W&B のプロジェクトでカスタムグラフを作成できます。任意のデータのテーブルを記録し、必要な方法で正確に可視化します。Vega の機能を使用して、フォント、色、ツールチップの詳細を制御します。
- コード: Colab Colabノートブック の例をお試しください。
- 動画: 解説動画 をご覧ください。
- 例: KerasとSklearnのデモ notebook
仕組み
- データ の ログ: スクリプトから、config とサマリーデータを記録します。
- グラフのカスタマイズ: GraphQL クエリでログに記録されたデータを取得します。強力な可視化文法である Vega を使用して、クエリの結果を可視化します。
- グラフのログ:
wandb.plot_table()を使用して、スクリプトから独自のプリセットを呼び出します。
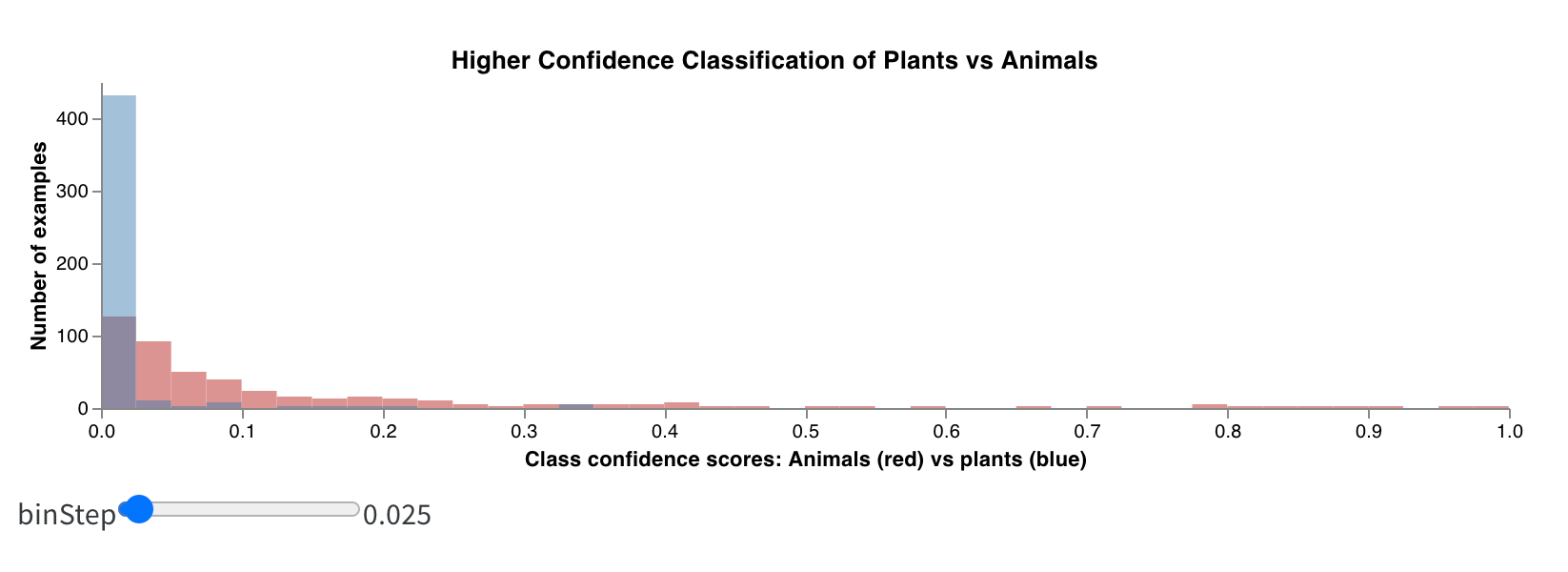
期待されるデータが表示されない場合は、探している列が選択された runs に記録されていない可能性があります。グラフを保存し、runs テーブルに戻り、目 のアイコンを使用して選択した runs を確認します。
スクリプトからグラフをログ
組み込みプリセット
W&B には、スクリプトから直接ログに記録できる多数の組み込みグラフプリセットがあります。これには、折れ線グラフ、散布図、棒グラフ、ヒストグラム、PR曲線、ROC曲線が含まれます。
wandb.plot.line()
任意の軸 x と y 上の接続された順序付けられた点 (x,y) のリストであるカスタム折れ線グラフをログに記録します。
data = [[x, y] for (x, y) in zip(x_values, y_values)]
table = wandb.Table(data=data, columns=["x", "y"])
wandb.log(
{
"my_custom_plot_id": wandb.plot.line(
