Log media and objects
8 minute read
画像、動画、音声など、様々な形式のメディアに対応しています。リッチメディアを ログ に記録して、結果を調査し、 run 、 model 、 dataset を視覚的に比較できます。例やハウツー ガイド については、以下をお読みください。
事前準備
W&B SDK でメディア オブジェクト を ログ に記録するには、追加の依存関係をインストールする必要がある場合があります。 これらの依存関係をインストールするには、次の コマンド を実行します。
pip install wandb[media]
画像
画像 を ログ に記録して、入力、出力、フィルターの重み、アクティベーションなどを追跡します。

画像 は、NumPy 配列から、PIL 画像 として、またはファイルシステムから直接 ログ に記録できます。
ステップから画像 を ログ に記録するたびに、UI に表示するために保存されます。画像 パネル を展開し、ステップ スライダーを使用して、異なるステップの画像 を確認します。これにより、 model の出力が トレーニング 中にどのように変化するかを簡単に比較できます。
torchvision の make_grid を使用するなどして、画像 を手動で構築する場合は、配列を直接指定します。
配列は Pillow を使用して png に変換されます。
images = wandb.Image(image_array, caption="Top: Output, Bottom: Input")
wandb.log({"examples": images})
最後の次元が 1 の場合はグレースケール画像、3 の場合は RGB、4 の場合は RGBA であると想定されます。配列に float が含まれている場合は、0 から 255 までの整数に変換します。画像 の正規化方法を変更する場合は、mode を手動で指定するか、この パネル の「PIL 画像 の ログ 記録」 タブ で説明されているように、PIL.Image を指定します。
配列から画像 への変換を完全に制御するには、PIL.Image を自分で構築し、直接指定します。
images = [PIL.Image.fromarray(image) for image in image_array]
wandb.log({"examples": [wandb.Image(image) for image in images]})
さらに細かく制御するには、好きな方法で画像 を作成し、ディスクに保存して、ファイルパスを指定します。
im = PIL.fromarray(...)
rgb_im = im.convert("RGB")
rgb_im.save("myimage.jpg")
wandb.log({"example": wandb.Image("myimage.jpg")})
画像 オーバーレイ
セマンティックセグメンテーション マスク を ログ に記録し、W&B UI で (不透明度を変更したり、経時的な変化を表示したりするなど) 操作します。

オーバーレイを ログ に記録するには、次の キー と 値 を持つ 辞書 を wandb.Image の masks キーワード 引数 に指定する必要があります。
- 画像 マスク を表す 2 つの キー のいずれか 1 つ。
"mask_data": 各ピクセル の整数クラス ラベル を含む 2D NumPy 配列"path": (string) 保存された画像 マスク ファイル へのパス
