PyTorch
7 minute read
Weights & Biases を使用して、 機械学習 の 実験管理 、 データセット の バージョン管理 、および プロジェクト の コラボレーションを行います。

この ノートブック の内容
この ノートブック では、 Weights & Biases を PyTorch コード に 統合して、 実験管理 を パイプライン に 追加する方法を紹介します。
# ライブラリをインポート
import wandb
# 新しい 実験 を開始
wandb.init(project="new-sota-model")
# config で ハイパーパラメーター の 辞書 をキャプチャ
wandb.config = {"learning_rate": 0.001, "epochs": 100, "batch_size": 128}
# モデル と データ をセットアップ
model, dataloader = get_model(), get_data()
# オプション: 勾配 を追跡
wandb.watch(model)
for batch in dataloader:
metrics = model.training_step()
# トレーニング ループ 内で メトリクス を ログ に記録して、 モデル の パフォーマンス を視覚化します。
wandb.log(metrics)
# オプション: 最後に モデル を保存
model.to_onnx()
wandb.save("model.onnx")
ビデオ チュートリアルをご覧ください。
注: Step で始まるセクションは、既存の パイプライン に W&B を 統合 するために必要なすべてです。残りの部分は、 データ を ロード し、 モデル を定義するだけです。
インストール、インポート、および ログイン
import os
import random
import numpy as np
import torch
import torch.nn as nn
import torchvision
import torchvision.transforms as transforms
from tqdm.auto import tqdm
# 決定論的な 振る舞い を確認
torch.backends.cudnn.deterministic = True
random.seed(hash("setting random seeds") % 2**32 - 1)
np.random.seed(hash("improves reproducibility") % 2**32 - 1)
torch.manual_seed(hash("by removing stochasticity") % 2**32 - 1)
torch.cuda.manual_seed_all(hash("so runs are repeatable") % 2**32 - 1)
# デバイス の 設定
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# MNIST ミラー の リスト から 低速 ミラー を削除
torchvision.datasets.MNIST.mirrors = [mirror for mirror in torchvision.datasets.MNIST.mirrors
if not mirror.startswith("http://yann.lecun.com")]
Step 0: W&B の インストール
まず、 ライブラリ を取得する必要があります。
wandb は pip を使用して簡単に インストール できます。
!pip install wandb onnx -Uq
Step 1: W&B の インポート と ログイン
データ を Web サービス に ログ に記録するには、 ログイン する必要があります。
W&B を初めて使用する場合は、表示される リンク で 無料 アカウント にサインアップする必要があります。
import wandb
wandb.login()
実験 と パイプライン を定義
wandb.init を使用して メタデータ と ハイパーパラメーター を追跡
プログラムで、最初に行うことは 実験 を定義することです。 ハイパーパラメーター は何ですか? どのような メタデータ がこの run に 関連付けられていますか?
この 情報 を config 辞書 (または同様の オブジェクト ) に保存し、必要に応じて アクセス するのは非常に一般的な ワークフロー です。
この 例 では、いくつかの ハイパーパラメーター のみを変えることができ、残りは手動で コーディング しています。
ただし、 モデル の 任意の部分を config の一部にすることができます。
また、いくつかの メタデータ も含めます。MNIST データセット と 畳み込み アーキテクチャー を使用しています。たとえば、後で同じ プロジェクト で CIFAR 上の完全に接続された アーキテクチャー を使用する場合、これは run を分離するのに役立ちます。
config = dict(
epochs=5,
classes=10,
kernels=[16, 32],
batch_size=128,
learning_rate=0.005,
dataset="MNIST",
architecture="CNN")
次に、 モデル トレーニング に非常に一般的な 全体的な パイプライン を定義しましょう。
- まず、 モデル 、 関連 データ 、および オプティマイザー を
