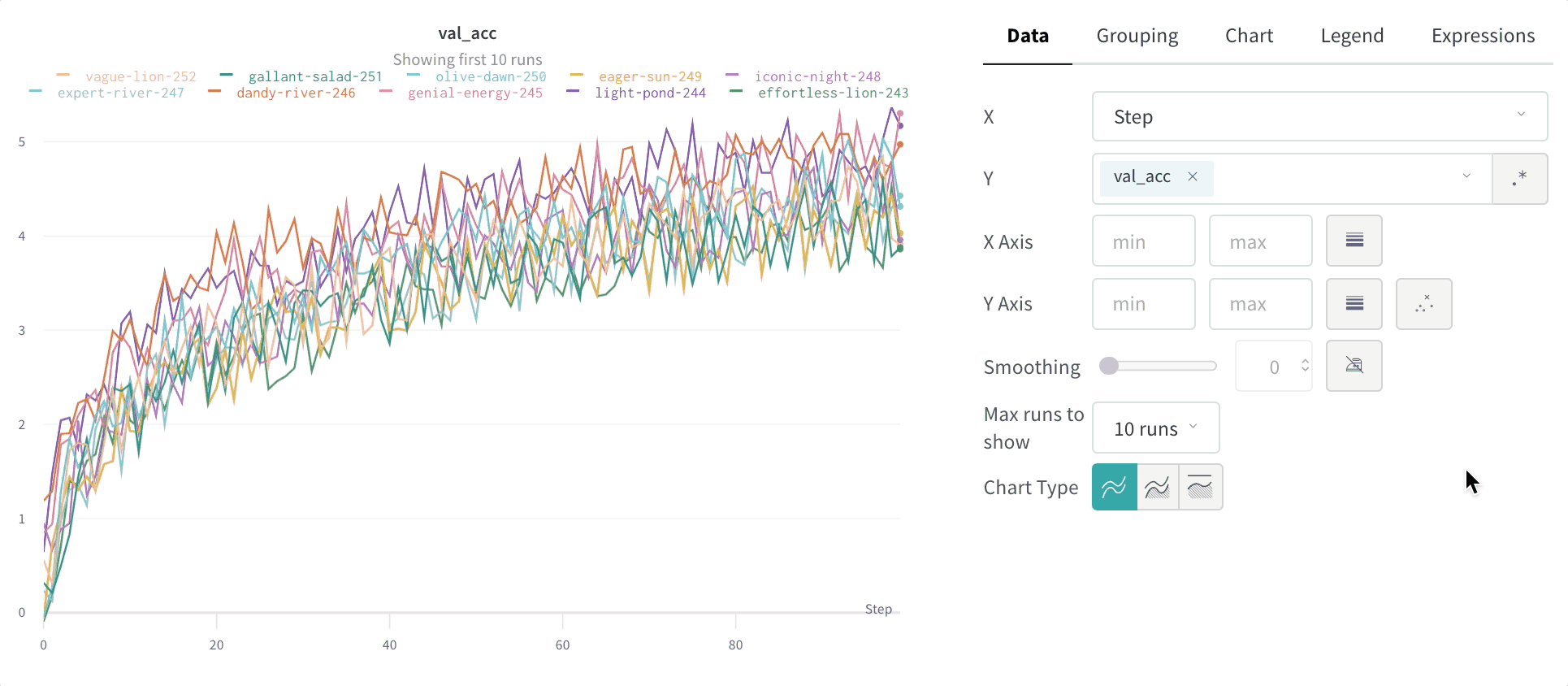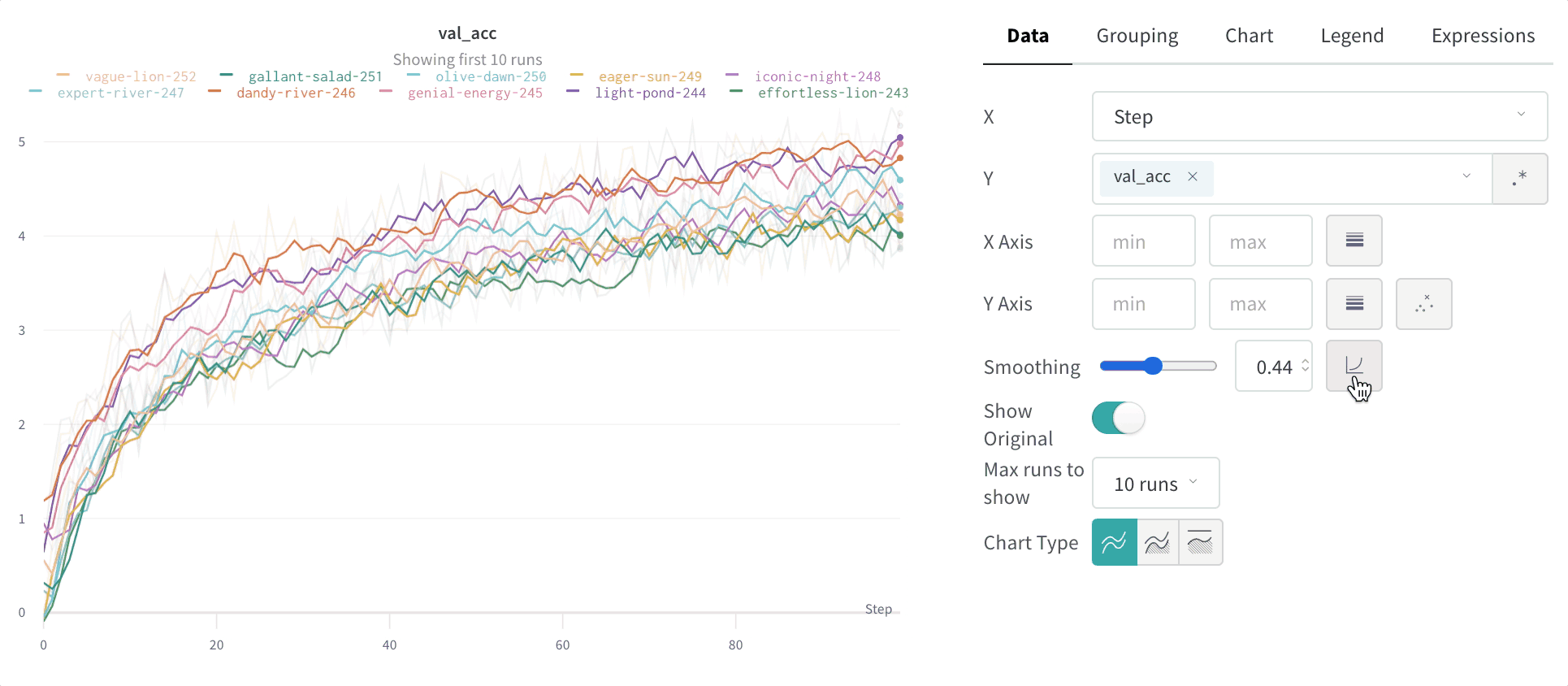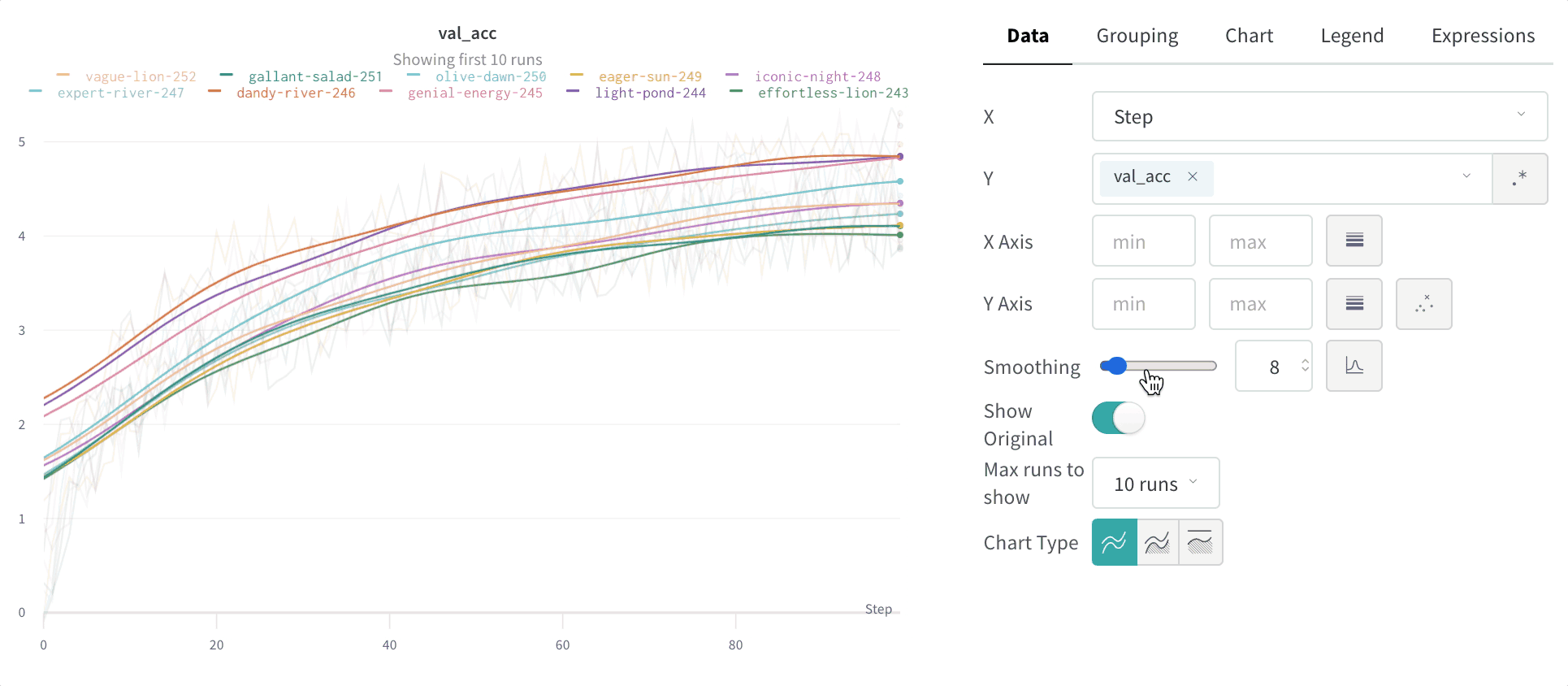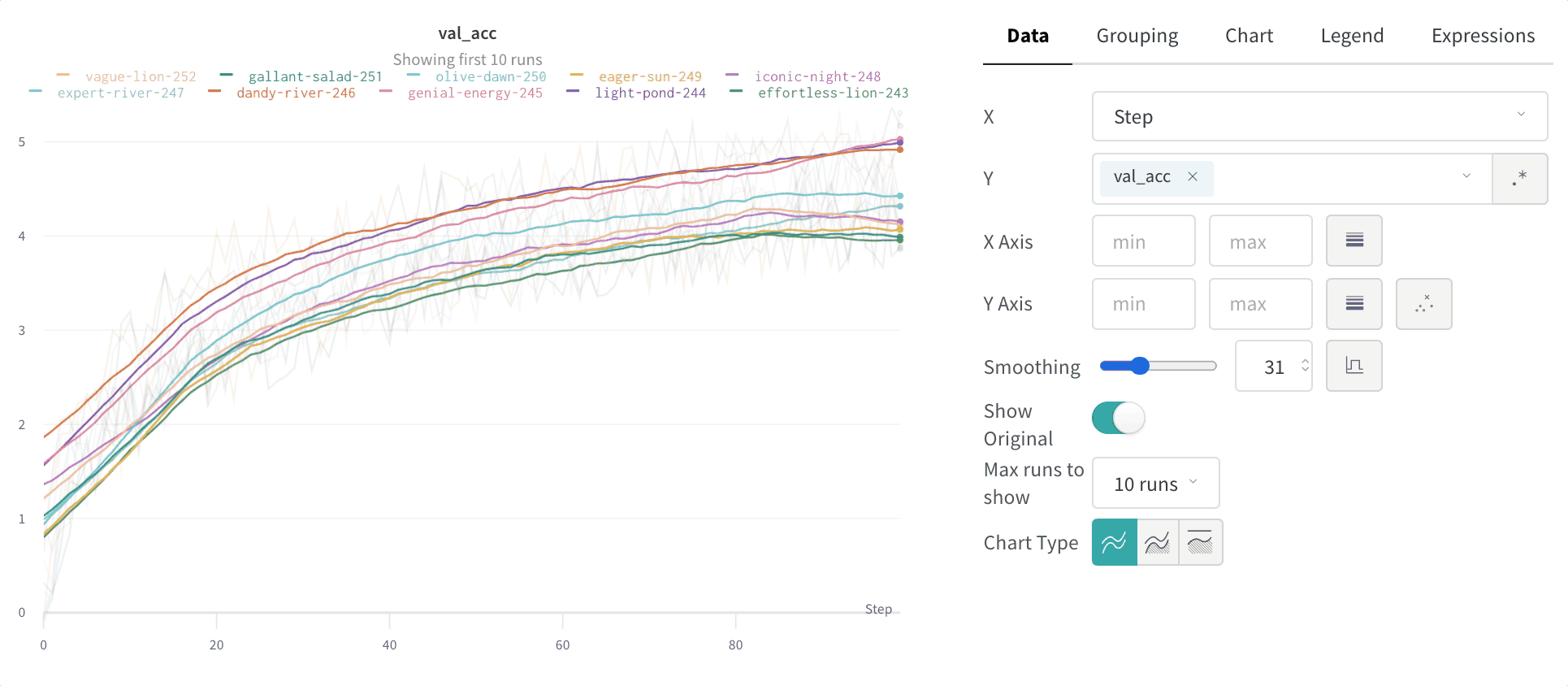
라인 플롯은 wandb.log() 로 시간에 따른 메트릭을 플롯할 때 기본적으로 표시됩니다. 차트 설정을 사용하여 동일한 플롯에서 여러 라인을 비교하고, 사용자 정의 축을 계산하고, 레이블 이름을 바꿀 수 있습니다.
라인 플롯 설정 편집
