Sweeps
W&B Sweeps を使用したハイパーパラメータ探索と モデル の最適化
W&B Sweeps を使用して、ハイパーパラメータの検索を自動化し、豊富なインタラクティブな 実験管理 を視覚化します。ベイズ、グリッド検索、ランダムなどの一般的な検索メソッドから選択して、ハイパーパラメータ空間を検索します。1つまたは複数のマシンに スイープ をスケールおよび並列化します。
仕組み
2つの W&B CLI コマンドで スイープ を作成します。
- スイープ を初期化する
wandb sweep --project <propject-name> <path-to-config file>
- sweep agent を起動する
上記の コードスニペット と、このページにリンクされている Colab は、W&B CLI で スイープ を初期化および作成する方法を示しています。 スイープ設定を定義し、 スイープ を初期化し、 スイープ を開始するために使用する W&B Python SDK コマンドのステップごとの概要については、Sweeps の
Walkthrough を参照してください。
開始方法
ユースケース に応じて、次のリソースを参照して W&B Sweeps を開始してください。
- スイープ設定を定義し、 スイープ を初期化し、 スイープ を開始するために使用する W&B Python SDK コマンドのステップごとの概要については、sweeps walkthrough を参照してください。
- この chapter では、次の方法について説明します。
- W&B Sweeps でハイパーパラメータ最適化を調査する 厳選された Sweep experiments のリスト を見てみましょう。 result は W&B Reports に保存されます。
ステップごとのビデオについては、Tune Hyperparameters Easily with W&B Sweeps を参照してください。
1 - Tutorial: Define, initialize, and run a sweep
Sweeps クイックスタート では、sweep の定義、初期化、および実行方法について説明します。主な手順は4つあります。
このページでは、sweep の定義、初期化、および実行方法について説明します。主な手順は4つあります。
- トレーニング コードのセットアップ
- sweep configuration での探索空間の定義
- sweep の初期化
- sweep agent の起動
次のコードをコピーして Jupyter Notebook または Python スクリプトに貼り付けます。
# W&B Python ライブラリをインポートして W&B にログインします
import wandb
wandb.login()
# 1: 目的関数/トレーニング関数を定義します
def objective(config):
score = config.x**3 + config.y
return score
def main():
wandb.init(project="my-first-sweep")
score = objective(wandb.config)
wandb.log({"score": score})
# 2: 探索空間を定義します
sweep_configuration = {
"method": "random",
"metric": {"goal": "minimize", "name": "score"},
"parameters": {
"x": {"max": 0.1, "min": 0.01},
"y": {"values": [1, 3, 7]},
},
}
# 3: sweep を開始します
sweep_id = wandb.sweep(sweep=sweep_configuration, project="my-first-sweep")
wandb.agent(sweep_id, function=main, count=10)
以下のセクションでは、コード サンプルの各ステップを分解して説明します。
トレーニング コードのセットアップ
wandb.config から ハイパーパラメーター の値を受け取り、それらを使用して model をトレーニングし、メトリクスを返すトレーニング関数を定義します。
必要に応じて、W&B Run の出力を保存する project の名前を指定します (wandb.init の project パラメータ)。project が指定されていない場合、run は「未分類」の project に配置されます。
sweep と run は両方とも同じ project に存在する必要があります。したがって、W&B を初期化するときに指定する名前は、sweep を初期化するときに指定する project の名前と一致する必要があります。
# 1: 目的関数/トレーニング関数を定義します
def objective(config):
score = config.x**3 + config.y
return score
def main():
wandb.init(project="my-first-sweep")
score = objective(wandb.config)
wandb.log({"score": score})
sweep configuration での探索空間の定義
辞書で sweep する ハイパーパラメーター を指定します。configuration オプションについては、sweep configuration の定義を参照してください。
上記の例は、ランダム検索 ('method':'random') を使用する sweep configuration を示しています。sweep は、バッチサイズ、エポック、および学習率について、configuration にリストされている値のランダムなセットをランダムに選択します。
W&B は、"goal": "minimize" が関連付けられている場合、metric キーで指定された メトリクス を最小化します。この場合、W&B は メトリクス score ("name": "score") の最小化のために最適化します。
# 2: 探索空間を定義します
sweep_configuration = {
"method": "random",
"metric": {"goal": "minimize", "name": "score"},
"parameters": {
"x": {"max": 0.1, "min": 0.01},
"y": {"values": [1, 3, 7]},
},
}
Sweep の初期化
W&B は Sweep Controller を使用して、クラウド (標準)、ローカル (ローカル) で1つまたは複数のマシンにわたる Sweeps を管理します。Sweep Controller の詳細については、ローカルでの検索と停止アルゴリズムを参照してください。
sweep 識別番号は、sweep を初期化するときに返されます。
sweep_id = wandb.sweep(sweep=sweep_configuration, project="my-first-sweep")
sweep の初期化の詳細については、sweep の初期化を参照してください。
Sweep の開始
wandb.agent API 呼び出しを使用して sweep を開始します。
wandb.agent(sweep_id, function=main, count=10)
結果の可視化 (オプション)
project を開いて、W&B App ダッシュボードでライブ結果を確認します。数回クリックするだけで、パラレル座標図、パラメーター の重要性分析 などの豊富なインタラクティブなグラフを構築できます。詳細
結果の可視化方法の詳細については、sweep 結果の可視化を参照してください。ダッシュボードの例については、このサンプルSweeps Projectを参照してください。
エージェント の停止 (オプション)
ターミナル で、Ctrl+C を押して現在の run を停止します。もう一度押すと、agent が終了します。
2 - Add W&B (wandb) to your code
W&B を Python コード スクリプトまたは Jupyter Notebook に追加します。
W&B Python SDK をスクリプトまたは Jupyter Notebook に追加する方法は多数あります。以下に、W&B Python SDK を独自のコードに統合する方法の「ベストプラクティス」の例を示します。
元のトレーニングスクリプト
Python スクリプトに次のコードがあるとします。ここでは、典型的なトレーニングループを模倣する main という関数を定義します。エポックごとに、トレーニングデータセットと検証データセットで精度と損失が計算されます。これらの値は、この例の目的のためにランダムに生成されます。
ここでは、ハイパーパラメータの値を格納する config という 辞書 を定義しました。セルの最後に、main 関数を呼び出して、モックトレーニングコードを実行します。
import random
import numpy as np
def train_one_epoch(epoch, lr, bs):
acc = 0.25 + ((epoch / 30) + (random.random() / 10))
loss = 0.2 + (1 - ((epoch - 1) / 10 + random.random() / 5))
return acc, loss
def evaluate_one_epoch(epoch):
acc = 0.1 + ((epoch / 20) + (random.random() / 10))
loss = 0.25 + (1 - ((epoch - 1) / 10 + random.random() / 6))
return acc, loss
# config variable with hyperparameter values
config = {"lr": 0.0001, "bs": 16, "epochs": 5}
def main():
# Note that we define values from `wandb.config`
# instead of defining hard values
# ハードコードされた値を定義する代わりに、`wandb.config` から値を定義することに注意してください
lr = config["lr"]
bs = config["bs"]
epochs = config["epochs"]
for epoch in np.arange(1, epochs):
train_acc, train_loss = train_one_epoch(epoch, lr, bs)
val_acc, val_loss = evaluate_one_epoch(epoch)
print("epoch: ", epoch)
print("training accuracy:", train_acc, "training loss:", train_loss)
print("validation accuracy:", val_acc, "training loss:", val_loss)
W&B Python SDK を使用したトレーニングスクリプト
次のコード例は、W&B Python SDK をコードに追加する方法を示しています。CLI で W&B Sweep ジョブを開始する場合は、[CLI] タブを確認してください。Jupyter Notebook または Python スクリプト内で W&B Sweep ジョブを開始する場合は、[Python SDK] タブを確認してください。
W&B Sweep を作成するために、次のコード例を追加しました。
- Weights & Biases Python SDK をインポートします。
- キーと値のペアで sweep configuration を定義する 辞書 オブジェクトを作成します。以下の例では、バッチサイズ (
batch_size)、エポック数 (epochs)、および学習率 (lr) の ハイパーパラメータ は、各 sweep 中に変化します。sweep configuration の作成方法の詳細については、sweep configuration の定義を参照してください。
- sweep configuration 辞書 を
wandb.sweep に渡します。これにより、sweep が初期化されます。これにより、sweep ID (sweep_id) が返されます。sweep の初期化方法の詳細については、sweep の初期化を参照してください。
wandb.init() API を使用して、W&B Run としてデータを同期およびログ記録するバックグラウンド プロセス を生成します。- (オプション) ハードコードされた値を定義する代わりに、
wandb.config から値を定義します。
- 最適化する メトリクス を
wandb.log でログに記録します。configuration で定義された メトリクス をログに記録する必要があります。configuration 辞書 (この例では sweep_configuration) 内で、val_acc 値を最大化するように sweep を定義しました。
wandb.agent API 呼び出しで sweep を開始します。sweep ID、sweep が実行する関数の名前 (function=main) を指定し、試行する run の最大数を 4 (count=4) に設定します。W&B Sweep の開始方法の詳細については、sweep agent の開始を参照してください。
import wandb
import numpy as np
import random
# Define sweep config
# sweep configuration を定義する
sweep_configuration = {
"method": "random",
"name": "sweep",
"metric": {"goal": "maximize", "name": "val_acc"},
"parameters": {
"batch_size": {"values": [16, 32, 64]},
"epochs": {"values": [5, 10, 15]},
"lr": {"max": 0.1, "min": 0.0001},
},
}
# Initialize sweep by passing in config.
# (Optional) Provide a name of the project.
# configuration を渡して sweep を初期化します。
# (オプション) Project の名前を指定します。
sweep_id = wandb.sweep(sweep=sweep_configuration, project="my-first-sweep")
# Define training function that takes in hyperparameter
# values from `wandb.config` and uses them to train a
# model and return metric
# `wandb.config` から ハイパーパラメータ 値を取得し、それらを使用して
# モデルをトレーニングし、メトリクス を返すトレーニング関数を定義する
def train_one_epoch(epoch, lr, bs):
acc = 0.25 + ((epoch / 30) + (random.random() / 10))
loss = 0.2 + (1 - ((epoch - 1) / 10 + random.random() / 5))
return acc, loss
def evaluate_one_epoch(epoch):
acc = 0.1 + ((epoch / 20) + (random.random() / 10))
loss = 0.25 + (1 - ((epoch - 1) / 10 + random.random() / 6))
return acc, loss
def main():
run = wandb.init()
# note that we define values from `wandb.config`
# instead of defining hard values
# ハードコードされた値を定義する代わりに、`wandb.config` から値を定義することに注意してください
lr = wandb.config.lr
bs = wandb.config.batch_size
epochs = wandb.config.epochs
for epoch in np.arange(1, epochs):
train_acc, train_loss = train_one_epoch(epoch, lr, bs)
val_acc, val_loss = evaluate_one_epoch(epoch)
wandb.log(
{
"epoch": epoch,
"train_acc": train_acc,
"train_loss": train_loss,
"val_acc": val_acc,
"val_loss": val_loss,
}
)
