クエリー パネルを使用して、データをクエリーし、インタラクティブに視覚化します。
クエリー パネルの作成
ワークスペースまたは レポート 内にクエリーを追加します。
- プロジェクト の ワークスペース に移動します。
- 右上隅にある「Add panel( パネル を追加)」をクリックします。
- ドロップダウンから「Query panel(クエリー パネル )」を選択します。
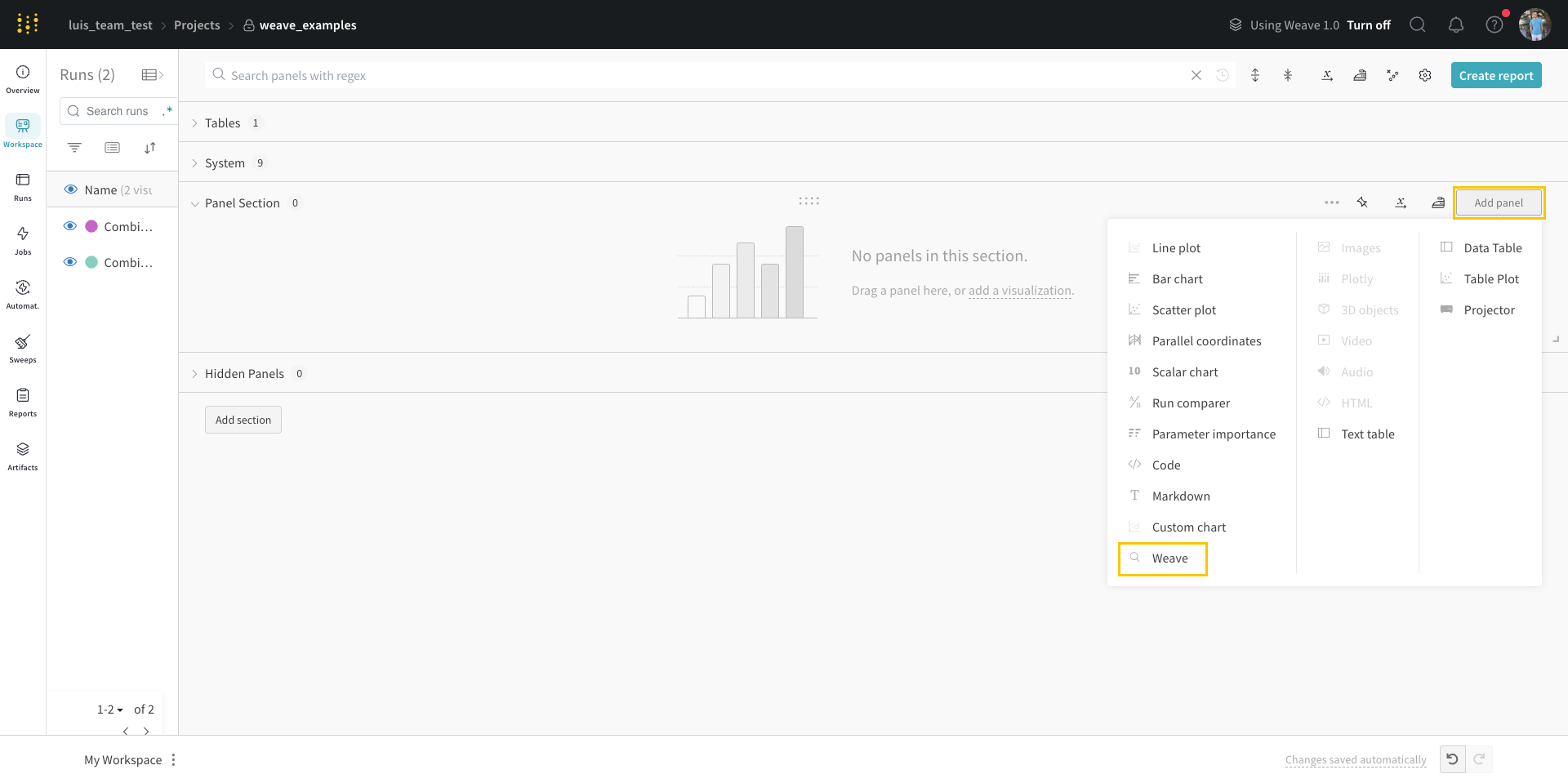
「/Query panel(/クエリー パネル )」と入力して選択します。
または、クエリーを 一連の Runs に関連付けることもできます。
- レポート 内で、「/Panel grid(/ パネル グリッド)」と入力して選択します。
- 「Add panel( パネル を追加)」ボタンをクリックします。
- ドロップダウンから「Query panel(クエリー パネル )」を選択します。
クエリーのコンポーネント
式
クエリー式を使用して、Runs、Artifacts、Models、Tables など、W&B に保存されているデータをクエリーします。
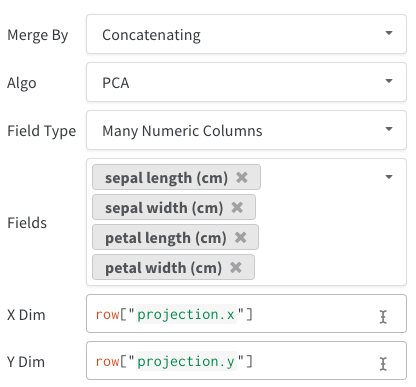
例: テーブル のクエリー
