Set up Launch
このページでは、W&B Launch を設定するために必要な大まかな手順について説明します。
キューの設定 : キューは FIFO であり、キュー設定を備えています。キューの設定は、ターゲットリソース上でジョブがどこでどのように実行されるかを制御します。エージェントの設定 : エージェントは、ユーザーのマシン/インフラストラクチャー上で実行され、Launch ジョブの 1 つ以上のキューをポーリングします。ジョブがプルされると、エージェントはイメージが構築され、利用可能であることを確認します。その後、エージェントはジョブをターゲットリソースに送信します。
キューの設定
Launch キューは、特定ターゲットリソースと、そのリソースに固有の追加設定を指すように設定する必要があります。たとえば、Kubernetes クラスターを指す Launch キューには、環境変数を含めたり、Launch キュー設定のカスタム名前空間を設定したりできます。キューを作成する際には、使用するターゲットリソースと、そのリソースが使用する設定の両方を指定します。
エージェントがキューからジョブを受信すると、キュー設定も受信します。エージェントがジョブをターゲットリソースに送信する際、ジョブ自体のオーバーライドとともにキュー設定が含まれます。たとえば、ジョブ設定を使用して、そのジョブインスタンスのみの Amazon SageMaker インスタンスタイプを指定できます。この場合、キュー設定テンプレート をエンドユーザーインターフェイスとして使用するのが一般的です。
キューの作成
wandb.ai/launch で Launch アプリケーションに移動します。画面右上の create queue ボタンをクリックします。
Entity ドロップダウンメニューから、キューが属するエンティティを選択します。Queue フィールドにキューの名前を入力します。Resource ドロップダウンから、このキューに追加されたジョブで使用するコンピュートリソースを選択します。このキューの Prioritization を許可するかどうかを選択します。優先順位付けが有効になっている場合、チームのユーザーは、エンキュー時に Launch ジョブの優先順位を定義できます。優先度の高いジョブは、優先度の低いジョブよりも先に実行されます。
Configuration フィールドに、JSON または YAML 形式でリソース設定を入力します。設定ドキュメントの構造とセマンティクスは、キューが指すリソースタイプによって異なります。詳細については、ターゲットリソースの専用設定ページを参照してください。
Launch エージェントの設定
Launch エージェントは、ジョブのために 1 つ以上の Launch キューをポーリングする、長時間実行されるプロセスです。Launch エージェントは、先入れ先出し(FIFO)順、またはプル元のキューに応じて優先順位順にジョブをデキューします。エージェントがキューからジョブをデキューすると、オプションでそのジョブのイメージを構築します。その後、エージェントはジョブをターゲットリソースに、キュー設定で指定された設定オプションとともに送信します。
W&B では、特定ユーザーの API キーではなく、サービスアカウントの API キーでエージェントを開始することをお勧めします。サービスアカウントの API キーを使用することには、次の 2 つの利点があります。
エージェントは、個々のユーザーに依存しません。
Launch を介して作成された run に関連付けられた作成者は、エージェントに関連付けられたユーザーではなく、Launch ジョブを送信したユーザーとして Launch によって認識されます。
エージェントの設定
launch-config.yaml という YAML ファイルで Launch エージェントを設定します。デフォルトでは、W&B は ~/.config/wandb/launch-config.yaml にある設定ファイルを確認します。Launch エージェントをアクティブ化するときに、別のディレクトリーをオプションで指定できます。
Launch エージェントの設定ファイルの内容は、Launch エージェントの環境、Launch キューのターゲットリソース、Docker ビルダーの要件、クラウドリポジトリの要件などによって異なります。
ユースケースに関係なく、Launch エージェントには、設定可能な主要オプションがあります。
max_jobs: エージェントが並行して実行できるジョブの最大数entity: キューが属するエンティティqueues: エージェントが監視する 1 つ以上のキューの名前
W&B CLI を使用して、Launch エージェントの普遍的な設定可能オプション(設定 YAML ファイルの代わりに)、ジョブの最大数、W&B エンティティ、および Launch キューを指定できます。詳細については、
wandb launch-agent コマンドを参照してください。
次の YAML コードスニペットは、主要な Launch エージェント設定キーを指定する方法を示しています。
# 実行する同時runsの最大数。 -1 = 無制限
max_jobs : -1
entity : <entity-name>
# ポーリングするキューのリスト。
queues :
- <queue-name>
コンテナビルダーの設定
Launch エージェントは、イメージを構築するように構成できます。git リポジトリまたはコード Artifacts から作成された Launch ジョブを使用する場合は、コンテナビルダーを使用するようにエージェントを設定する必要があります。 Launch ジョブの作成方法の詳細については、Launch ジョブの作成 を参照してください。
W&B Launch は、次の 3 つのビルダーオプションをサポートしています。
Docker: Docker ビルダーは、ローカル Docker デーモンを使用してイメージを構築します。
Kaniko : Kaniko は、Docker デーモンが利用できない環境でイメージを構築できる Google プロジェクトです。Noop: エージェントはジョブの構築を試行せず、代わりに構築済みのイメージのみをプルします。
エージェントが Docker デーモンが利用できない環境(Kubernetes クラスターなど)でポーリングしている場合は、Kaniko ビルダーを使用してください。
Kaniko ビルダーの詳細については、Kubernetes の設定 を参照してください。
イメージビルダーを指定するには、エージェント設定に builder キーを含めます。たとえば、次のコードスニペットは、Docker または Kaniko を使用するように指定する Launch 設定(launch-config.yaml)の一部を示しています。
builder :
type : docker | kaniko | noop
コンテナレジストリの設定
場合によっては、Launch エージェントをクラウドリポジトリに接続する必要があるかもしれません。Launch エージェントをクラウドリポジトリに接続する一般的なシナリオとしては、次のようなものがあります。
強力なワークステーションやクラスターなど、イメージを構築したのとは別の環境でジョブを実行する場合。
エージェントを使用してイメージを構築し、これらのイメージを Amazon SageMaker または VertexAI で実行する場合。
Launch エージェントに、イメージリポジトリからプルするための認証情報を提供させる場合。
コンテナレジストリとやり取りするようにエージェントを設定する方法の詳細については、エージェントの詳細設定 ページを参照してください。
Launch エージェントのアクティブ化
launch-agent W&B CLI コマンドで Launch エージェントをアクティブ化します。
wandb launch-agent -q <queue-1> -q <queue-2> --max-jobs 5
一部のユースケースでは、Kubernetes クラスター内から Launch エージェントにキューをポーリングさせたい場合があります。詳細については、キューの詳細設定ページ を参照してください。
1 - Configure launch queue
以下のページでは、 ローンチ キューのオプションを設定する方法について説明します。
