Tables
データセットを反復処理し、モデル の予測を理解する
W&B Tables を使用して、テーブル形式のデータを可視化およびクエリします。例:
- 同じテストセットで異なるモデルがどのように機能するかを比較する
- データ内のパターンを特定する
- サンプルモデルの予測を視覚的に確認する
- 一般的に誤分類された例を見つけるためにクエリする
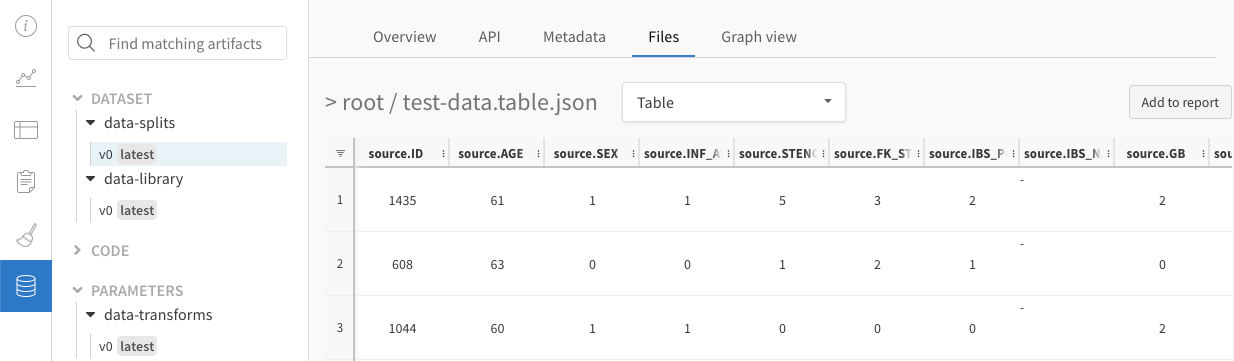
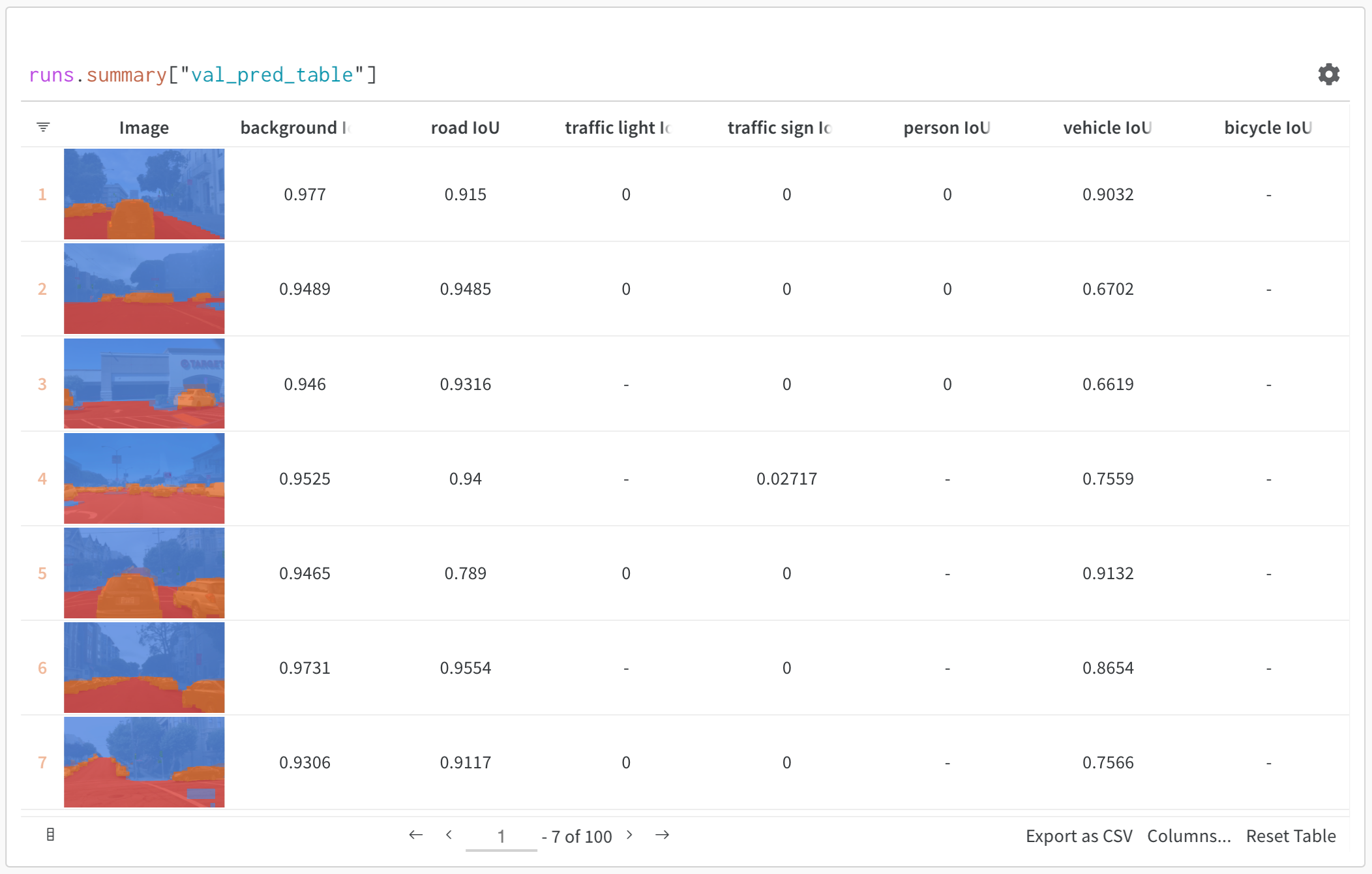 上の画像は、セマンティックセグメンテーションとカスタムメトリクスを含むテーブルを示しています。このテーブルは、W&B ML コースのサンプル project でご覧ください。
上の画像は、セマンティックセグメンテーションとカスタムメトリクスを含むテーブルを示しています。このテーブルは、W&B ML コースのサンプル project でご覧ください。
仕組み
Table は、各カラムが単一のデータ型を持つデータの二次元グリッドです。Tables は、プリミティブ型と数値型、およびネストされたリスト、辞書、リッチメディア型をサポートしています。
Table をログする
数行のコードで Table をログします。
import wandb
run = wandb.init(project="table-test")
my_table = wandb.Table(columns=["a", "b"], data=[["a1", "b1"], ["a2", "b2"]])
run.log({"Table Name": my_table})
開始方法
1 - Tutorial: Log tables, visualize and query data
W&B Tables の使い方を5分間の クイックスタート で見てみましょう。
次の クイックスタート では、データテーブル のログ記録、データの可視化、およびデータのクエリ方法について説明します。
下のボタンを選択して、MNIST データに関する PyTorch の クイックスタート のサンプル プロジェクト を試してください。
1. テーブル のログを記録する
W&B で テーブル のログを記録します。新しい テーブル を構築するか、Pandas Dataframe を渡すことができます。
-
-
新しい テーブル を構築してログに記録するには、以下を使用します。
