Scikit-Learn
4 minute read
数行のコードで、scikit-learn モデルのパフォーマンスを可視化して比較するために wandb を使用できます。サンプルを試す →
はじめに
サインアップして APIキー を作成する
APIキー は、W&B に対してお客様のマシンを認証します。APIキー は、ユーザー プロファイルから生成できます。
- 右上隅にあるユーザー プロファイル アイコンをクリックします。
- User Settings を選択し、API Keys セクションまでスクロールします。
- Reveal をクリックします。表示された APIキー をコピーします。APIキー を非表示にするには、ページをリロードします。
wandb ライブラリをインストールしてログインする
ローカルに wandb ライブラリをインストールしてログインするには:
-
APIキー に
WANDB_API_KEY環境変数 を設定します。export WANDB_API_KEY=<your_api_key> -
wandbライブラリをインストールしてログインします。pip install wandb wandb login
pip install wandb
import wandb
wandb.login()
!pip install wandb
import wandb
wandb.login()
メトリクス をログする
import wandb
wandb.init(project="visualize-sklearn")
y_pred = clf.predict(X_test)
accuracy = sklearn.metrics.accuracy_score(y_true, y_pred)
# If logging metrics over time, then use wandb.log
# 時間経過とともにメトリクスをログする場合は、wandb.log を使用します
wandb.log({"accuracy": accuracy})