makeし、次に - モデル をそれに応じて
trainし、最後に testして、 トレーニング の 結果 を確認します。
これらの 関数 を以下に実装します。
def model_pipeline(hyperparameters):
# wandb に 開始 するように指示
with wandb.init(project="pytorch-demo", config=hyperparameters):
# wandb.config を介してすべての HPs に アクセス して、 ログ が 実行 と一致するようにします。
config = wandb.config
# モデル 、 データ 、および 最適化 の 問題 を作成
model, train_loader, test_loader, criterion, optimizer = make(config)
print(model)
# それらを使用して モデル を トレーニング
train(model, train_loader, criterion, optimizer, config)
# 最終的な パフォーマンス を テスト
test(model, test_loader)
return model
標準的な パイプライン との唯一の違いは、それがすべて wandb.init の コンテキスト 内で発生することです。
この 関数 を 呼び出すと、 コード と サーバー 間の 通信回線 が 設定 されます。
config 辞書 を wandb.init に 渡すと、その 情報 がすべてすぐに ログ に記録されるため、 実験 で使用するように 設定 した ハイパーパラメーター の 値 を常に把握できます。
選択および ログ に記録した 値 が モデル で常に使用されるようにするために、 オブジェクト の wandb.config コピー を使用することをお勧めします。
いくつかの 例 を 参照 するには、以下の make の 定義 を確認してください。
サイド ノート: コード を 個別の プロセス で 実行 するように注意してください。これにより、こちら側の 問題 (巨大な海の モンスター が データセンター を攻撃するなど) によって コード が クラッシュ しないようにします。 クラーケン が 深海 に戻るなど、 問題 が解決されたら、
wandb syncで データ を ログ に記録できます。
def make(config):
# データ を作成
train, test = get_data(train=True), get_data(train=False)
train_loader = make_loader(train, batch_size=config.batch_size)
test_loader = make_loader(test, batch_size=config.batch_size)
# モデル を作成
model = ConvNet(config.kernels, config.classes).to(device)
# 損失 と オプティマイザー を作成
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(
model.parameters(), lr=config.learning_rate)
return model, train_loader, test_loader, criterion, optimizer
データ の ロード と モデル を定義
次に、 データ の ロード 方法と モデル の 外観を指定する必要があります。
この部分は非常に重要ですが、wandb がなくても同じであるため、詳しく説明しません。
def get_data(slice=5, train=True):
full_dataset = torchvision.datasets.MNIST(root=".",
train=train,
transform=transforms.ToTensor(),
download=True)
# [::slice] で スライス するのと同等
sub_dataset = torch.utils.data.Subset(
full_dataset, indices=range(0, len(full_dataset), slice))
return sub_dataset
def make_loader(dataset, batch_size):
loader = torch.utils.data.DataLoader(dataset=dataset,
batch_size=batch_size,
shuffle=True,
pin_memory=True, num_workers=2)
return loader
モデル を定義するのは通常楽しい部分です。
しかし、wandb では何も変わらないため、 標準的な ConvNet アーキテクチャー を使用します。
これをいじって 実験 を試すことを恐れないでください。すべての 結果 は wandb.ai に ログ 記録されます。
# 従来の畳み込み ニューラルネットワーク
class ConvNet(nn.Module):
def __init__(self, kernels, classes=10):
super(ConvNet, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(1, kernels[0], kernel_size=5, stride=1, padding=2),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2))
