Track experiments
5 minute read
W&B を使用して、機械学習 の実験管理、モデル のチェックポイント、チーム とのコラボレーションなどを行います。
この ノートブック では、単純な PyTorch モデル を使用して、機械学習 の 実験 を作成および追跡します。ノートブック の終わりまでに、チーム の他の メンバー と共有およびカスタマイズできるインタラクティブな プロジェクト ダッシュボード が作成されます。ダッシュボード の例はこちら
前提条件
W&B Python SDK をインストールして ログイン します。
!pip install wandb -qU
# W&B アカウントにログインします
import wandb
import random
import math
# wandb-core を使用します。wandb の新しい バックエンド 用に一時的に使用されます
wandb.require("core")
wandb.login()
W&B で 機械学習 の 実験 をシミュレートおよび追跡する
機械学習 の 実験 を作成、追跡、および視覚化します。これを行うには:
- W&B run を初期化し、追跡する ハイパーパラメータ を渡します。
- トレーニング ループ 内で、精度 や 損失 などの メトリクス を ログ に記録します。
import random
import math
# シミュレートされた 5 つの 実験 を起動します
total_runs = 5
for run in range(total_runs):
# 1️. この スクリプト を追跡するために新しい run を開始します
wandb.init(
# この run が ログ に記録される プロジェクト を設定します
project="basic-intro",
# run 名を渡します (そうでない場合は、sunshine-lollypop-10 のようにランダムに割り当てられます)
name=f"experiment_{run}",
# ハイパーパラメータ と run メタデータ を追跡します
config={
"learning_rate": 0.02,
"architecture": "CNN",
"dataset": "CIFAR-100",
"epochs": 10,
})
# この簡単な ブロック は、メトリクス を ログ に記録する トレーニング ループ をシミュレートします
epochs = 10
offset = random.random() / 5
for epoch in range(2, epochs):
acc = 1 - 2 ** -epoch - random.random() / epoch - offset
loss = 2 ** -epoch + random.random() / epoch + offset
# 2️. スクリプト から W&B に メトリクス を ログ に記録します
wandb.log({"acc": acc, "loss": loss})
# run に完了のマークを付けます
wandb.finish()
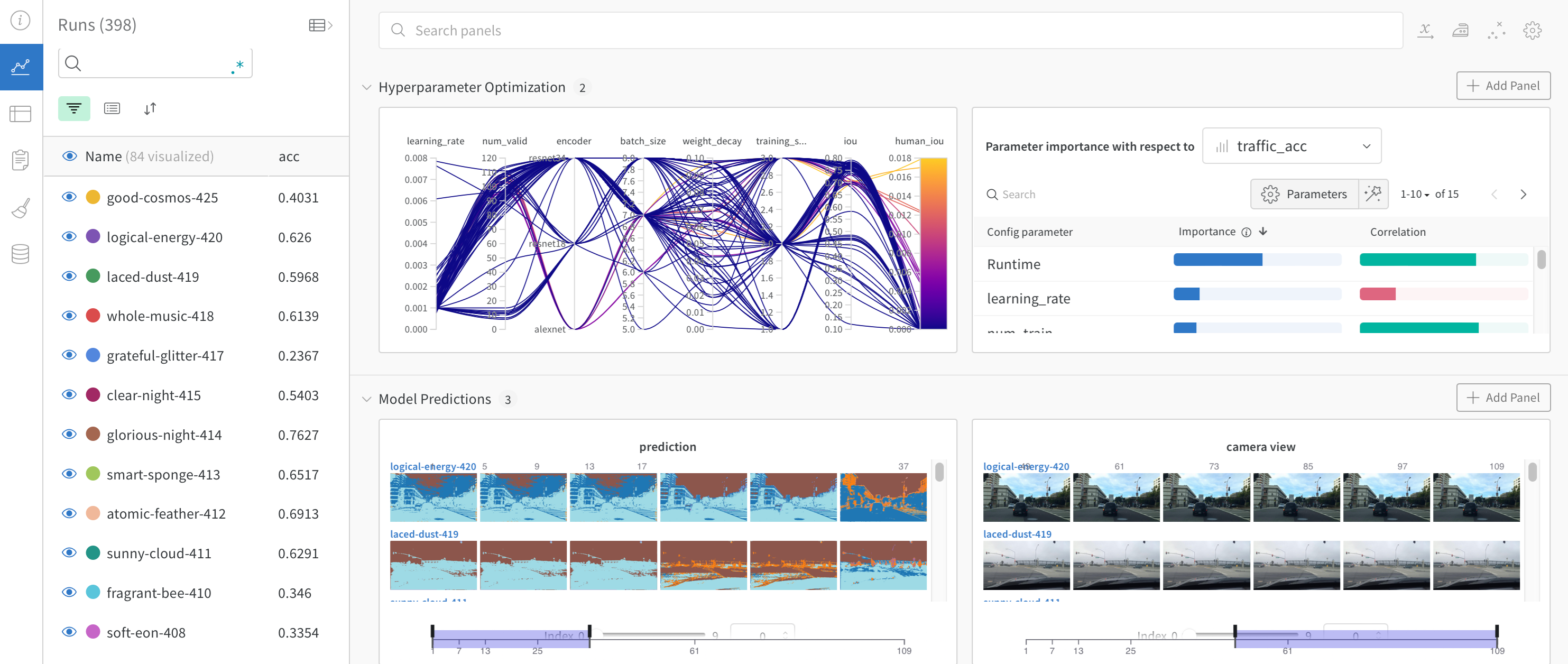
W&B プロジェクト で 機械学習 がどのように実行されたかを確認します。前の セル から出力された URL リンク をコピーして貼り付けます。URL は、グラフ を表示する ダッシュボード を含む W&B プロジェクト にリダイレクトされます。
次の画像は、ダッシュボード がどのように見えるかを示しています。
W&B を 疑似 機械学習 トレーニング ループ に統合する方法がわかったので、基本的な PyTorch ニューラルネットワーク を使用して 機械学習 の 実験 を追跡しましょう。次の コード は、組織 内の 他の チーム と共有できる モデル の チェックポイント を W&B にアップロードします。
Pytorch を使用して 機械学習 の 実験 を追跡する
次の コード セル は、単純な MNIST 分類器 を定義してトレーニングします。トレーニング 中に、W&B が URL を出力します。プロジェクト ページ リンク をクリックして、結果 が W&B プロジェクト に ライブ で ストリーミング されるのを確認します。
W&B run は、メトリクス、システム 情報、ハイパーパラメータ、ターミナル 出力 を自動的に ログ に記録し、モデル の 入力 と 出力 を含む インタラクティブな テーブル が表示されます。
PyTorch Dataloader を設定する
次の セル は、機械学習 モデル をトレーニングするために必要な便利な 関数 をいくつか定義しています。関数 自体は W&B 固有ではないため、ここでは詳細には説明しません。forward pass および backward pass トレーニング ループ の定義方法、PyTorch DataLoaders を使用して トレーニング 用の データ を ロードする方法、および torch.nn.Sequential クラス を使用して PyTorch モデル を定義する方法については、PyTorch ドキュメント を参照してください。
# @title
import torch, torchvision
import torch.nn as nn
from torchvision.datasets import MNIST
import torchvision.transforms as T
MNIST.mirrors = [
mirror for mirror in MNIST.mirrors if "http://yann.lecun.com/" not in mirror
]
device = "cuda:0" if torch.cuda.is_available() else "cpu"
def get_dataloader(is_train, batch_size, slice=5):
"トレーニング データローダー を取得します"
full_dataset = MNIST(
root=".", train=is_train, transform=T.ToTensor(), download=True
)