# OR to log a final metric at the end of training you can also use wandb.summary
# または、トレーニングの最後に最終メトリクスをログするには、wandb.summary を使用することもできます
wandb.summary["accuracy"] = accuracy
プロットを作成する
ステップ 1: wandb をインポートし、新しい run を初期化します
import wandb
wandb.init(project="visualize-sklearn")
ステップ 2: プロットを可視化します
個々のプロット
モデル をトレーニングして 予測 を行った後、wandb でプロットを生成して 予測 を分析できます。サポートされているチャートの完全なリストについては、以下の サポートされているプロット セクションを参照してください。
# Visualize single plot
# 単一のプロットを可視化します
wandb.sklearn.plot_confusion_matrix(y_true, y_pred, labels)
すべてのプロット
W&B には、いくつかの関連するプロットをプロットする plot_classifier などの関数があります。
# Visualize all classifier plots
# すべての分類器プロットを可視化します
wandb.sklearn.plot_classifier(
clf,
X_train,
X_test,
y_train,
y_test,
y_pred,
y_probas,
labels,
model_name="SVC",
feature_names=None,
)
# All regression plots
# すべての回帰プロット
wandb.sklearn.plot_regressor(reg, X_train, X_test, y_train, y_test, model_name="Ridge")
# All clustering plots
# すべてのクラスタリングプロット
wandb.sklearn.plot_clusterer(
kmeans, X_train, cluster_labels, labels=None, model_name="KMeans"
)
既存の Matplotlib プロット
Matplotlib で作成されたプロットも W&B ダッシュボードにログできます。そのためには、最初に plotly をインストールする必要があります。
pip install plotly
最後に、プロットは次のように W&B のダッシュボードにログできます。
import matplotlib.pyplot as plt
import wandb
wandb.init(project="visualize-sklearn")
# do all the plt.plot(), plt.scatter(), etc. here.
# ここに plt.plot(), plt.scatter() などをすべて記述します。
# ...
# instead of doing plt.show() do:
# plt.show() を実行する代わりに、次を実行します。
wandb.log({"plot": plt})
サポートされているプロット
学習曲線
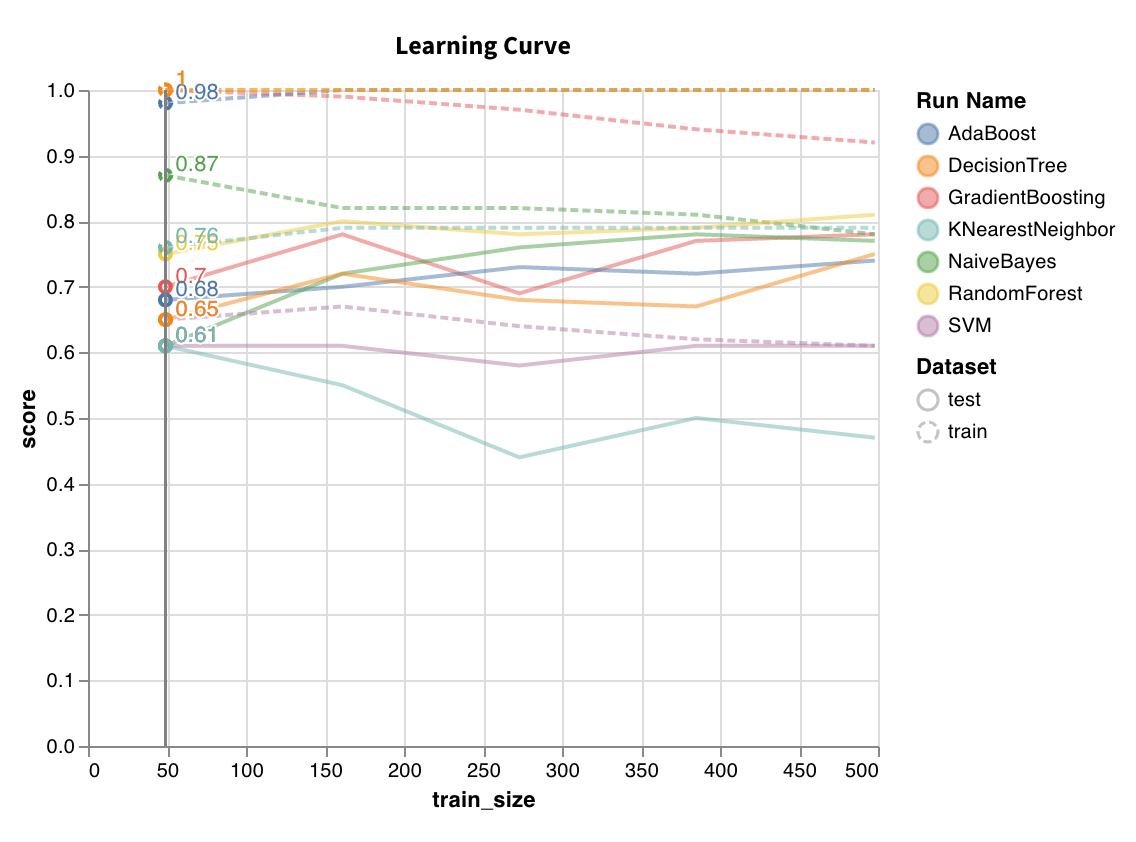
さまざまな長さの データセット でモデル をトレーニングし、トレーニング セットと テストセット の両方について、クロス検証されたスコアと データセット サイズのプロットを生成します。
wandb.sklearn.plot_learning_curve(model, X, y)
- model (clf または reg): 適合された回帰子または分類器を受け入れます。
- X (arr): データセット の特徴。
