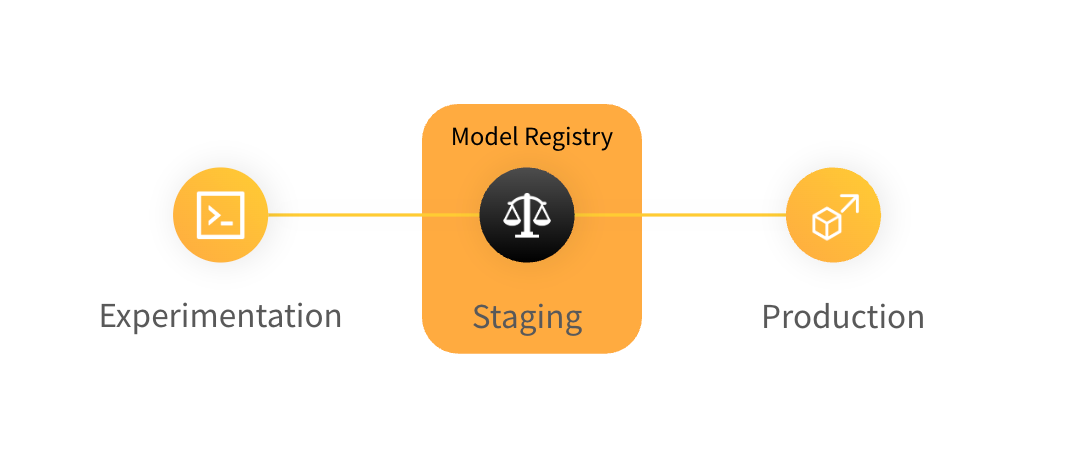
Model registry
モデルレジストリを使用して、トレーニングからプロダクションまでのモデルのライフサイクルを管理します。
W&B は最終的に W&B Model Registry のサポートを停止します。 ユーザー は、代わりにモデルアーティファクトの バージョン をリンクおよび共有するために、W&B Registry を使用することをお勧めします。 W&B Registry は、従来の W&B Model Registry の機能を拡張します。 W&B Registry の詳細については、Registry のドキュメント を参照してください。
W&B は、従来の Model Registry にリンクされている既存のモデルアーティファクトを、近い将来、新しい W&B Registry に移行します。 移行 プロセス の詳細については、従来の Model Registry からの移行 を参照してください。
W&B Model Registry には、 ML 実践者がプロダクション 用の候補を公開し、ダウンストリーム の チーム や関係者が利用できる、 チーム がトレーニング したモデルが格納されています。 これは、ステージング されたモデル/候補モデルを格納し、ステージング に関連する ワークフロー を管理するために使用されます。
W&B Model Registry では、次のことが可能です。
仕組み
いくつかの簡単なステップで、ステージング されたモデルを追跡および管理します。
- モデル バージョン を ログ に記録する: トレーニング スクリプト で、数行の コード を追加して、モデルファイルを Artifacts として W&B に保存します。
- パフォーマンス を比較する: ライブ チャート をチェックして、モデル トレーニング と検証からの メトリクス とサンプル 予測 を比較します。 どのモデル バージョン が最も優れた パフォーマンス を発揮したかを特定します。
- Registry にリンクする: Python でプログラムで、または W&B UI でインタラクティブに、登録されたモデルにリンクして、最適なモデル バージョン をブックマークします。
次の コード スニペット は、モデルを ログ に記録して Model Registry にリンクする方法を示しています。
import wandb
import random
# Start a new W&B run
run = wandb.init(project="models_quickstart")
# Simulate logging model metrics
run.log({"acc": random.random()})
# Create a simulated model file
with open("my_model.h5", "w") as f:
f.write("Model: " + str(random.random()))
# Log and link the model to the Model Registry
run.link_model(path="./my_model.h5", registered_model_name="MNIST")
run.finish()
- モデルの移行を CI/CD ワークフロー に接続する: 候補モデルを ワークフロー ステージを介して移行し、Webhooks で ダウンストリーム アクション を自動化 します。
開始方法
ユースケース に応じて、次の リソース を調べて W&B Models の使用を開始してください。
- 2 部構成のビデオ シリーズをご覧ください。
- モデルの ログ 記録と登録
- Model Registry での モデルの消費とダウンストリーム プロセス の自動化。
- W&B Python SDK コマンド のステップごとの概要については、モデルのウォークスルー を読んで、データセット Artifacts の作成、追跡、および使用に使用できます。
- 以下について学びます。
- Model Registry が ML ワークフロー にどのように適合し、モデル管理にそれを使用する利点については、こちら の レポート を確認してください。
- W&B Enterprise Model Management コース を受講して、以下を学びます。
- W&B Model Registry を使用して、モデルの管理と バージョン 管理、 リネージ の追跡、およびさまざまなライフサイクル ステージでのモデルのプロモーションを行います。
- Webhooks を使用して、モデル管理 ワークフロー を自動化します。
- Model Registry が、モデルの 評価、モニタリング 、および デプロイメント のためのモデル開発ライフサイクルにおいて、外部 ML システム および ツール とどのように統合されるかを確認します。
1 - Tutorial: Use W&B for model management
W&B を使用して Model Management を行う方法について説明します。
以下のチュートリアルでは、モデルを W&B に記録する方法を紹介します。このチュートリアルを終えるまでに、以下のことができるようになります。
- MNIST データセットと Keras フレームワークを使用してモデルを作成し、トレーニングする。
- トレーニングしたモデルを W&B の project に記録する
- 使用したデータセットを作成したモデルへの依存関係としてマークする
- モデルを W&B モデルレジストリにリンクする。
- レジストリにリンクするモデルのパフォーマンスを評価する
- モデルの version を production 用としてマークする。
- このガイドに記載されている順序で コード スニペットをコピーしてください。
- モデルレジストリに固有ではないコードは、折りたたみ可能なセルに隠されています。
セットアップ
始める前に、このチュートリアルに必要な Python の依存関係をインポートします。
import wandb
import numpy as np
from tensorflow import keras
from tensorflow.keras import layers
from wandb.integration.keras import WandbMetricsLogger
from sklearn.model_selection import train_test_split
W&B の entity を entity 変数に指定します。
データセット Artifact を作成する
まず、データセットを作成します。次の コード スニペットは、MNIST データセットをダウンロードする関数を作成します。
def generate_raw_data(train_size=6000):
eval_size = int(train_size / 6)
(x_train, y_train), (x_eval, y_eval) = keras.datasets.mnist.load_data()
x_train = x_train.astype("float32") / 255
x_eval = x_eval.astype("float32") / 255
x_train = np.expand_dims(x_train, -1)
x_eval = np.expand_dims(x_eval, -1)
print("Generated {} rows of training data.".format(train_size))
print("Generated {} rows of eval data.".format(eval_size))