이 섹션에서는 개별 라인 플롯 패널, 섹션의 모든 라인 플롯 패널 또는 워크스페이스의 모든 라인 플롯 패널에 대한 설정을 편집하는 방법을 보여줍니다.
wandb.log() 호출에서 기록해야 합니다.개별 라인 플롯
라인 플롯의 개별 설정은 섹션 또는 워크스페이스에 대한 라인 플롯 설정을 재정의합니다. 라인 플롯을 사용자 정의하려면:
- 마우스를 패널 위로 이동한 다음 기어 아이콘을 클릭합니다.
- 나타나는 모달 내에서 탭을 선택하여 설정을 편집합니다.
- 적용을 클릭합니다.
라인 플롯 설정
라인 플롯에 대해 이러한 설정을 구성할 수 있습니다.
날짜: 플롯의 데이터 표시 세부 정보를 구성합니다.
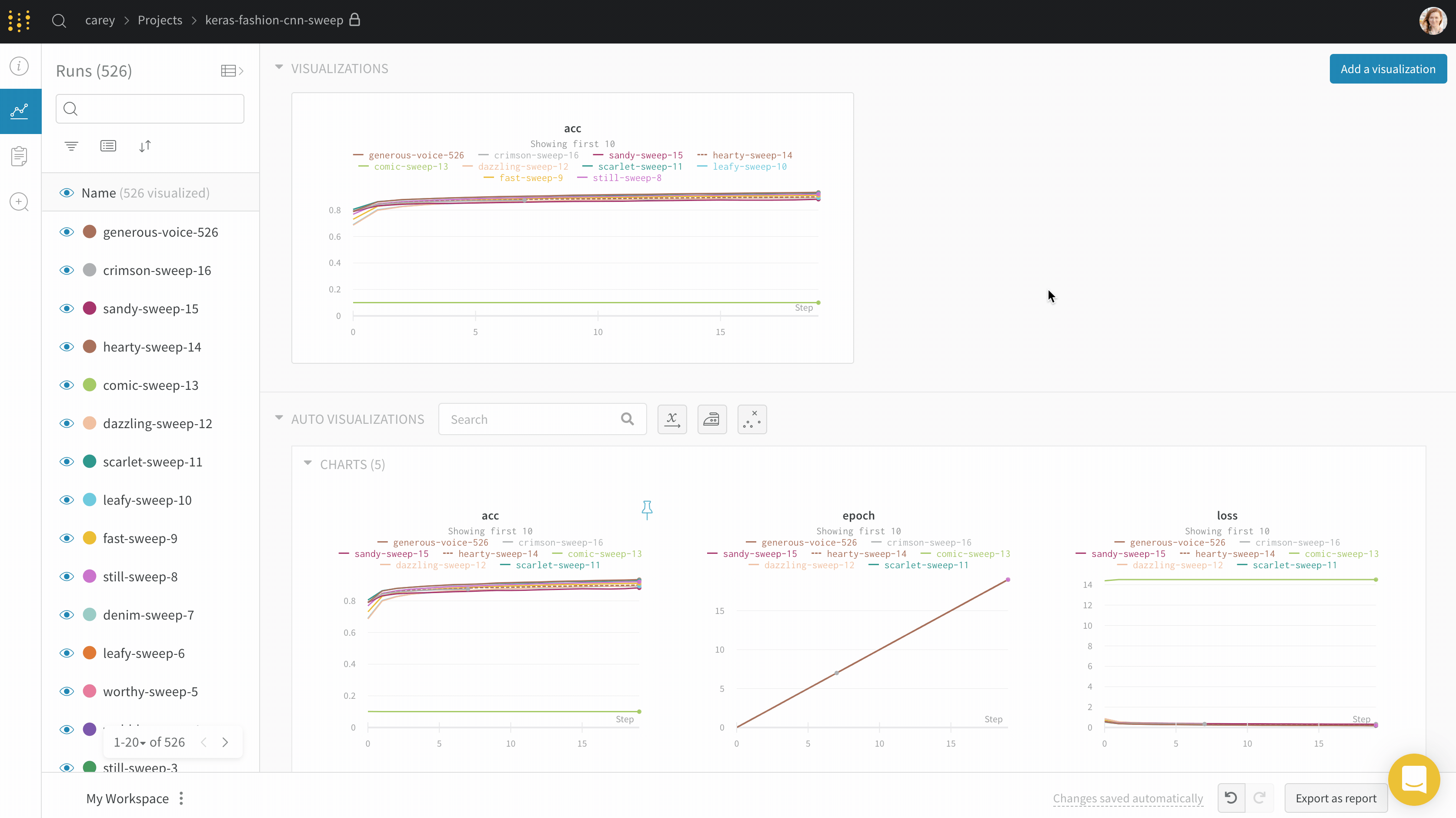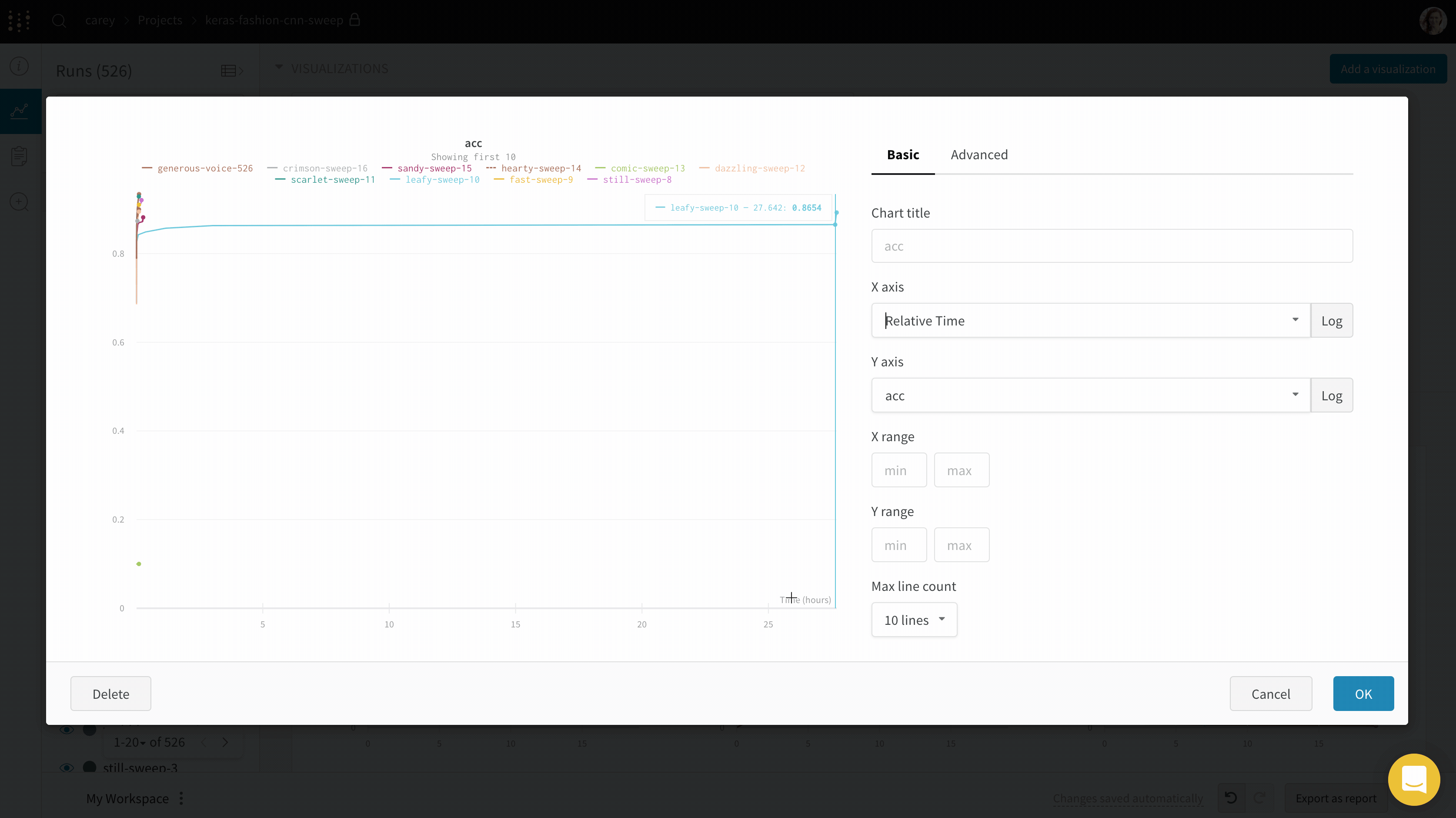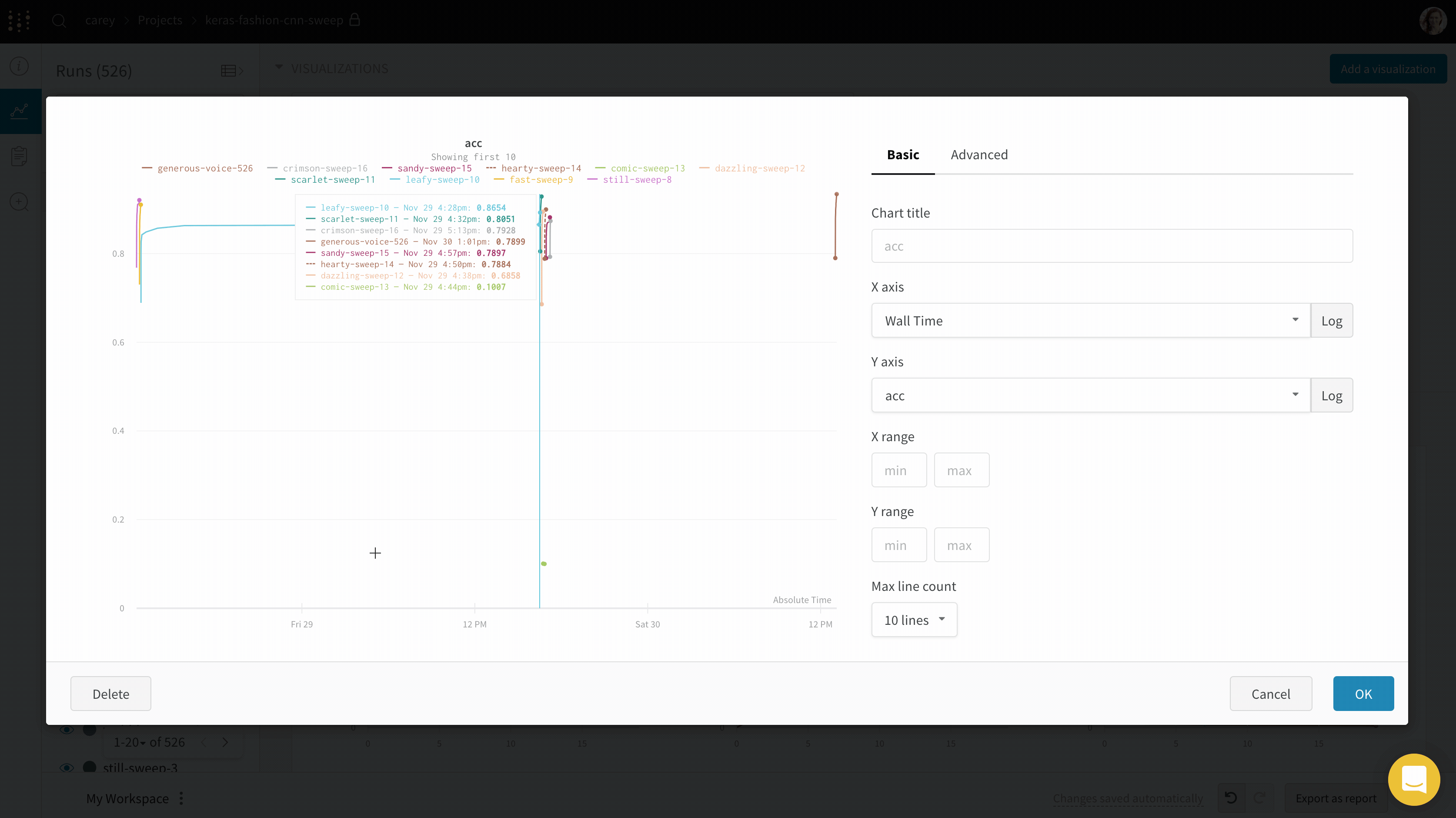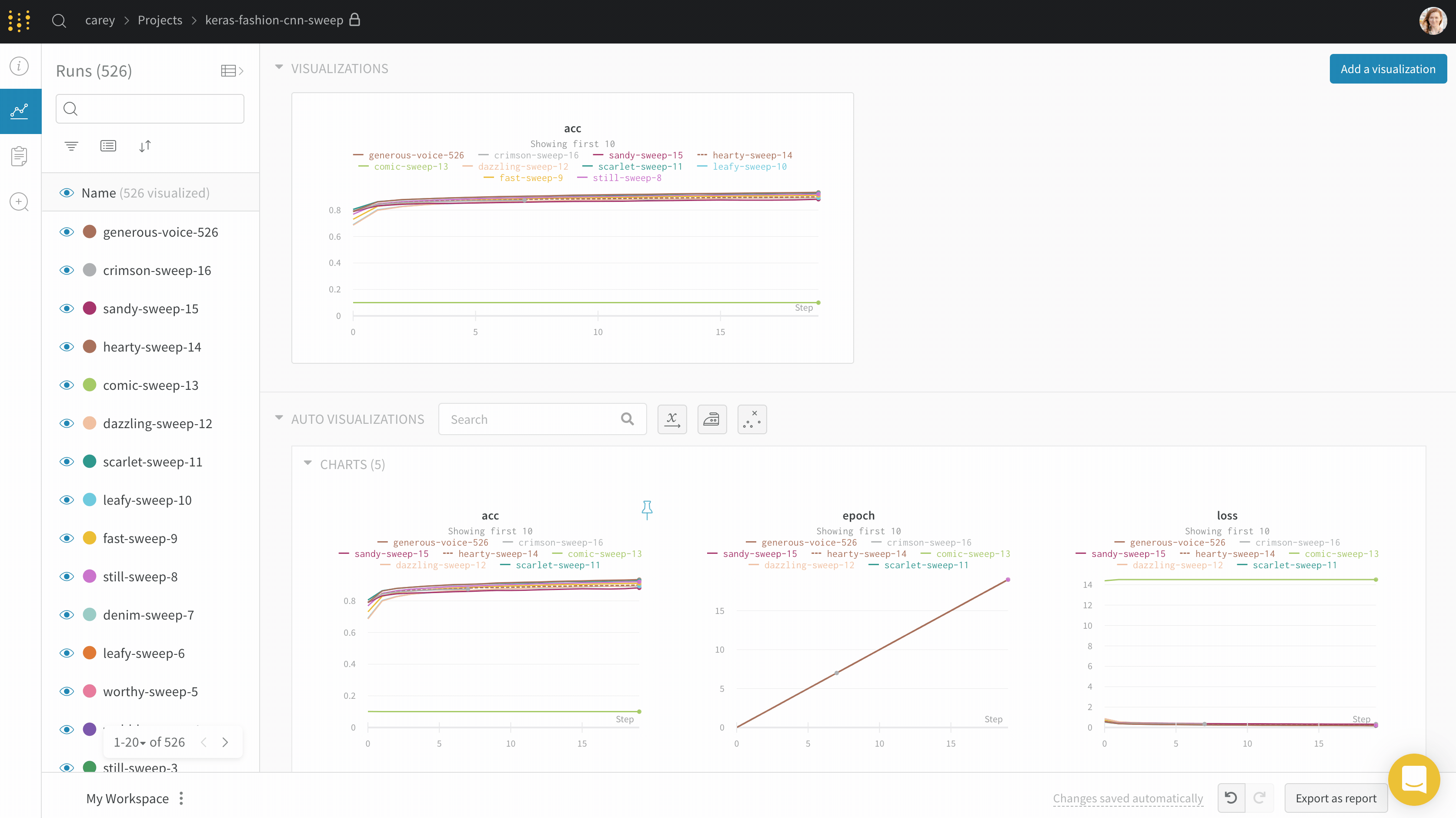
- X: X축에 사용할 값을 선택합니다 (기본값은 Step). x축을 Relative Time으로 변경하거나 W&B로 기록하는 값을 기반으로 사용자 정의 축을 선택할 수 있습니다.