- y (arr): データセット のラベル。
ROC
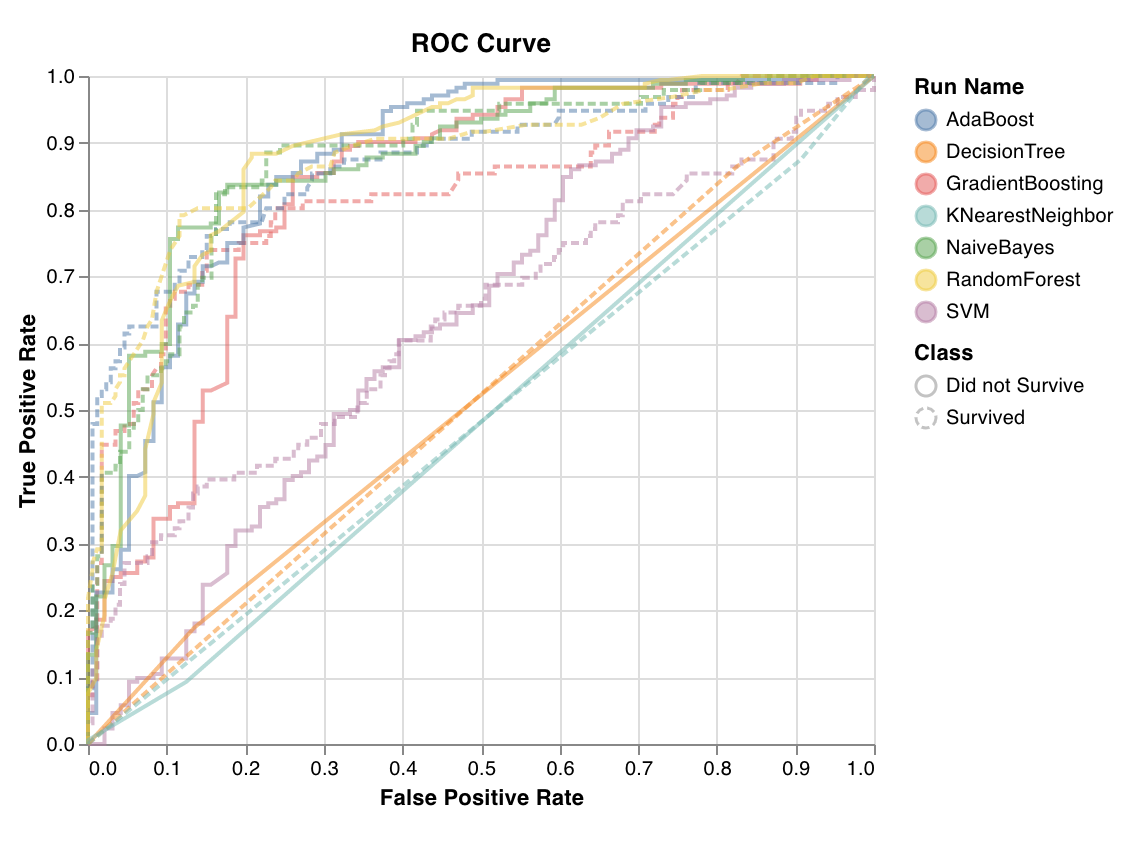
ROC 曲線は、真陽性率 (y 軸) 対 偽陽性率 (x 軸) をプロットします。理想的なスコアは TPR = 1 および FPR = 0 であり、これは左上の点です。通常、ROC 曲線下面積 (AUC-ROC) を計算し、AUC-ROC が大きいほど優れています。
wandb.sklearn.plot_roc(y_true, y_probas, labels)
- y_true (arr): テストセット のラベル。
- y_probas (arr): テストセット の 予測 確率。
- labels (list): ターゲット変数 (y) の名前付きラベル。
クラスの割合

トレーニング セットと テストセット のターゲット クラスの分布をプロットします。不均衡なクラスを検出し、1 つのクラスが モデル に不均衡な影響を与えないようにするのに役立ちます。
wandb.sklearn.plot_class_proportions(y_train, y_test, ['dog', 'cat', 'owl'])
- y_train (arr): トレーニング セットのラベル。
- y_test (arr): テストセット のラベル。
- labels (list): ターゲット変数 (y) の名前付きラベル。
適合率 - 再現率曲線
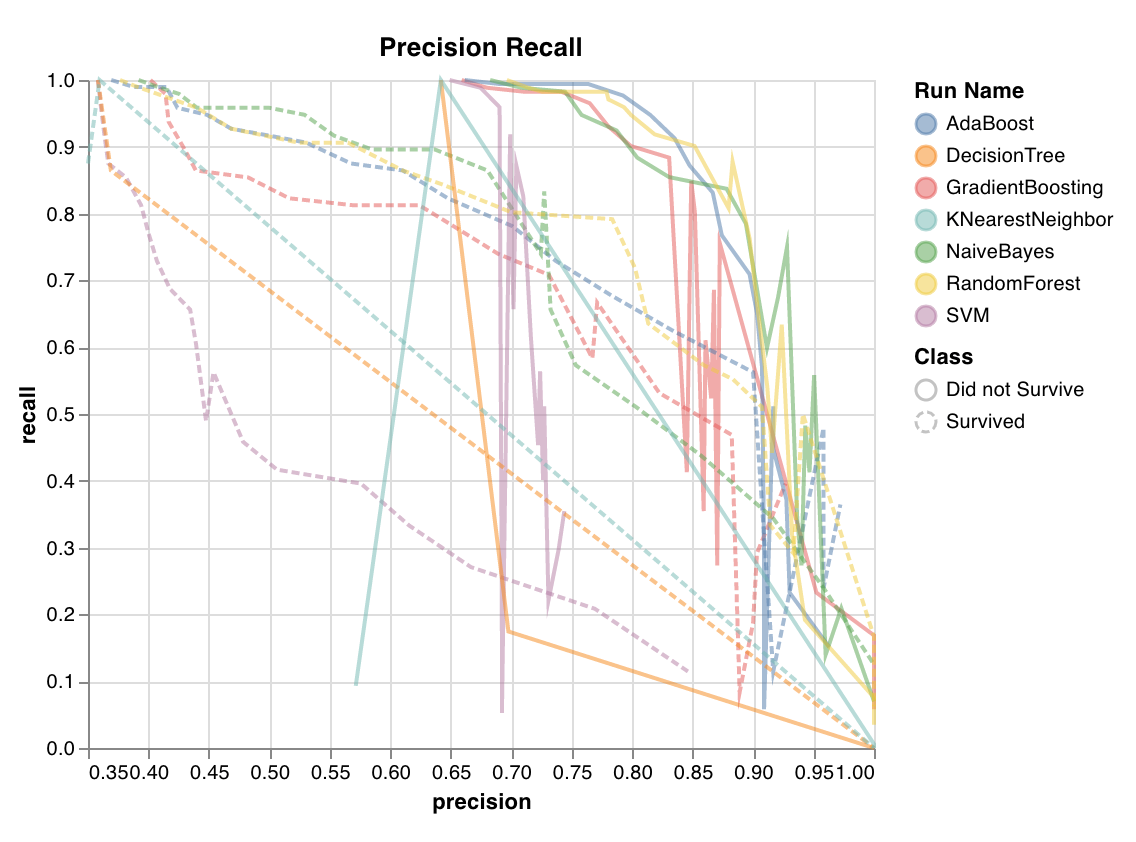
さまざまなしきい値に対する 適合率 と 再現率 の間のトレードオフを計算します。曲線下面積が大きいほど、高い 再現率 と高い 適合率 の両方を表し、高い 適合率 は低い 偽陽性率 に関連し、高い 再現率 は低い 偽陰性率 に関連します。
両方の高いスコアは、分類器が正確な 結果 を返している (高い 適合率 ) だけでなく、すべての陽性の 結果 の大部分を返している (高い 再現率 ) ことを示しています。PR 曲線は、クラスが非常に不均衡な場合に役立ちます。