return (x_train[:train_size], y_train[:train_size]), (
x_eval[:eval_size],
y_eval[:eval_size],
)
# データセットを作成します
(x_train, y_train), (x_eval, y_eval) = generate_raw_data()
次に、データセットを W&B にアップロードします。これを行うには、アーティファクト オブジェクトを作成し、そのアーティファクトにデータセットを追加します。
project = "model-registry-dev"
model_use_case_id = "mnist"
job_type = "build_dataset"
# W&B の run を初期化します
run = wandb.init(entity=entity, project=project, job_type=job_type)
# トレーニングデータ用の W&B テーブルを作成します
train_table = wandb.Table(data=[], columns=[])
train_table.add_column("x_train", x_train)
train_table.add_column("y_train", y_train)
train_table.add_computed_columns(lambda ndx, row: {"img": wandb.Image(row["x_train"])})
# 評価データ用の W&B テーブルを作成します
eval_table = wandb.Table(data=[], columns=[])
eval_table.add_column("x_eval", x_eval)
eval_table.add_column("y_eval", y_eval)
eval_table.add_computed_columns(lambda ndx, row: {"img": wandb.Image(row["x_eval"])})
# Artifact オブジェクトを作成します
artifact_name = "{}_dataset".format(model_use_case_id)
artifact = wandb.Artifact(name=artifact_name, type="dataset")
# wandb.WBValue オブジェクトを Artifact に追加します。
artifact.add(train_table, "train_table")
artifact.add(eval_table, "eval_table")
# Artifact に加えられた変更を永続化します。
artifact.save()
# W&B にこの run が完了したことを伝えます。
run.finish()
データセットなどのファイルを Artifact に保存すると、モデルの依存関係を追跡できるため、モデルのログを記録する際に役立ちます。
モデルをトレーニングする
前のステップで作成した Artifact データセットを使用してモデルをトレーニングします。
データセット Artifact を run への入力として宣言する
前のステップで作成したデータセット Artifact を W&B の run への入力として宣言します。Artifact を run への入力として宣言すると、特定のモデルのトレーニングに使用されたデータセット (およびデータセットの version) を追跡できるため、モデルのログを記録する際に特に役立ちます。W&B は、収集された情報を使用して、リネージマップ を作成します。
use_artifact API を使用して、データセット Artifact を run の入力として宣言し、Artifact 自体を取得します。
job_type = "train_model"
config = {
"optimizer": "adam",
"batch_size": 128,
"epochs": 5,
"validation_split": 0.1,
}
# W&B の run を初期化します
run = wandb.init(project=project, job_type=job_type, config=config)
# データセット Artifact を取得します
version = "latest"
name = "{}:{}".format("{}_dataset".format(model_use_case_id), version)
artifact = run.use_artifact(artifact_or_name=name)
# データフレームから特定の内容を取得します
train_table = artifact.get("train_table")
x_train = train_table.get_column("x_train", convert_to="numpy")
y_train = train_table.get_column("y_train", convert_to="numpy")
モデルの入力と出力を追跡する方法の詳細については、モデルリネージ マップの作成を参照してください。
モデルを定義してトレーニングする
このチュートリアルでは、Keras を使用して MNIST データセットから画像を分類する 2D Convolutional Neural Network (CNN) を定義します。
MNIST データで CNN をトレーニングする
# 設定ディクショナリの値を簡単にアクセスできるように変数に格納します
num_classes = 10
input_shape = (28, 28, 1)
loss = "categorical_crossentropy"
optimizer = run.config["optimizer"]
metrics = ["accuracy"]
batch_size = run.config["batch_size"]
epochs = run.config["epochs"]
validation_split = run.config["validation_split"]
# モデルアーキテクチャを作成します
model = keras.Sequential(
[
layers.Input(shape=input_shape),
layers.Conv2D(32, kernel_size=(3, 3), activation="relu"),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Conv2D(64, kernel_size=(3, 3), activation="relu"),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Flatten(),
layers.Dropout(0.5),
layers.Dense(num_classes, activation="softmax"),
]
)
model.compile(loss=loss, optimizer=optimizer, metrics=metrics)
# トレーニングデータのラベルを生成します
y_train = keras.utils.to_categorical(y_train, num_classes)
# トレーニングセットとテストセットを作成します
x_t, x_v, y_t, y_v = train_test_split(x_train, y_train, test_size=0.33)
次に、モデルをトレーニングします。
# モデルをトレーニングします
model.fit(
