Integrations
W&B の インテグレーション により、既存の プロジェクト 内で 実験管理 と データ バージョン管理 を迅速かつ簡単にセットアップできます。PyTorch などの ML フレームワーク、Hugging Face などの ML ライブラリ、または Amazon SageMaker などの クラウド サービス向けの インテグレーション をご確認ください。
VIDEO
関連リソース
1 - Add wandb to any library
任意のライブラリに wandb を追加する
このガイドでは、強力な 実験管理 、GPU とシステム監視、モデルチェックポイントなど、独自のライブラリのための機能を W&B と統合するためのベストプラクティスを提供します。
W&B の使用方法をまだ学習中の場合は、先に進む前に、
実験管理 など、これらのドキュメントにある他の W&B ガイドを確認することをお勧めします。
以下では、作業中のコードベースが単一の Python トレーニングスクリプトまたは Jupyter ノートブックよりも複雑な場合の、ベストなヒントとベストプラクティスについて説明します。取り上げるトピックは次のとおりです。
セットアップ要件
ユーザーログイン
wandb の Run の開始
Run の設定の定義
W&B へのログ記録
分散トレーニング
モデルチェックポイントなど
ハイパーパラメータの チューニング
高度な インテグレーション
セットアップ要件
開始する前に、ライブラリの依存関係に W&B を必須にするかどうかを決定します。
インストール時に W&B を必須とする
W&B Python ライブラリ(wandb)を依存関係ファイルに追加します。たとえば、requirements.txt ファイルに追加します。
torch== 1.8.0
...
wandb== 0.13 .*
インストール時に W&B をオプションにする
W&B SDK(wandb)をオプションにするには、2つの方法があります。
A. ユーザーが手動でインストールせずに wandb 機能を使用しようとしたときにエラーを発生させ、適切なエラーメッセージを表示します。
try :
import wandb
except ImportError :
raise ImportError (
"You are trying to use wandb which is not currently installed."
"Please install it using pip install wandb"
)
B. Python パッケージを構築している場合は、wandb をオプションの依存関係として pyproject.toml ファイルに追加します。
[project ]
name = "my_awesome_lib"
version = "0.1.0"
dependencies = [
"torch" ,
"sklearn"
]
[project .optional-dependencies ]
dev = [
"wandb"
]
ユーザーログイン
APIキー を作成する
APIキー は、クライアントまたはマシンを W&B に対して認証します。 APIキー は、ユーザープロフィールから生成できます。
右上隅にあるユーザープロフィールアイコンをクリックします。
[User Settings(ユーザー設定) ]を選択し、[API Keys(APIキー) ]セクションまでスクロールします。
[Reveal(表示) ]をクリックします。表示された APIキー をコピーします。 APIキー を非表示にするには、ページをリロードします。
wandb ライブラリをインストールしてログインするwandb ライブラリをローカルにインストールしてログインするには:
Command Line
Python
Python notebook
WANDB_API_KEY 環境変数 を APIキー に設定します。
export WANDB_API_KEY= <your_api_key>
wandb ライブラリをインストールしてログインします。
pip install wandb
wandb login
import wandb
wandb. login()
!pip install wandb
import wandb
wandb.login()
ユーザーが上記の手順に従わずに初めて wandb を使用する場合、スクリプトが wandb.init を呼び出すと、自動的にログインを求められます。
Run を開始する
W&B Run は、W&B によって記録される計算の単位です。通常、トレーニング実験ごとに単一の W&B Run を関連付けます。
W&B を初期化し、コード内で Run を開始するには:
オプションで、プロジェクトの名前を指定したり、エンティティパラメーターのユーザー名やチーム名(wandb_entity)とともに、コード内の wandb_project などのパラメーターを使用して、ユーザー自身に設定させたりできます。
run = wandb. init(project= wandb_project, entity= wandb_entity)
Run を終了するには、run.finish() を呼び出す必要があります。これがインテグレーションの設計で機能する場合は、Run をコンテキストマネージャーとして使用します。
# When this block exits, it calls run.finish() automatically.
# If it exits due to an exception, it uses run.finish(exit_code=1) which
# marks the run as failed.
with wandb. init() as run:
...
wandb.init をいつ呼び出すか?ライブラリは、W&B Run をできるだけ早く作成する必要があります。これは、エラーメッセージを含むコンソール内のすべての出力が W&B Run の一部として記録されるためです。これにより、デバッグが容易になります。
wandb をオプションの依存関係として使用するユーザーがライブラリを使用する際に wandb をオプションにしたい場合は、次のいずれかの方法があります。
trainer = my_trainer(... , use_wandb= True )
python train.py ... --use-wandb
または、wandb.init で wandb を disabled に設定します。
wandb. init(mode= "disabled" )
export WANDB_MODE= disabled
または
または、wandb をオフラインに設定します。これは、wandb を実行しますが、インターネット経由で W&B に通信しようとはしません。
Environment Variable
Bash
export WANDB_MODE= offline
または
os. environ['WANDB_MODE' ] = 'offline'
Run の設定を定義する
wandb の Run の設定を使用すると、W&B Run の作成時にモデル、データセットなどに関するメタデータを提供できます。この情報を使用して、さまざまな実験を比較し、主な違いをすばやく理解できます。
ログに記録できる一般的な設定パラメーターは次のとおりです。
モデル名、バージョン、アーキテクチャー パラメーターなど。
データセット名、バージョン、トレーニング/検証の例の数など。
学習率、 バッチサイズ 、 オプティマイザー などのトレーニングパラメーター。
次のコードスニペットは、設定をログに記録する方法を示しています。
config = {"batch_size" : 32 , ... }
wandb. init(... , config= config)
Run の設定を更新する
設定を更新するには、run.config.update を使用します。パラメーターが辞書の定義後に取得される場合に、設定辞書を更新すると便利です。たとえば、モデルのインスタンス化後にモデルのパラメーターを追加する場合があります。
run. config. update({"model_parameters" : 3500 })
設定ファイルの定義方法の詳細については、実験の設定 を参照してください。
W&B にログを記録する
メトリクス を記録する
キーの値が メトリクス の名前である辞書を作成します。この辞書オブジェクトをrun.log
for epoch in range(NUM_EPOCHS):
for input, ground_truth in data:
prediction = model(input)
loss = loss_fn(prediction, ground_truth)
metrics = { "loss" : loss }
run. log(metrics)
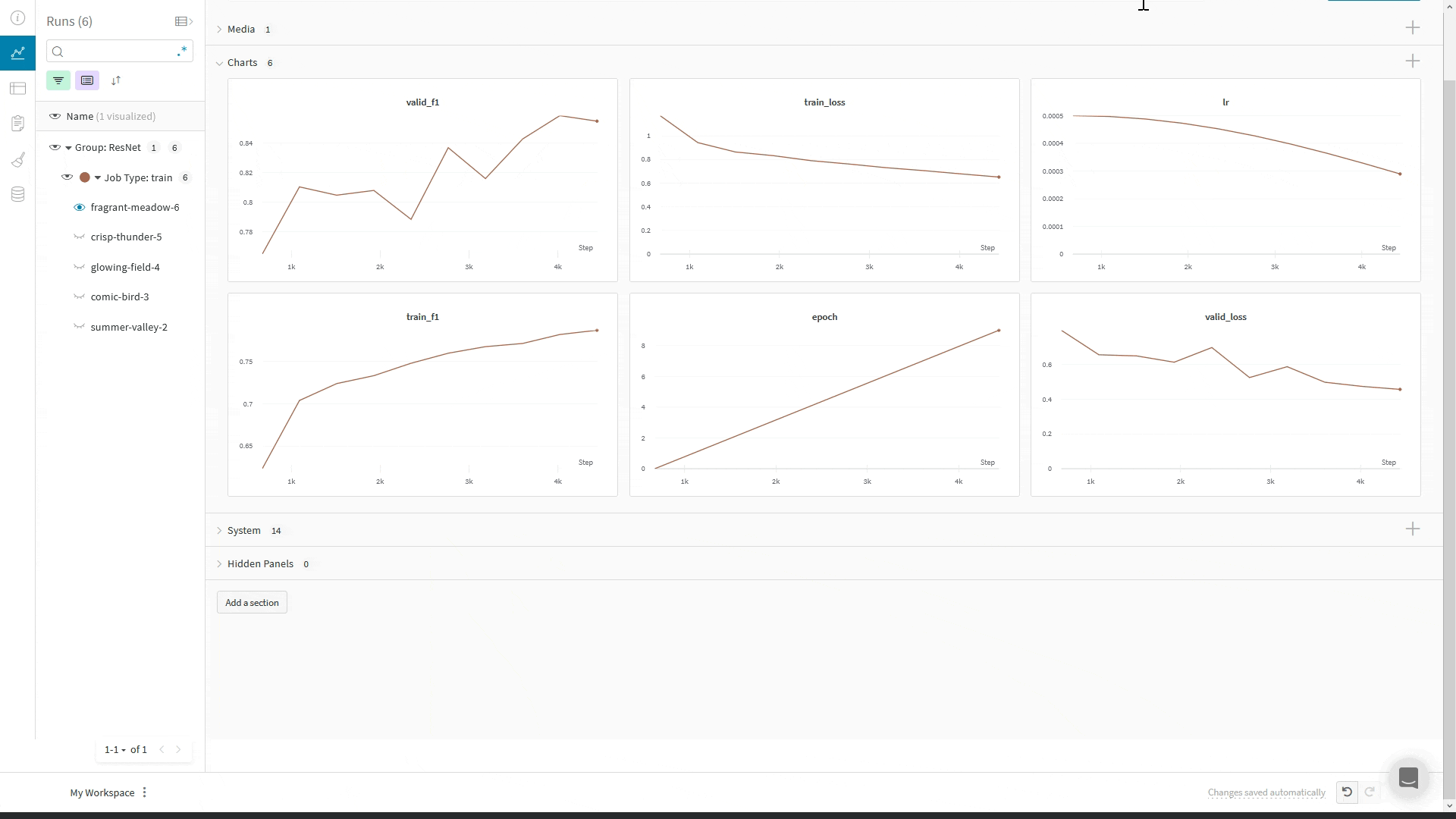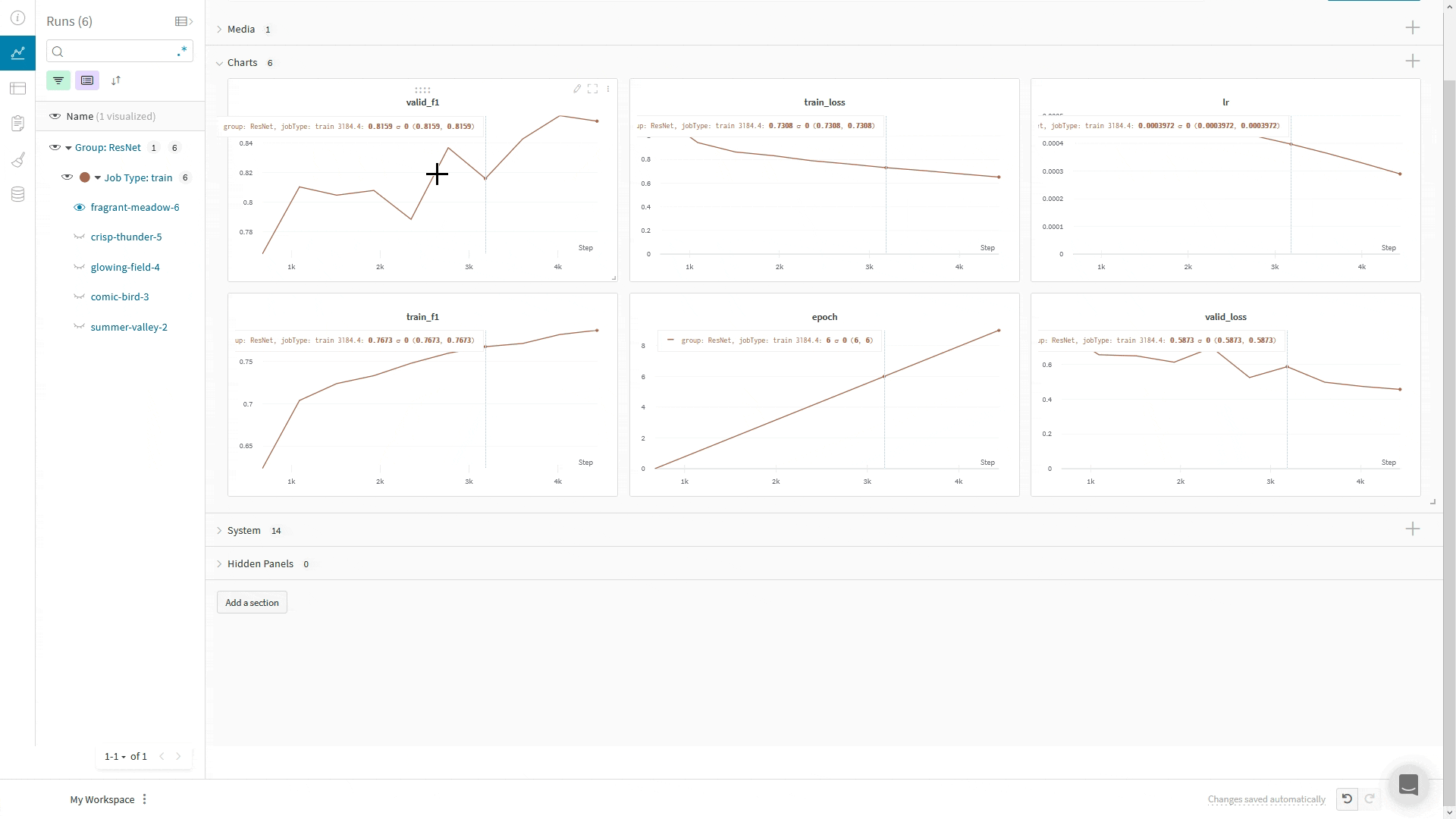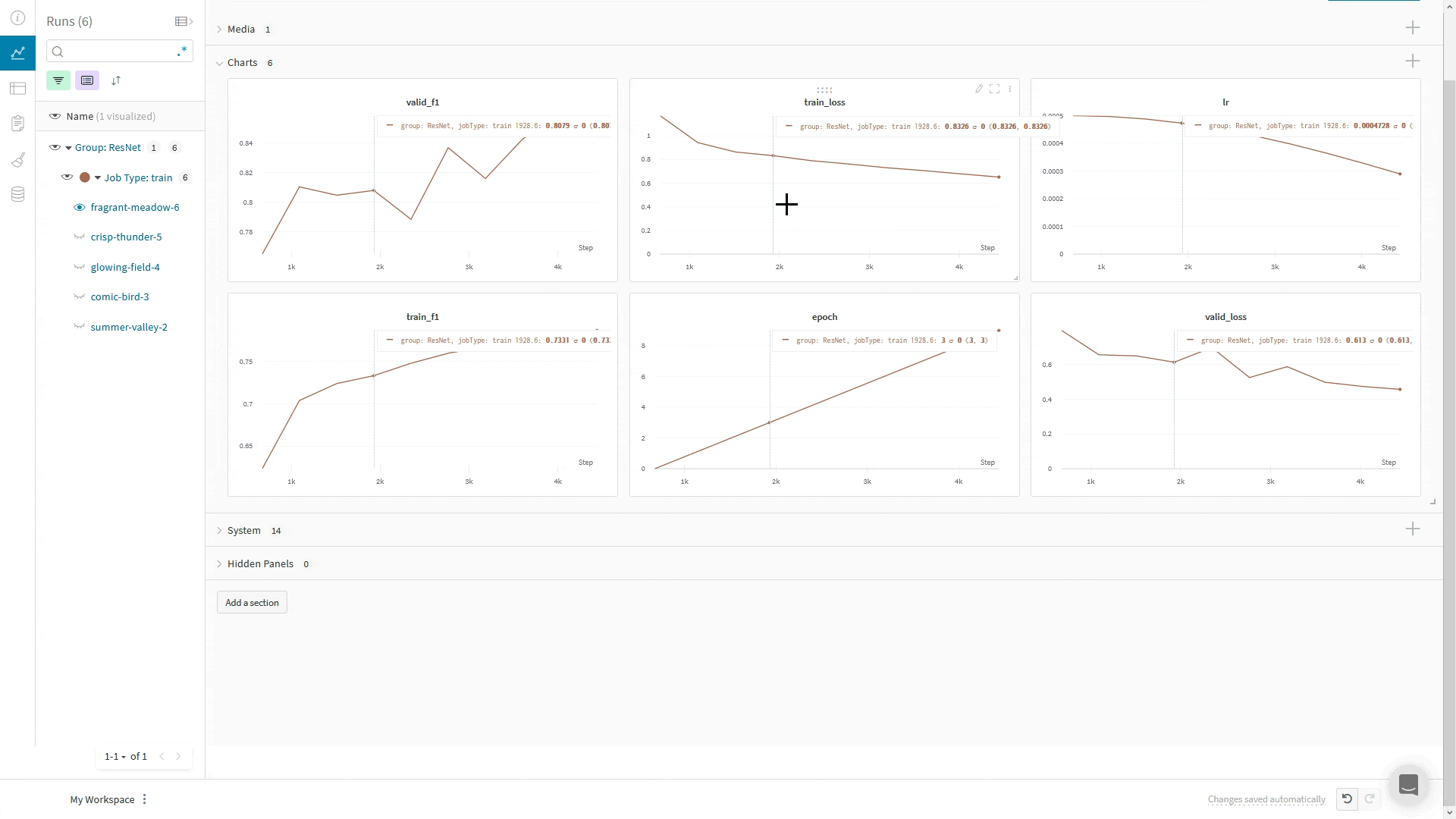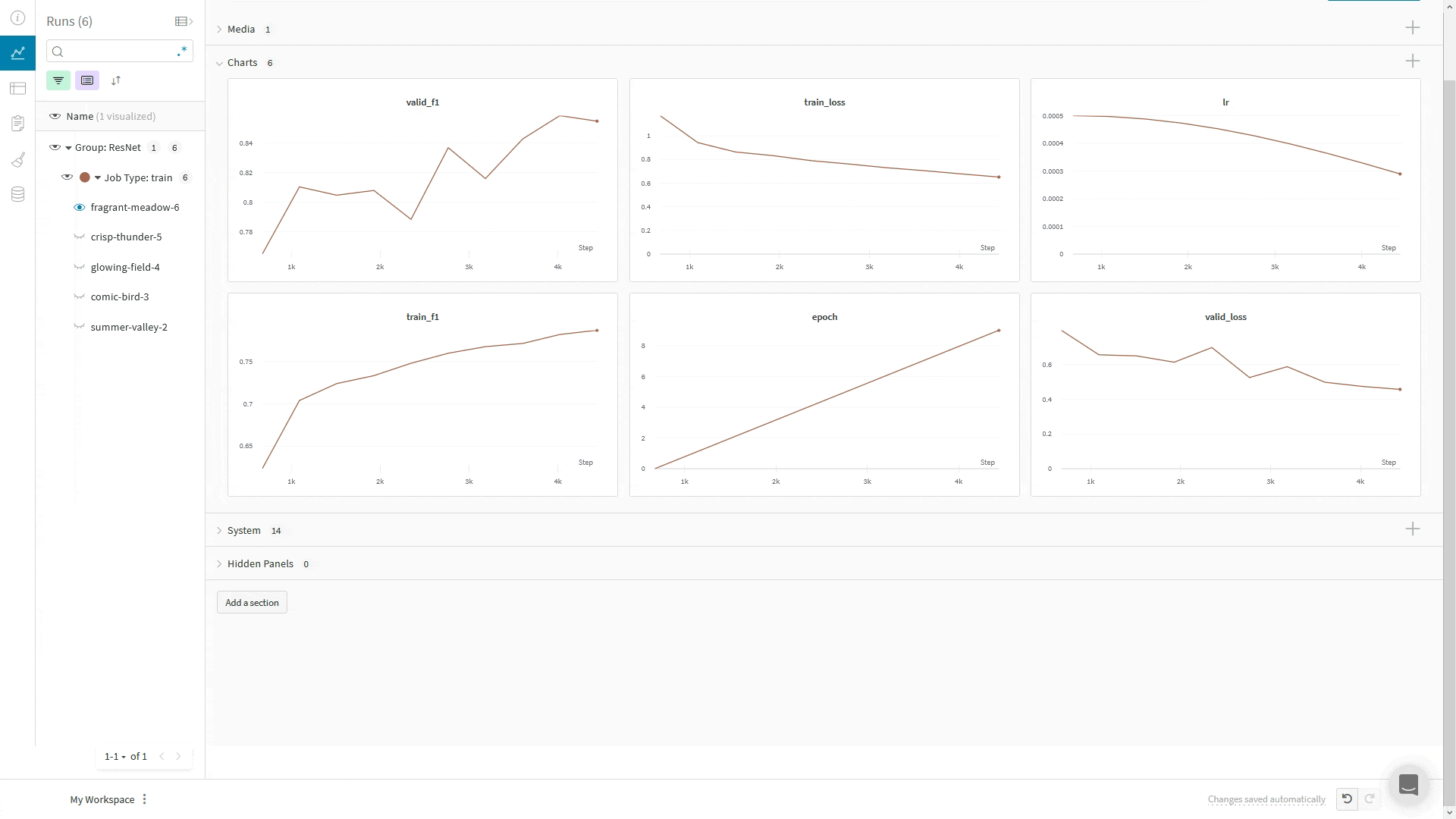
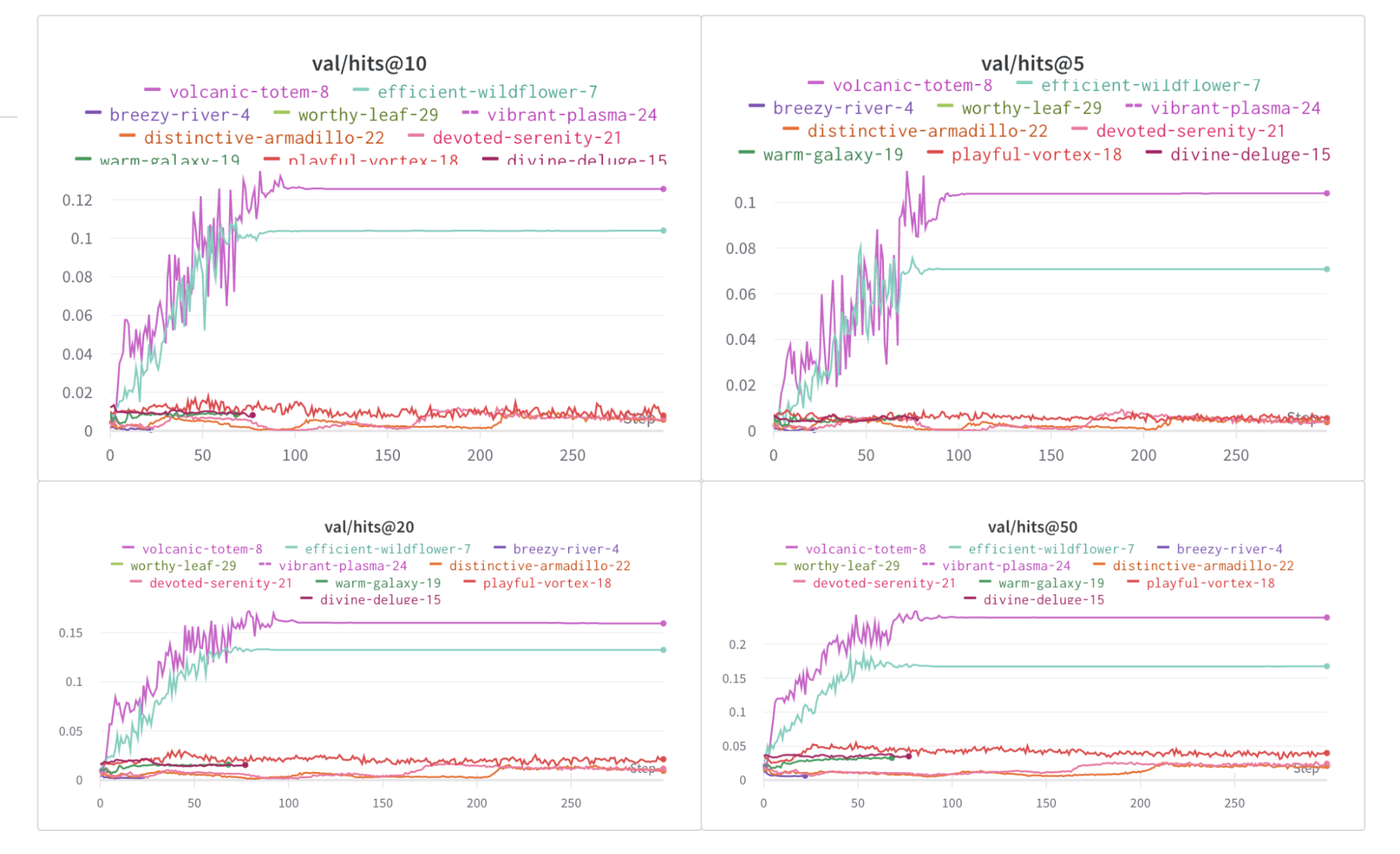
メトリクス がたくさんある場合は、train/... や val/... などの メトリクス 名にプレフィックスを使用することで、UI で自動的にグループ化できます。これにより、トレーニングと検証の メトリクス 、または分離したいその他の メトリクス タイプ用に、W&B Workspace に個別のセクションが作成されます。
metrics = {
"train/loss" : 0.4 ,
"train/learning_rate" : 0.4 ,
"val/loss" : 0.5 ,
"val/accuracy" : 0.7
}
run. log(metrics)
run.log の詳細を見る
X軸のずれを防ぐ
同じトレーニングステップに対して run.log を複数回呼び出すと、wandb SDK は run.log を呼び出すたびに内部ステップカウンターをインクリメントします。このカウンターは、トレーニングループのトレーニングステップと一致しない場合があります。
この状況を回避するには、run.define_metric で X軸ステップを明示的に定義します。wandb.init を呼び出した直後に1回定義します。
with wandb. init(... ) as run:
run. define_metric("*" , step_metric= "global_step" )
グロブパターン * は、すべての メトリクス がチャートで global_step を X軸として使用することを意味します。特定の メトリクス のみを global_step に対してログに記録する場合は、代わりにそれらを指定できます。
run. define_metric("train/loss" , step_metric= "global_step" )
次に、run.log を呼び出すたびに、 メトリクス 、step メトリクス 、および global_step をログに記録します。
for step, (input, ground_truth) in enumerate(data):
...
run. log({"global_step" : step, "train/loss" : 0.1 })
run. log({"global_step" : step, "eval/loss" : 0.2 })
たとえば、検証ループ中に「global_step」が利用できないなど、独立したステップ変数にアクセスできない場合、「global_step」の以前にログに記録された値が wandb によって自動的に使用されます。この場合、メトリクス に必要なときに定義されるように、 メトリクス の初期値をログに記録してください。
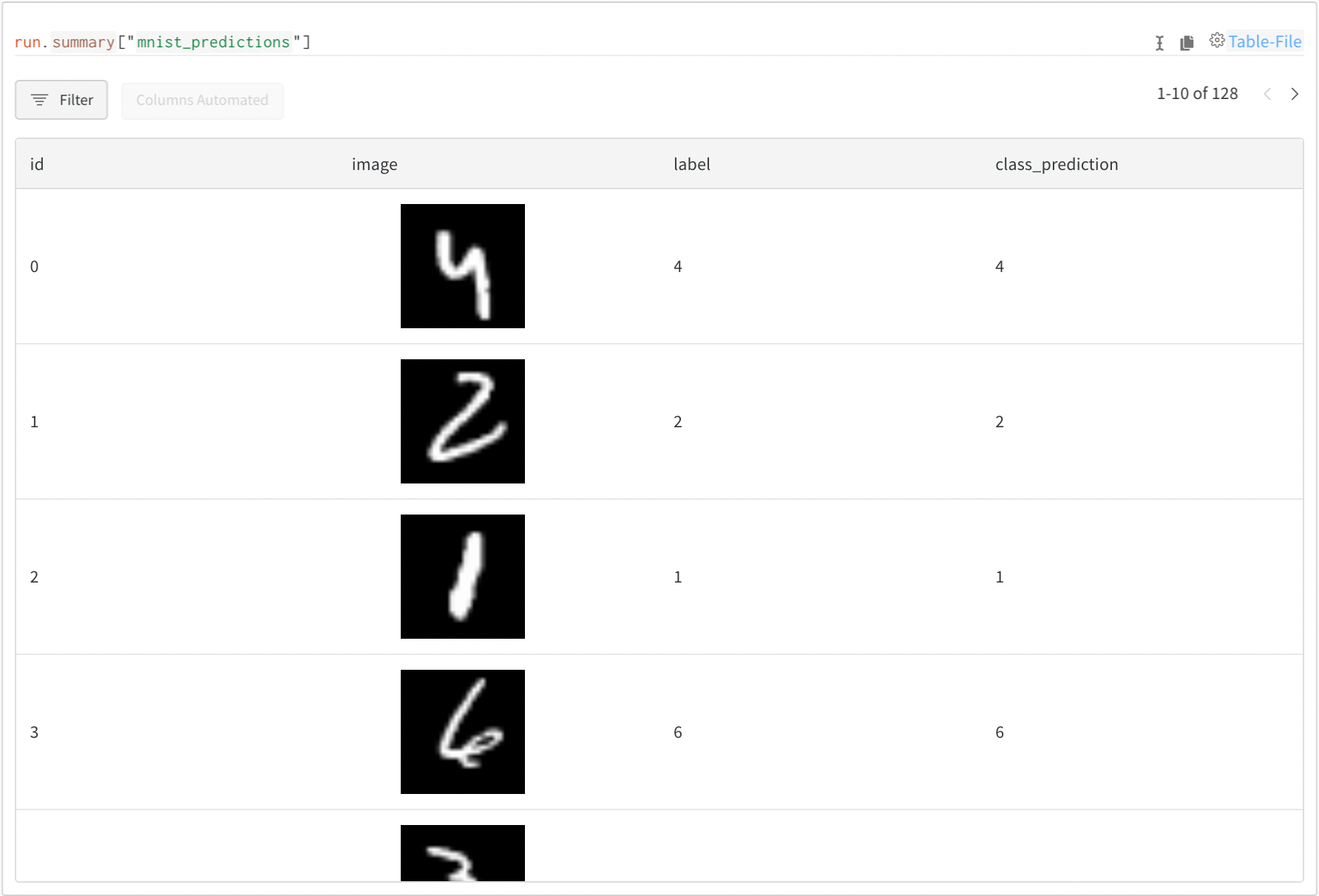
画像、テーブル、音声などをログに記録する
メトリクス に加えて、プロット、ヒストグラム、テーブル、テキスト、および画像、ビデオ、オーディオ、3D などのメディアをログに記録できます。
データをログに記録する際の考慮事項は次のとおりです。
メトリクス をログに記録する頻度はどのくらいですか? オプションにする必要がありますか?
視覚化に役立つデータの種類は何ですか?