キュー設定テンプレートの設定
キュー設定テンプレートを使用して、コンピュート消費に関するガードレールを管理します。メモリ消費量、 GPU 、ランタイム時間などのフィールドのデフォルト値、最小値、および最大値を設定します。
設定テンプレートでキューを設定すると、チームのメンバーは、定義した範囲内でのみ、定義したフィールドを変更できます。
キューテンプレートの設定
既存のキューでキューテンプレートを設定するか、新しいキューを作成できます。
https://wandb.ai/launch の ローンチ アプリに移動します。テンプレートを追加するキューの名前の横にある View queue を選択します。
Config タブを選択します。これにより、キューが作成された時期、キューの設定、既存の ローンチ 時のオーバーライドなど、キューに関する情報が表示されます。Queue config セクションに移動します。テンプレートを作成する設定の キー の 値 を特定します。
設定内の 値 をテンプレートフィールドに置き換えます。テンプレートフィールドは {{variable-name}} の形式を取ります。
Parse configuration ボタンをクリックします。設定を解析すると、作成した各テンプレートのタイルが自動的にキュー設定の下に作成されます。生成された各タイルについて、最初にキュー設定で許可する データ 型(文字列、整数、または浮動小数点)を指定する必要があります。これを行うには、Type ドロップダウンメニューから データ 型を選択します。
データ 型に基づいて、各タイル内に表示されるフィールドに入力します。
Save config をクリックします。
たとえば、チームが使用できる AWS インスタンスを制限するテンプレートを作成するとします。テンプレートフィールドを追加する前は、キュー設定は次のようになります。
RoleArn : arn:aws:iam:region:account-id:resource-type/resource-id
ResourceConfig :
InstanceType : ml.m4.xlarge
InstanceCount : 1
VolumeSizeInGB : 2
OutputDataConfig :
S3OutputPath : s3://bucketname
StoppingCondition :
MaxRuntimeInSeconds : 3600
InstanceType のテンプレートフィールドを追加すると、設定は次のようになります。
RoleArn : arn:aws:iam:region:account-id:resource-type/resource-id
ResourceConfig :
InstanceType : "{{aws_instance}}"
InstanceCount : 1
VolumeSizeInGB : 2
OutputDataConfig :
S3OutputPath : s3://bucketname
StoppingCondition :
MaxRuntimeInSeconds : 3600
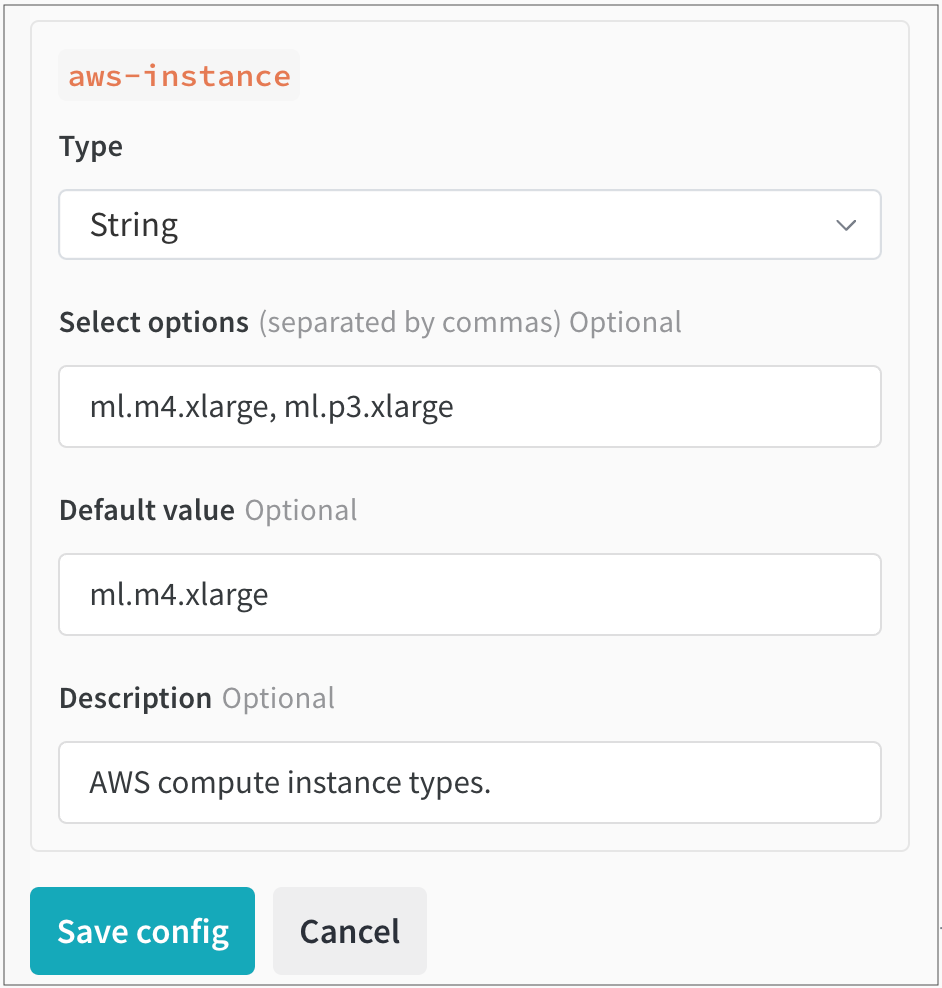
次に、Parse configuration をクリックします。aws-instance というラベルの新しいタイルが Queue config の下に表示されます。
そこから、Type ドロップダウンから String を データ 型として選択します。これにより、 ユーザー が選択できる 値 を指定できるフィールドが入力されます。たとえば、次の図では、チームの管理者が ユーザー が選択できる2つの異なる AWS インスタンスタイプ(ml.m4.xlarge と ml.p3.xlarge)を設定しています。
ローンチ ジョブの動的な設定
キュー設定は、 エージェント がキューからジョブをデキューするときに評価されるマクロを使用して動的に設定できます。次のマクロを設定できます。
Macro
Description
${project_name}run が ローンチ されている プロジェクト の名前。
${entity_name}run が ローンチ されている プロジェクト の所有者。
${run_id}ローンチ されている run の ID。
${run_name}ローンチ されている run の名前。
${image_uri}この run のコンテナ イメージの URI。
上記の表にリストされていないカスタムマクロ(${MY_ENV_VAR} など)は、 エージェント の 環境 から 環境 変数に置き換えられます。
ローンチ エージェント を使用して、アクセラレータ( GPU )で実行されるイメージを構築する
アクセラレータ 環境 で実行されるイメージを構築するために ローンチ を使用する場合は、アクセラレータ ベース イメージを指定する必要がある場合があります。
このアクセラレータ ベース イメージは、次の要件を満たしている必要があります。
Debian の互換性( ローンチ Dockerfile は apt-get を使用して python をフェッチします)
CPU と GPU のハードウェア命令セットの互換性(使用する予定の GPU で CUDA バージョンがサポートされていることを確認してください)
提供するアクセラレータ バージョンと ML アルゴリズムにインストールされているパッケージとの互換性
ハードウェアとの互換性を設定するために追加の手順が必要なインストール済みパッケージ
TensorFlow で GPU を使用する方法
TensorFlow が GPU を適切に利用していることを確認します。これを実現するには、キュー リソース 設定で builder.accelerator.base_image キーの Docker イメージとそのイメージ タグを指定します。
たとえば、tensorflow/tensorflow:latest-gpu ベース イメージは、TensorFlow が GPU を適切に使用することを保証します。これは、キュー内のリソース設定を使用して構成できます。
次の JSON スニペットは、キュー設定で TensorFlow ベース イメージを指定する方法を示しています。
{
"builder" : {
"accelerator" : {
"base_image" : "tensorflow/tensorflow:latest-gpu"
}
}
}
2 - Set up launch agent
高度なエージェントの設定
このガイドでは、さまざまな環境でコンテナイメージを構築するために W&B Launch エージェントをセットアップする方法について説明します。
ビルドは、git および コード Artifacts ジョブでのみ必要です。イメージジョブはビルドを必要としません。
ジョブタイプに関する詳細については、Launch ジョブの作成 を参照してください。
ビルダー
Launch エージェントは、Docker または Kaniko を使用してイメージを構築できます。
Kaniko: 特権コンテナとしてビルドを実行せずに、Kubernetes でコンテナイメージを構築します。
Docker: docker build コマンドをローカルで実行して、コンテナイメージを構築します。
ビルダータイプは、Launch エージェント設定の builder.type キーで制御でき、ビルドをオフにするには docker、kaniko、または noop のいずれかに設定します。デフォルトでは、エージェント Helm チャートは builder.type を noop に設定します。builder セクションの追加キーは、ビルドプロセスを設定するために使用されます。
エージェント設定でビルダーが指定されておらず、動作する docker CLI が見つかった場合、エージェントはデフォルトで Docker を使用します。Docker が利用できない場合、エージェントはデフォルトで noop になります。
Kubernetes クラスターでイメージを構築するには Kaniko を使用します。他のすべての場合は Docker を使用してください。
コンテナレジストリへのプッシュ
Launch エージェントは、構築するすべてのイメージに一意のソースハッシュでタグを付けます。エージェントは、builder.destination キーで指定されたレジストリにイメージをプッシュします。
