Log objects and media
メトリクス 、動画、カスタムプロットなどを追跡
W&B Python SDK を使用して、メトリクス、メディア、またはカスタム オブジェクトの辞書をステップと共にログに記録します。W&B は、各ステップ中にキーと値のペアを収集し、wandb.log() でデータをログに記録するたびに、それらを 1 つの統合された辞書に保存します。スクリプトからログに記録されたデータは、ローカル マシンの wandb というディレクトリーに保存され、W&B クラウドまたは プライベート サーバー に同期されます。
キーと値のペアは、各ステップで同じ値を渡す場合にのみ、1 つの統合された辞書に保存されます。step に対して異なる値をログに記録すると、W&B は収集されたすべてのキーと値をメモリーに書き込みます。
wandb.log の各呼び出しは、デフォルトで新しい step となります。W&B は、チャートとパネルを作成する際に、ステップをデフォルトの x 軸として使用します。オプションで、カスタム x 軸を作成して使用したり、カスタムの集計メトリクスをキャプチャしたりできます。詳細については、ログ軸のカスタマイズ を参照してください。
wandb.log() を使用して、各 step に対して連続した値 (0、1、2 など) をログに記録します。特定の履歴ステップに書き込むことはできません。W&B は、「現在」および「次」のステップにのみ書き込みます。
自動的にログに記録されるデータ
W&B は、W&B の Experiments 中に次の情報を自動的にログに記録します。
システム メトリクス : CPU と GPU の使用率、ネットワークなど。これらは、run ページ の [System] タブに表示されます。GPU の場合、これらは nvidia-smiコマンドライン : stdout と stderr が取得され、run ページ の [Logs] タブに表示されます。
アカウントの Settings page で Code Saving をオンにして、以下をログに記録します。
Git commit : 最新の git commit を取得し、run ページの Overview タブに表示します。また、コミットされていない変更がある場合は、diff.patch ファイルも表示します。依存関係 : requirements.txt ファイルがアップロードされ、run の files タブに表示されます。また、run の wandb ディレクトリーに保存したファイルも表示されます。
特定の W&B API 呼び出しでログに記録されるデータ
W&B を使用すると、ログに記録する内容を正確に決定できます。以下に、一般的にログに記録されるオブジェクトをいくつか示します。
Datasets : 画像またはその他の dataset サンプルを W&B にストリーミングするには、それらを具体的にログに記録する必要があります。プロット : wandb.plot を wandb.log と共に使用して、チャートを追跡します。詳細については、プロットのログ を参照してください。Tables : wandb.Table を使用してデータをログに記録し、W&B で視覚化およびクエリを実行します。詳細については、Tables のログ を参照してください。PyTorch 勾配 : wandb.watch(model) を追加して、UI で重みの勾配をヒストグラムとして表示します。設定情報 : ハイパーパラメータ、dataset へのリンク、または使用しているアーキテクチャーの名前を config パラメータとしてログに記録します。wandb.init(config=your_config_dictionary) のように渡されます。詳細については、PyTorch Integrations ページを参照してください。メトリクス : wandb.log を使用して、model からのメトリクスを表示します。トレーニング ループ内から精度や損失などのメトリクスをログに記録すると、UI でライブ更新グラフが表示されます。
一般的なワークフロー
最高精度を比較する : run 全体でメトリクスの最高値を比較するには、そのメトリクスの集計値を設定します。デフォルトでは、集計は各キーに対してログに記録した最後の値に設定されます。これは、UI のテーブルで役立ちます。UI では、集計メトリクスに基づいて run をソートおよびフィルター処理し、最終的な精度ではなく 最高 精度に基づいてテーブルまたは棒グラフで run を比較できます。例: wandb.run.summary["best_accuracy"] = best_accuracy1 つのチャートで複数のメトリクスを表示する : wandb.log({"acc'": 0.9, "loss": 0.1}) のように、wandb.log への同じ呼び出しで複数のメトリクスをログに記録すると、それらは両方とも UI でプロットに使用できるようになります。x 軸をカスタマイズする : 同じログ呼び出しにカスタム x 軸を追加して、W&B dashboard で別の軸に対してメトリクスを視覚化します。例: wandb.log({'acc': 0.9, 'epoch': 3, 'batch': 117})。特定のメトリクスのデフォルトの x 軸を設定するには、Run.define_metric() を使用します。リッチ メディアとチャートをログに記録する : wandb.log は、画像や動画などのメディア から Tables および Charts まで、さまざまなデータ型のログ記録をサポートしています。
ベストプラクティスとヒント
Experiments とログ記録のベストプラクティスとヒントについては、ベストプラクティス: Experiments とログ記録 を参照してください。
1 - Create and track plots from experiments
機械学習 の 実験 からプロットを作成および追跡します。
wandb.plot のメソッドを使用すると、トレーニング中に時間とともに変化するグラフを含め、wandb.log でグラフを追跡できます。カスタムグラフ作成フレームワークの詳細については、このガイド を確認してください。
基本的なグラフ
これらのシンプルなグラフを使用すると、メトリクスと結果の基本的な可視化を簡単に構築できます。
Line
Scatter
Bar
Histogram
Multi-line
wandb.plot.line()
カスタム折れ線グラフ (任意の軸上の接続された順序付きポイントのリスト) を記録します。
data = [[x, y] for (x, y) in zip(x_values, y_values)]
table = wandb. Table(data= data, columns= ["x" , "y" ])
wandb. log(
{
"my_custom_plot_id" : wandb. plot. line(
table, "x" , "y" , title= "Custom Y vs X Line Plot"
)
}
)
これを使用して、任意の2つの次元で曲線を記録できます。2つの値のリストを互いにプロットする場合、リスト内の値の数は正確に一致する必要があります。たとえば、各ポイントにはxとyが必要です。
アプリで表示
コードを実行
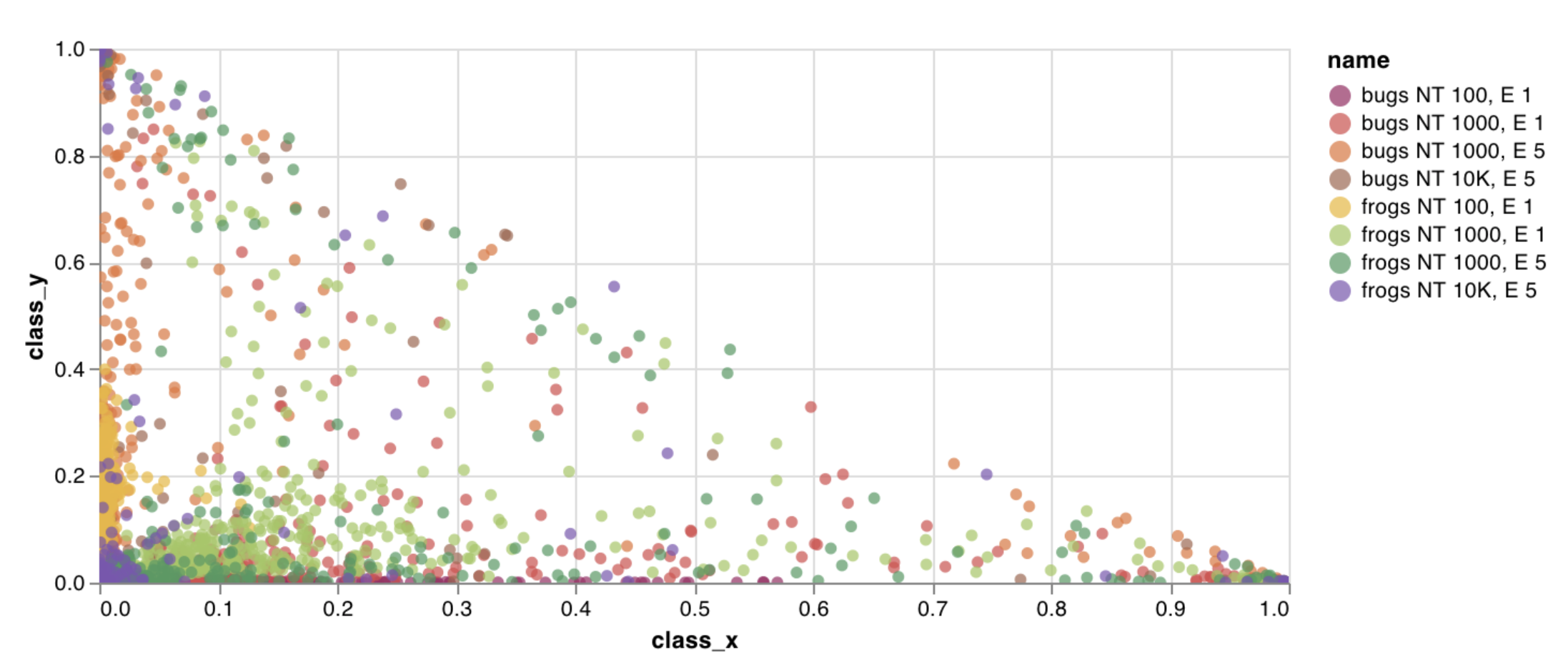
wandb.plot.scatter()
カスタム散布図 (任意の軸xとyのペア上のポイント (x、y) のリスト) を記録します。
data = [[x, y] for (x, y) in zip(class_x_scores, class_y_scores)]
table = wandb. Table(data= data, columns= ["class_x" , "class_y" ])
wandb. log({"my_custom_id" : wandb. plot. scatter(table, "class_x" , "class_y" )})
これを使用して、任意の2つの次元で散布ポイントを記録できます。2つの値のリストを互いにプロットする場合、リスト内の値の数は正確に一致する必要があります。たとえば、各ポイントにはxとyが必要です。
アプリで表示
コードを実行
wandb.plot.bar()
カスタム棒グラフ (ラベル付きの値のリストを棒として表示) を数行でネイティブに記録します。
data = [[label, val] for (label, val) in zip(labels, values)]
table = wandb. Table(data= data, columns= ["label" , "value" ])
wandb. log(
{
"my_bar_chart_id" : wandb. plot. bar(
table, "label" , "value" , title= "Custom Bar Chart"
)
}
)
これを使用して、任意の棒グラフを記録できます。リスト内のラベルと値の数は正確に一致する必要があります。各データポイントには、ラベルと値の両方が必要です。
アプリで表示
コードを実行
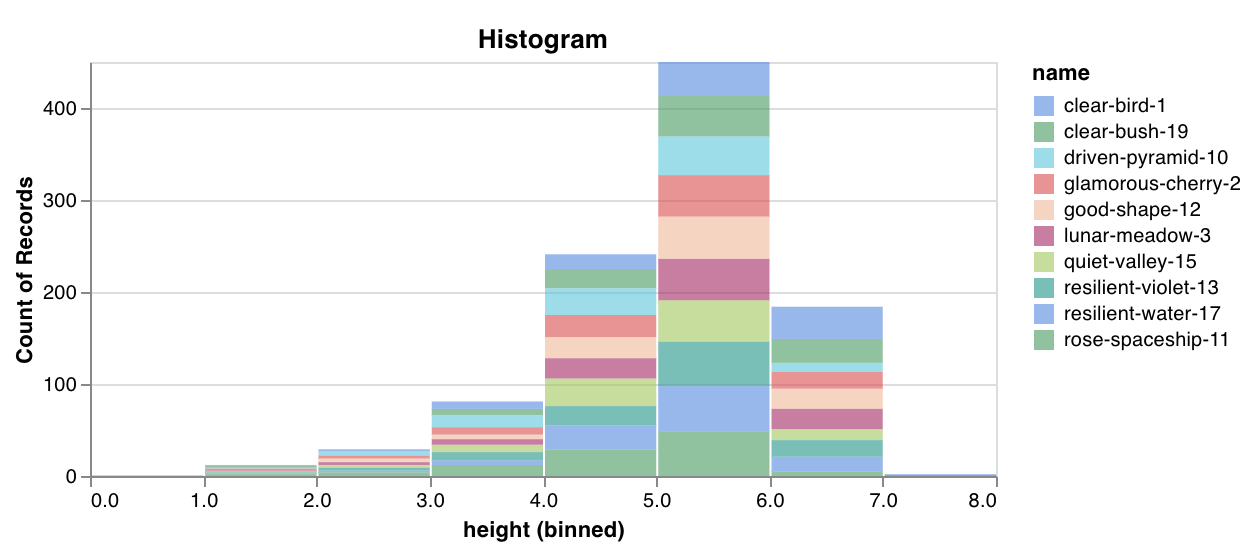
wandb.plot.histogram()
カスタムヒストグラム (値のリストを、出現のカウント/頻度でビンにソート) を数行でネイティブに記録します。予測信頼度スコアのリスト (scores) があり、その分布を可視化するとします。
data = [[s] for s in scores]
table = wandb. Table(data= data, columns= ["scores" ])
wandb. log({"my_histogram" : wandb. plot. histogram(table, "scores" , title= "Histogram" )})
これを使用して、任意のヒストグラムを記録できます。data は、行と列の2D配列をサポートすることを目的としたリストのリストであることに注意してください。
アプリで表示
コードを実行
wandb.plot.line_series()
複数の線、または複数の異なるx-y座標ペアのリストを、1つの共有x-y軸セットにプロットします。
wandb. log(
{
"my_custom_id" : wandb. plot. line_series(
xs= [0 , 1 , 2 , 3 , 4 ],
ys= [[10 , 20 , 30 , 40 , 50 ], [0.5 , 11 , 72 , 3 , 41 ]],
keys= ["metric Y" , "metric Z" ],
title= "Two Random Metrics" ,
xname= "x units" ,
)
}
)
xポイントとyポイントの数が正確に一致する必要があることに注意してください。複数のy値のリストに一致するx値のリストを1つ、またはy値のリストごとに個別のx値のリストを提供できます。
アプリで表示
モデル評価グラフ
これらのプリセットグラフには、wandb.plot メソッドが組み込まれており、スクリプトから直接グラフをすばやく簡単に記録し、UIで探している正確な情報を確認できます。
Precision-recall curves
ROC curves
Confusion matrix
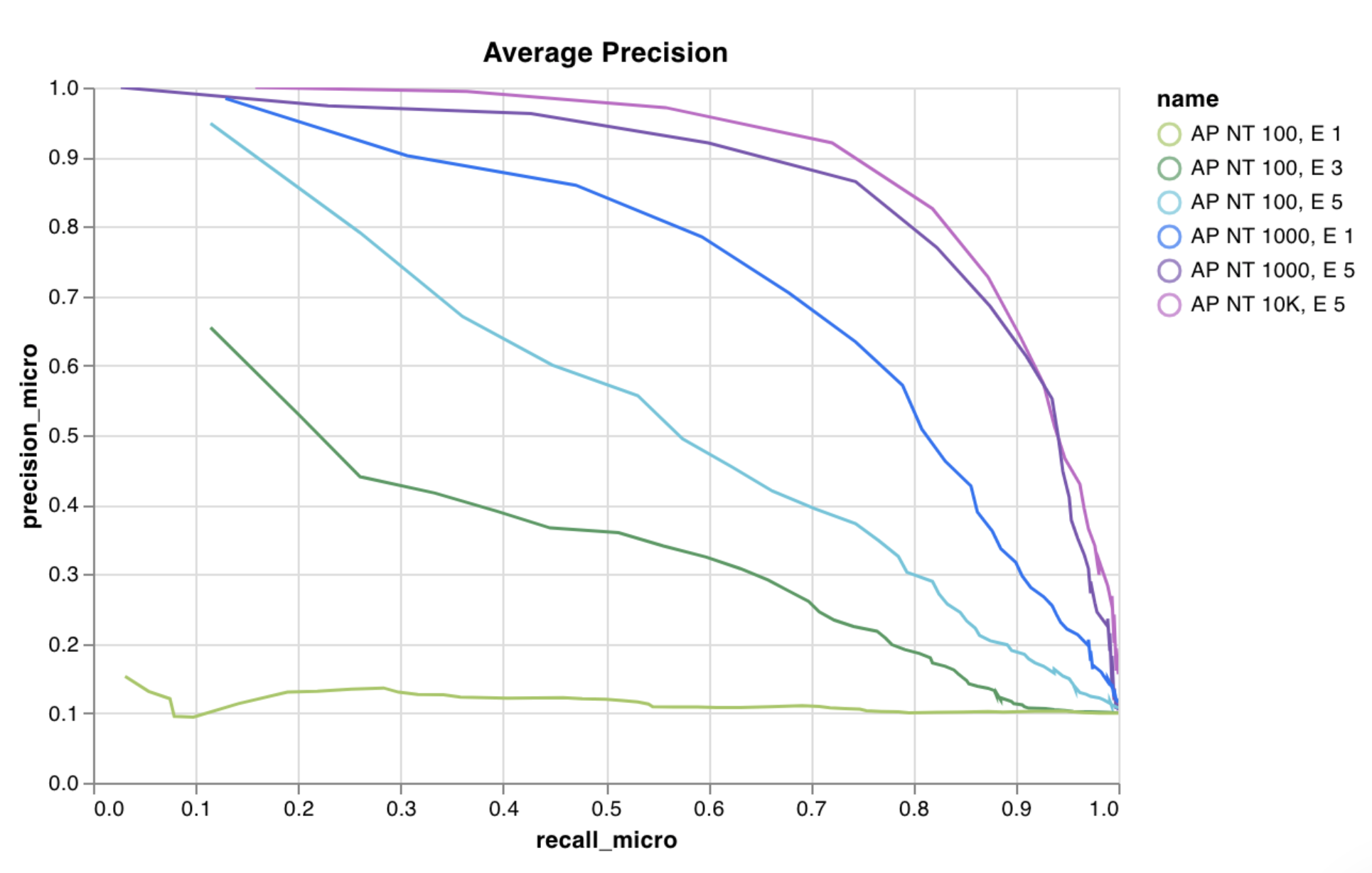
wandb.plot.pr_curve()
1行で PR曲線 を作成します。
wandb. log({"pr" : wandb. plot. pr_curve(ground_truth, predictions)})
コードが以下にアクセスできる場合は、いつでもこれを記録できます。
例のセットに対するモデルの予測スコア (predictions)
それらの例に対応する正解ラベル (ground_truth)
(オプション) ラベル/クラス名のリスト (labels=["cat", "dog", "bird"...] ラベルインデックス0がcat、1 = dog、2 = birdなどを意味する場合)
(オプション) プロットで可視化するラベルのサブセット (引き続きリスト形式)
アプリで表示
コードを実行
wandb.plot.roc_curve()
1行で ROC曲線 を作成します。
wandb. log({"roc" : wandb. plot. roc_curve(ground_truth, predictions)})
コードが以下にアクセスできる場合は、いつでもこれを記録できます。
例のセットに対するモデルの予測スコア (predictions)
それらの例に対応する正解ラベル (ground_truth)
(オプション) ラベル/クラス名のリスト (labels=["cat", "dog", "bird"...] ラベルインデックス0がcat、1 = dog、2 = birdなどを意味する場合)
(オプション) プロットで可視化するこれらのラベルのサブセット (引き続きリスト形式)
アプリで表示
コードを実行
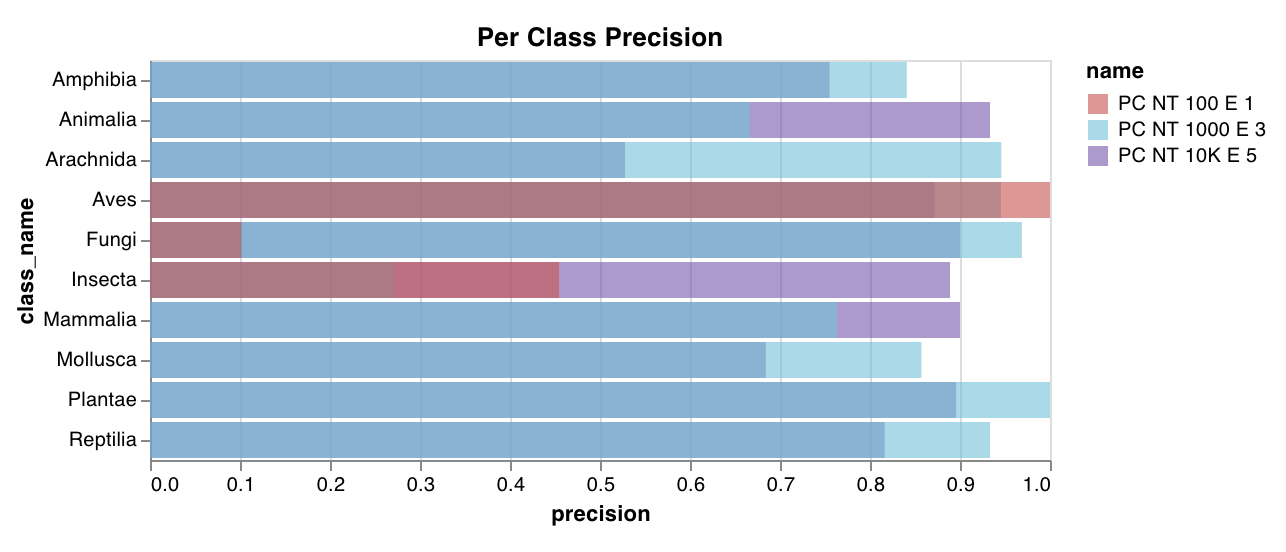
wandb.plot.confusion_matrix()
1行で多クラス 混同行列 を作成します。
cm = wandb. plot. confusion_matrix(
