Weave and Models integration demo
3 minute read
このノートブックでは、W&B Weave と W&B Models を組み合わせて使用する方法を紹介します。具体的には、この例では 2 つの異なる Teams を考慮します。
- The Model Team: モデル構築 Team は新しいチャット Model (Llama 3.2) をファインチューンし、W&B Models を使用してレジストリに保存します。
- The App Team: アプリ開発 Team はチャット Model を取得して、W&B Weave を使用して新しい RAG チャットボットを作成および評価します。
W&B Models と W&B Weave の両方のパブリック Workspace はこちらにあります。
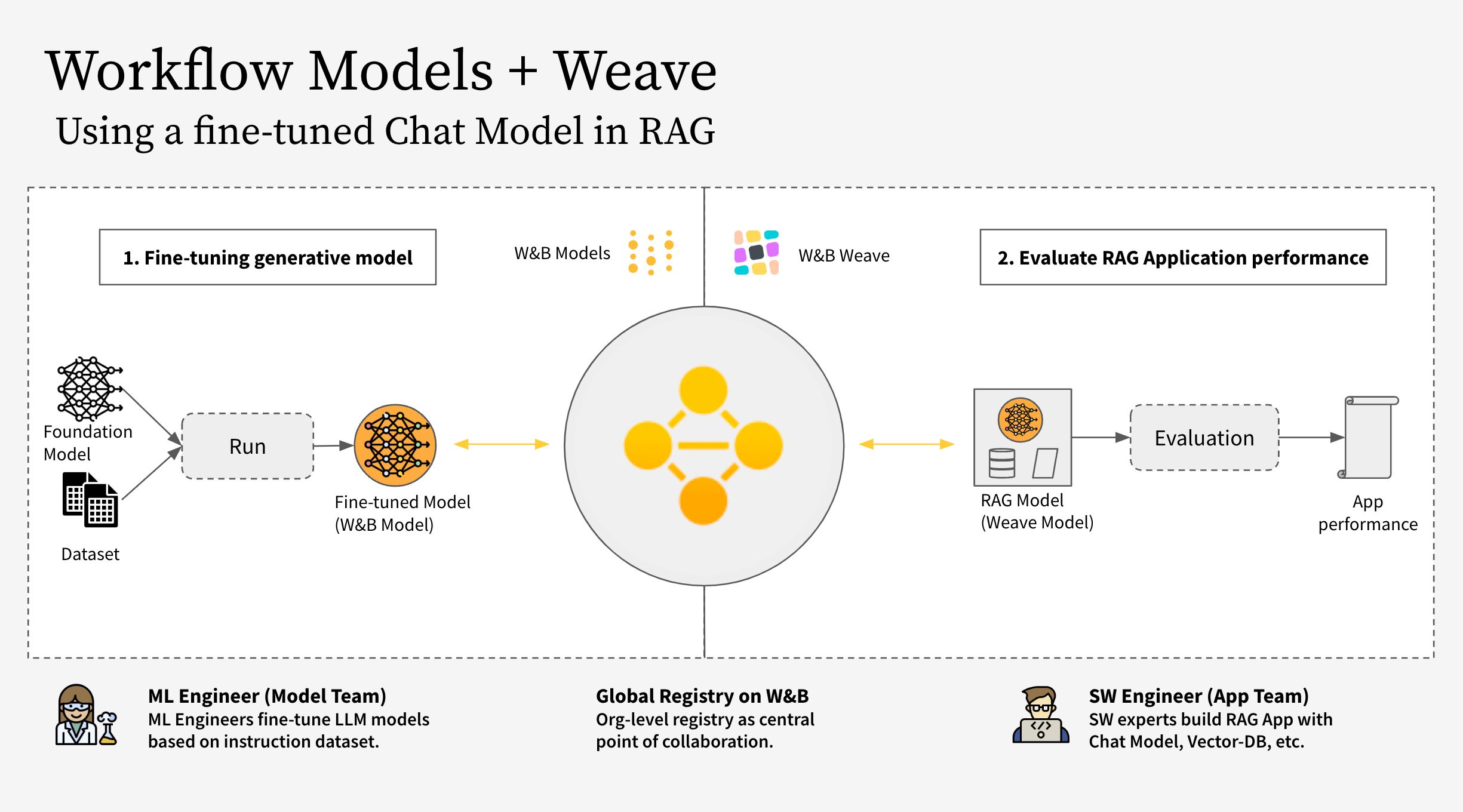
このワークフローは、次のステップで構成されています。
- W&B Weave で RAG アプリの コードをインストルメント化する
- LLM (Llama 3.2 など。他の LLM に置き換えることもできます) をファインチューンし、W&B Models で追跡する
- ファインチューンされた model を W&B Registry に記録する
- 新しいファインチューンされた model で RAG アプリを実装し、W&B Weave でアプリを評価する
- 結果に満足したら、更新された Rag アプリへの参照を W&B Registry に保存する
注:
以下で参照されている RagModel は、完全な RAG アプリと見なすことができるトップレベルの weave.Model です。これには、ChatModel、ベクター データベース、およびプロンプトが含まれています。ChatModel は別の weave.Model でもあり、W&B Registry から Artifact をダウンロードする コードが含まれており、RagModel の一部として他のチャット model をサポートするように変更できます。詳細については、Weave 上の完全な modelを参照してください。
1. セットアップ
まず、weave と wandb をインストールし、APIキー でログインします。APIキー は https://wandb.ai/settings で作成および表示できます。
pip install weave wandb
import wandb
import weave
import pandas as pd
PROJECT = "weave-cookboook-demo"
ENTITY = "wandb-smle"
wandb.login()
weave.init(ENTITY + "/" + PROJECT)
2. Artifact に基づいて ChatModel を作成する
Registry からファインチューンされたチャット model を取得し、そこから weave.Model を作成して、次のステップで RagModelに直接プラグインします。既存の ChatModel と同じ パラメータ を使用しますが、init と predict のみが変更されます。
pip install unsloth
pip uninstall unsloth -y && pip install --upgrade --no-cache-dir "unsloth[colab-new] @ git+https://github.com/unslothai/unsloth.git"
モデル Team は、unsloth ライブラリを使用してさまざまな Llama-3.2 model をファインチューンし、高速化しました。したがって、Registry からダウンロードした model をロードするには、アダプターを備えた特別な unsloth.FastLanguageModel または peft.AutoPeftModelForCausalLM model を使用します。「Use」タブからロード コードをコピーして、model_post_init に貼り付けます。
import weave
from pydantic import PrivateAttr
from typing import Any, List, Dict, Optional
from unsloth import FastLanguageModel
import torch
class UnslothLoRAChatModel(weave.Model):
"""
model 名だけでなく、より多くの パラメータ を保存および バージョン 管理するための追加の ChatModel クラスを定義します。
これにより、特定の パラメータ でのファインチューニングが可能になります。
"""
chat_model: str
cm_temperature: float