sub_dataset = torch.utils.data.Subset(
full_dataset, indices=range(0, len(full_dataset), slice)
)
loader = torch.utils.data.DataLoader(
dataset=sub_dataset,
batch_size=batch_size,
shuffle=True if is_train else False,
pin_memory=True,
num_workers=2,
)
return loader
def get_model(dropout):
"単純な モデル"
model = nn.Sequential(
nn.Flatten(),
nn.Linear(28 * 28, 256),
nn.BatchNorm1d(256),
nn.ReLU(),
nn.Dropout(dropout),
nn.Linear(256, 10),
).to(device)
return model
def validate_model(model, valid_dl, loss_func, log_images=False, batch_idx=0):
"検証 データセット での モデル の パフォーマンス を計算し、wandb.Table を ログ に記録します"
model.eval()
val_loss = 0.0
with torch.inference_mode():
correct = 0
for i, (images, labels) in enumerate(valid_dl):
images, labels = images.to(device), labels.to(device)
# Forward pass ➡
outputs = model(images)
val_loss += loss_func(outputs, labels) * labels.size(0)
# 精度 を計算して 累積します
_, predicted = torch.max(outputs.data, 1)
correct += (predicted == labels).sum().item()
# 画像 の 1 つの バッチ を ダッシュボード に ログ に記録します (常に同じ batch_idx)。
if i == batch_idx and log_images:
log_image_table(images, predicted, labels, outputs.softmax(dim=1))
return val_loss / len(valid_dl.dataset), correct / len(valid_dl.dataset)
予測値 と 真の 値 を比較する teble を作成する
次の セル は W&B 固有なので、見ていきましょう。
セル では、log_image_table という 関数 を定義します。厳密に言うと、オプション ですが、この 関数 は W&B テーブル オブジェクト を作成します。テーブル オブジェクト を使用して、モデル が 各画像 に対して 予測した内容を示す テーブル を作成します。
より具体的には、各 行 は、モデル に与えられた画像 と、予測値 および 実際の値 (ラベル) で構成されます。
def log_image_table(images, predicted, labels, probs):
"画像、ラベル、および 予測 を含む wandb.Table を ログ に記録します"
# 画像、ラベル、および 予測 を ログ に記録するための wandb テーブル を作成します
table = wandb.Table(
columns=["image", "pred", "target"] + [f"score_{i}" for i in range(10)]
)
for img, pred, targ, prob in zip(
images.to("cpu"), predicted.to("cpu"), labels.to("cpu"), probs.to("cpu")
):
table.add_data(wandb.Image(img[0].numpy() * 255), pred, targ, *prob.numpy())
wandb.log({"predictions_table": table}, commit=False)
モデル をトレーニングし、チェックポイント をアップロードします
次の コード は、モデル の チェックポイント をトレーニングして プロジェクト に保存します。通常どおり モデル の チェックポイント を使用して、トレーニング 中の モデル の パフォーマンス を評価します。
W&B を使用すると、保存された モデル と モデル の チェックポイント を チーム または 組織 の 他の メンバー と簡単に共有することもできます。モデル と モデル の チェックポイント を チーム 外の メンバー と共有する方法については、W&B Registry を参照してください。
# ドロップアウト率 を変えて 3 つの 実験 を起動します
for _ in range(3):
# wandb run を初期化します
wandb.init(
project="pytorch-intro",
config={
"epochs": 5,
"batch_size": 128,
"lr": 1e-3,
"dropout": random.uniform(0.01, 0.80),
},
)
# config をコピーします
config = wandb.config
# データ を取得します
train_dl = get_dataloader(is_train=True, batch_size=config.batch_size)
valid_dl = get_dataloader(is_train=False, batch_size=2 * config.batch_size)
n_steps_per_epoch = math.ceil(len(train_dl.dataset) / config.batch_size)
# 単純な MLP モデル
model = get_model(config.dropout)
