Kubeflow Pipelines (kfp)
2 minute read
Kubeflow Pipelines (kfp) は、Docker コンテナに基づいて、移植可能でスケーラブルな 機械学習 (ML) ワークフローを構築およびデプロイするためのプラットフォームです。
このインテグレーションにより、ユーザーはデコレーターを kfp python 関数コンポーネントに適用して、 パラメータと Artifacts を W&B に自動的に記録できます。
この機能は wandb==0.12.11 で有効になり、kfp<2.0.0 が必要です。
サインアップして API キーを作成する
API キーは、お使いのマシンを W&B に対して認証します。API キーは、ユーザープロファイルから生成できます。
- 右上隅にあるユーザープロファイルアイコンをクリックします。
- [User Settings] を選択し、[API Keys] セクションまでスクロールします。
- [Reveal] をクリックします。表示された API キーをコピーします。API キーを非表示にするには、ページをリロードします。
wandb ライブラリをインストールしてログインする
wandb ライブラリをローカルにインストールしてログインするには:
-
API キーに
WANDB_API_KEY環境変数 を設定します。export WANDB_API_KEY=<your_api_key> -
wandbライブラリをインストールしてログインします。pip install wandb wandb login
pip install wandb
import wandb
wandb.login()
!pip install wandb
import wandb
wandb.login()
コンポーネントをデコレートする
@wandb_log デコレーターを追加し、通常どおりにコンポーネントを作成します。これにより、パイプラインを実行するたびに、入力/出力 パラメータ と Artifacts が自動的に W&B に記録されます。
from kfp import components