self.layer2 = nn.Sequential(
nn.Conv2d(16, kernels[1], kernel_size=5, stride=1, padding=2),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2))
self.fc = nn.Linear(7 * 7 * kernels[-1], classes)
def forward(self, x):
out = self.layer1(x)
out = self.layer2(out)
out = out.reshape(out.size(0), -1)
out = self.fc(out)
return out
トレーニング ロジック を定義
model_pipeline で 進めて、train 方法を指定します。
ここでは、2 つの wandb 関数 が 役立ちます。watch と log です。
wandb.watch で 勾配 を追跡し、wandb.log で その他 すべてを追跡
wandb.watch は、 トレーニング のすべての log_freq ステップ で、 モデル の 勾配 と パラメータ を ログ に記録します。
必要なのは、 トレーニング を開始する前にそれを 呼び出すことだけです。
残りの トレーニング コード は同じままです。 エポック と バッチ を 反復処理し、 forward pass と backward pass を 実行 し、オプティマイザー を 適用 します。
def train(model, loader, criterion, optimizer, config):
# モデル が 実行 する 内容 ( 勾配 、 重み など) を wandb に 監視 させる。
wandb.watch(model, criterion, log="all", log_freq=10)
# トレーニング を 実行 し、wandb で 追跡
total_batches = len(loader) * config.epochs
example_ct = 0 # 確認された 例 の 数
batch_ct = 0
for epoch in tqdm(range(config.epochs)):
for _, (images, labels) in enumerate(loader):
loss = train_batch(images, labels, model, optimizer, criterion)
example_ct += len(images)
batch_ct += 1
# 25 回目の バッチ ごとに メトリクス を レポート
if ((batch_ct + 1) % 25) == 0:
train_log(loss, example_ct, epoch)
def train_batch(images, labels, model, optimizer, criterion):
images, labels = images.to(device), labels.to(device)
# Forward pass ➡
outputs = model(images)
loss = criterion(outputs, labels)
# Backward pass ⬅
optimizer.zero_grad()
loss.backward()
# オプティマイザー で ステップ
optimizer.step()
return loss
唯一の違いは ログ コード にあります。以前は ターミナル に 出力 して メトリクス を レポート していた可能性がありますが、 同じ 情報 を wandb.log に 渡すようになりました。
wandb.log は、 キー として 文字列 を持つ 辞書 を想定しています。これらの 文字列 は、 ログ に記録される オブジェクト を識別します。これらが 値 を 構成します。オプションで、 トレーニング のどの step にいるかを ログ に記録することもできます。
サイド ノート: バッチサイズ 全体で 比較 しやすくするために、 モデル が 確認 した 例 の 数を 使用するのが好きですが、 生の ステップ または バッチ カウント を使用できます。より 長い トレーニング run の 場合、
エポックごとに ログ に記録することも 理にかなっています。
def train_log(loss, example_ct, epoch):
# 魔法が起こる場所
wandb.log({"epoch": epoch, "loss": loss}, step=example_ct)
print(f"Loss after {str(example_ct).zfill(5)} examples: {loss:.3f}")
テスト ロジック を定義
モデル の トレーニング が完了したら、それを テスト します。たとえば、 プロダクション からの 新鮮な データ に対して 実行 したり、手作業で キュレーション された 例 に 適用 したりします。
(オプション) wandb.save を 呼び出す
これは、 モデル の アーキテクチャー と 最終的な パラメータ を ディスク に保存する絶好の機会でもあります。最大限の 互換性を得るために、Open Neural Network eXchange (ONNX) 形式で モデル を エクスポート します。
