Tutorial: Use W&B for model management
3 minute read
以下のチュートリアルでは、モデルを W&B に記録する方法を紹介します。このチュートリアルを終えるまでに、以下のことができるようになります。
- MNIST データセットと Keras フレームワークを使用してモデルを作成し、トレーニングする。
- トレーニングしたモデルを W&B の project に記録する
- 使用したデータセットを作成したモデルへの依存関係としてマークする
- モデルを W&B モデルレジストリにリンクする。
- レジストリにリンクするモデルのパフォーマンスを評価する
- モデルの version を production 用としてマークする。
- このガイドに記載されている順序で コード スニペットをコピーしてください。
- モデルレジストリに固有ではないコードは、折りたたみ可能なセルに隠されています。
セットアップ
始める前に、このチュートリアルに必要な Python の依存関係をインポートします。
import wandb
import numpy as np
from tensorflow import keras
from tensorflow.keras import layers
from wandb.integration.keras import WandbMetricsLogger
from sklearn.model_selection import train_test_split
W&B の entity を entity 変数に指定します。
entity = "<entity>"
データセット Artifact を作成する
まず、データセットを作成します。次の コード スニペットは、MNIST データセットをダウンロードする関数を作成します。
def generate_raw_data(train_size=6000):
eval_size = int(train_size / 6)
(x_train, y_train), (x_eval, y_eval) = keras.datasets.mnist.load_data()
x_train = x_train.astype("float32") / 255
x_eval = x_eval.astype("float32") / 255
x_train = np.expand_dims(x_train, -1)
x_eval = np.expand_dims(x_eval, -1)
print("Generated {} rows of training data.".format(train_size))
