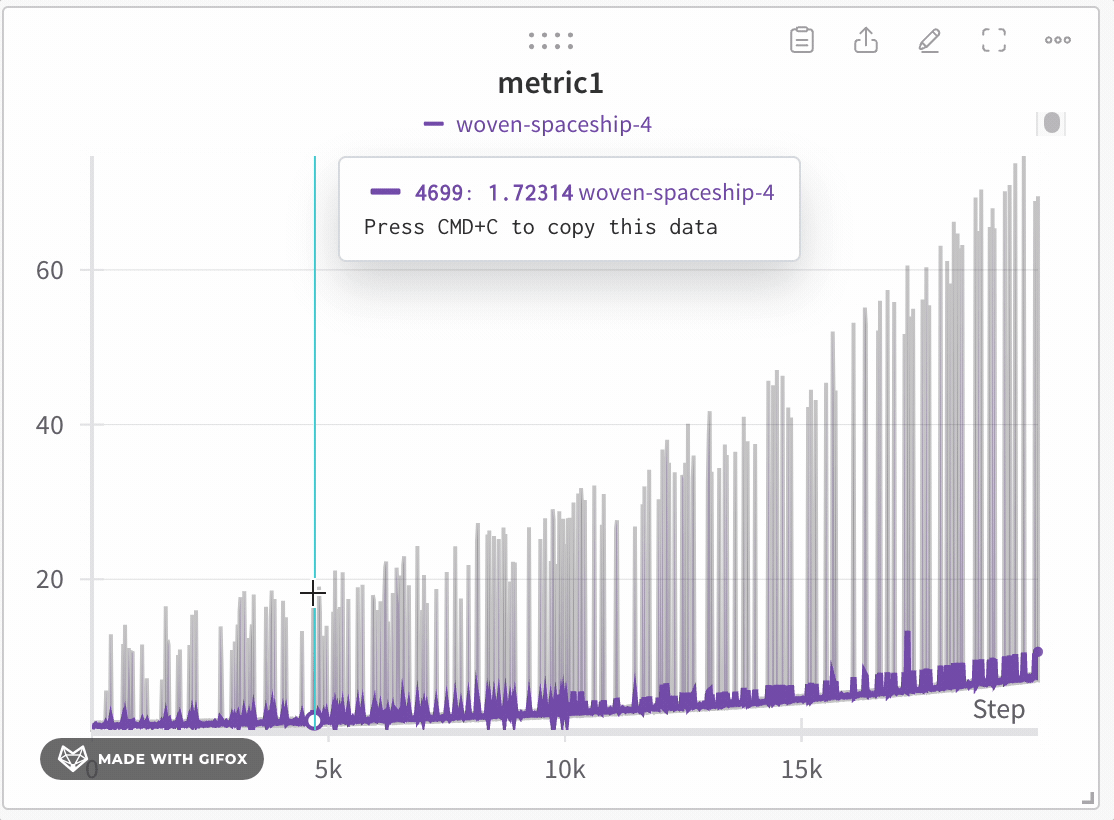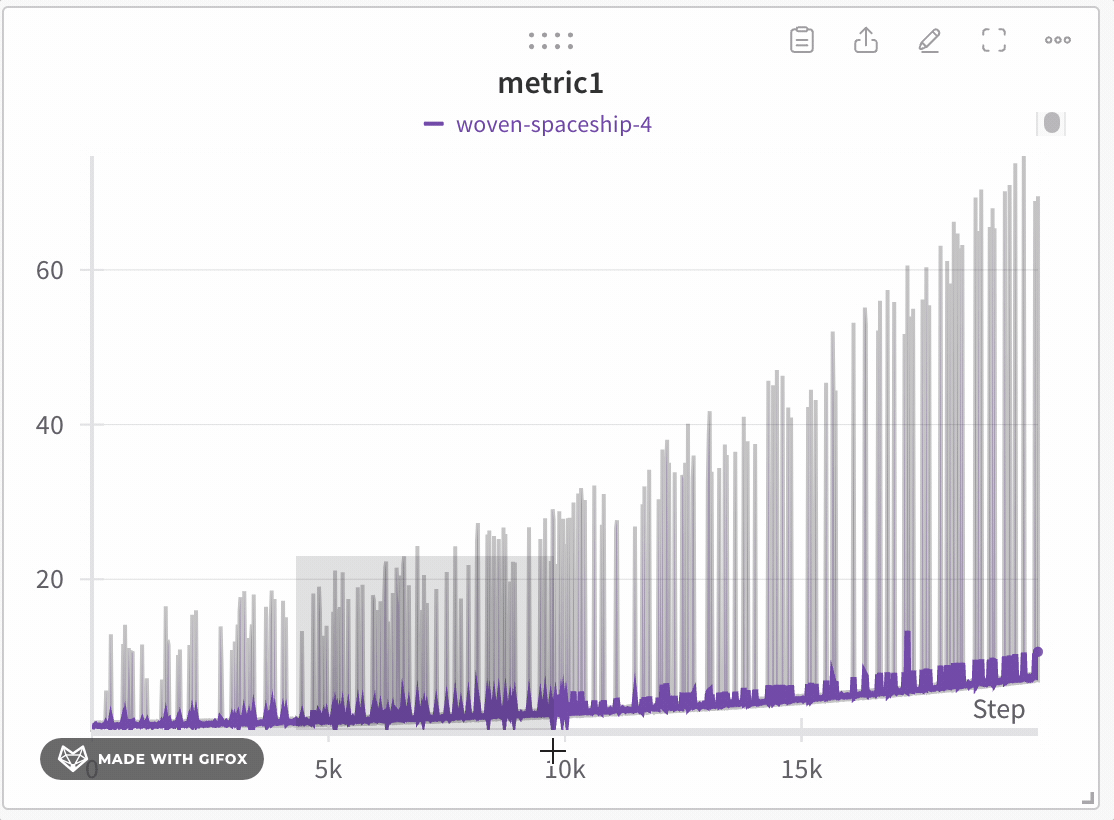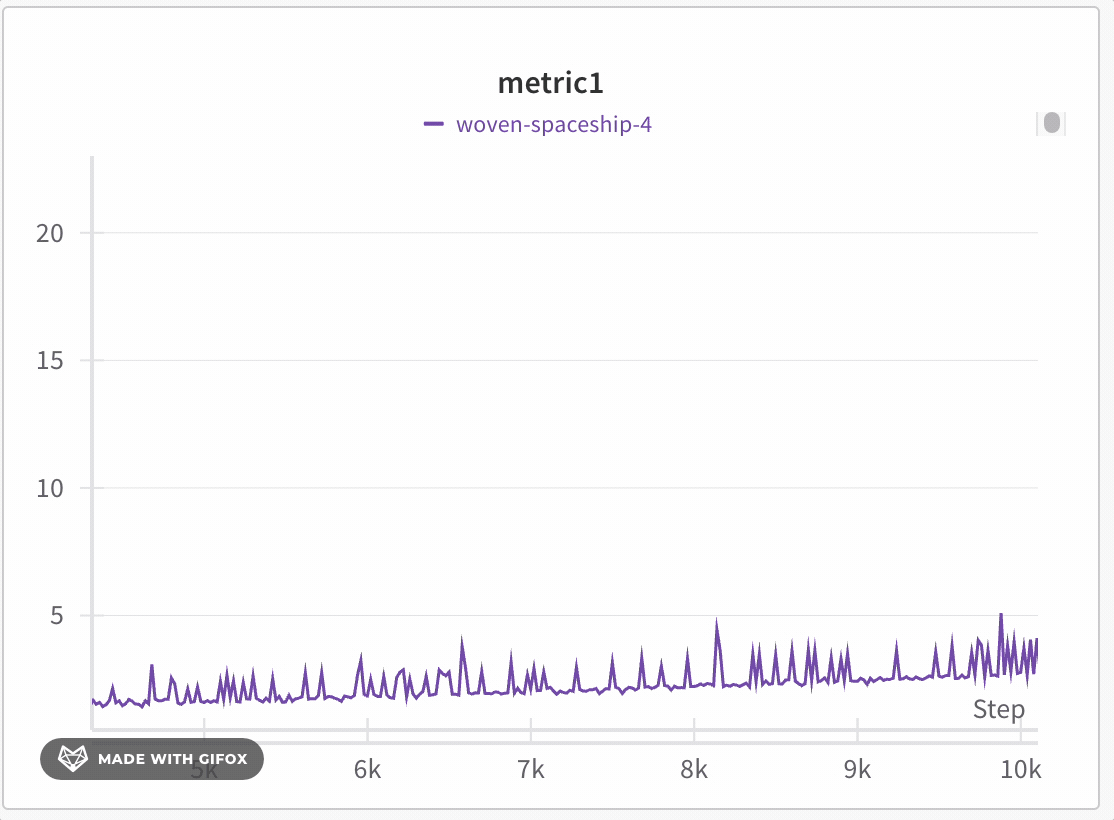
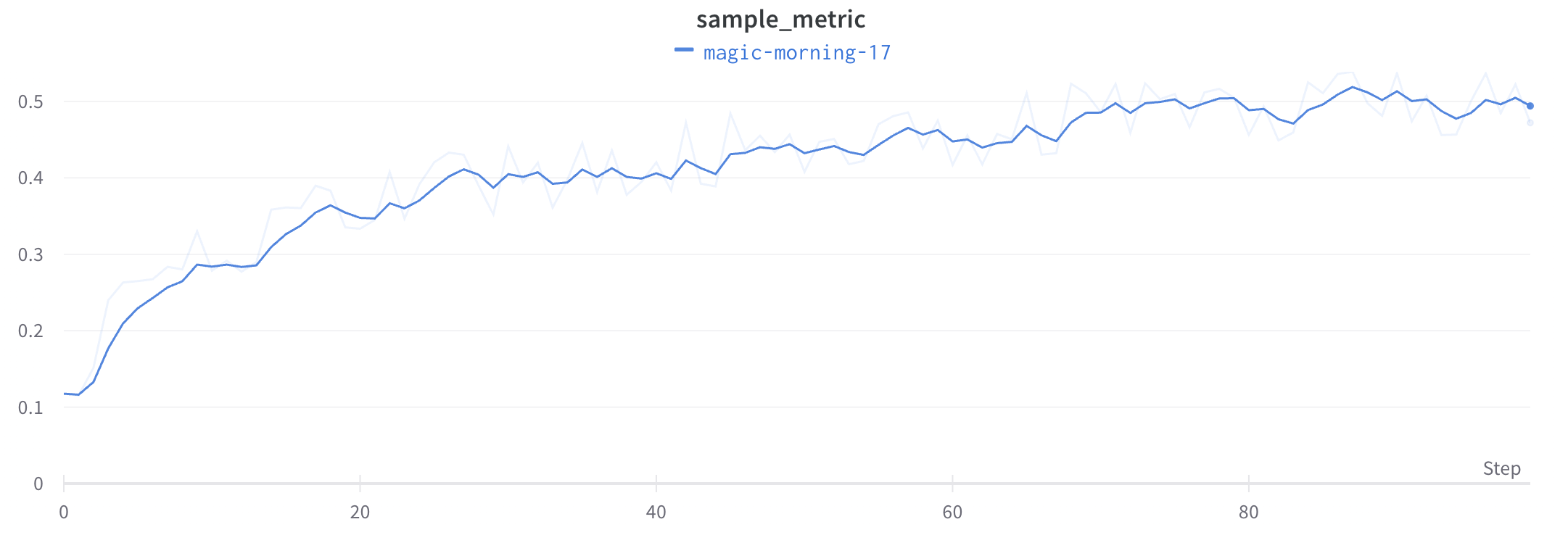
최소 및 최대 포인트 렌더링 방법 구성
라인 플롯 주위에 음영 영역을 사용하여 최소값과 최대값을 표시하거나 숨깁니다.
다음 이미지는 파란색 라인 플롯을 보여줍니다. 밝은 파란색 음영 영역은 각 버킷의 최소값과 최대값을 나타냅니다.
이동 평균은 주어진 x 값 이전과 이후의 창에서 점의 평균으로 점을 대체하는 평활화 알고리즘입니다. https://en.wikipedia.org/wiki/Moving_average의 “Boxcar Filter"를 참조하세요. 이동 평균에 대해 선택된 파라미터는 Weights and Biases에 이동 평균에서 고려할 점의 수를 알려줍니다.
모든 평활화 알고리즘은 샘플링된 데이터에서 실행됩니다. 즉, 1500개 이상의 점을 기록하면 평활화 알고리즘은 서버에서 점을 다운로드한 후에 실행됩니다. 평활화 알고리즘의 의도는 데이터에서 패턴을 빠르게 찾는 데 도움을 주는 것입니다. 많은 수의 기록된 점이 있는 메트릭에 대해 정확한 평활화된 값이 필요한 경우 API를 통해 메트릭을 다운로드하고 자체 평활화 methods를 실행하는 것이 좋습니다.
원본 데이터 숨기기
기본적으로 원본의 평활화되지 않은 데이터가 배경에 희미한 선으로 표시됩니다. 원본 보기 토글을 클릭하여 이 기능을 끄세요.
2 - Bar plots
메트릭을 시각화하고, 축을 사용자 정의하고, 범주형 데이터를 막대로 비교하세요.
막대 그래프는 범주형 데이터를 직사각형 막대로 나타내며, 이 막대는 수직 또는 수평으로 플롯할 수 있습니다. 모든 기록된 값이 길이가 1인 경우 막대 그래프는 기본적으로 wandb.log() 와 함께 표시됩니다.
차트 설정을 사용하여 표시할 최대 Runs 수를 제한하고, 모든 config별로 Runs를 그룹화하고, 레이블 이름을 바꿀 수 있습니다.
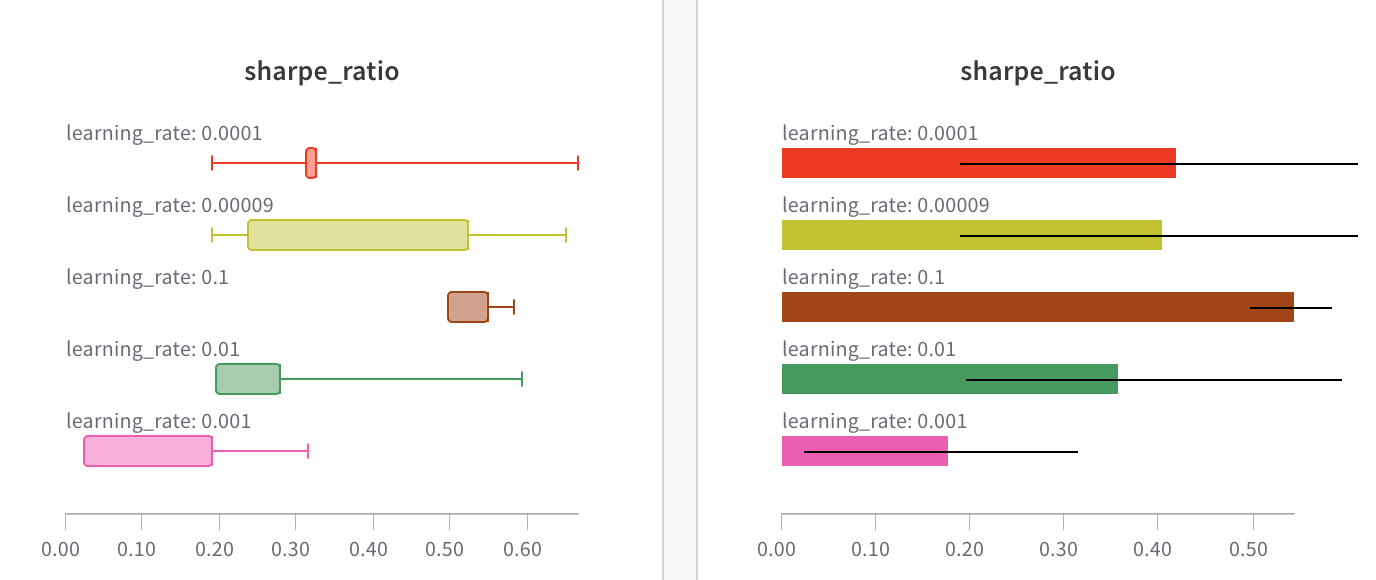
막대 그래프 사용자 정의
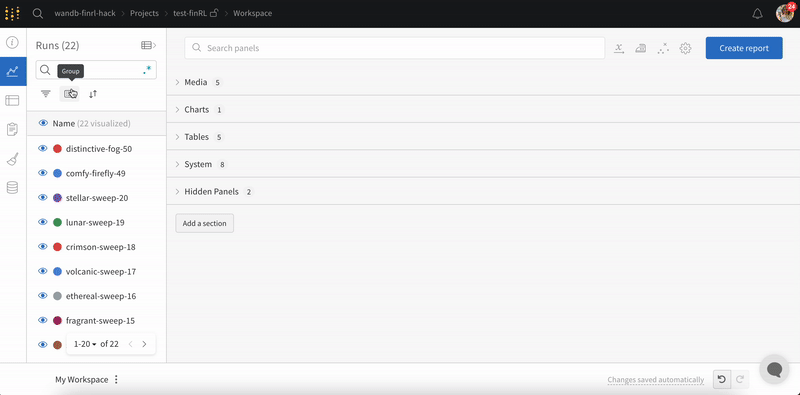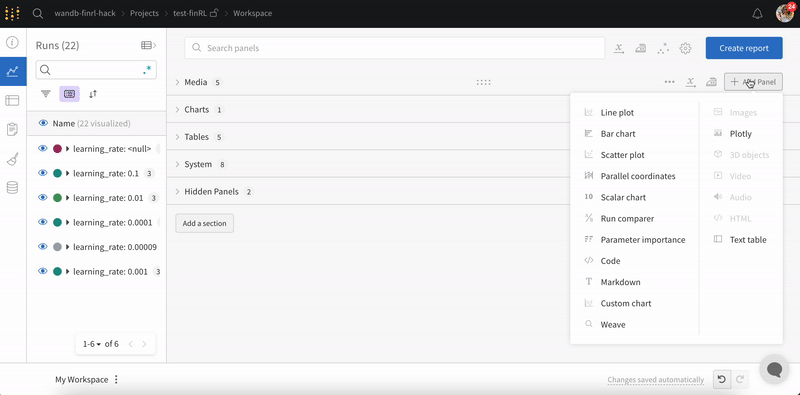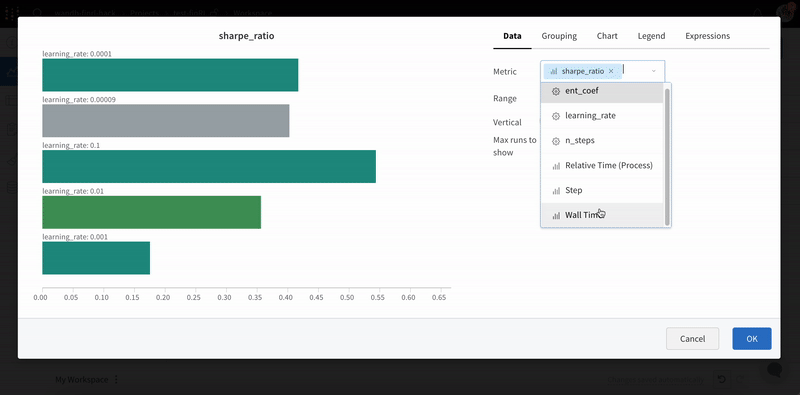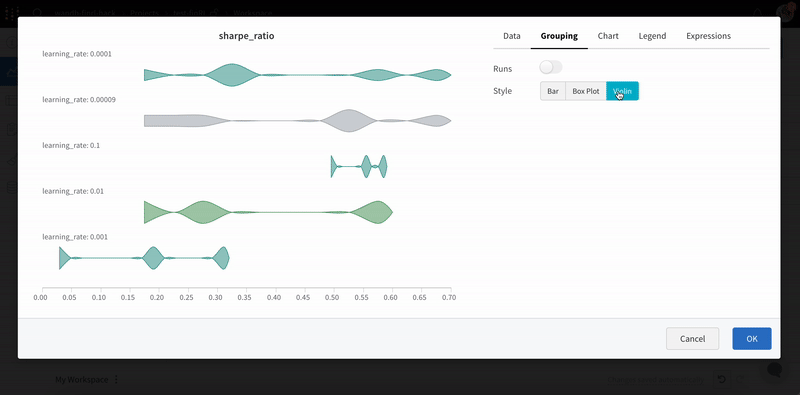
Box 또는 Violin 플롯을 생성하여 여러 요약 통계를 하나의 차트 유형으로 결합할 수도 있습니다.
Runs 테이블을 통해 Runs를 그룹화합니다.
워크스페이스에서 ‘패널 추가’를 클릭합니다.
표준 ‘막대 차트’를 추가하고 플롯할 메트릭을 선택합니다.
‘그룹화’ 탭에서 ‘box plot’ 또는 ‘Violin’ 등을 선택하여 이러한 스타일 중 하나를 플롯합니다.
이렇게 하면 현재 디렉토리와 모든 하위 디렉토리의 모든 파이썬 소스 코드 파일이 artifact로 캡처됩니다. 저장되는 소스 코드 파일의 유형 및 위치를 보다 세밀하게 제어하려면 참조 문서를 참조하세요.
UI에서 코드 저장 설정
프로그래밍 방식으로 코드 저장을 설정하는 것 외에도 W&B 계정 설정에서 이 기능을 토글할 수도 있습니다. 이는 계정과 연결된 모든 Teams에 대해 코드 저장을 활성화합니다.
기본적으로 W&B는 모든 Teams에 대해 코드 저장을 비활성화합니다.
