Point aggregation
4 minute read
Data Visualization 정확도와 성능을 향상시키려면 라인 플롯 내에서 포인트 집계 방법을 사용하세요. 포인트 집계 모드에는 전체 충실도와 임의 샘플링의 두 가지 유형이 있습니다. W&B는 기본적으로 전체 충실도 모드를 사용합니다.
전체 충실도
전체 충실도 모드를 사용하면 W&B는 데이터 포인트 수를 기반으로 x축을 동적 버킷으로 나눕니다. 그런 다음 라인 플롯에 대한 포인트 집계를 렌더링하는 동안 각 버킷 내의 최소값, 최대값 및 평균값을 계산합니다.
포인트 집계에 전체 충실도 모드를 사용하면 다음과 같은 세 가지 주요 이점이 있습니다.
- 극단값 및 스파이크 보존: 데이터에서 극단값 및 스파이크를 유지합니다.
- 최소 및 최대 포인트 렌더링 방법 구성: W&B 앱을 사용하여 극단(최소/최대) 값을 음영 영역으로 표시할지 여부를 대화식으로 결정합니다.
- 데이터 정확도를 잃지 않고 데이터 탐색: 특정 데이터 포인트를 확대하면 W&B가 x축 버킷 크기를 다시 계산합니다. 이는 정확도를 잃지 않고 데이터를 탐색하는 데 도움이 됩니다. 캐싱은 이전에 계산된 집계를 저장하여 로딩 시간을 줄이는 데 사용되며, 이는 대규모 데이터셋을 탐색할 때 특히 유용합니다.
최소 및 최대 포인트 렌더링 방법 구성
라인 플롯 주위에 음영 영역을 사용하여 최소값과 최대값을 표시하거나 숨깁니다.
다음 이미지는 파란색 라인 플롯을 보여줍니다. 밝은 파란색 음영 영역은 각 버킷의 최소값과 최대값을 나타냅니다.
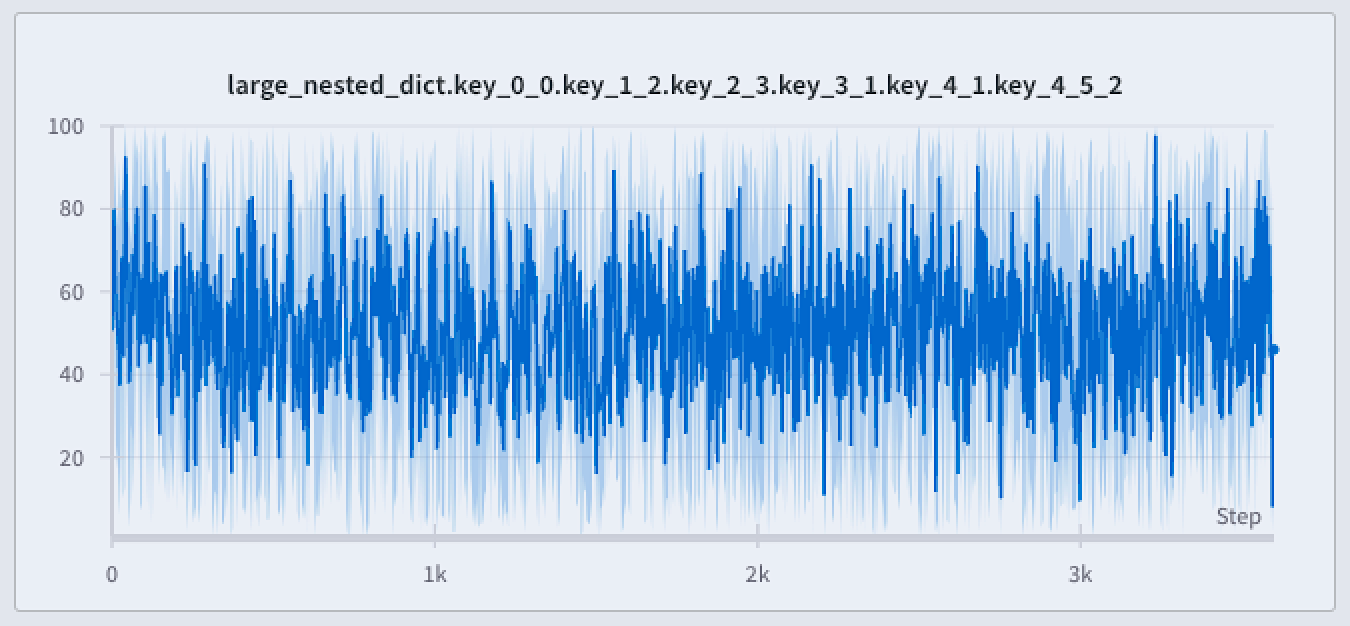
라인 플롯에서 최소값과 최대값을 렌더링하는 세 가지 방법이 있습니다.