print("Generated {} rows of eval data.".format(eval_size))
return (x_train[:train_size], y_train[:train_size]), (
x_eval[:eval_size],
y_eval[:eval_size],
)
# データセットを作成します
(x_train, y_train), (x_eval, y_eval) = generate_raw_data()
次に、データセットを W&B にアップロードします。これを行うには、アーティファクト オブジェクトを作成し、そのアーティファクトにデータセットを追加します。
project = "model-registry-dev"
model_use_case_id = "mnist"
job_type = "build_dataset"
# W&B の run を初期化します
run = wandb.init(entity=entity, project=project, job_type=job_type)
# トレーニングデータ用の W&B テーブルを作成します
train_table = wandb.Table(data=[], columns=[])
train_table.add_column("x_train", x_train)
train_table.add_column("y_train", y_train)
train_table.add_computed_columns(lambda ndx, row: {"img": wandb.Image(row["x_train"])})
# 評価データ用の W&B テーブルを作成します
eval_table = wandb.Table(data=[], columns=[])
eval_table.add_column("x_eval", x_eval)
eval_table.add_column("y_eval", y_eval)
eval_table.add_computed_columns(lambda ndx, row: {"img": wandb.Image(row["x_eval"])})
# Artifact オブジェクトを作成します
artifact_name = "{}_dataset".format(model_use_case_id)
artifact = wandb.Artifact(name=artifact_name, type="dataset")
# wandb.WBValue オブジェクトを Artifact に追加します。
artifact.add(train_table, "train_table")
artifact.add(eval_table, "eval_table")
