Visualize predictions with tables
3 minute read
ここでは、MNIST データで PyTorch を使用して、トレーニングの過程におけるモデルの予測を追跡、視覚化、および比較する方法について説明します。
学習内容:
- モデルのトレーニングまたは評価中に、メトリクス、画像、テキストなどを
wandb.Table()に ログ 記録する方法 - これらのテーブルの表示、並べ替え、フィルタリング、グループ化、結合、インタラクティブなクエリ、および探索
- 特定の画像、ハイパーパラメータ / モデル バージョン、またはタイム ステップ間でモデルの予測または 結果 を動的に比較します。
Examples
特定の画像の予測スコアを比較する
ライブ 例:トレーニングの 1 エポック後と 5 エポック後の予測を比較する →
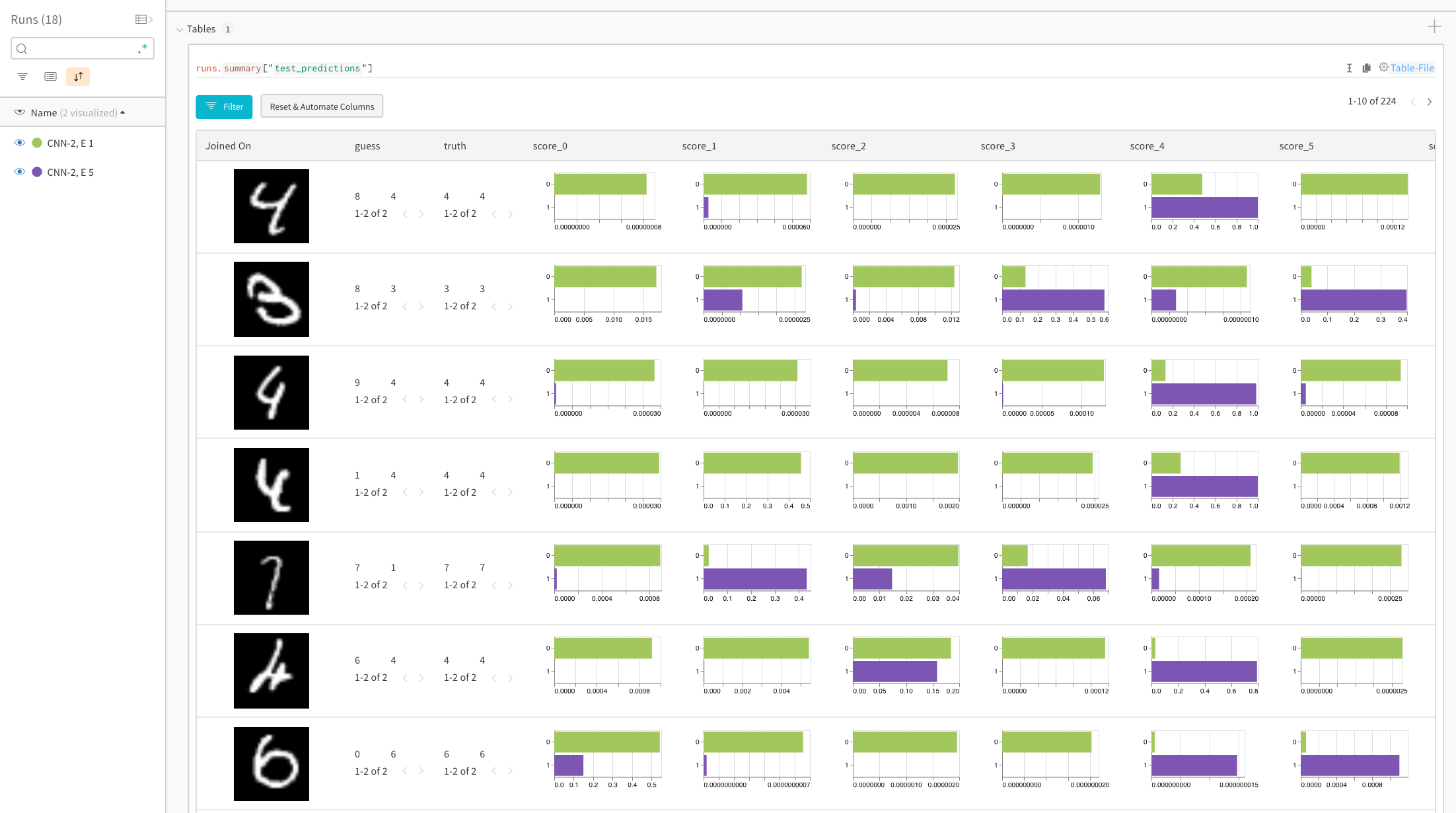
ヒストグラムは、2 つのモデル間のクラスごとのスコアを比較します。各ヒストグラムの上部の緑色のバーは、1 エポックのみトレーニングされたモデル「CNN-2, 1 epoch」(ID 0)を表します。下部の紫色のバーは、5 エポックトレーニングされたモデル「CNN-2, 5 epochs」(ID 1)を表します。画像は、モデルが一致しない場合にフィルタリングされます。たとえば、最初の行では、「4」は 1 エポック後、考えられるすべての数字で高いスコアを取得しますが、5 エポック後には、正しいラベルで最も高いスコアを獲得し、残りの部分では非常に低いスコアを獲得します。
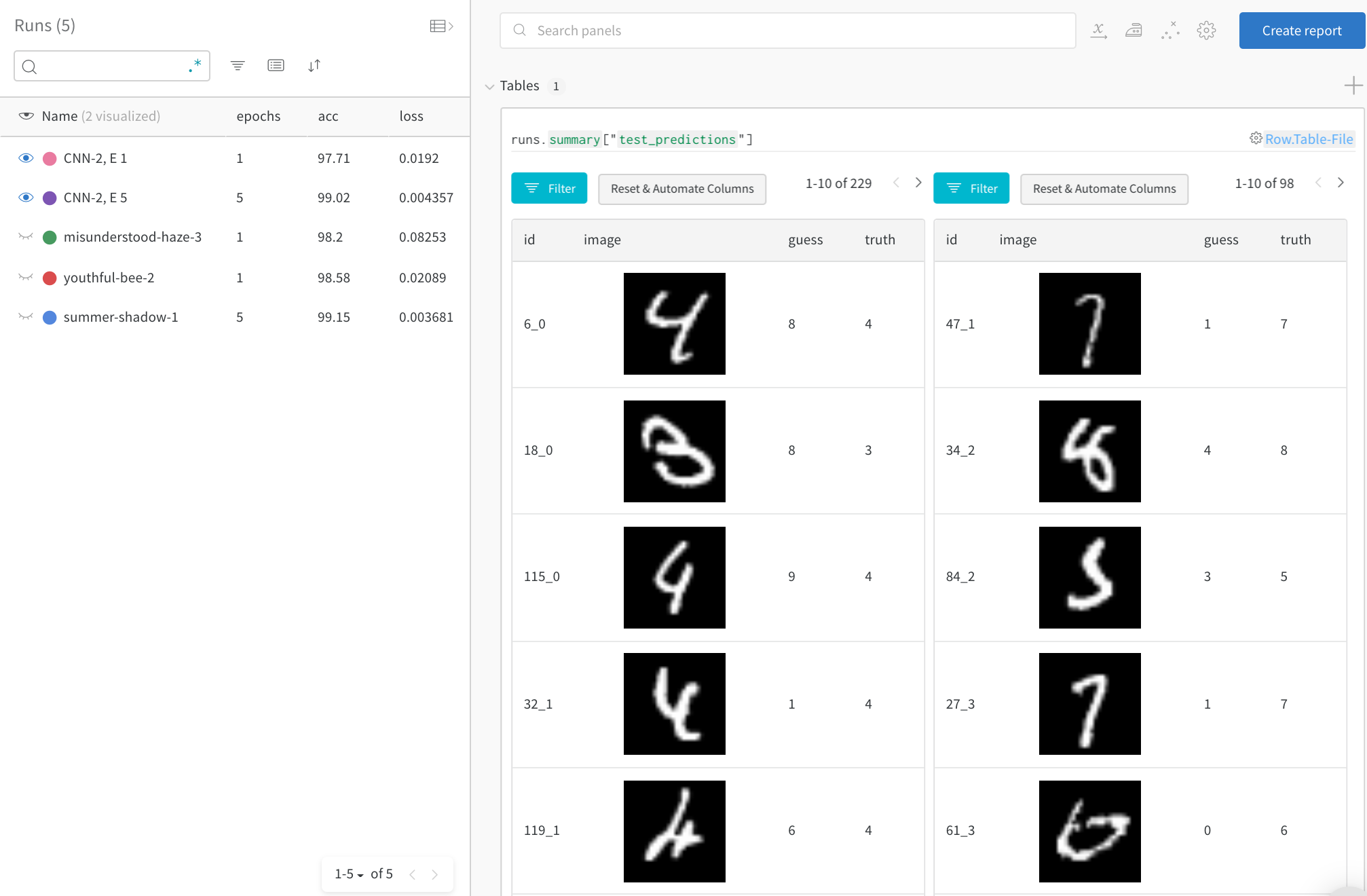
時間の経過に伴う上位のエラーに焦点を当てる
完全なテスト データで、誤った予測(「推測」!=「真実」の行にフィルタリング)を確認します。1 回のトレーニング エポック後には 229 個の間違った推測がありますが、5 エポック後には 98 個しかないことに注意してください。
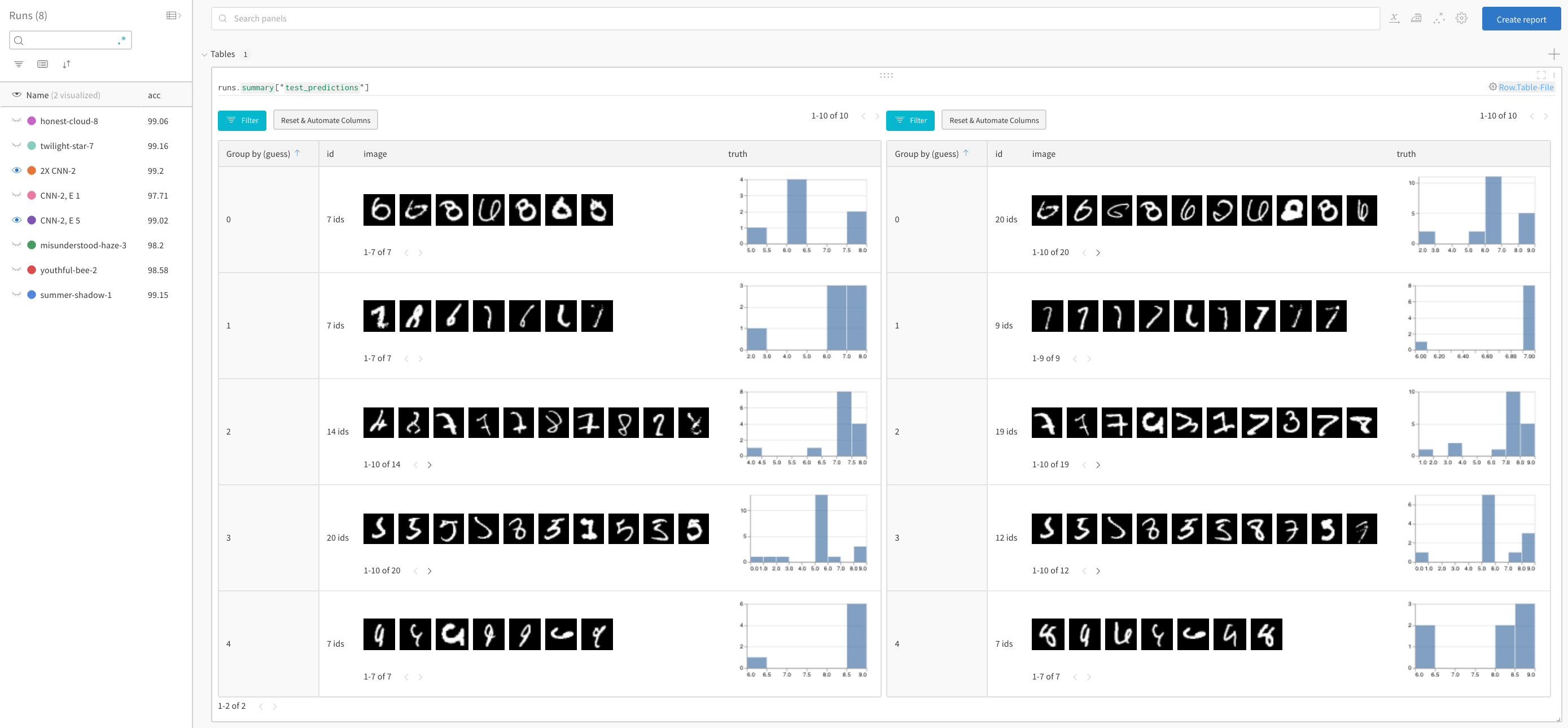
モデル のパフォーマンスを比較し、パターンを見つける
正解を除外し、推測ごとにグループ化して、誤って分類された画像の 例 と、真のラベルの基礎となる分布を、2 つのモデルを並べて表示します。レイヤー サイズと学習率が 2 倍のモデル バリアントが左側にあり、ベースラインが右側にあります。ベースラインでは、推測されたクラスごとにわずかに多くの間違いが発生することに注意してください。
サインアップまたはログイン
サインアップまたはログイン して W&B にアクセスし、ブラウザで 実験 を表示して操作します。
この例では、便利なホスト 環境として Google Colab を使用していますが、どこからでも独自のトレーニング スクリプト を実行し、W&B の 実験管理 ツール で メトリクス を視覚化できます。
!pip install wandb -qqq
