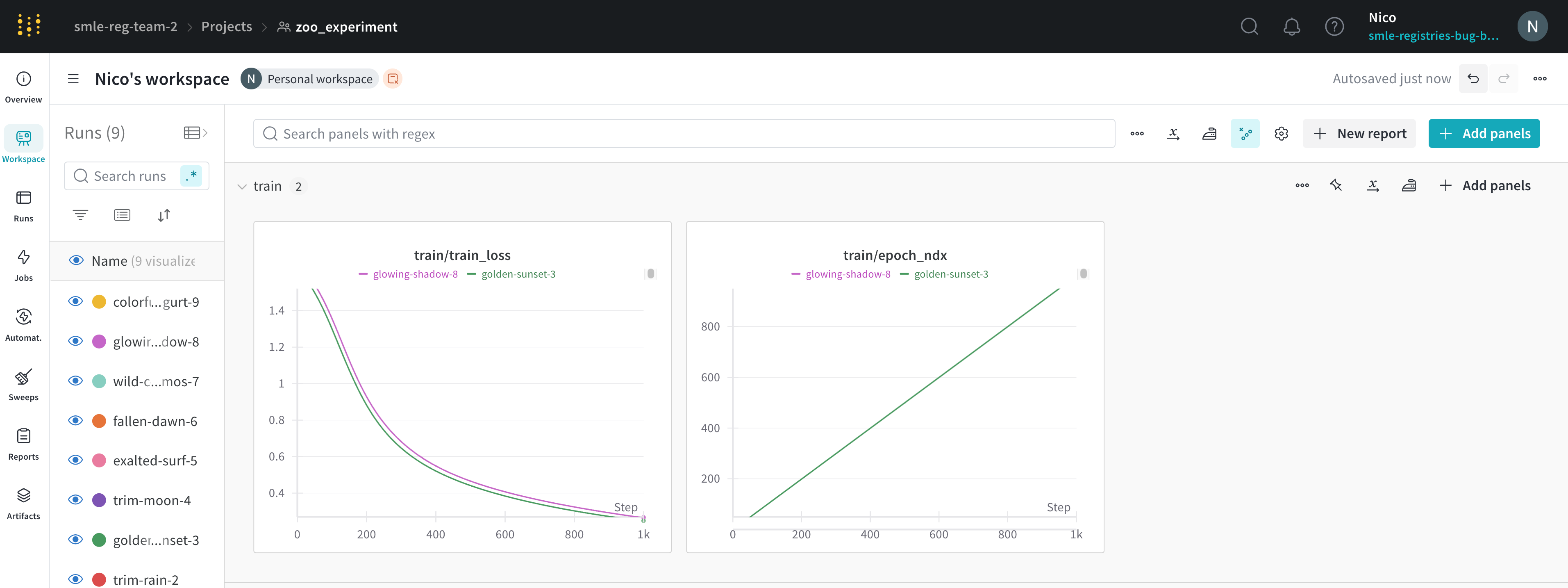
折れ線グラフは、wandb.log() で時間の経過とともにメトリクスをプロットすると、デフォルトで表示されます。チャートの設定をカスタマイズして、同じプロット上に複数の線を比較したり、カスタム軸を計算したり、ラベルの名前を変更したりできます。
折れ線グラフの設定を編集する
このセクションでは、個々の折れ線グラフ パネル、セクション内のすべての折れ線グラフ パネル、またはワークスペース内のすべての折れ線グラフ パネルの設定を編集する方法について説明します。
wandb.log() の呼び出しでログに記録されていることを確認してください。個々の折れ線グラフ
折れ線グラフの個々の設定は、セクションまたはワークスペースの折れ線グラフの設定よりも優先されます。折れ線グラフをカスタマイズするには:
- マウスをパネルの上に置き、歯車アイコンをクリックします。
- 表示されるモーダル内で、タブを選択して 設定 を編集します。
- 適用 をクリックします。
折れ線グラフの設定
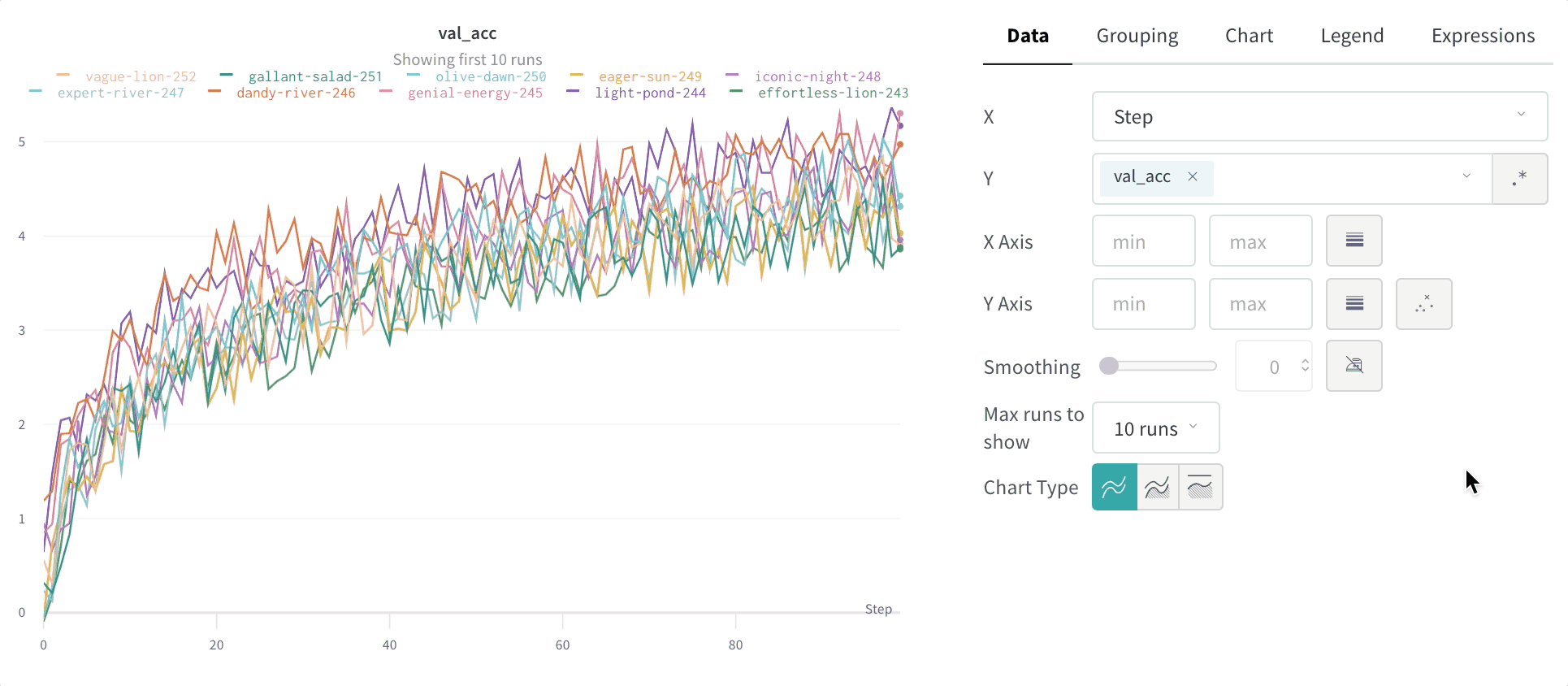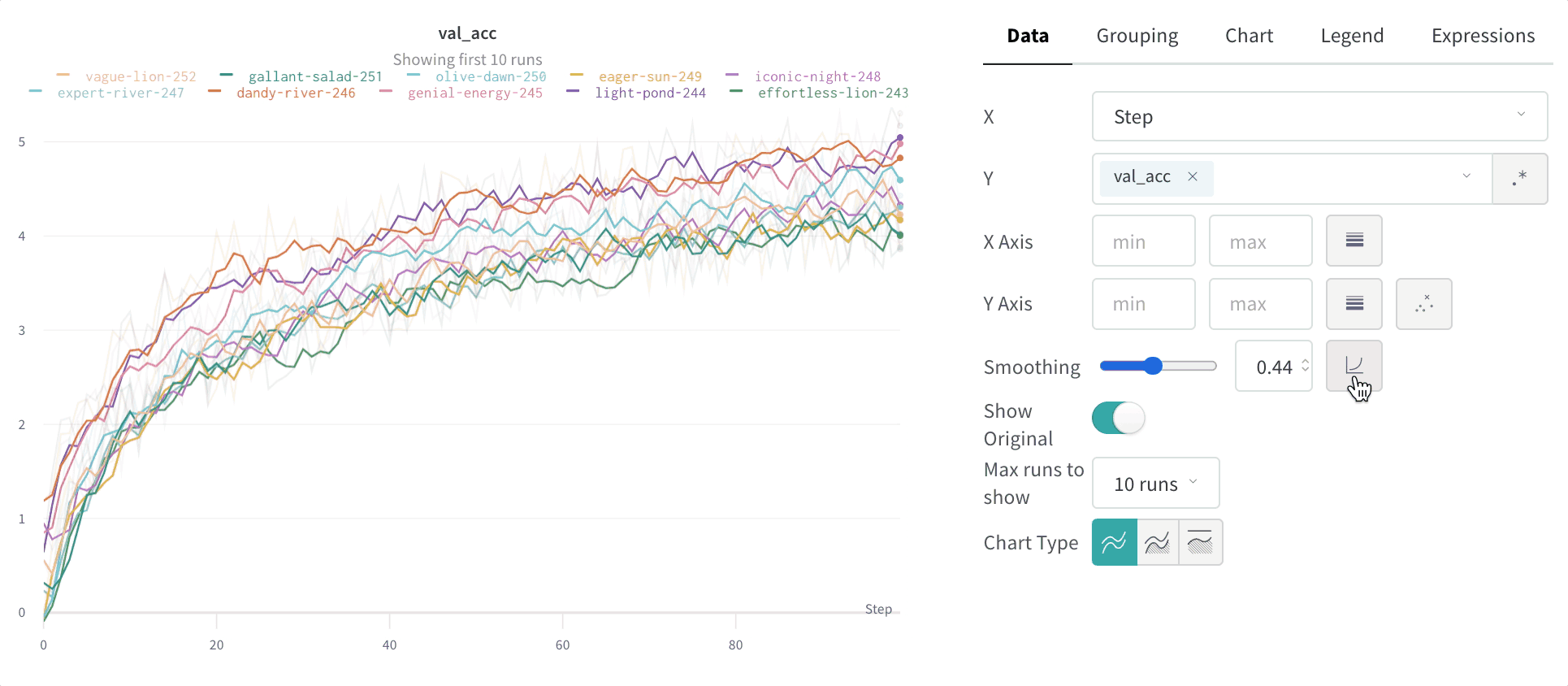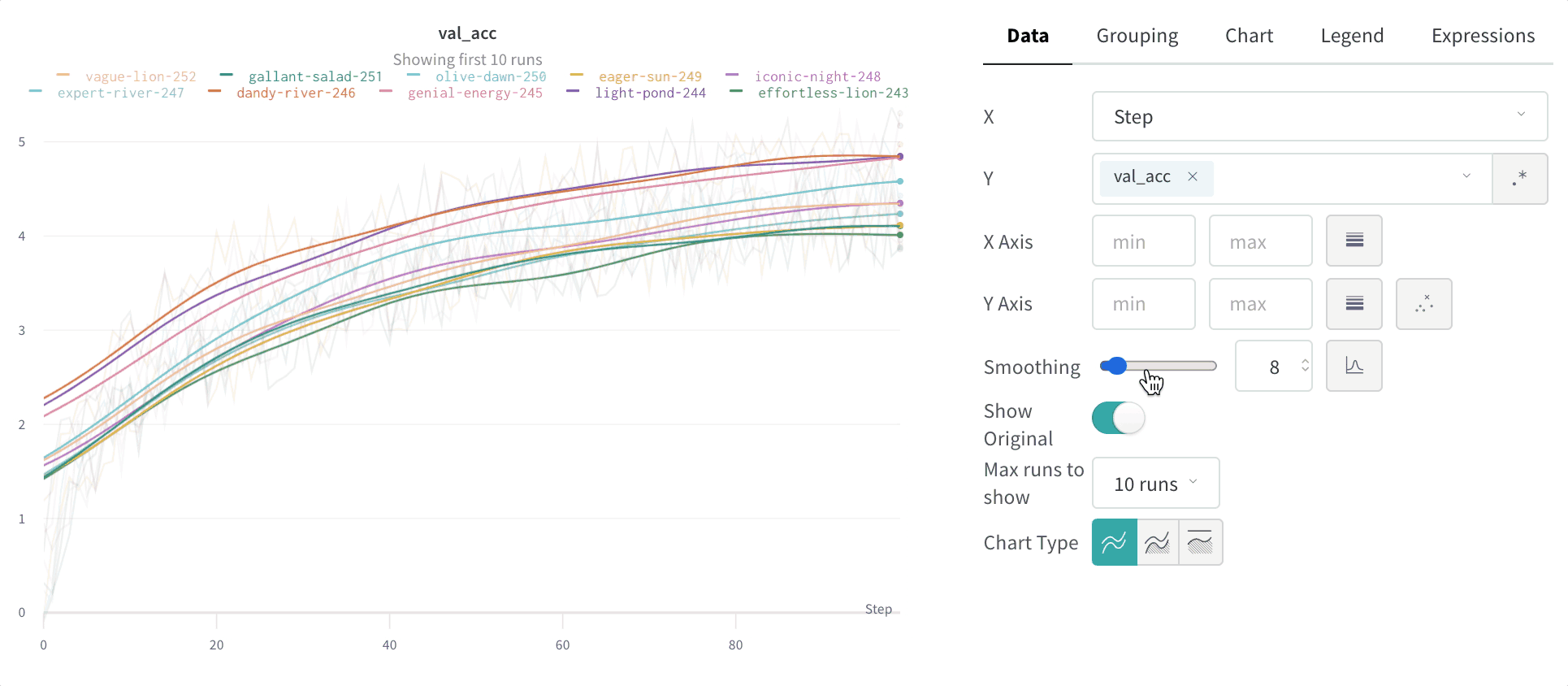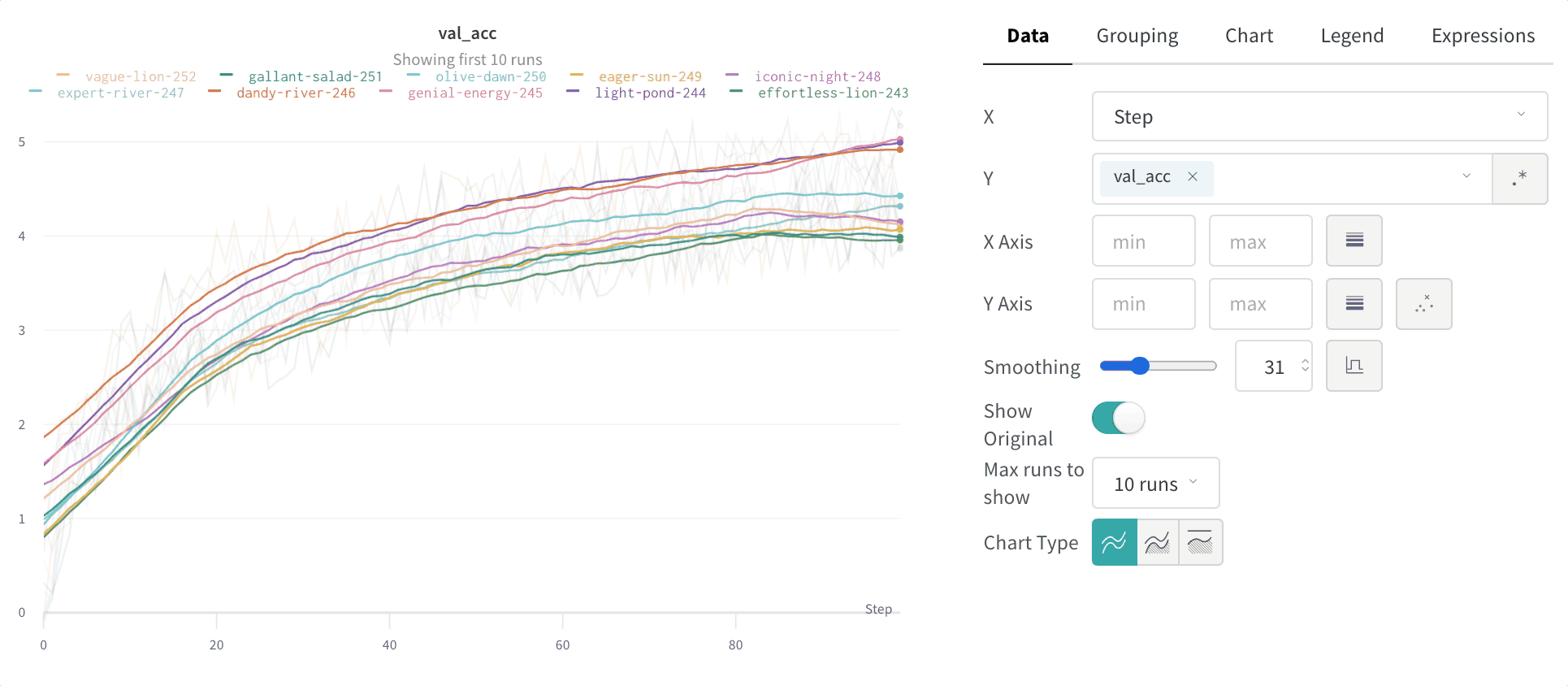