- 없음: 최소/최대값은 음영 영역으로 표시되지 않습니다. x축 버킷에서 집계된 라인만 표시합니다.
- 호버 시: 차트 위로 마우스를 가져가면 최소/최대값에 대한 음영 영역이 동적으로 나타납니다. 이 옵션은 뷰를 깔끔하게 유지하면서 범위를 대화식으로 검사할 수 있도록 합니다.
- 항상: 최소/최대 음영 영역이 차트의 모든 버킷에 대해 일관되게 표시되어 항상 전체 값 범위를 시각화할 수 있습니다. 차트에 시각화된 Runs가 많은 경우 시각적 노이즈가 발생할 수 있습니다.
기본적으로 최소값과 최대값은 음영 영역으로 표시되지 않습니다. 음영 영역 옵션 중 하나를 보려면 다음 단계를 따르세요.
- W&B 프로젝트로 이동합니다.
- 왼쪽 탭에서 Workspace 아이콘을 선택합니다.
- 화면 오른쪽 상단에서 패널 추가 버튼 바로 왼쪽에 있는 기어 아이콘을 선택합니다.
- 나타나는 UI 슬라이더에서 라인 플롯을 선택합니다.
- 포인트 집계 섹션 내에서 최소/최대값을 음영 영역으로 표시 드롭다운 메뉴에서 호버 시 또는 항상을 선택합니다.
- W&B 프로젝트로 이동합니다.
- 왼쪽 탭에서 Workspace 아이콘을 선택합니다.
- 전체 충실도 모드를 활성화할 라인 플롯 패널을 선택합니다.
- 나타나는 모달 내에서 최소/최대값을 음영 영역으로 표시 드롭다운 메뉴에서 호버 시 또는 항상을 선택합니다.
데이터 정확도를 잃지 않고 데이터 탐색