例を次に示します。
import wandb
run = wandb.init(project="table-test")
# Create and log a new table.
my_table = wandb.Table(columns=["a", "b"], data=[["a1", "b1"], ["a2", "b2"]])
run.log({"Table Name": my_table})
Pandas Dataframe を wandb.Table() に渡して、新しい テーブル を作成します。
import wandb
import pandas as pd
df = pd.read_csv("my_data.csv")
run = wandb.init(project="df-table")
my_table = wandb.Table(dataframe=df)
wandb.log({"Table Name": my_table})
サポートされている データ 型の詳細については、W&B API リファレンス ガイド の wandb.Table を参照してください。
2. プロジェクト ワークスペース で テーブル を可視化する
ワークスペース で結果の テーブル を表示します。
- W&B アプリ で プロジェクト に移動します。
- プロジェクト ワークスペース で run の名前を選択します。一意の テーブル の キー ごとに新しい パネル が追加されます。
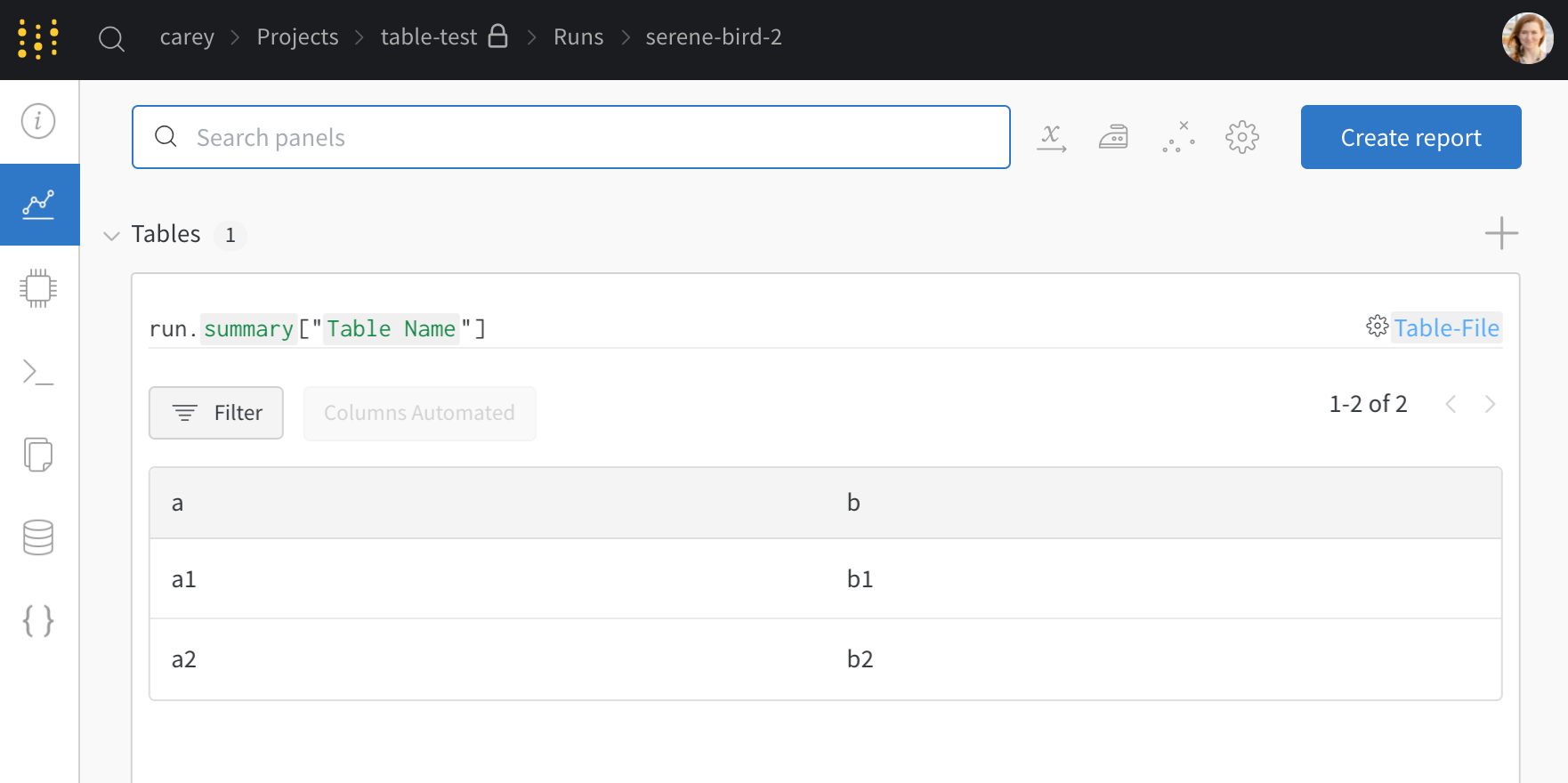
この例では、my_table は キー Table Name でログに記録されます。
3. モデル の バージョン 間で比較する
複数の W&B の Runs からサンプル テーブル をログに記録し、プロジェクト ワークスペース で結果を比較します。この サンプル ワークスペース では、同じ テーブル 内の複数の異なる バージョン から行を結合する方法を示します。
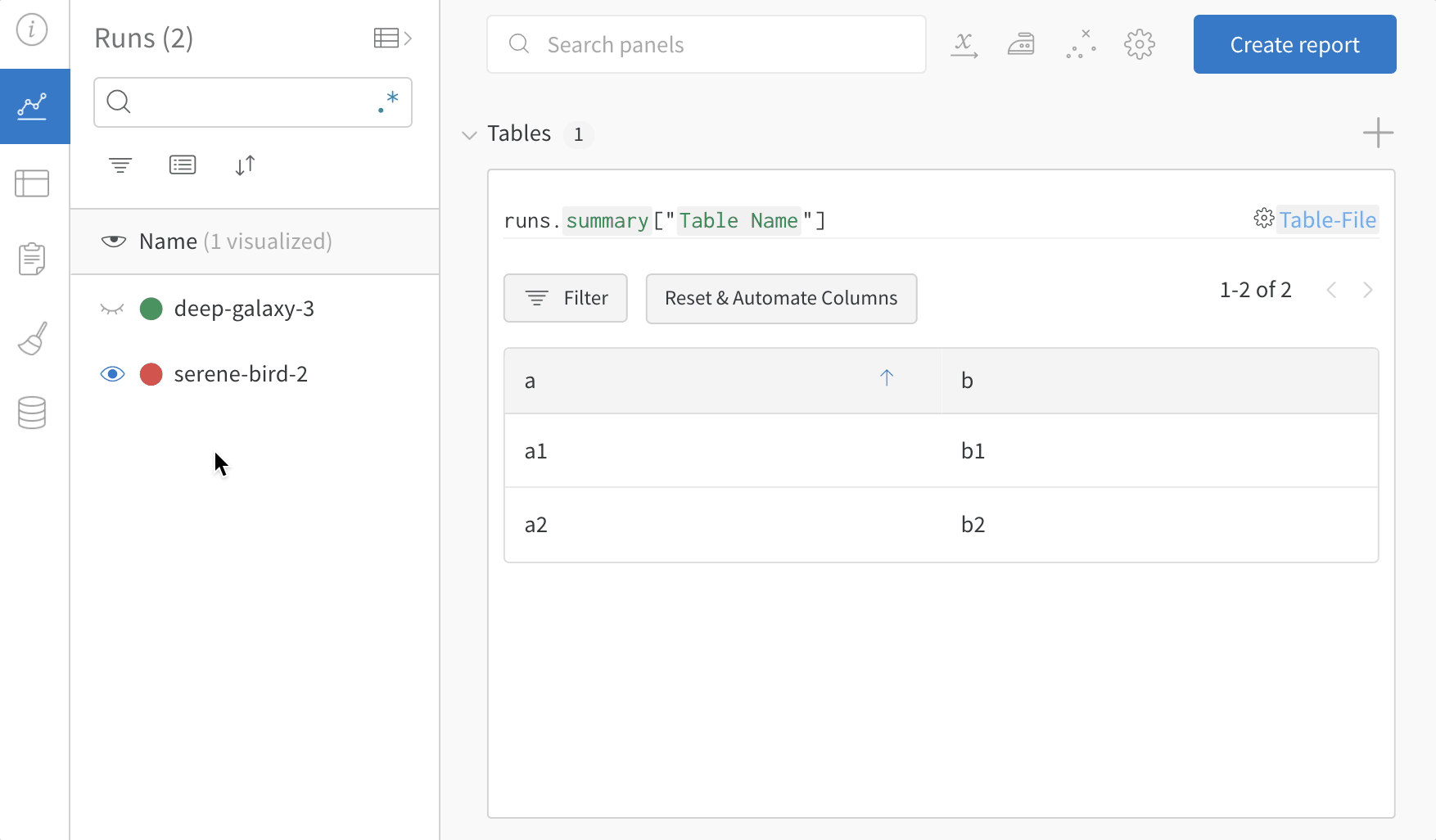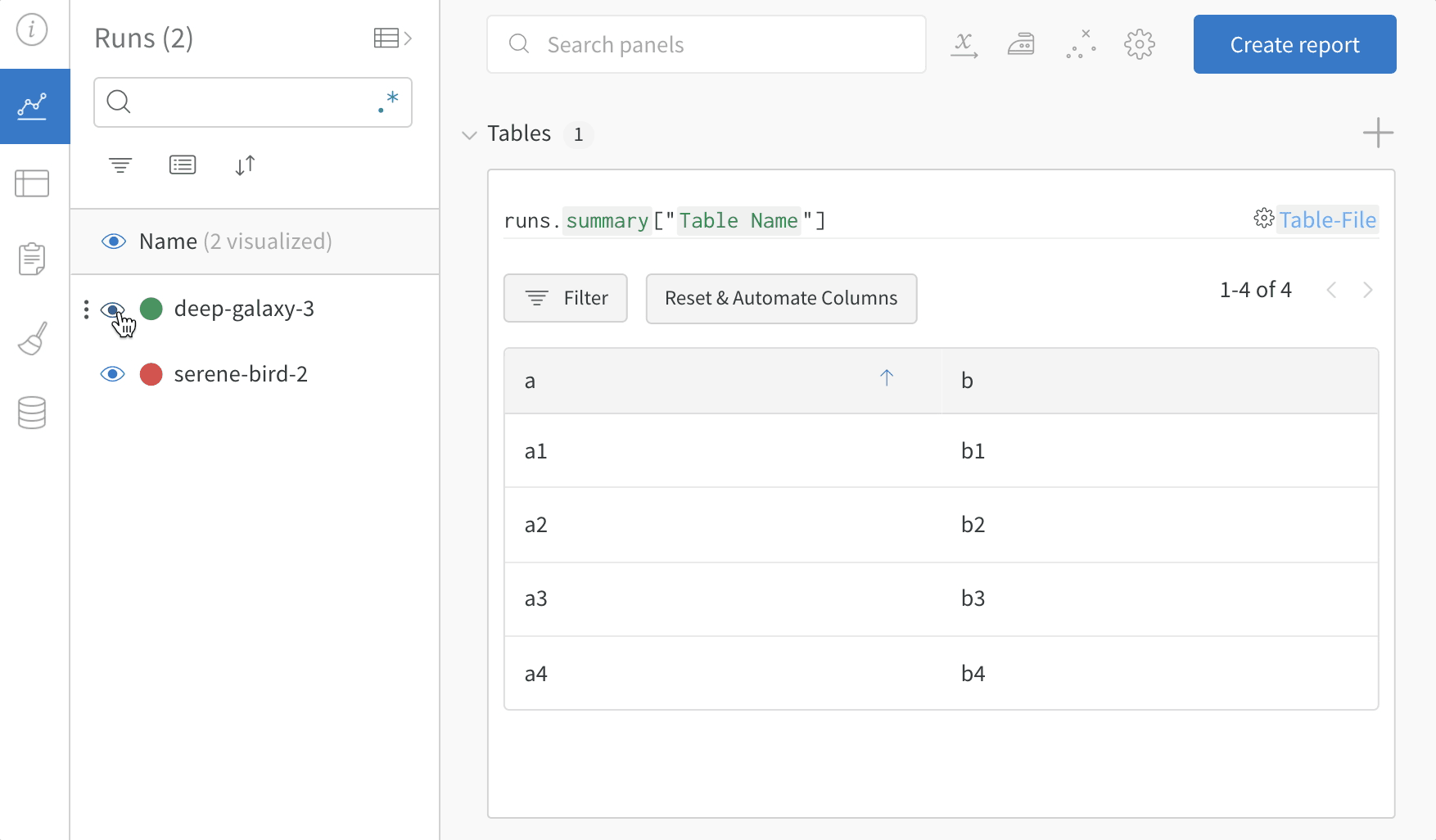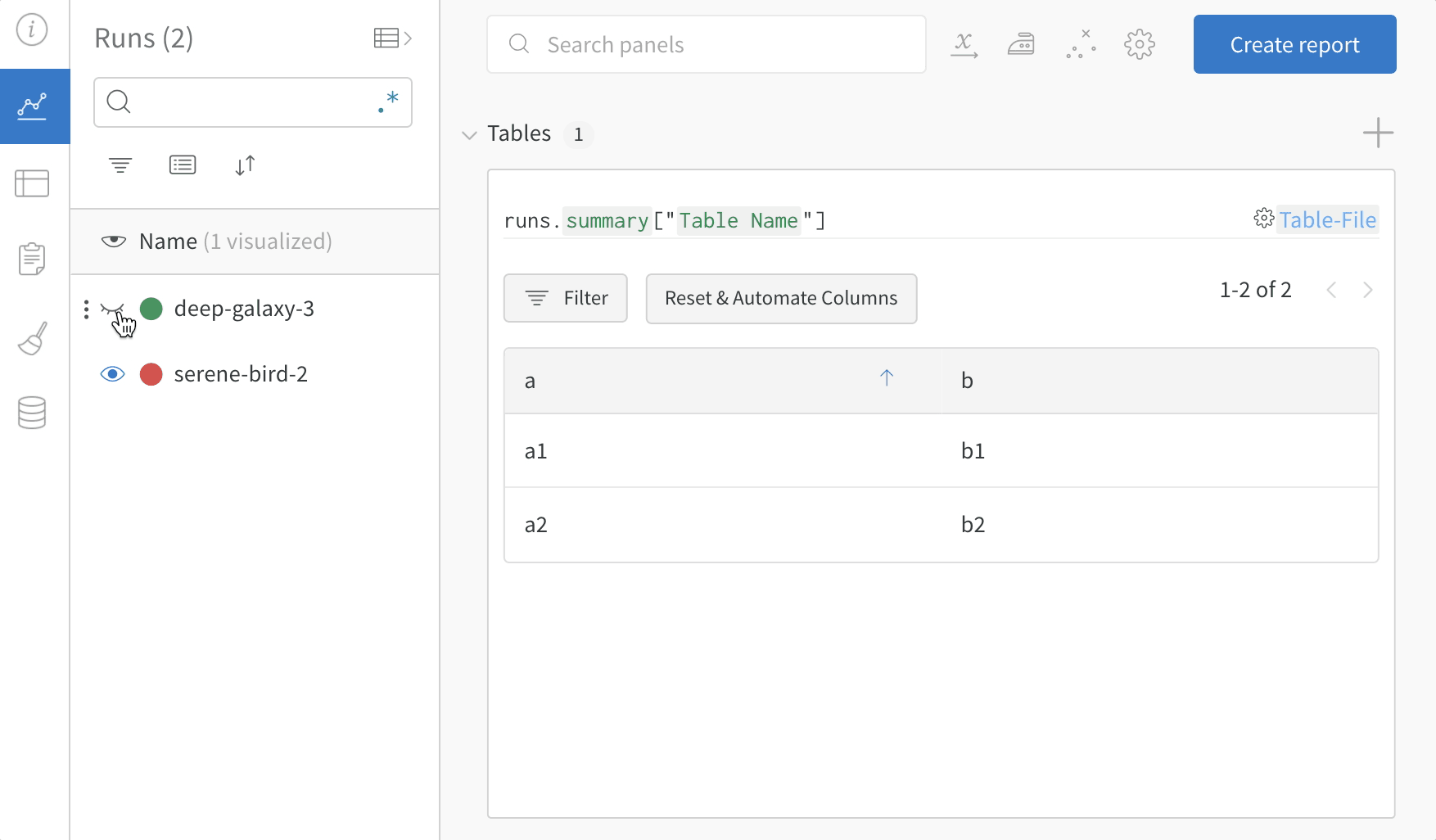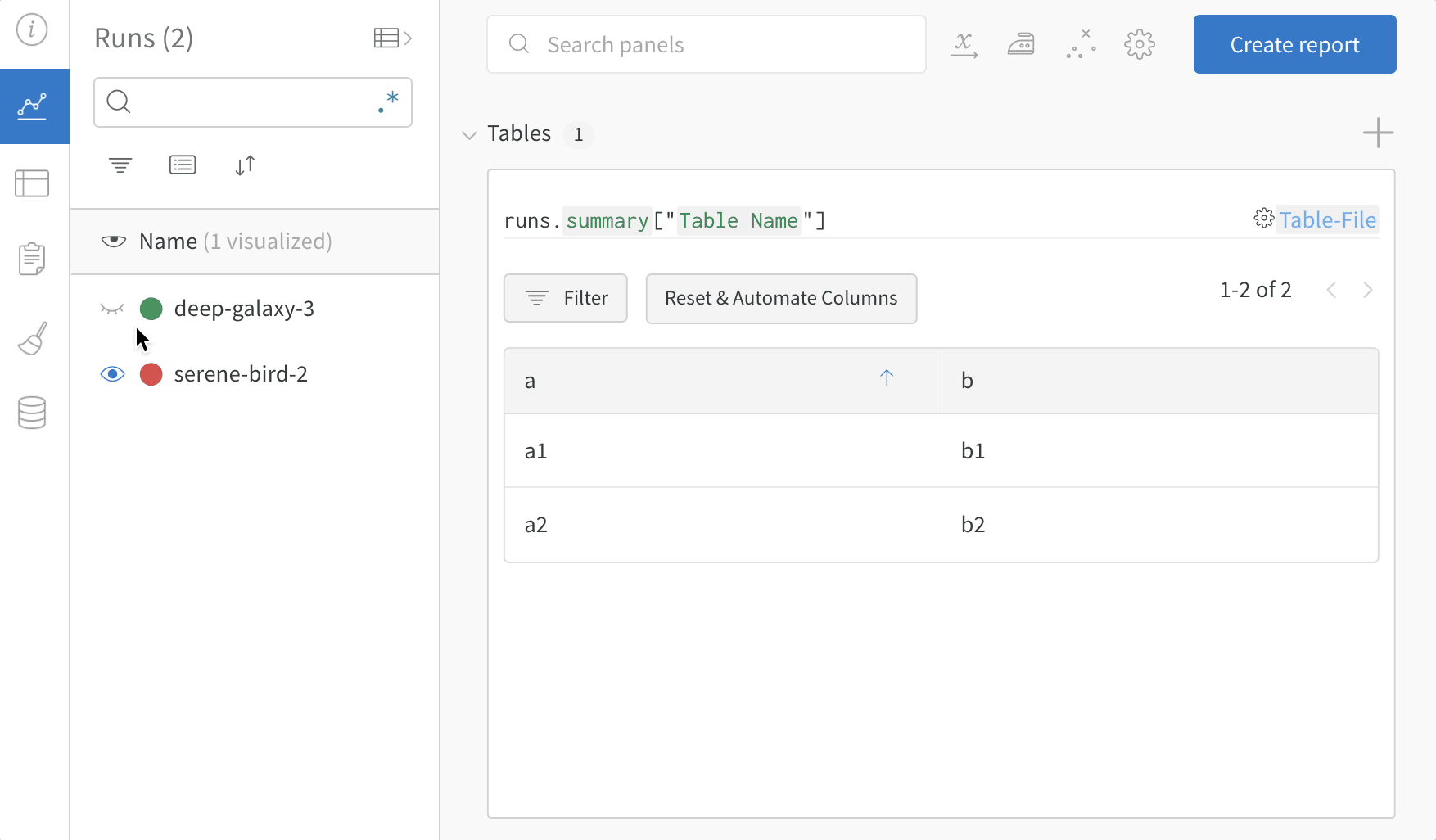
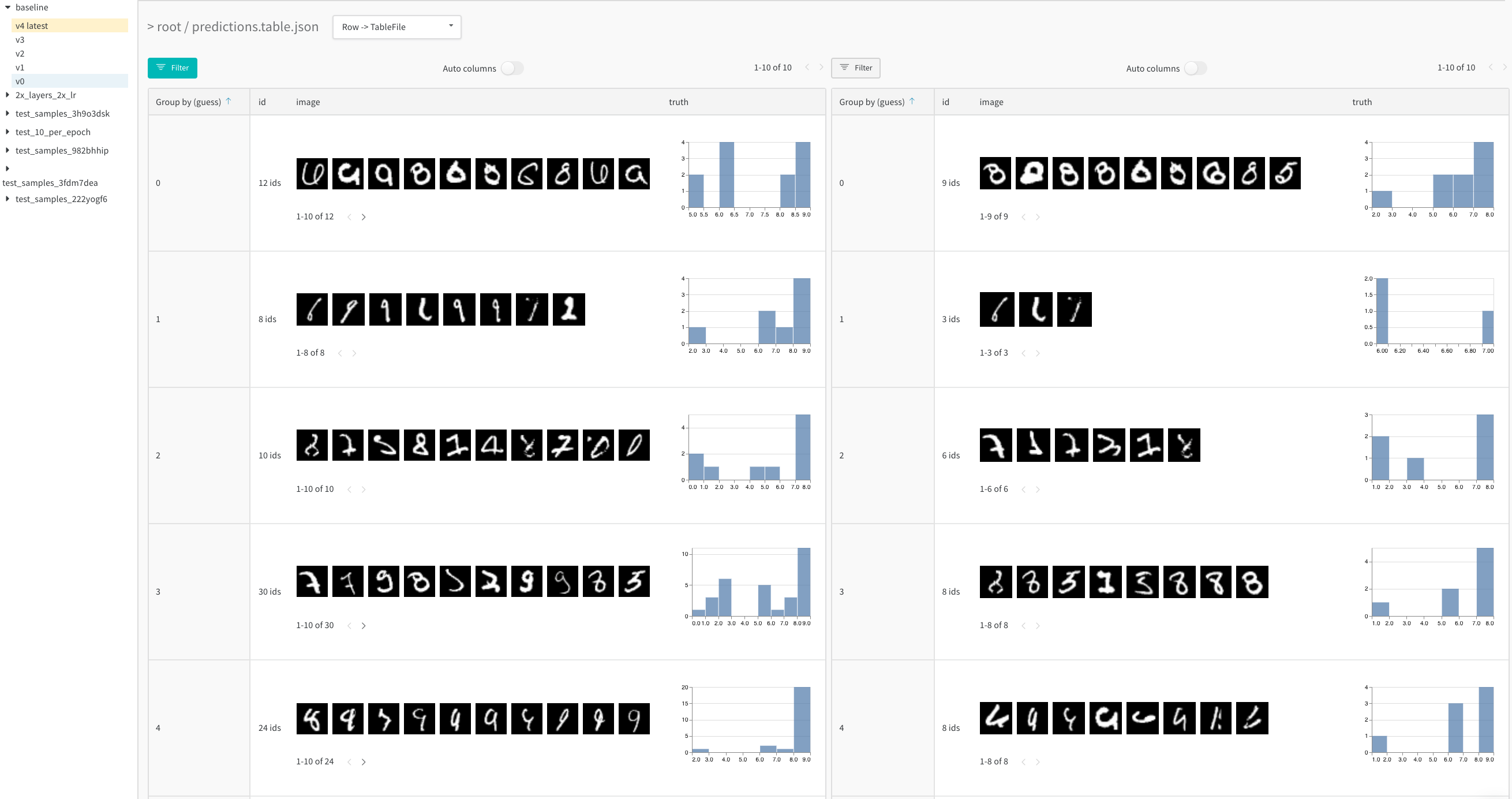