W&B Table をクエリーするとします。 トレーニング コード で、"cifar10_sample_table"というテーブルを ログ に記録します。
import wandb
wandb.log({"cifar10_sample_table":<MY_TABLE>})
クエリー パネル 内では、次のコードでテーブルをクエリーできます。
runs.summary["cifar10_sample_table"]

これを分解すると次のようになります。
runsは、クエリー パネル が ワークスペース にある場合、クエリー パネル 式に自動的に挿入される変数です。 その「値」は、特定の ワークスペース で表示できる Runs のリストです。 run で使用できるさまざまな属性については、こちらをお読みください。summaryは、Run の Summary オブジェクトを返す op です。 Op は mapped です。つまり、この op はリスト内の各 Run に適用され、Summary オブジェクトのリストが生成されます。["cifar10_sample_table"]は、predictionsという パラメータ を持つ Pick op(角かっこで示されます)です。 Summary オブジェクトは ディクショナリー または マップ のように動作するため、この操作は各 Summary オブジェクトからpredictionsフィールドを選択します。
独自のクエリーをインタラクティブに作成する方法については、この レポート を参照してください。
設定
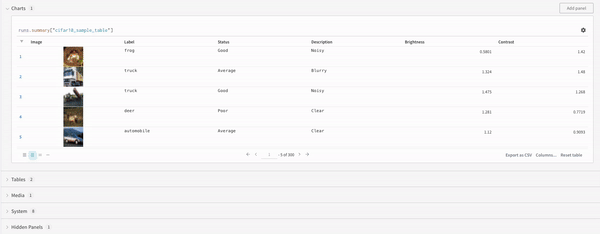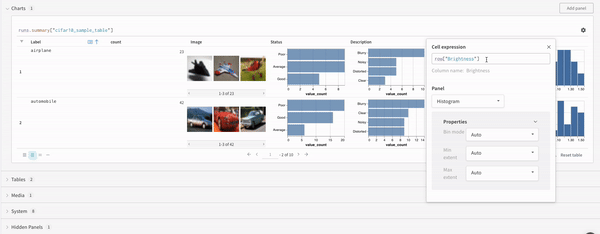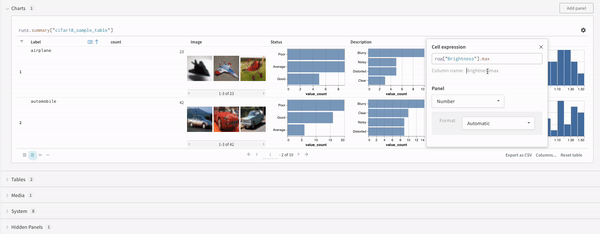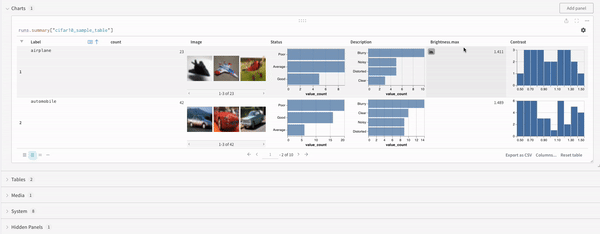
パネル の左上隅にある歯車アイコンを選択して、クエリー 設定 を展開します。 これにより、 ユーザー は パネル のタイプと、結果 パネル の パラメータ を 設定 できます。
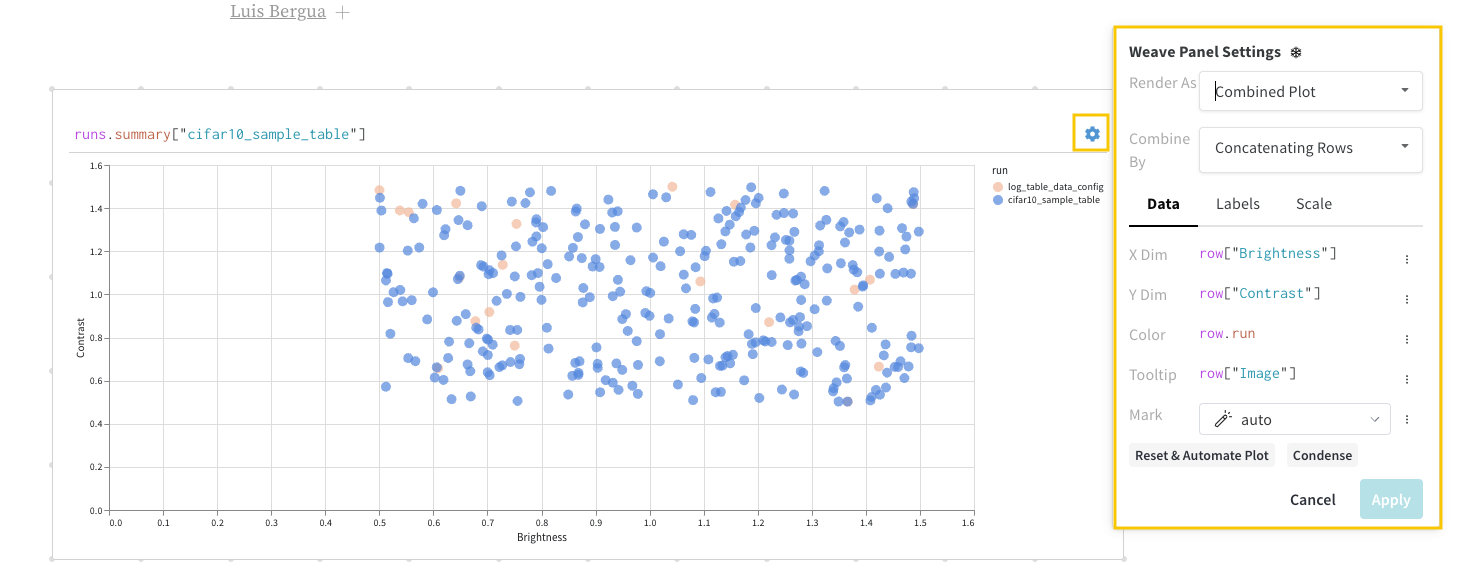
結果 パネル
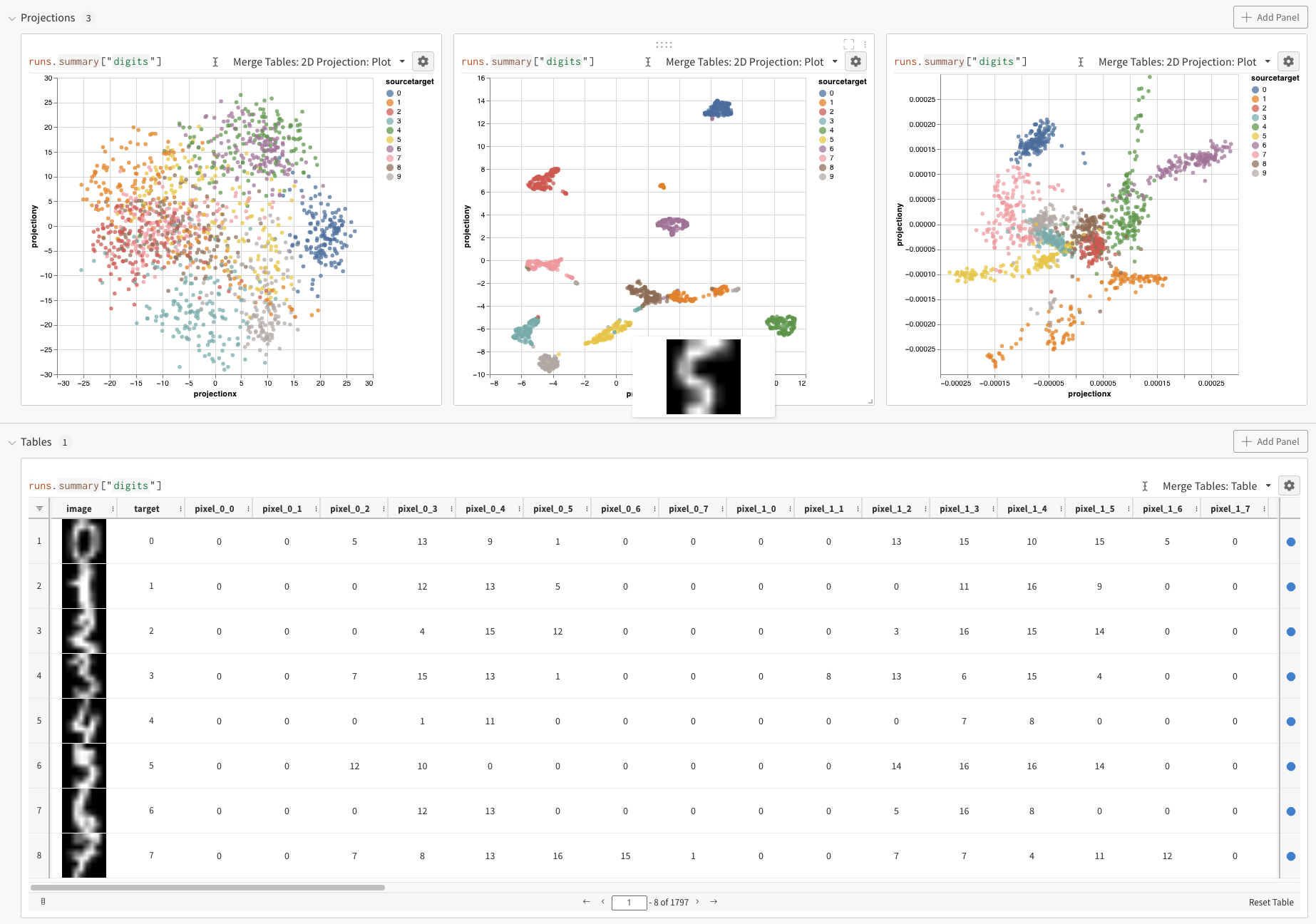
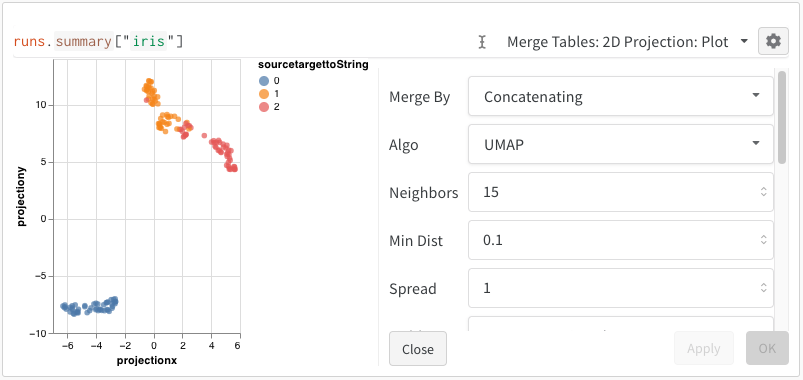
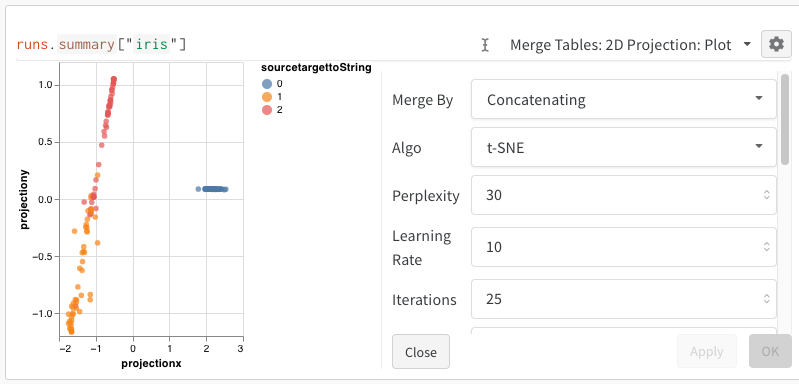
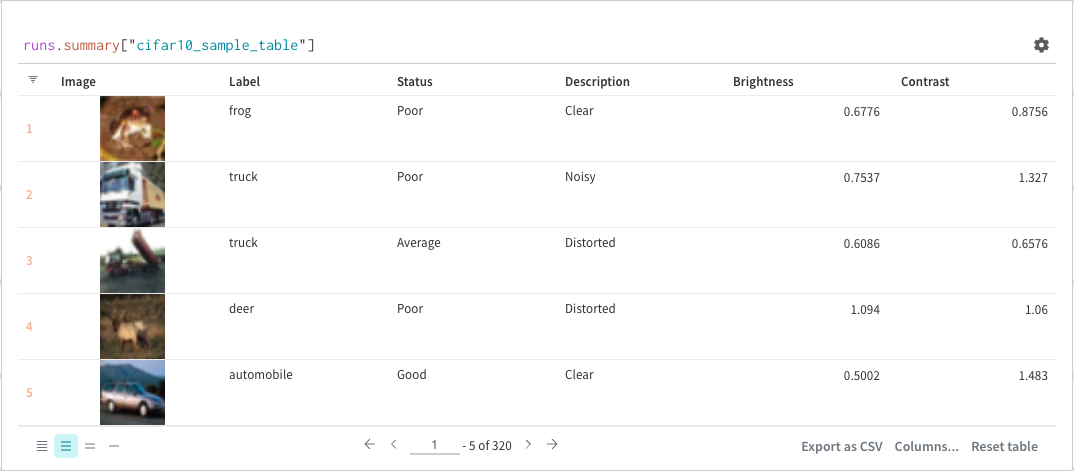
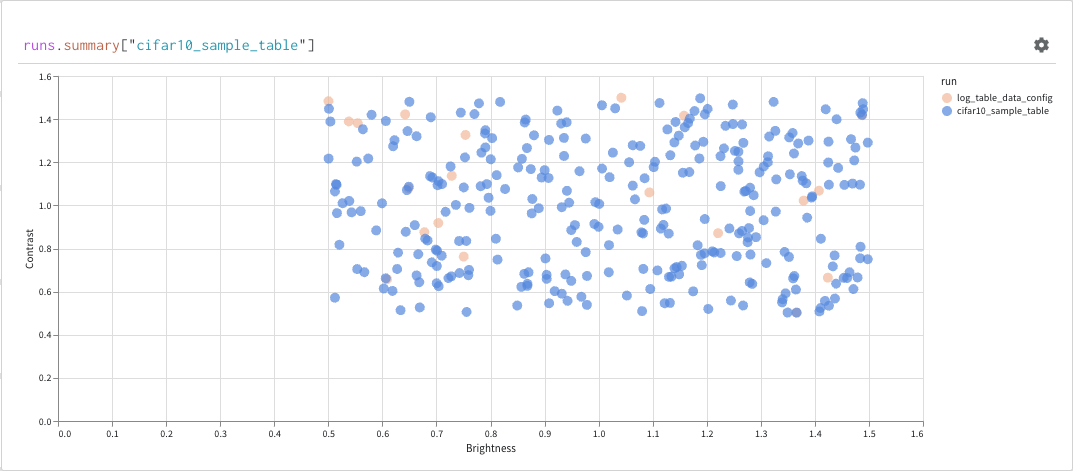
