Pytorch torchtune
2 minute read
torchtune は、大規模言語モデル(LLM)の作成、微調整、および実験 プロセスを効率化するために設計された PyTorch ベースのライブラリです。さらに、torchtune には W&B でのログ記録 のサポートが組み込まれており、トレーニング プロセスの追跡と 可視化が強化されています。
torchtune を使用した Mistral 7B の微調整 に関する W&B ブログ投稿を確認してください。
すぐに使える W&B ロギング
起動時に コマンドライン 引数をオーバーライドします。
tune run lora_finetune_single_device --config llama3/8B_lora_single_device \
metric_logger._component_=torchtune.utils.metric_logging.WandBLogger \
metric_logger.project="llama3_lora" \
log_every_n_steps=5
レシピの構成で W&B ロギングを有効にします。
# inside llama3/8B_lora_single_device.yaml
metric_logger:
_component_: torchtune.utils.metric_logging.WandBLogger
project: llama3_lora
log_every_n_steps: 5
W&B メトリクス ロガーを使用する
metric_logger セクションを変更して、レシピの構成ファイルで W&B ロギングを有効にします。_component_ を torchtune.utils.metric_logging.WandBLogger クラスに変更します。project 名と log_every_n_steps を渡して、ロギングの 振る舞いをカスタマイズすることもできます。
wandb.init メソッドと同様に、他の kwargs を渡すこともできます。たとえば、チームで作業している場合は、entity 引数を WandBLogger クラスに渡して、チーム名を指定できます。
# inside llama3/8B_lora_single_device.yaml
metric_logger:
_component_: torchtune.utils.metric_logging.WandBLogger
project: llama3_lora
entity: my_project
job_type: lora_finetune_single_device
group: my_awesome_experiments
log_every_n_steps: 5
tune run lora_finetune_single_device --config llama3/8B_lora_single_device \
metric_logger._component_=torchtune.utils.metric_logging.WandBLogger \
metric_logger.project="llama3_lora" \
metric_logger.entity="my_project" \
metric_logger.job_type="lora_finetune_single_device" \
metric_logger.group="my_awesome_experiments" \
log_every_n_steps=5
ログに記録される内容
W&B ダッシュボードを調べて、ログに記録されたメトリクスを確認できます。デフォルトでは、W&B は構成ファイルと起動オーバーライドからすべての ハイパーパラメーター を記録します。
W&B は、概要 タブで解決された構成をキャプチャします。W&B は、ファイル タブ に YAML 形式で構成も保存します。
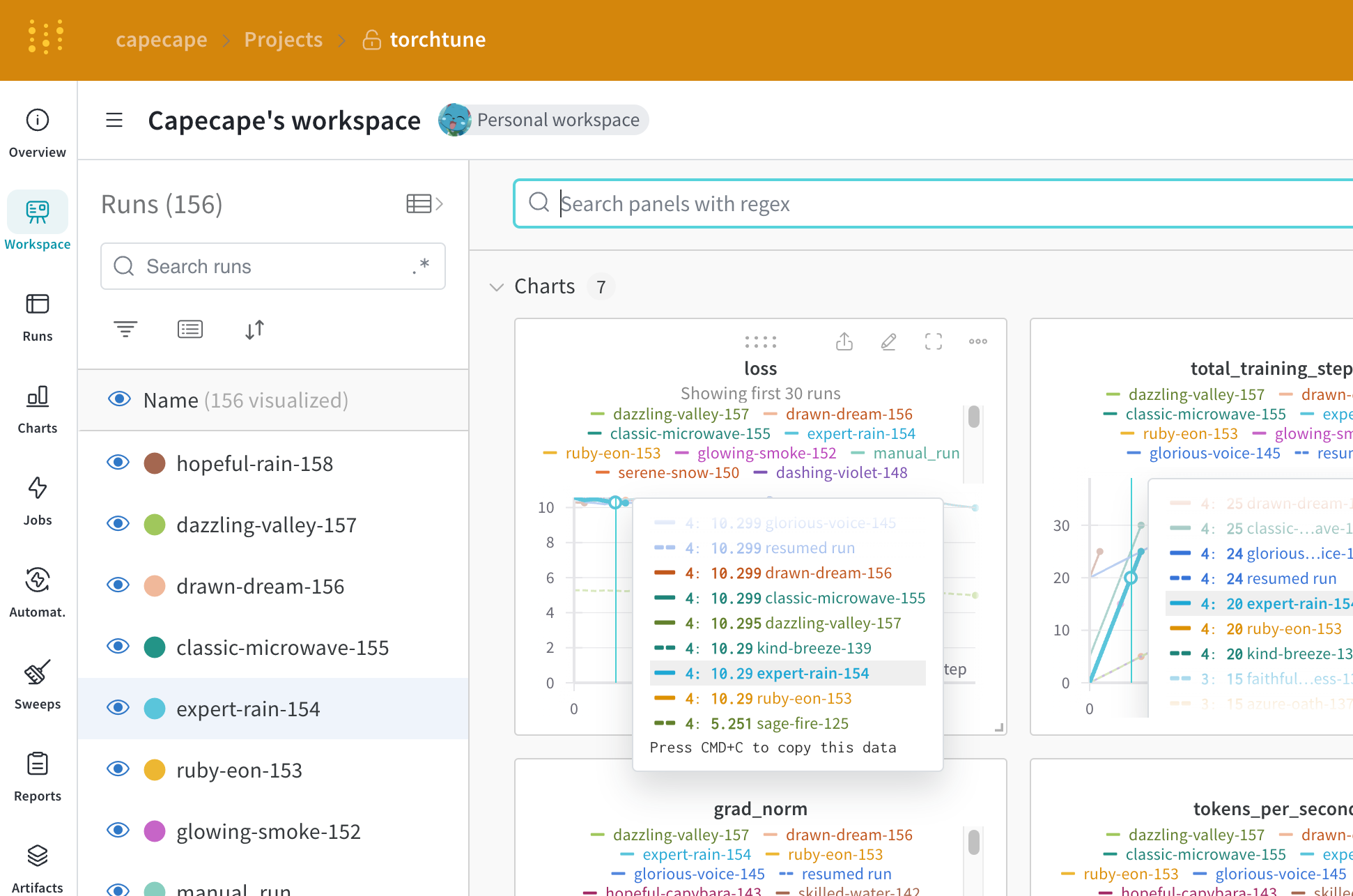
記録されたメトリクス
各レシピには、独自のトレーニング ループがあります。各レシピを確認して、ログに記録されたメトリクスを確認してください。これらはデフォルトで含まれています。
| メトリクス | 説明 |
|---|---|
loss |
モデルの損失 |
lr |
学習率 |
tokens_per_second |