# Artifact に加えられた変更を永続化します。
artifact.save()
# W&B にこの run が完了したことを伝えます。
run.finish()
モデルをトレーニングする
前のステップで作成した Artifact データセットを使用してモデルをトレーニングします。
データセット Artifact を run への入力として宣言する
前のステップで作成したデータセット Artifact を W&B の run への入力として宣言します。Artifact を run への入力として宣言すると、特定のモデルのトレーニングに使用されたデータセット (およびデータセットの version) を追跡できるため、モデルのログを記録する際に特に役立ちます。W&B は、収集された情報を使用して、リネージマップ を作成します。
use_artifact API を使用して、データセット Artifact を run の入力として宣言し、Artifact 自体を取得します。
job_type = "train_model"
config = {
"optimizer": "adam",
"batch_size": 128,
"epochs": 5,
"validation_split": 0.1,
}
# W&B の run を初期化します
run = wandb.init(project=project, job_type=job_type, config=config)
# データセット Artifact を取得します
version = "latest"
name = "{}:{}".format("{}_dataset".format(model_use_case_id), version)
artifact = run.use_artifact(artifact_or_name=name)
# データフレームから特定の内容を取得します
train_table = artifact.get("train_table")
x_train = train_table.get_column("x_train", convert_to="numpy")
y_train = train_table.get_column("y_train", convert_to="numpy")
モデルの入力と出力を追跡する方法の詳細については、モデルリネージ マップの作成を参照してください。
モデルを定義してトレーニングする
このチュートリアルでは、Keras を使用して MNIST データセットから画像を分類する 2D Convolutional Neural Network (CNN) を定義します。
MNIST データで CNN をトレーニングする