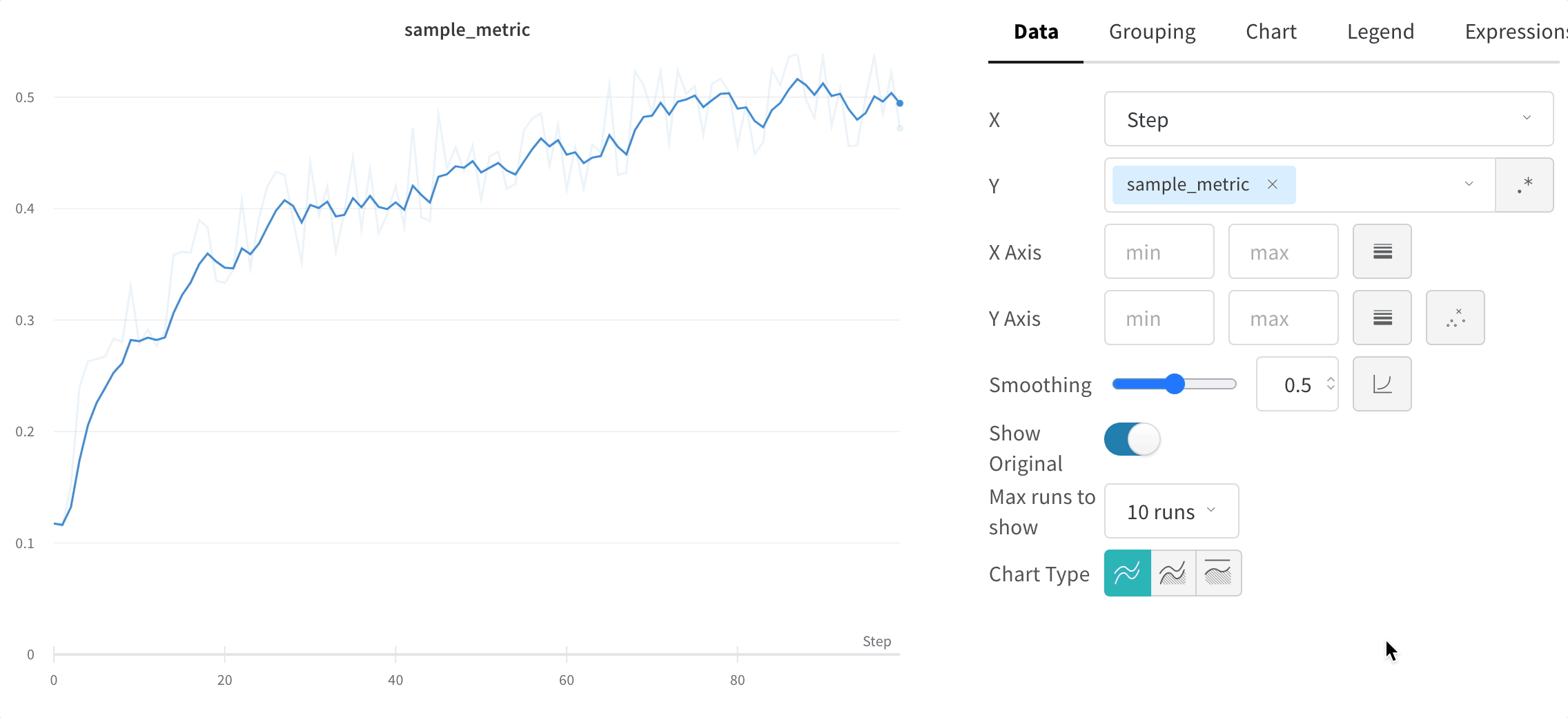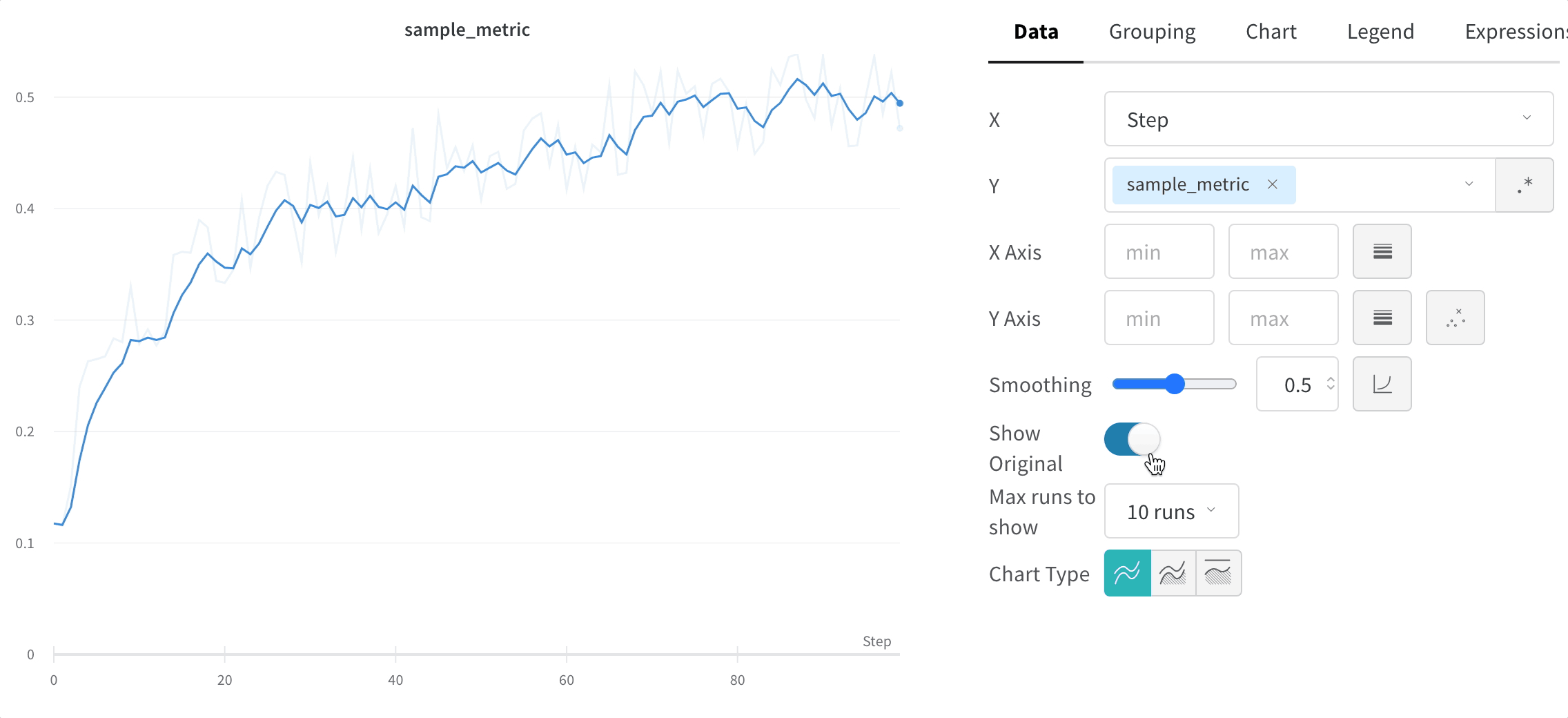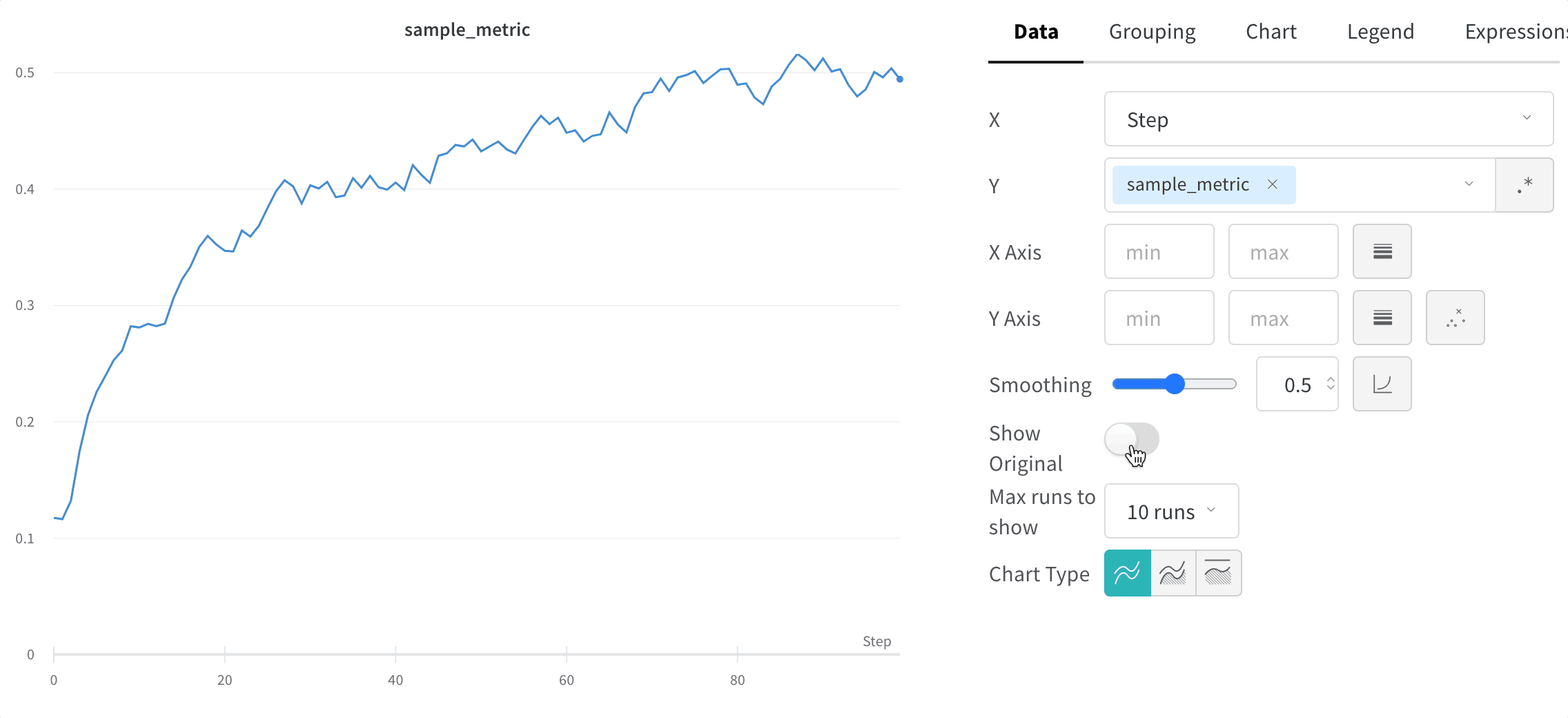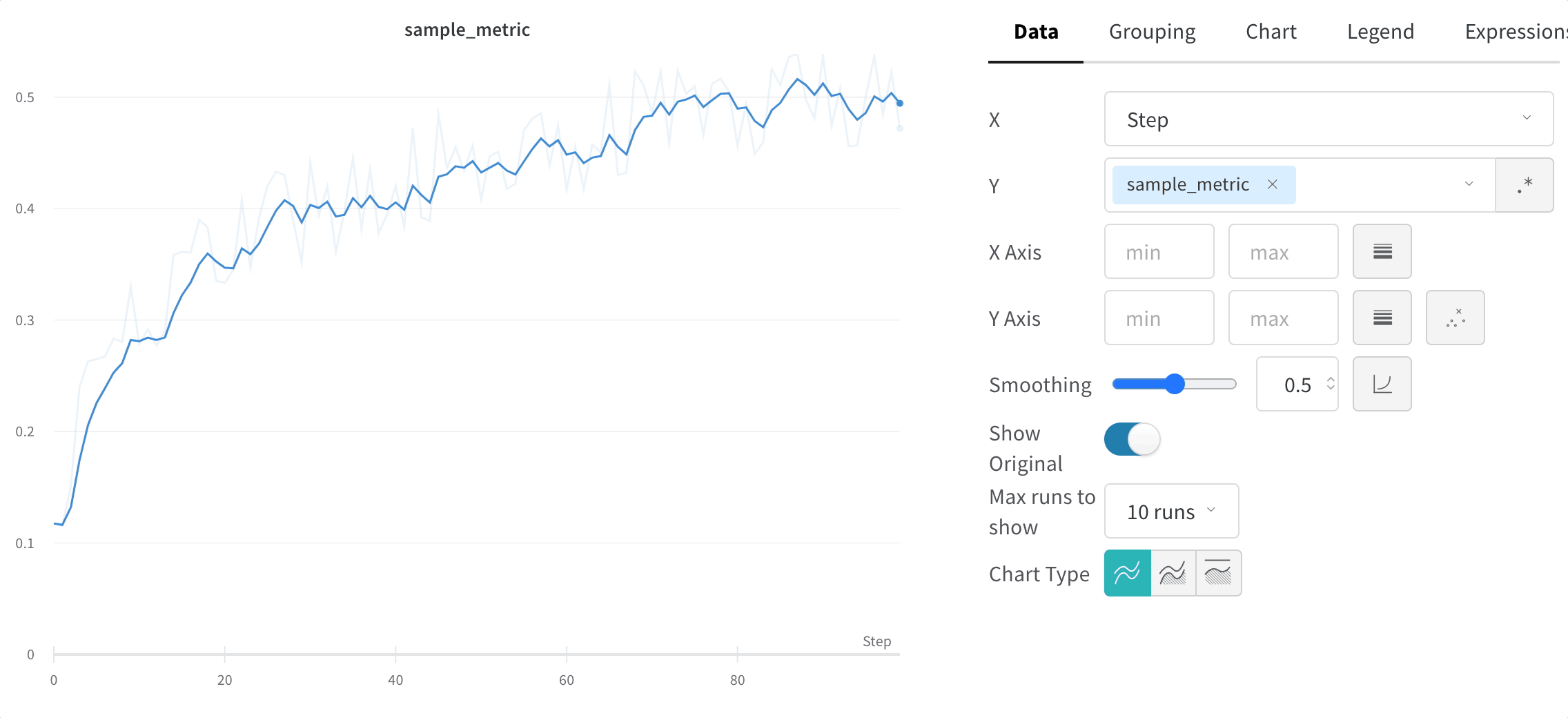
折れ線グラフでは、次の設定を構成できます。
日付: プロットのデータの表示に関する詳細を構成します。
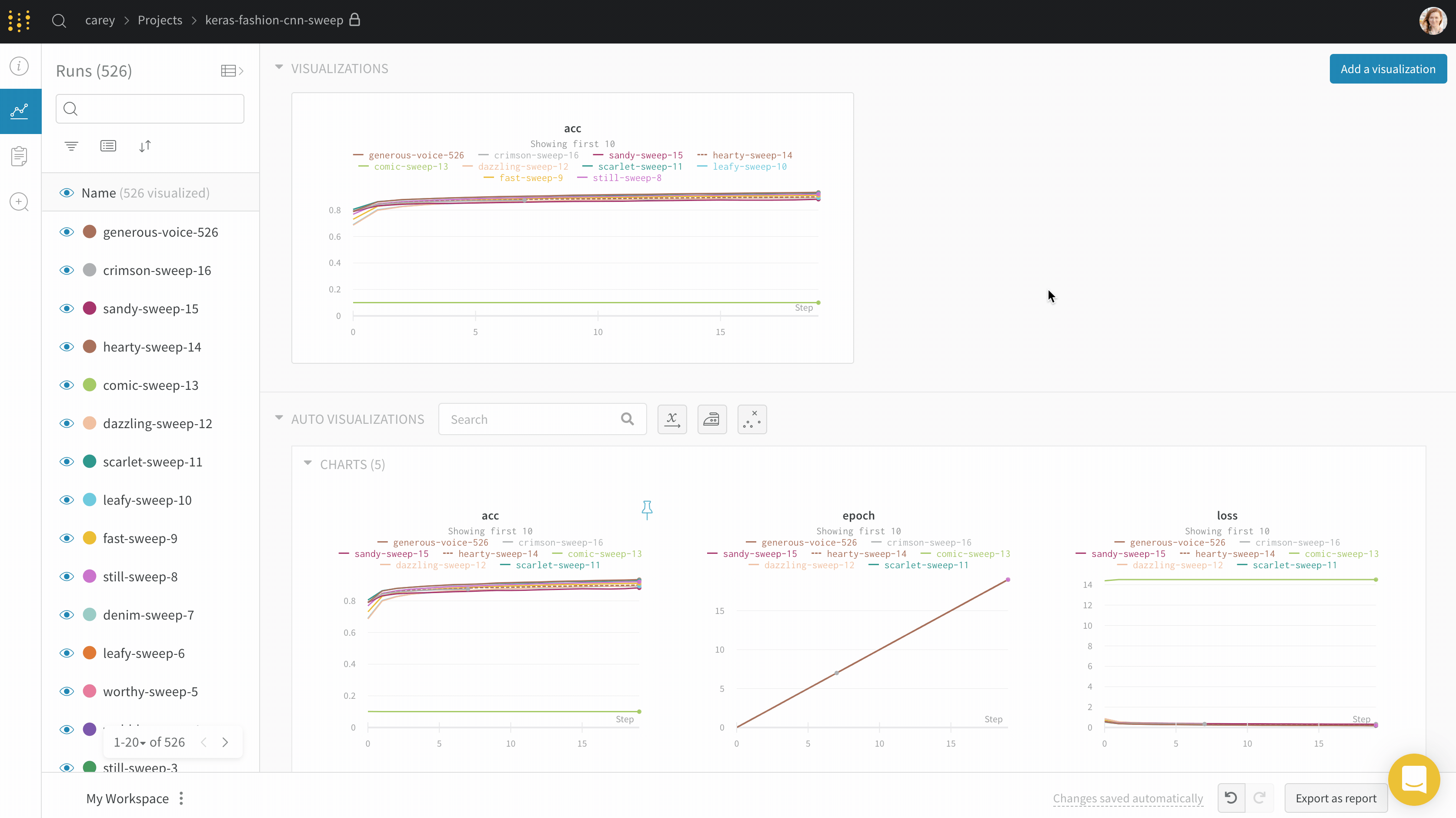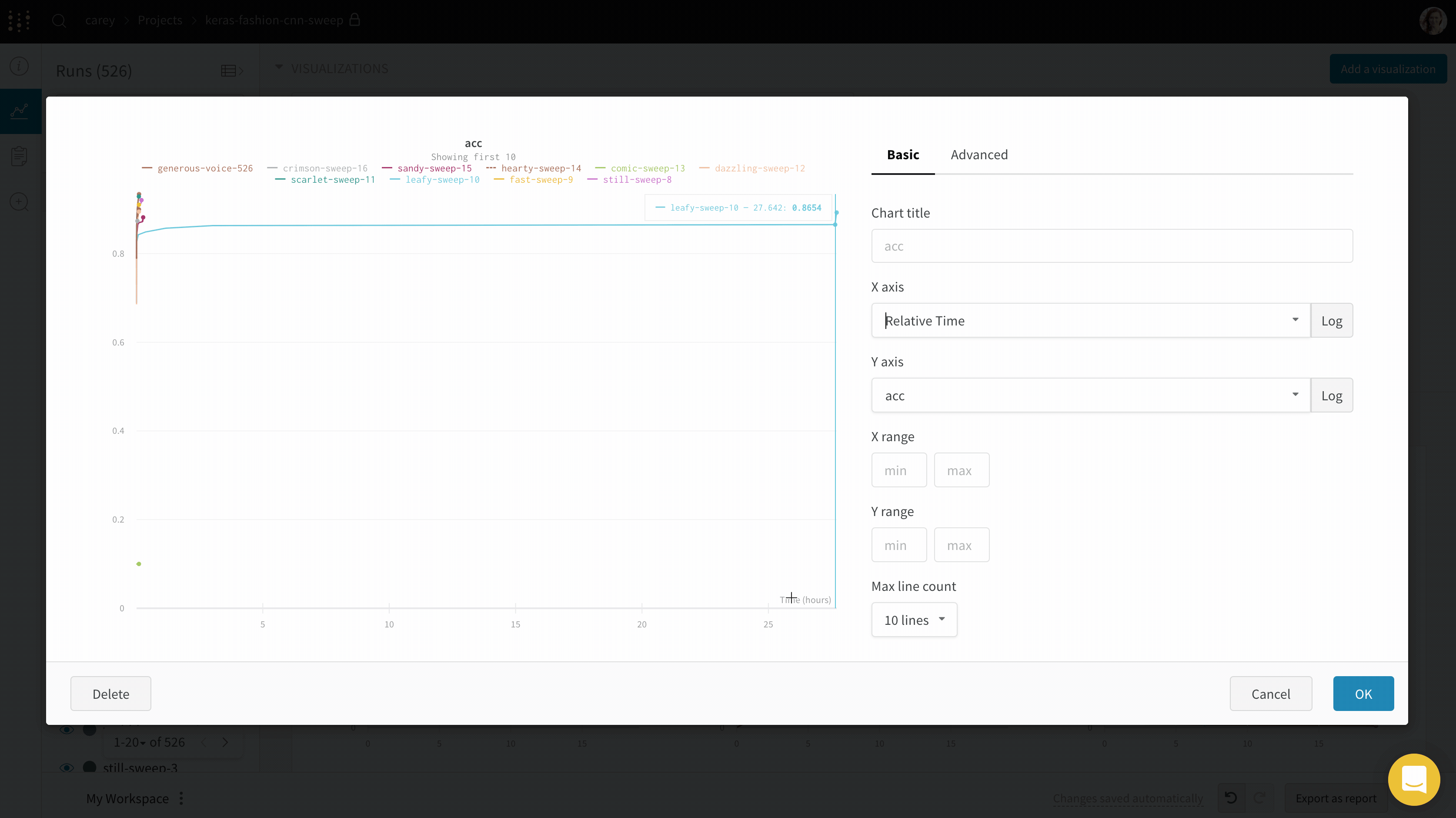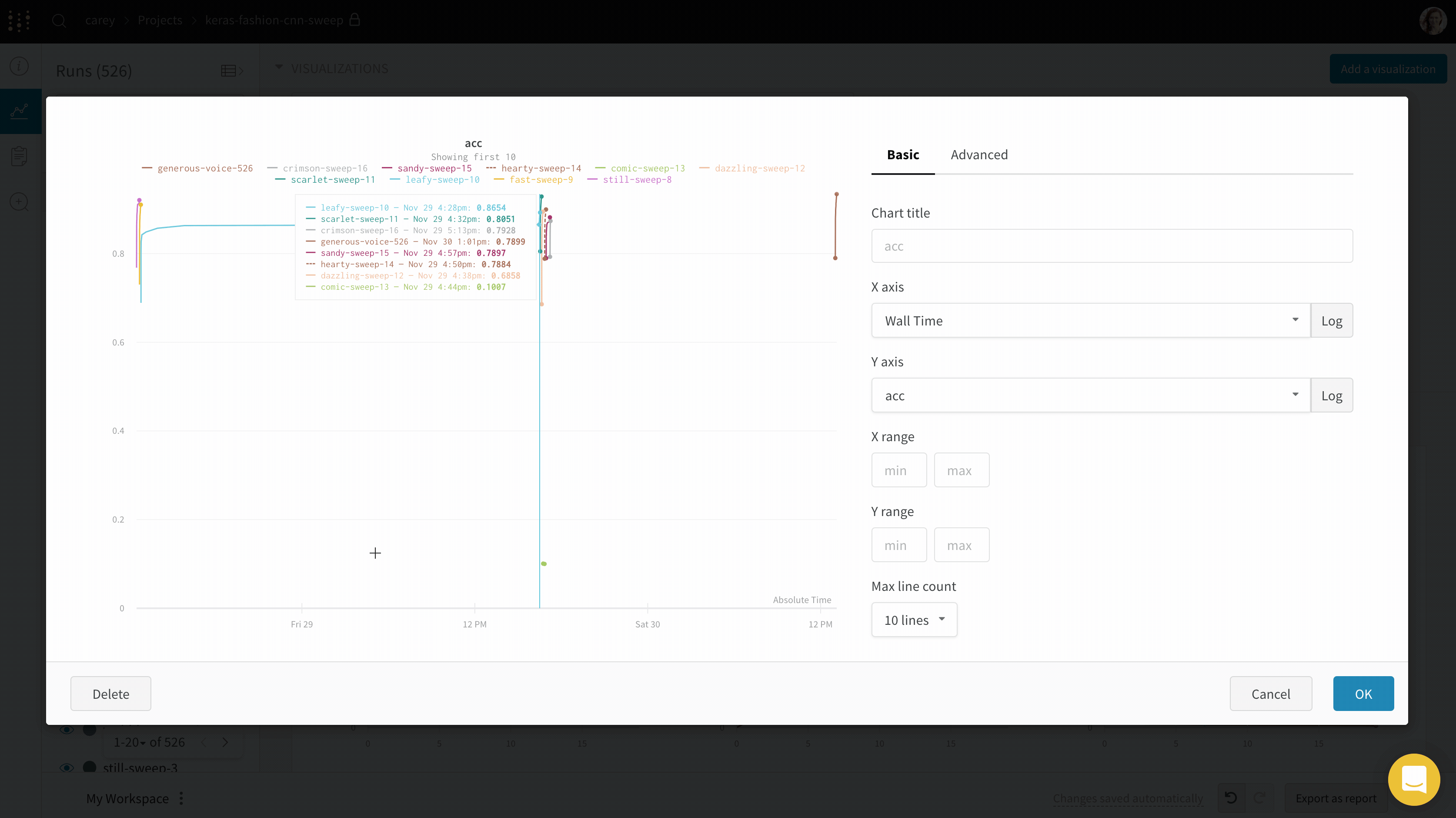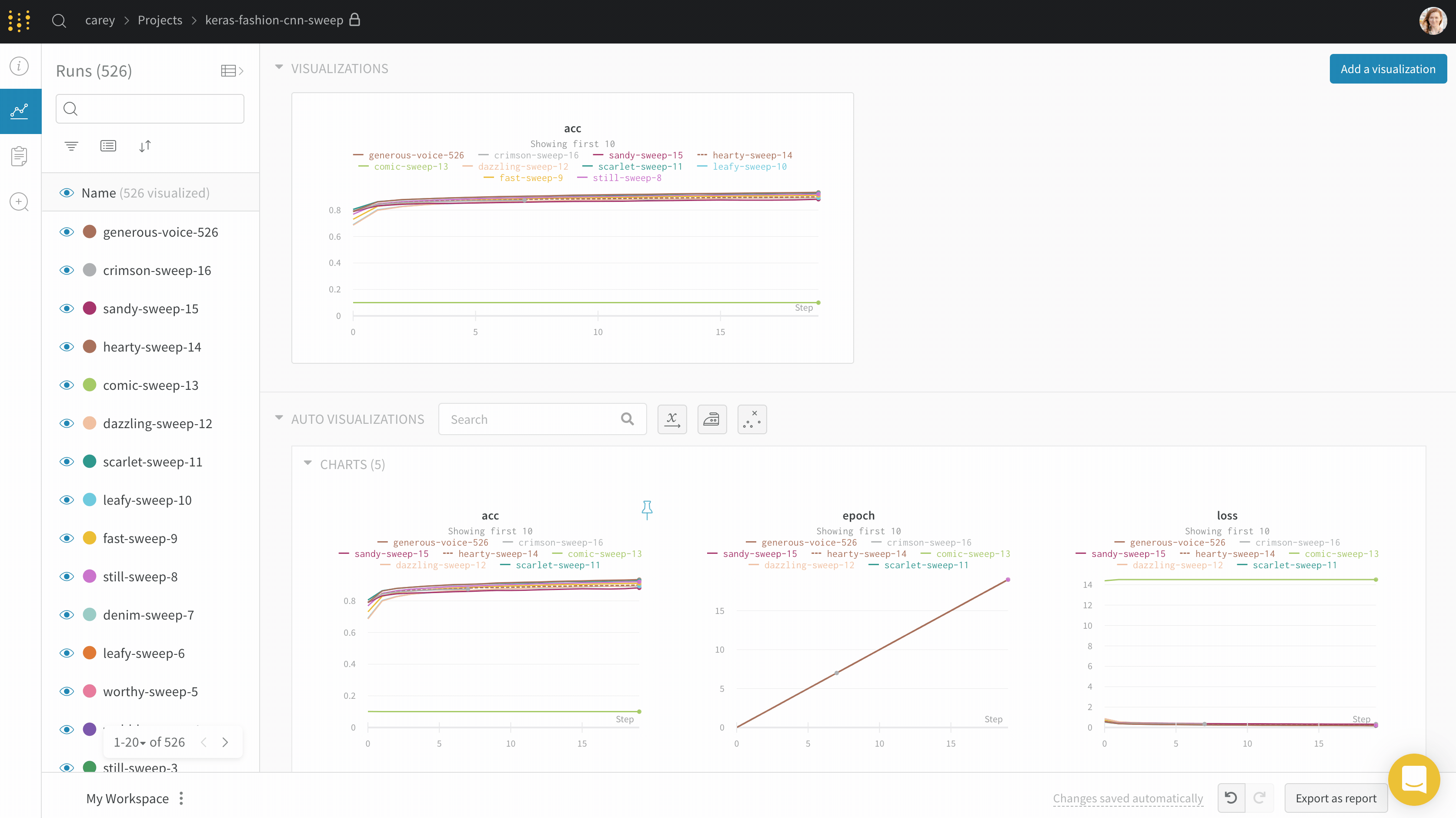
- X: X 軸に使用する値を選択します (デフォルトは ステップ)。X 軸を 相対時間 に変更するか、W&B でログに記録した値に基づいてカスタム軸を選択できます。
- 相対時間 (Wall) は、プロセスが開始してからのクロック時間です。したがって、run を開始して 1 日後に再開し、何かをログに記録した場合、24 時間後にプロットされます。
- 相対時間 (プロセス) は、実行中のプロセス内の時間です。したがって、run を開始して 10 秒間実行し、1 日後に再開した場合、そのポイントは 10 秒でプロットされます。
- Wall Time は、グラフ上の最初の run の開始からの経過時間 (分) です。