table, "x", "y", title="Custom Y vs X Line Plot"
)
}
)
折れ線グラフは、任意の2つの次元で曲線をログに記録します。2つの値のリストを互いにプロットする場合、リスト内の値の数は完全に一致する必要があります (たとえば、各ポイントには x と y が必要です)。
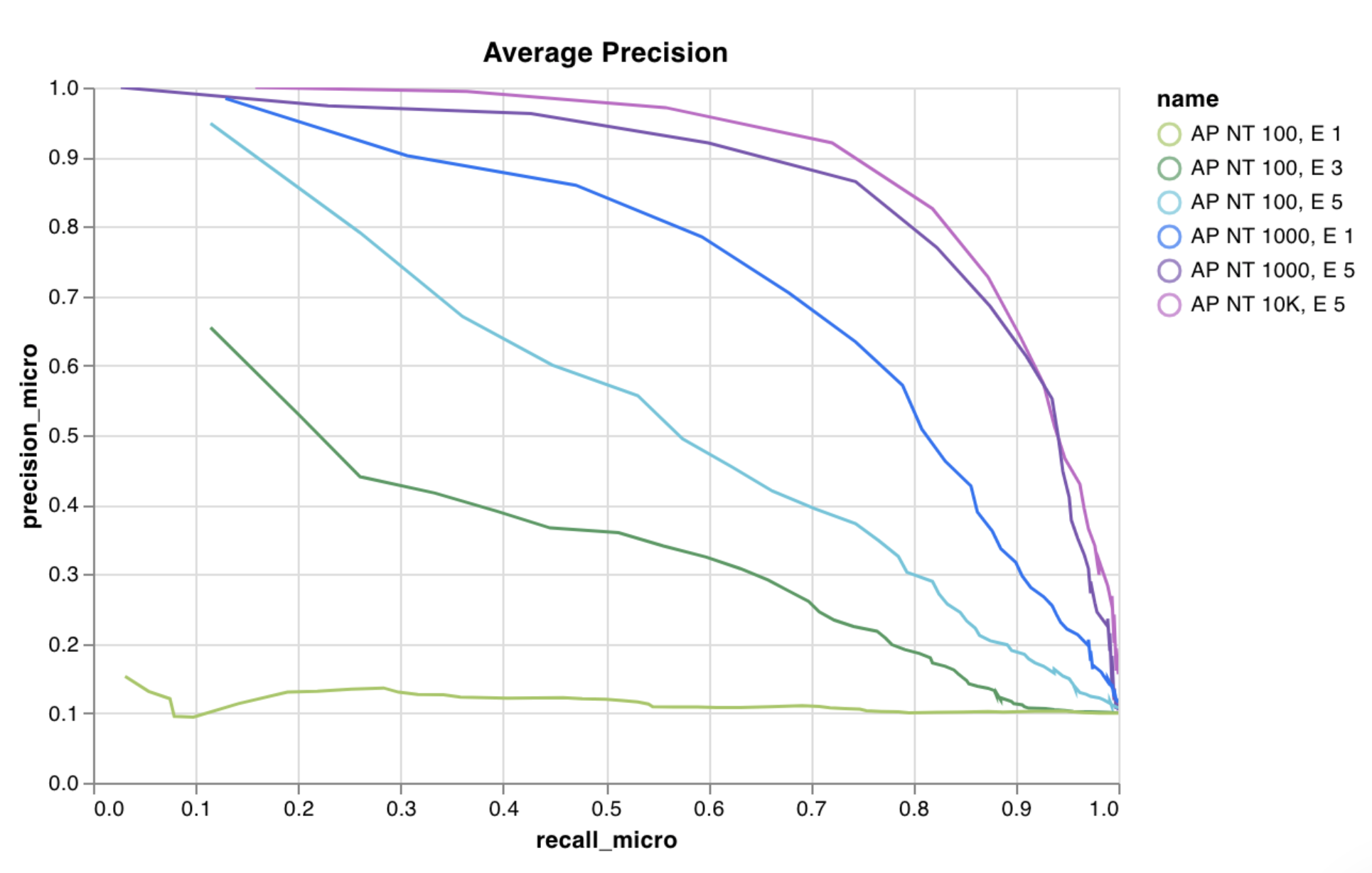
レポートの例 を参照するか、Google Colabノートブックの例 をお試しください。
wandb.plot.scatter()
カスタム散布図 (任意の軸 x と y のペア上の点のリスト (x, y)) をログに記録します。
data = [[x, y] for (x, y) in zip(class_x_prediction_scores, class_y_prediction_scores)]
table = wandb.Table(data=data, columns=["class_x", "class_y"])
wandb.log({"my_custom_id": wandb.plot.scatter(table, "class_x", "class_y")})
これを使用して、任意の2つの次元で散布点をログに記録できます。2つの値のリストを互いにプロットする場合、リスト内の値の数は完全に一致する必要があることに注意してください (たとえば、各ポイントには x と y が必要です)。
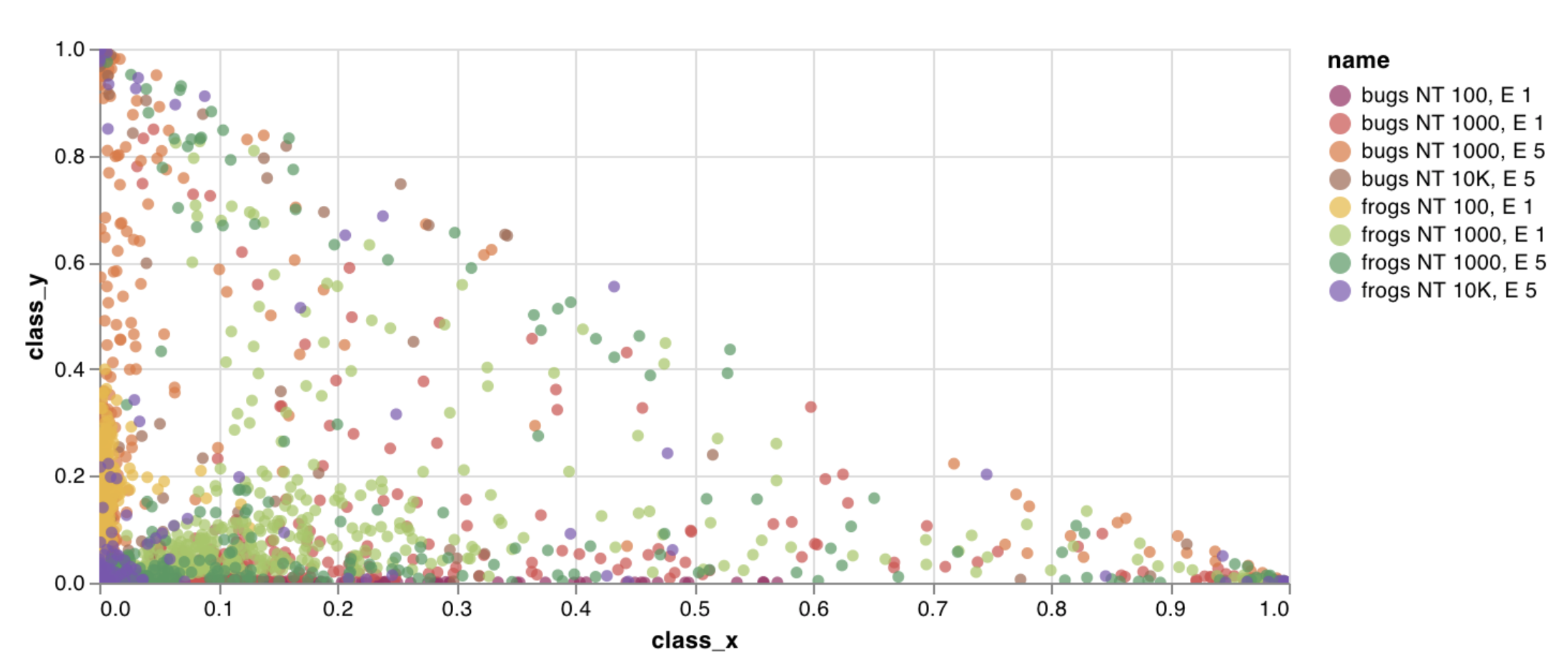
レポートの例 を参照するか、Google Colabノートブックの例 をお試しください。
wandb.plot.bar()
カスタム棒グラフ (ラベル付きの値のリストを棒として) を数行でネイティブにログに記録します。
data = [[label, val] for (label, val) in zip(labels, values)]
