Manage job inputs
4 minute read
Launch のコアな体験は、ハイパーパラメーターやデータセットのような様々なジョブ入力を容易に実験し、これらのジョブを適切なハードウェアにルーティングすることです。ジョブが作成されると、最初の作成者以外の ユーザー は、W&B GUIまたはCLIを介してこれらの入力を調整できます。CLIまたはUIから起動する際にジョブ入力を設定する方法については、ジョブをエンキューする ガイド を参照してください。
このセクションでは、ジョブで調整できる入力をプログラムで制御する方法について説明します。
デフォルトでは、W&B ジョブ は Run.config 全体をジョブへの入力としてキャプチャしますが、 Launch SDK は、run config 内の選択した キー を制御したり、JSONまたはYAMLファイルを 入力 として指定したりする機能を提供します。
wandb-core が必要です。詳細については、wandb-core README を参照してください。Run オブジェクト の再構成
ジョブ内の wandb.init によって返される Run オブジェクト は、デフォルトで再構成できます。 Launch SDK は、ジョブの起動時に Run.config オブジェクト のどの部分を再構成できるかをカスタマイズする方法を提供します。
import wandb
from wandb.sdk import launch
# Required for launch sdk use.
wandb.require("core")
config = {
"trainer": {
"learning_rate": 0.01,
"batch_size": 32,
"model": "resnet",
"dataset": "cifar10",
"private": {
"key": "value",
},
},
"seed": 42,
}
with wandb.init(config=config):
launch.manage_wandb_config(
include=["trainer"],
exclude=["trainer.private"],
)
# Etc.
関数 launch.manage_wandb_config は、Run.config オブジェクト の入力値を 受け入れる ようにジョブを構成します。オプションの include および exclude オプションは、ネストされた config オブジェクト 内のパスのプレフィックスを受け取ります。これは、たとえば、ジョブがエンド ユーザー に公開したくないオプションを持つ ライブラリ を使用する場合に役立ちます。
include プレフィックス が指定されている場合、include プレフィックス に一致する config 内のパスのみが入力値を 受け入れます。exclude プレフィックス が指定されている場合、exclude リスト に一致するパスは入力値から除外されません。パスが include と exclude の両方のプレフィックス に一致する場合、exclude プレフィックス が優先されます。
上記の例では、パス ["trainer.private"] は private キー を trainer オブジェクト から除外し、パス ["trainer"] は trainer オブジェクト にないすべての キー を除外します。
\ でエスケープされた . を使用して、名前に . が付いた キー を除外します。
たとえば、r"trainer\.private" は、trainer オブジェクト の下の private キー ではなく、trainer.private キー を除外します。
上記の r プレフィックス は、raw 文字列 を表すことに注意してください。
上記の コード がパッケージ化され、ジョブとして実行される場合、ジョブの入力 タイプ は次のようになります。
{
"trainer": {
"learning_rate": "float",
"batch_size": "int",
"model": "str",
"dataset": "str",
},
}
W&B CLI または UI からジョブを起動すると、 ユーザー は4つの trainer パラメータ のみをオーバーライドできます。
run config 入力 へのアクセス
run config 入力 で起動されたジョブは、Run.config を介して入力値に アクセス できます。ジョブ コード の wandb.init によって返される Run には、入力値が自動的に設定されます。ジョブ コード の任意の場所で run config 入力 値をロードするには、
from wandb.sdk import launch
run_config_overrides = launch.load_wandb_config()
を使用します。
ファイル の再構成
Launch SDK は、ジョブ コード の config ファイル に保存されている入力値を管理する方法も提供します。これは、この torchtune の例やこの Axolotl config のように、多くの ディープラーニング および大規模言語 モデル の ユースケース で一般的なパターンです。
Run.config オブジェクト を介して制御する必要があります。launch.manage_config_file 関数 を使用すると、config ファイル を Launch ジョブ への入力として追加できるため、ジョブの起動時に config ファイル 内の値を編集できます。
デフォルトでは、launch.manage_config_file が使用されている場合、run config 入力 はキャプチャされません。launch.manage_wandb_config を呼び出すと、この 振る舞い がオーバーライドされます。
次の例を考えてみましょう。
import yaml
import wandb
from wandb.sdk import launch
# Required for launch sdk use.
wandb.require("core")
launch.manage_config_file("config.yaml")
with open("config.yaml", "r") as f:
config = yaml.safe_load(f)
with wandb.init(config=config):