# 損失 と オプティマイザー を作成します
loss_func = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=config.lr)
# トレーニング
example_ct = 0
step_ct = 0
for epoch in range(config.epochs):
model.train()
for step, (images, labels) in enumerate(train_dl):
images, labels = images.to(device), labels.to(device)
outputs = model(images)
train_loss = loss_func(outputs, labels)
optimizer.zero_grad()
train_loss.backward()
optimizer.step()
example_ct += len(images)
metrics = {
"train/train_loss": train_loss,
"train/epoch": (step + 1 + (n_steps_per_epoch * epoch))
/ n_steps_per_epoch,
"train/example_ct": example_ct,
}
if step + 1 < n_steps_per_epoch:
# train メトリクス を wandb に ログ に記録します
wandb.log(metrics)
step_ct += 1
val_loss, accuracy = validate_model(
model, valid_dl, loss_func, log_images=(epoch == (config.epochs - 1))
)
# train および 検証 メトリクス を wandb に ログ に記録します
val_metrics = {"val/val_loss": val_loss, "val/val_accuracy": accuracy}
wandb.log({**metrics, **val_metrics})
# モデル の チェックポイント を wandb に保存します
torch.save(model, "my_model.pt")
wandb.log_model(
"./my_model.pt",
"my_mnist_model",
aliases=[f"epoch-{epoch+1}_dropout-{round(wandb.config.dropout, 4)}"],
)
print(
f"Epoch: {epoch+1}, Train Loss: {train_loss:.3f}, Valid Loss: {val_loss:3f}, Accuracy: {accuracy:.2f}"
)
# テスト セット がある場合、これは 概要 メトリクス として ログ に記録する方法です
wandb.summary["test_accuracy"] = 0.8
# wandb run を閉じます
wandb.finish()
これで、W&B を使用して 最初の モデル をトレーニングしました。上記の リンク のいずれかをクリックして、メトリクス を確認し、W&B アプリ UI の Artifacts タブ で保存された モデル の チェックポイント を確認してください
(オプション) W&B Alert を設定する
W&B Alerts を作成して、Python コード から Slack または メール に アラート を送信します。
コード からトリガーされた Slack または メール アラート を初めて送信する場合は、次の 2 つの 手順に従います。
- W&B の ユーザー 設定 で Alerts をオンにします
wandb.alert()を コード に追加します。例:
wandb.alert(title="Low accuracy", text=f"Accuracy is below the acceptable threshold")
次の セル は、wandb.alert の使用方法を示す最小限の例を示しています
# wandb run を開始します
wandb.init(project="pytorch-intro")
# モデル トレーニング ループ をシミュレートします
acc_threshold = 0.3
for training_step in range(1000):
# 精度 の 乱数 を生成します
accuracy = round(random.random() + random.random(), 3)
print(f"Accuracy is: {accuracy}, {acc_threshold}")
# 精度 を wandb に ログ に記録します
wandb.log({"Accuracy": accuracy})
# 精度 が しきい値 を下回る場合は、W&B Alert を起動して run を停止します
if accuracy <= acc_threshold:
# wandb Alert を送信します
wandb.alert(
title="Low Accuracy",
text=f"Accuracy {accuracy} at step {training_step} is below the acceptable theshold, {acc_threshold}",
)
print("Alert triggered")
break
# run に完了のマークを付けます (Jupyter ノートブック で役立ちます)
wandb.finish()
W&B Alerts の 完全な ドキュメント はこちら にあります。
次のステップ
次の チュートリアル では、W&B Sweeps を使用して ハイパーパラメータ の 最適化 を行う方法を学習します。 PyTorch を使用した ハイパーパラメータ sweep
[i18n] feedback_title
[i18n] feedback_question
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.