table = wandb.Table(data=data, columns=["label", "value"])
wandb.log(
{
"my_bar_chart_id": wandb.plot.bar(
table, "label", "value", title="Custom Bar Chart"
)
}
)
これを使用して、任意の棒グラフをログに記録できます。リスト内のラベルと値の数は完全に一致する必要があることに注意してください (たとえば、各データポイントには両方が必要です)。
レポートの例 を参照するか、Google Colabノートブックの例 をお試しください。
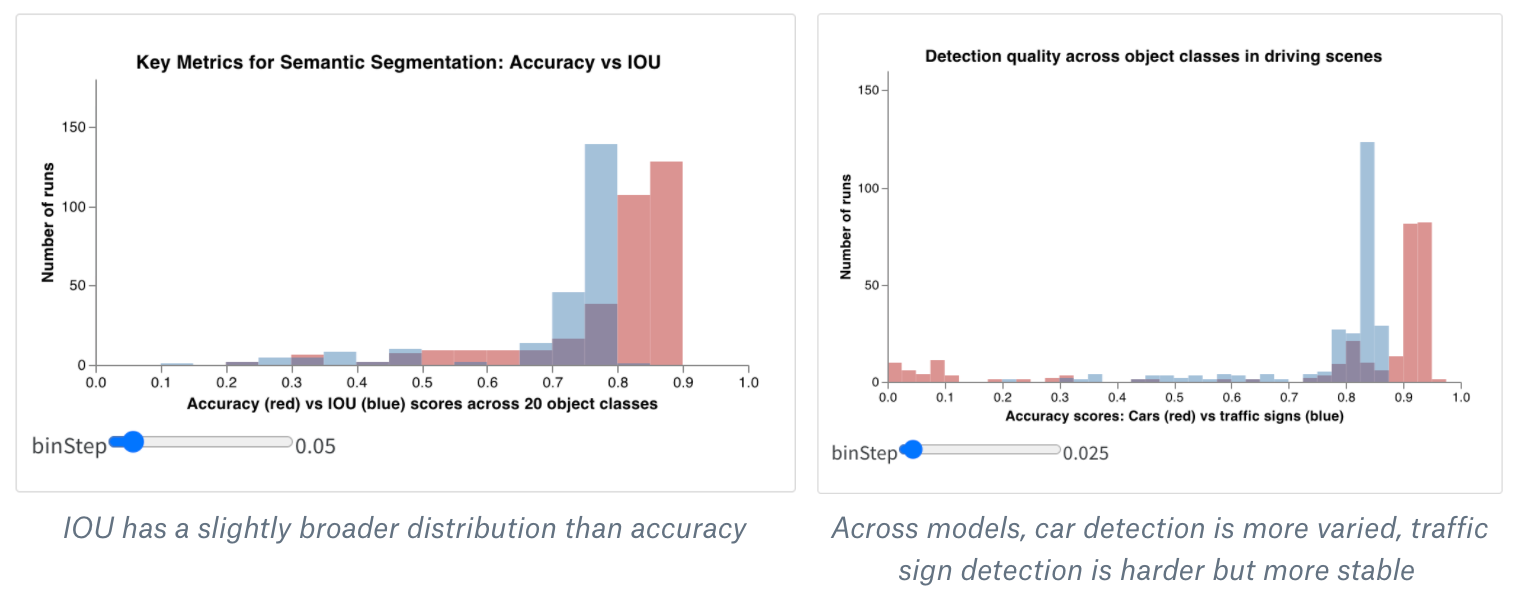
wandb.plot.histogram()
カスタムヒストグラム (値のソートされたリストを、発生のカウント/頻度でビンに分類) を数行でネイティブにログに記録します。予測信頼度スコア (scores) のリストがあり、その分布を可視化するとします。
data = [[s] for s in scores]
table = wandb.Table(data=data, columns=["scores"])
wandb.log({"my_histogram": wandb.plot.histogram(table, "scores", title=None)})
これを使用して、任意のヒストグラムをログに記録できます。data はリストのリストであり、行と列の2D配列をサポートすることを目的としています。
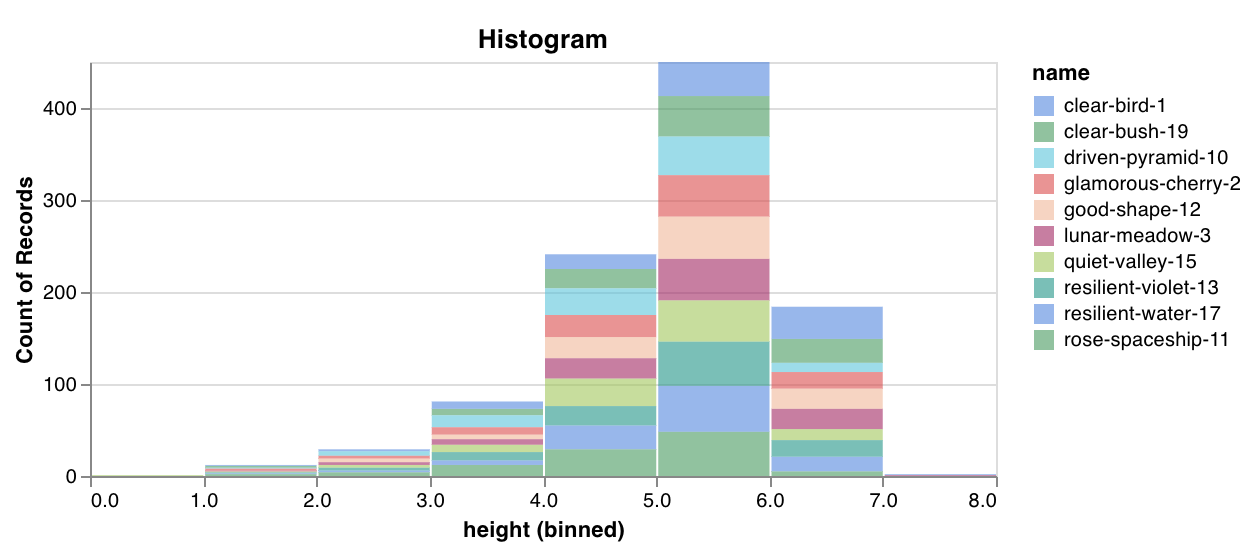
レポートの例 を参照するか、Google Colabノートブックの例 をお試しください。
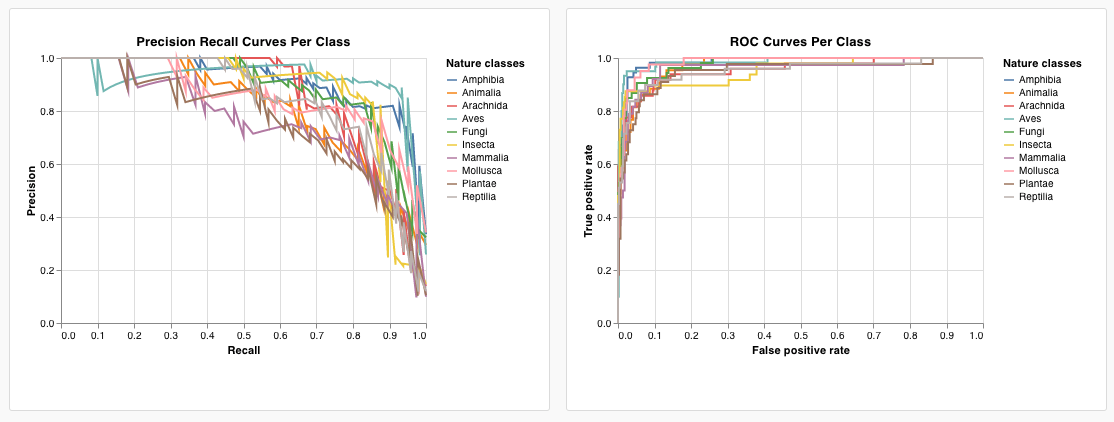