# Start sweep job.
# sweep ジョブを開始します。
wandb.agent(sweep_id, function=main, count=4)
W&B Sweep を作成するには、まず YAML configuration ファイルを作成します。configuration ファイルには、sweep で探索する ハイパーパラメータ が含まれています。以下の例では、バッチサイズ (batch_size)、エポック数 (epochs)、および学習率 (lr) の ハイパーパラメータ は、各 sweep 中に変化します。
# config.yaml
program: train.py
method: random
name: sweep
metric:
goal: maximize
name: val_acc
parameters:
batch_size:
values: [16,32,64]
lr:
min: 0.0001
max: 0.1
epochs:
values: [5, 10, 15]
W&B Sweep configuration の作成方法の詳細については、sweep configuration の定義を参照してください。
YAML ファイルの program キーに Python スクリプトの名前を指定する必要があることに注意してください。
次に、次のコード例を追加します。
- Wieghts & Biases Python SDK (
wandb) と PyYAML (yaml) をインポートします。PyYAML は、YAML configuration ファイルを読み込むために使用されます。
- configuration ファイルを読み込みます。
wandb.init() API を使用して、W&B Run としてデータを同期およびログ記録するバックグラウンド プロセス を生成します。config オブジェクトを config パラメータに渡します。- ハードコードされた値を使用する代わりに、
wandb.config から ハイパーパラメータ 値を定義します。
- 最適化する メトリクス を
wandb.log でログに記録します。configuration で定義された メトリクス をログに記録する必要があります。configuration 辞書 (この例では sweep_configuration) 内で、val_acc 値を最大化するように sweep を定義しました。
import wandb
import yaml
import random
import numpy as np
def train_one_epoch(epoch, lr, bs):
acc = 0.25 + ((epoch / 30) + (random.random() / 10))
loss = 0.2 + (1 - ((epoch - 1) / 10 + random.random() / 5))
return acc, loss
def evaluate_one_epoch(epoch):
acc = 0.1 + ((epoch / 20) + (random.random() / 10))
loss = 0.25 + (1 - ((epoch - 1) / 10 + random.random() / 6))
return acc, loss
def main():
# Set up your default hyperparameters
# デフォルトのハイパーパラメータを設定する
with open("./config.yaml") as file:
config = yaml.load(file, Loader=yaml.FullLoader)
run = wandb.init(config=config)
# Note that we define values from `wandb.config`
# instead of defining hard values
# ハードコードされた値を定義する代わりに、`wandb.config` から値を定義することに注意してください
lr = wandb.config.lr
bs = wandb.config.batch_size
epochs = wandb.config.epochs
for epoch in np.arange(1, epochs):
train_acc, train_loss = train_one_epoch(epoch, lr, bs)
val_acc, val_loss = evaluate_one_epoch(epoch)
wandb.log(
{
"epoch": epoch,
"train_acc": train_acc,
"train_loss": train_loss,
"val_acc": val_acc,
"val_loss": val_loss,
}
)
# Call the main function.
# main 関数を呼び出します。
main()
CLI に移動します。CLI 内で、sweep agent が試行する run の最大数を設定します。この手順はオプションです。次の例では、最大数を 5 に設定します。
次に、wandb sweep コマンドで sweep を初期化します。YAML ファイルの名前を指定します。オプションで、project フラグ (--project) の Project の名前を指定します。
wandb sweep --project sweep-demo-cli config.yaml
これにより、sweep ID が返されます。sweep の初期化方法の詳細については、sweep の初期化を参照してください。
sweep ID をコピーし、次の コードスニペット の sweepID を置き換えて、wandb agent コマンドで sweep ジョブを開始します。
wandb agent --count $NUM your-entity/sweep-demo-cli/sweepID
sweep ジョブの開始方法の詳細については、sweep ジョブの開始を参照してください。
メトリクス をログに記録する際の考慮事項
sweep configuration で指定した メトリクス を明示的に W&B にログに記録してください。サブディレクトリー内で sweep の メトリクス をログに記録しないでください。
たとえば、次の疑似コードを考えてみましょう。ユーザーは 検証 損失 ("val_loss": loss) をログに記録したいと考えています。最初に、値を 辞書 に渡します。ただし、wandb.log に渡される 辞書 は、辞書 内のキーと値のペアに明示的にアクセスしません。
# Import the W&B Python Library and log into W&B
# W&B Python ライブラリをインポートし、W&B にログインします
import wandb
import random
def train():
offset = random.random() / 5
acc = 1 - 2**-epoch - random.random() / epoch - offset
loss = 2**-epoch + random.random() / epoch + offset
val_metrics = {"val_loss": loss, "val_acc": acc}
return val_metrics
def main():
wandb.init(entity="<entity>", project="my-first-sweep")
val_metrics = train()
# Incorrect. You must explicitly access the
# key-value pair in the dictionary
# 間違いです。 辞書 のキーと値のペアに明示的にアクセスする必要があります
# 正しいメトリクス の記録方法については、次のコードブロックを参照してください
wandb.log({"val_loss": val_metrics})
sweep_configuration = {
"method": "random",
"metric": {"goal": "minimize", "name": "val_loss"},
"parameters": {
"x": {"max": 0.1, "min": 0.01},
"y": {"values": [1, 3, 7]},
},
}
sweep_id = wandb.sweep(sweep=sweep_configuration, project="my-first-sweep")
wandb.agent(sweep_id, function=main, count=10)
代わりに、Python 辞書 内のキーと値のペアに明示的にアクセスします。たとえば、次のコードは、辞書 を wandb.log メソッドに渡すときに、キーと値のペアを指定します。
# Import the W&B Python Library and log into W&B
# W&B Python ライブラリをインポートし、W&B にログインします
import wandb
import random
def train():
offset = random.random() / 5
acc = 1 - 2**-epoch - random.random() / epoch - offset
loss = 2**-epoch + random.random() / epoch + offset
val_metrics = {"val_loss": loss, "val_acc": acc}
return val_metrics
def main():
wandb.init(entity="<entity>", project="my-first-sweep")
val_metrics = train()
wandb.log({"val_loss", val_metrics["val_loss"]})
sweep_configuration = {
"method": "random",
"metric": {"goal": "minimize", "name": "val_loss"},
"parameters": {
"x": {"max": 0.1, "min": 0.01},
"y": {"values": [1, 3, 7]},
},
}
sweep_id = wandb.sweep(sweep=sweep_configuration, project="my-first-sweep")
wandb.agent(sweep_id, function=main, count=10)
3 - Define a sweep configuration
sweep の 設定ファイルを作成する方法について説明します。
W&B Sweep は、ハイパーパラメーターの値を探索する戦略と、それらを評価するコードを組み合わせたものです。この戦略は、すべてのオプションを試すという単純なものから、ベイズ最適化やHyperband (BOHB) のように複雑なものまであります。
Python 辞書または YAML ファイルで sweep configuration を定義します。sweep configuration の定義方法は、sweep の管理方法によって異なります。