"class_labels": (オプション) 画像 マスク 内の整数クラス ラベル を読み取り可能なクラス名に マッピング する 辞書
複数の マスク を ログ に記録するには、次の コード スニペット のように、複数の キー を持つ マスク 辞書 を ログ に記録します。
mask_data = np.array([[1, 2, 2, ..., 2, 2, 1], ...])
class_labels = {1: "tree", 2: "car", 3: "road"}
mask_img = wandb.Image(
image,
masks={
"predictions": {"mask_data": mask_data, "class_labels": class_labels},
"ground_truth": {
# ...
},
# ...
},
)
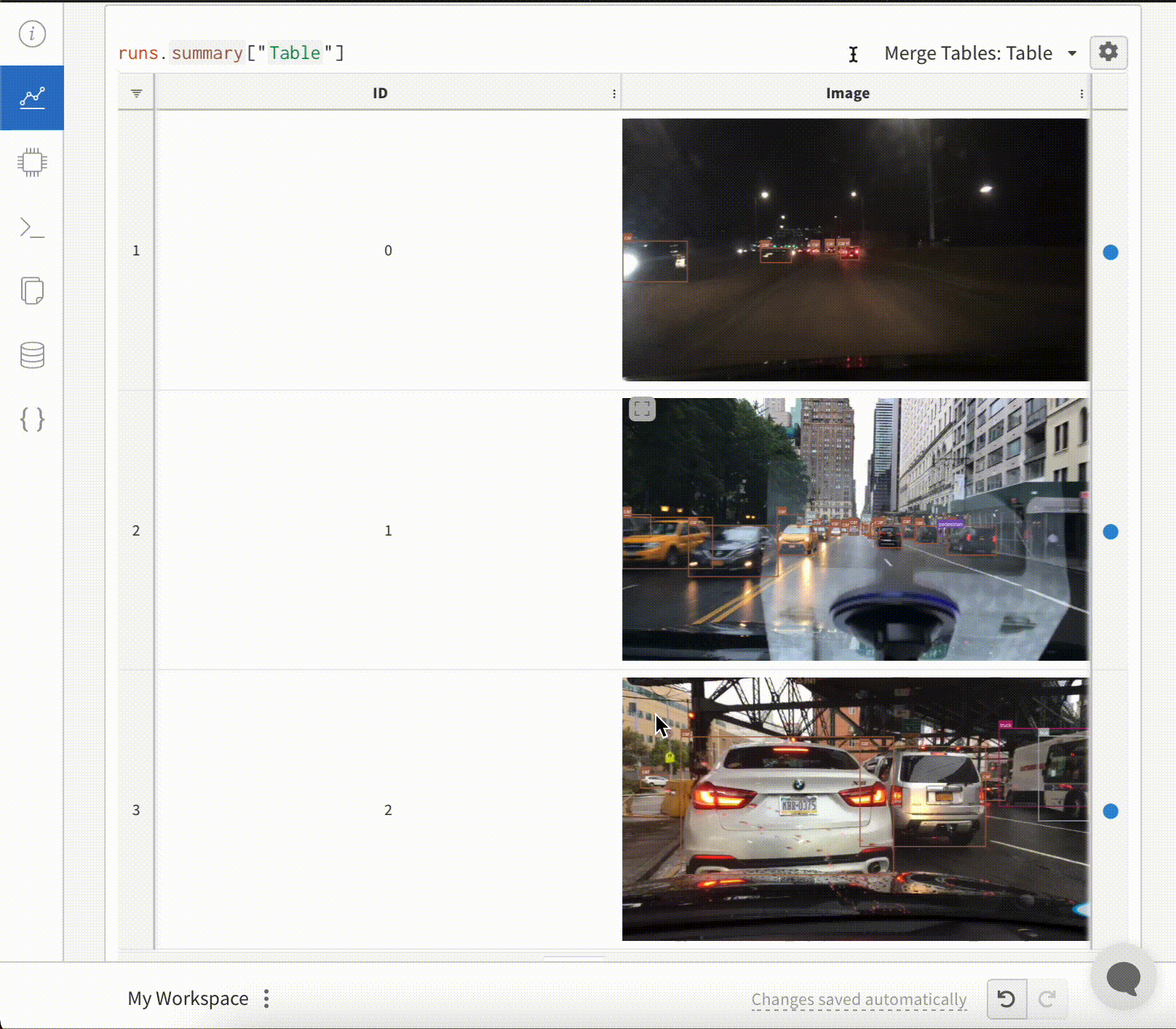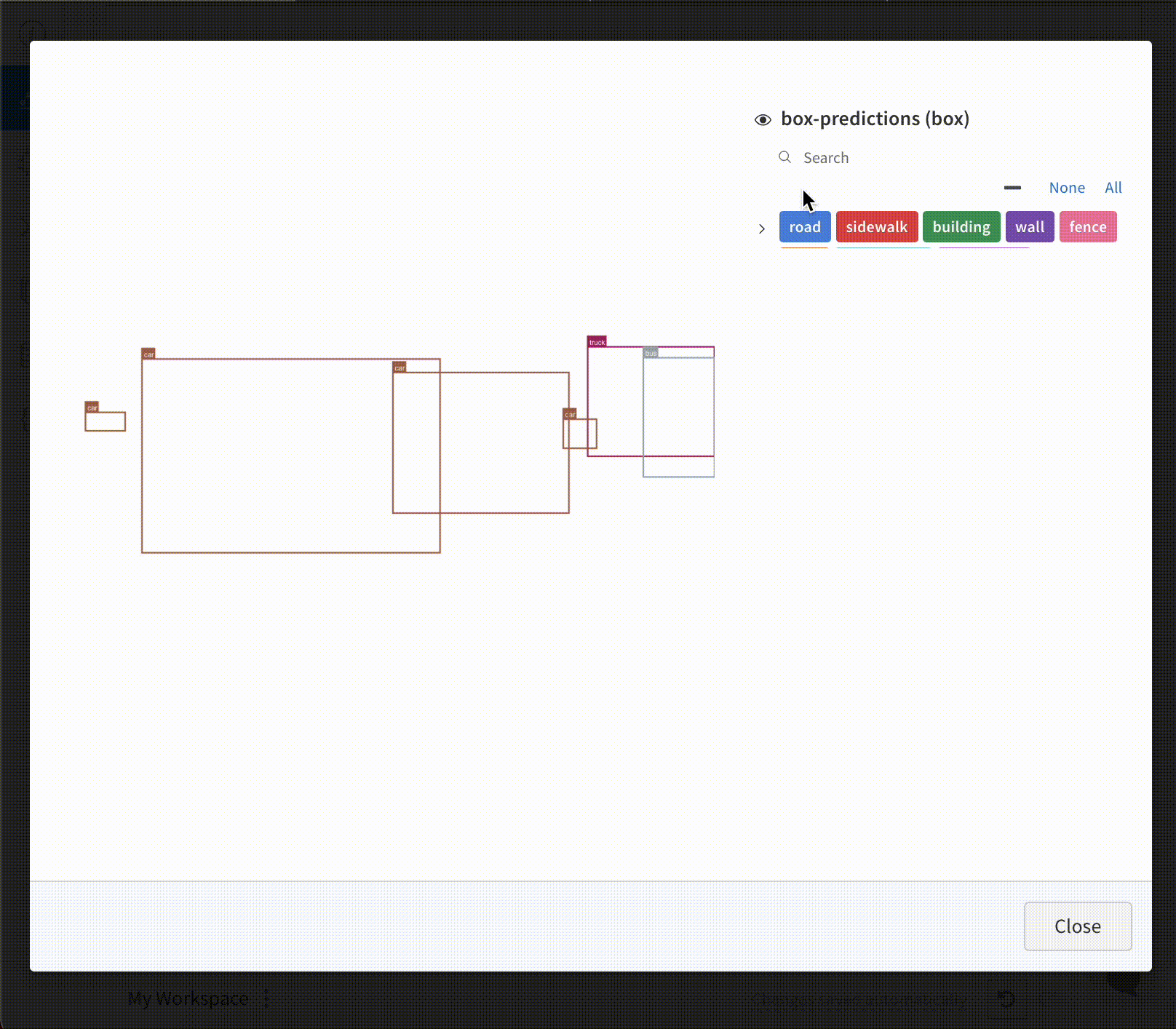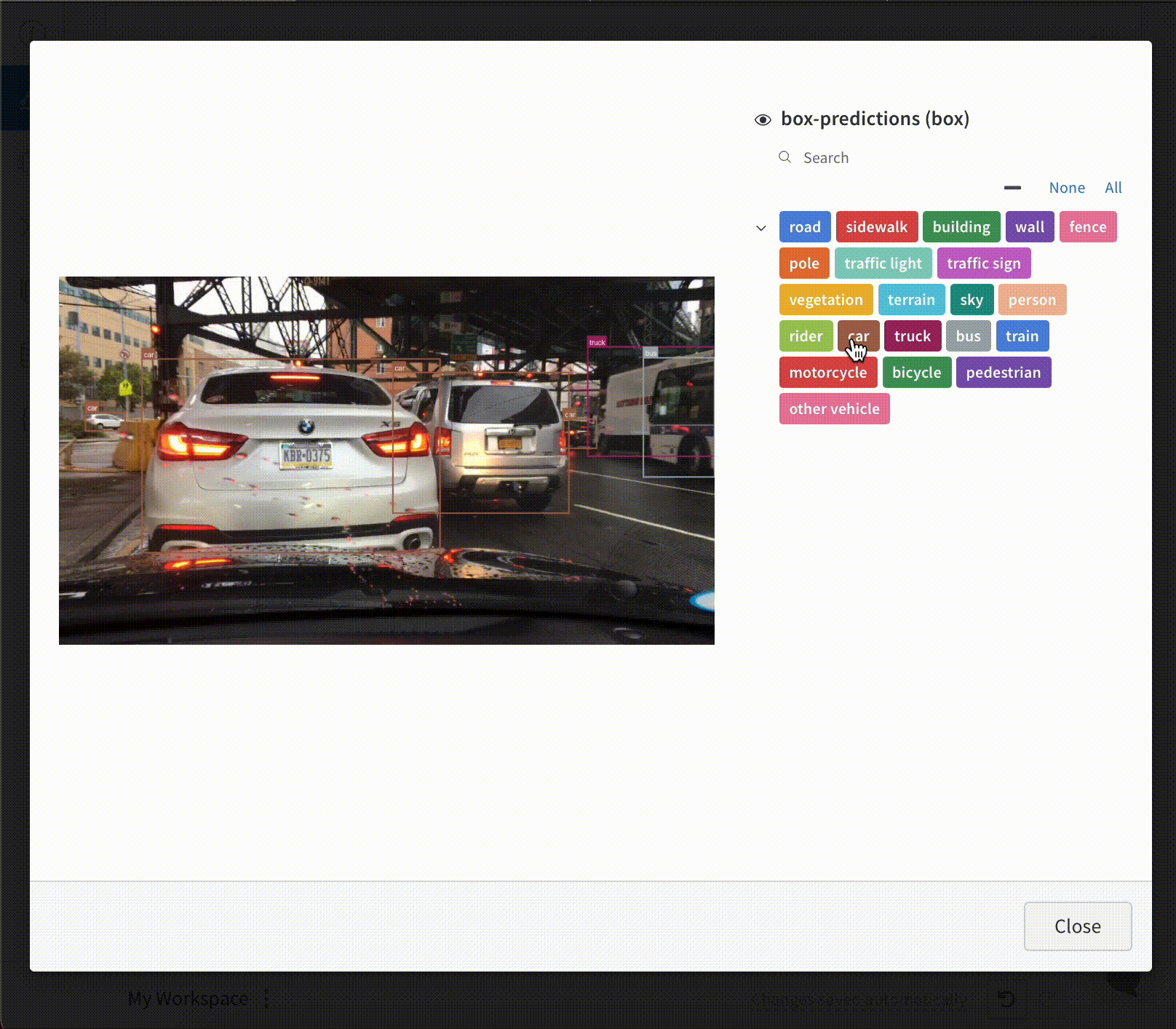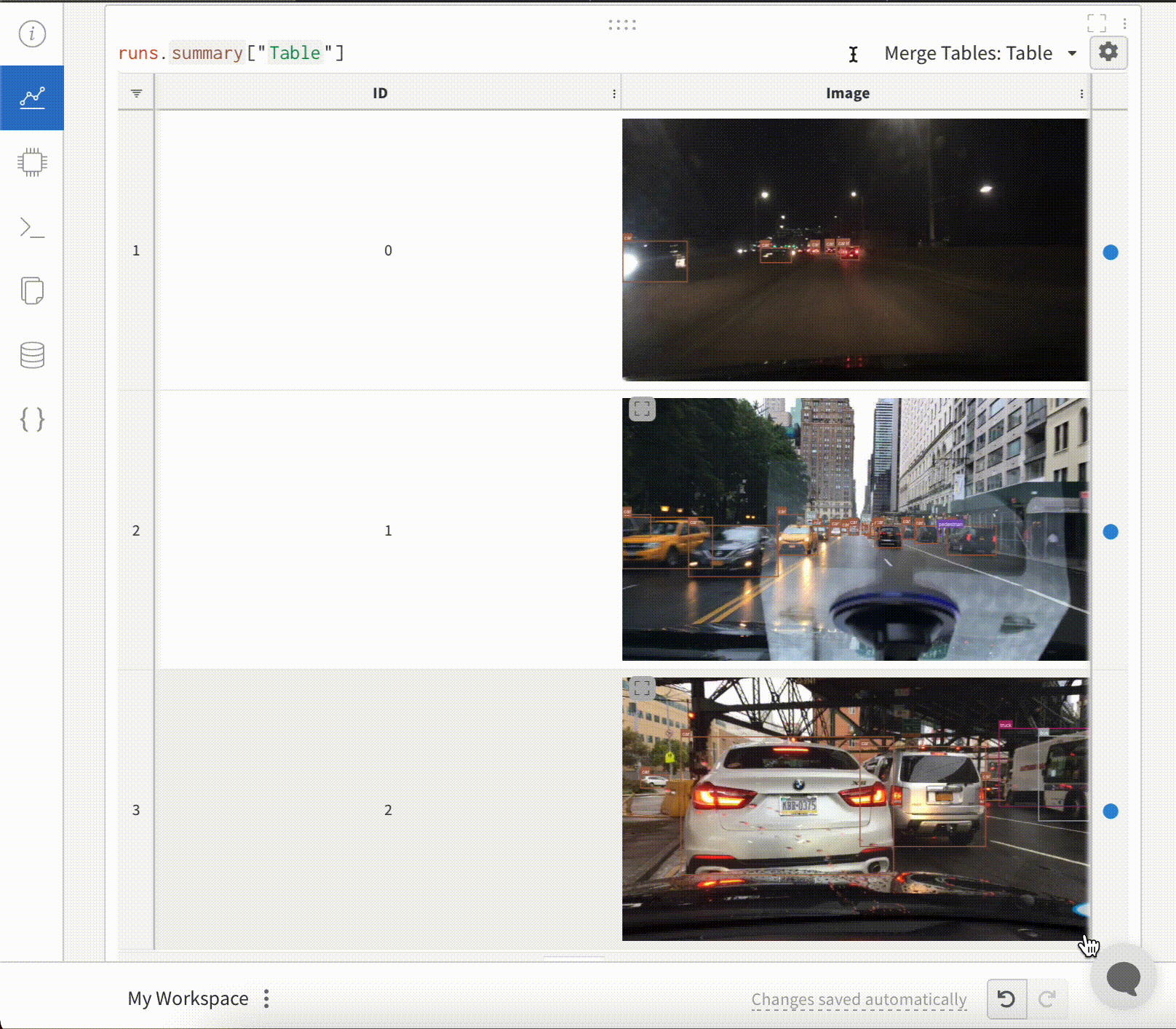
画像 と共に バウンディングボックス を ログ に記録し、フィルターとトグルを使用して、UI でさまざまなボックス セット を動的に 可視化 します。
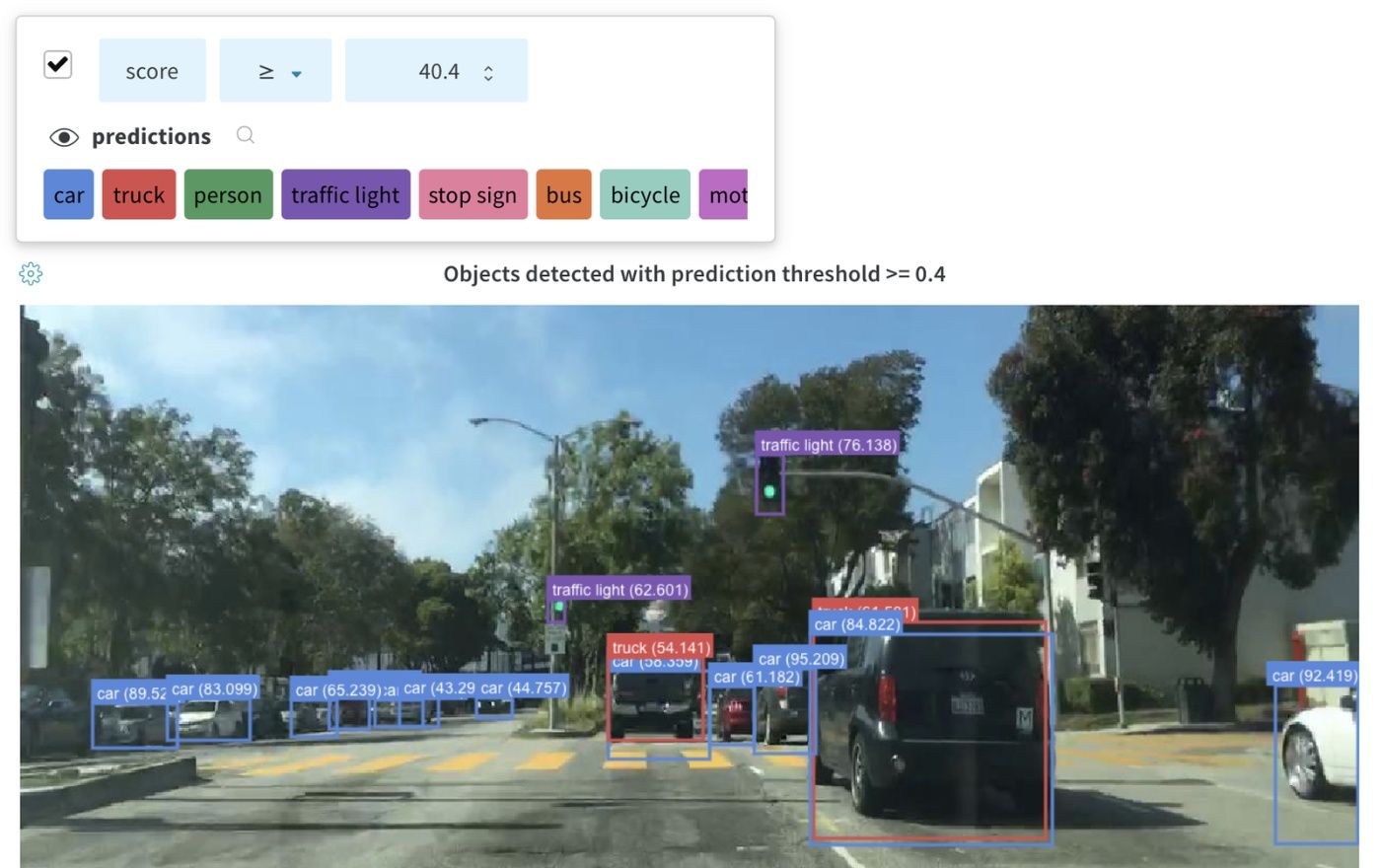
バウンディングボックス を ログ に記録するには、次の キー と 値 を持つ 辞書 を wandb.Image の boxes キーワード 引数 に指定する必要があります。