x=x_t,
y=y_t,
batch_size=batch_size,
epochs=epochs,
validation_data=(x_v, y_v),
callbacks=[WandbCallback(log_weights=True, log_evaluation=True)],
)
最後に、モデルをローカルマシンに保存します。
# モデルをローカルに保存します
path = "model.h5"
model.save(path)
モデルをログに記録してモデルレジストリにリンクする
link_model API を使用して、モデルの 1 つ以上のファイルを W&B の run に記録し、W&B モデルレジストリ にリンクします。
path = "./model.h5"
registered_model_name = "MNIST-dev"
run.link_model(path=path, registered_model_name=registered_model_name)
run.finish()
registered-model-name に指定した名前がまだ存在しない場合、W&B は登録済みモデルを作成します。
オプションのパラメータの詳細については、API リファレンスガイドのlink_model を参照してください。
モデルのパフォーマンスを評価する
1 つ以上のモデルのパフォーマンスを評価するのは一般的な方法です。
まず、前のステップで W&B に保存された評価データセット Artifact を取得します。
job_type = "evaluate_model"
# run を初期化します
run = wandb.init(project=project, entity=entity, job_type=job_type)
model_use_case_id = "mnist"
version = "latest"
# データセット Artifact を取得し、依存関係としてマークします
artifact = run.use_artifact(
"{}:{}".format("{}_dataset".format(model_use_case_id), version)
)
# 目的のデータフレームを取得します
eval_table = artifact.get("eval_table")
x_eval = eval_table.get_column("x_eval", convert_to="numpy")
y_eval = eval_table.get_column("y_eval", convert_to="numpy")
評価する W&B から モデル version をダウンロードします。use_model API を使用して、モデルにアクセスしてダウンロードします。
alias = "latest" # エイリアス
name = "mnist_model" # モデル Artifact の名前
# モデルにアクセスしてダウンロードします。ダウンロードした Artifact へのパスを返します
downloaded_model_path = run.use_model(name=f"{name}:{alias}")
Keras モデルをロードし、損失を計算します。
model = keras.models.load_model(downloaded_model_path)
y_eval = keras.utils.to_categorical(y_eval, 10)
(loss, _) = model.evaluate(x_eval, y_eval)
score = (loss, _)
最後に、損失メトリクスを W&B の run に記録します。
# # メトリクス、画像、テーブル、または評価に役立つデータを記録します。
run.log(data={"loss": (loss, _)})
モデル version を昇格させる
モデル エイリアス を使用して、機械学習 ワークフローの次の段階に向けてモデル version を準備完了としてマークします。各登録済みモデルには、1 つ以上のモデル エイリアスを設定できます。モデル エイリアスは、一度に 1 つのモデル version にのみ属することができます。
たとえば、モデルのパフォーマンスを評価した後、そのモデルが production の準備ができていると確信したとします。そのモデル version を昇格させるには、production エイリアスをその特定のモデル version に追加します。
production エイリアスは、モデルを production 準備完了としてマークするために使用される最も一般的なエイリアスの 1 つです。
W&B アプリ UI を使用してインタラクティブに、または Python SDK を使用してプログラムで、モデル version にエイリアスを追加できます。次の手順では、W&B モデルレジストリアプリでエイリアスを追加する方法を示します。
- https://wandb.ai/registry/model でモデルレジストリアプリに移動します。
- 登録済みモデルの名前の横にある [詳細を表示] をクリックします。
- [バージョン] セクション内で、昇格させるモデル version の名前の横にある [表示] ボタンをクリックします。
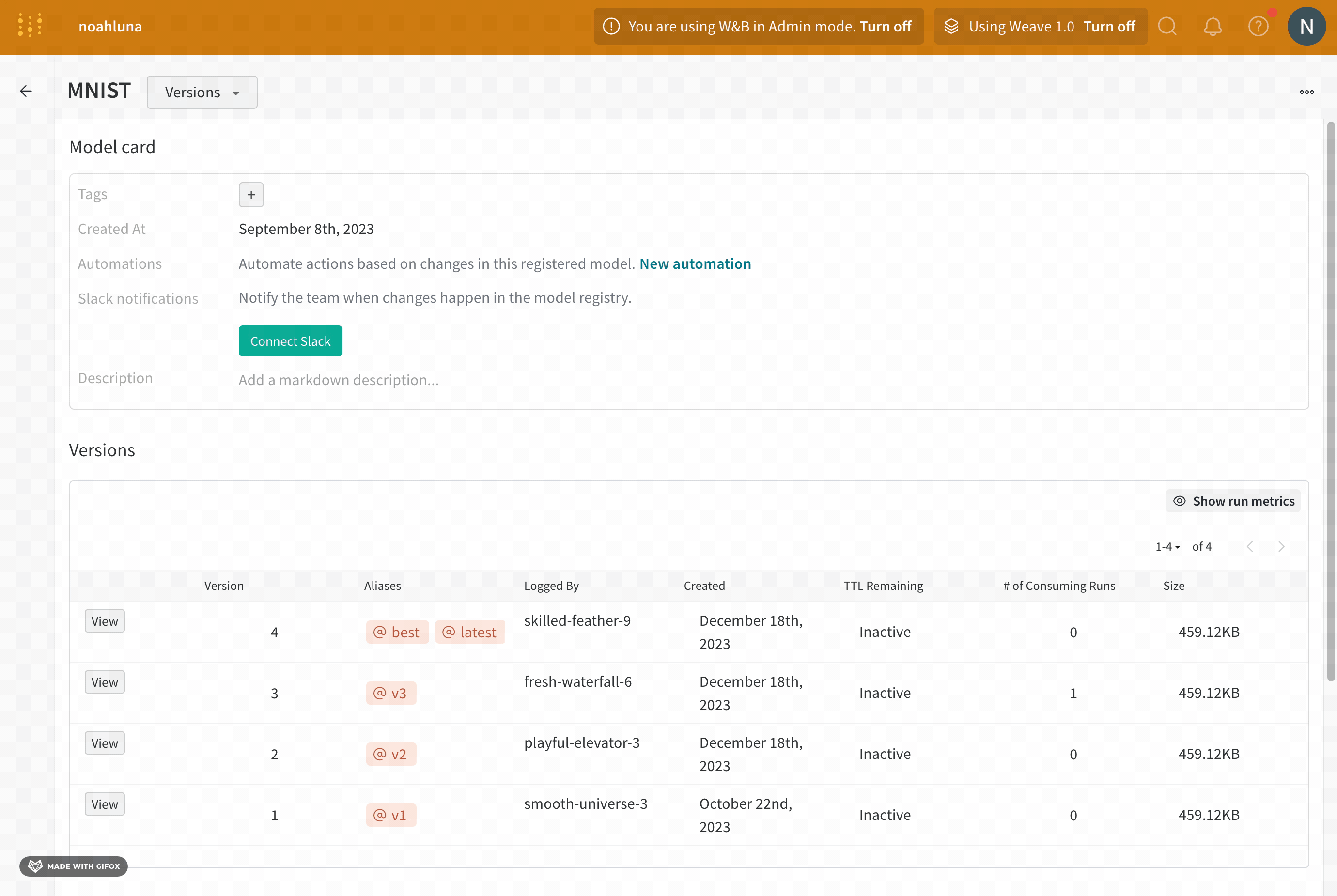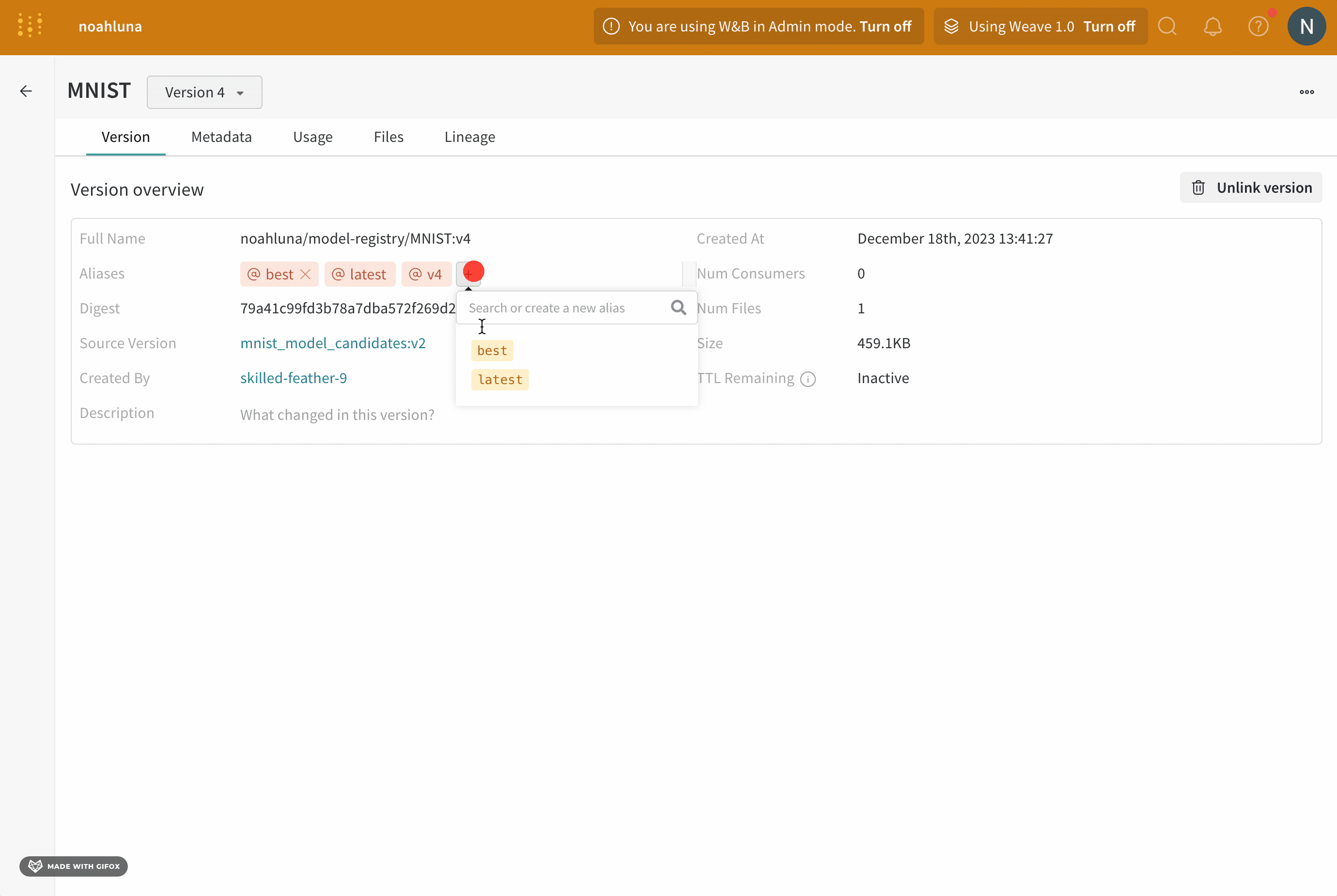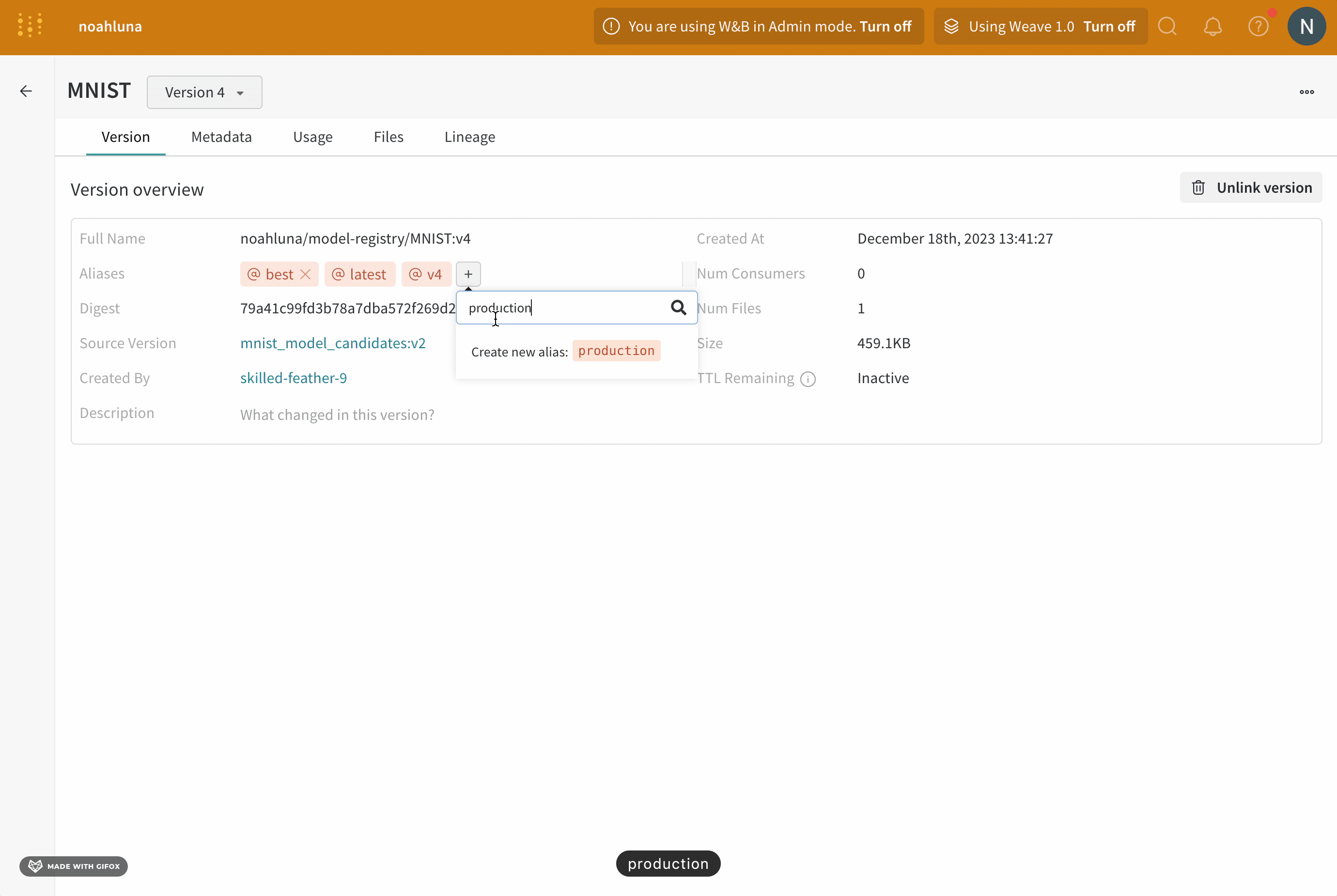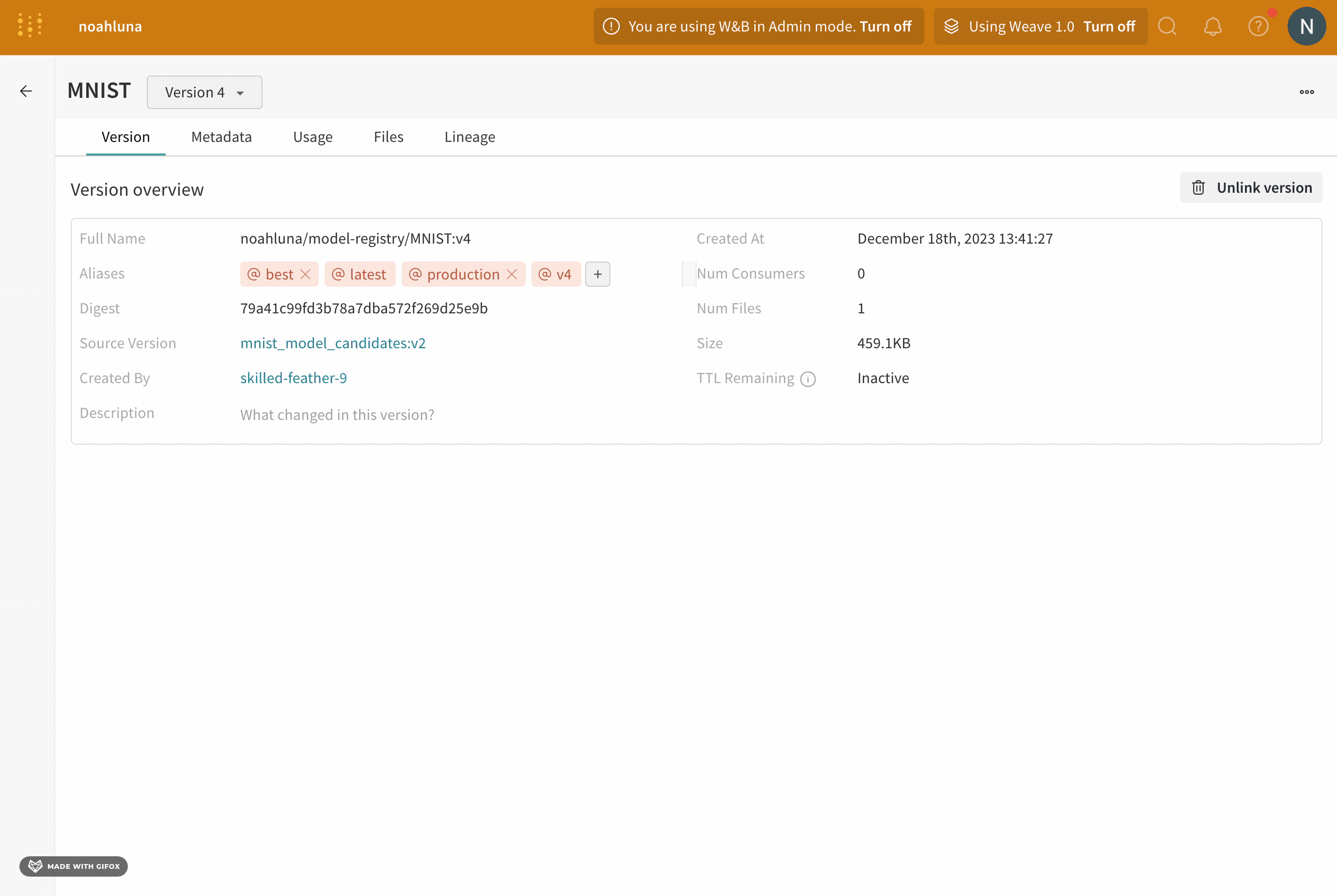
- [エイリアス] フィールドの横にあるプラス アイコン ([+]) をクリックします。
- 表示されるフィールドに
production と入力します。
- キーボードの Enter キーを押します。
2 - Model Registry Terms and Concepts
モデルレジストリ の用語と概念
W&B の モデルレジストリ の主要コンポーネントは、以下の用語で説明されます。モデル バージョン, モデル artifact, そして registered model。
モデル バージョン
モデル バージョンは、単一のモデル チェックポイント を表します。モデル バージョンは、実験 内におけるモデルとそのファイルの特定時点での スナップショット です。
モデル バージョンは、トレーニング されたモデルを記述するデータと メタデータ の不変の ディレクトリー です。W&B は、モデルの アーキテクチャー と学習済み パラメータ を後で保存(および復元)できるように、モデル バージョンにファイルを追加することをお勧めします。
モデル バージョンは、1つの モデル artifact にのみ属します。モデル バージョンは、ゼロまたは複数の registered model に属することができます。モデル バージョンは、モデル artifact に ログ された順にモデル artifact に保存されます。W&B は、(同じモデル artifact に) ログ するモデルの内容が以前のモデル バージョンと異なる場合、新しいモデル バージョンを自動的に作成します。
モデリング ライブラリ (たとえば、PyTorch や Keras) によって提供されるシリアル化 プロセス から生成されたファイルをモデル バージョン内に保存します。
モデル エイリアス