cm_max_new_tokens: int
cm_quantize: bool
inference_batch_size: int
dtype: Any
device: str
_model: Any = PrivateAttr()
_tokenizer: Any = PrivateAttr()
def model_post_init(self, __context):
# レジストリの「Use」タブからこれを貼り付けます
run = wandb.init(project=PROJECT, job_type="model_download")
artifact = run.use_artifact(f"{self.chat_model}")
model_path = artifact.download()
# unsloth バージョン (ネイティブの 2 倍高速な推論を有効にする)
self._model, self._tokenizer = FastLanguageModel.from_pretrained(
model_name=model_path,
max_seq_length=self.cm_max_new_tokens,
dtype=self.dtype,
load_in_4bit=self.cm_quantize,
)
FastLanguageModel.for_inference(self._model)
@weave.op()
async def predict(self, query: List[str]) -> dict:
# add_generation_prompt = true - 生成用に追加する必要があります
input_ids = self._tokenizer.apply_chat_template(
query,
tokenize=True,
add_generation_prompt=True,
return_tensors="pt",
).to("cuda")
output_ids = self._model.generate(
input_ids=input_ids,
max_new_tokens=64,
use_cache=True,
temperature=1.5,
min_p=0.1,
)
decoded_outputs = self._tokenizer.batch_decode(
output_ids[0][input_ids.shape[1] :], skip_special_tokens=True
)
return "".join(decoded_outputs).strip()
次に、レジストリからの特定のリンクを使用して新しい model を作成します。
MODEL_REG_URL = "wandb32/wandb-registry-RAG Chat Models/Finetuned Llama-3.2:v3"
max_seq_length = 2048
dtype = None
load_in_4bit = True
new_chat_model = UnslothLoRAChatModel(
name="UnslothLoRAChatModelRag",
chat_model=MODEL_REG_URL,
cm_temperature=1.0,
cm_max_new_tokens=max_seq_length,
cm_quantize=load_in_4bit,
inference_batch_size=max_seq_length,
dtype=dtype,
device="auto",
)
そして最後に、評価を非同期的に実行します。
await new_chat_model.predict(
[{"role": "user", "content": "What is the capital of Germany?"}]
)
3. 新しい ChatModel バージョンを RagModel に統合する
ファインチューンされたチャット model から RAG アプリを構築すると、特に会話型 AI システムのパフォーマンスと汎用性を強化する上で、いくつかの利点が得られます。
次に、既存の Weave プロジェクトから RagModel を取得し (以下の画像に示すように、[use] タブから現在の RagModel の Weave 参照を取得できます)、ChatModel を新しいものに交換します。他の コンポーネント (VDB、プロンプトなど) を変更または再作成する必要はありません。

pip install litellm faiss-gpu
RagModel = weave.ref(
"weave:///wandb-smle/weave-cookboook-demo/object/RagModel:cqRaGKcxutBWXyM0fCGTR1Yk2mISLsNari4wlGTwERo"
).get()