テーブル フィルター、ソート、およびグループ化機能を使用して、モデル の結果を探索および評価します。
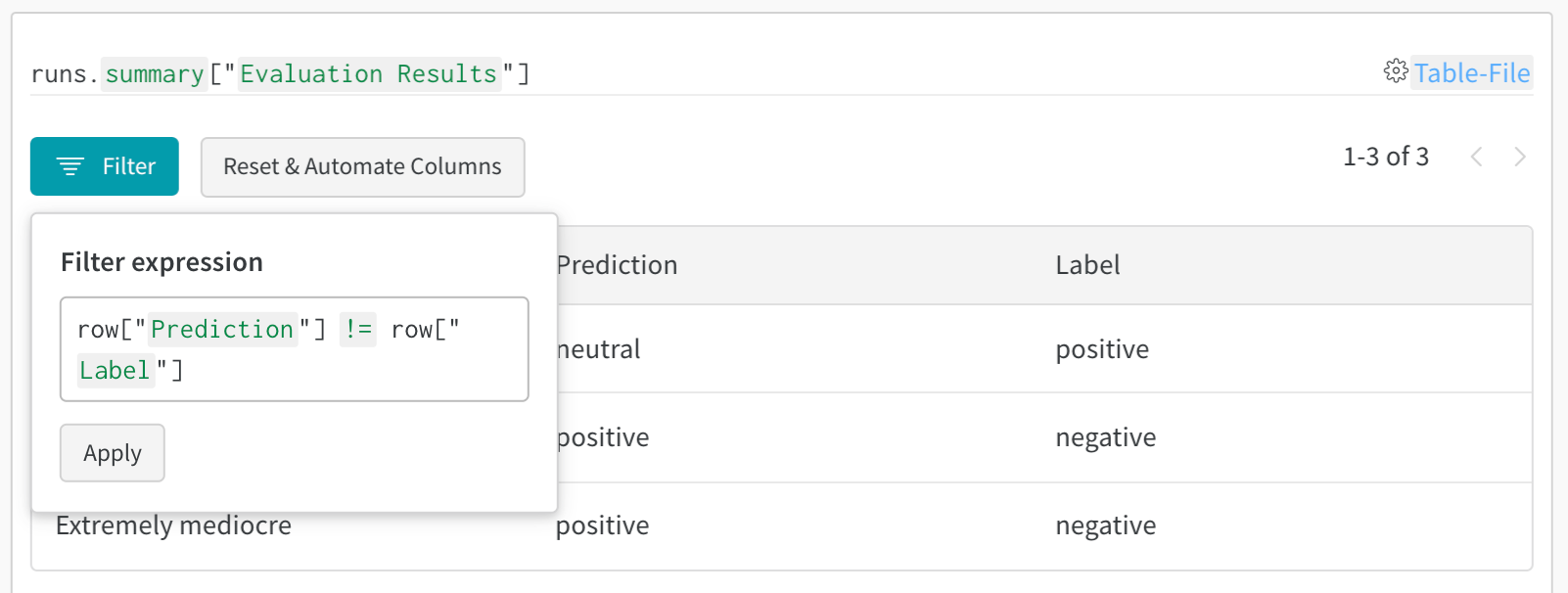
2 - Visualize and analyze tables
W&B Tables を可視化、分析します。
W&B Tables をカスタマイズして、 機械学習 モデルの性能に関する質問に答えたり、 データを分析したりできます。
インタラクティブにデータを探索して、以下を実現します。
- モデル、 エポック、 個々のサンプル間で、 変更を正確に比較する
- データにおけるより高レベルのパターンを理解する
- 可視化 サンプルでインサイトを捉え、 伝達する
W&B Tables は、 次の 振る舞い をします。
- Artifacts コンテキストではステートレス: Artifacts バージョンとともに記録されたテーブルは、 ブラウザ ウィンドウを閉じるとデフォルト状態にリセットされます。
- Workspace または Report コンテキストではステートフル: 単一 run の Workspace 、 複数 run の Project Workspace 、 または Report でテーブルに加えた変更は保持されます。
現在の W&B Table ビューを保存する方法については、 ビューを保存 を参照してください。
2つのテーブルを表示する方法
マージされたビュー または 並べて表示するビュー で2つのテーブルを比較します。 例えば、 下の図はMNIST データのテーブル比較を示しています。
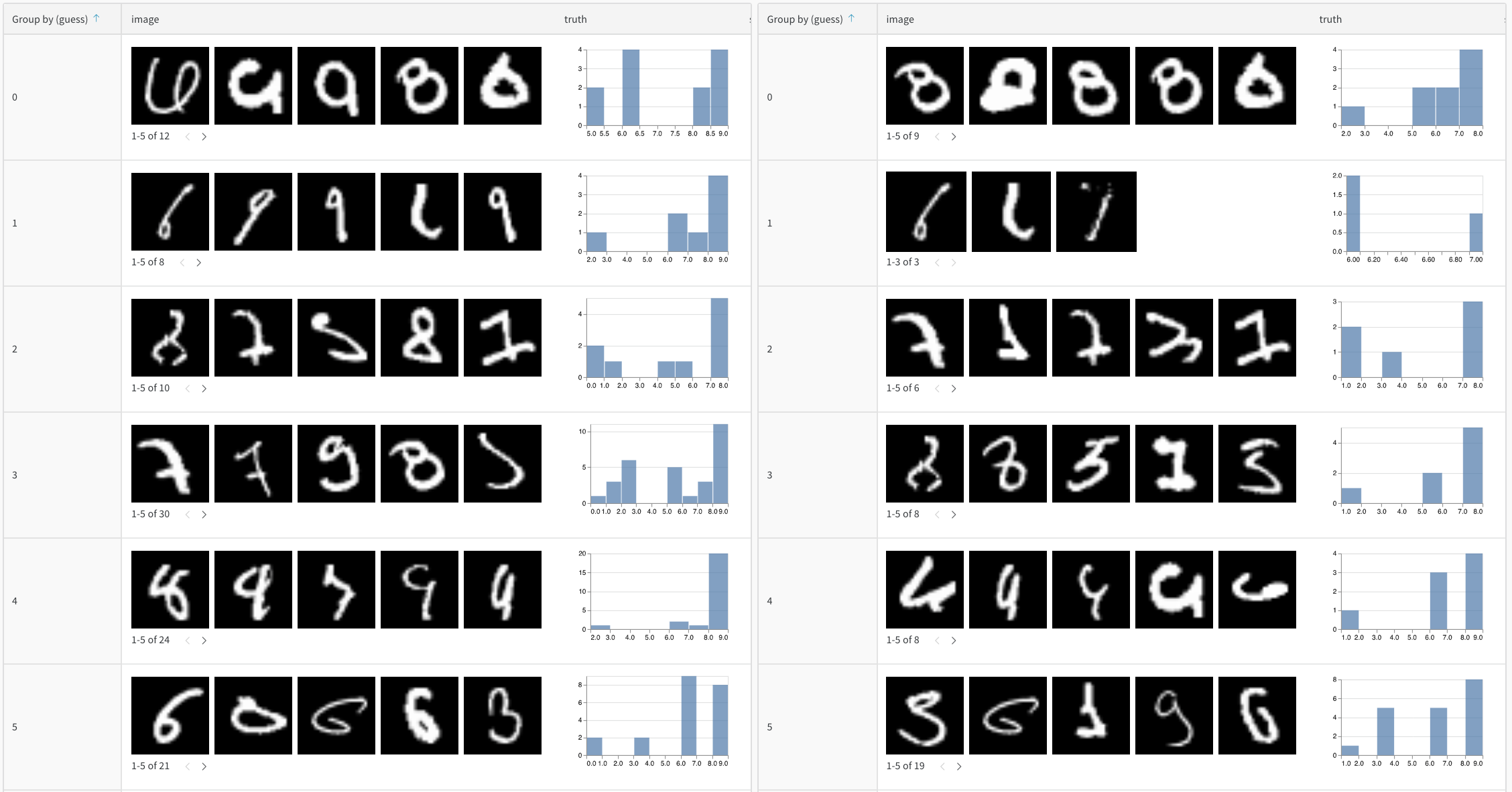
次の手順に従って、 2つのテーブルを比較します。
- W&B App で Project に移動します。
- 左側の パネル で Artifacts アイコンを選択します。
- Artifacts バージョンを選択します。
次の図では、 5 エポック (インタラクティブな例はこちら) の後、 MNIST 検証データに対するモデルの 予測 を示します。
![[予測] をクリックしてテーブルを表示します](https://docs.wandb.ai/images/data_vis/preds_mnist.png)
- サイドバー で比較する2番目の Artifacts バージョンにマウスを合わせ、 表示されたら [比較] をクリックします。 例えば、 下の図では、 トレーニング の5 エポック後に同じモデルによって行われたMNIST の 予測 と比較するために、 「v4」 というラベルの バージョン を選択します。