# 設定ディクショナリの値を簡単にアクセスできるように変数に格納します
num_classes = 10
input_shape = (28, 28, 1)
loss = "categorical_crossentropy"
optimizer = run.config["optimizer"]
metrics = ["accuracy"]
batch_size = run.config["batch_size"]
epochs = run.config["epochs"]
validation_split = run.config["validation_split"]
# モデルアーキテクチャを作成します
model = keras.Sequential(
[
layers.Input(shape=input_shape),
layers.Conv2D(32, kernel_size=(3, 3), activation="relu"),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Conv2D(64, kernel_size=(3, 3), activation="relu"),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Flatten(),
layers.Dropout(0.5),
layers.Dense(num_classes, activation="softmax"),
]
)
model.compile(loss=loss, optimizer=optimizer, metrics=metrics)
# トレーニングデータのラベルを生成します
y_train = keras.utils.to_categorical(y_train, num_classes)
# トレーニングセットとテストセットを作成します
x_t, x_v, y_t, y_v = train_test_split(x_train, y_train, test_size=0.33)
次に、モデルをトレーニングします。
# モデルをトレーニングします
model.fit(
x=x_t,
y=y_t,
batch_size=batch_size,
epochs=epochs,
validation_data=(x_v, y_v),
callbacks=[WandbCallback(log_weights=True, log_evaluation=True)],
)
最後に、モデルをローカルマシンに保存します。
# モデルをローカルに保存します
path = "model.h5"
model.save(path)
モデルをログに記録してモデルレジストリにリンクする