box_data: 各ボックス に対して 1 つの 辞書 の リスト。ボックス 辞書 の形式については、以下で説明します。position: 以下で説明するように、2 つの形式のいずれかでボックス の位置とサイズを表す 辞書。ボックス はすべて同じ形式を使用する必要はありません。- オプション 1:
{"minX", "maxX", "minY", "maxY"}。各ボックス の次元の上限と下限を定義する座標セットを指定します。 - オプション 2:
{"middle", "width", "height"}。[x,y]としてmiddle座標を指定する座標セットと、スカラーとしてwidthとheightを指定します。
- オプション 1:
class_id: ボックス のクラス ID を表す整数。以下のclass_labelsキー を参照してください。scores: スコア の文字列ラベルと数値の 値 の 辞書。UI でボックス をフィルタリングするために使用できます。domain: ボックス 座標の単位/形式を指定します。ボックス 座標が画像 の次元の範囲内の整数など、ピクセル空間で表される場合は、これを「pixel」に設定します。デフォルトでは、 domain は画像 の分数/パーセンテージであると見なされ、0 から 1 の間の浮動小数点数として表されます。box_caption: (オプション) このボックス のラベル テキストとして表示される文字列
class_labels: (オプション)class_idを文字列に マッピング する 辞書。デフォルトでは、クラス ラベルclass_0、class_1などを生成します。