y_true= ground_truth, preds= predictions, class_names= class_names
)
wandb. log({"conf_mat" : cm})
コードが以下にアクセスできる場合は、いつでもこれを記録できます。
例のセットに対するモデルの予測ラベル (preds) または正規化された確率スコア (probs)。確率は、(例の数、クラスの数) の形状である必要があります。確率または予測のいずれかを提供できますが、両方はできません。
それらの例に対応する正解ラベル (y_true)
class_names の文字列としてのラベル/クラス名の完全なリスト。例: インデックス0が cat、1が dog、2が bird の場合、class_names=["cat", "dog", "bird"]。
アプリで表示
コードを実行
インタラクティブなカスタムグラフ
完全にカスタマイズするには、組み込みの カスタムグラフプリセット を調整するか、新しいプリセットを作成し、グラフを保存します。グラフIDを使用して、スクリプトからそのカスタムプリセットに直接データを記録します。
# プロットする列を含むテーブルを作成します
table = wandb. Table(data= data, columns= ["step" , "height" ])
# テーブルの列からグラフのフィールドへのマッピング
fields = {"x" : "step" , "value" : "height" }
# テーブルを使用して、新しいカスタムグラフプリセットを設定します
# 独自の保存されたグラフプリセットを使用するには、vega_spec_nameを変更します
# タイトルを編集するには、string_fieldsを変更します
my_custom_chart = wandb. plot_table(
vega_spec_name= "carey/new_chart" ,
data_table= table,
fields= fields,
string_fields= {"title" : "Height Histogram" },
)
コードを実行
Matplotlib および Plotly プロット
wandb.plot を使用した W&B カスタムグラフ を使用する代わりに、matplotlib および Plotly で生成されたグラフを記録できます。
import matplotlib.pyplot as plt
plt. plot([1 , 2 , 3 , 4 ])
plt. ylabel("some interesting numbers" )
wandb. log({"chart" : plt})
matplotlib プロットまたは figure オブジェクトを wandb.log() に渡すだけです。デフォルトでは、プロットを Plotly プロットに変換します。プロットを画像として記録する場合は、プロットを wandb.Image に渡すことができます。Plotly グラフも直接受け入れます。
「空のプロットを記録しようとしました」というエラーが表示される場合は、fig = plt.figure() を使用してプロットとは別に figure を保存し、wandb.log の呼び出しで fig を記録できます。
カスタム HTML を W&B Tables に記録する
W&B は、Plotly および Bokeh からのインタラクティブなグラフを HTML として記録し、それらを Tables に追加することをサポートしています。
インタラクティブな Plotly グラフを HTML に変換して、wandb Tables に記録できます。
import wandb
import plotly.express as px
# 新しい run を初期化します
run = wandb. init(project= "log-plotly-fig-tables" , name= "plotly_html" )
# テーブルを作成します
table = wandb. Table(columns= ["plotly_figure" ])
# Plotly figure のパスを作成します
path_to_plotly_html = "./plotly_figure.html"
# Plotly figure の例
fig = px. scatter(x= [0 , 1 , 2 , 3 , 4 ], y= [0 , 1 , 4 , 9 , 16 ])
# Plotly figure を HTML に書き込みます
# auto_play を False に設定すると、アニメーション化された Plotly グラフが
# テーブル内で自動的に再生されるのを防ぎます
fig. write_html(path_to_plotly_html, auto_play= False )
# Plotly figure を HTML ファイルとして Table に追加します
table. add_data(wandb. Html(path_to_plotly_html))
# Table を記録します
run. log({"test_table" : table})
wandb. finish()
インタラクティブな Bokeh グラフを HTML に変換して、wandb Tables に記録できます。
from scipy.signal import spectrogram
import holoviews as hv
import panel as pn
from scipy.io import wavfile
import numpy as np
from bokeh.resources import INLINE
hv. extension("bokeh" , logo= False )
import wandb
def save_audio_with_bokeh_plot_to_html (audio_path, html_file_name):
sr, wav_data = wavfile. read(audio_path)
duration = len(wav_data) / sr
f, t, sxx = spectrogram(wav_data, sr)
spec_gram = hv. Image((t, f, np. log10(sxx)), ["Time (s)" , "Frequency (hz)" ]). opts(
width= 500 , height= 150 , labelled= []
)
audio = pn. pane. Audio(wav_data, sample_rate= sr, name= "Audio" , throttle= 500 )
slider = pn. widgets. FloatSlider(end= duration, visible= False )
line = hv. VLine(0 ). opts(color= "white" )
slider. jslink(audio, value= "time" , bidirectional= True )
slider. jslink(line, value= "glyph.location" )
combined = pn. Row(audio, spec_gram * line, slider). save(html_file_name)
html_file_name = "audio_with_plot.html"
audio_path = "hello.wav"
save_audio_with_bokeh_plot_to_html(audio_path, html_file_name)
wandb_html = wandb. Html(html_file_name)
run = wandb. init(project= "audio_test" )
my_table = wandb. Table(columns= ["audio_with_plot" ], data= [[wandb_html], [wandb_html]])
run. log({"audio_table" : my_table})
run. finish()
2 - Customize log axes
define_metric を使用して、カスタムのX軸 を設定します。カスタムのX軸は、トレーニング中に過去の異なるタイムステップに非同期で ログ を記録する必要がある場合に役立ちます。たとえば、エピソードごとの報酬とステップごとの報酬を追跡する強化学習で役立ちます。
Google Colab で define_metric を実際に試してみる →
軸のカスタマイズ
デフォルトでは、すべての メトリクス は同じX軸(W&Bの内部 step)に対して ログ が記録されます。場合によっては、前のステップに ログ を記録したり、別のX軸を使用したりすることがあります。
カスタムのX軸 メトリクス を設定する例を次に示します(デフォルトのステップの代わりに)。
import wandb
wandb. init()
# カスタムのX軸メトリクスを定義
wandb. define_metric("custom_step" )
# どのメトリクスをそれに対してプロットするかを定義
wandb. define_metric("validation_loss" , step_metric= "custom_step" )
for i in range(10 ):
log_dict = {
"train_loss" : 1 / (i + 1 ),
"custom_step" : i** 2 ,
"validation_loss" : 1 / (i + 1 ),
}
wandb. log(log_dict)
X軸は、グロブを使用して設定することもできます。現在、文字列のプレフィックスを持つグロブのみが使用可能です。次の例では、プレフィックス "train/" を持つ ログ に記録されたすべての メトリクス をX軸 "train/step" にプロットします。
import wandb
wandb. init()
# カスタムのX軸メトリクスを定義
wandb. define_metric("train/step" )
# 他のすべての train/ メトリクス がこのステップを使用するように設定
wandb. define_metric("train/*" , step_metric= "train/step" )
for i in range(10 ):
log_dict = {
"train/step" : 2 ** i, # 内部W&Bステップによる指数関数的な増加
"train/loss" : 1 / (i + 1 ), # X軸は train/step
"train/accuracy" : 1 - (1 / (1 + i)), # X軸は train/step
"val/loss" : 1 / (1 + i), # X軸は内部 wandb step
}
wandb. log(log_dict)
3 - Log distributed training experiments
W&B を使用して、複数の GPU を使用した分散型トレーニング の 実験管理 を ログ 記録します。
分散トレーニングでは、モデルは複数の GPU を並行して使用してトレーニングされます。W&B は、分散トレーニング の 実験管理 を追跡するための 2 つのパターンをサポートしています。
単一 プロセス : W&B (wandb.initwandb.logPyTorch Distributed Data Parallel (DDP) クラスを使用した分散トレーニング の 実験 を ログ 記録するための一般的なソリューションです。場合によっては、マルチプロセッシング キュー (または別の通信プリミティブ) を使用して、他の プロセス からメインの ログ 記録 プロセス にデータを送り込む ユーザー もいます。多数の プロセス : W&B (wandb.initwandb.loggroup パラメータ (wandb.init(group='group-name')) を使用して、共有 実験 を定義し、 ログ 記録された 値 を W&B App UI にまとめて グループ化します。
以下の例では、単一 マシン 上の 2 つの GPU で PyTorch DDP を使用して、W&B で メトリクス を追跡する方法を示します。PyTorch DDP (torch.nn の DistributedDataParallel) は、分散トレーニング 用の一般的な ライブラリ です。基本的な原則は、あらゆる分散トレーニング 設定に適用されますが、実装の詳細は異なる場合があります。
これらの例の背後にある コード を W&B GitHub の examples リポジトリ (
こちら ) で確認してください。特に、単一 プロセス および 多数 プロセス の メソッド を実装する方法については、
log-dpp.py Python スクリプトを参照してください。
方法 1: 単一 プロセス
この方法では、ランク 0 の プロセス のみを追跡します。この方法を実装するには、W&B (wandb.init) を初期化し、W&B Run を開始して、ランク 0 の プロセス 内で メトリクス (wandb.log) を ログ 記録します。この方法はシンプルで堅牢ですが、他の プロセス から モデル の メトリクス (たとえば、バッチからの 損失 値 または 入力) を ログ 記録しません。使用量 や メモリ などの システム メトリクス は、その情報がすべての プロセス で利用できるため、すべての GPU に対して ログ 記録されます。