その ファイル名 を wandb.save に 渡すと、 モデル の パラメータ が W&B の サーバー に 保存されます。どの .h5 または .pb がどの トレーニング run に 対応 するかを 追跡 できなくなることはありません。
モデル を保存、 バージョン管理 、および 配布 するための、より 高度な wandb 機能 については、Artifacts ツールを ご覧ください。
def test(model, test_loader):
model.eval()
# いくつかの テスト 例 で モデル を 実行
with torch.no_grad():
correct, total = 0, 0
for images, labels in test_loader:
images, labels = images.to(device), labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print(f"Accuracy of the model on the {total} " +
f"test images: {correct / total:%}")
wandb.log({"test_accuracy": correct / total})
# 交換可能な ONNX 形式 で モデル を保存
torch.onnx.export(model, images, "model.onnx")
wandb.save("model.onnx")
トレーニング を 実行 し、wandb.ai で メトリクス を ライブ で 監視
パイプライン 全体を定義し、いくつかの W&B コード を 挿入 したので、完全に 追跡 された 実験 を 実行 する 準備ができました。
ドキュメント、 プロジェクト ページ ( プロジェクト 内のすべての run を 整理します)、および この run の 結果 が 保存される Run ページへの リンク がいくつか レポート されます。
Run ページに 移動 し、これらの タブ を 確認 してください。
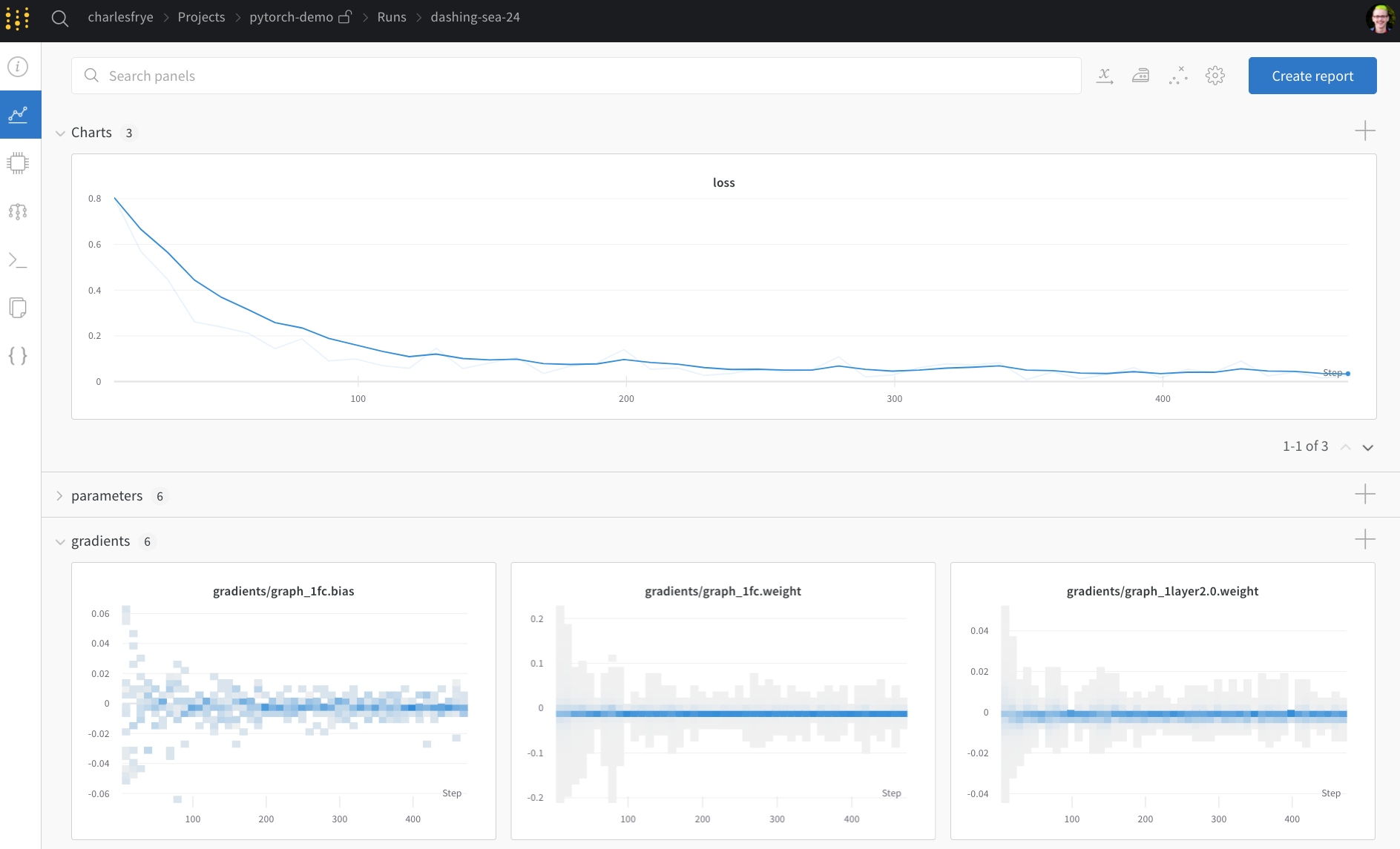
- Charts: トレーニング 全体で モデル の 勾配 、 パラメータ 値、および 損失 が ログ に記録されます。
- System: ディスク I/O 使用率、 CPU および GPU メトリクス (温度が急上昇するのを 監視 します) などの さまざまな システム メトリクス が含まれています。
- Logs: トレーニング 中に 標準出力 に プッシュ されたすべてのものの コピー があります。
- Files: トレーニング が完了すると、
model.onnxを クリック して、Netron モデル ビューアーで ネットワーク を 表示 できます。
run が 終了 すると、with wandb.init ブロック が 終了 するときに、 セル の 出力 に 結果 の 概要 も 出力 されます。
# パイプライン を使用して モデル を 構築、 トレーニング 、および 分析
model = model_pipeline(config)
Sweeps で ハイパーパラメーター を テスト
この 例 では、単一の ハイパーパラメーター セット のみを調べました。 しかし、ほとんどの ML ワークフロー の 重要な部分は、多くの ハイパーパラメーター を 反復処理することです。
Weights & Biases Sweeps を使用すると、 ハイパーパラメーター の テスト を 自動化し、 可能な モデル と 最適化 戦略 の スペース を 探索 できます。
W&B Sweeps を使用した PyTorch での ハイパーパラメーター の 最適化 を確認
Weights & Biases で ハイパーパラメーター sweep を 実行 するのは非常に簡単です。簡単な 3 つの ステップ があります。
-
sweep を定義: 検索 する パラメータ 、 検索 戦略、 最適化 メトリクス などを 指定する 辞書 または YAML ファイル を 作成 して、これを行います。
-
sweep を 初期化:
sweep_id = wandb.sweep(sweep_config) -
sweep agent を 実行:
wandb.agent(sweep_id, function=train)
これで、 ハイパーパラメーター sweep の 実行 はすべて完了です。
例 ギャラリー
ギャラリー →で W&B で 追跡 および 視覚化 された プロジェクト の 例 を ご覧ください
高度な 設定
- 環境変数: 管理対象 クラスター で トレーニング を 実行 できるように、 環境変数 で APIキー を 設定 します。
- オフライン モード:
dryrunモード を 使用 して オフライン で トレーニング し、後で 結果 を 同期 します。 - オンプレミス: プライベートクラウド または お客様の インフラストラクチャー 内の エアギャップ サーバー に W&B を インストール します。 学術関係者から エンタープライズ チーム まで、あらゆる ユーザー 向けの ローカル インストール があります。
- Sweeps: チューニング 用の 軽量 ツール を 使用 して、 ハイパーパラメーター 検索 を 迅速に 設定 します。
[i18n] feedback_title
[i18n] feedback_question
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.