# Etc.
pass
コード が隣接するファイル config.yaml で実行されると想像してください。
learning_rate: 0.01
batch_size: 32
model: resnet
dataset: cifar10
launch.manage_config_file の呼び出しは、config.yaml ファイル をジョブへの入力として追加し、W&B CLI または UI から起動するときに再構成できるようにします。
include および exclude キーワード arg は、launch.manage_wandb_config と同じ方法で、config ファイル の許容される入力 キー をフィルタリングするために使用できます。
config ファイル 入力 へのアクセス
Launch によって作成された run で launch.manage_config_file が呼び出されると、launch は config ファイル の内容を入力値でパッチします。パッチされた config ファイル は、ジョブ 環境 で使用できます。
launch.manage_config_file を呼び出してください。ジョブ の Launch ドロワー UI のカスタマイズ
ジョブ の入力 の スキーマ を定義すると、ジョブ を起動するためのカスタム UI を作成できます。ジョブ の スキーマ を定義するには、launch.manage_wandb_config または launch.manage_config_file の呼び出しに含めます。スキーマ は、JSON Schema の形式の python 辞書 、または Pydantic モデル クラス のいずれかになります。
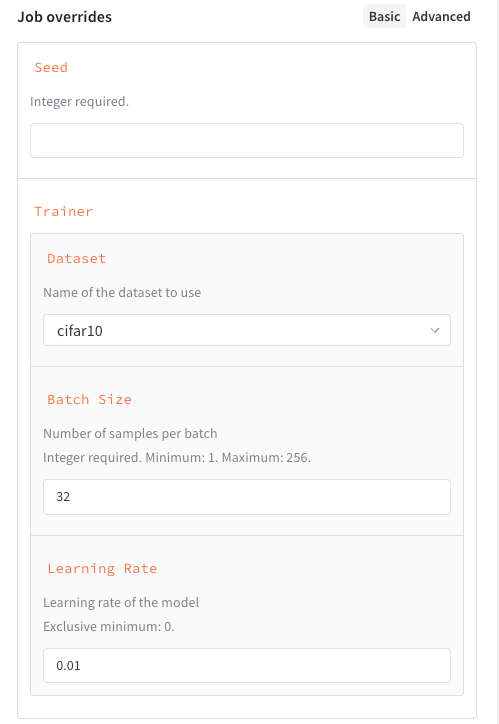
次の例は、次の プロパティ を持つ スキーマ を示しています。
seed、整数trainer、いくつかの キー が指定された 辞書 :trainer.learning_rate、ゼロより大きい floattrainer.batch_size、16、64、または256のいずれかである必要がある整数trainer.dataset、cifar10またはcifar100のいずれかである必要がある 文字列
schema = {
"type": "object",
"properties": {
"seed": {
"type": "integer"
}
"trainer": {
"type": "object",
"properties": {
"learning_rate": {
"type": "number",
"description": "Learning rate of the model",
"exclusiveMinimum": 0,
},
"batch_size": {
"type": "integer",
"description": "Number of samples per batch",
"enum": [16, 64, 256]
},
"dataset": {
"type": "string",
"description": "Name of the dataset to use",
"enum": ["cifar10", "cifar100"]
}
}
}
}
}
launch.manage_wandb_config(
include=["seed", "trainer"],
exclude=["trainer.private"],
schema=schema,
)
一般に、次の JSON Schema 属性 がサポートされています。
| 属性 | 必須 | 注記 |
|---|---|---|
type |
はい | number 、 integer 、 string 、または object のいずれかである必要があります。 |
title |
いいえ | プロパティ の表示名をオーバーライドします |
description |
いいえ | プロパティ ヘルパー テキスト を指定します |
enum |
いいえ | フリーフォーム テキスト 入力 の代わりに ドロップダウン 選択 を作成します |
minimum |
いいえ | type が number または integer の場合にのみ許可されます |
maximum |
いいえ | type が number または integer の場合にのみ許可されます |
exclusiveMinimum |
いいえ | type が number または integer の場合にのみ許可されます |
exclusiveMaximum |
いいえ | type が number または integer の場合にのみ許可されます |
properties |
いいえ | type が object の場合、ネストされた 構成 を定義するために使用されます |
次の例は、次の プロパティ を持つ スキーマ を示しています。
seed、整数trainer、いくつかのサブ 属性 が指定された スキーマ :trainer.learning_rate、ゼロより大きい floattrainer.batch_size、1〜256(両端を含む)の範囲の整数trainer.dataset、cifar10またはcifar100のいずれかである必要がある 文字列
class DatasetEnum(str, Enum):
cifar10 = "cifar10"
cifar100 = "cifar100"
class Trainer(BaseModel):
learning_rate: float = Field(gt=0, description="Learning rate of the model")
batch_size: int = Field(ge=1, le=256, description="Number of samples per batch")
dataset: DatasetEnum = Field(title="Dataset", description="Name of the dataset to use")
class Schema(BaseModel):
seed: int
trainer: Trainer
launch.manage_wandb_config(
include=["seed", "trainer"],
exclude=["trainer.private"],
schema=Schema,
)
クラス の インスタンス を使用することもできます。
t = Trainer(learning_rate=0.01, batch_size=32, dataset=DatasetEnum.cifar10)
s = Schema(seed=42, trainer=t)
launch.manage_wandb_config(
include=["seed", "trainer"],
exclude=["trainer.private"],
input_schema=s,
)
ジョブ 入力 スキーマ を追加すると、 Launch ドロワー に構造化されたフォームが作成され、ジョブ の起動が容易になります。
[i18n] feedback_title
[i18n] feedback_question
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.