sweep を初期化し、コマンドラインから sweep agent を開始する場合は、YAML ファイルで sweep configuration を定義します。Python スクリプトまたは Jupyter notebook 内で sweep を初期化して完全に開始する場合は、Python 辞書で sweep を定義します。
以下のガイドでは、sweep configuration のフォーマット方法について説明します。トップレベルの sweep configuration キーの包括的なリストについては、Sweep configuration options を参照してください。
基本構造
両方の sweep configuration フォーマットオプション (YAML と Python 辞書) は、キーと 値 のペアとネストされた構造を利用します。
sweep configuration 内のトップレベルキーを使用して、sweep の名前 (name キー)、検索するパラメータ (parameters キー)、パラメータ空間を検索する方法 (method キー) など、sweep 検索の特性を定義します。
たとえば、次のコードスニペットは、YAML ファイル内と Python 辞書内で定義された同じ sweep configuration を示しています。sweep configuration 内には、program、name、method、metric、および parameters という 5 つのトップレベルキーが指定されています。
-
-
コマンドライン (CLI) からインタラクティブに Sweeps を管理する場合は、YAML ファイルで sweep configuration を定義します。
program: train.py
name: sweepdemo
method: bayes
metric:
goal: minimize
name: validation_loss
parameters:
learning_rate:
min: 0.0001
max: 0.1
batch_size:
values: [16, 32, 64]
epochs:
values: [5, 10, 15]
optimizer:
values: ["adam", "sgd"]
Python スクリプトまたは Jupyter notebook でトレーニングアルゴリズムを定義する場合は、Python 辞書データ構造で sweep を定義します。
次のコードスニペットは、sweep_configuration という変数に sweep configuration を格納します。
sweep_configuration = {
"name": "sweepdemo",
"method": "bayes",
"metric": {"goal": "minimize", "name": "validation_loss"},
"parameters": {
"learning_rate": {"min": 0.0001, "max": 0.1},
"batch_size": {"values": [16, 32, 64]},
"epochs": {"values": [5, 10, 15]},
"optimizer": {"values": ["adam", "sgd"]},
},
}
トップレベルの parameters キー内には、learning_rate、batch_size、epoch、および optimizer というキーがネストされています。指定するネストされたキーごとに、1 つまたは複数の 値 、分布、確率などを指定できます。詳細については、Sweep configuration options の parameters セクションを参照してください。
二重にネストされたパラメータ
sweep configuration は、ネストされたパラメータをサポートしています。ネストされたパラメータを区切るには、トップレベルのパラメータ名の下に追加の parameters キーを使用します。sweep config は、複数レベルのネスティングをサポートしています。
ベイズまたはランダムなハイパーパラメータ検索を使用する場合は、確率分布をランダム変数に指定します。各ハイパーパラメータについて:
- sweep config にトップレベルの
parameters キーを作成します。
parameters キー内に、以下をネストします。
- 最適化するハイパーパラメータの名前を指定します。
distribution キーに使用する分布を指定します。ハイパーパラメータ名の下に distribution キーと 値 のペアをネストします。- 探索する 1 つまたは複数の 値 を指定します。値 (または 値 ) は、分布キーとインラインである必要があります。
- (オプション) トップレベルのパラメータ名の下に追加の parameters キーを使用して、ネストされたパラメータを区切ります。
sweep configuration で定義されたネストされたパラメータは、W&B run configuration で指定されたキーを上書きします。
たとえば、train.py Python スクリプトで次の設定で W&B run を初期化するとします (1 ~ 2 行を参照)。次に、sweep_configuration という辞書で sweep configuration を定義します (4 ~ 13 行を参照)。次に、sweep config 辞書を wandb.sweep に渡して、sweep config を初期化します (16 行を参照)。
def main():
run = wandb.init(config={"nested_param": {"manual_key": 1}})
sweep_configuration = {
"top_level_param": 0,
"nested_param": {
"learning_rate": 0.01,
"double_nested_param": {"x": 0.9, "y": 0.8},
},
}
# Sweep を config に渡して初期化します。
sweep_id = wandb.sweep(sweep=sweep_configuration, project="<project>")
# Sweep ジョブを開始します。
wandb.agent(sweep_id, function=main, count=4)
W&B run の初期化時に渡される nested_param.manual_key にはアクセスできません。run.config は、sweep configuration 辞書で定義されているキーと 値 のペアのみを保持します。
Sweep configuration テンプレート
次のテンプレートは、パラメータを構成し、検索制約を指定する方法を示しています。<> で囲まれた hyperparameter_name をハイパーパラメータの名前に置き換え、 値 を置き換えます。
program: <insert>
method: <insert>
parameter:
hyperparameter_name0:
value: 0
hyperparameter_name1:
values: [0, 0, 0]
hyperparameter_name:
distribution: <insert>
value: <insert>
hyperparameter_name2:
distribution: <insert>
min: <insert>
max: <insert>
q: <insert>
hyperparameter_name3:
distribution: <insert>
values:
- <list_of_values>
- <list_of_values>
- <list_of_values>
early_terminate:
type: hyperband
s: 0
eta: 0
max_iter: 0
command:
- ${Command macro}
- ${Command macro}
- ${Command macro}
- ${Command macro}
Sweep configuration の例
-
-
program: train.py
method: random
metric:
goal: minimize
name: loss
parameters:
batch_size:
distribution: q_log_uniform_values
max: 256
min: 32
q: 8
dropout:
values: [0.3, 0.4, 0.5]
epochs:
value: 1
fc_layer_size:
values: [128, 256, 512]
learning_rate:
distribution: uniform
max: 0.1
min: 0
optimizer:
values: ["adam", "sgd"]
sweep_config = {
"method": "random",
"metric": {"goal": "minimize", "name": "loss"},
"parameters": {
"batch_size": {
"distribution": "q_log_uniform_values",
"max": 256,
"min": 32,
"q": 8,
},
"dropout": {"values": [0.3, 0.4, 0.5]},
"epochs": {"value": 1},
"fc_layer_size": {"values": [128, 256, 512]},
"learning_rate": {"distribution": "uniform", "max": 0.1, "min": 0},
"optimizer": {"values": ["adam", "sgd"]},
},
}
Bayes hyperband の例
program: train.py
method: bayes
metric:
goal: minimize
name: val_loss
parameters:
dropout:
values: [0.15, 0.2, 0.25, 0.3, 0.4]
hidden_layer_size:
values: [96, 128, 148]
layer_1_size:
values: [10, 12, 14, 16, 18, 20]
layer_2_size:
values: [24, 28, 32, 36, 40, 44]
learn_rate:
values: [0.001, 0.01, 0.003]
decay:
values: [1e-5, 1e-6, 1e-7]
momentum:
values: [0.8, 0.9, 0.95]
epochs:
value: 27
early_terminate:
type: hyperband
s: 2
eta: 3
max_iter: 27
次のタブは、early_terminate の最小または最大イテレーション数を指定する方法を示しています。
-
-
この例のブラケットは [3, 3*eta, 3*eta*eta, 3*eta*eta*eta] で、これは [3, 9, 27, 81] と同じです。
early_terminate:
type: hyperband
min_iter: 3