- ステップ は、デフォルトで
wandb.log()が呼び出されるたびに増分され、モデルからログに記録したトレーニング ステップの数を反映することになっています。
- Y: メトリクスや時間の経過とともに変化するハイパーパラメーターなど、ログに記録された値から 1 つ以上の Y 軸を選択します。
- X 軸 および Y 軸 の最小値と最大値 (オプション)。
- ポイント集計メソッド。ランダム サンプリング (デフォルト) または フル フィデリティ。 サンプリング を参照してください。
- スムージング: 折れ線グラフのスムージングを変更します。デフォルトは 時間加重 EMA です。その他の値には、スムージングなし、移動平均、および ガウス があります。
- 外れ値: デフォルトのプロットの最小スケールと最大スケールから外れ値を排除するようにリスケールします。
- run またはグループの最大数: この数を増やすことで、折れ線グラフに一度に表示される線を増やします。デフォルトは 10 runs です。利用可能な run が 10 よりも多いが、グラフが表示数を制限している場合、チャートの上部に「最初の 10 runs を表示」というメッセージが表示されます。
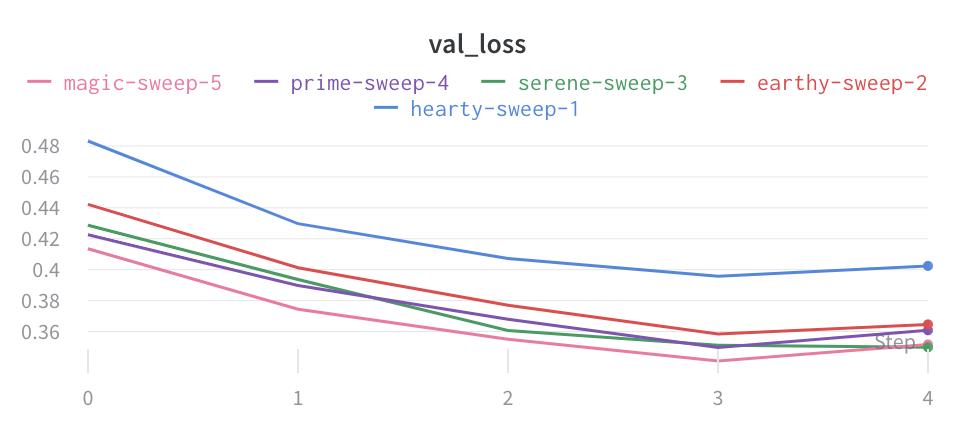
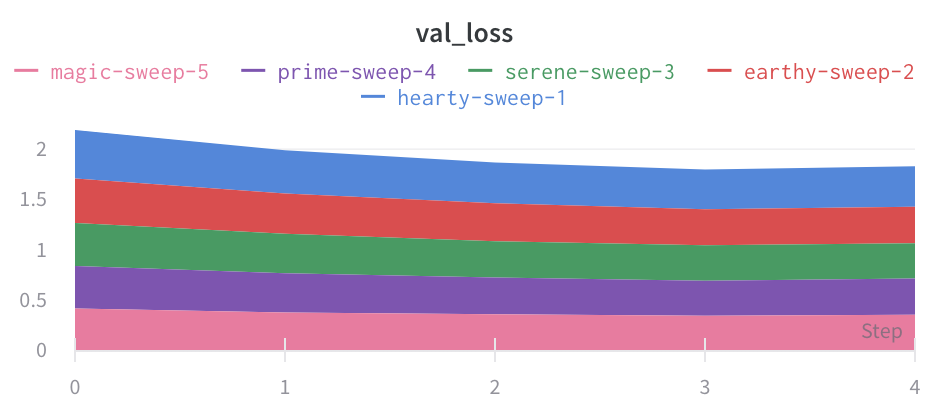
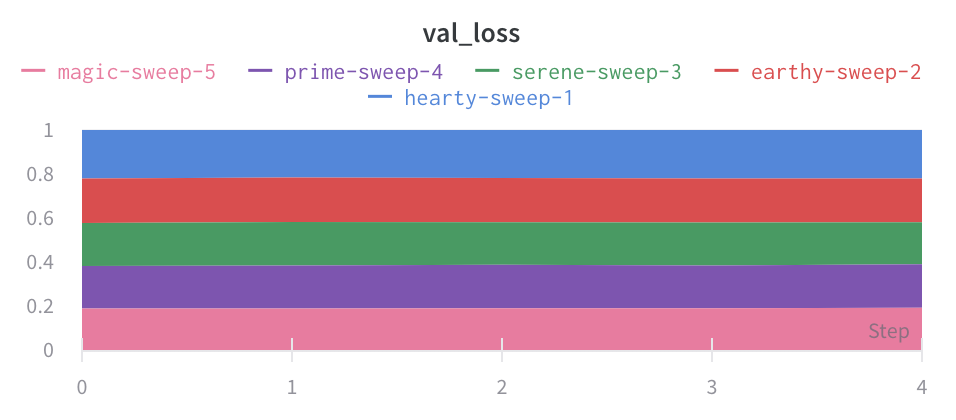