W&B 계정에 로그인합니다.
Settings > Privacy로 이동합니다.
Project and content security에서 Disable default code saving을 켭니다.
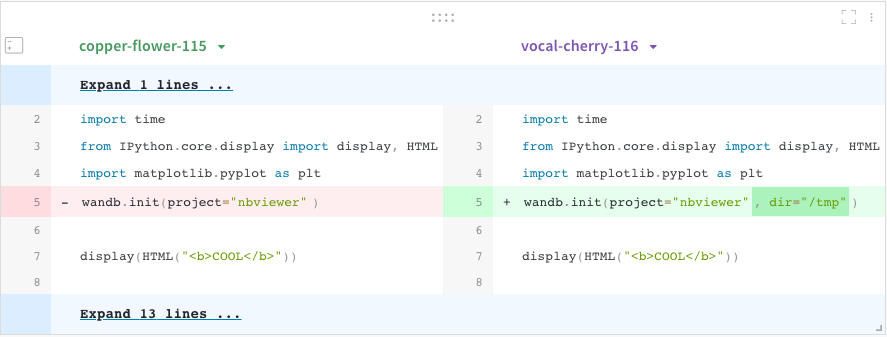
코드 비교기
서로 다른 W&B Runs에서 사용된 코드를 비교합니다.
페이지 오른쪽 상단에서 Add panels 버튼을 선택합니다.
TEXT AND CODE 드롭다운을 확장하고 Code를 선택합니다.
Jupyter 세션 기록
W&B는 Jupyter 노트북 세션에서 실행된 코드의 기록을 저장합니다. Jupyter 내에서 **wandb.init()**을 호출하면 W&B는 현재 세션에서 실행된 코드의 기록이 포함된 Jupyter 노트북을 자동으로 저장하는 훅을 추가합니다.
코드가 포함된 project 워크스페이스로 이동합니다.
왼쪽 네비게이션 바에서 Artifacts 탭을 선택합니다.
code artifact를 확장합니다.