from wandb.integration.kfp import wandb_log
@wandb_log
def add(a: float, b: float) -> float:
return a + b
add = components.create_component_from_func(add)
環境変数をコンテナに渡す
環境変数 をコンテナに明示的に渡す必要がある場合があります。双方向のリンクを行うには、環境変数 WANDB_KUBEFLOW_URL を Kubeflow Pipelines インスタンスのベース URL に設定する必要があります。たとえば、https://kubeflow.mysite.com です。
import os
from kubernetes.client.models import V1EnvVar
def add_wandb_env_variables(op):
env = {
"WANDB_API_KEY": os.getenv("WANDB_API_KEY"),
"WANDB_BASE_URL": os.getenv("WANDB_BASE_URL"),
}
for name, value in env.items():
op = op.add_env_variable(V1EnvVar(name, value))
return op
@dsl.pipeline(name="example-pipeline")
def example_pipeline(param1: str, param2: int):
conf = dsl.get_pipeline_conf()
conf.add_op_transformer(add_wandb_env_variables)
プログラムでデータにアクセスする
Kubeflow Pipelines UI 経由
W&B でログに記録された Kubeflow Pipelines UI の Run をクリックします。
- [
Input/Output] タブと [ML Metadata] タブで、入力と出力に関する詳細を確認します。 - [