最後に、クエリー結果 パネル は、選択したクエリー パネル を使用して、クエリー式の結果をレンダリングし、データ をインタラクティブな形式で表示するように 設定 によって 設定 されます。 次の画像は、同じデータの Table とプロットを示しています。
基本操作
クエリー パネル 内で実行できる一般的な操作を次に示します。
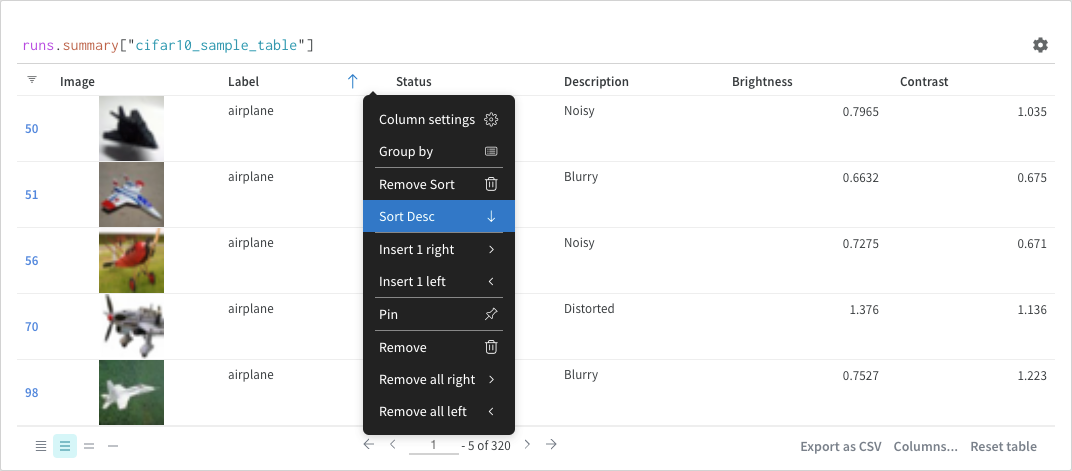
並べ替え
列オプションから並べ替えを行います。
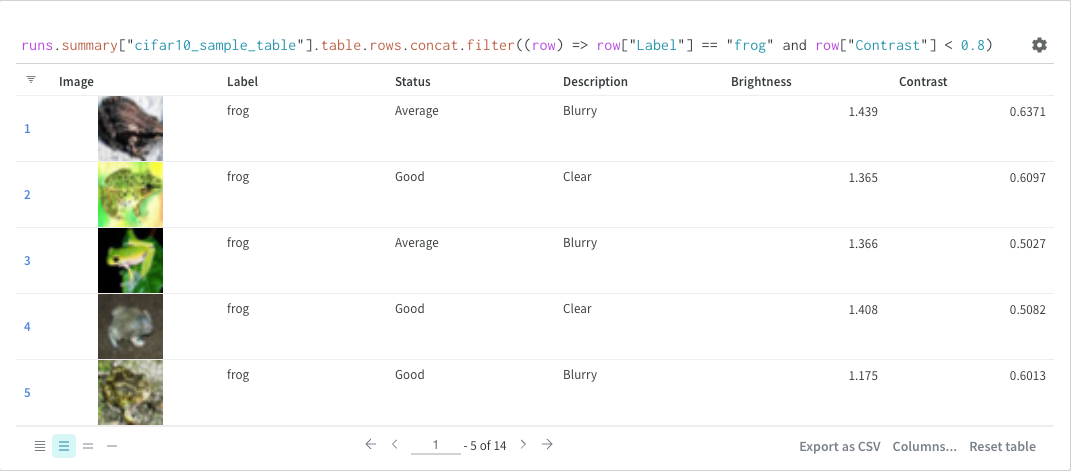
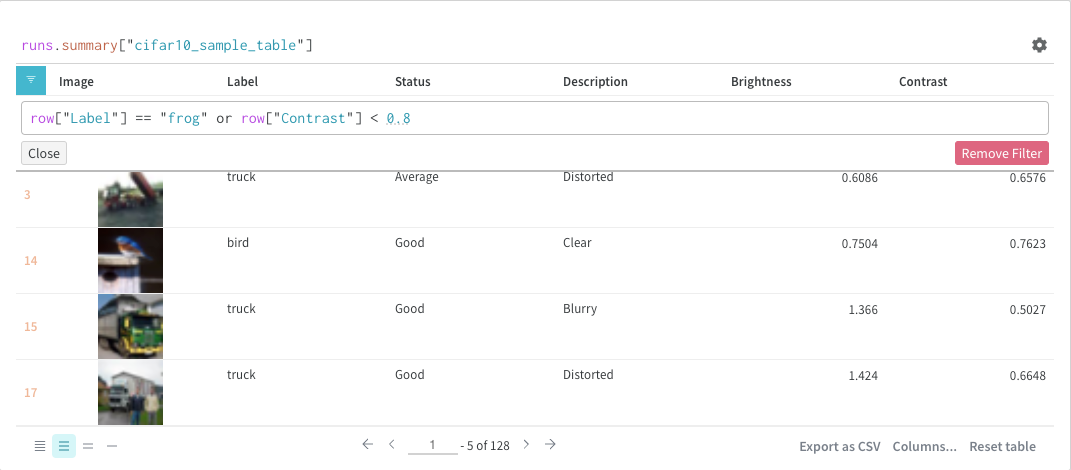
フィルター
クエリーで直接 フィルター するか、左上隅にある フィルター ボタンを使用できます(2 番目の画像)。
マップ
マップ 操作はリストを反復処理し、データ 内の各要素に関数を適用します。 これは、 パネル クエリー で直接行うか、列オプションから新しい列を挿入して行うことができます。
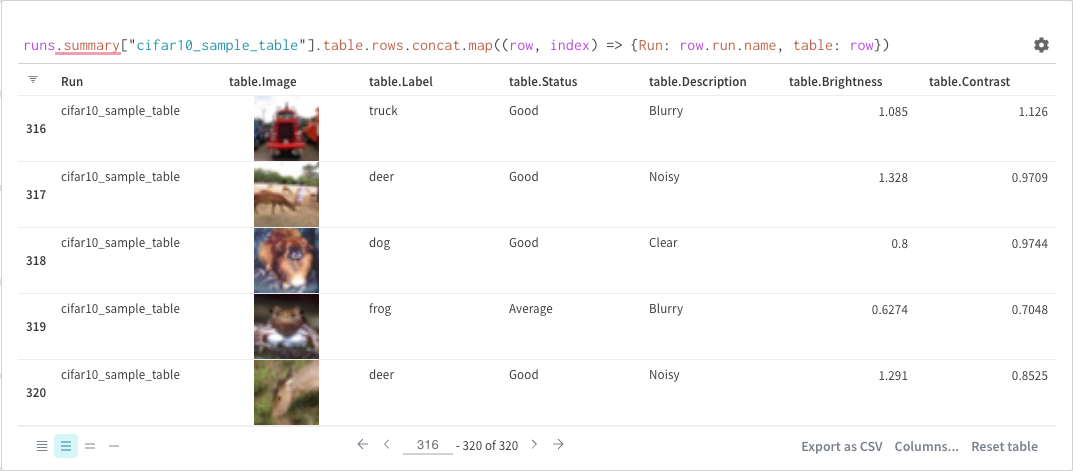

グループ化
クエリーまたは列オプションを使用してグループ化できます。
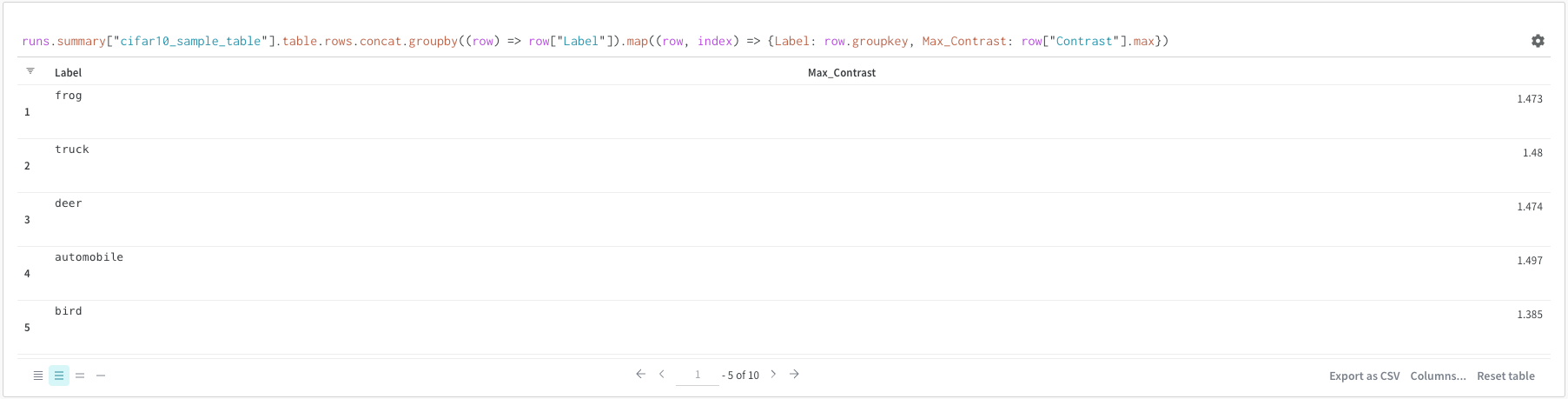