- Relative Time (Wall) 은 프로세스가 시작된 이후의 시계 시간이므로 run을 시작하고 하루 후에 다시 시작하여 기록한 경우 24시간으로 플롯됩니다.
- Relative Time (Process) 는 실행 중인 프로세스 내부의 시간이므로 run을 시작하고 10초 동안 실행한 다음 하루 후에 다시 시작하면 해당 지점이 10초로 플롯됩니다.
- Wall Time은 그래프에서 첫 번째 run이 시작된 이후 경과된 시간 (분) 입니다.
- Step은 기본적으로
wandb.log()가 호출될 때마다 증가하며 모델에서 기록한 트레이닝 스텝 수를 반영해야 합니다.
- Y: 시간에 따라 변하는 메트릭 및 하이퍼파라미터를 포함하여 기록된 값에서 하나 이상의 y축을 선택합니다.
- X축 및 Y축 최소 및 최대값 (선택 사항).
- 포인트 집계 방식. Random sampling (기본값) 또는 Full fidelity. Sampling을 참조하십시오.
- Smoothing: 라인 플롯의 Smoothing을 변경합니다. 기본값은 Time weighted EMA입니다. 다른 값으로는 No smoothing, Running average 및 Gaussian이 있습니다.
- Outliers: 기본 플롯 최소 및 최대 스케일에서 이상값을 제외하도록 스케일을 재조정합니다.
- 최대 run 또는 그룹 수: 이 숫자를 늘려 라인 플롯에 더 많은 라인을 한 번에 표시합니다. 기본값은 10개의 run입니다. 사용 가능한 run이 10개 이상이지만 차트가 보이는 수를 제한하는 경우 차트 상단에 “Showing first 10 runs"라는 메시지가 표시됩니다.
- 차트 유형: 라인 플롯, 영역 플롯 및 백분율 영역 플롯 간에 변경합니다.
Grouping: 플롯에서 run을 그룹화하고 집계할지 여부와 방법을 구성합니다.
- Group by: 열을 선택하면 해당 열에서 동일한 값을 가진 모든 run이 함께 그룹화됩니다.
- Agg: 집계— 그래프의 라인 값. 옵션은 그룹의 평균, 중앙값, 최소값 및 최대값입니다.
차트: 패널, X축 및 Y축의 제목과 -축을 지정하고 범례를 숨기거나 표시하고 위치를 구성합니다.
범례: 패널의 범례 모양을 사용자 정의합니다 (활성화된 경우).
- 범례: 플롯의 각 라인에 대한 범례의 필드입니다.
- 범례 템플릿: 범례에 대한 완전히 사용자 정의 가능한 템플릿을 정의하여 라인 플롯 상단에 표시할 텍스트와 변수 및 마우스를 플롯 위로 이동할 때 나타나는 범례를 정확하게 지정합니다.
Expressions: 사용자 정의 계산된 표현식을 패널에 추가합니다.
- Y축 표현식: 계산된 메트릭을 그래프에 추가합니다. 기록된 메트릭과 하이퍼파라미터와 같은 구성 값을 사용하여 사용자 정의 라인을 계산할 수 있습니다.
- X축 표현식: 사용자 정의 표현식을 사용하여 계산된 값을 사용하도록 x축의 스케일을 재조정합니다. 유용한 변수에는 기본 x축에 대한**_step**이 포함되며 요약 값을 참조하는 구문은
${summary:value}입니다.
섹션의 모든 라인 플롯
섹션의 모든 라인 플롯에 대한 기본 설정을 사용자 정의하려면 라인 플롯에 대한 워크스페이스 설정을 재정의합니다.
- 섹션의 기어 아이콘을 클릭하여 설정을 엽니다.
- 나타나는 모달 내에서 데이터 또는 표시 기본 설정 탭을 선택하여 섹션의 기본 설정을 구성합니다. 각 데이터 설정에 대한 자세한 내용은 이전 섹션인 개별 라인 플롯을 참조하십시오. 각 표시 기본 설정에 대한 자세한 내용은 섹션 레이아웃 구성을 참조하십시오.
워크스페이스의 모든 라인 플롯
워크스페이스의 모든 라인 플롯에 대한 기본 설정을 사용자 정의하려면:
- 워크스페이스의 설정을 클릭합니다. 여기에는 설정 레이블이 있는 기어가 있습니다.
- 라인 플롯을 클릭합니다.
- 나타나는 모달 내에서 데이터 또는 표시 기본 설정 탭을 선택하여 워크스페이스의 기본 설정을 구성합니다.
-
각 데이터 설정에 대한 자세한 내용은 이전 섹션인 개별 라인 플롯을 참조하십시오.
-
각 표시 기본 설정 섹션에 대한 자세한 내용은 워크스페이스 표시 기본 설정을 참조하십시오. 워크스페이스 수준에서 라인 플롯에 대한 기본 확대/축소 동작을 구성할 수 있습니다. 이 설정은 일치하는 x축 키가 있는 라인 플롯에서 확대/축소를 동기화할지 여부를 제어합니다. 기본적으로 비활성화되어 있습니다.
-
플롯에서 평균값 시각화
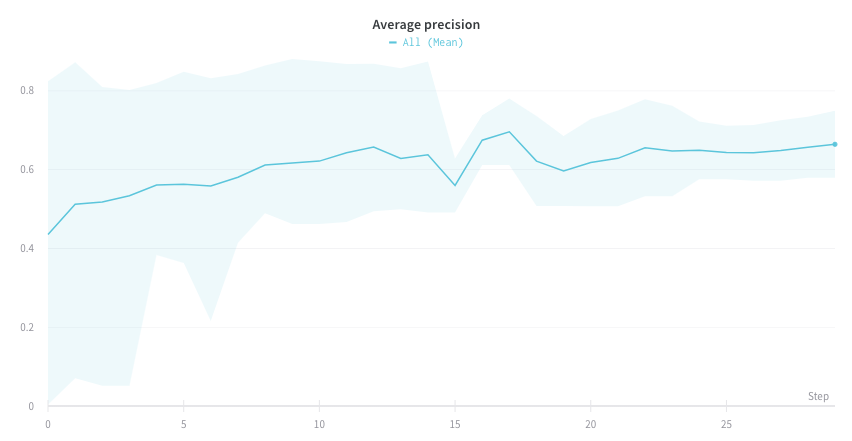
여러 개의 다른 Experiments가 있고 플롯에서 해당 값의 평균을 보려면 테이블에서 그룹화 기능을 사용할 수 있습니다. run 테이블 위에서 “그룹"을 클릭하고 “모두"를 선택하여 그래프에 평균값을 표시합니다.
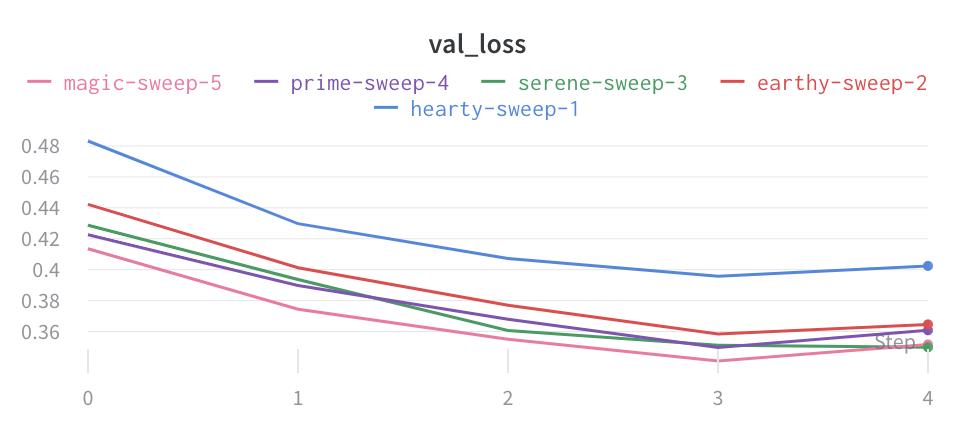
평균화하기 전의 그래프 모양은 다음과 같습니다.