Files 탭을 선택합니다.
이렇게 하면 iPython의 display 메소드를 호출하여 생성된 모든 출력과 함께 세션에서 실행된 셀이 표시됩니다. 이를 통해 지정된 Run 내에서 Jupyter 내에서 실행된 코드를 정확히 볼 수 있습니다. 가능한 경우 W&B는 코드 디렉토리에서도 찾을 수 있는 노트북의 최신 버전도 저장합니다.
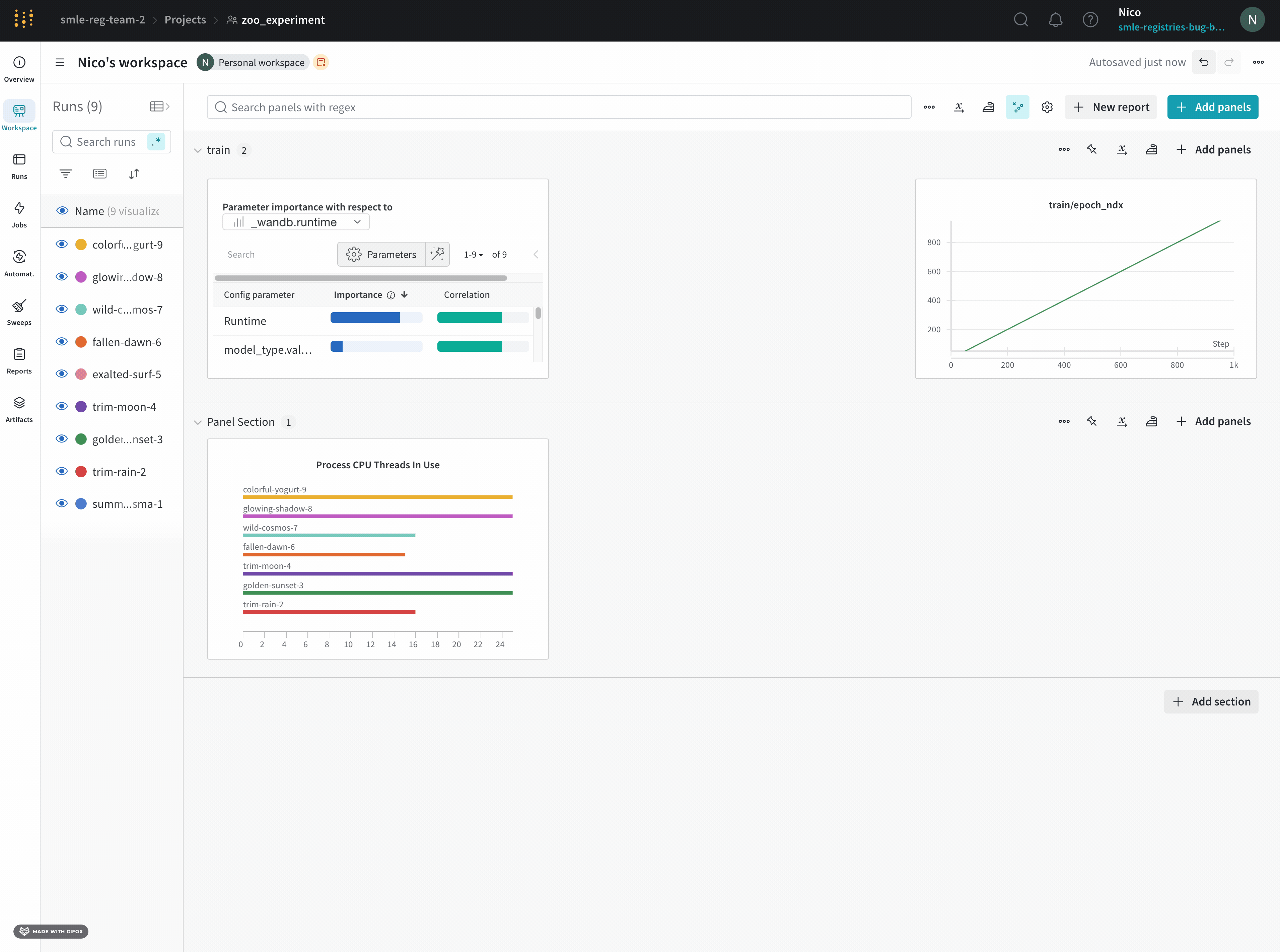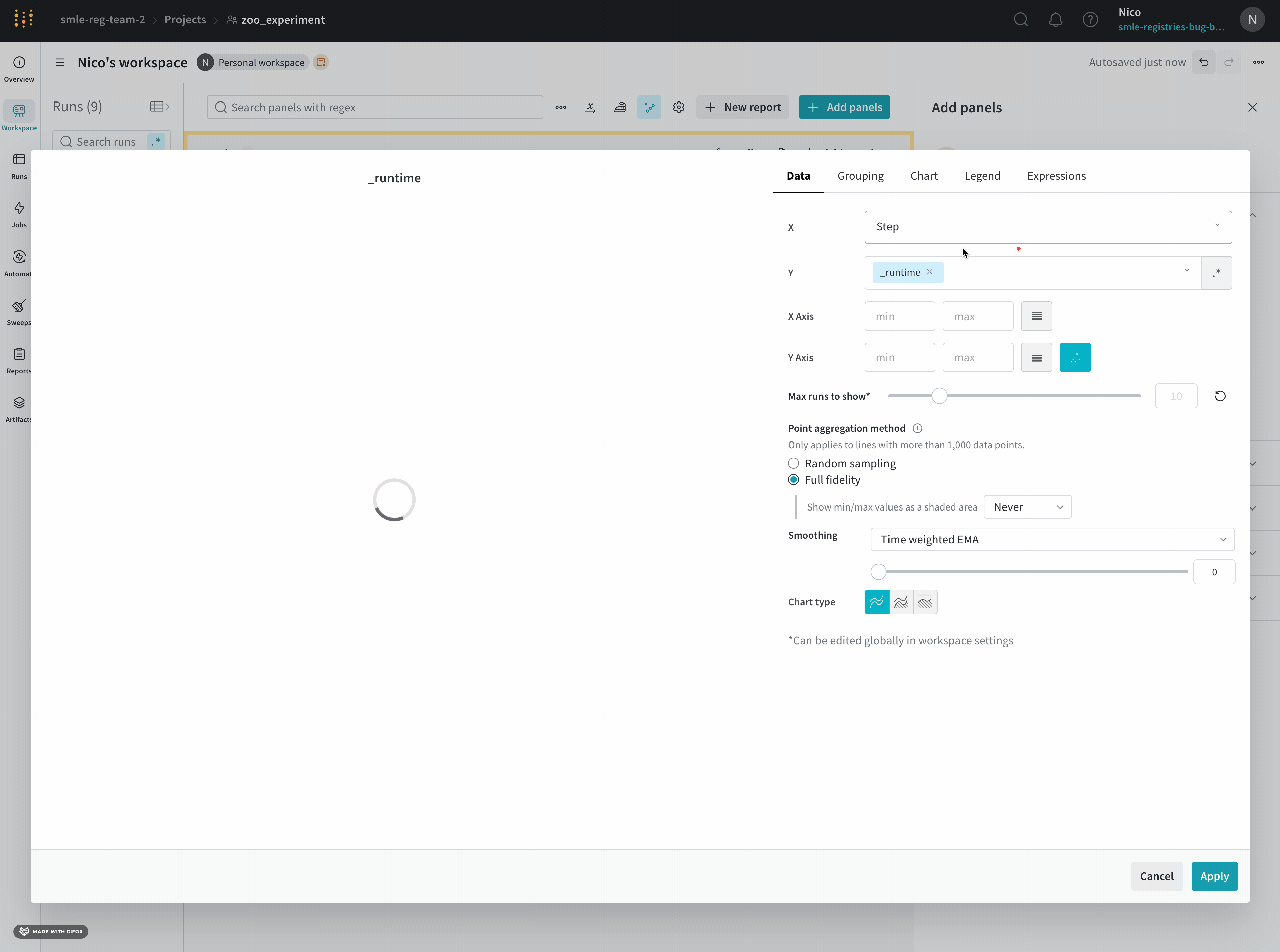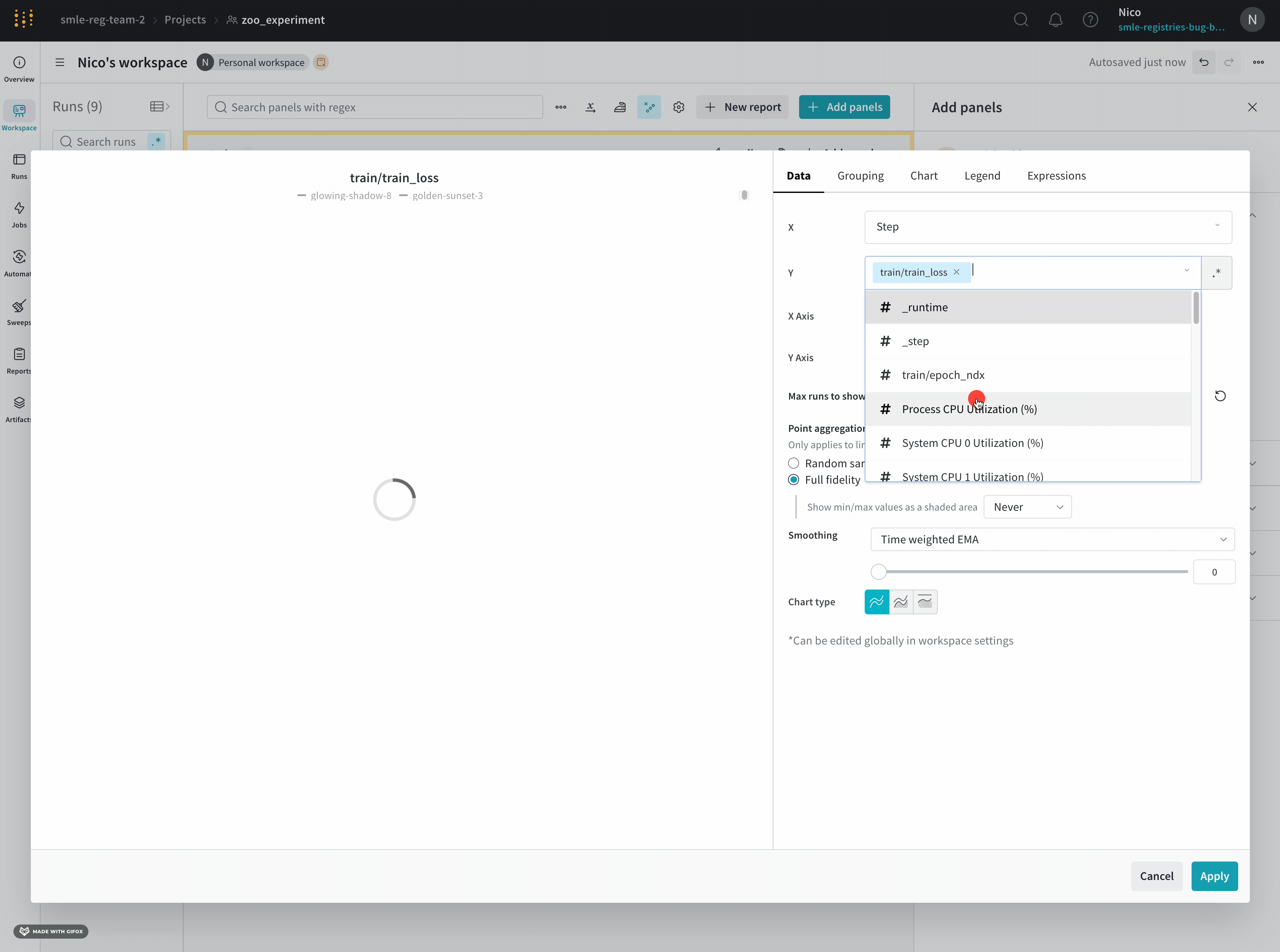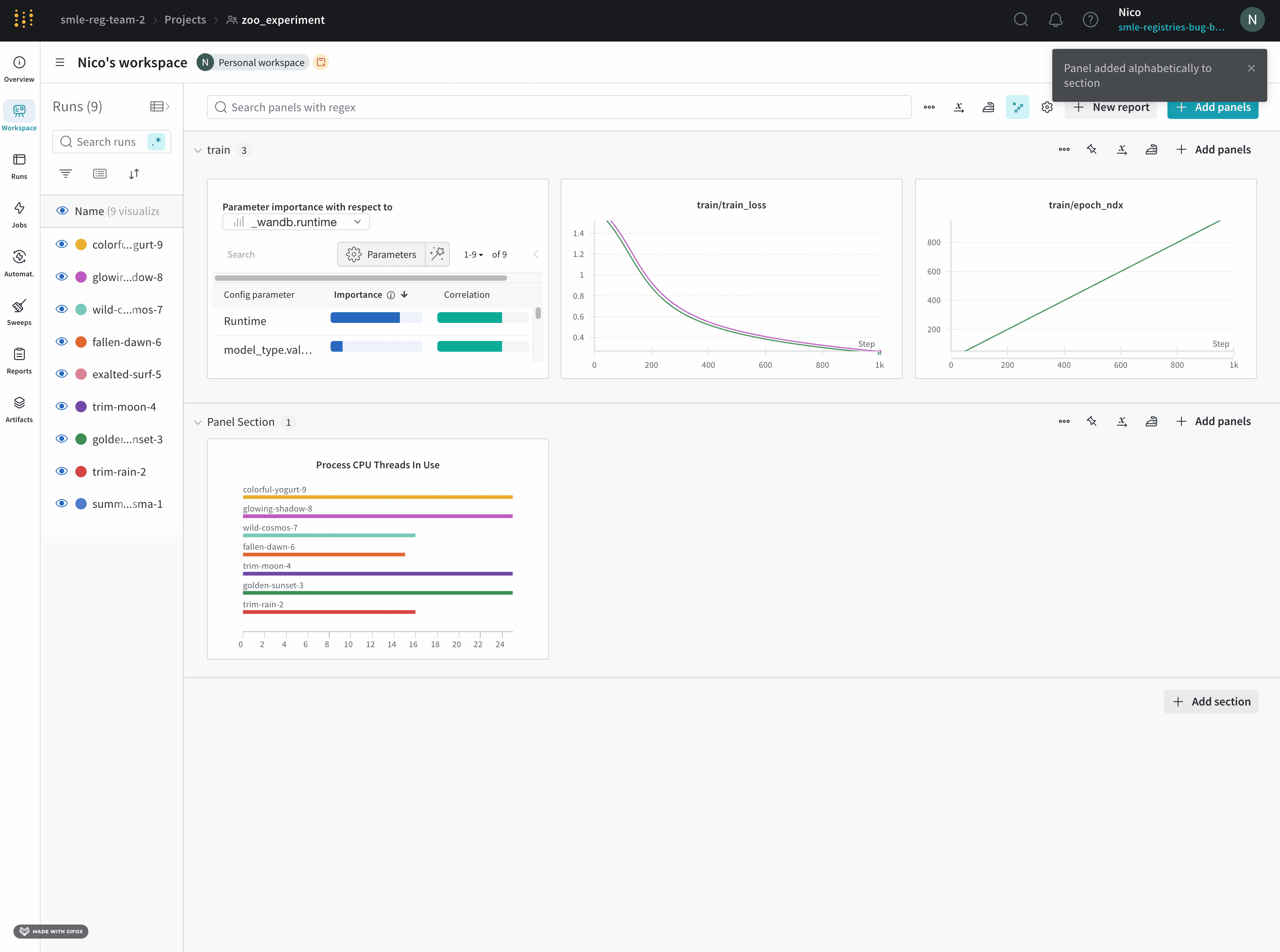
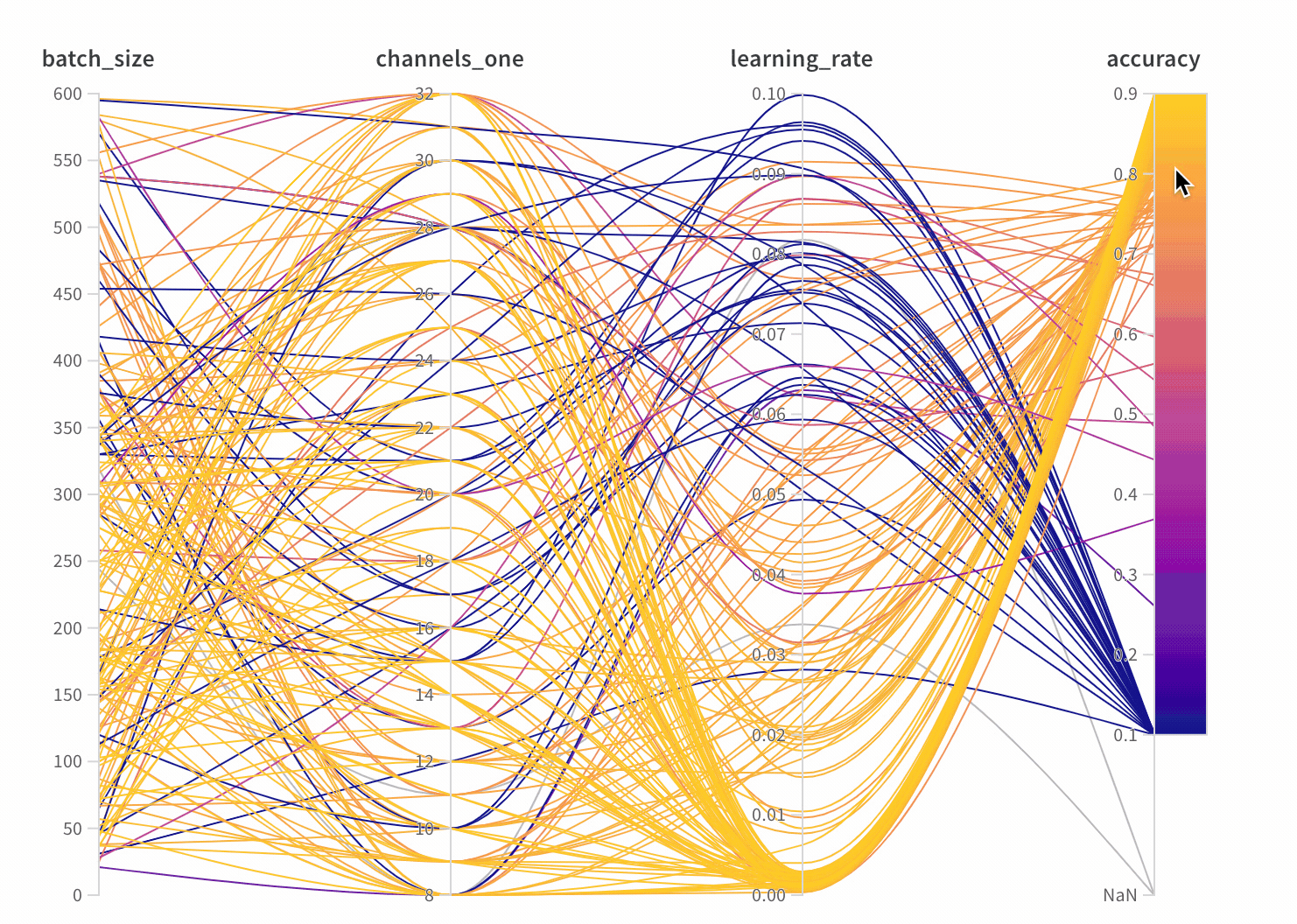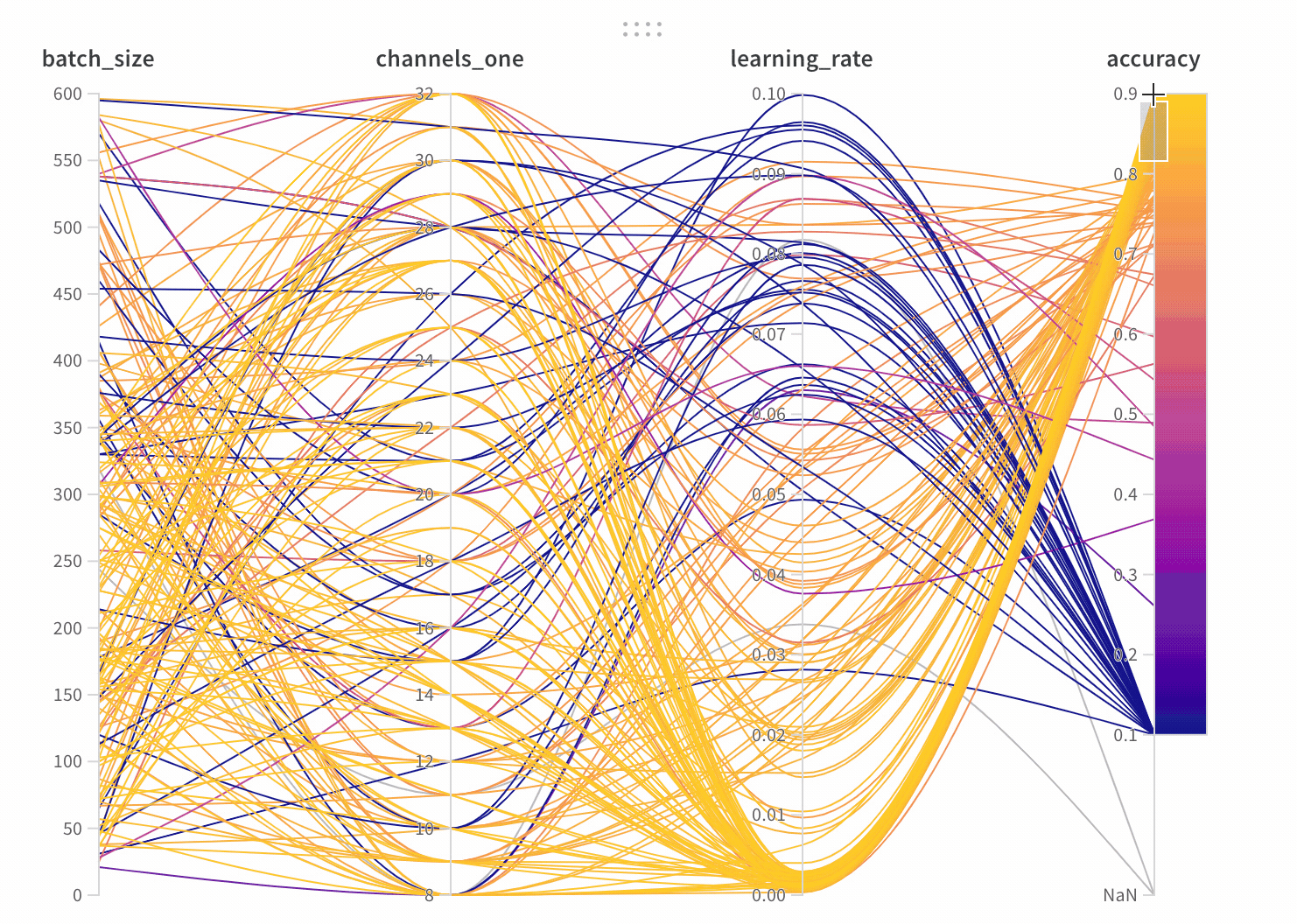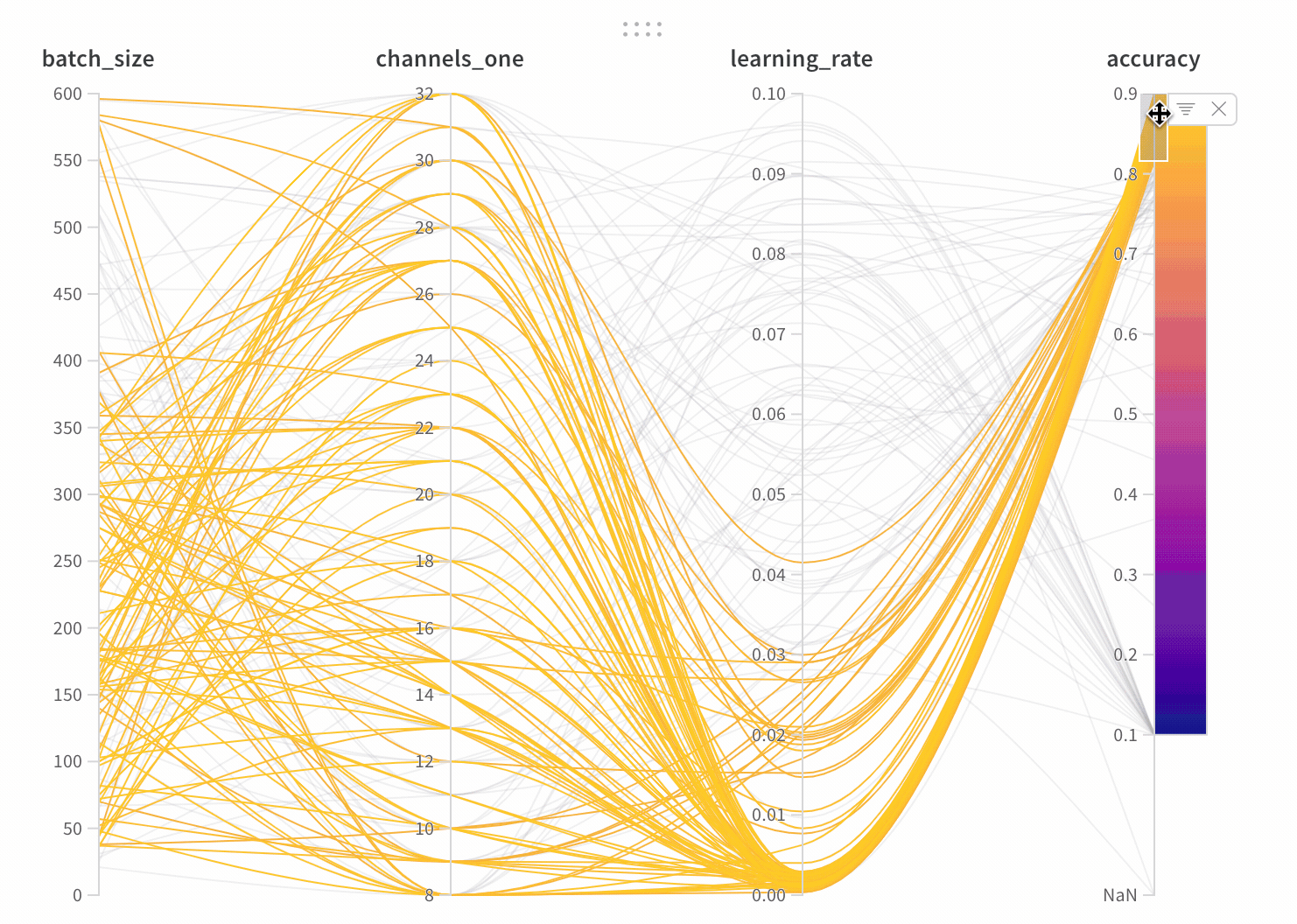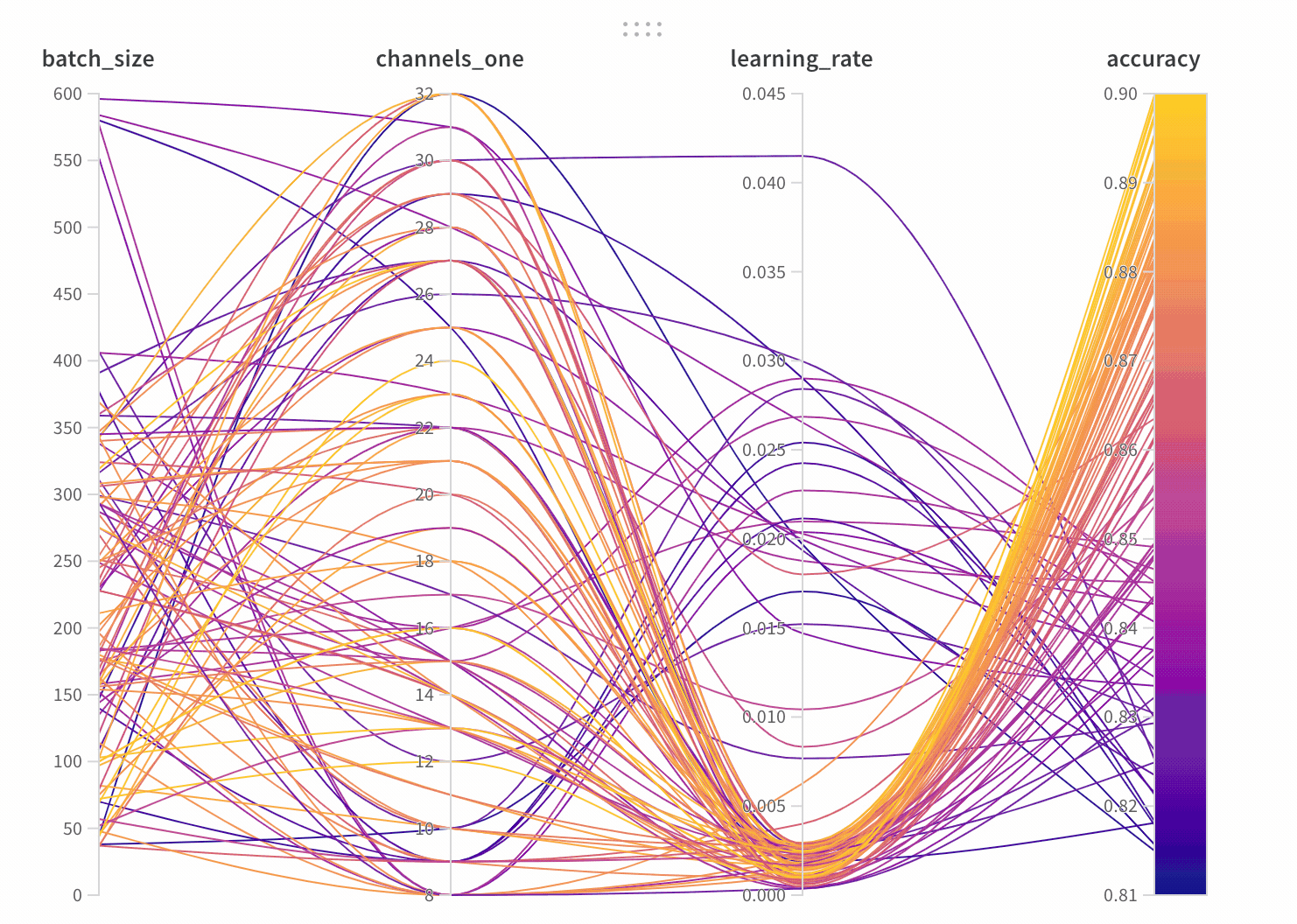