モデルの 1 秒あたりの トークン 数 |
grad_norm |
モデルの勾配ノルム |
global_step |
トレーニング ループの現在のステップに対応します。勾配の累積を考慮します。基本的に、オプティマイザー のステップが実行されるたびに、モデルが更新され、勾配が累積され、モデルが gradient_accumulation_steps ごとに 1 回更新されます |
global_step は、トレーニング ステップの数と同じではありません。トレーニング ループの現在のステップに対応します。勾配の累積を考慮します。基本的に、オプティマイザー のステップが実行されるたびに、global_step は 1 ずつ増加します。たとえば、データローダーに 10 個のバッチがあり、勾配累積ステップが 2 で、3 エポック実行する場合、オプティマイザー は 15 回ステップを実行します。この場合、global_step は 1 から 15 の範囲になります。torchtune の合理化された設計により、カスタム メトリクスを簡単に追加したり、既存のメトリクスを変更したりできます。たとえば、current_epoch をエポックの総数のパーセンテージとしてログに記録するなど、対応する レシピ ファイル を変更するだけで済みます。
# inside `train.py` function in the recipe file
self._metric_logger.log_dict(
{"current_epoch": self.epochs * self.global_step / self._steps_per_epoch},
step=self.global_step,
)
self._metric_logger.* 関数を呼び出す必要があります。チェックポイント の保存とロード
torchtune ライブラリは、さまざまな チェックポイント 形式 をサポートしています。使用しているモデルの 出所に応じて、適切な チェックポイント クラス に切り替える必要があります。
モデルの チェックポイント を W&B Artifacts に保存する場合は、対応するレシピ内で save_checkpoint 関数をオーバーライドするのが最も簡単な解決策です。
モデルの チェックポイント を W&B Artifacts に保存するために save_checkpoint 関数をオーバーライドする方法の例を次に示します。
def save_checkpoint(self, epoch: int) -> None:
...
## Let's save the checkpoint to W&B
## depending on the Checkpointer Class the file will be named differently
## Here is an example for the full_finetune case
checkpoint_file = Path.joinpath(
self._checkpointer._output_dir, f"torchtune_model_{epoch}"
).with_suffix(".pt")
wandb_artifact = wandb.Artifact(
name=f"torchtune_model_{epoch}",
type="model",
# description of the model checkpoint
description="Model checkpoint",
# you can add whatever metadata you want as a dict
metadata={
utils.SEED_KEY: self.seed,
utils.EPOCHS_KEY: self.epochs_run,
utils.TOTAL_EPOCHS_KEY: self.total_epochs,
utils.MAX_STEPS_KEY: self.max_steps_per_epoch,
},
)
wandb_artifact.add_file(checkpoint_file)
wandb.log_artifact(wandb_artifact)
[i18n] feedback_title
[i18n] feedback_question
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.