- チャートの種類: 折れ線グラフ、面グラフ、およびパーセンテージ面グラフを切り替えます。
グループ化: プロットで run をグループ化および集計するかどうか、またその方法を構成します。
- グループ化: 列を選択すると、その列に同じ値を持つすべての run がグループ化されます。
- 集計: 集計—グラフ上の線の値。オプションは、グループの平均、中央値、最小値、および最大値です。
チャート: パネル、X 軸、Y 軸、および -軸のタイトルを指定し、凡例の表示/非表示を切り替え、その位置を構成します。
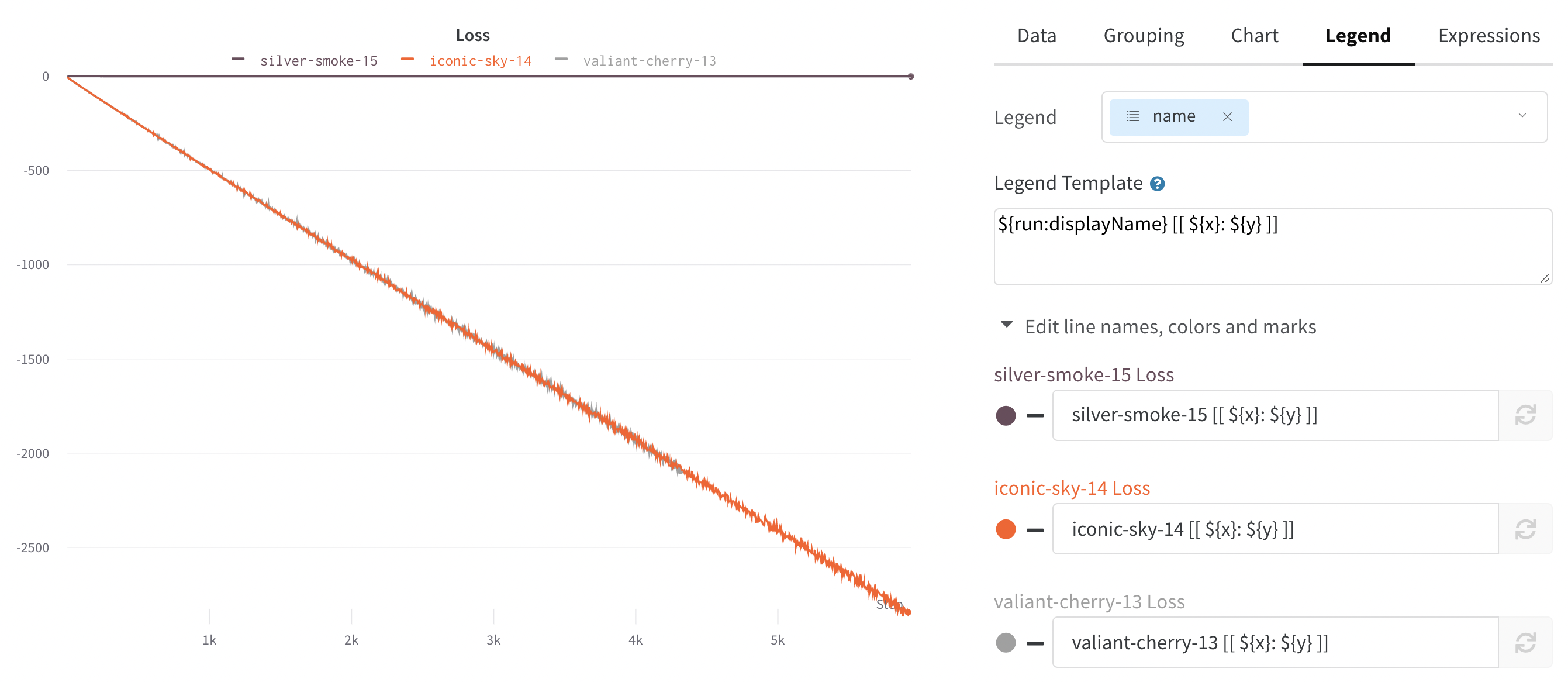
凡例: パネルの凡例の外観をカスタマイズします (有効になっている場合)。
- 凡例: プロットの凡例の各線の凡例のフィールド。
- 凡例テンプレート: 凡例の完全にカスタマイズ可能なテンプレートを定義します。線のプロットの上部にあるテンプレートに表示するテキストと変数、およびマウスをプロットの上に置いたときに表示される凡例を正確に指定します。
式: カスタム計算式をパネルに追加します。
- Y 軸式: 計算されたメトリクスをグラフに追加します。ログに記録されたメトリクスのいずれか、およびハイパーパラメーターなどの設定値を使用して、カスタム線を計算できます。
- X 軸式: カスタム式を使用して計算された値を使用するように X 軸をリスケールします。役立つ変数には、デフォルトの X 軸の **_step** が含まれ、要約値を参照するための構文は