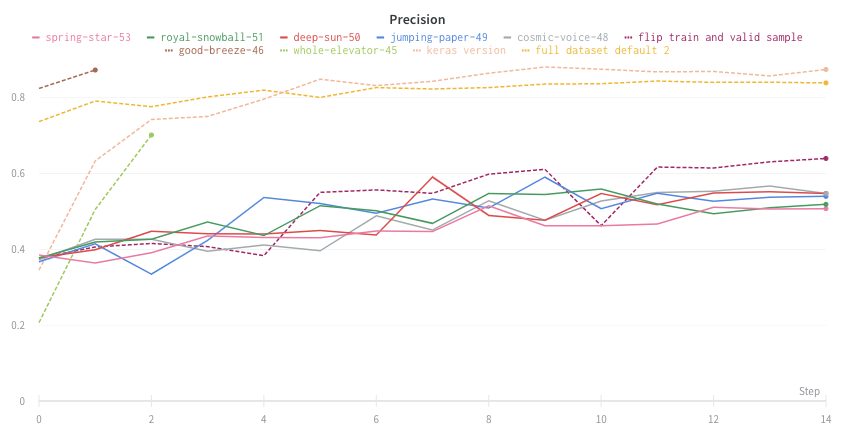
다음 이미지는 그룹화된 라인을 사용하여 run에서 평균값을 나타내는 그래프를 보여줍니다.
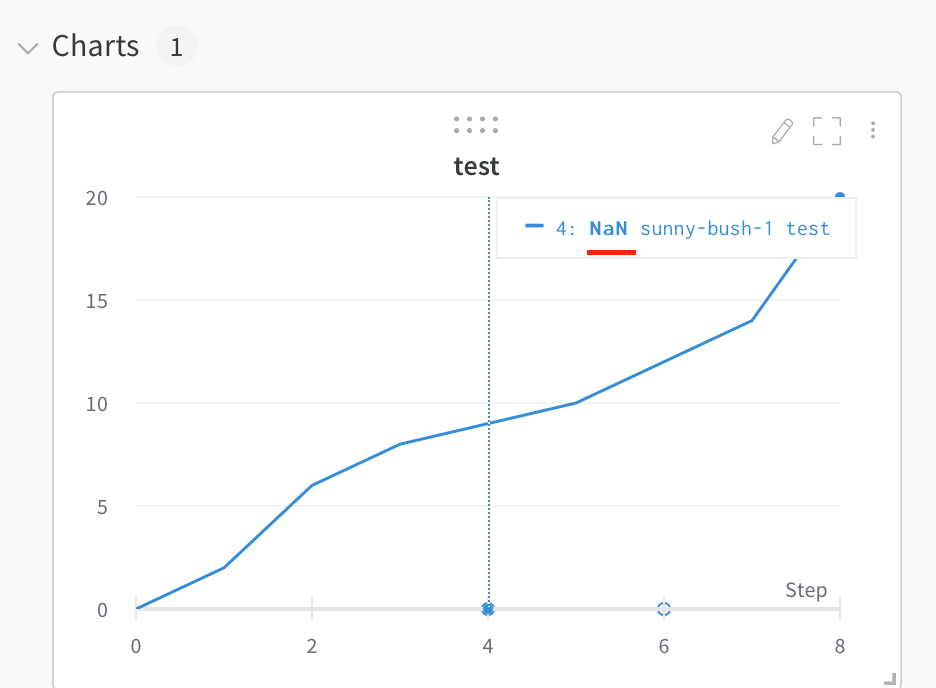
플롯에서 NaN 값 시각화
wandb.log를 사용하여 라인 플롯에 PyTorch 텐서를 포함한 NaN 값을 플롯할 수도 있습니다. 예:
wandb.log({"test": [..., float("nan"), ...]})
하나의 차트에서 두 개의 메트릭 비교
- 페이지 오른쪽 상단에서 패널 추가 버튼을 선택합니다.
- 나타나는 왼쪽 패널에서 평가 드롭다운을 확장합니다.
- Run comparer를 선택합니다.
라인 플롯의 색상 변경
경우에 따라 run의 기본 색상이 비교에 도움이 되지 않을 수 있습니다. 이를 극복하기 위해 wandb는 색상을 수동으로 변경할 수 있는 두 가지 인스턴스를 제공합니다.
각 run은 초기화 시 기본적으로 임의의 색상이 지정됩니다.

색상 중 하나를 클릭하면 색상 팔레트가 나타나고 여기에서 원하는 색상을 수동으로 선택할 수 있습니다.
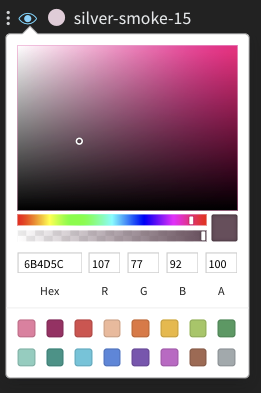