たとえば、builder.destination キーが my-registry.example.com/my-repository に設定されている場合、エージェントはイメージに my-registry.example.com/my-repository:<source-hash> というタグを付けてプッシュします。イメージがレジストリに存在する場合、ビルドはスキップされます。
エージェントの設定
Helm チャートを介してエージェントをデプロイする場合、エージェント設定は values.yaml ファイルの agentConfig キーで指定する必要があります。
wandb launch-agent でエージェントを自分で呼び出す場合は、--config フラグを使用して、エージェント設定を YAML ファイルへのパスとして指定できます。デフォルトでは、設定は ~/.config/wandb/launch-config.yaml からロードされます。
Launch エージェント設定(launch-config.yaml)内で、ターゲットリソース環境の名前と、environment および registry キーのコンテナレジストリの名前を指定します。
次のタブは、環境とレジストリに基づいて Launch エージェントを設定する方法を示しています。
AWS 環境設定には、region キーが必要です。region は、エージェントが実行される AWS リージョンである必要があります。
environment :
type : aws
region : <aws-region>
builder :
type : <kaniko|docker>
# エージェントがイメージを保存する ECR リポジトリの URI。
# リージョンが環境で設定したものと一致していることを確認してください。
destination : <account-id>.ecr.<aws-region>.amazonaws.com/<repository-name>
# Kaniko を使用する場合は、エージェントがビルドコンテキストを保存する S3 バケットを指定します。
build-context-store : s3://<bucket-name>/<path>
エージェントは boto3 を使用してデフォルトの AWS 認証情報をロードします。デフォルトの AWS 認証情報を設定する方法の詳細については、boto3 のドキュメント を参照してください。
Google Cloud 環境には、region および project キーが必要です。region をエージェントが実行されるリージョンに設定します。project をエージェントが実行される Google Cloud プロジェクトに設定します。エージェントは、Python で google.auth.default() を使用して、デフォルトの認証情報をロードします。
environment :
type : gcp
region : <gcp-region>
project : <gcp-project-id>
builder :
type : <kaniko|docker>
# エージェントがイメージを保存する Artifact Registry リポジトリとイメージ名の URI。
# リージョンとプロジェクトが、環境で設定したものと一致していることを確認してください。
uri : <region>-docker.pkg.dev/<project-id>/<repository-name>/<image-name>
# Kaniko を使用する場合は、エージェントがビルドコンテキストを保存する GCS バケットを指定します。
build-context-store : gs://<bucket-name>/<path>
エージェントが利用できるように、デフォルトの GCP 認証情報を設定する方法の詳細については、google-auth ドキュメント
Azure 環境は、追加のキーを必要としません。エージェントは起動時に azure.identity.DefaultAzureCredential() を使用して、デフォルトの Azure 認証情報をロードします。
environment :
type : azure
builder :
type : <kaniko|docker>
# エージェントがイメージを保存する Azure Container Registry リポジトリの URI。
destination : https://<registry-name>.azurecr.io/<repository-name>
# Kaniko を使用する場合は、エージェントがビルドコンテキストを保存する Azure Blob Storage コンテナーを指定します。
build-context-store : https://<storage-account-name>.blob.core.windows.net/<container-name>
デフォルトの Azure 認証情報を設定する方法の詳細については、azure-identity ドキュメント
エージェントの権限
必要なエージェントの権限は、ユースケースによって異なります。
クラウドレジストリの権限
以下は、Launch エージェントがクラウドレジストリとやり取りするために一般的に必要な権限です。
{
'Version' : '2012-10-17' ,
'Statement' :
[
{
'Effect' : 'Allow' ,
'Action' :
[
'ecr:CreateRepository' ,
'ecr:UploadLayerPart' ,
'ecr:PutImage' ,
'ecr:CompleteLayerUpload' ,
'ecr:InitiateLayerUpload' ,
'ecr:DescribeRepositories' ,
'ecr:DescribeImages' ,
'ecr:BatchCheckLayerAvailability' ,
'ecr:BatchDeleteImage' ,
],
'Resource' : 'arn:aws:ecr:<region>:<account-id>:repository/<repository>' ,
},
{
'Effect' : 'Allow' ,
'Action' : 'ecr:GetAuthorizationToken' ,
'Resource' : '*' ,
},
],
}
artifactregistry .dockerimages .list ;
artifactregistry .repositories .downloadArtifacts ;
artifactregistry .repositories .list ;
artifactregistry .repositories .uploadArtifacts ;
Kaniko ビルダーを使用する場合は、AcrPush ロール
Kaniko のストレージ権限
エージェントが Kaniko ビルダーを使用する場合、Launch エージェントはクラウドストレージにプッシュする権限が必要です。Kaniko は、ビルドジョブを実行しているポッドの外部にあるコンテキストストアを使用します。
AWS での Kaniko ビルダーの推奨コンテキストストアは Amazon S3 です。次のポリシーを使用して、エージェントに S3 バケットへのアクセス権を付与できます。
{
"Version" : "2012-10-17" ,
"Statement" : [
{
"Sid" : "ListObjectsInBucket" ,
"Effect" : "Allow" ,
"Action" : ["s3:ListBucket" ],
"Resource" : ["arn:aws:s3:::<BUCKET-NAME>" ]
},
{
"Sid" : "AllObjectActions" ,
"Effect" : "Allow" ,
"Action" : "s3:*Object" ,
"Resource" : ["arn:aws:s3:::<BUCKET-NAME>/*" ]
}
]
}
GCP では、エージェントがビルドコンテキストを GCS にアップロードするために、次の IAM 権限が必要です。
storage .buckets .get ;
storage .objects .create ;
storage .objects .delete ;