アカウントに ログ インします。
import wandb
wandb.login()
WANDB_PROJECT = "mnist-viz"
0. セットアップ
依存関係をインストールし、MNIST をダウンロードし、PyTorch を使用してトレーニング データセット と テストデータセット を作成します。
import torch
import torch.nn as nn
import torchvision
import torchvision.transforms as T
import torch.nn.functional as F
device = "cuda:0" if torch.cuda.is_available() else "cpu"
# トレーニングデータローダーを作成します
def get_dataloader(is_train, batch_size, slice=5):
"トレーニングデータローダーを取得します"
ds = torchvision.datasets.MNIST(root=".", train=is_train, transform=T.ToTensor(), download=True)
loader = torch.utils.data.DataLoader(dataset=ds,
batch_size=batch_size,
shuffle=True if is_train else False,
pin_memory=True, num_workers=2)
return loader
1. モデル と トレーニング スケジュールを定義する
- 実行する エポック 数を設定します。各 エポック は トレーニング ステップと検証 (テスト) ステップで構成されます。オプションで、テスト ステップごとに ログ に記録するデータ量を構成します。ここでは、デモを簡素化するために、視覚化するバッチ数とバッチあたりの画像数が少なく設定されています。
- ( pytorch-tutorial コードに従って) シンプルな畳み込み ニューラルネットワーク を定義します。
- PyTorch を使用してトレーニング セット と テスト セット にロードします。
# 実行するエポック数
# 各エポックにはトレーニングステップとテストステップが含まれるため、これにより、
# ログに記録するテスト予測のテーブル数が設定されます
EPOCHS = 1
# 各テストステップのテストデータからログに記録するバッチ数
# (デモを簡素化するためにデフォルトでは低く設定されています)
NUM_BATCHES_TO_LOG = 10 #79
# テストバッチごとにログに記録する画像数
# (デモを簡素化するためにデフォルトでは低く設定されています)
NUM_IMAGES_PER_BATCH = 32 #128
# トレーニング構成とハイパーパラメータ
NUM_CLASSES = 10
BATCH_SIZE = 32
LEARNING_RATE = 0.001