- 설정을 편집할 패널 위로 마우스를 가져갑니다.
- 나타나는 연필 아이콘을 선택합니다.
- 범례 탭을 선택합니다.
다른 x축에서 시각화
experiment가 소요된 절대 시간을 보거나 experiment가 실행된 날짜를 보려면 x축을 전환할 수 있습니다. 다음은 단계를 상대 시간으로 전환한 다음 벽 시간으로 전환하는 예입니다.
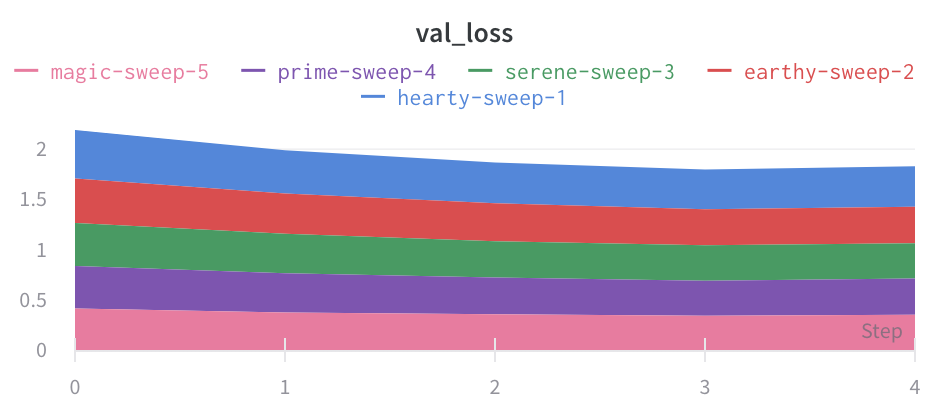
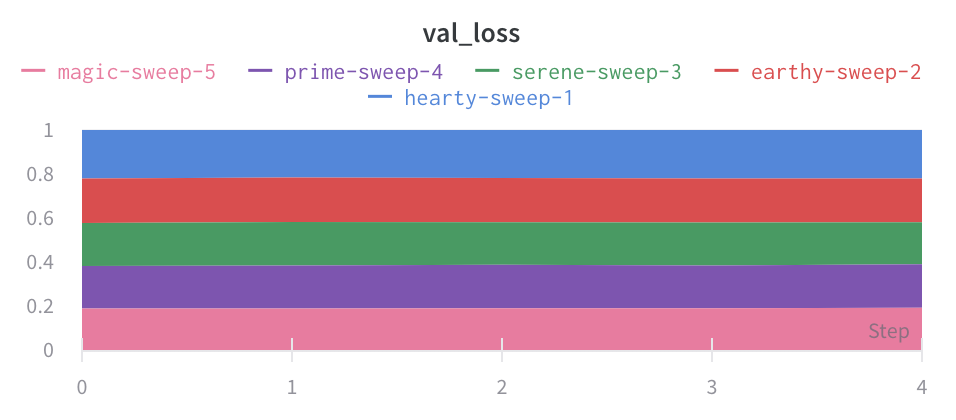
영역 플롯
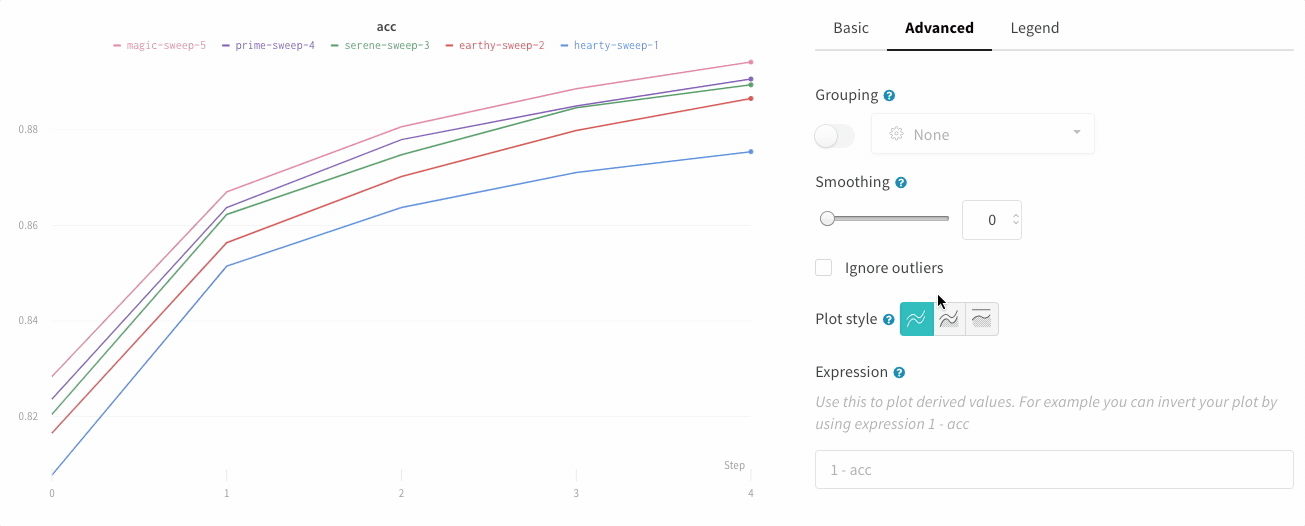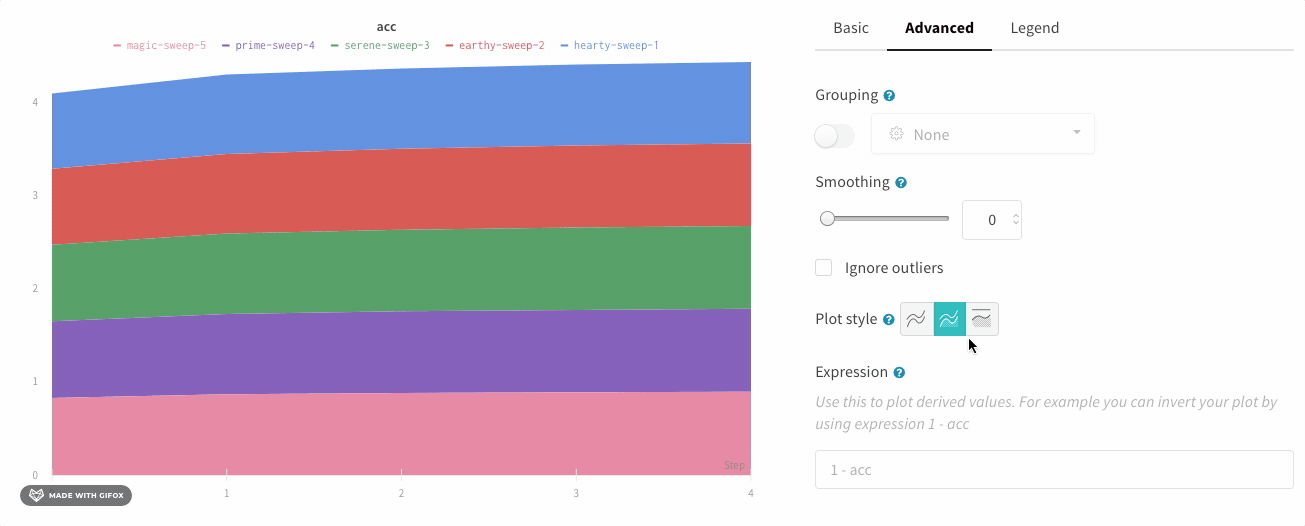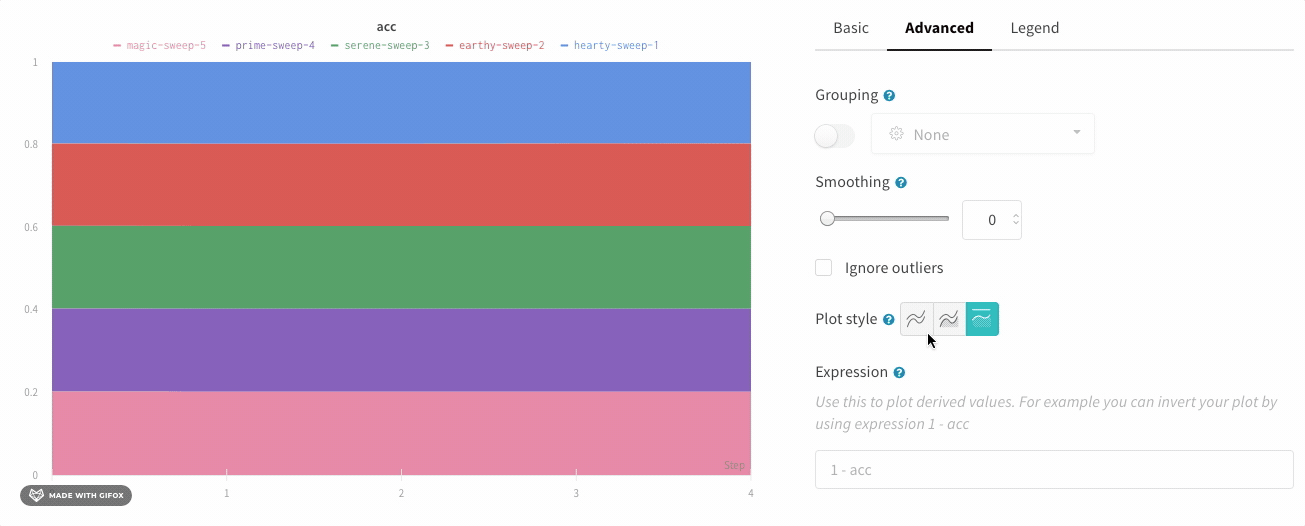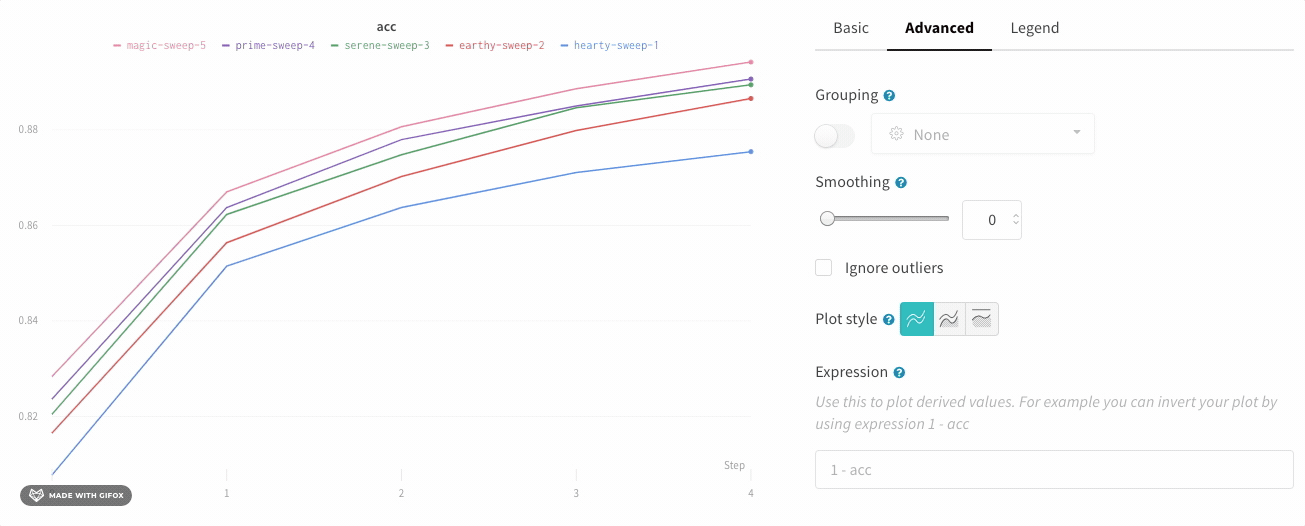
라인 플롯 설정의 고급 탭에서 다른 플롯 스타일을 클릭하여 영역 플롯 또는 백분율 영역 플롯을 얻습니다.
확대/축소
사각형을 클릭하고 드래그하여 수직 및 수평으로 동시에 확대/축소합니다. 그러면 x축 및 y축 확대/축소가 변경됩니다.