画像の場合は、サンプル予測、セグメンテーションマスクなどをログに記録して、時間の経過に伴う変化を確認できます。
テキストの場合は、サンプル予測のテーブルをログに記録して、後で調べることができます。
メディア、オブジェクト、プロットなどのログ記録の詳細 をご覧ください。
分散トレーニング
分散環境をサポートするフレームワークの場合は、次のいずれかの ワークフロー を採用できます。
どの プロセス が「メイン」 プロセス であるかを検出し、そこで wandb のみを使用します。他の プロセス からの必要なデータは、最初にメイン プロセス にルーティングする必要があります(この ワークフロー を推奨します)。
すべての プロセス で wandb を呼び出し、すべてに同じ一意の group 名を付けて自動的にグループ化します。
詳細については、分散トレーニング実験のログを記録する を参照してください。
モデルチェックポイントなどを記録する
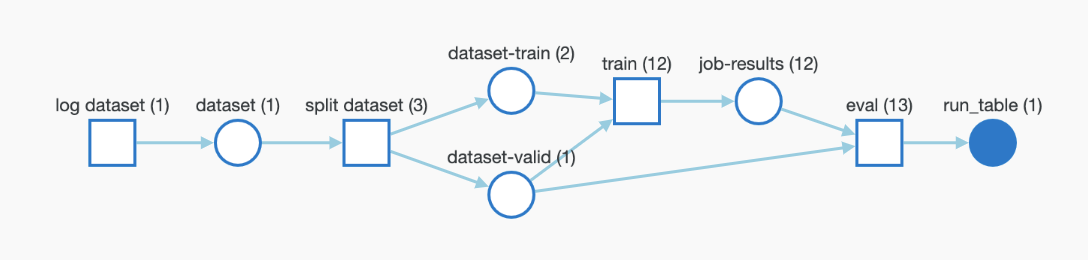
フレームワークがモデルまたはデータセットを使用または生成する場合は、それらをログに記録して完全なトレーサビリティを実現し、W&B Artifacts を介して パイプライン 全体を wandb で自動的に監視できます。
Artifacts を使用する場合、ユーザーに次のことを定義させることは役立つかもしれませんが、必須ではありません。
モデルチェックポイントまたはデータセットをログに記録する機能(オプションにする場合)。
入力として使用される Artifact のパス/参照(ある場合)。たとえば、user/project/artifact です。
Artifacts をログに記録する頻度。
モデルチェックポイント を記録する
モデルチェックポイント を W&B にログを記録できます。一意の wandb Run ID を利用して出力 モデルチェックポイント に名前を付け、Run 間で区別すると便利です。また、有用な メタデータ を追加することもできます。さらに、以下に示すように、各モデルに エイリアス を追加することもできます。
metadata = {"eval/accuracy" : 0.8 , "train/steps" : 800 }
artifact = wandb. Artifact(
name= f "model- { run. id} " ,
metadata= metadata,
type= "model"
)
artifact. add_dir("output_model" ) # local directory where the model weights are stored
aliases = ["best" , "epoch_10" ]
run. log_artifact(artifact, aliases= aliases)
カスタム エイリアス の作成方法については、カスタム エイリアス を作成する を参照してください。
出力 Artifacts は、任意の頻度(たとえば、エポックごと、500ステップごとなど)でログに記録でき、自動的に バージョン 管理されます。
学習済み モデル または データセット をログに記録および追跡する
学習済み モデル や データセット など、トレーニングへの入力として使用される Artifacts をログに記録できます。次のスニペットは、Artifact をログに記録し、上記のグラフに示すように、実行中の Run に入力として追加する方法を示しています。
artifact_input_data = wandb. Artifact(name= "flowers" , type= "dataset" )
artifact_input_data. add_file("flowers.npy" )
run. use_artifact(artifact_input_data)
Artifact をダウンロードする
Artifact(データセット、モデルなど)を再利用すると、wandb はローカルにコピーをダウンロード(およびキャッシュ)します。
artifact = run. use_artifact("user/project/artifact:latest" )
local_path = artifact. download("./tmp" )
Artifacts は W&B の Artifacts セクションにあり、自動的に生成される エイリアス (latest、v2、v3)またはログ記録時に手動で生成される エイリアス (best_accuracy など)で参照できます。
(wandb.init を介して)wandb Run を作成せずに Artifact をダウンロードするには(たとえば、分散環境または単純な推論の場合)、代わりにwandb API で Artifact を参照できます。
artifact = wandb. Api(). artifact("user/project/artifact:latest" )
local_path = artifact. download()
詳細については、Artifacts のダウンロードと使用 を参照してください。
ハイパーパラメーター を チューニング する
ライブラリで W&B ハイパーパラメーター チューニング 、W&B Sweeps を活用したい場合は、ライブラリに追加することもできます。
高度な インテグレーション
高度な W&B インテグレーション がどのようなものかについては、次の インテグレーション を参照してください。ほとんどの インテグレーション はこれほど複雑ではありません。
2 - Azure OpenAI Fine-Tuning
W&B を使用して Azure OpenAI モデルを ファインチューン する方法。
イントロダクション
Microsoft Azure 上で GPT-3.5 または GPT-4 モデルをファインチューニングする際、W&B を使用することで、メトリクスの自動的なキャプチャや W&B の 実験管理 および評価 ツールによる体系的な評価が促進され、モデルのパフォーマンスを追跡、分析、改善できます。
前提条件
ワークフローの概要
1. ファインチューニングのセットアップ
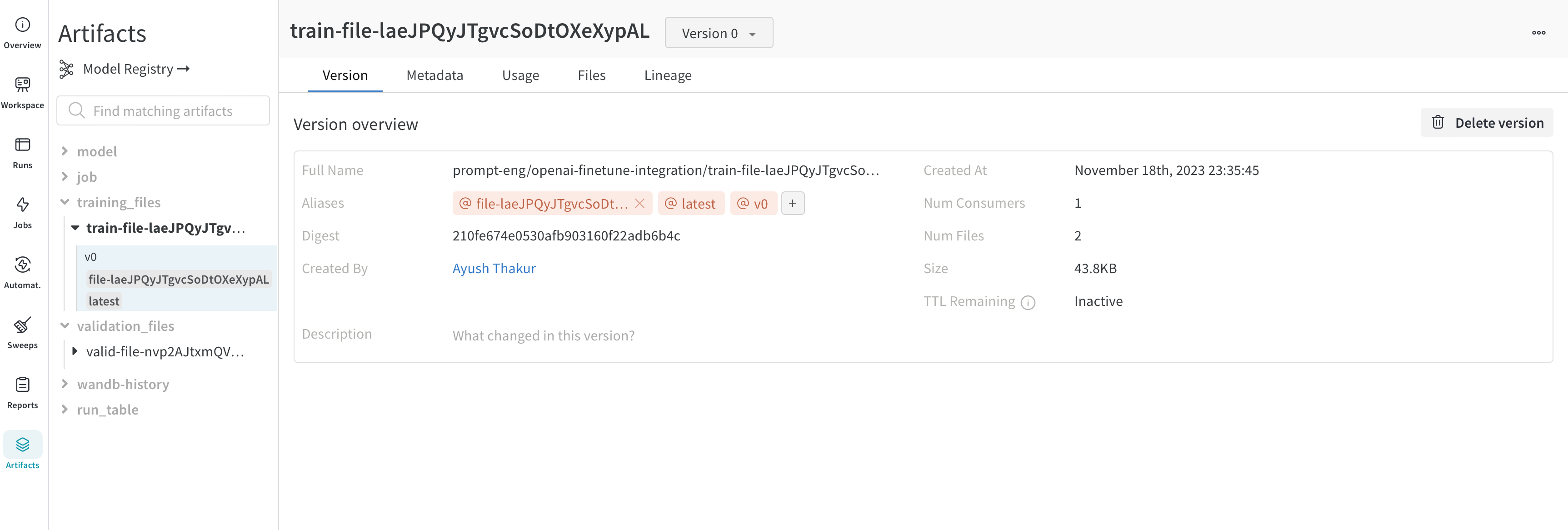
Azure OpenAI の要件に従ってトレーニングデータを準備します。
Azure OpenAI でファインチューニングジョブを設定します。
W&B は、ファインチューニングプロセスを自動的に追跡し、メトリクスとハイパーパラメータをログに記録します。
2. 実験管理
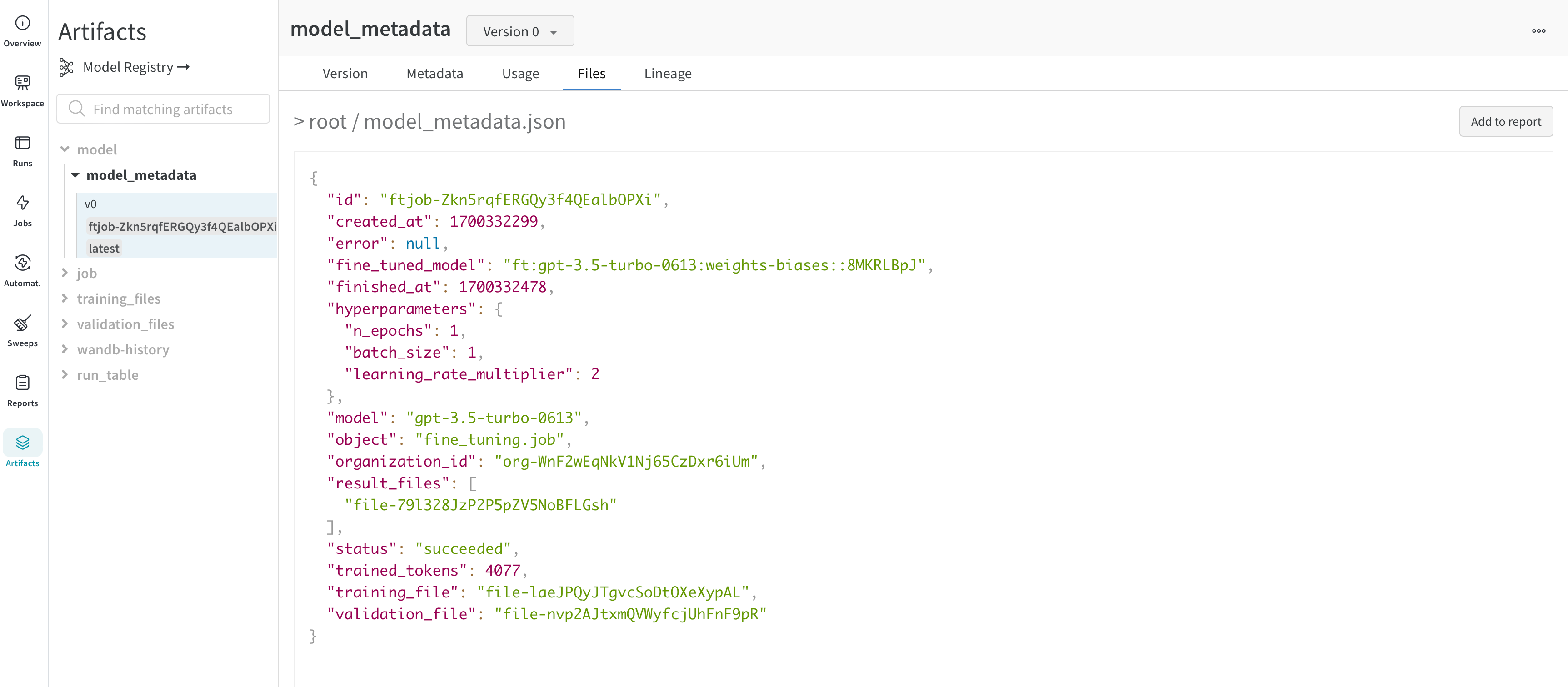
ファインチューニング中、W&B は以下をキャプチャします。
トレーニング および 検証メトリクス
モデル ハイパーパラメータ
リソース使用率
トレーニング Artifacts
3. モデルの評価
ファインチューニング後、W&B Weave を使用して以下を行います。
参照データセットに対するモデル出力を評価します
異なるファインチューニング Runs 全体のパフォーマンスを比較します
特定のテストケースにおけるモデルの 振る舞い を分析します
データに基づいたモデル選択の意思決定を行います
実際の例
追加リソース
3 - Catalyst
Pytorch のフレームワークである Catalyst に W&B を統合する方法。
Catalyst は、再現性 、迅速な実験 、およびコードベースの再利用に重点を置いたディープラーニング のR&D用 PyTorch フレームワーク で、新しいものを創造できます。
Catalyst には、 パラメータ 、 メトリクス 、画像、およびその他の Artifacts を ログ 記録するための W&B インテグレーション が含まれています。
Python と Hydra を使用した例を含む、インテグレーション のドキュメント を確認してください。
インタラクティブな例
Catalyst と W&B の インテグレーション の動作を確認するには、example colab を実行してください。
4 - Cohere fine-tuning
W&B を使用して Cohere モデル を ファインチューン する方法。
Weights & Biases を使用すると、Cohere モデルのファイン チューニング メトリクスと設定をログに記録して、モデルのパフォーマンスを分析および理解し、同僚と結果を共有できます。
この Cohere のガイド には、ファイン チューニング run を開始する方法の完全な例が記載されています。また、Cohere API ドキュメントはこちら にあります。
Cohere のファイン チューニング result をログに記録する
Cohere のファイン チューニング ログを W&B Workspace に追加するには:
W&B API キー、W&B entity、および project 名を使用して WandbConfig を作成します。W&B API キーは、https://wandb.ai/authorize で確認できます。
この設定を、モデル名、データセット、ハイパー パラメーターとともに FinetunedModel オブジェクトに渡して、ファイン チューニング run を開始します。
from cohere.finetuning import WandbConfig, FinetunedModel
# W&B の詳細を含む config を作成する
wandb_ft_config = WandbConfig(
api_key= "<wandb_api_key>" ,
entity= "my-entity" , # 提供された API キーに関連付けられている有効な entity である必要があります
project= "cohere-ft" ,
)
... # データセットとハイパー パラメーターを設定する
# cohere でファイン チューニング run を開始する
cmd_r_finetune = co. finetuning. create_finetuned_model(
request= FinetunedModel(
name= "command-r-ft" ,
settings= Settings(
base_model=...
dataset_id=...
hyperparameters=...
wandb= wandb_ft_config # ここに W&B config を渡す
),
),
)
作成した W&B project で、モデルのファイン チューニング トレーニング、検証メトリクス、およびハイパー パラメーターを表示します。
Runs を整理する
W&B の Runs は自動的に整理され、ジョブタイプ、ベース model、学習率、その他のハイパー パラメーターなどの任意の設定 parameter に基づいてフィルタリング/ソートできます。
さらに、Runs の名前を変更したり、メモを追加したり、タグを作成してグループ化したりできます。
リソース
5 - Databricks
W&B と Databricks を統合する方法。
W&B は、Databricks 環境で W&B Jupyter notebook のエクスペリエンスをカスタマイズすることにより、Databricks と統合されます。
Databricks の設定
クラスターに wandb をインストールする
クラスターの設定に移動し、クラスターを選択して、ライブラリ をクリックします。新規インストール をクリックし、PyPI を選択して、パッケージ wandb を追加します。
認証の設定
W&B アカウントを認証するには、notebook がクエリできる Databricks シークレットを追加します。
# databricks cli をインストールする
pip install databricks-cli
# databricks UI からトークンを生成する
databricks configure --token
# 次の 2 つのコマンドのいずれかを使用してスコープを作成します (Databricks でセキュリティ機能が有効になっているかどうかによって異なります)。
# セキュリティ アドオンを使用する場合
databricks secrets create-scope --scope wandb
# セキュリティ アドオンを使用しない場合
databricks secrets create-scope --scope wandb --initial-manage-principal users
# https://app.wandb.ai/authorize から api_key を追加します
databricks secrets put --scope wandb --key api_key
例
簡単な例
import os
import wandb
api_key = dbutils. secrets. get("wandb" , "api_key" )
wandb. login(key= api_key)
wandb. init()
wandb. log({"foo" : 1 })
Sweeps
wandb.sweep() または wandb.agent() を使用しようとする notebook に必要なセットアップ (一時的):
import os
# これらは将来的には不要になります
os. environ["WANDB_ENTITY" ] = "my-entity"
os. environ["WANDB_PROJECT" ] = "my-project-that-exists"
6 - DeepChecks
DeepChecks と W&B の統合方法。
DeepChecks は、機械学習 モデル と データの検証を支援します。たとえば、データの整合性の検証、分布の検査、データ分割の検証、モデル の評価、異なる モデル 間の比較などを、最小限の労力で行うことができます。
DeepChecks と wandb の インテグレーション についてもっと読む ->
はじめに
DeepChecks を Weights & Biases とともに使用するには、まず Weights & Biases アカウント にサインアップする 必要があります こちら 。DeepChecks の Weights & Biases の インテグレーション を使用すると、次のよう にすぐに開始できます。
import wandb
wandb. login()
# deepchecks から チェック をインポートします
from deepchecks.checks import ModelErrorAnalysis
# チェック を実行します
result = ModelErrorAnalysis()
# その 結果 を wandb にプッシュします
result. to_wandb()
DeepChecks テストスイート 全体 を Weights & Biases に ログ することもできます
import wandb
wandb. login()
# deepchecks から full_suite テスト をインポートします
from deepchecks.suites import full_suite
# DeepChecks テストスイート を作成して実行します
suite_result = full_suite(). run(... )
# thes の 結果 を wandb にプッシュします
# ここでは、必要な wandb.init の config と 引数 を渡すことができます
suite_result. to_wandb(project= "my-suite-project" , config= {"suite-name" : "full-suite" })
例
``この レポート
この Weights & Biases の インテグレーション に関する質問や問題がありますか? DeepChecks github repository で issue をオープンしてください。私たちがキャッチして回答します :)
7 - DeepChem
DeepChem ライブラリと W&B を統合する方法。
DeepChem library は、創薬、材料科学、化学、生物学における深層学習の利用を民主化するオープンソースのツールを提供します。この W&B の インテグレーション により、DeepChem を使用してモデルを トレーニング する際に、シンプルで使いやすい 実験管理 とモデルの チェックポイント が追加されます。
3 行のコードで DeepChem のログを記録
logger = WandbLogger(… )
model = TorchModel(… , wandb_logger= logger)
model. fit(… )
Report と Google Colab
W&B with DeepChem: Molecular Graph Convolutional Networks の記事で、W&B DeepChem インテグレーション を使用して生成されたチャートの例をご覧ください。
すぐにコードを試したい場合は、こちらの Google Colab
Experiments の追跡
KerasModel または TorchModel タイプの DeepChem モデル用に W&B をセットアップします。
サインアップして API キー を作成する
API キー は、W&B へのマシンの認証を行います。API キー は、 ユーザー プロフィールから生成できます。
右上隅にある ユーザー プロフィール アイコンをクリックします。
[User Settings ] を選択し、[API Keys ] セクションまでスクロールします。
[Reveal ] をクリックします。表示された API キー をコピーします。API キー を非表示にするには、ページをリロードします。
wandb ライブラリ をインストールしてログインするwandb ライブラリ をローカルにインストールしてログインするには:
Command Line
Python
Python notebook
WANDB_API_KEY 環境変数 を API キー に設定します。
export WANDB_API_KEY= <your_api_key>
wandb ライブラリ をインストールしてログインします。
pip install wandb
wandb login
import wandb
wandb. login()
!pip install wandb
import wandb
wandb.login()
トレーニング および 評価 データ を W&B に ログ 記録する
トレーニング 損失と 評価 メトリクス は、自動的に W&B に ログ 記録できます。オプションの 評価 は、DeepChem ValidationCallback を使用して有効にできます。WandbLogger は ValidationCallback コールバックを検出し、生成された メトリクス を ログ 記録します。
from deepchem.models import TorchModel, ValidationCallback
vc = ValidationCallback(… ) # optional
model = TorchModel(… , wandb_logger= logger)
model. fit(… , callbacks= [vc])
logger. finish()
from deepchem.models import KerasModel, ValidationCallback
vc = ValidationCallback(… ) # optional
model = KerasModel(… , wandb_logger= logger)
model. fit(… , callbacks= [vc])
logger. finish()
8 - Docker
W&B と Docker を統合する方法。
Docker インテグレーション
W&B は、 コード が実行された Docker イメージ へのポインターを保存できます。これにより、以前の 実験 を実行された環境に正確に復元できます。 wandb ライブラリ は、この状態を永続化するために WANDB_DOCKER 環境変数 を探します。この状態を自動的に設定するいくつかのヘルパーを提供します。
ローカル開発
wandb docker は、 dockerコンテナ を起動し、 wandb 環境変数 を渡し、 コード をマウントし、 wandb がインストールされていることを確認する コマンド です。デフォルトでは、この コマンド は TensorFlow、PyTorch、Keras、Jupyter がインストールされた Docker イメージ を使用します。同じ コマンド を使用して、独自の Docker イメージ を起動できます: wandb docker my/image:latest。この コマンド は、現在の ディレクトリー を コンテナ の “/app” ディレクトリー にマウントします。これは “–dir” フラグで変更できます。
本番環境
wandb docker-run コマンド は、 本番環境 の ワークロード 用に提供されています。これは nvidia-docker のドロップイン代替となることを意図しています。これは docker run コマンド へのシンプルなラッパーで、 認証情報 と WANDB_DOCKER 環境変数 を呼び出しに追加します。 “–runtime” フラグを渡さず、 nvidia-docker がマシンで利用可能な場合、これにより ランタイム が nvidia に設定されます。
Kubernetes
Kubernetes で トレーニング の ワークロード を実行し、 k8s API が pod に公開されている場合(デフォルトの場合)。 wandb は、 Docker イメージ のダイジェストについて API にクエリを実行し、 WANDB_DOCKER 環境変数 を自動的に設定します。
復元
run が WANDB_DOCKER 環境変数 で計測されている場合、 wandb restore username/project:run_id を呼び出すと、 コード を復元する新しいブランチをチェックアウトし、 トレーニング に使用された正確な Docker イメージ を元の コマンド で事前に設定して 起動 します。
9 - Farama Gymnasium
Farama Gymnasium と W&B を統合する方法。
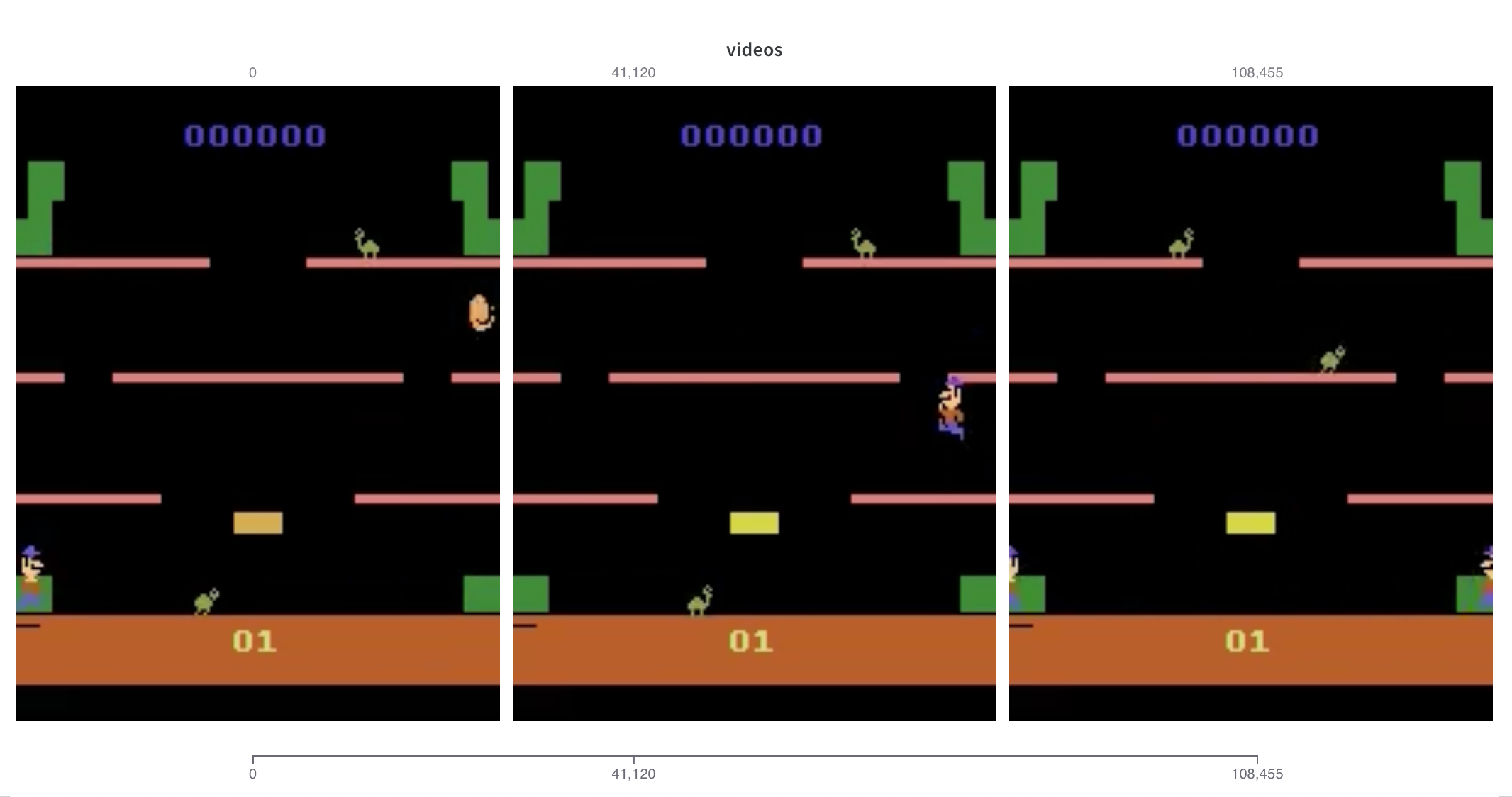
Farama Gymnasium を使用している場合、gymnasium.wrappers.Monitor で生成された環境の動画が自動的にログに記録されます。monitor_gym キーワード 引数 を wandb.initTrue に設定するだけです。
当社の Gymnasium インテグレーション は非常に軽量です。 gymnasium からログに記録されている 動画ファイルの名前を確認 し、その名前を付けます。一致するものが見つからない場合は、"videos" にフォールバックします。より詳細な制御が必要な場合は、いつでも手動で 動画をログに記録 できます。
CleanRL ライブラリ で Gymnasium を使用する方法の詳細については、こちらの Reports をご覧ください。
10 - fastai
fastai を使用してモデルをトレーニングする場合、W&B には WandbCallback を使用した簡単なインテグレーションがあります。インタラクティブなドキュメントと例はこちら →
サインアップして API キーを作成する
API キーは、W&B に対してお客様のマシンを認証します。API キーは、ユーザー プロフィールから生成できます。
右上隅にあるユーザー プロフィール アイコンをクリックします。
ユーザー設定 を選択し、API キー セクションまでスクロールします。表示 をクリックします。表示された API キーをコピーします。API キーを非表示にするには、ページをリロードします。
wandb ライブラリをインストールしてログインするwandb ライブラリをローカルにインストールしてログインするには:
コマンドライン
Python
Python notebook
WANDB_API_KEY 環境変数 を API キーに設定します。
export WANDB_API_KEY= <your_api_key>
wandb ライブラリをインストールしてログインします。
pip install wandb
wandb login
import wandb
wandb. login()
!pip install wandb
import wandb
wandb.login()
learner または fit メソッドに WandbCallback を追加するimport wandb
from fastai.callback.wandb import *
# start logging a wandb run
wandb. init(project= "my_project" )
# To log only during one training phase
learn. fit(... , cbs= WandbCallback())
# To log continuously for all training phases
learn = learner(... , cbs= WandbCallback())
WandbCallback 引数
WandbCallback は、次の引数を受け入れます。
Args
Description
log
モデルのログを記録するかどうか: gradients 、parameters、all または None (デフォルト)。損失とメトリクスは常にログに記録されます。
log_preds
予測サンプルをログに記録するかどうか (デフォルトは True)。
log_preds_every_epoch
エポックごとに予測をログに記録するか、最後にログに記録するか (デフォルトは False)
log_model
モデルをログに記録するかどうか (デフォルトは False)。これには SaveModelCallback も必要です
model_name
保存する file の名前。SaveModelCallback をオーバーライドします
log_dataset
False (デフォルト)True は、learn.dls.path で参照されるフォルダーをログに記録します。パスを明示的に定義して、ログに記録するフォルダーを参照できます。 注: サブフォルダー “models” は常に無視されます。
dataset_name
ログに記録されたデータセットの名前 (デフォルトは folder name)。
valid_dl
予測サンプルに使用されるアイテムを含む DataLoaders (デフォルトは learn.dls.valid からのランダムなアイテム。
n_preds
ログに記録された予測の数 (デフォルトは 36)。
seed
ランダム サンプルを定義するために使用されます。
カスタム ワークフローでは、データセットとモデルを手動でログに記録できます。
log_dataset(path, name=None, metadata={})log_model(path, name=None, metadata={})
注: サブフォルダー “models” はすべて無視されます。
分散トレーニング
fastai は、コンテキスト マネージャー distrib_ctx を使用して分散トレーニングをサポートします。W&B はこれを自動的にサポートし、すぐに使える Multi-GPU の Experiments を追跡できるようにします。
この最小限の例を確認してください。
import wandb
from fastai.vision.all import *
from fastai.distributed import *
from fastai.callback.wandb import WandbCallback
wandb. require(experiment= "service" )
path = rank0_first(lambda : untar_data(URLs. PETS) / "images" )
def train ():
dls = ImageDataLoaders. from_name_func(
path,
get_image_files(path),
valid_pct= 0.2 ,
label_func= lambda x: x[0 ]. isupper(),
item_tfms= Resize(224 ),
)
wandb. init("fastai_ddp" , entity= "capecape" )
cb = WandbCallback()
learn = vision_learner(dls, resnet34, metrics= error_rate, cbs= cb). to_fp16()
with learn. distrib_ctx(sync_bn= False ):
learn. fit(1 )
if __name__ == "__main__" :
train()
次に、ターミナルで次を実行します。
$ torchrun --nproc_per_node 2 train.py
この場合、マシンには 2 つの GPU があります。
ノートブック内で分散トレーニングを直接実行できるようになりました。
import wandb
from fastai.vision.all import *
from accelerate import notebook_launcher
from fastai.distributed import *
from fastai.callback.wandb import WandbCallback
wandb. require(experiment= "service" )
path = untar_data(URLs. PETS) / "images"
def train ():
dls = ImageDataLoaders. from_name_func(
path,
get_image_files(path),
valid_pct= 0.2 ,
label_func= lambda x: x[0 ]. isupper(),
item_tfms= Resize(224 ),
)
wandb. init("fastai_ddp" , entity= "capecape" )
cb = WandbCallback()
learn = vision_learner(dls, resnet34, metrics= error_rate, cbs= cb). to_fp16()
with learn. distrib_ctx(in_notebook= True , sync_bn= False ):
learn. fit(1 )
notebook_launcher(train, num_processes= 2 )
メイン プロセスでのみログを記録する
上記の例では、wandb はプロセスごとに 1 つの run を起動します。トレーニングの最後に、2 つの run が作成されます。これは混乱を招く可能性があるため、メイン プロセスでのみログに記録したい場合があります。そのためには、どのプロセスに手動でいるかを検出し、他のすべてのプロセスで run を作成 ( wandb.init を呼び出す) しないようにする必要があります。
import wandb
from fastai.vision.all import *
from fastai.distributed import *
from fastai.callback.wandb import WandbCallback
wandb. require(experiment= "service" )
path = rank0_first(lambda : untar_data(URLs. PETS) / "images" )
def train ():
cb = []
dls = ImageDataLoaders. from_name_func(
path,
get_image_files(path),
valid_pct= 0.2 ,
label_func= lambda x: x[0 ]. isupper(),
item_tfms= Resize(224 ),
)
if rank_distrib() == 0 :
run = wandb. init("fastai_ddp" , entity= "capecape" )
cb = WandbCallback()
learn = vision_learner(dls, resnet34, metrics= error_rate, cbs= cb). to_fp16()
with learn. distrib_ctx(sync_bn= False ):
learn. fit(1 )
if __name__ == "__main__" :
train()
ターミナルで次を呼び出します。
$ torchrun --nproc_per_node 2 train.py
import wandb
from fastai.vision.all import *
from accelerate import notebook_launcher
from fastai.distributed import *
from fastai.callback.wandb import WandbCallback
wandb. require(experiment= "service" )
path = untar_data(URLs. PETS) / "images"
def train ():
cb = []
dls = ImageDataLoaders. from_name_func(
path,
get_image_files(path),
valid_pct= 0.2 ,
label_func= lambda x: x[0 ]. isupper(),
item_tfms= Resize(224 ),
)
if rank_distrib() == 0 :
run = wandb. init("fastai_ddp" , entity= "capecape" )
cb = WandbCallback()
learn = vision_learner(dls, resnet34, metrics= error_rate, cbs= cb). to_fp16()
with learn. distrib_ctx(in_notebook= True , sync_bn= False ):
learn. fit(1 )
notebook_launcher(train, num_processes= 2 )
例
10.1 - fastai v1
このドキュメントは fastai v1 用です。
現在のバージョンの fastai を使用している場合は、
fastai のページ を参照してください。
fastai v1 を使用するスクリプトの場合、モデルのトポロジー、損失、メトリクス、重み、勾配、サンプル予測、および最高のトレーニング済みモデルを自動的にログに記録できる コールバック があります。
import wandb
from wandb.fastai import WandbCallback
wandb. init()
learn = cnn_learner(data, model, callback_fns= WandbCallback)
learn. fit(epochs)
リクエストされたログデータは、 コールバック コンストラクターを通じて設定可能です。
from functools import partial
learn = cnn_learner(
data, model, callback_fns= partial(WandbCallback, input_type= "images" )
)
トレーニング の開始時にのみ WandbCallback を使用することも可能です。この場合、インスタンス化する必要があります。
learn. fit(epochs, callbacks= WandbCallback(learn))
カスタム パラメータ は、その段階で指定することもできます。
learn. fit(epochs, callbacks= WandbCallback(learn, input_type= "images" ))
コード 例
この インテグレーション の動作を確認するためのいくつかの例を作成しました。
Fastai v1
オプション
WandbCallback() クラス は、多数のオプションをサポートしています。
キーワード 引数
デフォルト
説明
learn
N/A
フック する fast.ai の学習器。
save_model
True
各ステップで改善された場合、モデルを保存します。トレーニング の最後に最高のモデルもロードします。
mode
auto
min、max、または auto: monitor で指定された トレーニング メトリクス をステップ間で比較する方法。
monitor
None
最高のモデルを保存するためにパフォーマンスを測定するために使用される トレーニング メトリクス。None は、検証損失をデフォルトにします。
log
gradients
gradients、parameters、all、または None。損失と メトリクス は常にログに記録されます。
input_type
None
images または None。サンプル予測を表示するために使用されます。
validation_data
None
input_type が設定されている場合、サンプル予測に使用されるデータ。
predictions
36
input_type が設定され、validation_data が None の場合に行う予測の数。
seed
12345
input_type が設定され、validation_data が None の場合、サンプル予測のために乱数ジェネレーターを初期化します。
11 - Hugging Face Transformers
Hugging Face Transformers ライブラリを使用すると、BERTのような最先端の NLP モデルや、混合精度や勾配チェックポイントなどのトレーニング手法を簡単に使用できます。W&B integration は、使いやすさを損なうことなく、インタラクティブな集中ダッシュボードに、豊富で柔軟な実験管理とモデルの バージョン管理を追加します。
わずか数行で次世代のロギング
os. environ["WANDB_PROJECT" ] = "<my-amazing-project>" # W&B プロジェクトに名前を付ける
os. environ["WANDB_LOG_MODEL" ] = "checkpoint" # すべてのモデルチェックポイントをログに記録
from transformers import TrainingArguments, Trainer
args = TrainingArguments(... , report_to= "wandb" ) # W&B ロギングをオンにする
trainer = Trainer(... , args= args)
はじめに: 実験の トラッキング
サインアップして API キーを作成する
API キーは、お使いのマシンを W&B に対して認証します。API キーは、ユーザープロフィールから生成できます。
右上隅にあるユーザープロフィールアイコンをクリックします。
[User Settings ]を選択し、[API Keys ]セクションまでスクロールします。
[Reveal ]をクリックします。表示された API キーをコピーします。API キーを非表示にするには、ページをリロードします。
wandb ライブラリをインストールしてログインするwandb ライブラリをローカルにインストールしてログインするには:
Command Line
Python
Python notebook
WANDB_API_KEY 環境変数 を API キーに設定します。
export WANDB_API_KEY= <your_api_key>
wandb ライブラリをインストールしてログインします。
pip install wandb
wandb login
import wandb
wandb. login()
!pip install wandb
import wandb
wandb.login()
W&B を初めて使用する場合は、クイックスタート
プロジェクトに名前を付ける
W&B の Project とは、関連する run からログに記録されたすべてのチャート、データ、およびモデルが保存される場所です。プロジェクトに名前を付けると、作業を整理し、単一のプロジェクトに関するすべての情報を 1 か所にまとめて管理できます。
run をプロジェクトに追加するには、WANDB_PROJECT 環境変数をプロジェクト名に設定するだけです。WandbCallback は、このプロジェクト名の環境変数を取得し、run の設定時に使用します。
Command Line
Python
Python notebook
WANDB_PROJECT= amazon_sentiment_analysis
import os
os. environ["WANDB_PROJECT" ]= "amazon_sentiment_analysis"
%env WANDB_PROJECT=amazon_sentiment_analysis
Trainer を初期化する 前に 、必ずプロジェクト名を設定してください。
プロジェクト名が指定されていない場合、プロジェクト名はデフォルトで huggingface になります。
トレーニングの run を W&B に記録する
コード内またはコマンドラインで Trainer のトレーニング引数を定義する際に 最も重要なステップ は、W&B でのロギングを有効にするために、report_to を "wandb" に設定することです。
TrainingArguments の logging_steps 引数は、トレーニング中にトレーニングメトリクスが W&B にプッシュされる頻度を制御します。run_name 引数を使用して、W&B のトレーニング run に名前を付けることもできます。
これで完了です。モデルは、トレーニング中に損失、評価メトリクス、モデルトポロジー、および勾配を W&B に記録します。
python run_glue.py \ # Python スクリプトを実行する
--report_to wandb \ # W&B へのロギングを有効にする
--run_name bert-base-high-lr \ # W&B run の名前 (オプション)
# その他のコマンドライン引数
from transformers import TrainingArguments, Trainer
args = TrainingArguments(
# その他の args と kwargs
report_to= "wandb" , # W&B へのロギングを有効にする
run_name= "bert-base-high-lr" , # W&B run の名前 (オプション)
logging_steps= 1 , # W&B へのロギング頻度
)
trainer = Trainer(
# その他の args と kwargs
args= args, # トレーニングの引数
)
trainer. train() # トレーニングを開始して W&B にログを記録する
TensorFlow を使用していますか?PyTorch Trainer を TensorFlow TFTrainer に交換するだけです。
モデルチェックポイントをオンにする
Artifacts を使用すると、最大 100GB のモデルとデータセットを無料で保存し、Weights & Biases Registry を使用できます。Registry を使用すると、モデルを登録して探索および評価したり、ステージングの準備をしたり、本番環境にデプロイしたりできます。
Hugging Face モデルチェックポイントを Artifacts に記録するには、WANDB_LOG_MODEL 環境変数を次の いずれか に設定します。
checkpointTrainingArgumentsargs.save_steps ごとにチェックポイントをアップロードします。endload_best_model_at_end も設定されている場合は、トレーニングの最後にモデルをアップロードします。false
Command Line
Python
Python notebook
WANDB_LOG_MODEL= "checkpoint"
import os
os. environ["WANDB_LOG_MODEL" ] = "checkpoint"
%env WANDB_LOG_MODEL="checkpoint"
これから初期化する Transformers Trainer はすべて、モデルを W&B プロジェクトにアップロードします。ログに記録したモデルチェックポイントは、Artifacts UI で表示でき、完全なモデルリネージが含まれています (UI のモデルチェックポイントの例は こちら を参照してください)。
デフォルトでは、
WANDB_LOG_MODEL が
end に設定されている場合は
model-{run_id} として、
WANDB_LOG_MODEL が
checkpoint に設定されている場合は
checkpoint-{run_id} として、モデルは W&B Artifacts に保存されます。
ただし、
TrainingArguments で
run_name を渡すと、モデルは
model-{run_name} または
checkpoint-{run_name} として保存されます。
W&B Registry
チェックポイントを Artifacts に記録したら、最高のモデルチェックポイントを登録し、Registry 自動化 したりできます。
モデル Artifact をリンクするには、Registry を参照してください。
トレーニング中に評価出力を可視化する
トレーニング中または評価中にモデル出力を可視化することは、モデルのトレーニング方法を実際に理解するために不可欠なことがよくあります。
Transformers Trainer のコールバックシステムを使用すると、モデルのテキスト生成出力やその他の予測などの追加の役立つデータを W&B Tables に W&B に記録できます。
トレーニング中に評価出力を記録して、次のような W&B Table に記録する方法の詳細については、以下の カスタムロギングセクション
W&B Run を終了する (ノートブックのみ)
トレーニングが Python スクリプトにカプセル化されている場合、スクリプトが終了すると W&B run は終了します。
Jupyter または Google Colab ノートブックを使用している場合は、wandb.finish() を呼び出して、トレーニングが完了したことを伝える必要があります。
trainer. train() # トレーニングを開始して W&B にログを記録する
# トレーニング後の分析、テスト、その他のログに記録されたコード
wandb. finish()
結果を可視化する
トレーニング結果をログに記録したら、W&B Dashboard で結果を動的に調べることができます。柔軟でインタラクティブな可視化により、多数の run を一度に比較したり、興味深い発見を拡大したり、複雑なデータから洞察を引き出したりするのが簡単です。
高度な機能と FAQ
最適なモデルを保存するにはどうすればよいですか?