L1_SIZE = 32
L2_SIZE = 64
# これを変更すると、隣接するレイヤーの形状を変更する必要がある場合があります
CONV_KERNEL_SIZE = 5
# 2層の畳み込みニューラルネットワークを定義します
class ConvNet(nn.Module):
def __init__(self, num_classes=10):
super(ConvNet, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(1, L1_SIZE, CONV_KERNEL_SIZE, stride=1, padding=2),
nn.BatchNorm2d(L1_SIZE),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2))
self.layer2 = nn.Sequential(
nn.Conv2d(L1_SIZE, L2_SIZE, CONV_KERNEL_SIZE, stride=1, padding=2),
nn.BatchNorm2d(L2_SIZE),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2))
self.fc = nn.Linear(7*7*L2_SIZE, NUM_CLASSES)
self.softmax = nn.Softmax(NUM_CLASSES)
def forward(self, x):
# 特定のレイヤーの形状を確認するには、以下をコメント解除してください。
#print("x: ", x.size())
out = self.layer1(x)
out = self.layer2(out)
out = out.reshape(out.size(0), -1)
out = self.fc(out)
return out
train_loader = get_dataloader(is_train=True, batch_size=BATCH_SIZE)
test_loader = get_dataloader(is_train=False, batch_size=2*BATCH_SIZE)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
2. トレーニング を実行し、テスト予測を ログ に記録する
エポック ごとに、トレーニング ステップとテスト ステップを実行します。各テスト ステップで、テスト予測を格納する wandb.Table() を作成します。これらは、ブラウザで視覚化したり、動的にクエリしたり、並べて比較したりできます。
# W&B: このモデルのトレーニングを追跡するために、新しい run を初期化します
wandb.init(project="table-quickstart")
# W&B: config を使用してハイパーパラメータをログに記録します
cfg = wandb.config