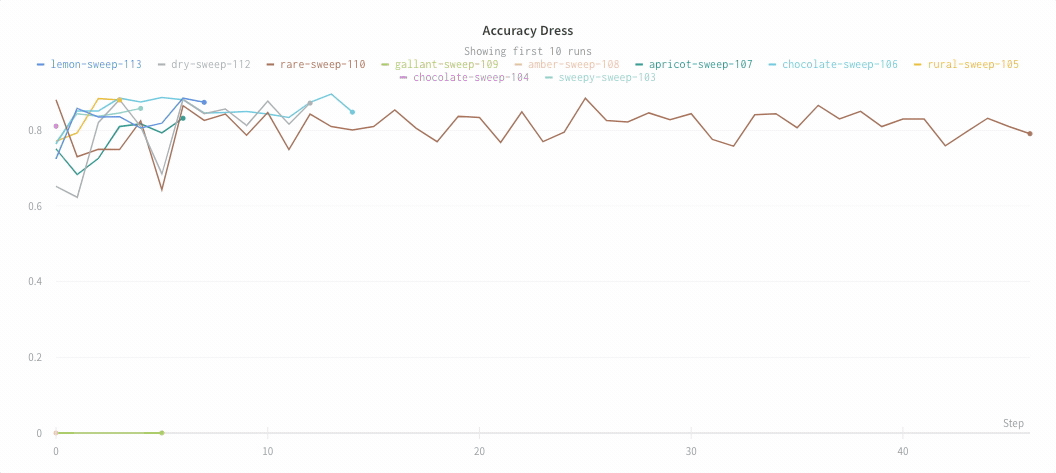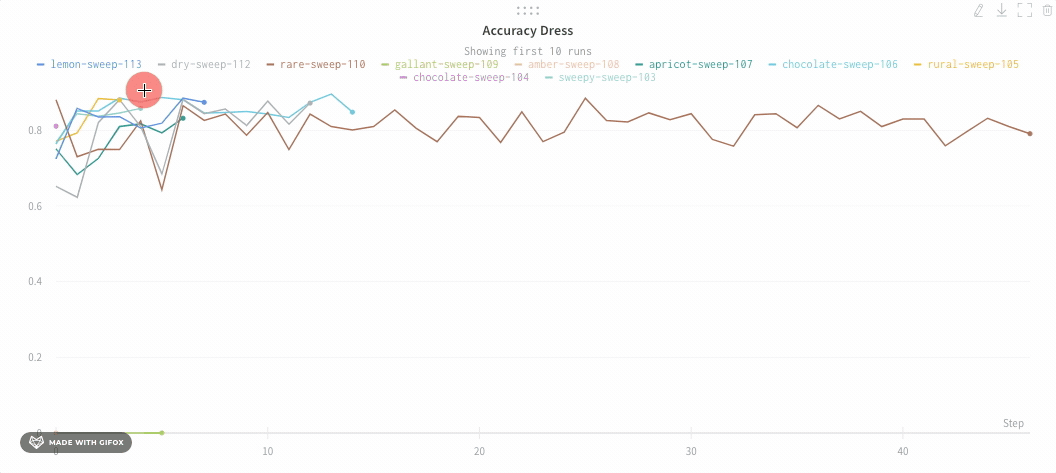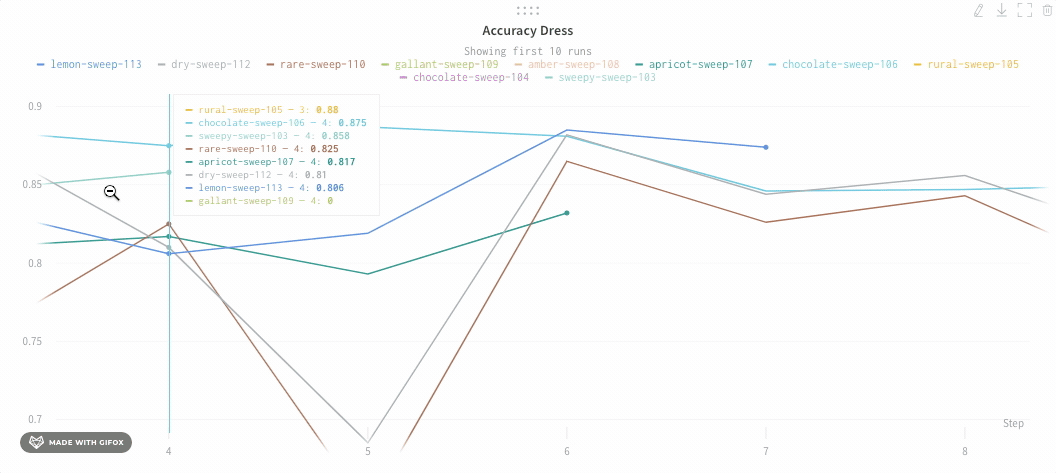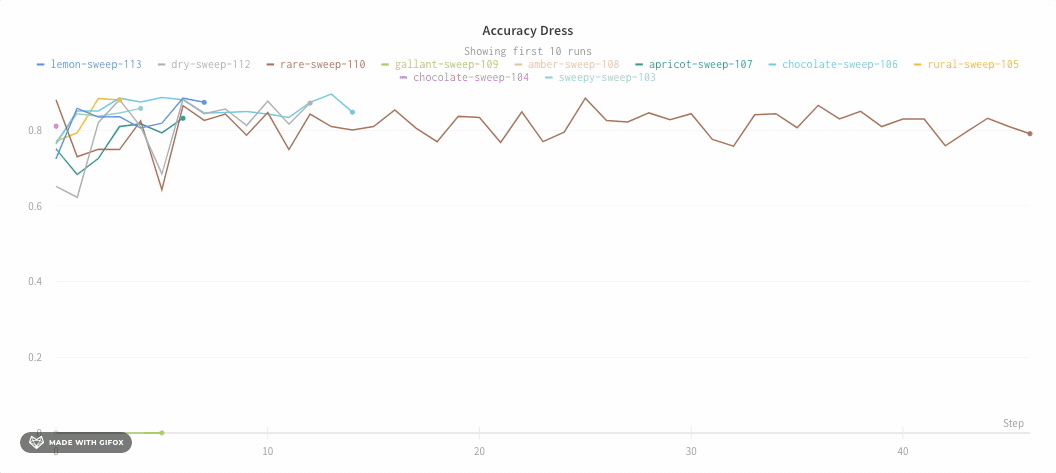