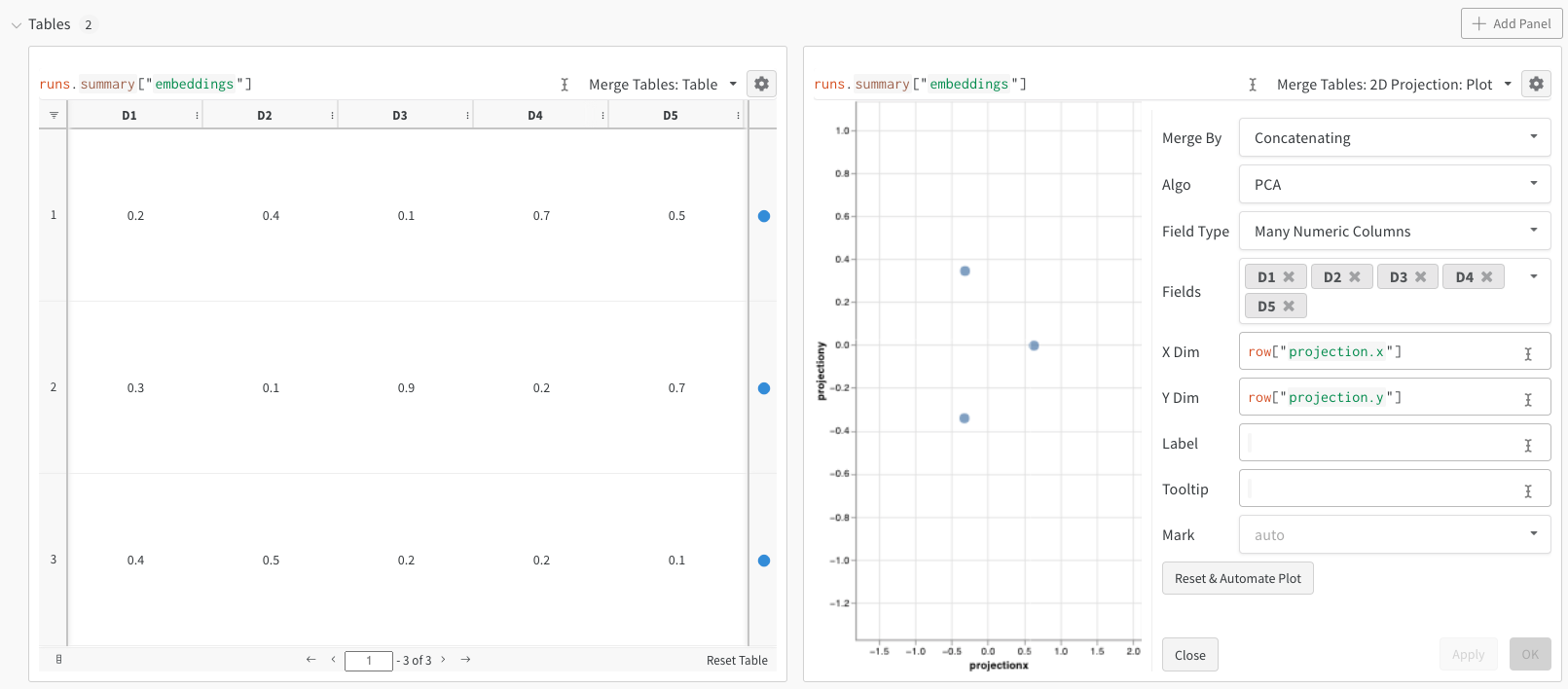
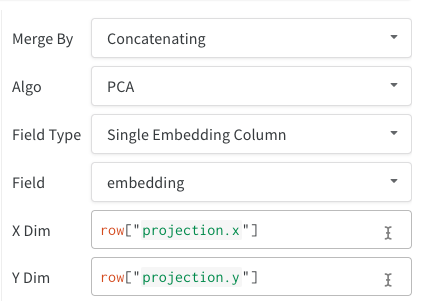
連結
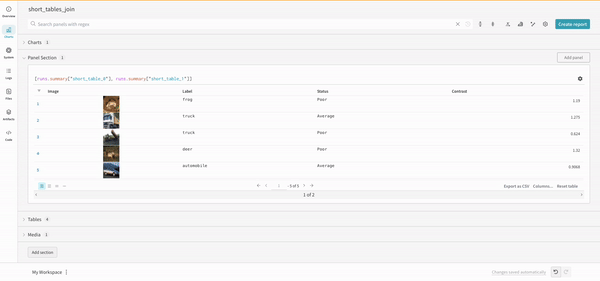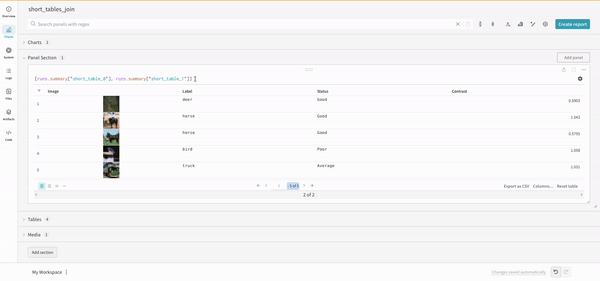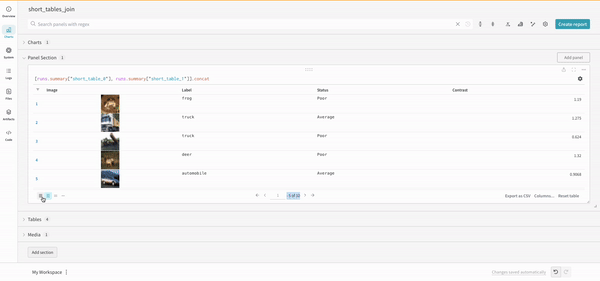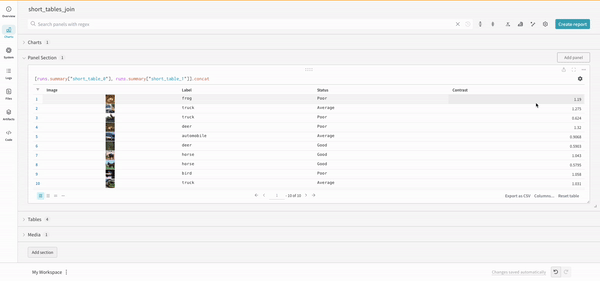
連結操作を使用すると、2 つのテーブルを連結し、 パネル 設定 から連結または結合できます。
結合
クエリーでテーブルを直接結合することも可能です。 次のクエリー式を検討してください。
project("luis_team_test", "weave_example_queries").runs.summary["short_table_0"].table.rows.concat.join(\
project("luis_team_test", "weave_example_queries").runs.summary["short_table_1"].table.rows.concat,\