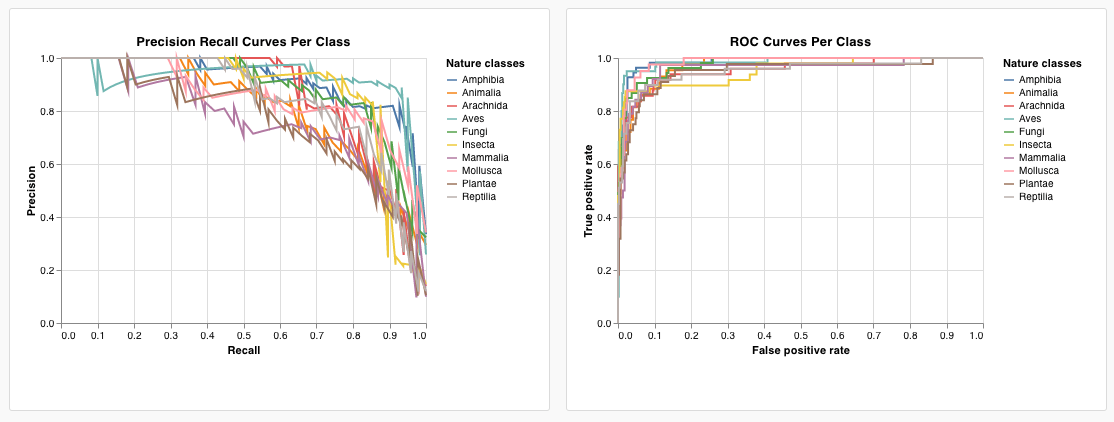
wandb.plot.pr_curve()
適合率-再現率曲線 を1行で作成します。
plot = wandb.plot.pr_curve(ground_truth, predictions, labels=None, classes_to_plot=None)
wandb.log({"pr": plot})
コードが以下にアクセスできる場合は、いつでもこれをログに記録できます。
- 例のセットに対するモデルの予測スコア (
predictions) - これらの例に対応する正解ラベル (
ground_truth) - (オプション) ラベル/クラス名のリスト (
labels=["cat", "dog", "bird"...](ラベルインデックス0がcat、1 = dog、2 = birdなどを意味する場合)) - (オプション) プロットで可視化するラベルのサブセット (リスト形式のまま)
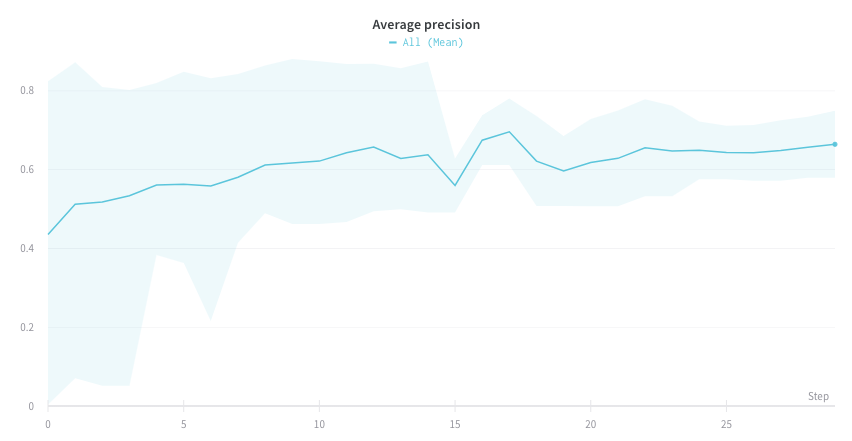
レポートの例 を参照するか、Google Colabノートブックの例 をお試しください。
wandb.plot.roc_curve()
ROC曲線 を1行で作成します。
plot = wandb.plot.roc_curve(
ground_truth, predictions, labels=None, classes_to_plot=None
)
wandb.log({"roc": plot})
コードが以下にアクセスできる場合は、いつでもこれをログに記録できます。
- 例のセットに対するモデルの予測スコア (
predictions) - これらの例に対応する正解ラベル (
ground_truth) - (オプション) ラベル/クラス名のリスト (