극단값 또는 스파이크와 같은 중요한 포인트를 놓치지 않고 데이터셋의 특정 영역을 분석합니다. 라인 플롯을 확대하면 W&B는 각 버킷 내에서 최소값, 최대값 및 평균값을 계산하는 데 사용되는 버킷 크기를 조정합니다.
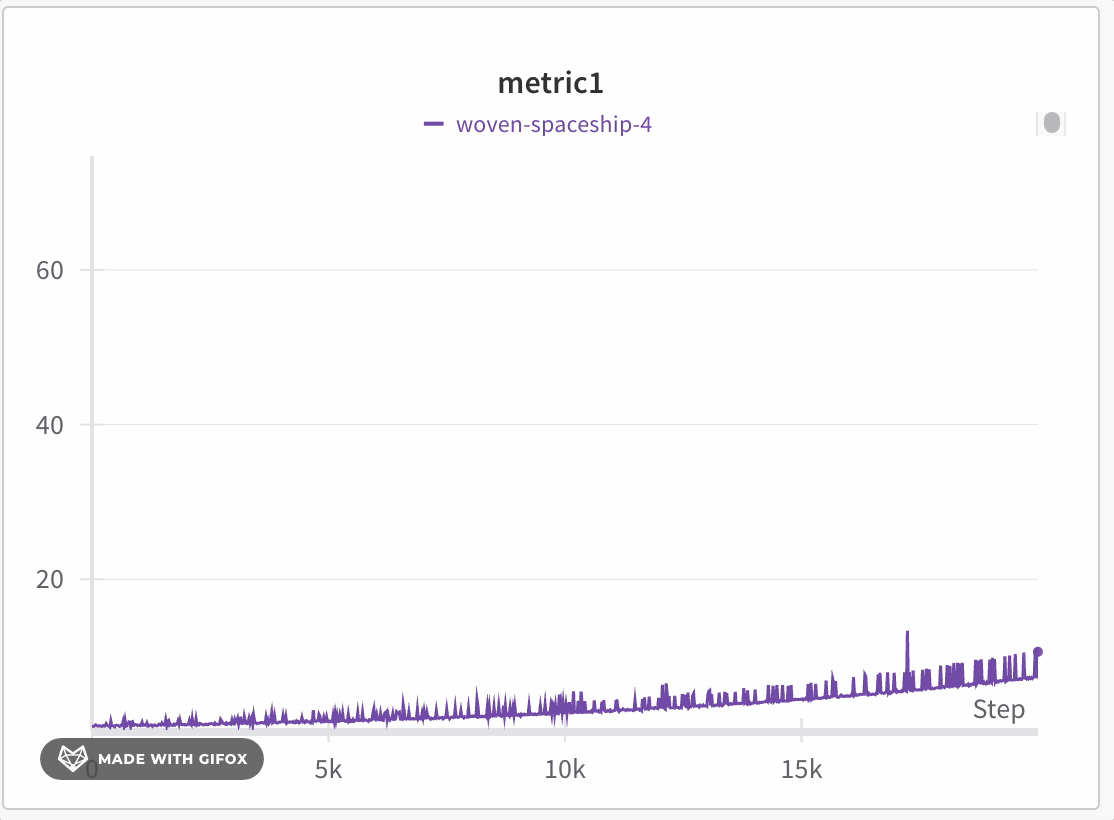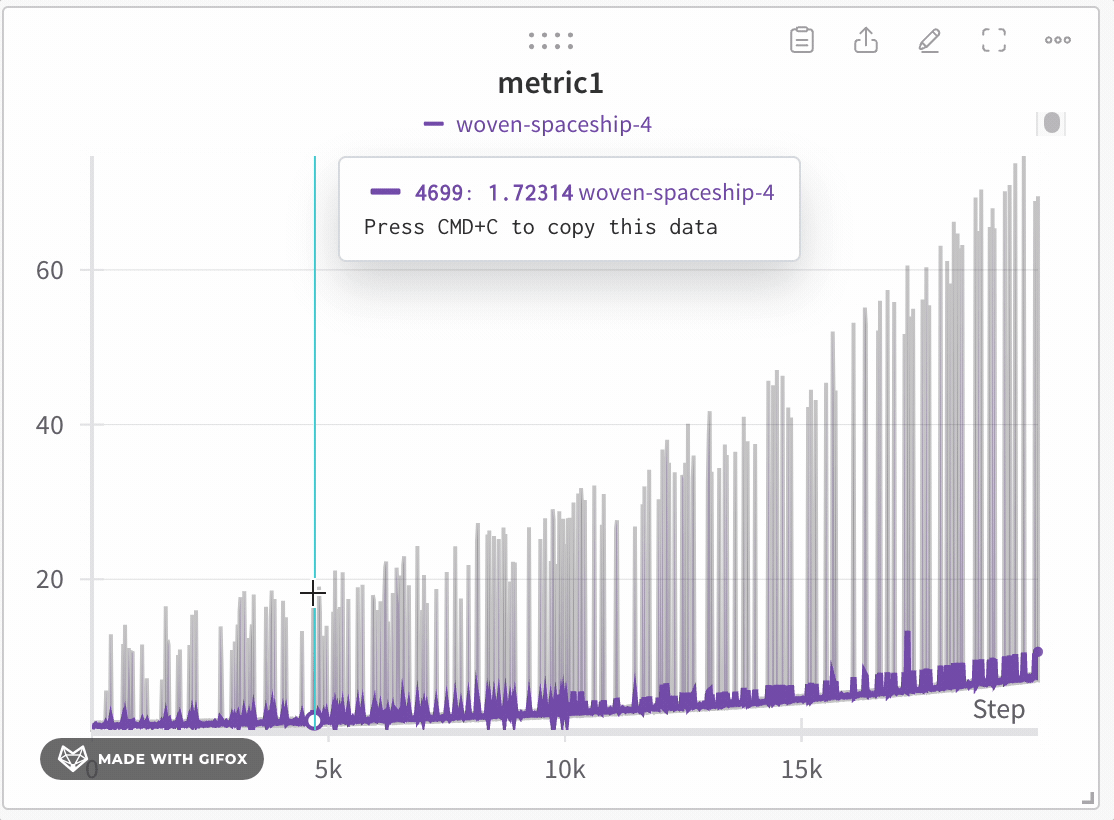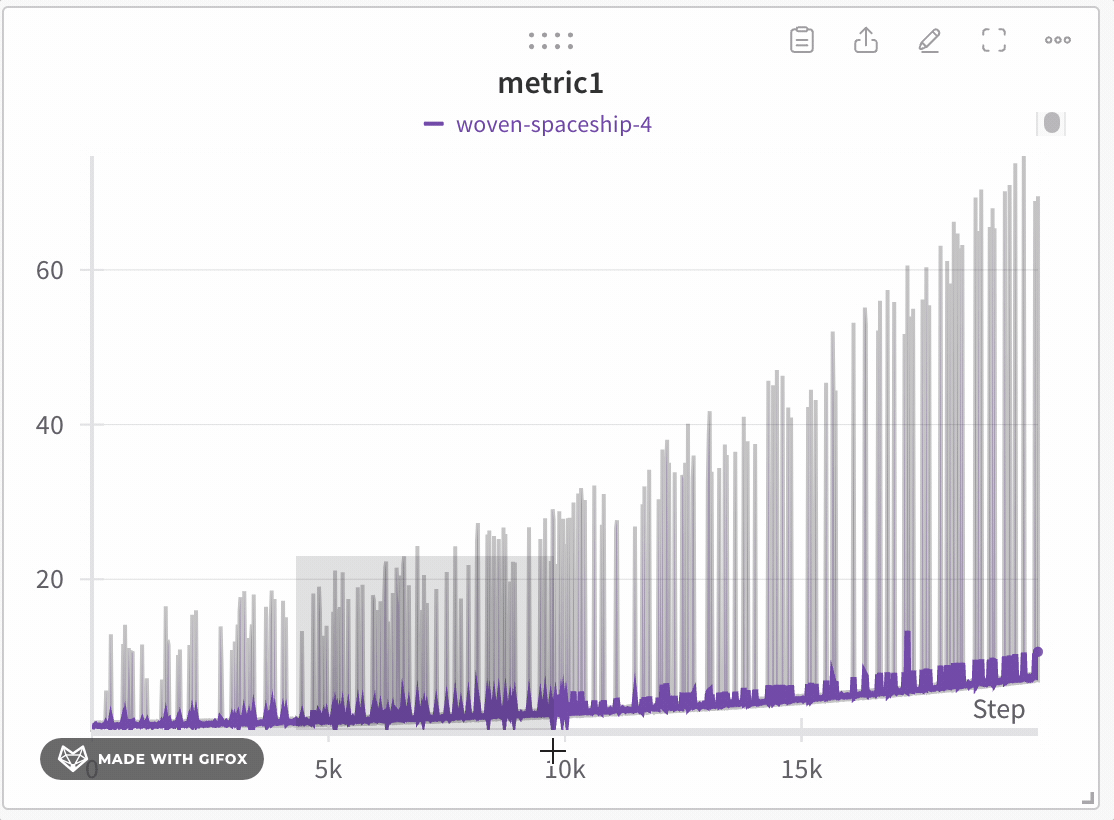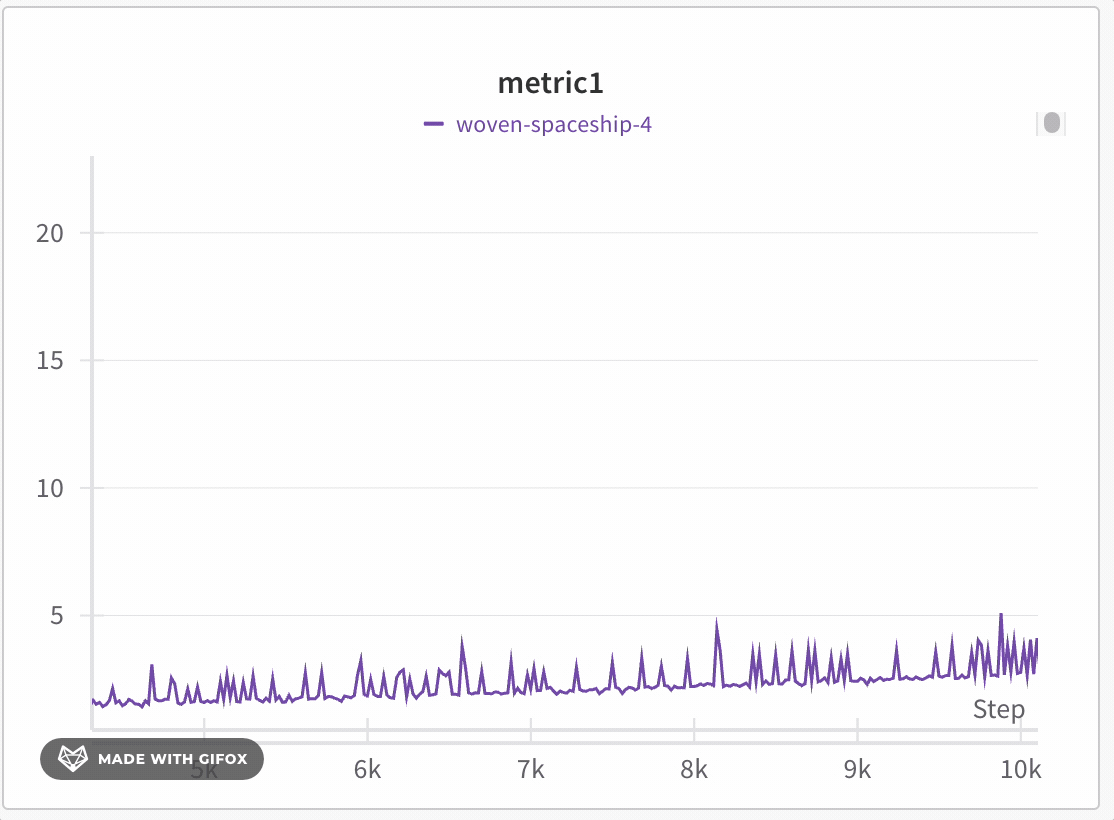
W&B는 x축을 기본적으로 1000개의 버킷으로 동적으로 나눕니다. 각 버킷에 대해 W&B는 다음 값을 계산합니다.