load_best_model_at_end=True で TrainingArguments を Trainer に渡すと、W&B は最適なパフォーマンスのモデルチェックポイントを Artifacts に保存します。
モデルチェックポイントを Artifacts として保存する場合は、Registry に昇格させることができます。Registry では、次のことができます。
ML タスクごとに最適なモデルバージョンを整理します。
モデルを一元化してチームと共有します。
本番環境用にモデルをステージングするか、詳細な評価のためにブックマークします。
ダウンストリーム CI/CD プロセスをトリガーします。
保存されたモデルをロードするにはどうすればよいですか?
WANDB_LOG_MODEL を使用してモデルを W&B Artifacts に保存した場合は、追加のトレーニングまたは推論を実行するためにモデルの重みをダウンロードできます。以前に使用したのと同じ Hugging Face アーキテクチャにロードするだけです。
# 新しい run を作成する
with wandb. init(project= "amazon_sentiment_analysis" ) as run:
# Artifact の名前とバージョンを渡す
my_model_name = "model-bert-base-high-lr:latest"
my_model_artifact = run. use_artifact(my_model_name)
# モデルの重みをフォルダーにダウンロードしてパスを返す
model_dir = my_model_artifact. download()
# 同じモデルクラスを使用して、そのフォルダーから Hugging Face モデルをロードする
model = AutoModelForSequenceClassification. from_pretrained(
model_dir, num_labels= num_labels
)
# 追加のトレーニングを実行するか、推論を実行する
チェックポイントからトレーニングを再開するにはどうすればよいですか?
WANDB_LOG_MODEL='checkpoint' を設定した場合は、model_dir を TrainingArguments の model_name_or_path 引数として使用し、resume_from_checkpoint=True を Trainer に渡すことで、トレーニングを再開することもできます。
last_run_id = "xxxxxxxx" # wandb ワークスペースから run_id を取得する
# run_id から wandb run を再開する
with wandb. init(
project= os. environ["WANDB_PROJECT" ],
id= last_run_id,
resume= "must" ,
) as run:
# Artifact を run に接続する
my_checkpoint_name = f "checkpoint- { last_run_id} :latest"
my_checkpoint_artifact = run. use_artifact(my_model_name)
# チェックポイントをフォルダーにダウンロードしてパスを返す
checkpoint_dir = my_checkpoint_artifact. download()
# モデルとトレーナーを再初期化する
model = AutoModelForSequenceClassification. from_pretrained(
"<model_name>" , num_labels= num_labels
)
# ここに素晴らしいトレーニング引数を記述する。
training_args = TrainingArguments()
trainer = Trainer(model= model, args= training_args)
# チェックポイントディレクトリを使用して、チェックポイントからトレーニングを再開する
trainer. train(resume_from_checkpoint= checkpoint_dir)
トレーニング中に評価サンプルを記録して表示するにはどうすればよいですか?
Transformers Trainer を介した W&B へのロギングは、Transformers ライブラリの WandbCallbackWandbCallback をサブクラス化し、Trainer クラスの追加メソッドを活用する追加機能を追加して、このコールバックを変更できます。
以下は、この新しいコールバックを HF Trainer に追加する一般的なパターンであり、さらに下には、評価出力を W&B Table に記録するコード完全な例があります。
# Trainer を通常どおりインスタンス化する
trainer = Trainer()
# 新しいロギングコールバックをインスタンス化し、Trainer オブジェクトを渡す
evals_callback = WandbEvalsCallback(trainer, tokenizer, ... )
# コールバックを Trainer に追加する
trainer. add_callback(evals_callback)
# 通常どおり Trainer トレーニングを開始する
trainer. train()
トレーニング中に評価サンプルを表示する
次のセクションでは、WandbCallback をカスタマイズして、モデルの予測を実行し、トレーニング中に評価サンプルを W&B Table に記録する方法について説明します。Trainer コールバックの on_evaluate メソッドを使用して、すべての eval_steps を実行します。
ここでは、tokenizer を使用してモデル出力から予測とラベルをデコードする decode_predictions 関数を作成しました。
次に、予測とラベルから pandas DataFrame を作成し、DataFrame に epoch 列を追加します。
最後に、DataFrame から wandb.Table を作成し、wandb に記録します。
さらに、予測を freq エポックごとに記録することで、ロギングの頻度を制御できます。
注 : 通常の WandbCallback とは異なり、このカスタムコールバックは、Trainer の初期化中ではなく、Trainer がインスタンス化された後 にトレーナーに追加する必要があります。
これは、Trainer インスタンスが初期化中にコールバックに渡されるためです。
from transformers.integrations import WandbCallback
import pandas as pd
def decode_predictions (tokenizer, predictions):
labels = tokenizer. batch_decode(predictions. label_ids)
logits = predictions. predictions. argmax(axis=- 1 )
prediction_text = tokenizer. batch_decode(logits)
return {"labels" : labels, "predictions" : prediction_text}
class WandbPredictionProgressCallback (WandbCallback):
"""Custom WandbCallback to log model predictions during training.
This callback logs model predictions and labels to a wandb.Table at each
logging step during training. It allows to visualize the
model predictions as the training progresses.
Attributes:
trainer (Trainer): The Hugging Face Trainer instance.
tokenizer (AutoTokenizer): The tokenizer associated with the model.
sample_dataset (Dataset): A subset of the validation dataset
for generating predictions.
num_samples (int, optional): Number of samples to select from
the validation dataset for generating predictions. Defaults to 100.
freq (int, optional): Frequency of logging. Defaults to 2.
"""
def __init__(self, trainer, tokenizer, val_dataset, num_samples= 100 , freq= 2 ):
"""Initializes the WandbPredictionProgressCallback instance.
Args:
trainer (Trainer): The Hugging Face Trainer instance.
tokenizer (AutoTokenizer): The tokenizer associated
with the model.
val_dataset (Dataset): The validation dataset.
num_samples (int, optional): Number of samples to select from
the validation dataset for generating predictions.
Defaults to 100.
freq (int, optional): Frequency of logging. Defaults to 2.
"""
super(). __init__()
self. trainer = trainer
self. tokenizer = tokenizer
self. sample_dataset = val_dataset. select(range(num_samples))
self. freq = freq
def on_evaluate (self, args, state, control, ** kwargs):
super(). on_evaluate(args, state, control, ** kwargs)
# control the frequency of logging by logging the predictions
# every `freq` epochs
if state. epoch % self. freq == 0 :
# generate predictions
predictions = self. trainer. predict(self. sample_dataset)
# decode predictions and labels
predictions = decode_predictions(self. tokenizer, predictions)
# add predictions to a wandb.Table
predictions_df = pd. DataFrame(predictions)
predictions_df["epoch" ] = state. epoch
records_table = self. _wandb. Table(dataframe= predictions_df)
# log the table to wandb
self. _wandb. log({"sample_predictions" : records_table})
# まず、Trainer をインスタンス化する
trainer = Trainer(
model= model,
args= training_args,
train_dataset= lm_datasets["train" ],
eval_dataset= lm_datasets["validation" ],
)
# WandbPredictionProgressCallback をインスタンス化する
progress_callback = WandbPredictionProgressCallback(
trainer= trainer,
tokenizer= tokenizer,
val_dataset= lm_dataset["validation" ],
num_samples= 10 ,
freq= 2 ,
)
# コールバックをトレーナーに追加する
trainer. add_callback(progress_callback)
詳細な例については、こちらの colab を参照してください。
その他の W&B 設定はありますか?
環境変数を設定することで、Trainer でログに記録される内容をさらに構成できます。W&B 環境変数の完全なリストは、こちら にあります。
環境変数
使用法
WANDB_PROJECTプロジェクトに名前を付けます (デフォルトでは huggingface)
WANDB_LOG_MODELモデルチェックポイントを W&B Artifact として記録します (デフォルトでは false)
false (デフォルト): モデルチェックポイントなしcheckpoint: チェックポイントは args.save_steps ごとにアップロードされます (Trainer の TrainingArguments で設定)。end: 最終的なモデルチェックポイントはトレーニングの最後にアップロードされます。
WANDB_WATCHモデルの勾配、パラメーター、またはそのどちらもログに記録するかどうかを設定します
false (デフォルト): 勾配またはパラメーターのロギングなしgradients: 勾配のヒストグラムをログに記録しますall: 勾配とパラメーターのヒストグラムをログに記録します
WANDB_DISABLEDロギングを完全にオフにするには true に設定します (デフォルトでは false)
WANDB_SILENTwandb によって出力される出力を抑制するには true に設定します (デフォルトでは false)
WANDB_WATCH= all
WANDB_SILENT= true
%env WANDB_WATCH=all
%env WANDB_SILENT=true
wandb.init をカスタマイズするにはどうすればよいですか?Trainer が使用する WandbCallback は、Trainer が初期化されるときに内部で wandb.init を呼び出します。Trainer が初期化される前に wandb.init を呼び出すことで、run を手動で設定することもできます。これにより、W&B run の構成を完全に制御できます。
init に渡したい可能性のあるものの例を以下に示します。wandb.init の使用方法の詳細については、リファレンスドキュメントをご確認ください 。
wandb. init(
project= "amazon_sentiment_analysis" ,
name= "bert-base-high-lr" ,
tags= ["baseline" , "high-lr" ],
group= "bert" ,
)
その他のリソース
以下は、Transformer と W&B に関連する 6 つの記事です。
Hugging Face Transformers のハイパーパラメーター最適化
Hugging Face Transformers のハイパーパラメーター最適化のための 3 つの戦略 (グリッド検索、ベイズ最適化、Population Based Training) が比較されます。
Hugging Face transformers から標準的な uncased BERT モデルを使用し、SuperGLUE ベンチマークから RTE データセットでファインチューニングしたいと考えています。
結果は、Population Based Training が Hugging Face transformer モデルのハイパーパラメーター最適化に最も効果的なアプローチであることを示しています。
完全なレポートは こちら をお読みください。
Hugging Tweets: ツイートを生成するモデルをトレーニングする
この記事では、著者は、誰かのツイートで学習済みの GPT2 HuggingFace Transformer モデルを 5 分でファインチューニングする方法を示しています。
このモデルは、ツイートのダウンロード、データセットの最適化、初期実験、ユーザー間の損失の比較、モデルのファインチューニングというパイプラインを使用しています。
完全なレポートは こちら をお読みください。
Hugging Face BERT および WB を使用した文分類
この記事では、自然言語処理における最近の画期的な進歩の力を活用して、文分類子を作成します。ここでは、NLP への転移学習の応用例に焦点を当てます。
単一文分類には、言語的許容度 (CoLA) データセットを使用します。これは、2018 年 5 月に初めて公開された、文法的に正しいか正しくないかというラベルが付けられた文のセットです。
Google の BERT を使用して、さまざまな NLP タスクで最小限の労力で高性能モデルを作成します。
完全なレポートは こちら をお読みください。
Hugging Face モデルのパフォーマンスを追跡するためのステップバイステップガイド
W&B と Hugging Face transformers を使用して、GLUE ベンチマークで DistilBERT (BERT より 40% 小さいが、BERT の精度の 97% を保持する Transformer) をトレーニングします。
GLUE ベンチマークは、NLP モデルをトレーニングするための 9 つのデータセットとタスクのコレクションです。
完全なレポートは こちら をお読みください。
HuggingFace での早期停止の例
早期停止の正規化を使用して Hugging Face Transformer をファインチューニングは、PyTorch または TensorFlow でネイティブに行うことができます。
TensorFlow での EarlyStopping コールバックの使用は、tf.keras.callbacks.EarlyStopping コールバックを使用すると簡単です。
PyTorch では、既製の早期停止メソッドはありませんが、GitHub Gist で利用できる作業中の早期停止フックがあります。
完全なレポートは こちら をお読みください。
カスタムデータセットで Hugging Face Transformers をファインチューンする方法
カスタム IMDB データセットでセンチメント分析 (バイナリ分類) 用に DistilBERT transformer をファインチューンします。
完全なレポートは こちら をお読みください。
ヘルプの入手または機能のリクエスト
Hugging Face W&B integration に関する問題、質問、または機能のリクエストについては、Hugging Face フォーラムのこのスレッド に投稿するか、Hugging Face Transformers GitHub repo で issue をオープンしてください。
12 - Hugging Face Diffusers
Hugging Face Diffusers は、画像、音声、さらには分子の3D構造を生成するための、最先端の学習済み拡散モデルのための頼りになるライブラリです。Weights & Biases のインテグレーションは、その使いやすさを損なうことなく、インタラクティブな集中 ダッシュボードに、豊富で柔軟な 実験管理、メディアの 可視化、パイプライン アーキテクチャ、および 設定管理を追加します。
たった2行で次世代のログ記録
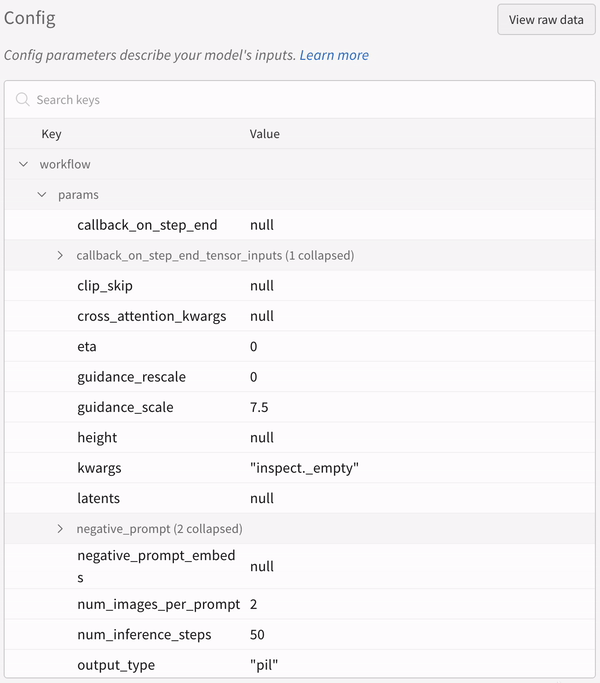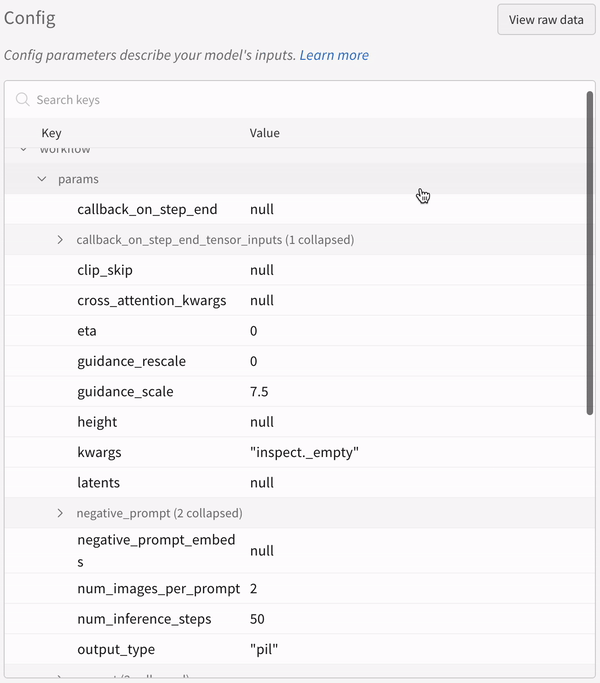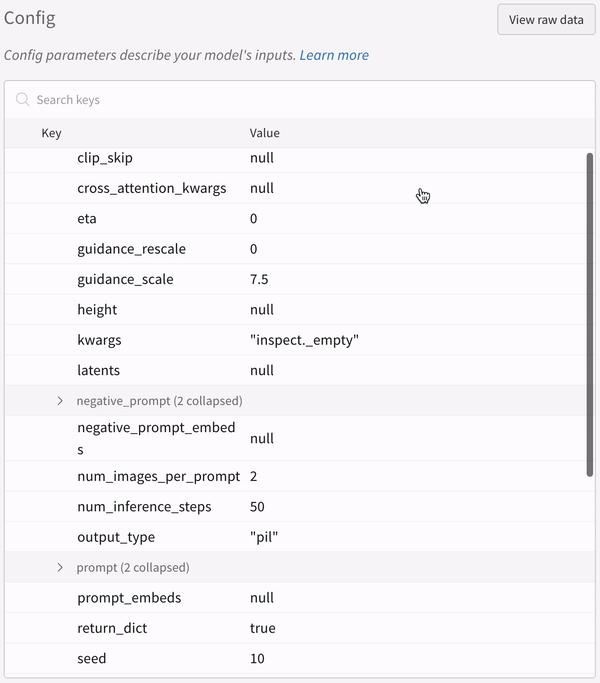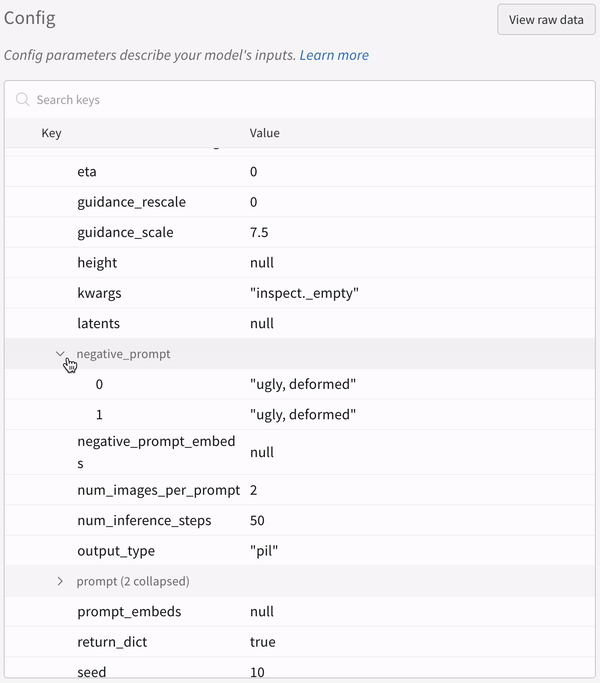
わずか2行のコードを含めるだけで、プロンプト、ネガティブプロンプト、生成されたメディア、および 実験 に関連付けられた config をすべて記録します。以下は、ログ記録を開始するための2行のコードです。
# import the autolog function
from wandb.integration.diffusers import autolog
# call the autolog before calling the pipeline
autolog(init= dict(project= "diffusers_logging" ))
実験 の 結果 がどのように記録されるかの例。
はじめに
diffusers、transformers、accelerate、および wandb をインストールします。
コマンドライン:
pip install --upgrade diffusers transformers accelerate wandb
ノートブック:
!pip install --upgrade diffusers transformers accelerate wandb
autolog を使用して Weights & Biases の run を初期化し、サポートされているすべての パイプライン 呼び出し からの入力と出力を自動的に追跡します。
wandb.init()init パラメータ を使用して、autolog() 関数を呼び出すことができます。
autolog() を呼び出すと、Weights & Biases の run が初期化され、サポートされているすべての パイプライン 呼び出し からの入力と出力が自動的に追跡されます。
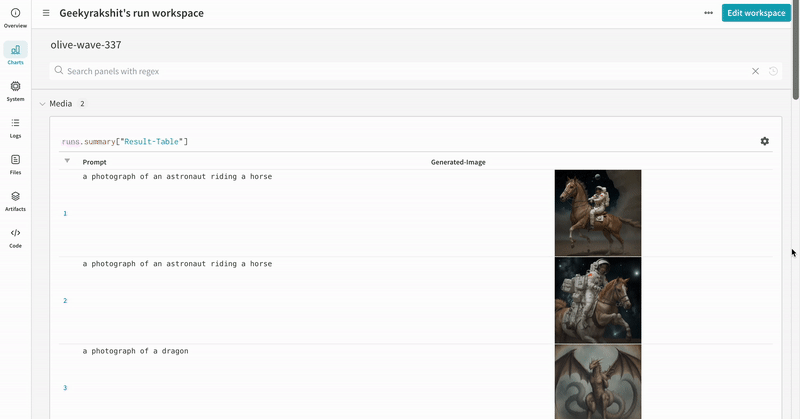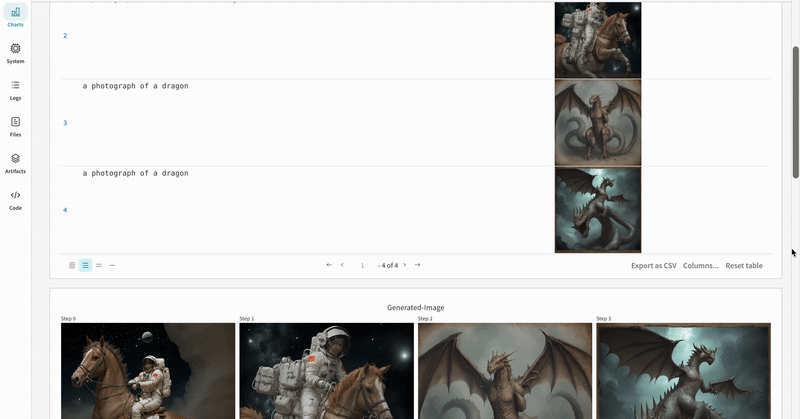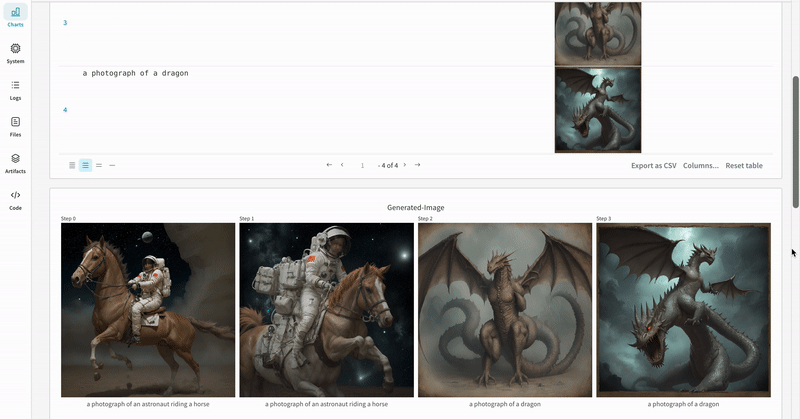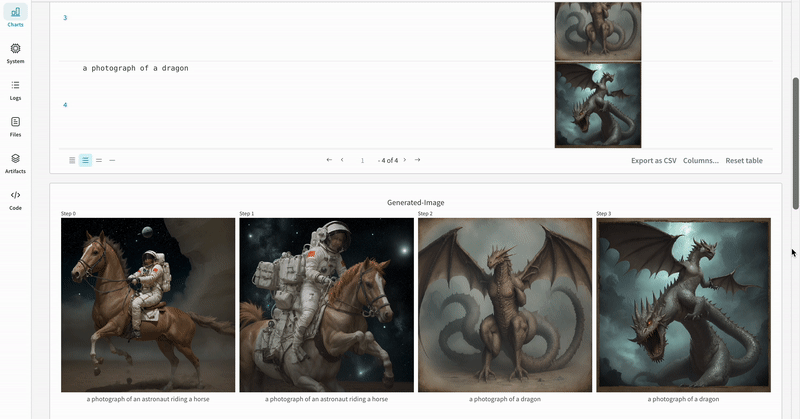
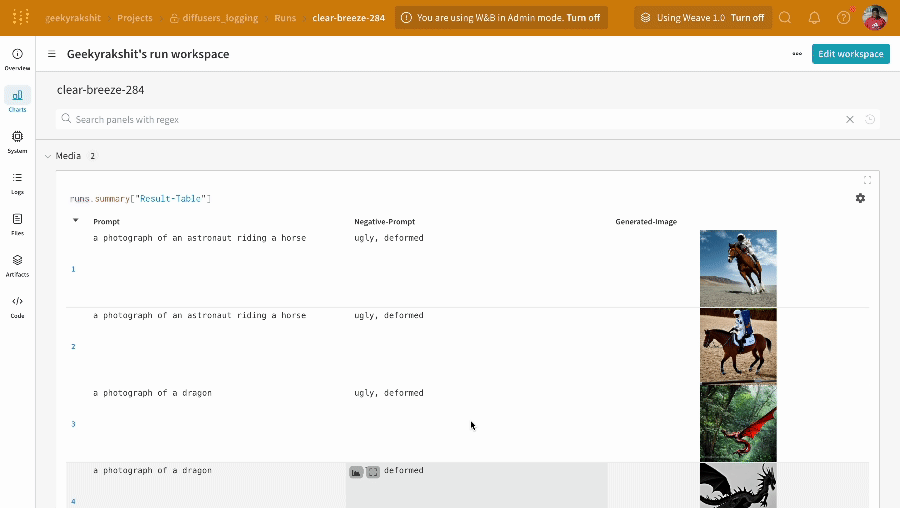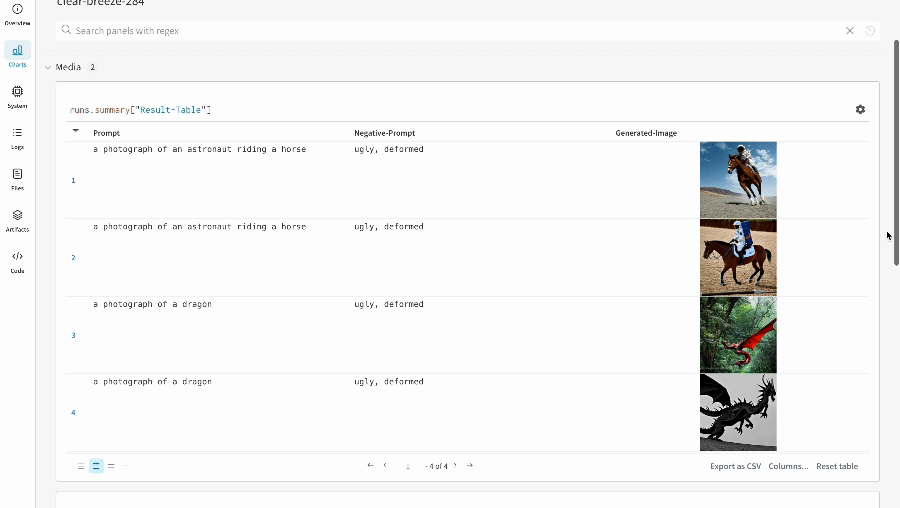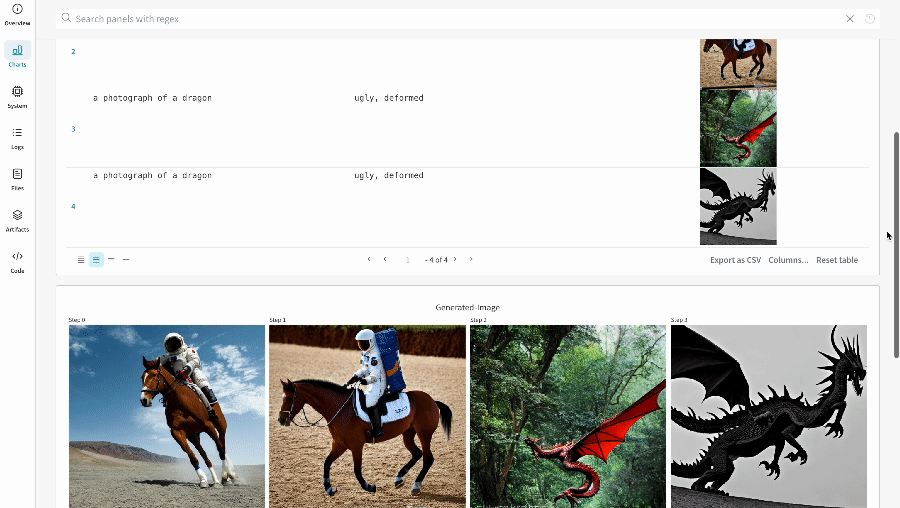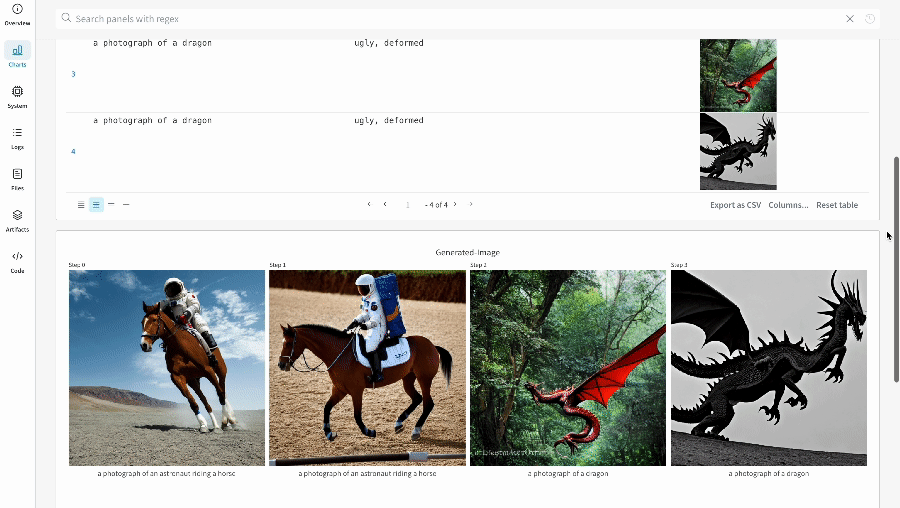
各 パイプライン 呼び出しは、ワークスペース 内の独自の テーブル に追跡され、パイプライン 呼び出しに関連付けられた config は、その run の config 内の ワークフロー のリストに追加されます。
プロンプト、ネガティブプロンプト、および生成されたメディアは、wandb.Table
シードや パイプライン アーキテクチャ を含む、実験 に関連付けられたその他すべての config は、run の config セクションに保存されます。
各 パイプライン 呼び出しで生成されたメディアは、run の メディア パネル にも記録されます。
サポートされている パイプライン 呼び出しのリストは、[こちら](https://github.com/wandb/wandb/blob/main/wandb/integration/diffusers/autologger.py#L12-L72)にあります。このインテグレーションの新しい機能をリクエストしたり、それに関連するバグを報告したりする場合は、[https://github.com/wandb/wandb/issues](https://github.com/wandb/wandb/issues) で issue をオープンしてください。
例
Autologging
以下は、動作中の autolog の簡単な エンドツーエンド の例です。
import torch
from diffusers import DiffusionPipeline
# import the autolog function
from wandb.integration.diffusers import autolog
# call the autolog before calling the pipeline
autolog(init= dict(project= "diffusers_logging" ))
# Initialize the diffusion pipeline
pipeline = DiffusionPipeline. from_pretrained(
"stabilityai/stable-diffusion-2-1" , torch_dtype= torch. float16
). to("cuda" )