${summary:value}です。
セクション内のすべての折れ線グラフ
セクション内のすべての折れ線グラフのデフォルト設定をカスタマイズするには、折れ線グラフのワークスペース設定をオーバーライドします。
- セクションの歯車アイコンをクリックして、その設定を開きます。
- 表示されるモーダル内で、データ または 表示設定 タブを選択して、セクションのデフォルト設定を構成します。各 データ 設定の詳細については、前のセクション 個々の折れ線グラフ を参照してください。各表示設定の詳細については、セクション レイアウトの構成 を参照してください。
ワークスペース内のすべての折れ線グラフ
ワークスペース内のすべての折れ線グラフのデフォルト設定をカスタマイズするには:
- ワークスペースの設定をクリックします。これには、設定 というラベルの付いた歯車が付いています。
- 折れ線グラフ をクリックします。
- 表示されるモーダル内で、データ または 表示設定 タブを選択して、ワークスペースのデフォルト設定を構成します。
-
各 データ 設定の詳細については、前のセクション 個々の折れ線グラフ を参照してください。
-
各 表示設定 セクションの詳細については、ワークスペースの表示設定 を参照してください。ワークスペース レベルでは、折れ線グラフのデフォルトの ズーム の振る舞いを構成できます。この設定は、一致する X 軸キーを持つ折れ線グラフ間でズームを同期するかどうかを制御します。デフォルトでは無効になっています。