# MAGIC: chat_model を交換して新しい バージョン を公開します (他の RAG コンポーネントを気にする必要はありません)
RagModel.chat_model = new_chat_model
# 最初に新しい バージョン を公開して、予測中に参照されるようにします
PUB_REFERENCE = weave.publish(RagModel, "RagModel")
await RagModel.predict("When was the first conference on climate change?")
4. 既存の Models run に接続する新しい weave.Evaluation を実行する
最後に、既存の weave.Evaluation で新しい RagModel を評価します。統合をできるだけ簡単にするために、次の変更を含めます。
Models の観点から:
- Registry から model を取得すると、チャット model の E2E リネージ の一部である新しい
wandb.runが作成されます - Trace ID (現在の eval ID を使用) を run config に追加して、モデル Team がリンクをクリックして対応する Weave ページに移動できるようにします
Weave の観点から:
- Artifact / Registry リンクを
ChatModel(つまりRagModel) への入力として保存します run.idをweave.attributesを使用して トレース の追加の列として保存します
# MAGIC: 評価 データセット とスコアラーを使用して評価を取得し、それらを使用します
WEAVE_EVAL = "weave:///wandb-smle/weave-cookboook-demo/object/climate_rag_eval:ntRX6qn3Tx6w3UEVZXdhIh1BWGh7uXcQpOQnIuvnSgo"
climate_rag_eval = weave.ref(WEAVE_EVAL).get()
with weave.attributes({"wandb-run-id": wandb.run.id}):
# Models に eval トレース を保存するために、結果と呼び出しの両方を取得するために .call 属性を使用します
summary, call = await climate_rag_eval.evaluate.call(climate_rag_eval, ` RagModel `)
5. 新しい RAG model を Registry に保存する
新しい RAG Model を効果的に共有するために、Weave バージョン を エイリアス として追加して、参照 Artifact として Registry にプッシュします。
MODELS_OBJECT_VERSION = PUB_REFERENCE.digest # weave オブジェクト バージョン
MODELS_OBJECT_NAME = PUB_REFERENCE.name # weave オブジェクト名
models_url = f"https://wandb.ai/{ENTITY}/{PROJECT}/weave/objects/{MODELS_OBJECT_NAME}/versions/{MODELS_OBJECT_VERSION}"
models_link = (
f"weave:///{ENTITY}/{PROJECT}/object/{MODELS_OBJECT_NAME}:{MODELS_OBJECT_VERSION}"
)
with wandb.init(project=PROJECT, entity=ENTITY) as run:
# 新しい Artifact を作成します
artifact_model = wandb.Artifact(
name="RagModel",
type="model",
description="Weave の RagModel からの Models リンク",
metadata={"url": models_url},
)
artifact_model.add_reference(models_link, name="model", checksum=False)
# 新しい Artifact を ログ に記録します
run.log_artifact(artifact_model, aliases=[MODELS_OBJECT_VERSION])
# Registry へのリンク
run.link_artifact(
artifact_model, target_path="wandb32/wandb-registry-RAG Models/RAG Model"
)
[i18n] feedback_title
[i18n] feedback_question
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.