# Define the prompts, negative prompts, and seed.
prompt = ["a photograph of an astronaut riding a horse" , "a photograph of a dragon" ]
negative_prompt = ["ugly, deformed" , "ugly, deformed" ]
generator = torch. Generator(device= "cpu" ). manual_seed(10 )
# call the pipeline to generate the images
images = pipeline(
prompt,
negative_prompt= negative_prompt,
num_images_per_prompt= 2 ,
generator= generator,
)
import torch
from diffusers import DiffusionPipeline
import wandb
# import the autolog function
from wandb.integration.diffusers import autolog
# call the autolog before calling the pipeline
autolog(init= dict(project= "diffusers_logging" ))
# Initialize the diffusion pipeline
pipeline = DiffusionPipeline. from_pretrained(
"stabilityai/stable-diffusion-2-1" , torch_dtype= torch. float16
). to("cuda" )
# Define the prompts, negative prompts, and seed.
prompt = ["a photograph of an astronaut riding a horse" , "a photograph of a dragon" ]
negative_prompt = ["ugly, deformed" , "ugly, deformed" ]
generator = torch. Generator(device= "cpu" ). manual_seed(10 )
# call the pipeline to generate the images
images = pipeline(
prompt,
negative_prompt= negative_prompt,
num_images_per_prompt= 2 ,
generator= generator,
)
# Finish the experiment
wandb. finish()
単一の 実験 の結果:
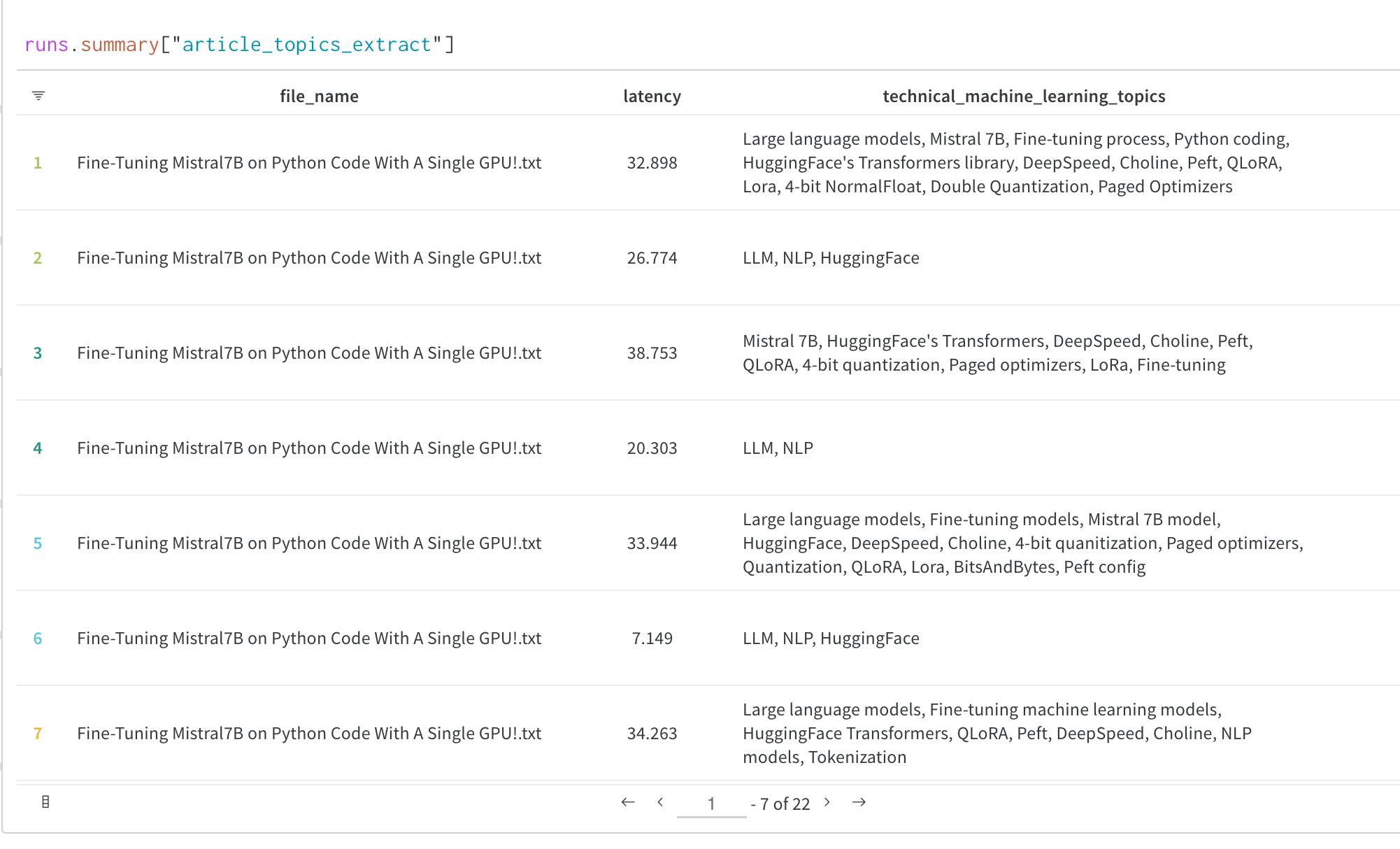
複数の 実験 の結果:
実験 の config:
パイプライン を呼び出した後、IPython ノートブック 環境でコードを実行する場合は、
wandb.finish()を明示的に呼び出す必要があります。これは、Python スクリプトを実行する場合は必要ありません。
複数 パイプライン ワークフロー の追跡
このセクションでは、StableDiffusionXLPipelineStable Diffusion XL + Refiner ワークフロー での autolog を示します。
import torch
from diffusers import StableDiffusionXLImg2ImgPipeline, StableDiffusionXLPipeline
from wandb.integration.diffusers import autolog
# initialize the SDXL base pipeline
base_pipeline = StableDiffusionXLPipeline. from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0" ,
torch_dtype= torch. float16,
variant= "fp16" ,
use_safetensors= True ,
)
base_pipeline. enable_model_cpu_offload()
# initialize the SDXL refiner pipeline
refiner_pipeline = StableDiffusionXLImg2ImgPipeline. from_pretrained(
"stabilityai/stable-diffusion-xl-refiner-1.0" ,
text_encoder_2= base_pipeline. text_encoder_2,
vae= base_pipeline. vae,
torch_dtype= torch. float16,
use_safetensors= True ,
variant= "fp16" ,
)
refiner_pipeline. enable_model_cpu_offload()
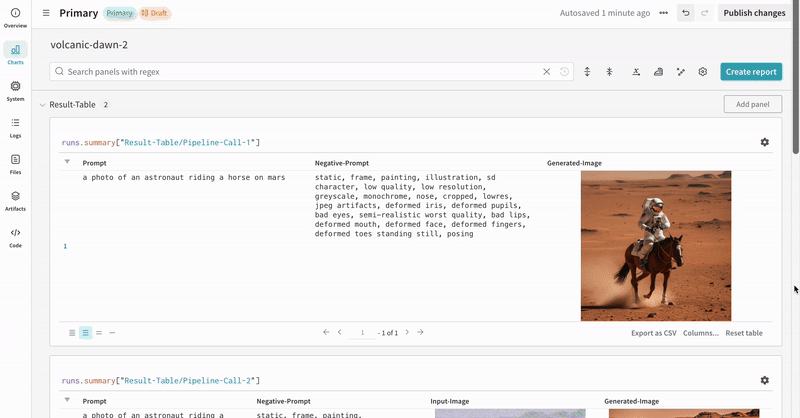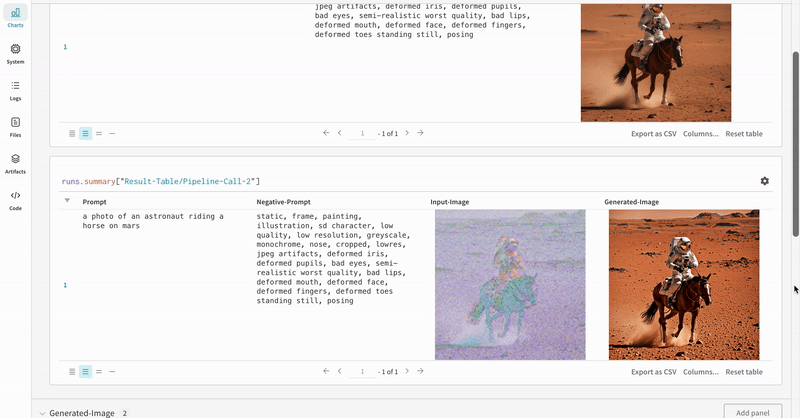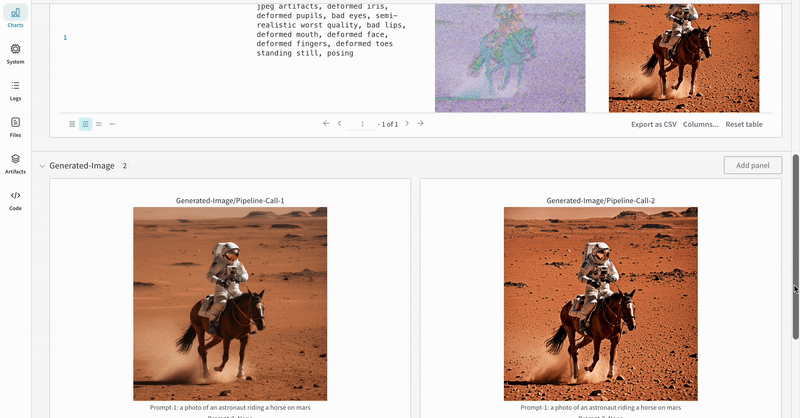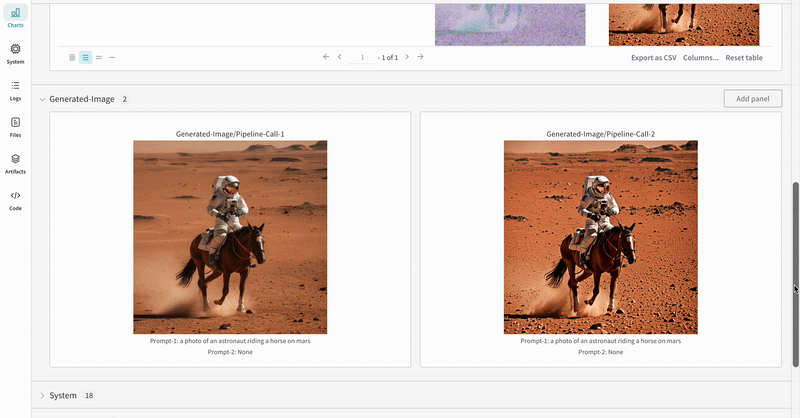
prompt = "a photo of an astronaut riding a horse on mars"
negative_prompt = "static, frame, painting, illustration, sd character, low quality, low resolution, greyscale, monochrome, nose, cropped, lowres, jpeg artifacts, deformed iris, deformed pupils, bad eyes, semi-realistic worst quality, bad lips, deformed mouth, deformed face, deformed fingers, deformed toes standing still, posing"
# Make the experiment reproducible by controlling randomness.
# The seed would be automatically logged to WandB.
seed = 42
generator_base = torch. Generator(device= "cuda" ). manual_seed(seed)
generator_refiner = torch. Generator(device= "cuda" ). manual_seed(seed)
# Call WandB Autolog for Diffusers. This would automatically log
# the prompts, generated images, pipeline architecture and all
# associated experiment configs to Weights & Biases, thus making your
# image generation experiments easy to reproduce, share and analyze.
autolog(init= dict(project= "sdxl" ))
# Call the base pipeline to generate the latents
image = base_pipeline(
prompt= prompt,
negative_prompt= negative_prompt,
output_type= "latent" ,
generator= generator_base,
). images[0 ]
# Call the refiner pipeline to generate the refined image
image = refiner_pipeline(
prompt= prompt,
negative_prompt= negative_prompt,
image= image[None , :],
generator= generator_refiner,
). images[0 ]
import torch
from diffusers import StableDiffusionXLImg2ImgPipeline, StableDiffusionXLPipeline
import wandb
from wandb.integration.diffusers import autolog
# initialize the SDXL base pipeline
base_pipeline = StableDiffusionXLPipeline. from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0" ,
torch_dtype= torch. float16,
variant= "fp16" ,
use_safetensors= True ,
)
base_pipeline. enable_model_cpu_offload()
# initialize the SDXL refiner pipeline
refiner_pipeline = StableDiffusionXLImg2ImgPipeline. from_pretrained(
"stabilityai/stable-diffusion-xl-refiner-1.0" ,
text_encoder_2= base_pipeline. text_encoder_2,
vae= base_pipeline. vae,
torch_dtype= torch. float16,
use_safetensors= True ,
variant= "fp16" ,
)
refiner_pipeline. enable_model_cpu_offload()
prompt = "a photo of an astronaut riding a horse on mars"
negative_prompt = "static, frame, painting, illustration, sd character, low quality, low resolution, greyscale, monochrome, nose, cropped, lowres, jpeg artifacts, deformed iris, deformed pupils, bad eyes, semi-realistic worst quality, bad lips, deformed mouth, deformed face, deformed fingers, deformed toes standing still, posing"
# Make the experiment reproducible by controlling randomness.
# The seed would be automatically logged to WandB.
seed = 42
generator_base = torch. Generator(device= "cuda" ). manual_seed(seed)
generator_refiner = torch. Generator(device= "cuda" ). manual_seed(seed)
# Call WandB Autolog for Diffusers. This would automatically log
# the prompts, generated images, pipeline architecture and all
# associated experiment configs to Weights & Biases, thus making your
# image generation experiments easy to reproduce, share and analyze.
autolog(init= dict(project= "sdxl" ))
# Call the base pipeline to generate the latents
image = base_pipeline(
prompt= prompt,
negative_prompt= negative_prompt,
output_type= "latent" ,
generator= generator_base,
). images[0 ]
# Call the refiner pipeline to generate the refined image
image = refiner_pipeline(
prompt= prompt,
negative_prompt= negative_prompt,
image= image[None , :],
generator= generator_refiner,
). images[0 ]
# Finish the experiment
wandb. finish()
Stable Diffisuion XL + Refiner の 実験 の例:
その他のリソース
13 - Hugging Face AutoTrain
Hugging Face AutoTrain は、自然言語処理(NLP)タスク、コンピュータビジョン(CV)タスク、音声タスク、さらには表形式タスクのために、最先端のモデルをトレーニングするためのノーコード ツールです。
Weights & Biases は Hugging Face AutoTrain に直接統合されており、実験管理と構成管理を提供します。これは、実験の CLI コマンドで単一の パラメータ を使用するのと同じくらい簡単です。
前提条件のインストール
autotrain-advanced と wandb をインストールします。
pip install --upgrade autotrain-advanced wandb
!pip install --upgrade autotrain-advanced wandb
これらの変更を示すために、このページでは、GSM8k Benchmarks で pass@1 の SoTA 結果を達成するために、数学 データセット で LLM を微調整します。
データセット を準備する
Hugging Face AutoTrain は、適切に機能するために、CSV カスタム データセット が特定の形式になっていることを想定しています。
トレーニング ファイルには、トレーニングで使用する text 列が含まれている必要があります。最良の結果を得るには、text 列のデータが ### Human: Question?### Assistant: Answer. 形式に準拠している必要があります。timdettmers/openassistant-guanaco
ただし、MetaMathQA dataset には、query、response、および type 列が含まれています。最初に、この データセット を前処理します。type 列を削除し、query 列と response 列の内容を ### Human: Query?### Assistant: Response. 形式の新しい text 列に結合します。トレーニングでは、結果の データセット rishiraj/guanaco-style-metamath
autotrain を使用してトレーニングするコマンドラインまたは ノートブック から autotrain advanced を使用してトレーニングを開始できます。--log 引数を使用するか、--log wandb を使用して、W&B run に 結果 を ログ します。
autotrain llm \
\
\
\
\
\
\
\
4 \
3 \
1024 \
\
16 \
32 \
\
\
4 \
10 \
\
\
\
\
\
\
# ハイパーパラメータ を設定する
learning_rate = 2e-5
num_epochs = 3
batch_size = 4
block_size = 1024
trainer = "sft"
warmup_ratio = 0.03
weight_decay = 0.
gradient_accumulation = 4
lora_r = 16
lora_alpha = 32
lora_dropout = 0.05
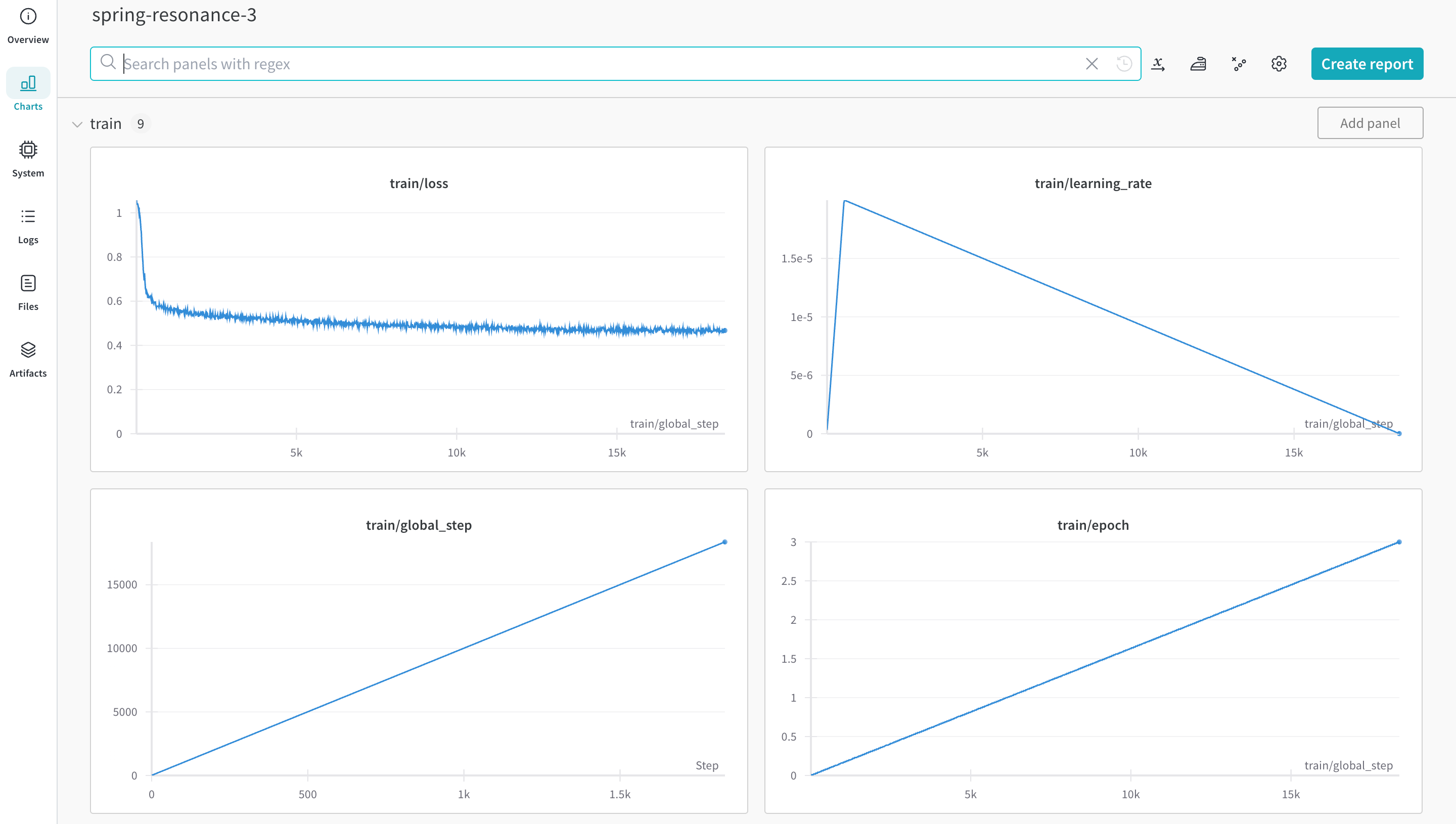
logging_steps = 10
# トレーニングを実行する
!autotrain llm \
--train \
--model "HuggingFaceH4/zephyr-7b-alpha" \
--project-name "zephyr-math" \
--log "wandb" \
--data-path data/ \
--text-column text \
--lr str(learning_rate) \
--batch-size str(batch_size) \
--epochs str(num_epochs) \
--block-size str(block_size) \
--warmup-ratio str(warmup_ratio) \
--lora-r str(lora_r) \
--lora-alpha str(lora_alpha) \
--lora-dropout str(lora_dropout) \
--weight-decay str(weight_decay) \
--gradient-accumulation str(gradient_accumulation) \
--logging-steps str(logging_steps) \
--fp16 \
--use-peft \
--use-int4 \
--merge-adapter \
--push-to-hub \
--token str(hf_token) \
--repo-id "rishiraj/zephyr-math"
その他のリソース
14 - Hugging Face Accelerate
大規模なトレーニングと推論を、シンプル、効率的、かつ適応的に
Hugging Face Accelerate は、あらゆる分散設定で同じ PyTorch コードを実行できるようにし、大規模なモデルトレーニングと推論を簡素化するライブラリです。
Accelerate には、以下に示す Weights & Biases Tracker が含まれています。Accelerate Trackers の詳細については、[こちら (https://huggingface.co/docs/accelerate/main/en/usage_guides/tracking) のドキュメント] を参照してください。
Accelerate でログ記録を開始する
Accelerate と Weights & Biases を使い始めるには、以下の疑似コードに従ってください。
from accelerate import Accelerator
# Tell the Accelerator object to log with wandb
accelerator = Accelerator(log_with= "wandb" )
# Initialise your wandb run, passing wandb parameters and any config information
accelerator. init_trackers(
project_name= "my_project" ,
config= {"dropout" : 0.1 , "learning_rate" : 1e-2 }
init_kwargs= {"wandb" : {"entity" : "my-wandb-team" }}
)
...
# Log to wandb by calling `accelerator.log`, `step` is optional
accelerator. log({"train_loss" : 1.12 , "valid_loss" : 0.8 }, step= global_step)
# Make sure that the wandb tracker finishes correctly
accelerator. end_training()
さらに詳しく説明すると、次のことが必要です。
Accelerator クラスを初期化するときに log_with="wandb" を渡します。
init_trackers
project_name を介したプロジェクト名ネストされた dict を介して wandb.initinit_kwargs
config を介して、wandb の run に記録するその他の実験設定情報
.log メソッドを使用して Weigths & Biases にログを記録します。step 引数はオプションです。トレーニングが終了したら、.end_training を呼び出します。
W&B tracker へのアクセス
W&B tracker にアクセスするには、Accelerator.get_tracker() メソッドを使用します。tracker の .name 属性に対応する文字列を渡すと、main プロセスの tracker が返されます。
wandb_tracker = accelerator. get_tracker("wandb" )
そこから、通常どおり wandb の run オブジェクトを操作できます。
wandb_tracker. log_artifact(some_artifact_to_log)
Accelerate に組み込まれた Trackers は、正しいプロセスで自動的に実行されるため、Tracker がメインプロセスでのみ実行されるように設計されている場合、自動的に実行されます。
Accelerate のラッピングを完全に削除したい場合は、次の方法で同じ結果を得ることができます。
wandb_tracker = accelerator. get_tracker("wandb" , unwrap= True )
with accelerator. on_main_process:
wandb_tracker. log_artifact(some_artifact_to_log)
Accelerate の記事
以下は、楽しめるかもしれない Accelerate の記事です。
Weights & Biases でスーパーチャージされた HuggingFace Accelerate
この記事では、HuggingFace Accelerate が提供するものと、結果を Weights & Biases に記録しながら、分散トレーニングと評価をどれだけ簡単に行えるかを見ていきます。
完全なレポートは こちら をお読みください。
15 - Hydra
W&B と Hydra を統合する方法。
Hydra は、 研究 および他の複雑な アプリケーション の開発を簡素化するオープンソースの Python フレームワーク です。主な機能は、構成ファイルと コマンドライン を介して、構成を構成してオーバーライドすることにより、階層的な構成を動的に作成できることです。
W&B のパワーを利用しながら、構成管理に Hydra を引き続き使用できます。
メトリクス の 追跡
wandb.init と wandb.log を使用して、通常どおりに メトリクス を 追跡 します。ここでは、 wandb.entity と wandb.project は hydra 構成ファイル内で定義されています。
import wandb
@hydra.main (config_path= "configs/" , config_name= "defaults" )
def run_experiment (cfg):
run = wandb. init(entity= cfg. wandb. entity, project= cfg. wandb. project)
wandb. log({"loss" : loss})
ハイパーパラメーター の 追跡
Hydra は、構成 辞書 とのインターフェースをとるためのデフォルトの方法として omegaconf を使用します。 OmegaConf の 辞書 は、プリミティブ 辞書 のサブクラスではないため、Hydra の Config を wandb.config に直接渡すと、 ダッシュボード で予期しない結果が生じます。 omegaconf.DictConfig をプリミティブな dict 型に変換してから wandb.config に渡す必要があります。
@hydra.main (config_path= "configs/" , config_name= "defaults" )
def run_experiment (cfg):
wandb. config = omegaconf. OmegaConf. to_container(
cfg, resolve= True , throw_on_missing= True
)
wandb. init(entity= cfg. wandb. entity, project= cfg. wandb. project)
wandb. log({"loss" : loss})
model = Model(** wandb. config. model. configs)
マルチプロセッシング の トラブルシューティング
開始時に プロセス がハングする場合は、この既知の問題 が原因である可能性があります。これを解決するには、次のいずれかとして、wandb.init に追加の settings パラメータ を追加して、wandb の マルチプロセッシング プロトコル を変更してみてください。
wandb. init(settings= wandb. Settings(start_method= "thread" ))
または、シェルから グローバル 環境変数 を設定します。
$ export WANDB_START_METHOD= thread
ハイパーパラメーター の 最適化
W&B Sweeps は、高度にスケーラブルな ハイパーパラメーター 検索 プラットフォーム であり、最小限の要件コードで W&B の 実験 に関する興味深い洞察と 可視化 を提供します。 Sweeps は、コーディング要件なしで Hydra プロジェクト とシームレスに統合されます。必要なのは、通常どおりにスイープするさまざまな パラメータ を記述した構成ファイルだけです。
簡単な sweep.yaml ファイルの例を次に示します。
program : main.py
method : bayes
metric :
goal : maximize
name : test/accuracy
parameters :
dataset :
values : [mnist, cifar10]
command :
- ${env}
- python
- ${program}
- ${args_no_hyphens}
sweep を呼び出します。
wandb sweep sweep.yaml` \
W&B は プロジェクト 内に sweep を自動的に作成し、sweep を実行する各マシンで実行する wandb agent コマンド を返します。
Hydra の デフォルト に存在しない パラメータ を渡す
Hydra は、 コマンド の前に + を使用して、デフォルト の構成ファイルに存在しない追加の パラメータ を コマンドライン から渡すことをサポートしています。たとえば、次のように呼び出すだけで、いくつかの 値 を持つ追加の パラメータ を渡すことができます。
$ python program.py +experiment= some_experiment
Hydra Experiments を構成するときと同様に、このような + 構成を スイープ することはできません。これを回避するには、デフォルト の空のファイルで experiment パラメータ を初期化し、W&B Sweep を使用して、呼び出しごとにこれらの空の構成をオーバーライドします。詳細については、この W&B Report
16 - Keras
Keras コールバック
W&B には Keras 用の 3 つのコールバックがあり、wandb v0.13.4 から利用できます。従来の WandbCallback については、下にスクロールしてください。
WandbMetricsLogger実験管理 には、このコールバックを使用します。トレーニングと検証のメトリクスをシステムメトリクスとともに Weights & Biases に記録します。
WandbModelCheckpointArtifacts に記録するには、このコールバックを使用します。
WandbEvalCallbackTables に記録して、インタラクティブな可視化を実現します。
これらの新しいコールバック:
Keras の設計理念に準拠しています。
すべてに単一のコールバック(WandbCallback)を使用することによる認知負荷を軽減します。
Keras ユーザーがコールバックをサブクラス化してニッチなユースケースをサポートすることで、コールバックを簡単に変更できるようにします。
WandbMetricsLogger で実験を追跡するWandbMetricsLogger は、on_epoch_end、on_batch_end などのコールバックメソッドが引数として受け取る Keras の logs 辞書を自動的に記録します。
これにより、以下が追跡されます。
model.compile で定義されたトレーニングおよび検証のメトリクス。システム (CPU/GPU/TPU) メトリクス。
学習率 (固定値と学習率スケジューラの両方)。
import wandb
from wandb.integration.keras import WandbMetricsLogger
# 新しい W&B の run を初期化します。
wandb. init(config= {"bs" : 12 })
# WandbMetricsLogger を model.fit に渡します。
model. fit(
X_train, y_train, validation_data= (X_test, y_test), callbacks= [WandbMetricsLogger()]
)
WandbMetricsLogger リファレンス
パラメータ
説明
log_freq(epoch、batch、または int): epoch の場合、各エポックの最後にメトリクスを記録します。batch の場合、各バッチの最後にメトリクスを記録します。int の場合、その数のバッチの最後にメトリクスを記録します。デフォルトは epoch です。
initial_global_step(int): 学習率スケジューラを使用している場合に、いくつかの initial_epoch からトレーニングを再開するときに学習率を正しく記録するには、この引数を使用します。これは step_size * initial_step として計算できます。デフォルトは 0 です。
WandbModelCheckpoint を使用してモデルをチェックポイントするWandbModelCheckpoint コールバックを使用して、Keras モデル (SavedModel 形式) またはモデルの重みを定期的に保存し、モデルの バージョン管理 用の wandb.Artifact として W&B にアップロードします。
このコールバックは tf.keras.callbacks.ModelCheckpoint
このコールバックは以下を保存します。
モニターに基づいて最高のパフォーマンスを達成したモデル。
パフォーマンスに関係なく、すべてのエポックの終わりにモデル。
エポックの終わり、または固定数のトレーニングバッチの後。
モデルの重みのみ、またはモデル全体。
SavedModel 形式または .h5 形式のいずれかでモデル。
このコールバックを WandbMetricsLogger と組み合わせて使用します。
import wandb
from wandb.integration.keras import WandbMetricsLogger, WandbModelCheckpoint
# 新しい W&B の run を初期化します。
wandb. init(config= {"bs" : 12 })
# WandbModelCheckpoint を model.fit に渡します。
model. fit(
X_train,
y_train,
validation_data= (X_test, y_test),
callbacks= [
WandbMetricsLogger(),
WandbModelCheckpoint("models" ),
],
)
WandbModelCheckpoint リファレンス
パラメータ
説明
filepath(str): モードファイルを保存するパス。
monitor(str): 監視するメトリック名。
verbose(int): 詳細モード、0 または 1。モード 0 はサイレントで、モード 1 はコールバックがアクションを実行するときにメッセージを表示します。
save_best_only(Boolean): save_best_only=True の場合、最新のモデル、または monitor および mode 属性で定義されている、最良と見なされるモデルのみを保存します。
save_weights_only(Boolean): True の場合、モデルの重みのみを保存します。
mode(auto、min、または max): val_acc の場合は max に、val_loss の場合は min に設定します。
save_freq(“epoch” または int): 「epoch」を使用する場合、コールバックは各エポックの後にモデルを保存します。整数を使用する場合、コールバックはこの数のバッチの終わりにモデルを保存します。val_acc や val_loss などの検証メトリクスを監視する場合、これらのメトリクスはエポックの最後にのみ使用できるため、save_freq を “epoch” に設定する必要があることに注意してください。
options(str): save_weights_only が true の場合はオプションの tf.train.CheckpointOptions オブジェクト、save_weights_only が false の場合はオプションの tf.saved_model.SaveOptions オブジェクト。
initial_value_threshold(float): 監視するメトリックの浮動小数点初期「最良」値。
N エポック後にチェックポイントを記録する
デフォルト (save_freq="epoch") では、コールバックは各エポックの後にチェックポイントを作成し、アーティファクトとしてアップロードします。特定の数のバッチの後にチェックポイントを作成するには、save_freq を整数に設定します。N エポック後にチェックポイントを作成するには、train データローダーのカーディナリティを計算し、それを save_freq に渡します。
WandbModelCheckpoint(
filepath= "models/" ,
save_freq= int((trainloader. cardinality()* N). numpy())
)
TPU アーキテクチャでチェックポイントを効率的に記録する
TPU でチェックポイントを作成しているときに、UnimplementedError: File system scheme '[local]' not implemented エラーメッセージが表示される場合があります。これは、モデルディレクトリー (filepath) がクラウドストレージバケットパス (gs://bucket-name/...) を使用する必要があり、このバケットが TPU サーバーからアクセスできる必要があるために発生します。ただし、チェックポイント作成にはローカルパスを使用できます。これは Artifacts としてアップロードされます。
checkpoint_options = tf. saved_model. SaveOptions(experimental_io_device= "/job:localhost" )
WandbModelCheckpoint(
filepath= "models/,
options= checkpoint_options,
)
WandbEvalCallback を使用してモデルの予測を可視化するWandbEvalCallback は、主にモデルの予測、次にデータセットの可視化のための Keras コールバックを構築するための抽象ベースクラスです。
この抽象コールバックは、データセットとタスクに関して不可知論的です。これを使用するには、このベースの WandbEvalCallback コールバッククラスから継承し、add_ground_truth メソッドと add_model_prediction メソッドを実装します。
WandbEvalCallback は、次のメソッドを提供するユーティリティクラスです。
データと予測の wandb.Table インスタンスを作成します。
データと予測の Tables を wandb.Artifact として記録します。
データテーブル on_train_begin を記録します。
予測テーブル on_epoch_end を記録します。
次の例では、画像分類タスクに WandbClfEvalCallback を使用しています。この例のコールバックは、検証データ (data_table) を W&B に記録し、推論を実行し、すべてのエポックの終わりに予測 (pred_table) を W&B に記録します。
import wandb
from wandb.integration.keras import WandbMetricsLogger, WandbEvalCallback
# モデル予測の可視化コールバックを実装します。
class WandbClfEvalCallback (WandbEvalCallback):
def __init__(
self, validation_data, data_table_columns, pred_table_columns, num_samples= 100
):
super(). __init__(data_table_columns, pred_table_columns)
self. x = validation_data[0 ]
self. y = validation_data[1 ]
def add_ground_truth (self, logs= None ):
for idx, (image, label) in enumerate(zip(self. x, self. y)):
self. data_table. add_data(idx, wandb. Image(image), label)
def add_model_predictions (self, epoch, logs= None ):
preds = self. model. predict(self. x, verbose= 0 )
preds = tf. argmax(preds, axis=- 1 )
table_idxs = self. data_table_ref. get_index()
for idx in table_idxs:
pred = preds[idx]
self. pred_table. add_data(
epoch,
self. data_table_ref. data[idx][0 ],
self. data_table_ref. data[idx][1 ],
self. data_table_ref. data[idx][2 ],
pred,
)