(row) => row["Label"],(row) => row["Label"], "Table1", "Table2",\
"false", "false")
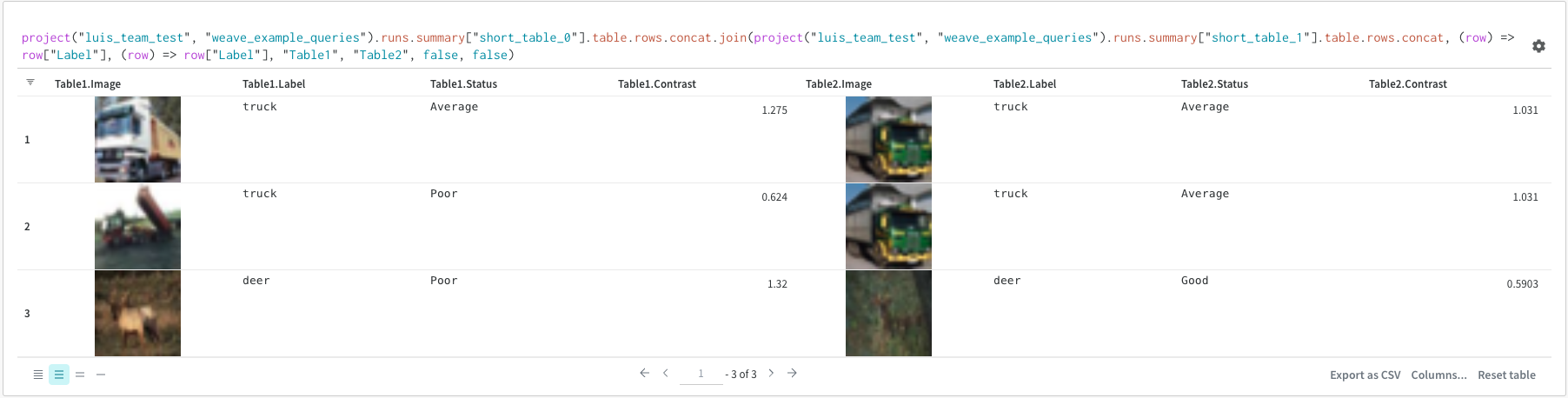
左側のテーブルは、次のように生成されます。
project("luis_team_test", "weave_example_queries").\
runs.summary["short_table_0"].table.rows.concat.join
右側のテーブルは、次のように生成されます。
project("luis_team_test", "weave_example_queries").\
runs.summary["short_table_1"].table.rows.concat
説明:
(row) => row["Label"]は各テーブルのセレクターであり、結合する列を決定します"Table1"と"Table2"は、結合時の各テーブルの名前ですtrueとfalseは、左側の内部/外部結合 設定 用です
Runs オブジェクト
クエリー パネル を使用して runs オブジェクトにアクセスします。 Run オブジェクトは、 Experiments のレコードを保存します。 詳細については、 レポート のこのセクションを参照してください。簡単にまとめると、runs オブジェクトには次のものが含まれます。