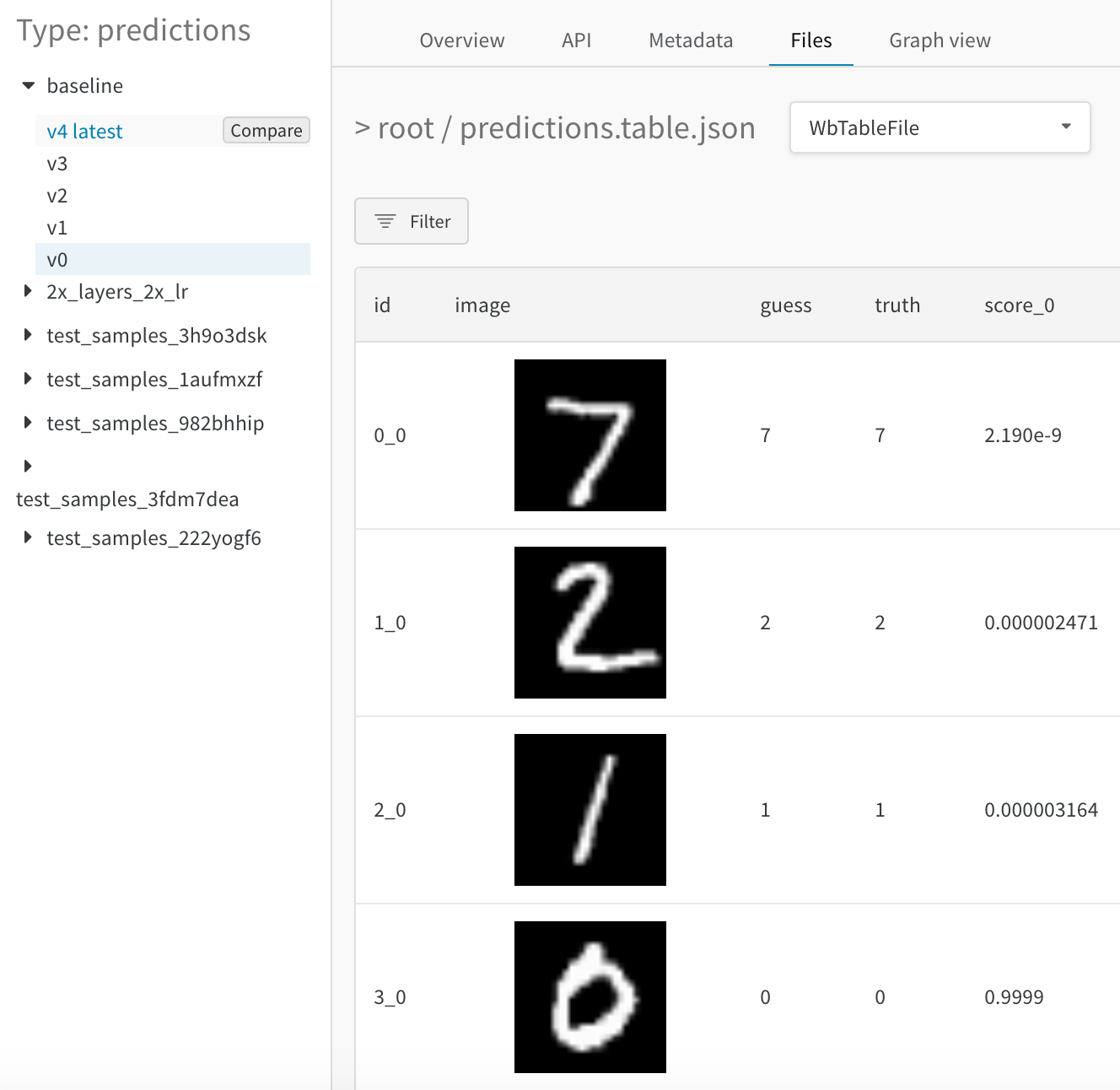
マージされたビュー
最初は、 両方のテーブルがマージされて表示されます。 最初に選択されたテーブルのインデックスは0で青色で強調表示され、 2番目のテーブルのインデックスは1で黄色で強調表示されます。マージされたテーブルのライブ例はこちら をご覧ください。
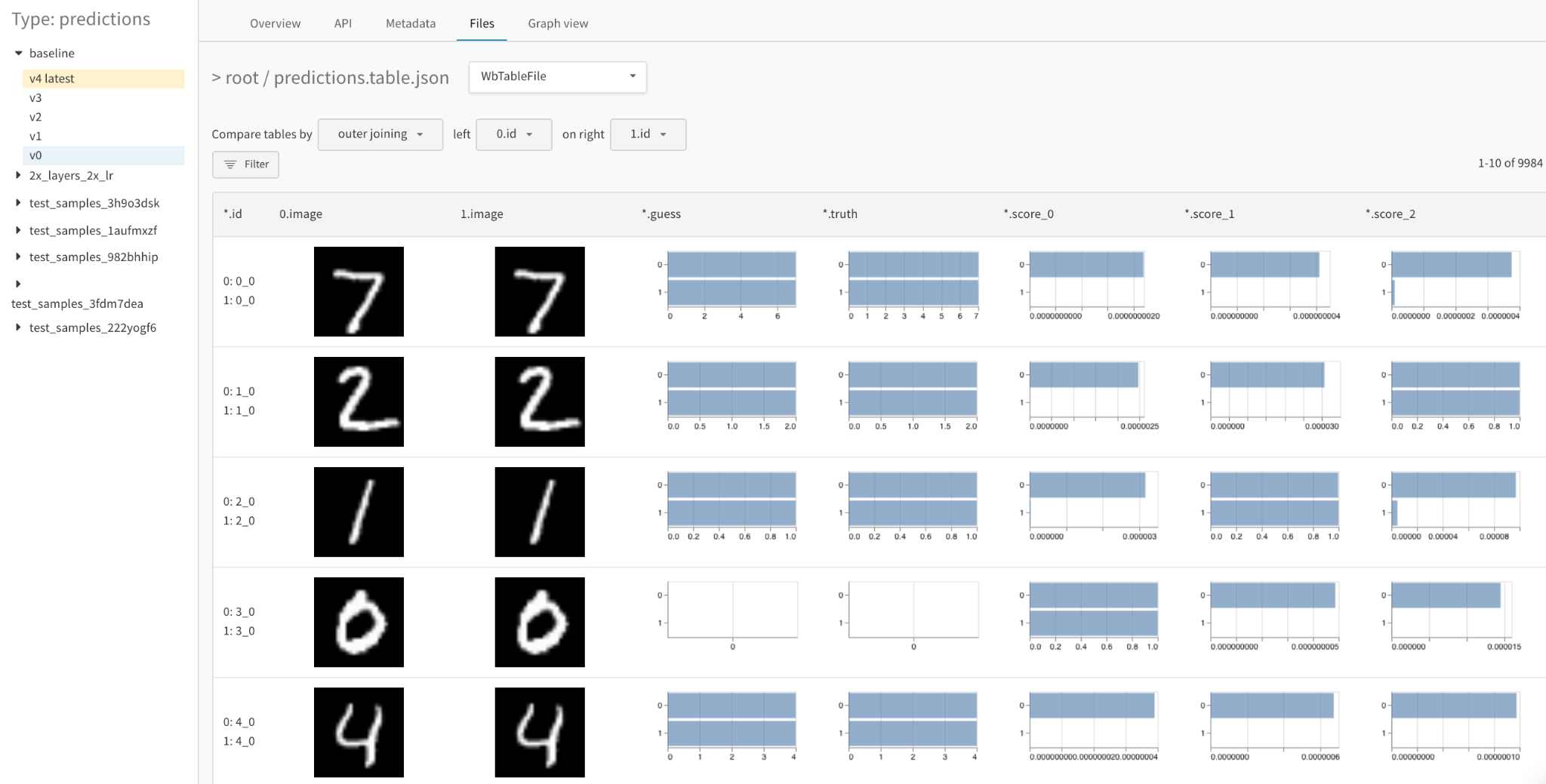
マージされたビューからは、 以下が可能です。
- 結合キーを選択する: 左上のドロップダウンを使用して、 2つのテーブルの結合キーとして使用する列を設定します。 通常、 これは データセット 内の特定の例のファイル名や、 生成されたサンプル のインクリメント インデックスなど、 各行の一意の識別子です。 現在、 任意の 列を選択できますが、 判読できないテーブルやクエリの速度低下が発生する可能性があることに注意してください。
- 結合する代わりに連結する: このドロップダウンで [すべてのテーブルを連結する] を選択すると、 列全体を結合する代わりに、 両方のテーブルから すべての行を結合 して、 より大きなテーブルにすることができます。
- 各テーブルを明示的に参照する: フィルター式で0、 1、 * を使用して、 1つまたは両方のテーブル インスタンス の列を明示的に指定します。
- 詳細な数値の差をヒストグラムとして可視化する: 任意のセルの値を一目で比較できます。
並べて表示するビュー
2つのテーブルを並べて表示するには、 最初のドロップダウンを [テーブルをマージ: テーブル] から [リスト: テーブル] に変更し、 それぞれ [ページ サイズ] を更新します。 ここで、 最初に選択したテーブルは左側にあり、 2番目のテーブルは右側にあります。 また、 [垂直] チェックボックスをクリックして、 これらのテーブルを垂直方向に比較することもできます。
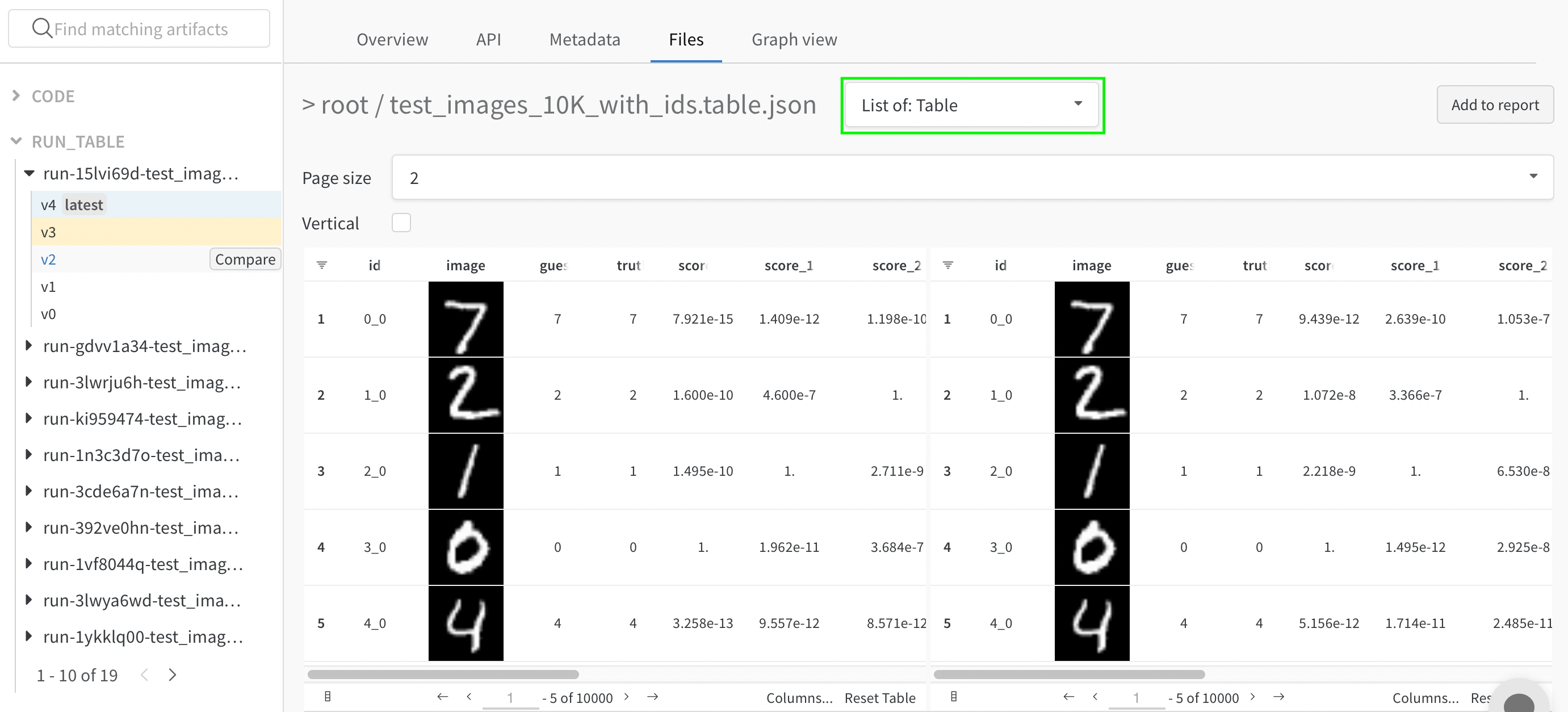
- テーブルを一目で比較する: 任意の操作 (ソート、 フィルタリング、 グループ化) を両方のテーブルにまとめて適用し、 変更や違いをすばやく見つけます。 例えば、 推測でグループ化された不正な 予測 、 全体で最も難しいネガティブ、 真のラベル ごとの信頼度スコア分布などを表示します。