# ...
# 新しい W&B の run を初期化します。
wandb. init(config= {"hyper" : "parameter" })
# コールバックを Model.fit に追加します。
model. fit(
X_train,
y_train,
validation_data= (X_test, y_test),
callbacks= [
WandbMetricsLogger(),
WandbClfEvalCallback(
validation_data= (X_test, y_test),
data_table_columns= ["idx" , "image" , "label" ],
pred_table_columns= ["epoch" , "idx" , "image" , "label" , "pred" ],
),
],
)
WandbEvalCallback リファレンス
パラメータ
説明
data_table_columns(list) data_table の列名のリスト
pred_table_columns(list) pred_table の列名のリスト
メモリフットプリントの詳細
on_train_begin メソッドが呼び出されると、data_table を W&B に記録します。W&B Artifact としてアップロードされると、data_table_ref クラス変数を使用してアクセスできるこのテーブルへの参照を取得します。data_table_ref は、self.data_table_ref[idx][n] のようにインデックスを付けることができる 2D リストです。ここで、idx は行番号で、n は列番号です。以下の例で使用法を見てみましょう。
コールバックをカスタマイズする
on_train_begin メソッドまたは on_epoch_end メソッドをオーバーライドして、よりきめ細かい制御を行うことができます。N バッチ後にサンプルを記録する場合は、on_train_batch_end メソッドを実装できます。
💡
WandbEvalCallback を継承してモデル予測の可視化のためのコールバックを実装していて、明確にする必要がある場合や修正する必要がある場合は、
issue を開いてお知らせください。
WandbCallback [レガシー]W&B ライブラリの WandbCallbackmodel.fit で追跡されるすべてのメトリクスと損失値を自動的に保存します。
import wandb
from wandb.integration.keras import WandbCallback
wandb. init(config= {"hyper" : "parameter" })
... # Keras でモデルをセットアップするコード
# コールバックを model.fit に渡します。
model. fit(
X_train, y_train, validation_data= (X_test, y_test), callbacks= [WandbCallback()]
)
短いビデオ 1 分以内に Keras と Weights & Biases を使い始める をご覧ください。
より詳細なビデオについては、Weights & Biases と Keras を統合する をご覧ください。Colab Jupyter Notebook を確認できます。
WandbCallback クラスは、監視するメトリックの指定、重みと勾配の追跡、training_data と validation_data での予測の記録など、さまざまなログ構成オプションをサポートしています。
詳細については、keras.WandbCallback のリファレンスドキュメント
WandbCallback
Keras によって収集されたメトリクスから履歴データを自動的に記録します: 損失と keras_model.compile() に渡されたもの。
monitor および mode 属性で定義されているように、「最良」のトレーニングステップに関連付けられた run の概要メトリクスを設定します。これはデフォルトで、最小の val_loss を持つエポックになります。WandbCallback はデフォルトで、最良の epoch に関連付けられたモデルを保存します。オプションで勾配とパラメーターのヒストグラムを記録します。
オプションで、wandb が可視化するためにトレーニングデータと検証データを保存します。
WandbCallback リファレンス
引数
monitor(str) 監視するメトリックの名前。デフォルトは val_loss。
mode(str) {auto、min、max} のいずれか。min - モニターが最小化されたときにモデルを保存します max - モニターが最大化されたときにモデルを保存します auto - モデルを保存するタイミングを推測しようとします (デフォルト)。
save_modelTrue - モニターが以前のエポックをすべて上回ったときにモデルを保存します False - モデルを保存しません
save_graph(boolean) True の場合、モデルグラフを wandb に保存します (デフォルトは True)。
save_weights_only(boolean) True の場合、モデルの重みのみを保存します (model.save_weights(filepath))。それ以外の場合は、完全なモデルを保存します)。
log_weights(boolean) True の場合、モデルのレイヤーの重みのヒストグラムを保存します。
log_gradients(boolean) True の場合、トレーニング勾配のヒストグラムを記録します
training_data(tuple) model.fit に渡されるのと同じ形式 (X,y)。これは勾配を計算するために必要です。log_gradients が True の場合は必須です。
validation_data(tuple) model.fit に渡されるのと同じ形式 (X,y)。wandb が可視化するためのデータのセット。このフィールドを設定すると、すべてのエポックで、wandb は少数の予測を行い、後で可視化するために結果を保存します。
generator(generator) wandb が可視化するための検証データを返すジェネレーター。このジェネレーターはタプル (X,y) を返す必要があります。wandb が特定のデータ例を可視化するには、validate_data またはジェネレーターのいずれかを設定する必要があります。
validation_steps(validation_data がジェネレーターの場合、完全な検証セットに対してジェネレーターを実行するステップ数 (int)。
labels(list) wandb でデータを可視化している場合、このラベルのリストは、複数のクラスを持つ分類子を構築している場合に、数値出力を理解可能な文字列に変換します。バイナリ分類子の場合、2 つのラベルのリスト [false のラベル、true のラベル] を渡すことができます。validate_data と generator の両方が false の場合、これは何も行いません。
predictions(int) 可視化のために各エポックで行う予測の数。最大は 100 です。
input_type(string) 可視化を支援するモデル入力のタイプ。(image、images、segmentation_mask) のいずれかになります。
output_type(string) モデル出力のタイプを可視化するのに役立ちます。(image、images、segmentation_mask) のいずれかになります。
log_evaluation(boolean) True の場合、各エポックで検証データとモデルの予測を含む Table を保存します。詳細については、validation_indexes、validation_row_processor、および output_row_processor を参照してください。
class_colors([float, float, float]) 入力または出力がセグメンテーションマスクの場合、各クラスの rgb タプル (範囲 0 ~ 1) を含む配列。
log_batch_frequency(integer) None の場合、コールバックはすべてのエポックを記録します。整数に設定すると、コールバックは log_batch_frequency バッチごとにトレーニングメトリクスを記録します。
log_best_prefix(string) None の場合、追加の概要メトリクスは保存されません。文字列に設定すると、監視対象のメトリックとエポックにプレフィックスを付加し、結果を概要メトリクスとして保存します。
validation_indexes([wandb.data_types._TableLinkMixin]) 各検証例に関連付けるインデックスキーの順序付きリスト。log_evaluation が True で、validation_indexes を提供する場合、検証データの Table は作成されません。代わりに、各予測を TableLinkMixin で表される行に関連付けます。行キーのリストを取得するには、Table.get_index() を使用します。
validation_row_processor(Callable) 検証データに適用する関数。通常はデータを可視化するために使用されます。この関数は、ndx (int) と row (dict) を受け取ります。モデルに単一の入力がある場合、row["input"] には行の入力データが含まれます。それ以外の場合は、入力スロットの名前が含まれます。適合関数が単一のターゲットを受け取る場合、row["target"] には行のターゲットデータが含まれます。それ以外の場合は、出力スロットの名前が含まれます。たとえば、入力データが単一の配列である場合、データを画像として可視化するには、プロセッサとして lambda ndx, row: {"img": wandb.Image(row["input"])} を指定します。log_evaluation が False であるか、validation_indexes が存在する場合は無視されます。
output_row_processor(Callable) validation_row_processor と同じですが、モデルの出力に適用されます。row["output"] には、モデル出力の結果が含まれます。
infer_missing_processors(Boolean) validation_row_processor と output_row_processor が欠落している場合に、推論するかどうかを決定します。デフォルトは True です。labels を指定すると、W&B は必要に応じて分類タイプのプロセッサを推論しようとします。
log_evaluation_frequency(int) 評価結果を記録する頻度を決定します。デフォルトは 0 で、トレーニングの最後にのみ記録します。すべてのエポックで記録するには 1 に、他のすべてのエポックで記録するには 2 に設定します。log_evaluation が False の場合は効果がありません。
よくある質問
Keras マルチプロセッシングを wandb で使用するにはどうすればよいですか?use_multiprocessing=True を設定すると、次のエラーが発生する可能性があります。
Error("You must call wandb.init() before wandb.config.batch_size" )
これを回避するには:
Sequence クラスの構築で、wandb.init(group='...') を追加します。main で、if __name__ == "__main__": を使用していることを確認し、残りのスクリプト ロジックをその中に入れます。
17 - Kubeflow Pipelines (kfp)
W&B と Kubeflow Pipelines を統合する方法。
Kubeflow Pipelines (kfp) は、Docker コンテナに基づいて、移植可能でスケーラブルな 機械学習 (ML) ワークフローを構築およびデプロイするためのプラットフォームです。
このインテグレーションにより、ユーザーはデコレーターを kfp python 関数コンポーネントに適用して、 パラメータと Artifacts を W&B に自動的に記録できます。
この機能は wandb==0.12.11 で有効になり、kfp<2.0.0 が必要です。
サインアップして API キーを作成する
API キーは、お使いのマシンを W&B に対して認証します。API キーは、ユーザープロファイルから生成できます。
右上隅にあるユーザープロファイルアイコンをクリックします。
[User Settings ] を選択し、[API Keys ] セクションまでスクロールします。
[Reveal ] をクリックします。表示された API キーをコピーします。API キーを非表示にするには、ページをリロードします。
wandb ライブラリをインストールしてログインするwandb ライブラリをローカルにインストールしてログインするには:
コマンドライン
Python
Python notebook
API キーに WANDB_API_KEY 環境変数 を設定します。
export WANDB_API_KEY= <your_api_key>
wandb ライブラリをインストールしてログインします。
pip install wandb
wandb login
import wandb
wandb. login()
!pip install wandb
import wandb
wandb.login()
コンポーネントをデコレートする
@wandb_log デコレーターを追加し、通常どおりにコンポーネントを作成します。これにより、パイプラインを実行するたびに、入力/出力 パラメータ と Artifacts が自動的に W&B に記録されます。
from kfp import components
from wandb.integration.kfp import wandb_log
@wandb_log
def add (a: float, b: float) -> float:
return a + b
add = components. create_component_from_func(add)
環境変数をコンテナに渡す
環境変数 をコンテナに明示的に渡す必要がある場合があります。双方向のリンクを行うには、環境変数 WANDB_KUBEFLOW_URL を Kubeflow Pipelines インスタンスのベース URL に設定する必要があります。たとえば、https://kubeflow.mysite.com です。
import os
from kubernetes.client.models import V1EnvVar
def add_wandb_env_variables (op):
env = {
"WANDB_API_KEY" : os. getenv("WANDB_API_KEY" ),
"WANDB_BASE_URL" : os. getenv("WANDB_BASE_URL" ),
}
for name, value in env. items():
op = op. add_env_variable(V1EnvVar(name, value))
return op
@dsl.pipeline (name= "example-pipeline" )
def example_pipeline (param1: str, param2: int):
conf = dsl. get_pipeline_conf()
conf. add_op_transformer(add_wandb_env_variables)
プログラムでデータにアクセスする
Kubeflow Pipelines UI 経由
W&B でログに記録された Kubeflow Pipelines UI の Run をクリックします。
[ Input/Output ] タブと [ ML Metadata ] タブで、入力と出力に関する詳細を確認します。
[ Visualizations ] タブから W&B Web アプリを表示します。
Web アプリ UI 経由
Web アプリ UI には、Kubeflow Pipelines の [ Visualizations ] タブと同じコンテンツがありますが、より広いスペースがあります。Web アプリ UI の詳細はこちら をご覧ください。
パブリック API 経由 (プログラムによるアクセス)
Kubeflow Pipelines から W&B へのコンセプトマッピング
Kubeflow Pipelines のコンセプトから W&B へのマッピングを次に示します。
きめ細かいロギング
ロギングをより細かく制御したい場合は、コンポーネントに wandb.log および wandb.log_artifact 呼び出しを追加できます。
明示的な wandb.log_artifacts 呼び出しを使用
以下の例では、モデルをトレーニングしています。@wandb_log デコレーターは、関連する入力と出力を自動的に追跡します。トレーニングプロセスをログに記録する場合は、次のように明示的にロギングを追加できます。
@wandb_log
def train_model (
train_dataloader_path: components. InputPath("dataloader" ),
test_dataloader_path: components. InputPath("dataloader" ),
model_path: components. OutputPath("pytorch_model" ),
):
...
for epoch in epochs:
for batch_idx, (data, target) in enumerate(train_dataloader):
...
if batch_idx % log_interval == 0 :
wandb. log(
{"epoch" : epoch, "step" : batch_idx * len(data), "loss" : loss. item()}
)
...
wandb. log_artifact(model_artifact)
暗黙的な wandb インテグレーションを使用
サポートするフレームワーク インテグレーション を使用している場合は、コールバックを直接渡すこともできます。
@wandb_log
def train_model (
train_dataloader_path: components. InputPath("dataloader" ),
test_dataloader_path: components. InputPath("dataloader" ),
model_path: components. OutputPath("pytorch_model" ),
):
from pytorch_lightning.loggers import WandbLogger
from pytorch_lightning import Trainer
trainer = Trainer(logger= WandbLogger())
... # do training
18 - LightGBM
W&B で ツリー を追跡しましょう。
wandb ライブラリには、 LightGBM 用の特別な コールバック が含まれています。また、 Weights & Biases の汎用的な ログ 機能を使用すると、 ハイパーパラメーター 探索 のような大規模な 実験 を簡単に追跡できます。
from wandb.integration.lightgbm import wandb_callback, log_summary
import lightgbm as lgb
# メトリクス を W&B に ログ 記録
gbm = lgb. train(... , callbacks= [wandb_callback()])
# 特徴量の インポータンスプロット を ログ 記録し、 モデル の チェックポイント を W&B にアップロード
log_summary(gbm, save_model_checkpoint= True )
Sweeps を使用した ハイパーパラメーター の調整
モデル のパフォーマンスを最大限に引き出すには、 ツリー の深さや学習率などの ハイパーパラメーター を調整する必要があります。Weights & Biases には、大規模な ハイパーパラメーター のテスト 実験 を構成、編成、分析するための強力な ツールキットである Sweeps が含まれています。
これらの ツール の詳細と、XGBoost で Sweeps を使用する方法の例については、このインタラクティブな Colab ノートブック をご覧ください。
19 - Metaflow
Metaflow と W&B を統合する方法。
概要
Metaflow は、ML ワークフローを作成および実行するために Netflix によって作成されたフレームワークです。
このインテグレーションを使用すると、Metaflow の ステップとフロー にデコレータを適用して、パラメータと Artifacts を自動的に W&B にログ記録できます。
ステップをデコレートすると、そのステップ内の特定の種類に対するログ記録をオフまたはオンにします。
フローをデコレートすると、フロー内のすべてのステップに対するログ記録をオフまたはオンにします。
クイックスタート
サインアップして APIキー を作成する
APIキー は、お使いのマシンを W&B に対して認証します。APIキー は、ユーザープロファイルから生成できます。
右上隅にあるユーザープロファイルアイコンをクリックします。
[User Settings ] を選択し、[API Keys ] セクションまでスクロールします。
[Reveal ] をクリックします。表示された APIキー をコピーします。APIキー を非表示にするには、ページをリロードします。
wandb ライブラリをインストールしてログインするwandb ライブラリをローカルにインストールしてログインするには:
コマンドライン
Python
Python notebook
WANDB_API_KEY 環境変数 を APIキー に設定します。
export WANDB_API_KEY= <your_api_key>
wandb ライブラリをインストールしてログインします。
pip install -Uqqq metaflow fastcore wandb
wandb login
pip install -Uqqq metaflow fastcore wandb
import wandb
wandb. login()
!pip install -Uqqq metaflow fastcore wandb
import wandb
wandb.login()
フローとステップをデコレートする
ステップをデコレートすると、そのステップ内の特定の種類に対するログ記録をオフまたはオンにします。
この例では、start 内のすべての Datasets と Models がログ記録されます。
from wandb.integration.metaflow import wandb_log
class WandbExampleFlow (FlowSpec):
@wandb_log (datasets= True , models= True , settings= wandb. Settings(... ))
@step
def start (self):
self. raw_df = pd. read_csv(... ). # pd.DataFrame -> upload as dataset
self. model_file = torch. load(... ) # nn.Module -> upload as model
self. next(self. transform)
フローをデコレートすることは、すべての構成ステップをデフォルトでデコレートすることと同じです。
この場合、WandbExampleFlow のすべてのステップは、Datasets と Models をデフォルトでログ記録します。これは、各ステップを @wandb_log(datasets=True, models=True) でデコレートするのと同じです。
from wandb.integration.metaflow import wandb_log
@wandb_log (datasets= True , models= True ) # decorate all @step
class WandbExampleFlow (FlowSpec):
@step
def start (self):
self. raw_df = pd. read_csv(... ). # pd.DataFrame -> upload as dataset
self. model_file = torch. load(... ) # nn.Module -> upload as model
self. next(self. transform)
フローをデコレートすることは、すべてのステップをデフォルトでデコレートすることと同じです。つまり、後で別の @wandb_log でステップをデコレートすると、フローレベルのデコレーションがオーバーライドされます。
この例では:
start と mid は Datasets と Models の両方をログ記録します。end は Datasets も Models もログ記録しません。
from wandb.integration.metaflow import wandb_log
@wandb_log (datasets= True , models= True ) # same as decorating start and mid
class WandbExampleFlow (FlowSpec):
# this step will log datasets and models
@step
def start (self):
self. raw_df = pd. read_csv(... ). # pd.DataFrame -> upload as dataset
self. model_file = torch. load(... ) # nn.Module -> upload as model
self. next(self. mid)
# this step will also log datasets and models
@step
def mid (self):
self. raw_df = pd. read_csv(... ). # pd.DataFrame -> upload as dataset
self. model_file = torch. load(... ) # nn.Module -> upload as model
self. next(self. end)
# this step is overwritten and will NOT log datasets OR models
@wandb_log (datasets= False , models= False )
@step
def end (self):
self. raw_df = pd. read_csv(... ).
self. model_file = torch. load(... )
プログラムでデータにアクセスする
キャプチャした情報には、次の 3 つの方法でアクセスできます。wandb クライアントライブラリweb アプリ UI を使用、または Public API を使用してプログラムでアクセスできます。Parameter は W&B の configOverview タブ にあります。datasets、models、および others は W&B Artifacts に保存され、Artifacts タブ にあります。Base python タイプは W&B の summaryPublic API のガイド を参照してください。
クイックリファレンス
データ
クライアントライブラリ
UI
Parameter(...)wandb.configOverview タブ, Config
datasets、models、otherswandb.use_artifact("{var_name}:latest")Artifacts タブ
Base Python タイプ (dict、list、str など)
wandb.summaryOverview タブ, Summary
wandb_log kwargs
kwarg
オプション
datasetsTrue: データセットであるインスタンス変数をログに記録しますFalse
modelsTrue: モデルであるインスタンス変数をログに記録しますFalse
othersTrue: シリアル化可能なものをピクルとしてログに記録しますFalse
settingswandb.Settings(…): このステップまたはフローに独自の wandb 設定を指定しますNone: wandb.Settings() を渡すのと同じですデフォルトでは、以下の場合:
settings.run_group が None の場合、{flow_name}/{run_id} に設定されますsettings.run_job_type が None の場合、{run_job_type}/{step_name} に設定されます
よくある質問
実際に何をログに記録しますか?すべてのインスタンス変数とローカル変数をログに記録しますか?
wandb_log はインスタンス変数のみをログに記録します。ローカル変数は決してログに記録されません。これは、不要なデータのログ記録を回避するのに役立ちます。
どのデータ型がログに記録されますか?
現在、これらのタイプをサポートしています。
ログ設定
タイプ
デフォルト (常にオン)
dict, list, set, str, int, float, bool
datasets
modelsnn.Modulesklearn.base.BaseEstimator
others
ログ記録の振る舞いを構成するにはどうすればよいですか?
変数の種類
振る舞い
例
データ型
インスタンス
自動ログ記録
self.accuracyfloat
インスタンス
datasets=True の場合にログ記録self.dfpd.DataFrame
インスタンス
datasets=False の場合はログ記録されませんself.dfpd.DataFrame
ローカル
決してログ記録されない
accuracyfloat
ローカル
決してログ記録されない
dfpd.DataFrame
Artifacts のリネージは追跡されますか?
はい。Artifact がステップ A の出力であり、ステップ B の入力である場合、リネージ DAG が自動的に構築されます。
この振る舞いの例については、この notebook と対応する W&B Artifacts ページ を参照してください。
20 - MMEngine
MMEngine は OpenMMLab によって開発された、PyTorch をベースとした ディープラーニング モデルのトレーニングを行うための基盤 ライブラリです。MMEngine は OpenMMLab アルゴリズム ライブラリの次世代トレーニング アーキテクチャーを実装し、OpenMMLab 内の 30 以上のアルゴリズム ライブラリに統一された実行基盤を提供します。そのコア コンポーネントには、トレーニング エンジン、評価エンジン、およびモジュール管理が含まれます。
Weights and Biases は、専用の WandbVisBackend
トレーニング および 評価 メトリクスを ログに記録する。
実験 の config を ログに記録および管理する。
グラフ、画像、スカラーなどの追加レコードを ログに記録する。
はじめに
openmim と wandb をインストールします。
pip install -q -U openmim wandb
!pip install -q -U openmim wandb
次に、mim を使用して mmengine と mmcv をインストールします。
mim install -q mmengine mmcv
!mim install -q mmengine mmcv
WandbVisBackend を MMEngine Runner で使用するこのセクションでは、mmengine.runner.RunnerWandbVisBackend を使用する典型的な ワークフロー を示します。
可視化 config から visualizer を定義します。
from mmengine.visualization import Visualizer
# 可視化 config を定義します
visualization_cfg = dict(
name= "wandb_visualizer" ,
vis_backends= [
dict(
type= 'WandbVisBackend' ,
init_kwargs= dict(project= "mmengine" ),
)
],
save_dir= "runs/wandb"
)
# 可視化 config から visualizer を取得します
visualizer = Visualizer. get_instance(** visualization_cfg)
[W&B run 初期化](/ja/ref/python/init/) の入力 パラメータ に、 引数 の 辞書 を `init_kwargs` に渡します。
visualizer で runner を初期化し、runner.train() を呼び出します。
from mmengine.runner import Runner
# PyTorch のトレーニング ヘルパーである mmengine Runner を構築します
runner = Runner(
model,
work_dir= 'runs/gan/' ,
train_dataloader= train_dataloader,
train_cfg= train_cfg,
optim_wrapper= opt_wrapper_dict,
visualizer= visualizer, # visualizer を渡します
)
# トレーニングを開始します
runner. train()
OpenMMLab コンピュータビジョン ライブラリで WandbVisBackend を使用する
WandbVisBackend は、MMDetection などの OpenMMLab コンピュータビジョン ライブラリ で 実験 を追跡するためにも簡単に使用できます。
# デフォルトの ランタイム config からベース config を継承します
_base_ = ["../_base_/default_runtime.py" ]
# `WandbVisBackend` config 辞書を、
# ベース config からの `visualizer` の `vis_backends` に割り当てます
_base_. visualizer. vis_backends = [
dict(
type= 'WandbVisBackend' ,
init_kwargs= {
'project' : 'mmdet' ,
'entity' : 'geekyrakshit'
},
),
]
21 - MMF
Meta AI の MMF と W&B を統合する方法。
Meta AI の MMF ライブラリの WandbLogger クラスを使用すると、Weights & Biases でトレーニング/検証 メトリクス、システム (GPU および CPU) メトリクス、モデル チェックポイント、および設定 パラメータをログに記録できます。
現在の機能
MMF の WandbLogger では、現在、次の機能がサポートされています。
トレーニングと検証の メトリクス
経時的な学習率
W&B Artifacts へのモデル チェックポイントの保存
GPU および CPU システム メトリクス
トレーニング設定 パラメータ
設定 パラメータ
wandb ロギングを有効化およびカスタマイズするために、MMF 設定で次のオプションを使用できます。
training:
wandb:
enabled: true
# エンティティは、run の送信先となる ユーザー名または Teams 名です。
# デフォルトでは、run は ユーザー アカウントにログ記録されます。
entity: null
# wandb で 実験 をログ記録する際に使用する Project 名
project: mmf
# wandb で プロジェクト の下に 実験 をログ記録する際に使用する 実験/run 名。
# デフォルトの 実験 名は次のとおりです: ${training.experiment_name}
name: ${training.experiment_name}
# モデル の チェックポイント を有効にして、チェックポイント を W&B Artifacts に保存します
log_model_checkpoint: true
# wandb.init() に渡す追加の 引数 値。
# 使用可能な 引数 (例:
# job_type: 'train'
# tags: ['tag1', 'tag2']
# については、/ref/python/init のドキュメントを参照してください。
env:
# wandb の メタデータ が保存される ディレクトリー への パス を変更するには
# (デフォルト: env.log_dir):
wandb_logdir: ${env:MMF_WANDB_LOGDIR,}
22 - MosaicML Composer
最先端のアルゴリズムでニューラルネットワークをトレーニング
Composer は、ニューラルネットワークのトレーニングをより良く、より速く、より安価にするためのライブラリです。ニューラルネットワークのトレーニングを加速させ、汎化性能を向上させるための多くの最先端の メソッド が含まれています。また、オプションの Trainer APIを使用すると、さまざまな拡張機能を簡単に 構成 できます。
Weights & Biases は、ML 実験 の ログ を記録するための軽量なラッパーを提供します。ただし、2つを自分で組み合わせる必要はありません。Weights & Biases は、WandBLogger を介して Composer ライブラリに直接組み込まれています。
Weights & Biases への ログ の記録を開始する
from composer import Trainer
from composer.loggers import WandBLogger
trainer = Trainer(... , logger= WandBLogger())
Composer の WandBLogger の使用
Composer ライブラリは、Trainer の WandBLogger クラスを使用して、 メトリクス を Weights & Biases に ログ します。ロガーをインスタンス化して Trainer に渡すのと同じくらい簡単です。
wandb_logger = WandBLogger(project= "gpt-5" , log_artifacts= True )
trainer = Trainer(logger= wandb_logger)
ロガーの 引数
WandbLogger の パラメータ については、完全なリストと説明について Composer のドキュメント を参照してください。
パラメータ
説明
projectWeights & Biases の プロジェクト 名 (str, optional)
groupWeights & Biases の グループ 名 (str, optional)
nameWeights & Biases の run 名。指定されていない場合、State.run_name が使用されます (str, optional)
entityWeights & Biases の エンティティ 名 ( ユーザー 名または Weights & Biases の Teams 名など) (str, optional)
tagsWeights & Biases の タグ (List[str], optional)
log_artifactsチェックポイント を wandb に ログ するかどうか、デフォルト: false (bool, optional)
rank_zero_onlyランク 0 の プロセス でのみ ログ を記録するかどうか。Artifacts を ログ に記録する場合は、すべてのランクで ログ に記録することを強くお勧めします。ランク ≥1 からの Artifacts は保存されず、関連情報が破棄される可能性があります。たとえば、Deepspeed ZeRO を使用する場合、すべてのランクからの Artifacts がないと チェックポイント から復元することは不可能です。デフォルト: True (bool, optional)
init_kwargswandb config などの wandb.init に渡す パラメータ 完全なリストについては、こちら wandb.init が受け入れます
一般的な使用法は次のとおりです。
init_kwargs = {"notes":"この 実験 でより高い学習率をテストする",
"config":{"arch":"Llama",
"use_mixed_precision":True
}
}
wandb_logger = WandBLogger(log_artifacts=True, init_kwargs=init_kwargs)
予測 サンプル の ログ
Composer の Callbacks システムを使用して、WandBLogger 経由で Weights & Biases に ログ を記録するタイミングを制御できます。この例では、検証画像と 予測 の サンプル が ログ に記録されます。
import wandb
from composer import Callback, State, Logger
class LogPredictions (Callback):
def __init__(self, num_samples= 100 , seed= 1234 ):
super(). __init__()
self. num_samples = num_samples
self. data = []
def eval_batch_end (self, state: State, logger: Logger):
"""バッチ ごとに 予測 を計算し、self.data に保存します"""
if state. timer. epoch == state. max_duration: #最後の val エポック で
if len(self. data) < self. num_samples:
n = self. num_samples
x, y = state. batch_pair
outputs = state. outputs. argmax(- 1 )
data = [[wandb. Image(x_i), y_i, y_pred] for x_i, y_i, y_pred in list(zip(x[:n], y[:n], outputs[:n]))]
self. data += data
def eval_end (self, state: State, logger: Logger):
"wandb.Table を作成して ログ に記録します"
columns = ['image' , 'ground truth' , 'prediction' ]
table = wandb. Table(columns= columns, data= self. data[:self. num_samples])
wandb. log({'sample_table' :table}, step= int(state. timer. batch))
...
trainer = Trainer(
...