labels=["cat", "dog", "bird"...](ラベルインデックス0がcat、1 = dog、2 = birdなどを意味する場合)) - (オプション) プロットで可視化するこれらのラベルのサブセット (リスト形式のまま)
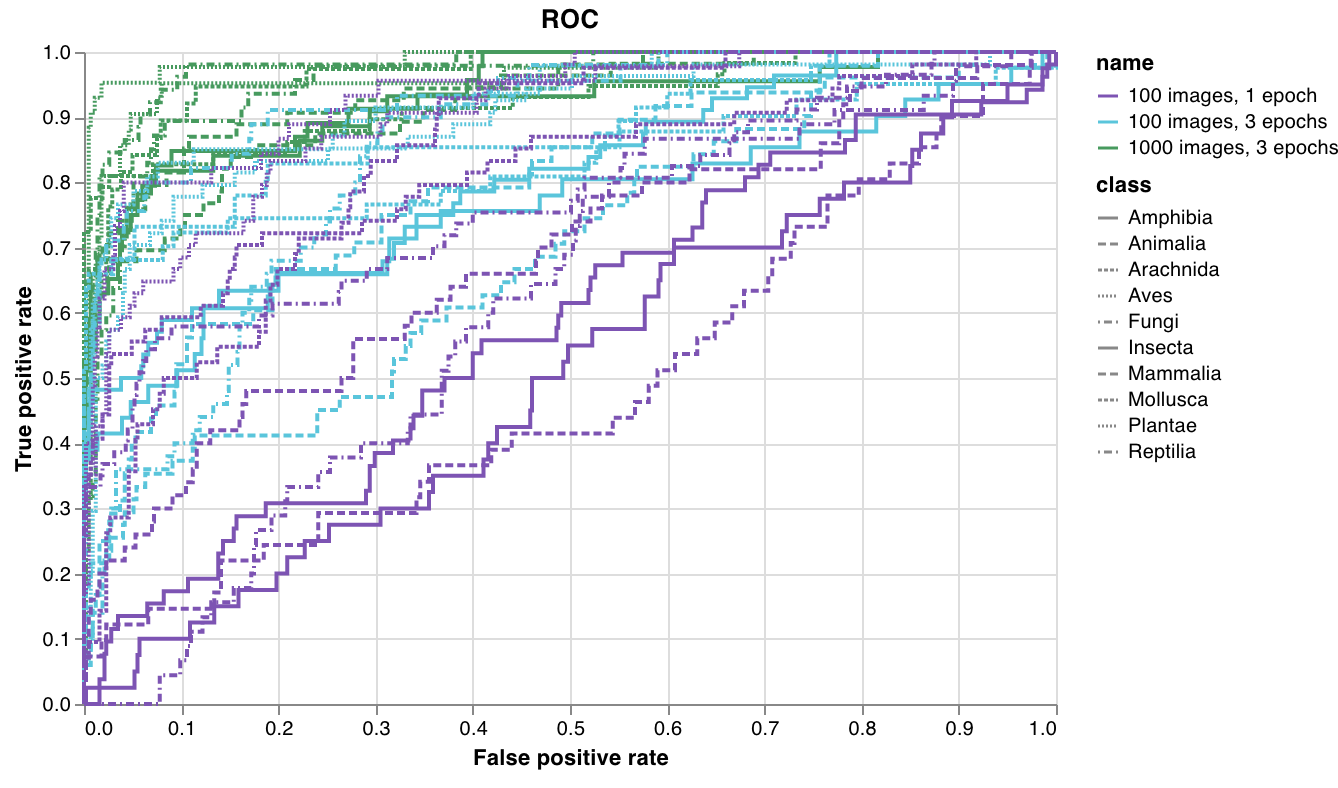
レポートの例 を参照するか、Google Colabノートブックの例 をお試しください。
カスタムプリセット
組み込みプリセットを調整するか、新しいプリセットを作成して、グラフを保存します。グラフIDを使用して、スクリプトからそのカスタムプリセットに直接データをログに記録します。Google Colabノートブックの例 をお試しください。
# プロットする列を含むテーブルを作成します
table = wandb.Table(data=data, columns=["step", "height"])
# テーブルの列からグラフのフィールドへのマッピング
fields = {"x": "step", "value": "height"}
# テーブルを使用して、新しいカスタムグラフプリセットを作成します
# 独自の保存されたグラフプリセットを使用するには、vega_spec_name を変更します
my_custom_chart = wandb.plot_table(
vega_spec_name="carey/new_chart",
data_table=table,
fields=fields,
)
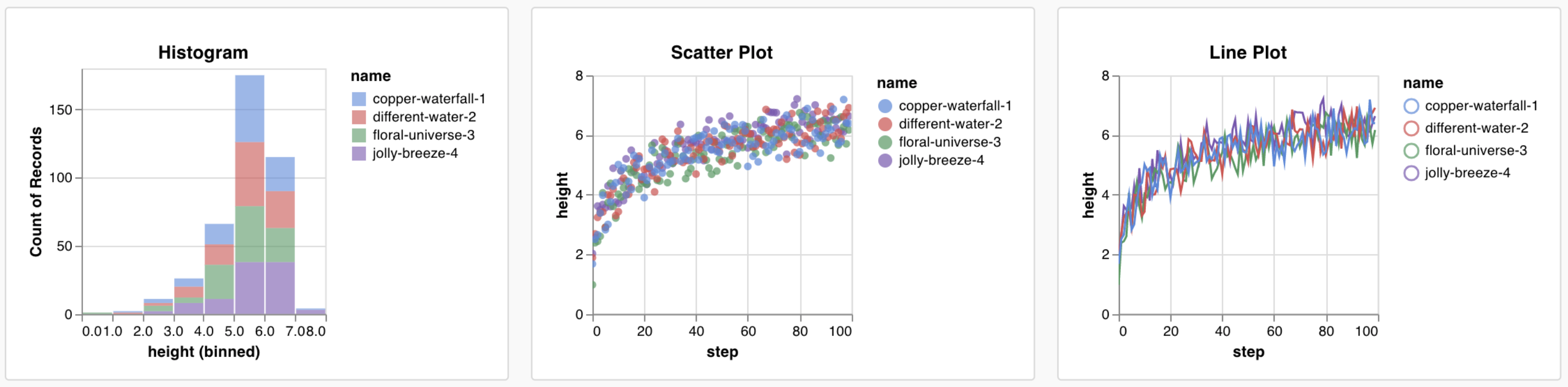
データの ログ
スクリプトから次のデータ型をログに記録し、カスタムグラフで使用できます。
- Config: experiment の初期設定 (独立変数)。これには、トレーニングの開始時に
wandb.configのキーとしてログに記録した名前付きフィールドが含まれます。例:wandb.config.learning_rate = 0.0001 - サマリー: トレーニング中にログに記録された単一の値 (結果または従属変数)。例:
wandb.log({"val_acc" : 0.8})。wandb.log()を介してトレーニング中にこのキーに複数回書き込むと、サマリーはそのキーの最終値に設定されます。 - 履歴: ログに記録されたスカラーの完全な時系列は、
historyフィールドを介してクエリで使用できます - summaryTable: 複数の値のリストをログに記録する必要がある場合は、
wandb.Table()を使用してそのデータを保存し、カスタム パネルでクエリを実行します。 - historyTable: 履歴データを確認する必要がある場合は、カスタムグラフ パネルで
historyTableをクエリします。wandb.Table()を呼び出すか、カスタムグラフをログに記録するたびに、そのステップの履歴に新しいテーブルが作成されます。
カスタムテーブルをログする方法
wandb.Table() を使用して、データを2D配列としてログに記録します。通常、このテーブルの各行は1つのデータポイントを表し、各列はプロットする各データポイントの関連フィールド/次元を示します。カスタム パネルを構成すると、テーブル全体が wandb.log() (custom_data_table below) に渡される名前付きキーを介してアクセスできるようになり、個々のフィールドは列名 (x、y、および z) を介してアクセスできるようになります。 experiment 全体で複数のタイムステップでテーブルをログに記録できます。各テーブルの最大サイズは10,000行です。Google Colab の例 をお試しください。
# データのカスタムテーブルをログ
my_custom_data = [[x1, y1, z1], [x2, y2, z2]]
wandb.log(