モデル エイリアス は、 registered model 内のモデル バージョンを、セマンティックに関連する識別子で一意に識別または参照できる、変更可能な文字列です。エイリアス は、 registered model の 1 つの バージョン にのみ割り当てることができます。これは、 エイリアス がプログラムで使用される場合に一意の バージョン を参照する必要があるためです。また、 エイリアス を使用してモデルの状態 (チャンピオン、候補、本番) をキャプチャすることもできます。
"best"、"latest"、"production"、"staging" などの エイリアス を使用して、特別な目的を持つモデル バージョン をマークするのが一般的な方法です。
たとえば、モデルを作成し、それに "best" エイリアス を割り当てるとします。run.use_model でその特定のモデルを参照できます。
import wandb
run = wandb.init()
name = f"{entity/project/model_artifact_name}:{alias}"
run.use_model(name=name)
モデル タグ
モデル タグ は、1 つまたは複数の registered model に属する キーワード または ラベル です。
モデル タグ を使用して、 registered model を カテゴリ に整理し、 モデルレジストリ の検索バーでそれらの カテゴリ を検索します。モデル タグ は、 Registered Model Card の上部に表示されます。これらを使用して、 registered model を ML タスク 、所有 チーム 、または 優先度 でグループ化することもできます。同じモデル タグ を複数の registered model に追加して、グループ化できます。
モデル タグ は、グループ化と発見可能性のために registered model に適用される ラベル であり、
モデル エイリアス とは異なります。モデル エイリアス は、プログラムでモデル バージョン を取得するために使用する一意の識別子または ニックネーム です。タグ を使用して モデルレジストリ 内の タスク を整理する方法の詳細については、
モデル の整理 を参照してください。
モデル artifact
モデル artifact は、 ログ された モデル バージョン のコレクションです。モデル バージョンは、モデル artifact に ログ された順にモデル artifact に保存されます。
モデル artifact には、1 つ以上のモデル バージョン を含めることができます。モデル バージョン が ログ されていない場合、モデル artifact は空になる可能性があります。
たとえば、モデル artifact を作成するとします。モデル トレーニング 中に、 チェックポイント 中にモデルを定期的に保存します。各 チェックポイント は、独自の モデル バージョン に対応します。モデル トレーニング 中に作成され、 チェックポイント の保存されたすべてのモデル バージョン は、 トレーニング スクリプト の開始時に作成した同じモデル artifact に保存されます。
次の図は、v0、v1、v2 の 3 つのモデル バージョン を含むモデル artifact を示しています。
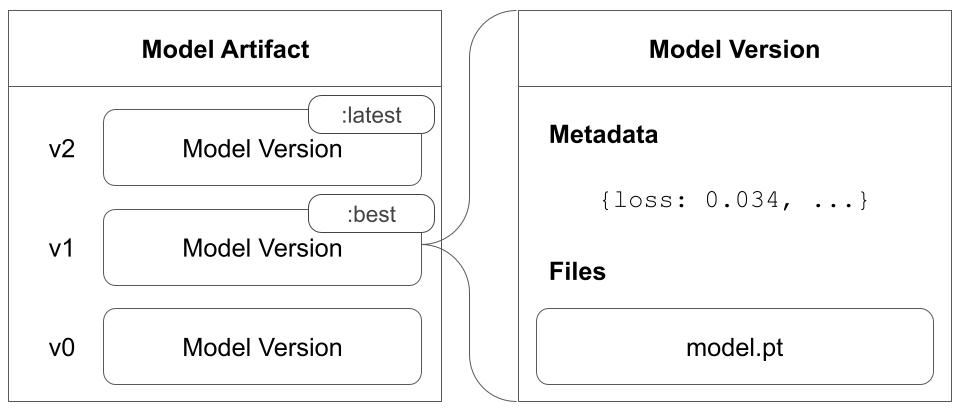
モデル artifact の例はこちら でご覧ください。
Registered model
Registered model は、モデル バージョン への ポインタ (リンク) のコレクションです。registered model は、同じ ML タスク の候補モデルの「 ブックマーク 」の フォルダー と考えることができます。registered model の各「 ブックマーク 」は、モデル artifact に属する モデル バージョン への ポインタ です。モデル タグ を使用して、 registered model をグループ化できます。
Registered model は、多くの場合、単一のモデリング ユースケース または タスク の候補モデルを表します。たとえば、使用するモデルに基づいて、さまざまな 画像分類 タスク の registered model を作成する場合があります:ImageClassifier-ResNet50、ImageClassifier-VGG16、DogBreedClassifier-MobileNetV2 など。モデル バージョン には、 registered model にリンクされた順に バージョン 番号が割り当てられます。
Registered Model の例はこちら でご覧ください。
3 - Track a model
W&B Python SDK で、 モデル 、 モデル の依存関係、およびその モデル に関連するその他の情報を追跡します。
W&B Python SDKで、モデル、モデルの依存関係、およびそのモデルに関連するその他の情報を追跡します。
W&Bは内部で、モデル Artifact のリネージを作成します。これは、W&B App UIで表示したり、W&B Python SDKでプログラム的に表示したりできます。詳細については、モデルリネージマップの作成 を参照してください。
モデルをログに記録する方法
モデルをログに記録するには、run.log_model APIを使用します。モデルファイルが保存されているパスを path パラメータに指定します。パスは、ローカルファイル、ディレクトリー、または s3://bucket/path などの外部バケットへの参照URI にすることができます。
オプションで、name パラメータにモデル Artifactの名前を指定します。name が指定されていない場合、W&Bはrun IDを先頭に付加した入力パスのベース名を使用します。
以下のコードスニペットをコピーして貼り付けます。<> で囲まれた値は、ご自身の値に置き換えてください。
import wandb
# W&B runを初期化する
run = wandb.init(project="<project>", entity="<entity>")
# モデルをログに記録する
run.log_model(path="<path-to-model>", name="<name>")
例: Keras モデルをW&Bにログする
以下のコード例は、畳み込みニューラルネットワーク (CNN) モデルをW&Bにログする方法を示しています。
import os
import wandb
from tensorflow import keras
from tensorflow.keras import layers
config = {"optimizer": "adam", "loss": "categorical_crossentropy"}
# W&B runを初期化する
run = wandb.init(entity="charlie", project="mnist-project", config=config)
# トレーニングアルゴリズム
loss = run.config["loss"]
optimizer = run.config["optimizer"]
metrics = ["accuracy"]
num_classes = 10
input_shape = (28, 28, 1)
model = keras.Sequential(
[
layers.Input(shape=input_shape),
layers.Conv2D(32, kernel_size=(3, 3), activation="relu"),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Conv2D(64, kernel_size=(3, 3), activation="relu"),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Flatten(),