- 2つのテーブルを個別に探索する: スクロールして、 目的の側面/行に焦点を当てます。
Artifacts を比較する
時間の経過とともにテーブルを比較 したり、 モデル バリアント を比較 したりすることもできます。
時間の経過とともにテーブルを比較する
トレーニング の意味のあるステップごとに Artifacts にテーブルを記録して、 トレーニング 時間中のモデルの性能を分析します。 例えば、 すべての検証ステップの終了時、 トレーニング の50 エポックごと、 または パイプライン に適した頻度でテーブルを記録できます。 並べて表示するビューを使用して、 モデル 予測 の変化を可視化します。
トレーニング 時間中の 予測 の可視化に関するより詳細なウォークスルーについては、 この Report およびこのインタラクティブな ノートブック の例 を参照してください。
モデル バリアント 全体でテーブルを比較する
2つの異なるモデルに対して同じステップで記録された2つの Artifacts バージョンを比較して、 異なる 設定 (ハイパーパラメーター 、 ベース アーキテクチャー など) 全体でモデルの性能を分析します。
例えば、 baseline と新しいモデル バリアント である 2x_layers_2x_lr の間で 予測 を比較します。この場合、 最初の畳み込みレイヤーは32から64に、 2番目のレイヤーは128から256に、 学習率は0.001から0.002に倍増します。このライブ例 から、 並べて表示するビューを使用して、 1 (左側のタブ) 対 5 トレーニング エポック (右側のタブ) 後の不正な 予測 に絞り込みます。
-
-
ビューを保存
run Workspace 、 Project Workspace 、 または Report で操作するテーブルは、 ビューの状態を自動的に保存します。 テーブル操作を適用して ブラウザ を閉じると、 次にテーブルに移動したときに、 テーブルには最後に表示された 設定 が保持されます。
Artifacts コンテキストで操作するテーブルはステートレスのままです。
特定の状態で Workspace からテーブルを保存するには、 W&B Report にエクスポートします。 テーブルを Report にエクスポートするには、 次の手順を実行します。