この例のブラケットは [27/eta, 27/eta/eta] で、これは [9, 3] と同じです。
early_terminate:
type: hyperband
max_iter: 27
s: 2
コマンドの例
program: main.py
metric:
name: val_loss
goal: minimize
method: bayes
parameters:
optimizer.config.learning_rate:
min: !!float 1e-5
max: 0.1
experiment:
values: [expt001, expt002]
optimizer:
values: [sgd, adagrad, adam]
command:
- ${env}
- ${interpreter}
- ${program}
- ${args_no_hyphens}
/usr/bin/env python train.py --param1=value1 --param2=value2
python train.py --param1=value1 --param2=value2
次のタブは、一般的なコマンドマクロを指定する方法を示しています。
-
-
-
-
{$interpreter} マクロを削除し、python インタープリターをハードコードするために 値 を明示的に指定します。たとえば、次のコードスニペットは、これを行う方法を示しています。
command:
- ${env}
- python3
- ${program}
- ${args}
以下は、sweep configuration パラメータで指定されていない追加のコマンドライン引数を追加する方法を示しています。
command:
- ${env}
- ${interpreter}
- ${program}
- "--config"
- "your-training-config.json"
- ${args}
プログラムが引数解析を使用していない場合は、引数をすべて渡すことを避け、wandb.init が sweep パラメータを wandb.config に自動的に取り込むことを利用できます。
command:
- ${env}
- ${interpreter}
- ${program}
Hydra などの ツール が期待する方法で引数を渡すようにコマンドを変更できます。詳細については、Hydra with W&B を参照してください。
command:
- ${env}
- ${interpreter}
- ${program}
- ${args_no_hyphens}
3.1 - Sweep configuration options
sweep configurationは、ネストされたキーと値のペアで構成されています。sweep configuration内のトップレベルキーを使用して、検索するパラメータ(parameter キー)、パラメータ空間を検索する方法(method キー)など、sweep検索の品質を定義します。
以下の表は、トップレベルのsweep configurationキーと簡単な説明を示しています。各キーの詳細については、それぞれのセクションを参照してください。
| トップレベルキー |
説明 |
program |
(必須)実行するトレーニングスクリプト |
entity |
このsweepのエンティティ |
project |
このsweepのプロジェクト |
description |
sweepのテキストによる説明 |
name |
sweepの名前。W&B UIに表示されます。 |
method |
(必須)検索戦略 |
metric |
最適化するメトリック(特定の検索戦略と停止基準でのみ使用されます) |
parameters |
(必須)検索するパラメータ範囲 |
early_terminate |
早期停止基準 |
command |
トレーニングスクリプトを呼び出し、引数を渡すためのコマンド構造 |
run_cap |
このsweepのrunの最大数 |
sweep configurationの構造化方法の詳細については、Sweep configurationの構造を参照してください。
metric
metric トップレベルのsweep configurationキーを使用して、最適化する名前、目標、およびターゲットメトリックを指定します。
| キー |
説明 |
name |
最適化するメトリックの名前。 |
goal |
minimize または maximize(デフォルトは minimize)。 |
target |
最適化しているメトリックの目標値。指定した目標値にrunが到達した場合、sweepは新しいrunを作成しません。(runがターゲットに到達すると)runを実行しているアクティブなエージェントは、エージェントが新しいrunの作成を停止するまでrunの完了を待ちます。 |
parameters
YAMLファイルまたはPythonスクリプトで、parametersをトップレベルキーとして指定します。parametersキーの中で、最適化するハイパーパラメータの名前を指定します。一般的なハイパーパラメータには、学習率、バッチサイズ、エポック、オプティマイザーなどがあります。sweep configurationで定義するハイパーパラメータごとに、1つまたは複数の検索制約を指定します。
次の表は、サポートされているハイパーパラメータ検索制約を示しています。ハイパーパラメータとユースケースに基づいて、以下の検索制約のいずれかを使用して、sweep agentに検索場所(分布の場合)または検索または使用するもの(value、valuesなど)を指示します。
| 検索制約 |
説明 |
values |
このハイパーパラメータの有効な値をすべて指定します。gridと互換性があります。 |
value |
このハイパーパラメータの単一の有効な値を指定します。gridと互換性があります。 |
distribution |
確率分布を指定します。デフォルト値については、この表の後の注記を参照してください。 |
probabilities |
randomを使用する場合に、valuesの各要素を選択する確率を指定します。 |
min、max |
(intまたは float)最大値と最小値。intの場合、int_uniform分散ハイパーパラメータ用。floatの場合、uniform分散ハイパーパラメータ用。 |
mu |
(float)normal - または lognormal - 分散ハイパーパラメータの平均パラメータ。 |
sigma |
(float)normal - または lognormal - 分散ハイパーパラメータの標準偏差パラメータ。 |
q |
(float)量子化されたハイパーパラメータの量子化ステップサイズ。 |
parameters |
ルートレベルのパラメータ内に他のパラメータをネストします。 |
分布が指定されていない場合、W&Bは次の条件に基づいて次の分布を設定します。
valuesを指定した場合はcategoricalmaxとminを整数として指定した場合はint_uniformmaxとminをfloatとして指定した場合はuniformvalueにセットを提供した場合はconstant
method
methodキーでハイパーパラメータ検索戦略を指定します。選択できるハイパーパラメータ検索戦略は、グリッド、ランダム、ベイズ探索の3つです。
グリッド検索
ハイパーパラメータ値のすべての組み合わせを反復処理します。グリッド検索は、各反復で使用するハイパーパラメータ値のセットについて、情報に基づかない決定を行います。グリッド検索は、計算コストが高くなる可能性があります。
グリッド検索は、連続検索空間内で検索している場合、永久に実行されます。
ランダム検索
分布に基づいて、各反復でランダムで情報に基づかないハイパーパラメータ値のセットを選択します。コマンドライン、Pythonスクリプト内、またはW&B App UIからプロセスを停止しない限り、ランダム検索は永久に実行されます。
ランダム(method: random)検索を選択した場合は、メトリックキーで分布空間を指定します。
ベイズ探索
ランダムおよびグリッド検索とは対照的に、ベイズモデルは情報に基づいた決定を行います。ベイズ最適化は、確率モデルを使用して、目的関数を評価する前に代用関数で値をテストする反復プロセスを通じて、使用する値を決定します。ベイズ探索は、連続パラメータの数が少ない場合にはうまく機能しますが、スケールは劣ります。ベイズ探索の詳細については、ベイズ最適化入門論文を参照してください。
ベイズ探索は、コマンドライン、Pythonスクリプト内、またはW&B App UIからプロセスを停止しない限り、永久に実行されます。
ランダムおよびベイズ探索の分布オプション
parameterキー内で、ハイパーパラメータの名前をネストします。次に、distributionキーを指定し、値の分布を指定します。
次の表は、W&Bがサポートする分布を示しています。
distributionキーの値 |
説明 |
constant |
定数分布。使用する定数(value)を指定する必要があります。 |
categorical |
カテゴリ分布。このハイパーパラメータの有効な値(values)をすべて指定する必要があります。 |
int_uniform |
整数に対する離散一様分布。maxとminを整数として指定する必要があります。 |
uniform |
連続一様分布。maxとminをfloatとして指定する必要があります。 |
q_uniform |
量子化された一様分布。round(X / q) * qを返します。ここで、Xは一様です。qのデフォルトは1です。 |
log_uniform |
対数一様分布。exp(min)とexp(max)の間の値Xを返します。自然対数はminとmaxの間で均等に分布します。 |
log_uniform_values |
対数一様分布。minとmaxの間の値Xを返します。log(X)はlog(min)とlog(max)の間で均等に分布します。 |
q_log_uniform |
量子化された対数一様分布。round(X / q) * qを返します。ここで、Xはlog_uniformです。qのデフォルトは1です。 |
q_log_uniform_values |
量子化された対数一様分布。round(X / q) * qを返します。ここで、Xはlog_uniform_valuesです。qのデフォルトは1です。 |
inv_log_uniform |
逆対数一様分布。Xを返します。ここで、log(1/X)はminとmaxの間で均等に分布します。 |
inv_log_uniform_values |
逆対数一様分布。Xを返します。ここで、log(1/X)はlog(1/max)とlog(1/min)の間で均等に分布します。 |
normal |
正規分布。平均mu(デフォルト0)および標準偏差sigma(デフォルト1)で正規分布した値を返します。 |
q_normal |
量子化された正規分布。round(X / q) * qを返します。ここで、Xはnormalです。Qのデフォルトは1です。 |
log_normal |
対数正規分布。自然対数log(X)が平均mu(デフォルト0)および標準偏差sigma(デフォルト1)で正規分布するように、値Xを返します。 |
q_log_normal |