wandb.sklearn.plot_precision_recall(y_true, y_probas, labels)
- y_true (arr): テストセット のラベル。
- y_probas (arr): テストセット の 予測 確率。
- labels (list): ターゲット変数 (y) の名前付きラベル。
特徴の重要度
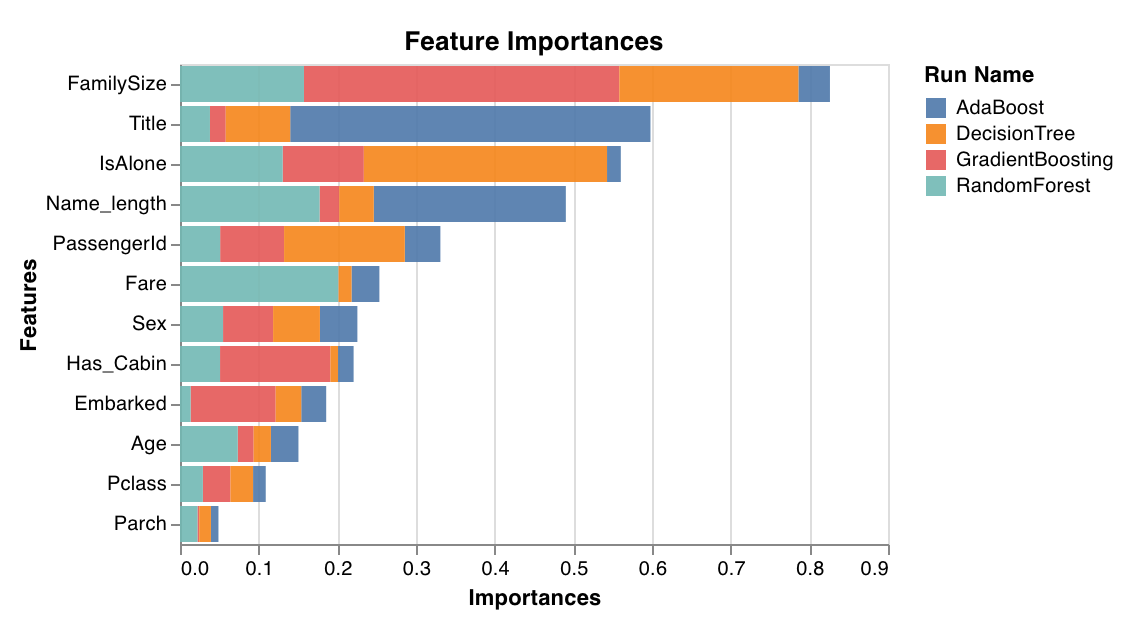
分類タスクにおける各特徴の重要度を評価およびプロットします。feature_importances_ 属性を持つ分類器 ( ツリー など) でのみ機能します。
wandb.sklearn.plot_feature_importances(model, ['width', 'height, 'length'])
- model (clf): 適合された分類器を受け入れます。
- feature_names (list): 特徴の名前。特徴インデックスを対応する名前に置き換えることで、プロットを読みやすくします。
較正曲線
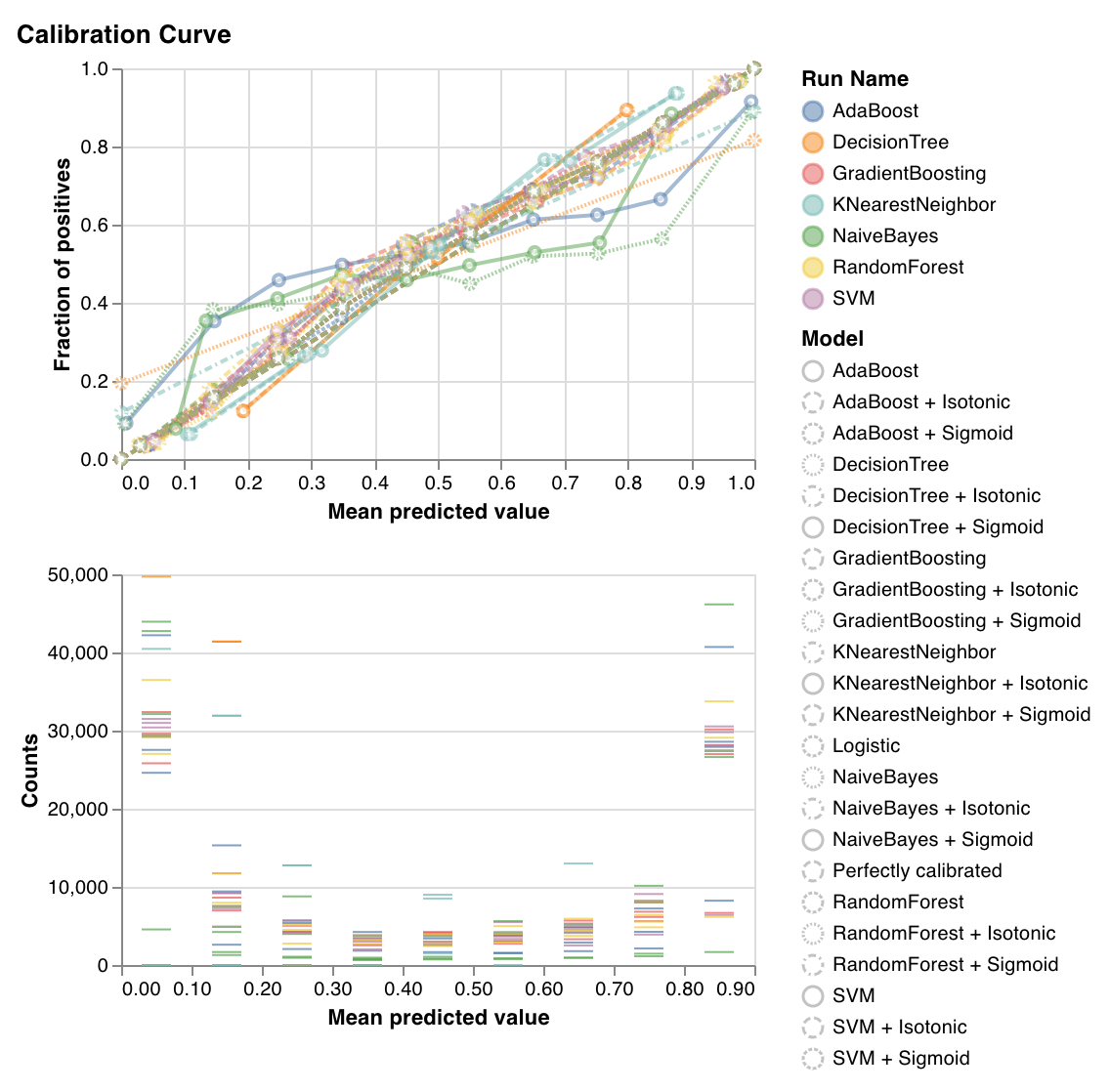
分類器の 予測 確率がどの程度較正されているか、および較正されていない分類器を較正する方法をプロットします。ベースラインのロジスティック回帰 モデル 、 引数 として渡された モデル 、およびその等方性較正とシグモイド較正の両方によって推定された 予測 確率を比較します。
較正曲線が対角線に近いほど優れています。転置されたシグモイドのような曲線は 過学習された 分類器を表し、シグモイドのような曲線は 学習不足 の分類器を表します。モデル の等方性較正とシグモイド較正をトレーニングし、それらの曲線を比較することで、モデル が 過学習 または 学習不足 であるかどうか、またそうである場合、どの較正 (シグモイドまたは等方性) がこれを修正するのに役立つかを把握できます。