-
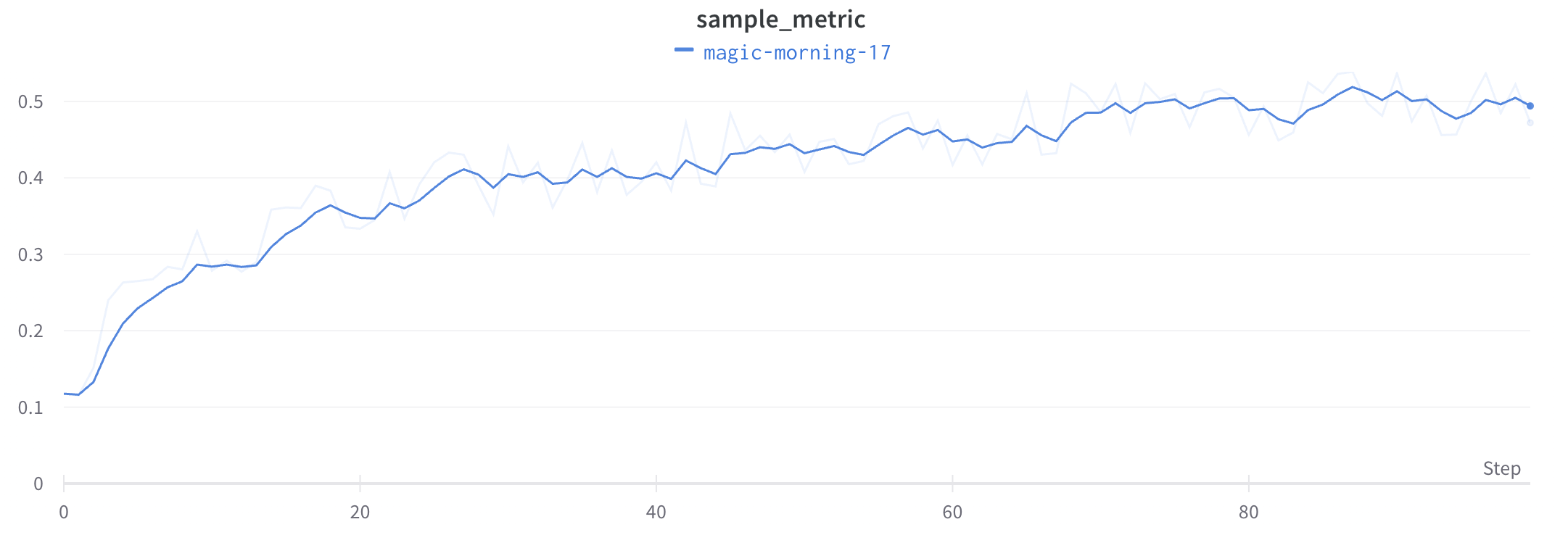
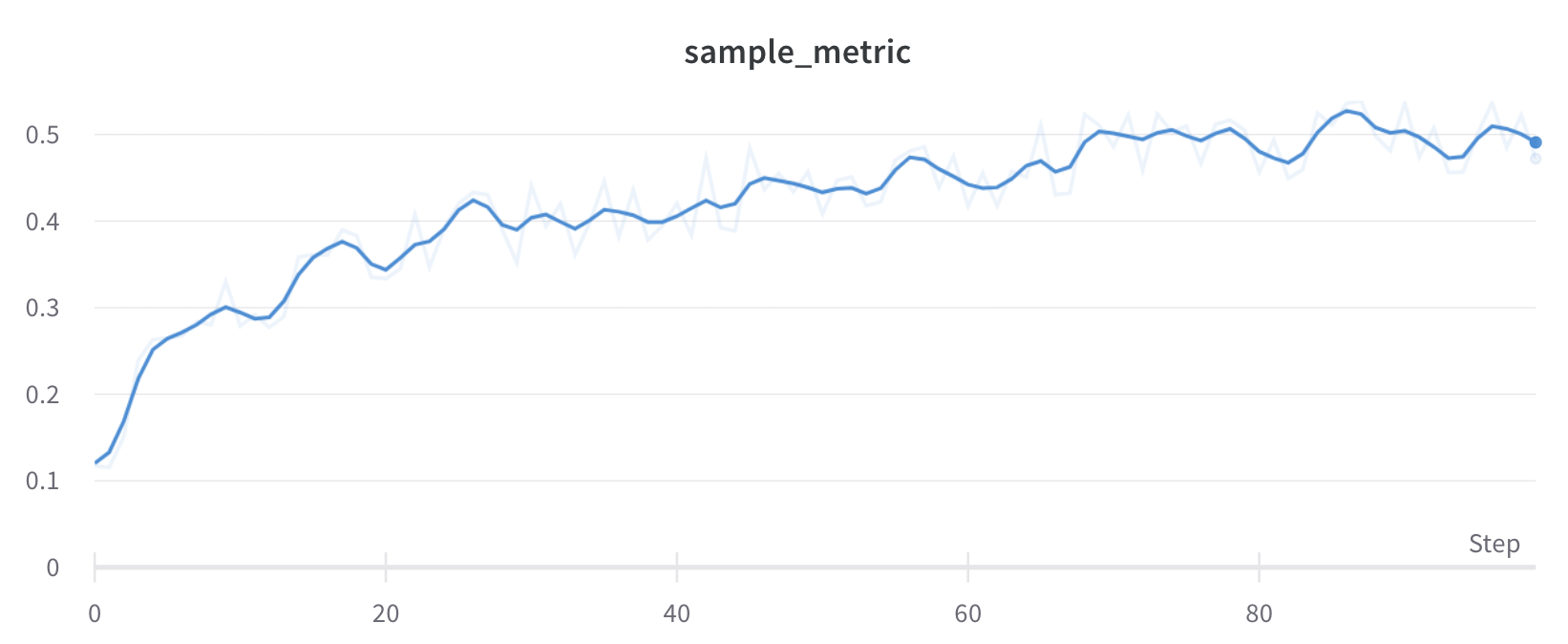
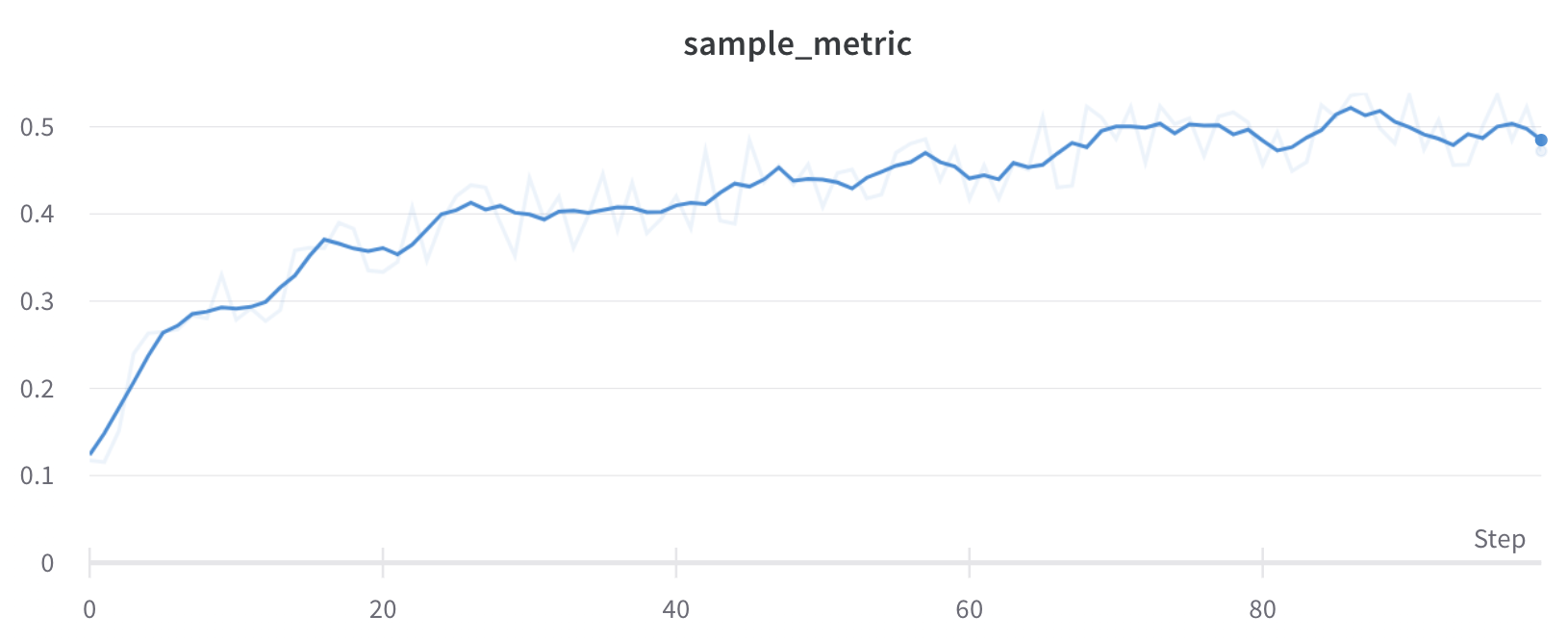
プロット上の平均値を可視化する
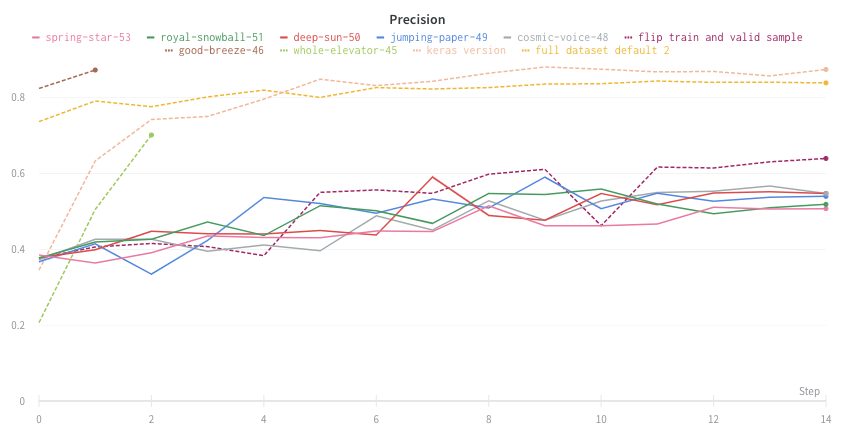
いくつかの異なる Experiments があり、プロット上の値の平均を表示する場合は、テーブルのグループ化機能を使用できます。run テーブルの上にある [グループ] をクリックし、[すべて] を選択して、グラフに平均値を表示します。
平均化する前のグラフは次のようになります。
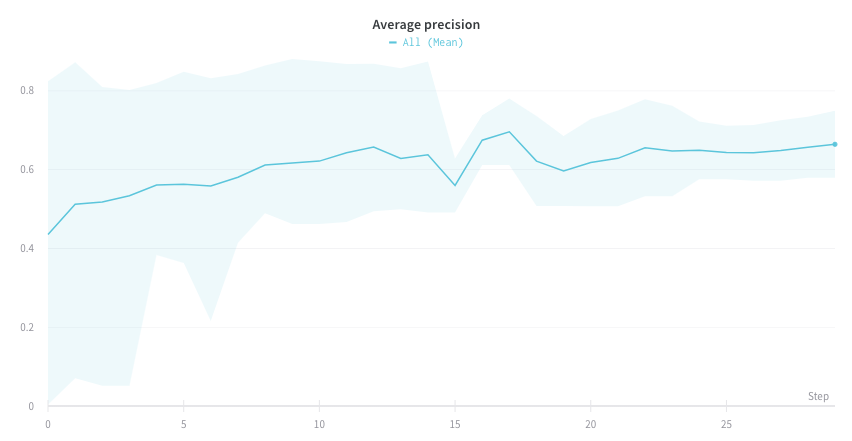
次の画像は、グループ化された線を使用して runs 全体の平均値を表すグラフを示しています。
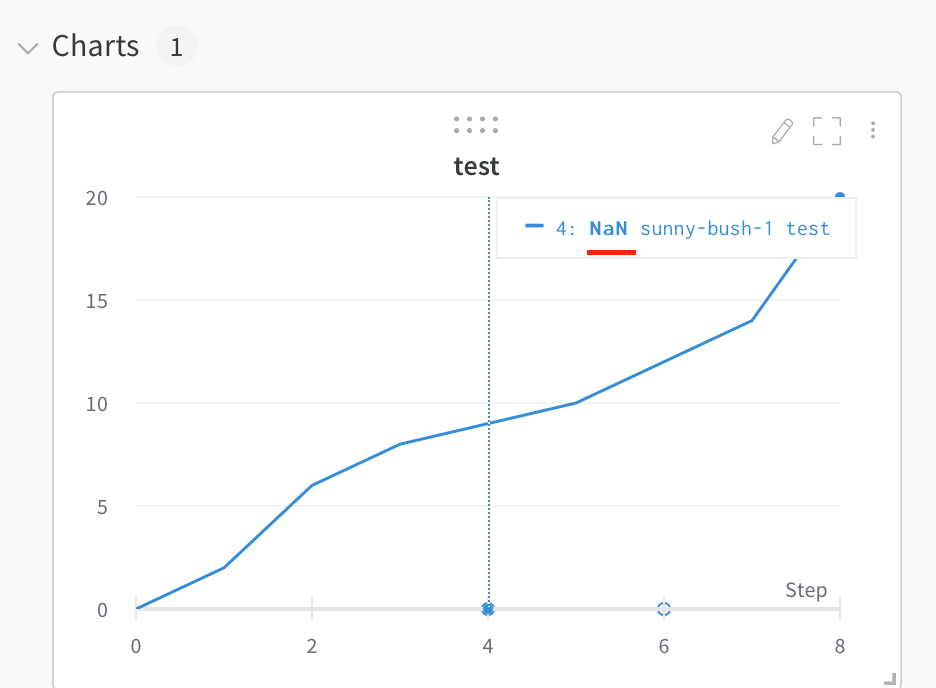
プロット上の NaN 値を可視化する
wandb.log を使用して、PyTorch テンソルを含む NaN 値を折れ線グラフにプロットすることもできます。例:
wandb.log({"test": [..., float("nan"), ...]})
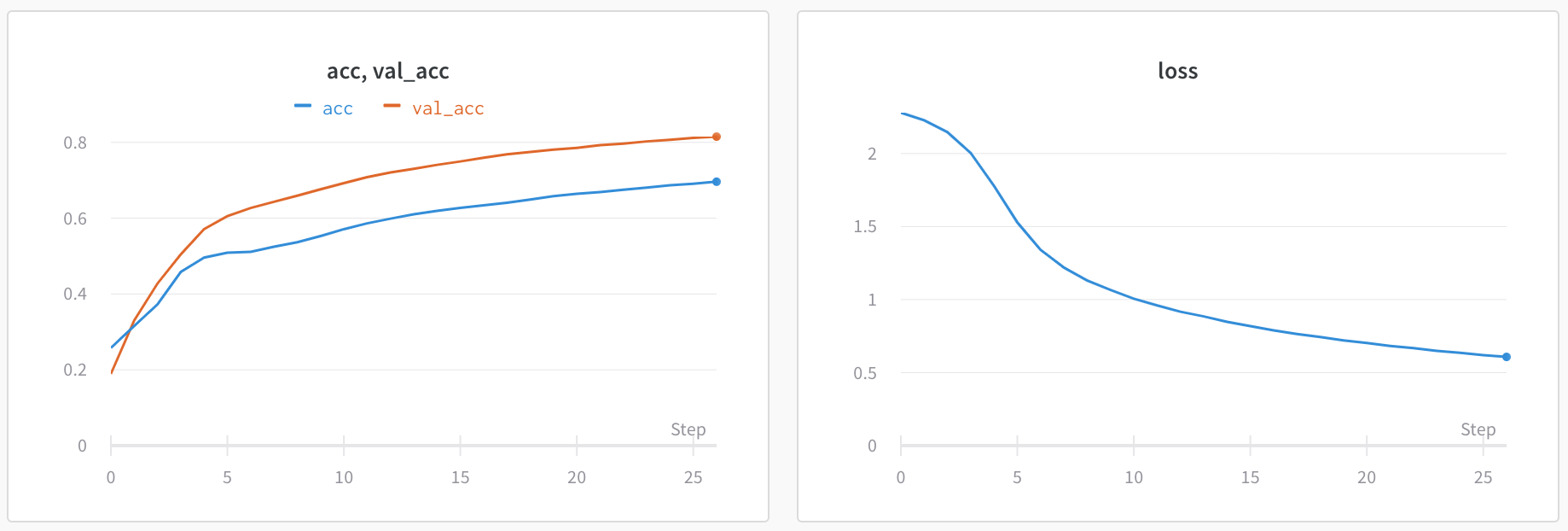
1 つのチャートで 2 つのメトリクスを比較する