storage .objects .get ;
エージェントがビルドコンテキストを Azure Blob Storage にアップロードするには、ストレージ BLOB データ共同作成者 ロールが必要です。
Kaniko ビルドのカスタマイズ
エージェント設定の builder.kaniko-config キーで、Kaniko ジョブが使用する Kubernetes ジョブスペックを指定します。次に例を示します。
builder :
type : kaniko
build-context-store : <my-build-context-store>
destination : <my-image-destination>
build-job-name : wandb-image-build
kaniko-config :
spec :
template :
spec :
containers :
- args :
- "--cache=false" # Args は "key=value" 形式である必要があります
env :
- name : "MY_ENV_VAR"
value : "my-env-var-value"
CoreWeave への Launch エージェントのデプロイ
オプションで、W&B Launch エージェントを CoreWeave Cloud インフラストラクチャにデプロイします。CoreWeave は、GPU アクセラレーションされたワークロード用に構築されたクラウドインフラストラクチャです。
Launch エージェントを CoreWeave にデプロイする方法については、CoreWeave ドキュメント を参照してください。
3 - Tutorial: Set up W&B Launch on Kubernetes
W&B Launch を使用して、ML ワークロードを Kubernetes クラスターにプッシュできます。これにより、ML エンジニアは、Kubernetes で既に管理しているリソースを使用するために、W&B 内でシンプルなインターフェースを利用できます。
W&B は、W&B が管理する 公式 Launch agent イメージ を保持しており、Helm chart を使用してクラスターにデプロイできます。
W&B は Kaniko ビルダーを使用して、Launch エージェントが Kubernetes クラスターで Docker イメージを構築できるようにします。Launch エージェント用に Kaniko をセットアップする方法、またはジョブの構築をオフにして、事前構築済みの Docker イメージのみを使用する方法の詳細については、エージェントの詳細設定 を参照してください。
Helm をインストールし、W&B の Launch エージェント Helm chart を適用またはアップグレードするには、Kubernetes リソースを作成、更新、および削除するための十分な権限を持つ kubectl アクセス権がクラスターに必要です。通常、cluster-admin または同等の権限を持つカスタムロールを持つユーザーが必要です。
Kubernetes のキューを設定する
Kubernetes ターゲットリソースの Launch キュー設定は、Kubernetes Job spec または Kubernetes Custom Resource spec のいずれかに類似します。
Launch キューを作成するときに、Kubernetes ワークロードリソース spec のあらゆる側面を制御できます。
Kubernetes job spec
Custom resource spec
spec :
template :
spec :
containers :
- env :
- name : MY_ENV_VAR
value : some-value
resources :
requests :
cpu : 1000m
memory : 1Gi
metadata :
labels :
queue : k8s-test
namespace : wandb
ユースケースによっては、CustomResource 定義を使用したい場合があります。たとえば、マルチノード分散トレーニングを実行する場合、CustomResource 定義が役立ちます。Volcano を使用したマルチノードジョブで Launch を使用するチュートリアルで、アプリケーションの例を参照してください。別のユースケースとして、W&B Launch を Kubeflow で使用したい場合もあります。
次の YAML スニペットは、Kubeflow を使用するサンプル Launch キュー設定を示しています。
kubernetes :
kind : PyTorchJob
spec :
pytorchReplicaSpecs :
Master :
replicas : 1
template :
spec :
containers :
- name : pytorch
image : '${image_uri}'
imagePullPolicy : Always
restartPolicy : Never
Worker :
replicas : 2
template :
spec :
containers :
- name : pytorch
image : '${image_uri}'
imagePullPolicy : Always
restartPolicy : Never
ttlSecondsAfterFinished : 600
metadata :
name : '${run_id}-pytorch-job'
apiVersion : kubeflow.org/v1
セキュリティ上の理由から、W&B は、指定されていない場合、次のリソースを Launch キューに挿入します。
securityContextbackOffLimitttlSecondsAfterFinished
次の YAML スニペットは、これらの値が Launch キューにどのように表示されるかを示しています。
spec :
template :
`backOffLimit` : 0
ttlSecondsAfterFinished : 60
securityContext :
allowPrivilegeEscalation : False ,
capabilities :
drop :
- ALL,
seccompProfile :
type : "RuntimeDefault"
キューを作成する
Kubernetes をコンピューティングリソースとして使用するキューを W&B アプリケーションで作成します。
Launch ページ に移動します。[キューを作成 ] ボタンをクリックします。
キューを作成する Entity を選択します。
[名前 ] フィールドにキューの名前を入力します。
[リソース ] として Kubernetes を選択します。
[設定 ] フィールドで、前のセクションで設定した Kubernetes Job ワークフロー spec または Custom Resource spec を指定します。
Helm で Launch エージェントを設定する
W&B が提供する Helm chart を使用して、Launch エージェントを Kubernetes クラスターにデプロイします。values.yaml ファイル で Launch エージェントの振る舞いを制御します。
通常は Launch エージェント設定ファイル (~/.config/wandb/launch-config.yaml) で定義される内容を、values.yaml ファイルの launchConfig キー内に指定します。
たとえば、Kaniko Docker イメージビルダーを使用する EKS で Launch エージェントを実行できるようにする Launch エージェント設定があるとします。
queues :
- <queue name>
max_jobs : <n concurrent jobs>
environment :
type : aws
region : us-east-1
registry :
type : ecr
uri : <my-registry-uri>
builder :
type : kaniko
build-context-store : <s3-bucket-uri>
values.yaml ファイル内では、次のようになります。
agent :