layers.Dropout(0.5),
layers.Dense(num_classes, activation="softmax"),
]
)
model.compile(loss=loss, optimizer=optimizer, metrics=metrics)
# モデルを保存
model_filename = "model.h5"
local_filepath = "./"
full_path = os.path.join(local_filepath, model_filename)
model.save(filepath=full_path)
# モデルをログに記録する
run.log_model(path=full_path, name="MNIST")
# W&B に run を終了することを明示的に伝える。
run.finish()
4 - Create a registered model
モデリングタスクのすべての候補モデルを保持するために、登録済み モデル を作成します。
モデリングタスクのすべての候補モデルを保持するために、registered modelを作成します。 registered model は、Model Registry 内でインタラクティブに、または Python SDK でプログラム的に作成できます。
プログラムで registered model を作成する
W&B Python SDK でモデルをプログラム的に登録します。 registered model が存在しない場合、W&B は自動的に registered model を作成します。
必ず、<> で囲まれた値を独自の値に置き換えてください。
import wandb
run = wandb.init(entity="<entity>", project="<project>")
run.link_model(path="<path-to-model>", registered_model_name="<registered-model-name>")
run.finish()
registered_model_name に指定した名前は、Model Registry App に表示される名前です。
インタラクティブに registered model を作成する
Model Registry App 内でインタラクティブに registered model を作成します。
- https://wandb.ai/registry/model で Model Registry App に移動します。
- Model Registry ページの右上にある New registered model ボタンをクリックします。
- 表示される パネル で、registered model が属する Entities を Owning Entity ドロップダウンから選択します。
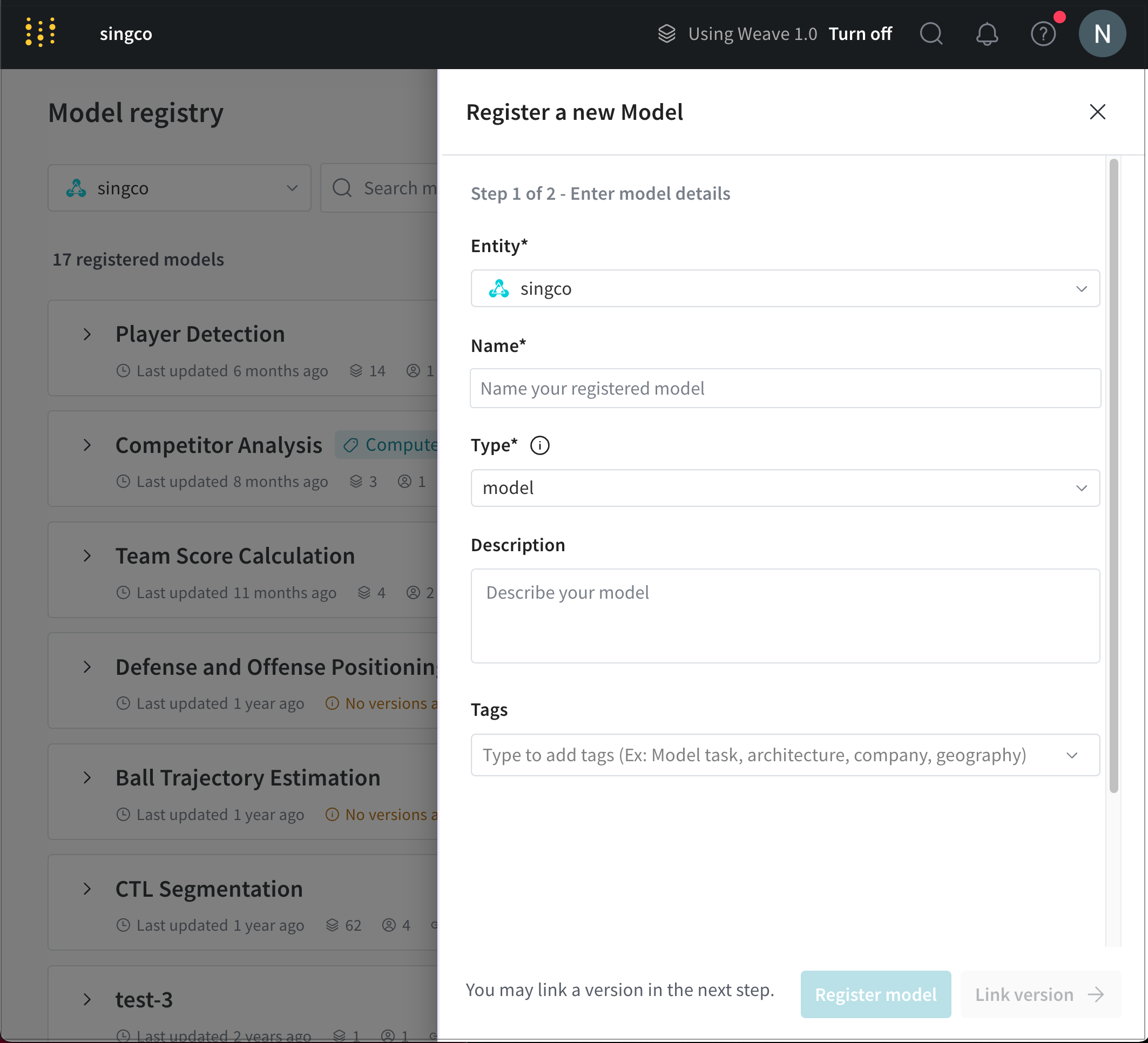
- Name フィールドにモデルの名前を入力します。
- Type ドロップダウンから、registered model にリンクする Artifacts のタイプを選択します。
- (オプション)Description フィールドにモデルに関する説明を追加します。
- (オプション)Tags フィールドに、1 つ以上のタグを追加します。
- Register model をクリックします。
モデルを Model Registry に手動でリンクすることは、1 回限りのモデルに役立ちます。ただし、多くの場合、プログラムでモデルバージョンを Model Registry にリンクすることが役立ちます。
たとえば、毎晩のジョブがあるとします。毎晩作成されるモデルを手動でリンクするのは面倒です。代わりに、モデルを評価するスクリプトを作成し、モデルのパフォーマンスが向上した場合、W&B Python SDK を使用してそのモデルを Model Registry にリンクすることができます。
5 - Link a model version
W&B App を使用するか、Python SDK でプログラム的に モデル の バージョン を Registered Model にリンクします。
W&B Appまたは Python SDK で、モデルのバージョンを登録済みモデルにリンクします。
プログラムでモデルをリンクする
link_model メソッドを使用して、モデルファイルをプログラムで W&B の run に ログ し、それをW&B モデルレジストリにリンクします。
必ず <> で囲まれた値を独自の値に置き換えてください。
import wandb
run = wandb.init(entity="<entity>", project="<project>")
run.link_model(path="<path-to-model>", registered_model_name="<登録済みモデル名>")
run.finish()
registered-model-name パラメータに指定した名前がまだ存在しない場合、W&B によって登録済みモデルが作成されます。
たとえば、モデルレジストリに「Fine-Tuned-Review-Autocompletion 」(registered-model-name="Fine-Tuned-Review-Autocompletion") という名前の既存の登録済みモデルがあるとします。また、いくつかのモデルバージョンがそれ(v0、v1、v2)にリンクされているとします。新しいモデルをプログラムでリンクし、同じ登録済みモデル名 (registered-model-name="Fine-Tuned-Review-Autocompletion") を使用すると、W&B はこのモデルを既存の登録済みモデルにリンクし、モデルバージョン v3 を割り当てます。この名前の登録済みモデルが存在しない場合は、新しい登録済みモデルが作成され、モデルバージョン v0 が割り当てられます。
“Fine-Tuned-Review-Autocompletion” 登録済みモデルの例はこちらをご覧ください。
インタラクティブにモデルをリンクする
モデルレジストリまたは Artifact ブラウザを使用して、インタラクティブにモデルをリンクします。
- https://wandb.ai/registry/model のモデルレジストリ App に移動します。
- 新しいモデルをリンクする登録済みモデルの名前の横にマウスを置きます。
- 詳細を表示 の横にあるミートボールメニューアイコン (3 つの水平ドット) を選択します。
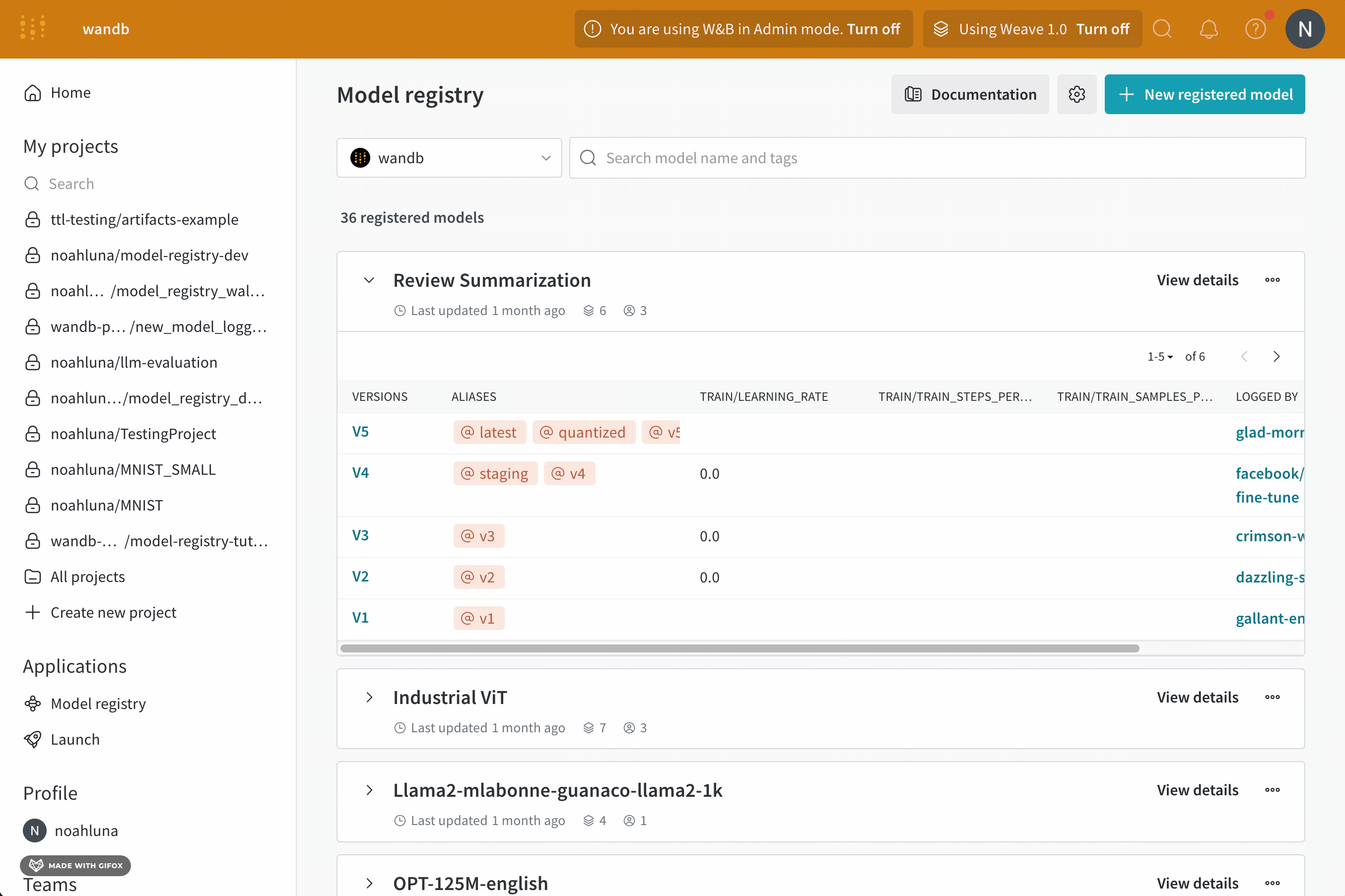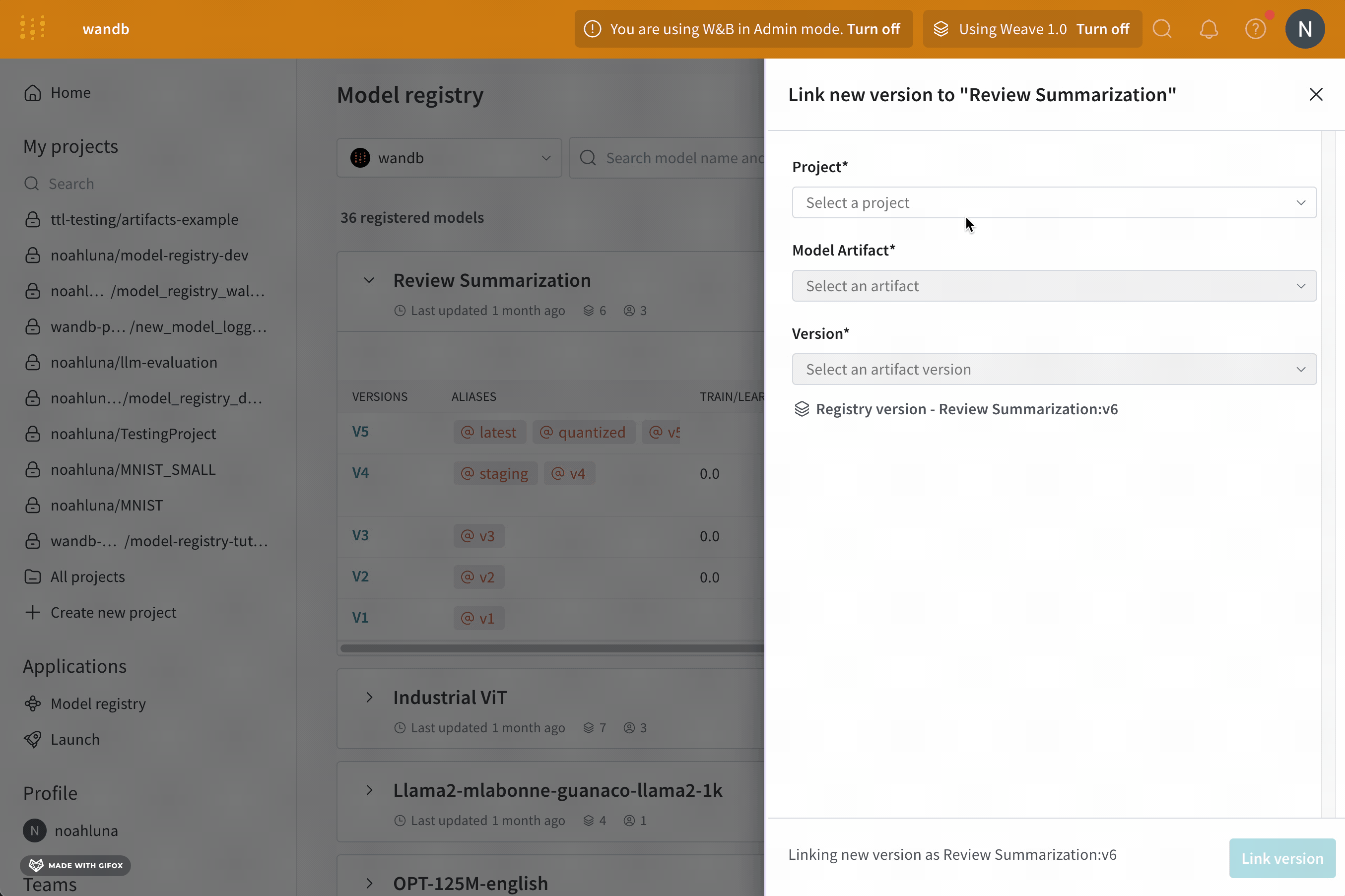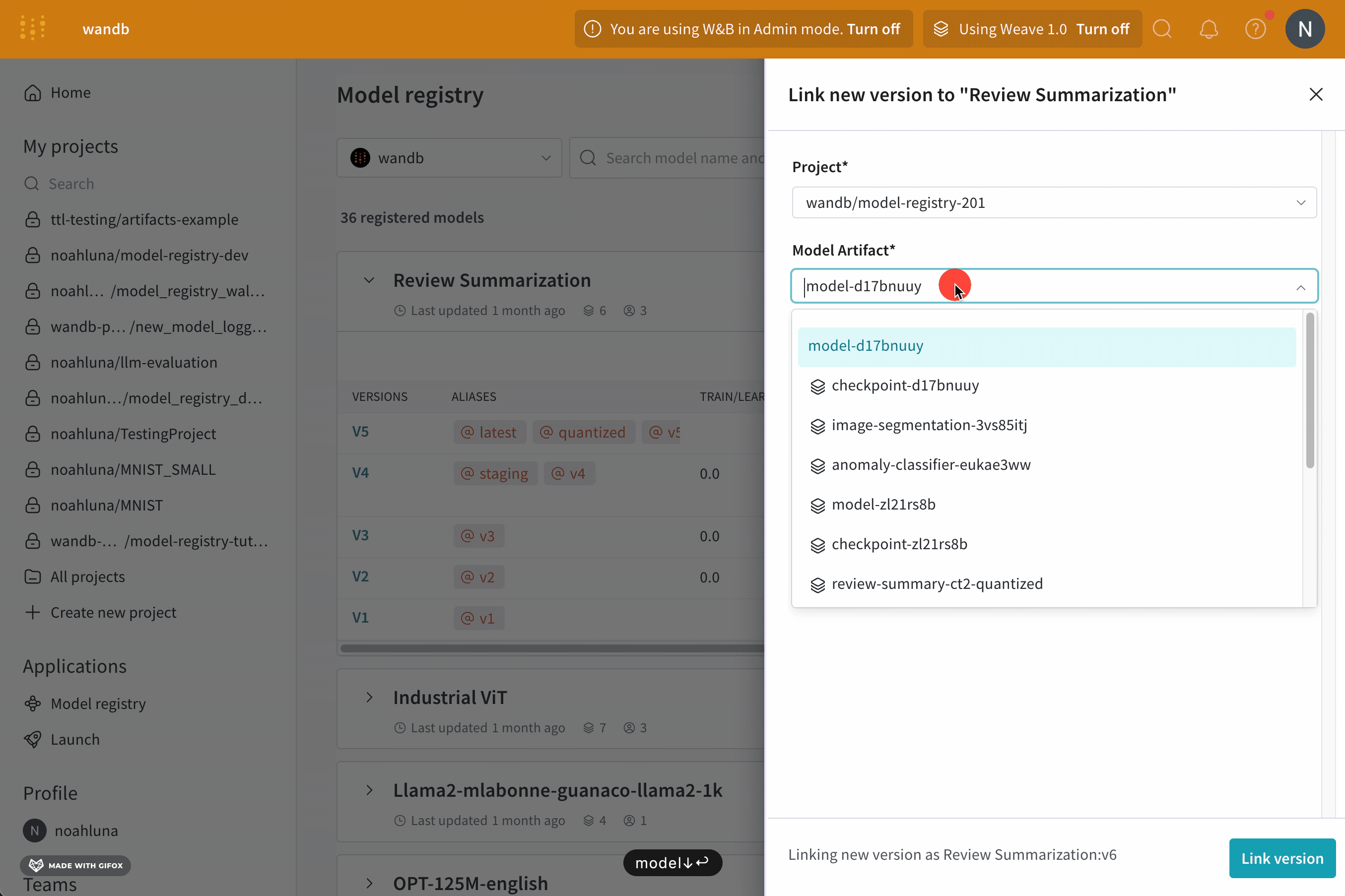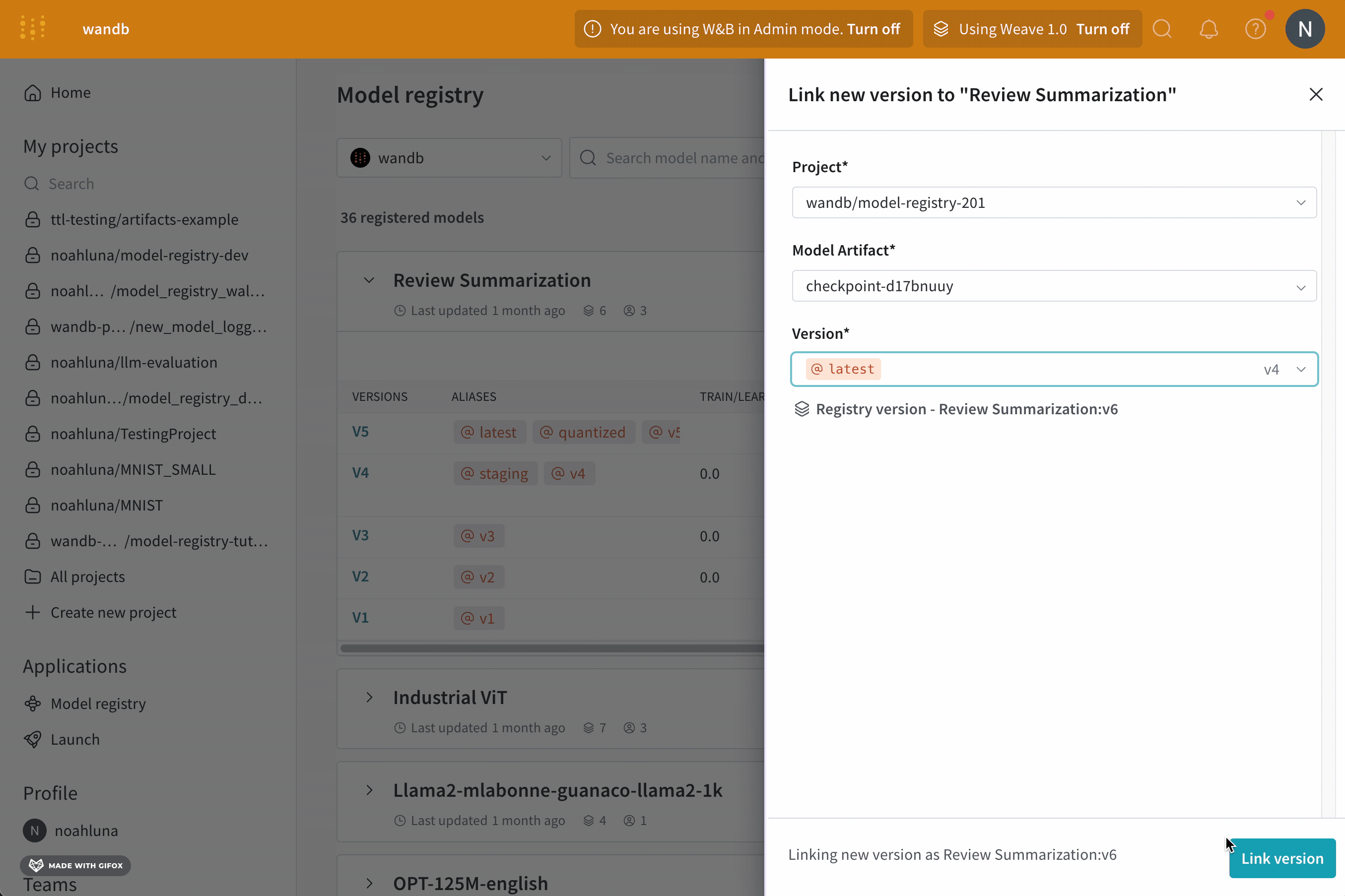
- ドロップダウンから、新しいバージョンをリンク を選択します。
- Project ドロップダウンから、モデルを含む project の名前を選択します。
- モデル Artifact ドロップダウンから、モデル artifact の名前を選択します。
- バージョン ドロップダウンから、登録済みモデルにリンクするモデル バージョンを選択します。
- W&B App の project の Artifact ブラウザに移動します:
https://wandb.ai/<entity>/<project>/artifacts
- 左側のサイドバーにある Artifacts アイコンを選択します。