この例をご覧ください。
class_id_to_label = {
1: "car",
2: "road",
3: "building",
# ...
}
img = wandb.Image(
image,
boxes={
"predictions": {
"box_data": [
{
# one box expressed in the default relative/fractional domain
"position": {"minX": 0.1, "maxX": 0.2, "minY": 0.3, "maxY": 0.4},
"class_id": 2,
"box_caption": class_id_to_label[2],
"scores": {"acc": 0.1, "loss": 1.2},
# another box expressed in the pixel domain
# (for illustration purposes only, all boxes are likely
# to be in the same domain/format)
"position": {"middle": [150, 20], "width": 68, "height": 112},
"domain": "pixel",
"class_id": 3,
"box_caption": "a building",
"scores": {"acc": 0.5, "loss": 0.7},
# ...
# Log as many boxes an as needed
}
],
"class_labels": class_id_to_label,
},
# Log each meaningful group of boxes with a unique key name
"ground_truth": {
# ...
},
},
)
wandb.log({"driving_scene": img})
テーブル の画像 オーバーレイ
テーブル に セグメンテーション マスク を ログ 記録するには、テーブル の各行に wandb.Image オブジェクト を指定する必要があります。
コード スニペット に例を示します。
table = wandb.Table(columns=["ID", "Image"])
for id, img, label in zip(ids, images, labels):
mask_img = wandb.Image(
img,
masks={
"prediction": {"mask_data": label, "class_labels": class_labels}
# ...
},
)
table.add_data(id, img)
wandb.log({"Table": table})
テーブル に バウンディングボックス を持つ 画像 を ログ 記録するには、テーブル の各行に wandb.Image オブジェクト を指定する必要があります。
コード スニペット に例を示します。
table = wandb.Table(columns=["ID", "Image"])
for id, img, boxes in zip(ids, images, boxes_set):
box_img = wandb.Image(
img,
boxes={
"prediction": {
"box_data": [
{
"position": {
"minX": box["minX"],
"minY": box["minY"],
"maxX": box["maxX"],
"maxY": box["maxY"],
},
"class_id": box["class_id"],
"box_caption": box["caption"],
"domain": "pixel",
}
for box in boxes
],
"class_labels": class_labels,
}
},
)
ヒストグラム
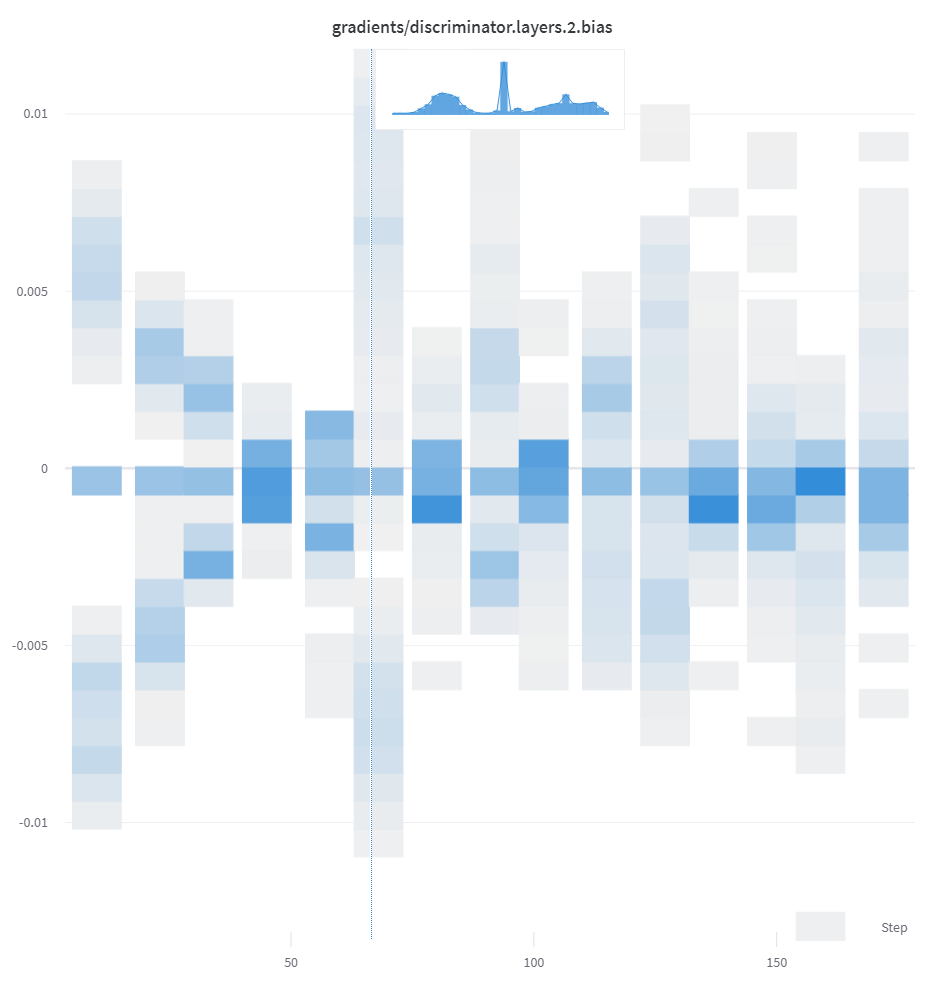
リスト、配列、 テンソル などの数値のシーケンスが最初の 引数 として指定された場合、np.histogram を呼び出すことで ヒストグラム を自動的に構築します。すべての配列/ テンソル はフラット化されます。オプションの num_bins キーワード 引数 を使用して、デフォルトの 64 ビン をオーバーライドできます。サポートされているビンの最大数は 512 です。
UI では、 ヒストグラム は x 軸に トレーニング ステップ、y 軸に メトリック 値、色で表されるカウントでプロットされ、 トレーニング 全体で ログ 記録された ヒストグラム の比較が容易になります。1 回限りの ヒストグラム の ログ 記録の詳細については、この パネル の「概要の ヒストグラム 」 タブ を参照してください。
wandb.log({"gradients": wandb.Histogram(grads)})
さらに詳細に制御する場合は、np.histogram を呼び出し、返された タプル を np_histogram キーワード 引数 に渡します。
np_hist_grads = np.histogram(grads, density=True, range=(0.0, 1.0))
wandb.log({"gradients": wandb.Histogram(np_hist_grads)})
wandb.run.summary.update( # if only in summary, only visible on overview tab
{"final_logits": wandb.Histogram(logits)}
)
'obj'、'gltf'、'glb'、'babylon'、'stl'、'pts.json' 形式のファイルを ログ 記録すると、 run 終了時に UI でレンダリングされます。
wandb.log(
{
"generated_samples": [
