Track CSV files with experiments
4 minute read
W&B Python 라이브러리를 사용하여 CSV 파일을 기록하고 W&B 대시보드에서 시각화하세요. W&B 대시보드는 기계 학습 모델의 결과를 구성하고 시각화하는 중심 공간입니다. 이는 W&B에 기록되지 않은 이전 기계 학습 Experiments의 정보가 포함된 CSV 파일이 있거나 데이터셋이 포함된 CSV 파일이 있는 경우 특히 유용합니다.
데이터셋 CSV 파일 가져오기 및 기록
CSV 파일의 내용을 더 쉽게 재사용할 수 있도록 W&B Artifacts를 활용하는 것이 좋습니다.
- 시작하려면 먼저 CSV 파일을 가져옵니다. 다음 코드 조각에서
iris.csv파일 이름을 CSV 파일 이름으로 바꿉니다.
import wandb
import pandas as pd
# CSV를 새 DataFrame으로 읽기
new_iris_dataframe = pd.read_csv("iris.csv")
- CSV 파일을 W&B Table로 변환하여 W&B 대시보드를 활용합니다.
# DataFrame을 W&B Table로 변환
iris_table = wandb.Table(dataframe=new_iris_dataframe)
- 다음으로 W&B Artifact를 생성하고 테이블을 Artifact에 추가합니다.
# 테이블을 Artifact에 추가하여 행
# 제한을 200000으로 늘리고 재사용을 용이하게 합니다.
iris_table_artifact = wandb.Artifact("iris_artifact", type="dataset")
iris_table_artifact.add(iris_table, "iris_table")
# 원시 CSV 파일을 Artifact 내에 기록하여 데이터를 보존합니다.
iris_table_artifact.add_file("iris.csv")
W&B Artifacts에 대한 자세한 내용은 Artifacts 챕터를 참조하세요.
- 마지막으로
wandb.init으로 새로운 W&B Run을 시작하여 W&B에 추적하고 기록합니다.
# 데이터를 기록하기 위해 W&B Run 시작
run = wandb.init(project="tables-walkthrough")
# Run으로 시각화하기 위해 테이블을 기록합니다...
run.log({"iris": iris_table})
# ...사용 가능한 행 제한을 늘리기 위해 Artifact로 기록합니다!
run.log_artifact(iris_table_artifact)