- レジストリにリンクするモデル バージョンをクリックします。
- バージョンの概要 セクション内で、レジストリにリンク ボタンをクリックします。
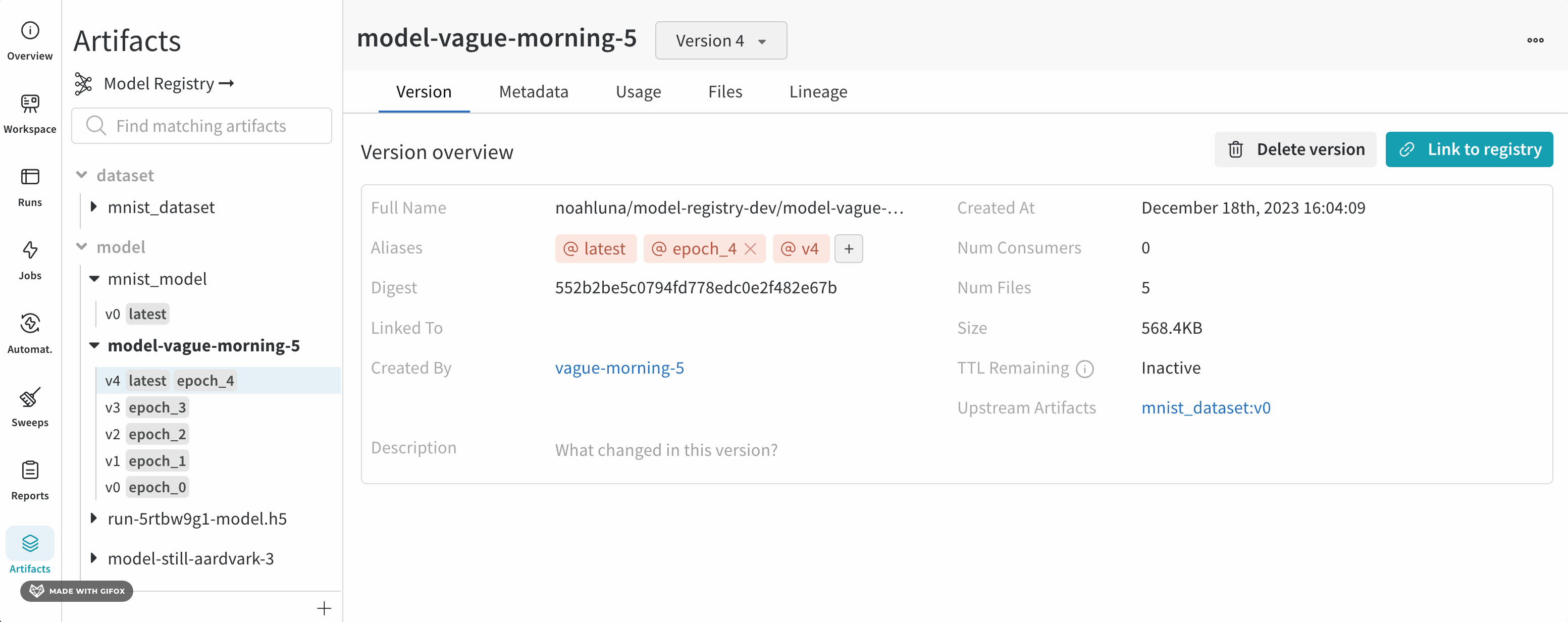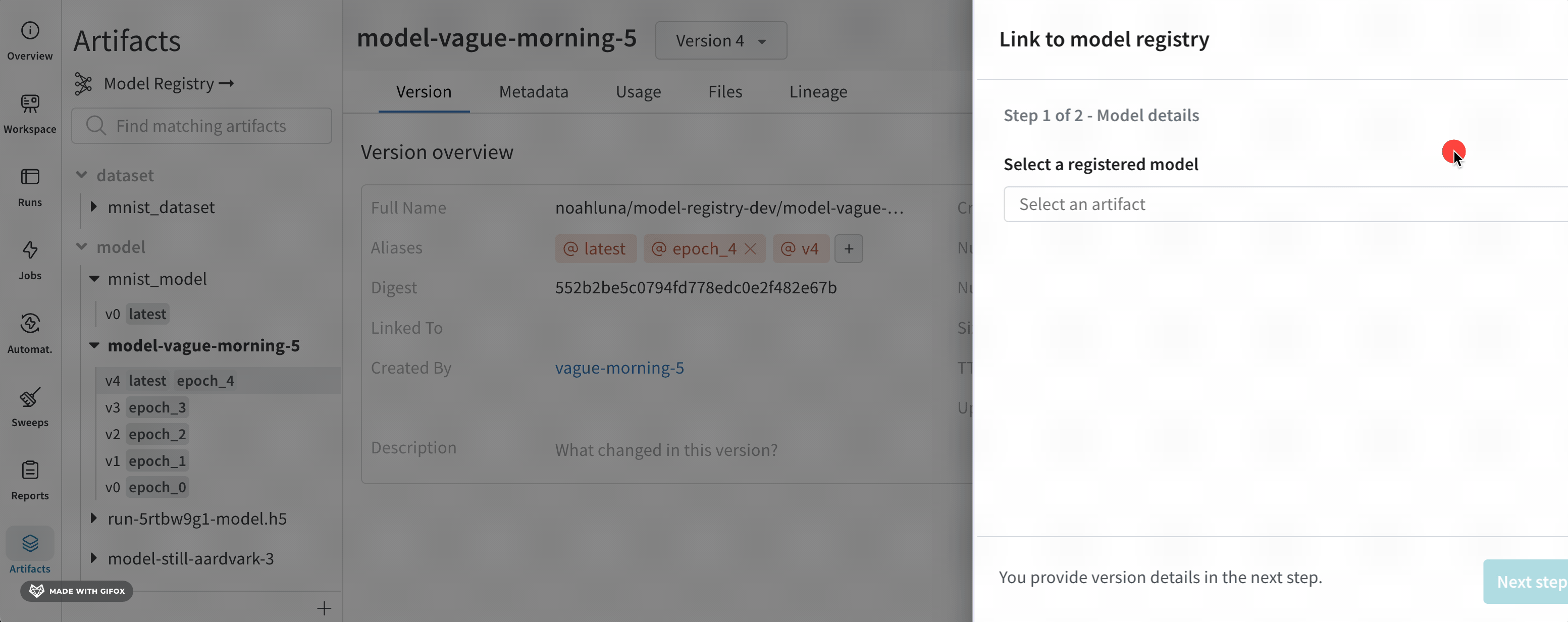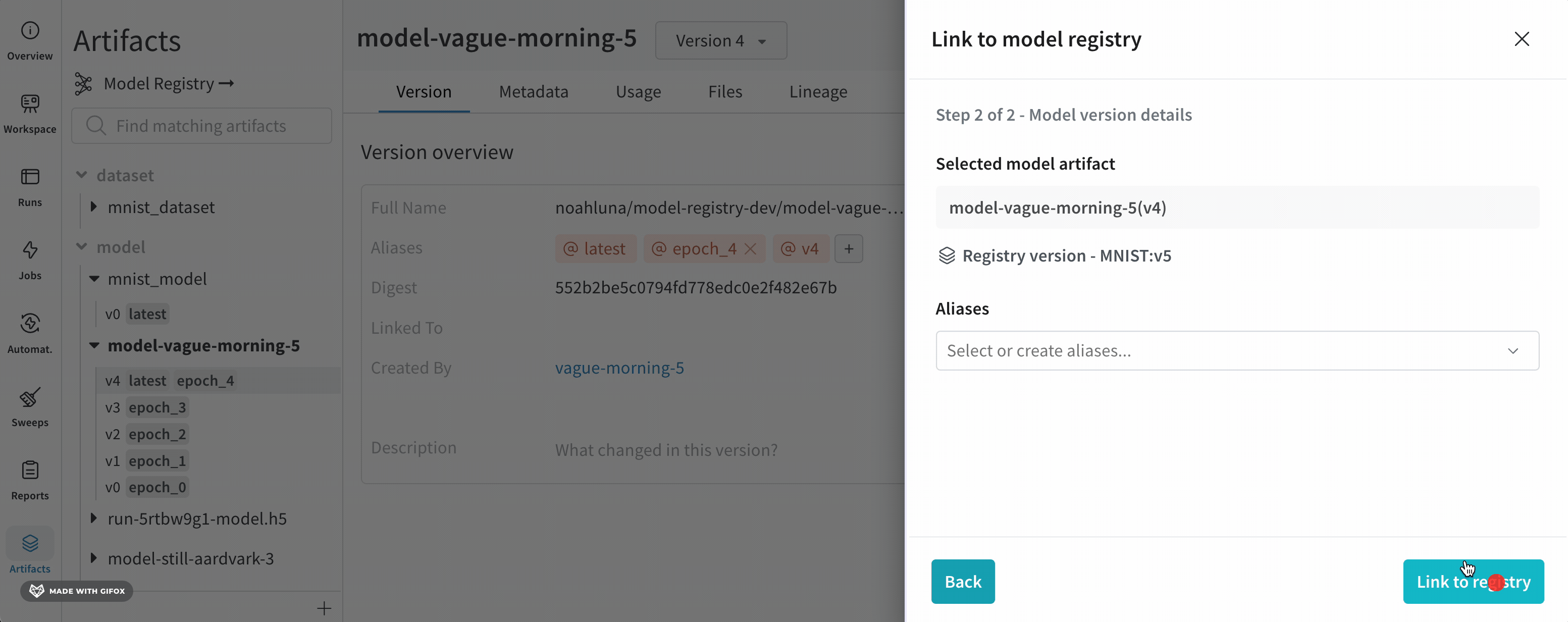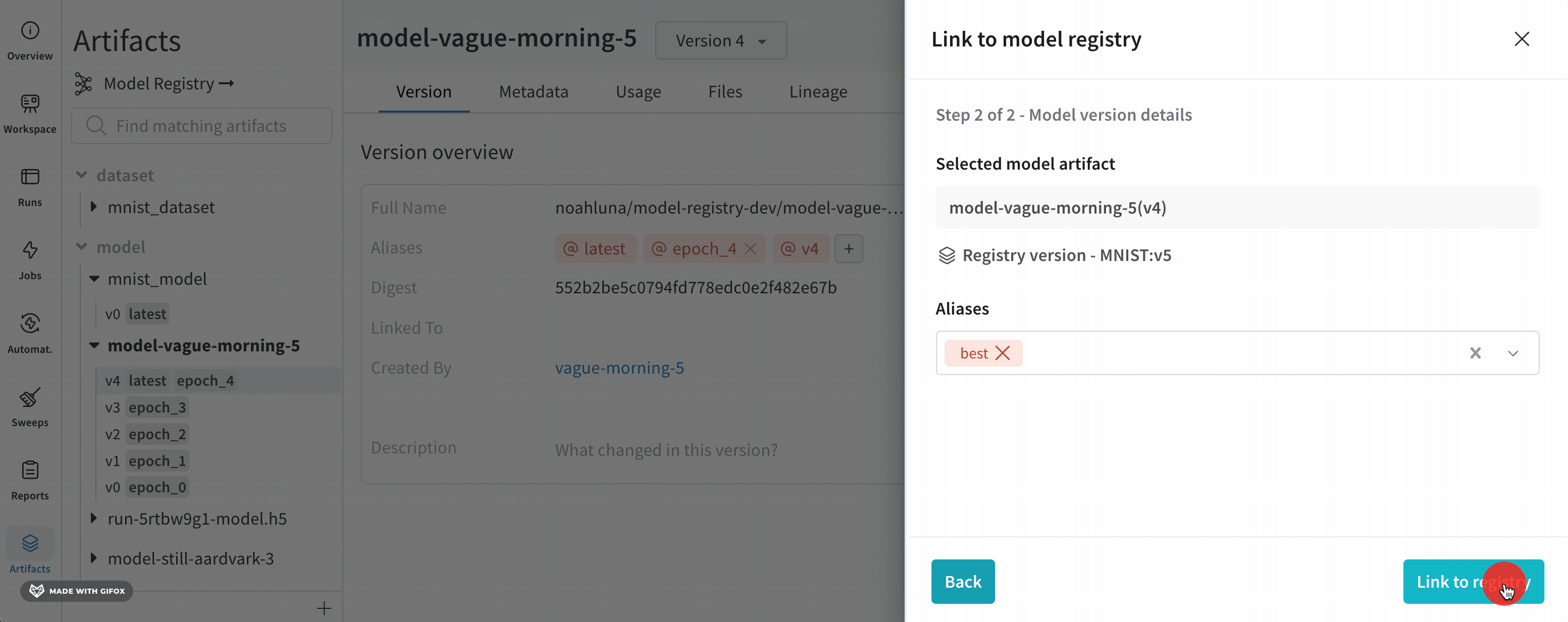
- 画面の右側に表示されるモーダルから、登録済みモデルを選択 メニューのドロップダウンから登録済みモデルを選択します。
- 次のステップ をクリックします。
- (オプション) エイリアス ドロップダウンからエイリアスを選択します。
- レジストリにリンク をクリックします。
リンクされたモデルのソースを表示する
リンクされたモデルのソースを表示する方法は 2 つあります。モデルが ログ されている project 内の Artifact ブラウザと W&B モデルレジストリです。
ポインタは、モデルレジストリ内の特定のモデルバージョンをソース モデル artifact (モデルが ログ されている project 内にある) に接続します。ソース モデル artifact には、モデルレジストリへのポインタもあります。
- https://wandb.ai/registry/model でモデルレジストリに移動します。
- 登録済みモデルの名前の横にある 詳細を表示 を選択します。
- バージョン セクション内で、調査するモデルバージョンの横にある 表示 を選択します。
- 右側の パネル 内の バージョン タブをクリックします。
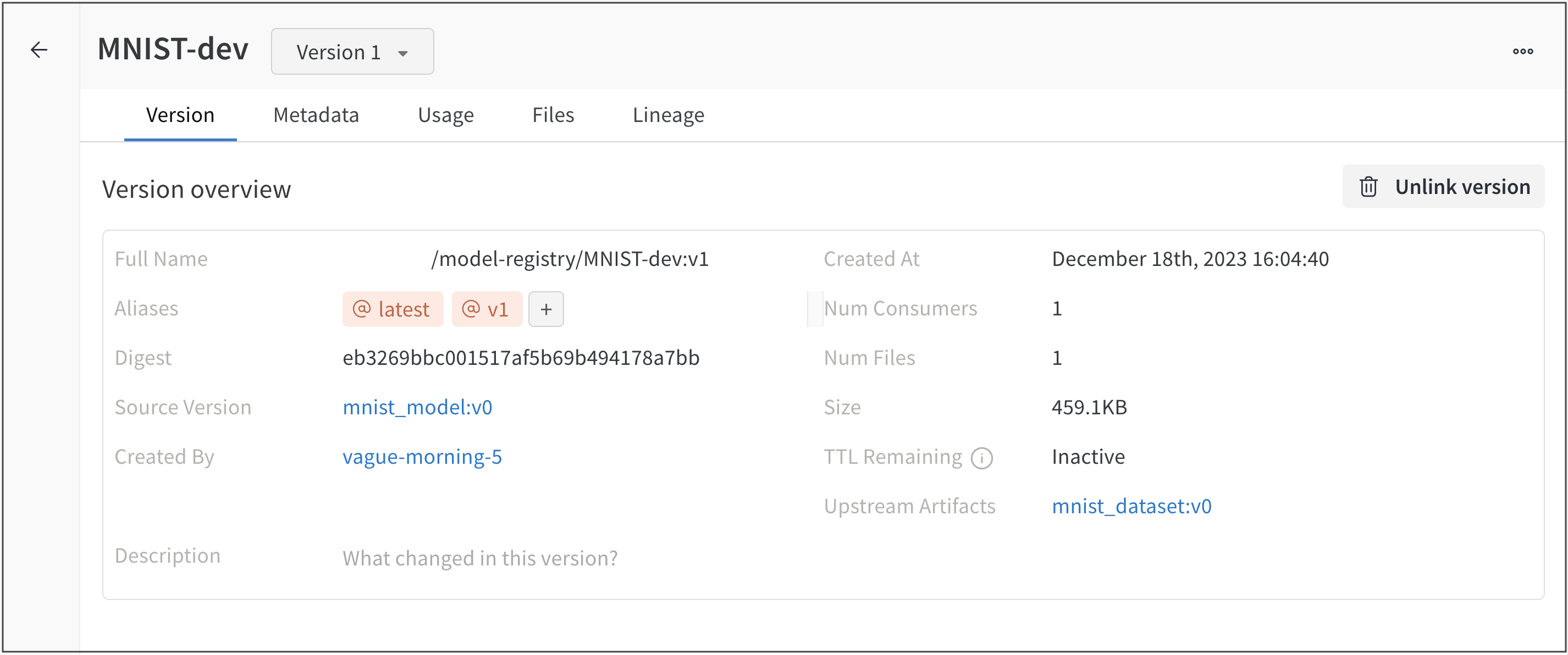
- バージョンの概要 セクション内に、ソースバージョン フィールドを含む行があります。ソースバージョン フィールドには、モデルの名前とモデルのバージョンの両方が表示されます。
たとえば、次の図は、MNIST-dev という名前の登録済みモデルにリンクされた mnist_model という名前の v0 モデル バージョンを示しています (ソースバージョン フィールド mnist_model:v0 を参照)。
- W&B App の project の Artifact ブラウザに移動します:
https://wandb.ai/<entity>/<project>/artifacts
- 左側のサイドバーにある Artifacts アイコンを選択します。
- Artifacts パネルから モデル ドロップダウン メニューを展開します。
- モデルレジストリにリンクされているモデルの名前とバージョンを選択します。
- 右側の パネル 内の バージョン タブをクリックします。
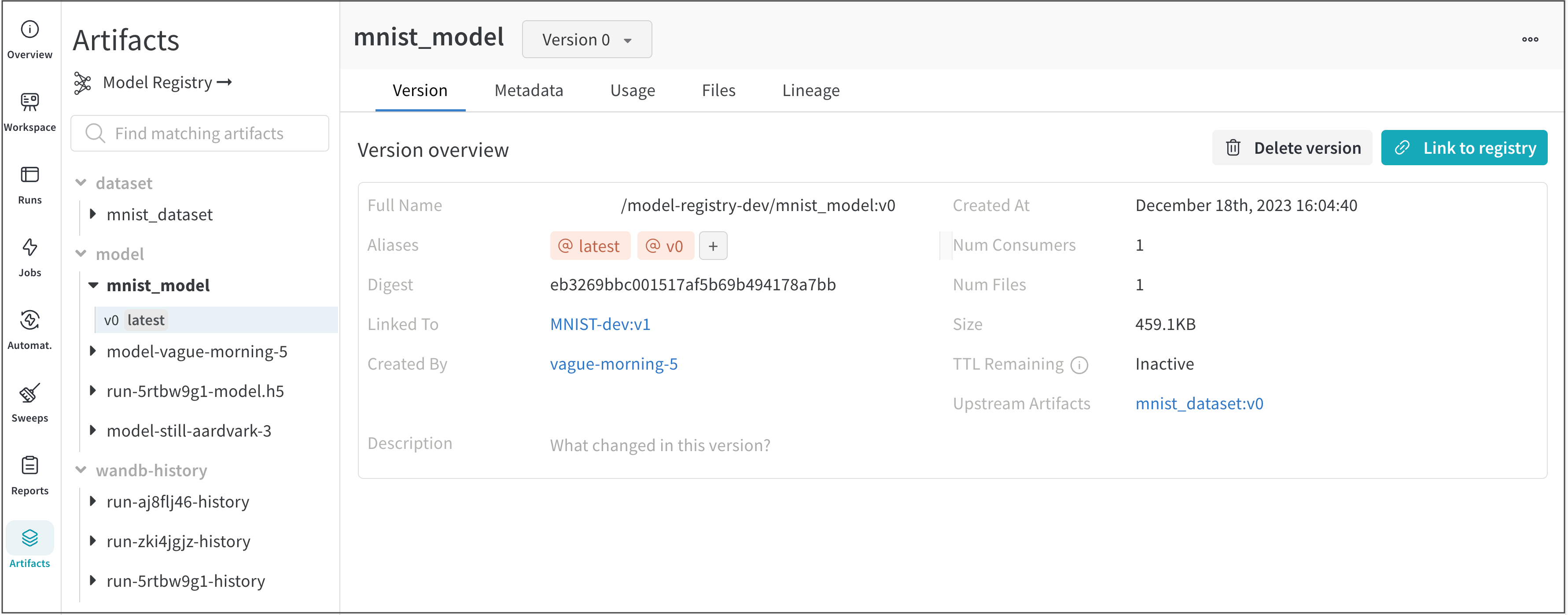
- バージョンの概要 セクション内に、リンク先 フィールドを含む行があります。リンク先 フィールドには、登録済みモデルの名前と、それが持つバージョン (
registered-model-name:version) の両方が表示されます。
たとえば、次の図では、MNIST-dev という名前の登録済みモデルがあります (リンク先 フィールドを参照)。バージョン v0 (mnist_model:v0) を持つ mnist_model という名前のモデル バージョンは、MNIST-dev 登録済みモデルを指しています。
6 - Organize models
モデルタグを使用すると、登録されたモデルをカテゴリに分類し、それらのカテゴリを検索できます。
-
https://wandb.ai/registry/model の W&B Model Registry アプリケーションに移動します。
-
モデルタグを追加する登録済みモデルの名前の横にある View details(詳細を見る) を選択します。
-
Model card(モデルカード) セクションまでスクロールします。
-
Tags(タグ) フィールドの横にあるプラスボタン(+)をクリックします。
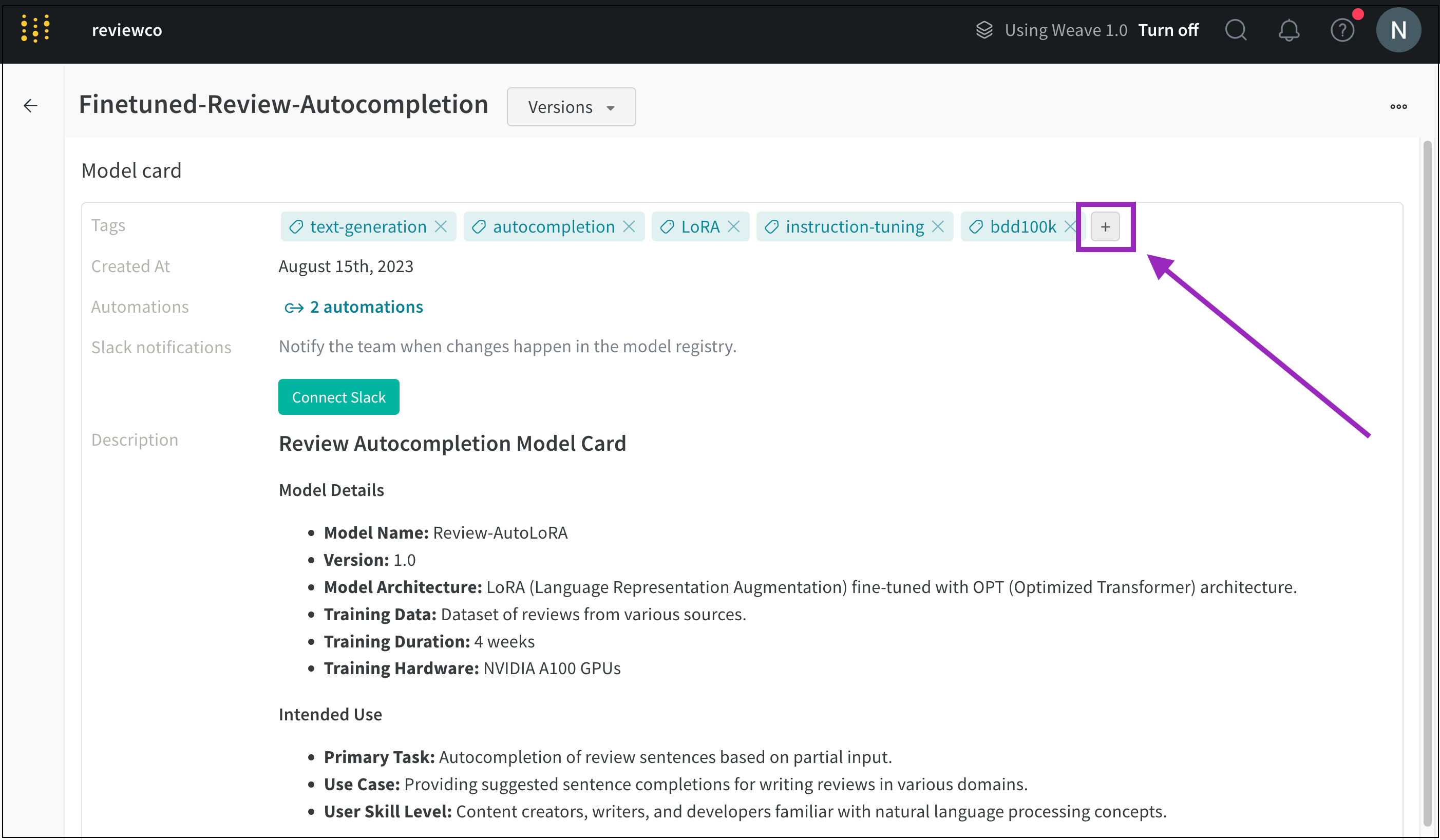
-
タグの名前を入力するか、既存のモデルタグを検索します。
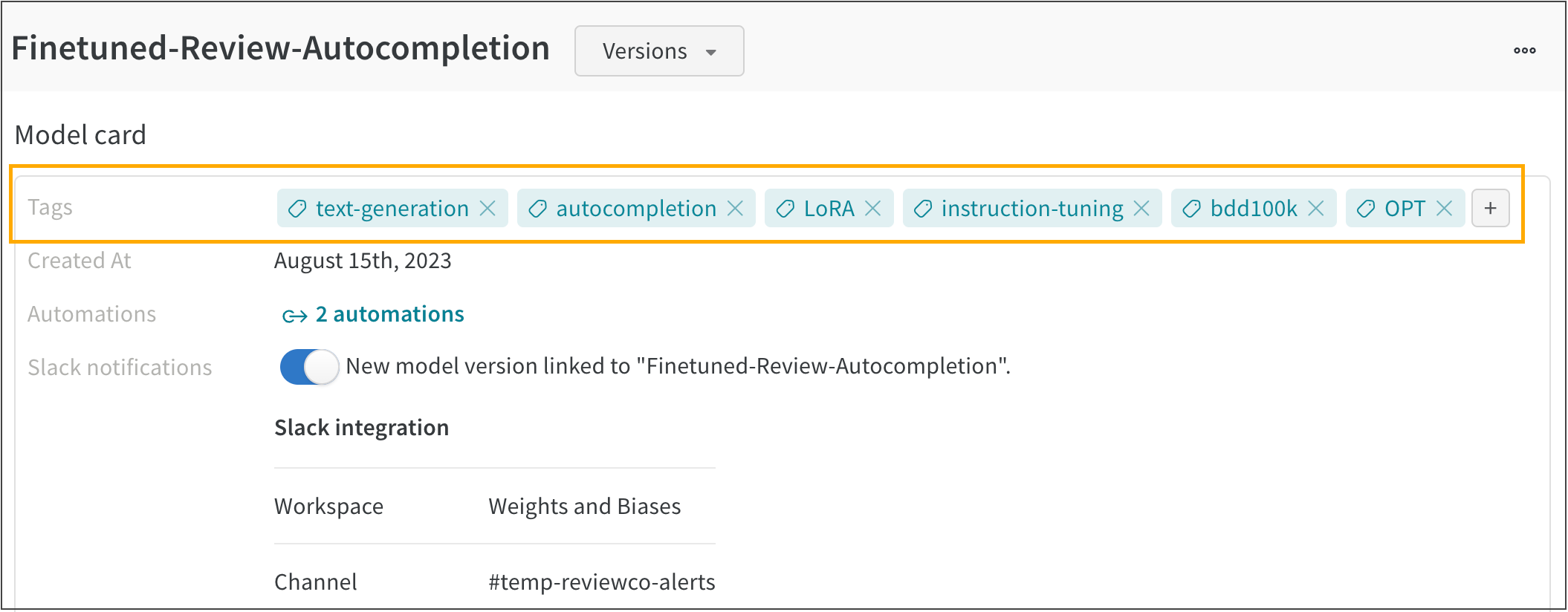
たとえば、次の図は、FineTuned-Review-Autocompletion という登録済みモデルに追加された複数のモデルタグを示しています。
7 - Create model lineage map
このページでは、従来の W&B Model Registry でリネージグラフを作成する方法について説明します。W&B Registry のリネージグラフについては、リネージマップの作成と表示を参照してください。
モデル アーティファクト を W&B に ログ 記録する便利な機能は、リネージグラフです。リネージグラフは、 run によって ログ 記録された アーティファクト と、特定の run で使用された アーティファクト を示します。
つまり、モデル アーティファクト を ログ 記録すると、少なくともモデル アーティファクト を使用または生成した W&B の run を表示できます。依存関係を追跡する場合、モデル アーティファクト で使用される入力も表示されます。
たとえば、次の図は、ML 実験 全体で作成および使用された アーティファクト を示しています。
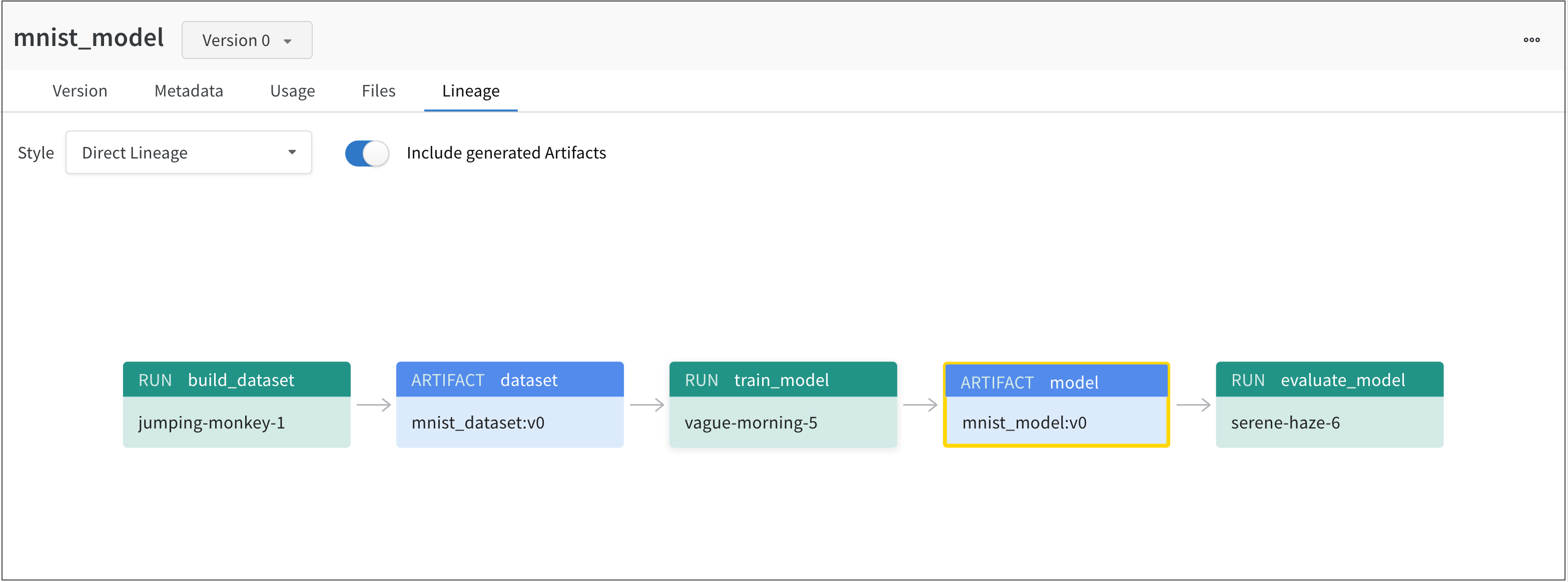
左から右へ、画像は以下を示しています。
jumping-monkey-1 W&B run は、mnist_dataset:v0 データセット アーティファクト を作成しました。vague-morning-5 W&B run は、mnist_dataset:v0 データセット アーティファクト を使用してモデルをトレーニングしました。この W&B run の出力は、mnist_model:v0 というモデル アーティファクト でした。serene-haze-6 という run は、モデル アーティファクト ( mnist_model:v0) を使用してモデルを評価しました。
アーティファクト の依存関係を追跡する
use_artifact API を使用して、データセット アーティファクト を W&B run への入力として宣言し、依存関係を追跡します。
次の コード スニペット は、use_artifact API の使用方法を示しています。
# run を初期化する
run = wandb.init(project=project, entity=entity)
# アーティファクト を取得し、依存関係としてマークします
artifact = run.use_artifact(artifact_or_name="name", aliases="<alias>")
アーティファクト を取得したら、その アーティファクト を使用して (たとえば) モデルのパフォーマンスを評価できます。
例: モデルをトレーニングし、データセット をモデルの入力として追跡します
job_type = "train_model"
config = {
"optimizer": "adam",
"batch_size": 128,
"epochs": 5,
"validation_split": 0.1,
}
run = wandb.init(project=project, job_type=job_type, config=config)
version = "latest"
name = "{}:{}".format("{}_dataset".format(model_use_case_id), version)