詳細については、sklearn のドキュメント を参照してください。
wandb.sklearn.plot_calibration_curve(clf, X, y, 'RandomForestClassifier')
- model (clf): 適合された分類器を受け入れます。
- X (arr): トレーニング セットの特徴。
- y (arr): トレーニング セットのラベル。
- model_name (str): モデル 名。デフォルトは ‘Classifier’
混同行列
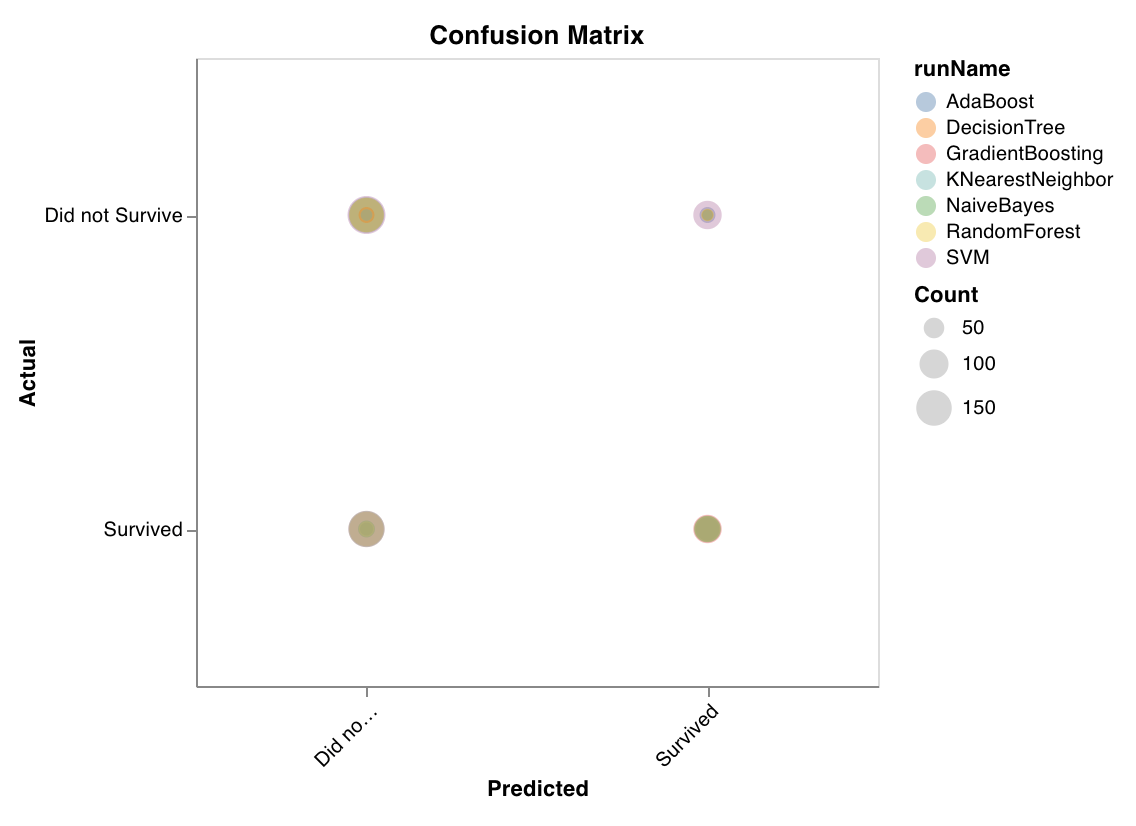
混同行列を計算して、分類の精度を評価します。モデル の 予測 の品質を評価し、モデル が間違える 予測 のパターンを見つけるのに役立ちます。対角線は、実際のラベルが 予測 されたラベルと等しい場合など、モデル が正しく取得した 予測 を表します。
wandb.sklearn.plot_confusion_matrix(y_true, y_pred, labels)
- y_true (arr): テストセット のラベル。
- y_pred (arr): テストセット の 予測 されたラベル。
- labels (list): ターゲット変数 (y) の名前付きラベル。
サマリーメトリクス
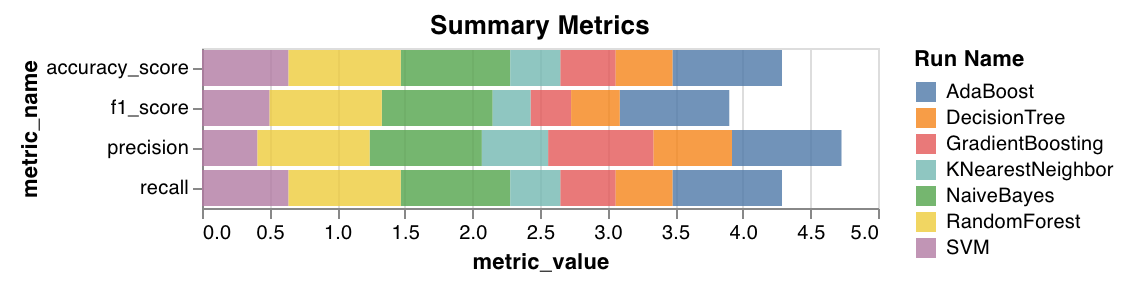
mse、mae、r2スコアなど、分類のサマリー メトリクス を計算します。f1、精度、 適合率 、 再現率 など、回帰のサマリー メトリクス を計算します。
wandb.sklearn.plot_summary_metrics(model, X_train, y_train, X_test, y_test)
- model (clf または reg): 適合された回帰子または分類器を受け入れます。
- X (arr): トレーニング セットの特徴。
- y (arr): トレーニング セットのラベル。