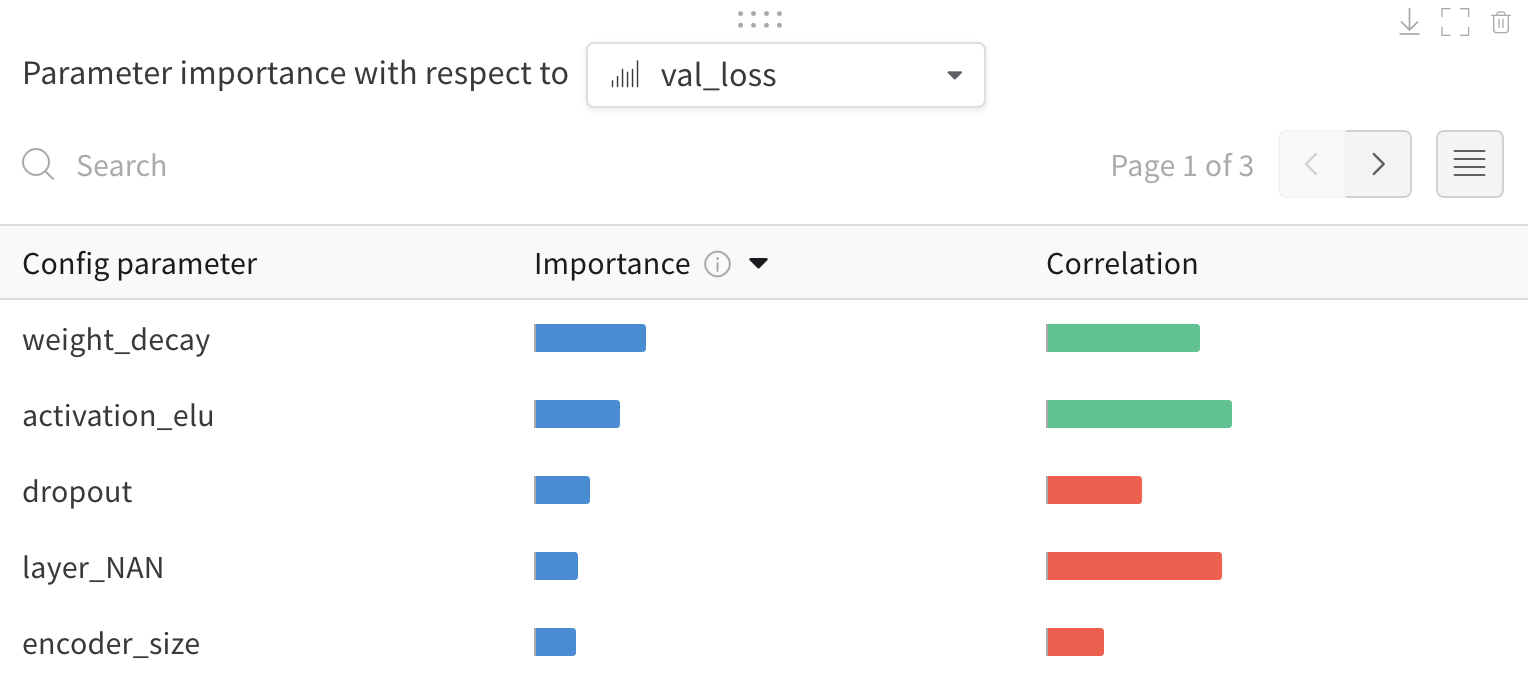
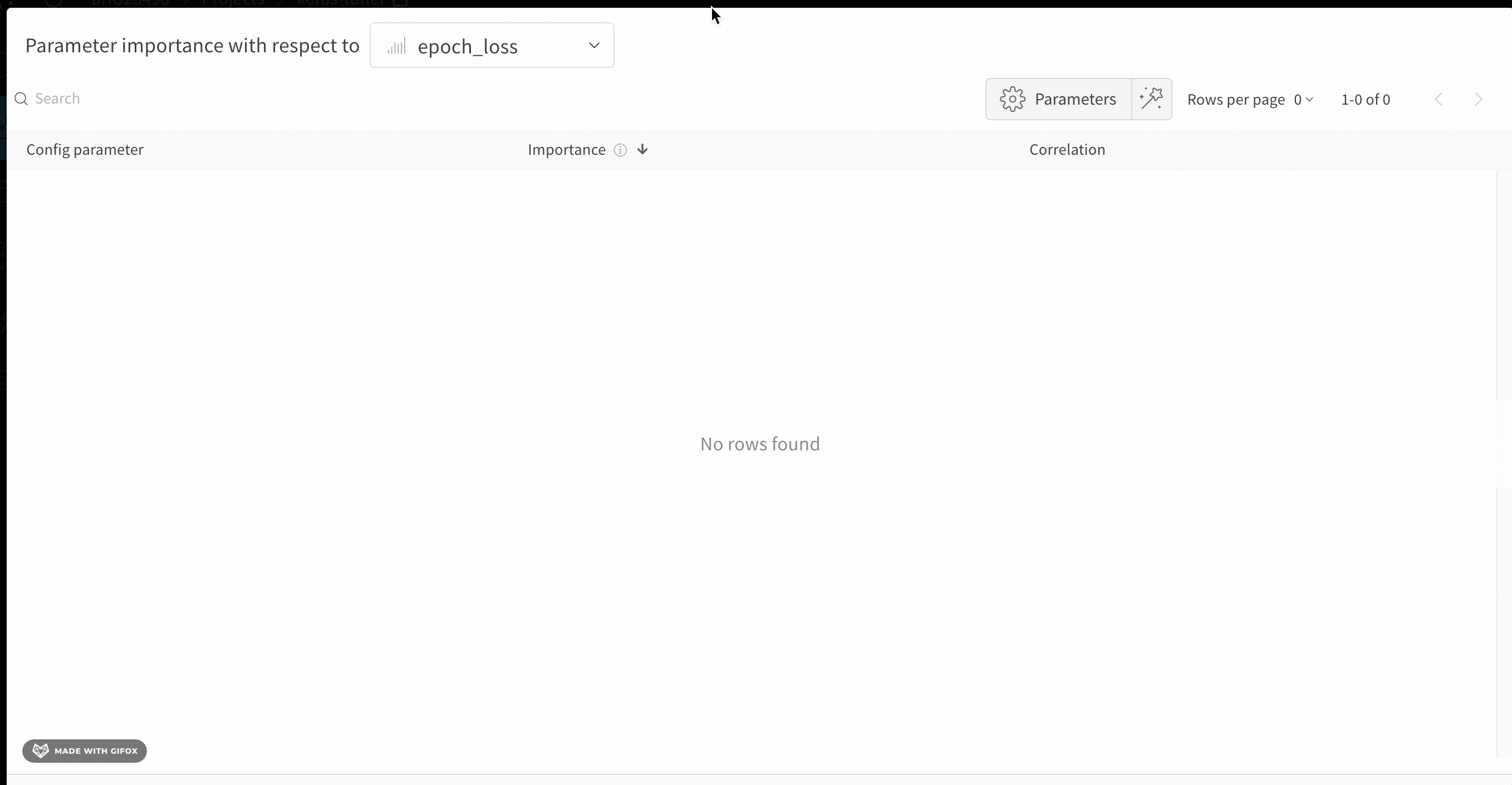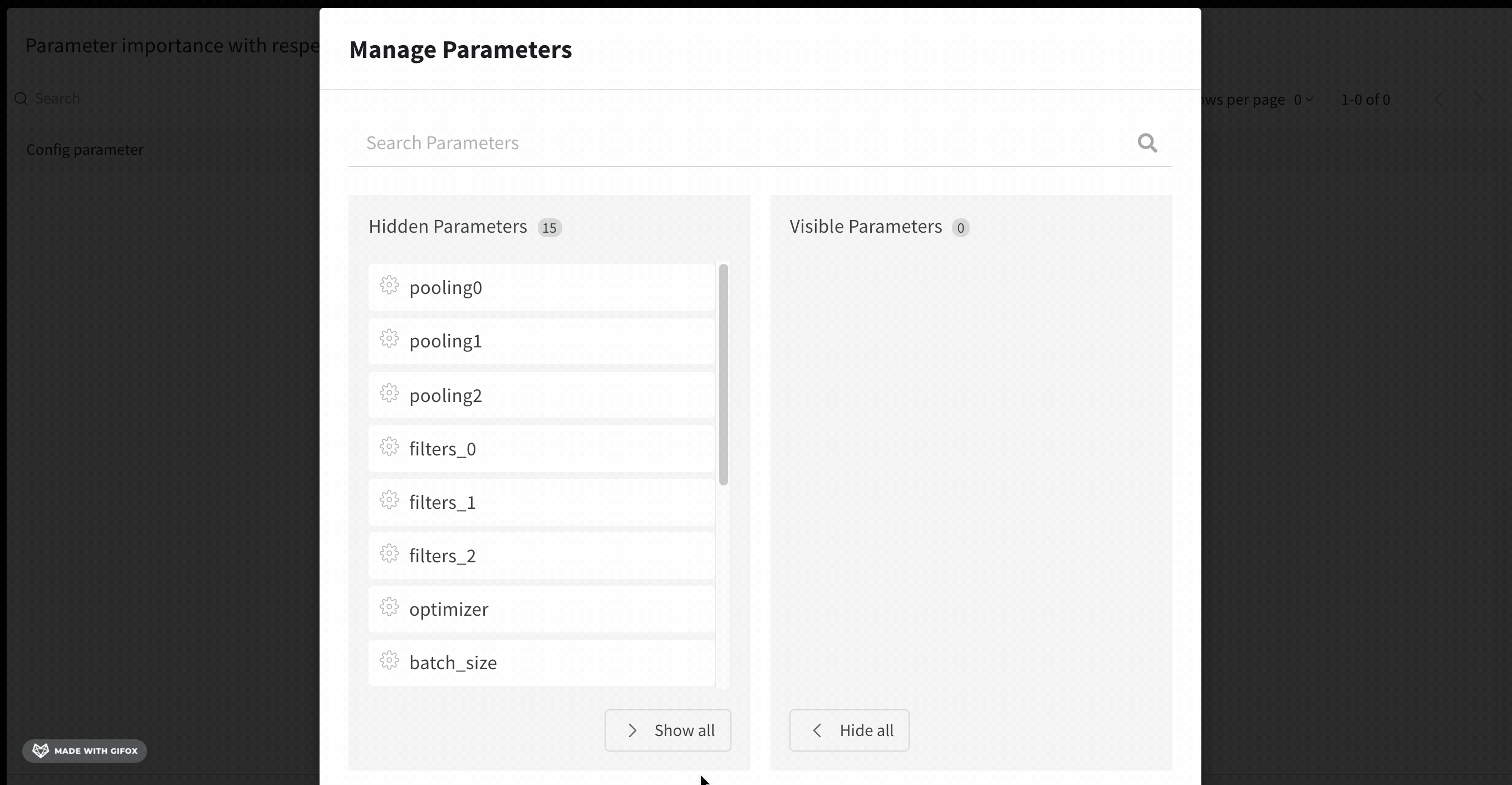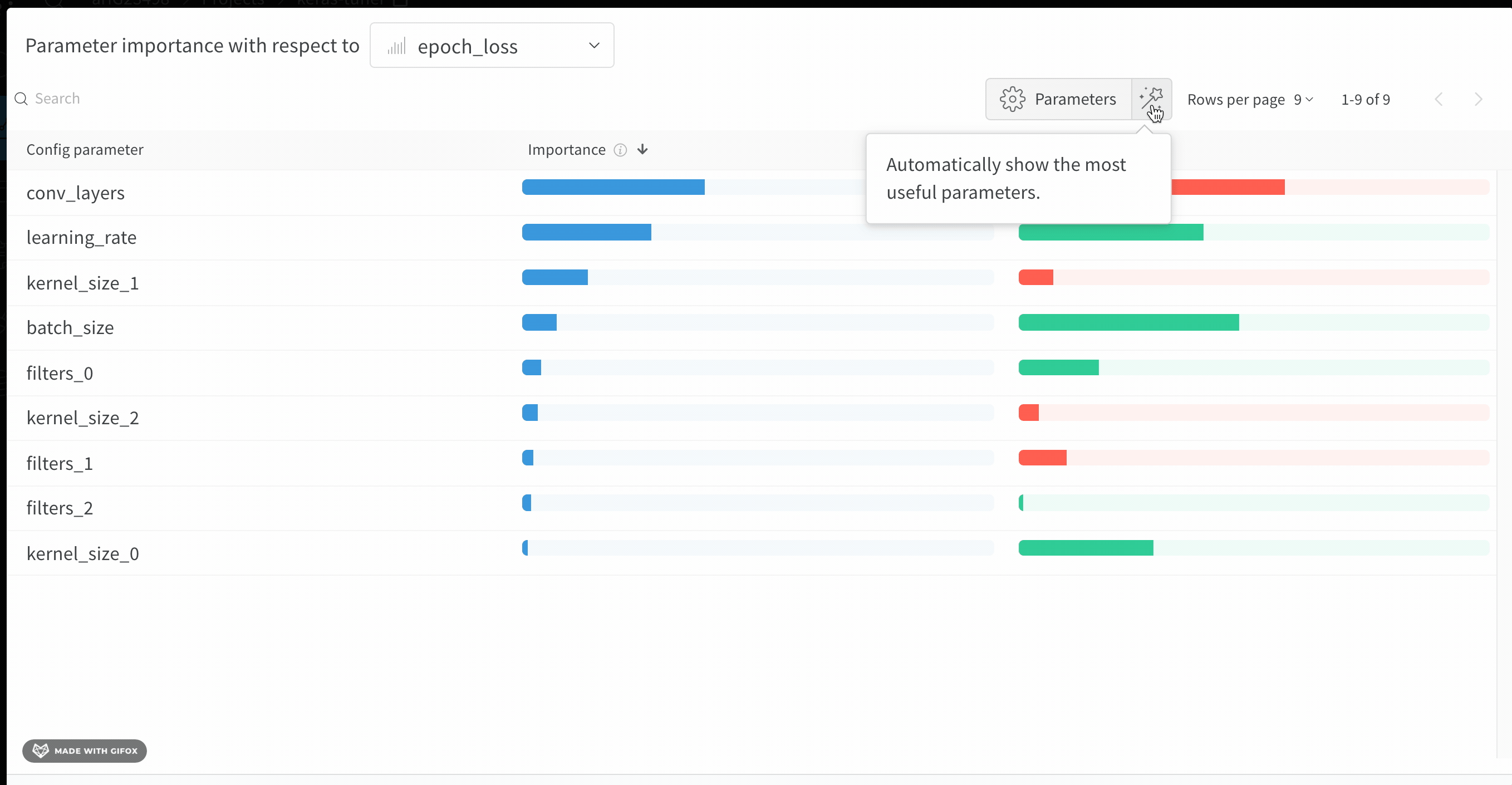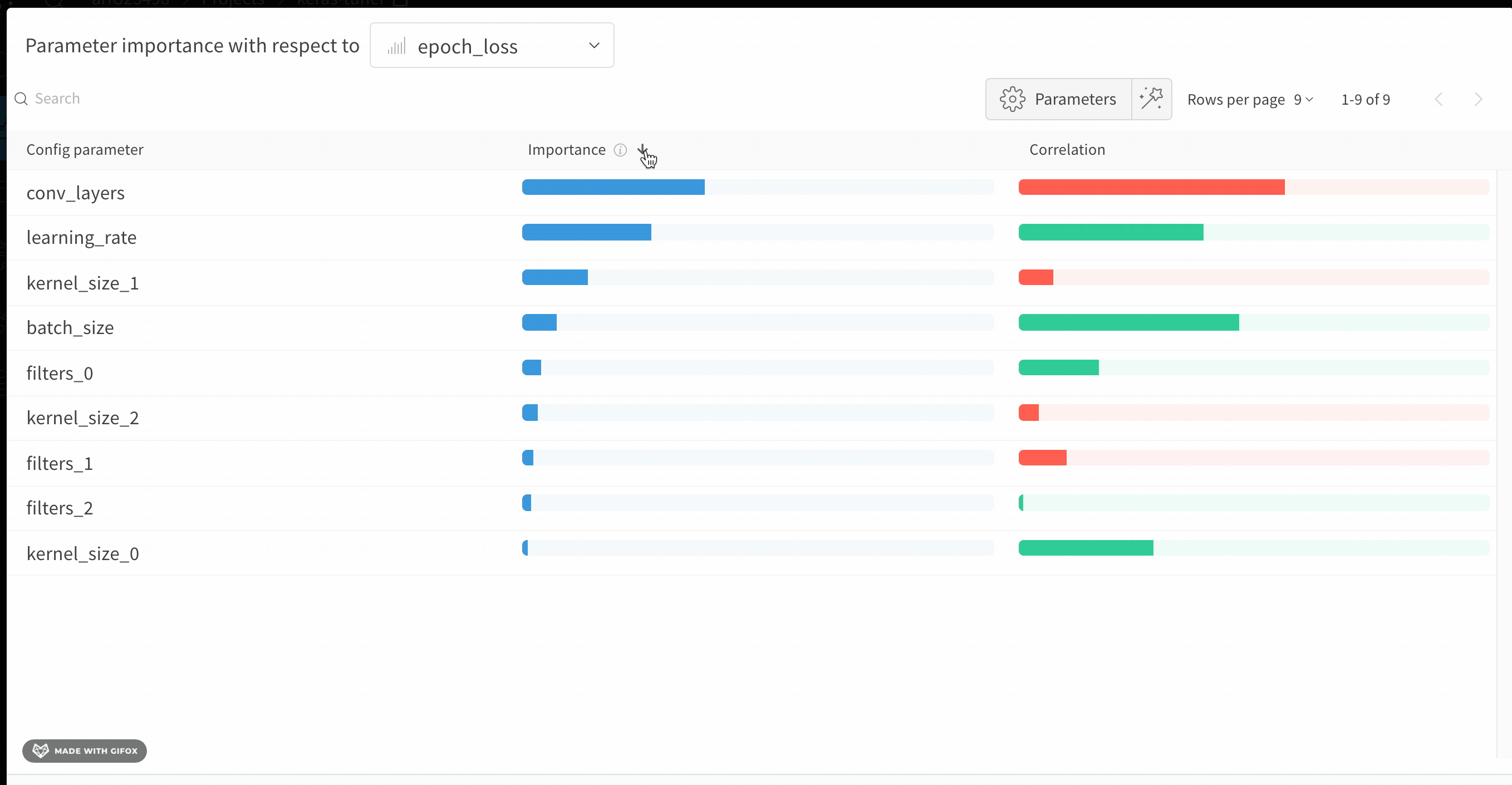
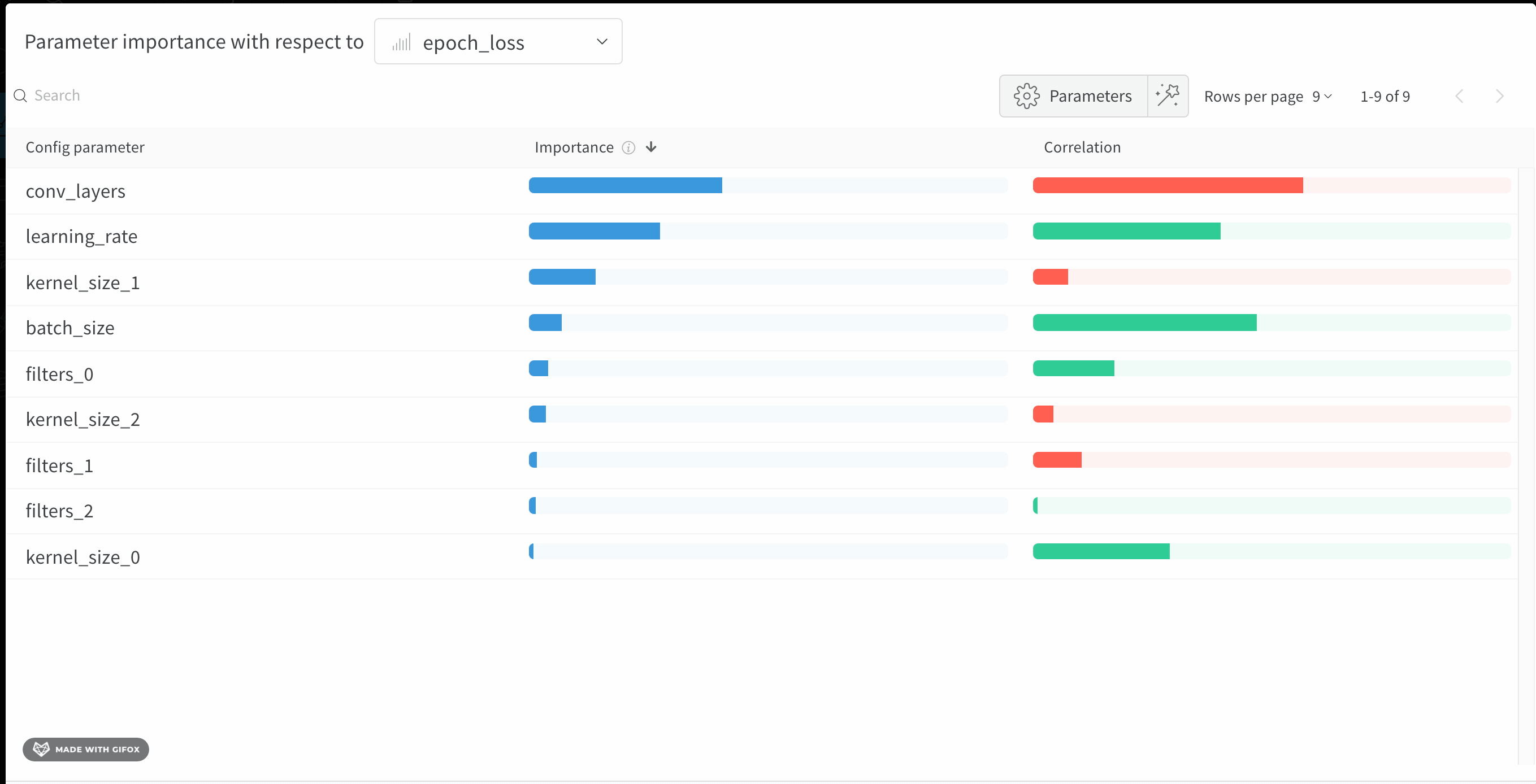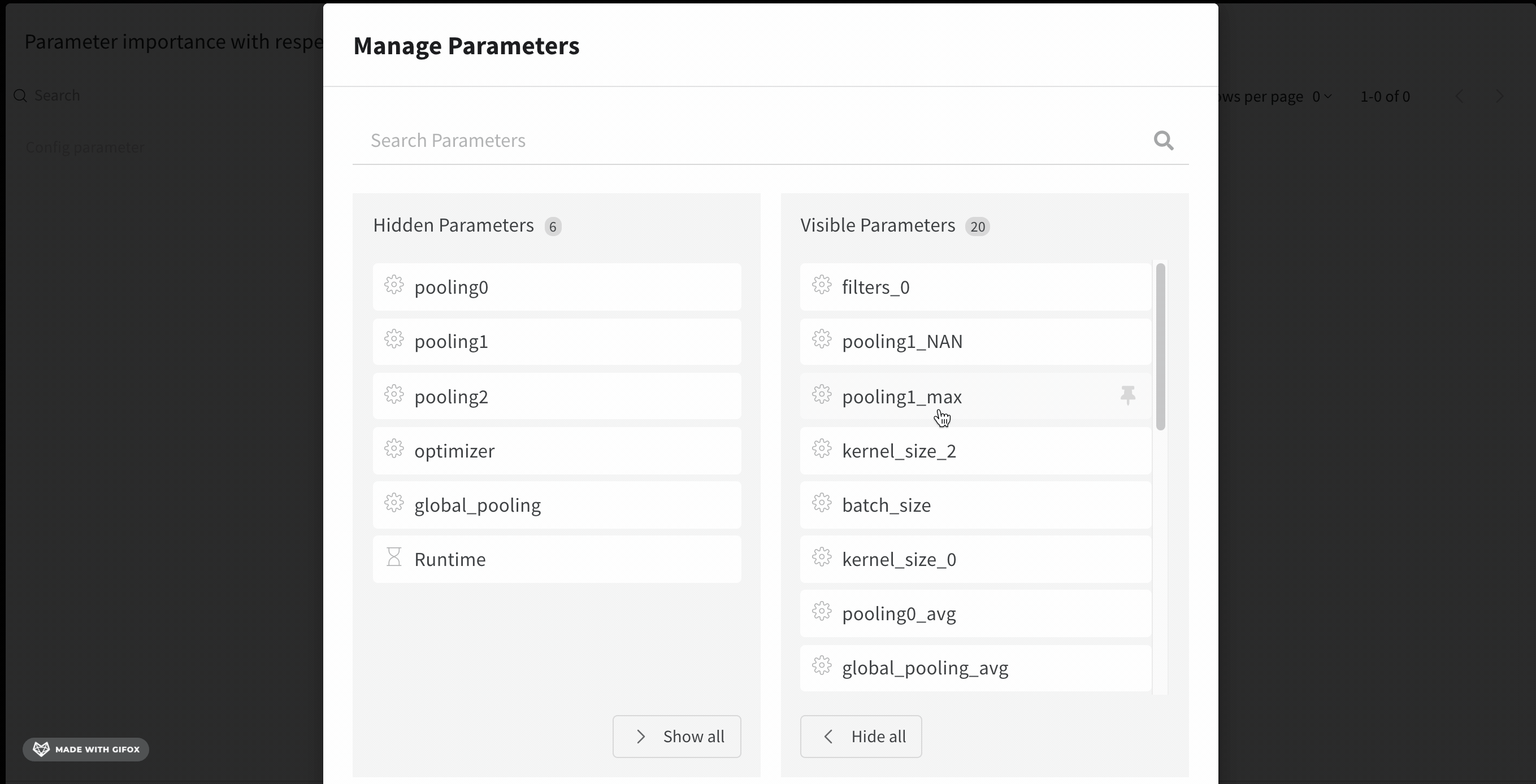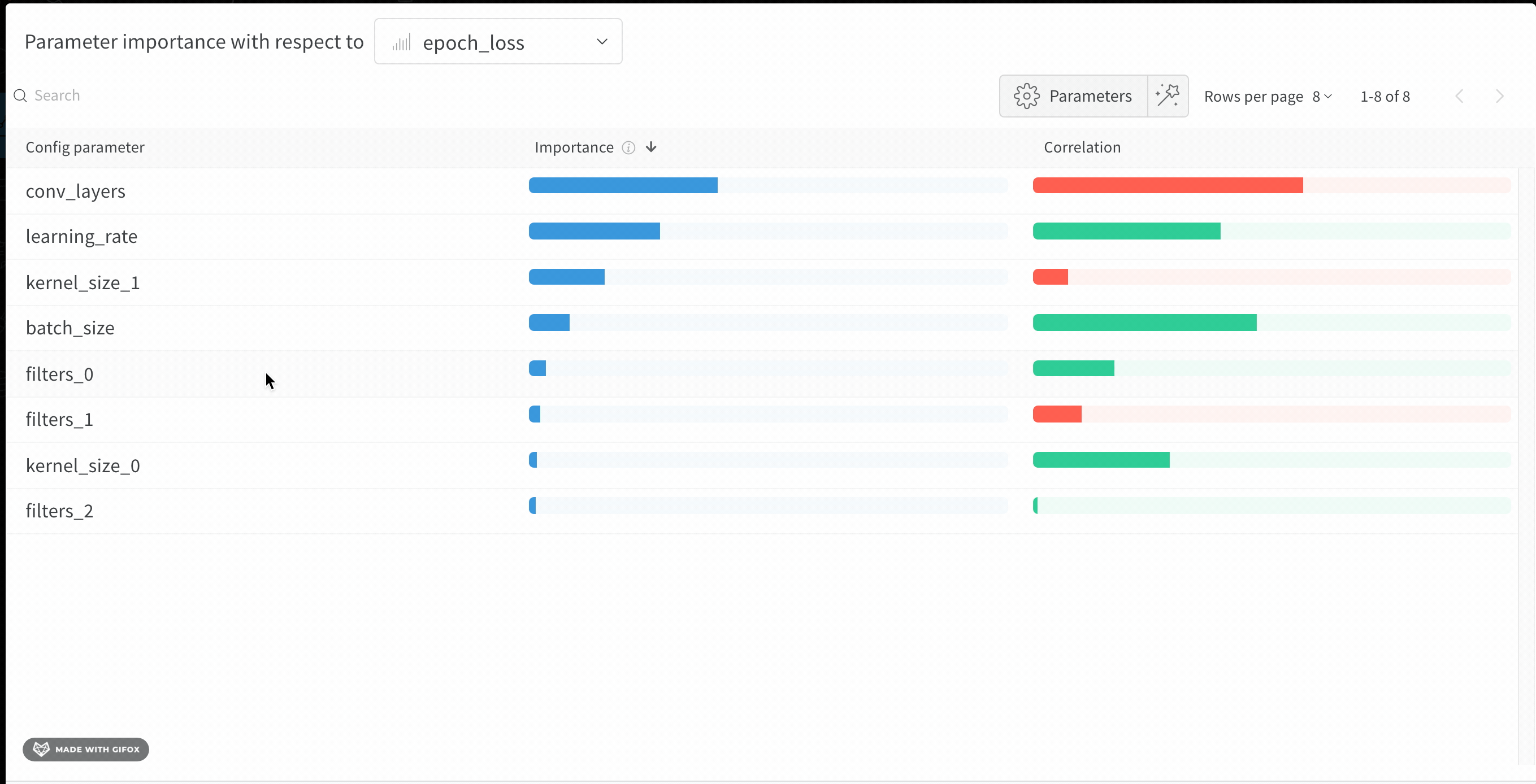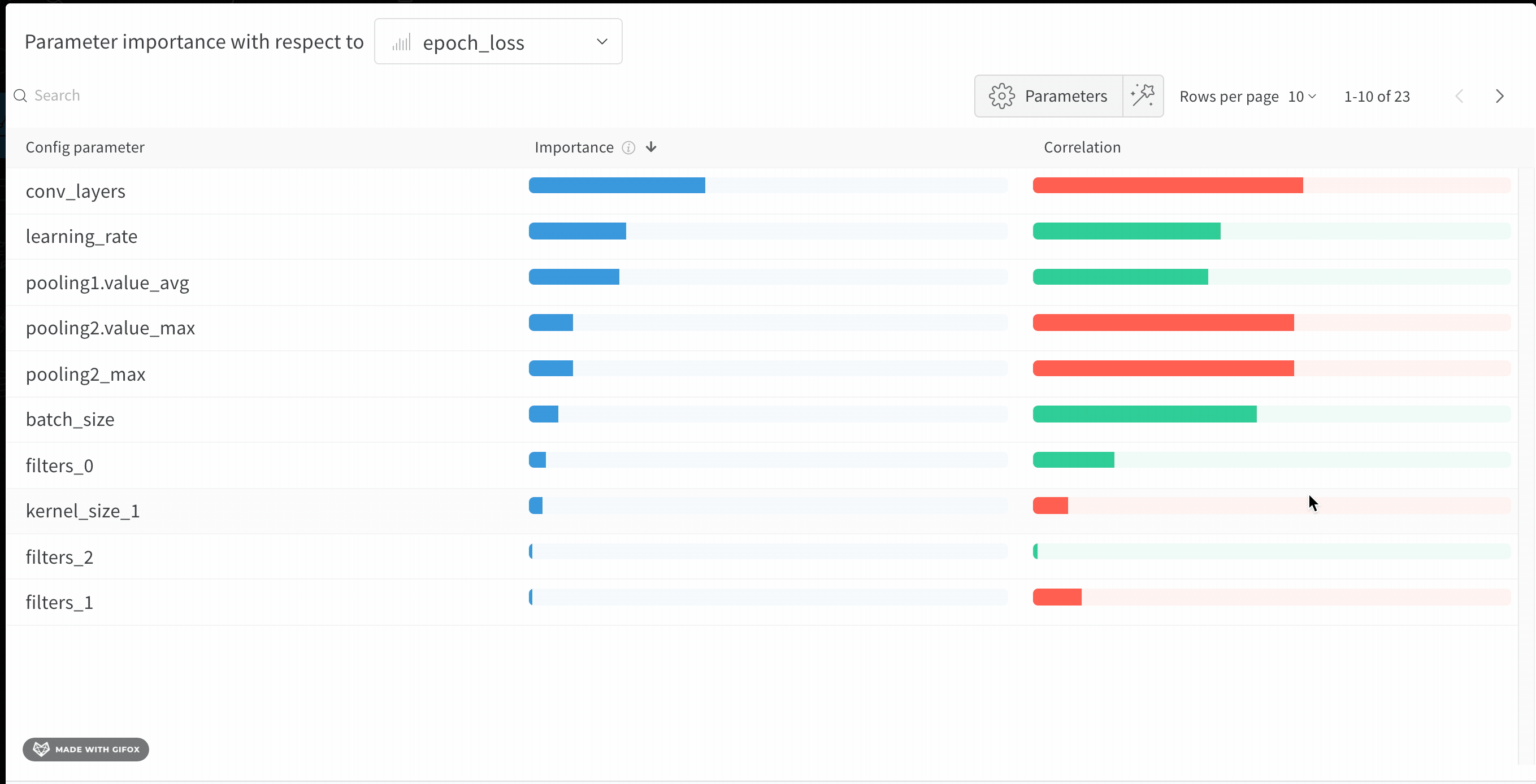
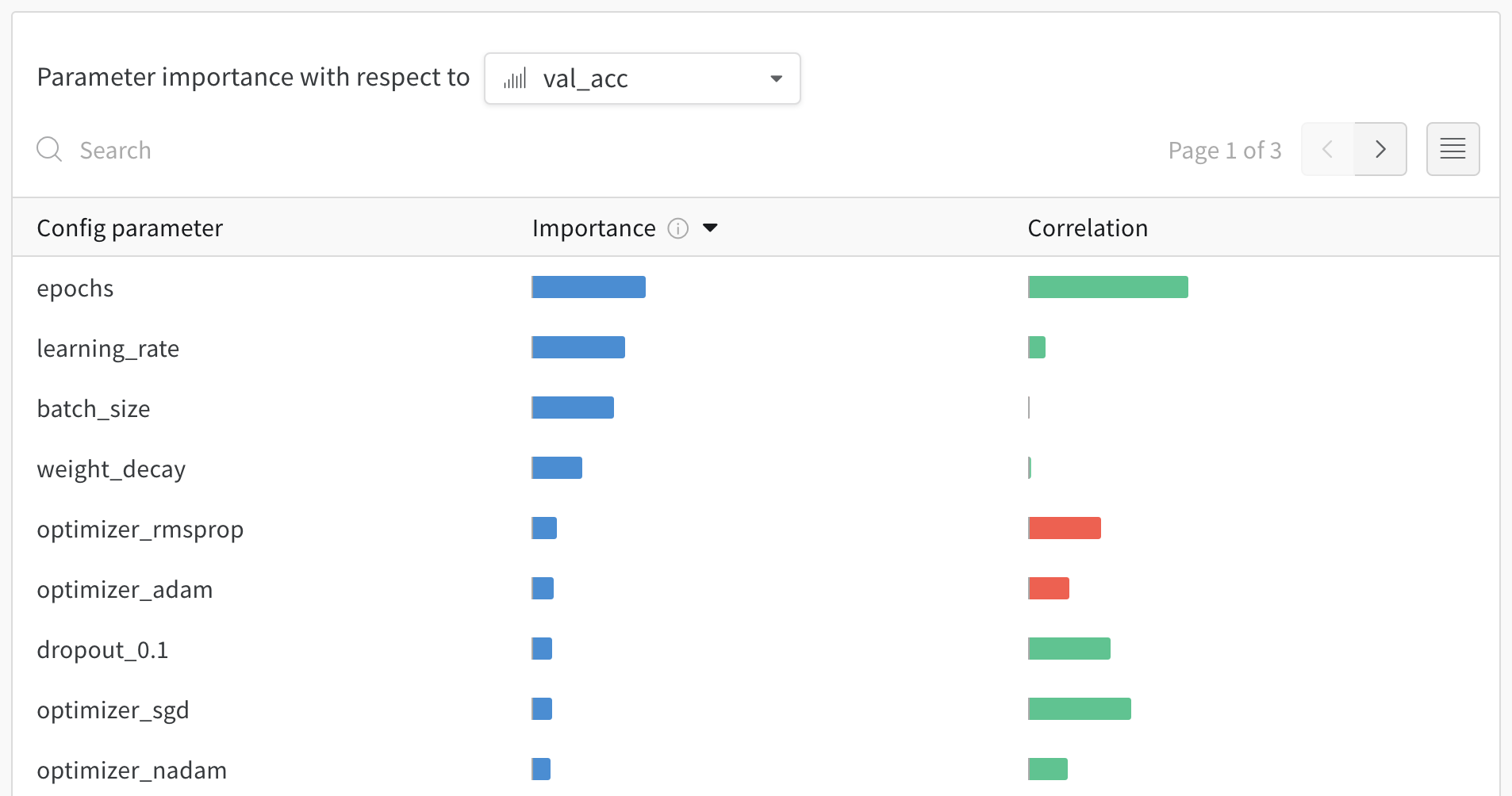
6 - Parameter importance
모델의 하이퍼파라미터와 출력 메트릭 간의 관계를 시각화합니다.