artifact = run.use_artifact(name)
train_table = artifact.get("train_table")
x_train = train_table.get_column("x_train", convert_to="numpy")
y_train = train_table.get_column("y_train", convert_to="numpy")
# config 辞書 からの値を簡単にアクセスできるように変数に格納します
num_classes = 10
input_shape = (28, 28, 1)
loss = "categorical_crossentropy"
optimizer = run.config["optimizer"]
metrics = ["accuracy"]
batch_size = run.config["batch_size"]
epochs = run.config["epochs"]
validation_split = run.config["validation_split"]
# モデル アーキテクチャ を作成する
model = keras.Sequential(
[
layers.Input(shape=input_shape),
layers.Conv2D(32, kernel_size=(3, 3), activation="relu"),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Conv2D(64, kernel_size=(3, 3), activation="relu"),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Flatten(),
layers.Dropout(0.5),
layers.Dense(num_classes, activation="softmax"),
]
)
model.compile(loss=loss, optimizer=optimizer, metrics=metrics)
# トレーニング データ のラベルを生成する
y_train = keras.utils.to_categorical(y_train, num_classes)
# トレーニング セット と テスト セット を作成する
x_t, x_v, y_t, y_v = train_test_split(x_train, y_train, test_size=0.33)
# モデルをトレーニングする
model.fit(
x=x_t,
y=y_t,
batch_size=batch_size,
epochs=epochs,
validation_data=(x_v, y_v),
callbacks=[WandbCallback(log_weights=True, log_evaluation=True)],
)
# モデルをローカルに保存する
path = "model.h5"
model.save(path)
path = "./model.h5"
registered_model_name = "MNIST-dev"
name = "mnist_model"
run.link_model(path=path, registered_model_name=registered_model_name, name=name)
run.finish()
8 - Document machine learning model
モデルカード に説明を追加して、 モデル を文書化します。
登録済みモデルのモデルカードに説明を追加して、 機械学習 モデルの側面を文書化します。文書化する価値のあるトピックには、次のものがあります。
- 概要: モデルの概要。モデルの目的。モデルが使用する 機械学習 フレームワークなど。
- トレーニングデータ: 使用したトレーニングデータ、トレーニングデータセットで実行された処理、そのデータの保存場所などを記述します。
- アーキテクチャー: モデルアーキテクチャー、レイヤー、および特定の設計の選択に関する情報。
- モデルのデシリアライズ: チームの誰かがモデルをメモリーにロードする方法に関する情報を提供します。
- タスク: 機械学習 モデルが実行するように設計されている特定のタイプのタスクまたは問題。モデルの意図された機能の分類です。
- ライセンス: 機械学習 モデルの使用に関連する法的条件と許可。モデル ユーザーがモデルを利用できる法的枠組みを理解するのに役立ちます。
- 参考文献: 関連する 研究 論文、データセット、または外部リソースへの引用または参考文献。
- デプロイメント: モデルのデプロイ方法と場所の詳細、および ワークフロー オーケストレーション プラットフォーム などの他のエンタープライズ システムへのモデルの統合方法に関するガイダンス。
モデルカードに説明を追加する
- https://wandb.ai/registry/model にある W&B Model Registry アプリケーションに移動します。
- モデルカードを作成する登録済みモデルの名前の横にある [詳細を表示] を選択します。
- [モデルカード] セクションに移動します。
- [説明] フィールドに、 機械学習 モデルに関する情報を提供します。Markdown マークアップ言語を使用して、モデルカード内のテキストの書式を設定します。
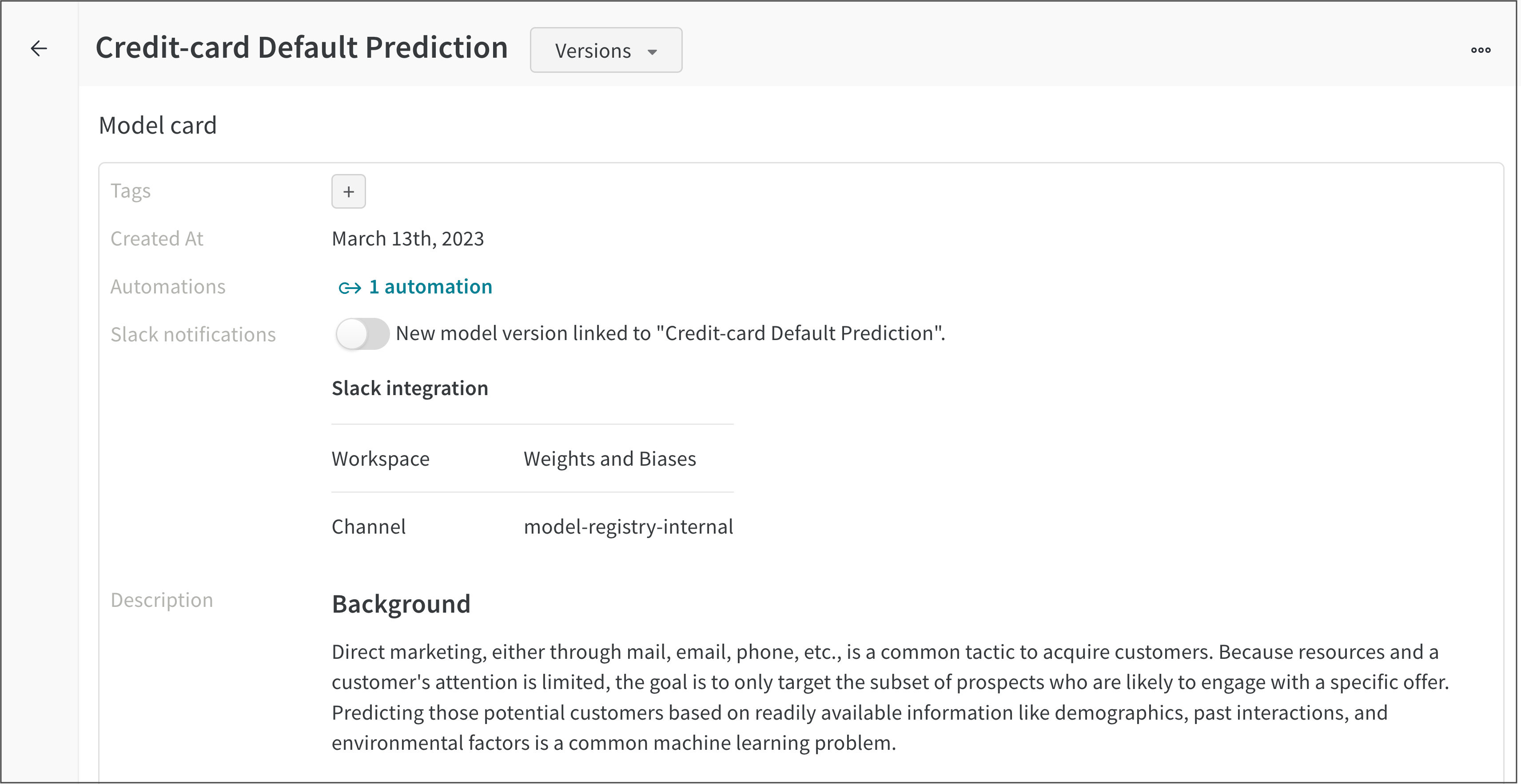
たとえば、次の図は、Credit-card Default Prediction 登録済みモデルのモデルカードを示しています。
9 - Download a model version
W&B Python SDK でモデルをダウンロードする方法
W&B Python SDK を使用して、Model Registry にリンクしたモデル artifact をダウンロードします。
モデルを再構築し、デシリアライズして、操作できる形式にするための追加の Python 関数、API 呼び出しはお客様の責任で提供する必要があります。
W&B では、モデルをメモリにロードする方法に関する情報をモデルカードに記載することをお勧めします。詳細については、機械学習モデルのドキュメント ページを参照してください。
<> 内の values はお客様ご自身のものに置き換えてください。
import wandb
# run を初期化する
run = wandb.init(project="<project>", entity="<entity>")
# モデルにアクセスしてダウンロードします。ダウンロードした artifact への path を返します
downloaded_model_path = run.use_model(name="<your-model-name>")
以下のいずれかの形式でモデル version を参照してください。
latest - 最新の latest エイリアスを使用して、最も新しくリンクされたモデル version を指定します。v# - v0、v1、v2 などを使用して、Registered Model 内の特定の version を取得しますalias - ユーザー と Teams がモデル version に割り当てたカスタム alias を指定します
可能なパラメータと戻り値の型について詳しくは、API Reference ガイドのuse_model を参照してください。
例: ログに記録されたモデルをダウンロードして使用する