wandb.Object3D(open("sample.obj")),
wandb.Object3D(open("sample.gltf")),
wandb.Object3D(open("sample.glb")),
]
}
)
ヒストグラム が概要にある場合、Run Page の Overviewタブ に表示されます。履歴にある場合、Chartsタブ に時間の経過に伴うビンのヒートマップをプロットします。
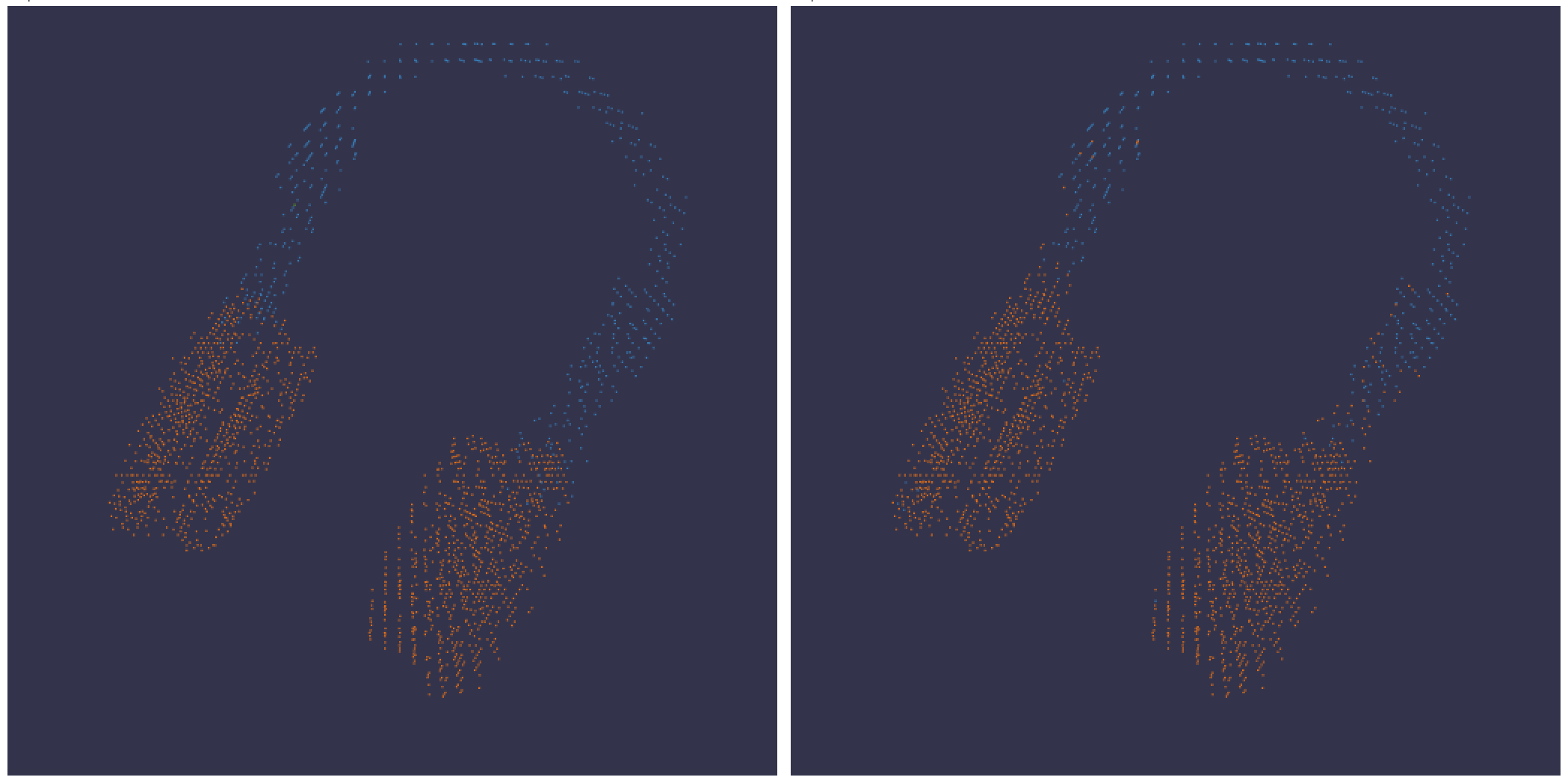
3D 可視化
バウンディングボックス を持つ 3D ポイントクラウド と Lidar シーンを ログ 記録します。レンダリングするポイントの座標と色を含む NumPy 配列を渡します。
point_cloud = np.array([[0, 0, 0, COLOR]])
wandb.log({"point_cloud": wandb.Object3D(point_cloud)})
:::info W&B UI はデータを 300,000 ポイント で切り捨てます。 :::
NumPy 配列形式
柔軟な配色に対応するため、3 つの異なる形式の NumPy 配列がサポートされています。
[[x, y, z], ...]nx3[[x, y, z, c], ...]nx4| c は[1, 14]` の範囲のカテゴリです (セグメンテーション に役立ちます)。[[x, y, z, r, g, b], ...]nx6 | r,g,bは赤、緑、青のカラー チャンネル の[0,255]の範囲の値です。
Python オブジェクト
このスキーマを使用すると、Python オブジェクト を定義し、以下に示すように from_point_cloud メソッドに渡すことができます。
pointsは、上記の単純な ポイントクラウド レンダラーと同じ形式を使用してレンダリングするポイントの座標と色を含む NumPy 配列です。boxesは、3 つの属性を持つ Python 辞書 の NumPy 配列です。corners- 8 つの角の リストlabel- ボックス にレンダリングされるラベルを表す文字列 (オプション)color- ボックス の色を表す RGB 値score- バウンディングボックス に表示される数値。表示される バウンディングボックス をフィルタリングするために使用できます (たとえば、score>0.75の バウンディングボックス のみを表示する場合)。(オプション)
typeは、レンダリングするシーン タイプを表す文字列です。現在、サポートされている値はlidar/betaのみです。
point_list = [
[
2566.571924017235, # x
746.7817289698219, # y
-15.269245470863748,# z
76.5, # red
127.5, # green
89.46617199365393 # blue
],
[ 2566.592983606823, 746.6791987335685, -15.275803826279521, 76.5, 127.5, 89.45471117247024 ],
[ 2566.616361739416, 746.4903185513501, -15.28628929674075, 76.5, 127.5, 89.41336375503832 ],
[ 2561.706014951675, 744.5349468458361, -14.877496818222781, 76.5, 127.5, 82.21868245418283 ],
[ 2561.5281847916694, 744.2546118233013, -14.867862032341005, 76.5, 127.5, 81.87824684536432 ],
[ 2561.3693562897465, 744.1804761656741, -14.854129178142523, 76.5, 127.5, 81.64137897587152 ],
[ 2561.6093071504515, 744.0287526628543, -14.882135189841177, 76.5, 127.5, 81.89871499537098 ],
# ... and so on
]
run.log({"my_first_point_cloud": wandb.Object3D.from_point_cloud(
points = point_list,
boxes = [{
"corners": [
[ 2601.2765123137915, 767.5669506323393, -17.816764802288663 ],
[ 2599.7259021588347, 769.0082337923552, -17.816764802288663 ],
[ 2599.7259021588347, 769.0082337923552, -19.66876480228866 ],
[ 2601.2765123137915, 767.5669506323393, -19.66876480228866 ],
[ 2604.8684867834395, 771.4313904894723, -17.816764802288663 ],
[ 2603.3178766284827, 772.8726736494882, -17.816764802288663 ],
[ 2603.3178766284827, 772.8726736494882, -19.66876480228866 ],
[ 2604.8684867834395, 771.4313904894723, -19.66876480228866 ]
],
"color": [0, 0, 255], # color in RGB of the bounding box
"label": "car", # string displayed on the bounding box
"score": 0.6 # numeric displayed on the bounding box