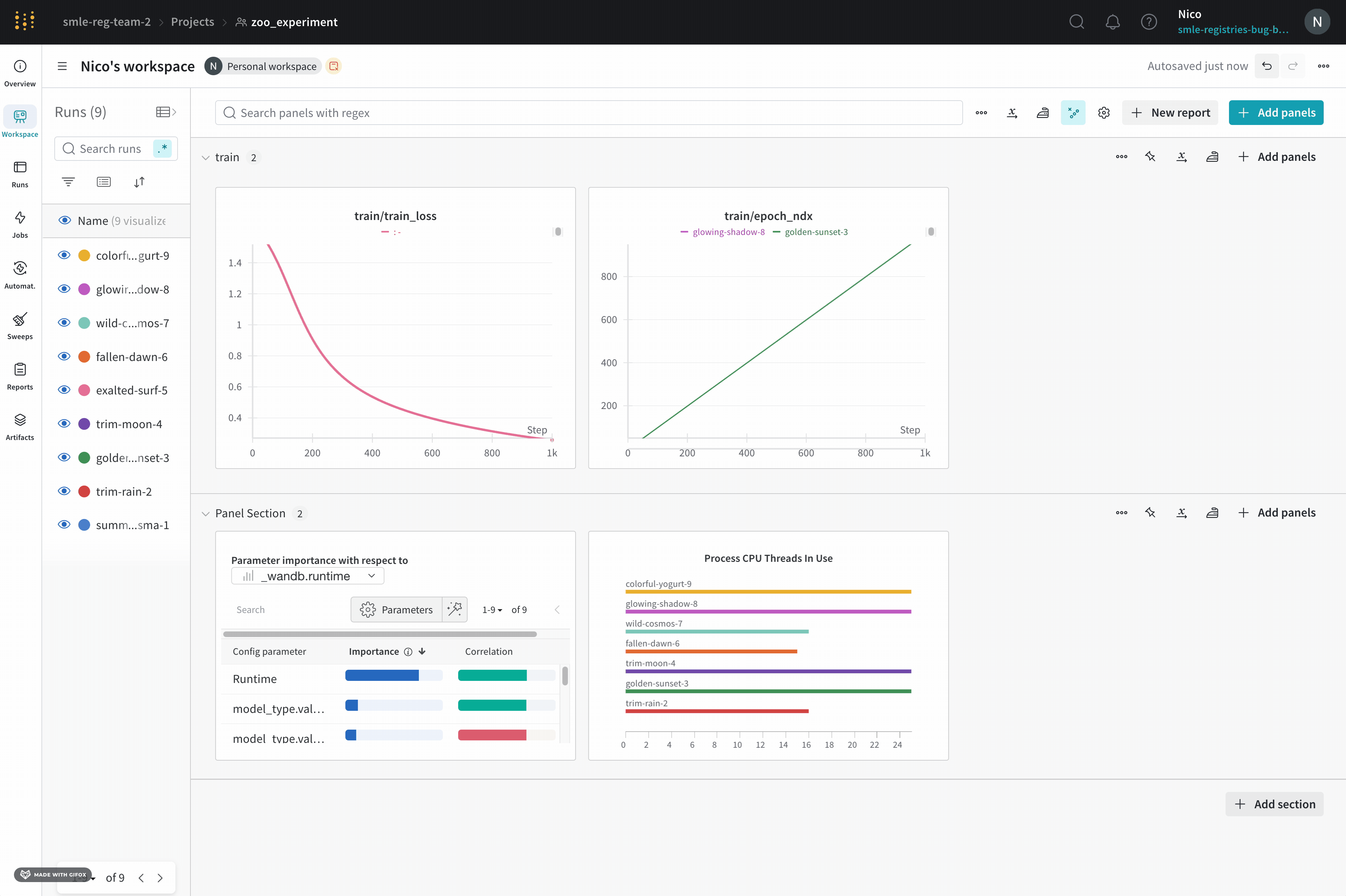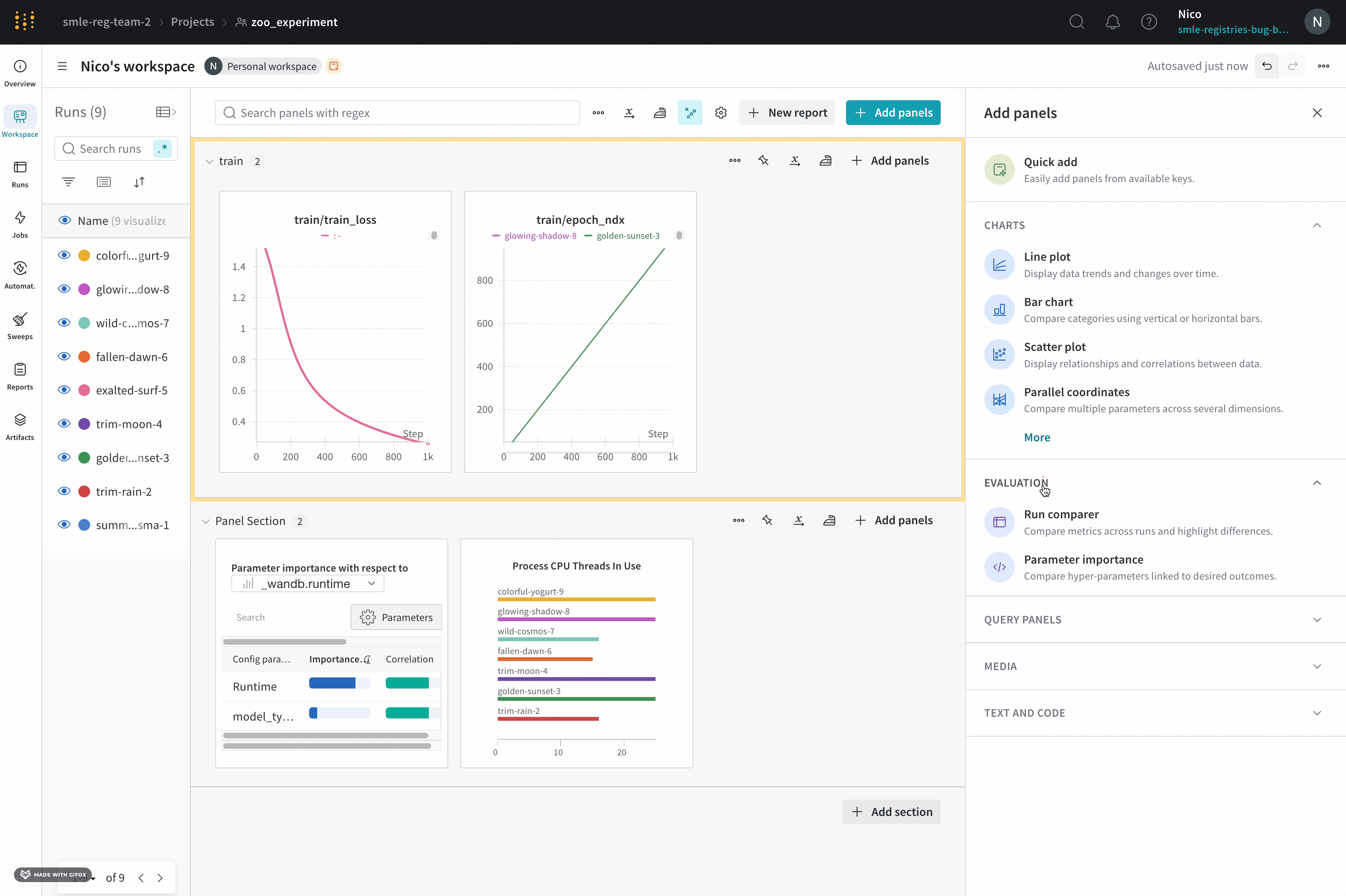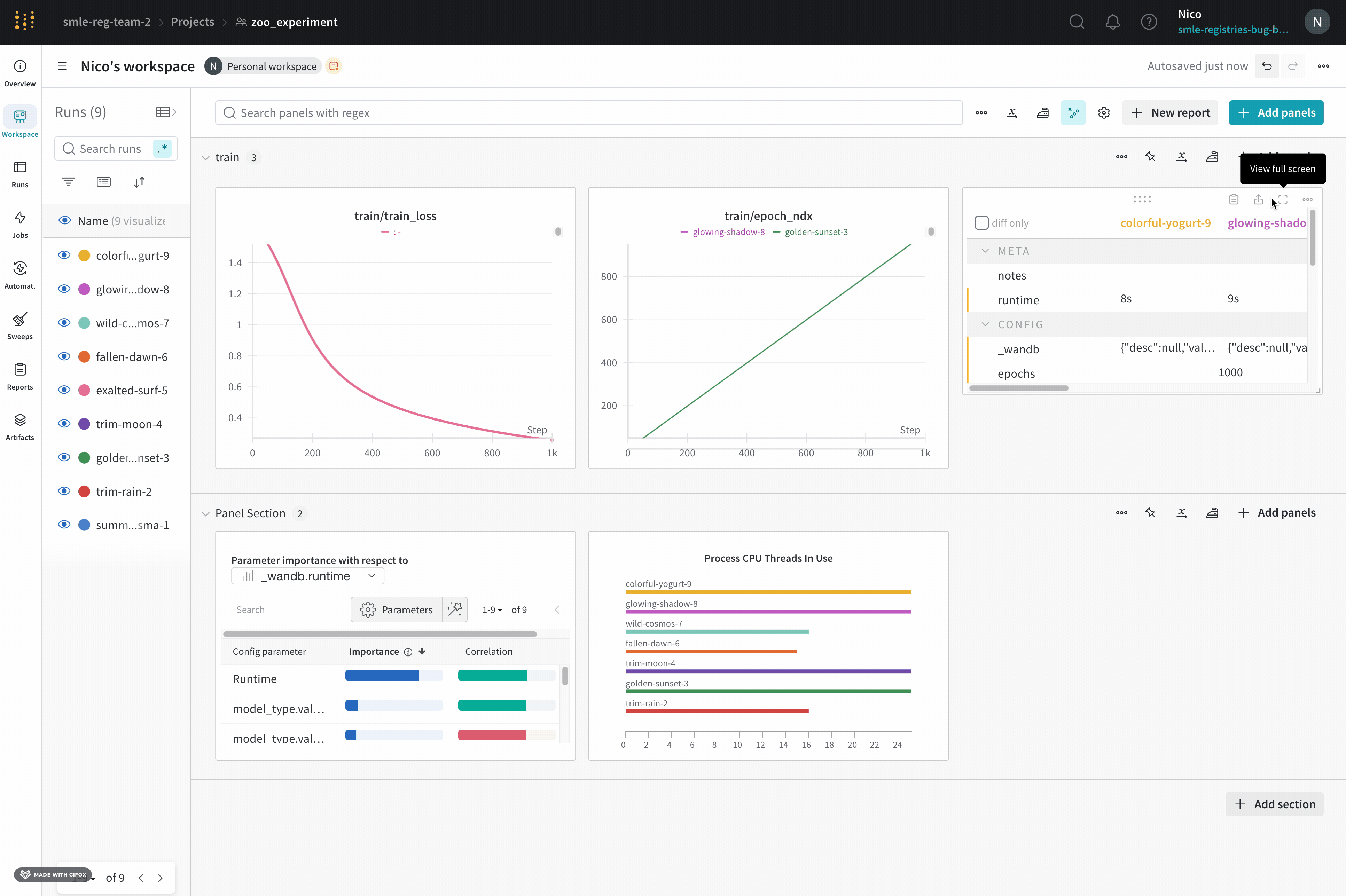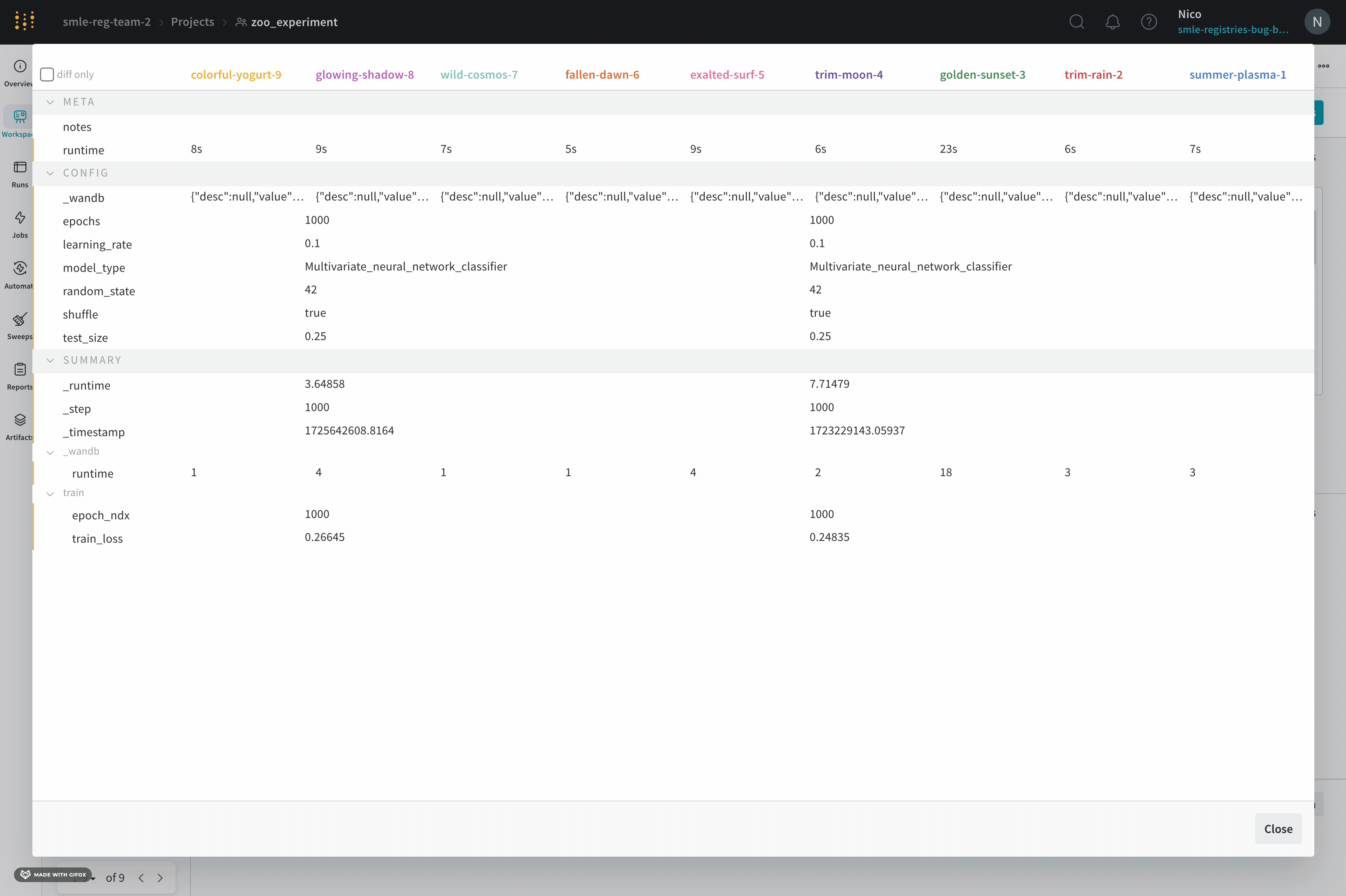
- ページの右上隅にある パネルを追加 ボタンを選択します。
- 表示される左側のパネルから、[評価] ドロップダウンを展開します。
- Run comparer を選択します。
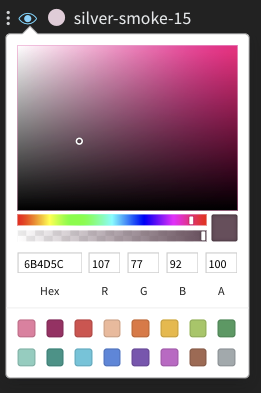
折れ線グラフの色を変更する
runs のデフォルトの色が比較に役立たない場合があります。これを克服するために、wandb には、手動で色を変更できる 2 つのインスタンスが用意されています。
各 run には、初期化時にデフォルトでランダムな色が割り当てられます。

いずれかの色をクリックすると、カラー パレットが表示され、そこから必要な色を手動で選択できます。
- 設定を編集するパネルの上にマウスを置きます。
- 表示される鉛筆アイコンを選択します。
- [凡例] タブを選択します。
異なる X 軸で可視化する
実験にかかった絶対時間を確認したり、実験が実行された曜日を確認したりする場合は、X 軸を切り替えることができます。ステップから相対時間、そして Wall Time に切り替える例を次に示します。
面グラフ