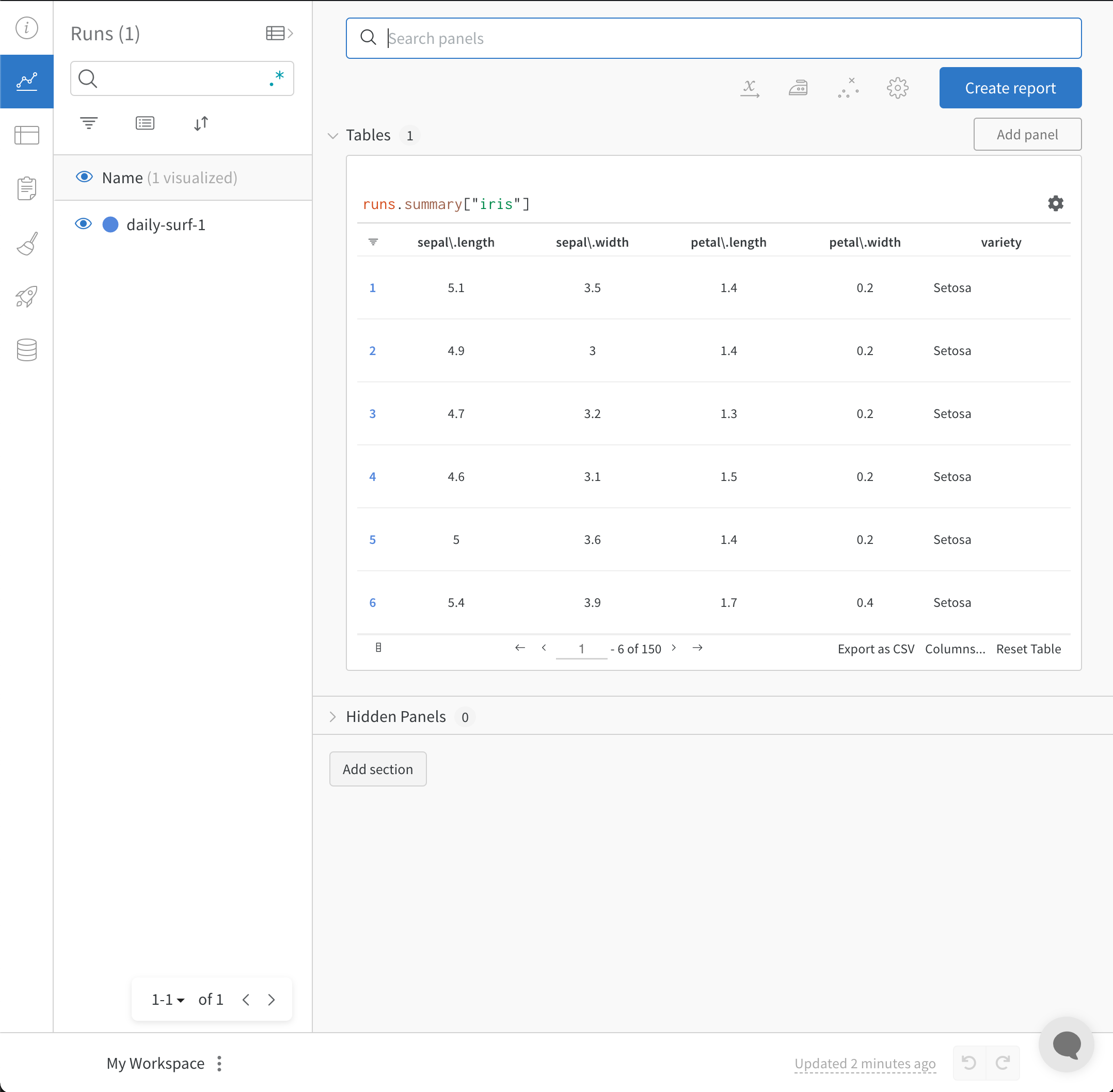
wandb.init() API는 데이터를 Run에 기록하기 위해 새로운 백그라운드 프로세스를 생성하고, wandb.ai에 데이터를 동기화합니다(기본적으로). W&B Workspace 대시보드에서 라이브 시각화를 확인하세요. 다음 이미지는 코드 조각 데모의 출력을 보여줍니다.
앞선 코드 조각이 포함된 전체 스크립트는 아래에서 찾을 수 있습니다.
import wandb
import pandas as pd
# CSV를 새 DataFrame으로 읽기
new_iris_dataframe = pd.read_csv("iris.csv")
# DataFrame을 W&B Table로 변환
iris_table = wandb.Table(dataframe=new_iris_dataframe)
# 테이블을 Artifact에 추가하여 행
# 제한을 200000으로 늘리고 재사용을 용이하게 합니다.
iris_table_artifact = wandb.Artifact("iris_artifact", type="dataset")
iris_table_artifact.add(iris_table, "iris_table")
# 원시 CSV 파일을 Artifact 내에 기록하여 데이터를 보존합니다.
iris_table_artifact.add_file("iris.csv")
# 데이터를 기록하기 위해 W&B Run 시작
run = wandb.init(project="tables-walkthrough")
# Run으로 시각화하기 위해 테이블을 기록합니다...
run.log({"iris": iris_table})
# ...사용 가능한 행 제한을 늘리기 위해 Artifact로 기록합니다!
run.log_artifact(iris_table_artifact)
# Run 완료 (노트북에서 유용)
run.finish()
Experiments의 CSV 가져오기 및 기록
경우에 따라 Experiments 세부 정보가 CSV 파일에 있을 수 있습니다. 이러한 CSV 파일에서 흔히 볼 수 있는 세부 정보는 다음과 같습니다.
- Experiment Run의 이름
- 초기 메모
- Experiments를 구별하기 위한 태그
- Experiment에 필요한 설정(Sweeps Hyperparameter Tuning을 활용할 수 있는 추가적인 이점 포함).