어떤 하이퍼파라미터가 가장 예측력이 높고 메트릭의 바람직한 값과 상관관계가 높은지 알아보세요.
**상관 관계(Correlation)**는 하이퍼파라미터와 선택한 메트릭 (이 경우 val_loss) 간의 선형 상관 관계입니다. 따라서 상관 관계가 높다는 것은 하이퍼파라미터의 값이 높을 때 메트릭도 더 높은 값을 갖고 그 반대도 마찬가지임을 의미합니다. 상관 관계는 살펴보기에 좋은 메트릭이지만 입력 간의 2차 상호 작용을 포착할 수 없으며 범위가 매우 다른 입력을 비교하는 것이 복잡해질 수 있습니다.
따라서 W&B는 중요도(importance) 메트릭도 계산합니다. W&B는 하이퍼파라미터를 입력으로, 메트릭을 대상 출력으로 사용하여 랜덤 포레스트를 트레이닝하고 랜덤 포레스트에 대한 특징 중요도 값을 리포트합니다.
이 기술에 대한 아이디어는 Fast.ai에서 하이퍼파라미터 공간을 탐색하기 위해 랜덤 포레스트 특징 중요도를 사용하는 것을 개척한 Jeremy Howard와의 대화에서 영감을 받았습니다. 이 강의 (및 이 노트)를 확인하여 이 분석의 동기에 대해 자세히 알아보는 것이 좋습니다.
하이퍼파라미터 중요도 패널은 상관관계가 높은 하이퍼파라미터 간의 복잡한 상호 작용을 해결합니다. 이를 통해 모델 성능 예측 측면에서 가장 중요한 하이퍼파라미터를 보여줌으로써 하이퍼파라미터 검색을 미세 튜닝하는 데 도움이 됩니다.
하이퍼파라미터 중요도 패널 만들기
W&B 프로젝트로 이동합니다.
패널 추가 버튼을 선택합니다.
차트 드롭다운을 확장하고 드롭다운에서 평행 좌표를 선택합니다.
빈 패널이 나타나면 Runs이 그룹 해제되었는지 확인하십시오.
파라미터 관리자를 사용하면 표시 및 숨겨진 파라미터를 수동으로 설정할 수 있습니다.
하이퍼파라미터 중요도 패널 해석하기
이 패널은 트레이닝 스크립트의 wandb.config오브젝트에 전달된 모든 파라미터를 보여줍니다. 다음으로 이러한 config 파라미터의 특징 중요도와 모델 메트릭과 관련된 상관 관계를 보여줍니다 (이 경우 val_loss).
중요도
중요도 열은 각 하이퍼파라미터가 선택한 메트릭을 예측하는 데 얼마나 유용한지를 보여줍니다. 수많은 하이퍼파라미터를 튜닝하기 시작하고 이 플롯을 사용하여 추가 탐색할 가치가 있는 하이퍼파라미터를 정확히 찾아내는 시나리오를 상상해 보십시오. 후속 스윕은 가장 중요한 하이퍼파라미터로 제한되어 더 좋고 저렴한 모델을 더 빠르게 찾을 수 있습니다.
W&B는 선형 모델보다 트리 기반 모델을 사용하여 중요도를 계산합니다. 전자는 범주형 데이터와 정규화되지 않은 데이터 모두에 더 관대하기 때문입니다.
위의 이미지에서 epochs, learning_rate, batch_size 및 weight_decay가 상당히 중요하다는 것을 알 수 있습니다.
상관 관계