labels : {}
# W&B API key.
apiKey : ''
# Container image to use for the agent.
image : wandb/launch-agent:latest
# Image pull policy for agent image.
imagePullPolicy : Always
# Resources block for the agent spec.
resources :
limits :
cpu : 1000m
memory : 1Gi
# Namespace to deploy launch agent into
namespace : wandb
# W&B api url (Set yours here)
baseUrl : https://api.wandb.ai
# Additional target namespaces that the launch agent can deploy into
additionalTargetNamespaces :
- default
- wandb
# This should be set to the literal contents of your launch agent config.
launchConfig : |
queues:
- <queue name>
max_jobs: <n concurrent jobs>
environment:
type: aws
region: <aws-region>
registry:
type: ecr
uri: <my-registry-uri>
builder:
type: kaniko
build-context-store: <s3-bucket-uri>
# The contents of a git credentials file. This will be stored in a k8s secret
# and mounted into the agent container. Set this if you want to clone private
# repos.
gitCreds : |
# Annotations for the wandb service account. Useful when setting up workload identity on gcp.
serviceAccount :
annotations :
iam.gke.io/gcp-service-account :
azure.workload.identity/client-id :
# Set to access key for azure storage if using kaniko with azure.
azureStorageAccessKey : ''
レジストリ、環境、および必要なエージェント権限の詳細については、エージェントの詳細設定 を参照してください。
4 - Tutorial: Set up W&B Launch on SageMaker
W&B の Launch を使用すると、提供された、またはカスタムのアルゴリズムを使用して、Amazon SageMaker に Launch ジョブを送信し、SageMaker プラットフォームで機械学習 モデルをトレーニングできます。SageMaker は、コンピューティングリソースの起動と解放を行うため、EKS クラスターを持たない Teams にとって良い選択肢となります。
Amazon SageMaker に接続された W&B Launch キューに送信された Launch ジョブは、CreateTrainingJob API を使用して SageMaker Training ジョブとして実行されます。Launch キューの設定を使用して、CreateTrainingJob API に送信される引数を制御します。
Amazon SageMaker は、Docker イメージを使用して Training ジョブを実行します 。SageMaker によってプルされるイメージは、Amazon Elastic Container Registry (ECR) に保存する必要があります。これは、トレーニングに使用するイメージが ECR に保存されている必要があることを意味します。
この ガイド では、SageMaker Training ジョブを実行する方法について説明します。Amazon SageMaker での推論のために Models をデプロイする方法については、
この Launch ジョブの例 を参照してください。
前提条件
開始する前に、次の前提条件を満たしていることを確認してください。
Launch エージェント に Docker イメージを構築させるかどうかを決定します。
W&B Launch エージェント に Docker イメージを構築させるかどうかを決定します。次の 2 つのオプションから選択できます。
Launch エージェント が Docker イメージを構築し、イメージを Amazon ECR にプッシュして、SageMaker Training ジョブを送信できるようにします。このオプションは、機械学習 エンジニアがトレーニング コードを迅速に反復処理する際に、ある程度の簡素化をもたらすことができます。
Launch エージェント は、トレーニング スクリプトまたは推論スクリプトを含む既存の Docker イメージを使用します。このオプションは、既存の CI システムとうまく連携します。このオプションを選択した場合は、Docker イメージを Amazon ECR のコンテナー レジストリに手動でアップロードする必要があります。
AWS リソースのセットアップ
優先する AWS リージョンで次の AWS リソースが構成されていることを確認してください。
コンテナー イメージを保存する ECR リポジトリ 。
SageMaker Training ジョブの入出力を保存する 1 つ以上の S3 バケット 。
SageMaker が Training ジョブを実行し、Amazon ECR および Amazon S3 とやり取りすることを許可する Amazon SageMaker の IAM ロール。
これらのリソースの ARN をメモしておきます。Launch キューの設定 を定義する際に、ARN が必要になります。
Launch エージェント の IAM ポリシーを作成する
AWS の IAM 画面から、新しいポリシーを作成します。
JSON ポリシー エディターに切り替え、ユースケースに基づいて次のポリシーを貼り付けます。<> で囲まれた値を独自の値に置き換えます。
エージェント が構築済みの Docker イメージを送信する
エージェント が Docker イメージを構築して送信する
{
"Version" : "2012-10-17" ,
"Statement" : [
{
"Effect" : "Allow" ,
"Action" : [
"logs:DescribeLogStreams" ,
"SageMaker:AddTags" ,
"SageMaker:CreateTrainingJob" ,
"SageMaker:DescribeTrainingJob"
],
"Resource" : "arn:aws:sagemaker:<region>:<account-id>:*"
},
{
"Effect" : "Allow" ,
"Action" : "iam:PassRole" ,
"Resource" : "arn:aws:iam::<account-id>:role/<RoleArn-from-queue-config>"
},
{
"Effect" : "Allow" ,
"Action" : "kms:CreateGrant" ,
"Resource" : "<ARN-OF-KMS-KEY>" ,
"Condition" : {
"StringEquals" : {
"kms:ViaService" : "SageMaker.<region>.amazonaws.com" ,
"kms:GrantIsForAWSResource" : "true"
}
}
}
]
}
{
"Version" : "2012-10-17" ,
"Statement" : [
{
"Effect" : "Allow" ,
"Action" : [
"logs:DescribeLogStreams" ,
"SageMaker:AddTags" ,
"SageMaker:CreateTrainingJob" ,
"SageMaker:DescribeTrainingJob"
],
"Resource" : "arn:aws:sagemaker:<region>:<account-id>:*"
},
{
"Effect" : "Allow" ,