量子化された対数正規分布。round(X / q) * qを返します。ここで、Xはlog_normalです。qのデフォルトは1です。 |
early_terminate
パフォーマンスの低いrunを停止するには、早期終了(early_terminate)を使用します。早期終了が発生した場合、W&Bは新しいハイパーパラメータ値のセットで新しいrunを作成する前に、現在のrunを停止します。
early_terminateを使用する場合は、停止アルゴリズムを指定する必要があります。sweep configuration内のearly_terminate内にtypeキーをネストします。
停止アルゴリズム
Hyperbandハイパーパラメータ最適化は、プログラムを停止するか、事前設定された1つ以上の反復回数(ブラケットと呼ばれる)で続行するかを評価します。
W&Bのrunがブラケットに到達すると、sweepはそのrunのメトリックを以前に報告されたすべてのメトリック値と比較します。runのメトリック値が高すぎる場合(目標が最小化の場合)、またはrunのメトリックが低すぎる場合(目標が最大化の場合)、sweepはrunを終了します。
ブラケットは、ログに記録された反復回数に基づいています。ブラケットの数は、最適化するメトリックをログに記録する回数に対応します。反復は、ステップ、エポック、またはその間の何かに対応できます。ステップカウンターの数値は、ブラケットの計算には使用されません。
ブラケットスケジュールを作成するには、min_iterまたはmax_iterのいずれかを指定します。
| キー |
説明 |
min_iter |
最初のブラケットの反復を指定します |
max_iter |
最大反復回数を指定します。 |
s |
ブラケットの総数を指定します(max_iterに必要)。 |
eta |
ブラケット乗数スケジュールを指定します(デフォルト:3)。 |
strict |
元のHyperband論文に厳密に従って、runをより積極的にプルーニングする「strict」モードを有効にします。デフォルトはfalseです。 |
Hyperbandは、数分ごとに終了する
W&B runを確認します。runまたは反復が短い場合、終了runのタイムスタンプは、指定されたブラケットと異なる場合があります。
command
commandキー内のネストされた値を使用して、形式と内容を変更します。ファイル名などの固定コンポーネントを直接含めることができます。
Unixシステムでは、/usr/bin/envは、OSが環境に基づいて正しいPythonインタープリターを選択するようにします。
W&Bは、コマンドの可変コンポーネントに対して次のマクロをサポートしています。
| コマンドマクロ |
説明 |
${env} |
Unixシステムでは/usr/bin/env、Windowsでは省略。 |
${interpreter} |
pythonに展開されます。 |
${program} |
sweep configurationのprogramキーで指定されたトレーニングスクリプトのファイル名。 |
${args} |
--param1=value1 --param2=value2の形式のハイパーパラメータとその値。 |
${args_no_boolean_flags} |
--param1=value1の形式のハイパーパラメータとその値。ただし、ブールパラメータはTrueの場合は--boolean_flag_paramの形式になり、Falseの場合は省略されます。 |
${args_no_hyphens} |
param1=value1 param2=value2の形式のハイパーパラメータとその値。 |
${args_json} |
JSONとしてエンコードされたハイパーパラメータとその値。 |
${args_json_file} |
JSONとしてエンコードされたハイパーパラメータとその値を含むファイルへのパス。 |
${envvar} |
環境変数を渡す方法。${envvar:MYENVVAR} はMYENVVAR環境変数の値に展開されます。 |
4 - Initialize a sweep
W&B Sweep の初期化
W&B は、クラウド(標準)、ローカル(ローカル)の 1 台以上のマシンで Sweeps を管理するために、 Sweep Controller を使用します。run が完了すると、sweep controller は、実行する新しい run を記述した新しい一連の指示を発行します。これらの指示は、実際に run を実行する エージェント によって取得されます。典型的な W&B Sweep では、コントローラは W&B サーバー上に存在します。エージェントは あなたの マシン上に存在します。
以下のコードスニペットは、CLI および Jupyter Notebook または Python スクリプト内で Sweeps を初期化する方法を示しています。
- sweep を初期化する前に、sweep configuration が YAML ファイルまたはスクリプト内のネストされた Python 辞書 object で定義されていることを確認してください。詳細については、sweep configuration の定義を参照してください。
- W&B Sweep と W&B Run は、同じ project 内にある必要があります。したがって、W&B を初期化するときに指定する名前 (
wandb.init) は、W&B Sweep を初期化するときに指定する project の名前 (wandb.sweep) と一致する必要があります。
-
-
W&B SDK を使用して sweep を初期化します。sweep configuration 辞書を sweep パラメータに渡します。オプションで、W&B Run の出力を保存する project パラメータ(project)の project 名を指定します。project が指定されていない場合、run は「未分類」の project に配置されます。
import wandb
# sweep configuration の例
sweep_configuration = {
"method": "random",
"name": "sweep",
"metric": {"goal": "maximize", "name": "val_acc"},
"parameters": {
"batch_size": {"values": [16, 32, 64]},
"epochs": {"values": [5, 10, 15]},
"lr": {"max": 0.1, "min": 0.0001},
},
}
sweep_id = wandb.sweep(sweep=sweep_configuration, project="project-name")
wandb.sweep 関数は、sweep ID を返します。sweep ID には、Entity 名と project 名が含まれます。sweep ID をメモしておいてください。
W&B CLI を使用して sweep を初期化します。configuration ファイルの名前を指定します。オプションで、project フラグの project 名を指定します。project が指定されていない場合、W&B Run は「未分類」の project に配置されます。
wandb sweep コマンドを使用して、sweep を初期化します。次のコード例では、sweeps_demo project の sweep を初期化し、configuration に config.yaml ファイルを使用します。
wandb sweep --project sweeps_demo config.yaml
このコマンドは、sweep ID を出力します。sweep ID には、Entity 名と project 名が含まれます。sweep ID をメモしておいてください。
5 - Start or stop a sweep agent
複数のマシン上で W&B Sweep エージェントを開始または停止します。
複数のマシン上の 1 つまたは複数のエージェントで W&B Sweep を開始します。W&B Sweep エージェントは、ハイパーパラメータのために W&B Sweep ( wandb sweep) を初期化したときに起動した W&B サーバーにクエリを実行し、それらを使用してモデルトレーニングを実行します。
W&B Sweep エージェントを開始するには、W&B Sweep を初期化したときに返された W&B Sweep ID を指定します。W&B Sweep ID の形式は次のとおりです。
以下に詳細を示します。
- entity: W&B のユーザー名または Team 名。
- project: W&B Run の出力を保存する Project の名前。Project が指定されていない場合、run は「未分類」Project に配置されます。
- sweep_ID: W&B によって生成された、疑似ランダムな一意の ID。
Jupyter Notebook または Python スクリプト内で W&B Sweep エージェントを開始する場合、W&B Sweep が実行する関数の名前を指定します。
以下のコードスニペットは、W&B でエージェントを開始する方法を示しています。設定ファイルが既にあって、W&B Sweep を初期化済みであることを前提としています。設定ファイルを定義する方法の詳細については、Sweep 設定の定義 を参照してください。
-
-
wandb agent コマンドを使用して sweep を開始します。sweep を初期化したときに返された sweep ID を指定します。以下のコードスニペットをコピーして貼り付け、sweep_id を sweep ID に置き換えます。
W&B Python SDK ライブラリを使用して sweep を開始します。sweep を初期化したときに返された sweep ID を指定します。さらに、sweep が実行する関数の名前を指定します。
wandb.agent(sweep_id=sweep_id, function=function_name)
W&B エージェントの停止
ランダム探索とベイズ探索は永久に実行されます。コマンドライン、python スクリプト内、または
Sweeps UI からプロセスを停止する必要があります。
オプションで、W&B Run の数を Sweep エージェントが試行する回数を指定します。次のコードスニペットは、CLI および Jupyter Notebook、Python スクリプト内で W&B Runs の最大数を設定する方法を示しています。
-
-
まず、sweep を初期化します。詳細については、Sweeps の初期化 を参照してください。
sweep_id = wandb.sweep(sweep_config)
次に、sweep ジョブを開始します。sweep の開始から生成された sweep ID を指定します。試行する run の最大数を設定するには、count パラメータに整数値を渡します。
sweep_id, count = "dtzl1o7u", 10
wandb.agent(sweep_id, count=count)
sweep agent の完了後、同じスクリプトまたは Notebook 内で新しい run を開始する場合は、新しい run を開始する前に wandb.teardown() を呼び出す必要があります。