この方法を使用して、単一の プロセス から利用可能な メトリクス のみを追跡します 。一般的な例としては、GPU/CPU の使用率、共有 検証セット での 振る舞い 、 勾配 と パラメータ 、および代表的な データ 例での 損失 値 などがあります。
サンプル Python スクリプト (log-ddp.py) 内で、ランクが 0 かどうかを確認します。これを行うには、まず torch.distributed.launch で複数の プロセス を 起動します。次に、--local_rank コマンドライン 引数 でランクを確認します。ランクが 0 に設定されている場合、train()wandb ログ 記録を条件付きで設定します。Python スクリプト内で、次のチェックを使用します。
if __name__ == "__main__" :
# Get args
args = parse_args()
if args. local_rank == 0 : # only on main process
# Initialize wandb run
run = wandb. init(
entity= args. entity,
project= args. project,
)
# Train model with DDP
train(args, run)
else :
train(args)
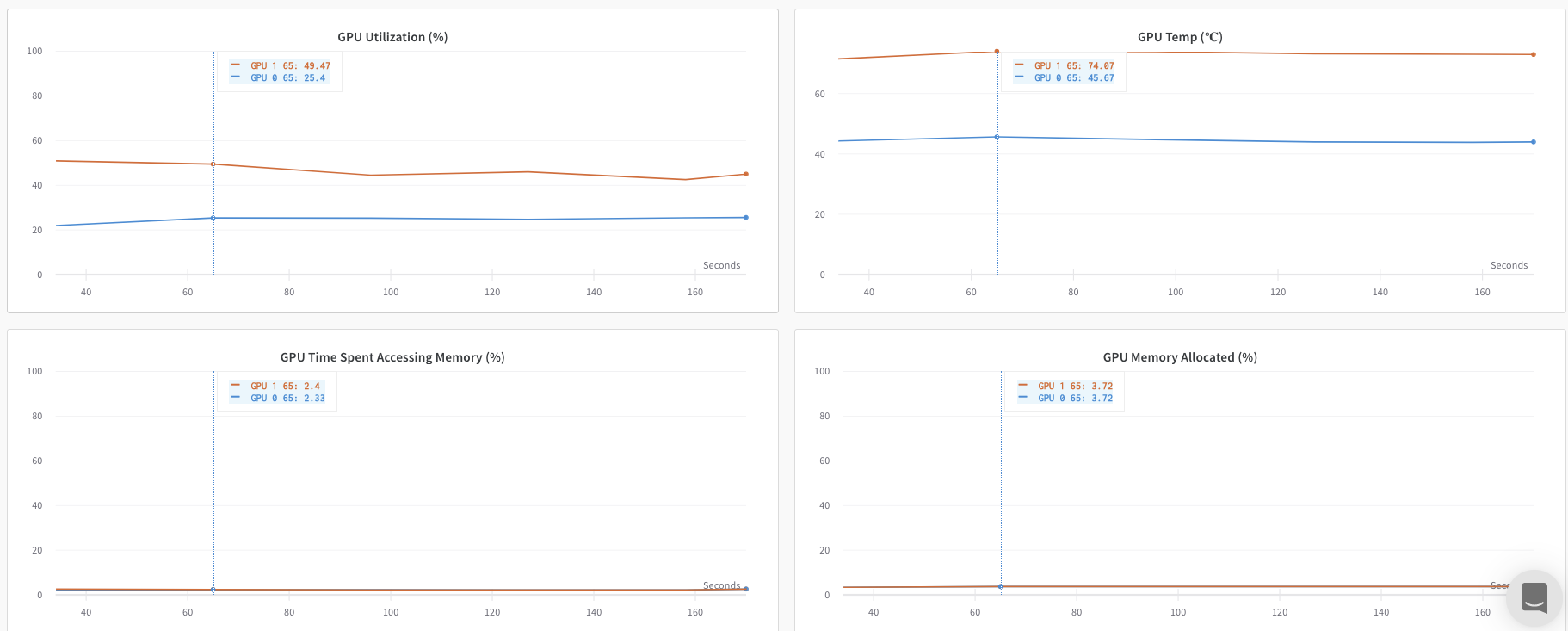
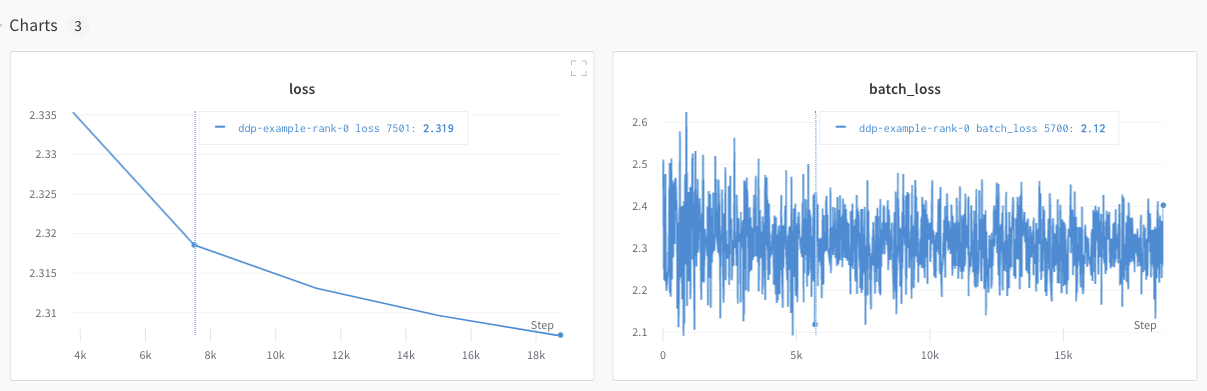
W&B App UI を調べて、単一の プロセス から追跡された メトリクス の ダッシュボード 例 を表示します。ダッシュボード には、両方の GPU で追跡された 温度 や 使用率 などの システム メトリクス が表示されます。
ただし、 エポック と バッチサイズ の関数としての 損失 値 は、単一の GPU からのみ ログ 記録されました。
方法 2: 多数の プロセス
この方法では、ジョブ内の各 プロセス を追跡し、各 プロセス から wandb.init() と wandb.log() を個別に呼び出します。すべての プロセス が適切に終了するように、トレーニング の最後に wandb.finish() を呼び出すことをお勧めします。これにより、run が完了したことを示します。
この方法により、より多くの情報が ログ 記録にアクセスできるようになります。ただし、複数の W&B Runs が W&B App UI に 報告 されることに注意してください。複数の 実験 にわたって W&B Runs を追跡することが難しい場合があります。これを軽減するには、W&B を初期化する際に group パラメータ に 値 を指定して、どの W&B Run が特定の 実験 に属しているかを追跡します。トレーニング と 評価 の W&B Runs を 実験 で追跡する方法の詳細については、Run のグループ化 を参照してください。
個々の プロセス から メトリクス を追跡する場合は、この方法を使用してください 。一般的な例としては、各 ノード 上の データ と 予測 (データ 分布 の デバッグ 用) や、メイン ノード 外の個々の バッチ 上の メトリクス などがあります。この方法は、すべての ノード から システム メトリクス を取得したり、メイン ノード で利用可能な概要 統計 を取得したりするために必要ではありません。
次の Python コード スニペット は、W&B を初期化するときに group パラメータ を設定する方法を示しています。
if __name__ == "__main__" :
# Get args
args = parse_args()
# Initialize run
run = wandb. init(
entity= args. entity,
project= args. project,
group= "DDP" , # all runs for the experiment in one group
)
# Train model with DDP
train(args, run)
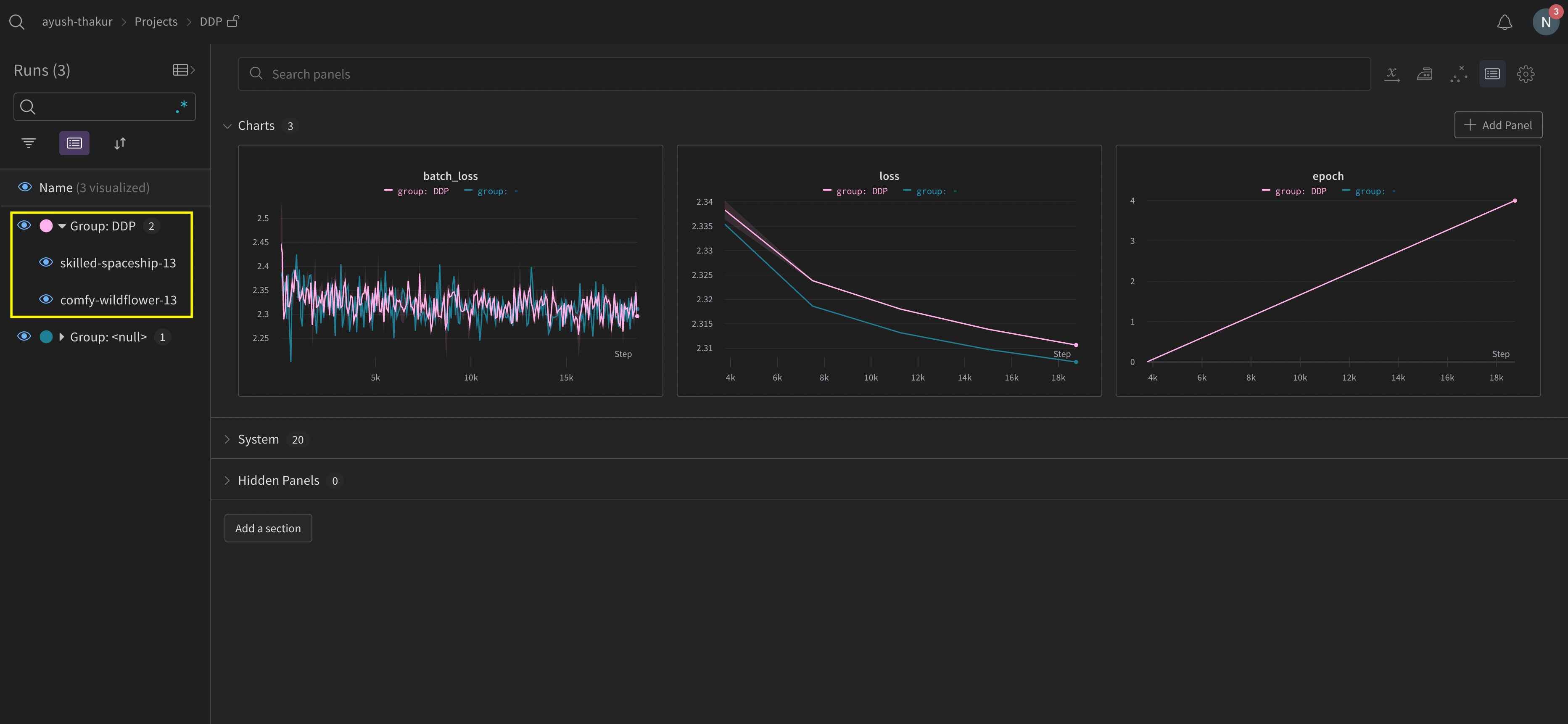
W&B App UI を調べて、複数の プロセス から追跡された メトリクス の ダッシュボード 例 を表示します。左側のサイドバーに 2 つの W&B Runs が グループ化 されていることに注意してください。グループ をクリックして、 実験 専用のグループ ページ を表示します。専用のグループ ページ には、各 プロセス からの メトリクス が個別に表示されます。
上記の画像は、W&B App UI ダッシュボード を示しています。サイドバーには、2 つの 実験 が表示されます。1 つは「null」というラベルが付いており、2 つ目 (黄色のボックスで囲まれています) は「DPP」と呼ばれています。グループ を展開すると (グループ ドロップダウン を選択)、その 実験 に関連付けられている W&B Runs が表示されます。
W&B Service を使用して、一般的な分散トレーニング の問題を回避する
W&B と分散トレーニング を使用する際に発生する可能性のある一般的な問題が 2 つあります。
トレーニング の開始時にハングする - wandb マルチプロセッシング が分散トレーニング からの マルチプロセッシング に干渉すると、wandb プロセス がハングする可能性があります。トレーニング の最後にハングする - wandb プロセス がいつ終了する必要があるかを認識していない場合、トレーニング ジョブ がハングする可能性があります。Python スクリプト の最後に wandb.finish() API を呼び出して、Run が完了したことを W&B に伝えます。wandb.finish() API は、データの アップロード を終了し、W&B を終了させます。
分散ジョブ の信頼性を向上させるために、wandb service を使用することをお勧めします。上記のトレーニング の問題はどちらも、wandb service が利用できない W&B SDK の バージョン でよく見られます。
W&B Service を有効にする
W&B SDK の バージョン によっては、W&B Service がデフォルトで有効になっている場合があります。
W&B SDK 0.13.0 以降
W&B Service は、W&B SDK 0.13.0 以降の バージョン ではデフォルトで有効になっています。
W&B SDK 0.12.5 以降
Python スクリプト を変更して、W&B SDK バージョン 0.12.5 以降で W&B Service を有効にします。wandb.require メソッド を使用し、メイン関数内で 文字列 "service" を渡します。
if __name__ == "__main__" :
main()
def main ():
wandb. require("service" )
# rest-of-your-script-goes-here
最適なエクスペリエンスを得るには、最新 バージョン に アップグレード することをお勧めします。
W&B SDK 0.12.4 以前
W&B SDK バージョン 0.12.4 以前を使用している場合は、マルチスレッド を代わりに使用するために、WANDB_START_METHOD 環境 変数 を "thread" に設定します。
マルチプロセッシング の ユースケース 例
次の コード スニペット は、高度な分散 ユースケース の一般的な方法を示しています。
プロセス の スポーン
スポーンされた プロセス で W&B Run を開始する場合は、メイン関数で wandb.setup() メソッド を使用します。
import multiprocessing as mp
def do_work (n):
run = wandb. init(config= dict(n= n))
run. log(dict(this= n * n))
def main ():
wandb. setup()
pool = mp. Pool(processes= 4 )
pool. map(do_work, range(4 ))
if __name__ == "__main__" :
main()
W&B Run を共有する
W&B Run オブジェクト を 引数 として渡して、 プロセス 間で W&B Runs を共有します。
def do_work (run):
run. log(dict(this= 1 ))
def main ():
run = wandb. init()
p = mp. Process(target= do_work, kwargs= dict(run= run))
p. start()
p. join()
if __name__ == "__main__" :
main()
ログ 記録の順序は保証されないことに注意してください。同期は スクリプト の作成者が行う必要があります。
4 - Log media and objects
3D ポイントクラウド や分子から、HTML やヒストグラムまで、リッチメディアを ログ に記録します。
画像、動画、音声など、様々な形式のメディアに対応しています。リッチメディアを ログ に記録して、結果を調査し、 run 、 model 、 dataset を視覚的に比較できます。例やハウツー ガイド については、以下をお読みください。
メディアタイプのリファレンス ドキュメントをお探しですか?
こちらのページ をご覧ください。
事前準備
W&B SDK でメディア オブジェクト を ログ に記録するには、追加の依存関係をインストールする必要がある場合があります。
これらの依存関係をインストールするには、次の コマンド を実行します。
画像
画像 を ログ に記録して、入力、出力、フィルターの重み、アクティベーションなどを追跡します。
画像 は、NumPy 配列から、PIL 画像 として、またはファイルシステムから直接 ログ に記録できます。
ステップから画像 を ログ に記録するたびに、UI に表示するために保存されます。画像 パネル を展開し、ステップ スライダーを使用して、異なるステップの画像 を確認します。これにより、 model の出力が トレーニング 中にどのように変化するかを簡単に比較できます。
トレーニング 中に ログ 記録がボトルネックになるのを防ぐため、また結果を表示する際に画像 の読み込みがボトルネックになるのを防ぐため、ステップごとに 50 枚未満の画像 を ログ に記録することをお勧めします。
配列を画像として ログ 記録
PIL 画像 の ログ 記録
ファイルから画像 の ログ 記録
torchvisionmake_grid
配列は Pillow を使用して png に変換されます。
images = wandb. Image(image_array, caption= "Top: Output, Bottom: Input" )
wandb. log({"examples" : images})
最後の次元が 1 の場合はグレースケール画像、3 の場合は RGB、4 の場合は RGBA であると想定されます。配列に float が含まれている場合は、0 から 255 までの整数に変換します。画像 の正規化方法を変更する場合は、modePIL.Image
配列から画像 への変換を完全に制御するには、PIL.Image
images = [PIL. Image. fromarray(image) for image in image_array]
wandb. log({"examples" : [wandb. Image(image) for image in images]})
さらに細かく制御するには、好きな方法で画像 を作成し、ディスクに保存して、ファイルパスを指定します。
im = PIL. fromarray(... )
rgb_im = im. convert("RGB" )
rgb_im. save("myimage.jpg" )
wandb. log({"example" : wandb. Image("myimage.jpg" )})
画像 オーバーレイ
セグメンテーション マスク
バウンディングボックス
セマンティックセグメンテーション マスク を ログ に記録し、W&B UI で (不透明度を変更したり、経時的な変化を表示したりするなど) 操作します。
オーバーレイを ログ に記録するには、次の キー と 値 を持つ 辞書 を wandb.Image の masks キーワード 引数 に指定する必要があります。
画像 マスク を表す 2 つの キー のいずれか 1 つ。
"mask_data": 各ピクセル の整数クラス ラベル を含む 2D NumPy 配列"path": (string) 保存された画像 マスク ファイル へのパス
"class_labels": (オプション) 画像 マスク 内の整数クラス ラベル を読み取り可能なクラス名に マッピング する 辞書
複数の マスク を ログ に記録するには、次の コード スニペット のように、複数の キー を持つ マスク 辞書 を ログ に記録します。
ライブ例を見る
サンプル コード
mask_data = np. array([[1 , 2 , 2 , ... , 2 , 2 , 1 ], ... ])