summary: Run の結果をまとめた情報の ディクショナリー 。 これは、精度や損失などのスカラー、または大きなファイルにすることができます。 デフォルトでは、wandb.log()は Summary を ログ に記録された 時系列 の最終値に 設定 します。 Summary の内容を直接 設定 できます。 Summary を Run の出力として考えてください。history: 損失など、モデル の トレーニング 中に変化する値を保存するための ディクショナリー のリスト。 コマンドwandb.log()はこの オブジェクト に追加されます。config: トレーニング Run の ハイパー パラメータ ーや、データセット Artifact を作成する Run の 前処理 メソッド など、Run の 設定 情報の ディクショナリー 。 これらを Run の「入力」と考えてください。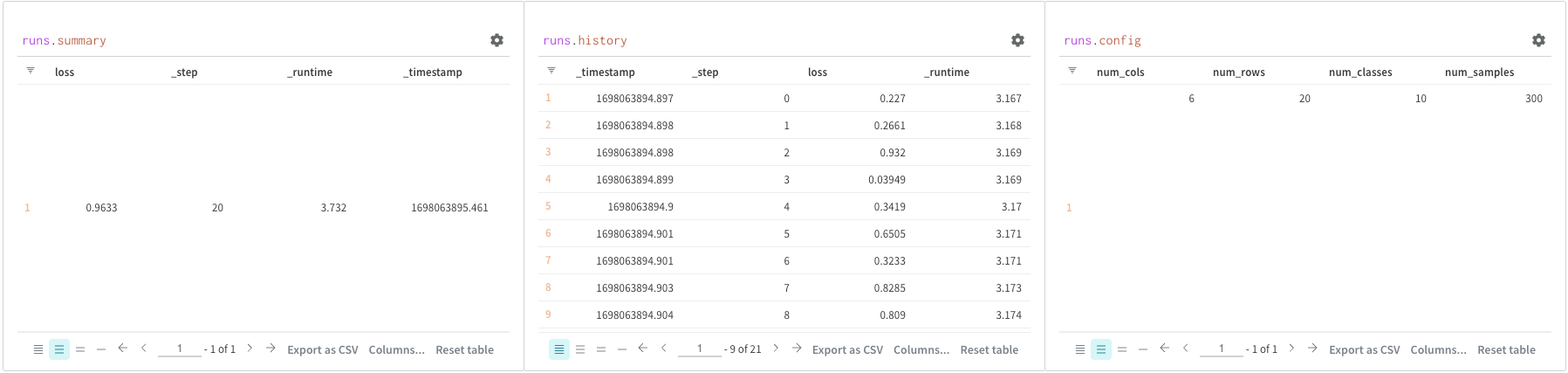
Artifacts へのアクセス
Artifacts は W&B の 中核となる概念です。 これらは、 バージョン 管理された名前付きのファイルと ディレクトリー のコレクションです。 