まず、wandb sweep コマンドで sweep を初期化します。詳細については、Sweeps の初期化 を参照してください。
wandb sweep config.yaml
試行する run の最大数を設定するには、count フラグに整数値を渡します。
NUM=10
SWEEPID="dtzl1o7u"
wandb agent --count $NUM $SWEEPID
6 - Parallelize agents
マルチコアまたはマルチ GPU マシンで W&B Sweep エージェント を並列化します。
マルチコアまたはマルチ GPU マシンで W&B Sweep エージェントを並列化します。開始する前に、W&B Sweep を初期化していることを確認してください。W&B Sweep の初期化方法の詳細については、Sweeps の初期化 を参照してください。
マルチ CPU マシンでの並列化
ユースケースに応じて、次のタブで CLI を使用するか、Jupyter Notebook 内で W&B Sweep エージェントを並列化する方法を検討してください。
wandb agent コマンドを使用して、ターミナルで複数の CPU に W&B Sweep エージェントを並列化します。sweep を初期化 したときに返された sweep ID を指定します。
- ローカルマシンで複数のターミナルウィンドウを開きます。
- 次の コードスニペット をコピーして貼り付け、
sweep_id を sweep ID に置き換えます。
W&B Python SDK ライブラリを使用して、Jupyter Notebook 内で複数の CPU に W&B Sweep エージェントを並列化します。sweep を初期化 したときに返された sweep ID があることを確認してください。さらに、sweep が function パラメータに対して実行する関数の名前を指定します。
- 複数の Jupyter Notebook を開きます。
- 複数の Jupyter Notebook に W&B Sweep ID をコピーして貼り付け、W&B Sweep を並列化します。たとえば、sweep ID が
sweep_id という変数に格納され、関数の名前が function_name の場合、次の コードスニペット を複数の Jupyter Notebook に貼り付けて、sweep を並列化できます。
wandb.agent(sweep_id=sweep_id, function=function_name)
マルチ GPU マシンでの並列化
次の手順に従って、CUDA Toolkit を使用してターミナルで複数の GPU に W&B Sweep エージェントを並列化します。
- ローカルマシンで複数のターミナルウィンドウを開きます。
- W&B Sweep ジョブ (
wandb agent) を開始するときに、CUDA_VISIBLE_DEVICES で使用する GPU インスタンスを指定します。CUDA_VISIBLE_DEVICES に、使用する GPU インスタンスに対応する整数値を割り当てます。
たとえば、ローカルマシンに 2 つの NVIDIA GPU があるとします。ターミナルウィンドウを開き、CUDA_VISIBLE_DEVICES を 0 (CUDA_VISIBLE_DEVICES=0) に設定します。次の例の sweep_ID を、W&B Sweep を初期化したときに返される W&B Sweep ID に置き換えます。
ターミナル 1
CUDA_VISIBLE_DEVICES=0 wandb agent sweep_ID
2 番目のターミナルウィンドウを開きます。CUDA_VISIBLE_DEVICES を 1 (CUDA_VISIBLE_DEVICES=1) に設定します。上記の コードスニペット で説明されている sweep_ID に同じ W&B Sweep ID を貼り付けます。
ターミナル 2
CUDA_VISIBLE_DEVICES=1 wandb agent sweep_ID
7 - Visualize sweep results
W&B App UIでW&B Sweepsの結果を可視化します。
W&B App UI で W&B Sweeps の結果を可視化します。https://wandb.ai/home にある W&B App UI に移動します。W&B Sweep を初期化する際に指定した project を選択します。project の workspace にリダイレクトされます。左側のパネルにある Sweep icon (ほうきのアイコン) を選択します。Sweep UI で、リストから Sweep の名前を選択します。
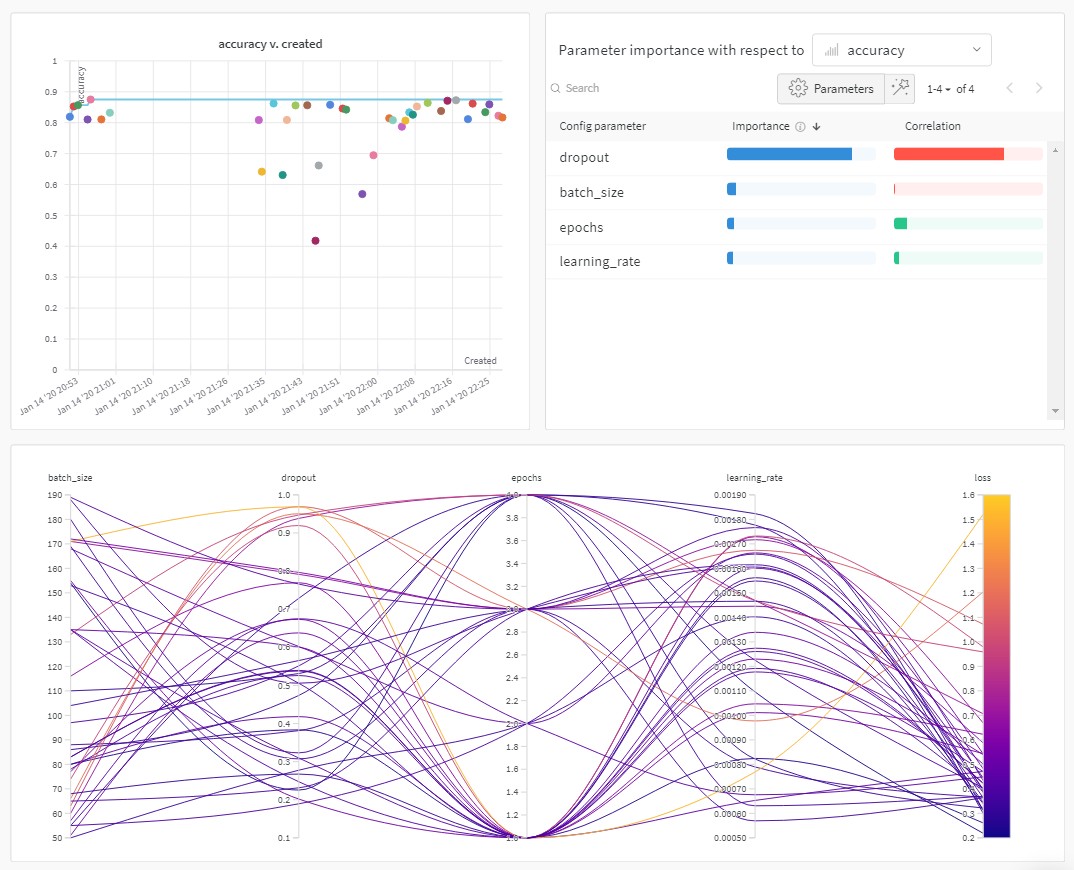
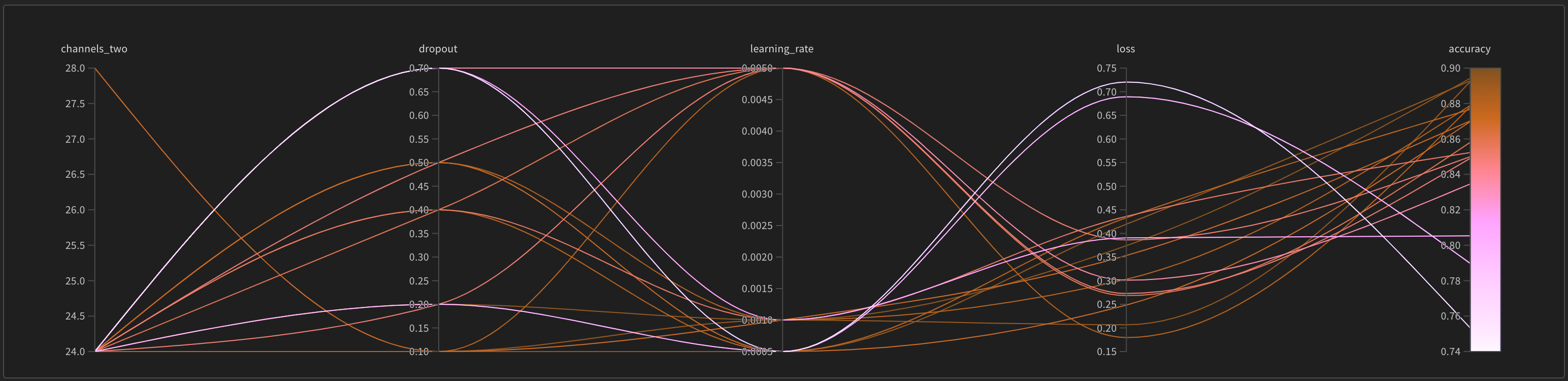
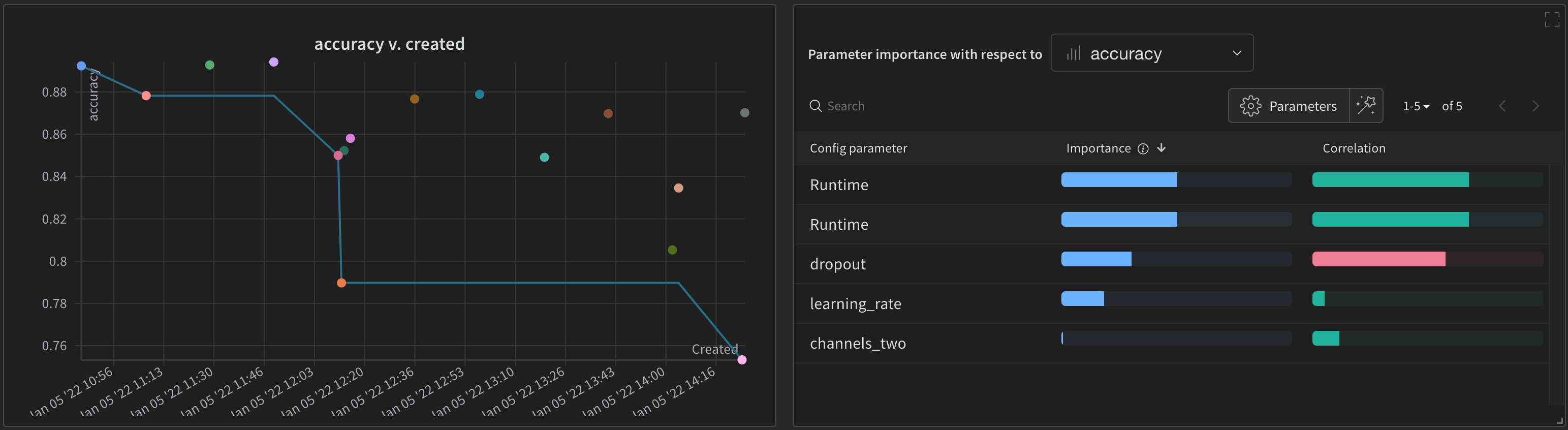
デフォルトでは、W&B は W&B Sweep ジョブを開始すると、自動的にパラレル座標図、パラメータのインポータンスプロット、および散布図を作成します。
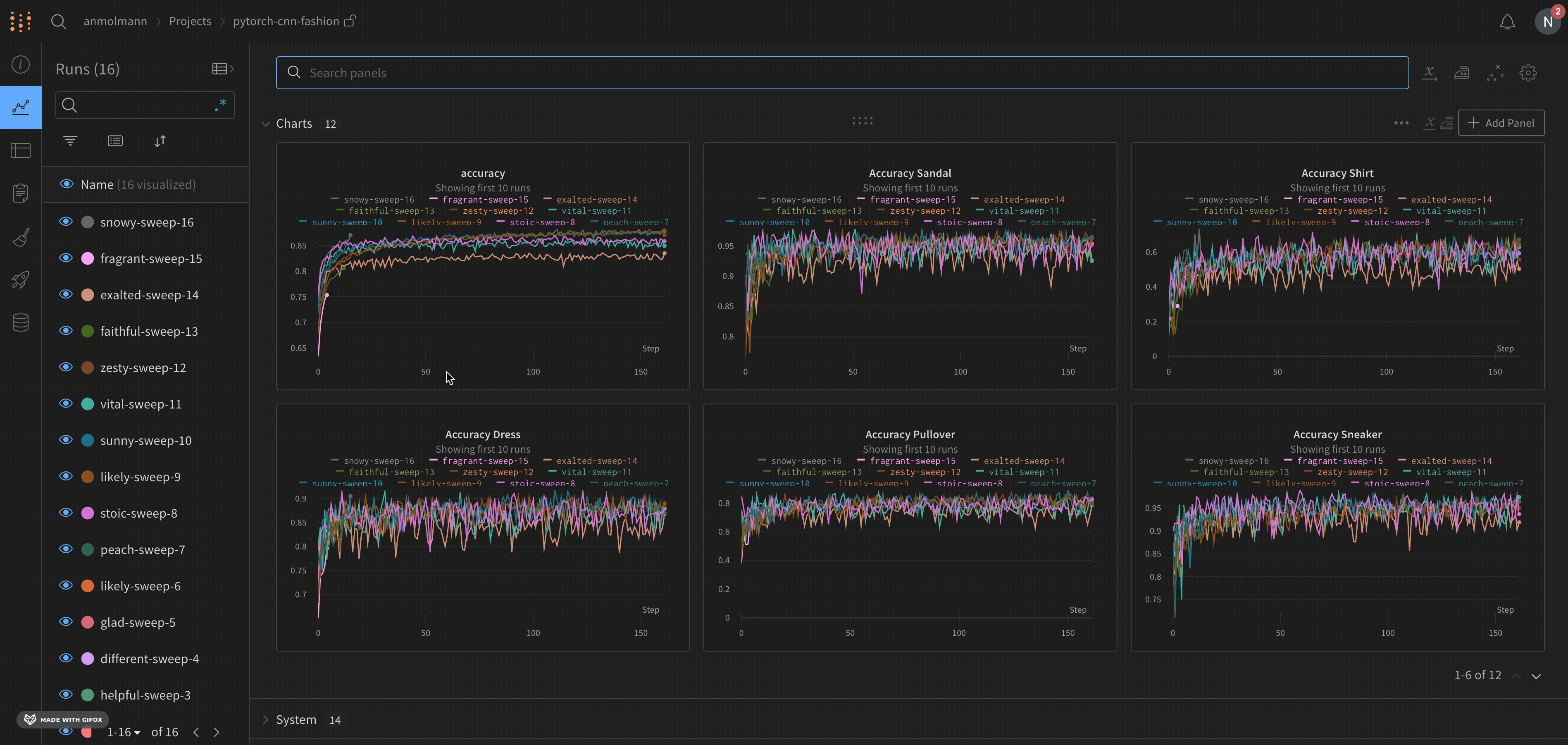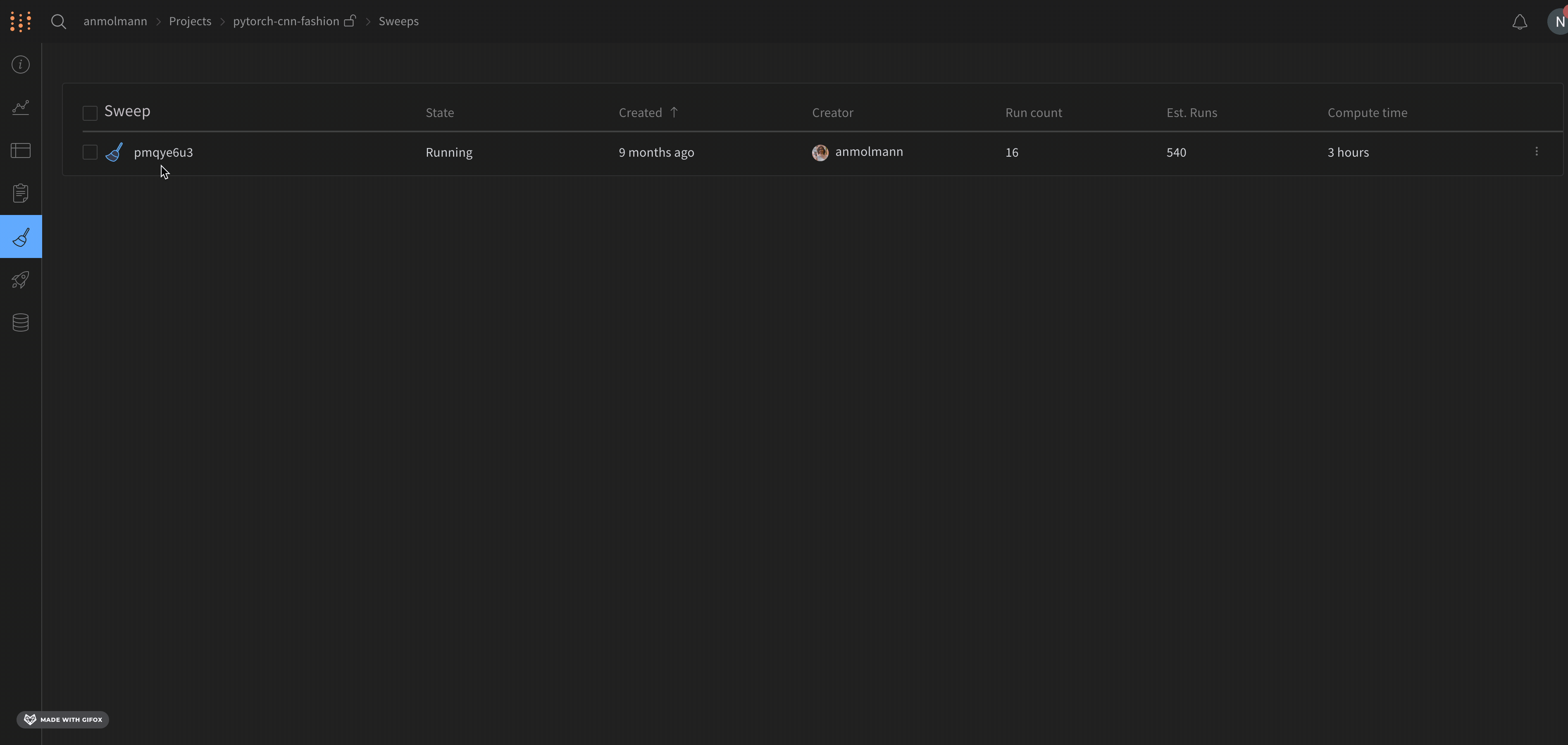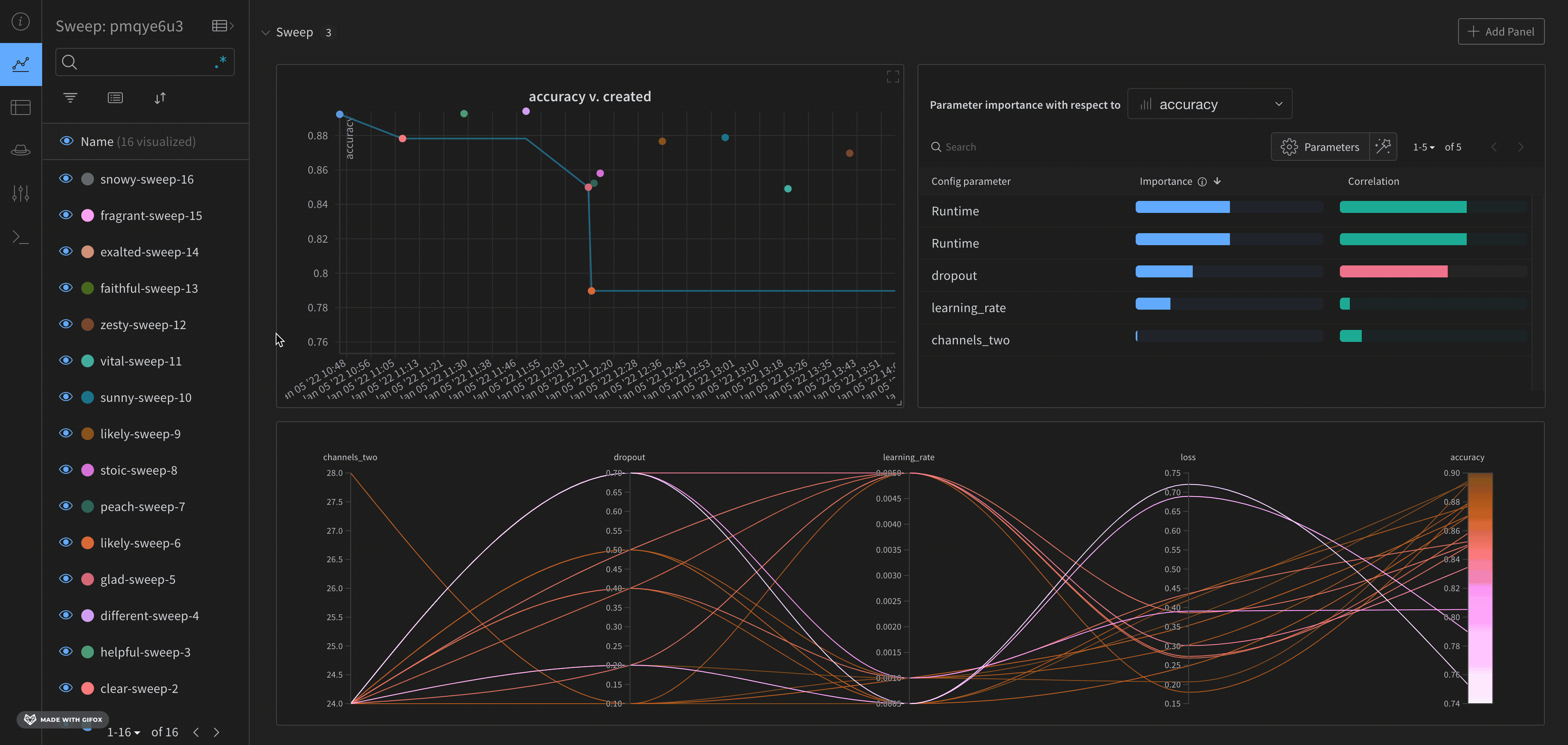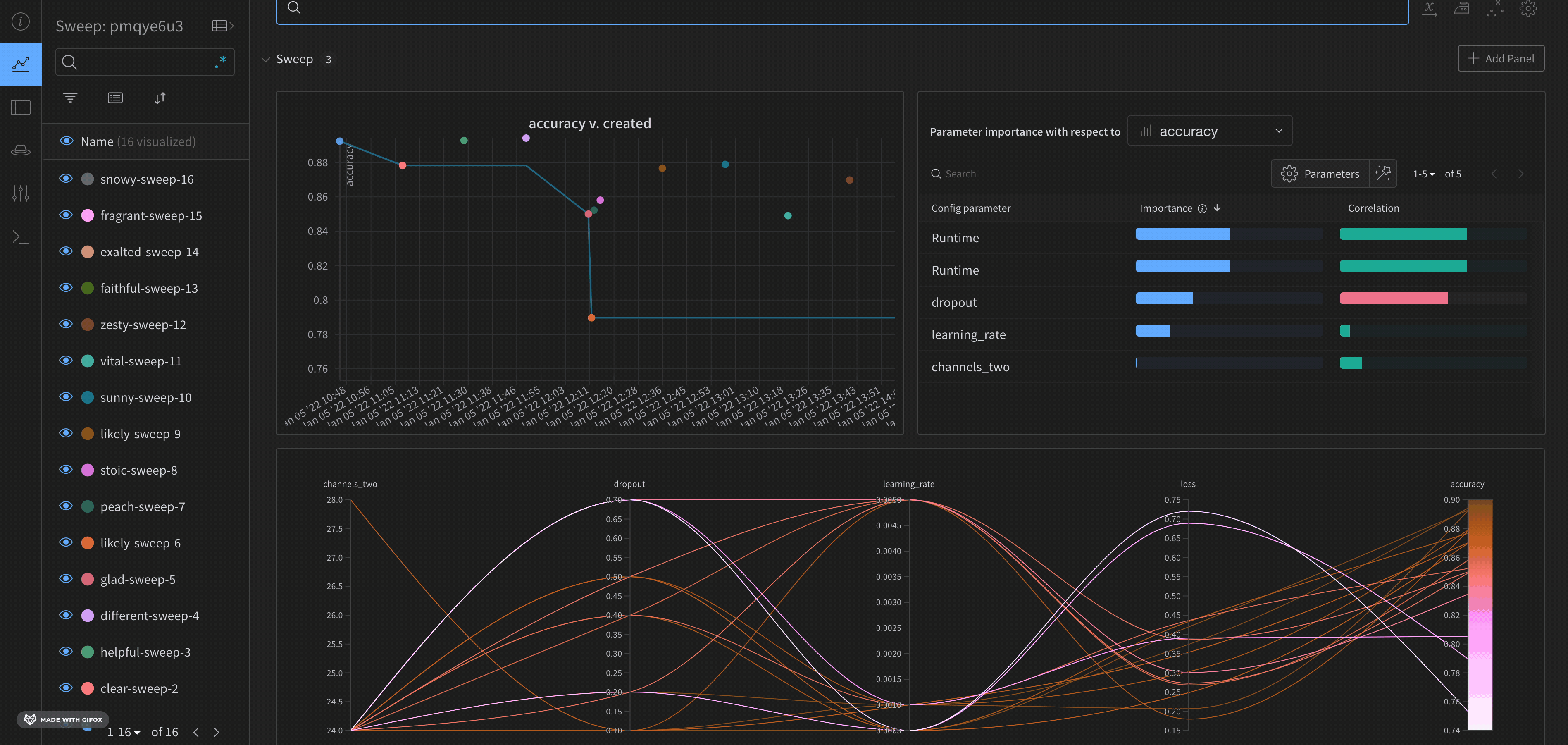
パラレル座標図は、多数のハイパーパラメータとモデルのメトリクスの関係を一目でまとめたものです。パラレル座標図の詳細については、パラレル座標 を参照してください。
散布図 (左) は、Sweep 中に生成された W&B Runs を比較します。散布図の詳細については、散布図 を参照してください。
パラメータのインポータンスプロット (右) は、メトリクスの望ましい値の最良の予測因子であり、メトリクスの望ましい値と高度に相関するハイパーパラメータをリストします。パラメータのインポータンスプロットの詳細については、パラメータの重要性 を参照してください。
自動的に使用される従属値と独立値 (x 軸と y 軸) を変更できます。各 panel 内には、Edit panel という鉛筆アイコンがあります。Edit panel を選択します。モデルが表示されます。モーダル内で、グラフの振る舞いを変更できます。
すべてのデフォルトの W&B 可視化オプションの詳細については、Panels を参照してください。W&B Sweep の一部ではない W&B Runs からプロットを作成する方法については、Data Visualization のドキュメント を参照してください。
8 - Manage sweeps with the CLI
CLI を使用して、W&B Sweep を一時停止、再開、およびキャンセルします。
CLI で W&B Sweep を一時停止、再開、キャンセルします。W&B Sweep を一時停止すると、Sweep が再開されるまで新しい W&B Run を実行しないように W&B エージェント に指示します。Sweep を再開すると、新しい W&B Run の実行を続行するようにエージェントに指示します。W&B Sweep を停止すると、新しい W&B Run の作成または実行を停止するように W&B Sweep エージェントに指示します。W&B Sweep をキャンセルすると、現在実行中の W&B Run を強制終了し、新しい Run の実行を停止するように Sweep エージェントに指示します。
いずれの場合も、W&B Sweep を初期化したときに生成された W&B Sweep ID を指定してください。必要に応じて、新しい ターミナル ウィンドウを開いて、次のコマンドを実行します。W&B Sweep が現在の ターミナル ウィンドウに出力ステートメントを出力している場合は、新しい ターミナル ウィンドウを開くとコマンドを実行しやすくなります。
次のガイダンスに従って、sweep を一時停止、再開、およびキャンセルします。
Sweep の一時停止
新しい W&B Run の実行を一時的に停止するように W&B Sweep を一時停止します。W&B Sweep を一時停止するには、wandb sweep --pause コマンドを使用します。一時停止する W&B Sweep ID を指定します。
wandb sweep --pause entity/project/sweep_ID
Sweep の再開
wandb sweep --resume コマンドを使用して、一時停止した W&B Sweep を再開します。再開する W&B Sweep ID を指定します。
wandb sweep --resume entity/project/sweep_ID
Sweep の停止
新しい W&B Run の実行を停止し、現在実行中の Run を終了させるには、W&B sweep を完了させます。
wandb sweep --stop entity/project/sweep_ID
Sweep のキャンセル
実行中のすべての run を強制終了し、新しい run の実行を停止するには、sweep をキャンセルします。W&B Sweep をキャンセルするには、wandb sweep --cancel コマンドを使用します。キャンセルする W&B Sweep ID を指定します。
wandb sweep --cancel entity/project/sweep_ID
CLI コマンドオプションの完全なリストについては、wandb sweep CLI リファレンス ガイドを参照してください。
複数のエージェントにまたがる sweep の一時停止、再開、停止、およびキャンセル
単一の ターミナル から複数のエージェントにまたがって W&B Sweep を一時停止、再開、停止、またはキャンセルします。たとえば、マルチコアマシンがあるとします。W&B Sweep を初期化した後、新しい ターミナル ウィンドウを開き、各新しい ターミナル に Sweep ID をコピーします。
任意の ターミナル 内から、wandb sweep CLI コマンドを使用して、W&B Sweep を一時停止、再開、停止、またはキャンセルします。たとえば、次の コードスニペット は、CLI を使用して複数の エージェント にまたがる W&B Sweep を一時停止する方法を示しています。
wandb sweep --pause entity/project/sweep_ID
エージェント 全体で Sweep を再開するには、Sweep ID と共に --resume フラグを指定します。
wandb sweep --resume entity/project/sweep_ID
W&B エージェント を並列化する方法の詳細については、エージェント の並列化 を参照してください。
9 - Learn more about sweeps
Sweeps に役立つ情報源を集めました。
学術論文
Li, Lisha, 他. “Hyperband: A novel bandit-based approach to hyperparameter optimization.” The Journal of Machine Learning Research 18.1 (2017): 6765-6816.