たとえば、次のコード snippet では、ユーザー が use_model API を呼び出しました。フェッチするモデル artifact の名前を指定し、version/alias も指定しました。次に、API から返された path を downloaded_model_path 変数に格納しました。
import wandb
entity = "luka"
project = "NLP_Experiments"
alias = "latest" # モデル version のセマンティックなニックネームまたは識別子
model_artifact_name = "fine-tuned-model"
# run を初期化する
run = wandb.init()
# モデルにアクセスしてダウンロードします。ダウンロードした artifact への path を返します
downloaded_model_path = run.use_model(name=f"{entity/project/model_artifact_name}:{alias}")
2024 年に予定されている W&B Model Registry の廃止
次のタブは、まもなく廃止される Model Registry を使用してモデル artifact を消費する方法を示しています。
W&B Registry を使用して、モデル artifact を追跡、整理、消費します。詳細については、Registry docsを参照してください。
<> 内の values はお客様ご自身のものに置き換えてください。
import wandb
# run を初期化する
run = wandb.init(project="<project>", entity="<entity>")
# モデルにアクセスしてダウンロードします。ダウンロードした artifact への path を返します
downloaded_model_path = run.use_model(name="<your-model-name>")
以下のいずれかの形式でモデル version を参照してください。
latest - 最新の latest エイリアスを使用して、最も新しくリンクされたモデル version を指定します。v# - v0、v1、v2 などを使用して、Registered Model 内の特定の version を取得しますalias - ユーザー と Teams がモデル version に割り当てたカスタム alias を指定します
可能なパラメータと戻り値の型について詳しくは、API Reference ガイドのuse_model を参照してください。
- https://wandb.ai/registry/model にある Model Registry App に移動します。
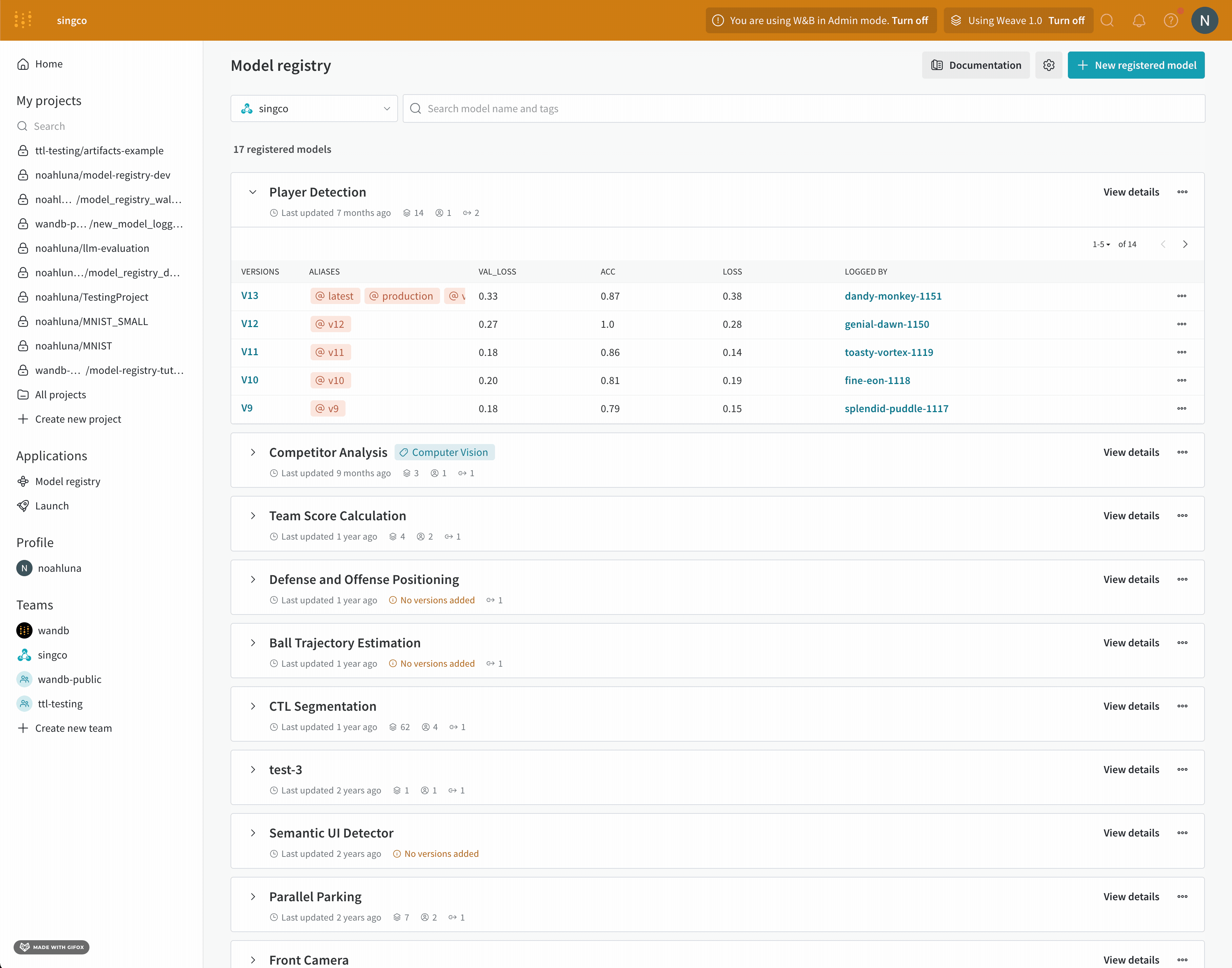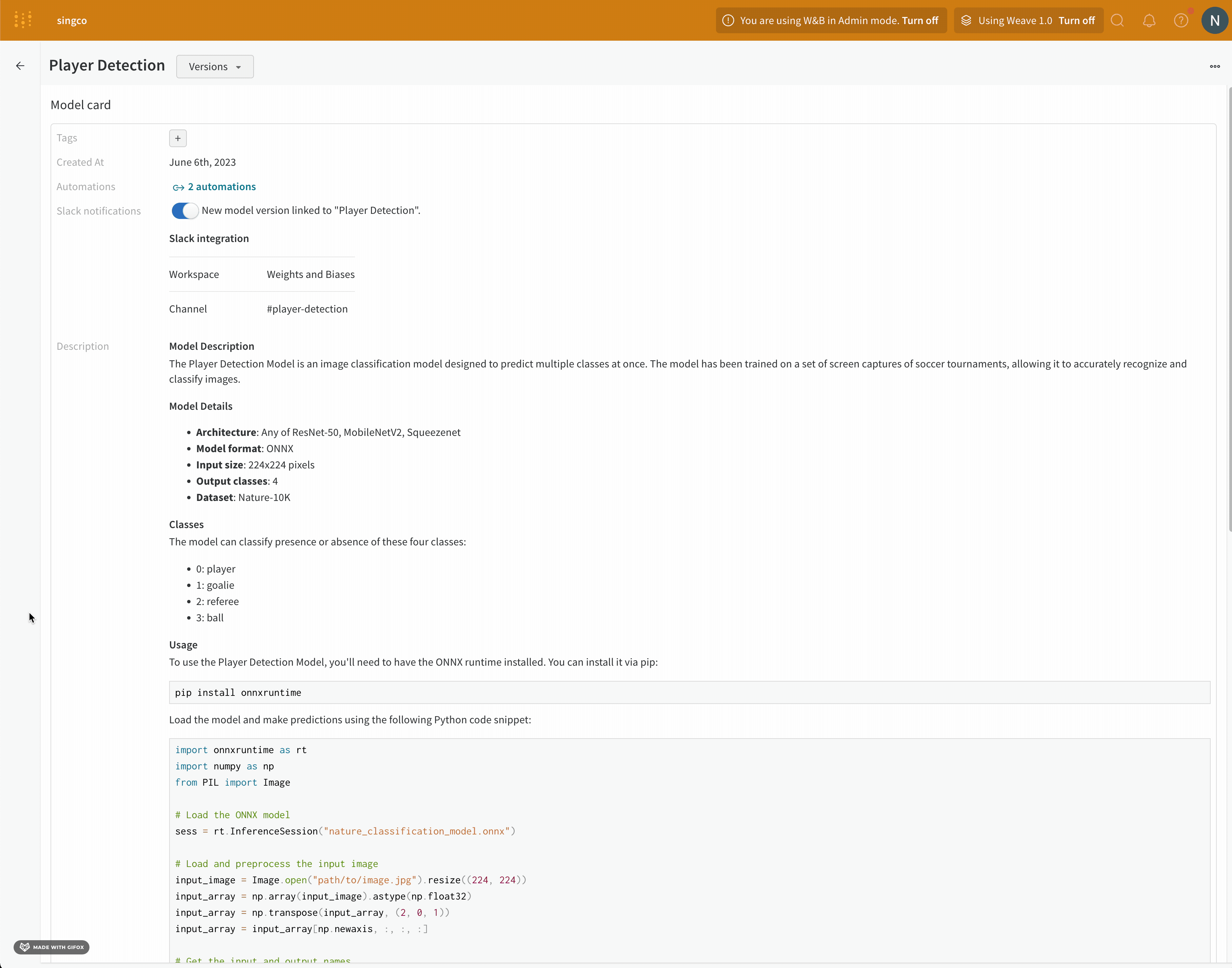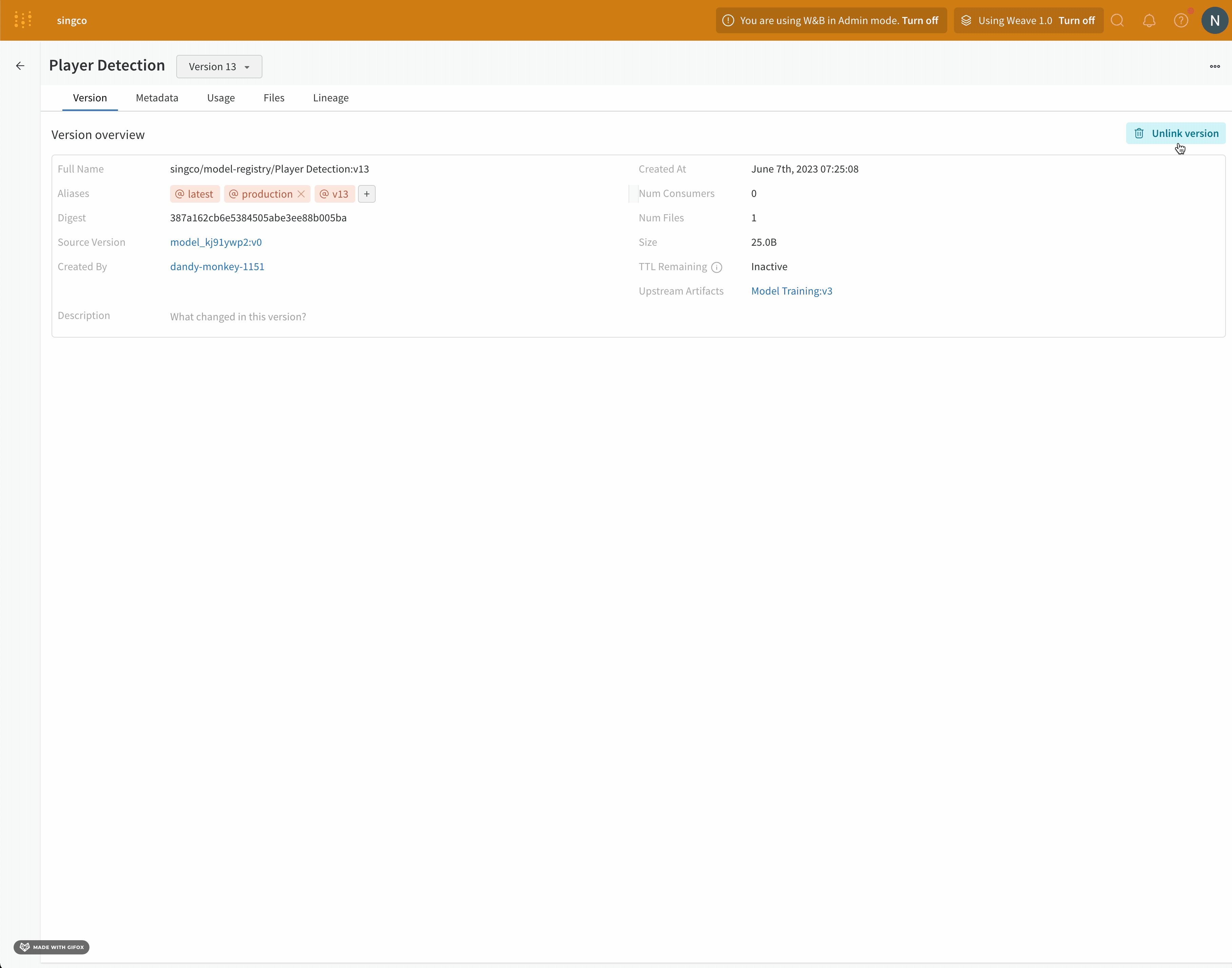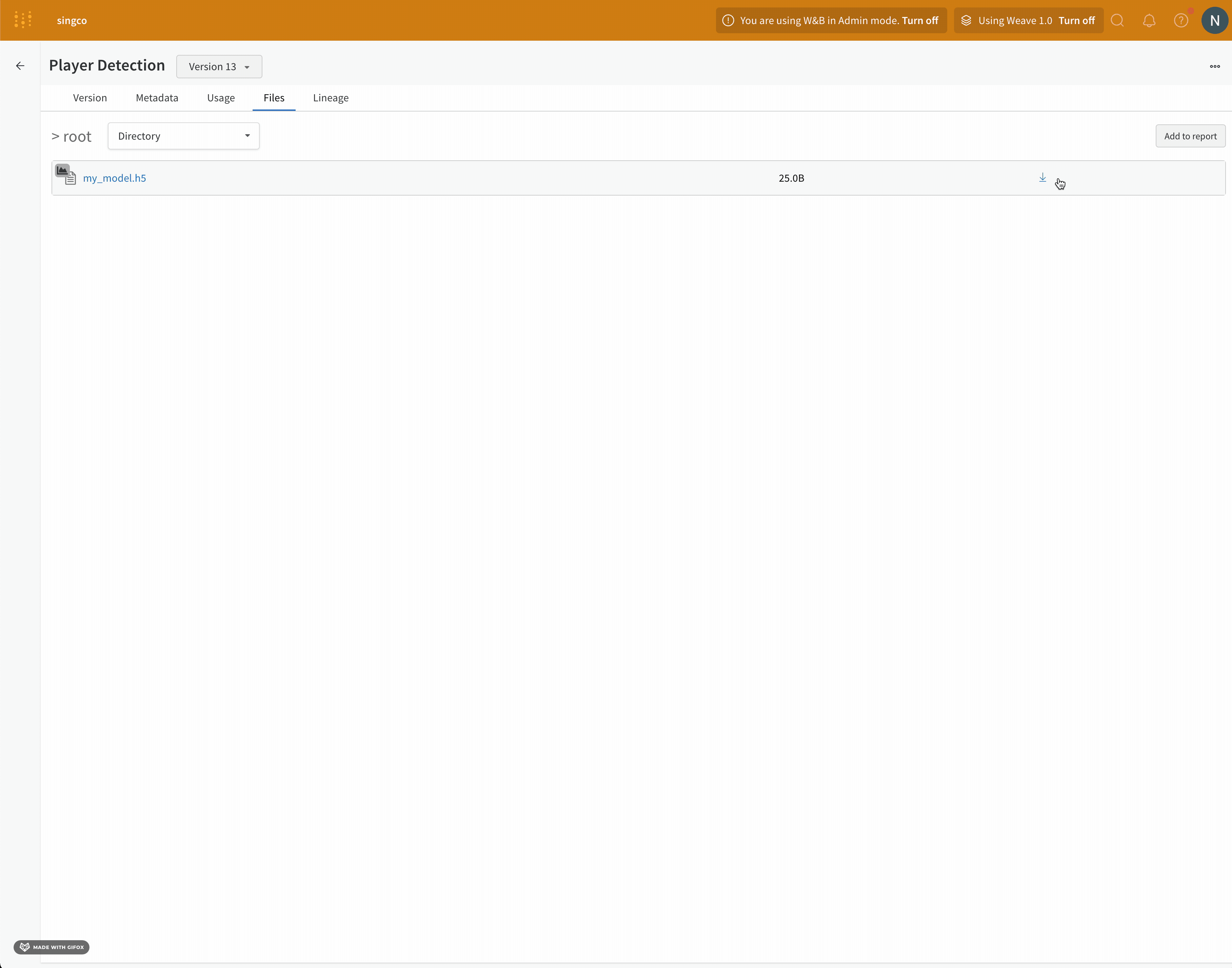
- ダウンロードするモデルが含まれている登録済みモデルの名前の横にある詳細を表示を選択します。
- [Versions] セクションで、ダウンロードするモデル version の横にある [View] ボタンを選択します。
- ファイル タブを選択します。
- ダウンロードするモデルファイルの横にあるダウンロードボタンをクリックします。
10 - Create alerts and notifications
新しい モデル バージョン が モデルレジストリ にリンクされたときに Slack 通知を受け取ります。
新しいモデル バージョンがモデルレジストリにリンクされたときに、Slack通知を受信します。
- W&B モデルレジストリのアプリ(https://wandb.ai/registry/model)に移動します。
- 通知を受信したい Registered Model を選択します。
- [Connect Slack] ボタンをクリックします。
- OAuth ページに表示される手順に従って、Slack workspace で W&B を有効にします。
チームの Slack 通知を設定すると、通知を受信する Registered Model を選択できます。
チームの Slack 通知が設定されている場合、[Connect Slack] ボタンの代わりに、[New model version linked to…] と表示されるトグルが表示されます。
以下のスクリーンショットは、Slack 通知が設定されている FMNIST 分類器の Registered Model を示しています。
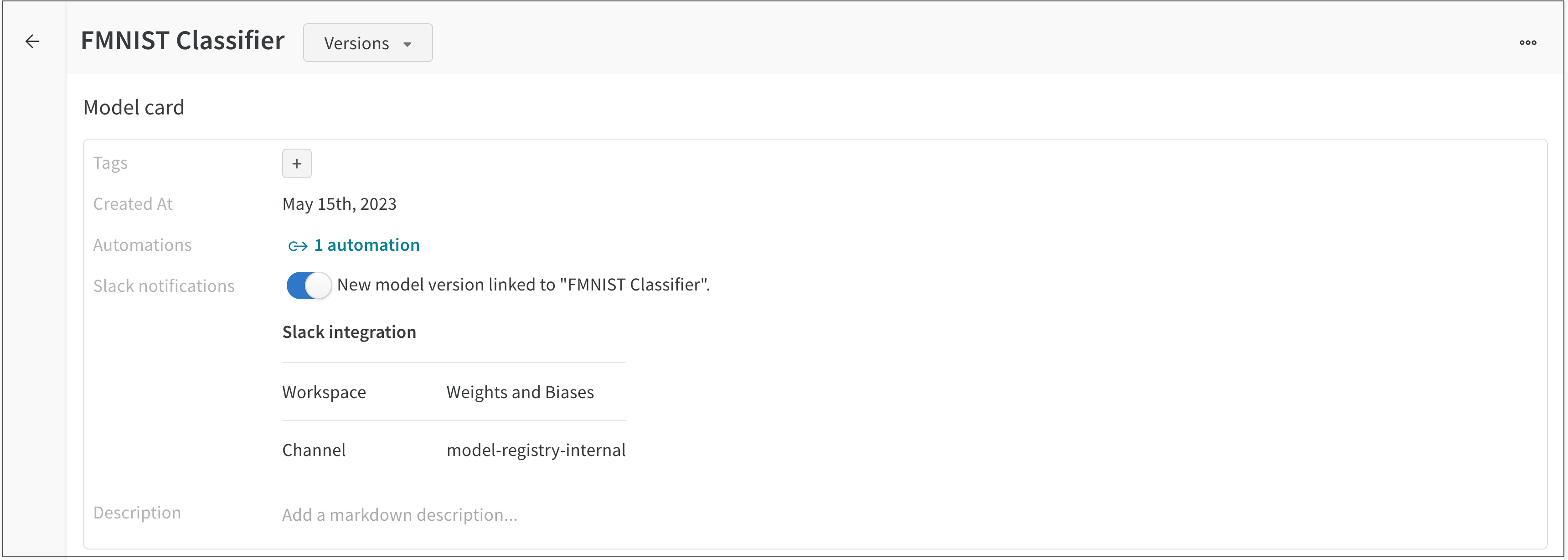
新しいモデル バージョンが FMNIST 分類器の Registered Model にリンクされるたびに、メッセージが接続された Slack チャンネルに自動的に投稿されます。
11 - Manage data governance and access control
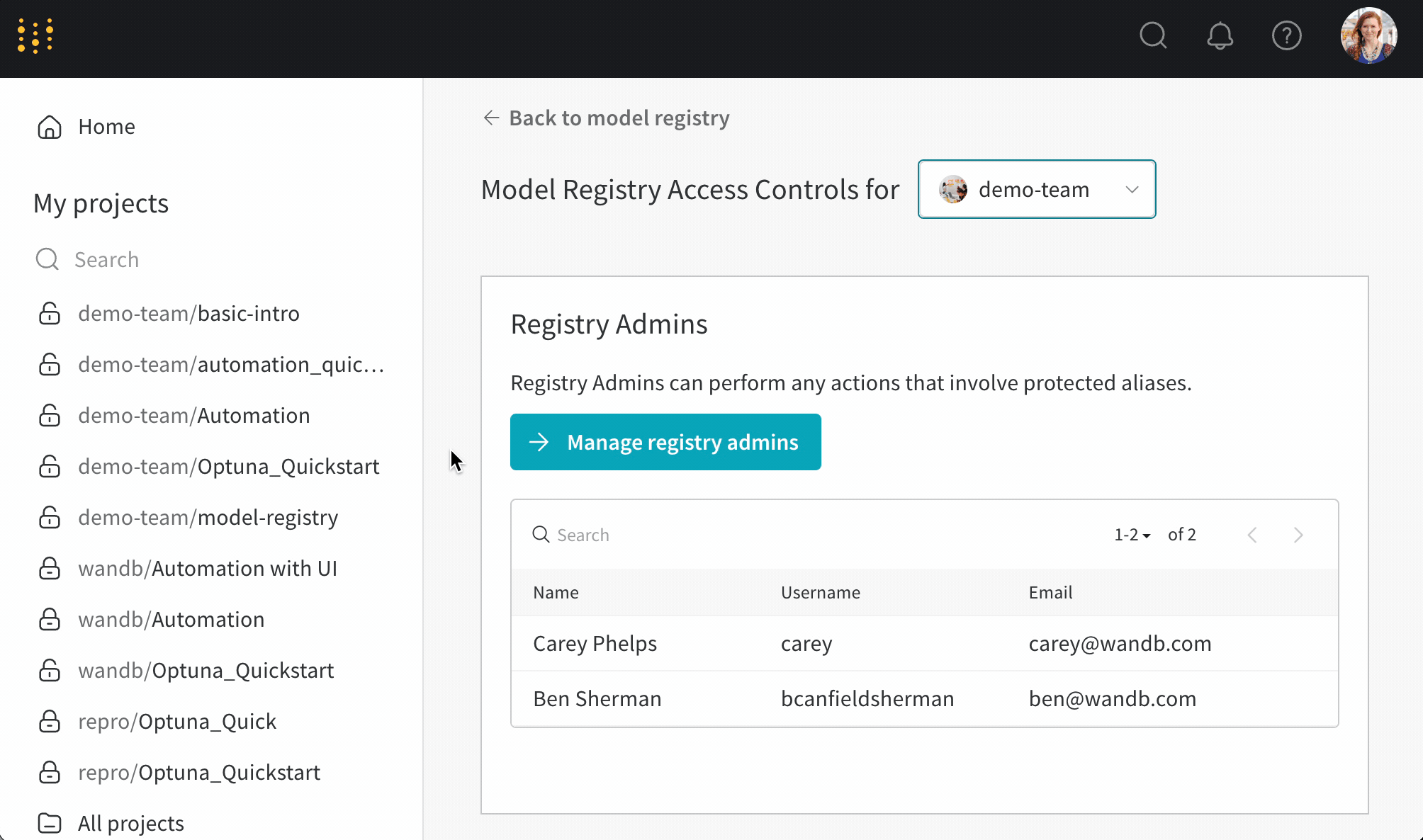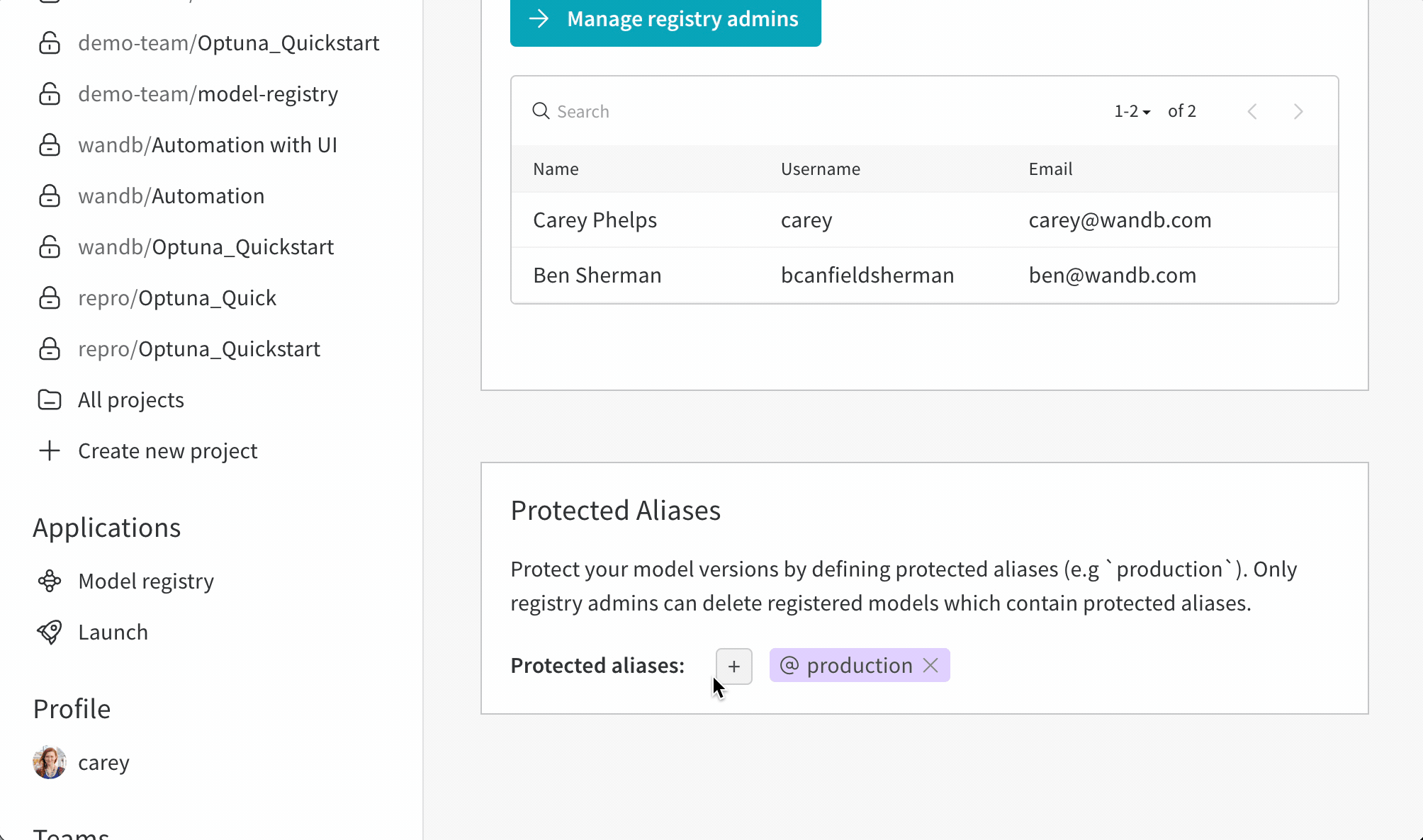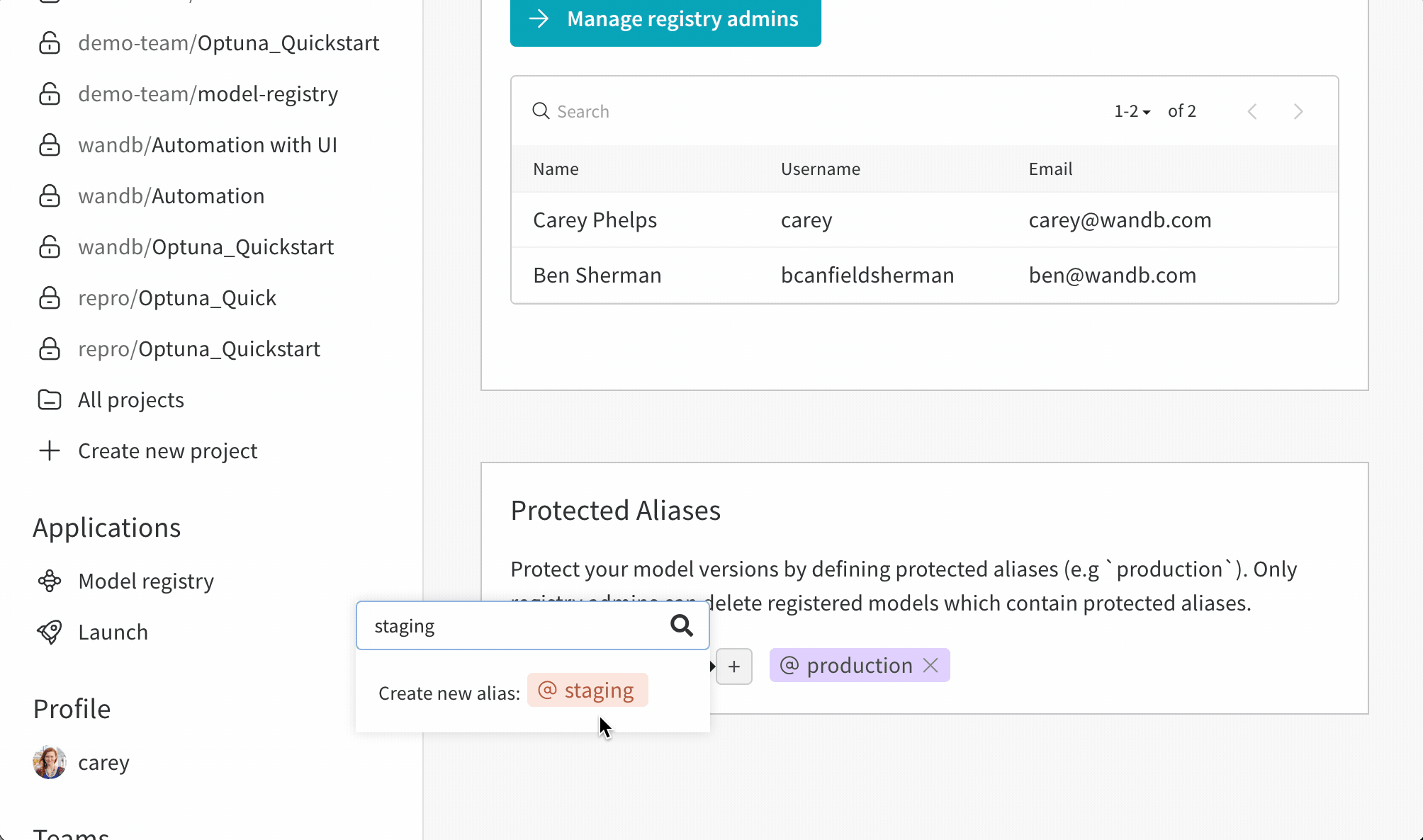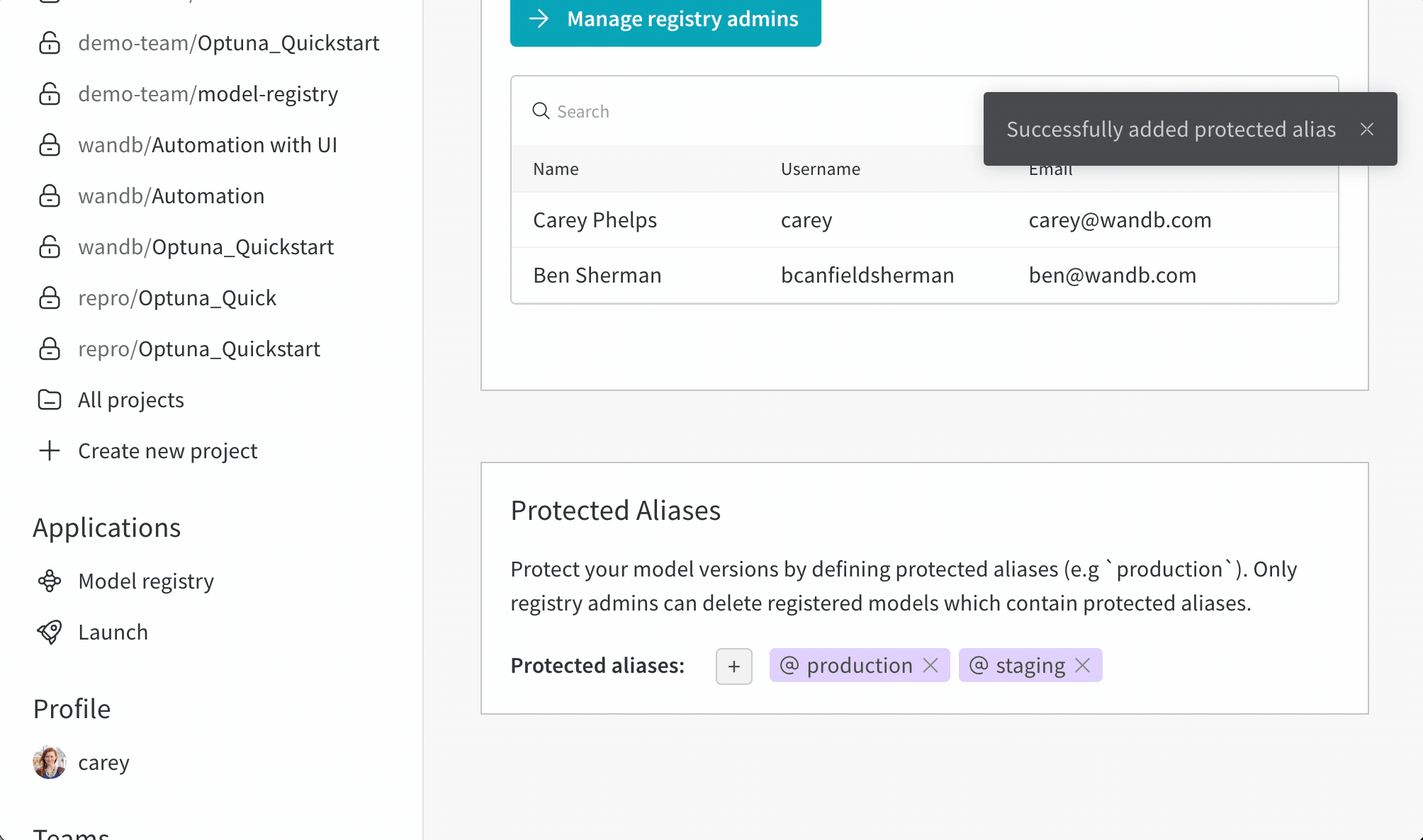
モデルレジストリのロールベース アクセス制御(RBAC)を使用して、保護されたエイリアスを更新できるユーザーを制御します。
モデル開発 パイプライン の主要な段階を表すために、 保護されたエイリアス を使用します。 モデルレジストリ管理者 のみが、保護されたエイリアスを追加、変更、または削除できます。モデルレジストリ管理者は、保護されたエイリアスを定義して使用できます。W&B は、管理者以外の ユーザー がモデル バージョン から保護されたエイリアスを追加または削除することをブロックします。
Team 管理者または現在のレジストリ管理者のみが、レジストリ管理者のリストを管理できます。
たとえば、 staging と production を保護されたエイリアスとして設定するとします。Team のメンバーは誰でも新しいモデル バージョンを追加できます。ただし、管理者のみが staging または production エイリアスを追加できます。
アクセス制御の設定
次の手順では、Team の モデルレジストリ の アクセス 制御を設定する方法について説明します。
- W&B モデルレジストリ アプリ ( https://wandb.ai/registry/model ) に移動します。
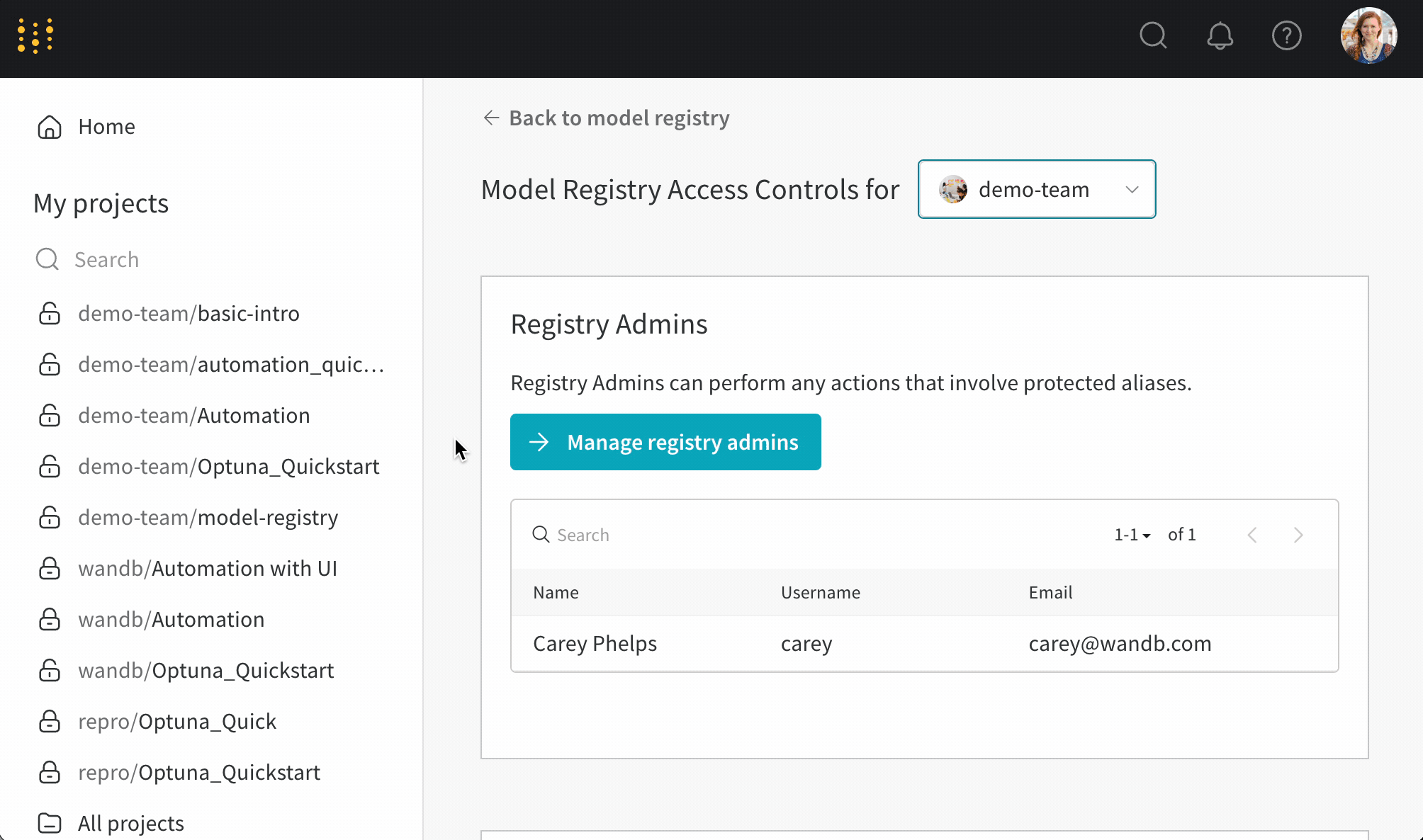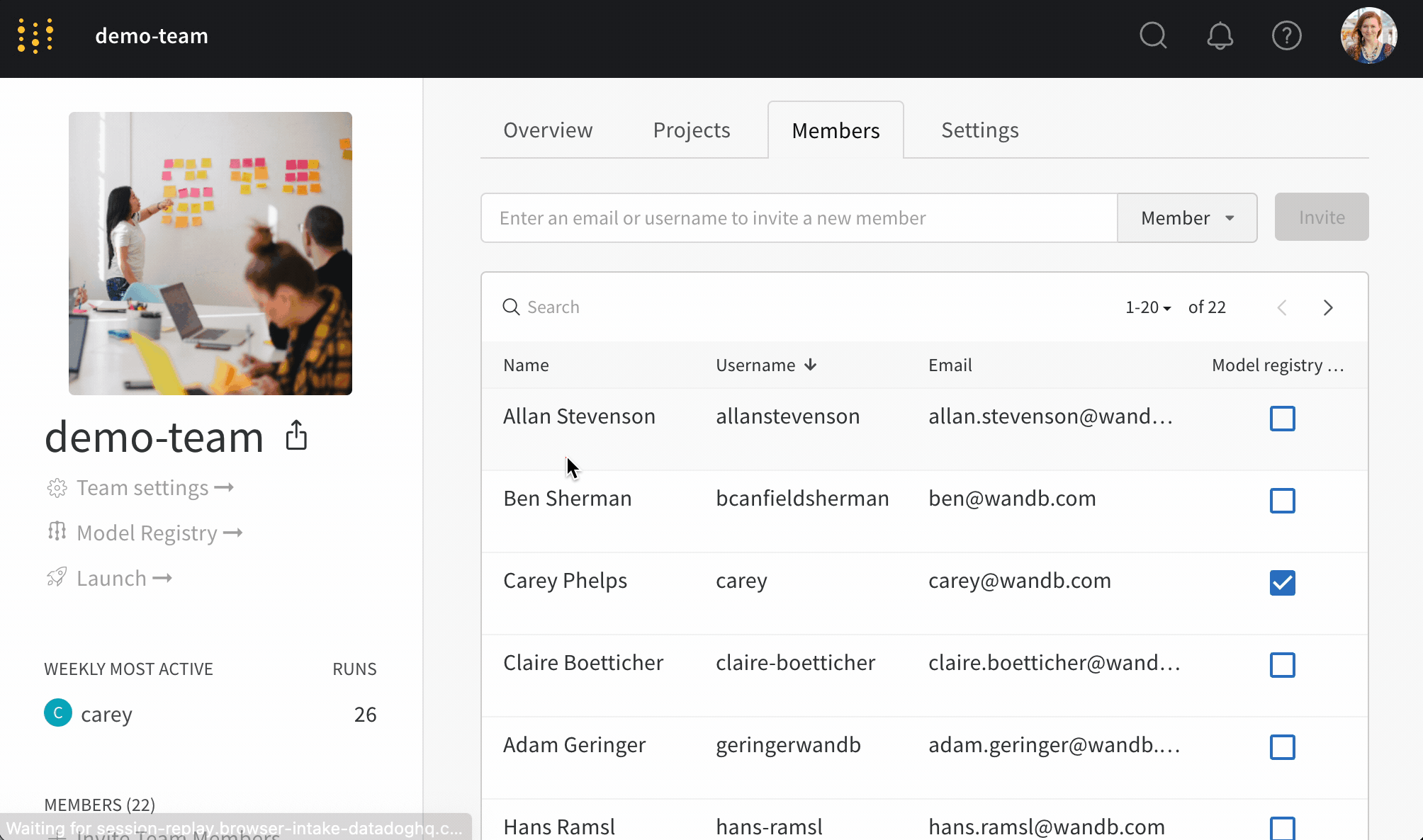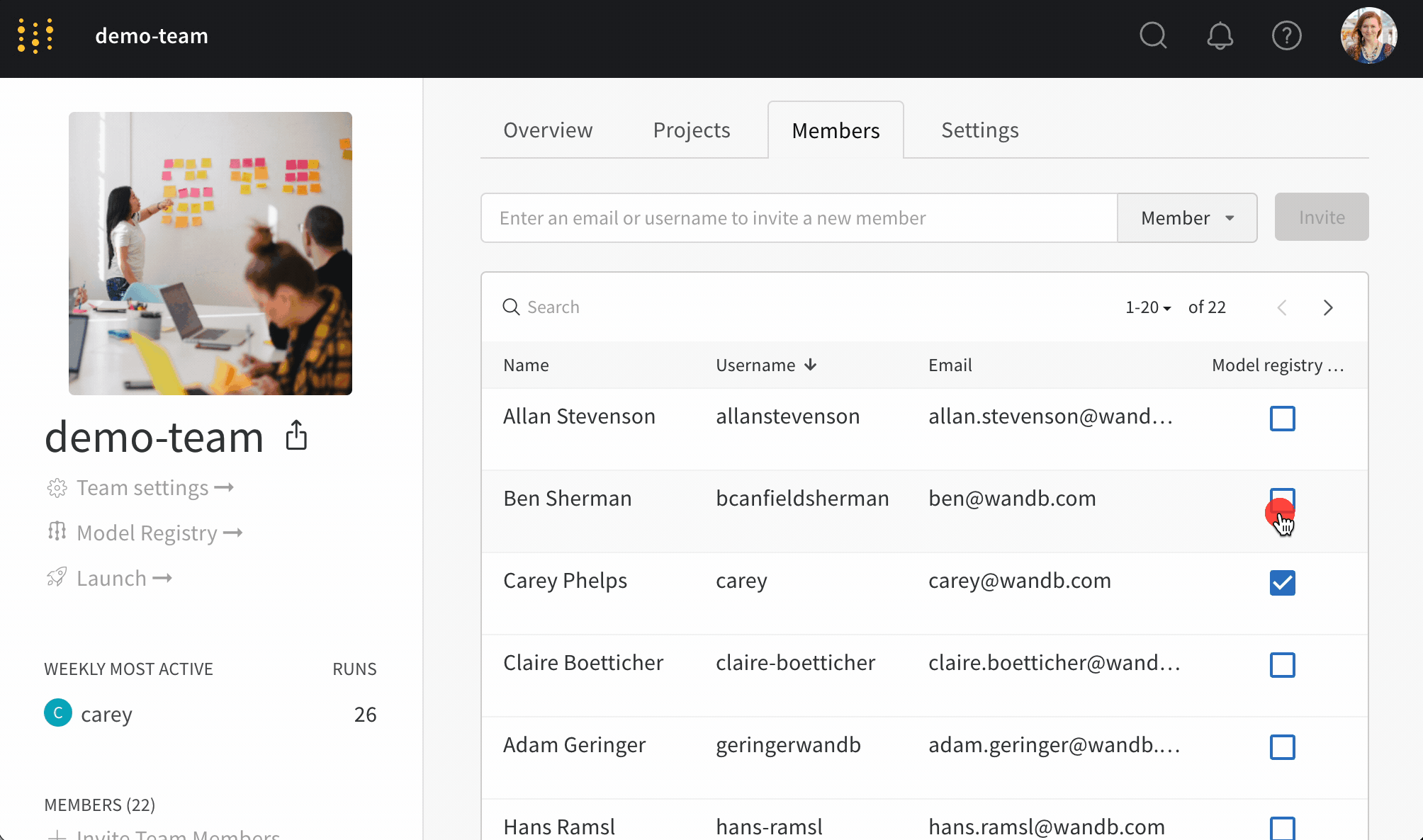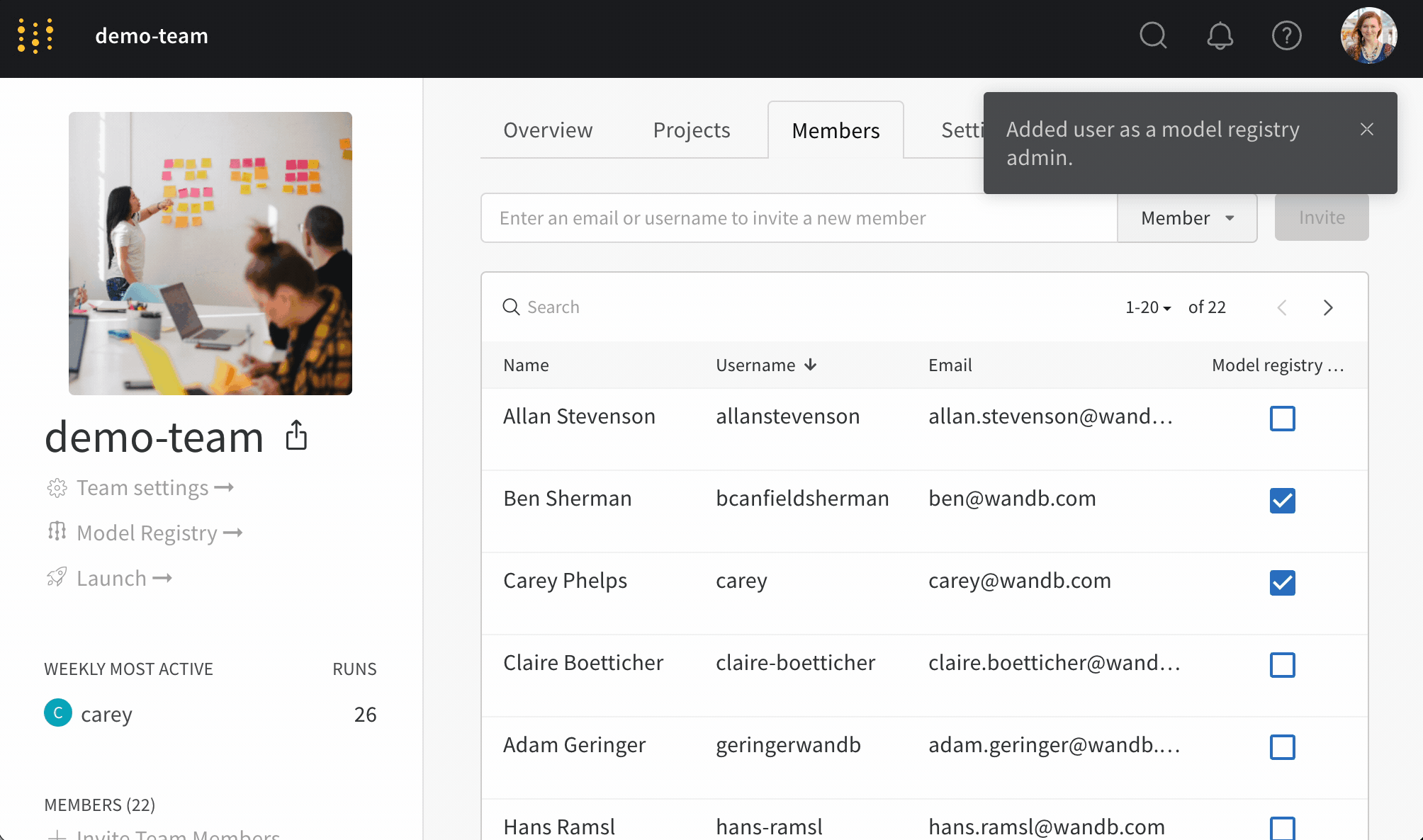
- ページの右上にある歯車ボタンを選択します。
- [レジストリ管理者の管理] ボタンを選択します。
- [メンバー] タブで、モデル バージョン から保護されたエイリアスを追加および削除する アクセス 権を付与する ユーザー を選択します。
保護されたエイリアスの追加
- W&B モデルレジストリ アプリ ( https://wandb.ai/registry/model ) に移動します。
- ページの右上にある歯車ボタンを選択します。
- [保護されたエイリアス] セクションまで下にスクロールします。
- プラス アイコン ( + ) アイコンをクリックして、新しいエイリアスを追加します。