cfg.update({"epochs" : EPOCHS, "batch_size": BATCH_SIZE, "lr" : LEARNING_RATE,
"l1_size" : L1_SIZE, "l2_size": L2_SIZE,
"conv_kernel" : CONV_KERNEL_SIZE,
"img_count" : min(10000, NUM_IMAGES_PER_BATCH*NUM_BATCHES_TO_LOG)})
# モデル、損失、およびオプティマイザーを定義します
model = ConvNet(NUM_CLASSES).to(device)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=LEARNING_RATE)
# テスト画像のバッチの予測をログに記録するための便利な関数
def log_test_predictions(images, labels, outputs, predicted, test_table, log_counter):
# すべてのクラスの信頼性スコアを取得します
scores = F.softmax(outputs.data, dim=1)
log_scores = scores.cpu().numpy()
log_images = images.cpu().numpy()
log_labels = labels.cpu().numpy()
log_preds = predicted.cpu().numpy()
# 画像の順序に基づいて ID を追加します
_id = 0
for i, l, p, s in zip(log_images, log_labels, log_preds, log_scores):
# 必要な情報をデータテーブルに追加します。
# ID、画像ピクセル、モデルの推測、真のラベル、すべてのクラスのスコア
img_id = str(_id) + "_" + str(log_counter)
test_table.add_data(img_id, wandb.Image(i), p, l, *s)
_id += 1
if _id == NUM_IMAGES_PER_BATCH:
break
# モデルをトレーニングします
total_step = len(train_loader)
for epoch in range(EPOCHS):
# トレーニングステップ
for i, (images, labels) in enumerate(train_loader):
images = images.to(device)
labels = labels.to(device)
# forward pass
outputs = model(images)
loss = criterion(outputs, labels)
# backward と最適化
optimizer.zero_grad()