link_model API を使用して、モデルの 1 つ以上のファイルを W&B の run に記録し、W&B モデルレジストリ にリンクします。
path = "./model.h5"
registered_model_name = "MNIST-dev"
run.link_model(path=path, registered_model_name=registered_model_name)
run.finish()
registered-model-name に指定した名前がまだ存在しない場合、W&B は登録済みモデルを作成します。
オプションのパラメータの詳細については、API リファレンスガイドのlink_model を参照してください。
モデルのパフォーマンスを評価する
1 つ以上のモデルのパフォーマンスを評価するのは一般的な方法です。
まず、前のステップで W&B に保存された評価データセット Artifact を取得します。
job_type = "evaluate_model"
# run を初期化します
run = wandb.init(project=project, entity=entity, job_type=job_type)
model_use_case_id = "mnist"
version = "latest"
# データセット Artifact を取得し、依存関係としてマークします
artifact = run.use_artifact(
"{}:{}".format("{}_dataset".format(model_use_case_id), version)
)
# 目的のデータフレームを取得します
eval_table = artifact.get("eval_table")
x_eval = eval_table.get_column("x_eval", convert_to="numpy")
y_eval = eval_table.get_column("y_eval", convert_to="numpy")
評価する W&B から モデル version をダウンロードします。use_model API を使用して、モデルにアクセスしてダウンロードします。
alias = "latest" # エイリアス
name = "mnist_model" # モデル Artifact の名前
# モデルにアクセスしてダウンロードします。ダウンロードした Artifact へのパスを返します
downloaded_model_path = run.use_model(name=f"{name}:{alias}")
Keras モデルをロードし、損失を計算します。
model = keras.models.load_model(downloaded_model_path)