상관 관계는 개별 하이퍼파라미터와 메트릭 값 간의 선형 관계를 캡처합니다. SGD 옵티마이저와 같은 하이퍼파라미터를 사용하는 것과 val_loss 사이에 중요한 관계가 있는지에 대한 질문에 답합니다 (이 경우 답은 ‘예’입니다). 상관 관계 값은 -1에서 1 사이이며, 양수 값은 양의 선형 상관 관계를 나타내고 음수 값은 음의 선형 상관 관계를 나타내고 값 0은 상관 관계가 없음을 나타냅니다. 일반적으로 어느 방향이든 0.7보다 큰 값은 강한 상관 관계를 나타냅니다.
이 그래프를 사용하여 메트릭과 더 높은 상관 관계가 있는 값을 추가로 탐색하거나 (이 경우 rmsprop 또는 nadam보다 stochastic gradient descent 또는 adam을 선택할 수 있음) 더 많은 에포크 동안 트레이닝할 수 있습니다.
상관 관계는 반드시 인과 관계가 아닌 연관성의 증거를 보여줍니다.
상관 관계는 이상치에 민감하며, 특히 시도한 하이퍼파라미터의 샘플 크기가 작은 경우 강한 관계를 보통 관계로 바꿀 수 있습니다.
마지막으로 상관 관계는 하이퍼파라미터와 메트릭 간의 선형 관계만 캡처합니다. 강한 다항 관계가 있는 경우 상관 관계에 의해 캡처되지 않습니다.
중요도와 상관 관계의 차이는 중요도가 하이퍼파라미터 간의 상호 작용을 고려하는 반면 상관 관계는 개별 하이퍼파라미터가 메트릭 값에 미치는 영향만 측정한다는 사실에서 비롯됩니다. 둘째, 상관 관계는 선형 관계만 캡처하는 반면 중요도는 더 복잡한 관계를 캡처할 수 있습니다.
보시다시피 중요도와 상관 관계는 모두 하이퍼파라미터가 모델 성능에 미치는 영향을 이해하는 데 유용한 툴입니다.
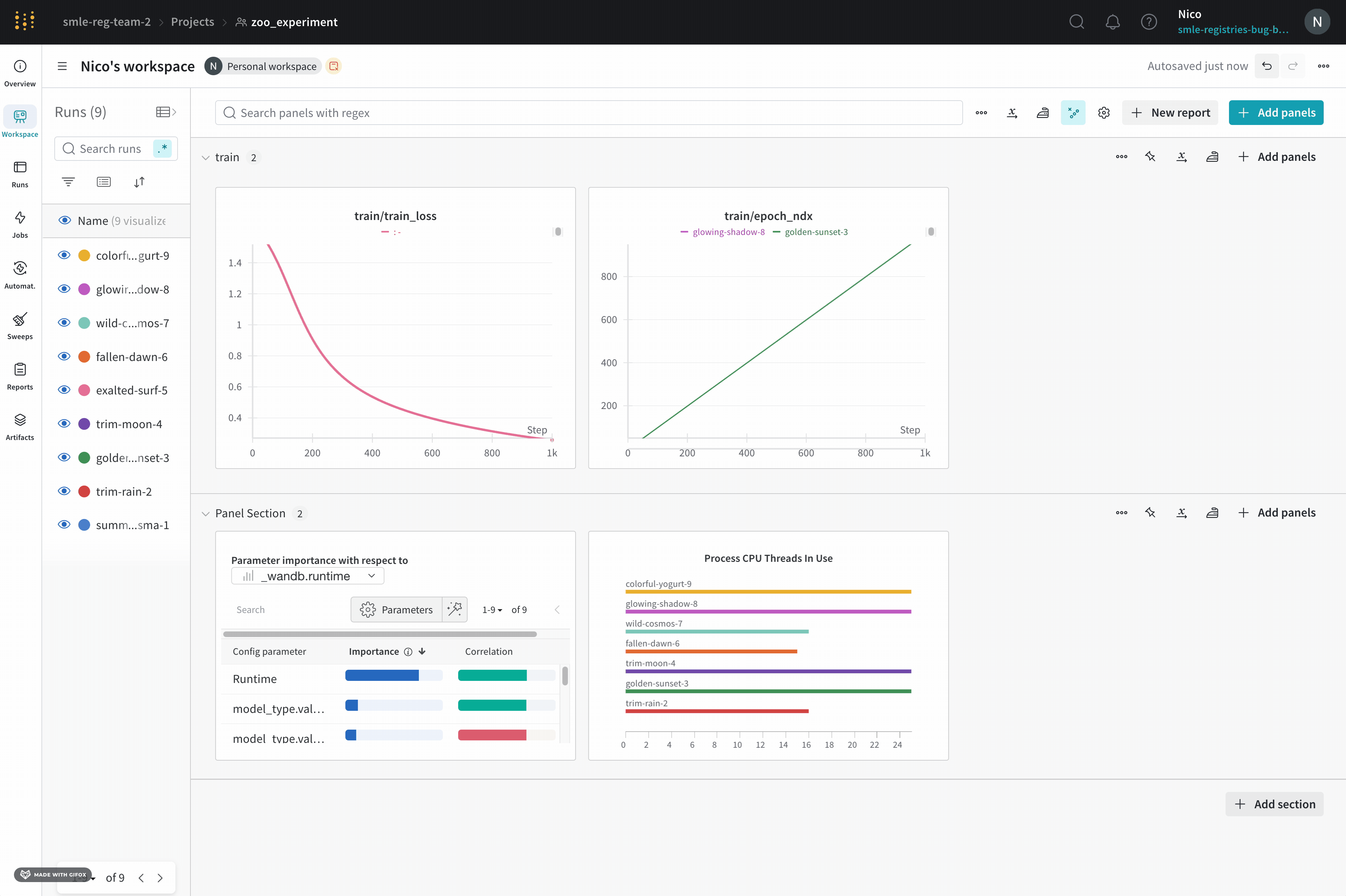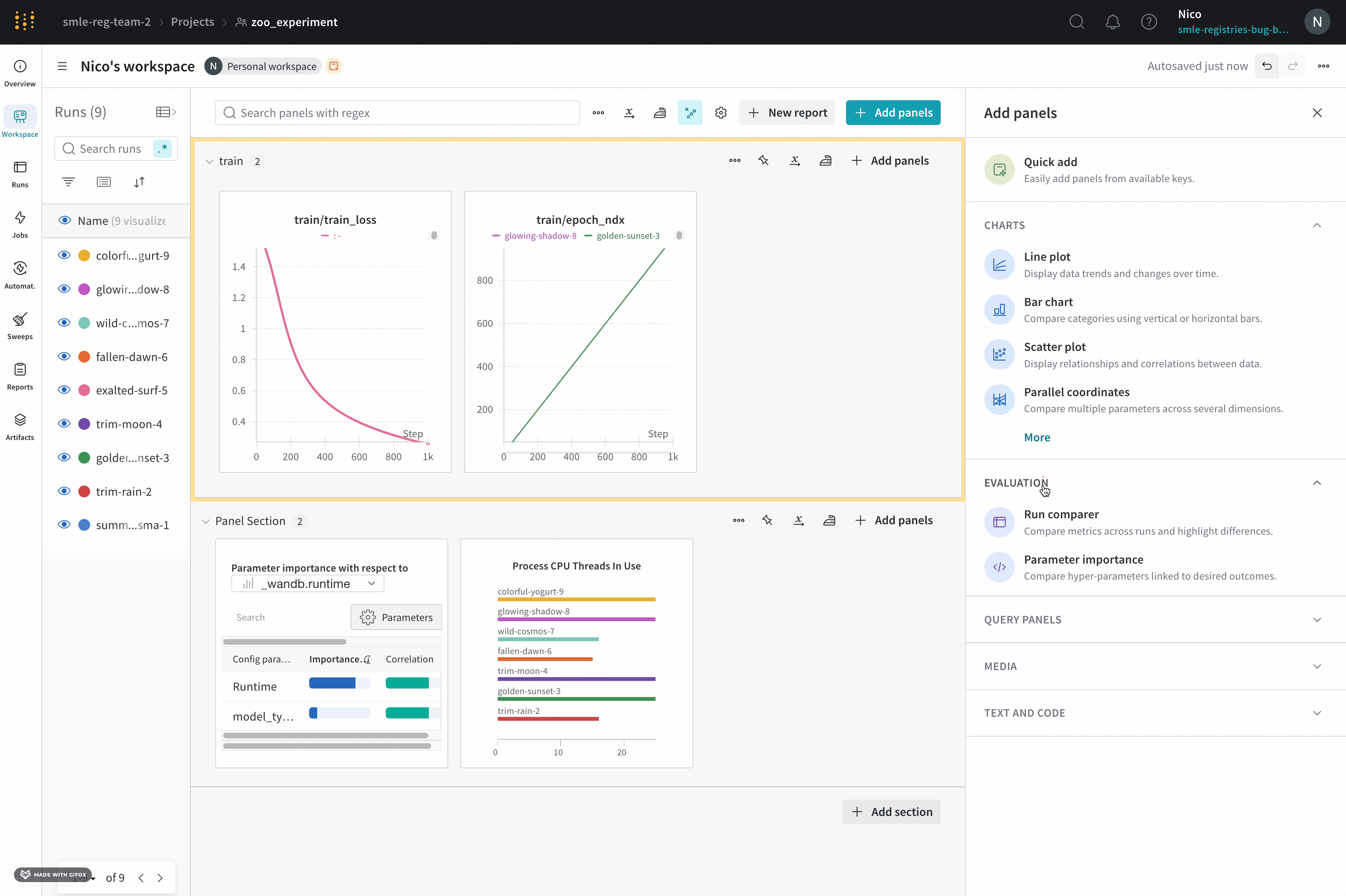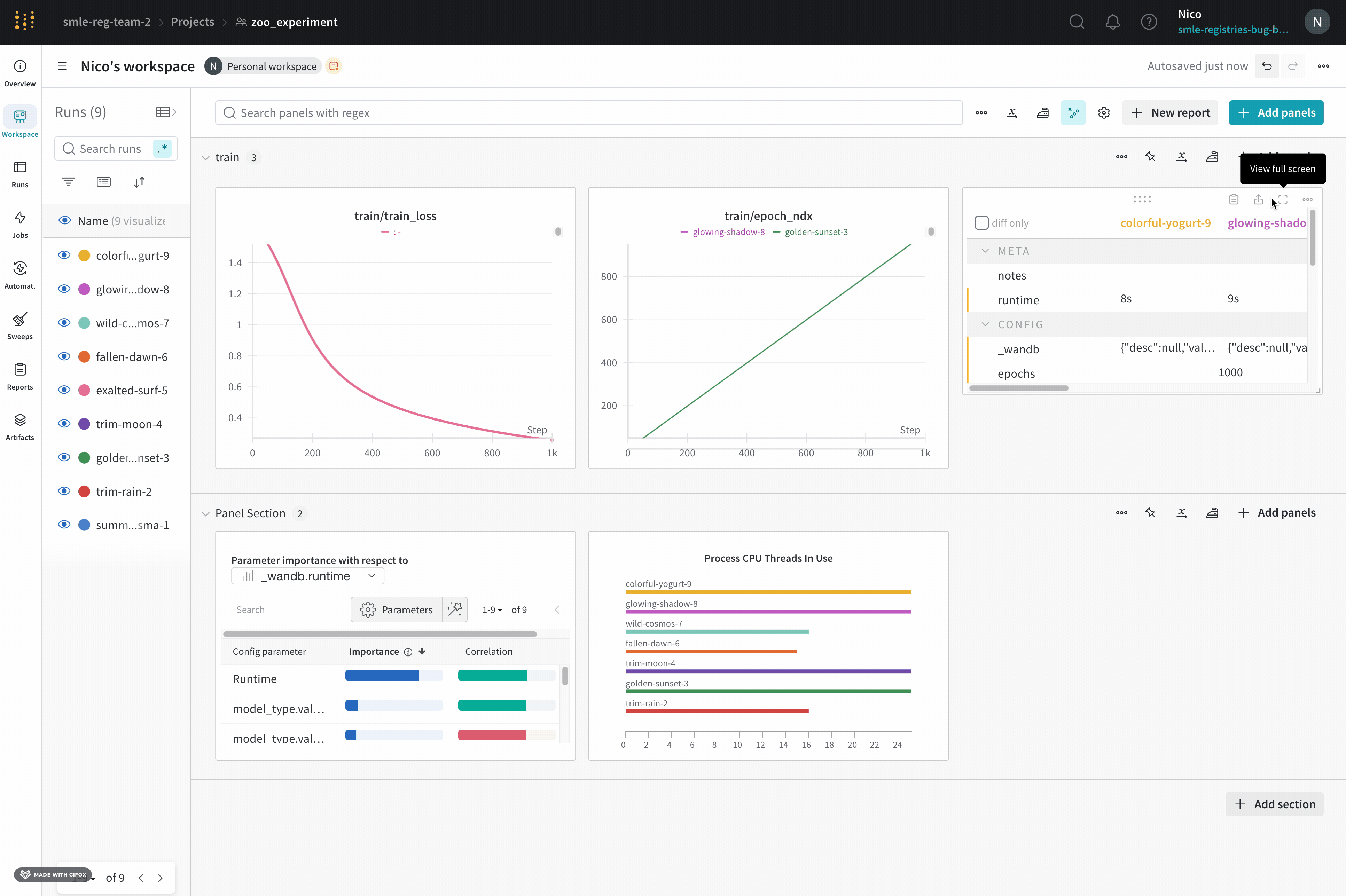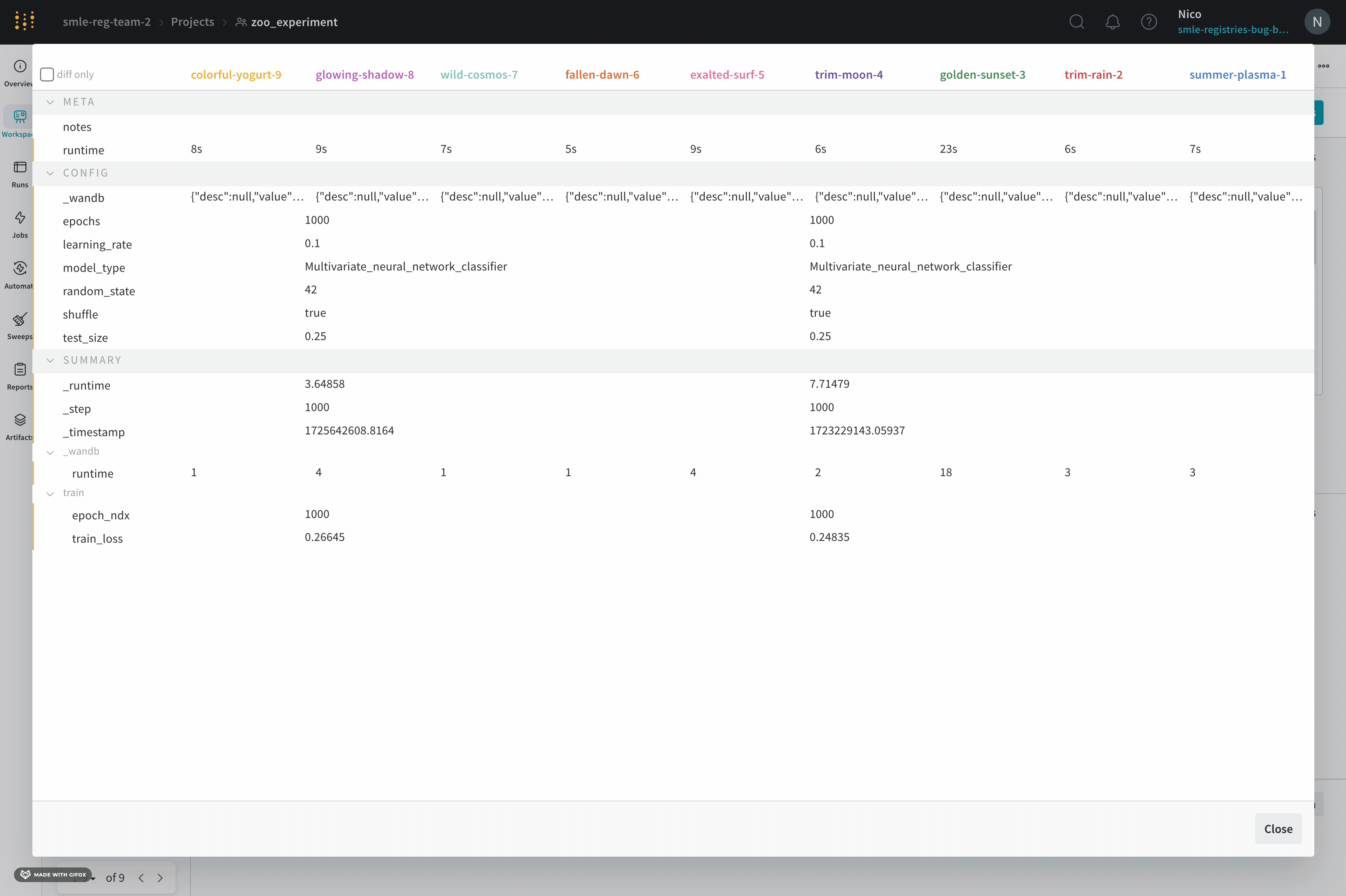
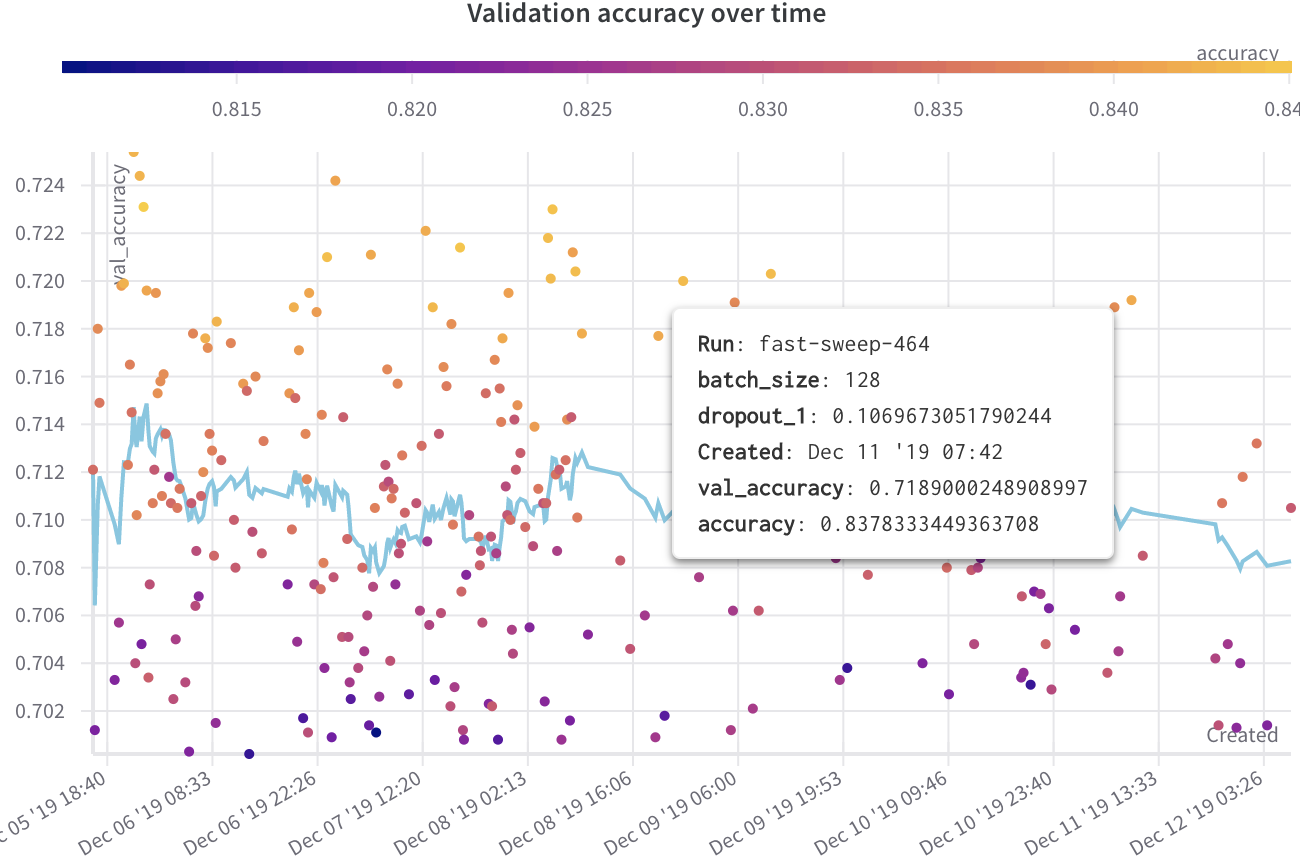
7 - Compare run metrics
여러 run에서 메트릭 비교
Run Comparer를 사용하여 여러 run에서 어떤 메트릭이 다른지 확인하세요.
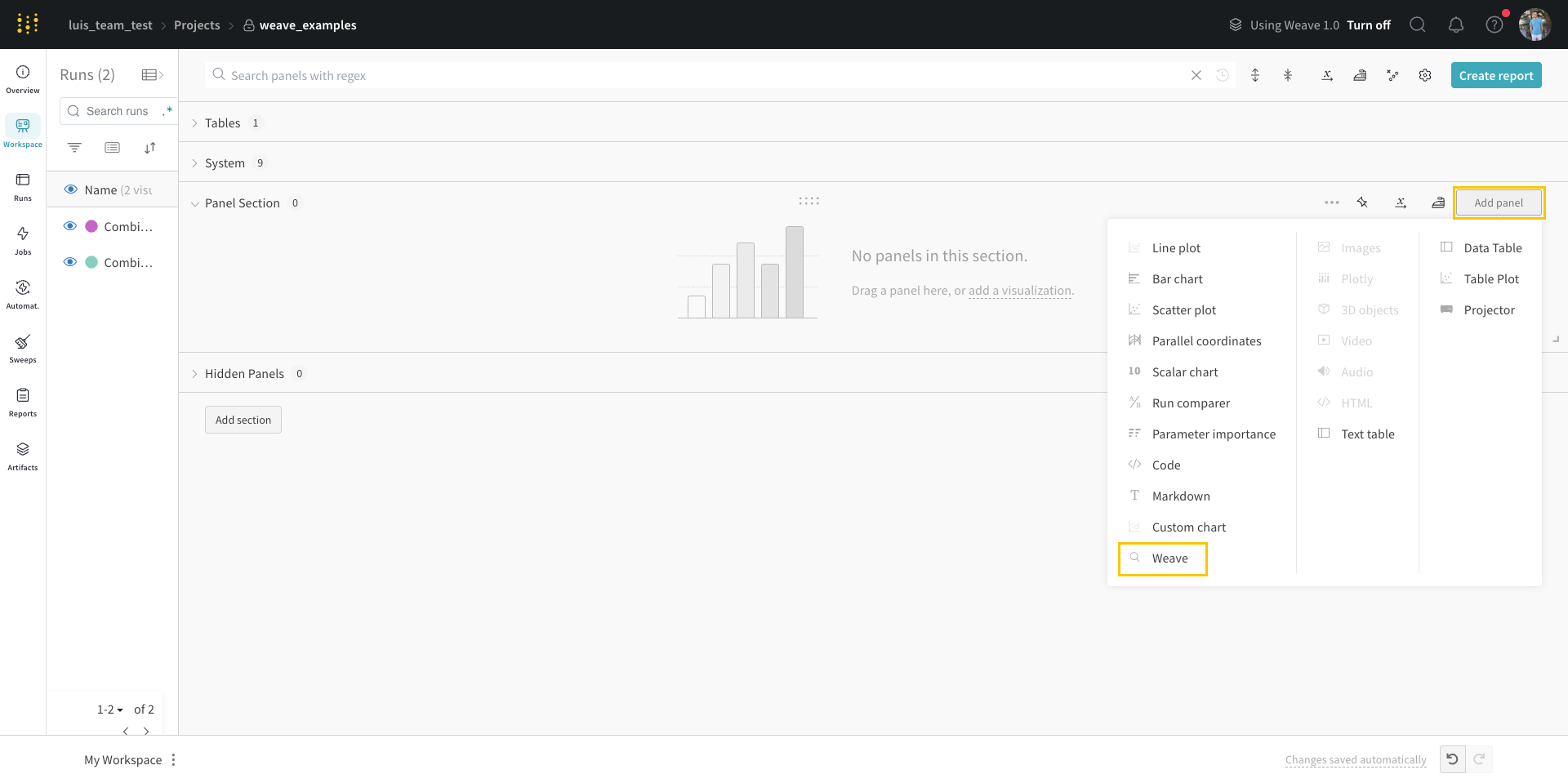
페이지 오른쪽 상단에서 패널 추가 버튼을 선택합니다.
나타나는 왼쪽 패널에서 Evaluation 드롭다운을 확장합니다.
Run Comparer를 선택합니다.
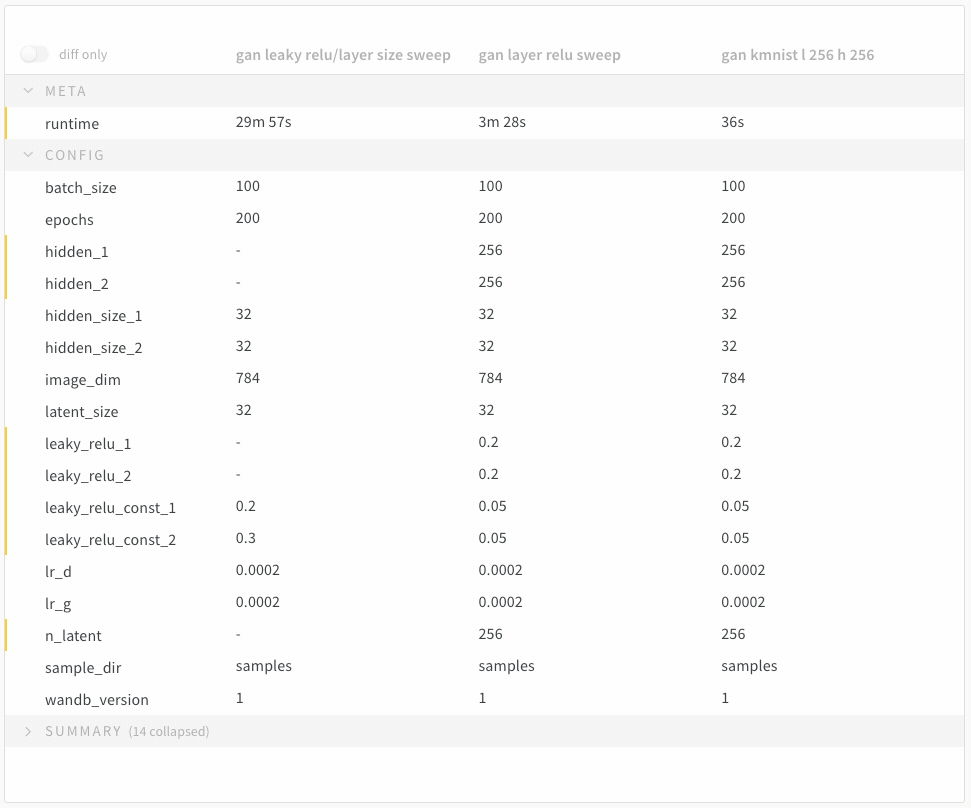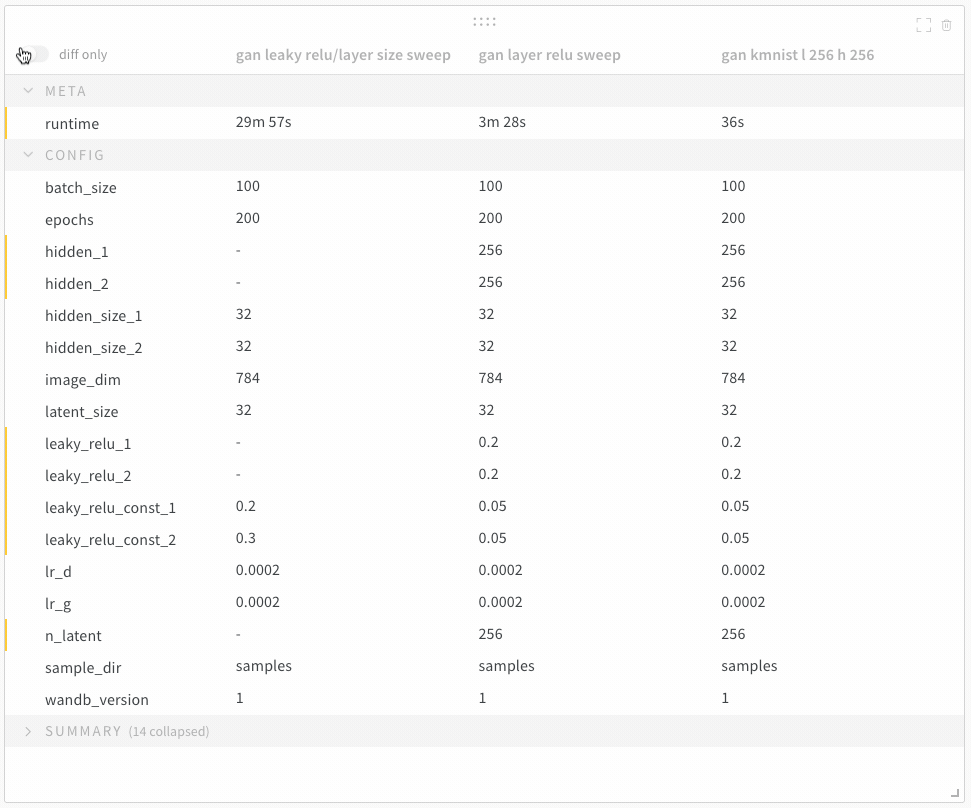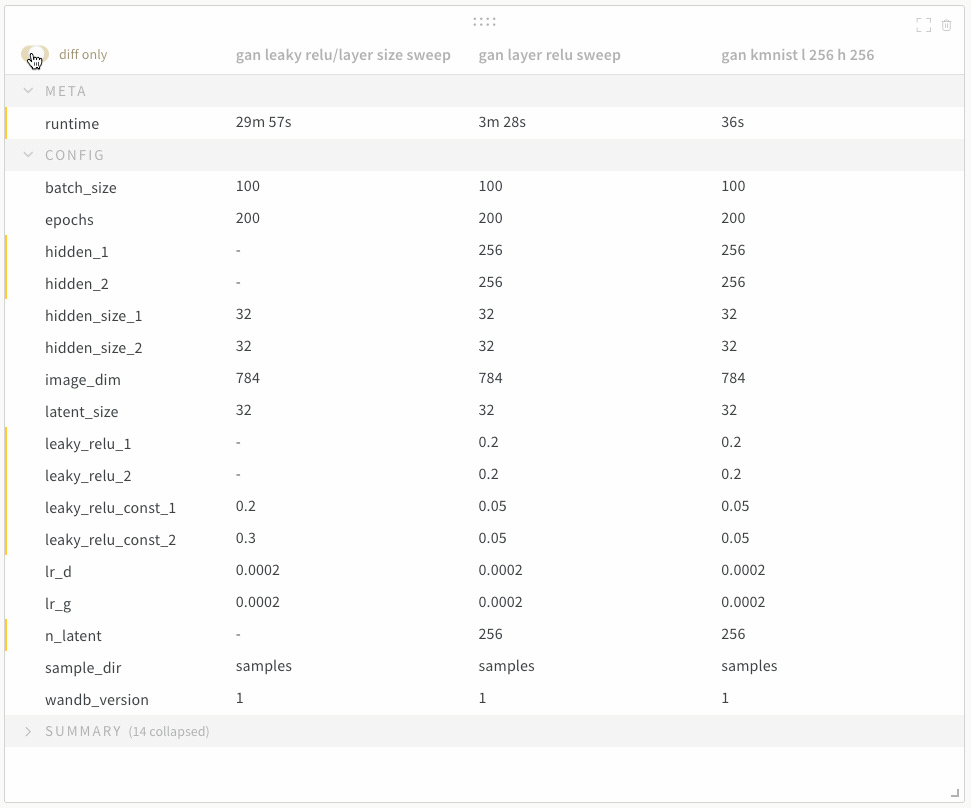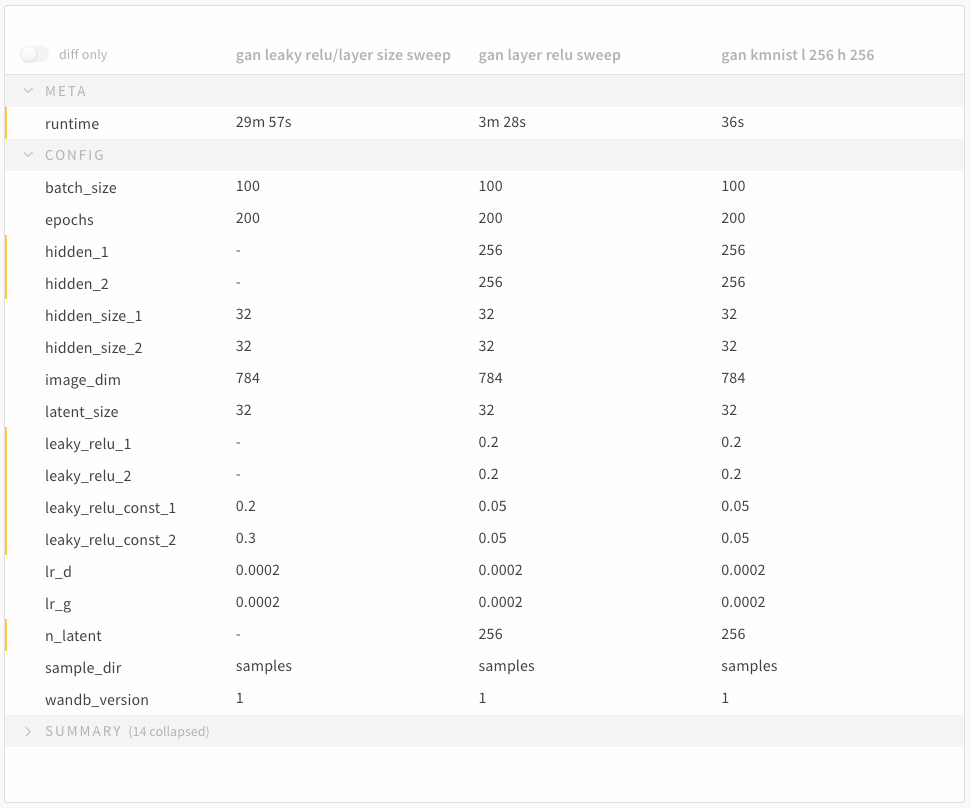
Diff Only 옵션을 켜서 여러 run에서 값이 동일한 행을 숨깁니다.