Sweep Experiments
以下の W&B Reports は、W&B Sweeps を使用したハイパーパラメーター最適化を調査する Projects の例を示しています。
selfm-anaged
次のハウツー ガイドでは、W&B を使用して実際の問題を解決する方法を示します。
Sweep GitHub リポジトリ
W&B はオープンソースを提唱し、コミュニティからの貢献を歓迎します。GitHub リポジトリは https://github.com/wandb/sweeps にあります。W&B オープンソースリポジトリへの貢献方法については、W&B GitHub のContribution guidelinesを参照してください。
10 - Manage algorithms locally
W&B クラウド でホストされているサービスを使用する代わりに、ローカルでアルゴリズムを検索して停止します。
ハイパーパラメータコントローラは、デフォルトで Weights & Biased によってクラウドサービスとしてホストされています。W&B エージェントはコントローラと通信して、トレーニングに使用するパラメータの次のセットを決定します。コントローラは、どの run を停止できるかを判断するために、早期停止アルゴリズムを実行する役割も担っています。
ローカルコントローラの機能を使用すると、ユーザーはローカルで検索および停止アルゴリズムを開始できます。ローカルコントローラを使用すると、ユーザーはコードを検査および調査して、問題をデバッグしたり、クラウドサービスに組み込むことができる新機能を開発したりできます。
この機能は、 Sweeps ツール用の新しいアルゴリズムのより迅速な開発とデバッグをサポートするために提供されています。実際のハイパーパラメータ最適化のワークロードを目的としたものではありません。
始める前に、W&B SDK(wandb)をインストールする必要があります。コマンドラインに次のコードスニペットを入力します。
pip install wandb sweeps
以下の例では、設定ファイルとトレーニングループが Python スクリプトまたは Jupyter Notebook で定義されていることを前提としています。設定ファイルを定義する方法の詳細については、sweep configuration の定義を参照してください。
コマンドラインからローカルコントローラを実行する
通常、Weights & Biased がクラウドサービスとしてホストするハイパーパラメータコントローラを使用する場合と同様に、sweep を初期化します。コントローラフラグ(controller)を指定して、W&B sweep ジョブにローカルコントローラを使用することを示します。
wandb sweep --controller config.yaml
または、sweep の初期化とローカルコントローラを使用することの指定を2つのステップに分けることもできます。
ステップを分けるには、まず、次のキーと値を sweep の YAML 設定ファイルに追加します。
次に、sweep を初期化します。
sweep を初期化したら、wandb controllerでコントローラを起動します。
# wandb sweep コマンドは sweep_id を出力します
wandb controller {user}/{entity}/{sweep_id}
ローカルコントローラを使用するように指定したら、1つ以上の Sweep agent を起動して sweep を実行します。通常と同じように W&B Sweep を開始します。詳細については、Sweep agent の開始を参照してください。
W&B Python SDK でローカルコントローラを実行する
次のコードスニペットは、W&B Python SDK でローカルコントローラを指定および使用する方法を示しています。
Python SDK でコントローラを使用する最も簡単な方法は、sweep ID をwandb.controllerメソッドに渡すことです。次に、return オブジェクトの run メソッドを使用して、sweep ジョブを開始します。
sweep = wandb.controller(sweep_id)
sweep.run()
コントローラーループをより細かく制御したい場合:
import wandb
sweep = wandb.controller(sweep_id)
while not sweep.done():
sweep.print_status()
sweep.step()
time.sleep(5)
または、提供されるパラメータをさらに制御することもできます。
import wandb
sweep = wandb.controller(sweep_id)
while not sweep.done():
params = sweep.search()
sweep.schedule(params)
sweep.print_status()
コードで sweep を完全に指定する場合は、次のようにします。
import wandb
sweep = wandb.controller()
sweep.configure_search("grid")
sweep.configure_program("train-dummy.py")
sweep.configure_controller(type="local")
sweep.configure_parameter("param1", value=3)
sweep.create()
sweep.run()
11 - Sweeps troubleshooting
W&B Sweep でよくある問題をトラブルシューティングします。
提案されたガイダンスに従って、一般的なエラーメッセージのトラブルシューティングを行います。
CommError, Run does not exist および ERROR Error uploading
これらの 2 つのエラーメッセージが両方とも返された場合、W&B の Run ID が定義されている可能性があります。例として、Jupyter Notebook または Python スクリプトのどこかに、次のようなコードスニペットが定義されている可能性があります。
wandb.init(id="some-string")
W&B は W&B Sweeps によって作成された Runs に対して、ランダムでユニークな ID を自動的に生成するため、W&B Sweeps の Run ID を設定することはできません。
W&B の Run ID は、1 つの project 内でユニークである必要があります。
W&B を初期化する際に、テーブルやグラフに表示されるカスタム名を付けたい場合は、name パラメータに名前を渡すことをお勧めします。例:
wandb.init(name="a helpful readable run name")
Cuda out of memory