- 최소값: 해당 버킷의 가장 낮은 값입니다.
- 최대값: 해당 버킷의 가장 높은 값입니다.
- 평균값: 해당 버킷의 모든 포인트의 평균값입니다.
W&B는 전체 데이터 표현을 보존하고 모든 플롯에 극단값을 포함하는 방식으로 버킷의 값을 플롯합니다. 1,000포인트 이하로 확대하면 전체 충실도 모드는 추가 집계 없이 모든 데이터 포인트를 렌더링합니다.
라인 플롯을 확대하려면 다음 단계를 따르세요.
- W&B 프로젝트로 이동합니다.
- 왼쪽 탭에서 Workspace 아이콘을 선택합니다.
- 필요에 따라 워크스페이스에 라인 플롯 패널을 추가하거나 기존 라인 플롯 패널로 이동합니다.
- 클릭하고 드래그하여 확대할 특정 영역을 선택합니다.
라인 플롯 그룹화 및 표현식
라인 플롯 그룹화를 사용하면 W&B는 선택한 모드를 기반으로 다음을 적용합니다.
- 비 윈도우 샘플링(그룹화): x축에서 Runs 간에 포인트를 정렬합니다. 여러 포인트가 동일한 x-값을 공유하는 경우 평균이 취해집니다. 그렇지 않으면 개별 포인트로 나타납니다.
- 윈도우 샘플링(그룹화 및 표현식): x축을 250개의 버킷 또는 가장 긴 라인의 포인트 수(더 작은 쪽)로 나눕니다. W&B는 각 버킷 내의 포인트 평균을 구합니다.
- 전체 충실도(그룹화 및 표현식): 비 윈도우 샘플링과 유사하지만 성능과 세부 정보의 균형을 맞추기 위해 Run당 최대 500개의 포인트를 가져옵니다.
임의 샘플링
임의 샘플링은 1500개의 임의로 샘플링된 포인트를 사용하여 라인 플롯을 렌더링합니다. 임의 샘플링은 데이터 포인트 수가 많은 경우 성능상의 이유로 유용합니다.
임의 샘플링 활성화
기본적으로 W&B는 전체 충실도 모드를 사용합니다. 임의 샘플링을 활성화하려면 다음 단계를 따르세요.
- W&B 프로젝트로 이동합니다.
- 왼쪽 탭에서 Workspace 아이콘을 선택합니다.
- 화면 오른쪽 상단에서 패널 추가 버튼 바로 왼쪽에 있는 기어 아이콘을 선택합니다.
- 나타나는 UI 슬라이더에서 라인 플롯을 선택합니다.
- 포인트 집계 섹션에서 임의 샘플링을 선택합니다.
- W&B 프로젝트로 이동합니다.
- 왼쪽 탭에서 Workspace 아이콘을 선택합니다.
- 임의 샘플링을 활성화할 라인 플롯 패널을 선택합니다.
- 나타나는 모달 내에서 포인트 집계 방법 섹션에서 임의 샘플링을 선택합니다.
샘플링되지 않은 데이터에 엑세스
W&B Run API를 사용하여 Run 중에 기록된 메트릭의 전체 기록에 엑세스할 수 있습니다. 다음 예제에서는 특정 Run에서 손실 값을 검색하고 처리하는 방법을 보여줍니다.
# W&B API 초기화
run = api.run("l2k2/examples-numpy-boston/i0wt6xua")
# 'Loss' 메트릭의 기록 검색
history = run.scan_history(keys=["Loss"])
# 기록에서 손실 값 추출
losses = [row["Loss"] for row in history]
Feedback
Was this page helpful?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.