8 - Query panels
이 페이지의 일부 기능은 베타 버전이며 기능 플래그 뒤에 숨겨져 있습니다. 프로필 페이지의 자기 소개에 weave-plot을 추가하여 관련된 모든 기능을 잠금 해제하세요.
W&B Weave를 찾고 계신가요? W&B의 Generative AI 애플리케이션 구축 툴 모음인가요? weave에 대한 문서는 여기에서 찾으세요: wandb.me/weave.
쿼리 패널을 사용하여 데이터를 쿼리하고 대화형으로 시각화하세요.
쿼리 패널 만들기
워크스페이스 또는 리포트 내에 쿼리를 추가하세요.
프로젝트 워크스페이스로 이동합니다.
오른쪽 상단 모서리에서 패널 추가를 클릭합니다.
드롭다운에서 쿼리 패널을 선택합니다.
/쿼리 패널을 입력하고 선택합니다.
또는 쿼리를 run 집합과 연결할 수 있습니다:
리포트 내에서 /패널 그리드를 입력하고 선택합니다.
패널 추가 버튼을 클릭합니다.
드롭다운에서 쿼리 패널을 선택합니다.
쿼리 구성 요소
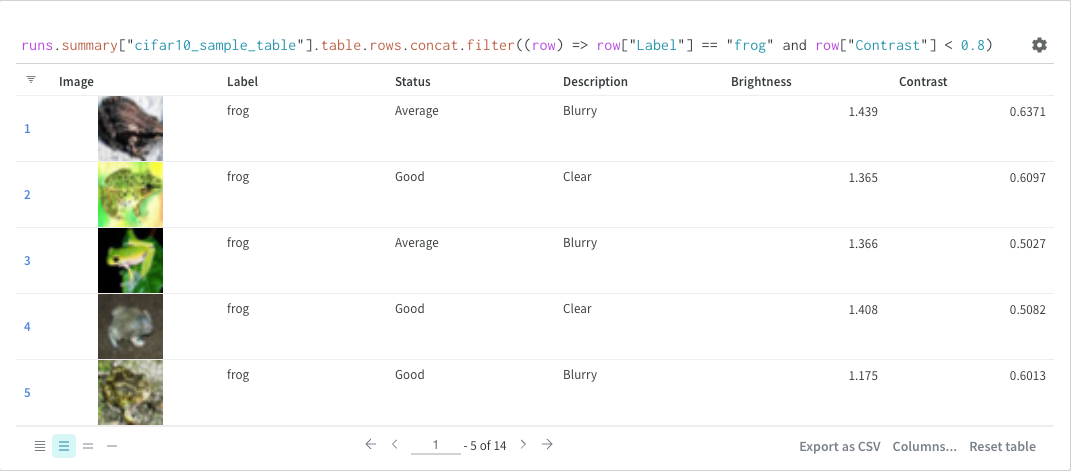
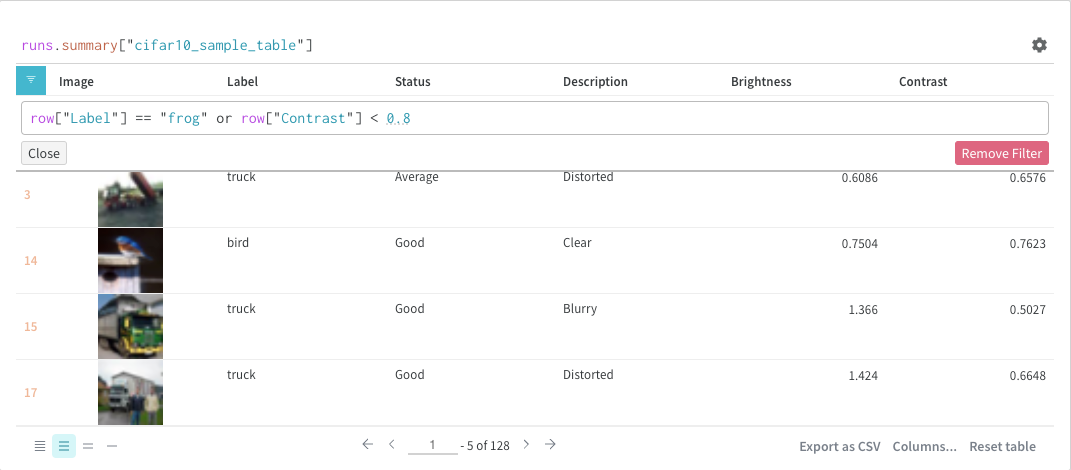
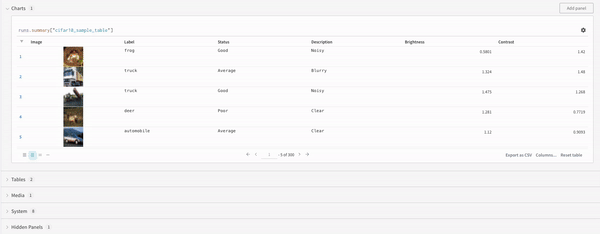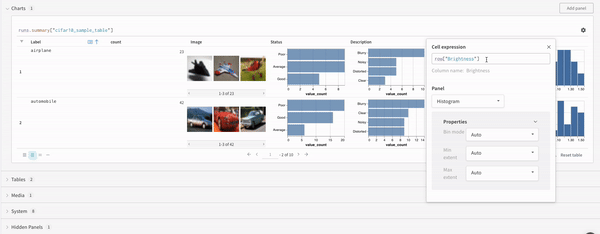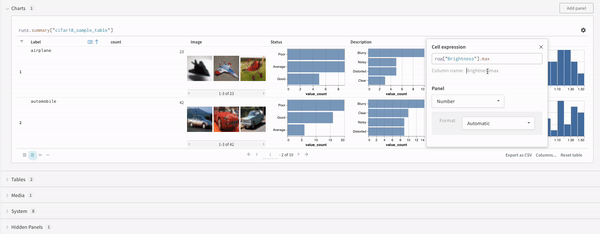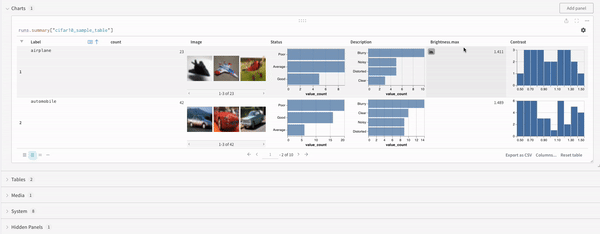
표현식
쿼리 표현식을 사용하여 run, Artifacts, Models, 테이블 등과 같이 W&B에 저장된 데이터를 쿼리합니다.
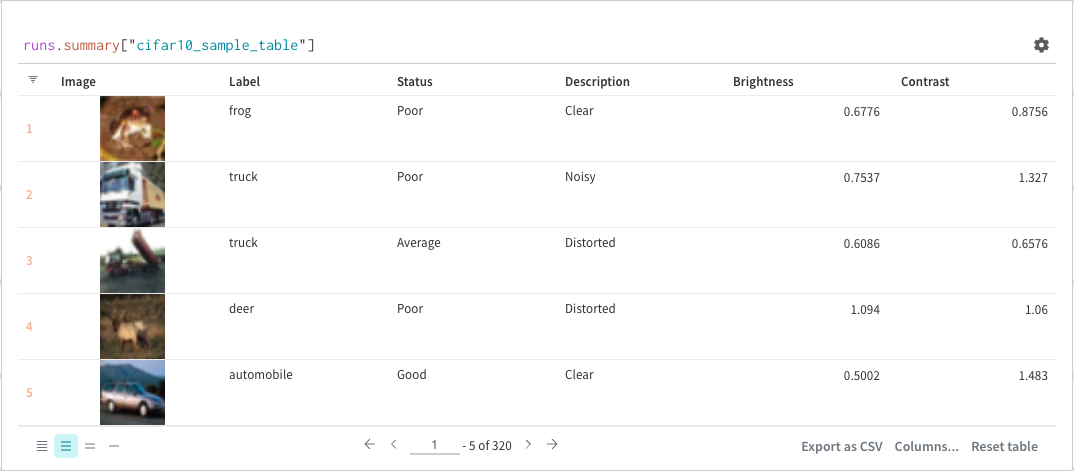
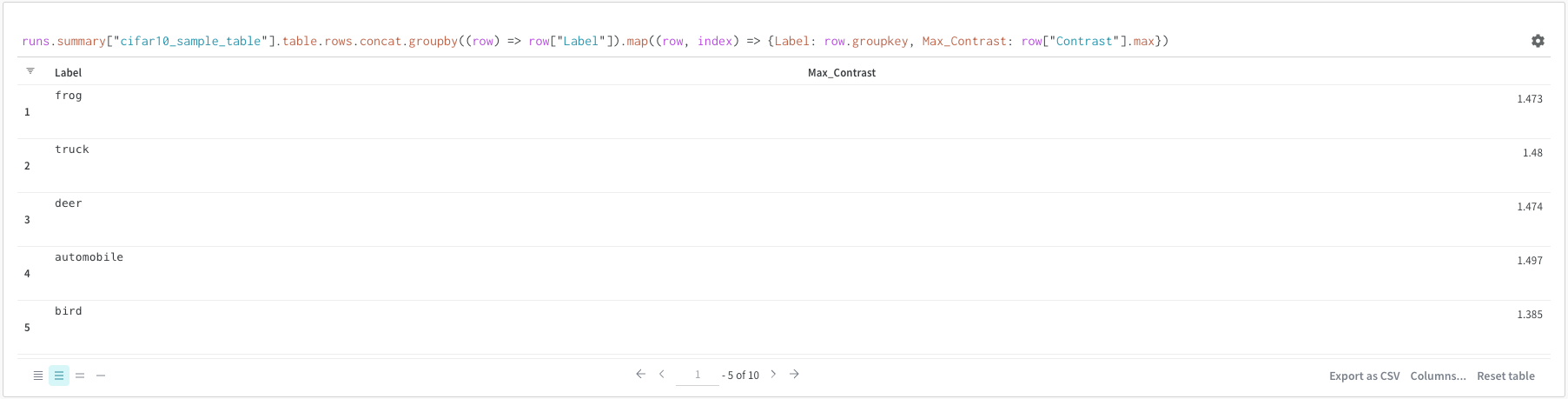
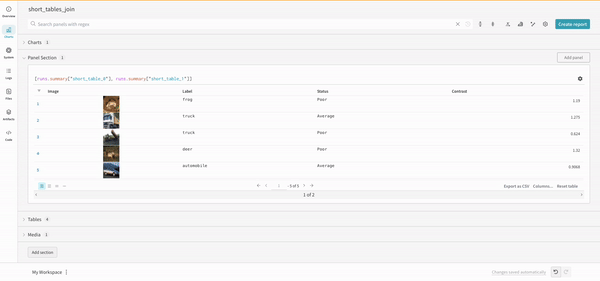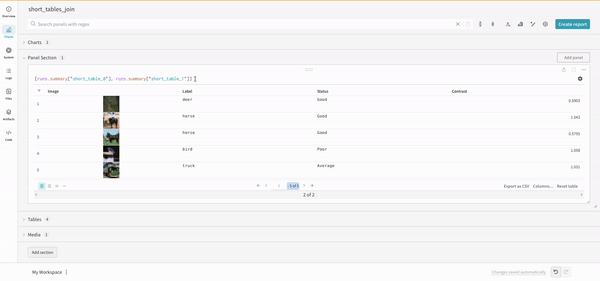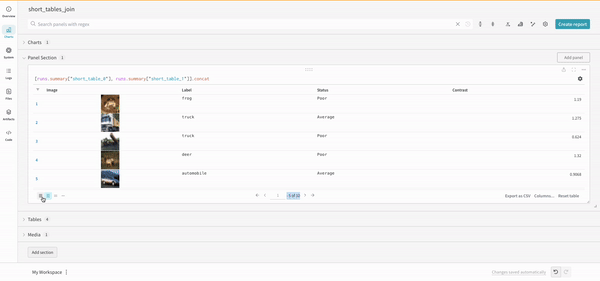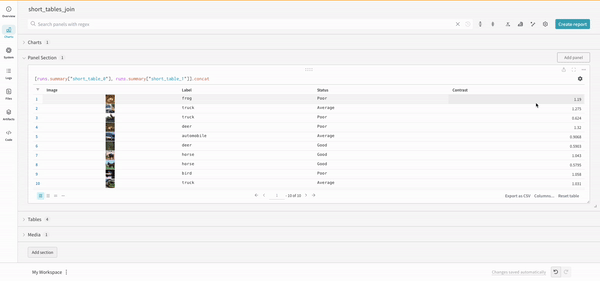
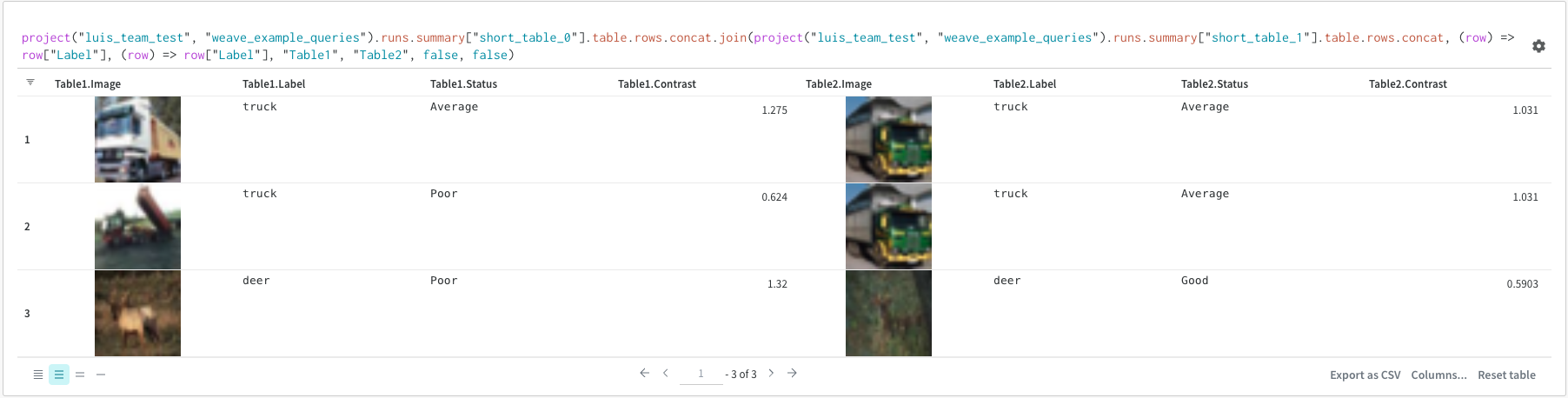
(row) => row["Label"]은 각 테이블에 대한 선택기이며 조인할 열을 결정합니다.
"Table1" 및 "Table2"는 조인될 때 각 테이블의 이름입니다.
true 및 false는 왼쪽 및 오른쪽 내부/외부 조인 설정을 위한 것입니다.
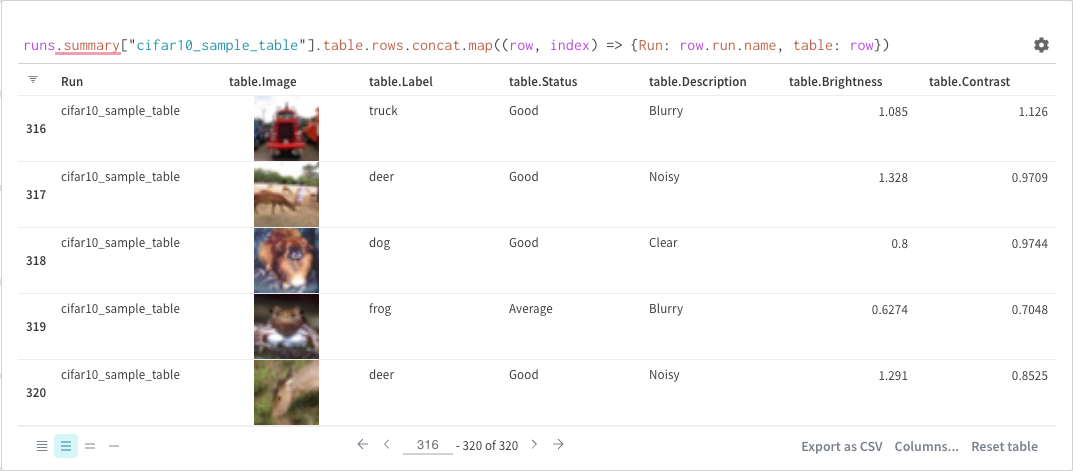
Runs 오브젝트
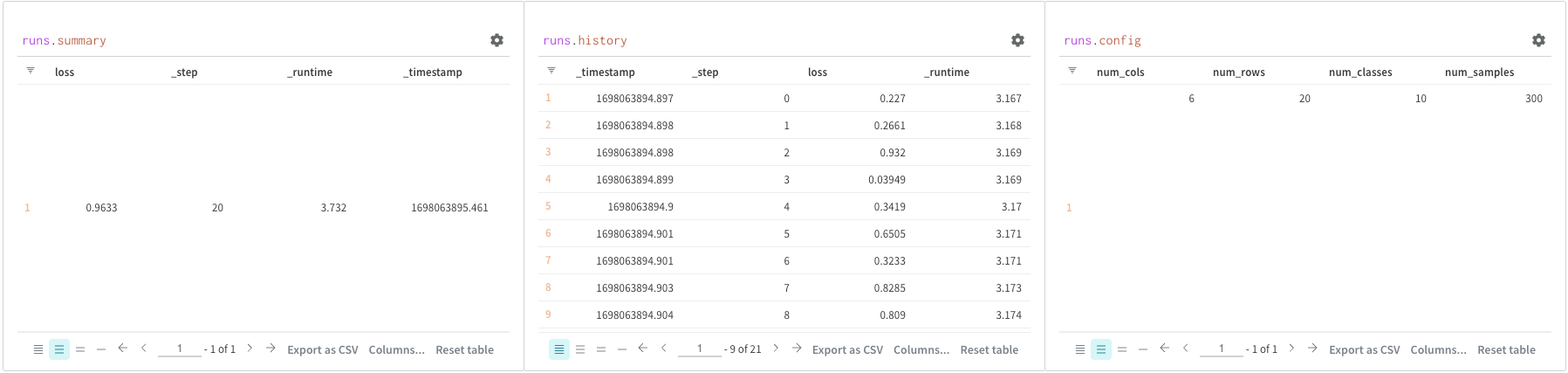
쿼리 패널을 사용하여 runs 오브젝트에 엑세스합니다. Run 오브젝트는 Experiments 기록을 저장합니다. 이 섹션의 리포트에서 자세한 내용을 확인할 수 있지만, 간략하게 살펴보면 runs 오브젝트는 다음과 같습니다.
summary: run 결과를 요약하는 정보 사전입니다. 여기에는 정확도 및 손실과 같은 스칼라 또는 큰 파일이 포함될 수 있습니다. 기본적으로 wandb.log()는 Summary를 로깅된 시계열의 최종 값으로 설정합니다. Summary 내용을 직접 설정할 수 있습니다. Summary를 run의 출력이라고 생각하세요.
history: 손실과 같이 모델이 트레이닝되는 동안 변경되는 값을 저장하기 위한 사전 목록입니다. wandb.log() 코맨드는 이 오브젝트에 추가됩니다.
config: 트레이닝 Run에 대한 하이퍼파라미터 또는 데이터셋 Artifact를 생성하는 Run에 대한 전처리 메소드와 같은 Run의 설정 정보 사전입니다. 이것을 Run의 “입력"이라고 생각하십시오.