class_labels = {1 : "tree" , 2 : "car" , 3 : "road" }
mask_img = wandb. Image(
image,
masks= {
"predictions" : {"mask_data" : mask_data, "class_labels" : class_labels},
"ground_truth" : {
# ...
},
# ...
},
)
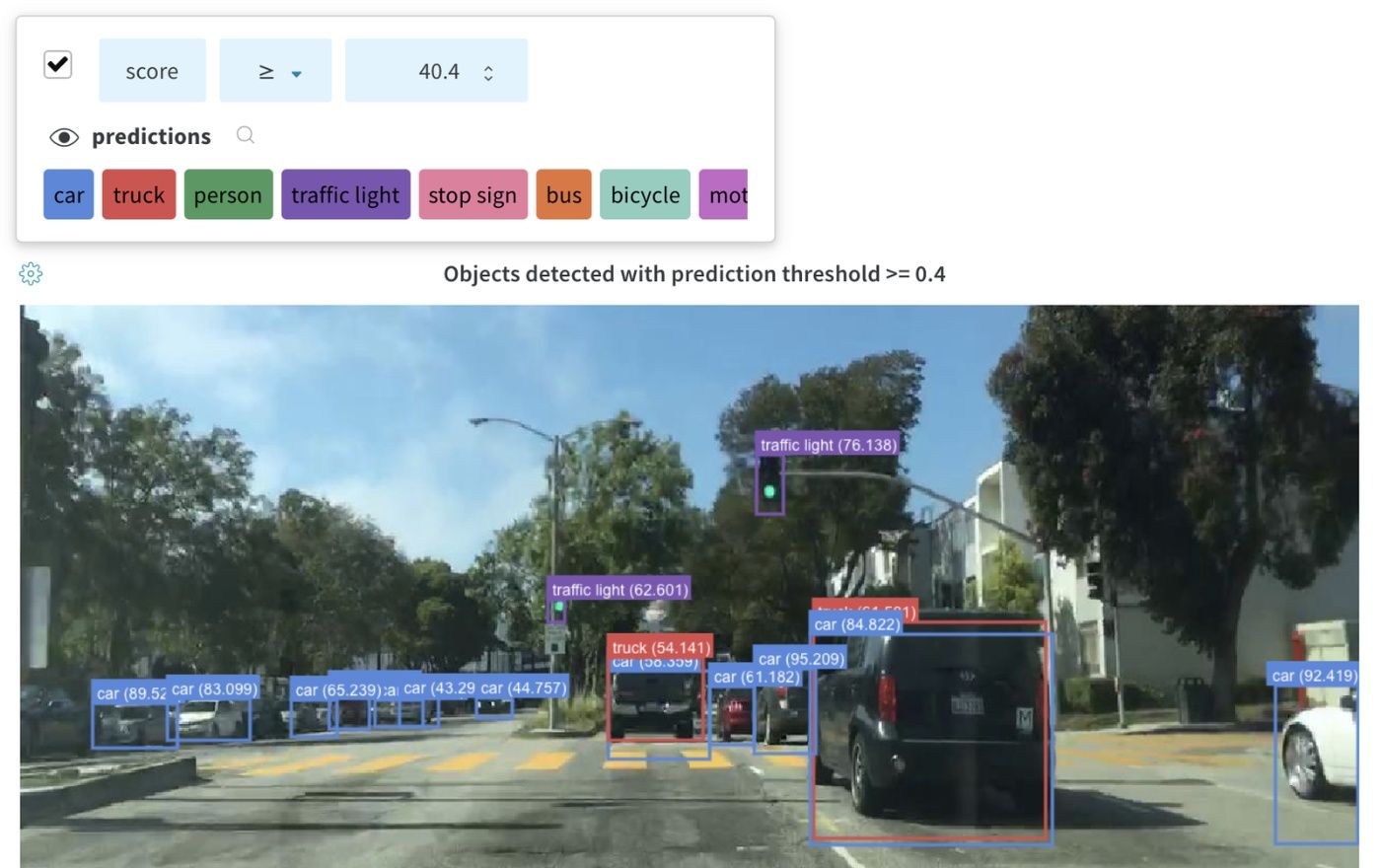
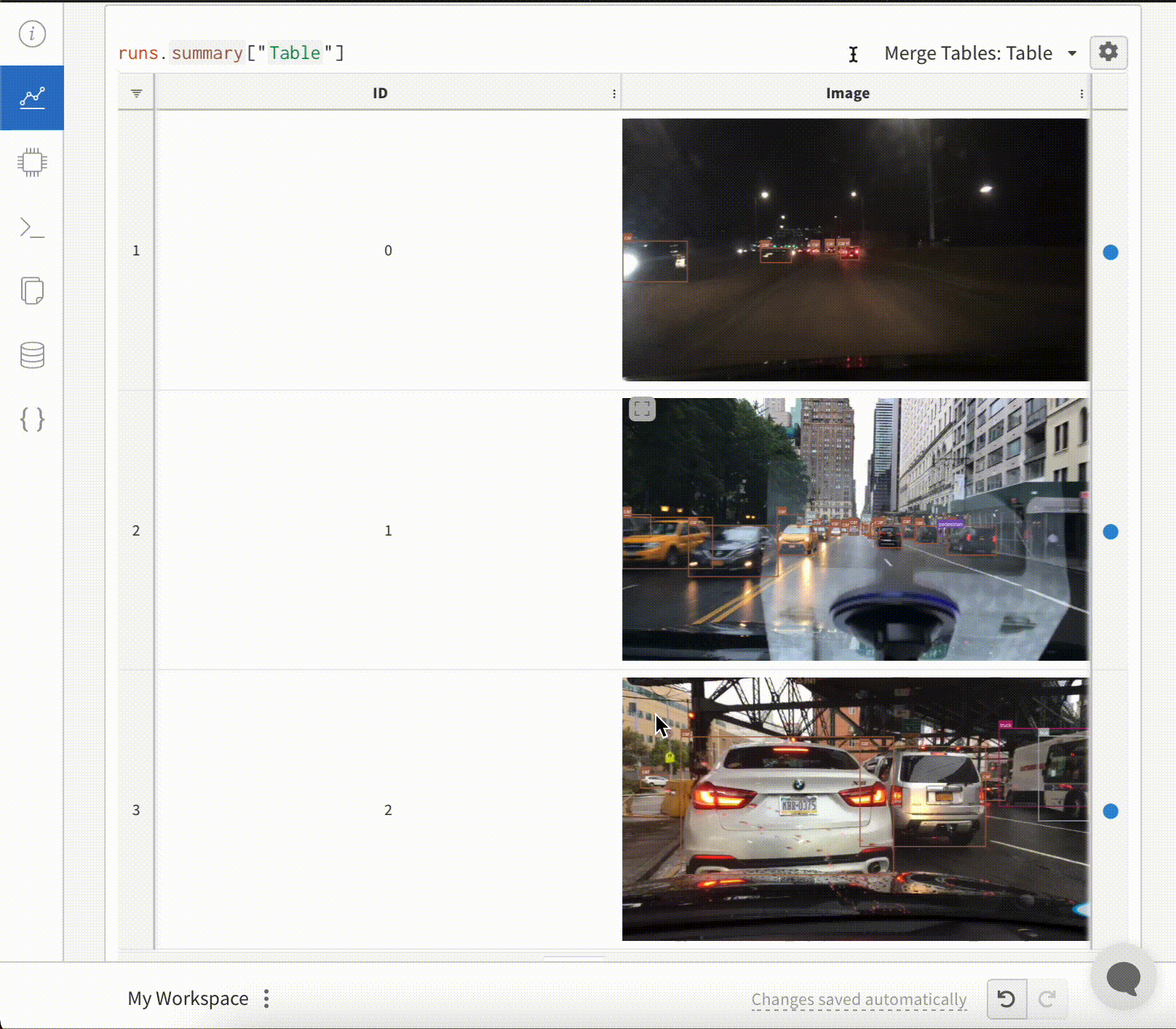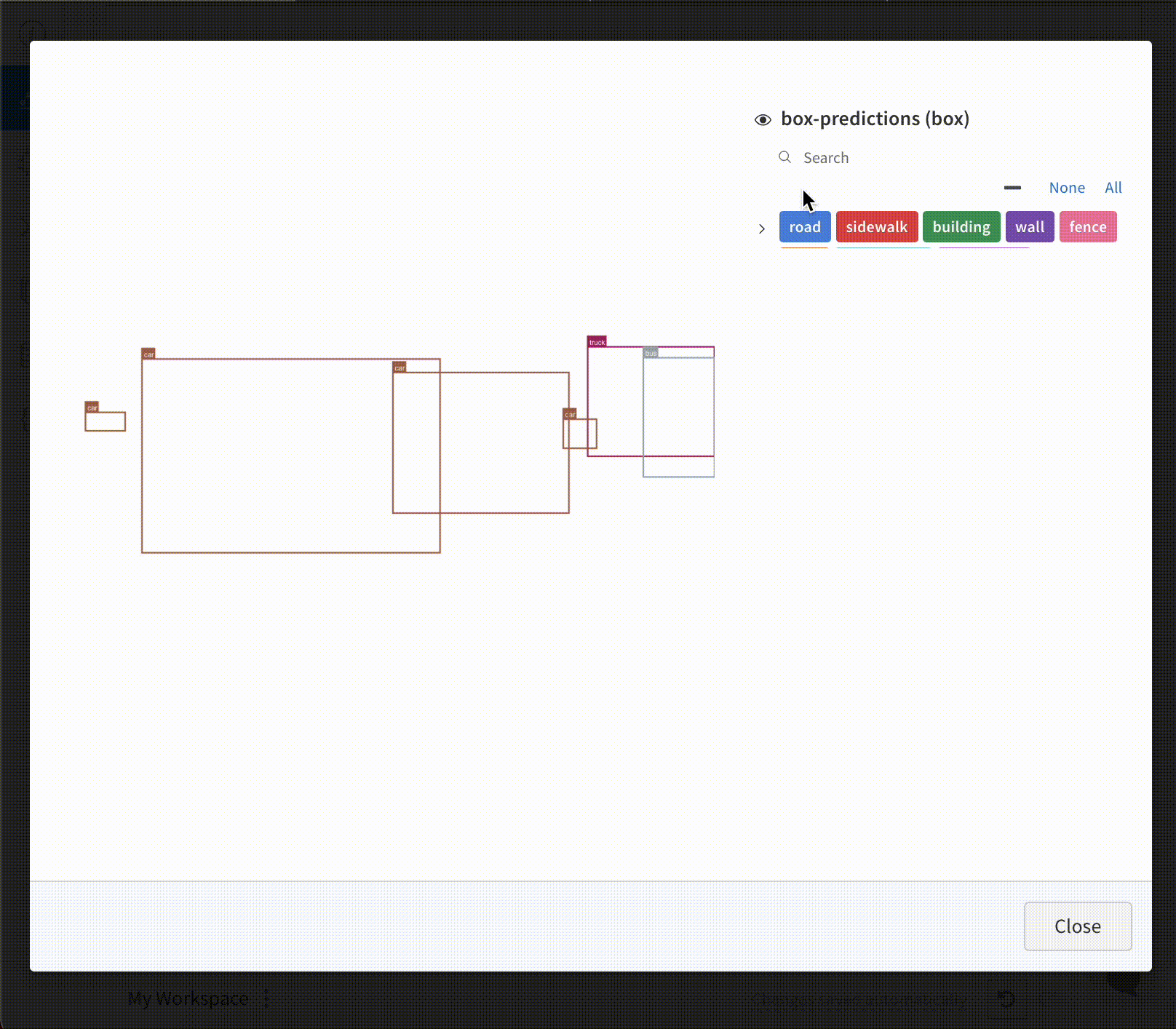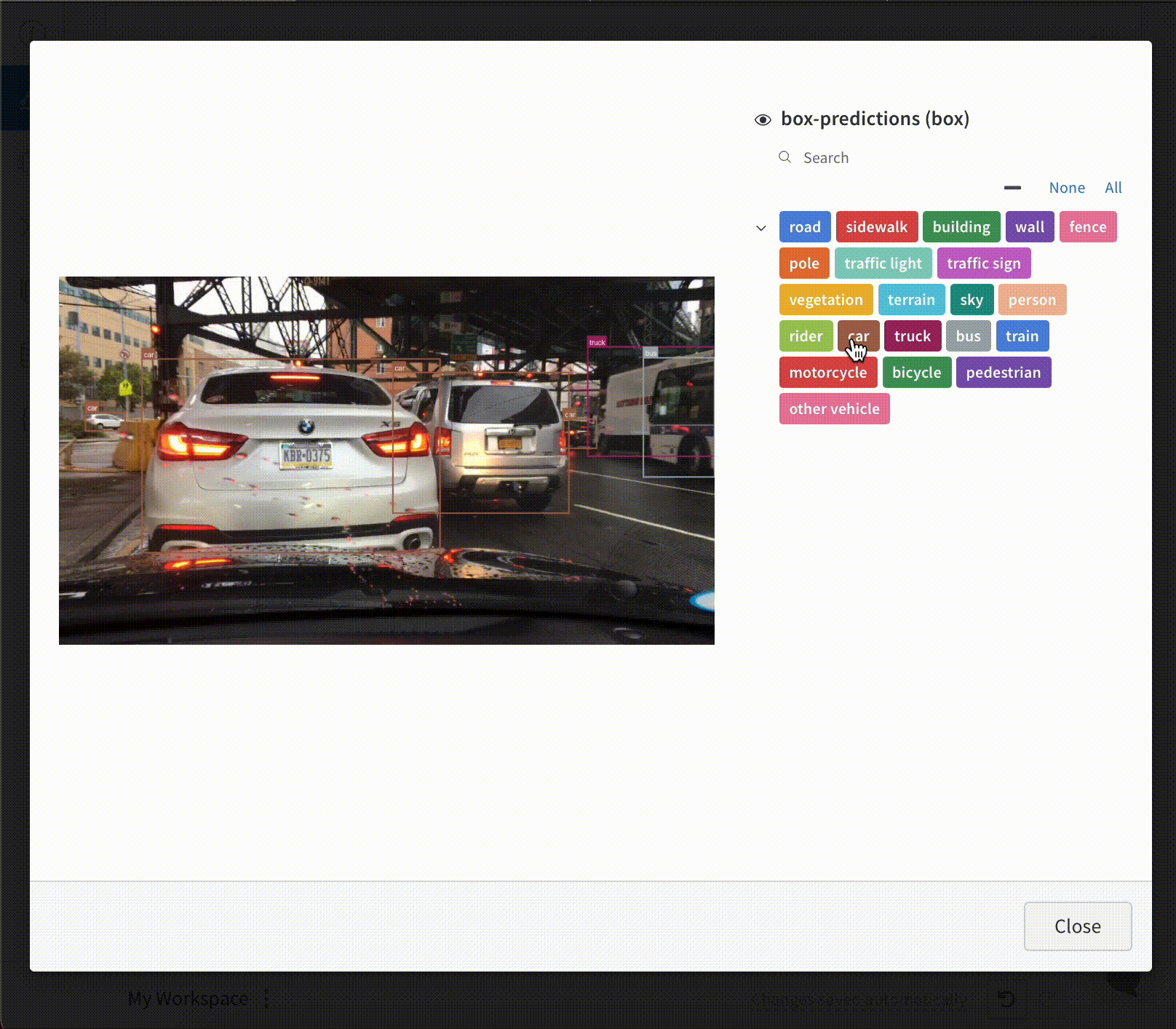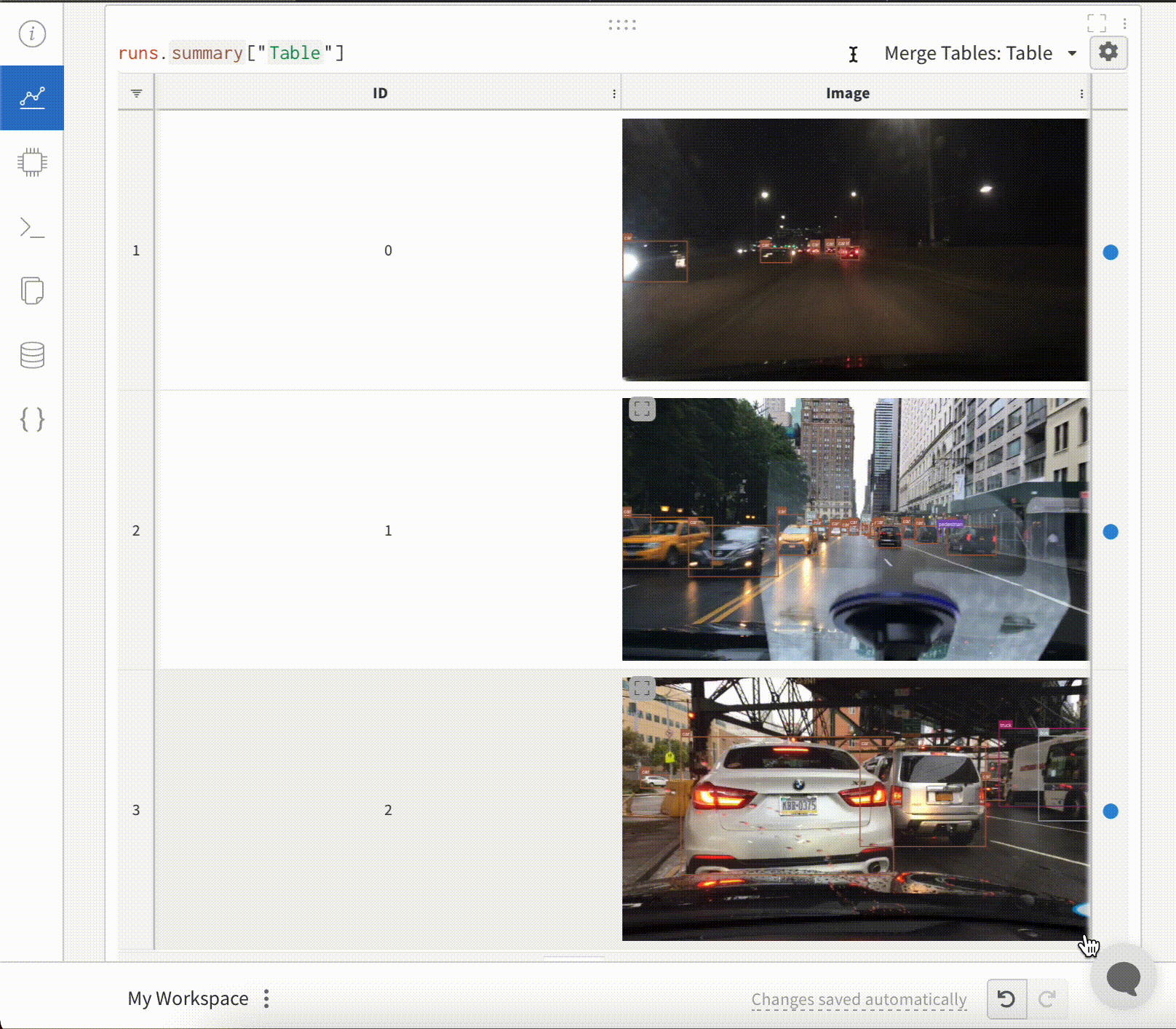
画像 と共に バウンディングボックス を ログ に記録し、フィルターとトグルを使用して、UI でさまざまなボックス セット を動的に 可視化 します。
ライブ例を見る
バウンディングボックス を ログ に記録するには、次の キー と 値 を持つ 辞書 を wandb.Image の boxes キーワード 引数 に指定する必要があります。
box_data: 各ボックス に対して 1 つの 辞書 の リスト。ボックス 辞書 の形式については、以下で説明します。
position: 以下で説明するように、2 つの形式のいずれかでボックス の位置とサイズを表す 辞書。ボックス はすべて同じ形式を使用する必要はありません。
オプション 1: {"minX", "maxX", "minY", "maxY"}。各ボックス の次元の上限と下限を定義する座標セットを指定します。オプション 2: {"middle", "width", "height"}。[x,y] として middle 座標を指定する座標セットと、スカラーとして width と height を指定します。
class_id: ボックス のクラス ID を表す整数。以下の class_labels キー を参照してください。scores: スコア の文字列ラベルと数値の 値 の 辞書。UI でボックス をフィルタリングするために使用できます。domain: ボックス 座標の単位/形式を指定します。ボックス 座標が画像 の次元の範囲内の整数など、ピクセル空間で表される場合は、これを「pixel」に設定します 。デフォルトでは、 domain は画像 の分数/パーセンテージであると見なされ、0 から 1 の間の浮動小数点数として表されます。box_caption: (オプション) このボックス のラベル テキストとして表示される文字列
class_labels: (オプション) class_id を文字列に マッピング する 辞書。デフォルトでは、クラス ラベル class_0、class_1 などを生成します。