loggers= [WandBLogger()],
callbacks= [LogPredictions()]
)
23 - OpenAI API
OpenAI API で W&B を使用する方法。
W&B OpenAI API インテグレーションを使用すると、ファインチューンされたモデルを含むすべての OpenAI モデルのリクエスト、レスポンス、トークン数、モデルの メタデータ を ログ に記録できます。
API の入力と出力を ログ に記録すると、さまざまなプロンプトのパフォーマンスを迅速に評価し、さまざまなモデル 設定 (温度など) を比較し、トークンの使用量などの他の使用状況 メトリクス を追跡できます。
OpenAI Python API ライブラリ をインストール
W&B autolog インテグレーションは、OpenAI バージョン 0.28.1 以前で動作します。
OpenAI Python API バージョン 0.28.1 をインストールするには、以下を実行します。
pip install openai== 0.28.1
OpenAI Python API の使用
1. autolog をインポートして初期化する
まず、wandb.integration.openai から autolog をインポートして初期化します。
import os
import openai
from wandb.integration.openai import autolog
autolog({"project" : "gpt5" })
オプションで、wandb.init() が受け入れる 引数 を持つ 辞書 を autolog に渡すことができます。これには、 プロジェクト 名、 チーム 名、 エンティティ などが含まれます。wandb.init
2. OpenAI API を呼び出す
OpenAI API への各呼び出しは、W&B に自動的に ログ 記録されるようになりました。
os. environ["OPENAI_API_KEY" ] = "XXX"
chat_request_kwargs = dict(
model= "gpt-3.5-turbo" ,
messages= [
{"role" : "system" , "content" : "You are a helpful assistant." },
{"role" : "user" , "content" : "Who won the world series in 2020?" },
{"role" : "assistant" , "content" : "The Los Angeles Dodgers" },
{"role" : "user" , "content" : "Where was it played?" },
],
)
response = openai. ChatCompletion. create(** chat_request_kwargs)
3. OpenAI API の入力とレスポンスを表示する
ステップ 1 で autolog によって生成された W&B run リンクをクリックします。これにより、W&B アプリ の プロジェクト ワークスペース にリダイレクトされます。
作成した run を選択して、トレース テーブル、トレース タイムライン、および使用された OpenAI LLM のモデル アーキテクチャ を表示します。
autolog をオフにする
OpenAI API の使用が終了したら、すべての W&B プロセス を閉じるために disable() を呼び出すことをお勧めします。
これで、入力と補完が W&B に ログ 記録され、 分析 の準備が整い、同僚と共有できます。
24 - OpenAI Fine-Tuning
W&B を使用して OpenAI モデルを ファインチューン する方法。
OpenAI GPT-3.5 または GPT-4 モデルのファインチューニングのメトリクスと設定を W&B に記録します。W&B の エコシステム を利用して、ファインチューニング の 実験 、 モデル 、 データセット を追跡し、同僚と 結果 を共有します。
W&B と OpenAI を ファインチューニング 用に 統合 する方法に関する補足情報については、OpenAI のドキュメントのWeights and Biases Integration セクションを参照してください。
OpenAI Python API のインストールまたはアップデート
W&B OpenAI ファインチューニング インテグレーション は、OpenAI バージョン 1.0 以降で動作します。OpenAI Python API ライブラリの最新バージョンについては、PyPI のドキュメントを参照してください。
OpenAI Python API をインストールするには、以下を実行します。
OpenAI Python API がすでにインストールされている場合は、以下を実行してアップデートできます。
OpenAI ファインチューニング の 結果 を 同期 する
W&B を OpenAI の ファインチューニング API と 統合 して、ファインチューニング の メトリクス と 設定 を W&B に 記録 します。これを行うには、wandb.integration.openai.fine_tuning モジュールの WandbLogger クラスを使用します。
from wandb.integration.openai.fine_tuning import WandbLogger
# Finetuning logic
WandbLogger. sync(fine_tune_job_id= FINETUNE_JOB_ID)
ファインチューン を 同期 する
スクリプト から 結果 を 同期 します。
from wandb.integration.openai.fine_tuning import WandbLogger
# one line command
WandbLogger. sync()
# passing optional parameters
WandbLogger. sync(
fine_tune_job_id= None ,
num_fine_tunes= None ,
project= "OpenAI-Fine-Tune" ,
entity= None ,
overwrite= False ,
model_artifact_name= "model-metadata" ,
model_artifact_type= "model" ,
** kwargs_wandb_init
)
リファレンス
引数
説明
fine_tune_job_id
これは、client.fine_tuning.jobs.create を使用して ファインチューン ジョブ を 作成 するときに取得する OpenAI Fine-Tune ID です。この 引数 が None (デフォルト) の場合、まだ W&B に 同期 されていないすべての OpenAI ファインチューン ジョブ が W&B に 同期 されます。
openai_client
初期化された OpenAI クライアント を sync に渡します。クライアント が 提供 されない場合、ロガー自体によって初期化されます。デフォルトでは None です。
num_fine_tunes
ID が 提供 されない場合、同期 されていないすべての ファインチューン が W&B に 記録 されます。この 引数 を使用すると、 同期 する 最新 の ファインチューン の 数 を 選択 できます。num_fine_tunes が 5 の場合、最新 の 5 つの ファインチューン が 選択 されます。
project
ファインチューン の メトリクス 、 モデル 、 データ などが 記録 される Weights and Biases プロジェクト 名。デフォルトでは、 プロジェクト 名は “OpenAI-Fine-Tune” です。
entity
run の送信先の W&B ユーザー 名または チーム 名。デフォルトでは、デフォルト の エンティティ が使用されます。通常は ユーザー 名です。
overwrite
同じ ファインチューン ジョブ の 既存 の wandb run を 強制的に ログ に 記録 して 上書き します。デフォルトでは False です。
wait_for_job_success
OpenAI の ファインチューニング ジョブ が 開始 されると、通常、少し時間がかかります。メトリクス が ファインチューン ジョブ の 完了後すぐに W&B に 記録 されるようにするために、この 設定 では、60 秒ごとに ファインチューン ジョブ の ステータス が succeeded に 変わるかどうかを チェック します。ファインチューン ジョブ が 成功 したと 検出 されると、メトリクス は 自動的に W&B に 同期 されます。デフォルトでは True に 設定 されています。
model_artifact_name
ログ に 記録 される モデル Artifacts の 名前。デフォルトは "model-metadata" です。
model_artifact_type
ログ に 記録 される モデル Artifacts の タイプ。デフォルトは "model" です。
**kwargs_wandb_init
wandb.init()
データセット の バージョン管理 と 可視化
バージョン管理
ファインチューニング 用に OpenAI に アップロード する トレーニング データ と 検証 データ は、より簡単な バージョン 管理のために W&B Artifacts として 自動的に ログ に 記録 されます。以下は、Artifacts の トレーニング ファイル の ビュー です。ここでは、この ファイル を ログ に 記録 した W&B run、ログ に 記録 された日時、これが データセット のどの バージョン であるか、メタデータ 、および トレーニングデータ から トレーニング された モデル への DAG リネージ を確認できます。
可視化
データセット は W&B テーブル として 可視化 され、データセット の 探索 、 検索 、および 操作 を行うことができます。以下の W&B テーブル を使用して 可視化 された トレーニング サンプル を チェック してください。
ファインチューニング された モデル と モデル の バージョン管理
OpenAI は、ファインチューニング された モデル の ID を 提供 します。モデル の 重み に アクセス できないため、WandbLogger は、 モデル の すべての 詳細 ( ハイパーパラメーター 、 データ ファイル ID など) と fine_tuned_model ID を含む model_metadata.json ファイル を 作成 し、W&B Artifacts として ログ に 記録 します。
この モデル ( メタデータ ) Artifacts は、W&B Registry の モデル にさらに リンク できます。
よくある質問
チーム で ファインチューン の 結果 を W&B で共有するにはどうすればよいですか?
以下を使用して、ファインチューン ジョブ を チーム アカウント に ログ に 記録 します。
WandbLogger. sync(entity= "YOUR_TEAM_NAME" )
run を 整理 するにはどうすればよいですか?
W&B run は 自動的に 整理 され、 ジョブタイプ 、 ベース モデル 、 学習率 、 トレーニング ファイル名 、その他の ハイパーパラメーター など、任意の設定 パラメータ に 基づいて フィルタリング/ソート できます。
さらに、run の 名前 を 変更 したり、メモ を 追加 したり、 タグ を 作成 して グループ化 したりできます。
満足したら、 ワークスペース を 保存 し、それを使用して レポート を 作成 し、run と 保存 された Artifacts ( トレーニング / 検証 ファイル ) から データ を インポート できます。
ファインチューニング された モデル に アクセス するにはどうすればよいですか?
ファインチューニング された モデル ID は、Artifacts (model_metadata.json) および 設定 として W&B に ログ に 記録 されます。
import wandb
ft_artifact = wandb. run. use_artifact("ENTITY/PROJECT/model_metadata:VERSION" )
artifact_dir = artifact. download()
ここで、VERSION は次のいずれかです。
v2 などの バージョン 番号ft-xxxxxxxxx などの ファインチューン IDlatest や 手動 で 追加 された エイリアス など、自動的に 追加 された エイリアス
次に、ダウンロード した model_metadata.json ファイル を 読み取ることで、fine_tuned_model ID に アクセス できます。
ファインチューン が 正常 に 同期 されなかった場合はどうなりますか?
ファインチューン が W&B に 正常 に ログ に 記録 されなかった場合は、overwrite=True を使用して、ファインチューン ジョブ ID を 渡すことができます。
WandbLogger. sync(
fine_tune_job_id= "FINE_TUNE_JOB_ID" ,
overwrite= True ,
)
W&B で データセット と モデル を 追跡 できますか?
トレーニング および 検証 データ は、Artifacts として W&B に 自動的に ログ に 記録 されます。ファインチューニング された モデル の ID を含む メタデータ も、Artifacts として ログ に 記録 されます。
wandb.Artifact、wandb.log などの 低レベル の wandb API を使用して パイプライン を 常に 制御 できます。これにより、 データ と モデル の 完全 な トレーサビリティ が 可能 になります。
リソース
25 - OpenAI Gym
W&B を OpenAI Gym と統合する方法。
2021年以降 Gym をメンテナンスしてきたチームは、今後の開発をすべて Gymnasium に移行しました。Gymnasium は Gym のドロップイン代替品 (import gymnasium as gym) であり、Gym は今後アップデートを受け取ることはありません。(出典 )
Gym はもはや活発にメンテナンスされているプロジェクトではないため、Gymnasium との インテグレーション をお試しください。
OpenAI Gym を使用している場合、Weights & Biases は gym.wrappers.Monitor によって生成された 環境 の動画を自動的に ログ します。wandb.initmonitor_gym キーワード 引数 を True に設定するか、wandb.gym.monitor() を呼び出すだけです。
当社の gym インテグレーション は非常に軽量です。gym から ログ されている動画ファイルの名前を 確認 し、それにちなんで名前を付けるか、一致するものが見つからない場合は "videos" にフォールバックします。より詳細な制御が必要な場合は、いつでも手動で 動画を ログ できます。
CleanRL による OpenRL Benchmark では、OpenAI Gym の例でこの インテグレーション を使用しています。gym での使用方法を示すソース コード (特定の Runs に使用される特定のコード を含む) を見つけることができます。
26 - PaddleDetection
PaddleDetection と W&B の統合方法。
PaddleDetection は、PaddlePaddle に基づくエンドツーエンドの オブジェクト検出開発キットです。ネットワークコンポーネント、データ拡張、損失などの構成可能なモジュールを使用して、さまざまな主流のオブジェクトを検出し、インスタンスをセグメント化し、キーポイントを追跡および検出します。
PaddleDetection には、すべての トレーニング および 検証 メトリクスに加えて、モデル チェックポイント とそれに対応する メタデータ をログに記録する、組み込みの W&B インテグレーションが含まれています。
PaddleDetection WandbLogger は、トレーニング 中にトレーニング および 評価 メトリクス を Weights & Biases に ログ 記録するだけでなく、モデル チェックポイント も ログ 記録します。
W&B の ブログ 記事を読む COCO2017 データセット の サブセット で、YOLOX モデル を PaddleDetection と 統合 する方法について説明します。
サインアップ して APIキー を作成する
APIキー は、W&B に対して マシン を 認証 します。APIキー は、 ユーザー プロフィールから生成できます。
右上隅にある ユーザー プロフィール アイコンをクリックします。
ユーザー 設定 を選択し、APIキー セクションまでスクロールします。表示 をクリックします。表示された APIキー をコピーします。APIキー を非表示にするには、ページをリロードしてください。
wandb ライブラリ を インストール して ログイン するwandb ライブラリ をローカルに インストール して ログイン するには:
コマンドライン
Python
Python ノートブック
WANDB_API_KEY 環境変数 を APIキー に設定します。
export WANDB_API_KEY= <your_api_key>
wandb ライブラリ を インストール して ログイン します。
pip install wandb
wandb login
import wandb
wandb. login()
!pip install wandb
import wandb
wandb.login()
トレーニング スクリプト で WandbLogger をアクティブにする
PaddleDetection の train.py への 引数 を介して wandb を使用するには:
--use_wandb フラグを追加します最初の wandb 引数 は -o を前に付ける必要があります (これは一度だけ渡す必要があります)
個々の wandb 引数 には、プレフィックス wandb- が含まれている必要があります。たとえば、wandb.initwandb- プレフィックス が付きます。
python tools/train.py
-c config.yml \
--use_wandb \
\
wandb-project= MyDetector \
= MyTeam \
= ./logs
wandb キー の下の config.yml ファイル に wandb 引数 を追加します。
wandb:
project: MyProject
entity: MyTeam
save_dir: ./logs
train.py ファイル を実行すると、W&B ダッシュボード への リンク が生成されます。
フィードバック または 問題点
Weights & Biases インテグレーション に関する フィードバック や 問題 がある場合は、PaddleDetection GitHub で 問題 を提起するか、support@wandb.com にメールを送信してください。
27 - PaddleOCR
PaddleOCR と W&B を統合する方法。
PaddleOCR は、多言語に対応した、素晴らしい、最先端の、そして実用的なOCRツールを開発し、PaddlePaddle で実装されたモデルのトレーニングをより良く行い、実際に活用できるようにすることを目的としています。PaddleOCR は、OCRに関連する様々な最先端のアルゴリズムをサポートし、産業ソリューションを開発しました。PaddleOCR には、トレーニング と評価メトリクスを、対応するメタデータ と共にモデル のチェックポイント をログ記録するための Weights & Biases のインテグレーションが付属しています。
ブログ と Colab の例
ICDAR2015 データセット で PaddleOCR を使用してモデル をトレーニングする方法については、こちら Google Colab こちら W&B对您的OCR模型进行训练和调试
サインアップ して APIキー を作成する
APIキー は、W&B に対してお客様のマシン を認証します。APIキー は、ユーザー プロファイル から生成できます。
右上隅にあるユーザー プロファイル アイコン をクリックします。
[User Settings ] を選択し、[API Keys ] セクション までスクロールします。
[Reveal ] をクリックします。表示された APIキー をコピーします。APIキー を非表示にするには、ページ をリロードします。
wandb ライブラリ をインストール してログイン するwandb ライブラリ をローカル にインストール してログイン するには:
コマンドライン
Python
Python notebook
WANDB_API_KEY 環境変数 を APIキー に設定します。
export WANDB_API_KEY= <your_api_key>
wandb ライブラリ をインストール してログイン します。
pip install wandb
wandb login
import wandb
wandb. login()
!pip install wandb
import wandb
wandb.login()
config.yml ファイル に wandb を追加するPaddleOCR では、yaml ファイル を使用して構成変数 を指定する必要があります。構成 yaml ファイル の末尾に次のスニペット を追加すると、すべてのトレーニング と検証メトリクス が、モデル チェックポイント と共に W&B ダッシュボード に自動的に記録されます。
wandb.initwandb ヘッダー の下に追加することもできます。
wandb:
project: CoolOCR # (オプション) これは wandb プロジェクト名 です
entity: my_team # (オプション) wandb team を使用している場合は、ここに team 名を渡すことができます
name: MyOCRModel # (オプション) これは wandb run の名前です
config.yml ファイル を train.py に渡すyaml ファイル は、PaddleOCR リポジトリ で利用可能な トレーニング スクリプト への 引数 として提供されます。
python tools/train.py -c config.yml
Weights & Biases をオンにして train.py ファイル を実行すると、W&B ダッシュボード に移動するためのリンク が生成されます。
フィードバック または問題点
Weights & Biases のインテグレーションに関するフィードバック や問題がある場合は、PaddleOCR GitHub で issue をオープン するか、support@wandb.com にメール でご連絡ください。
28 - Prodigy
W&B と Prodigy を統合する方法。
Prodigy は、機械学習モデルのトレーニング および 評価 データ、エラー分析、データ の検査 および クリーニングを作成するためのアノテーション ツールです。W&B テーブル を使用すると、W&B 内でデータセット (など) をログ記録、可視化、分析、および共有できます。
Prodigy との W&B インテグレーション は、Prodigy でアノテーションを付けたデータセットを W&B に直接アップロードして テーブル で使用するための、シンプルで使いやすい機能を追加します。
次のようなコードを数行実行します。
import wandb
from wandb.integration.prodigy import upload_dataset
with wandb. init(project= "prodigy" ):
upload_dataset("news_headlines_ner" )
次のような、視覚的でインタラクティブな共有可能な テーブル を取得します。
クイックスタート
wandb.integration.prodigy.upload_dataset を使用して、アノテーションが付けられた Prodigy データセットをローカルの Prodigy データベースから W&B の テーブル 形式で直接アップロードします。インストール および セットアップを含む Prodigy の詳細については、Prodigy ドキュメント を参照してください。
W&B は、画像 および 固有表現フィールドを wandb.Imagewandb.Html
詳細な例を読む
W&B Prodigy インテグレーションで生成された可視化の例については、W&B テーブル を使用した Prodigy データセットの可視化 を参照してください。
spaCy も使用しますか?
W&B には spaCy との インテグレーション もあります。ドキュメントはこちら をご覧ください。
29 - PyTorch
PyTorch は、Python の ディープラーニング において最も人気のある フレームワーク の 1 つで、特に 研究 者の間で人気があります。W&B は、 勾配 の ログ 記録から CPU および GPU での コード のプロファイリングまで、PyTorch を第一級でサポートします。
ぜひ、 Colabノートブック で インテグレーション をお試しください。
サンプルリポジトリ で スクリプト を確認することもできます。これには、Fashion MNIST で Hyperband を使用した ハイパーパラメーター 最適化に関するものや、それが生成する W&B Dashboard などがあります。
wandb.watch で 勾配 を ログ 記録する勾配 を自動的に ログ 記録するには、wandb.watch
import wandb
wandb. init(config= args)
model = ... # モデル をセットアップ
# Magic
wandb. watch(model, log_freq= 100 )
model. train()
for batch_idx, (data, target) in enumerate(train_loader):
output = model(data)
loss = F. nll_loss(output, target)
loss. backward()
optimizer. step()
if batch_idx % args. log_interval == 0 :
wandb. log({"loss" : loss})
同じ スクリプト で複数の モデル を追跡する必要がある場合は、各 モデル で wandb.watch を個別に呼び出すことができます。この関数の リファレンス ドキュメントは こちら にあります。
順方向と逆方向のパスの後に wandb.log が呼び出されるまで、 勾配 、 メトリクス 、および グラフ は ログ 記録されません。
画像とメディアを ログ 記録する
画像 データ を含む PyTorch の Tensors を wandb.Imagetorchvision
images_t = ... # PyTorch の Tensor として画像を生成またはロード
wandb. log({"examples" : [wandb. Image(im) for im in images_t]})
PyTorch およびその他の フレームワーク で リッチメディア を W&B に ログ 記録する方法の詳細については、メディア ログ 記録 ガイド を確認してください。
モデル の 予測 や派生した メトリクス など、メディアと一緒に 情報 を含める場合は、wandb.Table を使用します。
my_table = wandb. Table()
my_table. add_column("image" , images_t)
my_table. add_column("label" , labels)
my_table. add_column("class_prediction" , predictions_t)
# W&B に テーブル を ログ 記録
wandb. log({"mnist_predictions" : my_table})
データセット と モデル の ログ 記録と視覚化の詳細については、W&B Tables の ガイド を確認してください。
PyTorch コード のプロファイル
W&B は、PyTorch Kineto の Tensorboard plugin と直接 統合 されており、PyTorch コード のプロファイル、CPU と GPU の通信の詳細の検査、および ボトルネック と 最適化 の特定のための ツール を提供します。
profile_dir = "path/to/run/tbprofile/"
profiler = torch. profiler. profile(
schedule= schedule, # スケジューリング の詳細については、プロファイラー のドキュメントを参照してください
on_trace_ready= torch. profiler. tensorboard_trace_handler(profile_dir),
with_stack= True ,
)
with profiler:
... # ここでプロファイルするコードを実行
# 詳細な使用方法については、プロファイラー のドキュメントを参照してください
# wandb Artifact を作成
profile_art = wandb. Artifact("trace" , type= "profile" )
# pt.trace.json ファイルを Artifact に追加
profile_art. add_file(glob. glob(profile_dir + ".pt.trace.json" ))
# artifact をログに記録
profile_art. save()
動作する サンプル コード を この Colab で確認して実行してください。
インタラクティブな トレース 表示 ツール は Chrome Trace Viewer に基づいており、Chrome ブラウザー で最適に動作します。
30 - PyTorch Geometric
PyTorch Geometric 、または PyG は、幾何学的ディープラーニングで最も人気のあるライブラリの 1 つであり、W&B はグラフの可視化と Experiments の追跡において非常にうまく機能します。
Pytorch Geometric をインストールしたら、以下の手順に従って開始してください。
サインアップして API キーを作成する
API キー は、お使いのマシンを W&B に対して認証します。API キーは、 ユーザー プロフィールから生成できます。
右上隅にある ユーザー プロフィール アイコンをクリックします。
ユーザー 設定 を選択し、API キー セクションまでスクロールします。表示 をクリックします。表示された API キーをコピーします。API キーを非表示にするには、ページをリロードしてください。
wandb ライブラリをインストールしてログインするローカルに wandb ライブラリをインストールしてログインするには:
コマンドライン
Python
Python notebook
WANDB_API_KEY 環境 変数 を API キー に設定します。
export WANDB_API_KEY= <your_api_key>
wandb ライブラリをインストールしてログインします。
pip install wandb
wandb login
import wandb
wandb. login()
!pip install wandb
import wandb
wandb.login()
グラフを可視化する
エッジ数、ノード数など、入力グラフに関する詳細を保存できます。W&B は Plotly チャートと HTML パネル の ログ をサポートしているため、グラフ用に作成した 可視化 は W&B にも ログ できます。
PyVis を使用する
次のスニペットは、PyVis と HTML でそれを行う方法を示しています。
from pyvis.network import Network
Import wandb
wandb. init(project= ’ graph_vis’ )
net = Network(height= "750px" , width= "100%" , bgcolor= "#222222" , font_color= "white" )
# Add the edges from the PyG graph to the PyVis network
for e in tqdm(g. edge_index. T):
src = e[0 ]. item()
dst = e[1 ]. item()
net. add_node(dst)
net. add_node(src)
net. add_edge(src, dst, value= 0.1 )
# Save the PyVis visualisation to a HTML file
net. show("graph.html" )
wandb. log({"eda/graph" : wandb. Html("graph.html" )})
wandb. finish()
Plotly を使用する
Plotly を使用してグラフの 可視化 を作成するには、まず PyG グラフを networkx オブジェクトに変換する必要があります。次に、ノードとエッジの両方に対して Plotly 散布図を作成する必要があります。次のスニペットをこのタスクに使用できます。
def create_vis (graph):
G = to_networkx(graph)
pos = nx. spring_layout(G)
edge_x = []
edge_y = []
for edge in G. edges():
x0, y0 = pos[edge[0 ]]
x1, y1 = pos[edge[1 ]]
edge_x. append(x0)
edge_x. append(x1)
edge_x. append(None )
edge_y. append(y0)
edge_y. append(y1)
edge_y. append(None )
edge_trace = go. Scatter(
x= edge_x, y= edge_y,
line= dict(width= 0.5 , color= '#888' ),
hoverinfo= 'none' ,
mode= 'lines'
)
node_x = []
node_y = []
for node in G. nodes():
x, y = pos[node]
node_x. append(x)
node_y. append(y)
node_trace = go. Scatter(
x= node_x, y= node_y,
mode= 'markers' ,
hoverinfo= 'text' ,
line_width= 2
)
fig = go. Figure(data= [edge_trace, node_trace], layout= go. Layout())
return fig
wandb. init(project= ’ visualize_graph’ )
wandb. log({‘ graph’ : wandb. Plotly(create_vis(graph))})
wandb. finish()
メトリクス を ログ する
W&B を使用して、Experiments や、損失関数、精度などの関連 メトリクス を追跡できます。次の行を トレーニング ループに追加します。
wandb. log({
‘ train/ loss’ : training_loss,
‘ train/ acc’ : training_acc,
‘ val/ loss’ : validation_loss,
‘ val/ acc’ : validation_acc
})
その他のリソース
31 - Pytorch torchtune
torchtune は、大規模言語モデル(LLM)の作成、微調整、および実験 プロセスを効率化するために設計された PyTorch ベースのライブラリです。さらに、torchtune には W&B でのログ記録 のサポートが組み込まれており、トレーニング プロセスの追跡と 可視化が強化されています。
torchtune を使用した Mistral 7B の微調整 に関する W&B ブログ投稿を確認してください。
すぐに使える W&B ロギング
起動時に コマンドライン 引数をオーバーライドします。
tune run lora_finetune_single_device --config llama3/8B_lora_single_device \
= torchtune.utils.metric_logging.WandBLogger \
= "llama3_lora" \
= 5
レシピの構成で W&B ロギングを有効にします。
# inside llama3/8B_lora_single_device.yaml
metric_logger :
_component_ : torchtune.utils.metric_logging.WandBLogger
project : llama3_lora
log_every_n_steps : 5
W&B メトリクス ロガーを使用する
metric_logger セクションを変更して、レシピの構成ファイルで W&B ロギングを有効にします。_component_ を torchtune.utils.metric_logging.WandBLogger クラスに変更します。project 名と log_every_n_steps を渡して、ロギングの 振る舞いをカスタマイズすることもできます。
wandb.init メソッドと同様に、他の kwargs を渡すこともできます。たとえば、チームで作業している場合は、entity 引数を WandBLogger クラスに渡して、チーム名を指定できます。
# inside llama3/8B_lora_single_device.yaml
metric_logger :
_component_ : torchtune.utils.metric_logging.WandBLogger
project : llama3_lora
entity : my_project
job_type : lora_finetune_single_device
group : my_awesome_experiments
log_every_n_steps : 5
tune run lora_finetune_single_device --config llama3/8B_lora_single_device \
= torchtune.utils.metric_logging.WandBLogger \
= "llama3_lora" \
= "my_project" \
= "lora_finetune_single_device" \
= "my_awesome_experiments" \
= 5
ログに記録される内容
W&B ダッシュボードを調べて、ログに記録されたメトリクスを確認できます。デフォルトでは、W&B は構成ファイルと起動オーバーライドからすべての ハイパーパラメーター を記録します。
W&B は、概要 タブで解決された構成をキャプチャします。W&B は、ファイル タブ に YAML 形式で構成も保存します。
記録されたメトリクス
各レシピには、独自のトレーニング ループがあります。各レシピを確認して、ログに記録されたメトリクスを確認してください。これらはデフォルトで含まれています。
メトリクス
説明
lossモデルの損失
lr学習率
tokens_per_secondモデルの 1 秒あたりの トークン 数
grad_normモデルの勾配ノルム
global_stepトレーニング ループの現在のステップに対応します。勾配の累積を考慮します。基本的に、オプティマイザー のステップが実行されるたびに、モデルが更新され、勾配が累積され、モデルが gradient_accumulation_steps ごとに 1 回更新されます
global_step は、トレーニング ステップの数と同じではありません。トレーニング ループの現在のステップに対応します。勾配の累積を考慮します。基本的に、オプティマイザー のステップが実行されるたびに、global_step は 1 ずつ増加します。たとえば、データローダーに 10 個のバッチがあり、勾配累積ステップが 2 で、3 エポック実行する場合、オプティマイザー は 15 回ステップを実行します。この場合、global_step は 1 から 15 の範囲になります。
torchtune の合理化された設計により、カスタム メトリクスを簡単に追加したり、既存のメトリクスを変更したりできます。たとえば、current_epoch をエポックの総数のパーセンテージとしてログに記録するなど、対応する レシピ ファイル を変更するだけで済みます。
# inside `train.py` function in the recipe file
self. _metric_logger. log_dict(
{"current_epoch" : self. epochs * self. global_step / self. _steps_per_epoch},
step= self. global_step,
)
これは急速に進化しているライブラリであり、現在のメトリクスは変更される可能性があります。カスタム メトリクスを追加する場合は、レシピを変更して、対応する self._metric_logger.* 関数を呼び出す必要があります。
チェックポイント の保存とロード
torchtune ライブラリは、さまざまな チェックポイント 形式 をサポートしています。使用しているモデルの 出所に応じて、適切な チェックポイント クラス に切り替える必要があります。
モデルの チェックポイント を W&B Artifacts に保存する場合は、対応するレシピ内で save_checkpoint 関数をオーバーライドするのが最も簡単な解決策です。
モデルの チェックポイント を W&B Artifacts に保存するために save_checkpoint 関数をオーバーライドする方法の例を次に示します。
def save_checkpoint (self, epoch: int) -> None :
...