"Action" : "iam:PassRole" ,
"Resource" : "arn:aws:iam::<account-id>:role/<RoleArn-from-queue-config>"
},
{
"Effect" : "Allow" ,
"Action" : [
"ecr:CreateRepository" ,
"ecr:UploadLayerPart" ,
"ecr:PutImage" ,
"ecr:CompleteLayerUpload" ,
"ecr:InitiateLayerUpload" ,
"ecr:DescribeRepositories" ,
"ecr:DescribeImages" ,
"ecr:BatchCheckLayerAvailability" ,
"ecr:BatchDeleteImage"
],
"Resource" : "arn:aws:ecr:<region>:<account-id>:repository/<repository>"
},
{
"Effect" : "Allow" ,
"Action" : "ecr:GetAuthorizationToken" ,
"Resource" : "*"
},
{
"Effect" : "Allow" ,
"Action" : "kms:CreateGrant" ,
"Resource" : "<ARN-OF-KMS-KEY>" ,
"Condition" : {
"StringEquals" : {
"kms:ViaService" : "SageMaker.<region>.amazonaws.com" ,
"kms:GrantIsForAWSResource" : "true"
}
}
}
]
}
[Next ] をクリックします。
ポリシーに名前と説明を付けます。
[Create policy ] をクリックします。
Launch エージェント の IAM ロールを作成する
Launch エージェント に Amazon SageMaker Training ジョブを作成する権限が必要です。次の手順に従って、IAM ロールを作成します。
AWS の IAM 画面から、新しいロールを作成します。
[Trusted Entity ] で、[AWS Account ] (または組織のポリシーに適した別のオプション) を選択します。
権限画面をスクロールして、上記で作成したポリシー名を選択します。
ロールに名前と説明を付けます。
[Create role ] を選択します。
ロールの ARN をメモします。Launch エージェント を設定する際に、ARN を指定します。
IAM ロールの作成方法の詳細については、AWS Identity and Access Management のドキュメント を参照してください。
Launch エージェント にイメージを構築させる場合は、追加で必要な権限について、エージェント の高度な設定 を参照してください。
SageMaker キューの kms:CreateGrant 権限は、関連付けられた ResourceConfig に VolumeKmsKeyId が指定されていて、関連付けられたロールにこのアクションを許可するポリシーがない場合にのみ必要です。
SageMaker の Launch キューを設定する
次に、SageMaker をコンピューティング リソースとして使用するキューを W&B アプリ で作成します。
Launch アプリ に移動します。[Create Queue ] ボタンをクリックします。
キューを作成する [Entity ] を選択します。
[Name ] フィールドにキューの名前を入力します。
[Resource ] として [SageMaker ] を選択します。
[Configuration ] フィールド内で、SageMaker ジョブに関する情報を提供します。デフォルトでは、W&B は YAML および JSON の CreateTrainingJob リクエスト本文を生成します。
{
"RoleArn" : "<必須>" ,
"ResourceConfig" : {
"InstanceType" : "ml.m4.xlarge" ,
"InstanceCount" : 1 ,
"VolumeSizeInGB" : 2
},
"OutputDataConfig" : {
"S3OutputPath" : "<必須>"
},
"StoppingCondition" : {
"MaxRuntimeInSeconds" : 3600
}
}
少なくとも以下を指定する必要があります。
RoleArn: SageMaker 実行 IAM ロールの ARN (前提条件 を参照)。Launch エージェント IAM ロールと混同しないようにしてください。OutputDataConfig.S3OutputPath: SageMaker の出力が保存される Amazon S3 URI。ResourceConfig: リソース設定に必要な仕様。リソース設定のオプションはこちら に概説されています。StoppingCondition: Training ジョブの停止条件に必要な仕様。オプションはこちら に概説されています。
[Create Queue ] ボタンをクリックします。
Launch エージェント を設定する
次のセクションでは、エージェント をデプロイできる場所と、デプロイ場所に基づいて エージェント を構成する方法について説明します。
Amazon SageMaker の Launch エージェント をデプロイする方法には、いくつかのオプション があります。ローカル マシン、EC2 インスタンス、または EKS クラスターです。エージェント をデプロイする場所に基づいて、Launch エージェント を適切に構成 します。
Launch エージェント を実行する場所を決定する
本番環境のワークロードや、既に EKS クラスターをお持ちのお客様には、この Helm チャートを使用して、Launch エージェント を EKS クラスターにデプロイすることをお勧めします。
現在の EKS クラスターを使用しない本番環境のワークロードの場合、EC2 インスタンスは優れたオプションです。Launch エージェント インスタンスは常に実行され続けますが、エージェント には t2.micro サイズの EC2 インスタンス以上のものは必要ありません。これは比較的安価です。
実験的なユースケースや個人のユースケースの場合、ローカル マシンで Launch エージェント を実行すると、すばやく開始できます。
ユースケースに基づいて、次のタブに記載されている手順に従って、Launch エージェント を適切に構成してください。
W&B は、W&B 管理の Helm チャート を使用して、EKS クラスターに エージェント をインストールすることを強くお勧めします。
Amazon EC2 ダッシュボードに移動し、次の手順を実行します。
[Launch instance ] をクリックします。
[Name ] フィールドに名前を入力します。必要に応じて、タグを追加します。
[Instance type ] で、EC2 コンテナーのインスタンス タイプを選択します。1 vCPU と 1 GiB のメモリを超えるものは必要ありません (たとえば、t2.micro)。
[Key pair (login) ] フィールド内で、組織のキー ペアを作成します。このキー ペアを使用して、後の手順で SSH クライアントを使用してEC2 インスタンスに接続 します。
[Network settings ] 内で、組織に適したセキュリティ グループを選択します。
[Advanced details ] を展開します。[IAM instance profile ] で、上記で作成した Launch エージェント IAM ロールを選択します。
[Summary ] フィールドを確認します。正しい場合は、[Launch instance ] を選択します。
AWS の EC2 ダッシュボードの左側のパネルにある [Instances ] に移動します。作成した EC2 インスタンスが実行されていることを確認します ([Instance state ] 列を参照)。EC2 インスタンスが実行されていることを確認したら、ローカル マシンのターミナルに移動して、次の手順を実行します。
[Connect ] を選択します。
[SSH client ] タブを選択し、概要が示されている手順に従って EC2 インスタンスに接続します。
EC2 インスタンス内で、次のパッケージをインストールします。
sudo yum install python311 -y && python3 -m ensurepip --upgrade && pip3 install wandb && pip3 install wandb[ launch]