- Workspace 可視化 パネル の右上隅にあるケバブ アイコン (3つの垂直ドット) を選択します。
- [パネルを共有] または [レポートに追加] を選択します。
![[パネルを共有] を選択すると新しい Report が作成され、 [レポートに追加] を選択すると既存の Report に追加できます。](https://docs.wandb.ai/images/data_vis/share_your_view.png)
例
これらの Reports は、 W&B Tables のさまざまな ユースケース を示しています。
3 - Example tables
W&B テーブル の例
次のセクションでは、テーブルを使用できる方法のいくつかを紹介します。
データの表示
モデルトレーニングまたは評価中に、メトリクスとリッチメディアをログに記録し、クラウドまたは ホスティングインスタンス に同期された永続的なデータベースで結果を可視化します。
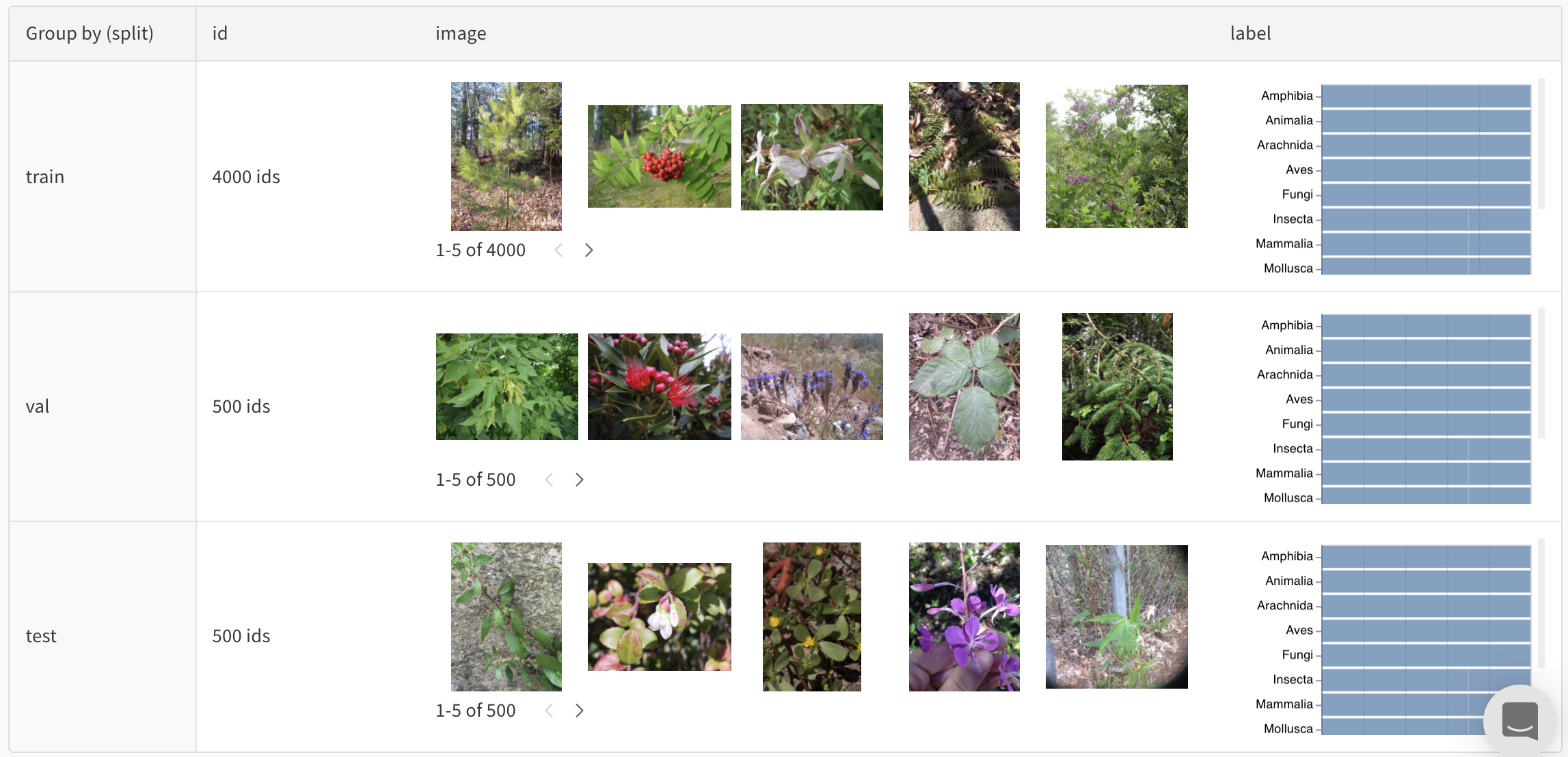
たとえば、写真データセットのバランスの取れた分割を示すこのテーブル を確認してください。
データをインタラクティブに探索する
テーブルの表示、並べ替え、フィルタリング、グループ化、結合、およびクエリを実行して、データとモデルのパフォーマンスを理解します。静的なファイルを参照したり、分析スクリプトを再実行したりする必要はありません。
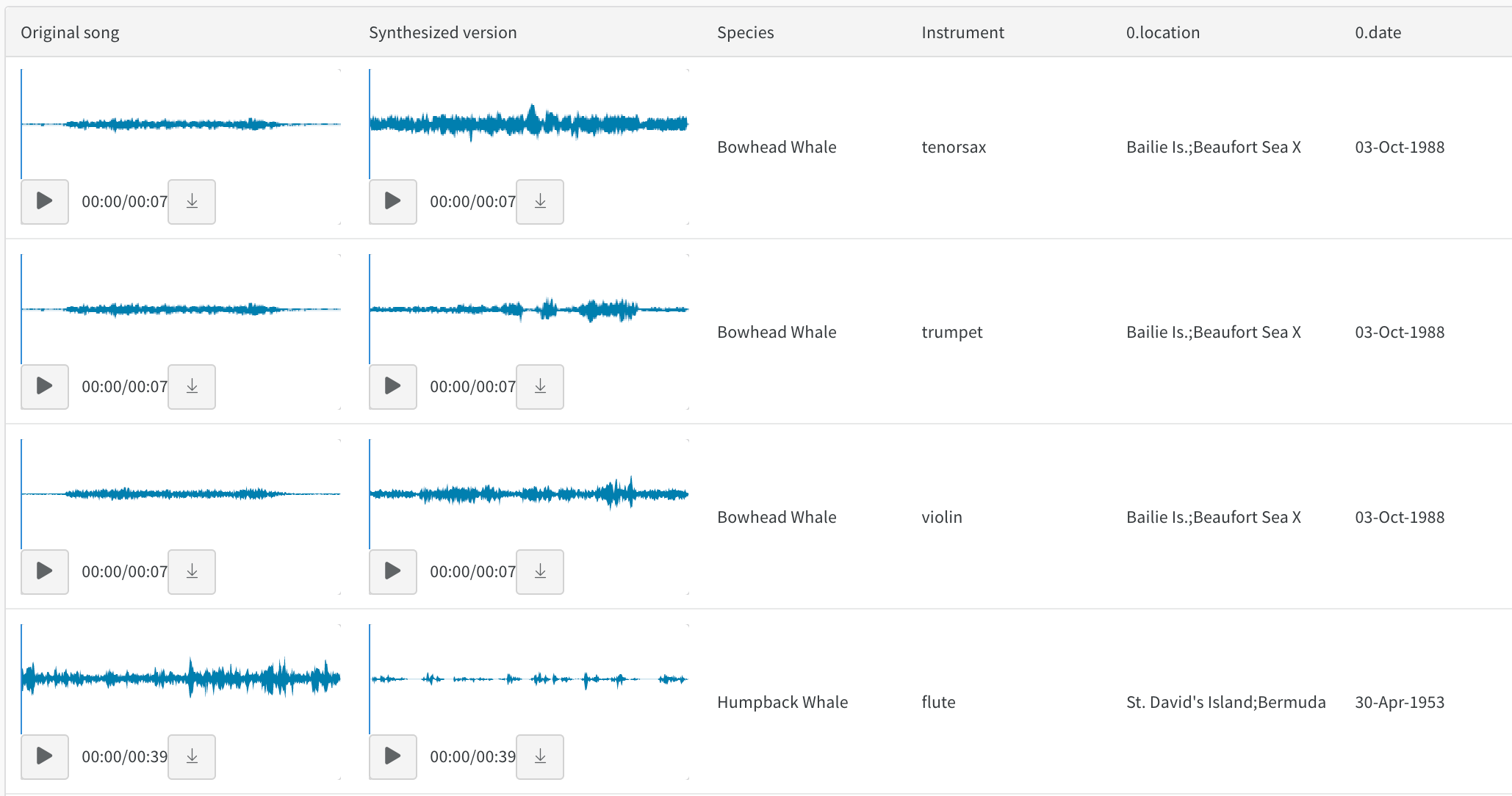
たとえば、スタイルが転送されたオーディオに関するこのレポート を参照してください。
モデルのバージョンを比較する
さまざまなトレーニングエポック、データセット、ハイパーパラメーターの選択、モデルアーキテクチャーなどで、結果をすばやく比較します。
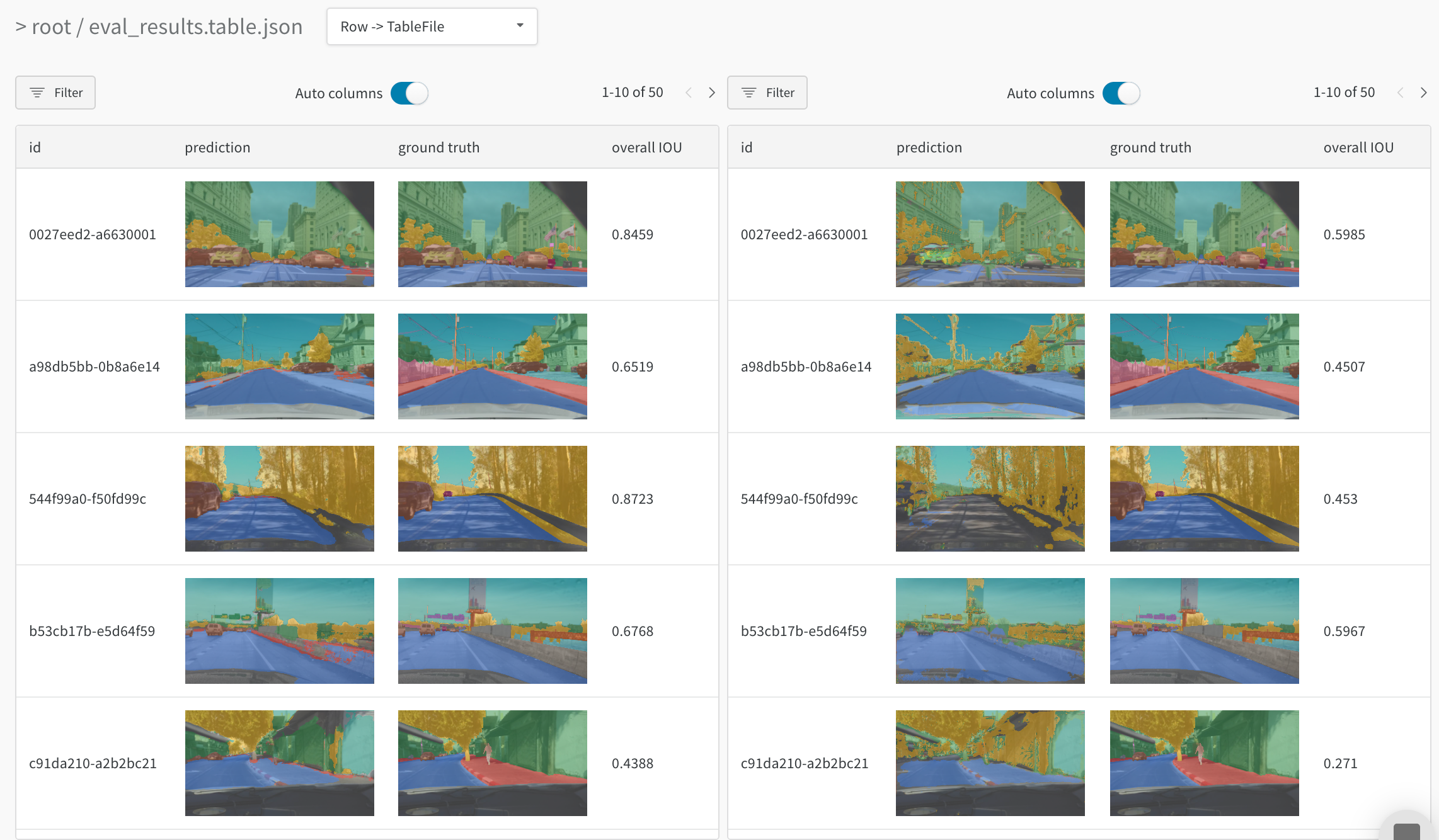
たとえば、同じテスト画像で 2 つのモデルを比較するこのテーブル を参照してください。
すべての詳細を追跡し、全体像を把握する
特定のステップで特定の予測を可視化するためにズームインします。集計統計を表示し、エラーのパターンを特定し、改善の機会を理解するためにズームアウトします。このツールは、単一のモデルトレーニングのステップを比較したり、異なるモデルバージョン間で結果を比較したりするために使用できます。
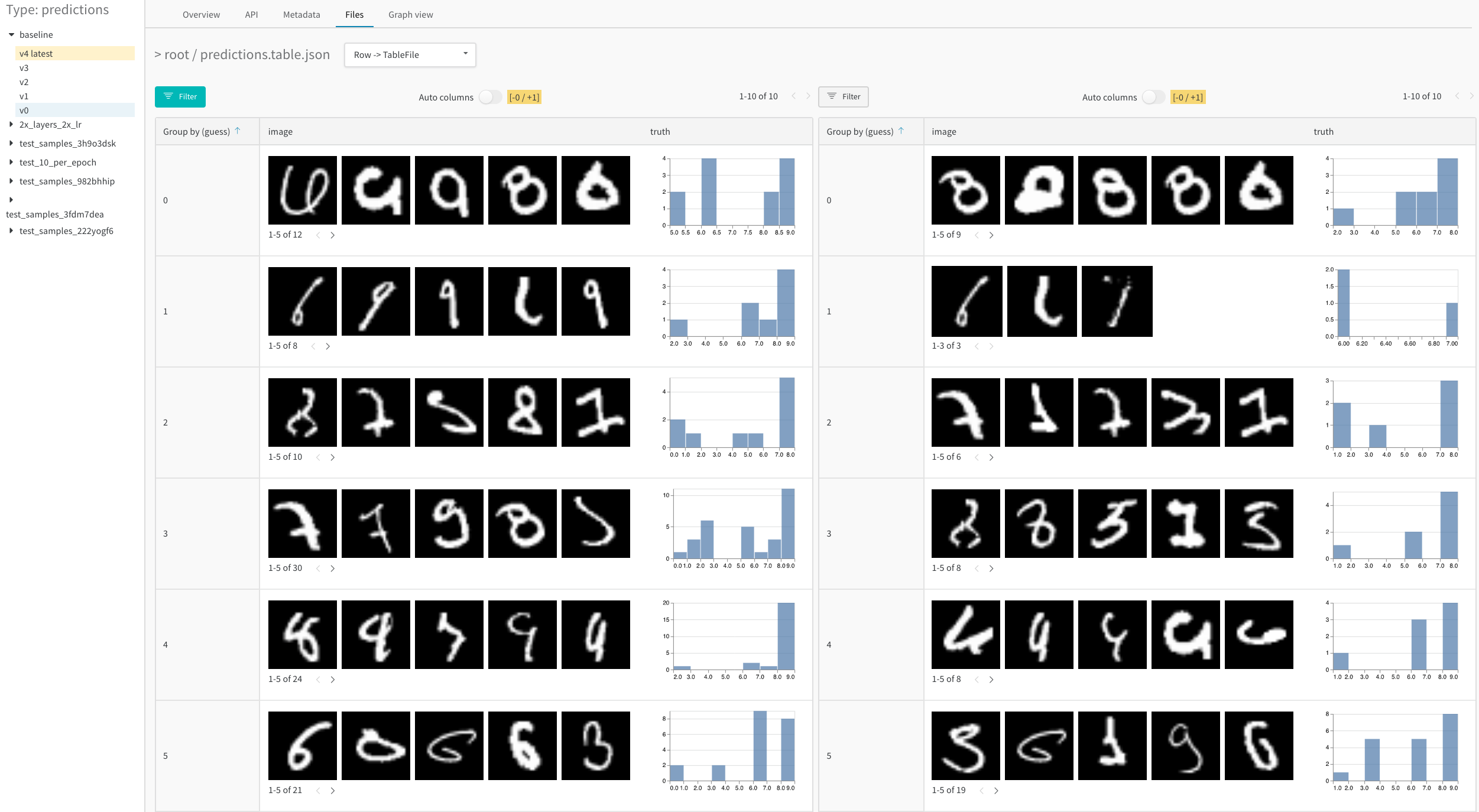