Visualizations] タブから W&B Web アプリを表示します。
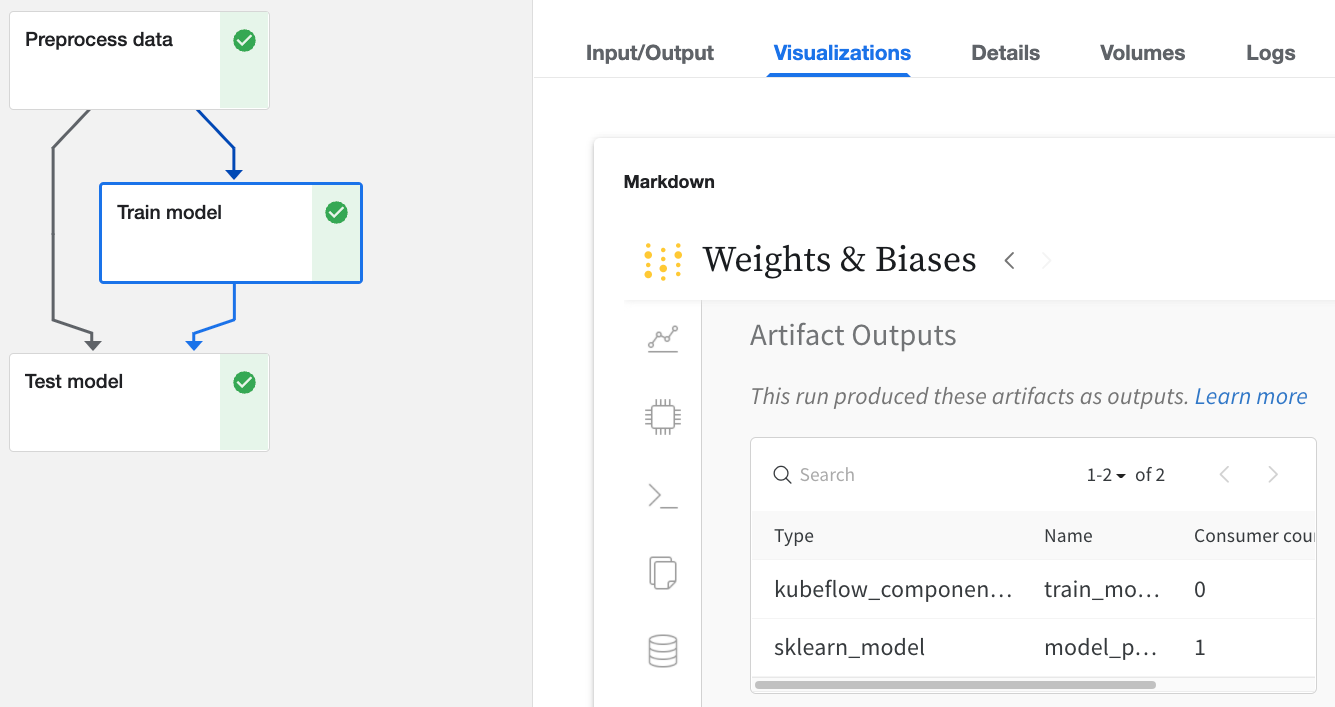
Web アプリ UI 経由
Web アプリ UI には、Kubeflow Pipelines の [ Visualizations ] タブと同じコンテンツがありますが、より広いスペースがあります。Web アプリ UI の詳細はこちらをご覧ください。
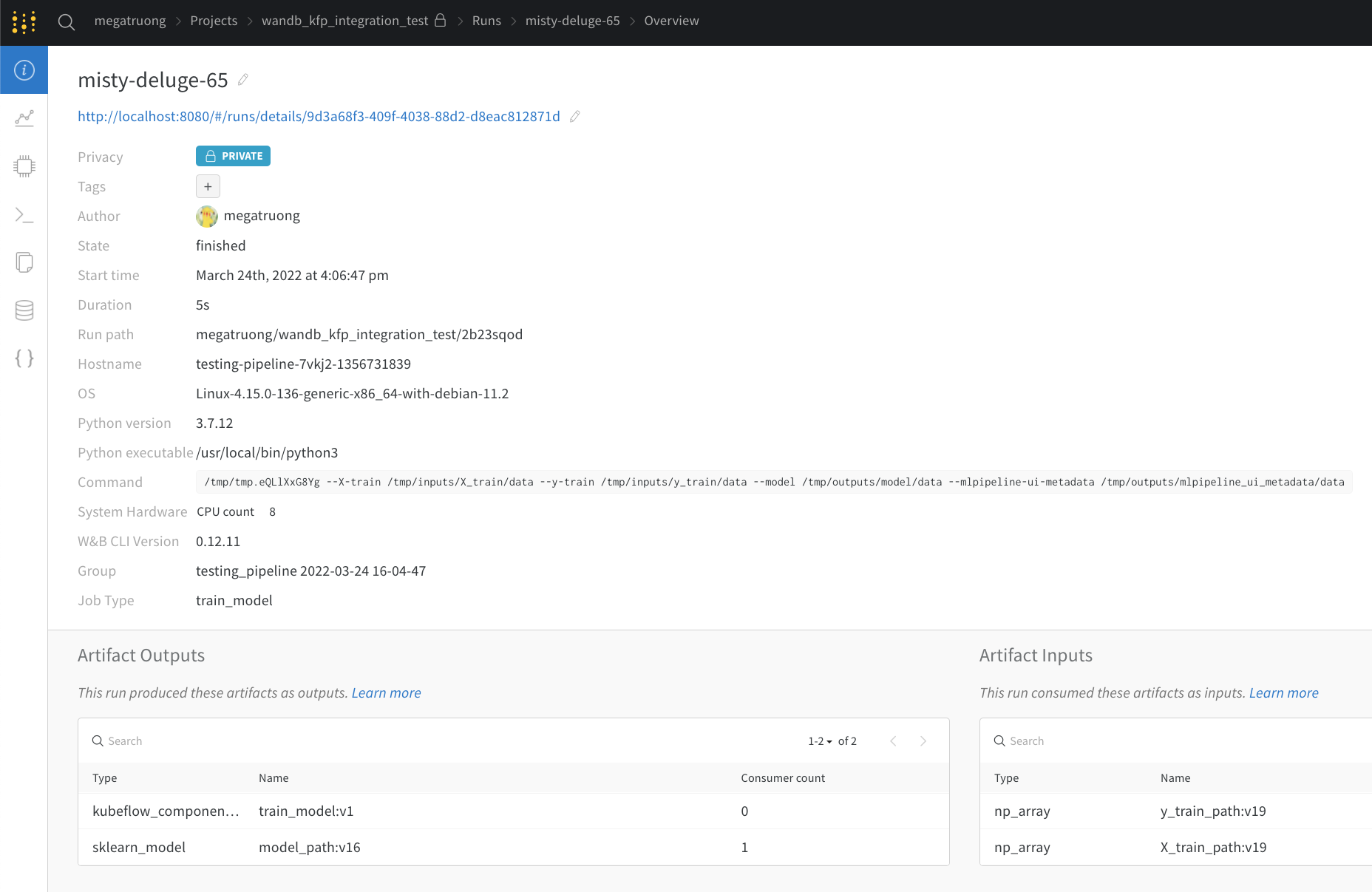
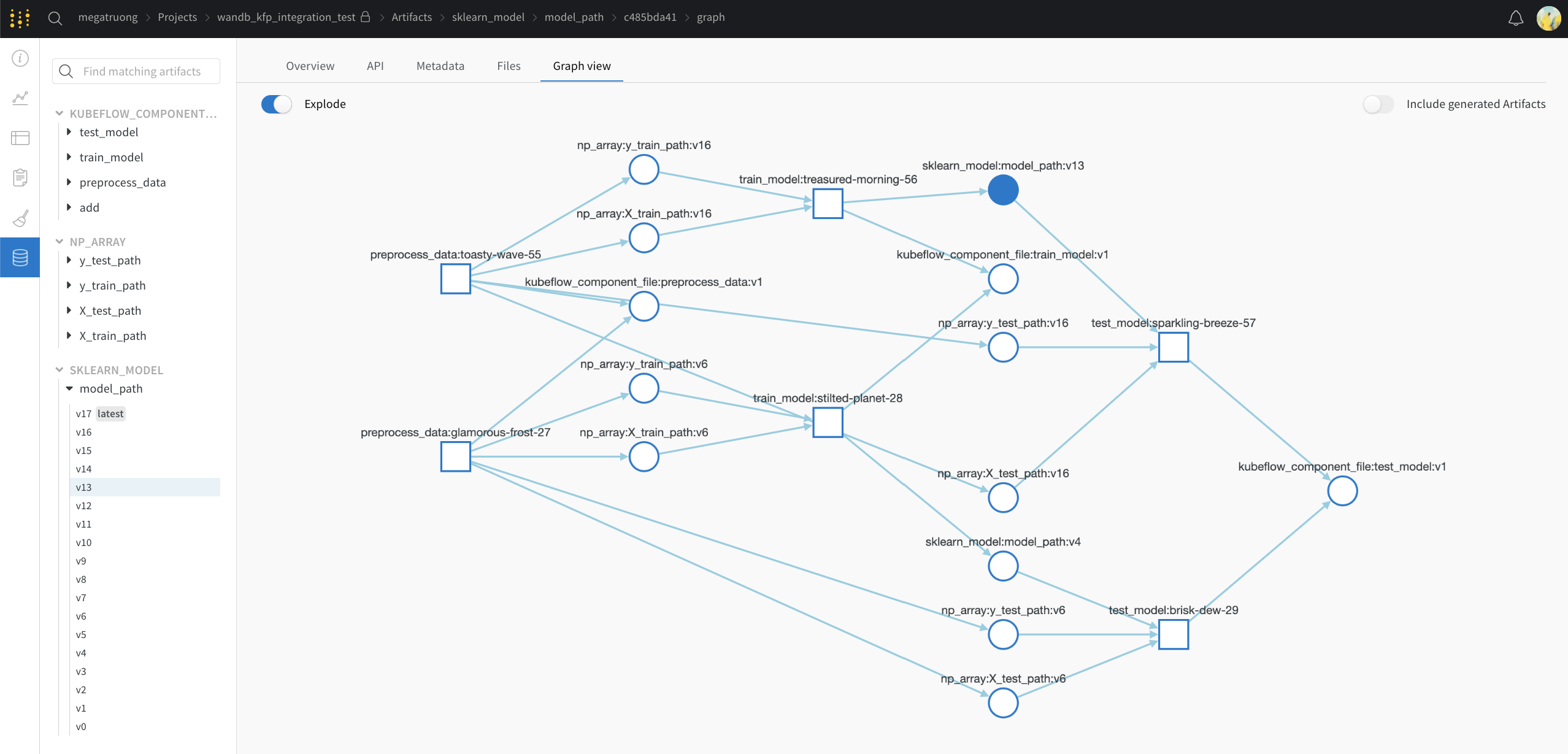
パブリック API 経由 (プログラムによるアクセス)
- プログラムによるアクセスについては、パブリック API を参照してください。
Kubeflow Pipelines から W&B へのコンセプトマッピング
Kubeflow Pipelines のコンセプトから W&B へのマッピングを次に示します。
| Kubeflow Pipelines | W&B | W&B の場所 |
|---|---|---|
| 入力スカラー | config |
Overviewタブ |
| 出力スカラー | summary |
Overviewタブ |
| 入力 Artifact | 入力 Artifact | Artifacts タブ |
| 出力 Artifact | 出力 Artifact | Artifacts タブ |
きめ細かいロギング
ロギングをより細かく制御したい場合は、コンポーネントに wandb.log および wandb.log_artifact 呼び出しを追加できます。
明示的な wandb.log_artifacts 呼び出しを使用
以下の例では、モデルをトレーニングしています。@wandb_log デコレーターは、関連する入力と出力を自動的に追跡します。トレーニングプロセスをログに記録する場合は、次のように明示的にロギングを追加できます。
@wandb_log
def train_model(
train_dataloader_path: components.InputPath("dataloader"),
test_dataloader_path: components.InputPath("dataloader"),
model_path: components.OutputPath("pytorch_model"),
):
...
for epoch in epochs:
for batch_idx, (data, target) in enumerate(train_dataloader):
...
if batch_idx % log_interval == 0:
wandb.log(
{"epoch": epoch, "step": batch_idx * len(data), "loss": loss.item()}
)
...
wandb.log_artifact(model_artifact)
暗黙的な wandb インテグレーションを使用
サポートするフレームワーク インテグレーション を使用している場合は、コールバックを直接渡すこともできます。
@wandb_log
def train_model(
train_dataloader_path: components.InputPath("dataloader"),
test_dataloader_path: components.InputPath("dataloader"),
model_path: components.OutputPath("pytorch_model"),
):
from pytorch_lightning.loggers import WandbLogger
from pytorch_lightning import Trainer
trainer = Trainer(logger=WandbLogger())
... # do training
[i18n] feedback_title
[i18n] feedback_question
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.