{"custom_data_table": wandb.Table(data=my_custom_data, columns=["x", "y", "z"])}
)
グラフのカスタマイズ
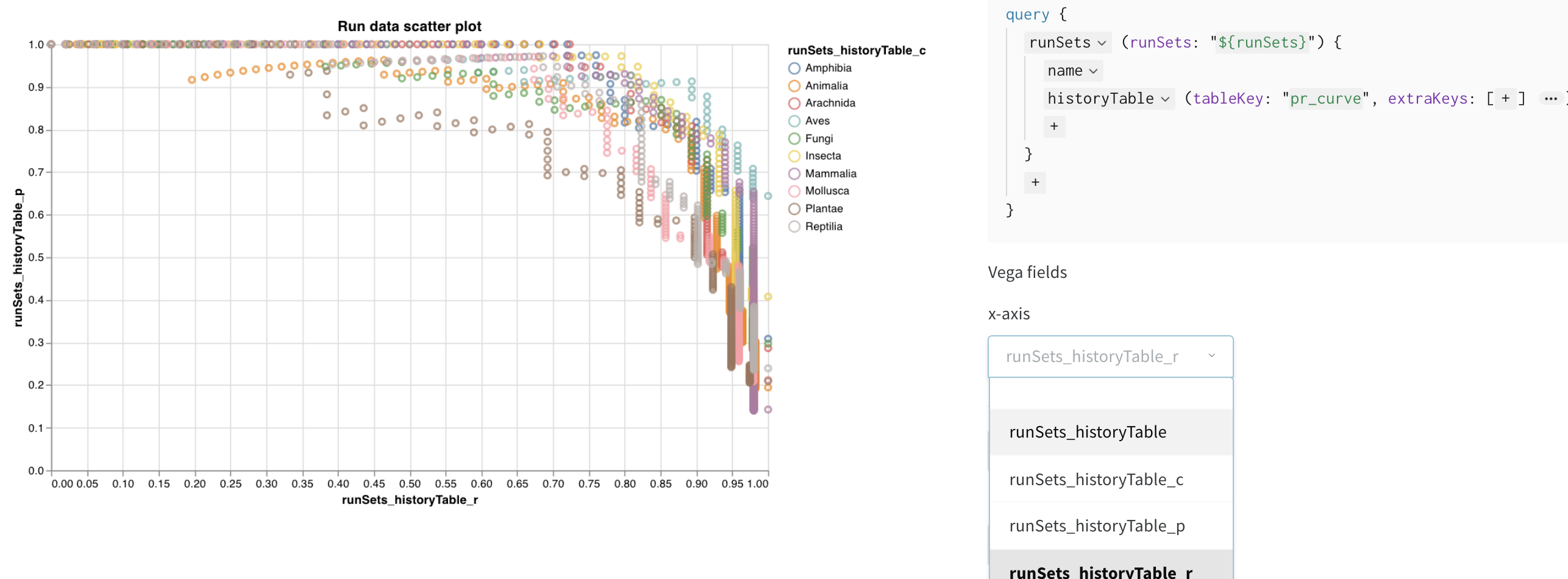
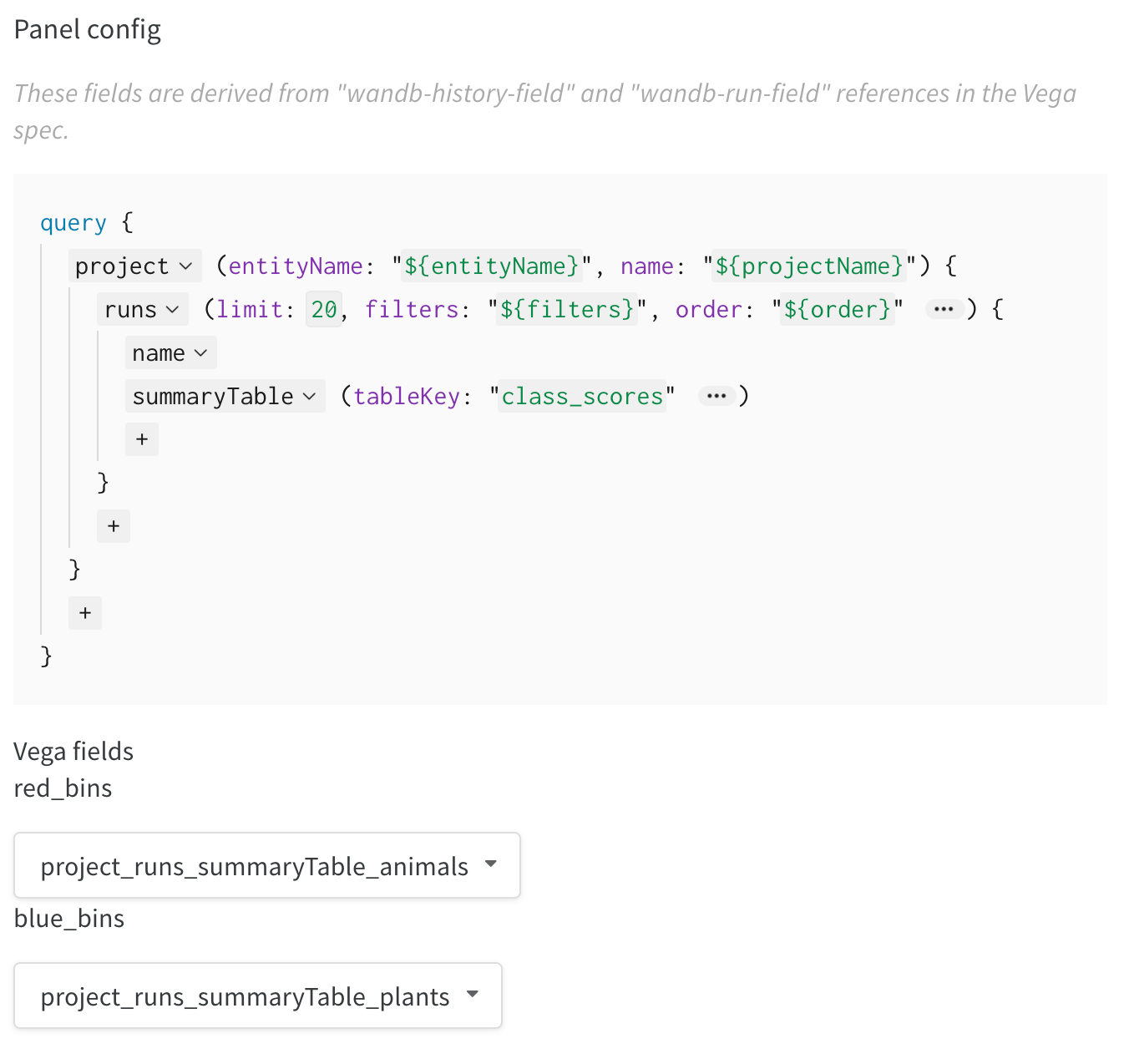
新しいカスタムグラフを追加して開始し、クエリを編集して表示されている runs からデータを選択します。クエリは GraphQL を使用して、runs の config、サマリー、および履歴フィールドからデータをフェッチします。
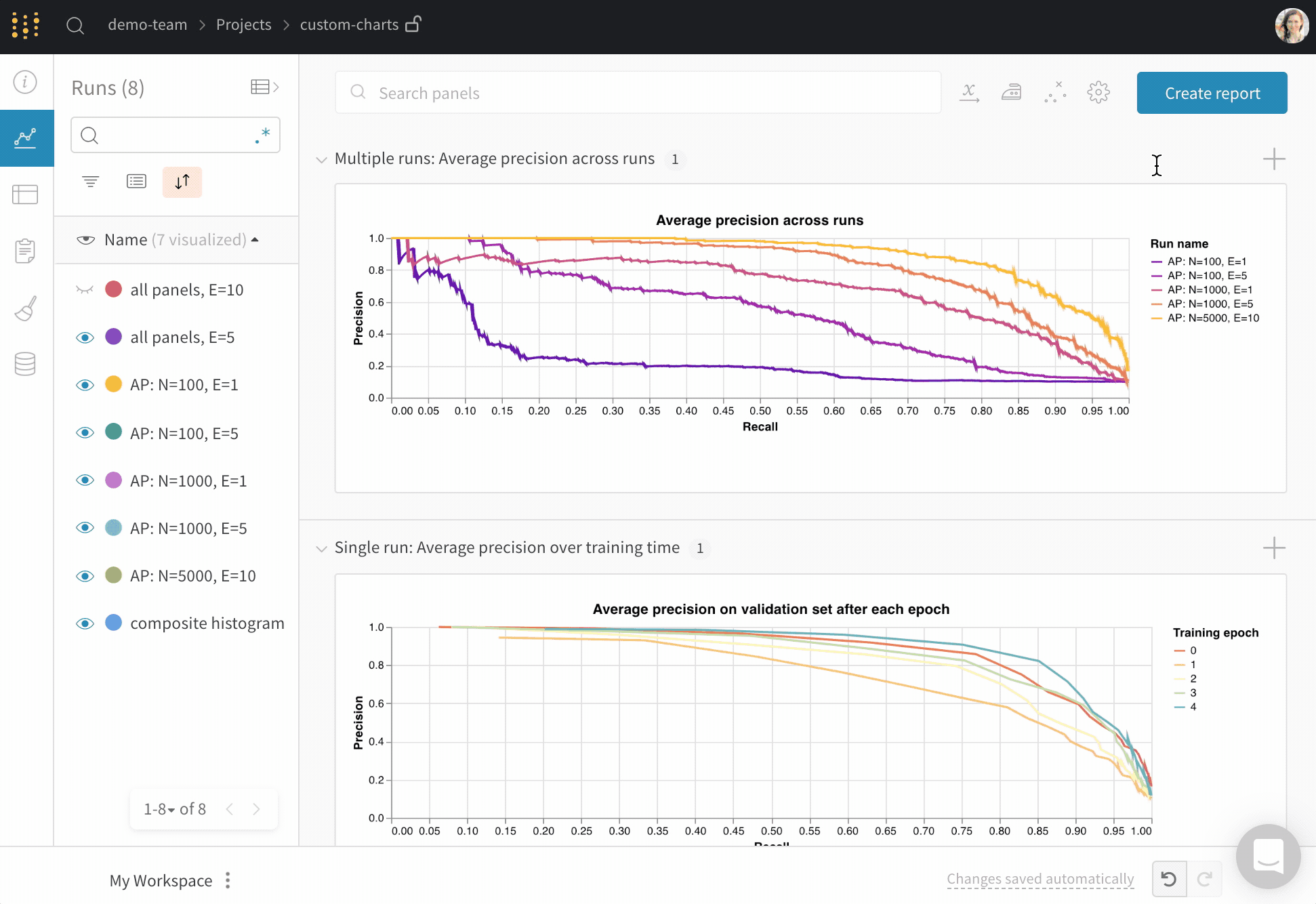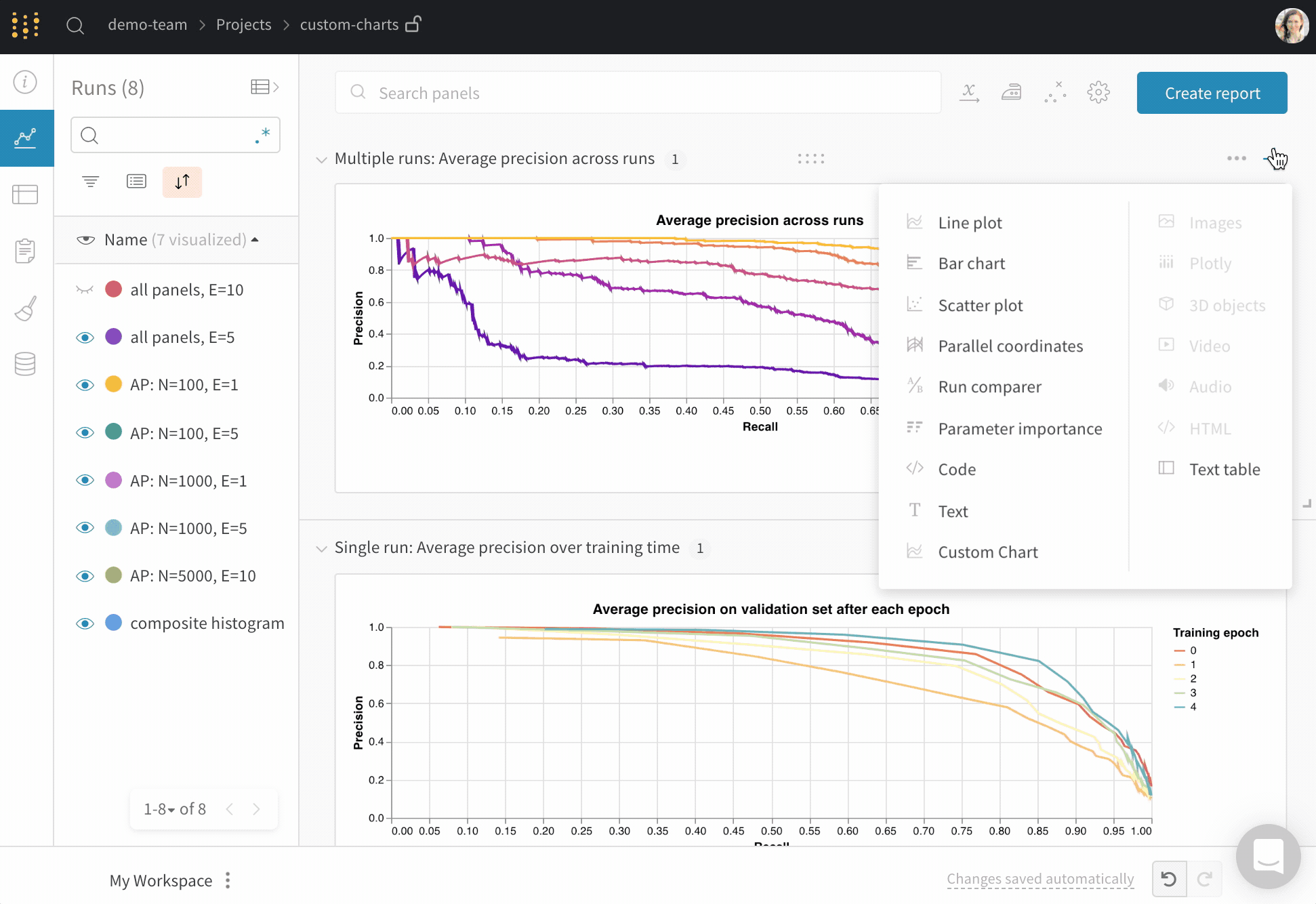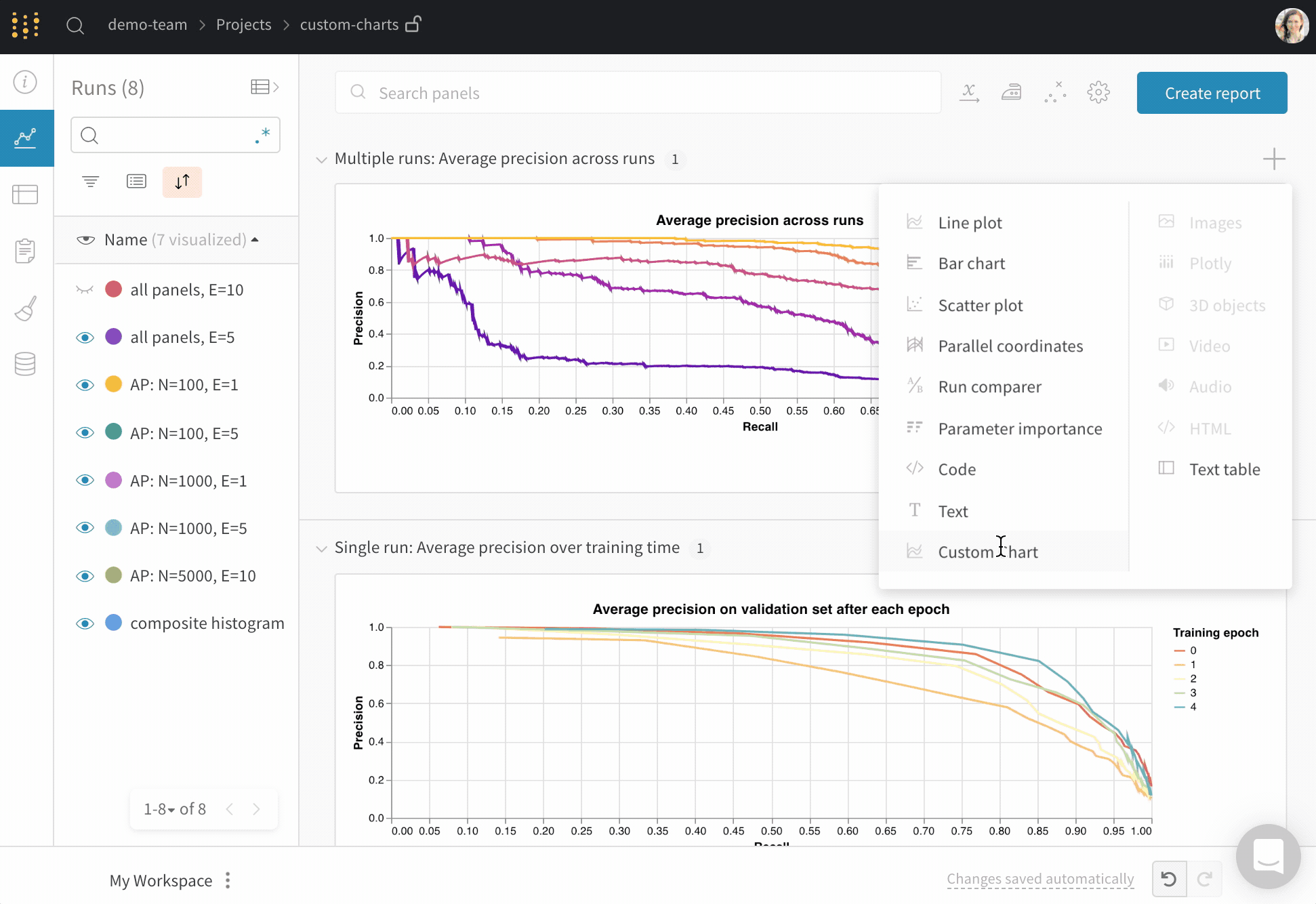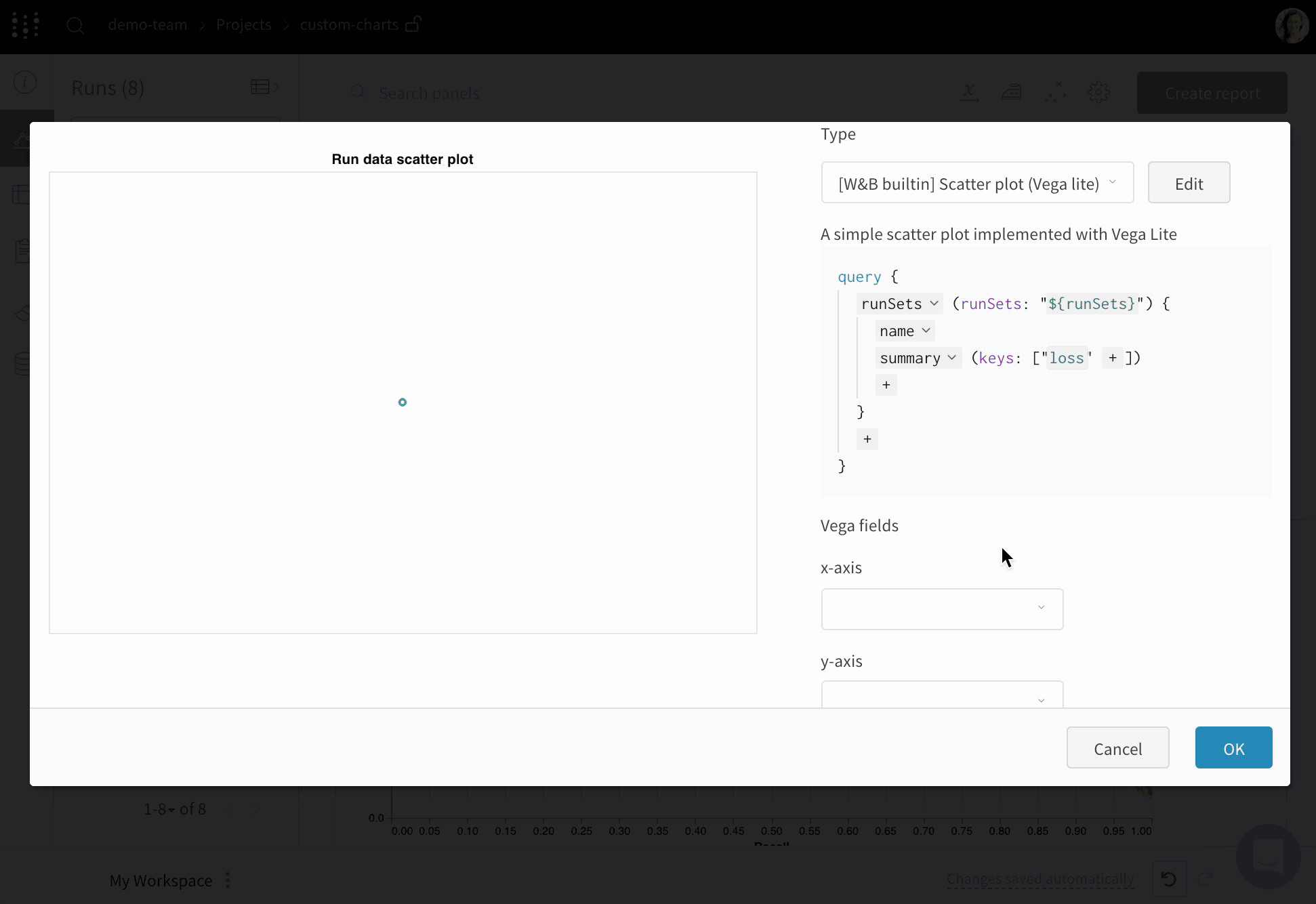
カスタム可視化
右上隅の グラフ を選択して、デフォルトのプリセットから開始します。次に、グラフフィールド を選択して、クエリから取得しているデータをグラフの対応するフィールドにマッピングします。
次の画像は、メトリクスを選択し、それを下の棒グラフフィールドにマッピングする方法の例を示しています。
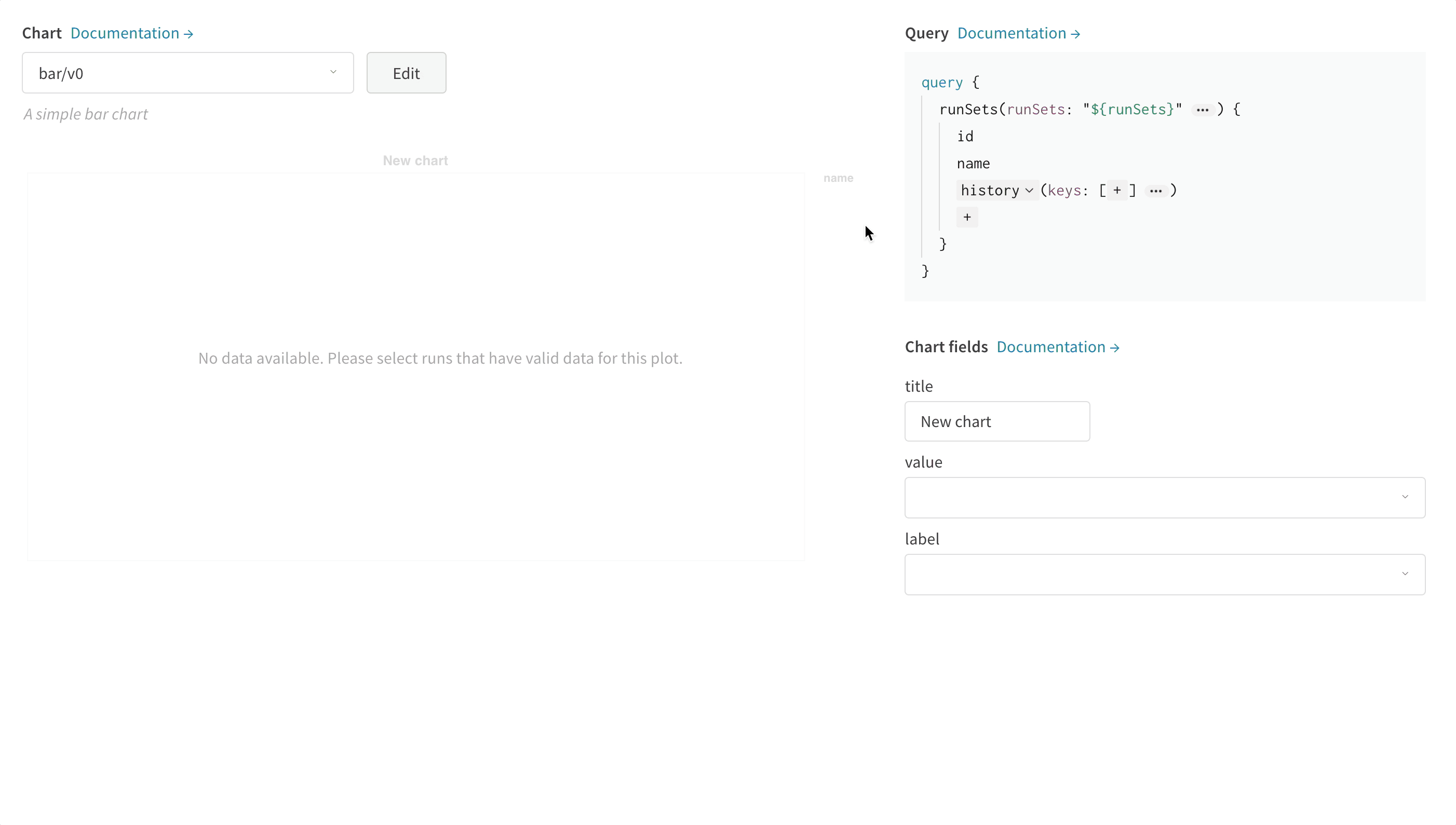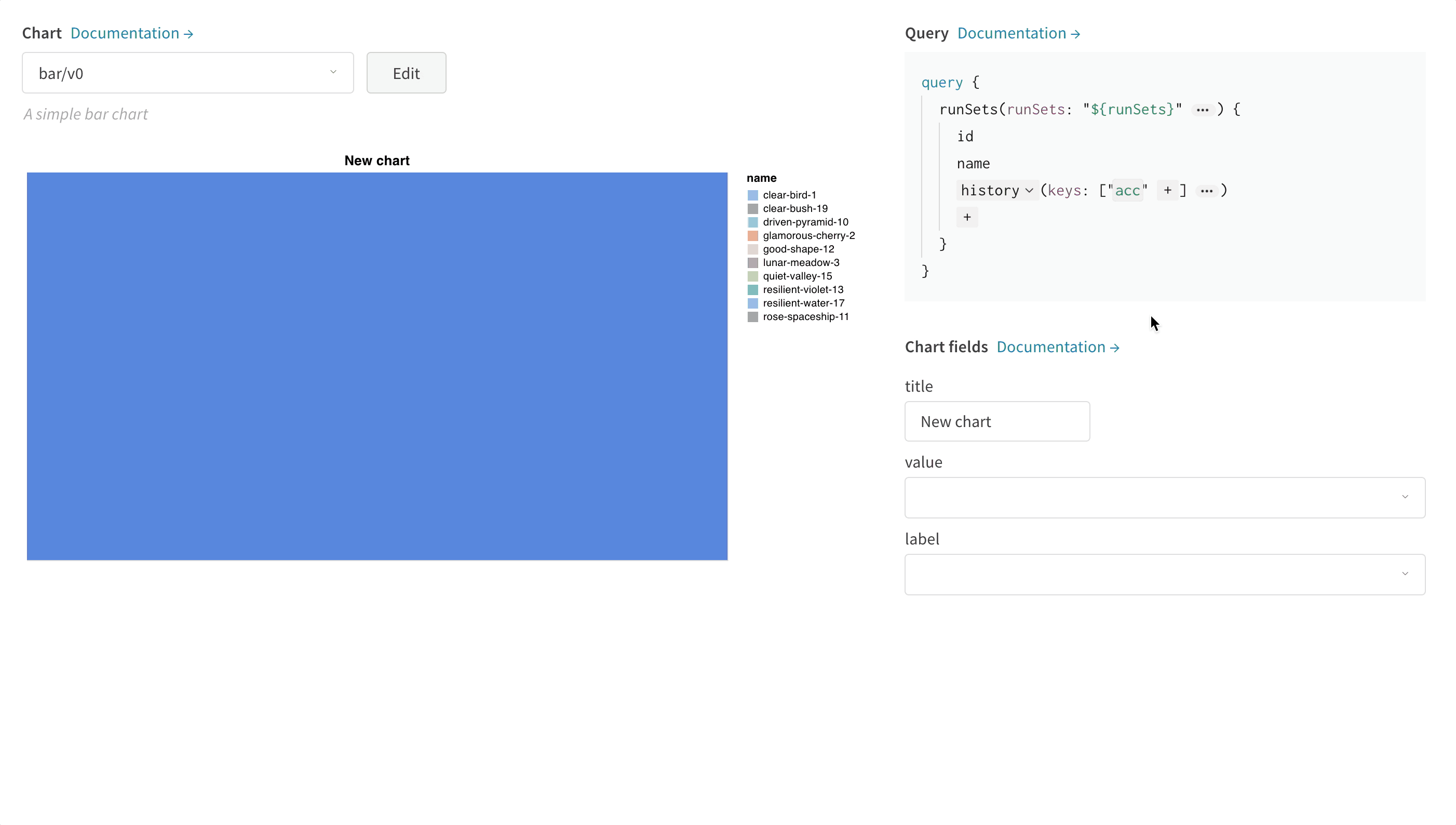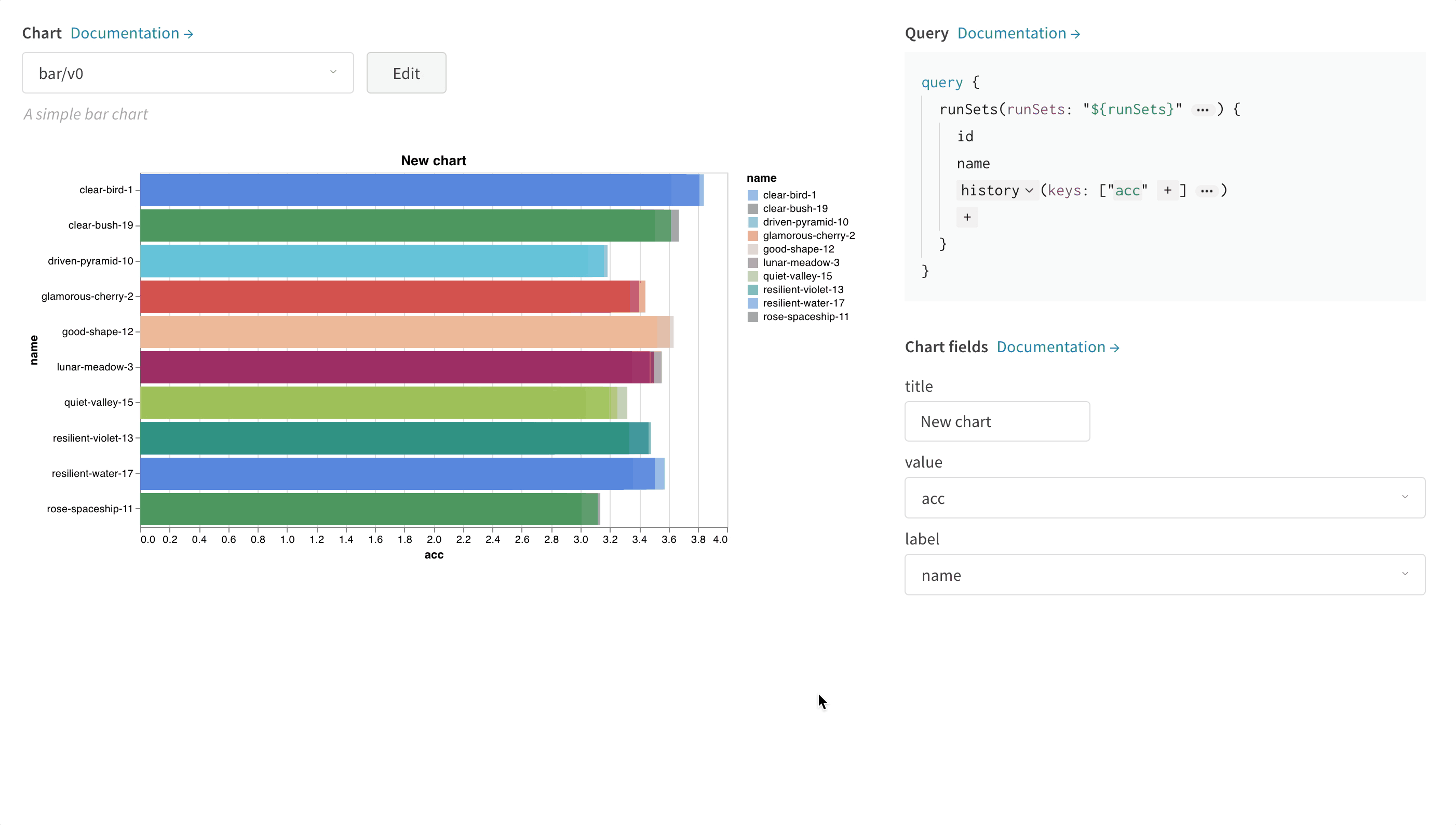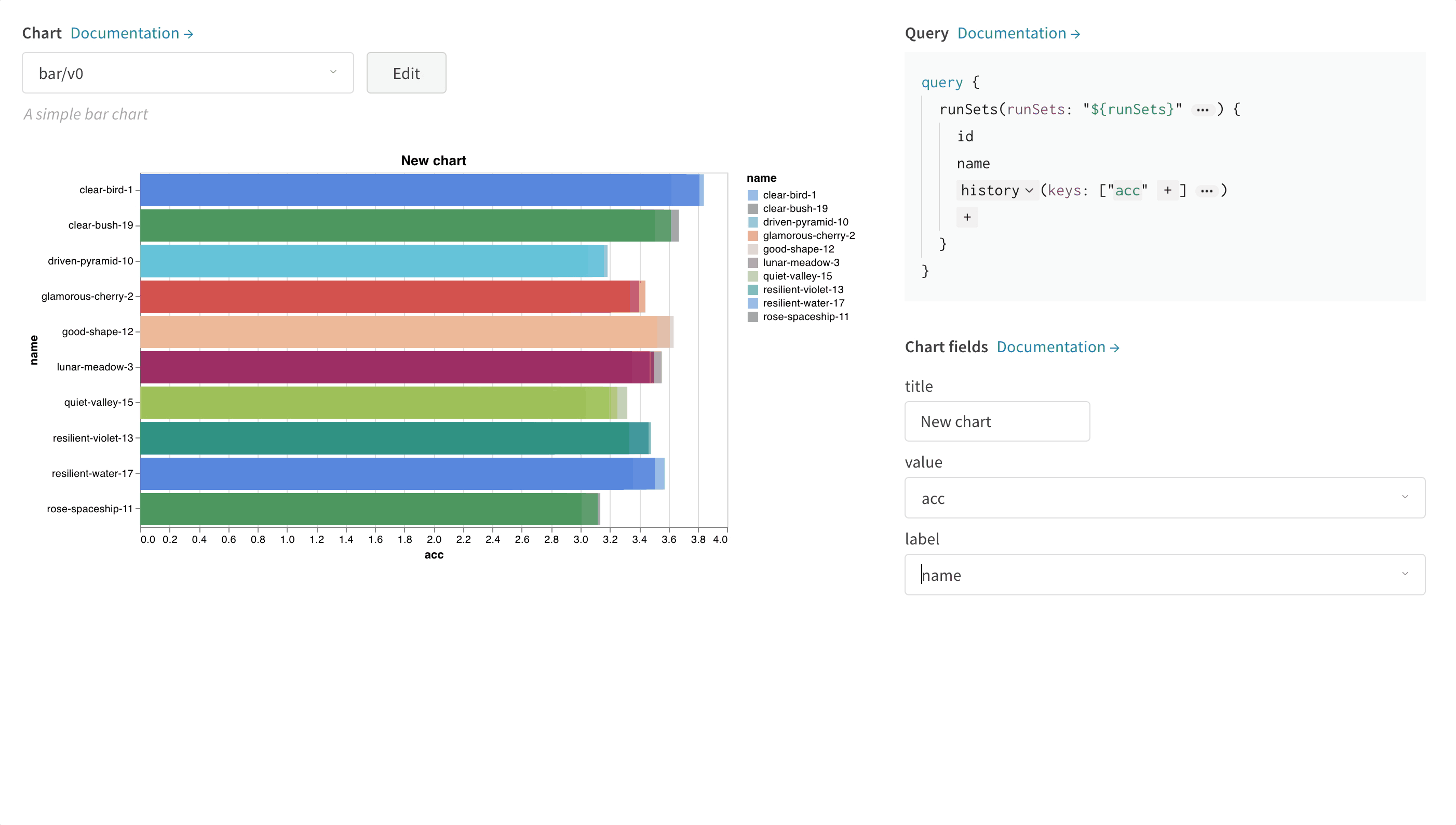
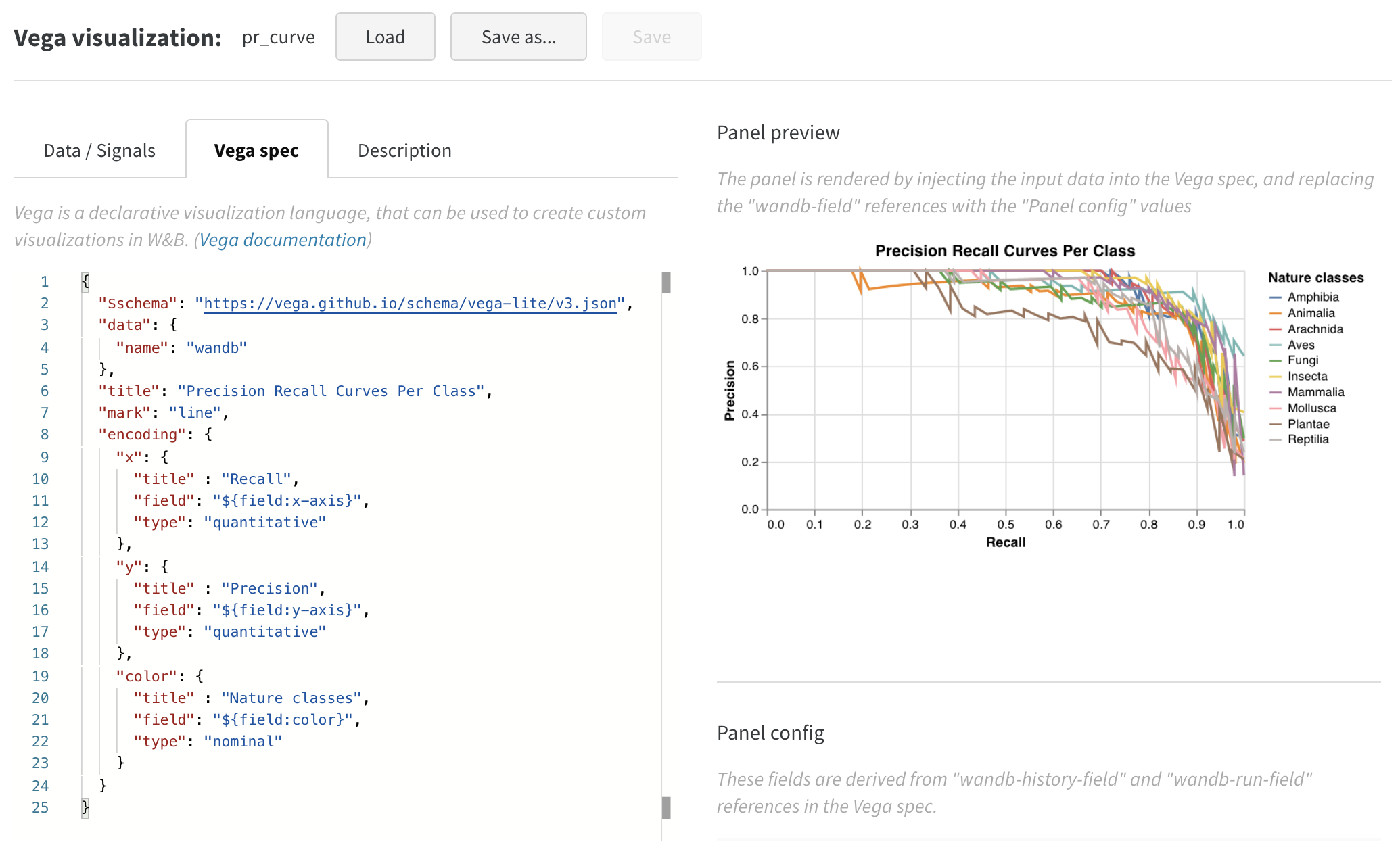
Vega を編集する方法