次に、EC2 インスタンス内で Docker をインストールして起動します。
sudo yum update -y && sudo yum install -y docker python3 && sudo systemctl start docker && sudo systemctl enable docker && sudo usermod -a -G docker ec2-user
newgrp docker
これで、Launch エージェント の構成に進むことができます。
~/.aws/config および ~/.aws/credentials にある AWS 構成ファイルを使用して、ローカル マシンでポーリングする エージェント にロールを関連付けます。前の手順で Launch エージェント 用に作成した IAM ロール ARN を指定します。
[profile SageMaker-agent]
role_arn = arn:aws:iam::<account-id>:role/<agent-role-name>
source_profile = default
[default]
aws_access_key_id=<access-key-id>
aws_secret_access_key=<secret-access-key>
aws_session_token=<session-token>
セッション トークンには、関連付けられているプリンシパルに応じて、最大長 が 1 時間または 3 日であることに注意してください。
Launch エージェント を構成する
YAML 構成ファイル launch-config.yaml を使用して Launch エージェント を構成します。
デフォルトでは、W&B は ~/.config/wandb/launch-config.yaml で構成ファイルを確認します。必要に応じて、-c フラグを使用して Launch エージェント をアクティブ化するときに、別のディレクトリーを指定できます。
次の YAML スニペットは、コア構成 エージェント オプションを指定する方法を示しています。
max_jobs : -1
queues :
- <queue-name>
environment :
type : aws
region : <your-region>
registry :
type : ecr
uri : <ecr-repo-arn>
builder :
type : docker
次に、wandb launch-agent で エージェント を開始します。
(オプション) Launch ジョブ Docker イメージを Amazon ECR にプッシュする
Launch ジョブを含む Docker イメージを Amazon ECR リポジトリにアップロードします。イメージベースのジョブを使用している場合は、新しい Launch ジョブを送信する前に、Docker イメージが ECR レジストリに存在する必要があります。
5 - Tutorial: Set up W&B Launch on Vertex AI
W&B Launch を使用して、 Vertex AI トレーニングジョブとして実行するジョブを送信できます。Vertex AI トレーニングジョブを使用すると、Vertex AI プラットフォーム上で、提供されたアルゴリズムまたはカスタム アルゴリズムを使用して、機械学習モデルをトレーニングできます。Launch ジョブが開始されると、Vertex AI は基盤となるインフラストラクチャー、スケーリング、およびオーケストレーションを管理します。
W&B Launch は、google-cloud-aiplatform SDK の CustomJob クラスを通じて Vertex AI と連携します。CustomJob のパラメータは、launch キュー設定で制御できます。Vertex AI は、GCP 外部のプライベートレジストリからイメージをプルするように構成できません。つまり、W&B Launch で Vertex AI を使用する場合は、コンテナイメージを GCP またはパブリックレジストリに保存する必要があります。コンテナイメージを Vertex ジョブからアクセスできるようにする方法については、Vertex AI のドキュメントを参照してください。
前提条件
Vertex AI API が有効になっている GCP プロジェクトを作成またはアクセスします。 API の有効化の詳細については、GCP API Console のドキュメント を参照してください。Vertex で実行するイメージを保存するための GCP Artifact Registry リポジトリを作成します。 詳細については、GCP Artifact Registry のドキュメント を参照してください。Vertex AI がそのメタデータを保存するためのステージング GCS バケットを作成します。 このバケットは、ステージングバケットとして使用するには、Vertex AI ワークロードと同じリージョンにある必要があることに注意してください。同じバケットをステージングおよびビルドコンテキストに使用できます。Vertex AI ジョブをスピンアップするために必要な権限を持つサービスアカウントを作成します。 サービスアカウントへの権限の割り当ての詳細については、GCP IAM ドキュメント を参照してください。Vertex ジョブを管理する権限をサービスアカウントに付与します
権限
リソーススコープ
説明
aiplatform.customJobs.create指定された GCP プロジェクト
プロジェクト内で新しい機械学習ジョブを作成できます。
aiplatform.customJobs.list指定された GCP プロジェクト
プロジェクト内の機械学習ジョブを一覧表示できます。
aiplatform.customJobs.get指定された GCP プロジェクト
プロジェクト内の特定の機械学習ジョブに関する情報を取得できます。
Vertex AI ワークロードに非標準のサービスアカウントの ID を引き受けさせる場合は、サービスアカウントの作成と必要な権限の手順について、Vertex AI のドキュメントを参照してください。Launch キュー設定の spec.service_account フィールドを使用して、W&B Runs のカスタムサービスアカウントを選択できます。
Vertex AI のキューを設定する
Vertex AI リソースのキュー設定では、Vertex AI Python SDK の CustomJob コンストラクタと、CustomJob の run メソッドへの入力を指定します。リソース設定は、spec キーと run キーに格納されます。
spec キーには、Vertex AI Python SDK の CustomJob コンストラクタrun キーには、Vertex AI Python SDK の CustomJob クラスの run メソッドの名前付き引数の値が含まれています。
実行環境のカスタマイズは、主に spec.worker_pool_specs リストで行われます。ワーカープールのスペックは、ジョブを実行するワーカーのグループを定義します。デフォルト設定のワーカーのスペックは、アクセラレータなしの単一の n1-standard-4 マシンを要求します。ニーズに合わせて、マシンの種類、アクセラレータの種類、および数を変更できます。
利用可能なマシンの種類とアクセラレータの種類について詳しくは、Vertex AI のドキュメント をご覧ください。
キューを作成する
Vertex AI をコンピューティングリソースとして使用するキューを W&B App で作成します。
Launch ページ に移動します。キューを作成 ボタンをクリックします。キューを作成する Entity を選択します。
名前 フィールドにキューの名前を入力します。リソース として GCP Vertex を選択します。設定 フィールド内で、前のセクションで定義した Vertex AI CustomJob に関する情報を提供します。デフォルトでは、W&B は次のような YAML および JSON リクエスト本文を生成します。
spec :
worker_pool_specs :
- machine_spec :
machine_type : n1-standard-4
accelerator_type : ACCELERATOR_TYPE_UNSPECIFIED
accelerator_count : 0
replica_count : 1
container_spec :
image_uri : ${image_uri}
staging_bucket : <REQUIRED>
run :
restart_job_on_worker_restart : false