}],
vectors = [
{"start": [0, 0, 0], "end": [0.1, 0.2, 0.5], "color": [255, 0, 0]}, # color is optional
],
point_cloud_type = "lidar/beta",
)})
ポイントクラウド を表示するときは、control キー を押しながらマウスを使用すると、スペース内を移動できます。
ポイントクラウド ファイル
the from_file メソッドを使用して、 ポイントクラウド データがいっぱいの JSON ファイルをロードできます。
run.log({"my_cloud_from_file": wandb.Object3D.from_file(
"./my_point_cloud.pts.json"
)})
ポイントクラウド データの形式設定方法の例を以下に示します。
{
"boxes": [
{
"color": [
0,
255,
0
],
"score": 0.35,
"label": "My label",
"corners": [
[
2589.695869075582,
760.7400443552185,
-18.044831294622487
],
[
2590.719039645323,
762.3871153874499,
-18.044831294622487
],
[
2590.719039645323,
762.3871153874499,
-19.54083129462249
],
[
2589.695869075582,
760.7400443552185,
-19.54083129462249
],
[
2594.9666662674313,
757.4657929961453,
-18.044831294622487
],
[
2595.9898368371723,
759.1128640283766,
-18.044831294622487
],
[
2595.9898368371723,
759.1128640283766,
-19.54083129462249
],
[
2594.9666662674313,
757.4657929961453,
-19.54083129462249
]
]
}
],
"points": [
[
2566.571924017235,
746.7817289698219,
-15.269245470863748,
76.5,
127.5,
89.46617199365393
],
[
2566.592983606823,
746.6791987335685,
-15.275803826279521,
76.5,
127.5,
89.45471117247024
],
[
2566.616361739416,
746.4903185513501,
-15.28628929674075,
76.5,
127.5,
89.41336375503832
]
],
"type": "lidar/beta"
}
NumPy 配列
上記で定義されている同じ配列形式を使用して、 from_numpy メソッドで numpy 配列を直接使用して、 ポイントクラウド を定義できます。
run.log({"my_cloud_from_numpy_xyz": wandb.Object3D.from_numpy(
np.array(
[
[0.4, 1, 1.3], # x, y, z
[1, 1, 1],
[1.2, 1, 1.2]
]
)
)})
run.log({"my_cloud_from_numpy_cat": wandb.Object3D.from_numpy(
np.array(
[
[0.4, 1, 1.3, 1], # x, y, z, category
[1, 1, 1, 1],
[1.2, 1, 1.2, 12],
[1.2, 1, 1.3, 12],
[1.2, 1, 1.4, 12],
[1.2, 1, 1.5, 12],
[1.2, 1, 1.6, 11],
[1.2, 1, 1.7, 11],
]
)
)})
run.log({"my_cloud_from_numpy_rgb": wandb.Object3D.from_numpy(
np.array(
[
[0.4, 1, 1.3, 255, 0, 0], # x, y, z, r, g, b
[1, 1, 1, 0, 255, 0],
[1.2, 1, 1.3, 0, 255, 255],
[1.2, 1, 1.4, 0, 255, 255],
[1.2, 1, 1.5, 0, 0, 255],
[1.2, 1, 1.1, 0, 0, 255],
[1.2, 1, 0.9, 0, 0, 255],
]
)
)})
wandb.log({"protein": wandb.Molecule("6lu7.pdb")})
10 個のファイルタイプ ( pdb、pqr、mmcif、mcif、cif、sdf、sd、gro、mol2、または mmtf) のいずれかで分子データを ログ 記録します。
W&B は、SMILES 文字列、rdkit mol ファイル、および rdkit.Chem.rdchem.Mol オブジェクト からの分子データの ログ 記録もサポートしています。
resveratrol = rdkit.Chem.MolFromSmiles("Oc1ccc(cc1)C=Cc1cc(O)cc(c1)O")
wandb.log(
{
"resveratrol": wandb.Molecule.from_rdkit(resveratrol),
"green fluorescent protein": wandb.Molecule.from_rdkit("2b3p.mol"),
"acetaminophen": wandb.Molecule.from_smiles("CC(=O)Nc1ccc(O)cc1"),
}
)
run が終了すると、UI で分子の 3D 可視化を操作できるようになります。