この例をご覧ください。
class_id_to_label = {
1 : "car" ,
2 : "road" ,
3 : "building" ,
# ...
}
img = wandb. Image(
image,
boxes= {
"predictions" : {
"box_data" : [
{
# one box expressed in the default relative/fractional domain
"position" : {"minX" : 0.1 , "maxX" : 0.2 , "minY" : 0.3 , "maxY" : 0.4 },
"class_id" : 2 ,
"box_caption" : class_id_to_label[2 ],
"scores" : {"acc" : 0.1 , "loss" : 1.2 },
# another box expressed in the pixel domain
# (for illustration purposes only, all boxes are likely
# to be in the same domain/format)
"position" : {"middle" : [150 , 20 ], "width" : 68 , "height" : 112 },
"domain" : "pixel" ,
"class_id" : 3 ,
"box_caption" : "a building" ,
"scores" : {"acc" : 0.5 , "loss" : 0.7 },
# ...
# Log as many boxes an as needed
}
],
"class_labels" : class_id_to_label,
},
# Log each meaningful group of boxes with a unique key name
"ground_truth" : {
# ...
},
},
)
wandb. log({"driving_scene" : img})
テーブル の画像 オーバーレイ
セグメンテーション マスク
バウンディングボックス
テーブル に セグメンテーション マスク を ログ 記録するには、テーブル の各行に wandb.Image オブジェクト を指定する必要があります。
コード スニペット に例を示します。
table = wandb. Table(columns= ["ID" , "Image" ])
for id, img, label in zip(ids, images, labels):
mask_img = wandb. Image(
img,
masks= {
"prediction" : {"mask_data" : label, "class_labels" : class_labels}
# ...
},
)
table. add_data(id, img)
wandb. log({"Table" : table})
テーブル に バウンディングボックス を持つ 画像 を ログ 記録するには、テーブル の各行に wandb.Image オブジェクト を指定する必要があります。
コード スニペット に例を示します。
table = wandb. Table(columns= ["ID" , "Image" ])
for id, img, boxes in zip(ids, images, boxes_set):
box_img = wandb. Image(
img,
boxes= {
"prediction" : {
"box_data" : [
{
"position" : {
"minX" : box["minX" ],
"minY" : box["minY" ],
"maxX" : box["maxX" ],
"maxY" : box["maxY" ],
},
"class_id" : box["class_id" ],
"box_caption" : box["caption" ],
"domain" : "pixel" ,
}
for box in boxes
],
"class_labels" : class_labels,
}
},
)
ヒストグラム
基本的な ヒストグラム の ログ 記録
柔軟な ヒストグラム の ログ 記録
概要の ヒストグラム
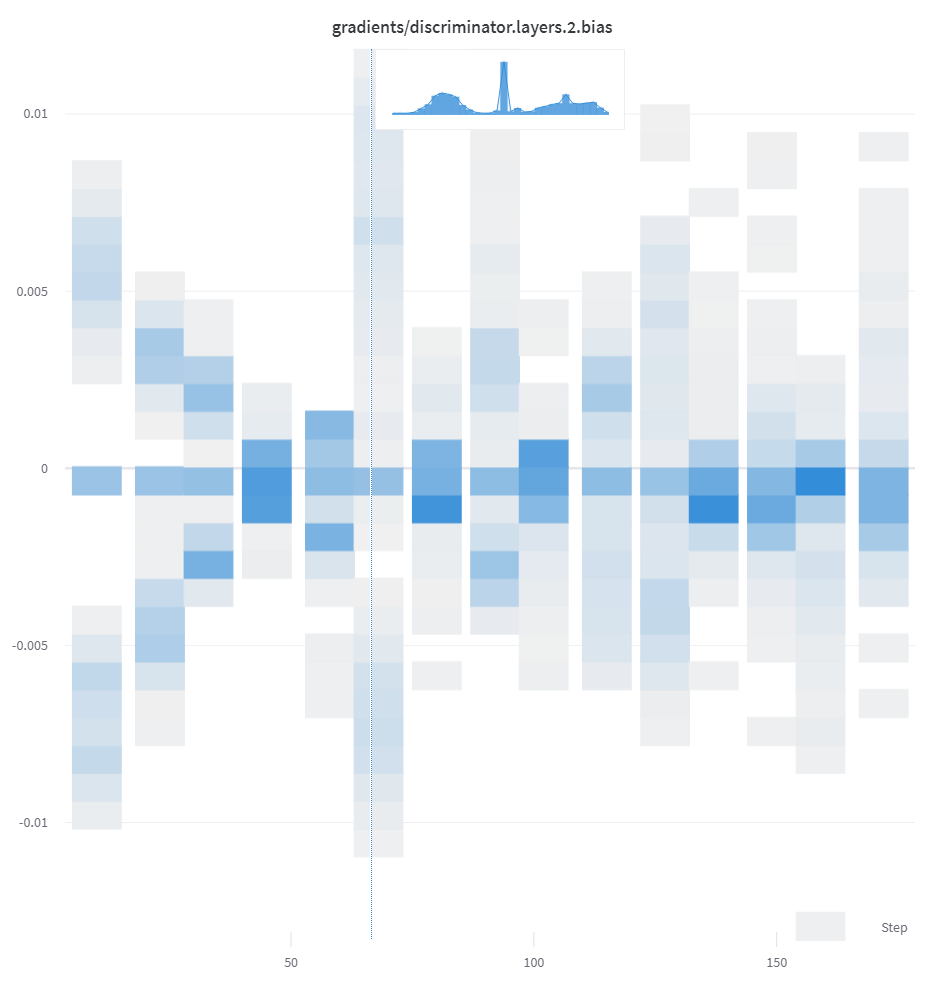
リスト、配列、 テンソル などの数値のシーケンスが最初の 引数 として指定された場合、np.histogram を呼び出すことで ヒストグラム を自動的に構築します。すべての配列/ テンソル はフラット化されます。オプションの num_bins キーワード 引数 を使用して、デフォルトの 64 ビン をオーバーライドできます。サポートされているビンの最大数は 512 です。
UI では、 ヒストグラム は x 軸に トレーニング ステップ、y 軸に メトリック 値、色で表されるカウントでプロットされ、 トレーニング 全体で ログ 記録された ヒストグラム の比較が容易になります。1 回限りの ヒストグラム の ログ 記録の詳細については、この パネル の「概要の ヒストグラム 」 タブ を参照してください。
wandb. log({"gradients" : wandb. Histogram(grads)})
さらに詳細に制御する場合は、np.histogram を呼び出し、返された タプル を np_histogram キーワード 引数 に渡します。
np_hist_grads = np. histogram(grads, density= True , range= (0.0 , 1.0 ))
wandb. log({"gradients" : wandb. Histogram(np_hist_grads)})
wandb. run. summary. update( # if only in summary, only visible on overview tab
{"final_logits" : wandb. Histogram(logits)}
)
'obj'、'gltf'、'glb'、'babylon'、'stl'、'pts.json' 形式のファイルを ログ 記録すると、 run 終了時に UI でレンダリングされます。
wandb. log(
{
"generated_samples" : [
wandb. Object3D(open("sample.obj" )),
wandb. Object3D(open("sample.gltf" )),
wandb. Object3D(open("sample.glb" )),
]
}
)
ライブ例を見る
ヒストグラム が概要にある場合、Run Page の Overviewタブ に表示されます。履歴にある場合、Chartsタブ に時間の経過に伴うビンのヒートマップをプロットします。
3D 可視化
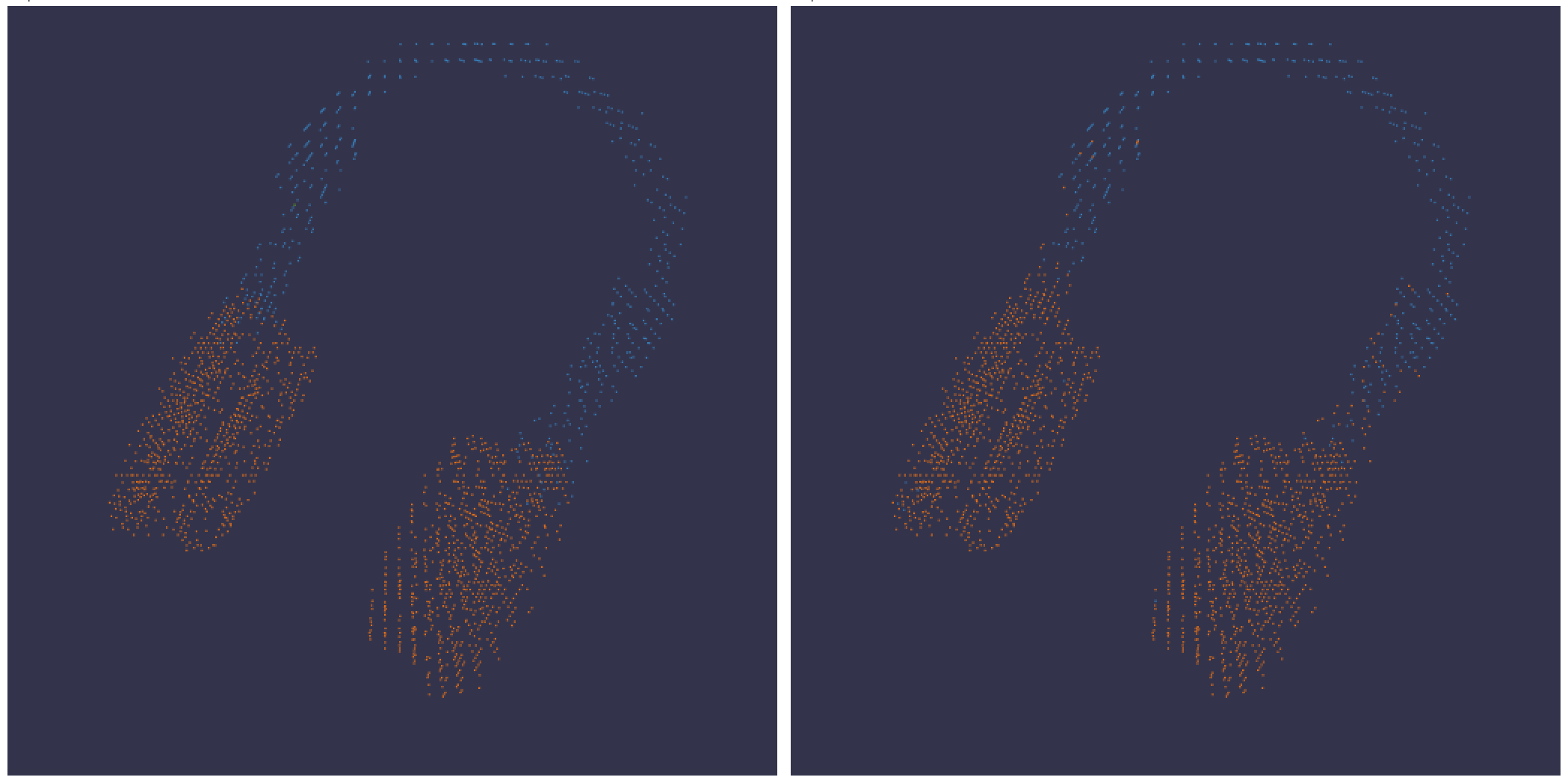
バウンディングボックス を持つ 3D ポイントクラウド と Lidar シーンを ログ 記録します。レンダリングするポイントの座標と色を含む NumPy 配列を渡します。
point_cloud = np. array([[0 , 0 , 0 , COLOR]])
wandb. log({"point_cloud" : wandb. Object3D(point_cloud)})
:::info
W&B UI はデータを 300,000 ポイント で切り捨てます。
:::
NumPy 配列形式
柔軟な配色に対応するため、3 つの異なる形式の NumPy 配列がサポートされています。
[[x, y, z], ...] nx3[[x, y, z, c], ...] nx4 | c は[1, 14]` の範囲のカテゴリです (セグメンテーション に役立ちます)。[[x, y, z, r, g, b], ...] nx6 | r,g,b は赤、緑、青のカラー チャンネル の [0,255] の範囲の値です。
Python オブジェクト
このスキーマを使用すると、Python オブジェクト を定義し、以下に示すように from_point_cloud メソッド に渡すことができます。
points は、上記の単純な ポイントクラウド レンダラーと同じ形式 を使用してレンダリングするポイントの座標と色を含む NumPy 配列です。boxes は、3 つの属性を持つ Python 辞書 の NumPy 配列です。
corners- 8 つの角の リストlabel- ボックス にレンダリングされるラベルを表す文字列 (オプション)color- ボックス の色を表す RGB 値score - バウンディングボックス に表示される数値。表示される バウンディングボックス をフィルタリングするために使用できます (たとえば、score > 0.75 の バウンディングボックス のみを表示する場合)。(オプション)
type は、レンダリングするシーン タイプを表す文字列です。現在、サポートされている値は lidar/beta のみです。
point_list = [
[
2566.571924017235 , # x
746.7817289698219 , # y
- 15.269245470863748 ,# z
76.5 , # red
127.5 , # green
89.46617199365393 # blue
],
[ 2566.592983606823 , 746.6791987335685 , - 15.275803826279521 , 76.5 , 127.5 , 89.45471117247024 ],
[ 2566.616361739416 , 746.4903185513501 , - 15.28628929674075 , 76.5 , 127.5 , 89.41336375503832 ],
[ 2561.706014951675 , 744.5349468458361 , - 14.877496818222781 , 76.5 , 127.5 , 82.21868245418283 ],
[ 2561.5281847916694 , 744.2546118233013 , - 14.867862032341005 , 76.5 , 127.5 , 81.87824684536432 ],
[ 2561.3693562897465 , 744.1804761656741 , - 14.854129178142523 , 76.5 , 127.5 , 81.64137897587152 ],
[ 2561.6093071504515 , 744.0287526628543 , - 14.882135189841177 , 76.5 , 127.5 , 81.89871499537098 ],
# ... and so on
]
run. log({"my_first_point_cloud" : wandb. Object3D. from_point_cloud(
points = point_list,
boxes = [{
"corners" : [
[ 2601.2765123137915 , 767.5669506323393 , - 17.816764802288663 ],
[ 2599.7259021588347 , 769.0082337923552 , - 17.816764802288663 ],
[ 2599.7259021588347 , 769.0082337923552 , - 19.66876480228866 ],
[ 2601.2765123137915 , 767.5669506323393 , - 19.66876480228866 ],
[ 2604.8684867834395 , 771.4313904894723 , - 17.816764802288663 ],
[ 2603.3178766284827 , 772.8726736494882 , - 17.816764802288663 ],
[ 2603.3178766284827 , 772.8726736494882 , - 19.66876480228866 ],
[ 2604.8684867834395 , 771.4313904894723 , - 19.66876480228866 ]
],
"color" : [0 , 0 , 255 ], # color in RGB of the bounding box
"label" : "car" , # string displayed on the bounding box
"score" : 0.6 # numeric displayed on the bounding box
}],
vectors = [
{"start" : [0 , 0 , 0 ], "end" : [0.1 , 0.2 , 0.5 ], "color" : [255 , 0 , 0 ]}, # color is optional
],
point_cloud_type = "lidar/beta" ,
)})
ポイントクラウド を表示するときは、control キー を押しながらマウスを使用すると、スペース内を移動できます。
ポイントクラウド ファイル
the from_file メソッド を使用して、 ポイントクラウド データがいっぱいの JSON ファイルをロードできます。
run. log({"my_cloud_from_file" : wandb. Object3D. from_file(
"./my_point_cloud.pts.json"
)})
ポイントクラウド データの形式設定方法の例を以下に示します。
{
"boxes" : [
{
"color" : [
0 ,
255 ,
0
],
"score" : 0.35 ,
"label" : "My label" ,
"corners" : [
[
2589.695869075582 ,
760.7400443552185 ,
-18.044831294622487
],
[
2590.719039645323 ,
762.3871153874499 ,
-18.044831294622487
],
[
2590.719039645323 ,
762.3871153874499 ,
-19.54083129462249
],
[
2589.695869075582 ,
760.7400443552185 ,
-19.54083129462249
],
[
2594.9666662674313 ,
757.4657929961453 ,
-18.044831294622487
],
[
2595.9898368371723 ,
759.1128640283766 ,
-18.044831294622487
],
[
2595.9898368371723 ,
759.1128640283766 ,
-19.54083129462249
],
[
2594.9666662674313 ,
757.4657929961453 ,
-19.54083129462249
]
]
}
],
"points" : [
[
2566.571924017235 ,
746.7817289698219 ,
-15.269245470863748 ,
76.5 ,
127.5 ,
89.46617199365393
],
[
2566.592983606823 ,
746.6791987335685 ,
-15.275803826279521 ,
76.5 ,
127.5 ,
89.45471117247024
],
[
2566.616361739416 ,
746.4903185513501 ,
-15.28628929674075 ,
76.5 ,
127.5 ,
89.41336375503832
]
],
"type" : "lidar/beta"
}
NumPy 配列
上記で定義されている同じ配列形式 を使用して、 from_numpy メソッド で numpy 配列を直接使用して、 ポイントクラウド を定義できます。
run. log({"my_cloud_from_numpy_xyz" : wandb. Object3D. from_numpy(
np. array(
[
[0.4 , 1 , 1.3 ], # x, y, z
[1 , 1 , 1 ],
[1.2 , 1 , 1.2 ]
]
)
)})
run. log({"my_cloud_from_numpy_cat" : wandb. Object3D. from_numpy(
np. array(
[
[0.4 , 1 , 1.3 , 1 ], # x, y, z, category
[1 , 1 , 1 , 1 ],
[1.2 , 1 , 1.2 , 12 ],
[1.2 , 1 , 1.3 , 12 ],
[1.2 , 1 , 1.4 , 12 ],
[1.2 , 1 , 1.5 , 12 ],
[1.2 , 1 , 1.6 , 11 ],
[1.2 , 1 , 1.7 , 11 ],
]
)
)})
run. log({"my_cloud_from_numpy_rgb" : wandb. Object3D. from_numpy(
np. array(
[
[0.4 , 1 , 1.3 , 255 , 0 , 0 ], # x, y, z, r, g, b
[1 , 1 , 1 , 0 , 255 , 0 ],
[1.2 , 1 , 1.3 , 0 , 255 , 255 ],
[1.2 , 1 , 1.4 , 0 , 255 , 255 ],
[1.2 , 1 , 1.5 , 0 , 0 , 255 ],
[1.2 , 1 , 1.1 , 0 , 0 , 255 ],
[1.2 , 1 , 0.9 , 0 , 0 , 255 ],
]
)
)})
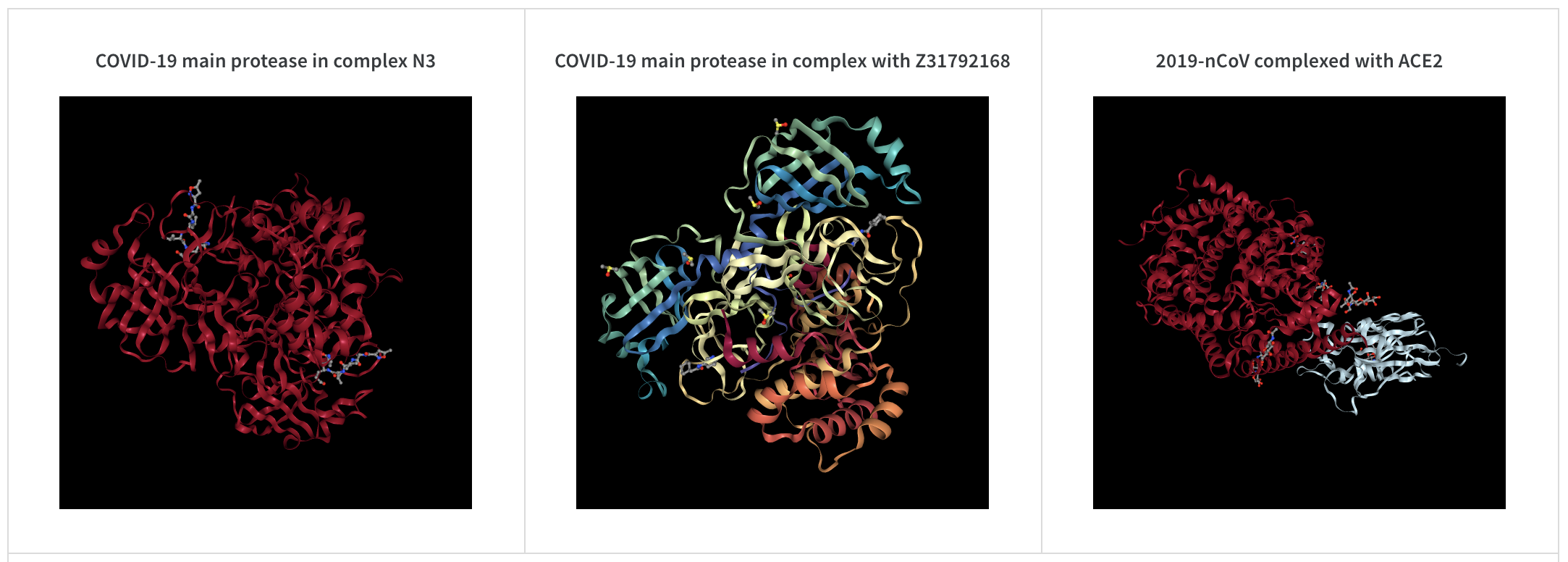