- X_test (arr): テストセット の特徴。
- y_test (arr): テストセット のラベル。
エルボープロット
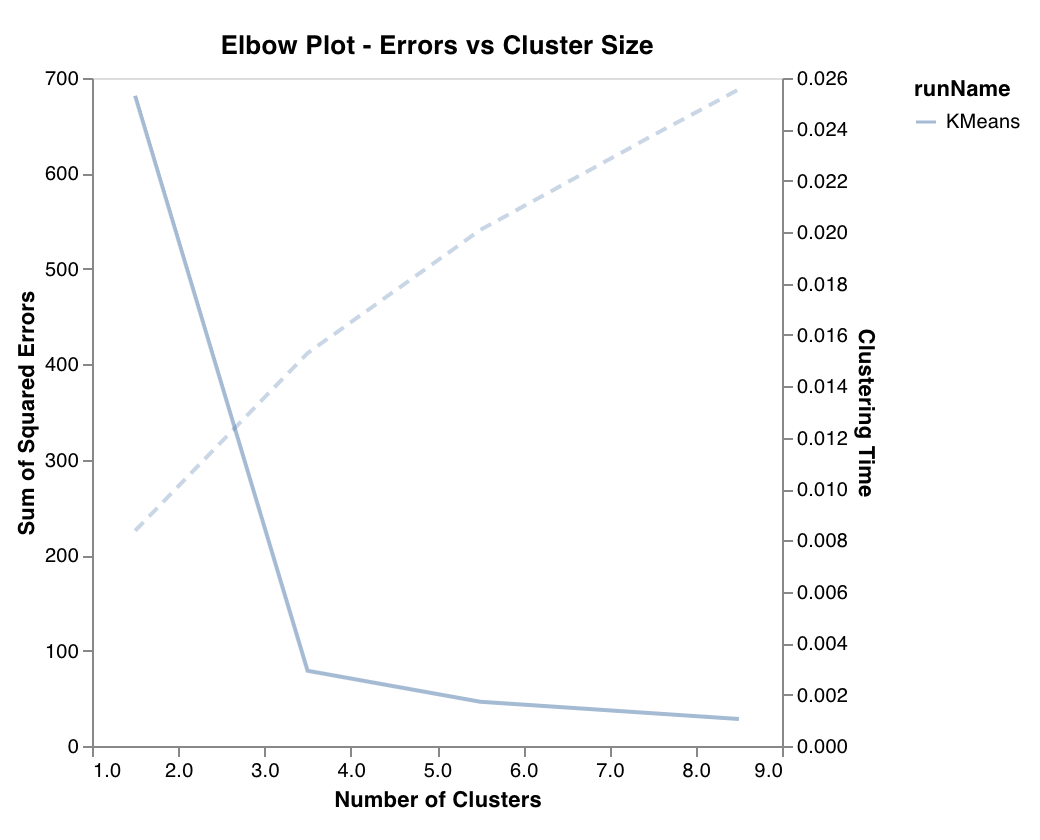
トレーニング時間とともに、クラスター の数に応じて説明される分散の割合を測定およびプロットします。最適な クラスター の数を選択するのに役立ちます。
wandb.sklearn.plot_elbow_curve(model, X_train)
- model (clusterer): 適合されたクラスタラーを受け入れます。
- X (arr): トレーニング セットの特徴。
シルエットプロット
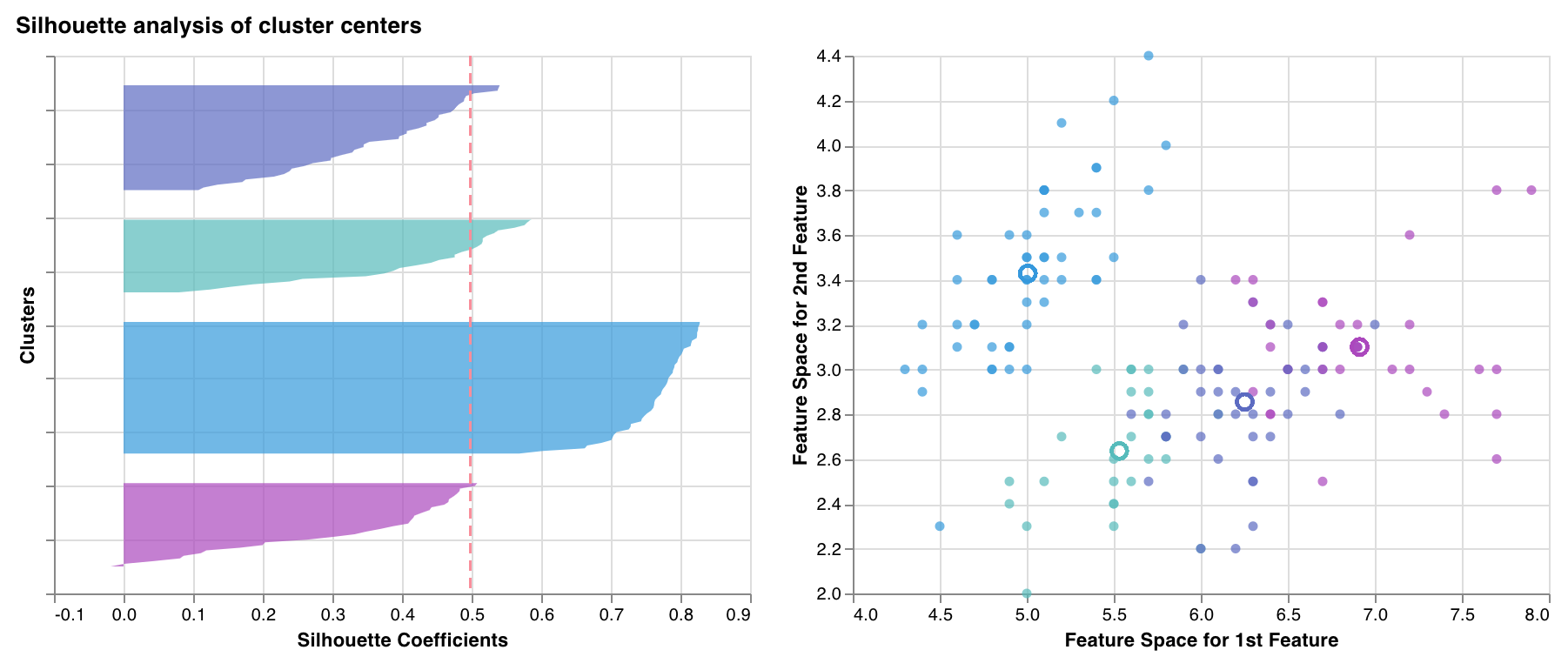
1 つの クラスター 内の各点が隣接する クラスター 内の点にどれだけ近いかを測定してプロットします。クラスター の太さは、 クラスター サイズに対応します。垂直線は、すべての点の平均シルエットスコアを表します。
+1 に近いシルエット係数は、サンプルが隣接する クラスター から遠く離れていることを示します。0 の値は、サンプルが 2 つの隣接する クラスター 間の決定境界上または非常に近いことを示し、負の値は、それらのサンプルが間違った クラスター に割り当てられた可能性があることを示します。
一般に、すべてのシルエット クラスター スコアが平均以上 (赤い線を超えている) であり、できるだけ 1 に近いことが望ましいです。また、 データ 内の基礎となるパターンを反映する クラスター サイズも推奨されます。
wandb.sklearn.plot_silhouette(model, X_train, ['spam', 'not spam'])
- model (clusterer): 適合されたクラスタラーを受け入れます。
- X (arr): トレーニング セットの特徴。