このエラーメッセージが表示された場合は、コードをリファクタリングして、プロセスベースの実行を使用するようにします。より具体的には、コードを Python スクリプトに書き換えます。さらに、W&B Python SDK ではなく、CLI から W&B Sweep Agent を呼び出します。
例として、コードを train.py という Python スクリプトに書き換えたとします。トレーニングスクリプトの名前 (train.py) を YAML Sweep configuration ファイル (config.yaml(この例)) に追加します。
program: train.py
method: bayes
metric:
name: validation_loss
goal: maximize
parameters:
learning_rate:
min: 0.0001
max: 0.1
optimizer:
values: ["adam", "sgd"]
次に、次のコードを train.py Python スクリプトに追加します。
if _name_ == "_main_":
train()
CLI に移動し、wandb sweep で W&B Sweep を初期化します。
返された W&B Sweep ID をメモします。次に、Python SDK (wandb.agent) ではなく、CLI で wandb agent を使用して Sweep ジョブを開始します。次のコードスニペットの sweep_ID を、前の手順で返された Sweep ID に置き換えます。
anaconda 400 error
次のエラーは通常、最適化しているメトリックをログに記録しない場合に発生します。
wandb: ERROR Error while calling W&B API: anaconda 400 error:
{"code": 400, "message": "TypeError: bad operand type for unary -: 'NoneType'"}
YAML ファイルまたはネストされた辞書の中で、最適化する「metric」という名前のキーを指定します。このメトリックを必ずログに記録 (wandb.log) してください。さらに、Python スクリプトまたは Jupyter Notebook 内で Sweep を最適化するために定義した 正確な メトリック名を使用してください。設定ファイルの詳細については、Sweep configuration の定義 を参照してください。
12 - Sweeps UI
Sweeps UI のさまざまなコンポーネントについて説明します。
State (ステート)、作成時間(Created)、sweep を開始した Entity (Creator)、完了した run の数(Run count)、sweep の計算にかかった時間(Compute time)は、Sweeps UI に表示されます。sweep が作成すると予想される run の数(Est. Runs)は、離散的な検索空間でグリッド検索を行う場合に提供されます。また、sweep をクリックして、インターフェースから sweep を一時停止、再開、停止、または強制終了することもできます。
13 - Tutorial: Create sweep job from project
既存の W&B プロジェクトから sweep ジョブを作成する方法のチュートリアル。
このチュートリアルでは、既存の W&B の プロジェクト から sweep job を作成する方法について説明します。ここでは、Fashion MNIST データセット を使用して、PyTorch の畳み込み ニューラルネットワーク に画像の分類方法を学習させます。必要な コード と データセット は、W&B のリポジトリにあります。https://github.com/wandb/examples/tree/master/examples/pytorch/pytorch-cnn-fashion
この W&B ダッシュボード で 結果 を確認してください。
1. プロジェクト を作成する
まず、 ベースライン を作成します。W&B examples GitHub リポジトリ から PyTorch MNIST データセット のサンプル モデル をダウンロードします。次に、 モデル を トレーニング します。トレーニング スクリプト は、examples/pytorch/pytorch-cnn-fashion ディレクトリー 内にあります。
- このリポジトリをクローンします
git clone https://github.com/wandb/examples.git
- このサンプルを開きます
cd examples/pytorch/pytorch-cnn-fashion
- run を手動で実行します
python train.py
オプションで、W&B App UI ダッシュボード に表示される例を確認してください。
プロジェクト ページの例を見る →
2. sweep を作成する
プロジェクト ページから、サイドバーの Sweep tab を開き、Create Sweep を選択します。
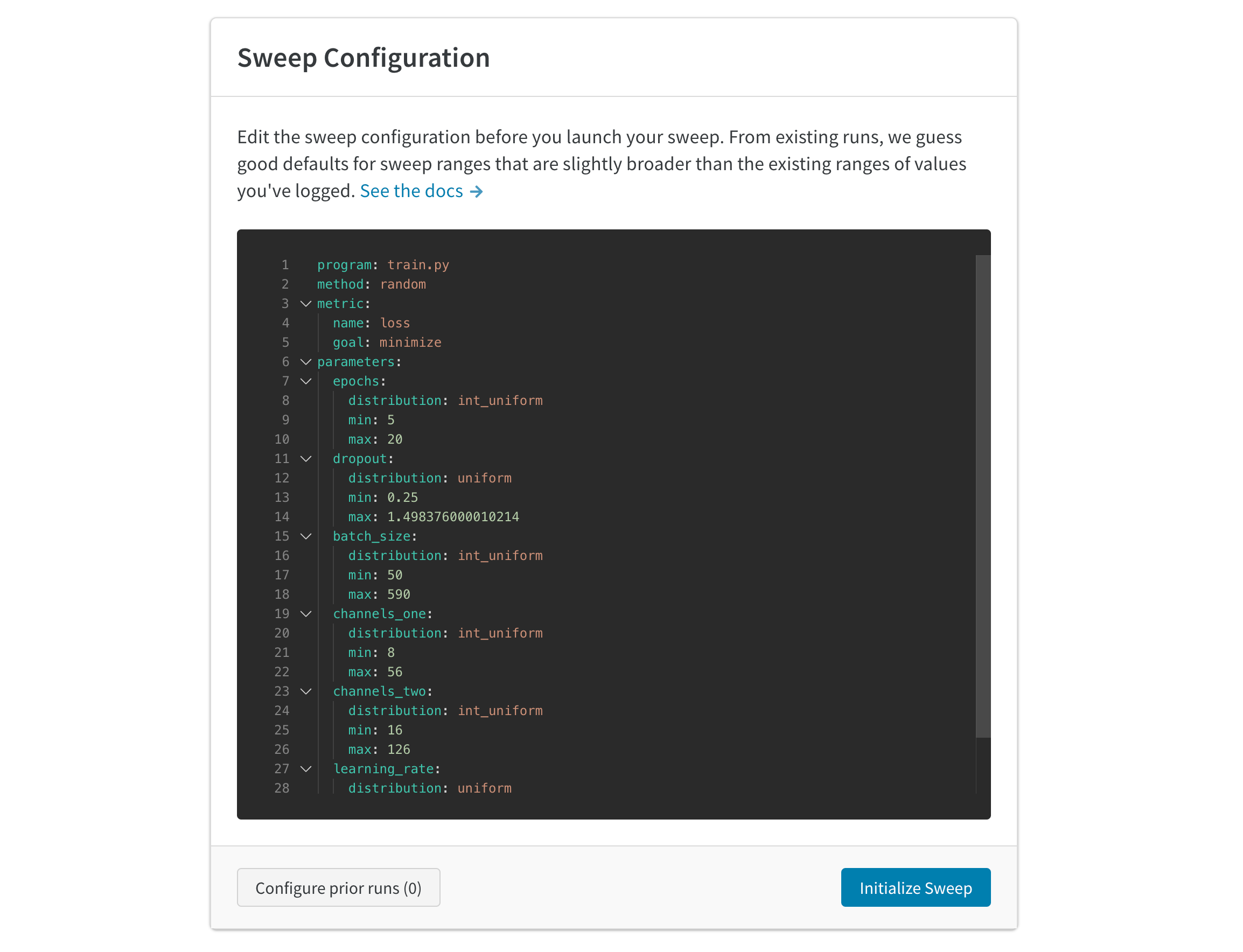
自動生成された 設定 は、完了した run に基づいて sweep する 値 を推測します。試したい ハイパーパラメーター の範囲を指定するには、 設定 を編集します。sweep を 起動 すると、ホストされている W&B sweep server で新しい プロセス が開始されます。この集中型 サービス は、 トレーニング job を実行している マシン である エージェント を調整します。
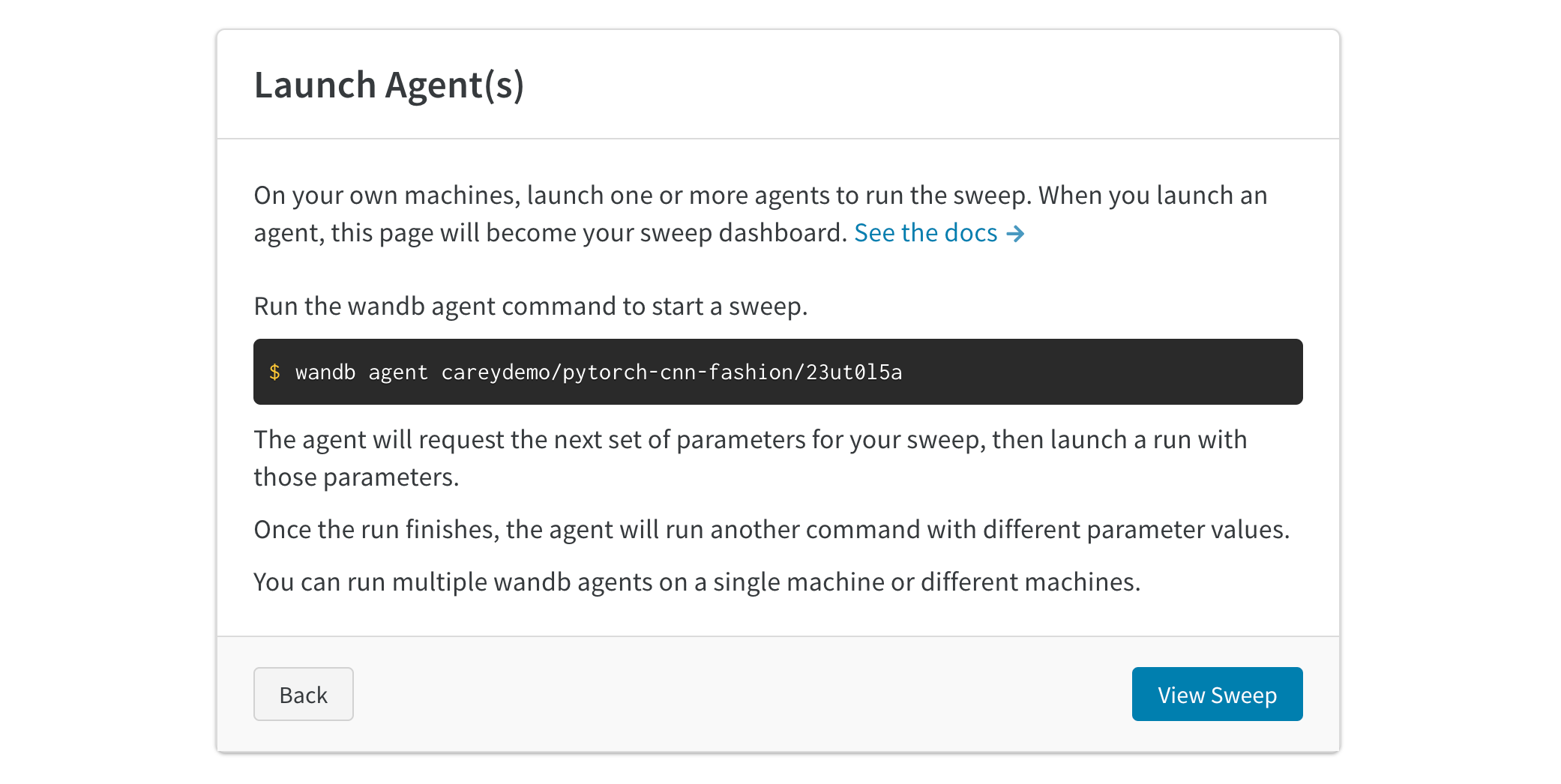
3. エージェント を 起動 する
次に、 ローカル で エージェント を 起動 します。作業を分散して sweep job をより迅速に完了したい場合は、最大 20 個の エージェント を異なる マシン で 並行 して 起動 できます。エージェント は、次に試す パラメータ のセットを出力します。
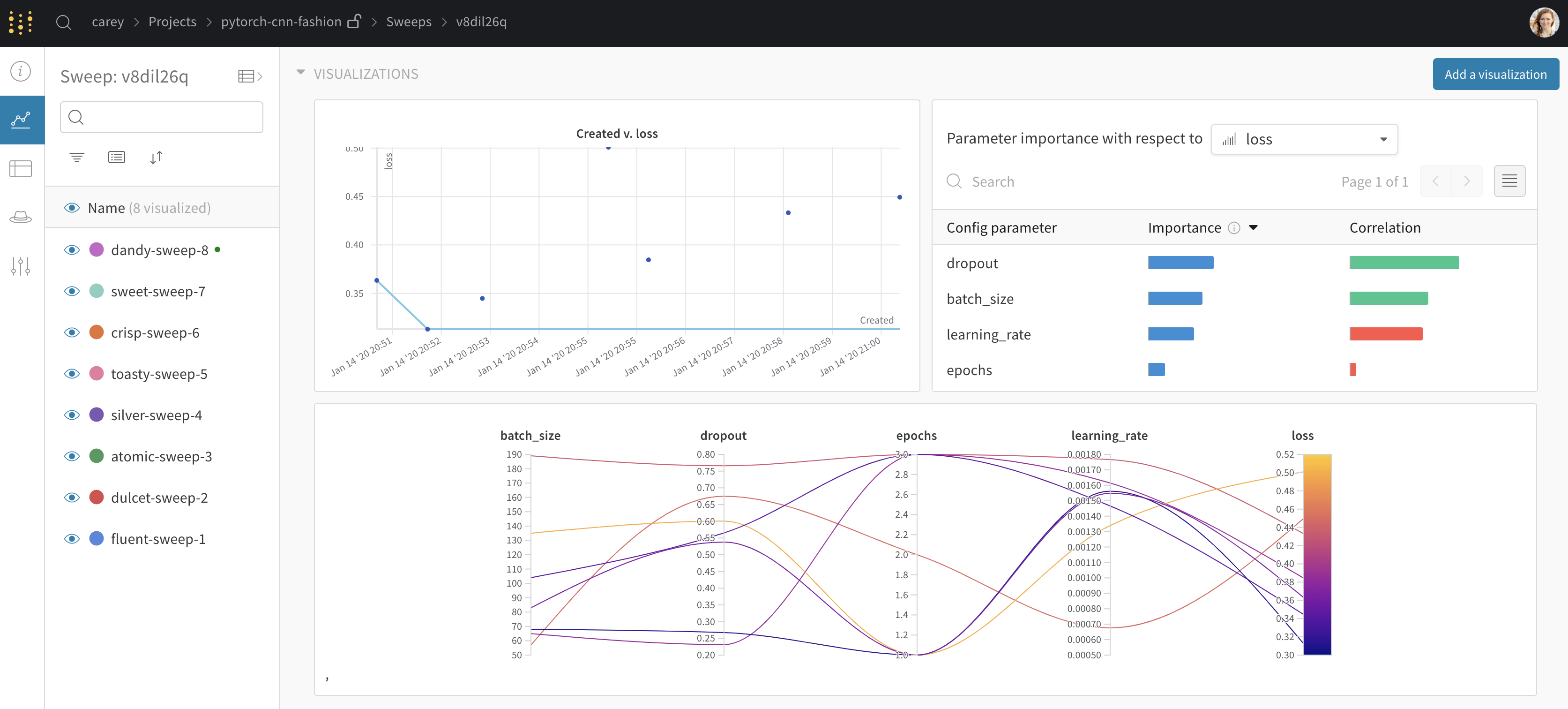
これで sweep が実行されました。次の図は、サンプル sweep job の実行中に ダッシュボード がどのように表示されるかを示しています。プロジェクト ページの例を見る →
既存の run で新しい sweep をシードする
以前に ログ に記録した既存の run を使用して、新しい sweep を 起動 します。
- プロジェクト テーブル を開きます。
- テーブル の左側にある チェックボックス で、使用する run を選択します。
- ドロップダウン をクリックして、新しい sweep を作成します。
これで、sweep が サーバー 上にセットアップされます。run の実行を開始するには、1 つ以上の エージェント を 起動 するだけです。
新しい sweep を ベイジアン sweep として開始すると、選択した run によって ガウス 過程 もシードされます。