Artifacts を使用して、モデル の重み、データセット 、およびその他のファイルまたは ディレクトリー を追跡します。 Artifacts は W&B に保存され、ダウンロードしたり、他の Runs で使用したりできます。 詳細と例については、 レポート のこのセクションを参照してください。 Artifacts には通常、project オブジェクト からアクセスします。
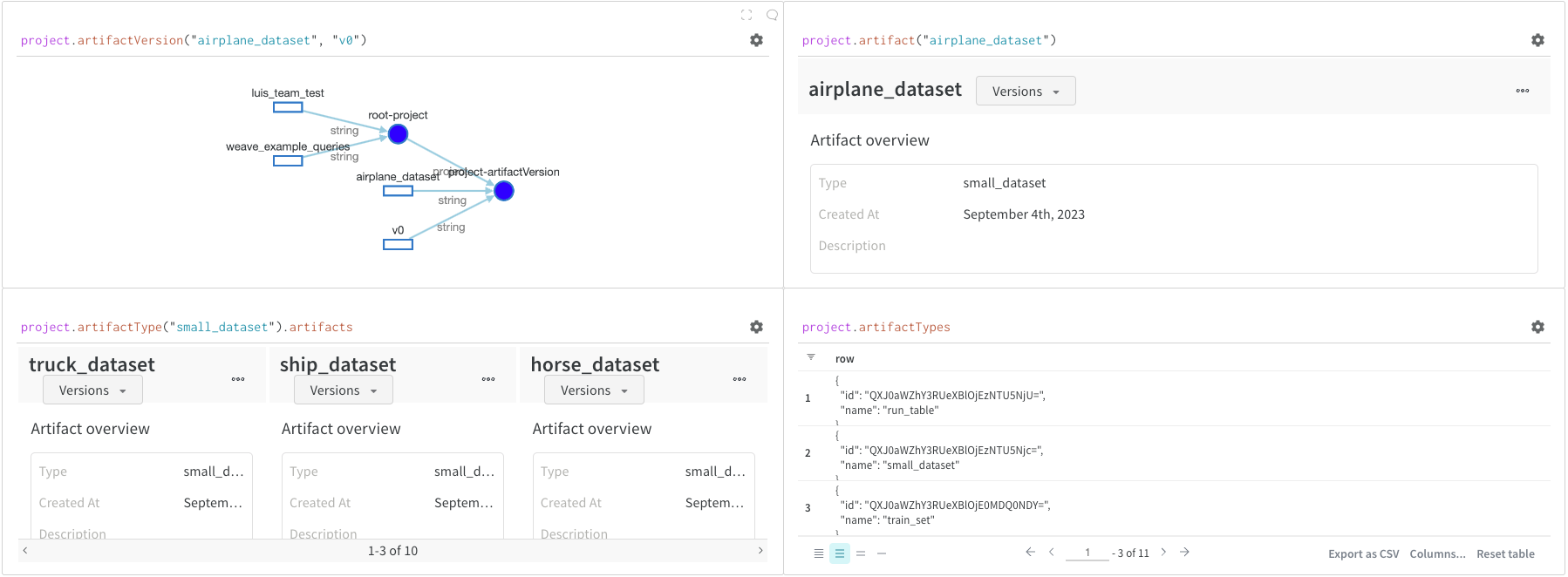
project.artifactVersion(): プロジェクト 内の指定された名前と バージョン の特定の Artifact バージョン を返します。project.artifact(""): プロジェクト 内の指定された名前の Artifact を返します。 次に、.versionsを使用して、この Artifact のすべての バージョン のリストを取得できます。project.artifactType(): プロジェクト 内の指定された名前のartifactTypeを返します。 次に、.artifactsを使用して、このタイプのすべての Artifacts のリストを取得できます。project.artifactTypes: プロジェクト 下にあるすべての Artifact タイプ のリストを返します。