y_eval = keras.utils.to_categorical(y_eval, 10)
(loss, _) = model.evaluate(x_eval, y_eval)
score = (loss, _)
最後に、損失メトリクスを W&B の run に記録します。
# # メトリクス、画像、テーブル、または評価に役立つデータを記録します。
run.log(data={"loss": (loss, _)})
モデル version を昇格させる
モデル エイリアス を使用して、機械学習 ワークフローの次の段階に向けてモデル version を準備完了としてマークします。各登録済みモデルには、1 つ以上のモデル エイリアスを設定できます。モデル エイリアスは、一度に 1 つのモデル version にのみ属することができます。
たとえば、モデルのパフォーマンスを評価した後、そのモデルが production の準備ができていると確信したとします。そのモデル version を昇格させるには、production エイリアスをその特定のモデル version に追加します。
production エイリアスは、モデルを production 準備完了としてマークするために使用される最も一般的なエイリアスの 1 つです。W&B アプリ UI を使用してインタラクティブに、または Python SDK を使用してプログラムで、モデル version にエイリアスを追加できます。次の手順では、W&B モデルレジストリアプリでエイリアスを追加する方法を示します。
- https://wandb.ai/registry/model でモデルレジストリアプリに移動します。
- 登録済みモデルの名前の横にある [詳細を表示] をクリックします。
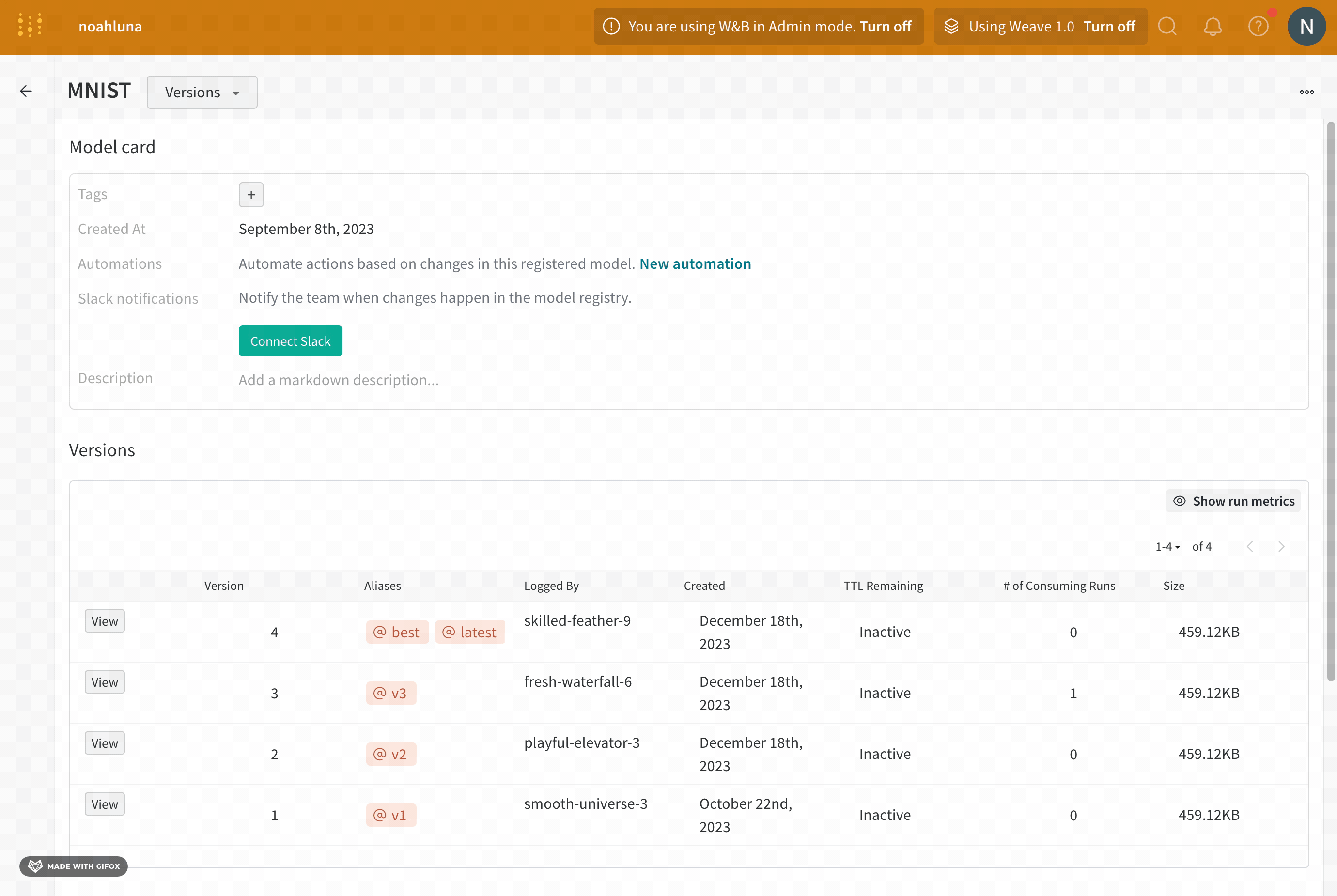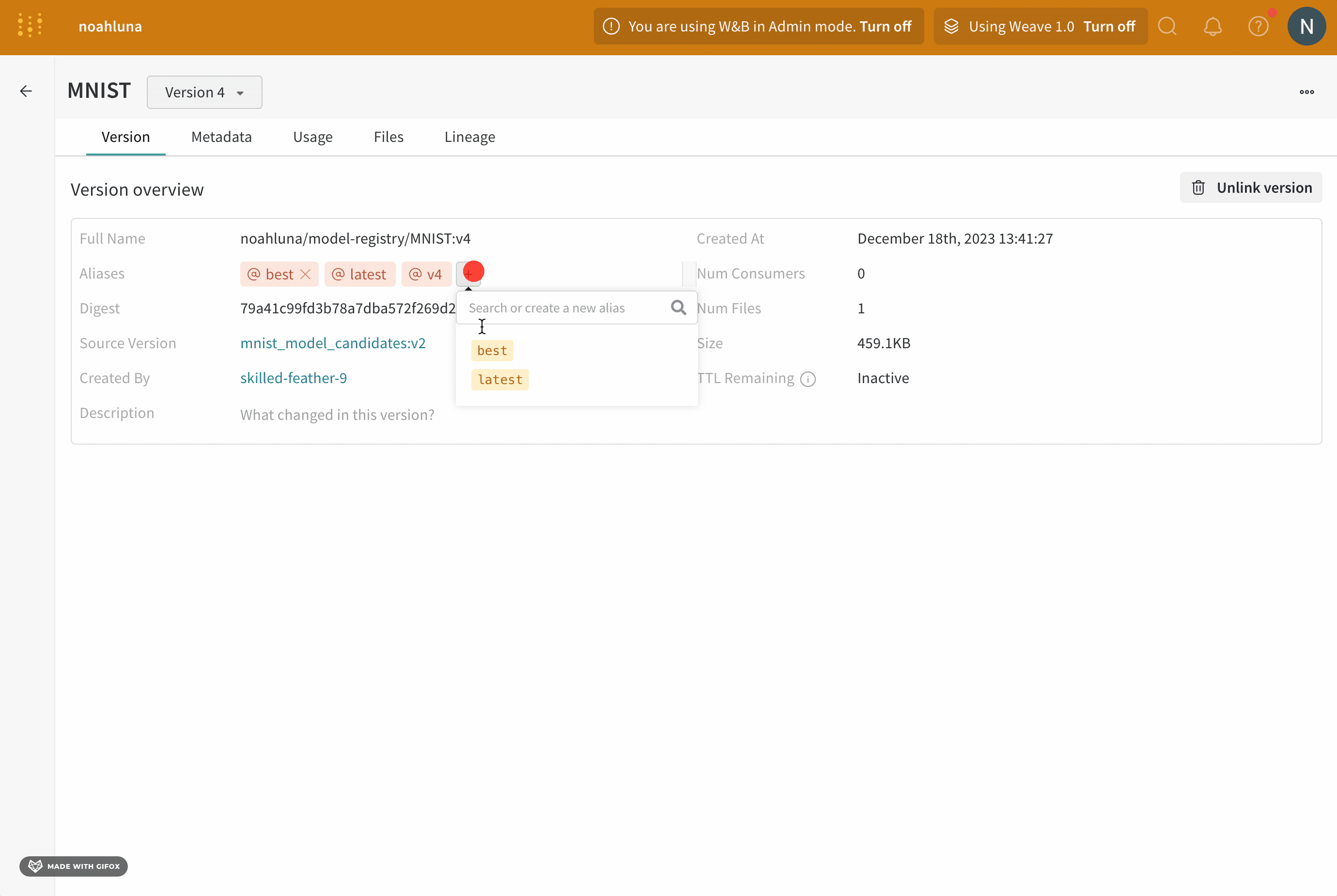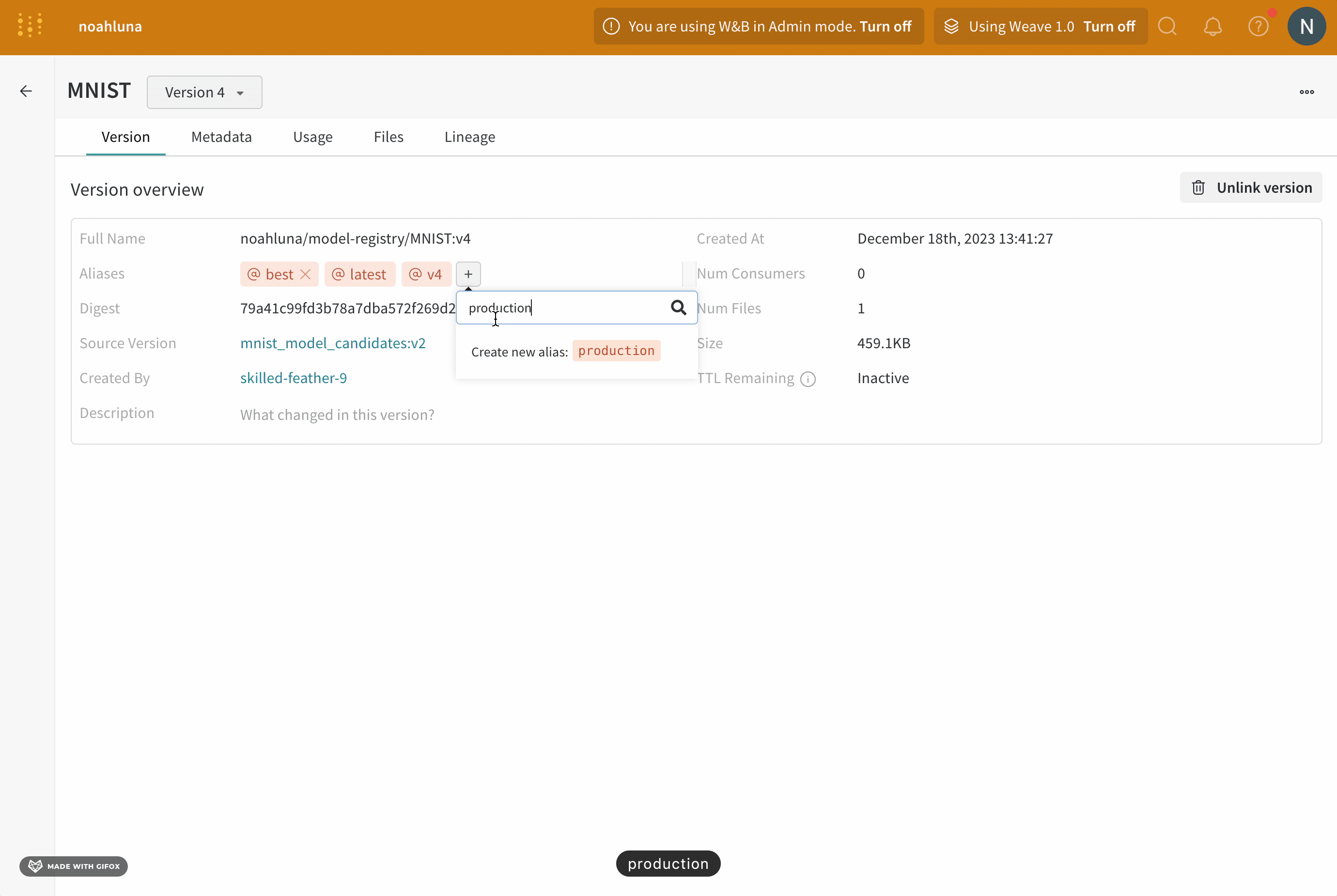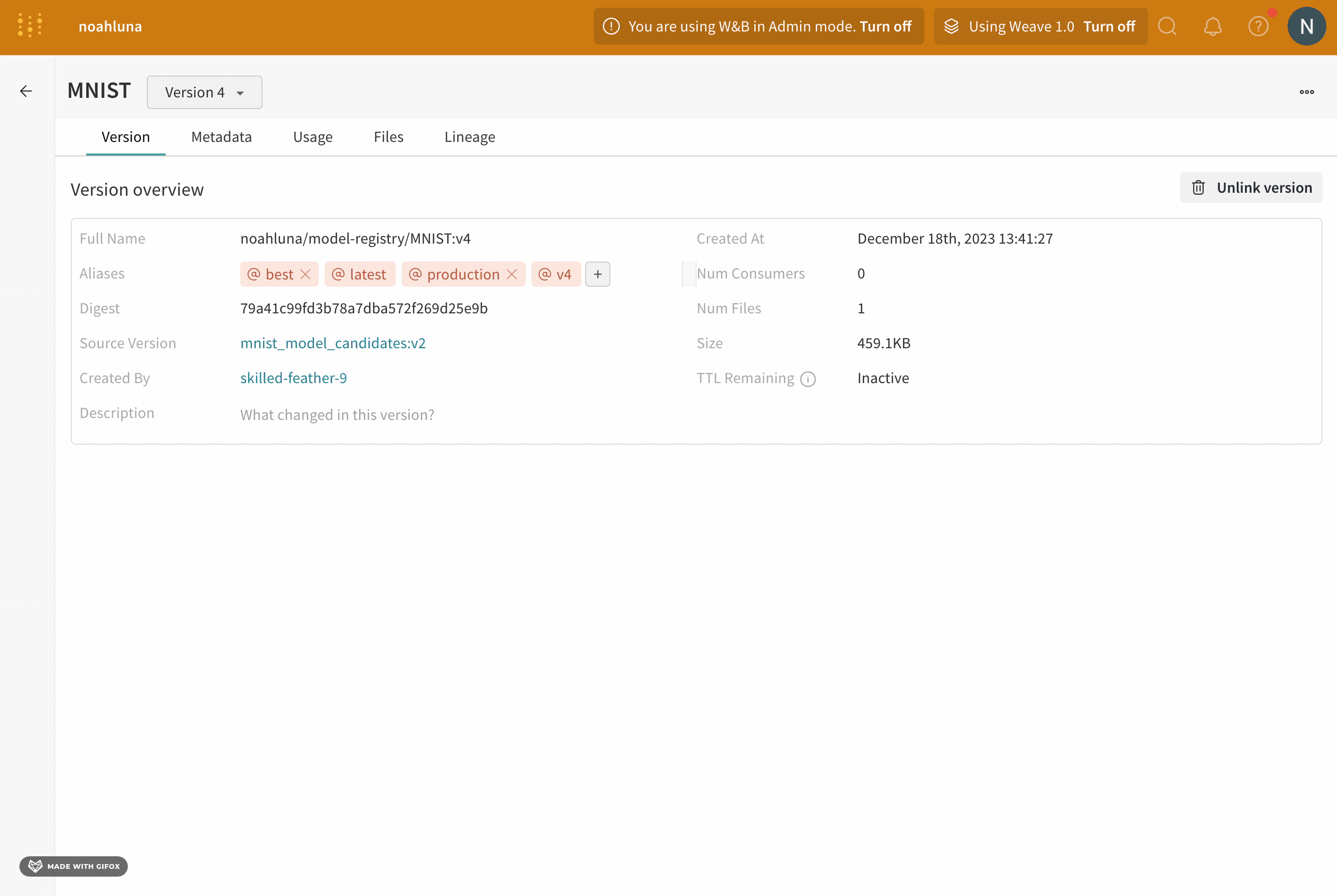
- [バージョン] セクション内で、昇格させるモデル version の名前の横にある [表示] ボタンをクリックします。
- [エイリアス] フィールドの横にあるプラス アイコン ([+]) をクリックします。
- 表示されるフィールドに
productionと入力します。 - キーボードの Enter キーを押します。
[i18n] feedback_title
[i18n] feedback_question
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.