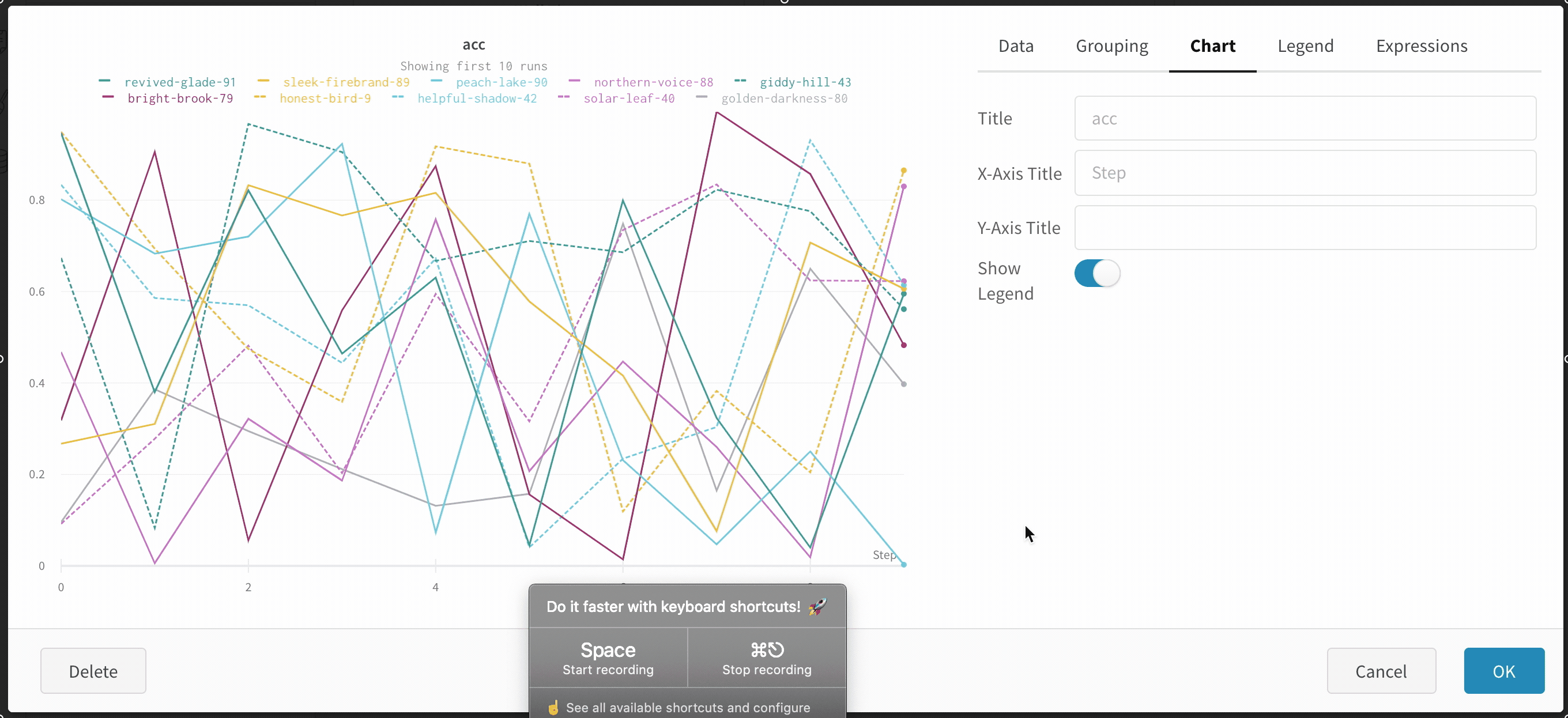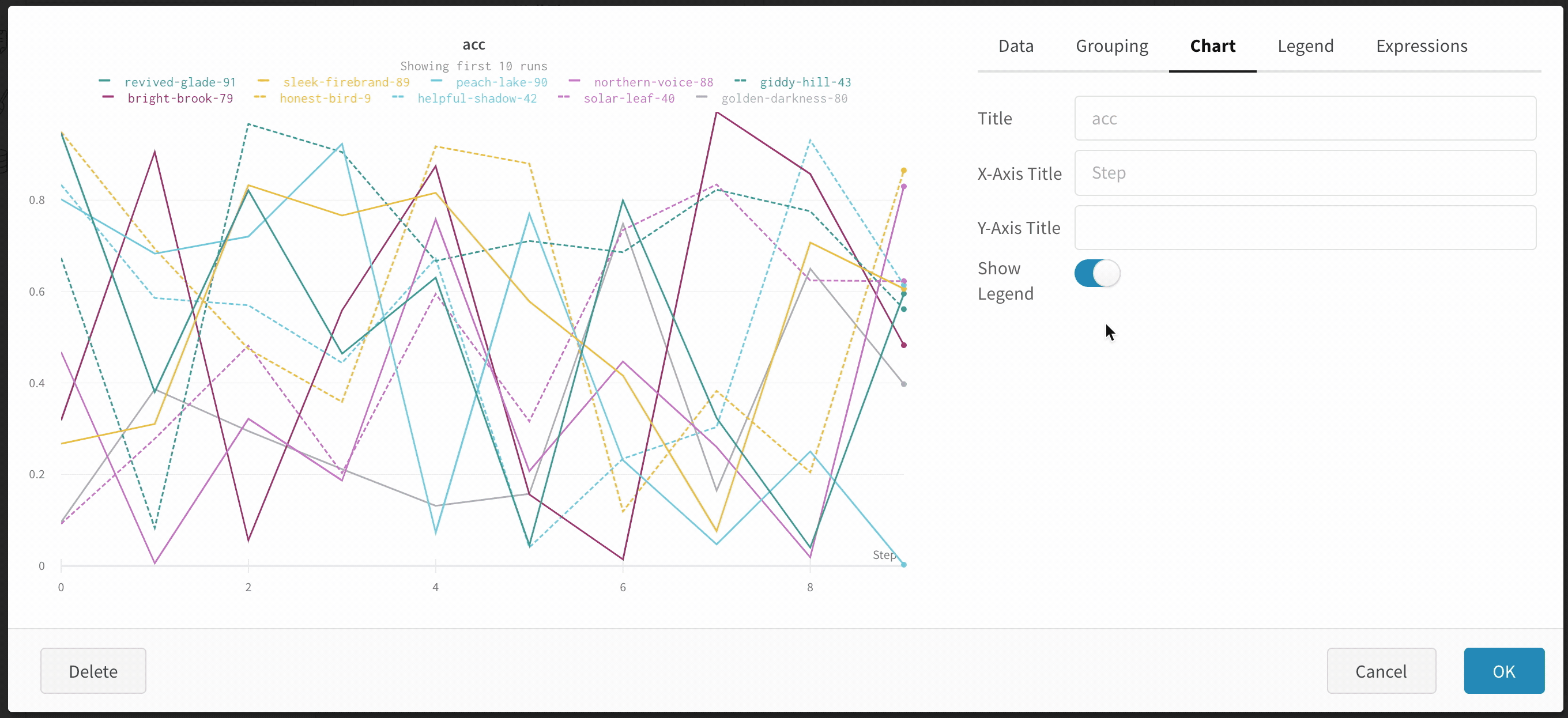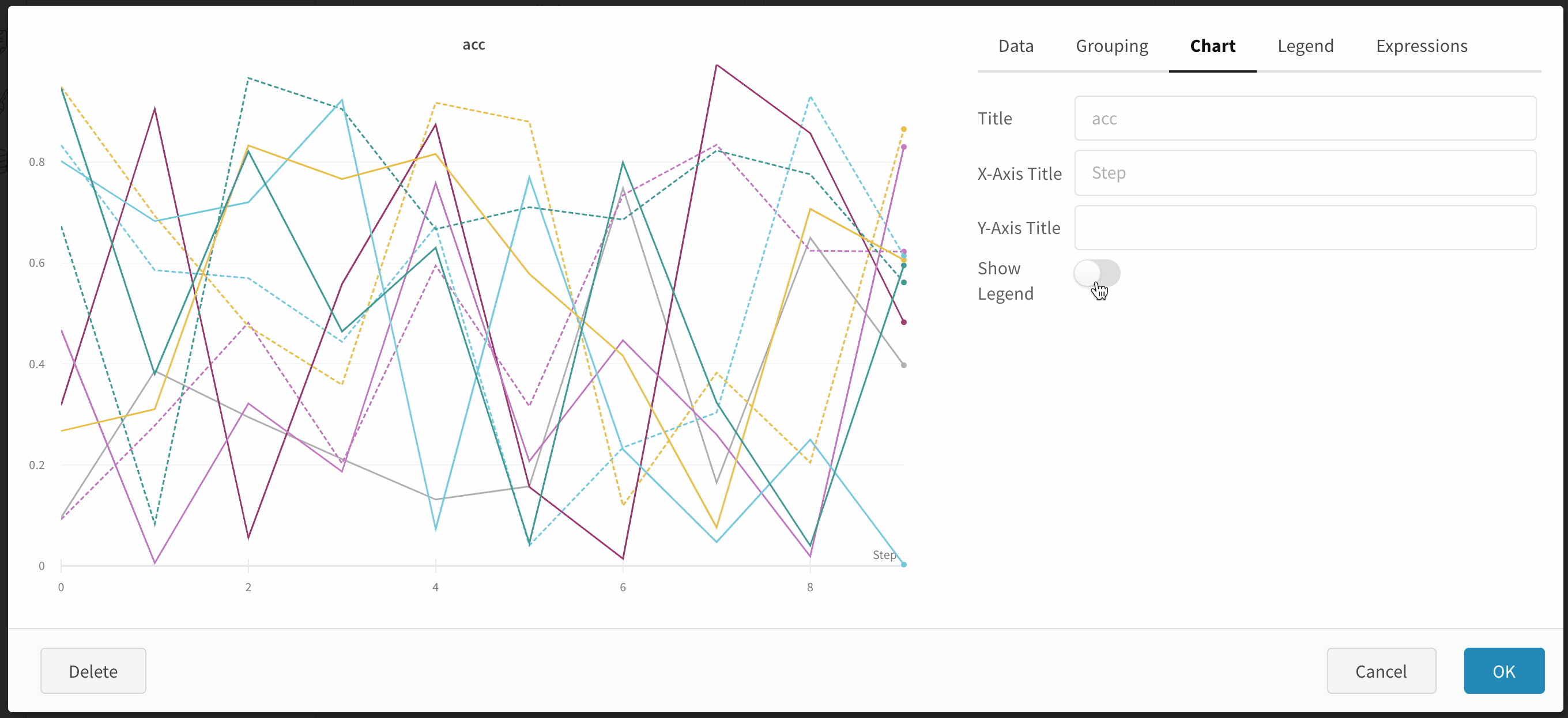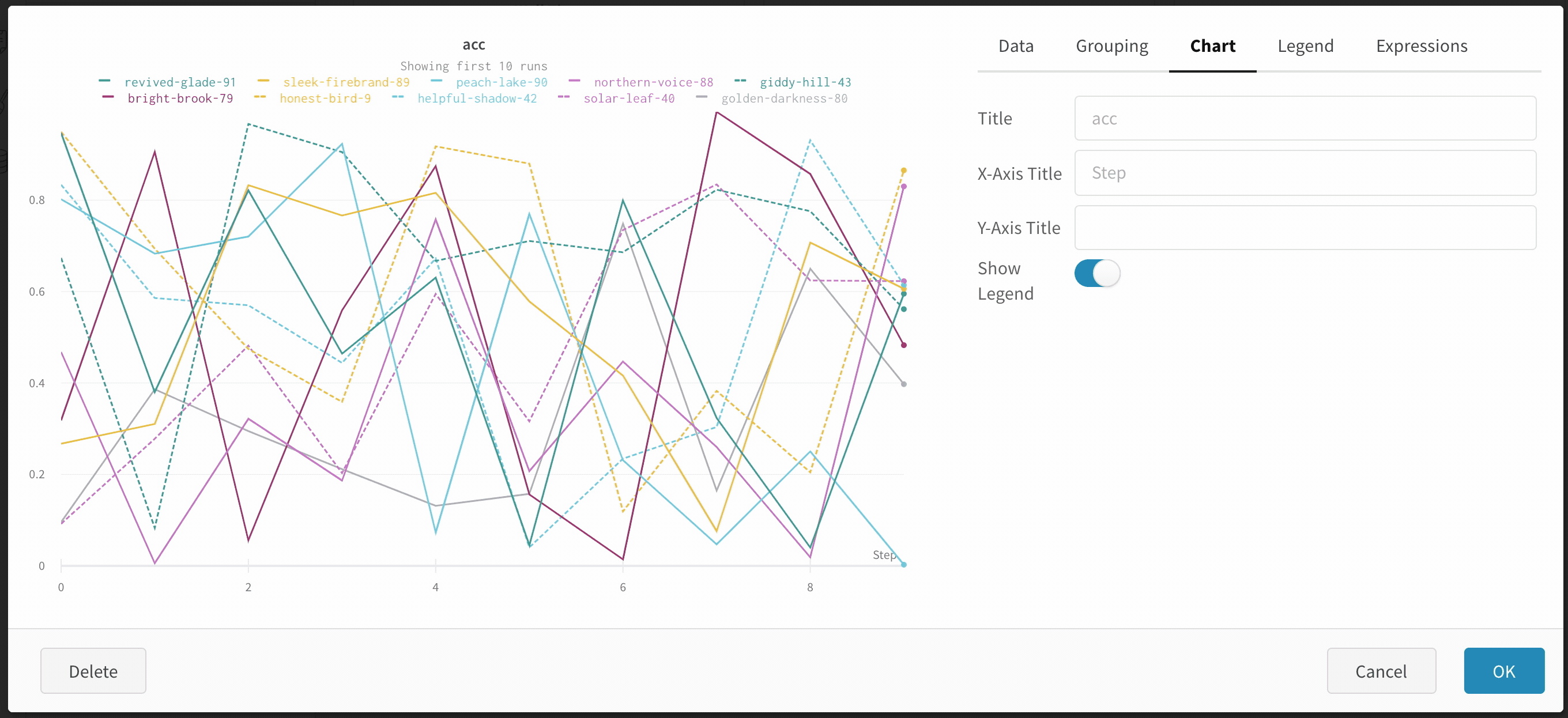
차트 범례 숨기기
이 간단한 토글로 라인 플롯에서 범례를 끕니다.