loss.backward()
optimizer.step()
# W&B: トレーニングステップ全体の損失をログに記録します。UI にライブで視覚化されます
wandb.log({"loss" : loss})
if (i+1) % 100 == 0:
print ('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}'
.format(epoch+1, EPOCHS, i+1, total_step, loss.item()))
# W&B: 各テストステップの予測を保存するための Table を作成します
columns=["id", "image", "guess", "truth"]
for digit in range(10):
columns.append("score_" + str(digit))
test_table = wandb.Table(columns=columns)
# モデルをテストします
model.eval()
log_counter = 0
with torch.no_grad():
correct = 0
total = 0
for images, labels in test_loader:
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
if log_counter < NUM_BATCHES_TO_LOG:
log_test_predictions(images, labels, outputs, predicted, test_table, log_counter)
log_counter += 1
total += labels.size(0)
correct += (predicted == labels).sum().item()
acc = 100 * correct / total
# W&B: UI で視覚化するために、トレーニングエポック全体の精度をログに記録します
wandb.log({"epoch" : epoch, "acc" : acc})
print('Test Accuracy of the model on the 10000 test images: {} %'.format(acc))
# W&B: 予測テーブルを wandb にログに記録します
wandb.log({"test_predictions" : test_table})
# W&B: run を完了としてマークします (マルチセル ノートブック に役立ちます)
wandb.finish()
次は何ですか?
次のチュートリアルでは、W&B Sweeps を使用してハイパーパラメータを最適化する方法 を学習します。
[i18n] feedback_title
[i18n] feedback_question
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.