wandb. log({"protein" : wandb. Molecule("6lu7.pdb" )})
10 個のファイルタイプ ( pdb、pqr、mmcif、mcif、cif、sdf、sd、gro、mol2、または mmtf) のいずれかで分子データを ログ 記録します。
W&B は、SMILES 文字列、rdkitmol ファイル、および rdkit.Chem.rdchem.Mol オブジェクト からの分子データの ログ 記録もサポートしています。
resveratrol = rdkit. Chem. MolFromSmiles("Oc1ccc(cc1)C=Cc1cc(O)cc(c1)O" )
wandb. log(
{
"resveratrol" : wandb. Molecule. from_rdkit(resveratrol),
"green fluorescent protein" : wandb. Molecule. from_rdkit("2b3p.mol" ),
"acetaminophen" : wandb. Molecule. from_smiles("CC(=O)Nc1ccc(O)cc1" ),
}
)
run が終了すると、UI で分子の 3D 可視化を操作できるようになります。
AlphaFold を使用したライブ例を見る
PNG 画像
wandb.Imagenumpy 配列または PILImage の インスタンス を PNG に変換します。
wandb. log({"example" : wandb. Image(... )})
# Or multiple images
wandb. log({"example" : [wandb. Image(... ) for img in images]})
動画
動画は、wandb.Video
wandb. log({"example" : wandb. Video("myvideo.mp4" )})
これで、メディア ブラウザー で動画を表示できます。プロジェクト ワークスペース 、 run ワークスペース 、または レポート に移動し、[可視化 を追加 ] をクリックして、リッチメディア パネル を追加します。
分子の 2D 表示
wandb.Imagerdkit
molecule = rdkit. Chem. MolFromSmiles("CC(=O)O" )
rdkit. Chem. AllChem. Compute2DCoords(molecule)
rdkit. Chem. AllChem. GenerateDepictionMatching2DStructure(molecule, molecule)
pil_image = rdkit. Chem. Draw. MolToImage(molecule, size= (300 , 300 ))
wandb. log({"acetic_acid" : wandb. Image(pil_image)})
その他のメディア
W&B は、さまざまなその他のメディアタイプの ログ 記録もサポートしています。
音声
wandb. log({"whale songs" : wandb. Audio(np_array, caption= "OooOoo" , sample_rate= 32 )})
ステップごとに最大 100 個のオーディオ クリップ を ログ 記録できます。詳細な使用方法については、audio-file
動画
wandb. log({"video" : wandb. Video(numpy_array_or_path_to_video, fps= 4 , format= "gif" )})
numpy 配列が指定されている場合、次元は時間、 チャンネル 、幅、高さの順であると想定されます。デフォルトでは、4 fps の gif 画像 を作成します (ffmpegmoviepy"gif"、"mp4"、"webm"、および "ogg" です。文字列を wandb.Video に渡すと、ファイルが存在し、サポートされている形式であることをアサートしてから、wandb にアップロードします。BytesIO オブジェクト を渡すと、指定された形式を拡張子として持つ一時ファイルが作成されます。
W&B Run ページと Project ページでは、[メディア] セクションに動画が表示されます。
詳細な使用方法については、video-file
テキスト
wandb.Table を使用して、UI に表示される テーブル にテキストを ログ 記録します。デフォルトでは、列 ヘッダー は ["Input", "Output", "Expected"] です。最適な UI パフォーマンスを確保するために、デフォルトの最大行数は 10,000 に設定されています。ただし、 ユーザー は wandb.Table.MAX_ROWS = {DESIRED_MAX} を使用して、最大値を明示的にオーバーライドできます。
columns = ["Text" , "Predicted Sentiment" , "True Sentiment" ]
# Method 1
data = [["I love my phone" , "1" , "1" ], ["My phone sucks" , "0" , "-1" ]]
table = wandb. Table(data= data, columns= columns)
wandb. log({"examples" : table})
# Method 2
table = wandb. Table(columns= columns)
table. add_data("I love my phone" , "1" , "1" )
table. add_data("My phone sucks" , "0" , "-1" )
wandb. log({"examples" : table})
pandas DataFrame オブジェクト を渡すこともできます。
table = wandb. Table(dataframe= my_dataframe)
詳細な使用方法については、string
HTML
wandb. log({"custom_file" : wandb. Html(open("some.html" ))})
wandb. log({"custom_string" : wandb. Html('<a href="https://mysite">Link</a>' )})
カスタム HTML は任意の キー で ログ 記録でき、これにより、 run ページに HTML パネル が表示されます。デフォルトでは、デフォルトのスタイルが挿入されます。inject=False を渡すことで、デフォルトのスタイルをオフにすることができます。
wandb. log({"custom_file" : wandb. Html(open("some.html" ), inject= False )})
詳細な使用方法については、html-file
5 - Log models
モデルのログ
以下のガイドでは、モデルを W&B の run に記録し、それらを操作する方法について説明します。
以下の API は、実験管理のワークフローの一部としてモデルを追跡するのに役立ちます。このページに記載されている API を使用して、モデルを run に記録し、メトリクス、テーブル、メディア、その他のオブジェクトにアクセスします。
以下のことを行いたい場合は、W&B Artifacts を使用することをお勧めします。
モデル以外に、データセット、プロンプトなど、シリアル化されたデータのさまざまなバージョンを作成および追跡する。
W&B で追跡されるモデルまたはその他のオブジェクトのリネージグラフ を調べる。
これらのメソッドで作成されたモデル artifacts を操作する(プロパティの更新 (メタデータ、エイリアス、および説明) など)。
W&B Artifacts および高度なバージョン管理のユースケースの詳細については、Artifacts のドキュメントを参照してください。
モデルを run に記録する
指定したディレクトリー内のコンテンツを含むモデル artifact を記録するには、log_modellog_model
モデルを W&B run の入力または出力としてマークすると、モデルの依存関係とモデルの関連付けを追跡できます。W&B App UI 内でモデルのリネージを表示します。詳細については、Artifacts チャプターの アーティファクトグラフの探索とトラバース ページを参照してください。
モデルファイルが保存されているパスを path パラメーターに指定します。パスは、ローカルファイル、ディレクトリー、または s3://bucket/path などの外部バケットへの参照 URI にすることができます。
<> で囲まれた値は、独自の値に置き換えてください。
import wandb
# W&B の run を初期化します
run = wandb. init(project= "<your-project>" , entity= "<your-entity>" )
# モデルをログに記録します
run. log_model(path= "<path-to-model>" , name= "<name>" )
オプションで、name パラメーターにモデル artifact の名前を指定します。name が指定されていない場合、W&B は入力パスのベース名を run ID を先頭に付加したものを名前として使用します。
ユーザーまたは W&B がモデルに割り当てる
name を記録しておいてください。
use_model メソッドでモデルパスを取得するには、モデルの名前が必要です。
可能なパラメーターの詳細については、API Reference ガイドの log_model
例: モデルを run にログ記録する
import os
import wandb
from tensorflow import keras
from tensorflow.keras import layers
config = {"optimizer" : "adam" , "loss" : "categorical_crossentropy" }
# W&B の run を初期化します
run = wandb. init(entity= "charlie" , project= "mnist-experiments" , config= config)
# ハイパーパラメーター
loss = run. config["loss" ]
optimizer = run. config["optimizer" ]
metrics = ["accuracy" ]
num_classes = 10
input_shape = (28 , 28 , 1 )
# トレーニングアルゴリズム
model = keras. Sequential(
[
layers. Input(shape= input_shape),
layers. Conv2D(32 , kernel_size= (3 , 3 ), activation= "relu" ),
layers. MaxPooling2D(pool_size= (2 , 2 )),
layers. Conv2D(64 , kernel_size= (3 , 3 ), activation= "relu" ),
layers. MaxPooling2D(pool_size= (2 , 2 )),
layers. Flatten(),
layers. Dropout(0.5 ),
layers. Dense(num_classes, activation= "softmax" ),
]
)
# トレーニング用にモデルを構成する
model. compile(loss= loss, optimizer= optimizer, metrics= metrics)
# モデルを保存
model_filename = "model.h5"
local_filepath = "./"
full_path = os. path. join(local_filepath, model_filename)
model. save(filepath= full_path)
# モデルを W&B run にログ記録する
run. log_model(path= full_path, name= "MNIST" )
run. finish()
ユーザーが log_model を呼び出すと、MNIST という名前のモデル artifact が作成され、ファイル model.h5 がモデル artifact に追加されました。ターミナルまたはノートブックには、モデルがログに記録された run に関する情報を見つける場所の情報が表示されます。
View run different- surf- 5 at: https:// wandb. ai/ charlie/ mnist- experiments/ runs/ wlby6fuw
Synced 5 W& B file(s), 0 media file(s), 1 artifact file(s) and 0 other file(s)
Find logs at: ./ wandb/ run- 20231206_103511 - wlby6fuw/ logs
ログに記録されたモデルをダウンロードして使用する
以前に W&B run に記録されたモデルファイルにアクセスしてダウンロードするには、use_model
取得するモデルファイルが保存されているモデル artifact の名前を指定します。指定する名前は、既存のログに記録されたモデル artifact の名前と一致する必要があります。
log_model でファイルを最初にログに記録したときに name を定義しなかった場合、割り当てられるデフォルトの名前は、入力パスのベース名に run ID が付加されたものです。
<> で囲まれた他の値は必ず置き換えてください。
import wandb
# run を初期化します
run = wandb. init(project= "<your-project>" , entity= "<your-entity>" )
# モデルにアクセスしてダウンロードします。ダウンロードされた artifact へのパスを返します
downloaded_model_path = run. use_model(name= "<your-model-name>" )
use_model 関数は、ダウンロードされたモデルファイルのパスを返します。このモデルを後でリンクする場合は、このパスを記録しておいてください。上記のコードスニペットでは、返されたパスは downloaded_model_path という名前の変数に格納されています。
例: ログに記録されたモデルをダウンロードして使用する
たとえば、上記のコードスニペットでは、ユーザーが use_model API を呼び出しました。取得するモデル artifact の名前と、バージョン/エイリアスを指定しました。次に、API から返されたパスを downloaded_model_path 変数に格納しました。
import wandb
entity = "luka"
project = "NLP_Experiments"
alias = "latest" # モデルバージョンのセマンティックニックネームまたは識別子
model_artifact_name = "fine-tuned-model"
# run を初期化します
run = wandb. init(project= project, entity= entity)
# モデルにアクセスしてダウンロードします。ダウンロードされた artifact へのパスを返します
downloaded_model_path = run. use_model(name = f " { model_artifact_name} : { alias} " )
可能なパラメーターと戻り値の型の詳細については、API Reference ガイドの use_model
モデルをログに記録して W&B Model Registry にリンクする
link_model メソッドは、現在、間もなく非推奨になる従来の W&B Model Registry とのみ互換性があります。新しいエディションのモデルレジストリにモデル artifact をリンクする方法については、Registry の
ドキュメント を参照してください。
link_modelW&B Model Registry にリンクします。登録済みモデルが存在しない場合、W&B は registered_model_name パラメーターに指定した名前で新しいモデルを作成します。
モデルをリンクすることは、チームの他のメンバーが表示および利用できるモデルの一元化されたチームリポジトリにモデルを「ブックマーク」または「公開」することに似ています。
モデルをリンクすると、そのモデルは Registry で複製されたり、project から移動してレジストリに移動したりすることはありません。リンクされたモデルは、project 内の元のモデルへのポインターです。
Registry を使用して、タスクごとに最適なモデルを整理し、モデルライフサイクルを管理し、ML ライフサイクル全体で簡単な追跡と監査を促進し、webhook またはジョブでダウンストリームアクションを自動化 します。
Registered Model は、Model Registry 内のリンクされたモデルバージョンのコレクションまたはフォルダーです。登録済みモデルは通常、単一のモデリングユースケースまたはタスクの候補モデルを表します。
上記のコードスニペットは、link_model<> で囲まれた他の値は必ず置き換えてください。
import wandb
run = wandb. init(entity= "<your-entity>" , project= "<your-project>" )