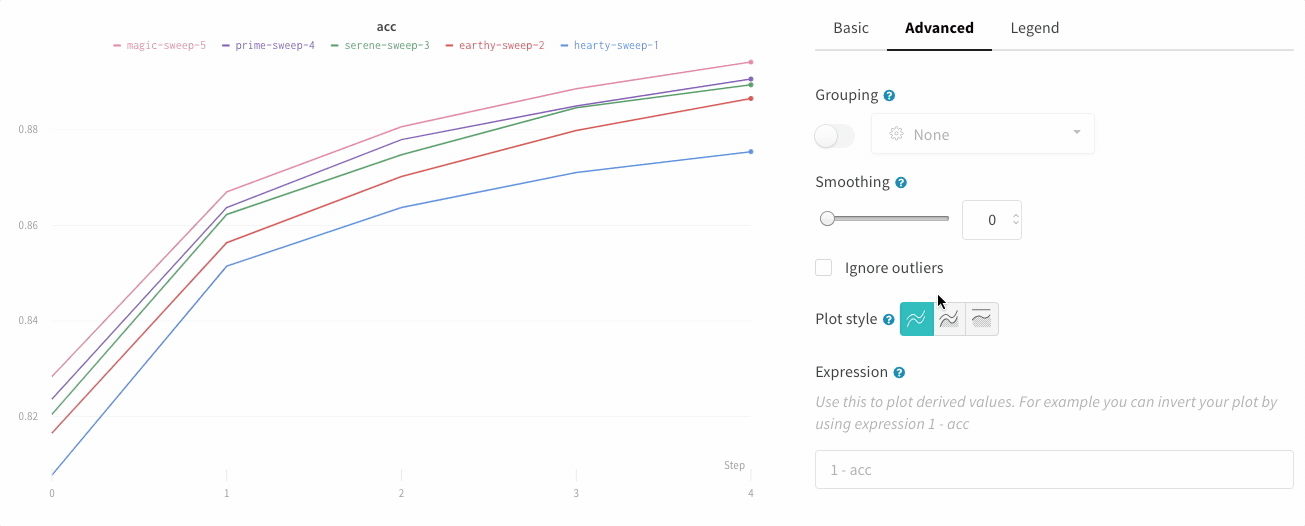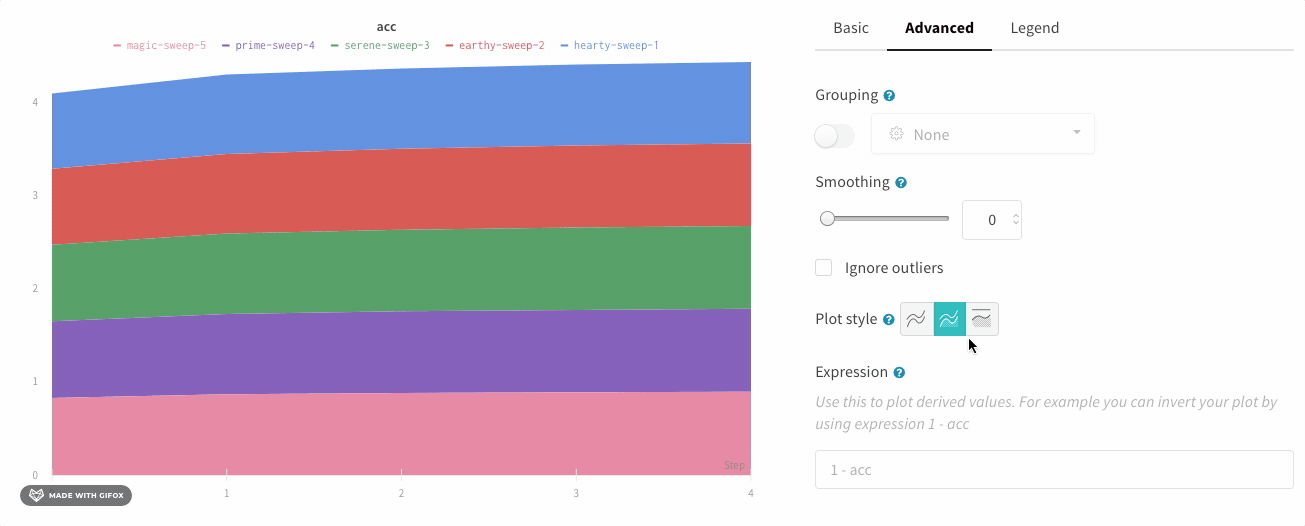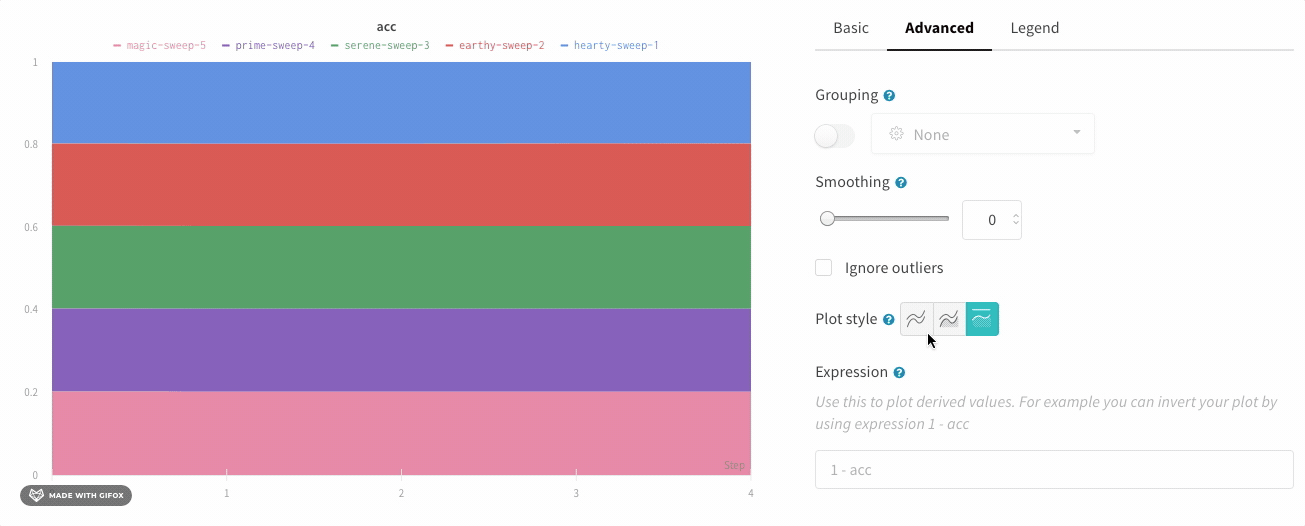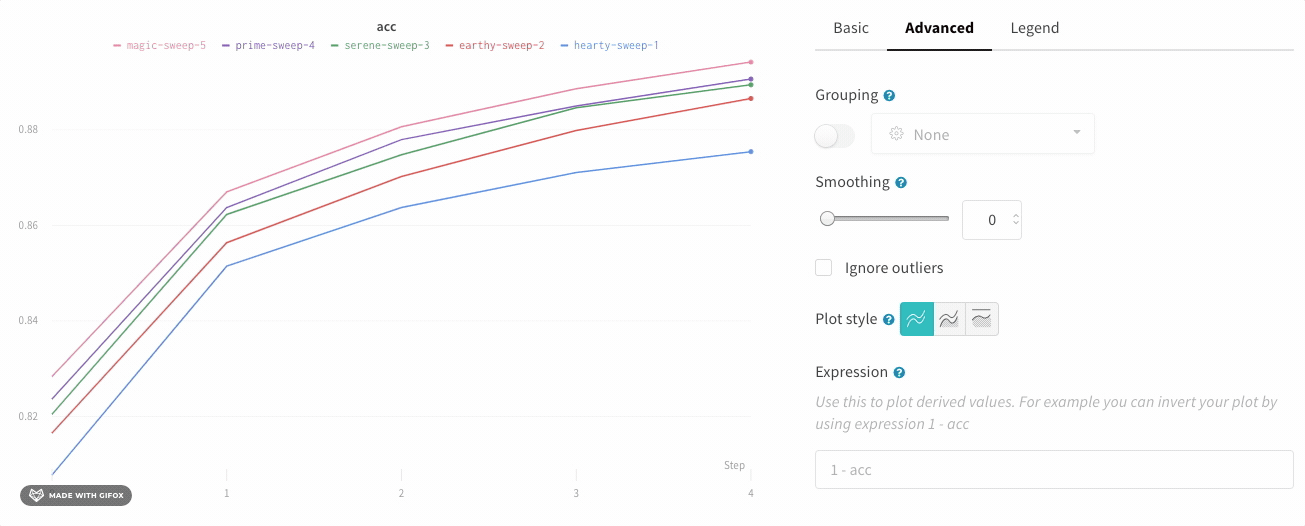
折れ線グラフの設定の [詳細設定] タブで、異なるプロット スタイルをクリックして、面グラフまたはパーセンテージ面グラフを取得します。
ズーム
長方形をクリックしてドラッグし、垂直方向と水平方向に同時にズームします。これにより、X 軸と Y 軸のズームが変更されます。
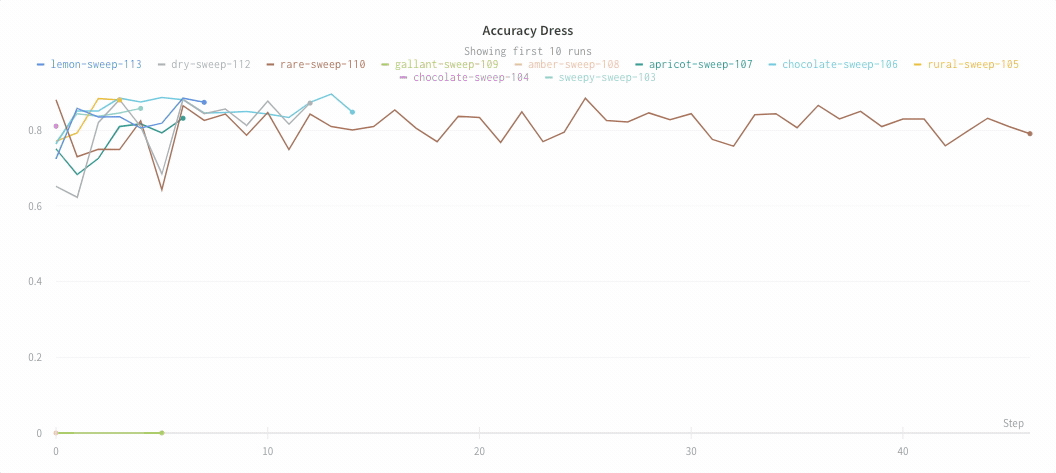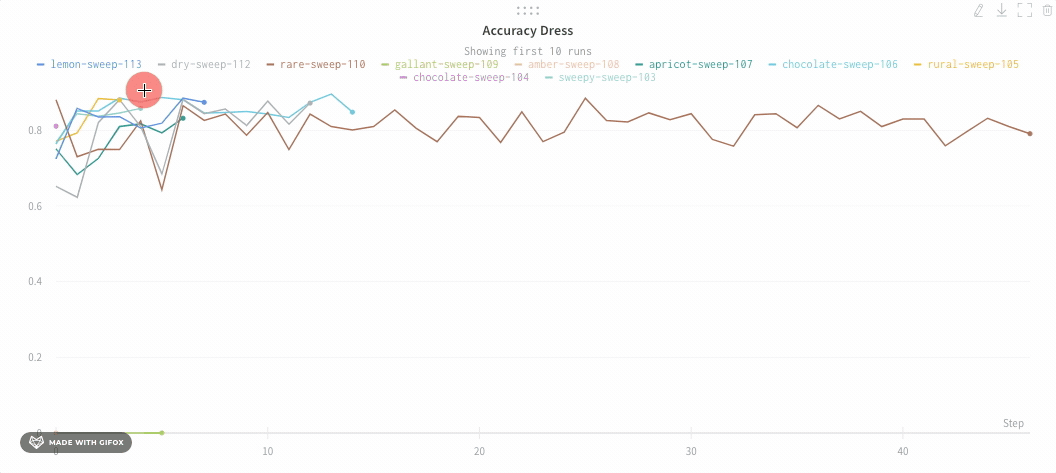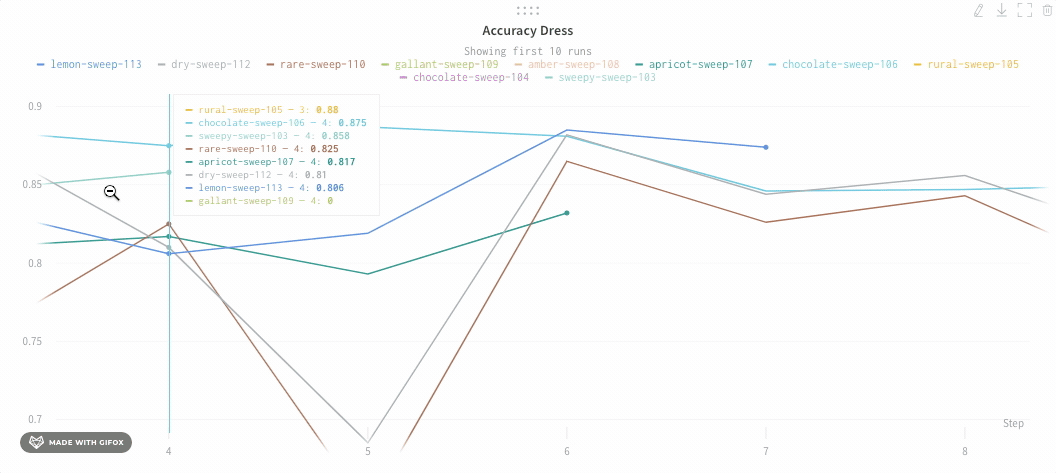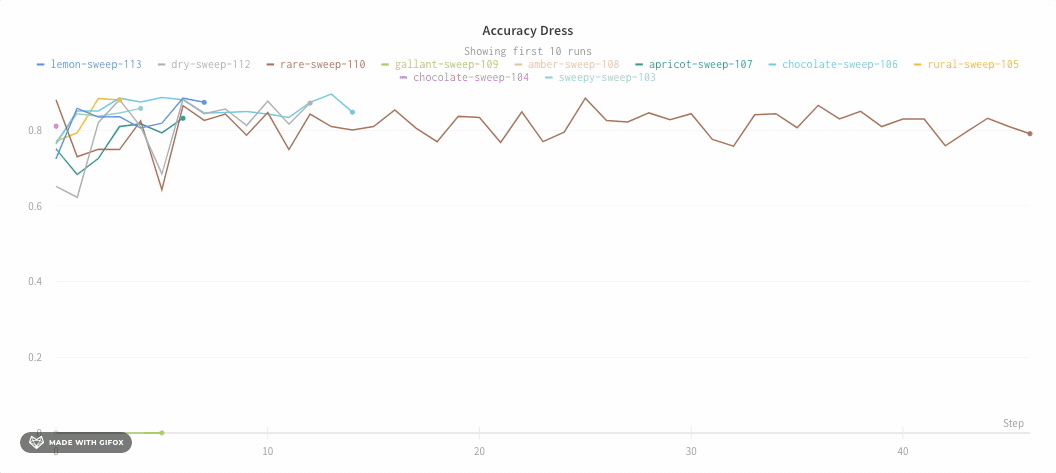
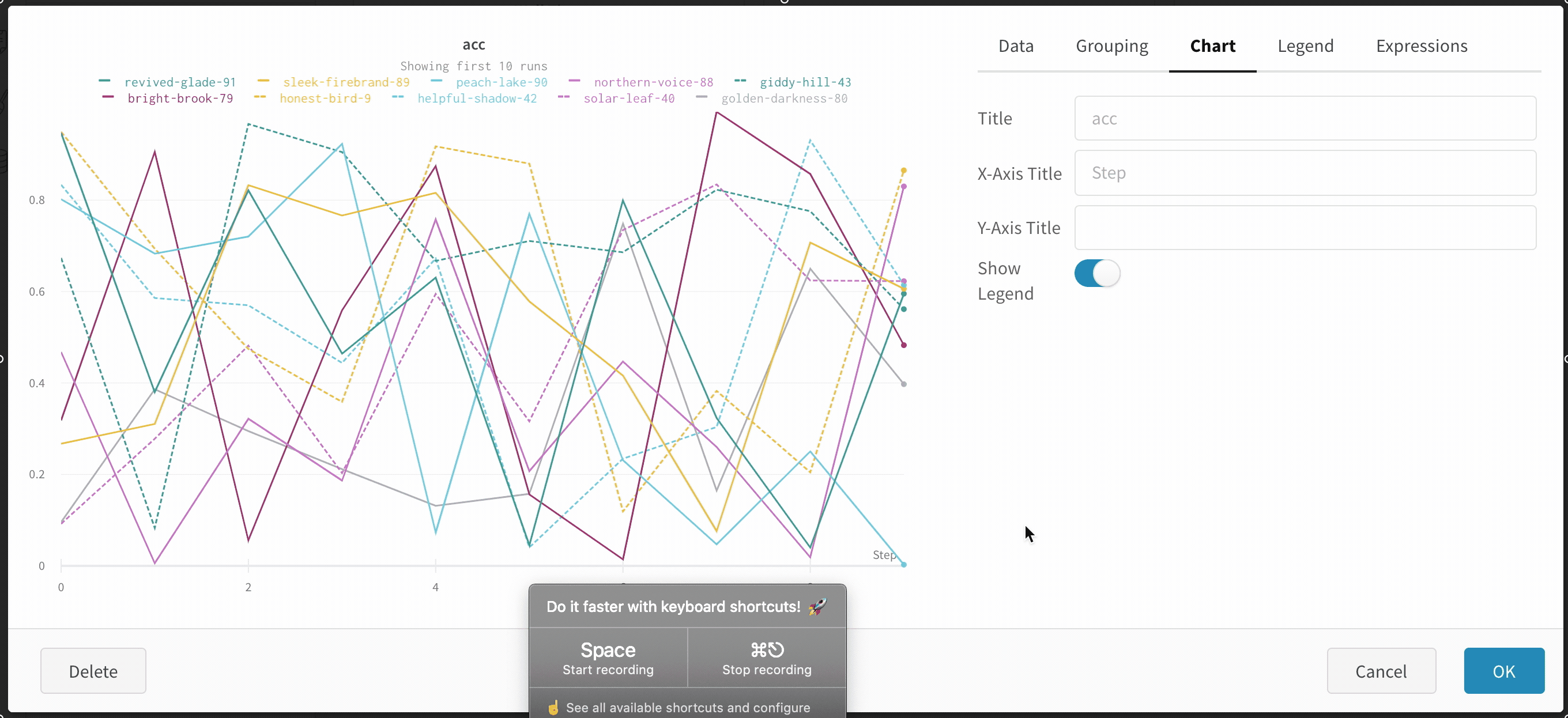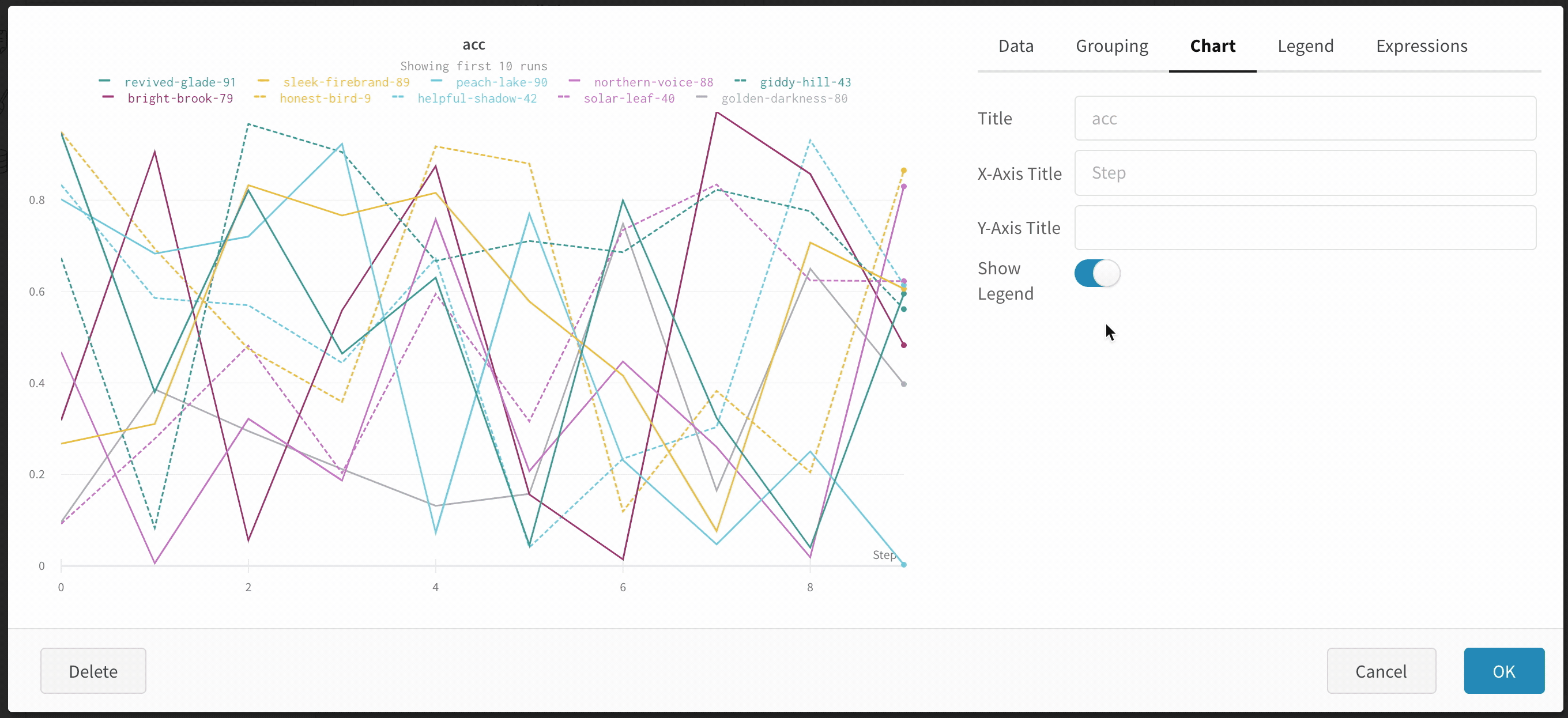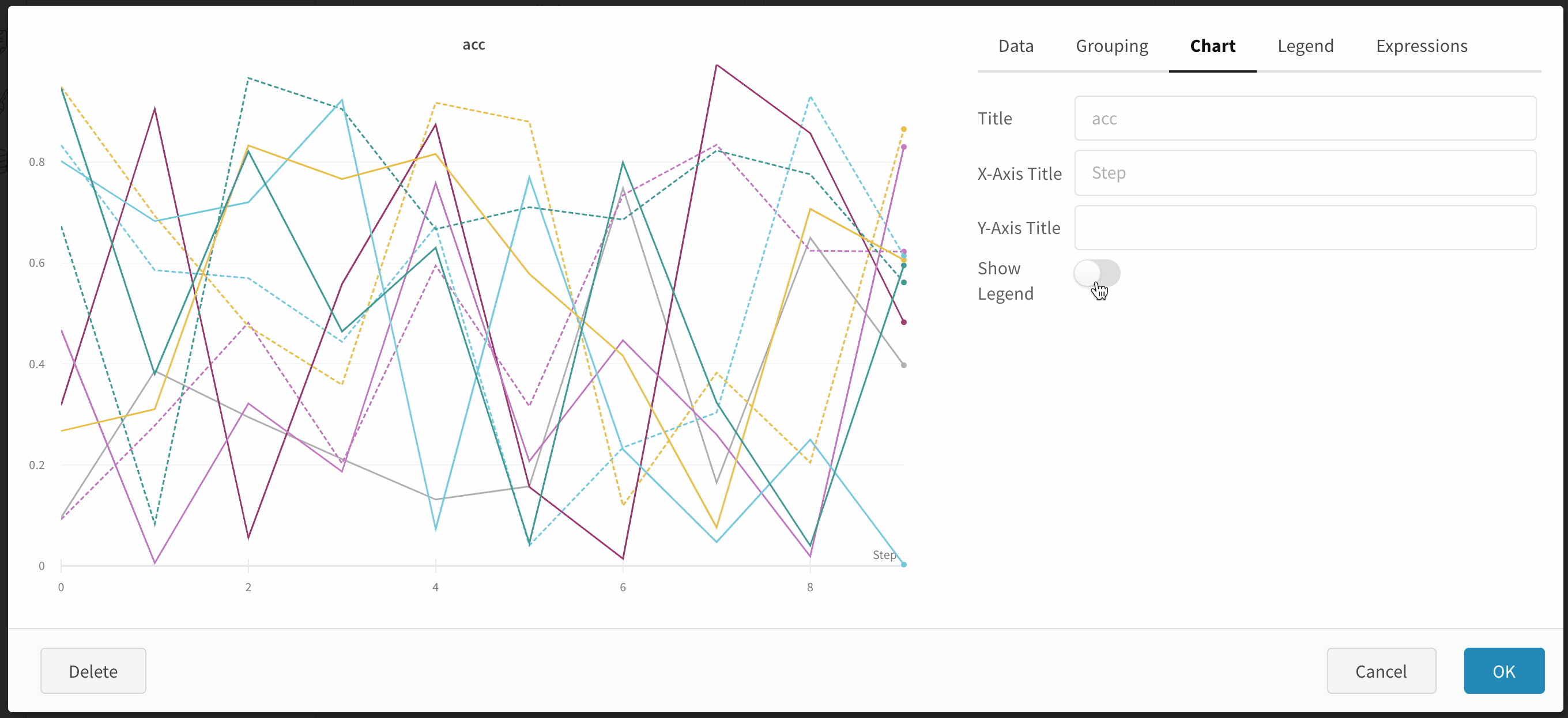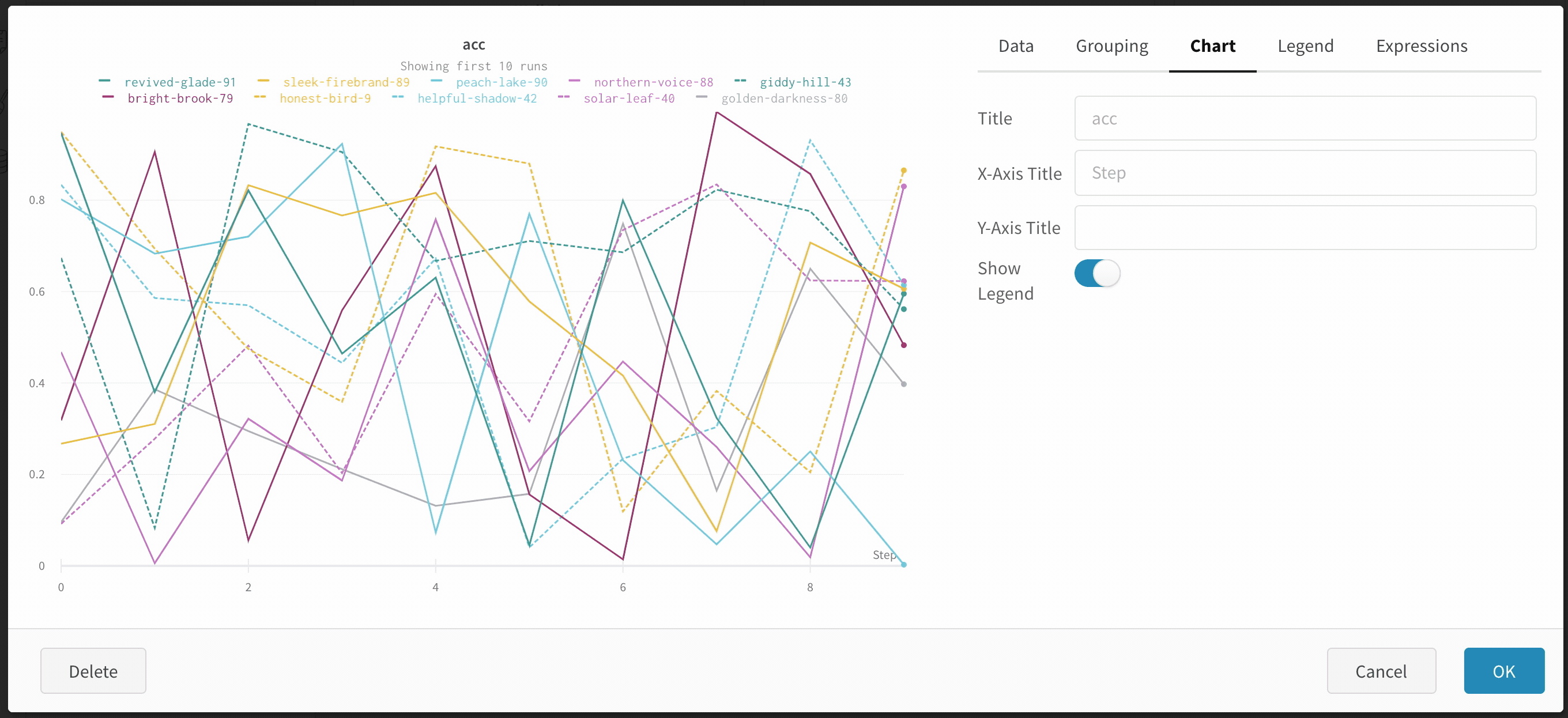
チャートの凡例を非表示にする
この単純なトグルを使用して、折れ線グラフの凡例をオフにします。