## Let's save the checkpoint to W&B
## depending on the Checkpointer Class the file will be named differently
## Here is an example for the full_finetune case
checkpoint_file = Path. joinpath(
self. _checkpointer. _output_dir, f "torchtune_model_ { epoch} "
). with_suffix(".pt" )
wandb_artifact = wandb. Artifact(
name= f "torchtune_model_ { epoch} " ,
type= "model" ,
# description of the model checkpoint
description= "Model checkpoint" ,
# you can add whatever metadata you want as a dict
metadata= {
utils. SEED_KEY: self. seed,
utils. EPOCHS_KEY: self. epochs_run,
utils. TOTAL_EPOCHS_KEY: self. total_epochs,
utils. MAX_STEPS_KEY: self. max_steps_per_epoch,
},
)
wandb_artifact. add_file(checkpoint_file)
wandb. log_artifact(wandb_artifact)
32 - PyTorch Ignite
PyTorch Ignite と W&B を統合する方法
Igniteは、トレーニングおよび検証中に、メトリクス、モデル/ オプティマイザー の パラメータ 、 勾配 を ログ に記録するための Weights & Biases ハンドラーをサポートしています。また、モデル の チェックポイント を Weights & Biases クラウド に ログ 記録するためにも使用できます。このクラスは、wandb モジュール のラッパーでもあります。つまり、このラッパーを使用して任意の wandb 関数を呼び出すことができます。モデル の パラメータ と 勾配 を保存する方法の例を参照してください。
基本的な設定
from argparse import ArgumentParser
import wandb
import torch
from torch import nn
from torch.optim import SGD
from torch.utils.data import DataLoader
import torch.nn.functional as F
from torchvision.transforms import Compose, ToTensor, Normalize
from torchvision.datasets import MNIST
from ignite.engine import Events, create_supervised_trainer, create_supervised_evaluator
from ignite.metrics import Accuracy, Loss
from tqdm import tqdm
class Net (nn. Module):
def __init__(self):
super(Net, self). __init__()
self. conv1 = nn. Conv2d(1 , 10 , kernel_size= 5 )
self. conv2 = nn. Conv2d(10 , 20 , kernel_size= 5 )
self. conv2_drop = nn. Dropout2d()
self. fc1 = nn. Linear(320 , 50 )
self. fc2 = nn. Linear(50 , 10 )
def forward (self, x):
x = F. relu(F. max_pool2d(self. conv1(x), 2 ))
x = F. relu(F. max_pool2d(self. conv2_drop(self. conv2(x)), 2 ))
x = x. view(- 1 , 320 )
x = F. relu(self. fc1(x))
x = F. dropout(x, training= self. training)
x = self. fc2(x)
return F. log_softmax(x, dim=- 1 )
def get_data_loaders (train_batch_size, val_batch_size):
data_transform = Compose([ToTensor(), Normalize((0.1307 ,), (0.3081 ,))])
train_loader = DataLoader(MNIST(download= True , root= "." , transform= data_transform, train= True ),
batch_size= train_batch_size, shuffle= True )
val_loader = DataLoader(MNIST(download= False , root= "." , transform= data_transform, train= False ),
batch_size= val_batch_size, shuffle= False )
return train_loader, val_loader
ignite で WandBLogger を使用することは、モジュール式の プロセス です。まず、WandBLogger オブジェクト を作成します。次に、メトリクス を自動的に ログ 記録するために、それを trainer または evaluator にアタッチします。この例:
トレーナー オブジェクト にアタッチされたトレーニング損失を ログ 記録します。
evaluator にアタッチされた検証損失を ログ 記録します。
学習率などのオプションの パラメータ を ログ 記録します。
モデル を監視します。
from ignite.contrib.handlers.wandb_logger import *
def run (train_batch_size, val_batch_size, epochs, lr, momentum, log_interval):
train_loader, val_loader = get_data_loaders(train_batch_size, val_batch_size)
model = Net()
device = 'cpu'
if torch. cuda. is_available():
device = 'cuda'
optimizer = SGD(model. parameters(), lr= lr, momentum= momentum)
trainer = create_supervised_trainer(model, optimizer, F. nll_loss, device= device)
evaluator = create_supervised_evaluator(model,
metrics= {'accuracy' : Accuracy(),
'nll' : Loss(F. nll_loss)},
device= device)
desc = "ITERATION - loss: {:.2f} "
pbar = tqdm(
initial= 0 , leave= False , total= len(train_loader),
desc= desc. format(0 )
)
#WandBlogger Object Creation
wandb_logger = WandBLogger(
project= "pytorch-ignite-integration" ,
name= "cnn-mnist" ,
config= {"max_epochs" : epochs,"batch_size" :train_batch_size},
tags= ["pytorch-ignite" , "mninst" ]
)
wandb_logger. attach_output_handler(
trainer,
event_name= Events. ITERATION_COMPLETED,
tag= "training" ,
output_transform= lambda loss: {"loss" : loss}
)
wandb_logger. attach_output_handler(
evaluator,
event_name= Events. EPOCH_COMPLETED,
tag= "training" ,
metric_names= ["nll" , "accuracy" ],
global_step_transform= lambda * _: trainer. state. iteration,
)
wandb_logger. attach_opt_params_handler(
trainer,
event_name= Events. ITERATION_STARTED,
optimizer= optimizer,
param_name= 'lr' # optional
)
wandb_logger. watch(model)
オプションで、ignite EVENTS を利用して、メトリクス を ターミナル に直接 ログ 記録できます。
@trainer.on (Events. ITERATION_COMPLETED(every= log_interval))
def log_training_loss (engine):
pbar. desc = desc. format(engine. state. output)
pbar. update(log_interval)
@trainer.on (Events. EPOCH_COMPLETED)
def log_training_results (engine):
pbar. refresh()
evaluator. run(train_loader)
metrics = evaluator. state. metrics
avg_accuracy = metrics['accuracy' ]
avg_nll = metrics['nll' ]
tqdm. write(
"Training Results - Epoch: {} Avg accuracy: {:.2f} Avg loss: {:.2f} "
. format(engine. state. epoch, avg_accuracy, avg_nll)
)
@trainer.on (Events. EPOCH_COMPLETED)
def log_validation_results (engine):
evaluator. run(val_loader)
metrics = evaluator. state. metrics
avg_accuracy = metrics['accuracy' ]
avg_nll = metrics['nll' ]
tqdm. write(
"Validation Results - Epoch: {} Avg accuracy: {:.2f} Avg loss: {:.2f} "
. format(engine. state. epoch, avg_accuracy, avg_nll))
pbar. n = pbar. last_print_n = 0
trainer. run(train_loader, max_epochs= epochs)
pbar. close()
if __name__ == "__main__" :
parser = ArgumentParser()
parser. add_argument('--batch_size' , type= int, default= 64 ,
help= 'input batch size for training (default: 64)' )
parser. add_argument('--val_batch_size' , type= int, default= 1000 ,
help= 'input batch size for validation (default: 1000)' )
parser. add_argument('--epochs' , type= int, default= 10 ,
help= 'number of epochs to train (default: 10)' )
parser. add_argument('--lr' , type= float, default= 0.01 ,
help= 'learning rate (default: 0.01)' )
parser. add_argument('--momentum' , type= float, default= 0.5 ,
help= 'SGD momentum (default: 0.5)' )
parser. add_argument('--log_interval' , type= int, default= 10 ,
help= 'how many batches to wait before logging training status' )
args = parser. parse_args()
run(args. batch_size, args. val_batch_size, args. epochs, args. lr, args. momentum, args. log_interval)
このコードは、これらの 可視化 を生成します。
詳細については、Ignite Docs を参照してください。
33 - PyTorch Lightning
PyTorch Lightning は、PyTorch のコードを整理し、分散トレーニングや 16 ビット精度などの高度な機能を簡単に追加できる軽量ラッパーを提供します。W&B は、ML 実験をログ記録するための軽量ラッパーを提供します。Weights & Biases は、WandbLogger
Lightning との統合
PyTorch Logger
Fabric Logger
from lightning.pytorch.loggers import WandbLogger
from lightning.pytorch import Trainer
wandb_logger = WandbLogger(log_model= "all" )
trainer = Trainer(logger= wandb_logger)
wandb.log() の使用: WandbLogger は、Trainer の global_step を使用して W&B にログを記録します。コード内で wandb.log を直接追加で呼び出す場合は、wandb.log() で step 引数を使用しないでください 。
代わりに、他のメトリクスと同様に、Trainer の global_step をログに記録します。
wandb. log({"accuracy" :0.99 , "trainer/global_step" : step})
import lightning as L
from wandb.integration.lightning.fabric import WandbLogger
wandb_logger = WandbLogger(log_model= "all" )
fabric = L. Fabric(loggers= [wandb_logger])
fabric. launch()
fabric. log_dict({"important_metric" : important_metric})
サインアップして APIキー を作成
APIキー は、W&B に対してマシンを認証します。APIキー は、ユーザープロフィールから生成できます。
右上隅にあるユーザープロフィールアイコンをクリックします。
ユーザー設定 を選択し、APIキー セクションまでスクロールします。表示 をクリックします。表示された APIキー をコピーします。APIキー を非表示にするには、ページをリロードします。
wandb ライブラリをインストールしてログインするローカルに wandb ライブラリをインストールしてログインするには:
コマンドライン
Python
Python notebook
WANDB_API_KEY 環境変数 を APIキー に設定します。
export WANDB_API_KEY= <your_api_key>
wandb ライブラリをインストールしてログインします。
pip install wandb
wandb login
import wandb
wandb. login()
!pip install wandb
import wandb
wandb.login()
PyTorch Lightning の WandbLogger を使用する
PyTorch Lightning には、メトリクスやモデルの重み、メディアなどをログに記録するための複数の WandbLogger クラスがあります。
Lightning と統合するには、WandbLogger をインスタンス化し、Lightning の Trainer または Fabric に渡します。
PyTorch Logger
Fabric Logger
trainer = Trainer(logger= wandb_logger)
fabric = L. Fabric(loggers= [wandb_logger])
fabric. launch()
fabric. log_dict({
"important_metric" : important_metric
})
一般的なロガーの引数
以下は、WandbLogger で最もよく使用されるパラメーターの一部です。すべてのロガー引数の詳細については、PyTorch Lightning のドキュメントを確認してください。
パラメータ
説明
projectログを記録する wandb Project を定義します。
namewandb run に名前を付けます。
log_modellog_model="all" の場合はすべてのモデルをログに記録し、log_model=True の場合はトレーニングの最後にログに記録します。
save_dirデータが保存されるパス
ハイパーパラメーター をログに記録する
PyTorch Logger
Fabric Logger
class LitModule (LightningModule):
def __init__(self, * args, ** kwarg):
self. save_hyperparameters()
wandb_logger. log_hyperparams(
{
"hyperparameter_1" : hyperparameter_1,
"hyperparameter_2" : hyperparameter_2,
}
)
追加の構成パラメーター をログに記録する
# パラメータ を 1 つ追加
wandb_logger. experiment. config["key" ] = value
# 複数の パラメータ を追加
wandb_logger. experiment. config. update({key1: val1, key2: val2})
# wandb モジュールを直接使用
wandb. config["key" ] = value
wandb. config. update()
勾配、 パラメータ のヒストグラム、およびモデルのトポロジをログに記録する
モデルオブジェクトを wandblogger.watch() に渡して、トレーニング中にモデルの勾配と パラメータ を監視できます。PyTorch Lightning WandbLogger ドキュメントを参照してください。
メトリクス をログに記録する
PyTorch Logger
Fabric Logger
WandbLogger を使用すると、LightningModule 内 (例: training_step メソッドまたは validation_step メソッド) で self.log('my_metric_name', metric_vale) を呼び出すことで、メトリクス を W&B にログ記録できます。
以下のコードスニペットは、メトリクス と LightningModule の ハイパーパラメーター をログ記録するように LightningModule を定義する方法を示しています。この例では、torchmetrics
import torch
from torch.nn import Linear, CrossEntropyLoss, functional as F
from torch.optim import Adam
from torchmetrics.functional import accuracy
from lightning.pytorch import LightningModule
class My_LitModule (LightningModule):
def __init__(self, n_classes= 10 , n_layer_1= 128 , n_layer_2= 256 , lr= 1e-3 ):
"""モデル パラメータ を定義するために使用されるメソッド"""
super(). __init__()
# mnist images are (1, 28, 28) (channels, width, height)
self. layer_1 = Linear(28 * 28 , n_layer_1)
self. layer_2 = Linear(n_layer_1, n_layer_2)
self. layer_3 = Linear(n_layer_2, n_classes)
self. loss = CrossEntropyLoss()
self. lr = lr
# ハイパー パラメータ を self.hparams に保存 (W&B によって自動的にログ記録)
self. save_hyperparameters()
def forward (self, x):
"""推論 input -> output に使用されるメソッド"""
# (b, 1, 28, 28) -> (b, 1*28*28)
batch_size, channels, width, height = x. size()
x = x. view(batch_size, - 1 )
# 3 x (linear + relu) を実行しましょう
x = F. relu(self. layer_1(x))
x = F. relu(self. layer_2(x))
x = self. layer_3(x)
return x
def training_step (self, batch, batch_idx):
"""単一のバッチから損失を返す必要があります"""
_, loss, acc = self. _get_preds_loss_accuracy(batch)
# 損失とメトリックをログに記録
self. log("train_loss" , loss)
self. log("train_accuracy" , acc)
return loss
def validation_step (self, batch, batch_idx):
"""メトリクス のログ記録に使用"""
preds, loss, acc = self. _get_preds_loss_accuracy(batch)
# 損失とメトリックをログに記録
self. log("val_loss" , loss)
self. log("val_accuracy" , acc)
return preds
def configure_optimizers (self):
"""モデル オプティマイザー を定義します"""
return Adam(self. parameters(), lr= self. lr)
def _get_preds_loss_accuracy (self, batch):
"""train/valid/test ステップが類似しているため、便利な関数"""
x, y = batch
logits = self(x)
preds = torch. argmax(logits, dim= 1 )
loss = self. loss(logits, y)
acc = accuracy(preds, y)
return preds, loss, acc
import lightning as L
import torch
import torchvision as tv
from wandb.integration.lightning.fabric import WandbLogger
import wandb
fabric = L. Fabric(loggers= [wandb_logger])
fabric. launch()
model = tv. models. resnet18()
optimizer = torch. optim. SGD(model. parameters(), lr= lr)
model, optimizer = fabric. setup(model, optimizer)
train_dataloader = fabric. setup_dataloaders(
torch. utils. data. DataLoader(train_dataset, batch_size= batch_size)
)
model. train()
for epoch in range(num_epochs):
for batch in train_dataloader:
optimizer. zero_grad()
loss = model(batch)
loss. backward()
optimizer. step()
fabric. log_dict({"loss" : loss})
メトリクス の最小値/最大値をログに記録する
wandb の define_metricdefine_metric _ が使用されていない場合、最後にログに記録された値がサマリーメトリックに表示されます。define_metric のリファレンスドキュメントはこちら 、ガイドはこちら をご覧ください。
W&B に W&B サマリーメトリックの最大検証精度を追跡するように指示するには、トレーニングの開始時に 1 回だけ wandb.define_metric を呼び出します。
PyTorch Logger
Fabric Logger
class My_LitModule (LightningModule):
...
def validation_step (self, batch, batch_idx):
if trainer. global_step == 0 :
wandb. define_metric("val_accuracy" , summary= "max" )
preds, loss, acc = self. _get_preds_loss_accuracy(batch)
# 損失とメトリックをログに記録
self. log("val_loss" , loss)
self. log("val_accuracy" , acc)
return preds
wandb. define_metric("val_accuracy" , summary= "max" )
fabric = L. Fabric(loggers= [wandb_logger])
fabric. launch()
fabric. log_dict({"val_accuracy" : val_accuracy})
モデル をチェックポイントする
モデル のチェックポイントを W&B Artifacts として保存するには、Lightning の ModelCheckpointWandbLogger で log_model 引数を設定します。
PyTorch Logger
Fabric Logger
trainer = Trainer(logger= wandb_logger, callbacks= [checkpoint_callback])
fabric = L. Fabric(loggers= [wandb_logger], callbacks= [checkpoint_callback])
latest および best エイリアスは、W&B Artifact からモデル のチェックポイントを簡単に取得できるように自動的に設定されます。
# 参照は Artifacts パネルで取得できます
# "VERSION" は、バージョン ("v2" など) またはエイリアス ("latest" または "best") にすることができます
checkpoint_reference = "USER/PROJECT/MODEL-RUN_ID:VERSION"
# チェックポイントをローカルにダウンロードします (まだキャッシュされていない場合)
wandb_logger. download_artifact(checkpoint_reference, artifact_type= "model" )
# チェックポイントをローカルにダウンロードします (まだキャッシュされていない場合)
run = wandb. init(project= "MNIST" )
artifact = run. use_artifact(checkpoint_reference, type= "model" )
artifact_dir = artifact. download()
PyTorch Logger
Fabric Logger
# チェックポイントを読み込む
model = LitModule. load_from_checkpoint(Path(artifact_dir) / "model.ckpt" )
# 未加工のチェックポイントを要求する
full_checkpoint = fabric. load(Path(artifact_dir) / "model.ckpt" )
model. load_state_dict(full_checkpoint["model" ])
optimizer. load_state_dict(full_checkpoint["optimizer" ])
ログに記録するモデル のチェックポイントは、W&B Artifacts UI で表示でき、完全なモデル リネージが含まれています (UI のサンプル モデル のチェックポイントをこちら で参照してください)。
最適なモデル のチェックポイントをブックマークし、チーム全体で一元化するには、W&B モデルレジストリ にリンクできます。
ここでは、タスクごとに最適なモデル を整理したり、モデル のライフサイクルを管理したり、ML ライフサイクル全体で簡単な追跡と監査を容易にしたり、Webhook またはジョブでダウンストリームアクションを自動化 したりできます。
画像、テキストなどをログに記録する
WandbLogger には、メディアをログ記録するための log_image、log_text、および log_table メソッドがあります。
また、wandb.log または trainer.logger.experiment.log を直接呼び出して、オーディオ、分子、点群、3D オブジェクトなどの他のメディアタイプをログに記録することもできます。
画像のログ記録
テキストのログ記録
テーブル のログ記録
# テンソル、numpy 配列、または PIL 画像を使用
wandb_logger. log_image(key= "samples" , images= [img1, img2])
# キャプションを追加
wandb_logger. log_image(key= "samples" , images= [img1, img2], caption= ["tree" , "person" ])
# ファイルパスを使用
wandb_logger. log_image(key= "samples" , images= ["img_1.jpg" , "img_2.jpg" ])
# trainer で .log を使用
trainer. logger. experiment. log(
{"samples" : [wandb. Image(img, caption= caption) for (img, caption) in my_images]},
step= current_trainer_global_step,
)
# データはリストのリストである必要があります
columns = ["input" , "label" , "prediction" ]
my_data = [["cheese" , "english" , "english" ], ["fromage" , "french" , "spanish" ]]
# 列とデータを使用
wandb_logger. log_text(key= "my_samples" , columns= columns, data= my_data)
# pandas DataFrame を使用
wandb_logger. log_text(key= "my_samples" , dataframe= my_dataframe)
# テキスト キャプション、画像、オーディオを含む W&B テーブル をログに記録
columns = ["caption" , "image" , "sound" ]
# データはリストのリストである必要があります
my_data = [
["cheese" , wandb. Image(img_1), wandb. Audio(snd_1)],
["wine" , wandb. Image(img_2), wandb. Audio(snd_2)],
]
# テーブル をログに記録
wandb_logger. log_table(key= "my_samples" , columns= columns, data= data)
Lightning のコールバックシステムを使用すると、この例では検証画像と予測のサンプルをログに記録します。WandbLogger 経由で Weights & Biases にログを記録するタイミングを制御できます。
import torch
import wandb
import lightning.pytorch as pl
from lightning.pytorch.loggers import WandbLogger
# or
# from wandb.integration.lightning.fabric import WandbLogger
class LogPredictionSamplesCallback (Callback):
def on_validation_batch_end (
self, trainer, pl_module, outputs, batch, batch_idx, dataloader_idx
):
"""検証バッチが終了したときに呼び出されます。"""
# `outputs` は `LightningModule.validation_step` から取得されます
# これは、この場合のモデル予測に対応します
# 最初のバッチから 20 個のサンプル画像予測をログに記録しましょう
if batch_idx == 0 :
n = 20
x, y = batch
images = [img for img in x[:n]]
captions = [
f "Ground Truth: { y_i} - Prediction: { y_pred} "
for y_i, y_pred in zip(y[:n], outputs[:n])
]
# オプション 1: `WandbLogger.log_image` で画像をログに記録する
wandb_logger. log_image(key= "sample_images" , images= images, caption= captions)
# オプション 2: 画像と予測を W&B テーブル としてログに記録する
columns = ["image" , "ground truth" , "prediction" ]
data = [
[wandb. Image(x_i), y_i, y_pred] or x_i,
y_i,
y_pred in list(zip(x[:n], y[:n], outputs[:n])),
]
wandb_logger. log_table(key= "sample_table" , columns= columns, data= data)
trainer = pl. Trainer(callbacks= [LogPredictionSamplesCallback()])
Lightning と W&B で複数の GPU を使用する
PyTorch Lightning には、DDP インターフェイスによるマルチ GPU サポートがあります。ただし、PyTorch Lightning の設計では、GPU のインスタンス化方法に注意する必要があります。
Lightning は、トレーニングループの各 GPU (またはランク) が、まったく同じ方法 (同じ初期条件) でインスタンス化される必要があると想定しています。ただし、ランク 0 プロセスのみが wandb.run オブジェクトにアクセスでき、ゼロ以外のランク プロセスの場合: wandb.run = None。これにより、ゼロ以外のプロセスが失敗する可能性があります。このような状況は、ランク 0 プロセスがゼロ以外のランク プロセスが参加するのを待機するため、デッドロック 状態になる可能性があります。
このため、トレーニングコードのセットアップ方法には注意してください。トレーニングコードを wandb.run オブジェクトから独立させることをお勧めします。
class MNISTClassifier (pl. LightningModule):
def __init__(self):
super(MNISTClassifier, self). __init__()
self. model = nn. Sequential(
nn. Flatten(),
nn. Linear(28 * 28 , 128 ),
nn. ReLU(),
nn. Linear(128 , 10 ),
)
self. loss = nn. CrossEntropyLoss()
def forward (self, x):
return self. model(x)
def training_step (self, batch, batch_idx):
x, y = batch
y_hat = self. forward(x)
loss = self. loss(y_hat, y)
self. log("train/loss" , loss)
return {"train_loss" : loss}
def validation_step (self, batch, batch_idx):
x, y = batch
y_hat = self. forward(x)
loss = self. loss(y_hat, y)
self. log("val/loss" , loss)
return {"val_loss" : loss}
def configure_optimizers (self):
return torch. optim. Adam(self. parameters(), lr= 0.001 )
def main ():
# すべての乱数シードを同じ値に設定します。
# これは、分散トレーニング環境では重要です。
# 各ランクは、独自の初期重みセットを取得します。
# 一致しない場合、勾配も一致しません。
# 収束しない可能性のあるトレーニングにつながります。
pl. seed_everything(1 )
train_loader = DataLoader(train_dataset, batch_size= 64 , shuffle= True , num_workers= 4 )
val_loader = DataLoader(val_dataset, batch_size= 64 , shuffle= False , num_workers= 4 )
model = MNISTClassifier()
wandb_logger = WandbLogger(project= "<project_name>" )
callbacks = [
ModelCheckpoint(
dirpath= "checkpoints" ,
every_n_train_steps= 100 ,
),
]
trainer = pl. Trainer(
max_epochs= 3 , gpus= 2 , logger= wandb_logger, strategy= "ddp" , callbacks= callbacks
)
trainer. fit(model, train_loader, val_loader)
例
Colab のビデオチュートリアルをこちら でフォローできます。
よくある質問
W&B は Lightning とどのように統合されますか?
コア統合は、Lightning loggers API に基づいており、フレームワークに依存しない方法で多くのログ記録コードを記述できます。Logger は、Lightning Trainer に渡され、その API の豊富なフックアンドコールバックシステム に基づいてトリガーされます。これにより、研究コードがエンジニアリングコードおよびログ記録コードから適切に分離されます。
追加のコードなしで統合は何をログに記録しますか?
モデル のチェックポイントを W&B に保存します。そこで表示したり、ダウンロードして将来の run で使用したりできます。システムメトリクス (GPU 使用率やネットワーク I/O など)、ハードウェアや OS 情報などの環境情報、コード の状態 (git コミットと差分パッチ、ノートブック の内容、セッション履歴を含む)、および標準出力に出力されるものをキャプチャします。
トレーニングのセットアップで wandb.run を使用する必要がある場合はどうすればよいですか?
アクセスする必要がある変数のスコープを自分で拡張する必要があります。つまり、初期条件がすべてのプロセスで同じであることを確認してください。
if os. environ. get("LOCAL_RANK" , None ) is None :
os. environ["WANDB_DIR" ] = wandb. run. dir
そうである場合は、os.environ["WANDB_DIR"] を使用してモデル のチェックポイントディレクトリーを設定できます。これにより、ゼロ以外のランクプロセスは wandb.run.dir にアクセスできます。
34 - Ray Tune
W&B と Ray Tune を統合する方法。
W&B は、2 つの軽量な インテグレーション を提供することで、Ray と統合します。
WandbLoggerCallback 関数は、 Tune に報告された メトリクス を Wandb API に自動的に ログ します。関数 API で使用できる setup_wandb() 関数は、 Tune の トレーニング 情報で Wandb API を自動的に初期化します。通常どおり Wandb API を使用できます。たとえば、wandb.log() を使用して、 トレーニング プロセスを ログ します。
インテグレーション の 設定
from ray.air.integrations.wandb import WandbLoggerCallback
Wandb の 設定 は、tune.run() の config パラメータに wandb の キー を渡すことによって行われます (以下の例を参照)。
wandb config エントリ の内容は、 キーワード 引数として wandb.init() に渡されます。例外として、次の 設定 は WandbLoggerCallback 自体を 設定 するために使用されます。
パラメータ
project (str): Wandb の プロジェクト 名。必須。
api_key_file (str): Wandb APIキー を含むファイルへのパス。
api_key (str): Wandb APIキー 。api_key_file を 設定 する代替手段。
excludes (list): ログ から除外する メトリクス のリスト。
log_config (bool): results ディクショナリ の config パラメータ を ログ するかどうか。デフォルトは False。
upload_checkpoints (bool): True の場合、 モデル の チェックポイント は Artifacts としてアップロードされます。デフォルトは False。
例
from ray import tune, train
from ray.air.integrations.wandb import WandbLoggerCallback
def train_fc (config):
for i in range(10 ):
train. report({"mean_accuracy" : (i + config["alpha" ]) / 10 })
tuner = tune. Tuner(
train_fc,
param_space= {
"alpha" : tune. grid_search([0.1 , 0.2 , 0.3 ]),
"beta" : tune. uniform(0.5 , 1.0 ),
},
run_config= train. RunConfig(
callbacks= [
WandbLoggerCallback(
project= "<your-project>" , api_key= "<your-api-key>" , log_config= True
)
]
),
)
results = tuner. fit()
setup_wandb
from ray.air.integrations.wandb import setup_wandb
このユーティリティ関数は、Ray Tune で使用するために Wandb を初期化するのに役立ちます。基本的な使用法では、 トレーニング 関数で setup_wandb() を呼び出します。
from ray.air.integrations.wandb import setup_wandb
def train_fn (config):
# Initialize wandb
wandb = setup_wandb(config)
for i in range(10 ):
loss = config["a" ] + config["b" ]
wandb. log({"loss" : loss})
tune. report(loss= loss)
tuner = tune. Tuner(
train_fn,
param_space= {
# define search space here
"a" : tune. choice([1 , 2 , 3 ]),
"b" : tune. choice([4 , 5 , 6 ]),
# wandb configuration
"wandb" : {"project" : "Optimization_Project" , "api_key_file" : "/path/to/file" },
},
)
results = tuner. fit()
コード例
インテグレーション の動作を確認するための例をいくつか作成しました。
35 - SageMaker
W&B と Amazon SageMaker の統合方法について。
W&B は Amazon SageMaker と連携し、ハイパーパラメータの自動読み取り、分散 run のグループ化、チェックポイントからの run の再開を自動で行います。
認証
W&B は、トレーニングスクリプトを基準とした secrets.env という名前のファイルを探し、wandb.init() が呼び出されると、それらを環境にロードします。secrets.env ファイルは、実験の launch に使用するスクリプトで wandb.sagemaker_auth(path="source_dir") を呼び出すことによって生成できます。このファイルを必ず .gitignore に追加してください!
既存のエスティメーター
SageMaker の事前構成済みエスティメーターのいずれかを使用している場合は、wandb を含む requirements.txt をソースディレクトリーに追加する必要があります。
Python 2 を実行しているエスティメーターを使用している場合は、wandb をインストールする前に、この wheel から直接 psutil をインストールする必要があります。
https://wheels.galaxyproject.org/packages/psutil-5.4.8-cp27-cp27mu-manylinux1_x86_64.whl
wandb
完全な例は GitHub で確認し、詳細については blog を参照してください。
SageMaker と W&B を使用したセンチメント分析アナライザーのデプロイに関する チュートリアル もお読みいただけます。
W&B の sweep agent は、SageMaker インテグレーションが無効になっている場合にのみ、SageMaker ジョブで期待どおりに動作します。wandb.init の呼び出しを変更して、SageMaker インテグレーションをオフにします。
wandb. init(... , settings= wandb. Settings(sagemaker_disable= True ))
36 - Scikit-Learn
数行のコードで、scikit-learn モデルのパフォーマンスを可視化して比較するために wandb を使用できます。サンプルを試す →
はじめに
サインアップして APIキー を作成する
APIキー は、W&B に対してお客様のマシンを認証します。APIキー は、ユーザー プロファイルから生成できます。
右上隅にあるユーザー プロファイル アイコンをクリックします。
User Settings を選択し、API Keys セクションまでスクロールします。Reveal をクリックします。表示された APIキー をコピーします。APIキー を非表示にするには、ページをリロードします。
wandb ライブラリをインストールしてログインするローカルに wandb ライブラリをインストールしてログインするには:
コマンドライン
Python
Python notebook
APIキー に WANDB_API_KEY 環境変数 を設定します。
export WANDB_API_KEY= <your_api_key>
wandb ライブラリをインストールしてログインします。
pip install wandb
wandb login
import wandb
wandb. login()
!pip install wandb
import wandb
wandb.login()
メトリクス をログする
import wandb
wandb. init(project= "visualize-sklearn" )
y_pred = clf. predict(X_test)
accuracy = sklearn. metrics. accuracy_score(y_true, y_pred)
# If logging metrics over time, then use wandb.log
# 時間経過とともにメトリクスをログする場合は、wandb.log を使用します
wandb. log({"accuracy" : accuracy})
# OR to log a final metric at the end of training you can also use wandb.summary
# または、トレーニングの最後に最終メトリクスをログするには、wandb.summary を使用することもできます
wandb. summary["accuracy" ] = accuracy
プロットを作成する
ステップ 1: wandb をインポートし、新しい run を初期化します
import wandb
wandb. init(project= "visualize-sklearn" )
ステップ 2: プロットを可視化します
個々のプロット
モデル をトレーニングして 予測 を行った後、wandb でプロットを生成して 予測 を分析できます。サポートされているチャートの完全なリストについては、以下の サポートされているプロット セクションを参照してください。
# Visualize single plot
# 単一のプロットを可視化します
wandb. sklearn. plot_confusion_matrix(y_true, y_pred, labels)
すべてのプロット
W&B には、いくつかの関連するプロットをプロットする plot_classifier などの関数があります。
# Visualize all classifier plots
# すべての分類器プロットを可視化します
wandb. sklearn. plot_classifier(
clf,
X_train,
X_test,
y_train,
y_test,
y_pred,
y_probas,
labels,
model_name= "SVC" ,
feature_names= None ,
)
# All regression plots
# すべての回帰プロット
wandb. sklearn. plot_regressor(reg, X_train, X_test, y_train, y_test, model_name= "Ridge" )
# All clustering plots
# すべてのクラスタリングプロット
wandb. sklearn. plot_clusterer(
kmeans, X_train, cluster_labels, labels= None , model_name= "KMeans"
)
既存の Matplotlib プロット
Matplotlib で作成されたプロットも W&B ダッシュボードにログできます。そのためには、最初に plotly をインストールする必要があります。
最後に、プロットは次のように W&B のダッシュボードにログできます。
import matplotlib.pyplot as plt
import wandb
wandb. init(project= "visualize-sklearn" )