たとえば、MNIST データセットで 1 回、次に 5 回のエポック後の結果を分析するこのサンプルテーブル を参照してください。
W&B Tables を使用したプロジェクト例
以下は、W&B Tables を使用する実際の W&B のProjectsのハイライトです。
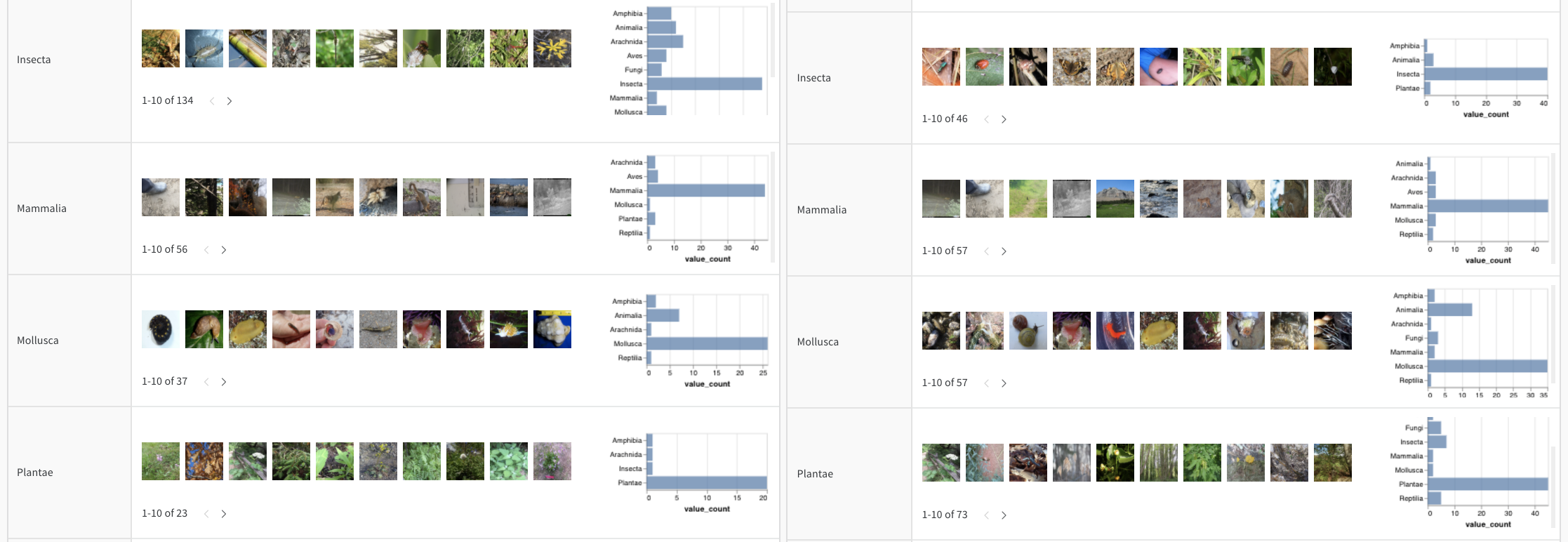
画像分類
このレポート を読むか、この colab に従うか、artifacts コンテキスト を調べて、CNN が iNaturalist の写真から 10 種類の生物(植物、鳥、昆虫など)を識別する方法を確認してください。
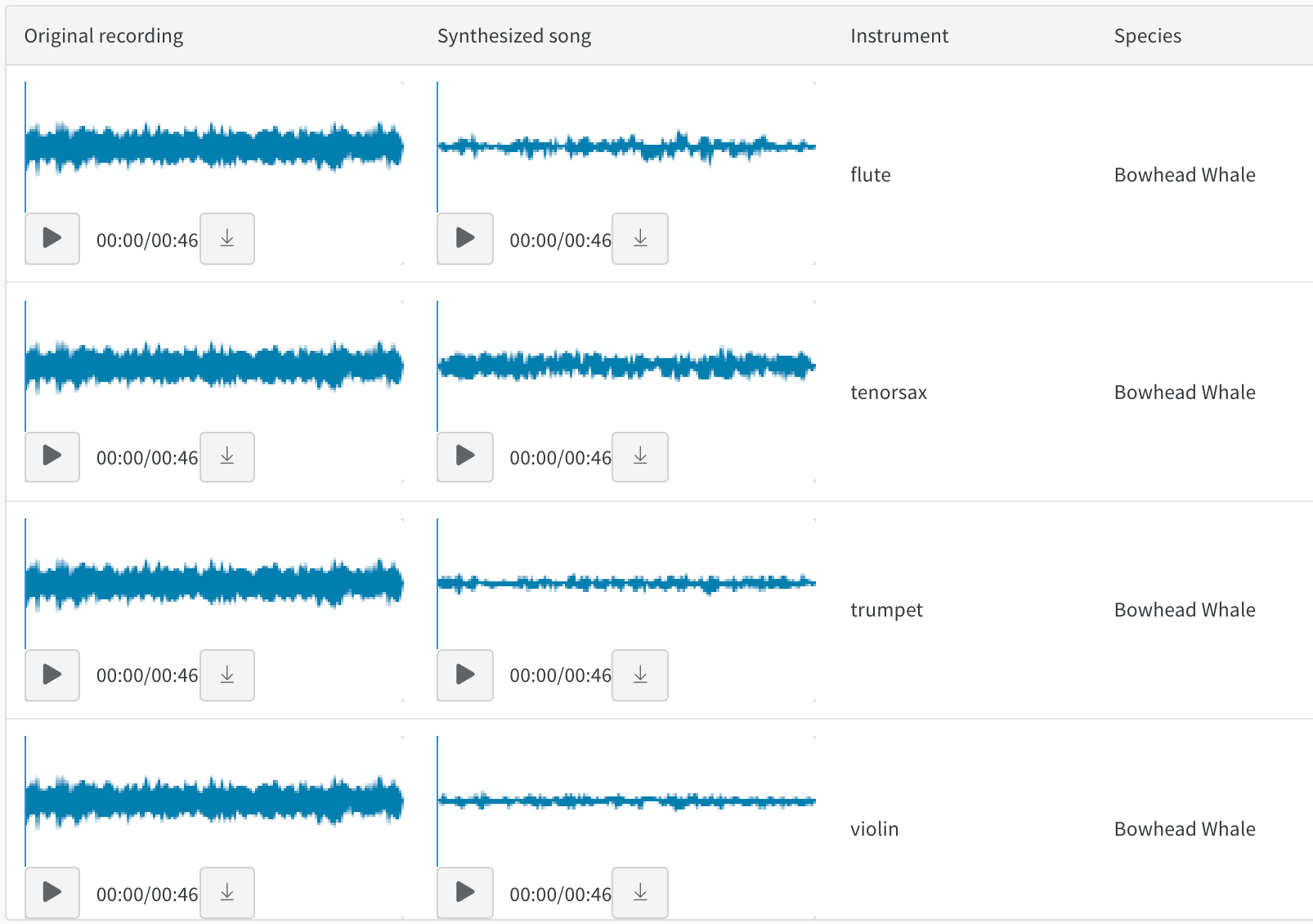
オーディオ
音色転送に関するこのレポート でオーディオテーブルを操作します。録音されたクジラの歌と、バイオリンやトランペットなどの楽器で同じメロディーをシンセサイズした演奏を比較できます。この colab を使用して、独自の曲を録音し、W&B でシンセサイズされたバージョンを探索することもできます。
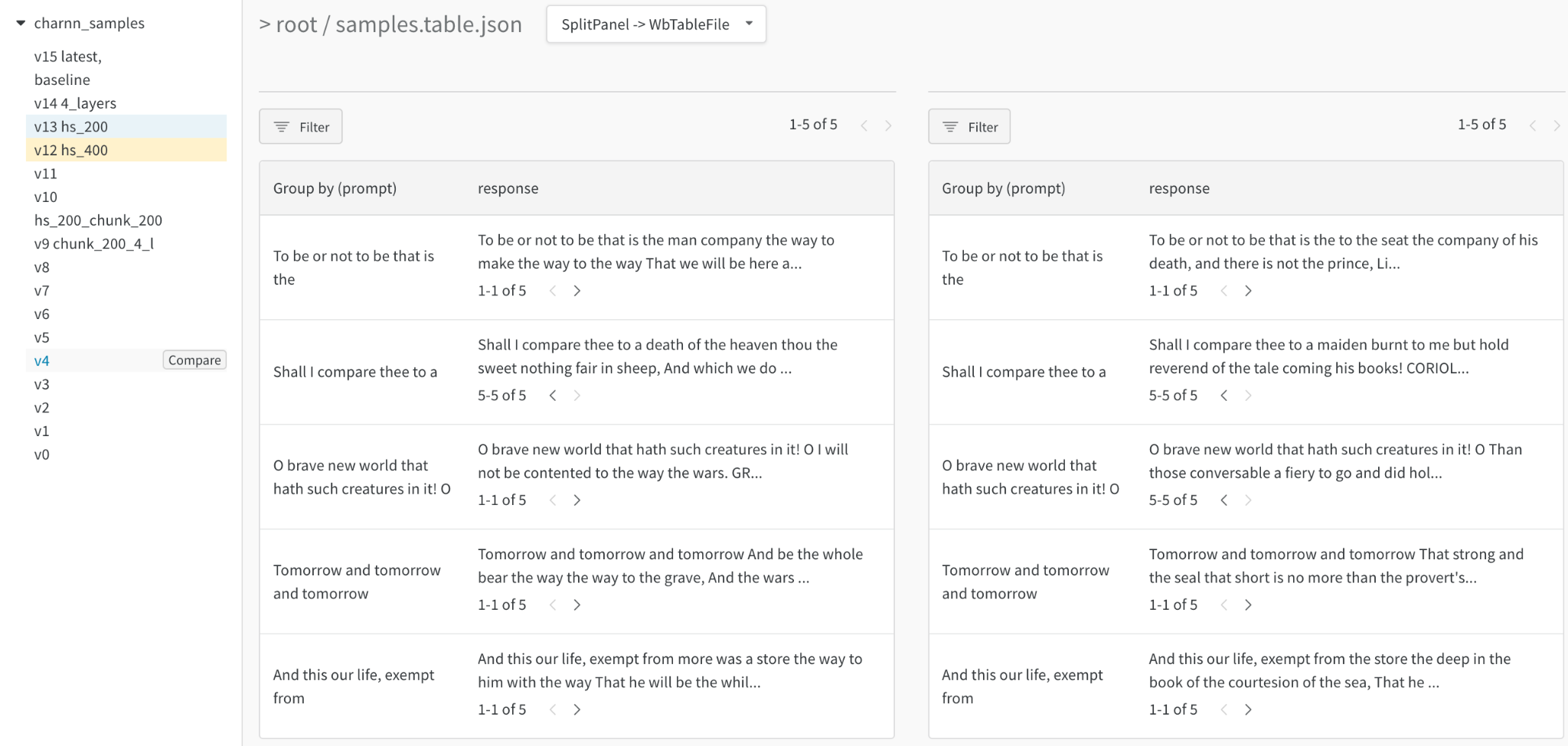
テキスト
トレーニングデータまたは生成された出力からテキストサンプルを参照し、関連フィールドで動的にグループ化し、モデルのバリアントまたは実験設定全体で評価を調整します。テキストを Markdown としてレンダリングするか、ビジュアル差分モードを使用してテキストを比較します。このレポート で、シェイクスピアを生成するための単純な文字ベースの RNN を探索してください。
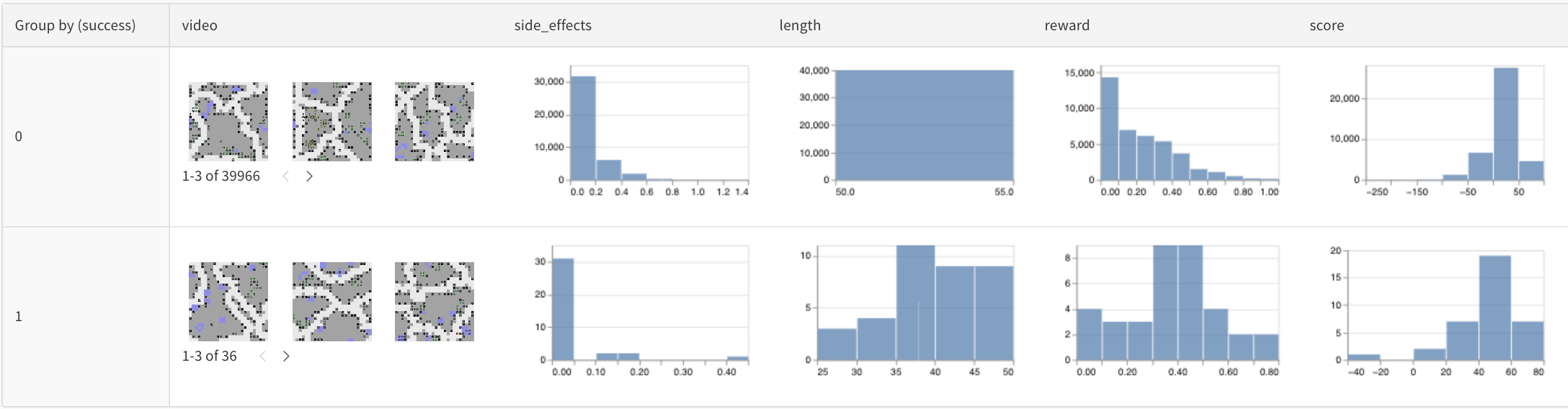
ビデオ
トレーニング中にログに記録されたビデオを参照および集計して、モデルを理解します。副作用を最小限に抑える ことを目指す RL エージェント向けの SafeLife ベンチマーク を使用した初期の例を次に示します。
表形式データ
バージョン管理と重複排除を使用して 表形式データを分割および事前処理する方法に関するレポート を表示します。
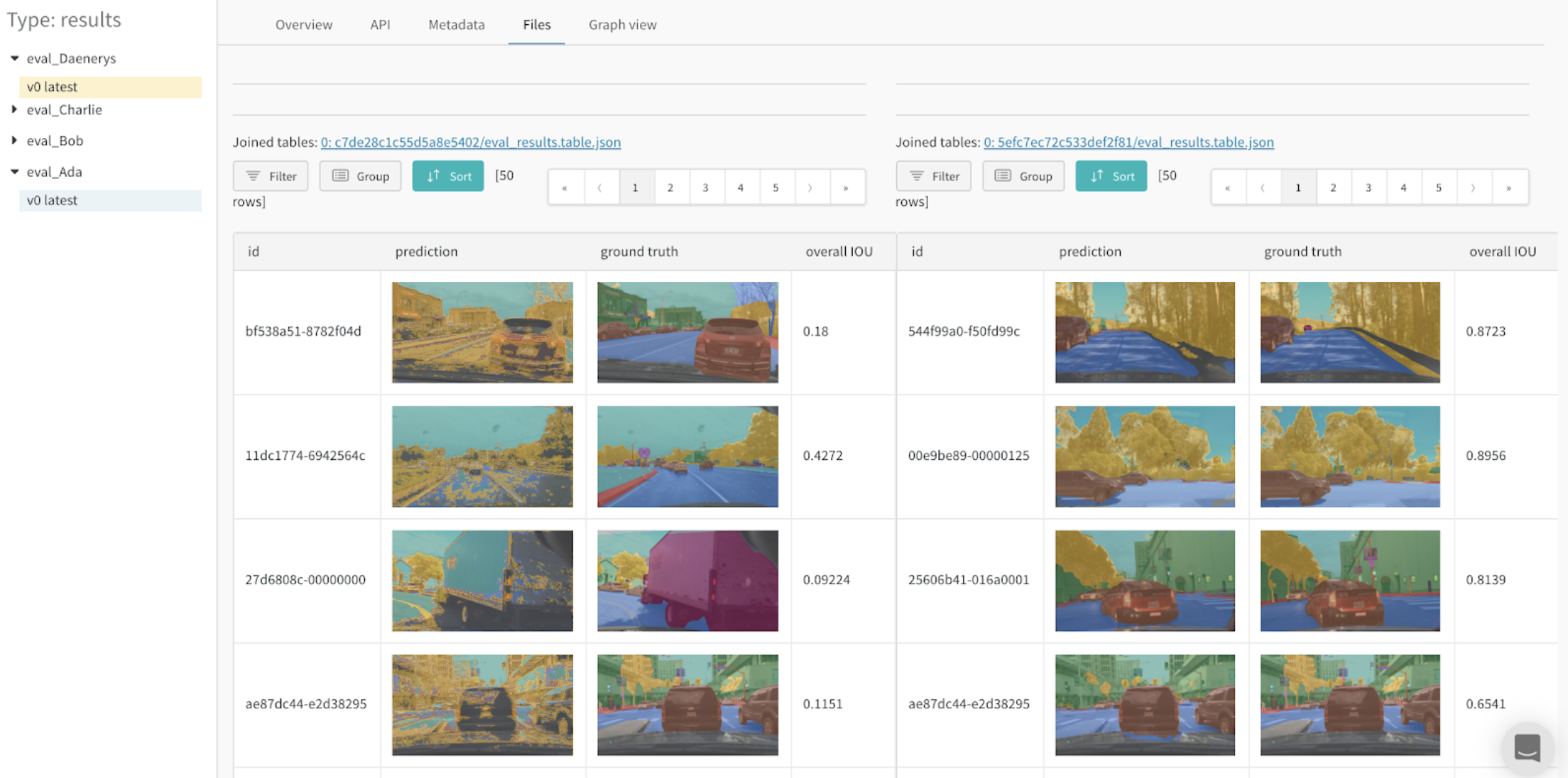
モデルバリアントの比較(セマンティックセグメンテーション)
セマンティックセグメンテーション用の Tables のログを記録し、異なるモデルを比較する インタラクティブノートブック と ライブ例。この Table で独自のクエリを試してください。