パネルの上部にある 編集 をクリックして、Vega 編集モードに移動します。ここでは、UI でインタラクティブなグラフを作成する Vega 仕様 を定義できます。グラフのあらゆる側面を変更できます。たとえば、タイトルを変更したり、別の配色を選択したり、曲線を接続された線としてではなく一連の点として表示したりできます。また、Vega 変換を使用して値の配列をヒストグラムにビン化するなど、データ自体に変更を加えることもできます。パネルプレビューはインタラクティブに更新されるため、Vega 仕様またはクエリを編集するときの変更の効果を確認できます。Vega のドキュメントとチュートリアル を参照してください。
フィールド参照
W&B からグラフにデータをプルするには、Vega 仕様の任意の場所に "${field:<field-name>}" 形式のテンプレート文字列を追加します。これにより、右側の グラフフィールド 領域にドロップダウンが作成され、ユーザーはクエリ結果の列を選択して Vega にマッピングできます。
フィールドのデフォルト値を設定するには、次の構文を使用します: "${field:<field-name>:<placeholder text>}"
グラフプリセットの保存
モーダルの下部にあるボタンを使用して、特定の可視化パネルに変更を適用します。または、Vega 仕様を保存して、プロジェクトの他の場所で使用することもできます。再利用可能なグラフ定義を保存するには、Vega エディターの上部にある 名前を付けて保存 をクリックし、プリセットに名前を付けます。
記事とガイド
一般的なユースケース
- エラーバー付きのカスタム棒グラフ
- カスタム x-y 座標を必要とするモデル検証メトリクスを表示する (適合率-再現率曲線など)
- 2つの異なるモデル/ experiment からのデータ分布をヒストグラムとしてオーバーレイする
- トレーニング中の複数のポイントでのスナップショットを介してメトリクスの変化を表示する
- W&B でまだ利用できない独自の可視化を作成する (そして、うまくいけばそれを世界と共有する)