# do all the plt.plot(), plt.scatter(), etc. here.
# ここに plt.plot(), plt.scatter() などをすべて記述します。
# ...
# instead of doing plt.show() do:
# plt.show() を実行する代わりに、次を実行します。
wandb. log({"plot" : plt})
サポートされているプロット
学習曲線
さまざまな長さの データセット でモデル をトレーニングし、トレーニング セットと テストセット の両方について、クロス検証されたスコアと データセット サイズのプロットを生成します。
wandb.sklearn.plot_learning_curve(model, X, y)
model (clf または reg): 適合された回帰子または分類器を受け入れます。
X (arr): データセット の特徴。
y (arr): データセット のラベル。
ROC
ROC 曲線は、真陽性率 (y 軸) 対 偽陽性率 (x 軸) をプロットします。理想的なスコアは TPR = 1 および FPR = 0 であり、これは左上の点です。通常、ROC 曲線下面積 (AUC-ROC) を計算し、AUC-ROC が大きいほど優れています。
wandb.sklearn.plot_roc(y_true, y_probas, labels)
y_true (arr): テストセット のラベル。
y_probas (arr): テストセット の 予測 確率。
labels (list): ターゲット変数 (y) の名前付きラベル。
クラスの割合
トレーニング セットと テストセット のターゲット クラスの分布をプロットします。不均衡なクラスを検出し、1 つのクラスが モデル に不均衡な影響を与えないようにするのに役立ちます。
wandb.sklearn.plot_class_proportions(y_train, y_test, ['dog', 'cat', 'owl'])
y_train (arr): トレーニング セットのラベル。
y_test (arr): テストセット のラベル。
labels (list): ターゲット変数 (y) の名前付きラベル。
適合率 - 再現率曲線
さまざまなしきい値に対する 適合率 と 再現率 の間のトレードオフを計算します。曲線下面積が大きいほど、高い 再現率 と高い 適合率 の両方を表し、高い 適合率 は低い 偽陽性率 に関連し、高い 再現率 は低い 偽陰性率 に関連します。
両方の高いスコアは、分類器が正確な 結果 を返している (高い 適合率 ) だけでなく、すべての陽性の 結果 の大部分を返している (高い 再現率 ) ことを示しています。PR 曲線は、クラスが非常に不均衡な場合に役立ちます。
wandb.sklearn.plot_precision_recall(y_true, y_probas, labels)
y_true (arr): テストセット のラベル。
y_probas (arr): テストセット の 予測 確率。
labels (list): ターゲット変数 (y) の名前付きラベル。
特徴の重要度
分類タスクにおける各特徴の重要度を評価およびプロットします。feature_importances_ 属性を持つ分類器 ( ツリー など) でのみ機能します。
wandb.sklearn.plot_feature_importances(model, ['width', 'height, 'length'])
model (clf): 適合された分類器を受け入れます。
feature_names (list): 特徴の名前。特徴インデックスを対応する名前に置き換えることで、プロットを読みやすくします。
較正曲線
分類器の 予測 確率がどの程度較正されているか、および較正されていない分類器を較正する方法をプロットします。ベースラインのロジスティック回帰 モデル 、 引数 として渡された モデル 、およびその等方性較正とシグモイド較正の両方によって推定された 予測 確率を比較します。
較正曲線が対角線に近いほど優れています。転置されたシグモイドのような曲線は 過学習された 分類器を表し、シグモイドのような曲線は 学習不足 の分類器を表します。モデル の等方性較正とシグモイド較正をトレーニングし、それらの曲線を比較することで、モデル が 過学習 または 学習不足 であるかどうか、またそうである場合、どの較正 (シグモイドまたは等方性) がこれを修正するのに役立つかを把握できます。
詳細については、sklearn のドキュメント を参照してください。
wandb.sklearn.plot_calibration_curve(clf, X, y, 'RandomForestClassifier')
model (clf): 適合された分類器を受け入れます。
X (arr): トレーニング セットの特徴。
y (arr): トレーニング セットのラベル。
model_name (str): モデル 名。デフォルトは ‘Classifier’
混同行列
混同行列を計算して、分類の精度を評価します。モデル の 予測 の品質を評価し、モデル が間違える 予測 のパターンを見つけるのに役立ちます。対角線は、実際のラベルが 予測 されたラベルと等しい場合など、モデル が正しく取得した 予測 を表します。
wandb.sklearn.plot_confusion_matrix(y_true, y_pred, labels)
y_true (arr): テストセット のラベル。
y_pred (arr): テストセット の 予測 されたラベル。
labels (list): ターゲット変数 (y) の名前付きラベル。
サマリーメトリクス
mse、mae、r2 スコアなど、分類のサマリー メトリクス を計算します。f1、精度、 適合率 、 再現率 など、回帰のサマリー メトリクス を計算します。
wandb.sklearn.plot_summary_metrics(model, X_train, y_train, X_test, y_test)
model (clf または reg): 適合された回帰子または分類器を受け入れます。
X (arr): トレーニング セットの特徴。
y (arr): トレーニング セットのラベル。
X_test (arr): テストセット の特徴。
y_test (arr): テストセット のラベル。
エルボープロット
トレーニング時間とともに、クラスター の数に応じて説明される分散の割合を測定およびプロットします。最適な クラスター の数を選択するのに役立ちます。
wandb.sklearn.plot_elbow_curve(model, X_train)
model (clusterer): 適合されたクラスタラーを受け入れます。
X (arr): トレーニング セットの特徴。
シルエットプロット
1 つの クラスター 内の各点が隣接する クラスター 内の点にどれだけ近いかを測定してプロットします。クラスター の太さは、 クラスター サイズに対応します。垂直線は、すべての点の平均シルエットスコアを表します。
+1 に近いシルエット係数は、サンプルが隣接する クラスター から遠く離れていることを示します。0 の値は、サンプルが 2 つの隣接する クラスター 間の決定境界上または非常に近いことを示し、負の値は、それらのサンプルが間違った クラスター に割り当てられた可能性があることを示します。
一般に、すべてのシルエット クラスター スコアが平均以上 (赤い線を超えている) であり、できるだけ 1 に近いことが望ましいです。また、 データ 内の基礎となるパターンを反映する クラスター サイズも推奨されます。
wandb.sklearn.plot_silhouette(model, X_train, ['spam', 'not spam'])
model (clusterer): 適合されたクラスタラーを受け入れます。
X (arr): トレーニング セットの特徴。
cluster_labels (list): クラスター ラベルの名前。クラスター インデックスを対応する名前に置き換えることで、プロットを読みやすくします。
外れ値候補プロット
Cook の距離を介して回帰 モデル に対する データポイント の影響を測定します。大きく歪んだ影響を持つインスタンスは、潜在的に外れ値である可能性があります。外れ値の検出に役立ちます。
wandb.sklearn.plot_outlier_candidates(model, X, y)
model (regressor): 適合された分類器を受け入れます。
X (arr): トレーニング セットの特徴。
y (arr): トレーニング セットのラベル。
残差プロット
予測 されたターゲット値 (y 軸) と実際のターゲット値と 予測 されたターゲット値の差 (x 軸) を測定してプロットし、残差誤差の分布を測定してプロットします。
一般に、適切に適合された モデル の残差はランダムに分布している必要があります。これは、優れた モデル はランダム誤差を除く データセット 内のほとんどの現象を考慮するためです。
wandb.sklearn.plot_residuals(model, X, y)
例
37 - Simple Transformers
Hugging Face の Transformers ライブラリ と W&B を統合する方法。
このライブラリは、Hugging Face の Transformers ライブラリをベースにしています。Simple Transformers を使用すると、Transformer モデルを迅速にトレーニングおよび評価できます。モデルの初期化、モデルのトレーニング、モデルの評価に必要なコードはわずか 3 行です。Sequence Classification(シーケンス分類)、Token Classification(トークン分類、固有表現認識)、Question Answering(質問応答)、Language Model Fine-Tuning(言語モデルのファインチューニング)、Language Model Training(言語モデルのトレーニング)、Language Generation(言語生成)、T5 モデル、Seq2Seq Tasks(Seq2Seq タスク)、Multi-Modal Classification(マルチモーダル分類)、Conversational AI(会話型 AI)をサポートしています。
モデルトレーニングを可視化するために Weights and Biases を使用するには、args 辞書の wandb_project 属性に W&B のプロジェクト名を設定します。これにより、すべてのハイパーパラメーター 値、トレーニング損失、評価メトリクスが指定されたプロジェクトに記録されます。
model = ClassificationModel('roberta' , 'roberta-base' , args= {'wandb_project' : 'project-name' })
wandb.init に渡される追加の 引数 は、wandb_kwargs として渡すことができます。
構造
このライブラリは、すべての NLP タスクに個別のクラスを持つように設計されています。同様の機能を提供するクラスはグループ化されています。
simpletransformers.classification - すべての Classification(分類)モデルが含まれます。
ClassificationModelMultiLabelClassificationModel
simpletransformers.ner - すべての Named Entity Recognition(固有表現認識)モデルが含まれます。
simpletransformers.question_answering - すべての Question Answering(質問応答)モデルが含まれます。
以下に最小限の例をいくつか示します。
MultiLabel Classification(マルチラベル分類)
model = MultiLabelClassificationModel("distilbert","distilbert-base-uncased",num_labels=6,
args={"reprocess_input_data": True, "overwrite_output_dir": True, "num_train_epochs":epochs,'learning_rate':learning_rate,
'wandb_project': "simpletransformers"},
)
# モデルをトレーニング
model.train_model(train_df)
# モデルを評価
result, model_outputs, wrong_predictions = model.eval_model(eval_df)
Question Answering(質問応答)
train_args = {
'learning_rate': wandb.config.learning_rate,
'num_train_epochs': 2,
'max_seq_length': 128,
'doc_stride': 64,
'overwrite_output_dir': True,
'reprocess_input_data': False,
'train_batch_size': 2,
'fp16': False,
'wandb_project': "simpletransformers"
}
model = QuestionAnsweringModel('distilbert', 'distilbert-base-cased', args=train_args)
model.train_model(train_data)
SimpleTransformers は、一般的な自然言語タスクのためのクラスとトレーニング スクリプトを提供します。以下は、このライブラリでサポートされているグローバル 引数 の完全なリストと、そのデフォルトの 引数 です。
global_args = {
"adam_epsilon": 1e-8,
"best_model_dir": "outputs/best_model",
"cache_dir": "cache_dir/",
"config": {},
"do_lower_case": False,
"early_stopping_consider_epochs": False,
"early_stopping_delta": 0,
"early_stopping_metric": "eval_loss",
"early_stopping_metric_minimize": True,
"early_stopping_patience": 3,
"encoding": None,
"eval_batch_size": 8,
"evaluate_during_training": False,
"evaluate_during_training_silent": True,
"evaluate_during_training_steps": 2000,
"evaluate_during_training_verbose": False,
"fp16": True,
"fp16_opt_level": "O1",
"gradient_accumulation_steps": 1,
"learning_rate": 4e-5,
"local_rank": -1,
"logging_steps": 50,
"manual_seed": None,
"max_grad_norm": 1.0,
"max_seq_length": 128,
"multiprocessing_chunksize": 500,
"n_gpu": 1,
"no_cache": False,
"no_save": False,
"num_train_epochs": 1,
"output_dir": "outputs/",
"overwrite_output_dir": False,
"process_count": cpu_count() - 2 if cpu_count() > 2 else 1,
"reprocess_input_data": True,
"save_best_model": True,
"save_eval_checkpoints": True,
"save_model_every_epoch": True,
"save_steps": 2000,
"save_optimizer_and_scheduler": True,
"silent": False,
"tensorboard_dir": None,
"train_batch_size": 8,
"use_cached_eval_features": False,
"use_early_stopping": False,
"use_multiprocessing": True,
"wandb_kwargs": {},
"wandb_project": None,
"warmup_ratio": 0.06,
"warmup_steps": 0,
"weight_decay": 0,
}
詳細なドキュメントについては、github の simpletransformers を参照してください。
最も人気のある GLUE ベンチマーク データセットで transformers のトレーニングをカバーするこちらの Weights and Biases report を確認してください。colab で自分で試してみてください 。
38 - Skorch
Skorch と W&B を統合する方法。
Skorch で Weights & Biases を使用すると、各エポック後に、すべてのモデルパフォーマンスメトリクス、モデルトポロジ、およびコンピューティングリソースとともに、最高のパフォーマンスを持つモデルを自動的にログ記録できます。 wandb_run.dir に保存されたすべてのファイルは、W&B サーバーに自動的にログ記録されます。
run の例 を参照してください。
パラメータ
パラメータ
タイプ
説明
wandb_runwandb.wandb_run. Runデータのログ記録に使用される wandb run。
save_modelbool (default=True)
最適なモデルのチェックポイントを保存し、W&B サーバー上の Run にアップロードするかどうか。
keys_ignoredstr または str のリスト (default=None)
tensorboard にログ記録しないキーまたはキーのリスト。 ユーザーが提供するキーに加えて、event_ で始まるキーや _best で終わるキーはデフォルトで無視されることに注意してください。
コード例
このインテグレーションの動作を確認するための例をいくつか作成しました。
# wandb をインストール
... pip install wandb
import wandb
from skorch.callbacks import WandbLogger
# wandb Run を作成
wandb_run = wandb. init()
# 代替案: W&B アカウントなしで wandb Run を作成
wandb_run = wandb. init(anonymous= "allow" )
# ハイパーパラメータをログ記録 (オプション)
wandb_run. config. update({"learning rate" : 1e-3 , "batch size" : 32 })
net = NeuralNet(... , callbacks= [WandbLogger(wandb_run)])
net. fit(X, y)
メソッドリファレンス
メソッド
説明
initialize()コールバックの初期状態を(再)設定します。
on_batch_begin(net[, X, y, training])各バッチの開始時に呼び出されます。
on_batch_end(net[, X, y, training])各バッチの終了時に呼び出されます。
on_epoch_begin(net[, dataset_train, …])各エポックの開始時に呼び出されます。
on_epoch_end(net, **kwargs)最後の履歴ステップから値をログ記録し、最適なモデルを保存します。
on_grad_computed(net, named_parameters[, X, …])勾配が計算された後、更新ステップが実行される前に、バッチごとに 1 回呼び出されます。
on_train_begin(net, **kwargs)モデルトポロジをログ記録し、勾配の hook を追加します。
on_train_end(net[, X, y])トレーニングの終了時に呼び出されます。
39 - spaCy
spaCy は、人気のある「産業用強度」の NLP ライブラリであり、高速かつ正確なモデルを最小限の手間で実現します。spaCy v3 以降、Weights & Biases を spacy train
サインアップして APIキー を作成する
APIキー は、お使いのマシンを W&B に対して認証します。APIキー は、ユーザープロフィール から生成できます。
右上隅にあるユーザープロフィールアイコンをクリックします。
ユーザー設定 を選択し、APIキー セクションまでスクロールします。公開 をクリックします。表示された APIキー をコピーします。APIキー を非表示にするには、ページをリロードしてください。
wandb ライブラリをインストールしてログインするローカルに wandb ライブラリをインストールしてログインするには:
コマンドライン
Python
Python notebook
WANDB_API_KEY 環境変数 を APIキー に設定します。
export WANDB_API_KEY= <your_api_key>
wandb ライブラリをインストールしてログインします。
pip install wandb
wandb login
import wandb
wandb. login()
!pip install wandb
import wandb
wandb.login()
WandbLogger を spaCy 設定ファイルに追加するspaCy の設定ファイルは、ロギングだけでなく、トレーニングのあらゆる側面(GPU 割り当て、オプティマイザー の選択、データセット のパスなど)を指定するために使用されます。最小限の構成として、[training.logger] の下に、キー @loggers に値 "spacy.WandbLogger.v3" と project_name を指定する必要があります。
spaCy のトレーニング設定ファイルの仕組みと、トレーニングをカスタマイズするために渡すことができるその他のオプションの詳細については、
spaCy のドキュメント を参照してください。
[training. logger]
@loggers = "spacy.WandbLogger.v3"
project_name = "my_spacy_project"
remove_config_values = ["paths.train" , "paths.dev" , "corpora.train.path" , "corpora.dev.path" ]
log_dataset_dir = "./corpus"
model_log_interval = 1000
Name
Description
project_namestr 。W&B の Project の名前。まだ存在しない場合、Project は自動的に作成されます。
remove_config_valuesList[str] 。W&B にアップロードする前に、設定から除外する値のリスト。デフォルトは [] です。
model_log_intervalOptional int。デフォルトは None。設定すると、モデルのバージョン管理 が Artifacts で有効になります。モデルのチェックポイントのロギング間隔までのステップ数を渡します。デフォルトは None です。
log_dataset_dirOptional str。パスを渡すと、トレーニングの開始時にデータセット が Artifacts としてアップロードされます。デフォルトは None です。
entityOptional str 。渡された場合、run は指定された entity に作成されます
run_nameOptional str 。指定された場合、run は指定された名前で作成されます。
トレーニングを開始する
WandbLogger を spaCy トレーニング設定に追加したら、通常どおり spacy train を実行できます。
コマンドライン
Python
Python notebook
python - m spacy train \
config. cfg \
-- output ./ output \
-- paths. train ./ train \
-- paths. dev ./ dev
python - m spacy train \
config. cfg \
-- output ./ output \
-- paths. train ./ train \
-- paths. dev ./ dev
!python -m spacy train \
config.cfg \
--output ./output \
--paths.train ./train \
--paths.dev ./dev
トレーニングが開始されると、トレーニング run の W&B ページ へのリンクが出力されます。このリンクをクリックすると、Weights & Biases Web UI で、この run の 実験管理 ダッシュボード に移動します。
40 - Stable Baselines 3
Stable Baseline 3 と W&B を統合する方法。
Stable Baselines 3 (SB3) は、PyTorch で記述された強化学習アルゴリズムの信頼性の高い実装のセットです。W&B の SB3 インテグレーション:
損失やエピソードリターンなどのメトリクスを記録します。
エージェントがゲームをプレイする動画をアップロードします。
トレーニング済みのモデルを保存します。
モデルのハイパーパラメーターをログに記録します。
モデルの勾配ヒストグラムをログに記録します。
W&B を使用した SB3 のトレーニング run の 例 を確認してください。
SB3 の 実験管理
from wandb.integration.sb3 import WandbCallback
model. learn(... , callback= WandbCallback())
WandbCallback の引数
引数
使い方
verbosesb3 出力の詳細度
model_save_pathモデルが保存されるフォルダーへのパス。デフォルト値は `None` なので、モデルはログに記録されません。
model_save_freqモデルを保存する頻度
gradient_save_freq勾配をログに記録する頻度。デフォルト値は 0 なので、勾配はログに記録されません。
基本的な例
W&B SB3 インテグレーションは、TensorBoard からのログ出力を使用してメトリクスを記録します。
import gym
from stable_baselines3 import PPO
from stable_baselines3.common.monitor import Monitor
from stable_baselines3.common.vec_env import DummyVecEnv, VecVideoRecorder
import wandb
from wandb.integration.sb3 import WandbCallback
config = {
"policy_type" : "MlpPolicy" ,
"total_timesteps" : 25000 ,
"env_name" : "CartPole-v1" ,
}
run = wandb. init(
project= "sb3" ,
config= config,
sync_tensorboard= True , # sb3 の tensorboard メトリクスを自動アップロード
monitor_gym= True , # エージェントがゲームをプレイする動画を自動アップロード
save_code= True , # オプション
)
def make_env ():
env = gym. make(config["env_name" ])
env = Monitor(env) # リターンなどの統計を記録
return env
env = DummyVecEnv([make_env])
env = VecVideoRecorder(
env,
f "videos/ { run. id} " ,
record_video_trigger= lambda x: x % 2000 == 0 ,
video_length= 200 ,
)
model = PPO(config["policy_type" ], env, verbose= 1 , tensorboard_log= f "runs/ { run. id} " )
model. learn(
total_timesteps= config["total_timesteps" ],
callback= WandbCallback(
gradient_save_freq= 100 ,
model_save_path= f "models/ { run. id} " ,
verbose= 2 ,
),
)
run. finish()
41 - TensorBoard
W&B は、W&B マルチテナント SaaS 用の埋め込み TensorBoard をサポートしています。
TensorBoard の ログ を クラウド にアップロードし、同僚やクラスメートとすばやく 結果 を共有して、 分析 を一元的な場所に保管できます。
はじめに
import wandb
# `sync_tensorboard=True` で wandb の run を開始します。
wandb. init(project= "my-project" , sync_tensorboard= True )
# TensorBoard を使用したトレーニングコード
...
# [オプション] W&B に TensorBoard の ログ をアップロードするために、wandb の run を終了します ( Colabノートブック で実行している場合)。
wandb. finish()
例 を確認してください。
run が完了すると、W&B で TensorBoard イベントファイルに アクセス し、ネイティブの W&B チャートで メトリクス を視覚化できます。さらに、システムの CPU や GPU の使用率、git の状態、run が使用した ターミナル コマンドなど、役立つ追加情報も表示できます。
W&B は、すべての TensorFlow バージョンで TensorBoard をサポートしています。W&B は、PyTorch および TensorBoardX を使用した TensorBoard 1.14 以降もサポートしています。
よくある質問
TensorBoard に ログ 記録されない メトリクス を W&B に ログ 記録するにはどうすればよいですか?
TensorBoard に ログ 記録されていない追加のカスタム メトリクス を ログ 記録する必要がある場合は、コードで wandb.log を呼び出すことができます。wandb.log({"custom": 0.8})
Tensorboard を同期すると、wandb.log の step 引数 の設定はオフになります。別の step カウントを設定する場合は、step メトリクス とともに メトリクス を ログ 記録できます。
wandb.log({"custom": 0.8, "global_step": global_step})
wandb で TensorBoard を使用している場合、TensorBoard をどのように構成しますか?TensorBoard の パッチ 適用方法をより詳細に制御する場合は、wandb.init に sync_tensorboard=True を渡す代わりに、wandb.tensorboard.patch を呼び出すことができます。
import wandb
wandb. tensorboard. patch(root_logdir= "<logging_directory>" )
wandb. init()
# W&B に TensorBoard の ログ をアップロードするために、wandb の run を終了します ( Colabノートブック で実行している場合)。
wandb. finish()
TensorBoard > 1.14 を PyTorch で使用している場合は、バニラ TensorBoard に パッチ が適用されていることを確認するために tensorboard_x=False をこの メソッド に渡し、 パッチ が適用されていることを確認するために pytorch=True を渡すことができます。これらのオプションには両方とも、これらのライブラリのどの バージョン がインポートされたかに応じて、スマートなデフォルトがあります。
デフォルトでは、tfevents ファイルと .pbtxt ファイルも同期します。これにより、お客様に代わって TensorBoard インスタンスを ローンンチ することができます。run ページに TensorBoard タブ が表示されます。この 振る舞い は、save=False を wandb.tensorboard.patch に渡すことでオフにできます。
import wandb
wandb. init()
wandb. tensorboard. patch(save= False , tensorboard_x= True )
# Colabノートブック で実行している場合は、wandb の run を終了して、TensorBoard の ログ を W&B にアップロードします。
wandb. finish()
tf.summary.create_file_writer を呼び出すか、torch.utils.tensorboard を介して SummaryWriter を構築する 前に 、wandb.init または wandb.tensorboard.patch のいずれかを呼び出す必要があります。
履歴 TensorBoard の run を同期するにはどうすればよいですか?
既存の tfevents ファイルがローカルに保存されていて、それらを W&B にインポートする場合は、wandb sync log_dir を実行します。ここで、log_dir は tfevents ファイルを含むローカル ディレクトリー です。
Google Colab または Jupyter を TensorBoard で使用するにはどうすればよいですか?
Jupyter または Colabノートブック でコードを実行している場合は、トレーニングの最後に wandb.finish() を呼び出すようにしてください。これにより、wandb の run が終了し、TensorBoard の ログ が W&B にアップロードされて視覚化できるようになります。wandb は スクリプト の完了時に自動的に完了するため、.py スクリプト を実行する場合はこれは必要ありません。
ノートブック 環境で シェル コマンド を実行するには、!wandb sync directoryname のように ! を先頭に付ける必要があります。
PyTorch を TensorBoard で使用するにはどうすればよいですか?
PyTorch の TensorBoard インテグレーション を使用する場合は、PyTorch Profiler JSON ファイルを手動でアップロードする必要がある場合があります。
wandb. save(glob. glob(f "runs/*.pt.trace.json" )[0 ], base_path= f "runs" )
42 - TensorFlow
はじめに
TensorBoard をすでに使用している場合、wandb との連携は簡単です。
import tensorflow as tf
import wandb
wandb. init(config= tf. flags. FLAGS, sync_tensorboard= True )
カスタム メトリクスのログ
TensorBoard に記録されていない追加のカスタム メトリクスを記録する必要がある場合は、コード内で wandb.log を呼び出すことができます。wandb.log({"custom": 0.8})
Tensorboard を同期すると、wandb.log の step 引数の設定はオフになります。別のステップ数を設定する場合は、次のようにステップ メトリクスを使用してメトリクスを記録できます。
wandb. log({"custom" : 0.8 , "global_step" :global_step}, step= global_step)
TensorFlow estimators hook
ログに記録する内容をより詳細に制御したい場合は、wandb は TensorFlow estimators 用の hook も提供します。グラフ内のすべての tf.summary の値を記録します。
import tensorflow as tf
import wandb
wandb. init(config= tf. FLAGS)
estimator. train(hooks= [wandb. tensorflow. WandbHook(steps_per_log= 1000 )])
手動でのログ
TensorFlow でメトリクスをログに記録する最も簡単な方法は、TensorFlow ロガーで tf.summary をログに記録することです。
import wandb
with tf. Session() as sess:
# ...
wandb. tensorflow. log(tf. summary. merge_all())
TensorFlow 2 では、カスタム ループでモデルをトレーニングするための推奨される方法は、tf.GradientTape を使用することです。詳細については、こちら をご覧ください。wandb を組み込んでカスタム TensorFlow トレーニング ループでメトリクスをログに記録する場合は、次のスニペットに従ってください。
with tf. GradientTape() as tape:
# Get the probabilities
predictions = model(features)
# Calculate the loss
loss = loss_func(labels, predictions)
# Log your metrics
wandb. log("loss" : loss. numpy())
# Get the gradients
gradients = tape. gradient(loss, model. trainable_variables)
# Update the weights
optimizer. apply_gradients(zip(gradients, model. trainable_variables))
完全な例はこちら にあります。
W&B と TensorBoard の違いは何ですか?
共同創設者が W&B の開発を開始したとき、OpenAI の不満を抱えた TensorBoard ユーザーのためにツールを構築することに触発されました。改善に重点を置いている点をいくつかご紹介します。
モデルの再現 : Weights & Biases は、実験 、探索、および後でモデルを再現するのに適しています。メトリクスだけでなく、ハイパーパラメーターとコードのバージョンもキャプチャし、プロジェクトを再現できるように、バージョン管理ステータスとモデルのチェックポイントを保存できます。自動編成 : コラボレーターからプロジェクトを引き継ぐ場合でも、休暇から戻ってきた場合でも、古いプロジェクトを整理する場合でも、W&B を使用すると、試行されたすべてのモデルを簡単に確認できるため、誰も時間、 GPU サイクル、またはカーボンを無駄に実験を再実行することはありません。高速で柔軟なインテグレーション : W&B を 5 分でプロジェクトに追加します。無料のオープンソース Python パッケージをインストールし、コードに数行追加するだけで、モデルを実行するたびに、適切なログに記録されたメトリクスとレコードが得られます。永続的で集中化されたダッシュボード : ローカル マシン、共有ラボ クラスター、クラウドのスポット インスタンスなど、モデルをどこでトレーニングする場合でも、結果は同じ集中化されたダッシュボードに共有されます。さまざまなマシンから TensorBoard ファイルをコピーして整理する時間を費やす必要はありません。強力な テーブル : さまざまなモデルの結果を検索、フィルタリング、ソート、およびグループ化します。数千のモデル バージョンを確認し、さまざまなタスクに最適なモデルを簡単に見つけることができます。TensorBoard は、大規模なプロジェクトでうまく機能するように構築されていません。コラボレーション ツール : W&B を使用して、複雑な 機械学習 プロジェクトを整理します。W&B へのリンクを簡単に共有でき、プライベート Teams を使用して、全員が結果を共有プロジェクトに送信できます。Reports を介したコラボレーションもサポートしています。インタラクティブな 可視化を追加し、markdown で作業内容を記述します。これは、作業ログを保持し、上司と学びを共有したり、ラボや Teams に学びを提示したりするのに最適な方法です。
無料アカウント を始めましょう
例
インテグレーションの仕組みを示すために、いくつかの例を作成しました。
43 - W&B for Julia
W&B を Julia と統合する方法。
Julia プログラミング言語で機械学習 の 実験 を実行している方のために、コミュニティの貢献者の方が、wandb.jl と呼ばれる Julia バインディングの非公式セットを作成しました。
wandb.jl リポジトリのドキュメント に例があります。以下は「はじめに」の例です。
using Wandb, Dates, Logging
# Start a new run, tracking hyperparameters in config
lg = WandbLogger(project = "Wandb.jl" ,
name = "wandbjl-demo- $ (now())" ,
config = Dict ("learning_rate" => 0.01 ,
"dropout" => 0.2 ,
"architecture" => "CNN" , # アーキテクチャー
"dataset" => "CIFAR-100" )) # データセット
# Use LoggingExtras.jl to log to multiple loggers together
global_logger(lg)
# Simulating the training or evaluation loop
for x ∈ 1 : 50
acc = log(1 + x + rand() * get_config(lg, "learning_rate" ) + rand() + get_config(lg, "dropout" ))
loss = 10 - log(1 + x + rand() + x * get_config(lg, "learning_rate" ) + rand() + get_config(lg, "dropout" ))
# Log metrics from your script to W&B
@info "metrics" accuracy= acc loss= loss
end
# Finish the run
close(lg)
44 - XGBoost
W&B で ツリー を追跡します。
wandb ライブラリには、XGBoost でのトレーニングからメトリクス、config、および保存されたブースターを記録するための WandbCallback コールバックがあります。ここでは、XGBoost WandbCallback からの出力を含む、ライブの Weights & Biases ダッシュボード
始め方
XGBoost のメトリクス、config、およびブースターモデルを Weights & Biases に記録するには、WandbCallback を XGBoost に渡すだけです。
from wandb.integration.xgboost import WandbCallback
import xgboost as XGBClassifier
...
# Start a wandb run
run = wandb. init()
# Pass WandbCallback to the model
bst = XGBClassifier()
bst. fit(X_train, y_train, callbacks= [WandbCallback(log_model= True )])
# Close your wandb run
run. finish()
XGBoost と Weights & Biases でのロギングの詳細については、この notebook
WandbCallback リファレンス機能
WandbCallback を XGBoost モデルに渡すと、次のようになります。
ブースターモデルの構成を Weights & Biases に記録します。
XGBoost によって収集された評価 メトリクス (rmse、accuracy など) を Weights & Biases に記録します。
XGBoost によって収集されたトレーニング メトリクス (eval_set にデータを提供する場合) を記録します。
最高のスコアと最高のイテレーションを記録します。
トレーニング済みのモデルを保存して Weights & Biases Artifacts にアップロードします (log_model = True の場合)。
log_feature_importance=True (デフォルト) の場合、特徴量のインポータンスプロットを記録します。define_metric=True (デフォルト) の場合、wandb.summary で最適な評価 メトリクスをキャプチャします。
引数
log_model: (boolean) True の場合、モデルを保存して Weights & Biases Artifacts にアップロードします。
log_feature_importance: (boolean) True の場合、特徴量のインポータンス棒グラフを記録します。
importance_type: (str) ツリー モデルの場合は {weight, gain, cover, total_gain, total_cover} のいずれか。線形モデルの場合は weight。
define_metric: (boolean) True (デフォルト) の場合、wandb.summary でトレーニングの最後のステップではなく、最適なステップでのモデルのパフォーマンスをキャプチャします。
WandbCallback のソース コード を確認できます。
その他の例については、GitHub の examples リポジトリ を確認してください。
Sweeps でハイパーパラメータを チューニングする
モデルのパフォーマンスを最大限に引き出すには、ツリーの深さや学習率などのハイパーパラメータを チューニングする必要があります。Weights & Biases には、大規模なハイパーパラメータ テスト実験を構成、調整、および分析するための強力な ツールキットである Sweeps が含まれています。
この XGBoost & Sweeps Python スクリプト を試すこともできます。
45 - YOLOv5
Ultralytics’ YOLOv5 (「You Only Look Once」) モデルファミリーは、苦痛を伴うことなく、畳み込みニューラルネットワークによるリアルタイムの オブジェクト検出を可能にします。
Weights & Biases は YOLOv5 に直接統合されており、実験の メトリクス 追跡、モデルと データセット の バージョン管理 、豊富なモデル 予測 の 可視化 などを提供します。YOLO の 実験 を実行する前に、pip install を 1 回実行するだけで簡単に利用できます。
W&B のすべての ログ 機能は、
PyTorch DDP などの データ並列マルチ GPU トレーニングと互換性があります。
コアな 実験 を追跡する
wandb をインストールするだけで、組み込みの W&B ログ 機能 が有効になります。システム メトリクス 、モデル メトリクス 、および インタラクティブな ダッシュボード に ログ されるメディアです。
pip install wandb
git clone https:// github. com/ ultralytics/ yolov5. git
python yolov5/ train. py # 小さなデータセットで小さなネットワークをトレーニングします。
wandb によって標準出力に出力されたリンクをたどってください。
インテグレーション をカスタマイズする
いくつかの簡単な コマンドライン 引数 を YOLO に渡すことで、さらに多くの W&B 機能を活用できます。
--save_period に数値を渡すと、W&B は save_period エポック の終了ごとに モデル バージョン を保存します。モデル バージョン には、モデルの 重み が含まれており、 検証セット で最高のパフォーマンスを発揮するモデルにタグを付けます。--upload_dataset フラグをオンにすると、 データ バージョン管理 のために データセット もアップロードされます。--bbox_interval に数値を渡すと、データ可視化 が有効になります。bbox_interval エポック の終了ごとに、 検証セット 上のモデルの出力が W&B にアップロードされます。
モデルの バージョン管理 のみ
モデルの バージョン管理 と データ可視化
python yolov5/ train. py -- epochs 20 -- save_period 1
python yolov5/ train. py -- epochs 20 -- save_period 1 \
-- upload_dataset -- bbox_interval 1
すべての W&B アカウントには、 データセット と モデル 用に 100 GB の無料ストレージが付属しています。
このようになります。
データ と モデル の バージョン管理 により、セットアップなしで、一時停止またはクラッシュした 実験 を任意のデバイスから再開できます。詳細については、
Colab をご覧ください。
46 - Ultralytics
Ultralytics は、画像分類、オブジェクト検出、画像セグメンテーション、姿勢推定などのタスクのための、最先端のコンピュータビジョン モデルの本拠地です。リアルタイムオブジェクト検出モデルの YOLO シリーズの最新版である YOLOv8 をホストするだけでなく、SAM (Segment Anything Model) 、RT-DETR 、YOLO-NAS などの他の強力なコンピュータビジョン モデルもホストしています。これらのモデルの実装を提供するだけでなく、Ultralytics は、使いやすい API を使用してこれらのモデルをトレーニング、ファインチューン、および適用するための、すぐに使える ワークフローも提供します。
始めましょう
ultralytics と wandb をインストールします。
```shell
pip install --upgrade ultralytics==8.0.238 wandb
# or
# conda install ultralytics
```
```bash
!pip install --upgrade ultralytics==8.0.238 wandb
```
開発チームは、ultralyticsv8.0.238 以下のバージョンとの インテグレーションをテストしました。インテグレーションに関する問題点を報告するには、yolov8 タグを付けて GitHub issue を作成してください。
実験管理の追跡と検証結果の可視化
このセクションでは、トレーニング、ファインチューン、および検証に Ultralytics モデルを使用し、W&B を使用して実験管理の追跡、モデルのチェックポイント、およびモデルのパフォーマンスの可視化を実行する典型的なワークフローを示します。
この レポートで インテグレーションについて確認することもできます。W&B で Ultralytics を強化する
Ultralytics で W&B インテグレーションを使用するには、wandb.integration.ultralytics.add_wandb_callback 関数をインポートします。
import wandb
from wandb.integration.ultralytics import add_wandb_callback
from ultralytics import YOLO
選択した YOLO モデルを初期化し、モデルで推論を実行する前に、そのモデルで add_wandb_callback 関数を呼び出します。これにより、トレーニング、ファインチューン、検証、または推論を実行すると、実験 ログと画像が自動的に保存され、W&B 上の コンピュータビジョン タスクのインタラクティブなオーバーレイ を使用して、グラウンドトゥルースとそれぞれの予測結果が重ねられ、追加の洞察が wandb.Table
# Initialize YOLO Model
model = YOLO("yolov8n.pt" )
# Add W&B callback for Ultralytics
add_wandb_callback(model, enable_model_checkpointing= True )
# Train/fine-tune your model
# At the end of each epoch, predictions on validation batches are logged
# to a W&B table with insightful and interactive overlays for
# computer vision tasks
model. train(project= "ultralytics" , data= "coco128.yaml" , epochs= 5 , imgsz= 640 )
# Finish the W&B run
wandb. finish()
Ultralytics のトレーニングまたはファインチューン ワークフローのために W&B を使用して追跡された実験は、次のようになります。
YOLO Fine-tuning Experiments W&B Table を使用して、エポックごとの検証結果を可視化する方法を次に示します。
WandB Validation Visualization Table 予測結果の可視化
このセクションでは、推論に Ultralytics モデルを使用し、W&B を使用して結果を可視化する典型的なワークフローを示します。
Google Colab でコードを試すことができます:Open in Colab 。
この レポートで インテグレーションについて確認することもできます。W&B で Ultralytics を強化する
Ultralytics で W&B インテグレーションを使用するには、wandb.integration.ultralytics.add_wandb_callback 関数をインポートする必要があります。
import wandb
from wandb.integration.ultralytics import add_wandb_callback
from ultralytics.engine.model import YOLO
インテグレーションをテストするために、いくつかの画像をダウンロードします。静止画像、ビデオ、またはカメラ ソースを使用できます。推論ソースの詳細については、Ultralytics のドキュメント を確認してください。
!wget https://raw.githubusercontent.com/wandb/examples/ultralytics/colabs/ultralytics/assets/img1.png
!wget https://raw.githubusercontent.com/wandb/examples/ultralytics/colabs/ultralytics/assets/img2.png
!wget https://raw.githubusercontent.com/wandb/examples/ultralytics/colabs/ultralytics/assets/img4.png
!wget https://raw.githubusercontent.com/wandb/examples/ultralytics/colabs/ultralytics/assets/img5.png
次に、wandb.init を使用して W&B run を初期化します。
# Initialize W&B run
wandb. init(project= "ultralytics" , job_type= "inference" )
次に、目的の YOLO モデルを初期化し、モデルで推論を実行する前に、そのモデルで add_wandb_callback 関数を呼び出します。これにより、推論を実行すると、コンピュータビジョン タスクのインタラクティブなオーバーレイ でオーバーレイされた画像が自動的にログに記録され、追加の洞察が wandb.Table
# Initialize YOLO Model
model = YOLO("yolov8n.pt" )
# Add W&B callback for Ultralytics
add_wandb_callback(model, enable_model_checkpointing= True )
# Perform prediction which automatically logs to a W&B Table
# with interactive overlays for bounding boxes, segmentation masks
model(
[
"./assets/img1.jpeg" ,
"./assets/img3.png" ,
"./assets/img4.jpeg" ,
"./assets/img5.jpeg" ,
]
)
# Finish the W&B run
wandb. finish()
トレーニングまたはファインチューン ワークフローの場合、wandb.init() を使用して run を明示的に初期化する必要はありません。ただし、コードに予測のみが含まれる場合は、run を明示的に作成する必要があります。
インタラクティブな bbox オーバーレイは次のようになります。
WandB Image Overlay W&B 画像オーバーレイの詳細については、こちら を参照してください。
その他のリソース
47 - YOLOX
W&B と YOLOX を統合する方法。
YOLOX は、 オブジェクト検出において強力なパフォーマンスを発揮する、アンカーフリー版の YOLO です。 YOLOX W&B インテグレーションを使用すると、トレーニング、検証、およびシステムに関連する メトリクス の ログ 記録をオンにすることができ、単一の コマンドライン 引数で 予測 をインタラクティブに検証できます。
サインアップして APIキー を作成する
APIキー は、W&B へのあなたの マシン を認証します。APIキー は、 ユーザー プロフィールから生成できます。
右上隅にある ユーザー プロフィール アイコンをクリックします。
[User Settings ](ユーザー 設定 )を選択し、[API Keys ](APIキー )セクションまでスクロールします。
[Reveal ](表示)をクリックします。表示された APIキー をコピーします。APIキー を非表示にするには、ページをリロードします。
wandb ライブラリをインストールしてログインするwandb ライブラリをローカルにインストールしてログインするには:
コマンドライン
Python
Python notebook
WANDB_API_KEY 環境変数 をあなたの APIキー に設定します。
export WANDB_API_KEY= <your_api_key>
wandb ライブラリをインストールしてログインします。
pip install wandb
wandb login
import wandb
wandb. login()
!pip install wandb
import wandb
wandb.login()
メトリクス を ログ 記録する
--logger wandb コマンドライン 引数を使用して、wandb での ログ 記録をオンにします。オプションで、wandb.initwandb- を付けます。
num_eval_imges は、 モデル の評価のために W&B の テーブル に ログ 記録される 検証セット の画像と 予測 の数を制御します。
# wandb にログイン
wandb login
# `wandb` ロガー 引数 を使用して yolox トレーニング スクリプトを呼び出す
python tools/train.py .... --logger wandb \
\
wandb-name <run-name> \
\
\
\
例
YOLOX のトレーニング および 検証 メトリクス を使用した ダッシュボード の例 ->
この W&B インテグレーション に関する質問や問題がありますか?YOLOX repository で issue をオープンしてください。