| Experiment | Model Name | Notes | Tags | Num Layers | Final Train Acc | Final Val Acc | Training Losses |
|---|---|---|---|---|---|---|---|
| Experiment 1 | mnist-300-layers | 트레이닝 데이터에서 너무 많이 과적합 | [최신] | 300 | 0.99 | 0.90 | [0.55, 0.45, 0.44, 0.42, 0.40, 0.39] |
| Experiment 2 | mnist-250-layers | 현재 최고의 모델 | [prod, 최고] | 250 | 0.95 | 0.96 | [0.55, 0.45, 0.44, 0.42, 0.40, 0.39] |
| Experiment 3 | mnist-200-layers | 베이스라인 모델보다 성능이 더 나빴습니다. 디버그해야 합니다. | [디버그] | 200 | 0.76 | 0.70 | [0.55, 0.45, 0.44, 0.42, 0.40, 0.39] |
| … | … | … | … | … | … | … | |
| Experiment N | mnist-X-layers | NOTES | … | … | … | … | […, …] |
W&B는 Experiments의 CSV 파일을 가져와 W&B Experiment Run으로 변환할 수 있습니다. 다음 코드 조각과 코드 스크립트는 Experiments의 CSV 파일을 가져와 기록하는 방법을 보여줍니다.
- 시작하려면 먼저 CSV 파일을 읽고 Pandas DataFrame으로 변환합니다.
"experiments.csv"를 CSV 파일 이름으로 바꿉니다.
import wandb
import pandas as pd
FILENAME = "experiments.csv"
loaded_experiment_df = pd.read_csv(FILENAME)
PROJECT_NAME = "Converted Experiments"
EXPERIMENT_NAME_COL = "Experiment"
NOTES_COL = "Notes"
TAGS_COL = "Tags"
CONFIG_COLS = ["Num Layers"]
SUMMARY_COLS = ["Final Train Acc", "Final Val Acc"]
METRIC_COLS = ["Training Losses"]
# Pandas DataFrame의 형식을 지정하여 작업하기 쉽게 만듭니다.
for i, row in loaded_experiment_df.iterrows():
run_name = row[EXPERIMENT_NAME_COL]
notes = row[NOTES_COL]
tags = row[TAGS_COL]
config = {}
for config_col in CONFIG_COLS:
config[config_col] = row[config_col]
metrics = {}
for metric_col in METRIC_COLS:
metrics[metric_col] = row[metric_col]
summaries = {}
for summary_col in SUMMARY_COLS:
summaries[summary_col] = row[summary_col]
- 다음으로
wandb.init()으로 새로운 W&B Run을 시작하여 W&B에 추적하고 기록합니다.
run = wandb.init(
project=PROJECT_NAME, name=run_name, tags=tags, notes=notes, config=config
)
Experiment가 실행되면 W&B에서 보고 쿼리하고 분석할 수 있도록 메트릭의 모든 인스턴스를 기록할 수 있습니다. run.log() 코맨드를 사용하여 이를 수행합니다.
run.log({key: val})
선택적으로 Run의 결과를 정의하기 위해 최종 요약 메트릭을 기록할 수 있습니다. W&B define_metric API를 사용하여 이를 수행합니다. 이 예제에서는 run.summary.update()를 사용하여 요약 메트릭을 Run에 추가합니다.
run.summary.update(summaries)
요약 메트릭에 대한 자세한 내용은 요약 메트릭 기록을 참조하세요.
아래는 위의 샘플 테이블을 W&B 대시보드로 변환하는 전체 예제 스크립트입니다.
FILENAME = "experiments.csv"
loaded_experiment_df = pd.read_csv(FILENAME)
PROJECT_NAME = "Converted Experiments"
EXPERIMENT_NAME_COL = "Experiment"
NOTES_COL = "Notes"
TAGS_COL = "Tags"
CONFIG_COLS = ["Num Layers"]
SUMMARY_COLS = ["Final Train Acc", "Final Val Acc"]
METRIC_COLS = ["Training Losses"]
for i, row in loaded_experiment_df.iterrows():
run_name = row[EXPERIMENT_NAME_COL]
notes = row[NOTES_COL]
tags = row[TAGS_COL]
config = {}
for config_col in CONFIG_COLS:
config[config_col] = row[config_col]
metrics = {}
for metric_col in METRIC_COLS:
metrics[metric_col] = row[metric_col]
summaries = {}
for summary_col in SUMMARY_COLS:
summaries[summary_col] = row[summary_col]
run = wandb.init(
project=PROJECT_NAME, name=run_name, tags=tags, notes=notes, config=config
)
for key, val in metrics.items():
if isinstance(val, list):
for _val in val:
run.log({key: _val})
else:
run.log({key: val})
run.summary.update(summaries)
run.finish()
Feedback
Was this page helpful?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.