トレーニング時間に対する改善の分析
時間経過に伴う予測の可視化 と、それに付随する インタラクティブノートブック に関する詳細なレポート。
4 - Export table data
テーブルからデータをエクスポートする方法。
すべての W&B Artifacts と同様に、Tables は pandas のデータフレームに変換して、簡単にデータのエクスポートができます。
table を artifact に変換する
まず、テーブルを artifact に変換する必要があります。これを行うには、artifact.get(table, "table_name") を使用するのが最も簡単です。
# 新しいテーブルを作成してログに記録します。
with wandb.init() as r:
artifact = wandb.Artifact("my_dataset", type="dataset")
table = wandb.Table(
columns=["a", "b", "c"], data=[(i, i * 2, 2**i) for i in range(10)]
)
artifact.add(table, "my_table")
wandb.log_artifact(artifact)
# 作成した artifact を使用して、作成したテーブルを取得します。
with wandb.init() as r:
artifact = r.use_artifact("my_dataset:latest")
table = artifact.get("my_table")
artifact を Dataframe に変換する
次に、テーブルをデータフレームに変換します。
# 前のコード例から続けて:
df = table.get_dataframe()
データのエクスポート
これで、データフレームがサポートする任意の方法を使用してエクスポートできます。
# テーブルデータを .csv に変換する
df.to_csv("example.csv", encoding="utf-8")
次のステップ
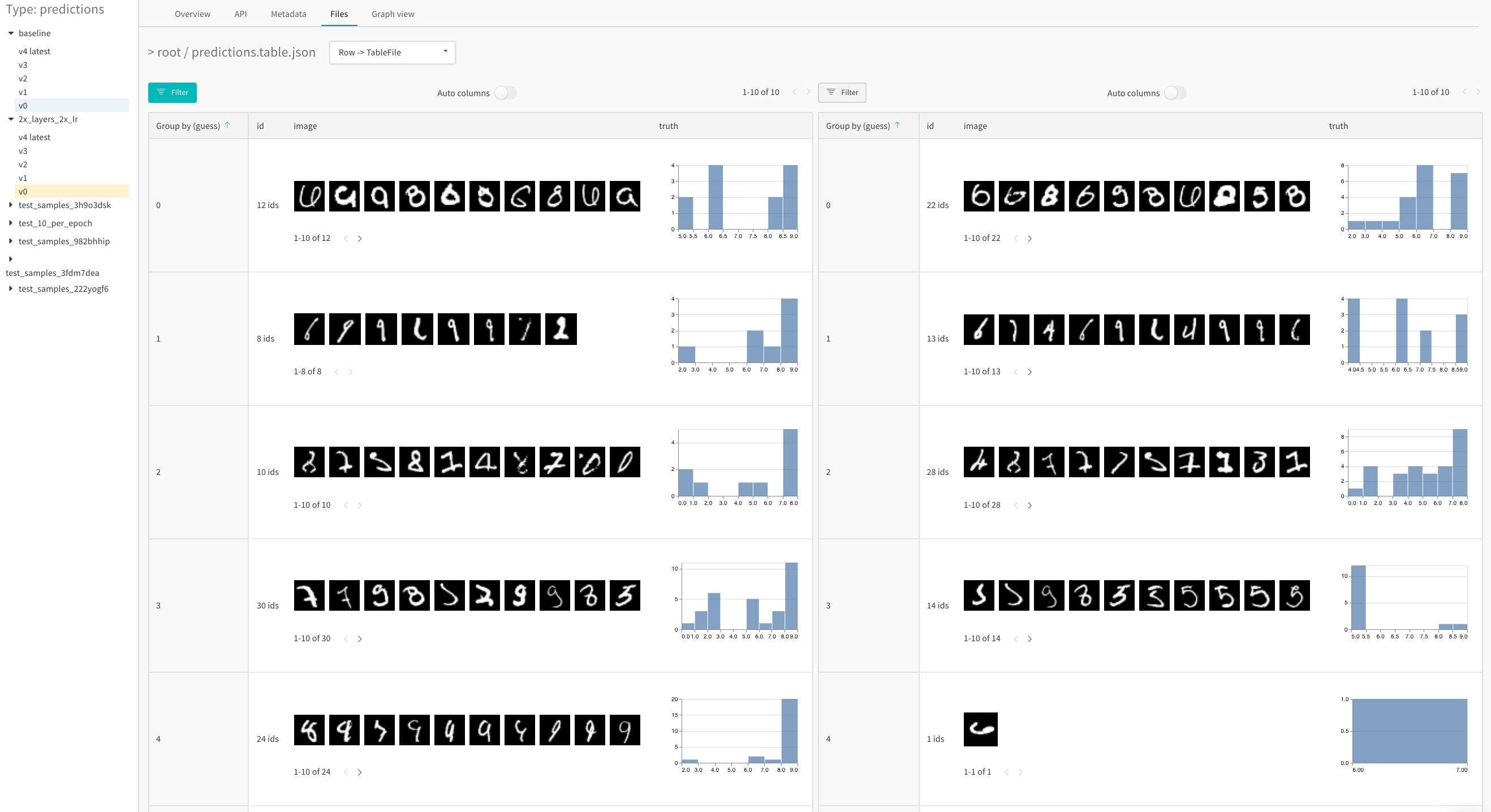
![5 エポック後、 [ダブル] バリアント は ベースライン に追いついています。](https://docs.wandb.ai/images/data_vis/compare_across_variants_after_5_epochs.png)