- cluster_labels (list): クラスター ラベルの名前。クラスター インデックスを対応する名前に置き換えることで、プロットを読みやすくします。
外れ値候補プロット
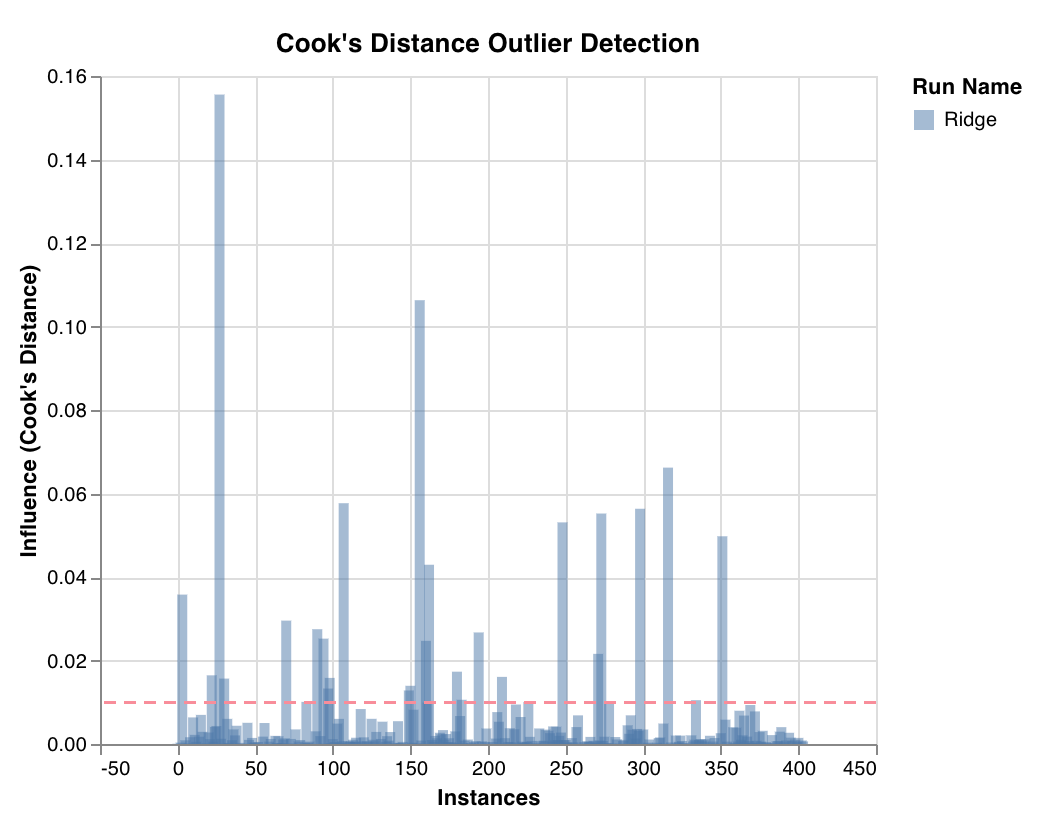
Cook の距離を介して回帰 モデル に対する データポイント の影響を測定します。大きく歪んだ影響を持つインスタンスは、潜在的に外れ値である可能性があります。外れ値の検出に役立ちます。
wandb.sklearn.plot_outlier_candidates(model, X, y)
- model (regressor): 適合された分類器を受け入れます。
- X (arr): トレーニング セットの特徴。
- y (arr): トレーニング セットのラベル。
残差プロット
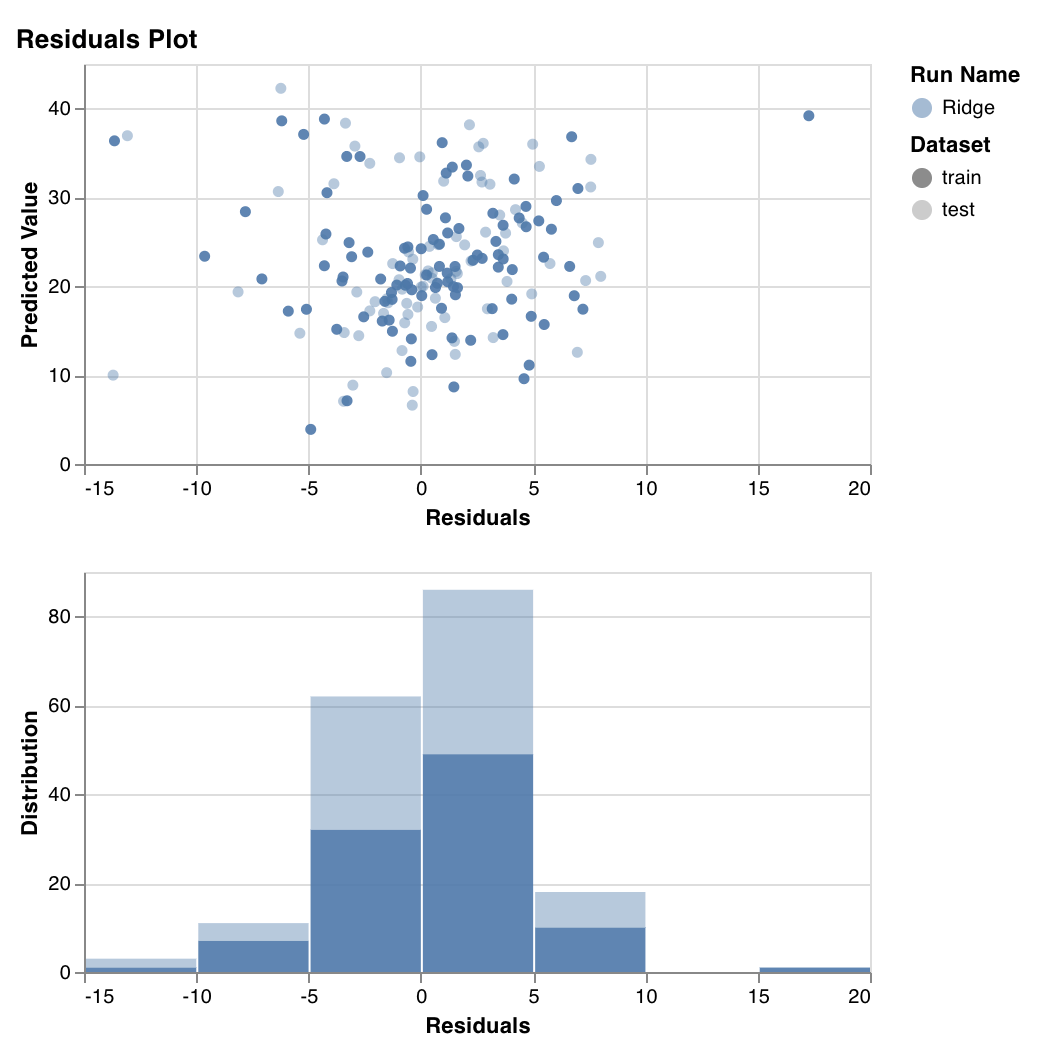
予測 されたターゲット値 (y 軸) と実際のターゲット値と 予測 されたターゲット値の差 (x 軸) を測定してプロットし、残差誤差の分布を測定してプロットします。
一般に、適切に適合された モデル の残差はランダムに分布している必要があります。これは、優れた モデル はランダム誤差を除く データセット 内のほとんどの現象を考慮するためです。
wandb.sklearn.plot_residuals(model, X, y)
-
model (regressor): 適合された分類器を受け入れます。
-
X (arr): トレーニング セットの特徴。
-
y (arr): トレーニング セットのラベル。
ご不明な点がございましたら、Slack コミュニティ でお気軽にお問い合わせください。
例
- Colab で実行: 使い始めるための簡単な ノートブック
[i18n] feedback_title
[i18n] feedback_question
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.