run. link_model(path= "<path-to-model>" , registered_model_name= "<registered-model-name>" )
run. finish()
オプションのパラメーターの詳細については、API Reference ガイドの link_model
registered-model-name が Model Registry 内に既に存在する登録済みモデルの名前と一致する場合、モデルはその登録済みモデルにリンクされます。そのような登録済みモデルが存在しない場合は、新しいモデルが作成され、モデルが最初にリンクされます。
たとえば、Model Registry に "Fine-Tuned-Review-Autocompletion" という名前の既存の登録済みモデルがあるとします (例はこちら を参照)。また、いくつかのモデルバージョンが既にリンクされているとします: v0、v1、v2。link_model を registered-model-name="Fine-Tuned-Review-Autocompletion" で呼び出すと、新しいモデルはこの既存の登録済みモデルに v3 としてリンクされます。この名前の登録済みモデルが存在しない場合は、新しいモデルが作成され、新しいモデルは v0 としてリンクされます。
例: モデルをログに記録して W&B Model Registry にリンクする
たとえば、上記のコードスニペットはモデルファイルをログに記録し、モデルを登録済みモデル名 "Fine-Tuned-Review-Autocompletion" にリンクします。
これを行うには、ユーザーは link_model API を呼び出します。API を呼び出すときに、モデルのコンテンツを指すローカルファイルパス (path) と、リンク先の登録済みモデルの名前 (registered_model_name) を指定します。
import wandb
path = "/local/dir/model.pt"
registered_model_name = "Fine-Tuned-Review-Autocompletion"
run = wandb. init(project= "llm-evaluation" , entity= "noa" )
run. link_model(path= path, registered_model_name= registered_model_name)
run. finish()
リマインダー: 登録済みモデルには、ブックマークされたモデルバージョンのコレクションが格納されています。
6 - Log summary metrics
トレーニング中に時間とともに変化する値に加えて、モデルや前処理ステップを要約する単一の値を追跡することも重要です。この情報を W&B の Run の summary 辞書に記録します。Run の summary 辞書は、numpy 配列、PyTorch テンソル、または TensorFlow テンソルを処理できます。値がこれらの型のいずれかである場合、バイナリファイルにテンソル全体を保持し、min、平均、分散、パーセンタイルなどの高度な メトリクス を summary オブジェクトに格納します。
wandb.log で最後に記録された値は、W&B Run の summary 辞書として自動的に設定されます。summary メトリクス 辞書が変更されると、前の値は失われます。
次の コードスニペット は、カスタム summary メトリクス を W&B に提供する方法を示しています。
wandb. init(config= args)
best_accuracy = 0
for epoch in range(1 , args. epochs + 1 ):
test_loss, test_accuracy = test()
if test_accuracy > best_accuracy:
wandb. summary["best_accuracy" ] = test_accuracy
best_accuracy = test_accuracy
トレーニングが完了した後、既存の W&B Run の summary 属性を更新できます。W&B Public API を使用して、summary 属性を更新します。
api = wandb. Api()
run = api. run("username/project/run_id" )
run. summary["tensor" ] = np. random. random(1000 )
run. summary. update()
summary メトリクス のカスタマイズ
カスタム summary メトリクス は、wandb.summary でトレーニングの最適なステップでモデルのパフォーマンスをキャプチャするのに役立ちます。たとえば、最終値の代わりに、最大精度または最小損失値をキャプチャしたい場合があります。
デフォルトでは、summary は履歴からの最終値を使用します。summary メトリクス をカスタマイズするには、define_metric で summary 引数に渡します。これは、次の値を受け入れます。
"min""max""mean""best""last""none"
"best" は、オプションの objective 引数を "minimize" または "maximize" に設定した場合にのみ使用できます。
次の例では、損失と精度の最小値と最大値を summary に追加します。
import wandb
import random
random. seed(1 )
wandb. init()
# 損失の最小値と最大値のsummary値
wandb. define_metric("loss" , summary= "min" )
wandb. define_metric("loss" , summary= "max" )
# 精度に対する最小値と最大値のsummary値
wandb. define_metric("acc" , summary= "min" )
wandb. define_metric("acc" , summary= "max" )
for i in range(10 ):
log_dict = {
"loss" : random. uniform(0 , 1 / (i + 1 )),
"acc" : random. uniform(1 / (i + 1 ), 1 ),
}
wandb. log(log_dict)
summary メトリクス の表示
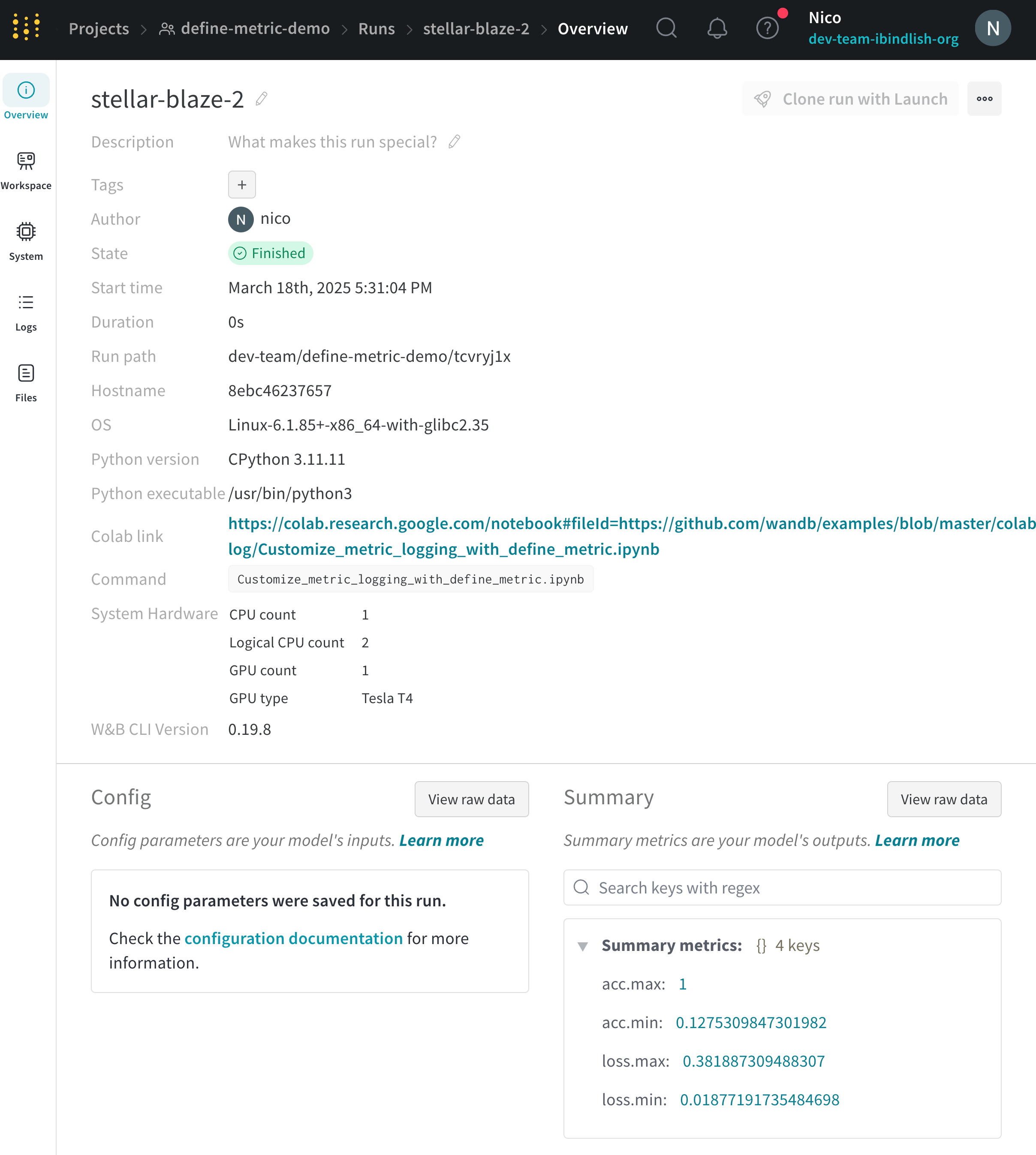
run の Overview ページまたは project の runs テーブルで summary 値を表示します。
Run Overview
Run Table
W&B Public API
W&B App に移動します。
Workspace タブを選択します。runs のリストから、summary 値を記録した run の名前をクリックします。
Overview タブを選択します。Summary セクションで summary 値を表示します。
W&B App に移動します。
Runs タブを選択します。runs テーブル内で、summary 値の名前に基づいて、列内の summary 値を表示できます。
W&B Public API を使用して、run の summary 値を取得できます。
次の コード例 は、W&B Public API と pandas を使用して、特定の run に記録された summary 値を取得する方法の 1 つを示しています。
import wandb
import pandas
entity = "<your-entity>"
project = "<your-project>"
run_name = "<your-run-name>" # summary 値を持つ run の名前
all_runs = []
for run in api. runs(f " { entity} / { project_name} " ):
print("Fetching details for run: " , run. id, run. name)
run_data = {
"id" : run. id,
"name" : run. name,
"url" : run. url,
"state" : run. state,
"tags" : run. tags,
"config" : run. config,
"created_at" : run. created_at,
"system_metrics" : run. system_metrics,
"summary" : run. summary,
"project" : run. project,
"entity" : run. entity,
"user" : run. user,
"path" : run. path,
"notes" : run. notes,
"read_only" : run. read_only,
"history_keys" : run. history_keys,
"metadata" : run. metadata,
}
all_runs. append(run_data)
# DataFrameに変換
df = pd. DataFrame(all_runs)
# カラム名 (run) に基づいて行を取得し、dictionary に変換します。
df[df['name' ]== run_name]. summary. reset_index(drop= True ). to_dict()
7 - Log tables
W&B でテーブルをログします。
wandb.Table を使用してデータをログに記録し、Weights & Biases(W&B)で視覚化およびクエリを実行します。このガイドでは、次の方法について説明します。
テーブルの作成 データの追加 データの取得 テーブルの保存
テーブルの作成
Tableを定義するには、データの各行に表示する列を指定します。各行は、トレーニングデータセット内の単一のアイテム、トレーニング中の特定のステップまたはエポック、テストアイテムに対するモデルによる予測、モデルによって生成されたオブジェクトなどです。各列には、数値、テキスト、ブール値、画像、動画、音声などの固定タイプがあります。タイプを事前に指定する必要はありません。各列に名前を付け、その型のデータのみをその列インデックスに渡してください。詳細な例については、こちらのレポート をご覧ください。
wandb.Table コンストラクターは、次の2つの方法で使用します。
行のリスト: 名前付きの列とデータの行をログに記録します。たとえば、次のコードスニペットは、2行3列のテーブルを生成します。
wandb. Table(columns= ["a" , "b" , "c" ], data= [["1a" , "1b" , "1c" ], ["2a" , "2b" , "2c" ]])
Pandas DataFrame: wandb.Table(dataframe=my_df) を使用して DataFrame をログに記録します。列名は DataFrame から抽出されます。
既存の配列またはデータフレームから
# モデルが4つの画像に対する予測を返したと仮定します
# 次のフィールドが利用可能です:
# - 画像ID
# - wandb.Image() にラップされた画像ピクセル
# - モデルの予測ラベル
# - 正解ラベル
my_data = [
[0 , wandb. Image("img_0.jpg" ), 0 , 0 ],
[1 , wandb. Image("img_1.jpg" ), 8 , 0 ],
[2 , wandb. Image("img_2.jpg" ), 7 , 1 ],
[3 , wandb. Image("img_3.jpg" ), 1 , 1 ],
]
# 対応する列を持つ wandb.Table() を作成します
columns = ["id" , "image" , "prediction" , "truth" ]
test_table = wandb. Table(data= my_data, columns= columns)
データの追加
テーブルは変更可能です。スクリプトの実行中に、最大200,000行までテーブルにデータを追加できます。テーブルにデータを追加する方法は2つあります。
行の追加 : table.add_data("3a", "3b", "3c")。新しい行はリストとして表されないことに注意してください。行がリスト形式の場合は、スター表記 * を使用して、リストを位置引数に展開します: table.add_data(*my_row_list)。行には、テーブルの列数と同じ数のエントリが含まれている必要があります。列の追加 : table.add_column(name="col_name", data=col_data)。col_data の長さは、テーブルの現在の行数と等しくなければならないことに注意してください。ここで、col_data はリストデータまたは NumPy NDArray にすることができます。
データの増分追加
このコードサンプルは、W&Bテーブルを段階的に作成および入力する方法を示しています。可能なすべてのラベルの信頼性スコアを含む、事前定義された列を持つテーブルを定義し、推論中にデータを1行ずつ追加します。runの再開時にテーブルにデータを段階的に追加する こともできます。
# 各ラベルの信頼性スコアを含む、テーブルの列を定義します
columns = ["id" , "image" , "guess" , "truth" ]
for digit in range(10 ): # 各桁 (0-9) の信頼性スコア列を追加します
columns. append(f "score_ { digit} " )
# 定義された列でテーブルを初期化します
test_table = wandb. Table(columns= columns)
# テストデータセットを反復処理し、データをテーブルに行ごとに追加します
# 各行には、画像ID、画像、予測ラベル、正解ラベル、および信頼性スコアが含まれます
for img_id, img in enumerate(mnist_test_data):
true_label = mnist_test_data_labels[img_id] # 正解ラベル
guess_label = my_model. predict(img) # 予測ラベル
test_table. add_data(
img_id, wandb. Image(img), guess_label, true_label
) # 行データをテーブルに追加します
runの再開時にデータを追加する
Artifactから既存のテーブルをロードし、データの最後の行を取得して、更新されたメトリクスを追加することにより、再開されたrunでW&Bテーブルを段階的に更新できます。次に、互換性のためにテーブルを再初期化し、更新されたバージョンをW&Bに記録します。
# アーティファクトから既存のテーブルをロードします
best_checkpt_table = wandb. use_artifact(table_tag). get(table_name)
# 再開のためにテーブルからデータの最後の行を取得します
best_iter, best_metric_max, best_metric_min = best_checkpt_table. data[- 1 ]
# 必要に応じて最適なメトリクスを更新します
# 更新されたデータをテーブルに追加します
best_checkpt_table. add_data(best_iter, best_metric_max, best_metric_min)
# 互換性を確保するために、更新されたデータでテーブルを再初期化します
best_checkpt_table = wandb. Table(
columns= ["col1" , "col2" , "col3" ], data= best_checkpt_table. data
)
# 更新されたテーブルを Weights & Biases に記録します
wandb. log({table_name: best_checkpt_table})
データの取得
データがTableにある場合、列または行でアクセスします。
行イテレーター : ユーザーは、for ndx, row in table.iterrows(): ... などのTableの行イテレーターを使用して、データの行を効率的に反復処理できます。列の取得 : ユーザーは、table.get_column("col_name") を使用してデータの列を取得できます。便宜上、ユーザーは convert_to="numpy" を渡して、列をプリミティブの NumPy NDArray に変換できます。これは、列に wandb.Image などのメディアタイプが含まれている場合に、基になるデータに直接アクセスできるようにする場合に役立ちます。
テーブルの保存
スクリプトでデータのテーブル(たとえば、モデル予測のテーブル)を生成したら、結果をライブで視覚化するために、W&Bに保存します。
テーブルをrunに記録する
wandb.log() を使用して、次のようにテーブルをrunに保存します。
run = wandb. init()
my_table = wandb. Table(columns= ["a" , "b" ], data= [["1a" , "1b" ], ["2a" , "2b" ]])
run. log({"table_key" : my_table})