PNG 画像
wandb.Image は、デフォルトで numpy 配列または PILImage の インスタンス を PNG に変換します。
wandb.log({"example": wandb.Image(...)})
# Or multiple images
wandb.log({"example": [wandb.Image(...) for img in images]})
動画
動画は、wandb.Video データ型を使用して ログ 記録されます。
wandb.log({"example": wandb.Video("myvideo.mp4")})
これで、メディア ブラウザー で動画を表示できます。プロジェクト ワークスペース 、 run ワークスペース 、または レポート に移動し、[可視化 を追加] をクリックして、リッチメディア パネル を追加します。
分子の 2D 表示
wandb.Image データ型と rdkit を使用して、分子の 2D 表示を ログ 記録できます。
molecule = rdkit.Chem.MolFromSmiles("CC(=O)O")
rdkit.Chem.AllChem.Compute2DCoords(molecule)
rdkit.Chem.AllChem.GenerateDepictionMatching2DStructure(molecule, molecule)
pil_image = rdkit.Chem.Draw.MolToImage(molecule, size=(300, 300))
wandb.log({"acetic_acid": wandb.Image(pil_image)})
その他のメディア
W&B は、さまざまなその他のメディアタイプの ログ 記録もサポートしています。
音声
wandb.log({"whale songs": wandb.Audio(np_array, caption="OooOoo", sample_rate=32)})
ステップごとに最大 100 個のオーディオ クリップ を ログ 記録できます。詳細な使用方法については、audio-fileを参照してください。
動画
wandb.log({"video": wandb.Video(numpy_array_or_path_to_video, fps=4, format="gif")})
numpy 配列が指定されている場合、次元は時間、 チャンネル 、幅、高さの順であると想定されます。デフォルトでは、4 fps の gif 画像 を作成します (ffmpeg および moviepy python ライブラリ は、numpy オブジェクト を渡す場合に必要です)。サポートされている形式は、"gif"、"mp4"、"webm"、および "ogg" です。文字列を wandb.Video に渡すと、ファイルが存在し、サポートされている形式であることをアサートしてから、wandb にアップロードします。BytesIO オブジェクト を渡すと、指定された形式を拡張子として持つ一時ファイルが作成されます。
W&B Run ページと Project ページでは、[メディア] セクションに動画が表示されます。
詳細な使用方法については、video-fileを参照してください。
テキスト
wandb.Table を使用して、UI に表示される テーブル にテキストを ログ 記録します。デフォルトでは、列 ヘッダー は ["Input", "Output", "Expected"] です。最適な UI パフォーマンスを確保するために、デフォルトの最大行数は 10,000 に設定されています。ただし、 ユーザー は wandb.Table.MAX_ROWS = {DESIRED_MAX} を使用して、最大値を明示的にオーバーライドできます。
columns = ["Text", "Predicted Sentiment", "True Sentiment"]
# Method 1
data = [["I love my phone", "1", "1"], ["My phone sucks", "0", "-1"]]
table = wandb.Table(data=data, columns=columns)
wandb.log({"examples": table})
# Method 2
table = wandb.Table(columns=columns)
table.add_data("I love my phone", "1", "1")
table.add_data("My phone sucks", "0", "-1")
wandb.log({"examples": table})
pandas DataFrame オブジェクト を渡すこともできます。
table = wandb.Table(dataframe=my_dataframe)
詳細な使用方法については、stringを参照してください。
HTML
wandb.log({"custom_file": wandb.Html(open("some.html"))})
wandb.log({"custom_string": wandb.Html('<a href="https://mysite">Link</a>')})
カスタム HTML は任意の キー で ログ 記録でき、これにより、 run ページに HTML パネル が表示されます。デフォルトでは、デフォルトのスタイルが挿入されます。inject=False を渡すことで、デフォルトのスタイルをオフにすることができます。
wandb.log({"custom_file": wandb.Html(open("some.html"), inject=False)})
詳細な使用方法については、html-fileを参照してください。
[i18n] feedback_title
[i18n] feedback_question
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.