キューを設定したら、キューを作成 ボタンをクリックします。
少なくとも、以下を指定する必要があります。
spec.worker_pool_specs: ワーカープールの仕様の空でないリスト。spec.staging_bucket: Vertex AI のアセットとメタデータのステージングに使用される GCS バケット。
Vertex AI のドキュメントの一部には、すべてのキーがキャメルケース (たとえば、 workerPoolSpecs) のワーカープールの仕様が示されています。Vertex AI Python SDK は、これらのキーにスネークケース (たとえば、worker_pool_specs) を使用します。
Launch キュー設定のすべてのキーは、スネークケースを使用する必要があります。
Launch エージェントを設定する
Launch エージェントは、デフォルトで ~/.config/wandb/launch-config.yaml にある構成ファイルを使用して設定できます。
max_jobs : <n-concurrent-jobs>
queues :
- <queue-name>
Launch エージェントに Vertex AI で実行されるイメージを構築させる場合は、エージェントの詳細設定 を参照してください。
エージェントの権限を設定する
このサービスアカウントとして認証するには、複数の方法があります。これは、Workload Identity、ダウンロードされたサービスアカウント JSON、環境変数、Google Cloud Platform コマンドライン ツール、またはこれらの方法の組み合わせによって実現できます。
6 - Tutorial: Set up W&B Launch with Docker
以下のガイドでは、 W&B Launch を設定して、 ローンチ エージェント環境とキューのターゲットリソースの両方でローカルマシン上の Docker を使用する方法について説明します。
ジョブの実行に Docker を使用すること、および同じローカルマシン上で ローンチ エージェントの環境として使用することは、お使いのコンピューティングが (Kubernetes などの) クラスター 管理システムを持たないマシンにインストールされている場合に特に役立ちます。
また、 Docker キューを使用して、強力なワークステーションでワークロードを実行することもできます。
この設定は、ローカルマシンで実験を実行するユーザーや、SSH で接続して ローンチ ジョブを送信するリモートマシンを持つユーザーによく見られます。
W&B Launch で Docker を使用すると、W&B は最初にイメージを構築し、次にそのイメージからコンテナを構築して実行します。イメージは、Docker docker run <image-uri> コマンドで構築されます。キュー構成は、 docker run コマンドに渡される追加の 引数 として解釈されます。
Docker キューの構成
(Docker ターゲットリソースの) ローンチ キュー構成は、 docker run
エージェント は、キュー構成で定義されたオプションを受け取ります。次に、 エージェント は、受信したオプションを ローンチ ジョブの構成からのオーバーライドとマージして、ターゲットリソース (この場合はローカルマシン) で実行される最終的な docker run コマンドを生成します。
次の 2 つの構文変換が行われます。
繰り返されるオプションは、キュー構成でリストとして定義されます。
フラグオプションは、キュー構成で値が true のブール値として定義されます。
たとえば、次のキュー構成があるとします。
{
"env" : ["MY_ENV_VAR=value" , "MY_EXISTING_ENV_VAR" ],
"volume" : "/mnt/datasets:/mnt/datasets" ,
"rm" : true ,
"gpus" : "all"
}
次の docker run コマンドになります。
docker run \
= value \
\
"/mnt/datasets:/mnt/datasets" \
\
ボリュームは、文字列のリストまたは単一の文字列として指定できます。複数のボリュームを指定する場合は、リストを使用します。
Docker は、値が割り当てられていない 環境 変数を ローンチ エージェント環境から自動的に渡します。つまり、 ローンチ エージェントに 環境 変数 MY_EXISTING_ENV_VAR がある場合、その 環境 変数はコンテナで使用できます。これは、キュー構成で公開せずに他の構成 キー を使用する場合に役立ちます。
docker run コマンドの --gpus フラグを使用すると、Docker コンテナで使用できる GPU を指定できます。 gpus フラグの使用方法の詳細については、 Docker のドキュメント を参照してください。
Docker コンテナ内で GPU を使用するには、 NVIDIA Container Toolkit をインストールします。
コードまたは Artifacts ソースのジョブからイメージを構築する場合、 エージェント で使用されるベースイメージをオーバーライドして、NVIDIA Container Toolkit を含めることができます。
たとえば、 ローンチ キュー内で、ベースイメージを tensorflow/tensorflow:latest-gpu にオーバーライドできます。
{
"builder" : {
"accelerator" : {
"base_image" : "tensorflow/tensorflow:latest-gpu"
}
}
}
キューの作成
W&B CLI を使用して、Docker をコンピューティングリソースとして使用するキューを作成します。
Launch page に移動します。[Create Queue ] ボタンをクリックします。
キューを作成する Entities を選択します。
[Name ] フィールドにキューの名前を入力します。
[Resource ] として Docker を選択します。
[Configuration ] フィールドで Docker キュー構成を定義します。
[Create Queue ] ボタンをクリックしてキューを作成します。
ローカルマシンでの ローンチ エージェント の構成
launch-config.yaml という名前の YAML 構成ファイルを使用して、 ローンチ エージェント を構成します。デフォルトでは、W&B は ~/.config/wandb/launch-config.yaml で構成ファイルを確認します。オプションで、 ローンチ エージェント をアクティブ化するときに別の ディレクトリー を指定できます。
W&B CLI を使用して、 ローンチ エージェント のコア構成可能オプション (ジョブの最大数、W&B Entity、 ローンチ キュー) を指定できます (構成 YAML ファイルの代わりに)。詳細については、
wandb launch-agent コマンドを参照してください。
コア エージェント 構成オプション
次のタブは、W&B CLI および YAML 構成ファイルを使用して、コア構成 エージェント オプションを指定する方法を示しています。
wandb launch-agent -q <queue-name> --max-jobs <n>
max_jobs : <n concurrent jobs>
queues :
- <queue-name>
Docker イメージビルダー
マシン上の ローンチ エージェント は、Docker イメージを構築するように構成できます。デフォルトでは、これらのイメージはマシンのローカルイメージリポジトリーに保存されます。 ローンチ エージェント が Docker イメージを構築できるようにするには、 ローンチ エージェント 構成の builder キー を docker に設定します。
エージェント に Docker イメージを構築させたくない場合は、代わりにレジストリーから事前に構築されたイメージを使用し、 ローンチ エージェント 構成の builder キー を noop に設定します。
コンテナレジストリ
Launch は、 Dockerhub、Google Container Registry、Azure Container Registry、Amazon ECR などの外部コンテナレジストリを使用します。
ジョブを構築した環境とは異なる環境でジョブを実行する場合は、コンテナレジストリからプルできるように エージェント を構成します。
ローンチ エージェント を クラウド レジストリに接続する方法の詳細については、 高度な エージェント のセットアップ ページを参照してください。