テーブルが同じキーに記録されるたびに、テーブルの新しいバージョンが作成され、バックエンドに保存されます。これは、モデルの予測が時間の経過とともにどのように改善されるかを確認したり、同じキーに記録されている限り、異なるrun間でテーブルを比較したりするために、複数のトレーニングステップで同じテーブルを記録できることを意味します。最大200,000行をログに記録できます。
200,000行を超える行をログに記録するには、次の制限をオーバーライドできます。
wandb.Table.MAX_ARTIFACT_ROWS = X
ただし、これにより、UIでのクエリの遅延など、パフォーマンスの問題が発生する可能性があります。
プログラムでテーブルにアクセスする
バックエンドでは、Tables は Artifacts として保持されます。特定のバージョンにアクセスする場合は、Artifact API を使用してアクセスできます。
with wandb. init() as run:
my_table = run. use_artifact("run-<run-id>-<table-name>:<tag>" ). get("<table-name>" )
Artifactsの詳細については、開発者ガイドのArtifactsチャプター を参照してください。
テーブルの視覚化
このように記録されたテーブルは、runページとプロジェクトページの両方の Workspace に表示されます。詳細については、テーブルの視覚化と分析 を参照してください。
Artifact テーブル
artifact.add() を使用して、ワークスペースではなく、runの Artifacts セクションにテーブルをログに記録します。これは、一度ログに記録して、将来のrunで参照するデータセットがある場合に役立ちます。
run = wandb. init(project= "my_project" )
# 意味のあるステップごとに wandb Artifact を作成します
test_predictions = wandb. Artifact("mnist_test_preds" , type= "predictions" )
# [上記のように予測データを構築します]
test_table = wandb. Table(data= data, columns= columns)
test_predictions. add(test_table, "my_test_key" )
run. log_artifact(test_predictions)
画像データを使用した artifact.add() の詳細な例 と、Artifacts と Tables を使用して 表形式データのバージョン管理と重複排除を行う方法 の例については、このレポートを参照してください。
Artifact テーブルの結合
ローカルで構築したテーブル、または他の Artifacts から取得したテーブルを wandb.JoinedTable(table_1, table_2, join_key) を使用して結合できます。
引数
説明
table_1
(str, wandb.Table, ArtifactEntry) Artifact 内の wandb.Table へのパス、テーブルオブジェクト、または ArtifactEntry
table_2
(str, wandb.Table, ArtifactEntry) Artifact 内の wandb.Table へのパス、テーブルオブジェクト、または ArtifactEntry
join_key
(str, [str, str]) 結合を実行するキー
Artifact コンテキストで以前に記録した2つの Tables を結合するには、Artifact からそれらを取得し、結果を新しい Table に結合します。
たとえば、'original_songs' という元の曲の Table と、同じ曲の合成バージョンの別の Table 'synth_songs' を読み取る方法を示します。次のコード例では、2つのテーブルを "song_id" で結合し、結果のテーブルを新しい W&B Table としてアップロードします。
import wandb
run = wandb. init(project= "my_project" )
# 元の曲のテーブルを取得します
orig_songs = run. use_artifact("original_songs:latest" )
orig_table = orig_songs. get("original_samples" )
# 合成された曲のテーブルを取得します
synth_songs = run. use_artifact("synth_songs:latest" )
synth_table = synth_songs. get("synth_samples" )
# テーブルを "song_id" で結合します
join_table = wandb. JoinedTable(orig_table, synth_table, "song_id" )
join_at = wandb. Artifact("synth_summary" , "analysis" )
# テーブルを Artifact に追加し、W&B に記録します
join_at. add(join_table, "synth_explore" )
run. log_artifact(join_at)
異なる Artifact オブジェクトに保存されている2つの以前に保存されたテーブルを結合する方法の例については、このチュートリアル を参照してください。
8 - Track CSV files with experiments
W&B へのデータのインポートとログ記録
W&B Python Library を使用して CSV ファイルをログに記録し、W&B Dashboard で可視化します。 W&B Dashboard は、機械学習モデルの結果を整理して可視化するための中央の場所です。これは、W&B にログ記録されていない以前の機械学習実験の情報を含む CSV ファイル がある場合、またはデータセットを含む CSV ファイル がある場合に特に役立ちます。
データセットのCSVファイルをインポートしてログに記録する
CSV ファイルの内容を再利用しやすくするために、W&B Artifacts を利用することをお勧めします。
まず、CSV ファイルをインポートします。次のコードスニペットで、iris.csv ファイル名を CSV ファイルの名前に置き換えます。
import wandb
import pandas as pd
# Read our CSV into a new DataFrame
new_iris_dataframe = pd. read_csv("iris.csv" )
CSV ファイルを W&B テーブルに変換して、W&B Dashboards を利用します。
# Convert the DataFrame into a W&B Table
iris_table = wandb. Table(dataframe= new_iris_dataframe)
次に、W&B Artifact を作成し、テーブルを Artifact に追加します。
# Add the table to an Artifact to increase the row
# limit to 200000 and make it easier to reuse
iris_table_artifact = wandb. Artifact("iris_artifact" , type= "dataset" )
iris_table_artifact. add(iris_table, "iris_table" )
# Log the raw csv file within an artifact to preserve our data
iris_table_artifact. add_file("iris.csv" )
W&B Artifacts の詳細については、Artifacts のチャプター を参照してください。
最後に、wandb.init で W&B Run を開始し、W&B に追跡およびログを記録します。
# Start a W&B run to log data
run = wandb. init(project= "tables-walkthrough" )
# Log the table to visualize with a run...
run. log({"iris" : iris_table})
# and Log as an Artifact to increase the available row limit!
run. log_artifact(iris_table_artifact)
wandb.init() API は、Run にデータをログ記録するための新しいバックグラウンド プロセスを生成し、(デフォルトで) データを wandb.ai に同期します。 W&B Workspace Dashboard でライブ可視化を表示します。次の画像は、コードスニペットのデモの出力を示しています。
上記のコードスニペットを含む完全なスクリプトは、以下にあります。
import wandb
import pandas as pd
# Read our CSV into a new DataFrame
new_iris_dataframe = pd. read_csv("iris.csv" )
# Convert the DataFrame into a W&B Table
iris_table = wandb. Table(dataframe= new_iris_dataframe)
# Add the table to an Artifact to increase the row
# limit to 200000 and make it easier to reuse
iris_table_artifact = wandb. Artifact("iris_artifact" , type= "dataset" )
iris_table_artifact. add(iris_table, "iris_table" )
# log the raw csv file within an artifact to preserve our data
iris_table_artifact. add_file("iris.csv" )
# Start a W&B run to log data
run = wandb. init(project= "tables-walkthrough" )
# Log the table to visualize with a run...
run. log({"iris" : iris_table})
# and Log as an Artifact to increase the available row limit!
run. log_artifact(iris_table_artifact)
# Finish the run (useful in notebooks)
run. finish()
Experiments の CSV ファイルをインポートしてログに記録する
場合によっては、CSV ファイルに experiment の詳細が含まれている場合があります。このような CSV ファイルにある一般的な詳細は次のとおりです。
Experiment
Model Name
Notes
Tags
Num Layers
Final Train Acc
Final Val Acc
Training Losses
Experiment 1
mnist-300-layers
Overfit way too much on training data
[latest]
300
0.99
0.90
[0.55, 0.45, 0.44, 0.42, 0.40, 0.39]
Experiment 2
mnist-250-layers
Current best model
[prod, best]
250
0.95
0.96
[0.55, 0.45, 0.44, 0.42, 0.40, 0.39]
Experiment 3
mnist-200-layers
Did worse than the baseline model. Need to debug
[debug]
200
0.76
0.70
[0.55, 0.45, 0.44, 0.42, 0.40, 0.39]
…
…
…
…
…
…
…
Experiment N
mnist-X-layers
NOTES
…
…
…
…
[…, …]
W&B は、experiments の CSV ファイルを取得し、W&B Experiment Run に変換できます。次のコードスニペットとコードスクリプトは、experiments の CSV ファイルをインポートしてログに記録する方法を示しています。
まず、CSV ファイルを読み込み、Pandas DataFrame に変換します。 experiments.csv を CSV ファイルの名前に置き換えます。
import wandb
import pandas as pd
FILENAME = "experiments.csv"
loaded_experiment_df = pd. read_csv(FILENAME)
PROJECT_NAME = "Converted Experiments"
EXPERIMENT_NAME_COL = "Experiment"
NOTES_COL = "Notes"
TAGS_COL = "Tags"
CONFIG_COLS = ["Num Layers" ]
SUMMARY_COLS = ["Final Train Acc" , "Final Val Acc" ]
METRIC_COLS = ["Training Losses" ]
# Format Pandas DataFrame to make it easier to work with
for i, row in loaded_experiment_df. iterrows():
run_name = row[EXPERIMENT_NAME_COL]
notes = row[NOTES_COL]
tags = row[TAGS_COL]
config = {}
for config_col in CONFIG_COLS:
config[config_col] = row[config_col]
metrics = {}
for metric_col in METRIC_COLS:
metrics[metric_col] = row[metric_col]
summaries = {}
for summary_col in SUMMARY_COLS:
summaries[summary_col] = row[summary_col]
次に、wandb.init()
run = wandb. init(
project= PROJECT_NAME, name= run_name, tags= tags, notes= notes, config= config
)
experiment の実行中に、W&B で表示、クエリ、および分析できるように、メトリクスのすべてのインスタンスをログに記録することができます。これを行うには、run.log()
オプションで、run の結果を定義するために、最終的なサマリーメトリクスをログに記録できます。これを行うには、W&B define_metricrun.summary.update() を使用して、サマリーメトリクスを run に追加します。
run. summary. update(summaries)
サマリーメトリクスの詳細については、サマリーメトリクスのログ記録 を参照してください。
以下は、上記のサンプルテーブルを W&B Dashboard に変換する完全なスクリプトの例です。
FILENAME = "experiments.csv"
loaded_experiment_df = pd. read_csv(FILENAME)
PROJECT_NAME = "Converted Experiments"
EXPERIMENT_NAME_COL = "Experiment"
NOTES_COL = "Notes"
TAGS_COL = "Tags"
CONFIG_COLS = ["Num Layers" ]
SUMMARY_COLS = ["Final Train Acc" , "Final Val Acc" ]
METRIC_COLS = ["Training Losses" ]
for i, row in loaded_experiment_df. iterrows():
run_name = row[EXPERIMENT_NAME_COL]
notes = row[NOTES_COL]
tags = row[TAGS_COL]
config = {}
for config_col in CONFIG_COLS:
config[config_col] = row[config_col]
metrics = {}
for metric_col in METRIC_COLS:
metrics[metric_col] = row[metric_col]
summaries = {}
for summary_col in SUMMARY_COLS:
summaries[summary_col] = row[summary_col]
run = wandb. init(
project= PROJECT_NAME, name= run_name, tags= tags, notes= notes, config= config
)
for key, val in metrics. items():
if isinstance(val, list):
for _val in val:
run. log({key: _val})
else :
run. log({key: val})
run. summary. update(summaries)
run. finish()