Artifacts 엑세스
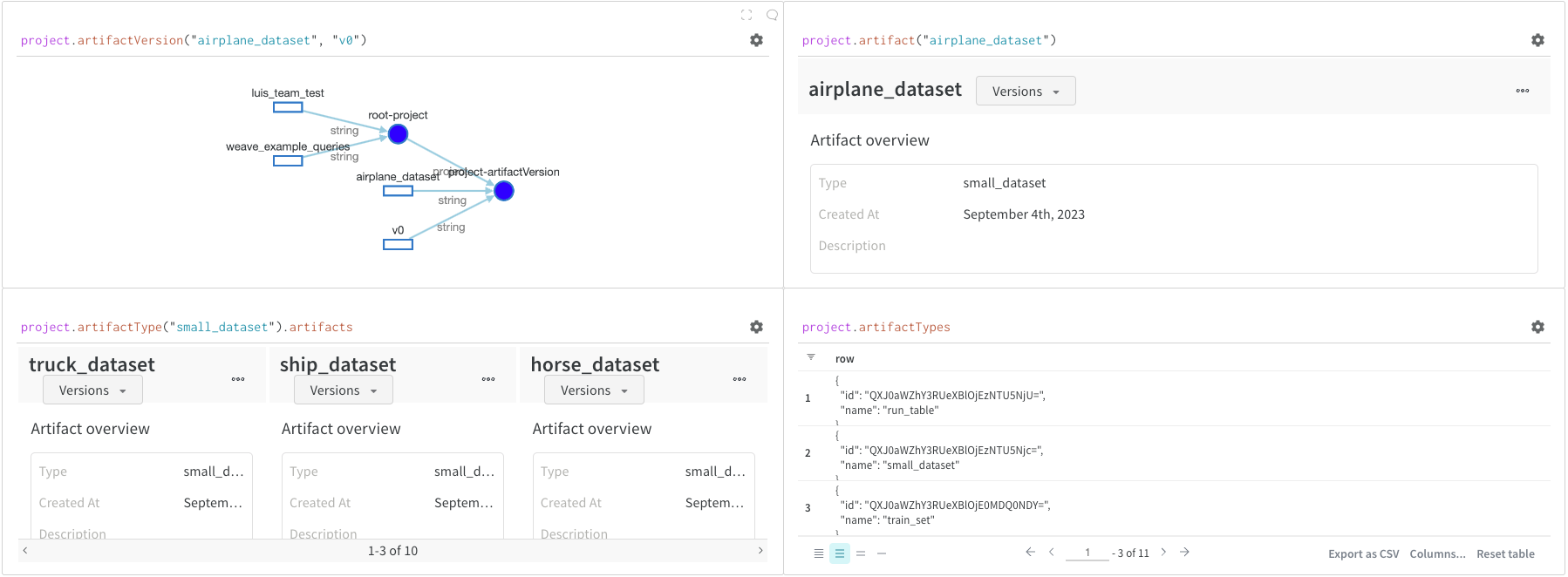
Artifacts는 W&B의 핵심 개념입니다. 버전이 지정된 명명된 파일 및 디렉토리 모음입니다. Artifacts를 사용하여 모델 가중치, 데이터셋 및 기타 파일 또는 디렉토리를 추적합니다. Artifacts는 W&B에 저장되며 다운로드하거나 다른 Run에서 사용할 수 있습니다. 이 섹션의 리포트에서 자세한 내용과 예제를 확인할 수 있습니다. Artifacts는 일반적으로 project 오브젝트에서 엑세스됩니다.
project.artifactVersion(): 프로젝트 내에서 주어진 이름과 버전에 대한 특정 아티팩트 버전을 반환합니다.
project.artifact(""): 프로젝트 내에서 주어진 이름에 대한 아티팩트를 반환합니다. 그런 다음 .versions를 사용하여 이 아티팩트의 모든 버전 목록을 가져올 수 있습니다.
project.artifactType(): 프로젝트 내에서 주어진 이름에 대한 artifactType을 반환합니다. 그런 다음 .artifacts를 사용하여 이 유형의 모든 아티팩트 목록을 가져올 수 있습니다.
project.artifactTypes: 프로젝트 아래의 모든 아티팩트 유형 목록을 반환합니다.
8.1 - Embed objects
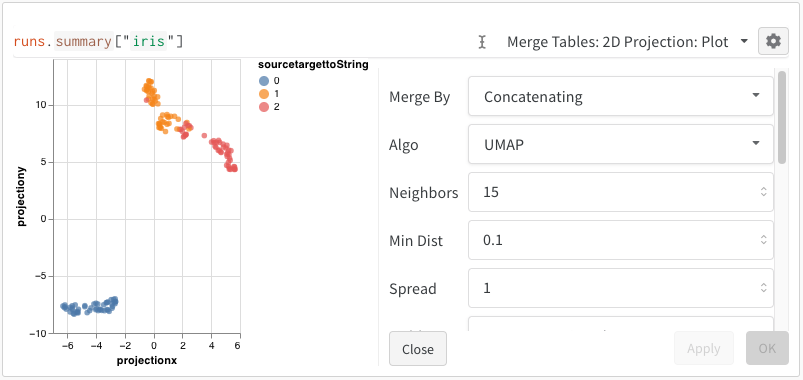
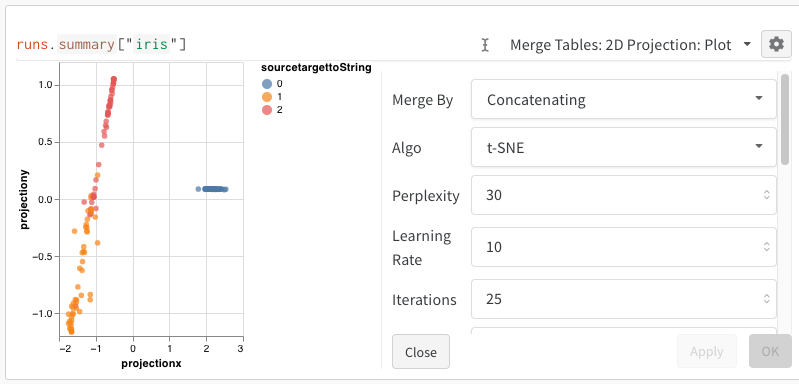
W&B의 Embedding Projector를 통해 PCA, UMAP, t-SNE와 같은 일반적인 차원 축소 알고리즘을 사용하여 다차원 임베딩을 2D 평면에 플롯할 수 있습니다.
Embeddings는 오브젝트 (사람, 이미지, 게시물, 단어 등)를 숫자 목록 ( vector 라고도 함)으로 나타내는 데 사용됩니다. 기계 학습 및 데이터 과학 유스 케이스에서 Embeddings는 다양한 애플리케이션에서 다양한 접근 방식을 사용하여 생성할 수 있습니다. 이 페이지에서는 독자가 Embeddings에 익숙하고 W&B 내에서 Embeddings를 시각적으로 분석하는 데 관심이 있다고 가정합니다.
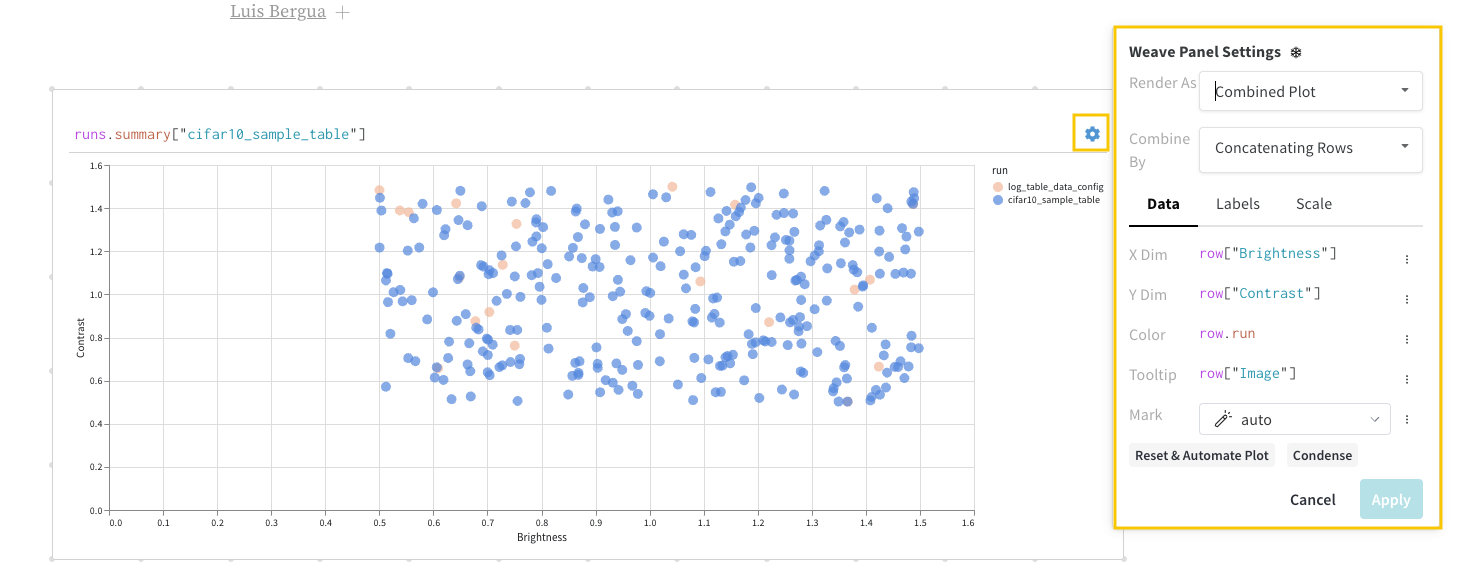
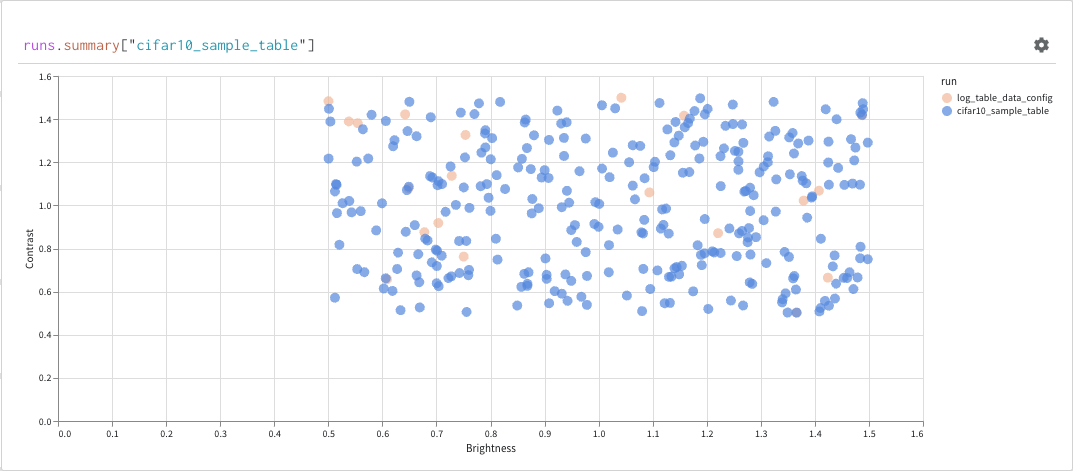
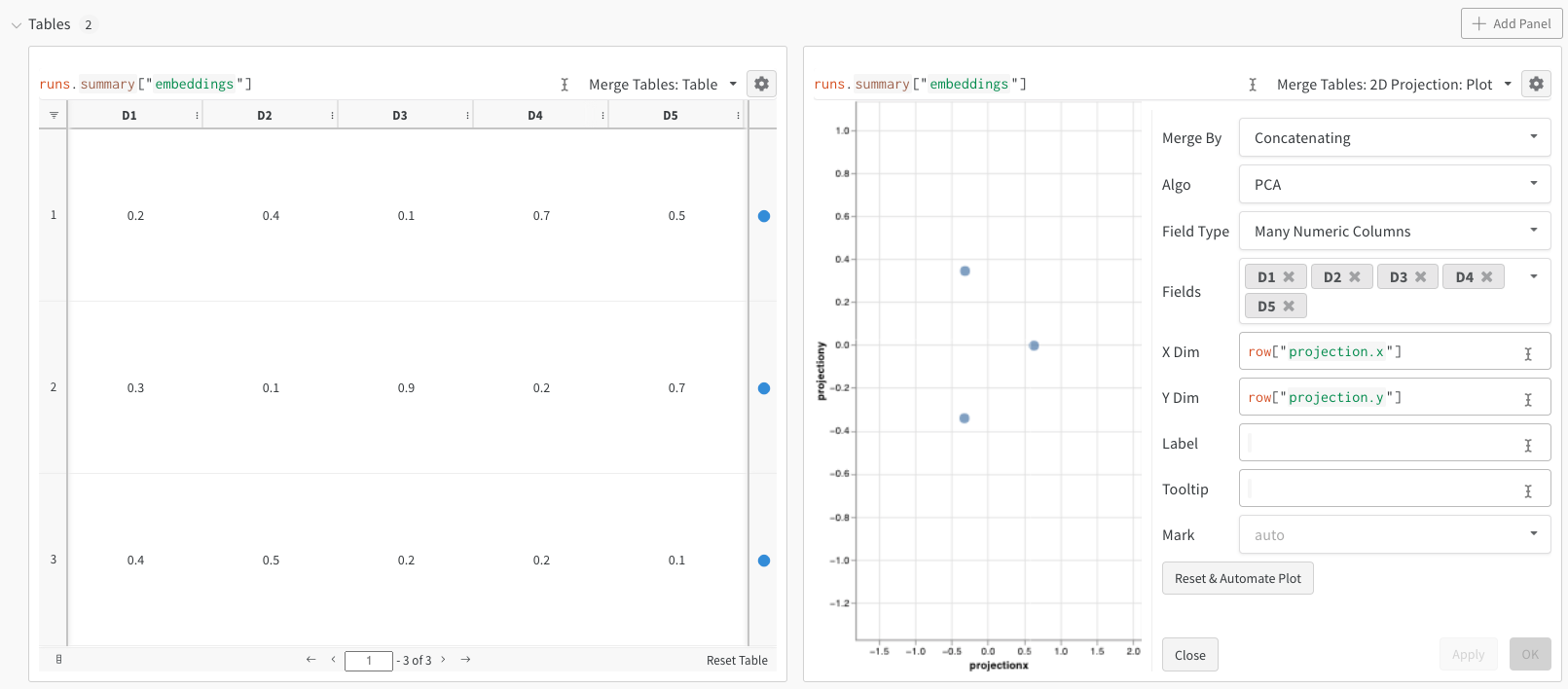
위의 코드를 실행하면 W&B 대시보드에 데이터가 포함된 새 Table이 표시됩니다. 오른쪽 상단 패널 선택기에서 2D Projection을 선택하여 Embeddings를 2차원으로 플롯할 수 있습니다. 스마트 기본값이 자동으로 선택되며, 기어 아이콘을 클릭하여 엑세스할 수 있는 설정 메뉴에서 쉽게 재정의할 수 있습니다. 이 예제에서는 사용 가능한 5개의 숫자 차원을 모두 자동으로 사용합니다.
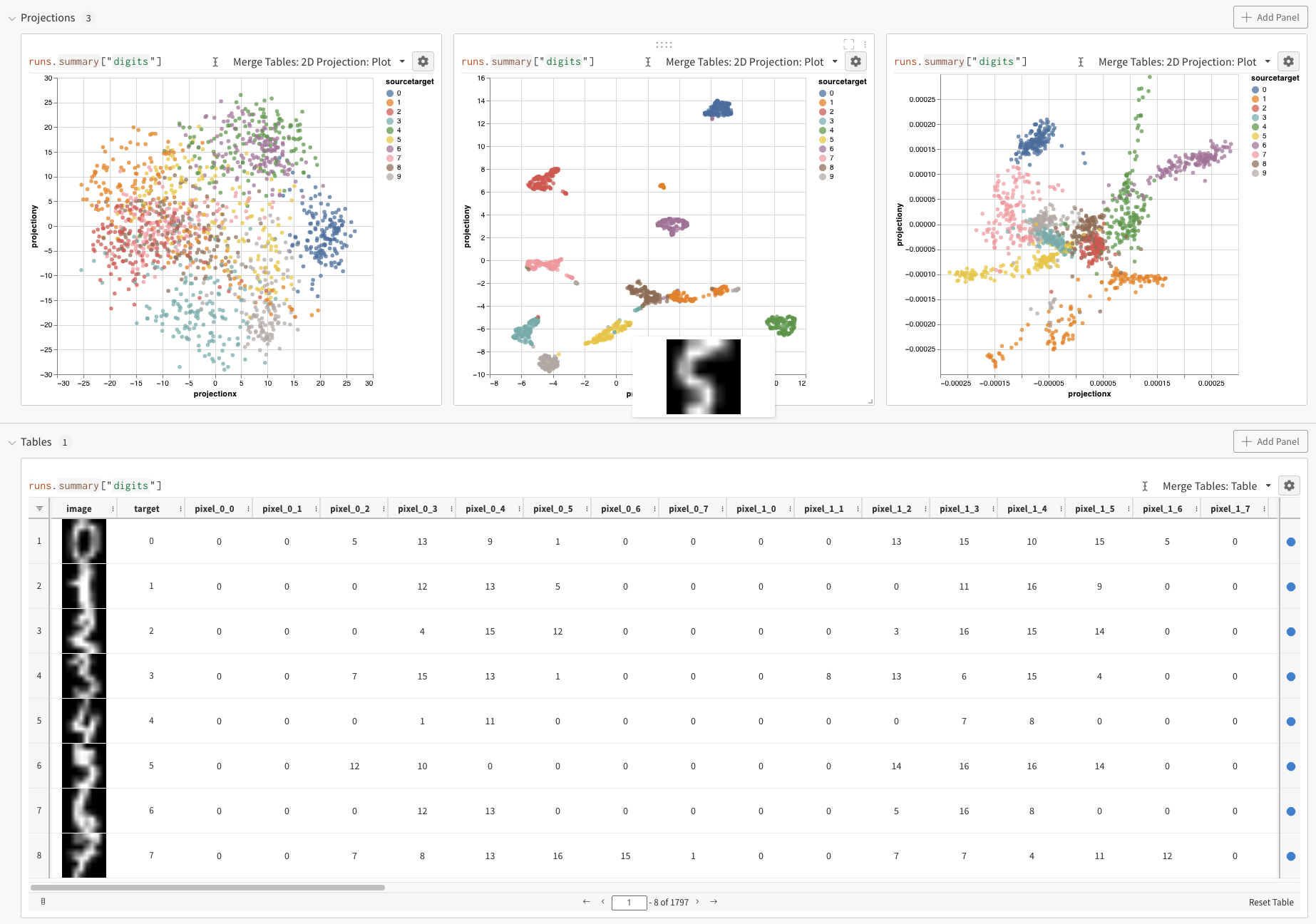
Digits MNIST
위의 예제는 Embeddings 로깅의 기본 메커니즘을 보여 주지만 일반적으로 훨씬 더 많은 차원과 샘플을 사용합니다. MNIST Digits 데이터셋 (UCI ML 손으로 쓴 숫자 데이터셋s)을 고려해 보겠습니다. SciKit-Learn을 통해 사용할 수 있습니다. 이 데이터셋에는 각각 64개의 차원을 가진 1797개의 레코드가 있습니다. 문제는 10개의 클래스 분류 유스 케이스입니다. 시각화를 위해 입력 데이터를 이미지로 변환할 수도 있습니다.
위의 코드를 실행하면 UI에 Table이 다시 표시됩니다. 2D Projection을 선택하면 Embedding 정의, 색상, 알고리즘 (PCA, UMAP, t-SNE), 알고리즘 파라미터를 구성하고 오버레이할 수도 있습니다 (이 경우 점 위로 마우스를 가져갈 때 이미지가 표시됨). 이 특정 경우에서는 이 모든 것이 “스마트 기본값"이며 2D Projection에서 한 번의 클릭으로 매우 유사한 내용을 볼 수 있습니다. (이 예제와 상호 작용하려면 여기를 클릭하십시오.).
로깅 옵션
다양한 형식으로 Embeddings를 로그할 수 있습니다.
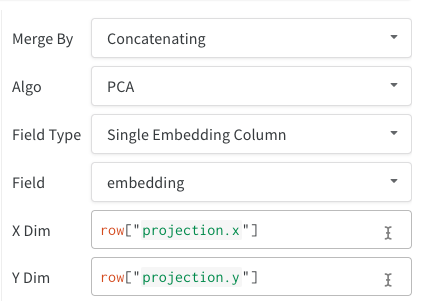
단일 Embedding 열: 데이터가 이미 “매트릭스"와 유사한 형식인 경우가 많습니다. 이 경우 셀 값의 데이터 유형이 list[int], list[float] 또는 np.ndarray일 수 있는 단일 Embedding 열을 만들 수 있습니다.
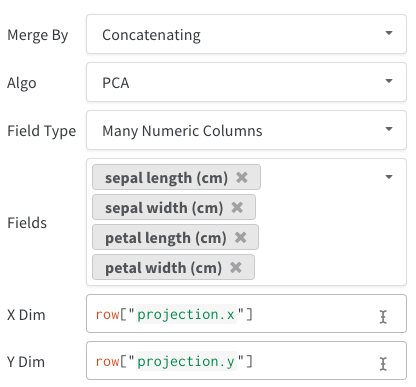
여러 숫자 열: 위의 두 예제에서는 이 접근 방식을 사용하고 각 차원에 대한 열을 만듭니다. 현재 셀에 대해 python int 또는 float를 허용합니다.
또한 모든 테이블과 마찬가지로 테이블 구성 방법에 대한 많은 옵션이 있습니다.
wandb.Table(dataframe=df)를 사용하여 데이터프레임에서 직접
wandb.Table(data=[...], columns=[...])를 사용하여 데이터 목록에서 직접
테이블을 점진적으로 행 단위로 빌드합니다 (코드에 루프가 있는 경우에 적합). table.add_data(...)를 사용하여 테이블에 행을 추가합니다.
테이블에 Embedding 열을 추가합니다 (Embedding 형식의 예측 목록이 있는 경우에 적합): table.add_col("col_name", ...)
계산된 열을 추가합니다 (테이블에서 매핑하려는 함수 또는 model이 있는 경우에 적합): table.add_computed_columns(lambda row, ndx: {"embedding": model.predict(row)})
플로팅 옵션
2D Projection을 선택한 후 기어 아이콘을 클릭하여 렌더링 설정을 편집할 수 있습니다. 원하는 열을 선택하는 것 외에도 (위 참조) 원하는 알고리즘 (원하는 파라미터와 함께)을 선택할 수 있습니다. 아래에서 UMAP 및 t-SNE에 대한 파라미터를 각각 볼 수 있습니다.
참고: 현재 세 가지 알고리즘 모두에 대해 임의의 1000개 행과 50개 차원의 서브셋으로 다운샘플링합니다.